Результат интеллектуальной деятельности: ОПТИМИЗАЦИИ КОДА С ИСПОЛЬЗОВАНИЕМ КОМПИЛЯТОРА С ДВУМЯ ПОРЯДКАМИ СЛЕДОВАНИЯ БАЙТОВ
Вид РИД
Изобретение
Уровень техники
Порядок следования байтов является атрибутом хранения и извлечения данных, когда хранение и извлечение данных поддерживают многочисленные размеры доступа (например, 8-битные, 16-битные, 32-битные, 64-битные). Доступы с более мелкой степенью структурирования позволяют программисту видеть порядок, в котором более крупные доступы позволяют хранить байты в памяти. Переменные с обратным порядком байтов хранятся в памяти в порядке байтов, противоположном переменным с прямым порядком байтов. Переменные с прямым порядком байтов хранятся с младшим значащим байтом в самом нижнем байтовом адресе памяти. Переменные с прямым и обратным порядком байтов, содержащие одно и то же значение, идентичны, когда присутствуют в регистре процессора. Их отличает только порядок следования в памяти.
Порядок байтов внутри 16-разрядных, 32-разрядных и 64-разрядных данных видим программисту. В языке программирования С программист может получать доступ к байтам, используя объединения, тип оверлейной структуры данных или преобразуя указатель данных многочисленных байтов в указатель одиночных байтов. Исторически эти способы использовались для повышения производительности. Таким образом, один и тот же код C/C++, прогоняемый на архитектуре с различным порядком следования байтов, может приводить к различным результатам. Например, для кода С: int i=0×12345678; и char с=*((char*)&i), значение "с" будет равно 0×12, если код компилируется и прогоняется на архитектуре с обратным порядком байтов, и будет равно 0×78, если код компилируется и прогоняется на архитектуре с прямым порядком байтов.
Компилятор по технологии с двумя порядками байтов позволяет компилировать исходный код, который первоначально разрабатывался для архитектуры с обратным порядком байтов, для работы на архитектуре с прямым порядком байтов. Если код компилируется в специальном режиме, то в большинстве случаев он работает таким же способом, которым он мог бы работать, если бы был скомпилирован и прогонялся на архитектуре с обратным порядком, то есть "с" равно 0×12 в приведенном выше примере. Это поведение достигается, добавляя операции "перестановки байтов" перед загрузкой и хранением в памяти данных, определенных как данные с обратным порядком байтов.
Компилятор по технологии с двумя порядками байтов обычно используется для компиляции наследованного кода, чтобы работать на модемной архитектуре по технологии с прямым порядком байтов. Программист обычно помечает весь наследованный код как имеющий обратный порядок байтов, вместо того, чтобы определить, имеет ли каждый определенный фрагмент данных обратный или прямой порядок байтов. Таким образом, компилятор добавляет перестановки байтов перед загрузкой и хранением данных, даже когда порядок байтов в них неважен для программиста. Это неблагоприятно влияет на производительность.
Краткое описание чертежей
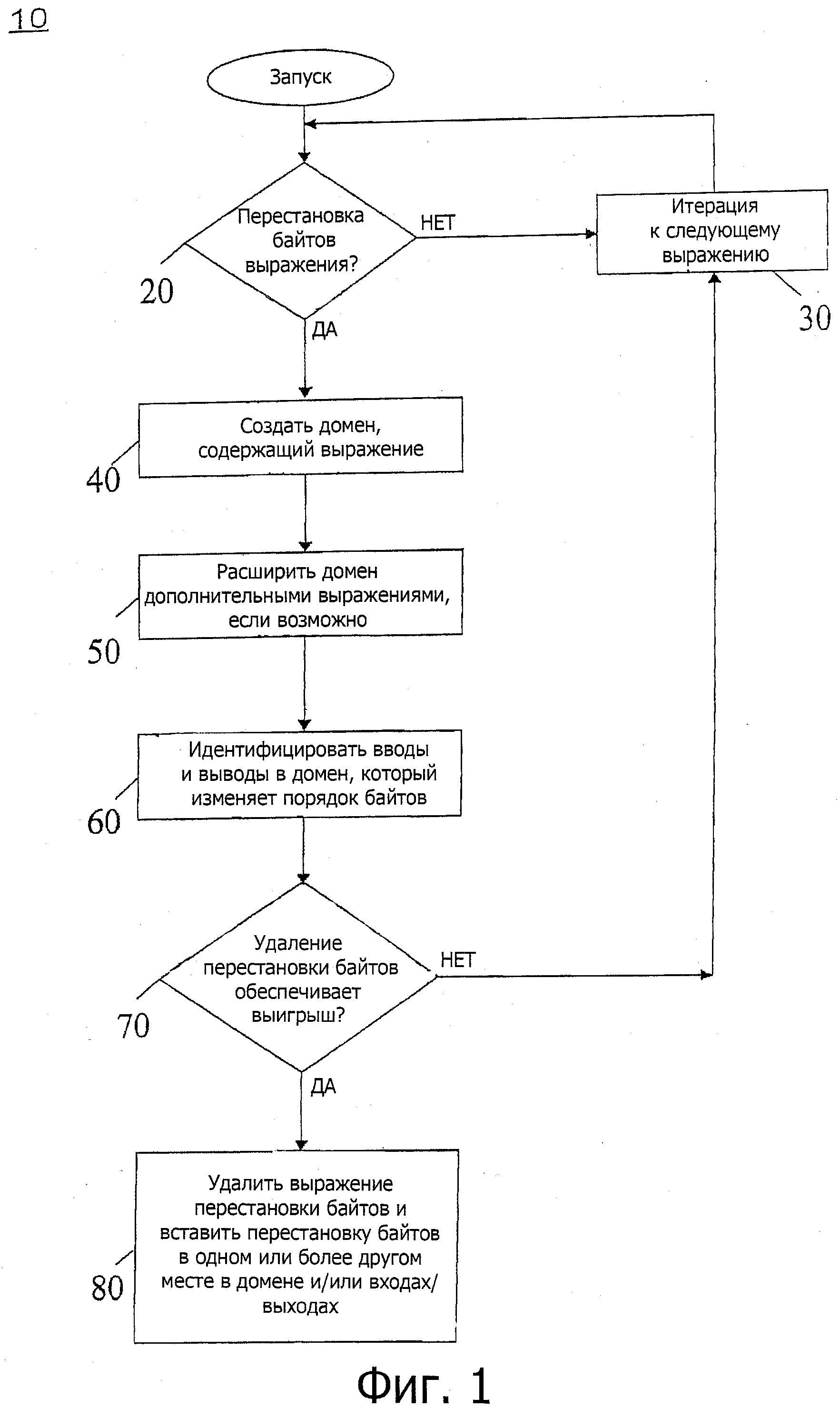
Фиг.1 - блок-схема последовательности выполнения операций способа для осуществления исключения перестановки байтов в соответствии с одним вариантом осуществления настоящего изобретения.
