Результат интеллектуальной деятельности: ПРОГНОЗИРОВАНИЕ ЗАГОЛОВКОВ ФРАГМЕНТОВ ДЛЯ КАРТ ГЛУБИНЫ В ТРЕХМЕРНЫХ ВИДЕОКОДЕКАХ
Вид РИД
Изобретение
[0001] Данная заявка испрашивает приоритет предварительных заявок на патент США № 61/510,738, поданной 22 июля 2011 года, № 61/522,584, поданной 11 августа 2011 года, № 61/563,772, поданной 26 ноября 2011 года, и № 61/624,031, поданной 13 апреля 2012 года, каждая из которых настоящим полностью содержится в данном документе по ссылке.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Данное раскрытие сущности относится к области кодирования видео, например, к кодированию трехмерных видеоданных.
УРОВЕНЬ ТЕХНИКИ
[0003] Возможности цифрового видео могут быть встроены в широкий диапазон устройств, включающих в себя цифровые телевизоры, системы цифровой прямой широковещательной передачи, устройства беспроводной связи, такие как переносные радиотелефоны, беспроводные широковещательные системы, персональные цифровые устройства (PDA), дорожные или настольные компьютеры, цифровые камеры, цифровые записывающие устройства, устройства для видеоигр, консоли для видеоигр и т.п. Цифровые видеоустройства реализуют такие технологии сжатия видеоизображения, как MPEG-2, MPEG-4 или H.264/MPEG-4, часть 10, усовершенствованное кодирование видео (AVC), чтобы более эффективно передавать и принимать цифровое видео. Технологии сжатия видеоизображений выполняют пространственное и временное прогнозирование для того, чтобы уменьшать или удалять избыточность, присутствующую в видеопоследовательностях.
[0004] Технологии сжатия видео выполняют пространственное прогнозирование и/или временное прогнозирование для того, чтобы уменьшать или удалять избыточность, внутренне присутствующую в видеопоследовательностях. Для кодирования видео на основе блоков видеокадр или фрагмент может быть сегментирован на макроблоки. Каждый макроблок может быть дополнительно сегментирован. Макроблоки в кадре или фрагменте, подвергнутом внутреннему кодированию (I), кодируются с использованием пространственного прогнозирования относительно соседних макроблоков. Макроблоки в кадре или фрагменте, подвергнутом внешнему кодированию (P или B), могут использовать пространственное прогнозирование относительно соседних макроблоков в идентичном кадре или фрагменте, либо временное прогнозирование относительно других опорных кадров.
[0005] После того, как видеоданные кодированы, видеоданные могут быть пакетированы для передачи или хранения. Видеоданные могут ассемблироваться в видеофайл, соответствующий любому из множества стандартов, таких как базовый формат мультимедийных файлов Международной организации по стандартизации (ISO) и его расширения, к примеру, AVC.
[0006] Прилагаются усилия для того, чтобы разрабатывать новые стандарты кодирования видео на основе H.264/AVC. Один такой стандарт представляет собой стандарт масштабируемого кодирования видео (SVC), который является масштабируемым расширением H.264/AVC. Другой стандарт представляет собой кодирование многовидового видео (MVC), которое становится многовидовым расширением H.264/AVC. Совместный проект MVC описан в документе JVT-AB204 "Joint Draft 8.0 on Multiview Video Coding", 28th JVT meeting, Ганновер, Германия, июль 2008 года, доступном по адресу http://wftp3.itu.int/av-arch/jvt-site/2008_07_Hannover/JVT-AB204.zip. Версия AVC-стандарта описывается в документе JVT-AD007 "Editors' draft revision to ITU-T Rec. H.264 ISO/IEC 14496-10 Advanced Video Coding - in preparation for ITU-T SG 16 AAP Consent (in integrated form)", 30th JVT meeting, Женева, CH, февраль 2009 года", доступном по адресу http://wftp3.itu.int/av-arch/jvt-site/2009_01_Geneva/JVT-AD007.zip. Этот документ интегрирует SVC и MVC в технических требованиях AVC.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0007] В общем, это раскрытие сущности описывает технологии для поддержки воспроизведения трехмерного (3D) видео. В частности, технологии этого раскрытия сущности относятся к кодированию и декодированию трехмерного видеоконтента. Это раскрытие сущности также предлагает технологии передачи служебных сигналов для единиц кодированных блоков видеоданных. Например, это раскрытие сущности предлагает многократное использование элементов синтаксиса, включенных в заголовок фрагмента компонентов видов текстуры для соответствующих компонентов видов глубины. Дополнительно, это раскрытие сущности предлагает многократное использование элементов синтаксиса в информации заголовка фрагмента компонентов видов глубины для компонентов видов текстуры.
[0008] В трехмерном кодеке компонент вида для каждого вида видеоданных в конкретный момент времени может включать в себя компонент вида текстуры и компонент вида глубины. Компонент вида текстуры может включать в себя компоненты яркости (Y) и компоненты цветности (Cb и Cr). Компоненты сигнала яркости (светлоты) и цветности (цвета) совместно упоминаются в данном документе в качестве компонентов "текстуры". Компонент вида глубины может быть из карты глубины изображения. При воспроизведении трехмерных изображений карты глубины включают в себя компоненты глубины, которые представляют значения глубины, например, для соответствующих компонентов текстуры. Компоненты видов глубины могут использоваться для формирования виртуальных видов с предусмотренной перспективы просмотра.
[0009] Элементы синтаксиса для компонентов глубины и компонентов текстуры могут быть переданы в служебных сигналах с единицей кодированного блока. Единицы кодированных блоков, также упоминаемые просто в качестве "кодированных блоков" в этом раскрытии сущности, могут соответствовать макроблокам в ITU-T H.264/AVC (усовершенствованное кодирование видео) или единицам кодирования стандарта высокоэффективного кодирования видео (HEVC).
[0010] В одном аспекте, способ декодирования включает в себя прием фрагмента текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Способ дополнительно включает в себя прием фрагмента глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Способ дополнительно содержит декодирование первого фрагмента, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий полные элементы синтаксиса, представляющие характеристики первого фрагмента, и определение общих элементов синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента. Способ дополнительно может включать в себя декодирование второго фрагмента после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0011] В другом аспекте, устройство для декодирования данных включает в себя видеодекодер, выполненный с возможностью принимать фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры, принимать фрагмент глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующей компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа, декодировать первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий полные элементы синтаксиса, представляющие характеристики первого фрагмента, определять общие элементы синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента и декодировать второй фрагмент после декодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0012] В другом аспекте, компьютерный программный продукт содержит машиночитаемый носитель данных, имеющий сохраненные инструкции, которые при выполнении предписывают процессору устройства декодирования видео принимать фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Инструкции дополнительно предписывают процессору устройства декодирования видео принимать фрагмент глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Инструкции дополнительно предписывают процессору устройства декодирования видео декодировать первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента, и определять общие элементы синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента. Инструкции дополнительно предписывают процессору устройства декодирования видео декодировать второй фрагмент после декодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0013] В другом аспекте, предоставляется устройство, которое содержит средство для приема фрагмента текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Устройство дополнительно содержит средство для приема фрагмента глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Устройство дополнительно содержит средство для декодирования первого фрагмента, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента. Устройство дополнительно содержит средство для декодирования второго фрагмента после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0014] В одном аспекте, способ кодирования включает в себя прием фрагмента текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Способ дополнительно включает в себя прием фрагмента глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Способ дополнительно содержит кодирование первого фрагмента, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента, и определение общих элементов синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента. Способ дополнительно может включать в себя кодирование второго фрагмента после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0015] В другом аспекте, устройство для кодирования данных включает в себя видеокодер, выполненный с возможностью принимать фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры, принимать фрагмент глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Видеокодер дополнительно выполнен с возможностью кодировать первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента, определять общие элементы синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента и кодировать второй фрагмент после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0016] В другом аспекте, компьютерный программный продукт содержит машиночитаемый носитель данных, имеющий сохраненные инструкции, которые при выполнении предписывают процессору устройства кодирования видео принимать фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Инструкции дополнительно предписывают процессору устройства кодирования видео принимать фрагмент глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Инструкции дополнительно предписывают процессору устройства кодирования видео кодировать первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента, и определять общие элементы синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента. Инструкции дополнительно предписывают процессору устройства кодирования видео кодировать второй фрагмент после декодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0017] В другом аспекте, предоставляется устройство, которое содержит средство для приема фрагмента текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Устройство дополнительно содержит средство для приема фрагмента глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины, и при этом компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа. Устройство дополнительно содержит средство для декодирования первого фрагмента, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента. Устройство дополнительно содержит средство для определения общих элементов синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента. Устройство дополнительно содержит средство для кодирования второго фрагмента после окончания первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0018] Технологии, описанные в данном раскрытии сущности, могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или в любой комбинации вышеозначенного. Если реализованы в программном обеспечении, программное обеспечение выполняться в процессоре, который может означать один или более процессоров, таких как микропроцессор, специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA) или процессор цифровых сигналов (DSP), либо в другой эквивалентной интегральной или дискретной логической схеме. Программное обеспечение, содержащее инструкции, чтобы осуществлять технологии, может быть первоначально сохранено в машиночитаемом носителе и загружено и выполнено посредством процессора.
[0019] Соответственно, это раскрытие сущности также предполагает машиночитаемые носители, содержащие инструкции для того, чтобы предписывать процессору осуществлять любую из множества технологий, описанных в данном раскрытии сущности. В некоторых случаях, машиночитаемый носитель может формировать часть компьютерного программного продукта, который может продаваться производителям и/или использоваться в устройстве. Компьютерный программный продукт может включать в себя машиночитаемый носитель, а в некоторых случаях также может включать в себя упаковку.
[0020] Это раскрытие сущности также может применяться к электромагнитным сигналам, переносящим информацию. Например, электромагнитный сигнал может содержать информацию, связанную с полнопиксельной поддержкой, используемой для того, чтобы интерполировать значение для субцелочисленного пиксела опорной выборки. В некоторых примерах, сигнал может быть сформирован или передан посредством устройства, реализующего технологии, описанные в данном документе. В других примерах, это раскрытие сущности может применяться к сигналам, которые могут быть приняты в устройстве, реализующем технологии, описанные в данном документе.
[0021] Подробности одного или более вариантов осуществления данного раскрытия сущности изложены на прилагаемых чертежах и в нижеприведенном описании. Другие признаки, цели и преимущества технологий, описанных в данном раскрытии сущности, должны становиться очевидными из описания и чертежей, а также из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0022] Фиг. 1 является блок-схемой, иллюстрирующей один пример системы кодирования и декодирования видео, согласно технологиям настоящего раскрытия сущности.
[0023] Фиг. 2 является блок-схемой, подробнее иллюстрирующей пример видеокодера по фиг. 1, согласно технологиям настоящего раскрытия сущности.
[0024] Фиг. 3 является схемой одного примера структуры MVC-прогнозирования для кодирования многовидового видео, согласно технологиям настоящего раскрытия сущности.
[0025] Фиг. 4 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу видеокодера, согласно технологиям настоящего раскрытия сущности.
[0026] Фиг. 5 является блок-схемой, подробнее иллюстрирующей пример видеодекодера по фиг. 1, согласно технологиям настоящего раскрытия сущности.
[0027] Фиг. 6 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу видеодекодера, согласно технологиям настоящего раскрытия сущности.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0028] Это раскрытие сущности описывает технологии передачи служебных сигналов, которые может применять кодер, и может использовать декодер, по меньшей мере, в ходе стадии взаимного прогнозирования, по меньшей мере, процесса кодирования или декодирования видео. Описанные технологии связаны с кодированием трехмерного ("3D") видеоконтента. Трехмерный видеоконтент может быть представлен, например, в качестве кодированных блоков многовидового видео плюс глубины (MVD). Иными словами, эти технологии могут применяться для того, чтобы кодировать или декодировать поток битов, напоминающий поток битов для кодирования многовидового видео (MVC), при этом любые или все виды MVC-потока битов дополнительно могут включать в себя информацию глубины.
[0029] Более конкретно, некоторые технологии согласно этому раскрытию сущности заключают в себе прием, по меньшей мере, одного двумерного изображения, имеющего компоненты видов текстуры и компоненты видов глубины. Некоторые компоненты видов текстуры и компоненты видов глубины могут быть кодированы вместе в один кодированный блок или в качестве отдельных блоков. Изображение может быть разбито на фрагменты изображений. Элементы синтаксиса для кодирования компонентов видов текстуры могут быть переданы в служебных сигналах в заголовке фрагмента. Некоторые элементы синтаксиса для компонентов видов глубины могут быть прогнозированы из элементов синтаксиса для компонентов видов текстуры, соответствующих компонентам видов глубины. Технологии этого раскрытия сущности относятся к кодированию, декодированию и передаче в служебных сигналах данных, используемых для того, чтобы воспроизводить трехмерные видеоданные из двумерных видеоданных на основе оцененных данных карты глубины для двумерных видеоданных. В некоторых примерах, компоненты видов текстуры кодируются с использованием технологий, отличных от технологий, используемых для кодирования информации глубины. В этом раскрытии сущности, термин "кодирование" может означать любое или оба из кодирования и декодирования.
[0030] Преобразование видео на основе оценки глубины и синтеза виртуальных видов используется для того, чтобы создавать трехмерные изображения, к примеру, для трехмерных видеоприложений. В частности, виртуальные виды сцены могут быть использованы для того, чтобы создавать трехмерный вид сцены. Формирование виртуального вида сцены на основе существующего вида сцены традиционно достигается посредством оценки значений глубины объектов перед синтезированием виртуального вида. Оценка глубины является процессом оценки абсолютных или относительных расстояний между объектами и плоскостью камеры от стереопар или моноскопического контента. При использовании в данном документе, информация глубины включает в себя информацию, полезную при формировании трехмерного видео, к примеру, карту глубины (например, значения глубины на попиксельной основе) или параллактическую карту (например, горизонтальную диспаратность на попиксельной основе).
[0031] Оцененная информация глубины, обычно представленная посредством карты глубины изображений на основе уровня градаций серого, может быть использована для того, чтобы формировать произвольный угол для виртуальных видов с использованием технологий воспроизведения на основе изображений глубины (DIBR). По сравнению с традиционными системами трехмерного телевидения (3DTV), в которых многовидовые последовательности сталкиваются со сложностями при эффективном межвидовом сжатии, система на основе карт глубины может сокращать потребление полосы пропускания посредством передачи только одного или нескольких видов вместе с картой(ами) глубины, которая может быть эффективно кодирована. Карта(ы) глубины, используемая в преобразовании на основе карт глубины, может быть управляемой (например, посредством масштабирования) конечными пользователями до того, как карта(ы) глубины используется в синтезе видов. Настраиваемые виртуальные виды могут быть сформированы с различной величиной воспринимаемой глубины. Кроме того, оценка глубины может быть выполнена с использованием моноскопического видео, в котором доступен только один двумерный контент видов.
[0032] Технологии, описанные в данном документе, могут применяться для того, чтобы прогнозировать элементы синтаксиса для компонента вида глубины из элементов синтаксиса, сохраненных в заголовке фрагмента для совместно размещенных компонентов видов текстуры идентичного вида. Например, значения для элементов синтаксиса, которые являются общими для фрагмента глубины и фрагмента текстуры, могут быть включены в заголовок фрагмента для компонентов видов текстуры, но не в фрагмент для ассоциированных компонентов видов глубины. Иными словами, видеокодер или декодер могут кодировать элементы синтаксиса, которые являются общими для фрагмента глубины и фрагмента текстуры, в заголовке фрагмента для компонентов видов текстуры, которые не присутствуют в заголовке фрагмента для компонентов видов глубины. Например, первое значение может предоставляться для первого элемента синтаксиса в заголовке фрагмента для компонентов видов текстуры. Заголовок фрагмента для компонентов видов глубины также совместно использует первый элемент синтаксиса, что означает то, что первый элемент синтаксиса является общим как для заголовка фрагмента текстуры, так и для заголовка фрагмента глубины. Первый элемент синтаксиса для компонентов видов глубины имеет второе значение. Тем не менее, заголовок фрагмента для компонента вида глубины не включает в себя первый элемент синтаксиса. Согласно технологиям, описанным в данном документе, второе значение первого элемента синтаксиса может быть прогнозировано из первого значения.
[0033] В некоторых примерах, только идентификатор набора параметров изображения (PPS) и параметр дельта-квантования (QP) фрагмента передаются в служебных сигналах для заголовка фрагмента компонента вида глубины. В других примерах, дополнительная информация для составления списков опорных изображений передается в служебных сигналах в дополнение к идентификационным данным PPS и дельта-QP. Другие элементы синтаксиса унаследованы или определены из заголовка фрагмента компонента вида текстуры. В некоторых примерах, значения для общих элементов синтаксиса задаются идентичными соответствующим элементам синтаксиса. Иными словами, другие элементы синтаксиса для заголовка фрагмента компонента вида глубины задаются равными соответствующим значениям в заголовке фрагмента для соответствующего компонента вида текстуры.
