Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ ДОКУМЕНТОВ
Вид РИД
Изобретение
Настоящее изобретение относится к способу и устройству для обеспечения безопасности документов. Его целью, в частности, являются однозначная идентификация документа, его аутентификация, т.е. способность распознавания его копии, и/или нанесение на документ относящейся к последнему информации, например идентификационной информации о правообладателе прав интеллектуальной собственности, удостоверяемых документом, и/или информации о месте изготовления документа. Термин "документ" означает любой носитель информации, например бумажный или плоский документ, упаковку, готовые изделия, литые изделия и карты, например, идентификационные или банковские.
Различные виды печати на документах объединяют в два типа: первый, называемый аналоговым, согласно которому каждый документ получает одну и ту же печатную маркировку, например способ аналоговой офсетной печати, и второй, называемый промышленным цифровым (серийным), согласно которому на каждый документ наносят индивидуализированную информацию, например способ струйной печати, управляемой индивидуализационной программой, и способ печати серийного номера.
При офсетной печати, являющейся одним из самых распространенных способов печати на футлярах и упаковках, для каждого цвета, используемого при печати документа, получают печатную форму, причем содержание указанной формы используется при печати сотни тысяч и даже миллионы раз. В этом случае одно и то же содержание, заключенное в печатной форме, печатается на каждом документе при каждой операции печати. Другими примерами аналоговой печати являются флексографическая, типографская и ротационная глубокая печать. При аналоговой печати индивидуальная идентификация документов в принципе является невозможной, поскольку при печати каждой раз наносится одна и та же маркировка. Кроме того, поскольку в данном виде печати используют аналоговые процессы, точное число отпечатанных документов трудно контролировать. Поэтому существенным является риск изготовления подделок путем печати большего количества документов по сравнению с количеством, санкционированным правообладателем. В связи с указанным возникают проблемы обеспечения соблюдения количества операций печати, указанного в заказе на изготовление и часто меньшего предельного количества копий, изготовление которых возможно с применением данной печатной формы, и предотвращения попадания в руки изготовителей подделок неиспользованных оттисков (начала или конца серии, брака, аннулированных заказов и т.д.), а также печатных форм, пленок и других объектов, позволяющих воспроизводить документы.
Промышленная цифровая печать, обеспечивающая точную и однозначную идентификацию каждого документа, обычно является более предпочтительной по сравнению с аналоговой. Поскольку при серийной цифровой печати каждый идентификационный элемент печатается только один раз, чтение дубликата элемента идентификации может сигнализировать о подделке. Дубликатом элемента идентификации является элемент идентификации, идентичный прежде считанному.
Как правило, при защите маркировок, предназначенных для защиты от копирования и/или идентификации, должна быть обеспечена безопасность файла исходных данных, файла настольной издательской системы, который может содержать указанный файл исходных данных, и кроме того, в случае офсетной печати безопасность печатных форм и, возможно, пленки.
Является возможным выполнение эквивалента серийной печати маркировки, предназначенной для защиты от копирования, на изделии, на котором уже выполнена аналоговая печать, путем последующей печати уникального кода или серийного номера в явном или, предпочтительно, в зашифрованном виде. Подобная серийная печать может быть выполнена, например, в форме двумерного штрих-кода. На первый взгляд, подобный способ позволяет индивидуально размечать каждый документ при создании надежного средства распознавания копий. Фальшивые документы, на которые не нанесено серийное печатное изображение, в этом случае не имеют действительного элемента идентификации.
Однако подобный подход не дает полного решения проблем. В самом деле, даже в случае невозможности идентификации злоумышленником поддельных документов аналогично возможному для изготовителя подлинника, уникальный код, напечатанный путем серийной печати на принтере, в общем, имеющем ограниченное качество печати, не является защищенным от копирования.
Таким образом, изготовитель подделок, обладающий документами, подлежащими идентификации на подлинность, может скопировать одну или несколько действительных копий и повторно скопировать их на документы, подлежащие идентификации как подлинные.
Известны многие способы, в которых для определения характеристик и однозначной идентификации каждого документа используют измеримые физические характеристики. Обычно выбранные измеримые физические характеристики имеют случайную природу и по состоянию науки и техники на сегодняшний день не могут быть скопированы по меньшей мере коммерчески выгодным путем. Подобные способы позволяют осуществлять контроль над всеми документами, рассматриваемыми как "действительные"; таковыми рассматриваются только документы, физические характеристики которых, составляющие уникальную совокупность, введены в память.
Например, в патенте США US 4423415 описан способ, обеспечивающий идентификацию листа бумаги согласно его местным характеристикам прозрачности. Некоторые другие способы основаны на установлении уникальных и невоспроизводимых физических свойств для создания уникальной и не способной к переносу подписи данного документа. Например, публикация РСТ WO 2006016114 и заявка на патент США US 2006/104103 основаны на определении дифракционной картины, индуцированной воздействием излучения лазера на заданный участок объекта.
Хотя решение вышеуказанных проблем в данных заявках является интересным, подходы, основанные на чтении подписи с материала, трудно применять по нескольким причинам. Во-первых, запись подписей в ходе изготовления документов требует дорогостоящего оптического считывающего устройства, с трудом интегрируемого в производственный процесс. Кроме того, последний должен работать в очень высоком темпе. Как правило, оказывается, что подобные технологии являются применимыми только в мелкосерийном производстве. Кроме того, считывающее устройство, используемое на местах при проверке подлинности, также для многих областей применения является слишком дорогостоящим. Оно также является громоздким и неудобным в работе, в то время как контроль на местах часто должен выполняться быстро и четко. Наконец, извлечение подписи из всех без исключения материалов является невозможным: в частности, исключениями являются стекло и объекты со слишком сильными отражательными свойствами, по меньшей мере в случае использования измерений дифракции излучения лазера.
Целью настоящего изобретения является устранение указанных неудобств и, в частности, трудностей и пределов применимости способов идентификации, основанных на уникальных физических свойствах материала документа.
Цифровые аутентификационные коды, также называемые далее CNA, представляют собой цифровые изображения, которые однократно наносят на подложку, например, путем печати или местного изменения подложки, и которые созданы таким образом, что некоторые из их свойств, обычно пригодных для автоматического измерения исходя из захваченного изображения, изменяются в случае копирования нанесенного изображения. Цифровые аутентификационные коды обычно основаны на искажении одного или нескольких сигналов, чувствительных к копированию на этапе копирования, причем указанные сигналы исходят от элементов изображения, обладающих измеримыми характеристиками, чувствительными к копированию. Некоторые типы цифровых аутентификационных кодов также могут содержать информацию, позволяющую идентифицировать или трассировать содержащий его документ.
Существует несколько типов цифровых аутентификационных кодов. Шаблоны распознавания копий, далее также называемые MDC, являются плотными изображениями, обычно псевдослучайной природы. Принцип их чтения основан на сравнении изображений для измерения индекса сходства (или различия) между исходным шаблоном и шаблоном, захваченным, например, устройством захвата изображений: если захваченный шаблон является копией, индекс сходства окажется меньшим, чем в случае оригинала.
Защищенные информационные матрицы, далее также называемые MIS, представляют собой, как и двумерные штрих-коды, изображения, созданные для надежной передачи большого количества информации. Однако, в противоположность двумерным штрих-кодам, защищенные информационные матрицы являются чувствительными к копированию. При чтении производится измерение уровня ошибок кодированного сигнала, полученного из матрицы; уровень ошибок является более высоким для копий по сравнению с оригиналами, что позволяет отличить копии от оригинальных оттисков.
Если шаблоны распознавания копий и защищенные информационные матрицы не маркированы особым образом, например, невидимыми чернилами, указанные элементы идентификации являются видимыми. Кроме того, их невидимая маркировка не всегда является возможной вследствие технологических причин или высокой цены. Видимость маркировки, предназначенной для защиты от копирования, может представлять собой недостаток в эстетическом плане и, в некоторых случаях, в плане безопасности, так как изготовителю подделок становится известно о существовании маркировки.
Также существуют цифровые аутентификационные коды, являющиеся невидимыми естественным образом или по меньшей мере трудно обнаружимые визуально.
Например, некоторые цифровые филиграни (известные под названием водяных знаков), включенные в печатные изображения, созданы таким образом, что при воспроизведении печатного изображения, например при ксерокопировании, они повреждаются. Измерение степени искажения цифровой филиграни, менее высокое для оригинального оттиска по сравнению с его копией, позволяет распознавать указанные копии.
Сравнение нескольких филиграней с различной степенью чувствительности к копированию позволяет при сопоставлении соответствующих уровней энергии распознавать копии. Однако интеграция цифровых филиграней в процесс производства документов является более сложной, что ограничивает их использование: в самом деле, в противоположность шаблонам распознавания копий и защищенным информационным матрицам, цифровая филигрань не может быть просто "добавлена" к изображению; в реальности она является сложной функцией добавляемой информации и оригинального изображения, причем энергия цифровой филиграни регулируется по ее участкам в зависимости от маскирующей способности оригинального изображения. Введение цифровой филиграни в документы или изделия связано с передачей исходного изображения на центральное маркировочное/печатающее устройство, интегрирующее цифровую филигрань и возвращающее маркированное изображение. Подобная процедура применяется редко по причине размера файлов, часто очень большого, и связанных с ней проблем безопасности изображения. Напротив, при нанесении маркировки/печати шаблона распознавания копий или защищенной информационной матрицы исходное изображение не должно передаваться на центральное маркировочное/печатающее устройство; напротив, обладателю файлов изображений, наносимых на документ или продукт, передается изображение шаблона распознавания копий или защищенной информационной матрицы, обычно имеющее очень малый размер, например в несколько килобайт. Кроме того, чтение цифровых филиграней особенно трудно стабилизировать, что делает распознавание копии по отношению к оригиналу более сомнительным. В самом деле, риск ошибки при использовании цифровых филиграней по сравнению с шаблонами распознавания копий и защищенными информационными матрицами обычно существенно выше.
Также известны способы пространственной маркировки с асимметричной модуляцией, далее также называемой MSMA, подобные описанным в публикации РСТ WO 2006087351 и патенте Швейцарии 694233. Как и цифровые филиграни, MSMA допускают видимую или по меньшей мере скрытую маркировку документов. MSMA обычно являются группами точек, добавляемых к маркируемому документу в качестве дополнительного слоя. Например, в случае применения способа офсетной печати документ допечатывается печатной формой, содержащей только MSMA. Кроме того, MSMA легче интегрировать в процесс производства документов, чем цифровые филиграни, поскольку наличие исходного изображения на центральном маркировочном/печатающем устройстве не является необходимым. В то же время, в противоположность шаблонам распознавания копий и защищенным информационным матрицам, MSMA обычно требуют дополнительных печатной формы и чернил, что делает их использование более сложным и дорогостоящим. Кроме того, как и для цифровых филиграней, способы идентификации MSMA могут быть неточными. Известно, что нанесение маркировки/печать порождает недостоверность аналоговой природы, связанную с точным положением маркировочного изображения. Подобная недостоверность, размером порядка одной печатной точки и даже менее, в случае, если маркированная поверхность имеет значительный размер, оказывает влияние на распознавание копий, которым нельзя пренебречь. Однако способы распознавания MSMA, основанные на автокорреляции и перекрестной корреляции, не могут учитывать подобную недостоверность положения. Это увеличивает неточность чтения маркировки и, как следствие, снижает способность различения оригиналов от копий.
При захвате планшетными сканерами, одновременно обеспечивающими большую поверхность захвата и достаточное разрешение захвата, MSMA позволяют распознавать простые копии, в частности ксерокопии, и даже копии высокого качества, изготовленные с использованием сканеров высокой точности или высокого разрешения с последующей перепечаткой. В то же время MSMA обеспечивают ограниченную защиту от копирования конкретными изготовителями подделок. В самом деле, после регистрации изображения высокого разрешения изготовитель подделок может использовать средства ручной обработки изображений, например, Photoshop (зарегистрированная торговая марка), возможно, в сочетании со средствами автоматизированной обработки изображений (например, Matlab, зарегистрированная торговая марка), для восстановления всех детектированных точек в их исходной форме. В случае высококачественных копий точки в копии маркировки не окажутся более слабыми, чем в оригинальной маркировке, и вероятность того, что копия не окажется распознанной, окажется очень высокой. Таким образом, конкретный изготовитель подделок, вообще говоря, может точно повторить информацию, содержащуюся в MSMA, что не позволяет рассматривать данный способ как обеспечивающий долговременную безопасность.
Различные способы печати документов объединяют в два типа: первый, называемый статическим, согласно которому каждый документ получает одну и ту же печатную маркировку, например способ аналоговой офсетной печати, и второй, называемый промышленным цифровым (серийным), согласно которому на каждый документ наносят индивидуализированную информацию, например способ струйной печати, управляемой индивидуализационной программой, и способ печати серийного номера. В наиболее распространенных способах печати (в частности, в офсетном способе) MSMA (и другие цифровые аутентификационные коды) печатаются аналоговым способом. Поскольку типы печати, чаще всего используемые для MSMA и цифровых аутентификационных кодов, являются аналоговыми, варьирование маркировки и содержащейся в ней информации при каждой операции печати является невозможным.
Однако возможность однозначного определения характеристик и идентификации каждого оттиска одного и того же исходного изображения является желательной.
Таким образом, объектом настоящего изобретения является способ идентификации документа, включающий:
- создание изображения; - нанесение маркировки на множество документов с формированием на каждом указанном документе указанного изображения, содержащего отклонения, уникальные для каждого документа, причем большинство изображений, сформированных на указанных документах, обладает некоторой физической характеристикой, обеспечивающей защиту от копирования и отвечающей заранее заданному критерию, а указанная характеристика большинства копий этих изображений, которые могут быть сформированы, не отвечает указанному критерию;
- получение для каждого указанного документа характеристик указанных отклонений для получения уникального образа полученной маркировки для каждого указанного документа и
- запоминание указанного уникального образа.
Таким образом, одна и та же маркировка, воспроизводящая предварительно созданное изображение, одновременно позволяет распознавать копию оригинального документа и индивидуально выделять каждый документ из группы оригиналов. При этом исключена необходимость дорогостоящего добавления идентификатора к каждому документу для его распознавания среди всех оригиналов. Настоящее изобретение также позволяет создавать, например, путем печати и использовать изображения, созданные для идентификации каждого документа с применением уникальных характеристик каждой маркировки.
В частном варианте указанное изображение является двухцветным.
Таким образом, по причине контраста между точками, представляющими собой изображение, его площадь может быть уменьшена, а его обработка может стать более простой и быстрой. Изображение также легче интегрируется в большинство способов печати.
В частном варианте на этапе определения характеристик отклонений используют частотный анализ. Таким образом, определение характеристик является менее чувствительным к легким отклонениям, например, субпиксельного порядка, положения, обеспечивающего его устройства захвата изображений.
В частном варианте на этапе определения характеристик отклонений используют секретный ключ. Таким образом, определение характеристик по своему принципу исполнения является защищенным.
В частном варианте, на этапе запоминания образ запоминают в базе данных. Вследствие данного положения в течение срока службы и при перемещениях документа устройство, предназначенное для распознавания образа, может обратиться к указанной базе данных. Изображения документа или образы могут быть также переданы на сравнивающее устройство для сравнения с образами, сохраненными в указанной базе данных, для получения идентификатора документа.
В частном варианте, на этапе запоминания документ маркируют характерной маркировкой образа, отдельно наносимой на документ. Вследствие данного положения распознающее устройство не нуждается в базе данных для идентификации документа. Следует отметить, что характерная маркировка образа может представлять собой, например, штрих-код, двумерный штрих-код или код datamatrix (зарегистрированный товарный знак).
В частном варианте, указанная характерная маркировка образа является зашифрованной. В соответствии с другими частными признаками в шифре, использованном для шифрования образа, использован асимметричный ключ. Вследствие каждого из данных положений содержание образа является защищенным шифром, причем последний является особенно надежным при использовании асимметричного ключа.
В частном варианте указанное изображение приобретает способность искажаться в ходе копирования документа, полученного на этапе нанесения маркировки.
Таким образом, в одном объекте аутентификационные свойства цифровых аутентификационных кодов и их трассируемость в отсутствие связи оказываются объединенными с возможностью уникального распознавания, характерной для идентификационных шаблонов.
Еще одна задача настоящего изобретения состоит в использовании оттиска идентификационного шаблона в "идентификационном" режиме, в котором образ, созданный исходя из захваченного изображения идентификационного шаблона, сравнивают со всеми предварительно вычисленными образами для определения его соответствия указанным предварительно вычисленным образам.
Еще одной задачей настоящего изобретения является использование данных, содержащихся в цифровом аутентификационном коде, используемом в качестве идентификационного шаблона, для облегчения поиска соответствующего образа в базе данных, причем указанные данные позволяют определить подсистему, в которой будет осуществлен поиск.
Еще одной задачей настоящего изобретения является использование образа идентификационного шаблона в "верификационном" режиме, в котором созданный образ сравнивают только с предварительно вычисленным образом данного документа, причем последний, например, нанесен на документ или может быть получен из данных документа (например, серийного номера и информации, касающейся обращения к базе данных).
Вторым объектом настоящего изобретения является способ обработки документов, включающий;
- захват изображения маркировки, напечатанной на указанном документе;
- получение физической характеристики, обеспечивающей защиту от копирования, из указанного изображения;
- определение соответствия указанной характеристики заранее заданному критерию;
- получение уникальных отклонений указанного напечатанного изображения путем обработки указанного изображения;
- определение образа указанных отклонений и
- определение соответствия этого образа образу, сохраненному в памяти.
Третьим объектом настоящего изобретения является способ аутентификации объекта, отличающийся тем, что он включает:
- нанесение на указанный объект маркировки, осуществляемое таким образом, что нанесенная маркировка обладает непредвиденными ошибками вследствие физических характеристик средств, использованных при ее нанесении;
- захват изображения указанной маркировки;
- определение физических характеристик указанных непредвиденных ошибок путем обработки указанного изображения.
Таким образом, физические характеристики ошибок маркировки обеспечивают уникальную идентификацию каждой маркировки и каждого связанного с ней объекта, хотя при этом на множестве объектов используют один и тот же неизменный способ нанесения маркировки, например, гравирование или печать. Можно утверждать, что каждая маркировка содержит уникальный цифровой образ, так что осуществление способа, являющегося объектом настоящего изобретения, является недорогим и одновременно индивидуализированным.
В частном варианте способ, подобный изложенному выше, кроме того, включает запоминание информации, содержащей физические характеристики непредвиденных ошибок. Таким образом, при захвате нового изображения маркированного объекта и новой обработке изображения результат подобной обработки изображения может быть сопоставлен с введенной в память информацией для идентификации объекта.
В частном варианте на этапе нанесения маркировки производят нанесение маркировки, образованной матрицей точек, при таком разрешении, при котором по меньшей мере два процента точек маркировки оказываются ошибочными по сравнению с оригинальной матрицей точек. Вследствие указанных положений количество ошибок является значимым и обеспечивает однозначную идентификацию маркировки объекта.
В частном варианте на этапе нанесения маркировки производят нанесение характерной маркировки данных, относящихся к маркируемому объекту.
Таки образом, чтение данных, относящихся к маркированному объекту, позволяет получить адрес и/или средства доступа к базе данных физических характеристик ошибок.
В частном варианте на этапе нанесения маркировки маркировку, имеющую непредвиденные ошибки, наносят с таким разрешением, что ее копирование повышает уровень ошибок в копии маркировки по меньшей мере на пятьдесят процентов по сравнению с исходной маркировкой.
В частном варианте, на этапе обработки изображения проводят определение характеристик распределения непредвиденных ошибок в указанной маркировке в качестве физических характеристик указанных ошибок. Таким образом, при любых условиях захвата нового изображения указанной маркировки является возможным нахождение характеристик распределения ошибок.
В частном варианте способ аутентификации, подобный изложенному выше, также включает в себя этап надежного маркирования, в ходе которой на указанный объект наносят надежную маркировку, содержащую информацию, относящуюся к физическим характеристикам непредвиденных ошибок. Благодаря надежности указанной второй маркировки она является стойкой к точному копированию и позволяет идентифицировать объект.
В частном варианте на этапе надежного маркирования используют ключ кодирования физических характеристик непредвиденных ошибок.
В частном варианте указанный ключ представляет собой асимметричный ключ.
Вследствие каждого из указанных положений оказывается возможной однозначная идентификация маркировки и объекта, на который она нанесена, с использованием надежной маркировки.
Четвертым объектом настоящего изобретения является устройство для аутентификации объекта, отличающееся тем, что оно включает:
- средства нанесения маркировки на указанный объект таким образом, что в нанесенной маркировке имеются непредвиденные ошибки вследствие физических характеристик указанных средств нанесения маркировки;
- средства захвата изображения указанной маркировки; и
- средства определения физических характеристик указанных непредвиденных ошибок путем обработки указанного изображения.
Некоторые объекты настоящего изобретения также направлены на устранение недостатков или пределов применимости цифровых филиграней, MSMA, защищенных информационных матриц и шаблонов распознавания копий.
В этой связи пятым объектом настоящего изобретения является способ обеспечения безопасности документа, отличающийся тем, что он включает:
- печать на указанном документе распределения точек, при которой вследствие случайных ошибок имеет место непредвиденное отклонение по меньшей мере одного геометрического параметра напечатанных точек;
- перед печатью создание указанного распределения точек с условием, чтобы:
- по меньшей мере половина точек каждого распределения не соприкасалась сторонами с четырьмя другими точками распределения и
- по меньшей мере один размер по меньшей мере части точек указанного распределения имел тот же порядок величины, что и среднее абсолютное значение указанного непредвиденного отклонения.
