Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ В ПРОЦЕССЕ ЧТЕНИЯ
Вид РИД
Изобретение
УРОВЕНЬ ТЕХНИКИ
[0001] Оптическое распознавание символов (OCR) представляет собой технологию, с помощью которой отсканированные или сфотографированные изображения машинописного или печатного текста преобразуются в машинозакодированный/машиночитаемый текст. При использовании обычного подхода компьютер получает изображение текстовых данных и сопоставляет части изображения с образцами форм символов/эталонами. Однако современные технологии OCR все еще допускают ошибки при распознавании символов, путая символы с похожими по форме символами и получая на выходе текст с ошибками. Такой текст с ошибками неприемлем для большинства вариантов дальнейшего использования. Поэтому после распознавания текста из него следует устранить ошибки.
[0002] Обычный процесс устранения таких ошибок заключается в том, что пользователь полностью читает распознанный текст и исправляет ошибки вручную. Однако такое решение требует много времени и крайне трудоемко. Проблема исправления ошибок осложняется тем, что пользователи иногда не могут определить, какая буква в слове является неправильной, даже если они установили, что данное слово является неправильным.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Согласно одному варианту реализации изобретения, описываемый способ включает в себя получение набора неуверенно распознанных символов, полученных в результате распознавания изображения текста. Полученный набор символов включает изображение неуверенно распознанного символа, гипотезу об этом символе и уровень уверенности этой гипотезы. Этот способ также включает вызов устройства отображения для того, чтобы вывести изображение неуверенно распознанного символа поверх текста для вычитки. Дополнительно способ включает получение маркировочных данных для неуверенно распознанного символа и изменение уровня уверенности гипотезы, связанной с неуверенно распознанным символом, исходя из маркировочных данных, чтобы получить подтвержденную гипотезу о неуверенно распознанном символе.
[0004] Согласно другому варианту реализации изобретения, некий взятый в качестве примера машиночитаемый носитель содержит программные инструкции для выполнения процессором определенных функций. Эти функции включают в себя получение набора неуверенно распознанных символов, полученных в результате процесса распознавания изображения текста. Полученный набор символов включает в себя изображение неуверенно распознанного символа, гипотезу об этом символе и уровень уверенности этой гипотезы. Эти функции также включают вызов устройства отображения для того, чтобы вывести изображение неуверенно распознанного символа поверх текста для вычитки. Дополнительно эти функции включают получение маркировочных данных для неуверенно распознанного символа и изменение уровня уверенности гипотезы, связанной с неуверенно распознанным символом, исходя из маркировочных данных, чтобы получить подтвержденную гипотезу о неуверенно распознанном символе.
[0005] В еще одном варианте реализации изобретения взятая в качестве примера система содержит коммуникационный интерфейс и процессор. Этот коммуникационный интерфейс настроен на прием набора неуверенно распознанных символов, полученных в результате распознавания изображения текста. Полученный набор символов включает в себя изображение неуверенно распознанного символа, гипотезу об этом символе и уровень уверенности этой гипотезы. Процессор настроен на вызов устройства отображения для того, чтобы вывести изображение неуверенно распознанного символа поверх текста для вычитки. Дополнительно процессор и коммуникационный интерфейс настроены на получение маркировочных данных для неуверенно распознанного символа и изменение уровня уверенности гипотезы, связанной с неуверенно распознанным символом, исходя из маркировочных данных, чтобы получить подтвержденную гипотезу о неуверенно распознанном символе.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Фиг.1 представляет собой упрощенную схему, иллюстрирующую ряд аспектов примера сетевой системы согласно одному из вариантов реализации изобретения.
[0007] Фиг.2 представляет собой блок-схему, иллюстрирующую некоторые аспекты вычислительного устройства в соответствии с одним из вариантов реализации изобретения.
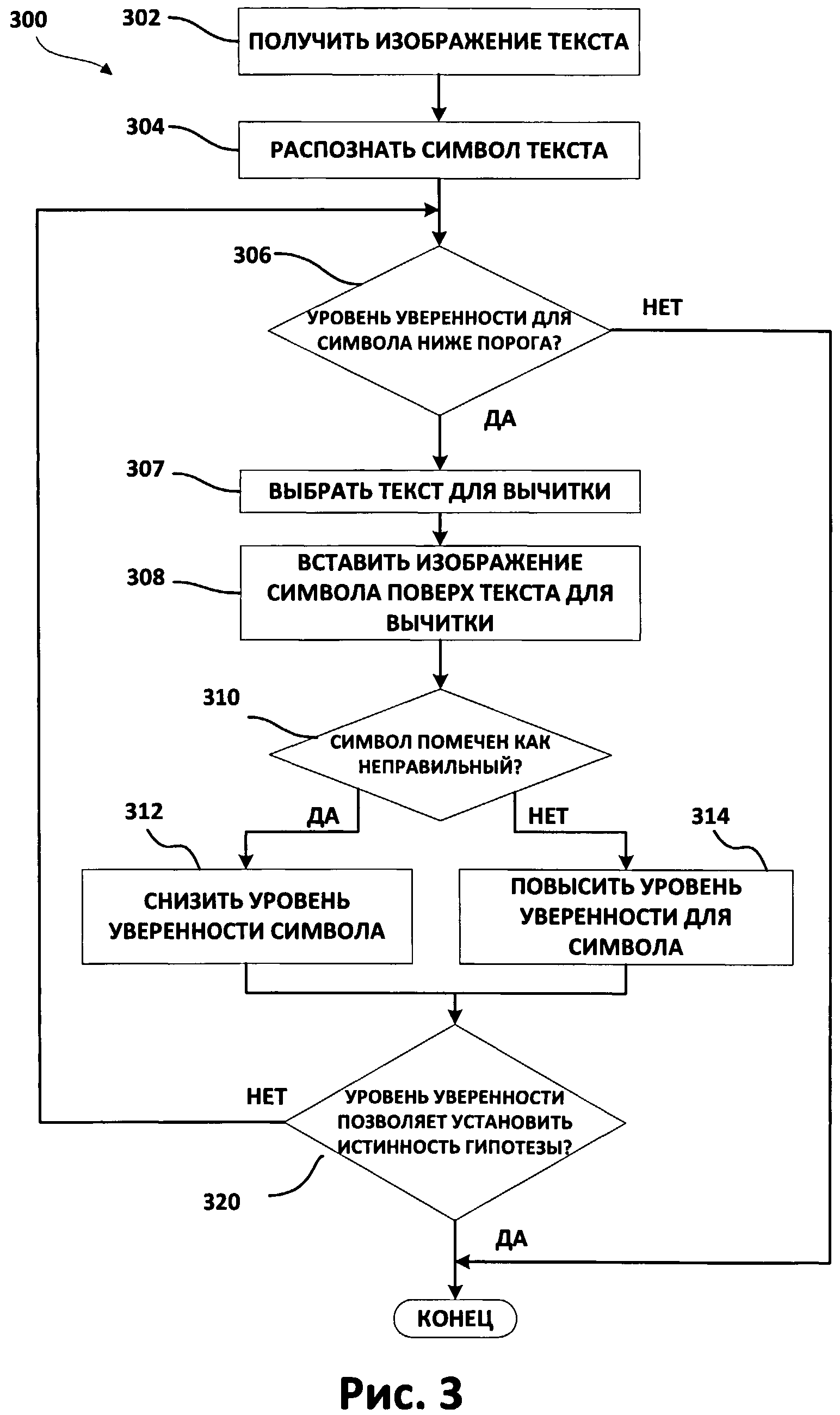
[0008] Фиг.3 представляет собой блок-схему, иллюстрирующую некоторые аспекты способа согласно одному из вариантов реализации изобретения.
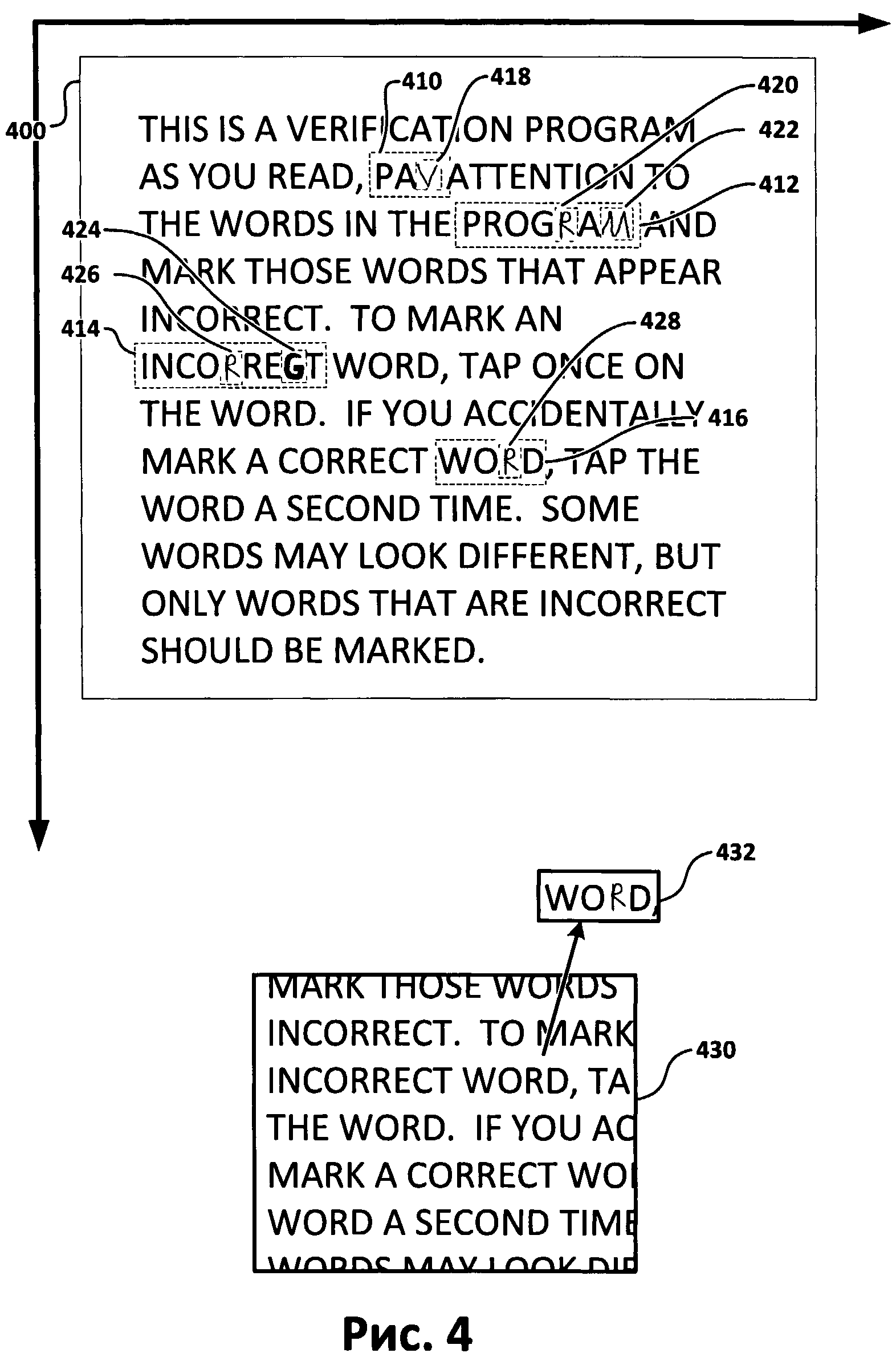
[0009] Фиг.4 представляет собой иллюстрацию графического интерфейса пользователя в соответствии с одним из вариантов реализации изобретения.
