Результат интеллектуальной деятельности: ПРОГРЕССИВНОЕ КОДИРОВАНИЕ ПОЗИЦИИ ПОСЛЕДНЕГО ЗНАЧИМОГО КОЭФФИЦЕНТА
Вид РИД
Изобретение
По настоящей заявке на патент испрашивается приоритет:
предварительной заявки США № 61/557317, поданной 8 ноября 2011 г., и
предварительной заявки США № 61/561909, поданной 20 ноября 2011 г.,
каждая из которых полностью включена в этот документ по ссылке.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Это раскрытие относится к кодированию видео.
УРОВЕНЬ ТЕХНИКИ
Возможности цифрового видео могут быть включены в широкий диапазон устройств, включающих в себя цифровые телевизоры, системы прямого цифрового вещания, беспроводные вещательные системы, персональные цифровые секретари (PDA), портативные или настольные компьютеры, планшетные компьютеры, устройства для чтения электронных книг, цифровые камеры, цифровые записывающие устройства, цифровые медиаплееры, видеоигровые устройства, видеоигровые консоли, сотовые или спутниковые радиотелефоны, так называемые "смартфоны", устройства видеоконференцсвязи, устройства потокового видео и т.п. Цифровые видеоустройства реализуют способы сжатия видео, например, способы, описанные в стандартах, определяемых MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Часть 10, Advanced Video Coding (AVC, усовершенствованное кодирование видео), в настоящее время разрабатываемом стандарте High Efficiency Video Coding (HEVC, высокоэффективное кодирование видео) и расширениях этих стандартов. С реализацией этих способов сжатия видео видеоустройства могут более эффективно передавать, принимать, кодировать, декодировать и/или сохранять цифровую видеоинформацию.
В способах сжатия видео выполняется пространственное (внутрикадровое) предсказание и/или временное (межкадровое) предсказание для уменьшения или удаления избыточности, свойственной видеопоследовательностям. Для блочного кодирования видео видеослайс (то есть видеокадр или часть видеокадра) может быть разделен на видеоблоки, которые также могут называться древовидными блоками (treeblock), единицами кодирования (CU) и/или узлами кодирования. Видеоблоки в слайсе с интракодированием (I-слайс) картинки кодируются с использованием пространственного предсказания относительно опорных отсчетов в соседних блоках в той же самой картинке. Видеоблоки в слайсах с интеркодированием (P-слайс или B-слайс) картинки могут использовать пространственное предсказание относительно опорных отсчетов в соседних блоках в той же картинке или временное предсказание относительно опорных отсчетов в других опорных картинках. Картинки могут называться кадрами, а опорные картинки могут называться опорными кадрами.
В результате пространственного или временного предсказания получается прогнозирующий блок для блока, который должен быть закодирован. Остаточные данные представляют пиксельные разности между исходным блоком, который должен быть закодирован, и прогнозирующим блоком. Блок с интеркодированием кодируется согласно вектору движения, который указывает на блок опорных отсчетов, формирующих прогнозирующий блок, и остаточные данные, указывающие разность между закодированным блоком и прогнозирующим блоком. Блок с интракодированием кодируется согласно режиму интракодирования и остаточным данным. Для дополнительного сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования, результатом чего являются остаточные коэффициенты преобразования, которые после этого могут быть подвергнуты квантованию. Для создания одномерного вектора коэффициентов преобразования квантованные коэффициенты преобразования, которые первоначально организованы в двумерный массив, могут быть подвергнуты сканированию, и для достижения еще большего сжатия может быть применено энтропийное кодирование.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является структурной схемой, которая иллюстрирует пример системы кодирования и декодирования видео, которая может использовать способы, описанные в этом раскрытии предмета изобретения.
На Фиг. 2A-2D изображены иллюстративные порядки сканирования значений коэффициентов.
На Фиг. 3 изображен один пример карты значимости, относящейся к блоку значений коэффициентов.
Фиг. 4 является структурной схемой, которая иллюстрирует пример видеокодера, который может реализовать способы, описанные в этом раскрытии.
Фиг. 5 является структурной схемой, которая иллюстрирует пример энтропийного кодера, который может реализовать способы, описанные в этом раскрытии.
Фиг. 6 является блок-схемой, иллюстрирующей пример способа определения двоичной строки для значения, указывающего позицию последнего значимого коэффициента, согласно способам этого раскрытия предмета изобретения.
Фиг. 7 является структурной схемой, которая иллюстрирует пример видеодекодера, который может реализовать способы, описанные в этом раскрытии предмета изобретения.
Фиг. 8 является блок-схемой, иллюстрирующей пример способа определения значения, указывающего позицию последнего значимого коэффициента из двоичной строки, согласно способам этого раскрытия.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В общем, в этом раскрытии описываются способы кодирования видеоданных. Кодирование видео обычно предусматривает предсказание блока видеоданных с использованием конкретного режима предсказания и кодирование остаточных значений для блока на основе разностей между предсказанным блоком и фактическим блоком, который кодируется. Остаточный блок включает в себя эти попиксельные разности. Остаточный блок может подвергаться преобразованию и квантованию. Видеокодер может включать в себя блок квантования, который отображает коэффициенты преобразования в дискретные значения уровня. Это раскрытие обеспечивает способы кодирования позиции последнего значимого коэффициента внутри видеоблока.
В одном примере способ кодирования видеоданных содержит получение значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, определение первой двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, определение второй двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы кодирования с фиксированной длиной слова и кодирование первой и второй двоичных строк в битовый поток.
В еще одном примере способ декодирования видеоданных содержит получение первой двоичной строки и второй двоичной строки из закодированного битового потока, определение значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, и определение значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В еще одном примере устройство для кодирования видеоданных содержит устройство кодирования видео, выполненное с возможностью получения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, определения первой двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, определения второй двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы кодирования с фиксированной длиной слова и кодирования первой и второй двоичных строк в битовый поток.
В еще одном примере устройство для декодирования видеоданных содержит устройство декодирования видео, выполненное с возможностью получения первой двоичной строки и второй двоичной строки из закодированного битового потока, определения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, и определения значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В еще одном примере устройство для кодирования видеоданных содержит средство для получения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, средство для определения первой двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, средство для определения второй двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы кодирования с фиксированной длиной слова и средство для кодирования первой и второй двоичных строк в битовый поток.
В еще одном примере устройство для декодирования видеоданных содержит средство для получения первой двоичной строки и второй двоичной строки из закодированного битового потока, средство для определения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, и средство для определения значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В еще одном примере считываемый компьютером носитель информации содержит хранящиеся на нем инструкции, которые при исполнении вызывают кодирование процессором устройства видеоданных для того, чтобы вызывать получение одним или более процессорами значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, определение первой двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, определение второй двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы кодирования с фиксированной длиной слова и кодирование первой и второй двоичных строк в битовый поток.
В еще одном примере считываемый компьютером носитель информации содержит хранящиеся на нем инструкции, которые при исполнении вызывают получение процессором устройства для декодирования видеоданных первой двоичной строки и второй двоичной строки из закодированного битового потока, определение значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, и определение значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В одном примере способ декодирования видеоданных содержит получение первой двоичной строки и второй двоичной строки из закодированного битового потока, определение значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством log2(T)+1, и определение значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В одном примере способ декодирования видеоданных содержит получение первой двоичной строки и второй двоичной строки из закодированного битового потока, определение значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством log2(T), и определение значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
В нижеследующем описании и прилагаемых чертежах подробно изложены один или несколько примеров. Другие признаки, цели и преимущества будут очевидны из упомянутых описания и чертежей и из формулы изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
В этом раскрытии обеспечены способы сокращения длины строки битов, используемой для указания позиции последнего значимого коэффициента внутри блока коэффициентов преобразования. Упомянутая строка битов может быть, в частности, полезной для контекстно-адаптивного двоичного арифметического кодирования (context adaptive binary arithmetic coding, CABAC). В одном примере для указания позиции последнего значимого коэффициента может быть использована прогрессивная структура кодового слова с сокращенным количеством бинов (bin) и более короткими усеченными унарными кодами. Кроме того, в одном примере с сокращением максимальной длины усеченного унарного кода количество контекстных моделей CABAC для позиции последнего значимого коэффициента может также быть сокращено.
Видеокодер может быть выполнен с возможностью определения первой и второй двоичных строк для значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T. Видеодекодер может быть выполнен с возможностью определения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, на основе первой и второй двоичных строк. В одном примере первая двоичная строка может быть основана на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, и вторая двоичная строка может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-2. В еще одном примере первая двоичная строка может быть основана на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством log2(T)+1, и вторая двоичная строка может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-1. В еще одном примере первая двоичная строка может быть основана на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством log2(T), и вторая двоичная строка может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-1.
Фиг. 1 является структурной схемой, которая иллюстрирует пример системы 10 кодирования и декодирования видео, которая может использовать способы, описанные в этом раскрытии. Как представлено на Фиг. 1, система 10 включает в себя устройство-источник 12, которое генерирует закодированные видеоданные, которые впоследствии должны быть декодированы устройством-адресатом 14. Устройство-источник 12 и устройство-адресат 14 могут содержать любое из широкого диапазона устройств, включающих в себя настольные компьютеры, компьютеры-ноутбуки (то есть переносные компьютеры), планшетные компьютеры, телевизионные приставки, микротелефонные трубки, например, так называемые "смартфоны", так называемые "смартпады", телевизоры, камеры, устройства отображения, цифровые медиаплееры, видеоигровые консоли, устройство потокового видео и т.п. В некоторых случаях устройство-источник 12 и устройство-адресат 14 могут быть оснащены беспроводной связью.
Устройство-адресат 14 может принимать закодированные видеоданные, которые должны быть декодированы, через линию 16 связи. Линия 16 связи может содержать любой тип носителя или устройства, посредством которых можно перемещать закодированные видеоданные из устройства-источника 12 в устройство-адресат 14. В одном примере линия 16 связи может содержать среду связи для обеспечения возможности передачи устройством-источником 12 закодированных видеоданных непосредственно в устройство-адресат 14 в реальном времени. Закодированные видеоданные могут модулироваться согласно стандарту связи, например, протоколу беспроводной связи, и передаваться в устройство-адресат 14. Среда связи может содержать любую среду беспроводной или проводной связи, например, спектр радиочастот (RF) или одну или несколько физических линий передачи. Среда связи может являться частью пакетной сети, например, локальной сети, широкомасштабной сети или глобальной сети, например, Internet. Среда связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может являться полезным для содействия передаче информации из устройства-источника 12 в устройство-адресат 14.
В качестве альтернативы, закодированные данные могут выводиться из выходного интерфейса 22 в запоминающее устройство 32. Аналогично, может быть осуществлен доступ к закодированным данным из запоминающего устройства 32 посредством входного интерфейса 28. Запоминающее устройство 32 может включать в себя любой из множества распределенных или локальных накопителей данных, например, жесткий диск, диски блю-рей (Blu-ray), DVD, CD-ROM, флэш-память, энергозависимую или энергонезависимую память или любые другие подходящие цифровые носители информации для хранения закодированных видеоданных. В еще одном примере запоминающее устройство 32 может соответствовать файловому серверу или другому промежуточному запоминающему устройству, которое может хранить закодированное видео, генерируемое устройством-источником 12. Устройство-адресат 14 может осуществлять доступ к хранящимся видеоданным из запоминающего устройства 32 через поток или загрузку. Файловый сервер может являться любым типом сервера, на котором могут храниться закодированные видеоданные и который может передавать эти закодированные видеоданные в устройство-адресат 14. Примеры файловых серверов включают в себя web-сервер (например, для веб-сайта), FTP-сервер, сетевое устройство хранения данных (NAS) или локальный накопитель на дисках. Устройство-адресат 14 может осуществлять доступ к закодированным видеоданным через любое стандартное информационное соединение, включающее в себя Internet-соединение. Оно может включать в себя канал беспроводной связи (например, соединение Wi-Fi), проводное соединение (например, DSL, кабельный модем и т.д.) или комбинацию обоих, которая является подходящей для осуществления доступа к закодированным видеоданным, хранящимся на файловом сервере. Передача закодированных видеоданных из запоминающего устройства 32 может быть потоковой передачей, передачей посредством загрузки или комбинацией обеих.
Способы этого раскрытия не обязательно ограничиваются беспроводными применениями или установками. Упомянутые способы могут быть применены к кодированию видео в поддержку любого из множества мультимедийных приложений, например, вещательных передач эфирного телевидения, передач кабельного телевидения, передач спутникового телевидения, передач потокового видео, например, через Internet, кодирования цифрового видео для хранения на накопителе данных, декодирования цифрового видео, хранящегося на накопителе данных, или других приложений. В некоторых примерах система 10 может быть выполнена с возможностью поддержки односторонней или двухсторонней видеопередачи для поддержки таких приложений, как потоковое видео, воспроизведение видео, видеовещание и/или видеотелефония.
В примере по Фиг. 1 устройство-источник 12 включает в себя видеоисточник 18, видеокодер 20 и выходной интерфейс 22. В некоторых случаях выходной интерфейс 22 может включать в себя модулятор/демодулятор (модем) и/или передатчик. В устройстве-источнике 12 видеоисточник 18 может включать в себя такой источник, как устройство видеозахвата, например, видеокамеру, видеоархив, содержащий ранее захваченное видео, интерфейс для внешнего видео для приема видео от провайдера видеоконтента и/или систему компьютерной графики для генерации данных компьютерной графики как исходного видео, или комбинацию таких источников. В качестве одного примера, если видеоисточник 18 является видеокамерой, то устройство-источник 12 и устройство-адресат 14 могут являться так называемыми камерофонами или видеотелефонами. Однако способы, описанные в этом раскрытии, могут быть применены к кодированию видео вообще и могут быть применены к беспроводным и/или проводным приложениям.
Захваченное, предварительно захваченное или генерируемое компьютером видео может быть закодировано посредством видеокодера 12. Закодированные видеоданные из устройства-источника 20 могут передаваться непосредственно в устройство-адресат 14 через выходной интерфейс 22. Закодированные видеоданные могут также (или в качестве альтернативы) быть сохранены на запоминающем устройстве 32 для последующей выборки устройством-адресатом 14 или другими устройствами для декодирования и/или воспроизведения.
