Результат интеллектуальной деятельности: Расширение частотной полосы и удаление шума в аудиозаписях речи
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Предложенное изобретение относится к области вычисления, в частности к способам обработки и анализа аудиозаписей. Изобретение может использоваться в различных устройствах, передающих, принимающих и генерирующих речевые записи для улучшения ощущений пользователя при прослушивании этих записей.
ОПИСАНИЕ УРОВНЯ ТЕХНИКИ
Проблема условной генерации речи, при обработке аудиосигнала, чрезвычайно важна с практической точки зрения. Обработка аудиосигнала применяется в том числе для расширения частотной полосы (BWE), улучшения речевого сигнала (SE, также именуемое подавление шума в речевом сигнале), и многих других. Один недавний успех в области условной генерации речи связан с применением генеративных состязательных сетей (Kumar et al., 2019; Kong et al., 2020). Генератор HiFi (Kong et al., 2020) недавно был предложен как полностью сверточная сеть высокой вычислительной эффективности, которая обеспечивает нейронное вокодирование речевых сигналов, причем качество речевого сигнала сравнимо с авторегрессивным аналогом, но на несколько порядков величины быстрее. Ключевой частью этой архитектуры является модуль слияния мультирецептивных полей (MRF), который позволяет моделировать разнообразные паттерны рецептивных полей. Благодаря регулировке параметров архитектуры HiFi можно достичь хорошего компромисса между вычислительной эффективностью и качеством выборки модели. Настоящее изобретение предлагает адаптировать известную модель HiFi (Kong et al., 2020) к задачам расширения частотной полосы и улучшения речевого сигнала за счет разработки нового генератора.
Расширение частотной полосы (Kuleshov et al., 2017; Lin et al., 2021) (также известное как сверхразрешение аудиосигнала) можно рассматривать как реалистическое увеличение частоты дискретизации сигнала. Полоса или частота дискретизации речевого сигнала может быть усечена вследствие низкого качества устройств записи или каналов передачи. Поэтому модели сверхразрешения играют важную практическую роль в электросвязи.
Несколько предыдущих работ (Birnbaum et al., 2019; Lin et al., 2021; Wang & Wang, 2020) посвящены проблеме расширения частотной полосы от формы волны к форме волны или посредством совместных временно-частотных нейронных архитектур, снабженных различными контролируемыми реконструкционными потерями. В работе Birnbaum et al. (2019) (TFiLM) предложен слой линейной модуляции по временным размерностям, который использует рекуррентную нейронную сеть для изменения активаций сверточной модели. Авторы применяли этот слой к сверточной нейронной архитектуре кодер-декодер, действующей в области формы волны (Kuleshov et al., 2017) и наблюдали значительные преимущества этих слоев для качества расширения частотной полосы. В работе Lin et al. (2021) (2S-BWE) рассмотрен двухстадийный подход к расширению частотной полосы. На первой стадии спектр сигнала прогнозируется либо временной сверточной сетью (TCN) (Bai et al., 2018), либо сверточной рекуррентной сетью (CRN) (Tan & Wang, 2018), тогда как на второй стадии необработанная форма волны уточняется моделью WaveUNet.
С другой стороны, подавление шума в аудиосигнале (Fu et al., 2019; Tagliasacchi et al., 2020) всегда представляет наибольший интерес среди специалистов по обработке аудиосигнала ввиду его важности и трудности. В этой задаче необходимо очистить исходный сигнал (чаще всего речь) от посторонних искажений.
Недавние работы по глубокому обучению темы образуют две линии исследования. Первая действует на уровне форм волны, или во временной области. В работе Stoller et al. (2018) предложено адаптировать модель UNet (Ronneberger et al., 2015) к одномерной обработке сигнала во временной области для решения проблемы разделения источников аудиосигнала, которая является общим случаем проблемы подавления шума в речевом сигнале. Предложенная архитектура сверточный кодер-декодер (CED) стала обычной для моделей нейронной сети улучшения речевого сигнала. Например, Pascual et al. (2017) следуют конвейеру состязательного обучения и используют сеть CED в качестве генератора, использующего полностью сверточный дискриминатор для обучения. Модель SEANet (Tagliasacchi et al., 2020) также решает проблему подавления шума в речевом сигнале и использует полностью сверточные архитектуры генераторов и дискриминаторов. В работе Defossez et al. (2020) предложена архитектура DEMUCS для проблемы подавления шума в речевом сигнале. DEMUCS (Dйfossez et al., 2019) является сетью CED с логически управляемыми свертками и модулями долгой краткосрочной памяти в части узкого места. Модель обучается с использованием совместных реконструкционных потерь во временной и частотной области. Недавно, Gulati et al. (2020) эффективно объединенные сверточные нейронные сети и преобразователи во временной области. Полученная модель называется Conformer и продемонстрировала самые современные характеристики в различных задачах обработки звука.
Некоторые работы не опираются на информацию временной области и вместо этого используют представление аудиосигнала в виде высокоуровневой спектрограммы. Многие подходы, образующие эту линию, используют метод спектрального маскирования, т.е. для каждой точки спектрограммы они прогнозируют действительнозначный мультипликативный коэффициент, заключенный в [0, 1]. Например, в документах MetricGAN (Fu et al., 2019) и MetricGAN+ (Fu et al., 2021) используется двунаправленный LSTM, объединенный со спектральным маскированием для непосредственной оптимизации объективных метрик общего качества речевого сигнала, достижения результатов уровня техники для этих метрик.
Предложенное изобретение может использоваться для расширения частотной полосы речевых записей и улучшения ощущений пользователя при прослушивании этих записей. Кроме того, предложенное изобретение можно использовать для подавления шума в речи, записанной в зашумленном окружении.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение решает задачи улучшения речевого сигнала в составе аудиосигнала и расширения частотной полосы аудиосигнала.
