СИСТЕМА И СПОСОБ РАСПРЕДЕЛЕННЫХ ВЫЧИСЛЕНИЙ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Изобретение относится к сильно-связанным многопроцессорным и распределенным вычислительным системам и, в частности, определяет требования к устройству системы, к коду распределенного приложения, к организации памяти и к последовательности действий при распределенном исполнении приложения.
Уровень техники
Разработка распределенных приложений является существенно более сложной, по сравнению с разработкой нераспределенных приложений. Можно выделить две основные причины этого:
1) Рассматривая приложение как конечный автомат с определенной логикой переходов из одного состояния в другое, можно утверждать, что распределенное приложение имеет очень сложное и зачастую непредсказуемое глобальное состояние.
2) Для взаимодействия между отдельными узлами требуется разработка протокола взаимодействия приложений. Учитывая первый пункт, из этого следует, что сложность логики такого протокола, которая будет работать с приемлемой надежностью, сильно ограничена. Это означает, что функционал распределенного приложения должен быть достаточно простой, и его усложнение ведет к нелинейному росту сложности разработки.
Указанные причины особенно актуальны в слабосвязанных распределенных системах, основанных на обмене сообщениями между независимо разрабатываемыми составными частями.
Одним из решений указанных проблем можно рассматривать мобильные агенты, вариант реализации которых приведен в патенте "System and method for distributed computation based upon the movement, execution and interaction of processes in a network", US 5603031, James E. White et al., Feb.11, 1997. Это решение основано на перемещении мобильного кода и агентов, которые имеют одну логику исполнения на разных узлах. Предлагаемая этим патентом вычислительная модель сильно ограничена и в основном хорошо работает при однопоточном распределенном исполнении. Модель взаимодействия агентов тоже малофункциональна. Инструкция передачи управления "Go", предлагаемая в патенте, определяет только узел, на котором должен выполняться агент, а точка запуска фиксируется при компиляции.
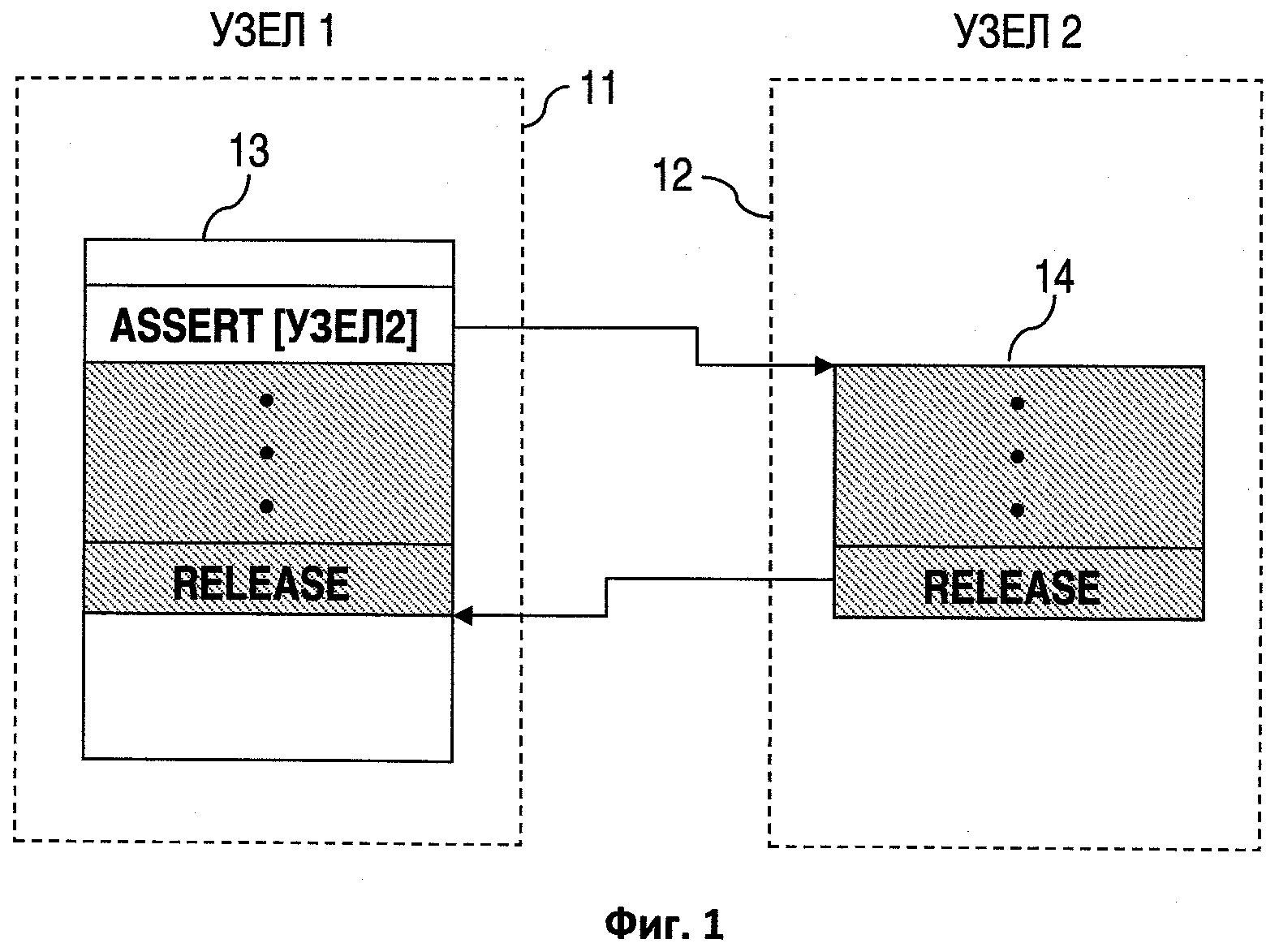
Другой вариант решения указанных проблем приведен в патенте "Computerised method and system for implementing distributed application", US 6694370, Joerg Bischofet al., Feb. 17, 2004, который выбран прототипом заявляемого изобретения. Данное решение основано на делении последовательности инструкций приложения на блоки, которые должны выполняться на разных узлах сети. Каждый участок начинается с инструкции, которая позволяет динамически вычислить узел, на который необходимо перенести и выполнить участок кода, следующий за этой инструкцией. На фиг.1 приведена схема применения указанного прототипа. Здесь 11, 12 - узлы, на которых исполняется распределенное приложение. 13 - последовательность инструкций, загруженных на узле 11, 14 - инструкции, которые должны быть выполнены на узле 12. Инструкция ASSERT определяет, на каком узле должна быть выполнена следующая инструкция. Инструкция RELEASE указывает на то, что следующая инструкция может быть выполнена на любом узле (на рисунке управление возвращается на исходный узел).
