Результат интеллектуальной деятельности: СПОСОБЫ ВЫБОРА ПРИЗНАКОВ, ИСПОЛЬЗУЮЩИЕ ОСНОВАННЫЕ НА ГРУППЕ КЛАССИФИКАТОРОВ ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ
Вид РИД
Изобретение
Данная заявка заявляет приоритет предварительной заявки на патент США порядковый № 60/826593, зарегистрированной 22 сентября 2006 г., которая включена здесь в полном виде в качестве ссылки.
Обеспечены способы выбора признаков, использующие генетические алгоритмы.
Генетический алгоритм (GA) является классом эволюционных алгоритмов, используемых в вычислении в качестве метода поиска для нахождения решений для задач оптимизации и поиска. GA использует терминологию и понятия для развития методов, побуждаемых эволюционной биологией, включая такие понятия, как наследование, мутация, селекция и кроссинговер.
Выбор признаков, также известный как выбор подмножеств или выбор переменных, является способом, используемым в машинном обучении. Перед применением алгоритма обучения к набору данных, выбирается подмножество признаков, доступных из этого набора данных. Процесс выбора признаков используется потому, что вычислительно невозможно использовать все доступные признаки в наборе данных. Выбор признаков также используется для минимизации проблем оценки и излишнего приближения, когда набор данных имеет ограниченные выборки данных, содержащие большое количество признаков.
Типичной областью, для которой используется выбор признаков, является диагностика с помощью компьютера (CADx). CADx является способом, который использует технологию машинного обучения для прогнозирования медицинского исхода, например для классификации неизвестных поражений, таких как злокачественных или доброкачественных. Например, в визуализации с помощью компьютерной томографии (CT) легкого для диагностики рака легких, эти введенные признаки могут включать в себя результаты алгоритмов обработки изображений, примененных к исследуемому узелковому образованию в легких. Усовершенствование диагностической точности систем CADx является ключевой стадией для успешного введения этой технологии в клинические исследования.
Из-за большого числа признаков изображений и клинических признаков, которые могут быть вычислены и извлечены для каждого поражения, выбор признаков является важной стадией, обусловленной неосуществимостью использования всех доступных признаков в наборе данных и проблемами вычисления, когда набор данных имеет ограниченные выборки данных, содержащие большое количество признаков. Было показано, что выбор признаков с использованием GA и машин векторной поддержки (SVM) является эффективным способом выбора признаков для компьютеризированной системы обнаружения (CAD; Boroczky и др., IEEE Transaction on Biomedical Engineering, 10(3), pp. 504-551, 2006).
Хотя было показано, что основанный на GA выбор признаков является успешным в ряде областей, часто возникают проблемы и ошибки, обусловленные искаженными и малыми медицинскими наборами данных. Это вызывается случайным разделением внутри GA, который может генерировать смещенные наборы данных тренировки и смещенные наборы данных тестирования из обучающего набора данных.
Соответственно, здесь обеспечены способы осуществления основанного на генетическом алгоритме выбора признаков. Эти способы в одном варианте осуществления включают в себя этапы, на которых применяют множественные шаблоны разделения данных к обучающему набору данных для построения множественных классификаторов для получения, по меньшей мере, одного результата классификации; интегрируют, по меньшей мере, один результат классификации из множественных классификаторов для получения интегрального результата точности; и выводят интегральный результат точности для генетического алгоритма в качестве пригодного значения для подмножества признаков-кандидатов, при этом осуществляется основанный на генетическом алгоритме выбор признаков.
Зависимый вариант осуществления дополнительно включает в себя использование генетического алгоритма для получения подмножества признаков-кандидатов.
В зависимом варианте осуществления множественные шаблоны разделения данных делят обучающий набор данных на данные тренировки и данные тестирования. Обучающие наборы данных используются для настройки параметров правила обучения. Набор данных тренировки включает в себя входной вектор (включающий в себя доступные признаки) и ответный вектор (включающий в себя известный диагноз, т.е. злокачественный/доброкачественный) и используется вместе с контролируемым способом обучения для тренировки компьютера с использованием базы данных, имеющей эти случаи и известные диагнозы. Набор данных тестирования включает в себя известные примеры, которые используются для тестирования работы классификатора, построенного на данных тренировки.
В другом зависимом варианте осуществления множественные классификаторы выбирают из, по меньшей мере, одного из машины векторной поддержки, дерева решений, линейного дискриминантного анализа и нейронной сети.
В другом зависимом варианте осуществления построение множественных классификаторов дополнительно включает в себя использование метода повторной выборки для получения каждого из множества тренировочных наборов и множества тестирующих наборов из обучающего набора данных.
В еще одном другом зависимом варианте осуществления построение множественных классификаторов дополнительно включает в себя использование множества тренировочных наборов.
В другом варианте осуществления способ дополнительно включает в себя этапы, на которых комбинируют результаты классификации из множественных классификаторов для формирования группового прогнозирования.
В зависимом варианте осуществления интеграция, по меньшей мере, одного результата классификации дополнительно включает в себя вычисление, по меньшей мере, одного результата, выбранного из группы, состоящей из среднего, взвешенного среднего, мажоритарного голосования, взвешенного мажоритарного голосования и срединного значения.
В другом зависимом варианте осуществления способ дополнительно включает в себя этап, на котором используют генетический алгоритм для повторяемой оценки подмножеств признаков-кандидатов с использованием пригодных значений для генерации новых подмножеств признаков-кандидатов и получения оптимального конечного подмножества признаков.
В зависимом варианте осуществления способ используют в приеме рентгенографии, выбранном из группы из, по меньшей мере, одного из CT, MRI, облучения рентгеновскими лучами и ультразвука.
В другом варианте осуществления способ используют в компьютеризированной системе обнаружения (CAD). В зависимом варианте осуществления способ используют в CAD заболевания, выбранного из группы из, по меньшей мере, одного из рака легких, рака молочной железы, рака предстательной железы и колоректального рака.
В еще одном другом варианте осуществления способ используют в диагностике с помощью компьютера (CADx). В зависимом варианте осуществления способ используют в CADx заболевания, выбранного из группы из, по меньшей мере, одного из рака легких, рака молочной железы, рака предстательной железы и колоректального рака.
Способы, обеспеченные здесь, интегрируют способы группы классификаторов в эволюционный процесс выбора признаков для усовершенствования основанного на GA выбора признаков. GA оценивает каждое подмножество признаков с использованием интегрированного результата прогнозирования, основанного на множественных шаблонах разделения данных, а не на оценке единственного шаблона разделения данных. Это особенно полезно для искаженных данных, которые в противном случае могут вызывать смещенное вычисление пригодных значений.
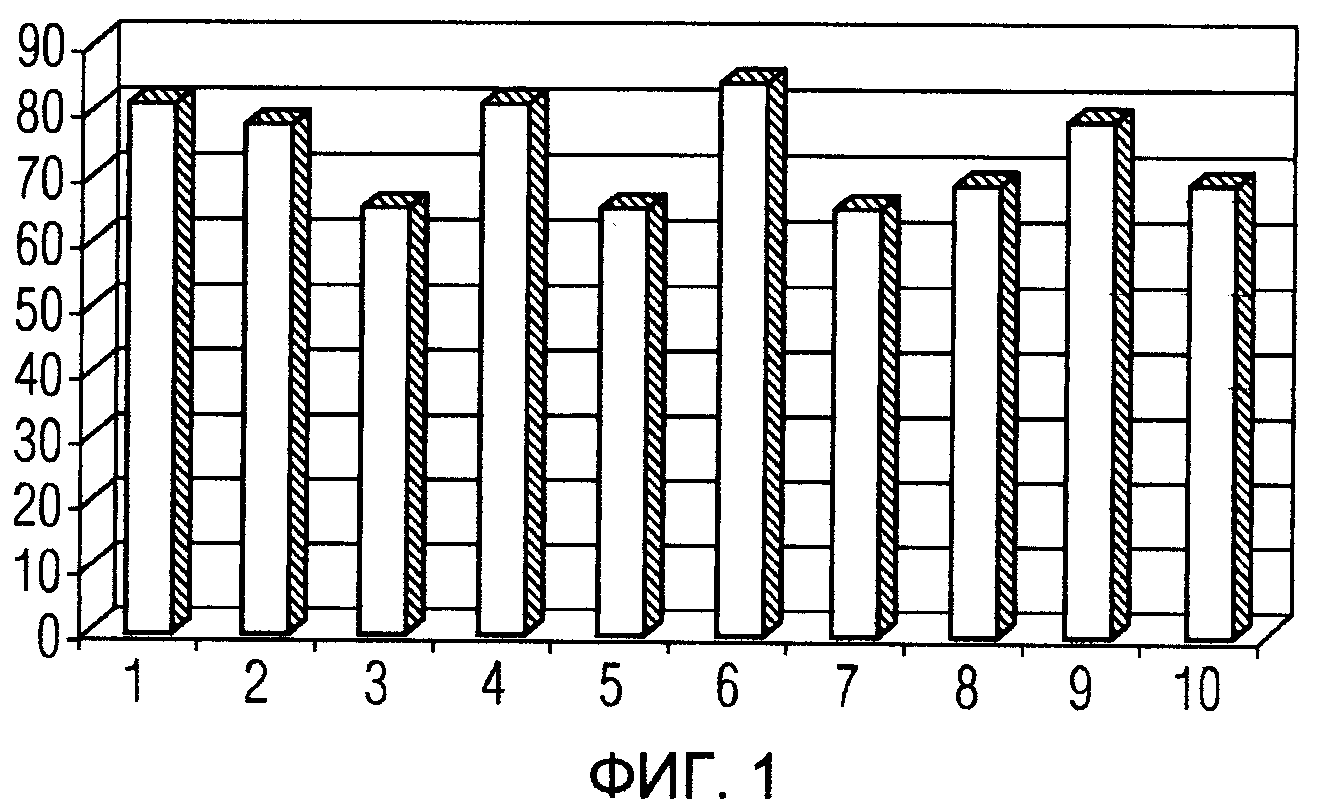
Фиг. 1 является столбчатой диаграммой, которая показывает влияние разделения данных на точность классификации.
