Результат интеллектуальной деятельности: ПРЕДЛОЖЕНИЕ РЕЛЕВАНТНЫХ ТЕРМИНОВ ВО ВРЕМЯ ВВОДА ТЕКСТА
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Изобретение относится к предложению терминов автозавершения во время ввода текста отчета. Изобретение дополнительно относится к анализу множества отчетов.
Уровень техники
Клинические встречи, такие как обследования пациентов, часто документируются в форме текстовых отчетов. Эти отчеты могут быть продиктованы или набраны клиницистом, например врачом или медицинской сестрой. Примером такого отчета является отчет о радиологии, который обычно содержит некоторые элементы истории пациента (клиническое показание и/или повод для исследования), описание процедуры получения изображений, которая была выполнена, и исход радиологического изучения (полученные данные и впечатление).
Для ускорения ввода текста следующее слово или слова могут быть спрогнозированы с использованием автозавершения. Это может быть сделано посредством сопоставления шаблонов строк. Когда начало слова набрано, завершение этого слова может быть предложено. Для этого алгоритм автозавершения может найти одно или более слов в словаре, которое начинается с тех же символов, что и символы, которые были только что набраны. Например, ввод «прос» может быть сопоставлен со строками, такими как «простата» или «простагландин». Более сложные алгоритмы могут осуществлять сопоставление с фразами: например, «увеличенная прос» будет сопоставлена с «увеличенная простата», а не с «простагландин», поскольку первая фраза по статистике появляется значительно чаще. Эти сопоставления часто представляются пользователю в качестве меню возможных вариантов, так что корректный возможный вариант может быть быстро выбран.
Документ, озаглавленный «Semantic autocompletion» («Семантическое автозавершение»), E. Hyvönen и E. Mäkalä в трудах первой Азиатской Веб-Конференции по Семантике (Asia Semantic Web Conference, ASWC 2006), Beijing, Springer-Verlag, New York, 4-9 Августа, 2006, в дальнейшем Hyvönen et al., раскрывает автозавершение, основанное на сопоставлении вводимых строк со списком используемых слов в словаре. Документ дополнительно раскрывает завершение записываемого пользователем текста не только в схожие слова, но и в соответствующие онтологические понятия, текстовые данные которых могут не быть отнесены к вводу на буквенном уровне.
Сущность изобретения
Было бы полезным обладать улучшенными терминами автозавершения во время ввода текста отчета. Для лучшего решения данной задачи, первый аспект изобретения обеспечивает систему, содержащую
блок ввода текста для предоставления возможности пользователю вводить текст в текущий отчет;
анализатор секций для определения множества секций текущего отчета;
средство обнаружения текущей секции для обнаружения секции текущего отчета над которой работает пользователь, получающее таким образом текущую секцию;
средство извлечения терминов для извлечения термина, возникающего в текущем отчете, получающее таким образом извлеченный термин, и идентификации секции текущего отчета, в которой возникает извлеченный термин, получающее таким образом секцию извлеченного термина, при этом секция извлеченного термина и текущая секция являются разными секциями;
блок осуществления доступа к сочетаемости для осуществления доступа к множеству статистических показателей сочетаемости, статистический показатель сочетаемости указывает по меньшей мере один первый термин, по меньшей мере одну первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат по меньшей мере один первый термин по меньшей мере в одной первой секции совместно со вторым термином во второй секции;
средство выбора терминов для выбора по меньшей мере одного часто сочетающегося термина, основываясь на извлеченном термине, секции извлеченного термина, текущей секции и по меньшей мере одном из статистических показателей сочетаемости; и
индикатор для обеспечения указания по меньшей мере одного часто сочетающегося термина пользователю.
Часто сочетающийся термин, который указывается пользователю, обладает относительно высокой вероятностью того, что он является словом, которое пользователь намеревается ввести в отчет, поскольку выбор термина основан на статистическом показателе сочетаемости, который учитывает секцию, в которой сочетающиеся термины обычно возникают. Статистический показатель сочетаемости может быть специфическим для заданного контекста предметной области (например, радиология, кардиология, неврология). В сравнении с традиционным сопоставлением строк, улучшение получают, учитывая термины, записанные в других секциях отчета, что предоставляет возможность предложения терминов автозавершения, которые являются более характерными для отчета, который вводится. Это улучшение основано на понимании того, что конкретные секции отчета могут включать в себя конкретные виды информации, которая может коррелировать по-разному с терминами в текущей секции. В качестве частного примера, термин, возникающий в секции истории пациента отчета о радиологии, может коррелировать по-разному с терминами в секции диагноза (диагностики), чем когда тот же самый термин возникает в секции полученных данных отчета.
В другом аспекте, изобретение обеспечивает систему для анализа множества отчетов, содержащую
анализатор секций для определения разделения отчетов на секции;
определитель общих секций для определения множества секций общих для множества отчетов;
средство извлечения терминов для извлечения множества терминов из общих секций отчетов и связывания каждого термина с секцией и отчетом, где он возникает;
генератор статистических показателей сочетаемости для генерирования множества статистических показателей сочетаемости, статистический показатель сочетаемости указывает по меньшей мере один первый термин, по меньшей мере одну первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат по меньшей мере один первый термин по меньшей мере в одной первой секции совместно со вторым термином во второй секции, при этом по меньшей мере одна первая секция отличается от второй секции.
Эта система генерирует статистические показатели сочетаемости, которые могут быть использованы предлагаемой системой автозавершения. Статистические показатели сочетаемости предоставляют возможность генерирования более полезных предложений автозавершения, поскольку статистические показатели сочетаемости обеспечивают информацию о сочетающихся терминах, которые сочетаются в конкретных, различных секциях отчетов. Система для анализа множества отчетов может быть объединена с системой для предложения терминов автозавершения; в качестве альтернативы, системы могут быть реализованы в различных окружениях. Когда статистический показатель сочетаемости указывает множество первых терминов и множество первых секций, по меньшей мере одна первая секция из множества первых секций отличается от второй секции.
Отчет может содержать документ, при этом секция содержит заголовок секции и основную часть секции. Заголовок секции позволяет обнаруживать существование секции, и это помогает предлагаемой системе извлекать термины и связывать извлеченные термины с надлежащей секцией.
В качестве альтернативы или в дополнение, отчет может содержать множество файлов, при этом различные файлы содержат различные секции отчета. Это облегчает вовлечение информации более ранних периодов или созданной одним или более разными клиницистами в процесс автозавершения. Таким образом, пользователю могут быть обеспечены более релевантные термины автозавершения.
Отчет может содержать цифровую форму, при этом поля должны быть заполнены пользователем. Информация, которую используют для заполнения в некоторых полях, может поступать из различных систем и может быть сохранена в качестве записей в одной или множестве баз данных.
Термин может содержать одно слово или фразу, составленную из множества слов. Например, извлеченный термин и/или первый термин может содержать выражение, содержащее множество слов. Это предоставляет улучшенные предложения, поскольку комбинация из множества слов для извлеченного термина и/или первого термина может иметь результатом более специфические статистические показатели сочетаемости.