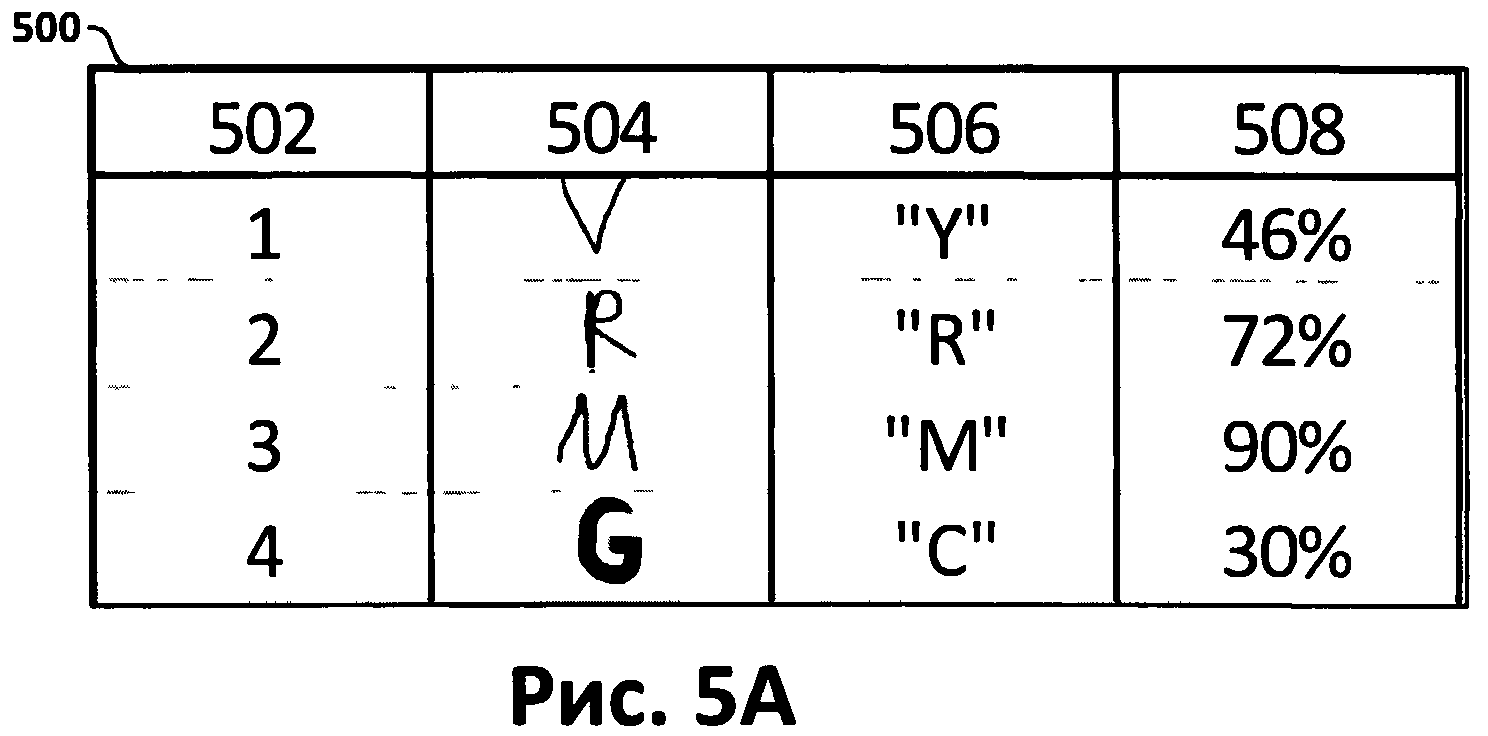
[0010] На Фиг.5А приведена таблица, содержащая некоторые аспекты массива неуверенно распознанных символов.
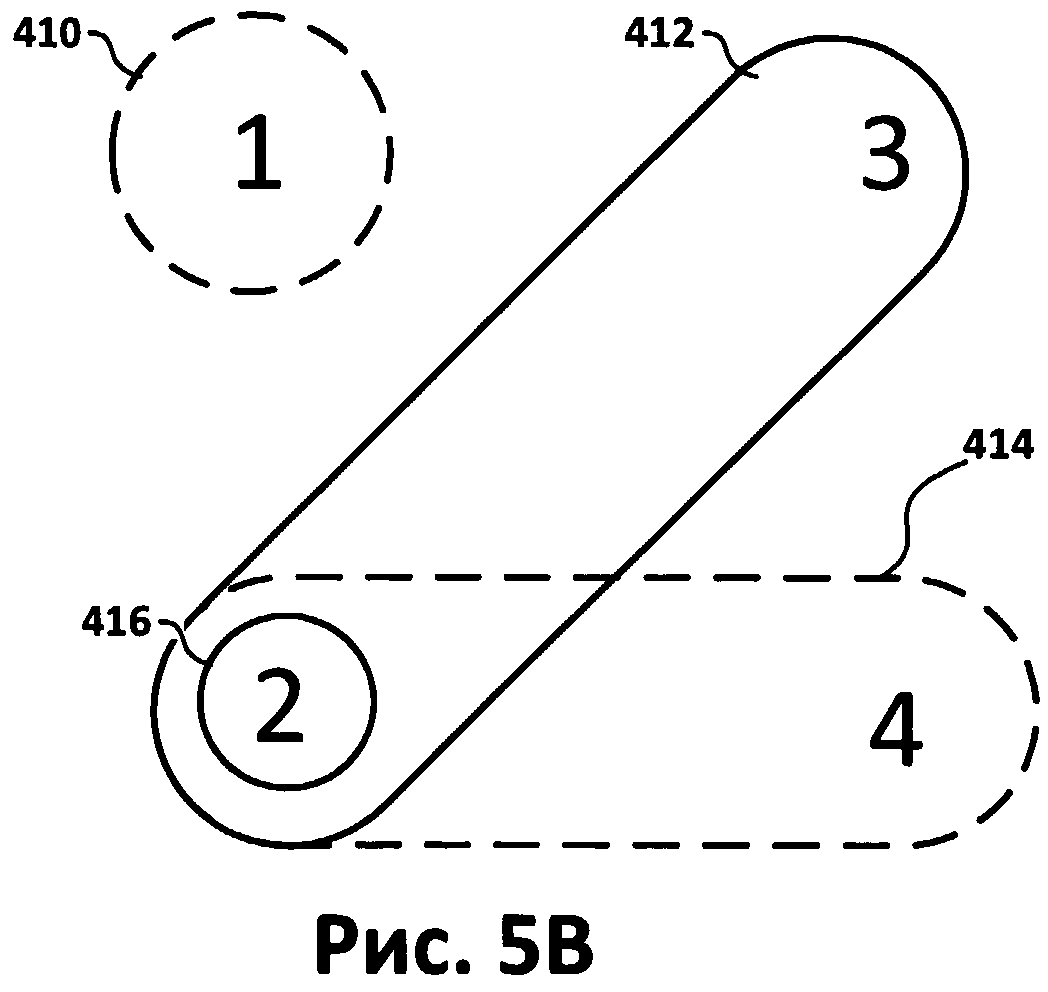
[0011] Фиг.5В представляет собой диаграмму состояния, на которой показаны связи между неуверенно распознанными символами в тексте, приведенном на Фиг.4.
[0012] На Фиг.6А и 6В приведен пример структуры массива неуверенно распознанных символов.
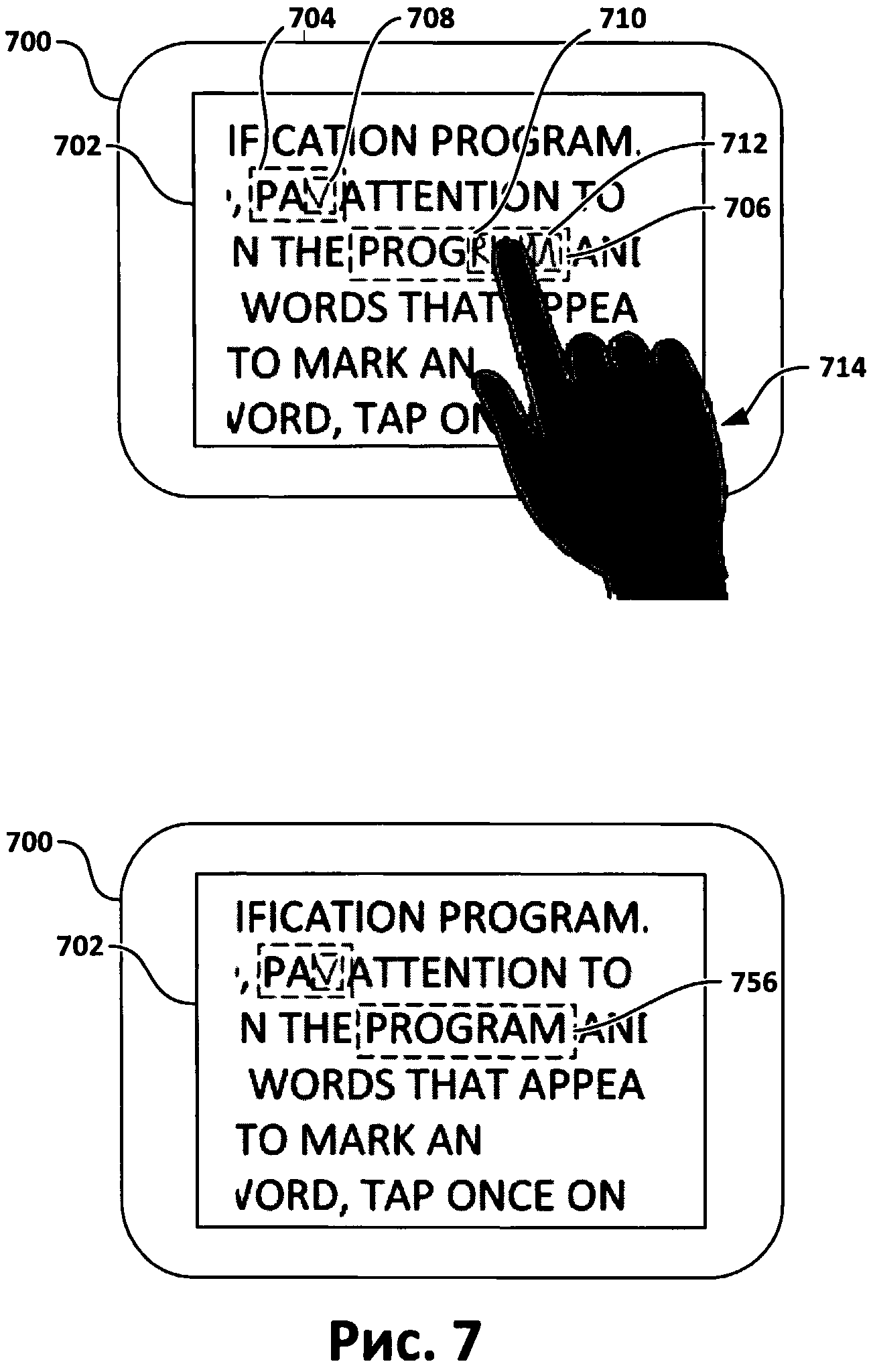
[0013] Фиг.7 представляет собой иллюстрацию взаимодействия пользователя с устройством, на котором проводится верификация, согласно одному из вариантов реализации изобретения.
[0014] Фиг.8 представляет собой иллюстрацию взаимодействия пользователя с устройством, на котором проводится верификация, согласно одному из вариантов реализации изобретения.
