Результат интеллектуальной деятельности: ПРОЦЕССОР, СПОСОБ, СИСТЕМА И ИЗДЕЛИЕ ДЛЯ ВЕКТОРНОГО ИНДЕКСИРОВАННОГО ДОСТУПА К ПАМЯТИ ПЛЮС АРИФМЕТИЧЕСКОЙ И/ИЛИ ЛОГИЧЕСКОЙ ОПЕРАЦИИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Варианты осуществления, описанные в данном документе, в основном, относятся к микропроцессорам. В частности, варианты осуществления, описанные в данном документе, в основном, относятся к микропроцессорам, обеспечивающим доступ к памяти в ответ на инструкции.
Уровень техники
Процессоры обычно используются для выполнения инструкций для доступа к системной памяти. Например, процессоры могут выполнять инструкции загрузки для загрузки или считывания данных из системной памяти и/или инструкции сохранения для хранения или записи данных в системной памяти.
Некоторые процессоры используются для выполнения векторных индексированных инструкций загрузки (например, для загрузки векторных элементов с использованием векторных индексов). Эти векторные индексированные инструкции загрузки также упоминаются в данной области техники как векторные инструкции сбора или просто gather-инструкции. Intel® справочник по программированию по усовершенствованному вектору расширения, справочный номер документа 319433-011, опубликовано в июне 2011, описывает несколько векторных gather-инструкций (VGATHER). Примеры включают в себя VGATHERDPD, VGATHERQPD, VGATHERDPS, VGATHERQPS, VPGATHERDD, VPGATHERQD, VPGATHERDQ и VPGATHERQQ. Эти инструкции сбора могут использоваться для сбора или загрузки множества элементов данных из памяти с использованием множества соответствующих индексов памяти.
Некоторые процессоры используются для выполнения векторных индексированных инструкций для сохранения данных (например, сохранить векторные элементы с использованием векторных индексов). Эти векторные индексированные инструкции на сохранение данных также упоминаются в данной области техники, как векторные инструкции разброса или просто scatter-инструкции. Intel® справочник по программированию по архитектуре расширения набора инструкций, справочный номер документа 319433-015, опубликован в июле 2013, описывает несколько векторных scatter-инструкций (VSCATTER). Эти инструкции разброса могут использоваться для разнесенияпо разным участкам памяти или хранения нескольких элементов данных из исходного операнда в системную память, используя множество соответствующих индексов памяти.
Краткое описание чертежей
Изобретение описывается со ссылкой на прилагаемые чертежи, иллюстрирующие варианты осуществления, а именно:
Фиг. 1 представляет собой блок-схему варианта осуществления процессора, который выполнен с возможностью выполнять одну или более инструкций векторного индексированного доступа к памяти плюс арифметическую и/или логическую операцию.
Фиг. 2 представляет блок-схему варианта осуществления устройства обработки инструкции, которое выполнено с возможностью выполнять одну или более инструкций векторного индексированного доступа к памяти плюс арифметическую и/или логическую операцию.
Фиг. 3 представляет собой блок-схему, иллюстрирующую один вариант осуществления структуры расположения исполнительного блока в процессоре.
Фиг. 4 является блок-схемой алгоритма варианта осуществления способа обработки варианта осуществления векторной индексированной инструкции загрузки плюс арифметической и/или логической операции плюс хранение.
Фиг. 5 представляет собой блок-схему, иллюстрирующую вариант осуществления векторной индексированной инструкции загрузки плюс арифметической и/или логической операции плюс операции сохранения.
Фиг. 6 представляет собой блок-схему, иллюстрирующую вариант осуществления замаскированной векторной индексированной инструкции загрузки плюс арифметической и/или логической операции плюс операции сохранения.
Фиг. 7 представляет блок-схему, иллюстрирующую вариант осуществления векторной индексированной инструкции загрузки плюс арифметической и/или логической операции.
Фиг. 8 является блок-схемой варианта осуществления формата для векторной индексированной инструкции загрузки плюс арифметической и/или логической операции плюс инструкции сохранения.
Фиг. 9 является блок-схемой варианта осуществления формата для векторной индексированной инструкции загрузки плюс арифметической и/или логической операции.
Фиг. 10 представляет собой блок-схему примера варианта осуществления конкретного подходящего набора упакованных данных регистров.
Фиг. 11 представляет собой блок-схему примера варианта осуществления конкретного подходящего набора упакованных данных операции маскирования регистров.
Фиг. 12 является схемой, иллюстрирующей пример варианта осуществления конкретных подходящих 64-разрядных упакованных данных операции маскирования регистров.
Фиг. 13А является блок-схемой, иллюстрирующей универсальный векторный дружественный формат инструкции и шаблоны инструкции класса А согласно вариантам осуществления изобретения.
Фиг. 13В является блок-схемой, иллюстрирующей универсальный векторный дружественный формат инструкции и шаблоны инструкции класса В согласно вариантам осуществления изобретения.
Фиг. 14А представляет собой блок-схему, иллюстрирующую примерный конкретный векторный дружественный формат инструкции согласно вариантам осуществления изобретения.
Фиг. 14В является блок-схемой, иллюстрирующей поля конкретного векторного дружественного формата инструкции, образующие полное поле кода операции согласно одному варианту осуществления изобретения.
Фиг. 14С является блок-схемой, иллюстрирующей поля конкретного векторного дружественного формата инструкции, образующие поле индекса регистра согласно одному варианту осуществления изобретения.
Фиг. 14D является блок-схемой, иллюстрирующей поля конкретного векторного дружественного формата инструкции, образующие поле операции приращения согласно одному варианту осуществления изобретения.
Фиг. 15 представляет блок-схему архитектуры регистра согласно одному варианту осуществления изобретения.
Фиг. 16А представляет собой блок-схему, иллюстрирующую оба примерный упорядоченный конвейер и примерный порядок переименования регистров, конвейер с изменением выполнения последовательности команд согласно вариантам осуществления изобретения.
Фиг. 16В показывает ядро процессора, включающее в себя блок предварительной обработки данных, соединенный с блоком механизма исполнения, и оба соединены с блоком памяти.
Фиг. 17А является блок-схемой одноядерного процессора, подключенного к накристальному межсетевому соединению и с ее локальным подмножеством кэша уровня 2 (L2), согласно вариантам осуществления изобретения.
Фиг.17В представляет собой развернутый вид части ядра процессора, показанного на фиг. 17А, согласно вариантам осуществления изобретения.
Фиг. 18 представляет собой блок-схему процессора, который может иметь более одного ядра, может иметь интегрированный контроллер памяти и может иметь интегрированный графический блок согласно вариантам осуществления изобретения.
Фиг. 19 показывает блок-схему системы в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 20 показывает блок-схему первого более конкретного примера системы в соответствии с вариантом осуществления настоящего изобретения.
Фиг. 21 показывает блок-схему второго более конкретного примера системы в соответствии с вариантом осуществления настоящего изобретения.
Фиг. 22 показывает блок-схему SoC в соответствии с вариантом осуществления настоящего изобретения.
Фиг. 23 представляет собой блок-схему, на которой представлена сравнительная информация относительно использования преобразователя инструкций для преобразования двоичных инструкций в исходном наборе инструкций в двоичные инструкции в целевом наборе инструкций согласно вариантам осуществления изобретения.
Подробное описание вариантов осуществления
Приведенное в настоящем документе описание относится к инструкциям векторного индексированного доступа к памяти плюс арифметической и/или логической (A/L) операции, процессорам для исполнения таких инструкций, способам, выполняемых процессорами при обработке или выполнении таких инструкций, и системам, включающие в себя один или более процессоров для обработки или выполнения таких инструкций. В следующем описании приводятся многочисленные конкретные подробные детали (напр., конкретные инструкции операций, форматы данных, конфигурации процессора, детали микроархитектуры, системные конфигурации, форматы команд, последовательности операций и др.). Впрочем, варианты осуществления могут быть реализованы на практике без этих конкретных деталей. В других случаях известные схемы, структуры и способы не были подробно проиллюстрированы, чтобы не усложнять понимание описания.
Фиг. 1 представляет собой блок-схему варианта осуществления процессора 100, выполненный с возможностью реализовывать или выполнять одну или более инструкций 104 векторного индексированного доступа к памяти плюс арифметической и/или логической (A/L) операции. Процессор соединен с возможной внешней памятью 126 (например, динамическая память с произвольным доступом (DRAM), флэш-память, другие системы памяти и др.). Память 126 показана, как возможная, потому что в некоторых вариантах осуществления процессор 100 описывается без памяти 126.
В некоторых вариантах осуществления процессор может быть процессором общего назначения (например, настольный, ноутбук, планшет, КПК, сотовый телефон как вычислительные устройства). В качестве альтернативы, процессор может быть специализированным процессором. Примеры подходящих специализированных процессоров включают в себя, но не ограничиваясь этим, графические процессоры, сетевые процессоры, коммуникационные процессоры, криптографические процессоры, сопроцессоры и цифровые сигнальные процессоры (DSPs), что представляет собой только несколько примеров. Процессор может быть любым из различных процессоров со сложным набором команд (CISC), различных процессоров с сокращенным набором команд (RISC), различных процессоров со сверх длинным командным словом (VLIW), различных их гибридных вариаций или других типов процессоров целиком.
Процессор включает в себя архитектурно-видимые или архитектурные регистры 110. Термин архитектурные регистры часто используется в данной области техники для обозначения тех регистров, которые видимы для программного обеспечения (например, программатор) и/или регистры, указанные инструкциями набора инструкций для идентификации операндов. Эти архитектурные регистры противопоставляются другим неархитектурным или неархитектурно видимым регистрам в данной микроархитектуре (например, регистры временного запоминания используются инструкциями и др.). Для простоты, эти архитектурные регистры будут часто упоминаться в данном документе просто как регистры. Регистры, как правило, представляют местоположения хранения данных на кристальном процессоре. Регистры могут быть реализованы по-разному в разных микроархитектурах, используя известные технологии, и не ограничиваются каким-либо конкретным типом схемы. Примеры подходящих типов регистров включают в себя, но не ограничиваются этим, выделенные физические регистры, динамически выделенные физические регистры, используя переименование регистров и их комбинации. Иллюстрированные регистры включают в себя набор векторных или упакованных данных регистров 112, каждый выполнен с возможностью хранить векторные или упакованные данные. В некоторых вариантах осуществления регистры могут также возможно включать в себя упакованные данные операции маскировки регистров 118, хотя это не обязательно. В некоторых вариантах осуществления регистры могут также включать в себя регистры 120 общего назначения, хотя это не обязательно.
Процессор имеет набор 102 инструкций. Набор инструкций включает в себя набор инструкций, которые поддерживаются процессором. Инструкции из набора команд представляют собой инструкции языка ассемблера, инструкции машинного уровня, макроинструкции или инструкции для выполнения процессором, в отличие от микроинструкций, микро-ops или инструкции, которые являются результатом декодирования макроинструкций посредством блока декодирования и предоставляются для выполнения в исполнительный блок. Набор инструкций включает в себя одну или более инструкций 104 векторного индексированного доступа к памяти плюс арифметической и/или логической (A/L) операции. Каждая одна или более инструкций векторного индексированного доступа к памяти плюс A/L операции выполнена с возможностью вызывать процессор выполнить операцию векторного индексированного доступа к памяти совместно с векторной A/L операцией.
В некоторых вариантах осуществления одна или более инструкций 104 векторного индексированного доступа к памяти плюс A/L операции может возможно включать в себя одну или более инструкций 106 векторной индексированной загрузки плюс A/L операции плюс операции сохранения (например, одну или более gather-плюс A/L операции плюс scatter-инструкции). Для примера, в некоторых вариантах осуществления инструкция 106 векторной индексированной загрузки плюс A/L операции плюс операции сохранения (например, инструкция gather-плюс A/L операции плюс scatter-инструкция) может быть выполнена с возможностью вызывать процессор собирать элементы данных из ячеек памяти во внешней памяти 126, указанные исходным операндом 114 упакованных индексов памяти, выполнять A/L операции на собранных элементах данных и элементов данных исходного операнда 116 упакованных данных, и разбрасывать полученные элементы данных в ячейках памяти во внешней памяти 126, указанные исходным операндом 114 упакованных индексов памяти.
В некоторых вариантах осуществления, одна или более инструкции 104 векторного индексированного доступа к памяти плюс A/L операции может возможно включать в себя одну или более инструкций 108 векторной индексированной загрузки плюс A/L операции (например, одну или более gather-инструкции плюс A/L операции). Для примера, в некоторых вариантах осуществления, инструкция 108 векторной индексированной загрузки плюс A/L операции (например, gather-инструкция плюс A/L операции) может быть выполнена с возможностью вызывать процессор собирать элементы данных из ячеек памяти во внешней памяти 126, указанными исходным операндом 114 упакованных индексов памяти, выполнять A/L операцию на собранных элементах данных и элементах данных исходного операнда 116 упакованных данных, и сохранение полученных элементов данных, как результат упаковки данных, на местах хранения процессора (например, в одном или более упакованных данных регистров).
Различные типы векторных A/L операций пригодны для инструкций 104. Некоторые примеры подходящих A/L операций включают в себя, но не ограничиваются этим, векторные или упакованные операции сложения, операции вычитания, операции умножения, операции деления, операции умножения-сложения, операции сдвига, операции поворота, операции логики И, операции логики ИЛИ, операции логики НЕТ, операции логики И-НЕТ, операции осреднения, операции максимизации, операции минимизации и операции сравнения, что представляет собой только некоторые из возможных примеров. В различных вариантах осуществления, могут использоваться в любом месте от одной инструкции 104 векторного индексированного доступа к памяти плюс A/L операции до многих таких разных инструкций. Например, может быть несколько или много gather-инструкций плюс операция плюс scatter-инструкций для различных типов A/L операций (например, добавление, умножение, сдвиг и др.) и/или несколько или много gather-инструкций плюс различные типы A/L операций.
В некоторых вариантах осуществления, инструкции 104 могут возможно указывать на упакованные данные операции маскировки операнда в маскированных регистрах 118, хотя это не обязательно. Упакованные данных операции маскировки операндов и упакованные данные операции маскированных регистров будут дополнительно рассмотрены ниже. В некоторых вариантах осуществления, инструкции 104 могут возможно указывать на (например, неявно указывать) регистр 120 общего назначения (например, один, имеющий базовый адрес или другую адресную информацию памяти), хотя это не обязательно. Альтернативно, адресная информация памяти может быть предоставлена иным способом.
Процессор также включает в себя один или несколько исполнительных блоков 124. Исполнительный блок(и) выполнен с возможностью реализовывать или выполнять инструкцию(и) 104 векторного индексированного доступа к памяти плюс A/L операции. Примеры подходящих исполнительных блоков включают в себя, но не ограничены этим, блоки доступа к памяти, исполнительные блоки памяти, блоки сбора данных, блоки разброса данных, арифметические и/или логические блоки (ALUs) и тому подобное, и их комбинации. В некоторых вариантах осуществления исполнительный блок памяти (или другой блок, способный осуществлять сбор или разброс данных или другую операцию векторного индексированного доступа к памяти) может быть модифицирован, чтобы включать в себя арифметический и/или логический блок или схему. В других вариантах осуществления исполнительный блок памяти (или другие блоки, способные осуществлять сбор или разброс данных или другую операцию векторного индексированного доступа к памяти) могут быть соединены с A/L блоком или схемой. В некоторых вариантах осуществления один или несколько исполнительных блоков 124 могут быть включены в состав подсистемы 122 памяти, которая используется для доступа к внешней памяти 126.
Фиг. 2 представляет собой блок-схему варианта осуществления устройства 200 обработки инструкции. В некоторых вариантах осуществления, устройство 200 обработки инструкции может быть, или может быть включено в состав, процессора 100, показанного на фиг. 1. Признаки и детали, описанные выше, для процессора 100 могут также возможно применяться к устройству 200 обработки инструкции. Альтернативно, устройство 200 обработки инструкции может быть, или может быть включено в состав, аналогичным или другим процессором, чем процессор 100. Кроме того, процессор 100 может включать в себя аналогичное или иное устройство обработки инструкции, чем устройство 200 обработки инструкции.
Устройство 200 обработки инструкции соединено к возможной внешней памяти 226 (например, динамической памяти с произвольным доступом (DRAM), флэш-памяти, другим системам памяти и др.). Например, устройство обработки инструкции и внешняя память могут быть соединены посредством шины или других межсоединений на печатной плате, через набор микросхем или другим образом, известным в данной области техники. Внешняя память отображается как возможная, потому что некоторые варианты осуществления относятся к устройству обработки инструкции без внешней памяти (например, перед установкой процессора в систему).
Устройство 200 обработки инструкции может принимать инструкцию 206 векторной индексированной загрузки плюс A/L операции плюс сохранения. Например, инструкция может быть принята из блока доставки инструкции, очереди команд, памяти и т.д. В некоторых вариантах осуществления, инструкция 206 может представлять собой инструкцию сбора плюс A/L операции плюс разброса. Инструкция 206 может четко определять (например, через один или более битов или поле) или иным образом (например, неявно указывать, указывать косвенно посредством эмуляции сопоставления регистра и др.) указывать исходный операнд 214 упакованных индексов памяти, имеющий множество упакованных индексов памяти. Каждый индекс памяти в исходном операнде упакованных индексов памяти может указывать на соответствующее место в памяти во внешней памяти 226. В некоторых вариантах осуществления индексы памяти могут быть 16-бит, 32-бит или 64-битными индексами памяти, хотя объем изобретения этим не ограничен. В некоторых вариантах осуществления, инструкция 206 может также явно указывать (например, через один или более битов или поле) или иным образом (например, неявно указывать, указывать косвенно через эмуляцию сопоставление регистров и др.) указывать исходный операнд 216 упакованных данных, имеющий множество элементов упакованных данных.
Устройство включает в себя набор регистров 212 упакованных данных. Регистры упакованных данных могут представлять собой архитектурные регистры. Регистры могут быть реализованы по-разному в различных микроархитектурах, используя известные технологии, и не ограничиваются каким-либо конкретным типом схемы. Примеры подходящих типов регистров включают в себя, но не ограничиваются этим, выделенные физические регистры, динамически выделенные физические регистры, используя переименование регистров, и их комбинации. Как показано, в некоторых вариантах осуществления исходный операнд 214 упакованных индексов памяти и исходный операнд 216 упакованных данных могут храниться в регистрах упакованных данных. Например, инструкция 206 может иметь одно или более полей или набор битов, чтобы указать эти регистры упакованных данных в качестве исходных операндов. Альтернативно, в других местах хранения может возможно использоваться для одного или более из этих операндов.
Устройство 200 обработки инструкции включает в себя блок декодирования инструкций или декодер 230. В некоторых вариантах осуществления блок декодирования может располагаться в ядре. Блок декодирования может принимать и декодировать машинные инструкции более высокого уровня или макроинструкции (например, инструкция 206) и выводить одну или более микроинструкций низкого уровня, микрокод точки входа, микроинструкции или другие низкоуровневые инструкции или управляющие сигналы 236, что соответствуют и/или получают из исходной инструкции более высокого уровня. Одна или более низкоуровневых инструкций или управляющие сигналы могут выполнять операцию инструкции более высокого уровня в рамках одной или более низкоуровневой операции (например, уровня схемы или на аппаратном уровне). Блок декодирования может быть реализован с помощью различных механизмов, включающие в себя, но не ограничиваясь этим, памяти микрокода только для чтения (ROMs), справочные таблицы, аппаратные реализации, программируемые логические матрицы (PLAs) и другие механизмы, известные в данной области техники. В других вариантах осуществления, вместо блока декодирования могут быть использованы эмулятор инструкций, переводчик, интерпретатор или другие логические блоки преобразования инструкции (например, реализованные в программном обеспечении, аппаратных средствах, микропрограммном обеспечении или их комбинациях). В еще других вариантах осуществления может быть использована комбинация логических блоков преобразования инструкции (например, модуль эмуляции) и блока декодирования. Некоторые или все логические блоки преобразования инструкций могут потенциально быть размещены вне кристалла от остальной части устройства обработки инструкций, например, на отдельном кристалле и/или памяти.
Обращаясь снова к фиг. 2, один или несколько исполнительных блоков 224 соединены с блоком 230 декодирования, регистрами 212 упакованных данных и с внешней памятью 226. В некоторых вариантах осуществления один или несколько исполнительных блоков могут также возможно быть соединены с регистрами 220 общего назначения, которые могут возможно использоваться для хранения базового адреса и/или другой адресной информации памяти для преобразования индексов памяти в адреса памяти. Альтернативно, адресная информация памяти может быть предоставлена иным образом.
Исполнительный блок выполнен с возможностью, в ответ на и/или как результат инструкции 206 векторной индексированной загрузки плюс A/L операции плюс сохранения (например, в ответ на один или более управляющих сигналов 236 декодированный или иным образом преобразованный из инструкции 206, или в ответ на один или более управляющий сигнал 236 декодированный из одной или более инструкций, используемый для эмуляции инструкция 206) выполнять операцию векторной индексированной загрузки плюс A/L операцию плюс операцию сохранения. Операция загрузки, A/L операция и операция сохранения могут все представлять собой векторные операции. В некоторых вариантах осуществления, операция может включать в себя процессорный сбор данных или иной способ загрузки множества элементов данных из потенциально несмежных ячейках памяти во внешней памяти 226, обозначаемой соответствующими индексами памяти исходного операнда 214 упакованных индексов памяти, выполнения A/L операцию на собранных или загруженных элементах данных и ассоциированных элементах данных исходного операнда 216 упакованных данных, и разброс или иной способ сохранения результирующих элементов данных в соответствующих ячейках памяти во внешней памяти 226, указанные соответствующими индексами памяти исходного операнда 214 упакованных индексов памяти.
В иллюстрируемом примере варианта осуществления, первая ячейка 232 памяти изначально включает в себя элемент А1 данных, вторая ячейка 233 памяти изначально включает в себя элемент А2 данных, третья ячейка 234 памяти изначально включает в себя элемент A3 данных и четвертая ячейка 235 памяти изначально включает в себя элемент А4 данных. Каждая из этих ячеек памяти соответственно может соответствовать с первого по четвертый индексы памяти исходного операнда 214 упакованных индексов памяти. Исходный операнд 216 упакованных данных включает в себя соответствующие элементы B1, В2, В3 и В4 данных. В результате выполнения инструкции, элемент А1 данных в первой ячейке 232 памяти может быть перезаписан с А1 посредством операции (ОР) на В1, элемент А2 данных во второй ячейке 233 памяти может быть перезаписан с А2 OP В2, элемент A3 данных в третьей ячейке 234 памяти может быть перезаписан с A3 ОР В3 и данные А4 элемента в четвертой ячейке 235 памяти может быть перезаписан с А4 OP В4. В этом примерном варианте осуществления, операция (ОР) может представлять собой любую подходящую операцию "вертикального" типа упакованных данных, например, упакованное сложение, упакованное вычитание, упакованное умножение, упакованное деление, упакованное умножение-сложение, упакованный сдвиг (например, сдвиг А1 на В1, сдвиг А2 на В2 и т.д.), упакованный поворот (например, поворот А1 на В1, поворот А2 на В2 и т.д.), упакованная логическая И, упакованная логическая ИЛИ, упакованная логическая НЕ, упакованная логическая И-НЕТ, упакованные усреднения, упакованная максимизация, упакованная минимизация, упакованное сравнение или тому подобное. Хотя в этом примере "вертикальные" операции будут использоваться в операции, выполняемой на паре соответствующих элементов данных (например, элементов данных в соответствующих позициях битов в операндах), и "вертикальный" тип операции не требуется. В других вариантах осуществления, другие виды операций могут быть выполнены, такие как, например, "горизонтальный" тип операции, часть "горизонтальной" операции, часть "вертикальной" операции, операции с участием более чем просто один элемент данных и т.д.
Примеры подходящих исполнительных блоков включают в себя, но не ограничены этим, блоки доступа к памяти, исполнительные блоки памяти, блоки сбора данных, блоки разброса данных, арифметические и/или логические блоки (ALUs) и тому подобное, и их комбинации. В некоторых вариантах осуществления исполнительный блок памяти (или другой блок, способный осуществлять операцию сбора и/или разброса и/или другие операции векторного индексированного доступа к памяти), может быть изменен, чтобы включать в себя арифметический и/или логический блок или схему. В других вариантах осуществления исполнительный блок памяти (или другой блок, способный осуществлять операцию сбора и/или разброса и/или другие операции векторного индексированного доступа к памяти) может быть соединен с арифметическим и/или логическим блоком или схемой. Один или несколько исполнительных блоков и/или устройство может содержать специфическую или конкретную логику (например, схему, транзисторы или другие аппаратные средства, потенциально объединенные с программным обеспечением и/или аппаратно-программным обеспечением), выполненную с возможностью выполнять и/или обрабатывать инструкцию 206. В некоторых вариантах осуществления один или несколько исполнительных блоков могут включать в себя, по меньшей мере, некоторые транзисторы, интегральную схему, часть интегральной схемы или другую схему или оборудование.
В некоторых вариантах осуществления, один или несколько исполнительных блоков 224 могут быть включены в состав подсистемы 222 памяти, которая используется для доступа к внешней памяти 226, хотя это не обязательно. Как будет рассмотрено дополнительно ниже, как правило, чем ближе один или несколько исполнительных блоков 224 к внешней памяти 226, тем выше эффективность. Например, это может быть отчасти из-за не необходимости хранить данные на одном или более высоком уровне кэша и/или нет необходимости передавать данные по межсоединению всем, вплоть до самого высокого уровня кэша и/или в ядро.
С целью упрощения описания, была проиллюстрирована простая структура устройства 200 обработки инструкции, хотя устройство обработки инструкции может возможно включать в себя один или более других компонентов. Примеры таких обычных компонентов включают в себя, но не ограничиваются ими, блок выборки инструкций, блок планирования инструкции, блок предсказания ветви, кэш данных и инструкции, буферы предыстории преобразования данных (TLB), буферы предварительной выборки, очереди микроинструкции, устройства, задающие последовательность микроинструкций, блоки шинного интерфейса, блок удаления/подтверждения, блок переименования регистра и другие компоненты, обычно используемые в процессорах. Кроме того, варианты осуществления могут иметь несколько ядер, логические процессоры или блок механизма исполнения, имеющие тот же или другой набор инструкций и/или ISA. Есть множество различных комбинаций и конфигураций таких компонентов в процессорах и варианты осуществления не ограничиваются какой-либо конкретной такой комбинацией или конфигурацией.
В некоторых вариантах осуществления, операция может быть выполнена посредством исполнительного блока, находящегося за пределами ядер (например, с помощью исполнительного блока, расположенного с и/или непосредственно последнего уровня кэша, предпоследнего уровня кэша или одного из последних уровней кэша. В некоторых вариантах осуществления, операция может быть выполнена с помощью исполнительного блока на данных, поставленных или полученных из последнего уровня кэша, предпоследнего уровня кэша или одного из последних уровней кэша. В некоторых вариантах осуществления один или несколько исполнительных блоков 224 могут быть логически развернуты на том же уровне иерархии памяти, как последний уровень кэшпамяти (или один из самых низких уровней кэш-памяти), в противоположность логическому развертыванию одного или нескольких исполнительных блоков 224 на высшем уровне кэша (или один из самых высоких уровней кэша). Обычно, чем выше уровень кэша между высоким уровнем кэша и уровнем иерархии памяти, на котором работает один или несколько исполнительных блоков, тем выше эффективность. В некоторых вариантах осуществления, операция может быть выполнена над данными, которые обходят все или, по меньшей мере, один или более высоких уровней кэша, что выше, чем кэш, из которого данные предоставляются (например, последний уровень кэша). В таких вариантах осуществления, собранные или иным образом загруженные данные, не должны передаваться ни в какой-либо более высокий уровень кэша и/или в ядро, до обработки и затем разбросаны или иным образом сохранены обратно в памяти. Целесообразно, избегая необходимости хранить эти данные на более высоких уровнях кэша, способствует освобождению пространства на более высоких уровнях кэша. Это освобожденное пространство может использоваться для хранения других данных, которые могут помочь улучшить производительность. Более того, в некоторых вариантах осуществления, операция может быть выполнена на данных, содержащихся в регистрах временного запоминания, в отличие архитектурных регистров. Это может помочь освободить архитектурные регистры так, чтобы они были доступны для использования другими инструкциями. Это может также помочь улучшить производительность (например, помогая уменьшить подкачку данных в регистрах и др.). Более того, может быть также уменьшена полоса пропускания соединения и/или других ресурсов, которые иным образом были бы необходимы для передачи данных на самый высокий или более высокий уровень кэша и/или в ядро. Такая ширина полосы пропускания соединения и/или иные ресурсы могут быть использованы для других целей, которые также могут помочь повысить производительность.
Фиг. 3 представляет собой блок-схему, иллюстрирующую один вариант осуществления расположения исполнительного блока 324 в процессоре 300. Процессор включает в себя один или более ядер 350. На чертеже, процессор включает в себя первое ядро 350-1, возможно N-e ядро 350-N, где N может представлять собой любое подходящее количества ядер. Первое ядро включает в себя блок 330 декодирования, который может быть аналогичен блокам декодирования, описанными в данном документе, и может декодировать инструкцию векторного индексированного доступа к памяти плюс A/L операции. Первое ядро также включает в себя исполнительный блок 351. Ядро также включает в себя архитектурные регистры 310, которые могут быть указаны инструкциями, выполненными первым ядром. Первое ядро дополнительно включает в себя кэш 352 первого уровня (L1) и возможно кэш 353 второго уровня (L2). Энное ядро может возможно быть схожим или таким же, как первой ядро, хотя это не обязательно. Процессор также включает в себя кэш 354 последнего уровня (LLC), соединенный с ядрами. Процессор также включает в себя блок 355 памяти, соединенный с LLC и ядрами. Блок памяти соединен с внешней памятью 326.
В некоторых вариантах осуществления блок памяти может включать в себя исполнительный блок, используемый для выполнения или реализации инструкции векторного индексированного доступа к памяти плюс A/L операции. Исполнительный блок включает в себя блок 356 доступа к памяти, который выполнен с возможностью выполнять операцию векторного индексированного доступа к памяти (например, операцию сбора и/или операцию разброса). Исполнительный блок также включает в себя блок 357 A/L, соединенный с блоком доступа к памяти. Блок A/L может быть выполнен с возможностью выполнить A/L операцию на данных, к которым разрешен доступ (например, загруженные векторные данные с помощью индексов). Блок 356 доступа к памяти и блок 357 A/L могут взаимодействовать или работать вместе, чтобы выполнять вариант реализации инструкции векторного индексированного доступа к памяти плюс A/L операции. В некоторых вариантах осуществления исполнительный блок 324 может выполнять операции над данными, загруженными из внешней памяти 326 перед загрузкой в LLC, будучи загруженными в LLC, или на данных, полученных из LLC после загрузки в LLC. В некоторых вариантах осуществления исполнительный блок 324 может выполнять операции над данными, которые отсутствуют в ядре 350, L1 кэш 352 или кэш L2 353. В некоторых вариантах осуществления исполнительный блок может включать в себя регистры 358 временного запоминания для содействия в выполнении этих инструкций. Например, регистры временного запоминания могут использоваться для хранения загруженных данных и/или промежуточных или временных данных, сгенерированных при выполнении инструкции. Использование таких регистров временного запоминания помогает избежать необходимости занимать архитектурные регистры 310.
