Результат интеллектуальной деятельности: СПОСОБ СЖАТИЯ ИЗОБРАЖЕНИЙ (ВАРИАНТЫ)
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Изобретения относятся к области обработки изображений, точнее к сжатию изображений без потерь с помощью кодирования данных.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Наиболее известными способами сжатия изображений без потерь являются стандарты JPEG-LS, JPEG-2000 и алгоритм сжатия изображений CALIC.
Алгоритм LOCO-I из стандарта JPEG-LS ("lnformation Technology Lossless and Near-lossless Compression of Continuous-Tone Still Images: Baseline," ISO/IEC, ISO/IEC 14495-1:1999), также описанный в патентных заявках US 5764374, публ. 09.06.1998 и US 5680129, публ. 21.10.1997, содержит следующие операции: выбор режима кодирования пикселя на основе значений соседей, адаптивное предсказание, режим кодирования длин серий, контекстное моделирование значений ошибок предсказания, процедура выбора параметров кодов Голомба. Адаптивное предсказание, используемое в LOCO-I алгоритме, может использоваться для формирования ошибок предсказания в заявленном способе, но процедура кодирования самих ошибок предсказания в заявленном способе существенно отличается от представленной в алгоритме LOCO-I. В частности, значения ошибок в заявленном способе представляются в виде пар значений модуля и знака ошибки предсказания с последующим кодированием, в LOCO-I алгоритме диапазон значений сокращается с помощью модульной арифметики, а сами значения отображаются в положительную полуплоскость перед кодированием.
Алгоритм сжатия без потерь CALIC по заявке US 5903676, публ. 11.05.1999, содержит операции: предсказание значения текущего пиксела по окружению, классификацию контекста, контекстное моделирование ошибки предсказания и ее коррекция, а также энтропийное кодирование скорректированной ошибки предсказания. Изобретение CALIC разработано для сжатия 8-ми битных однокомпонентных изображений, тем самым, в настоящее время область его применения сильно ограничена.
Предложенная схема кодирования содержит схожий набор операций, но имеет принципиальные различия в их исполнении. В предложенной схеме предсказания отсутствуют операции умножения и деления, что положительно сказывается на производительности схемы. Контекстное моделирование в предложенной схеме выполняется по двоичным данным битовых плоскостей и строго по ошибкам предсказания, в то время как в изобретении CALIC для моделирования используются как значения ошибок предсказания, так и значения пикселей изображения в их оригинальном представлении. В предложенном изобретении отсутствует процедура уточнения ошибок предсказания. В предложенной схеме кодирование знаков и модулей ошибок предсказания выполняется независимо, что кардинально отличает ее от последовательности операций, предложенной в изобретении CALIC, где кодирование модулей ошибок и знаков выполняется совместно.
Наиболее близким к заявляемому изобретению является стандарт JPEG-2000 ("Information Technology JPEG 2000 image coding system: Core coding system," ISO/IEC 15444-1:2004, Dec. 2009), содержащий описание способа сжатия изображений, имеющий специальный режим для сжатия без потерь, состоящих из следующих операций: процедуры представления кодируемых значений в виде битовых плоскостей и послойного энтропийного кодирования значений из битовых слоев, в котором используется контекстное моделирование и двоичный арифметический кодер - MQ кодер. Концепция представления значений в виде двоичных слоев с последующим кодированием схожа с процедурой кодирования из заявленного способа сжатия. Но, в отличие от алгоритма сжатия из стандарта JPEG-2000, в заявленном способе кодирования изображений описываемая методика представления значений в виде двоичных слоев позволяет использовать данные из ранее обработанных слоев при выполнении контекстного моделирования для значений модулей ошибок предсказания для повышения степени сжатия обрабатываемых данных.
Несмотря на то, что достигнуты значительные успехи в сжатии изображений, остается актуальной задача разработки новых способов сжатия изображений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Заявляемые изобретения связаны единым изобретательским замыслом.
Техническим результатом заявляемого первого изобретения является метод сжатия изображений без потерь с высокой степенью сжатия.
Первый способ сжатия изображений характеризуется тем, что первоначально, для каждого из пикселей входного изображения, определяют значение ошибки предсказания, которую затем формируют в виде пары значений: значение модуля ошибки предсказания и значение знака ошибки предсказания. Затем отображают значение модуля ошибки каждого из пикселей всего изображения в двоичную последовательность в соответствии с унарным кодом. Полученный набор двоичных последовательностей представляют в виде набора двоичных уровней, сформированных из двоичных значений, чьи порядковые позиции в коде совпадают с номером соответствующего двоичного уровня. На каждом двоичном уровне производят контекстное моделирование для каждого бита, используя значения бит отображения значений модулей ошибок соседних пикселей на данном и предыдущем двоичном уровне унарного кода. Далее производят контекстное моделирование для значений знаков ошибки каждого пикселя изображения, используя значения знаков ошибок предсказания соседних пикселей. И затем сформированные с помощью контекстного моделирования, выполняемого для значений модулей и знаков ошибок предсказания, двоичные потоки обрабатывают путем сжатия двоичным арифметическим кодером.
В частном случае при формировании значения знака ошибки предсказания учитывают значение модуля ошибки предсказания для этого же пикселя. При значении модуля, равном «0», значение знака не кодируют.
При отображении значения модуля ошибки каждого из пикселей в унарный код формируют двоичную последовательность, в которой количество «0» соответствует значению модуля ошибки и служебного значения «1» в конце последовательности из «0».
Также производят обработку значений из двоичных уровней, один уровень за другим, начиная с уровня, сформированного из двоичных значений, выбранных с первой порядковой позиции унарного кода модуля ошибки предсказания каждого пикселя.
Кроме того, производят обработку значений из двоичного уровня только на тех позициях, на которых присутствуют значения двоичного кода модуля ошибки предсказания. Таким образом, на двоичных уровнях, расположенных выше двоичного уровня, на котором в данной позиции находилась "1", эта позиция не будет обрабатываться.
В частности, информацию о позициях, на которых находятся обрабатываемые значения, передают от предыдущего обработанного двоичного уровня.
При контекстном моделировании, выполняемом для каждого бита, подвергающегося кодированию на текущем уровне, в одном случае используют биты отображения значений модулей ошибок четырех ближайших пикселей с текущего двоичного уровня, которые расположены левее и выше текущей позиции, а также четырех ближайших пикселей с предыдущего двоичного уровня, которые расположены правее и ниже текущей позиции.
При контекстном моделировании, выполняемом для каждого бита, подвергающегося кодированию на текущем уровне, в другом случае используют биты отображения значений модулей ошибок десяти ближайших пикселей с текущего двоичного уровня, которые расположены левее и выше текущей позиции, а также десяти ближайших пикселей с предыдущего двоичного уровня, которые расположены правее и ниже текущей позиции.
При контекстном моделировании, выполняемом для значений знаков ошибок предсказания, в одном случае используют значения знаков четырех ближайших уже обработанных ошибок предсказания.
При контекстном моделировании, выполняемом для значений знаков ошибок предсказания, в другом случае используют значения знаков шести ближайших уже обработанных ошибок предсказания.
Техническим результатом заявляемого второго изобретения является повышение скорости кодирования без потерь изображения по сравнению с первым изобретением при несущественных изменениях степени сжатия изображений, особенно при обработке изображений с большим динамическим диапазоном по яркости.
Второй способ сжатия изображений характеризуется тем, что первоначально, для каждого из пикселей входного изображения, определяют значение ошибки предсказания, которое затем формируют в виде пары значений: значение модуля ошибки предсказания и значение знака ошибки предсказания. Далее отображают значение модуля ошибки каждого из пикселей всего изображения в двоичную последовательность в соответствии с унарным кодом. Полученный набор двоичных последовательностей представляют в виде набора двоичных уровней, сформированных из двоичных значений, чьи порядковые позиции в коде совпадают с номером соответствующего двоичного уровня. Следом производят контекстное моделирование для каждого бита, используя значения бит отображения значений модулей ошибок соседних пикселей на данном и предыдущем двоичном уровне унарного кода для тех двоичных уровней, для которых значение модуля ошибки предсказания изображения не превышает определенный порог. На остальных двоичных уровнях необработанные значения преобразуют в двоичный код и производят контекстное моделирование для значений полученного двоичного кода. Производят контекстное моделирование для значений знаков ошибки предсказания для каждого пикселя изображения с учетом значений знаков ошибки предсказания соседних пикселей. И затем сформированные с помощью контекстного моделирования, выполняемого для значений модулей и знаков ошибок предсказания, двоичные потоки обрабатывают путем сжатия двоичным арифметическим кодером.
