Результат интеллектуальной деятельности: СПОСОБЫ И СИСТЕМЫ ЗАГРУЗКИ ДАННЫХ В ХРАНИЛИЩА ВРЕМЕННЫХ ДАННЫХ
Вид РИД
Изобретение
Уровень техники
Область настоящего изобретения относится в основном к хранилищу двоичных данных (CDW), и в частности к способам и системам сбора данных, управляемого метаданными, для хранилища временных нормализованных данных.
Существует необходимость быстро загружать и синхронизировать во времени последовательность входных данных разного объема по единой универсальной схеме без обращения к последовательным методам. Последовательные методы в общем не являются эффективным средством для инициализации и для использования событий с большим объемом входных данных. Кроме того, иногда существует необходимость снижения интенсивной предварительной обработки для обнаружения изменений данных и/или для обеспечения уникальных реальных временных периодов, чтобы дать возможность создания загрузочного набора строк-кандидатов для каждой целевой таблицы независимо от типа интерфейса. Наконец, из-за расходов, связанных с хранением данных, необходимо определить изменения данных всех типов и избежать загрузки новых строк данных без нового контента, выходящего за пределы новой авторизированной временной метки (реального времени). Такая практика может помочь уменьшить использование памяти сворачиванием следующих друг за другом одинаковых строк данных в течение некоторого временного периода.
В настоящее время сложные пользовательские программы загрузки данных, обычно выполняющихся на больших внешних серверах приложений, являются решением, которое было реализовано в попытке загрузки хранилищ временных данных. Такие программы обрабатывают и загружают данные последовательно по первичному ключу, что может привести к долговременному выполнению программ и к всестороннему, относительно интрузивному обновлению целевых таблиц. В некоторых случаях, чтобы постоянно поддерживать пользователей, два набора целевых таблиц используются и откачиваются, когда загрузка завершена. Однако, в таких системах, как правило, некоторые данные, уже находящиеся в базе данных, выгружаются, обрабатываются внешне на сервере приложений наряду с входными данными и повторно загружаются, чтобы довести до конца загрузку данных, что дополнительно нагружает сеть и базу данных. Другие известные существующие решения также имеют тенденцию к размещению только в прогнозируемых ситуациях, а не во всех возможных ситуациях, и к нарушению, отмене загрузки или к отклонению данных в непредвиденных случаях (например, реальная временная связь в пределах первичного ключа).
Другие предполагаемые решения в общем имеют другие недостатки. Например, разработка, которая имеет жесткую кодировку для ввода частных типов входных данных и точных целевых схем, нежелательна из-за затрат на разработку. Кроме того, расходы по обслуживанию могут быть проблемой при обращении к первичному ключу или при изменении атрибутов источника данных, цели данных или способа взаимодействия. Применение средств извлечения, преобразования и загрузки (ETL) для выполнения работ за пределами базы данных на сервере является возможным решением, но неэффективным, и может влиять на объем сетевого трафика. Потери эффективности в предполагаемых решениях становятся особенно большими при использовании внешнего или последовательного решения на массивно-параллельной архитектуре (МРР), широко применяемой хранилищами данных. Кроме того, собственные инструментальные средства базы данных требуют специальных знаний и не переносимы на другие платформы (например, Oracle PL/SQL). Эти решения являются неэффективными для больших объемов данных, которые могут сделать близкую к реальному времени неинтрузивную загрузку невозможной и требуют разное кодирование для инициализации или больших объемов данных для достижения приемлемой производительности.
Сущность изобретения
Одним из аспектов настоящего изобретения является система загрузки набора входных данных в хранилища временных данных. Система включает в себя запоминающее устройство и процессорный блок, связанный с этим запоминающим устройством. Запоминающее устройство содержит хранилище временных данных и набор входных данных. Процессорный блок запрограммирован на разбиение набора входных данных на множество разделов, включающих первый раздел и второй раздел. Каждый раздел этого множества включает в себя множество записей данных. Процессор также запрограммирован на импортирование первого раздела в таблицу предварительной загрузки, импортирование второго раздела в таблицу предварительной загрузки и загрузку таблицы предварительной загрузки в хранилище временных данных.
Другим аспектом настоящего изобретения является способ загрузки множества записей данных в хранилище временных данных. Способ включает в себя разбиение посредством компьютерного устройства записей данных на множество разделов, включающих первый раздел и второй раздел. Первый раздел и второй раздел импортируются компьютерным устройством в таблицу предварительной загрузки. Таблица предварительной загрузки загружается компьютерным устройством в хранилище временных данных.
Еще одним аспектом настоящего изобретения является компьютерный программный продукт. Компьютерный программный продукт включает неизменный во времени машиночитаемый носитель с внедренными в него машиноисполняемыми инструкциями для загрузки хранилища чистыми изменениями данных. Исполнение машиноисполняемых инструкций хотя бы одним процессором приводит к разбиению набора входных данных на множество разделов, включающих первый раздел и второй раздел. Каждый раздел из этого множества включает в себя множество записей данных. Исполнение машинных инструкций процессором также приводит к импортированию первого раздела в таблицу предварительной загрузки, импортированию второго раздела в таблицу предварительной загрузки и загрузке таблицы предварительной загрузки в хранилище данных.
Краткое описание чертежей
Фиг.1 представляет упрощенную блок-схему компьютерной системы.
Фиг.2 представляет блок-схему компьютерной сети.
Фиг.3 представляет схему последовательности операций процесса захвата изменений данных, представленного в качестве примера.
Фиг.4 представляет схему последовательности операций процесса загрузки разделов, представленного в качестве примера.
Фиг.5 представляет схему последовательности операций процесса загрузки данных, представленных в качестве примера.
Фиг.6 представляет схему потока данных, связанную с шагом 100, показанных на фиг.4.
Фиг.7 представляет схему потока данных, связанную с шагом 101, показанных на фиг.4.
Фиг.8 представляет схему потока данных, связанную с шагом 102, показанных на фиг.4.
Фиг.9 представляет схему потока данных, связанную с шагом 103, показанных на фиг.4.
Фиг.10 представляет схему потока данных, связанную с шагом 104, показанных на фиг.4.
Фиг.11 представляет схему потока данных, связанную с шагом 105, показанных на фиг.4.
Фиг.12 представляет схему потока данных, связанную с шагом 106, показанных на фиг.4.
Фиг.13 представляет схему потока данных, связанную с шагом 107, показанных на фиг.4.
Фиг.14 представляет схему потока данных, связанную с шагом 108, показанных на фиг.4.
Фиг.15 представляет схему потока данных, связанную с шагом 109, показанных на фиг.4.
Фиг.16 представляет схему потока данных, связанную с шагом 110, показанных на фиг.4.
Фиг.17 представляет схему потока данных, связанную с шагом 111, показанных на фиг.4.
Фиг.18 представляет схему потока данных, связанную с шагом 112, показанных на фиг.4.
Фиг.19 представляет схему потока данных, связанную с загрузочным шагом 202, показанного на фиг.5.
Фиг.20 представляет схему потока данных, связанную с загрузочным шагом 203, показанного на фиг.5.
Фиг.21 представляет схему потока данных, связанную с загрузочным шагом 204, показанного на фиг.5.
Фиг.22 представляет схему потока данных, связанную с загрузочным шагом 205, показанного на фиг.5.
Фиг.23 представляет схему потока данных, связанную с загрузочным шагом 206, показанного на фиг.5.
Фиг.24 представляет блок-схему вычислительного устройства, представленного в качестве примера.
Подробное описание
Варианты осуществления описаны в данном документе с применением процесса захвата изменений данных (CDC). В настоящем документе термин «CDC» означает процесс захвата и загрузки изменения в хранилище временных данных. Информация на входе в процесс CDC, набор входных данных, уже может быть преобразован, чтобы соответствовать модели данных целевого хранилища (например, нормализованный, бизнес или естественный ключ), но без временной обработки, такой как упорядоченность во времени, временная нормализация и/или временное разрешение конфликтных ситуаций. Набор входных данных уже может быть загружен в систему базы данных, так что он непосредственно доступен для обработки CDC.
Настоящее изобретение может быть описано в общем контексте машинного кода или машиноиспользуемых инструкций, в том числе и машиноисполняемых инструкций, как например программные модули, исполняемых компьютером или другой машиной, такой как карманный компьютер или другой переносной прибор. Как правило, программные модули, в том числе процедуры, программы, объекты, компоненты, структуры данных и тому подобные, относятся к коду, который выполняет конкретные задачи или реализует конкретные типы абстрактных данных. Настоящее изобретение может осуществляться на практике в различных системных конфигурациях, включая портативные устройства, бытовую электронику, компьютеры общего назначения, более специализированные вычислительные устройства и т.п. Настоящее изобретение может осуществляться на практике также и в распределенных вычислительных средах, где задачи выполняются с помощью устройств дистанционной обработки, которые связаны через коммуникационные сети.
Описанные системы пригодны для анализа набора входных данных, который может называться входным набором данных по отношению к указанным системам и к существующему хранилищу данных, идентификации и упорядочения чистых изменений данных относительно данных, уже хранящихся в хранилище данных, с применением набора операторов реляционной алгебры и применения обновления хранилища данных. Набор входных данных включает в себя множество записей данных, которые могут представлять собой снимок исходной базы данных (например, все записи данных в исходной базе данных в некоторый момент времени) и/или множество сообщений или транзакций (например, операции вставки, обновления и/или удаления), которые были выполнены по отношению к исходной базе данных.
Чтобы осуществить такой способ, код программного обеспечения, такой как язык структурированных запросов (SQL), соответствующий хранилищу данных, может быть сгенерирован, когда программное обеспечение, описанное в настоящем документе, создается (например, компилируется), когда программное обеспечение вводится в действие, и/или когда метаданные (например, структуры базы данных) пересматриваются. Сгенерированный код затем может быть исполнен системой каждый раз, когда данные загружаются в хранилище данных. В некоторых вариантах осуществления генерируемый код создается одним или несколькими хранимыми процедурами (например, функциональным кодом, сохраненным в базе данных и исполняемым ею), которые сохраняют генерируемый код в базе данных. Во время загрузки данных сгенерированные операторы извлекаются и исполняются над входными данными.
Рабочие характеристики, такие как время выполнения и/или использование вычислительных ресурсов, процесса загрузки входных данных в хранилище данных могут быть улучшены при использовании одного или нескольких оптимизационных опций. Использование вычислительных ресурсов может включать, без ограничения, использование процессора, использование памяти и/или использование сетевых ресурсов. Оптимизационные опции включают в себя, например, разбиение входных данных на разделы и раздельную обработку каждого раздела, импорт входных данных в энергозависимые таблицы перед загрузкой данных в целевые таблицы, фильтрация истории из целевой таблицы сравнений, когда они не требуются для входных данных, и способ нормализации по времени данных.
Варианты осуществления, описанные в настоящем документе, относятся к проекту загрузки хранилища временных данных, управляемой базовыми метаданными, который включает в себя генераторы SQL-кода, выдающие код загрузки данных. При выполнении загрузки код загрузки данных может эффективно обрабатывать и загружать в хранилище нормализованных временных данных любой объем (начальной загрузки, миграции, посуточной, почасовой) и любой тип данных исходной системы (проталкиваемые или выталкиваемые, новые или старые), идентифицируя и упорядочивая во времени данные чистых изменений по временной схеме, основанной на наличии реальной начальной временной метки в первичном ключе каждой таблицы и на заполнении соответствующей конечной реальной временной метки или эквивалентного временного периода, используя только набор операторов SQL для создания эквивалента реального временного периода. Такие процессы иногда в совокупности именуются как захват изменений данных (CDC).
Раскрываемый в данном изобретении план загрузки хранилища временных данных работает путем анализа набора входных данных, как в отношении их самих, так и в отношении имеющихся в хранилище данных, чтобы определить чистое изменение. Соответствующий реальный временной порядок следования (временное планирование), следовательно, назначается и эффективно применяется к новым последовательным во времени строкам и обновляет конечные временные метки, определяющие временной период в целевом хранилище данных, используя только ANSI SQL. Этот процесс предварительно генерирует SQL-операторы (например, вставки и временные обновления) и при загрузке данных получает и исполняет SQL-операторы исключительно в пределах базы данных хранилища.
Иллюстративные технические действия в вариантах осуществления, описанных в данном документе, могут включать, без ограничения:
(a) разбиение набора входных данных на множество разделов, в том числе первый раздел и второй раздел, в котором каждый раздел этого множества включает в себя множество записей данных;
(b) разбиение набора входных данных, основанных на хеш-функции и заданного количества разделов;
(c) импортирование первого раздела и второго раздела в таблицу предварительной загрузки, либо последовательно во времени, либо параллельно (например, одновременно);
(d) загрузка таблицы предварительной загрузки в хранилище временных данных;
(e) импортирование разделов в соответствующие энергозависимые таблицы;
(f) копирование разделов из энергозависимой таблицы в таблицу предварительной загрузки;
(g) идентификацию записей данных в первом разделе, который включает множество полей, отличных от поля временной метки, таких же, как и неключевые поля, предыдущей импортированной записи данных;
(h) исключение идентифицированных записей при импорте первого раздела в таблицу предварительной загрузки;
(i) исключение неявного удаления активной записи данных, основанное на том, что активная запись данных в хранилище временных данных не связана с записью данных в набор входных данных;
(j) определение самой ранней исходной временной метки, соответствующей первой записи данных из набора входных данных;
(k) идентификацию набора первичных ключей, представляющих запись данных в хранилище временных данных, соответствующую исходной временной метке, непосредственно предшествующей самой ранней исходной временной метке, и одну или несколько записей данных в хранилище временных данных, которые соответствуют исходной временной метке более поздней, чем самая ранняя исходная временная метка; и
(I) импорт первого раздела и второго раздела на основе идентифицированного набора первичных ключей.
Варианты осуществления могут быть далее описаны со ссылкой на конкретные приложения, такие как хранилище данных, которое хранит информацию о спецификациях материалов (ВОМ) и/или сведения о деталях (например, механических деталях оборудования). Предполагается, что такие варианты осуществления, применимы к любому хранилищу временных данных.
На фиг.1 приведена упрощенная блок-схема иллюстративной системы 10, включающей серверную систему 12 и множество клиентских подсистем, также называемых клиентскими системами 14, подключенных к серверной системе 12. Автоматизированное моделирование и группировка инструментов, как описано ниже более подробно, хранятся в серверной системе 12, и могут быть доступны посредством запроса любой из клиентских систем 14 (например, компьютеров). Как показано на фиг.1, клиентскими системами являются компьютеры 14, включающие веб-браузер, так чтобы серверная система 12 была доступной для клиентских систем 14, использующих Интернет. Клиентские системы 14 связаны с Интернетом через множество интерфейсов, включающих сеть, такую как локальную вычислительную сеть (LAN) или глобальную сеть (WAN), подключение к сети по коммутируемой телефонной линии, кабельные модемы и специальные высокоскоростные ISDN линии. Клиентскими системами 14 могут быть любые устройства, способные обмениваться информацией с Интернетом, в том числе Интернет-телефон, электронная записная книжка (PDA) и другое веб-подключаемое оборудование. Сервер базы данных 16 подключается к базе данных 20, содержащей информацию о самых разнообразных вопросах, как описано ниже более подробно. В одном варианте осуществления, централизованная база данных 20 хранится на системном сервере 12 и может быть доступна потенциальным пользователям одной из клиентских систем 14 посредством регистрации на системном сервере 12 через одну из клиентских систем 14. В альтернативном варианте осуществления база данных 20 хранится удаленно от системного сервера 12 и может быть нецентрализованной.
На фиг.2 приведена развернутая блок-схема иллюстративного варианта осуществления системы 22. Система 22 является всего лишь одним примером подходящей вычислительной среды и не предназначена для какого-либо ограничения объема настоящего изобретения. Также систему 22 не следует интерпретировать как относящуюся к какой-либо одной компоненте или комбинации компонент, проиллюстрированных в настоящем документе. Компоненты в системе 22, идентичные компонентам системы 10 (показанной на фиг.1), указаны на фиг.2 с использованием тех же самых ссылочных номеров, что и на фиг.1. Система 22 включает в себя системный сервер 12 и клиентские системы 14. Системный сервер 12 включает еще сервер базы данных 16, сервер 24 приложений, веб-сервер 26, факс-сервер 28, сервер 30 каталогов и почтовый сервер 32. Блок 34 дисковых накопителей (который включает в себя базу данных 20) связан с сервером базы данных 16 и сервером 30 каталогов. Серверы 16, 24, 26, 28, 30 и 32 соединены в локальную вычислительную сеть (LAN) 36. Кроме того, рабочая станция 38 системного администратора, рабочая станция 40 пользователя и рабочая станция 42 руководителя подсоединены к локальной вычислительной сети 36. В альтернативном исполнении рабочие станции 38, 40 и 42 подключены к локальной сети 36 посредством Интернет-канала или соединены через Интернет. В некоторых вариантах исполнения сервер базы данных 16 связан с дисковым накопителем 34, который недоступен для других устройств, таких как сервер каталогов 30.
Каждая рабочая станция 38, 40 и 42 является персональным компьютером, имеющим веб-браузер. Хотя функции, выполняемые на рабочих станциях, обычно представляются как совершаемые на респектабельных рабочих станциях 38, 40 и 42, такие функции могут быть выполнены одним из многочисленных персональных компьютеров, связанных с локальной сетью 36. Рабочие станции 38, 40 и 42 проиллюстрированы как соотнесенные с отдельной функцией только для облегчения понимания различных типов функций, которые могут выполнять лица, имеющие доступ к LAN 36.
Серверная система 12 сконфигурирована так, чтобы быть коммуникативно связанной с различными лицами, включая сотрудников 44 и третьих лиц, например клиентами/контрактниками 46, использующими Интернет-подключение 48 через поставщика услуг Интернета (ISP). Связь в иллюстративном варианте осуществления показана как осуществляемая посредством Интернета, однако любой другой тип глобальных вычислительных сетей (WAN) может быть использован в других вариантах осуществления, т.е. системы и процессы, не ограничиваются практикой использования Интернета. Кроме того и даже скорее всего, вместо WAN 50 может быть использована локальная вычислительная сеть 36.
В иллюстративном варианте осуществления любое уполномоченное лицо, имеющее рабочую станцию 54, может получить доступ к системе 22. По меньшей мере одна из клиентских систем включает удаленную рабочую станцию 56 администратора. Рабочие станции 54 и 56 являются персональными компьютерами, имеющими веб-браузер. Кроме того, рабочие станции 54 и 56 сконфигурированы для осуществления связи с системным сервером 12. Кроме того, факс-сервер 28 осуществляет связь с удаленными клиентскими системами, включая рабочую станцию 56, посредством телефонной связи. Факс-сервер 28 сконфигурирован для осуществления связи с другими клиентскими системами и/или с рабочими станциями 38, 40 и 42.
Используя системы, изображенные на фиг.1 и фиг.2, высокоэффективные и относительно неинтрузивные работающие почти в реальном масштабе времени загрузки активируются заданными мини-пакетными прогонами без прерывания запросов пользователя. Процесс основан на стандартных операторах ANSI SQL, поэтому он применим к любой платформе базы данных, по-новому использующей мощность системы управления базы данных (СУБД), обеспечивающей сверхлинейную масштабируемость особенно на архитектурах с массивно параллельной обработкой (МРР), и не требует никакой обработки данных на внешних серверах (например, SQL-операторы могут быть вызваны из любого места). В одном из вариантов загрузка хранилища данных во время выполнения управляется полностью метаданными посредством использования заданий первичного ключа и табличных имен в качестве параметров. Еще одно преимущество заключается в том, что изменения схемы не требует повторной компиляции или перезагрузки системы захвата изменений данных и оперативные метаданные могут быть изменены в любое время (например, явное или неявное удаление формы, количество разделов и/или уровень параллелизма). В противном случае любой тип интерфейса и все таблицы в модели данных (реальное время включается в каждый первичный ключ) могут быть предоставлены посредством одной программы. Только строки-кандидаты требуются в качестве входных данных (колонки+реальная временная метка), при этом никакой идентификации того, что изменилось, если таковое произошло, не нужно иметь в качестве входных данных системы захвата изменений данных. Для интерфейсов снапшот ни в какой идентификации удаления нет необходимости. Связи реальных времен могут быть разорваны в пределах первичного ключа с очень короткими временами следования в наборах данных и многократными вызовами. Обновления, датированные задним числом и/или связанные с историей, выполняются путем обновления временной последовательности как входных, так и существующих данных.
Вышеуказанные усовершенствования реализованы посредством существующих решений, так как существующие решения часто настроены на тип интерфейса и обычно полностью жестко кодированы для каждого столбца в каждой таблице. Кроме того, существующие подходы к заданию временной последовательности являются построчными, а не массовыми, задаваемыми посредством набора операторов SQL (например, посредством реляционной алгебры набора операторов). Поэтому эти решения не являются сверхлинейными, как в системе захвата изменений данных. Например, варианты осуществления, описанные в данном изобретении, могут обрабатывать 1000 строк за менее чем десять промежутков времени, т.е. времени, необходимого для обработки 100 строк. В обычных вариантах никакие данные не удаляются из базы данных во время обработки и форма вызова системы захвата изменений данных может быть внешней (например, Perl) или внутренней процедурой базы данных.
Описанные варианты осуществления способствуют сокращению и потенциально исключению затраты на разработку, связанную с выявлением изменений (например, вставка, обновление, исключение, повторное подтверждение и/или обновление истории) и способствуют внесению изменений в хранилище временных данных, которые сохраняют историю посредством временного периода, задаваемого реальными временными метками типа начало-конец. Описывается эффективный и очень масштабируемый план, по-новому использующий механизм СУБД и архитектуру с набором операторов SQL, в отличие от существующих решений, которые используют неэффективные курсоры (строки за раз), серверы загрузки внешних данных и генерируют соответствующий сетевой трафик. Минимально интрузивный проект предоставляет непрерывные запросы во время загрузки посредством очень быстрого набора SQL операторов на загрузку транзакции, максимизированную для эффективного (одну и ту же структуру завершающей стадии и цели, чтобы минимизировать нагрузку и повысить пропускную способность СУБД) применения различных методологий запросов, включающих, но не ограничивающих, методы блокировки конечного пользователя и использования истории посредством SQL-модификаторов.
Как далее описано в настоящем документе, варианты осуществления могут быть реализованы по меньшей мере частично в виде последовательности SQL-генераторов, которые создают и сохраняют SQL-операторы для загрузки данных посредством запроса каталога базы данных (например, имени столбца и информации о типе базовых данных) и таблицы метаданных первичного ключа. Предварительно сгенерированный SQL-оператор может быть исполнен во время прогона входных данных. Ниже описана последовательность шагов анализа, подготовки и затем загрузки строк-кандидатов в целевую базу данных в виде единой эффективной транзакции. Эти шаги могут быть реализованы на любом языке программирования, скрипта или процедуры с доступом к исполнению SQL-генератора базы данных, выборке полученного SQL-оператора, а затем исполнению этого выбранного оператора базы данных.
Ниже приведены определения некоторых терминов и сокращений, используемых в настоящем документе. Оперативная (онлайновая) обработка транзакций (OLTP) базы данных - это основанная на транзакции база данных, которая обычно включает нормализованные структуры базы данных. Например, запись данных (например, строка в таблице) в OLTP может включать ссылку на другую запись данных (например, строка еще в одной таблице), а не копию данных в указанной записи данных. Далее, база данных OLTP может воздействовать на целостность ссылочных данных для обеспечения того, чтобы такие ссылки были реальными (например, обращение к существующей записи данных и/или к записи данных определенного типа).
Первичный ключ (РК) - это полный первичный ключ, как это определено в способе моделирования данных для целевой таблицы (например, основная таблица, вспомогательная таблица или производный слой). Используемый в настоящем документе термин «вспомогательная» таблица - это нормированная временная целевая таблица, представленная в настоящем документе в качестве слоя целевой базы данных. РК включает в себя колонку исходной системной начальной временной метки, именуемой SOURCE_START_TS (доступной в базе данных под именем CDW_PK_COLS_V), при этом колонка поддерживает сохранение истории. Исходная временная метка представляет собой начало реального периода строки в системе авторизации, которая его создала и во многих системах может называться как временная метка создания или последней модификации. Реальный временной период в хранилище временных данных может быть выражен в виде пары временных меток (например, временная метка начала и окончания), представляющей собой период времени, в данном случае включая SOURCE_START_TS и не включая SOURCE_END_TS.
PK_Latest - это первичный ключ, исключая SOURCE_START_TS, который обычно является коммерческим ключом онлайновой системы обработки транзакций (предоставляемый в базе данных в виде CDW_PK_COLS_LATEST_V).
W-таблица - это целевой объект преобразования набора входных данных. В иллюстративных вариантах осуществления W-таблица включает копию вспомогательной таблицы с 2 парами стандартных временных меток начало-конец, отображающих оба опущенных временных периода, но с наличием временной метки исходной системы с именем SRC_START_TS. В случае, когда опция ALL_VT (более детально описанная ниже) имеет значение Y, может быть использована энергозависимая копия W-таблицы.
Х-таблица - это таблица предварительной загрузки, источник всех строк, которые загружаются в целевую таблицу. Х-таблица может быть копией целевой таблицы с добавлением столбца для сохранения назначенного действия (индикатор ETL) и двух исходных временных меток, обозначенных как src вместо source.
Целевой объект - это однослойное хранилище двоичных данных, соответствующее единой базе данных с однозначно именованными таблицами, которые представляют область применения хранилища данных. Вспомогательная таблица является примером целевой таблицы. Другие потенциальные слои таблицы базы данных являются основными (например, полностью интегрированные в третью нормальную форму, или 3NF) и производными (например, предварительно-присоединенными, агрегированными). Все процессы могут загружать эти три слоя, если не указано иное, полученными исходными данными возможно из вспомогательной или основной таблицы, но все еще представленные как входные данные W-таблицы до активации процесса. В случае, когда опция ALL_VT (более детально описанная ниже) имеет значение Y, может быть использована энергозависимая копия целевого объекта.
ALL_VT опция указывает, должна ли система использовать энергозависимые рабочие таблицы. Когда опция ALL_VT отключена (например, установлена в значение N), система использует две сгенерированные рабочие таблицы (например, в W_table и X_table) в промежуточной области базы данных, которые основаны на их целевых прототипах. Третья энергозависимая или нестабильная таблица может быть использована вплоть до выполнения процедуры загрузки W-таблицы, описанной в этом документе. Для каждой целевой таблицы могут быть созданы до трех скрипт-генерируемых вариантов этих таблиц, встроенных в промежуточные области базы данных, в дополнение к любым другим таблицам, используемым внешне для преобразования наборов входных данных, чтобы воспользоваться процессом CDC. Энергозависимые табличные копии этих вариантов создаются, когда ALL_VT опция включена (например, установлена в значение Y). Эти три таблицы являются дополнительными таблицами, которые могут и не быть непосредственно смоделированы средствами моделирования базы данных. Скорее, они могут быть встроены с помощью скрипта во время построения и включены в целевые скрипты построения, за исключением энергозависимых таблиц, которые сформированы во время прогона.
В иллюстративных вариантах осуществления, скрипт создает и именует каждую таблицу, как показано в Таблице 1.
