Результат интеллектуальной деятельности: СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее изобретение относится к автоматизированному анализу текстовых документов и может быть использовано при разработке новых и совершенствовании существующих систем проверки текстовых документов на наличие в них фраз или частей текста из других документов.
Уровень техники
В настоящее время весьма остро стоит проблема так называемого перехвата данных. Такая проблема может встретиться в случае отслеживания документов, проходящих по сети компании, на предмет наличия в них конфиденциальной информации.
В настоящее время известно несколько систем или способов, позволяющих решить эту проблему.
Например, в патенте России №2420800 (опубл. 10.06.2011) раскрыт способ поиска похожих по смысловому содержимому электронных документов, в котором задают правила формирования уникальных слов, взвешивают уникальные слова и связи между ними, строят на основе этого семантическую сеть и сравнивают семантические сети документов. Этот способ достаточно трудоемок и пригоден лишь в ограниченной области.
В заявке на патент РФ №2007141666 (опубл. 20.05.2009) предложен способ сбора, обработки и каталогизации целевой информации из неструктурированных источников, в котором сравнивают лексические признаки документов с контрольными информационными признаками. Сходное решение представлено в заявке на патент Японии № 2008-257444 (опубл. 23.10.2008), которая описывает устройство, способ и программу для менеджмента сходных файлов. В этой заявке выделяют в файле особенности за счет использования предписанных выражений и вычисляют сходство между файлами путем сравнения этих особенностей. Эти способы также имеют лишь ограниченное применение.
В заявке на патент США №2010/0205525 (опубл. 12.08.2010) описан способ для автоматической классификации текста с помощью компьютерной системы, в котором определяют качественные характеристики слова и частоту появления этих характеристик в классифицируемом тексте. Этот способ также имеет ограниченное применение.
Патент США №6810375 (опубл. 26.10.2004), который можно считать ближайшим аналогом настоящего изобретения, раскрывает способ сегментации текста, в котором сегментируют проверяемый текст на клаузы из заранее заданного числа элементов и проверяют их сопряжение с паттернами, составленными по заранее заданным правилам. При этом на каждом шаге проверки перемещаются по строке элементов на одну или несколько позиций. Этот способ требует длительного времени на обработку и имеет ограниченное применение.
Раскрытие изобретения
Таким образом, существует потребность в расширении арсенала технических средств за счет создания сравнительно быстрого и универсального способа, который позволил бы выявлять в каком-либо документе выражения, фразы или даже текстовые отрывки из других документов и который бы преодолевал недостатки известных решений.
Для решения этой задачи и получения указанного технического результата в настоящем изобретении предложен способ автоматизированного анализа текстовых документов, заключающийся в том, что: преобразуют в заранее заданный формат все электронные файлы эталонных документов, выделяя в каждом из них осмысленные фрагменты, именуемые клаузами; сохраняют преобразованные электронные файлы эталонных документов в базе данных; преобразуют каждый электронный файл анализируемого документа в заранее заданный формат; выявляют совпадение выделенных клауз в электронном файле анализируемого документа с выделенными клаузами в электронных файлах эталонных документов; подсчитывают относительное число клауз в электронном файле анализируемого документа, совпавших с соответствующими клаузами каждого из электронных файлов эталонных документов; сравнивают найденные относительные числа совпадений с заранее заданным пороговым значением для выявления наличия в электронном файле анализируемого документа отрывков текста какого-либо из эталонных документов.
Особенность способа по настоящему изобретению состоит в том, что файл текстового документа может быть предварительно преобразован в бинарный поток, байты которого соответствуют значащим символам или знакам препинания используемого в упомянутом текстовом документе естественного языка.
Еще одна особенность способа по настоящему изобретению состоит в том, что преобразование электронного файла текстового документа в упомянутый заранее заданный формат могут осуществлять за счет того, что: заранее выделяют в каждом из используемых естественных языков множество его значащих символов, а также знаков препинания; выделяют из текста преобразуемого документа клаузы; удаляют из каждой клаузы незначащие символы; преобразуют все оставшиеся значащие символы каждой клаузы в нижний регистр, получая так называемый шингл; подсчитывают хэш-значение каждого шингла; помещают пару из подсчитанного хэш-значения каждого шингла и позиции этого шингла в документе в инвертированный индекс соответствующего документа, представляющий собой отсортированный список пар с идентификатором данного документа.