Система может содержать процессор естественного языка для связывания извлеченного термина и/или первого термина с онтологическим понятием в онтологии, и при этом статистический показатель сочетаемости относится к вероятности сочетаемости онтологического понятия со вторым термином. Это улучшает точность статистических показателей сочетаемости и/или предлагаемых терминов.
Средство выбора терминов может быть функционально соединено с блоком ввода текста и скомпоновано для приема части термина, который вводится пользователем, и выполнено с возможностью выбора часто сочетающегося термина, основываясь на принятой части термина. Таким образом, предлагаемый термин является релевантным для слова, которое было частично введено пользователем.
Средство выбора терминов может быть выполнено с возможностью выбора часто сочетающегося термина, начало которого совпадает с принятой частью термина. Это обеспечивает процесс естественного автозавершения, при котором пользователь вводит начало термина и ему обеспечивают завершенные термины, совпадающие с введенным началом.
Отчеты могут включать в себя медицинские отчеты о пациенте, и секции могут включать в себя секцию истории пациента, секцию клинических данных и/или секцию диагноза. Это описывает типичный сценарий медицинского отчета.
В другом аспекте, изобретение обеспечивает рабочую станцию, содержащую одну или более из предлагаемых систем.
В дополнительном другом аспекте изобретение обеспечивает способ предложения терминов автозавершения во время ввода текста отчета, содержащий этапы, на которых
предоставляют возможность пользователю вводить текст в текущий отчет;
определяют множество секций текущего отчета;
обнаруживают секцию текущего отчета, над которой работает пользователь, получая таким образом текущую секцию;
извлекают термин, возникающий в текущем отчете, получая таким образом извлеченный термин, и идентифицируют секцию текущего отчета, в которой возникает извлеченный термин, получая таким образом секцию извлеченного термина, при этом секция извлеченного термина и текущая секция являются разными секциями;
осуществляют доступ ко множеству статистических показателей сочетаемости, статистический показатель сочетаемости указывает по меньшей мере один первый термин, по меньшей мере одну первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции;
выбирают по меньшей мере один часто сочетающийся термин, основываясь на извлеченном термине, секции извлеченного термина, текущей секции и по меньшей мере одном из статистических показателей сочетаемости; и
обеспечивают указание по меньшей мере одного часто сочетающегося термина пользователю.
В другом аспекте изобретение обеспечивает способ анализа множества отчетов, содержащий этапы, на которых
определяют разделение отчетов на секции;
определяют множество секций, общих для множества отчетов;
извлекают множество терминов из общих секций отчетов и связывают каждый термин с секцией и отчетом, где он возникает; и
генерируют множество статистических показателей сочетаемости, статистический показатель сочетаемости указывает по меньшей мере один первый термин, по меньшей мере одну первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции, при этом по меньшей мере одна первая секция отличается от второй секции.
В другом аспекте изобретение обеспечивает компьютерный программный продукт, содержащий инструкции для предписания процессорной системе выполнять один или более из способов, предлагаемых в данном документе.
Специалисту в данной области техники следует принять во внимание, что два или более из вышеуказанных вариантов осуществления, реализаций и/или аспектов изобретения могут быть объединены любым образом, считающимся полезным.
Модификации и изменения устройства получения изображений, рабочей станции, системы и/или компьютерного программного продукта, которые соответствуют описанным модификациям и изменениям системы, могут быть осуществлены специалистом в данной области техники на базе настоящего описания.
Краткое описание чертежей
Эти и другие аспекты изобретения очевидны из и будут разъяснены со ссылкой на варианты осуществления, описанные ниже по тексту. На чертежах
Фиг.1 представляет собой блок-схему системы для предложения терминов автозавершения во время ввода текста;
Фиг.2 представляет собой блок-схему системы для анализа отчетов;
Фиг.3 представляет собой блок-схему последовательности операций способа анализа отчетов; и
Фиг.4 представляет собой блок-схему последовательности операций способа предложения терминов автозавершения во время ввода текста.
Подробное описание вариантов осуществления
В нижеследующем варианты осуществления будут описаны посредством примеров.
Например, рассмотрим клинический документ, который набран следующим образом: «32 года, мужчина с присутствующим тиннитусом в левом ухе. МДКТ показала образование, негативно влияющее на левый слуховой канал». Во время, когда автор набрал «слу» («au») в «слуховой канал» («auditory canal»), сопоставляющее строки автозавершение может представить «слу» («au»), «слушатель» («auditor»), «слуховой» («auditory»), «слушание» («audition»), «слуховой» («auditory»), «слуховой канал» («auditory canal»), «аутосомный» («autosomal») и т.д. Используя методологию, описанную в данном документе, «слуховой канал» будет выдвинут в начало списка, поскольку он имеет относительно высокую частоту сочетаемости с «тиннитусом».
В качестве второго примера рассмотрим радиологический отчет о рассеянном склерозе, содержащий предложение: «Аномальная интенсивность не наблюдается в белом веществе». Известные в данное время способы могут сопоставить букву «б» в «белом веществе» со всеми словами, начинающимися с буквы «б» или даже всеми общими радиологическими терминами, начинающимися с буквы «б». Однако, принимая во внимание предшествующий контекст, список может быть сужен и сохранен таким образом, что наиболее релевантные термины перемещаются к началу.
Подсистема может быть выполнена с возможностью анализа предыдущих отчетов и клинических документов для того, чтобы «обучить» и сохранить корреляции между различными терминами. Другая подсистема может быть выполнена с возможностью анализа вводимого в настоящий момент отчета, так что новые термины могут быть предложены, основываясь на (a) уже введенном текущем содержимом отчета и (b) ранее обученных корреляциях между терминами. Кроме того, подсистема может быть выполнена с возможностью отображения предложенных терминов пользователю.
Фиг.1 иллюстрирует систему для предложения терминов автозавершения. Эти термины автозавершения могут быть предложены во время ввода текста отчета. Система может быть реализована, по меньшей мере частично, в компьютерной системе. Такая система может содержать рабочую станцию. Часть системы может быть реализована на серверной системе, к которой осуществляется доступ через клиентскую систему, при этом клиентская система может содержать рабочую станцию. Система может содержать устройство отображения, устройство ввода текста, такое как клавиатура и/или ввод диктовкой, включающий в себя программное обеспечение распознавания речи в реальном времени, мышку для управления системой, порт связи для осуществления связи с сервером и/или для получения отчетов, статистических данных и/или для передачи завершенных отчетов получателю. Система может содержать средство хранения для хранения отчетов и/или статистических данных и других данных.