[0034] В другом примере, начальная позиция кодированного блока (макроблока или единицы кодирования) дополнительно передается в служебных сигналах. Иными словами, заголовок фрагмента для фрагмента информации глубины передает в служебных сигналах местоположение первого блока (например, первого макроблока или CU) фрагмента без передачи в служебных сигналах других синтаксических данных для заголовка фрагмента (которые могут быть определены как идентичные соответствующим синтаксическим данным фрагмента, включающей в себя соответствующую информацию текстуры). Когда начальная позиция фрагмента не передается в служебных сигналах, она логически выводится равной 0 в некоторых примерах. Frame_num и POC-значение компонента вида глубины могут быть дополнительно переданы в служебных сигналах. Флаг используется для того, чтобы указывать то, являются или нет один или более параметров контурного фильтра, используемых для компонента вида глубины, идентичными одному или более параметров контурного фильтра, передаваемых в служебных сигналах для компонентов видов текстуры.
[0035] Внешнее кодирование на основе блоков является технологией кодирования, которая основана на временном прогнозировании для того, чтобы уменьшать или удалять временную избыточность между видеоблоками последовательных кодированных единиц видеопоследовательности. Кодированные единицы могут содержать видеокадры, фрагменты видеокадров, группы изображений или другую заданную единицу кодированных видеоблоков. Для внешнего кодирования, видеокодер выполняет оценку движения и компенсацию движения для того, чтобы оценивать движение между видеоблоками двух или более смежных кодированных единиц. С использованием технологий для оценки движения видеокодер формирует векторы движения, которые указывают смещение видеоблоков относительно соответствующих прогнозных видеоблоков в одном или более опорных кадров или других кодированных единиц. С использованием технологий для компенсации движения видеокодер использует векторы движения для того, чтобы формировать прогнозные видеоблоки из одного или более опорных кадров или других кодированных единиц. После компенсации движения видеокодер вычисляет остаточные видеоблоки посредством вычитания прогнозных видеоблоков из кодируемых исходных видеоблоков.
[0036] Компоненты опорных видов (RVC) могут включать в себя несколько фрагментов текстуры или глубины. В некоторых примерах, в которых компоненты опорных видов содержат несколько фрагментов, совместно размещенный фрагмент может быть использован при определении элементов синтаксиса текущего фрагмента. Альтернативно, первый фрагмент в RVC может быть использован для того, чтобы определять элементы синтаксиса текущего фрагмента. В других примерах, другой фрагмент в RVC может быть использован для того, чтобы определять общие элементы синтаксиса текущего фрагмента.
[0037] Фиг. 1 является блок-схемой, иллюстрирующей один пример системы 10 кодирования и декодирования видео, согласно технологиям настоящего раскрытия сущности. Как показано в примере по фиг. 1, система 10 включает в себя исходное устройство 12, которое передает кодированное видео в целевое устройство 14 через линию 15 связи. Линия 16 связи может содержать любой тип носителя или устройства, допускающего перенос кодированных видеоданных из исходного устройства 12 в целевое устройство 14. В одном примере, линия 16 связи содержит среду связи, чтобы предоставлять возможность исходному устройству 12 передавать кодированные видеоданные непосредственно в целевое устройство 14 в реальном времени. Кодированные видеоданные могут быть модулированы согласно стандарту связи, такому как протокол беспроводной связи, и переданы в целевое устройство 14. Среда связи может содержать любую беспроводную или проводную среду связи, такую как радиочастотный (RF) спектр или одна или более физических линий передачи. Среда связи может формировать часть сети с коммутацией пакетов, такой как локальная вычислительная сеть, глобальная вычислительная сеть либо глобальная сеть, такая как Интернет. Среда связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть полезным для того, чтобы упрощать передачу из исходного устройства 12 в целевое устройство 14.
[0038] Исходное устройство 12 и целевое устройство 14 могут содержать любое из широкого диапазона устройств. В некоторых примерах, одно или оба из исходного устройства 12 и целевого устройства 14 могут содержать устройства беспроводной связи, к примеру, беспроводные телефоны, так называемые сотовые или спутниковые радиотелефоны либо любые беспроводные устройства, которые могут передавать видеоинформацию по линии 15 связи, когда линия 15 связи является беспроводной. Тем не менее, технологии этого раскрытия сущности, которые относятся к кодированию блоков видеоданных, которые включают в себя информацию текстуры и глубины, не обязательно ограничены приложениями или настройками беспроводной связи. Технологии также могут быть применимыми в широком диапазоне других настроек и устройств, в том числе устройств, которые обмениваются данными через физические провода, оптоволокно или другие физические или беспроводные среды. Помимо этого, технологии кодирования или декодирования также могут применяться в автономном устройстве, которое не обязательно обменивается данными с любым другим устройством. Например, видеодекодер 28 может постоянно размещаться в цифровом мультимедийном проигрывателе или другом устройстве и принимать кодированные видеоданные через потоковую передачу, загрузку или носители хранения данных. Следовательно, иллюстрация исходного устройства 12 и целевого устройства 14 как поддерживающих связь друг с другом предоставляется в целях иллюстрации примерной реализации и не должна считаться ограничением в отношении технологий описанным в этом раскрытии сущности, которые могут быть применимыми к кодированию видео в целом во множестве окружений, вариантов применения или реализаций.
[0039] В примере по фиг. 1, исходное устройство 12 включает в себя видеоисточник 20, процессор 21 обработки глубины, видеокодер 22 и интерфейс 24 вывода. Целевое устройство 14 включает в себя интерфейс 26 ввода, видеодекодер 28 и устройство 30 отображения. В соответствии с этим раскрытием сущности, видеокодер 22 исходного устройства 12 может быть выполнен с возможностью применять одну или более технологий этого раскрытия сущности как часть процесса кодирования видео. Аналогично, видеодекодер 28 целевого устройства 14 может быть выполнен с возможностью применять одну или более технологий этого раскрытия сущности как часть процесса декодирования видео.
[0040] Видеокодер 22 также может применять процессы преобразования, квантования и энтропийного кодирования для того, чтобы дополнительно уменьшать скорость передачи битов, ассоциированную с передачей остаточных блоков. Технологии преобразования могут содержать дискретные косинусные преобразования (DCT) или концептуально аналогичные процессы. Альтернативно, могут использоваться вейвлет-преобразования, целочисленные преобразования или другие типы преобразований. В DCT-процессе, в качестве примера, набор пиксельных значений преобразуется в коэффициенты преобразования, которые представляют энергию пиксельных значений в частотной области. Видеокодер 22 также может квантовать коэффициенты преобразования, что может, в общем, заключать в себе процесс, который уменьшает число битов, ассоциированное с соответствующим коэффициентом преобразования. Энтропийное кодирование может включать в себя один или более процессов, которые совместно сжимают данные для вывода в поток битов, при этом сжатые данные могут включать в себя, например, последовательность режимов кодирования, информацию движения, шаблоны кодированных блоков и квантованные коэффициенты преобразования. Примеры энтропийного кодирования включают в себя, но не только, контекстно-адаптивное кодирование переменной длины (CAVLC) и контекстно-адаптивное двоичное арифметическое кодирование (CABAC).
[0041] Кодированный видеоблок может быть представлен посредством информации прогнозирования, которая может быть использована для того, чтобы создавать или идентифицировать прогнозный блок и остаточный блок данных, который может применяться к прогнозному блоку, чтобы воссоздавать исходный блок. Информация прогнозирования может содержать один или более векторов движения, которые используются для того, чтобы идентифицировать прогнозный блок данных. С использованием векторов движения видеодекодер 28 может иметь возможность восстанавливать прогнозные блоки, которые использованы для того, чтобы кодировать остаточные блоки. Таким образом, с учетом набора остаточных блоков и набора векторов движения (и, возможно, некоторого дополнительного синтаксиса), видеодекодер 28 может восстанавливать видеокадр, который первоначально кодирован. Внешнее кодирование на основе оценки движения и компенсации движения позволяет достигать относительно большой величины сжатия без чрезмерных потерь данных, поскольку последовательные видеокадры или другие типы кодированных единиц зачастую являются аналогичными. Кодированная видеопоследовательность может содержать блоки остаточных данных, векторы движения (при кодировании с внешним прогнозированием), указания относительно режимов внутреннего прогнозирования для внутреннего прогнозирования и элементы синтаксиса.
[0042] Видеокодер 22 также может использовать технологии внутреннего прогнозирования для того, чтобы кодировать видеоблоки относительно соседних видеоблоков общего кадра или фрагмента. Таким образом, видеокодер 22 пространственно прогнозирует блоки. Видеокодер 22 может быть выполнен с множеством режимов внутреннего прогнозирования, которые, в общем, соответствуют различным направлениям пространственного прогнозирования. Аналогично оценке движения, видеокодер 22 может быть выполнен с возможностью выбирать режим внутреннего прогнозирования на основе компонента сигнала яркости блока, затем многократно использовать режим внутреннего прогнозирования для того, чтобы кодировать компоненты сигнала цветности блока. Кроме того, в соответствии с технологиями этого раскрытия сущности, видеокодер 22 может многократно использовать режим внутреннего прогнозирования для того, чтобы кодировать компонент глубины блока.
[0043] Посредством многократного использования информации движения и режима внутреннего прогнозирования для того, чтобы кодировать компонент глубины блока, эти технологии могут упрощать процесс кодирования карт глубины. Кроме того, технологии, описанные в данном документе, могут повышать эффективность потока битов. Иными словами, поток битов должен указывать некоторые элементы синтаксиса только один раз в заголовке фрагмента для компонента вида текстуры, а не сообщать в служебных сигналах дополнительный элемент синтаксиса в заголовке фрагмента для фрагмента компонентов видов глубины.
[0044] Необязательно, компонент вида текстуры также может многократно использовать свой соответствующий компонент вида глубины аналогичным образом.
[0045] Так же, проиллюстрированная система 10 по фиг. 1 является просто одним примером. Различные технологии этого раскрытия сущности могут выполняться посредством любого устройства кодирования, которое поддерживает прогнозирующее кодирование на основе блоков, или любого устройства декодирования, которое поддерживает прогнозирующее декодирование на основе блоков. Исходное устройство 12 и целевое устройство 14 представляют собой просто примеры таких устройств кодирования, при этом исходное устройство 12 формирует кодированные видеоданные для передачи в целевое устройство 14. В некоторых случаях, устройства 12 и 16 могут работать практически симметрично так, что каждое из устройств 12 и 16 включает в себя компоненты кодирования и декодирования видео. Следовательно, система 10 может поддерживать одностороннюю и двухстороннюю передачу видео между видеоустройствами 12 и 16, к примеру, для потоковой передачи видео, воспроизведения видео, широковещательной передачи видео или видеотелефонии.
[0046] Видеоисточник 20 исходного устройства 12 включает в себя устройство видеозахвата, такое как видеокамера, видеоархив, содержащий ранее захваченное видео, или видеопередачу от поставщика видеосодержимого. Альтернативно, видеоисточник 20 может формировать данные на основе компьютерной графики в качестве исходного видео или комбинации передаваемого вживую видео, заархивированного видео и/или машиногенерируемого видео. В некоторых случаях, если видеоисточник 20 является видеокамерой, исходное устройство 12 и целевое устройство 14 могут формировать так называемые камерофоны или видеотелефоны либо другие мобильные устройства, выполненные с возможностью обрабатывать видеоданные, к примеру, планшетные вычислительные устройства. В каждом случае, захваченное, предварительно захваченное или машиногенерируемое видео может быть кодировано посредством видеокодера 22. Видеоисточник 20 захватывает вид и предоставляет его в процессор 21 глубины.
[0047] Видеоисточник 20 предоставляет вид 2 в процессор 21 глубины для вычисления изображения глубины для объектов в виде 2. В некоторых примерах, вид 2 содержит несколько видов. Изображение глубины определяется для объектов в виде 2, захваченном посредством видеоисточника 20. Процессор 21 глубины выполнен с возможностью автоматически вычислять значения глубины для объектов в изображении вида 2. Например, процессор 21 глубины вычисляет значения глубины для объектов на основе информации яркости. В некоторых примерах, процессор 21 глубины выполнен с возможностью принимать информацию глубины от пользователя. В некоторых примерах, видеоисточник 20 захватывает два вида сцены при различных перспективах и затем вычисляет информацию глубины для объектов в сцене на основе диспаратности между объектами в двух видах. В различных примерах, видеоисточник 20 содержит стандартную двумерную камеру, систему с двумя камерами, которая предоставляет стереоскопический вид сцены, матрицу камер, которая захватывает несколько видов сцены, или камеру, которая захватывает информацию одного вида плюс глубины.
[0048] Процессор 21 глубины предоставляет компоненты 4 видов текстуры и компоненты 6 видов глубины в видеокодер 22. Процессор 21 глубины также может предоставлять вид 2 непосредственно в видеокодер 22. Информация 6 глубины содержит изображение карты глубины для вида 2. Изображение карты глубины может содержать карту значений глубины для каждой области пикселов, ассоциированных с областью (например, блоком, фрагментом или кадром), которая должна отображаться. Область пикселов включает в себя один пиксел или группу из одного или более пикселов. Некоторые примеры карт глубины имеют один компонент глубины в расчете на пиксел. В других примерах, предусмотрено несколько компонентов глубины в расчете на пиксел. Карты глубины могут быть кодированы способом, практически аналогичным данным текстуры, например, с использованием внутреннего прогнозирования или внешнего прогнозирования относительно других ранее кодированных данных глубины. В других примерах, карты глубины кодируются способом, отличным от способа, которым кодируются данные текстуры.
[0049] Карта глубины может быть оценена в некоторых примерах. Когда присутствуют несколько видов, стереосогласование может быть использовано для того, чтобы оценивать карты глубины. Тем не менее, при преобразовании из двумерной в трехмерную форму, оценка глубины может быть более затруднительной. Несмотря на это, карта глубины, оцененная посредством различных способов, может использоваться для трехмерного воспроизведения на основе воспроизведения на основе изображений глубины (DIBR).
[0050] Хотя видеоисточник 20 может предоставлять несколько видов сцены, и процессор 21 глубины может вычислять информацию глубины на основе нескольких видов, исходное устройство 12 может, в общем, передавать информацию одного вида плюс глубины для каждого вида сцены.
[0051] Когда вид 2 является цифровым неподвижным изображением, видеокодер 22 может быть выполнен с возможностью кодировать вид 2 в качестве, например, изображения в формате Совместной экспертной группы по фотографии (JPEG). Когда вид 2 является кадром видеоданных, видеокодер 22 выполнен с возможностью кодировать первый вид 50 согласно такому стандарту кодирования видео, как, например, MPEG-1 Visual Экспертной группы по киноизображению (MPEG), Международной организации по стандартизации (ISO)/Международной электротехнической комиссии (IEC), ISO/IEC MPEG-2 Visual, ISO/IEC MPEG-4 Visual, H.261 Международного союза по телекоммуникациям (ITU), ITU-T H.262, ITU-T H.263, H.264/MPEG-4 ITU-T, стандарт усовершенствованного кодирования видео (AVC) H.264, разрабатываемый стандарт высокоэффективного кодирования видео (HEVC) (также называемый H.265) или другие стандарты кодирования видео. Видеокодер 22 может включать в себя информацию 6 глубины вместе с кодированным изображением, чтобы формировать кодированный блок 8, который включает в себя кодированные данные изображений вместе с информацией 6 глубины. Видеокодер 22 передает кодированный блок 8 в интерфейс 24 вывода. Кодированный блок 8 может быть передан в интерфейс 26 ввода в потоке битов, включающем в себя служебную информацию, вместе с кодированным блоком 8 по линии 15 связи.
[0052] Информация кодированного видео включает в себя компоненты 4 текстуры и информацию 6 глубины. Компоненты 4 текстуры могут включать в себя компоненты яркости (сигнала яркости) и цветности (сигнала цветности) видеоинформации. Компоненты сигнала яркости, в общем, описывают яркость, в то время как компоненты сигнала цветности, в общем, описывают оттенки цвета. Процессор 21 глубины извлекает информацию 6 глубины из карты глубины вида 2. Видеокодер 22 может кодировать компоненты 4 видов текстуры и компоненты 6 видов глубины в один кодированный блок 8 кодированных видеоданных. Аналогично, видеокодер 22 может кодировать блок таким образом, что информация движения или режима внутреннего прогнозирования для компонента сигнала яркости многократно используется для компонентов сигнала цветности и компонента глубины. Элементы синтаксиса, используемые для компонентов видов текстуры, могут быть использованы для того, чтобы прогнозировать аналогичные элементы синтаксиса для компонентов видов глубины.
[0053] В некоторых примерах, компонент вида карты глубины не может быть кодирован с использованием технологий межвидового прогнозирования, даже когда соответствующий компонент вида текстуры кодируется с использованием технологий межвидового прогнозирования. Например, компонент вида карты глубины может быть прогнозирован с использованием внутривидового прогнозирования, когда соответствующий компонент вида текстуры прогнозируется с использованием межвидового прогнозирования. Например, межвидовое прогнозирование компонента вида текстуры прогнозирует информацию видов текстуры из данных другого вида в качестве вида, соответствующего компоненту вида текстуры. Напротив, информация видов глубины для внутривидового прогнозирования прогнозирует информацию глубины из данных вида, идентичного виду, соответствующему информации видов глубины.
