Результат интеллектуальной деятельности: Устройство, способ и компьютерная программа для трехмерного видеокодирования
Вид РИД
Изобретение
Область техники
Настоящее изобретение относится к устройству, способу и компьютерной программе для кодирования и декодирования видеоданных.
Предпосылки создания изобретения
Данный раздел предназначен для описания предпосылок к созданию изобретения, охарактеризованного в формуле изобретения. Описание данного раздела может включать идеи, которые могли быть реализованы, но не обязательно те идеи, которые уже были предложены или разработаны ранее. Таким образом, если не указано иное, информация, представленная в данном разделе не является описанием уровня техники для предлагаемого изобретения и не признается таковой вследствие включения в данный раздел.
Система видеокодирования может содержать кодер, который преобразует входные видеоданные в сжатое представление, подходящее для хранения и передачи, а также декодер, который распаковывает сжатое представление видеоданных обратно в форму, пригодную для просмотра. В кодере часть информации исходной видеопоследовательности может отбрасываться для представления видеоинформации в более компактной форме, например, для обеспечения возможности передачи или хранения видеоинформации с меньшей битовой скоростью, чем это потребовалось бы в противном случае.
Масштабируемое видеокодирование относится к структуре кодирования, в которой один битовый поток может содержать несколько представлений контента с различными битовыми скоростями, разрешением, частотой кадров и/или другими типами масштабируемости. Масштабируемый битовый поток может включать базовый уровень, обеспечивающий самое низкое доступное качество видеоинформации, а также один или более уровней расширения, которые позволяют повысить качество видеоинформации при их приеме и декодировании вместе с нижними уровнями. Для повышения эффективности кодирования уровней расширения их кодированные представления могут зависеть от нижних уровней. Каждый уровень вместе со всеми зависимыми от него уровнями является одним из представлений видеосигнала с определенным пространственным разрешением, временным разрешением, уровнем качества и/или рабочей точкой масштабирования других типов.
В настоящее время ведутся исследования и разработки различных технологий предоставления трехмерного (3D) видеоконтента. В частности, активно исследуются различные применения многоракурсных видеоизображений, в которых зритель с одной точки наблюдения может видеть одну пару стереоскопических видеоизображений, а с другой точки наблюдения - еще одну пару стереоскопических видеоизображений. Одним из наиболее подходящих подходов для практической реализации подобных применений многоракурсного видео стал подход, в котором на сторону декодера передают только ограниченное количество входных ракурсов, например моно- или стереоскопическое видеоизображение плюс некоторые дополнительные данные, а все необходимые ракурсы затем воспроизводятся (то есть синтезируются) локально декодером для отображения на дисплее.
При кодировании трехмерного видеоконтента могут применяться такие системы сжатия видеоинформации, как стандарт улучшенного видеокодирования (Advanced Video Coding) H.264/AVC или его расширение, многоракурсное видеокодирование (Multiview Video Coding, MVC).
Сущность изобретения
В некоторых из вариантов осуществления настоящего изобретения предлагается механизм выполнения обратного предсказания на основе синтеза ракурсов, в котором блок предсказания на основе синтеза ракурсов для текущего блока текстуры одного из ракурсов формируют на основе сорасположенного блока глубины/диспарантности этого же ракурса. В некоторых из вариантов осуществления настоящего изобретения задают набор операций кодирования и декодирования, а также операции для выполнения синтеза ракурсов, что обеспечивает возможность простой реализации поблочного предсказания на основе синтеза ракурсов внутри цикла обработки видеоинформации. В некоторых из вариантов осуществления настоящего изобретения для кодирования выбирают текущий блок кадра первого ракурса, и выбирают текущий блок кадра первого ракурса для кодирования. Получают информацию о дальности, связанную с блоком текстуры текущего блока. Информацию диспарантности относительно опорного кадра во втором ракурсе определяют на основе упомянутой информации о дальности, при этом на основе этой информации диспарантности определяют опорную область. Предсказание на основе синтеза ракурсов выполняют с использованием этой опорной области для получения предсказания текущего блока.
В соответствии с первым аспектом настоящего изобретения предлагается способ, включающий:
получение первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получение информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определение информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получение опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнение предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии со вторым аспектом настоящего изобретения предлагается устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, которая содержит компьютерный программный код, при этом упомянутые по меньшей мере одна память и компьютерный программный код сконфигурированы для обеспечения, с помощью упомянутого по меньшей мере одного процессора, выполнения упомянутым устройством по меньшей мере следующего:
получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с третьим аспектом настоящего изобретения предлагается вычислительное устройство, сконфигурированное для
получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с четвертным аспектом настоящего изобретения предлагается устройство, содержащее:
средства для получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
средства для получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
средства для определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
средства для получения опорных отсчетов второго ракурса на основе упомянутой информации диспарантности и
средства для выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с пятым аспектом настоящего изобретения предлагается способ, включающий:
получение первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получение информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определение информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получение опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнение предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В соответствии с шестым аспектом настоящего изобретения предлагается устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, которая содержит компьютерный программный код, при этом упомянутые по меньшей мере одна память и компьютерный программный код сконфигурированы для обеспечения, с помощью упомянутого по меньшей мере одного процессора, выполнения упомянутым устройством следующего:
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В соответствии с седьмым аспектом настоящего изобретения предлагается компьютерный программный продукт, содержащий одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение устройством по меньшей мере следующего:
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В соответствии с восьмым аспектом настоящего изобретения предлагается устройство, содержащее:
средства для получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
средства для получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
средства для определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
средства для получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
средства для выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В соответствии с девятым аспектом осуществления настоящего изобретения предлагается видеокодер, сконфигурированный для
получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с десятым аспектом осуществления настоящего изобретения предлагается видеодекодер, сконфигурированный для
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
Краткое описание чертежей
Для лучшего понимания настоящего изобретения сделаны ссылки на приложенные чертежи.
На фиг. 1 проиллюстрирована упрощенная двумерная модель конфигурации стереоскопической камеры.
На фиг. 2 проиллюстрирована упрощенная модель конфигурации многоракурсной камеры.
На фиг. 3 проиллюстрирована упрощенная модель многоракурсного автостереоскопического дисплея (multiview autostereoscopic display, ASD).
На фиг. 4 проиллюстрирована упрощенная модель системы 3DV на основе DIBR.
На фиг. 5 проиллюстрирован один из примеров видеоинформации с данными глубины.
На фиг. 6 показана визуализация горизонтально-вертикального соответствия и соответствия диспарантности между изображениями текстуры и глубины в первом и втором кодированных ракурсах.
На фиг. 7а показана пространственная окрестность текущего кодируемого блока, из которой берутся кандидаты для внутреннего предсказания.
На фиг. 7b показана временная окрестность текущего кодируемого блока, из которой берутся кандидаты для внешнего предсказания;
На фиг. 8 в виде упрощенной схемы показан один из примеров многоракурсного видеокодера с функцией синтеза ракурсов.
На фиг. 9 в виде упрощенной схемы показан один из примеров многоракурсного видеодекодера с функцией синтеза ракурсов.
На фиг. 10 схематично проиллюстрировано электронное устройство, подходящее для применения некоторых вариантов осуществления настоящего изобретения.
На фиг. 11 схематично проиллюстрировано пользовательское устройство, подходящее для применения некоторых вариантов настоящего изобретения.
На фиг. 12 также схематично проиллюстрированы электронные устройства, в которых применяются варианты осуществления настоящего изобретения, связанные между собой с помощью проводных и беспроводных сетевых соединений.
На фиг. 13 в виде блок-схемы проиллюстрирован способ кодирования в соответствии с одним из примеров осуществления настоящего изобретения.
На фиг. 14 в виде блок-схемы проиллюстрирован способ декодирования в соответствии с одним из примеров осуществления настоящего изобретения.
Подробное описание некоторых примеров осуществления изобретения
Для обеспечения понимания различных аспектов настоящего изобретения и вариантов его осуществления далее кратко описаны некоторые из тесно связанных с ними аспектов видеокодирования.
В настоящем разделе приведены ключевые определения, описаны структура битового потока и структура кодирования, а также концепции стандарта H.264/AVC в качестве примера видеокодера, декодера, способа кодирования, способа декодирования и структуры битового потока, в которых могут быть реализованы варианты осуществления настоящего изобретения. Аспекты настоящего изобретения не ограничены стандартом H.264/AVC, напротив, данное описание приведено лишь в качестве возможной основы для частичной или полной реализации настоящего изобретения.
Стандарт H.264/AVC был разработан объединенной командой по видео (Joint Video Team, JVT) группы экспертов по видеокодированию (Video Coding Experts Group, VCEG) отдела стандартизации телекоммуникаций Международного союза электросвязи (International Telecommunication Union, ITU-T) и группой экспертов по движущимся изображениям (Moving Picture Experts Group, MPEG) Международной организации по стандартизации (International Organization for Standardization, ISO) / Международной электротехнической комиссии (International Electrotechnical Commission, IEC). Стандарт H.264/AVC был опубликован обеими родительскими организациями по стандартизации и получил наименование Рекомендации Н.264 ITU-T и Международного стандарта ISO/IEC 14496-10, известного также как улучшенное видеокодирование (Advanced Video Coding, AVC), MPEG-4, часть 10. Были выпущены несколько версий стандарта H.264/AVC, в которых добавлялись новые расширения или элементы в спецификацию. Эти расширения включают масштабируемое видеокодирование (Scalable Video Coding, SVC) и многоракурсное видеокодирование (Multiview Video Coding, MVC).
Аналогично многим предшествующим стандартам видеокодирования, в стандарте H.264/AVC описаны синтаксис и семантика битового потока, а также процесс декодирования безошибочных битовых потоков. Процесс кодирования не определен, однако кодеры должны формировать битовые потоки, соответствующие стандарту. Соответствие битового потока и декодера стандарту может быть проверено с помощью гипотетического опорного декодера (Hypothetical Reference Decoder, HRD), который определен в приложении С (Annex С) стандарта H.264/AVC. Стандарт включает инструменты кодирования, помогающие справиться с ошибками и потерями при передаче, однако использование этих инструментов при кодировании не является обязательным, при этом процесс декодирования для битовых потоков с ошибками не определен.
Элементарной единицей для ввода в кодер H.264/AVC и вывода из декодера H.264/AVC является изображение. Изображение может представлять собой кадр или поле. Кадр, как правило, включает матрицу отсчетов яркости и соответствующих отсчетов цветности. Поле представляет собой набор чередующихся строк отсчетов кадра и может использоваться в качестве входных данных для кодера в случае, когда исходный сигнал является чересстрочным. Макроблок (macroblock, MB) представляет собой блок отсчетов яркости размером 16×16 и соответствующие блоки отсчетов цветности. Блок имеет граничные отсчеты, которые представляют собой отсчеты в самой верхней и самой нижней строках, а также в самом левом и самом правом столбцах. Граничные отсчеты, смежные с другим кодируемым или декодируемым блоком, могут использоваться, например, для внутреннего предсказания. Разрешение изображений цветности может быть пониженным, по сравнению с разрешением изображений яркости. Например, при схеме выборки отсчетов 4:2:0 пространственное разрешение изображений цветности будет равно половине разрешения изображений яркости по обеим координатным осям, и, следовательно, макроблок будет содержать один блок размером 8×8 отсчетов цветности для каждого компонента цветности. Изображение разбивается на одну или более групп слайсов, при этом каждая группа слайсов содержит один или более слайсов. Слайс состоит из целого числа макроблоков, упорядоченных в порядке сканирования растра в данной группе слайсов.
Элементарной единицей для вывода из кодера H.264/AVC и ввода в декодер H.264/AVC является блок уровня сетевой абстракции (Network Abstraction Layer, NAL). Декодирование NAL-блоков с частичными потерями или искажениями обычно является сложным. Для передачи по сетям пакетной передачи данных или хранения в структурированных файлах NAL-блоки, как правило, инкапсулируются в пакеты или в аналогичные структуры. В стандарте H.264/AVC для сред передачи или хранения, не поддерживающих структуру кадров, определен формат байтового потока. В формате байтового потока NAL-блоки отделяются друг от друга с помощью прикрепления стартового кода перед каждым NAL-блоком. Чтобы исключить ложное обнаружение границ NAL-блоков в кодерах исполняется байтовый алгоритм предотвращения эмуляции стартового кода, который добавляет байт предотвращения эмуляции к полезной нагрузке NAL-блока, если в противном случае в ней будет присутствовать стартовый код. Для обеспечения прозрачного шлюзового взаимодействия между системами пакетной и потоковой передачи данных предотвращение эмуляции стартового кода должно выполняться в любом случае, независимо от того, применяется формат байтового потока или нет.
В стандарте H.264/AVC, как и во многих других стандартах видеокодирования, допускается разбиение кодированного изображения на слайсы. Предсказание внутри изображения с пересечением границ слайсов не допускается. Соответственно, использование слайсов можно рассматривать как деление кодированного изображения на независимо декодируемые части, поэтому слайсы часто считаются элементарными единицами передачи.
Некоторые профили стандарта H.264/AVC обеспечивают возможность применения вплоть до восьми групп слайсов в каждом кодированном изображении. Если используется более одной группы слайсов, изображение разбивают на блоки карт групп слайсов, которые равны двум последовательным по вертикали макроблокам, если используется адаптивное к макроблокам кодирование кадров-полей (macroblock-adaptive frame-field, MBAFF), или равны макроблоку в противном случае. Набор параметров изображения содержит данные, на основе которых каждый блок карты групп слайсов может быть связан с конкретной группой слайсов. Группа слайсов может содержать любые блоки карты групп слайсов, включая несмежные блоки карты. Если для изображения заданы более одной группы слайсов, используется функция гибкого упорядочения макроблоков (flexible macroblock ordering, FMO), определенная в стандарте.
В стандарте H.264/AVC слайс включает один или более последовательных макроблоков (или пар макроблоков в случае применения MBAFF), упорядоченных в порядке сканирования растра в соответствующей группе слайсов. Если используется только одна группа слайсов, то слайсы согласно стандарту H.264/AVC содержат последовательные макроблоки в порядке сканирования растра и, следовательно, аналогичны слайсам во многих предшествующих стандартах кодирования. В некоторых профилях стандарта H.264/AVC слайсы кодированного изображения могут появляться в битовом потоке в любом порядке относительно друг друга, что называется функцией произвольного упорядочения слайсов (arbitrary slice ordering, ASO). В других случаях слайсы должны располагаться в битовом потоке в порядке сканирования растра.
NAL-блоки включают заголовок и полезную нагрузку. Заголовок NAL-блока указывает на тип данного NAL-блока, а также на то, является ли кодированный слайс, содержащийся в данном NAL-блоке, частью опорного изображения или неопорного изображения. Заголовок NAL-блоков расширений SVC и MVC может дополнительно содержать различные указания, связанные с масштабированием и иерархией многоракурсного кодирования.
NAL-блоки в стандарте H.264/AVC могут быть разделены на две категории: NAL-блоки уровня видеокодирования (Video Coning Layer, VCL) и NAL-блоки, не являющиеся блоками VCL. NAL-блоки VCL могут быть NAL-блоками кодированного слайса, NAL-блоками разбиения данных кодированного слайса или префиксными NAL-блоками VCL. В стандарте H.264/AVC кодированные NAL-блоки слайса содержат синтаксические элементы, представляющие собой один или более кодированных макроблоков, каждый из которых соответствует блоку отсчетов несжатого изображения. Существуют четыре типа NAL-блоков кодированного слайса: кодированный слайс в изображении мгновенного обновления декодирования (Instantaneous Decoding Refresh, IDR), кодированный слайс в изображении, не являющемся IDR-изображением, кодированный слайс во вспомогательном кодированном изображении (например, альфа-плоскость) и расширение кодированного слайса (для SVC-слайсов не в базовом уровне или MVC-слайсов не в базовом ракурсе). Набор из трех NAL-блоков разбиения данных кодированного слайса содержит те же синтаксические элементы, что и кодированный слайс. Разбиение А данных кодированного слайса включает заголовки макроблоков и векторы движения слайса, тогда как разбиения В и С данных кодированного слайса включают кодированные разностные данные для внутренних макроблоков и внешних макроблоков, соответственно. Следует отметить, что поддержка разбиений данных слайса включена только в некоторые из профилей стандарта H.264/AVC. Префиксный NAL-блок VCL предшествует кодированному слайсу базового уровня в битовых потоках SVC и MVC и содержит указания на иерархию масштабирования соответствующего кодированного слайса.
NAL-блок, не являющийся блоком VCL, в стандарте H.264/AVC может иметь один из следующих типов: набор параметров последовательности, набор параметров изображения, NAL-блок дополнительной информации расширения (supplemental enhancement information, SEI), ограничитель блока доступа, конец последовательности NAL-блоков, конец потока NAL-блоков или NAL-блок с данными наполнения. Наборы параметров необходимы для восстановления декодированных изображений, в то время как другие NAL-блоки, не являющиеся блоками VCL, не являются необходимыми для восстановления декодированных изображений и служат для других целей, которые описаны ниже.
Набор параметров последовательности включает многие параметры, которые остаются неизменными в течение всей кодированной видеопоследовательности. В дополнение к параметрам, которые необходимы для процедуры декодирования, набор параметров последовательности опционально может содержать информацию об используемости видео (video usability information, VUI), включающую параметры, важные для буферизации, синхронизации вывода изображения, воспроизведения изображения и резервирования ресурсов. Набор параметров изображения содержит параметры, которые с большой вероятностью будут неизменными для нескольких кодированных изображений. В битовых потоках H.264/AVC отсутствуют заголовки изображений, однако часто изменяющиеся данные уровня изображения повторяются в каждом заголовке слайса, а остальные параметры уровня изображения передаются в наборах параметров изображения. Синтаксис H.264/AVC допускает использование множества экземпляров наборов параметров последовательности и изображения, при этом каждый экземпляр имеет уникальный идентификатор. Каждый заголовок слайса включает идентификатор набора параметров изображения, который является активным для декодирования изображения, содержащего этот слайс, при этом каждый набор параметров изображения содержит идентификатор активного набора параметров последовательности. Следовательно, передача наборов параметров изображения и последовательности не обязательно должна быть точно синхронизирована с передачей слайсов. Вместо этого достаточно, чтобы активные наборы параметров последовательности и изображения были приняты до момента осуществления ссылки на них, что позволяет передавать наборы параметров с использованием более надежного механизма передачи, по сравнению с протоколами, применяемыми для данных слайса. Например, наборы параметров могут включаться в качестве параметра в описание сеанса для сеансов H.264/AVC транспортного протокола реального времени (Real-time Transport Protocol, RTP). Если наборы параметров передаются по основному каналу, то для повышения устойчивости к ошибкам они могут повторяться.
NAL-блок SEI по стандарту H.264/AVC содержит одно или более SEI-сообщений, которые не требуются для декодирования выходных изображений, но могут быть полезными в связанных с этим процедурах, например, синхронизации вывода изображения, воспроизведения, обнаружения ошибок, маскирования ошибок и резервирования ресурсов. В стандарте H.264/AVC определены несколько типов SEI-сообщений, при этом SEI-сообщения с пользовательскими данными позволяют организациям и компаниям определять SEI-сообщения для собственного использования. Стандарт H.264/AVC содержит синтаксис и семантику сообщений SEI, однако процедура обработки сообщений на стороне приемника не определена. Следовательно, кодер должен следовать стандарту H.264/AVC при формировании SEI-сообщений, при этом от декодера, отвечающего стандарту H.264/AVC, не требуется обрабатывать SEI-сообщения так, чтобы обеспечивать соответствие порядка вывода. Одной из причин включения синтаксиса и семантики SEI-сообщений в стандарт H.264/AVC является обеспечение идентичной интерпретации дополнительной информации в различных системных спецификациях и, следовательно, возможности их взаимодействия. Предполагается, что системные спецификации могут требовать применения конкретных SEI-сообщений как на стороне кодера, так и на стороне декодера, при этом может быть дополнительно определена процедура обработки конкретных SEI-сообщений на стороне приемника.
Кодированное изображение в стандарте H.264/AVC включает NAL-блоки VCL, которые необходимы для декодирования изображения. Кодированное изображение может быть либо первичным кодированным изображением, либо резервным кодированным изображением. Первичное кодированное изображение используется в процессе декодирования правильных битовых потоков, тогда как резервное кодированное изображение является резервным представлением и декодируется только тогда, когда первичное кодированное изображение не может быть успешно декодировано.
В стандарте H.264/AVC блок доступа включает первичное кодированное изображение и те NAL-блоки, которые с ним связаны. Порядок появления NAL-блоков внутри блока доступа задан следующим образом. На начало блока доступа может указывать опциональный NAL-блок ограничителя блока доступа. За ним следует нуль или более NAL-блоков SEI. Далее идут кодированные слайсы или разбиения данных слайсов первичного кодированного изображения, за которыми следуют кодированные слайсы нуля или более резервных кодированных изображений.
Блок доступа в MVC определен как набор NAL-блоков, следующих друг за другом в порядке декодирования и содержащих в точности одно первичное кодированное изображение, включающее один или более компонентов ракурса. В дополнение к первичному кодированному изображению блок доступа может также включать одно или более резервных кодированных изображений, одно вспомогательное кодированное изображение или другие NAL-блоки, не содержащие слайсов или разбиений данных слайсов кодированного изображения. В результате декодирования блока доступа всегда получают одно декодированное изображение, включающее один или более компонентов ракурса. Другими словами, блок доступа в MVC содержит компоненты ракурсов для одного момента времени вывода.
Под компонентом ракурса в MVC понимается кодированное представление ракурса в одном блоке доступа.