Недостатками прототипа являются:
1) Несоответствие общепринятой модели разработки программ, заключающейся в выделении участков кода с определенной функциональностью в процедуры, которые размещаются в произвольном месте исполняемого файла и могут вызываться из произвольного места программы. Процедуры также могут принимать различные параметры и возвращать значения, чего нет в рассматриваемом прототипе. Это несоответствие делает возможным применения патента - прототипа только в относительно простых приложениях.
2) Для разработки программы необходим специальной компилятор и компоновщик, поддерживающие эту технологию, а также специальный загрузчик кода для исполнения приложений. Для интерпретируемых приложений данная технология должна поддерживаться на уровне интерпретатора.
3) Патент ограничивается рассмотрением последовательностей инструкции, которые выполняются на различных узлах сети.
Раскрытие изобретения
Заявляемое изобретение решает следующие задачи:
1) Распределенное приложение может работать как на одном, так и на многих узлах, при этом количество и состав узлов, на которых исполняется приложение, может изменяться во время исполнения программы.
2) Код исполняемого файла, загруженный на одном из узлов системы, может удаленно вызвать любую процедуру, входящую в состав этого файла, на любом другом узле системы. При этом последовательность удаленных вызовов может быть любой и разработка протокола взаимодействия не требуется.
3) Распределенное приложение имеет предсказуемое глобальное состояние и приемлемую сложность разработки.
4) При разработке приложения может быть использован стандартный компилятор, который ничего не знает о распределенном исполнении приложения, например, со стандартного языка C++, и стандартный компоновщик. Как следствие, такое приложение можно загружать стандартным загрузчиком операционной системы или среды исполнения.
Общая идея изобретения заключается в том, что если на два или более компьютера загружена копия одной и той же программы, эти компьютеры превращаются в распределенную систему для исполнения этой программы. Далее будут описаны требования к коду такой программы и к тому, как указанные компьютеры должны взаимодействовать друг с другом.
Заявляемое изобретение может быть использовано для разработки программ, содержащих натуральные инструкции процессора, и выполняться в среде операционной системы, или содержать промежуточный код и выполняться на виртуальной машине, или состоять из интерпретируемых инструкций.
Система в соответствии с настоящим изобретением может быть реализована аппаратно или представлять собой реализованные программно виртуальные машины, исполняющие промежуточный код или интерпретируемые инструкции.
Настоящее изобретение опирается на модель, по которой исполнительный модуль-процессор выполняет инструкции программы, которые расположены в модуле памяти этого процессора. В памяти также могут быть расположены данные, с которыми процессор выполняет вычисления. Отдельным исполнительным модулем может быть ядро в многоядерном процессоре, или процессор в многопроцессорной системе, или отдельный компьютер, подключенный к сети, или реализованная программно виртуальная система времени выполнения, работающая на некотором вычислительном устройстве. Так же возможно локальное взаимодействие между программами, загруженными на одном процессоре в разные адресные пространства. При этом каждое адресное пространство рассматривается как отдельно адресуемый виртуальный процессор. Логика изобретения не меняется от типа исполнительного модуля, и разные типы исполнительных модулей могут взаимодействовать в рамках исполнения одного распределенного приложения. Процессор может быть только один, или их может быть несколько. Если система содержит несколько процессоров, то с точки зрения заявляемого изобретения не имеет существенного значения, имеет каждой процессор свой модуль памяти или модуль памяти общий у некоторого подмножества процессоров, так как в каждый модуль памяти загружена копия одной и той же программы. Для изобретения способ взаимодействия между процессорами также является несущественным. Это могут быть средства межпроцессорной связи в многопроцессорной системе, или средства сетевого взаимодействия, или комбинация этих способов. Ключевым является возможность идентификации отдельного процессора или группы процессоров при групповой адресации. Для идентификации процессоров может быть использован номер процессора, его сетевой адрес, некоторая структура данных, или это может быть идентификатор, определяющий не адрес, а функциональное назначение процессора. Также возможен специальный идентификатор или специальная инструкция, указывающая на то, что процессор может быть выбран произвольно на основании текущего состояния системы. Общая логика изобретения подразумевает, что процессоры должны взаимодействовать каждый с каждым. Тем не менее, возможно отсутствие некоторых связей. При использовании отсутствующих связей в программе возможна сигнализация через программные исключения. Кроме этого, возможно функциональное разделение процессоров, например, на клиентов и сервер. При этом клиент может вызывать процедуры сервера, а вызов процедур клиента со стороны сервера может быть ограничен или невозможен из соображений безопасности.
Основное отличие рассматриваемого в изобретении распределенного приложения заключается в наличии одного явного или неявного дополнительного параметра в инструкциях передачи управления. Обычная инструкция передачи управления, такая как инструкция условного или безусловного перехода, перехода с возвратом или вызова процедуры, содержит один обязательный параметр - прямой или косвенный указатель на инструкцию, которую следует выполнить следующей (безусловно, или при определенном условии). На языке высокого уровня это обычно метка или имя процедуры, для которой компоновщик может вычислить относительный адрес в результирующем исполняемом файле или этот адрес будет находиться в определенной таблице, размещаемой в таком файле. Так же адрес инструкции может быть ассоциативным. При исполнении программы физический адрес этой инструкции может быть вычислен через смещение от начала исполняемого файла либо взят из таблицы, положение которой в файле обычно фиксировано. При этом данные, на основании которых вычисляется физический адрес, будут одни и те же на всех узлах, на которых загружена копия приложения. Таким образом, если в инструкцию передачи управления добавить еще один параметр - адрес или идентификатор процессора, на котором эту инструкцию следует выполнить, можно организовать распределенное исполнение приложения. Для этого логика взаимодействия между процессорами должна решать следующие задачи:
1) Принимать от одного процессора параметры инструкций передачи управления и передавать их процессору-получателю управления.
2) Инициировать выполнение вычислительного потока с определенной инструкции на процессоре-получателе управления.
В общем случае, адрес процессора в такой инструкции передачи управления может отсутствовать в явном виде. При этом инструкция будет подразумевать, что адрес процессора должен быть вычислен на основании текущего состояния системы или дополнительных параметров вызова.
В зависимости от конкретной архитектуры, процессоры могут обмениваться данными через общую память и/или через обмен сообщениями. Так как удаленный вызов и исполнение процедуры выполняет копия одной программы, согласования формата параметров вызова и возвращаемого значения не требуется. Можно передавать сообщение, содержащее относительный адрес инструкции, с двоичной копией кадра стека, либо приложение может использовать свой алгоритм упаковки сообщения, в общем случае, уникальный для этого приложения. При этом упаковку и распаковку сообщения может выполнять код самого приложения, аналогично тому, как это происходит при передаче параметров через стек при локальных вызовах.
