Результат интеллектуальной деятельности: УСТРОЙСТВО И СПОСОБ АВТОМАТИЧЕСКОГО ПОСТРОЕНИЯ ПРИЛОЖЕНИЙ ИЗ СПЕЦИФИКАЦИЙ И ИЗ ИМЕЮЩИХСЯ В НАЛИЧИИ КОМПОНЕНТОВ, ВЫБРАННЫХ С ПОМОЩЬЮ СЕМАНТИЧЕСКОГО АНАЛИЗА
Вид РИД
Изобретение
Настоящее изобретение относится к проектированию приложений и, в частности, к способу и устройству для формирования приложений из имеющихся в наличии компонентов программного обеспечения.
В соответствии с принятыми определениями, используемыми как ссылки в области объектно-ориентированной и компонентно-ориентированной разработки приложений, термин «проектирование» означает здесь стадию приложения, которая описывает, как это приложение будет реализовано на логическом уровне над кодом. В целях проектирования предлагаются стратегические и тактические решения, чтобы выполнить требуемые функциональные требования или требования качества приложения. В соответствии с описанием, приведенным, например, Грэди Бушем в книге «Объектно-ориентированный анализ и проектирование приложений», 3-е издание - в жестком переплете, Эдисон-Уэстли (2007), ISBN 9780201895513, результаты этой стадии представлены с помощью моделей уровня проектирования: статический вид, вид конечного автомата и вид взаимодействия. Действия проектирования приводят к архитектуре приложения, которая представляет собой организационную структуру этого приложения, включающую в себя: ее разбиение на компоненты программного обеспечения, связность между этими компонентами программного обеспечения, механизмы взаимодействия и руководящие принципы, которые объясняют проектирование приложения.
Многие авторы описывали несколько способов для указания пути создания компонентно-ориентированных приложений (программного обеспечения), но эти способы имеют два основных недостатка: они полностью неавтоматизированные, а процесс нахождения и объединения правильных компонентов не вытекает непосредственно из спецификации приложения, которое должно быть создано, причем эта спецификация описывает функциональные и нефункциональные требования, которым приложение должно соответствовать.
Задача настоящего изобретения заключается в предложении нового способа и соответствующего устройства, предназначенных для автоматического создания приложений из имеющихся в наличии компонентов программного обеспечения посредством семантического анализа спецификаций приложения и учитывая, что архитектура приложения (т.е. архитектура решения) может быть выведена из взаимосвязи между требованиями, выраженными в тексте спецификации приложения (т.е. архитектуры проблемы).
Для решения этой задачи предложен способ построения приложений из спецификаций и («имеющихся в наличии») компонентов программного обеспечения, состоящий из, каждый раз при приеме спецификации, описывающей приложение, которое должно быть создано:
- выполнения семантического анализа этой спецификации, чтобы выделить элементарные требования из текста спецификации и связи между этими элементарными требованиями, при этом набор этих связей называется далее как «общая структура спецификации», затем
- выделения для каждого элементарного требования пертинентных терминов, которые оно содержит, и создания для каждого элементарного требования «семантического описания», основанного на собственных выделенных пертинентных требований и которое представляет «семантику этого элементарного требования», затем
- осуществления доступа к, по меньшей мере, одному хранилищу компонентов, в котором каждый компонент зарегистрирован и описан как «семантический компонент программного обеспечения» (это значит, что каждый компонент связан с «семантическим описанием», содержащим, по меньшей мере, один пертинентный термин, чтобы определить каждую публичную операцию, которую этот компонент программного обеспечения способен выполнить), чтобы определить (выбрать) для каждого выделенного элементарного требования путем сравнения семантик этого элементарного требования и семантических описаний компонентов, какой(ие) компонент(ы) может(гут) охватывать упомянутое выделенное элементарное требование, и,
- окончательного объединения этих определенных компонентов программного обеспечения в соответствии с общей структурой спецификации, чтобы построить приложение.
Таким образом, семантические описания могут быть связаны с элементарными требованиями, а также с компонентами программного обеспечения:
- семантические описания элементарных требований определяются и связываются с текстом элементарного требования как таковым, т.е. с предложением(ями), содержащим(и) выражение элементарного требования;
- семантические описания компонентов программного обеспечения определяются и связываются с публичной(ыми) операцией(ями), которую(ые) способен выполнять этот компонент, как это подробно описано ниже.
Способ в соответствии с настоящим изобретением может включать в себя дополнительные характеристики, принятые во внимание по отдельности или вместе, а именно:
- по меньшей мере некоторые семантические описания компонентов программного обеспечения могут содержать: i) задачу операции, которую компонент программного обеспечения способен выполнять, ii) по меньшей мере один доменный идентификатор, указывающий домен, в котором определены термины, описывающие операционную задачу и входной(ые)/выходной параметры этой операции, и iii) пертинентные термины и/или особые метаданные, связанные с этими входным(ми)/выходным параметрами;
- для каждого выделенного элементарного требования можно определить семантическую дистанцию между его семантическим описанием и семантическим описанием каждого из сохраненных компонентов программного обеспечения, затем можно выбрать сохраненный компонент программного обеспечения, соответствующий минимальной семантической дистанции, и поэтому этот выбранный компонент программного обеспечения предназначен для реализации элементарного требования;
- можно связывать первичный кортеж (с фр., т.н. «N-uplet») слов, например, синонимов, причем для синонимов такой кортеж будет упоминаться здесь как «syn-uplet», с каждым пертинентным термином элементарного требования, такой syn-uplet будет затем упоминаться далее как «req-uplet»; таким же образом, можно также связывать syn-uplet с каждым пертинентным термином задачи каждой публичной операции каждого компонента программного обеспечения, тогда такой syn-uplet будет далее упоминаться как «comp-uplet», и можно сравнивать каждый из упомянутых req-uplet с каждым из упомянутых comp-uplet, чтобы определить семантическую дистанцию между каждым элементарным требованием и сохраненным компонентом программного обеспечения;
- можно определять семантическую близость, представляющую число слов, которые являются общими для каждого req-uplet и для каждого comp-uplet, и, для каждого элементарного требования можно создать вторичный кортеж (n-uplet), например, названный как «sem-uplet» и выражающий семантические близости между каждым из req-uplet и таковым для каждого из comp-uplet, причем каждый вторичный кортеж определяет семантическую дистанцию, затем можно выбрать сохраненный компонент программного обеспечения, соответствующий вторичному кортежу, который определяет минимальную семантическую дистанцию;
- можно устанавливать те же самые пертинентные связи, как те, которые определяют общую структуру спецификации между выбранными сохраненными компонентами программного обеспечения, которые соответствуют выделенным элементарным требованиям, чтобы оптимизировать структуру приложения;
- чтобы определять эту общую структуру спецификации, можно определить семантическую близость, представляющую число слов, которые являются общими для req-uplet каждой пары элементарных требований, и для каждого элементарного требования можно создать вторичный кортеж, названный sem-uplet, содержащий семантические близости между собственным req-uplet и таковыми для других элементарных требований, причем каждый sem-uplet определяет семантическую дистанцию, затем можно установить пертинентную связь между двумя различными элементарными требованиями, когда значение их sem-uplet максимально.