В частном случае при формировании значения знака ошибки предсказания учитывают значение модуля ошибки предсказаний для этого же пикселя. При значении модуля, равном «0», значение знака не кодируют.
При отображении значения модуля ошибок каждого из пикселей в унарный код формируют двоичную последовательность, в которой количество «0» соответствует значению модуля ошибки, и служебного значения «1» в конце последовательности из «0».
Также производят обработку значений из двоичных уровней, один уровень за другим, начиная с уровня, сформированного из двоичных значений, выбранных с первой порядковой позиции унарного кода модуля ошибки предсказания каждого пикселя.
Кроме того, производят обработку значений из двоичного уровня только на тех позициях, на которых присутствуют значения двоичного кода модуля ошибки предсказания. Таким образом, на двоичных уровнях, расположенных выше двоичного уровня, на котором в данной позиции находилась "1", эта позиция не будет обрабатываться.
В частности, информацию о позициях, на которых находятся обрабатываемые значения, передают от предыдущего обработанного двоичного уровня.
При контекстном моделировании, выполняемом для значений модулей ошибок каждого пикселя, в одном случае используют биты отображения значений модулей ошибок четырех ближайших пикселей с текущего двоичного уровня, которые расположены левее и выше текущей позиции, а также четырех ближайших пикселей с предыдущего двоичного уровня, которые расположены правее и ниже текущей позиции.
При контекстном моделировании, выполняемом для значений модулей ошибок каждого пикселя, в другом случае используют биты отображения значений модулей ошибок десяти ближайших пикселей с текущего двоичного уровня, которые расположены левее и выше текущей позиции, а также десяти ближайших пикселей с предыдущего двоичного уровня, которые расположены правее и ниже текущей позиции.
При контекстном моделировании, выполняемом для значений знаков ошибок предсказания каждого пикселя, в одном случае используют значения знаков четырех ближайших уже обработанных ошибок предсказания.
При контекстном моделировании, выполняемом для значений знаков ошибок предсказания каждого пикселя, в другом случае используют значения знаков шести ближайших уже обработанных ошибок предсказания.
Кроме того, упомянутый порог при выполнении контекстного моделирования определяют заранее и считают параметром, задаваемым пользователем с целью управления скоростью работы алгоритма сжатия.
При этом значения из двоичных уровней, составленных из значений унарного кода, чьи порядковые номера в коде превышают заданный порог, отображаются в двоичные последовательности в соответствии с равномерным кодом.
При контекстном моделировании, выполняемом для значений полученного двоичного кода, используют информацию о позиции двоичного значения в равномерном коде.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Изобретение поясняется рисунками.
На Фиг. 1 приведена общая структурная схема выполнения способа сжатия изображения.
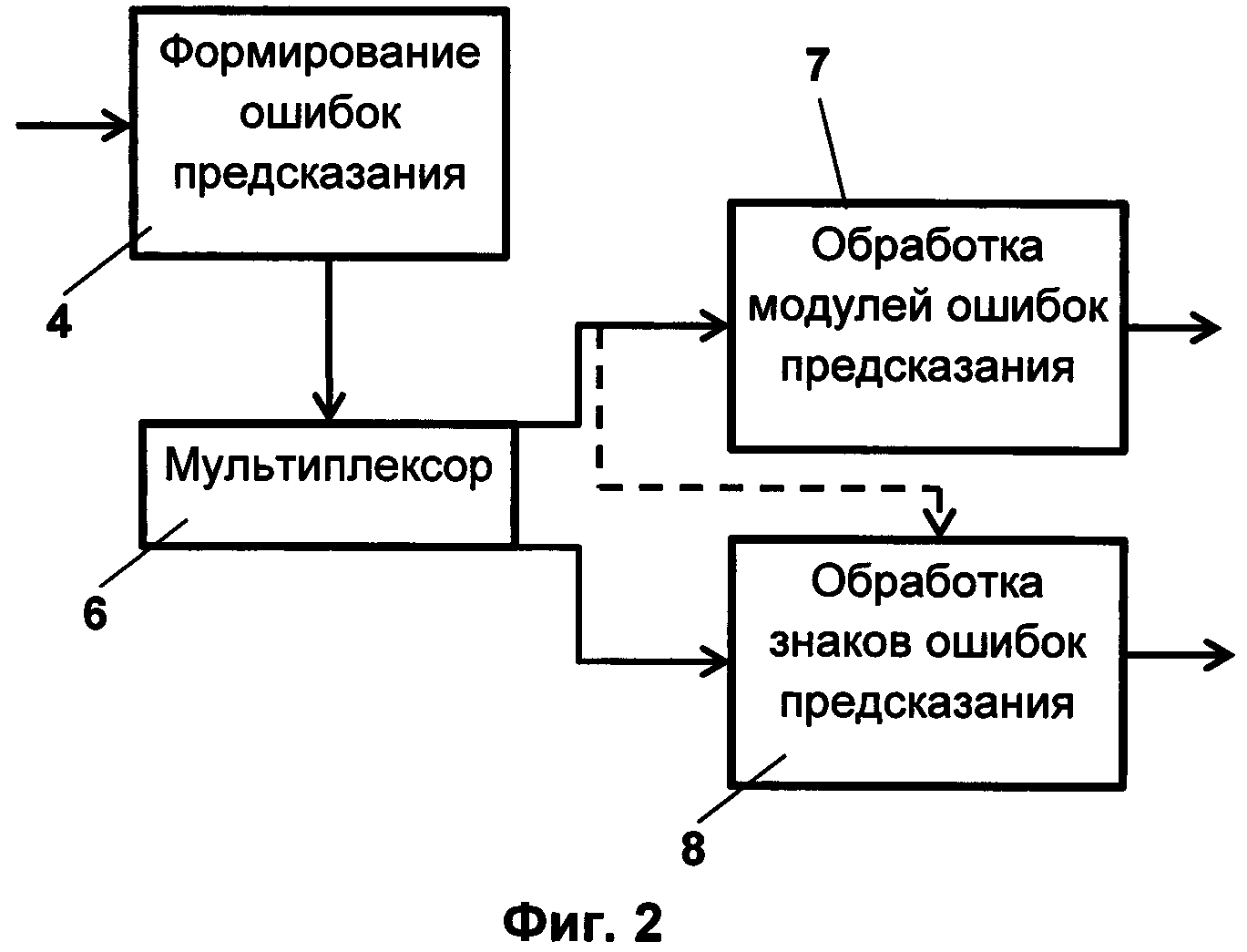
На Фиг. 2 представлена схема формирования модуля ошибки предсказания и знака ошибки предсказания.