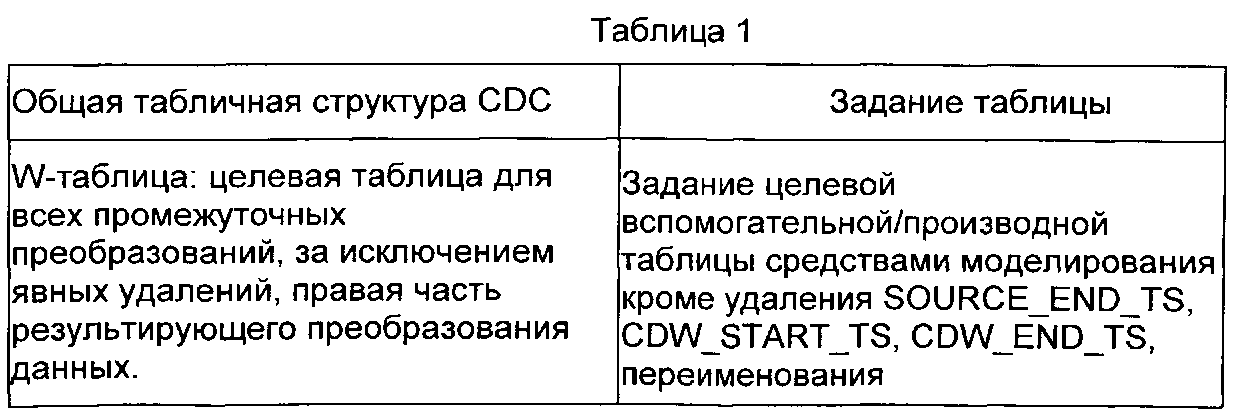
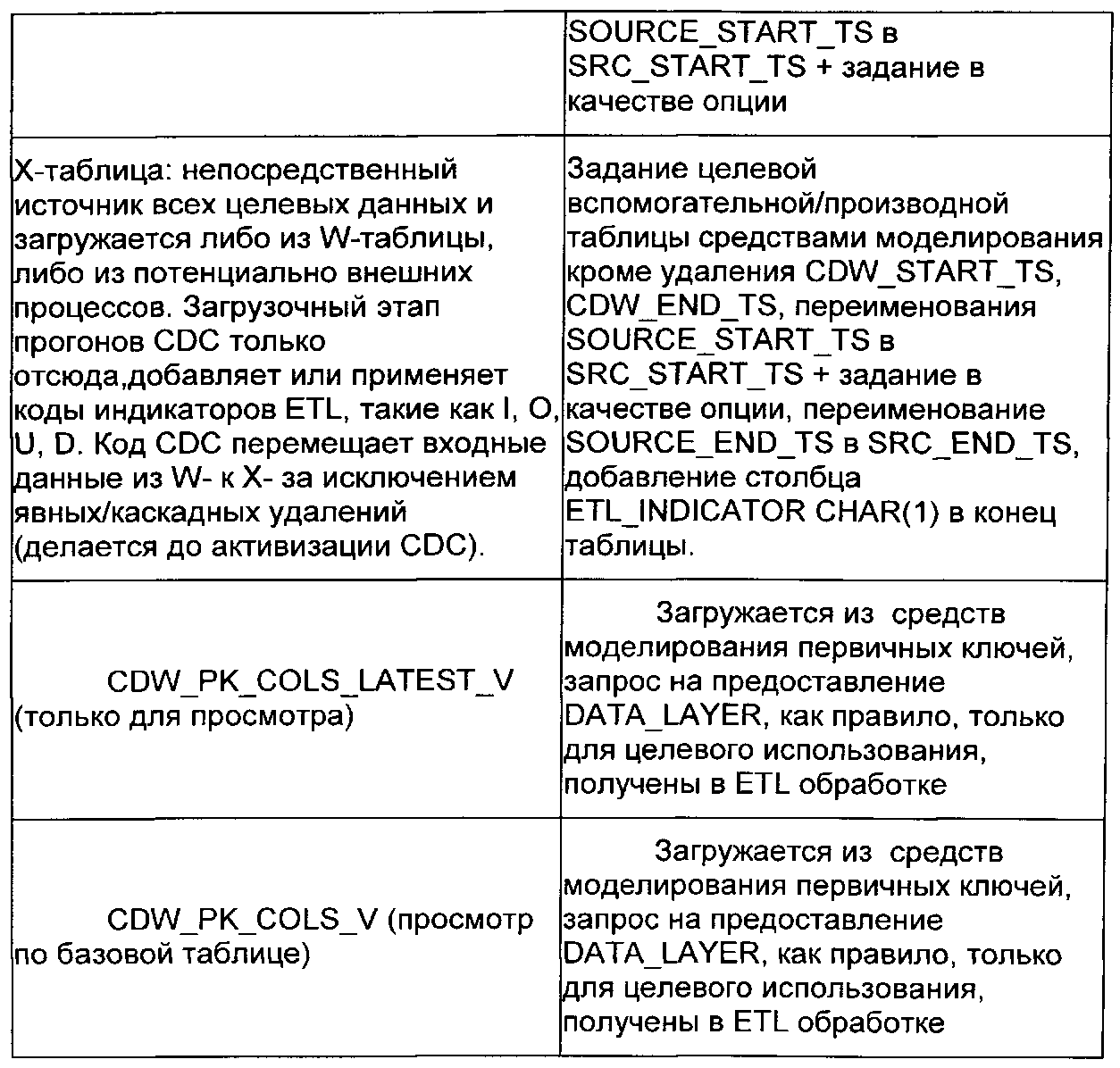
W-таблица является целевой таблицей для всех промежуточных преобразований до вызова системы CDC, за исключением явных удалений. Х-таблица является непосредственным источником всех целевых данных и загружается либо из W-таблицы, либо посредством потенциально внешних процессов в случае явно выраженных или каскадных удалений. Загрузочная стадия CDC системы добавляет или использует коды индикатора ETL в Х-таблице, такие как I, О, U и D, которые заданы в другом месте настоящего документа. Коды, связанные с системой CDC, инициализируются или устанавливаются при перемещении данных из W-таблицы к Х-таблице и далее обновляются в Х-таблице вплоть до контроля окончательного внесения изменения в целевую базу данных.
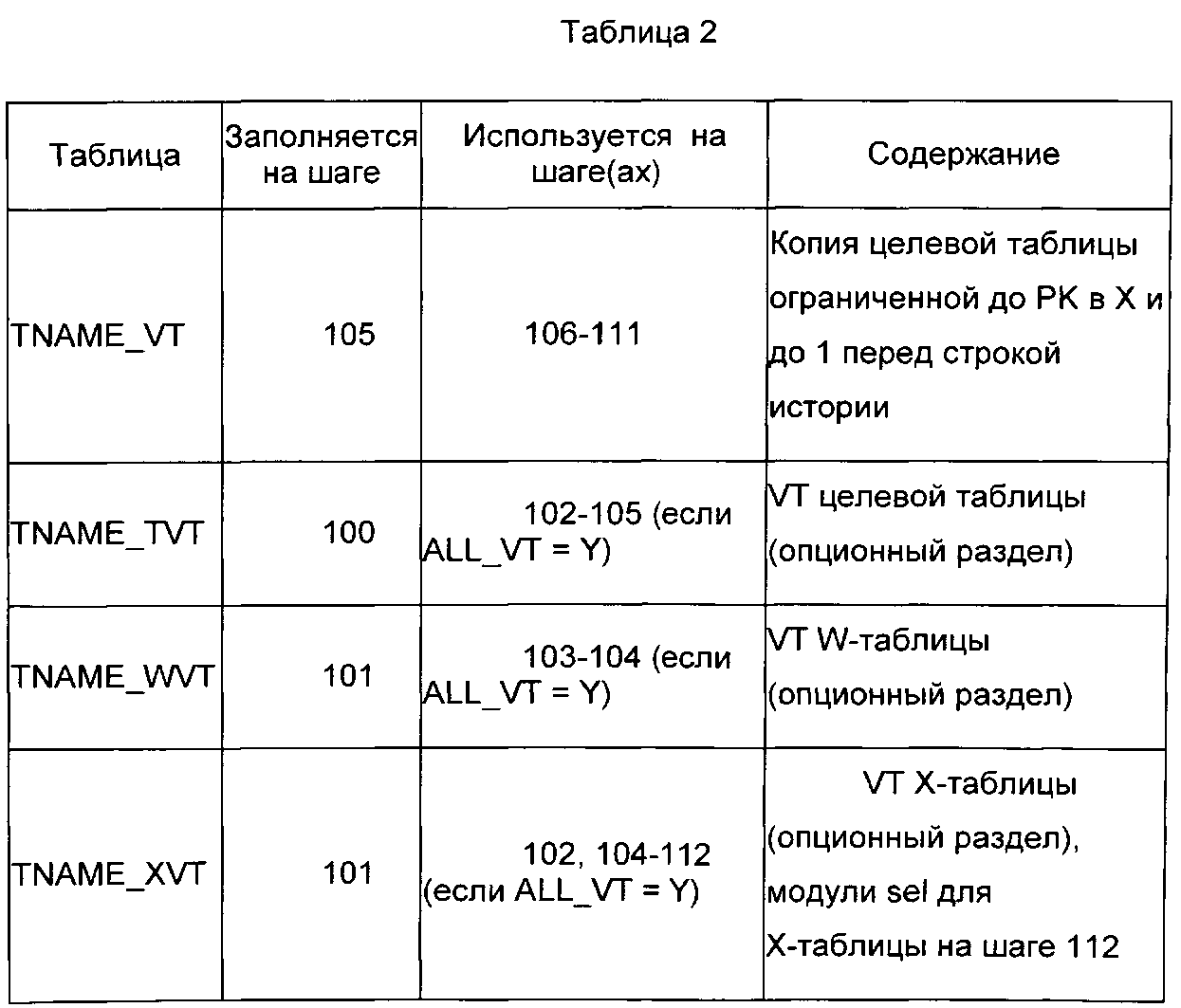
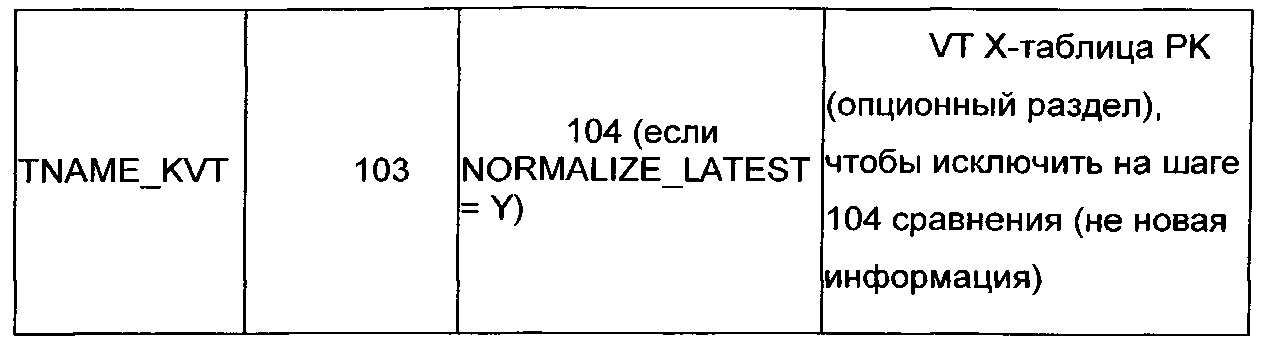
В иллюстративных вариантах осуществления, когда опция ALL_VT включена, скрипт создает и обращается к таблицам, как показано в Таблице 2, где TNAME соответствует действующему имени целевой таблицы.
Операции извлечения, преобразования и загрузки (ETL) могут быть переданы с использованием ETL-индикаторов, приведенных в Таблице 3.

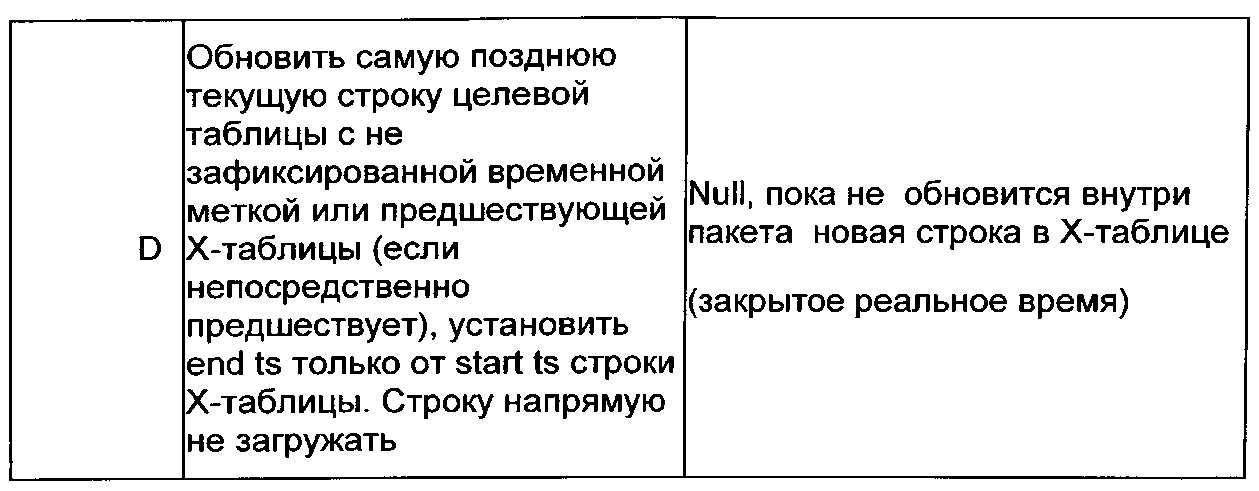
Как показано выше, индикаторы извлечения, преобразования и загрузки (ETL) представляют собой I, U, О, D, и каждый из них связан с действиями над одной или несколькими целевыми вспомогательными таблицами, такими как загрузка новой целевой строки или установка конечной временной метки на существующей строке. Для ETL-индикатора ′I′ вспомогательным действием является вставка новой строки, при этом конечная временная метка новой целевой строки равна NULL (самая поздняя строка, не имеет окончания периода фиксации), пока эта строка не заменена или логически не удалена. Для ETL-индикатора U вспомогательными действиями являются вставка новой строки, изменение конечной временной метки (если она еще не просрочена) самой поздней вспомогательной строки на начальную временную метку самой ранней U строки, которая находится в пределах первичного ключа (РК) в Х-таблице. Любая конечная временная метка поступает из записей другой Х-таблицы. Конечная временная метка новой целевой строки для индикатора U является NULL, если самая поздняя строка находится в пределах РК в X-таблице, или начальной временной меткой следующей строки Х-таблицы. Пока разрыв временного периода заранее явно не задан посредством логического удаления или иным образом, конечная временная метка или конец временного периода в строке обеспечивается начальной временной меткой последующей строки в пределах первичного ключа. Таким образом, конечная временная метка или период действия новых строк по умолчанию принимает значение ″до замены″.
Для ETL-индикатора О вспомогательными действиями являются вставка новой строки, которая находится вне последовательности обновления, в ту, которая не является самой поздней временной меткой в пределах самого позднего первичного ключа (PK_Latest), или это самая последняя строка, но ее начальная временная метка старше, чем самое позднее время фиксации в пределах первичного ключа. В любом случае, строка связана с конечной временной меткой (т.е. предварительно зафиксирована), либо в Х-таблице, либо после загрузки во вспомогательную таблицу. Для индикатора D (логическое удаление) вспомогательными действиями являются обновление самой поздней текущей строки целевой таблицы с незафиксированной конечной временной меткой или предшествующей Х-таблицы (в случае непосредственно предшествующей) и установка конечной временной метки из начальной временной метки строки Х-таблицы. Строка не загружается напрямую. Конечная временная метка новой целевой строки для индикатора D изначально равна NULL и позже может быть обновлена на основе более новой строки в Х-таблице.
В иллюстративных вариантах осуществления обработка ETL CDC и генераторы кода основаны на метаданных первичного ключа, предварительно занесенных в промежуточную таблицу. Два режима просмотра созданы для предоставления либо полного первичного ключа хранилища данных, включая SOURCE_START_TS, либо самый последний вид этого ключа, обычно бизнес-ключа OLTP, исключая SOURCE_START_TS. Кроме того, генераторы кода основываются на стандартных видах представления каталога базы данных, которые предоставляют информацию с описанием структур баз данных (например, базы данных, таблицы и/или столбцы). Первый вид, который может быть реализован только как вид, может быть назван CDW_PK_COLS_LATEST_V. Второй вид, который может быть видом базовой таблицы, может быть назван CDW_PK_COLS_V. Как первый вид, так и второй вид загружаются из первичных ключей в средства моделирования, делают запрос на предоставление DATA_LAYER и, как правило, используют вспомогательные, производные слои в обработке ETL.
Процесс захвата изменений данных функционирует на основе заданной стандартной схемы построения рабочих таблиц, а именно на универсальной форме W-таблиц и Х-таблиц и на доступности метаданных первичного ключа через два вида, отмеченных ранее.
Что касается функциональной сущности процесса захвата изменений данных, основанный на исходной системе, процесс специфичного преобразования посредством вспомогательной, производной и любой другой загрузки связанных данных, через преобразования и загрузку исходных данных в W-таблицу (в промежуточную область базы данных) из промежуточных таблиц выполняется до вызова процесса захвата изменений данных, за исключением явного удаления сообщений. Процесс загрузки W-таблиц обычно является независимым для каждой таблицы, но может быть и не полностью независимым, основанным на процессе специфичного преобразования, заданного для базы данных.
В одном варианте осуществления, W-таблицы и Х-таблицы очищают до начала каждого CDC прогона исходной системы. Процесс захвата изменений данных загружает данные из W-таблицы в слой данных хранилища двоичных данных (CDW) (например, вспомогательный) посредством Х-таблицы, за исключением явных удалений. В иллюстративных вариантах осуществления этот процесс запараллеливается, насколько это возможно, через целевые таблицы и не имеет никаких взаимозависимостей.
В иллюстративных вариантах осуществления, система CDC применяет синхронные загрузки каждой целевой таблицы в одну транзакцию базы данных с помощью набора операторов SQL за относительно короткий промежуток времени (обычно несколько секунд или менее). Эти транзакции распараллеливаются по таблицам насколько это возможно и не имеют никаких взаимозависимостей. Система и способы захвата изменений данных, описанных в настоящем документе, относятся к мини пакетному проекту, предоставляющему возможность гибкой быстрой загрузки хранилища двоичных данных (CDW) без нарушения отчетности, основанный на подходящих способах доступа к запросу, которые могут по-новому применить временные критерии. Никакие утилиты базы данных не используются для загрузки целевых таблиц. Для данной исходной системы или набора связанных таблиц прогон всего пакета может быть завершен до начала нового пакетного запуска. Иными словами, часть загрузки данных, связанная с CDC, осуществляется без распараллеливания или перекрытия с целевой таблицей.
Система CDC обновляет только две стандартные конечные временные метки (исходную или реальную и транзакционную или ETL) существующих целевых строк, причем исходная конечная временная метка (source_end_ts) обычно устанавливается только к указанной временной метке удаления (для удалений) исходной системы или к исходной начальной временной метке последующей строки за исключением пропусков, созданных логическими удалениями. Это эффективно обновляет реальный временной период, который без потери общности может быть реализован, используя тип периода, если такой имеется в наличие, вместо пары временных меток. Все новые данные (например, любое новое ключевое или не ключевое атрибутное значение) дают в результате новую целевую строку. Никакие другие CDW столбцы не разрешено обновлять в целевых таблицах посредством процесса CDC за исключением некоторых случаев, когда указанные производные таблицы могут быть полностью обновлены.
Система CDC гарантирует уникальность первичного ключа посредством метаданных хранилища двоичных данных, загружаемых непосредственно из модели данных. Никаких активных ограничений целостности не предполагается и не требуется для выполнения. Соответственно, пассивный проверочный скрипт может быть запущен в качестве еще одной контрольной проверки. Система CDC также гарантирует, что диапазоны временных меток являются реальными. Например, система может проконтролировать, чтобы конечная исходная или реальная временная метка была больше или равна начальной временной метке, и/или чтобы в пределах РК исходная начальная временная метка была равна исходной конечной временной метке предыдущей строки, за исключением удаленных строк, и/или чтобы исходная конечная временная метка была равна null для самой последней строки в первичном ключе, до тех пор пока логически не удалена. Подобная функциональность может быть предусмотрена, при работе с типом данных, ограниченных временным периодом вместо пары временных меток.
Система CDC заполняет все четыре стандартизованные временные метки, представляющие оба временных периода, причем исходная начальная временная метка является единственной временной меткой, всегда загружаемой из строки исходных данных (под именем SRC_START_TS в W-таблицах и Х-таблицах). Атрибут исходной конечной временной метки также получается из источника посредством начальной временной метки следующей строки в пределах первичного ключа с уникальным контентом или временем удаления текущей строки (если она известна, в противном случае текущей временной меткой), но может быть равна null, когда строка представляет последнюю информацию.
Две временные метки CDW отражают фактическое время загрузки (время транзакции), но могут быть стандартизованы для данного мини пакетного запуска заданной таблицы. Например, временные метки CDW могут быть получены непосредственно перед загрузкой и установкой в качестве фиксированного значения для обеспечения легкой идентификации всех строк, загруженных указанным мини пакетным запуском заданной таблицы. Система CDC также собирает или обновляет статистические данные после загрузки каждой таблицы (W-таблица в pre-CDC, Х-таблица как часть шага 104, если ALL_VT отключена, или в конце последней итерации шага 112). Система захвата изменений данных также может запустить проверку единственности пассивного первичного ключа и целостности внешнего ключа, если проверка не запущена раздельно согласно функциональным требованиям.
В системе CDC неявное удаление связи «родитель-потомок» может быть реализовано как «заполнитель», чтобы показать, что поток обработки должен быть размещен. Вариации, необходимые для сложного промежуточного преобразования и электронной публикации смешанных моделей (например, нажать и сделать снимок одной таблицы) не рассматриваются. Как уже отмечалось, любые явные и любые сложные неявные удаления могут быть загружены в Х-таблицу до запуска CDC посредством кода конкретного преобразования исходной системы. Система CDC позволяет удаленной записи быть восстановленной или «заново родиться», даже в том же самом пакете. Такое состояние может быть обнаружено, когда замечено, что начальная временная метка источника больше или равна исходной конечной временной метке предварительной записи, что является указанием на удаление.
В иллюстративном варианте осуществления номер новой вспомогательной строки равен номеру старой вспомогательной строки+I+О+U количества. Система может подсчитывать обновления (О и U могут отслеживаться по отдельности) и делать проверку этих номеров по сравнению с номерами О и U в Х-таблице, где конечная временная метка не является null.
Предварительно сформированные запросы, полученные посредством генераторов кода, могут включать условие, связанное со слоем данных для предотвращения табличных имен с возможным повторением в разных слоях (например, вспомогательных, основных и производных). В иллюстративных вариантах осуществления столбцы с временной меткой, не указанные временными метками CDW и ИСТОЧНИК, включают временную зону и шесть цифр точности. Один или оба из этих требований могут быть пропущены с соответствующими изменениями в генераторах кода.
Иллюстративные методы загрузки входных данных в хранилище данных описаны ниже со ссылкой на шаги или операции конкретной обработки. Предлагаются раздельные модули на основе подходящих предпосылок, причем активация осуществляется единожды через целевую W-таблицу или Х-таблицу, с опцией запуска множества разделов параллельно с множеством итераций на шагах загрузки раздела (показано на фиг.4) посредством установок метаданных. Например, на шагах 100-200, описанных в данном документе, может потребоваться, чтобы все W-таблицы, которые имеют отношение к исходной системе, были полностью загружены вплоть до начала обработки в случае, если имеются взаимозависимости входных данных. Сам процесс CDC, однако, не вносит никаких взаимозависимостей.
В иллюстративных вариантах осуществления, каждый шаг выполняется как отдельный оператор SQL, позволяя избежать потерь производительности базы данных. Более того, шаги 100-112, не могут быть включены в одну транзакцию базы данных. Скорее, например, каждый шаг или каждая из нескольких групп шагов могут выполняться в отдельной транзакции. В некоторых вариантах осуществления, весь процесс загрузки прерывается в случае любой ошибки в базе данных, но может продолжаться в случае информационного сообщения и/или предупреждающего сообщения. Загрузка шагов 201-207 может быть запущена как единичная транзакция базы данных в результате множества единичных запросов с явным откатом, происходящим при любой ошибке. Все процессы CDC могут быть завершены, прежде чем новый мини пакетный прогон активируется для заданной исходной системы.
Имена базы данных для промежуточной и целевой баз данных могут быть параметризованы соответственно для каждой CDW среды. Имена таблиц параметризованы на основе имени целевой таблицы и приписываются к корректному имени базы данных (W-, Х-, и _Х-таблицы находятся в промежуточной базе данных, и целевая таблица может находиться в вспомогательной, основной или производной базе данных). Обращаем внимание, что некоторые иллюстративные таблицы не квалифицируются как база данных. Например, W- и Х- могут быть в STAGE (в промежуточной области), в то время как целевая таблица является типично NONCORE (вспомогательной).
Соответствующие блокирующие модификаторы добавляются CDC-генератором кода для минимизации конфликтов блокировок на целевые таблицы или на совместно используемые долговременные промежуточные области. В иллюстративных вариантах осуществления, ETL не контролирует доступ к целевым данным во время транзакции, которая инкапсулирует фазу загрузки. Общая архитектура хранилищ данных содержит «грязное чтение», эквивалентное клавише «БЛОКИРОВКА ДОСТУПА» для экспортируемых видов базы данных. Порядок загружающих шагов в пределах вышеописанной транзакции установлен с целью минимизации этой проблемы. В альтернативных вариантах осуществления, задаются дополнительные режимы просмотра SQL, которые при необходимости ожидают завершения транзакции.
В иллюстративных вариантах осуществления процесс CDC управляется на уровне целевой таблицы с точками синхронизации, управляемыми на уровне исходной системы, соответствующем заданиям, документированным и структурированным в соответствии с кодом ETL. Загрузочные шаги (одна транзакция базы данных на таблицу) для всех таблиц в некоторой исходной системе могут быть распараллелены насколько это возможно, чтобы обеспечить согласованной просмотр новых данных и свести к минимуму проблемы целостности ссылочных данных в запросах. Следует отметить, что истинная целостность ссылочных данных может и не вводиться в действие с обычными ограничениями, благодаря тому, что исходная начальная временная метка является частью первичного ключа и варьируется между предком и потомком в некоторых вариантах осуществления. Использование типа данных временной период, если это возможно, может учитывать ограничения временного РК и внешнего ключа (ВК), которые должны быть выполнены.
Далее рассматривается фиг.3, которая представляет схему 70 последовательности шагов, иллюстрирующую представленный в качестве примера процесс захвата изменений данных совместно с поддержкой процессов внешней загрузки с предварительными условиями, если это необходимо. Явные строки-кандидаты вставляются на шаге 72 в W-таблицу внешними процессами (например, процессами, отличными от процесса CDC). В иллюстративных вариантах осуществления все классифицированные табличные строки исходной системы (например, сообщения или снимки) записываются в W-таблицу с помощью специфично-табличного преобразования. Может быть использована установочная логика «INSERT SELECT». В одном альтернативном исполнении шага 72, строки-кандидаты вставляются и заполняют W-таблицу с отправной точки или с базового уровня для кода CDC одного «пакетного» прогона. Полное дублирование строк исключается посредством «DISTINCT» в операторе «SELECT». После вставки на шаге 72 W-таблица содержит полный отчетливый снимок набора преобразованных входных данных, который может включать предысторию, если она сохранена и предоставлена источником. Для интерфейса, основанном на сообщениях, этот шаг может исключать сообщения «Удалить».
На шаге 74 явные удаления вставляются в Х-таблицу из промежуточной области без или в сочетании с шагом 101, который описан ниже. Промежуточная область/преобразование SQL кода загружает атрибуты РК и ETL указатель «D» (удалить) в Х-таблицу в таких случаях. В одном альтернативном исполнении Х-таблица очищается (например, опустошается) перед вставкой в шаг 74 явных удалений. В другом альтернативном исполнении шаг 74 включает вставку явных удалений, пропущенных для интерфейса типа снимок, который возможно не содержит каких-либо явных удалений, за исключением случая, когда LOAD_TYPE=В, и в этом случае сочетание обоих может быть разрешено. Когда используются неявные удаления вместо явных удалений, шаг 74 может быть опущен.
На шаге 76 процесс CDC ожидает 76 загрузочные задания, связанные с завершением загрузки исходных таблиц. В необязательном шаге 78, когда загрузочные задания завершены, выполняется каскадное удаление. Для некоторых таблиц (например, зависимые потомки), строки удаления записываются в Х-таблицу. Процесс преобразования операторов SQL исходной системы напрямую загружает РК, родительскую src_start_ts, ETL-индикатор «D» и исходную начальную временную метку строки для фиксации. В одном иллюстративном варианте осуществления каскадное удаление на шаге 78 является необязательным условием процесса CDC, основанного на исходном преобразовании для родительских удалений, которые каскадно загружаются в дочерние и явно не предоставляются. Для целевых строк, которые не являются самыми поздними, эти удаления могут быть выполнены на шаге приложения 206, более подробно описанного ниже.
На необязательном шаге 80 выполняется неявное удаление связи родитель-потомок. В альтернативном исполнении удаляемые строки записываются в Х-таблицу одной или нескольких таблиц (например, дочерних) в результате обновления. Процесс преобразования операторов SQL исходной системы загружает РК, прародитель src_start_ts, ETL индикатор «D», и исходную временную метку предшествующей родительской строки, не переданной с дочерней, хранящейся в src_end_ts. В другом варианте осуществления схема варьируется на основе взаимодействия с исходной системой (например, унаследованная родительская TS). В одном из альтернативных исполнений шага 80 неявное удаление связи родитель-потомок является необязательным условием процесса CDC, основанного на исходном преобразовании обновлений зависимой дочерней строки, которые подразумевают удаление всех предшествующих дочерних строк. В одном из альтернативных вариантов осуществления для целевых строк, которые не являются самыми поздними, эти удаления выполняются в соответствии с шагом приложения 206, описанного ниже. В некоторых вариантах осуществления шаги от 72 до 82 следуют до процесса CDC и не относятся к процессам, описанным в данном изобретении.
На шаге 82 процесс CDC ожидает задания, связанные с исходными таблицами, для их завершения. Когда эти задания завершены, в шаге 84, создается сессия в базе данных, шаг 84 может включать создание сессии базы данных в некотором процессе и/или потока данных, специфичного для сессии базы данных, так что операции, выполняемые в одной сессии, не влияют на операции, выполняемые в другой сессии.
На шаге 86 количество созданных сессий сравнимо с SESSION_PARALLELISM. Если количество сессий меньше чем SESSION_PARALLELISM, шаг 84 выполняется еще раз, чтобы создать сессию в другой базе данных. В противном случае на шаге 88 процесс CDC ожидает завершения обработки во всех сессиях базы данных.
Для каждой сессии базы данных, которая создается на шаге 84, процесс CDC на шаге 90 определяет, имеются ли какие-либо разделы для загрузки. Если да, то на шаге 92 загрузка раздела выполняется посредством доступной сессии базы данных, созданной на шаге 84, как описано ниже согласно фиг.4. В одном из вариантов осуществления на шаге 92 предусматривается загрузка раздела, чтобы выполнить импортирование одного раздела входных данных в таблицу предварительной загрузки, такую как Х-таблица.
В некоторых вариантах осуществления входные данные делятся на множество разделов (например, установкой NUM_PARTITIONS в значение, превышающее 1), и шаг 92 может быть выполнен для каждого раздела. Например, входные данные могут быть разделены четко по отношению к РК и главным образом равномерно (например, с 1%, 5% или 10% вариацией размеров разделов), используя метаданные. В одном случае количество разделов может быть задано с помощью параметра NUM_PARTITIONS, предоставленного пользователем. Настройка NUM_PARTITIONS на значение 1 может фактически отключить разбиение набора входных данных, заставляя рассматривать набор всех входных данных, как единый раздел.
Когда NUM_PARTITIONS>1, множество разделов может быть загружено параллельно на основе другого параметра SESSION_PARALLELISM, определяемого пользователем, который представляет собой необходимую степень параллелизма выполнения отдельных разделов. Кроме того, разделы могут быть загружены последовательно или параллельно. Например, установка SESSION_PARALLELISM в значение равное 1 может привести к последовательной обработке разделов.
Когда на шаге 90 процесс CDC определяет, что нет разделов для импортирования в сессию базы данных, сессия завершает обработку и исполнение продолжается на шаге 88, в котором процесс CDC ожидает завершения всех сессий базы данных.