Фиг. 4 представляет собой блок-схему варианта осуществления способа 460 обработки варианта осуществления инструкции векторной индексированной загрузки плюс A/L операции плюс операции сохранения. В различных вариантах осуществления способ может быть выполнен процессором общего назначения, процессором специального назначения или другим устройством обработки инструкций или цифровым логическим устройством. В некоторых вариантах осуществления, операции и/или способ, показанный на фиг. 4, могут быть выполнены посредством и/или в любых устройствах, показанных на фиг. 1-3. Компоненты, признаки и конкретные возможные детали, описанные в настоящем документе для устройства, показанного на фиг. 1-3, также возможно применяются к операциям и/или способу, показанному на фиг. 4. Альтернативно, операции и/или способ на фиг. 4 могут быть выполнены посредством и/или в пределах аналогичного или другого процессора или устройства. Кроме того, устройство, показанное на любом из фиг. 1-3, может выполнять такие же операции и/или способы, схожие или отличающиеся от фиг. 4.
Способ включает в себя прием инструкции векторной индексированной загрузки плюс A/L операции плюс сохранение, на этапе 461. В различных аспектах, инструкция может быть принята посредством процессора, устройством обработки инструкции или их частью (например, блок выборки инструкции, блок декодирования, модуль преобразования инструкции и др.). В различных аспектах, инструкция может быть принята из внешнего источника (например, из DRAM, диска, межсоединения и т.д.) или из внутреннего источника (например, из кэша команд, из блока выборки и др.). В некоторых вариантах осуществления, инструкция может указывать или иным образом указывать исходный операнд упакованных индексов памяти, который должен иметь множество упакованных индексов памяти. В некоторых вариантах осуществления, инструкция может указать или иным образом указать исходный операнд упакованных данных, который должен иметь множество упакованных элементов данных.
Способ включает в себя выполнение инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения, на этапе 462. В некоторых вариантах осуществления это может включать в себя загрузку множества элементов данных из ячеек памяти, соответствующих множеству упакованных индексов памяти, на этапе 463, выполнение A/L операции на множестве упакованных элементов данных исходного операнда упакованных данных и множества загруженных элементов данных, на этапе 464, и хранить множество результирующих элементов данных в ячейках памяти, соответствующих множеству упакованных индексов памяти, на этапе 465. Те же индексы, используемые для операции загрузки, могут также использоваться для операции сохранения.
Иллюстрированный способ включает в себя архитектурно видимые операции (например, видимое программное обеспечение и/или программатор). В других вариантах осуществления способ может возможно включать одну или более микроархитектурные операции. Например, инструкция может быть извлечена, расшифрована, запланирована с изменением последовательности выполнения команд, исходные операнды могут быть доступны, исполнительный блок может быть выполнен с возможностью выполнять микроархитектурные операции для реализации операций инструкции (например, в упакованные данные могут быть сохранены из кэша в регистре временного хранения, упакованные данные могут быть получены из регистра временного хранения, результирующие упакованные данные могут быть сохранены из регистра временного хранения обратно в кэше или памяти и др.) и т.д.
Фиг. 5 представляет блок-схему, иллюстрирующую вариант осуществления операции 566 векторной индексированной загрузки плюс A/L операции плюс сохранения, которая может выполняться в ответ на вариант осуществления инструкции векторной индексированной загрузки плюс A/L операции плюс сохранение. В некоторых вариантах осуществления инструкция может представлять собой инструкцию сбора плюс AIL операции плюс операции разброса.
Инструкция может указать или иным образом указать на исходный операнд 514 упакованных индексов памяти, имеющий множество упакованных индексов памяти. В иллюстрируемом варианте осуществления исходный операнд упакованных индексов памяти является 512-бит шириной и содержит шестнадцать 32-разрядных индексов памяти, хотя объем изобретения не ограничен. В иллюстрируемом примере значения индексов памяти равны, от наименее значимой позиции (слева) к самой значимой позиции (справа), 134 бит [31:0], 231 бит [63:32], 20 бит [95:64] и 186 бит [511:480]. Очевидно, что эти значения являются только иллюстративными примерами. Главное, что есть значения, которые указывают или соответствуют различным ячейкам памяти. Альтернативно, другие размеры индексов памяти, которые возможно могут быть использованы, такие как, например, 16-битные индексы памяти, 64-разрядные индексы памяти или другие размерности индексов памяти известны в данной области техники. Кроме того, в других вариантах осуществления исходный операнд упакованных индексов памяти может иметь любую другую приемлемую ширину, кроме 512-бит, такую как, например, 64-бит, 128-бит, 256-бит или 1024 бит.
Инструкция может также указывать или иным образом указать на исходный операнд 516 упакованных данных, имеющее множество упакованных элементов данных. В показанном варианте исходный операнд упакованных данных является также 512-бит шириной и содержит шестнадцать 32-разрядных элементов данных, хотя объем изобретения этим не ограничен. В иллюстрируемом примере, значения данных элементов, от наименее значимой позиции (слева) до самой значимой позиции (справа), В1 бит [31:0], В2 бит [63:32], ВЗ бит [95:64] до В16 бит [511:480]. В качестве альтернативы, другие размеры элементов данных могут возможно использоваться, такие как, например, 8-разрядные элементы данных, 16-разрядные элементы данных, 64-разрядные элементы данных или другие размеры элементов данных, известные в данной области техники. Кроме того, в других вариантах осуществления исходный операнд упакованных данных может иметь любую другую ширину, кроме 512-бит, такую как, например, 64-бит, 128-бит, 256-бит или 1024 бита. Отсутствует требование к битовой ширине индексов памяти, которые должны совпадать с битовой шириной элементов данных. Часто, число элементов данных будет таким же, как количество индексов памяти, хотя этого не требуется в зависимости от конкретного типа операции.
Операция векторной индексированной загрузки, A/L операции и операции сохранения может быть выполнена в ответ на и/или в результате реализации маскированной инструкции. Операция может собрать или иным образом загрузить элементы данных из ячейки памяти в память, в соответствии с указанием соответствующих индексов памяти исходного операнда упакованных индексов памяти. Каждый индекс памяти может указывать соответствующую ячейку памяти и/или элемент данных, хранящийся в ней. Например, в показанном варианте осуществления, индекс 134 памяти может указывать на ячейку памяти, в которой хранится элемента А1 данных, индекс 231 памяти может указывать на ячейку памяти, в которой хранится элемент А2 данных, индекс 20 памяти может указывать на ячейку памяти, в которой хранится элемент A3 данных и так далее вплоть до индекса 186 памяти, указывающий на ячейку памяти, в которой хранится элемент А16 данных. A/L операция (ОР) может быть выполнена на собранных или иным образом загруженных элементах данных и элементах данных исходного операнда 516 упакованных данных. Полученные элементы данных (т.е. те, которые возникают в результате совершения операции) могут быть разбросаны или иным образом сохранены обратно в соответствующие ячейки памяти, указанные индексами памяти исходного операнда упакованных индексов памяти. В некоторых вариантах осуществления, в зависимости от конкретной инструкции операции, результирующие элементы данных могут быть такого же размера, что и элементы данных исходного операнда упакованных данных (например, 32-разрядные элементы данных). Альтернативно, результирующие элементы данных могут быть больше или меньше, чем элементы данных исходного операнда упакованных данных, такие как, например, 8-бит, 16-бит, 64-бит, и т.д.
В показанном варианте осуществления, для простоты описания, выполняется вертикальный тип операции для генерирования первого результирующего элемента данных, равного A1 OP В1, второго результирующего элемента данных, равного А2 ОР В2, третьего результирующего элемента данных, равного A3 ОР В3 и четвертого результирующего элемента данных, равного А16 ОР В16. Хотя термин "равный" был использован, очевидно, что насыщение может возможно быть выполнено, чтобы насытить значения до максимального или минимального значения. Любая из ранее упомянутых вертикальных операций, описанных в данном документе, может быть использована (например, упакованное сложение, упакованная разность, упакованное произведение, упакованный сдвиг, упакованный поворот, различные типы логических операций (например, И, ИЛИ, НЕ, И-НЕ и др.). Например, в случае операции упакованного сложения, результирующие элементы данных могут включать в себя A1+B1, А2+В2, А3+В3 до А16+В16. В качестве другого примера, в случае операции упакованного сдвига, результирующие элементы данных могут включать в себя А1 со сдвигом на шаг сдвига в B1, А2 сдвинут на шаг сдвига в В2 и так далее. В других вариантах осуществления другие виды операций, такие как, например, операции горизонтального типа, операции части вертикального типа и горизонтального типа, операции с участием более чем двух элементов данных или тому подобное, может быть возможно выполнено. Как показано на чертеже, значение А1 в ячейке памяти, соответствующее индексу 134 памяти, может быть перезаписано значением A1 OP В1, значение А2 в ячейке памяти, соответствующее индексу 231 памяти, может быть перезаписано со значением А2 OP В2, значение A3 в ячейке памяти, соответствующее индексу 20 памяти, может быть перезаписано значением A3 ОР В3 и значение А16 в ячейке памяти, соответствующее индексу 186 памяти, может быть перезаписано со значением А16 ОР В16.
Фиг. 6 представляет собой блок-схему, иллюстрирующую вариант выполнения операции 668 векторной маскированной индексированной загрузки плюс A/L операции плюс операции сохранения, которая может выполняться в ответ на реализацию инструкции маскированной векторной индексированной загрузки плюс A/L операции плюс сохранение. В некоторых вариантах осуществления инструкция может представлять собой инструкцию маскированной операции сбора плюс A/L операции плюс операции разброса. Маскированная операция и маскированная инструкция, показанные на фиг. 6, имеют определенные сходства с незамаскированной операцией и незамаскированной инструкцией, показанной на фиг. 5. Чтобы не усложнять описание, различные и/или дополнительные характеристики для маскированной операции/инструкции на фиг. 6 будут в первую очередь описаны без повторения всех похожих или общих характеристик по отношению к незамаскированной операции/инструкции, показанной на фиг. 5. Однако, следует отметить, что ранее описанные характеристики немаскированной операции/инструкции, показанные на фиг. 5, также возможно применимы к фиг. 6, если не оговорено иначе или иным образом является очевидным.
Инструкция может указать или иным образом указать на исходный операнд 614 упакованных индексов памяти, имеющий множество упакованные индексов памяти. Инструкция может также указывать или иным образом указать на исходный операнд 616 упакованных данных, имеющий множество упакованных элементов данных. Каждый из них может быть схожим или таким же, как те ранее описано на фиг. 5, и может иметь одинаковые вариации и альтернативы.
В некоторых вариантах осуществления, маскированная инструкция также может указывать или иным образом указывать на исходный операнд 618 замаскированной операции упакованных данных. Исходный операнд замаскированной операции упакованных данных может представлять собой предикативный операнд или операндом условного управления, который выполнен с возможностью маскировать, предсказывать или условно управлять или или нет соответствующий набор операций, ассоциированный с инструкцией, которая должна быть выполнена, и/или сохранять соответствующий результат. Операция маскировки упакованных данных может также упоминаться здесь как операция маскировки, предикат маскировки или просто маскировка. В некоторых вариантах осуществления, маскировка или предикация могут быть на каждом уровне детализации элемента данных так, что операции на различных элементах данных могут быть предсказаны или условно управляемы отдельно и/или независимо от других. Маскировка может включать в себя множество маскированных элементов, предикат элементов или условно управляемые элементы. В одном аспекте, маскированные элементы могут быть включены в состав взаимно однозначных отображений с соответствующими исходными элементам данных и/или результирующими элементами данных. В некоторых вариантах осуществления, каждый маскированный элемент может быть одним битом маски. Значение каждого отдельного бита маски может управлять или нет соответствующим набором операций, ассоциированным с инструкцией, которая должна выполняться на соответствующих элементах данных, и/или нет соответствующий результат будет сохранен в целевой ячейке памяти. Согласно одному возможному правилу, каждый бит маски может иметь первое значение (например, может быть установлен в двоичную 1), чтобы позволить соответствующему набору операций быть выполненному, и разрешить соответствующему результирующему элементу данных хранится в соответствующей целевой ячейке памяти, или может иметь второе значение (например, может быть сброшено в двоичный 0), чтобы не позволить соответствующему набору операций быть выполненному и/или не разрешить соответствующему результирующему элементу данных сохранится в соответствующей ячейке памяти.
Как показано, в случае исходного операнда 614 упакованных индексов памяти, имеющий 512-битную ширину, и имеющий шестнадцать 32-разрядных индексов памяти, исходный операнд 618 маскировочной операции упакованных данных может иметь 16-битную ширину, в которой каждый бит представляет собой бит маски. Каждый бит маски может соответствовать индексу памяти в соответствующей позиции и/или может соответствовать результирующему элементу данных, который должен быть сохранен в соответствующей ячейке памяти, на которую указывает индекс памяти. На чертеже соответствующие позиции вертикально выровнены относительно друг друга. В других вариантах осуществления, когда есть более или менее результирующих элементов данных, может быть больше или меньше битов маски. Например, маска может иметь ширину в битах равную количеству индексов памяти в исходных упакованных индексах 614 памяти (например, четыре, восемь, тридцать два, шестьдесят четыре и т.д.). В иллюстрируемом примере, биты маски от младшего значащего бита (слева) к старшему биту (справа) являются 1, 0, 1, … 0. Это лишь один показательный пример. Согласно иллюстрированному правилу, значение бита маски двоичного 0 представляет собой отсутствие маскировки результирующего элемента и/или набора операций, которые не должны выполняться, в то время как значение бита маски двоичной 1 указывает на немаскированный результирующий элемент и/или набор операций, которые будут выполняться. Для каждого незамаскированного элемента выполняется соответствующая операция векторной индексированной загрузки, A/L операция и операция сохранения. В отличие от них, для каждого маскируемого элемента, соответствующая операция векторной индексированной загрузки, A/L операция и операция сохранения не выполняется, или если они выполняются, ассоциированный результат не должен храниться в ассоциированной ячейки памяти. Часто, есть преимущества, которые заключаются в том, что даже при неисполнении операции маскировки, такой как, например, возможность избежать ошибок (например, ошибки страниц) при выполнении операции, они не должны выполняться.
Маскированная операция векторной индексированной загрузки, A/L операция и операция сохранения могут быть выполнены в ответ на и/или в результате реализации маскированной инструкции. В некоторых вариантах осуществления набор операций (например, операции загрузки, A/L и сохранения) могут или не могут быть выполнены на соответствующих элементах данных с учетом, которые подвергнуты условному управлению битов маски. В некоторых вариантах осуществления элементы данных могут быть выборочно собраны или иным образом загружены из соответствующих ячеек памяти, указанные соответствующими индексами памяти только тогда, когда соответствующие биты маски не замаскированы (например, установлена двоичная 1). Элементы данных, соответствующие битам маски маскированной операции упакованных данных операции (например, сброшенные до двоичного 0), не могут быть загружены. Затем, A/L операция (ОР) может быть выборочно выполнена только на нагруженных элементах данных и соответствующих элементах данных исходного операнда 616 упакованных данных. Затем, полученные элементы данных могут быть селективно разбросаны или иным образом сохранены обратно в соответствующие ячейки памяти, указанные индексами памяти, только тогда, когда соответствующие биты маски не замаскированы (например, установка двоичной 1).
В иллюстрируемом примере, поскольку биты маски на битовых позициях [0] и [2] исходной маскированной операции упакованных данных не маскируются (например, значение двоичной 1), то значение А1 в ячейке памяти, соответствующей индексу 134 памяти, может быть перезаписано значением A1 OP В1, и значение A3 в ячейке памяти, соответствующей индексу 20 памяти, может быть перезаписано значением A3 ОР В3. В показанном варианте осуществления, для простоты описания, выполняется только операция вертикального типа. Любая из ранее описанных операций вертикального типа является подходящей. В других вариантах осуществления, операции горизонтального типа, часть операций вертикального типа часть операций горизонтального типа, операции с участием более чем двух элементов данных или тому подобное, может быть выполнена вместо этого.
В иллюстрируемом примере, поскольку биты маски на битовых позициях [1] и [15] маски скрыты (например, сброс на двоичный 0), то результаты набора операций, ассоциированные с инструкцией, не хранятся в ячейках памяти, обозначенные соответствующими индексами памяти. Скорее, в некоторых случаях, эти ячейки памяти могут удерживать или сохранять их прежние значения до инструкции (например, не могут быть изменены посредством инструкции). Как показано на чертеже, ячейка памяти, ассоциированная с индексом 231 памяти, может сохранить начальное значение А1, и ячейка памяти, ассоциированная с индексом 186 памяти, может сохранить первоначальное значение А16. Альтернативно, нули или другие заданные значения могут храниться в маскированных ячейках памяти.
Фиг. 7 представляет собой блок-схему, иллюстрирующую вариант осуществления операции 770 векторной индексированной загрузки плюс A/L операции, которые могут выполняться в ответ на реализацию инструкции векторной индексированной загрузки плюс A/L операции. В некоторых вариантах осуществления инструкции могут представлять собой инструкцию сбора плюс A/L операции. Операция и инструкция, показанные на фиг. 7, имеют определенные сходства с операцией и инструкцией, показной на фиг. 5. Чтобы избежать усложнений описания, различные и/или дополнительные характеристики операции/инструкции на фиг. 7 будет описаны без повторения всех похожих или общих характеристик относительно операции/инструкции на фиг. 5. Однако, следует отметить, что описанные ранее характеристики операции/инструкции на фиг. 5 также возможно применяются к фиг. 7, если не указано иное или очевидное.
Инструкция может указать или иным образом указать исходный операнд 714 упакованных индексов памяти, имеющий множество упакованных индексов памяти. Инструкция может также указывать или иным образом указать исходный операнд 716 упакованных данных, имеющий множество упакованных элементов данных. Каждый из них может быть схожим или таким же, как ранее описанные на фиг. 5, и может иметь одинаковые вариации и альтернативы.
Векторная индексированная загрузка плюс A/L операция могут быть выполнены в ответ на и/или в результате реализации инструкции. Операция может собирать или иным образом загружать элементы данных из ячеек памяти, указанных соответствующими индексами памяти исходного операнда 714 упакованных индексов памяти. Например, в иллюстрируемом варианте осуществления элемент А1 данных может быть собран из ячейки памяти, указанной индексом 134 памяти, элемент А2 данных может быть собран из ячейки памяти, указанной индексом 231 памяти, элемент A3 данных может быть собран из ячейки памяти, указанной индексом 20 памяти и так далее до элемента А16 данных, собранного из ячейки памяти, указанной индексом 186 памяти. Затем, A/L операция (ОР) может быть выполнена на собранных или иным образом загруженных элементах данных и соответствующих элементах данных исходного операнда упакованных данных. Это может генерировать множество результирующих элементов данных.
В отличие от операции/инструкции на фиг. 5, в этом варианте осуществления результирующие элементы данных не могут быть разбросаны или иным образом сохранены обратно в памяти 726. Скорее, полученные элементы данных могут храниться в результирующем операнде упакованных данных в области хранения, которая находится на кристалле или в процессоре. Например, в некоторых вариантах осуществления, результирующие элементы данных могут храниться в результирующих упакованных данных в регистре упакованных данных процессора. В некоторых вариантах осуществления, инструкция может иметь поле или набор битов для явного указания регистра упакованных данных. Альтернативно, регистр упакованных данных может возможно быть неявно указан инструкцией. В других вариантах осуществления, регистры для временного хранения могут использоваться для хранения результирующих упакованных данных.
В показанном варианте осуществления, для простоты описания, выполняется операция вертикального типа для генерирования первого результирующего элемента данных, равного A1 OP В1, второго результирующего элемента данных, равного А2 ОР В2, третьего результирующего элемента данных, равного A3 ОР В3 и шестнадцатого результирующего элемента данных, равного А16 ОР В16. Любая из ранее упомянутых операций вертикального типа, описанная в данном документе, может использоваться. В других вариантах осуществления другие виды операций, такие как, например, операции горизонтального типа, часть операции вертикального типа и часть операции горизонтального типа, операции с участием более чем двух элементов данных или тому подобное могут возможно выполняться. Результирующие элементы данных хранятся в результирующем операнде 772 упакованных данных (например, в регистре упакованных данных). Как показано, первый результирующий элемент данных хранится в битах [31:0], второй результирующий элемент данных хранится в битах [63:32], третий результирующий элемент данных хранится в битах [95:64] и шестнадцатый результирующий элемент данных хранится в битах [511:480]. В других вариантах осуществления, в зависимости от конкретной операции инструкции, результирующий элемент данных может быть больше или меньше элементов данных исходного операнда упакованных данных, такие как, например, 8-бит, 16-бит, 64-бит и т.д.
Фиг. 7 показывает вариант осуществления немаскированной операции/инструкции. Другие варианты осуществления могут включать в себя соответствующие маскируемые операции/инструкции. Маски и маскирование может быть выполнено, по существу, как описано выше со ссылкой на фиг. 6, за исключением того, что результаты будут сохранены или не сохранены в результирующих упакованных данных 772 вместо памяти 726. Характеристики маски и маскировки, ранее описанные со ссылкой на фиг. 6, могут также применяться к данной инструкции/операции.
В различных вариантах осуществления операции, описанные на любом из чертежей с 5 по 7, могут быть выполнены устройством, описанном на любом из чертежей с 1 по 3. Компоненты, признаки и конкретные возможные детали, описанные в настоящем документе для устройства, описанного на любом чертеже с 1 по 3, могут также возможно применяться к операциям на любом из чертежей с 5 по 7. Альтернативно, операции на любом чертеже с 5 по 7 могут быть выполнены посредством и/или в пределах аналогичного или иного устройства, чем те, которые описаны на чертежах с 1 по 3. Кроме того, устройство, описанное со ссылкой на любой чертеж с 1 по 3, может выполнять операции, которые аналогичны или отличаются от описанных на чертежах с 5 по 7. Операции, описанные на любом чертеже с 5 по 7, могут также выполняться как часть способа, описанного на фиг. 4. Альтернативно, способ на фиг. 4 может выполнять аналогичные или разные операции, чем те, которые описаны со ссылкой на фигуры 5-7.
Инструкции, описанные в настоящем документе, являются инструкциями общего назначения, и могут быть использованы для различных целей. Для дополнительной иллюстрации определенных понятий, рассмотрим следующий подробный пример. Рассмотрим следующий цикл:
FOR I=1, N
DATA [INDEX [I]] = DATA [INDEX [I]] + COUNT
Без инструкций, описанных в настоящем документе, такие циклы могут быть закодированы в инструкции x86 следующим образом:
MOV ZMM2, [INDEX+RSI]
GATHERDPS ZMM1, [DATA + ZMM2 * SCALE]
ADDPS ZMM1, ZMM1, ZMM3
SCATTERDPS [DATA + ZMM2 * SCALE], ZMM1
Впрочем, в варианте осуществления инструкции сбора плюс упакованного сложения плюс разброса, такие циклы могут быть закодированы более кратко следующим образом:
MOV ZMM2, [INDEX+RSI]
GATADDSCATDPS [DATA + ZMM2 * SCALE], ZMM3
Преимущественно, данный пример иллюстрирует, что инструкция сбора плюс упакованное сложение плюс разброс может помочь устранить или уменьшить некоторые инструкции, которые могут помочь увеличить плотность кода и увеличить производительность. Более того, прирост производительности может также быть получен от сокращения служебных сигналов при генерации адреса и обработки загрузки/сохранения для каждого элемента. Как уже говорилось выше, фактический прирост производительности может зависеть от местоположения блока или схемы, в которой реализуется инструкция в конвейере. Как правило, чем ближе реализуется инструкция к памяти или, наоборот, чем дальше от наивысшего уровня кэша в системе, тем будет получен выше прирост производительности. Как уже упоминалось выше, это может быть связано, частично, для того, чтобы избежать необходимости хранить данные, ассоциированные с исполнением инструкции на самом высоком или более высоком уровне кэша, избегая необходимости передавать данные на межсоединение с самым высоким или более высоким уровнем кэша и др.
Фиг. 8 является блок-схемой варианта осуществления формата для инструкции 806 векторной индексированной загрузки плюс A/L операции плюс сохранения. Инструкция включает в себя код операции либо опкод 880. Опкод может представлять собой множество битов или одно или нескольких полей, которые выполнены с возможностью идентифицировать выполняемый тип инструкции и/или операции. Инструкция также включает в себя исходное поле 881 упакованных индексов памяти, которое предназначено для указания исходного операнда упакованных индексов памяти. Инструкция также включает в себя исходное поле 882 упакованных данных, которое предназначено для указания исходного операнда упакованных данных. В некоторых вариантах осуществления, инструкция может также возможно включать в себя исходное поле 883 операции маскировки упакованных данных, которое предназначено для указания исходной операции маскировки упакованных данных. В некоторых вариантах осуществления, инструкция может также возможно включать в себя исходное поле 885 адресной информации памяти для указания источника (например, регистр общего назначения), имеющего базовый адрес или другую адресную информацию. Альтернативно, инструкция может косвенно указывать на регистр или другой источник, имеющий такую адресную информацию памяти.
Фиг. 9 является блок-схемой варианта осуществления формата инструкции 908 векторной индексированной загрузки плюс A/L операции. Инструкция включает в себя код операции либо опкод 980. Код операции может представлять множество битов или одно или нескольких полей, которые предназначены для определения типа инструкции и/или операции. Инструкция также включает в себя исходное поле 981 упакованных индексов памяти, которое предназначено для указания исходного операнда упакованных индексов памяти. Инструкция также включает в себя исходное поле 982 упакованных данных, предназначенное для указания исходного операнда упакованных данных. В некоторых вариантах осуществления, инструкция может также возможно включать в себя исходное поле 983 операции маскировки упакованных данных, предназначенное для указания источника операции маскировки упакованных данных. Инструкции могут также возможно включать в себя поле 984 адресата упакованных данных, предназначенное для указания назначенной области хранения упакованных данных. В некоторых вариантах осуществления, назначенная область хранения упакованных данных может быть регистром упакованных данных или другой областью хранения на кристалле или в процессоре. В некоторых вариантах осуществления, инструкция может также возможно включать в себя поле 985 источника адресной информации памяти для указания источника (например, регистра общего назначения), имеющего базовый адрес памяти или другую адресную информацию. Альтернативно, инструкция может косвенно указывать на регистр или другой источник, имеющий такую адресную информацию памяти.
Как показано на фигурах 8-9, каждое из различных полей может включать в себя набор битов, достаточный для указания адреса регистра или в другой области хранения, которое имеет операнды. Биты полей могут быть непрерывными и/или фрагментированными. В других вариантах осуществления, одно или более различные поля могут быть неявными для инструкции (например, неявно обозначается опкодом инструкции) вместо того, чтобы явно указать посредством поля. Альтернативные варианты осуществления могут добавить дополнительные поля или опустить некоторые поля. Дополнительно, показанный порядок/расположения полей не является обязательным. Скорее, поля могут быть переупорядочены, некоторые поля могут перекрываться и др.
В некоторых вариантах осуществления формат команды может соответствовать EVEX кодированию или формату инструкции, хотя это не обязательно. EVEX кодирование будет рассмотрен ниже. В одном варианте осуществления два унаследованных префикса могут использоваться для переопределения управления 62. Например, префикс F2 может подразумевать использование форматирования операции загрузки и VSIB. В одном варианте осуществления этот префикс F2 может быть использован для инструкции векторной индексированной загрузки плюс A/L операции, как раскрыто в данном описании. Префикс F3 может подразумевать использование форматирования операции сохранения и VSIB. В одном варианте осуществления этот префикс F3 может быть использован для инструкции векторной индексированной загрузки плюс A/L операции плюс сохранение, как раскрыто в данном описании. Например, для VADDPS кодирования:
EVEX.U1.NDS.512.0F.WO 58 /r VADDPS zmm1, {k1}, zmm2, [rax]
Инструкция сбора плюс упакованное сложение может быть выражена как:
F2.EVEX.U1.NDS.512.0F.W0 58/r и VGATHERADDPS zmm1, {k1}, zmm2, [rax+zmm3 *scale]
Инструкция сбора плюс упакованное сложение плюс разброс может быть выражена как:
F3.EVEX.U1.HCP.512.0F. W0 58 /r и VGATSCATADDPS [rax+zmm3*scale] {k1}, zmm1, zmm2
zmm1, zmm2 и zmm3 относятся к 512-битным регистрам упакованных данных, {k1} представляет собой 64-разрядный регистр маски. Rax представляет собой целое число регистров общего назначения, используемые для удержания адресной информации памяти. Эти примеры являются просто иллюстративными примерами подходящих кодировок. Объем изобретения не ограничивается этими кодировками.
Для дополнительной иллюстрации определенных понятий, рассмотрим несколько примеров подходящих форматов упакованных данных. 128-битный формат упакованного слова является 128-битной шириной и включает в себя восемь 16-разрядных элементов данных слова. 128-битный формат упакованного двойного слова является 128 битами и содержит четыре 32-битные элементы данных двойного слова. 128-разрядный формат 846 упакованного учетверенного слова является 128 битами и содержит два 64-разрядных элемента данных учетверенного слова. 256-битный формат упакованного слова является 256-битной шириной и включает в себя шестнадцать 16-разрядных элементов данных слова. 256-битный формат 850 двойного слова является 256 битами и включает в себя восемь 32-битных элемента данных двойного слова. 256-разрядный формат упакованного учетверенного слова является 256 битами и включает в себя четыре 64-разрядных элемента данных учетверенного слова. 512-битный формат упакованного слова представляет собой 512-битовую ширину и включает в себя тридцать два 16-разрядных элементов данных слова. 512-битный формат упакованного двойного слова представляет собой 512-бит и содержит шестнадцать 32-битных элемента данных двойного слова. 512-битный формат упакованного учетверенного слова представляет собой 512-бит и включает в себя восемь 64-битных элементов данных учетверенного слова. Другие форматы упакованных данных могут включать в себя форматы упакованных 32-бит с плавающей точкой одинарной точности или форматы упакованные 64-битные двойной точности с плавающей точкой. Любой другой размер элемента данных (например, более широкие или более узкие), пригодный для инструкций сбора и/или разброса, также подходят. Кроме того, более широкие или более узкие ширины упакованных данных также подходят, такие как, например, 64-разрядные упакованные данные, 1024-разрядные упакованные данные и др. Как правило, число элементов упакованных данных равно размеру в битах упакованных данных, разделенного на размер в битах элементов упакованных данных.