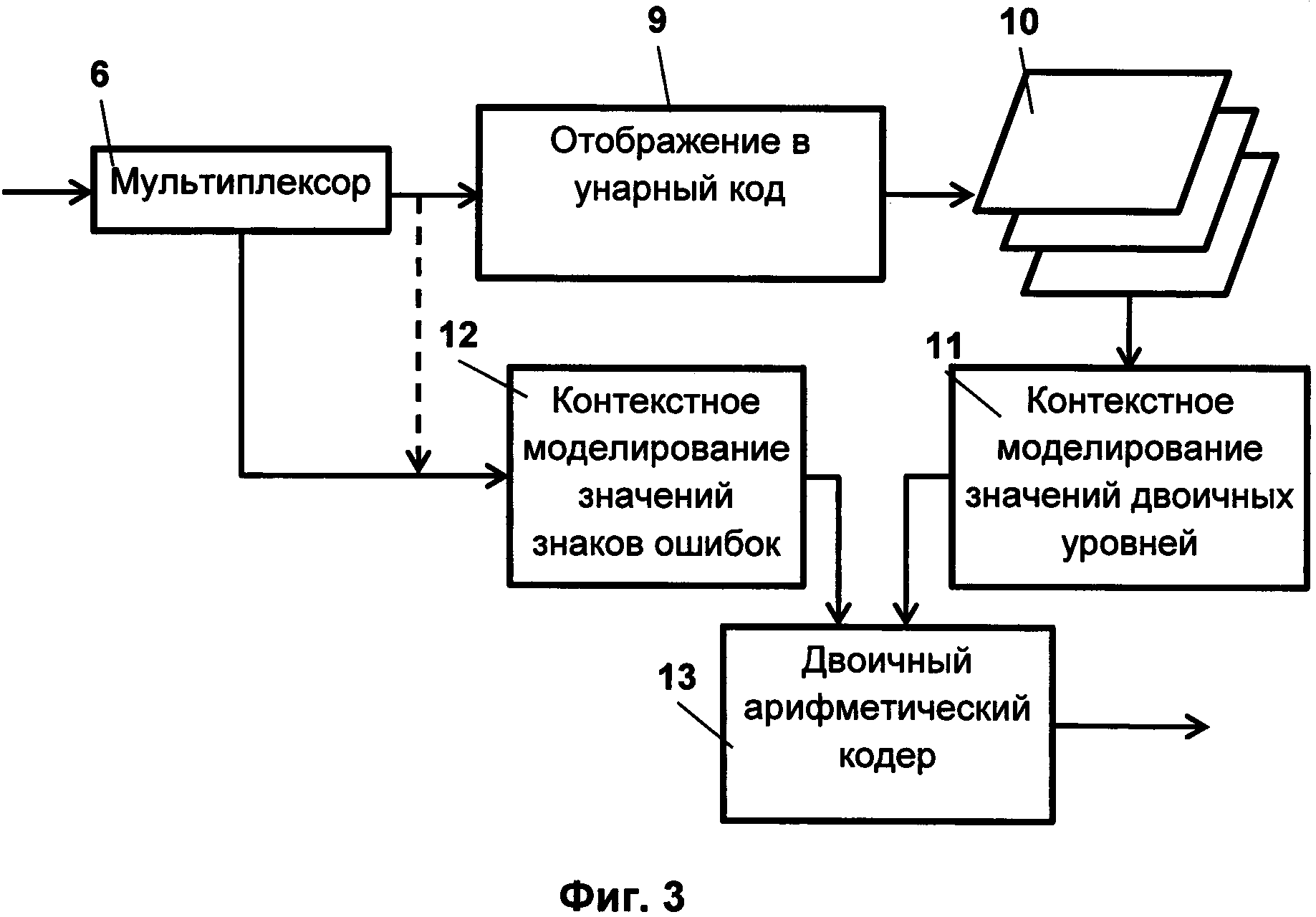
На Фиг. 3 представлена схема операций по обработке значений модулей ошибок предсказания по первому изобретению.
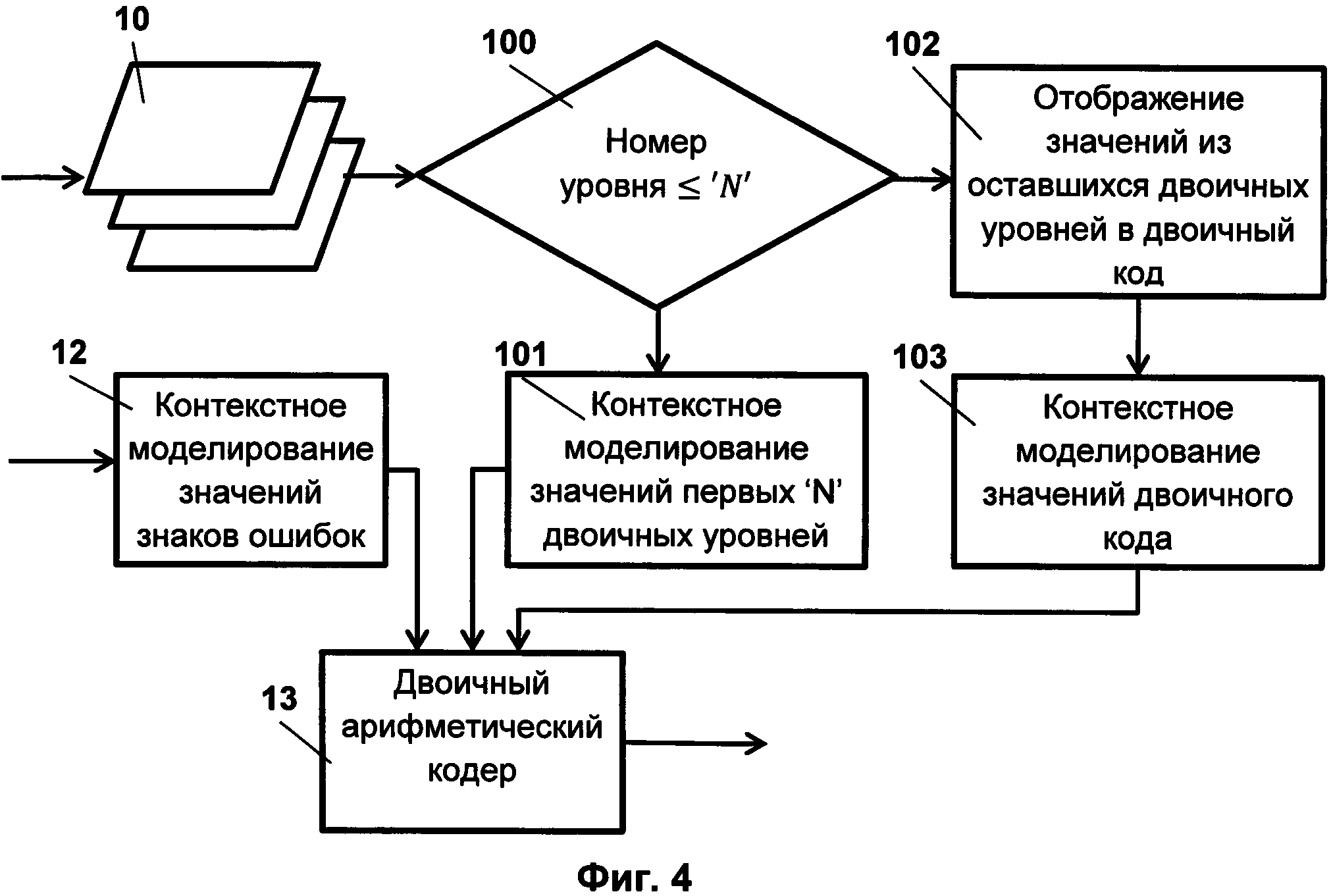
На Фиг. 4 представлена схема операций по обработке значений модулей ошибок предсказания по второму изобретению.
На Фиг. 5 приведен рисунок, поясняющий процесс формирования набора двоичных уровней по значениям модулей ошибок предсказания.
На Фиг. 6 представлен рисунок, поясняющий порядок обработки двоичных уровней.
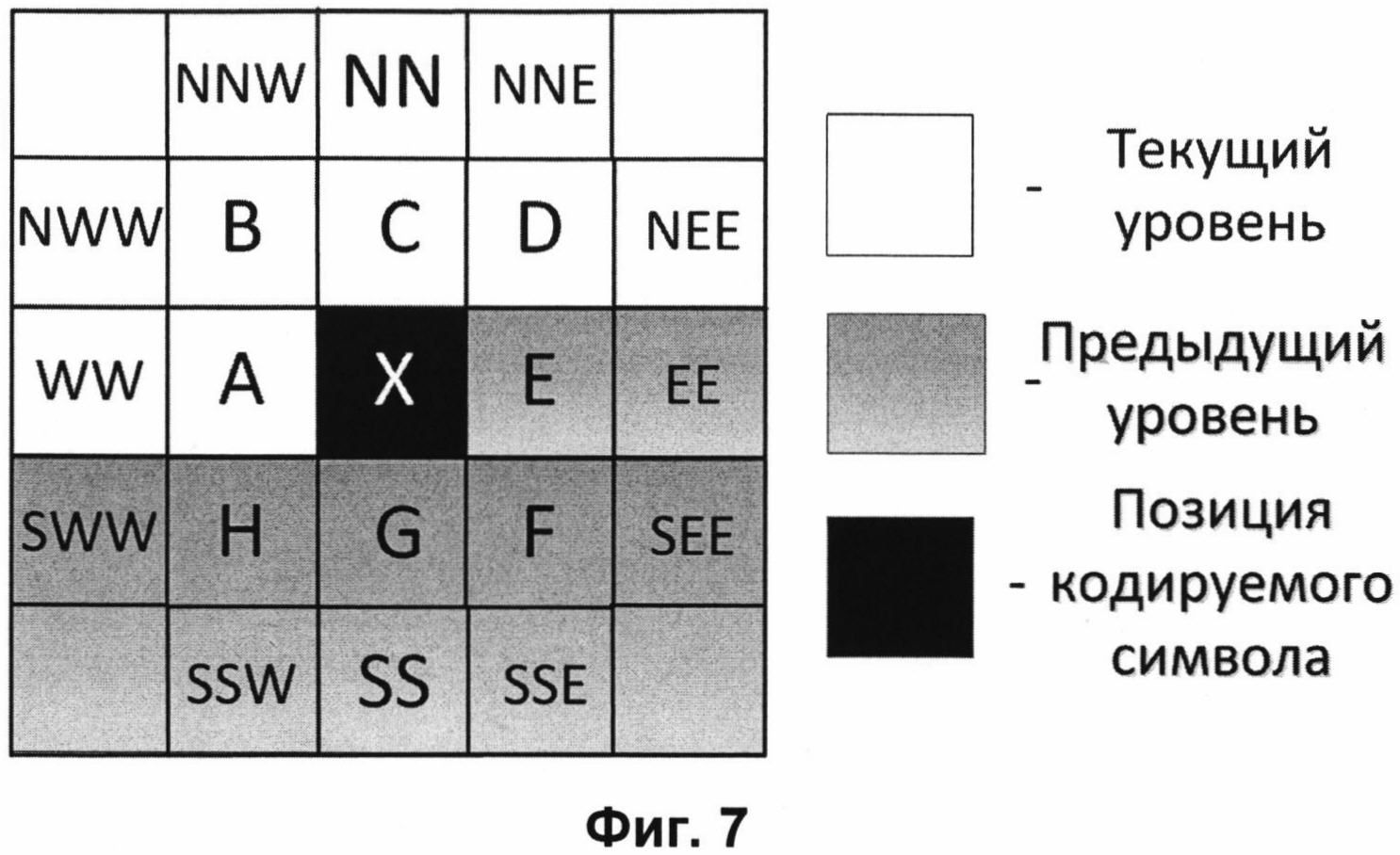
На Фиг. 7 представлена схема, демонстрирующая набор доступных значений при контекстном моделировании.
