Результат интеллектуальной деятельности: Система и способ обнаружения фишинговых сценариев
Вид РИД
Изобретение
Область техники
Изобретение относится к антивирусным технологиям, а более конкретно к системам и способам обнаружения фишинговых сценариев.
Уровень техники
Бурное развитие интернет-технологий в последнее десятилетие, появление большого числа устройств, передающих данные через интернет (таких как персональные компьютеры, ноутбуки, планшеты, мобильные телефоны и т.д.), а также простота и удобство их эксплуатации привели к тому, что огромное число людей в своих повседневных делах стало пользоваться интернетом, будь то получение информации, работа с банковскими счетами, осуществление покупок, чтение почты, посещение социальных сетей, развлечения и т.д. Часто при работе в интернете (например, при покупке товаров, переводе денег, регистрации и т.д.) пользователям приходится передавать на внешние сервера свою конфиденциальную информацию (такую как номера кредитных карт и банковских счетов, пароли к учетным записям и т.д.), ту самую информацию, от сохранности которой зависит финансовая безопасность пользователей.
Огромное число пользователей, использующих интернет, стало причиной увеличения активности мошенников, получающих с помощью разнообразных техник и методов доступ к конфиденциальным данным пользователей с целью кражи данных для дальнейшего использования в собственных целях. Одним из самых популярных методов является так называемый фишинг (англ. phishing), т.е. получение доступа к конфиденциальной информации пользователя с помощью проведения рассылок писем от имени популярных брендов, личных сообщений внутри различных сервисов (например, внутри социальных сетей или систем мгновенного обмена сообщениями), а также создания и регистрации в поисковых сервисах сайтов, выдающих себя за легальные сайты банков, интернет-магазинов, социальных сетей и т.д. В письме или сообщении, посылаемом мошенниками пользователям, часто содержатся ссылки на вредоносные сайты, внешне неотличимые от настоящих, или на сайты, с которых будет осуществлен переход на вредоносные сайты. После того, как пользователь попадает на поддельную страницу, мошенники, используя различные приемы социальной инженерии, пытаются побудить пользователя ввести свою конфиденциальную информацию, которую он использует для доступа к определенному сайту, что позволяет мошенникам получить доступ к аккаунтам и банковским счетам. Кроме однократного раскрытия своей конфиденциальной информации, пользователь рискует загрузить с такого сайта-подделки одно из вредоносных приложений, осуществляющих регулярный сбор и передачу мошенникам информации с компьютера жертвы.
Для борьбы с описанным выше способом мошенничества применяются технологии, направленные на выявление фишинговых сообщений (например, в электронной почте), а также поддельных сайтов. Для этого в сообщениях осуществляется поиск данных используемых для фишинга (например, характерные изображения, способы формирования сообщений, в частности сценарии, содержащиеся в сообщениях, и т.д.), для чего используются базы доверенных и недоверенных адресов сайтов, шаблоны фраз из фишинговых сообщений и т.д. Одним из вариантов описанного выше подхода является поиск данных, используемых для фишинга, по похожести сигнатур или журналов поведения с найденными ранее данными, используемыми для фишинга. При обнаружении факта присутствия подозрительного объекта, пользователь информируется о потенциальной опасности.
Например, в публикации US 20150096023 А1 описана технология обнаружения вредоносных файлов, заключающаяся в вычислении нечетких хэш-сумм (англ. fuzzy hash) на основании данных (таких как идентификаторы и параметры команд, дампы памяти и т.д.), описывающих поведение исследуемого файла, и использование полученных хэш-сумм для определения, является ли исследуемый файл вредоносным, для чего полученные хэш-суммы сравниваются с хэш-суммами ранее обнаруженных и обработанных вредоносных файлов. К недостаткам данной технологии можно отнести следующие:
- неэффективность исследования обфусцированных (англ. software obfuscation) файлов, поскольку вычисленные хэш-суммы по похожим, но обфусцированным файлам, имеют низкую степень схожести;
- неэффективность исследования файлов с защитой от эмуляции, поскольку вычисленные хэш-суммы от таких файлов имеют низкую степень схожести;
- неэффективность обнаружения зараженных компьютерных систем, поскольку описанная технология рассматривает каждый файл индивидуально и независимо от остальных файлов компьютерной системы, поэтому не способна обнаруживать сборные вредоносные программы, которые включают в себя несколько файлов, каждый из которых не несет в себе вредоносного функционала.
В другой публикации US 9118703 B2 описана технология обнаружения вредоносных программ, схожих по своим характеристикам с доверенными программами, посредством формирования нечетких белых списков (англ. fuzzy whitelist). Недостаток данной технологии заключается в неэффективности обнаружения зараженных компьютерных систем, поскольку описанная технология рассматривает каждый файл индивидуально и независимо от остальных файлов компьютерной системы, в связи с чем не позволяет обнаруживать сборные вредоносные программы, которые включают в себя несколько файлов, каждый из которых не несет в себе вредоносного функционала.
Описанные выше публикации могут использоваться для поиска данных, используемых для фишинга. Для этого в качестве вредоносных файлов должны рассматриваться файлы, содержащие данные, используемые для фишинга.
Еще в одной публикации US 8448245 B2 описана технология определения фишинговой страницы на основании данных, полученных с анализируемой страницы (а также со страниц, на которые указывают ссылки с проверяемой страницы), и данных, полученных из базы данных, содержащей информацию о данных, используемых для фишинга. Недостаток данной технологии заключается в том, что все собранные на проверяемых страницах данные анализируются (сравниваются с данными из базы данных) индивидуально, без какой-либо кластеризации, что в свою очередь сильно снижает эффективность или делает совершенно невозможным анализ новых, ранее не встречаемых, данных. Таким образом, проверка страниц с новыми подходами в использовании фишинга, с новыми типами данных имеет низкую эффективность и высокий уровень ложных срабатываний.
Хотя описанные выше способы работы хорошо решают определенные задачи в области обнаружения фишинга (в частности фишинговых сценариев) на основе анализа известных способов фишинга и типов данных, используемых для фишинга, они зачастую не помогают в случае с новыми подходами в использовании фишинга, а также с новыми типами данных и используемых для фишинга.
Настоящее изобретение позволяет решать задачу обнаружения фишинговых сценариев более эффективно.
Раскрытие изобретения
Изобретение предназначено для обнаружения фишинговых сценариев.
Технический результат настоящего изобретения заключается в обнаружении фишинговых сценариев, содержащихся на сетевых ресурсах, к которым обращается пользователь.
Данный результат достигается с помощью использования системы обнаружения фишинговых сценариев, где под фишинговым сценарием понимается сценарий, содержащий данные, предназначенные для осуществления фишинга (англ. phishing), которая содержит средство сбора, предназначенное для выборки по меньшей мере одного сценария из сетевого ресурса, содержащего по меньшей мере один сценарий, и передачи выбранного сценария средству формирования промежуточного кода; упомянутое средство формирования промежуточного кода, предназначенное для формирования промежуточного кода (англ. bytecode) выбранного сценария, где промежуточный код представляет собой совокупность команд сценария (англ. opcode), состоящую по меньшей мере из одной команды сценария, содержащейся в выбранном сценарии, и передачи сформированного промежуточного кода средству вычисления хэш-сумм; упомянутое средство вычисления хэш-сумм, предназначенное для вычисления хэш-суммы от сформированного промежуточного кода, и передачи вычисленной хэш-суммы средству поиска; базу данных хэш-сумм, предназначенную для хранения по меньшей мере одной группы, представляющей собой набор данных, включающий в себя по меньшей мере одну хэш-сумму, коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных двух хэш-сумм установленному пороговому значению схожести хэш-сумм, коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга; упомянутое средство поиска, предназначенное для выборки из базы данных хэш-сумм по меньшей мере одной группы, в которой по меньшей мере одна хэш-сумма схожа с вычисленной хэш-суммой, где схожесть хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных хэш-сумм установленному пороговому значению схожести хэш-сумм, и передачи коэффициента компактности группы, коэффициента доверия группы и вычисленной степени схожести хэш-сумм средству сбора статистики; базу данных шаблонов вердиктов, предназначенную для хранения по меньшей мере одного шаблона вердикта, представляющего собой набор данных, включающий в себя по меньшей мере один индекс группы, коэффициент доверия шаблона вердикта, указывающий на то, сколько сценариев, использованных для формирования групп, по которым были определены индексы группы из шаблона вердикта, содержат данные, предназначенные для осуществления фишинга; упомянутое средство сбора статистики, предназначенное для вычисления индекса группы по меньшей мере для одной выбранной группы на основании коэффициента компактности группы, коэффициента доверия групп и степени схожести хэш-сумм, полученных от средства поиска, где индекс группы указывает на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы, и передачи определенного индекса группы средству анализа; упомянутое средство анализа, предназначенное для выборки из базы данных шаблонов вердиктов по меньшей мере одного шаблона вердикта, в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным средством сбора статистики, и вычисленной степени схожести указанных индексов группы, где схожесть двух индексов группы определяется на основании соответствия вычисленной степени схожести указанных индексов группы установленному пороговому значению схожести индексов группы, и передачи коэффициента доверия шаблона вердикта выбранного шаблона вердикта и вычисленной степени схожести индексов группы средству вынесения вердикта; упомянутое средство вынесения вердикта, предназначенное для вынесения решения о том, является ли сценарий, выбранный средством сбора, фишинговым на основании соответствия по меньшей мере одного полученного коэффициента доверия шаблона вердикта и по меньшей мере одной полученной степени схожести индексов группы, установленному пороговому значению фишинга.