Еще одна особенность способа по настоящему изобретению состоит в том, что преобразование бинарного потока в упомянутый заранее заданный формат могут осуществлять за счет того, что: заранее выделяют в каждом из используемых естественных языков множество его значащих символов, а также знаков препинания; выделяют из текста преобразуемого документа клаузы; удаляют из каждой клаузы незначащие символы; преобразуют все оставшиеся значащие символы каждой клаузы в нижний регистр, получая так называемый шингл; подсчитывают хэш-значение каждого шингла; выбирают случайным образом из заранее заданного промежутка в каждом бинарном документе шинглы и их хэш-значения; помещают пару из подсчитанного хэш-значения каждого выбранного шингла и позиции этого шингла в документе в инвертированный индекс соответствующего документа, представляющий собой отсортированный список пар с идентификатором данного документа.
Наконец, еще одна особенность способа по настоящему изобретению состоит в том, что подсчет относительного числа совпадений, именуемого коэффициентом схожести, выполняют в соответствии с выражением:
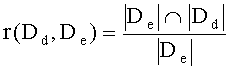 ,
,
где Dd - эталонный документ, De - анализируемый документ, |D| - количество найденных шинглов в документе D, r(Dd, De) - коэффициент схожести.
Краткое описание чертежей
На фиг.1 представлен пример текстового документа, к которому применяется способ по настоящему изобретению.
На фиг.2 представлена последовательность шинглов, полученных из документа по фиг.1.
Подробное описание изобретения
Настоящее изобретение может быть реализовано в любой вычислительной системе, например в персональном компьютере, на сервере и т.п. Для осуществления изобретения необходимо также наличие соответствующей базы данных, в которой хранятся электронные файлы текстовых документов.
Способ автоматизированного анализа текстовых документов по настоящему изобретению предназначен для осуществления так называемого копирайтного анализа (английский аналог - fingerprint detection), задачей которого является установление схожести бинарных и (или) текстовых документов документам, переданным ранее в базу данных (библиотеку) в качестве эталонных. Бинарные документы рассматриваются как поток байтов (бинарный поток), поэтому для документов этого класса определяется только мера схожести, выраженная как мера доли оцениваемого документа в эталонном документе (число от нуля до единицы). Для текстовых документов находятся также все общие для оцениваемого и эталонного документов фрагменты текстов с указанием их позиций в эталонном документе. Алгоритм работает с точностью до 80 значимых символов, за которые считаются символы алфавита и цифры. Согласно требованиям безопасности, тексты эталонных документов не сохраняются, что позволяет избежать их несанкционированного чтения.
Как правило, электронный файл текстового документа предварительно преобразуется в бинарный поток, байты которого соответствуют значащим символам или знакам препинания используемого в упомянутом текстовом документе естественного языка. Этот этап не является обязательным, поскольку при анализе документа, поступающего, скажем, по сети в виде уже сформированного потока байтов такого преобразования не потребуется.
Однако бинарный поток в способе по настоящему изобретению сначала трансформируется в специализированный формат для дальнейшей обработки. Предпочтительно такое преобразование бинарного потока в заранее заданный формат осуществляют следующим образом.
Поскольку в качестве языка анализируемого текстового документа могут использоваться разные естественные языки, сначала заранее в каждом из используемых естественных языков выделяют множество его значащих символов, а также знаков препинания. Например, в японском языке знаком окончания предложения является символ «o», а в испанском языке встречается знак «¿» в начале предложения. Всем таким значащим символам и знакам препинания конкретного языка ставят в соответствие определенные байты, совокупность которых образует основу для дальнейшей обработки текста на данном естественном языке. Этот предварительный этап осуществляют специалисты в автоматизированном режиме.
При поступлении документа на конкретном естественном языке на обработку по заявленному способу из этого текста выделяют так называемые клаузы, т.е. осмысленные фрагменты текста. Этот этап также осуществляют специалисты в автоматизированном режиме. Все дальнейшие этапы могут выполняться автоматически без участия операторов.