Фиг. 10 представляет блок-схему примера варианта осуществления конкретного подходящего набора регистров 1012 упакованных данных. Иллюстрированные регистры упакованных данных включают в себя тридцать два 512-разрядных регистров упакованных данных или векторных регистров. Эти тридцать два 512-разрядных регистры обозначены как с ZMM0 по ZMM31. В показанном варианте осуществления 256-биты младшего разряда нижних шестнадцать из этих регистров, а именно ZMM0 по ZMM15 имеют псевдоним или накладываются на соответствующие 256-битные регистры упакованных данных или векторные регистры, обозначенные как YMM0-YMM15, хотя это не обязательно. Кроме того, в показанном варианте осуществления 128-биты младшего разряда YMM0-YMM15 имеют псевдоним или накладываются на соответствующие 128-разрядные регистры упакованных данных или векторные регистры, обозначенные как ХММ0-ХММ1, хотя это также не требуется. 512-битные регистры с ZMM0 по ZMM31 выполнены с возможностью удерживать 512-разрядные упакованные данные, 256-битные упакованные данные или 128-разрядные упакованные данные. 256-битные регистры с YMM0-YMM15 выполнены с возможностью удерживать 256-битные упакованные данные или 128-разрядные упакованные данные. 128-битные регистры от ХММ0-ХММ1 выпилены с возможностью удерживать 128-битные упакованные данные. Каждый из регистров может использоваться для хранения упакованных данных с плавающей запятой или целочисленных упакованных данных. Другие размеры элемента данных поддерживаются, включая в себя, по меньшей мере, 8-битный байт данных, 16-битное слово данных, 32-битное двойное слово, данные с плавающей точкой одинарной точности, 64-разрядное учетверенное слово и данные с плавающей точкой двойной точности. Альтернативные варианты осуществления подходящих регистров упакованных данных могут включать в себя разное количество регистров, различные размеры регистров, может или не может задавать псевдоним большим регистрам на малых регистрах и может или не может также использоваться для данных с плавающей запятой.
Фиг. 11 представляет блок-схему примера варианта осуществления конкретного подходящего набора регистров 1118 маскированных упакованных данных. Каждый из регистров маскированных упакованных данных может использоваться для хранения маскированных упакованных данных. В иллюстрируемом варианте осуществления выполнения набор включает в себя восемь регистров упакованных данных операции маскировки, обозначенных как с k0 по k7. Альтернативные варианты осуществления могут включать в себя либо меньше чем восемь (например, два, четыре, шесть и т.д.) или больше, чем восемь (напр., шестнадцать, двадцать, тридцать два и т.д.) регистров упакованных данных операции маскировки. В показанном варианте осуществления, каждый из регистров упакованных данных операции маскировки является 64-битным. В альтернативных вариантах осуществления, величины ширин регистров упакованных данных операции маскировки могут быть либо шире, чем 64-бит (например, 80-бит, 128-бит и др.) или уже, чем 64-бит (например, 8-бит, 16-бит, 32-бит и т.д.). Например, инструкция может использовать три бита (например, 3-битовое поле) для кодирования или указания любого из восьми регистров с k0 по k7 упакованных данных операции маскировки. В альтернативных вариантах осуществления, либо меньшее или большее число битов может быть использовано, когда есть меньше или больше регистров упакованных данных операции маскировки, соответственно.
Фиг. 12 представляет собой схему, иллюстрирующую пример конкретного пригодного 64-разрядного регистра 1218 упакованных данных операции маскировки, и иллюстрирующую, что число битов, используемых как упакованные данные операции маскировки и/или для маскировки, зависит от ширины упакованных данных и ширины элемента данных. Иллюстрированный регистр маски является 64-битным, хотя как говорилось выше, это не требуется. Как правило, когда используется один бит управления для маскировки элемента, то число битов, используемых для маскировки, равно ширине упакованных данных в битах, деленной на ширину элемента упакованных данных в битах. Для дополнительной иллюстрации рассмотрим несколько возможных примеров вариантов осуществления. Только 8-бит, например, только младшие 8 бит могут быть использованы для 256-разрядных упакованных данных, имеющие 32-разрядные элементы данных. Только 16-бит, например, только младшие 16-бит могут быть использованы либо для 512-битных упакованных данных, имеющие 32-разрядные элементы данных. Только 32-бит, например, только младшие 32-бита могут использоваться либо для 1024-разрядных упакованных данных, имеющие 32-разрядные элементы данных. Все 64-биты могут быть использованы для 1024-разрядных упакованных данных, имеющие 16-разрядные элементы данных.
Как было описано выше, векторные операции вертикального типа были выделены для облегчения иллюстрации и описания, хотя объем изобретения этим не ограничен. Любой из вариантов осуществления, описанный здесь, использующий векторные операции вертикального типа, может быть изменен для другой векторной операции невертикального типа (например, часть вертикального и часть горизонтального типа операции, операции на более чем паре соответствующих элементов вертикально расположенных данных и др.).
В других вариантах осуществления, вместо инструкции, использующие одну арифметическую и/или логическую операцию (например, операцию упакованного умножения или упакованного сложения), вариант осуществления инструкции может включать в себя несколько различных арифметических и/или логических операций, которые будут выполняться последовательно. Например, после того, как операция векторной индексированной загрузки, первая арифметическая и/или логическая операция могут быть выполнены, как описано здесь в другом месте, затем вторая арифметическая и/или логическая операция может возможно выполняться, используя результат первой арифметической и/или логической операции и потенциально другие данные, и затем результаты второй арифметической и/или логической операции могут быть сохранены в памяти.
Компоненты, признаки и детали, описанные для любых фигур 3 и 5-12, могут также возможно использоваться в любых чертежах 1-2 и 4. Кроме того, компоненты, признаки и детали, описанные в настоящем документе для любого устройства, могут также возможно использоваться в любом из способов, описанных в данном документе, который в вариантах осуществления может быть выполнен посредством и/или с таким устройством.
Набор инструкций включает в себя один или несколько форматов инструкции. Данный формат инструкции определяет различные поля (число битов, расположение битов) для указания, среди прочего, операции (опкод), которые должны быть выполнены, и операнд(ы), на которых данная операция может быть выполнена. Некоторые форматы инструкций дополнительно подвергаются дальнейшей разбивке для определения шаблонов инструкций (или подформатов). Например, шаблоны инструкции заданного формата инструкции могут быть определены для различных подмножеств полей формата инструкции (полей расположенных, как правило, в том же порядке, но, по меньшей мере, некоторые имеют различные битовые позиции, поскольку есть меньше полей) и/или определенное заданное поле должно интерпретироваться иначе. Таким образом, каждая инструкция ISA выражается, используя данный формат инструкции (и, если определен заданный один из шаблонов инструкций формата инструкции) и включает в себя поля для указания операции и операндов. Например, примерная инструкция ADD имеет конкретный опкод и формат инструкции, который включает в себя поле кода операции, чтобы указать, что код операции и поля операнда для выбора операндов (источник 1 / адресат и источник 2); и появление инструкции ADD в потоке инструкций будет иметь конкретный контент в полях операнда для выбора конкретных операндов. Набор SIMD расширений, упомянутых в векторных расширениях набора команд (AVX) (AVX1 и AVX2), и с использованием схемы кодирования векторных расширений (VEX), был выпущен и/или опубликован (см., например, справочник Intel® 64 и IA-32 разработчиков архитектуры программного обеспечения, октябрь 2011 г.; и см. справочник по программированию Intel® Векторные расширения набора команд, июнь 2011).
Форматы иллюстративной инструкции
Варианты осуществления инструкции(й), описанные здесь, могут быть реализованы в разных форматах. Кроме того, далее приводится подробное описание иллюстративной системы, архитектуры и конвейера. Варианты осуществления инструкции(й) могут быть выполнены на таких системах, архитектурах и конвейерах, но не ограничиваются ими.
Общий векторный дружественный формат инструкции
Векторный дружественный формат инструкции представляет собой формат инструкции, который подходит для векторных инструкций (например, есть определенные поля для векторных операций). Описанные варианты осуществления, в которых как векторные, так и скалярные операции поддерживаются посредством векторного дружественного формата инструкции, альтернативные варианты осуществления используют только векторные операции векторного дружественного формата инструкции.
Фигуры 13А-13В являются блок-схемами, иллюстрирующие общий векторный дружественный формат инструкции и шаблоны инструкции согласно вариантам осуществления изобретения. Фиг. 13А показывает блок-схему, иллюстрирующую общий векторный дружественный формат инструкции и шаблоны инструкции класса А согласно вариантам осуществления изобретения; фиг. 13В показывает блок-схему, иллюстрирующую общий векторный дружественный формат инструкции и шаблоны инструкции класса В согласно вариантам осуществления изобретения. В частности, общий векторный дружественный формат инструкции 1300, для которого определяются шаблоны инструкции класса А и класса В, оба включают в себя шаблоны инструкции без доступа 1305 к памяти и шаблоны инструкции с доступом 1320 к памяти 1320. Термин общий в контексте векторного дружественного формата инструкции относится к формату инструкции, не будучи привязанным к какому-либо конкретному набору инструкций.
Варианты осуществления изобретения будут описаны, в которых векторный дружественный формат инструкции поддерживает следующие: 64 байтную длину векторного операнда (или размер) с 32 битной (4 байт) или 64 битной (8 байт) шириной элемента данных (или размера) (и, таким образом, 64 байтовый вектор состоит из либо 16 элементов двойного слова или, альтернативно, 8 элементов учетверенного слова); 64 байтная длина векторного операнда (или размер) содержит 16 бит (2 байта) или 8 бит (1 байт) ширину элемента данных (или размера); 32-байтовая длина векторного операнда (или размер) содержит 32 бит (4 байт), 64 бит (8 байт), 16 бит (2 байта) или 8 бит (1 байт) ширину элементов данных (или размер); и 16 байтная длина векторного операнда (или размер) содержит 32 бит (4 байт), 64 бит (8 байт), 16 бит (2 байт) или 8 бит (1 байт) ширину элементов данных (или размер); альтернативные варианты осуществления могут поддерживать больше, меньше и/или различные размеры векторных операндов (например, 256 байтные векторные операнды) с более, менее или другой шириной элементов данных (например, 128 бит (16 байт) шириной элемента данных).
Шаблоны инструкции класса А на фиг. 13А включают в себя: 1) в пределах шаблонов инструкции без доступа 1305 к памяти, где проиллюстрировано отсутствие доступа к памяти, полный цикл шаблона инструкции операции 1310 управления без доступа к памяти, шаблон инструкции операции 1315 преобразования данных; и 2) в пределах шаблонов инструкции с доступом 1320 к памяти, где показаны с доступом к памяти, временной 1325 шаблон инструкции с доступом к памяти и невременной 1330 шаблон инструкции. Шаблоны инструкции класса В на фиг. 13В включают в себя: 1) в пределах шаблонов инструкции без доступа 1305 к памяти, показаны без доступа к памяти, шаблон инструкции операции 1312 записи маски, частичного цикла управления без доступа к памяти и шаблон инструкции операции 1317 управления записью маски, vsize; и 2) в пределах шаблонов инструкции с доступом 1320 к памяти, где показаны с доступом к памяти, шаблон инструкции управления 1327 записью маски.
Общий векторный дружественный формат 1300 инструкции включает в себя следующие поля, приведенные ниже в порядке, как это проиллюстрировано на чертежах 13А-13В.
Поле 1340 формата - конкретное значение (значение идентификатора формата инструкции), в этом поле однозначно определяется векторный дружественный формат инструкции, и таким образом, обеспечивается указание на инструкции в векторном дружественном формате инструкции в потоках инструкций. Таким образом, данное поле является возможным, в том смысле, что оно не требуется для набора инструкций, который имеет только общий векторный дружественный формат инструкции.
Поле 1342 базовой операции - его содержание выделяет различные базовые операции.
Поле 1344 индекса регистра - его содержание напрямую или посредством генерирования адреса, указывает местоположения исходного операнда и операнда назначения, будь то в регистрах или в памяти. Они включают в себя достаточное количество битов, чтобы выбрать N регистров из P×Q (например 32×512, 16×128, 32×1024, 64×1024) файла регистра. В то время, как в одном варианте N может быть до трех источников и один регистр назначения, альтернативные варианты осуществления могут поддерживать более или менее источников и регистров назначения (например, может поддерживать до двух источников, где один из этих источников также выступает в качестве адресата, может поддерживать до трех источников, где один из этих источников также выступает в качестве адресата, может поддерживать до двух источников и один адрес назначения).
Поле 1346 модификатора - ее содержание отличает присутствие инструкций в общем векторном формате инструкции, который определяет доступ к памяти из тех, что не имеют; то есть, между шаблонами инструкций без доступа 1305 к памяти и шаблонами инструкций с доступом 1320 к памяти. Обеспечивается доступ к памяти операции чтения и/или записи в иерархии памяти (в некоторых случаях с указанием источника и/или адреса назначения с помощью значений в регистрах), в то время, как операции без доступа к памяти не имеют (например, источник и адресат являются регистрами). В то время, как в одном варианте осуществления это поле также выбирает между тремя различными способами выполнять вычисления адреса памяти, альтернативные варианты осуществления могут поддерживать больше, меньше или различные способы выполнения вычисления адресов памяти.
Поле 1350 добавления операции - его содержание указывает, которая одна из множества различных операций будет выполняться в дополнение к базовой операции. Это поле всегда привязано к конкретному контексту. В одном варианте осуществления изобретения, данное поле разделено на поле 1368 класса, альфа-поле 1352 и бета-поле 1354. Поле 1350 добавления операции позволяет выполняться общими группами операций в одной инструкции, а не в 2, 3 или 4 инструкциях.
Поле 1360 масштаба - его содержание обеспечивает масштабирование контента индексного поля для генерирования адреса памяти (например, для генерирования адреса, который использует 2 масштаб * индекс + база).
Поле 1362А перестановки - его содержимое используется как часть генерирования адреса памяти (например, для генерирования адреса, который использует 2масштаб * индекс + база + перестановка).
Поле 1362В коэффициента перестановки (обратите внимание, что наложение поля 13 62А перестановки напрямую на поле 1362В коэффициента перестановки указывает на то, что используется один или другой) - его содержимое используется как часть генерации адресов; это указывает на коэффициент перестановки, который должен масштабироваться по размеру доступа (N) к памяти - где N-это число байтов доступа к памяти (например, для генерации адресов, где используется 2 масштаб * индекс + база + масштабируемая перестановка). Избыточные младшие биты игнорируются и, следовательно, контент поля коэффициента перестановки умножается на общий размер (N) операндов памяти в целях получения окончательной перестановки, которая может использоваться для вычисления эффективного адреса. Значение N определяется процессором во время работы на основе поля 1374 полного опкода (описано далее в настоящем документе) и поля 1354С манипулирования данными. Поле 1362А перестановки и поле 1362В коэффициента перестановки являются возможными, в том смысле, что они не используются для шаблонов инструкции без доступа 1305 к памяти и/или различные варианты осуществления могут реализовать только один или ни одного из двух.
Поле 1364 ширины элемента данных - его содержание отличает одну ширину элементов данных от другой, которая будет использоваться (в некоторых вариантах осуществления для всех инструкции; в других вариантах осуществления только для некоторых инструкций). Это поле является возможным, в том смысле, что оно не нужно, если поддерживается только одна ширина элемента данных и/или ширины элементов данных поддерживаются, используя некоторый аспект опкодов.
Поле 1370 записи маски - его контент осуществляет управление на каждой базовой позиции элемента данных так, что позиция элемента данных в векторного операнда адресата отражает результат базовой операции и операции добавления. Шаблоны инструкции класса А поддерживают слияние-запись маски, в то время, как шаблоны инструкции класса В поддерживают как слияние, так и обнуление-записи маски. При слиянии, векторные маски позволяют любому набору элементов в адресате быть защищенным от обновлений во время выполнения любой операции (указанной базовой операцией и операцией добавления); в другом варианте осуществления, сохранение прежнего значения каждого элемента адресата, где соответствующий бит маски имеет 0. В отличие от этого, при обнулении векторные маски позволяют любому набору элементов в адресате быть обнуленным во время выполнения любой операции (указанная базовой операцией и операцией добавления); в одном варианте осуществления элемент адресата устанавливается на 0, когда соответствующий бит маски имеет значение 0. Подмножество функциональности предоставляет возможность управлять векторной длинной выполняемой операции (то есть, диапазон элементов изменяется, от первого до последнего); однако, не обязательно, чтобы элементы, которые изменены, были последовательными. Таким образом, поле 1370 записи маски обеспечивает частичные векторные операции, включающие в себя загрузку, сохранение, арифметические операции, логические операции и др. Хотя варианты осуществления изобретения описаны с учетом того, что контент поля 1370 записи маски выбирает один из ряда используемых регистров записи маски, содержащий запись маски (и соответственно, контент поля 1370 записи маски косвенно определяет, что маскировка будет выполнена), альтернативные варианты осуществления вместо, или дополнительно, обеспечивают возможность контенту поля 1370 записи маски напрямую указать маскировку, которая должна быть выполнена.
Поле 1372 с непосредственным опрандом - его содержание учитывает спецификацию с непосредственным операндом. Это поле является возможным, в том смысле, что оо не учитывается при использовании общего векторного дружественного формата, который не поддерживает непосредственный операнд и его нет в инструкции, что не используется в данный момент.
Поле 1368 класса - его содержание различает разные классы инструкций. Со ссылками на фиг. 13А-В, контент этого поля выбирает между инструкцией класса А и класса В. На фигурах 13А-В, квадраты с закругленными углами используются для указания конкретного значения в поле (например, класс А 1368А класс В 1368В для поля 1368 класса, соответственно на фигурах 13А-В).
Шаблоны инструкции класса А
В случае использования шаблонов инструкции без доступа 1305 к памяти класса А, альфа-поле 1352 интерпретируется как RS поле 1352А, содержание которого отличает который один из различных типов операции добавления будет выполнен (например, квадраты с округлыми углами 1352А.1 и преобразования 1352А.2 данных соответственно указан для отсутствия доступа к памяти, округленный тип операции 1310 и без доступа к памяти, шаблоны инструкции операции 1315 преобразования данных) в то время, как бета-поле 1354 отличает, какая из операций указанного типа должна быть выполнена. В шаблонах инструкции без доступа 1305 к памяти, отсутствуют поле 1360 масштаба, поле 1362А перестановки и поле 1362В коэффициента перестановки.
Шаблоны инструкции без доступа к памяти - операция управления полного округления
В шаблоне инструкции операции 1310 управления полного округления без доступа к памяти, бета-поле 1354 интерпретируется как поле 1354А управления, чей контент предоставляет статическое округление. В то время, как в описанных вариантах осуществления изобретения поле 1354А управления округлением включает в себя подавление всех исключений с плавающей точкой (SAE) поля 1356 и поля 1358 управления округлением, альтернативные варианты осуществления могут поддерживать кодирование обоих этих данных в том же поле или иметь только одни или другие из этих данных/полей (например, могут иметь только поле 1358 операции управления округлением).
SAE поле 1356 - его содержание отличает следует ли отключить исключение события отчетности; когда контент SAE поля 1356 указывает на включение подавления, то заданная инструкция не направляет информацию о любом типе флага исключения с плавающей точкой и не вызывает обработчика исключений с плавающей точкой.
Поле 1358 управления операцией округления - его содержание отличает, которая одна из групп операций округления выполняется (например, округление с повышением, округление с понижением, округление к нулю и округление к ближайшему). Таким образом, поле 1358 управления операцией округления позволяет изменять режим округления для каждой инструкции. В одном варианте осуществления изобретения, где процессор содержит регистр управления для определения режима округления, контент поля 1350 операции управления округления переопределяет значение регистра.
Шаблоны инструкции без доступа к памяти - Тип операции преобразования данных
В шаблонах инструкции операции 1315 преобразования данных без доступа к памяти, бета-поле 1354 интерпретируется как поле 1354В преобразования данных, чей контент отличает одни из множества данных, которые должны быть преобразованы (например, без преобразования данных, выборка, трансляция).
В случае шаблона инструкции с доступом 1320 к памяти класса А, альфа-поле 1352 интерпретируется как поле 1352 В замещения подсказки, чей контент отличает какие подсказки будут использоваться (на фиг. 13А, временный 1352В.1 и невременный 1352В.2 соответственно, указанный для доступа к памяти временный 1325 шаблон инструкции, с доступом к памяти невременный 1330 шаблон инструкции), в то время как бета-поле 1354 интерпретируется как поле 1354С манипуляции данных, чей контент отличает одну операцию манипулирования данными (также известных как примитивы), которая должна быть выполнена (например, отсутствие манипуляций; трансляция; преобразование источника с повышением; преобразование адресата с понижением). Шаблоны инструкции с доступом 1320 к памяти включают в себя поле 1360 масштаба, и возможно, поле 1362А перестановки или поле 1362В коэффициента перестановки.
Векторные инструкции памяти выполняют векторные загрузки и векторное сохранение в памяти, с поддержкой преобразования. Как с помощью регулярных векторных инструкций, векторные инструкции памяти передают данные в/из памяти поэлементно, с элементами, которые фактически передаются, как указано контентом векторной маски, выбранный, как запись маски.
Шаблоны инструкции с доступом к памяти - Временной
Временные данные - это данные, которые, скорее всего, будут повторно использоваться достаточно быстро, чтобы извлечь выгоду от кэширования. Это, однако, является подсказкой, и разные процессоры могут реализовывать это по-разному, в том числе игнорировать подсказку полностью.
Шаблоны инструкции с доступом к памяти - Невременной
Невременные данные являются данными, которые вряд ли могут быть повторно использованы достаточно скоро, чтобы извлечь выгоду от кэширования и 1-го уровня кэша, и должны иметь приоритет для замещения. Однако, эту подсказку разные процессоры могут реализовывать по-разному, в том числе игнорировать подсказку полностью.
Шаблоны инструкции класса В
В случае шаблонов инструкции класса В, альфа-поле 1352 интерпретируется, как поле 1352С управления (Z) записи маску, содержание которого отличает, следует ли выполнить слияние или обнуление поля 1370 записи маски, которое управляет записью маски.
В случае шаблонов инструкции без доступа 1305 к памяти класса В, часть бета поля 1354 интерпретируется, как RL поле 1357А, содержание которого отличает, который один из различных типов операции добавления будет выполнен (например, округление 1357А.1 и векторная длина (VSIZE) 1357А.2 соответственно, как указано для отсутствия доступа к памяти, управления записи маски, шаблона инструкции операции 1312 управления частичного округления и без доступа к памяти, управление записи маски, шаблон инструкции VSIZE тип операции 1317), остальное бета поле 1354 отличает, какие из операций указанного типа должны быть выполнены. В шаблонах инструкции без доступа 1305 к памяти, поле 1360 масштаба, поле 1362А перестановки и поле 1362В коэффициента перестановки отсутствуют.
Без доступа к памяти, управление записи маски, шаблоны инструкции операции 1310 управления частичного округления, остальное бета поле 1354 интерпретируются, как поле 1359А операции округления и исключение отчетного события отключено (данная инструкция не сообщает о любом типе флага исключения с плавающей точкой и не вызывает каких-либо операций с плавающей запятой).
Поле 1359А управления операцией округления - просто как поле 1358 управления операцией округления, его содержание отличает, которая одна из групп операций округления будет выполнена (например, округление с повышением, округление с понижением, округление к нулю и округление к ближайшему). Таким образом, поле 1359А управления операцией округления позволяет изменять режим округления для инструкции. В одном варианте осуществления изобретения, в котором процессор содержит регистр управления для определения режима округления, контент поля 1350 управления операцией округления переопределяет значение регистра.
Без доступа к памяти, управление записи маски, шаблон инструкции VSIZE типа операции 1317, остальное бета поле 1354 интерпретируются, как поле 1359В длины вектора, чей контент отличает, которая одна из ряда данных векторных длин будет выполнена (например, 128, 256 или 512 байт).
В случае шаблона инструкции с доступом 1320 к памяти класса В, часть бета поля 1354 интерпретируется, как поле 1357В трансляции, содержание которого отличает будет или нет выполнена операция манипуляции данных относительно вещания, в то время как остальная часть бета поля 1354 интерпретируется, как поле 1359В векторной длины. Шаблоны инструкции с доступом 1320 к памяти включают в себя поле 1360 масштаба и возможно поле 1362А перестановки или поле 1362В коэффициента перестановки.
Что касается общего векторного дружественного формата 1300 инструкции, то поле 1374 полного опкода показано, как включающее в себя и поле 1340 формата, поле 1342 базовой операции и поле 1364 ширины элемента данных. При одном варианте осуществления показано, где поле 1374 полного опкода включает в себя все эти поля, поле 1374 полного опкода включает в себя меньше, чем все эти поля в вариантах осуществления, которые не поддерживают их все. Поле 1374 полного опкода обеспечивает код операции (опкод).
Поле 1350 добавления операции, поле 1364 ширины элемента данных и поле 1370 записи маски обеспечивают эти признаки, указываемые для каждой инструкции в общем векторном дружественном формате инструкции.
Сочетание поля записи маски и поля ширины элемента данных формирует типизированные инструкции, что позволяют применять маскировку на основании различных значений ширины элемента данных.
Различные шаблоны инструкции находятся в пределах класса А и класса В, что являются полезным в различных ситуациях. В некоторых вариантах осуществления изобретения, различные процессоры или различные ядра в процессоре могут поддерживать только класс А, только класса В или оба класса. Например, ядро высокой производительности общего назначения с выполнением с изменением последовательности команд, предназначенный для вычислений общего назначения, может поддерживать только класса В, ядро, предназначенное в первую очередь для графики и/или научных вычислений, может работать только в классе А, и ядро, предназначенное для обоих случаев, может поддерживать оба класса (конечно, ядро, которое имеет определенный набор шаблонов и инструкции от обоих классов, но не все шаблоны и инструкции от обоих классов, входит в компетенцию изобретения). Также, один процессор может включать в себя несколько ядер, которые поддерживают один и тот же класс, или разные ядра, которые поддерживают разные классы. Например, в процессоре с отдельной графикой и ядрами общего назначения, один из графических ядер, предназначенных в первую очередь для графики и/или научных вычислений, может поддерживать только класс А, в то время, как одно или более ядер общего назначения может быть ядром высокой производительности общего назначения с выполнением с изменением последовательности команд, и переименование регистра, предназначенное для вычислений общего назначения, поддерживающий только класса В. Еще один процессор, который не имеет отдельного графического ядра, может включать в себя одно и более ядер общего назначения упорядоченного выполнения команд или с изменением последовательности выполнения команд, поддерживающих оба класса А и класса В. Конечно, признаки одного класса могут быть реализованы в другом классе в различных вариантах осуществления изобретения. Программы, написанные на языке высокого уровня, будет поставлены (например, точно в срок скомпилированы или статически компилируется) в исполняемые различные формы, включающие в себя: 1) форму, имеющую только инструкции класса(ов), поддерживаемых процессором для выполнения; или 2) форму, имеющую альтернативные подпрограммы, написанные с использованием разных сочетаний инструкций всех классов, и имеющие код управления потоком, который выбирает для выполнения подпрограммы на основе инструкции, поддерживаемой процессором, который в настоящий момент выполняет код.
Иллюстративный конкретный векторный дружественный формат инструкции
Фиг. 14А представляет собой блок-схему, иллюстрирующую примерный конкретный векторный дружественный формат инструкции согласно вариантам осуществления изобретения. Фиг. 14А показывает конкретный векторный дружественный формат 1400 инструкции, который является конкретным в том смысле, что он указывает на местоположение, размер, интерпретацию и порядок полей, а также значения некоторых из этих полей. Конкретный векторный дружественный формат 1400 инструкции может быть использован для расширения набора инструкций х86, и поэтому некоторые поля являются аналогичными или такими, как те, которые используются в существующем наборе команд х86 и расширения оного (например, AVX). Этот формат остается согласующимся с полем префикса кодирования, полем байта реального кода операции, MOD R/M поля, SIB поля, поля перестановки и полей с непосредственным операндом существующего набора инструкций х86 с расширениями. Иллюстрируются поля, показанные на фиг. 13, в котором поля на фиг. 14 сопоставлены.
Следует понимать, что, хотя варианты осуществления изобретения описаны со ссылкой на конкретный векторный дружественный формат 1400 инструкции в контексте общего векторного дружественного формата 1300 инструкции для целей иллюстрации, изобретение не ограничивается конкретным векторным дружественным форматом 1400 инструкции за исключением случаев, которые описаны в формуле изобретения. Например, общий векторный дружественный формат 1300 инструкции предполагает наличие разнообразных возможных размеров для различных полей, в то время, когда конкретный векторный дружественный формат 1400 инструкции показан, как имеющий поля определенных размеров. Как показано на конкретном примере, поле 1364 ширины элемента данных иллюстрируется в качестве одного битового поля в конкретном векторном дружественном формате 1400 инструкции, изобретение не ограничивается этим (то есть, общий векторный дружественный формат 1300 инструкции содержит другие размеры поля 1364 ширины элемента данных).
Общий векторный дружественный формат 1300 инструкции включает в себя следующие поля, приведенные ниже в порядке проиллюстрировано на фиг. 14А.
EVEX Префикс (байты 0-3) 1402 - кодируется в четырехбайтовой форме.
Поле 1340 формата (EVEX байт-0, биты [7:0]) - первый байт (байт 0 EVEX) является полем 1340 формата и содержит 0×62 (уникальное значение, используемое для различения векторного дружественного формата инструкции в одном варианте осуществления изобретения).
Второй-четвертый байт (EVEX байты 1-3) включают в себя ряд битовых полей, обеспечивающих конкретные функции.
REX поле 1405 (EVEX байт 1, биты [7-5]) - состоит из EVEX.R битового поля (EVEX байт 1, бит [7] - R), EVEX.X битовое поле (EVEX байт 1, бит [6] - X), и 1357 ВЕХ байт 1, бит[5] - В). EVEX.R, EVEX.X, и EVEX.B битовые поля обеспечивают ту же функциональность, соответствующую VEX битовым полям, и кодируются, используя Is дополнительную форму, т.е. ZMM0 кодируется как 1111B, ZMM15 кодируется как 0000 В. Другие поля инструкций кодируют младшие три бита регистра индексов, как известно в данной области техники (rrr, ххх и bbb), так что Rrrr, Хххх и Bbbb могут быть образованы путем добавления EVEX.r, EVEX.X и EVEX.B.