В другом частном случае реализации системы в качестве сетевого ресурса выступает по меньшей мере интернет-страница, письмо электронной почты, сообщение системы мгновенного обмена сообщениями.
Еще в одном частном случае реализации системы хэш-сумма вычисляется по меньшей мере путем вычисления нечетких хэш-сумм (англ. fuzzy hash), нечеткого поиска с индексацией (англ. fuzzy searching).
В другом частном случае реализации системы степень схожести хэш-сумм вычисляется по меньшей мере путем сравнения нечетких хэш-сумм, вычисления метрик (англ. similarity metric) для нечеткого поиска с индексацией.
Еще в одном частном случае реализации системы коэффициент компактности группы вычисляется по меньшей мере путем поиска минимальной степень схожести среди всех пар хэш-сумм, содержащихся в группе, вычисления меры центральной тенденции (англ. central tendency) от степеней схожести по меньшей мере двух пар хэш-сумм, содержащихся в группе.
В другом частном случае реализации системы коэффициент доверия группы, вычисляется путем определения значения в пределах от 0, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются фишинговыми, до 1, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются доверенными.
Еще в одном частном случае реализации системы индекс группы представляет собой пару чисел, где первое число вычисляется как произведение коэффициента компактности группы и степени схожести хэш-сумм группы, а второе число вычисляется как произведение коэффициента доверия группы и степени схожести группы.
В другом частном случае реализации системы степень схожести индексов группы вычисляется путем нахождения скалярного произведения многомерных векторов, где в качестве элементов многомерных векторов выступают данные, содержащиеся в группе.
Еще в одном частном случае реализации системы коэффициент доверия шаблона вердикта, вычисляется путем определения значения в пределах от 0, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются фишинговыми, до 1, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются доверенными.
В другом частном случае реализации системы шаблоны вердикта из базы данных шаблонов вердиктов, совокупно включают в себя индексы групп, для определения которых были использованы все группы из базы данных хэш-сумм.
Еще в одном частном случае реализации системы перед выборкой из базы данных шаблонов вердиктов производится преобразование определенных средством сбора статистики индексов групп по меньшей мере путем дискретного Фурье-преобразования (англ. discrete Fourier transform), вейвлет-преобразования (англ. wavelet transform).
Данный результат достигается с помощью использования способа обнаружения фишинговых сценариев, где под фишинговым сценарием понимается сценарий, содержащий данные, предназначенные для осуществления фишинга (англ. phishing), реализованный средствами из системы по п. 1, по которому выбирают по меньшей мере один сценарий из сетевого ресурса, содержащего по меньшей мере один сценарий; формируют промежуточный код (англ. bytecode) выбранного сценария, где промежуточный код представляет собой совокупность команд сценария (англ. opcode), состоящую по меньшей мере из одной команды сценария, содержащейся в выбранном сценарии; вычисляют хэш-сумму от сформированного промежуточного кода; выбирают из базы данных хэш-сумм по меньшей мере одну группу, в которой по меньшей мере одна хэш-сумма схожа с вычисленной хэш-суммой, где схожесть двух хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных двух хэш-сумм установленному пороговому значению схожести хэш-сумм, и вычисленную степень схожести указанных двух хэш-сумм, при этом выбранная группа содержит по меньшей мере одну хэш-сумму, коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных двух хэш-сумм установленному пороговому значению схожести хэш-сумм, коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга; определяют индекс группы по меньшей мере для одной выбранной группы на основании коэффициента компактности группы, коэффициента доверия групп, содержащихся в выбранной на предыдущем этапе группе, и степени схожести хэш-сумм, вычисленной на предыдущем этапе, при этом индекс группы, указывает на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы; выбирают из базы данных шаблонов вердиктов по меньшей мере один шаблона вердикта в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным на этапе д), где схожесть двух индексов группы определяется на основании соответствия вычисленной степени схожести указанных индексов группы установленному пороговому значению схожести индексов группы, и вычисленную степень схожести этих индексов группы, при этом выбранный шаблон вердикта содержит по меньшей мере один индекс группы, указывающий на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы, коэффициент доверия шаблона вердикта, указывающий на то, сколько сценариев, использованных для формирования групп, по которым были определены индексы группы из шаблона вердикта, содержат данные, предназначенные для осуществления фишинга; выносят решение о том, является ли сценарий, выбранный на предыдущем этапе, фишинговым на основании соответствия установленному пороговому значению фишинга по меньшей мере одного коэффициента доверия шаблона вердикта, содержащегося в выбранном на предыдущем этапе шаблоне вердикта и по меньшей мере одной степени схожести индексов группы, вычисленной на предыдущем этапе.
В другом частном случае реализации способа в качестве сетевого ресурса выступает по меньшей мере интернет-страница, письмо электронной почты, сообщение системы мгновенного обмена сообщениями.
Еще в одном случае реализации способа хэш-сумма вычисляется по меньшей мере путем вычисления нечетких хэш-сумм (англ. fuzzy hash), нечеткого поиска с индексацией (англ. fuzzy searching).
В другом частном случае реализации способа степень схожести хэш-сумм вычисляется по меньшей мере путем сравнения нечетких хэш-сумм, вычисления метрик (англ. similarity metric) для нечеткого поиска с индексацией.
Еще в одном случае реализации способа коэффициент компактности группы вычисляется по меньшей мере путем поиска минимальной степень схожести среди всех пар хэш-сумм, содержащихся в группе, вычисления меры центральной тенденции (англ. central tendency) от степеней схожести по меньшей мере двух пар хэш-сумм, содержащихся в группе.
В другом частном случае реализации способа коэффициент доверия группы, вычисляется путем определения значения в пределах от 0, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются фишинговыми, до 1, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются доверенными.
Еще в одном случае реализации способа индекс группы представляет собой пару чисел, где первое число вычисляется как произведение коэффициента компактности группы и степени схожести хэш-сумм группы, а второе число вычисляется как произведение коэффициента доверия группы и степени схожести группы.
В другом частном случае реализации способа степень схожести индексов группы вычисляется путем нахождения скалярного произведения многомерных векторов, где в качестве элементов многомерных векторов выступают данные, содержащиеся в группе.
Еще в одном случае реализации способа коэффициент доверия шаблона вердикта, вычисляется путем определения значения в пределах от 0, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются фишинговыми, до 1, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются доверенными.
В другом частном случае реализации способа шаблоны вердикта из базы данных шаблонов вердиктов, совокупно включают в себя индексы групп, для определения которых были использованы все группы из базы данных хэш-сумм.
Еще в одном случае реализации способа перед выборкой из базы данных шаблонов вердиктов производится преобразование определенных средством сбора статистики индексов групп по меньшей мере путем дискретного Фурье-преобразования (англ. discrete Fourier transform), вейвлет-преобразования (англ. wavelet transform).