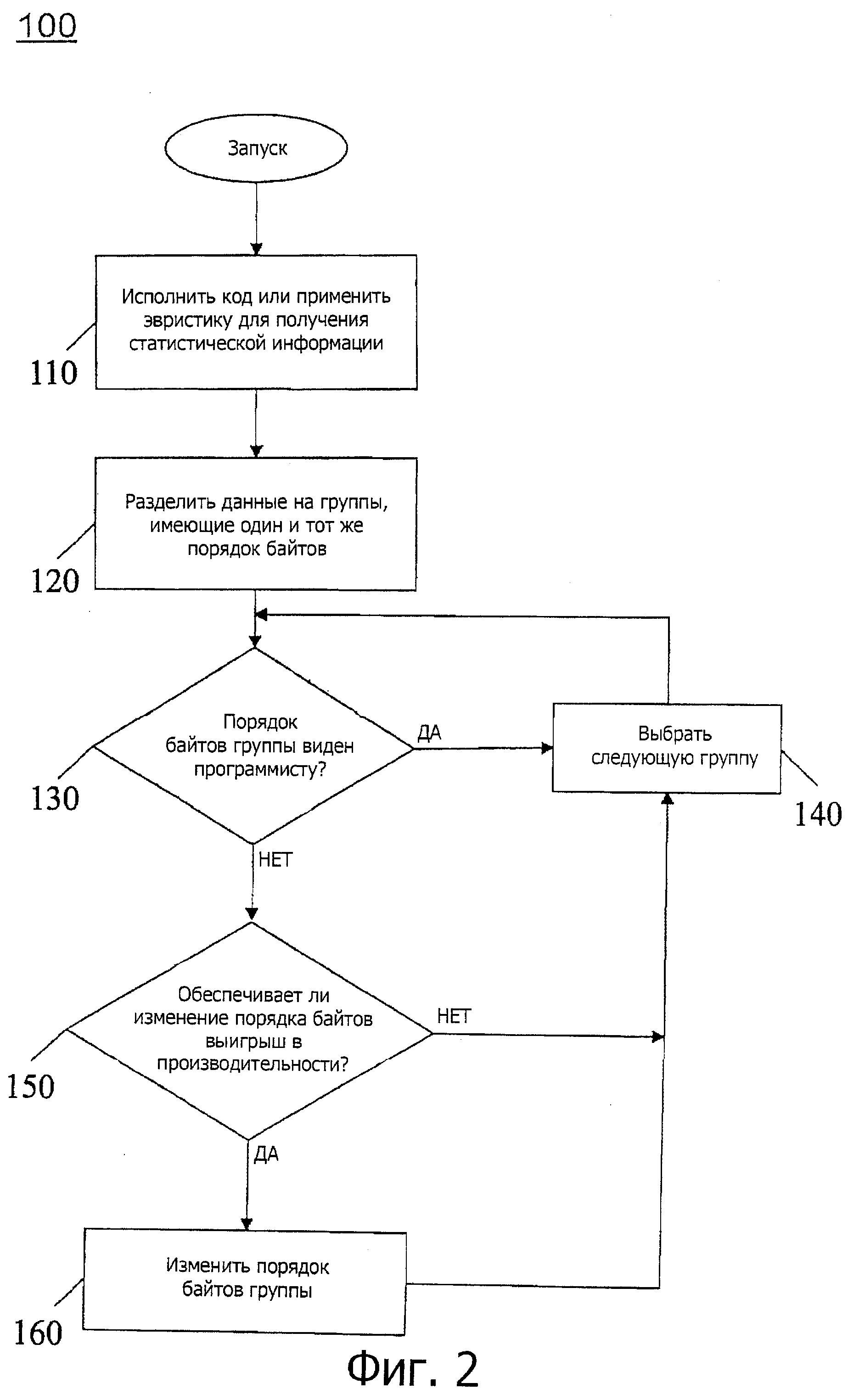
Фиг.2 - блок-схема способа оптимизации кода с управлением порядком байтов данных в соответствии с одним вариантом осуществления настоящего изобретения.
