Результат интеллектуальной деятельности: ТЕХНОЛОГИИ ОТОБРАЖЕНИЯ РЕГИСТРА ДЛЯ ЭФФЕКТИВНОЙ ДИНАМИЧЕСКОЙ ДВОИЧНОЙ ТРАНСЛЯЦИИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее раскрытие относится к динамической двоичной трансляции и, более конкретно, к эффективной технологии для выполнения динамической двоичной трансляции из архитектуры системы команд ("ISA") с большим количеством регистров в ISA с меньшим количеством регистров.
Уровень техники
Динамическая двоичная трансляция (DBT) получила широкое распространение как средство работы приложений, созданных для одной архитектуры системы команд (ISA) поверх другой ISA. Учитывая количество программного обеспечения, которое было разработано ранее для PC на основе х86 ISA, было уделено внимание трансляции х86 в другие ISA. Последние тенденции в отрасли как для меньших ультрамобильных ПК, так и для более мощных встроенных и мобильных Интернет-устройств (например, смартфонов) размывают границы между этими отдельными рынками. В результате такого схождения рынков формируется большой интерес к DBT из ISA, которые в настоящий момент доминируют на рынках встроенных и мобильных Интернет-устройств (например, ARM (ARM Holdings), MIPS (MIPS Technologies) и PowerPC (APPLE-IBM-Motorola alliance)) в х86 (Intel Corporation).
Двоичная трансляция ("ВТ") представляет собой общую технологию для перевода двоичных кодов, построенных для одной ISA источника ("гость") в другую целевую ISA ("хост"). Используя ВТ, становится возможным выполнить двоичные коды приложений, построенных для одного процессора ISA на процессоре с другой архитектурой, без необходимости повторной компиляции исходного кода на высоком уровне или перезаписи кода ассемблера. Поскольку большинство старых компьютерных приложений доступно в только двоичных форматах, ВТ является очень привлекательным, учитывая ее потенциал, для обеспечения выполнения процессором приложений, которые не построены и не доступны для него. Несколько успешных проектов ВТ привели к определенному процессу предшествующего уровня техники в последние десятилетия, включая в себя Digital Equipment Corporation ("DEC") FX!32, IA-32 EL компании Intel, GMS ("программное обеспечение для трансформации кода") компании Transmeta, Godson-3 (архитектура MIPS), и DAISY ("Динамически спроектированная система команд из Иорктауна") компании IBM. Большинство этих инструментов предназначены для обеспечения работы старых приложений х86 на таких процессорах, как Alpha (DEC), Itanium (Intel), Crusoe (Transmeta) и MIPS (MIPS Technologies).
Большинство указанных выше инструментов используют динамическую ВТ (DBT), что означает, что они выполняют трансляцию "на ходу", по мере выполнения приложения, то есть, во время выполнения. В качестве альтернативы, ВТ может быть выполнена в автономном режиме, то есть, статическая ВТ (SBT). Модель динамического использования обычно является предпочтительной, поскольку она является более общей (например, выполнена с возможностью обработки самомодифицирующегося кода), и она работает прозрачно для пользователя с простым изменением OS, для автоматического вызова DBT при появлении "неродных" двоичных файлов. Основной недостаток DBT, по сравнению с SBT, состоит в чрезмерно большом объеме служебной информации. Циклы, выполняемые во время трансляции и оптимизации приложения, представляют собой циклы, которые, в противном случае, можно было бы использовать для фактического выполнения кода программы. Поэтому, инструменты DBT вынуждены идти на компромисс между временем, затраченным на трансляцию/оптимизацию, и качеством получаемого в результате кода, что, в свою очередь, отражается на времени исполнения транслированного кода.
Трудности, с которыми сталкивается DBT, в большой степени зависят от ISA источника и целевой ISA. В последнее время возникает большой интерес в расширении использования х86 ISA на сегменты рынка ультрамобильных и встроенных устройств (например, процессор Atom компании Intel). С точки зрения пользователя, это очень удобно, поскольку может обеспечить возможность эффективной работы программного обеспечения PC на встроенных и ультрамобильных платформах. Однако для того, чтобы адаптировать х86 в эти новые домены, также необходимо обеспечить возможность для х86 выполнения огромную базу программного обеспечения, доступную в этих сегментах, которые, в основном, основаны на ISA, таких компаний, как ARM (ARM Holdings), MIPS (MIPS Technologies) и PowerPC (APPLE-MOTOROLA alliance). Например, в будущих смартфонах на основе х86, помимо возможности исполнения приложений PC, было бы предпочтительно обеспечить возможность загрузки и работы без стыков приложений на основе ARM, поставляемых, например, iPhone Apple App Store компании Apple. Проблемы обеспечения этого сценария включают в себя поддержание рабочих характеристик для DBT и низкий уровень непроизводительных затрат энергии.
Хотя было предложено множество систем DBT, большинство из них следует одному и тому же потоку исполнения. Вначале двоичный файл, созданный для архитектуры источника (хост), загружают в запоминающее устройство. Участки этого двоичного файла источника затем транслируют в целевой (хост) двоичный код. Эту трансляцию обычно выполняют "по требованию". Другими словами, инструкции исходного кода транслируют по мере того, как поток управления достигает их. Как правило, трансляцию выполняют с грануляцией основных блоков, которые представляют собой последовательности инструкций с одним входом и потенциально множеством выходов. После трансляции основного блока, результат трансляции сохраняют в кэше трансляции (также называется кэшем кода) в запоминающем устройстве для будущего повторного использования. Наиболее агрессивные системы DBT выполняют разные уровни оптимизации. В соответствии с системами CMS Transmeta и другими системами DBT, такие уровни оптимизации называются "приводами". Вначале используют очень быструю трансляцию (Привод 1). Этот привод направлен на очень быстрое выполнение, за счет низкого качества транслируемого кода. Такой компромисс приводит к идеальным результатам для редко исполняемого кода, такого, как код начальной загрузки OS. В Приводе 1, DBT также воплотили пробы (счетчики) для детектирования "горячих" (то есть, часто выполняемых) основных блоков. Как только блок становится горячим, его и его окружающие скоррелированные с ним блоки объединяют в область. Эту область затем повторно транслируют, используя более высокий привод, который применяет дополнительную оптимизацию к коду. Такую же стратегию можно повторять для произвольного количества приводов. Например, CMS компании Transmeta используют четыре привода. В действительности, система на основе приводов обеспечивает, что, чем больший вклад область кода вносит в общее время исполнения, тем больше времени затрачивают на ее оптимизацию для получения более быстрого кода.
Набор, количество и степень агрессивности прикладываемой оптимизации в значительной степени изменяются от одной DBT к другой. Типичная оптимизация включает в себя: планирование инструкций, устранение "мертвого" кода и устранение избыточности. Фактически, аналогично статической оптимизации компилятора, набор для большинства соответствующих оптимизаций зависит от целевой архитектуры. Хотя, в отличие от оптимизации компилятора, в DBT такая оптимизация имеет точную информацию о времени выполнения, которое можно использовать для получения кода более высокого качества. Основной недостаток DBT по сравнению со статическими компиляторами представляет собой намного более плотный бюджет времени оптимизации.