Обычно код процедуры создается таким образом, чтобы процедуру можно было вызвать из любого места программы. Контекст выполнения потока управления не является особенным для этой процедуры, но могут быть исключения (например, для инструкций перехода). Для таких исключений процессоры должны обмениваться не только параметрами вызова, но и контекстом выполнения.
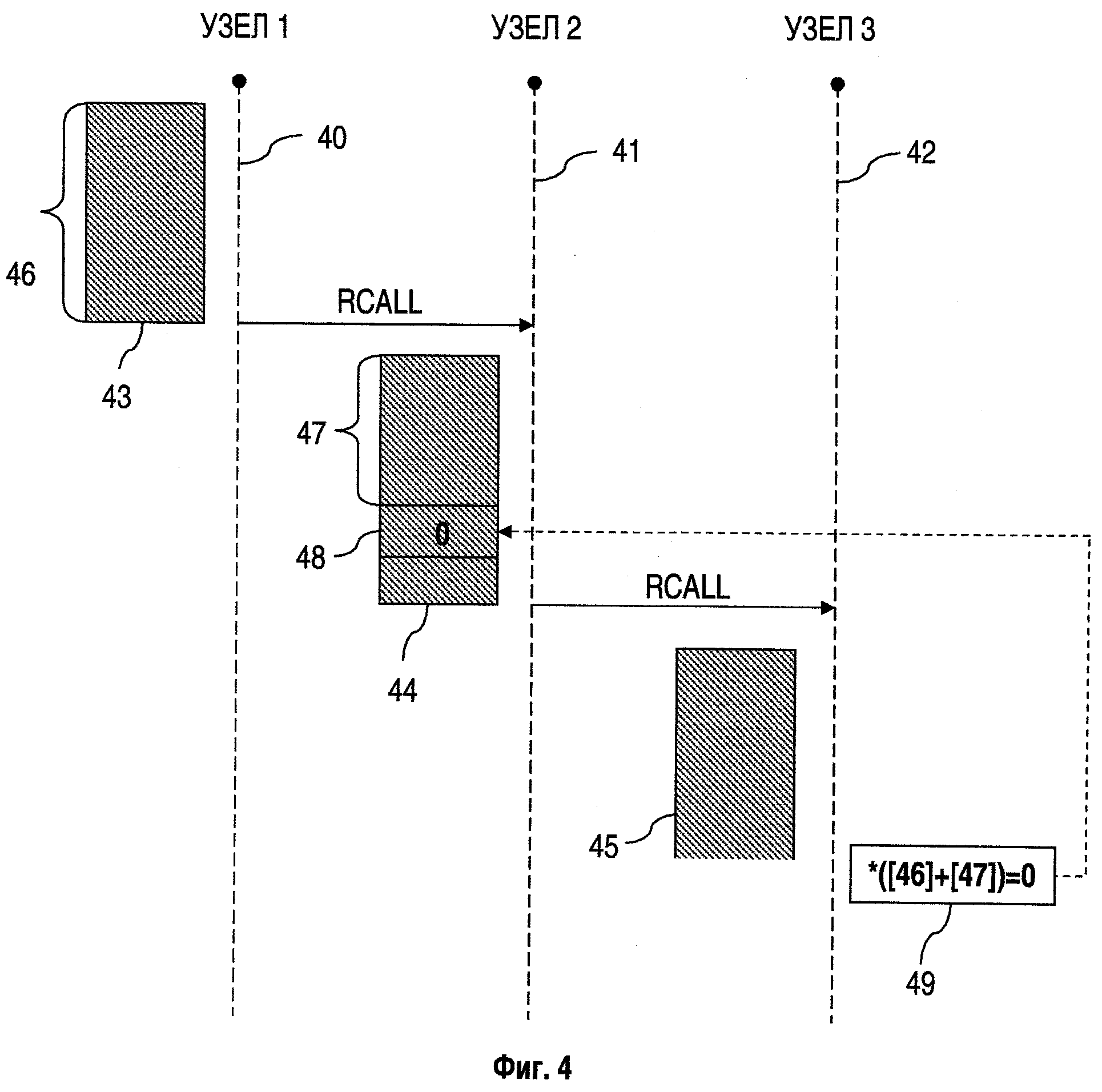
На фиг.2 показано выполнение инструкции вызова процедуры в соответствии с заявляемым изобретением (для простоты отображения инструкция не имеет параметров и возвращаемого значения). Распределенное приложение выполняется на двух узлах. Здесь 21 и 22 - узлы, на которых выполняется приложение, 23 и 24 - копии исполняемого файла программы, загруженной на этих узлах, 25 - смещение от начала исполняемого файла для вызываемой процедуры, 26 - инструкция вызова процедуры, условно названная RCALL, 27 - инструкции возврата из процедуры. Приведенная в качестве примера идентификация процедуры в удаленном вызове по относительному адресу в исполняемом файле является простой и универсальной, но не безопасной, так как позволяет выполнить удаленный вызов любого кода в приложении. Возможным вариантом может быть преобразование адреса процедуры в идентификатор (например, уникальное имя процедуры), для передачи его в удаленном вызове, и обратном преобразовании на узле получателя. Поскольку на обоих узлах загружена копия одного приложения, однозначное преобразование может быть легко выполнено, например, при помощи специальных таблиц, включенных в приложение. Кроме идентификатора и адреса функции, такие таблицы могут содержать параметры безопасности вызова этих процедур. Кроме того, возможны другие варианты, например вместо таблиц использовать списки со статическим указателем на первый элемент, которые могут создаваться динамически, или какой-либо другой способ. Для настоящего изобретения способ идентификации инструкций является несущественным, так как он однозначно известен на обоих концах удаленного вызова (за счет того, что взаимодействуют копии одного приложения), и зависит в основном от использованного языка программирования и требований безопасности.