[0054] Несмотря на использование различных технологий прогнозирования, некоторые элементы синтаксиса для компонента вида карты глубины могут быть прогнозированы из соответствующих элементов синтаксиса в заголовке фрагмента соответствующего компонента вида текстуры. Тем не менее, информация заголовка фрагмента для компонента вида карты глубины может содержать информацию, связанную с составлением списков опорных изображений. Иными словами, информация, связанная с составлением списков опорных изображений, может быть передана в служебных сигналах в заголовке фрагмента для компонента вида карты глубины. Например, число опорных изображений, которые используются и указание того, какие опорные изображения используются для того, чтобы прогнозировать компонент вида карты глубины, могут быть переданы в служебных сигналах в заголовке фрагмента для компонента вида карты глубины. Аналогичная информация также может быть передана в служебных сигналах в заголовке фрагмента для соответствующего компонента вида текстуры.
[0055] В некоторых примерах, исходное устройство 12 включает в себя модем, который модулирует кодированный блок 8 согласно стандарту связи, такому как, например, множественный доступ с кодовым разделением каналов (CDMA) или другой стандарт связи. Модем 27 может включать в себя различные микшеры, фильтры, усилители или другие компоненты, спроектированные с возможностью модуляции сигналов. Интерфейс 24 вывода может включать в себя схемы, спроектированные с возможностью передачи данных, включающие в себя усилители, фильтры и одну или более антенн. Кодированный блок 8 передается в целевое устройство 14 через интерфейс 24 вывода и линию 15 связи. В некоторых примерах, вместо передачи по каналу связи, исходное устройство 12 сохраняет кодированные видеоданные, включающие в себя блоки, имеющие компоненты текстуры и глубины, на устройство 32 хранения данных, к примеру, на цифровой видеодиск (DVD), Blu-Ray-диск, флэш-накопитель и т.п.
[0056] Интерфейс 26 ввода целевого устройства 14 принимает информацию по линии 15 связи. В некоторых примерах, целевое устройство 14 включает в себя модем, который демодулирует информацию. Аналогично интерфейсу 24 вывода, интерфейс 26 ввода может включать в себя схемы, спроектированные с возможностью приема данных, в том числе усилители, фильтры и одну или более антенн. В некоторых случаях, интерфейс 24 вывода и/или интерфейс 26 ввода может быть включено в один компонент приемо-передающего устройства, который включает в себя как приемную, так и передающую схему. Модем 27 может включать в себя различные микшеры, фильтры, усилители или другие компоненты, спроектированные с возможностью демодуляции сигналов. В некоторых случаях, модем может включать в себя компоненты для выполнения как модуляции, так и демодуляции.
[0057] С другой стороны, процесс кодирования видео, выполняемый посредством видеокодера 22, может реализовывать одну или более технологий, описанных в данном документе, в ходе внешнего прогнозирующего кодирования, которое может включать в себя оценку движения и компенсацию движения, а также внутреннее прогнозирующее кодирование. Процесс декодирования видео, выполняемый посредством видеодекодера 28, также может выполнять такие технологии в ходе стадии компенсации движения процесса декодирования.
[0058] Термин "кодер" используется в данном документе, чтобы означать специализированное компьютерное устройство или аппарат, который выполняет кодирование видео или декодирование видео. Термин "кодер", в общем, означает любое из видеокодера, видеодекодера или комбинированного кодера/декодера (кодека). Термин "кодирование" означает кодирование или декодирование. Термины "кодированный блок", "единица кодированного блока" или "кодированная единица" могут означать любую независимо декодируемую единицу видеокадра, к примеру, целый кадр, фрагмент кадра, блок видеоданных или другую независимо декодируемую единицу, заданную согласно используемым технологиям кодирования.
[0059] Устройство 30 отображения отображает декодированные видеоданные пользователю и может содержать любое из множества из одного или более устройств отображения, таких как дисплей на электронно-лучевой трубке (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED) или другой тип устройства отображения. В некоторых примерах, устройство 30 отображения соответствует устройству, допускающему трехмерное воспроизведение. Например, устройство 30 отображения может содержать стереоскопическое отображение, которое используется вместе с защитными очками, носимыми зрителем. Защитные очки могут содержать активные очки, когда устройство 30 отображения быстро чередуется между изображениями различных видов синхронно с попеременным закрытием линз активных очков. Альтернативно, защитные очки могут содержать пассивные очки, когда устройство 30 отображения отображает изображения из различных видов одновременно, и пассивные очки могут включать в себя поляризованные линзы, которые, в общем, поляризуются в ортогональных направлениях с тем, чтобы фильтровать между различными видами.
[0060] В примере по фиг. 1, линия 15 связи может содержать любую беспроводную и проводную среду связи, такую как радиочастотный (RF) спектр или одна или более физических линий передачи, либо любую комбинацию беспроводных и проводных сред. Линия 15 связи может формировать часть сети с коммутацией пакетов, такой как локальная вычислительная сеть, глобальная вычислительная сеть либо глобальная сеть, такая как Интернет. Линия 15 связи, в общем, представляет любую подходящую среду связи или набор различных сред связи для передачи видеоданных из исходного устройства 12 в целевое устройство 14. Линия 15 связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть применимым для того, чтобы упрощать передачу данных из исходного устройства 12 в целевое устройство 14.
[0061] Видеокодер 22 и видеодекодер 28 могут работать согласно стандарту сжатия видео, такому как стандарт ITU-T H.264, альтернативно описанный как MPEG-4, часть 10, усовершенствованное кодирование видео (AVC). Дополнительные стандарты сжатия видео, которые основаны на стандарте ITU H.264/AVC, который может быть использован посредством видеокодера 22 и видеодекодера 28, включают в себя стандарт масштабируемого кодирования видео (SVC), который является масштабируемым расширением стандарта ITU H.264/AVC. Другой стандарт, согласно которому могут работать видеокодер 22 и видеодекодер 28, включает в себя стандарт кодирования многовидового видео (MVC), который является многовидовым расширением стандарта ITU H.264/AVC. Тем не менее, технологии этого раскрытия сущности не ограничены каким-либо конкретным стандартом кодирования видео.
[0062] В некоторых аспектах, видеокодер 22 и видеодекодер 28 могут быть интегрированы с аудиокодером и декодером, соответственно, и могут включать в себя соответствующие модули мультиплексора-демультиплексора либо другие аппаратные средства и программное обеспечение, чтобы обрабатывать кодирование аудио и видео в общем потоке данных или в отдельных потоках данных. Если применимо, блоки мультиплексора-демультиплексора могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
[0063] Видеокодер 22 и видеодекодер 28 могут быть реализованы как один или более микропроцессоров, процессоров цифровых сигналов (DSP), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), дискретная логика, программное обеспечение, аппаратные средства, микропрограммное обеспечение или любые комбинации вышеозначенного. Когда любые из технологий этого раскрытия сущности реализуются в программном обеспечении, устройство реализации дополнительно может включать в себя аппаратные средства для сохранения и/или выполнения инструкций для программного обеспечения, например, запоминающее устройство для сохранения инструкций и один или более модулей обработки для выполнения инструкций. Каждый из видеокодера 22 и видеодекодера 28 может быть включен в один или более кодеров или декодеров, любой из которых может быть интегрирован как часть комбинированного кодека, который предоставляет возможности кодирования и декодирования в соответствующем мобильном устройстве, абонентском устройстве, широковещательном устройстве, сервере и т.п.
[0064] Видеопоследовательность типично включает в себя последовательность видеокадров, также называемых в качестве видеоизображений. Видеокодер 22 управляет видеоблоками в пределах отдельных видеокадров с тем, чтобы кодировать видеоданные. Видеоблоки могут иметь фиксированный или варьирующийся размер и могут отличаться по размеру согласно заданному стандарту кодирования. Каждый видеокадр включает в себя последовательность из одного или более фрагментов. В стандарте ITU-T H.264, например, каждый фрагмент включает в себя последовательность макроблоков, которые могут компоноваться в субблоки. Стандарт H.264 поддерживает внутреннее прогнозирование при различных размерах блоков для кодирования двумерного видео, таких как 16x16, 8x8, 4x 4 для компонентов сигнала яркости и 8x8 для компонентов сигнала цветности, а также внешнее прогнозирование при различных размерах блоков, таких как 16x16, 16x8, 8x16, 8x8, 8x4, 4x8 и 4x4 для компонентов сигнала яркости и соответствующие масштабированные размеры для компонентов сигнала цветности. Видеоблоки могут содержать блоки пиксельных данных или блоки коэффициентов преобразования, к примеру, после процесса преобразования, такого как дискретное косинусное преобразование (DCT) или концептуально аналогичный процесс преобразования. Эти технологии могут быть расширены на трехмерное видео.
[0065] Меньшие видеоблоки могут предоставлять лучшее разрешение и могут быть использованы для местоположений видеокадра, которые включают в себя высокие уровни детальности. В общем, макроблоки и различные субблоки могут считаться видеоблоками. Помимо этого, фрагмент может считаться серией видеоблоков, таких как макроблоки и/или субблоки. Каждый фрагмент может быть независимо декодируемой единицей видеокадра. Альтернативно, сами кадры могут быть декодируемыми единицами, или другие части кадра могут быть заданы как декодируемые единицы.
[0066] Двумерные макроблоки стандарта ITU-T H.264 могут быть расширены до трехмерного формата посредством кодирования информации глубины из карты глубины или параллактической карты вместе с ассоциированными компонентами сигнала яркости и сигнала цветности (т.е. компонентами текстуры) для этого видеокадра или фрагмента. Параллактическое преобразование (также называемое преобразованием виртуального смещения или преобразованием смещения) смещает компоненты видов текстуры в пиксельном местоположении на основе функции угла от обзора и карты высоты в пиксельном местоположении. Видеокодер 22 может кодировать информацию глубины в качестве монохроматического видео.
[0067] Чтобы кодировать видеоблоки, к примеру, кодированный блок, видеокодер 22 выполняет внутреннее или внешнее прогнозирование для того, чтобы формировать один или более прогнозных блоков. Видеокодер 22 вычитает прогнозные блоки из исходных видеоблоков, которые должны быть кодированы, чтобы формировать остаточные блоки. Таким образом, остаточные блоки могут представлять попиксельные разности между кодируемыми блоками и прогнозными блоками. Видеокодер 22 может выполнять преобразование для остаточных блоков для того, чтобы формировать блоки коэффициентов преобразования. После технологий внутреннего или внешнего прогнозирующего кодирования и преобразования, видеокодер 22 может квантовать коэффициенты преобразования. Квантование, в общем, означает процесс, в котором коэффициенты квантуются, чтобы, возможно, уменьшать объем данных, используемый для того, чтобы представлять коэффициенты. После квантования, энтропийное кодирование может выполняться согласно технологии энтропийного кодирования, такой как контекстно-адаптивное кодирование переменной длины (CAVLC) или контекстно-адаптивное двоичное арифметическое кодирование (CABAC). Дополнительные подробности процесса кодирования, выполняемого посредством видеокодера 22, описываются ниже относительно фиг. 2.
[0068] В данный момент проводится работа, нацеленная на разработку нового стандарта кодирования видео, на сегодня называемого "стандартом высокоэффективного кодирования видео (HEVC)". Разрабатываемый стандарт также упоминается как H.265. Работа по стандартизации основана на модели устройства кодирования видео, называемой "тестовой моделью HEVC (HM)". HM предполагает несколько дополнительных возможностей устройств кодирования видео по сравнению с устройствами согласно, например, ITU-T H.264/AVC. Например, тогда как H.264 предоставляет девять режимов внутреннего прогнозирующего кодирования, HM предоставляет целых тридцать три режима внутреннего прогнозирующего кодирования. HEVC может быть расширено таким образом, что оно поддерживает технологии информации заголовка фрагмента, как описано в данном документе.
[0069] HM ссылается на блок видеоданных в качестве единицы кодирования (CU). Синтаксические данные в потоке битов могут задавать наибольшую единицу кодирования (LCU), которая является наибольшей единицей кодирования с точки зрения числа пикселов. В общем, CU имеет назначение, аналогичное назначению макроблока H.264 за исключением того, что CU не имеет различия размера. Кодированный блок может представлять собой CU согласно HM-стандарту. Таким образом, CU может разбиваться на суб-CU. В общем, ссылки в этом раскрытии сущности на CU могут ссылаться на наибольшую единицу кодирования (LCU) изображения или суб-CU LCU. LCU может разбиваться на суб-CU, и каждая суб-CU может разбиваться на суб-CU. Синтаксические данные для потока битов могут задавать максимальное число раз, которое может разбиваться LCU, что называется " CU-глубиной". Соответственно, поток битов также может задавать наименьшую единицу кодирования (SCU). Это раскрытие сущности также использует термин "блок", чтобы ссылаться на любую из CU, единицы прогнозирования (PU) или единицы преобразования (TU).
[0070] LCU может быть ассоциирована со структурой данных в виде дерева квадрантов. В общем, структура данных в виде дерева квадрантов включает в себя один узел в расчете на CU, при этом корневой узел соответствует LCU. Если CU разбивается на четыре суб-CU, узел, соответствующий CU, включает в себя четыре концевых узла, каждый из которых соответствует одной из суб-CU. Каждый узел структуры данных в виде дерева квадрантов может предоставлять синтаксические данные для соответствующей CU. Например, узел в дереве квадрантов может включать в себя флаг разбиения, указывающий то, разбивается или нет CU, соответствующая узлу, на суб-CU. Элементы синтаксиса для CU могут быть заданы рекурсивно и могут зависеть от того, разбивается или нет CU на суб-CU.
[0071] CU, которая не разбивается, может включать в себя одну или более единиц прогнозирования (PU). В общем, PU представляет всю или часть соответствующей CU и включает в себя данные для извлечения опорной выборки для PU. Например, когда PU кодируется во внутреннем режиме, PU может включать в себя данные, описывающие режим внутреннего прогнозирования для PU. В качестве другого примера, когда PU кодируется во внешнем режиме, PU может включать в себя данные, задающие вектор движения для PU. Данные, задающие вектор движения, могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешение для вектора движения (например, точность в одну четверть пиксела или точность в одну восьмую пиксела), опорный кадр, на который указывает вектор движения, и/или опорный список (например, список 0 или список 1) для вектора движения. Вектор движения также может обрабатываться как имеющий различные разрешения для компонентов видов текстуры и компонентов видов глубины. Данные для CU, задающей PU, также могут описывать, например, сегментирование CU на одну или более PU. Режимы секционирования могут отличаться между тем, является CU некодированной, кодированной в режиме внутреннего прогнозирования или кодированной в режиме внешнего прогнозирования.
[0072] CU, имеющая одну или более PU, также может включать в себя одну или более единиц преобразования (TU). После прогнозирования с использованием PU, видеокодер 22 может вычислять остаточное значение для части CU, соответствующей PU. Остаточное значение может быть преобразовано, сканировано и квантовано. TU не обязательно ограничивается размером PU. Таким образом, TU могут быть больше или меньше соответствующих PU для идентичной CU. В некоторых примерах, максимальный размер TU может соответствовать размеру соответствующей CU.
[0073] Как отмечено выше, внутреннее прогнозирование включает в себя прогнозирование PU текущей CU изображения из ранее кодированных CU идентичного изображения. Более конкретно, видеокодер 22 может внутренне прогнозировать текущую CU изображения с использованием конкретного режима внутреннего прогнозирования. HM-кодер может быть выполнен с тридцатью тремя режимами внутреннего прогнозирования. Следовательно, для того чтобы поддерживать преобразование "один-к-одному" между режимами направленного внутреннего прогнозирования и направленными преобразованиями, HM-кодеры и декодеры должны сохранять 66 матриц для каждого поддерживаемого размера преобразования. Кроме того, размеры блоков, для которых поддерживаются все тридцать три режима внутреннего прогнозирования, могут быть относительно большими блоками, например, 32x32 пикселов, 64x64 пикселов или даже больше.
[0074] В целевом устройстве 14 видеодекодер 28 принимает кодированные видеоданные 8. Видеодекодер 28 энтропийно декодирует принятые кодированные видеоданные 8, к примеру, кодированный блок, согласно технологии энтропийного кодирования, такой как CAVLC или CABAC, чтобы получать квантованные коэффициенты. Видеодекодер 28 применяет функции обратного квантования (деквантования) и обратного преобразования для того, чтобы восстанавливать остаточный блок в пиксельной области. Видеодекодер 28 также формирует прогнозный блок на основе управляющей информации или синтаксической информации (к примеру, режим кодирования, векторы движения, синтаксис, который задает коэффициенты фильтрации, и т.п.), включенной в кодированные видеоданные. Видеодекодер 28 вычисляет сумму прогнозного блока и восстановленного остаточного блока с тем, чтобы формировать восстановленный видеоблок для отображения. Дополнительные подробности примерного процесса декодирования, выполняемого посредством видеодекодера 28, описываются ниже относительно фиг. 5.