В MVC может использоваться межракурсное предсказание, под которым понимается предсказание компонента ракурса на основе декодированных отсчетов различных компонентов ракурса одного и того же блока доступа. В MVC межракурсное предсказание реализуется аналогично внешнему предсказанию. К примеру, опорные изображения межракурсного предсказания помещаются в один и тот же список (или списки) опорных изображений, что и опорные изображения для внешнего предсказания, а указатель на опорное изображение, как и вектор движения, кодируются или вычисляются аналогично для опорных изображений межракурсного предсказания и внешнего предсказания.
Якорное изображение в MVC представляет собой кодированное изображение, для всех слайсов которого в качестве опорных могут использоваться только слайсы в том же блоке кодирования, то есть может использоваться межракурсное предсказание, но внешнее предсказание не используется; при этом для всех последующих кодированных изображений в порядке вывода не используется внешнее предсказание на основе изображений, предшествующих этому кодированному изображению в порядке декодирования. Межракурсное предсказание может использоваться для компонентов ракурса IDR, образующих часть ракурса, не являющегося базовым. Базовый ракурс в MVC представляет собой ракурс, который имеет минимальное значение порядкового номера ракурса в кодированной видеопоследовательности. Базовый ракурс может быть декодирован независимо от остальных ракурсов, при этом для него не используется межракурсное предсказание. Базовый ракурс может декодироваться с помощью декодеров, соответствующих стандарту H.264/AVC, которые поддерживают только одноракурсные профили, например, базовый профиль (Baseline Profile) или верхний профиль (High Profile) стандарта H.264/AVC.
В стандарте MVC во многих из подпроцедур процедуры декодирования MVC используются соответствующие подпроцедуры стандарта H.264/AVC с заменой терминов «изображение», «кадр» и «поле» в спецификации этих процедур в стандарте H.264/AVC на «компонент ракурса», «компонент ракурса кадра» и «компонент ракурса поля», соответственно. Аналогично, термины «изображение», «кадр» и «поле» далее часто используются как обозначающие «компонент ракурса», «компонент ракурса кадра» и «компонент ракурса поля», соответственно.
Кодированная видеопоследовательность определена как ряд последовательных блоков доступа в порядке декодирования от блока доступа IDR, включая его, до следующего блока доступа IDR, не включая его, или до конца битового потока, в зависимости от того, что появится раньше.
Далее приведено определение и характеристики группы изображений (group of pictures, GOP). Группа GOP может быть декодирована независимо от того, были ли декодированы какие-либо предшествующие изображения или нет. Открытая группа изображений представляет собой такую группу изображений, в которой изображения, предшествующие исходному изображению с внутренним предсказанием в порядке вывода, могут быть декодированы некорректно, если декодирование начинается с исходного изображения с внутренним предсказанием открытой группы изображений. Другими словами, изображения открытой группы GOP могут ссылаться (для внешнего предсказания) на изображения из предшествующей группы GOP. Декодер стандарта H.264/AVC способен распознавать изображение с внутренним предсказанием в начале открытой группы GOP на основе SEI-сообщения в точке восстановления в битовом потоке стандарта H.264/AVC. Закрытая группа изображений представляет собой группу изображений, в которой все изображения могут быть декодированы корректно, если декодирование начинается с первого изображения с внутренним предсказанием закрытой группы изображений. Другими словами, ни одно из изображений в закрытой группе GOP не ссылается на изображение из предшествующих групп GOP. В стандарте H.264/AVC закрытая группа GOP начинается с блока доступа IDR. В результате структура закрытой группы GOP имеет более высокий потенциал устойчивости к ошибкам, по сравнению со структурой открытой группы GOP, однако за счет возможного понижения эффективности сжатия. Структура кодирования с открытой группой GOP дает потенциально более эффективное сжатие благодаря большей гибкости при выборе опорных изображений.
Синтаксис битового потока стандарта H.264/AVC указывает на то, является ли конкретное изображение опорным для внешнего предсказания другого изображения. Изображения с любым типом кодирования (I, Р, В, SB) в стандарте H.264/AVC могут быть как опорными изображениями, так и неопорными изображениями. Заголовок NAL-блока указывает на тип данного NAL-блока, а также на то, является ли кодированный слайс, содержащийся в данном NAL-блоке, частью опорного изображения или неопорного изображения.
В настоящее время ведется работа над проектом стандарта высокоэффективного видеокодирования (High Efficiency Video Coding, HEVC). Многие из ключевых определений, структур битового потока и кодирования, а также концепций стандарта HEVC совпадают с соответствующими определениями, структурами и концепциями стандарта H.264/AVC или аналогичны им. В настоящем разделе приведены ключевые определения, описаны структура битового потока и структура кодирования, а также концепции стандарта HEVC, в качестве примера видеокодера, декодера, способа кодирования, способа декодирования и структуры битового потока, в которых могут быть реализованы варианты осуществления настоящего изобретения. Аспекты настоящего изобретения не ограничены стандартом HEVC, напротив, данное описание приведено лишь в качестве возможной основы для частичной или полной реализации настоящего изобретения.
Аналогично стандарту H.264/AVC битовый поток HEVC включает блоки доступа, каждый из которых включает кодированные данные, связанные с изображением. Каждый блок доступа разделен на NAL-блоки, включающие один или более NAL-блоков VCL (то есть NAL-блоков кодированного слайса) и нуль или более NAL-блоков, не являющихся блоками VCL, например, NAL-блоков набора параметров или NAL-блоков дополнительной информации расширения (SEI). Каждый NAL-блок включает заголовок NAL-блока и полезную нагрузку NAL-блока. В проекте стандарта HEVC для всех определенных типов NAL-блоков используется двухбайтный заголовок NAL-блока. Первый байт заголовка NAL-блока содержит один зарезервированный бит, однобитный индикатор nal_ref_idc, первоначально указывающий на то, является ли передаваемое в данном блоке доступа изображение опорным или неопорным, и шестибитный индикатор типа NAL-блока. Второй байт заголовка NAL-блока включает трехбитный идентификатор temporal_id временного уровня и пятибитное зарезервированное поле (называемое reserved_one_5bits), которое в проекте стандарта HEVC должно иметь значение, равное 1. Это пятибитное зарезервированное поле предназначено для использования расширениями, например, будущими расширениями масштабируемого или трехмерного видео. Подразумевается, что эти пять битов могут нести информацию об иерархии масштабирования, например, параметр quality_id или аналогичную информацию, параметр dependency_id или аналогичную информацию, или идентификатор уровня любого другого типа, порядковой номер ракурса или аналогичную информацию, идентификатор ракурса, идентификатор, аналогичный priority_id в стандарте SVC, указывающий на корректность выделения битового подпотока, если из битового потока удалены все NAL-блоки со значениями идентификаторов, превышающими заданное значение идентификатора. Без потери общности в некоторых примерах осуществления настоящего изобретения на основе значения reserved_one_5bits вычисляют переменную Layerld, например, следующим образом: Layerld = reserved_one_5bits - 1.
В проекте стандарта HEVC некоторые из ключевых определений и концепций, связанных с разбиением изображения, определены следующим образом. Разбиением называется разделение множества на подмножества таким образом, что каждый элемент множества находится только в одном из подмножеств.
Видеоизображения могут быть разделены на блоки кодирования (coding units, CU), покрывающие область изображения. Блок кодирования включает один или более блоков предсказания (prediction unit, PU), определяющих процедуру предсказания отсчетов в блоке кодирования, а также один или более блоков преобразования (transform units, TU), определяющих процедуру кодирования ошибки предсказания для отсчетов в блоке кодирования. Блок кодирования может включать квадратный блок отсчетов, размер которого выбирается из заранее заданного множества допустимых размеров блока кодирования. Блок кодирования максимально допустимого размера может быть назван наибольшим блоком кодирования (largest coding unit, LCU), при этом видеоизображение разделяется на неперекрывающиеся блоки LCU. Наибольший блок кодирования, в свою очередь, может быть разбит на комбинацию меньших блоков кодирования, например, с помощью рекурсивного разбиения наибольшего блока кодирования и полученных в результате блоков кодирования. Каждый полученный в результате блок кодирования может иметь связанные с ним по меньшей один блок предсказания и по меньшей мере один блок преобразования. Каждый блок предсказания и блок преобразования также могут быть разбиты на меньшие блоки предсказания и блоки преобразования для повышения степени разбиения в процедурах предсказания и кодирования ошибки предсказания, соответственно. Каждый блок предсказания имеет связанную с ним информацию предсказания, которая определяет, предсказание какого типа должно применяться к пикселям в данном блоке предсказания (например, информацию вектора движения для блоков предсказания с внешним предсказанием или информацию направления внутреннего предсказания для блока предсказания с внутренним предсказанием). Аналогично, каждый блок преобразования связан с информацией, описывающей процедуру декодирования ошибки предсказания для отсчетов в данном блоке преобразования (включая, например, информацию о коэффициентах DCT). На уровне блока кодирования может сигнализироваться, применяется ли кодирование ошибки предсказания для каждого блока кодирования. Если нет разностной ошибки предсказания, связанного с блоком кодирования, то можно считать, что для данного блока кодирования отсутствуют блоки преобразования. Информация о разделении изображения на блоки кодирования и о разделении блоков кодирования на блоки предсказания и блоки преобразования может сигнализироваться в битовом потоке, что позволяет воспроизводить заданную структуру этих блоков в декодере.
Многие гибридные видеокодеки, включающие функциональность H.264/AVC и HEVC, кодируют видеоинформацию в два этапа. На первом этапе выполняется предсказание значений пикселей или отсчетов в некоторой области изображения или «блоке». Эти значения пикселей или отсчетов могут предсказываться, например, с использованием механизмов компенсации движения, подразумевающих нахождение и указание области в одном из ранее кодированных видеокадров, которая близко соответствует кодируемому в текущий момент блоку. Дополнительно, значения пикселей или отсчетов могут предсказываться с использованием пространственных механизмов, подразумевающих нахождение и указание взаимосвязи пространственных областей.
Подходы для предсказания, в которых используется информация ранее кодированных изображений, могут также называться методами внешнего предсказания, а также временным предсказанием и компенсацией движения. Подходы для предсказания, в которых используется информация этого же изображения, могут называться методами внутреннего предсказания.
Второй этап представляет собой этап кодирования расхождения между предсказанным блоком пикселей или отсчетов и исходным блоком пикселей или отсчетов. Это может осуществляться с помощью преобразования разности значений пикселей или отсчетов с использованием заданного преобразования. Таким преобразованием может быть дискретное косинусное преобразование (Discrete Cosine Transform, DCT) или его вариант. После преобразования разности преобразованную разность квантуют и выполняют ее энтропийное кодирование.
С помощью изменения точности процесса квантования кодер может управлять балансом между точностью представления пикселей или отсчетов (то есть визуальным качеством изображения) и размером результирующего кодированного представления видео (то есть размером файла или битовой скоростью передачи).
Декодер восстанавливает выходное видео путем применения механизма предсказания, аналогичного используемому в кодере, для формирования предсказанного представления блоков пикселей или отсчетов (с использованием информации о движении или пространственной информации, созданной кодером и хранимой в сжатом представлении изображения) и декодирования ошибки предсказания (операция, обратная кодированию ошибки предсказания, для восстановления квантованного сигнала ошибки предсказания в пространственной области).
После применения процедур предсказания пикселей или отсчетов и декодирования ошибки декодер объединяет сигналы предсказания и ошибки предсказания (значений пикселей или отсчетов) для формирования выходного видеокадра.
В декодере (и кодере) могут также применяться дополнительные процедуры фильтрации для повышения качества выходного видеоизображения перед передачей его для отображения и/или хранения в качестве опорного для предсказания последующих изображений видеопоследовательности.
Во многих видеокодеках, включая H.264/AVC и HEVC, информацию о движении указывают с помощью векторов движения, связанных с каждым из блоков изображения с компенсацией движения. Каждый из таких векторов движения представляет смещение блока изображения в кодируемом изображении (на стороне кодера) или декодируемом изображении (на стороне декодера) и исходного блока предсказания в одном из ранее кодированных или декодированных изображениях. В стандартах H.264/AVC и HEVC, как и во многих других стандартах сжатия видео, изображение разделяется на сетку из прямоугольников, для каждого из которых указывается аналогичный блок в одном из опорных изображений для внешнего предсказания. Местоположение блока предсказания кодируется как вектор движения, указывающий на положение блока предсказания относительно кодируемого бока. Для эффективного представления векторов движения может применяться их разностное кодирование относительно предсказанных векторов движения, зависящих от блока. Во многих видеокодеках предсказанные векторы движения формируются заранее заданным способом, например, с помощью вычисления медианного вектора между кодированным или декодированным векторами движения соседних блоков. Другим способом создания предсказаний векторов движения является формирование списка возможных предсказаний на основе соседних блоков и/или сорасположенных блоков во временных опорных изображениях и сигнализация выбранного кандидата в качестве предсказания вектора движения. В дополнение к предсказанию значений векторов движения может также выполняться предсказание указателя на опорное изображение для ранее кодированного или декодированного изображения. Указатель на опорное изображение может предсказываться на основе соседних блоков и/или сорасположенных блоков во временном опорном изображении. Кроме того, во многих кодеках стандарта высокоэффективного видеокодирования применяется дополнительный механизм кодирования/декодирования информации о движении, часто называемый режимом слияния, в котором вся информация поля движения, включающая вектор движения и указатель на соответствующее опорное изображения для каждого доступного списка опорных изображений, является предсказываемой и применяется без какого-либо изменения или без какой-либо коррекции. Аналогично, предсказание информации поля движения выполняют с использованием информации поля движения соседних блоков и/или сорасположенных блоков во временных опорных изображениях, а использованную информацию поля движения сигнализируют в списке возможных полей движения вместе с информацией поля движения доступных смежных и/или сорасположенных блоков.
Процедура внешнего предсказания может быть охарактеризована с помощью одного или более из описанных ниже факторов.
Точность представления вектора движения. Например, векторы движения могут иметь четверть-пиксельную точность, при этом значения отсчетов с дробнопиксельными положениями могут быть получены с помощью фильтра с конечной импульсной характеристикой (finite impulse response, FIR).
Разбиение на блоки для внешнего предсказания. Многие стандарты кодирования, включая H.264/AVC и HEVC, допускают выбор размера и формы блока, для которого применяется вектор движения для компенсации движения в кодере, при этом выбранный размер и форма указываются в битовом потоке, чтобы декодеры могли воспроизвести предсказание с компенсацией движения, выполняемое в кодере.
Количество опорных изображений для внешнего предсказания. Источниками для внешнего предсказания являются ранее декодированные изображения. Во многих стандартах кодирования, включая H.264/AVC и HEVC, обеспечивается возможность хранения множества опорных изображений для внешнего предсказания и выбора используемого опорного изображения для каждого блока. Например, опорные изображения могут выбираться на уровне макроблока или разбиения макроблока в стандарте H.264/AVC и на уровне блока предсказания или блока кодирования в стандарте HEVC. Многие стандарты кодирования, такие как H.264/AVC и HEVC, имеют синтаксические структуры битового потока, обеспечивающие возможность создания в декодере одного или более списков опорных изображений. Для указания на то, какое из опорных изображений следует использовать для внешнего предсказания конкретного блока, используется указатель на опорное изображение в списке опорных изображений. Указатель на опорное изображение в некоторых режимах кодирования с внешним предсказанием может кодироваться кодером в битовый поток или в других режимах кодирования с внешним предсказанием может определяться (например, кодером и декодером), например, с использованием соседних блоков.
Предсказание векторов движения. Для эффективного представления векторов движения в битовом потоке может выполняться их разностное кодирование относительно предсказанного вектора движения, зависящего от блока. Во многих видеокодеках предсказанные векторы движения формируются заранее заданным способом, например, с помощью вычисления медианного вектора между кодированным или декодированным векторами движения смежных блоков. Другим способом создания предсказаний векторов движения является формирование списка возможных предсказаний на основе соседних блоков и/или сорасположенных блоков во временных опорных изображениях предсказания и сигнализация выбранного кандидата в качестве предсказания вектора движения. В дополнение к предсказанию значений векторов движения может также выполняться предсказание указателя на опорное изображение для ранее кодированного или декодированного изображения. Указатель на опорное изображение, как правило, предсказывается на основе соседних блоков и/или сорасположенных блоков во временном опорном изображении. Разностное кодирование векторов движения через границы слайса, как правило, не разрешено.
Многогипотезное предсказание с компенсацией движения. Стандарты H.264/AVC и HEVC позволяют использовать один блок предсказания в Р-слайсах (в настоящем документе также называемых слайсами с однонаправленным предсказанием) или линейную комбинацию двух блоков предсказания с компенсацией движения для слайсов с двунаправленным предсказанием, которые в настоящем документе также называются В-слайсами. Для отдельных блоков в В-слайсах может использоваться двунаправленное предсказание, однонаправленное предсказание или внутреннее предсказание, а для отдельных блоков в Р-слайсах может использоваться однонаправленное предсказание или внутреннее предсказание. Опорные изображения для изображения с двунаправленным предсказанием не ограничиваются последующим и предыдущим изображениям в порядке вывода, а напротив, могут использоваться любые опорные изображения.
Во многих стандартах кодирования, в том числе в стандартах H.264/AVC и HEVC, один список опорных изображений, который называется списком 0 опорных изображений, создается для Р-слайсов и SP-слайсов, и два списка опорных изображений, список 0 и список 1, создаются для В-слайсов. Для В-слайсов предсказание в прямом направлении может представлять собой предсказание на основе опорного изображения из списка 0 опорных изображений, а предсказание в обратном направлении может представлять собой предсказание на основе опорного изображения из списка 1 опорных изображений, хотя опорные изображения предсказания могут иметь любой порядок декодирования или вывода, по отношению друг к другу или к текущему изображению. В некоторых из вариантов осуществления настоящего изобретения опорные изображения, предшествующие текущему изображению в порядке воспроизведения или вывода, помещают в список 0 в порядке убывания, а опорные изображения, следующие за текущим изображением, помещают в список 1 в порядке возрастания. Опорные изображения могут быть отсортированы по расстоянию между опорным изображением и текущим изображением.
Поскольку в кодеках многоракурсного видеокодирования обеспечивается возможность применения межракурсной избыточности, в буфер опорных изображений могут также добавляться декодированные межракурсные кадры.
Взвешенное предсказание. Во многих стандартах кодирования применяется вес предсказания, равный 1, для блоков предсказания изображения с внешним предсказанием (Р) и вес, равный 0,5, для каждого блока предсказания В-изображения (в результате чего происходит усреднение). В стандарте H.264/AVC обеспечивается возможность взвешенного предсказания и для Р-слайсов, и для В-слайсов. При неявном взвешенном предсказании веса пропорциональны порядковым номерам изображений, тогда как при явном взвешенном предсказании веса предсказания указываются явно.
Во многих видеокодеках разность предсказания после компенсации движения сначала преобразуют с помощью ядра преобразования (например, DCT) и только затем кодируют. Причиной этому является то, что часто имеется некоторая корреляция в разностной ошибке, а преобразование во многих случаях позволяет снизить эту корреляцию и дает в результате более эффективное кодирование.
В проекте стандарта HEVC каждый блок предсказания имеет связанную с ним информацию предсказания, которая определяет, предсказание какого типа должно применяться к пикселям данного блока предсказания (например, информацию вектора движения для блоков предсказания с внешним предсказанием или информацию о направленности внутреннего предсказания для блоков предсказания с внутренним предсказанием). Аналогично, каждый блок преобразования связан с информацией, описывающей процедуру декодирования ошибки предсказания для отсчетов в данном блоке преобразования (включая, например, информацию о коэффициентах DCT). Как правило, сигнализируется, применяется ли кодирование ошибки предсказания для каждого блока кодирования. Если нет разностной ошибки предсказания, связанного с блоком кодирования, то можно считать, что для данного блока кодирования отсутствуют блоки преобразования.
В стандартах видеокодирования, таких как H.264/AVC или HEVC, выполняется энтропийное кодирование многих синтаксических элементов в кодере и их энтропийное декодирование в декодере. Энтропийное кодирование может выполняться, например, с помощью контекстно-адаптивного двоичного арифметического кодирования (context adaptive binary arithmetic coding, CABAC), основанного на контексте кодирования с кодами переменной длины, кодирования Хаффмана или любого аналогичного энтропийного кодирования.
Во многих видекодерах для поиска режимов кодирования с оптимальным соотношением "битовая скорость - искажение", например, для поиска необходимого режима макроблоков и связанных с ними векторов движения, используется целевая функция Лагранжа. В целевой функции такого типа используется весовой коэффициент, или λ, связывающий точное или оцененное искажение изображения в результате кодирования с потерями и точное или оцененное количество информации, необходимое для представления значений пикселей или отсчетов в некоторой области изображения. Целевая функция Лагранжа может быть представлена следующим уравнением:
C=D+λR,
где С - минимизируемое значение целевой функции, D - искажение изображения (например, среднеквадратичная ошибка между значениями пикселей или отсчетов в исходном блоке изображения и в кодированном блоке изображения) для рассматриваемых в текущий момент режима и векторов движения, λ - коэффициент Лагранжа, a R - количество битов, необходимых для представления данных, требуемых для восстановления блока изображения в декодере (включая количество данных для представления возможных векторов движения).
В некоторых форматах кодирования и кодеках вводится различие между так называемыми краткосрочными и долгосрочными опорными изображениями. Такое различие может влиять на часть процедур декодирования, например, масштабирование векторов движения во временном прямом режиме предсказания или при неявном взвешенном предсказании. Если оба опорных изображения, используемых во временном режиме предсказания, являются краткосрочными опорными изображениями, то вектор движения, используемый при предсказании, может масштабироваться в соответствии с разностью порядковых номеров кадра (picture order count, РОС) между текущим изображением и каждым из опорных изображений. Однако, если по меньшей мере одно опорное изображение для временного прямого режима предсказания является долгосрочным опорным изображением, то используется заданное по умолчанию масштабирование вектора движения, например, масштабирование движения в два раза.