Краткое описание чертежей
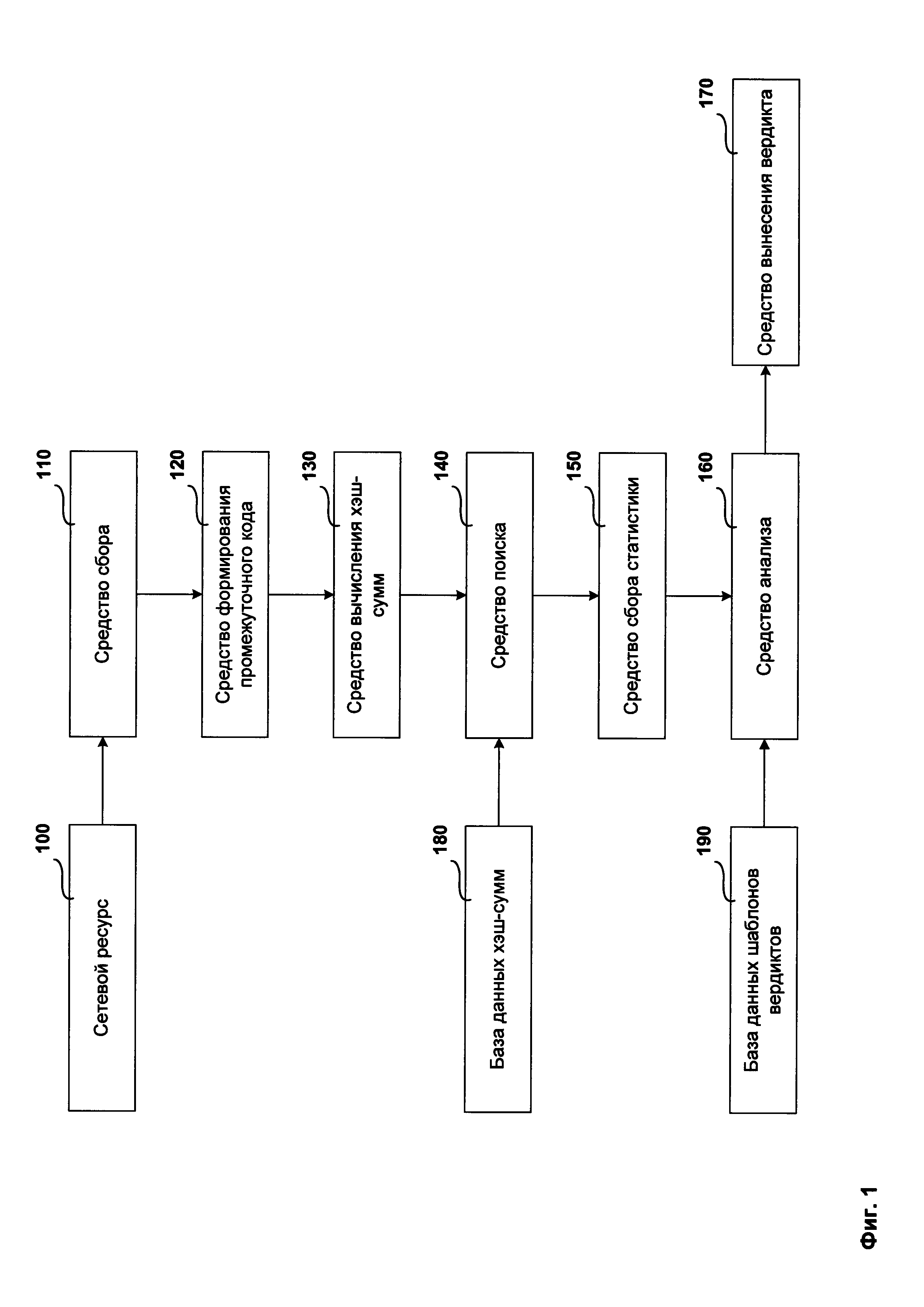
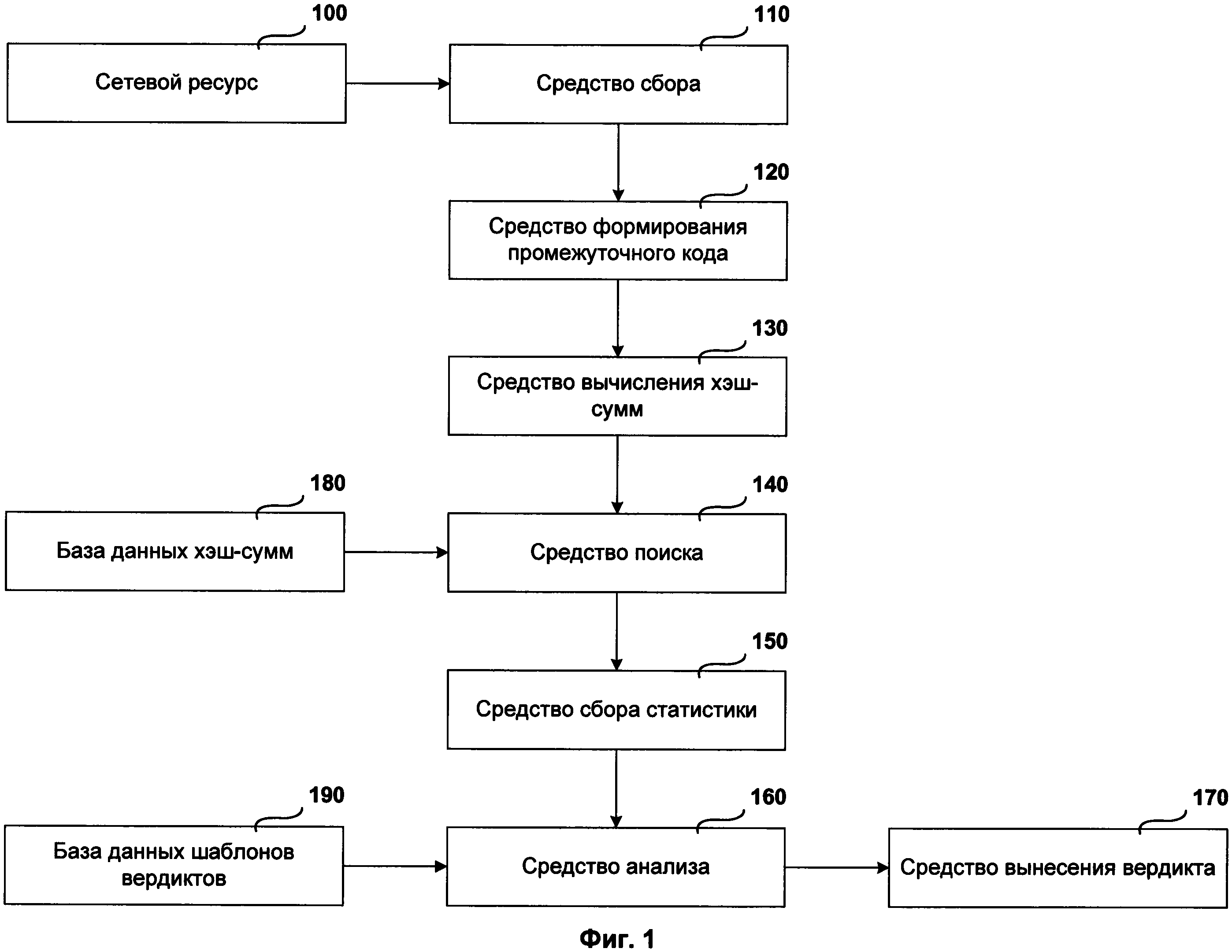
Фиг. 1 представляет структурную схему системы обнаружения фишинговых сценариев.
Фиг. 2 представляет структурную схему способа обнаружения фишинговых сценариев.
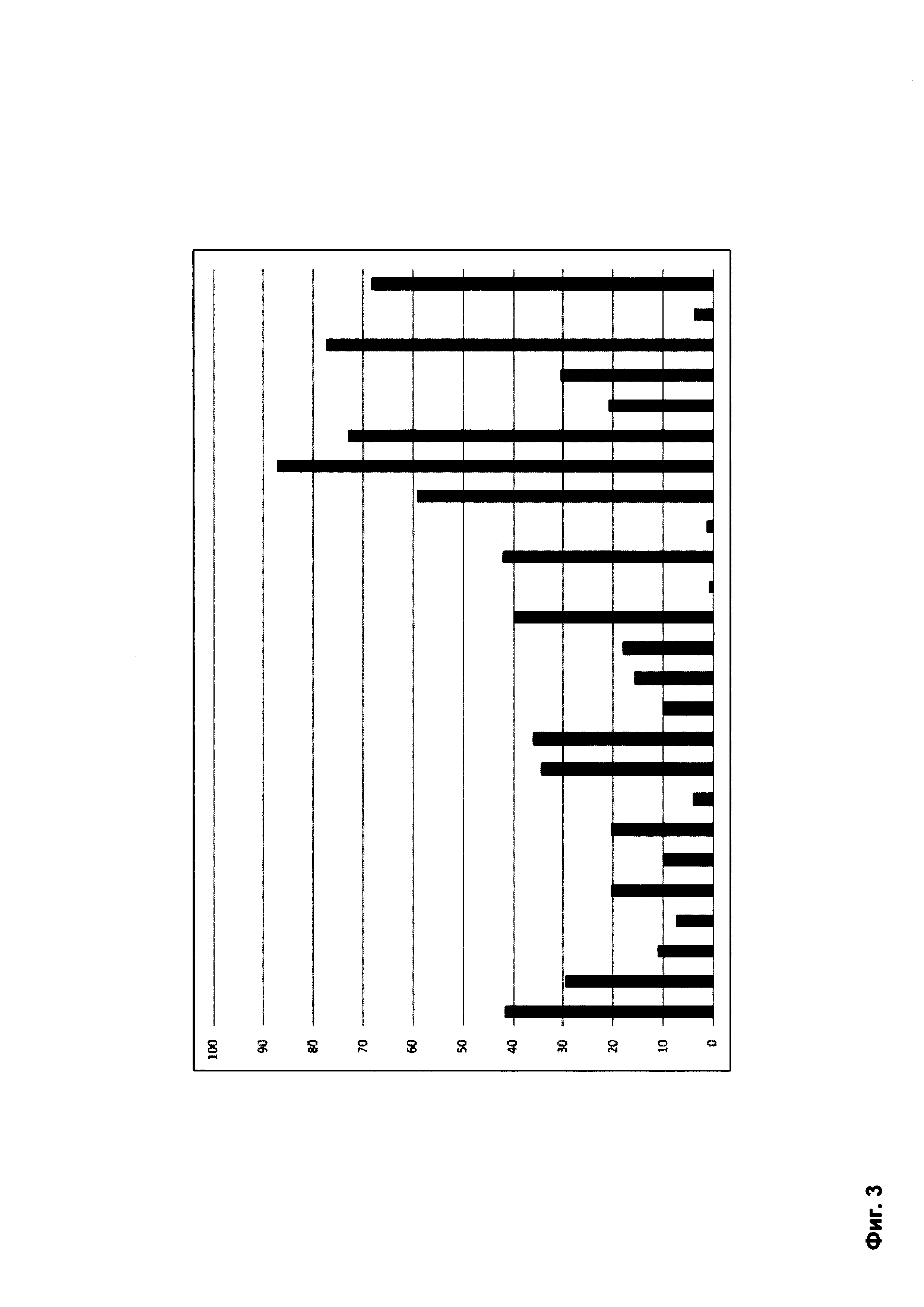
Фиг. 3 представляет собой схему одного из вариантов зависимости коэффициента доверия группы от коэффициента компактности группы.