[0075] Как описано в данном документе, Y может представлять яркость, Cb и Cr могут представлять два различных значения цветности трехмерного цветового пространства YCbCr (например, синий и красный оттенки), и D может представлять информацию глубины. В некоторых примерах, каждое пиксельное местоположение может фактически задавать три пиксельных значения для трехмерного цветового пространства и одно пиксельное значение для глубины пиксельного местоположения. В других примерах, могут быть различные числа компонентов сигнала яркости в расчете на компонент сигнала цветности. Например, может быть четыре предусмотрено компонента сигнала яркости в расчете на компонент сигнала цветности. Дополнительно, компоненты глубины и текстуры могут иметь различные разрешения. В данном примере, может не быть взаимосвязи "один-к-одному" между компонентами видов текстуры (например, компонентами сигнала яркости) и компонентами видов глубины. Тем не менее, технологии этого раскрытия сущности, могут означать прогнозирование относительно одной размерности для простоты. В степени, в которой технологии описываются относительно пиксельных значений в одной размерности, аналогичные технологии могут быть расширены на другие размерности. В частности, в соответствии с одним аспектом этого раскрытия сущности, видеокодер 22 и/или видеодекодер 28 могут получать блок пикселов, при этом блок пикселов включает в себя компоненты видов текстуры и компоненты видов глубины.
[0076] В некоторых примерах, видеокодер 22 и видеодекодер 28 могут использовать одну или более технологий интерполяционной фильтрации в ходе компенсации движения. Иными словами, видеокодер 22 и/или видеодекодер 28 могут применять интерполяционный фильтр для поддержки фильтра, содержащего наборы полноцелочисленнопиксельных позиций.
[0077] Видеодекодер 28 целевого устройства 14 принимает один или более кодированных блоков как часть кодированного потока видеобитов вместе с дополнительной информацией, включающей в себя элементы синтаксиса, связанные с компонентами видов текстуры. Видеодекодер 28 может подготавливать посредством воспроизведения видеоданные для трехмерного воспроизведения на основе кодированного блока 8 и элементов синтаксиса. В соответствии с технологиями этого раскрытия сущности и как подробнее поясняется ниже, элементы синтаксиса, передаваемые в служебных сигналах для компонентов 4 видов текстуры, могут быть использованы для того, чтобы прогнозировать элементы синтаксиса для компонентов 6 видов глубины. Элементы синтаксиса могут быть переданы в служебных сигналах в заголовке фрагмента для компонентов 4 видов текстуры. Соответствующие элементы синтаксиса для компонентов 6 видов глубины могут быть определены из связанных элементов синтаксиса для компонентов 4 видов текстуры.
[0078] Некоторые элементы синтаксиса для компонентов 6 видов глубины могут быть переданы в служебных сигналах в заголовке фрагмента для компонентов 6 видов глубины, такие как разность параметров квантования между компонентом карты глубины и одним из одного или более компонентов текстуры для фрагмента. Атрибут также может быть флагом на уровне фрагмента, указывающим то, являются или нет параметры контурного фильтра, используемые для компонента вида глубины, идентичными параметрам контурного фильтра, передаваемым в служебных сигналах для компонентов видов текстуры. В других примерах, элементы синтаксиса могут быть переданы в служебных сигналах на уровне последовательности (например, в структуре данных набора параметров последовательности (SPS)), на уровне изображения (например, в структуре данных набора параметров изображения (PPS) или заголовке кадра) или на уровне блока (например, в заголовке блока), в дополнение к уровню фрагмента (например, в заголовке фрагмента).
[0079] Фиг. 2 является блок-схемой, подробнее иллюстрирующей пример видеокодера 22 по фиг. 1. Видеокодер 22 кодирует единицы блоков, которые передают в служебных сигналах элементы синтаксиса для компонентов видов текстуры, которые могут быть использованы для того, чтобы прогнозировать элементы синтаксиса для компонентов видов глубины, согласно технологиям этого раскрытия сущности. Видеокодер 22 является одним примером специализированного компьютерного видеоустройства или аппарата, упоминаемого в данном документе как "кодер". Как показано на фиг. 2, видеокодер 22 соответствует видеокодеру 22 исходного устройства 12. Тем не менее, в других примерах, видеокодер 22 может соответствовать другому устройству. В дополнительных примерах, другие модули (такие как, например, другие кодеры/декодеры (кодеки)) также могут осуществлять технологии, аналогичные технологиям, осуществляемым посредством видеокодера 22.
[0080] Видеокодер 22 может выполнять, по меньшей мере, одно из внутреннего и внешнего кодирования блоков в пределах видеокадров, хотя компоненты внутреннего кодирования не показаны на фиг. 2 для простоты иллюстрации. Внутреннее кодирование основано на пространственном прогнозировании, чтобы уменьшать или удалять пространственную избыточность видео в данном видеокадре. Внешнее кодирование основано на временном прогнозировании, чтобы уменьшать или удалять временную избыточность видео в смежных кадрах видеопоследовательности. Внутренний режим (I-режим) может означать режим пространственного сжатия. Внешние режимы, к примеру, прогнозирование (P-режим) или двунаправленный (B-режим), могут означать режимы временного сжатия. Технологии этого раскрытия сущности применяются в ходе внешнего кодирования и внутреннего кодирования. Тем не менее, для простоты иллюстрации, модули внутреннего кодирования, такие как модуль пространственного прогнозирования, не иллюстрируются на фиг. 2.
[0081] Как показано на фиг. 2, видеокодер 22 принимает текущий видеоблок в видеокадре, который должен быть кодирован. В одном примере, видеокодер 22 принимает компоненты 4 видов текстуры и компоненты 6 видов глубины. В другом примере, видеокодер принимает вид 2 из видеоисточника 20.
[0082] В примере по фиг. 2, видеокодер 22 включает в себя процессор 32 прогнозирования для единиц прогнозирующего кодирования (MCU), модуль 33 обработки многовидового видео плюс глубины (MVD), запоминающее устройство 34, первый сумматор 48, процессор 38 преобразования, модуль 40 квантования и модуль 46 энтропийного кодирования. Для восстановления видеоблоков видеокодер 22 также включает в себя модуль 42 обратного квантования, процессор 44 обратного преобразования, второй сумматор 51 и модуль 43 удаления блочности. Модуль 43 удаления блочности является фильтром удаления блочности, который фильтрует границы блоков для того, чтобы удалять артефакты блочности из восстановленного видео. Если включен в видеокодер 22, модуль 43 удаления блочности типично должен фильтровать вывод второго сумматора 51. Модуль 43 удаления блочности может определять информацию удаления блочности для одного или более компонентов видов текстуры. Модуль 43 удаления блочности также может определять информацию удаления блочности для компонента карты глубины. В некоторых примерах, информация удаления блочности для одного или более компонентов текстуры может отличаться от информации удаления блочности для компонента карты глубины. В одном примере, как показано на фиг. 2, процессор 38 преобразования представляет функциональный блок, в противоположность "TU" в терминах HEVC.
[0083] Модуль 33 обработки многовидового видео плюс глубины (MVD) принимает один или более видеоблоков (помечены как "видеоблок" на фиг. 2) содержащих компоненты текстуры и информацию глубины, к примеру, компоненты 4 видов текстуры и компоненты 6 видов глубины. MVD-модуль 33 предоставляет функциональность для видеокодера 22 для того, чтобы кодировать компоненты глубины в единице блока. MVD-модуль 33 предоставляет компоненты видов текстуры и компоненты видов глубины, комбинированными или по отдельности, в процессор 32 прогнозирования в формате, который позволяет процессору 32 прогнозирования обрабатывать информацию глубины. MVD-модуль 33 также может передавать в служебных сигналах в процессор 38 преобразования то, что компоненты видов глубины включаются в видеоблок. В других примерах, каждый модуль видеокодера 22, к примеру, процессор 32 прогнозирования, процессор 38 преобразования, модуль 40 квантования, модуль 46 энтропийного кодирования и т.д., содержит функциональность для того, чтобы обрабатывать информацию глубины в дополнение к компонентам видов текстуры.
[0084] В общем, видеокодер 22 кодирует информацию глубины способом, аналогичным информации цветности, так что модуль 37 компенсации движения выполнен с возможностью многократно использовать векторы движения, вычисленные для компонента сигнала яркости блока при вычислении прогнозированного значения для компонента глубины идентичного блока. Аналогично, модуль внутреннего прогнозирования видеокодера 22 может быть выполнен с возможностью использовать режим внутреннего прогнозирования, выбранный для компонента сигнала яркости (т.е. на основе анализа компонента сигнала яркости), при кодировании компонента вида глубины с использованием внутреннего прогнозирования.
[0085] Процессор 32 прогнозирования включает в себя модуль 35 оценки движения (ME) и модуль 37 компенсации движения (MC). Процессор 32 прогнозирования прогнозирует информацию глубины для пиксельных местоположений, а также для компонентов текстуры. Один или более интерполяционных фильтров 39 (упоминаемых в данном документе в качестве "фильтра 39") могут быть включены в процессор 32 прогнозирования и могут активироваться посредством одного или обоих из ME-модуля 35 и MC-модуля 37 для того, чтобы выполнять интерполяцию как часть оценки движения и/или компенсации движения. Интерполяционный фильтр 39 может фактически представлять множество различных фильтров, чтобы упрощать множество различных типов интерполяционной и аналогичной интерполяционной фильтрации. Таким образом, процессор 32 прогнозирования может включать в себя множество интерполяционных или аналогичных интерполяционным фильтров.
[0086] В ходе процесса кодирования видеокодер 22 принимает видеоблок, который должен кодироваться (помечен как "видеоблок" на фиг. 2), и процессор 32 прогнозирования выполняет кодирование с внешним прогнозированием для того, чтобы формировать прогнозный блок (помечен как "прогнозный блок" на фиг. 2). Прогнозный блок включает в себя как компоненты видов текстуры, так и информацию видов глубины. В частности, ME-модуль 35 может выполнять оценку движения для того, чтобы идентифицировать прогнозный блок в запоминающем устройстве 34, и MC-модуль 37 может выполнять компенсацию движения для того, чтобы формировать прогнозный блок.
[0087] Оценка движения типично считается процессом формирования векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может указывать смещение прогнозного блока в пределах прогнозного или опорного кадра (или другой кодированной единицы, к примеру, фрагмента) относительно блока, который должен быть кодирован в пределах текущего кадра (или другой кодированной единицы). Вектор движения может иметь полноцелочисленную или субцелочисленную пиксельную точность. Например, как горизонтальный компонент, так и вертикальный компонент вектора движения могут иметь соответствующие полноцелочисленные компоненты и субцелочисленные компоненты. Опорный кадр (или часть кадра) может временно находиться до или после видеокадра (или части видеокадра), которому принадлежит текущий видеоблок. Компенсация движения типично считается процессом выборки или формирования прогнозного блока из запоминающего устройства 34, который может включать в себя интерполяцию или иное формирование фильтрованных прогнозирующих данных на основе вектора движения, определенного посредством оценки движения.
[0088] ME-модуль 35 вычисляет, по меньшей мере, один вектор движения для видеоблока, который должен кодироваться, посредством сравнения видеоблока с опорными блоками одного или более опорных кадров (к примеру, предыдущего и/или последующего кадра). Данные для опорных кадров могут быть сохранены в запоминающем устройстве 34. ME-модуль 35 может выполнять оценку движения с дробнопиксельной точностью, иногда называемой дробнопиксельной, субцелочисленной или субпиксельной оценкой движения. При дробнопиксельной оценке движения ME-модуль 35 вычисляет вектор движения, который указывает смещение в местоположение, отличное от целопиксельного местоположения. Таким образом, вектор движения может иметь дробнопиксельную точность, например, точность в одну вторую пиксела, точность в одну четвертую пиксела, точность в одну восьмую пиксела или другие дробнопиксельные точности. Таким образом, дробнопиксельная оценка движения дает возможность процессору 32 прогнозирования оценивать движение с более высокой точностью, чем целопиксельные (или полнопиксельные) местоположения, и в силу этого процессор 32 прогнозирования формирует более точный прогнозный блок. Дробнопиксельная оценка движения дает возможность процессору 32 прогнозирования прогнозировать информацию глубины при первом разрешении и прогнозировать компоненты текстуры при втором разрешении. Например, компоненты текстуры прогнозируются с полнопиксельной точностью, тогда как информация глубины прогнозируется с точностью в одну вторую пиксела. В других примерах, другие разрешения вектора движения могут использоваться для информации глубины и компонентов текстуры.
[0089] ME-модуль 35 может активировать один или более фильтров 39 для всех необходимых интерполяций в ходе процесса оценки движения. В некоторых примерах, запоминающее устройство 34 может сохранять интерполированные значения для субцелочисленных пикселов, которые могут быть вычислены, например, посредством сумматора 51 с использованием фильтров 39. Например, сумматор 51 может применять фильтры 39 к восстановленным блокам, которые должны быть сохранены в запоминающем устройстве 34.
[0090] После того как процессор 32 прогнозирования формирует прогнозный блок, видеокодер 22 формирует остаточный видеоблок (помечен как "остаточный блок" на фиг. 2) посредством вычитания прогнозного блока из кодируемого исходного видеоблока. Это вычитание может выполняться между компонентами текстуры в исходном видеоблоке и компонентами текстуры в прогнозном блоке, а также для информации глубины в исходном видеоблоке или карты глубины из информации глубины в прогнозном блоке. Сумматор 48 представляет компонент или компоненты, которые выполняют эту операцию вычитания.
[0091] Процессор 38 преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT) или концептуально аналогичное преобразование, к остаточному блоку, формируя видеоблок, содержащий остаточные блочные коэффициенты преобразования. Следует понимать, что процессор 38 преобразования представляет компонент видеокодера 22, который применяет преобразование к остаточным коэффициентам блока видеоданных, в отличие от TU CU, как задано посредством HEVC. Процессор 38 преобразования, например, может выполнять другие преобразования, заданные посредством стандарта H.264, которые являются концептуально аналогичными DCT. Такие преобразования включают в себя, например, направленные преобразования (к примеру, преобразования на основе теоремы Карунена-Лоэва), вейвлет-преобразования, целочисленные преобразования, подполосные преобразования или другие типы преобразований. В любом случае, процессор 38 преобразования применяет преобразование к остаточному блоку, формируя блок остаточных коэффициентов преобразования. Процессор 38 преобразования может применять идентичный тип преобразования как к компонентам текстуры, так и к информации глубины в соответствующих остаточных блоках. Предусмотрены отдельные остаточные блоки для каждого компонента текстуры и глубины. Преобразование преобразует остаточную информацию из пиксельной области в частотную область.
[0092] Модуль 40 квантования квантует остаточные коэффициенты преобразования, чтобы дополнительно уменьшать скорость передачи битов. Процесс квантования может уменьшать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Модуль 40 квантования может квантовать остаток кодирования изображений глубины. После квантования, модуль 46 энтропийного кодирования энтропийно кодирует квантованные коэффициенты преобразования. Например, модуль 46 энтропийного кодирования может выполнять CAVLC, CABAC или другую технологию энтропийного кодирования.
[0093] Модуль 46 энтропийного кодирования также может кодировать один или более векторов движения и поддерживать информацию, полученную из процессора 32 прогнозирования или другого компонента видеокодера 22, такого как модуль 40 квантования. Один или более прогнозных элементов синтаксиса могут включать в себя режим кодирования, данные для одного или более векторов движения (например, горизонтальные и вертикальные компоненты, идентификаторы опорных списков, индексы списков и/или служебную информацию по разрешению векторов движения), указание относительно используемой технологии интерполяции, набор коэффициентов фильтрации, указание относительного разрешения изображения глубины по сравнению с разрешением компонента сигнала яркости, матрицу квантования для остатка кодирования изображений глубины, информацию удаления блочности для изображения глубины или другую информацию, ассоциированную с формированием прогнозного блока. Эти прогнозные элементы синтаксиса могут предоставляться на уровне последовательности или на уровне изображения.
[0094] Один или более элементов синтаксиса также могут включать в себя разность параметров квантования (QP) между компонентом сигнала яркости и компонентом глубины. QP-разность может быть передана в служебных сигналах на уровне фрагмента и может быть включена в заголовок фрагмента для компонентов видов текстуры. Другие элементы синтаксиса также могут быть переданы в служебных сигналах на уровне единиц кодированных блоков, включающие в себя шаблон кодированного блока для компонента вида глубины, дельта-QP для компонента вида глубины, разность векторов движения или другую информацию, ассоциированную с формированием прогнозного блока. Разность векторов движения может быть передана в служебных сигналах в качестве дельта-значения между целевым вектором движения и вектором движения компонентов текстуры или в качестве дельта-значения между целевым вектором движения (т.е. вектором движения кодируемого блока) и предиктором из соседних векторов движения для блока (например, PU CU). После энтропийного кодирования посредством модуля 46 энтропийного кодирования, кодированное видео и элементы синтаксиса могут быть переданы в другое устройство или заархивированы (например, в запоминающем устройстве 34) для последующей передачи или извлечения.