[0015] На Фиг.9 приведен пример изображения неуверенно распознанного символа и несколько гипотез, связанных с этим неуверенно распознанным символом.
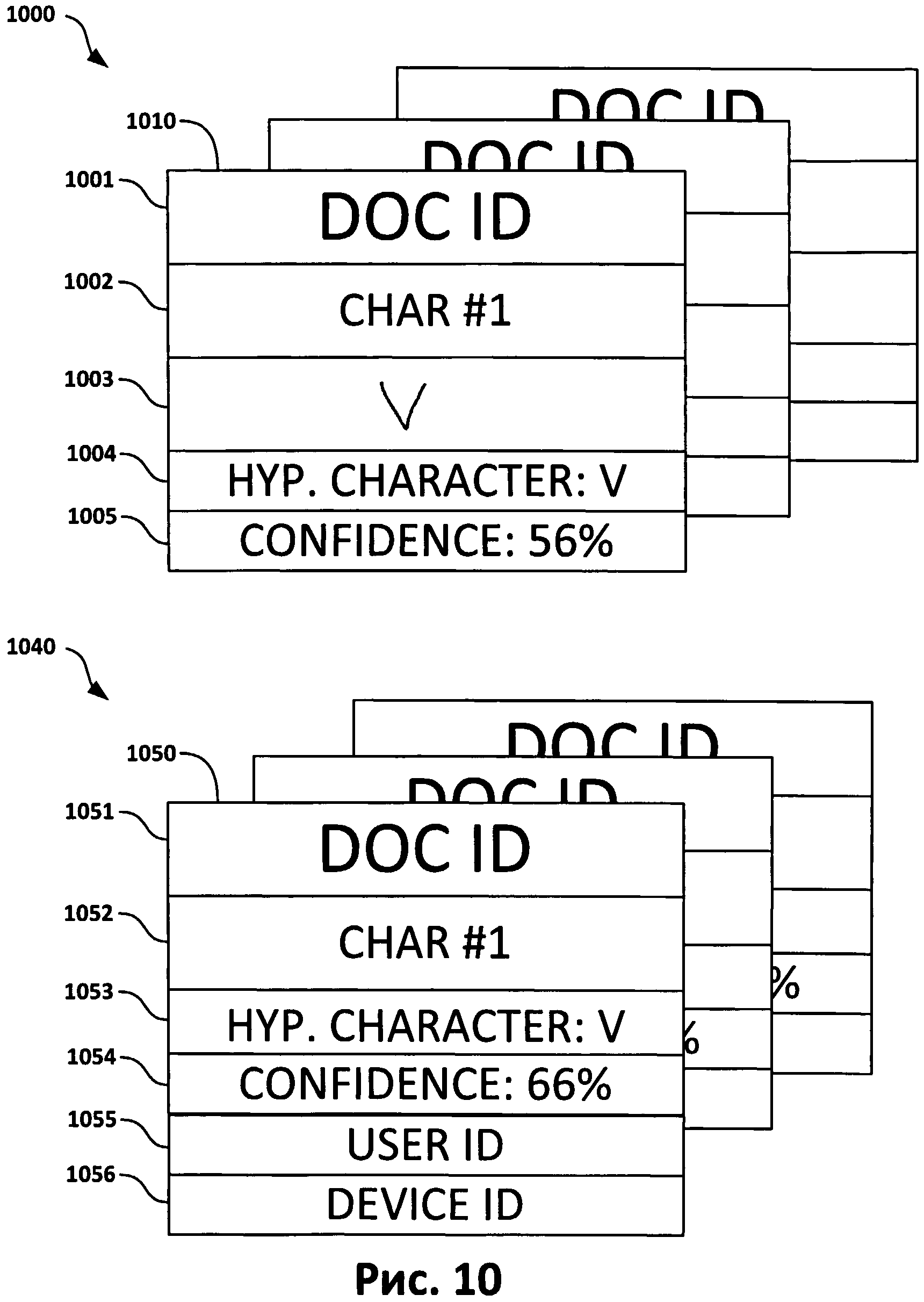
[0016] Фиг.10 иллюстрирует примеры структур массивов неуверенно распознанных символов согласно одному из вариантов реализации изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
I. Пример архитектуры системы
[0017] Описанные в этом документе функции и процедуры могут выполняться в соответствии с любым из нескольких вариантов реализации изобретения. Например, процедуры могут выполняться специализированным оборудованием, предназначенным для выполнения определенных функций. В другом примере функции могут выполняться универсальным оборудованием, которое выполняет команды, связанные с процедурами. В еще одном примере каждая функция может выполняться своей частью оборудования, причем один блок оборудования играет роль блока управления, либо может использоваться отдельное устройство управления. В еще одном примере процедуры могут быть определены как команды программ, записанных на машиночитаемый носитель.
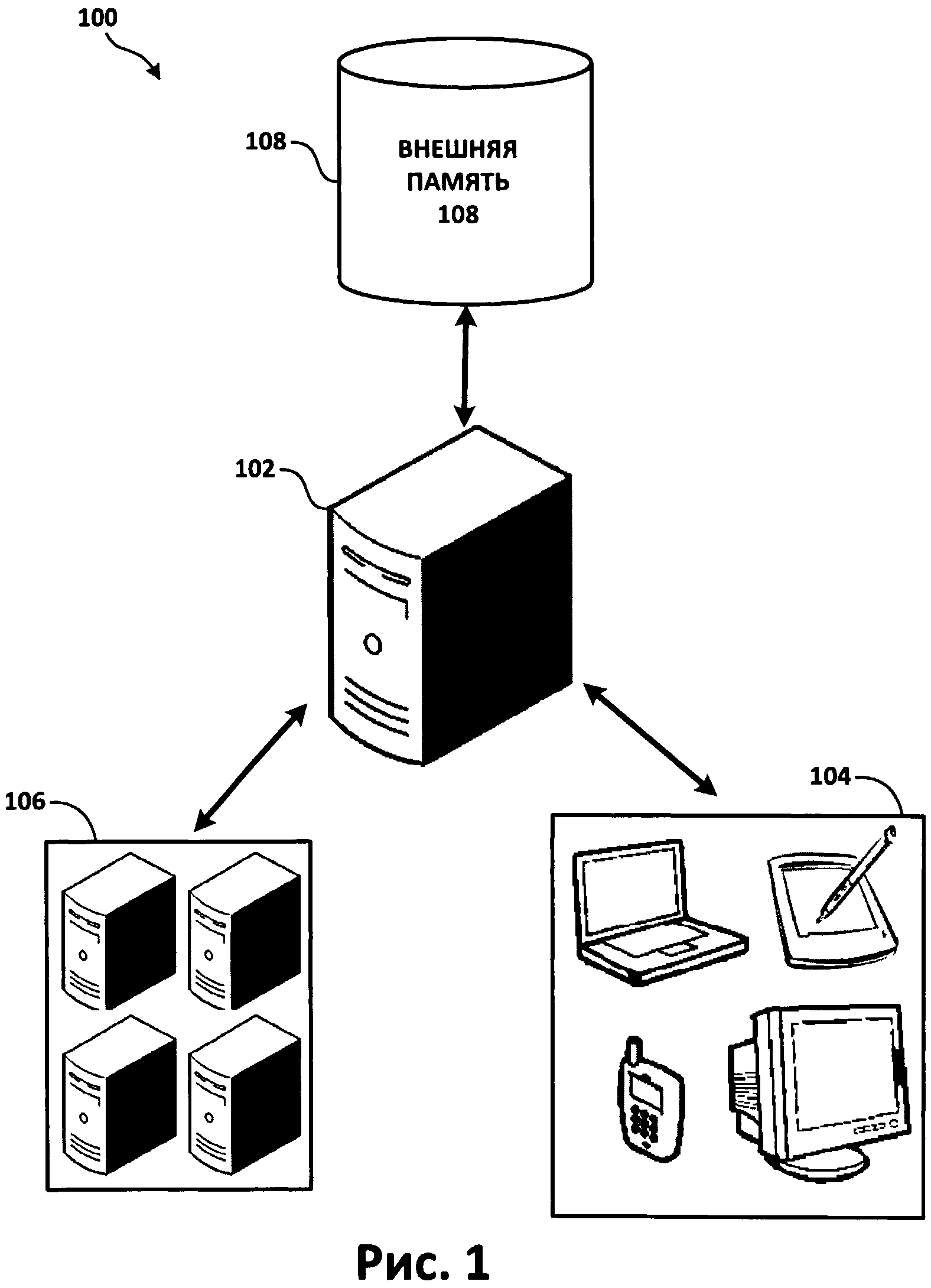
[0018] На Фиг.1 приведена сетевая система (100) согласно одному из примеров реализации изобретения. Как показано на Фиг.1, эта система включает в себя сервер (102), для которого организована связь с множеством удаленных устройств для просмотра (104). В некоторых вариантах реализации, как например в сети, приведенной на Фиг.1, сервер (102) может быть подключен к устройству памяти (108) и/или к внешним системам обработки (106). Между всеми элементами системы (100) организованы линии связи. Такие линии связи могут представлять собой связь любого типа. Например, эти линии связи могут представлять собой проводные электрические соединения, волоконно-оптические соединения, беспроводные интерфейсы и акустические сети передачи данных внутри помещений.
[0019] Сервер (102) может представлять собой любое универсальное вычислительное устройство, в котором хранятся команды для выполнения примера необходимого процесса. При альтернативном подходе сервер (102) может быть специализированным вычислительным устройством, настроенным на выполнение определенных необходимых функций за счет аппаратных средств. В других вариантах реализации изобретения сервер (102) может представлять собой набор различных вычислительных устройств, которые либо выполняют одну и ту же функцию, либо по отдельности настроены для выполнения конкретной функции. Обычно сервер (102) содержит машиночитаемый носитель, процессор и коммуникационные интерфейсы, а также другие возможные компоненты.
[0020] Как показано на Фиг.1, удаленные устройства (104) могут представлять собой устройства различных типов. Как будет объяснено ниже, устройства (104) используются в некоторых вариантах реализации для чтения текста, формирования маркировочных данных и сохранения/анализа этих данных с целью подготовки к передаче на сервер (102). Соответственно, любое известное в настоящее время или в будущем устройство, способное выполнять эти функции, может использоваться в качестве устройства (104). Неисключительными примерами такого устройства являются устройства для чтения электронных книг, планшеты, ноутбуки, смартфоны, видеотелефоны, телевизоры, настольные компьютеры, КПК и/или факсимильные машины.
[0021] Серверы (106) и память (108) являются примерами дополнительных устройств, которые могут быть связаны с функциями процесса, взятого в качестве примера. Например, серверы (106) могут использоваться для обеспечения дополнительной вычислительной мощности для сервера (102). В другом примере серверы (106) могут быть отдельными серверами с установленными OCR системами, например, серверами ABBYY FlexiCapture или серверами ABBYY Recognition Servers.