По меньшей мере этот объект настоящего изобретения позволяет использовать индивидуальные геометрические характеристики точек маркировки и измерять отклонение характеристик указанных точек для их внесения в метрику (т.е. определения их соответствия по меньшей мере одному критерию, применяемому при измерении), позволяющую отличать оригиналы от копий или нелегальных оттисков.
В частном варианте, на этапе создания распределения точек более половины указанных точек не касаются никакой другой точки указанного распределения.
Таким образом, в противоположность защищенным информационным матрицам и шаблонам распознавания копий и аналогично MSMA и цифровым филиграням, настоящее изобретение позволяет наносить невидимые или трудноразличимые маркировки. Кроме того, подобные маркировки легче интегрируются в объекты, чем цифровые филиграни или MSMA. Они обеспечивают распознавание копий более надежным путем, чем цифровые филиграни, и могут быть однозначно охарактеризованы в ходе процесса аналоговой печати, что обеспечивает однозначную идентификацию каждого документа.
В частном варианте на этапе создания распределения точек получают точки, по меньшей мере одна геометрическая характеристика которых является переменной, причем геометрическая амплитуда полученного отклонения имеет порядок величины среднего размера по меньшей мере части точек.
Настоящее изобретение также позволяет создавать и использовать оптимальным образом изображения шаблонов точек с переменными характеристиками, также называемых далее MPCV, созданных так, чтобы сделать более трудным и даже невозможным копирование путем идентичного воспроизведения.
В частном варианте, указанное отклонение соответствует отклонению положения точек по меньшей мере в одном направлении по отношению к положению, при котором центры точек выровнены по параллельным линиям, перпендикулярным указанному направлению, и удалены от них в данном направлении по меньшей мере на один размер указанных точек.
Настоящее изобретение, таким образом, позволяет использовать точные характеристики положения точек и измерять совсем небольшие отклонения в точном положении точек для их внесения в метрику, позволяющую отличать оригиналы от копий.
В частном варианте указанное отклонение соответствует отклонению по меньшей мере на один размер точек по меньшей мере в одном направлении по отношении к среднему размеру точек в указанном направлении.
В частном варианте указанное отклонение соответствует отклонению в форме точек по отношению к средней форме точек в указанном направлении.
В частном варианте на этапе создания указанное распределение точек представляет кодированную информацию.
Таким образом, настоящее изобретение позволяет хранить или передавать информацию в распределении точек с переменными характеристиками. При одинаковом количестве содержащейся информации распределения точек могут занимать существенно меньшую поверхность, чем MSMA, например, несколько квадратных миллиметров, что обеспечивает их захват с высоким разрешением переносными средствами захвата и, как следствие, высокую точность чтения.
В частном варианте способ, подобный кратко изложенному выше, включает захват изображения напечатанного распределения точек и определение уникальной подписи указанного напечатанного распределения в зависимости от указанного непредвиденного отклонения при печати.
Таким путем настоящее изобретение позволяет использовать отклонение точек, присущее каждому оттиску, для получения однозначных характеристик каждого оттиска одного и того же исходного шаблона точек с переменными характеристиками.
В частном варианте способ, подобный кратко изложенному выше, включает этап определения характерной величины непредвиденного отклонения при печати, причем создание распределения точек зависит от указанной величины.
В частном варианте способ, подобный кратко изложенному выше, включает этап распознавания копий в зависимости от характерной величины непредвиденного отклонения при печати, который, в свою очередь, включает этап сравнения указанной характерной величины с заранее заданным значением и этап принятия решения о подлинности документа в зависимости от результата сравнения.
Шестым объектом настоящего изобретения является способ защиты документов от копирования, вызывающий вследствие случайностей при копировании непредвиденное отклонение "при копировании" по точкам по меньшей мере одной геометрической характеристики напечатанных точек, отличающийся тем, что он включает:
- печать на указанном документе распределения точек, причем указанная печать вызывает вследствие случайностей при печати непредвиденное отклонение при печати по точкам указанной геометрической характеристики напечатанных точек, средняя амплитуда которого имеет тот же порядок, что и минимальная средняя амплитуда непредвиденного отклонения указанных копий;
и
- определение физической величины, характеризующей непредвиденное отклонение при печати.
Следует отметить, что определение физической величины может предшествовать печати, как и в способе, являющемся пятым объектом настоящего изобретения, или за печатью образцов для получения характеристик печати.
Седьмым объектом настоящего изобретения является устройство для обеспечения безопасности документа, отличающееся тем, что оно включает:
- средства печати распределения точек на указанном документе, причем указанная печать вызывает вследствие случайностей при печати непредвиденное отклонение по точкам по меньшей мере одной геометрической характеристики напечатанных точек;
- средства создания распределения точек, выполненные с возможностью создания указанного распределения точек перед печатью с условием, чтобы:
- по меньшей мере половина точек указанного распределения не соприкасалась сторонами с четырьмя другими точками указанного распределения точек;
- по меньшей мере один размер по меньшей мере части точек указанного распределения имел тот же порядок величины, что и среднее абсолютное значение указанного непредвиденного отклонения.
Восьмым объектом настоящего изобретения является устройство для обеспечения защиты документов от копирования, вызывающее вследствие случайностей при копировании непредвиденное отклонение при копировании по точкам по меньшей мере одной геометрической характеристики напечатанных точек, отличающееся тем, что оно включает:
- средства печати распределения точек на указанном документе, причем указанная печать вызывает вследствие случайностей при печати непредвиденное отклонение при печати по точкам указанной геометрической характеристики напечатанных точек, средняя амплитуда которого имеет тот же порядок, что и минимальная средняя амплитуда непредвиденного отклонения указанных копий;
и
- средства определения физической величины, характеризующей непредвиденное отклонение при печати.
Девятым объектом настоящего изобретения является способ чтения распределения точек на документе, отличающийся тем, что он включает:
- захват изображения указанного распределения точек;
- определение физической величины, характеризующей геометрическое отклонение точек указанного распределения; и
- определение подлинности указанного распределения точек в зависимости от указанной физической величины.
Десятым объектом настоящего изобретения является устройство для чтения распределения точек на документе, отличающееся тем, что оно включает:
- средства захвата изображения указанного распределения точек;
- средства определения физической величины, характеризующей геометрическое отклонение точек каждого распределения; и
- средства определения подлинности указанного распределения точек в зависимости от указанной физической величины.
Одиннадцатым объектом настоящего изобретения является программа, способная к загрузке в информационную систему, содержащая инструкции, обеспечивающие осуществление способа, являющегося объектом настоящего изобретения и кратко изложенного выше.
Двенадцатым объектом настоящего изобретения является носитель информации, способный к чтению компьютером или микропроцессором, съемным или встроенным, сохраняющий инструкции компьютерной программы и отличающийся тем, что он обеспечивает осуществление способа, являющегося объектом настоящего изобретения и кратко изложенного выше.
Поскольку преимущества, цели и частные признаки подобных способа обеспечения безопасности, приспособлений для обеспечения безопасности, способа и устройства для чтения, компьютерной программы и носителя информации являются сходными с таковыми для способа обеспечения безопасности, изложенного выше, они не указаны.
Различные объекты настоящего изобретения и соответствующие им существенные, предпочтительные и/или частные признаки предназначены для комбинирования в едином способе или устройстве для обеспечения безопасности документа. Поэтому частные признаки каждого из объектов настоящего изобретения составляют частные признаки других объектов настоящего изобретения.
Другие преимущества, цели и признаки настоящего изобретения вытекают из следующего далее описания, выполненного в пояснительных и ни в коей мере не в ограничительных целях в соответствии с прилагаемыми чертежами, на которых:
- на фиг.1 показана цифровая маркировка, увеличенная примерно в 20 раз;
- на фиг.2 показана увеличенная маркировка, показанная на фиг.1, после печати;
- на фиг.3 показана увеличенная ксерокопия печатной маркировки, показанной на фиг.2;
- на фиг.4 показана увеличенная высококачественная копия печатной маркировки, показанной на фиг.2;
- на фиг.5 показан увеличенный MPCV, переменной характеристикой которого является высота точек;
- на фиг.6 показан фрагмент отпечатанного MPCV, показанного на фиг.5, увеличенный примерно в 200 раз;
- на фиг.7 показаны два увеличенных оттиска одного и того же MPCV с постоянным размером точек до печати;
- на фиг.8 показана увеличенная защищенная информационная матрица, содержащая в центре MPCV;
- на фиг.9 показана увеличенная защищенная информационная матрица, окруженная MPCV;
- на фиг.10 показан увеличенный MPCV, в четырех углах которого находятся по одной точке в окружении четырех соседних точек;
- на фиг.11 показан увеличенный MPCV, содержащий линии из точек по четырем сторонам;
- на фиг.12 показан увеличенный участок MPCV в форме решетки;
- на фиг.13 показано абсолютное значение двумерного Фурье-образа MPCV, показанного на фиг.12;
- на фиг.14 показан увеличенный фрагмент MPCV, содержащий кодированную информацию;
- на фиг.15 показана блок-схема частного случая варианта осуществления устройства, являющегося объектом настоящего изобретения;
- на фиг.16А-20 в виде блок-схем проиллюстрированы этапы, осуществляемые в частных случаях реализации различных вариантов осуществления способа, являющегося объектом настоящего изобретения.
- на фиг.21 показан увеличенный фрагмент MPCV высокой плотности;
- на фиг.22 показан увеличенный фрагмент MPCV с градиентом размера точек;
- на фиг.23 в виде блок-схемы проиллюстрированы этапы, осуществляемые в частном случае реализации способа, являющегося объектом настоящего изобретения;
- на фиг.24 показан увеличенный вид цифрового идентификационного шаблона, используемого в частных случаях реализации способа, являющегося объектом настоящего изобретения.
- на фиг.25 показан увеличенный цифровой идентификационный шаблон, показанный на фиг.24, напечатанный на объект в ходе первой операции печати в серии;
- на фиг.26 показан увеличенный цифровой идентификационный шаблон, показанный на фиг.24, напечатанный на объект в ходе второй операции печати в серии;
- на фиг.27 показано дискретное косинус-преобразование захваченного изображения одного из идентификационных шаблонов, показанных на фиг.25 и 26;
- на фиг.28А-28С в виде блок-схем проиллюстрированы этапы, осуществляемые в частных случаях реализации способа, являющегося объектом настоящего изобретения;
- на фиг.29 показаны распределения показателей двух групп идентификационных шаблонов, использованных в частных случаях реализации способа, являющегося объектом настоящего изобретения.
Далее перед подробным описанием различных частных случаев реализации настоящего изобретения приводятся определения, используемые в описании.
- информационная матрица: физическое представление информации, обычно нанесенное на однотонную поверхность (в отличие от водяных знаков или цифровых филиграней, изменяющих характеристики пикселей печатаемого рисунка) и способное к машинному считыванию. Определение информационной матрицы охватывает, например, двумерные штрих-коды, одномерные штрих-коды и другие средства представления информации, являющиеся менее общепринятыми, в том числе датаглифы (при маркировке данных);
- документ: любой материальный объект, содержащий информационную матрицу;
- нанесение маркировки или печать: любой процесс, при котором происходит переход от цифрового изображения к его реальному воплощению (с вовлечением информационной матрицы и документа), причем указанное воплощение обычно производится на поверхности и включает в себя струйную или лазерную печать, офсетную термическую печать, а также гравировку, лазерную гравировку, получение голограмм. Также указанное представление включает в себя более сложные способы, в том числе модельное литье, при котором цифровое изображение вначале гравируют на модели, затем отливают на каждом объекте. Следует отметить, что "литое" изображение может быть рассмотрено как имеющее три размерности в материальном мире, даже если его цифровое представление является двумерным. Следует также отметить, что некоторые из упомянутых способов включают в себя несколько трансформаций, например классическая офсетная печать (в противоположность офсетной технологии "computer-to-plate") включает создание пленки, которая служит для создания печатной формы, которая, в свою очередь, используется при печати. Другие способы также позволяют печатать информацию в невидимой области либо с использованием частот, лежащих вне видимого спектра, либо путем записи информации внутрь поверхности, и т.д.;
- идентификационный шаблон или MI: изображение, напечатанное исходя из исходного (цифрового) изображения, созданное и напечатанное таким образом, чтобы каждый из оттисков указанного изображения мог быть идентифицирован с большой вероятностью;
- уникальные характеристики: уникальные физические свойства идентификационного шаблона, позволяющие отличить его от любого другого оттиска того же исходного изображения;
- образ: совокупность значений измеренных характеристик, позволяющая охарактеризовать идентификационный шаблон и сравнить его с другими охарактеризованными идентификационными шаблонами;
- захват: любой способ, которым получают цифровое представление реального мира, в том числе цифровое представление материального документа, содержащего информационную матрицу;
- ячейка: участок MPCV правильной, обычно прямоугольной, даже квадратной формы, в котором находится не более заранее заданного количества точек, причем указанное заранее заданное количество точек обычно равно единице, за исключением особо отмеченных случаев;
- создаваемый пиксель: наименьший участок, рассматриваемый при создании MPCV;
- точка: элементарный напечатанный участок очень небольшого, возможно переменного размера, составляющий контраст с фоном, причем точка обычно является представлением одного или нескольких создаваемых пикселей;
- пиксель захвата или пиксель изображения: участок, изображение которого соответствует элементарной светочувствительной точке, или пикселю, устройства захвата изображений;
- порядок величины: физическая величина А имеет тот же порядок величины, что и физическая величина В, если значение А составляет от одной десятой до десяти значений В.
В вариантах осуществления настоящего изобретения, описанных ниже в соответствии с фиг.24-29, осуществляют:
- этапы 701-703 создания идентификационного шаблона в цифровом виде;
- этапы 711-715 вычисления образа идентификационного шаблона (согласно одному из способов, изложенных далее);
- этапы 720-726 оптимизации печати идентификационных шаблонов;
- этапы 731-734 хранения и представления образов или уникальных характеристик документов;
- этапы 741-749 идентификации образа с использованием баз данных;
- этапы 751-756 верификации образа без использования базы данных;
- этапы 761-763 совместного использования идентификационного шаблона и цифрового аутентификационного кода;
- этапы 771-780 обеспечения безопасности документа.
В отношении создания идентификационного шаблона в цифровом виде и определения параметров печати идентификационного шаблона следует указать, что в основе некоторых частных признаков настоящего изобретения лежит наблюдение того, что в случае многократной печати одного и того же исходного изображения защищенной информационной матрицы последняя содержит различные для каждой операции печати ошибки. Тот же эффект наблюдали и для шаблонов распознавания копий. Более общим образом было отмечено, что для любого изображения, обладающего достаточной плотностью, 1) печать изображения приводит к его искажению, и что 2) печать приводит к искажениям, различным для каждого оттиска.
Следует уточнить, что подобное явление не ограничивается случаем цифровых аутентификационных кодов. В самом деле, какова бы ни была плотность цифрового изображения, каждый из его оттисков будет отличаться от всех остальных в силу наличия случайных процессов в ходе печати. Только для изображений небольшой плотности различия являются гораздо менее многочисленными и значимыми. Для захвата различий, которые иногда являются ничтожными, в таких случаях необходимо гораздо более высокое разрешение. Напротив, для цифровых аутентификационных кодов, напечатанных с адекватным разрешением, использование особенно высокого разрешения захвата не является необходимым (сканер разрешением 1200 точек на дюйм оказывается достаточным). Кроме того, если различия являются значительными, получение уникальных характеристик не обязательно должно производиться с очень большой точностью, что является преимуществом с точки зрения цены и стабильности алгоритмов чтения.
Идентификационные шаблоны являются изображениями, созданными и напечатанными с тем, чтобы максимизировать различия между каждым оттиском одного и того же исходного идентификационного шаблона. Подобные изображения предпочтительно создаются псевдослучайным способом (например, с использованием одного или нескольких криптографических ключей), однако они могут быть полностью случайными (различие состоит в том, что в последнем случае криптографического ключа не существует либо он не сохраняется). В то же время следует отметить, что исходный цифровой идентификационный шаблон в принципе может быть придан огласке без риска для безопасности: в самом деле, легальными являются только идентификационные шаблоны, сохраненные (имеющие образ) в базе данных, и контроль случайностей при печати в принципе невозможен. Таким образом, владение исходным изображением не дает изготовителю подделок реальных преимуществ, что является другим преимуществом идентификационных шаблонов в области безопасности.
Поскольку искажения имеют случайную природу и приводят к результату, различному для каждого оттиска одного и того же исходного изображения, каждый оттиск идентификационного шаблона содержит уникальные, невоспроизводимые и непереносимые характеристики. Поэтому каждый оттиск одного и того же идентификационного шаблона отличается от всех остальных и, таким образом, неявно содержит средства недвусмысленной идентификации. Возможно вычисление образа идентификационного шаблона и его использование различными путями для повышения безопасности содержащего его документа, в частности, в идентификационном и верификационном режимах.
Идентификационные шаблоны могут представлять собой простые прямоугольники, возможно, обрамленные бордюром, облегчающим их обнаружение, но они также могут иметь особую форму, например форму логотипа и др. В то же время прямоугольная форма оказывается преимуществом с точки зрения чтения (легко определить ее местоположение) и совместимости с обычными формами цифровых аутентификационных кодов или других кодов, в том числе одномерных или двумерных штрих-кодов.
Далее описывается алгоритм создания идентификационного шаблона.
- на этапе 701 получают криптографический ключ, например, последовательность из 32 байт (256 бит);
- на этапе 702 с использованием функции хеширования или рекурсивного шифрования и при инициализации алгоритма с использованием криптографического ключа генерируется надлежащее число случайных битов. Например, для черно-белого идентификационного шаблона размером 10000 пикселей (1 бит на пиксель) необходимо 10000 бит; для шаблона в оттенках серого необходимо в 8 раз больше информации (при одинаковой вероятности оттенков). Предположим, что используется функция хеширования SHA-1 (по 256 бит на входе и выходе); тогда для получения необходимых битов следует произвести 40 (при 1 бит на пиксель) или 320 (при 8 бит на пиксель) обращений к функции (поскольку 40×256>=10000 или 320×256>=80000). Считывающее устройство может использовать стандарты FIPS (Federal information processing standard, Федеральный стандарт обработки информации) и AES (Advanced Encryption Standard, Улучшенный стандарт шифрования);
- на этапе 703 биты собирают в изображение, например, размером 100×100 точек, возможно, дополненное бордюром.
На фиг.24 показан подобный идентификационный шаблон до печати. На фиг.25 и 26 показаны два различных оттиска идентификационного шаблона, приведенного на фиг.24.
Функциональные свойства цифрового аутентификационного кода могут сочетаться с функциями идентификационного шаблона, поскольку характеристики создания и печати цифровых аутентификационных кодов близки к требуемым для идентификационных шаблонов. Например, алгоритмы создания шаблонов распознавания копий, требующие использования криптографического ключа, приближаются к алгоритму, описанному выше, хотя цель алгоритма является совершенно другой. Алгоритмы создания защищенных информационных матриц одновременно требуют использования одного или нескольких криптографических ключей и одного или нескольких блоков информации. Однако результат оказывается сходным, т.е. изображением с псевдослучайными характеристиками.
Как будет ясно в дальнейшем, оказывается, что идеальные условия печати идентификационных шаблонов близки к идеальным условиям печати цифровых аутентификационных кодов. Поэтому является возможным, как в плане создания, так и в плане напечатанного результата, комбинирование функциональных свойств цифровых аутентицикационных кодов и информационных матриц.
В отношении способов получения и сравнения образа идентификационного шаблона в ходе верификации документа далее вначале описывается способ получения и сравнения генерического образа, состоящий в получении системы точек из захваченного идентификационного шаблона:
- на этапе 711 определяют положение идентификационного шаблона на изображении напечатанного документа. Для идентификационного шаблона прямоугольной формы возможно, например, получение положения (ширины и высоты) четырех вершин шаблона;
- на этапе 712 определяют положение заданного числа получаемых точек в захваченном изображении и получают значение положения для каждой точки. Например, в случае дальнейшего использования FFT (быстрого Фурье-преобразования) или DCT (дискретного косинус-преобразования) при 256 точках по горизонтали и 256 точках по вертикали общим числом 2562 предпочтительным является число точек, равное двум в целочисленной степени. Определение положения точек может выполняться с использованием стандартных геометрических методов, известных в уровне техники: определения положения реперных точек (например, четырех вершин идентификационного шаблона в случае, если он является прямоугольным), определения положения точек исходя из предположения, что захваченное изображение подверглось, например, аффинному или перспективному преобразованию. Значения положения обычно лежат в интервале от 0 до 255, как и в захваченном изображении. Поскольку положения могут быть дробными, значение для отдельно взятой точки может быть значением для "ближайшего соседа"; данный способ является экономичным, но неточным. Возможно также использование алгоритмов интерполяции с затратами, возрастающими с возрастанием требуемой точности, в том числе бикубической, билинейной интерполяции и т.д. Результатом является матрица целых чисел (при определении положений по способу "ближайшего соседа") или чисел с плавающей запятой (при интерполяции) размером 256×256;
- на этапе 713 проводят двумерное дискретное косинус-преобразование матрицы. Дискретное косинус-преобразование является предпочтительным, поскольку оно позволяет сильно сжать энергию сигнала на небольшом числе составляющих;
- на этапе 714 выбирают заданное число коэффициентов, например 10×10 коэффициентов самой низкой частоты, и, возможно, вычитают постоянный коэффициент, известный под названием коэффициента DC, в положении (0,0);
- на этапе 715 коэффициенты приводят в форму вектора, составляющего образ защищенной информационной матрицы.