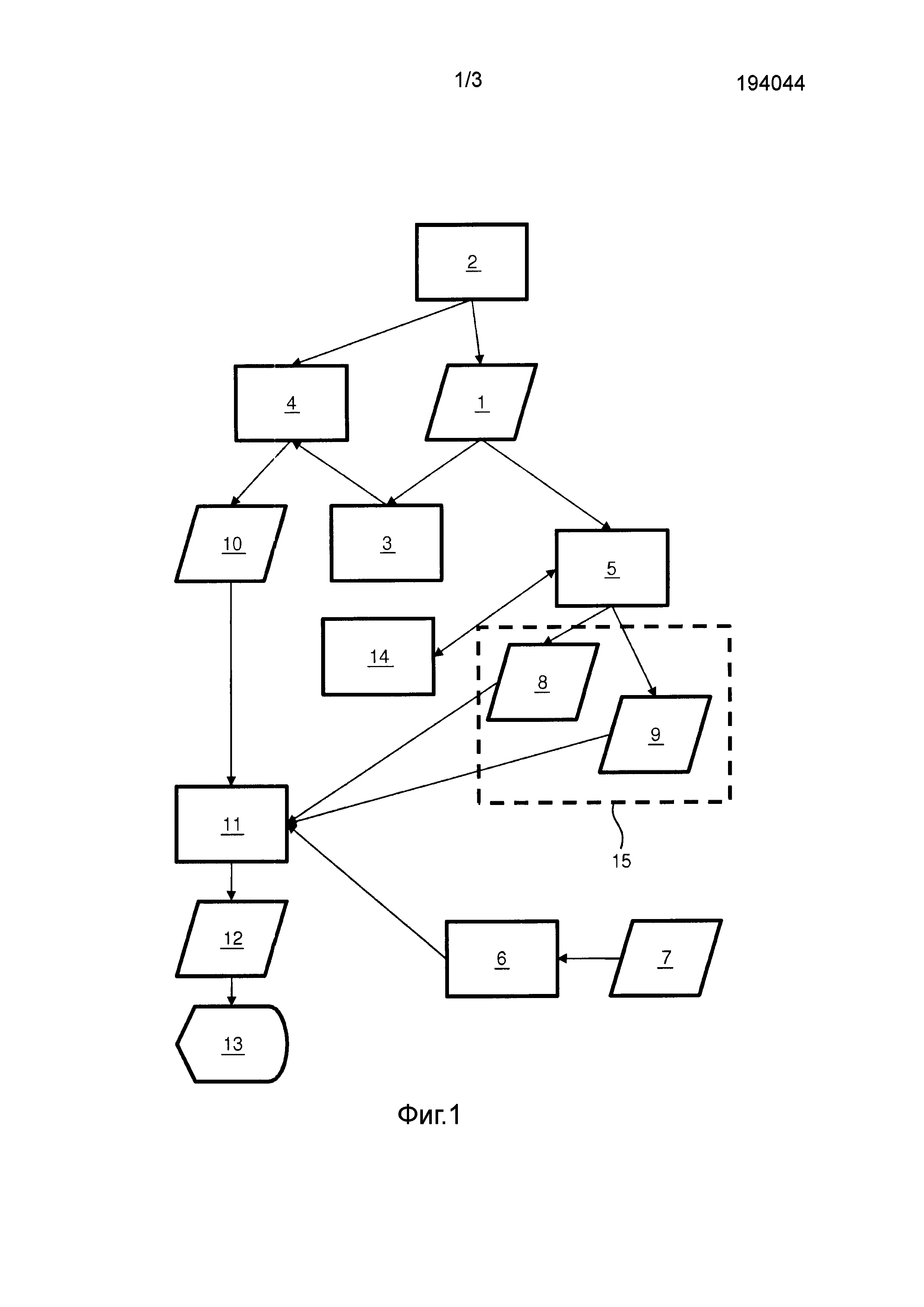
Система может содержать блок 2 ввода текста для предоставления возможности пользователю вводить текст в текущий отчет 1. Блок 2 ввода текста, например может содержать текстовый редактор или текстовый процессор для предоставления возможности пользователю создавать текстовый документ, возможно оставляя на усмотрение пользователя возможность форматирования отчета и обеспечения заголовков для секций в соответствии с присущим пользователю пониманием. Также возможно, чтобы блок 2 ввода текста показывал множество полей ввода текста, в которых пользователь может набирать надлежащий текст, при этом поля ввода текста могут соответствовать общим секциям отчета. Когда отчет завершен, блок 2 ввода текста может осуществлять слияние полей в один документ или сохранять поля в записи данных, например в электронной записи данных пациента. Блок 2 ввода текста может быть скомпонован для приема вывода подсистемы распознавания речи, предоставления возможности пользователю вводить отчет буквально произнося слова текста.
Система может содержать анализатор 3 секций для определения множества секций текущего отчета. Анализатор 3 секций может содержать средство анализа текста для определения секций в отчете. Анализатор 3 секций может делать это посредством обнаружения заголовков секций и соответствующих основных частей секций. В качестве альтернативы, анализатор 3 секций может использовать обработку естественного языка для распознавания различных секций посредством анализа содержимого текста, такого как клиническая история, исследование, полученные данные, основываясь на предметах обсуждения, обычно появляющихся в таких секциях. Когда блок 2 ввода текста использует отдельные поля ввода для секций, анализатор 3 секций может по меньшей мере до некоторой степени быть интегрирован в блок ввода текста, поскольку секции определяются полями ввода.
Система может содержать средство 4 обнаружения для обнаружения секции текущего отчета, над которой работает пользователь. Эту секцию называют в данном документе как текущая секция 10. Для этого средство 4 обнаружения текущей секции может быть функционально соединено с блоком 2 ввода текста и анализатором 3 секций. Средство 4 обнаружения текущей секции может использовать, например позицию курсора или местоположение, в котором было добавлено последнее слово или символ, в качестве текущей секции 10.
Система может содержать средство 5 извлечения терминов для извлечения термина, возникающего в текущем отчете, получающее таким образом извлеченный термин 8. Средство 5 извлечения терминов использует обнаруженные секции для определения того, в какой секции текущего отчета возникает извлеченный термин, получая таким образом секцию 9 извлеченного термина. Извлеченный термин 8 и секция 9 извлеченного термина могут быть рассмотрены как извлеченная пара 15. Средство 5 извлечения терминов может обрабатывать весь или по меньшей мере часть текущего отчета 1 для извлечения слов, возникающих в нем и связывания этих слов с соответствующими секциями. Один или более из извлеченных терминов могут возникнуть в секции 9 извлеченного термина, которая отличается от текущей секции 10.
Система может содержать блок 6 осуществления доступа к сочетаемости для осуществления доступа ко множеству статистических показателей 7 сочетаемости. Для этой цели блок 6 осуществления доступа к сочетаемости может обеспечивать интерфейс, например для базы данных или области хранения. Статистические показатели сочетаемости обеспечивают информацию о терминах, которые часто сочетаются в отчетах в конкретной области знаний. Таким образом, извлеченный термин 8 и секция 9 извлеченного термина могут быть сопоставлены с терминами и секциями, для которых имеются статистические показатели сочетаемости, и эти статистические показатели сочетаемости могут обеспечивать информацию о возможных словах, которые пользователь намеревается ввести. Статистический показатель сочетаемости может указывать первый термин, первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции. Для некоторых статистических показателей сочетаемости, первая секция может быть отличной от второй секции, тогда как для некоторых других статистических показателей сочетаемости, первая секция может быть такой же, как вторая секция. Статистический показатель сочетаемости также может относится к более чем двум словам, распространенным по одной, двум или более секциям. Например, статистический показатель сочетаемости может указывать множество пар, где каждая пара содержит термин и соответствующую секцию, в которой возникает термин, частоту сочетаемости терминов и секций, которая указывает, как часто отчет содержит все термины в секциях, как указано множеством пар.