Настоящее изобретение также предусматривает устройство для построения приложений из спецификаций и компонентов программного обеспечения и содержащее:
- средство хранения для хранения семантических компонентов программного обеспечения, причем каждый из них выполнен из компонента программного обеспечения, связанного с семантическим описанием, содержащим, по меньшей мере, один пертинентный термин для определения каждой публичной операции, которую способен выполнить этот компонент программного обеспечения,
- анализирующее средство, выполненное с возможностью, каждый раз, когда принимается спецификация, описывающая приложение, которое должно быть создано: i) выполнения семантического анализа этой спецификации, чтобы выделить элементарные требования из текста спецификации, и связи между этими элементарными требованиями, причем набор этих связей далее упоминается как «общая структура спецификации», ii) выделения, для каждого элементарного требования, пертинентных терминов, которые оно содержит, и для создания, для каждого элементарного требования «семантического описания», основанного на его выделенных подходящих терминах и которое представляет «семантику этого элементарного требования», iii) осуществления доступа к средству хранения, чтобы определить (выбрать), для каждого элементарного требования, путем сравнения семантик этого элементарного требования и семантических описаний компонентов, какой(ие) компонент(ы) способен(ны) охватывать это выделенное элементарное требование, и,
- средство обработки для объединения определенных компонентов программного обеспечения в соответствии с общей структурой спецификацией, чтобы построить приложение.
Устройство в соответствии с настоящим изобретением может включать в себя дополнительные характеристики, принятые во внимание по отдельности или совместно, а именно:
- анализирующее средство может быть выполнено с возможностью определения, для каждого выделенного элементарного требования, семантической дистанции между его семантическим описанием и семантическим описанием каждого из сохраненных компонентов программного обеспечения, затем для выбора сохраненного компонента программного обеспечения, соответствующего минимальной семантической дистанции, причем этот выбранный компонент программного обеспечения предназначен для выполнения элементарного требования;
- анализирующее средство может быть выполнено с возможностью связывания первичного кортежа слов, например синонимов, такой кортеж далее обозначается как «syn-uplet», с каждым пертинентным термином элементарного требования, такой syn-uplet затем далее называется как «req-uplet», и для сравнения каждого из этих req-uplet с каждым из comp-uplet (syn-uplet, связанным с каждым пертинентным термином задачи каждой публичной операции каждого компонента программного обеспечения), чтобы определить семантическую дистанцию между каждым элементарным требованием и каждым сохраненным компонентом программного обеспечения;
- анализирующее средство может быть выполнено с возможностью: i) определения семантической близости представленной количеством слов, которые являются общими для каждого req-uplet и для каждого comp-uplet, ii) создания для каждого элементарного требования вторичного кортежа, например называемого «sem-uplet» и выражающего семантические близости между каждым из req-uplet и таковым для каждого из comp-uplet, при этом каждый вторичный кортеж определяет семантическую дистанцию, и iii) выбора сохраненного компонента программного обеспечения, соответствующего вторичному кортежу, который определяет минимальную семантическую дистанцию;
- средство обработки выполнено с возможностью установления тех же самых подходящих связей, как и те, которые определяют общую структуру спецификации, между выбранными сохраненными компонентами программного обеспечения, которые соответствуют выделенным элементарным требованиям, чтобы оптимизировать структуру приложения;
- чтобы определить общую структуру, анализирующее средство может быть выполнено с возможностью i) определения семантической близости, представленной количеством слов, которые являются общими для req-uplet каждой пары элементарных требований, и ii) создания, для каждого требования, вторичного кортежа (или «sem-uplet»), содержащего семантические близости между своим req-uplet и таковыми для других элементарных требований, причем каждый sem-uplet определяет семантическую дистанцию, затем для установления пертинентной связи между двумя отдельными элементарными требованиями, когда значение их sem-uplet максимально.
Другие свойства и преимущества изобретения станут ясны при дальнейшем изучении подробных описаний и прилагаемого чертежа, где единственная фигура схематически иллюстрирует пример варианта осуществления устройства в соответствии с настоящим изобретением.
Прилагаемый чертеж может служить не только для дополнения изобретения, но также, чтобы способствовать его пояснению, если будет нужно.
Задача настоящего изобретения - предложить устройство и соответствующий способ, предназначенные для автоматического построения приложений из текста их спецификаций с помощью имеющихся в наличии компонентов программного обеспечения.
Изобретение рассматривает любой тип приложения, описанного спецификацией и которое может быть создано из совокупности имеющихся в наличии компонентов программного обеспечения.
Термин «приложение» означает в этом документе набор взаимосвязанных компонентов (программного обеспечения), каждый из них имеет функциональность, выраженную как набор, по меньшей мере, из одной публичной функции, называемой операцией, и инкапсулирующих и управляющих своими собственными данными. Это определение представляет собой компонентную парадигму, выведенную из объектной ориентации, и является на сегодняшний день стандартом разработки.
Более того, выражение «имеющиеся в наличии компоненты программного обеспечения» означает здесь часть выполняемой программы, предназначенной для выполнения точной элементарной функции (т.е. «атома» функциональности), такой, как механизм управления файлами, доступ к базе данных, дисплейный механизм GUI, перевод текста, модуль преобразования, считывание HTML страницы из URL, элементарная функция для обработки текста и так далее.