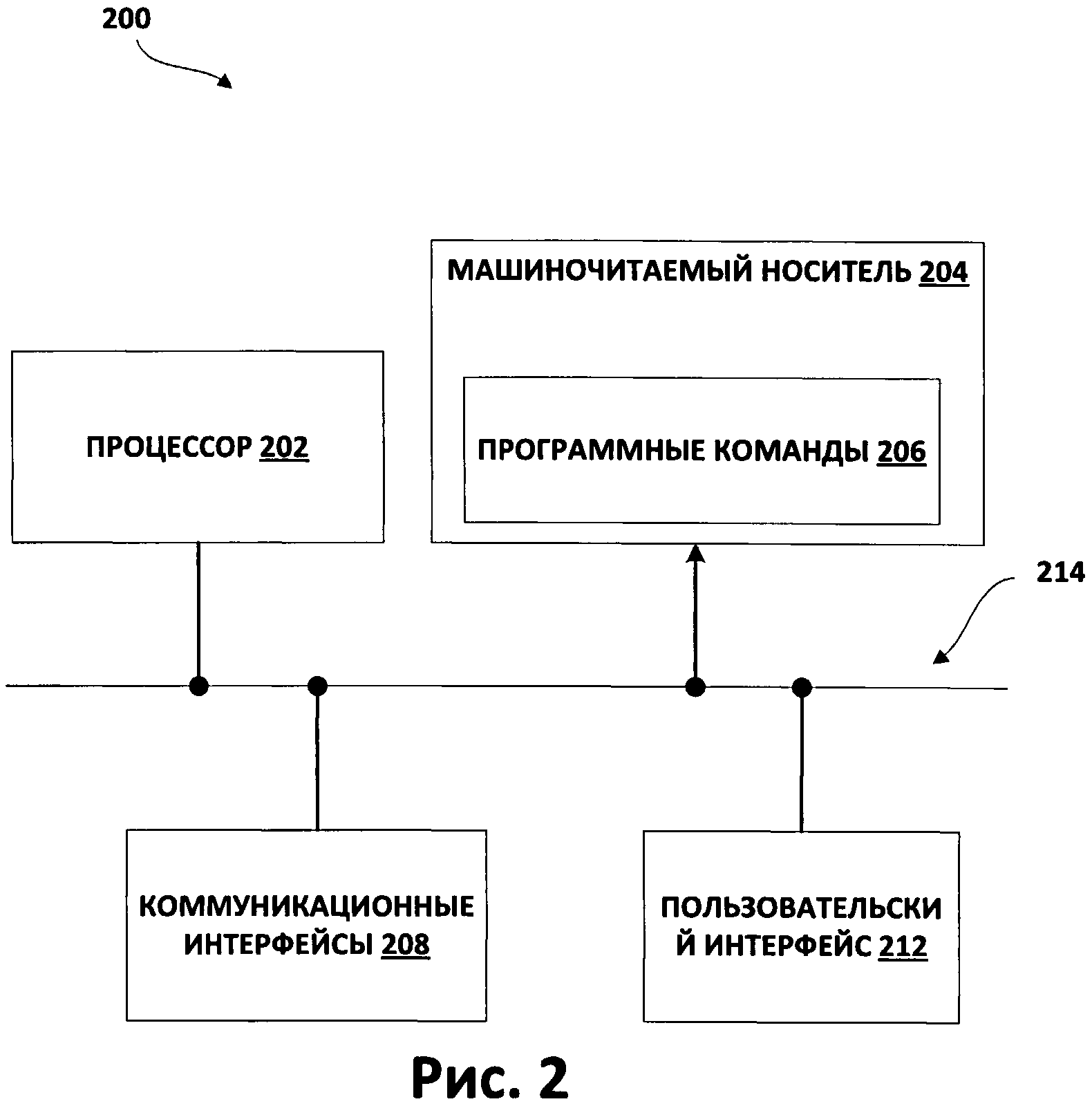
[0022] Один из примеров устройства (200) приведен на Фиг.2. Как показано на этом чертеже, устройство (200) содержит процессор (202), машиночитаемый носитель данных (CRM) (204), коммуникационный интерфейс (208) и пользовательский интерфейс (212), причем все они подключены с помощью системной шины (214). Кроме того, как показано, команды программы (206) хранятся на машиночитаемом носителе (204). В настоящем раскрытии изобретения это устройство может рассматриваться как сервер (102) либо устройство удаленной верификации (104).
[0023] Процессор (202) может означать процессоры любого типа, способные исполнять команды программы (206) для выполнения описанных в этом документе функций. Например, процессор (202) может представлять собой любой универсальный процессор, специализированный процессор, или устройство, содержащее процессорные элементы. В некоторых случаях несколько устройств обработки могут быть соединены и использоваться совместно для выполнения различных функций процессора (202).
[0024] Машиночитаемый носитель данных (204) может представлять собой любой доступный носитель, к которому может обращаться процессор (202), и любые другие процессорные элементы, содержащиеся в устройстве (200). Например, машиночитаемый носитель данных (204) может означать оперативную память (RAM), постоянное запоминающее устройство (ROM), электрически программируемое постоянное запоминающее устройство (EPROM), электрически стираемое постоянное запоминающее устройство (EEPROM), накопитель на оптическом диске формата CD-ROM или другом оптическом диске, накопитель на магнитных дисках или другие магнитные запоминающие устройства, а также любой другой носитель данных, который может использоваться для передачи или хранения требуемого программного кода в виде команд программы или структур данных, которые могут быть выполнены процессором. Если информация передается или предоставляется по сети или через другое коммуникационное соединение (проводное, беспроводное или комбинацию проводного и беспроводного соединений) в машину, то эта машина рассматривает это соединение как машиночитаемый носитель данных (CRM). Таким образом, любое такое соединение с вычислительным устройством или процессором корректно называется CRM (машиночитаемый носитель данных). Комбинации перечисленного оборудования также считаются машиночитаемым носителем данных.
[0025] Команды программы (206), например, могут содержать команды и данные, при получении которых блок обработки данных, универсальный компьютер, специальный компьютер, машины для обработки данных специального назначения или серверные системы выполняют определенные функции или группы функций.
[0026] Коммуникационные интерфейсы (208) могут содержать, например, беспроводные наборы микросхем, антенны, проводные порты, конверторы сигналов, коммуникационные протоколы и другое оборудование и программное обеспечение для взаимодействия с внешними системами. Например, устройство (200) может принимать текстовую информацию, аудиоданные, исполняемый код, видеоданные, цифровую информацию или другие данные через коммуникационные интерфейсы (208) от удаленных источников данных (например, удаленных серверов, интернет-сайтов, сетей Интернет, беспроводных сетей передачи данных и т.д.) или из локальных носителей данных (например, внешних накопителей, карт памяти, специализированных систем ввода, соединений проводных портов, беспроводных терминалов и т.д.). Примерами сетей связи являются коммутируемые телефонные сети общего пользования (ТфОП), коммутируемые сети передачи данных общего пользования (PSDN), сети службы коротких сообщений (SMS), локальные сети (LAN), сети передачи голоса поверх IP (VoIP), глобальные сети (WAN), виртуальные частные сети (VPN), сети кампуса и сеть Интернет. Во взятой в качестве примера сети данные могут передаваться с помощью беспроводных, проводных, механических и/оптических линий связи. Многие другие сети связи также могут использовать для вариантов реализации изобретения, описанных в настоящем документе.
[0027] Пользовательский интерфейс (212) может облегчить ввод данных и команд пользователя в устройство (200), а также вывод информации и подсказок для представления пользователю. Несмотря на то, что такие интерфейсы, как правило, взаимодействуют с людьми, пользовательский интерфейс (212) может альтернативно соединяться с пользователями-автоматами, пользователями-животными или другими «пользователями», которые не являются людьми. Кроме того, если описанные в настоящем документе ввод и вывод производятся в присутствии пользователя, то не требуется, чтобы пользовательский интерфейс (212) представлял информацию любому фактическому пользователю для выполнения указанных функций. Например, пользовательский ввод может осуществляться в виде беспроводных или дистанционных сигналов управления, ввода через сенсорный экран, нажимания кнопок или переключателей, звукового ввода, распознавания движений, отсутствия взаимодействия в течение заранее заданного периода времени и/или других сигналов пользовательского интерфейса. Информация может быть представлена пользователю, например, в виде видео, изображений, звуковых сигналов, текста, работы удаленного устройства, механических сигналов, записи файла на носитель данных и т.д. В некоторых случаях могут использоваться отдельные устройства, облегчающие выполнение функций пользовательского интерфейса.
[0028] Взятая в качестве примера система может также содержать множество устройств или элементов, которые отличаются от элементов, приведенных на Фиг.2. Например, устройство (200) может содержать дисплеи или устройства вывода звука, представляющие результаты процесса, взятого в качестве примера. В другом примере машиночитаемый носитель данных CRM (204) может хранить компьютерные приложения для конкретных функций формирования данных или обработки данных. Возможны и другие примеры.
II. Примеры способов реализации
[0029] На Фиг.3 приводится способ (300) согласно одному из примеров реализации изобретения. Как показано на Фиг.3, способ (300) включает в себя получение изображения текста (шаг 302). Способ (300) также включает в себя распознавание по меньшей мере одного текстового символа из полученного изображения (шаг 304). Однако есть вероятность, что этот символ был неправильно распознан системой. Поэтому способ (300) дополнительно содержит определение того, достигает ли уровень уверенности для этого распознанного текстового символа предварительно заданного ненулевого порогового значения (шаг 306). Если уровень уверенности для символа выше этого порога, то способ (300) переходит к шагу (320). Если уровень уверенности для символа ниже этого порога, то выбирается текст для вычитки (шаг 307), и изображение, представляющее этот символ, вставляется в текст для вычитки, закрывая часть этого текста (шаг 308). После вставки этого символа в текст для вычитки способ (300) включает определение того, был ли этот символ помечен как неправильный пользователем-верификатором (например, пользователем, который верифицирует правильность текста или проверяет текст на наличие ошибок) (шаг 310). Если этот символ был помечен как неправильный, то система далее понижает уровень уверенности для этого символа (шаг 312). Если этот символ не был помечен как неправильный (или если он был отмечен как правильный), то уровень уверенности для этого символа повышается.
[0030] В некоторых случаях пороговое значение может регулироваться, чтобы устанавливать желаемый уровень точности верификации. Например, некоторый проект по распознаванию может иметь целью оставить не более чем заданное количество неуверенно распознанных символов. Неуверенно распознанные символы - это символы, которые могли быть распознаны программой неверно. Указанное пороговое значение может изменяться системой автоматически (при получении команды, указывающей максимальное количество неуверенно распознанных символов), так что набор символов, имеющих самый низкий уровень уверенности, организуется исходя из требуемого количества символов. В других случаях система может определить пороговое значение исходя из относительного среднего значения и разброса уровней уверенности. Например, пороговое значение может быть снижено, если все символы из фрагмента текста менее вероятны.
[0031] Несмотря на то, что шаги (302) и (304) показаны как часть способа (300), некоторые варианты реализации изобретения могут предполагать совместное получение изображения и распознанного текста. В других случаях данные изображения могут получаться отдельно. Также в некоторых случаях «получение» изображения может означать получение изображения на устройстве, а затем передачу изображения в процессор из локальной памяти. Если шаг (304) выполняется, то для распознавания текста может быть использована любая OCR система, например, ABBYY FlexiCapture или ABBYY Recognition Server.
[0032] После того как документ был распознан, для каждого символа получены изображение и набор данных (гипотеза и уровень уверенности). В данном случае гипотезой может быть символ, который OCR система ассоциирует с данными изображения этого символа. Уровень уверенности может представлять собой числовое значение (например, процент) или качественный дескриптор, указывающий, с какой вероятностью гипотеза является истинной.
[0033] Как показано на шаге (306), символы, для которых уровень уверенности гипотезы меньше порогового значения, могут считаться неуверенно распознанными символами или неправильными символами. Эти символы могут быть помещены в отдельный массив от символов с высоким уровнем уверенности. Массив неуверенно распознанных символов представляет собой массив символов, которые могут быть верифицированы и сохранены на устройстве в долговременной памяти. В случаях, когда изображение и текст получены в уже распознанном состоянии, полученные данные могут также уже содержать символы, разделенные на неуверенно распознанные и правильные (то есть символы с высоким уровнем уверенности).