Система может содержать средство 11 выбора терминов для выбора по меньшей мере одного часто сочетающегося термина 12. Для этой цели средство 11 выбора терминов может принимать информацию об извлеченных терминах 8, секциях 9 извлеченных терминов, текущей секции 10 и по меньшей мере одном из статистических показателей 7 сочетаемости. Средство 11 выбора терминов может быть специально выполнено с возможностью принимать во внимание один или более извлеченных терминов 8, извлеченных из секции 9 извлеченного термина отчета, которая отличается от текущей секции 10. Например, средство 11 выбора терминов может быть скомпоновано для приема от блока 6 осуществления доступа к сочетаемости всех статистических показателей сочетаемости для извлеченных терминов 8, извлеченных средством 5 извлечения терминов. Также, средство 11 выбора терминов может быть выполнено с возможностью приема от блока 6 осуществления доступа к сочетаемости всех статистических показателей сочетаемости, указывающих множество первых терминов и секций первых терминов, при этом каждое из первых терминов и секций первых терминов из этих принятых статистических показателей сочетаемости согласуется с извлеченными парами 15 извлеченных терминов 8 и секций 9 извлеченных терминов. После этого, средство 11 выбора терминов может сортировать принятые статистические показатели сочетаемости по частоте сочетаемости, так что наиболее часто сочетающиеся термины находятся в начале списка. Список может быть ограничен, чтобы содержать только наиболее часто сочетающиеся термины. Принятые статистические показатели сочетаемости также могут быть отсортированы по числу первых терминов, чтобы дать предпочтение более конкретным, предлагаемым терминам, которые часто сочетаются с относительно большим числом извлеченных терминов, появляющихся в текущем отчете. Список может быть показан пользователю. Для этой цели система может содержать индикатор 13 для обеспечения указания по меньшей мере одного часто сочетающегося термина 12 пользователю. Пользователь может выбрать термин из списка, используя элемент пользовательского интерфейса, и блок 2 ввода текста может быть выполнен с возможностью вставки выбранного термина в текущую секцию. Когда отчет завершен, система может быть сконфигурирована или пользователю может быть предоставлена возможность сохранять или передавать отчет при необходимости.
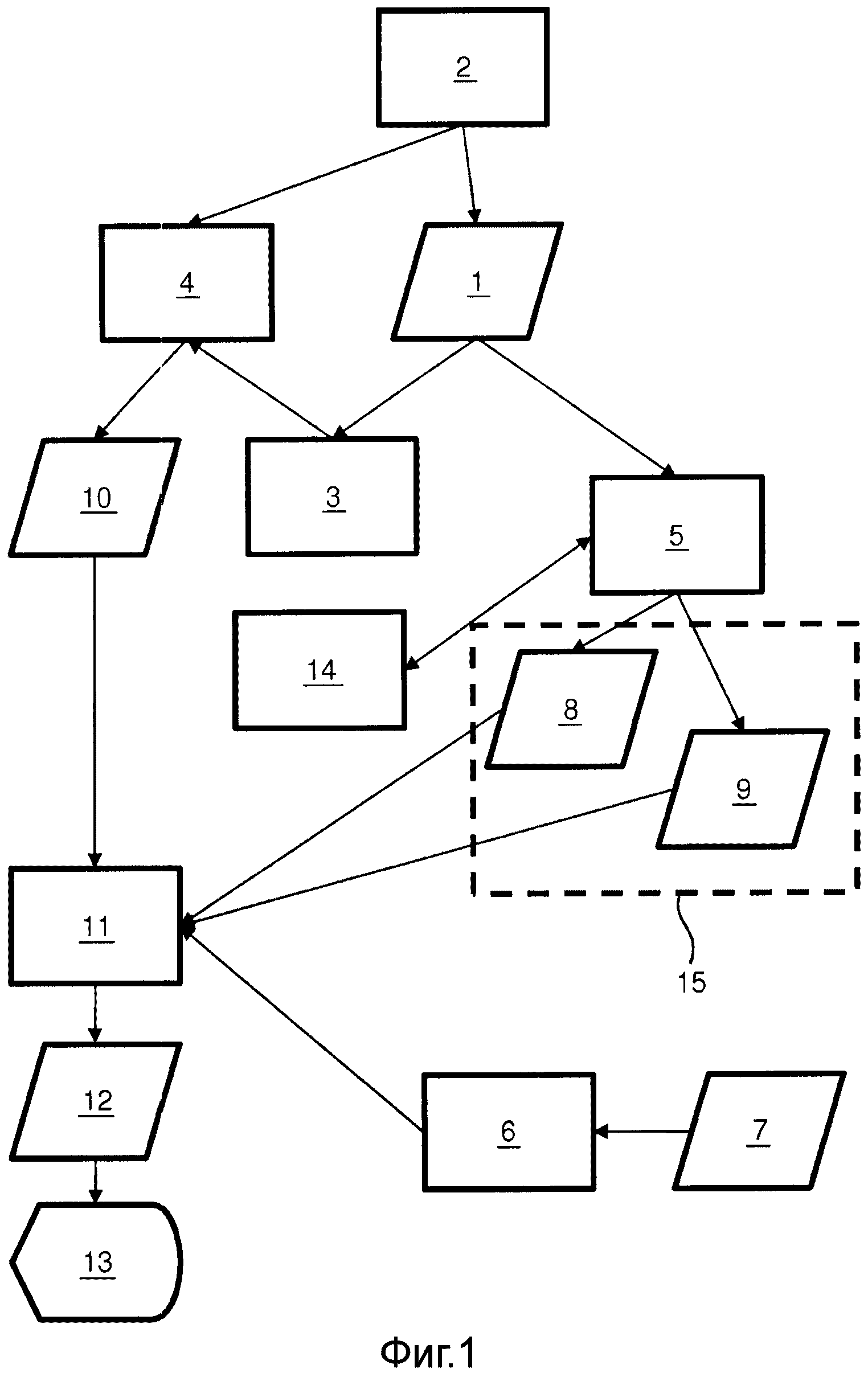
Фиг.2 показывает блок-схему системы для анализа отчетов. Система может быть реализована на аналогичном виде аппаратного обеспечения, что и система для предложения терминов автозавершения. Множество статистических показателей 7 сочетаемости указано тем же самым ссылочным номером, что и на Фиг.1, поскольку оно относится к той же самой или аналогичной структуре данных. Система для анализа отчетов имеет доступ к множеству или совокупности отчетов 21. Эта совокупность отчетов 21 может быть организована в базе данных или как простая совокупность документов, хранимых в файловой структуре.