Следует отметить, что в способе, описанном выше, не используются никакие секретные процедуры, что позволяет вычислить образ кому угодно. В некоторых случаях это может быть желательным, если это не составляет риска для безопасности. Напротив, в других случаях является желательным, чтобы образ могли вычислить только уполномоченные лица. Для этого используют криптографический ключ, находящийся в секрете и позволяющий определить коэффициенты, составляющие образ. Данный ключ выдается только лицам или организациям, уполномоченным воспроизводить образ. Для выбора коэффициентов исходя из ключа существуют технологии, известные в уровне техники, доступные специалисту в данной области техники и обычно использующие алгоритмы хеширования или шифрования.
Два образа, соответствующие различным операциям захвата, могут в этом случае сравниваться различными путями для получения меры сходства или, напротив, меры различия. При измерении, например, коэффициента корреляции между ними получают меру сходства, называемую далее "показателем".
Для проверки указанного способа получения уникальных характеристик был создан идентификационный шаблон размером 100×100 пикселей, который отпечатали 100 раз на лазерном принтере с разрешением 600 точек на дюйм. Для выполнения трех захватов каждого напечатанного идентификационного шаблона использовали планшетный сканер с разрешением 1200 точек на дюйм. Затем вычисляли образ каждого из 300 выполненных захватов. Для каждой из 44850 пар (вычислено как 300×(300-1)/2) образов вычисляли показатель. Указанные 44850 пар образов разделили на две группы:
- группу А из 600 пар образов, соответствующих различным захватам одного и того же напечатанного идентификационного шаблона;
- группу В из 44250 пар образов, соответствующих захватам различных идентификационных шаблонов.
Значение показателя составляло от 0,975 до 0,998 для группы А и от 0,693 до 0,945 для группы В. На фиг.29 показано распределение показателей для групп А и В. На основании значений показателей можно заключить, что перепутать пары из разных групп совершенно невозможно. Итак, с использованием способа вычисления образа, описанного выше, можно недвусмысленно определить, какому из 100 оттисков соответствует захваченное изображение.
Определение "степени разделения образов" состояло в вычислении различия средних значений показателя для групп А и В (в данном случае 0,992 и 0,863 соответственно) и проведении нормализации указанного различия по стандартному отклонению показателя в группе А, в данном случае равному 0,005. Полученное значение оказалось равным 25,8. Как будет ясно из изложенного далее, данный индекс является полезным при определении параметров печати и создания шаблонов, дающих лучшие результаты.
Далее описан второй способ получения образа, относящийся к защищенным информационным матрицам. Данный способ применяется, в частности, в случае, когда идентификационный шаблон также обладает функциональными свойствами защищенной информационной матрицы. Объясняется, каким образом из захваченной защищенной информационной матрицы получают информацию, содержащую помехи. Данная информация, содержащая помехи, обладает ненулевым уровнем ошибок и используется в качестве образа.
Преимуществом данного способа является то, что он позволяет использовать программное обеспечение, созданное для чтения защищенных информационных матриц. Это сводит к минимуму стоимость необходимых вычислений.
В то же время точное чтение защищенной информационной матрицы требует использования ключа, служащего для создания выровненных блоков, если таковой существует. Разглашение данного ключа во всех случаях является крайне нежелательным. Кроме того, отклонения внутреннего выравнивания, специфичные для каждого оттиска, по возможности устраняются. Это является крайне нежелательным, поскольку данные отклонения используются при проведении различий между разными оттисками защищенной информационной матрицы.
В отношении способа определения оптимальных параметров создания и печати идентификационных шаблонов следует указать, что существует оптимальная степень искажения, позволяющая как можно более надежно различить разные оттиски одного и того же исходного идентификационного шаблона. Так, в случае очень небольшой степени искажения оттиска, например 1% или 2% (1 или 2% ячеек или пикселей идентификационного шаблона после качественного захвата являются плохо считанными), различные оттиски одного и того же идентификационного шаблона являются очень близкими друг к другу, и надежно идентифицировать их при отсутствии очень точного захвата изображения и/или очень точного алгоритма анализа трудно. Сходным образом, при очень высокой степени искажения, например 45-50% (45 или 50% ячеек защищенной информационной матрицы после качественного захвата являются плохо считанными, причем 50% является достаточным для того, чтобы статистическая корреляция между считанной и исходной матрицами отсутствовала), напечатанные идентификационные шаблоны являются практически неотличимыми друг от друга. На практике оптимальная степень искажения близка к 25%, и предпочтительно приближается к ней, если условия применения позволяют подобное. В самом деле, для 25% искажения, если предположить, что отклонения при печати и, стало быть, искажения имеют вероятностную природу, в каждой точке напечатанного идентификационного шаблона вероятность того, что он будет отличаться от других напечатанных идентификационных шаблонов, будет максимальной.
Далее описывается возможный алгоритм оптимизации параметров печати:
- на этапе 720 получают поверхность, доступную для идентификационного шаблона, например, квадрат стороной 1/6 дюйма;
- на этапе 721 проводится генерация нескольких цифровых изображений идентификационных шаблонов различной численной размерности, соответствующей различным возможным разрешениям печати, например, одного идентификационного шаблона размером 66×66 пикселей для разрешения 400 точек на дюйм, одного размером 100×100 пикселей - для разрешения 600 точек на дюйм, одного размером 133×133 пикселя - для разрешения 800 точек на дюйм и одного размером 200×200 пикселей - для разрешения 1200 точек на дюйм;
- на этапе 722 много раз, например 100 раз, проводится печать каждого идентификационного шаблона различной численной размерности при соответствующем разрешении таким образом, чтобы размеры при печати соответствовали доступной поверхности;
- на этапе 723 несколько раз, например 3 раза, проводится захват каждого напечатанного идентификационного шаблона каждого типа;
- на этапе 724 проводится вычисление образа каждого идентификационного шаблона;
- на этапе 725 вычисляют показатели сходства для всех пар захваченных идентификационных шаблонов, напечатанных при одном и том же разрешении;
- на этапе 726 следуют способу, описанному выше в экспериментальной части способа получения генерического образа, для измерения "степени разделения образов" для каждого разрешения печати и выбора разрешения, при котором значение степени разрешения является максимальным.
В соответствии с вариантом осуществления возможна печать нескольких защищенных информационных матриц при различных разрешениях печати с определением разрешения при печати, при котором уровень ошибок составляет 25%, согласно вычисленному в одном из приведенных выше алгоритмов.
В соответствии с вариантом осуществления возможен выбор разрешения печати, при котором различие является наибольшей из двух величин: наименьшего значения показателя, вычисленного при сравнении образов, соответствующих одинаковым оттискам, и наибольшего значения показателя, вычисленного при сравнении образов, соответствующих различным оттискам.
В отношении способа представления и хранения характеристик, следует указать, что предпочтительно сократить объем данных образа, насколько возможно. В случае идентификации речь идет о сравнении образа с большим числом образов, сохраненных в базе данных, что является очень дорогостоящим. Издержки снижают путем снижения размера сравниваемых образов, в частности путем отказа от использования чисел с плавающей запятой.
Рассмотрим случай генерического способа получения образа. Исходный вектор данных, полученный из захваченного идентификационного шаблона, представляет собой матрицу полученных значений размером 256×256; его представление в виде дискретного косинус-преобразования после выбора коэффициентов содержит 10×10 значений. Предпочтительным является представление матрицы значений одним байтом на значение, т.е. 100 байтами.
На этапе 727 производится печать по меньшей мере одного объекта с идентификационным шаблоном для получения защищенного документа.
Напротив, коэффициенты дискретной косинус-трансформации могут принимать как положительные, так и отрицательные значения и в принципе не являются ограниченными. Чтобы представить подобные значения фиксированным количеством информации, значения должны быть квантифицированы для их представления в двоичной форме. Возможный подход является следующим:
- на этапе 731 определяют минимальное и максимальное значения каждого коэффициента. Обычно минимальное и максимальное значения имеют одну и ту же абсолютную величину;
- на этапе 732 определяют число бит и байт, позволяющее представить каждое значение;
- на этапе нормализации 733 из каждого коэффициента дискретной косинус-трансформации вычитают минимальное значение, затем делят разность на максимальное значение;
- на этапе 734 результат умножают на возможное число значений квантифицированных данных, т.е. на 256, если на каждое значение отводится один байт. Целочисленное значение результата соответствует квантифицированной исходной величине.
В качестве варианта этапа квантификации оптимизируют для минимизации ошибки квантификации.
В отношении способа идентификации с использованием базы данных следует указать, что в случае идентификации идентификационный шаблон должен сравниваться с каждым идентификационным шаблоном базы данных для определения его соответствия одному из идентификационных шаблонов базы данных, причем в данном случае идентификационный шаблон рассматривается как действительный и может быть найдена соответствующая информация о трассируемости. В противном случае идентификационный шаблон рассматривается как недействительный.
В вариантах осуществления выполняют следующие этапы:
- на этапе 741 определяют образ идентификационного шаблона, содержащегося в захваченном изображении;
- на этапе 742 вычисляют показатель, или степень сходства, полученного образа с каждым из образов, хранящихся в базе данных;
- на этапе 743 определяют максимальную полученную степень сходства;
- на этапе 744, если максимальная степень сходства превосходит пороговое значение, идентификационный шаблон рассматривается как действительный;
- на этапе 745 находят связанную с ним информацию о трассируемости;
- в противном случае на этапе 746 идентификационный шаблон рассматривается как недействительный.
В вариантах осуществления:
- на этапе 747, если идентификационный шаблон также обладает функциональными свойствами цифрового аутентификационного кода, получают информацию о трассируемости;
- на этапе 748 информация о трассируемости, позволяющая сузить пространство поиска, может также исходить из другого источника, например из присоединенного штрих-кода, сведений контролера и т.д.;
- на этапе 749 указанную информацию используют для сужения пространства поиска в базе данных. Например, информация о заказе на изготовление позволяет выполнить предварительный выбор сравниваемых образов среди подсистемы образов, соответствующих данному заказу на изготовление.
В отношении способа верификации без использования базы данных следует указать, что он требует, чтобы предварительно вычисленный образ идентификационного шаблона сохранялся на документе. Например, на этапе вычисления образа каждого из легальных оттисков последние могут быть одновременно предназначены для хранения в базе данных и для безопасного хранения на документе.
Хранение образа на документе предпочтительно осуществляется путем произвольно меняющейся, т.е. различной для каждого документа, печати. Образ может быть сохранен в одно- или двумерном штрих-коде либо в цифровом аутентификационном коде в зависимости от средств печати, качество которых может быть ограниченным.
Обычно является предпочтительным хранение образа защищенным способом, например, с использованием криптографического алгоритма, снабженного секретным шифровальным ключом. Таким образом устраняется риск использования изготовителем подделок нелегальных документов в отсутствие соединения с контрольной базой данных. Для этого осуществляют следующие этапы:
- на этапе 751 определяют образ идентификационного шаблона, содержащегося в захваченном изображении;
- на этапе 752 получают предварительно вычисленный образ;
- на этапе 753 вычисляют показатель, или степень сходства, путем сравнения полученного образа с предварительно вычисленным образом;
- на этапе 754, если максимальная степень сходства превосходит пороговое значение, идентификационный шаблон рассматривается как действительный;
- в противном случае на этапе 756 идентификационный шаблон рассматривается как недействительный.
В отношении использования комбинированного идентификационного шаблона с функциональными свойствами цифрового аутентификационного кода следует указать, что способы получения однозначных характеристик документа в уровне техники используют характеристики, интерпретация которых без обращения к базе данных является невозможной. Хотя идентификационные шаблоны могут быть простыми изображениями, не имеющими значения, как было показано выше, они могут также представлять собой изображения, содержащие другие функциональные свойства. В частности, они могут представлять собой цифровые аутентификационные коды и в таком случае могут содержать защищенную информацию (для их чтения необходимы один или несколько ключей) и/или иметь аутентификационные свойства (отличения оригинала от копии).
Образ идентификационного шаблона может быть создан так, чтобы он имел точность, достаточную для идентификации документа, но недостаточную для его воспроизведения. В самом деле, рассмотрим генерический способ определения образа, основанный на 100 коэффициентах низкочастотной дискретной косинус-трансформации, каждый из которых, возможно, представлен одним байтом. В принципе кто угодно может получить указанные коэффициенты и создать изображение той же размерности, что и идентификационный шаблон, путем обращения указанных коэффициентов. Ясно, что полученное изображение резко отличается от напечатанных идентификационных шаблонов. Однако показатель, полученный при сравнении вычисленного образа захваченного обращенного изображения и исходного образа, составляет 0,952. Хотя такое значение показателя меньше всех значений показателя, полученных при сравнении образов одного и того же напечатанного идентификационного шаблона, он существенно выше показателей, полученных при сравнении напечатанных образов различных идентификационных шаблонов. Таким образом, существует риск того, что изготовитель подделок будет искать возможность воспроизведения образа легального идентификационного шаблона.
Более качественный и/или более тонкий захват изображения позволил бы снизить и даже устранить риск того, чтобы такая возможность подделки была реализована. Однако это не всегда является возможным. В этом случае, если идентификационный шаблон также является цифровым аутентификационным кодом, предпочтительно совместное использование их аутентификационных свойств с осуществлением следующих этапов:
- на этапе 761 происходит идентификация или верификация идентификационного шаблона;
- на этапе 762 получают ключ или ключи, необходимые для аутентификации цифрового аутентификационного кода;
- на этапе 763 определяют, является ли цифровой аутентификационный код оригиналом или копией.
Цифровые аутентификационные коды обычно основаны на искажении одной или нескольких физических характеристик, обеспечивающих защиту от копирования, чувствительных к копированию в ходе такового.
Так, цифровые водяные знаки имеют более низкий уровень энергии в копии либо различное отношение уровней энергии между водяным знаком, малочувствительным к копированию, и водяным знаком, высокочувствительным к копированию. То же самое имеет место в случае технологий нанесения пространственной маркировки - у копий наблюдается более низкий уровень энергии или корреляции. В случае шаблонов распознавания копий, основанных на сравнении изображений, производится измерение индекса сходства (или различия) между оригинальным шаблоном распознавания копий и шаблоном распознаваний копий захваченной копии; в случае, если последний действительно является копией, индекс сходства окажется меньшим. Наконец, для защищенных информационных матриц производится измерение степени ошибок кодированной информации, полученной из матрицы; указанная степень ошибок оказывается более высокой для копий (отметим, что вследствие избыточности кодированной информации заключенная в ней информация обычно способна декодироваться без ошибок).
Следует отметить, что в каждом из указанных способов производится измерение одной или нескольких величин, которые обычно являются непрерывными и не указывают явно на природу документа (оригинал или копию). Обычно требуется применение заданного критерия распознавания оригиналов и копий, например, путем сравнения одной или нескольких полученных величин с одним или несколькими "пороговыми" значениями для определения соответствия определенных значений "копии" или "оригиналу".
В отношении вариантов осуществления способа обеспечения безопасности документов, основанных на идентификационных шаблонах, следует указать, что могут быть осуществлены следующие этапы:
- на этапе 771 правообладатель выдает лицензию изготовителю на изготовление некоторого числа документов;
- на этапе 772 правообладатель передает изготовителю один или несколько идентификационных шаблонов, возможно, обладающих функциональными свойствами цифрового аутентификационного кода, в виде цифрового изображения, предназначенного для печати на документах. Идентификационный шаблон может являться частью дизайна цифрового документа или быть передан отдельно. В варианте осуществления изготовитель получает идентификационный шаблон через третью сторону, уполномоченную правообладателем;
- на этапе 773 изготовитель производит печать предусмотренного числа документов с одним или несколькими идентификационными шаблонами, предусмотренными на каждом документе;
- на этапе 774 предусмотренное число документов передается правообладателю. В варианте осуществления документы передаются сборщику, уполномоченному правообладателем. В другом варианте осуществления предусмотренное число напечатанных документов обрабатывается непосредственно изготовителем согласно изложенному в варианте данного этапа;
- на этапе 775 правообладатель/сборщик осуществляет сборку готового изделия (которое может содержать несколько документов);
- на этапе 776 производится захват одного или нескольких изображений одного или нескольких идентификационных шаблонов. В принципе процесс проводится автоматически, причем изделия, например, движутся на конвейере под объективом промышленной камеры. Последняя приводится в действие автоматически или с использованием внешнего сигнала активации, исходящего от датчика;
- на этапе 777 каждое захваченное изображение идентификационного шаблона вводится в базу данных вместе со связанной с ним информацией (заказ на изготовление, дата и т.д.);
- на этапе 778 производится вычисление одного или нескольких образов каждого действительного изображения захваченного идентификационного шаблона в реальном времени или после захвата;
- на этапе 779 в целях возможного использования идентификационного шаблона в верификационном режиме (в отсутствие соединения с базой данных) один из образов, обычно занимающий наименьший объем, квантифицируется и/или сжимается с получением его компактного представления. Генерируется информационная матрица (datamatrix, штрих-код, защищенная информационная матрица (MIS) и т.д.), предпочтительно защищенная при помощи ключа и содержащая представление образа. Информационная матрица печатается на документе, содержащем идентификационный шаблон;
- на этапе 780 при необходимости совокупность отпечатанных образов пересылается по безопасной связи на центральный сервер, с которым соединяются инспекторы для проверки валидности образов.
В вариантах осуществления:
- место, в котором производится захват изображений идентификационных шаблонов, может находиться в месте печати или изготовления. Преимуществом при этом является то, что данная операция может быть интегрирована в процесс производства; недостатком является то, что она осуществляется в общедоступной зоне. При этом установка, служащая для вычисления и/или хранения образов, может быть защищенной; и/или
- указанное место может находиться у третьей стороны, уполномоченной правообладателем, обычно у той же третьей стороны, которая производит выдачу используемых идентификационных шаблонов.
На фиг.23 показаны:
- этап 605 определения характерной матрицы точек, содержащей информацию, связанную с аутентифицируемым объектом;
- этап 610 нанесения маркировки на указанный объект таким образом, чтобы в ней существовали непредвиденные ошибки вследствие физических характеристик средств, использованных на этапе нанесения маркировки;
- этап 615 захвата изображения указанной маркировки;
- этап 625 запоминания характерной информации о физических характеристиках непредвиденных ошибок;
- этап 630 нанесения надежной маркировки, в ходе которой на указанный объект наносят надежную маркировку, содержащую информацию о физических характеристиках непредвиденных ошибок.
На этапе 605 производится определение информационной матрицы, например, в виде матрицы зон, каждая из которых содержит сотни точек и представляет двоичную информацию. Связанная с изделием информация представляет собой, например, название изготовителя, заказ на изготовление изделия и/или дату изготовления.
На этапе 610 производится нанесение полученной маркировки, состоящей из матрицы точек, с таким разрешением, чтобы по меньшей мере два процента точек маркировки являлись ошибочными по сравнению с оригинальной матрицей точек. Используют, например, максимальное разрешение принтера. Указанное разрешение, в частности, имеет следствием то, что копирование объекта, подразумевающее копирование маркировки, например, оптическими или фотографическими способами, повышает уровень ошибок в копии маркировки по меньшей мере на пятьдесят процентов по сравнению с исходной маркировкой.
На этапе 620 производится определение характеристик распределения непредвиденных ошибок в указанной маркировке в качестве физических характеристик непредвиденных ошибок. Например, вычисляют вектор, исходящий из центра маркировки и направленный к центру тяжести ошибок маркировки; затем характеризуют ошибки статистическим весом в зависимости от их положения, вычисляют новый вектор, исходящий из центра маркировки и направленный к центру тяжести ошибок маркировки, и так далее.
На этапе 630 надежной маркировкой является, например, одномерный или двумерный штрих-код или матрица данных, известная под названием Datamatrix (зарегистрированная торговая марка). Поскольку вторая маркировка является надежной, она может быть стойкой к точному копированию и позволяет идентифицировать объект. Предпочтительно на этапе 630 используют ключ кодирования физических характеристик непредвиденных ошибок, предпочтительно асимметричный.
Путем использования настоящего изобретения, несмотря на то, что один и тот же способ нанесения маркировки, например гравирование или печать, используется без изменения на многих объектах, физические характеристики ошибок маркировки позволяют произвести однозначную идентификацию каждой маркировки и, стало быть, каждого связанного с ней объекта.
При выполнении нового захвата изображения маркированного объекта и новой обработки изображения результат обработки изображения может быть сопоставлен с хранящейся в памяти информацией для идентификации объекта.
Количество ошибок является значимым и обеспечивает однозначную идентификацию маркировки и объекта.
Чтение данных, относящихся к маркированному объекту, предоставляет адрес и/или средства доступа к базе данных физических характеристик ошибок.
Каковы бы ни были условия захвата нового изображений указанной маркировки, характеристики распределения ошибок могут быть получены.
При реализации некоторых вариантов осуществления настоящего изобретения авторы изобретения обнаружили, что некоторые характеристики печати могут позволить распознавать оригиналы и копии весьма эффективным образом. В частности, отклонение величины ("размера"), точного положения или формы маркированных точек может быть определено и введено в метрику, позволяющую распознавать оригиналы и копии. Следует отметить, что отклонение оттенка цвета (или оттенка серого) в предназначенном для печати изображении сводится при помощи растра к отклонению формы или размеров. Цифровые аутентификационные коды, упомянутые выше, создаются так, что они являются непригодными для точного измерения указанных характеристик. Напротив, характеристики всех цифровых аутентификационных кодов известных типов являются искаженными вследствие отклонений в положении, являющихся следствием случайностей при печати, причем указанные отклонения влияют на используемые способы измерений. В лучшем случае производится поиск способов их устранения. Напротив, цифровые филиграни и MSMA созданы так, чтобы существовала возможность измерения глобальных характеристик сигнала (например, энергии), точность которых для распознавания оригиналов и копий является невысокой.