Предложенная система принимает на входе форму волны аудиосигнала, которая представляет собой последовательность действительных чисел, зашумленную или с уменьшенной частотной полосой и выводит чистую форму волны аудиосигнала (без шума, с высоким качеством). Технический эффект состоит в повышении качества аудиозаписи (аудиосигнал не содержит шум в случае задачи улучшения речевого сигнала или его частотная полоса увеличивается в случае задачи расширения частотной полосы). В объеме принципов настоящего изобретения рассматриваются улучшение речевого сигнала и расширение частотной полосы, однако следует отметить, что предложенный способ может обучаться для ослабления и других различных артефактов в аудиозаписях.
Предложенный способ, осуществляемый электронным устройством, может осуществляться с использованием модели искусственного интеллекта. Электронным устройством может быть любое подходящее электронное устройство, способное воспроизводить аудиосигнал. Нейронная сеть может быть реализована подходящими программными и аппаратными средствами, например, специализированным вычислительным устройством.
Модель искусственного интеллекта может обрабатываться специальным устройством обработки искусственного интеллекта, выполненным в качестве аппаратной структуры, приспособленной для обработки модели искусственного интеллекта. Модель искусственного интеллекта может быть получена путем обучения. Здесь, "полученный путем обучения" означает, что заранее заданный правило работы или модель искусственного интеллекта, выполненная с возможностью осуществления желаемой особенности (или цели), получается путем обучения базовой модели искусственного интеллекта множественными экземплярами обучающих данных согласно алгоритму обучения. Модель искусственного интеллекта может включать в себя несколько слоев нейронной сети. Каждый из нескольких слоев нейронной сети включает в себя несколько весовых значений и осуществляет нейронно-сетевое вычисление путем вычисления между результатом вычисления предыдущим слоем и несколькими весовыми значениями.
Ниже приведена общая формулировка задач расширения частотной полосы и улучшения речевого сигнала для аудиосигнала.
Для данного аудиосигнала  с низкой частотой дискретизации s, модель расширения частотной полосы служит для восстановления записи с высоким разрешением
с низкой частотой дискретизации s, модель расширения частотной полосы служит для восстановления записи с высоким разрешением 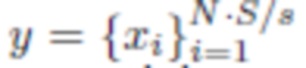 с частотой дискретизации S (т.е. расширения эффективной частотной полосы). x - численное представление входного аудиосигнала, xi - отдельные метки времени, содержащие аудиосигнал, N - количество меток времени, s - исходная частота дискретизации, S - целевая частота дискретизации, y - численное представление выходного сигнала. Обучающие и оценочные данные генерируются путем применения низкочастотных фильтров к сигналу с высокой частотой дискретизации с последующей понижающей дискретизацией сигнала до частоты дискретизации s:
с частотой дискретизации S (т.е. расширения эффективной частотной полосы). x - численное представление входного аудиосигнала, xi - отдельные метки времени, содержащие аудиосигнал, N - количество меток времени, s - исходная частота дискретизации, S - целевая частота дискретизации, y - численное представление выходного сигнала. Обучающие и оценочные данные генерируются путем применения низкочастотных фильтров к сигналу с высокой частотой дискретизации с последующей понижающей дискретизацией сигнала до частоты дискретизации s:
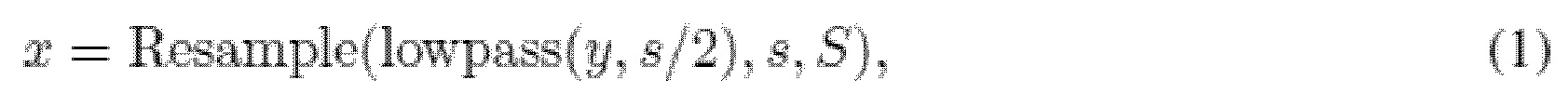
где lowpass (y, s/2) означает применение фильтра нижних частот с частотой отсечки s/2 (найквистовой частотой при частоте дискретизации s), Resample…, s, S) обозначает понижающую дискретизацию сигнала от частоты дискретизации S до частоты s. Согласно недавним работам (Wang & Wang, 2021; Sulun & Davies, 2020; Liu et al., 2021), тип фильтра нижних частот и порядок в ходе обучения рандомизируются для устойчивости модели.
При решении проблемы подавления шума в аудиосигнале, необходимо очистить исходный сигнал от посторонних искажений. В настоящем изобретении, аддитивный внешний шум означает искажение.
Говоря формально, выражая зашумленный сигнал в виде x=y+n, алгоритм подавления шума прогнозирует чистый сигнал y, т.е. подавляет шум n.
Предлагается способ обработки аудиосигнала, причем способ осуществляется на вычислительном устройстве, имеющем внутреннюю память, где хранится несколько форм волны аудиосигнала, причем способ содержит этапы:
извлечения формы волны аудиосигнала из внутренней памяти устройства или другого источника сигнала;
обработки формы волны аудиосигнала с помощью операции оконного преобразования Фурье для получения мел-спектрограммы;
обработки мел-спектрограмма с помощью модуля спектральной предобработки, который применяет двухмерные сверточные блоки к мел-спектрограмме, причем выходной сигнал модуля спектральной предобработки является первым тензором;
обработки первого тензора с помощью модуля полностью сверточной нейронной сети, что повышает временное разрешение обработанного первого тензора, причем выходной сигнал модуля полностью сверточной нейронной сети является вторым тензором, содержащим несколько одномерных последовательностей действительных чисел, длина которых согласуется с длиной упомянутой формы волны аудиосигнала;
конкатенации второго тензора с формой волны аудиосигнала, причем результирующий третий тензор содержит соединенные одномерные последовательности;
обработки третьего тензора одномерной сверточной нейронной архитектурой Unet во временной области, которая применяет одномерные свертки в нескольких масштабах третьего тензора во временном измерении, причем выходной сигнал одномерной сверточной нейронной архитектуры Unet во временной области является четвертым тензором, который состоит из 1d последовательностей;
обработки четвертого тензора обучаемым модулем спектрального маскирования, который применяет поканальное оконное преобразование Фурье (STFT) к четвертому тензору, и изменяет абсолютные величины коэффициентов STFT, причем выходной сигнал обучаемого модуля спектрального маскирования является пятым тензором;
обработки пятого тензора одномерным сверточным слоем, причем выходным сигналом одномерного сверточного слоя является выходная форма волны аудиосигнала.