Устройство-адресат 14 включает в себя входной интерфейс 28, видеодекодер 30 и устройство 32 отображения. В некоторых случаях входной интерфейс 28 может включать в себя приемник и/или модем. Входной интерфейс 28 устройства-адресата 14 принимает закодированные видеоданные по линии 16 связи. Закодированные видеоданные, передаваемые по линии 16 связи или обеспечиваемые на запоминающем устройстве 32, могут включать в себя множество синтаксических элементов, генерируемых видеокодером 20 для использования видеодекодером, например, видеодекодером 30, при декодировании видеоданных. Такие синтаксические элементы могут быть включены в закодированные видеоданные, передаваемые по среде связи, хранящиеся на накопителе информации или хранящиеся на файловом сервере.
Устройство 32 отображения может быть интегрировано с устройством-адресатом 14 или являться внешним по отношению к нему. В некоторых примерах устройство-адресат 14 может включать в себя интегрированное устройство отображения, а также быть выполнено с возможностью обеспечения интерфейса с внешним устройством отображения. В других примерах устройство-адресат 14 может являться устройством отображения. В общем, устройство 32 отображения выводит на экран декодированные видеоданные пользователю и может содержать любое из множества устройств отображения, например, жидкокристаллическое устройство отображения (LCD), плазменное устройство отображения, устройство отображения на основе органического светодиода (OLED) или другой тип устройства отображения.
Видеокодер 20 и видеодекодер 30 могут функционировать согласно стандарту сжатия видео, например, разрабатываемому в настоящее время стандарту высокоэффективного кодирования видео (HEVC), и могут отвечать Тестовой модели HEVC (HEVC Test Model) (HM). В качестве альтернативы, видеокодер 20 и видеодекодер 30 могут функционировать согласно другим частным или отраслевым стандартам, например, стандарту ITU-T H.264, в качестве альтернативы называемому MPEG-4, Часть 10, Усовершенствованному кодированию видео (Advanced Video Coding, AVC) или расширениям таких стандартов. Способы этого раскрытия, однако, не ограничиваются каким-либо конкретным стандартом кодирования. Другие примеры стандартов сжатия видео включают в себя MPEG-2 и ITU-T H.263.
Несмотря на то, что на Фиг. 1 не изображено, согласно некоторым аспектам каждый из видеокодера 20 и видеодекодера 30 может быть интегрирован с аудиокодером и аудиодекодером и может включать в себя надлежащие блоки MUX-DEMUX или другие аппаратные и программные средства, оперировать кодированием как аудио, так и видео в общем потоке данных или отдельных потоках данных. В соответствующих случаях, в некоторых примерах, блоки MUX-DEMUX могут отвечать протоколу мультиплексора ITU H.223 или другим протоколам, например, протоколу передачи дейтаграмм пользователя (UDP).
Каждый из видеокодера 20 и видеодекодера 30 может быть реализован как любая из множества подходящих схем кодера, например, один или несколько микропроцессоров, цифровые сигнальные процессоры (DSP), специализированные интегральные схемы (ASIC), программируемые пользователем вентильные матрицы (FPGA), дискретная логика, программные средства, аппаратные средства, программно-аппаратные средства или любые их комбинации. Для выполнения способов этого раскрытия, при частичной реализации этих способов в программных средствах, устройство может сохранять инструкции для этих программных средств на подходящем не промежуточном считываемом компьютером носителе и исполнять эти инструкции в аппаратных средствах с использованием одного или нескольких процессоров. Каждый из видеокодера 20 и видеодекодера 30 может быть включен в один или несколько кодеров или декодеров, любой из которых может быть интегрирован как часть объединенного кодера/декодера (КОДЕК) в соответствующее устройство.
Над разработкой стандарта HEVC работает JCT-VC. Усилия по стандартизации HEVC направлены на разработку модели устройства кодирования видео, называемой Тестовая модель HEVC (HEVC Test Model, HM). HM предполагает несколько дополнительных возможностей устройств кодирования видео по сравнению с существующими устройствами в соответствии с, например, ITU-T H.264/AVC. Например, тогда как H.264 обеспечивает девять режимов кодирования с интрапредсказанием, HM может обеспечить целых тридцать три режима кодирования с интрапредсказанием.
В общем, рабочая модель HM описывает то, что видеокадр или картинка могут быть разделены на последовательность древовидных блоков или наибольших единиц кодирования (largest coding unit, LCU), которые включают в себя отсчеты как цветности, так и яркости. Назначение древовидного блока является аналогичным назначению макроблока в стандарте H.264. Слайс включает в себя несколько последовательных древовидных блоков в порядке кодирования. Видеокадр или картинка может быть разделена на один или несколько слайсов. Каждый древовидный блок может быть разделен на единицы кодирования (CU) согласно квадрадереву. Например, древовидный блок, как корневой узел квадрадерева, может быть разделен на четыре дочерних узла, и каждый дочерний узел в свою очередь может являться родительским узлом и быть разделен еще на четыре дочерних узла. Конечный, неразделенный дочерний узел, как листовой узел квадрадерева, содержит узел кодирования, то есть закодированный видеоблок. Синтаксические данные, ассоциированные с закодированным битовым потоком, могут определять максимально возможное число делений древовидного блока и могут также определять минимальный размер узлов кодирования.
CU включает в себя узел кодирования и единицы предсказания (PU) и единицы преобразования (TU), ассоциированные с упомянутым узлом кодирования. Размер CU соответствует размеру узла кодирования и должен иметь квадратную форму. Размер CU может измениться в пределах от 8Ч8 пикселов до размера древовидного блока с максимумом 64Ч64 пикселов или больше. Каждый CU может содержать один или несколько PU и один или несколько TU. Синтаксические данные, ассоциированные с CU, могут описывать, например, разделение CU на одну или несколько PU. Режимы разделения могут отличаться в зависимости от того, кодируется ли CU в прямом режиме или с пропуском, в режиме с интрапредсказанием или в режиме с интерпредсказанием. PU могут быть разделены на блоки неквадратной формы. Синтаксические данные, ассоциированные с CU, также могут описывать, например, разделение CU на одну или несколько TU в соответствии с квадрадеревом. TU может иметь квадратную или неквадратную форму.
Стандарт HEVC обеспечивает возможность преобразований в соответствии с TU, которые могут быть разными для разных CU. Размер единиц TU обычно задается на основе размера единиц PU в пределах данной CU, определенной для разделенной LCU, хотя это может не всегда иметь место. TU обычно имеют размер, идентичный размеру PU, или меньше, чем у нее. В некоторых примерах остаточные отсчеты, соответствующие CU, могут подразделяться на меньшие единицы с использованием структуры квадрадерева, известной как "остаточное квадрадерево" (RQT). Листовые узлы RQT могут называться единицами преобразования (TU). Значения разности пикселов, ассоциированные с TU, могут быть преобразованы для создания коэффициентов преобразования, которые могут квантоваться.
В общем, PU включает в себя данные, относящиеся к процессу предсказания. Например, когда PU кодируется в режиме с интрапредсказанием, PU может включать в себя данные, описывающие режим с интрапредсказанием для PU. В качестве другого примера, когда PU кодируется в интеррежиме, PU может включать в себя данные, определяющие вектор движения для PU. Данные, определяющие вектор движения для PU, могут описывать, например, горизонтальную составляющую вектора движения, вертикальную составляющую вектора движения, разрешение для вектора движения (например, точность до одной четверти пиксела или точность до одной восьмой пиксела), опорную картинку, на которую указывает вектор движения, и/или список опорных картинок (например, список 0, список 1 или список C) для вектора движения.
В общем, TU используется для процессов квантования и преобразования. Данная CU, имеющая одну или несколько PU, также может включать в себя одну или несколько TU. После предсказания видеокодер 20 может вычислять остаточные значения, соответствующие PU. Остаточные значения содержат значения разности пикселов, которые могут преобразовываться в коэффициенты преобразования, квантоваться и сканироваться с использованием TU для создания преобразованных в последовательную форму коэффициентов преобразования для энтропийного кодирования. Термин "видеоблок" в этом раскрытии может относиться к узлу кодирования CU или блоку коэффициентов преобразования. Один или несколько блоков коэффициентов преобразования могут определять TU. В некоторых конкретных случаях в этом раскрытии термин "видеоблок" также может использоваться для ссылки на древовидный блок, то есть LCU или CU, которая включает в себя узел кодирования и блоки PU и TU.
Видеопоследовательность обычно включает в себя ряд видеокадров или картинок. Группа картинок (group of pictures, GOP) обычно содержит ряд из одного или нескольких видеокадров. GOP может включать в себя синтаксические данные в своем заголовке, заголовке одной или нескольких упомянутых картинок или в каком-либо другом месте, которые описывают несколько картинок, включенных в эту GOP. Каждый слайс картинки может включать в себя синтаксические данные слайса, которые описывают режим кодирования для соответствующего слайса. Видеокодер 20 обычно выполняет ряд операций над видеоблоками внутри отдельных видеослайсов для кодирования видеоданных. Видеоблок может включать в себя одну или несколько TU или PU, которые соответствуют узлу кодирования внутри CU. Видеоблки могут иметь фиксированные или переменные размеры и могут отличаться по размеру согласно заданному стандарту кодирования.
В качестве примера, HM поддерживает предсказание при различных размерах PU. С предположением того, что размер конкретной CU равен 2N×2N, HM поддерживает интрапредсказание при размерах PU 2N×2N или N×N и интерпредсказание при симметричных размерах PU 2N×2N, 2N×N, N×2N или N×N. HM также поддерживает асимметричное разделение для интерпредсказания при размерах PU 2N×nU, 2N×nD, nL×2N и nR×2N. При асимметричном разделении CU в одном направлении не делится, тогда как в другом направлении делится на 25% и 75%. Часть CU, соответствующая сегменту в 25%, обозначена "n", за которым следует обозначение "Up" ("Вверху"), "Down" ("Внизу"), "Left" ("Слева") или "Right" ("Справа"). Соответственно, например, "2N×nU" относится к CU 2N×2N, которая разделена по горизонтали с PU 2N×0,5N наверху и PU 2N×1,5N внизу.
В этом раскрытии "N×N" и "N на N" являются взаимозаменяемыми и относятся к размерам видеоблоков в пикселах в отношении размеров по вертикали и по горизонтали, например, 16×16 пикселов или 16 на 16 пикселов. В общем, блок 16×16 содержит 16 пикселов в вертикальном направлении (y=16) и 16 пикселов в горизонтальном направлении (x=16). Аналогично, блок N×N обычно содержит N пикселов в вертикальном направлении и N пикселов в горизонтальном направлении, где N представляет неотрицательное целочисленное значение. Пикселы в блоке могут быть организованы в строки и столбцы. Кроме того, блоки не обязательно должны иметь одинаковое количество пикселов в горизонтальном направлении и в вертикальном направлении. Например, блоки могут содержать N×M пикселов, где M не обязательно равно N.
После кодирования с интрапредсказанием или с интерпредсказанием с использованием единиц PU единицы CU, видеокодер 20 может вычислять остаточные данные для единиц TU единицы CU. PU могут содержать данные пикселов в пространственной области (также называемой пиксельной областью), и TU могут содержать коэффициенты в области преобразования после применения преобразования, например, дискретного косинусного преобразования (DCT), целочисленного преобразования, вейвлет-преобразования или концептуально аналогичного преобразования остаточных видеоданных. Остаточные данные могут соответствовать разностям пикселов между пикселами незакодированной картинки и значениями предсказания, соответствующими блокам PU. Из одного или нескольких блоков коэффициентов преобразования видеокодер 20 может формировать TU. TU могут включать в себя остаточные данные для CU. Видеокодер 20 может после этого преобразовать TU для создания коэффициентов преобразования для CU.
После любых преобразований для создания коэффициентов преобразования видеокодер 20 может выполнять квантование этих коэффициентов преобразования. Квантование обычно относится к процессу, в котором коэффициенты преобразования квантуются с целью максимально возможного сокращения объема данных, используемых для представления коэффициентов, с обеспечением дополнительного сжатия. Процесс квантования может сокращать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Например, во время квантования n-битовое значение может округляться в меньшую сторону до m-битового значения, где n больше, чем m.
В некоторых примерах видеокодер 20 может использовать предопределенный порядок сканирования для сканирования квантованных коэффициентов преобразования для создания преобразованного в последовательную форму вектора, который может быть закодирован с использованием энтропийного кодирования. В других примерах видеокодер 20 может выполнять адаптивное сканирование. На Фиг. 2A-2D изображены некоторые разные иллюстративные порядки сканирования. Также могут использоваться другие определенные порядки сканирования или адаптивные (изменяющиеся) порядки сканирования. На Фиг. 2A изображен зигзагообразный порядок сканирования, на Фиг. 2B изображен горизонтальный порядок сканирования, на Фиг. 2C изображен вертикальный порядок сканирования и на Фиг. 2D изображен диагональный порядок сканирования. Также могут быть определены и использоваться комбинации этих порядков сканирования. В некоторых примерах способы этого раскрытия могут конкретно применяться в процессе кодирования видео во время кодирования так называемой карты значимости.
Для указания позиции последнего значимого коэффициента (то есть ненулевого коэффициента), который может зависеть от порядка сканирования, ассоциированного с блоком коэффициентов, могут быть определены один или несколько синтаксических элементов. Например, один синтаксический элемент может определять позицию столбца последнего значимого коэффициента внутри блока значений коэффициентов, а другой синтаксический элемент может определять позицию строки последнего значимого коэффициента внутри блока значений коэффициентов.
