Результат интеллектуальной деятельности: СПОСОБ КЛАССИФИКАЦИИ ТЕКСТОВ, ПОЛУЧЕННЫХ В РЕЗУЛЬТАТЕ РАСПОЗНАВАНИЯ РЕЧИ
Вид РИД
Изобретение
Изобретение относится к области анализа и обработки текстов и может быть использовано для классификации потока текстовых файлов, полученных в результате распознавания слитной речи в каналах телефонной связи, по заранее неизвестным классам. Изобретения также предоставляет возможность создания программных систем для автоматической классификации телефонных переговоров в колл-центрах.
Известен способ обработки текста, основанный на методе статистического анализа текстов, основанный на предварительной подготовке данных, в которой предложения или группа предложений с помощью опытных лингвистов классифицируют тематическими маркерами из фиксированного множества тематических маркеров. Предполагают, что текст (последовательность предложений) порождается последовательностью тематических переменных, которые подчинены скрытой модели Маркова. Скрытая модель Маркова определяется условными вероятностями следования друг за другом тематических переменных и условными вероятностями возникновения тематического маркера при известных предложениях и тематической переменной. С помощью ЕМ-алгоритма эти условные вероятности можно найти на основе предварительно подготовленных данных (Christina Sauper, Aria Haghighi, Regina Barzilay, Incorporating Content Structure into Text Analysis Applications // Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pages 377-387, MIT, Massachusetts, USA, 9-11 October 2010. 2010 Association for Computational Linguistics).
Данный способ обладает существенным недостатком, который связан с тем, что классификация текстов возможна только в рамках известного множества тем документов, В случае появления документа, не принадлежащего ни одному из существующих классов, такой документ будет классифицирован случайным образом.
Известен также способ обработки текста, основанный на методе k-ближайших соседей и дополненный матрицей совместной встречаемости терминов в документах, определяющих класс (Нгуен Ба Нгок, А.Ф. Тузовский. Классификация текстов на основе оценки семантической близости терминов // Известия Томского политехнического университета, 2012, т. 320, №5). Способ обладает высокой точностью, но и существенным недостатком, а именно невозможностью его применения для работы с искаженным текстом в виду искажения терминов и/или возможной заменой.
Наиболее близким к предлагаемому способу, является способ, принятый в качестве наиболее близкого аналога, используемый при построении семантической модели документа, по которому из информационных источников извлекают онтологию, в качестве информационных источников используют электронные ресурсы, анализируют описания и определяют значения терминов с помощью онтологии, извлеченных из гипертекстовых энциклопедий, вычисляют частоту совместного использования каждого текстового представления концепции и информативность для каждого текстового представления, также определяют, какому естественному языку принадлежит текстовое представление, и сохраняют полученную информацию, получают текст анализируемого документа, осуществляют поиск терминов текста и их возможных значений путем сопоставления частей текста и текстовых представлений концепций из контролируемого словаря для каждого термина из его возможных значений, используя алгоритм разрешения лексической многозначности терминов, выбирают одно, которое считают значением термина, а затем концепции, соответствующие значениям терминов, ранжируют по важности к тексту, и наиболее важные концепции считают семантической моделью документа (патент РФ на изобретение №2487403).
Недостатком наиболее близкого аналога является низкая точность, которая связана с использованием только ключевых терминов для построения семантической модели документа. Таким образом, технический результат, достигаемый при создании заявленного способа, состоит в повышении точности классификации текстовых файлов, полученных при распознавании слитной речи в каналах телефонной связи, а также в возможности полной автоматизации такой классификации текстов независимо от тематики.