[0034] Имеется определенное количество удаленных устройств (104), доступ к которым предоставляется на шаге (308) для того, чтобы вставить изображения неуверенно распознанных символов поверх текста для вычитки. Эти устройства могут быть приписаны процессу изначально (например, устройства, принадлежащие сотрудниками компании, выполняющим проект), также это могут быть устройства, принадлежащие волонтерам, участвующим в проекте добровольно. Следующие действия могут выполняться с каждым типом устройств независимо друг от друга.
[0035] Как показано на шаге (307), пользователь-верификатор, работающий на удаленных устройствах для просмотра (104), выбирает текст для вычитки для использования при верификации неуверенно распознанного символа. В некоторых случаях это текст для вычитки, который пользователь желает прочитать. Это может быть любой текст, например, текст, который этот пользователь написал сам, нашел в Интернете, распознанный текст или сообщение электронной почты, сообщение из форума или, в общем случае, любой текстовый документ. Другими словами, текст для вычитки - это другой файл и/или другой фрагмент текста, нежели полученное изображение текста. В частности, может быть предпочтительным, чтобы текст для вычитки не имел отношения к первоначально распознанному документу, чтобы избежать исходного контекста.
[0036] Далее выбранные для соответствующего устройства неуверенно распознанные символы вставляются (308) в текст, который был выбран пользователем. Это означает, что система идентифицирует гипотетические символы для неуверенно распознанных символов в выделенном тексте и вставляет изображение неуверенно распознанных символов поверх идентифицированных символов так, чтобы вместо гипотетического символа выводилось изображение неуверенно распознанного символа. Обновленный текст передается обратно на устройство.
[0037] После этого пользователь устройства может читать двухслойный текст. Если пользователь считает, что слово написано неправильно, то пользователь касается (в случае сенсорного устройства) или кликает (в случае устройства, не имеющего сенсорного экрана) все слово. Могут использоваться и другие методы выбора (например, обнаружение пристального взгляда или голосовые команды). В некоторых случаях, когда неправильное слово отмечено, то изображение неуверенно распознанного символа или изображение слова удаляется из документа таким образом, чтобы пользователь видел простой текст в той области, где отображался неуверенно распознанный символ. Таким образом пользователь может понять, что его маркировка принята.
[0038] Статистика по гипотезам о неуверенно распознанных символах может собираться с использованием касания или клика, а после появления доступа в сеть Интернет данные могут отсылаться на сервер (102). Если касание/клик не зарегистрирован, то устройство может обнаружить, что верификатор перешел на новую страницу, на новую книгу и т.д., и такое действие указывает, что данное слово не является неправильным. Кроме того, первое касание/клик, за которым следует второе касание/клик, может означать, что это слово было выбрано и верифицировано, то есть что оно является правильным.
[0039] После этого данные могут возвращаться на сервер, а неуверенно распознанные символы могут быть удалены с устройств для верификации (104).
[0040] После того как данные, собранные удаленными устройствами для верификации (104), приняты на сервере, обновляется статистика по всем проверенным гипотезам. Таким образом, значение уровня уверенности для каждой гипотезы может увеличиваться или уменьшаться. В зависимости от обновленного значения уровня уверенности система может определить, нуждается ли гипотеза в дополнительной верификации или же уровень уверенности для гипотезы достаточен (шаг 320). Если значение уровня уверенности превышает выбранное пороговое значение, то гипотеза подтверждается (т.е. она считается истинной, а неуверенно распознанный символ верифицирован); если уровень уверенности меньше выбранного порогового значения, но выше выбранного минимального значения уверенности (например, 0% при измерении уровня уверенности в процентах), то эта гипотеза передается на дополнительный этап верификации (символ с соответствующей гипотезой добавляется к новому набору неуверенно распознанных символов и соответствующих гипотез, и этот набор отсылается следующему пользователю-верификатору); если уровень уверенности меньше или равен выбранному минимальному значению, то гипотеза отвергается (т.е. она считается ложной и исключается из списка гипотез для данного неуверенно распознанного символа). После каждого этапа верификации (на шаге 320) получаемые уровни уверенности и количество допустимых неуверенно распознанных символов может анализироваться для того, чтобы определить, завершен ли процесс верификации документа. В некоторых случаях процесс верификации может завершаться при достижении конкретного количества неуверенно распознанных символов. В других случаях признаком завершения процесса может быть то, что уровень уверенности для всех символов превышает пороговое значение. Таким образом, программа может повторяться до тех пор, пока правильные результаты не будут отделены от неправильных результатов (т.е. система достигнет того уровня, когда разрешены все неопределенности распознавания символов). Этот уровень может изменяться от одного документа к другому документу в зависимости от требований к качеству (точности) распознавания и верификации.
[0041] В некоторых случаях сервер (102) получает исходное изображение. Исходным изображением может быть отсканированная(-ый) книга, журнал, газета, документ или любая текстовая информация, представленная в графической форме. Этот текст может быть написан на любом достаточно хорошо известном языке.
[0042] Отсканированные изображения могут представлены в формате PDF, JPEG, TIFF, JPEG 2000, BMP или в других форматах. В одном в одном из вариантов реализации изобретения процесс распознавания может быть реализован внешними системами обработки (106) и выполняться любым известным способом. В результате процесса распознавания может предоставляться следующая информация:
- распознанный символ;
- изображение одного символа;
- расположение (координаты) одного символа на изображении;
- числовой параметр, представляющий собой уровень уверенности распознавания.
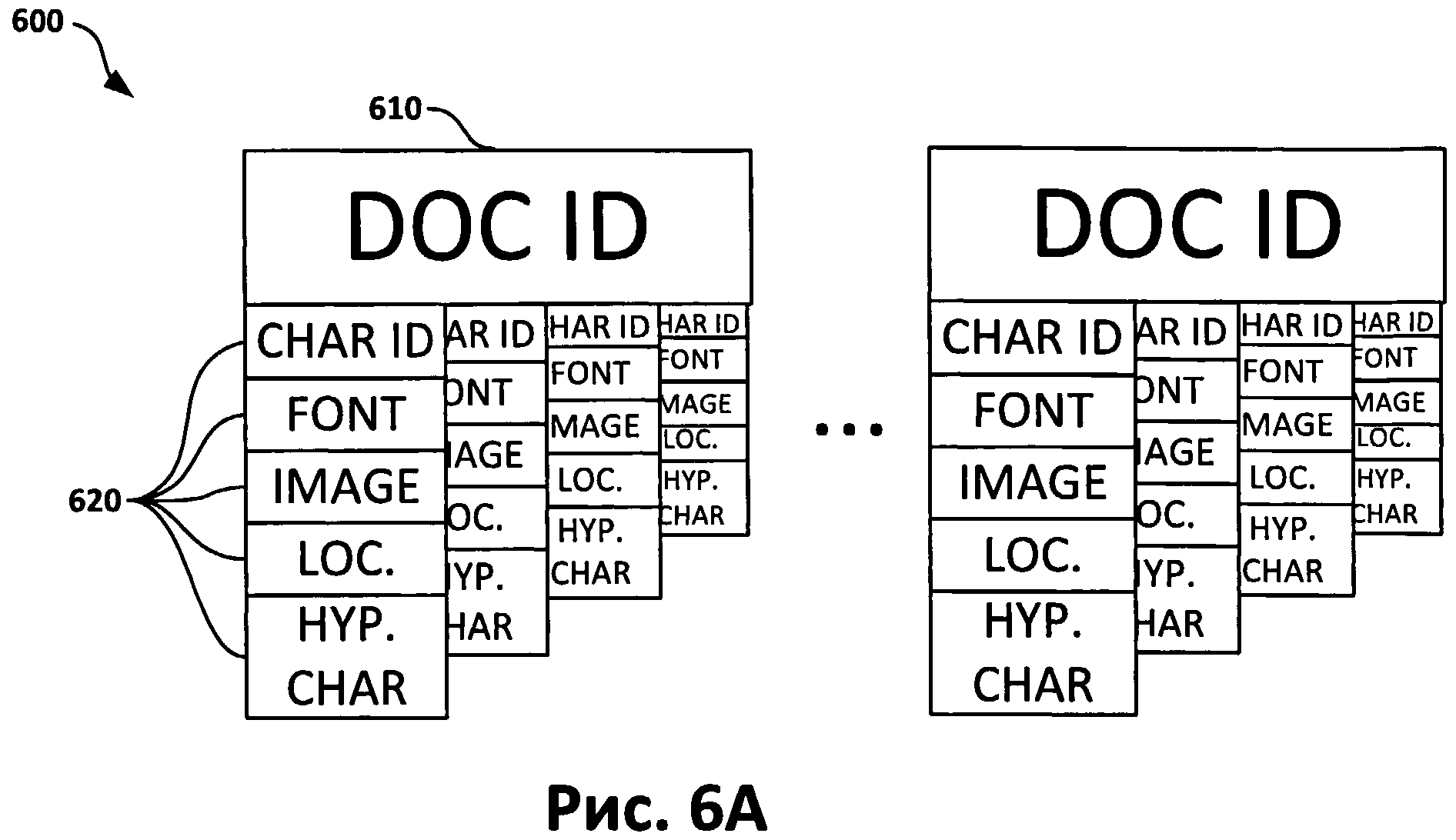
[0043] Распознанный набор символов, который содержится в документе, возвращается на сервер (102). В проекте каждый документ имеет уникальный идентификатор, который называется «глобальный уникальный идентификатор» (GUID). Проект может содержать несколько документов. Каждому набору символов документа может соответствовать одномерный массив. Множество массивов образует массив, соответствующий проекту, содержащему несколько документов. На Фиг.6А показана структура массива, соответствующего проекту, содержащего несколько документов (600). Каждый массив, соответствующий документу (610), также может состоять из элементов (620). Каждый элемент массива (620) в массиве, соответствующем документу, может содержать порядковый номер соответствующего символа в документе (идентификатор символа, ID), характеристики шрифта этого символа, изображение этого символа, координаты изображения (например, его местоположение, Loc.) символа и набор гипотез о символе, упорядоченных по уровню уверенности. Также в массив может включаться дополнительная информация.