Аналогично, если краткосрочное опорное изображение используется для неявного взвешенного предсказания, то весовой коэффициент предсказания может масштабироваться в соответствии с разностью РОС между текущим изображением и опорным изображением. Однако если для неявного взвешенного предсказания используется долговременное опорное изображение, то может использоваться заданный по умолчанию весовой коэффициент предсказания, например, равный 0,5, при неявном взвешенном предсказании блоков с двунаправленным предсказанием.
В некоторых форматах видеокодирования, например, H.264/AVC, имеется синтаксический элемент frame_num, который используется в различных процедурах декодирования, связанных с множеством опорных изображений. В стандарте H.264/AVC значение frame_num для IDR-изображений равно 0. Значение frame_num для изображений, не являющихся IDR-изображениями, равно номеру frame_num предыдущего опорного изображения в порядке декодирования, увеличенному на 1 (в модульной арифметике, то есть значение frame_num циклически возвращается в 0 после максимального значения frame_num).
В стандартах H.264/AVC и HEVC существует понятие порядкового номера изображения (РОС). Значение РОС вычисляется для каждого изображения и является неубывающим с увеличением позиции изображения в порядке вывода. Соответственно, РОС указывает на порядок вывода изображений. РОС может использоваться в процессе декодирования, например, для неявного масштабирования векторов движения во временном прямом режиме слайсов с двунаправленным предсказанием, для неявно вычисляемых весовых коэффициентов при взвешенном предсказании и для инициализации списка опорных изображений. Кроме того, РОС может использоваться при проверке соответствия порядка вывода. В стандарте H.264/AVC РОС определяется относительно предыдущего IDR-изображения или изображения, содержащего операцию управления памятью, с помощью которой все изображения помечаются как «не используемые в качестве опорных».
В стандарте H.264/AVC определена процедура маркировки декодированного опорного изображения для управления потреблением памяти в декодере. Максимальное количество опорных изображений для внешнего предсказания обозначается M и определяется в наборе параметров последовательности. При декодировании опорного изображения оно маркируется как «используемое в качестве опорного». Если в результате декодирования опорного изображения более M изображений были помечены как «используемые в качестве опорного», то по меньшей мере одно из этих изображений помечают как «не используемое в качестве опорного». Имеется два типа операций маркировки декодированного опорного изображения: адаптивное управление памятью и скользящее окно. Режим маркировки декодированного опорного изображения может выбираться для каждого изображения. Адаптивное управление памятью обеспечивает явную сигнализацию, при которой изображения помечаются как «не используемые в качестве опорных», причем также возможно назначение долгосрочных указателей на краткосрочные опорные изображения. Адаптивное управление памятью может требовать наличия в битовом потоке параметров операций управления памятью (memory management control operation, MMCO). Если применяется режим работы со скользящим окном и M изображений помечены как «используемые в качестве опорных», то краткосрочное опорное изображение, которое было первым декодированным изображением среди краткосрочных опорных изображений, помеченных как «используемые в качестве опорных», помечается как «не используемое в качестве опорного». Другими словами, режим работы со скользящим окном обеспечивает работу с краткосрочными опорными изображениями по типу буфера «первый вошел, первый вышел».
Одна из операций управления памятью в стандарте H.264/AVC обеспечивает маркировку всех опорных изображений, кроме текущего изображения, как «не используемых в качестве опорных». Изображение мгновенного обновления декодирования (IDR) содержит только слайсы с внутренним предсказанием и вызывает аналогичный «сброс» опорных изображений.
В проекте стандарта HEVC синтаксические структуры для маркировки опорных изображений и соответствующие процедуры декодирования не применяются, но вместо этого для аналогичных целей используется синтаксическая структура и процедура декодирования набора опорных изображений (reference picture set, RPS). Набор опорных изображений, являющийся действительным или активным для изображения, включает все опорные изображения для данного изображения и все опорные изображения, которые остаются помеченными как «используемые в качестве опорных» для последующих изображений в порядке декодирования. В наборе опорных изображений имеется шесть подмножеств, которые обозначаются RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll. Нотация обозначений этих шести подмножеств имеет следующее значение. "Curr" относится к опорным изображениям, которые включены в списки опорных изображений для текущего изображения и, следовательно, могут быть использованы как опорное изображение при внешнем предсказании для текущего изображения. "Foll" относится к опорным изображениям, которые не включены в списки опорных изображений для текущего изображения, но могут быть использованы в качестве опорных изображений для последующих изображений в порядке декодирования. "St" относится к краткосрочным опорным изображениям, которые в общем случае могут идентифицироваться с помощью определенного количества младших битов в их значении РОС."Lt" относится к долгосрочным опорным изображениям, которые идентифицируются и, как правило, имеют большее отличие в значениях РОС от текущего изображения, чем это может быть отражено с помощью упомянутого определенного количества младших битов. "0" обозначает те опорные изображения, которые имеют меньшее значение РОС, тем текущее изображение. "1" обозначает те опорные изображения, которые имеют большее значение РОС, чем текущее изображение. RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0 и RefPicSetStFoll1 совместно называются краткосрочным подмножеством набора опорных изображений. RefPicSetLtCurr и RefPicSetLtFoll совместно называются долгосрочным подмножеством набора опорных изображений.
В стандарте HEVC набор опорных изображений может быть задан в наборе параметров последовательности и может использоваться в заголовке слайса с помощью указателя на набор опорных изображений. Набор опорных изображений может задаваться также и в заголовке слайса. Долгосрочное подмножество набора опорных изображений, как правило, задается только в заголовке слайса, тогда как краткосрочные подмножества того же набора опорных изображений могут задаваться в наборе параметров изображения или в заголовке слайса. Набор опорных изображений может кодироваться независимо или может быть предсказываемым на основе другого набора опорных изображений (это называется внешним предсказанием RPS). При независимом кодировании набора опорных изображений синтаксическая структура включает до трех циклов с итерацией по различным типам опорных изображений: краткосрочные опорные изображения со значениями РОС, меньшими текущего изображения, краткосрочные опорные изображения со значениями РОС, большими текущего изображения, и долгосрочные опорные изображения. Каждая такая циклическая запись определяет, что изображение должно быть помечено как «используемое в качестве опорного». В общем случае изображение определяется с использованием дифференциального значения РОС. При внешнем предсказании RPS используется то, что набор опорных изображений для текущего изображения может быть предсказан на основе набора опорных изображений ранее декодированного изображения. Это возможно, поскольку все опорные изображения для текущего изображения являются либо опорными изображениями для предыдущего изображения, либо ранее декодированным изображением. Необходимо только указать, какие из этих изображений должны быть опорными и использоваться для предсказания текущего изображения. В обоих типах кодирования набора опорных изображений для каждого опорного изображения дополнительно передают флаг (used_by_curr_pic_X_flag), который указывает на то, используется ли данное изображение в качестве опорного для текущего изображения (то есть входит в список *Curr) или нет (то есть входит в список *Foll). Изображения из набора опорных изображений, используемых для текущего слайса, помечают как «используемые в качестве опорных», а изображения, не входящие в набор опорных изображений, используемых для текущего слайса, помечают как «не используемые в качестве опорных». Если текущее изображение является IDR-изображением, то RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll установлены пустыми.
В кодере и/или декодере может применяться буфер декодированных изображений (Decoded Picture Buffer, DPB). Имеются две причины для буферизации декодированных изображений: для использования в качестве опорных при внешнем предсказании и для изменения порядка декодированных изображений в выходной последовательности. Стандарты H.264/AVC и HEVC дают значительную гибкость как для маркировки опорных изображений, так и для переупорядочения выходной последовательности, однако отдельные буферы для опорных изображений и изображений выходной последовательности могут приводить к нерациональному расходованию ресурсов памяти. Следовательно, DPB может включать унифицированную процедуру буферизации декодированных опорных изображений и переупорядочения выходной последовательности. Декодированное изображение может удаляться из буфера DPB, когда оно больше не используется в качестве опорного и не требуется для вывода.
Во многих режимах кодирования стандартов H.264/AVC и HEVC на опорное изображение внешнего предсказания указывают с помощью указателя на список опорных изображений. Указатель может кодироваться с использованием кодов переменной длины, что обычно дает меньшие указатели с меньшим числовым значением для соответствующего синтаксического элемента. В стандартах H.264/AVC и HEVC формируются два списка опорных изображений (список 0 опорных изображений и список 1 опорных изображений) для каждого слайса с двунаправленным предсказанием (В-слайса) и один список опорных изображений (список О опорных изображений) для каждого слайса, кодируемого с внешним предсказанием (Р-слайса). В дополнение для В-слайсов в стандарте HEVC строится комбинированный список (список С), называемый также списком слияния, после завершения построения финальных списков опорных изображений (списка 0 и списка 1). Комбинированный список может использоваться для однонаправленного предсказания в В-слайсах.
Список опорных изображений, например список 0 или список 1, как правило, формируется в два шага; сначала формируют первичный список опорных изображений. Первичный список опорных изображений может формироваться, например, на основе параметров frame_num, РОС, temporal_id или информации об иерархии предсказания, например, из структуры GOP, или на основе какой-либо комбинации перечисленного. На втором шаге первичный список опорных изображений может быть переупорядочен с помощью команд переупорядочения списка опорных изображений (reference picture list reordering, RPLR), также называемых синтаксической структурой модификации списка опорных изображений, которая может содержаться в заголовках слайсов. Команды RPLR указывают на изображения, которые переставлены в начало соответствующего списка опорных изображений. Этот второй шаг может также быть назван процедурой модификации списка опорных изображений, а команды RPLR могут включаться в синтаксическую структуру модификации списка опорных изображений. Если используются наборы опорных изображений, то список О опорных изображений может инициализироваться включением в него сначала RefPicSetStCurr0, за которым следует RefPicSetStCurr1 и затем RefPicSetLtCurr. Список 1 опорных изображений может инициализироваться включением в него сначала RefPicSetStCurr1 и затем RefPicSetStCulr0. Первичные списки опорных изображений могут модифицироваться с помощью синтаксической структуры модификации списка опорных изображений, в которой изображения в первичных списках опорных изображений могут идентифицироваться с помощью записи-указателя на список.
Поскольку в кодерах и декодерах многоракурсного видеокодирования обеспечивается возможность применения межракурсной избыточности, в список (или списки) опорных изображений могут также добавляться декодированные кадры межракурсного предсказания.
Комбинированные списки в стандарте HEVC могут строиться следующим образом. Если флаг модификации для комбинированного списка имеет нулевое значение, то комбинированный список строится с помощью неявного механизма; в противном случае он строится с помощью команд комбинирования опорных изображений, включенных в битовый поток. В случае неявного механизма опорные изображения в списке С назначаются в соответствие опорным изображениям из списка 0 и списка 1 с чередованием, начиная с первой записи списка 0, за которой следует первая запись списка 1 и т.д. Если какое-либо изображение было уже назначено в списке С, оно не назначается повторно. В случае явного механизма сигнализируется количество записей в списке С, за ним следует информация о соответствии записи из списка 0 или списка 1 каждой записи из списка С. В дополнение, если список 0 и список 1 являются идентичными, в кодере есть возможность установить флаг ref_pic_list_combination_flag в значение 0, что указывает на отсутствие опорных изображений из списка 1, назначенных в список С, и, следовательно, на то, что список С эквивалентен списку 0.
В типовых кодеках эффективного видеокодирования, например, в кодеках, соответствующих проекту стандарта HEVC, применяется дополнительный механизм кодирования/декодирования информации о движении, часто называемый режимом/процессом/механизмом слияния, в котором вся информация о движении блока / блока предсказания предсказывается и используется без какой-либо модификации или коррекции. Упомянутая выше информация о движении для блока предсказания включает: 1) информацию о том, применяется ли для данного блока предсказания однонаправленное предсказание с использованием только списка 0 опорных изображений, или применяется ли для данного блока предсказания однонаправленное предсказание с использованием только списка 1 опорных изображений, или применяется ли для данного блока предсказания двунаправленное предсказание с использованием обоих списков опорных изображений, списка 0 и списка 1; 2) значение вектора движения, соответствующее списку 0 опорных изображений; 3) указатель на опорное изображение в списке 0 опорных изображений; 4) значение вектора движения, соответствующее списку 1 опорных изображений; 5) указатель на опорное значение в списке 1 опорных изображений. Аналогично, предсказание информации о движении выполняют с использованием информации о движении соседних блоков и/или сорасположенных блоков во временных опорных изображениях. Как правило, список, часто называемый списком слияния, строится с помощью включения возможных предсказаний движения, связанных с доступными смежными/сорасположенными блоками, при этом сигнализируется указатель на выбранное возможное предсказание движения в списке. Затем информацию о движении выбранного кандидата копируют в информацию о движении текущего блока предсказания. Если применяется механизм слияния для всего блока кодирования, и при этом сигнал предсказания для блока кодирования используется в качестве сигнала восстановления, то есть ошибка предсказания не обрабатывается, то такой тип кодирования/декодирования блока кодирования называется, как правило, режимом пропуска или режимом пропуска на основе слияния. В дополнение к режиму пропуска для отдельных блоков предсказания применятся также механизм слияния (не обязательно для всего блока кодирования, как в режиме пропуска), и в этом случае ошибка предсказания может использоваться для повышения качества предсказания. Такой тип режима предсказания называют, как правило, режимом с внешним слиянием.
В системе видеокодирования может присутствовать синтаксическая структура для маркировки опорных изображений. Например, после завершения декодирования изображения, синтаксическая структура для маркировки декодированных опорных изображений, если она имеется, может использоваться для адаптивной маркировки изображений как «не используемых в качестве опорных» или «используемых в качестве долгосрочных опорных». Если синтаксической структуры для маркировки декодированных опорных изображений нет, и количество изображений, помеченных как «используемые в качестве опорных» больше увеличиваться не может, то может применяться маркировка изображений с помощью скользящего окна, при которой самое раннее (в порядке декодирования) декодированное опорное изображение помечается как «не используемое в качестве опорного».
При предсказании векторов движения (motion vector, MV), определенных в стандарте H.264/AVC и его расширении, MVC, используют корреляцию, которая может присутствовать в соседних блоках одного и того же изображения (пространственная корреляция) или в ранее кодированном изображении (временная корреляция). На фиг. 7а показана пространственная окрестность текущего кодируемого блока (cb), а на фиг. 7b показана временная окрестность текущего кодируемого блока, из которых берут кандидатов для предсказания векторов движения в стандарте H.264/AVC.
Векторы движения текущего блока cb могут быть вычислены с помощью процедуры оценки и компенсации движения и могут кодироваться с использованием дифференциальной импульсно-кодовой модуляции (differential pulse code modulation, DPCM) и передаваться в виде разности между предсказанием вектора движения (MVp) и фактическим вектором MV движения: MVd(x, у)=MV(x, у)-MVp(x, у).
Может вычисляться медианное значение векторов движения для разбиений или подразбиений макроблока непосредственно над (блок В), по диагонали сверху и справа (блок С), непосредственно слева (блока А) от текущего разбиения или подразбиения.
В некоторых вариантах осуществления настоящего изобретения вычисление предсказания Mvp вектора движения может быть определено следующим образом:
Если только один из пространственно смежных блоков (А, В, С) имеет указатель на опорное изображение, идентичный текущему блоку,

Если более одного или ни один из смежных блоков (А, В, С) имеют указатель на опорное изображение, идентичный текущему блоку,
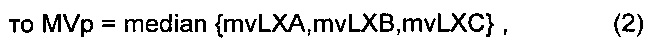
где mvLXA, mvLXB, mvLXC - векторы движения (без идентификатора опорного кадра) пространственно смежных блоков.
В некоторых ситуациях может использоваться режим Р-пропуска или В-пропуска. В режиме Р-пропуска указатель на опорный кадр текущего блока всегда равен 0, при этом всегда используется первый список 0 (refldxL0=0). Векторы движения вычисляют исключительно с использованием блоков, расположенных непосредственно слева (блок А) и непосредственно сверху (блок В) от текущего блока. Если блоков непосредственно слева и непосредственно сверху нет, то выбирают предсказание MVp вектора движения с нулевым значением. Поскольку в режиме Р-пропуска нет векторов движения, для которых (MV=MVp), то разность dMV векторов движения не передают.
В режиме В-пропуска могут использоваться две процедуры оценки векторов движения: пространственный прямой режим, в котором предсказание вектора движения вычисляют на основе пространственно смежных блоков, как показано на фиг. 7а, и временной прямой режим, в котором предсказание вектора движения вычисляют на основе смежных во времени блоков, как показано на фиг. 7b.
Процедура предсказания вектора движения включает вычисление следующих значений:
a. указатели на опорные изображения refldxL0, refldxL1,
b. векторы движения mvL0 и mvL1.
В пространственном прямом режиме процедура предсказания указателя на опорное изображение и вектора движения выполняется независимо для обоих списков опорных изображений (списка 0 опорных изображений и списка 1 опорных изображений). В каждом из списков выбирают минимальный положительный указатель на опорное изображение и применяют процедуру предсказания вектора движения для каждого списка опорных изображений для получения mvpL0 и mvpL1.
Каждая из составляющих предсказания mvpLX вектора движения задается медианным значением соответствующих компонентов векторов mvLXA, mvLXB и mvLXC движения.
mvpLX[0]=Median(mvLXA[0], mvLXB[0], mvLXC[0]),
mvpLX[1]=Median(mvLXA[1], mvLXB[1], mvLXC[1]).
Во временном прямом режиме векторы движения текущего блока в списке 0 и списке 1 могут быть вычислены с помощью интерполяции по времени векторов движения соседних (по времени) блоков. В качестве коэффициента для интерполяции может использоваться расстояние между порядковыми номерами изображений (РОС) текущего и опорного кадров.
MV0=MVc*(TDb/TDd),
MV1=MVc* (TDb-TDD)/TDd,
где TDb - расстояние между порядковыми номерами изображений текущего и опорного кадров в списке 0; TDd - расстояние между порядковыми номерами изображений опорных кадров в списке 0 и списке 1; a MVc - вектор движения сорасположенного блока опорного изображения из списка 0.
Далее для лучшего понимания вариантов осуществления настоящего изобретения будут кратко описаны некоторые из аспектов применения трехмерного (3D) многоракурсного видеокодирования, а также связанные с ними понятия информации глубины и информации диспарантности.
Стереоскопические видеоизображения включают пары смещенных изображений, отображаемых отдельно для левого и правого глаз зрителя.
Такие смещенные изображения записывают с помощью камер в специальной стереоскопической конфигурации, которая предполагает определенное расстояние базовой линии между камерами для получения стереоскопического эффекта.
На фиг. 1 проиллюстрирована упрощенная двумерная модель конфигурации стереоскопической камеры. На фиг. 1 С1 и С2 обозначают камеры в стереоскопической конфигурации, более конкретно, положения центров камер, b - расстояние между центрами двух камер (то есть стереоскопическая базовая линия), f - фокусное расстояние камер, а X - объект в реальной трехмерной сцене, запись которой ведется. Объект X реальной сцены проецируется в изображениях, записываемых камерами С1 и С2, в различные местоположения, которые обозначены х1 и х2, соответственно. Расстояние по горизонтали между х1 и х2 в абсолютных координатах называют диспарантностью. Изображения, записываемые камерами в данной конфигурации, называют стереоскопическими, при этом присутствующая в них диспарантность создает или усиливает иллюзию глубины. Для обеспечения возможности отображения изображений отдельно для правого и левого глаз зрителя может быть необходимо применение специальных 3D-очков. Для комфортного просмотра стереоскопических видеоизображений на различных дисплеях ключевой является адаптация диспарантности.
Однако адаптация диспарантности не является простой процедурой. Она требует либо наличия дополнительных ракурсов камер с различным расстоянием базовой линии (то есть переменной b) или воспроизведения виртуальных ракурсов камеры, не доступных в реальной сцене. На фиг. 2 проиллюстрирована упрощенная модель многоракурсной конфигурации камер, отвечающая требованиям подобного решения. Такая конфигурация позволяет получить стереоскопические видеоизображения, записываемые с несколькими различными дискретными значениями стереоскопической базовой линии и, следовательно, позволяет выбирать для стереоскопического дисплея пару камер, подходящих для конкретных условий просмотра.
Более совершенным подходом для получения трехмерного изображения является использование многоракурсного автостереоскопического дисплея (multiview autostereoscopic display, ASD) 300, который не требует использования очков. ASD-дисплей излучает более одного ракурса в один момент времени, однако излучение локализовано в пространстве таким образом, что зритель видит стереопару только с определенной точки наблюдения, как показано на фиг. 3, где дом отображен в середине ракурса при просмотре с крайней правой точки. Кроме того, пользователь может видеть другую стереопару с другой точки наблюдения, например, на фиг. 3 дом виден у правой границы ракурса при просмотре с крайней левой точки. Таким образом, поддерживается параллакс движения, если эти последовательные ракурсы представляют собой стереопары и упорядочены должным образом. ASD-технологии могут допускать отображение, например, 52 или более различных изображений одновременно, из которых только одна стереопара видна из любой заданной точки наблюдения. Это позволяет обеспечить многопользовательское стереоскопическое проецирование без использования очков, например, в условиях жилой комнаты.
Описанные выше приложения стереоскопического проецирования и ASD-дисплеев требуют наличия многоракурсных видеоизображений, доступых для отображения. Расширение MVC стандарта видеокодирования H.264/AVC позволяет использовать многоракурсную функциональность на стороне декодера. Базовый ракурс битовых потоков MVC может быть декодирован любым декодером H.264/AVC, что позволяет использовать стереоскопический и многоракурсный контент в существующих услугах. В MVC имеется возможность межракурсного предсказания, что позволяет значительно сократить битовую скорость по сравнению с независимым кодированием всех ракурсов, в зависимости от степени корреляции смежных ракурсов. Тем не менее, битовая скорость кодированных видеоизображений в MVC обычно пропорциональна количеству ракурсов. Учитывая тот факт, что ASD-дисплеи, например, могут требовать 52 ракурса в качестве входной информации, общая битовая скорость для такого количества ракурсов может столкнуться с ограничением доступной пропускной способности.