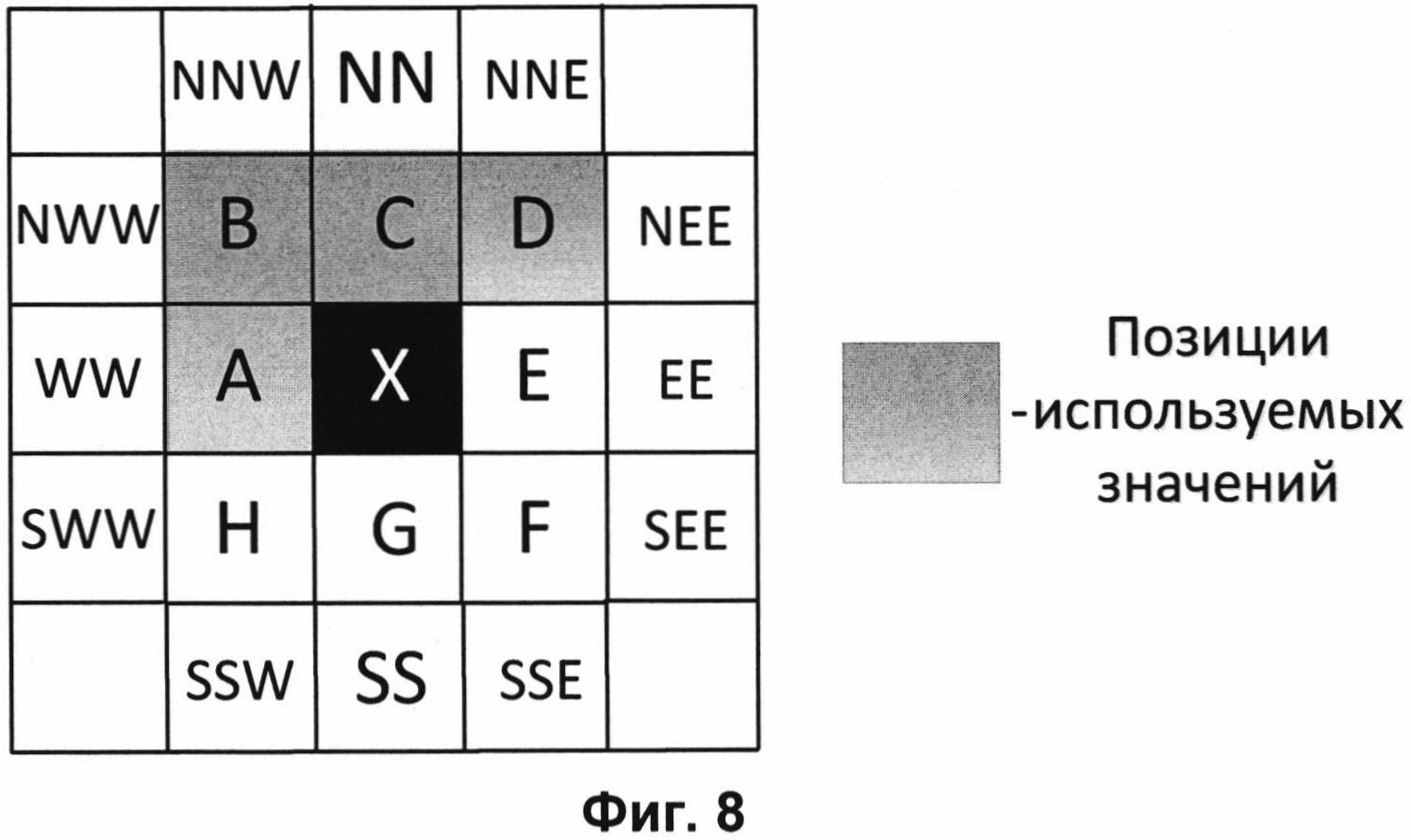
На Фиг. 8 представлена схема контекстного моделирования для значений знаков ошибок предсказания по первому варианту осуществления контекстного моделирования.
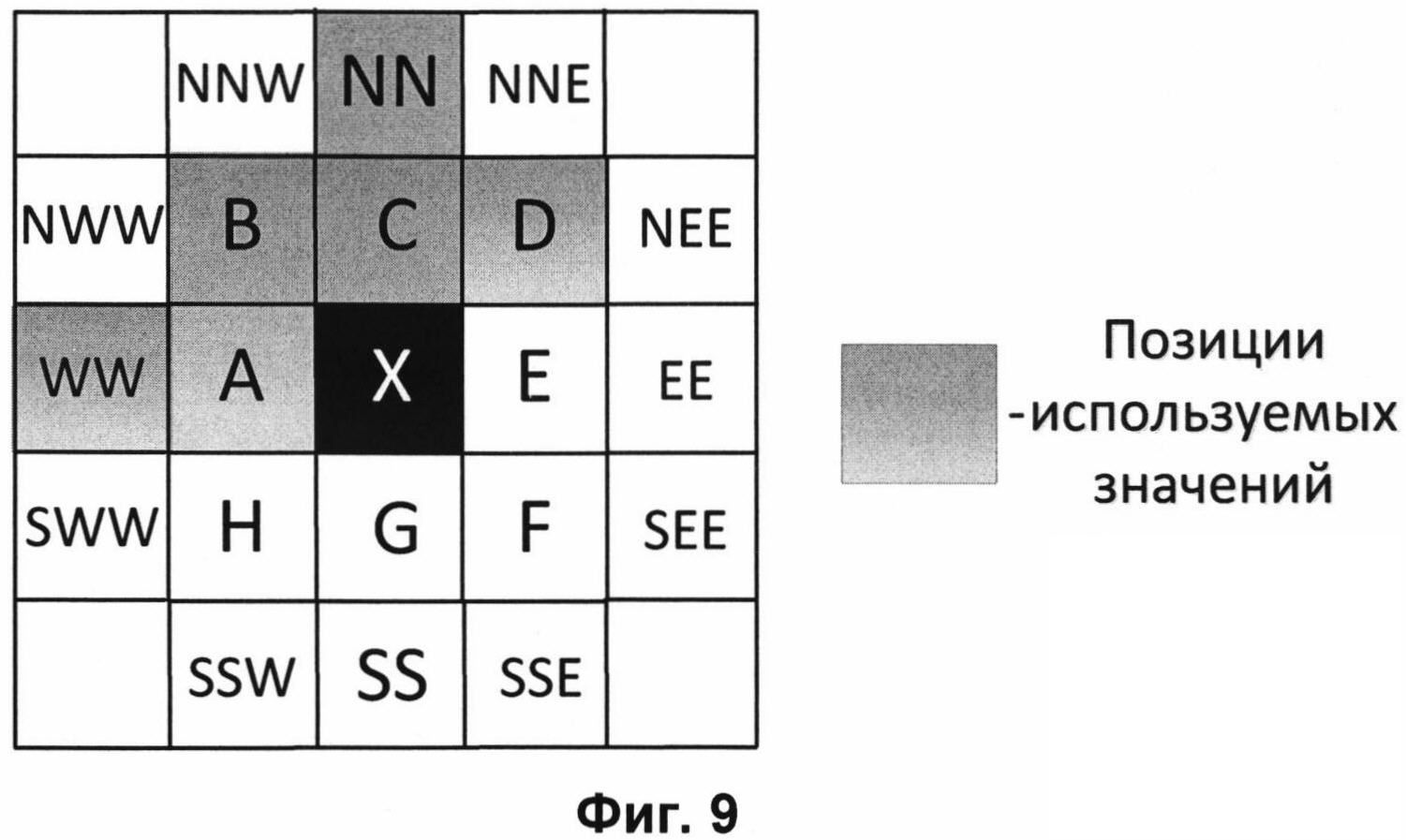
На Фиг. 9 представлена схема контекстного моделирования для значений знаков ошибок предсказания по второму варианту осуществления контекстного моделирования.