На фиг.1 показана цифровая маркировка 105, состоящая из совокупности точек 110 со случайными положениями, окруженной черным контуром 115. Следует отметить, что все точки 110 в данной исходной маркировке имеют одинаковый размер, т.е. 1 пиксель на печатное изображение разрешением 600 пикселей на дюйм. На фиг.2 показан оттиск 120 данной цифровой маркировки. На фиг.3 показана ксерокопия 125 данной маркировки. Следует отметить, что в ксерокопии 125 точки 110 исчезли. При простом измерении, например измерении числа точек, еще оставшихся в маркировке, изображение которой захвачено электронным устройством захвата изображений, или измерении коэффициента корреляции относительно контрольной маркировки, легко отличить оригинал 120 от ксерокопии 125 или копии низкого качества.
На фиг.4 показана высококачественная копия 130. Данная копия была изготовлена на основе захвата (обычно называемого "сканом") изображения сканером высокого разрешения с восстановлением исходного положения автоматически детектированных точек 110 (например, при помощи программного обеспечения Matlab, зарегистрированная торговая марка), зная, что последние являются черными и имеют размер 1/600 дюйма. Следует отметить, что все или по крайней мере большинство точек 110, присутствующих в оригинале на фиг.2, присутствуют на фиг.4. Задача возможного изготовителя подделок, к несчастью, облегчается тем, что, поскольку все точки в оригинале имеют один и тот же размер, он может позволить себе не проводить измерения размера или оттенков серого точек и просто восстановить точки в исходном размере (который является фиксированным и тривиальным образом определимым на большой совокупности).
Предпочтительно при реализации некоторых объектов настоящего изобретения простого подсчета числа присутствующих точек недостаточно для того, чтобы отличить оригинал от копии. Способ, основанный на корреляции или уровнях энергии, подобный используемому в MSMA, также является неэффективным для распознавания копий высокого качества.
Вследствие этого в предпочтительных вариантах осуществления для расширения возможностей использования шаблонов точек определение подлинности документа вынуждает обратить особое внимание на геометрические характеристики точек, которые изучаются на локальном уровне, в противоположность способам, известным в уровне техники. В частности, для обнаружения копий, хранения информации и/или получения однозначных характеристик документов использованы размер, форма и/или точное положение точек. MPCV, являющиеся объектом некоторых вариантов осуществления настоящего изобретения, таким образом, обладают той особенностью, что размер, форма и/или точное положение их точек являются переменными. Предпочтительно для создания распределения точек в указанном MPCV получают точки, по меньшей мере одна геометрическая характеристика которых является переменной, причем геометрическая амплитуда созданного отклонения имеет тот же порядок величины, что и средний размер по меньшей мере части точек.
В следующем далее описании изложены:
- численные способы создания MPCV;
- способы измерения геометрических характеристик MPCV;
- способы комбинирования измеренных геометрических характеристик MPCV в метрике, позволяющие отличить оригинальные MPCV от их копий;
- способы оптимизации печати MPCV;
- способы идентификации MPCV на основе их геометрических характеристик;
- способы верификации MPCV;
- способы хранения информации в MPCV;
- способ обеспечения безопасности документов.
Далее вначале описан способ создания шаблона точек с переменными характеристиками. Для создания MPCV предварительно определяют количество оттисков печатающей системы, используемой в дальнейшем при печати MPCV на документах на этапе 300. Качество печати характеризуется непредвиденным отклонением по точкам по меньшей мере одной геометрической характеристики напечатанных точек, вызванным печатью вследствие случайностей при печати.
Затем, на этапе 302, производится определение площади, доступной для печати MPCV, разрешения системы печати и требуемой максимальной плотности точек. Например, доступный размер может составлять примерно 1/6×1/6 дюймов, а плотность 1/100 (примерно 1 пиксель на 100 может быть заполнен печатью). Максимальная плотность зависит от допустимой степени заметности MPCV, зависящей от условий применения (например, цвета чернил, подложки, способа печати, эстетики документа). Плотность может быть более высокой, например возможна плотность 1/16 или 1/9, даже 1/4. MPCV предпочтительно генерируют так, чтобы напечатанные точки не касались друг друга.
В некоторых случаях доступный размер может быть гораздо большим, например составлять несколько квадратных дюймов. Однако большинство средств захвата, например фотографические аппараты, содержащие матричное устройство захвата изображений, обладают поверхностью захвата, не позволяющей охватить такую площадь (планшетные сканеры в общем случае не являются доступными при необходимости чтения документов "на местах"). В таком случае возможно составление "мозаики", т.е. наложение друг на друга идентичных MPCV или MPCV, различающихся по соображениям безопасности. В продолжении описания "мозаикой" называют оба типа наложения MPCV, соответственно идентичных или различных.
Если предположить, что средство захвата может быть применено к участку печатного изображения в произвольном положении, то максимальный размер MPCV, гарантирующий, что на захваченной поверхности будет полностью содержаться по меньшей мере один MPCV, равна половине наименьшей стороны захваченной поверхности. Для примера CCD размером 640×480, работающего при разрешении 1220 точек на дюйм (поверхности 1,33×1 см), приведенного выше, длина стороны MPCV не должна превышать 0,5 см.
Затем производится генерация MPCV таким образом, чтобы:
- по меньшей мере половина точек указанного распределения не соприкасалась сторонами с четырьмя другими точками указанного распределения точек;
- по меньшей мере один размер по меньшей мере части точек указанного распределения точек имел тот же порядок величины, что и среднее абсолютное значение непредвиденного отклонения.
Авторы изобретения обнаружили, что печать оригинала должна обеспечивать такое отношение порядков величины для получения наивысшей эффективности функций обеспечения безопасности (аутентификации и идентификации) документа.
Кроме того, авторы изобретения обнаружили, что в некоторых вариантах осуществления для обеспечения безопасности документа по отношению к копированию, вызывающему по причине случайностей при копировании непредвиденное отклонение "при копировании" по точкам по меньшей мере одной геометрической характеристики напечатанных точек, является предпочтительным, чтобы в ходе печати распределения точек на документе указанная печать вызвала вследствие случайностей при печати непредвиденное отклонение "при печати" по точкам указанной геометрической характеристики напечатанных точек, причем средняя амплитуда непредвиденного отклонения имеет тот же порядок величины, что и минимальная средняя амплитуда непредвиденного отклонения при копировании. Предпочтительно в таком случае осуществляется этап определения физической величины, характеризующей непредвиденное отклонение при печати, согласно изложенному в другом месте настоящего описания в отношении функций аутентификации и идентификации документа.
Например, возможно использование MPCV размером 200×200 пикселей, напечатанного с разрешением 1200 пикселей на дюйм, на поверхности печати величиной 1/6 дюйма, "точки" которого имеют размер 2×2 генерационных пикселя при среднем абсолютном значении непредвиденного отклонения, лежащим между 0,2 и 20 пикселями. Отметим, что MPCV размером 100×100 пикселей, напечатанный с разрешением 600 точек на дюйм с точками размером 1×1 пиксель, привел бы к сравнимым результатам. В то же время более высокое разрешение изображения (при том же размере зоны печати) является более гибким для варьирования размера и/или положения точек, согласно детально изложенному далее.
Перекрывания, соединения или очень сильного сближения точек предпочтительно избегать. Для этого MPCV разделяют на смежные участки, например, на 10×10 участков размером 20×20 пикселей каждый в случае MPCV размером 200×200 пикселей. Оставив поля величиной 1 пиксель на каждой из сторон каждого участка, получают участок величиной 18×18 пикселей, доступный для точки. Тогда на отведенном точке участке имеется 17×17=289 возможных положений каждой точки (если точка занимает 2×2 пикселя, ее, например, левый верхний угол может занимать лишь 17 положений по длине и 17 по ширине).
По соображениям безопасности является желательным, чтобы MPCV имел псевдослучайную природу, например, был создан исходя из криптографического алгоритма, снабженного ключом, держащимся в тайне. Данный ключ используют в качестве средства запуска алгоритма создания псевдослучайных чисел, которые могут быть воспроизведены всяким, кому известен ключ, но которые очень трудно найти не обладающему ключом.
Как видно из фиг.16А, для создания MPCV осуществляют следующие этапы:
- этап 302 получения или определения доступной поверхности, разрешения системы печати и плотности печати;
- этап 304 получения криптографического ключа, например, последовательности из 32 байт (256 бит);
- этап 306 создания двоичных значений, например, с использованием функции хеширования или рекурсивного шифрования, причем алгоритм запускается криптографическим ключом. Например, в примере, упомянутом выше, существует 289 положений точки, стало быть, для определения положения точки на отведенном ей участке необходимо 9 бит.Таким образом, для определения положений 100 точек на соответствующих им участках необходимо 900 бит. Если предположить, что используется функция хеширования SHA-1 с 256 битами на входе и выходе, для получения необходимых двоичных данных требуется произвести четыре вызова функции;
- этап 308 включения точки в каждую ячейку и сборки ячеек в изображение, для данного примера размером 200×200 пикселей. Например, на этапе 308 для определения положения точки в каждой ячейке используют последовательности, состоящие из девяти последовательных битов. Когда значение, представленное данной последовательностью, превосходит 289, выбирают следующую последовательность. В противном случае точку помещают в положение, определенное последовательностью, например, путем отсчета положения в каждой возможной строке положений. Затем ячейки накладывают друг на друга, например, последовательно в каждой строке ячеек.
После этапа 308 MPCV включают в печатные пленки и печатают документ на этапе 310.
В вариантах осуществления каждая точка может иметь различный размер. Например, точки могут иметь площадь, меньшую или большую 2×2 пикселей. Таким образом, точки могут иметь различные размеры, что предоставляет возможность измерения других геометрических характеристик, трудновоспроизводимых для изготовителя подделок. Например, точки могут иметь два возможных размера, либо 2×2 пикселя, как задано выше, либо 3×3 пикселя; неравные горизонтальные и вертикальные размеры, например 2×3 или 3×2 пикселя, также являются возможными. Следует отметить, что в случае двух квадратных точек для идентификации размера точки необходима одна дополнительная двоичная величина, которая добавляется к девяти другим двоичным величинам, определяющим положение точки на отведенном ей участке. Таким образом, на участок требуется десять двоичных величин, а на 100 ячеек - 1000 двоичных величин.
На фиг.5 показан MPCV 135, содержащий точки, размеры которых меняются псевдослучайным образом (точки размером 2×2 и 3×3 пикселя), и бордюр 140, окружающий MPCV 135. На фиг.6 показан участок 145 результата печати MPCV 135, показанного на фиг.5.
Следует отметить, что в вариантах осуществления к MPCV добавляют бордюры, в данном случае 140, или произвольные геометрические формы, позволяющие определить его положение. Например, на бордюры или внутрь MPCV на место участков, содержащих точки, добавляют блоки синхронизации.
В отношении измерений характеристик положения MPCV следует указать, что авторы изобретения установили, что, хотя точки, составляющие MPCV, могут быть определены и с практически полной достоверностью воспроизведены изготовителем подделок, последний с большим трудом способен снизить недостоверность точного положения точек. В самом деле, в ходе печати MPCV точки не обязательно будут напечатаны в точном положении: подобная недостоверность является следствием случайностей при печати, а также перехода от цифровых величин к аналоговым. При переходе от цифровых величин к аналоговым в ходе печати, затем при возврате к цифровым величинам при захвате изображения средняя недостоверность положения точек составляет порядка половины пикселя (соответственно пикселя печати и захвата изображения), поэтому данная недостоверность не зависит от недостоверности, связанной со случайностями при печати. Следует отметить, что в зависимости от стабильности устройства печати может возникнуть дополнительная недостоверность положения. В ходе изготовления высококачественной копии к уже существующей недостоверности положения добавляется недостоверность положения при перепечатке. Таким образом, различие между положением точки в захваченном изображении и положением той же точки в исходном изображении в среднем является более высоким, если захваченное изображение является копией, чем если оно является оригиналом.
Далее описан алгоритм измерения геометрических характеристик положения MPCV. На входе используют захваченное на этапе 320 изображение участка документа, содержащего MPCV, и криптографический ключ. На выходе этапов, составляющих данный алгоритм, получают вектор характеристик положения точек MPCV;
- на этапе 322 с применением алгоритма создания MPCV производится определение исходного положения каждой точки;
- на этапе 324 производится определение положения совокупности форм отсчета положения в захваченном изображении, при этом подразумевается, что сам MPCV или его часть может служить формой отсчета, поскольку он является известным. Например, ячейками отсчета могут служить индикаторы углов или края квадрата. Также возможно использование других известных способов определения положения, например автокорреляции мозаичных изображений;
- на этапе 326, исходя из форм отсчета, составляют изображение размером, равным исходному или умноженному на целое число исходному размеру;
- на этапе 328 для каждой ячейки в захваченном изображении определяют участок поиска, в котором может находиться изображение точки. (Например, если MPCV напечатан с разрешением 600 ppi (points per inch, точек на дюйм) и захвачен при разрешении 1200 dpi (dip per inch, пикселей захвата на дюйм), участок размером в +/- 5 пикселей соответствует участку размером в +/- 2,5 пикселей в исходном изображении). Необходим относительно большой участок поиска, так как исходное положение ячеек отсчета может быть неточным;
- на этапе 330, если точка имеет темный цвет на светлом фоне, в воспроизведенном или захваченном изображении проводят определение положения пикселя, имеющего минимальное значение яркости на определенном участке или, если точка имеет светлый цвет на темном фоне, положения пикселя, имеющего максимальное значение яркости на определенном участке. Положение данного пикселя рассматривается в качестве положения центра точки в захваченном изображении;
- на этапе 332 проводят измерение расстояний между двумя положениями в каждом направлении;
- на этапе 334 совокупность результатов измерений расстояний соединяют в вектор геометрических характеристик.
Для MPCV из 100 ячеек получают вектор размером 100×2. По причине неточностей в положении ячеек отсчета может иметь место систематическая ошибка. На этапе 332 предпочтительно производят компенсацию указанной систематической ошибки путем вычисления средних расстояний по горизонтали и вертикали и вычитают данное среднее из соответствующих расстояний (предполагается, что средняя величина неточностей положения равна нулю).
В вариантах осуществления:
- для определения положения каждой точки используют другие характерные величины, например значение яркости центрального пикселя точки, значение отклика на фильтр точек, соответствующее пикселям, и т.д., и/или
- положения точек определяют без воспроизведения изображения с учетом масштабного фактора захваченного изображения, а также его поворота и перемещения при определении участков поиска точного положения каждой точки.
В отношении распознавания, или различения, оригинальных MPCV и их копий с использованием вектора характеристик положений следует указать, что можно поступать следующим образом:
- на этапе 340 для каждой точки вычисляют эвклидово расстояние между положением точки, определенным из захваченного изображения, и исходным положением;
- на этапе 342 вычисляют среднюю, или медиану, указанного расстояния по совокупности точек с получением меры среднего расстояния;
- на этапе 344 указанное среднее расстояние сравнивают с заранее заданной пороговой величиной;
- на этапе 346 определяют, является ли MPCV оригиналом или копией, следующим образом:
- если среднее расстояние меньше порогового, MPCV рассматривается как оригинал;
- в противном случае он рассматривается как копия.
Предложенный способ иллюстрируется следующим примером. Один и тот же MPCV был напечатан и захвачен три раза. Средние расстояния, вычисленные из векторов характеристик положений исходных изображений, составляли 0,454, 0,514 и 0,503 пикселей изображения. Были изготовлены три высококачественные копии, каждая исходя из трех напечатанных MPCV. Средние расстояния, вычисленные из векторов характеристик положений указанных копий, составили 0,965, 1,088 и 0,929 пикселей изображения. Можно утверждать, что на основе средних расстояний исходные MPCV могут быть с уверенностью отличены от их копий простым сравнением с пороговой величиной. Возможными являются несколько значений порога в соответствии с издержками, связанными с возможными ошибками ("положительный порог" - распознавание копии в качестве оригинала, или "отрицательный порог" - распознавание оригинала в качестве копии). Если издержки, связанные с обоими типами ошибок, эквивалентны, то приемлемым компромиссом является порог величиной в 0,75 пикселей (изображения).
Для того чтобы отличить оригинальные MPCV от копий, могут быть использованы другие известные математические методы, например, основанные на статистических методах и/или методах распознавания формы.
В отношении распознавания, или различения, оригинальных MPCV и их копий исходя из значений геометрических характеристик точек, следует указать, что, как было отмечено выше, если размер точек является постоянным, для изготовителя подделок достаточно воспроизвести соответствующий размер точек, даже если точки в оригинальной маркировке могут казаться обладающими различным размером. В одном из вариантов осуществления в ходе создания MPCV изменяют один или два размера точек.
На этапе 352 при анализе подлинности документов после захвата изображения MPCV на этапе 350 определяют размер или размеры точек в зависимости от степени яркости их центрального пикселя изображения, их отклик по меньшей мере на один матричный фильтр, соответствующий пикселям изображения, и т.д.
Затем производится распознавание оригинальных MPCV и копий в зависимости от степени сходства между размерами точек в оригинальном цифровом MPCV и соответствующими размерами в захваченном изображении аутентифицируемого MPCV. Например, поступают следующим образом:
- на этапе 354 с применением алгоритма создания MPCV определяют вектор ожидаемых характеристик размеров. Например, вектор ожидаемых характеристик может состоять из значений площади точек или двух их размеров - горизонтального и вертикального;
- на этапе 356 вычисляют индекс сходства, например коэффициент корреляции между вектором ожидаемых характеристик и вектором характеристик, полученных после обработки захваченного изображения MPCV;
- на этапе 358 определяют, является ли MPCV подлинным, путем сравнения индекса сходства с заранее заданным пороговым значением:
- если значение индекса превосходит пороговое, MPCV рассматривается как оригинал;
- в противном случае он рассматривается как копия.
Предложенный способ иллюстрируется следующим примером. Один и тот же оригинальный MPCV, показанный на фиг.5, размеры точек которого меняются между 2×2 и 3×3 пикселями, печатали и захватывали три раза. Вектор характеристик состоит из значений площади, равных 4 и 9 пикселей для точек размером 2×2 и 3×3 пикселей соответственно. Векторы характеристик содержат среднее значение яркости области, окружающей точку, за вычетом значения яркости точки. Таким образом, чем темнее напечатанная точка, тем больше полученное значение, что обычно справедливо для точек размером 3×3 пикселя.
Вычисленные индексы сходства для трех оригинальных оттисков составили 0,654, 0,673 и 0,701. Затем изготовили три высококачественные копии, каждую исходя из отдельного напечатанного MPCV из трех указанных. При изготовлении копий определяли положение точек, затем измеряли их степень яркости.
Рассчитывали среднюю степень яркости точек MPCV; точки, имеющие яркость, меньшую средней степени яркости, рассматривали как точки исходным размером 3×3 пикселя, размер 2×2 пикселя приписывался точкам со степенью яркости, превышающей среднюю степень яркости. Копии печатали и захватывали. Вычисленные значения индекса сходства для трех копий составляли 0,451, 0,423 и 0,446. Можно утверждать, что на основе характеристик точек оригинальные MPCV могут быть значимо отличены от их копий простой сверкой с пороговым значением. Возможны несколько значений пороговой величины в соответствии с издержками, связанными с возможными ошибками. Если издержки, связанные с обоими типами ошибок, эквивалентны, то пороговое значение индекса сходства, равное 0,55, является приемлемым компромиссом.
Для того чтобы отличить оригинальные MPCV от их копий, могут быть использованы другие известные математические методы, например, основанные на статистических методах и/или методах распознавания формы.
Вышеприведенное описание касается прежде всего обеспечения безопасности документов по отношению к копированию. В продолжении описания речь идет о двух других формах обеспечения безопасности документа, с одной стороны, для однозначной идентификации документов, которые не были напечатаны "переменным" способом печати, с другой стороны, для получения информации, касающейся документа, например серийного номера, даты, места выпуска и заказа на изготовление, названия правообладателя прав интеллектуальной собственности, удостоверяемых документом, или его назначения.
Далее описаны способы идентификации MPCV на основе их геометрических характеристик. Речь идет об использовании измеренных характеристик MPCV для однозначной идентификации каждого оттиска одного и того же исходного цифрового изображения MPCV. Получение каждого оттиска MPCV приводит к уникальным случайностям при печати, которые могут быть обнаружены при различных захватах того же оттиска. Поэтому при сохранении последовательных характеристик печати MPCV в базе данных или на документе, содержащем MPCV, предпочтительно защищенным образом (например, в двумерном штрих-коде), возможна дальнейшая идентификация оттиска MPCV и, как следствие, печатного документа, на который он нанесен, т.е возможно однозначное распознавание путем нахождения соответствия между геометрическими характеристиками MPCV, изображение которого захвачено, и сохраненными геометрическими характеристиками.
Идентификация и аутентификация предпочтительно являются комбинированными между собой, причем одно и то же устройство для захвата и обработки изображений одновременно обеспечивает индикацию подлинности и идентификацию документа.
Могут быть использованы несколько видов геометрических характеристик точек, в том числе точное положение, измерение яркости, размера или размеров точек и их формы. Степень яркости, измеренная по среднему либо минимальному оттенку серого в точке или по оттенку серого в ее центре, является особенно пригодной для установления различий, поскольку она значимо и непредвиденным образом меняется на различных оттисках одного и того же исходного изображения. Следует отметить, что использование точек переменных размера или формы в исходном MPCV не является необходимым для того, чтобы характеристики точек менялись от одного оттиска к другому. Для иллюстрации данного положения на фиг.7 показаны два оттиска одного и того же MPCV с постоянным размером точек: точка 151 напечатана на нижнем изображении темнее, чем на верхнем, тогда как точка 152 - на верхнем изображении темнее, чем на нижнем.