Для достижения поставленного результата предлагается способ классификации текста, полученного в результате распознавания устной речи, включающий первоначальное создание (использование) хранилища начальных форм (семантических характеристик) слов (семантический словарь) и последующее проведение, например, посредством вычислительного устройства (компьютера) по меньшей мере один раз следующей последовательности действий:
- распознают устную речь с получением текста;
- в полученном в результате распознавания устной речи тексте выделяют каждое слово, находят каждому выделенному слову множество семантических характеристик в семантическом словаре, на основе выявленного множества семантических характеристик определяют семантическую согласованность по меньшей мере одной последовательности слов с получением фразы, выделяют из текста множество фраз со сравнением их семантических характеристик и выделением по результатам сравнения доминирующей семантической характеристики, преобразуют множество фраз во множество ключевых фраз, содержащих доминирующую семантическую характеристику, и формируют из первых полученных ключевых фраз и их семантических характеристик класс;
- сравнивают последующие ключевые фразы и их семантические характеристики по меньшей мере с одним из предыдущих классов;
- классифицируют по меньшей мере один текст по результатам сравнения упомянутых последующих ключевых фраз и их семантических характеристик.
Сущность изобретения состоит в том, что предложен способ построения семантической модели документа, основанный на подготовленном заранее семантическом словаре.
Поставленный технический результат достигается за счет последовательности используемых процедур. В заявленном способе используется множество так называемых семантем или семем, в терминах которых определяется семантическая согласованность каждой пары слов языка, которые содержатся в семантическом словаре, примером которого может служить семантический словарь «РУСЛАН» (Леонтьева Н.Н. и др. Семантический словарь РУСЛАН как инструмент компьютерного понимания // Понимание в коммуникации - 2003, Материалы научно-практической конференции. М., 2003, с. 41-46) - см. таблицу 1 (далее). Для специалиста в области лингвистики очевидно, что ссылка на указанный словарь «РУСЛАН» приведена для понимания вариантов конкретного воплощения заявленного способа и никоим образом не должна ограничивать объем испрашиваемой в рамках заявленной формулы изобретения правовой охраны. В описываемом способе последовательно используются два метода семантического анализа. С помощью первого применения метода семантического анализа определяются семантически согласованные последовательности слов (фразы) и их семантические характеристики. С помощью второго применения метода семантического анализа определяются множества фраз, обладающих хотя бы одной эквивалентной семантической характеристикой. Из семантических характеристик и слов таких фраз строится вектор семантической категории текста. Вектор семантической категории текста используется для сравнения различных текстов и проводится их автоматическая классификация.
Для понимания существа заявленного решения к описанию приложены следующие графические материалы, на которых представлены пример описания слова в семантическом словаре (рис. 1), пример согласованности двух слов при эквивалентности их общих семантических характеристик (рис. 2а), пример согласованности двух слов при эквивалентности общей семантической характеристики одного слова и семантической характеристики другого слова (рис. 2б), а также блок-схема примерного устройства для реализации способа (рис. 3).
Согласно предлагаемому способу все процедуры обработки текста можно разделить на пять этапов:
а) предварительная обработка;
б) обучение, связанное с вычислением совместной встречаемости слов в предложении;
в) вычисление оценок семантической согласованности слов во фразах;
г) принятие решения об описании семантической категории текста;
д) операция классификации текста.
Предварительная обработка состоит из двух процедур. Первая процедура состоит в чтении словаря семантических характеристик слов, в котором каждому слову приписаны:
- общие семантические характеристики (OCX);
- валентности (ВАЛ), как взаимные отношения между словом и окружающими его семантически связанными словами;
- семантические характеристики (CXn) окружающих слов в соответствующей валентности, где n - номер соответствующей валентности.
Каждая семантическая характеристика и валентность определены на множестве семантем. Пример описания слова в семантическом словаре приведен на рис. 1. Список используемых семантем и их значений приведен в таблице 1. Вторая процедура стоит в морфологическом анализе слов из текста, на основе которого определяется их части речи и начальные формы.
Обучение связано с вычислением совместной вероятности встречаемости начальных форм слов внутри предложения при условии, что слова не являются частицами, союзами, междометиями, наречиями или местоимениями. Обучение состоит из последовательности следующих процедур:
- автоматическое чтение корпуса текстов, полученных из открытых источников, например интернета;
- морфологический анализ слов с получением их частей речи и начальных форм;
- создание словаря начальных форм;
- расчет частоты встречаемости пар начальных форм слов в предложении и расчет общего количества всевозможных пар слов;
- применение процедуры сглаживания Каца с получением значений матрицы совместной встречаемости слов в предложении.