На шаге 94, после того, как загрузки всех разделов завершены, все загруженные данные выгружаются в одну сессию базы данных, как описано со ссылкой на фиг.6. В одном представленном примере NUM_PARTITIONS установлен в 5 и SESSION_PARALLELISM установлен в 3. Шаг 84 выполняется три раза, чтобы создать три сессии базы данных. Первая сессия исполняет шаг 92, чтобы выполнить загрузку первого раздела, вторая сессия исполняет шаг 92, чтобы выполнить загрузку второго раздела, третья сессия исполняет шаг 92, чтобы выполнить загрузку третьего раздела. Предполагая в этом примере, что разделы в значительной степени сходны по размеру первая сессия базы данных завершает шаг 92 (по отношению к первому разделу) и выполняет шаг 90, определяющий, что несколько разделов (т.е., четвертый и пятый разделы), готовы к загрузке. Первая сессия базы данных исполняет шаг 92, чтобы выполнить загрузку четвертого раздела. Вторая сессия базы данных завершает шаг 92 (относительно второго раздела) и выполняет шаг 90, определяющий, что еще один раздел (т.е., пятый раздел) готов к загрузке. Вторая сессия базы данных исполняет шаг 92, чтобы выполнить загрузку пятого раздела. Третья сессия базы данных завершает шаг 92 (в отношении третьего раздела), выполняет шаг 90, определяя, что нет разделов, пригодных для загрузки, и продвигается к шагу 88, ожидая завершения всех сессий. Аналогично, как первая, так и вторая сессии базы данных завершают шаг 92 (в отношении четвертого и пятого разделов, соответственно), выполняют шаг 90, определяющий, что нет разделов, пригодных для загрузки, и переходят к шагу 88, ожидая завершения всех сессий. По завершении всех сессий базы данных процесс CDC продвигается к шагу 94, чтобы выгрузить все загруженные разделы в одну сессию базы данных.
На фиг.4 представлена схема 98 последовательности шагов иллюстративного процесса загрузки раздела. В иллюстративных вариантах осуществления процесс, представленный схемой 98 последовательности шагов, выполняется для каждого из разделов NUM_PARTITIONS последовательно и/или параллельно. Шаги, описанные ниже, могут быть зависимыми от одного или нескольких параметров метаданных, как показано в Таблице 4.
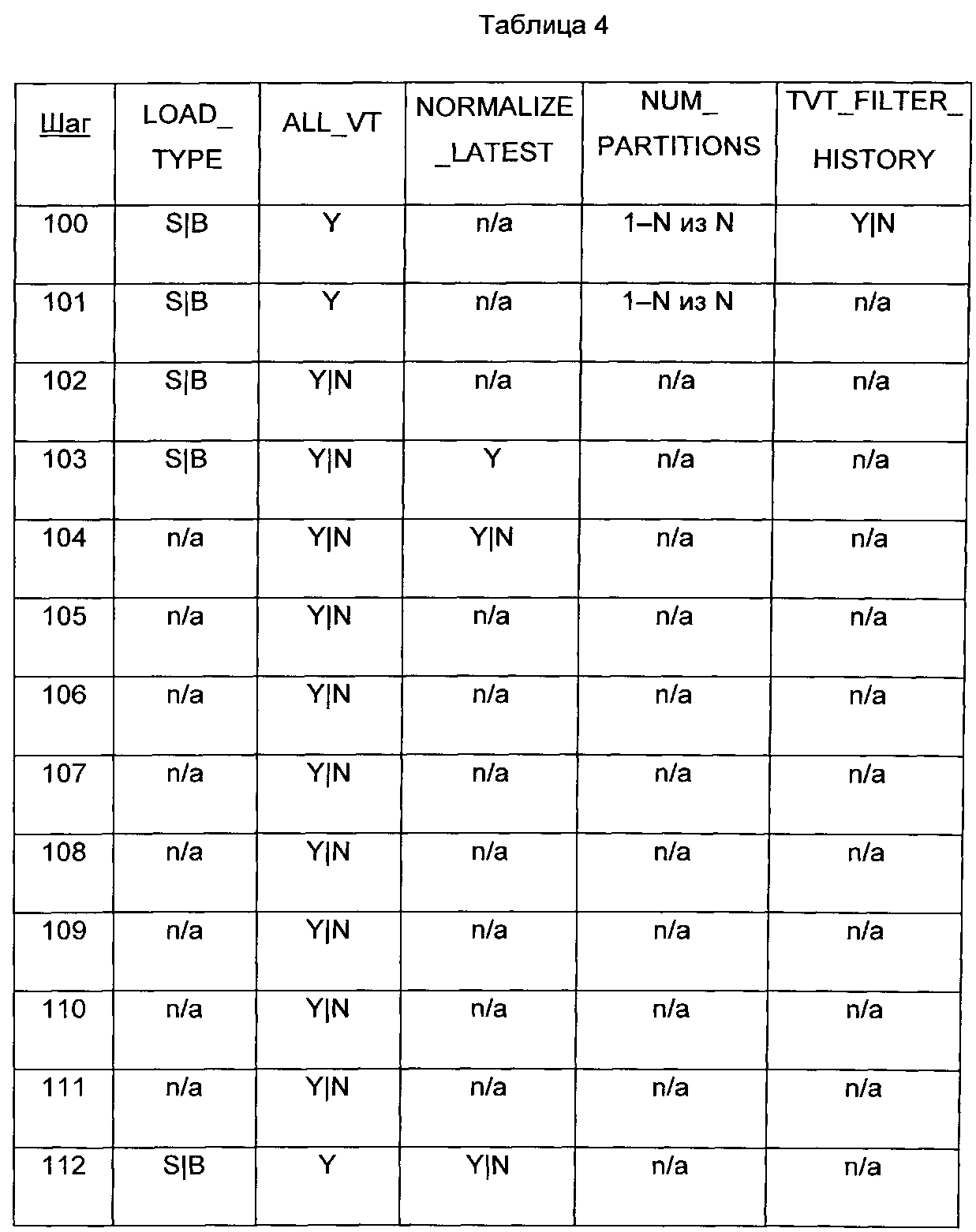
В вариантах осуществления, представленных в качестве примеров, символ (например, ′Y′ или ′S′) в таблице 4 указывает на то, что шаг выполняется только тогда, когда параметр метаданных равен этому буквенному значению. Символ конвейеризации (′I′) обозначает дизъюнктивное отношение («или») между символами, в случае которых шаг выполняется, когда параметр метаданных равен любому из перечисленных символов. Кроме того, ′n/а′ указывает на то, что параметр метаданных не распространяется на шаг процесса. В таких случаях шаг может быть выполнен независимо от значения параметра метаданных.
На шаге 100 загрузка целевого раздела исполняется для загрузки снимка (например, LOAD_TYPE=S или В) когда ALL_VT=Y и NUM_PARTITIONS>1. В итоге шаг 100 запрашивается для больших таблиц, где затраты на создание четкого логического разделения таблицы на отдельные энергозависимые таблицы уменьшает время использования ресурсов процессора и/или время, затраченное на выполнение, становятся большими, чем затраты на добавление этого шага. В одном варианте осуществления шаг 100 может быть инициирован при тех же условиях, что и в шаге 101.
На шагах 100 и 101 логическое разделение создается посредством функции HASHBUCKET(HASHROW), которая еще в одном варианте осуществления, представленном в качестве примера, создает целое число в пределах от одного до одного миллиона, основанное на столбцах первичного ключа, за исключением исходной начальной временной метки. Это обеспечивает относительно равномерное разделение (например, на разделы аналогичных размеров) и низко затратный (например, с точки зрения вычислительных ресурсов) способ детерминировано приписывать строку данных в определенно-выраженный раздел. MOD (разделение по модулю) функция используется для параметра метаданных NUM_PARTITIONS, причем остаток от 1 до N становится значением метаданных для CURRENT_PARTITION. Генератор кода подвергает обработке эти значения в SQL операторах для шагов 100 и 101 и сохраняет их соответствующим образом для извлечения в таблицу CDW_CDC_SQL на основе табличных параметров в CDW_CDC_PARM.
Шаг 100
В вариантах осуществления, представленных в качестве примера, на шаге 100 используется параметр фильтрации истории, обозначаемый TVT_FILTER_HISTORY, с типичным значением N (нет). Когда TVT_FILTER_HISTORY равен Y, система CDC отсекает более старые строки в целевой таблице, не являющиеся необходимой во время прогона CDC, основанные на входных данных в W-таблице. Самая ранняя временная метка для каждого РК W-таблицы запрашивается и сравнивается, для того чтобы построить набор первичных ключей целевой таблицы, которые действуют как фильтр на разделенную энергозависимую таблицу. Производная таблица построена с использованием предложения WITH более ранней исходной временной метки посредством первичного ключа W-таблицы, применяя фильтр разделов. Это затем используется для создания отличительного набора необходимых первичных ключей из целевой таблицы, которая исключает все более старые истории.
В одном варианте осуществления набор включает более новые строки, чем самая ранняя строка W-таблицы, строку, предшествующую самой ранней строке W-таблицы, и самую позднюю строку, если она уже не включена, для того, чтобы обеспечить надлежащую обработку предполагаемого удаления в шаге 102. В одном из альтернативных исполнений представление раздела загружается в каждом случае. Кроме того, LOAD_TYPE=В может влиять на работу этой опции из-за того, что добавляется дополнительное условие запроса для обеспечения строкам из целевой таблицы подгонку первичных ключей любой явной удаляемой строки через условие раздельного запроса.
В еще одном варианте осуществления, представленном в качестве примера, TVT_FILTER_HISTORY активирована, что приводит к использованию меньших вычислительных ресурсов в последующих шагах таких, как шаг 104. В продолжение этого примера осуществления TVT_FILTER_HISTORY может быть эффективен в уменьшении использования ресурсов для таблиц, которые являются довольно большими (например, содержат миллионы строк) и имеют относительно большой процент строк истории (например, более 75% содержания таблиц).
Преимущество активации ALL_VT заключается в использовании PK_Latest в качестве основного индекса PI, способе распределения данных в системе массивно параллельной обработки (МРР) базы данных посредством реализации алгоритма хэширования на один или большее число заданных столбцов. Определенное преимущество заключается в том, что эта опция обеспечивает для PK_Latest меньший перекос, чем в таблицах, где PI имеет гораздо меньшее количество столбцов, чем РК. Кроме того, когда ALL_VT активирован, система считывает данные из базовой таблицы с модификатором блокировки доступа, чтобы избежать любого риска наличия фильтров в отображении базовой таблицы. Повышение эффективности может быть достигнуто путем создания энергозависимой таблицы (VT) на одном шаге, считывающем из базовой таблицы список явных имен столбцов. Это приводит к сохранению за столбцами атрибута ″not null″, в отличие от создания его из отображения доступа. В одном альтернативном исполнении, когда NUM_PARTITIONS=1, хеш-раздел шунтируется на этом шаге, чтобы сэкономить вычислительные ресурсы. Например, NUM_PARTITIONS может быть установлен в 1 для скошенной таблицы, которая в противном случае не является достаточно большой для вычислительных затрат, связанных с процедурой разделения, чтобы быть компенсированной за счет уменьшения вычислительных ресурсов, связанных с обработкой данных в относительно небольших разделах.
Шаг 101
В вариантах осуществления, представленных в качестве примера, шаг 101 исполняется для загрузок снимков (например, LOAD_TYPE=S или В), когда ALL_VT=Y и NUM_PARTITIONS>1. Другими словами, этот шаг может быть вызван для больших таблиц, для которых затраты на создание четкого логического разделения таблицы на отдельные энергозависимые таблицы уменьшает время использования ресурсов процессора и/или время, затраченное на исполнение, более, чем затраты на добавления этого шага. В одном альтернативном исполнении шаг 101 вызывается при тех же условиях, что и шаг 100, и завершает процесс создания временных таблиц для W-таблицы, Х-таблицы и целевой таблицы, чтобы предоставить возможность выполнить обработку в логических разделах раздельно и в параллельных сессиях, если необходимо.
Логический раздел создается с помощью функции HASHBUCKET(HASHROW(), которая в иллюстративном варианте осуществления создает целое число в пределах от одного до одного миллиона на основе столбцов первичного ключа, за исключением исходной начальной временной метки. Это обеспечивает относительно равномерное разделение (например, разделы сходных размеров) и низко затратный (например, с точки зрения вычислительных ресурсов) способ определенного присвоения строки данных к четко различимому разделу. Функция MOD (деление по модулю) используется для параметра метаданных NUM_PARTITIONS, причем остаток от 1 до N становится значением метаданных для CURRENT_PARTITION. Генератор кода подвергает обработке эти значения в SQL-операторах для настоящего шага и шага 100 и сохраняет их соответствующим образом для извлечения в таблицу CDW_CDC_SQL на основе табличных параметров в CDW_CDC_PARM.
Создается незаполненная временная копия Х-таблицы. При LOAD_TYPE=В третий оператор SQL может быть выполнен, чтобы вставить явные строки удаления (например, ETL_INDICATOR=′D′) из Х-таблицы соответствующего текущего хеш-раздела. В этом случае никакие другие строки не считываются из Х-таблицы за исключением тех, которые в противном случае полностью не заполнены в начале процесса CDC при LOAD_TYPE=′S′ или заполнены только с явными удалениями при LOAD_TYPE=′В′.
Шаг 102
В вариантах осуществления, представленных в качестве примера, на шаге 101 исполняются загрузок снимков (например, LOAD_TYPE=S или В) и возможно нет разницы в коде шага 102 между типами загрузок S и В. Другими словами, построение строк Х-таблицы для явных удалений может запускаться, когда завершенный снимок исходных данных готов и для таблиц, существование которых не зависит от исходной таблицы. Эти более поздние случаи являются удалением, вытекающим из отношения родитель-потомок. В некоторых вариантах осуществления шаг 102 используется, когда никакая альтернатива интерфейсу снапшот, как например использование временных меток модификации строк для загрузки только измененных строк, не является реализуемой.
В одном варианте осуществления шаг 102 включает шаг неявного удаления. Удаление определяется выявлением того, что самый поздний первичный ключ (PK_Iatest) является активной строкой во вспомогательной таблице (конечная временная метка есть null) и не содержится больше во входном снимке; таким образом, предполагается, что она уже удалена в исходной системе, с тех пор как последние данные были введены. В одном из вариантов осуществления временная метка текущей базы данных вставляется в SRC_START_TS для применения на загрузочном шаге (например, загрузочном шаге 202). Например, на единичном прикладном шаге можно совершать неявные и явные удаления, используя временную метку текущей базы данных. Эта временная метка становится конечной временной меткой в целевой таблице. Поскольку нет времени срабатывания или удаления из исходной системы текущая временная метка используется как время предполагаемого удаления в исходной системе.
Шаг 103
В вариантах осуществления, представленных в качестве примера, шаг 103 выполняется для загрузок снимков (например, LOAD_TYPE=S или В), когда NORMALIZE_LATEST=Y, при отсутствии разницы в коде между типами загрузки S и В. Этот шаг может быть вызван, например, если таблица имеет значительный объем новых строк без нового контента. В частности, этот шаг устраняет только очередную последующую строку посредством первичного ключа с более новой SOURCE_START_TS, лишь только самая последняя активная строка в целевой таблице и все другие неключевые атрибуты равны. Например, шаг 103 может быть эффективен там, где большой процент строк W-таблицы представляет собой строку текущей целевой таблицы с более новой временной отметкой и отсутствием нового присваивания атрибутов.
Добавление шага 103 может привести к более низко затратному процессу, чем при использовании только шага 104 для выявления изменений и загрузки первичных ключей неизменных более новых строк в энергозависимую таблицу с именем table_KVT, которая в свою очередь используется только в шаге 104 для исключения строк из более сложного полного упорядочения и сравнения. Экономия вычислительных ресурсов этого подхода могут быть существенными, так как полное сравнение не требует шага 104.
Шаг 104
В иллюстративных вариантах осуществления шаг 104 загружает X-таблицу строками-кандидатами из W-таблицы, которые отличаются хотя бы одним атрибутом более чем на последние 3 цифры исходной временной метки от строк целевой таблицы (когда ALL_VT=N) или отфильтрованных целевых строк, хранящихся в VT (когда ALL_VT=Y). Такие строки первоначально закодированы как ETL-индикатор ′I′ и SOURCE START TS однозначно упорядочивается во времени, при необходимости, через одну микросекунду. Этот процесс позволяет изменениям неключевых атрибутов обновляться в целевой таблице (с соответствующим прибавлением 1 миллисекунды к исходной начальной TS), например повторной активацией самой последней записи, ранее логически удаленной по ошибке. Это решает проблему нарушений уникальности с реальным временем и обеспечивает загрузку только определенных строк набора входных данных.
Например, если сбой задания ведет к необходимости повторного запуска задания, который обновляет некоторый столбец в W-таблице, но не обновляет исходную начальную временную метку, система захвата изменений данных обнаруживает новый неключевой атрибут и вставляет новую строку в вспомогательную таблицу с упорядоченной во времени исходной начальной временной меткой, которая должна быть уникальной. В любом случае, любые новые исходные начальные временные метки для заданного первичного ключа приводят к новым строкам с неключевыми атрибутами отличными от непосредственно предшествующей строки первичного ключа, при наличии таковой, принимая во внимание как входные, так и существующие данные.
В некоторых вариантах осуществления часть повторного упорядочения временных меток на шаге 104 пропускается (например, если исходная система гарантирует уникальность бизнес-ключей, исключая исходную начальную временную метку. Минимальное приращение времени, например одна микросекунда, добавляется к исходной начальной временной метке последующих строк, которые имеют одинаковый первичный ключ, без какого-либо дополнительного упорядочения, полагаясь на функцию упорядочения в РК, такую как эквивалент функции row_number().
Повторное упорядочение временных меток используется для изначальной гарантии уникальности первичного ключа (с меткой времени), так чтобы обновляемые процессы обеспечивали операцию присваивания строк «один к одному». Некоторые строки, которые упорядочены (во времени), могут впоследствии удаляться из-за отсутствия четко выраженной неключевой атрибуции (см. шаг 107). С такой старейшей строкой вероятность нового упорядочения сводится к минимуму (например, старейшая строка не имеет добавленного к ней времени). Сбор или обновление статистики Х-таблицы на шаге 104, когда Х-таблица не является энергозависимой таблицей (например, ALL_VT отключена), содействует достижению оптимальных рабочих характеристик процесса загрузки.
В иллюстративных вариантах осуществления функционирование шага 104 варьируется на основе опций оптимизации. Например, когда ALL_VT включена, шаг 104 может принять энергозависимые таблицы и оперировать на основании этих таблиц, а не обычных или долговременных таблиц. Кроме того, когда NORMALIZE_LATEST=Y, дополнительный подзапрос добавляется в конце SQL-оператора, чтобы исключить строки из _KVT энергозависимой таблицы, заполненной на шаге 103, как описано выше. Этим избегается дорогостоящее самосоединение гораздо большего набора более новых, но неизмененных строк, обнаруженных в том шаге. NORMALIZE_LATEST может быть включена в сопряжении с ALL_VT.
Шаг 105
В иллюстративных вариантах осуществления шаг 105 исполняется после загрузки Х-таблицы вставленными строками-кандидатами в предыдущем шаге. Следовательно, выборочный запрос не нужен для объединения входных строк в W-таблице и удаления строк в Х-таблице, чтобы определить набор первичных ключей, характеризующих текущий прогон программы. Такой подход может привести к сравнительно небольшому размеру энергозависимой таблицы, когда входные стоки W-таблицы исключаются прежде, чем они загружены, в частности в случае загрузок снимков.
Как и на шаге 104, шаг 105 может принять имена энергозависимых таблиц и оперировать этими именами, когда ALL_VT включена. Кроме того, опция ALL_VT может воздействовать на первичный индекс результирующей энергозависимой таблицы. Когда ALL_VT=N, может быть использован первичный индекс, который соответствует первичному индексу W-таблицы и Х-таблицы. И наоборот, когда ALL_VT=Y, используемый первичный индекс может быть первичным ключом без учета SOURCE_START_TS, чтобы привести в соответствие три другие энергозависимые таблицы.
Шаг 105 может способствовать существенной оптимизации производительности для снижения затрат на анализ, выполненный в шагах 106-110, в частности на временную нормализацию на шаге 107, используя ограниченное подмножество строк целевой таблицы, сохраненных во временной таблице. Улучшение может быть заметным для проталкиваемых взаимодействий, которые отправляют только строки с новыми кандидатами в W-таблицу, и/или когда обширная предыстория присутствует в целевой таблице. Вероятно, возможны два аспекта улучшения производительности. Во-первых, CDC система может рассматривать только строки целевой таблицы для первичных ключей (без учета исходной начальной временной метки), содержащиеся в W-таблице и Х-таблице. При чистом изменении или взаимодействий проталкивания, чем чаще происходит загрузка, тем этот шаг может быть более эффективным для снижения затрат на шаги по анализу. Количество присоединенных томов данных может быть снижено по крайней мере в 100 раз (например, 1% за каждую загрузку представленных первичных ключей).
Во-вторых, CDC система может ограничить временной период таких РК-строк из целевой таблицы до строк, если таковые имеются, предшествующих старейшей входной исходной начальной временной метки W-таблицы и Х-таблицы и всех последующих строк. Иными словами, CDC система может не принимать во внимание связанные с историей строки, не нужные в шагах по анализу, исключая строки более ранние, чем строка, предшествующая старейшей в W-таблице или X-таблице для каждого РК. Эта оптимизация не всегда может определить минимальное количество строк, так как некоторые промежуточные более новые целевой строки также могут быть не нужными. Только строки, непосредственно предшествующие входной строке или следующие за ней являются необходимыми для временного упорядочивания. Такой подход к временной фильтрации, как ожидается, обеспечивает значительную выгоду при относительно низких вычислительных затратах. Пересмотр истории происходит, в общем, редко. Следовательно, новые входные данные, являются обычно более новыми, чем все ранее сохраненные данные. Следовательно, этот шаг обычно читает только самую последнюю текущую строку посредством РК, выбранного в первом аспекте повышения производительности, описанном выше.
Шаг 105 может заполнить долговременную таблицу, которая очищается при каждом прогоне или временную таблицу любой формы, применимой к вовлеченной СУБД. Без потери общности, энергозависимая временная таблица выбрана, с памятью, выделенной из буфера учетной записи пользователя (уже достаточно большой, чтобы поддерживать включенные операции соединения). Таблица определяется и материализуется автоматически с выходными данными выбранного оператора для целевой таблицы без воздействий на каталог базы данных или необходимости для разрешения создания таблицы.
В некоторых вариантах осуществления CDC система предполагает, что когда NUM_PARTITIONS=1 (не сделано никакой операции разделения), любое последующее исполнение шага 100 (например, следующего CDC прогона) использует отдельную сессию базы данных, которая будет гарантировать, что энергозависимая таблица и ее контент уничтожаются, и, следовательно, созданная табличная команда разрешена без ошибки. При использовании разбиения на разделы (например, NUM_PARTITIONS>1), шаг 111 запускает эту таблицу, чтобы разрешить повторяющиеся итерации в одной сессии, как описано ниже.
Шаг 106
В иллюстративных вариантах осуществления, шаг 106 направляет дубликаты полных первичных ключей между Х-таблицей и вспомогательной таблицей для вставки кандидатов (например, исключающие удаления). В некоторых вариантах осуществления упорядочивание в Х-таблице может быть выполнено на шаге 104. Шаг 106 может принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена.
Добавлением некоторого значения, начиная со значения большего, чем самая большая последовательность, содержащая иным образом неиспользованные последние три цифры из шести цифр субсекундной временной метки, CDC система гарантирует, что первичные ключи уникальны и упорядочены в существующих и ожидаемых строках данных. Более новые мини пакетные загрузки получают новую временную метку каждый раз и потенциально представляют самую последнюю запись, если значительная часть временной метки является уникальной.
Шаг 106 может стать предпосылкой для шагов 107 и последующих за ним и исключает случай равенства первичного ключа, так как запись данных с дубликатом первичного ключа могла бы быть упорядочена в пределах уникальной временной метки, если бы она имела новое содержание. Удаленные записи исключаются. Кроме того, ″основа″ (например, все цифры, кроме последних трех цифр последовательности) временной метки может быть использована для последующих ′групповых′ операций, чтобы позволить множеству значений первичного ключа отличаться только по временной метке, которую необходимо упорядочить.
Шаг 107
В иллюстративных вариантах осуществления шаг 107 может принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена. На шаге 107 удаляются строки-кандидаты W-таблицы, которые не содержат новый ключ или неключевую атрибуцию, отличную от исходной начальной временной отметки, при сравнении с предшествующей строкой, отсортированной по исходной временной метке в пределах первичного ключа. Этот шаг представляет собой блок сжатия процесса, обычно называемый временной нормализацией.
Вычислительные ресурсы могут быть потрачены впустую, если строка с одними и теми же данными загружена более чем один раз. Соответственно, на шаге 104 реализуется блок сжатия на временном отрезке сжатия. Однако, все еще остается необходимым записывать любые изменения данных от «А» до «В» и затем возвращаться в «А». Таким образом, первая копия каждой отдельной строки, за исключением начальной временной отметки, удерживается в Х-таблице. Конкретнее, данные в Х-таблице удаляются, если PK_latest та же самая, и если все столбцы, кроме временной отметки, такие же, как и предыдущая строка, отсортированная по исходной начальной временной метке в пределах PK_Latest, в объединении Х-таблицы со вспомогательной таблицей.
В некоторых вариантах осуществления включение опции ALL_VT может существенно снизить уровень вычислительных ресурсов на шаге 107, в частности, в случае ограниченного числа входных строк (например, проталкиваемое взаимодействие с частыми загрузками) и целевую таблицу с обширной предысторией (например, включающие части пересмотров). Степень улучшения в этом спланированном объединении продукции может возрасти на несколько порядков. Например, употребление процессорной обработки и/или использование памяти, может быть сокращено. Кроме того, благодаря улучшению использования вычислительных ресурсов, продолжительность времени, затраченного на шаг 107, также может быть уменьшена.
В случае двух или более одинаковых следующих подряд друг за другом строк (например, одинаковых и в РК и в атрибутах), CDC система может гарантировать, что не все строки удаляются как избыточные, как только новейшая строка начинается после окончания текущей целевой строки с самой поздней фиксацией, а более ранние строки-кандидаты запускаются в пределах временного периода самой последней целевой строки. Эта ситуация может быть названа «реактивирование», которое может произойти, например, когда исходная система логически удаляет данные на время, и затем восстанавливает данные без обновления временной метки. Добавление одной миллисекунды к конечной временной метке зафиксированной строки позволяет CDC системе начинать новую строку, даже со всеми другими атрибутами, соответствующими предыдущей строке, обеспечивающими минимальную временную детализацию. В частности, дополнительное объединение (с псевдонимом как у таблицы С) может быть включено в шаг 107 с помощью запроса интерактивной аналитической обработки (OLAP), чтобы найти новейшую исходную начальную временную метку, даже если она логически удалена, и вернуть назад начальные данные (или год 2500, если таковой строки не существует) и дату окончания для сравнивания с последней строкой из Х-таблицы. Логика, добавляемая к SQL-оператору может предотвратить удаление самой последней строки Х-таблицы (А.), если следующая самая последняя строка (В.) имеется в Х-таблице, но содержится во временном промежутке самой последней целевой строки С таблицы и, следовательно, строка В должна быть удалена на этом шаге. В иллюстративных вариантах осуществления дополнительные вычислительные затраты на объединение строки С минимальны.
Поскольку хранилище двоичных данных сохраняет время действия в виде диапазона или периода, задаваемого начальной и конечной временной меткой, понимая, что такая же входная строка, до сих пор действующая, не является новой информацией, при условии, что она является самой последней строкой в вспомогательной таблице. Аналогично, понимая, что две одинаковые строки в W-таблице, следующие друг за другом с различными начальными временами, также не является новой информацией, начальное время самой ранней строки фиксирует этот контент уже на временном отрезке между начальной и конечной временными метками, поскольку конечная временная метка присваивается для случая входных данных. В иллюстративных вариантах осуществления на шаге 107 размещается история обновлений и удаляются смежные одинаковые строки в Х-таблице. SQL-оператор, связанный с шагом 107, может быть относительно большим, если таблица имеет много столбцов, в частности с необходимостью проверки на null значений на каждой стороне сравнения. В то время как одна система общего применения включает ограничение в один мегабайт (1 МБ) на оператор, другие инструменты могут накладывать ограничение меньшего размера, которые могут потребовать множество шагов, чтобы разбить сравнения вспомогательных атрибутов на исполняемые блоки меньшей сложности или размера. Null защита осуществляется посредством функции Coalesce, при сравнении всех необязательных столбцов (в общем случае это все столбцы, не принадлежащие к РК). Использование функции строка-число (row_number) опирается на конкретную исходную начальную TS между Х-таблицей и вспомогательной таблицей, которая обеспечивается шагом 106.
Шаг 108
В иллюстративных вариантах осуществления на шаге 108 можно принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена. Шаг 108 является первым из двух шагов, на котором обновляется индикатор извлечения, преобразования и загрузки (ETL) для подходящих вставляемых строк («I»), в данном случае от I до U для более новых обновлений. Используемый в настоящем изобретении термин «более новый» касается записи данных, имеющих первичный ключ, включающий исходную начальную временную метку, которая является более поздней, чем первичный ключ самой последней строки в пределах той же опции PK_Iatest в вспомогательной строке, даже если она помечена как удаленная. В этом шаге может быть обновлен ETL индикатор строки более чем одной Х-таблицы в пределах первичного ключа при условии, что каждый представляет новый контент и не был удален на шаге 107. В иллюстративных вариантах осуществления, только самые поздние активные вспомогательные конечные временные метки строки обновляются в загрузочной фазе (например, нижеследующий загрузочный шаг 202), который ищет только самую раннюю U-строку посредством РК, чтобы загрузить ее начальную временную метку в качестве конечной временной метки самой поздней вспомогательной строки. На шаге 110, описанном ниже, могут быть предоставлены конечные временные метки, когда имеется более чем одна строка, установленная на значение ′U′ посредством РК в Х-таблице, чтобы отразить, что все, кроме самой поздней строки, будут вставлены в целевые предварительно зафиксированные строки.