Соответственно, было найдено, что для подобных применений многоракурсного видео более рациональным решением является наличие ограниченного количества входных ракурсов, например, моно- или стереоракурс плюс некоторые дополнительные данные, и воспроизведение (то есть синтез) всех требуемых ракурсов локально на стороне декодера. Из нескольких существующих технологий воспроизведения ракурса конкурентоспособной альтернативой показало себя воспроизведение на основе изображения глубины (depth image-based rendering, DIBR).
Упрощенная модель 3DV-системы на основе DIBR показана на фиг. 4. На вход трехмерного видеокодека поступают стереоскопическое видео и соответствующая информация глубины со стереоскопической базовой линией b0. Затем трехмерный видеокодек синтезирует набор виртуальных ракурсов между двумя входными ракурсами с базовой линией (bi<b0). Алгоритмы DIBR могут также обеспечивать возможности экстраполяции ракурсов за границы двух входных ракурсов, а не только между ними. Аналогично, алгоритмы DIBR могут обеспечивать возможности синтеза ракурсов на основе одного ракурса текстуры и соответствующего ракурса глубины. Однако для возможности многоракурсного воспроизведения на базе DIBR на стороне декодера должны быть доступны данные текстуры вместе с соответствующими данными глубины.
В таких 3DV-системах информация глубины формируется на стороне кодера в форме изображений глубины (называемых также картами глубины) для каждого видеокадра. Карта глубины представляет собой изображение с информацией глубины для каждого пикселя. Каждый отсчет карты глубины отражает расстояние соответствующего отсчета текстуры от плоскости расположения камеры. Другими словами, если ось z лежит на оси съемки камер (и, следовательно, перпендикулярно плоскости расположения камер), то отсчет карты глубины представляет собой значение на оси z.
Информация глубины может быть получена с помощью различных средств. Например, глубина в трехмерной сцене может вычисляться на основе диспарантности, регистрируемой ведущими съемку камерами. Алгоритм вычисления глубины принимает стереоскопический ракурс на входе и вычисляет локальную диспарантность между двумя смещенными изображениями ракурса. Каждое изображение обрабатывается попиксельно в перекрывающихся блоках, при этом для каждого блока пикселей выполняют горизонтальный локализованный поиск соответствующего блока в смещенном изображении. После вычисления пиксельной диспарантности соответствующее значение z глубины получают с помощью уравнения (3):

где f - фокусное расстояние камеры, a b - расстояние базовой линии между камерами, как показано на фиг. 1. При этом d обозначает диспарантность, наблюдаемую между двумя камерами, а смещение Δd камеры отражает возможное несовпадение оптических центров двух камер по горизонатали.
Альтернативно или дополнительно к описанному выше вычислению глубины стереоракурса, значение глубины может быть получено на основе принципа времени прохождения (time-of-flight, TOF), например, с использованием камеры, оснащенной источником света, к примеру, инфракрасным излучателем, для освещения сцены. Такой осветитель может быть выполнен с возможностью электромагнитного излучения с модулируемой мощностью, например, в диапазоне частот 10-100 МГц, что может требовать применения светодиодов или лазерных диодов. Как правило, инфракрасный свет позволяет сделать такое освещение незаметным. Свет, отражаемый объектами сцены, регистрируют с помощью датчика изображений, который модулируется синхронно с осветителем, с использованием той же частоты. Датчик изображений оснащен оптикой: объективом, собирающим отраженный свет и оптическим полосовым фильтром для пропускания света той же длины волны, что излучается осветителем, что позволяет подавить фоновую засветку. С помощью датчика изображений для каждого пикселя измеряют время прохождения света от осветителя до объекта и обратно. Расстояние до объекта представлено в виде сдвига фаз при модуляции осветителя, которая может быть определена на основе данных измерений одновременно для всех пикселей сцены.
В случае многоракурсного кодирования с использованием информации глубины может применяться синтез ракурсов в цикле кодирования кодера и цикле декодирования декодера, что дает возможность использовать предсказание на основе синтеза ракурсов (view synthesis prediction, VSP). Изображение синтеза ракурса (опорный компонент) может синтезироваться на основе кодированных ракурсов текстуры и ракурсов глубины и может содержать отсчеты, используемые для предсказания на основе синтеза ракурсов. Чтобы предсказание на основе синтеза ракурсов во время кодирования текущего ракурса было возможным, для синтеза ракурса могут использоваться ранее кодированные компоненты ракурса текстуры и глубины в одном и том же блоке доступа. Такой синтез ракурса, в котором применяют ранее кодированные компоненты ракурса текстуры и глубины одного и того же блока доступа, может быть назван прямым синтезом ракурса или синтезом ракурса с прямой проекцией, и аналогично, предсказание на основе синтеза ракурсов с использованием такого синтеза ракурсов может быть названо предсказанием с прямым синтезом ракурсов или предсказанием на основе синтеза ракурсов с прямой проекцией.
Изображение синтеза ракурса может также называться синтезированным опорным компонентом, который может быть определен как содержащий отсчеты, используемые для предсказания на основе синтеза ракурсов. Синтезированный опорный компонент может использоваться в качестве опорного изображения для предсказания на основе синтеза ракурсов, но, как правило, не выводится и не отображается. Изображение синтеза ракурсов обычно формируют для того же расположения камеры и с использованием тех же параметров камеры, что и для кодируемого или декодируемого изображения. Пример контура декодирования проиллюстрирован на фиг. 8.
В одном из вариантов осуществления алгоритма синтеза ракурса для предсказания на основе синтеза ракурсов может применяться преобразование карты (d) глубины в диспарантность (D) с последующим назначением пикселей исходного изображения s(x, y) в новое местоположение в синтезированном целевом изображении t(x+D, y).
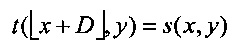

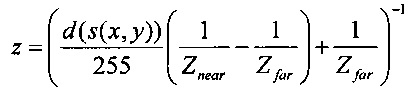
В случае проецирования изображения текстуры s(x, y) представляет собой отсчет изображения текстуры, a d(s(x, y)) представляет собой значение карты глубины, связанное с s(x, y). Если для опорного кадра синтеза используется схема выборки отсчетов 4:2:0 (то есть пространственное разрешение изображений компонента цветности равно половине пространственного разрешения изображения компонента яркости по обеим координатным осям), разрешение компонентов цветности может быть повышено до 4:4:4 с помощью повтора значения отсчета:
где  - значение отсчета цветности в полном разрешении, а
- значение отсчета цветности в полном разрешении, а  - значение отсчета цветности в половинном разрешении. В случае проецирования значений карты глубины s(x, y)=d(x, y), при этом данный отсчет проецируют с использованием его собственного значения d(s(x, y))=d(x, y).
- значение отсчета цветности в половинном разрешении. В случае проецирования значений карты глубины s(x, y)=d(x, y), при этом данный отсчет проецируют с использованием его собственного значения d(s(x, y))=d(x, y).
Предсказание на основе синтеза ракурсов может включать варпинг (warping) с дробнопиксельной точностью, для чего может выполняться повышение разрешения опорного кадра перед варпингом, а разрешение синтезированного кадра может понижаться обратно до исходного разрешения.
Процедура синтеза ракурса может включать два основных шага: направленный вперед варпинг и заполнение пробелов. При направленном вперед варпинге каждый пиксель опорного изображения отображается в синтезированное изображение, например, с использованием приведенного выше уравнения. При отображении нескольких пикселей опорного изображения в одно и то же местоположение отсчета синтезированного ракурса для представления этого местоположения отсчета может быть выбран пиксель, связанный с большим значением глубины (более близкий к камере). После варпинга всех пикселей могут остаться определенные «пустые» пиксели, которым не были поставлены в соответствие значения отсчетов из опорного кадра; эти пустые пиксели могут заполняться с использованием линейно направленного заполнения пробелов, где под «пробелом» понимаются последовательные пустые пиксели в горизонтальной строке между двумя непустыми пикселями. Пустые пиксели в пробеле могут заполняться с использованием одного из двух смежных непустых пикселей, имеющих меньшее значение отсчета глубины (более удаленных от камеры).
Варпинг и заполнение пробелов могут выполняться в одном цикле обработки, например, в соответствии с приведенным ниже описанием. Выполняется проход по каждой строке пикселей во входном опорном изображении, например, слева направо, при этом каждый пиксель входного опорного изображения обрабатывается следующим образом.
Текущий пиксель отображается в целевое синтезированное изображение в соответствии с приведенным выше уравнением отображения/варпинга с преобразованием глубины в диспарантность. Для пикселей в окрестности границ глубины может использоваться сплэттинг (splatting), при котором один пиксель отображается на два смежных местоположения. Обнаружение границы может выполняться каждые N пикселей в каждой строке опорного изображения. Пиксель может считаться граничным пикселем глубины, если разность между значением отсчета глубины пикселя и значением отсчета глубины соседнего пикселя в той же строке (N-ый пиксель справа от данного пикселя) превосходит порог (соответствующий разности диспарантности в M пикселей при целочисленной точности варпинга в синтезированное изображение). Для граничного пикселя глубины и К смежных пикселей справа от него может применяться сплэттинг. Более конкретно, N=4⋅UpRefs, M=4, K=16⋅UpRefs-1, где UpRefs - коэффициент повышения разрешения опорного изображения перед варпингом.
Если текущий пиксель побеждает при z-буферизации, то есть если текущий пиксель отображается путем варпинга в местоположение, не имеющее ранее отображенного в него путем варпинга пикселя, или имеющее пиксель с меньшим значением глубины, то данная итерация считается успешной и могут быть выполнены следующие шаги. В противном случае итерация считается неуспешной, и обработка продолжается со следующего пикселя во входном опорном изображении.
Если между отображенными местоположениями пикселей на данной итерации и на предыдущей выполненной итерации имеется зазор, может быть сделан вывод о наличии пробела.
Если был обнаружен пробел, и при этом текущее местоположение отображенного пикселя находится справа от предыдущего, этот пробел может быть заполнен.
Если был обнаружен пробел, и на текущей итерации пиксель был отображен в местоположение слева от местоположения пикселя на предыдущей успешной итерации, то последующие пиксели непосредственно слева от этого местоположения могут быть обновлены, если они образуют пробел.
Для формирования синтезированного изображения ракурса на основе левого опорного ракурса опорное изображение сначала должно быть перевернуто и затем должна быть применена описанная выше процедура варпинга и заполнения пробелов для формирования промежуточного синтезированного изображения. Промежуточное синтезированное изображение может быть перевернуто для получения синтезированного изображения. Альтернативно, описанная выше процедура допускает изменения, то есть может выполняться преобразование глубины в диспарантность, сплэттинг с учетом границ и другие процедуры для предсказания на основе синтеза ракурсов, но, в сущности, с обратными допущениями относительно горизонтальных направлений и порядка.
В другом примере осуществления предсказания на основе синтеза ракурсов могут использоваться описанные ниже процедуры. Входными данными для этого примера процедуры получения изображения синтеза ракурса являются декодированный компонент srcPicY яркости, два компонента srcPicCb и srcPicCr цветности с разрешением, повышенным до разрешения компонента srcPicY, а также изображение DisPic глубины.
Выходными данными для этого примера процедуры получения изображения синтеза ракурса является массив отсчетов синтезированного опорного компонента vspPic, который получают с помощью варпинга на основе диспарантности, что может быть проиллюстрировано приведенным ниже псевдокодом:
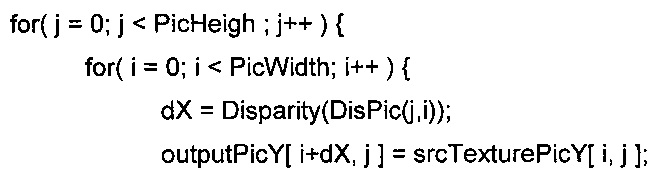

где функция "Disparity())" преобразует значение карты глубины с пространственным разрешением i, j в значение dX диспарантности, PicHeigh - высота изображения, Pic_Width - ширина изображения, srcTexturePicY - исходное изображение текстуры, outputPicY - компонент Y выходного изображения, outputPicCb - компонент Cb выходного изображения, а outputPicCr - компонент Cr выходного изображения.
Диспарантность вычисляют с учетом настроек камер, например, смещения b между двумя ракурсами, фокусного расстояния f камер и параметров представления (Znear, Zfar) карты глубины, как это проиллюстрировано ниже.
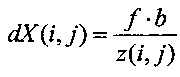 ;
; 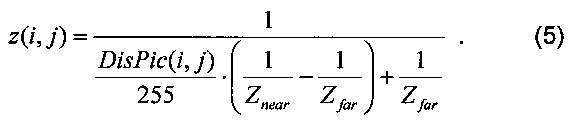
Изображение vspPic, полученное в результате выполнения описанной выше процедуры, может включать различные артефакты варпинга, например, пробелы и/или окклюзии, и для подавления этих артефактов, соответственно, могут применяться различные операции постобработки, такие как заполнение пробелов.
Однако для снижения вычислительной сложности эти операции могут быть опущены, так как изображение vspPic синтеза ракурса используется для опорных изображений предсказания и не выводится на дисплей.
Синтезированное изображение {outputPicY, outputPicCb, outputPicCr} может быть добавлено в список опорных изображений аналогичным способом, как для межракурсных опорных изображений. Передача списка опорных изображений и операции с ним в случае предсказания на основе синтеза ракурсов могут оставаться идентичными или аналогичными тем, что определены в стандартах H.264/AVC или HEVC.
Аналогично, процедуры вычисления информации о движении и ее применения при предсказании на основе синтеза ракурсов могут оставаться идентичными или аналогичными процедурам, определенным в стандартах H.264/AVC или HEVC для внешнего предсказания и межракурсного предсказания.
Предсказание на основе синтеза ракурсов может быть введено в процедуры трехмерного видеокодирования и декодирования без влияния на такие низкоуровневые операции, как сигнализация и декодирование информации о движении, что, следовательно, позволяет сохранить совместимость на низком уровне с существующими стандартами кодирования H.264/AVC или HEVC.
Альтернативно или дополнительно, кодером могут задаваться и передаваться в битовом потоке конкретные режимы кодирования для предсказания на основе синтеза ракурсов. Например, в режиме пропуска с VSP-предсказанием или прямом режиме может быть опущено (де)кодирование разности векторов и (де)кодирование разностной ошибки предсказания, например, с использованием кодирования на основе преобразования. К примеру, если в битовом потоке указано, что макроблок кодирован с использованием режима пропуска или прямого режима, то в битовом потоке может также присутствовать указание на то, был ли использован кадр VSP-предсказания в качестве опорного.
Кодер в соответствии с некоторыми из примеров осуществления настоящего изобретения может включать одну или более из описанных ниже операций. Следует отметить, что в данном случае аналогичные принципы могут применяться на стороне декодера для декодирования.
Кодирование или декодирование блока Cb текстуры/видеоизображения в ракурсе с номером N выполняется с использованием опорных данных текстуры/видеоизображения для ракурса с номером i (где i≠Ν), обозначаемого также как Ti, который служит в качестве исходного изображения VSP-предсказания и предоставляет значения отсчетов изображения для процедуры синтеза ракурса.
Далее кратко описаны отличительные аспекты некоторых из вариантов осуществления настоящего изобретения.
Доступность информации глубины/диспарантности d(Cb).
Кодирование или декодирование блока Cb в ракурсе текстуры/видеоизображения с номером N может выполняться с использованием информации глубины, информации карты глубины, информации диспарантности или любой другой информации о дальности d(Cb), которая связана с этой информацией текстуры блока Cb и информацией о дальности и доступна перед кодированием или декодированием блока текстуры.
Опорная область R(Cb) для VSP-предсказания.
В некоторых вариантах осуществления настоящего изобретения в результате предсказания на основе синтеза ракурсов для блока Cb текстуры получают или вычисляют значения пикселей или опорных отсчетов в опорной области R(Cb) опорного изображения VSP-предсказания для ракурса с номером М, где M!=N. В некоторых вариантах осуществления настоящего изобретения отсчеты опорной области R(Cb) могут представлять собой блок предсказания для блока Cb текстуры, тогда как в некоторых других вариантах осуществления настоящего изобретения отсчеты в опорной области R(Cb) могут использоваться для получения отсчетов блока предсказания для блока Cb текстуры, например, с помощью предсказания с компенсацией движения и/или субпиксельной интерполяции значений в опорной области R(Cb), или с помощью совместной обработки нескольких опорных областей R(Cb), полученных из различных ракурсов.
Обратное проецирование
В некоторых вариантах осуществления настоящего изобретения процедуру предсказания на основе синтеза ракурсов выполняют с использованием подхода обратного проецирования, при этом могут применяться следующие шаги.
Информацию dN(Cb) о дальности, связанную с кодированным блоком Cb в ракурсе с номером N, преобразуют в информацию Di(Cb) диспарантности, которая задает смещение пространственных координат между отсчетами текущего ракурса с номером N и опорного ракурса с номером i.
Преобразование в информацию Di(Cb) диспарантности может выполняться попиксельно, при этом для каждого отсчета информации Di(Cb) диспарантности текущего ракурса с номером N вычисляют или оценивают независимую информацию Di(Cb) диспарантности. Альтернативно, преобразование к диспарантности может выполняться поблочно, то есть вычисленное значение dN(Cb') информации о дальности получают, например, с помощью усреднения значений dN(Cb) информации о дальности, применения медианного фильтра к значениям dN(Cb) информации о дальности или применения любой другой функции или фильтра ко всем отсчетам в значениях dN(Cb) информации о дальности. Затем вычисленное значение информации dN(Cb') о дальности может быть преобразовано в соответствующее значение Di(Cb') диспарантности, например, с использованием отображения преобразования «глубина-диспарантность». Альтернативно, преобразование к диспарантности может выполняться поблочно, то есть информацию Di(Cb) диспарантности обрабатывают, например, с помощью усреднения значений информации Di(Cb) диспарантности, применения медианного фильтра к значениям информации Di(Cb) диспарантности или применения любой другой функции или фильтра ко всем отсчетам в информации Di(Cb) диспарантности для получения соответствующего значения Di(Cbʺ) диспарантности.
Информация Di(Cb) диспарантности или, соответственно, Di(Cb') или Di(Cbʺ) может использоваться для нахождения значений отсчетов в текстуре опорного ракурса с номером i и связанной с этими отсчетами текстуры информацией di(Cb) о дальности, например, отсчетов карты глубины в опорном ракурсе с номером i. Если информация Di(Cb) диспарантности представляет собой блок значений диспарантности, то значения отсчетов опорного ракурса текстуры с номером i могут находиться попиксельно. Если информация Di(Cb) диспарантности представляет собой единое значение диспарантности для блока пикселей, то поиск значений отсчетов опорного ракурса текстуры с номером i может выполняться поблочно. Найденные отсчеты могут использоваться для формирования R(Cb). Такое нахождение и/или копирование может называться проецированием, отображением, фильтрацией или варпингом.
При формировании опорной области R(Cb) могут быть задействованы различные процедуры обработки опорного вида с номером i (то есть Ti), например, пространственная или временная фильтрация, фильтрация с использованием параметров взвешененного предсказания для компенсации изменений яркости или нелинейной обработки для обработки окклюзий, пробелов и т.д. Такая обработка может выполняться перед проецированием пикселей в опорную область R(Cb) или после него.
Вследствие применения обратного проецирования при предсказании на основе синтеза ракурсов порядок вычисления опорной области R(Cb) может быть произвольным. Другими словами, значения пикселей в опорной области R(Cb) в VSP-изображении могут формироваться независимо для каждого блока Cb, при этом не предполагается никакой зависимости от порядка обработанных блоков Cb(s). Следовательно, в процедуре синтеза ракурса для одного блока Cb или в процедуре синтеза ракурса в целом на уровне кадра могут формироваться идентичные значения пикселей для опорной области R(Cb). Это свойство позволяет реализовать обратное предсказание при синтезе ракурсов на уровне кадра или на уровне слайса, что не требует изменений в кодировании или декодировании на уровне блока относительно существующих методов кодирования, например, стандарта H.264/MVC. Однако это свойство дает также возможность реализации на уровне блока, что позволяет снизить потребление памяти.
Ниже кратко описаны дополнительные отличительные аспекты некоторых из вариантов осуществления настоящего изобретения. Один или более из этих аспектов могут дополнительно применяться в сочетании с перечисленными выше аспектами.
Многогипотезное предсказание на уровне блока на основе более одного опорного кадра VSP-предсказания
Для двунаправленного предсказания или при любом типе многогипотезного предсказания в качестве опорных могут применяться два или более опорных кадра VSP-предсказания. Двунаправленное предсказание может быть взвешенным, например, для компенсации разности яркостей в различных ракурсах.
Вычисление R(Cb) на уровне отсчетов на основе нескольких исходных изображений VSP-предсказания
Если доступны несколько изображений VSP-предсказания для вычисления значений отсчетов R(Cb), то для получения фактического отсчета текстуры для R(Cb) могут применяться различные процедуры обработки. Такая обработка может включать, без ограничения перечисленным, выбор по условию (например, может быть выбран отсчет текстуры с более близким значением глубины или меньшим значением глубины) или агрегацию нескольких возможных отсчетов.