Краткое описание чертежей
Свойства и преимущества заявленного предмета изобретения будут понятны из следующего подробного описания вариантов осуществления, соответствующих им, и это описание следует рассматривать со ссылкой на приложенные чертежи, на которых:
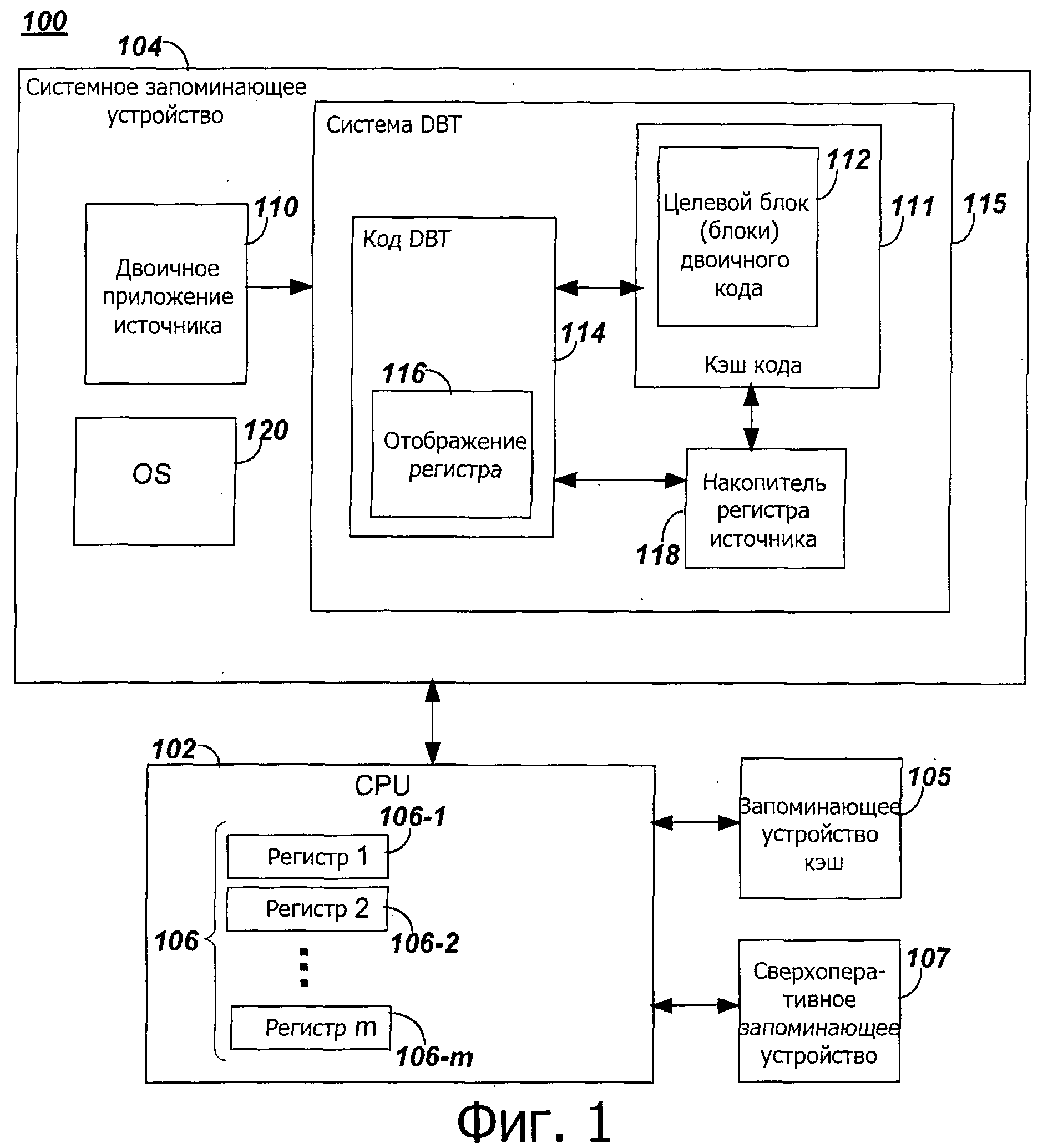
на фиг.1 представлена система запоминающего устройства, соответствующая настоящему изобретению;
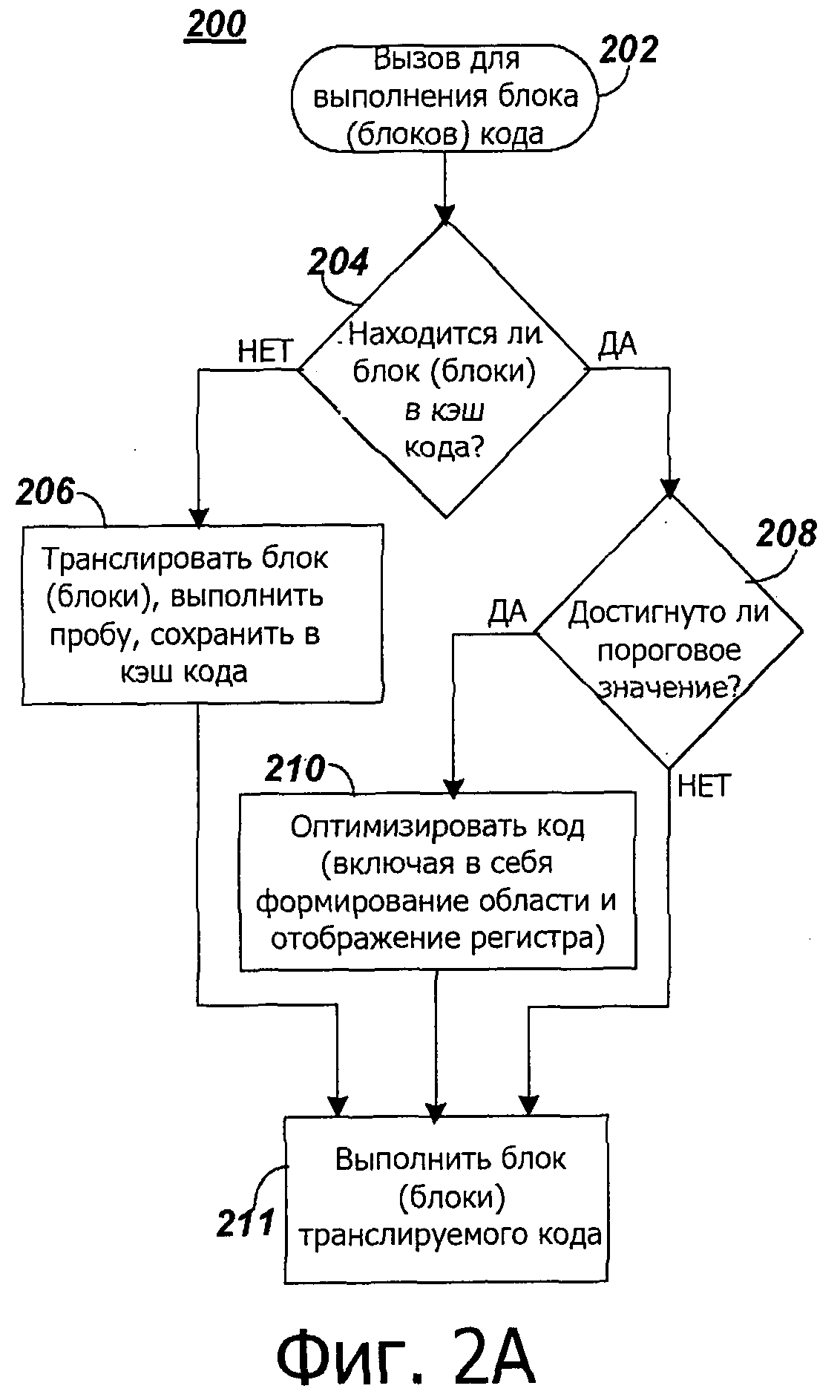
на фиг.2A представлена блок-схема последовательности операций примерных операций для динамического двоичного транслятора, соответствующего настоящему изобретению;
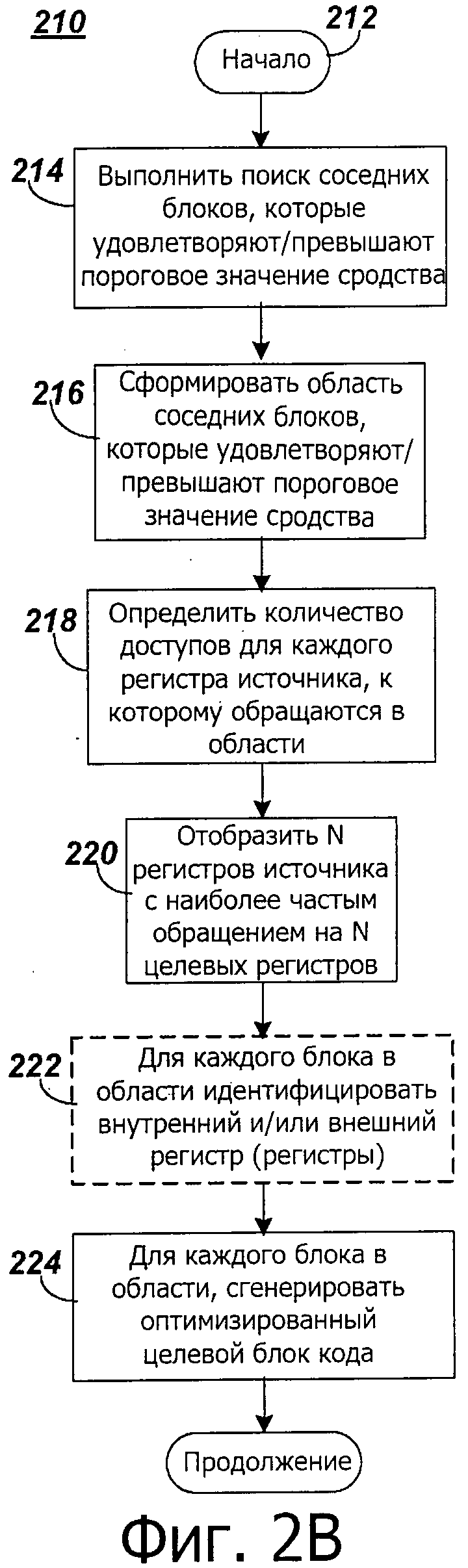
на фиг.2B представлена блок-схема последовательности операций примерных операций для оптимизации кода, соответствующего настоящему изобретению;
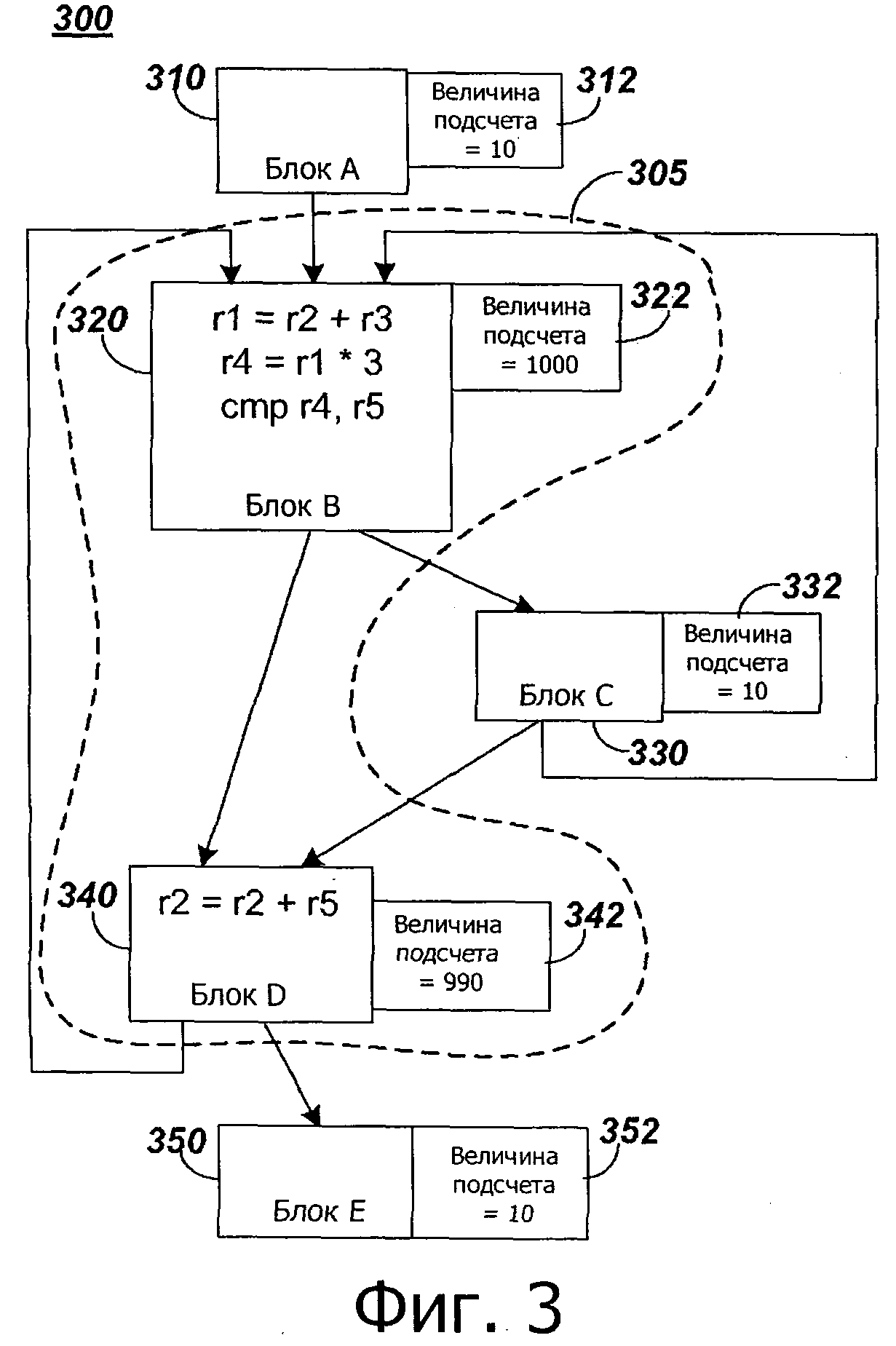
на фиг.3 представлена примерная блок-схема управления, включающая в себя область часто исполняемых кодовых блоков;
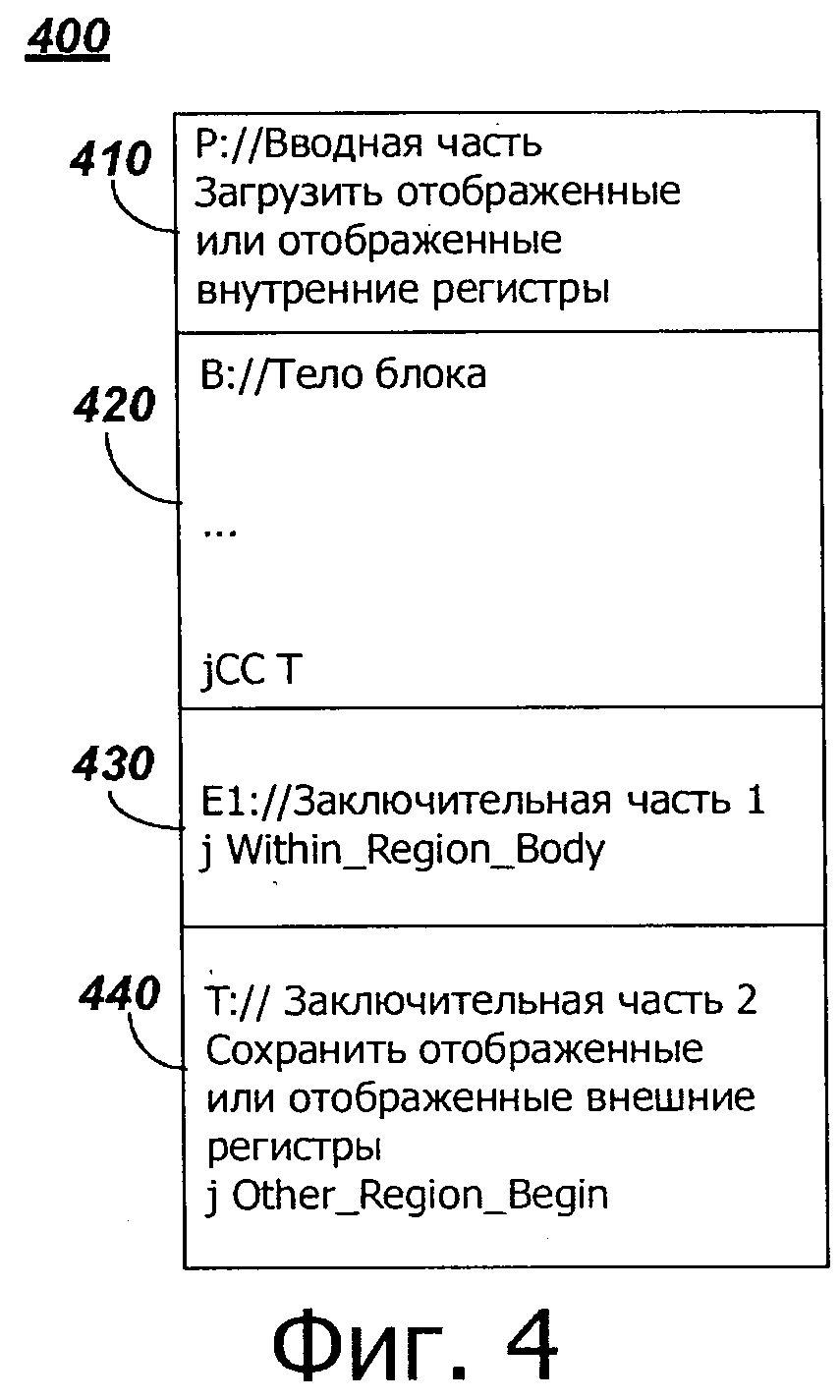
на фиг.4 представлен примерный оптимизированный целевой блок двоичного кода, включающий в себя вводную часть, тело, условный переход и, по меньшей мере, одну заключительную часть, в соответствии с настоящим изобретением;