Шаг 109
В иллюстративных вариантах осуществления на шаге 109 можно принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена. На шаге 109 предоставляется возможность добавления новых исторических строк в хранилище двоичных данных. Этот шаг является вторым из двух шагов, которые обновляют индикатор ETL вставляемых строк-кандидатов (′I′ или ′U′), в данном случае от ′I′ или ′U′ до ′О′ для обновлений «более старых» данных. Есть два случая «старых» обновлений посредством ETL-индикатора ′О′:
1. Исходная начальная временная метка предшествует самой поздней вспомогательной строке в пределах того же самого PK_latest даже если она помечена как удаленная, который также называют внеочередным обновлением; и
2. Случай 1 не удовлетворяется, так что начальная временная метка новее любой строки с PK_latest в вспомогательной таблице, но начальная временная метка также меньше, чем самая поздняя конечная временная метка в вспомогательной таблице.
Другими словами, эта строка является более новым обновлением, но будет уже логически удалена и помечена зафиксированной в силу более поздней даты фиксации во вспомогательной таблице. По определению, эта строка не является удалением самой поздней строки и уже помечается как ′U′ из-за ее начальной временной метки, являющейся более новой, чем самая поздняя вспомогательная начальная временная метка.
Шаг 110
В иллюстративных вариантах осуществления на шаге 110 можно принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена. На шаге 110 предоставляются конечные временные метки, когда имеется более чем одна строка с установленным значением ′U′ посредством первичного ключа в Х-таблице, чтобы отразить, что все, кроме самой поздней строки, будут вставлены во вспомогательные предварительно зафиксированные строки. На шаге 110 устанавливается конечная временная метка для всех новых предварительно зафиксированных строк, которые не предназначены стать самой последней строкой в вспомогательной таблице. Все строки с ETL-индикатором ′О′ нуждаются в конечной временной метке и только те строки с ETL-индикатором ′U′, которые не являются самыми поздними в Х-таблице и вспомогательной таблице, также получат конечную временную метку, равную времени начала следующей строки. ′О′ строки получают свою конечную временную метку от последующей вспомогательной строки, по определению, в загрузочной фазе (например, загрузочный шаг 204, описанный ниже). Этот шаг может быть выполнен одним SQL-выражением посредством оператора объединения или исключения.
Шаг 111
В иллюстративных вариантах осуществления на шаге 110 можно принимать имена энергозависимых таблиц и оперировать ими, когда опция ALL_VT включена. На шаге 111 устанавливается точная начальная временная метка строки, которая должна быть логически удалена для всех удаляемых строк (ETL-индикатор ′D′) в Х-таблице, и сохраняется это значение в столбце src_end_ts этой строки. Это обеспечивает точный полный первичный ключ для загрузочной фазы (например, шаг 206, описанный ниже), чтобы определить местоположение единичной вспомогательной строки для фиксации посредством нахождения предшествующей строки из строк вспомогательной таблицы и Х-таблицы, к которым процесс удаления должен применяться. Самая поздняя строка и другие предварительно зафиксированные строки Х-таблицы могут быть обновлены, но это обновление не является обязательным, и на других шагах могут быть зафиксированы эти строки. Исходная конечная временная метка строк для удаления является исходной начальной временной меткой строки для фиксации, и становится конечной временной меткой строки, которая существовала в то время. В иллюстративных вариантах осуществления на шаге 111 поддерживается целостность ссылочных данных, когда предварительные CDC шаги (например, шаги, предшествующие шагу 92, показанному на фиг.3) определяют каскадное и неявное удаление потомков. Шаг 111, тем самым, способствует убеждению в том, что родительские записи имеют соответствующие исторические удаления, примененные к ним, не требующие предварительного CDC-процесса для определения точной временной метки до момента вызова CDC.
Шаг 112
[0028] В иллюстративных вариантах осуществления, шаг 112 исполняется только тогда, когда LOAD_TYPE=S (снимок загрузки) или В (снимок загрузки как с явными, так и неявными удалениями) и ALL_VT=Y (используя энергозависимые таблицы). Шаг 112 загружает итоговые данные, из энергозависимой Х-таблицы в фактическую (например, постоянную или «физическую») Х-таблицу, позволяя параллельные сессии, для процесса конкретного разделения табличных данных с помощью энергозависимых таблиц конкретной сессии.
Когда LOAD_TYPE=В, на шаге 112 сначала удаляются явные удаления, уже загруженные в Х-таблицу, текущего раздела. Эти явные удаления были загружены на шаге 101 в XVT таблицу и обработаны во время текущего прогона. Это может быть сделано в первую очередь для предотвращения повторяющихся строк в Х-таблице и удаления необработанных явных удалений. Например, CDC может упорядочивать и устанавливать подходящую временную метку в целевой таблице во время выполнения шага 100.
Как показано на фиг.3, когда NUM_PARTITIONS>1, шаги от 100 до 112 повторяются (например, последовательно или параллельно согласно параметру SESSION_PARALLELISM) для каждого раздела от 1 до NUM_PARTITIONS посредством предварительно сгенерированного SQL-оператора, согласующего шаг, раздел и сессию перед исполнением загрузочных шагов. В случае ошибки процесс, проиллюстрированный схемой 70 последовательности операций (показанной на фиг.3), может быть остановлен. В некоторых вариантах осуществления, статистические данные по действующей Х-таблице собраны в загрузке последнего раздела (например, где CURRENT_PARTITION=NUM_PARTITIONS).
На фиг.5 представлена схема 200 последовательности операций, иллюстрирующая процесс загрузки данных, приведенный в качестве примера. В иллюстративных вариантах осуществления загрузочные шаги 201-207, описанные ниже, исполняются вместе в рамках единой транзакции базы данных для каждой целевой таблицы одним запуском на целевую таблицу. Все шаги 201-207 могут быть объединены в один многооператорный запрос при условии, что проверка на ошибки и массивы количества строк управляются должным образом. Если эти шаги представляются индивидуально и какой-то шаг наталкивается на ошибку, то исполнение загрузочных шагов 201-207 может быть прекращено и никакие SQL-операторы далее могут не выполняться. При таком сценарии вся транзакция отменяется или «откатывается назад». В зависимости от требований к исходному преобразованию CDC процесс может ожидать завершения всех исходных таблиц на шагах от 100 через 112, прежде чем начать какой-либо из загрузочных шагов 201-207. Загрузочные шаги могут исполняться параллельно для всех применяемых таблиц, чтобы использовать по максимуму ссылочную целостность целевой базы данных в процессе непрерывного доступа по запросам.
Загрузочный шаг 201
В иллюстративных вариантах осуществления загрузочный шаг 201 начинает транзакцию базы данных, в которой SQL-операторы, связанные со всеми последующими шагами вплоть до загрузочного шага 207, т.е. шага END TRANSACTION, описанного ниже, либо полностью исполняются, либо не исполняются вообще в случае ошибки где-либо в пределах SQL-операторов. Это способствует визуализации целевой таблицы в реальном состоянии, например, не более одной исходной конечной временной метки на PK_latest, не более одной активной строки до тех пор, пока эта строка не будет логически удалена.
Загрузочный шаг 202
Загрузочный шаг 202 обновляет одну самую позднюю активную строку (исходная конечная временная метка равна null) с PK_latest для установления обеих конечных временных меток (исходной и CDW), чтобы пометить эту строку как логически удаленную ETL-индикатором ′U′, что приводит к фиксации самой поздней вспомогательной временной метки благодаря поступлению одной или нескольких новых строк. Обработка всех удалений или индикатора ′D′ происходит в загрузочном шаге 206. Условия, предоставляемые на шаге 202, учитывают, что исходная начальная временная метка Х-таблицы, которая становится начальным временем, является по меньшей мере такой же большой, как вспомогательное начальное время (т.е. период>0).
Загрузочный шаг 203
В иллюстративных вариантах осуществления загрузочный шаг 203 представляет собой единственный загрузочный шаг для вставки новых строк во вспомогательную таблицу. Все ETL-индикаторы, кроме индикатора удаления, приводят в результате к новым вспомогательным строкам (I, О и U). Строки могут быть с предварительной фиксацией (например, благодаря столбцу исходной конечной временной метки Х-таблицы, имеющему некое значение) или нет. Как и в любом шаге, который может указать транзакционную временную метку или временную метку CDW, это значение представляет текущую временную метку загрузочной фазы, обычно определенной до загрузочных шагов и используемой последовательно в каждом шаге, так что постоянная начальная временная метка CDW также однозначно устанавливает запуск CDC на целевую таблицу.
Загрузочный шаг 204
Загрузочный шаг 204 исправляет начальную временную метку предшествующей вспомогательной строки, если новая строка, вставленная в загрузочный шаг 203 (один случай ′О′ строки), имеет самую позднюю исходную начальную временную метку, но эта временная метка является более ранней, чем самая поздняя исходная конечная временная метка, уже существующая в вспомогательной таблице. Это довольно редкий случай строки ′О′, которая является уже фиксированной строкой, получающей внеочередное обновление с начальной временной меткой меньшей, чем существующая фиксированная временная метка.
Использование вычислительных ресурсов загрузочного шага 204 может быть уменьшено включением подзапроса к самому позднему первичному ключу Х-таблицы, чтобы избежать для целевой таблицы, полностью присоединенной к себе самой, операции, связанной с потенциально большой загрузкой процессора и потенциально дополнительного перекоса в случаях, когда таблицы имеют обширную историю.
Загрузочный шаг 205
Загрузочный шаг 205 вызывается для строк, отмеченных ETL-индикатором ′О′. Шаг 205 присоединяет все строки ′О′ Х-таблицы к вспомогательной таблице, чтобы установить предшествующую вспомогательную строку, если таковая имеется, и затем обновить эти строки начальной временной меткой строки Х-таблицы в качестве конечной временной метки, а также обновить конечную временную метку CDW. Загрузочный шаг 205 завершает процесс последовательно-параллельного пошагового изменения исходных временных меток у внеочередных новых строк для обеспечения четких неперекрывающихся временных периодов в исходной временной метке. За исключением любых строк, отмеченных как логически удаленных, исходная начальная временная метка - это исходная конечная временная метка непосредственно предшествующей строки (если таковая имеется), когда она отсортирована по исходной начальной временной метке в пределах оставшейся части первичного ключа.
Загрузочный шаг 206
Загрузочный шаг 206 осуществляется для строк, отмеченных ETL-индикатором ′D′, и распространяется как на исторические, так и на текущие строки из вспомогательных или вновь загруженных в пакет таблиц. Этот процесс изменяет существующие конечные временные метки в вспомогательных строках на начальную временную метку удаленной строки (например, ETL-индикатор=′D′). Для строк, непосредственно вставленных в Х-таблицу (например, неявное удаление связи родитель-потомок), предварительный процесс CDC, который выстраивает строку, гарантирует, что конечная временная метка по-прежнему превышает начальную временную метку и меньше или равна исходной начальной временной метке последующей строки.
Для обеспечения присоединения один к одному исходная начальная временная метка вспомогательной целевой строки хранится в столбце src_end_ts Х-таблицы с момента, когда исходная начальная временная метка в Х-таблице уже использована, чтобы записать исходную временную метку в событии удаления, которая в целевой таблице становится конечной временной меткой строки. Это окончательное условие, осуществленное на шаге 206, размещает логическое удаление самых последних вспомогательных строк и размещает историю удалений, чтобы гарантировать, что когда обновляется конечная временная метка, то новая конечная временная метка становится меньше (например, может сократить срок службы или только временной период строки, не удлиняя его, чтобы обеспечить отсутствие перекрытия периодов, заданных исходными временными метками - начальной и конечной - через строки в пределах PK_latest).
Загрузочный шаг 207
На окончательном загрузочном шаге 207 предоставляется инструкция SQL для завершения транзакции базы данных, которая закрывает транзакционную область всех предыдущих операторов, начиная с предшествующего оператора начала транзакции, при условии отсутствия каких-либо ошибок. Если это еще не сделано, статистические данные могут быть собраны или обновлены по целевой таблице на это время.
Фиг.6-23 представляют собой схемы потока данных, которые дополнительно объясняют каждый из шагов, связанных с описанной системой захвата изменений данных. Например, фиг.6 представляет собой схему потока данных 300, связанную с шагом 100, загрузкой раздела входных данных из вспомогательных данных 302. Энергозависимая таблица 304 создается 306 посредством выбора сегмента записей данных из вспомогательных данных 302 в соответствии с хеш-функцией. Кроме того, когда фильтрация истории включена (например, TVT_FILTER_HISTORY=Y), создание 306 энергозависимой таблицы 304 может включать в себя пропущенные записи данных из вспомогательных данных 302, исходя из данных в W_table 308. В дополнение, когда фильтрация истории включена и LOAD_TYPE=В, X_table 310 можно использовать как входные данные для шага 100.
Далее следует пример псевдокода, который связан с шагом 100, когда TVT_FILTER_HISTORY=N и LOAD_TYPE=S.
Шаг 100 - псевдокод (TVT_FILTER_HISTORY=N, LOAD_TYPE=S):
Create volatile table_TVT as
Select*from target table
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
Primary Index PK Latest;
Далее следует пример псевдокода, который связан с шагом 100, когда TVT_FILTER_HISTORY=Y и LOAD_TYPE=S.
Шаг 100 - псевдокод (TVT_FILTER_HISTORY=N, LOAD_TYPE=S):
WITH W table minimum primary key and src start TS where
HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS=CURRENT_PARTITION
Create volatile table_TVT as
Select*from target table
Where full primary key in (
Select newer rows in target table than derived W table with hash partition
Union
Select latest older row in target table relative to derived W table with hash partition
Union
Select latest row from target table)
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
Primary Index PK Latest;
Далее следует пример псевдокода, который связан с шагом 100, когда TVT_FILTER_HISTORY=Y и LOAD_TYPE=В.
Шаг 100 - псевдокод (TVT_FILTER_HISTORY=Y, LOAD_TYPE=B):
WITH W table minimum primary key and src start TS where
HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS=CURRENT_PARTITION
Create volatile table_TVT as
Select*from target table
Where full primary key in (
Select newer rows in target table than derived W table with hash partition
Union
Select latest older row in target table relative to derived W table with hash partition
Union
Select latest row from target table)
Or PK_Latest in (select PK_Latest from X table where ETL_Indicator is D from hash partition)
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
Primary Index PK Latest;
Фиг.7 представляет собой схему потока данных 320, относящуюся к шагу 101, загрузки раздела входных данных из W_table 322. Создаются 328 энергозависимые таблицы _WVT 324 и _XVT 326. _WVT таблица 324 загружена посредством выбора сегмента записей данных из W_table 322 в соответствии с хеш-функцией. Когда LOAD_TYPE=В, ′D′ строки из X_table 330 загружаются 332 в энергозависимую таблицу _XVT 326.
Далее следует пример псевдокода, который связан с шагом 101, когда LOAD_TYPE=S.
Шаг 101 - псевдокод (LOAD_TYPE=S):
Create volatile table _WVT as
Select*from W table
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
Primary Index PK Latest;
Create volatile table_XVT as
X table with no data
Primary Index PK Latest;
Далее следует пример псевдокода, который связан с шагом 101, когда LOAD_TYPE=В.
Шаг 101 - псевдокод (LOAD_TYPE=В):
Create volatile table_WVT as
Select*from W table
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
Primary Index PK Latest;
Create volatile table_XVT as
X table with no data
Primary Index PK Latest;
Insert into_XVT (PK, 4 row marking columns)
Select PK, 4 row marking columns from X table
Where HASHBUCKET(HASHROW(PK Latest)) MOD NUM_PARTITIONS
=CURRENT_PARTITION
AND ETL_INDICATOR=′D′
Фиг.8 представляет собой схему потока данных 340, связанную с шагом 102, построения строк X_table для неявных удалений. Схема 340 показывает, что если строка из вспомогательных данных 342 больше не появляется в W_table 344, то считается, что она уже удалена из источника. Строка вставляется 346 в X_table 348 с самым поздним первичным ключом (PK_latest) из вспомогательных данных 342, текущей временной метки и ETL-индикатора ′D′, при этом «текущий» вспомогательный первичный ключ не находится в W_table 344. Эта представляет собой простой случай, когда таблица не зависит от родителя.
Далее следует пример псевдокода, который связан с шагом 102.
Шаг 102 - псевдокод:
Insert into X table
Select [*, Current_Timestamp, ′D′] from target
WHERE PK-Latest NOT IN
(Select [PK_Latest] from W-table);
Фиг.9 представляет собой схему потока данных 360, связанную с шагом 103. Записи данных в W_table 362 сравниваются с записями данных в вспомогательных данных 364, чтобы идентифицировать 366 первичные ключи никогда не изменяемых строк. Эти первичные ключи самой ранней строки входных данных с идентичным контентом сохранены в энергозависимой таблице _KVT 368.
Далее следует пример псевдокода, который связан с шагом 103.
Шаг 103 - псевдокод:
Create VT of W table full PK»s to exclude in step 104
Select full PK from W table
Where full PK in (
Select earliest full PK row from W table joined to target table
Where target table is latest row and W table is next newest row
And all attributes of both rows are identical excluding source TS
Фиг.10 представляет собой схему потока данных 380, относящуюся к шагу 104 построения строк X_table для новых и изменяемых записей, последовательности нечетких полных первичных ключей и сбора статистических данных на X_table 382. Строки вставляются 384 в X_table 382, если по меньшей мере одна колонка отличается от всех других строк в вспомогательных данных 386, которые предоставляют возможность загрузки истории новых данных в X_table. Посредством выбора всех строк W_table 388 за вычетом (кроме SQL) всех вспомогательных 386 строк по умолчанию указатель ETL устанавливается в I. Система захвата изменений данных и целостность первичного ключа требуют такой шаг, который может не всегда быть необходим, если он гарантированы в данных. К временной метке src_start_ts в таблице W_table 388 для строк со второй по n-ый в PK_latest добавляется одна микросекунда. Аналогично последние три субсекундные цифры исходной временной метки, которые зарезервированы для упорядочения по временным меткам, исключаются из сравнения изменений между W_table и вспомогательными данными.
Далее следует пример псевдокода, который связан с шагом 104.
Шаг 104 - псевдокод:
Insert into X_table
Select [*] from W_table -- 1 microsecond sequencing added to start TS
Where*not in (-- exclude microsecond sequencing when selecting start TS
Select [*] from target); -- exclude ns sequencing when selecting start TS
Collect statistics on X_table;
Кроме того, когда NORMALIZE_LATEST=Y, таблица 390 _KVT может быть заполнена первичными ключами посредством шага 103, как описано выше. В таком сценарии шаг 104 исключает (например, не вставлять 384 в X_table 382) записи данных связанные с первичным ключом, который возникает в _KVT таблице 390.
Фиг.11 представляет собой схему потока данных 400, связанную с шагом 105. Записи данных в вспомогательных данных 402, которые связаны с PK_Latest, возникающих в Х_Table 404, фильтруются исходя из исходной начальной временной метки в вспомогательных данных 402 и вставляются 406 в энергозависимую целевую таблицу 408.
Далее следует пример псевдокода, который связан с шагом 105.
Шаг 105 - псевдокод:
Insert into Target_Table_VT (create volatile temporary table via select statement)
Select*from Target Table where
PK_Latest in (select PK_Latest from X_table)
And (SOURCE_START_TS gt=MIN SRC_START_TS in X table for that exact PK
OR SOURCE_START_TS is MAX for PK It MIN SRC_START_TS in X)
Фиг.12 представляет собой схему потока данных 420, связанную с шагом 106 переупорядочивания строк X_table 422, которые будут, в свою очередь, обновлять существующие вспомогательные 424 строки. Целью шага 106 является обновление исходной начальной временной метки, связанной с X_table 422, добавлением максимальной вспомогательной временной метки (TS_microseconds) ко всем строкам ′I′ таблицы X_table, другими словами, одинаковыми начальными временными метками (исключая последние 3 субсекундные цифры) в пределах одного и того же РК. Если новые последовательные (в шаге 104) строки 426 для первичного ключа (РК) принимаются с такими же временными метками (TS), как у существующих строк, то это гарантирует, что новые строки выстраиваются в последовательность после вспомогательных строк 424.
Далее следует пример псевдокода, который связан с шагом 106.
Шаг 106 - псевдокод:
UPDATE X-alias
FROM X-table X-alias
,(SELECT
PK_Latest
,CAST (MAX (src_start_ts) as char(23)) F23C
,substring (cast (max(source_start_ts) as char(26)) from 24 for 3)+1 L3C
,substring (cast (source_start_ts as char(32)), from 27 for 6)+1 L3C
FROM target
GROUP BY PK_Latest, F23C, TSTZ) QQQ
SET SRC_START_TS
=F23C SUBSTRING(CAST((L3C/1000+
(SUBSTRING(cast(xpm.src_start_ts as char(26)) FROM 24 FOR 3))/1000) AS DEC(4, 3)) FROM
4 FOR 3)
WHERE X-alias. PK_Latest=QQQ. PK_Latest
AND CAST (X-alias.src_start_ts AS CHAR(23))=QQQ. F23C
AND X-alias. ETL_INDICATOR=′I′;
Фиг.13 представляет собой схему потока данных 440, связанную с шагом 107 отбрасывания смежных зарезервированных строк X_table внутри объединения, например, X_table 442 и вспомогательной таблицы 444 и дополнительно объединения X_table 446 и вспомогательной таблицы 448. Два объединения соединяются по первичному ключу последовательных строк и предоставляют возможность регистрации идущих подряд строк, повторяющих всю неключевую атрибуцию и, кроме того, соединенную с новейшей целевой таблицей РК. Шаг 107 представляет распознавание того, что ресурсы растрачиваются, когда строка, включающая одни и те же данные, загружаются больше одного раза, и реализует блок сжатия периода времени. Однако все еще необходимо записать любые изменения в данных от «А» до «В», затем вернуться к «А». Таким образом, первый образец каждой отличающейся строки, исключая начальную временную метку, сохраняется в X_table 450. В частности, данные в X_table 450 удаляются, если PK_latest является такой же и если все колонки кроме временных меток такие же, как и в предыдущей строке, когда они отсортированы по исходной начальной временной метке в пределах PK_Latest, в объединении X_table и вспомогательной таблицы.
В иллюстративных вариантах осуществления дополнительное соединение (с псевдонимом таблица С) X_table 452 и вспомогательной таблицы 454 включается в поиск новейшей исходной начальной временной метки, даже если она логически удалена, и возвращается начальная дата (или 2500 год, если такая строка не существует) и конечная дата для сравнения с самой поздней строкой X_table.
Далее следует пример псевдокода, который связан с шагом 107.
Шаг 107 - псевдокод:
Delete from X_table where PK IN (
(Select PK from
(Select A.*from
(Select*, table_source, Row_Number() from X_table union noncore
partition by PK_Latest Order by SRC_START_TS to create Row_Number) A
INNER JOIN (Select*, table_source, Row_Number() from X_table union noncore
partition by PK_Latest Order by SRC_START_TS to create Row_Number) В
Where A. PK_Latest=B. PK_Latest
and B. Row_Number=A. Row_Number-1
and all non-key attribute are the same (values equal or both null)
)
AND A. Table Source=«X»
Left Outer Join (Select PK_Latest, If not null then Source Start TS else Year 2500,
SOURCE_END_TS
From Target partition PK_Latest and present newest Source Start ts) С
ON A. PK_Latest=C. PK_Latest
WHERE (B. Table Source=«X»
AND A. Time period is newer than the latest target row
Фиг.14 представляет собой схему потока данных 460, связанную с шагом 108, в котором выделяются строки X_table 462 и обновляются текущими строками вспомогательных данных 464. В шаге 108 для обновления 466 X_table индикатор ETL устанавливается в ′U′ на строках ′I′, чтобы обновить существующие вспомогательные «текущие» строки, когда входная исходная временная метка больше самой поздней исходной временной метки во вспомогательной таблице. На загрузочном шаге 202, описанного в данном документе, самая ранняя начальная временная метка из этих строк ′U′ применяется в пределах первичного ключа для фиксации самой поздней вспомогательной строки.
Далее следует пример псевдокода, который связан с шагом 108.
Шаг 108 - псевдокод:
UPDATE X_tbI
FROM X_TABLE X_tbI
,(select PK_Latest
,max(src_start_ts) src_start_ts
from target
group by PK_Latest) NC_tbI
SET ETL_INDICATOR=′U′
WHERE X_tbI. PK_Latest=NC_tbI. PK_Latest
AND X_tbI. SRC_START_TS gt NC_tbI. SRC_START_TS
AND X_tbI. ETL_INDICATOR=′I′;
Фиг.15 представляет собой схему 480 потока данных, изображающую шаг 109, на котором выделяются строки X_table 482 и обновляются «исторической» строкой вспомогательных данных 484. Схема 480 потока данных относится к обновлениям, которые совершаются вне очереди. На шаге 109 для обновления 486 данных в X_table 482, ETL-индикатор устанавливается в ′О′ в строках, ранее установленных в ′I′ или ′U′ для обновления существующих вспомогательных строк «истории». В таких строках входные исходные временные метки меньше самых поздних исходных начальных временных меток в вспомогательных строках, когда строки X_table и вспомогательной таблицы рассматриваются как одно целое. Это достигается посредством объединения сравнений временных меток как из вспомогательной таблицы, так и X_table для достижения глобального максимума в расчете на каждого PK_latest. В альтернативном исполнении входная исходная временная метка меньше самой поздней исходной временной метки, следовательно строка должна быть предварительно зафиксирована. Эти ′О′ строки обновляют конечную временную метку во вспомогательных данных до правильной исторической последовательности. Эти обновления совершаются вне очереди, так что большая часть получит конечную временную метку следующей строки на шаге 110. Остальные получают конечную временную метку в загрузочном шаге 204.
Далее следует пример псевдокода, который связан с шагом 109.
Шаг 109 - псевдокод:
UPDATE X_tbI
FROM X_TABLE X_tbI
,(select PK_Latest
,max(src_end_ts)max_end_ts
,max(src_start_ts)max_start_ts
from target
group by PK_Latest)Max_tbI
SET ETL_INDICATOR=′O′
WHERE X_tbI.PK_Latest=Max_tbI.PK_Latest
AND((X_tbI.SRC_START_TS It Max_tbI.MAX_END_TS
OR(X_tbI.SRC_START_TS It Max_tbI.MAX_START_TS))
AND X_tbI.ETL_INDICATOR IN (′I′, ′U′);
Фиг.16 представляет собой схему потока данных 500, изображающую шаг 110 оканчивания строк (′О′ или ′U′) X_table, которые уже обновлены в вспомогательной или X_table таблицах. Конечная временная метка в строках X_table устанавливается в значение начальной временной метки предыдущей строки (либо вспомогательной, либо X_table). Строки, где индикатор ETL установлен в ′О′, предоставляют возможность загрузки обновлений истории. Это входные строки, которые не являются самой поздней строкой в пределах их первичного ключа, то есть они уже обновлены посредством Х_Table 502 и вспомогательной таблицей 504 через соединение 506. Они вставляются в вспомогательные данные как строки истории исходя из своей конечной временной метки.
Далее следует пример псевдокода, который связан с шагом 110.
Шаг 110 - псевдокод:
Update X-tbI
FROM X-table X-tbI
,(Select AAA.PK-Latest, min(BBB.START_TS) as END_TS
From (Select PK
From X-table) AAA,
(Select PK
From X-table
UNION
Select PK
From target) BBB
Where BBB.PK_Latest=AAA.PK_Latest
And BBB.START_TS gt AAA.START_TS
Group By AAA.PK
)QQQ
SET END_TS=QQQ.END_TS
WHERE X-table.PK=QQQ.PK
and X-table. ETL_Indicator IN (′O′, ′U′);
Фиг.17 представляет собой схему потока данных 520, изображающую шаг 111 предоставления полного ключа (с исходной начальной временной меткой) для всех удаленных строк (ETL-индикатор ′D′) посредством нахождения временной метки самой поздней вспомогательной строки, которую загружает процесс логического удаления. Более конкретно конечная временная метка установлена на строках X_table в значение начальной временной метки непосредственно предшествующей строки X_table или вспомогательной таблицы, исходя из временной метки удаления. Эти строки, подлежащие логическому удалению, являются дополнением к строкам, связанным отношением родитель-потомок и уже приготовленным к неявному или каскадному удалению до фиксации данных изменения. Такие случаи исполнены на загрузочном шаге 206.
Далее следует пример псевдокода, который связан с шагом 111.
Шаг 111 - псевдокод:
Update X-tbI
FROM X-table X-tbI
,(Select AAA.PK_Latest, min(BBB.START_TS) as END_TS
From (Select PK
From X-table) AAA,
(Select PK, Max Start TS
From X-table
UNION
Select PK, Max Start TS
From target) BBB
Where BBB.PK_Latest=AAA.PK_Latest
And BBB.START_TS gt AAA.START_TS
Group By AAA.PK, BBB.Max Start TS
)QQQ
SET END_TS=QQQ.END_TS
WHERE X-table.PK=QQQ.PK and X-table. Start TS It QQQ.Start TS
and X-table.ETL_Indicator=′D′;
Фиг.18 представляет собой схему потока данных 540, изображающую шаг 112 вставки 542 записей данных из _XVT таблицы 544 в X_table 546. После того, как данные вставлены 542 в Х_Table 546, шаг 112 включает в себя удаление 548 всех энергозависимых таблиц созданных для раздела. В определенных случаях (например, когда NORMALIZE_LATEST=N и LOAD_TYPE=В) шаг 112 может включать в себя удаление 550 строки в X_table 546 с ETL-указателем ′D′, который находится в текущем разделе.
Далее следует пример псевдокода, который связан с шагом 112, когда NORMALIZE_LATEST=N и LOAD_TYPE=S.
Шаг 112 - псевдокод (NORMALIZE_LATEST=N, LOAD_TYPE=S):
INSERT INTO X_table SELECT*FROM_XVT;
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
COLLECT STATISTICS X-table; (last partition only)
Далее следует пример псевдокода, который связан с шагом 112, когда NORMALIZE_LATEST=Y и LOAD_TYPE=S.
Шаг 112 - псевдокод (NORMALIZE_LATEST=Y, LOAD_TYPE=S):
INSERT INTO X_table SELECT*FROM_XVT;
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
DROP TABLE_KVT
COLLECT STATISTICS X-table; (last partition only)
Далее следует пример псевдокода, который связан с шагом 112, когда NORMALIZE_LATEST=N и LOAD_TYPE=В.