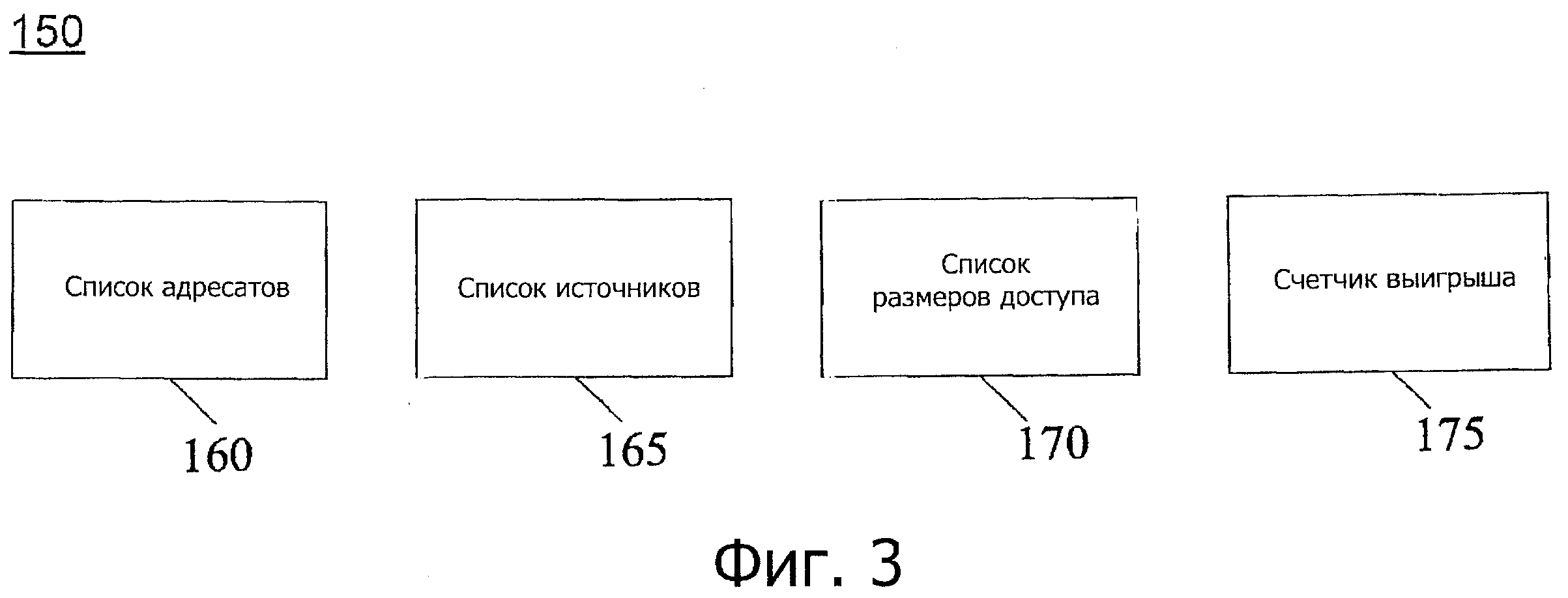
Фиг.3 - блок-схема различных хранилищ данных для хранения статистики производительности в соответствии с одним вариантом осуществления настоящего изобретения.
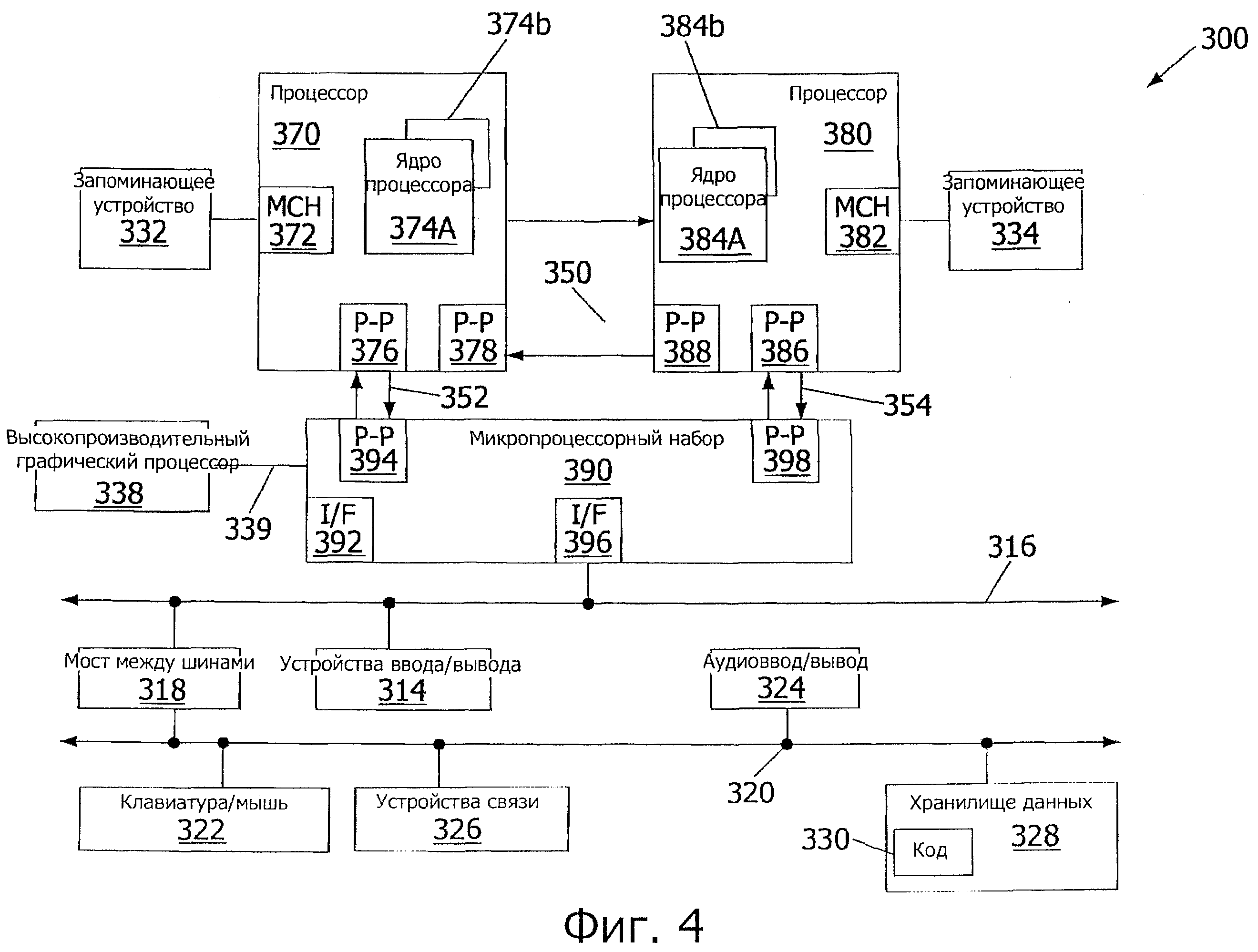
Фиг.4 - блок-схема системы в соответствии с вариантом осуществления настоящего изобретения.