[0095] Модуль 42 обратного квантования и процессор 44 обратного преобразования применяют обратное квантование и обратное преобразование, соответственно, чтобы восстанавливать остаточный блок в пиксельной области, к примеру, для последующего использования в качестве опорного блока. Восстановленный остаточный блок (помечен как "восстановленный остаточный блок" на фиг. 2) может представлять восстановленную версию остаточного блока, предоставленного в процессор 38 преобразования. Восстановленный остаточный блок может отличаться от остаточного блока, сформированного посредством сумматора 48, вследствие потери детальности, вызываемой посредством операций квантования и обратного квантования. Сумматор 51 суммирует восстановленный остаточный блок с блоком прогнозирования с компенсацией движения, сформированным посредством процессора 32 прогнозирования, для того чтобы формировать восстановленный видеоблок для хранения в запоминающем устройстве 34. Восстановленный видеоблок может использоваться посредством процессора 32 прогнозирования в качестве опорного блока, который может использоваться для того, чтобы затем кодировать единицу блока в последующем видеокадре или последующей кодированной единице.
[0096] Таким образом, видеокодер 22 представляет пример видеокодера, выполненного с возможностью принимать единицу кодированного блока, содержащую компонент вида, указывающий вид изображения, при этом компонент вида содержит один или более компонентов видов текстуры и компонент вида глубины, формировать заголовок фрагмента текстуры для одного или более компонентов видов текстуры, включающих в себя элементы синтаксиса текстуры, при этом элементы синтаксиса глубины для компонента вида глубины могут быть определены из элементов синтаксиса текстуры в заголовке фрагмента текстуры.
[0097] В некоторых случаях, информация, связанная с кодированием компонентов видов текстуры и компонентов видов глубины, указывается в качестве одного или более элементов синтаксиса для включения в кодированный поток битов. В некоторых примерах, заголовок фрагмента глубины содержит элементы синтаксиса, включающие в себя, по меньшей мере, одно из местоположения стартового микроблока, типа фрагмента, набора параметров изображения (PPS), который должен быть использован, дельта-QP между начальным QP фрагмента и QP, передаваемым в служебных сигналах в PPS, порядка опорных изображений (представленного в качестве frame_num) и порядка отображения текущего изображения (POC). Заголовок фрагмента глубины также может содержать, по меньшей мере, одно из составления списков опорных изображений и связанных элементов синтаксиса, операции управления запоминающим устройством и связанных элементов синтаксиса и взвешенного прогнозирования и связанных элементов синтаксиса.
[0098] Фиг. 3 является схемой одного примера структуры MVC-прогнозирования для кодирования многовидового видео. MVC является расширением H.264/AVC. Структура MVC-прогнозирования включает в себя как межкадровое прогнозирование в пределах каждого вида, так и межвидовое прогнозирование. На фиг. 3, прогнозирования указываются посредством стрелок, при этом указываемый объект использует указывающий объект для опорного элемента прогнозирования. Структура MVC-прогнозирования по фиг. 3 может быть использована в сочетании с компоновкой порядка первого по времени декодирования. В порядке первого по времени декодирования каждая единица доступа может быть задана так, что она содержит кодированные изображения всех видов для одного выходного момента времени. Порядок декодирования единиц доступа может не быть идентичным порядку вывода или отображения.
[0099] В MVC, межвидовое прогнозирование поддерживается посредством компенсации движения на основе диспаратности, которая использует синтаксис компенсации движения H.264/AVC, но дает возможность размещения изображения в другом виде в качестве опорного изображения. Кодирование двух видов также может поддерживаться посредством MVC. MVC-кодер может получать более двух представлений в качестве трехмерного видеоввода, и MVC-декодер может декодировать многовидовое представление. Модуль воспроизведения с MVC-декодером может декодировать трехмерный видеоконтент с несколькими видами.
[0100] Изображения в идентичной единице доступа (т.е. с идентичным моментом времени) могут быть подвергнуты межвидовому прогнозированию в MVC. При кодировании изображения в одном из небазовых видов, изображение может добавляться в список опорных изображений, если оно находится в другом виде, но в идентичный момент времени. Опорное изображение межвидового прогнозирования может быть помещено в любую позицию списка опорных изображений, точно так же, как любое опорное изображение внешнего прогнозирования.
[0101] В MVC, межвидовое прогнозирование может быть реализовано так, как будто компонент вида в другом виде является опорным элементом внешнего прогнозирования. Потенциальные межвидовые опорные элементы могут быть переданы в служебных сигналах в MVC-расширении набора параметров последовательности (SPS). Потенциальные межвидовые опорные элементы могут быть модифицированы посредством процесса составления списков опорных изображений, который обеспечивает гибкое упорядочение опорных элементов внешнего прогнозирования или межвидового прогнозирования.
[0102] Напротив, в HEVC заголовок фрагмента соответствует принципу проектирования, аналогичному принципу проектирования из H.264/AVC. Дополнительно, заголовок HEVC-фрагмента может содержать синтаксис параметров адаптивного контурного фильтра (ALF) в текущих технических требованиях HEVC. В некоторых примерах, заголовок фрагмента глубины содержит один или более параметров адаптивного контурного фильтра.
[0103] В 3DV-кодеке, компонент вида для каждого вида в конкретный момент времени может включать в себя компонент вида текстуры и компонент вида глубины. Структура фрагмента может использоваться для целей обеспечения устойчивости к ошибкам, т.е. чтобы предоставлять устойчивость к ошибкам. Тем не менее, компонент вида глубины может быть значимым только тогда, когда соответствующий компонент вида текстуры корректно принимается. При включении всех элементов синтаксиса для компонента вида глубины, заголовок фрагмента для NAL-единицы компонента вида глубины может быть относительно большим. Размер заголовка фрагмента глубины может быть сокращен посредством прогнозирования некоторых элементов синтаксиса из элементов синтаксиса в заголовке фрагмента текстуры для компонентов видов текстуры.
[0104] Поток битов может быть использован для того, чтобы передавать единицы блоков многовидового видео плюс глубины и элементы синтаксиса, например, между исходным устройством 12 и целевым устройством 14 по фиг. 1. Поток битов может соответствовать стандарту кодирования ITU H.264/AVC и, в частности, подчиняется структуре потока битов для кодирования многовидового видео (MVC). Иными словами, в некоторых примерах, поток битов соответствует MVC-расширению H.264/AVC. В других примерах, поток битов соответствует многовидовому расширению HEVC или многовидовому расширению другого стандарта. В еще одних других примерах, используются другие стандарты кодирования.
[0105] Типичная компоновка порядка MVC-потока битов (порядка декодирования) представляет собой кодирование сначала по времени. Каждая единица доступа задается так, что она содержит кодированные изображения всех видов для одного выходного момента времени. Порядок декодирования единиц доступа может быть идентичным или не идентичным порядку вывода или отображения. Типично, MVC-прогнозирование может включать в себя как межкадровое прогнозирование в пределах каждого вида, так и межвидовое прогнозирование. В MVC, межвидовое прогнозирование может поддерживаться посредством компенсации движения на основе диспаратности, которая использует синтаксис компенсации движения H.264/AVC, но дает возможность использования изображения в другом виде в качестве опорного изображения.
[0106] Кодирование двух видов поддерживается посредством MVC. Одно из преимуществ MVC заключается в том, что MVC-кодер может получать более двух представлений в качестве трехмерного видеоввода, и MVC-декодер может декодировать два вида в многовидовое представление. Таким образом, модуль воспроизведения с MVC-декодером может обрабатывать трехмерный видеоконтент как имеющий несколько видов. Ранее, MVC не обрабатывал ввод карту глубины с вводимыми, аналогично H.264/AVC, сообщениями с дополнительной улучшающей информацией (SEI) (стереоинформацией или пространственными перемежающимися изображениями).
[0107] В стандарте H.264/AVC задаются единицы уровня абстрагирования от сети (NAL), чтобы предоставлять "оптимизированное для использования в сети" представление видео, нацеленное на такие варианты применения, как видеотелефония, хранение данных или потоковое видео. NAL-единицы могут классифицироваться на NAL-единицы уровня кодирования видео (VCL) и не-VCL NAL-единицы. VCL-единицы могут содержать основной механизм сжатия и содержать уровни блока, макроблока (MB) и фрагмента. Другие NAL-единицы являются не-VCL NAL-единицами.
[0108] В примере кодирования двумерного видео каждая NAL-единица содержит однобайтовый заголовок NAL-единицы и рабочие данные варьирующегося размера. Пять битов используются для того, чтобы указывать тип NAL-единицы. Три бита используются для nal_ref_idc, который указывает то, насколько важной является NAL-единица с точки зрения возможности обращения посредством других изображений (NAL-единиц). Например, задание nal_ref_idc равным 0 означает то, что NAL-единица не используется для взаимного прогнозирования. Поскольку H.264/AVC расширяется так, что он включает в себя кодирование трехмерного видео, к примеру, стандарт масштабируемого кодирования видео (SVC), заголовок NAL может быть аналогичным заголовку двумерного сценария. Например, один или более битов в заголовке NAL-единицы используются для того, чтобы идентифицировать то, что NAL-единица является четырехкомпонентной NAL-единицей.
[0109] Заголовки NAL-единиц также могут использоваться для MVC NAL-единиц. Тем не менее, в MVC, структура заголовка NAL-единицы может сохраняться за исключением NAL-единиц префикса и MVC-кодированных NAL-единиц фрагментов. MVC-кодированные NAL-единицы фрагментов могут содержать четырехбайтовый заголовок и рабочие данные NAL-единицы, которые могут включать в себя единицу блока, такую как кодированный блок 8 по фиг. 1. Элементы синтаксиса в заголовке MVC NAL-единицы могут включать в себя priority_id, temporal_id, anchor_pic_flag, view_id, non_idr_flag и inter_view_flag. В других примерах, другие элементы синтаксиса включаются в заголовок MVC NAL-единицы.
[0110] Элемент anchor_pic_flag синтаксиса может указывать то, является изображение прикрепленным изображением или неприкрепленным изображением. Прикрепленные изображения и все изображения, следующие за ними в порядке вывода (т.е. в порядке отображения), могут быть корректно декодированы без декодирования предыдущих изображений в порядке декодирования (т.е. в порядке потока битов) и в силу этого могут быть использованы в качестве точек произвольного доступа. Прикрепленные изображения и неприкрепленные изображения могут иметь различные зависимости, обе из которых могут быть переданы в служебных сигналах в наборе параметров последовательности.
[0111] Структура потока битов, заданная в MVC, может отличаться посредством двух элементов синтаксиса: view_id и temporal_id. Элемент view_id синтаксиса может указывать идентификатор каждого вида. Этот идентификатор в заголовке NAL-единицы обеспечивает простую идентификацию NAL-единиц в декодере и быстрый доступ для декодированных видов для отображения. Элемент temporal_id синтаксиса может указывать иерархию временной масштабируемости либо, косвенно, частоту кадров. Например, рабочая точка, включающая в себя NAL-единицы с меньшим максимальным значением temporal_id, может иметь более низкую частоту кадров, чем рабочая точка с большим максимальным значением temporal_id. Кодированные изображения с более высоким значением temporal_id типично зависят от кодированных изображений с более низкими значениями temporal_id в виде, но могут вообще не зависеть от кодированных изображений с более высоким temporal_id.
[0112] Элементы view_id и temporal_id синтаксиса в заголовке NAL-единицы могут использоваться для извлечения и адаптации потока битов. Элемент priority_id синтаксиса может быть, главным образом, использован для простого процесса адаптации потока битов с одним трактом. Элемент inter_view_flag синтаксиса может указывать то, должна или нет эта NAL-единица использоваться для межвидового прогнозирования другой NAL-единицы в другом виде.
[0113] MVC также может использовать наборы параметров последовательности (SPS) и включать в себя SPS MVC-расширение. Наборы параметров используются для передачи служебных сигналов в H.264/AVC. Наборы параметров последовательности содержат информацию заголовка уровня последовательности. Наборы параметров изображения (PPS) содержат нечасто изменяющуюся информацию заголовка уровня изображения. В наборах параметров эта нечасто изменяющаяся информация не всегда повторяется для каждой последовательности или изображения, и как следствие, повышается эффективность кодирования. Кроме того, использование наборов параметров обеспечивает внеполосную передачу информации заголовка, исключая необходимость избыточных передач для устойчивости к ошибкам. В некоторых примерах внеполосной передачи NAL-единицы из набора параметров передаются на канале, отличном от канала для других NAL-единиц. В MVC, зависимость от вида может быть передана в служебных сигналах в SPS MVC-расширении. Все межвидовое прогнозирование может выполняться в пределах объема, указываемого посредством SPS MVC-расширения.
[0114] В некоторых предшествующих технологиях кодирования трехмерного видео контент кодируется таким образом, что цветовые компоненты, например, в цветовом пространстве YCbCr, кодируются в одной или более NAL-единиц, в то время как изображение глубины кодируется в одной или более отдельных NAL-единиц. Тем не менее, когда ни одна NAL-единица не содержит кодированные выборки изображений текстуры и глубины единицы доступа, могут возникать несколько проблем. Например, в декодере трехмерного видео предполагается, что после декодирования изображения текстуры и глубины каждого кадра, воспроизведение вида на основе карты глубины и текстуры активируется с тем, чтобы формировать виртуальные виды. Если NAL-единица изображения глубины и NAL-единица текстуры для единицы доступа кодируются последовательным способом, воспроизведение вида может не начинаться до тех пор, пока вся единица доступа не будет декодирована. Это может приводить к увеличению времени, которое требуется для подготовки посредством воспроизведения трехмерного видео.
[0115] Кроме того, изображение текстуры и ассоциированное изображение карты глубины могут совместно использовать некоторую информацию на различных уровнях в кодеке, например, на уровне последовательности, уровне изображения, уровне фрагмента и уровне блока. Кодирование этой информации в две NAL-единицы может создавать дополнительную нагрузку по реализации при совместном использовании или прогнозировании информации. Таким образом, кодер, возможно, должен выполнять оценку движения для кадра два раза, один раз для текстуры и еще раз для карты глубины. Аналогично, декодер, возможно, должен выполнять компенсацию движения два раза для кадра.
[0116] Как описано в данном документе, в существующие стандарты, такие как MVC, добавляются технологии с тем, чтобы поддерживать трехмерное видео. Многовидовое видео плюс глубина (MVD) может добавляться в MVC для обработки трехмерного видео. Технологии кодирования трехмерного видео могут предоставлять большую гибкость и расширяемость для существующих видеостандартов, например, для плавного изменения угла обзора или регулирования восприятия сходимости или глубины обратно или вперед, что может быть основано, например, на технических требованиях устройств или настройках пользователя. Стандарты кодирования также могут быть расширены таким образом, чтобы использовать карты глубины для формирования виртуальных видов в трехмерном видео.
[0117] Фиг. 4 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу видеокодера, согласно технологиям настоящего раскрытия сущности. В некоторых примерах, видеокодер представляет собой видеокодер, такой как видеокодер 22, показанный на фиг. 1 и 2. В других примерах, видеокодер представляет собой видеодекодер, такой как видеодекодер 28, показанный на фиг. 1 и 5. Видеокодер принимает фрагмент текстуры, содержащий заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры (102). Например, видеокодер принимает фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры. Способ дополнительно включает в себя прием фрагмента глубины, содержащего заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины (104). Например, видеокодер принимает фрагмент глубины для компонента вида глубины, ассоциированного с одним или более кодированных блоков информации глубины, соответствующего компоненту вида текстуры, при этом фрагмент глубины содержит один или более кодированных блоков информации глубины и заголовок фрагмента глубины, содержащий элементы синтаксиса, представляющие характеристики фрагмента глубины. В некоторых примерах, компонент вида глубины и компонент вида текстуры принадлежат виду и единице доступа.
[0118] Способ дополнительно содержит кодирование первого фрагмента, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента (106). Например, видеокодер 22 кодирует первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента. В одном примере, заголовок фрагмента содержит все элементы синтаксиса, используемые для того, чтобы кодировать ассоциированный фрагмент. В другом примере, видеодекодер 28 декодирует первый фрагмент, при этом первый фрагмент содержит один из фрагмента текстуры и фрагмента глубины, при этом первый фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики первого фрагмента.
[0119] Способ дополнительно содержит определение общих элементов синтаксиса для второго фрагмента из заголовка фрагмента для первого фрагмента (108). Дополнительно, способ содержит кодирование второго фрагмента после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента (110). Например, видеокодер 22 может кодировать второй фрагмент после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента. Аналогично, видеодекодер 28 может декодировать второй фрагмент после кодирования первого фрагмента, по меньшей мере, частично на основе определенных общих элементов синтаксиса, при этом второй фрагмент содержит один из фрагмента текстуры и фрагмента глубины, который не является первым фрагментом, при этом второй фрагмент имеет заголовок фрагмента, содержащий элементы синтаксиса, представляющие характеристики второго фрагмента, за исключением значений для элементов синтаксиса, которые являются общими для первого фрагмента.
[0120] В других примерах, способ дополнительно содержит передачу в служебных сигналах указания того, какие элементы синтаксиса явно передаются в служебных сигналах в заголовке фрагмента для второго фрагмента в наборе параметров последовательности.