Шаг 112 - псевдокод (NORMALIZE_LATEST=N, LOAD_TYPE=В):
DELETE FROM X_table
WHERE ETL_INDICATOR=′D′
AND HASHBUCKET(HASHROW(USAGE_INSTANCE_NUM_ID)) MOD NUM_PARTITIONS=0;
INSERT INTO X_table SELECT*FROM_XVT;
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
COLLECT STATISTICS X-table; (last partition only)
Первый загрузочный шаг, шаг 201, гарантирует, что если последовательные SQL-операторы вплоть до загрузочного шага 207, END TRANSACTION, выполняются полностью или не выполняются вообще в случае ошибки где-либо в пределах последовательности операторов. Необходимо, чтобы при этом целевая таблица оставалась в достоверном состоянии (например, не более одной SOURCE_END_TS на PK_latest, не более одной активной строки, пока эта строка логически не удалена).
Далее следует пример псевдокода, который связан с загрузочным шагом 201.
Шаг 201 - псевдокод:
START TRANSACTION
Фиг.19 представляет собой схему потока данных 600, изображающую загрузочный шаг 202, который представляет собой фиксацию предшествующей версии обновленной вспомогательной 602 строки. Чтобы обновить вспомогательные строки, конечная временная метка обновляется 604 от null до начальной временной метки самой ранней последующей строки в пределах самого позднего первичного ключа из X_table 606, где ETL-указатель установлен в ′U′. На этом шаге закрывается установка параметров конечной временной метки самой поздней вспомогательной строки для обновлений, при этом конечная временная метка одной строки является начальной временной меткой следующей строки.
Далее следует пример псевдокода, который связан с загрузочным шагом 202.
Шаг 202 - псевдокод:
UPDATE noncore
SET SOURCE_END_TS=MIN(X-table.SRC_START_TS)
CDW_END_TS=current timestamp for table
WHERE noncore.PK_Latest=X-table.PK_Latest
AND SOURCE_END_TS IS NULL
AND X-table.SRC_START_TS gt=noncore.SOURCE_START_TS
AND X-table.ETL_INDICATOR=′U′
AND src_start_ts is the earliest within the PK_Latest;
Фиг.20 представляет собой схему потока данных 620, изображающую загрузочный шаг 203, который представляет собой вставку 622 новых строк в вспомогательную таблицу 624 для ETL-указателей I, О и U. Все входные строки загружаются, кроме строк, выделенных для удаления. Строки, имеющие ETL-индикатор I, и некоторые строки, имеющие ETL-индикатор U, становятся самыми поздними, оставшиеся строки U и все строки О предварительно зафиксированы. Оператор выбора применяется для установки конечной временной метки в закрепленную, текущую временную метку, когда конечная временная метка для источника не равна null в X_table 626 (ETL-указатели О и U в большинстве случаев). Все входные строки загружаются кроме удалений. I-строки и одна U-строка на каждый первичный ключ может стать самым поздним (нет конечной временной метки) пока дополнительные U-строки предварительно фиксируются.
Далее следует пример псевдокода, который связан с загрузочным шагом 203.
Шаг 203 - псевдокод:
INSERT into noncore
Select*from X-table
Where ETL_Indicator=′I′, ′O′ or ′U′;
Фиг.21 представляет собой схему потока данных 640, изображающую загрузочный шаг 204, который представляет собой обновление только что вставленной строки ′О′ в вспомогательных данных 642, когда ей следует наследовать более позднюю дату фиксации из предшествующей строки. Это представляет собой случай, когда строка уже удалена (зафиксирована 644), но получено внеочередное обновление, что случается перед удалением, но после начального времени логического удаления строки. Только что вставленная строка должна получить более позднюю конечную временную метку, поскольку она имеет самую позднюю исходную начальную временную метку. На загрузочном шаге 204 можно фильтровать только строки с РК из X_table 646.
Далее следует пример псевдокода, который связан с загрузочным шагом 204.
Шаг 204 - псевдокод
UPDATE NC_TbI
FROM
noncore NC_TbI,
(SELECT PK_Latest MAX (SOURCE_END_TS) MAX_END_TS
FROM noncore
WHERE (PK_Latest in (SELECT PK_Latest FROM X_table))
GROUP BY PK_Latest) Max_NC
SET SOURCE_END_TS=Max_NC.MAX_END_TS,
CDW_END_TS=current timestamp for table
WHERE NC_TbI.PK_Latest=Max_NC.PK_Latest
AND NC_TbI.SOURCE_START_TS It Max_NC.MAX_END_TS
AND NC_TbI.SOURCE_END_TS IS NULL;
Фиг.22 представляет собой схему потока данных 660, изображающую загрузочный шаг 205, который представляет собой обновление конечной временной метки на вспомогательных 662 строках уже зафиксированных, но имеющих «отсутствующее» обновление 664, вставленное непосредственно после них во время загрузочного шага 203. На загрузочном шаге 205 из X_table 666 используются строки ′О′ для коррекции конечной временной метки строк, которые теперь имеют другую последующую строку из-за вставленной строки ′О′. Новая конечная временная метка представляет собой начальную временную метку только что вставленной строки ′О′.
Далее следует пример псевдокода, который связан с загрузочным шагом 205.
Шаг 205 - псевдокод
UPDATE NC_TbI
FROM noncore NC_TbI,
(SELECT NC_TbI.PK_Latest
,X_TbI.SRC_START_TS SRC_END_TS
,MAX (NC_TbI.SOURCE_START_TS) SOURCE_START_TS
FROM (SELECT PK_Latest
,SRC_START_TS
FROM X-Table
WHERE ETL_INDICATOR=′O′) X_TbI
,(SELECT PK_Latest
,SOURCE_START_TS
FROM noncore) NC_TbI
WHERE NC_TbI.PK_Latest=X_TbI.PK_Latest
AND NC_TbI.SOURCE_START_TS It X_TbI.SRC_START_TS
GROUP BY NC_TbI.PK_Latest, X_TbI.SRC_START_TS
)QQQ
SET SOURCE_END_TS=QQQ.SRC_END_TS,
CDW_END_TS=current timestamp for table
WHERE NC_TbI.PK_Latest=QQQ.PK_Latest
AND NC_TbI.SOURCE_START_TS=QQQ.SOURCE_START_TS;
Фиг.23 представляет собой схему потока данных 680, изображающую загрузочный шаг 206, который представляет собой фиксацию вспомогательных строк, благодаря логическим удалениям. Для ETL-индикатора ′D′ исходная начальная временная метка сохранена в исходной конечной временной метке в X_table 682, чтобы предоставить полный целевой первичный ключ и обновить 684 конечную временную метку значением удаленной временной метки.
Далее следует пример псевдокода, который связан с загрузочным шагом 206.
Шаг 206 - псевдокод
UPDATE NC_TbI
FROM noncore NC_TbI, x table X_TbI
Set NC_TbI source end ts=X tbI source start ts,
NC_TbI.cdw end ts=current timestamp for table
Where NC_TbI.PK_Iatest=X_TbI.PK_Iatest
And NC_TbI.source_start_ts=X_TbI.src_end ts -- ensures 1-to-1
And X_Table. ETL_Indicator is ′D′
And NC_TbI source end ts is null or greater than X table start ts
Далее следует пример псевдокода, который связан с загрузочным шагом 207.
Шаг 207 - псевдокод
END TRANSACTION
Evaluate whether to refresh noncore statistics
В иллюстративных вариантах осуществления все процессы захвата изменений данных (CDC) (описанные выше шаги и загрузочные шаги) завершаются до того, как блок загрузки любых очередных мини пакетных данных начинает с записи в W_table и/или Х-таблицу или запуска CDC для заданной исходной системы или набора целевых таблиц. По существу, весь процесс загрузки не упорядочен, только запись в W_table и/или X_table и запуск CDC.
Вышеописанные варианты осуществления применяются для загрузки любого объема данных из любой исходной системы без модификации с достаточно эффективной поддержкой мини пакетных программ с частотой в 10 или 15 минут в беспрерывно доступное хранилище временных нормализованных данных. Эти варианты осуществления, с вспомогательной базой данных и конкретными настройками (например, наименование списка колонок таблицы каталога), могут быть использованы на любой реляционной базе данных, поддерживающей стандарт ANSI SQL-2003 (или более низкий стандарт с некоторой переделкой), для загрузки хранилища временных нормализованных данных, которое сохраняет историю и не нуждается в активной поддержке ссылочной целостности. Более того, использование реализованных параметров оптимизации метаданных, особенно по отношению к созданию разделов рабочей нагрузки, способствует уменьшению стоимости вычислительного ресурса процесса загрузки, достаточному для предоставления возможности загрузки данных при увеличенной задержке, на серийных вычислительных серверах посредством симметричной многопроцессорной (SMP) структуры в отличие от более дорогой массивно-параллельной (МРР) структуры, обычно применяемой в хранилищах данных. Варианты осуществления работают в пределах набора строк-кандидатов и между теми строками и целевой базой данных, предоставляя возможность обработки многих строк в пределах первичного ключа одновременно, последовательно и свернуто, если смежные строки одинаковы относительно некоторого промежутка времени.
Таким образом, по меньшей мере в одном варианте осуществления, предлагается способ начальной загрузки временного нормализованного хранилища данных, который включает в себя анализ набора входных данных применительно к ним самим и существующим в хранилище данным, определяя и упорядочивая чистые изменения данных посредством набора операторов алгебры отношений (набор SQL), и загружая вставки и временные обновления в хранилище данных полностью, в то время как сами данные остаются в хранилище данных. Чтобы осуществить вышеописанный способ, программный код может динамически создаваться для выполнения вставок данных и временных обновлений с последующим исполнением созданного кода. Кроме того, смежные данные сжаты в минимальное число временных промежутков и микросекундный уровень последовательностей, в которых создаются и поддерживаются уникальные временные метки в случае необходимости.
По меньшей мере в одном варианте осуществления предлагается система, которая включает в себя хранилище данных, возможность приема наборов входных данных, подлежащих сохранению в хранилище данных, и блок упорядочения для идентификации и упорядочения чистых изменений полученных данных по сравнению с ранее сохраненными в хранилище данных. Система может включать в себя один или несколько блоков сжатия, предназначенных для сжатия смежных данных в минимальные периоды времени, блок автокодера для создания кода с целью выполнения обновлений хранилища данных и блок исполнения, предназначенный для исполнения созданного кода. Блок упорядочения предназначен для применения набора операторов алгебры отношений с целью идентификации и упорядочения данных, реализованных в этом примере посредством такого общепринятого ANSI-стандарта языка манипулирования данными (DML), как структурированный язык запросов (SQL).
Общепризнанно, что наиболее преуспевающие компании стремятся иметь отдельное или малое количество нормализованных хранилищ временных данных для большинства, если не всех, аналитических потребностей путем замены сотен рабочих хранилищ и киосков данных. Эта парадигма привела к значительной потребности в полностью новом типе эффективного и относительно неинтрузивного загружаемого программного обеспечения. Описанные варианты осуществления приводят к резкому сокращению расходов на развитие и поддержку хранилища временных данных, большую экономию расходов на эксплуатацию сервера загрузки данных и сетевой трафик, поскольку работа намного эффективно проводится в SQL базы данных и очень хорошо обходит любую потребность во второй копии целевой базы данных во время периодов загрузки для поддержки возможности непрерывных запросов (вторая копия может использоваться для других случаев). Описанные варианты осуществления пригодны для базы данных на любой платформе, поскольку применение хранилища временных данных растет глобально и никакое существующее техническое решение не предоставляет аналогичные возможности, и в то же время однозначно предоставляет стратегию хранилища данных для поддержки многих типов аналитических потребностей (рабочих, тактических, стратегических) из отдельной копии доступных в непрерывном режиме данных, охватывающих область применения хранилища данных, как одну или несколько предметных областей, так и отрасли в целом.
Описанные системы и способы поддерживают почти в реальном масштабе времени минимально интрузивную загрузку отдельного нормализованного хранилища данных, которое, в свою очередь, предоставляет возможность непрерывный и практически мгновенный внешный доступ через подходящие элементы управления безопасностью и авторизацией к единственной копии всех данных в единственной системе с полной временной историей, нормализованной в требуемые минимальные периоды времени.
В иллюстративных вариантах осуществления создание разделов набора входных является необязательным. Разделы могут обрабатываться независимо, так чтобы исполняющие процессы не имели доступ к данным из более чем одного раздела. Скорее, результаты обработки каждого раздела могут быть накоплены в X_table для применения лишь в одном загрузочном шаге (не распараллеленном или разделенном), как описано выше.
В некоторых вариантах осуществления используют энергозависимые (например, непостоянные) таблицы при импортировании наборов входных данных. Полный набор энергозависимых таблиц можно использовать, например, когда разделы указаны. Кроме того, данные могут быть нормализованными (например, нормализованными во времени) между существующими данными в хранилище двоичных данных (CDW) и набором входных данных посредством ли традиционных, постоянных (″физических″) таблиц и без разделов или посредством разделов и энергозависимых копий физических таблиц, один набор на раздел (например, четыре виртуальные таблицы на раздел).
Варианты осуществления изобретения можно осуществить посредством одного или нескольких вычислительных устройств, таких как сервер 16 базы данных и/или сервер 24 приложения (показанный на фиг.2). Фиг.24 представляет собой блок-схему иллюстративного вычислительного устройства 700. В иллюстративном варианте осуществления вычислительное устройство 700 включает в себя волоконную линию связи 705, которая предоставляет связь между процессорным блоком 710, памятью 715, постоянным запоминающим устройством 720, блоком связей 725, блоком 730 ввода-вывода (I/O) и интерфейсом представления, таким как дисплей 735. В дополнение или альтернативно интерфейс представления данных может включать в себя аудио устройство (не показано) и/или любое устройство, способное доставлять информацию пользователю.
Процессорный блок 710 исполняет инструкции программного обеспечения, которые могут быть загружены в память 715. Процессорный блок 710 может представлять собой набор из одного или нескольких процессоров или может включать в себя несколько процессорных ядер в зависимости от конкретной реализации. Кроме того, процессорный блок 710 может быть реализован посредством одного или нескольких гетерогенных процессорных систем, в которых основной процессор находится вместе с вторичными процессорами на одном чипе. В другом варианте осуществления процессорный блок 710 может представлять собой гомогенную процессорную систему, содержащую несколько процессоров одного типа.
Память 715 и постоянное запоминающее устройство 720 представляют собой примеры запоминающих устройств. В данном документе запоминающее устройство является любой частью аппаратного обеспечения, которое способно хранить информацию как на временной основе, так и на постоянной основе. Память 715 может быть, в качестве примера, а не ограничения, оперативным запоминающим устройством и/или любым другим подходящим энергозависимым или энергонезависимым запоминающим устройством. Постоянное запоминающее устройство 720 может быть разных типов в зависимости от конкретной реализации и содержать один или несколько компонентов или устройств. Например, постоянное запоминающее устройство 720 может представлять собой накопитель на жестком диске, флэш-память, перезаписываемый оптический диск, перезаписываемую магнитную ленту и/или некоторую комбинацию из вышеизложенного. Носитель, используемый постоянным запоминающим устройством 720, может быть также съемным. В качестве примера, а не ограничения, съемный накопитель на жестком диске можно использовать для постоянного запоминающего устройства 720.
Запоминающее устройство, такое как память 715 и/или постоянное запоминающее устройство 720, может быть выполнено с возможностью хранить данные для применения в процессах, описанных в данном документе. Например, запоминающее устройство может хранить машиноисполняемые инструкции, исполняемые компонентами программного обеспечения (например, компонентом загрузки данных и/или компонентом хранилища данных), данные, принимаемые из источников данных, данные конфигурации (например, опций оптимизации) и/или любую другую информацию, подходящую для, использования со способами, описанными в данном документе.
Модуль 725 передачи данных в этих примерах предназначен для связи с другими вычислительными устройствами или системами. В иллюстративном варианте осуществления модуль 725 передачи данных является сетевым адаптером. Модуль 725 передачи данных может предоставить связь посредством использования физической и беспроводной линии связи по отдельности или вместе.
Блок 730 ввода-вывода предоставляет возможность ввода данных в другие устройства и вывода данных из этих устройств, которые могут быть подключены к вычислительному устройству 700. В качестве примера, а не ограничения, блок 730 ввода-вывода может предоставить возможность ввода данных пользователем посредством пользовательского устройства ввода, такого как клавиатура и/или мышь. Кроме того, блок 730 ввода-вывода может отправлять выходные данные на принтер. Дисплей 735 предоставляет механизм вывода информации на экран пользователя. Например, интерфейс представления информации, такой как дисплей 735 может вывести информацию на экран графического интерфейса пользователя.
Инструкции операционной системы и приложений или программ находятся в постоянном запоминающем устройстве 720. Эти инструкции могут быть загружены в память 715 для исполнения процессорным блоком 710. Процессы разных вариантов осуществления можно реализовать процессорным блоком 710 посредством машиночитаемых и/или машиноисполняемых инструкций, которые могут находиться в памяти, такой как память 715. Эти инструкции в данном документе называются программный код (например, целевой код и/или исходный код), который может быть считан и исполнен процессором в процессорном блоке 710. Программный код в разных вариантах осуществления может быть реализован на разном физическом или материальном машиночитаемом носителе, таком как память 715 или постоянном запоминающем устройстве 720.
Программный код 740 находится в виде функций на долговременном машиночитаемом носителе 745, который может быть съемным и может быть загружен или перенесен в вычислительное устройство 700 для исполнения процессорным блоком 710. Программный код 740 и машиночитаемый носитель 745 в этих примерах образуют компьютерный программный продукт 750. В одном из примеров машиночитаемый носитель 745 может быть в материальной форме, такой как, например, оптический или магнитный диск, который вставляется в дисковод или другое устройство, которое является частью постоянного запоминающего устройства 720, для переноса в запоминающее устройство, такое как накопитель на жестком диске, который является частью постоянного запоминающего устройства 720. В материальной форме машиночитаемый носитель 745 также может быть представлен в виде постоянного запоминающего устройства, такого как накопитель на жестком диске, флеш-накопитель или флэш-память, которое подключено к вычислительному устройству 700. Физическая форма машиночитаемого носителя 745 также называется машиночитаемым запоминающим носителем. В некоторых примерах машиночитаемый носитель 745 может быть несъемным.
В альтернативном исполнении программный код 740 может переноситься в вычислительное устройство 700 из машиночитаемого носителя 745 посредством линии связи и модуля 725 передачи данных и/или посредством подключения блока 730 ввода-вывода. Линия связи и/или подключение в иллюстративных примерах могут быть физическим или беспроводным. Машиночитаемый носитель также может быть представлен в виде не физического носителя, такого как линия связи или беспроводные передачи, содержащие программный код.
В некоторых демонстрационных вариантах осуществления программный код 740 может быть загружен по сети в постоянное запоминающее устройство 720 из другого вычислительного устройства или компьютерной системы для использования в вычислительном устройстве 700. Например, программный код, сохраненный на машиночитаемом запоминающем носителе в серверном вычислительном устройстве, может быть загружен по сети из сервера в вычислительное устройство 700. Вычислительное устройство, предоставляющее программный код 740, может представлять собой серверный компьютер, рабочую станцию, клиентский компьютер, или некоторое другое устройство способное хранить и передавать программный код 740.
Программный код 740 может быть организован в функционально связанные машиноисполняемые компоненты. Каждый компонент может включать в себя машиноисполняемые инструкции, которые при их исполнении посредством процессорного блока 710, приводят к выполнению процессорным блоком 710 одну или несколько операций, описанных в данном документе.
Различные компоненты вычислительного устройства 700, представленные в данном документе, не предназначены для структурных ограничений способа, который может быть реализован разными вариантами осуществления. Разные демонстрационные варианты осуществления могут быть реализованы в компьютерной системе, включающей компоненты в дополнение или вместо тех, которые изображены для вычислительного устройства 700. Например, другие компоненты, показанные на фиг.24, могут отличаться от показанных иллюстративных примеров.
В качестве примера, запоминающее устройство в вычислительном устройстве 700 является любым устройством аппаратного обеспечения, которое может хранить данные. Память 715, постоянное запоминающее устройство 720 и машиночитаемый носитель 745 представляют собой примеры запоминающих устройств в материальной форме существования.
В другом примере магистральная система может быть применена для реализации коммутируемой линия связи 705 и может включать в себя одну или несколько шин, таких как системная шина или шина ввода-вывода. Конечно, магистральная система может быть реализована посредством структуры любого подходящего типа, которая обеспечивает передачу данных между разными компонентами или устройствами, подключенными к магистральной системе. Кроме того, модуль передачи данных может включать в себя одно или несколько устройств, используемых для передачи и приема данных, таких как модем или адаптер сети. Кроме того, память может быть, в качестве примера, а не ограничения, памятью 715 или кешем, таким как тот, что встречается в интерфейсе и концентраторе контроллера памяти, который может находиться в линии связи 705.
Вышеописанные варианты осуществления относятся к системе для загрузки набора входных данных в хранилище временных данных. Такие системы включают в себя запоминающее устройство, включающее хранилище временных данных и набор входных данных, и процессорный блок, соединенный с запоминающим устройством. Процессор по меньшей мере в одном варианте осуществления запрограммирован на разбиение набора входных данных на множество разделов, включающих первый раздел и второй раздел, при этом каждый раздел из множества разделов, включает в себя множество записей данных, импорт первого раздела в таблицу предварительной загрузки, импорт второго раздела в таблицу предварительной загрузки, и загрузка таблицы предварительной загрузки в хранилище временных данных. В другом варианте осуществления процессорный блок запрограммирован на разбиение набора входных данных на множество разделов по меньшей мере частично посредством применения хеш-функции к первичному ключу, связанному по меньшей мере с одной записью данных, чтобы выдать хеш-значение, соответствующее по меньшей мере одной записи данных. В другом варианте осуществления процессорный блок дополнительно запрограммирован на импорт второго раздела в таблицу предварительной загрузки после предварительной загрузки первого раздела в таблицу. Еще в одном варианте осуществления процессорный блок дополнительно запрограммирован на импорт второго раздела в таблицу предварительной загрузки, пока первый раздел импортируется в таблицу предварительной загрузки. В таких вариантах осуществления процессорный блок запрограммирован на импорт второго раздела в таблицу предварительной загрузки, пока первый раздел импортируется в таблицу предварительной загрузки, исходя из определения того, что текущее количество параллельных каналов импорта меньше, чем заданное максимальное количество параллельных каналов импорта.
В альтернативных вариантах осуществления процессорный блок запрограммирован на импорт по меньшей мере одного из первого раздела и второго раздела по меньшей мере частично посредством импорта записей данных раздела в энергозависимую таблицу, соответствующую разделу, и копии записей данных из энергозависимой таблицы в таблицу предварительной загрузки.
В отдельных вариантах осуществления процессорный блок дополнительно запрограммирован на идентификацию записи данных в первом разделе, который включает в себя множество полей, отличных от временной метки, равной неключевым полям ранее импортированных записей данных, и исключение идентифицированной записи данных, когда импортируется первый раздел в таблицу предварительной загрузки. Входные данные могут включают в себя снимок данных из исходной базы данных, и в таких вариантах осуществления процессорный блок дополнительно запрограммирован на регистрацию того, что активная запись данных в хранилище временных данных не связана с записью данных в наборе входных данных, и исполняет неявное удаление активной записи данных, исходя из указанного обнаружения. Процессорный блок может быть дополнительно запрограммирован на определение самой ранней исходной временной метки, связанной с первой записью данных в наборе входных данных, идентификацию набора первичных ключей, которые представляют: запись данных в хранилище временных данных, связанную с исходной временной меткой, предшествующей самой ранней исходной временной метке, и один или несколько записей данных в хранилище временных данных, которые связаны с исходной временной меткой, более поздней чем самая ранняя исходная временная метка, и импорт первого раздела и второго раздела исходя из идентифицированного набора первичных ключей.
В дополнение в вариантах осуществления, описанных в данном документе, представлен способ для загрузки множества записей данных в хранилище временных данных. Такие способы включают в себя разбиение, посредством вычислительного устройства, записи данных на множество разделов, включающих первый раздел и второй раздел, импортирование, посредством вычислительного устройства, первого раздела в таблицу предварительной загрузки, импортирование, посредством вычислительного устройства, второго раздела в таблицу предварительной загрузки, и загрузки, посредством вычислительного устройства, таблицы предварительной загрузки в хранилище временных данных. В конкретных вариантах осуществления способа первый раздел и второй раздел импортируются в параллельно. Способ может дополнительно включать определение того, что текущее количество параллельных каналов импорта меньше заданного максимального количества параллельных каналов импорта, при этом первый раздел и второй раздел импортируются параллельно, исходя из упомянутого определения. Способ может дополнительно включать определение того, что текущее количество параллельных каналов импорта больше или равно максимальному количеству параллельных каналов импорта, при этом первый раздел и второй раздел импортируются последовательно, исходя из упомянутого определения.
В альтернативном варианте осуществления способа рассматривается разбиение данных, посредством вычислительного устройства, на множество разделов, которое включает применение хеш-функции по меньшей мере к одной записи данных, чтобы создать хеш-значение, связанное по меньшей мере с одной записью данных, и применение оператора деления по модулю к хеш-значению, исходя из заданного количества разделов, чтобы определить число разделов, соответствующих и связанных по меньшей мере с одной записью данных.
Варианты осуществления способа могут также включать идентификацию записи данных в первом разделе, содержащем множество полей, отличных от временной метки, которые равны неключевым полям ранее импортированной записи данных, и исключение идентифицированной записи данных, когда импортируется первый раздел в таблицу предварительной загрузки.
Вышеописанные варианты осуществления могут дополнительно характеризоваться как компьютерный программный продукт, содержащий постоянный машиночитаемый носитель с записанными на нем машиноисполняемыми инструкциями для загрузки хранилища данных чистыми данными изменений. Исполнение по меньшей мере одним процессором машиноисполняемых инструкций приводит к разбиению набора входных данных на множество разделов, включающих первый раздел и второй раздел, при этом по меньшей мере один раздел из этого множества, включает в себя множество записей данных, к импорту первого раздела в таблицу предварительной загрузки, к импорту второго раздела в таблицу предварительной загрузки и к загрузке таблицы предварительной загрузки в хранилище данных.
В дополнительных вариантах осуществления машиноисполняемые инструкции приводят к выполнению по меньшей мере одним процессором одновременного импорта первого раздела и второго раздела. В других вариантах осуществления машиноисполняемые инструкции дополнительно приводят к выполнению по меньшей мере одним процессором сравнения текущего количества параллельных каналов импорта с заданным максимальным количеством параллельных каналов импорта, импорта второго раздела параллельно с импортированием первого раздела, когда текущее количество меньше максимального количества параллельных каналов импорта, и импорта второго раздела после импорта первого раздела, когда текущее количество больше или равно максимальному количеству параллельных каналов импорта.
В отдельных вариантах осуществления машиноисполняемые инструкции приводят к выполнению по меньшей мере одним процессором импорта первого раздела и второго раздела по меньшей мере частично посредством импортирования записей данных первого раздела в первую энергозависимую таблицу, соответствующую первому разделу, импортирования записей данных второго раздела во вторую энергозависимую таблицу, соответствующую второму разделу, и копирования записей данных первой энергозависимой таблицы и второй энергозависимой таблицы в таблицу предварительной загрузки.
В отдельных вариантах осуществления набор входных данных включает в себя снимок данных исходной базы, а машиноисполняемые инструкции дополнительно приводят к выполнению по меньшей мере одним процессором регистрации активной записи данных в хранилище данных, которая не связана с записью данных в наборе входных данных, и к исполнению неявного удаления активной записи данных в результате упомянутой регистрации.
В этом описании для раскрытия настоящего изобретения используются примеры, включающие наилучший вариант, а также предоставляющие возможность специалисту в данной области техники применить изобретение на практике, включая создание и использование любых устройств или систем и осуществление любых включенных в данный документ способов. Патентоспособный объем изобретения задается формулой изобретения и может включать в себя другие примеры, которые возникают у специалистов в данной области техники. Подразумевается, что другие подобные примеры находятся в пределах объема формулы изобретения, если они имеют структурные элементы, не отличающиеся от буквального толкования формулы изобретения, или если они включают в себя эквивалентные структурные элементы с незначительными расхождениями от буквального толкования формулы изобретения.