Из каждой выделенной клаузы удаляют все незначащие символы, например пробелы. Оставшиеся значащие символы каждой клаузы преобразуют в нижний регистр, т.е. заменяют заглавные буквы строчными, в результате чего получается так называемый шингл, т.е. байтовая строка. Для каждого шингла подсчитывают его хэш-значение с помощью заранее заданной хэш-функции, как это известно специалистам.
В каждом бинарном документе выбирают случайным образом из заранее заданного промежутка шинглы и их хэш-значения. Если же документ поступает на обработку уже в виде бинарного потока, этап этого выбора опускают. Затем помещают пару из подсчитанного хэш-значения каждого шингла и позиции этого шингла в документе в инвертированный индекс соответствующего документа, представляющий собой отсортированный список упомянутых пар с идентификатором данного документа. В данном описании под позицией шингла понимается указание на начало данного шимгла, отсчитанное от его конца. Именно поэтому индекс документа именуется инвертированным индексом.
Пример преобразования документа в такой формат приведен на фиг.1 и 2. На фиг.1 приведен отрывок примерного документа, а на фиг.2 показаны сформированные из этого документа шинглы.
Приведенный пример преобразования в заранее заданный формат служит лишь иллюстративным целям, и любые иные форматы также могут использоваться для преобразования клауз в шинглы. К примеру, клаузы могут иметь равную длину, либо в шинглах могут отмечаться особые признаки символов (заглавные буквы, пробелы и т.п.).
Рассмотренное выше (или любое иное возможное) преобразование выполняется над так называемыми эталонными документами. Это могут быть как заранее установленные документы, так и новые, поступающие на анализ уже в процессе работы, документы, которым присвоен статус эталонных. Сведения о таких эталонных документах, т.е. их инвертированные индексы, сохраняются в базе данных.
Когда поступает электронный файл любого анализируемого документа, его преобразуют в тот же заранее заданный формат. Далее выявляют совпадение выделенных клауз анализируемого документа с выделенными клаузами эталонных документов. Это можно осуществлять по совпадению рассмотренных выше шинглов с соответствующими шинглами эталонных документов, либо любым иным известным специалистам образом, например, так, как это делается в упомянутом патенте США №6810375.
При этом выявлении совпадений подсчитывают относительное число клауз в анализируемом документе, совпавших с соответствующими клаузами каждого из эталонных документов. Этот подсчет относительного числа совпадений, который именуется коэффициентом схожести, выполняют, например, в соответствии с выражением:
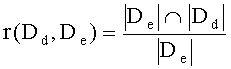 ,
,
где Dd - эталонный документ, De - анализируемый документ, |D| - количество найденных шинглов в документе D, r(Dd, De) - коэффициент схожести. Специалистам понятно, что такой подсчет можно проводить и иным способом, например, так, как в упомянутой заявке на патент США №2010/0205525.
После подсчета совпадений осуществляют сравнение найденных относительных чисел совпадений с заранее заданным пороговым значением для выявления наличия в анализируемом документе отрывков текста какого-либо из эталонных документов. При этом получают статистическую меру релевантности анализируемого документа с имеющимися эталонными документами.
При необходимости позицию клаузы в анализируемом документе, совпавшей с аналогичной клаузой в каком-либо эталонном документе, можно найти по ее инвертированному индексу.
Следует подчеркнуть, что сами эталонные документы хранятся в базе данных в виде упомянутых инвертированных индексов, что позволяет избежать их несанкционированного прочтения.
Таким образом, способ автоматизированного анализа текстовых документов по настоящему изобретению обеспечивает расширение арсенала технических средств и позволяет сравнительно быстро выявлять в каком-либо документе выражения, фразы или даже текстовые отрывки из других документов, преодолевая тем самым недостатки известных решений в виде ограниченности их применения.


Способ классификации документов по категориям
Способ обнаружения текстовых объектов
Способ автоматизированного определения языка и (или) кодировки текстового документа
Способ автоматизированного анализа выгрузок из баз данных
Способ автоматизированного поиска эталонных печатей
Способ автоматизированного анализа эталонных форм
Способ классификации документов по категориям
Способ обнаружения текстовых объектов
Способ автоматизированного определения языка и (или) кодировки текстового документа
Способ автоматизированного анализа выгрузок из баз данных
Способ автоматизированного поиска эталонных печатей
Способ автоматизированного анализа эталонных форм