Подробное описание изобретения
Варианты осуществления могут улучшить производительность созданного кода через исключение/удаления на более холодные пути операций перестановки байтов, основанным на концепции доменной перестановки байтов. Кроме того, дополнительно, варианты осуществления могут переопределить выбор типа порядка байтов данных, когда возможно, чтобы улучшить производительность.
Выражение "толерантный к перестановке", как оно используется здесь, является выражением компилируемого кода, которое может быть заменено выражением дубликата, работающего на некоторых (или всех) аргументах с другим порядком байтов и создающего достоверный результат для того же самого или другого порядка байтов. В качестве некоторых примеров сравнение с константой (например, х=0×12345678) является толерантным к перестановке, так как она имеет дубликат (у=0×78563412), для которого, если он задан, перестановленный аргумент SWAP(x) должен привести к тому же самому результату, что и исходное выражение, где SWAP является выражением для выполнения операции перестановки байтов. Битовая операция AND является толерантной к перестановке, так как существует такая операция (та же самая битовая операция AND), что взятие перестановленных аргументов должно создавать правильный, но другой результат в отношении порядка байтов. Однако арифметические операции (например, +, -*, /) не толерантны к перестановке, так как они строго требуют данных с определенным порядком байтов и приводят к ошибочному результату, если берутся перестановленные аргументы.
Домен является набором выражений компилируемого кода, в то время как вход домена является выражением вне домена, результат которого берется в качестве аргумента посредством выражения, принадлежащего домену. Выход домена является выражением вне домена, который берет результат выражения, принадлежащего домену, в качестве аргумента. Толерантный к перестановке домен является набором толерантных к перестановке выражений, которые могут быть заменены их выражениями дубликатов, так чтобы если некоторые (или все) доменные входы заменяются данными с другим порядком байтов, то все доменные выходы должны быть действительными результатами с тем же самым или другим порядком байтов.
Доменная перестановка является преобразованием компилируемого кода, которое:
(1) изменяет порядок следования байтов некоторых или всех входов и выходов доменов путем размещения или перемещения операций перестановки байтов в необходимых доменных входах и выходах; и (2) заменяет все выражения в домене на выражения дубликатов, работающие с другим порядком байтов, так чтобы семантика кода была сохранена. Для доменной перестановки в отношении входов и выходов перестановка байтов может быть удалена, если выражение входа или выхода является перестановкой байтов, в противном случае может быть вставлена перестановка байтов.
Как пример,
T1=SWAP(A)
Т2=SWAP(B)
RES=T1=Т2
Выражение "T1=Т2" является толерантным к перестановке доменов, выражения "SWAP(A)" и "SWAP(B)" являются доменными входами, и присвоение "RES=…" является доменным выходом. Вот то, как могла бы выглядеть перестановка доменов для этого кода:
T1=А// перестановка байтов удаляется
Т2=ВУ/ перестановка байтов удаляется
RES=T1=Т2// порядок байтов в результате является тем же самым: ничто не добавлено или не удалено.
Таким образом, для каждого толерантного к перестановке выражения известно, какой из входов (то есть, аргументов) и выходов (то есть, результатов) будет изменять порядок байтов, если выполняется доменная перестановка. Например, в выражении X?Y:Z (если X then Y, else Z), порядок байтов Y и Z будет изменяться и порядок байтов Х будет сохранен: X? Y':Z'. Таким образом, известно, какие входы и выходы домена изменяют свой порядок байтов и операция перестановки байтов (SWAP) вставляется/удаляется только для них.
Преимущество доменной перестановки состоит в выигрыше в производительности от доменной перестановки, так что объем вставленного кода минус объем удаленного кода (учитывая веса конкретных введенных/удаленных команд, а также оцененные счетчики исполнений) дает в результате положительное число.
Как пример,
Т1=А
Т2=SWAP(B)
RES=T1=Т2
Здесь доменная перестановка должна выглядеть следующим образом;
T1=SWAP(A)// помещена перестановка байтов
Т2=В// перестановка байтов удаляется
RES=T1=Т2// ничто не добавляется или не удаляется
Выигрыш от перестановки байтов является положительным, если "T1=А" в исходном коде является более холодным, чем "Т2=SWAP(B)". Заметим, что термины "холодный" и "горячий" относятся к относительной частоте или использованию заданного сегмента кода. "Холодный" сегмент кода используется менее часто или более редко во времени относительно другого сегмента кода. Поэтому, как показано этим примером, доменная перестановка может привести в результате к перемещениям SWAP в коде.
Обратимся теперь к фиг.1, где показана блок-схема последовательности выполнения операций способа для выполнения исключения перестановки байтов в соответствии с одним вариантом осуществления настоящего изобретения. Способ 10 может быть выполнен компилятором, который выполняется на одном или более процессорах компьютерной системы. Хотя объем настоящего изобретения не ограничивается в этом отношении, некоторые варианты осуществления могут быть выполнены, чтобы оптимизировать код, который написан для архитектуры с обратным порядком байтов, для архитектуры с прямым порядком байтов. Таким образом, компилятор может выполняться на процессоре, имеющем архитектуру с прямым порядком байтов.
Как видно на фиг.1, способ 10 может начинаться с определения, содержит ли выражение кода, который должен оптимизироваться, операцию перестановки байтов (ромб 20). Если не содержит, управление может выполнить итерацию к следующему выражению (блок 30). При встрече с выражением перестановки байтов, управление передается в блок 40, где может быть создан домен, содержащий это выражение. Хотя объем настоящего изобретения не ограничивается в этом отношении, варианты осуществления могут стремиться расширить объем домена, чтобы, таким образом, позволить оптимизацию нескольких выражений в едином проходе. Подробности создания домена дополнительно обсуждаются ниже. В ходе создания домена, домен может быть расширен с помощью дополнительных выражений, если возможно (блок 50). Дополнительные подробности расширения домена также обсуждаются ниже. В конце создания домена могут быть идентифицированы различные входы и выходы в домене, которые изменяют порядок байтов (блок 60). Как обсуждалось выше, входы в домен могут быть различными аргументами, являющимися вводами в домен, в то время как выходами могут быть различные результаты, которые используются в качестве аргументов за пределами домена.
Обращаясь еще раз к фиг.1, в ромбе 70 может определяться, обеспечивает ли выигрыш удаление перестановки байтов (ромб 70). Как обсуждалось выше, это определение может выполняться компилятором, основываясь на различной информации профилирования, в том числе, на определении разности между объемом выражений, вставленных в код, и объемом выражений, удаленных из кода, и информации профилирования относительно различных результатов подсчета исполнений, связанных с такими выражениями. Дополнительно может быть определено, является ли этот выигрыш больше порогового. В одном варианте осуществления этот порог должен указать, что обеспечиваемый выигрыш может быть нулевым, так что если результаты определения выигрыша являются положительным числом, выигрыш может быть обеспечен. Заметим, что если выигрыш не может быть обеспечен удалением перестановки байтов, никакое устранение перестановки байта не выполняется и компилятор может выполнить итерации к следующему выражению (в отношении блока 30, обсуждавшегося выше).
Если вместо этого определено, что перемещение обеспечивает выигрыш, управление переходит к блоку 80. В блоке 80 выражение перестановки байтов может быть удалено, заменяя, таким образом, это выражение выражением дубликата. Также, дополнительно, одна или более дополнительных перестановок байтов могут быть вставлены/удалены в других местах внутри домена (блок 80). Дополнительно, такие выражения перестановки байтов могут также вставляться или удаляться в одном или более доменных входов и/или выходов. Модифицированный код может затем быть сохранен в соответствующем хранилище, таком как системная память или энергонезависимое хранилище для исполнения в дальнейшем, когда вызывается программа, содержащая модифицированный код. Хотя это показано на конкретной реализации в варианте осуществления, показанном на фиг.1, следует понимать, что объем настоящего изобретения не ограничивается в этом отношении и возможны другие реализации.
Для создания толерантного к перестановкам домена можно начать с любого толерантного к перестановкам выражения или с той перестановки байтов, которую желательно удалить, и расширить домен с помощью присоединенных толерантных к перестановкам выражений. Если дополнительное расширение домена невозможно или не имеет смысла с точки зрения производительности, может быть выполнена доменная перестановка и созданы другие домены. Расширение домена возможно, когда существуют смежные, толерантные к перестановкам выражения. Однако несколько доменов все еще могут быть созданы, потому что для каждого смежного, толерантного к перестановкам выражения может быть решено не добавлять его к текущему домену и несколько доменов будут обладать различными выигрышами от доменной перестановки. Таким образом, либо может быть выполнен полный поиск, чтобы обнаружить наилучший созданный домен, либо может быть применена некая эвристика. Некоторые варианты осуществления могут быть основаны на использовании эвристики. Исключение перестановки байтов может, таким образом, идентифицировать и переставлять все толерантные к перестановкам домены, которые обеспечивают положительный выигрыш от перестановок, как описано выше.
Таким образом, в различных вариантах осуществления операции на данных с некоторым порядком байтов заменяются эквивалентными операциями над теми же самыми данными с другим порядком байтов. Дополнительно, многочисленные присоединенные выражения и многочисленные присоединенные данные могут быть оптимизированы сразу в одном проходе. В результате оптимизации исключаются не только некоторые из перестановок байтов, но и другие перемещаются на более холодные пути. Таким образом, выражения могут заменяться выражением дубликата, работающего на данных с другим порядком байтов, перестановки могут удаляться внутри кода и многочисленные присоединенные данные могут изменять свой порядок следования байтов. Таким образом, перестановки байтов могут быть исключены путем замены части кода, работающей на данных с одним порядком байтов, эквивалентной частью кода, работающей на данных с другим порядком байтов.