На Фиг. 3 изображен один пример карты значимости, относящейся к блоку значений коэффициентов. Справа изображена карта значимости, в которой однобитовые флажки идентифицируют коэффициенты в видеоблоке слева, которые являются значимыми, то есть ненулевыми. В одном примере задан набор значимых коэффициентов (например, определяемый картой значимости) и порядок сканирования, (посредством которого) может быть определена позиция последнего значимого коэффициента. В выходящем стандарте HEVC коэффициенты преобразования могут быть сгруппированы в порцию. Порция может содержать всю TU, или в некоторых случаях TU могут быть подразделены на меньшие порции. Для каждого коэффициента в порции кодируются карта значимости и информация об уровне (абсолютное значение и знак). В одном примере порция состоит из 16 последовательных коэффициентов в порядке обратного сканирования (например, диагональном, горизонтальном или вертикальном) для TU 4×4 и TU 8×8. Для TU 16×16 и 32×32 коэффициенты внутри субблока 4×4 обрабатываются как порция. Для представления информации об уровне коэффициентов внутри порции кодируют и сигнализируют синтаксические элементы. В одном примере все символы кодируются в порядке обратного сканирования. Способы этого раскрытия могут улучшить кодирование синтаксического элемента, используемого для определения этой позиции последнего значимого коэффициента блока коэффициентов.
В качестве одного примера, способы этого раскрытия могут быть использованы для кодирования позиции последнего значимого коэффициента блока коэффициентов (например, TU или порции TU). Далее, после кодирования позиции последнего значимого коэффициента может быть закодирована информация об уровне и знаке. При кодировании информации об уровне и знаке может выполняться обработка согласно подходу с пятью проходами посредством кодирования следующих символов в порядке обратного сканирования (например, для TU или порции TU):
significant_coeff_flag (сокр. sigMapFlag): этот флажок может указывать значимость каждого коэффициента в порции. Считают, что коэффициент, значение которого больше или равно единице, является значимым.
coeff_abs_level_greater1_flag (сокр. gr1Flag): этот флажок может указывать на то, является ли абсолютное значение коэффициента для ненулевых коэффициентов (то есть коэффициентов с sigMapFlag, равным 1) большим, чем единица.
coeff_abs_level_greater2_flag (сокр. gr2Flag): этот флажок может указывать на то, является ли абсолютное значение коэффициента для коэффициентов с абсолютным значением, большим, чем единица (то есть коэффициентов с gr1Flag, равным 1), большим, чем два.
coeff_sign_flag (сокр. signFlag): этот флажок может указывать на информацию о знаке для ненулевых коэффициентов. Например, ноль для этого флажка указывает на положительный знак, тогда как 1 указывает на знак минус.
coeff_abs_level_remain (сокр. levelRem): является остатком абсолютного значения от уровня коэффициента преобразования. Для этого флажка абсолютное значение коэффициента - x кодируется (abs(level)-x) для каждого коэффициента с амплитудой, большей чем x, при этом значение x зависит от данных gr1Flag и gr2Flag.
Соответственно, коэффициенты преобразования для TU или порции TU могут быть закодированы. В любом случае, для окончательного кодирования информации об уровне и знаке коэффициентов преобразования, способы этого раскрытия, которые касаются кодирования синтаксического элемента, используемого для определения позиции последнего значимого коэффициента блока коэффициентов, также могут использоваться с другими типами способов. Подход с пятью проходами для кодирования информации о знаке, уровне и значимости является только одним иллюстративным способом, который может использоваться после кодирования позиции последнего значимого коэффициента блока, как изложено в этом раскрытии.
После сканирования квантованных коэффициентов преобразования для формирования одномерного вектора видеокодер 20 может кодировать одномерный вектор с использованием энтропийного кодирования, например, согласно контекстно-адаптивному кодированию с переменной длиной (context adaptive variable length coding, CAVLC), контекстно-адаптивному двоичному арифметическому кодированию (context adaptive binary arithmetic coding, CABAC), контекстно-адаптивному двоичному арифметическому кодированию на основе синтаксиса (syntax-based context-adaptive binary arithmetic coding, SBAC), энтропийному кодированию с разделением на интервалы вероятности (Probability Interval Partitioning Entropy, PIPE) или другой методологии энтропийного кодирования. Видеокодер 20 также может кодировать синтаксические элементы, ассоциированные с кодируемыми видеоданными, с использованием энтропийного кодирования для использования видеодекодером 30 при декодировании этих видеоданных. Способы энтропийного кодирования этого раскрытия конкретно описаны для применения к CABAC, хотя эти способы также могут быть применены к другим способам энтропийного кодирования, например, CAVLC, SBAC, PIPE или другим способам.
Для выполнения CABAC видеокодер 20 может в пределах контекстной модели назначать контекст символу, который должен быть передан. Контекст может относиться, например, к тому, являются ли соседние значения символа ненулевыми или нет. Для выполнения CAVLC видеокодер 20 может выбирать для символа, который должен быть передан, код переменной длины. Кодовые слова в кодировании с переменной длиной (VLC) могут конструироваться так, что относительно более короткие коды соответствуют более вероятным символам, тогда как более длинные коды соответствуют менее вероятным символам. Следовательно, с использованием VLC можно достичь некоторой экономии, например, по сравнению с использованием для каждого символа, который должен быть передан, кодовых слов равной длины. Определение вероятности может быть основано на контексте, назначенном символу.
В общем, символы данных кодирования с использованием CABAC могут подразумевать один или несколько из следующих этапов:
(1) Преобразование в двоичную форму: если символ, который должен быть закодирован, не является двоичным значением, то он отображается в последовательность так называемых "бинов". Каждый бин имеет значение "0" или "1".
(2) Назначение контекста: каждый бин (в обычном режиме) назначается контексту. Контекстная модель определяет то, как вычисляется контекст для данного бина, на основе информации, доступной для этого бина, например, значения ранее закодированных символов или номера бина.
(3) Кодирование бина: бины кодируются посредством арифметического кодера. Для кодирования бина, арифметическому кодеру в качестве входных данных требуется вероятность значения бина, т.е. вероятность того, что значение бина равно "0", и вероятность того, что значение бина равно "1". (Оцененная) вероятность каждого контекста представляется целочисленным значением, называемым "состоянием контекста". Каждый контекст имеет состояние, и, соответственно, это состояние (то есть оцененная вероятность) является идентичным для бинов, назначенных одному контексту, и отличается между контекстами.
(4) Обновление состояния: вероятность (состояние) для выбранного контекста обновляется на основе фактического закодированного значения бина (например, если значение бина было "1", то вероятность "1" увеличивается).
Следует отметить, что энтропийное кодирование с разделением на интервалы вероятности (PIPE) использует принципы, аналогичные принципам арифметического кодирования, и может использовать способы, аналогичные способам этого раскрытия, которые первоначально описаны в отношении CABAC. Способы этого раскрытия, однако, могут использоваться с CABAC, PIPE или другими методологиями энтропийного кодирования, которые используют технологии преобразования в двоичную форму.
Один способ, недавно принятый для HM4.0, описан в V. Seregin, I.-K Kim, "Binarisation modification for last position coding", JCTVC-F375, 6th JCT-VC Meeting, Torino, IT, July, 2011 (в этом описании "Seregin"). Способ, принятый в HM4.0, сокращает контексты, используемые при кодировании последней позиции, для CABAC посредством введения кодов с фиксированной длиной слова с режимом обхода. Режим обхода означает, что процедура контекстного моделирования отсутствует, и каждый символ кодируется c состоянием равной вероятности. Увеличение числа бинов, кодируемых в режиме обхода, наряду с сокращением бинов в обычном режиме может способствовать ускорению и распараллеливанию кодека.
В способе, принятом в HM4.0, максимально возможная величина компонента последней позиции, max_length, делится поровну на две половины. Первая половина кодируется посредством усеченного унарного кода, а вторая половина кодируется посредством кодов с фиксированной длиной слова (причем количество бинов равно log2(max_length/2)). При самом плохом сценарии количество бинов, которые используют контекстное моделирование, равно max_length/2. В таблице 1 представлено преобразование в двоичную форму для TU 32×32 в HM4.0.
|
Это раскрытие обеспечивает способы для контекстно-адаптивного двоичного арифметического кодирования (CABAC) позиции последнего значимого коэффициента. В одном примере может использоваться прогрессивная структура кодового слова с сокращенным количеством бинов и более короткими усеченными унарными кодами. Кроме того, в одном примере с сокращением максимальной длины усеченного унарного кода количество контекстных моделей для позиции последнего значимого коэффициента может быть сокращено на два.
Фиг. 4 является структурной схемой, которая иллюстрирует пример видеокодера 20, в котором могут быть реализованы способы, описанные в этом раскрытии. Видеокодер 20 может выполнять интра- и интеркодирование видеоблоков внутри видеослайсов. Интракодирование основано на пространственном предсказании для сокращения или удаления пространственной избыточности в видео внутри данного видеокадра или картинки. Интеркодирование основано на временном предсказании для сокращения или удаления временной избыточности в видео внутри смежных кадров или картинок видеопоследовательности. Интрарежим (I-режим) может относиться к любому из нескольких пространственных режимов сжатия. Интеррежимы, например, однонаправленное предсказание (P-режим) или двунаправленное предсказание (B-режим), могут относиться к любому из нескольких временных режимов сжатия.
В примере на Фиг. 4 видеокодер 20 включает в себя блок 35 разделения, модуль 41 предсказания, память 64 для опорных картинок, сумматор 50, модуль 52 преобразования, блок 54 квантования и блок 56 энтропийного кодирования. Модуль 41 предсказания включает в себя блок 42 оценки движения, блок 44 компенсации движения и модуль 46 интрапредсказания. Для восстановления видеоблока видеокодер 20 также включает в себя блок 58 обратного квантования, модуль 60 обратного преобразования и сумматор 62. Для фильтрации границ блока для устранения артефактов блочности из восстановленного видео в состав также может быть включен фильтр для удаления блочности (не изображен на Фиг. 2). Если требуется, то фильтр для удаления блочности может в основном фильтровать выходные данные сумматора 62. В дополнение к фильтру для удаления блочности также могут использоваться дополнительные контурные фильтры (в цикле или после цикла).
Как представлено на Фиг. 4, видеокодер 20 принимает видеоданные, и блок 35 разделения разделяет данные на видеоблоки. Это разделение также может включать в себя разделение на слайсы, мозаичные фрагменты или другие большие единицы, а также разделение на видеоблоки, например, согласно структуре квадрадерева единиц LCU и CU. В видеокодере 20 обычно иллюстрируются компоненты, посредством которых кодируют видеоблоки внутри видеослайса, который должен быть закодирован. Слайс может быть разделен на множество видеоблоков (и, возможно, на наборы видеоблоков, называемые мозаичными фрагментами). Модуль 41 предсказания для текущего видеоблока может выбирать один из множества возможных способов кодирования, например, один из множества режимов интракодирования или один из множества режимов интеркодирования, на основе результатов рассогласования (например, скорость кодирования и уровень искажения). Модуль 41 предсказания может обеспечивать результирующий блок, закодированный посредством интра- или интеркодирования, в сумматор 50 для генерации данных остаточного блока и в сумматор 62 для восстановления закодированного блока для использования в качестве опорной картинки.
Модуль 46 интрапредсказания внутри модуля 41 предсказания может выполнять кодирование с интрапредсказанием текущего видеоблока относительно одного или нескольких соседних блоков в идентичном кадре или слайсе как текущего блока, который должен быть закодирован, для обеспечения пространственного сжатия. Блок 42 оценки движения и блок 44 компенсации движения внутри модуля 41 предсказания выполняют кодирование с интерпредсказанием текущего видеоблока относительно одного или нескольких прогнозирующих блоков в одной или нескольких опорных картинках для обеспечения временного сжатия.
Блок 42 оценки движения может быть выполнен с возможностью определения режима интерпредсказания для видеослайса согласно предопределенному конкретному набору для видеопоследовательности. В предопределенном конкретном наборе видеослайсы в последовательности могут маркироваться как прогнозирующие слайсы (P-слайсы), слайсы с двунаправленным предсказанием (B-слайсы) или обобщенные P- и B-слайсы (GPB-слайсы). P-слайс может ссылаться на предшествующую картинку последовательности. B-слайс может ссылаться на предшествующую картинку последовательности или последующую картинку последовательности. GPB-слайсы относятся к случаю, когда два списка опорных картинок являются идентичными. Блок 42 оценки движения и блок 44 компенсации движения могут быть высокоинтегрированными, но изображены отдельно для представления в виде схемы. Оценка движения, выполняемая блоком 42 оценки движения, является процессом генерации векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может указывать смещение PU видеоблока внутри текущего видеокадра или картинки относительно прогнозирующего блока внутри опорной картинки.
Прогнозирующий блок является блоком, который согласно вычислениям лучше всего согласуется с PU видеоблока, который должен быть закодирован, в смысле разности пикселов, которая может определяться суммой абсолютных значений разности (sum of absolute difference, SAD), суммой квадратов разностей (sum of square difference, SSD) или другими разностными метриками. В некоторых примерах видеокодер 20 может вычислять значения для позиций меньше, чем целого пиксела, опорных картинок, хранящихся в памяти 64 для опорных картинок. Например, видеокодер 20 может интерполировать значения позиций одной четверти пиксела, позиций одной восьмой пиксела или других позиций дробного пиксела опорного картинки. Следовательно, блок 42 оценки движения может выполнять поиск движения относительно позиций полного пиксела и позиций дробного пиксела и выводить вектор движения с точностью дробного пиксела.
Блок 42 оценки движения вычисляет вектор движения для PU видеоблока в слайсе с интеркодированием посредством сравнения позиции PU с позицией прогнозирующего блока опорной картинки. Опорная картинка может быть выбрана из первого списка опорных картинок (список 0) или второго списка опорных картинок (список 1), каждый из которых идентифицирует одну или несколько опорных картинок, хранящихся в памяти 64 для опорных картинок. Блок 42 оценки движения отправляет вычисленный вектор движения в блок 56 энтропийного кодирования и блок 44 компенсации движения.