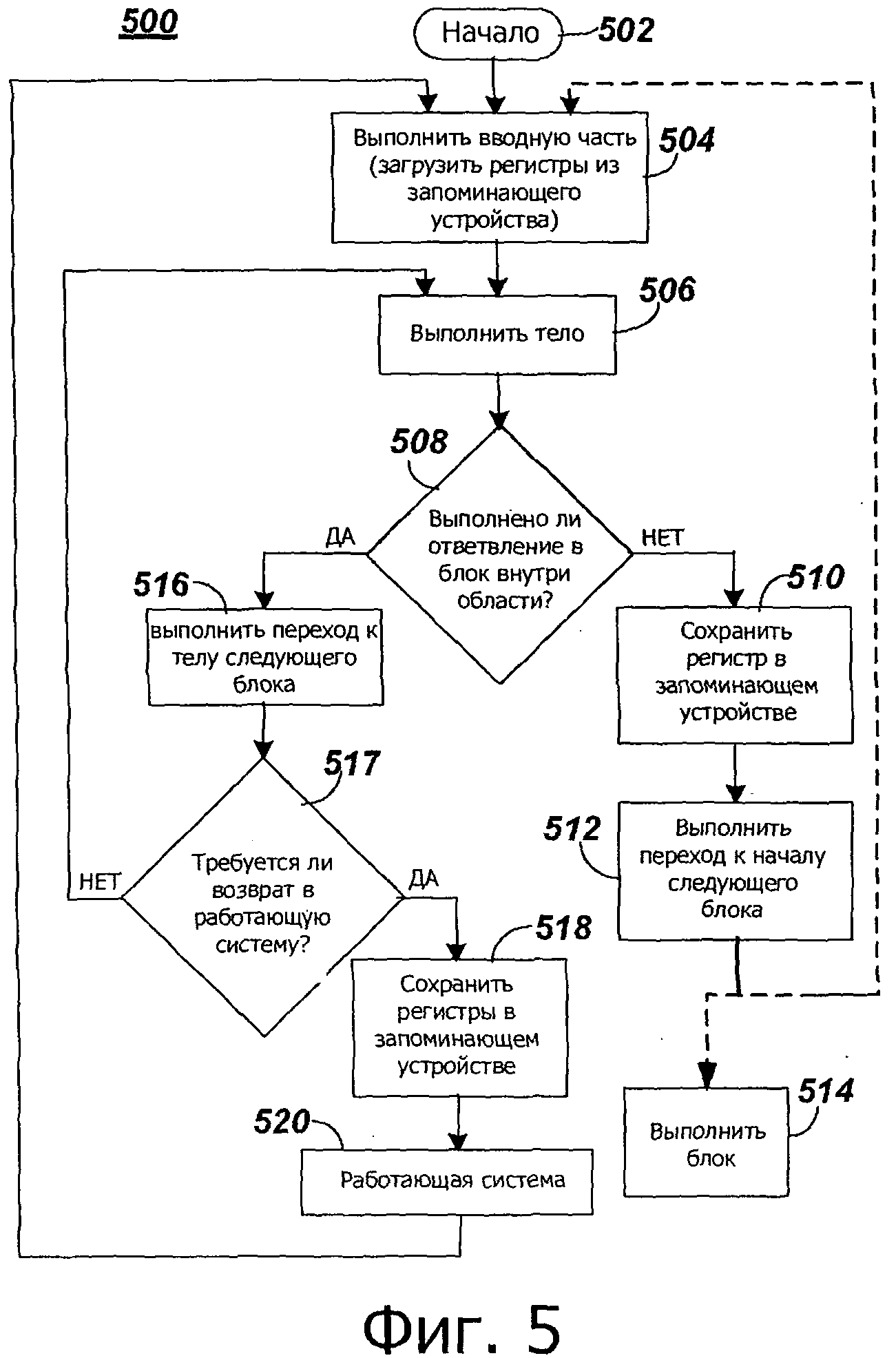
на фиг.5 представлена блок-схема последовательности операций примерных операций для выполнения целевых блоков двоичного кода, включая в себя оптимизацию, в соответствии с настоящим изобретением;
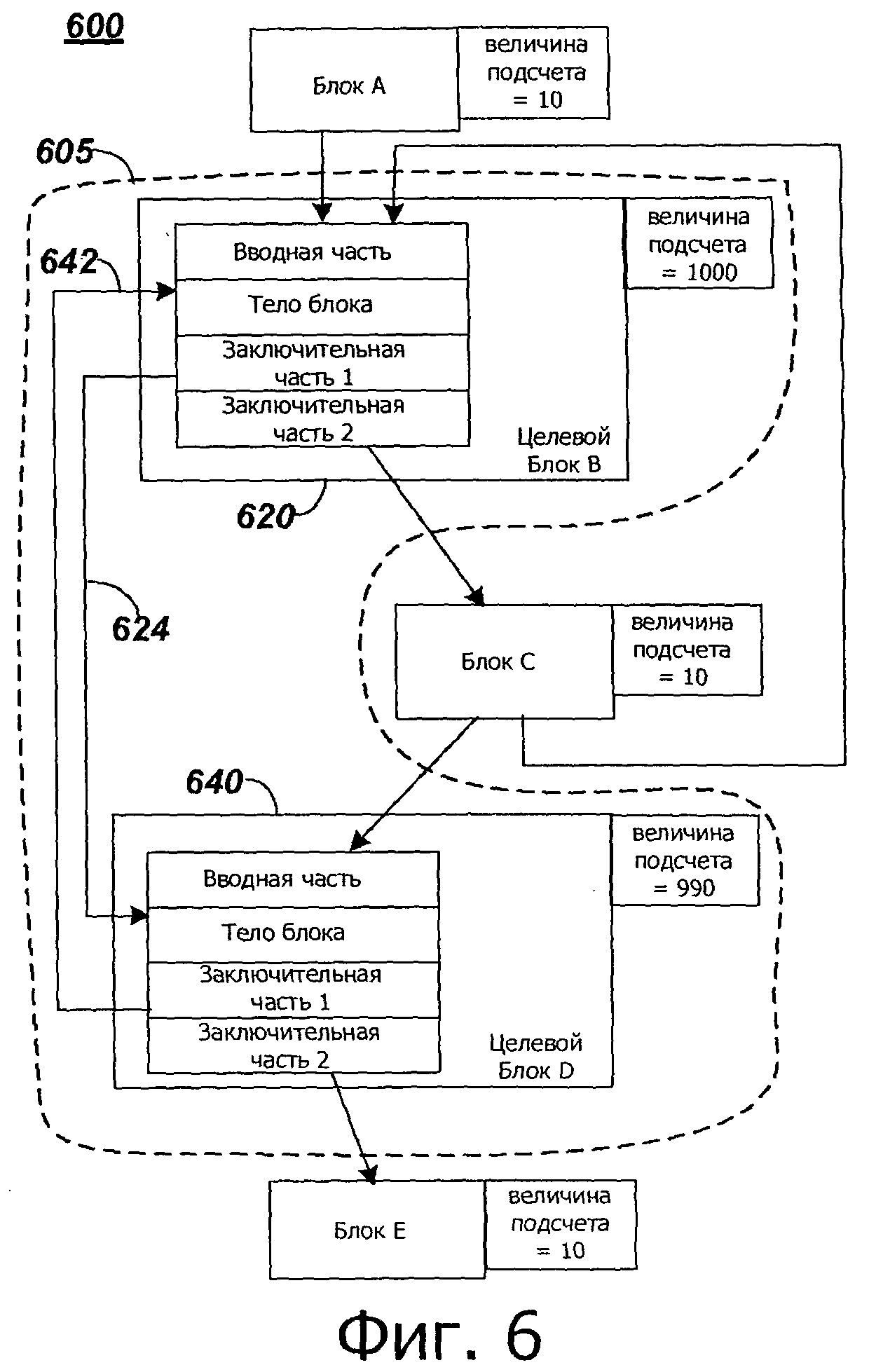
на фиг.6 представлена примерная оптимизированная блок-схема управления, соответствующая блок-схеме управления по фиг.3; и
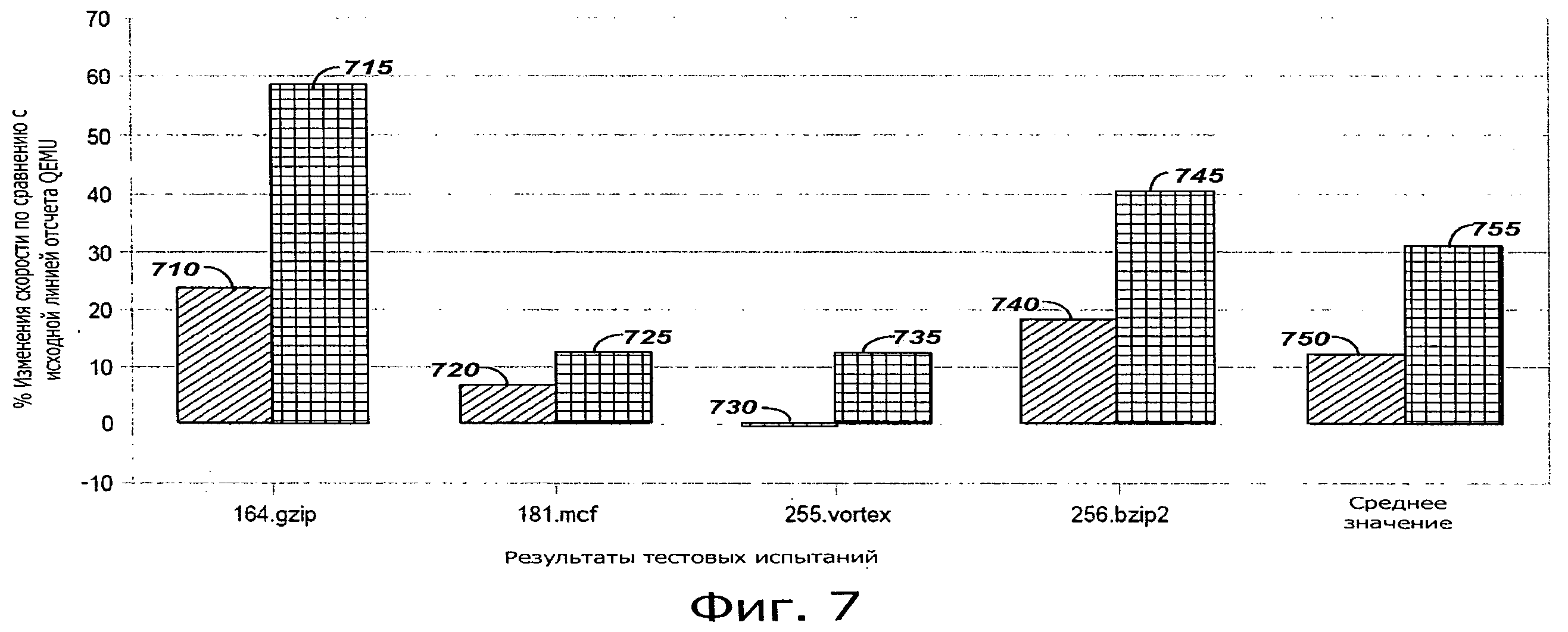
на фиг.7 показан график, иллюстрирующий сравнение результатов сравнительных тестов рабочих характеристик динамической двоичной трансляции, включающей в себя отображение регистра блочного уровня и отображение регистра уровня области, в соответствии с настоящим изобретением.
Подробное описание изобретения
Проблема, с которой сталкивается динамическая двоичная трансляция ("DBT"), представляет собой непроизводительные издержки, которым она подвергается. Такие непроизводительные издержки, в основном, возникают из-за относительно часто используемых особенностей в ISA ("источника") хоста, которые не просто отображаются на ("целевые") ISA хоста. Например, когда ISA-источник имеет больший набор регистров, чем у целевой ISA, становится важным использовать эффективное отображение регистра из регистров источника в целевые регистры для уменьшения непроизводительных издержек во время эмуляции регистра, например, при доступе к памяти. Это, в частности, важно для целевых ISA, таких как х86 и х86-64, которые имеют относительно небольшое количество регистров общего назначения/регистров целых чисел (например, 8 и 16) по сравнению с другими ISA, например, PowerPC, ARM и MIPS, которые имеют 32 регистра и Itanium, которые имеют 128 регистров.
Проблема отображения регистра осложняется тем фактом, что оптимальное отображение (то есть, отображение, которое приводит к наименьшим не производительным издержкам), в высокой степени зависит от последовательности исходного двоичного кода и, таким образом, изменяется от одного участка кода к другому участку. В идеале, каждая область кода должна использовать отображение регистра, которое оптимально для нее.