Вычисление R(Cb) на основе глубины/диспарантности
Соответствующие значения отсчетов di(Cb) и dN(Cb) могут сравниваться с использованием различных метрик сходства или различия, например, суммы абсолютных разностей (Sum of Absolute Differences, SAD). Метрики разности могут вычисляться для блока di(Cb) или для отдельных отсчетов di(Cb). Если разность лежит в определенном диапазоне, то отсчеты текстуры опорного ракурса с номером i, заданные диспарантностью Di(Cb), могут использоваться для формирования значений отсчетов в опорной области R(Cb).
Ниже более подробно описаны некоторые из вариантов осуществления настоящего изобретения.
На фиг. 8 показана блок-схема для одного из вариантов осуществления цепочки оценки движения или предсказания с компенсацией движения для кодирования текстуры с использованием предсказания на основе синтеза ракурсов в соответствии с некоторыми из примеров осуществления настоящего изобретения. При предсказании для синтеза ракурса не обязательно в результате получают кадр VSP-предсказания полностью, а может формироваться только опорная область R(Cb) на основе запроса в цепочке оценки движения или предсказания с компенсацией движения.
На фиг. 5 проиллюстрирован один из примеров видеоинформации, сопровождаемой информацией глубины. На фиг. 5 блоком 152 проиллюстрирован текущий кодируемый блок Cb текстуры 150, при этом блок 156 связан с данной информацией d(Cb) о дальности для текстуры, например, с картой 151 глубины. Остальные блоки 153, 154, 155 текстуры 150 представляют собой соседний блок S слева от текущего блока cb, соседний блок Τ в верхнем правом углу от текущего блока cb и несмежный блок U в текстуре 150. Блоками 157, 158, 159 проиллюстрирована информация d(s), d(T), d(U) блоков S, Τ, U текстуры, соответственно.
В дальнейшем описании предполагается, что данные многоракурсного кодирования, сопровождаемые информацией глубины (multiview plus depth video coding, MVD), содержат компоненты текстуры и карты глубины, которые представляют несколько видеоизображений, возможно, записанных с использованием конфигурации с параллельно расположенными камерами, при этом выполняют исправление записанных ракурсов.
Обозначения Ti и di отностятся, соответственно, к компонентам текстуры и карты глубины ракурса с номером i. Компоненты текстуры и карты глубины MVD-данных могут кодироваться в другом порядке кодирования, например, T0d0T1d1 или d0d1 T0T1. В некоторых из вариантов осуществления настоящего изобретения предполагается, что компонент di карты глубины доступен (декодирован) до компонента Ti текстуры, при этом компонент di карты глубины используют для кодирования или декодирования компонента Ti текстуры.
Ниже более подробно проиллюстрирован первый вариант осуществления настоящего изобретения, который основан на обратном попиксельном предсказании на основе синтеза ракурсов для текущего блока Cb. Например, могут приниматься следующие допущения: используется порядок кодирования T0d0d1T1, компонент Ti текстуры кодируют с использованием предсказания на основе синтеза видео, а текущий кодируемый блок СМ имеет разбиение 16×16. Текущий кодируемый блок СМ связан с данными d(CM) карты глубины, при этом данные карты глубины включают блок такого же размера, 16×16. В некоторых из вариантов осуществления настоящего изобретения кодирование данных видеоизображений, сопровождаемых информацией глубины, может быть реализовано с помощью описанных ниже шагов.
Преобразование глубины к диспарантности
Блок данных d(Cbl) карты глубины преобразуют в блок D(Cbl) отсчетов диспарантности. Процедура преобразования может выполняться с использованием приведенных ниже уравнений или с использованием их целочисленных арифметических реализаций:
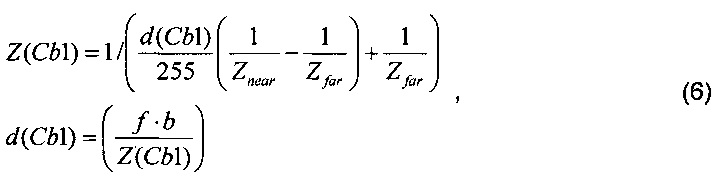
где d0 - значение карты глубины для ракурса с номером 0, Z - фактическое значение глубины, a D - диспарантность относительно конкретного ракурса.
Параметры b, Z_near и Z_far могут быть получены из конфигурации камеры, то есть применяемого фокусного расстояния (f), расстояния (b) между камерами для ракурса с номером 0 и ракурса с номером i, при этом диапазон (Z_near, Z_far) глубины представляет собой параметры преобразования карты глубины. Результирующее значение D диспарантности используют в качестве смещения (dX) горизонтальных координат, которое применяют для преобразования пространственных координат в ракурсе с номером 1 в пространственные координаты в ракурсе с номером i.
В общем случае предполагается, что в уравнении (5) используется арифметика с плавающей точкой. Однако вследствие конечной природы сетки измерений значение диспарантности может быть округлено либо до ближайшего целого (в этом случае достигается попиксельное соответствие) или до определенной субпиксельной точности (в этом случае разрешение опорного изображения Ti должно быть повышено до требуемой точности). С использованием данного принципа значение диспарантности, вычисленное с помощью уравнения (5), не отличается от компонента mv_x вектора движения, представленного с субпиксельной точностью.
Проецирование пикселей текстуры в R(Cb)
Диспарантность D1(i,j) вычисляют для каждого значения d1(i,j) карты глубины и применяют для поиска местоположения соответствующих пикселей текстуры в ракурсе с номером 0. Применение значений диспарантности для ракурсов в диапазоне от текущего кодируемого ракурса с номером 1 до ракурса с номером i дает местоположение пикселей Ti текстуры в ракурсе с номером i, связанных с текущим объектом. Пиксели, взятые из указанных местоположений, используют для формирования пикселей опорного блока R(Cb), который может иметь размер, равный размеру текущего блока Cb.
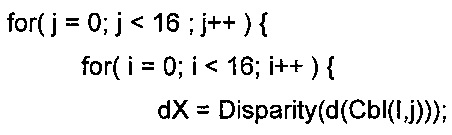

В некоторых реализациях опорный блок R(Cb) может иметь более крупный размер по сравнению с текущим блоком Cb, например, для обеспечения возможности уточнения смещения между Cb и R(Cb) с помощью кодирования с использованием векторов движения или аналогичных средств. Более крупная область R(Cb) может формироваться, например, с помощью сплэттинга отображенных пикселей на большую область, нежели одно положение отсчета в R(Cb), и/или с помощью использования для вычисления R(Cb) блока глубины/диспарантности больше, чем Cb.
В случае использования информации диспарантности, имеющей субпиксельную точность, значение DX диспарантности может быть перемасштабировано таким образом, чтобы отражать разность разрешения исходного изображения VSP-предсказания и текущего кодируемого изображения, при этом пиксели R(Cb) могут формироваться с помощью процедуры интерполяции, в которой N ближайших отсчетов Ti могут использоваться для формирования отсчета, например, следующим образом.

где индекс "А:В" обозначает все индексы, принадлежащие диапазону от А до В. В данном конкретном примере это означает, что функция интерполяции учитывает все Ti пикселей, расположенных в диапазоне между i+DX-N/2 и i+DX+N/2-1.
Другие примеры интерполяции могут включать, без ограничения этим, интерполяцию внутри цикла обработки видеоинформации, применяемую в стандартах H.264/AVC и HEVC.
В некоторых из вариантов осуществления настоящего изобретения пиксели источника предсказания на основе синтеза видео, помеченного для формирования R(Cb), могут проходить дополнительный анализ связанной с ними информации о дальности или соседних отсчетов с использованием следующей процедуры:

где di - информация о дальности для ракурса с номером i, d1 - информация карты глубины для ракурса с номером 1, a function - функция обработки.
В некоторых из вариантов осуществления настоящего изобретения для формирования R(Cb) может быть доступно множество исходных изображений предсказания на основе синтеза видео. Конкретный источник предсказания на основе синтеза видео, использованный для R(Cb), может сигнализироваться в декодер в битовом потоке или определяться в декодере с использованием процедуры определения.
Кодер может выполнять выбор исходного изображения предсказания на основе синтеза видео с помощью оптимизации по соотношению "скорость - искажения" (Rate-Distortion Optimization, RDO) или с помощью оптимизации другой целевой метрики. В таких вариантах осуществления изобретения выбранное исходное изображение предсказания на основе синтеза видео используют для кодирования текущего блока текстуры с использованием предсказания на основе синтеза видео, при этом идентификатор выбранного исходного изображения предсказания на основе синтеза видео передают на сторону декодера.
Не ограничивающие изобретение примеры сигнализации информации об использованном исходном изображении предсказания на основе синтеза видео могут включать сигнализацию указателя опорного кадра, связанного с компонентами векторов движения на уровне разбиения блока, сигнализацию с помощью заданной информации разбиения (например, режимов кодирования) на уровне макроблока или ниже, сигнализацию на уровне слайса (указанное исходное изображение предсказания на основе синтеза видео будет использовано при предсказании на основе синтеза видео для всех блоков текстуры текущего слайса, кодируемых с использованием предсказания на основе синтеза видео) или сигнализацию посредством набора параметров последовательности или ниже (все кодированные текстуры текущих последовательностей с предсказанием на основе синтеза видео кодируются с использованием идентифицированного исходного изображения при предсказании на основе синтеза видео).
В еще одном из вариантов осуществления настоящего изобретения может быть заранее задан (и/или заранее передан в декодер) набор возможных источников для предсказания на основе синтеза видео. В таких вариантах осуществления настоящего изобретения кодер передает указатель на один из кандидатов или передает указание на способ определения идентификатора исходного изображения предсказания на основе синтеза видео из информации, доступной на стороне декодера, например, с помощью извлечения указателя из уже кодированной информации.
В кодере и декодере может выполняться определение исходного изображения предсказания на основе синтеза видео для R(Cb) или отдельных отсчетов R(Cb) с помощью заданной процедуры определения, которая одинакова на стороне кодера и декодера. Не ограничивающие изобретение примеры таких процедур определения могут включать: выбор в зависимости от глубины (например, выбирают источник для предсказания на основе синтеза видео со значениями глубины, наиболее близкими к d(Cb), или источник для предсказания на основе синтеза видео с меньшим значением глубины, представляющий ближайший к камере объект трехмерной сцены), или определение оптимального источника для предсказания на основе синтеза видео на основе ранее кодированных блоков или смежных блоков. Процедура определения может выполняться на уровне отсчетов или на уровне блоков. Если процедура определения выполняется на уровне блоков, то такое определение может включать фильтрацию, например, усреднение d(Cb) соответствующих возможных блоков R(Cb).
В некоторых из вариантов осуществления настоящего изобретения в кодере и декодере может использоваться заранее заданный набор процедур определения. В декодер может передаваться указание на используемую процедуру на уровне макроблока или ниже, на уровне слайса или ниже, на уровне набора параметров последовательности или ниже, или такая процедура может быть указана с помощью использованного профиля кодирования.
Предсказание Cb на основе R(Cb)
Предсказание текущего блока Cb на основе R(Cb) может выполняться традиционным способом предсказания с компенсацией движения, при этом указатель на опорное изображение указывает на конкретное опорное изображение VSP-предсказания, а компоненты mv_x и mv_y вектора движения указывают на конкретное пространственное местоположение в этом опорном кадре.
Указатель на опорное изображение и компоненты вектора движения могут кодироваться традиционным образом и передаваться в декодер.
В некоторых из вариантов осуществления настоящего изобретения предсказание Cb на основе R(Cb) может выполняться с использованием дробнопиксельных векторов движения, следовательно, опорная область R(Cb) имеет больший размер блока, чем текущий блок Cb.
В некоторых из вариантов осуществления настоящего изобретения предсказание на основе синтеза видео для текущего блока Cb может быть получено на основе R(Cb) с использованием нулевых векторов движения (mv_x=mv_y=0). В таких вариантах осуществления настоящего изобретения опорная область R(Cb) может иметь такой же размер блока, как размер текущего блока Cb.
В некоторых из вариантов осуществления настоящего изобретения информация ошибки векторов движения может считаться известной априори или может вычисляться на стороне декодера, при этом информация ошибки векторов движения в декодер не передается. Определение вектора движения на стороне декодера может быть основано, например, на минимизации разности глубины/диспарантности с использованием конкретной метрики сходства/различия, такой как суммы абсолютных разностей в конкретном диапазоне поиска или среди возможных векторов движения, которые могут выбираться, например, из пространственно смежных блоков или конкретных временных блоков или блоков межракурсного предсказания, например, с конкретным пространственным местоположением относительно текущего блока Cb.
В некоторых вариантах осуществления настоящего изобретения указатель на опорное изображение предсказания на основе синтеза видео считается известным априори или может определяться на стороне декодера, то есть указатель на опорное изображение предсказания на основе синтеза ракурсов в декодер не передается.
В некоторых из вариантов осуществления настоящего изобретения информация об использовании предсказания на основе синтеза видео для кодирования/декодирования текущего блока Cb может передаваться не в форме указателя на опорное изображение в качестве части сигнализации информации о движении, но с использованием альтернативных форм сигнализации. Не ограничивающие изобретение примеры такой сигнализации могут включать использование конкретного флага, задающего использование предсказания на основе синтеза видео для текущего блока Cb. Такой флаг в кодеке, соответствующем стандарту H.264/AVC, может сигнализироваться на уровне макроблока или на уровне разбиений блока, или на уровне блока кодирования (CU) или ниже в кодеке, соответствующем стандарту HEVC, или с помощью указателя на возможные предсказания, априори известные на стороне декодера, как это осуществляется в HEVC-кодеке. Флаг может быть кодирован с помощью САВАС или другого арифметического кодека или аналогичных средств и, следовательно, не обязательно является представленным битом в битовом потоке.
Ниже более подробно проиллюстрирован второй вариант осуществления настоящего изобретения, который основан на обработке информации о дальности при предсказании на основе синтеза ракурсов. Приведены отличия второго варианта осуществления настоящего изобретения от первого варианта осуществления настоящего изобретения.
Перед преобразованием к диспарантности, которое проиллюстрировано уравнением (5), компонент глубины многоракурсного видеокодирования и кодирование глубины могут подвергаться определенной обработке, например, в соответствии с приведенным ниже описанием.
Карта глубины может подвергаться различной фильтрации, которая может включать линейную и/или нелинейную фильтрацию, фильтрацию усреднения или медианную фильтрацию.
В случае фильтрации усреднения вычисляют среднюю величину значений d(Cb) диспарантности, которую используют в уравнении (5) для получения единого среднего значения D(Cb) диспарантности для всего блока Cb:
Av_d=mean(d(Cb)).
Альтернативно, вместо фильтрации усреднения может использоваться медианная фильтрация:
median d=median(d(Cb)).
Альтернативно в уравнении (5) могут быть использованы минимальные или максимальные значения карты глубины:
min d=min(d(Cb)),
max d=max(d(Cb)).
В некоторых из вариантов осуществления настоящего изобретения может быть получена попиксельная диспарантность на основе значений d(Cb) диспарантности, в соответствии с уравнением (5), и после этого шага может быть сформировано единое значение диспарантности, представляющее текущий блок Cb, с помощью операций в области диспарантности. Единое значение диспарантности может формироваться с использованием линейной или нелинейной обработки, примеры которой включают операции усреднения, нахождения медианного значения или операции нахождения минимума и максимума.
В некоторых из вариантов осуществления настоящего изобретения может использоваться операция прореживания значений d(Cb) диспарантности для получения представления карты глубины для текущего блока Cb в уравнении (5).
В еще одном из вариантов осуществления настоящего изобретения представление карты глубины для текущего блока Cb может быть определено на основе ранее кодированных компонентов (ракурсов) карты глубины или на основе ранее кодированных блоков текстуры.
В еще одном из вариантов осуществления настоящего изобретения в кодере и декодере могут быть доступны возможные карты глубины для представления текущего блока Cb перед кодированием или декодированием текущего блока Cb. Указатель на конкретное значение глубины, используемое для кодирования или декодирования текущего блока Cb, может сигнализироваться в битовом потоке или определяться на стороне кодера и декодера.
Остальные шаги варианта осуществления настоящего изобретения могут затем выполняться аналогично приведенному выше описанию первого варианта осуществления изобретения.
Ниже более подробно проиллюстрирован третий вариант осуществления настоящего изобретения, который основан на многонаправленном предсказании на основе синтеза видео с использованием RDO.
В случае многоракурсного кодирования трехмерных видеоизображений в результате синтеза ракурсов на основе множества опорных ракурсов может формироваться кадр VSP-предсказания. Например, в случае трехракурсного кодирования, компоненты многоракурсной видеоинформации, включающей информацию глубины, могут кодироваться в следующем порядке: T0-d0-d1-d2-T1-T2. При таком порядке для ракурса Т1 текстуры может использоваться предсказание на основе синтеза ракурсов, при этом соответствующий кадр VSP-предсказания может быть спроецирован на основе ракурса с номером 0. В отличие от него, для ракурса Т2 текстуры может использоваться кадр VSP-предсказания, полученный на основе ракурса с номером 0 и ракурса с номером 1. Следовательно, для его кодирования или декодирования может использоваться несколько кадров VSP-предсказания, или конкурирующие кадры VSP-предсказания могут сливаться для повышения качества предсказания на основе синтеза ракурсов.
Формирование и работа с несколькими опорными кадрами VSP-предсказания на стороне декодера может предъявлять требования к вычислительной мощности и объему памяти в декодере. Однако поскольку схема, предложенная в некоторых из вариантов осуществления настоящего изобретения, реализуется на уровне блоков, то формируется только опорная область R(Cb), а не обязательно полные кадры.
Операции декодирования в третьем варианте осуществления настоящего изобретения отличаются от первого и второго вариантов его осуществления в отношении преобразования глубины к диспарантности. Декодер считывает из битового потока или извлекает из доступной в декодере информации указатель, задающий ракурс (идентификатор ракурса), на основе которого должно выполняться предсказание на основе синтеза ракурсов. Для другого идентификатора ракурса (направления VSP-предсказания) входные данные, например, параметр b смещения или фокусное расстояние, в процедуру преобразования глубины к диспарантности могут отличаться и, следовательно, могут давать отличающиеся значения диспарантности. После этого в декодере остальные шаги первого или второго вариантов осуществления настоящего изобретения могут выполняться без изменений.
Напротив, в кодере будут полностью выполняться первый и второй вариант осуществления настоящего изобретения для всех доступных ракурсов, в результате чего могут быть получены множественные копии кодированного блока Cb. Для кодирования и для сигнализации на сторону декодера может быть выбран идентификатор ракурса, обеспечивающего минимальное значение целевой функции применяемой оптимизации соотношения "скорость - искажения".
Альтернативно, в кодере информация о направлении предсказания на основе синтеза ракурсов может быть получена из имеющейся информации, при этом кодирование текущего блока Cb может выполняться без сигнализации. В таких вариантах осуществления настоящего изобретения в декодере будет выполняться извлечение идентификатора ракурса в ходе соответствующей процедуры. Например, в кодере и в декодере может быть выбран исходный кадр VSP-предсказания, физически ближайший к текущему ракурсу в отношении смещения камеры. Если имеются два (или более) ракурсов, равноудаленных от текущего ракурса в отношении смещения камеры, то в кодере и декодере может быть сделан выбор между этими ракурсами на основе детерминированного правила, например, может выбираться ракурс с меньшим порядковым номером.
Ниже более подробно проиллюстрирован четвертый вариант осуществления настоящего изобретения, который основан на многонаправленном предсказании на основе синтеза ракурсов и в котором применяется выбор с учетом глубины.
Альтернативно или в дополнение к третьему варианту осуществления настоящего изобретения направление VSP-предсказания может выбираться на стороне кодера и декодера на основе информации глубины, доступной на стороне кодера и декодера перед кодированием или декодированием текущего блока Cb.
Поскольку информация d(Cb) глубины в ракурсе с номером 2, соответствующая VSP-предсказанию D0 на основе ракурса с номером 0 и VSP-предсказанию D1 на основе ракурса с номером 1, доступна на стороне кодера и декодера перед кодированием текущего блока Cb, она может быть использована при принятии решения о предпочтительном направлении предсказания на основе синтеза ракурсов для текущего блока Cb. Например, для предсказания может быть выбрано направление, дающее минимальное Евклидово расстояние между d(Cb) и VSP_D.
Cost1=min(average(d(Cb))-average(VSP_D1),
Cost2=min(average(d(Cb))-average(VSP_D2),
If(Cost1<Cost2), то Vsp_id=1 Else Vsp_id=2.
Следует отметить, что в четвертом варианте осуществления настоящего изобретения может применяться и другая метрика искажений.
Ниже более подробно проиллюстрирован пятый вариант осуществления настоящего изобретения, который основан на двунаправленном VSP-предсказании.
Альтернативно или в дополнение к третьему и четвертому вариантам осуществления настоящего изобретения текущий блок Cb в ракурсе с номером 2 может быть предсказан с использованием двунаправленного предсказания на основе синтеза ракурсов. В таких вариантах осуществления настоящего изобретения опорные области R0(Cb) и R1(Cb) будут создаваться на основе опорных ракурсов с номерами 0 и 1 и использоваться для предсказания текущего блока Cb в ракурсе с номером 2 в форме взвешенного предсказания.
Ниже более подробно проиллюстрирован шестой вариант осуществления настоящего изобретения, который основан на взвешивании однонаправленных, многонаправленных или двунаправленных предсказаний на основе синтеза ракурсов из предыдущих вариантов осуществления настоящего изобретения.
В некоторых из вариантов осуществления настоящего изобретения полный кадр VSP-предсказания не доступен ни на стороне кодера, ни на стороне декодере, поэтому вычисление весовых коэффициентов для взвешенного предсказания на основе полного кадра традиционным образом может быть затратным в отношении требуемых вычислений, потребляемой памяти и пропускной способности канала доступа к памяти. При этом использование вычисления взвешенных параметров на основе порядковых номеров изображений (РОС) также не является оптимальным, поскольку порядковый номер изображения не отражает качество изображения, полученного в результате предсказания на основе синтеза ракурсов.