Компенсация движения, выполняемая блоком 44 компенсации движения, может содержать выборку или генерацию прогнозирующего блока на основе вектора движения, определяемого посредством оценки движения, возможно, с выполнением интерполяции с точностью меньше, чем целый пиксел. После приема вектора движения для PU текущего видеоблока блок 44 компенсации движения может определять местоположение прогнозирующего блока, на который указывает вектор движения в одном из списков опорных картинок. Видеокодер 20 формирует остаточный видеоблок посредством вычитания значений пикселов прогнозирующего блока из значений пикселов текущего кодируемого видеоблока с формированием значений разностей пикселов. Значения разностей пикселов формируют остаточные данные для блока и могут включать в себя компоненты разности как цветности, так и яркости. Сумматор 50 представляет компонент или компоненты, которые выполняют эту операцию вычитания. Блок 44 компенсации движения также может генерировать синтаксические элементы, ассоциированные с видеоблоками и видеослайсом, для использования видеодекодером 30 при декодировании видеоблоков видеослайса.
Модуль 46 интрапредсказания может выполнять интрапредсказание текущего блока как альтернативу интерпредсказанию, выполняемому блоком 42 оценки движения и блоком 44 компенсации движения, как описано выше. В частности, модуль 46 интрапредсказания может определять режим интрапредсказания для использования его для кодирования текущего блока. В некоторых примерах модуль 46 интрапредсказания может кодировать текущий блок с использованием различных режимов интрапредсказания, например, во время отдельных проходов кодирования, и модуль 46 интрапредсказания (или блок 40 выбора режима в некоторых примерах) может выбирать для использования адекватный режим интрапредсказания из тестируемых режимов. Например, модуль 46 интрапредсказания может вычислять значения скорость-искажение с использованием анализа скорость-искажение для различных тестируемых режимов интрапредсказания и выбирать из числа упомянутых тестируемых режимов режим интрапредсказания с лучшими характеристиками скорость-искажение. Анализ скорость-искажение обычно определяет степень искажения (или ошибку) между закодированным блоком и исходным, незакодированным блоком, которая была закодирована для создания закодированного блока, а также скорость передачи битов (то есть количество битов), используемую для создания закодированного блока. Модуль 46 интрапредсказания может вычислять отношения, исходя из искажений и скоростей для различных закодированных блоков для определения того, какой режим интрапредсказания демонстрирует лучшее значение скорость-искажение для этого блока.
В любом случае, после выбора режима интрапредсказания для блока модуль 46 интрапредсказания может обеспечивать информацию, указывающую выбранный режим интрапредсказания для упомянутого блока, в блок 56 энтропийного кодирования. Блок 56 энтропийного кодирования может кодировать информацию, указывающую выбранный режим интрапредсказания, в соответствии со способами этого раскрытия. Видеокодер 20 может включать в передаваемые данные конфигурации битового потока, которые могут включать в себя множество таблиц индексов режима интрапредсказания и множество модифицированных таблиц индексов режима интрапредсказания (также называемых таблицами отображения кодовых слов), определения контекстов кодирования для различных блоков и указания самого вероятного режима интрапредсказания, таблицу индексов режима интрапредсказания и модифицированную таблицу индексов режима интрапредсказания для использования для каждого из контекстов.
После того как модуль предсказания 41 генерирует прогнозирующий блок для текущего блока видеоданных, либо посредством интерпредсказания или посредством интрапредсказания, видеокодер 20 формирует остаточный блок видеоданных посредством вычитания прогнозирующего блока из текущего блока видеоданных. Остаточные видеоданные в остаточном блоке могут быть включены в одну или несколько TU и применяться в модуле 52 преобразования. С использованием преобразования, например, дискретного косинусного преобразования (DCT) или концептуально аналогичного преобразования, модуль 52 преобразования преобразует остаточные видеоданные в остаточные коэффициенты преобразования. Модуль 52 преобразования может преобразовывать остаточные видеоданные из пиксельной области в область преобразования, например, в частотную область.
Модуль 52 преобразования может отправлять результирующие коэффициенты преобразования в блок 54 квантования. Блок 54 квантования квантует коэффициенты преобразования для дальнейшего сокращения скорости передачи битов. Процесс квантования может сокращать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть модифицирована посредством настройки параметров квантования. В некоторых примерах блок 54 квантования может после этого выполнять сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. В качестве альтернативы, упомянутое сканирование может выполнять блок 56 энтропийного кодирования. Блок 58 обратного квантования и модуль 60 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, для восстановления остаточного блока в пиксельной области для последующего использования как опорного блока опорной картинки. Блок 44 компенсации движения может вычислять опорный блок посредством прибавления остаточного блока к прогнозирующему блоку одной из опорных картинок в пределах одного из списков опорных картинок. Блок 44 компенсации движения также может применять один или несколько фильтров-интерполяторов к восстановленному остаточному блоку для вычисления значений меньше, чем целого пиксела, для использования при оценке движения. Сумматор 62 прибавляет восстановленный остаточный блок к блоку предсказания с компенсированным движением, созданному блоком 44 компенсации движения, для создания опорного блока для хранения в памяти 64 для опорных картинок. Упомянутый опорный блок может использоваться блоком 42 оценки движения и блоком 44 компенсации движения как опорный блок для интерпредсказания блока в последующем видеокадре или картинке.
После квантования блок 56 энтропийного кодирования кодирует квантованные коэффициенты преобразования с использованием энтропийного кодирования. Например, блок 56 энтропийного кодирования может выполнять контекстно-адаптивное кодирование с переменной длиной (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), контекстно-адаптивное двоичное арифметическое кодирование на основе синтаксиса (SBAC), энтропийное кодирование с разделением на интервалы вероятности (PIPE) или другой способ или методологию энтропийного кодирования. После энтропийного кодирования блоком 56 энтропийного кодирования закодированный битовый поток может передаваться в видеодекодер 30 или архивироваться для последующих передачи или извлечения видеодекодером 30. Блок 56 энтропийного кодирования также может кодировать с использованием энтропийного кодирования векторы движения и другие синтаксические элементы для текущего кодируемого видеослайса.
В одном примере блок 56 энтропийного кодирования может кодировать позицию последнего значимого коэффициента с использованием способа, принятого в HM4.0, описанном выше. В других примерах блок 56 энтропийного кодирования может кодировать позицию последнего значимого коэффициента с использованием способов, которые могут обеспечивать улучшенное кодирование. В частности, блок 56 энтропийного кодирования может использовать прогрессивную схему кодирования последней позиции для нескольких возможных размеров TU.
В одном примере кодовое слово для позиции последнего значимого коэффициента может включать в себя префикс усеченного унарного кода, за которым следует суффикс кода с фиксированной длиной слова. В одном примере каждая величина последней позиции может использовать идентичное преобразование в двоичную форму для всевозможных размеров TU, кроме тех случаев, когда последняя позиция равна размеру TU минус 1. Эта исключительная ситуация имеет место из-за свойств усеченного унарного кодирования. В одном примере позиция последнего значимого коэффициента в пределах коэффициента ортогонального преобразования может быть задана посредством задания значения x-координаты и значения y-координаты. В другом примере блок коэффициентов преобразования может быть в виде вектора 1×N, и позиция последнего значимого коэффициента внутри этого вектора может задаваться значением позиции сигнала.
В одном примере размер TU может определяться T. Как подробно описано выше, TU может иметь квадратную или неквадратную форму. Соответственно, T может относится либо к количеству строк или столбцов двумерной TU или к длине вектора. В примере, где схема усеченного унарного кодирования обеспечивает несколько нулевых битов, за которыми следует единичный бит, количество нулей префикса усеченного унарного кода, кодирующего позицию последнего значимого коэффициента, может быть определено согласно N={0, …, 2log2(T)-1}. Следует отметить, что в примере, где схема усеченного унарного кодирования обеспечивает несколько единичных битов, за которыми следует нулевой бит, N={0, …, 2log2(T)-1} также может определять количество единиц. В каждом из этих альтернативных вариантов усеченного унарного кодирования 2log2(T)-1 может определять максимальную длину усеченного унарного префикса для TU размера T. Например, для TU, когда T равно 32, максимальная длина усеченного унарного префикса равна девяти, и когда T равно 16, максимальная длина усеченного унарного префикса равна семи.
Для усеченного унарного кода, значение n, суффикс кода с фиксированной длиной слова может включать в себя следующие b битов двоичного кода с фиксированной длиной слова со значением из определяемых следующим образом: f_value={0, …, 2b-1}, где b=max(0, n/2-1). Соответственно, величина последней позиции, last_pos, может быть получена из n и f_value как:
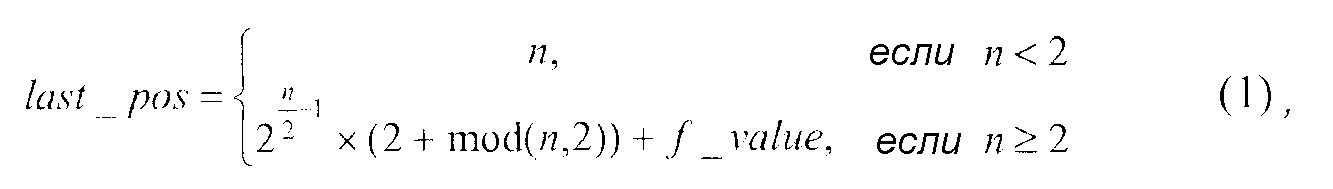
где mod(.) представляет модулярную операцию, и f_value представляет значение кода с фиксированной длиной слова.
В таблице 2 представлен пример преобразования в двоичную форму позиции последнего значимого коэффициента согласно определениям, обеспечиваемым согласно уравнению 1 для TU 32×32. Второй столбец таблицы 2 предусматривает соответствующие значения усеченного унарного префикса для возможных значений позиции последнего значимого коэффициента внутри TU размера T из определяемых максимальной длиной усеченного унарного префикса 2log2(T)-1. Третий столбец таблицы 2 обеспечивает соответствующий суффикс с фиксированной длиной слова для каждого усеченного унарного префикса. Для краткости таблица 2 включает в себя значения X, которые указывают на значение бита либо единицу или ноль. Следует отметить то, что значения X однозначно отображают каждое значение с совместным использованием усеченного унарного префикса согласно коду с фиксированной длиной слова. Величина компонента последней позиции в таблице 2 может соответствовать значению x-координаты и/или значению y-координаты.
|
В таблицах 3 и 4 представлено сравнение максимальной длины строк битов для примера схемы преобразования в двоичную форму, описанной в отношении таблицы 1, и примера схемы преобразования в двоичную форму, (описанной) в отношении таблицы 2. Как представлено в таблице 3, в примере, описанном в отношении таблицы 1, упомянутый префикс унарного кода может иметь максимальную длину 16 бинов для TU 32×32. В то же время, в примере, описанном в отношении таблицы 2, упомянутый префикс унарного кода может иметь максимальную длину 16 бинов для TU 32×32. Кроме того, как представлено в таблице 4, общая длина (на основе) усеченного унарного префикса и суффикса с фиксированной длиной слова, максимальное количество бинов для примера, описанного в отношении таблицы 2, может быть равно 24 в самом плохом случае, то есть тогда, когда последняя позиция находится в конце TU 32×32, тогда как самый плохой случай для примера, описанного со ссылкой на таблицу 1, может быть 40.
|
|
В другом примере схемы усеченного унарного кодирования, которая обеспечивает несколько нулевых битов, за которыми следует единичный бит или несколько единичных битов, за которыми следует единичный бит, префикс усеченного унарного кода, кодирующий позицию последнего значимого коэффициента, может быть определен согласно N={0, …, log2(T)+1}. В каждой из этих схем усеченного унарного кодирования log2(T)+1 может определять максимальную длину усеченного унарного префикса для TU размера T. Например, для TU, когда T равно 32, максимальная длина усеченного унарного префикса равна шести, и когда T равно 8, максимальная длина усеченного унарного префикса равна пяти.
Для усеченного унарного кода, значение n, суффикс кода с фиксированной длиной слова может включать в себя следующие b битов двоичного кода с фиксированной длиной слова со значением из определяемых следующим образом: f_value={0, …, 2b-1}, где b=n-2. Соответственно, величина последней позиции, last_pos, может быть получена из n и f_value как:
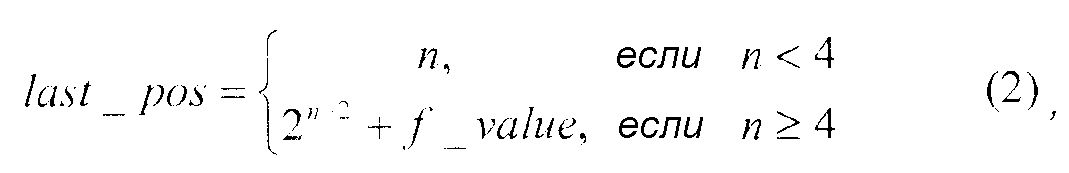
где f_value представляет значение кода с фиксированной длиной слова.
В таблице 5 представлен пример преобразования в двоичную форму позиции последнего значимого коэффициента согласно определениям, обеспечиваемым согласно уравнению 2 для TU 32×32. Второй столбец таблицы 5 предусматривает соответствующие значения усеченного унарного префикса для возможных значений позиции последнего значимого коэффициента внутри TU размера T из определяемых максимальной длиной усеченного унарного префикса log2(T)+1. Третий столбец таблицы 5 обеспечивает соответствующий суффикс с фиксированной длиной слова для каждого усеченного унарного префикса. Для краткости таблица 2 включает в себя значения X, которые указывают на значение бита либо единицу или ноль. Следует отметить то, что значения X однозначно отображают каждое значение с совместным использованием усеченного унарного префикса согласно коду с фиксированной длиной слова. Величина компонента последней позиции в таблице 5 может соответствовать значению x-координаты и/или значению y-координаты.
|
В другом примере схемы усеченного унарного кодирования, которая обеспечивает несколько нулевых битов, за которыми следует единичный бит или несколько единичных битов, за которыми следует единичный бит, префикс усеченного унарного кода, кодирующий позицию последнего значимого коэффициента, может быть определен согласно N={0, …, log2(T)}. В каждой из этих схем усеченного унарного кодирования log2(T) может определять максимальную длину усеченного унарного префикса для TU размера T. Например, для TU, когда T равно 32, максимальная длина усеченного унарного префикса равна пяти, и когда T равно 8, максимальная длина усеченного унарного префикса равна пяти.