REX' поле 1310 - представляет собой первую часть REX' поля 1310 и является EVEX.R' битовым полем (EVEX байт 1, бит [4] - R'), которое используется для кодирования либо верхнего 16 и нижнего 16 из 32 расширенного набора регистров. В одном варианте осуществления изобретения, этот разряд, наряду с другими, как указано ниже, хранятся в инвертированном виде для отличия от (в известной х86 в 32-битном режиме) BOUND инструкции, чей байт реального опкода равен 62, но не принимает в поле MOD R/M поле (описано ниже) значение 11 в MOD поле; альтернативные варианты осуществления изобретения не хранят это и другие указанные ниже биты в инвертированном виде. Значение 1 используется для кодирования младших 16 регистров. Иными словами, R'Rrrr формируется путем объединения EVEX.R', EVEX.R м другого RRR из других полей.
Поле 1415 сопоставление опкода (EVEX байт 1, биты [3:0] - мммм) - его содержание кодирует байт подразумеваемого ведущего кода операции (OF, OF 38 или 0F3).
Поле 1364 ширины элемента данных (EVEX байт 2, бит [7] - W) - представлено нотацией EVEX.W. EVEX.W используется для определения степени детализации (размера) типа данных (либо 32-разрядные элементы данных, или 64-разрядные элементы данных).
EVEX.vvvv 1420 (EVEX байт 2, биты [6:3]-vvvv) - роль EVEX.vvvv может включать в себя следующее: 1) EVEX.vvvv кодирует первый регистр исходного операнда, указанного в инвертированной (обратный двоичный код) форме и действительно для инструкций с 2 или более исходными операндами; 2) EVEX.vvvv кодирует регистр операнда-адресата, указанного в форме обратного двоичного кода для определенных векторных смещений; или 3) EVEX.vvvv не кодирует какой-либо операнд, поле зарезервировано и должно содержать 1111b. Таким образом, EVEX.vvvv поле 1420 кодирует 4 младших бита первого спецификатора исходного регистра, хранящиеся в инвертируемой (обратный двоичный код) форме. В зависимости от инструкции, дополнительное иное EVEX битовое поле используется для расширения размера спецификатор до 32 регистров.
EVEX.U 1368 поле класса (EVEX байт 2, бит [2]-U) - если EVEX.U=0, то это указывает на класс А или EVEX.U0; если EVEX.U=1, то это указывает на класс В или EVEX.U1.
Поле 1425 префикса кодировки (EVEX байт 2, биты [1:0]-рр) - предоставляет дополнительные биты для поля базовой операции. В дополнение к предоставлению поддержки унаследованных SSE инструкций в EVEX префиксе формата, это также обеспечивает преимущество при сжатии SIMD префикса (вместо того, чтобы требовать байт для отражения SIMD префикса, EVEX префикс требует только 2 бита). В одном варианте осуществления, для поддержки унаследованных SSE инструкций, которые используют SIMD префикс (66Н, F2H, F3H) как унаследованный формат и в EVEX префиксе формата, эти унаследованные SIMD префиксы кодируются в поле кодирования SIMD префикса; и во время работы расширяются в унаследованный SIMD префикс до того, чтобы быть предоставить в PLA декодера (так PLA может выполнять оба унаследованный и EVEX формат этих унаследованных инструкций без изменений). Хотя новые инструкции могли непосредственно использовать контент поля кодировки EVEX префикса как расширение кода операции, некоторые варианты осуществления расширения в аналогичной виде для корректности, но обеспечивают для различных значений, которые должны быть указаны посредством этих унаследованных SIMD префиксов. Альтернативный вариант осуществления может перекомпоновать PLA для поддержки 2 бит SIMD префикса кодировки, и таким образом, не требуют расширение.
Альфа-поле 1352 (EVEX байт 3 бит [7] - ЕН; известно также как EVEX.EH, EVEX.rs, EVEX.RL, EVEX. Управление записи маски и EVEX.N; также показано посредством а) - как было описано ранее, это поле является конкретным контекстом.
Бета поле 1354 (EVEX байт 3, биты [6:4]-SSS, также известный как EVEX.s2-0, EVEX.r2-0, EVEX.rr1, EVEX.LLO, EVEX.LLB; также проиллюстрированы посредством βββ) - как было описано ранее, это поле всегда привязана к конкретному контексту.
REX' поле 1310 - это остаток REX' поля и является битовым полом EVEX.V' (EVEX байт 3 бит [3] - V'), которое может быть использовано для кодирования либо верхних 16 или нижних 16 из расширенного 32 набора регистров. Этот бит хранится в инвертированном виде. Значение 1 используется для кодирования младших 16 регистров. Иными словами, V'VVVV формируется путем объединения EVEX.C V' и EVEX.vvvv.
Поле 1370 записи маски (EVEX (байт 3, биты [2:0]-ккк) - его содержание определяет индекс регистра регистров записи маски, как описано ранее. В одном варианте осуществления изобретения, конкретное значение EVEX.kkk=000 означает не применять запись маски для конкретной инструкции (это может быть реализовано различными способами, включающие в себя использование устройств записи маски или аппаратного обеспечения, которое обходит устройство маскировки).
Поле 1430 реального опкода (4 байта) также известно, как байт опкода. Часть опкода указана в этом поле.
MOD R/M поле 1440 (байт 5) включает в себя MOD поле 1442, Reg поле 1444 и R/M поле 1446. Как ранее описано, контент MOD поле 1442 проводится различие между операциями с доступом к памяти и без доступа к памяти. Reg поле 1444 предназначено для использования в двух ситуациях: либо кодирование регистра операнда-адресата, или регистра исходного операнда, или рассматриваться как расширение кода операции и не используются для кодирования любого операнда инструкции. R/M поле 1446 предназначено для: кодирования операнда инструкции, ссылающийся на адрес памяти, либо кодирования либо регистра операнда-адресата, или регистра исходного операнда.
Масштаб, индекс, база (SIB) байт (6 байт) - как было описано ранее, контент поля 1350 масштаба используется для формирования адресов памяти. SIB.xxx 1454 и SIB.bbb 1456 - содержимое этих полей были ранее упомянуто с учетом индексов Хххх и Bbbb регистров.
Поле 1362А перестановки (байты 7-10) - когда MOD поле 1442 содержит 10 байтов 7-10 являются полем 1362А перестановки, и она работает так же, как унаследованные 32-бита перестановки (disp32) и работает на байте детализации.
Поле 1362В коэффициента перестановки (байт 7) - когда MOD поле 1442 содержит 01, байт 7 является полем 1362В коэффициента перестановки. Расположение этого поля, такое е же, что унаследованный х86 набор команд 8-разрядной перестановки (disp8), который работает на байте детализации. Поскольку disp8 является расширенным знаком, то он может иметь только адрес между 128 и 127 байтами смещения; относительно 64-байтовых строк кэша, disp8 использует 8 битов, которые могут быть установлены только четыре действительно полезных значений -128, -64, 0 и 64; в связи с тем, что большой диапазон часто необходим, то disp32 используется; однако, disp32 требует 4 байта. В отличие от disp8 и disp32, поле 1362 В коэффициента перестановки является переинтерпретацией disp8; при использовании поля 1362 В коэффициента перестановки, фактическое смещение определяется содержанием поля коэффициента перестановки, умноженным на размер операнда доступ (N) к памяти. Этот тип перестановки называется disp8*N. Это снижает среднюю длину команды (один байт используется для перестановки, но с гораздо большим диапазоном). Такие сжатые перестановки основаны на предположении, что эффективная перестановка кратна детализации доступа к памяти, и, следовательно, лишние младшие биты адреса смещения не должны быть закодированы. Иными словами, поле 1362В коэффициента перестановки заменяет унаследованный набор инструкций х86 8-разрядного смещения. Таким образом, поле 1362В коэффициента перестановки кодируется тем же способом, что набор х86 инструкций 8-битного смещения (так что никаких изменений в ModRM/SIB правилах кодирования нет) с единственным исключением, что disp8 перегружен в disp8*N. Иными словами, нет изменений в правилах кодирования или кодирования длин, но только в интерпретации посредством аппаратного обеспечения значения перестановки (который должен масштабировать перемещение посредством размера операнда памяти, чтобы получить байтовый адрес смещения).
Поле 1372 с непосредственным операндом работает, как описано выше.
Поле полного опкода
Фиг. 14b показывает блок-схему, иллюстрирующую поля конкретного векторного дружественного формата 1400 инструкции, что составляет поле 1374 полного опкода согласно одному варианту осуществления изобретения. В частности, поле 1374 полного опкода включает в себя поле 1340 формата, поле 1342 базовой операции и поле 1364 ширины (W) элемента данных. Поле 1342 базовой операции включает в себя поле 1425 префикса кодировки, поле 1415 сопоставления опкода и поле 1430 реального опкода.
Поле индекса регистра
Фиг. 14С показывает блок-схему, иллюстрирующую поля конкретного векторного дружественного формата 1400 инструкции, составляющие поле 1344 индекса регистра согласно одному варианту осуществления изобретения. В частности, поле 1344 индекса регистра включает в себя REX поле 1405, REX' поле 1410, MODR/M.reg поле 1444, MODR/M. r/m поле 1446, VVVV поле 1420, ххх поле 1454, и bbb поле 1456.
Поле операции добавления
Фиг. 14D показывает блок-схему, иллюстрирующую поля конкретного векторного дружественного формата 1400 инструкции, составляющие поле 1350 добавления инструкции согласно одному варианту осуществления изобретения. Когда поле 1368 класса (U) содержит 0, то это означает EVEX.U0 (класс А 1368А); если оно содержит 1, это означает EVEX.U1 (класс В 1368В). При U=0 и MOD поле 1442 содержит 11 (что означает операцию без доступа к памяти), альфа-поле 1352 (EVEX байт 3 бит [7] - ЕН) интерпретируется как rs поле 1352А. Когда rs поле 1352А содержит 1 (округленный 1352А.1), бета-поле 1354 (EVEX байт 3, биты [6:4] - SSS) интерпретируется, как поле 1354А управления округлением. Поле 1354А управления округлением включает в себя один бит SAE поля 1356 и два бита поля 1358 операции округления. Когда rs поле 1352А содержит 0 (преобразование 1352А.2 данных), бета-поле 1354 (EVEX байт 3, биты [6:4] - SSS) интерпретируется, как три бита поля 1354В преобразования данных. При U=0 и MOD поле 1442 содержит 00, 01 или 10 (что означает операцию доступа к памяти), альфа-поле 1352 (EVEX байт 3 бит [7] - ЕН) интерпретируется, как поле 1352В намека (ЕН) удаления, и бета поле 1354 (EVEX байт 3, биты [6:4]- SSS) интерпретируется, как три бита поля 1354С манипуляции данных.
При U=1, альфа-поле 1352 (EVEX байт 3 бит [7] - ЕН) интерпретируется, как поле 1352С управления (Z) записи маски. Когда U=1 и MOD поле 1442 содержит 11 (что означает, операцию без доступа к памяти), часть бета поля 1354 (EVEX байт 3 бит [4] - So) интерпретируется, как RL поле 1357А; когда в нем содержится 1 (округленный 1357А.1), то остаток бета поля 1354 (EVEX байт 3 бит [6-5] - S2-1) интерпретируется, как поле 1359А операции округления, так как когда RL поле 1357А содержит 0 (VSIZE 1357.А2), то остальное бета поле 1354 (EVEX байт 3 бит [6-5] - S2-1) интерпретируется как поле 1359В векторной длины (EVEX байт 3 бит [6-5] - S2-1). Когда U=1 и MOD поле 1442 содержит 00, 01 или 10 (что означает операцию доступа к памяти), то бета-поле 1354 (EVEX байт 3, биты [6:4] - SSS) интерпретируется, как поле 1359В векторной длины (EVEX байт 3 бит [6-5] - L1-0) и поле 1357В вещания (EVEX байт 3 бит [4] - В).
Иллюстративная архитектура регистра
Фиг. 15 представляет блок-схему архитектуры 1500 регистра согласно одному варианту осуществления изобретения. В проиллюстрированном варианте осуществления есть 32 векторных регистров 1510, которые имеют 512-битную ширину; эти регистры упоминаются, как с zmmO по zmm31. 256 бит нижнего порядка в младших 16 zmm регистров накладываются на регистры ymmO-16. 128 бит нижнего порядка младших 16 zmm регистров (128 бит нижнего порядка регистров ymm) накладываются на регистры xmmO-15. Конкретный векторный дружественный формат 1400 инструкции работает на этих наложенном наборе регистров, как показано в таблицах ниже.
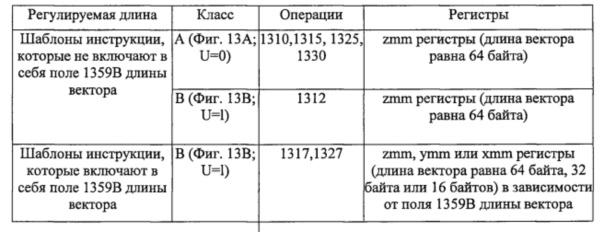
Другими словами, поле 1359В длины вектора выбирает между максимальной длиной и одной или другими более короткими длинами, где каждая такая короткая длина составляет половину длины предыдущей длины; шаблоны инструкции без поля 1359В длины вектора работает на максимальной длине вектора. Далее, в одном варианте осуществления шаблоны инструкции класса В конкретного векторного дружественного формата 1400 инструкции работают на упакованных или скалярных данных с плавающей точкой одинарной/двойной точности и упакованных или скалярных целочисленных данных. Скалярные операции представляют собой операции, выполняемые на позиции элемента данных низкого порядка в zmm/ymm/xmm регистре; позиции элемента данных более высокого порядка остаются такими же, как они были до инструкции или обнулены, в зависимости от варианта осуществления.
Регистры 1515 записи маски, в показанном варианте осуществления, имеют 8 регистров записи маски (с k0 по k7), каждый имеет размер в 64 бита. В альтернативном варианте осуществления регистры 1515 записи маски имеют 16 битный размер. Как описано выше, в одном варианте осуществления изобретения, регистр k0 вектора маски не может быть использован в качестве записи маски; когда используется кодирование, которое обычно указывается k0, для записи маски, выбирается жестко закодированная запись маски 0xFFFF, эффективно отключая запись маски для этой инструкции.
Регистры 1525 общего назначения в проиллюстрированном варианте осуществления, есть шестнадцать 64-битных регистров общего назначения, которые используются наряду с существующими х86 режимами адресации, для адресации операндов памяти. Эти регистры поименованы как RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP и с R8 по R15.
Набор 1545 стеков скалярных регистров с плавающей точкой (х87 стек), на котором используется в качестве псевдонима ММХ упакованный целочисленный плоский набор 1550 регистра - в проиллюстрированном варианте осуществления, стек х87 представляет собой восемь элементов стека, используемый для выполнения скалярных операций с плавающей точкой на 32/64/80-разрядных данных с плавающей запятой с использованием расширения х87 набора инструкций; когда ММХ регистры используются для выполнения операций над 64-битными упакованными целочисленными данными, а также выполнения операндов некоторых операций, выполняемых между ММХ и ХММ регистрами.
Альтернативные варианты осуществления изобретения могут использовать более широкие или более узкие регистры. Кроме того, альтернативные варианты осуществления изобретения могут использовать большие, меньшие или разные наборы регистров и регистры.
Примерные архитектуры ядра, процессоров и вычислительных архитектур
Ядра процесса могут быть реализованы разными способами, для разных целей и для разных процессоров. Например, варианты реализации таких ядер могут включать в себя: 1) ядро общего назначения с последовательным выполнением команд, предназначенное для вычислений общего назначения; 2) высокопроизводительное ядро общего назначения с произвольной последовательностью выполнения команд, предназначенный для вычислений общего назначения; 3) ядро специального назначения, предназначено, в первую очередь, для графики и/или научных вычислений. Варианты реализации разных процессоров могут включать в себя: 1) центральный процессор, включающий в себя одно или более ядер общего назначения с последовательным выполнением команд, предназначенные для вычислений общего назначения и/или одно или более ядер общего назначения с произвольной последовательностью выполнения команд, предназначенные для вычислений общего назначения; и 2) сопроцессор, включающий в себя одно или более ядер специального назначения, предназначенные, в первую очередь, для графики и/или научных вычислений. Наличие таких разных процессоры приводит к наличию различных архитектур вычислительных систем, которые могут включать в себя: 1) сопроцессор на отдельной микросхеме CPU; 2) сопроцессор на отдельном кристалле в одном и том же пакете как процессор; 3) сопроцессор на одном кристалле, как процессор (в этом случае, такой сопроцессор иногда называют логикой специального назначения, такие как встроенная графика и/или научная логика, или, как ядра специального назначения; и 4) система на микросхеме, которая может включать в себя тот же кристалл описанного процессора (иногда называемое ядро(а) приложения или процессор(ы) приложения), описанный выше сопроцессор, и дополнительную функциональность. Примерные архитектуры ядра описаны далее после описания примерных процессоров и компьютерных архитектур.
Иллюстративные архитектуры ядра
Блок-схема ядра с упорядоченной и изменяемой последовательностью выполнения команд
Фиг. 16А представляет собой блок-схему, иллюстрирующую примерный упорядоченный конвейер и иллюстративное переименование регистра, конвейер с выполнением изменяемой последовательностью команд согласно вариантам осуществления изобретения. Фиг. 16В представляет собой блок-схему, иллюстрирующую как иллюстративный вариант осуществления архитектуры ядра с упорядоченной последовательностью выполнения команд и иллюстративное переименование регистра, так и архитектуру ядра с выполнением изменяемой последовательностью команд, которые должны быть включены в состав процессора, согласно вариантам осуществления изобретения. Посредством сплошных линий на фигурах 16А-В показан упорядоченный конвейер и ядро с упорядоченной последовательностью выполнения команд, в то время, как возможно дополнительно пунктирной линией иллюстрируется переименование регистра, конвейер выполнения команд с измененной последовательностью и ядро. Далее приведено описание с учетом того, что аспект упорядочения выполнения команд является подмножеством аспекта выполнения команд с изменяемой последовательностью, на порядок аспект.
На фиг. 16А, процессорный конвейер 1600 включает в себя этап 1602 выборки, этап 1604 декодирования длины, этап 1606 декодирования, этап 1608 выделения, этап 1610 переименования, этап 1612 планирования (также известный, как диспетчер или выпуск), этап 1614 чтения регистра /чтения памяти, этап 1616 исполнения, этап 1618 обратной записи/записи памяти, этап 1622 обработки исключений и этап 1624 подтверждения.
Фиг. 16В показывает процессорное ядро 1690, включающее в себя блок 1630 предварительной обработки, подключенного к блоку 1650 механизма исполнения, и оба соединены с блоком 1670 памяти. Ядро 1690 может представлять собой ядро компьютера с сокращенным набором команд (RISC), ядром компьютера (CISC) со сложным набором команд, ядром с очень длинным командным словом (VLIW) или гибридным или альтернативным типом ядра. В качестве еще одного варианта, ядро 1690 может быть ядром специального назначения, таким как, например, сетевым или коммуникационным ядром, механизмом исполнения компрессии, сопроцессорным ядром, ядром графического процессора общего назначения (GPGPU), графическим ядром или тому подобное.
Блок 1630 предварительной обработки включает в себя блок 1632 предсказания ветви, соединенный с блоком 1634 кэша инструкции, который соединен с буфером 1636 (TLB) предысторий трансляции инструкции, соединенный блоком 1638 выборки инструкции, который соединен с блоком 1640 декодирования. Блок 1640 декодирования (или декодер) может декодировать инструкции и генерировать, как выходной сигнал одну или несколько микроопераций, точки входа микрокода, микроинструкции, другие инструкции или другие управляющие сигналы, которые декодируются из, или иным образом отражаются, или иным образом извлекаются из исходных инструкций. Блок 1640 декодирования может быть реализован с помощью различных механизмов. Примеры подходящих механизмов включают в себя, но не ограничиваются этим, справочные таблицы, аппаратные реализации, программируемые логические матрицы (PLAs), микрокод только для чтения памяти (ROMs) и др. В одном варианте осуществления ядро 1690 включает в себя ROM микрокода или любой другой носитель, который хранит микрокод для некоторых макроинструкций (например, в блоке 1640 декодирования или иным образом в блоке 1630 предварительной обработки). Блок 1640 декодирования соединен с блоком 1652 переименования/выделения в блоке 1650 механизма исполнения.
Блок 1650 механизма исполнения включает в себя блок 1652 переименования/выделения, соединенного с блоком 1654 удаления и с набором одного или более блоков 1656 планировщика. Блок 1656 планировщик представляет любое число различных планировщиков, включающий в себя станции резервирования, центральное окно инструкции и др. Блок(и) 1656 планировщик соединен с блоком(ми) 1658 физического набора регистров. Каждый из блоков 1658 физического набора регистров представляет собой один или более физических наборов регистров, отличного от того, который хранят один или более различных типов данных, таких как скалярное целое число, скалярное значение с плавающей точкой, упакованное целое число, упакованные с плавающей точкой, целочисленный вектор, вектор с плавающей точкой,, статус (например, указатель инструкции, являющийся адресом следующей инструкции для выполнения) и др. В одном варианте осуществления блок 1658 физического набора регистров содержит блок векторных регистров, блок регистров записи маски и блок скалярных регистров. Эти регистровые блоки могут предоставить архитектурные регистры вектора, регистры вектора маски и регистры общего назначения. Блок 1658 физического набора регистров перекрывается блоком 1654 удаления, чтобы проиллюстрировать различные способы переименования регистров и может быть реализовано выполнение с изменением последовательности команд (например, с помощью буфера(ов) переупорядочивания и набора(ов) регистров удаления; с помощью файла(ов) будущих событий, буфер(ов) истории и набора(ов) регистров удаления; используя схемы размещения регистров и пул регистров; и др.). Блок 1654 удаления и блок 1658 физического набора регистров соединены с исполнительным кластеров(ми) 1660. Исполнительный кластер(ы) 1660 включает в себя набор из одного или нескольких исполнительных блоков 1662 и набор из одной или более блоков 1664 доступа к памяти. Исполнительные блоки 1662 могут выполнять различные операции (например, сдвиги, сложение, вычитание, умножение) и на различных типах данных (например, скалярное значение с плавающей точкой, упакованное целое число, упакованное число с плавающей точкой, вектор целого числа, вектор с плавающей точкой). В то время, как некоторые варианты осуществления могут включать в себя ряд исполнительных блоков, выделенных для выполнения отдельных функций или наборов функций, другие варианты осуществления могут содержать только один исполнительный блок или несколько исполнительных блоков, которые выполняют все функции. Блок(и) 1656 планировщик, блок(и) 1658 физического набора(ов) регистров и исполнительный кластера(ы) 1660 показаны, как возможно, имеющие множественное число, потому что некоторые варианты осуществления создают отдельные конвейеры для определенных типов данных/операций (например, скалярный целочисленный конвейер, конвейер скалярного числа с плавающей запятой/упакованные целочисленные значения/упакованные числа с плавающей точкой/вектор целого числа/вектор с плавающей точкой и/или конвейер доступа к памяти, что каждый имеет свой собственный блок планировщик, блок физического набора регистров и/или исполнительный кластер - и в случае отдельного конвейера доступа к памяти, реализуются некоторые варианты осуществления, в которых только исполнительный кластер этого конвейера имеет блок(и) 1664 доступа к памяти). Следует также понимать, что когда используются отдельные конвейеры, то один или более из этих конвейеров может быть конвейером с выполнением с изменением последовательности команд и остальные упорядоченными конвейерами.
Набор блоков 1664 доступа к памяти соединен с блоком 1670 памяти, который включает в себя блок 1672 TLB данных, соединенный с блоков 1674 кэша данных, соединенный с блоком 1676 кэша 2 уровня (L2). В одном примерном варианте осуществления блок 1664 доступа к памяти может включать в себя блок загрузки, блок хранения адреса и блок хранения данных, каждый из которых соединен с блоком 1672 TLB данных в блоке 1670 памяти. Блок 1634 кэша инструкции дополнительно соединен с блоком 1676 кэша 2 уровня (L2) в блоке 1670 в памяти. Блок 1676 кэша L соединен с одним или более других уровней кэша и в конечном итоге к основной памяти.
Например, примерная архитектура переименования регистра, архитектура ядра выполнения с изменением последовательности команд может реализовать конвейер 1600 следующим образом: 1) выборка 1638 инструкции реализует этапы 1602 и 1604 выборки и декодирование длины; 2) блок 1640 декодирования выполняет этап 1606 декодирования; 3) блок 1652 переименования/выделения осуществляет этап 1608 выделения и этап 1610 переименование; 4) блок(и) 1656 планировщик выполняет этап 1612 планирования; 5) блок(и) 1658 физического набора(ов) регистров и блок 1670 памяти выполняют этап 1614 чтения регистра/чтения памяти; исполнительный кластер 1660 выполняет этап 1616 исполнения; 6) блок 1670 памяти и блок(и) 1658 физического набора(ов) регистров выполняют этап 1618 обратной записи/записи памяти; 7) различные блоки могут быть вовлечены в обработку исключений на этапе 1622; и 8) блок 1654 удаления и блок(и) 1658 физического набора(ов) регистров выполняют этап 1624 подтверждения.
Ядро 1690 может поддерживать один или более наборов инструкций (например, набор инструкций х86 (с некоторыми расширениями, которые были добавлены новыми версиями); MIPS набор инструкций и MIPS Technologies of Sunnyvale, CA; ARM набор инструкций (с возможностью дополнительных расширений, таких как NEON) ARM Holdings of Sunnyvale, CA), включающий в себя инструкцию(и), описанные в настоящем документе. В одном варианте осуществления, ядро 1690 включает в себя логику, чтобы поддержать набор команд расширения упакованных данных (например, AVX1, AVX2), тем самым, позволяя операциям, используемыми многими мультимедийными приложениями, выполняться с использованием упакованных данных.
Следует понимать, что ядро может поддерживать многопоточность (выполнение двух или более параллельных множеств операций или потоков) и может сделать это разными способами, включающие в себя многопоточность с квантованием по времени, одновременную многопоточность (где, одно физическое ядро обеспечивает логическое ядро для каждого из потоков, что физическое ядро обеспечивает одновременную многопоточность) или их комбинации (например, выборка с квантованием по времени и декодирование и одновременная многопоточность в дальнейшем, например, как Intel® гиперпотоковая технология).
В то время как переименование регистра описывается в контексте выполнения с изменением последовательности команд, следует понимать, что переименование регистра может быть использовано в упорядоченной архитектуре. В то время, как иллюстрируемый вариант осуществления процессора также включает в себя блоки 1634/1674 кэша отдельных инструкций и данных и блок 1676 кэш общего L2, альтернативные варианты осуществления могут иметь один внутренний кэш для инструкций и данных таких, как например, внутренний кэш первого уровня (L1) или внутренний кэш нескольких уровней. В некоторых вариантах осуществления система может включать в себя комбинацию внутреннего и внешнего кэша, что является внешним по отношению к ядру и/или процессору. Альтернативно, все кэш может быть внешним по отношению к ядру и/или процессору.
Конкретная примерная архитектура упорядоченного ядра
Фигуры 17А-В иллюстрируют блок-схему более конкретной примерной архитектуры упорядоченного ядра, где ядро будет одним из нескольких логических блоков (включающие в себя другие ядра того же типа и/или разных типов) в микросхеме. Логические блоки взаимодействуют посредством широкополосного сетевого соединения (например, кольцевой сети) с некоторой логикой фиксированной функции, I/O интерфейсами памяти и другие необходимыми I/O логическими блоками, в зависимости от приложения.
Фиг. 17А показывает блок-схему одного ядра процессора, вместе с его подключением к сети 1702 и с локальным подмножеством кэш 1704 уровня 2 (L2), согласно вариантам осуществления изобретения. В одном варианте осуществления декодер 1700 инструкции поддерживает набор команд х86 с расширением набора инструкций упакованных данных. L1 кэш 1706 обеспечивает доступ к кэш-памяти с низкой задержкой в скалярных и векторных блоках. В то время, как в одном варианте осуществления (упрощение конструкции), скалярный блок 1708 и векторный блок 1710 используют отдельные наборы регистров (соответственно, скалярные регистры 1712 и векторные регистры 1714) и данные, передаваемые между ними, записываются в память и считываются обратно в из кэш 1706 1-го уровня (L1), альтернативные варианты осуществления изобретения могут использовать разные подходы (например, использовать один набор регистров или включать в себя канал связи, который позволяет передавать данные между двумя наборами регистров без записи и обратного считывания).
Локальное подмножество L2 кэш 1704 является частью глобального L2 кэш, которая делится на отдельные локальные подмножества, по одному на ядро процессора. Каждый процессор имеет прямой доступ к собственному локальному подмножеству L2 кэш 1704. Данные, считанные процессорным ядром, хранятся в его L2 кэш подмножестве 1704 и могут быть обработаны быстрее, параллельно с другими процессорными ядрами, имеющими доступ к их собственному локальному L2 кэш подмножеству. Данные, записанные процессорным ядром, хранятся в собственном L2 кэш подмножестве 1704 и очищаются из других подмножеств, в случае необходимости. Кольцевая сеть обеспечивает согласованность с общими данными. Кольцевая сеть является двунаправленной, чтобы позволить агентам, таким как процессорные ядра, L2 кэш и другие логические блоки взаимодействовать друг с другом в пределах микросхемы. Каждый кольцевой тракт данных имеет 1012-бит ширину в каждом направлении.
Фиг. 17В представляет собой развернутый вид части процессорного ядра, показанного на фиг. 17А, согласно вариантам осуществления изобретения. Фиг. 17В включает в себя кэш 1706А данных L1 часть кэша 1704 L1, а также более подробное описание векторного блока 1710 и векторных регистров 1714. В частности, векторный блок 1710 является блоком (VPU) обработки вектора, имеющий 16-битовую ширину (см. 16-ти битный ALU 1728), который выполняет одну или более инструкции целого числа, с плавающей точкой одиночной точности и с плавающей точкой с двойной точностью. VPU поддерживает сквизлинг регистра, поступившего на вход, посредством блока 1720 сквизлинга, числовые преобразования посредством блоков 1722А-В числового преобразования и репликацию, используя блок 1724 репликации на входном сигнале памяти. Регистры 1726 записи маски позволяют обеспечить предсказание результирующей векторной записи.