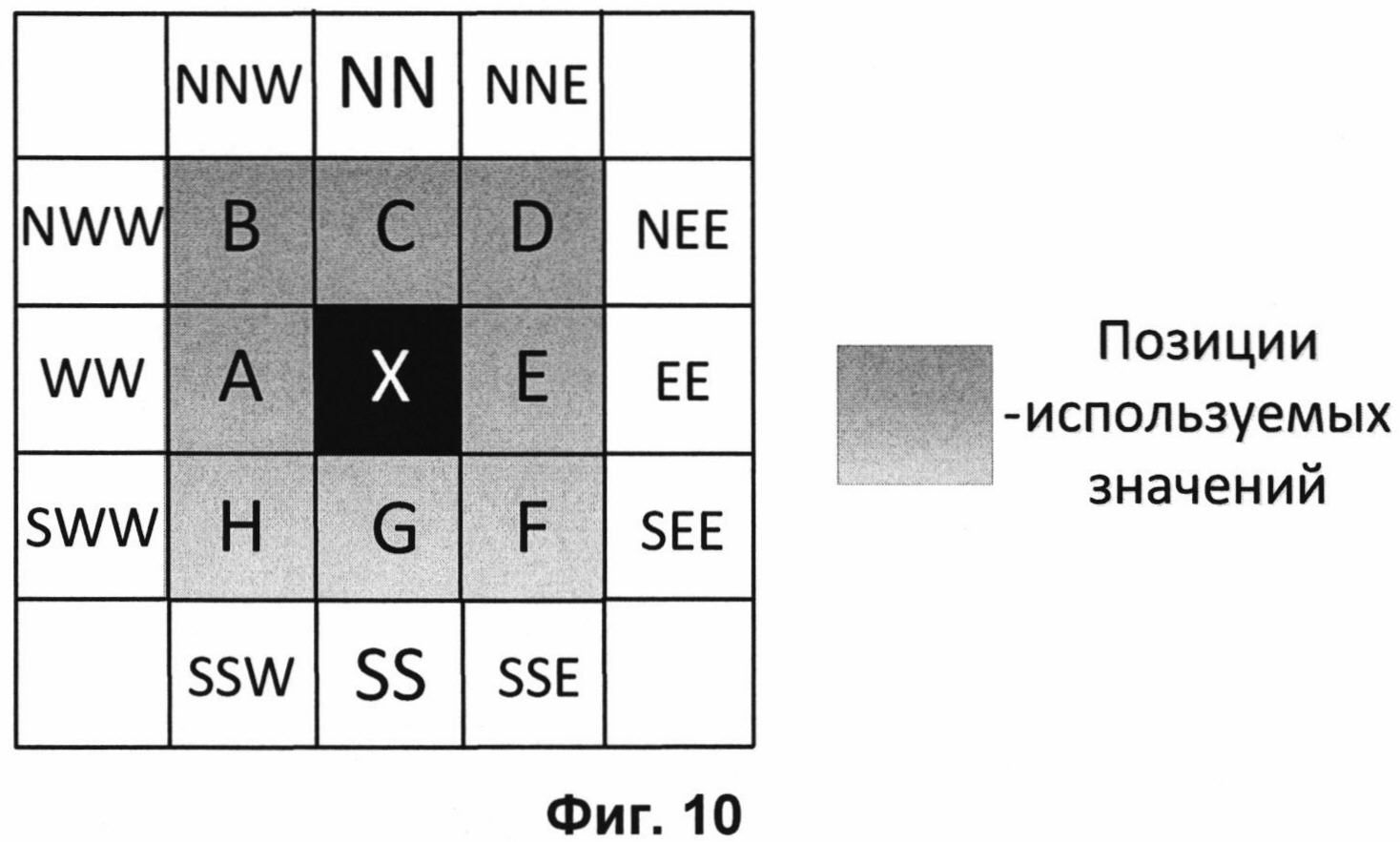
На Фиг. 10 представлена схема контекстного моделирования для значений двоичного уровня по первому варианту осуществления контекстного моделирования.
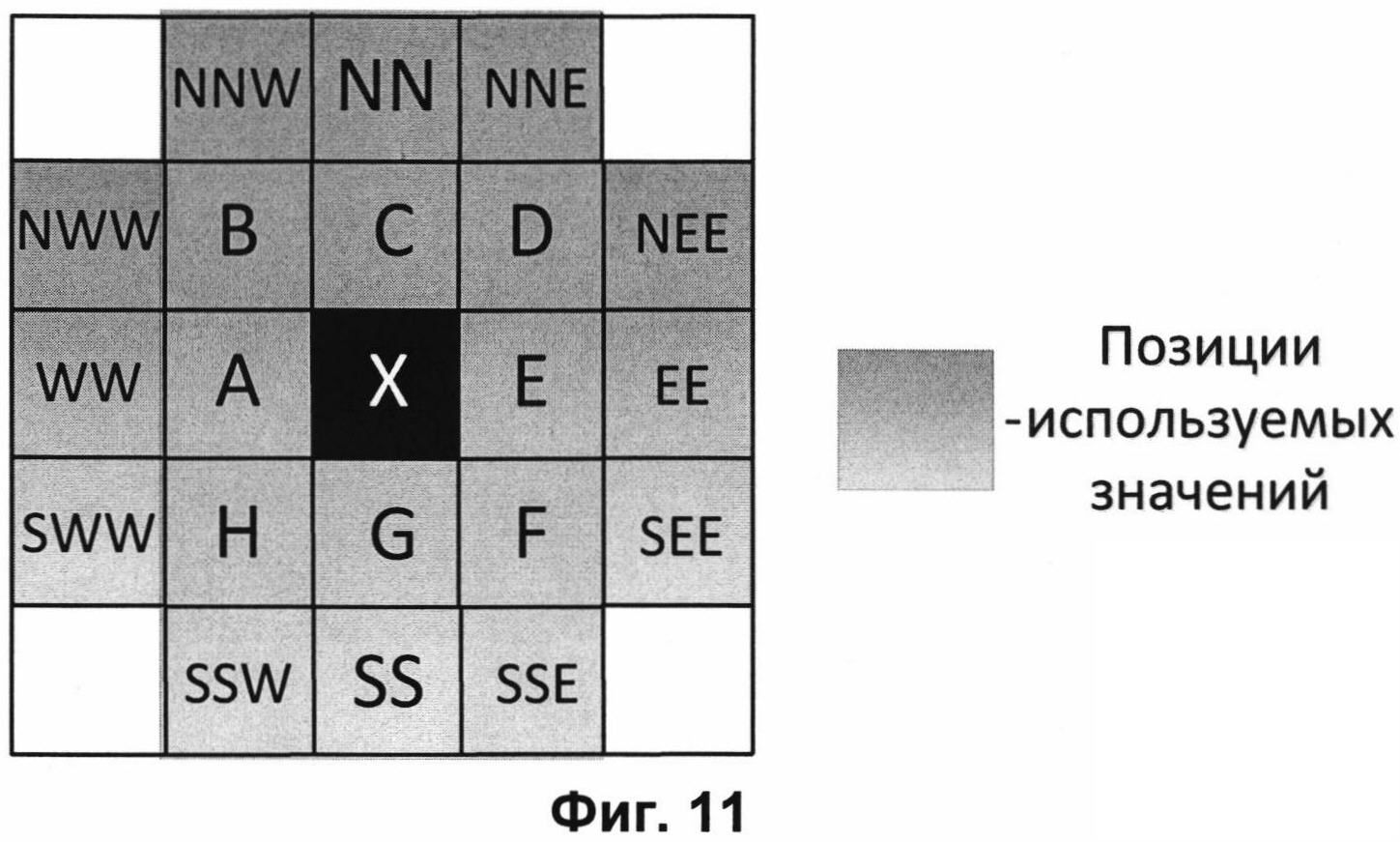
На Фиг. 11 представлена схема контекстного моделирования для значений двоичного уровня по второму варианту осуществления контекстного моделирования.