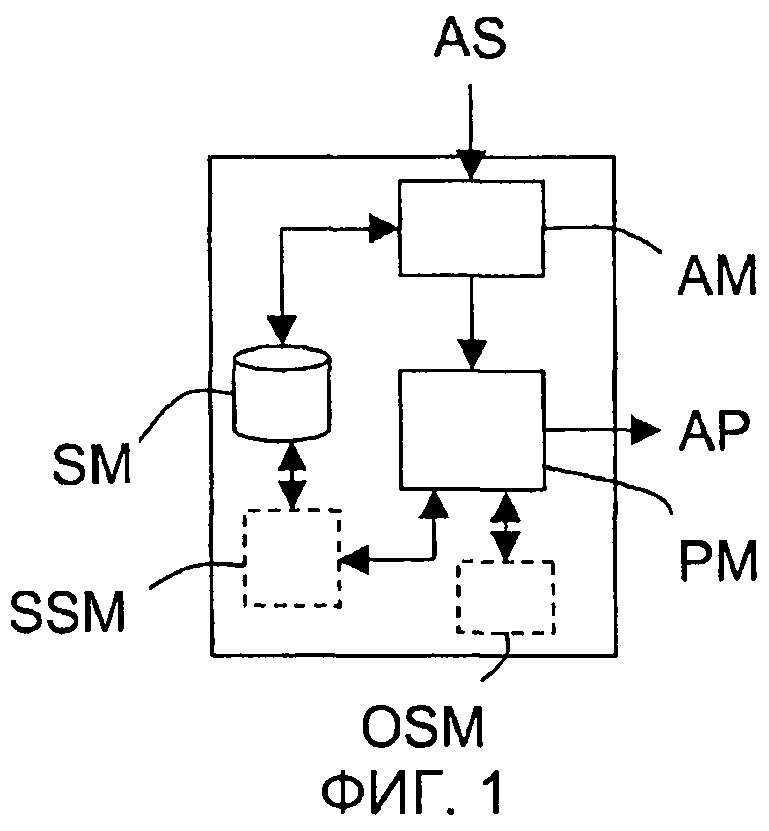
Как схематично показано на единственной фигуре, устройство D в соответствии с изобретением содержит, по меньшей мере, средство SM хранения, анализирующий модуль AM и обрабатывающий модуль РМ.
Средство SM хранения предназначено для хранения, по меньшей мере, семантических компонентов SSC программного обеспечения. Каждый семантический компонент SSC программного обеспечения выполнен из компонента SC программного обеспечения, который связан с семантическим описанием SD.
Выражение «семантическое описание компонента программного обеспечения» означает здесь описание, содержащее, по меньшей мере, один пертинентный термин, который определяет задачу публичной операции (или функции), которую связанный компонент SD программного обеспечения может выполнить. Эта задача предпочтительно выражена просто на естественном языке (т.е. с пертинентными терминами) и описывает ясно, что компонент SC действительно делает, какова его функция(и) и какими данными он манипулирует (т.е. вход(ы)/выход(ы) его операции(й)). Желательно, чтобы семантическое описание SD каждого компонента (названное «семантическая карта», например) также содержало, по меньшей мере, один доменный идентификатор, который обозначает домен, где определены термины, описывающие каждую операцию.
Например, каждое семантическое описание SD компонента программного обеспечения является XML представлением, где входные и выходные данные описываются тремя основными атрибутами:
- имя элемента данных (или идентификатор);
- концепт (или пертинентный термин), связанный с данными, выраженными в применении к концепту, определенному как класс во внешней онтологии или во внешнем словаре или тезаурусе, чтобы точно определить семантику данных. Здесь онтология относится, например, к домену, адресуемому компонентом SC, и чье имя упомянуто в заголовке семантической карты; и
- семантическая метка данных (называемая «semTag», например), которая отражает стереотип типа семантических данных и точно определяет характер данных. Эта semTag будет полезна для определения и оптимизации взаимодействий компонентов, как это будет объяснено ниже.
Может быть использован любой тип запоминающего средства SM, способного хранить семантические компоненты программного обеспечения SSC и знакомого специалисту в данной области техники, а именно, базы данных, флэш-памяти, постоянные запоминающие устройства (ROM) и оперативная память (RAM), системы неструктурированных файлов и любой другой вид хранилища данных.
Анализирующий модуль AM предназначен для того, чтобы начинать действовать каждый раз, когда его устройство D принимает спецификацию AS, которое описывает приложение АР, которое должно быть создано.
Выражение «спецификация приложения» означает здесь, по меньшей мере, одно предложение, которое указывает, по меньшей мере, одно требование, что нужное приложение следует выполнить. Более точно требования приложения описывают, что приложение АР будет делать, и что представляют собой его функциональные и нефункциональные свойства. Эти требования предпочтительно выражаются на естественном языке, но они могут быть выражены в форме любого формального или неформального тестового представления.
Анализирующий модуль АМ предназначен каждый раз при приеме спецификации AS приложения:
для выполнения семантического анализа этой принятой спецификации AS приложения, чтобы:
выделять элементарные требования SR из текста спецификации AS, например, посредством грамматического анализатора, и связи между этими элементарными требованиями SR, при этом набор этих связей далее упоминается как «общая структура (или логическая совокупность) спецификации», затем
выделять для каждого элементарного требования SR пертинентные термины, которые оно содержит, и создавать для каждого элементарного требования SR «семантическое описание» на основании его выделенных пертинентных терминов, которое представляет «семантику этого элементарного требования», затем
для осуществления доступа к средству SM хранения, чтобы определить (выбрать), для каждого выделенного элементарного требования SR путем сравнения семантик этого элементарного требования SR и семантических описаний SD компонентов, какой(ие) компонент(ы) может(ут) охватывать это выделенное элементарное требование SR.
Важно отметить, что анализирующий модуль АМ может быть разделен на два подмодуля, причем первый подмодуль предназначен для выполнения семантического анализа, а второй подмодуль - для определения в средстве хранения (или хранилище компонента данных) SM компонента(ов), который(ые) может(гут) охватывать элементарное требование SR, выделенное первым подмодулем.