В настоящем раскрытии предусмотрена система и способ, выполненные с возможностью обеспечения отображения регистра на уровне области. Способ включает в себя, для каждого блока двоичного кода в области, отображение, по меньшей мере, некоторых из наиболее часто используемых регистров процессора источника, в области для регистров целевого процессора. Наиболее часто используемые регистры процессора источника могут быть определены по пробе (пробам), включающей в себя счетчики, воплощенные с блоками целевого двоичного кода, соответствующими блокам двоичного кода источника. Блок оптимизированного целевого двоичного кода может быть затем сгенерирован для каждого блока двоичного кода источника в области, выбранной для оптимизации. Блок оптимизированного целевого двоичного кода может включать в себя вводную часть, тело, включающее в себя транслированный двоичный код источника, условный переход и, по меньшей мере, одну заключительную часть. Вводная часть выполнена с возможностью загрузки отображаемых или отображаемых внутренних регистров для области. Условный переход выполнен с возможностью управления потоком на основе, выполняется ли переход на границе блока двоичного кода источника к следующему двоичному блоку в области или к следующему двоичному блоку, который не находится в этой области. Заключительную часть (части) выполняют с возможностью перехода в тело блока, если следующий двоичный блок находится в области, или вначале следующего двоичного блока, если следующий двоичный блок не находится в области. Начало может соответствовать вводной части оптимизированного целевого блока двоичного кода в другой области или неоптимизированного целевого блока двоичного кода. Если следующий двоичный блок не является областью, внешние регистры для области могут быть сохранены в запоминающем устройстве. Предпочтительно, доступ к запоминающему устройству может быть уменьшен путем загрузки отображаемых или отображаемых внешних регистров для области при пересечении границ области, вместо выполнения каждый раз оптимизированного блока целевого двоичного кода.
Способ и/или система, соответствующая настоящему раскрытию, выполнена для обеспечения отображения регистра на уровне области. Области могут быть относительно сложными. Например, область может включать в себя произвольное количество вложенных контуров, то есть, произвольную комбинацию (комбинации) контуров, например, множество одноуровневых элементов могут включать в себя родительский контур, как будет понятно для специалиста в данной области техники. В другом примере область может включать в себя целевые блоки двоичного кода, соответствующие не сокращаемому потоковому графу, например множество возможных входов в контур. Область может быть сформирована из непрерывных и/или не являющихся непрерывными целевых блоков двоичного кода.
На фиг.1 представлена система 100 в соответствии с настоящим раскрытием. Система 100 включает в себя процессор ("CPU") 102, соединенный с системным запоминающим устройством 104. Система 100 может включать в себя запоминающее устройство 105 кэш (которое может быть включено в системное запоминающее устройство 104) и/или сверхоперативное запоминающее устройство 107, аналогичное запоминающему устройству кэш, но управляемое программным средством. CPU 102 может включать в себя множество регистров 106-1, 106-2, …, 106 m процессора, совместно обозначенных 106. CPU 102 может включать в себя множество модулей обработки кода ядро (ниже "ядер" или в единственном числе "ядро"), и каждое ядро может быть выполнено с возможностью выполнения множества потоков. Системное запоминающее устройство 104 может содержать двоичное приложение 110 - источник, систему 115 динамической двоичной трансляции и операционную систему-хост управления ("OS") 120. Система 115 динамической двоичной трансляции может включать в себя целевой блок (блоки) 112 двоичного кода, код 114 динамического двоичного транслятора, включающий в себя модуль 116 отображения регистра, и/или накопитель 118 регистра источника. Двоичное приложение 110 - источник может включать в себя множество блоков двоичного кода источника, соответствующих источнику ISA. Целевой блок (блоки) двоичного кода соответствует целевой ISA. Блок двоичного кода источника представляет собой последовательность из одной или больше инструкций, которые включают в себя, например, окончание с командами перехода. Целевой блок двоичного кода выполнен с возможностью включения функций соответствующего блока двоичного кода источника. Оптимизированный целевой блок двоичного кода может включать в себя функции соответствующего блока двоичного кода источника в теле оптимизированного целевого блока двоичного кода. Оптимизированный целевой блок двоичного кода может включать в себя дополнительную функцию, как описано здесь.
Целевой блок (блоки) 112 двоичного кода может быть сохранен в области системного запоминающего устройства, обозначенного "кэш" 111 кода. Кэш 111 кода можно понимать, как накопитель для целевого блока (блоков) 112 двоичного кода, то есть, одного или больше целевого блока (блоков) 112 двоичного кода, которые были транслированы из одного или больше соответствующих блока (блоков) двоичного кода источника. Системное запоминающее устройство 104 может содержать накопитель 118 регистра источника, выполненный с возможностью загрузки/сохранения данных в/из регистров 106 процессора. В некоторых вариантах осуществления запоминающее устройство 105 кэш и/или сверхоперативное запоминающее устройство 107 выполнены с возможность загрузки/сохранения данных в/из регистра (регистров) 106 процессора.
Код 114 динамического двоичного транслятора и модуль 116 отображения регистра могут быть выполнены с помощью одного или больше ядер, которые предназначены для работы над двоичным приложением 110 источника, для преобразования блока (блоков) двоичного приложения 110 источника в целевой блок (блоки) 112 двоичного кода. Блок двоичного кода источника может быть транслирован в целевой блок двоичного кода динамически. Другими словами, блок двоичного кода источника может быть транслирован в целевой блок двоичного кода, в ответ на вызов на выполнение двоичного блока, а не статически, то есть, еще до времени выполнении программы. Целевой блок двоичного кода может затем быть сохранен в системном запоминающее устройстве 104 в кэш 111 кода и может быть предоставлен в CPU 102 для исполнения. Блок (блоки) преобразования двоичного кода 110 источника в целевой блок (блоки) 112 двоичного кода может включать в себя отображение одного или больше регистров источника на один или больше целевых регистров, например, на регистр (регистры) 106 процессора, на основе, по меньшей мере, частично частоты доступа регистра в область. Например, ISA-источник может включать в себя Ns регистров источника, и целевая ISA может включать в себя Nt целевых регистров, например, регистры 106, где Nt меньше, чем Ns.
На фиг.2A представлена блок-схема 200 последовательности операций для динамического двоичного транслятора. Операции в блок-схеме 200 последовательности операций могут быть выполнены кодом 114 динамического двоичного транслятора. Ход выполнения программы может начаться с приема вызова для выполнения блока (блоков) 202 двоичного кода. Предполагается, что перед вызовом для выполнения блока (блоков) 202 двоичного кода, двоичное приложение 110 источника было загружено в системное запоминающее устройство 104. Во время операции 204 может определяться, находится или нет один или больше блоков целевого двоичного кода в кэш для кода, например в кэш 111 кода. Каждый блок целевого двоичного кода соответствует блоку двоичного кода источника двоичного приложения 110 источника. Если блок (блоки) целевого двоичного кода не находится в кэш для кода, операция 206 может включать в себя трансляцию блока (блоков) двоичного кода источника в целевой двоичный блок (блоки), осуществляя пробу (пробы) и сохранение целевого двоичного блока (блоков) и пробу (пробы) в кэш для кода. Такая трансляция может быть организована для относительно быстрого применения. Например, проба (пробы) может включать в себя счетчик (счетчики), выполненный с возможностью поддерживания величины подсчета количества раз, какой двоичной блок был выполнен. Регистр (регистры) процессора источника могут быть отображены на накопителе регистров, например накопитель 118 регистра источника, в системном запоминающем устройстве 104, в запоминающем устройстве 105 кэш и/или в сверхоперативном запоминающем устройстве 107. Ход выполнения программы может затем перейти к операции 211. Во время операции 211 может быть выполнен транслированный блок (блоки) кода. Если во время операции 204 целевой блок (блоки) двоичного кода находится в кэш для кода, ход выполнения программы может перейти к операции 208.
Во время операции 208 может определяться, было ли достигнуто пороговое значение. Было ли достигнуто пороговое значение, может быть определено на основе, по меньшей мере, частично, пробы (проб), воплощенной при операции 206, в ответ на предыдущий вызов, для выполнения блока (блоков) кода. Например, величина подсчета может быть последовательно увеличена каждый раз, когда выполняют двоичный блок. Если величина подсчета достигает заданного порогового значения, тогда проба может быть выполнена с возможностью возврата потока программы (то есть, перехода) в динамический двоичный транслятор для дальнейшей обработки. Заданное пороговое значение может быть выполнено с возможностью обозначения относительно часто выполняемого двоичного блока, который мог быть получен предпочтительно после оптимизации. Если пороговое значение не было достигнуто, поток программы (ход выполнения программы) может перейти к операции 211, выполнить блок (блоки) транслированного кода. Если пороговое значение было достигнуто, поток программы может перейти к операции 210 для оптимизации кода. Оптимизация кода 210 выполняется так, что она включает в себя формирование области и отображение регистра, как описано здесь. Поток программы может затем перейти к операции 211, выполнить блок (блоки) транслированного кода.
На фиг.2B представлена блок-схема 210 последовательности операций для оптимизации кода, в соответствии с настоящим раскрытием. Поток программы может начаться в начале 212. Операции блок-схемы 210 последовательности операций могут быть выполнены с помощью динамического двоичного транслятора кода 114, включая в себя модуль 116 отображения регистра. Во время операции 214 может быть произведен поиск соседних двоичных блоков, которые удовлетворяют и/или превышают пороговое значение сродства. Соседние двоичные блоки могут быть сопоставлены с двоичным блоком, который инициировал оптимизацию кода. Например, соседний двоичный блок (блоки) может быть выполнен так, чтобы он выполнялся непосредственно перед или сразу после двоичного блока, который инициировал оптимизацию кода. Соседний двоичный блок (блоки) может быть непрерывным с инициирующим двоичным блоком и/или может быть связан с инициирующим двоичным блоком, ответвлением или переходом. Под сродством между или внутри двоичных блоков можно понимать корреляцию при вероятности выполнения двоичных блоков. Например, корреляция может возникать из-за ответвления от одного двоичного блока в другой двоичный блок. Во время операции 216 затем может быть сформирована область, включающая в себя соседние двоичные блоки, которые достигают и/или превышают пороговое значение сродства.