Однако поскольку предсказание на основе синтеза ракурсов предполагает проецирование фактических значений пикселей из конкретного ракурса (направления предсказания на основе синтеза ракурсов), взвешенные параметры для этих пикселей могут наследоваться из соответствующих ракурсов, например, могут повторно использоваться параметры wp1, которые были использованы для межракурсного предсказания ракурса с номером 2 на основе ракурса с номером 0, и параметры wp2, которые были использованы для межракурсного предсказания ракурса с номером 2 на основе ракурса с номером 1.
В вариантах осуществления настоящего изобретения с первого по четвертый данные R(Cb) пикселей, проецируемые из конкретного ракурса, могут быть перемасштабированы (нормализованы) с использованием соответствующего параметра взвешивания. В пятом варианте осуществления настоящего изобретения данные R(Cb) пикселей вычисляются как взвешенное среднее данных пикселей, проецируемых из ракурса с номером 0 и ракурса с номером 1.
Альтернативно или дополнительно, параметры взвешенного предсказания могут вычисляться на основе информации глубины, доступной на стороне кодера и на стороне декодера.
Wp1=function(d(Cb), VSP D1),
Wp2=function(d(Cb), VSP D2).
Альтернативно, функция function может быть определена как возвращающая одновременно Wp1 и Wp2, например, [Wp1, Wp2] = function(d(Cb), VSP_D1, VSP_D2). Например, данная функция может быть определена следующим образом:
Cost1=sad(d(Cb), VSP_D1),
Cost2=sad(d(Cb), VSP_D2),
где sad(d(Cb), VDP_Dx) возвращает сумму абсолютных разностей между каждой парой отсчетов в d(Cb) и соответствующим отсчетом в VSP Dx. Тогда общее значение целевой функции Total_Cost будет определено как Cost1+Cost2. Наконец, Wp1 определено как Cost2/Total_Cost, a Wp2 определено как Cost1/Total_Cost (с допущением, что весовые коэффициенты для взвешенного предсказания в сумме дают 1).
На фиг. 8 в виде упрощенной блок-схемы показан один из примеров кодера 800, а работа кодера в соответствии с одним из примеров осуществления настоящего изобретения проиллюстрирована в виде блок-схемы на фиг. 13. Кодер 800 принимает (802) блок текущего кадра ракурса текстуры для кодирования. Этот блок может также быть обозначен как текущий блок Cb. Текущий блок подают в первый объединитель 804, например, вычитающий элемент, и в устройство 806 оценки движения. Устройство 806 оценки движения имеет доступ к буферу 812 кадров, в котором хранится ранее кодированный кадр (или кадры), или устройству 806 оценки движения могут быть предоставлены другими средствами один или более блоков из одного или более ранее кодированных кадров. Устройство 806 оценки движения определяет, какой из одного или более ранее кодированных блоков может обеспечить хорошую основу для использования этого блока в качестве опорного при предсказании текущего блока. Если подходящий опорный блок для предсказания не был найден, устройство 806 оценки движения вычисляет вектор движения, который указывает на местоположение выбранного блока в опорном кадре относительно местоположения текущего блока в текущем кадре. Информация вектора движения может кодироваться с помощью первого энтропийного кодера 814. Информация об опорном блоке предсказания подается также в устройство 810 предсказания движения, которое вычисляет предсказанный блок.
Первый объединитель 804 определяет разность между текущим блоком и предсказанным блоком 808. Эта разность может быть определена, например, с помощью вычисления разности между значениями пикселей текущего блока и соответствующими значениями пикселей предсказанного блока. Эта разность может быть названа ошибкой предсказания. Ошибку предсказания преобразуют в область предсказания с помощью элемента 816 преобразования. Это преобразование может представлять собой, например, дискретное косинусное преобразование (discrete cosine transform, DCT). Преобразованные значения квантуют с помощью квантователя 818. Квантованные значения могут кодироваться с помощью второго энтропийного кодера 820. Квантованные значения могут быть также поданы в обратный квантователь 822, который восстанавливает преобразованные значения. Над восстановленными преобразованными значениями затем выполняют обратное преобразование с помощью элемента 824 обратного преобразования и получают восстановленные значения ошибки предсказания. Восстановленные значения ошибки предсказания объединяют с предсказанным блоком с помощью второго объединителя 826 и получают восстановленные значения текущего блока. Эти восстановленные значения блока упорядочивают в правильном порядке с помощью элемента 828 упорядочения и сохраняют в буфер 812 кадров.
В некоторых из вариантов осуществления настоящего изобретения кодер 800 также включает устройство 830 предсказания на основе синтеза ракурсов, в котором могут использоваться кадры ракурсов текстуры одного или более других ракурсов 832 и информация 834 глубины (например, карта глубины) для синтеза других ракурсов 836 на основе, например, карты глубины сорасположенного блока в ракурсе, отличающемся от ракурса текущего блока, как было показано выше на примере нескольких вариантов осуществления настоящего изобретения. Другие кадры 832 ракурсов текстуры и/или синтезированные ракурсы 836 могут также сохраняться в буфер 812 кадров, чтобы в устройстве 806 оценки движения эти другие ракурсы и/или синтезированные ракурсы могли использоваться при выборе опорного блока для предсказания текущего блока.
Компоненты векторов движения, используемые для предсказания на основе синтеза ракурсов, межракурсного предсказания и межуровневого предсказания, могут быть ограничены в диапазоне своего применения, в результате чего получают набор синтаксических элементов и набор операций декодирования. Например, могут быть ограничены диапазон значений и/или точность компонентов векторов движения или разностей компонентов векторов движения относительно значений предсказания. Кроме того, в некоторых из вариантов осуществления настоящего изобретения разностные компоненты векторов движения, используемые для предсказания на основе синтеза ракурсов, межракурсного предсказания и/или межуровневого предсказания, могут иметь начальный контекст, отличающийся от разностных компонентов векторов движения, используемых для внешнего предсказания или временного предсказания с компенсацией движения. Кроме того, в некоторых из вариантов осуществления настоящего изобретения разностные компоненты векторов движения, используемые для предсказания на основе синтеза ракурсов, межракурсного предсказания и/или межуровневого предсказания, могут переводиться в двоичную форму для основанного на контексте арифметического кодирования и декодирования другим образом, по сравнению с переводом в двоичную форму разностных компонентов векторов движения, используемых для внешнего предсказания или временного предсказания с компенсацией движения.
Во время кодирования, с помощью кодера, информации текстуры блока кадра или изображения в кодере может определяться (102), доступна ли информация о дальности для текущего блока. Это определение может включать проверку, имеется ли сорасположенный блок глубины/диспарантности в одном и том же ракурсе, что и ракурс текущего блока, в памяти, или доступен ли он иным образом для предсказания на основе синтеза ракурсов. Кодированный блок был введен в кодер, что проиллюстрировано блоком 100 на фиг. 13. Если определение показало, что сорасположенный блок глубины/диспарантности в одном и том же ракурсе, что и ракурс текущего блока, доступен для предсказания на основе синтеза ракурсов, то для блока текстуры текущего блока выполняют предсказание на основе синтеза ракурсов для получения опорной области R(Cb). Если это определение показывает, что сорасположенный блок глубины/диспарантности в одном и том же ракурсе, что и ракурс текущего блока, недоступен для предсказания на основе синтеза ракурсов, то может применяться традиционное предсказание (114) движения. В варианте осуществления настоящего изобретения, проиллюстрированном на фиг. 13, предсказание на основе синтеза ракурсов включает преобразование (104) информации о дальности в информацию диспарантности, которая задает смещение пространственных координат между отсчетами текущего ракурса с номером N и опорного ракурса с номером i. Эту информацию диспарантности используют для нахождения (106) значений отсчетов в текстуре опорного ракурса с номером i. Найденные значения отсчетов в текстуре опорного ракурса с номером i могут быть скопированы (108) в опорную область R(Cb). Предсказание на основе синтеза ракурсов для блока текстуры текущего блока может включать также обработку (110) отсчетов опорного ракурса с номером i. Обработка (110) может выполняться до или после копирования (108). Если обработку (110) выполняют до копирования, то обработанные значения или их часть копируют в отсчеты опорной области R(Cb).
После построения опорной области R(Cb) может выполняться предсказание (112) текущего блока 112 на основе информации опорной области R(Cb).
Далее будет рассмотрена работа одного из примеров осуществления декодера 900 со ссылками на фиг. 9 и блок-схему на фиг. 14. Декодер 900 принимает (200, 902) битовый поток или часть битового потока, где содержится кодированная видеоинформация. Кодированная видеоинформация может содержать значения ошибок предсказания, векторы движения, указатели на опорные изображения и т.п. Следует отметить, что в данном случае вся информация не обязательно должна быть включена в один и тот же битовый поток: часть информации может передаваться в других битовых потоках с использованием синтаксических элементов других типов.
Далее главным образом описано декодирование, относящееся к обработке векторов движения, при этом описание остальных операций (904) декодирования, таких как восстановление блоков, в настоящем описании большей частью опущено.
Декодер 900 может включать энтропийный декодер 906, который декодирует принятую энтропийно-кодированную информацию. Декодированная информация может быть передана в декодер 908 векторов движения. Декодер 908 векторов движения может включать элемент 910 проверки типа опорного изображения, который может анализировать декодированную информацию и определять, был ли включен в принятый битовый поток указатель на опорное изображение или другой тип указания на опорное изображение для текущего блока. Если указание на опорное изображение было принято, то элемент 910 проверки типа опорного изображения может определять (202) тип опорного изображения на основе этого указания на опорное изображение. Если указание на опорное изображение не было принято, то элемент 910 проверки типа опорного изображения может использовать для определения типа опорного изображения другие данные.
Декодер 908 векторов движения может также включать элемент 912 восстановления вектора движения, который может восстанавливать компоненты вектора движения для текущего блока.
Если указание на опорное изображение указывает на то, что текущий блок был предсказан с использованием традиционного внутреннего предсказания, то текущий блок может быть восстановлен (220) с использованием принятой информации ошибки предсказания и информации ранее декодированных блоков в том же текущем кадре. Если указание на опорное изображение указывает на то, что текущий блок был предсказан с использованием традиционного внешнего предсказания, то декодируется информация вектора движения и информация ошибки предсказания, которые используются вместе с опорным блоком предсказания, то есть блоком из другого ранее декодированного кадра, который использовался в кодере 800 при построении (220) опорного изображения для текущего кадра.
Если указание на опорное изображение указывает на то, что текущий блок был предсказан с использованием предсказания (204) на основе синтеза ракурсов, то в некоторых вариантах осуществления настоящего изобретения в декодере 900 могут выполняться описанные ниже операции. Декодер 900 может определять (206) или может принимать из кодера 800 информацию об изображении или изображениях, использованных в качестве исходных для предсказания на основе синтеза ракурсов, и использовать (208) эти исходные изображения для формирования блоков VSP-предсказания с использованием процедур, соответствующих стороне кодера.
Если указание на опорное изображение указывает на то, что текущий блок не был предсказан с использованием предсказания (204) на основе синтеза ракурсов, то для декодирования текущего блока могут использоваться (210) другие способы предсказания.
В различных вариантах осуществления настоящего изобретения может использоваться общая нотация арифметических операторов, логических операторов, операторов отношений, битовых операторов, операторов назначений и нотация диапазонов, например, определенная в стандарте H.264/AVC или в проекте стандарта HEVC. Кроме того, могут использоваться общие математические функции, например, определенные в стандарте H.264/AVC или проекте стандарта HEVC, и общий порядок предшествования и исполнения (слева направо или справа налево) операторов, например, определенные в стандарте H.264/AVC или в проекте стандарта HEVC.
В различных примерах осуществления настоящего изобретения для описания процедуры анализа синтаксических элементов могут использоваться следующие обозначения.
- ae(v): синтаксический элемент с контекстно-адаптивным арифметическим (САВАС) и энтропийным кодированием.
- b(8): байт из битовой строки с любой последовательностью битов (8 битов).
- se(v): синтаксический элемент, представляющий собой целое значение со знаком, кодируемое методом экспоненциального кодирования Голомба, начиная с левого бита.
- u(n): Целое без знака с использованием n битов. Если в синтаксической таблице n равно "v", то количество битов изменяется в зависимости от значения других синтаксических элементов. Процедура синтаксического разбора данного дескриптора определяется следующими n битами в битовом потоке, которые интерпретируются как двоичное представление целого числа без знака, старший бит которого идет первым.
- ue(v): синтаксический элемент, представляющий собой целое значение без знака, кодируемое методом экспоненциального кодирования Голомба, начиная с левого бита.
Битовая строка, кодированная методом экспоненциального кодирования Голомба, может быть преобразована в кодовое число, например, с использованием следующей таблицы:

Кодовое число, соответствующее битовой строке, кодированной методом экспоненциального кодирования Голомба, может быть преобразовано в se(v), например, с использованием следующей таблицы:
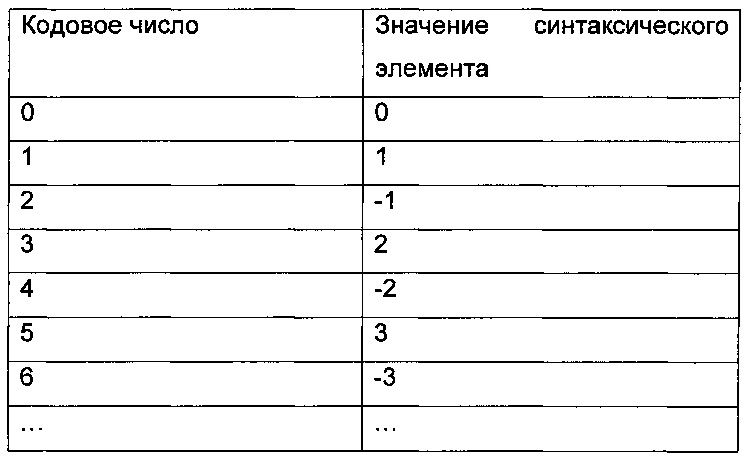
Варианты осуществления настоящего изобретения были описаны с использованием лежащих в их основе конкретных стандартов кодирования и их расширений, однако настоящее изобретение может быть также применено и для других кодеков, форматов битового потока и структуры кодирования.
Предлагаются описанные ниже элементы, которые могут быть объединены в одно решение в соответствии с последующим описанием или которые могут использоваться по отдельности. Как уже было описано ранее, и в видеокодере, и в видеодекодере, как правило, применяется механизм предсказания, следовательно, описанные ниже элементы могут быть применимы в равной степени к видеокодеру и к видеодекодеру.
В различных вариантах осуществления настоящего изобретения, представленных выше, выбирают блоки, соседние с текущим кодируемым/декодируемым блоком cb. Примеры выбора соседних блоков включают пространственно соседние блоки (например, как это показано на фиг. 7а). Другие примеры включают соседние по времени блоки в предыдущих и/или последующих кадрах того же ракурса (например, как это показано на фиг. 7b), пространственно соседние блоки в смежных ракурсах, пространственно соседние блоки в различных уровнях и пространственно соседние блоки в синтезированных ракурсах. Аспекты настоящего изобретения не ограничены упомянутыми способами выбора соседних блоков, напротив, данное описание приведено в качестве основы для частичной или полной реализации других вариантов осуществления настоящего изобретения.
Многие из вариантов осуществления настоящего изобретения были описаны для предсказания яркости, однако нужно понимать, что во многих системах кодирования информация для предсказания цветности может выводиться из информации для предсказания яркости с использованием заранее заданных соотношений. Например, может быть сделано допущение о том, что для компонентов цветности используются те же опорные отсчеты, что и для компонентов яркости.
Ниже более подробно описано устройство и возможные механизмы, подходящие для реализации вариантов осуществления настоящего изобретения. В связи с этим, для начала рассмотрим фиг. 10, на которой показана эскизная структурная схема примера аппаратуры или электронного устройства 50, которое может включать кодек, соответствующий одному из вариантов осуществления настоящего изобретения.
Электронное устройство 50 может являться, например, мобильным терминалом или пользовательским устройством системы беспроводной связи. Однако следует отметить, что варианты настоящего изобретения могут быть реализованы в рамках любого электронного устройства или устройства, для которого может потребоваться кодирование и/или декодирование видеоизображений.
Устройство 50 может содержать корпус 30 для размещения и защиты компонентов устройства. Устройство 50 может также содержать дисплей 32, выполненный в виде жидкокристаллического дисплея. В других вариантах осуществления настоящего изобретения дисплей может быть выполнен в соответствии с любой подходящей технологией для воспроизведения изображений или видео. Устройство 50 может также содержать клавиатуру 34. В других вариантах осуществления настоящего изобретения могут использоваться любые подходящие механизмы интерфейса ввода данных или пользовательского интерфейса. Например, пользовательский интерфейс может быть реализован в виде виртуальной клавиатуры или системы ввода данных, являющейся частью сенсорного экрана. Устройство может содержать микрофон 36 или любое подходящее средство ввода аудиосигнала, которое может являться средством ввода цифрового или аналогового сигнала. Устройство 50 может также содержать средство вывода аудиосигнала, которое в вариантах осуществления настоящего изобретения может представлять собой одно из следующих средств: наушники 38, динамик либо аналоговое или цифровое подключение к аудиовыходу. Устройство 50 может также содержать батарею 40 (или в других вариантах осуществления настоящего изобретения устройство может получать питание от любого подходящего мобильного источника энергии, такого как солнечный фотоэлемент, топливный элемент или аккумулятор часового механизма). Устройство может также содержать инфракрасный порт 42 для ближней связи с другими устройствами. В других вариантах осуществления настоящего изобретения устройство 50 может также содержать любое подходящее решение для ближней связи, такое как беспроводное соединение Bluetooth или проводное соединение USB/firewire.
Устройство 50 может включать контроллер 56 или процессор для управления устройством 50. Контроллер 56 может быть соединен с памятью 58, в которой, согласно вариантам осуществления настоящего изобретения, могут храниться данные изображения и аудиоданные и/или инструкции для выполнения контроллером 56. Контроллер 56 может быть также соединен со схемой 54 кодека, подходящей для выполнения кодирования и декодирования аудио и/или видео или участия в кодировании и декодировании, выполняемых контроллером 56.
Устройство 50 может также содержать считыватель 48 с карты и смарт-карту 46, например, UICC, и считыватель UICC для предоставления пользовательской информации, которые подходят для предоставления аутентификационной информации для аутентификации и авторизации пользователя в сети.
Устройство 50 может содержать схему 52 радиоинтерфейса, соединенную с контроллером и позволяющую генерировать сигналы для беспроводной связи, например, для связи с сетью сотовой связи, системой беспроводной связи или локальной сетью беспроводной связи. Устройство 50 также может включать антенну 44, соединенную со схемой 52 радиоинтерфейса для передачи радиочастотных сигналов, формируемых в схеме 52 радиоинтерфейса, в другое устройство (или устройства), а также для приема радиочастотных сигналов от другого устройства (или устройств).
В некоторых вариантах осуществления настоящего изобретения устройство 50 содержит камеру, позволяющую записывать или обнаруживать отдельные кадры, которые затем передаются для обработки в кодек 54 или в контроллер. В других вариантах осуществления настоящего изобретения устройство может принимать для обработки данные видеоизображения от соседнего устройства перед передачей и/или сохранением этих данных. В других вариантах осуществления настоящего изобретения устройство 50 может принимать изображение для кодирования/декодирования по беспроводному или проводному соединению.
На фиг. 12 показана система, в которой могут использоваться варианты осуществления настоящего изобретения. Система 10 содержит множество устройств связи, которые могут взаимодействовать друг с другом через одну или более сетей. Система 10 может включать любое объединение проводных или беспроводных сетей, включая, не ограничиваясь этим, беспроводную телефонную сотовую сеть (например, сеть GSM, UMTS, CDMA и т.д.), локальную беспроводную сеть (WLAN, wireless local area network), определенную, например, любым из стандартов IEEE 802.x, персональную сеть Bluetooth, локальную сеть Ethernet, кольцевую локальную сеть с маркерным доступом (token ring), глобальную сеть и Интернет.
Система 10 может содержать как проводные, так и беспроводные средства связи или устройства 50, подходящие для реализации вариантов настоящего изобретения.
Например, система, показанная на фиг. 3, включает мобильную телефонную сеть 11 и Интернет 28. Соединение с Интернетом 28 может включать, не ограничиваясь этим, беспроводные соединения для дальней связи, беспроводные соединения для ближней связи и различные проводные соединения, включая, не ограничиваясь этим, телефонные линии, кабельные линии, линии электропитания и аналогичные тракты связи.
Примеры устройств связи, показанные в системе 10, могут включать, не ограничиваясь этим, электронное устройство или устройство 50, объединение персонального цифрового помощника (PDA, personal digital assistant) и мобильного телефона 14, PDA 16, интегрированное устройство 18 обмена сообщениями (IMD, integrated messaging device), настольный компьютер 20, ноутбук 22. Устройство 50 может быть стационарным или мобильным устройством, перемещаемым отдельным пользователем. Устройство 50 может также располагаться в транспортном средстве, включая, не ограничиваясь этим, легковой автомобиль, грузовик, такси, автобус, поезд, судно, самолет, велосипед, мотоцикл или любое аналогичное подходящее транспортное средство.
Некоторые устройства могут посылать и принимать вызовы и сообщения и осуществлять связь с провайдерами услуг через беспроводное соединение 25 с базовой станцией 24. Базовая станция 24 может соединяться с сетевым сервером 26, который позволяет выполнять связь между мобильной телефонной сетью 11 и Интернетом 28. Система может содержать дополнительные устройства связи и устройства связи различных типов.
Устройства связи могут осуществлять связь с использованием различных технологий передачи, включая, не ограничиваясь этим, множественный доступ с кодовым разделением каналов (CDMA, code division multiple access), глобальные системы мобильной связи (GSM, global system for mobile communications), универсальную систему мобильной связи (UMTS, universal mobile telecommunications system), множественный доступ с временным разделением каналов (TDMA, time divisional multiple access), множественный доступ с частотным разделением каналов (FDMA, frequency division multiple access), протокол управления передачей/Интернет-протокол (TCP-IP, transmission control protocol-internet protocol), службу обмена короткими сообщениями (SMS, short messaging service), службу обмена мультимедийными сообщениями (MMS, multimedia messaging service), электронную почту, службу мгновенного обмена сообщениями (IMS, instant messaging service), Bluetooth, IEEE 802.11 и любые другие аналогичные технологии беспроводной связи. Устройства связи, задействованные в реализации различных вариантов осуществления настоящего изобретения, могут осуществлять связь с использованием различных сред передачи, включая, не ограничиваясь этим, радиосоединения, инфракрасные, лазерные, кабельные соединения и любые другие подходящие соединения.
Хотя в приведенных выше примерах описываются варианты осуществления настоящего изобретения, работающие в рамках кодека внутри электронного устройства, следует принимать во внимание, что изобретение, как будет описано ниже, может быть реализовано как часть любого видеокодека. Таким образом, например, варианты осуществления настоящего изобретения могут быть реализованы в видеокодеке, который может выполнять кодирование видеосигнала, передаваемого по фиксированным или проводным трактам связи.
Таким образом, пользовательское устройство может содержать видеокодек, такой как кодеки, описанные в представленных выше вариантах осуществления настоящего изобретения. Следует отметить, что термин пользовательское устройство охватывает пользовательское оборудование беспроводной связи любого подходящего типа, например, мобильные телефоны, портативные устройства обработки данных или портативные веб-браузеры.
Кроме того, элементы наземной сети мобильной связи общего пользования (PLMN, public land mobile network) также могут содержать описанные выше видеокодеки.
В целом, различные варианты осуществления настоящего изобретения могут быть реализованы в виде аппаратного обеспечения или специализированных схем, программного обеспечения, логических схем или любой комбинации указанных средств. Например, некоторые аспекты могут быть реализованы в виде аппаратных средств, в то время как другие аспекты могут быть реализованы в виде встроенного программного или программного обеспечения, которое может выполняться контроллером, микропроцессором или другим вычислительным устройством, хотя изобретение не ограничено перечисленными средствами. Хотя различные аспекты настоящего изобретения могут быть проиллюстрированы и описаны в виде структурных схем, блок-схем или с использованием некоторых других графических представлений, очевидно, что описанные здесь блоки, устройства, системы, методы или способы могут быть реализованы, не ограничиваясь приведенными примерами, в виде аппаратного, программного, встроенного программного обеспечения, специализированных схем или логических схем, универсальных аппаратных средств или контроллера или других вычислительных устройств, или некоторой их комбинации.
Варианты изобретения могут быть реализованы с помощью компьютерного программного обеспечения, выполняемого процессором данных мобильного устройства, например, блоком процессора, или с помощью аппаратного обеспечения, или комбинации программного и аппаратного обеспечения. Кроме того, в этом отношении следует отметить, что любые показанные на чертежах блоки логических алгоритмов могут представлять собой шаги программы или взаимосвязанные логические схемы, блоки и функции, или комбинацию шагов программы и логических схем, блоков и функций. Программное обеспечение может храниться на таких физических носителях, как микросхемы памяти или блоки памяти, реализованные внутри процессора, магнитные носители, например, жесткий диск или гибкий диск, и оптические носители, например, DVD и их варианты для хранения данных, CD.
Блоки памяти могут быть любого типа, подходящего к локальной технической среде, и могут быть реализованы с использованием любых подходящих технологий хранения данных и представлять собой, например, устройства полупроводниковой памяти, устройства и системы магнитной памяти, устройства и системы оптической памяти, несъемную и съемную память. Процессоры данных могут быть любого типа, подходящего для локальной технической среды, и могут включать в качестве не ограничивающих изобретение примеров один или более универсальных компьютеров, специализированных компьютеров, микропроцессоров, цифровых сигнальных процессоров (DSP, digital signal processor) и процессоров на основе многоядерной архитектуры.
Варианты осуществления настоящего изобретения могут быть выполнены в виде различных компонентов, таких как модули интегральных схем. В целом, конструирование интегральных схем является высокоавтоматизированным процессом. Имеются комплексные и эффективные программные средства для преобразования разработки логического уровня в полупроводниковую схему, подготовленную для травления и формирования полупроводниковой основы.
Программы, производимые, например, компаниями Synopsys, Inc., Маунтин Вью, Калифорния, и Cadence Design, Сан Хосе, Калифорния, автоматически разводят проводники и размещают компоненты на полупроводниковом кристалле с использованием установленных правил разработки, а также библиотек заранее сохраненных модулей разработки. По окончании разработки полупроводниковой схемы полученный в результате проект в стандартизованном электронном формате (например, Opus, GDSII и т.п.) может быть передан на производство полупроводникового устройства для изготовления.
Приведенное описание является полным и информативным описанием вариантов осуществления настоящего изобретения, представленных в качестве примеров, не ограничивающих изобретение. Из описания, приложенных чертежей и формулы изобретения специалисту могут быть очевидны различные модификации и адаптации изобретения. Однако все такие модификации изобретения остаются в пределах объема настоящего изобретения, определенного прилагаемой формулой изобретения.
Далее будут приведены некоторые из примеров осуществления изобретения.
В соответствии с первым примером предлагается способ, включающий:
получение первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получение информации о дальности, связанной с упомянутым первым блоком текстуры;
определение информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получение опорных отсчетов второго ракурса на основе упомянутой информации диспарантности и
выполнение предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает обеспечение двух или более опорных ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает определение информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает:
использование упомянутой информации диспарантности для нахождения опорных отсчетов в текстуре упомянутого второго ракурса и
получение предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления настоящего изобретения получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование значений отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование значений отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование опорного кадра VSP-предсказания в качестве упомянутого опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания на основе двух или более исходных ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование двух или более опорных кадров VSP-предсказания на основе двух или более исходных кадров или с использованием двух или более способов синтеза ракурсов и
выбор одного из упомянутых двух или более кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения способ включает обеспечение по меньше мере одного из следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров предсказания на основе синтеза ракурсов, использованных для формирования упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает обеспечение по меньшей мере одного из следующего:
сигнализации указания в декодер с помощью кодированного битового потока и
определения уточнения упомянутого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование упомянутого указания для кодирования или декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает предоставление по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ используют в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления настоящего изобретения упомянутая видеоинформация представляет собой многоракурсную видеоинформацию.
В соответствии со вторым примером предлагается устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, которая содержит компьютерный программный код, при этом упомянутые по меньшей мере одна память и компьютерный программный код сконфигурированы для обеспечения, с помощью упомянутого по меньшей мере одного процессора, выполнения упомянутым устройством следующего:
получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством двух или более ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также определение этим устройством информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также выполнение этим устройством следующего:
использования упомянутой информации диспарантности для нахождения опорных отсчетов в текстуре упомянутого второго ракурса и
получения предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления упомянутого устройства получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством значений отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством значений отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством опорного кадра VSP-предсказания в качестве упомянутого опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания на основе двух или более исходных ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также выполнение этим устройством следующего:
формирования двух или более опорных кадров VSP-предсказания на основе двух или более опорных кадров или с использованием двух или более способов синтеза ракурсов и
выбора одного из упомянутых двух или более кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством по меньшей мере одного из следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров предсказания на основе синтеза ракурсов, использованных для формирования опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством по меньшей мере одного из следующего:
сигнализации указания в декодер с помощью кодированного битового потока и
определения уточнения упомянутого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством упомянутого указания для кодирования или декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством упомянутого способа в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления упомянутого устройства упомянутая видеоинформация представляет собой многоракурсную видеоинформацию.
В соответствии с третьим примером предлагается компьютерный программный продукт, содержащий одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение устройством по меньшей мере следующего:
получения первого несжатого блока текстуры из первого несжатого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством двух или более опорных ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают определение этим устройством информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение упомянутым устройством следующего:
использования упомянутой информации диспарантности для нахождения опорных отсчетов в текстуре упомянутого второго ракурса и
получения предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления упомянутого компьютерного программного продукта получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством значений отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством значений отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством опорного кадра VSP-предсказания в качестве упомянутого опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания на основе двух или более исходных ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение упомянутым устройством следующего:
формирования двух или более опорных кадров VSP-предсказания на основе двух или более исходных кадров или с использованием двух или более способов синтеза ракурсов и
выбора одного из упомянутых двух или более опорных кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством по меньшей мере следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров VSP-предсказания, использованных для формирования опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством по меньшей мере следующего:
сигнализации указания в декодер с помощью кодированного битового потока и
определения уточнения упомянутого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование устройством упомянутого указания для кодирования или декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование устройством упомянутого способа в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает видеоинформацию, которая представляет собой многоракурсную видеоинформацию.
В соответствии с четвертым примером предлагается устройство, содержащее:
средства для получения первого несжатого блока текстуры из первого несжатого изображения текстуры, представляющего первый ракурс;
средства для получения информации о дальности, связанной с упомянутым первым несжатым блоком текстуры;
средства для определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
средства для получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
средства для выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с пятым примером предлагается способ, включающий:
прием битового потока, включающего кодированную информацию, относящуюся к текущему блоку кадра первого ракурса;
получение первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получение информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определение информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получение опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнение предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает обеспечение двух или более опорных ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает определение информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает:
использование упомянутой информации диспарантности для нахождения опорных отсчетов в текстуре упомянутого второго ракурса и
получение предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления упомянутого способа получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование опорного кадра VSP-предсказания в качестве опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания на основе двух или более исходных ракурсов. В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает формирование опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает:
формирование двух или более опорных кадров VSP-предсказания на основе двух или более опорных кадров или с использованием двух или более способов синтеза ракурсов и
выбор одного из упомянутых двух или более опорных кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения способ включает обеспечение по меньшей мере одного из следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров VSP-предсказания, использованных для формирования опорного блока.
В некоторых из вариантов осуществления настоящего изобретения способ включает обеспечение по меньшей мере одного из следующего:
получения упомянутого указания от кодера с помощью кодированного битового потока и
определения уточнения упомянутого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование упомянутого указания для декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает предоставление по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутый способ включает использование упомянутого способа в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления упомянутого способа упомянутая видеоинформация представляет собой многоракурсную видеоинформацию.
В соответствии с шестым примером предлагается устройство, содержащее по меньшей мере один процессор и по меньшей мере одну память, которая содержит компьютерный программный код, при этом упомянутые по меньшей мере одна память и компьютерный программный код сконфигурированы для обеспечения, с помощью упомянутого по меньшей мере одного процессора, выполнения упомянутым устройством по меньшей мере следующего:
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с этим первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством двух или более опорных ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также определение этим устройством информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также выполнение этим устройством следующего:
использования упомянутой информации диспарантности для нахождения опорных отсчетов в текстуре упомянутого второго ракурса и
получения предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления упомянутого устройства получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством значений отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством значений отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством опорного кадра VSP-предсказания в качестве упомянутого опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания на основе двух или более исходных ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также формирование этим устройством опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также выполнение этим устройством следующего:
формирования двух или более опорных кадров VSP-предсказания на основе двух или более исходных кадров или с использованием двух или более способов синтеза ракурсов и
выбора одного из упомянутых двух или более кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров VSP-предсказания, использованных для формирования опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также выполнение этим устройством по меньшей мере одного из следующего:
получения упомянутого указания от кодера с помощью кодированного битового потока и
определения уточнения для этого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством упомянутого указания для декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также предоставление этим устройством по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутое устройство включает упомянутую по меньшей мере одну память с хранимым в ней кодом, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает также использование этим устройством упомянутого способа в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления упомянутого устройства упомянутая видеоинформация представляет собой многоракурсную видеоинформацию.
В соответствии с седьмым примером предлагается компьютерный программный продукт, содержащий одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение устройством по меньшей мере следующего:
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством двух или более опорных ракурсов для получения упомянутого опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают определение этим устройством информации диспарантности для задания смещения пространственных координат между отсчетами текстуры текущего блока в упомянутом первом ракурсе и опорными отсчетами в упомянутом втором ракурсе.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение упомянутым устройством следующего:
использования упомянутой информации диспарантности для нахождения значений опорных отсчетов в текстуре упомянутого второго ракурса и
получения предсказанных значений отсчетов на основе этих найденных значений отсчетов.
В некоторых из вариантов осуществления упомянутого компьютерного программного продукта получение значений отсчетов упомянутой опорной области включает
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса и/или
фильтрацию значений отсчетов текстуры упомянутого опорного ракурса с использованием одного или более параметров взвешенного предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством значений отсчетов более одного опорного кадра при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством значений отсчетов более одного опорного ракурса при упомянутой фильтрации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование упомянутым устройством опорного кадра VSP-предсказания в качестве упомянутого опорного кадра.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания на основе двух или более исходных кадров.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания на основе двух или более исходных ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают формирование упомянутым устройством опорного кадра VSP-предсказания с использованием двух или более способов синтеза ракурсов.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение упомянутым устройством следующего:
формирования двух или более опорных кадров VSP-предсказания на основе двух или более исходных кадров или с использованием двух или более способов синтеза ракурсов и
выбора одного из упомянутых двух или более кадров VSP-предсказания для использования в качестве опорного кадра VSP-предсказания.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление упомянутым устройством по меньшей мере следующего:
указания на один или более опорных кадров;
указания на один или более способов предсказания на основе синтеза ракурсов, использованных для формирования опорного блока, и
указания на один или более исходных кадров VSP-предсказания, использованных для формирования опорного блока.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают выполнение упомянутым устройством по меньшей мере следующего:
получения упомянутого указания от кодера с помощью кодированного битового потока и
определения уточнения упомянутого указания на стороне декодера на основе ранее декодированной информации текстуры и/или информации о дальности с помощью заранее заданной процедуры принятия решений.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование устройством упомянутого указания для декодирования пикселя, блока, слайса или полной текстуры видеопоследовательности.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают предоставление устройством по меньшей мере первого списка опорных изображений, указывающего на изображения, использованные в качестве опорных изображений, из которых может быть выбран упомянутый опорный блок.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает одну или более последовательностей из одной или более инструкций, которые при их исполнении одним или более процессорами обеспечивают использование устройством упомянутого способа в устройстве мобильной связи для кодирования видеоинформации.
В некоторых из вариантов осуществления настоящего изобретения упомянутый компьютерный программный продукт включает видеоинформацию, которая представляет собой многоракурсную видеоинформацию.
В соответствии с восьмым примером предлагается устройство, содержащее:
средства для получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
средства для получения информации о дальности, связанной с этим первым кодированным блоком текстуры;
средства для определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
средства для получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
средства для выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
В соответствии с девятым примером предлагается видеодекодер, сконфигурированный для
получения первого несжатого блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с этим первым несжатым блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для кодирования упомянутого первого несжатого блока текстуры.
В соответствии с десятым примером предлагается видеодекодер, сконфигурированный для
получения первого кодированного блока текстуры из первого изображения текстуры, представляющего первый ракурс;
получения информации о дальности, связанной с упомянутым первым кодированным блоком текстуры;
определения информации диспарантности относительно опорного кадра во втором ракурсе на основе упомянутой информации о дальности;
получения опорных отсчетов упомянутого второго ракурса на основе упомянутой информации диспарантности и
выполнения предсказания на основе синтеза ракурсов с использованием упомянутых опорных отсчетов для получения опорного блока для декодирования упомянутого первого кодированного блока текстуры.