Для усеченного унарного кода, значение n, суффикс кода с фиксированной длиной слова может включать в себя следующие b битов двоичного кода с фиксированной длиной слова со значением из определяемых следующим образом: f_value={0, …, 2b-1}, где b=n-1. Соответственно, величина последней позиции, last_pos, может быть получена из n и f_value как:
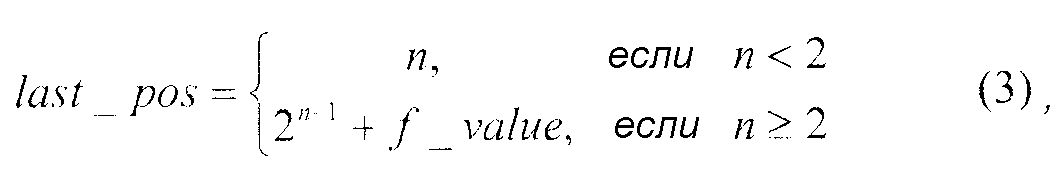
где f_value представляет значение кода с фиксированной длиной слова.
В таблице 6 представлен пример преобразования в двоичную форму позиции последнего значимого коэффициента согласно определениям, обеспечиваемым согласно уравнению 3 для TU 32×32. Второй столбец таблицы 6 предусматривает соответствующие значения усеченного унарного префикса для возможных значений позиции последнего значимого коэффициента внутри TU размера T из определяемых максимальной длиной усеченного унарного префикса log2(T). Третий столбец таблицы 6 обеспечивает соответствующий суффикс с фиксированной длиной слова для каждого усеченного унарного префикса. Для краткости таблица 6 включает в себя значения X, которые указывают на значение бита либо единицу или ноль. Следует отметить то, что значения X однозначно отображают каждое значение с совместным использованием усеченного унарного префикса согласно коду с фиксированной длиной слова. Величина компонента последней позиции в таблице 6 может соответствовать значению x-координаты и/или значению y-координаты.
|
В таблицах 5 и 6 представлены некоторые альтернативные примеры использования усеченного унарного префикса и суффикса с фиксированной длиной слова для кодирования позиции последнего значимого коэффициента. Примеры, представленные в таблицах 5 и 6, обеспечивают возможность более коротких бинов, чем пример, обеспеченный в отношении таблицы 2. Следует отметить, что в примере, где позиция последнего значимого коэффициента определяется на основе значения x-координаты и значения y-координаты, любая из иллюстративных схем преобразования в двоичную форму, представленных в таблицах 1, 2, 5 и 6, может быть выбрана независимо для значения x-координаты и значения y-координаты. Например, значение x-координаты может кодироваться на основе схемы преобразования в двоичную форму, описанной в отношении таблицы 2, тогда как значение y-координаты может кодироваться на основе схемы преобразования в двоичную форму, описанной в отношении таблицы 6.
Как описано выше, символы данных кодирования с использованием CABAC могут подразумевать один или несколько из следующих этапов преобразования в двоичную форму и назначения контекста. В одном примере контекстное моделирование значения последней позиции может использоваться для арифметического кодирования усеченных унарных строк, тогда как контекстное моделирование не может использоваться для арифметического кодирования фиксированных двоичных строк (то есть с обходом). В случае, когда усеченные унарные строки кодируются с использованием контекстного моделирования, каждому индексу бина двоичной строки назначают контекст. Отдельные индексы бина могут совместно использовать назначение контекста. Количество назначений контекста равно количеству индексов бина или длине усеченной унарной строки. Соответственно, в случаях примеров, иллюстрируемых в таблицах 1, 2, 5 и 6, ассоциированные контекстные таблицы могут быть заданы соответственно схеме преобразования в двоичную форму. В таблице 7 иллюстрируется возможная контекстная индексация для каждого бина разных размеров TU для иллюстративных преобразований в двоичную форму, обеспеченных выше со ссылкой на вышеприведенную таблицу 2. Следует отметить то, что иллюстративная контекстная индексация, обеспеченная в таблице 7, обеспечивает в два раза меньше контекстов, чем контекстная индексация, обеспеченная в Seregin.
|
Каждая из таблиц 8-11 иллюстрирует несколько примеров контекстной индексации согласно нижеследующим правилам, созданным для контекстного моделирования:
1. Первые K бинов совместно не используют контекст, где K>1. K может быть разным для каждого размера TU.
2. Один контекст может быть назначен только последовательным бинам. Например, бин 3 - бин 5 могут использовать контекст 5. Но не допускается, что бин 3 и бин 5 используют контекст 5, а бин 4 использует контекст 6.
3. Последние N (бинов), N>=0, разных размеров TU могут совместно использовать идентичный контекст.
4. Количество бинов, которые совместно используют идентичный контекст, увеличивается с увеличением размеров TU.
Вышеприведенные правила 1-4 могут быть, в частности, полезными для преобразования в двоичную форму, обеспеченного в таблице 2. Однако контекстное моделирование можно настраивать соответственно на основе реализованной схемы преобразования в двоичную форму.
|
|
|
|
Фиг. 5 является структурной схемой, которая иллюстрирует пример энтропийного кодера 56, в котором могут быть реализованы способы, описанные в этом раскрытии. Энтропийный кодер 56 принимает синтаксические элементы, например, один или несколько синтаксических элементов, представляющих позицию последнего значимого коэффициента преобразования в пределах коэффициентов блока преобразования, и кодирует этот синтаксический элемент в битовый поток. Синтаксические элементы могут включать в себя синтаксический элемент, задающий x-координату позиции последнего значимого коэффициента внутри блока коэффициентов преобразования, и синтаксический элемент, задающий y-координату позиции последнего значимого коэффициента внутри блока коэффициентов преобразования. В одном примере энтропийный кодер 56, изображенный на Фиг. 5, может являться кодером CABAC. Иллюстративный энтропийный кодер 56 на Фиг. 5 может включать в себя блок 502 преобразования в двоичную форму, блок 504 арифметического кодирования и блок 506 назначения контекста.
Блок 502 преобразования в двоичную форму принимает синтаксический элемент и создает строку бинов. В одном примере блок 502 преобразования в двоичную форму принимает значение, представляющее последнюю позицию значимого коэффициента внутри блока коэффициентов преобразования, и создает строку битов или значение бина согласно примерам, описанным выше. Блок 504 арифметического кодирования принимает строку битов из блока 502 преобразования в двоичную форму и выполняет арифметическое кодирование этого кодового слова. Как представлено на Фиг. 5, арифметический кодер 504 может принимать значения бинов по пути обхода или из блока 506 контекстного моделирования. В случае, когда блок 504 арифметического кодирования принимает значения бинов из блока 506 контекстного моделирования, блок 504 арифметического кодирования может выполнять арифметическое кодирование на основе назначения контекстов, обеспечиваемых блоком 506 назначения контекста. В одном примере блок 504 арифметического кодирования может использовать назначение контекстов для кодирования части префикса строки битов и может кодировать часть суффикса строки битов без использования назначения контекстов.
В одном примере блок 506 назначения контекста может назначать контексты на основе иллюстративной контекстной индексации, обеспеченной в вышеприведенных таблицах 7-11. Соответственно, видеокодер 20 представляет видеокодер, выполненный с возможностью получения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, определения первой двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, log2(T)+1 или log2(T), определения второй двоичной строки для значения, указывающего позицию последнего значимого коэффициента, на основе схемы кодирования с фиксированной длиной слова и кодирования первой и второй двоичных строк в битовый поток.
Фиг. 6 является блок-схемой, иллюстрирующей пример способа определения двоичной строки для значения, указывающего позицию последнего значимого коэффициента, согласно способам этого раскрытия. Способ, описанный на Фиг. 6, может быть выполнен любым из иллюстративных видеокодеров или энтропийных кодеров, описанных в этом документе. На этапе 602 получают значение, указывающее позицию последнего значимого коэффициента преобразования внутри видеоблока. На этапе 604 определяют двоичную строку префикса для значения, указывающего позицию последнего значимого коэффициента. Двоичная строка префикса может быть определена с использованием любого из способов, описанных в этом документе. В одном примере двоичный код префикса может быть основан на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, где T определяет размер видеоблока. В еще одном примере двоичный код префикса может быть основан на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством log2(T)+1, где T определяет размер видеоблока. В еще одном примере двоичный код префикса может быть основан на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством log2(T), где T определяет размер видеоблока. Двоичная строка префикса может определяться кодером, выполняющим ряд вычислений, кодером, использующим таблицы соответствия, или их комбинацией. Например, для определения двоичной строки префикса кодер может использовать любую из таблиц 2, 5 и 6.
На этапе 606 определяют двоичную строку суффикса для значения, указывающего позицию последнего значимого коэффициента. Двоичная строка суффикса может быть определена с использованием любого из способов, описанных в этом документе. В одном примере двоичная строка суффикса может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-2, где T определяет размер видеоблока. В еще одном примере двоичная строка суффикса может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-1, где T определяет размер видеоблока. Двоичная строка суффикса может определяться кодером, выполняющим ряд вычислений, кодером, использующим таблицы соответствия, или их комбинацией. Например, для определения двоичной строки суффикса кодер может использовать любую из таблиц 2, 5 и 6. На этапе 608 двоичные строки суффикса и префикса кодируются в битовый поток. В одном примере двоичные строки суффикса и префикса могут кодироваться с использованием арифметического кодирования. Следует отметить то, что часть суффикса и префикса битового потока можно поменять местами. Арифметическое кодирование может являться частью процесса кодирования CABAC или частью другого процесса энтропийного кодирования.
Таблицы 12-14 обеспечивают сводку результатов моделирования выполнения кодирования иллюстративной схемы преобразования в двоичную форму, описанной со ссылкой на таблицу 1, и иллюстративной схемы преобразования в двоичную форму, описанной со ссылкой на таблицу 2. Результаты моделирования в таблицах 12-14 были получены с использованием общих условий тестирования с высокоэффективным кодированием, как определено в: F. Bossen, "Common test conditions and software reference configurations", JCTVC-F900. Отрицательные значения в таблицах 12-14 указывают на более низкую скорость передачи битов схемы преобразования в двоичную форму, описанной со ссылкой на таблицу 2, по сравнению со схемой преобразования в двоичную форму, описанной со ссылкой на таблицу 1. Время код и Время декод в таблицах 12-14 описывают время, требуемое для кодирования и декодирования, соответственно, битового потока, обусловленное использованием схемы преобразования в двоичную форму, описанной со ссылкой на таблицу 2, в сопоставлении со временем, требуемым для кодирования (или декодирования) битового потока, обусловленным использованием схемы преобразования в двоичную форму, описанной со ссылкой на таблицу 1. Как видно из экспериментальных результатов, предоставленных в таблицах 12-14, схема преобразования в двоичную форму, описанная со ссылкой на таблицу 2, обеспечивает соответствующий выигрыш в производительности по BD-скорости -0,04%, -0,01% и -0,03% при условиях тестирования с высокоэффективным только интракодированием, с произвольным доступом и малой задержкой.
Классы A-E в нижеприведенных таблицах представляют различные последовательности видеоданных. Столбцы Y, U и V соответствуют данным для яркости, U-цветности и V-цветности, соответственно. В таблице 12 эти данные обобщены для конфигурации, в которой все данные кодируются в интрарежиме. В таблице 13 эти данные обобщены для конфигурации, в которой все данные кодируются при "произвольном доступе", где оба режима интра- и интеркодирования являются доступными. В таблице 14 эти данные обобщены для конфигурации, в которой картинки кодируются в режиме B с малой задержкой.
|
|
|
Фиг. 7 является структурной схемой, которая иллюстрирует пример видеодекодера 30, в котором могут быть реализованы способы, описанные в этом раскрытии. В примере по Фиг. 7 видеодекодер 30 включает в себя блок 80 энтропийного декодирования, модуль 81 предсказания, блок 86 обратного квантования, модуль 88 обратного преобразования, сумматор 90 и память 92 для опорных картинок. Модуль 81 предсказания включает в себя блок 82 компенсации движения и модуль 84 интрапредсказания. Видеодекодер 30, в некоторых примерах, выполняет проход декодирования, обычно обратный к проходу кодирования, описанному со ссылкой на видеокодер 20 из Фиг. 4.
Во время процесса декодирования видеодекодер 30 принимает битовый поток закодированного видео, который представляет видеоблоки закодированного видеослайса, и ассоциированные синтаксические элементы из видеокодера 20. Блок 80 энтропийного декодирования видеодекодера 30 декодирует битовый поток с использованием энтропийного декодирования для генерации квантованных коэффициентов, векторов движения и других синтаксических элементов. Блок 80 энтропийного декодирования может определять значение, указывающее позицию последнего значимого коэффициента в пределах коэффициента преобразования, на основе способов, описанных в этом документе. Блок 80 энтропийного декодирования пересылает векторы движения и другие синтаксические элементы в модуль 81 предсказания. Видеодекодер 30 может принимать синтаксические элементы на уровне видеослайса и/или на уровне видеоблока.
Когда видеослайс закодирован как слайс с интракодированием (I), модуль 84 интрапредсказания модуля 81 предсказания может генерировать данные предсказания для видеоблока текущего видеослайса на основе сигнализированного режима интрапредсказания и данные из ранее декодированных блоков текущего кадра или картинки. Когда видеокадр закодирован как слайс с интеркодированием (то есть B, P или GPB), блок 82 компенсации движения модуля 81 предсказания создает прогнозирующие блоки для видеоблока текущего видеослайса на основе векторов движения и других синтаксических элементов, принятых из блока 80 энтропийного декодирования. Прогнозирующие блоки могут создаваться из одной из опорных картинок в пределах одного из списков опорных картинок. Видеодекодер 30 может конструировать списки опорных кадров, список 0 и список 1, с использованием способов конструирования по умолчанию на основе опорных картинок, хранящихся в памяти 92 для опорных кадров.