Предложена система для обработки формы волны аудиосигнала на основе генератора GAN, содержащая следующие модули:
модуль спектральной предобработки (SpectralUnet), выполненный с возможностью:
- принимать входной аудиосигнал, преобразованный в мел-спектрограмму посредством операции оконного преобразования Фурье (STFT),
- применять двухмерные сверточные блоки Unet к мел-спектрограмму для очистки мел-спектрограммы от шума и восстанавливать высокие частоты;
модуль полностью сверточной нейронной сети (HiFi-генератор), выполненный с возможностью преобразования выходного сигнала, полученного из SpetralUNet, в область формы волны;
одномерный сверточный Unet нейронный модуль (WaveUNet) во временной области, выполненный с возможностью коррекции полученной формы волны во временной области;
обучаемый модуль спектрального маскирования (SpectralMaskNet), выполненный с возможностью коррекции выходного сигнала из WaveUNet в частотной области для удаления артефактов и шума, причем выходной сигнал из SpectralMaskNet, обработанный одномерным сверточным слоем, является скорректированной формой волны аудиосигнала.
WaveUNet принимает на входе выходной сигнал генератора HiFi, конкатенированный с формой волны входного аудиосигнала. Система дополнительно содержит по меньшей мере три идентичных полностью сверточных дискриминатора, сконфигурированных для обучения системы для расширения частотной полосы формы волны аудиосигнала. Система дополнительно содержит по меньшей мере три идентичных полностью сверточных дискриминатора, сконфигурированных для обучения системы для подавления шума в речевом сигнале формы волны аудиосигнала. Система дополнительно содержит по меньшей мере три идентичных полностью сверточных дискриминатора, сконфигурированных для обучения системы для подавления шума в речевом сигнале и расширения частотной полосы формы волны аудиосигнала. Дискриминаторы являются дискриминаторами SSD с уменьшенными количеством весов.
Предложен способ обработки формы волны аудиосигнала с использованием вышеописанной системы, причем способ осуществляется на вычислительном устройстве, причем способ содержит этапы:
приема формы волны аудиосигнала от источника сигнала;
обработки, посредством операций STFT, формы волны аудиосигнала для получения мел-спектрограммы;
применения, посредством SpectralUnet, двухмерных сверточных блоков Unet к мел-спектрограмме для очистки мел-спектрограммы от шума и восстановления высоких частот;
преобразования, посредством HiFi-генератора, выходного сигнала, полученного из SpetralUNet, в область формы волны;
конкатенации выходного сигнала генератора HiFi с формой волны аудиосигнала;
коррекции, посредством WaveUNet, выходной формы волны во временной области;
коррекции выходной формы волны в частотной области для удаления артефактов и шума, посредством SpectralMaskNet;
обработки выходного сигнала SpectralMaskNet одномерным сверточным слоем;
вывода скорректированной формы волны аудиосигнала.
Выходной сигнал SpectralUnet является первым тензором; причем этап преобразования посредством HiFi-генератора реализует повышение временного разрешения обработанного первого тензора, причем выходной сигнал HiFi-генератора является вторым тензором, содержащим несколько одномерных последовательностей длина которых согласуется с длиной упомянутой формы волны аудиосигнала; причем тензор, полученный в результате конкатенации, является третьим тензором, содержащим соединенные одномерные последовательности; причем этап коррекции посредством WaveUNet содержит обработку третьего тензора одномерной сверточной нейронной архитектурой Unet во временной области, которая применяет одномерные свертки на нескольких разрешениях третьего тензора во временном измерении, причем выходной сигнал одномерной сверточной нейронной архитектуры Unet во временной области является четвертым тензором, который состоит из 1d последовательностей; причем этап коррекции посредством SpectralMaskNet содержит обработку четвертого тензора обучаемым модулем спектрального маскирования, который применяет поканальное оконное преобразование Фурье (STFT) к четвертому тензору, и изменяет абсолютные величины коэффициентов STFT, причем выходной сигнал обучаемого модуля спектрального маскирования является пятым тензором.
Способ дополнительно содержит этап обработки пятого тензора одномерным сверточным слоем причем выходным сигналом одномерного сверточного слоя является выходная форма волны аудиосигнала. Способ дополнительно содержит этап обучения суммой состязательных функций потерь, функций потерь на согласование особенностей и мел-спектрограммных функций потерь, причем состязательные потери и потери на согласование особенностей вычисляются посредством по меньшей мере трех идентичных полностью сверточных дискриминаторов.
ЧЕРТЕЖИ
Вышеупомянутые и/или другие аспекты будут более понятны из нижеследующего описания иллюстративных вариантов осуществления со ссылкой на прилагаемые чертежи, в которых:
фиг. 1 демонстрирует архитектуру HiFi++ и обучающий конвейер.
Фиг. 2 демонстрирует архитектуру модуля SpectralUNet.
Фиг. 3 демонстрирует архитектуру HiFi.
Фиг. 4 демонстрирует блоки генератора HiFi.
Фиг. 5 демонстрирует архитектуру модуля WaveUNet.
Фиг. 6 демонстрирует обучающий конвейер архитектуры HiFi++.
ПОДРОБНОЕ ОПИСАНИЕ
Предложенный способ позволяет расширять частотную полосу речевых записей за счет соответствующего обучения нейронной модели и улучшать ощущения пользователя при прослушивании этих записей.