[0121] В других примерах, по меньшей мере, один элемент синтаксиса глубины определяется и передается в служебных сигналах в заголовке фрагмента компонента вида глубины. По меньшей мере, один элемент синтаксиса глубины может включать в себя идентификатор набора параметров изображения, разность параметров квантования между параметром квантования фрагмента и параметром квантования, передаваемым в служебных сигналах в наборе параметров изображения, начальную позицию единицы кодированного блока, порядок опорных изображений или порядок отображения текущего изображения компонента вида глубины. Например, заголовок фрагмента для второго фрагмента содержит, по меньшей мере, передаваемый в служебных сигналах элемент синтаксиса идентификационных данных набора параметров изображения, к которому следует обращаться. В другом примере, заголовок фрагмента для второго фрагмента содержит, по меньшей мере, передаваемый в служебных сигналах элемент синтаксиса разности параметров квантования между параметром квантования второго фрагмента и параметром квантования, передаваемым в служебных сигналах в наборе параметров изображения. В другом примере, заголовок фрагмента для второго фрагмента содержит, по меньшей мере, передаваемый в служебных сигналах элемент синтаксиса начальной позиции кодированного блока. Дополнительно, заголовок фрагмента для второго фрагмента может содержать, по меньшей мере, один из номера кадра и номера в последовательности изображений второго фрагмента. В другом примере, заголовок фрагмента для второго фрагмента содержит, по меньшей мере, одно из элементов синтаксиса, связанных с составлением списков опорных изображений, числа активных опорных кадров для каждого списка, синтаксических таблиц модификации списков опорных изображений и таблицы весовых коэффициентов прогнозирования.
[0122] Начальная позиция единицы кодированного блока может определяться равной нулю, когда начальная позиция кодированного блока не передается в служебных сигналах в заголовке фрагмента текстуры или заголовке фрагмента глубины. Параметр контурного фильтра, по меньшей мере, для одного компонента вида текстуры может быть передан в служебных сигналах, как и набор флагов, который указывает то, что параметр контурного фильтра, используемый для компонента вида глубины, является идентичным параметру контурного фильтра, по меньшей мере, для одного компонента вида текстуры. Например, заголовок фрагмента для второго фрагмента содержит, по меньшей мере, один из элементов синтаксиса, связанных с параметрами фильтра удаления блочности или параметрами адаптивной контурной фильтрации для второго фрагмента.
[0123] В другом примере, один или более блоков видеоданных, представляющих информацию текстуры, кодируются с использованием межвидового прогнозирования, в то время как значения глубины для соответствующей части кадра кодируются с использованием внутривидового прогнозирования. Видеокадр, имеющий компоненты видов текстуры и компоненты видов глубины, может соответствовать первому виду. Кодирование одного или более блоков видеоданных, представляющих информацию текстуры, может включать в себя прогнозирование, по меньшей мере, части, по меньшей мере, одного из блоков видеоданных, представляющих информацию текстуры относительно данных второго вида, при этом второго вид отличается от первого вида. Кодирование информации глубины, представляющей значения глубины для части кадра дополнительно, содержит прогнозирование, по меньшей мере, части информации глубины, представляющей значения глубины относительно данных первого вида. Заголовок фрагмента глубины дополнительно может передавать в служебных сигналах элементы синтаксиса, представляющие составление списков опорных изображений для компонента вида карты глубины.
[0124] Таблица 1 показывает MVC-расширение набора параметров последовательности (SPS). Межвидовые опорные элементы могут быть переданы в служебных сигналах в SPS и могут быть модифицированы посредством процесса составления списков опорных изображений, который обеспечивает гибкое упорядочение опорных элементов внешнего прогнозирования или межвидового прогнозирования.
|
|
|
[0125] Индикатор на уровне последовательности может указывать то, как компоненты видов глубины прогнозируются из соответствующих компонентов видов текстуры в идентичном виде. В наборе параметров последовательности для карты глубины может быть передан в служебных сигналах следующий синтаксис:
pred_slice_header_colocated_idc ue(v) или u(2)
[0126] В примерах, в которых один или более блоков видеоданных, представляющих информацию текстуры, кодируются с использованием межвидового прогнозирования, в то время как значения глубины для соответствующей части кадра кодируются с использованием внутривидового прогнозирования, num_ref_idx_active_override_flag и ref_pic_list_reordering могут быть переданы в служебных сигналах в заголовке фрагмента для компонентов видов карт глубины.
[0127] Таблица 2 предоставляет примерную синтаксическую таблицу заголовка фрагмента для фрагмента глубины. Элемент pred_slice_header_colocated_idc синтаксиса указывает то, что элементы синтаксиса многократно используются между заголовком фрагмента компонента вида текстуры и заголовком фрагмента компонента вида глубины, следующими способами. Задание pred_slice_header_colocated_idc равным 0 указывает то, что отсутствует прогнозирование между заголовком фрагмента компонента вида текстуры и его соответствующим компонентом вида глубины. Следует отметить, что соответствующий компонент вида текстуры компонента вида карты глубины означает компонент вида текстуры в идентичный момент времени в идентичном виде.
[0128] Задание pre_slice_header_colocated_idc равным 3 указывает то, что набор параметров изображения и дельта-QP NAL-единицы компонента вида глубины передаются в служебных сигналах в заголовке фрагмента, в то время как другие элементы синтаксиса уровня фрагмента NAL-единицы компонента вида глубины являются идентичными или прогнозируемыми из элементов синтаксиса соответствующего компонента вида текстуры.
[0129] Задание pred_slice_header_colocated_idc равным 2 указывает то, что набор параметров изображения и дельта-QP, а также местоположение первого MB или CU NAL-единицы компонента вида глубины передаются в служебных сигналах в заголовке фрагмента глубины, в то время как другие элементы синтаксиса являются идентичными или прогнозируемыми из соответствующих элементов синтаксиса совместно размещенного компонента вида текстуры из идентичного вида.
[0130] Задание pred_slice_header_colocated_idc равным 1 указывает то, что набор параметров изображения и дельта-QP, местоположение первого MB или CU NAL-единицы компонента вида глубины, а также frame_num и POC-значения передаются в служебных сигналах в заголовке фрагмента, в то время как другие элементы синтаксиса являются идентичными или прогнозируемыми из соответствующих элементов синтаксиса совместно размещенного компонента вида текстуры из идентичного вида. В одном примере, когда pred_slice_header_colocated_idc равен 3, first_mb_in_slice логически выводится как имеющий значение, равное 0. С другой стороны, когда pred_slice_header_colocated_idc меньше 3, значение для first_mb_in_slice может быть явно передано в служебных сигналах, как показано в таблице 2.
[0131] Как также показано в таблице 2, когда pred_slice_header_colocated_idc имеет значение, которое меньше единицы, флаг энтропийного фрагмента и тип фрагмента передаются в служебных сигналах. Флаг энтропийного фрагмента имеет значение, которое указывает то, является или нет соответствующий фрагмент энтропийным фрагментом, т.е. энтропийно кодирован или нет фрагмент независимо от контекстов для других фрагментов. Таким образом, контекстные модели могут инициализироваться или сбрасываться в начале каждого энтропийного фрагмента. Тип фрагмента указывает тип для фрагмента, например, I, P или B. Кроме того, когда pred_slice_header_colocated_idc имеет значение, которое меньше единицы, заголовок фрагмента указывает то, подвергаются или нет блоки фрагмента полевому кодированию (например, для полевого кодирования с перемежением).
|
|
[0132] Таблица 3 предоставляет одну примерную схему заголовка фрагмента для компонента вида глубины на основе HEVC. Следует отметить, что в этом примере, когда pred_slice_header_colocated_idc равен 3, first_tb_in_slice логически выводится как имеющий значение, равное 0.
|
|
|
[0133] Таблица 4 является примерной синтаксической таблицей заголовка фрагмента для фрагмента глубины. Таблица 4 предоставляет одну примерную схему синтаксиса заголовка фрагмента глубины, чтобы дополнительно указывать многократное использование синтаксиса для компонента вида глубины. В этом примере, индикатор на уровне последовательности указывает то, как компоненты видов глубины прогнозируются из соответствующих компонентов видов текстуры в идентичном виде.
[0134] В этом наборе параметров последовательности для карты глубины может быть передан в служебных сигналах следующий синтаксис:
pred_slice_header_colocated_idc ue(v) или u(2)
[0135] Элемент pre_slice_header_colocated_idc синтаксиса указывает многократное использование элемента синтаксиса между заголовком фрагмента компонента вида текстуры и заголовком фрагмента компонента вида глубины. Например, задание pred_slice_header_colocated_idc равным 0 указывает то, что отсутствует прогнозирование между заголовком фрагмента компонента вида текстуры и его соответствующим компонентом вида глубины. Задание pre_slice_header_colocated_idc равным 3 указывает то, что набор параметров изображения и дельта-QP NAL-единицы компонента вида глубины передаются в служебных сигналах в заголовке фрагмента, в то время как другие элементы синтаксиса уровня фрагмента NAL-единицы компонента вида глубины являются идентичными или прогнозируются из элементов синтаксиса соответствующего компонента вида текстуры.
[0136] Задание pred_slice_header_colocated_idc равным 2 указывает то, что набор параметров изображения и дельта-QP, а также местоположение первого MB или CU NAL-единицы компонента вида глубины передаются в служебных сигналах в заголовке фрагмента, в то время как другие элементы синтаксиса являются идентичными или прогнозируются из соответствующих элементов синтаксиса совместно размещенного компонента вида текстуры из идентичного вида. Задание pred_slice_header_colocated_idc равным 1 указывает то, что набор параметров изображения и дельта-QP, местоположение первого MB или CU NAL-единицы компонента вида глубины, а также frame_num и POC-значения передаются в служебных сигналах в заголовке фрагмента, в то время как другие элементы синтаксиса являются идентичными или прогнозируются из соответствующих элементов синтаксиса совместно размещенного компонента вида текстуры из идентичного вида.
[0137] Флаг синтаксиса, pred_default_syntax_flag, указывает то, прогнозируются или нет элементы синтаксиса заголовка фрагмента компонента вида карты глубины из элементов синтаксиса совместно размещенного компонента вида текстуры. В одном примере, pred_default_syntax_flag логически выводится равным 0, если pred_slice_header_colocated_idc равен 0. Когда pred_slice_header_colocated_idc равен 3, и pred_default_syntax_flag равен 1 в этом примере, first_mb_in_slice равен 0.
|
|
|
[0138] Таблица 5 является примерной синтаксической таблицей заголовка фрагмента для компонента вида глубины на основе HEVC. В примере таблицы 5, pred_default_syntax_flag указывает то, прогнозируются или нет элементы синтаксиса заголовка фрагмента компонента вида карты глубины из элементов синтаксиса совместно размещенного компонента вида текстуры. Флаг pred_default_syntax_flag логически выводится равным 0, если pred_slice_header_colocated_idc равен 0. Когда pred_slice_header_colocated_idc равен 3, и pred_default_syntax_flag равен 1 в этом примере, first_tb_in_slice равен 0.
|
|
|
[0139] Следует отметить, что когда активируется прогнозирование заголовков фрагментов, имеется такая предпосылка, что если фрагмент A основан на фрагменте B, учитывая, что один из фрагмента A или B является фрагментом глубины, а другой является фрагментом текстуры, и они принадлежат виду идентичного момента времени, удовлетворяется одно из следующего: все фрагменты в изображении, содержащем фрагмент B, имеют идентичный заголовок фрагмента; любой MB в фрагменте A имеет совместно размещенный MB в фрагменте B; или если какой-либо MB в фрагменте A имеет совместно размещенный MB в фрагменте C изображения, содержащего фрагмент B, фрагмент C должен иметь заголовок фрагмента, идентичный заголовку фрагмента для фрагмента B.
[0140] Альтернативно, другая реализация описанной технологии может заключаться в следующем для компонента вида глубины. Таблица 6 предоставляет пример расширения глубины заголовка фрагмента.
|
|
[0141] В этом примере, элемент sameRefPicList синтаксиса извлекается или передается в служебных сигналах на уровне SPS или PPS. Например, disable_depth_inter_view_flag, передаваемый в служебных сигналах в SPS, указывает то, деактивировано или нет межвидовое прогнозирование для глубины.
[0142] Для компонента вида текстуры другая реализация описанной технологии может быть такой, как показано в таблице 7. В этом примере, элементы синтаксиса для заголовка фрагмента текстуры для компонентов видов текстуры могут быть прогнозированы из коррелированных элементов синтаксиса для заголовка фрагмента глубины для компонентов видов глубины.
|
|
[0143] Аналогично, в этом примере, элемент sameRefPicList синтаксиса извлекается или передается в служебных сигналах на уровне SPS или PPS.
[0144] Альтернативно, такой флаг может быть явно передан в служебных сигналах в заголовке фрагмента, как показано в таблице 8.
|
|
[0145] Элемент синтаксиса, slice_header_prediction_flag, указывает то, обеспечивается или нет прогнозирование заголовков фрагментов из текстуры в глубину или из глубины в текстуру. Иными словами, по меньшей мере, один из фрагмента текстуры или фрагмента глубины содержит элемент синтаксиса, который указывает то, осуществляется прогнозирование заголовков фрагментов из заголовка фрагмента текстуры в заголовок фрагмента глубины или из заголовка фрагмента глубины в заголовок фрагмента текстуры.
[0146] Альтернативно, флаги уровня фрагмента или другие индикаторы указывают то, до какой степени применяется прогнозирование фрагмента. Примеры этих индикаторов включают в себя то, прогнозируются или нет элементы синтаксиса для составления списков опорных изображений, прогнозируется или нет slice_qp_delta, и прогнозируются или нет взвешенные прогнозные элементы синтаксиса.
[0147] В некоторых примерах, также указывается то, прогнозируются или нет связанные с контурным фильтром элементы синтаксиса. Если связанные с контурным фильтром элементы синтаксиса не прогнозируются, дополнительный флаг для того, чтобы указывать то, присутствуют или нет эти элементы синтаксиса, включается в заголовок фрагмента глубины.
[0148] Альтернативно, другой флаг, используемый для того, чтобы передавать в служебных сигналах фильтр удаления блочности, deblocking_pred_flag, может быть использован вместо pred_default_syntax_flag или pred_slice_header_colocated_idc для параметров фильтра удаления блочности. Этот флаг передается в служебных сигналах в идентичном заголовке фрагмента или PPS, или SPS. Таблица 9 показывает примерную синтаксическую таблицу заголовка фрагмента для компонента вида глубины на основе HEVC. В контексте HEVC ALF-параметры компонента вида глубины, как предполагается, не являются идентичными ALF-параметрам соответствующего компонента вида текстуры, если только ALF не используется как для компонента вида текстуры, так и для компонента вида глубины.
|
[0149] Фиг. 5 является блок-схемой, подробнее иллюстрирующей пример видеодекодера 28 по фиг. 1, согласно технологиям настоящего раскрытия сущности. Видеодекодер 28 является одним примером специализированного компьютерного видеоустройства или аппарата, упоминаемого в данном документе как "кодер". Как показано на фиг. 5, видеодекодер 28 соответствует видеодекодеру 28 целевого устройства 14. Тем не менее, в других примерах, видеодекодер 28 соответствует другому устройству. В дополнительных примерах, другие модули (такие как, например, другие кодеры/декодеры (кодеки)) также могут осуществлять технологии, аналогичные технологиям видеодекодера 28.
[0150] Видеодекодер 28 включает в себя модуль 52 энтропийного декодирования, который энтропийно декодирует принимаемый поток битов, чтобы формировать квантованные коэффициенты и элементы синтаксиса прогнозирования. Поток битов включает в себя кодированные блоки, имеющие компоненты текстуры и компонент глубины для каждого пиксельного местоположения, чтобы подготавливать посредством воспроизведения трехмерное видео и элементы синтаксиса. Прогнозные элементы синтаксиса включают в себя, по меньшей мере, одно из режима кодирования, одного или более векторов движения, информации, идентифицирующей используемую технологию интерполяции, коэффициентов для использования в интерполяционной фильтрации и другой информации, ассоциированной с формированием прогнозного блока.
[0151] Прогнозные элементы синтаксиса, например коэффициенты, перенаправляются в процессор 55 прогнозирования. Процессор 55 прогнозирования включает в себя модуль 66 прогнозирования синтаксиса глубины. Если прогнозирование используется для того, чтобы кодировать коэффициенты относительно коэффициентов неперестраиваемого фильтра либо относительно друг друга, процессор 55 прогнозирования декодирует элементы синтаксиса, чтобы задавать фактические коэффициенты. Модуль 66 прогнозирования синтаксиса глубины прогнозирует элементы синтаксиса глубины для компонентов видов глубины из элементов синтаксиса текстуры для компонентов видов текстуры.
[0152] Если квантование применяется к какому-либо из прогнозных элементов синтаксиса, модуль 56 обратного квантования удаляет такое квантование. Модуль 56 обратного квантования может обрабатывать компоненты глубины и текстуры для каждого пиксельного местоположения кодированных блоков в кодированном потоке битов по-разному. Например, когда компонент глубины квантован отлично от компонентов текстуры, модуль 56 обратного квантования обрабатывает компоненты глубины и текстуры отдельно. Коэффициенты фильтрации, например, могут прогнозирующе кодироваться и квантоваться согласно этому раскрытию сущности, и в этом случае модуль 56 обратного квантования используется посредством видеодекодера 28 для того, чтобы прогнозирующе декодировать и деквантовать такие коэффициенты.