Во время операции 218 множество доступов может быть определено для каждого регистра источника, доступ к которому осуществляют в области. Инструкция в области может использовать регистр источника, то есть, считывать из него, и/или может определять регистр источника, то есть, записывать в него. Доступ к регистру, то есть, использование регистра, включает в себя использование и/или определение регистра. Отображение регистра может быть основано на общем количестве доступов в каждом регистре источника в области.
Например, область, сформированная во время операции 216, может включать в себя один или больше блока (блоков) двоичного кода. Проба, включающая в себя величину подсчета количества исполнений двоичного блока, может быть ассоциирована с каждым блоком двоичного кода. Для каждого двоичного блока количество доступов к регистру может быть определено на основе величины подсчета количества исполнений двоичного блока, инструкций в двоичном блоке и регистров, доступ к которым осуществляет каждая инструкция. Общее количество доступов к каждому регистру, доступ к которому осуществляют в области, может быть затем определено путем суммирования количества доступов для каждого регистра в каждом двоичном блоке в области.
На фиг.3 представлен примерный график 300 потока управления, включающий в себя примерную область 305 кода. График 300 потока управления включает в себя пять блоков кода: блок А 310, блок В 320, блок С 330, блок D 340 и блок Е 350. Каждый блок имеет ассоциированный подсчет 312, 322, 332, 342, 352, соответствующий количеству исполнений блока, определенный на основе воплощенной пробы (проб), например, во время операции 206 (фигура 2A). Например, каждый из блока А, блока С и блока Е имеет ассоциированную величину подсчета десять. Блок В имеет ассоциированную величину подсчета одна тысяча, и блок D имеет ассоциированную величину подсчета девятьсот девяносто. В этом примере блок В может соответствовать заданному порогу, описанному в отношении операции 208 по фиг.2A, то есть, блок В является часто исполняемым блоком двоичного кода источника. Блок А, блок С и блок D могут быть соседними блоками для блока В. При выполнении операции 214 на фиг.2B, поиск соседних блоков, которые удовлетворяют/превышают пороговое значение сродства, может привести к блоку D. Блок D представляет собой соседний блок двоичного кода источника, который удовлетворяет или превышает пороговое значение сродства для блока В.
Сродство соответствует корреляции вероятностей выполнения часто выполняемого блока двоичного кода источника и соседнего блока двоичного кода источника. Другими словами, блок В имеет относительно высокую вероятность исполнения (величина подсчета = 1000). Блок D также имеет относительно высокую вероятность исполнения (величина подсчета = 990). "Вероятность исполнения" используется, поскольку информация подсчета является исторической, и будущие частоты исполнения могут изменяться. Вероятность исполнения блока D взаимосвязана с вероятностью исполнения блока В, например, на основе ответвления между блоком В и блоком D. Другими словами, вероятность исполнения блока D скоррелирована с вероятностью исполнения блока В.
В этом примере, из пяти блоков кода блок В и блок D с относительно высокими частотами исполнения (то есть, величины подсчета) 1000 и 990, соответственно, и которые удовлетворяют или превышают пороговое значение сродства, включены в область 305. Инструкции в блоке В обращаются к регистрам r1, r2, r3, r4 и r5. Регистры r1 и r4 определены (в них записывают) и регистры r1, r2, r3, r4 и r4 используются (из них считывают). Другими словами, для каждого исполнения блока В, к r1 и r4 обращаются дважды, и к каждому из остальных регистров обращаются один раз. В соответствии с этим, для блока В с частотой исполнения 1000, к каждому из r1 и r4 обращаются 2000 раз, и к каждому из остальных регистров обращаются 1000 раз. Блок D включает в себя одну инструкцию, которая обращается к регистру r2 дважды (один раз для считывания и второй раз для записи) и к регистру r5 один раз (считывание). Соответственно, для блока D, с частотой исполнения 990, доступ к r2 выполняют 1980 раз, и доступ к r5 выполняют 990 раз. Поэтому, для области 305, которая включает в себя блок В и блок D, к r1 в сумме обращаются 2000 раз, к r2 в сумме обращаются 2980 раз, к r3 обращаются в сумме 1000 раз, к r4 обращаются, в общем, 2000 раз, и к r5 обращаются, в общем, 1990 раз. Сортируя регистры по количеству доступов к регистру, начиная с регистров с наиболее частым обращением и кончая регистрами с наименее частым обращением, получают: r2, r1 и r4, r5 и затем r3.
Снова возвращаясь к фиг.2B, во время операции 220, регистры источника могут быть отображены в целевые регистры. Регистр (регистры) источника, соответствующие наибольшему количеству доступов, то есть, с наиболее частым обращением, для области могут быть отображены на целевой регистр (регистры). Например, целевая ISA может иметь Ns целевых регистров процессора, и ISA источника может иметь Ns регистров источника процессора, где Nt меньше, чем Ns. Среди Nt целевых регистров процессора N могут быть доступны для отображения, где N меньше чем или равно Nt. Продолжая пример, показанный на фиг.3, если N равно трем, тогда регистры r1, r2 и r4 могут быть отображены на целевые регистры процессора для этой области. Регистры r3 и r5 могут не быть отображены на целевые регистры процессора и могут, поэтому, быть вызваны из запоминающего устройства, по мере необходимости.
В некоторых вариантах осуществления число N целевых регистров процессора, доступных для отображения, может быть меньше, чем число Nt регистров процессора целевой ISA. Другими словами, один или больше целевых регистров процессора могут быть зарезервированы для инструкций, которые, например, используют или определяют не отображенные регистры источника. Например, один или два регистра целевого процессора могут быть зарезервированы для таких инструкций.
Таблица 1 включает в себя псевдокод, соответствующий одному примеру, для определения общего количества доступов к регистру для каждого регистра источника в области и отображения N регистров источника на N целевых регистров.
|
|
В соответствии с этим, после окончания операции 220, N регистров источника могут быть отображены на N целевых регистров. Регистр (регистры) источника, не отображенный на целевой регистр (регистры), может быть отображен на накопитель 118 в регистре источника в системном запоминающем устройстве 104, в запоминающем устройстве 105 кэш и/или в сверхоперативном запоминающем устройстве 107.
Во время операции 222, внутренние регистры и/или внешние регистры могут быть идентифицированы для каждого двоичного блока в области. Внутренние регистры обозначают регистры, которые используются (то есть, из которых считывают) в двоичном блоке, без необходимости их вначале определить (то есть, записать в них) в двоичном блоке. Например, в области 305, представленной на фиг.3, регистры r2, r3 и r5 используются, без необходимости вначале их определения в блоке В, и регистр r2 используется до его определения в блоке D. В соответствии с этим, регистры r2, r3 и r5 представляют собой внутренние регистры для области 305. Внешние регистры соответствуют регистру (регистрам), значение (значения) которых могут быть изменены по инструкциям в двоичном блоке. Например, в области 305, значения регистров r1 и r4 могут быть изменены по инструкциям в Блоке В, и значение r2 может быть изменено по инструкции в Блоке D. В соответствии с этим, r1, r2 и r4 представляют собой внешние регистры для области 305. В некоторых вариантах осуществления, операция 222 может не быть выполнена, что обозначено пунктирной линией, окружающей прямоугольник, окружающий операцию 222.
Во время операции 224, для каждого двоичного блока в области, например в области 305, может быть сгенерирован оптимизированный целевой блок двоичного кода. Например, каждый оптимизированный целевой блок двоичного кода может включать в себя вводную часть, тело блока, которое включает в себя транслированный код источника соответствующего блока двоичного кода источника, и условный переход, и, по меньшей мере, одну заключительную часть. На фиг.4 представлен пример блока 400 целевого кода, включающего в себя вводную часть 410, тело 420 блока и две заключительные части 430, 440. Условный переход включен в тело 420 блока.
Вводная часть выполнена с возможностью загрузки в целевые регистры данных, соответствующих отображенным или отображенным внутренним регистрам источников из, например, накопителя 118 регистров источников. Будут ли отображенные или отображенные и внутренние регистры источника загружены, может зависеть от непродуктивных расходов, то есть, непродуктивных расходов, связанных с идентификацией внутренних регистров источника для каждого блока двоичного кода источника в области, в зависимости от непродуктивных расходов, ассоциированных с нагрузкой всех отображенных регистров источника после входа в область. Например, для области 305, представленной на фиг.3, регистры r1, r2 и r4 отображены на целевые регистры для области 305. В соответствии с этим, в этом примере, каждая вводная часть, ассоциированная с блоком В и блоком D, соответственно, может быть выполнена с возможностью загрузки регистров r1, r2 и r4 источника из запоминающего устройства в целевые регистры. В другом примере, регистр r2 является одновременно отображенным и внутренним для области 305. В соответствии с этим, каждая вводная часть, ассоциированная с блоком В и блоком D, соответственно, выполнена с возможностью загрузки регистра r2, в результате чего выполняется меньшее количество доступов к запоминающему устройству по сравнению с загрузкой всех (то есть, r1, r2 и r4) отображенных регистров источника.
По меньшей мере, одна заключительная часть может включать в себя первую заключительную часть и вторую заключительную часть. Условный переход выполнен с возможностью управления, будет ли продолжаться поток обработки до первой заключительной части или второй заключительной части, на основе, должно ли ответвление, которое заканчивает блок двоичного кода источника, находиться в пределах блока целевого двоичного кода области или блока целевого двоичного кода, не находящегося в области. Блок целевого двоичного кода внутри области представляет собой оптимизированный блок целевого двоичного кода, как описано ниже. Целевой блок двоичного кода, не находящийся в области, может быть неоптимизированным целевым блоком двоичного кода или оптимизированным целевым блоком двоичного кода, ассоциированным с другой областью.