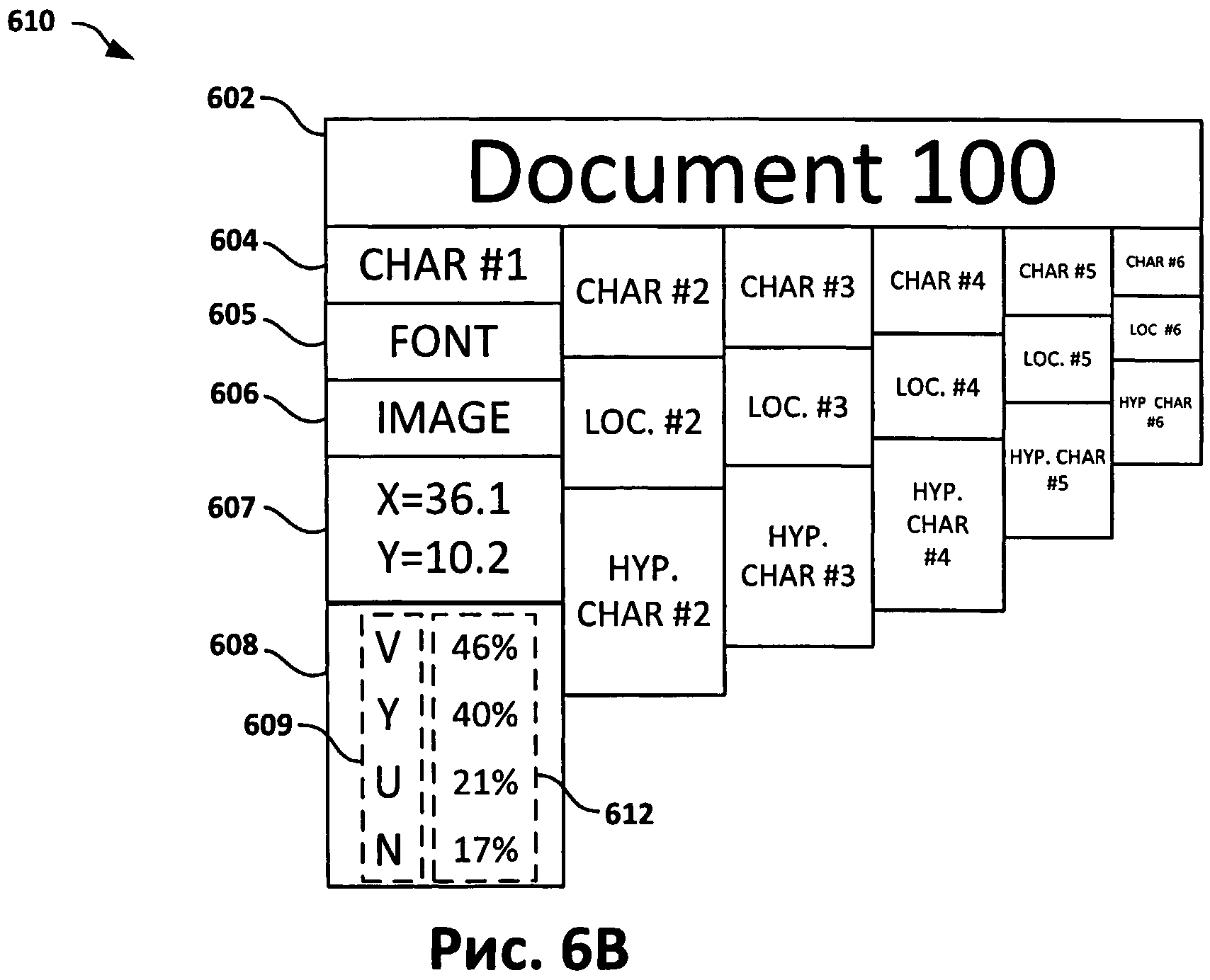
[0044] На Фиг.6В показан конкретный пример массива, который соответствует документу. Согласно этому рисунку, документ ID 602 (документ 100) хранится вместе с массивом символов, включающим в себя символ №1 (604), для которого заданы характеристики шрифта (605), изображение символа (606), координаты (607) и гипотетическое множество символов (608), включающее в себя список возможных символов (609) и уровень уверенности (612) для каждого возможного символа.
[0045] Для каждого символа, полученного в результате распознавания изображения, указывается процент уверенности. Те символы, для которых процент уверенности меньше, чем отсеивающий процент (т.е. пороговое значение уверенности, представляющее собой установленную границу между неуверенно распознанными символами (неправильными символами) и уверенно распознанными символами (правильными символами)), будут верифицироваться описанным способом. Те символы, для которых процент уверенности больше отсеивающего процента, не нуждаются в верификации. В некоторых вариантах реализации изобретения вместо процентов могут использоваться другие меры уровня уверенности.
[0046] В зависимости от внешних обстоятельств (заказ клиента, срок выполнения заказа, количество документов, желательное качество распознавания), количество требующих верификации символов может быть увеличено путем повышения отсеивающего процента. Если необходимо уменьшить число верифицируемых символов, то этого можно добиться путем снижения отсеивающего процента. Например, если клиенту требуется 100% качество, то можно верифицировать каждый распознанный символ (значение отсеивающего процента 100%), чтобы исключить ошибки в отправляемых клиенту документах. С другой стороны, если для клиента приемлем уровень качества в 5 ошибок на страницу, то можно верифицировать только те символы, для которых уровень уверенности ниже, например, 70%.
[0047] Эта идея основана на том факте, что верификация может выполняться не столько сотрудниками компании, сколько добровольцами, участвующими в проекте в качестве «удаленных» пользователей (то есть удаленных помощников). Верификация заключается в установке на устройство приложения, в котором может быть реализован способ, представленный на Фиг.3, и в использовании этого приложения для чтения произвольных текстов (то есть текстов, которые могут отличаться от распознанных текстов).
[0048] Неуверенно распознанные символы могут быть напечатаны различными шрифтами. Характеристики шрифта включают в себя гарнитуру (Times New Roman, Arial и т.д.), размер и начертание шрифта (курсив, полужирный и т.д.). Для лучшего восприятия того, является ли данное слово правильным, характеристики шрифта текста для вычитки могут выбираться так, чтобы они соответствовали характеристикам шрифта распознанного текста, из которого взяты неуверенно распознанные символы, либо были близки к ним.
[0049] Это может быть достигнуто одним из нескольких описанных ниже способов.
[0050] В одном из вариантов реализации изобретения пользователь-верификатор выбирает текст для вычитки из хранилища художественных текстов на сервере (102) или на подключенном устройстве. Перед тем как этот текст передается на удаленное устройство для верификации (104), характеристики шрифта могут быть изменены так, чтобы внешний вид выбранного текста для вычитки соответствовал внешнему виду распознанного текста, содержащего неуверенно распознанные символы.
[0051] В другом варианте реализации изобретения символы могут выбираться из массива символов, верифицируемых в данный момент на сервере (102) таким образом, чтобы эти символы относились к соответствующему языку, и гарнитура, размер и начертание шрифта были наиболее близки к гарнитуре, размеру и начертанию, используемым на устройстве для верификации (104) (то есть наиболее близки к характеристикам шрифта текста для вычитки).
[0052] Если в распознанном тексте присутствует несколько шрифтов, то символы в распознанных текстах могут быть структурированы по шрифту. Таким образом, может быть сформирован массив.
[0053] Массив для конкретного пользователя и конкретной книги или страницы может состоять из символов только одного шрифта. В другом возможном варианте реализации изобретения этот массив может содержать символы, выделенные курсивом, полужирным шрифтом и т.д. в случае различного форматирования текста, используемого на физическом устройстве для верификации: например, в эпиграфах, сносках, заголовках и подзаголовках.
[0054] Если текст является рукописным или иным текстом, не имеющим постоянных характеристик шрифта и размера, то сервер (102) или устройство (104) может быть запрограммировано на выбор шрифта и размера, наиболее близкого к данному тексту.
[0055] Массив неуверенно распознанных символов сначала может передаваться с сервера (102) на устройство для верификации (104). Затем соответствующий массив верифицированных данных передается обратно на сервер. На Фиг.10 приведена структура элементов массива, передаваемого с сервера (102) на устройство (104), и структура элементов массива, передаваемого обратно с устройства (104) на сервер (102).
[0056] На Фиг.10 показана структура элементов массива, передаваемого с сервера на устройство. Каждый из этих элементов массива (например, 1010) состоит из номера документа (DOC ID 1001), идентификатора символа в документе (1002), изображения символа (1003), гипотезы о символе (1004) и уровня уверенности, соответствующего этой гипотезе (1005).
[0057] На Фиг.10 показана структура элементов массива, передаваемого обратно с устройства на сервер. Каждый из этих элементов массива (например, элемент 1050) состоит из номера документа (DOC ID (1051)), идентификатора символа в документе (1052), гипотезы о символе (1053), уровня уверенности, соответствующего этой гипотезе (1054), идентификатора пользователя-верификатора (1055) и идентификатора устройства (1056).
[0058] В одном из вариантов реализации изобретения книга может передаваться отдельно от массива, т.е. массив прикрепляется к книге на устройстве пользователя (планшете, смартфоне или ноутбуке). В другом варианте реализации изобретения это может выполняться на сервере. Если пользователь-верификатор читает текст в браузере, то изображения символов могут внедряться с помощью подключаемого модуля (плагина). Например, пользователь может читать электронную почту или форумы, при этом подключаемый модуль может внедрять в их текст изображения символов. Подключаемый модуль также может работать с любыми приложениями на компьютере, смартфоне или планшете и заменять символы изображениями символов или изображениями слов повсюду. При чтении текста в браузере передается только сам массив.
[0059] В одном из вариантов реализации изобретения устройство для верификации может получать всю книгу. В другом варианте реализации изобретения устройство для верификации может получать за один раз одну главу или одну страницу и так далее. Преимущество разбиения книги на части заключается в том, что если с платформой работает много пользователей-верификаторов, и они читают быстро, то символы верифицируются несколько раз. Преимущество загрузки целой книги заключается в том, что это удобнее пользователю-верификатору, если Интернет-соединение имеет ограниченную пропускную способность. В различных вариантах реализации может использоваться тот или иной подход.
[0060] Верификатор может читать текст с изображениями на любом из электронных устройств 104, которые могут визуально воспроизводить текст и принимать запросы от верификатора. Примерами электронного устройства могут служить электронная книга (с сенсорным экраном или без него), смартфон, ноутбук, медиаплеер или проектор.
[0061] В одном из вариантов реализации изобретения верификация может производиться при чтении на мобильном устройстве, имеющем сенсорный экран. В этом варианте реализации изобретения пользователь-верификатор будет читать текст на экране и отмечать неправильные слова, используя тот же экран.
[0062] Способ обладает тем преимуществом, что пользователь может непосредственно видеть ошибку в слове, даже если он не знает точно, в чем состоит эта ошибка. Это может происходить автоматически и зависит от того, какой объем пользователь уже прочитал. Согласно некоторым исследованиям, человек способен легко распознать слово с ошибками, при этом искаженные слова не мешают ему понимать текст. В этом заключается основное отличие способа настоящего изобретения - пользователь отмечает неправильные слова, а не буквы. Слово может содержать несколько вставленных символов, и пользователю не нужно думать о том, какая именно вставленная буква была вставлена неправильно. Помеченное слово эквивалентно выбору всех вставленных неуверенно распознанных символов в слове как неправильных, т.е. как неуверенно распознанных символов, имеющих неправильные гипотезы.
[0063] Здесь «маркировка» или «отметка» означает, что пользователь-верификатор кликнул, коснулся слова или нажал на слово, другими словами, он указал на него в той или иной форме. Для этого можно использовать любой известный способ, в зависимости от способа реализации и типа устройства (104), используемого для верификации.
[0064] Если читающий текст пользователь-верификатор замечает слово, которое по его мнению написано неправильно, то он может коснуться (или кликнуть) в области этого слова. Когда выполняется такое касание (или клик), изображения всех символов в области этого слова (или, в другом варианте реализации изобретения, изображение самого слова) удаляются, и пользователь видит простой текст в области, где ранее отображался неуверенно распознанный символ.
[0065] Данные о выборе пользователем неправильно написанных слов сохраняются. Эти данные могут сохраняться на устройстве пользователя, например, на встроенной флэш-памяти или на карте памяти либо в другом месте во встроенной памяти устройства в зависимости от варианта реализации способа. В некоторых описанных вариантах реализации данные могут сохраняться в массиве, состоящем из элементов, каждый из которых может включать в себя номер документа (1051), порядковый номер символа (1052) (идентификатор символа), гипотезу о символе (1053), уровень уверенности этой гипотезы (1054), идентификатор пользователя (1055) и идентификатор устройства (1056). Если имеется подключение к Интернету, то эти данные передаются на сервер. Для подключения к Интернету, а также в качестве способа (протокола) передачи данных может применяться любой способ, который используется в настоящее время, или любые другие способы, если они обеспечивают установление соединения и передачу данных. Передаваемая информация может содержать:
a. идентификатор пользователя-верификатора (это может быть логин, имя пользователя или любой другой уникальный идентификатор);
b. идентификатор устройства (чтобы различать планшеты, настольные компьютеры, смартфоны с сенсорным экраном и т.д.);
c. результаты верификации (номер документа, порядковый номер символа и т.д.).