Блок 82 компенсации движения определяет информацию предсказания для видеоблока текущего видеослайса посредством проведения синтаксического анализа векторов движения и других синтаксических элементов и использует эту информацию предсказания для создания прогнозирующих блоков для текущего декодируемого видеоблока. Например, блок 82 компенсации движения использует некоторые из принятых синтаксических элементов для определения режима предсказания (например, интра- или интерпредсказание), использованного для кодирования видеоблоков видеослайса, типа слайса интерпредсказания (например, B-слайс, P-слайс или GPB-слайс), информации конструирования для одного или нескольких из списков опорных картинок для слайса, векторов движения для каждого видеоблока с интеркодированием слайса, статуса интерпредсказания для каждого видеоблока с интеркодированием слайса и другой информации для декодирования видеоблоков в текущем видеослайсе.
Блок 82 компенсации движения также может выполнять интерполяцию на основе фильтров-интерполяторов. Блок 82 компенсации движения может использовать фильтры-интерполяторы, используемые видеокодером 20 во время кодирования видеоблоков, для вычисления интерполированных значений для меньше, чем целых пикселов опорных блоков. В этом случае блок 82 компенсации движения может определять фильтры-интерполяторы, используемые видеокодером 20, исходя из принятых синтаксических элементов, и использовать эти фильтры-интерполяторы для создания прогнозирующих блоков.
Блок 86 обратного квантования выполняет обратное квантование, то есть деквантует квантованные коэффициенты преобразования, обеспеченные в битовом потоке и декодированные блоком 80 энтропийного декодирования. Процесс обратного квантования может включать в себя использование параметра квантования, вычисляемого видеокодером 20 для каждого видеоблока в видеослайсе, для определения степени квантования, а также степени обратного квантования, которые должны быть применены. Модуль 88 обратного преобразования применяет обратное преобразование, например, обратное DCT, обратное целочисленное преобразование или концептуально аналогичный процесс обратного преобразования, к коэффициентам преобразования для создания остаточных блоков в пиксельной области.
После генерации модулем 81 предсказания прогнозирующего блока для текущего видеоблока на основе либо интер- или интрапредсказания видеодекодер 30 формирует декодированный видеоблок посредством суммирования остаточных блоков из модуля 88 обратного преобразования с соответствующими прогнозирующими блоками, сгенерированными модулем 81 предсказания. Сумматор 90 представляет компонент или компоненты, которые выполняют эту операцию суммирования. Если требуется, для устранения артефактов блочности также может быть применен фильтр для удаления блочности для фильтрации декодированных блоков. Для сглаживания переходов между пикселами или улучшения качества видео иным образом также могут использоваться другие контурные фильтры (либо в цикле кодирования или после цикла кодирования). Декодированные видеоблоки в данном кадре или картинке после этого сохраняются в памяти 92 для опорных картинок, в которой хранятся опорные картинки, используемые для последующей компенсации движения. В памяти 92 для опорных кадров также хранится декодированное видео для последующего воспроизведения на устройстве отображения, например, на устройстве 32 отображения по Фиг. 1. Соответственно, видеодекодер 30 представляет видеодекодер, выполненный с возможностью получения первой двоичной строки и второй двоичной строки из закодированного битового потока, определения значения, указывающего позицию последнего значимого коэффициента внутри видеоблока размера T, основываясь частично на первой двоичной строке, при этом эта первая двоичная строка определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, и определения значения, указывающего позицию последнего значимого коэффициента, основываясь частично на второй двоичной строке, при этом эта вторая двоичная строка определяется схемой кодирования с фиксированной длиной слова.
Фиг. 8 является блок-схемой, иллюстрирующей пример способа определения значения, указывающего позицию последнего значимого коэффициента в пределах коэффициента преобразования, из двоичной строки согласно способам этого раскрытия. Способ, описанный на Фиг. 8, может быть выполнен любым из иллюстративных видеодекодеров или блоков энтропийного декодирования, описанных в этом документе. На этапе 802 получают закодированный битовый поток. Закодированный битовый поток может быть извлечен из памяти или через передачу. Закодированный битовый поток может быть закодирован согласно процессу кодирования CABAC или другому процессу энтропийного кодирования. На этапе 804 получают двоичную строку префикса. На этапе 806 получают двоичную строку суффикса. Двоичная строка префикса и двоичная строка суффикса могут быть получены посредством декодирования закодированного битового потока. Декодирование может включать в себя арифметическое декодирование. Арифметическое декодирование может быть частью процессора для декодирования CABAC или другого процесса энтропийного декодирования. На этапе 808 в пределах видеоблока размера T определяют значение, указывающее позицию последнего значимого коэффициента. В одном примере позиция последнего значимого коэффициента определяется, основываясь частично на двоичной строке префикса, причем двоичная строка префикса определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством 2log2(T)-1, где T определяет размер видеоблока. В одном примере позиция последнего значимого коэффициента определяется, основываясь частично на двоичной строке префикса, причем двоичная строка префикса определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством log2(T)+1, где T определяет размер видеоблока. В одном примере позиция последнего значимого коэффициента определяется, основываясь частично на двоичной строке префикса, причем двоичная строка префикса определяется схемой усеченного унарного кодирования с максимальной длиной в битах, определяемой посредством log2(T), где T определяет размер видеоблока. В одном примере позиция последнего значимого коэффициента (основана) частично на двоичной строке суффикса, причем двоичная строка суффикса определяется схемой кодирования с фиксированной длиной слова с максимальной длиной в битах, определяемой посредством log2(T)-2, где T определяет размер видеоблока. В еще одном примере вторая двоичная строка может быть основана на схеме кодирования с фиксированной длиной слова, определяемой максимальной длиной в битах, определяемой посредством log2(T)-1, где T определяет размер видеоблока. Следует отметить то, что часть суффикса и префикса битового потока можно поменять местами.
В одном или нескольких примерах описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, программно-аппаратных средствах или любой их комбинации. Если функции реализованы в программном обеспечении, то они могут храниться на считываемом компьютером носителе или передаваться через него в виде одной или нескольких инструкций или кода, и исполняться аппаратным блоком обработки данных. Считываемые компьютером носители могут включать в себя считываемые компьютером носители информации, которые соответствуют материальному носителю, например, накопителям данных или среде связи, включающему в себя любой носитель, который способствует передаче компьютерной программы из одного места в другое, например, согласно протоколу связи. Следовательно, считываемые компьютером носители обычно могут соответствовать (1) материальным считываемым компьютером носителям информации, которые не являются промежуточными, или (2) средам связи, например, сигналу или несущей волне. Накопители данных могут быть любыми доступными носителями, к которым можно получить доступ посредством одного или нескольких компьютеров или одного или нескольких процессоров для извлечения инструкций, кода и/или структур данных для реализации способов, описанных в этом раскрытии. Компьютерный программный продукт может включать в себя считываемый компьютером носитель.
В других примерах это раскрытие предполагает считываемый компьютером носитель, содержащий структуру данных, хранящуюся на нем, причем эта структура данных включает в себя закодированный битовый поток, соответствующий этому раскрытию. В частности, закодированный битовый поток может включать в себя битовый поток с энтропийным кодированием, включающий в себя первую двоичную строку и вторую двоичную строку, причем первая двоичная строка указывает на значение, указывающее позицию последнего значимого коэффициента, и основана на схеме усеченного унарного кодирования, определяемой максимальной длиной в битах, определяемой посредством 2log2(T)-1, и вторая двоичная строка указывает на значение, указывающее позицию последнего значимого коэффициента, и основана на схеме кодирования с фиксированной длиной слова.
Например, такие считываемые компьютером носители информации могут содержать RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптических дисках, накопитель на магнитных дисках, или другие магнитные запоминающие устройства, флэш-память или любой другой носитель, который может быть использован для хранения требуемого кода программы в виде инструкций или структур данных и к которому компьютер может получить доступ. Кроме того, любое соединение соответственно называют считываемым компьютером носителем. Например, если инструкции передают из web-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, оптоволоконного кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, например инфракрасного излучения, радиовещания и сверхвысокочастотных волн, то коаксиальный кабель, оптоволоконный кабель, витая пара, DSL или беспроводные технологии, например инфракрасное излучение, радиовещание и сверхвысокочастотные волны, включают в определение носителя. Однако следует понимать, что считываемые компьютером носители информации и накопители данных не включают в себя соединения, несущие волны, сигналы или другие кратковременные среды, а являются вместо этого направленными на постоянные, материальные носители информации. Магнитный и немагнитный диски, используемые в этом описании, включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск блю-рей (Blu-ray), причем магнитные диски обычно воспроизводят данные магнитным способом, в то время как немагнитные диски воспроизводят данные оптически посредством лазеров. Комбинации приведенных выше носителей также должны быть включены в считываемые компьютером носители.
Инструкции могут исполняться одним или более процессорами, например, одним или более цифровыми сигнальными процессорами (DSP), универсальными микропроцессорами, специализированными интегральными схемами (ASIC), программируемыми пользователем логическими матрицами (FPGA) или другой эквивалентной интегрированной или отдельной логической схемой. Соответственно, термин "процессор", используемый в этом документе, может относиться к любой вышеизложенной структуре или любой другой структуре, подходящей для реализации способов, описанных в этом документе. Кроме того, в некоторых аспектах функциональные возможности, описанные в этом документе, могут быть обеспечены в специализированных аппаратных и/или программных модулях, выполненных с возможностью кодирования и декодирования, или включены в состав объединенного кодека. Также упомянутые способы могут быть полностью реализованы в одной или нескольких схемах или в одном или нескольких логических элементах.
Способы этого раскрытия могут быть реализованы в самых разных устройствах или приборах, включающих в себя беспроводную микротелефонную трубку, интегральную схему (IC) или набор IC (например, набор микросхем). В этом раскрытии для выделения функциональных аспектов устройств, выполненных с возможностью выполнения раскрытых способов, но без обязательного требования реализации разными аппаратными блоками, описаны различные компоненты, модули или блоки. Наоборот, как описано выше, различные блоки могут быть объединены в аппаратном блоке кодека или обеспечены совокупностью взаимодействующих аппаратных блоков, включающих в себя один или несколько процессоров, как описано выше, вместе с подходящими программными средствами и/или программно-аппаратными средствами.
Описаны различные примеры. Эти и другие примеры включены в объем нижеследующей формулы изобретения.