Выполняют захват каждого из трех напечатанных MPCV по три раза, всего получают девять захваченных изображений. Вычисляют вектор характеристик, содержащий значение минимальной яркости точек для каждого из девяти захватов. Затем рассчитывают индекс сходства, т.е. коэффициент корреляции между векторами характеристик каждой из 9×8/2=36 возможных пар захваченных изображений. Из данных 36 пар 9 соответствуют различным захватам одного и того же оттиска, а 25 - захватам различных оттисков. Среднее значение индекса сходства в первой группе составляет 0,9566 при стандартном отклонении, равном 0,0073, и минимальном значении, равном 0,9474, а во второй - 0,6203 при стандартном отклонении, равном 0,0272, и максимальном значении, равном 0,6679. Разница между индексами сходства является сильно значимой и показывает, что напечатанный MPCV может быть недвусмысленно идентифицирован на основе вектора характеристик точек.
На фиг.18 детально проиллюстрированы этапы способа идентификации, соответствующего такому подходу. На этапе 402 производится захват печатных изображений MPCV. Затем на этапе 404 происходит расчет вектора характеристик, содержащего средние значения минимальной яркости точек. Указанный вектор характеристик, или "подпись" напечатанного MPCV, содержит среднюю измеренную яркость каждой точки и, возможно, стандартное отклонение между измерениями яркости для каждой точки. Следует отметить, что некоторые измерения яркости могут быть исключены на основе их различия со средними значениями других измерений и стандартного отклонения между другими измерениями. Затем, на этапе 406, вектор характеристик вводится в базу данных вместе с указаниями, касающимися изготовления и/или обращения документа.
В ходе попытки идентификации на этапе 410 захватывают изображение напечатанного MPCV. Затем, на этапе 412, вычисляют вектор характеристик, соответствующий сохраненному вектору. На этапе 414 определяют сохраненный вектор характеристик, наиболее близкий к вектору, вычисленному на этапе 412, и получают связанную с ним информацию.
В варианте осуществления также надежным, т.е. стойким к копированию, путем сохраняют вектор характеристик, определенный на этапе 404, на самом документе, например, при помощи двумерного штрих-кода или в Datamatrix (зарегистрированная торговая марка), предпочтительно зашифрованных по соображениям безопасности. В этом случае возможна аутентификация документа путем сравнения индекса сходства между двумя векторами характеристик и пороговым значением, заданным заранее или сохраненным в штрих-коде на этапе 416.
Для хранения информации в MPCV можно, например, определить два возможных положения или размера либо две возможные формы каждой точки внутри ячейки, которая отведена ей, при этом на один участок приходится один бит. Каждому положению, размеру или форме присваивается значение бита (ноль или единица).
В соответствии с фиг.5, на которой показан MPCV с двумя размерами точек, точки малого размера (2×2 пикселя) могут, например, представлять значение бита "0", а точки большого размера (3×3 пикселя) - значение бита "1".
Для MPCV, содержащего 100 ячеек, можно таким путем хранить 100 бит при отсутствии избыточной информации. Для обнаружения и/или исправления ошибок желательно использование кода обнаружения и/или коррекции ошибок.
В случае использования положения для представления двоичной информации является предпочтительным, чтобы положения, соответствующие каждому из двух значений, были удалены друг от друга. Возможный способ обеспечения удаленности двух положений друг от друга состоит в разделении ячейки на две части равного размера, соответствующие двум значениям бита, и псевдослучайном присваивании зоне положения, соответствующего значению кодируемого бита. Следует отметить, что положение точки в ячейке может представлять более одного двоичного значения вследствие множественности возможных положений. Например, как показано выше, указанное положение может представлять 8 бит в 289 различных положениях или 6 бит, если исключить одно положение из двух в каждом направлении для ограничения риска ошибки интерпретации положения в ходе чтения.
При чтении MPCV производится определение участка поиска в окрестности двух возможных положений точки для каждой подъячейки. Для того чтобы определить, какая из двух подъячеек содержит точку, определяют минимальное значение яркости для каждой из двух подъячеек: участок с более низким значением яркости рассматривается как тот, в котором находится точка. В варианте осуществления каждому значению бита можно присвоить статистический вес в зависимости от разности или отношения яркостей каждой из двух подъячеек.
В вариантах осуществления:
- для представления одного бита информации (используемого далее в "решетках") используют присутствие или отсутствие точки;
- представляют более одной двоичной величины путем возможности более чем двух положений точки на ячейку;
- представляют более одной двоичной величины путем возможности более чем двух размеров точки на ячейку;
- представляют более одной двоичной величины путем возможности более чем двух форм точки на ячейку, и/или
- перед кодированием информации производится ее шифрование.
В отношении интеграции с другими цифровыми аутентификационными кодами следует указать, что MPCV могут быть интегрированы с другими цифровыми аутентификационными кодами для получения дополнительного слоя защиты и/или незаметного средства трассировки документов. На фиг.8 показана защищенная информационная матрица 155, содержащая в центре участок, в который вставлен MPCV 156. На фиг.9 показана защищенная информационная матрица 160, окруженная MPCV 161. Следует отметить, что в последнем случае элементы, позволяющие определить положение цифрового аутентификационного кода 160, например его углы, могут быть использованы для приблизительной локализации и определения положения точек MPCV 161.
В вариантах осуществления используют средства включения реперов в MPCV путем дискретных маркировок. В некоторых случаях желательно, чтобы реперные маркировки были более дискретными, чем бордюр, с тем, чтобы положение и даже присутствие MPCV можно было обнаружить с трудом: например, возможны вставка ограниченных, прерывных бордюров или угловых маркировок либо определение положения по цифровому аутентификационному коду или другим связанным символам.
Если один и тот же шаблон точек повторяется несколько раз, например, путем составления мозаики, определение положения и локализация точек может производиться с использованием методов автокорреляции и перекрестной корреляции согласно описанному в статье M.Kutter, "Watermarking resisting to translation, rotation and scaling", Proc. of SPIE: Multimedia systems and applications, Volume 3528, pp.423-431, Boston, USA, November 1998.
Другой путь включения дискретных реперных маркировок в MPCV состоит во вставке ячеек, состоящих из совокупности точек, имеющих характерную форму и поэтому легко находимых. Например, если желательно, чтобы репером служила точка, производится вставка значительного числа точек, соседствующих с реперной, с получением легко находимого скопления точек. На фиг.10 показан MPCV 165, каждый из четырех углов 166 которого состоит из одной ячейки, содержащей центральную точку и четыре очень близкие к ней соседние точки, образующие углы квадрата с центром в центральной точке. При обнаружении вначале производится детектирование всех точек на достаточной площади, служащих "кандидатами". Затем для каждой точки определяют число соседних точек, находящихся на расстоянии от нее, меньшем или равном заданного расстояния. Это может быть проделано быстро, если точки-кандидаты" расположены по решетке, позволяющей быстро подсчитать число соседних точек в промежутках решетки. Ограниченное число "кандидатов", например шесть, обладающих наибольшим числом соседних точек, сохраняют. Затем возможно использование известных геометрических методов для определения, какие "кандидаты" соответствуют контрольным точкам, в данном случае углам MPCV. Например, для MPCV 165 известно, что три подходящих "кандидата" должны образовывать прямоугольный равнобедренный треугольник.
Другой путь включения дискретных реперных маркировок состоит во вставке точек по одной линии. На фиг.11 показан MPCV 170, содержащий по краям линии 171 с более высоким числом точек по сравнению с параллельными им линиями, находящимися внутри MPCV 170. Указанные бордюрные линии могут быть обнаружены с использованием различных алгоритмов обнаружения линий, например, с применением преобразования Хафа и/или фильтра Собеля, обеспечивающего фильтрацию шума.
В варианте осуществления производится наложение одного и того же MPCV или различных MPCV, содержащих линии точек или реперные маркировки, например скопления точек, подобные изображенному на фиг.10.
В предпочтительном варианте осуществления MPCV располагают в форме регулярной решетки. В самом деле, в некоторых случаях является преимуществом повтор MPCV на большой поверхности и даже на всем подлежащем защите документе путем составления мозаики. Таким способом уничтожение MPCV оказывается очень трудным и даже невозможным; гибкость положения захвата изображения повышается. В частности, можно вставить один и тот же MPCV несколько раз. Также возможна вставка одного MPCV, частично отличающегося от всех остальных. Для корректного определения положения при чтении MPCV возможно использование реперных средств, описанных выше. В то же время на практике контрольные, синхронизационные или реперные элементы могут быть трудными для корректного детектирования.
Как будет показано далее, при размещении точек в форме решетки можно облегчить их детектирование. Точки вставляют через регулярные промежутки, например, с расстоянием между ними, равным 4-12 пикселей в каждом направлении. Существует несколько способов представления информации на основе подобного принципа:
- присутствие точки или ее отсутствие позволяет представить один бит информации, как в MPCV 175, показанном на фиг.12, на котором присутствие точки соответствует значению бита "1", а ее отсутствие - значению бита "0";
- информацию позволяет представить размер, форма и разность амплитуд, меньших по меньшей мере одного размера MPCV. Например, выбор точки среди четырех форм или четыре выбора размеров позволяют представить два бита информации в каждой точке MPCV 180, как показано на фиг.14, на которой представлен увеличенный фрагмент MPCV 180. Видно, что точки этого MPCV могут принимать следующие размеры в пикселях (первое число означает высоту, второе - ширину): 1×1,2×2,1×2 и 2×1, что соответствует значениям битов "00", "01", "10" и "11". Разумеется, являются возможными многие другие сочетания и формы точек.
В варианте осуществления, основанном на принципе совершенной решетки, представление информации обеспечивает небольшое смещение точки. Например, смещение точки, составляющее по меньшей мере два пикселя поверхности, смещение на один пиксель по горизонтали и/или вертикали позволяет представить два бита информации. Возможны, разумеется, многие другие варианты. Следует отметить, что подобное смещение точек не приводит к значимому изменению геометрических характеристик и, стало быть, не влияет на преимущества при использовании решеток, в частности, в качестве реперов.
Решетка особенно пригодна при определении угла поворота и масштабного фактора применительно к захваченному изображению. В частности, можно взять за основу преобразование Хафа изображения или определение максимумов энергии в пространстве Фурье. На фиг.13 показано абсолютное значение двумерного Фурье-образа решетки, изображенной на фиг.12, при этом светлые точки соответствуют максимумам энергии. Обнаружение указанных максимумов энергии позволяет специалисту в данной области техники вычислить угол поворота и масштабный фактор изображения, что, в свою очередь, позволяет получить его нормализованные размеры для обработки.
Если угол поворота и масштаб изображения являются известными и, возможно, скорректированными, производится определение значения трансляции, т.е. перемещения изображения, необходимого для корректного выравнивания точек решетки. Для этого возможно использование различных способов. Общей чертой всех указанных способов является фиксирование значений для совокупности точек решетки, которые затем находятся для выравнивания решетки. Например, возможно фиксирование значений для совокупности точек, выбранных псевдослучайным образом в зависимости от ключа. При перекрестной корреляции между захваченным и скорректированным изображением решетки и изображением, созданным исходя из известных значений для точек, в положении, соответствующем перемещенной решетке, образуется корреляционный максимум.
В отношении алгоритма записи возможно использование многих способов, известных специалисту в данной области техники. В качестве примера предположим, что имеется решетка, размещенная в виде мозаики или нет, размером 20×20 ячеек, печать выполнена при разрешении 600 точек на дюйм и маркированным может быть 1% поверхности (чтобы свести к минимуму визуальное воздействие маркировки), тогда в среднем одна точка из каждых 10 в каждом направлении входит в состав решетки. Размер элемента мозаики в оригинале составляет 200×200 пикселей; устройство захвата изображений позволяет получать изображения размером 640×480 пикселей при разрешении захвата 720 пикселей на дюйм. Следует отметить, что следует удостовериться в том, чтобы в захваченном изображении целиком содержался по меньшей мере один элемент мозаики.
На этапе 502 на входе получают сообщение, например, состоящее из 8 байт, криптографический ключ и ключ создания помех (при этом ключи могут быть идентичными). На этапе 504 производится шифрование указанного сообщения. На этапе 506 возможно добавление к сообщению битов обнаружения ошибок, например, двух байт, позволяющих снизить риск ошибок декодирования сообщения на 2 в степени 16. На этапе 508 после конкатенации зашифрованного сообщения с кодом обнаружения ошибок, в данному случае размером 10 байт, вычисляют сообщение, устойчивое по отношению к ошибкам, например, путем применения конволюционного кода. Для конволюционного кода второго уровня с памятью размером семь при восьми байтах на входе получают код, составляющий 142 бит. На этапе 510, если имеется 20×20 точек=400 положений, можно реплицировать данное сообщение два раза, получив реплику сообщения размером в 284 бит. Тогда остается 400-284=116 неиспользованных положений, которые служат для хранения битов синхронизации, используемых при детектировании для выравнивания элемента мозаики согласно описанному ниже. На этапе 512 в реплику сообщения вводят помехи, т.е. производят пошаговые перестановку и преобразование функцией "или-не". Перестановка и преобразование, использованные в функции "или-не", вычисляются с использованием ключа создания помех. Получают 284 перепутанных бита.
На этапе 514 псевдослучайным путем при помощи ключа генерируют 116 бит синхронизации; определение их положения также может быть псевдослучайным, при этом они равномерно распределяются в элементе мозаики.
Изображение MPCV модулируют путем простого добавления в определенных положениях точки для бита "1" (для бита "0" изменения не происходит). Очевидно, что точка может быть составлена так, чтобы она имела переменные размер или размеры, форму и/или положение согласно ранее рассмотренным способам.
Если требуется покрыть большую поверхность, элементы мозаики на этапе 516 добавляются один за другой. Тогда согласно вариантам осуществления можно наносить один и тот же элемент мозаики или изменять сообщение в каждом элементе мозаики. Например, во втором варианте часть сообщения может остаться неизменной, тогда как другая часть, например один байт, определяется для каждого элемента мозаики случайным образом. Тогда можно применить случайный угол вращения, умноженный на 90°, к каждому элементу мозаики с тем, чтобы затруднить попытки анализа кода изготовителем подделок. Кроме того, можно производить случайную вставку синхронизационных битов или их обратных величин, т.е. для синхронизационных битов производится обращение положения вставки точек. Преимуществом последнего подхода является то, что число возможных конфигураций повышается, но чтение при этом не становится более сложным, как будет показано далее. Если учитывать отклонения ориентации, то можно получить 8 возможных конфигураций синхронизационных битов, что усложняет их анализ при попытке взлома изготовителем подделок.
Решетка 200×200 в приведенном примере может быть реплицирована согласно изложенному выше.
Далее, на этапе 518, MPCV вводят в печатные пленки и производят печать документа.
В отношении алгоритма чтения следует указать, что при его выполнении осуществляют следующие этапы:
- этап 548 захвата изображения документа;
- этап предварительной обработки 550: предварительная обработка изображения, в частности, для выполнения следующего за ней этапа определения точек-кандидатов" является предпочтительной. При предварительной обработке желательно удалить паразитные шумы и артефакты, вызванные освещением. Например, применение многонаправленного фильтра верхних частот, результат которого уравновешивается исходным изображением, позволяет убрать артефакты освещения; применение медианного фильтра позволяет снизить шум от отдельных пикселей;
- на этапе 552 производится определение точек-кандидатов": последние соответствуют пикселям изображения, яркость которых лежит ниже порогового значения. Данное пороговое значение представляет собой, например, процентиль гистограммы, например 1%, таким образом, чтобы не более 1% точек оказалось в числе точек-"кандидатов". Чтобы оставить только те "кандидаты", значение яркости которых является самым низким на участке, слишком близкие "кандидаты" (например, расстояние между которыми составляет менее пяти пикселей) исключают;
- на этапе 554 производят определение векторов соседних точек-"кандидатов" и оценивают угол вращения и масштабный фактор: задаются предельным расстоянием между соседними "кандидатами" и находят все пары точек, расстояние между которыми меньше указанного порога. Если этот порог достаточно низок, только четыре точки, непосредственно соседствующие с данной точкой, могут быть объединены в вектор, в противном случае возможно объединение непрямых (диагональных) соседних точек. Последнего предпочтительно избегать. Для этого избегают того, чтобы пороговое значение было слишком высоким. Тогда можно оценить угол вращения, приводя угол каждого из векторов к значению, составляющему от 0 до 90 градусов;
- на этапе 556, если непрямые соседи исключены, производится разделение векторов на две группы в зависимости от их размера (который больше в квадратный корень из двух раз для непрямых соседей) и вычитают 45 градусов из угла, вычисленного для непрямых соседей. Также можно оценить масштабный фактор путем измерения среднего расстояния между точками одной и той же группы, разделенного на расстояние в оригинальном изображении, если таковое известно;
- возможно, на этапе 558 производится восстановление изображения для получения изображения, не подвергнутого повороту, в исходном размере или в исходном размере, умноженном на целое число;
- на этапе 560 получают матрицу значений, представленных точками: среднее расстояние между точками, составляющее, например, 10 пикселей, и размер воспроизведенного изображения, например, 500 х 500 пикселей, являются при этом известными. Тогда генерируют таблицу размеров, содержащую 50 строк и 50 столбцов и предназначенную для хранения оценок значений, содержащихся в сообщении, зная, что отношение между размерами воспроизведенного изображения и оцененным расстоянием между точками соответствует максимальному числу точек в изображении. На практике, если решетка точек в захваченном изображении имеет значительный угол поворота, число точек в воспроизведенном изображении может быть существенно менее высоким;
- на этапе 562 для заполнения указанной таблицы оценками значений, содержащихся в сообщении, производят поиск отправной точки для развертки изображения. Данная точка может, например, представлять собой первую обнаруженную точку-"кандидат", начиная от верхнего левого края изображения, либо точку-"кандидат", имеющую наибольшую вероятность оказаться точкой (например, точку с наименьшим значением уровня серого). Следует отметить, что важно не допустить ошибки в выборе точки, поскольку ошибка может иметь неблагоприятные последствия для дальнейших расчетов. К отправной точке можно вернуться и повторить расчет итерационным методом, если дальнейшие этапы чтения сообщения окажутся неудачными. Для выбранной точки в таблицу заносят значение, например ее уровень серого или наименьшее значение уровня серого на некотором участке вокруг ее центрального положения, с тем, чтобы избежать ошибочного измерения, если оцененное положение точки слегка отличается от реального положения, причем отклонение либо является следствием псевдослучайных отклонений, предназначенных для распознавания копии, либо следствием любых других неточностей положения. Полученное значение сохраняется в соответствующей ячейке таблицы; номера ячеек которой в рассматриваемом примере меняются от (0,0) до (49,49), например, в положении (0,0), если отправная точка является первой точкой вверху слева, или в положении (32,20), если отправная точка с наибольшей вероятностью находится в положении (322,204). Затем производится развертка всех положений изображения, начиная с отправной точки, путем сохранения найденного для каждой точки значения в соответствующее положение таблицы;
- на этапе 564 производится выравнивание решетки: обычно таблица значений сдвинута относительно начала мозаики. Чтобы обратить эту разницу, используют значения значащих либо синхронизационных битов, которые позволяют определить сдвиг. Так, возможна корреляция известных синхронизационных битов с таблицей значений для каждого возможного значения сдвига и для четырех возможных главных направлений (0, 90, 180 или 270 градусов). Самое высокое значение корреляции определяет сдвиг и ориентацию относительно главных направлений. В другом варианте осуществления определение может быть выполнено по самому низкому значению или абсолютному значению корреляции, если мозаика напечатана в негативе, по отношению к другой мозаике. В случае, если возможна случайная вставка битов синхронизации или обратных им значений, для определения сдвига используют абсолютное значение самой высокой корреляции. Корреляция может быть выполнена в пространстве фурье-образов для снижения количества вычислений. Следует отметить, что мозаики могут быть также ограничены непрерывными линиями либо скоплениями отдельных точек, способными служить реперами при выравнивании;
- на этапе 566 проводят воспроизведение сообщения, содержащего помехи. Например, если сообщение содержится в решетке 20×20, создают матрицу 20×20 и вводят в нее найденные значения. Остальная часть процесса декодирования сообщения может быть выполнена в соответствии со стандартными способами, известными в уровне техники. После того как содержащее помехи сообщение вычислено, применяют операции, описанные в приведенном выше алгоритме чтения, в обратном порядке;
- на этапе 568, возможной, как и другие измерения, в случае, когда решетка обладает особыми характеристиками, позволяющими распознавать копии, например точным положением или размером точек, указанные характеристики могут быть измерены на определенной решетке для принятия решения о природе документа (оригинал или копия) или однозначных идентификации/получения характеристик документа.
На фиг.21 показан увеличенный участок MPCV высокой плотности, каждая строка матрицы точек которого содержит ровно столько черных точек, сколько и белого фона или заднего плана и представляет кодированную или некодированную информацию. В верхней строке 185 является переменным положение каждой точки по ширине, тогда как в нижней строке 186 переменными являются размеры точек, в данном случае меняющиеся между двумя значениями, соответствующими 3×3 и 2×2 генерационных пикселя. Является понятным, что подобные MPCV обладают преимуществом компактности с точки зрения вставки заданного числа точек в документ при сохранении преимуществ изменений размеров, положения и/или формы, средняя амплитуда которых имеет тот же порядок величины, что и по меньшей мере один размер части указанных точек, и предпочтительно является меньшей указанного размера. Как ясно показано, по меньшей мере половина точек данного MPCV не соприкасается с другими четырьмя точками. При этом менее половины точек не касаются никакой другой.
На фиг.22 показан увеличенный участок MPCV 190 с градиентом размеров точек. Данный участок соответствует углу MPCV, в котором размеры точек уменьшаются последовательными кольцами, в данном случае толщиной в один ряд, однако на практике толщиной в несколько рядов, Например, на участке, показанном на фиг.22, размеры точек составляют 6×6 пикселей для наружного кольца внизу и справа, затем - 5×5 пикселей для следующего кольца, затем - 4×4 пикселя и так далее.