Вычисление оценок семантической согласованности слов во фразах состоит из следующих процедур:
- поиск слов текста в словаре семантических характеристик слов;
- сегментация текста на последовательности, состоящие из m слов (окно анализа текста или фрейм);
- смещения окна анализа текста на s слов;
- перебор всевозможных пар начальных форм слов в окне анализа текста;
- поиск семантической согласованности в этих парах, при которой два слова являются семантически согласованными, если существуют эквивалентные семантемы в полях OCX одного из слов и в полях CXn другого слова;
- поиск наиболее вероятной семантически согласованной фразы в окне анализа, вычисление ее вероятности и семантических характеристик.
Процедура определения семантической согласованности пары слов состоит в сравнении общих семантических характеристик (OCX) одного слова с общими семантическими характеристиками (OCX) или семантическими характеристиками (CXn) окружающих его слов в соответствующей валентности.
Пример согласованности двух слов - «абзац книги» при эквивалентности их общих семантических характеристик приведен на рисунке 2а. В этом случае результатом операции согласования является объединение OCX и CXn двух слов.
Пример согласованности двух слов - «банковский клерк» при эквивалентности общей семантической характеристики одного слова и семантической характеристики другого слова приведен на рисунке 2б. В этом случае результатом операции согласования является объединение OCX и CXn двух слов с поглощением эквивалентной CXn и ее валентности.
В качестве вероятности согласованной пары слов используется сглаженная вероятность совместной встречи пары этих слов в предложении.
В результате работы блока оценок семантической согласованности слов во фразах формируется множество фраз, каждая из которых определена набором своих семантических характеристик и валентностей.
Метод оценок семантической согласованности слов во фразах можно пояснить с помощью следующего представления. Расположим все слова фрейма в столбце и в строке. Между каждой парой слов была найдена согласованность слов со своими характеристиками и своей вероятностью. Если согласованность не найдена, то вероятность их согласованности принимается значению из сглаженной матрицы совместной встречаемости слов. Формально, необходимо найти такую последовательность слов (траекторию), чтобы, с одной стороны, функционал (1)
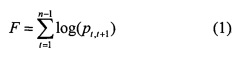
обладал максимальной вероятностью среди всех прочих последовательностей, а с другой стороны, слово в этой траектории не встречалось дважды. Такого рода задачи решаются с помощью известного алгоритма Витерби или т.п.
Семантически согласованные фразы, найденные во фреймах, образуют множество фраз, каждое из которых описывается своими общими семантическим характеристиками, которые получены путем объединения общих семантических характеристик, входящих во фразу слов.
Каждая фраза из этого множества сравнивается со всеми прочими фразами множества на предмет эквивалентности семантем. Таким образом, каждая фраза начинает обладать своим подмножеством фраз, в каждой из которых у нее есть по крайней мере одна эквивалентная семантема. Из всех этих подмножеств выбирают подмножество максимальной мощности. Подмножество фраз вместе со своими описаниями передается в блок формирования семантического вектора текста.
Вектор описания семантической категории текста состоит из двух частей. Первая часть состоит из множества различных семантем, которые встречались в подмножестве семантически согласованных фраз, вторая - из различных начальных форм слов, входящих в подмножество семантически согласованных фраз.
Процедура классификации текстов состоит в сравнении векторов описания семантической категории двух различных текстов. Процедура сравнения проводится отдельно для каждой части вектора. Для первой части вектора если текст 1 характеризует k1 семантем, а текст 2 характеризует k2 семантем, при этом d семантем совпадают, то мера близости μ1 текста 1 к тексту 2 определяется выражением (2)
 .
.