Система для анализа отчетов может содержать анализатор 22 секций для определения разделения множества отчетов 21 на секции. Для этой цели, анализатор 22 секций может быть выполнен с возможностью обработки отчетов один за другим или параллельно и обнаружения заголовков секций и основных частей секций каждого обрабатываемого отчета. Другие пути обнаружения секций описаны выше по тексту относительно анализатора 3 секций системы для предложения терминов автозавершения.
Система для анализа отчетов может содержать определитель 23 общих секций для определения множества секций, общих для множества отчетов 21. Таким образом, получают множество общих секций. Определитель 23 общих секций может быть выполнен с возможностью сравнения заголовков секций из секций различных отчетов, и когда достаточно большое число отчетов имеют один и тот же заголовок секции или аналогичный заголовок секции, секция может быть обозначена идентификатором секции и помечена как общая секция.
Система для анализа отчетов может содержать средство 24 извлечения терминов для извлечения множества терминов 25 из общих секций отчетов и связывания каждого термина с секцией и отчетом, где он возникает. Средство 24 извлечения терминов может быть аналогично средству 5 извлечения терминов системы для предложения терминов автозавершения, однако средство 24 извлечения терминов выполнено с возможностью обработки некоторого числа завершенных отчетов, а не отчетов, которые находятся в процессе их создания.
Система для анализа отчетов может содержать генератор 26 статистических показателей сочетаемости для генерирования множества статистических показателей 7 сочетаемости. Такой статистический показатель сочетаемости может указывать первый термин, первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции. Генератор 26 статистических показателей сочетаемости может объединять термины, извлекаемые из различных секций, для получения статистического показателя сочетаемости, который относится к сочетаемости терминов в различных секциях, и таким образом первая секция статистического показателя сочетаемости может быть отличной от второй секции. Множество статистических показателей сочетаемости могут дополнительно содержать статистические показатели сочетаемости, которые относятся к сочетаемости терминов в одной и той же секции, в таком случае первая секция и вторая секция являются идентичными. Сгенерированное множество статистических показателей сочетаемости может быть использовано системой для предложения терминов автозавершения, как описано относительно Фиг.1.
Система для анализа отчетов и система для предложения терминов автозавершения могут быть интегрированы в единую систему, которая способна генерировать статистические показатели сочетаемости, основываясь на множестве отчетов, и предлагать термины автозавершения во время создания нового отчета. Однако, также возможно, что две системы реализованы как отдельные субъекты, так что разработчик продукции или технический специалист могут использовать систему для анализа отчетов для подготовки набора статистических показателей 7 сочетаемости, который может быть использован большим числом пользователей в качестве ввода в систему для предложения терминов автозавершения. Нижеследующие признаки могут быть применены и к системе автозавершения и к системе анализа отчетов.
Отчеты могут быть обеспечены во многих различных форматах, по существу не влияя на работу систем. Например, отчет может иметь формат документа, такой как документ обычного текста или документ форматируемого текста. Отчет также может иметь формат документа XML. Коды XML таких документов XML могут быть использованы для кодирования ряда сущностей; например, коды XML могут быть использованы для указания секций. Секция документа может быть создана из заголовка секции и основной части секции. Например, за пустой строкой идет строка, которая является заголовком секции, и за заголовком секции идет пустая строка и основная часть секции. В документах форматируемого текста или документах XML местоположение заголовка и/или секции может быть указано посредством метаданных. Анализатор 3, 22 секций может содержать средство синтаксического анализа (парсер) для получения любой такой информации о секциях.
Отчет 1, 21 может содержать множество файлов. Например, различные файлы содержат различные секции отчета. Это облегчает идентификацию различных секций.
Извлеченный термин 8, извлеченный средством 5 извлечения терминов и/или первый термин используемый генератором 26 сочетаемости или в статистическом показателе сочетаемости может содержать множество слов, например выражение или фразу, содержащую последовательность слов. Это выражение может, например содержать прилагательное, за которым следует существительное. Также возможно, чтобы множество слов не представляли собой фиксированное последовательное выражение, а множество слов, которые могут возникнуть где-нибудь в конкретной секции. Когда каждое из этого множества слов возникает в этой секции, статистический показатель сочетаемости указывает частоту сочетаемости со вторым термином. Однако, также возможно конфигурировать систему так, что каждый статистический показатель сочетаемости относится только к одному первому термину (который может быть выражением из последовательности слов), и что для различных слов, возникающих в объеме секции, генерируются независимые статистические показатели сочетаемости. Средство выбора терминов может объединять многокомпонентную информацию от релевантных статистических показателей сочетаемости для улучшения выбора часто сочетающегося термина 12.
Система может содержать процессор 14, 27 естественного языка. Процессор 14, 27 естественного языка может быть выполнен с возможностью связывания извлеченного термина 8 и/или первого термина с онтологическим понятием в онтологии. Это может быть сделано с использованием методологий, по сути известных в технике обработки естественного языка. Может быть использована онтология, которая является релевантной для области знаний множества отчетов 21. Соответственно статистический показатель сочетаемости может относиться к вероятности сочетаемости онтологического понятия со вторым термином. Второй термин также может соответствовать онтологическому понятию.
Средство 11 выбора терминов может быть функционально соединено с блоком 2 ввода текста и выполнено с возможностью приема части термина, который вводится пользователем, и выполнено с возможностью выбора часто сочетающегося термина 12, основываясь на принятой части термина. Таким образом, предложенные термины могут быть более релевантными, так как они соответствуют части термина, которую ввел пользователь. Например, средство 11 выбора терминов скомпоновано для выбора по меньшей мере одного часто сочетающегося термина 12, начало которого совпадает с принятой частью термина. Однако это не является ограничением. Средство 11 выбора терминов может выбирать любой термин, имеющий набранную часть в качестве подстроки термина.
Отчеты 1, 21 могут включать в себя медицинские отчеты о пациенте, и секции включают в себя секцию истории пациента, секцию клинических данных и/или секцию диагноза. Однако система также может быть использована для других областей знаний.