Обратимся теперь к таблице 1, где показан псевдокод, представляющийвозможную реализацию алгоритма в соответствии с одним вариантом осуществления настоящего изобретения. Как видно в таблице 1, для исключения перестановки байтов и создания домена могут быть обеспечены несколько функций. Как видно, функция перестановки байтов вызывает функцию создания домена. Кроме того, при определении, дает ли выигрыш удаление выражения перестановки байтов, может быть выполнена другая функция, называемая BENEFIT. Как обсуждалось выше, эта функция может решить, что выигрыш присутствует, если вычисление приводит в результате к положительному значению. Если это положительное значение найдено, может быть выполнена другая функция под названием SWAP_DOMAIN, чтобы осуществить фактическое удаление и вставку операций перестановки байтов в соответствующих местах внутри домена, а также доменных входов и выходов. Заметим, что этот псевдокод является примером и возможны другие реализации.


Варианты осуществления могут дополнительно управлять выбором порядка следования байтов данных. То есть вместо того, чтобы выбирать порядок байтов данных, как его указал программист, компилятор может проверить, влияет ли порядок байтов каждой конкретной части данных на семантику программы, и, если не влияет, порядок байтов для этой конкретной части данных может быть установлен с точки зрения производительности.
Как он используется здесь, порядок байтов данных (например, переменные, структуры данных, неупорядоченный массив данных, аргументы функции и т.д.) не виден программисту, если все хранения и восстановления данных имеют один и тот же размер. Чтобы доказать, что все хранения и извлечения данных имеют один и тот же размер, компилятор гарантирует следующее: к данным нельзя получить доступ через другие переменные (например, члены объединения) различного размера; адрес данных (если когда-либо получен) не виден напрямую извне (то есть вне компилируемого кода), не сохраняется к переменной, которая видна извне, не передается/не принимается от внешней функции, не участвует/не принимается в выражениях, которым не может следовать компилятор; и если адрес данных берется и приводится к указателю на данные другого размера, тогда не существует считывания/записи с помощью этого указателя. Однако компилятор может позволить известные исключения из этих предварительных условий для внешних функций, подобных maloc/free/и т.д., и все еще гарантировать, что все извлечения и хранения имеют один и тот же размер.
Видимость порядка байтов данных может быть вычислена консервативно. Например, порядок байтов может рассматриваться как видимый, если не доказано обратное. Чтобы определить видимость порядка байтов аргументов функции, компилятор дополнительно может гарантировать, что все вызовы функции известны (в том числе косвенные вызовы). В качестве примеров порядок байтов статической переменной высокого уровня, адрес которой никогда не берется, невидим программисту, тогда как порядок байтов глобальной переменной в компиляции на каждый модуль рассматривается как видимый программисту.
Части данных составляют группу, если они должны иметь один и тот же порядок байтов. В приведенном ниже примере переменные "а" и "b" должны иметь один и тот же порядок байтов и, таким образом, компилятор должен сохранить этот порядок:
int* ptr=condition?&a:&b
ptr [3]=10.
Чтобы определить, какой порядок байтов конкретных данных имеет больший смысл с точки зрения производительности, компилятор, соответствующий варианту осуществления настоящего изобретения, проверяет, как используются данные. Если согласно счетчикам исполнений данные используются более часто в контексте обратного порядка байтов, компилятор делает эти данные с обратным порядком байтов, когда возможно. Иногда порядок байтов контекста неизвестен (например, данные копируются из одной переменной в другую и компилятор еще не принял решение о порядке байтов обеих переменных). В этом случае может использоваться эвристика, чтобы выбрать лучший порядок байтов, имеющий более высокую вероятность.
Таким образом, компилятор в соответствии с вариантом осуществления настоящего изобретения может выполнить следующее: 1) разбить все данные, с которыми работает программа, на группы, которые должны иметь один и тот же порядок байтов; 2) выбрать группы так, чтобы порядок байтов всех данных в группе был невидим программисту; 3) уточнить выбор, отбирая только те группы, которые, если порядок байтов будет изменен, дадут положительный выигрыш в производительности; и 4) изменить порядок байтов в выбранных группах, регулируя все считывания/записи данных групп.
Обратимся теперь к фиг.2, где показана блок-схема последовательности выполнения операций способа оптимизации кода для управления порядком следования байтов данных в соответствии с одним вариантом осуществления настоящего изобретения. Как показано на фиг.2, способ 100 может быть реализован, используя компилятор с двумя порядками следования байтов, который работает на процессоре системы, например, на процессоре, имеющем архитектуру с прямым порядком байтов. Как видно на фиг.2, способ 100 может начинаться с исполнения кода или применения эвристики для получения статистической информации в отношении заданного сегмента кода (блок 110). Такая статистическая информация может быть получена при выполнении первого прохода компилятора, который может исполнить код или выполнить другие операции, чтобы получить статистическую информацию. Затем данные могут быть разделены на группы (блок 120). Более конкретно, данные могут быть разбиты на группы, в которых каждые из данных имеют один и тот же порядок байтов. Таким образом, все данные группы могут иметь обратный или прямой порядок байтов.
Для каждой группы может затем быть определено, видим ли порядок байтов в группе программисту (ромб 130). Как будет обсуждаться дополнительно ниже, могут быть проведены различные анализы, чтобы определить, видим ли порядок байтов. Эти анализы могут основываться, по меньшей мере, частично на статистической информации, полученной во время первого прохода. Если порядок байтов видим, управление передается блоку 140, где может быть выбрана следующая группа, поскольку на этой группе данных никакая оптимизация невозможна.
В противном случае управление переходит от ромба 130 к ромбу 150, где может быть определено, может ли изменение порядка байтов в данных группы дать выигрыш. Как дополнительно будет обсуждено ниже для различных реализаций, могут быть выполнены различные вычисления, чтобы определить, будет ли обеспечен выигрыш в производительности. Если никакой выигрыш не обеспечивается, никакая оптимизация не выполняется и может быть выбрана следующая группа (блок 140). В противном случае, если изменение порядка байтов должно обеспечить выигрыш в производительности, управление передается в блок 160, где порядок байтов группы может быть изменен. Модифицированный код может затем быть сохранен в соответствующем хранилище, таком как системная память или энергонезависимое хранилище, для более позднего исполнения, когда будет вызвана программа, содержащая модифицированный код. Хотя на фиг.2 показана такая конкретная реализация варианта осуществления, объем настоящего изобретения не ограничивается в этом отношении.
В одной реализации оптимизация с помощью компилятора может работать при двух проходах компиляции. При первом проходе накапливается информация об использовании данных и вычисляется предпочтительный порядок байтов с точки зрения производительности. При втором проходе использование данных регулируется в соответствии с выбранным порядком байтов для каждой конкретной части данных. Таким образом, может быть определено, видим ли порядок байтов для определенной части данных. Во-вторых, может быть идентифицирован порядок байтов, более целесообразный с точки зрения производительности. Наконец, порядок байтов для конкретных данных может быть конвертирован.
Каждая часть данных (переменная, аргумент функции, функция и т.д.) имеет псевдоуказатель DATA_ADDRESS, который обрабатывается как обычный указатель, содержащий адрес этих данных. В одном варианте осуществления каждый указатель (и псевдоуказатели DATA_ADDRESS) поддерживает различные структуры данных.
В одном варианте осуществления структуры могут быть сохранены в таблице 150 монитора производительности, такой как показано на фиг.3, на которой показана блок-схема различных хранилищ для сохранения статистики производительности в соответствии с одним вариантом осуществления настоящего изобретения. В некоторых вариантах осуществления таблица 150 может храниться в системной памяти, хотя в других реализациях таблица может храниться в кэш-памяти процессора, на котором исполняется компилятор. Как показано на фиг.3, таблица 150 может содержать список 160 адресатов, чтобы хранить для каждого указателя и указателя положения адресов данных, список указателей, в который копируется указатель. Аналогично, в списке 165 источников хранится список источников, связанных с соответствующим указателем. Кроме того, список 170 размеров доступа может хранить размер считывания/записи, связанный с соответствующим указателем. В свою очередь, счетчик 175 выигрыша может получать положительные/отрицательные приращения в зависимости от того, может ли изменение порядка байтов (положительно или отрицательно) повлиять на производительность в отношении выражения, связанного с указателем. Таким образом, каждый указатель и псевдоуказатель могут поддерживать каждый из этих списков. В одном варианте осуществления списки VALUE_COPIED_TO и VALUE_COPIED FROM (соответствующие списку 160 адресатов и списку 165 источников) могут содержать другие указатели; список ACCESS_SIZE (соответствующий списку 170 доступа) содержит целые числа; и счетчик 175 выигрыша накапливает статистику использования данных. Первоначально, список ACCESSJSIZE для псевдоуказателей DATA_ADDRESS, соответствующих внешне видимым символам (переменные функции), а также переменные, к которым можно получить доступ через другие переменные (например, члены объединения), и те другие переменные, которые имеют разный размер, содержат нулевое значение (в варианте осуществления, в котором нулевой размер доступа указывает видимый порядок байтов). Другие списки первоначально пусты и счетчики выигрыша первоначально установлены на ноль.
При первом проходе компилятор заполняет эти списки реальными данными. Каждый раз, когда значение копируется из одного указателя в другой, список VALUE_COPIED_TO источников и список VALUE_COPIED_FROM адресатов соответственно расширяются. Каждый раз, когда адрес данных сохраняется, список VALUE_COPIED_TO источников, список ADDRESSJDATA и список VALUE_COPIED_FROM адресатов соответственно расширяются.
Каждый раз, когда обнаруживается считывание/запись, соответствующий ввод в список ACCESS_SIZE расширяется на размер считывания/записи. При этом счет в счетчике выигрыша увеличивается или уменьшается эвристическим счетчиком исполнений текущего выражения или остается нетронутым, в зависимости от того, как изменение порядка байтов могло бы модифицировать выражение. В приведенных ниже примерах изменения различных выражений отражают изменение порядка байтов переменной А:
А=SWAP(В)→А=В// счетчик выигрыша растет
А=0×12345678→А=0×78563412// счетчик выигрыша остается нетронутым
А=В→А=SWAP(B) // счетчик выигрыша уменьшается.
Каждый раз, когда на указателе или на адресе данных обнаруживается неподдерживаемая операция, соответствующий список ACCESS_SIZE расширяется с помощью нулевого значения. В конце первого прохода создаются все списки и компилятор имеет достаточно информации, чтобы определить видимость порядка байтов. Если для заданных данных объединение списков ACCESS_SIZE всех переменных указателя, транзитивно достижимых через список VALUE_COPIED_TO списка ADDRESS DATA, содержит не более одного элемента (и тот элемент является ненулевым), то все считывания/записи данных имеют этот конкретный размер и, таким образом, порядок байтов для этих конкретных данных не видим программисту.