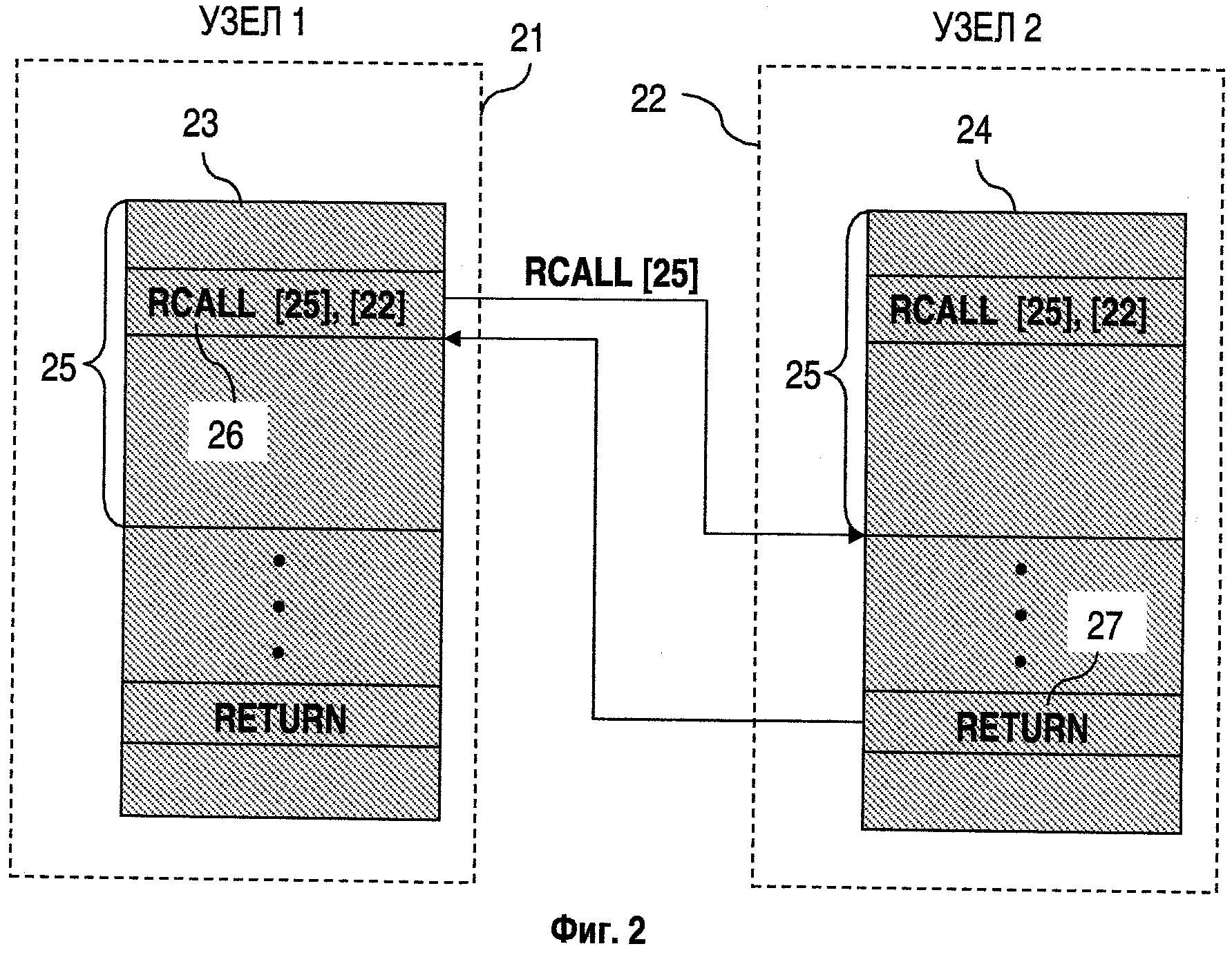
Алгоритм выполнения одного потока управления для распределенного приложения в соответствии с заявляемым изобретением приведен на фиг.3. В общем случае, в зависимости от архитектуры и требований к приложению, один процессор может одновременно выполнять один или несколько потоков управления, которые могут относиться к одному или более приложениям. При этом инструкция удаленной передачи управления может быть выполнена следующими способами:
1) Синхронно - процессор, выполняющий удаленный вызов, переходит в состояние ожидания возврата управления.
2) Асинхронно - процессор, выполняющий удаленный вызов, не ждет возврата управления и переходит к выполнению инструкции, следующей в памяти за инструкцией передачи управления.
3) Одна инструкция удаленной передачи управления инициирует выполнение следующей инструкции сразу на множестве процессоров. Для идентификации процессоров может быть использован групповой адрес, или список, или группа процессоров вычисляется исполнительной системой. При этом каждый процессор может получить одну и ту же копию параметров вызова процедуры, или каждый процессор получит свое подмножество параметров вызова, например, если исходная инструкция в качестве параметров указала массив, или диапазон значений, или коллекцию.
4) Новые распределенные потоки могут создаваться при помощи API исполнительной системы или в результате удаленных вызовов, приведенных в пп.2) и 3).
Данный список способов может быть расширен без изменения существенной логики изобретения, а рассмотренные команды передачи управления необязательно должны явно поддерживаться на уровне компилятора или интерпретатора. Если рассматривать обычный локальный вызов процедуры, то компилятор создает специальный код процессора, который записывает в стек адрес возврата и параметры вызова, и код процессора, который принимает возвращаемый результат. Если же рассматривать классический удаленный вызов процедуры (основанный на обмене сообщениями), то создается код proxy/stub, которые разнесены между клиентом и сервером и создаются независимо на основании некоторой спецификации интерфейса. Заявляемое изобретение предлагает создавать код proxy/stub одновременно с кодом локального вызова процедуры и включать код, необходимый для удаленного вызова, в исполняемый файл. Учитывая, что на всех узлах выполняется один исполняемый файл, получаем полностью согласованные на двоичном уровне удаленные вызовы, а код proxy/stub можно рассматривать как расширение обычного локального вызова процедуры. При этом регистрация процедур удаленного вызова в исполнительной системе не является обязательной (ни статическая, ни динамическая). Перед вызовом процедуры выполняется проверка, удаленный или локальный вызов необходимо выполнить, и выполняется вызов соответствующего кода, который либо записывает параметры в стек и выполняет локальный вызов, либо вызывает код заглушки. Заглушка формирует буфер с параметрами вызова процедуры и взаимодействует с исполнительной системой для выполнения удаленного вызова. Некоторые языки программирования, например стандартный C++, позволяют скрыть такую проверку на уровне исходного текста и разрабатывать распределенное приложение, как обычное нераспределенное. Таким образом, для разработки программы можно использовать обычные компиляторы, и компоновщики, и обычные загрузчики. При этом операционная система или среда исполнения должна быть расширена модулем взаимодействия, выполняющим описанные здесь функции взаимодействия между процессорами, к которому будет обращаться код proxy/stub.
Рассмотренная выше инструкция распределенной передачи управления позволяет создавать работоспособное приложение, в котором обмен данными выполняется через параметры вызовов процедур. Тем не менее, для разработки полноценного приложения необходим доступ к данным в статической памяти (глобальные переменные) и динамической памяти (куча). Здесь возможно множество вариантов, некоторые из которых приведены ниже:
- Общая для всех процессоров куча может быть выполнена, как отдельный модуль памяти с прямым доступом для любого процессора. Это является неплохим решением для многопроцессорной системы, но может приводить к дополнительному трафику при взаимодействии через сеть.