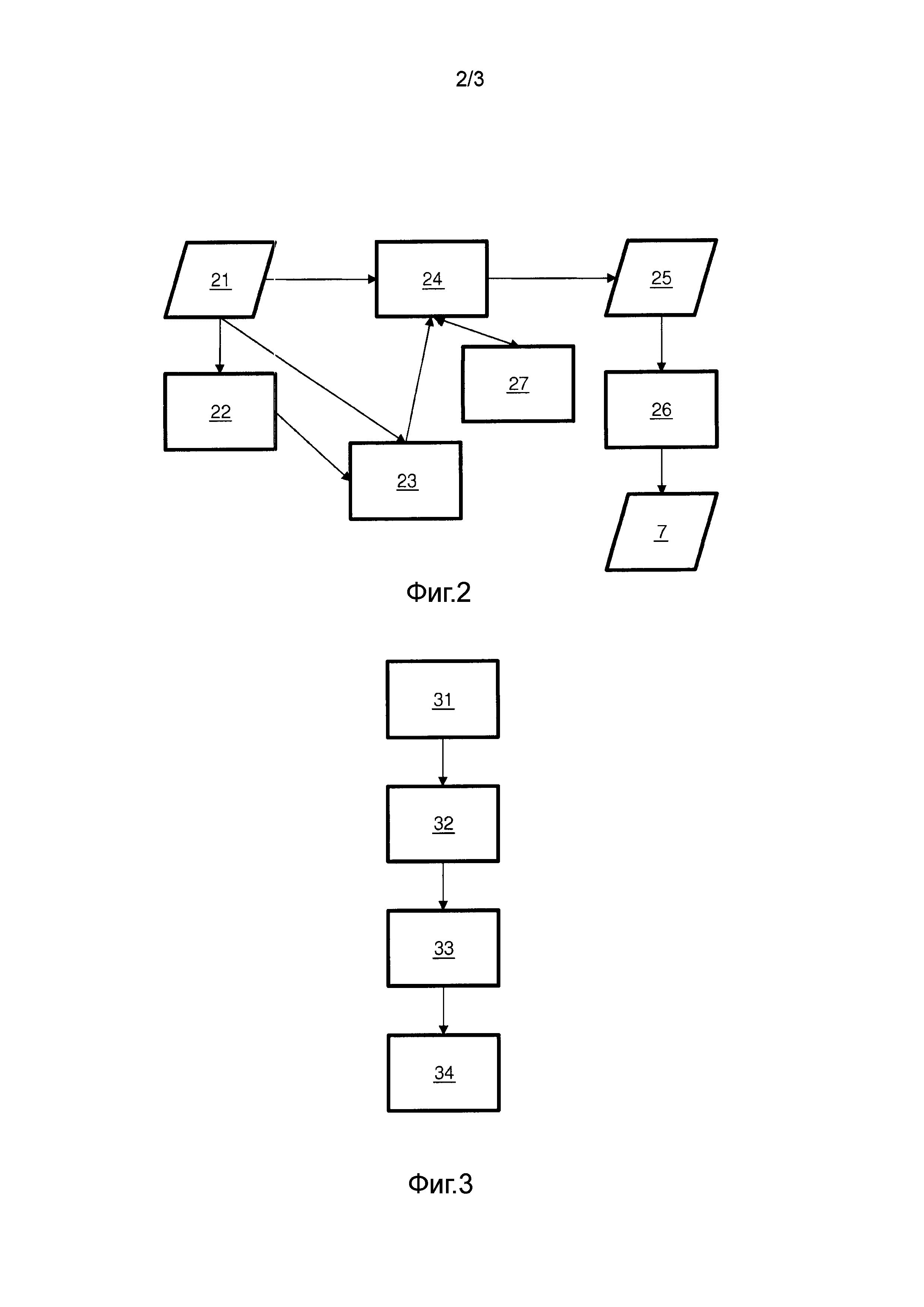
Фиг.3 показывает блок-схему последовательности операций способа анализа множества отчетов. Способ может содержать этап 31 определения разделения отчетов на секции. Способ может содержать этап 32 определения множества секций, общих для множества отчетов. Способ может содержать этап 33 извлечения множества терминов из общих секций отчетов и связывания каждого термина с секцией и отчетом, где он возникает. Способ может содержать этап 34 генерирования множества статистических показателей сочетаемости, где статистический показатель сочетаемости указывает первый термин, первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции. Способ может содержать дополнительные этапы или быть подвержен модификациям, что будет очевидно для специалиста ввиду настоящего описания, в том числе описания систем.
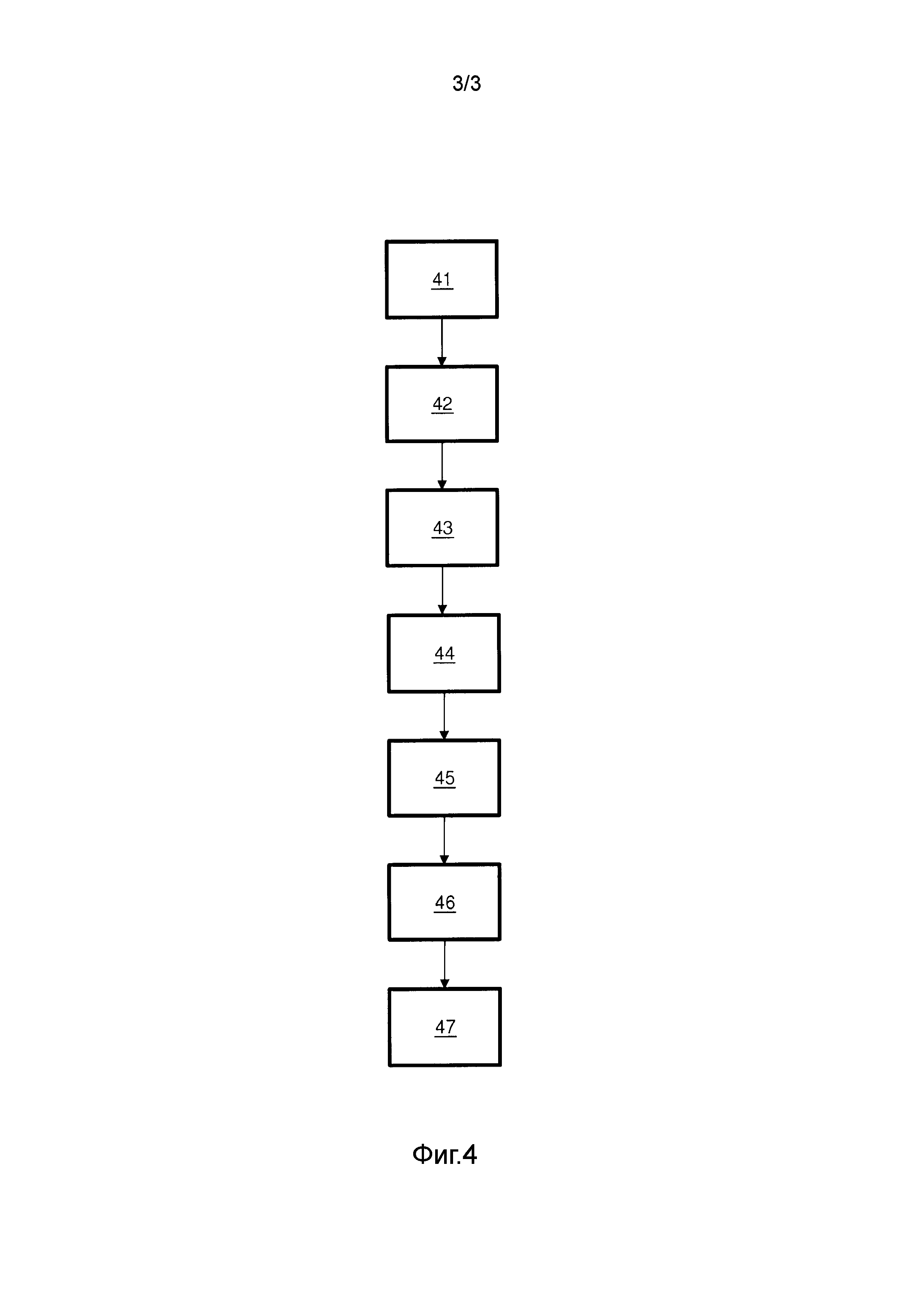
Фиг.4 показывает блок-схему последовательности операций способа предложения терминов автозавершения во время ввода текста отчета. Способ может содержать этап 41 предоставления возможности пользователю вводить текст в текущий отчет. Способ может содержать этап 42 определения множества секций текущего отчета. Способ может содержать этап 43 обнаружения секции текущего отчета, над которой работает пользователь, получая таким образом текущую секцию. Способ может содержать этап 44 извлечения термина, возникающего в текущем отчете, получая таким образом извлеченный термин, и идентификации секции текущего отчета, в которой возникает извлеченный термин, получая таким образом секцию извлеченного термина, при этом секция извлеченного термина и текущая секция являются разными секциями. Способ может содержать этап 45 осуществления доступа к множеству статистических показателей сочетаемости, где статистический показатель сочетаемости указывает первый термин, первую секцию, второй термин, вторую секцию и частоту, с которой отчеты содержат первый термин в первой секции совместно со вторым термином во второй секции. Способ может содержать этап 46 выбора по меньшей мере одного часто сочетающегося термина, основываясь на извлеченном термине, секции извлеченного термина, текущей секции и по меньшей мере одном из статистических показателей сочетаемости. Способ может содержать этап 47 обеспечения указания по меньшей мере одного часто сочетающегося термина пользователю. Способ может содержать дополнительные этапы или быть подвержен модификациям, что будет очевидно специалисту в виду настоящего описания, в том числе описания систем.