[0153] Процессор 55 прогнозирования формирует прогнозирующие данные на основе прогнозных элементов синтаксиса и одного или более ранее декодированных блоков, которые сохраняются в запоминающем устройстве 62, почти идентично тому, как подробно описано выше относительно процессора 32 прогнозирования видеокодера 22. В частности, процессор 55 прогнозирования выполняет одну или более технологий многовидового видео плюс глубины этого раскрытия сущности в ходе компенсации движения для того, чтобы формировать компоненты глубины включения прогнозного блока, а также компоненты текстуры. Прогнозный блок (а также кодированный блок) может иметь различное разрешение для компонентов глубины в сравнении с компонентами текстуры. Например, компоненты глубины имеют четвертьпиксельную точность, в то время как компоненты текстуры имеют полнопиксельную точность. По сути, одна или более технологий этого раскрытия сущности используются посредством видеодекодера 28 при формировании прогнозного блока. В некоторых примерах, процессор 55 прогнозирования может включать в себя модуль компенсации движения, который содержит фильтры, используемые для технологий интерполяционной и аналогичной интерполяционной фильтрации этого раскрытия сущности. Компонент компенсации движения не показан на фиг. 5 для простоты и удобства иллюстрации.
[0154] Модуль 56 обратного квантования обратно квантует, т.е. деквантует квантованные блочные коэффициенты. Процесс обратного квантования является процессом, заданным для декодирования H.264 или для любого другого стандарта декодирования. Процессор 58 обратного преобразования применяет обратное преобразование, к примеру, обратное DCT или концептуально аналогичный процесс обратного преобразования, к коэффициентам преобразования, чтобы формировать остаточные блоки в пиксельной области. Сумматор 64 суммирует остаточный блок с соответствующим прогнозным блоком, сформированным посредством процессора 55 прогнозирования, для того чтобы формировать восстановленную версию исходного блока, кодированного посредством видеокодера 22. Если требуется, фильтр удаления блочности также применяется для того, чтобы фильтровать декодированные блоки, чтобы удалять артефакты блочности. Декодированные видеоблоки затем сохраняются в запоминающем устройстве 62, которое предоставляет опорные блоки для последующей компенсации движения, а также формирует декодированное видео, чтобы возбуждать дисплейное устройство (такое как устройство 28 по фиг. 1).
[0155] Декодированное видео может быть использовано для того, чтобы подготавливать посредством воспроизведения трехмерное видео. Трехмерное видео может содержать трехмерный виртуальный вид. Информация глубины используется для того, чтобы определять горизонтальное смещение (горизонтальную диспаратность) для каждого пиксела в блоке. Обработка затемнения также может быть выполнена для того, чтобы формировать виртуальный вид. Элементы синтаксиса для компонентов видов глубины могут быть прогнозированы из элементов синтаксиса для компонентов видов текстуры.
[0156] Фиг. 6 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу видеодекодера, согласно технологиям настоящего раскрытия сущности. Процесс по фиг. 6 может рассматриваться процессом взаимно-обратного декодирования относительно процесса кодирования по фиг. 4. Фиг. 6 описывается с точки зрения видеодекодера 28 по фиг. 5, хотя другие устройства могут выполнять аналогичные технологии.
[0157] Видеодекодер, к примеру, видеодекодер 28, принимает фрагмент текстуры для компонента вида текстуры, ассоциированного с одним или более кодированных блоков видеоданных, представляющих информацию текстуры, по меньшей мере, части кадра видеоданных, причем фрагмент текстуры содержит кодированные один или более блоков и заголовок фрагмента текстуры, содержащий элементы синтаксиса, представляющие характеристики фрагмента текстуры (122). Видеодекодер принимает фрагмент глубины для компонента вида глубины, соответствующего компоненту вида текстуры, причем фрагмент глубины содержит кодированную информацию глубины и заголовок фрагмента глубины, содержащий, по меньшей мере, один элемент синтаксиса, представляющий характеристики фрагмента глубины, за исключением значений для элементов синтаксиса, которые являются общими для фрагмента глубины и фрагмента текстуры (124). Видеодекодер прогнозирует элементы синтаксиса, по меньшей мере, для одной из фрагмента глубины или фрагмента текстуры из значений для элементов синтаксиса, которые являются общими для фрагмента глубины и фрагмента текстуры (126).
[0158] В других примерах, по меньшей мере, один элемент синтаксиса глубины определяется и передается в служебных сигналах в заголовке фрагмента компонента вида глубины. По меньшей мере, один элемент синтаксиса глубины включает в себя, по меньшей мере, одно из идентификатора набора параметров изображения, разности параметров квантования между параметром квантования фрагмента и параметром квантования, передаваемым в служебных сигналах в наборе параметров изображения, начальной позиции единицы кодированного блока, порядка опорных изображений и порядка отображения текущего изображения компонента вида глубины. Начальная позиция единицы кодированного блока определяется равной нулю, когда начальная позиция кодированного блока не передается в служебных сигналах в заголовке фрагмента текстуры или заголовке фрагмента глубины. Параметр контурного фильтра, по меньшей мере, для одного компонента вида текстуры может быть передан в служебных сигналах, как и набор флагов, который указывает то, что параметр контурного фильтра, используемый для компонента вида глубины, является идентичным параметру контурного фильтра, по меньшей мере, для одного компонента вида текстуры.
[0159] В другом примере, видеодекодер 28 прогнозирует компонент вида текстуры с использованием технологий межвидового прогнозирования и прогнозирует компонент вида глубины с использованием технологий внутривидового прогнозирования. Видеодекодер 28 принимает заголовок фрагмента глубины, который дополнительно содержит элементы синтаксиса, представляющие составление списков опорных изображений для компонента вида глубины. В примере, в котором компонент вида текстуры и компонент вида глубины соответствуют первому виду, декодирование компонента вида текстуры включает в себя прогнозирование, по меньшей мере, части компонента вида текстуры относительно данных второго вида. Второго вид отличается от первого вида. В некоторых примерах, декодирование компонента вида глубины может включать в себя прогнозирование, по меньшей мере, части компонента вида глубины относительно данных первого вида.