- Для глобальных переменных компилятор обычно выделяет место в исполняемом файле программы. Можно или вообще отказаться от использования глобальных переменных, которые изменяют после инициализации, или реплицировать изменения, которые выполнены на одном модуле памяти, на все остальные. При этом репликация может быть выполнена как транзакция. Этот способ целесообразно применять для данных, которые изменяются относительно редко.
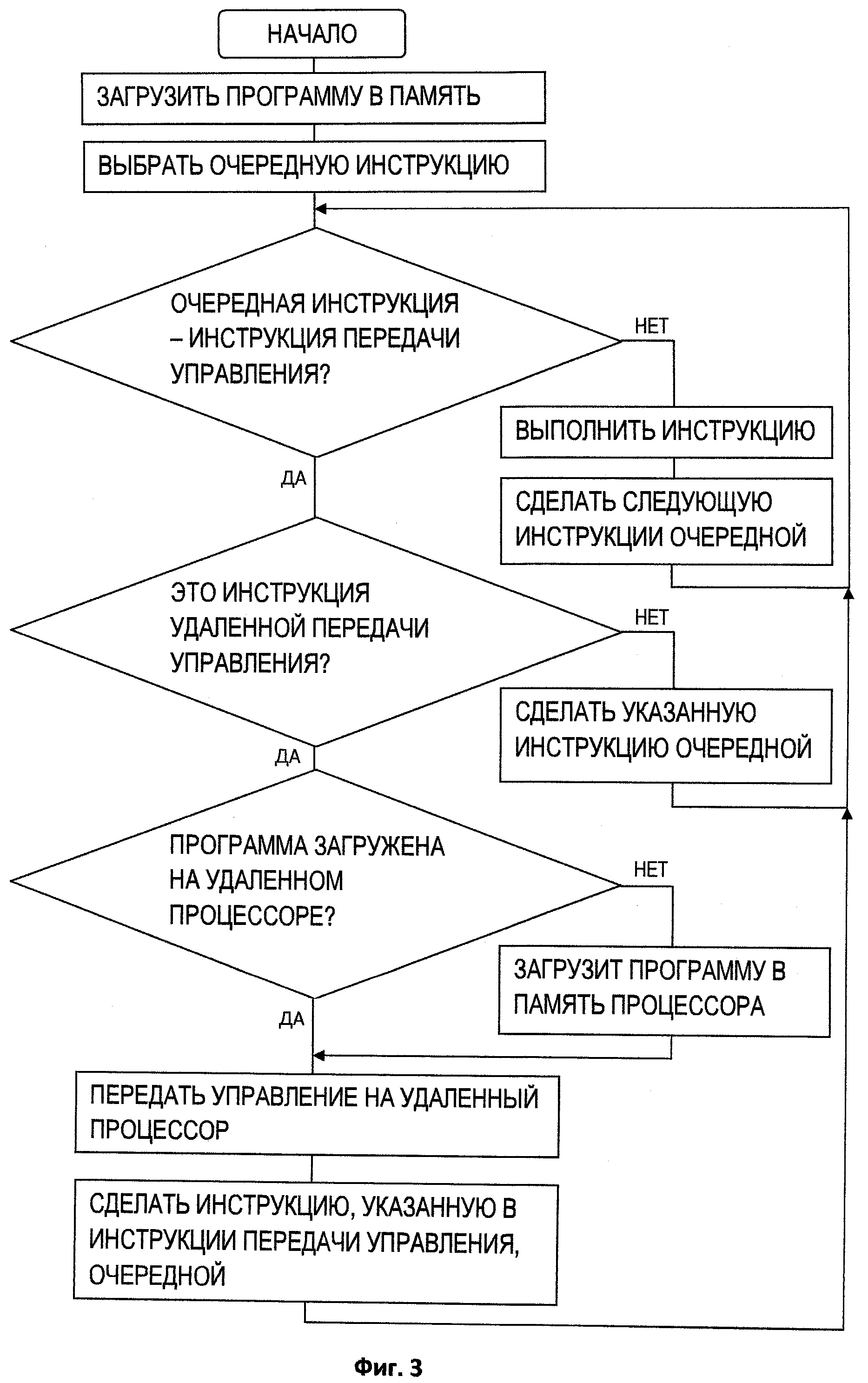
- Использование распределенной памяти с базовой адресацией, приведенной на фиг.4. Здесь 40, 41, 42 - временная диаграмма распределенного потока управления, выполняющегося на трех процессорах. Каждый процессор выделяет некоторую область памяти (43, 44, 45). При передаче управления на следующий процессор блок памяти текущего процессора фиксируется (43, 44) и суммарный размер всех выделенных блоков передается в вызове следующему процессору. При возврате управления в цепочке распределенных вызовов блоки памяти освобождаются. Адрес памяти 48 рассчитывается как смещение от начала самого первого блока. Если процессор обращается к памяти, которая находится не в его модуле памяти (инструкция 49, записывающая в ячейку по смещению ([46]+[47]) значение 0), передается запрос назад по цепочке распределенных вызовов, пока не будет найден необходимый блок памяти. Распределенная базовая адресация позволяет адресовать переменные, расположенные в локальных стеках, и передавать адреса этих переменных в параметрах удаленных вызовов. В общем случае, выделяемые блоки памяти необязательно являются кадрами локального стека текущего распределенного вызова.
- Использование распределенной прямой адресации, предложенной в ″Unified Memory Space Protocol Specification″, A. Bogdanov, RFC 3018, December 2000, п. 2.1, стр. 5-7. При данной адресации указатель на память включает сетевой адрес узла и локальный адрес памяти. Такая структура позволяет прямо адресовать ячейки памяти на любом узле в сети с любого другого узла. На уровне приложения такая память может рассматриваться как общая, и указателями можно свободно обмениваться между узлами.
В общем случае, выбранный способ управления памятью является несущественным для заявляемого изобретения и может зависеть от задач, которые решает приложение.
Во всех случаях возможность удаленной адресации данных позволяет включать указатели в параметры удаленных вызовов процедур. Это позволяет обмениваться указателями на объекты и удаленно вызывать их методы, так как единственное существенное отличие между вызовом процедуры и вызовом метода объекта заключается в наличии в вызове одного дополнительного параметра - указателя на объект (обычно скрытого на уровне исходного текста метода). Таким образом, в инструкции удаленного вызова метода объекта достаточно иметь указатель на объект, который явно или неявно указывает на процессор, в памяти которого этот объект расположен, и идентификатор или адрес метода объекта для вызова.
Для заявляемого изобретения способ загрузки приложения является несущественным. Существенным является только факт наличия в памяти инструкции, которая должна быть выполнена в текущий момент. Одними из возможных вариантов загрузки приложения могут быть следующие:
- В статичных многопроцессорных системах приложение на все узлы может быть загружено заранее, включая возможность использования ПЗУ. Предварительная загрузка может быть использована для системных программ, которые загружаются в память один раз и, как правило, не выгружаются.