Таким образом, по меньшей мере для одного из колец средняя амплитуда непредвиденных отклонений по точкам по меньшей мере одной геометрической характеристики точек имеет тот же порядок величины, что и размер точек данного кольца.
Можно заключить, что подобные MPCV обладают преимуществом компактности при вставке в документ заданного числа точек с сохранением преимуществ отклонения размеров, положения и/или формы, средняя амплитуда которых имеет тот же порядок величины, что и по меньшей мере один размер части точек, и предпочтительно является меньшей указанного размера.
На фиг.15 показан особый вариант осуществления устройства, являющегося объектом настоящего изобретения. Данное устройство 201, например персональный компьютер с различными периферийными устройствами, образует коммуникационный интерфейс 218, соединенный с сетью связи 202, способной к передаче и приему цифровых данных. Устройство 201 также содержит средства хранения 214, например жесткий диск. Также в нем имеется дисковод 215. Дискета 224 может содержать подлежащие обработке или обрабатываемые данные, а также программный код, используемый для реализации настоящего изобретения, причем данный программный код после однократного чтения устройством 101 хранится на жестком диске 114. Согласно варианту осуществления программа, обеспечивающая реализацию устройством настоящего изобретения, хранится в постоянном запоминающем устройстве 110 (ПЗУ, ROM, read-only memory). Во втором варианте осуществления, программу получают для сохранения описанным выше путем посредством сети связи 202.