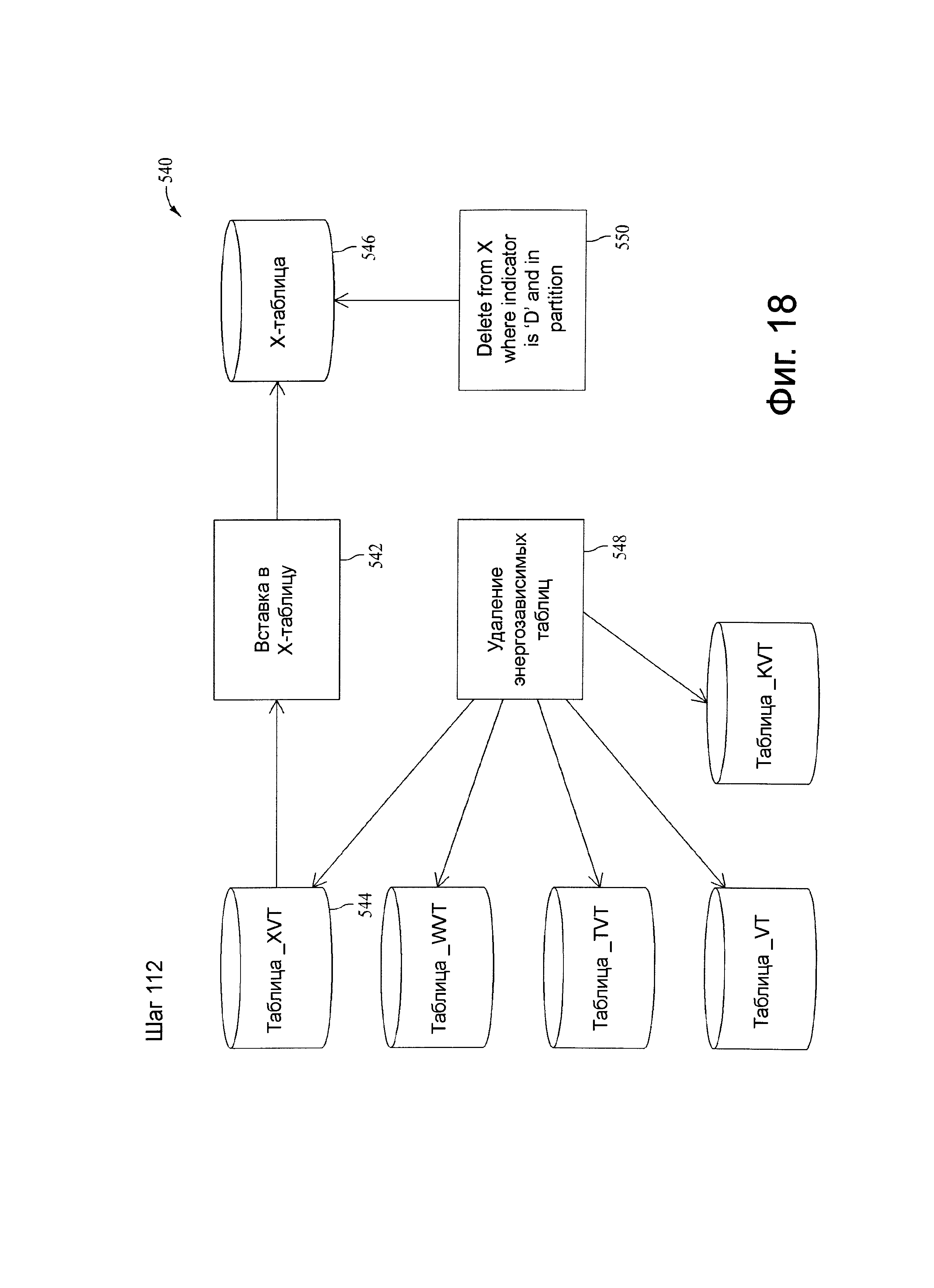
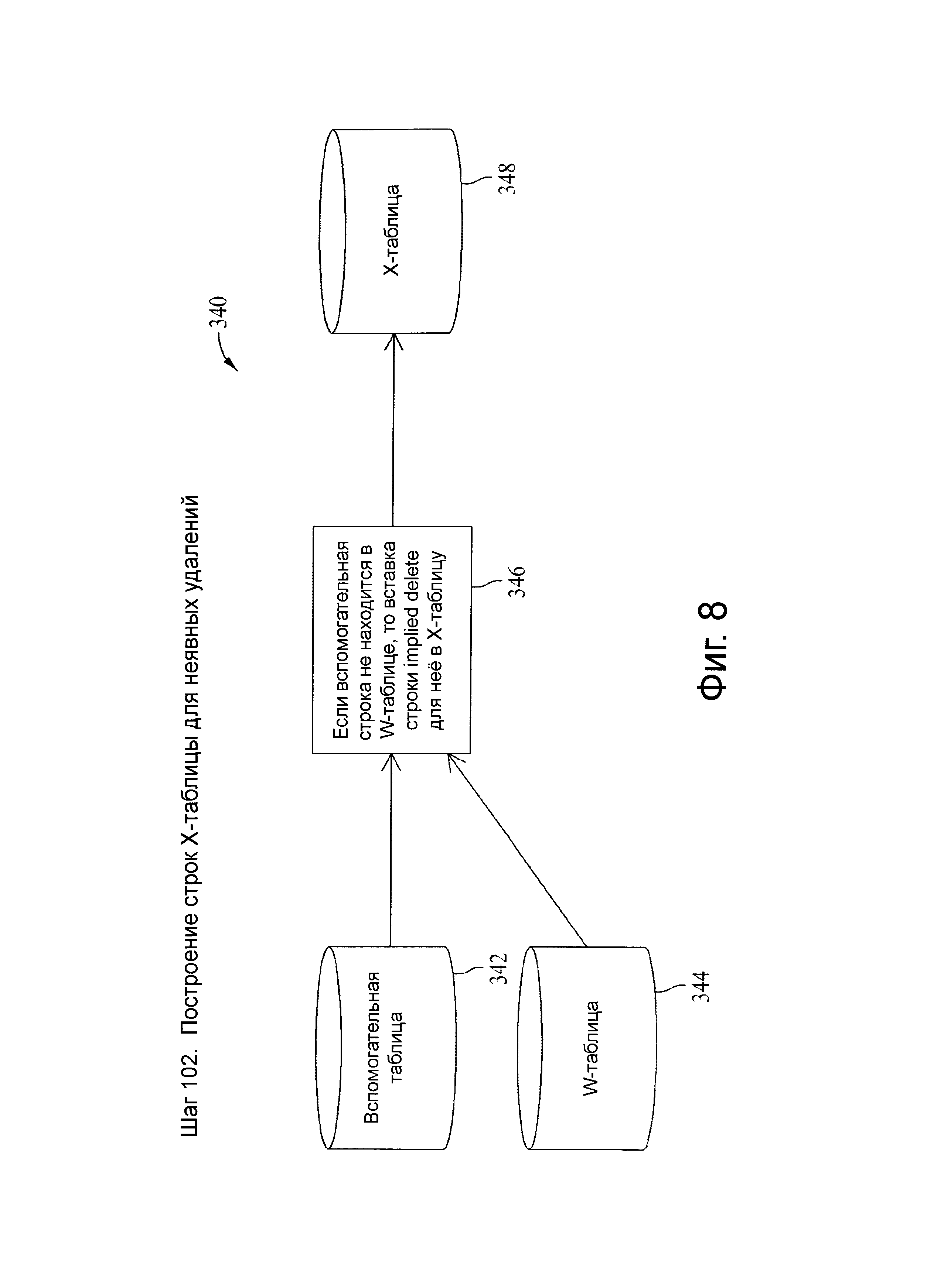
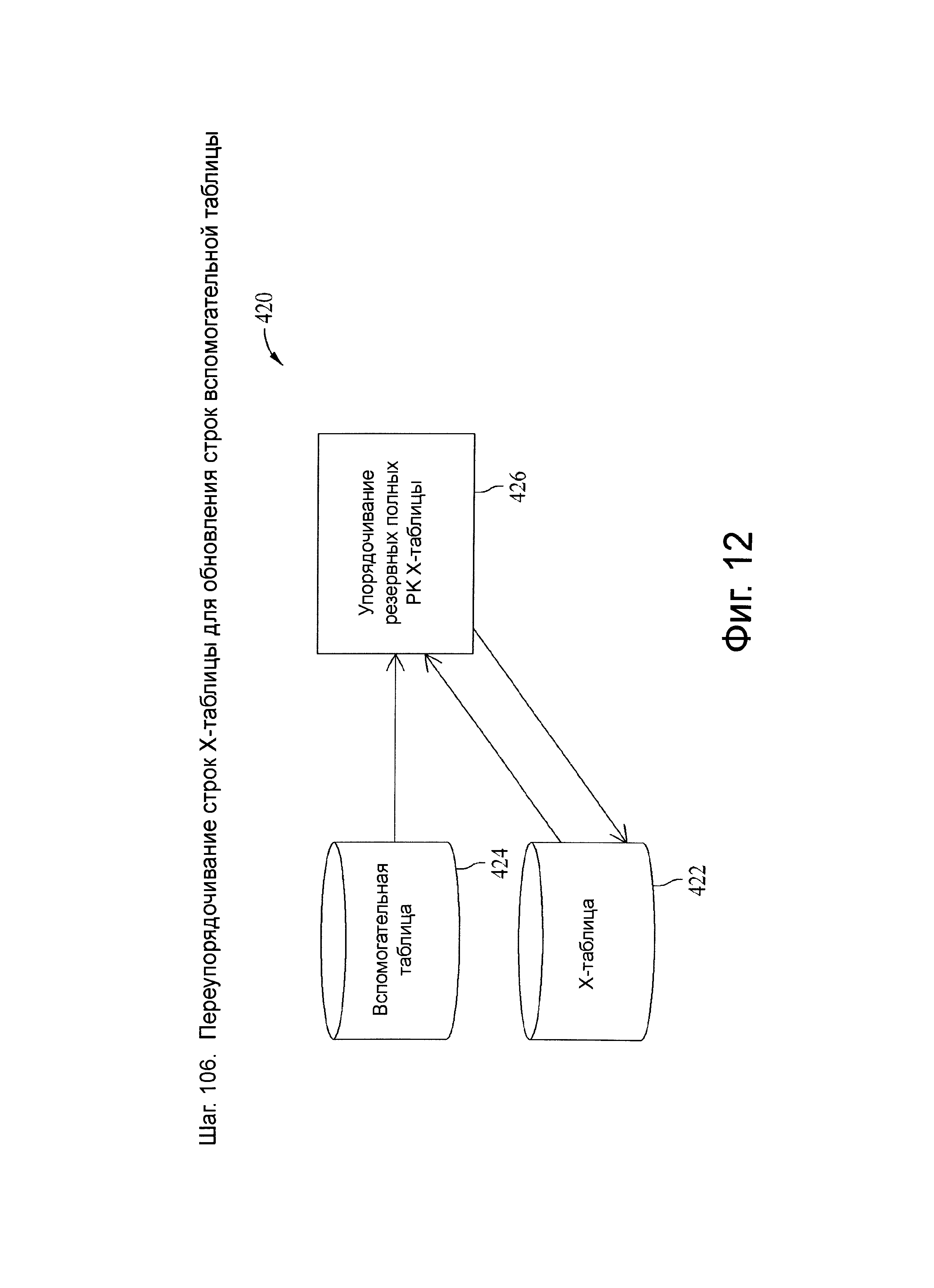
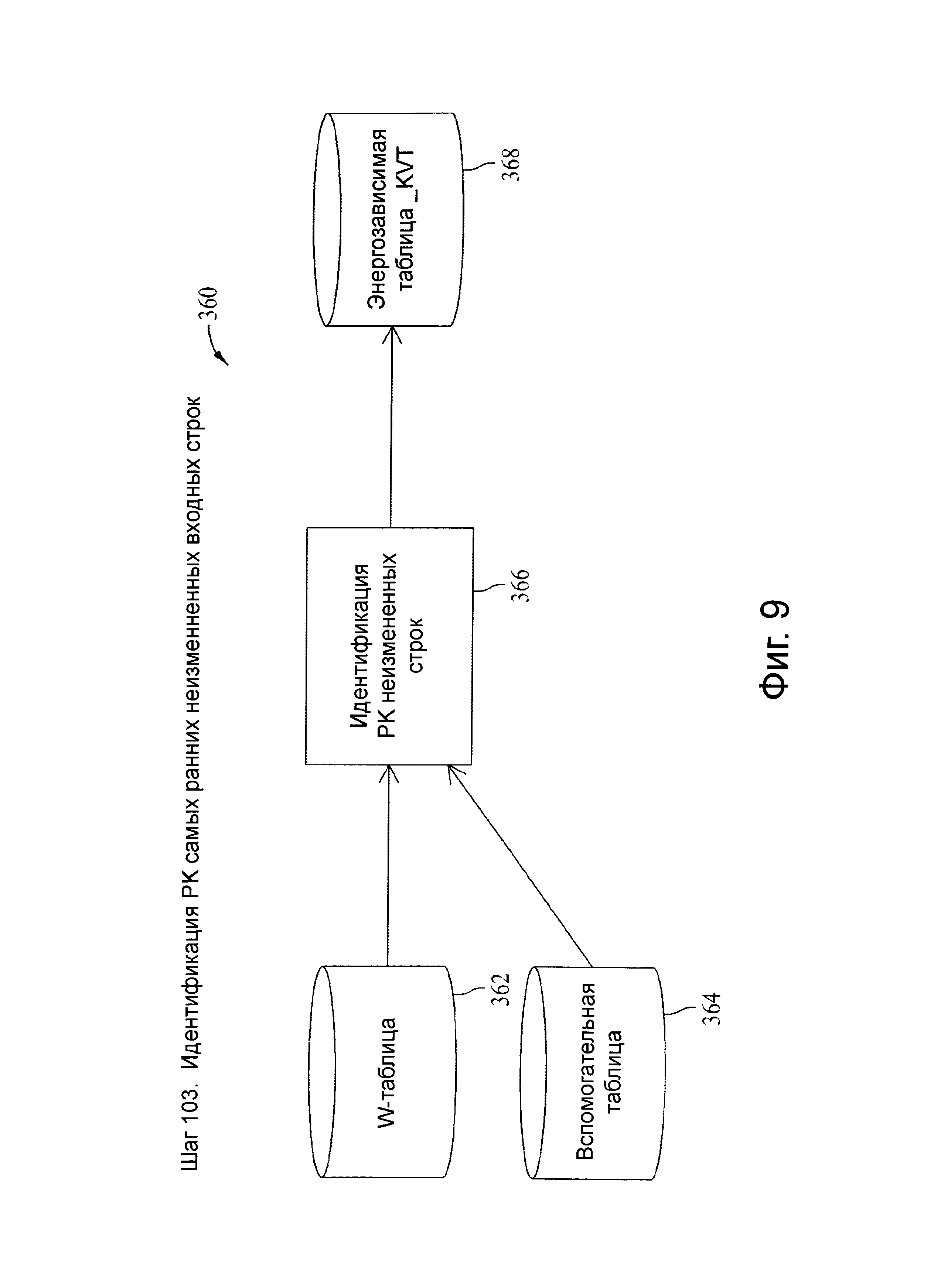
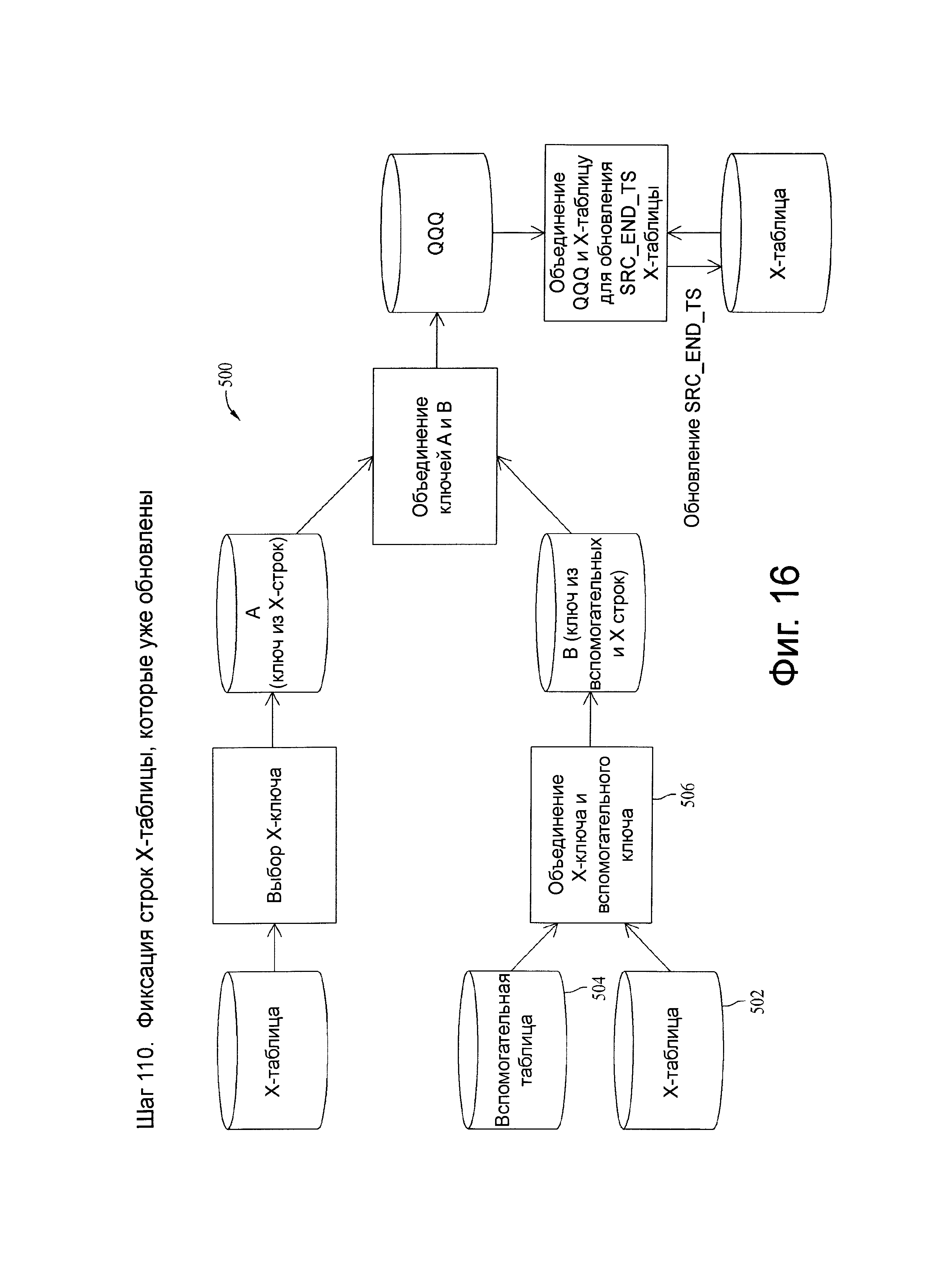
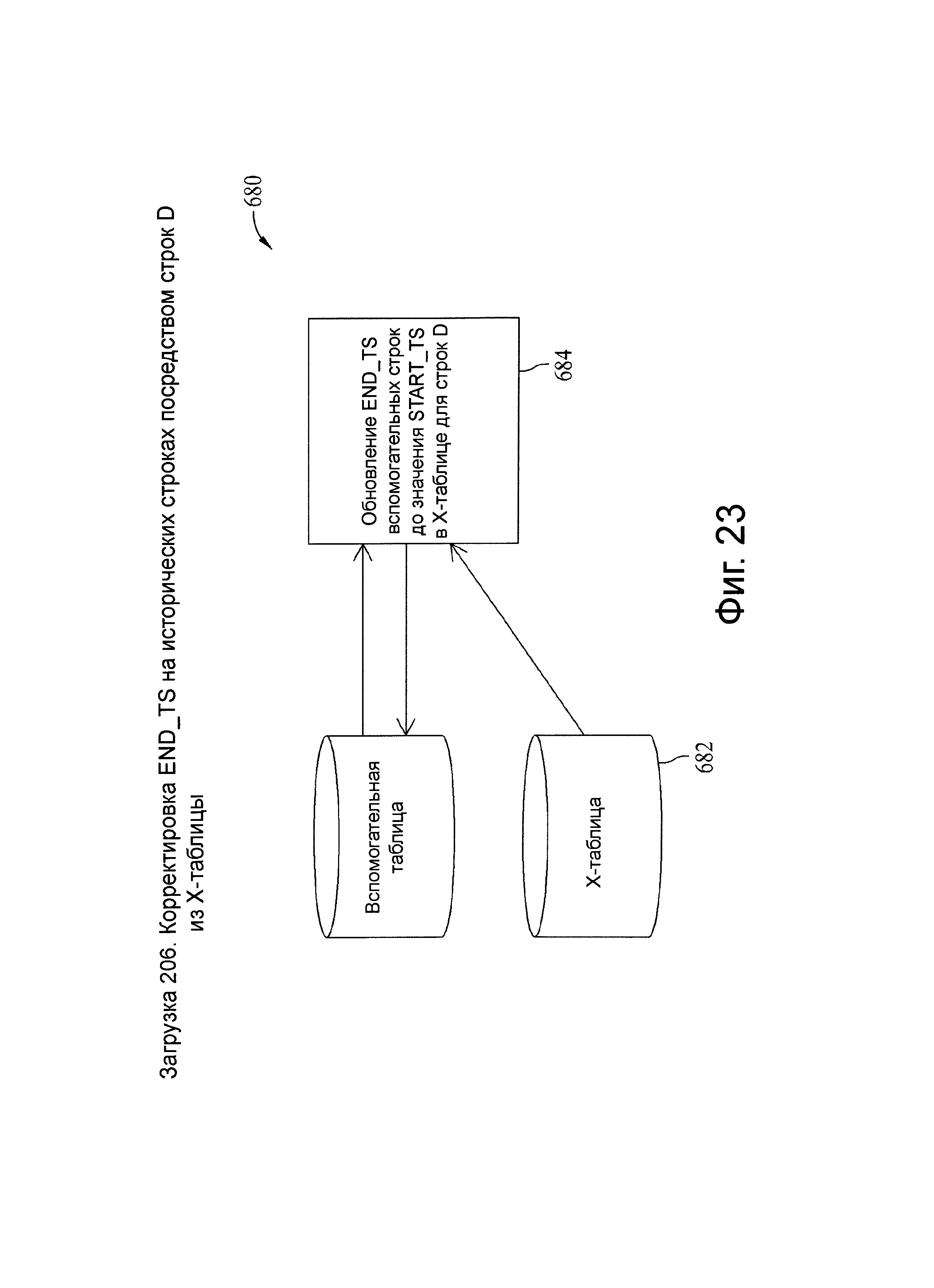
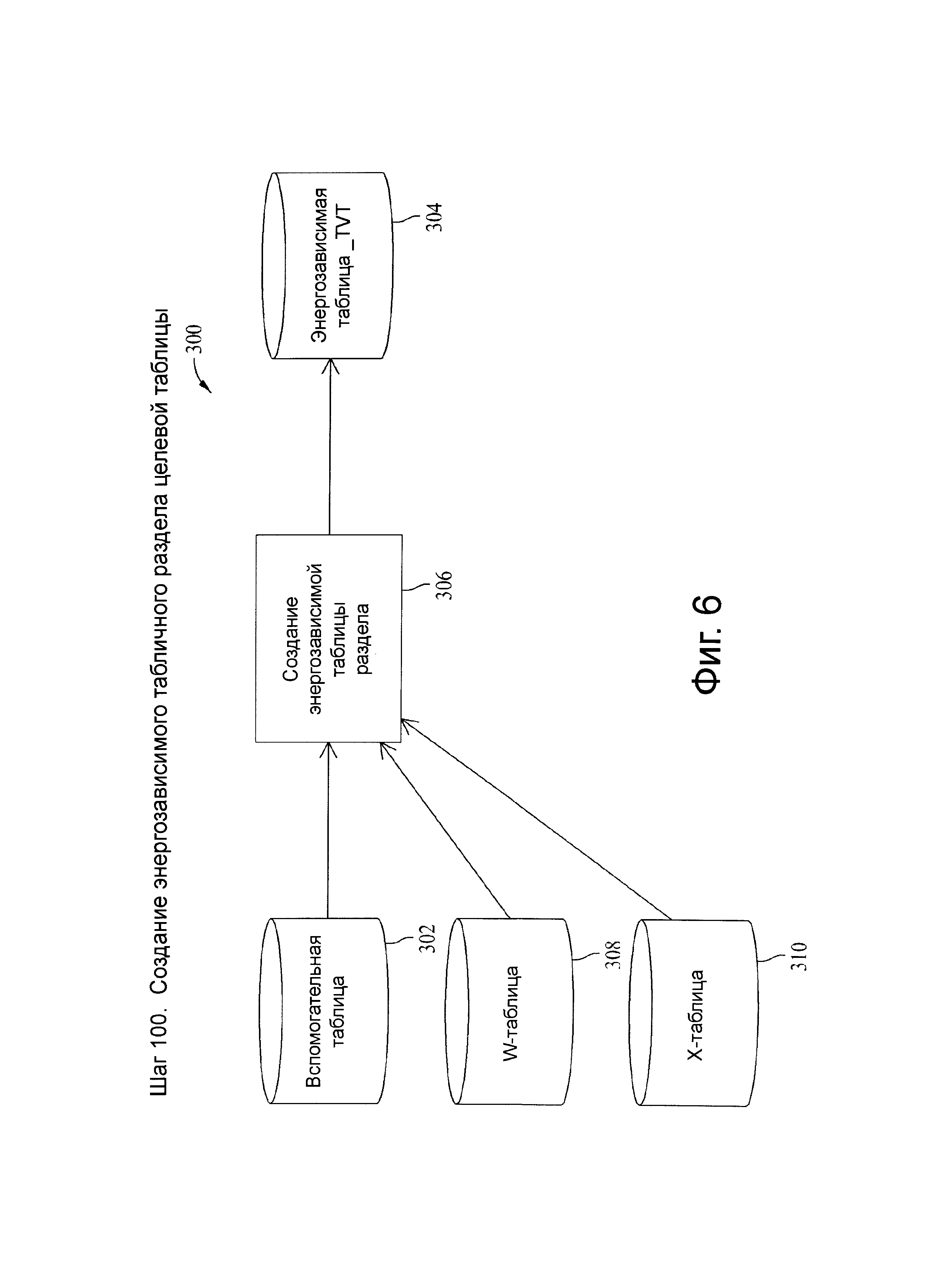
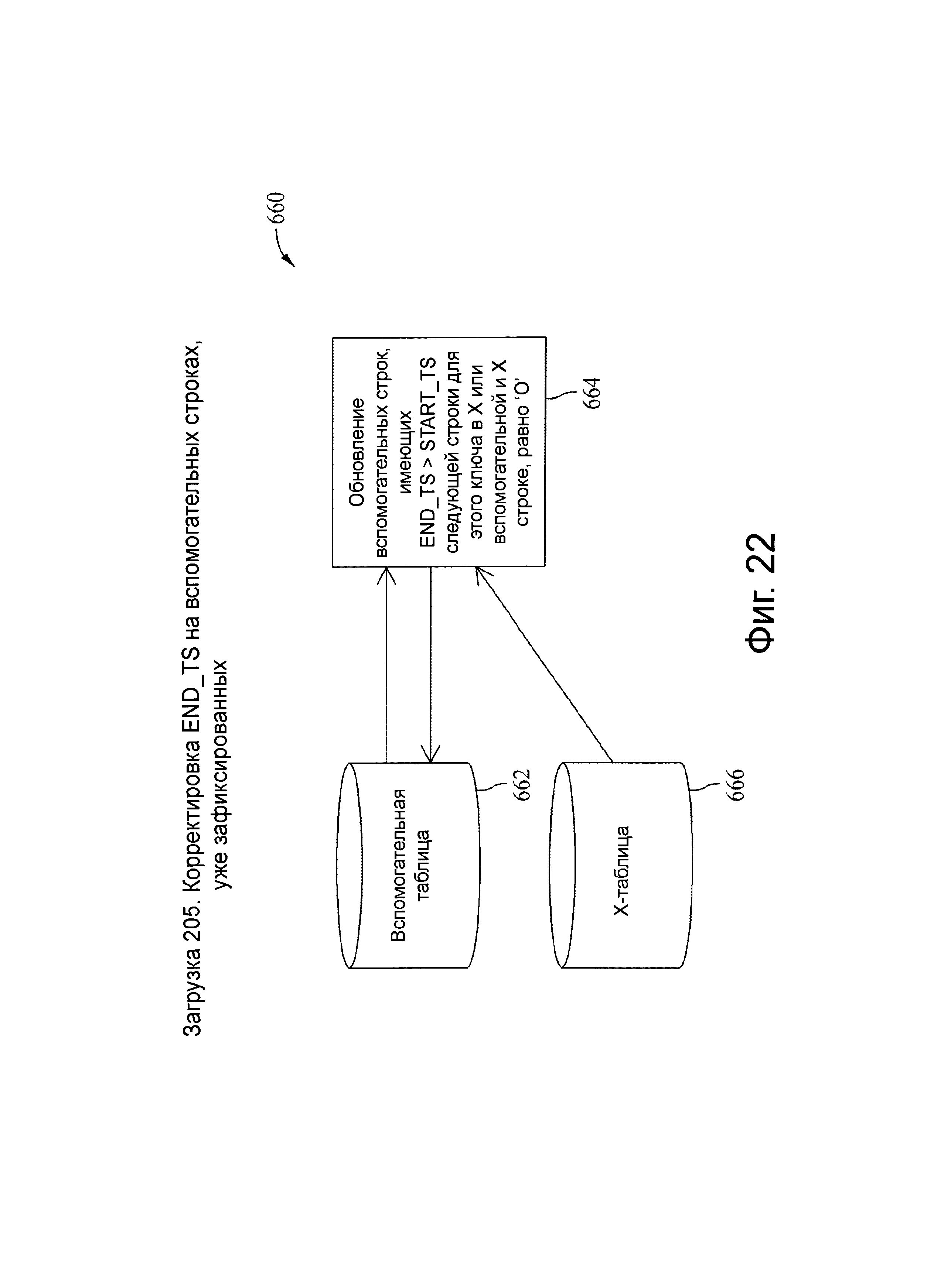
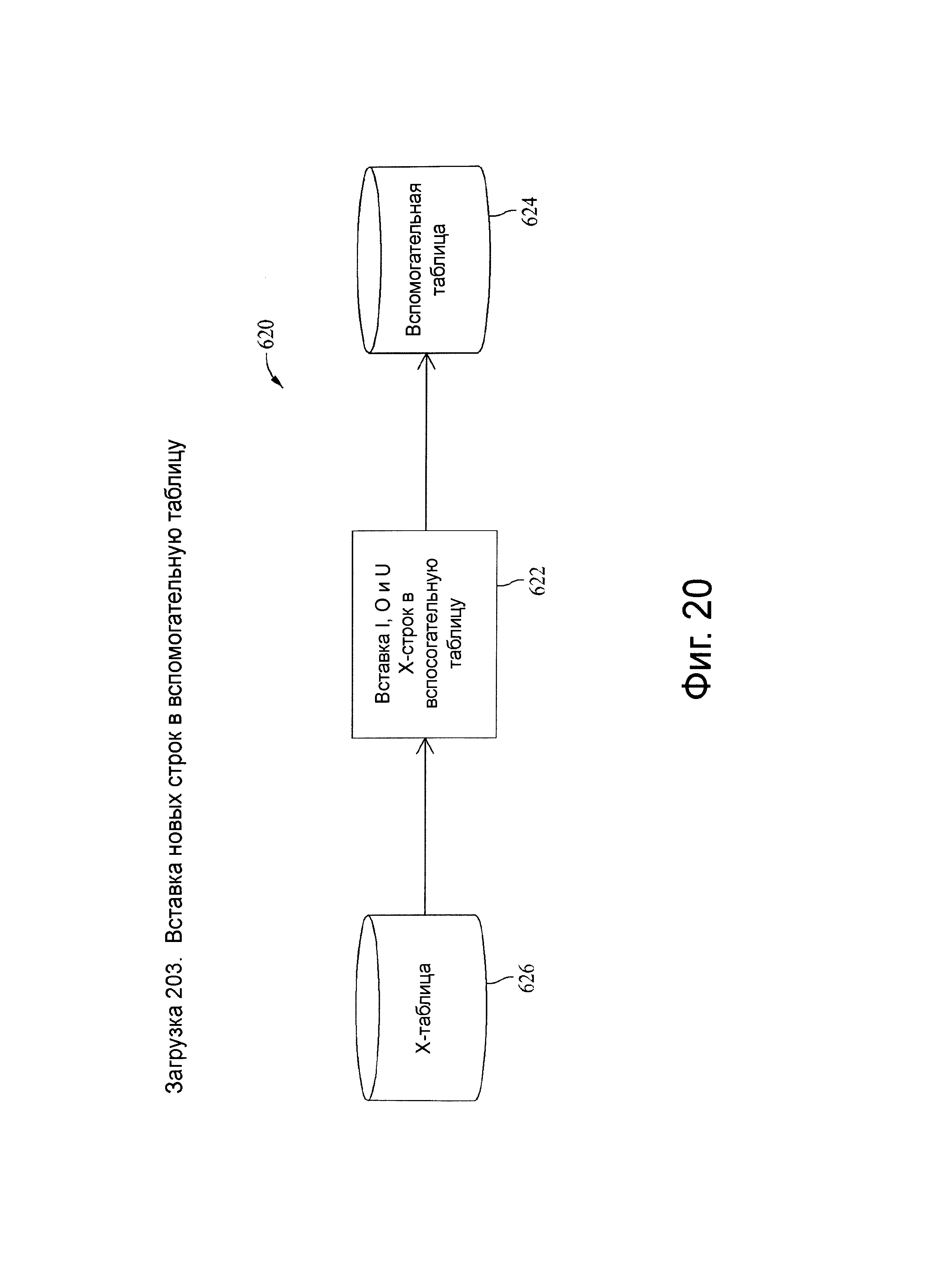
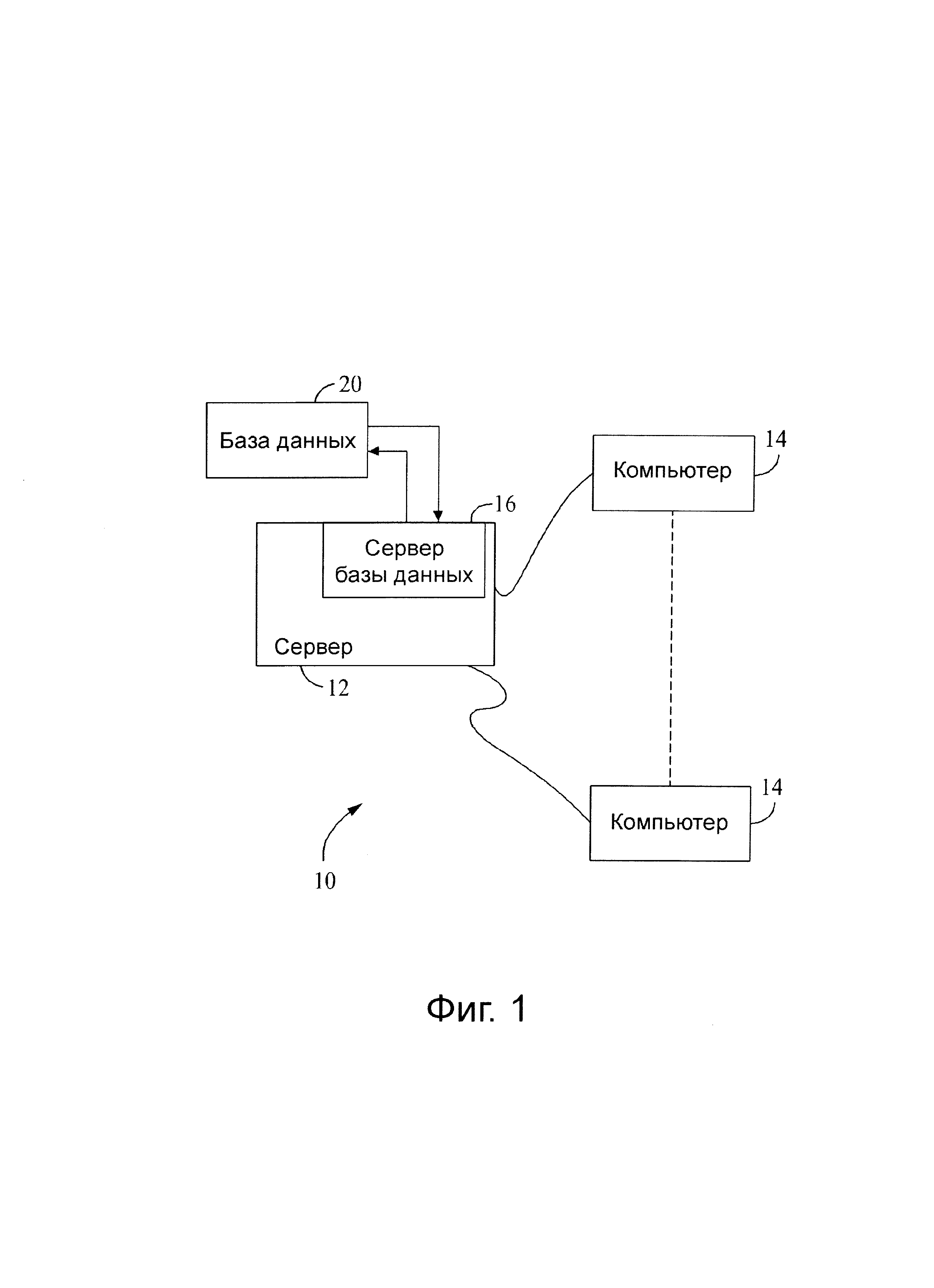
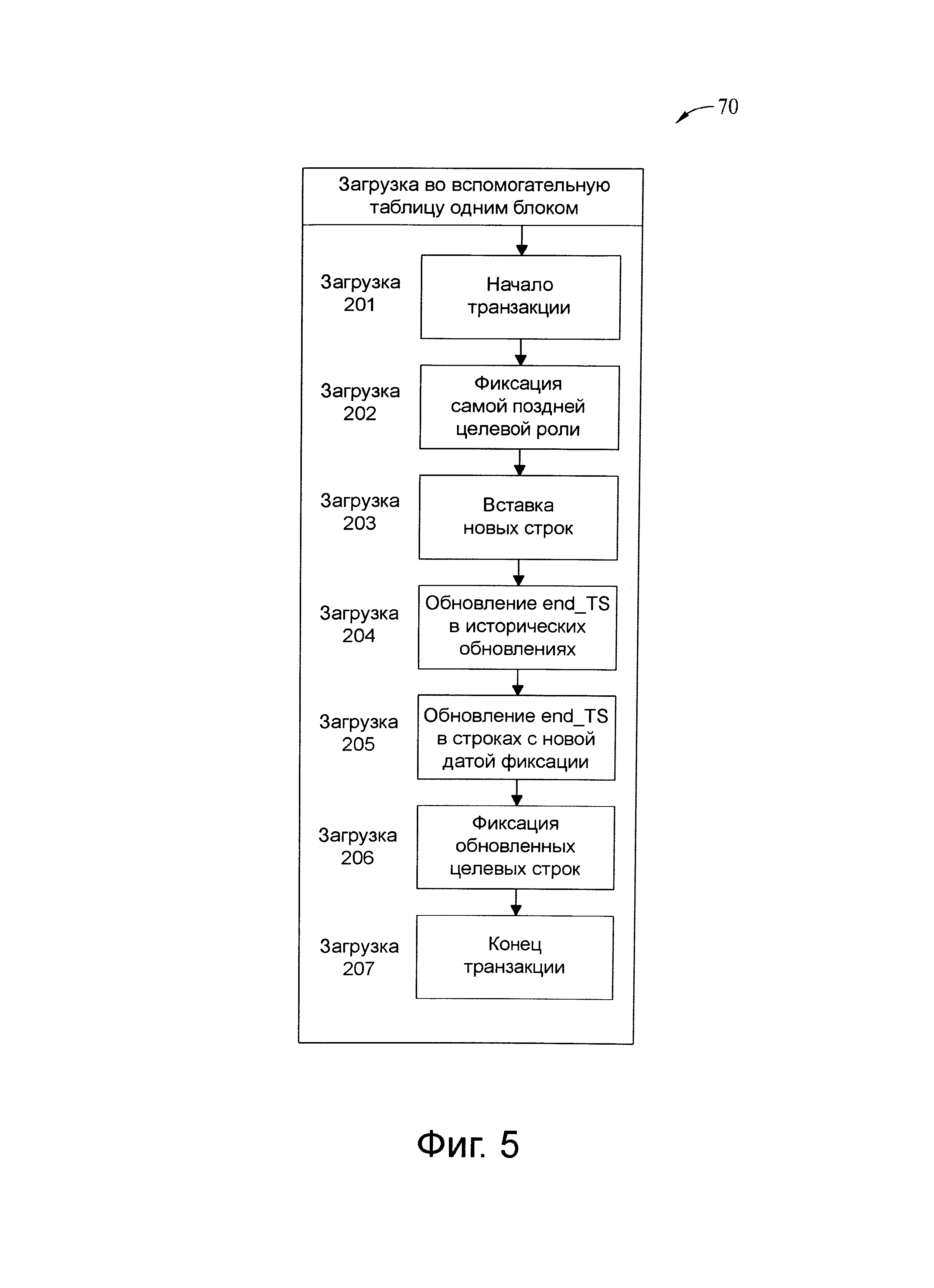
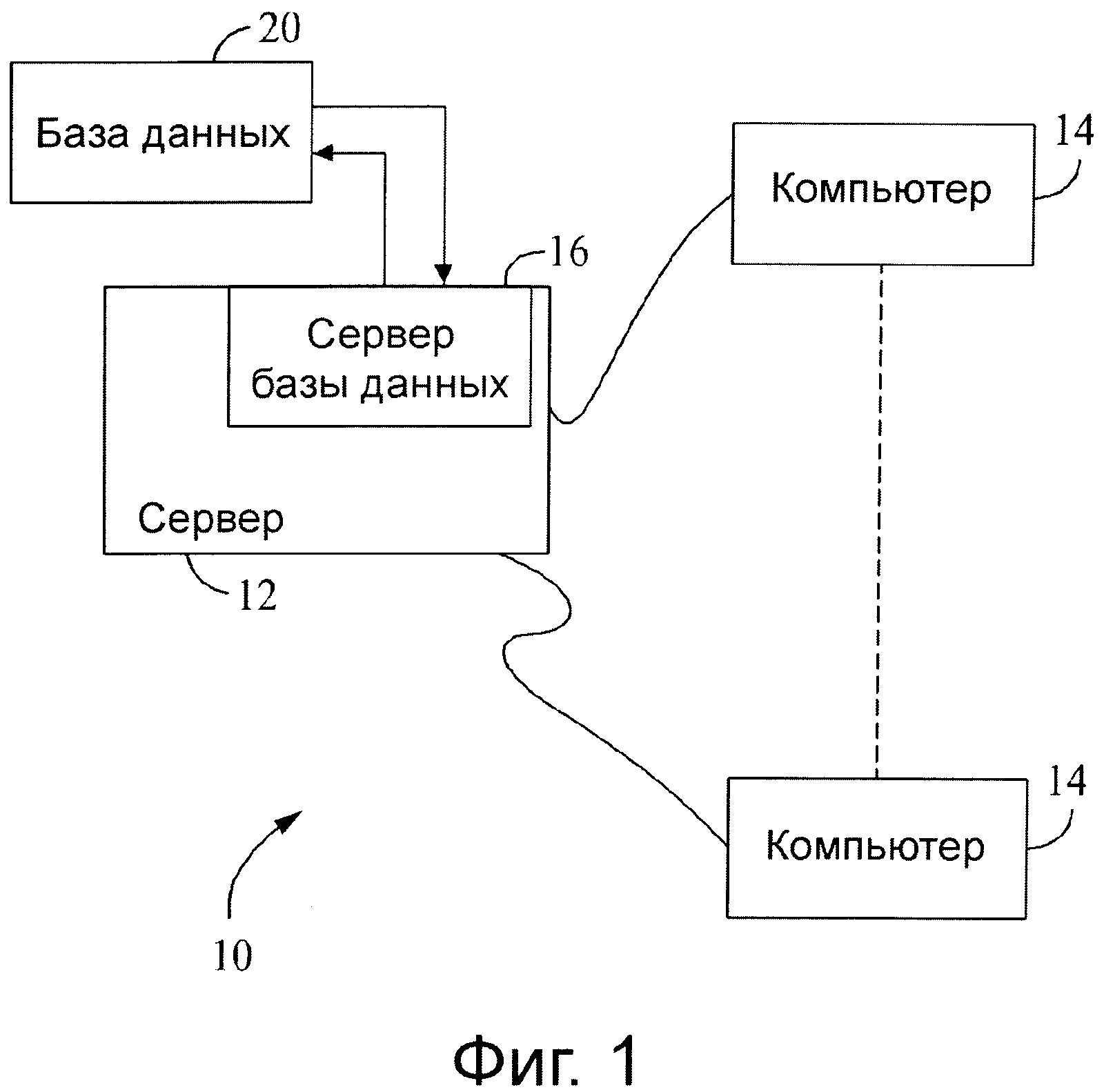
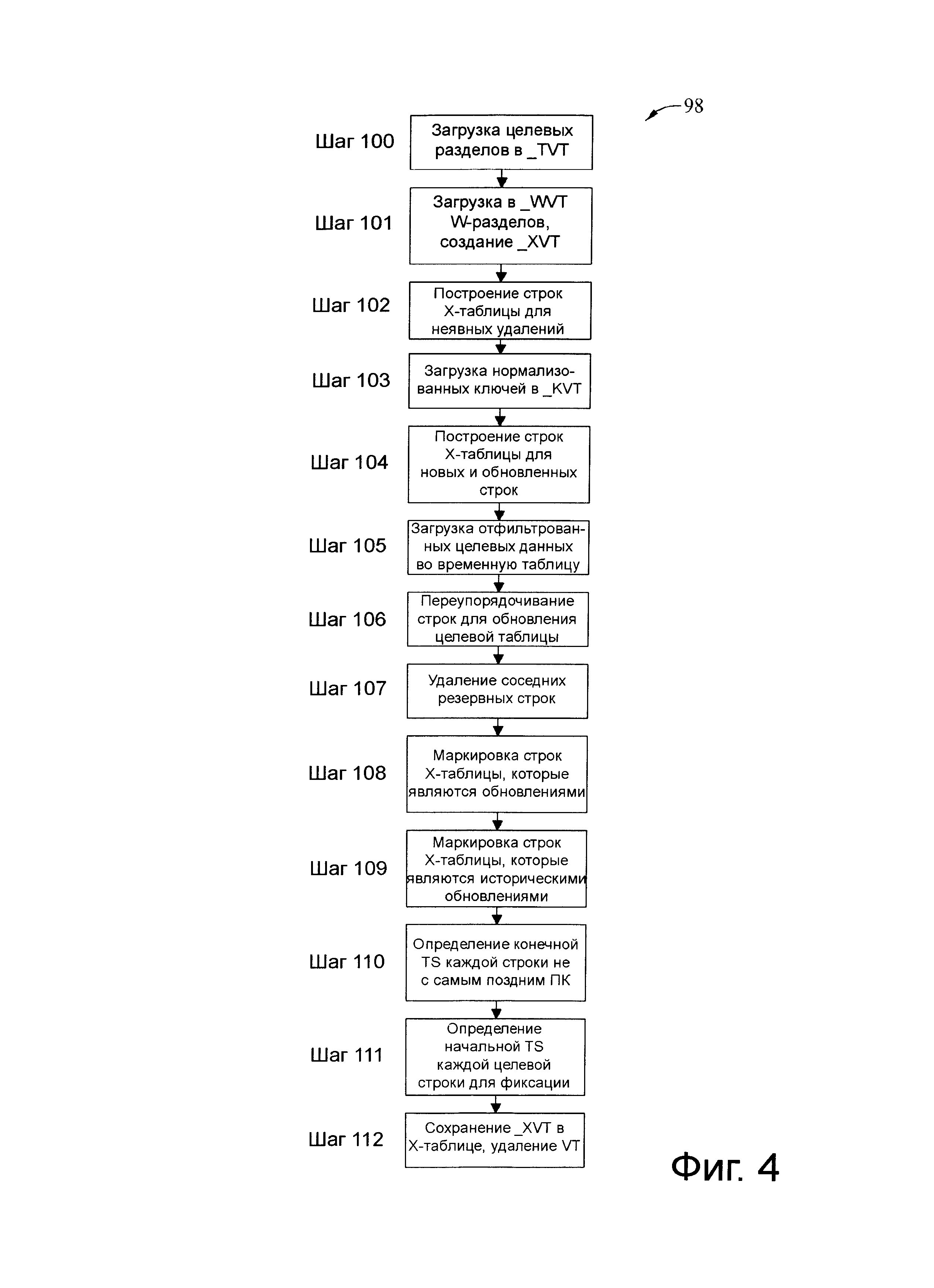
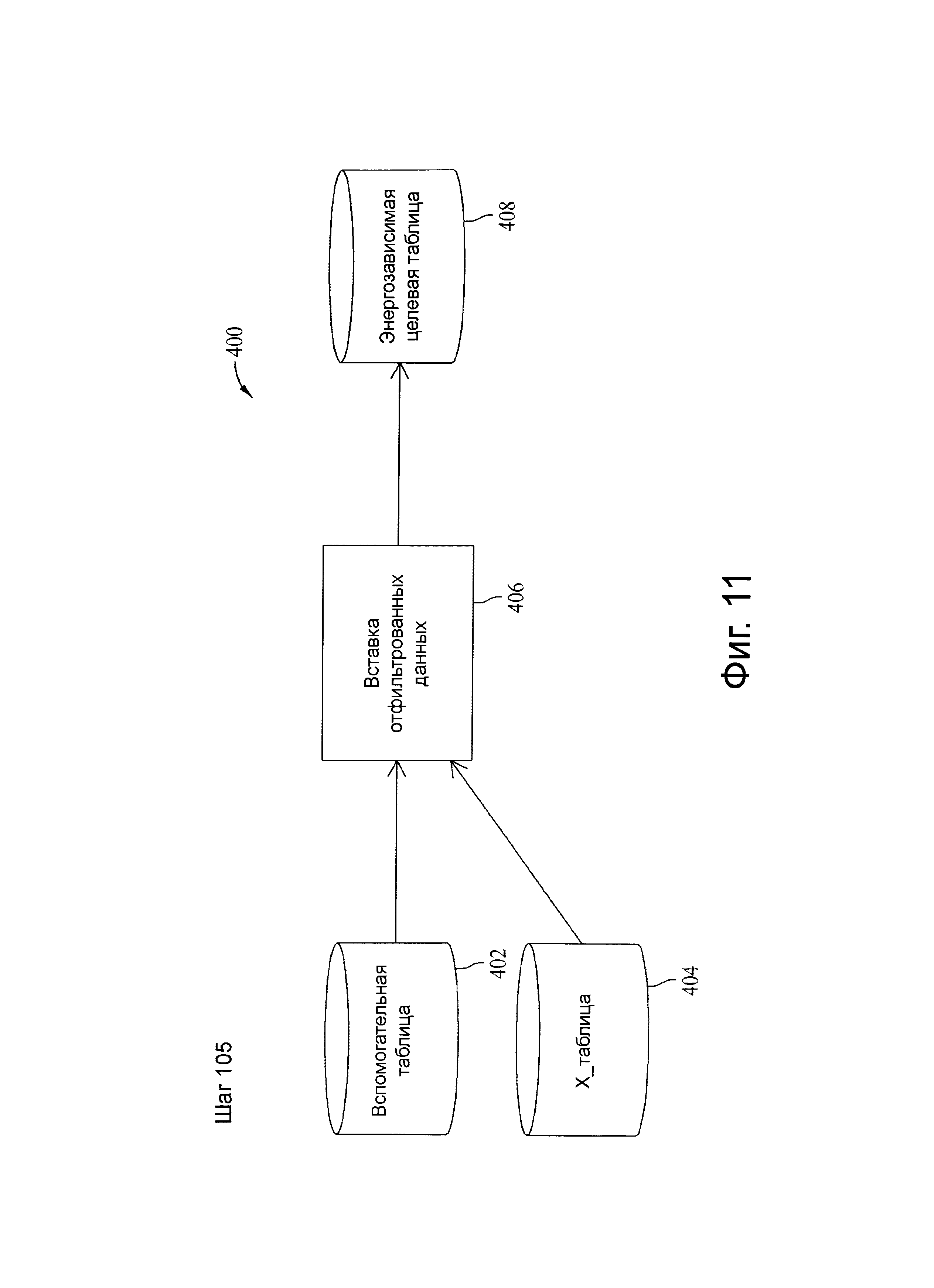
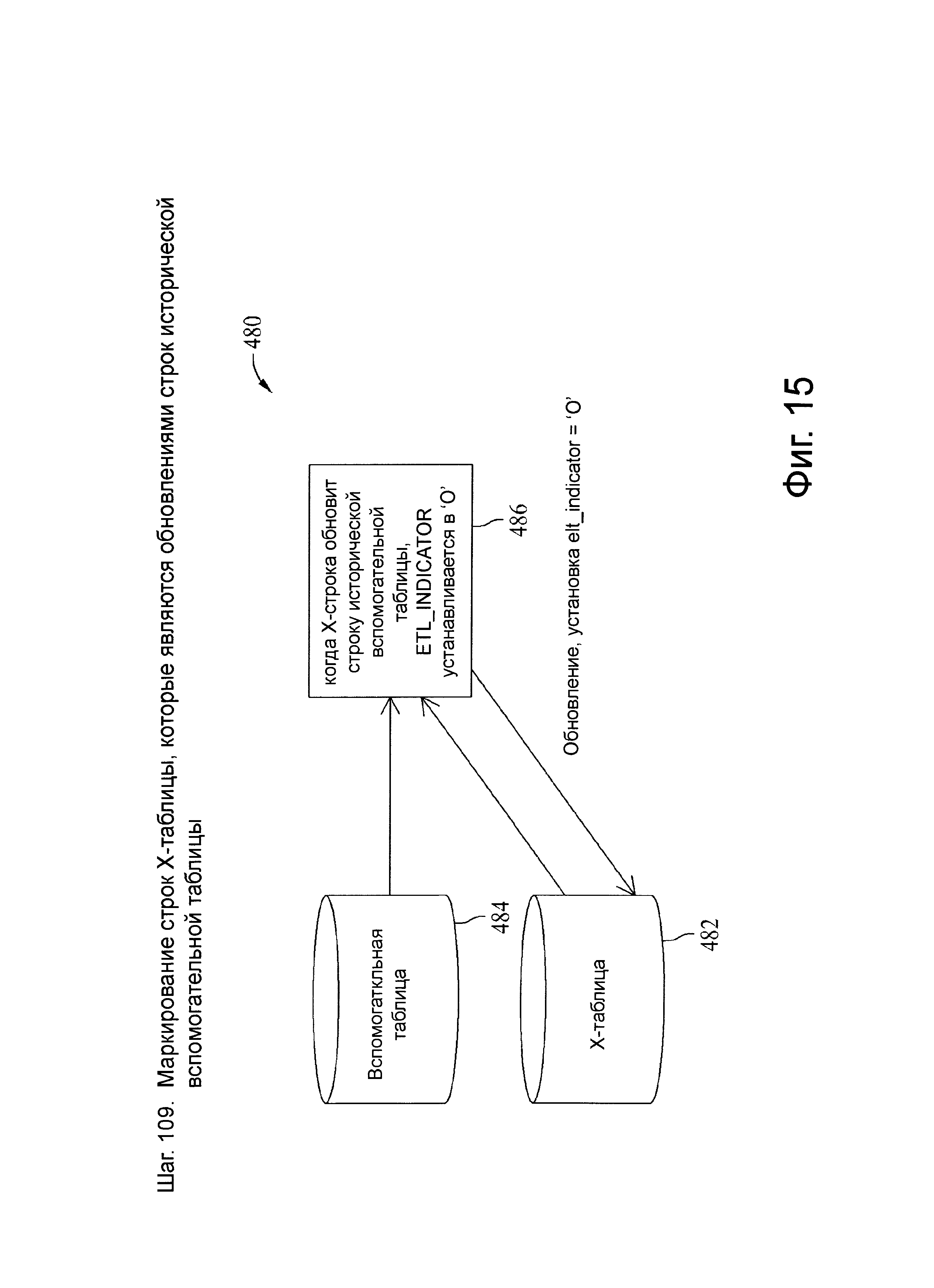
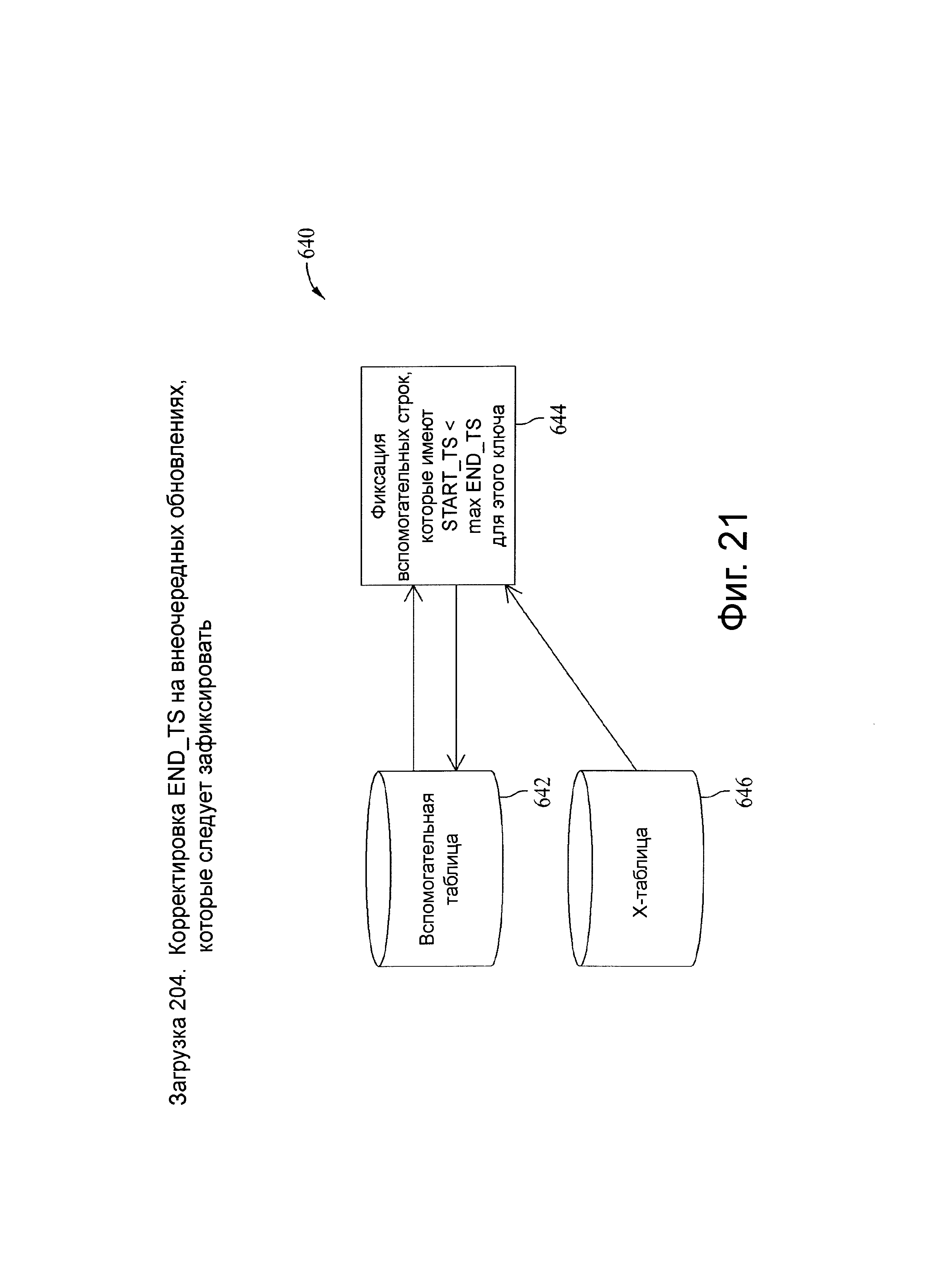
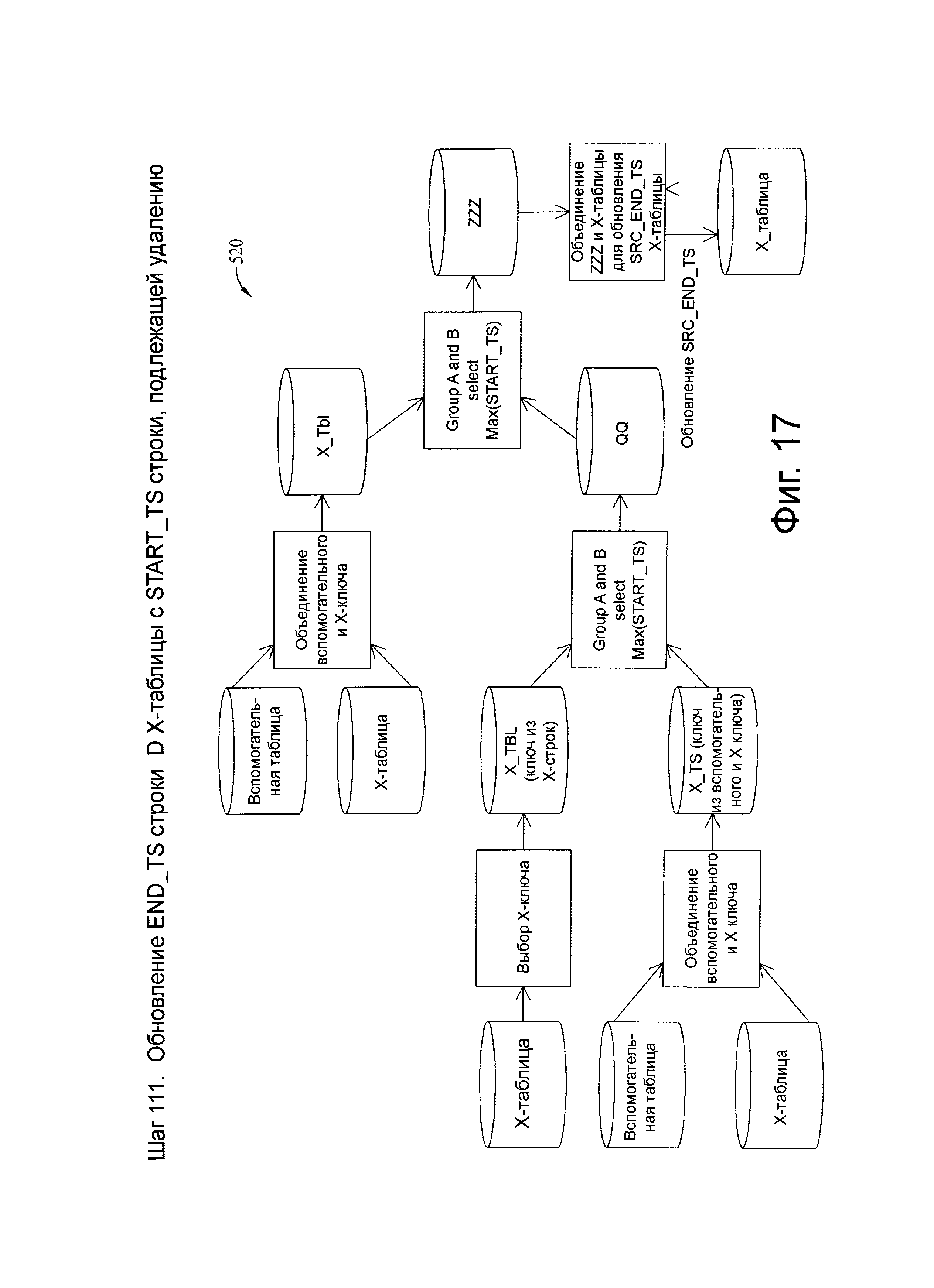
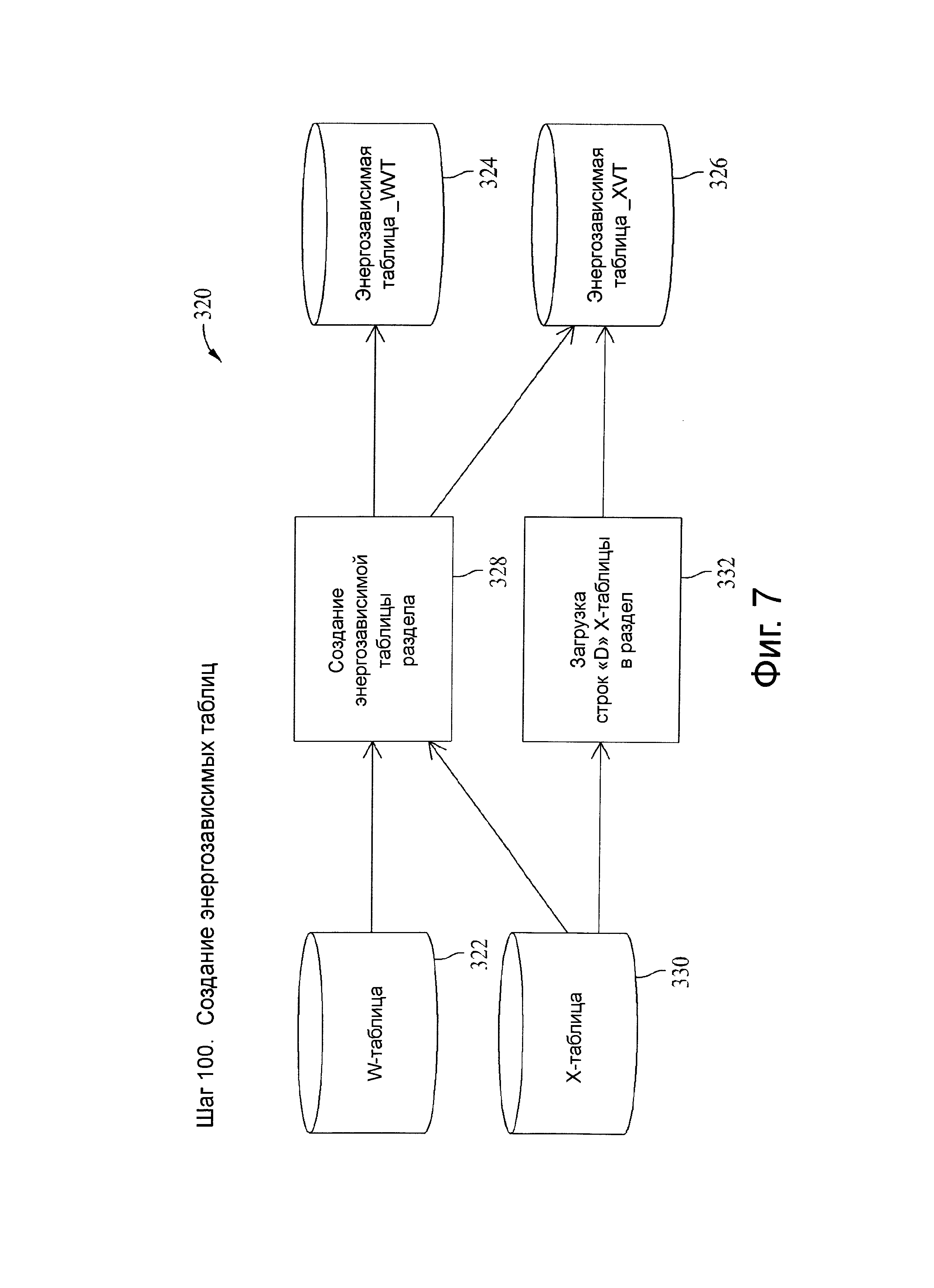
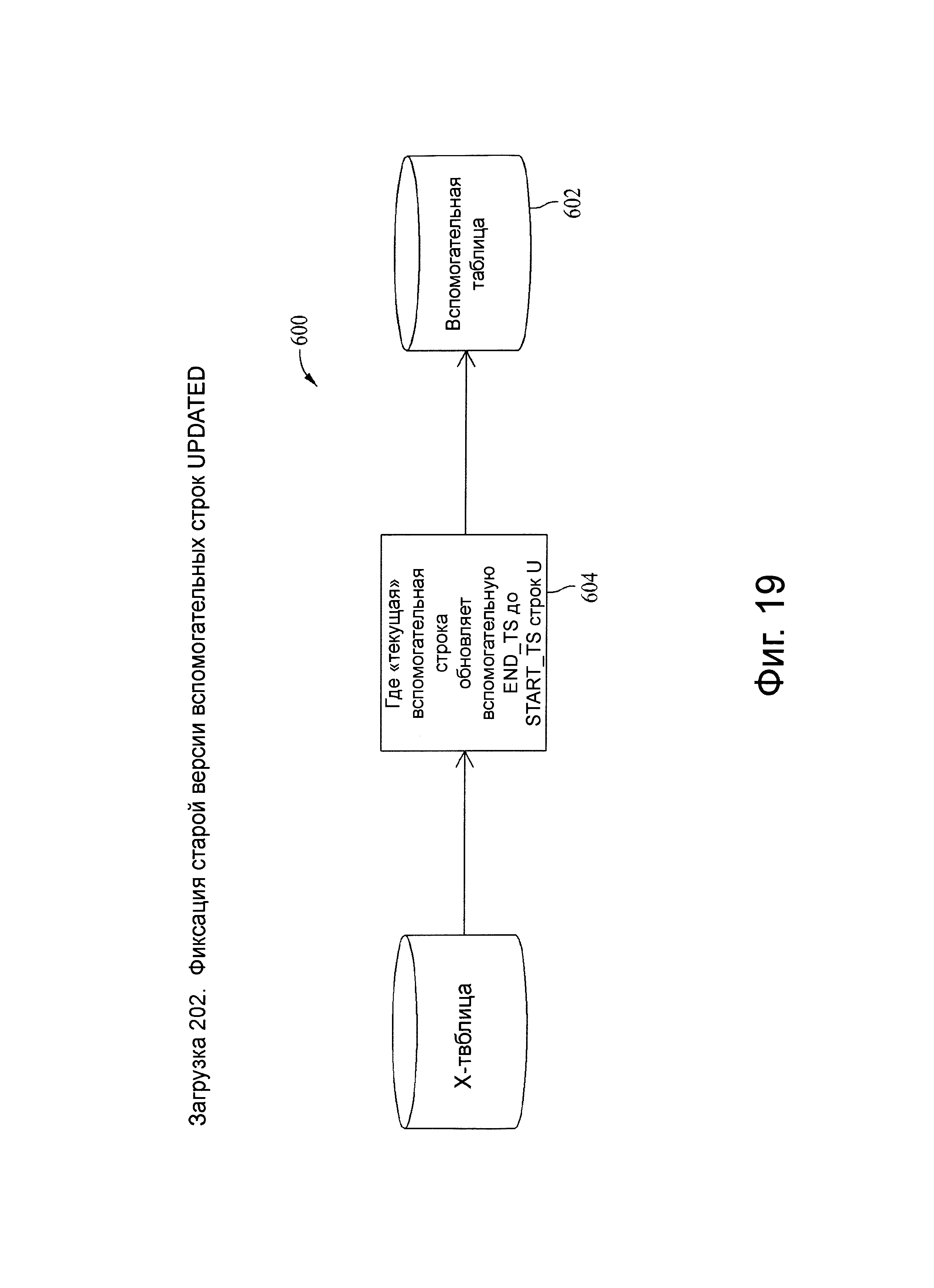
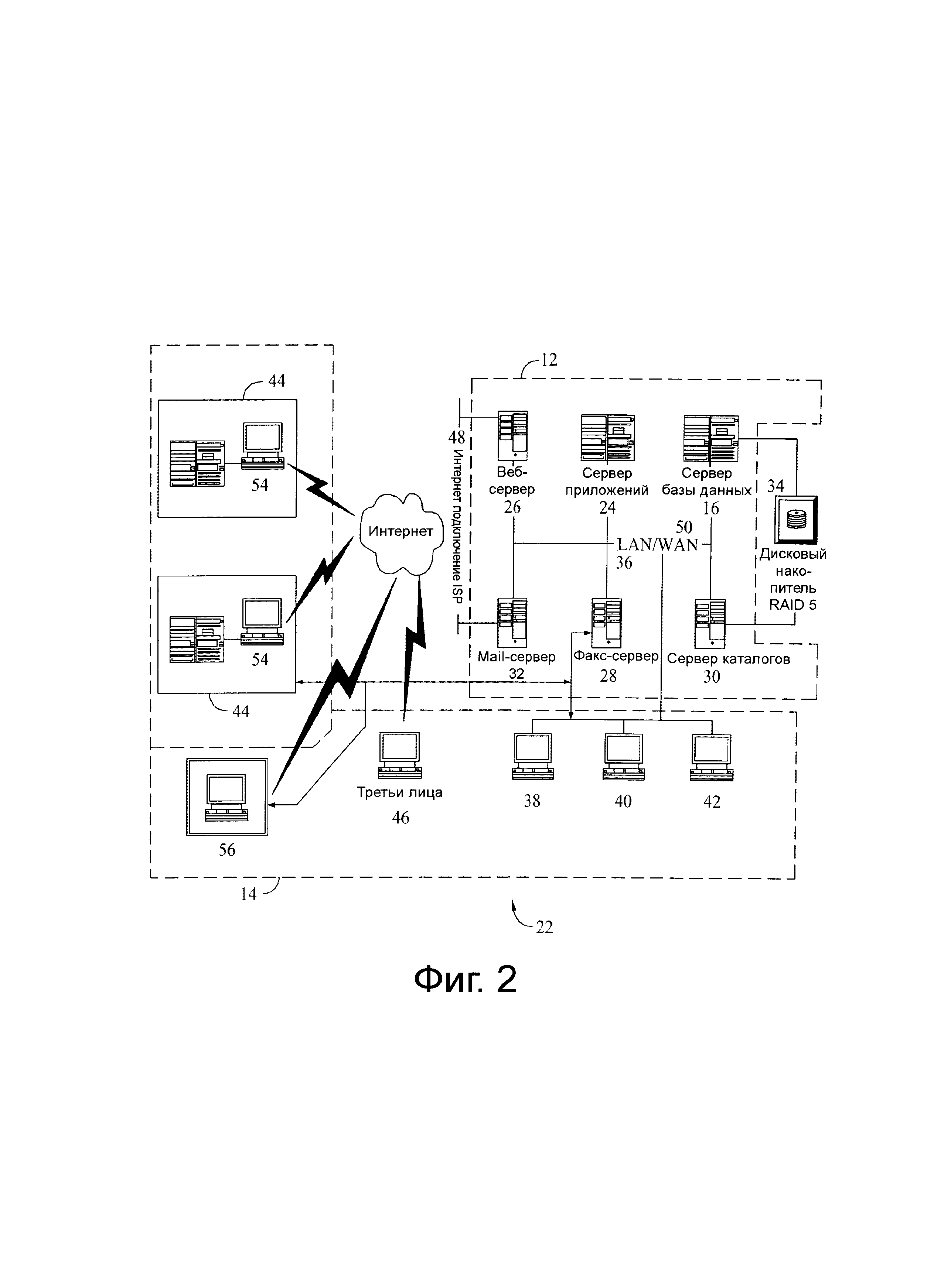
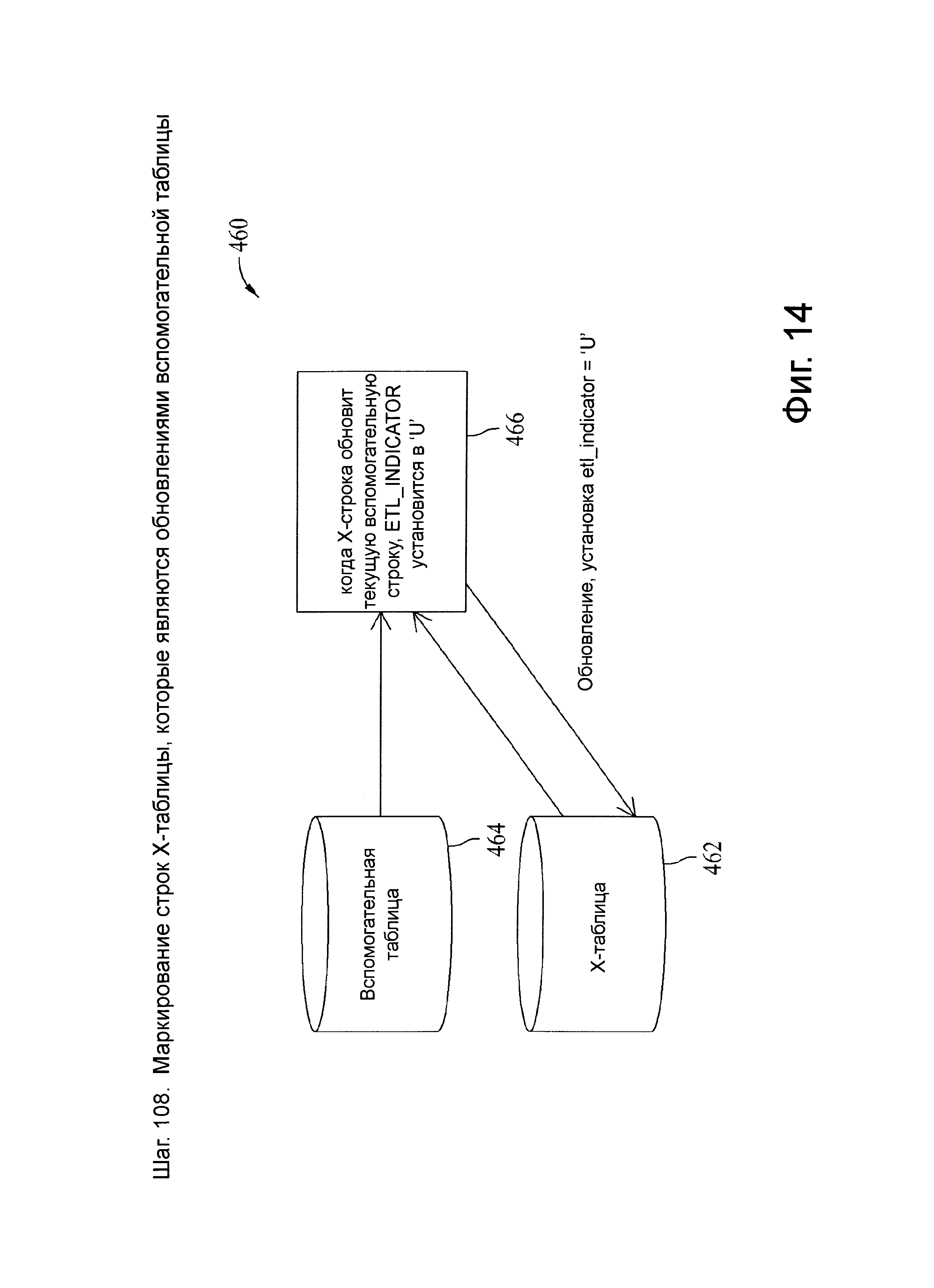
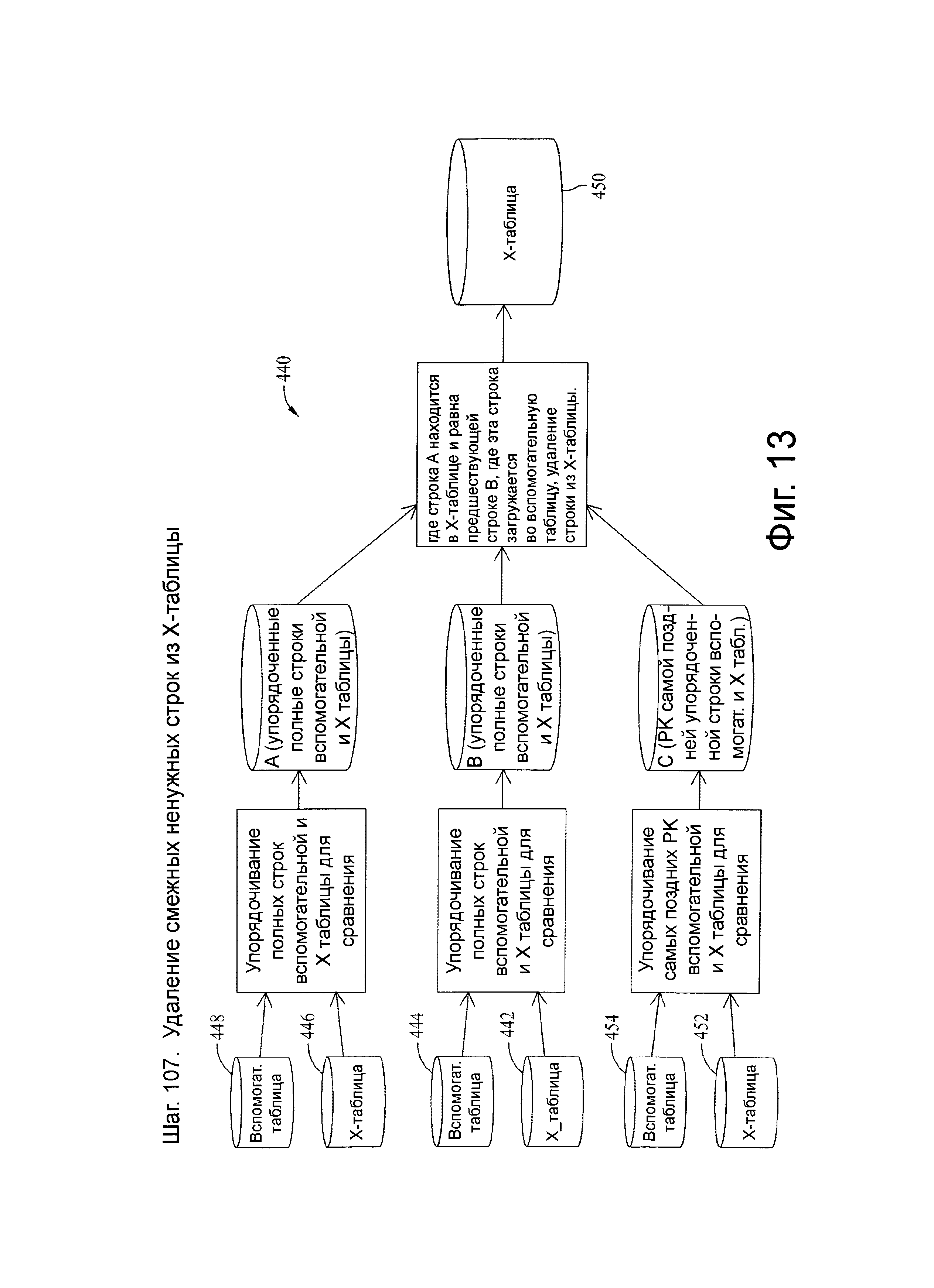