- Приложение пользователя обычно загружается на одном из узлов в сети, и распределенное исполнение происходит в интересах этого узла. В этом случае приложение сначала загружается на узле инициатора, а на других узлах загрузка происходит динамически, при необходимости выполнить на этом узле удаленный вызов, то есть в результате исполнения инструкции передачи управления. Когда приложение завершается на узле инициатора, оно выгружается из памяти на всех остальных узлах. Возможный вариант централизованного управления распределенным приложением описан в ″Unified Memory Space Protocol Specification″, A. Bogdanov, Internet-Draft, draft-bogdanov-umsp-rfc3018-update-00.txt, August 2003, expires February 2004, п. 4.5, стр. 9-10.
- Приложение может быть загружено независимо на нескольких узлах, а на других загружаться динамически при необходимости. В этом случае распределенное исполнение приложения завершается, когда выполнение завершено на всех узлах, на которых приложение было загружено независимо или пока не завершено распределенное исполнение программы.
- Приложение на определенном процессоре может быть выгружено явно путем выполнения специальной инструкции.
- Если приложение загружено на процессоре независимо от остальных процессоров, оно может быть завершено, когда завершаются все вычислительные потоки приложения на этом процессоре.
- Если приложение на процессоре загружено по инициативе другого процессора, оно может быть выгружено, если не исполняет ни один распределенный поток управления. Дополнительно, приложение и исполнительная система может вести учет ресурсов, которые использует приложение на этом процессоре, и выгружать приложение, только если все ресурсы освобождены.
- Если некоторый узел предоставляет свои вычислительные или иные ресурсы для приложений, инициированных на других узлах, он может вести учет использования этих ресурсов в целях получения оплаты или для ограничения их использования.
- При загрузке приложения на каждом узле процессор может выполнять некоторый код инициализации этого приложения.
Вопрос, откуда приложение может быть загружено, также является несущественным для изобретения и определяется в основном приведенными выше требованиями к загрузке приложения и топологией конкретной системы.
Здесь возможны следующие варианты:
- Приложение загружает в память из своего локального источника процессор - инициатор запуска приложения. На остальные процессоры загрузку выполняют, используя копию, загруженную в модуль памяти процессора, который исполняет инструкцию удаленного вызова (в его памяти приложение уже загружено). Таким образом, приложение распространяется на все необходимые узлы.
- Приложение может загружаться из одного или нескольких общедоступных источников, например из сетевых папок или через URL. При этом исполнительные модули обмениваются информацией о местонахождении приложения.
- Исполнительные модули могут обмениваться информацией, позволяющей однозначно идентифицировать копию приложения (например, цифровые подписи исполняемых файлов), а также передавать контекст безопасности исполнения приложения.
Загрузка монолитного приложения на все узлы распределенной системы, как показано на фиг.2, является простым решением, но неоптимальным с точки зрения расходования памяти и сетевого графика. Возможны следующие решения, которые позволяют уменьшить эти недостатки:
- Виртуальная память. Память под приложение выделяется на всех узлах, но загрузка отдельных сегментов исполняемого файла выполняется по мере необходимости.
- Выделение кода для распределенного исполнения в отдельные модули, например, DLL или классы Java. Код определенной DLL может выполнять распределенные вызовы своих функций. Код приложения, которое загружает эту DLL, может выполнять локальные вызовы функций загруженной DLL. Если разные или одинаковые приложения загрузили на разных процессорах одну распределенную DLL, копии этой DLL могут взаимодействовать, как описано в заявляемом изобретении. Такая DLL может быть загружена динамически. Для этого в удаленном вызове процедуры должна передаваться информация об исполняемом файле, который необходимо загрузить. При этом таких DLL может быть несколько, и они могут загружаться приложением как динамически, так и статически. В общем случае, для выполнения удаленного вызова на узле, получающем управление, должна быть загружена только DLL, получающая управление. Хотя распределенная DLL может удаленно вызывать только свои функции, это не означает, что распределенное взаимодействие ограничено логикой этой DLL. Приложение может регистрировать в DLL адреса функций обратного вызова, которые будут получать управление в результате удаленных вызовов, или предоставлять данные, которые функции DLL будут передавать на удаленные узлы. Таким образом, исполняемое приложение состоит из нескольких программ, распределенное исполнение поддерживает только определенное подмножество, состоящее из одной или более указанных программ, указанная инструкция передачи управления должна указывать на следующие инструкции только в границах указанного подмножества программ, и при выполнении удаленной передачи управления модуль памяти исполнительного модуля, получающего управление, должен содержать копию программы, инструкция которой получает управление. Кроме этого, копия указанного подмножества программ, поддерживающих распределенное исполнение, может входить в состав разных приложений, и эти приложения одновременно загружены в память указанных исполнительных модулей в произвольном сочетании.
Таким образом, заявленный технический результат достигается за счет:
1) Распределенное приложение может работать как на одном, так и многих узлах и динамически менять конфигурацию, так как оно разрабатывается, как обычное нераспределенное, инструкции распределенной передачи управления могут передавать управление как локально, так и удаленно, а приложение может динамически загружаться и выгружаться на разных процессорах.
2) Распределенные приложения могут иметь сложную и динамически изменяющуюся логику взаимодействия между частями, выполняющимися на разных узлах, так как
это обеспечивается рассмотренной инструкцией удаленной передачи управления и загрузкой копии приложения на все узлы. В этом случае протокола взаимодействия на прикладном уровне, как такового, не существует. Не требуется ни согласовывать формат сообщений, ни определять допустимые последовательности вызовов процедур и допустимые глобальные состояния приложения. Одно приложение работает на множестве узлов, и из любого узла и любого места кода можно вызвать любую функцию на любом узле в той последовательности, которая требуется для решения задачи (если это не противоречит требованиям безопасности или функциональному разделению узлов).
3) Глобальное состояние приложения может быть простым, так как приложение разрабатывается, как обычное нераспределенное, и имеет ограниченное и определенное число переменных состояния.
4) Для разработки приложений могут применяться стандартные компиляторы и компоновщики, так как единственным существенным отличием разработки приложения по заявляемому изобретению является один дополнительный параметр в вызовах процедур - указатель на процессор, который может просто явно указываться в исходном тексте программы или вычисляться. В остальном логика разработки распределенного приложения не отличается от логики разработки нераспределенного приложения. Для исполнения распределенного приложения можно использовать стандартные загрузчики исполнительной системы, так как в код приложения можно встроить код proxy/stub, необходимый для поддержки удаленных вызовов на аппаратуре или среде исполнения, которая такие вызовы явно не поддерживает. При этом встроенный код proxy/stub, по сути, является расширением обычного кода локального вызова процедуры.