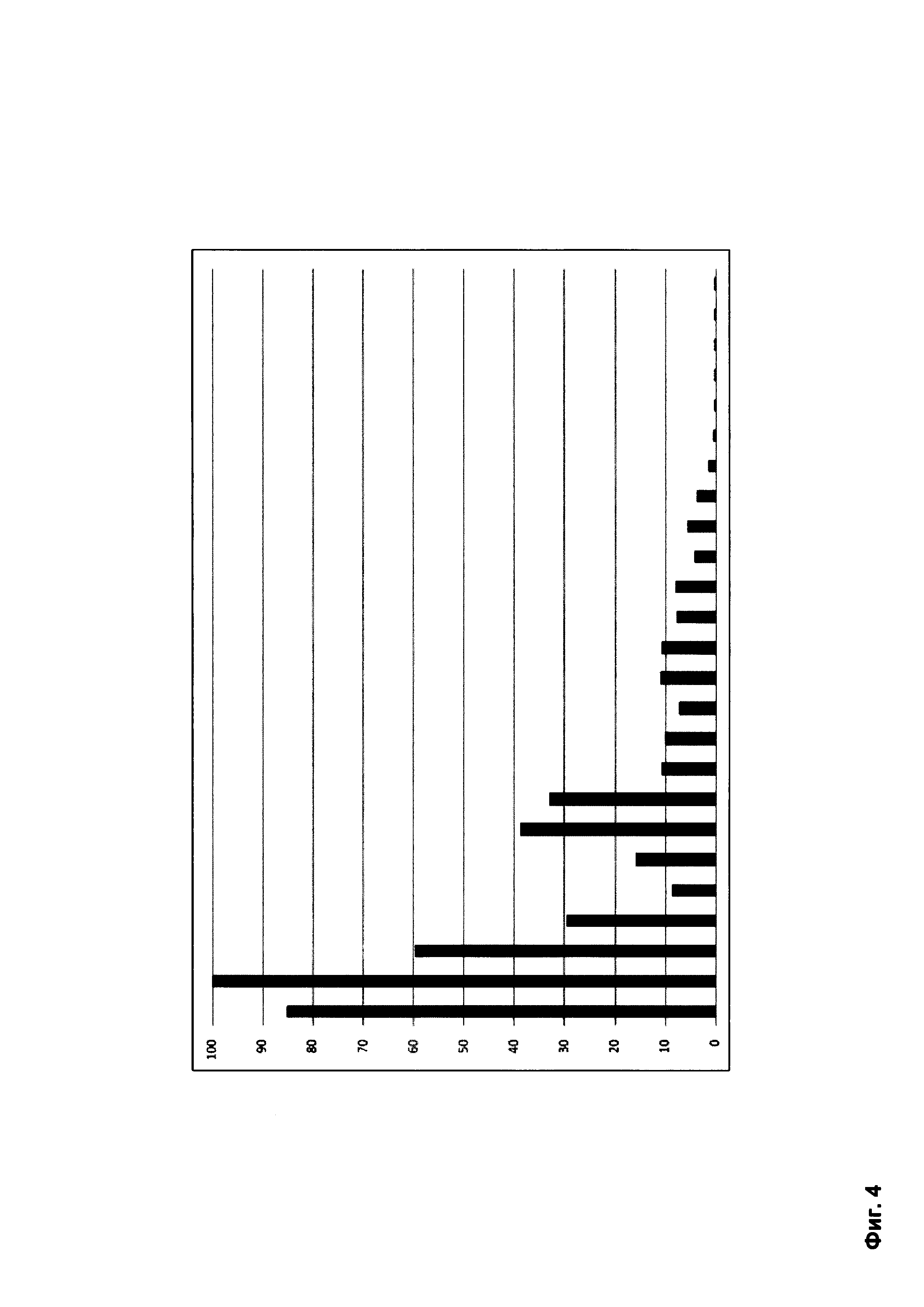
Фиг. 4 представляет собой схему одного из вариантов зависимости коэффициента доверия группы от коэффициента компактности группы после дискретного Фурье-преобразования.
Фиг. 5 представляет собой схему одного из вариантов схожести двух зависимостей коэффициента доверия группы от коэффициента компактности группы.
Фиг. 6 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
Введем ряд определений и понятий, которые будут использоваться при описании вариантов осуществления изобретения.
Фишинговый сценарий - сценарий (англ. script), содержащий данные, используемые для фишинга, и способный нанести вред компьютеру или данным пользователя компьютера. В качестве нанесенного вреда может выступать неправомерный доступ к ресурсам компьютера, в том числе к данным, хранящимся на компьютере, с целью хищения, а также неправомерное использование ресурсов, в том числе для хранения данных, проведения вычислений и т.п.
Доверенный сценарий - сценарий, который не наносит вреда компьютеру или его пользователю. Доверенным сценарием может считаться сценарий, разработанный доверенным производителем ПО, загруженный из доверенного источника (например, сайт, занесенный в базу данных доверенных сайтов) или сценарий, идентификатор которого (например, MD5 файла сценария) хранится в базе данных доверенных сценариев. Идентификатор производителя, например, цифровой сертификат, может также храниться в базе данных доверенных сценариев.
Фиг. 1 представляет структурную схему системы обнаружения фишинговых сценариев.
Структурная схема системы обнаружения фишинговых сценариев состоит из сетевого ресурса 100, средства сбора 110, средства формирования промежуточного кода 120, средства вычисления хэш-сумм 130, средства поиска 140, средства сбора статистики 150, средства анализа 160, средства вынесения вердикта 170, базы данных хэш-сумм 180 и базы данных шаблонов вердиктов 190.
В качестве сетевого ресурса 100 может выступать:
- интернет-страница;
- письмо электронной почты;
- сообщение системы мгновенного обмена сообщениями.
Средство сбора 110 предназначено для:
- выборки по меньшей мере одного сценария из сетевого ресурса 100, содержащего по меньшей мере один сценарий;
- и передачи выбранного сценария средству формирования промежуточного кода 120;
В одном из вариантов реализации сценарии могут выбираться из сетевых ресурсов, ссылки на которые были найденные в других сценариях (например, JavaScript сценарий может быть выбран по ссылке, расположенной в другом JavaScript сценарии в виде, 'document.getElementById(''new_tag'').src=''new_script.js''').
Средство формирования промежуточного кода 120 предназначено для:
- формирования промежуточного кода (англ. bytecode) выбранного сценария, где промежуточный код представляет собой совокупность команд сценария (англ. opcode), состоящую по меньшей мере из одной команды сценария, содержащейся в выбранном сценарии;
- и передачи сформированного промежуточного кода средству вычисления хэш-сумм 130;
В одном из вариантов реализации промежуточный код выбранного сценария формируется следующим способом:
- из сценария выделяется последовательность из всех команд сценария;
- часть команд сценария, не реализующих заданный функционал (например, вывод информации на экран, переход по гиперссылкам, загрузка изображений и т.д.) удаляется из выделенной последовательности;
- оставшиеся в выделенной последовательности команды сценария объединяются в группы команд, содержащие по меньшей мере по одной команде сценария (например, последовательность команд сценария, отвечающих за вывод информации на экран и загрузки изображений, может объединяться в одну группу);
- каждой команде сценария или группе команд сценария ставится в соответствие уникальное двухбайтовое значение;
- получившая последовательность двухбайтовых значений представляет собой сформированный промежуточный код.