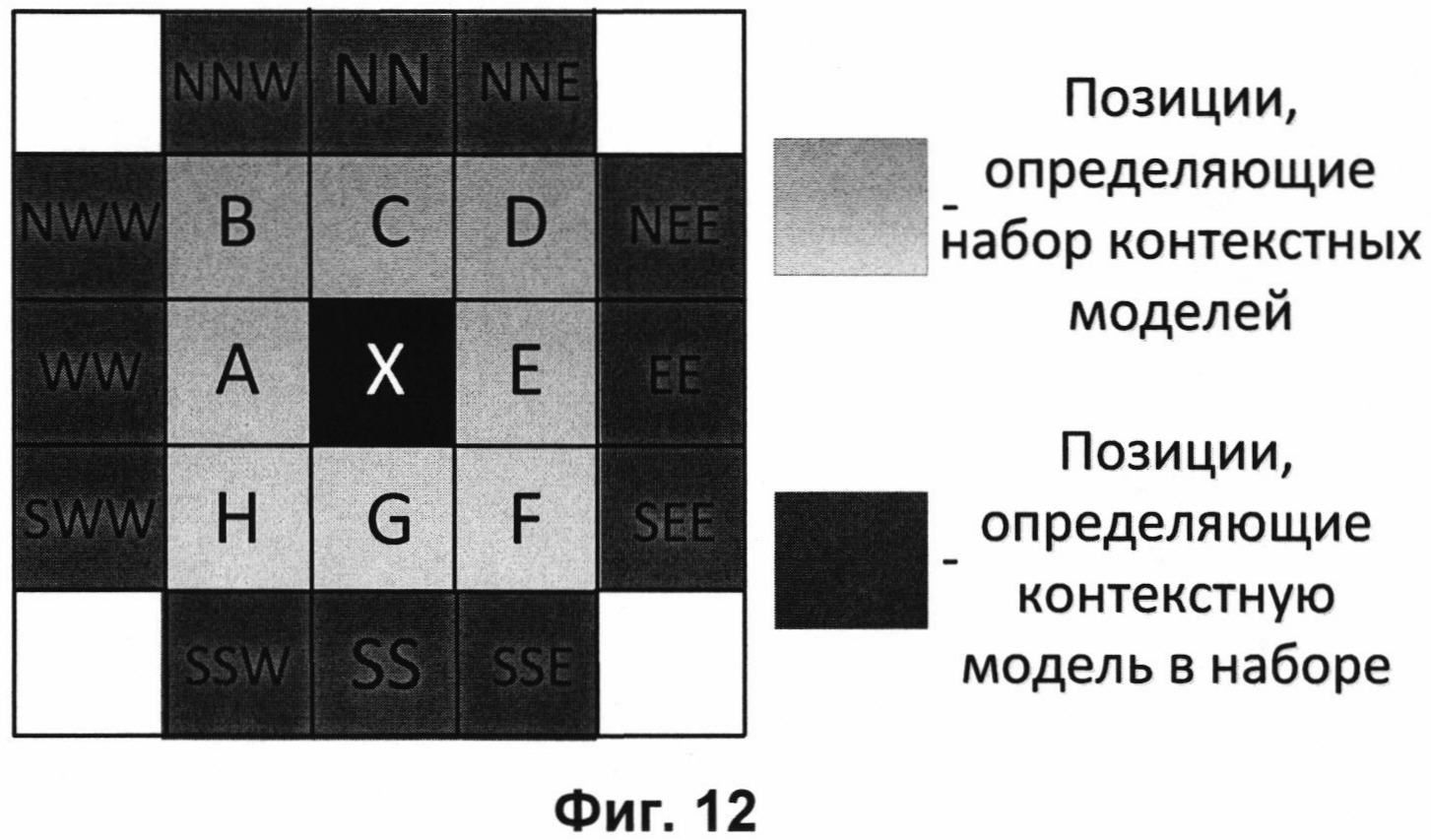
На Фиг. 12 представлена схема контекстного моделирования для значений двоичного уровня по третьему варианту осуществления контекстного моделирования.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
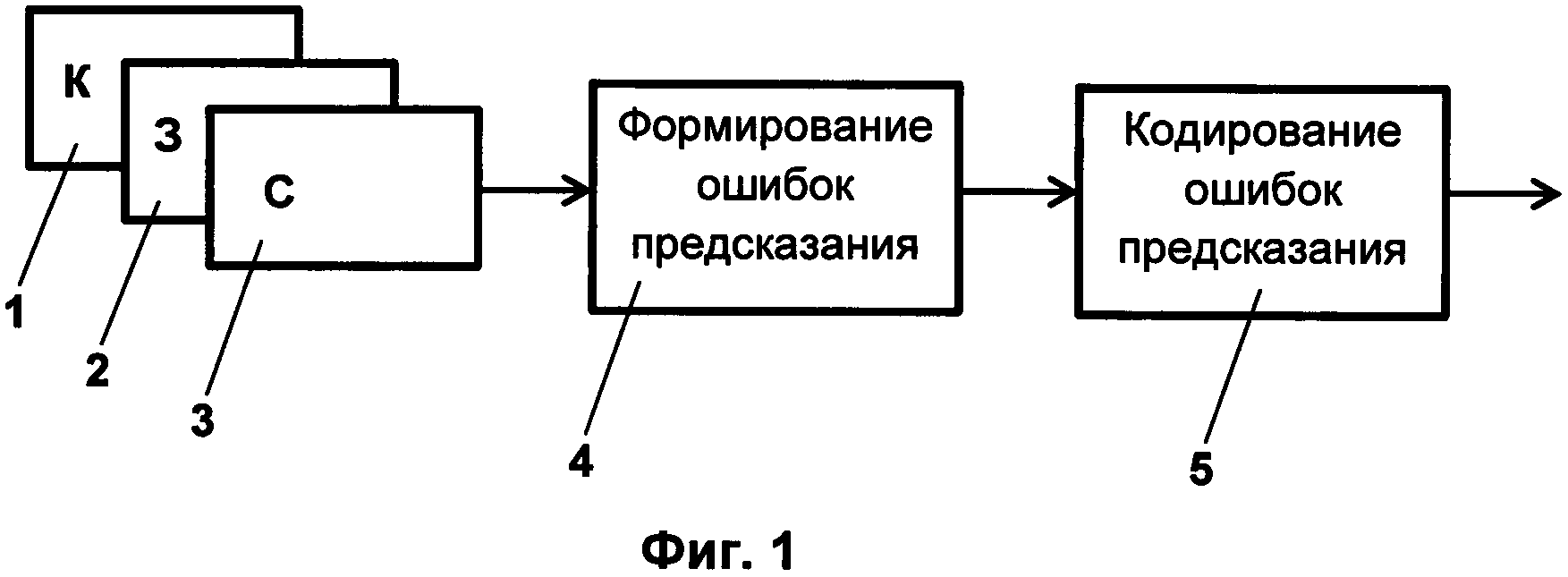
Данный способ может применяться для изображений, состоящих из одной компоненты, например, черно-белых изображений, или из нескольких компонент 1, 2, 3 в случае цветных изображений (Фиг. 1). Для RGB изображений этими компонентами будет являться зеленая, красная и синяя соответственно. В данном способе наборы ошибок предсказания, сформированные по различным цветовым компонентам, сжимаются независимо.
Работа способа по первой реализации изобретения осуществляется следующим образом.
Изображение состоит из отдельных пикселей. Первоначально для каждого пикселя формируют 4 (Фиг. 1) значение ошибки предсказания, которое представляет собой разницу между значением яркостной составляющей пикселя и предсказанным значением. В качестве процедуры формирования ошибки предсказания может использоваться методика, описанная в одном из известных стандартов сжатия изображений (смотри, например, MED предсказание из стандарта сжатия изображений без потерь JPEG-LS).
Далее производится вторая часть - кодирование ошибок предсказания 5. Первоначально (Фиг. 2) с помощью мультиплексора 6 из каждой ошибки предсказания формируют пару значений: значение модуля ошибки предсказания и значение знака ошибки предсказания. При формировании значения знака ошибки предсказания учитывают значение модуля ошибки предсказания для этого же пикселя. При значении модуля, равном «0», значение знака не кодируют. Дальнейшая обработка модулей ошибок предсказания 7 и обработка знаков ошибок предсказания 8 производится раздельно.