Реализация изобретения
Рассматриваемая реализация изобретения предназначена для операционной системы Windows и процессоров, которые на аппаратном уровне явно не поддерживают рассматриваемую архитектуру. Узлы сети Internet являются отдельными исполнительными модулями. В качестве средства взаимодействия исполнительных модулей использована реализация приведенного выше экспериментального Internet - протокола UMSP, который реализован как служба Windows. Его основными функциями является управление запуском и завершением распределенного исполнения приложений и создание динамической общей распределенной памяти, которая может быть доступна в границах отдельного распределенного приложения. Кроме этого, протокол предоставляет транспортный уровень для выполнения удаленных вызовов процедур.
Распределенное приложение является обычным исполняемым ехе - файлом Windows, созданным с использованием стандартного компилятора C++. При компиляции приложения используется специальная библиотека шаблонов C++ um.h.
Логика рассматриваемой инструкции передачи управления реализована на уровне компилятора и системных служб операционной системы. В то же время можно однозначно утверждать, что предлагаемая простая программная реализация может быть перенесена на другие платформы, а также на уровень микропрограмм процессора или реализована аппаратно. Более низкий уровень реализации является предпочтительным в случае использования рассматриваемой архитектуры в многопроцессорных или многоядерных системах, а также для реализации системного программного обеспечения. В этих случаях протокол UMSP может быть заменен на средства межпроцессорного взаимодействия или другими специальными средствами.
Для описания работы распределенной системы приведем пример исходного текста минимального распределенного приложения ″Hello, World!″ на C++, который в значительной мере пересекается с фиг. 2:

9}
Отличием от обычной минимальной программы является наличие трех дополнительных строк 1, 6 и 7.
Строка 1 включает библиотеку um.h, которая реализует набор шаблонов, необходимых для создания распределенных приложений.
В строке 6 команда UM_ADD_FUN объявляет функцию functHello доступной для удаленного вызова. В общем случае, эта строка может отсутствовать, так как заявляемое изобретение позволяет удаленно работать напрямую с адресами функций без предварительного объявления. Однако возможность удаленного вызова любой инструкции в программе является недопустимой в распределенной сети с точки зрения безопасности (тем не менее, это является возможным в закрытых доверенных системах, например, многопроцессорных). В рассматриваемой реализации при регистрации адрес функции связывается с ее символическим представлением, сформированным по некоторому алгоритму. Полученная связка сохраняется в памяти приложения. В последующем, в сетевых примитивах удаленного вызова используется символическое представление, и при выполнении функции происходит обратное преобразование. Так как на всех узлах выполняется копия одного приложения, такие преобразования выполняются однозначно (на двоичном уровне) без предварительного согласования протокола и без регистрации функций в исполнительной системе.
В строке 7 команда lnitJob() регистрирует в UMSP данный экземпляр запущенного приложения. Это строка является особенностью рассматриваемой реализации и в общем случае может отсутствовать (например, если рассматриваемая технология поддерживается на уровне стандартного загрузчика, который знает, что данное приложение является распределенным). В рамках рассматриваемой реализации все узлы, выполняющие распределенное приложение, делятся на узел-инициатор запуска приложения и все остальные. Типично, запуск приложения инициирует пользователь на узле-инициаторе. Распределенное выполнение продолжается до тех пор, пока приложение не завершится на узле инициаторе. Команда lnitJob() реализует эту логику. На узле-инициаторе после выполнения необходимой инициализации эта команда возвращает управление в программу. На остальных узлах команда lnitJob() никогда не возвращает управление. При этом приложение может выполнять входящие запросы удаленного вызова процедур. На узле-инициаторе приложение завершается обычным образом (например, через завершение функции main). На остальных узлах код инструкции lnitJob() ждет соответствующую команду от UMSP.
В строке 8 выполняется удаленный вызов процедуры. Шаблон rcall является реализацией рассматриваемой в изобретении инструкции передачи управления. Этот шаблон предоставляет компилятору инструкции для создания кода удаленного вызова. Реализация шаблона основана на стандартной методике C++ рекурсивного вызова шаблонной функции. Результатом является код, адаптирующий выполнение рассматриваемой в изобретении инструкции передачи управления для выполнения на процессорах, которые такую инструкцию не поддерживают в явном виде (код proxy/stub). Этот адаптирующий код выполняет следующие функции:
- упаковывает параметры вызова процедуры и обращается к функциям UMSP для выполнения удаленного вызова,
- на принимающей стороне распаковывает параметры и выполняет вызов соответствующей процедуры,
- при необходимости, упаковывает результат и обратно распаковывает на исходном узле при возврате управления.
Так как на всех узлах выполняется копия одного приложения, получаем полностью согласованный на двоичном уровне код удаленного вызова, не требующий протокола взаимодействия и регистрации в исполнительной системе. Адаптирующий код включается компилятором в исполняемый файл приложения и по своим функциям является аналогом кода обычного вызова процедуры (например, stdcall), являясь просто надстройкой над ним.
Первый параметр шаблона rcall в приведенном примере является сетевым адресом узла, на котором нужно выполнить функцию (указанный сетевой адрес выбран просто для примера). Второй параметр - функция для исполнения. Третьим параметром является параметр этой функции. Результатом выполнения удаленного вызова является:
1) Загрузка на узле 10.0.1.28 копии исполняемого файла. Способы загрузки могут быть различными. В качестве простого варианта файл может быть помещен в сетевую папку и его URL передан через UMSP. В качестве варианта, не требующего никаких действий при разворачивании приложения, исполняемый файл может быть реплицирован средствами протокола UMSP как результат выполнения удаленного вызова. Возможны и другие варианты, в том числе, описанные ранее.
2) После загрузки исполняемого файла будет выполнен код функции main() до инструкции InitJob().
3) Далее будет выполнен входящий удаленный вызов функции functHello(), и приложение на этом узле будет ожидать следующего удаленного вызова.
После возврата управления на узел-инициатор приложение завершит свою работу на узле-инициаторе (для рассматриваемого примера программы). Одновременно UMSP завершит процесс приложения на узле 10.0.1.28.
Рассматривая приведенный пример программы, необходимо отметить, что распределенное приложение получено из нераспределенного добавлением в исходный текст всего трех декларативных строк, которые не усложняют логику приложения. При этом не требуется никаких дополнительных действий. Существующий уровень техники не предлагает подобной простоты разработки.
Кроме вызовов статических функций в стиле Си, библиотека um.h поддерживает удаленное создание объектов и удаленный вызов их методов. В качестве иллюстрации приведем модифицированный пример простейшей программы:


Рассмотрим строки, которые отличают этот код от предыдущего примера.