Средство вычисления хэш-сумм 130 предназначено для:
- вычисления хэш-суммы от сформированного промежуточного кода;
- и передачи вычисленной хэш-суммы средству поиска 140;
Хэш-сумма может вычисляться по меньшей мере путем:
- вычисления нечетких хэш-сумм (англ. fuzzy hash), где нечеткая хэш-сумма от данных представляет собой набор хэш-сумм, вычисленных от разных областей данных, по которым вычисляется нечеткая хэш-сумма;
- нечеткого поиска с индексацией (англ. fuzzy searching), представляющего собой технологию поиска элемента в множестве с использованием структур данных (элементы евклидового пространства, древовидного пространства и т.д.), позволяющую вычислять расстояния между элементами множества (представляющую собой хэш-сумму) и проводить быстрый поиск ближайшего элемента множества к элементу, по которому производится поиск, с малым числом сравнений в любых пространствах.
Средство поиска 140 предназначено для:
- выборки из базы данных хэш-сумм 180 по меньшей мере одной группы хэш-сумм, в которой по меньшей мере одна хэш-сумма схожа с вычисленной хэш-суммой, и вычисленной степени схожести этих хэш-сумм;
- и передачи выбранных группы и степени схожести хэш-сумм средству сбора статистики 150;
Степень схожести хэш-сумм может вычисляться по меньшей мере путем:
- сравнения нечетких хэш-сумм, представляющего собой вычисление численного значения, характеризующего схожесть данных для которых были рассчитаны хэш-суммы;
- вычисления метрик для нечеткого поиска с индексацией (англ. fuzzy searching metric), представляющего собой вычисление расстояния между искомым и найденным элементами множества, по которому производится поиск.
Средство сбора статистики 150 предназначено для:
- вычисления индекса группы по меньшей мере для одной выбранной группы на основании коэффициента компактности группы, коэффициента доверия групп и степени схожести хэш-сумм, полученных от средства поиска 140, где индекс группы указывает на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы;
- и передачи определенного индекса группы средству анализа 160.
В одном из вариантов реализации индекс группы может представлять собой пару чисел {x,y}, характеризующую собой элемент в зависимости коэффициента доверия группы от коэффициента компактности группы (как это показано на Фиг. 3), где компонента {х} представляет собой произведение коэффициента компактности группы и степени схожести хэш-сумм группы, а компонента {y} представляет собой произведение коэффициента доверия группы и степени схожести группы.
Перед выборкой из базы данных шаблонов вердиктов 190 может производиться преобразование определенных средством сбора статистики 150 индексов групп (как это показано на Фиг. 4) по меньшей мере путем:
- дискретного Фурье-преобразования (англ. discrete Fourier transform);
- вейвлет-преобразования (англ. wavelet transform).
В результате такого преобразования индексы групп с более высоким коэффициентом компактности группы и более высоким коэффициентом доверия группы, как более значимые, будут перемещены в левую сторону зависимости, что должно повысить средству анализа 150 точность сравнения определенной и выбранной последовательностей.
Средство анализа 160 предназначено для:
- выборки из базы данных шаблонов вердиктов 190 по меньшей мере одного шаблона вердикта в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным средством сбора статистики 150, и вычисленной степени схожести этих индексов группы, где схожесть двух индексов группы определяется соответствием их вычисленной степени схожести установленному пороговому значению;
- и передачи выбранных шаблона вердикта и степени схожести индексов группы средству вынесения вердикта 170;
Степень схожести индексов группы может вычисляться путем нахождения скалярного произведения многомерных векторов, где в качестве элементов многомерных векторов выступают данные, содержащиеся в группе (как это показано на Фиг. 5).
Средство вынесения вердикта 170 предназначено для:
- вынесения решения о том, является ли сценарий, выбранный средством сбора 110, фишинговым на основании соответствия по меньшей мере одного коэффициента доверия шаблона вердикта и по меньшей мере одной степени схожести индексов группы, полученных от средства анализа 160, установленному пороговому значению.
В одном из вариантов реализации вынесение решения о том, является ли сценарий, выбранный средством сбора 110, фишинговым, осуществляется следующим образом:
- для каждой полученной пары коэффициента доверия шаблона вердикта и степени схожести индексов группы вычисляется их произведение;
- находится наименьшее из полученных произведений и проверяется, не превышает ли оно установленное пороговое значение;
- если описанное выше условие выполняется, то сценарий, выбранный средством сбора 110, признается фишинговым.
База данных хэш-сумм 180 предназначена для:
- хранения по меньшей мере одной группы, представляющей собой набор данных, включающий в себя:
○ по меньшей мере одну хэш-сумму;
○ коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется соответствием их вычисленной степени схожести установленному пороговому значению;
○ коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга;
Коэффициент компактности группы может вычисляться по меньшей мере путем:
- поиска минимальной степень схожести среди всех пар хэш-сумм, содержащихся в группе;
- вычисления меры центральной тенденции (англ. central tendency) от степеней схожести по меньшей мере двух пар хэш-сумм, содержащихся в группе.
Коэффициент доверия группы может вычисляться путем определения значения в пределах от 0, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются фишинговыми, до 1, означающего, что все сценарии, используемые для формирования хэш-сумм из данной группы, являются доверенными.
База данных шаблонов вердиктов 190 предназначена для:
- хранения по меньшей мере одного шаблона вердикта, представляющего собой набор данных, включающий в себя
○ по меньшей мере один индекс группы, указывающий на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы;
○ коэффициент доверия шаблона вердикта, указывающий на то, сколько сценариев, использованных для формирования групп, по которым были определены индексы группы из шаблона вердикта, содержат данные, предназначенные для осуществления фишинга;
Коэффициент доверия шаблона вердикта может вычисляться путем определения значения в пределах от 0, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются фишинговыми, до 1, означающего, что все сценарии, использованные для формирования групп, по которым были определены индексы группы из шаблона вердикта, являются доверенными.
Шаблоны вердикта из базы данных шаблонов вердиктов 190 совокупно могу включать в себя индексы групп, для определения которых были использованы все группы из базы данных хэш-сумм 180.
Рассмотрим работу системы обнаружения фишинговых сценариев на примере обнаружения фишингового сценария, содержащегося на интернет-странице сайта http://gimmeyourmoney.com, выдающей себя за легальную интернет-страницу банка http://givemeyourmoney.com.
Пользователь с помощью браузера заходит на сетевой ресурс 100, в качестве которого выступает интернет-страница сайта http://gimmeyourmoney.com. Средство перехвата 110 в качестве которого выступает поисковый робот (англ. web crawler), выбирает с указанного сайта сценарии, которые так или иначе связаны с просматриваемой пользователем страницей. В качестве выбираемых сценариев могут выступать не только сценарии, содержащиеся на самой просматриваемой странице, но и на страницах, ссылки на которые содержатся на просматриваемой странице, и передает выбранные сценарии средству формирования промежуточного кода 120.
Средство промежуточного кода 120 формирует промежуточный код перехваченного сценария. Для этого
- из выбранного сценария выделяется последовательность из всех команд сценария;
- часть команд сценария, не реализующих заданный функционал (например, вывод информации на экран, переход по гиперссылкам, загрузка изображений и т.д.) удаляется из выделенной последовательности;
- оставшиеся в выделенной последовательности команды сценария объединяются в группы команд, содержащие по меньшей мере по одной команде сценария (например, последовательность команд сценария, отвечающих за вывод информации на экран и загрузки изображений, могут объединяться в одну группу);
- каждой команде сценария или группе команд сценария ставится в соответствие уникальное двухбайтовое значение;
- получившая последовательность двухбайтовых значений представляет собой сформированный промежуточный код.
Средство вычисления хэш-сумм 130 вычисляет от полученного промежуточного кода нечеткую хэш-сумму (например, с помощью open-source алгоритма fuzzyHash), представляющую собой набор данных, содержащий размер блоков, на которые разбивается промежуточный код, и хэш-сумм от этих блоков. После чего передает вычисленную хэш-сумму средству поиска 140.
Средство поиска 140 осуществляет выборку из базы данных хэш-сумм 180 групп хэш-сумм, где группа представляет собой набор данных, включающих в себя:
- заранее вычисленные хэш-суммы от фишинговых сценариев;
- коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется соответствием их вычисленной степени схожести установленному пороговому значению;
- коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга.