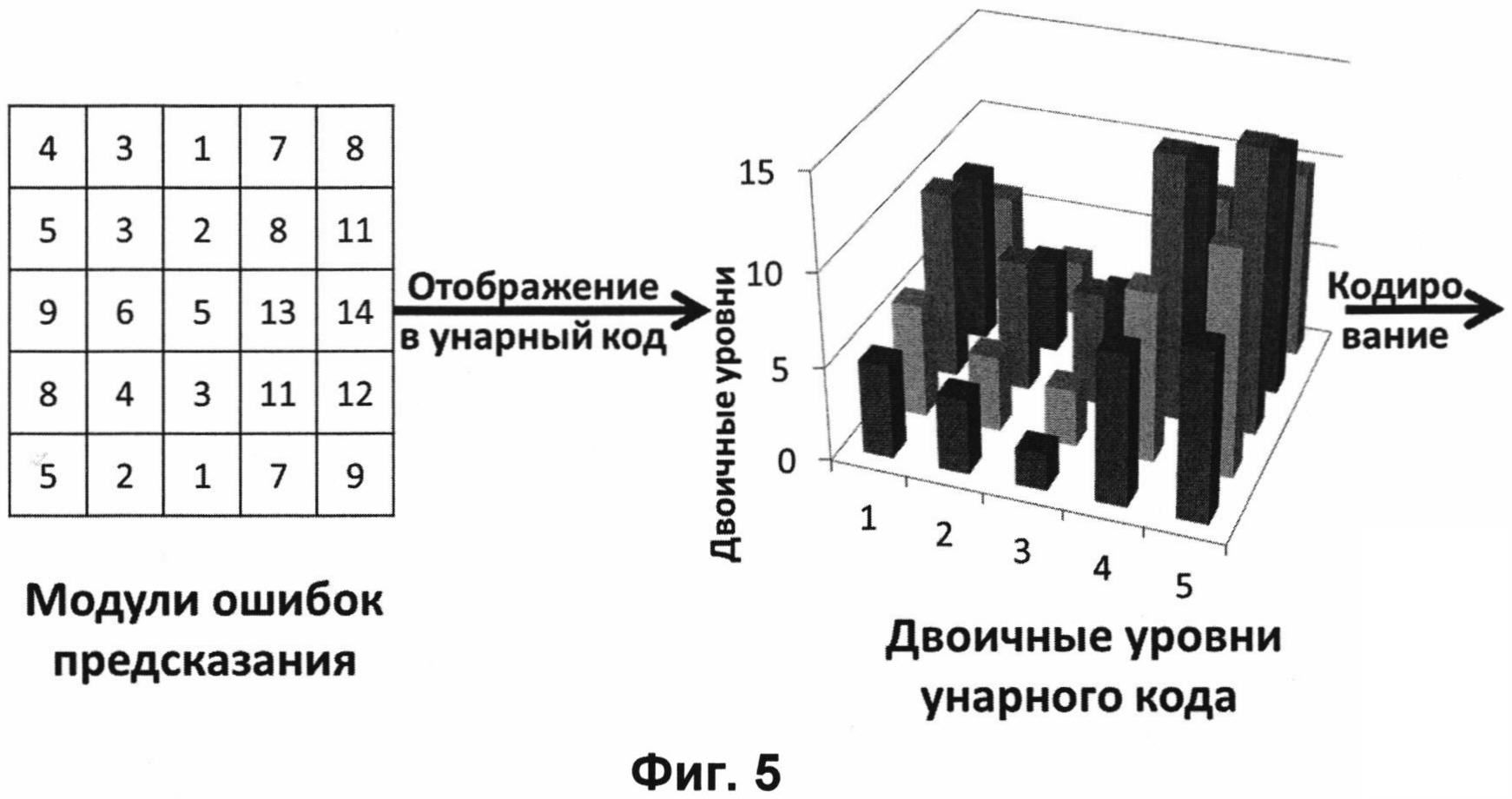
При обработке значений модулей ошибок предсказаний первоначально отображают значение модуля ошибки каждого из пикселей всего изображения в двоичную последовательность в соответствии с унарным кодом (Фиг. 3). На Фиг. 5 представлен пример отображения значений модулей ошибок в унарный код. В получаемой двоичной последовательности количество «0» соответствует значению модуля ошибки предсказания. Кроме того, в конце последовательности из «0» записывается служебное значение «1». Полученные последовательности представлены на диаграмме в виде столбцов.
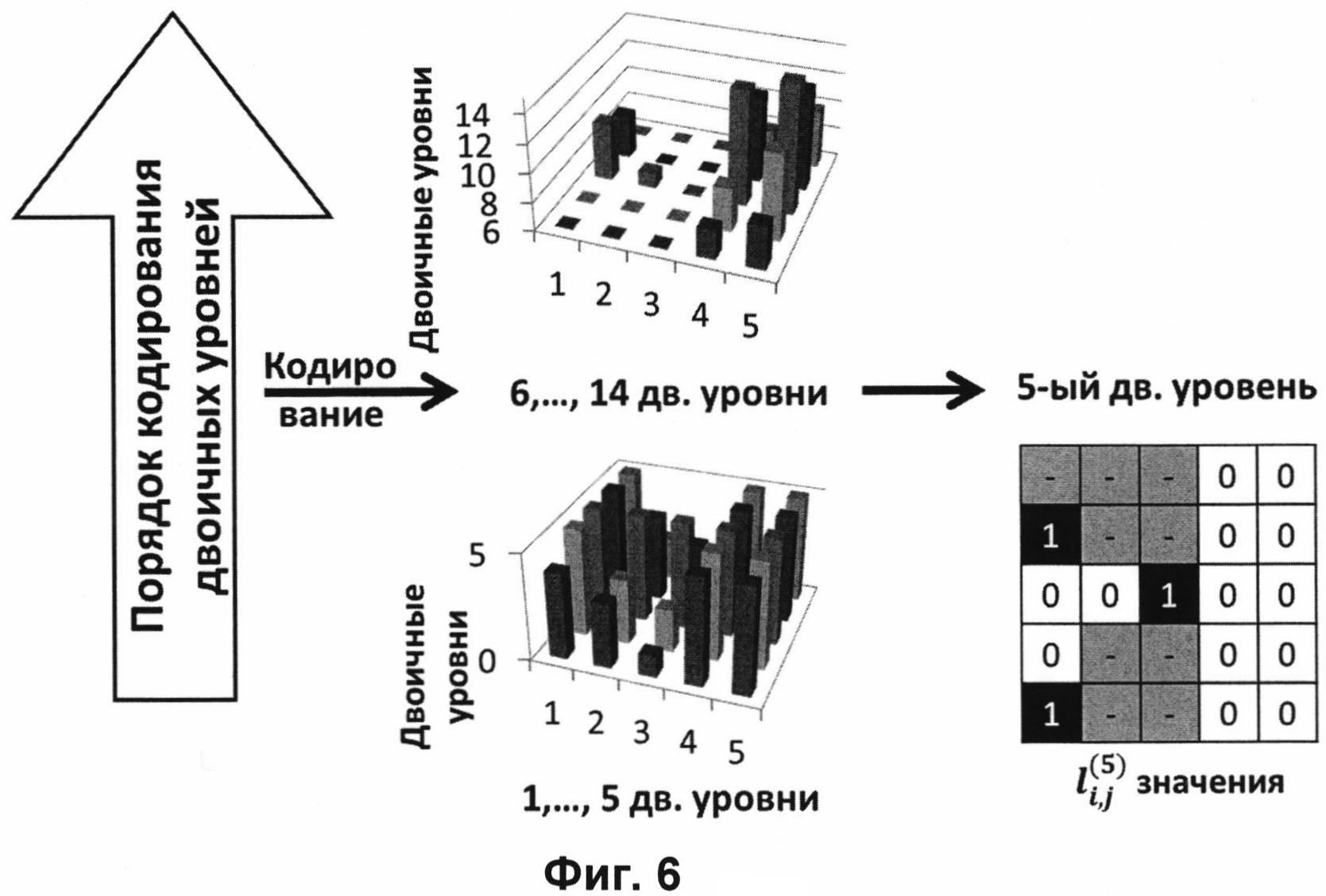
Полученный набор двоичных последовательностей представляют в виде набора двоичных уровней 10, сформированных из двоичных значений, чьи порядковые позиции в коде совпадают с номером соответствующего двоичного уровня. Дальнейшая обработка значений из двоичных уровней производится по уровням, один за другим, начиная с уровня, сформированного из двоичных значений, выбранных с первой порядковой позиции унарного кода модуля ошибки предсказания каждого пикселя. Эта процедура схематически показана на Фиг. 6. В нижней части рисунка показаны двоичные последовательности с 1 (первого) по 5 (пятый) уровень. В верхней части рисунка Фиг. 6. показаны двоичные последовательности с 6 (шестого) по 14 (четырнадцатый) уровень. Также приведен пример значений 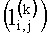 , содержащихся на 5 (пятом) уровне двоичного кода, где k - индекс двоичного уровня, (i,j) - координаты значения в двоичном уровне. А значения '-', выделенные серым цветом, показывают отсутствие двоичного значения для данного двоичного уровня на указанной позиции. Производят обработку значений (контекстное моделирование) из двоичного уровня только на тех позициях, на которых присутствуют значения двоичного кода модулей ошибок предсказания. «Пустые» пиксели, выделенные серым цветом, обработке не подвергаются.