Способы и системы, описанные в данном документе, также могут быть реализованы в программном обеспечении в качестве компьютерного программного продукта. На практике, способы и системы могут быть реализованы с использованием одной или более компьютерных систем. Одна система может анализировать отчеты, хранящиеся, например, в больничной радиологической информационной системе (RIS). Извлеченные корреляции между терминами сохраняются для последующего использования. С набором или диктовкой нового отчета, отчет непрерывно анализируется компьютерной системой, в сочетании с извлеченными корреляциями. Оперативный анализ используется для предложения потенциально надлежащих терминов, которые затем отображаются на компьютерном экране, основываясь на комбинированном анализе предшествующих отчетов и текущих отчетов.
Обработка естественного языка (NLP), по сути известная в технике, может быть использована для извлечения релевантных терминов или понятий из свободно-текстовых (текст на естественном языке) клинических документов и идентификации их содержимого в документе. Они могут быть сохранены в базе данных или другом структурированном формате (например, XML). В качестве примера рассмотрим секцию отчета:
«HISTORY: 45 years old female presenting with tinnitus in left-ear and tingling on hands» («ИСТОРИЯ: 45 лет, женщина, с присутствующим тиннитусом в левом ухе и покалыванием в руках»).
Способы NLP могут быть использованы для преобразования этого текста в формат, описывающий содержимое (демографические данные, полученные данные, проблемы), подробную информацию (локализации на теле, пол, возраст), алфавитно-цифровые коды для однозначной идентификации понятий (например, коды UMLS) и секцию отчета (например, «past history» (анамнез)). Например, указанная выше по тексту секция отчета может быть преобразована в следующее:
finding:demographics
age>>[45,[idref,4],year,[idref6]]
sectname>> report past history item
sex>>female
problem:tinnitus
bodyloc>>ear
region>>left
code>>UMLS:C0521421_Entire ear
sectname>> report past history item
code>>UMLS:C0040264_Tinnitus
problem:tingling
bodyloc>>hand
code>> UMLS:C0018563_Hand
certainty>> high certainty
sectname>> report past history item
code>> UMLS:C0423572_Pins and needles
Этот процесс может быть выполнен над большим набором отчетов. Этот этап может быть выполнен в отношении всех текстовых данных, содержащихся в радиологической информационной системе (RIS), лабораторной информационной системе (LIS) или больничной информационной системе (HIS). Возможно ограничивать анализируемый набор отчетов теми отчетами, которые созданы конкретным набором авторов, например медицинскими специалистами. Этот набор авторов может представлять собой одного индивидуума, таким образом осуществляя персонализацию системы предложения. Набор авторов также может быть выбран для того, чтобы получить предложения, которые являются применимыми для релевантной области знаний. Для этой цели, набор авторов может содержать набор главных врачей, отделение в больнице, секцию в отделении или в многочисленных больницах.
Элементы структурированных данных, извлекаемые из каждого отчета, могут быть сохранены в базе данных. В простом варианте осуществления база данных содержит список идентификаторов отчета и терминов. Более того, секция, в которой был найден термин, может быть сохранена в базе данных. В примере, мы можем иметь следующую упрощенную базу данных, приведенную в таблице:
|
Для улучшения системы большие базы данных могут быть созданы на основе большего количества различных отчетов и вовлечения большего количества терминов. Однако, используя вышеупомянутую базу данных для объяснения системы, может быть логически выведено, что существует корреляция между «тиннитус» и «слуховой канал». Если разрабатывается достаточно большая база данных, еще большее количество соотношений может быть логически выведено.
Корреляция между терминами может быть однозначно сохранена. Этот список корреляций может быть отфильтрован и сохранен на основе количественных мер: числа отчетов с сочетаемостью, статистического p-значения, например вычисленного посредством хи-квадратного (chi-squared) теста или точного критерия Фишера (Fisher), или байесовской вероятности P (термин X | термин A, термин B,…, термин N) (которая должна быть интерпретирована как вероятность того, что конкретный термин X появляется при условии, что мы уже наблюдали термин A, B,…, N) в (конкретных секциях) отчете). Для сравнения следует отметить, что публикация «A hybrid approach to improving automatic speech recognition via NPL» («Гибридный метод для улучшения автоматического распознавания голоса посредством NLP»), K. Voll в: Advances in artificial intelligence: Proceedings of 20th Conference of the Canadian Society for Comptutational Studies of Intelligence («Достижения в Области Искусственного Интеллекта: Труды 20-ой Конференции Канадского Общества по вопросам Вычислительных Исследований Интеллекта»), Canadian AI 2007, Монреаль, Канада, 2007 раскрывает способ обнаружения ошибки пост-автоматического распознавания речи. Документ раскрывает эвристику, основанную на связях сочетаемости в контекстном окне, которое задано как n слов, возникающих с любой стороны слова. Эти связи сочетаемости могут быть условными вероятностями, использующими теорему Байеса.