Другими словами, анализирующий модуль АМ определяет значение каждого предложения, представляющего элементарные требования SR (т.е. его семантику), и выражает его в терминах подходящей вычисляемой структуры данных. Идея заключается в маркировке каждого семантического атома функциональности со своей подходящей структурой семантических данных, чтобы сравнить позже эту структуру с эквивалентной структурой семантических данных сохраненных компонентов SC программного обеспечения, чтобы определить, какой компонент способен охватывать какое (элементарное) требование SR. Действительно, каждое предложение (или атом требования) может быть оценено и промаркировано, чтобы принять свои собственные семантические данные. Важно отметить, что этот процесс отличается от подхода к анализу требования на основании онтологии, в котором способ анализа требования программного обеспечения основан на технике доменной онтологии, где может быть установлено соответствие между спецификацией требования программного обеспечения и несколькими доменными онтологиями. Напомним, что онтология - это формальное описание концептов, которыми манипулируют в данном домене и взаимосвязи между этими концептами. В настоящем изобретении внешняя онтология используется для помощи при анализе требований, потому что семантика выделяется из текста самостоятельно.
Семантика задач операции желательно определяется точными правилами, например, следующими:
- задачи выражаются на естественном языке, используя определенные слова;
- эти определенные слова принадлежат к «списку концептов», которые вставлены в семантическую карту SD и суммируют пертинентные слова, которые должны быть использованы для написания задач; и
- этот «список концептов» может быть, например, описан во внешних онтологиях, т.е. в формальных описаниях соответствующих доменов, которые указаны в семантической карте SD, или могут быть просто ссылками на определения внешнего словаря или тезауруса.
Такие правила помогают написать операционные задачи, которые являются лаконичными и однозначно определенными.
Неограничивающий пример семантической карты SD, связанный c компонентом средства доступа RSS-ленты, приведен ниже:

Логическая совокупность (или общая структура) пертинентных терминов требований SR заключается в пертинентных связях между пертинентными терминами и логическим порядком между ними. Например, в предложении «Приложение имеет доступ в Интернет, чтобы генерировать скрипт (сценарий) из файла «Параметры.txt» и выделить этот скрипт», пертинентными терминами (или концептами), отражающими требования, являются «доступ в Интернет», «генерировать скрипт», «файл «Параметры.txt» и «вычислить скрипт», а логический порядок этих пертинентных терминов есть «доступ в Интернет», «читать файл «Параметры.txt», «генерировать скрипт» и «вычислить скрипт».
Важно отметить, что анализирующий модуль АМ выполнен с возможностью определения логической совокупности между элементарными требованиями SR спецификации. Действительно, допустим, что в наборе элементарных требований SR, составляющим спецификацию AS, требования SR логически связаны друг с другом. Это вытекает из того факта, что связь между двумя разными требованиями приводит к связи между компонентами, выполняющими эти требования (два фрагмента требования связаны друг с другом, если они оба говорят о заданных данных, ограничении, функциональности или свойстве заданного приложения АР). Здесь допускается, что если некоторые пертинентные связи существуют между требованиями SR, то те же самые пертинентные связи существуют между компонентами SC, осуществляющими эти требованиями SR. Таким образом «сеть требования» определяется анализированием связей между требованиями (или атомами требований) SR, чтобы определить общую структуру спецификации приложения AS, которая описывает проблему. Другими словами проблема структуры заключается в изоморфности структуры решения.
Например, рассмотрим приложение, предназначенное для вычисления НДС счета-фактуры, и предположим, что текст спецификации AS приложения содержит два разных параграфа, относящихся к вычислению НДС: первый объясняет общий способ вычисления НДС, а второй (возможно, занимающий несколько страниц ниже в спецификации AS) представляет различные процентные ставки НДС соответствующие категориям товаров. Эти два параграфа представляют два фрагмента требований SR, которые связаны вместе из-за того, что они адресуют одни те же данные. Следовательно, два компонента SC, выполняющие эти требования SR, должны будут связаны вместе, потому что вычисление НДС для данного товара нуждается в общем способе для вычисления суммы НДС.
Каждый раз, как только анализирующий модуль АМ определил «семантику требований SR» принятой спецификации AS приложения и логическую совокупность этих требований SR, он осуществляет доступ к средству SM хранения, чтобы выбрать семантические компоненты SSC программного обеспечения, чьи семантические описания SD соответствуют семантике требований.
Для этой цели анализирующий модуль АМ должен сравнивать значение требования, выделенного из спецификации AS приложения, с задачей каждого компонента, которая является семантической картой SD компонента. Это делается, чтобы было возможно выбрать этот компонент SC, потому что он предназначен, чтобы охватывать требование.
Как упомянуто выше, это сравнение требует определения значения текста спецификации. Здесь предполагается, что значение составлено из конкатенации элементарных значений всех пертинентных терминов, которые составляют каждое предложение текста спецификации. Таким образом, сравнение значения двух разных текстов подразумевает сравнение различных терминов или концептов (попарно), чтобы определить, близки они семантически или нет.
Следовательно, необходимо иметь в распоряжении способ для выражения значения элементарного термина, чтобы было возможно обработать это сравнение. Для этого можно создать первичный кортеж с синонимами термина, которые могут быть найдены в тезаурусе. Такой первичный кортеж далее называется «syn-uplet».
Например, syn-uplet терминов «сражение», «война» и «мир» могут быть соответственно:
сражение = {битва, столкновение, бой, схватка, перестрелка, драка, рукопашная, конфликт, конфронтация, потасовка, стычка, боевые действия, сражение, поход, война, кампания, атака, спор, обстрел},
война = {конфликт, бой, боевые действия, бой, конфронтация, военные действия, битва, кампания, сражение, поход, соревнование, соперничество, вражда}, и
мир = {согласие, мирное время, мирное отношение, гармония, перемирие, урегулирование, прекращение огня, единство, добрая воля, соглашение, пакт, умиротворение, нейтралитет, переговоры}.
Отметим, что если syn-uplet создается для термина требования SR, он может быть назван «reg-uplet», а если syn-uplet создается для термина задачи публичной операции компонента SC программного обеспечения, то он может быть назван «comp-uplet».
По syn-uplet, т.е. по reg-uplet и comp-uplet, можно определить следующие функции:
- syn(слово) - это syn-uplet для термина «слово»,
- N1 обозначает syn-uplet для «слово1» и N2 обозначает syn-uplet для «слово2»: N1 = syn(слово1) и N2 = syn(слово2),
- карта (N1) - это кардинальное число syn-uplet N1, т.е. число синонимов внутри N1,
- общее (N1, N2) - это число синонимов, которые являются общими для N1 и N2, и
- среднее (N1,N2) - это среднее из кардинальных чисел N1 и N2,
затем, с учетом вышеупомянутых примеров syn-uplet, карта(общее(syn(«сражение»), syn(«война»))) = 9. Другими словами, существует девять синонимов, общих для «сражение» и «война».
Также возможно определить семантическую близость между двумя терминами Т1 и Т2 путем вычисления отношения, принимающего во внимание общие синонимы в двух syn-uplet syn(Т1) и syn(Т2), например.
Такая семантическая близость (называемая «semProx», например) может быть задана следующей формулой, например:
semProx(Т1,Т2)=100*карта(общее(synT1),syn(Т2)))/среднее(synT1),synT2)).
С вышеупомянутыми примерами syn-uplet семантическая близость syn-uplet «сражение» и «война» задается посредством semProx(«сражение», «война»)=100*9/0,5*(19+13)=900/16=56,25. Другими словами, в объединении наборов синонимов для «сражение» и «война», 56,25% элементов найдены в двух экземплярах. В качестве другого образца, семантическая близость syn-uplet слов «война» и «мир» задается с помощью semProx(«война», «мир») = 0, что является логичным.
Семантическая близость выражает отношение близости между двумя терминами. Например, если семантическая близость больше, чем первый выбранный порог А (например 50), или ближе к 100, то подразумевается, что два термина семантически близки. Наоборот, если семантическая близость меньше, чем второй выбранный порог В (например 10), или ближе к нулю, то подразумевается, что два термина семантически далеки. Значения порогов А и В могут быть «настроены» в соответствии с категорией текстов, которые должны быть обработаны.
Например, определение значения заданного предложения может быть выполнено в следующей последовательности.
На первом этапе предложение анализируется, и выделяются пертинентные термины (слова). Непертинентные слова такие, как артикли, предлоги, союзы и т.д., игнорируются.
На втором этапе, для каждого пертинентного термина (слова), создается соответствующий syn-uplet.
Окончательно, на третьем этапе единый кортеж для целого предложения создается путем объединения syn-uplet пертинентных слов, содержащихся в предложении. Такой единый кортеж может быть назван «phrase-uplet» (его можно рассматривать, как супер-кортеж, т.е. кортеж из кортежей).
В качестве примера, если требование SR, выделенное из спецификации AS системы управления вызовами, представляет собой «Вызывающий абонент вызывает принимающего абонента путем создания сообщения, которое содержит тему вызова, посланное принимающему абоненту в то же самое время», то тогда пертинентными терминами являются: вызывающий абонент, вызов, вызывать, принимающий абонент, сообщение, тема и посылать. Phrase-uplet для этого требования SR может быть соединением следующих syn-uplet:
- вызывающий абонент = {телефонный абонент, посетитель, гость, компания},
- звонок = {телефонный звонок, зуммер, колокольчик, звонок, требование, запрос, заявление, обращение, заявка, приглашение},
- вызывать = {телефон, предъявлять требование, посылать запрос},
- принимающий абонент = {получатель, наследник, адресат, бенефициар, продолжатель, преемник},
- сообщение = {передача, памятка, меморандум, замечание, письмо, послание, отправка},
- тема = {предмет обсуждения, предмет, фокус, тематика, область обсуждения, вопрос, проблема, сущность, дело, суть, текст, поле, изучение, дисциплина, область},
- посылать = {выдвигать предложение, представлять, намереваться, предлагать, подавать}.
Сравнение одного предложения S1 спецификации AS с двумя другими предложениями S2 и S3 семантических описаний (или карт) SD, связанных с компонентами SC программного обеспечения, может быть сделано путем сравнения их phrase-uplet. Это сравнение обеспечивает результат, который может быть использован для вычисления семантической дистанции между предложениями, как будет пояснено ниже. Этапы сравнения phrase-uplet могут быть следующими:
- внутренние syn-uplet двух phrase-uplet сравниваются попарно. Другими словами, каждый syn-uplet phrase-uplet из S1 сравнивается с каждым syn-uplet phrase-uplet из S2 и S3,
- семантическая близость (semProx) вычисляется для каждой пары syn-uplet,
- создаются упорядоченные вторичные кортежи, например названные «sem-uplet».
Каждый семантический кортеж (или sem-uplet) содержит семантические близости между каждым syn-uplet из S1 и syn-uplet из S2 или S3, и определяет семантическую дистанцию,
- семантический кортеж, предлагающий минимальную семантическую дистанцию, остается, и предложение S2 или S3, которое описывается этим семантическим кортежем, рассматривается, как наиболее семантически близкое к S1 и поэтому выбирается его соответствующий компонент SC программного обеспечения.
Таблица, приведенная далее, является неограничительным примером поиска соответствий между требованиями SR «Вызывающий абонент вызывает принимающего абонента путем создания сообщения, которое содержит тему вызова, посланное принимающему абоненту в то же самое время», и образцом набора компонентов, хранящихся в хранилище SM компонентов. Пертинентными терминами требования являются: {вызывающий абонент, вызов, вызывать, принимающий абонент, сообщение, тема, посылать}. Sem-uplet, показанные в последней правой колонке следующей таблицы, являются результатом сравнения между syn-uplet и пертинентными терминами и вычислены из задачи компонента. Быстрый обзор этих sem-uplet помогает легко определить компоненты SC, способные полностью выполнить требование.
|
|
|
Обрабатывающий модуль РМ предназначен для объединения компонентов SM программного обеспечения определенных компонентов SSC программного обеспечения в соответствии с логической совокупностью спецификации (т.е. структурой общей спецификации, которая была определена анализирующим модулем АМ), чтобы создать нужное приложение АР.
Как упоминалось прежде, это объединение основано на исходной предпосылке о том, что пертинентные связи между требованиями спецификации AS приложения (или проблемы) имеют одинаковое соответствие со связями между определенными компонентами SSC программного обеспечения (блоками решения).
Итак, обрабатывающий модуль РМ организовывает выбранные компоненты SC, у которых семантические дистанции самые короткие, с семантическими атомами требований, чтобы сконструировать начальную архитектуру приложения AS. Эта начальная архитектура создается путем повторения структуры проблемы (или сети требования) и использованием атомов решения (или компонентов SC) вместо атомов проблемы (или требований).
Как упоминалось ранее, сеть требований, которая суммирует и представляет пертинентные связи между требованиями спецификации, определяется анализирующим модулем АМ. С этой целью анализирующий модуль АМ может использовать упомянутый sem-uplet (вторичный кортеж) подход для обнаружения пертинентных связей между требованиями (или атомами требования). Предложения спецификации AS семантически сравниваются попарно, используя phrase-uplet плюс sem-uplet подход. Более точно, в случае сравнения между требованием R1 спецификации AS и двумя другими требованиями R2 и R3 той же самой спецификации AS:
- внутренние sem-uplet двух phrase-uplet сравниваются попарно. Другими словами, каждый syn-uplet phrase-uplet из R1 сравнивается с каждым syn-uplet phrase-uplet из R2 и R3,
- семантическая близость (semProx) вычисляется для каждой пары,
- создаются упорядоченные вторичные кортежи (семантические кортежи, называемые sem-uplet).
Каждый sem-uplet содержит семантические близости между каждым syn-uplet из R1 и другими syn-uplet из R2 или R3 и определяет семантическую дистанцию. Итак, он формирует набор кортежей, который представляет связи, в терминах семантической дистанции, каждого требования относительно других. Возможно «настроить» уровень семантических дистанций, чтобы сохранить только «лучшие» sem-uplet в терминах семантической близости, т.е. наиболее семантически пертинентные связи для заданного требования. Это значит, что допускается, что каждое требование имеет ограниченное число семантически наиболее близких других требований. Таким образом, что оно предполагает, что требование может быть формально описано в контексте целой спецификации AS с помощью ограниченного набора sem-uplet, который представляет другие семантически самые близкие требования.
Например, если R2 связано с R1 или R3, но sem-uplet(R2,R3) > sem-uplet(R2,R1), тогда только связь R2-R3 сохраняется в окончательной модели. Это вопрос оптимизации. Настройка модели возможна с помощью определения максимально приемлемого промежутка между двумя sem-uplet. Например, она может учитывать, что связь R2-R3 будет сохранена, если только diff(sem-uplet(R2,R3), sem-uplet(R2,R1))>10, где diff() - это функциональная разница (или вычитание). В одном варианте предел (или порог) для функции «diff()» может быть равен 5 или 15, в зависимости от категории проблемы или вида требований. В другом варианте все связи, соответствующие функции diff() большей, чем минимальный критический уровень, могут быть сохранены в модели проблемы (или сети требований) и, следовательно, продублированы в модели решения.
«Молекула» решения имеет ту же самую пространственную структуру, как и «молекула» проблемы, хотя они не содержат и не используют те же самые виды атомов: атомы проблемы являются требованиями, атомы решения являются компонентами SC. Атомы проблемы связаны вместе, потому что они совместно используют те же самые концепты и адресуют те же самые требования, в то время как атомы решения связаны вместе, потому что они совместно используют или обмениваются теми же самыми данными. Однако сеть требований (или молекула проблемы), которая содержит пертинентные связи между требованиями, содержит те же самые связи, что и архитектура приложения (или решения).
Эти два вида атомов разные и имеют не точно одинаковую природу, при этом связи, которые являются пертинентными в сети требований, могут быть не пертинентными в начальной компонентной структуре. Действительно, тот факт, что два требования разделяют те же самые концепты, необязательно является причиной взаимного воздействия двух соответствующих компонентов друг на друга. Поэтому, обрабатывающий модуль РМ может быть приспособлен, чтобы оптимизировать начальную архитектуру приложения AS, и более точно, чтобы определить лучшую модель взаимодействия компонентов.
Процесс оптимизации нацелен на сохранение только наиболее полезных из всех связей, вытекающих из структуры проблемы, т.е. ассоциация, соответствующая актуальным данным, обменивается между двумя компонентами SC (Comp1 и Comp2), где выход компонента Comp1 - это вход для Comp2 или наоборот.
Этот процесс оптимизации может использовать семантические метки, прикрепленные как семантические метаданные к описаниям данных или операциям компонентов (и более точно к их входам и выходам), чтобы определить и оптимизировать взаимодействия между выбранными компонентами SC.
Если эти семантические метки выбраны подходящим образом и установлены, то компоненты SC могут быть соединены и их связность может быть формально выражена. Например, если выход Comp1.operation_A() семантически совпадает со входом Comp2.operation_B(), то тогда Comp1 может быть связан с Comp2 через связь «выход А» к «входу В», и возможно записать:
out_A = Comp1.operation_A(A_parameters);
out_B = Comp2.operation_B(out A);
или, более конкретно:
out_В = Comp2.operation_В(Comp1.operation_A(A_parameters)).
Это означает, что два связанных массива данных имеют один и тот же семантический «размер», т.е. они семантически соответствуют друг другу (или они могут подвергаться совместной обработке), потому что они совместно используют не только одинаковый тип данных, но также и одинаковую природу данных. Этот тип семантических данных может быть выражен параметром «semTag», который схож с заданным значением UML и прикреплен к входам и выходам в семантических описаниях (или семантических картах) SD.
Тот факт, что возможно соединить выход Comp1 с входом Comp2, потому что они семантически совпадают друг с другом (например, Comp1 создает текст, а Comp2 воспринимает текст), необязательно свидетельствует о том, что Comp2 действительно ожидает выход Comp1, вместо, например, выхода Comp4, который является другим компонентом, создающим текст. Фактически, связность Comp1-Comp2 подтверждается, поскольку взаимодействия создаются отслеживанием связей, которые присутствуют в структуре решения. Даже если Comp4 создает текст, он непосредственно не связан с Comp2. Следовательно, нет причины пытаться объединять их входы-выходы.
SemTags гарантируют постоянство интерфейсов компонентов, и по этой причине они являются очень важными элементами для взаимодействия оптимизирующих компонентов. Напомним, что в смысле UML интерфейс компонента SC выполнен в виде набора его публичных операций со своими параметрами. Например, предположим, что Comp1.operation_A() создает текст, и Comp2.operation_В() - это операция перевода («translate()») компонента «Translator». Так как это имеет смысл перевода текста, выход Comp1.operation_A() должен совпадать со входом Translator.translate(). Но предположим, что если Comp1.operation_A() обеспечивает стандартный символ ценных бумаг для данной компании, то этот символ и текст, принятые как входная информация с помощью Translator.translate(), могут иметь тот же самый тип данных (String), но они семантически не эквивалентны, потому, что не имеет смысла стараться перевести стандартный символ ценных бумаг. Поэтому семантическая информация, прикрепленная к этим двум данным, должна быть разной, и, следовательно, две операции, и их два компонента SC не способны соединяться (или связываться).
Далее приведен неограничивающий пример семантической карты SD компонента Translator, чтобы показать полезность semTag:

Если компоненты SC являются веб-службами, то, например, их семантические описания (семантические карты) SD могут быть получены из WSDL (Языка Описания Веб-Служб) службы. Но чтобы автоматически установить семантические метки, может быть использован опциональный и специальный семантический модуль SSM устройства D, как показано на единственной фигуре. Этот модуль SSM мог бы быть частью обрабатывающего модуля РМ.
Этот семантический модуль SSM может анализировать имена и типы параметров операций, как описано на WSDL, и может искать семантические соответствия в конкретной онтологии.
Эта конкретная онтология содержит связи между семантикой текущих имен и типами входных и выходных данных, как обычно используется программистами, и соответствующими семантическими метками.
Например, данные, именованные как «текст» или «контент» или «переведенная_страница» или «описание», с типом «строка» могут иметь семантическую метку «текст», потому что данные имеют «размер» текста. Данные, именованные как «дата» или «текущая_дата», с типом «Дата» или «Строка» могут иметь семантическую метку «дата» и т.д.
Такая конкретная онтология, предназначенная для автоматической установки семантической метки в семантических картах SD, может быть выражена как простая таблица соответствий. Пример такой таблицы соответствий приведен далее.
|
Такая конкретная онтология может быть легко создана специалистом в данной области техники, и её можно постепенно усовершенствовать путем анализа контентов публичных компонентов интерфейсов, которые показывают навыки программистов, и суммирования их лучших использований.
Пример, показывающий, как семантические метки принимаются во внимание при создании модели автоматического взаимодействия компонентов, приведен далее.
В этом неограничивающем примере допускается, что требование спецификации AS (выраженное на естественном языке) указывает, что приложение АР предназначено для получения переведенной версии ленты новостей. Более того, допускается, что подход sem-uplet плюс компонент-открытие назначил два компонента SC этому требованию: компонент RSS-доступ и компонент Translator (примеры семантических карт SD которых приведены выше).
Например, компонент RSS-доступ предназначается для сбора информации из RSS-лент, получаемых через Интернет, а его интерфейс содержит две операции: getAllTitles() получает основные заголовки лент для данного URL, а getDescriptionOfTitle() получает текст коротких статей для этого заголовка.
Например, компонент «Translator» - это классический компонент, чья операция translate() преобразует текст (приведенный в качестве входного параметра), написанный на данном языке оригинала (входной параметр) в переведенный текст (выход), написанный на заданном языке (входной параметр).
Теперь, вопрос заключается в том, чтобы объединить автоматически и логически эти два компонента, т.е. их три операции, чтобы полностью выполнить требование спецификации (т.е. обеспечить переведенную версию ленты новостей). С этой целью должны быть приняты во внимание две следующие особенности.
Первая особенность заключается в рассматривании семантических меток в качестве входов и выходов операций компонентов вместо данных. Это позволяет пояснить некоторые возможные связности, но не вполне достаточно, чтобы создать полностью достаточную композицию.
Вторая особенность заключается в рассматривании основного выхода заданной совокупности компонентов, чтобы найти, какие операции компонентов могут обеспечить ее входы, и выполнить итерацию процесса для этих операций: искать, какие другие операции могут обеспечить их входы. Затем, возвращаясь обратно постепенно от основных выходных данных к входным данным, необходимым для их получения, и делая это, он автоматически объединяет операции разных компонентов с помощью связывания своих выходов и входов.
В то же самое время связи могут быть сохранены в стеке FILO (алгоритм «первым пришел, последним вышел») в форме псевдокода, выражающего операционные вызовы. В конце этого процесса содержимое стека представляет собой корректные взаимодействия между выбранными компонентами.
Основной выход совокупности компонентов задается выражением требования спецификации. В этом примере, где требуется переведенная версия, основной выход - это переведенный текст, т.е. выход операции Translator.translate(). Итак, можно поместить этот основной выход в стек, выраженный как «возвращение» функции, представленной совокупностью заданных компонентов:
translated_text=Translator.translate(text_to_translate,src_lang, dest_lang);
return translated_text.
Если теперь вернуться к входам этой операции, чьими соответствующими семантическими метками являются “language”, “language” и “text”, то видно, что данные с семантической меткой “text” обеспечиваются операцией RSS.getDescriptionOfTitle(). Итак, можно связать эту операцию с Translator.translate(), и можно добавить вызов к операции RSS.getDescriptionOfTitle() в стек, связывая Translator.translate() через имя измененного параметра, как указано далее:
text_to_translate=RSS.getDescriptionOfTitle(site_address,title),
translated_text=Translator.translate(text_to_translate,
src_lang,dest_lang),
return translated_text.
Теперь, если вернуться к входам RSS.getDescriptionOfTitle(), чьими семантическими метками являются “URL” и “title”, можно видеть, что данные с семантической меткой “title” обеспечиваются операцией RSS.getAllTitles(). Итак, можно также связать эти две операции, помещая новый операционный вызов в стек:
titles=RSS.getRSSTitles(adr_site);
text_to_translate=RSS.getDescriptionOfTitle(site_address,title);
translated_text=Translator.translate(text_to_translate;
src_lang,dest_lang);
return translated_text.
Все компоненты SC присвоены требованиям спецификации, используемые и связанные вместе, причем стек теперь содержит полную структуру совокупности компонентов в форме наиболее выполнимого псевдокода. Однако желательно внести уточнения в этот псевдокод перед его выполнением. Некоторые из этих уточнений перечислены ниже:
- типы данных должны быть приняты в расчет. Например, RSS.getAllTitles() возвращает матрицу строк (String), а не единственную строку,
- имена некоторых параметров могут быть разрешены через их семантику, т.е. с помощью их semTagoв. Например, “adr_site” и “site_address” охватывают один и тот же концепт и имеют одну и ту же semTag,
- некоторые другие параметры могут быть разрешены с некоторой полезной информацией, содержащейся в исходном требовании. Например, если требование определяет французский перевод, то тогда параметр “dest_lang” операции Translator.translate() должен быть установлен в состояние “French”, и
- некоторые дополнительные компоненты SC или операции компонентов могут быть использованы для разрешения других параметров. Например, параметр “src_lang” может быть установлен с использованием компонента утилиты, “Language Finder”, чтобы автоматически определить исходный язык данного текста, или операцию getSourceLanguage() над компонентом RSS-ленты.
Другой необязательный и конкретный модуль OSM устройства D может быть предусмотрен, чтобы выполнить уточнения, предназначенные для завершения псевдокода. Этот модуль OSM может быть частью обрабатывающего модуля РМ, или объединенным с обрабатывающим модулем РМ, как показано на единственной фигуре. Например, этот модуль OSM может быть модулем программного обеспечения таким, как следующий:
Vector ComponentAssembly(String site_address){
Vector result;
titles = RSS.getAllTitles(site_address);
foreach title in titles{
text_to_translate=RSS.getDescriptionOfTitle(site_address,
title);
source_lang=LanguageFinder.getLanguage(text_to_translate);
translated_text = Translator.translate(text_to_translate,
source_lang,”french”);
result.add(title+translated_text);
}
return result;
}.
После того как псевдокод был по возможности уточнен, он может быть окончательно преобразован в исполняемый Java файл, например, чтобы проверить достоверность совокупности компонентов, полученных с помощью процесса оптимизации.
Так как семантический анализ оригинального текста спецификации AS является автоматическим, и учитывая, что обнаружение и объединение компонентов SC программного обеспечения также является автоматическим, с учетом что оптимизация архитектуры приложения также является автоматической, и окончательно учитывая, что компилируемая и выполняемая генерация кода возможна из оптимизированной архитектуры, изобретение может рассматриваться как средство для получения выполняемого приложения АР прямо из текста своей спецификации AS.
Устройство D и более точно его анализирующий модуль АМ и обрабатывающий модуль РМ, и возможно его средство SM хранения, являются предпочтительно модулями программного обеспечения. Но они могут быть также соответственно выполнены из электронной схемы(м) или модулей аппаратного обеспечения, или комбинации модулей аппаратного обеспечения и программного обеспечения.
Изобретение может также быть рассмотрено в рамках способа для создания приложения АР из компонентов SC программного обеспечения.
Такой способ может быть выполнен посредством устройства D, такого как вышеописанное со ссылкой на единственную фигуру. Поэтому только его основные характеристики буду упомянуты далее.
Способ в соответствии с изобретением состоит в том, что каждый раз при приеме спецификации AS (описывающей приложение, которое должно быть создано):
- выполняют семантический анализ этой спецификации AS, чтобы выделить элементарные требования SR из текста спецификации AS и связи между этими элементарными требованиями SR, причем набор этих связей назван «общая структура спецификации», затем
- выделяют, для каждого элементарного требования SR, пертинентные термины, которые он содержит, и формируют, для каждого элементарного требования SR, «семантическое описание», основанное на его выделенных пертинентных терминах и которое представляет «семантику этого элементарного требования», затем
- осуществляют доступ, по меньшей мере, к одному хранилищу SM компонентов, где каждый компонент SC регистрируется и описывается как «семантический компонент SSC программного обеспечения», чтобы определить для каждого выделенного элементарного требования SR путем сравнения семантики этого элементарного требования SR и семантических описаний SD компонентов, какой(ие) компонент(ы) может(ут) охватывать выделенное элементарное требование SR, и
- окончательно объединяют эти определенные компоненты SC программного обеспечения, соответствующие общей структуре спецификации, чтобы построить приложение АР.
Изобретение не ограничивается вариантами осуществления способа и устройства, описанными выше только в качестве примеров, но оно охватывает все возможные варианты осуществления, которые могут быть рассмотрены специалистом в данной области техники в объеме формулы изобретения, приведенной далее.
Способ для распределения ресурсов терминалам пользователя, базовая станция, терминал пользователя и сеть связи
Способ, устройство и модуль для оптимизации удаленного управления устройствами домашней сети
Способ, вм-sc и базовая станция для мультиплексирования услуг mbms в mbsfn
Способ передачи данных по восходящей линии связи от пользовательского терминала, базовая станция, координирующее устройство и сеть связи для их осуществления
Способ, базовая станция и центр широковещательного и многоадресного сервиса для создания, обновления и высвобождения объектов синхронизации
Способ и ассоциированное устройство для сохранения когерентности канала предварительного кодирования в сети связи
Способ и устройство для построения кодовой книги и способ, устройство и система для предварительного кодирования
Прикладной модуль и сервер удаленного управления с моделью описания параметров
Информация обратной связи в беспроводной телекоммуникационной сети с множественными несущими
Способ и устройство для переупорядочивания и мультиплексирования мультимедийных пакетов из мультимедийных потоков, принадлежащих взаимосвязанным сеансам
Способ для распределения ресурсов терминалам пользователя, базовая станция, терминал пользователя и сеть связи
Способ, устройство и модуль для оптимизации удаленного управления устройствами домашней сети
Способ, вм-sc и базовая станция для мультиплексирования услуг mbms в mbsfn
Способ передачи данных по восходящей линии связи от пользовательского терминала, базовая станция, координирующее устройство и сеть связи для их осуществления
Способ сокращения трафика в системе e-mbms и центр bm-sc для осуществления упомянутого способа
Способ, базовая станция и центр широковещательного и многоадресного сервиса для создания, обновления и высвобождения объектов синхронизации
Способ и ассоциированное устройство для сохранения когерентности канала предварительного кодирования в сети связи
Способ и устройство для построения кодовой книги и способ, устройство и система для предварительного кодирования
Прикладной модуль и сервер удаленного управления с моделью описания параметров
Информация обратной связи в беспроводной телекоммуникационной сети с множественными несущими