[0160] В одном или более примеров, описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или любой комбинации вышеозначенного. При реализации в программном обеспечении, функции могут быть сохранены или переданы, в качестве одной или более инструкций или кода, по машиночитаемому носителю и выполнены посредством аппаратного процессора. Машиночитаемые носители могут включать в себя машиночитаемые носители хранения данных, которые соответствуют материальному носителю, такие как носители хранения данных, или среды связи, включающие в себя любой носитель, который упрощает перенос компьютерной программы из одного места в другое, например, согласно протоколу связи. Таким образом, машиночитаемые носители, в общем, могут соответствовать (1) материальному машиночитаемому носителю хранения данных, который является энергонезависимым, или (2) среде связи, такой как сигнал или несущая. Носители хранения данных могут быть любыми доступными носителями, к которым может осуществляться доступ посредством одного или более компьютеров или одного или более процессоров, с тем чтобы извлекать инструкции, код и/или структуры данных для реализации технологий, описанных в этом раскрытии сущности. Компьютерный программный продукт может включать в себя машиночитаемый носитель.
[0161] В качестве примера, а не ограничения, эти машиночитаемые носители хранения данных могут содержать RAM, ROM, EEPROM, CD-ROM или другое устройство хранения на оптических дисках, устройство хранения на магнитных дисках или другие магнитные устройства хранения, флэш-память либо любой другой носитель, который может быть использован для того, чтобы сохранять требуемый программный код в форме инструкций или структур данных, и к которому можно осуществлять доступ посредством компьютера. Так же, любое подключение корректно называть машиночитаемым носителем. Например, если инструкции передаются из веб-узла, сервера или другого удаленного источника с помощью коаксиального кабеля, оптоволоконного кабеля, "витой пары", цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасные, радиопередающие и микроволновые среды, то коаксиальный кабель, оптоволоконный кабель, "витая пара", DSL или беспроводные технологии, такие как инфракрасные, радиопередающие и микроволновые среды, включаются в определение носителя. Тем не менее, следует понимать, что машиночитаемые носители хранения данных и носители хранения данных не включают в себя соединения, несущие, сигналы или другие энергозависимые носители, а вместо этого направлены на энергонезависимые материальные носители хранения данных. Диск (disk) и диск (disc) при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск Blu-Ray, при этом диски (disk) обычно воспроизводят данные магнитно, тогда как диски (disc) обычно воспроизводят данные оптически с помощью лазеров. Комбинации вышеперечисленного также следует включать в число машиночитаемых носителей.
[0162] Инструкции могут выполняться посредством одного или более процессоров, например, одного или более процессоров цифровых сигналов (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) либо других эквивалентных интегральных или дискретных логических схем. Соответственно, термин "процессор" при использовании в данном документе может означать любую вышеуказанную структуру или другую структуру, подходящую для реализации технологий, описанных в данном документе. Помимо этого, в некоторых аспектах функциональность, описанная в данном документе, может быть предоставлена в пределах специализированных программных и/или аппаратных модулей, выполненных с возможностью кодирования или декодирования либо встроенных в комбинированный кодек. Кроме того, технологии могут быть полностью реализованы в одной или более схем или логических элементов.
[0163] Технологии этого раскрытия сущности могут быть реализованы в широком спектре устройств или приборов, в том числе в беспроводном переносном телефоне, в интегральной схеме (IC) или в наборе IC (к примеру, в наборе микросхем). Различные компоненты, модули или блоки описываются в этом раскрытии сущности для того, чтобы подчеркивать функциональные аспекты устройств, выполненных с возможностью осуществлять раскрытые технологии, но не обязательно требуют реализации посредством различных аппаратных модулей. Наоборот, как описано выше, различные модули могут быть комбинированы в аппаратный модуль кодека или предоставлены посредством набора взаимодействующих аппаратных модулей, включающих в себя один или более процессоров, как описано выше, в сочетании с надлежащим программным обеспечением и/или микропрограммным обеспечением.
[0164] Описаны различные примеры раскрытия сущности. Эти и другие примеры находятся в пределах объема прилагаемой формулы изобретения.
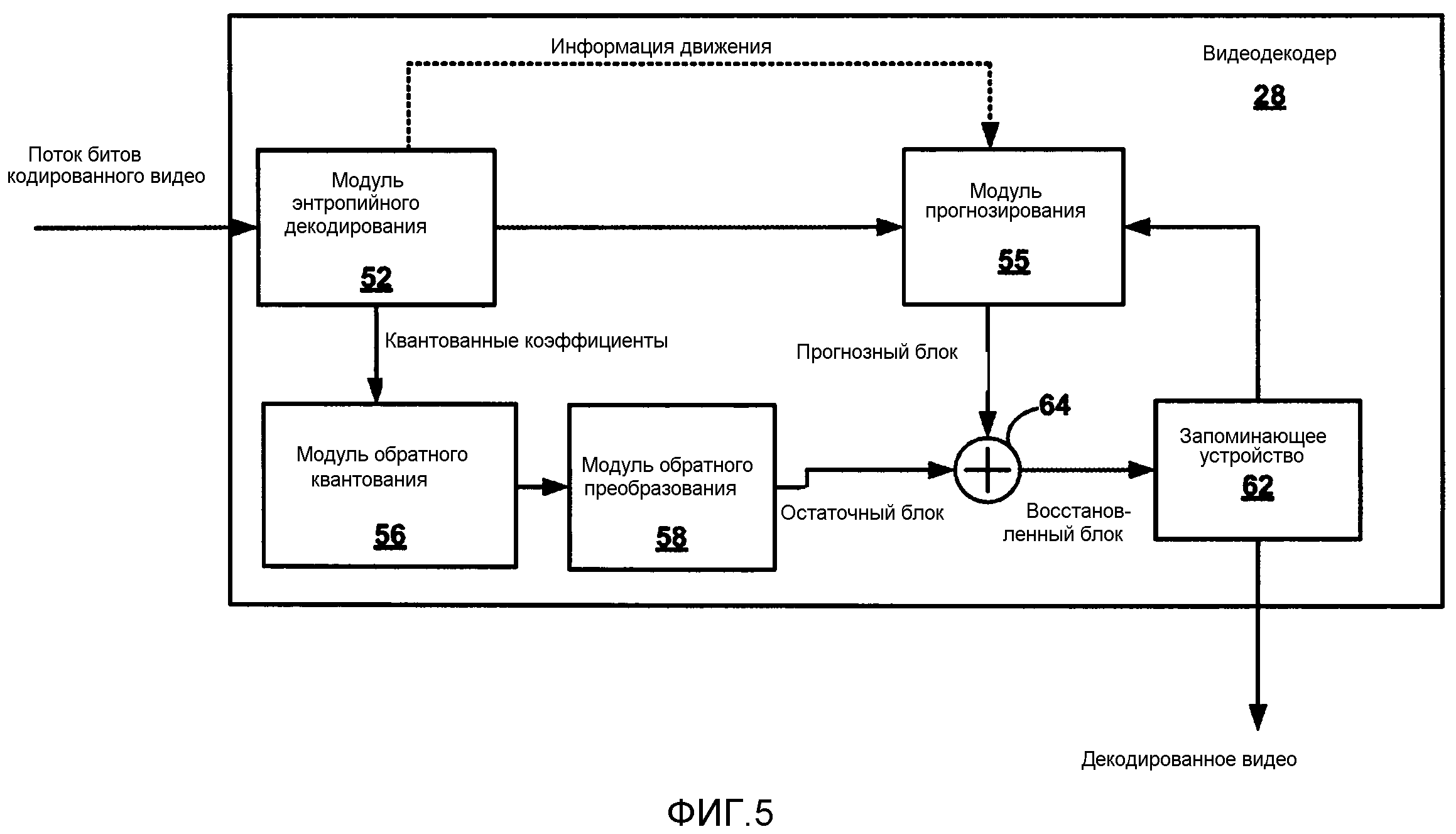
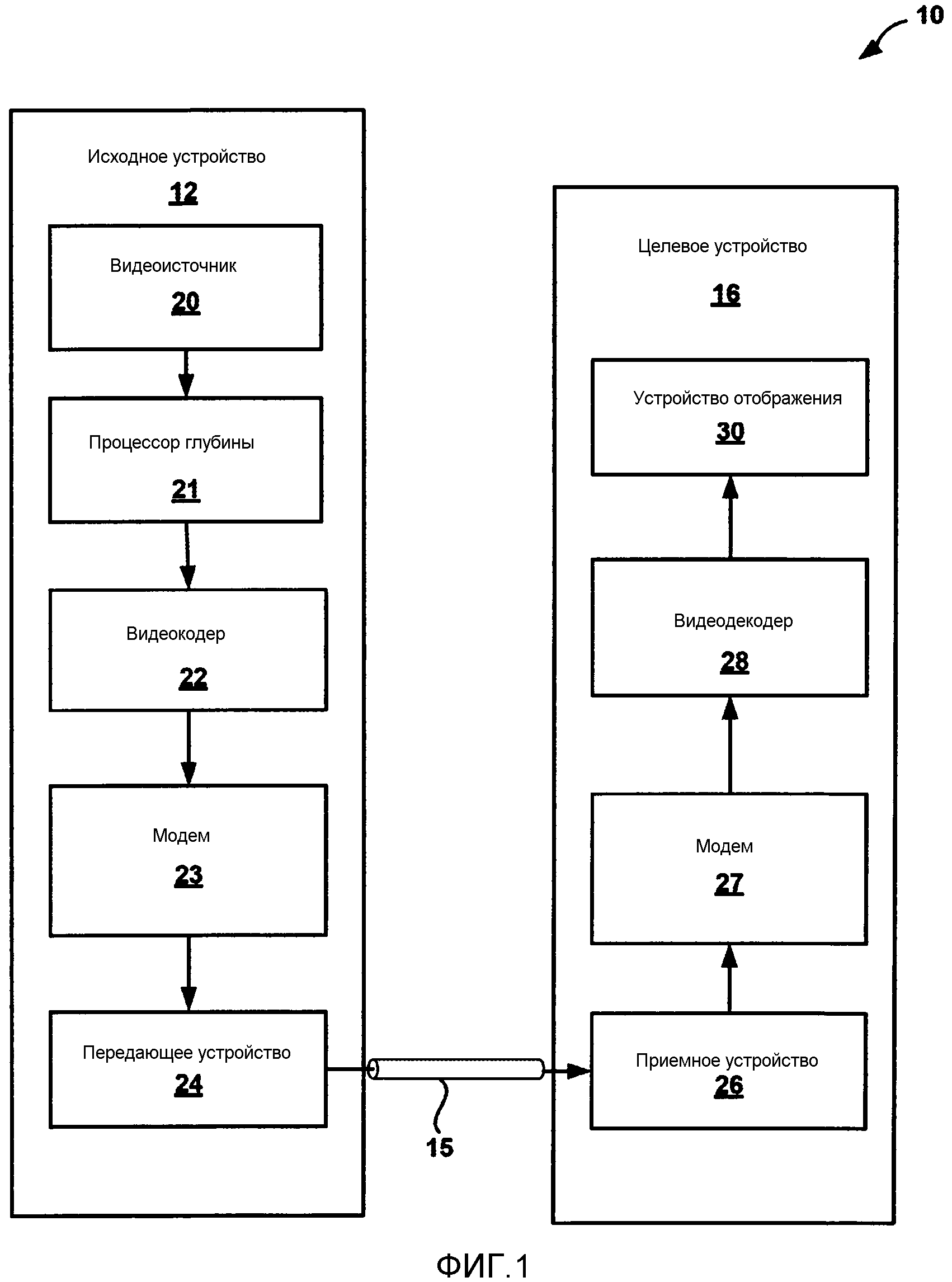
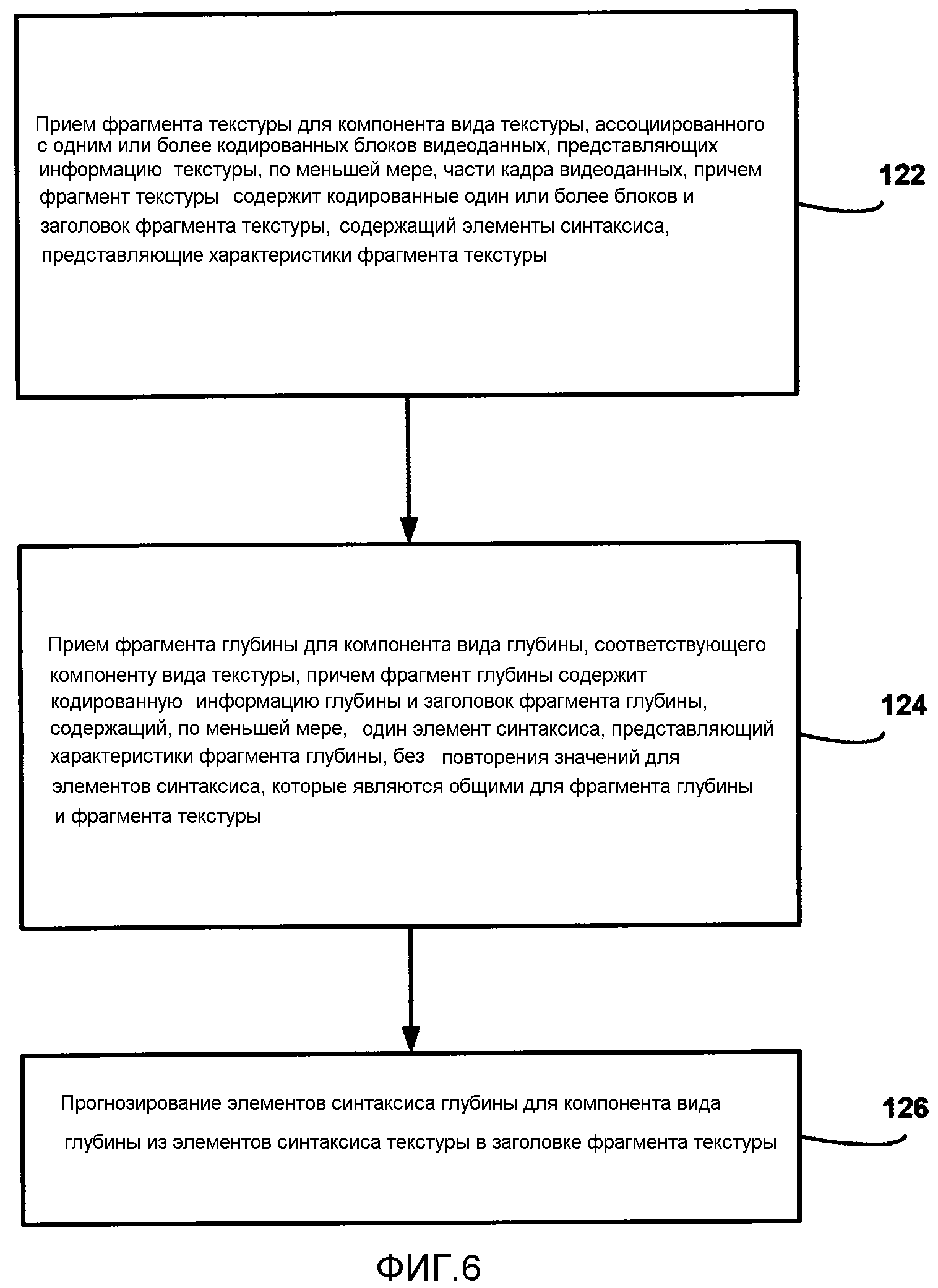
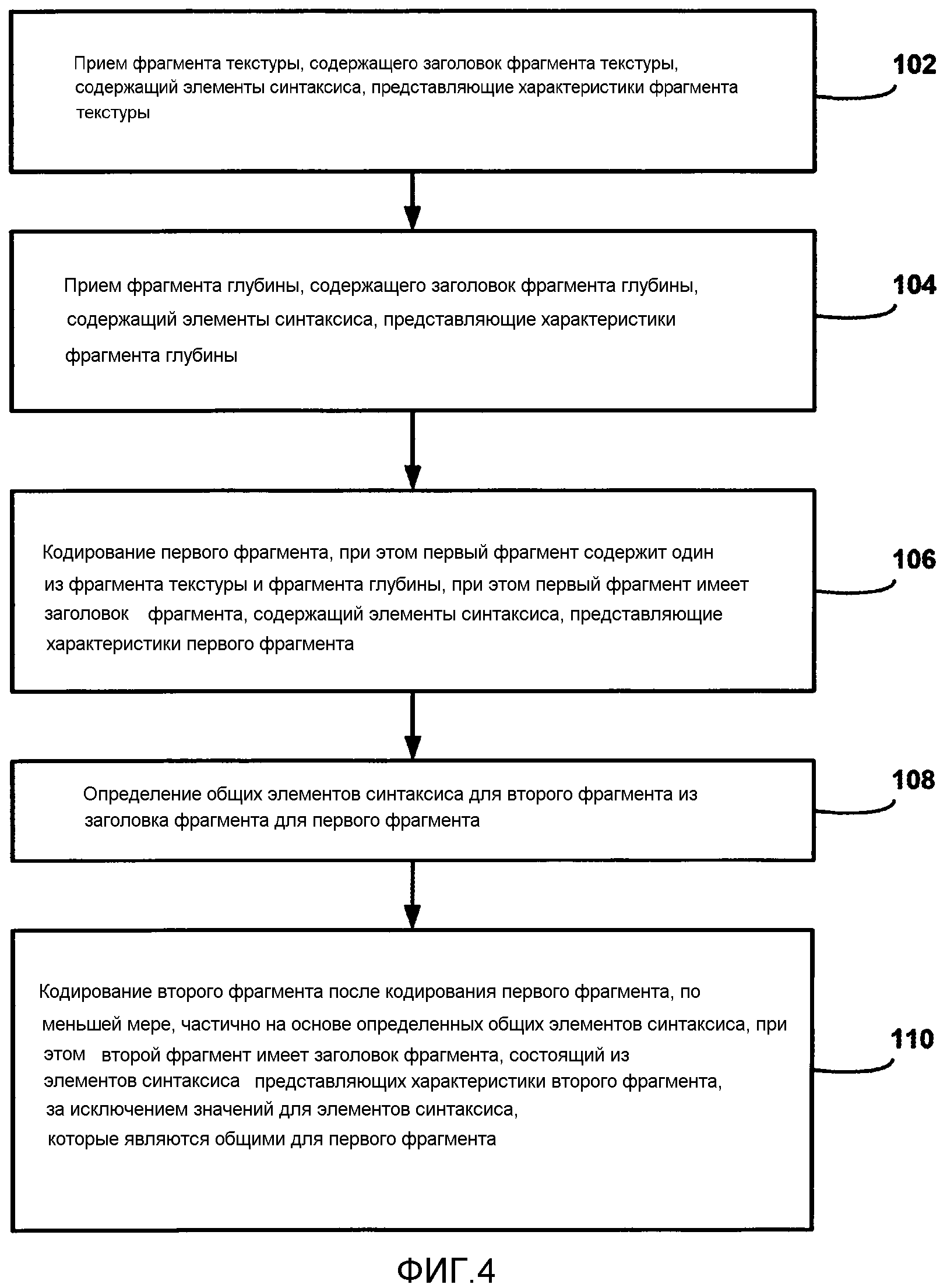
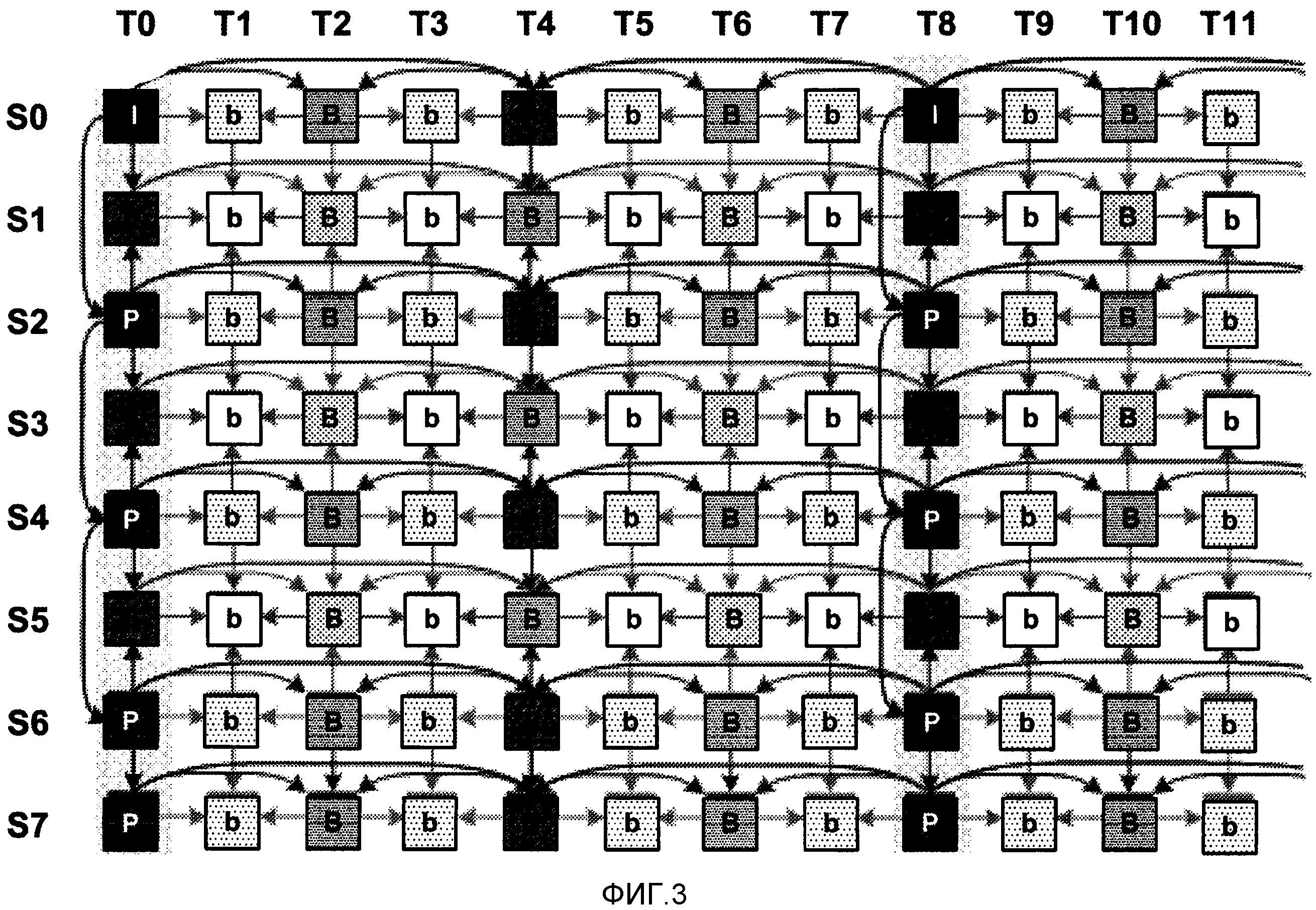
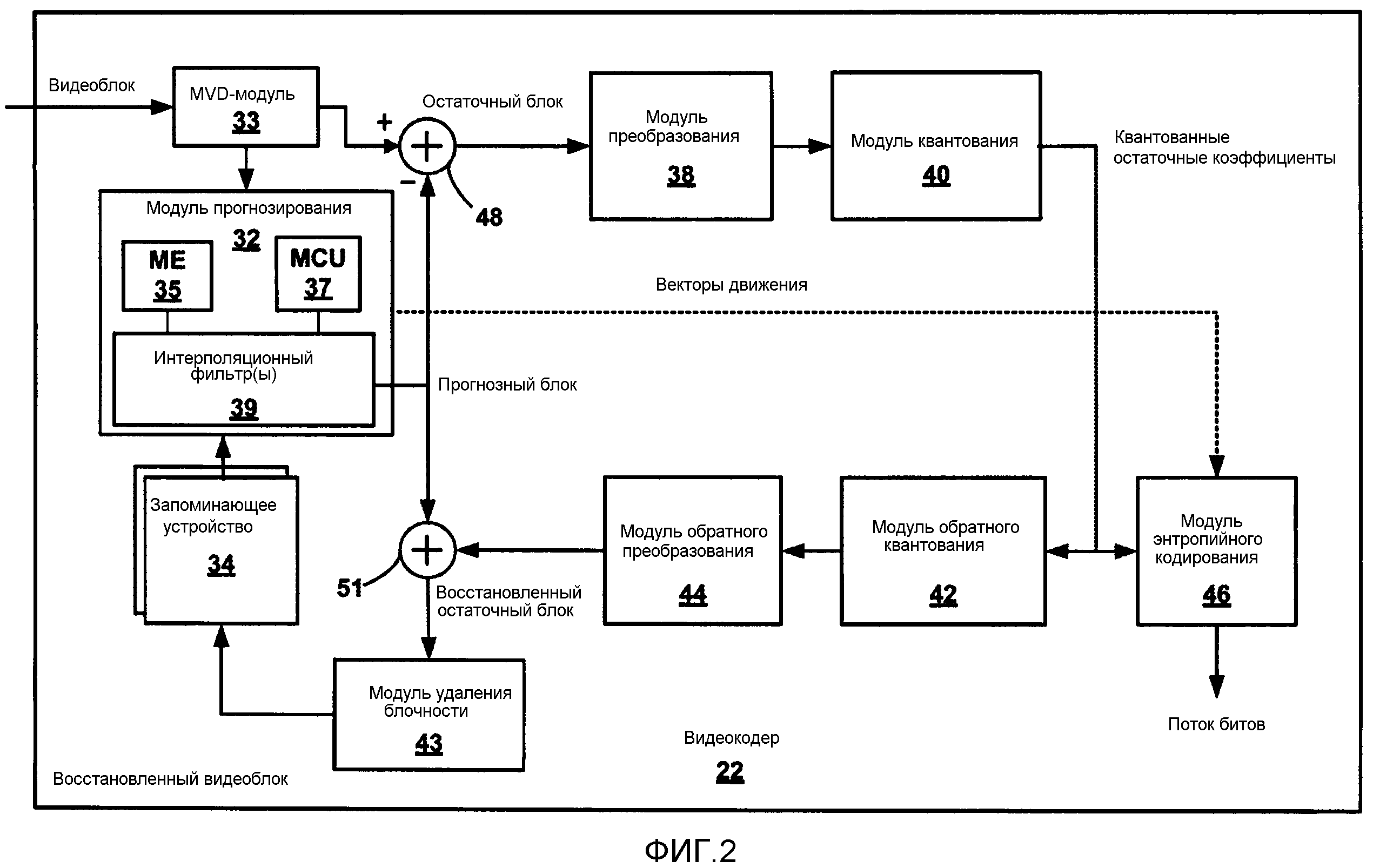
Обнаружение многолучевого распространения для принимаемого sps-сигнала
Способ для указания местоположения и направления элемента графического пользовательского интерфейса
Виртуальное планирование в неоднородных сетях
Кодирование и мультиплексирование управляющей информации в системе беспроводной связи
Система беспроводной связи с конфигурируемой длиной циклического префикса
Способ и устройство для осуществления информационного запроса сеанса для определения местоположения плоскости пользователя
Универсальная корректировка блочности изображения
Основанная на местоположении и времени фильтрация информации широковещания
Способ и устройство для поддержки экстренных вызовов (ecall)
Виртуальная sim-карта для мобильных телефонов
Обнаружение многолучевого распространения для принимаемого sps-сигнала
Способ для указания местоположения и направления элемента графического пользовательского интерфейса
Виртуальное планирование в неоднородных сетях
Кодирование и мультиплексирование управляющей информации в системе беспроводной связи
Система беспроводной связи с конфигурируемой длиной циклического префикса
Способ и устройство для осуществления информационного запроса сеанса для определения местоположения плоскости пользователя
Универсальная корректировка блочности изображения
Основанная на местоположении и времени фильтрация информации широковещания
Способ и устройство для поддержки экстренных вызовов (ecall)
Виртуальная sim-карта для мобильных телефонов