С вводом нового отчета (обычно посредством набора или диктовки) система, описываемая в этом описании, может обрабатывать его. Аналогичные или схожие способы обработки естественного языка могут быть использованы, как описано выше по тексту. Еще раз, термины и понятия в отчете могут быть извлечены и структурированы. Этот анализ может быть выполнен непрерывно по мере диктовки новых слов или набора новых букв. В набираемых отчетах с вводом каждой буквы, этап предсказания, описанный в данном документе, может быть активирован для предложения терминов, которые могут завершить вводимое слово или фразу. В случае с диктовкой слово может быть неоднозначно введено вследствие ограничений известных алгоритмов распознавания речи. Например, известные способы распознавания речи могут не быть способны разделять с достоверностью произносимые слова «креатинин» и «креатин». В этих случаях, этап предсказания, описанный в этом документе, может быть активирован.
Система может осуществлять поиск соответствующих слов в списке медицинских терминов. Таким образом, если введена буква «с», идентифицируются все медицинские термины, начинающиеся с буквы «с». После этого, извлеченная информация из текущего отчета и сохраненные анализы из исторических (прошлых) отчетов могут быть объединены для определения приоритетов некоторых терминов. Например, может быть осуществлен поиск в базе данных, отыскивающий все прошлые отчеты, которые содержат одни и те же термины или онтологические понятия как таковые из текущего отчета. Таким образом, термины, часто сочетающиеся с теми терминами, могут быть найдены, и для них могут быть определены приоритеты на основе частоты сочетаемости.
В качестве примера рассмотрим набор нового отчета, при этом секция истории содержит термин «тиннитус». В этом примере, в настоящий момент набираемое слово начинается с буквы «c». Используя известные способы, возможный список слов может быть ограничен теми словами, которые начинаются c «c». Затем, при сравнении с небольшой примерной базой данных по Этапу 2, выясняется, что «тиннитус» часто сочетается с термином «слуховой канал». Этот термин затем может быть продвинут к началу списка возможных вариантов и указан пользователю в качестве предложения для автозавершения набираемого термина.
Сравнение может быть выполнено в контексте секций отчета. Когда обрабатывают исторические данные для нахождения сочетаемостей, обработка может учитывать секции, в которых появляются термины. Например, если текущий отчет показывает «глиобластома» в секции истории, то система может быть выполнена с возможностью только учета более ранних отчетов, в которых «глиобластома» находится в секции истории. Аналогичным образом, в зависимости от того, в какой секции набирается термин, предлагаются только термины, найденные в той же самой секции в предшествующих отчетах.
Результаты могут быть показаны как экранное меню, перечисляющее возможные совпадения в порядке очередности. Приоритет может быть основан на частоте сочетаемости предложенного слова, принимая во внимание извлеченные термины и понятия и их секции. Предложенные термины могут быть представлены отдельно для различных типов терминов, например термины, относящиеся к заболеваниям, симптомам, полученным данным и процедурам.
Следует отметить, что изобретение также применяет компьютерные программы, в частности компьютерные программы в или на носителе, приспособленные для осуществления изобретения на практике. Программа может быть в форме исходного кода, объектного кода, кода, представляющего промежуточный исходный и объектный код, например в частично компилированной форме, или в любой другой форме, подходящей для использования при реализации способа, согласно изобретению. Следует отметить, что такая программа может иметь различные архитектурные разработки. Например, программный код, реализующий функциональность способа или системы согласно изобретению, может быть подразделен на одну или более подпрограмм. Многие другие методы распределения функциональности по этим подпрограммам станут очевидны для специалиста в данной области техники. Подпрограммы могут быть сохранены вместе в одном исполняемом файле для формирования независимой программы. Такой исполняемый файл может содержать исполняемые компьютером инструкции, например, инструкции обработчика и/или инструкции интерпретатора (например, инструкции интерпретатора Java). В качестве альтернативы одна или более или все подпрограммы могут быть сохранены по меньшей мере в одном файле внешней библиотеки и связаны с основной программой либо статично, либо динамично, например во время прогона программы. Основная программа содержит по меньшей мере один вызов по меньшей мере одной из подпрограмм. Подпрограммы также могут содержать вызовы функции друг к другу. Вариант осуществления, относящийся к компьютерному программному продукту, содержит исполняемые компьютером инструкции, соответствующие каждому этапу обработки по меньшей мере одного из предлагаемых в данном документе способов. Эти инструкции могут быть подразделены на подпрограммы и/или сохранены в одном или более файлов, которые могут быть связаны статично или динамично. Другой вариант осуществления, относящийся к компьютерному программному продукту, содержит исполняемые компьютером инструкции для каждого средства по меньшей мере одной из предлагаемых в данном документе систем и/или продуктов. Эти инструкции могут быть подразделены на подпрограммы и/или сохранены в одном или более файлах, которые могут быть связаны статично или динамично.
Носитель компьютерной программы может быть любым объектом или устройством способным переносить программу. Например, носитель может включать в себя запоминающий носитель, такой как ROM, например, CD-ROM или полупроводниковое ROM, или магнитный носитель записи, например флоппи диск или жесткий диск. Кроме того, носитель может быть передаваемым носителем, таким как электрический или оптический сигнал, который может быть перенесен по электрическому или оптическому кабелю или посредством радиосвязи или другого средства. Когда программа воплощена в таком сигнале, носитель может быть составлен такими кабелем или другими устройством или средствами. В качестве альтернативы носитель может быть интегральной схемой, в которую встроена программа, причем интегральная схема выполнена с возможностью осуществления или использования при осуществлении соответствующего способа.
Следует отметить, что вышеупомянутые варианты осуществления иллюстрируют не ограничения изобретения, и специалисты в данной области техники смогут сконструировать много альтернативных вариантов осуществления, не отходя от объема приложенной формулы изобретения. В формуле изобретения любые ссылочные обозначения, помещенные между круглыми скобками, не должны быть истолкованы как ограничивающие формулу изобретения. Использование слова «содержит» и его объединений не исключает наличия элементов или этапов, отличных от тех, что указаны в формуле изобретения. Указание элемента в единственном числе не исключает множества таких элементов. Изобретение может быть реализовано посредством аппаратного обеспечения, содержащего несколько различных элементов, и посредством подходящим образом запрограммированного компьютера. В пункте формулы изобретения на устройство, перечисляющем несколько средств, несколько из этих средств могут быть воплощены одним и аналогичным элементом аппаратного обеспечения. Лишь факт того, что некоторые меры указаны во взаимно различных зависимых пунктах формулы изобретения, не указывает, что эти меры не могут быть использованы для получения преимущества.
Устройство и способ для получения напитка
Подставка для поддержания чашки и кофе-машина или подобное ей устройство, содержащее упомянутую подставку
Освещающее устройство
Цифровая обработка импульсов в схемах счета мультиспектральных фотонов
Уменьшение эффектов захвата в сцинтилляторе за счет применения вторичного излучения
Пространственная мышь - устройство связи
Органическое светоизлучающее устройство с регулируемой инжекцией носителей заряда
Способ определения, по меньшей мере, одного приемлемого параметра для процесса приготовления напитка
Устройство для перфорирования порционных капсул
Светоизлучающий ворсовый ковер