Строка 2 содержит обычное объявление класса myObj. Пример иллюстрирует удаленный вызов метода этого класса.
В строках 6-9 объявляется статическая производящая функция. Эта функция возвращает структуру uptr<>, которая является специальным распределенным указателем на объект. Этот указатель, кроме адреса объекта, в локальной памяти содержит сетевой адрес узла, на котором размещен экземпляр объекта. Такие распределенные указатели могут свободно передаваться в параметрах и возвращаемых значениях удаленных вызовов функций. Шаблон umake<> (в строке 7) выполняет функции стандартного оператора new для распределенных объектов. Этот шаблон создает экземпляр объекта myObj в локальной памяти узла вместе со специальным объектом-оболочкой. Распределенный указатель uptr<> содержит адрес объекта-оболочки. Объект-оболочка позволяет выполнять удаленные вызовы методов объекта.
В результате выполнения строки 15 на узле 10.0.1.28 создается экземпляр объекта myObj и указатель на него присваивается переменной ptr. При создании объекта выполняется удаленный вызов статической производящей функции myObj::make() (удаленный вызов статических функций подробно рассмотрен в предыдущем примере).
В строке 16 выполняется вызов метода functHello с параметром ″Hello, World!″ для объекта, на который указывает переменная ptr. Для вызова используется шаблон удаленного вызова метода объекта rcall. Последовательность действий при выполнении удаленного вызова метода объекта такая же, как и при вызове статической функции.
Отличием является неявный дополнительный параметр вызова - распределенный указатель на объект (как и в случае классических локальных вызовов методов объектов).
В строке 17 выполняется удаление объекта и освобождение памяти, которую он занимал на своем узле (аналогично стандартному оператору delete). Результатом выполнения этой строки является удаленный вызов специальной статической функции, реализованной в um.h.
Во всех случаях, если для вызова функции или метода объекта использован сетевой адрес узла, на котором выполняется этот вызов, вместо удаленного вызова выполняется обычный локальный вызов. Таким образом, приложение может выполняться как на одном узле, так и на множестве узлов и выбирать между локальным или удаленным вызовом функций исходя из текущей возможности или необходимости.
Еще один небольшой пример программы иллюстрирует использование предложенной в изобретении распределенной памяти с базовой адресацией для объектов, расположенных в стеке:

Рассмотрим отличия данного примера программы от предыдущих. В строке 14 создается экземпляр объекта myObj в объекте оболочке uobj<>, как это было описано выше дляфункции umake<>. Отличием является то, что объект создается в стеке, а не в куче. В строке 15 создается распределенный указатель на этот объект uptr<>. При создании указателя определяется, что объект находится в стеке. При этом в uptr<> устанавливается специальный флаг стека и в качестве адреса объекта записывается его смещение от базы распределенной памяти, которая при инициировании программы установлена на базу локального стека. Далее для простоты будем называть компьютер, на котором была запущена программа как «узел 1», а компьютер с условным адресом 10.0.1.28 как «узел 2». При выполнении строки 16 происходит следующая последовательность действий:
- Узел 1 выполняет удаленный вызов функции runHello на узле 2. В качестве параметра функции передается распределенный указатель ptr. При этом на узле 1 фиксируется кадр стека от локальной базы стека до текущей вершины. Размер зафиксированного кадра стека передается в удаленном вызове как текущий размер распределенной памяти.
- Узел 2 при выполнении инструкции rcall в строке 8 определяет, что объект, на который ссылается указатель ptr, находится не в его стеке (его смещение относительно распределенной базы меньше размера распределенной памяти, полученной в удаленном вызове функции).
- Узел 2 формирует удаленный вызов функции functHello и передает его узлу 1 (предыдущему узлу в стеке распределенных вызовов).
- Узел 1 определяет, что объект, в контексте которого выполняется функция functHello, находится в его памяти, и выполняет вызов этой функции.
- Узел 1 возвращает управление узлу 2.
- Узел 2 завершает выполнение функции runHello и возвращает управление узлу 1.
Каждый входящий удаленный вызов функции, включая обратный вызов узла 1 с узла 2, открывает новый кадр стека в локальном стеке и добавляет его к распределенной памяти с базовой адресаций (в приведенной последовательности действий это не указано для простоты изложения, так как является несущественным для данного примера).
Рассматриваемая реализация использует стандартные средства разработки и выполняется в исполнительной системе общего применения. Это обеспечивает возможность широкого использования данной реализации. В случае использования специализированного компилятора, компоновщика и среды исполнения (в любой комбинации) функциональность этой реализации может быть расширена. В качестве одного из возможных вариантов можно предложить компиляцию одной процедуры в код для процессоров с различной системой команд. Это может быть код центрального процессора и специализированного процессора (например, графического ускорителя или контроллера ввода-вывода). В общем случае, код процедуры может создаваться не для всех типов процессоров системы, или для отдельных процессоров может создаваться код заглушки (например, просто выбрасывающей исключение или возвращающей ошибку). Специальный компоновщик может собрать несколько вариантов кода процедуры в специальный исполняемый файл. При выполнении вызова процедуры будет вычисляться на процессор, какого типа можно (или оптимально) передать управление. Кроме выбора типа процессора может быть выбран сетевой узел. Возможны и другие варианты усовершенствования рассматриваемой реализации изобретения.
Несмотря на кажущуюся простоту приведенных примеров программ, они являются полноценными распределенными приложениями, которые могут быть масштабированы до систем любой сложности. Можно утверждать, что рассмотренная реализация изобретения подтверждает заявленный технический результат. Во-первых, простоту разработки, так как она позволяет оперировать обычными нераспределенными примитивами и создавать распределенное приложение как простое нераспределенное. Во-вторых, предсказуемое глобальное состояние. По своей сути, заявляемое изобретение является переносом классической вычислительной модели со стеком и динамической памятью в распределенную среду. При условии, что узлы системы абсолютно надежны (или выходят из строя/выключаются одновременно), состояние распределенного приложения может быть полностью предсказуемым, как и в случае его локального исполнения.
Поскольку сложность разработки является основным фактором, который на известном уровне техники ограничивает функциональность распределенных приложений, заявляемое изобретение позволяет в значительной степени решить эту проблему.
Краткое описание чертежей
Фиг. 1. Показывает схему применения прототипа заявляемого изобретения.
Фиг. 2. Показывает применения заявляемого изобретения на примере программы, состоящей из одного файла.
Фиг. 3. Показывает алгоритм вычисления следующей инструкции при исполнении программы.
Фиг. 4. Показывает применение распределенной памяти с базовой адресацией.
Усилитель и способ коррекции амплитудно-частотной характеристики
Усилитель и способ коррекции амплитудно-частотной характеристики