В процессе выборки из базы данных хэш-сумм 180 для хэш-сумм из каждой группы, содержащейся в базе данных хэш-сумм 180, выполняется нечеткое сравнение (англ. fuzzy searching) с хэш-суммой, полученной от средства вычисления хэш-сумм 130. Результатом нечеткого сравнения двух хэш-сумм является число в диапазоне от 0 до 1, выражающее собой, насколько сравниваемые хэш-суммы схожи между собой и называемое степенью схожести двух хэш-сумм (например, схожесть нечетких хэш-сумм, вычисленных от промежуточных кодов сценариев, содержащих 10% отличных друг от друга команд сценария, будет равно 0,9). В случае, когда хотя бы одна хэш-сумма из сравниваемой группы имеет степень схожести с полученной от средства вычисления хэш-сумм 130 выше установленного порога (например, 0,85), считается, что группа найдена, а хэш-сумма, полученная от средства вычисления хэш-сумм 130, принадлежит сравниваемой группе. После чего выбранные группы и определенные степени схожести передаются средству сбора статистики 150. Для собранных сценариев с интернет-страницы сайта http://gimmeyourmoney.com были выбраны группы, содержащие хэш-суммы от сценариев, содержащих функционал:
- для группы #1 - отображение изображений с параметрами, используемыми для отображения логотипов (например, банка) (схожесть 0,98);
- для группы #2 - передача данных из формы ввода пароля на несколько адресов (схожесть 0,95);
- для группы #3 - формирования структуры интернет-страницы идентичной заданному шаблону интернет-страницы банков (схожесть 0,90);
- для группы #4 - обфускация кода, выполняемого при нажатии на кнопку передачи данных из формы ввода пароля (схожесть 0,87).
Выбранные группы передаются средству анализа 160.
Средство анализа 160 осуществляет выборку из базы шаблонов вердиктов 190 шаблоны вердикта в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным средством сбора статистики 150. Схожесть индексов групп определяется следующим образом:
- каждая совокупность индексов групп, представляющая собой совокупность пар {x,y}, где {х} - коэффициент компактности группы, а {y} - коэффициент доверия группы, принимается за многомерный вектор V, где элемент вектора - пара {x,y};
- вычисляется скалярное произведение двух принятых векторов;
- вычисленное скалярное произведение сравнивается с установленным пороговым значением и, если не превышает его, то совокупности индексов групп, из которых были получены описанные выше вектора, считаются схожими.
Для индексов групп, полученных от средства сбора статистики 150, были выбраны следующие шаблоны вердикта:
- шаблон #1 "маскировка под банк": коэффициент доверия шаблона 0.1, степень схожести 0.9;
- шаблон #2 "маскировка под регистрацию": коэффициент доверия шаблона 0.3, степень схожести 0.8.
Выбранные шаблоны вердикта и степени схожести индексов группы передаются средству вынесения вердикта 170.
Средство вынесения вердикта 170 выполняет следующие действия:
- для каждой полученной пары коэффициента доверия шаблона вердикта и степени схожести индексов группы вычисляется их произведение:
○ шаблон #1 "маскировка под банк": 0,1×0,9=0,09;
○ шаблон #2 "маскировка под регистрацию": 0,3×0,8=0,24;
- находится наименьшее из полученных произведений (0,09) и проверяется, не превышает ли оно установленное пороговое значение (0,15);
- поскольку описанное выше условие выполняется, то сценарий, содержащийся на интернет-странице http://gimmeyourmoney.com и выбранный средством сбора 110, признается фишинговым, как и интернет-страница http://gimmeyourmoney.com;
- после вынесения вердикта о нем информируется пользователь.
Поскольку пользователь информирован о том, что интернет-страница http://gimmeyourmoney.com является фишинговой, он не будет указывать на ней свои конфиденциальные данные, а значит будет защищен от такой формы мошенничества, как фишинг.
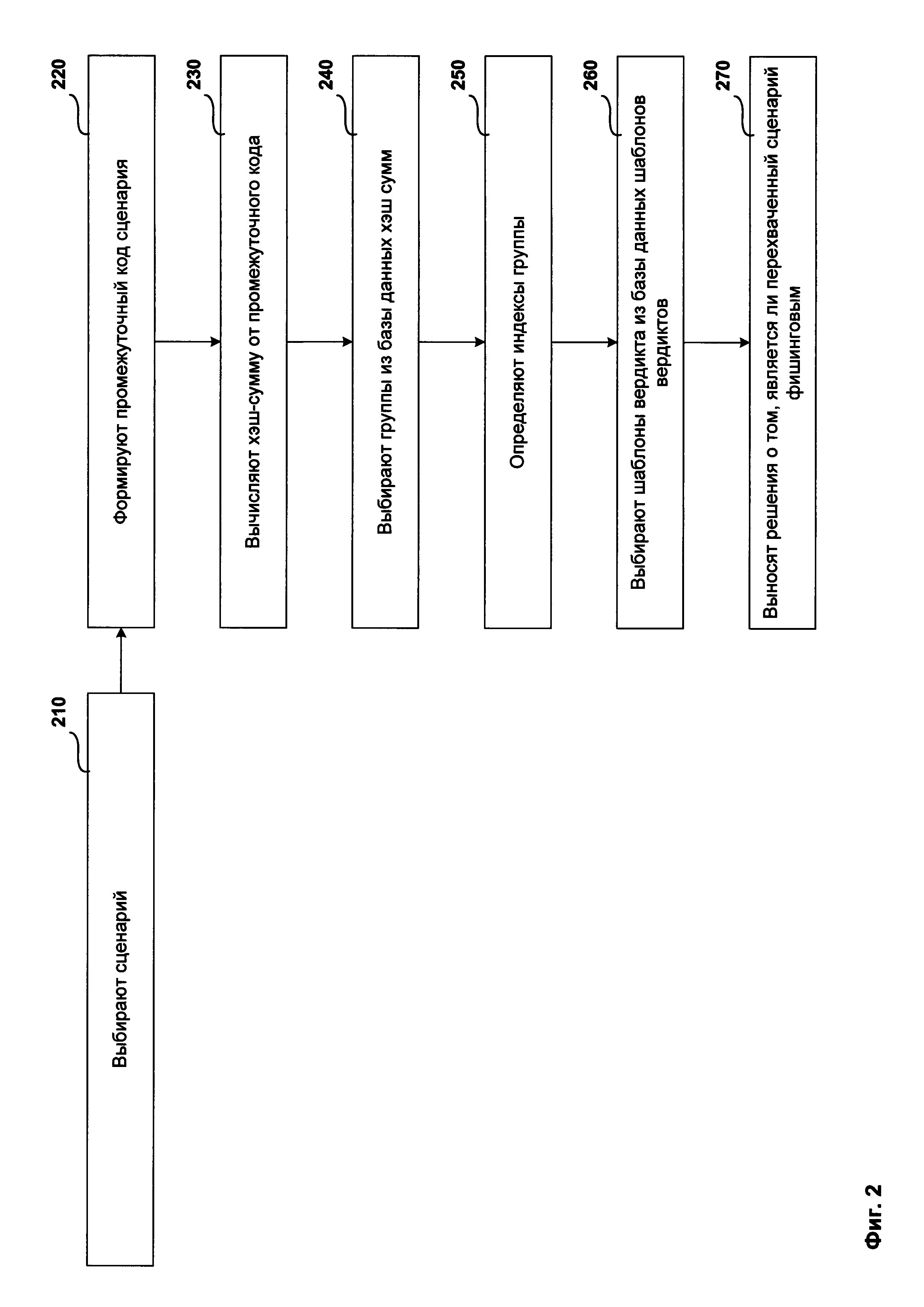
Фиг. 2 представляет пример структурной схемы способа обнаружения фишинговых сценариев.
Структурная схема способа системы обнаружения фишинговых сценариев состоит из этапа, на котором выбирают сценарий 210, этапа, на котором формируют промежуточный код сценария 220, этапа, на котором вычисляют хэш-сумму от промежуточного кода 230, этапа, на котором выбирают группы из базы данных хэш-сумм 240, этапа, на котором вычисляют индексы группы 250, этапа, на котором выбирают шаблоны вердикта из базы данных шаблонов вердиктов 260, этапа, на котором выносят решения о том, является ли перехваченный сценарий фишинговым 270.
На этапе 210 выбирают по меньшей мере один сценарий из сетевого ресурса 100, содержащего по меньшей мере один сценарий.
На этапе 220 формируют промежуточный код (англ. bytecode) выбранного сценария, где промежуточный код представляет собой совокупность команд сценария (англ. opcode), состоящую по меньшей мере из одной команды сценария, содержащейся в выбранном сценарии.
На этапе 230 вычисляют хэш-сумму от сформированного промежуточного кода.
На этапе 240 выбирают из базы данных хэш-сумм 180 по меньшей мере одну группу, в которой по меньшей мере одна хэш-сумма схожа с вычисленной хэш-суммой, где схожесть двух хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных двух хэш-сумм установленному пороговому значению схожести хэш-сумм, и вычисленную степень схожести указанных двух хэш-сумм,
- при этом выбранная группа содержит:
• по меньшей мере одну хэш-сумму;
• коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется на основании соответствия вычисленной степени схожести указанных двух хэш-сумм установленному пороговому значению схожести хэш-сумм,
• коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга.
На этапе 250 определяют индекс группы по меньшей мере для одной выбранной группы на основании коэффициента компактности группы, коэффициента доверия групп, содержащихся в выбранной на этапе 240 группе, и степени схожести хэш-сумм, вычисленной на этапе 240, при этом индекс группы, указывает на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы.