, содержащихся на 5 (пятом) уровне двоичного кода, где k - индекс двоичного уровня, (i,j) - координаты значения в двоичном уровне. А значения '-', выделенные серым цветом, показывают отсутствие двоичного значения для данного двоичного уровня на указанной позиции. Производят обработку значений (контекстное моделирование) из двоичного уровня только на тех позициях, на которых присутствуют значения двоичного кода модулей ошибок предсказания. «Пустые» пиксели, выделенные серым цветом, обработке не подвергаются.
Контекстное моделирование предполагает разделение исходного потока данных на подпотоки, которые будут в дальнейшем обрабатываться независимо. При контекстном моделировании, выполняемом для значения двоичного уровня на позиции «X», соседние двоичные значения с позиций, изображенных на Фиг. 7, могут использоваться в качестве контекста пикселя на позиции «X». На Фиг. 7 белым цветом выделены позиции двоичных значений, взятых с текущего двоичного уровня, а серым цветом - с предыдущего уровня. Контекстная модель для обрабатываемого значения определяется идентификационным номером, вычисляемым как количество нулевых соседей в контексте текущего обрабатываемого значения. Идентификационный номер контекстной модели вычисляется по следующей формуле:
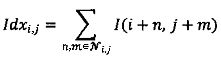 ,
,
где Ni,j - множество соседних позиций, значения на которых используются в качестве контекста;
I(.,.)- следующая функция индикатор:
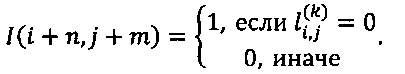
В первом варианте осуществления контекстного моделирования, выполняемого для значения модуля ошибки предсказания каждого пикселя, в качестве контекста используют биты отображения значений модулей ошибок с позиций, выделенных серым цветом на Фиг. 10. На Фиг. 10 позиции соседних значений n, m заменены на буквенные представления: Ni,j∈{А, В, С, D, Е, F, G, Н}.
Во втором варианте осуществления контекстного моделирования, выполняемого для значения модуля ошибки предсказания каждого пикселя, в качестве контекста используют биты отображения значений модулей ошибок с позиций, выделенных серым цветом на Фиг. 11. Что означает следующее:
Ni,j ∈{A, B, C, D, E, F, G, H, NN, NNE, NEE, EE, SEE, SSE, SS, SSW, SWW, WW, NWW, NNW}.
В третьем варианте осуществления контекстного моделирования, выполняемого для значения модуля ошибки предсказания каждого пикселя, используется схема двухуровневого контекстного моделирования, т.е. сначала на основе контекста 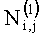 определяется используемый набор контекстных модель. А после этого на основе контекста
определяется используемый набор контекстных модель. А после этого на основе контекста 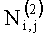 определяется используемая контекстная модель из выбранного набора. В качестве контекста для определения используемого набора контекстных моделей используют биты отображения значений модулей ошибок с позиций, выделенных светло-серым цветом на Фиг. 12. В качестве контекста для определения контекстной модели из выбранного набора моделей используют биты отображения значений модулей ошибок с позиций, выделенных темно-серым цветом на Фиг. 12. Что означает следующее:
определяется используемая контекстная модель из выбранного набора. В качестве контекста для определения используемого набора контекстных моделей используют биты отображения значений модулей ошибок с позиций, выделенных светло-серым цветом на Фиг. 12. В качестве контекста для определения контекстной модели из выбранного набора моделей используют биты отображения значений модулей ошибок с позиций, выделенных темно-серым цветом на Фиг. 12. Что означает следующее:

Как было сказано выше, значение знака ошибки предсказания каждого пикселя обрабатывается независимо от значения модуля ошибки предсказания этого же пикселя. (Фиг. 2, Фиг. 3). При контекстном моделировании, выполняемом для значений знаков ошибок предсказания 12, используют значения знаков ближайших уже обработанных пикселей в качестве контекста. Идентификационный номер контекстной модели определяется размещением соседних знаков ошибок предсказаний и вычисляется по следующей формуле:
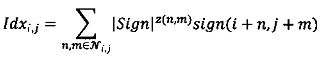 ,
,
где |Sign| - мощность множества значений знаков ошибки предсказания (равна трем);
sign(.,.) - значение знака ошибки предсказания на позиции
z(.,.) - индекс, указывающий на позицию используемого значения в контексте.
В одном варианте осуществления контекстного моделирования, выполняемого для значения модуля ошибки предсказания каждого пикселя, используют значения знаков четырех ближайших уже обработанных пикселей с позиций, выделенных серым цветом на Фиг. 8. Что означает следующее: Ni,j∈{А, В, С, D}
В другом варианте осуществления контекстного моделирования, выполняемого для значения модуля ошибки предсказания каждого пикселя, используют значения знаков шести ближайших уже обработанных пикселей с позиций, выделенных серым цветом на Фиг. 9. Что означает следующее: Ni,j∈{А, В, С, D, WW, NN}
Далее сформированные с помощью контекстного моделирования по значениям модулей и знаков ошибок предсказания двоичные потоки обрабатывают (Фиг. 3) путем сжатия арифметическим кодером 13. Данная операция производится известными методами. В качестве примера использования данной методики для сжатия потоков данных, сформированных с помощью контекстного моделирования, можно рассмотреть процедуры (методы) кодирования из стандарта сжатия неподвижных изображений JPEG-2000 ("Information Technology JPEG 2000 image coding system: Core coding system," ISO/IEC 15444-1:2004, Dec. 2009) и стандарта сжатия видеопоследовательностей Н.264 (" The Н.264 Advanced Video Compression Standard", lain E. Richardson, ISBN: 978-0-470-51692-8, 2010).
Вторая реализация изобретения показана на Фиг. 4. Данное изобретение от первого отличается только тем, что процедура контекстного моделирования 101 производится только для двоичных уровней, сформированных из двоичных значений унарного кода, чьи порядковые позиции в коде не превышают заданный порог. Упомянутый порог при выполнении контекстного моделирования определяют заранее и считают параметром, задаваемым пользователем с целью управления скоростью работы алгоритма сжатия. На остальных двоичных уровнях необработанные значения преобразуют в двоичный код 102 и производят контекстное моделирование для значений полученного двоичного кода 103.
При этом значения из двоичных уровней, составленных из значений унарного кода, чьи порядковые номера в коде превышают заданный порог, отображаются в двоичные последовательности в соответствии с равномерным кодом.
При контекстном моделировании, выполняемом для значений полученного двоичного кода, используют информацию о позиции двоичного значения в равномерном коде.
Далее сформированные с помощью контекстного моделирования по значениям модулей и знаков ошибок предсказания двоичные потоки обрабатывают путем сжатия арифметическим кодером, по аналогии с первой реализацией изобретения.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
Изобретения могут применяться для сжатия изображений в самых различных областях техники, в том числе для сжатия неподвижных изображений и видеопоследовательностей. Наиболее эффективно применение данных способов для сжатия натуралистичных и медицинских изображений.
Способ восстановления записей в запоминающем устройстве и система для его осуществления
Способ контроля корректности записи данных в двухконтроллерной системе хранения данных на массиве энергонезависимых носителей и устройство для его осуществления
Способ формирования профиля приложений для управления запросами и способ предоставления уровня обслуживания по запросам в системе хранения данных
Способ устранения избыточности при сжатии последовательности изображений
Способ восстановления записей в запоминающем устройстве и система для его осуществления
Способ контроля корректности записи данных в двухконтроллерной системе хранения данных на массиве энергонезависимых носителей и устройство для его осуществления
Способ формирования профиля приложений для управления запросами и способ предоставления уровня обслуживания по запросам в системе хранения данных
Способ устранения избыточности при сжатии последовательности изображений