Процессор с интегрированным контроллером памяти и графикой
Фиг. 18 представляет блок-схему процессора 1800, который может иметь более одного ядра, может иметь интегрированный контроллер памяти и может иметь интегрированную графику согласно вариантам осуществления изобретения. Сплошные линии на фиг. 18 иллюстрируют процессор 1800 с одним ядром 1802А, системный агент 1810, набор из одного или более контроллеров 1816 шины, в то время как возможное добавление, показанное пунктирной линией, иллюстрирует альтернативный процессор 1800 с несколькими ядрами 1802A-N, набор из одного или более интегрированных контроллеров 1814 памяти в блоке 1810 системного агента и логический блок 1808 специального назначения.
Таким образом, в различные варианты осуществления процессора 1800 могут включать в себя: 1) процессор с логическим блоком 1808 специального назначения, будучи интегрированным с блоком графики, и/или научной логикой (которая может включать в себя один или более ядер) и ядра 1802A-N, являющиеся одним или более ядрами общего назначения (например, упорядоченными ядрами общего назначения, ядрами общего назначения, выполнения с изменением последовательности команд, их комбинацией); 2) сопроцессор с ядрами 1802A-N, имеющими большое количество ядер специального назначения, предназначенных, в первую очередь, для графики и/или обработки научной информации; и 3) сопроцессор с ядрами 1802A-N, имеющие большое количество упорядоченных ядер общего назначения. Таким образом, процессор 1800 может быть процессором общего назначения, сопроцессором или специализированным процессором, таким как, например, сетевым или коммуникационным процессором, механизма исполнения сжатия данных, графическим процессором, GPGPU (Графический процессор общего назначения), высокопроизводительным многоядерным интегрированным (MIC) сопроцессором (включающий в себя 30 или более ядер), встроенный процессор или тому подобное. Процессор может быть реализован на одной или более микросхемах. Процессор 1800 может быть частью и/или может быть реализован на одной или более подложках с использованием любого технологического процесса, такого как, например, BiCMOS, CMOS и NMOS.
Иерархия памяти включает в себя один или несколько уровней кэш-памяти в ядре, набор или один или более блоков 1806 общего кэша и внешней памяти (не показано), соединенные с набором интегрированных контроллеров 1814 памяти. Набор блоков 1806 общего кэша может включать в себя один или более кэшей среднего уровня, таких как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или другие уровни кэша, кэш последнего уровня (LLC) и/или их комбинации. В то время, как в одном варианте осуществления кольцо основано на блоке 1812 межсоединений, который взаимодействует с интегрированным графическим логическим блоком 1808, набором блоков 1806 общего кэша и блоком 1810 системного агента/интегрированным контроллером(и) 1814 памяти, альтернативные варианты осуществления могут использовать любое количество хорошо известных способов для обеспечения взаимодействия таких блоков. В одном варианте осуществления, когерентность сохраняется между одним или более блоками 1806 кэша и ядрами 1802-A-N.
В некоторых вариантах осуществления одно или несколько ядер 1802A-N способны обеспечить многопоточность. Системный агент 1810 включает в себя те компоненты, координирующие и управляющие ядрами 1802A-N. Блок 1810 системного агента может включать в себя, например, блок управления питанием (PCU) и блок отображения. PCU может быть или включать в себя логику и компоненты, необходимые для регулирования параметров питания ядер 1802A-N и интегрированной графической логикой 1808. Блок отображения предназначен для управления одним или более внешних подключенных дисплеев.
Ядра 1802A-N могут быть однородными или неоднородными в плане архитектуры набора инструкций, то есть два или более ядер 1802A-N могут быть способны реализовать тот же набор инструкций, в то время, как другие могут быть способны выполнить только подмножество этого набора инструкций или разный набор инструкций.
Иллюстративные архитектуры компьютера
Фигуры 19-22 являются блок-схемами примерных компьютерных архитектур. Другие структуры системы и конфигурации известны в данной области техники для ноутбуков, настольных компьютеров, портативных компьютеров, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, интегрированных процессоров, цифровых сигнальных процессоров (DSPs), графических устройств, устройств для видеоигр, приставок, микроконтроллеров, сотовых телефонов, портативных медиаплееров, портативных устройств и различных других электронных устройствах также подходят. В общем, огромное разнообразие систем или электронных устройств, которые способны совмещать процессор и/или другие исполнительные логические схемы, описанные в данном документе, как правило, подходят.
Обращаясь теперь к фиг. 19, показывающей блок-схему системы 1900 в соответствии с одним вариантом осуществления настоящего изобретения. Система 1900 может включать в себя один или более процессоров 1910, 1915, которые соединены с контроллером концентратора 1920. В одном варианте осуществления контроллер концентратора 1920 включает в себя графический контроллер концентратора (GMCH) 1990 памяти и концентратор (IOH) 1950 ввода/вывода (который может быть реализован на отдельной микросхеме); GMCH 1990 включает в себя контроллеры памяти и графики, которые соединены с памятью 1940 и сопроцессором 1945; IOH 1950 соединяется с устройствами 1960 ввода/вывода (I/O) и GMCH 1990. Альтернативно, один или оба контроллеров памяти и графики встроены в процессор (как описано здесь), память 1940 и сопроцессор 1945 соединены напрямую с процессором 1910, и контроллер концентратора 1920 на одной микросхеме с IOH 1950.
Возможные дополнительные процессоры 1915 обозначены на фиг.19 пунктирными линиями. Каждый процессор 1910, 1915 может включать в себя один или несколько процессорных ядер, описанных в данном документе, и может представлять собой некоторые версии процессора 1800.
Память 1940 может представлять собой, например, динамическую память с произвольным доступом (DRAM), память на фазовых переходах (PCM) или комбинацию двух. По меньшей мере, один вариант осуществления обеспечивает контроллер концентратора 1920, который взаимодействует с процессором(и) 1910, 1915 через многоточечную шину, например, системную шину (FSB), интерфейс точка-точка, такой как последовательная кэш-когерентная шина (QPI) или аналогичные соединения 1995.
В одном варианте осуществления, сопроцессор 1945 является специализированным процессором, таким как, например, высокопроизводительным MIC процессором, сетевым или коммуникационным процессором, механизмом исполнения сжатия, графическим процессором, GPGPU, встроенным процессором или тому подобным. В одном варианте осуществления контроллер-концентратор 1920 может включать в себя интегрированный графический акселератор.
Существует множество различий между физическими ресурсами 1910, 1915 в плане спектра эксплуатационных параметров, включающие в себя архитектурные, микроархитектурные, тепловые, характеристики энергопотребления и тому подобное.
В одном варианте осуществления процессор 1910 выполняет инструкции, которые управляют операциями обработки данных общего типа. Внедренные в рамках инструкции могут быть сопроцессорными инструкциями. Процессор 1910 распознает эти инструкции сопроцессора в качестве типа, который должен быть выполнен прилагаемым сопроцессором 1945. Соответственно, процессор 1910 направляет эти сопроцессорные инструкции (или управляющие сигналы, представляющие сопроцессорные инструкции) на сопроцессор шины или другие соединения, для сопроцессора 1945. Сопроцессор(ы) 1945 принимать и исполнять полученные инструкции сопроцессора.
Обращаясь теперь к фиг. 20, где показана блок-схема первой более конкретной примерной системы 2000, в соответствии с вариантом осуществления настоящего изобретения. Как показано на фиг. 20, многопроцессорная система 2000 представляет собой систему соединения точка-точка, и включает в себя первый процессор 2070 и второй процессор 2080, соединенные посредством соединения 2050 точка-точка. Каждый из процессоров 2070 и 2080 может быть некоторой версией процессора 1800. В одном варианте осуществления изобретения, процессоры 2070 и 2080 являются соответственно процессорами 1910 и 1915, и сопроцессор 2038 является сопроцессором 1945. В другом варианте осуществления процессоры 2070 и 2080 являются соответственно процессором 1910 и сопроцессором 1945.
Процессоры 2070 и 2080 показаны, как включающие в себя блоки 2072 и 2082 интегрированного контроллера памяти (IMC), соответственно. Процессор 2070 также включает в себя как часть шины блоков контроллера интерфейсы 2076 и 2078 точка-точка (Р-Р); аналогично, второй процессор 2080 включает в себя Р-Р интерфейсы 2086 и 2088. Процессоры 2070, 2080 могут обмениваться информацией через интерфейс 2050 точка-точка (Р-Р), используя схемы 2078, 2088 Р-Р интерфейса. Как показано на фиг. 20, IMCs 2072 и 2082 соединены с соответствующей памятью, а именно к памяти 2032 и памяти 2034, которые могут быть частями основной памяти, локально подключенными к соответствующим процессорам.
Процессоры 2070, 2080 каждый может обмениваться информацией с набором микросхем 2090 с помощью отдельных Р-Р интерфейсов 2052, 2054, используя схемы 2076, 2094, 2086, 2098 интерфейса точка-точка. Набор микросхем 2090 может возможно обмениваться информацией с сопроцессором 2038 через высокопроизводительный интерфейс 2039. В одном варианте осуществления сопроцессор 2038 является специализированным процессором, таким как, например, высокопроизводительный MIC процессор, сетевой или коммуникационный процессор, механизм исполнения сжатия, графический процессор, GPGPU, встроенный процессор или тому подобное.
Общий кэш (не показан) может быть включен в состав либо процессора, либо вне обоих процессоров, но соединенных с процессорами через Р-Р соединение, так что либо одна, или обе информации локального кэша процессора могут храниться в общем кэше, если процессор переводится в режим пониженного энергопотребления.
Набор микросхем 2090 может быть подсоединен к первой шине 2016 через интерфейс 2096. В одном варианте осуществления первая шина 2016 может быть шиной межсоединения периферийных компонентов (PCI) или шиной, такой как шина PCI-Express или другая шина третьего поколения I/O соединения, хотя объем настоящего изобретения не ограничен этим.
Как показано на фиг. 20, различные I/O устройства 2014 могут быть соединены с первой шиной 2016, наряду с внутренней шиной 2018, которая соединяет первую шину 2016 со второй шиной 2020. В одном варианте осуществления один или более дополнительный процессор(ы) 2015, такой как сопроцессоры, высокопроизводительные MIC процессоры, графические процессоры, акселераторы (таких как, например, графические акселераторы или блоки цифровой обработки сигнала (DSP), программируемые пользователем вентильные матрицы) или любой другой процессор, соединенный с первой шиной 2016. В одном варианте осуществления, вторая шина 2020 может быть шиной с малым числом выводов (LPC). Различные устройства могут быть соединены со второй шиной 2020, включающие в себя, например, клавиатуру и/или мышь 2022, коммуникационные устройства 2027 и устройство 2028 хранения, такое как дисковод или другое запоминающее устройство, которое может включать в себя инструкции/код и данные 2030, в одном варианте осуществления. Дополнительно, аудио I/O 2024 может быть соединен со второй шиной 2020. Обратите внимание, что возможны другие архитектуры. Например, вместо архитектуры точка-точка на фиг. 20, система может реализовать многоточечную шину или другую подобную архитектуру.
Обращаясь теперь к фиг. 21, где показана блок-схема второй более конкретной примерной системы 2100 в соответствии с вариантом осуществления настоящего изобретения. Аналогичные элементы, показанным на фигурам 20 и 21, имеют одинаковые цифровые обозначения, и некоторые аспекты, показанные на фиг. 20, были опущены на фиг. 21, чтобы избежать усложнений описания других аспектов на фиг. 21.
Фиг. 21 демонстрирует, что процессоры 2070, 2080 могут включать в себя интегрированную память и I/O логику 2072 и 2082 управления ("CL"), соответственно. Таким образом, CL 2072, 2082 включают в себя блоки интегрированного контроллера памяти и включают в себя I/O логику управления. Фиг. 21 демонстрирует, что не только память 2032, 2034 соединена с CL 2072, 2082, но также I/O устройства 2114 также соединены с логикой 2072, 2082 управления. Унаследованные I/O устройства 2115 соединены с набором микросхем 2090.
Обращаясь теперь к фиг. 22, где показана блок-схема SoC 2200 в соответствии с вариантом осуществления настоящего изобретения. Аналогичные элементы на фиг.18 имеют одинаковые цифровые обозначения. Также, квадраты, обозначенные пунктирными линиями, представляют возможные признаки на более усовершенствованных SoCs. На фиг.22, блок(и) 2202 межсоединения соединены с: процессором 2210 приложения, который включает в себя набор из одного или нескольких ядер 202A-N и блок(и) 1810 общего кэша; блок(и) 1810 системного агента; блок(и) 1816 контроллера шины; блок(и) 1814 контролера интегрированной памяти; набор или один или более сопроцессоров 2220, которые могут включать в себя интегрированную графическую логику, процессор обработки изображений, процессор обработки аудио и графический процессор; блок 2230 статической оперативной памяти (SRAM); блок 2232 непосредственного доступа к памяти (DMA); блока 2240 отображения для соединения с одним или несколькими внешними дисплеев. В одном варианте осуществления сопроцессор(ы) 2220 включает в себя специализированный процессор, такой как, например, сетевой или коммуникационный процессор, механизм исполнения сжатия, GPGPU, высокопроизводительный MIC процессор, встроенный процессор или тому подобное.
Варианты осуществления механизмов, раскрытых здесь, могут быть реализованы в аппаратных средствах, посредством программного обеспечения, микропрограммного обеспечения или комбинации таких подходов к ее реализации. Варианты осуществления изобретения могут быть реализованы как компьютерные программы или программы выполнения кода на программируемых системах, включающие в себя, по меньшей мере, один процессор, систему хранения (включающую в себя энергозависимую и энергонезависимую память и/или элементы хранения), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода.
Программный код, такой как код 2030, показанный на фиг. 20, может быть применен для ввода инструкции для выполнения функций, описанных в данном документе и генерировать выходную информацию. Выходная информация может быть применена к одной или более устройств вывода, известным способом. Для целей настоящего приложения, система обработки включает в себя любую систему, которая имеет процессор, такой как, например; цифровой сигнальный процессор (DSP), микроконтроллер, специализированную интегральную схему (ASIC) или микропроцессор.
Программный код может быть реализован на высокоуровневом процедурном или объектно-ориентированном языке программирования для взаимодействия с системой обработки. Программный код может также быть реализован на ассемблере или машинном языке, при желании. По сути, механизмы, описанные здесь, не ограничены в использовании какого-либо конкретного языка программирования. В любом случае, язык может представлять собой скомпилированный или интерпретируемый язык.
Один или более аспектов, по меньшей мере, один вариант осуществления может быть реализован посредством репрезентативных инструкций, хранящиеся на машиночитаемом носителе, которые представляют различные логики в процессоре, которые, когда считываются машиной, вызывает машину обрабатывать логику для выполнения описанных здесь способов. Такие представления, известные как "IP-ядра", могут храниться на материальном, машиночитаемой носителе и поставляться различным клиентам или производственным предприятиям для загрузки в процессе изготовления машин, которые, на самом деле, формируют логику или процессор.
Такие машиночитаемые носители могут включать в себя, без ограничений, невременные материальные механизмы изделий, изготовленных или сформированных с помощью машины или устройства, включающие в себя носитель информации, такие как жесткие диски, любые другие типы дисков, включающие в себя гибкие диски, оптические диски, компакт-диски только для чтения памяти (CD-ROMs), перезаписываемый компакт-диск (CD-RWs) и магнитооптические диски, полупроводниковые устройства, такие как постоянные запоминающие устройства (ROMs), оперативная память (RAMs), такая как динамическая оперативная память (DRAMs), статическая оперативная память (SRAMs), стираемая программируемая постоянная память (EPROMs), флеш память, электрически стираемая программируемая постоянная память (EEPROMs), память на фазовых переходах (PCM), магнитные или оптические карты или любой другой тип носителей, подходящий для хранения электронных инструкций.
Соответственно, варианты осуществления изобретения также включают в себя невременный материальный машиночитаемый носитель, содержащий инструкции, содержащий организацию данных, таких как язык описания технических средств (HDL), который определяет структуры, схемы, устройства, процессоры и/или системные признаки, описанные в настоящем документе. Такие варианты осуществления могут также относиться к программным продуктам.
Эмуляция (включающая в себя двоичную трансляцию, морфинг кода и др.)
В некоторых случаях, преобразователь инструкции может использоваться для преобразования инструкции из исходного набора инструкций в целевой набор инструкций. Например, преобразователь инструкции может транслировать (например, с помощью статической двоичной трансляции, динамической двоичной трансляции, включающая в себя динамическую компиляцию), осуществлять морфинг, эмулировать или иным образом преобразовать инструкцию в одну или несколько инструкций, для обработки ядром. Преобразователь инструкции может быть реализован посредством программного обеспечения, аппаратных средствах, микропрограммным обеспечении или их комбинацией. Преобразователь инструкции может быть реализован в процессоре, вне процессора или на части процессора или вне процессора.
Фиг. 23 представляет собой блок-схему, которая иллюстрирует использование программного обеспечения преобразователя инструкции для преобразования двоичных инструкций из исходного набора команд в целевой набор двоичных инструкций согласно вариантам осуществления изобретения. В показанном варианте осуществления преобразователь инструкции представляет собой программное обеспечение преобразователя инструкции, хотя альтернативно, преобразователь инструкции может быть реализован посредством программного обеспечения, аппаратно-программного обеспечения, аппаратного обеспечения или различных их комбинаций. Фиг. 23 показывает пример программы на языке 2302 высокого уровня, которая может быть компилирована с помощью х86 компилятора 2304 для генерирования х86 двоичного кода, который может быть изначально выполнен с помощью процессора, по меньшей мере, посредством одного набора х86 инструкций ядром 2316. Процессор, по меньшей мере, с одним набором х86 инструкций ядра 2316 представляет собой любой процессор, который может выполнять практически те же функции, что и Intel процессор, по меньшей мере, с одним набором х86 инструкций ядра посредством выполнения или иной обработки (1) существенной части набора х86 инструкций Intel набора х86 инструкций ядра или (2) версий объектного кода приложений или другие пакеты программ, предназначенные для выполнения на Intel процессоре, по меньшей мере, с одним набором х86 инструкций ядра, для достижения, по существу, того же результата, что и Intel процессор, по меньшей мере, с одним набором х86 инструкций ядра. х86 компилятор 2304 представляет собой компилятор, который выполнен с возможностью генерировать х86 двоичный код 2306 (например, объектный код), который может, с или без дополнительной обработки связи, выполняться на процессоре, по меньшей мере, с одним набором х86 инструкций ядра 2316. Аналогично, фиг.23 показывает программу на языке 2302 высокого уровня, которая может быть скомпилирована с использованием альтернативного набора команд компилятора 2308 для генерирования альтернативного набора команд двоичного кода 2310, что может быть изначально выполнено процессором, по меньшей мере, без одного набора х86 инструкций ядра 2314 (например, процессор с ядрами, которые выполняют MIPS набор инструкций MIPS Technologies of Sunnyvale, CA и/или выполнить набор ARM инструкций ARM Holdings of Sunnyvale, CA). Преобразователь 2312 инструкций используется для преобразования х86 двоичного кода 2306 в код, который может быть изначально выполнен процессором без х86 набора инструкций ядра 2314. Этот преобразованный код вряд ли будет таким же, как альтернативный набор инструкций двоичного кода 2310, потому что преобразователь инструкций не способен это реализовать; однако, преобразованный код будет выполнять общие операции и составлять инструкции из альтернативного набора команд. Таким образом, преобразователь 2312 инструкций представляет собой программное обеспечение, аппаратно-программное обеспечение, аппаратные средства или их комбинацию, что, посредством эмуляции, моделирования или любого другого процесса процессор или другие электронные устройства, которые не имеют набор х86 инструкции процессора или ядра для выполнения х86 двоичного кода 2306.
В описании и в формуле изобретения, термины "соединенный" и/или "подключенный", а также их производные должны быть использованы. Следует понимать, что эти термины не являются синонимами друг друга. Скорее, в конкретных вариантах осуществления, "соединенный" может использоваться для указания того, что два или более элементов находятся в непосредственном физическом или электрическом контакте друг с другом. "Соединенный" может означать, что два или более элементов находятся в непосредственном физическом или электрическом контакте. Однако, "соединенный" может также означать, что два или более элементов не находятся в непосредственном контакте друг с другом, но все же по-прежнему взаимодействуют друг с другом. Например, блок декодирования может быть соединен с исполнительным блоком и/или регистром посредством одного или более промежуточных компонентов. На фигурах стрелки используются для отображения соединения и/или подключений.
В описании и/или в формуле изобретения, термин "логика" может быть использован. Логика может включать в себя аппаратные средства, микропрограммное обеспечение, программное обеспечение или различные их комбинации. Примеры логики включают в себя интегральные схемы, специализированные интегральные схемы, аналоговые схемы, цифровые схемы, программируемые логические устройства, устройства памяти, включающие в себя инструкции и тому подобное и их комбинации. В некоторых вариантах осуществления, логика может включать в себя транзисторы и/или шлюзы и/или другие электронные компоненты. В различных вариантах осуществления логика может также упоминаться и/или представляют собой модуль, блок, компонент, схема, логическое устройство или тому подобное.
В приведенном выше описании, конкретные детали изложены, чтобы обеспечить полное понимание вариантов осуществления. Однако, в других вариантах осуществления они могут быть реализованы на практике без некоторых из этих конкретных деталей. Объем изобретения не должен определяться исходя из конкретных примеров, приведенных выше, но только формулой изобретения, приведенной ниже. Все эквивалентные отношения, приведенные на чертежах и описанные в спецификации, осуществляются в вариантах осуществления. В других случаях, известные схемы, структуры, устройства и операции были показаны в виде блок-схем или без деталей, для упрощения описания. В некоторых случаях, когда несколько компонентов были показаны и описаны, они могут быть включены в состав одного компонента. В некоторых случаях, когда один компонент был показан и описан, но может быть разделен на два или более компонентов.
Определенные операции могут быть выполнены посредством аппаратных компонентов или могут быть воплощены в машинно-исполняемых или схемно-исполняемых инструкций, которые могут быть использованы, чтобы обеспечить выполнение запрограммированных операций посредством машины, цепи или аппаратного компонента (например, процессор, часть процессора, схемы и др.). Операции также могут возможно быть выполнены с помощью комбинации аппаратного и программного обеспечения. Процессор, машина, схема или оборудование может включать в себя конкретные или специфические схемы или другую логику (например, оборудование, потенциально объединенное с аппаратно-программным обеспечением и/или программным обеспечением) выполненные с возможностью реализовать процесс и/или инструкцию.
Некоторые варианты осуществления включают в себя промышленное изделие (например, компьютерный программный продукт), который включает в себя машиночитаемый носитель. Носитель информации может включать в себя механизм, который обеспечивает, например, сохранения информации в форме, читаемой машиной. Машиночитаемый носитель может обеспечить или сохранить на нем инструкцию или последовательность инструкций, которые, если и/или когда исполняются машиной, вызывают машину выполнить операции, способы или технологии, описанные здесь. Машиночитаемый носитель может обеспечить, например, сохранение информации, один или несколько вариантов осуществления инструкций, описанные в данном документе.
В некоторых вариантах осуществления машиночитаемый носитель может включать в себя материальный и/или невременный машиночитаемый носитель. Например, материальный и/или невременный машиночитаемый носитель информации может включать в себя дискету, оптический носитель информации, оптический диск, оптическое устройство хранения данных, компакт-диск, магнитный диск, магнитооптический диск, постоянное запоминающее устройство (ROM), программируемое ROM (PROM), электронное стираемое и программируемое ROM (EPROM), электрически-стираемое и программируемое ROM (EEPROM), оперативную память (RAM), статическое RAM (SRAM), динамическое RAM (DRAM), флэш-память, память на фазовых переходах, материал хранения на фазовых переходах, энергонезависимую память, энергонезависимое устройство хранения данных, невременную память, невременное запоминающее устройство данных или тому подобное. Невременный машиночитаемый носитель информации состоит не только из временного распространяемого сигнала (например, несущая волна).
Примеры подходящих машин включают в себя, но не ограничиваются этим, процессоры общего назначения, специализированные процессоры, устройство для обработки инструкций, цифровые логические схемы, интегральные схемы и тому подобное. Еще другие примеры подходящих машин включают в себя вычислительные устройства и другие электронные устройства, которые включают в себя такие процессоры, устройства обработки инструкций, цифровые логические схемы или интегральные схемы. Примеры таких вычислительных устройств и электронных устройств включают в себя, но не ограничиваются этим, персональные компьютеры, портативные компьютеры, ноутбуки, планшетные компьютеры, нетбуки, смартфоны, сотовые телефоны, сервера сетевых устройств (например, маршрутизаторы и коммутаторы.), мобильные интернет-устройства (MIDs), медиаплееры, смарт-телевизоры, неттопы, приставки, контроллеры видеоигр.
Ссылка по всей этой спецификации на "один вариант осуществления" "вариант осуществления" "один или более вариантов осуществления", "некоторые варианты осуществления", например, указывает, что определенный признак может быть включен в состав варианта реализации изобретения, но не обязательно требуется. Аналогично, в описании различных признаки иногда сгруппированы вместе в одном варианте осуществления, чертеже или их описания в целях оптимизации раскрытия и для упрощения понимания различных изобретательских аспектов. Этот способ раскрытия, однако, не следует интерпретировать как отражающий намерение, что изобретение требует больше признаков, чем недвусмысленно читается в каждом пункте формулы изобретения. Скорее, прилагаемая формула изобретения отражает изобретательские аспекты, которые описаны в менее чем во всех признаках одного раскрытого варианта осуществления. Таким образом, следующая за разделом «Подробное описание» формула изобретения, явным образом включена в состав этого раздела «Подробное описание», где каждый пункт формулы изобретения сам по себе выступает в качестве отдельного варианта осуществления изобретения.
ПРИМЕРНЫЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
Следующие примеры относятся к дополнительным вариантам осуществления. Конкретика в примерах может быть использована в любом месте в одном или более вариантах осуществления.
Пример 1 представляет собой процессор, который включает в себя блок декодирования для приема инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения предназначена для указания исходного операнда упакованных индексов памяти, который должен иметь множество упакованных индексов памяти, и указания исходного операнда упакованных данных, который должен иметь множество элементов упакованных данных. Исполнительный блок соединен с блок декодирования. Исполнительный блок, в ответ на инструкцию векторной индексированной загрузки плюс A/L операции плюс сохранения, загружает множество элементов данных из ячеек памяти, соответствующие множеству упакованных индексов памяти, выполняет A/L операцию на множестве элементов упакованных данных исходного операнда упакованных данных и загруженного множества элементов данных, и сохраняет множество результирующих элементов данных в ячейках памяти, соответствующие множеству упакованных индексов памяти.
Пример 2 включает в себя процессор по примеру 1, и возможно в котором инструкция содержит инструкцию сбора плюс A/L операции плюс разброса.
Пример 3 включает в себя процессор по любому из предшествующих примеров и, возможно в котором A/L операция содержит, по меньшей мере, одно из операции упакованного сложения, операции упакованного вычитания, операции упакованного умножения, операции упакованного деления, операции упакованного умножения-сложения, операции упакованного сдвига, операции упакованного поворота, операции упакованного логического И, операций упакованного логического ИЛИ, операции упакованного логического НЕ и операции упакованного логического И-НЕТ.
Пример 4 включает в себя процессор по любому из предшествующих примеров и возможно, в котором A/L операции включают в себя, по меньшей мере, одно из операции упакованного сложения и операции упакованного умножения.
Пример 5 включает в себя процессор любому из предшествующих примеров и возможно в котором процессор выполняет инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения без передачи загруженных элементов данных в ядро.
Пример 6 включает в себя процессор по любому из предшествующих примеров и возможно в котором исполнительный блок является внеядерной частью процессора в пределах подсистемы памяти.
Пример 7 включает в себя процессор по любому из предшествующих примеров, и возможно в котором, блок декодирования находится в пределах ядра, и в котором исполнительный блок находится ближе к кэш последнего уровня, чем к ядру, имеющему блок декодирования.
Пример 8 включает в себя процессор по любому из предшествующих примеров, и возможно в котором, часть исполнительного блока, который будет выполнять A/L операцию, должна принять загруженные элементы данных из одного из кэша последнего уровня и кэша предпоследнего уровня.
Пример 9 включает в себя процессор по любому из предшествующих примеров, и возможно в котором, блок декодирования предназначен для декодирования инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения, которая является маскированной инструкцией векторной индексированной загрузки плюс A/L операции плюс сохранения, что указывает на исходный операнд операции маскировки упакованных данных.
Пример 10 включает в себя процессор по любому из предшествующих примеров и возможно в котором, блок декодирования предназначен для декодирования инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения, что указывает на исходный операнд упакованных данных, что имеет, по меньшей мере, 512-битную ширину.
Пример 11 представляет собой способ в процессоре, который включает в себя прием инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения указывает исходный операнд упакованных индексов памяти, который должен иметь множество упакованных индексов памяти, и указывает на исходный операнд упакованных данных, который должен иметь множество элементов упакованных данных. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения выполняется. Это может включать в себя загрузку множества элементов данных из ячеек памяти, соответствующие множеству упакованных индексов памяти. A/L операции могут осуществляться на множестве элементов упакованных данных исходного операнда упакованных данных и загруженного множества элементов данных. Множество результирующих элементов данных может храниться в ячейках памяти, соответствующие множеству упакованных индексов памяти.
Пример 12 содержит способ по примеру 11, и возможно в котором прием содержит прием инструкции сбора плюс A/L операции плюс разброс.
Пример 13 включает в себя способ по любому из предшествующих примеров и возможно в которой выполнение A/L операции содержит выполнение, по меньшей мере, одно из операции упакованного сложения, операции упакованного вычитания, операции упакованного умножения, операции упакованного деления, операции упакованного умножения-сложения, операции упакованного сдвига, операции упакованного поворота, операции упакованного логического И, операций упакованного логического ИЛИ, операции упакованного логического НЕ и операции упакованного логического И-НЕТ.
Пример 14 включает в себя способ по любому из предшествующих примеров и возможно в котором выполнение A/L операции включает в себя выполнение, по меньшей мере, одно из операции упакованного сложения и операции упакованного умножения.
Пример 15 включает в себя способ по любому из предшествующих примеров и возможно в котором, выполнение инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения завершается без передачи загруженных элементов данных в ядро.
Пример 16 включает в себя способ по любому из предшествующих примеров и возможно в котором, выполнение A/L операций осуществляется посредством блока в внеядерной части процессора в пределах подсистемы памяти, и в котором блок находится ближе к кэш последнего уровня, чем к ядру, в которое инструкция была принята.
Пример 17 включает в себя способ по любому из предшествующих примеров и возможно в котором, прием содержит прием маскированной инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения, что указывает на исходный операнд операции маскировки упакованных данных.