Чтобы обнаружить, какие части данных должны иметь один и тот же порядок байтов в качестве заданных данных (то есть какие части данных составляют группу), компилятор создает список указателей ADDRES_DATA, транзитивно доступный через списки VALUE_COPIED_FROM и VALUE_COPIED_TO. Оптимизация по всей группе возможна, если объединение списков ACCESS_SIZE всех указателей, транзитивно доступных через VALUE_COPIED_TO, и списки VALUE_COPIED_FROM содержит не более одного элемента и этот элемент является ненулевым.
Если порядок байтов всей группы не видим программисту и выбор другого порядка байтов для всей группы может дать выигрыш в производительности (например, сумма BENEFITS для всех транзитивно доступных указателей положительна), компилятор делает перестановку и регулирует использование данных.
Таким образом, варианты осуществления проверяют, как используется каждая конкретная часть данных, и принимают решение о порядке байтов, основываясь на счетчиках исполнений и использовании данных. Дополнительно, варианты осуществления могут применяться ко всем данным, соответствующим критериям, а не к определенным классам данных (только таким, как возвращаемые значения). Выбор порядка байтов основан на использовании данных в компилируемом приложении; решение принимается для каждой определенной части данных для каждого конкретного приложения, а не в соответствии с моделью "один пригоден для всего". Таким образом, вместо того, чтобы полагаться на решение пользователя, компилятор может решать, какие данные должны иметь другой порядок байтов, позволяя создавать код с более высокой производительностью.
Обратимся теперь к таблице 2, показывающей упрощенный псевдокод для обеспечения двух проходов в соответствии с одним вариантом осуществления настоящего изобретения. Как видно из таблицы 2, два прохода выполняются компилятором, чтобы управлять выбором порядка байтов для конкретных данных. Как видно, первый проход может использоваться для исполнения кода или выполнения другой эвристики, чтобы собрать статистику использования, которая содержит обновление различных списков, связанных с каждой переменной и указателем кода. Затем выполняется второй проход, чтобы оптимизировать код, основываясь на собранной статистике использования. Когда определено, что изменение порядка байтов оптимизирует код, такие операции перестановки байтов вставляются/удаляются из кода.



Варианты осуществления могут быть реализованы во многих различных типах систем. Обратимся теперь к фиг.4, где показана блок-схема системы, соответствующей варианту осуществления настоящего изобретения. Как показано на фиг.4, многопроцессорная система 300 является взаимосвязанной двухточечной системой и содержит первый процессор 370 и второй процессор 380, связанные через взаимное соединение 350 "точка-точка". Как показано на фиг.4, каждый из процессоров 370 и 380 может быть многоядерным процессором, содержащим первое и второе ядра процессора (то есть ядра 374а и 374b процессора и ядра 384а и 384b процессора).
Снова со ссылкой на фиг.4, первый процессор 370 дополнительно содержит концентратор 372 контроллера памяти (МСН) и поточечные (Р-Р) интерфейсы 376 и 378. Точно так же второй процессор 380 содержит МСН 382 и поточечные интерфейсы 386 и 388. Как показано на фиг.4, МСН 372 и 382 связывают процессоры с соответствующими запоминающими устройствами, а именно запоминающим устройством 332 и запоминающим устройством 334, которые могут быть частями оперативной памяти (например, динамической оперативной памяти (DRAM)), локально присоединенной к соответствующим процессорам. Первый процессор 370 и второй процессор 380 могут быть соединены с микропроцессорным набором 390 через взаимные поточечные соединения 352 и 354 соответственно. Как показано на фиг.4, микропроцессорный набор 390 содержит поточечные интерфейсы 394 и 398.
Дополнительно, микропроцессорный набор 390 содержит интерфейс 392, чтобы связать микропроцессорный набор 390 с высокопроизводительным графическим процессором 338. В свою очередь, микропроцессорный набор 390 может быть присоединен к первой шине 316 через интерфейс 396. Как показано на фиг.4, различные устройства 314 ввода-вывода могут быть присоединены к первой шине 316 наряду с мостом 318 между шинами, который связывает первую шину 316 со второй шиной 320. В одном варианте осуществления ко второй шине 320 могут быть присоединены различные устройства, в том числе, например, клавиатура/мышь 322, устройства 326 связи и устройство 328 хранения данных, такое как дисковод или другое устройство памяти большой емкости, которые могут содержать код 330. Такой код может содержать компилятор в соответствии с вариантом осуществления настоящего изобретения, который может исполняться на одном или более процессорах 370 и 380. Дополнительно, со второй шиной 320 может быть связан аудиоввод-вывод 324.
Варианты осуществления могут быть реализованы в коде и могут храниться на носителе данных, хранящем команды, которые могут использоваться для программирования системы, чтобы выполнять команды. Носитель данных может содержать, в частности, любой тип диска, в том числе дискеты, оптические диски, универсальные оптические диски, твердотельные диски (SSD), ПЗУ на компакт-дисках (CD-ROM), перезаписываемые компакт-диск (CD-RW) и магнитооптические диски, полупроводниковые устройства, такие как постоянные запоминающие устройства (ROM), оперативное запоминающее устройство (RAM), такое как динамическое оперативное запоминающее устройство (DRAM), статическое оперативное запоминающее устройство (SRAM), стираемое программируемое постоянное запоминающее устройство (EPROM), флэш-память, электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), магнитные или оптические карты или любой другой тип носителей, пригодных для хранения электронных команд.
Хотя настоящее изобретение было описано со ссылкой на ограниченное количество вариантов осуществления, специалисты в данной области техники могут предложить свои многочисленные изменения и вариации. Подразумевается, что приложенная формула изобретения относится ко всем таким изменениям и вариациям, которые попадают в пределы истинной сущности и объема этого настоящего изобретения.
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении