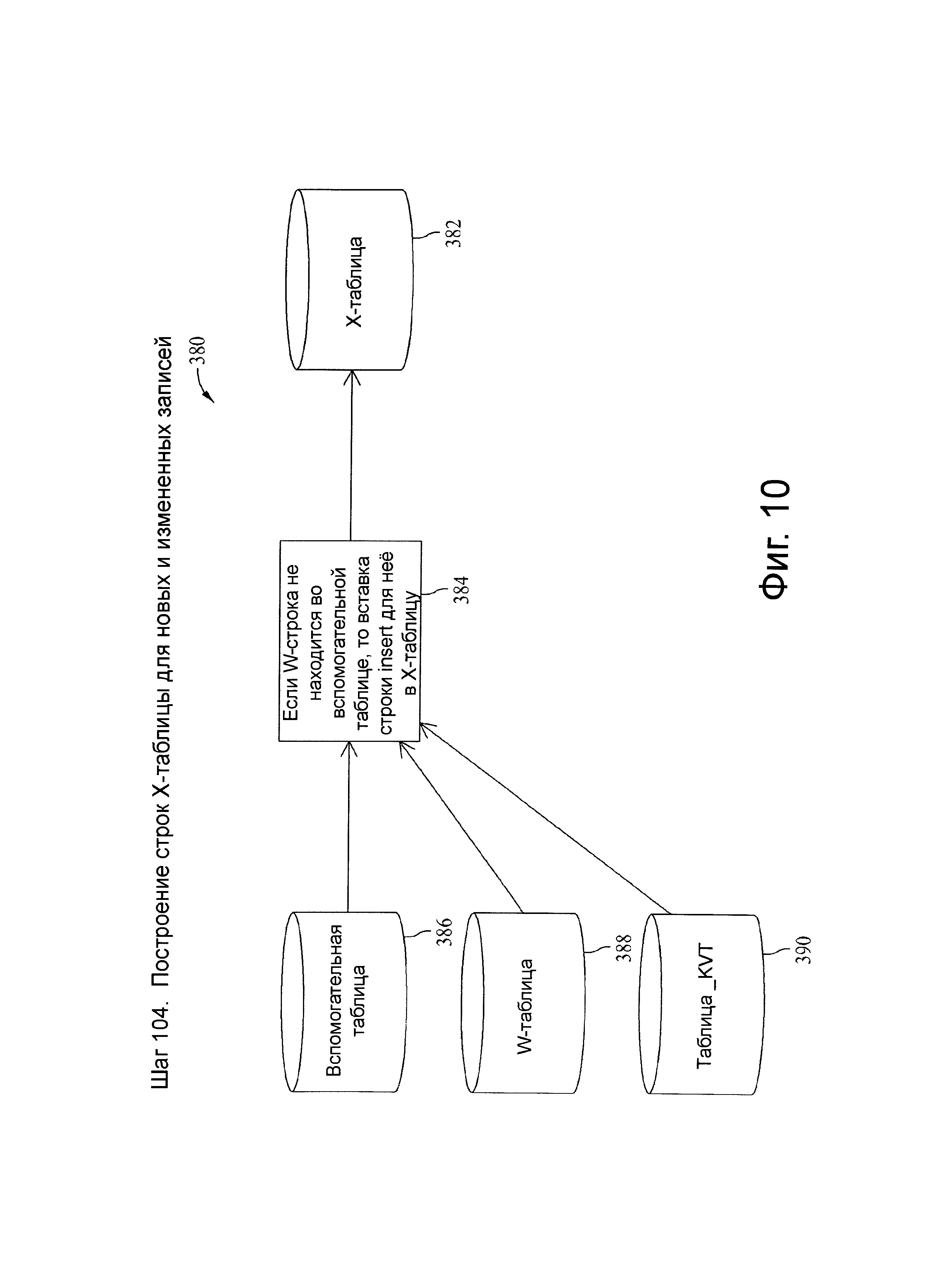
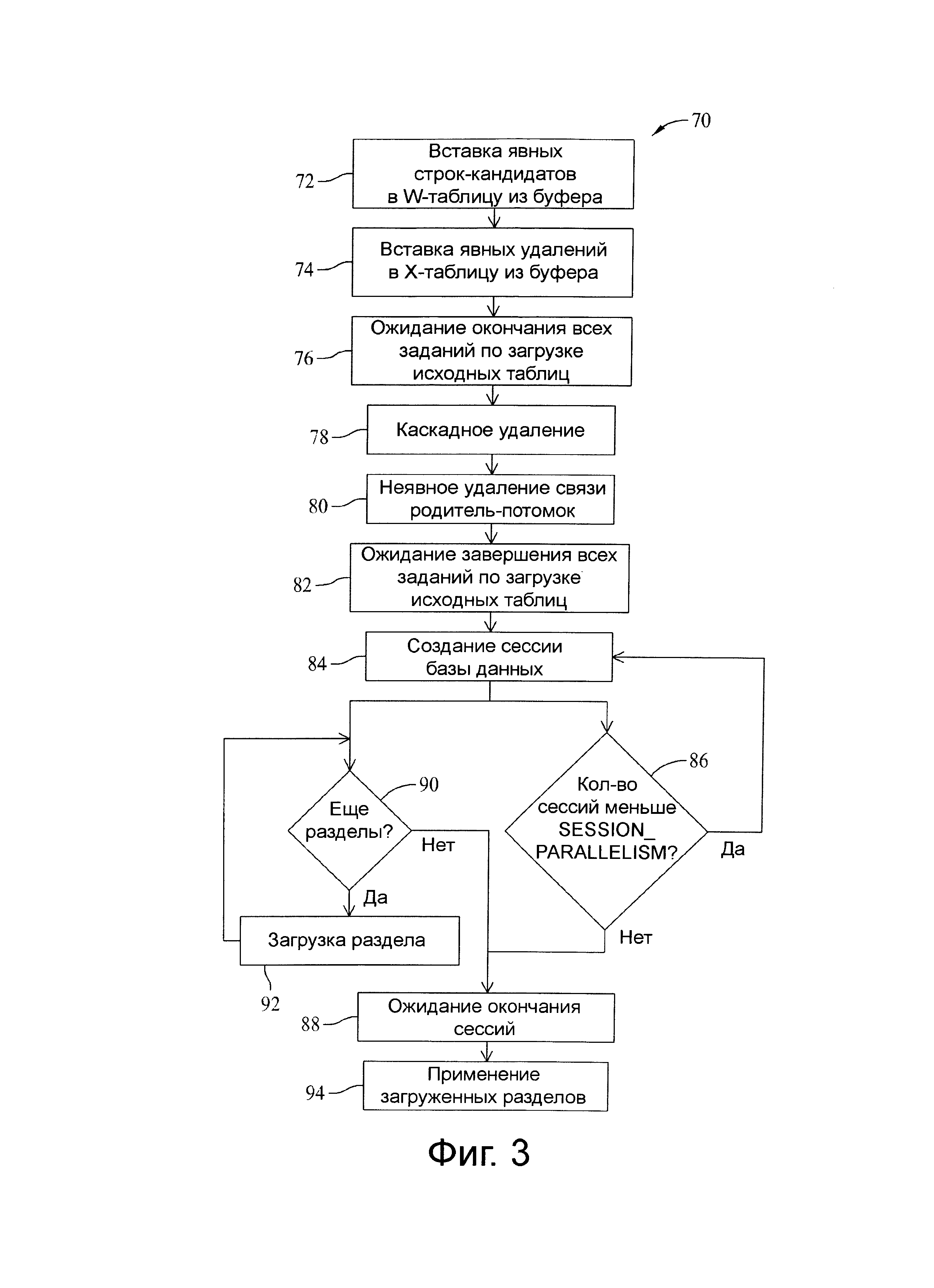
Активатор для управления потоком плазмы и способ управления потоком плазмы
Устройство и способ управления потоком плазмы на задней кромке аэродинамического профиля
Система управления потоком с использованием плазменного актуатора и способ ее использования для управления потоком, обтекающим оружейный отсек высокоскоростного подвижного носителя
Усиленные элементы жесткости и способ их изготовления
Нагнетательное насосное устройство с диэлектрическим барьером и способ формирования такого устройства
Система с датчиками
Регистрация радиолокационных импульсов посредством цифрового радиолокационного приемника
Полурычажное шасси и способ размещения балки тележки такого шасси
Инструмент в виде шаблона и способ для быстрого ремонта композитной структуры
Малошумящая система предкрылка с элеметами, размещенными в передней кромке крыла и выполненными с возможностью развертывания
Активатор для управления потоком плазмы и способ управления потоком плазмы
Устройство и способ управления потоком плазмы на задней кромке аэродинамического профиля
Система управления потоком с использованием плазменного актуатора и способ ее использования для управления потоком, обтекающим оружейный отсек высокоскоростного подвижного носителя
Усиленные элементы жесткости и способ их изготовления
Нагнетательное насосное устройство с диэлектрическим барьером и способ формирования такого устройства
Система с датчиками
Регистрация радиолокационных импульсов посредством цифрового радиолокационного приемника
Полурычажное шасси и способ размещения балки тележки такого шасси
Инструмент в виде шаблона и способ для быстрого ремонта композитной структуры
Малошумящая система предкрылка с элеметами, размещенными в передней кромке крыла и выполненными с возможностью развертывания