Пример 18 включает в себя способ по любому из предшествующих примеров и возможно в котором, прием содержит прием инструкции, что указывает на исходный операнд упакованных данных, имеющий, по меньшей мере, 512-битную ширину.
Пример 19 представляет собой систему для обработки инструкций, включающую в себя межсоединение, динамическую память с произвольным доступом (DRAM), соединенную с межсоединением, и процессор, соединенный с межсоединением. Процессор принимает инструкцию векторной индексированной загрузки плюс A/L операции плюс сохранения, что указывает на исходный операнд упакованных индексов памяти, который должен иметь множество упакованных индексов памяти, и указывает на исходный операнд упакованных данных, который должен иметь множество элементов упакованных данных. Процессор выполнен с возможностью, в ответ на инструкцию векторной индексированной загрузки плюс A/L операции плюс сохранения, загружать множество элементов данных из ячеек памяти в DRAM, в соответствии с множеством упакованных индексов памяти, выполнять A/L операции на множестве элементах упакованных данных исходного операнда упакованных данных и загруженного множества элементов данных, и сохранять множество результирующих элементов данных в целевых ячейках памяти.
Пример 20 включает в себя систему по примера 19 и возможно в котором, целевые ячейки памяти содержат ячейки памяти, соответствующие множеству упакованных индексов памяти в DRAM.
Пример 21 включает в себя систему по любому из предшествующих примеров и возможно в котором, инструкция содержит инструкцию сбора плюс A/L операцию плюс разброс.
Пример 22 представляет собой промышленное изделие, включающее в себя невременный машиночитаемый носитель информации. Машиночитаемый носитель информации хранит инструкцию векторной индексированной загрузки плюс A/L операции плюс сохранения. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения указывает исходный операнд упакованных индексов памяти, который должен иметь множество упакованных индексов памяти, и указывает исходный операнд упакованных данных, который должен иметь множество элементов упакованных данных. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения, при выполнении машиной, выполнена с возможностью вызывать машину выполнить операции, включающие в себя загрузку множества элементов данных из ячеек памяти, в соответствии с множеством упакованных индексов памяти, выполнение A/L операции на множестве элементов упакованных данных исходного операнда упакованных данных и загруженного множества элементов данных, и сохранение множества результирующих элементов данных в целевых ячейках памяти.