Первая заключительная часть включает в себя переход к целевому блоку двоичного кода, находящемуся внутри области. Например, обращаясь снова к фиг.3, переход из блока В в блок D соответствует переходу к целевому блоку двоичного кода внутри области. Вторая заключительная часть включает в себя переход к целевому блоку двоичного кода, который находится за пределами области, например, не находится в области 305. Вторая заключительная часть дополнительно выполнена с возможностью сохранения отдельных регистров перед переходом к следующему целевому блоку двоичного кода. Аналогично загрузке внутренних регистров, как описано здесь, вторая заключительная часть может быть выполнена с возможностью сохранения отображенных или отображенных внешних регистров перед переходом к следующему целевому блоку двоичного кода.
Рассмотрим снова фигуру 3, переход из блока В в блок С соответствует переходу в целевой блок двоичного кода, который находится за пределами области. Этот переход к целевому блоку двоичного кода в пределах области выполнен с возможностью перехода к телу блока двоичного кода области, находящегося в пределах области, с обходом вводной части, ассоциированной с блоком двоичного кода, находящегося в пределах области. Переход к целевому блоку двоичного кода за пределами области выполнен с возможностью перехода к началу целевого блока двоичного кода за пределами области. Если целевой блок двоичного кода за пределами области представляет собой оптимизированный целевой блок двоичного кода, ассоциированный с другой областью, переход осуществляют к вводной части оптимизированного целевого блока двоичного кода.
Следует понимать, что система во время работы, то есть, операционная система - хост 120, выполнена с возможностью выполнения функции, которые могут не обрабатываться непосредственно целевым кодом, например, обработки прерывания. Для того, чтобы эти функции работали правильно, важно, чтобы состояние гостя представляло собой последовательную точку, то есть, последовательное состояние гостя представляет собой соответствующие структуры данных в запоминающем устройстве. Состояния гостя могут не быть последовательными во время выполнения блока, но являются последовательными в границах блока. В соответствии с этим, динамический двоичный транслятор, такой как QEMU с открытым исходным кодом, выполнен для задержки обработки прерываний до конца блока кода. Для того, что иметь последовательное состояние гостя в конце блока, внешние регистры могут быть сохранены (например, в накопителе 118 регистра источника) после перехода к блоку в пределах области, перед возвратом к работающей системе. Для переход к блоку, не находящемуся в данной области, внешние регистры могут быть сохранены перед переходом в блок, который не находится в данной области. После перехода к блоку, который не находится в данной области, управление может возвратиться к работающей системе.
На фиг.5 представлена примерная блок-схема 500 последовательности операций для выполнения целевых блоков двоичного кода, соответствующих двоичному приложению источника, которое включает в себя, по меньшей мере, одну оптимизированную область кода, которая включает в себя, по меньшей мере, один оптимизированный целевой блок двоичного кода. Поток обработки программы может начаться в начале 502. Начало 502 соответствует входу в первую область оптимизированного целевого двоичного кода, который включает в себя, по меньшей мере, один оптимизированный целевой блок кода. Во время операции 504 может быть выполнена вводная часть первого оптимизированного целевого блока двоичного кода в первой области. Вводная часть выполнена с возможностью загрузки отображенных или отображенных внутренних регистров из запоминающего устройства, как описано здесь.
Тело первого оптимизированного целевого блока двоичного кода может быть затем выполнено во время операции 506. Во время операции 508 может определяться, следует ли выполнить ответвление, на границе блока двоичного кода источника, соответствующего первому оптимизированному целевому блоку двоичного кода, в целевой блок двоичного кода в первой области. Если ответвление должно быть выполнено в целевой блок двоичного кода, который не находится в первой области, отображенные или отображенные внешние регистры могут быть сохранены в запоминающем устройстве, например в накопителе 118 регистра источника, во время операции 510. Переход к началу следующего целевого блока двоичного кода, не в первой области, может быть выполнен во время операции 512. Следующий целевой блок двоичного кода может быть или может не быть оптимизирован. Если следующий целевой блок двоичного кода не будет оптимизирован, следующий целевой блок двоичного кода, соответствующий следующему блоку двоичного кода источника, может быть выполнен во время операции 514. Если следующий целевой блок двоичного кода будет оптимизирован, например, во второй области, вводная часть (следующего целевого блока двоичного кода во второй области) может быть затем выполнена во время операции 504, после чего следует выполнение тела следующего целевого блока двоичного кода во время операции 506.
Если при операции 508 определяют, что ответвление выполняют в целевой блок двоичного кода в первой области, переход к телу следующего целевого блока двоичного кода может быть выполнен во время операции 516. В некоторых вариантах осуществления регистры могут быть сохранены, например, в запоминающем устройстве, чтобы способствовать обработке прерывания со стороны работающей системы. В этих вариантах осуществления может быть определено, следует ли возвратиться к системе времени выполнения, во время операции 517, имеется ли необходимость возврата к работающей системе, если нет необходимости возврата к работающей системе, поток программы может перейти к операции 506, и тело (следующего целевого блока двоичного кода) может быть затем выполнено во время операции 506. Если необходимо вернуться в работающую систему, регистры могут быть сохранены в запоминающем устройстве во время операции 518, и поток обработки программы может перейти к работающей системе во время операции 520. После возврата из системы поддержки исполнения программы, поток обработки программы может перейти к операции 504, может выполнить вводную часть, где регистры могут быть загружены из запоминающего устройства.
Что касается фиг.4 и фиг.5, операция 508, определяющая, является ли ответвление к следующему целевому блоку двоичного кода находящимся в области или не находящимся в области, соответствует условному переходу (jCC Т) тела 420 оптимизированного целевого блока двоичного кода. Операция 516 соответствует первой заключительной части 430, переходу к телу в пределах области. Операции 510 и 512 соответствуют второй заключительной части 440.
На фиг.6 представлена оптимизированное управление для графика 600, которое соответствует примеру графика 300 потока управления, представленного на фиг.3. При оптимизированном графике 600 потока управления целевой блок В 620 соответствует блоку В 320 графика 300 потока управления на фиг.3, и целевой блок D 640 соответствует блоку D 340 графика 300 потока управления. Целевой блок В и целевой блок D выполнены в соответствии с целевым блоком 400 кода по фиг.4. Поток управления между целевыми блоками двоичного кода при оптимизированном графе 600 потока управления зависит от того, находится ли поток между целевыми блоками двоичного кода в области или между целевым блоком двоичного кода в области и целевым блоком двоичного кода не в области. Целевой блок двоичного кода не в области может представлять собой оптимизированный целевой блок двоичного кода, ассоциированный с другой областью, или может быть неоптимизированным целевым блоком двоичного кода. Например, поток управления из целевого блока В в блок С, за пределами области 605, происходит из заключительной части 2 (сохранение, отображенных или отображенных внешних) для целевых блока В, блока С (то есть, для начала блока С) и управление потоком из блока С в целевой блок D происходит из блока С во вводную часть (загрузить отображенные или отображенные внутренние) целевого блока D. Управление потоком между целевым блоком В и целевым блоком D, оба из которых находятся в области 605, происходит из заключительной части 1 блока В или блока D в тело блока D или блока В, соответственно, как представлено путем 624 и путем 642.
В соответствии с этим, как показано на оптимизированном графике 600 потока управления, вводная часть может выполняться только после входа в область. Переходы между целевыми блоками двоичного кода в пределах области конфигурируют для перехода к телу целевого блока двоичного кода, обхода вводной части и обращения к запоминающему устройству, ассоциированному с загрузкой отображенных или отображенных внутренних регистров. Предпочтительно, это может привести к улучшению рабочих характеристик, например увеличению скорости, для относительно часто исполняемых областей кода.
Множество областей оптимизированных целевых блоков двоичного кода могут быть сгенерированы для применения источника. Предпочтительно, отображение регистра может быть оптимизировано для каждой области, независимо от того, было ли оптимизировано отображение регистра, для другой области (областей). Таким образом, оптимизация является специфичной для области. В некоторых вариантах осуществления, сохранение отображенных или отображенных внутренних регистров может выполняться только при выходе из области, что дополнительно улучшает рабочие характеристики.
На фиг.7 показан график, иллюстрирующий сравнение результатов проведенных тестов для динамической двоичной трансляции, воплощающей отображение 710, 720, 730, 740, 750 регистра на уровне блока, и отображение регистра на уровне области, в соответствии с настоящим раскрытием 715, 725, 735, 745, 755. Рабочие характеристики показаны в отношении динамического двоичного транслятора QEMU с открытым исходным кодом (который отображает регистры в запоминающее устройство). При отображении регистра на уровне блока отображенные внутренние регистры загружают после ввода в каждый целевой блок кода и отображаемые внешние регистры сохраняют после выхода из каждого целевого блока кода. Иллюстрируемый вариант осуществления отображения регистра на уровне области, в соответствии с настоящим раскрытием, выполнен с возможностью загрузки отображенных внутренних регистров (из запоминающего устройства) для ввода в область и для сохранения внешних регистров (в запоминающем устройстве) после выхода из области. Для всех результатов тестовых испытаний, отображение регистра на уровне области, соответствующее настоящему раскрытию, улучшило рабочие характеристики по сравнению с исходной линией отсчета QEMU и отображением регистра на уровне блока. В среднем, улучшение рабочих характеристик для результатов тестовых испытаний составило приблизительно 17% по сравнению с отображением регистра на уровне блока и приблизительно 31% по сравнению с исходной линией отсчета для QEMU.