[0066] Если устройство для верификации (104) представляет собой электронную книгу или другое устройство, которое не имеет своего собственного модуля для подключения к Интернету, то эти данные могут передаваться на компьютер через любой беспроводной или проводной стандартный интерфейс, например, через интерфейс USB, а затем загружаться на сервер.
[0067] Если пользователь использует устройство, не имеющее сенсорного экрана, то он каким-либо образом помещает курсор поверх слова (с помощью мыши, перемещая курсор с помощью клавиатуры или с помощью кнопок на устройстве), а затем нажимает на него.
[0068] Пользователь может отклонить свой выбор. Это может делаться различными способами. В одном из вариантов реализации изобретения выбор может рассматриваться как отклоненный, если обнаруживается, что то же самое слово выбрано повторно. В другом варианте реализации изобретения может использоваться специальная кнопка «Reject» (Отклонить), которая выполняет эту функцию за счет аппаратных или программных средств. Кроме того, этот выбор может быть изменен специальным движением (жестом) на сенсорном экране.
[0069] Книга, которую пользователь читает и верифицирует, может состоять из двух или более видимых слоев. Нижний фоновый слой может содержать обычный текст, например, в текстовом формате. Следующий слой может содержать изображения символов или изображения слов, предложенных для верификации в рамках этого способа. Другие слои могут содержать дополнительную информацию, например, количество прочитанных страниц, количество верифицированных символов, персональную оценку верификатора и так далее.
[0070] На Фиг.7 показан экран (702) устройства (700). На этом экране отображается текст, в который могут вставляться изображения символов (708, 710, 712) или слов (704, 706). Как показано на чертеже, пользователь может пометить слово, нажимая на область (706), в которой расположено это слово. Пример, в котором пользователь (714) нажимает на слово (706), показан на экране устройства (700). На Фиг.7 также показан экран (702) устройства (700), в качестве примера того, как устройство (700) может выглядеть после нажатия (714). Как показано на Фиг.7, слово (706), которое содержало изображения (710), (712) и (706) для верификации, было изменено на слово (756), которое не содержит изображений для верификации.
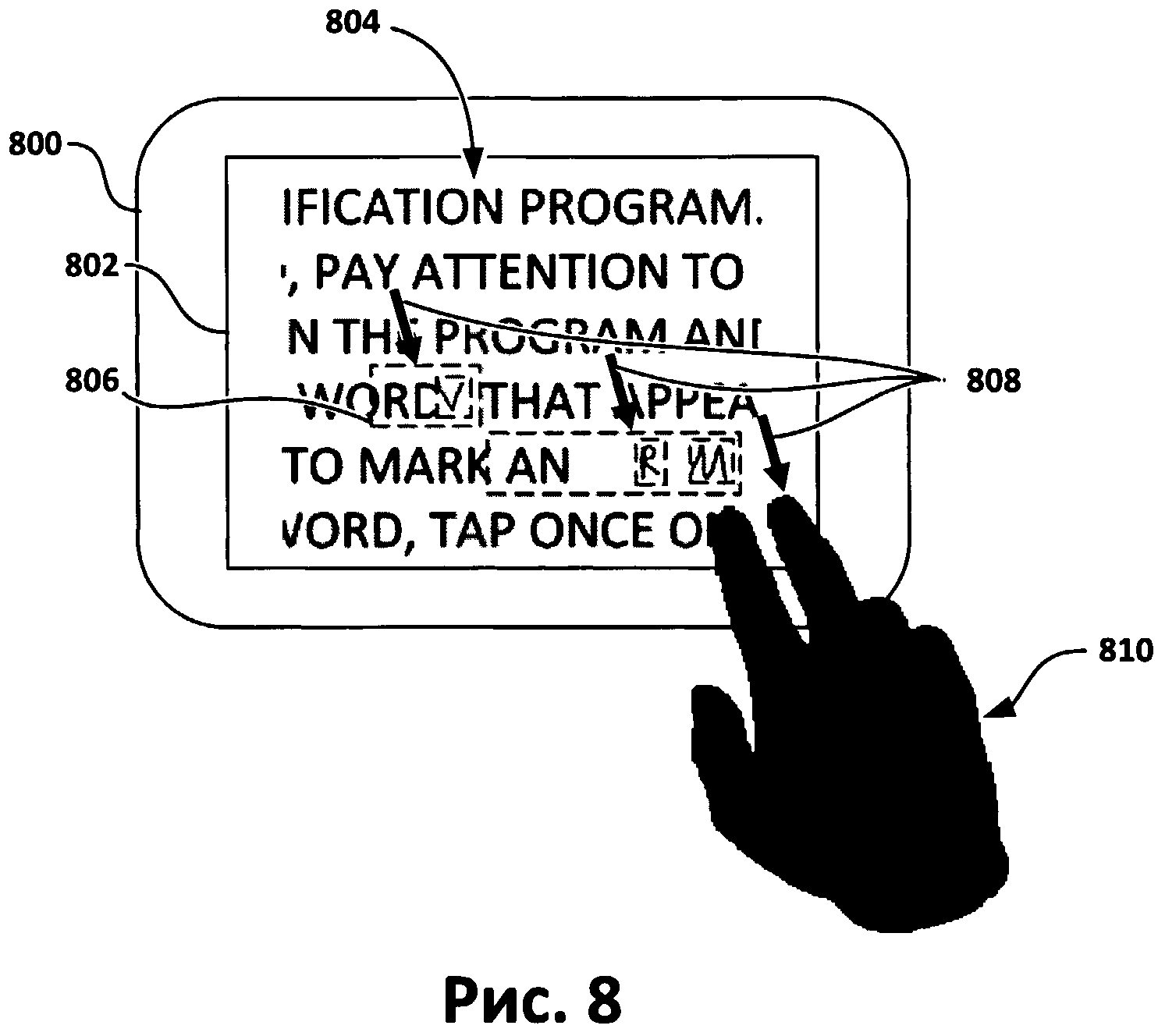
[0071] Для мультисенсорных экранов может предусматриваться использование двух пальцев, чтобы переместить слой изображения и увидеть, что расположено под изображением. Этот подход иллюстрируется на Фиг.8. На нем показан рисунок мультисенсорного экрана (802) устройства (800) с текстом (804) и слоем изображения (806). Слой изображения (806) перемещается рукой (810), которая касается экрана (802), в направлении, показанном стрелками (808). Изображения (806) перемещаются в направлении (808), при этом становится виден текст (804), который ранее был скрыт под изображениями (806).
[0072] Каждое из изображений слов (или изображений символов, выводимых над словами) может быть принято (что повышает уровень уверенности), отмечено как неправильное (что понижает уровень уверенности) или отмечено как неправильное, а затем отклонено (что сильно повышает уровень уверенности). Символ принимается, если пользователь не кликнул на область/коснулся области этого слова. Символ помечается как неправильный, если пользователь кликнул по слову/коснулся слова. Символ помечается и отклоняется, если после пометки его как неправильного, пользователь снова кликнул по слову/коснулся слова.
[0073] После верификации, т.е. когда пользователь закончил чтение текста, если имеется подключение к сети Интернет, то данные с устройства пользователя могут быть переданы на сервер.
[0074] После того как данные получены от следующего пользователя-верификатора, значения уверенности для символов, участвующих в верификации, могут быть изменены для учета мнения этого пользователя-верификатора. Это может осуществляться следующим образом.
[0075] Пусть m1, m2, m3 - это количество пропусков символа (отсутствие отметки), количество отметок символа (слов, которые содержат этот символ) как неправильного, и количество отклонений отметки символа соответственно (отклонение - это действие, которое «убирает» уже поставленную отметку символа как неправильного).
[0076] Тогда уверенность гипотезы о конкретном символе после получения данных от конкретного пользователя может быть вычислена по формуле:
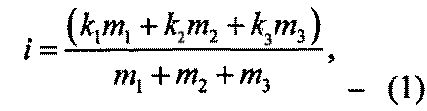
где k1, k2 и k3 - числовые коэффициенты, которые используются для подсчета количества пропусков символа (или слова, в котором встречается этот символ) (отмена отметки), отметок символа (или слова, в котором встречается этот символ) как неправильного и отклонений таких отметок, соответственно.
[0077] Значения этих коэффициентов могут определяться разработчиками системы на этапе разработки или на этапе настройки. В одном из возможных вариантов реализации значения коэффициентов могут быть динамическими и задаваться в зависимости от внешних условий.
[0078] На Фиг.4 показано два примера дисплеев (400) и (430) с двухслойным текстом для вычитки, содержащим изображения неуверенно распознанных символов, расположенных поверх некоторых слов. Как показано на Фиг.4, четыре слова (410), (412), (414) и (416) имеют неуверенно распознанные символы (418), (420), (422), (424), (426) и (428), которые отображаются поверх исходного текста. В окне (400) изображения символов расположены поверх исходного текста, они перекрывают исходные символы. В окне (430) на слово (412) нажали или кликнули, что привело к удалению изображения слова (412) из окна (430). Как показано на Фиг.4, исходный текст, который находился под словом (432), теперь стал виден. Таким образом пользователь-верификатор может проверить и убедиться в том, что это слово на самом деле является неправильным (а не просто незнакомым).
[0079] Фиг.5А и 5В иллюстрируют другие аспекты примера, показанного на Фиг.4. Фиг.5А иллюстрирует таблицу, содержащую некоторые аспекты массива неуверенно распознанных символов (500). В этом случае символы, предназначенные для верификации (символы 418-428 на Фиг.4) имеют уровень уверенности ниже порогового значения, равного 95%. Символы (418-428) последовательно нумеруются в документе, они имеют номер символа (502) в документе (400), изображение символа (504), гипотетический символ (506) и уровень уверенности гипотезы (508). В этом примере пользователь-верификатор может выбрать слова «PAV» и «INCORREGT» как слова, содержащие неверные символы.
[0080] Символы, предназначенные для верификации (418-428), помещаются в текст, выбранный пользователем-верификатором. Текст (400) содержит слова (410-416), в которые помещены неуверенно распознанные символы (418-428), в частности, слова, которые пользователь может выбрать как неправильные. Текст (430) иллюстрирует текст (400) после того, как пользователь выбрал слово (412).
[0081] На Фиг.5В показаны символы (418-428), которые соответствуют последовательным номерам (502) в таблице (500). Символы, соединенные пунктирными линиями (410 и 414), содержались в словах, которые были выбраны пользователем как неправильные. Символы, соединенные сплошными линиями (412 и 416), содержались в словах, которые не были отмечены пользователем как неправильные.
[0082] Уровень уверенности гипотезы в отношении символа может вычисляться по следующей формуле:
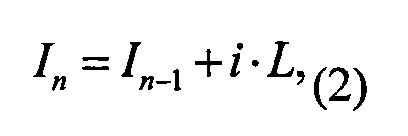
[0083] где L - это рейтинг пользователя-верификатора, In - это новое значение уровня уверенности конкретной гипотезы в отношении данного символа, a In-1 - это значение уровня уверенности конкретной гипотезы до учета данных от пользователя-верификатора, имеющего рейтинг L.
[0084] В различных вариантах реализации вычисления по этим формулам могут проводиться либо на сервере, либо на устройстве пользователя. В варианте реализации изобретения, подробно описанном в этой заявке, формула (1) вычисляется на устройстве пользователя, и результат вычислений также хранится на устройстве пользователя, например, на встроенной флэш-памяти или на карте памяти, в массиве в поле уровень уверенности гипотезы. Эти данные также передаются на сервер в виде массива, а формула (2) вычисляется на сервере после получения данных и при обновлении уровня уверенности гипотезы.
[0085] Данные загружаются на сервер в виде массива. Массив состоит из элементов, каждый из которых состоит из номера документа, порядкового номера символа в документе, ASCII-кода гипотезы, уровня уверенности гипотезы, идентификатора пользователя-верификатора и идентификатора устройства.
[0086] Рейтинг пользователя-верификатора используется для того, чтобы отличать пользователей, которые являются хорошими верификаторами, от пользователей, которые являются плохими верификаторами. В одном из вариантов реализации этот рейтинг может определяться заранее с помощью проверки грамотности. Затем он можно изменяться в зависимости от того, сколько книг проверил пользователь-верификатор и насколько хорошо он выполнил проверку.
[0087] В одном из вариантов реализации в каждой книге/на каждой странице для каждого пользователя может также вводиться коэффициент корректности верификации. Он может вычисляться, например, следующим образом: поместить заведомо правильные символы (изображение буквы «а» вместо буквы «а» и так для всего алфавита, далее такие символы будут называться «символами из определенного набора») или (в другом варианте реализации изобретения) вставить слова, составленные из символов из определенного набора - в этом случае процент символов с правильной реакцией будет равен коэффициенту корректности верификации. Также возможен отсев пользователей, которые плохо проводят верификацию всегда либо в данный момент (например, из-за невнимательности или плохого настроения): если коэффициент корректности верификации α меньше определенного процента αcutoff, то верификация от этого пользователя не должна приниматься ни при каких обстоятельствах, то есть в данном случае мы установим α=0.
[0088] Тогда уровень уверенности гипотезы о символе можно вычислить по следующей формуле:
[0089] 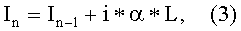 где In, In-1, i и L были ранее введены в формуле (2), а α представляет собой процент символов из достоверного набора с правильными ответами.
где In, In-1, i и L были ранее введены в формуле (2), а α представляет собой процент символов из достоверного набора с правильными ответами.
[0090] После верификации данные передаются на сервер, где уровень уверенности для символа изменяется исходя из формулы (2) или формулы (3), в зависимости от того, используется ли проверка корректности верификации.
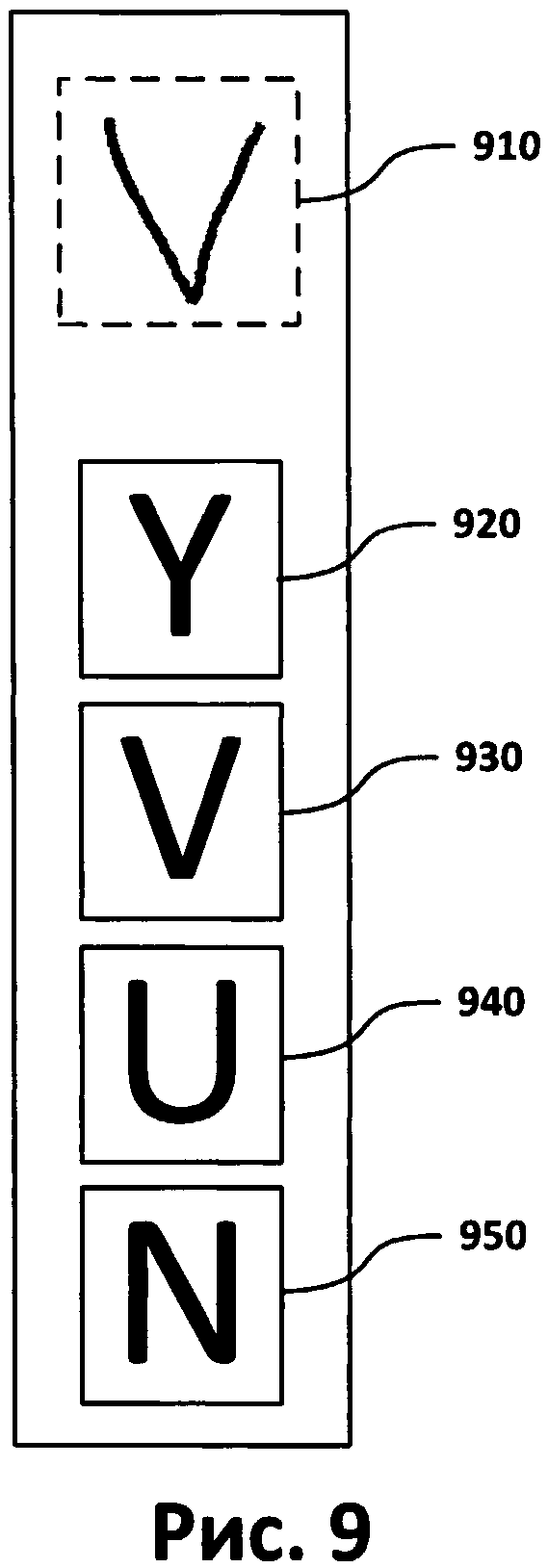
[0091] В ситуации, показанной на Фиг.4 и Фиг.5А, определенное количество гипотез может быть проверено для определенного числа символов. Если определенная гипотеза была отклонена пользователями-верификаторами, то необходимо проверить другие гипотезы о том же символе. Например, как показано на Фиг.9, гипотетическое слово (410) с изображением символа (910) было отвергнуто. Соответственно, была отвергнута гипотеза о том, что символ (910) эквивалентен символу (920) («Y»). Затем проверяются гипотезы, что неуверенно распознанный символ (910) представляет собой любой из символов (930), (940) или (950). В соответствии с Фиг.3, шаги (306-320) могут повторяться до тех пор, пока все гипотезы не будут отвергнуты или пока все возможные символы не будут перебраны. Количество гипотез можно искусственно ограничить, кроме того, можно осуществлять перебор, не включая в него все возможные символы.
[0092] Если все возможные гипотезы о всех символах перебраны, то можно получить на 100% правильно распознанные данные. Этот результат можно передать во внешнюю память (108) для документов или клиенту, в зависимости от дальнейших действий с полученным текстом.
[0093] После получения верифицированного текста рейтинги пользователей-верификаторов снова обновляются. Рейтинг пользователя-верификатора может быть повышен, если ответы верификатора соответствуют определенным «правильным» данным. Рейтинг пользователя-верификатора может быть снижен, если ответы верификатора не соответствуют определенным «правильным» данным. Оценка пользователя после верификации следующего фрагмента может быть вычислена по формуле
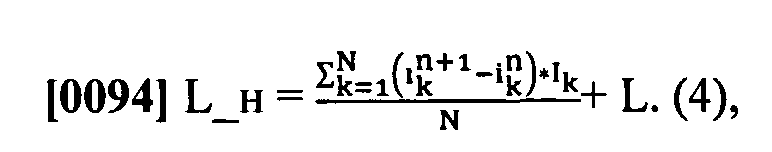
[0095] где N - это количество верифицируемых символов, k - это номер выдвинутой гипотезы, a Ik показывает, оказалась ли гипотеза истинной в результате окончательной верификации (после верификации большим числом пользователей-верификаторов). Ik=1, если гипотеза оказалась истинной и Ik=-1, если гипотеза оказалась ложной, 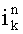 - уровень уверенности гипотезы до проверки пользователем-верификатором,
- уровень уверенности гипотезы до проверки пользователем-верификатором, 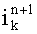 - уровень уверенности гипотезы после проверки этим верификатором, L - это текущий рейтинг пользователя-верификатора, a L_н - это новый рейтинг пользователя-верификатора после окончательной верификации.
- уровень уверенности гипотезы после проверки этим верификатором, L - это текущий рейтинг пользователя-верификатора, a L_н - это новый рейтинг пользователя-верификатора после окончательной верификации.
[0096] Взаимное расположение и сочетания элементов систем и способов, которые показаны в различных вариантах реализации изобретения, представляют собой лишь возможные примеры. Несмотря на то, что только несколько вариантов реализации настоящего изобретения были раскрыты подробно, специалисты в данной области техники при изучении описания легко поймут, что возможны многие модификации без существенного отхода от новой идеи и преимуществ сущности раскрытого изобретения.
[0097] Кроме того, в описании предмета изобретения используется слово «пример», указывающее, что предмет приводится в качестве примера, частного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должна обязательно рассматриваться как предпочтительная или преимущественная по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. Соответственно, все такие модификации должны быть включены в объем настоящего изобретения. Порядок или последовательность любого процесса или шагов способа может изменяться в соответствии с альтернативными вариантами реализации. Любые пункты формулы «средство плюс функция» предназначены для охвата структур, описанных в настоящем документе как выполняющих указанную функцию, причем это относится не только к структурным эквивалентам, но также и к эквивалентным структурам. Прочие замены, модификации, изменения и пропуски могут допускаться в конструкции, условиях эксплуатации и расположении предпочтительных вариантов реализации и прочих примеров реализации, не выходя за рамки настоящего раскрытия или из объема прилагаемой формулы изобретения.
[0098] Несмотря на то, что цифры предполагают определенный порядок шагов для способа, порядок шагов может отличаться от приведенного. Кроме того, два шага или большее количество шагов могут выполняться одновременно или с частичным перекрытием. Такое изменение зависит от выбранного программного обеспечения и оборудования, а также от мнения проектировщика. Все такие вариации входят в объем раскрытия изобретения. Кроме того, программные реализации могут быть получены с помощью стандартных способов программирования с логикой на основе правил и с другой логикой для выполнения различных шагов подключения, шагов обработки, шагов сравнения и шагов принятия решения.
Способ и подсистема определения содержащих документ фрагментов цифрового изображения
Способ и система определения ориентации изображения текста
Способ и система определения протяженных контуров на цифровых изображениях
Способ и система подготовки содержащих текст изображений к оптическому распознаванию символов
Способ и устройство для определения пригодности документа для оптического распознавания символов (ocr) на сервере
Способы и системы эффективного автоматического распознавания символов
Способ определения приоритета задач, находящихся в очереди серверной системы
Способы и устройства, которые преобразуют изображения документов в электронные документы с использованием trie-структуры данных, содержащей непараметризованные символы для определения слов и морфем на изображении документа
Способ и система исправления перспективных искажений в изображениях, занимающих двухстраничный разворот
Оптимизация обмена данными между клиентским устройством и сервером
Способ и подсистема определения содержащих документ фрагментов цифрового изображения
Способ и система определения ориентации изображения текста
Способ и система определения протяженных контуров на цифровых изображениях
Способ и система подготовки содержащих текст изображений к оптическому распознаванию символов
Способ и устройство для определения пригодности документа для оптического распознавания символов (ocr) на сервере
Способы и системы эффективного автоматического распознавания символов
Способ определения приоритета задач, находящихся в очереди серверной системы
Способы и устройства, которые преобразуют изображения документов в электронные документы с использованием trie-структуры данных, содержащей непараметризованные символы для определения слов и морфем на изображении документа
Способ и система исправления перспективных искажений в изображениях, занимающих двухстраничный разворот
Оптимизация обмена данными между клиентским устройством и сервером