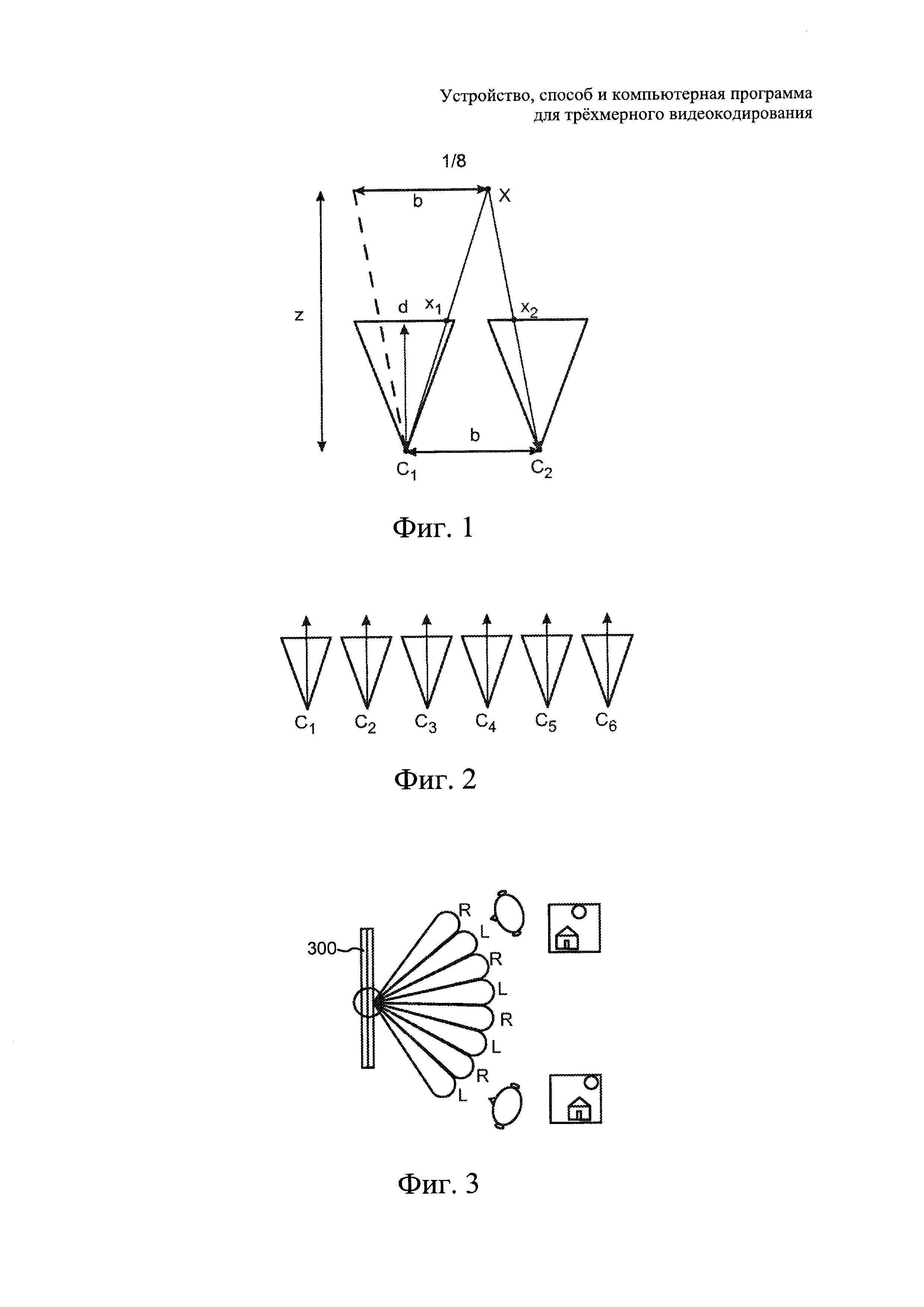
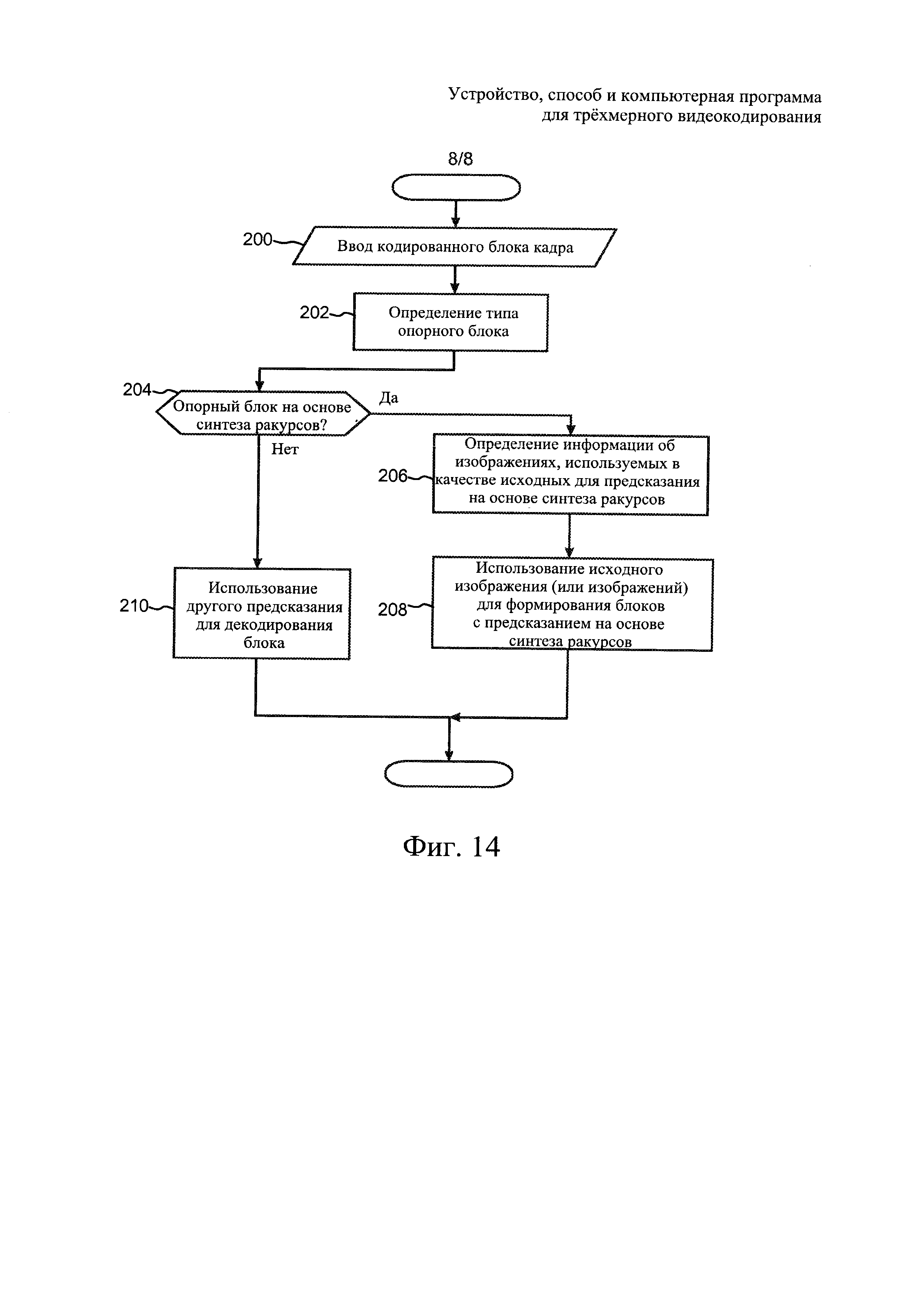
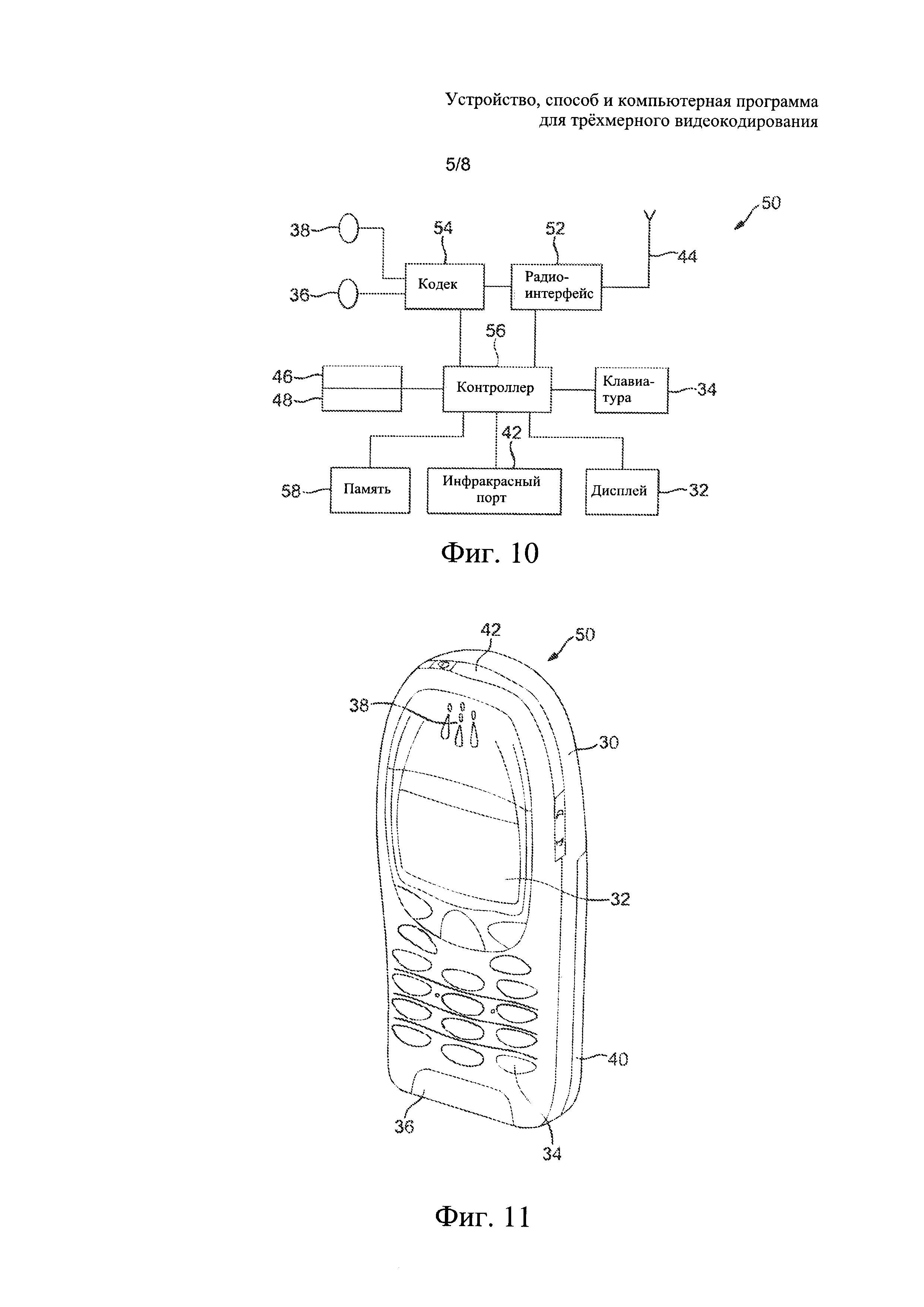
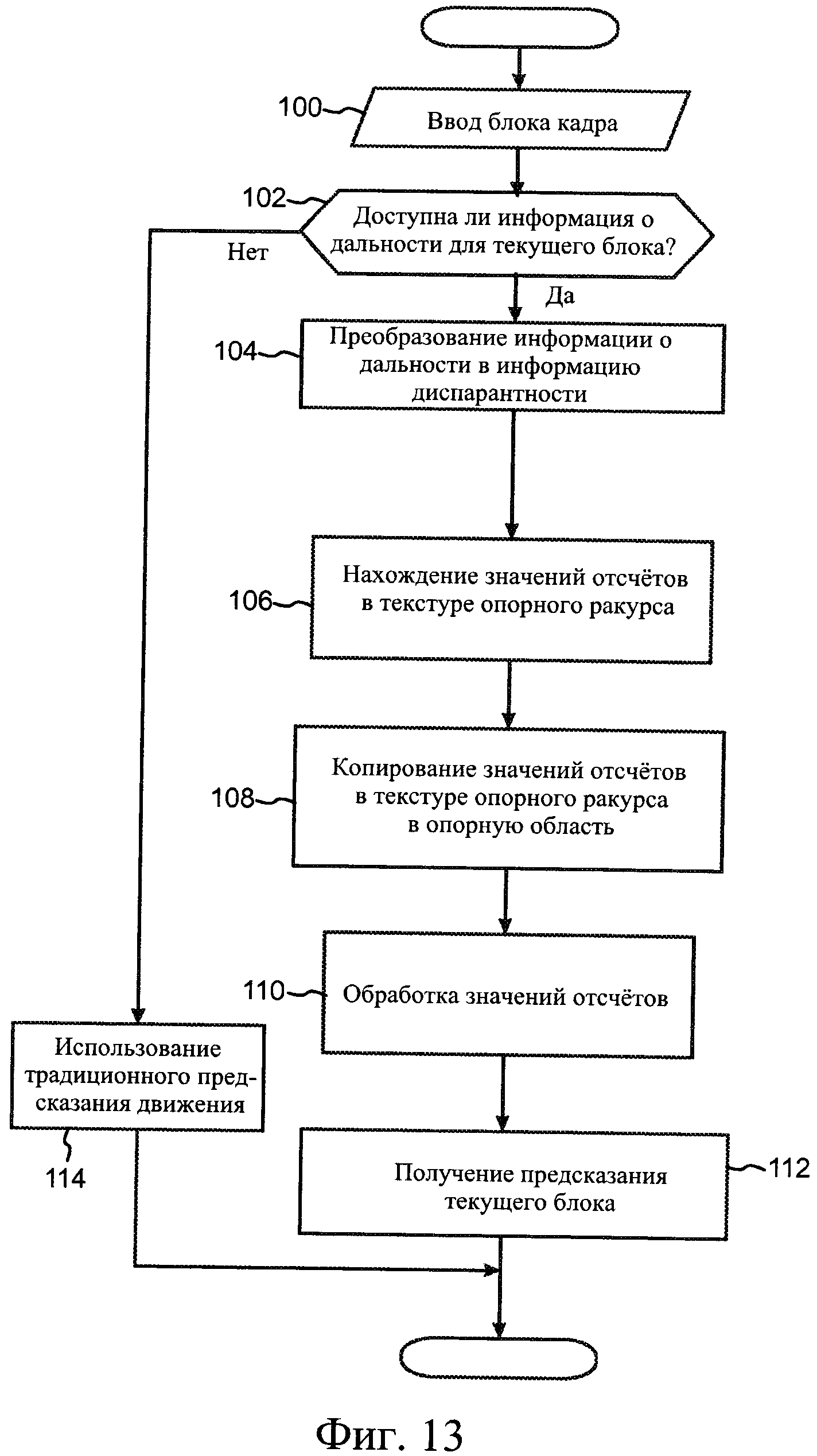
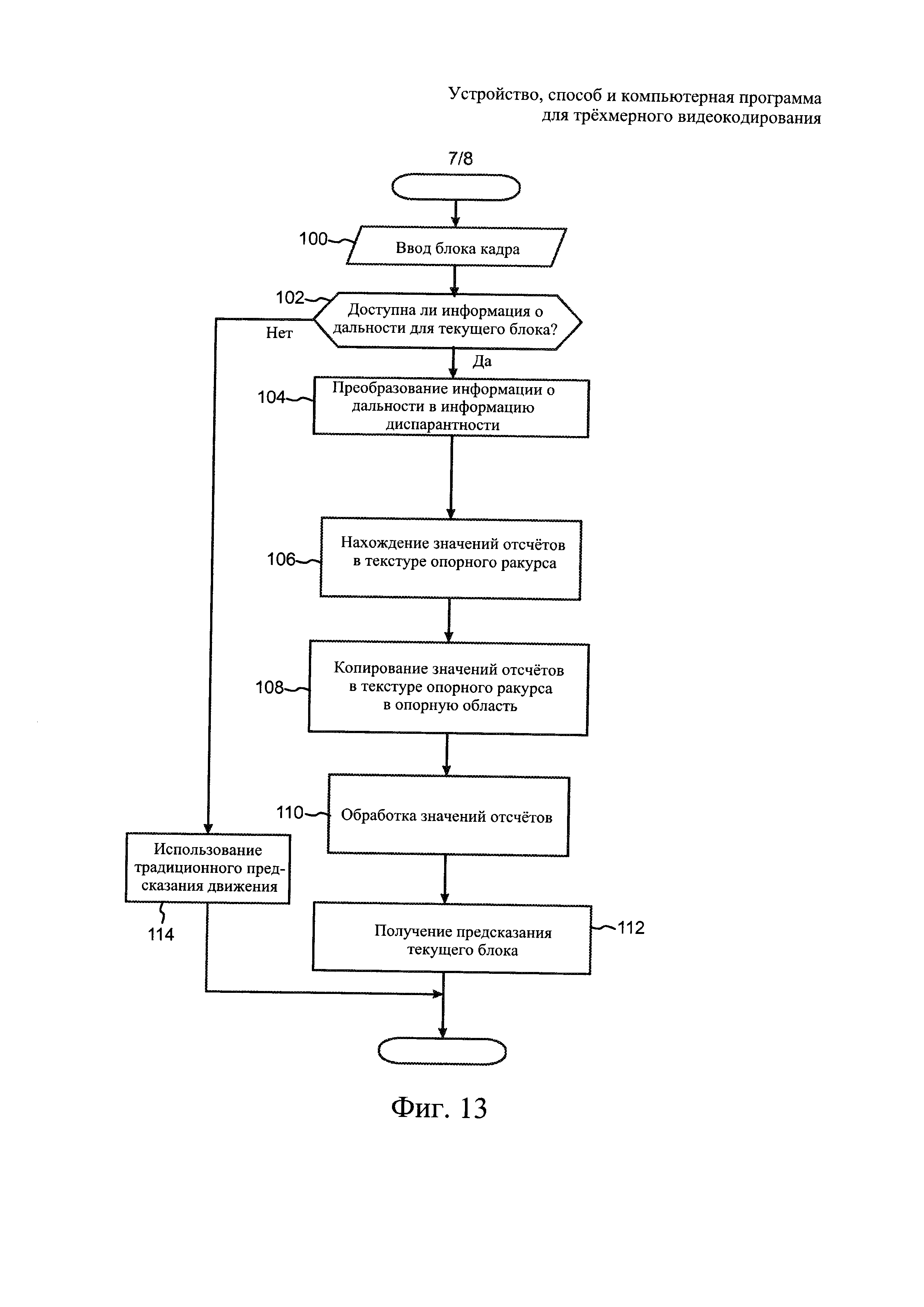
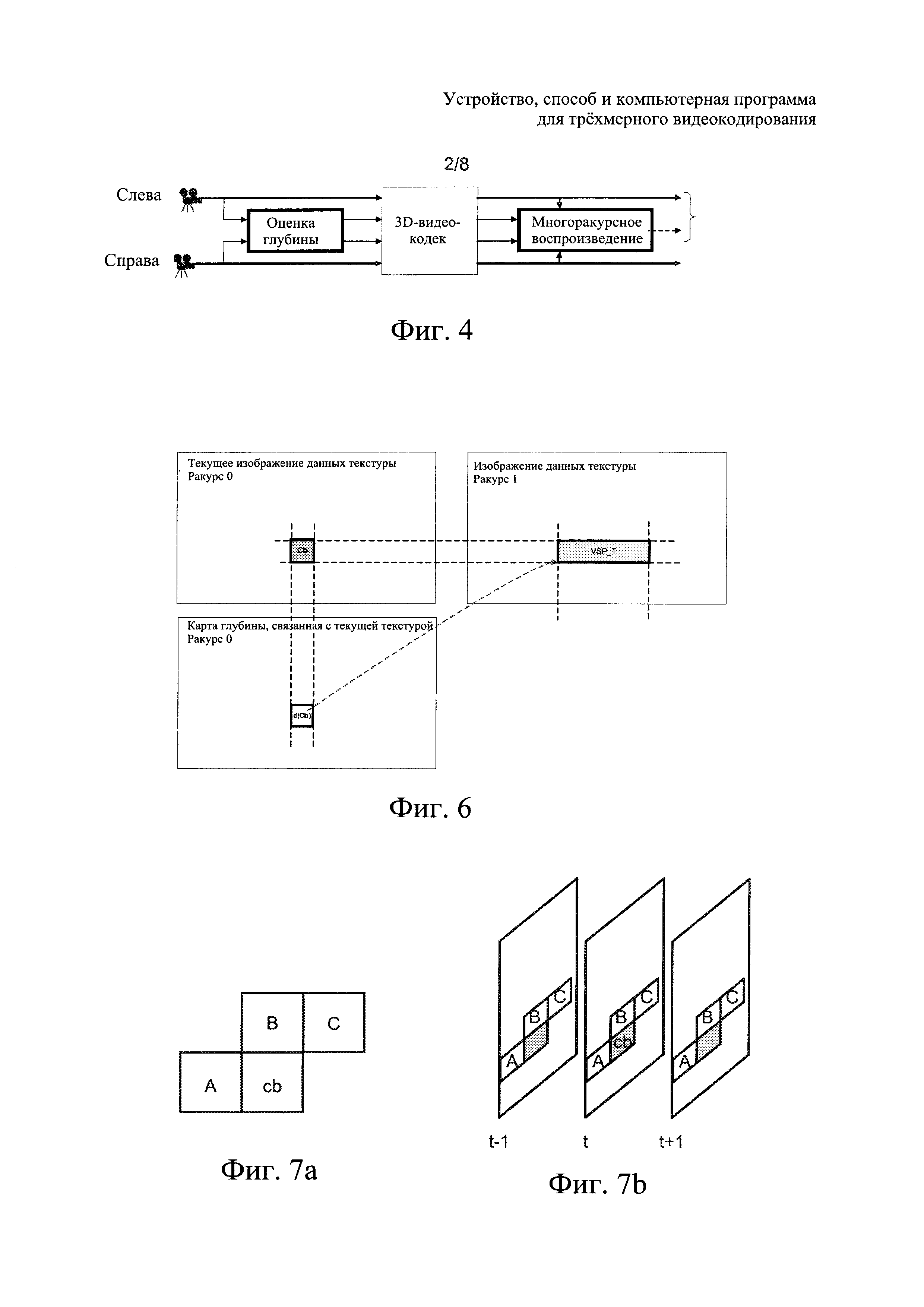
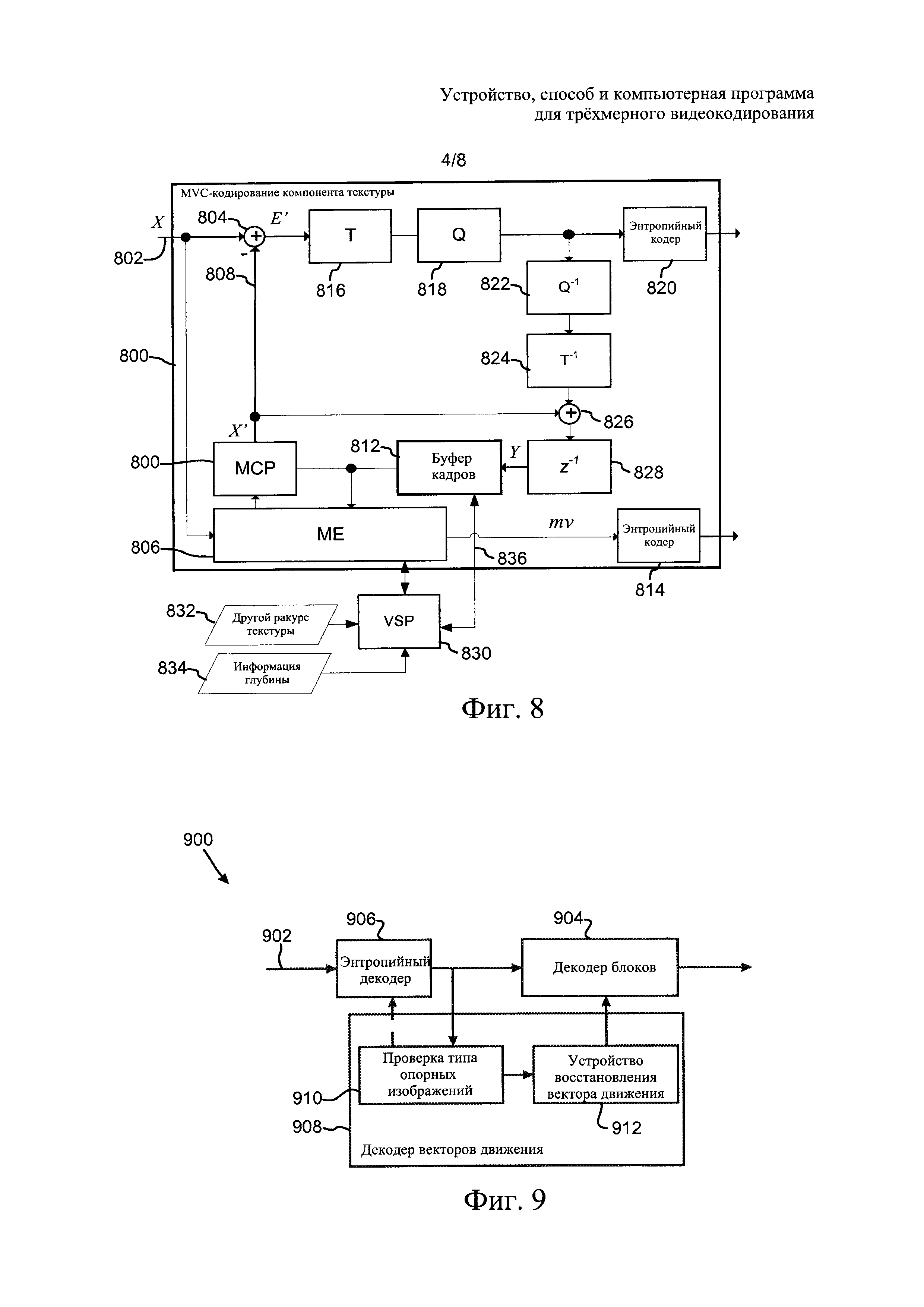
Формирование тактильного воспринимаемого воздействия
Система и способ для удаленной связи
Устройство и способ для обеспечения тактильной и звуковой обратной связи в сенсорном пользовательском интерфейсе
Способ и устройство для совместного использования параметров подключения посредством социальных сетей
Устройство, содержащее дисплей, способ и компьютерная программа
Способ и устройство для видеокодирования
Использование биосигналов для управления оповещением пользователя
Способ и устройство для кодирования видеосигналов
Гибкое электронное устройство
Способ, устройство и компьютерное программное изделие для отображения объектов на множестве этажей в многоуровневых картах
Формирование тактильного воспринимаемого воздействия
Система и способ для удаленной связи
Устройство и способ для обеспечения тактильной и звуковой обратной связи в сенсорном пользовательском интерфейсе
Способ и устройство для совместного использования параметров подключения посредством социальных сетей
Устройство, содержащее дисплей, способ и компьютерная программа
Способ и устройство для видеокодирования
Использование биосигналов для управления оповещением пользователя
Способ и устройство для кодирования видеосигналов
Гибкое электронное устройство
Способ, устройство и компьютерное программное изделие для отображения объектов на множестве этажей в многоуровневых картах