В соответствии с этим, способ и система, в соответствии с настоящим раскрытием, включают в себя отображение регистров процессора источника в целевые регистры процессора при динамической двоичной трансляции, когда имеется меньшее количество целевых регистров процессора, чем регистров процессора источника. Для области кода, определенной как "горячая", то есть относительно часто выполняемой, может быть определено количество доступов каждого регистра источника. Регистры источника, с наиболее частым доступом, могут быть затем отображены на доступные целевые регистры. Для каждого блока двоичного кода источника в области может быть сгенерирован соответствующий блок оптимизированного целевого двоичного кода, который включает в себя вводную часть, тело, включающее в себя транслируемый код источника и условный переход, и, по меньшей мере, одну заключительную часть. Условный переход и, по меньшей мере, одна заключительная часть, выполненные с возможностью управления потоком на основе, выполняется ли ответвление от первого целевого блока двоичного кода к следующему целевому блоку двоичного кода в пределах области или к следующему целевому блоку двоичного кода, который не находится в этой области. Если следующий целевой блок двоичного кода находится в области, то переход направляют в тело следующего целевого блока двоичного кода, обходя вводную часть. Если следующий целевой блок двоичного кода не находится в области, тогда переход выполняют в начало следующего целевого блока двоичного кода. Вводная часть выполнена с возможностью загрузки отображенных или отображенных внутренних регистров для данной области из запоминающего устройства. Если следующий целевой блок двоичного кода не находится в данной области, тогда заключительная часть выполнена с возможностью сохранения отображенных или отображенных внешних регистров перед выполнением перехода к началу следующего целевого блока двоичного кода. Таким образом, отображенные или отображенные внутренние регистры загружают из запоминающего устройства при входе в область, и отображенные или отображенные внешние регистры сохраняют в запоминающем устройстве при выходе из области, что уменьшает количество доступов к запоминающему устройству по сравнению с загрузками/сохранениями регистра на уровне блока.
Как описано здесь, оптимизация зависит от пробы (проб), включающих в себя счетчики, вставленные в целевые блоки двоичного кода. В соответствии с этим, частота исполнения, определенная на основе счетчиков, представляет конечный период времени. Если частота исполнения для области кода изменяется с течением времени, улучшение рабочих характеристик, обеспечиваемое первоначально в результате оптимизации, может деградировать, то есть может стать менее оптимальным. Хотя оптимизация может быть повторена, следует ли повторить процедуру, описанную здесь, может зависеть от учета времени для выполнения оптимизации по сравнению со временем для исполнения ранее оптимизированных целевых блоков двоичного кода.
Конечно, в то время как на фиг.2A, 2B и 5 представлены примерные операции в соответствии с некоторыми вариантами осуществления, следует понимать, что в других вариантах осуществления все операции, представленные на фиг.2A, фиг.2B и/или фиг.5, могут не быть необходимыми. Действительно, здесь полностью предполагается, что другие варианты осуществления настоящего раскрытия могут включать в себя подкомбинации операций, представленных на фиг.2A, фиг.2B и/или фиг.5, и/или дополнительные операции. Таким образом, формула изобретения, направленная на особенности и/или операции, которые не показаны точно на одном чертеже, рассматриваются, как находящиеся в пределах объема и содержания настоящего раскрытия.
Запоминающее устройство 104, запоминающее устройство 105 кэш и/или сверхоперативное запоминающее устройство 107 могут содержать один или больше из следующих типов запоминающих устройств: полупроводниковое запоминающее устройство для встроенного программного обеспечения, программируемое запоминающее устройство, энергонезависимое запоминающее устройство, постоянное запоминающее устройство, электрически программируемое запоминающее устройство, оперативное запоминающее устройство, запоминающее устройство типа флэш, запоминающее устройство на магнитном диске и/или запоминающее устройство на оптическом диске. Либо в дополнение, или в качестве альтернативы, запоминающее устройство 104, запоминающее устройство 105 типа кэш и/или сверхоперативное запоминающее устройство 107 могут содержать другие, и/или которые будут разработаны в будущем, типы считываемого компьютером запоминающего устройства.
Варианты осуществления способов, описанных здесь, могут быть воплощены с использованием процессора и/или другого программируемого устройства. С этой целью, способы, описанные здесь, могут быть воплощены на материальном, считываемом в компьютере носителе информации, в котором записаны инструкции, которые при их выполнении одним или больше процессорами выполняют способы. Носитель информации может включать в себя любой тип материального носителя информации, например любой тип диска, включая в себя гибкие диски, оптические диски, постоянное запоминающие устройство на компактных дисках (CD-ROM), компакт-диски с возможностью перезаписи (CD-RW), и магнитооптические диски, полупроводниковые запоминающие устройства, такие как постоянные запоминающие устройства (ROM), оперативные запоминающее устройства (RAM), такие как динамические и статические RAM, стираемые программируемые постоянные запоминающие устройства (EPROM), электрически стираемые программируемые постоянные запоминающие устройства (EEPROM), запоминающие устройства типа флэш, магнитные или оптические карты или любого типа носители информации, пригодные для сохранения электронных инструкций.
Если только, в частности, не будет указано другое, как очевидно из предыдущего описания, следует понимать, что во всем описании, использование таких терминов как "операции", "обработка", "вычисление", "расчеты", "определение" и т.п., относится к действию и/или процессам компьютера или вычислительной системы, или аналогичного электронного вычислительного устройства или устройства, которые манипулируют данными и/или преобразуют данные, представленные как физические данные, такие как электронные, количественные данные в пределах регистров вычислительной системы и/или в запоминающих устройствах в другие данные, аналогично представленные как физические величины в пределах запоминающих устройств вычислительной системы, регистрах или в других таких накопителях информации, устройствах передачи или отображения.
"Схемы", используемые в любом варианте осуществления, представленном здесь, могут содержать, например, одну или любую комбинацию, представленную в виде аппаратного решения схемы, программируемой схемы, схемы конечного автомата, и/или встроенных программных средств, в которых содержатся инструкции, выполняемые программируемой схемой.
В соответствии с одним аспектом здесь раскрыт способ. Способ может включать в себя загрузку двоичного приложения источника, включая в себя множество блоков двоичного кода источника для выполнения вычислительной системой. Вычислительная система может включать в себя запоминающее устройство и модуль обработки, включающий в себя Nt целевых регистров, где Nt меньше, чем количество Ns регистров источника в соответствующей архитектуре системы команд источника. Способ может дополнительно включать в себя идентификацию, во время рабочего цикла двоичного приложения источника, часто исполняемого блока двоичного кода источника в пределах двоичного приложения источника; определение области, включающей в себя часто исполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника, который превышает пороговое значение сродства, часто исполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника включают в себя, по меньшей мере, один доступ к регистру источника, и каждый из них связан с инструкцией ответвления. Способ может дополнительно включать в себя: определяют частоту доступа для каждого регистра источника, доступ к которому осуществляется в данной в области; отображают каждый из N регистров источника с наиболее частым доступом в области для соответствующего одного из Nt целевых регистров, где N меньше чем или равно Nt; и генерирует оптимизированный блок целевого двоичного кода, соответствующий каждому блоку двоичного кода источника, в области, на основе, по меньшей мере, частичного отображения регистра.
В соответствии с другим аспектом, в статье раскрыто, включая в себя материальный носитель записи для сохранения, на котором сохранены инструкции, которые при исполнении их процессором могут привести к следующим операциям: загрузка приложения двоичного кода источника, включающая в себя множество блоков двоичного кода источника для исполнения, в котором процессор включает в себя Nt целевых регистров, в котором Nt меньше, чем число Ns регистров источника в соответствии с архитектурой системы команд источника; идентифицируют, во время работы упомянутого двоичного приложения источника, часто исполняемый блок двоичного кода источника в пределах упомянутого двоичного приложения источника; определяют область, включающую в себя часто исполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника, который превышает пороговое значение сродства, часто выполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника включают в себя, по меньшей мере, один доступ к регистру источника и каждый из них соединен инструкцией ответвления; определяют частоту доступа для каждого регистра источника, доступ к которому выполняют в области; отображают каждый из N регистров источника с наиболее частым доступом в области на соответствующий один из Nt целевых регистров, где N меньше чем или равно Nt; и генерируют оптимизированный целевой блок двоичного кода, соответствующий каждому блоку двоичного кода источника, в области, на основе, по меньшей мере, частично, отображения регистра.
В еще одном аспекте раскрыта система. Система может включать в себя процессор, включающий в себя Nt целевых регистров, в котором Nt меньше, чем число Ns регистров источника в соответствующей архитектуре набора инструкций источника; и запоминающее устройство, выполненное с возможностью размещения в нем динамического двоичного транслятора, модуля отображения регистра и двоичного приложения источника, включая в себя множество блоков двоичного кода источника, предназначенных для выполнения в процессоре, в котором когда динамический двоичный транслятор и модуль отображения регистра выполняются в процессоре, по меньшей мере, один из динамического двоичного транслятора и модуля отображения регистра могут обеспечить выполнение процессором: идентификации, во время рабочего цикла двоичного приложения источника, часто исполняемого блока двоичного кода источника в пределах двоичного приложения источника; определения области, включающей в себя часто исполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника, который превышает пороговое значение сродства, часто исполняемый блок двоичного кода источника и, по меньшей мере, один соседний блок двоичного кода источника включают в себя, по меньшей мере, один доступ к регистру источника и каждый из них соединен инструкцией ответвления; определяют частоту доступа для каждого из регистра источника, доступ к которому осуществляют в области; отображают каждый из N регистров источника с наиболее частым доступом в области для соответствующего из Nt целевых регистров, в котором N меньше чем или равно Nt; и генерируют оптимизированный целевой блок двоичного кода, соответствующий каждому блоку двоичного кода источника в области, на основе, по меньшей мере, частично, отображения регистра.
Термины и выражения, которые использовались здесь, используются как термины описания, а не для ограничения, и при этом нет какого-либо намерения, при использовании таких терминов и выражений, исключать какие-либо эквиваленты представленных и описанных свойств (или их частей), и при этом распознается, что различные модификации возможны в пределах объема формулы изобретения. В соответствии с этим, формула изобретения предназначена для охвата всех таких эквивалентов.
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении