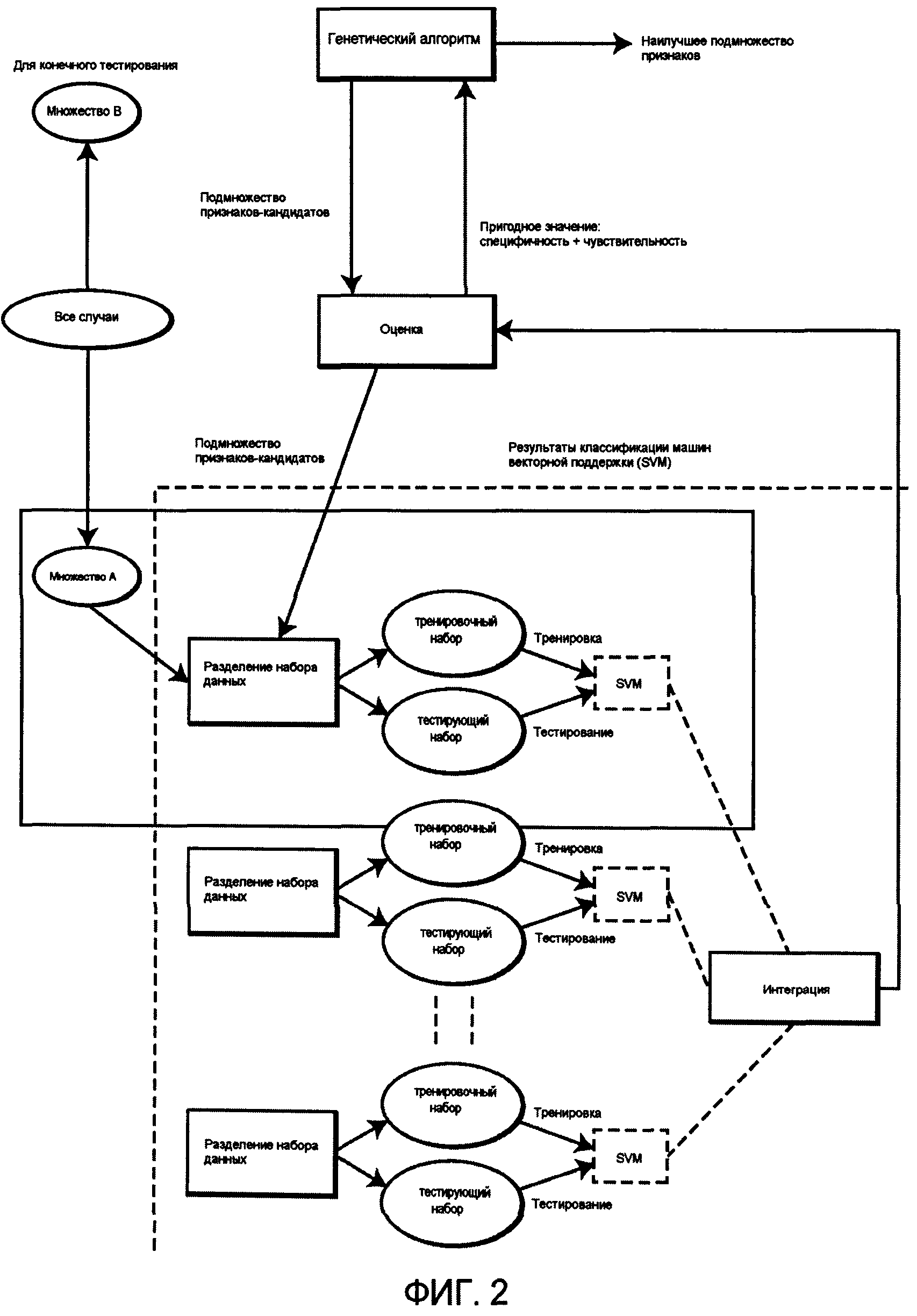
Фиг. 2 является блок-схемой, которая показывает стадии в построении множественных классификаторов для анализа набора данных и получения наилучшего подмножества признаков.
Выбор признаков используется в определении оптимального подмножества признаков для построения классификатора. Используется основанный на GA и SVM процесс выбора признаков. Классификатор строится на основе оптимального подмножества признаков.
Классификаторы используются в CAD и CADx различных заболеваний, например для рака легких и других типов рака, имеющих солидные опухоли. В области машинного обучения, классификаторы используются для группировки элементов, которые имеют схожие значения признаков. Возможные классификаторы включают в себя SVM, деревья решений, линейный дискриминантный анализ и нейронные сети. SVM являются линейными классификаторами и часто используются, так как они показали лучшую работу по отношению к классификаторам. Дерево решений является моделью прогнозирования, которая преобразует наблюдения о некотором элементе в выводы о требуемом значении этого элемента. Линейный дискриминантный анализ используется для нахождения линейной комбинации признаков, которая наилучшим образом разделяет два или более классов объектов или событий. Полученные в результате комбинации используются в качестве линейного классификатора или в уменьшении размерности перед последующей классификацией. Нейронная сеть является инструментом нелинейного моделирования статистических данных, который используется для моделирования отношений между вводами и выводами и/или для нахождения шаблонов в данных.
Система CADx, которая обеспечивает высокую достоверность для врачей, усовершенствует рабочий поток врача посредством обеспечения быстрого и точного диагноза (меньшего количества ложноположительных и ложноотрицательных). Система CADx может использоваться в качестве второго устройства считывания для повышения уверенности врачей в их диагнозе и приводит к значительному снижению ненужных биопсий повреждений легких, таких как узелковые образования, и приводит к значительному снижению ненужной задержки лечения. Кроме того, система CADx может облегчить скрининг на рак легких бессимптомных пациентов, так как диагноз может быть достигнут быстро и точно. Сканеры MSCT, включающие в себя, но не ограниченные этим, серию Phillips Brilliance, предлагают возрастающее разрешение и позволяют наблюдать более тонкие структуры при формировании возрастающих количеств данных изображений, подлежащих интерпретации рентгенологами.
В области CADx, основанной на машинном обучении, одной из наиболее общих проблем является то, что данные тренировки обычно искажены. Искажение особенно превалируют, когда набор данных тренировки не является достаточно большим. Это имеет существенное влияние на эффективность выбора признаков. Поскольку GA полагается на случайное разделение данных для оценки каждой хромосомы, представляющей собой некоторое подмножество признаков, искаженные данные дают неточную оценку того, как работает подмножество признаков. В результате, хорошее подмножество признаков может быть отвергнуто из-за его работы на «плохом» случайном разделении данных. Это впоследствии влияет на успешную сходимость к оптимальному подмножеству признаков.
Фиг. 1 показывает диаграмму результатов эксперимента с использованием данных из 129 случаев рака легких. Случайно выбранное подмножество данных было использовано для тренировки, т.е. построения классификатора SVM, а оставшиеся данные были использованы для тестирования. Это известно как разделение данных. Результат на фиг. 1 показывает, что когда используются различные разделения данных, точность классификации, т.е. точность тестирования, отличается значительно.
Предыдущие способы обычно предполагают, что компонент искажения случайным образом извлечен из несмещенного, т.е. со средним, равным нулю, нормального распределения. Пригодное значение обычно корректируется путем вычисления смещения искажения и вычитания его из пригодного значения (Miller и др., Evolutionary Computation, 1996, доступно в http://leitl.org/docs/ecj96.ps.gs). Пригодное значение является объективной мерой качества решения.
Не все данные в реальном мире имеют несмещенное распределение, или смещение сложно вычислить. Для решения этих проблем обеспеченные здесь способы используют группы классификаторов для снижения влияния искажения при оценке подмножества признаков во время эволюции GA.
Было теоретически и эмпирически доказано, что группа классификаторов является более точной, чем любой из индивидуальных классификаторов, образующих группы (Opitz и др., Journal of Artificial Intelligence Research, pp.169-198, 1999). Способы, обеспеченные здесь, используют следующие переменные: полагание на методы повторной выборки для получения различных наборов тренировки для построения множественных классификаторов и использование множественных подмножеств признаков для построения множественных классификаторов. Результаты классификации из множественных классификаторов комбинируются вместе для формирования группового прогнозирования.
Вместо построения одного классификатора (т.е. использования одного шаблона разделения данных) согласно прежним способам для оценки работы подмножества признаков, способы, обеспеченные здесь, строят множественные классификаторы, также известные как группа, и интегрируют результаты классификации из этих классификаторов. В этом случае несколько классификаторов строятся на различных разделениях данных. Каждый классификатор приведет к решению, например, является ли поражение злокачественным или доброкачественным. Способом интеграции может быть мажоритарное голосование, т.е. прогнозирование, выбираемое большинством классификаторов-участников. Альтернативные способы интеграции включают в себя вычисление среднего, взвешенного среднего или срединного значения (Kuncheva L.I., IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(2), pp. 281-286, 2002). Точность, полученная группой классификаторов, является лучшей, чем любой единственный классификатор. Интегральная точность, определенная группой классификаторов, возвращается к GA как пригодное значение для одного конкретного подмножества признаков.
Фиг. 2 показывает выборки данных, разделенные на два множества, множество А (обучающий набор данных) и множество В (набор данных, зарезервированный для конечного тестирования). Множество А подвергается разделению данных, делящему данные множества А на тренировочное множество и тестирующее множество. Множественные шаблоны разделения данных применяются для построения множественных классификаторов, т.е. SVM. Результаты от множественных классификаторов интегрируются и оцениваются. Точность классификации осуществляется на наборе данных тестирования, который является частью первоначального набора данных. Результаты точности классификации, которые являются интегральными результатами от каждого классификатора, возвращаются к GA как пригодное значение для подмножества признаков-кандидатов. Пригодное значение может включать в себя как специфичность, так и чувствительность. После того как интегральные результаты возвращены к GA, GA определяет, какие признаки сохранены/отброшены, и генерирует новое подмножество (подмножества) признаков-кандидатов через операции внутренней мутации и кроссинговера. GA повторяет эволюционный процесс, пока не достигнуты критерии завершения, когда определено наилучшее подмножество признаков.
Способы, обеспеченные здесь, могут использоваться с несколькими приемами рентгенографии, например MRI, CT, облучением рентгеновскими лучами или ультразвуком. Способы, обеспеченные здесь, применяются к приемам рентгенографии, включающим в себя приемы рентгенографии, которые используются для обнаружения и диагностики ненормальных поражений в человеческом теле, например, данные, собираемые от систем визуализации, т.е. электронных сканеров. Способы и системы, обеспеченные здесь, могут использоваться в радиологических рабочих станциях, включающих в себя, но не ограниченных этим, Philips Extended Brilliance Workstation, Philips Mx8000 и ряд Philips Brilliance CT сканеров, или включенных в PACS системы, включающие в себя, но не ограниченные этим, Stentor iSite системы. Изобретение, обеспеченное здесь, также используется в CAD и CADx. При применении к CAD и CADx, изобретение, обеспеченное здесь, используется для обнаружения и диагностики таких заболеваний, как рак легких, полипы ободочной кишки, колоректальный рак, рак предстательной железы, рак молочной железы и других раковых и нераковых повреждений.
Кроме того, будет ясно, что другие и дополнительные формы изобретения и варианты осуществления, отличные от конкретных и примерных вариантов осуществления, описанных выше, могут быть придуманы не выходя за рамки сущности и объема прилагаемой формулы изобретения и ее эквивалентов, и следовательно, подразумевается, что объем данного изобретения охватывает эти эквиваленты, и подразумевается, что описание и формула изобретения являются примерными и не должны толковаться как ограничительные. Содержание всех ссылок, цитированных здесь, включено в качестве ссылки.
Способ и устройство для поддержки принятия решения на базе случаев
Система и способ для объединения клинических признаков и признаков изображений для диагностики с применением компьютера
Системы и способы поддержки клинических решений
Способы и системы для идентификации пациентов с умеренными когнитивными нарушениями с риском перехода в болезнь альцгеймера
Масштабирование отображаемого изображения
Система, содержащая множество модулей обнаружения объекта
Быстрое формирование магнитно-резонансного изображения с двойной контрастностью
Устройство для генерирования аэрозоля для распыления жидкости, и способ управления температурой распыляемой жидкости
Создание политики управления доступом на основе предпочтений конфиденциальности клиента
Мониторинг послеродового кровотечения
Мониторинг тревожности
Частота дискретизации динамической регистрации для компьютерной томографической визуализации перфузии (стр)
Основанное на местоположении беспроводное медицинское устройство