Устройство 201 снабжено экраном 212, обеспечивающим визуализацию результатов обработки и взаимодействие с ним, например, при помощи графических интерфейсов. При помощи клавиатуры 213 пользователь может вводить данные, значения площади, плотности, разрешения, параметров или ключи либо осуществлять выбор выполняемых команд. Центральный блок 211 (CPU, central processing unit) выполняет инструкции, относящиеся к реализации изобретения и хранящиеся в ПЗУ 210 или в других устройствах хранения информации. При подаче напряжения программы, имеющие отношение к реализации способа, являющегося объектом настоящего изобретения, и хранящиеся в постоянной памяти, например в ROM 210, передаются в оперативную память RAM 217, в которой после этого оказывается исполняемый код программы, являющейся объектом настоящего изобретения, и имеются регистры для ввода в память переменных, необходимых для реализации изобретения. Разумеется, дискеты 224 могут быть заменены на любой носитель информации, например компакт-диск или карту памяти. Более общим образом, программа, реализующая способ, являющийся объектом настоящего изобретения, запоминается на средствах хранения информации, способных к чтению компьютером или микропроцессором, интегрированным или не интегрированным в устройство и, возможно, съемным. Коммуникационная шина 221 обеспечивает связь между различными элементами, содержащимися в персональном компьютере 201 или связанными с ним. Наличие шины 221 не является ограничительным, в частности, центральный блок 211 может обмениваться инструкциями с любым элементом персонального компьютера 201 непосредственно или через другой элемент персонального компьютера 201.