На этапе 260 выбирают из базы данных шаблонов вердиктов 190 по меньшей мере один шаблона вердикта, в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным на этапе 250, где схожесть двух индексов группы определяется на основании соответствия вычисленной степени схожести указанных индексов группы установленному пороговому значению схожести индексов группы, и вычисленную степень схожести этих индексов группы,
- при этом выбранный шаблон вердикта содержит:
• по меньшей мере один индекс группы, указывающий на то, насколько коэффициент доверия группы зависит от коэффициента компактности группы,
• коэффициент доверия шаблона вердикта, указывающий на то, сколько сценариев, использованных для формирования групп, по которым были определены индексы группы из шаблона вердикта, содержат данные, предназначенные для осуществления фишинга.
На этапе 270 выносят решение о том, является ли сценарий, выбранный на этапе 210, фишинговым на основании соответствия установленному пороговому значению фишинга по меньшей мере одного коэффициента доверия шаблона вердикта, содержащегося в выбранном на этапе 260 шаблоне вердикта и по меньшей мере одной степени схожести индексов группы, вычисленной на этапе 260.
Рассмотрим работу системы обнаружения фишинговых сценариев на примере обнаружения фишингового сценария, содержащегося полученном пользователем по электронной почте письмо, выдающее себя за письмо от легальной коммерческой организации "Всемирные скобяные товары".
Пользователь с помощью почтового клиента (например, Microsoft Outlook) заходит на сетевой ресурс 100, представляющий собой почтовый сервер, и получает электронное письмо якобы от коммерческой организации "Всемирные скобяные товары". На этапе 210 средство перехвата 110 в качестве которого выступает встраиваемый модуль почтового клиента (англ. plugin), выбирает из полученного электронного письма сценарии. В качестве выбираемых сценариев могут выступать не только сценарии, содержащиеся в самом электронном письме, но и на интернет-страницах, ссылки на которые содержатся в полученном электронном письме, и передает выбранные сценарии средству формирования промежуточного кода 120.
На этапе 220 средство промежуточного кода 120 формирует промежуточный код перехваченного сценария. Для этого
- из выбранного сценария выделяется последовательность из всех команд сценария;
- часть команд сценария, не реализующих заданный функционал (например, вывод информации на экран, переход по гиперссылкам, загрузка изображений и т.д.) удаляется из выделенной последовательности;
- оставшиеся в выделенной последовательности команды сценария объединяются в группы команд, содержащие по меньшей мере по одной команде сценария (например, последовательность команд сценария, отвечающих за вывод информации на экран и загрузки изображений, может объединиться в одну группу);
- каждой команде сценария или группе команд сценария ставится в соответствие уникальное двухбайтовое значение;
- получившая последовательность двухбайтовых значений представляет собой сформированный промежуточный код.
На этапе 230 средство вычисления хэш-сумм 130 вычисляет от полученного промежуточного кода нечеткую хэш-сумму (например, с помощью open-source алгоритма fuzzyHash), представляющую собой набор данных, содержащий размер блоков, на которые разбивается промежуточный код, и хэш-суммы от этих блоков. После чего передает вычисленную хэш-сумму средству поиска 140.
На этапе 240 средство поиска 140 осуществляет выборку из базы данных хэш-сумм 180 групп хэш-сумм, где группа представляет собой набор данных, включающих в себя:
- заранее вычисленные хэш-суммы от фишинговых сценариев;
- коэффициент компактности группы, указывающий на то, со сколькими хэш-суммами из группы будет схожа вычисленная хэш-сумма, будучи схожей по меньшей мере с одной хэш-суммой из группы, где схожесть двух хэш-сумм определяется соответствием их вычисленной степени схожести установленному пороговому значению;
- коэффициент доверия группы, указывающий на то, сколько сценариев, использованных для формирования хэш-сумм из группы, содержат данные, предназначенные для осуществления фишинга.
В процессе выборки из базы данных хэш-сумм 180 для хэш-сумм из каждой группы, содержащейся в базе данных хэш-сумм 180, выполняется нечеткое сравнение (англ. fuzzy searching) с хэш-суммой, полученной на этапе 230. Результатом нечеткого сравнения двух хэш-сумм является число в диапазоне от 0 до 1, выражающее собой, насколько сравниваемые хэш-суммы схожи между собой и называемое степенью схожести двух хэш-сумм (например, схожесть нечетких хэш-сумм, вычисленных от промежуточных кодов сценариев, содержащих 10% отличных друг от друга команд сценария, будет равно 0,9). В случае, когда хотя бы одна хэш-сумма из сравниваемой группы имеет степень схожести с полученной на этапе 230 выше установленного порога (например, 0,85), считается, что группа найдена, а хэш-сумма, полученная на этапе 230, принадлежит сравниваемой группе. После чего выбранные группы и определенные степени схожести передаются средству сбора статистики 150. На этапе 250 для выбранных сценариев из электронного письма были выбраны группы, содержащие хэш-суммы от сценариев, содержащих функционал:
- для группы #1 - отображение изображений с параметрами, используемыми для отображения логотипов (например, банка) (схожесть 0,9);
- для группы #2 - передача данных из формы ввода на несколько адресов (схожесть 0,99);
Данные из выбранных групп передаются средству анализа 160.
На этапе 260 средство анализа 160 осуществляет выборку из базы шаблонов вердиктов 190 шаблона вердикта, в котором по меньшей мере один индекс группы схож с по меньшей мере одним индексом группы, определенным на этапе 250. Схожесть индексов групп определяется следующим образом:
- каждая совокупность индексов групп, представляющая собой совокупность пар {x,y}, где {x} - коэффициент компактности группы, а {y} - коэффициент доверия группы, принимается за многомерный вектор V, где элемент вектора - пара {x,y};
- вычисляется скалярное произведение двух принятых векторов;
- вычисленное скалярное произведение сравнивается с установленным пороговым значением и, если не превышает его, то совокупности индексов групп, из которых были получены описанные выше вектора, считаются схожими.
Для индексов групп, полученных от средства сбора статистики 150, были выбраны следующие шаблоны вердикта:
- шаблон #1 "маскировка под регистрацию": коэффициент доверия шаблона 0.05, степень схожести 0.97.
Выбранные шаблоны вердикта и степени схожести индексов группы передаются средству вынесения вердикта 170.
На этапе 270 средство вынесения вердикта 170 выполняет следующие действия:
- для полученной пары коэффициента доверия шаблона вердикта и степени схожести индексов группы вычисляется их произведение:
○ шаблон #2 "маскировка под регистрацию": 0,05×0,97=0,0485;
- проверяется, не превышает ли полученное значение установленное пороговое значение (0,1);
- поскольку описанное выше условие выполняется, то сценарий, содержащийся в электронном письме и выьранных на этапе 210, признается фишинговым;
- после вынесения вердикта о нем информируется пользователь.
Поскольку пользователь информирован о том, что полученное электронное письмо является фишинговой, он не будет указывать в нем свои конфиденциальные данные, а значит будет защищен от такой формы мошенничества, как фишинг.
Фиг. 3 представляет собой схему одного из вариантов зависимости коэффициента доверия группы от коэффициента компактности группы.
Фиг. 4 представляет собой схему одного из вариантов зависимости коэффициента доверия группы от коэффициента компактности группы после дискретного Фурье-преобразования.
Фиг. 5 представляет собой схему одного из вариантов схожести двух зависимостей коэффициента доверия группы от коэффициента компактности группы.