Для второй части вектора если текст 1 характеризует w1 начальными формами слов из фраз, а текст 2 характеризует w2 начальными формами слов из фраз, при этом  слов совпадают, то мера близости μ2 текста 1 к тексту 2 определяется выражением (3)
слов совпадают, то мера близости μ2 текста 1 к тексту 2 определяется выражением (3)

Решение о принадлежности текстов к одному и тому же классу принимается на основе расчета выражения (4), при котором, если по результатам вычисления значение r менее заранее заданного порога Q (выбирают эмпирически или расчетным путем), то принимается решение, что оба текста принадлежат к одному и тому же классу
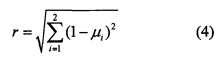
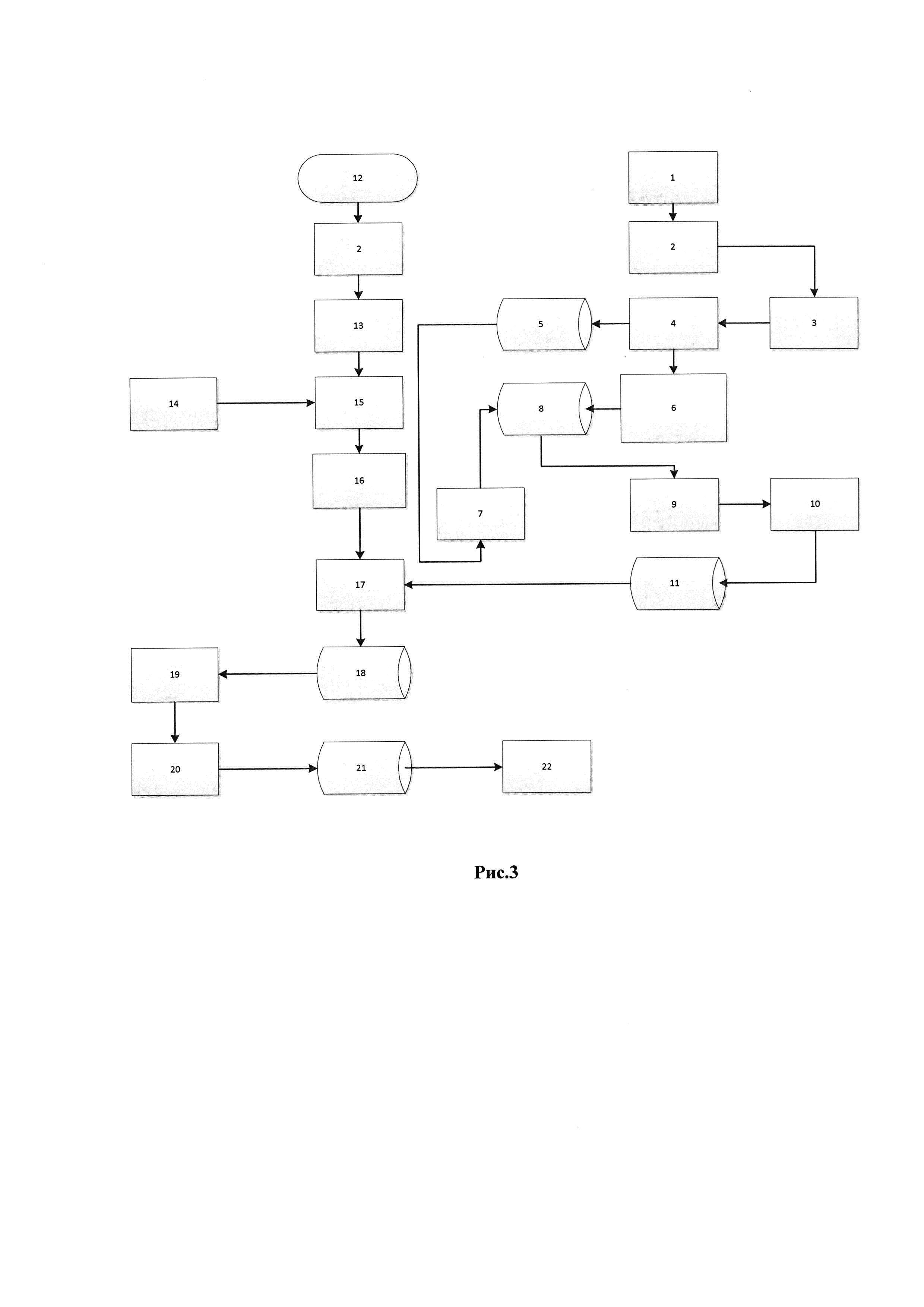
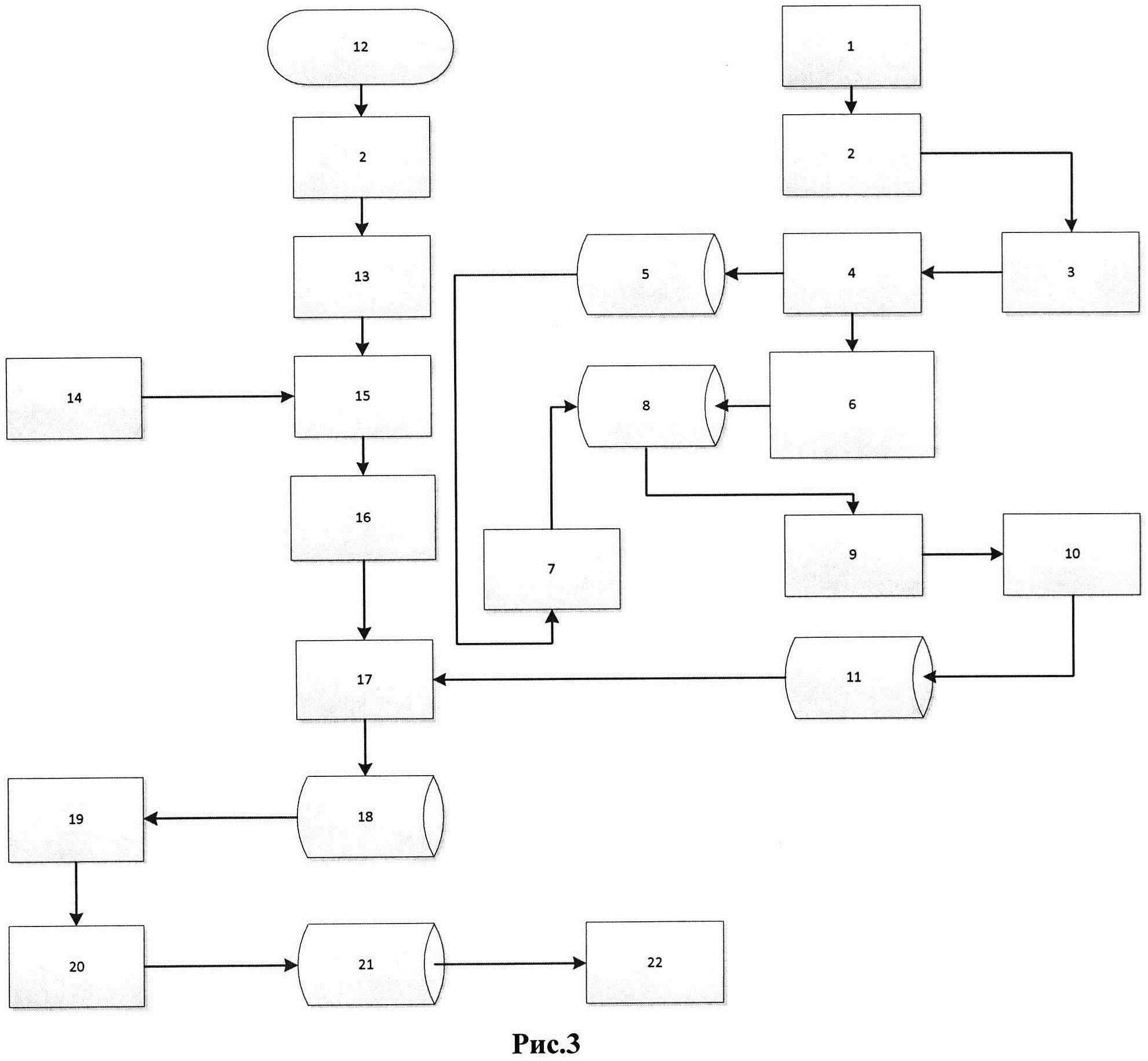
Изобретение поясняется блок-схемой устройства для реализации способа (рис. 3).
Устройство включает в себя блок 1 чтения текстов из заранее подготовленного корпуса текстов и передачи таких текстов по одному слову в блок морфологического анализа 2.