Пример 23 включает в себя промышленное изделие по примеру 22 и возможно в котором, сохранение результирующих элементов данных в целевых ячейках памяти содержит сохранение результирующих элементов данных в ячейках памяти, соответствующих упакованным индексам памяти.
Пример 24 включает в себя промышленное изделие по любому из предшествующих примеров и возможно в котором, инструкция содержит инструкцию сбора плюс A/L операции плюс разброса.
Пример 25 включает в себя промышленное изделие по любому из предшествующих примеров и возможно в котором, выполнение A/L операций содержит выполнение, по меньшей мере, одно из операции упакованного сложения и операции упакованного умножения.
Пример 26 включает в себя промышленное изделие по любого из предшествующих примеров и возможно дополнительно включает в себя завершение выполнения инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения без передачи загруженных элементов данных в ядро процессора.
Пример 27 включает в себя процессор или другое устройство, которое выполнено с возможностью реализовывать способ по любому из примеров 11-18.
Пример 28 включает в себя процессор или другое устройство, которые включает в себя средство для осуществления способа по любому из примеров 11-18.
Пример 29 включает в себя компьютерную систему, включающую в себя процессор и возможно включающую в себя, по меньшей мере, одно из динамическую память с произвольным доступом (DRAM), сетевой процессор, графический процессор, микросхему беспроводной связи, процессор выполнен с возможностью реализовывать способ по любому из примеров 11-18.
Пример 30 включает в себя невременный машиночитаемый носитель информации для хранения инструкций, которые, если и/или когда исполняются машиной, выполнены с возможностью вызвать машину реализовать способ по любому из примеров 11-18.
Пример 31 включает в себя процессор или другое устройство для выполнения одной или нескольких операций или любого способа, по существу, как описано в настоящем документе.
Пример 32 включает в себя процессор или другое устройство, включающее в себя средство для выполнения одной или нескольких операций или любого способа, по существу, как описано в настоящем документе.