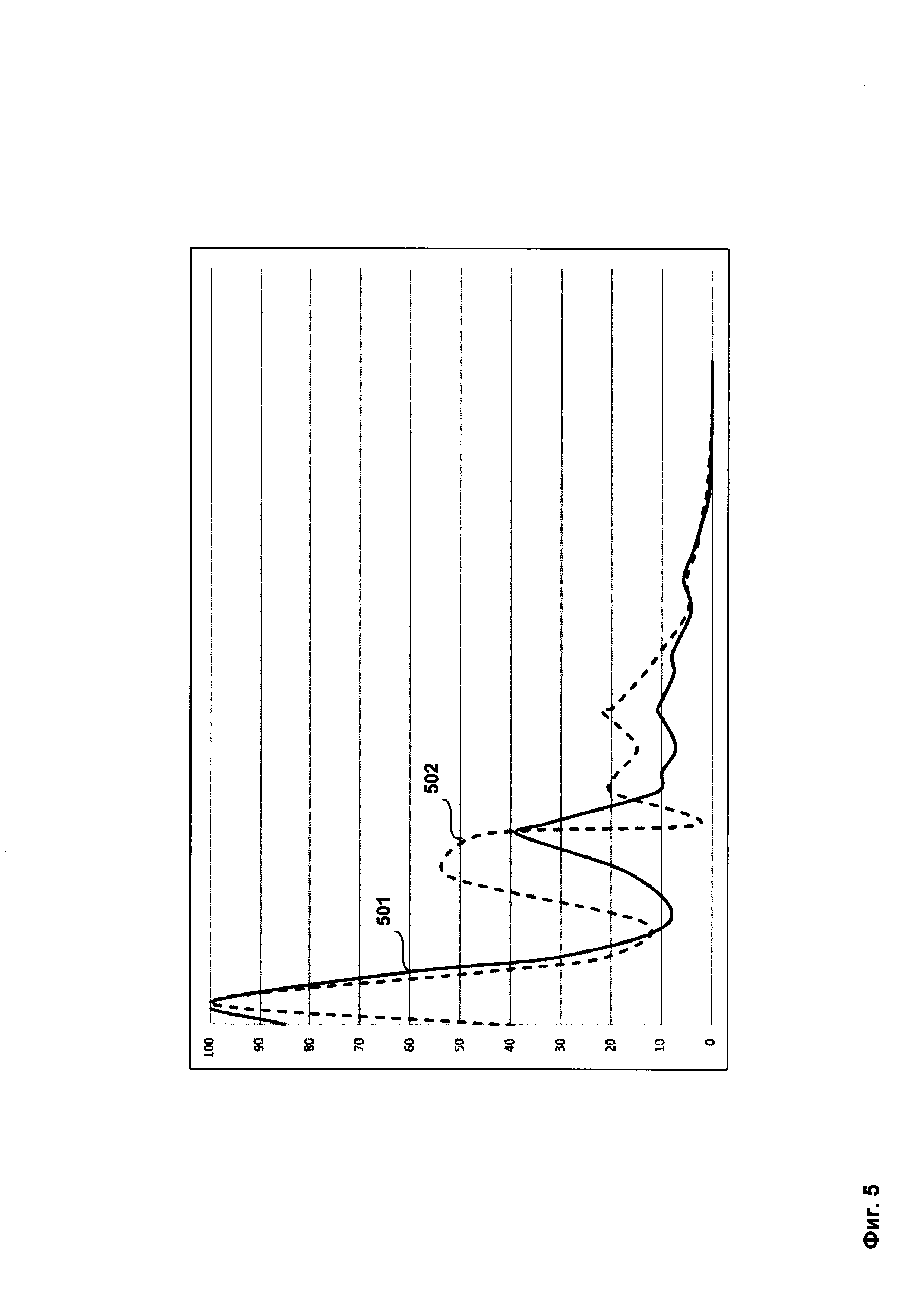
Поскольку зависимость коэффициента доверия группы от коэффициента компактности группы может быть представлена в виде дискретного сигнала, как это показано на Фиг. 3, то для более точного сравнения двух зависимостей и определения степени схожести можно предварительно провести дискретное Фурье-преобразование зависимости коэффициента доверия группы от коэффициента компактности группы, в результате которого амплитудное представление сигнала-зависимости будет преобразовано в частотное представление как это показано на Фиг. 4. Таким образом часто используемые индексы групп будут собраны ближе к началу зависимости, а редко используемые будут собраны дальше от начала зависимости и могут быть удалены, поскольку слабо влияют на результат сравнения зависимостей.
На Фиг. 5 показано сравнение совокупности индексов групп 501, образующих зависимость коэффициента доверия группы от коэффициента компактности группы, полученной от средства сбора статистики 150, и совокупности индексов групп 502, образующих зависимость коэффициента доверия группы от коэффициента компактности группы, полученных их базы данных шаблонов вердиктов 190.
Сравнение происходит следующим образом:
- каждая совокупность индексов групп, представляющая собой совокупность пар {x,y}, где {х} - коэффициент компактности группы, а {y} - коэффициент доверия группы, принимается за многомерный вектор V, где элемент вектора - пара {x,y};
- вычисляется скалярное произведение двух принятых векторов;
- вычисленное скалярное произведение сравнивается с установленным пороговым значением и если не превышает его, то совокупности индексов групп, из которых были получены описанные выше вектора, считаются схожими.
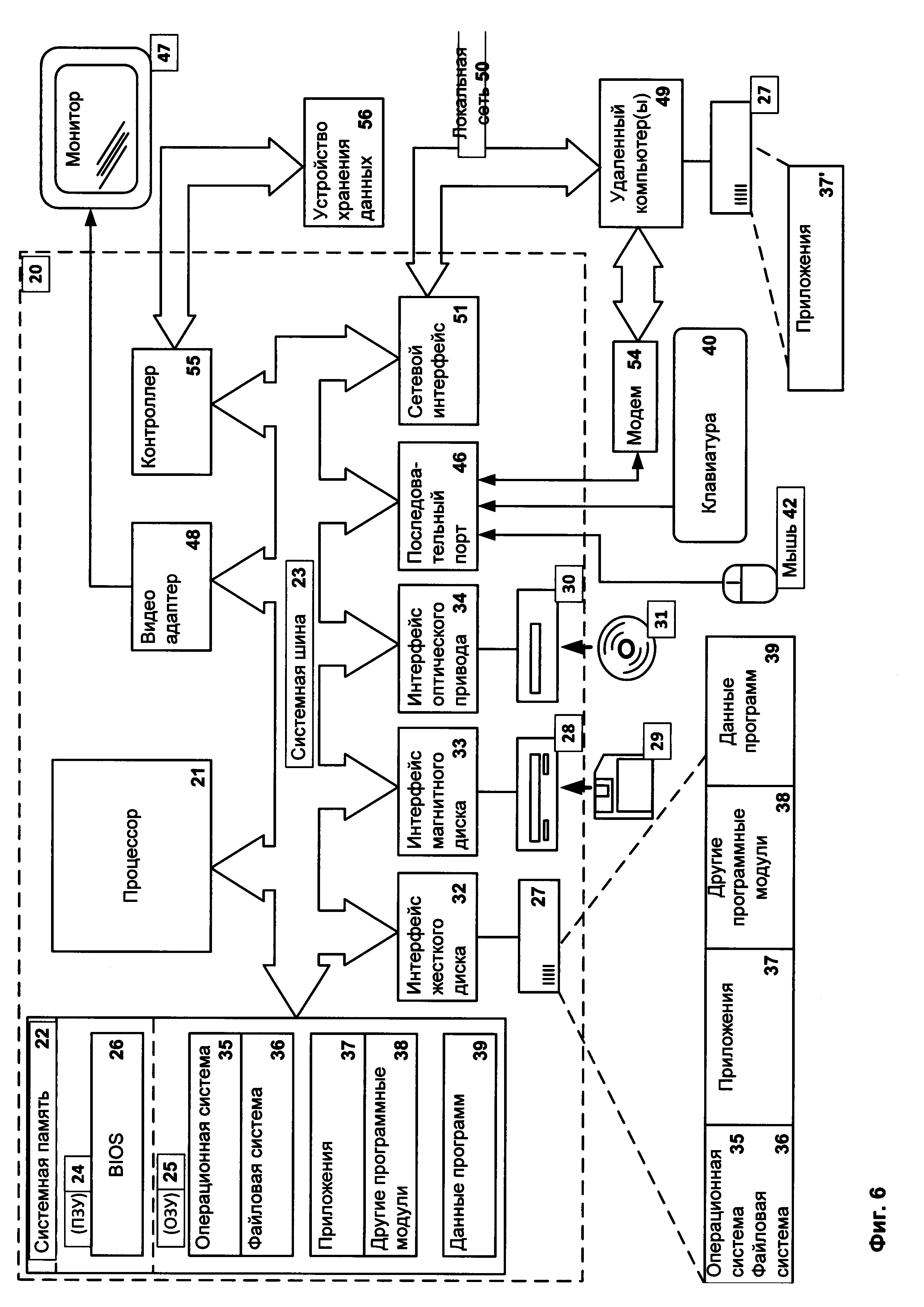
Фиг. 6 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 6. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
Способ автоматической установки приложения без участия человека
Система и способ обнаружения вредоносных файлов определенного типа
Способ исключения процессов из антивирусной проверки на основании данных о файле
Способ выполнения кода в режиме гипервизора
Система и способ выполнения запросов процессов операционной системы к файловой системе
Система и способ оптимизации антивирусной проверки файлов
Система и способ блокировки выполнения сценариев
Способ устранения уязвимостей роутера
Способ передачи антивирусных записей, используемых для обнаружения вредоносных файлов
Система и способ шифрования при передаче веб-страницы приложению пользователя
Способ автоматической установки приложения без участия человека
Система и способ обнаружения вредоносных файлов определенного типа
Способ исключения процессов из антивирусной проверки на основании данных о файле
Способ выполнения кода в режиме гипервизора
Система и способ выполнения запросов процессов операционной системы к файловой системе
Система и способ оптимизации антивирусной проверки файлов
Система и способ блокировки выполнения сценариев
Способ устранения уязвимостей роутера
Способ передачи антивирусных записей, используемых для обнаружения вредоносных файлов
Система и способ шифрования при передаче веб-страницы приложению пользователя