На выходе блока 2 морфологического анализа в ответ на входное слово возникают начальная форма слова и его часть речи. Эти параметры передаются в блок отбора слов по его части речи 3. На выходе этого блока возникают начальные формы слов в случае, если они не являются частицами, союзами, междометиями, наречиями или местоимениями. Один из выходов блока 4 связан с хранилищем начальных форм слов 5 для сравнения поступающих на вход блока 4 начальных форм слов с начальными формами, содержащимися в хранилище 5. Если на входе блока 4 возникает слово, которое не содержится в хранилище 5, то блок 4 вносит такое новое слово в хранилище. По результатам обработки корпуса текстов в хранилище 5 содержатся все возможные начальные формы, содержащиеся в корпусе с получением числа N различных начальных форм. Такое число передают в блок 7, в котором происходит инициализация матрицы N*N, поступающей в хранилище матрицы частот встречаемости пар слов в предложении 8. Второй из выходов блока 4 связан с блоком 6 сравнения пар слов, поступивших из блока 4 с парами слов, содержащимися в хранилище 8, и суммирует в элемент матрицы, соответствующий поступившей паре слов, единицу. Результатом работы блока 6 является заполнение хранилища 8 частотами встречаемости пар слов в ходе обработки корпуса текстов. Блок 9 вычисляет значения матрицы совместной вероятности пар слов на основе матрицы встречаемости пар слов, содержащихся в хранилище 8. Поскольку корпус текстов содержит не все слова языка, то вероятно, что некоторые частоты встречаемости некоторых пар слов будут равны нулю. С другой стороны, велика вероятность встретить такую пару слов в каком-либо неизвестном тексте. В этом случае на основе такой статистической модели вероятность встретить новую последовательность слов будет равна нулю. Блок 10 использует сглаживание матрицы совместных вероятностей слов методом Каца. Элементы матрицы совместных вероятностей помещаются в хранилище 11, связанное с блоком 17. Особо следует отметить, что наличие описанной последовательности действия является следствием речевого разнообразия языка и является своего рода параллельным этапом при выполнении нижеописанной последовательности действий.
Текстовые файлы, полученные в результате распознавания речи, поступают в блок 12 для прочтения. Слова из блока 12 поступают на вход морфологического анализатора 2, в котором определяются их начальные формы и части речи, и далее в блок 13 сегментации текста на фреймы заданного размера. Слова из выделенного блоком 13 фрейма поочередно передаются в блок 15 поиска слова в семантическом словаре, который был предварительно прочитан блоком 14. Блок 16 проводит сравнение семантических характеристик слов и определение их по парной согласованности. Далее, в блоке 17 находят значение максимума функционала (1) и последовательность слов (фразу) доставившую функционалу этот максимум. Из блока 17 найденную фразу со своими семантическими характеристиками передают в хранилище семантически согласованных фраз 18, связанное с блоком 19. В блоке 19 (компараторе) проводят попарное сравнение семантических характеристик накопленных в хранилище 18 фраз и каждой фразе ставят в соответствие подмножество фраз, в которых есть по крайней мере одна эквивалентная семантема. Затем происходит выбор подмножества максимальной мощности. Элементы этого подмножества (фразы) вместе со своими семантическими характеристиками передаются в блок 20 формирования семантического вектора текста.
В блоке 20 формируется семантический вектор текста, который состоит из двух частей: а) множества различных семантем, которые встречались в подмножестве семантически согласованных фраз; б) различных начальных форм слов, входящих в подмножество семантически согласованных фраз. Семантический вектор текста помещается в хранилище 21 семантических векторов текстов. Когда в хранилище 21 поступает более одного семантического вектора, эти семантические вектора сравниваются в блоке 22 с помощью формул (2)÷(4). Если для любых сохраненных в хранилище семантических векторов параметр r больше порога Q, то вновь поступивший семантический вектор сохраняется и считается, что он определяет новую семантическую категорию. Если же в хранилищ t нашелся такой семантический вектор, для которого параметр r меньше порога, то считается, что связанная с ним семантическая категория уже существует, и он не сохраняется.
Таким образом, в хранилище 21 автоматически сохраняются только новые семантические категории поступающих текстов.





Система голосовой идентификации диктора