Пример 33 включает в себя процессор или другое устройство для выполнения любой инструкции, описанных в данном документе.
Пример 34 включает в себя процессор или другое устройство, включающее в себя средство для выполнения любой инструкции, описанных в данном документе.
Пример 35 включает в себя процессор, содержащий средство для приема инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения. Инструкция векторной индексированной загрузки плюс A/L операции плюс сохранения предназначена для указания исходного операнда упакованных индексов памяти, который должен иметь множество упакованных индексов памяти, и указания исходного операнда упакованных данных, который должен иметь множество элементов упакованных данных.
Процессор включает в себя средство для выполнения инструкции векторной индексированной загрузки плюс A/L операции плюс сохранения, включающее в себя средством для загрузки множества элементов данных из ячеек памяти, соответствующие множеству упакованных индексов памяти. Средство выполняет A/L операции на множестве элементов упакованных данных исходного операнда упакованных данных и загруженного множества элементов данных. Средство сохраняет множество результирующих элементов данных в ячейках памяти, соответствующие множеству упакованных индексов памяти.
Пример 36 включает в себя процессор по примеру 35, в котором средство для приема содержит средство для приема инструкции сбора плюс A/L операции плюс разброса.
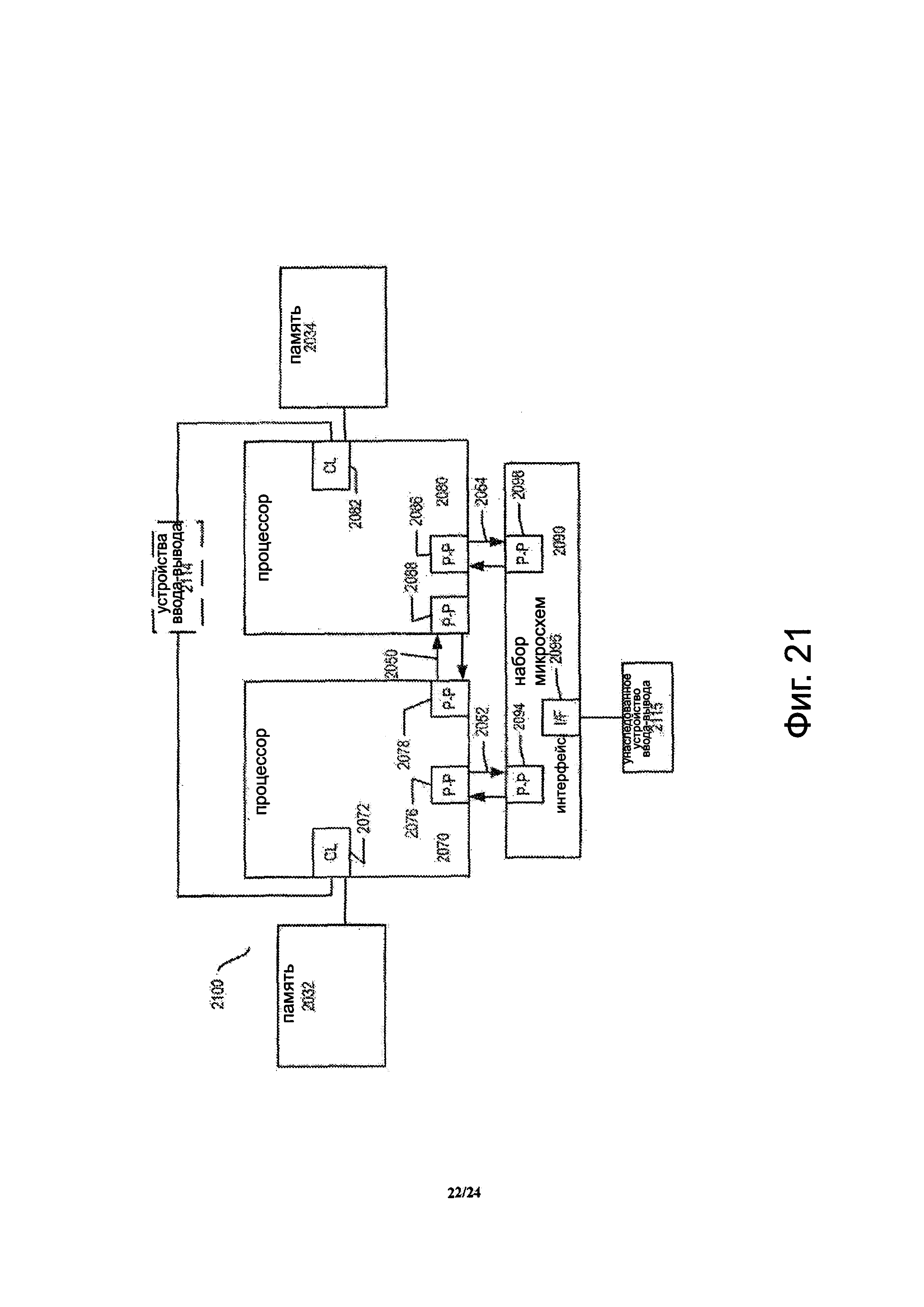
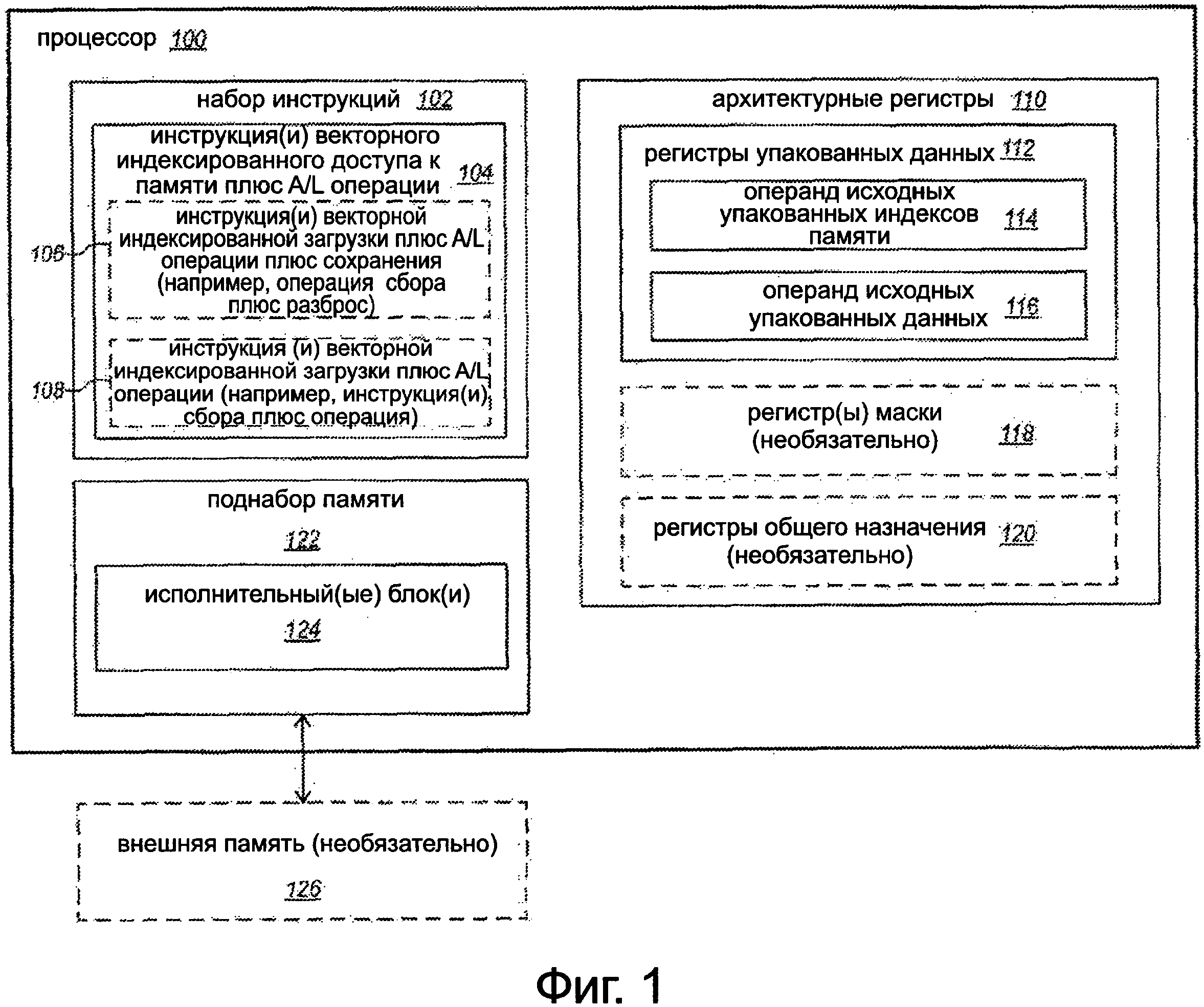
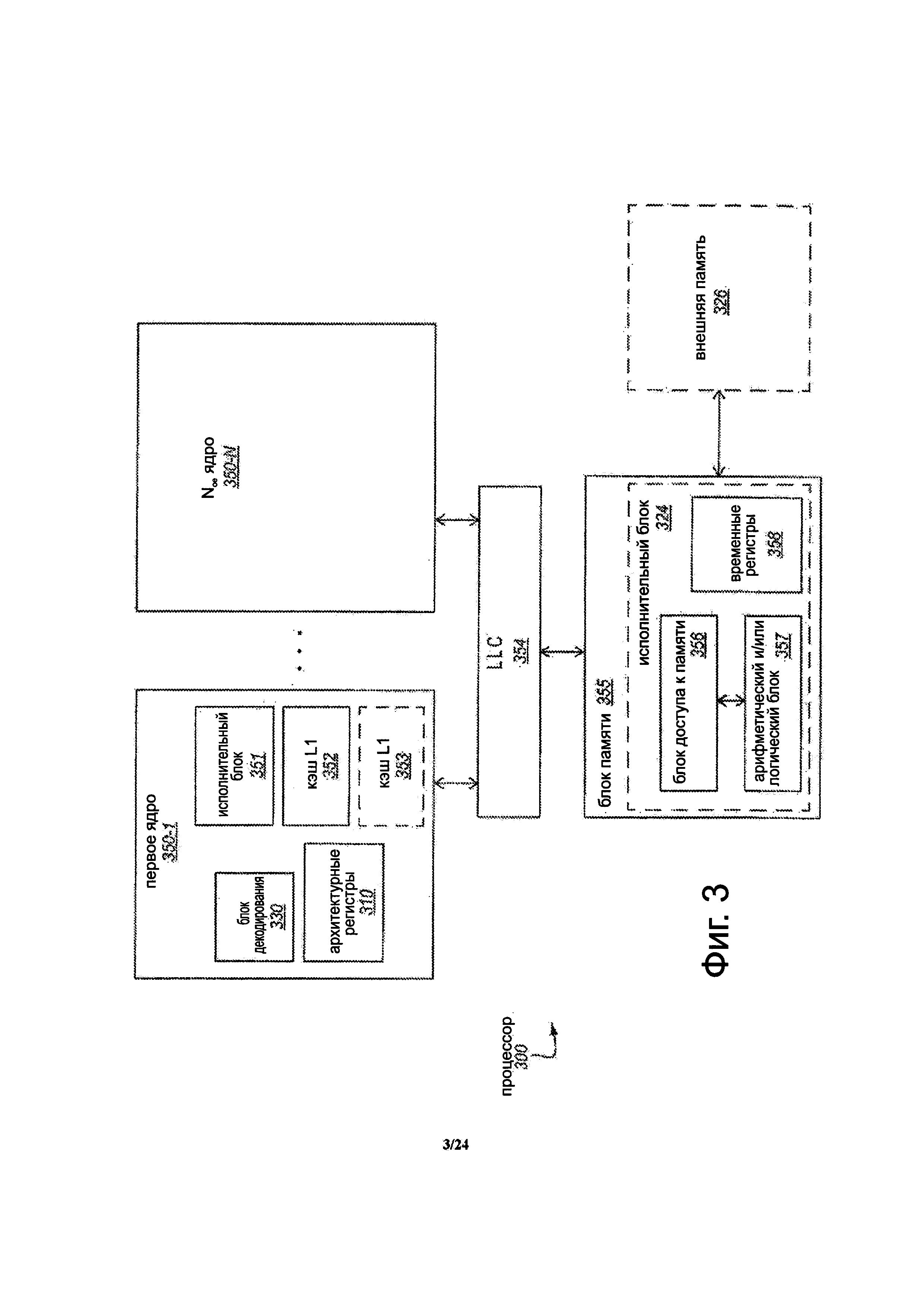
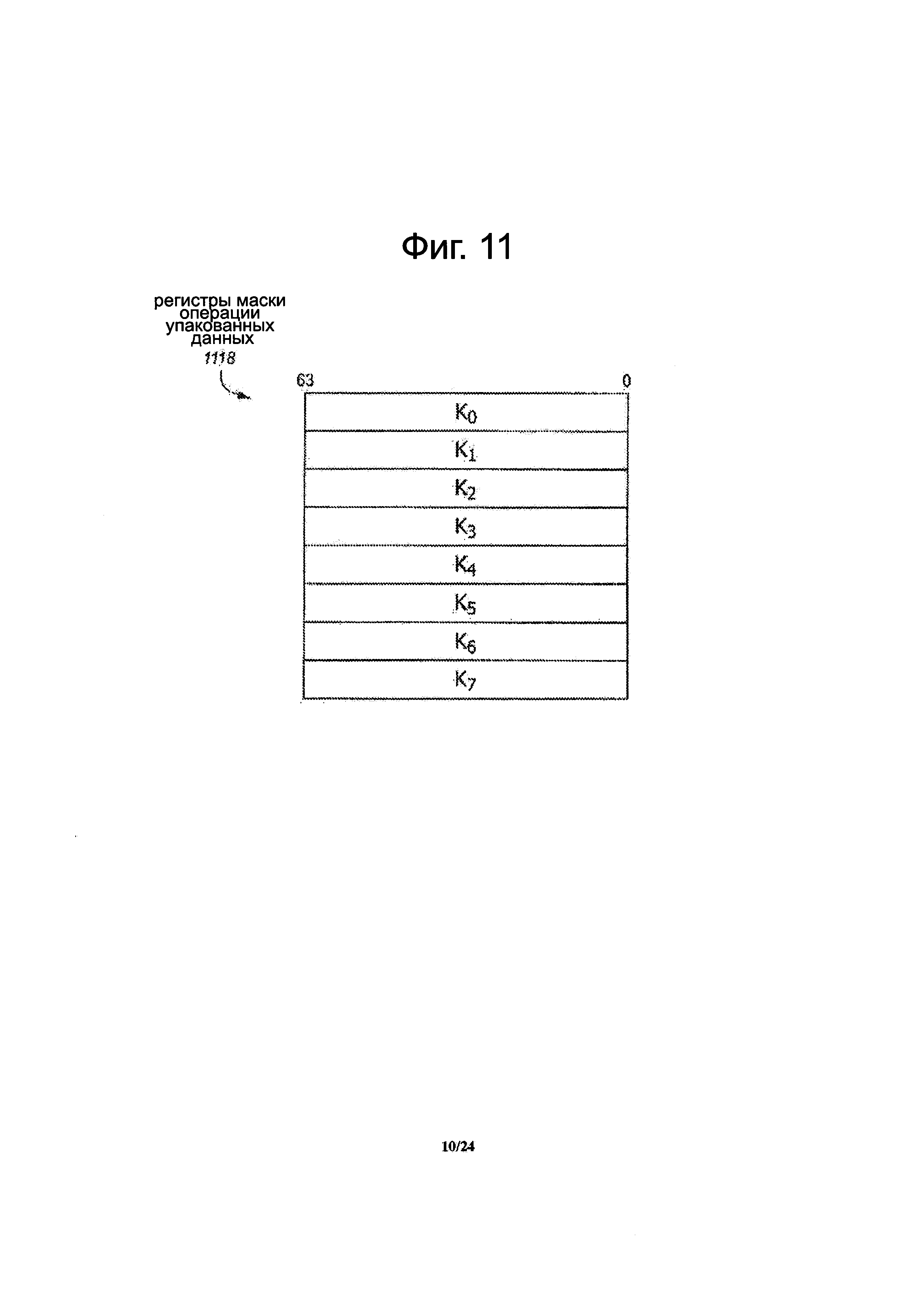
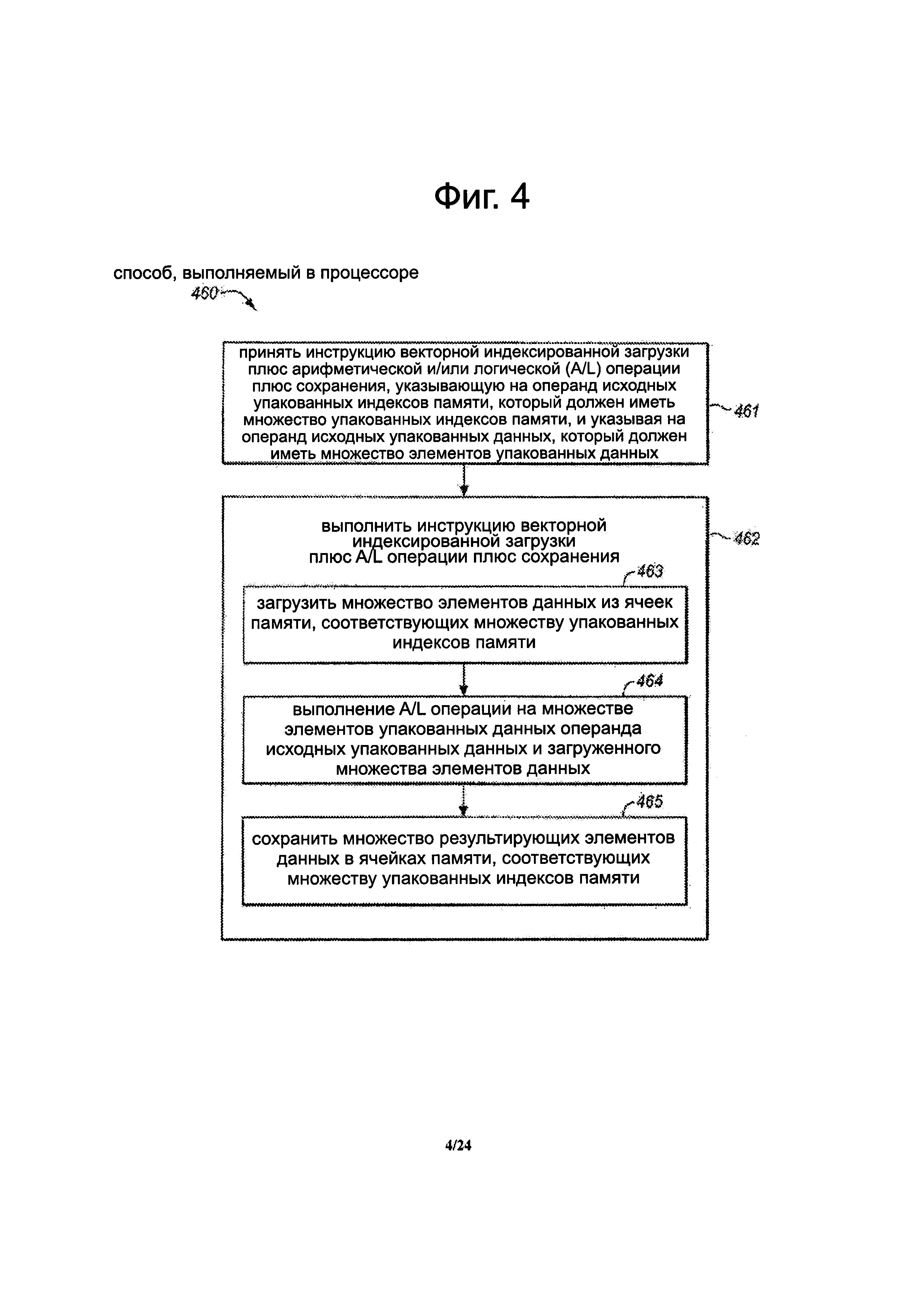
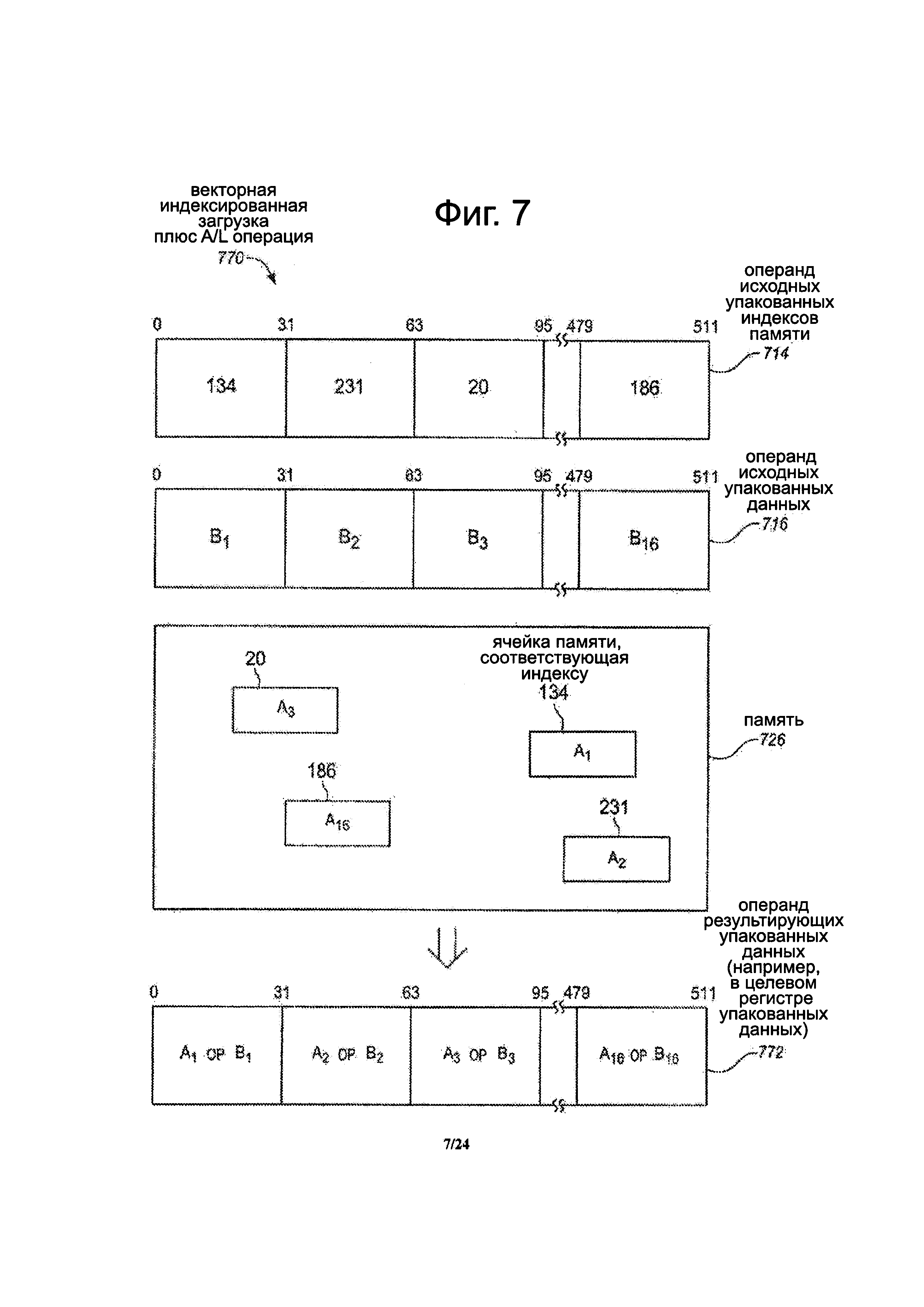
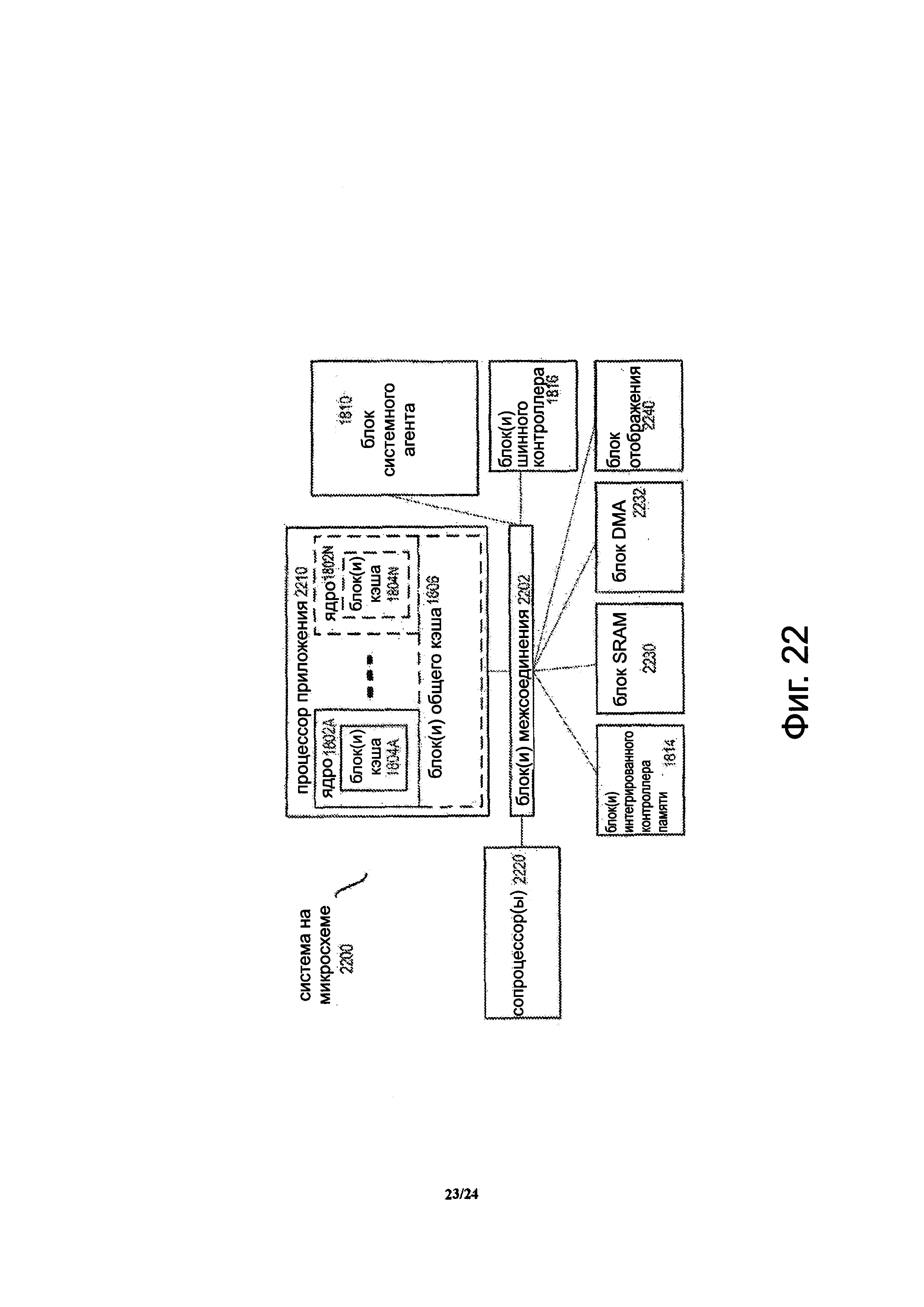
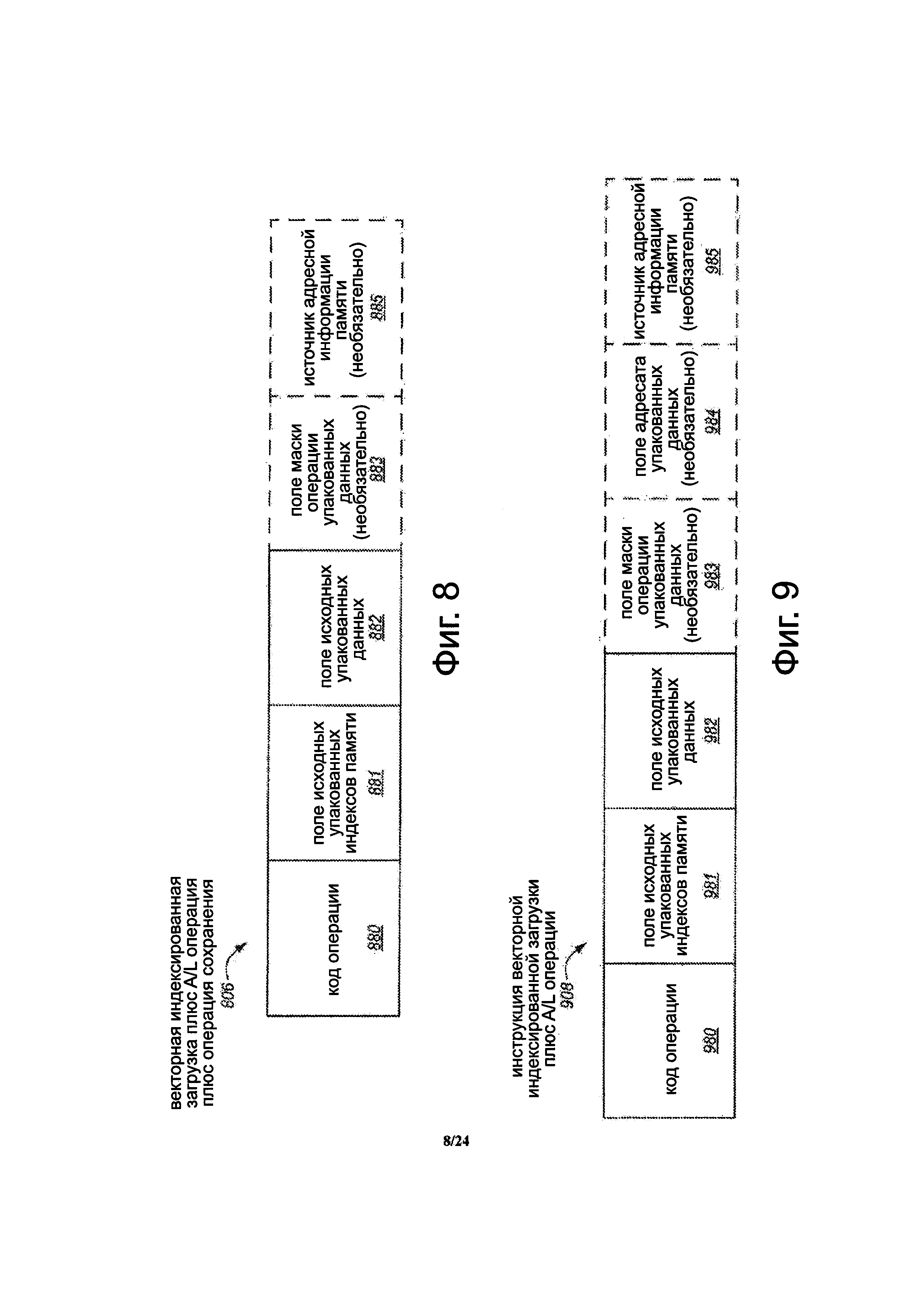
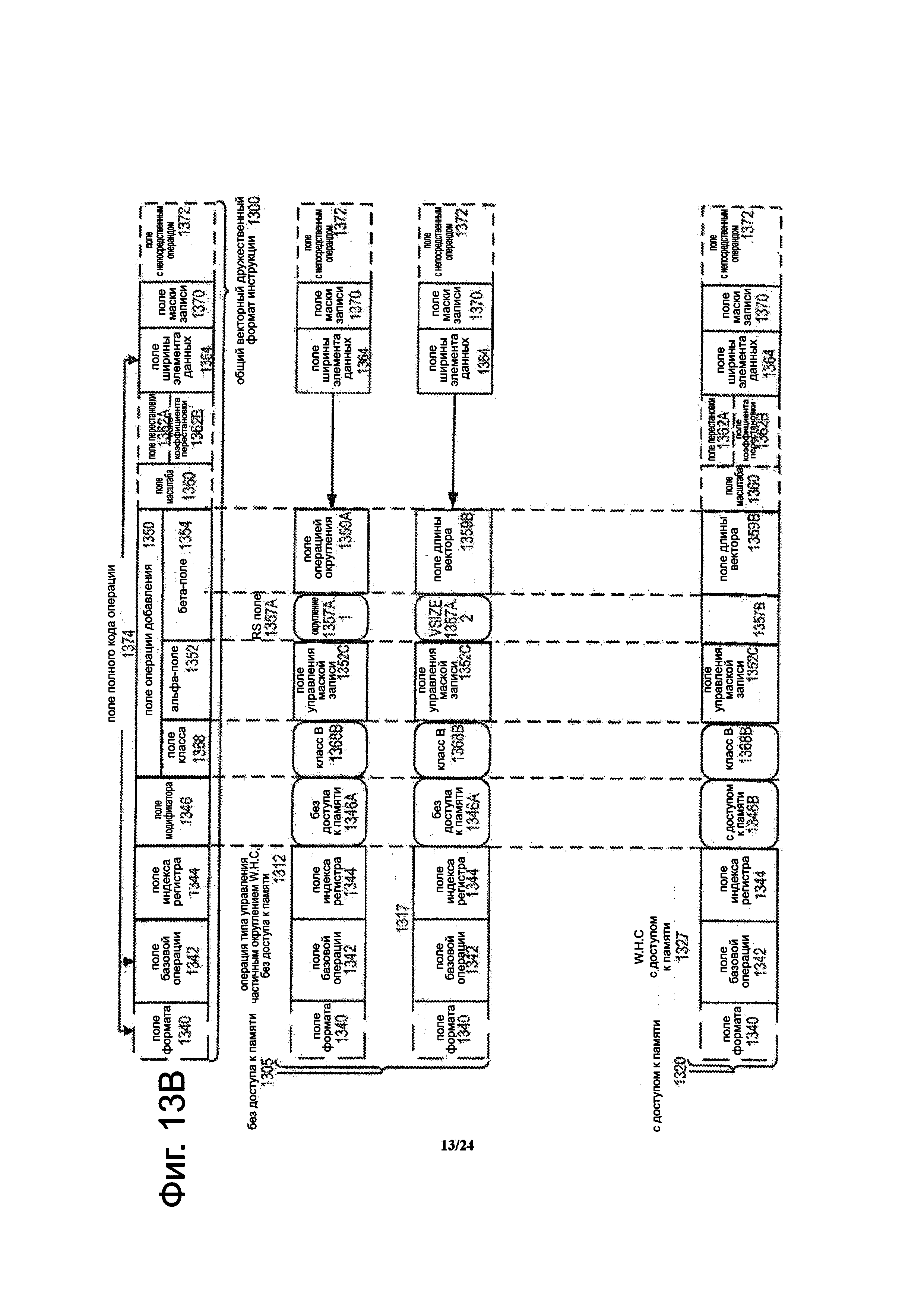
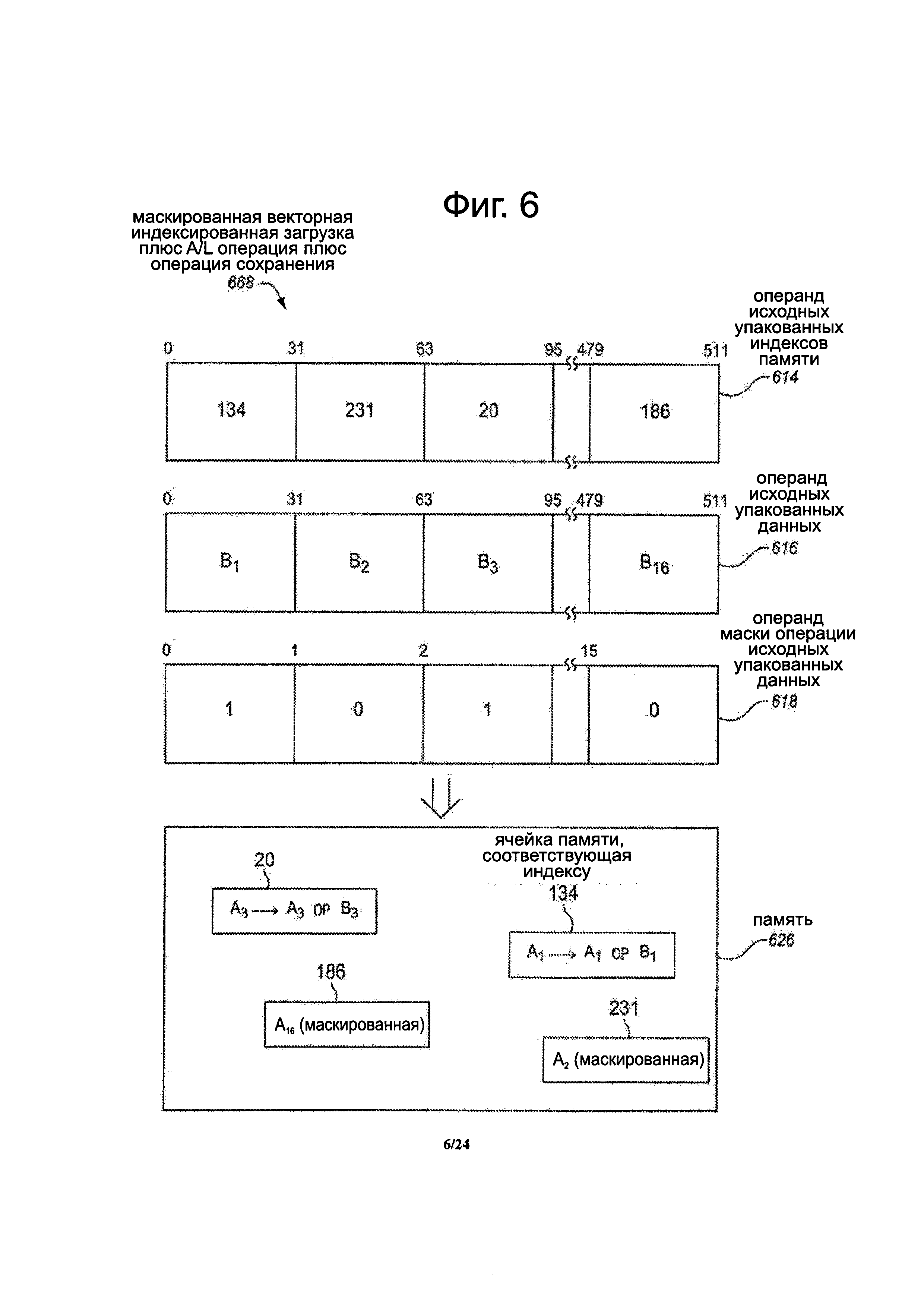
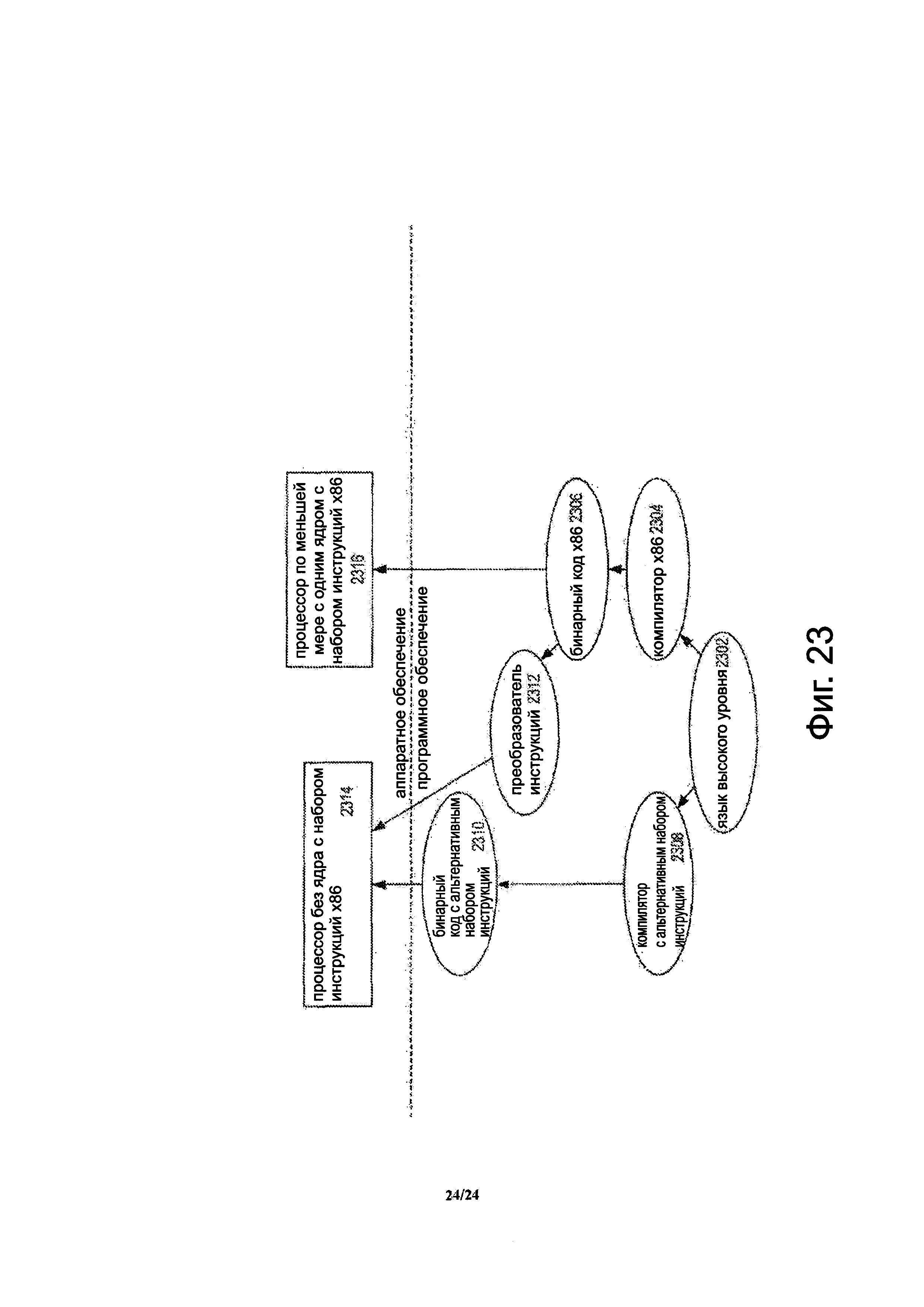
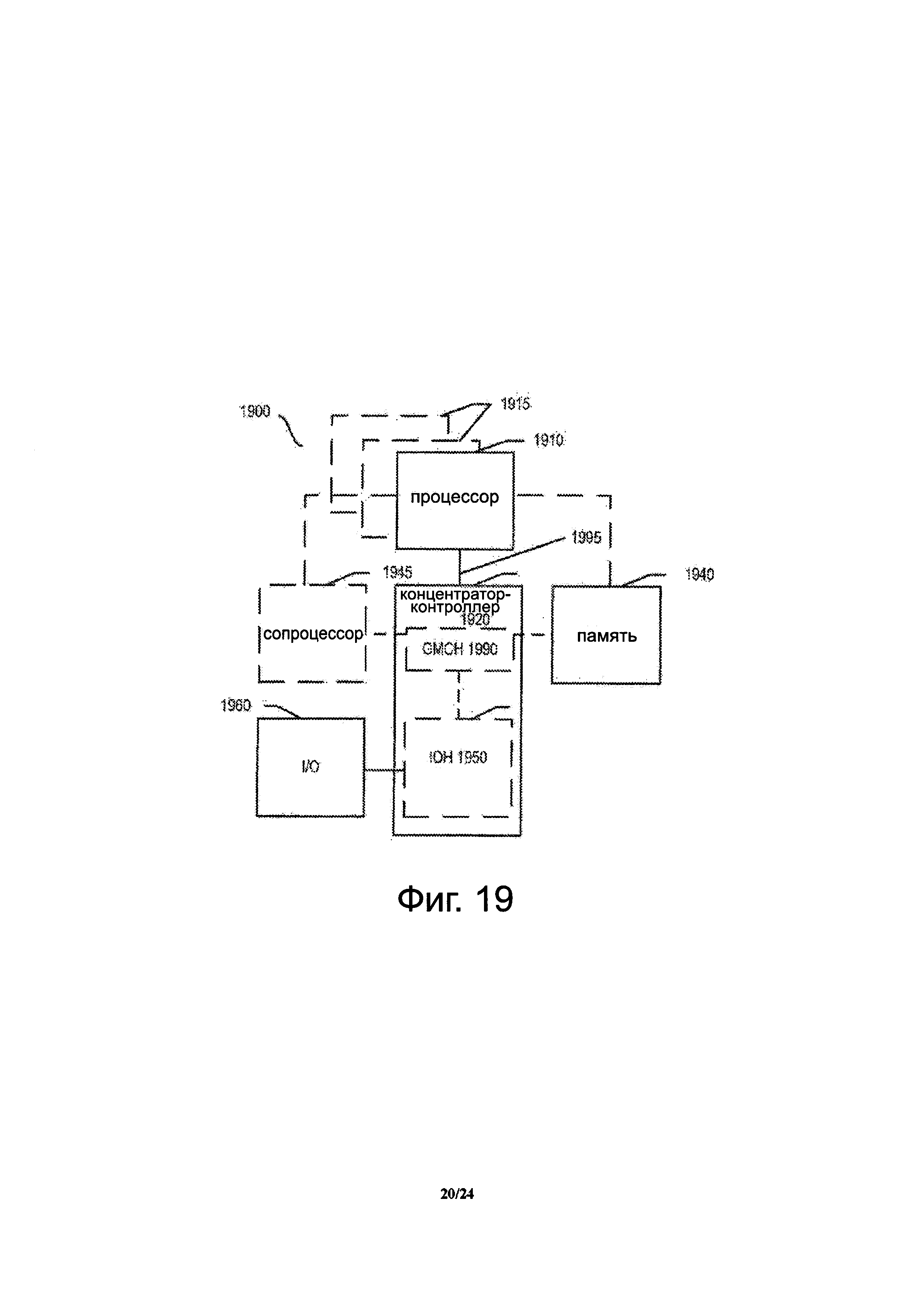
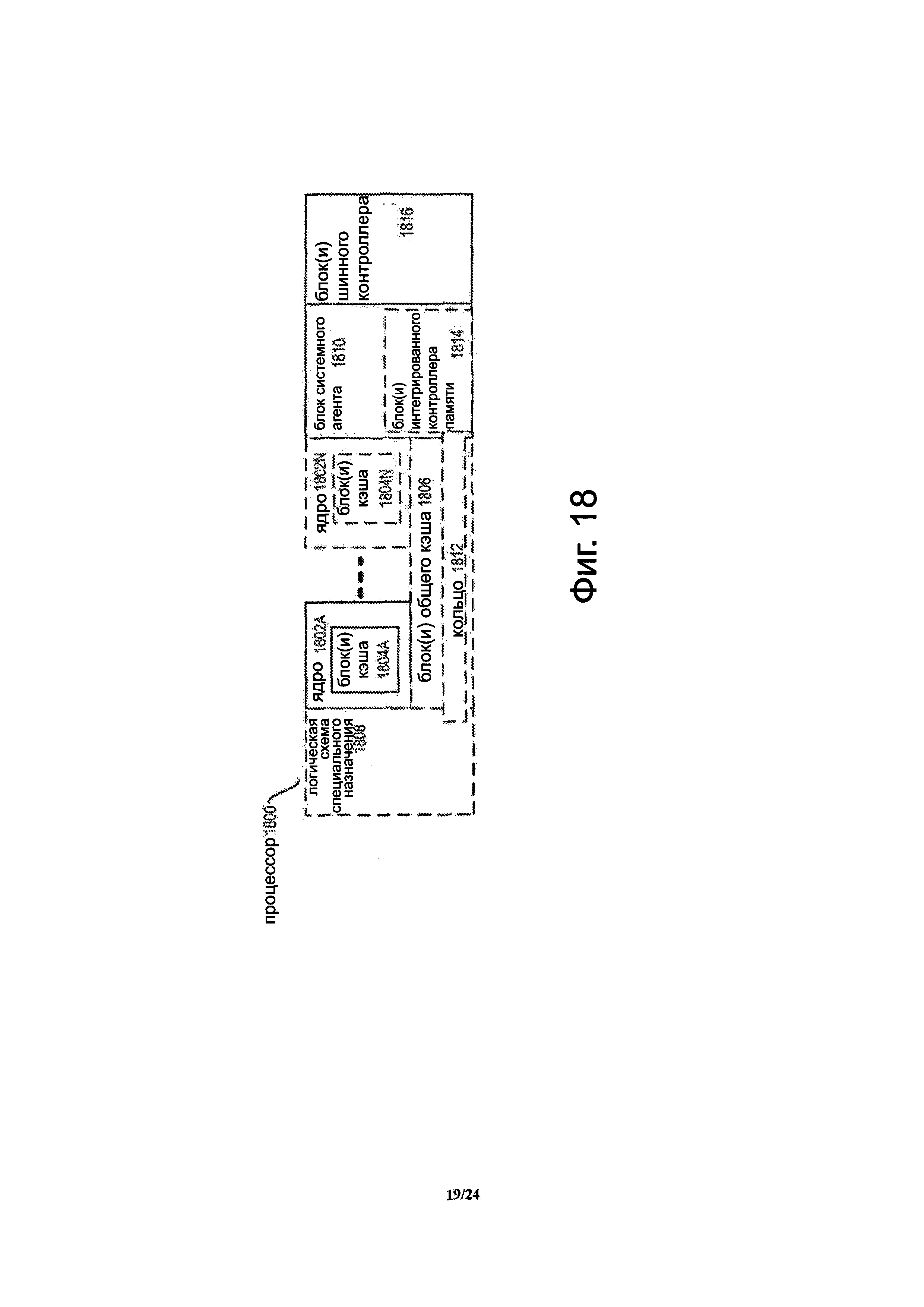
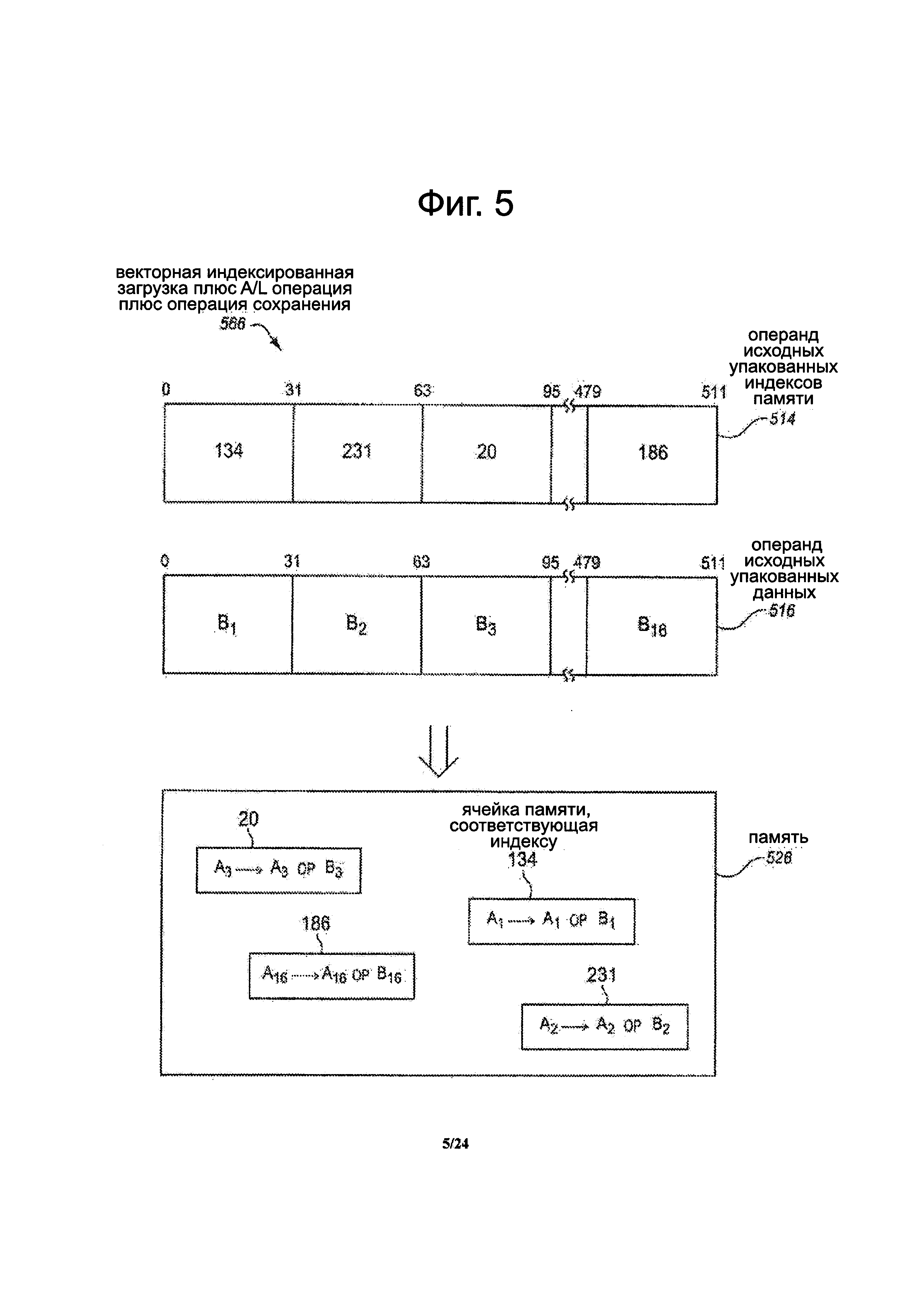
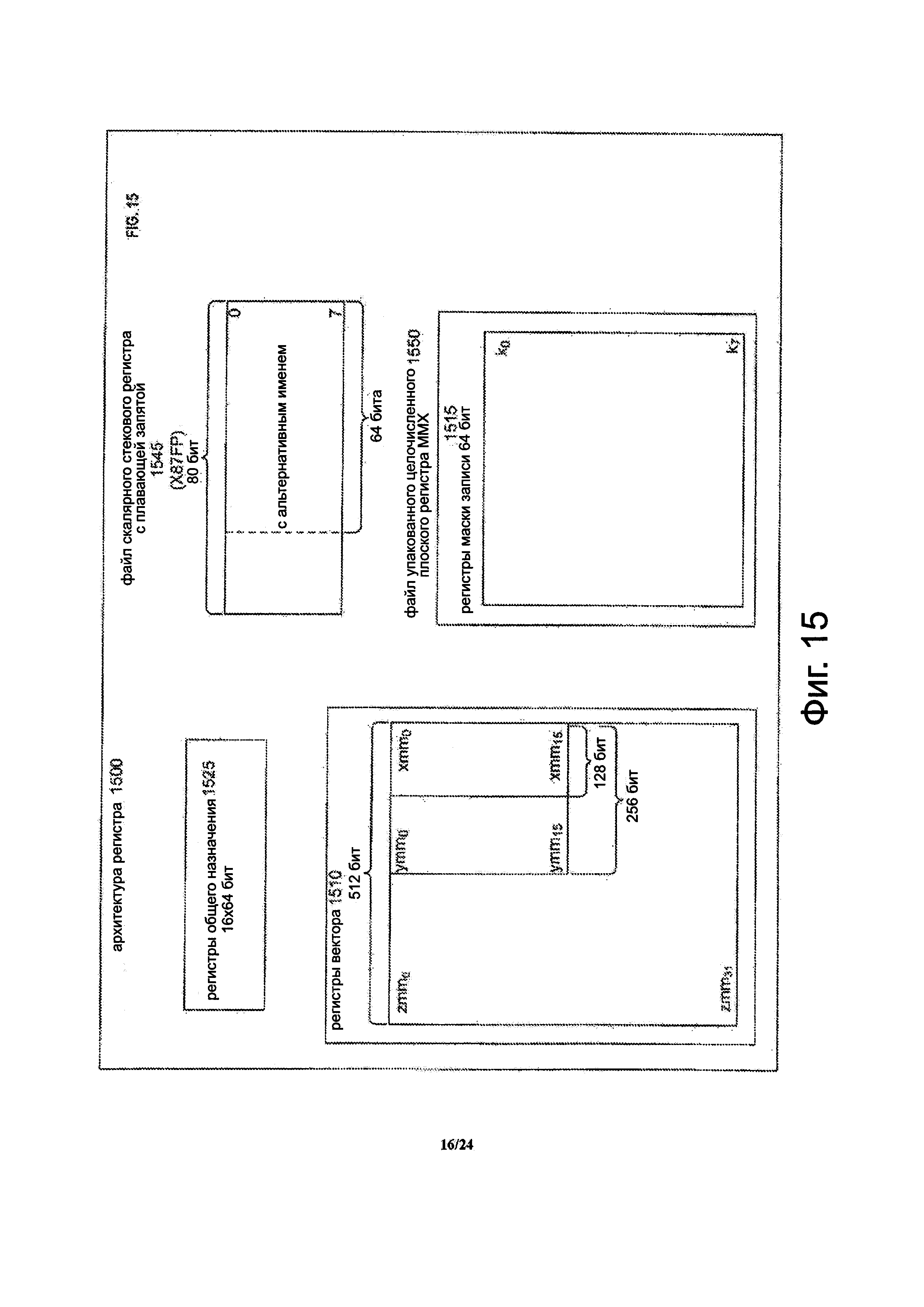
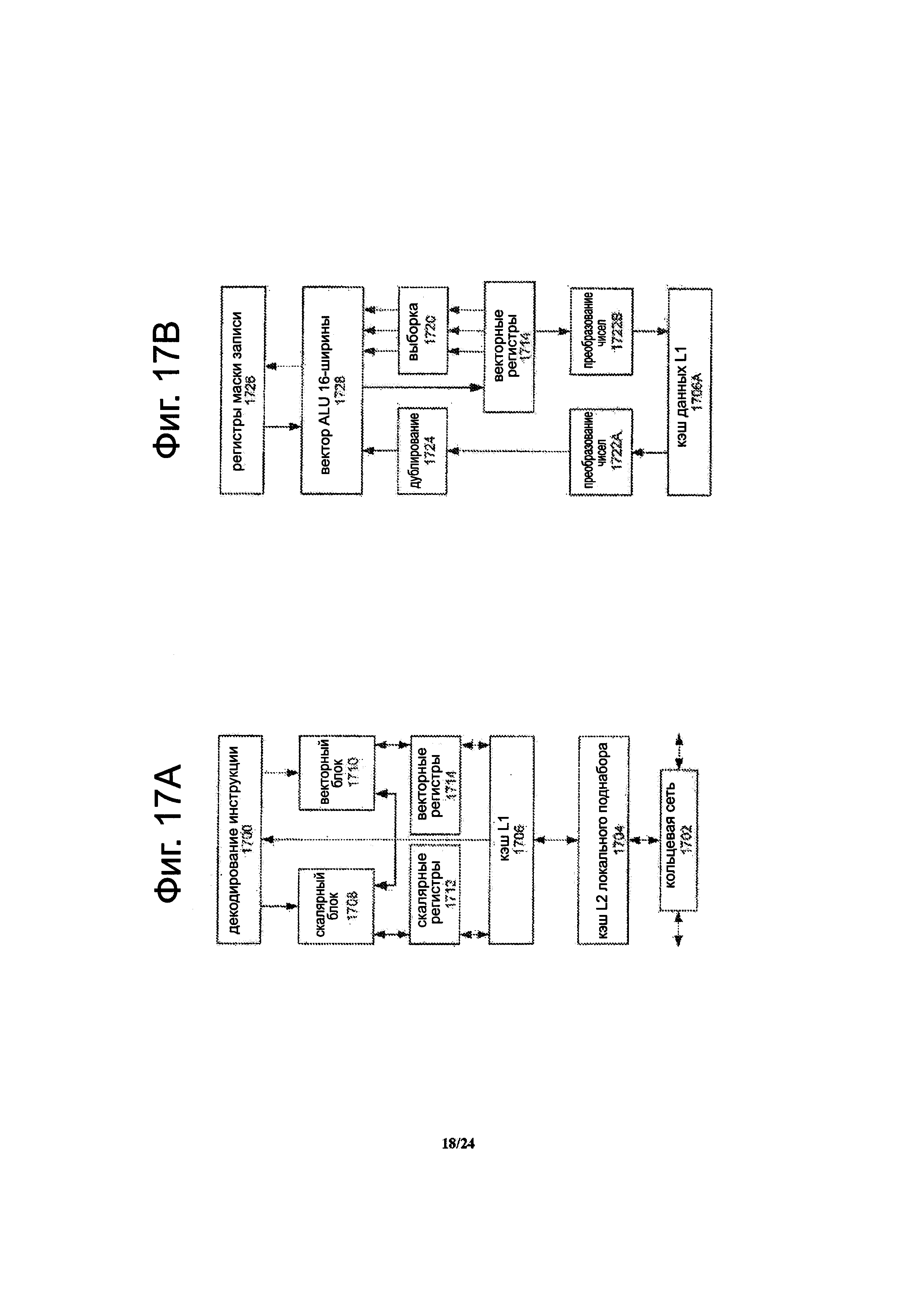

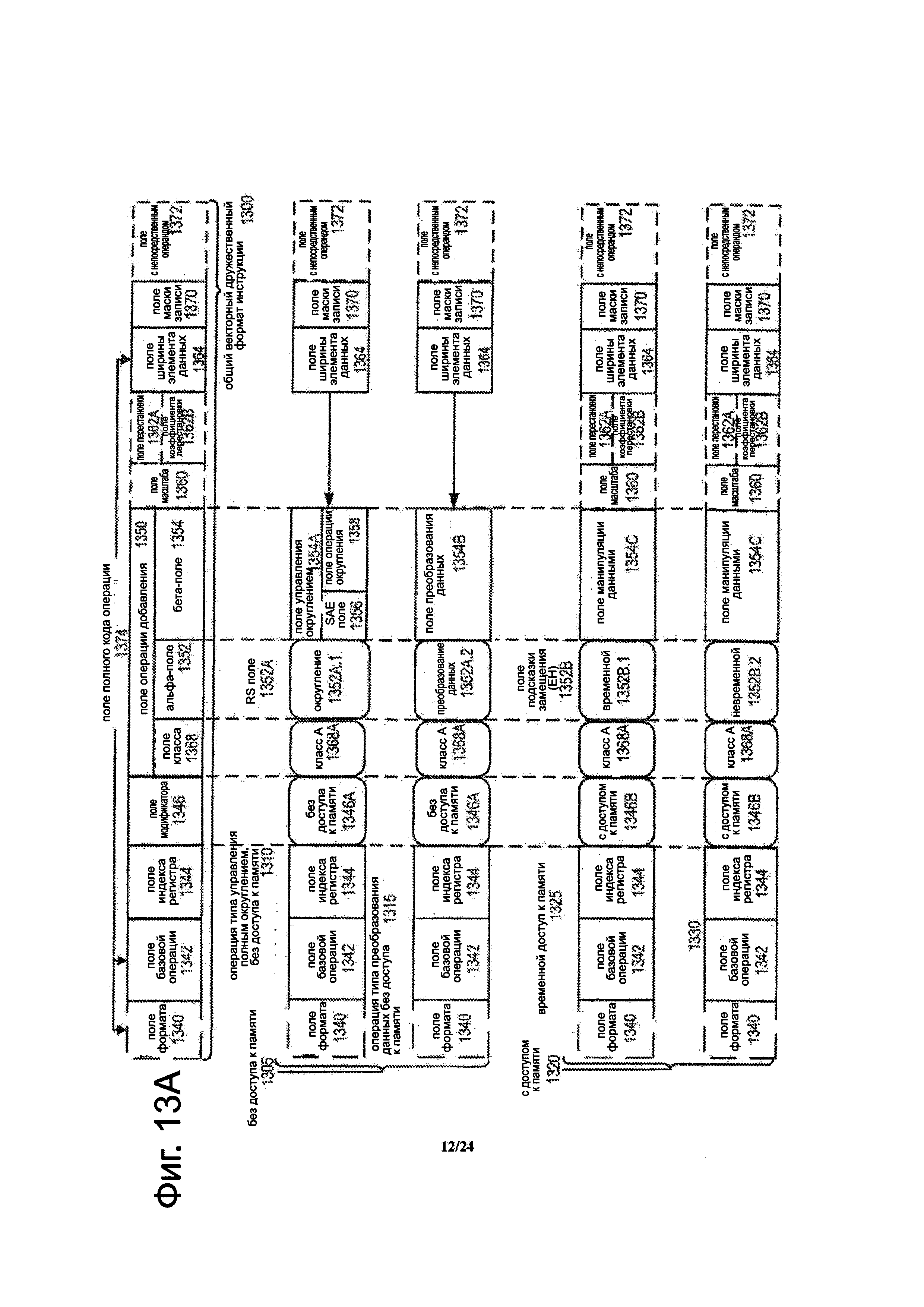
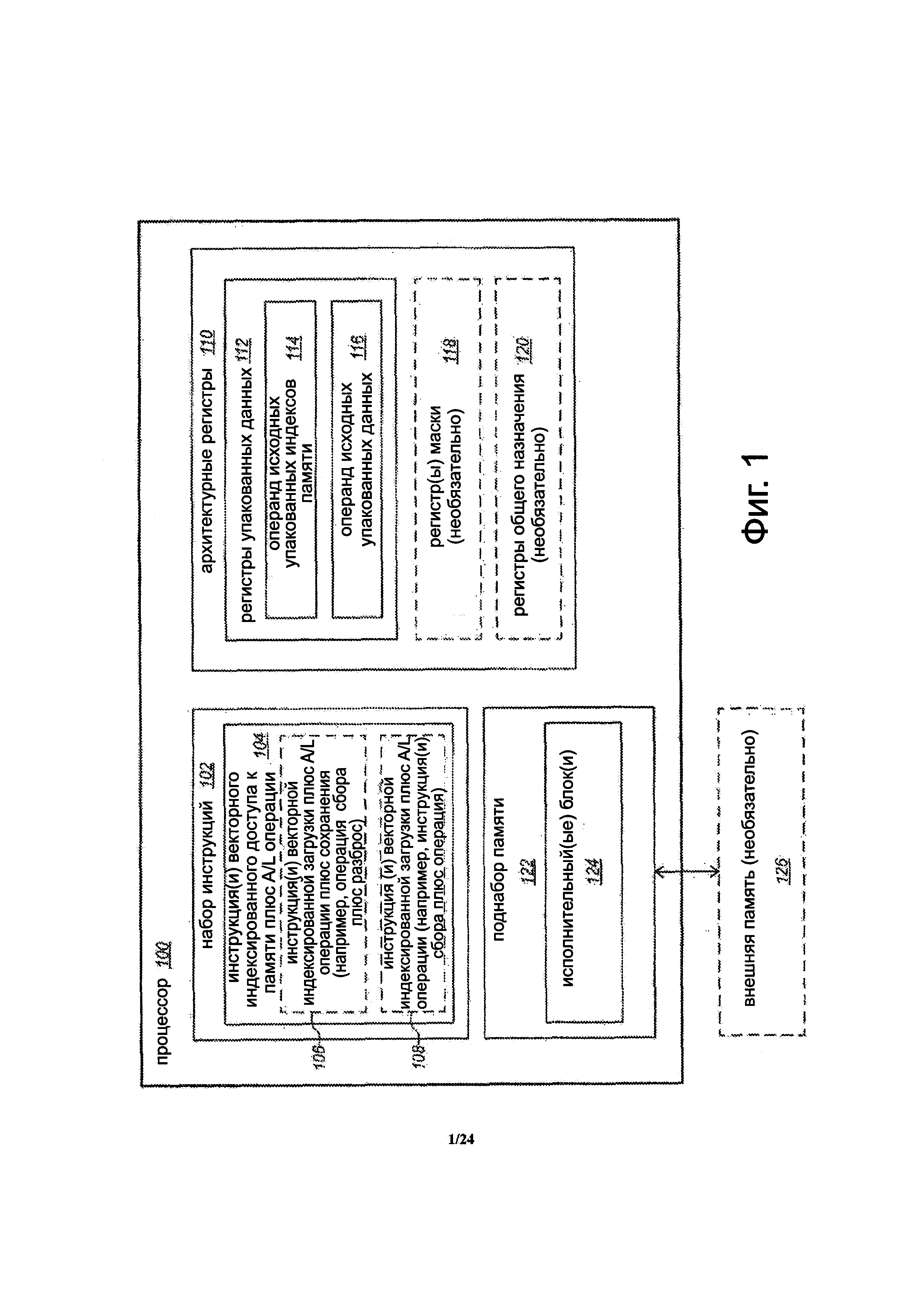
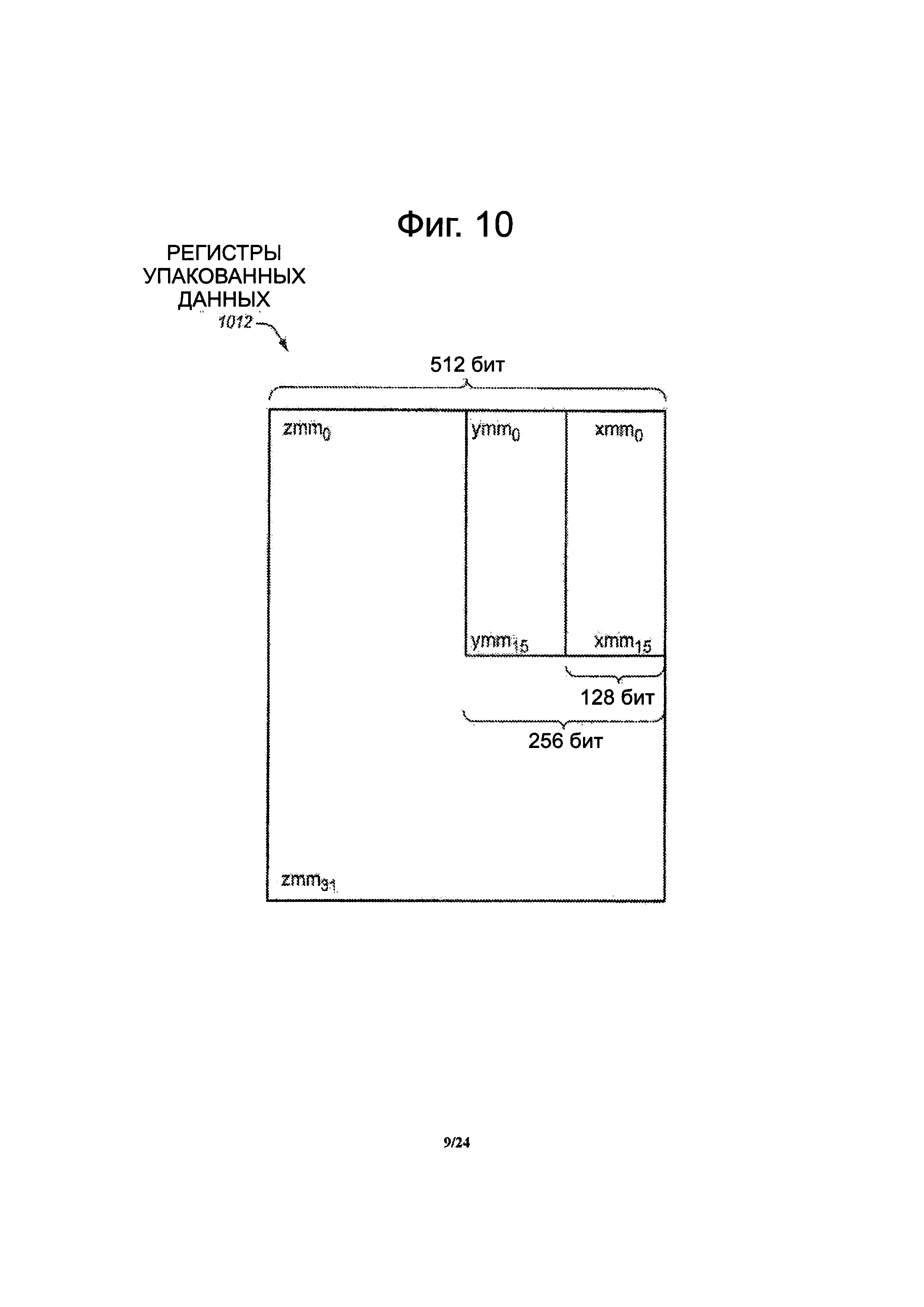
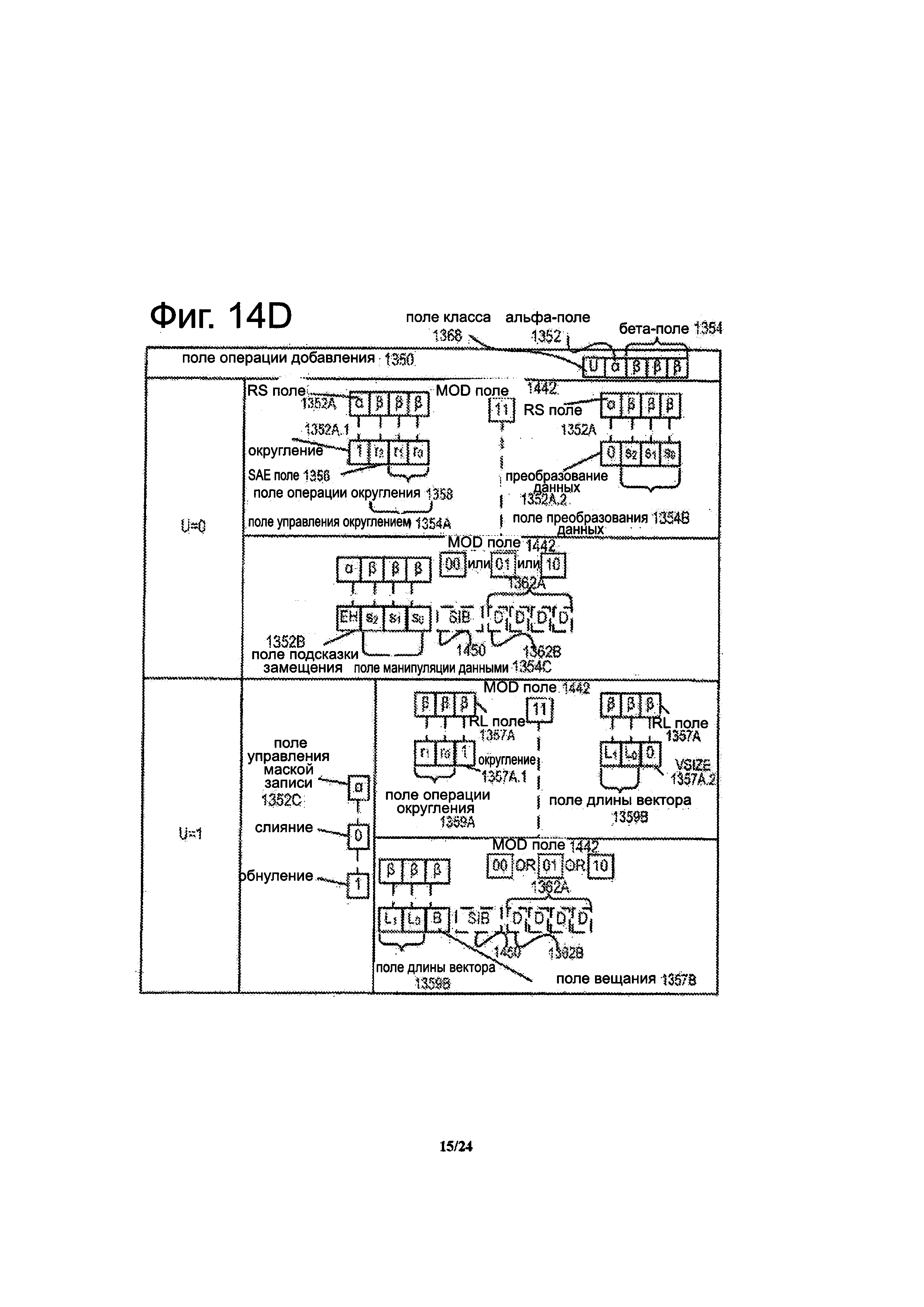
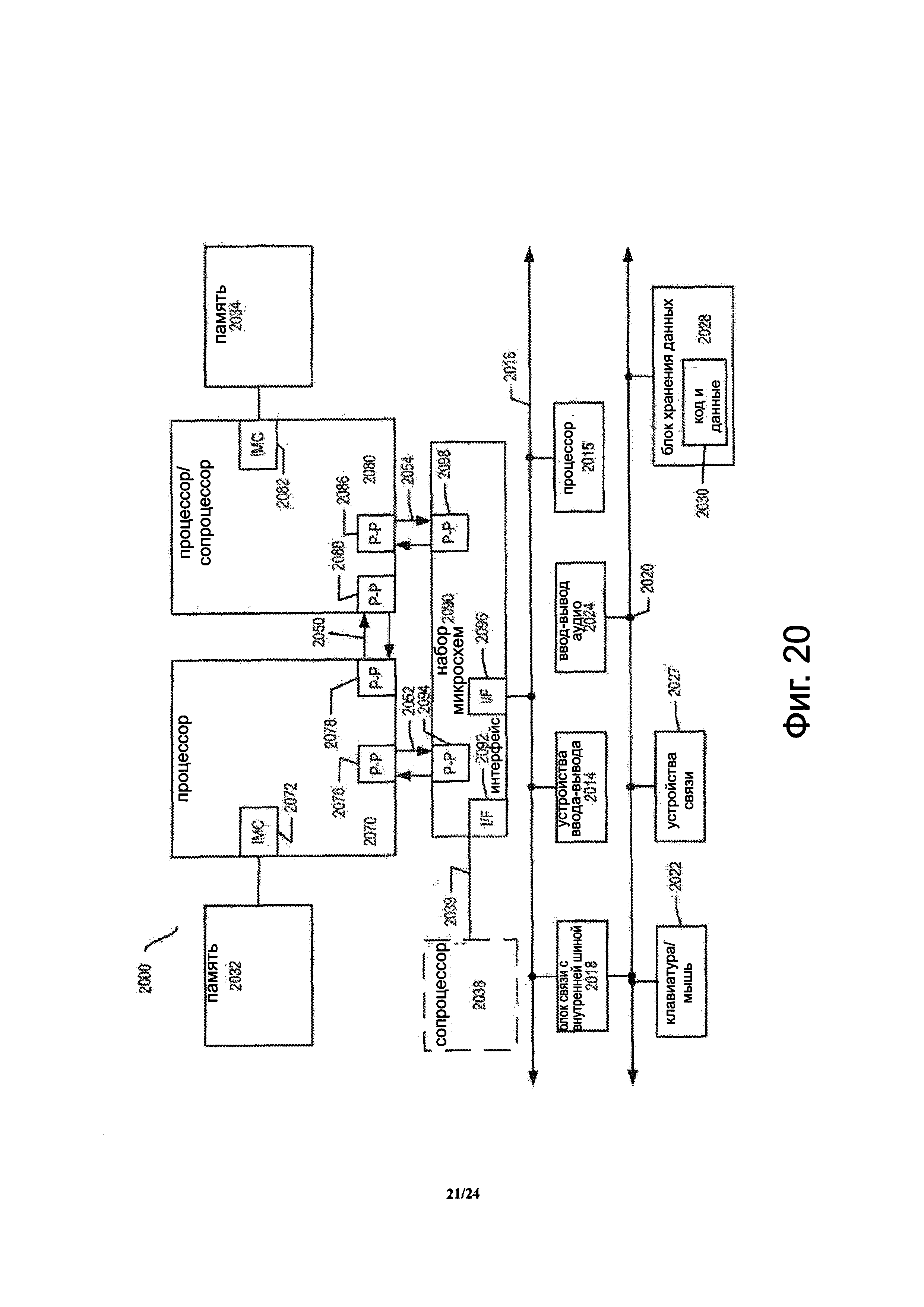
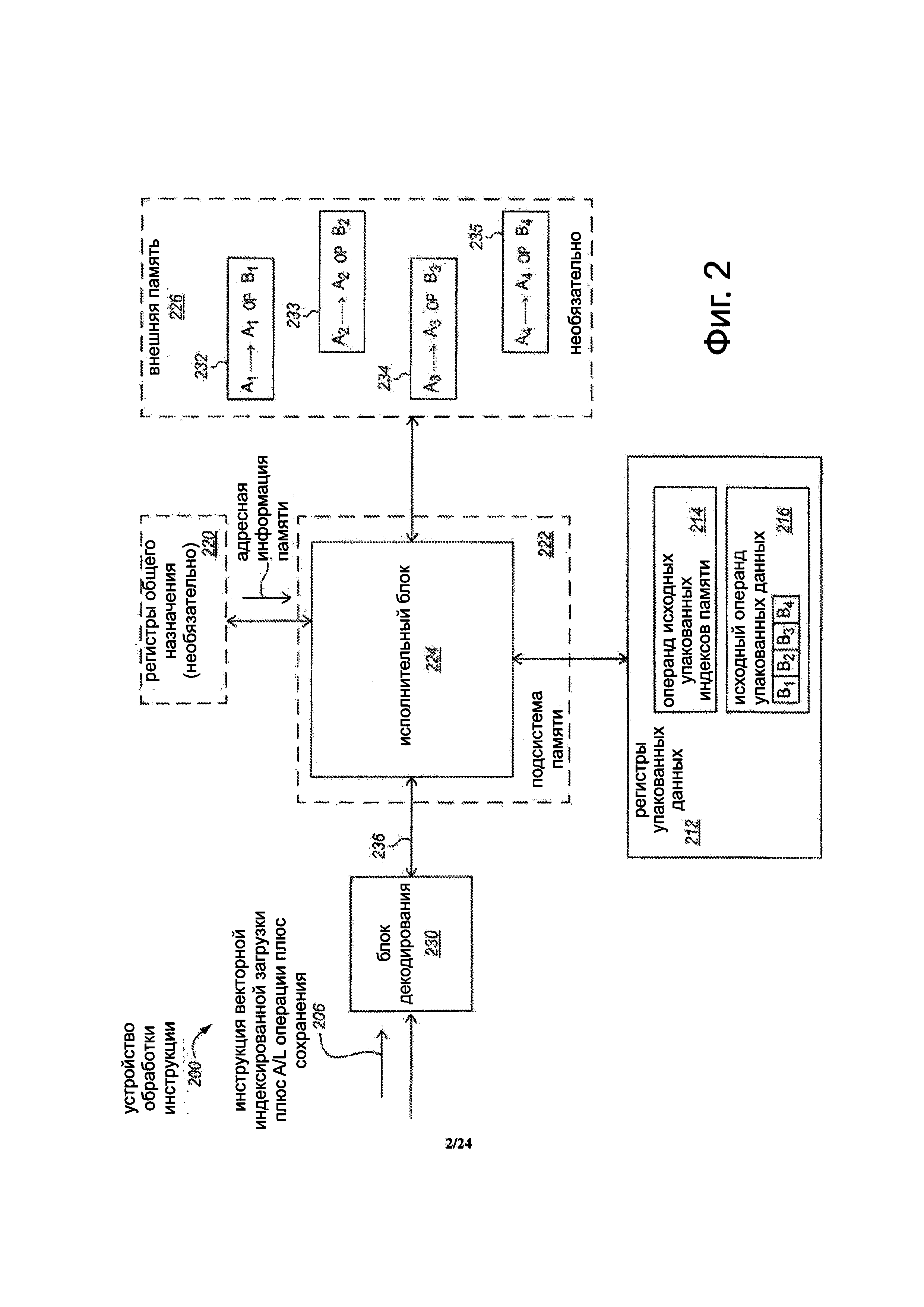
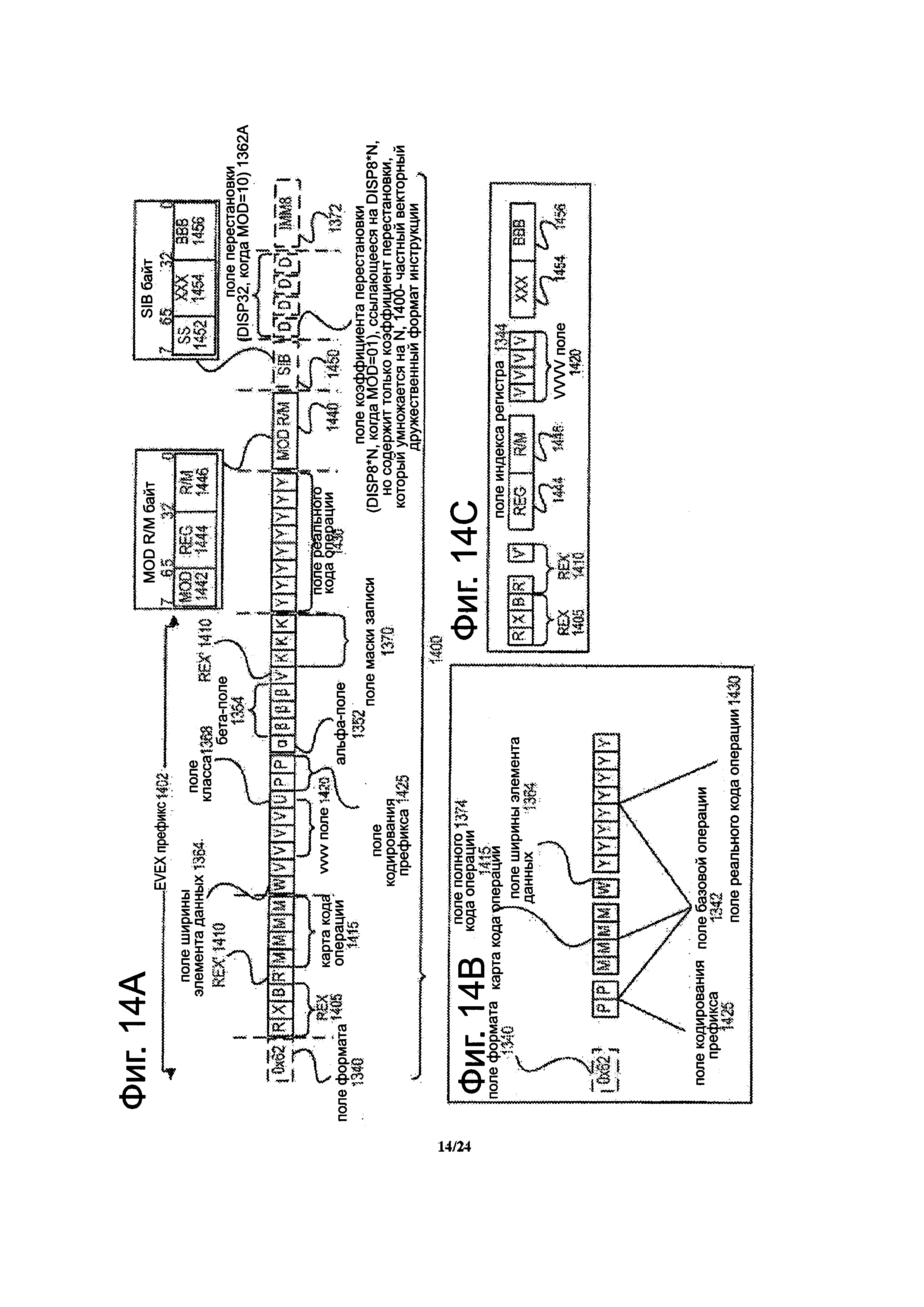
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении