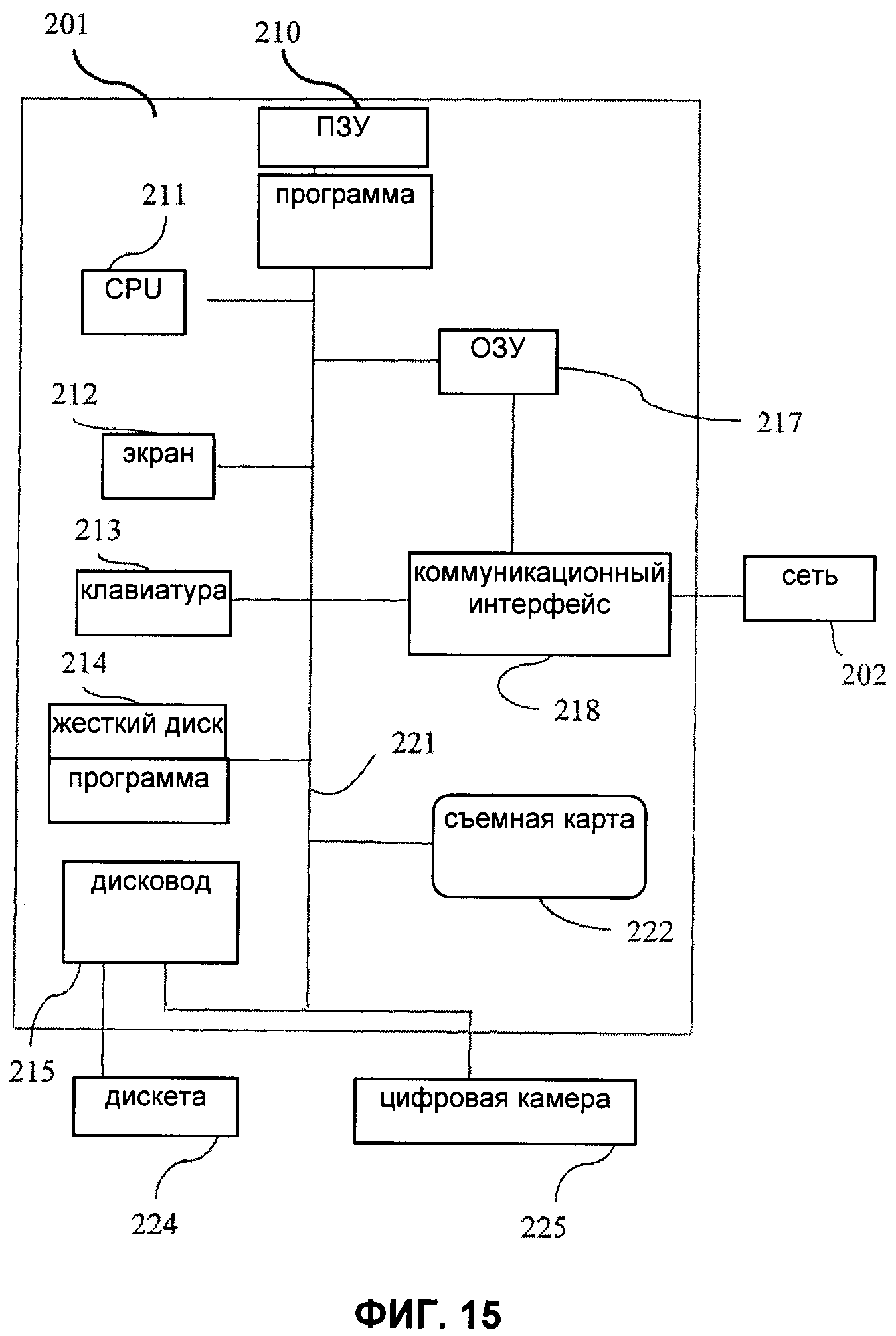
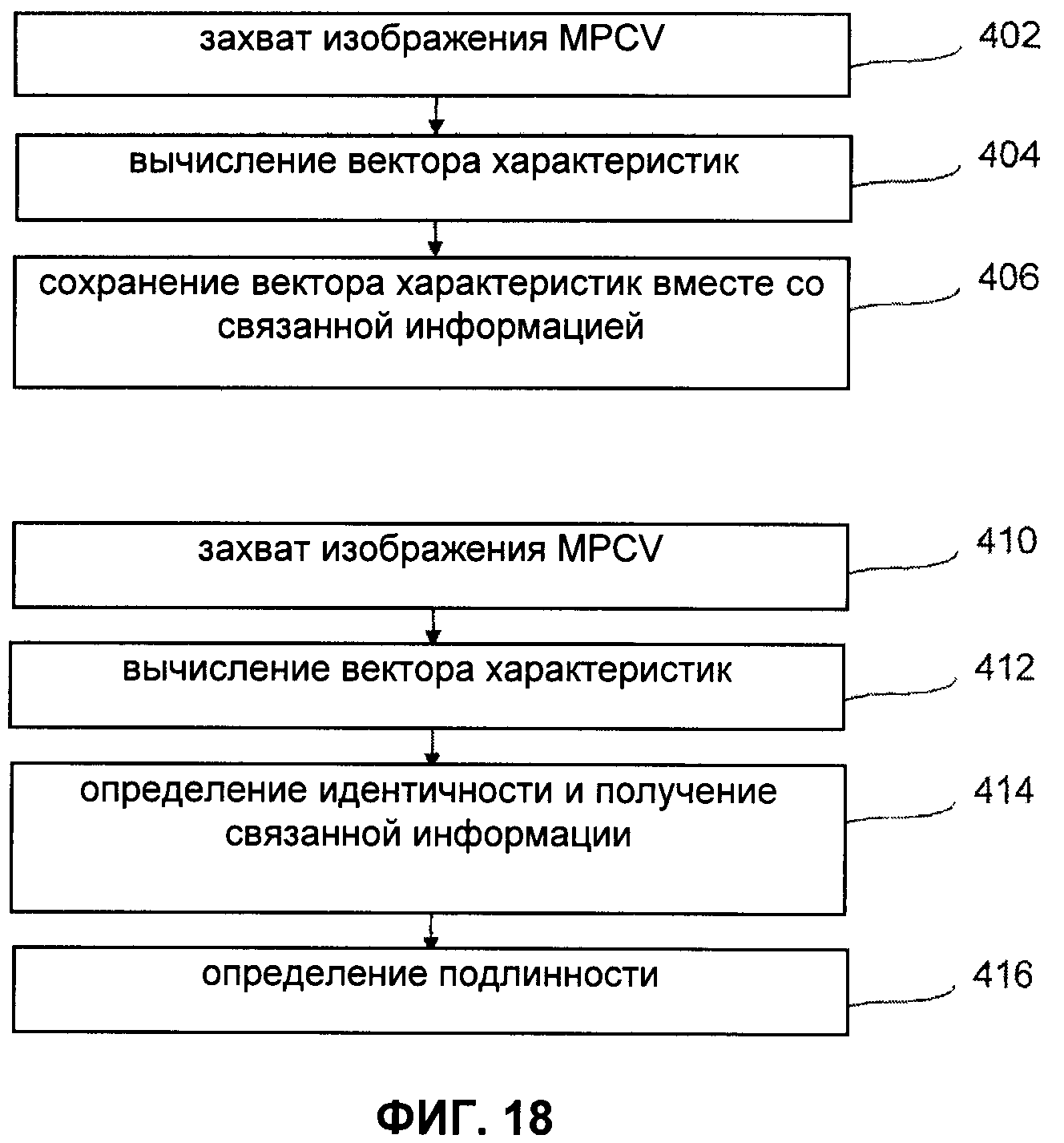



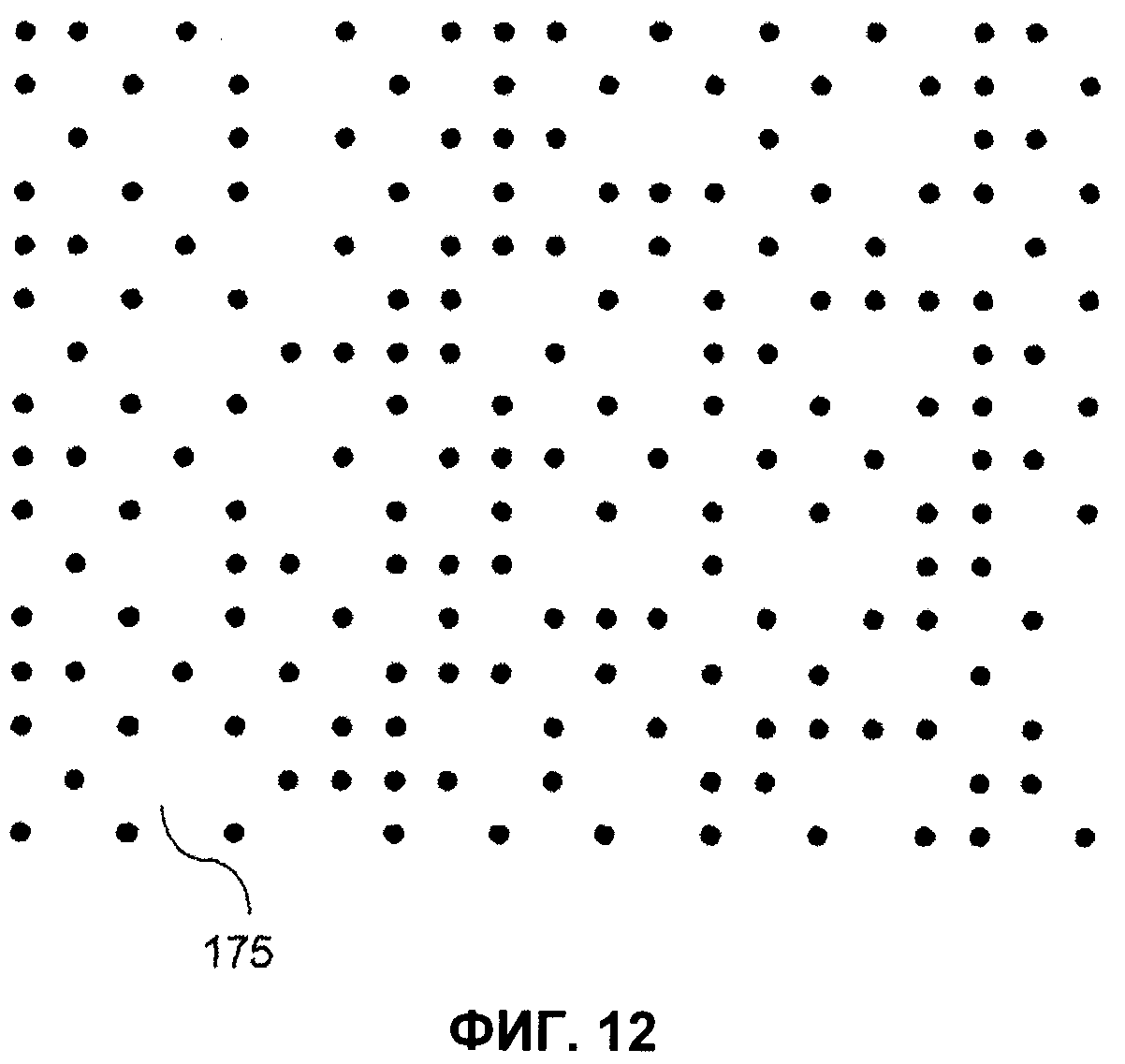
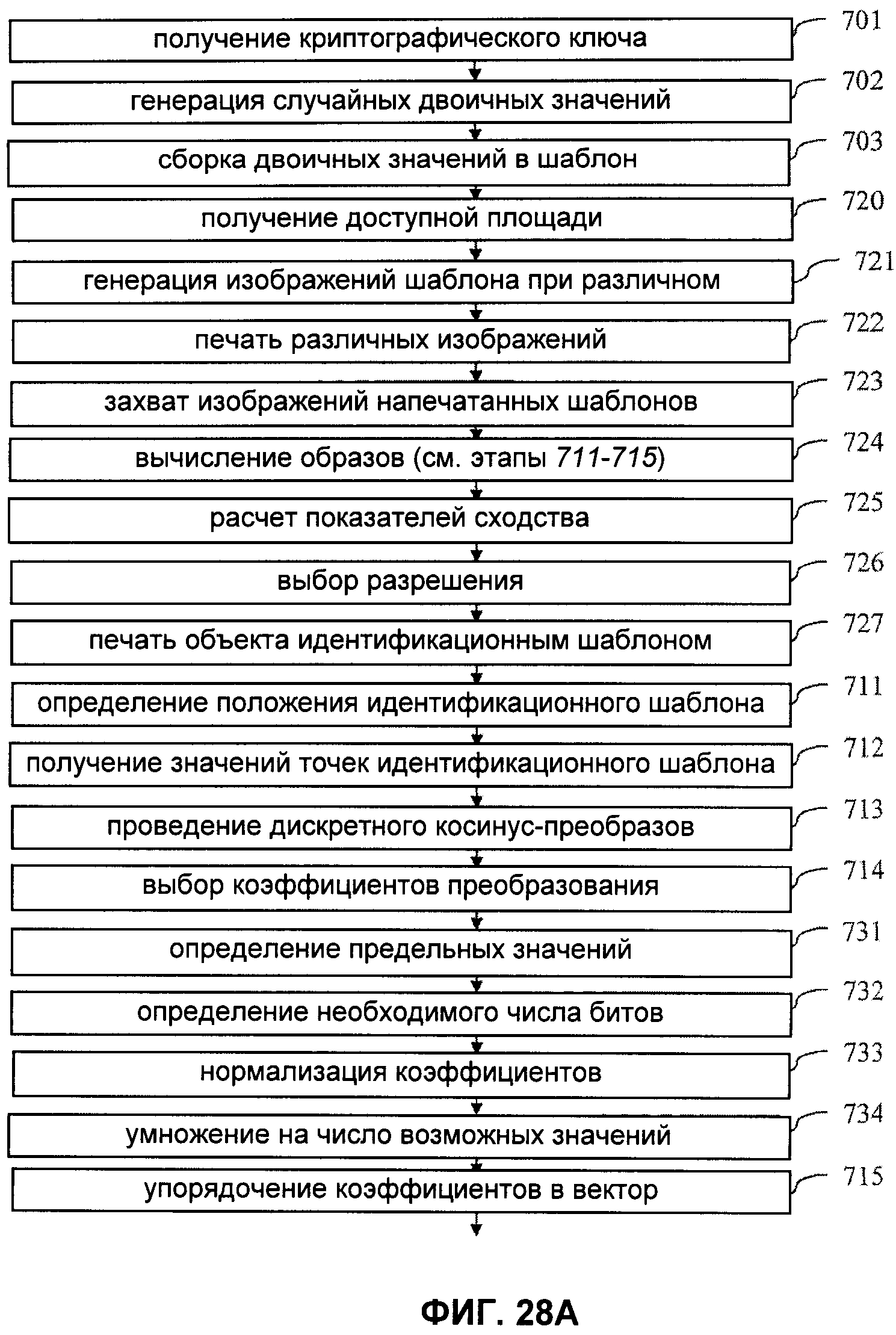
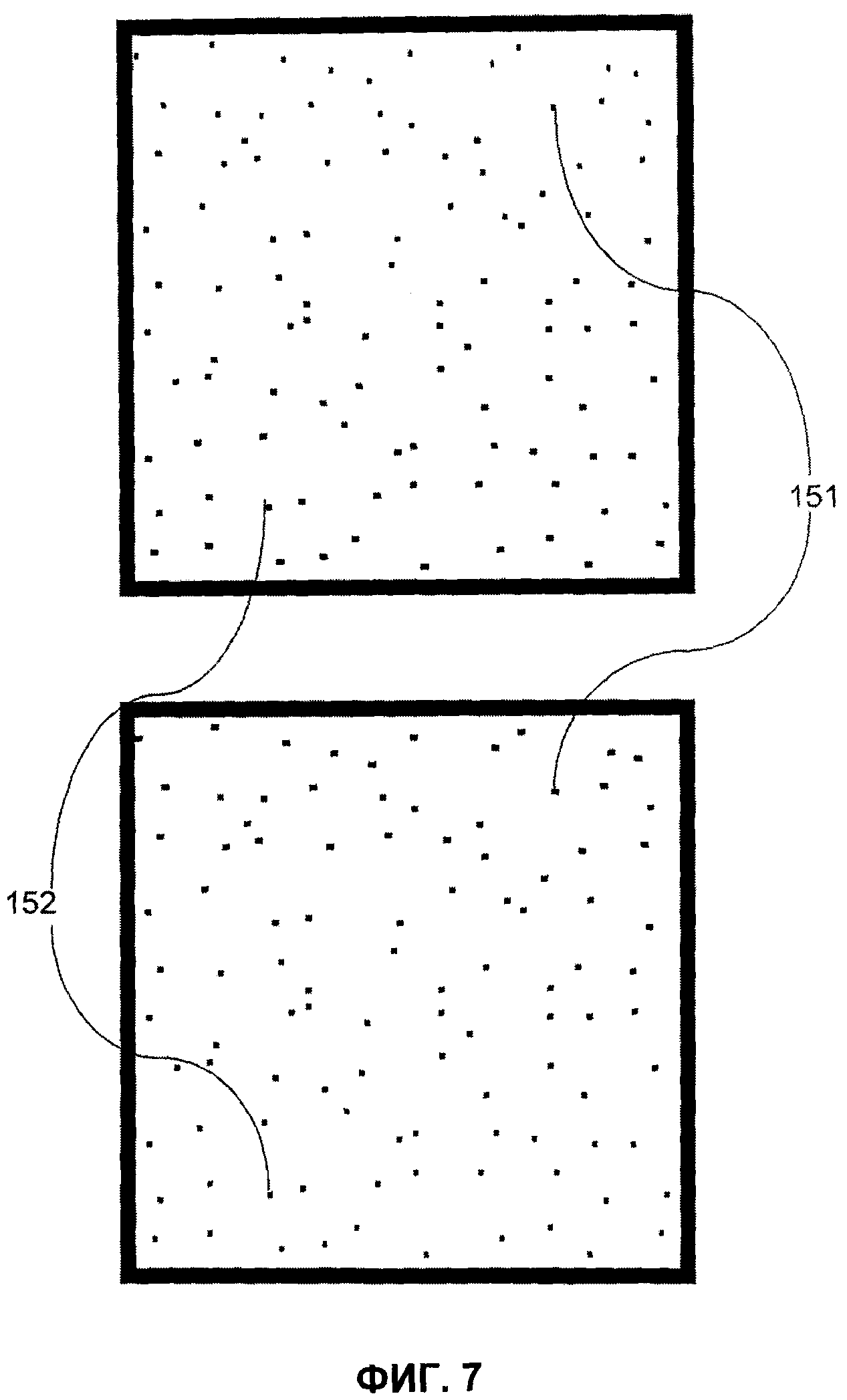
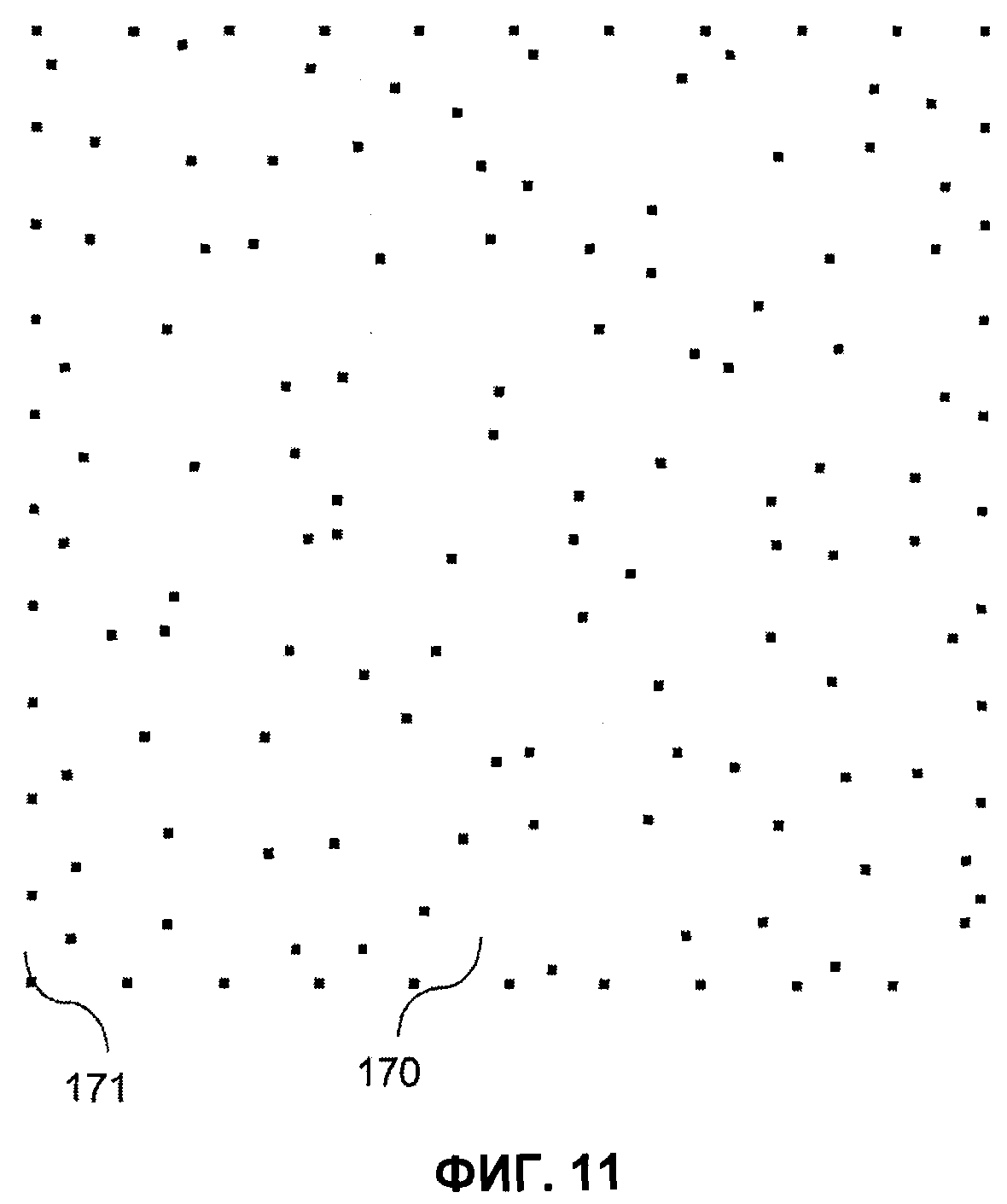
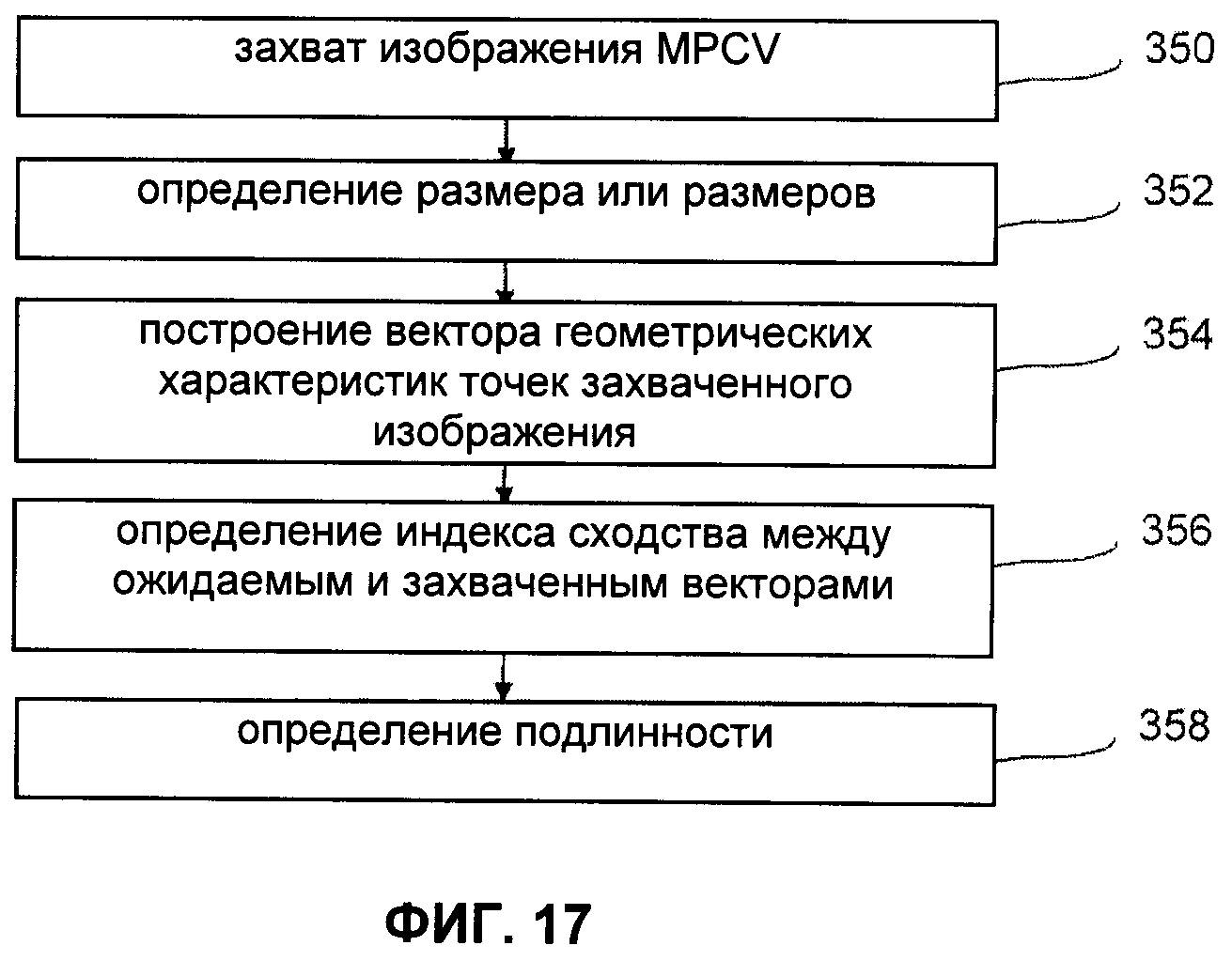
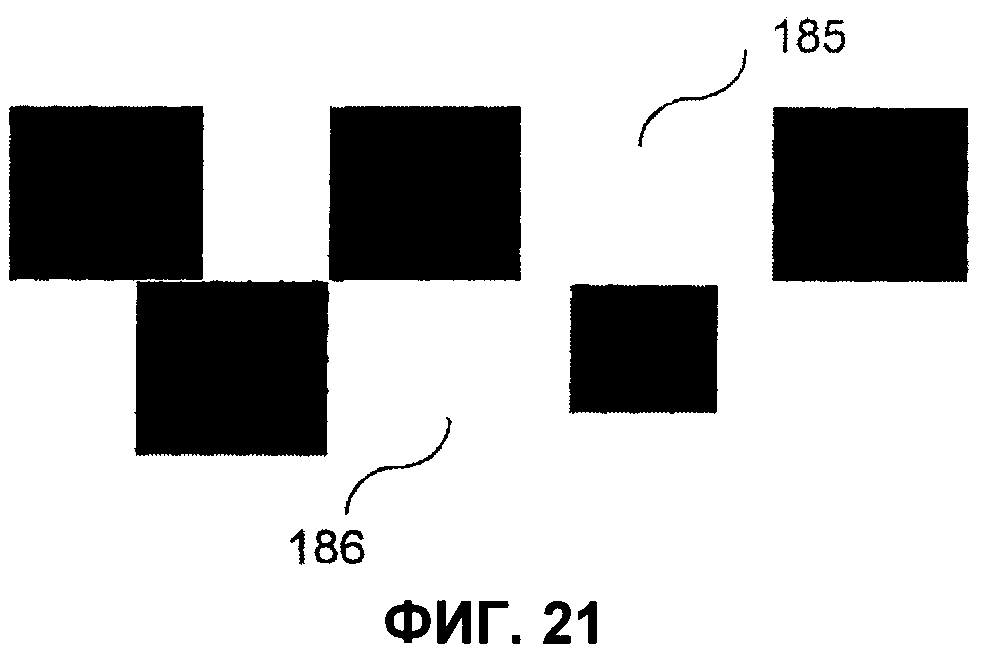

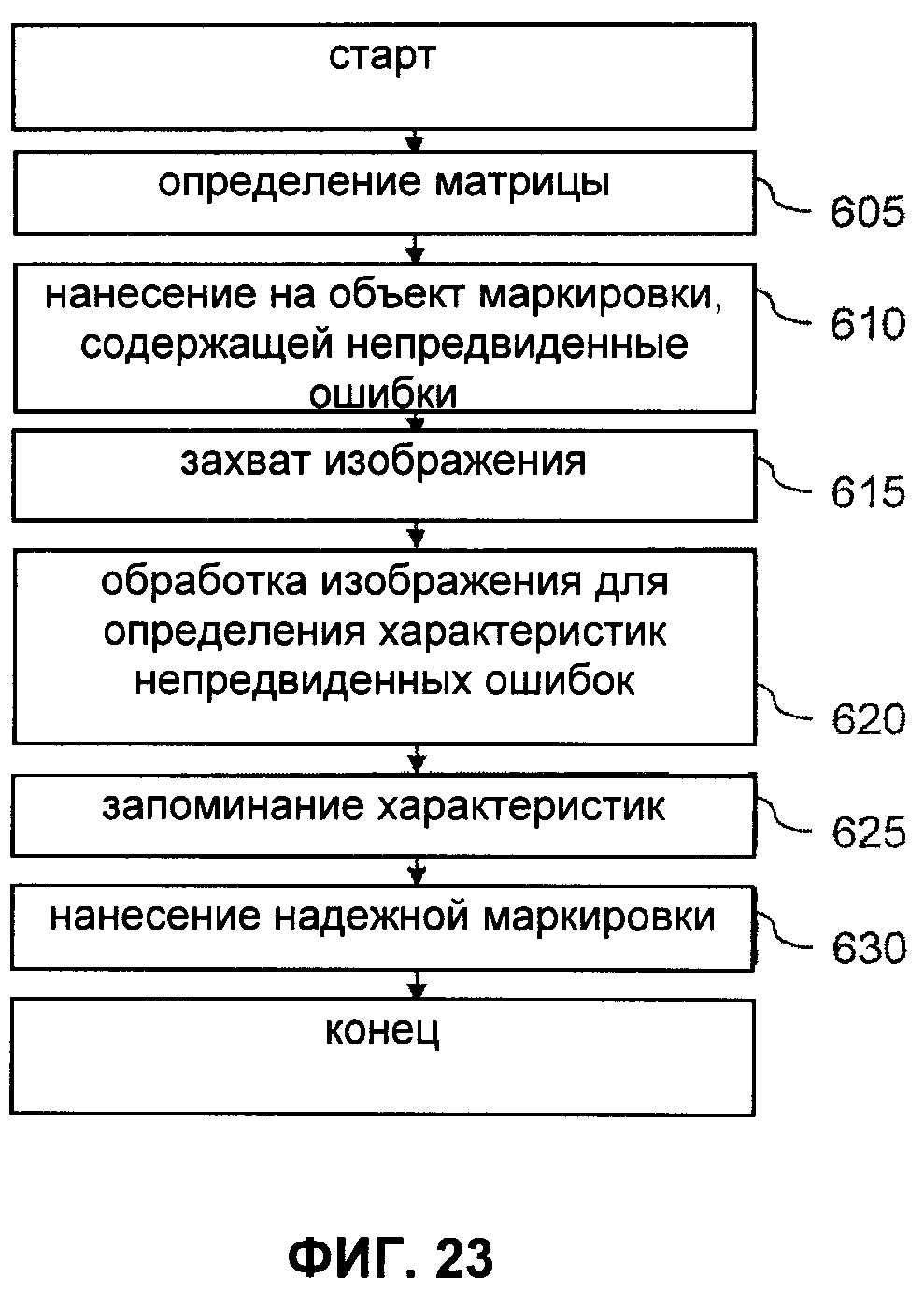
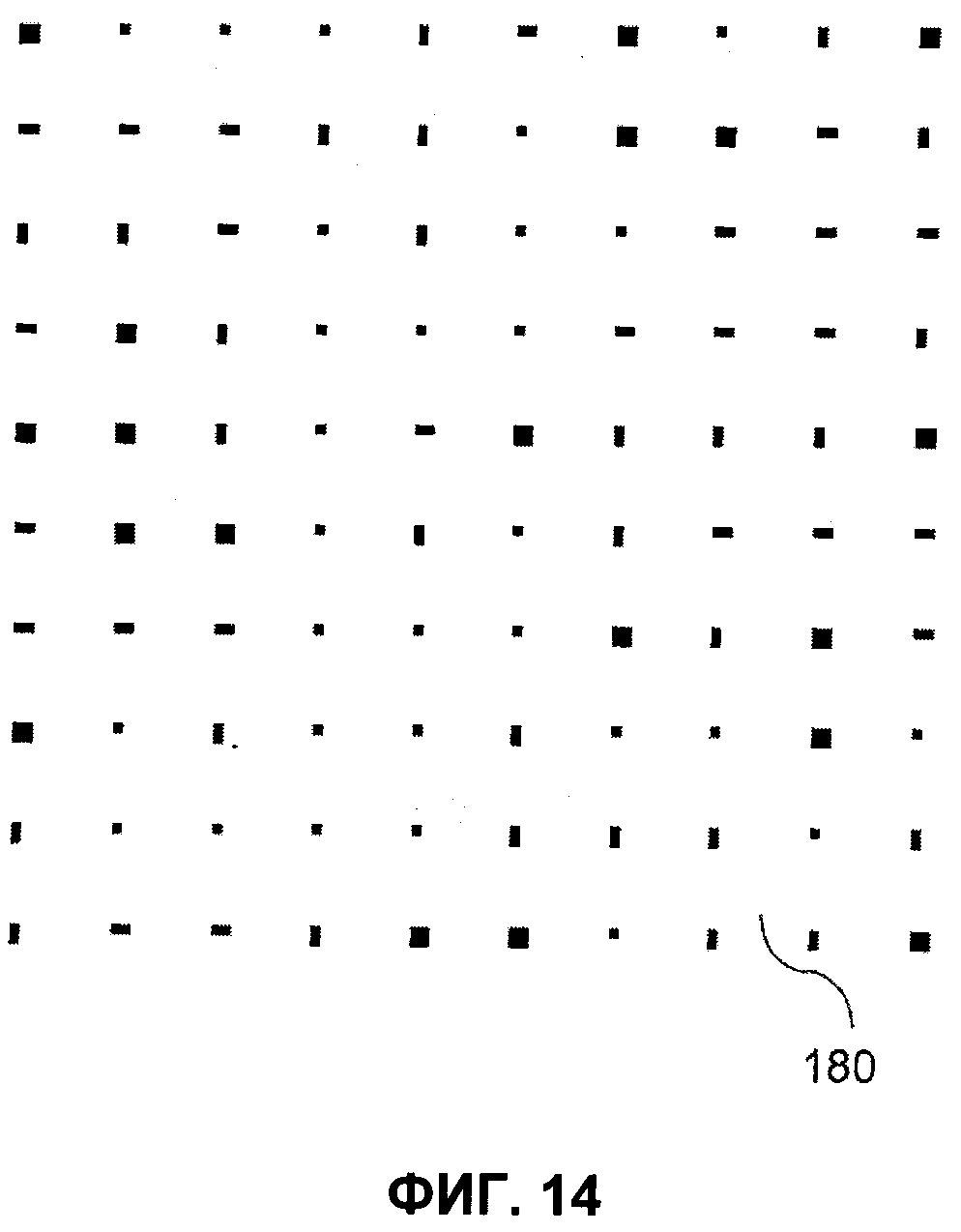


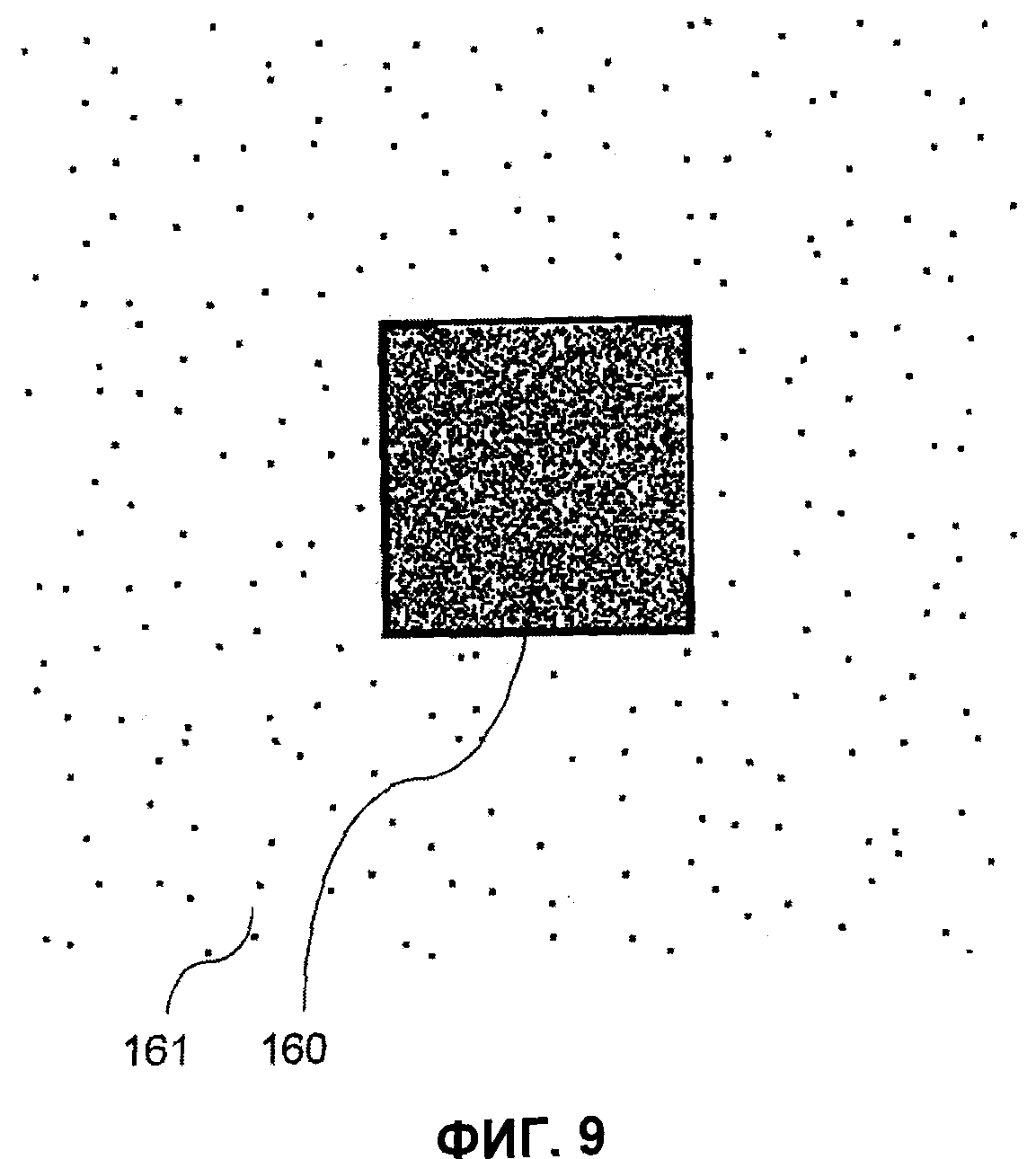

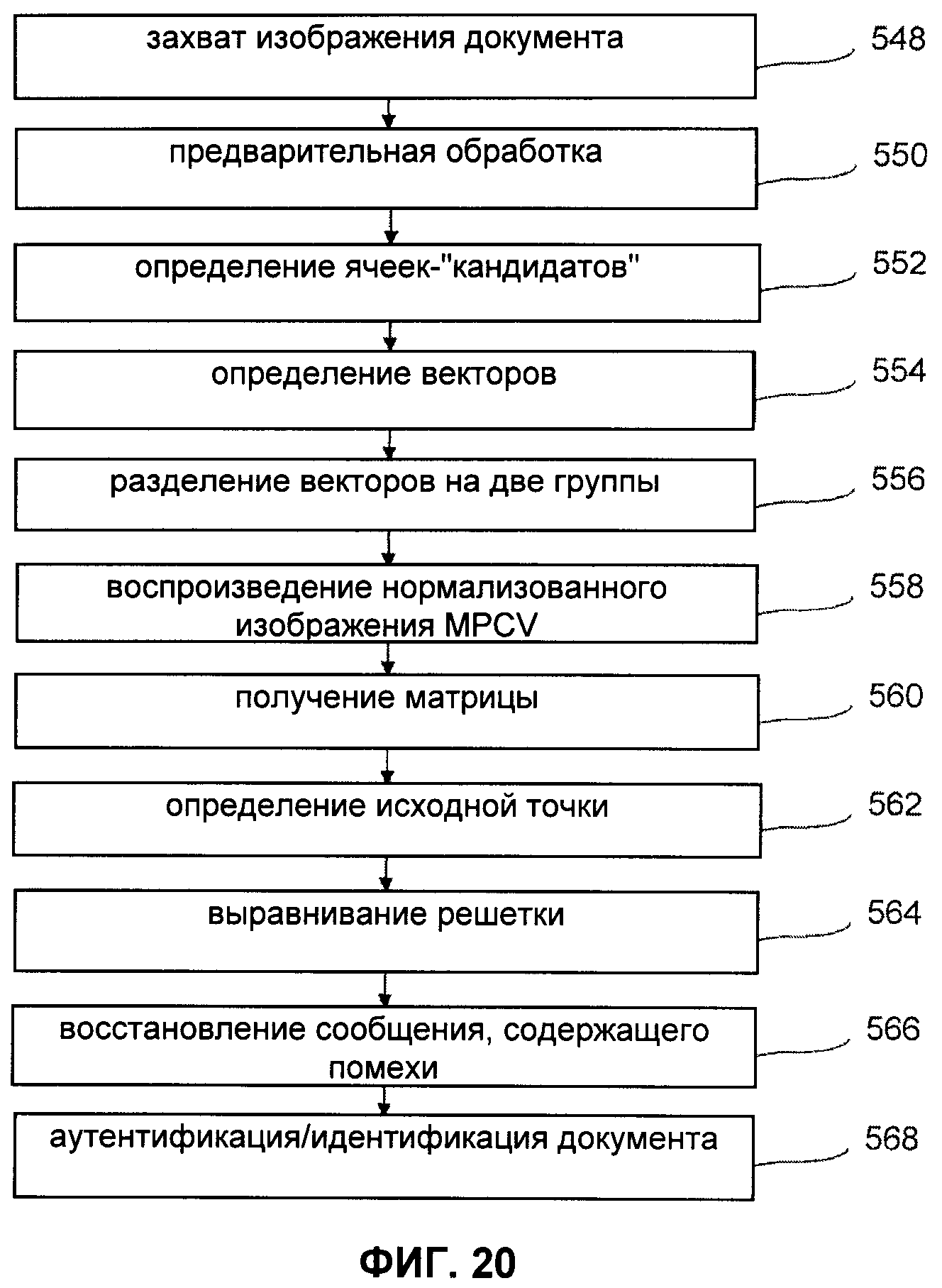

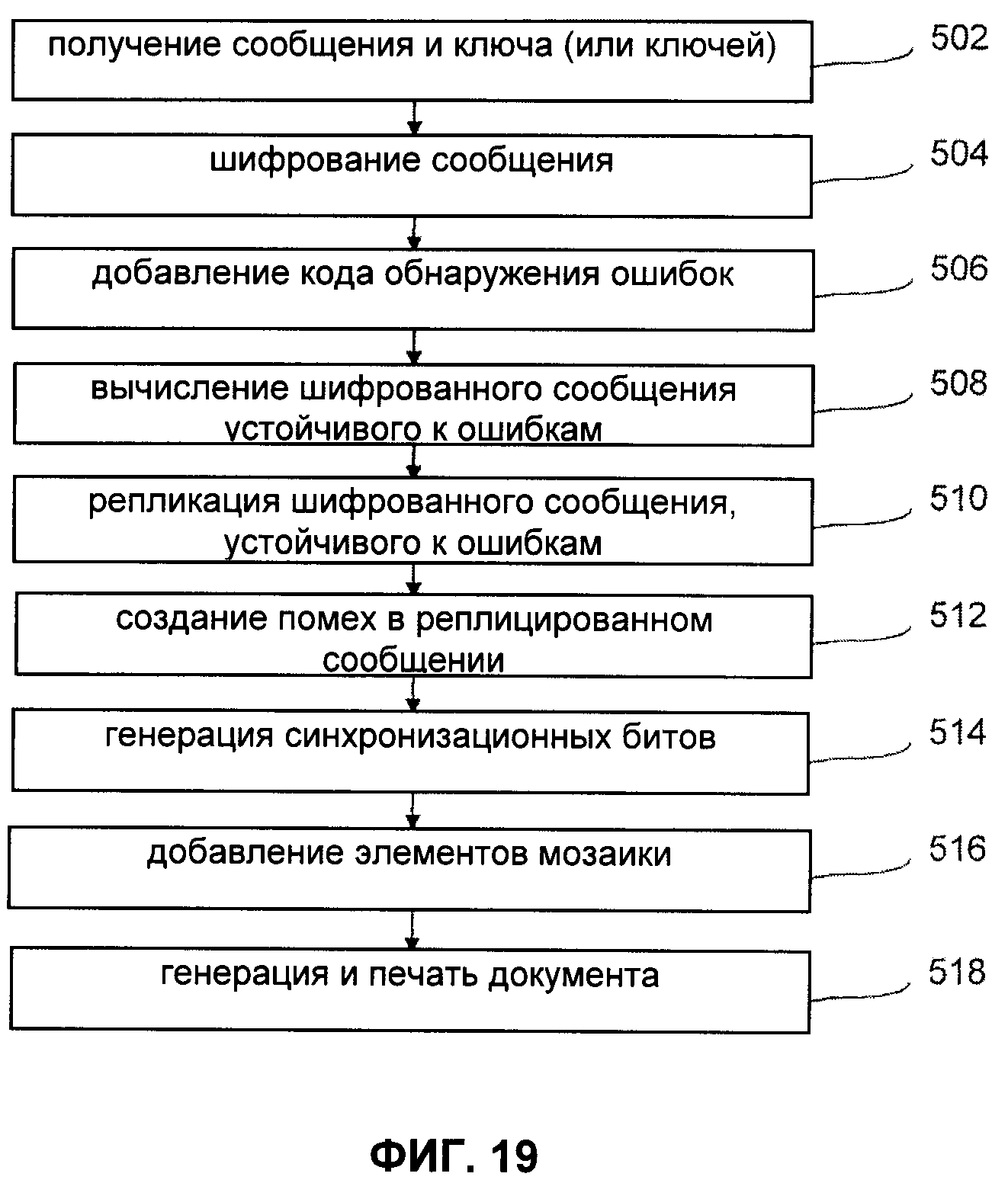
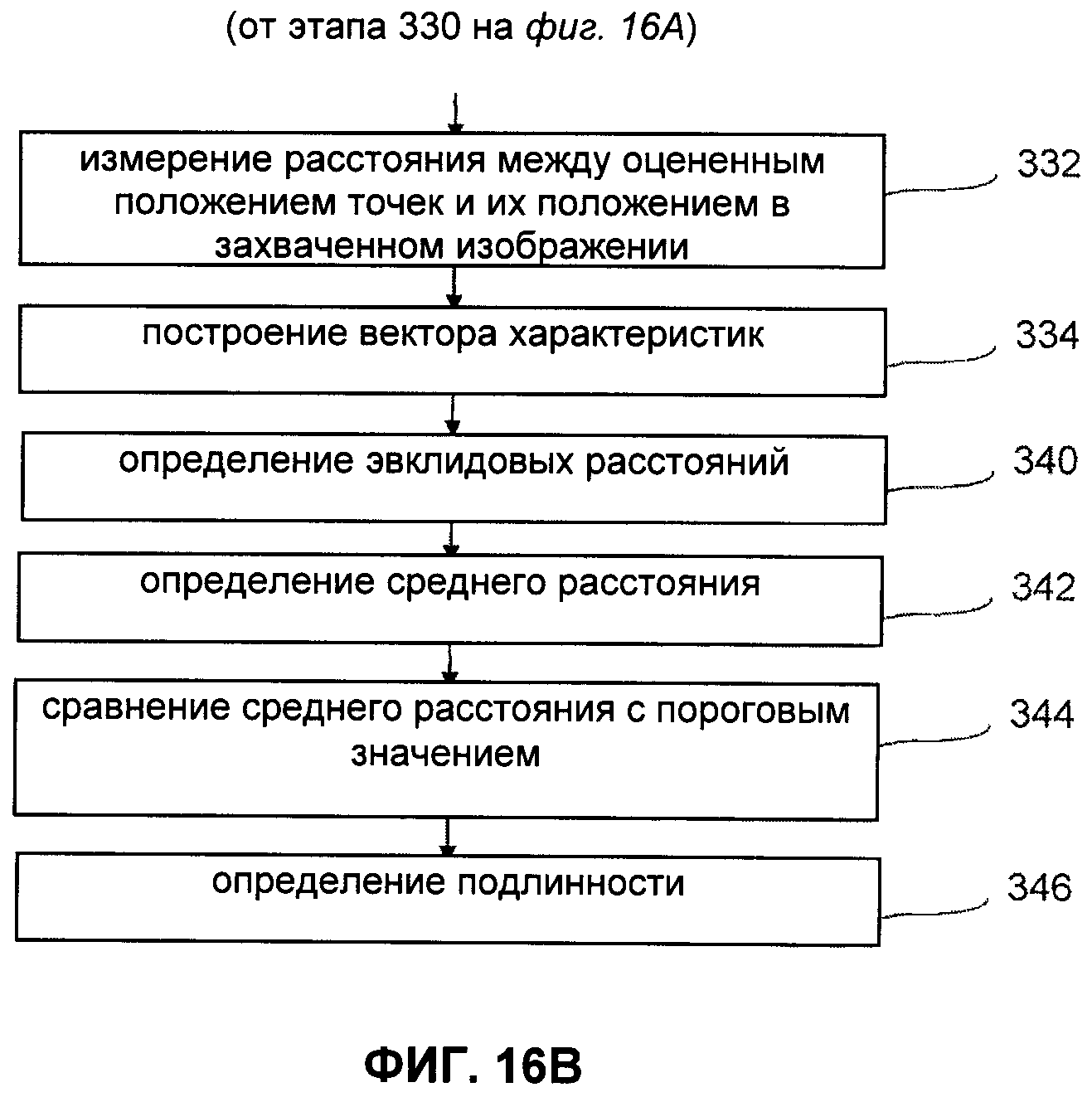
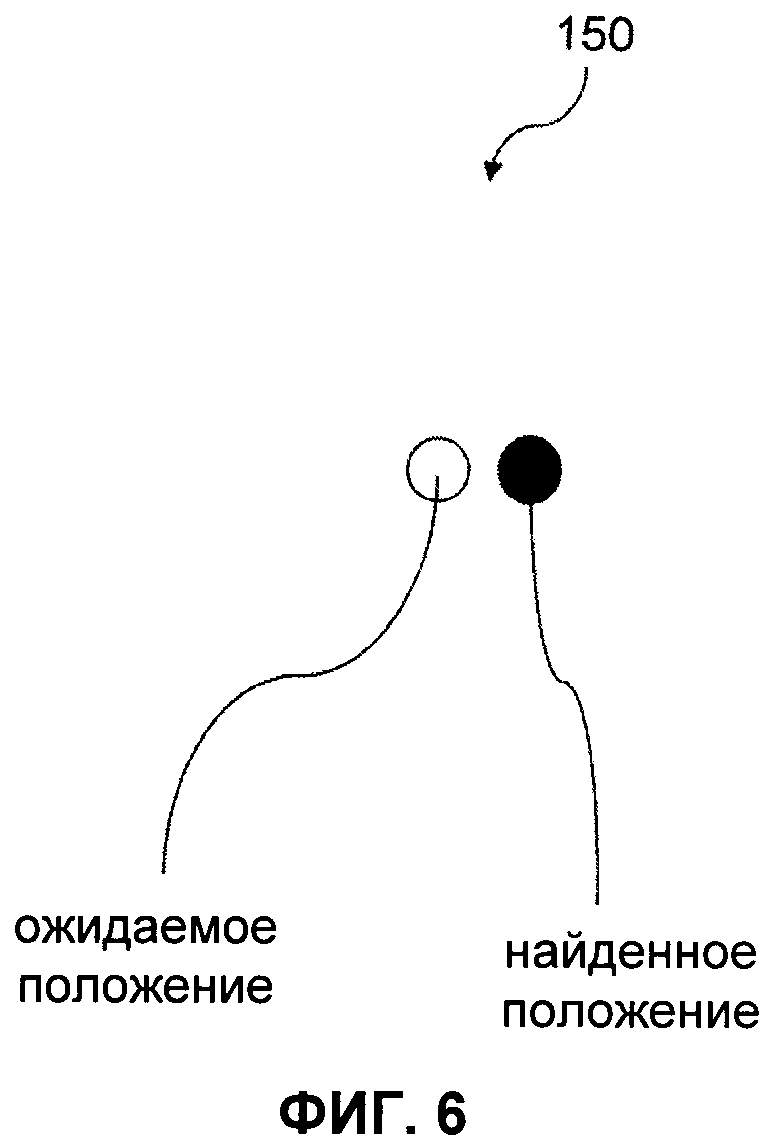
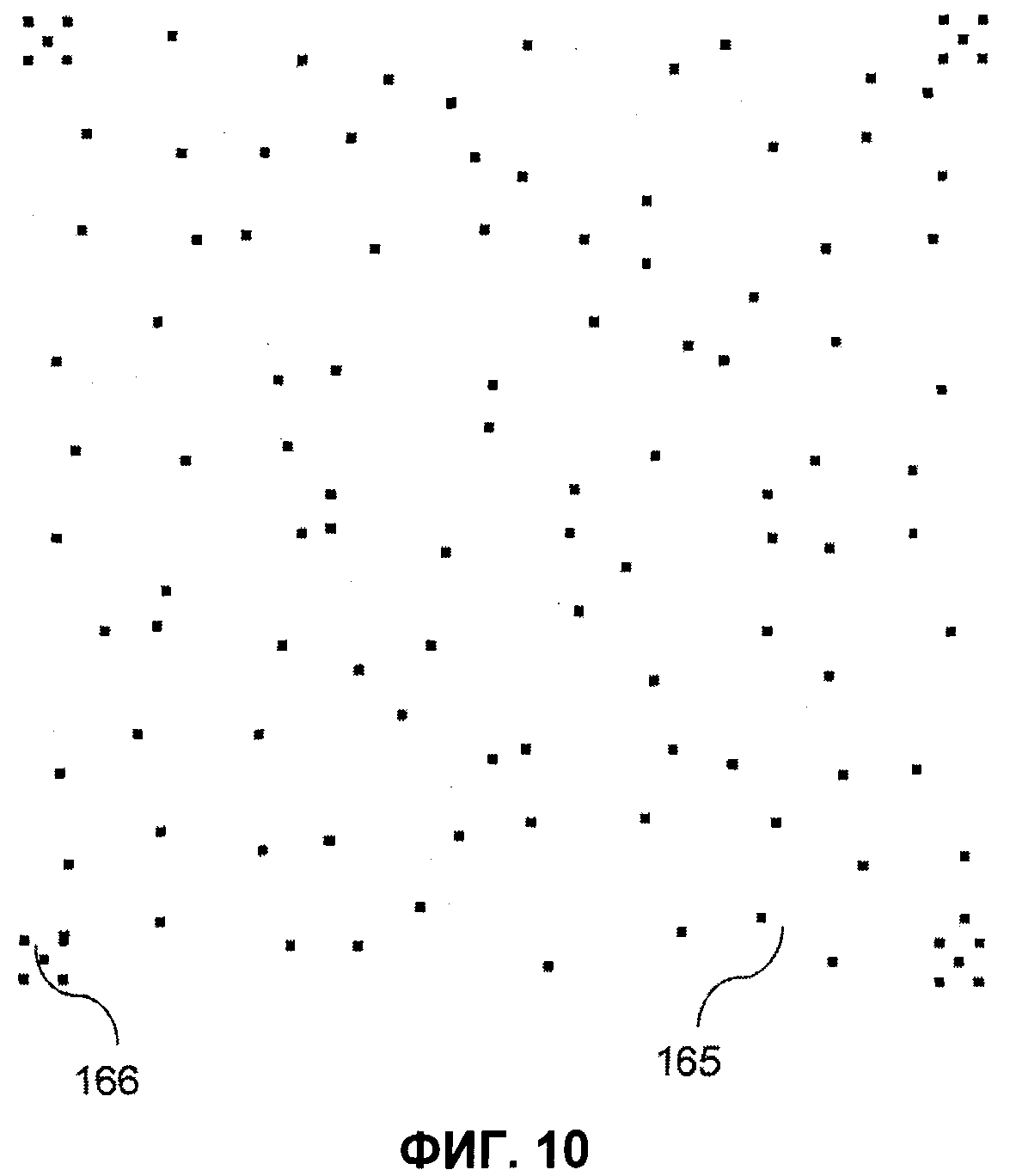
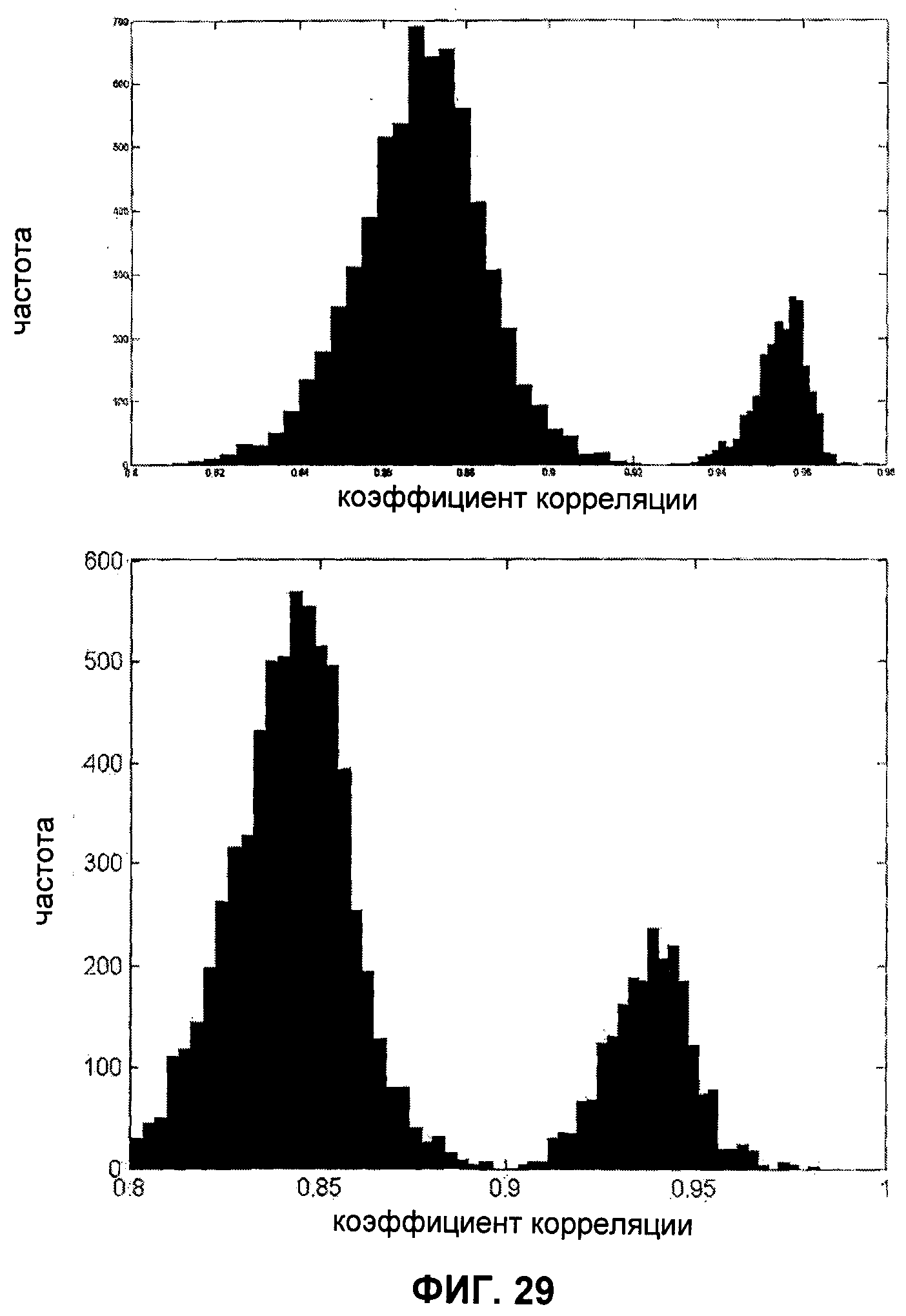
Способ и устройство для маркировки поверхности контролируемыми периодическими наноструктурами
Способ идентификации печатной формы документа и устройство для этой цели
Способ и устройство для аутентификации геометрического кода
Способ и устройство для считывания физических характеристик объекта
Способ и устройство для защиты и аутентификации документов
Способ и устройство для обеспечения безопасности документов
Способ и устройство для обеспечения защиты документов
Способ и устройство для маркировки поверхности контролируемыми периодическими наноструктурами
Способ идентификации печатной формы документа и устройство для этой цели
Способ и устройство для аутентификации геометрического кода
Способ и устройство для считывания физических характеристик объекта
Способ и устройство для защиты и аутентификации документов
Способ и устройство для обеспечения безопасности документов
Способ и устройство для обеспечения защиты документов