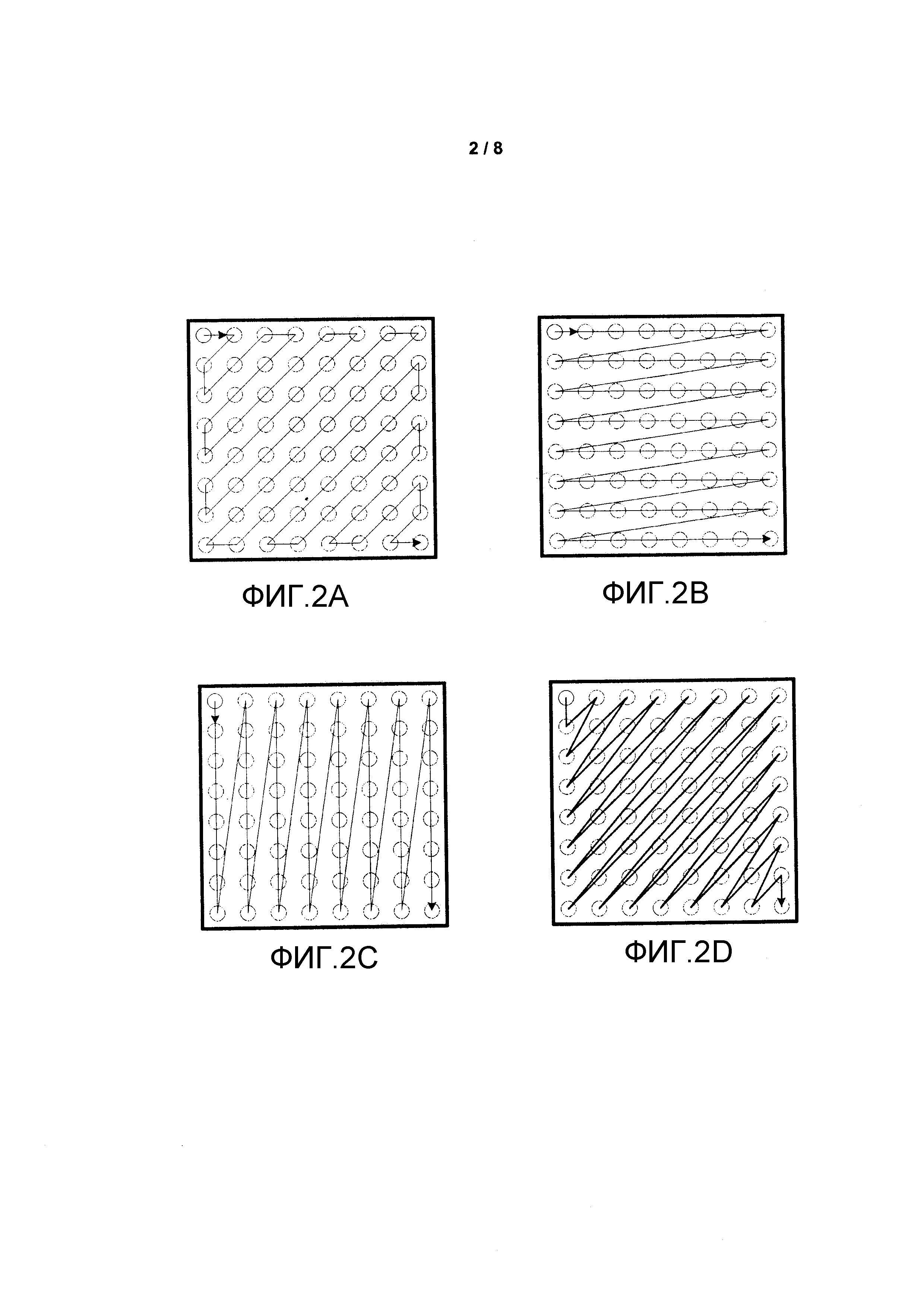
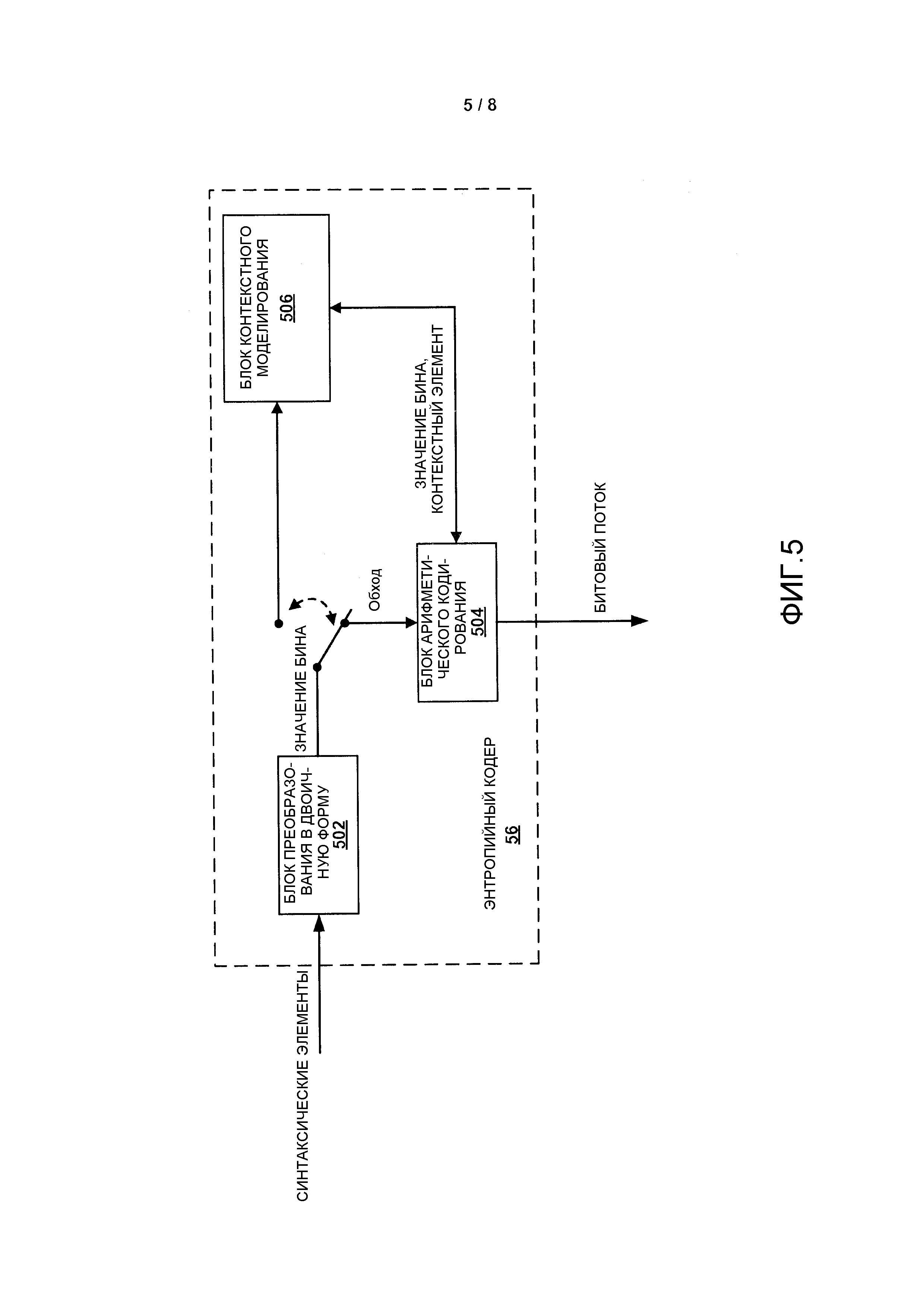
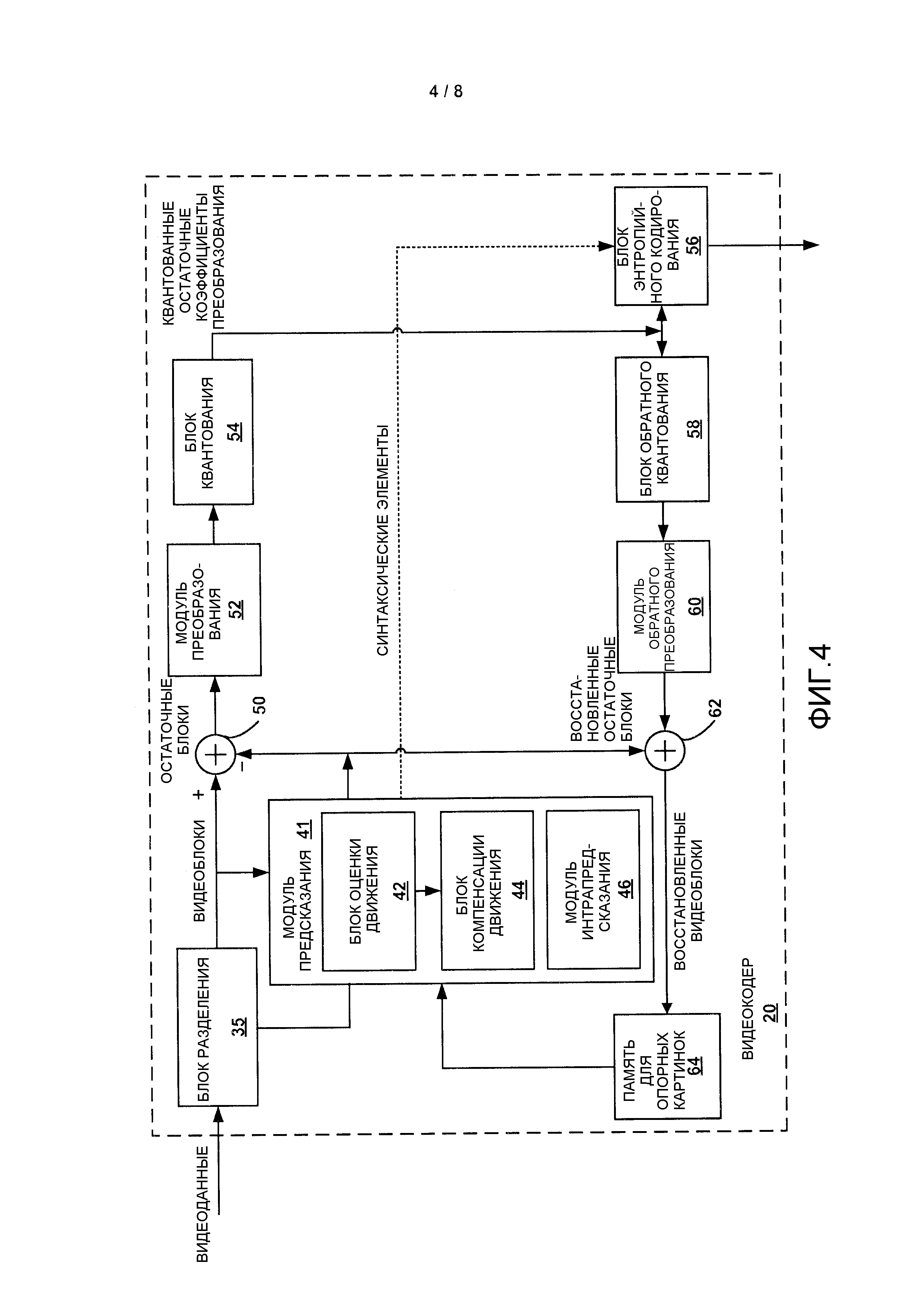
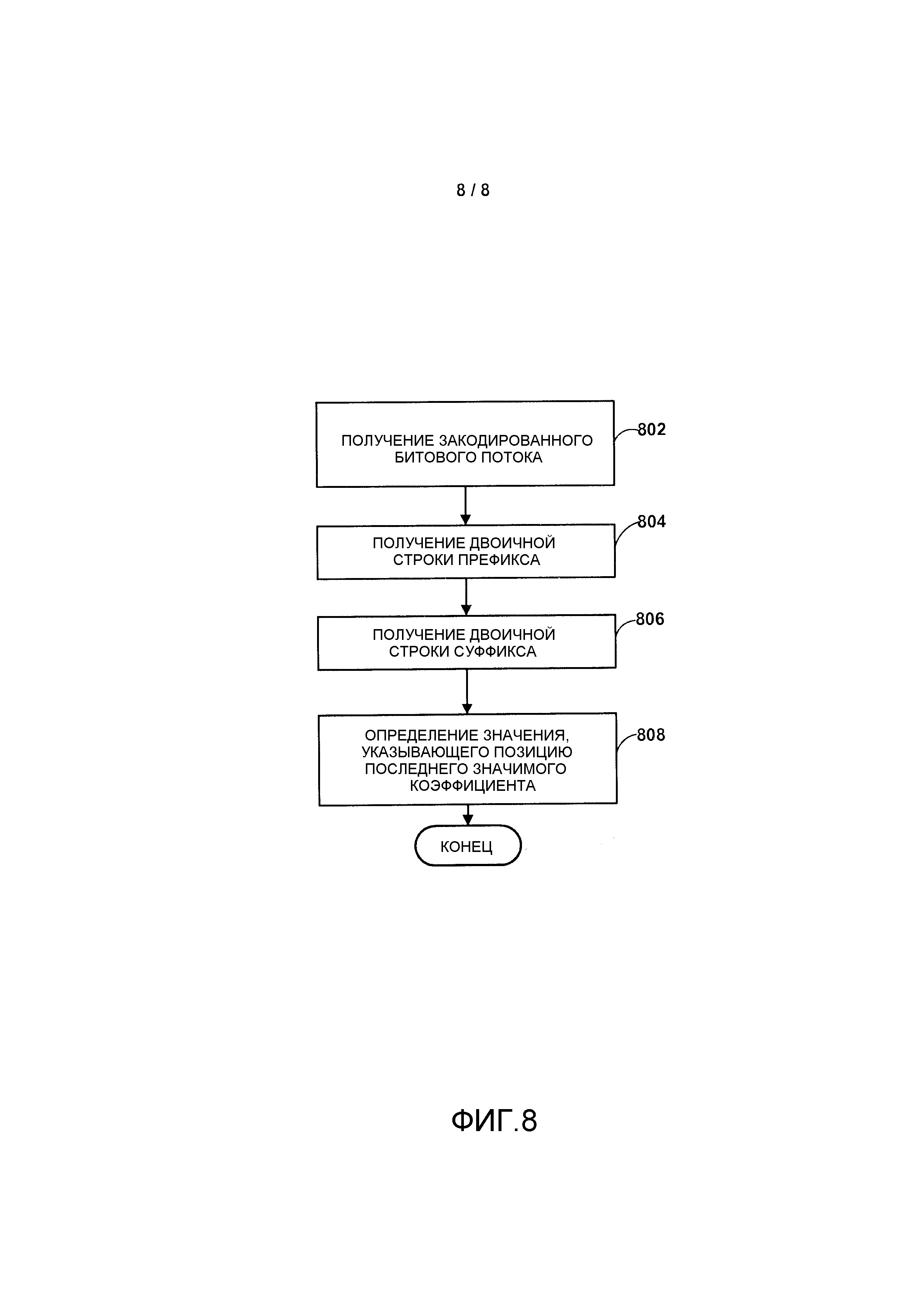
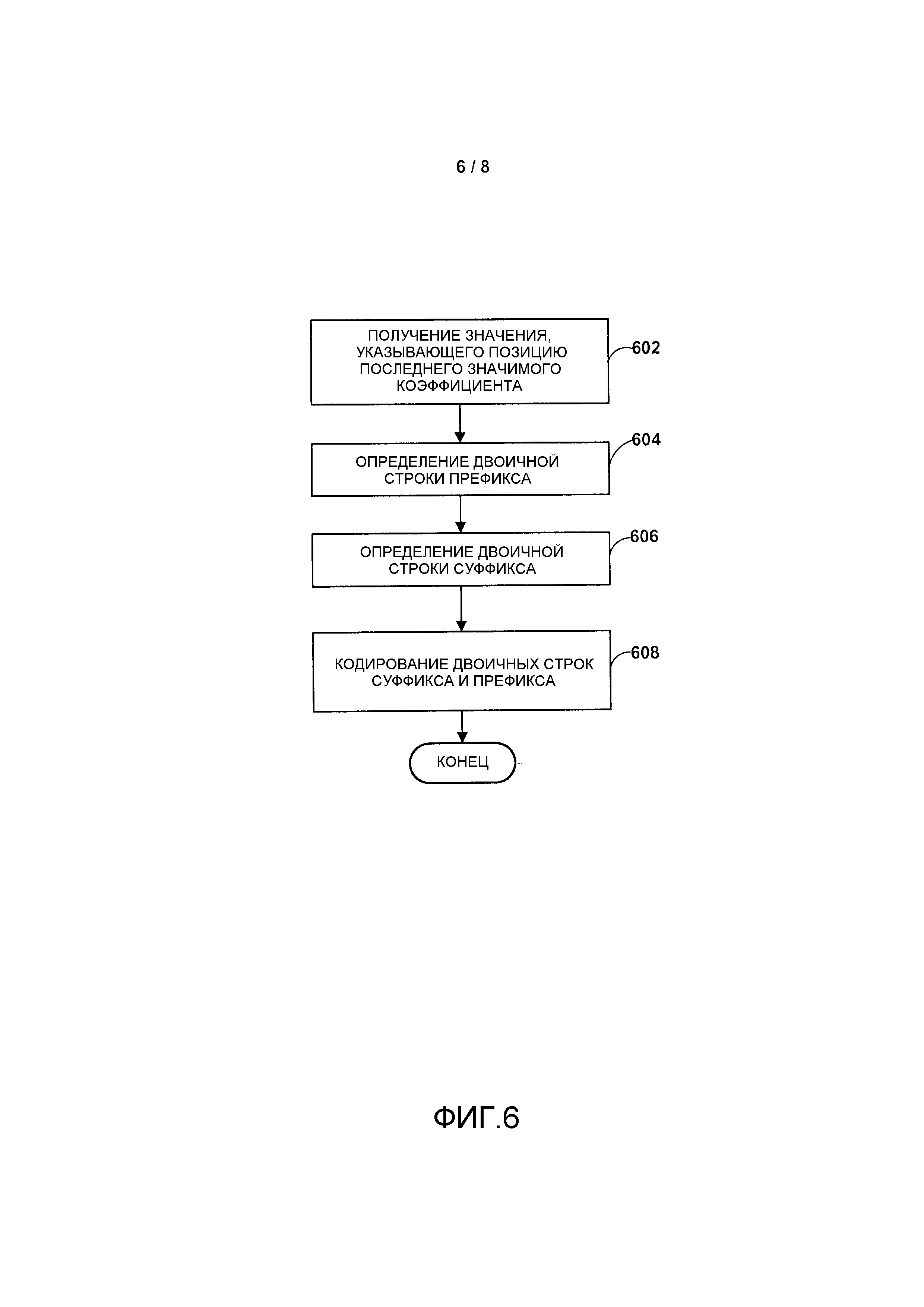
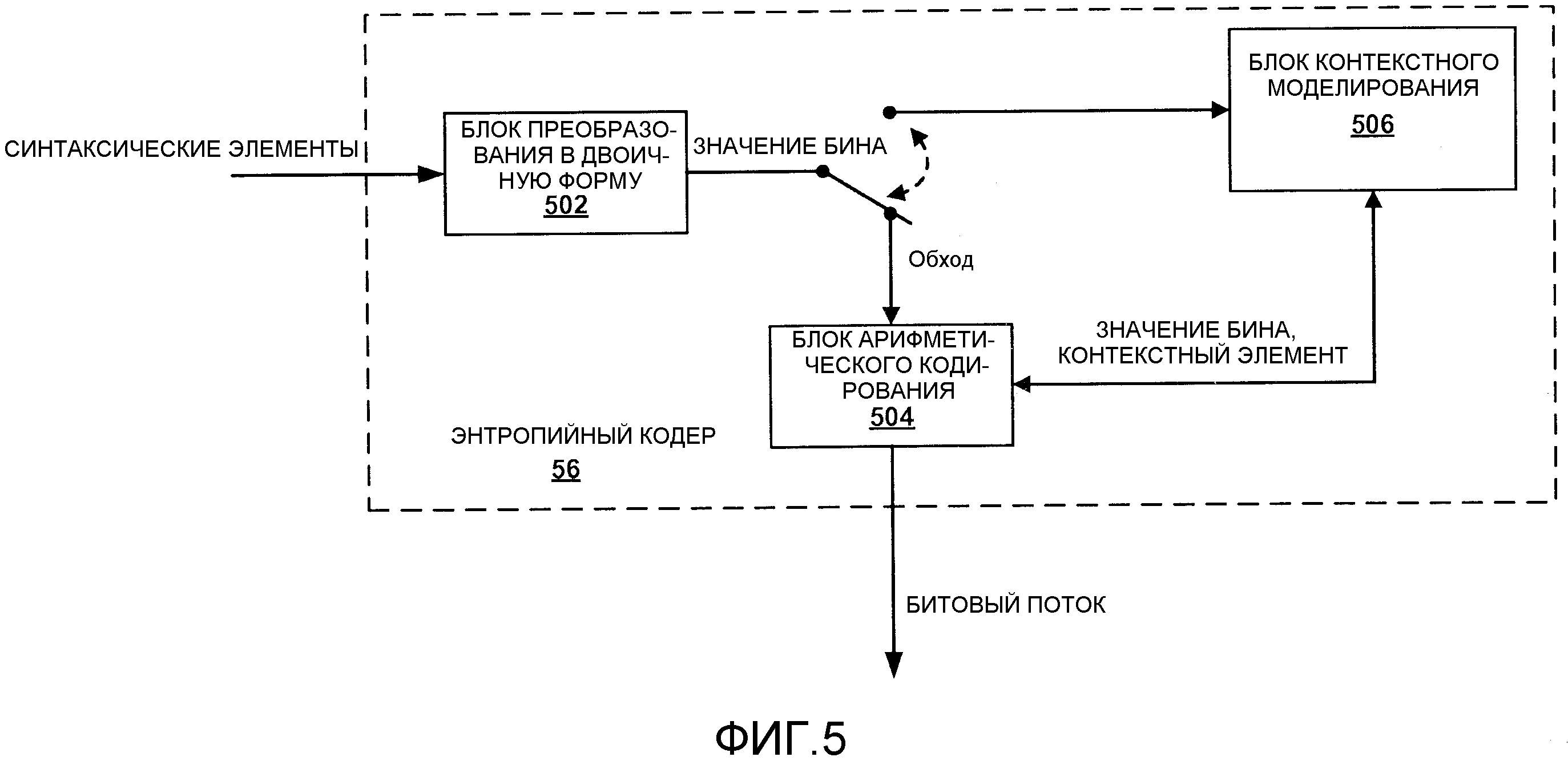
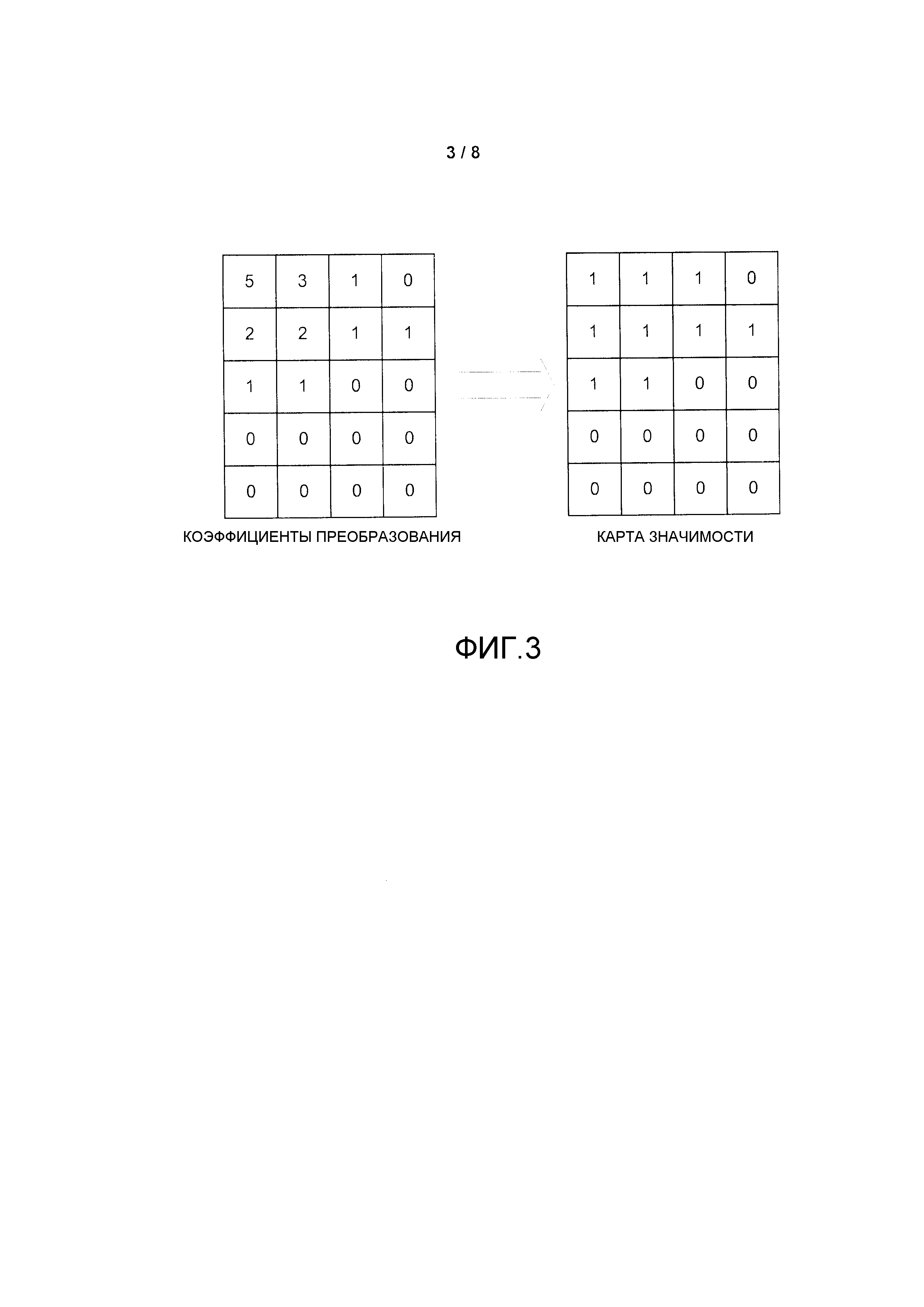
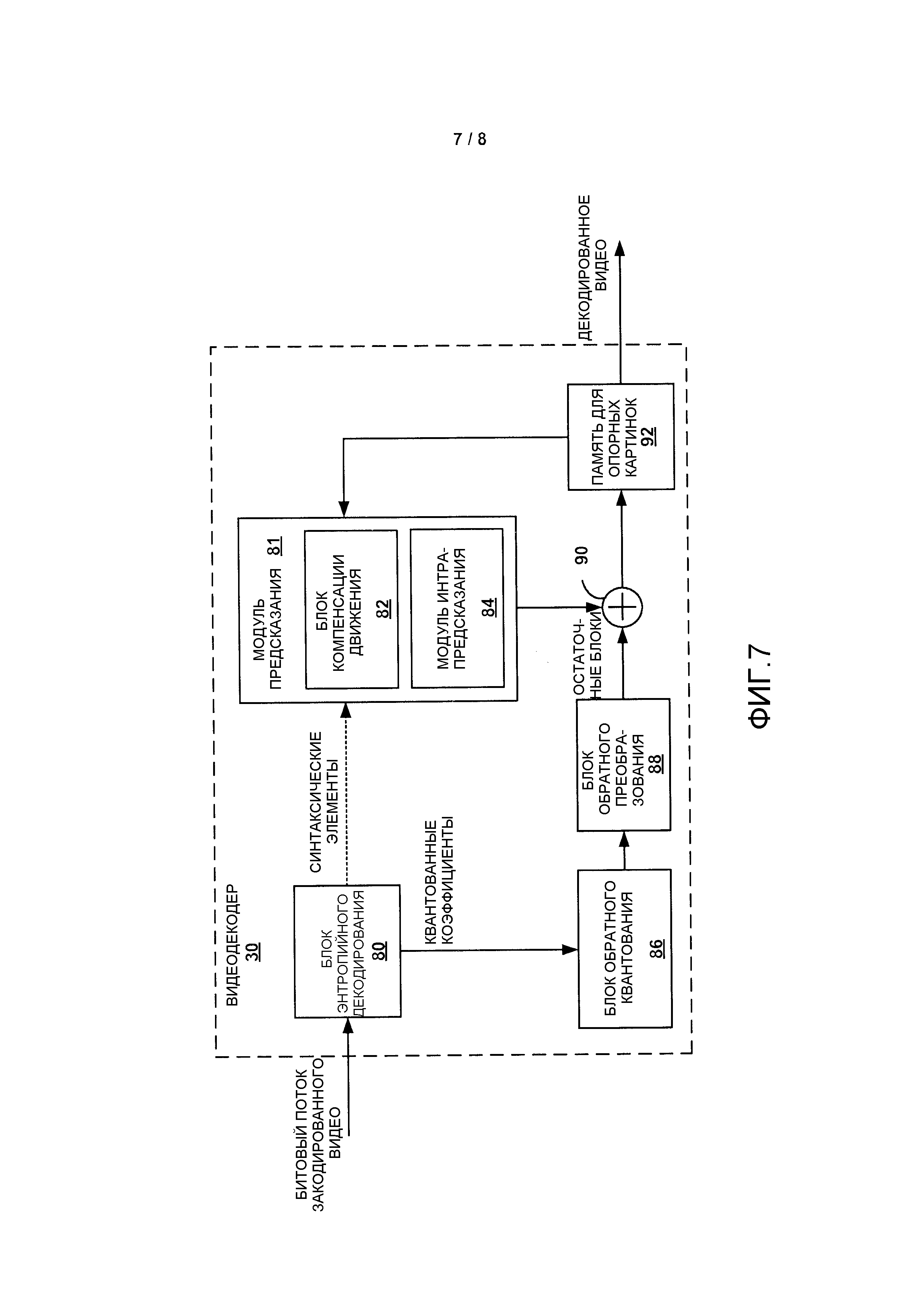
Снижение непроизводительных затрат сигнализации, используя sub-dl-ul-map и harq-map в мобильном wimax
Механизмы обмена информацией о помехах между точками доступа для достижения целевого качества обслуживания сети в системах беспроводной сотовой связи
Способ и устройство для использования mbsfn-субкадров для отправки одноадресной информации
Индексирование ретрансляционных антенн для связи посредством совместно используемых антенн
Качество обслуживания, инициированное сетью и мобильным устройством
Устройства и способы для передачи данных по беспроводной ячеистой сети
Запоминающее устройство для применений основанной на сопротивлении памяти
Передача пилот-сигнала и оценивание канала для систем с множеством входов и одним выходом (miso) и с множеством входов и множеством выходов (mimo)
Схема конфигурирования сетевого элемента
Система с множеством входов и множеством выходов (mimo) с множеством режимов пространственного мультиплексирования
Концентратор для мультиплексирования соединений точек доступа с беспроводной сетью
Снижение непроизводительных затрат сигнализации, используя sub-dl-ul-map и harq-map в мобильном wimax
Механизмы обмена информацией о помехах между точками доступа для достижения целевого качества обслуживания сети в системах беспроводной сотовой связи
Способ и устройство для использования mbsfn-субкадров для отправки одноадресной информации
Индексирование ретрансляционных антенн для связи посредством совместно используемых антенн
Качество обслуживания, инициированное сетью и мобильным устройством
Сигнализация подтверждения активности на уровне сети радиодоступа (ran)
Устройства и способы для передачи данных по беспроводной ячеистой сети
Запоминающее устройство для применений основанной на сопротивлении памяти
Передача пилот-сигнала и оценивание канала для систем с множеством входов и одним выходом (miso) и с множеством входов и множеством выходов (mimo)