Кроме того, способ можно использовать для подавления шума в речи, записанной в зашумленном окружении, посредством другого процесса обучения нейронной модели. Технический эффект по сравнению с аналогичными методами состоит в том, что способ обеспечивает более удачный компромисс между качеством генерируемой речи и размером модели и имеет более низкую вычислительную сложность. Предложенное изобретение обеспечивает более высокое качество, которое измеряется на основании реакции людей-аннотаторов на улучшение речевого сигнала и расширение частотной полосы, по сравнению с аналогичными методами и имеет меньше параметров, что позволяет использовать меньше ресурсов памяти.
Предложенное изобретение принимает на входе зашумленную, или с уменьшенной частотной полосой, форму волны аудиосигнала (форма волны аудиосигнала представляет собой длинный вектор действительных чисел, которые представляют амплитуды аудиосигнала (громкость) в течение короткого периода времени) и выводит чистую форму волны аудиосигнала высокого качества без шума.
В заявке используются следующие термины:
1. Операция оконного преобразования Фурье (STFT) представляет собой последовательность преобразований Фурье оконного сигнала. STFT обеспечивает в качестве выходного сигнала локализованную по времени частотную информацию для ситуаций, в которых частотные компоненты сигнала изменяются со временем. Оконное преобразование Фурье широко используется для обработки речи, поскольку эти сигналы обычно представляют собой гармонические структуры.
2. Мел-спектрограмма представляет собой амплитудную STFT-спектрограмму, преобразованный к частотной шкале мелов, которая определяется как перцептивная шкала основных тонов, которые слушатели ощущают равноотстоящими друг от друга. Мел-спектрограмма обычно имеет более низкую размерность в частотном измерении, чем входная спектрограмма, и доказала свою полезность в качестве промежуточного представления для систем преобразования аудиосигнала.
3. Генеративно-состязательные сети (GANs) являются широко используемым типом нейронный генеративной модели. GAN состоят из генераторных и дискриминаторных нейронных сетей, которые состязаются друг с другом. Генераторная сеть обучается отображению из исходной области в целевую область, тогда как дискриминатор обучается отличать реальные объекты от сгенерированных в целевой области. Таким образом, дискриминатор предписывает генератору вырабатывать выборки, неотличимые от реальных.
Известный генератор HiFi (Kong et al., 2020) недавно был предложен в качестве полностью сверточной сети с высокой вычислительной эффективностью, которая обеспечивает нейронное вокодирование речевых сигналов, причем качество речевого сигнала сравнимо с авторегрессивным аналогом, но на несколько порядков величины быстрее. Ключевой частью этой архитектуры является модуль слияния мультирецептивных полей (MRF) (Kong, J., Kim, J., & Bae, J. (2020). Hifi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33, 17022-17033), которая позволяет моделировать разнообразные паттерны рецептивных полей. Благодаря регулировке параметров архитектуры HiFi можно достичь хорошего компромисса между вычислительной эффективностью и качеством выборки модели.
В настоящем изобретении, модель HiFi (Kong et al., 2020) адаптирована к задачам расширения частотной полосы и улучшения речевого сигнала (подавления шума в речевом сигнале) за счет конструирования нового генератора и оптимизации нейронных дискриминаторных сетей.
Kong et al. (2020); You et al. (2021) утверждают, что успех модели HiFi по большей части обусловлен инструментарием дискриминации с несколькими уровнями разрешения. Это изобретение демонстрирует, что этот инструментарий можно значительно упростить до нескольких абсолютно идентичных дискриминаторов, действующих при одном и том же разрешении и обеспечивающих при этом сравнимое качество. Таким образом, успех дискриминаторов с несколькими уровнями разрешения в основном связан с эффектом генеративных мультисостязательных сетей (Durugkar et al., 2016), т.е. использованием нескольких дискриминаторов в ходе состязательного обучения. Помимо принципиального упрощения инструментария дискриминации, количество параметров дискриминаторов и их вычислительная сложность уменьшается, облегчая ускоренное обучение.
Ключевой вклад предложенного изобретения состоит в новой архитектуре генератора HiFi++, которая позволяет эффективно адаптировать генератор HiFi-GAN к расширению частотной полосы и улучшению речевого сигнала аудиозаписи. Предложенная архитектура базируется на известном генераторе HiFi с добавлением новых модулей. В частности, в архитектуру генератора вводятся спектральная предобработка (SpectralUnet), сеть сверточных кодеров-декодеров (WaveUNet) и модули обучаемого спектрального маскирования (SpectralMaskNet). Снабженный этими модификациями, предложенный генератор может успешно применяться для решения задач расширения частотной полосы и улучшения речевого сигнала. Модель является значительно более облегченной, чем испытанные аналоги, хотя и имеющие более высокое качество.
Настоящее изобретение вносит следующие вклады:
1. Предложена система для обработки аудиосигнала на основе архитектуры генератора HiFi++, которая обеспечивается введением трех дополнительных модулей в генератор HiFi-GAN: подсетей SpectralUnet, WaveUNet и SpectralMaskNet. Эта новая архитектура генератора позволяет построить унифицированный инструментарий для расширения частотной полосы и улучшения речевого сигнала, доставляющую результаты уровня техники в этих областях.
2. Описана важность инструментария дискриминации с несколькими уровнями разрешения для условной генерации форма волны и предложены новые дискриминаторы, легкие, простые и быстрые, но в то же время способные обеспечивать качество, сравнимое с исходными дискриминаторами HiFi.
Фиг. 1 демонстрирует архитектуру HiFi++ и обучающий конвейер после блока “выходной аудиосигнал”. Архитектура HiFi++ по сравнению с генератором HiFi дополнительно имеет следующие модули (подсети): SpectralUNet, WaveUNet и SpectralMaskNet. Генератор HiFi++ базируется на части HiFi, на вход которой поступает представление мел-спектрограммы, обогащенное посредством SpectralUnet, и его выходной сигнал проходит через модули постобработки: WaveUNet корректирует выходную форму волны во временной области, тогда как SpectralMaskNet очищает его в частотной области.
Раскрыта конкретная архитектура нейронной сети, где гиперпараметры нейронных модулей заданы равными конкретным числам, однако специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретным выбором гиперпараметров.
Предложенная система установлена, и предложенный способ действует на любом подходящем электронном вычислительном устройстве, имеющем внутреннюю память, где хранится форма волны аудиосигнала. Форма волны аудиосигнала может извлекаться пользователем из памяти устройства или из интернета, или из аудиозаписи, осуществляемой пользователем в настоящее время или из другого подходящего источника. Введенная форма волны аудиосигнала (которая является вектором действительных чисел, которые представляют амплитуды аудиосигнала в течение короткого периода времени) обрабатывается посредством операции оконного преобразования Фурье (“STFT и шкала мел” на фиг. 1 и 6) для получения мел-спектрограммы, которая является входной мел-спектрограммой для генератора HiFi++.
Модуль SpectralUNet вводится как предшествующая часть генератора HiFi++, которая принимает входную мел-спектрограмму (см. фиг. 1), которая является тензором. Мел-спектрограмма имеет двухмерную структуру, и двухмерные сверточные блоки модели SpectralUnet предназначены для облегчения работы с этой структурой на начальной стадии преобразования мел-спектрограммы. Идея состоит в том, чтобы упростить задачу для оставшейся части генератора HiFi++, которая должна преобразовывать это 2d представление в 1d последовательность. Модуль SpectralUNet сконструирован как UNet-подобная архитектура с 2d свертками.
фиг. 2 демонстрирует архитектуру описанного ниже модуля SpectralUNet.
Экспериментально было установлено, что, применительно к настоящему изобретению, модуль SpectralUNet может быть преимущественно включен в качестве части предварительной обработки, которая подготавливает входную мел-спектрограмму, корректируя и извлекая из нее информацию, необходимую для расширения частотной полосы и улучшения речевого сигнала. Например, SpectralUNet может неявно извлекать чистую мел-спектрограмму из зашумленной в случае улучшения речевого сигнала или восстанавливать высокие частоты в случае расширения частотной полосы. SpectralUNet осуществляет обработку в спектральной области. Выходной сигнал модуля спектральной предобработки является первым тензором, поступающим на вход модуля полностью сверточной нейронной сети - генератора HiFi.
Модуль генератора HiFi является модулем полностью сверточной нейронной сети, детально изображенным на фиг. 3. Модуль генератора HiFi осуществляет обработку и выводит данные в области формы волны (времени). Генератор является полностью сверточной нейронной сетью. Он обрабатывает выходной сигнал модуля SpeсtralUNet последовательностью транспонированных сверток, каждая из которых сопровождается модулем слияния мультирецептивных полей (MRF) (см. фиг. 4). Каждая транспонированная свертка увеличивает временное разрешение обработанного тензора с коэффициентами (шагами), указанными на фиг. 3.
Мел-спектрограмма имеет более низкое временное разрешение, чем форма волны (которое может регулироваться параметрами мел-спектрограммы, например, можно использовать размер скачка, равный 256, размер окна, равный 1024, и количеством мел-частотных бинов, равным 128. Такие параметры соответствуют в 256 раз более низкому временному разрешению мел-спектрограммы по сравнению с формой волны), число транспонированных сверток и длину их шагов следует выбирать так, чтобы разрешение тензора, выработанный генератором HiFi, было равно разрешению формы волны.
Количество транспонированных сверток также влияет на количество параметров и вычислительную сложность генератора HiFi++. Предложенное изобретение не ограничивается конкретным количеством транспонированных сверток и длин шагов.
На фиг. 3, Conv1d и ConvTranspose1d обозначают, в порядке примера, одномерную свертку и одномерную транспонированную свертку, соответственно, с размерами ядра, шагами и коэффициентами растяжения (стандартными параметрами), указанными на фигуре, LeakyReLU является стандартной функцией активации (нелинейность). Специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретным выбором размера ядра, шага и коэффициентов растяжения.
На фиг. 4 показан пример схемы модуля слияния мультирецептивных полей (MRF). Модуль состоит из нескольких сверточных остаточных блоков (ResBlock) с различными размерами ядра и коэффициентами растяжения для моделирования разнообразных паттернов рецептивных полей. Количество ResBlock-ов влияет на размер модели. Чем больше количество ResBlock-ов, тем больше размер модели и выше качество речевого сигнала и шире частотная полоса модели. Поэтому нужен компромисс между размером и качеством модели. На фиг. 4 количество ResBlock задано равным 3, причем размеры ядра и коэффициенты растяжения указаны на фиг. 3 в порядке примера, и принцип изобретения не ограничивается конкретными размером ядра, шагом и коэффициентами растяжения. Структура единичного ResBlock также указана на фиг. 4.
ResBlock состоит из одномерной свертки (Conv1d) и функции активации LeakyReLU (понятие остаточных блоков было введено в He K. et al. Deep residual learning for image recognition //Proceedings of the IEEE conference on computer vision and pattern recognition. - 2016. - С. 770-778). На вход ResBlock поступают промежуточные тензоры, полученные на предыдущих стадиях обработки. Транспонированные свертки (ConvTranponse1d, указанные на фиг. 3) генератора HiFi увеличивают временное разрешение входного тензора, благодаря чему результирующий второй тензор на выходе модуля HiFi в целом имеет размерность 8xT, то есть 8 последовательностей действительных чисел, причем длина этих последовательностей равна длине входной формы волны. Эти 8 последовательностей образуют промежуточный тензор. Заметим, что количество блоков conv1d не влияет на размерность указанного тензора. Размерность тензора определяется количеством выходных каналов последней свертки. Целью этого модуля является преобразования представлений, полученных из SpetralUNet, в область формы волны. Структура каждого ResBlock, показанная на фиг. 4, хорошо известна для нейронных сетей (см., например, He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778)).
Все значения на фиг. 4 указаны в порядке примера, и специалистам в данной области техники будет очевидно, что принцип изобретения не ограничивается конкретными примерами.
Далее, результирующий второй тензор конкатенируется с начальной формой волны аудиосигнала оператором конкатенации (пунктирный стрелка от “аудиосигнал” до стрелки между “генератор Hi-Fi” и “WaveUNet” на фиг. 1), давая третий тензор, и далее третий тензор обрабатывается моделью WaveUNet, т.е. одномерной сверточной нейронной архитектурой Unet во временной области. Одномерная сверточная нейронная архитектура Unet во временной области, показанная в нижней части фиг. 1 как архитектура UNet с 1d свертками, принимает на входе выходной сигнал подмодуля генератора HiFi, конкатенированный с начальной формой волны аудиосигнала, для объединения информации, извлеченной из мел-спектрограммы, с информацией, содержащейся в начальной форме волны аудиосигнала, поскольку мел-спектрограмма не содержит полной информации о начальной форме волны аудиосигнала. Входной третий тензор, подаваемый на одномерную сверточную нейронную архитектуру Unet во временной области, является тензором, содержащим несколько одномерных последовательностей, причем каждая последовательность имеет такую же длину, как начальная форма волны аудиосигнала. Модель WaveUNet обрабатывает входной третий тензор с разными разрешениями, причем такой тип обработки облегчается за счет многомасштабной структуры модели WaveUNet. Каждый уровень многомасштабной структуры построен из блоков повышающей дискретизации и понижающей дискретизации, соответствующих друг другу, которые обрабатывают информацию с конкретным разрешением. Все пары соответствующих блоков повышающей дискретизации и понижающей дискретизации образуют многомасштабную структуру. Многомасштабная структура обрабатывает тензоры с разными разрешениями. Выходным сигналом многомасштабной структуры является обработанный четвертый тензор. Обработка тензора блоками понижающей дискретизации и блоками повышающей дискретизации является известной стандартной процедурой, используемой для различных задач в уровне техники.
Фиг. 5 содержит схему модуля нейронной сети WaveUNet генератора HiFi++.
Модуль WaveUNet располагается после части HiFi и действует непосредственно во временной области и может рассматриваться как механизм постобработки во временной области, который улучшает выходной сигнал части HiFi, обрабатывая ее одновременно с входной формой волны (обеспеченный в форме третьего тензора). Модуль WaveUNet является примером общеизвестной архитектуры WaveUNet (Stoller et al., 2018), которая представляет собой полностью сверточную 1D-UNet-подобную нейронную сеть. Этот модуль выводит четвертый двухмерный тензор.
Заметим, что предложенное изобретение использует стандартные полностью сверточные многомасштабные архитектуры кодер-декодер для сетей WaveUNet и SpectralUNet (понятие Unet было введено в Ronneberger O., Fischer P., Brox T. U-net: Convolutional networks for biomedical image segmentation //International Conference on Medical image computing and computer-assisted intervention. - Springer, Cham, 2015. - С. 234-241). Архитектуры этих сетей изображены на фиг. 5 и 2.
Согласно фиг. 5, каждый блок понижающей дискретизации модели WaveUNet осуществляет понижающую дискретизацию (например, понижающую дискретизацию с коэффициентом 4) третьего тензора во временном измерении. Аналогично, согласно фиг. 2, каждый блок понижающей дискретизации в SpectralUNet прореживает мел-спектрограмму (например, осуществляет понижающую дискретизацию с коэффициентом 2) во временном и частотном измерениях (для каждого измерения). Значения ширины W1, W2, W3, W4 и параметры глубины блока определяют количество параметров и вычислительную сложность результирующих сетей.
Входным сигналом модуля WaveUNet является третий тензор, содержащий соединенные одномерные последовательности после конкатенации второго тензора с формой волны аудиосигнала. Как упомянуто выше, выходной сигнал (второй тензор) модуля генератора HiFi (модуля полностью сверточной нейронной сети) конкатенируется с начальной формой волны аудиосигнала для объединения информации, извлеченной из мел-спектрограммы, с информацией, содержащейся в форме волны аудиосигнала, поскольку не содержит полной информации о входном сигнале. Создание и обработка мел-спектрограммы позволяет использовать информацию спектральной области в ходе обработки аудиосигнала. С другой стороны, конкатенация объединяет информацию, извлеченную в спектральной области, с необработанной формой волны, что позволяет модели осуществлять совместную обработку аудиосигнала во временно-частотной области в модуле WaveUNet.
Третий тензор представляет собой тензор, содержащий 9 одномерных последовательностей, причем каждая последовательность имеет такую же длину, как начальная форма волны аудиосигнала. Третий тензор обрабатывается последовательностью сверточных остаточных блоков. Модуль WaveUNet обрабатывает входной третий тензор с разными разрешениями, причем такой тип обработки облегчается многомасштабной структурой нейронной сети WaveUNet, которая использует сверточные блоки понижающей дискретизации совместно со сверточными блоками повышающей дискретизации и перепускные соединения конкатенации (что является стандартной WaveUNet нейронная архитектура). Каждый сверточный блок имеет некоторую ширину, которая выражается количеством каналов в сверточных слоях, содержащих блок. Значения ширины W1, W2, W3, W4 блока, указанные на фиг. 4, равны 10, 20, 40, 80 (специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретным выбором значений ширины блока. Значения ширины могут изменяться, влияя на размер модели), соответственно. Числа 10, 20, 40, 80 указывают параметры архитектуры модели WaveUNet. В частности, они указывают количество каналов, используемых в сверточных слоях в блоках (значения ширины блока). Выходной сигнал одномерной сверточной нейронной архитектуры Unet во временной области (нейронной сети WaveUNet) является четвертым тензором, который состоит из 1d последовательностей.
Модуль SpectralMaskNet (обучаемый модуль спектрального маскирования) (показанный в нижней части фиг. 1 - архитектура UNet с 1d свертками принимает на входе выходной сигнал модуля WaveUNet (четвертый тензор), который является тензором с формой 8xT, где T - длина входной формы волны. Она применяет поканальное оконное преобразование Фурье (STFT и шкала мел) к этому тензору, т.е. вычисляет оконное преобразование Фурье комплекснозначных спектрограмм (тензор в форме 512x(T/256)x2) для каждой из 8 последовательностей, содержащих тензор, независимо (таким образом, результирующий тензор имеет форму 8Ч512x(T/256)x2). Каждую комплекснозначную спектрограмму можно разложить на амплитудную и фазовую спектрограммы, причем амплитудная спектрограмма (“амплитуды” на фиг. 1) состоит из абсолютных значений комплексных чисел, содержащих комплекснозначную спектрограмму, и фазовая спектрограмма (“фазы” на фиг. 1) состоит из аргументов комплексных чисел, содержащих комплекснозначную спектрограмму. Дополнительно, нейронная сеть SpectralUnet принимает амплитудные спектрограммы (тензор в форме 8Ч512x(T/256), состоящий из абсолютных значений комплексных чисел, образующих комплекснозначную спектрограмму) для прогнозирования мультипликативных коэффициентов для абсолютных величин. Мультипликативные коэффициенты содержат тензор из положительных действительных чисел, форма которого совпадает с формой амплитудной спектрограммы (8Ч512x(T/256)). Положительность мультипликативных коэффициентов гарантируется функцией активации Softplus (которая является общеизвестной функцией) применяемой к выходному сигналу SpectralUNet. Спрогнозированные мультипликативные коэффициенты используются для коррекции комплекснозначной спектрограммы путем умножения каждого комплексного значения в комплекснозначной спектрограмме с соответствующим мультипликативным коэффициентом, который является действительным числом. Заключительная часть (“обратное поканальное STFT” на фиг. 1) состоит из обратного оконного преобразования, Фурье применяемого к каждой из 8 комплекснозначных спектрограмм, в результате чего образуются 8 одномерных последовательностей (таким образом, выходной сигнал тензор имеет форму 8xT, где T - длина входной (и выходной) формы волны). Такая обработка эквивалентна применению мультипликативной коррекции к абсолютной величине сигнала при неизменной фазе. Целью этого модуля является осуществление постобработки сигнала в частотной области. Это эффективный механизм удаления артефактов и шума в частотной области из выходной формы волны на основе обучения. Выходной сигнал SpectralMaskNet, который является пятым тензором с формой 8xT, обрабатывается одномерным сверточным слоем (не показанным на фиг. 1) для формирования выходной формы волны аудиосигнала (последовательности действительных чисел длиной T).
Фиг. 2 демонстрирует схему модуля нейронной сети SpectralUNet генератора HiFi++. Нейронные сети с этой архитектурой используются как на начальной стадии преобразования мел-спектрограммы в форму волны в модуле SpectralUNet, так и как часть модуля SpectralMaskNet. Структура одинакова в обоих случаях, но параметры сверточных слоев отличаются и выучиваются независимо. Подмодуль SpectralUnet обрабатывает входной тензор с разными разрешениями двухмерными сверточными слоями, причем такой тип обработки облегчается многомасштабной структурой нейронной сети SpectralUnet, который использует сверточные блоки понижающей дискретизации совместно со сверточными блоками повышающей дискретизации и перепускные соединения конкатенации (что является стандартной нейронной архитектурой UNet). Каждый сверточный блок имеет некоторую ширину, которая выражается количеством каналов в сверточных слоях, содержащих блок, Значения ширины W1, W2, W3, W4 блока, указанные на фигуре, равны, например, 8, 12, 24, 32, соответственно. Эти числа (8, 12, 24, 32) указывают параметры архитектуры модели WaveUNet. В частности, они указывают количество каналов, используемых в сверточных слоях в блоках (ширину блока). Специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретными значениями ширины блока.
Следует отметить, что блоки WaveUNet и SpectralUNet одинаковую архитектурную структуру за исключением того, что SpectralUNet использует 2d свертки с размером ядра 3Ч3 вместо 1d сверток с размером ядра, равным 5 в WaveUNet. Блоковая глубина (количество остаточных блоков) равна 4 для WaveUnet. Специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретными размерами. Архитектурная структура каждого из блоков WaveUNet и SpectralUNet состоит из:
- сверточного остаточного блока с одномерной сверткой и функцией активации LeakyReLU;
- сверточного блока понижающей дискретизации, который состоит из нескольких сверточных остаточных блоков и шаговой одномерной свертки с перепускным соединением U-Net;
- сверточного блока повышающей дискретизации, который состоит из нескольких сверточных остаточных блоков, интерполяции по ближайшим соседям (UpsampleNearestInterpolation) и перепускного соединения U-Net. UpsampleNearestInterpolation увеличивает разрешение тензора, за счет повторения соседних значений. Conv1d обозначает одномерную свертку с размером ядра, обозначенным как ker, размером заполнения (паддинг), обозначенным как pad, и количеством входных и выходных каналов, LeakyReLU - стандартная функция активации (нелинейность). Concat обозначает операцию конкатенации по канальным измерениям;
- сверточных блоков узкого места, которые состоят из нескольких сверточных остаточных блоков.
Короче говоря, как упомянуто выше со ссылкой на фиг. 1, сначала мел-спектрограмма исходного сигнала обрабатывается посредством модели SpectralUnet с использованием 2-мерных сверточных блоков. Сигнал обрабатывается путем слияния блоков мультирецептивных полей исходного генератора HiFi-GAN. После этого обработанный сигнал конкатенируется посредством операции конкатенации с начальной (входной) формой волны аудиосигнала. Результирующий тензор поступает в блок WaveUNet. Выходной сигнал модели WaveUNet обрабатывается модулем SpectralMaskNet. Затем выходная форма волны формируется одномерным сверточным слоем.
HiFi++ обучается посредством состязательных функций потерь, потерь на согласование особенностей и потерь на мел-спектрограмме, которые предписывают генератору HiFi++ вырабатывать аудиосигналы высокого качества. Отметим, что расширение частотной полосы аудиосигнала и улучшение речевого сигнала для аудиосигнала (удаление артефактов и шумов из аудиосигнала) обусловлены тем, что HiFi++ был обучен для этого, и тензорные преобразования HiFi++ происходят таким образом, чтобы удалить шум и артефакты.
Фиг. 6 демонстрирует обучающий конвейер архитектуры HiFi++. Выходной аудиосигнал, вырабатываемый генератором HiFi++ в ходе процедуры обучения, обрабатывается нейронной сетью дискриминатора совместно с эталонными аудиосигналами (опорным набором). Показатели реалистичности, полученные нейронными дискриминаторными сетями из выходных аудиосигналов архитектуры HiFi++ и из эталонных аудиосигналов, используются для вычисления среднеквадратических состязательных потерь (LS-GAN, уравнение 2). Промежуточные особенности используются для вычисления потерь на согласование особенностей, которые указаны ниже в уравнении 3. Мел-спектрограммы используются для вычисления потерь на мел-спектрограмме (уравнение 4). Все функции потерь являются числами, полученными взвешенным суммированием с мультипликативными коэффициентами, как показано в уравнении 5, для выработки окончательной функции потерь. Из результирующей функции потерь вычисляются градиенты, которые используются для итерационного обучения генератора HiFi++ и дискриминаторов с использованием оптимизатора Adam, что является стандартной практикой для обучения нейронных сетей.
Каждый выходной аудиосигнал, вырабатываемый HiFi++ по завершении процедуры обучения, должен соответствовать эталонному аудиосигналу (т.е. желаемому выходному сигналу, без шума и/или с увеличенной частотной полосой).
Если набор данных который содержит как шум, так и уменьшенную частоту, используется для обучения, то во время работы генератора HiFi++ одновременно будет происходить и расширение частотной полосы, и устранение шума. Кроме того, процесс обучения может осуществляться отдельно для задач расширения частотной полосы и улучшения речевого сигнала, в результате чего различные результирующие модели получаются для расширения частотных полос и улучшения речевого сигнала, однако специалистам в данной области техники очевидно, что объем изобретения не ограничивается этими задачами (компенсации только этих артефактов отдельно), поскольку модель может обучаться ослаблять различные артефакты, в том числе комбинацию уменьшенной частотной полосы и шума в аудиосигналах путем обеспечения различных массивов данных в ходе обучения.
Таким образом, задачи расширения частотных полос и улучшения речевого сигнала решаются ввиду того, что модель обучается решать эти задачи в процессе обучения. Весовые коэффициенты модели регулируются в процессе обучения таким образом, что, посредством вычислительных операций, осуществляемых нейронной сетью, численное представление аудиосигнала, содержащего эти артефакты, преобразуется в численное представление аудиосигнала, не содержащее артефактов. Процесс обучения определяется вышеописанными функциями потерь.
Как известно из уровня техники, генератор HiFi обучается в состязательном режиме на основе двух типов дискриминаторов: многопериодного дискриминатора (MPD) и многомасштабного дискриминатора (MSD). MPD состоит из нескольких субдискриминаторов, каждый из которых обрабатывает различные периодические подсигналы входного аудиосигнала. Цель дискриминаторов MPD состоит в идентификации различных периодических паттернов речи. MSD также состоит из нескольких субдискриминаторов, которые оценивают входные формы волны с различными временными разрешениями. В MelGAN (Kumar et al., 2019) было предложено обрабатывать последовательные паттерны и долговременные зависимости. Обучение HiFi состоит из 5 дискриминаторов MPD и 3 дискриминаторов MSD, которые суммарно имеют размер почти в 5 раз больше, чем генератор HiFi V1 и значительно замедляют процесс обучения. В Kong et al. (2020) утверждается, что такой сложный и дорогостоящий инструментарий дискриминации с несколькими уровнями разрешения является одним из ключевых факторов производительности высокого качества модели HiFi, которая поддерживается абляционным исследованием. Структуру модели HiFi, известной из уровня техники, можно упростить до нескольких идентичных дискриминаторов, которые меньше, чем дискриминаторы HiFi и сильно сокращают время обучения, обеспечивая при этом сравнимое качество. Прежде всего, абляционное исследование из документа HiFi (Kong et al., 2020) может вводить в заблуждение, поскольку оно демонстрирует, что без дискриминаторов MPD производительность модели резко снижается. Однако это является следствием неправильного выбора гиперпараметров и, точнее, модель может достигать качество, сравнимое с отсутствием MPD. Дополнительно, полезно заменять дискриминаторы MSD, которые действуют на различных входных разрешениях для идентичных гораздо меньших дискриминаторов, которые обрабатывают форму волны с единым начальным разрешением (дискриминаторов SSD). Архитектура дискриминаторов SSD такая же, как в дискриминаторах MSD, за исключением того, что количество каналов уменьшается с коэффициентом 4 в каждом слое для снижения вычислительной сложности. Поэтому преимущество дискриминаторов HiFi с несколькими уровнями разрешения может в значительный степени объясняться общеизвестным эффектом в литературе по GAN генеративных мультисостязательных сетей (Durugkar et al., 2016).
Главный смысл эффекта генеративных мультисостязательных сетей (Durugkar et al., 2016) состоит в том, что производительность генеративной модели можно легко повысить путем обучения на основе множественных дискриминаторов с одинаковой архитектурой, но разной инициализацией. Чем больше дискриминаторов, тем более высокого качества выборки может достигать модель, однако этот эффект очень быстро насыщается с количеством дискриминаторов. В целях сокращения времени обучения и вычислительных ресурсов, предложенное изобретение использует по меньшей мере 3 идентичных дискриминатора SSD для обучения модели HiFi++. Можно использовать меньшее количество дискриминаторов, но эксперименты показали, что качество выходного аудиосигнала снижается. Кроме того, в настоящем изобретении для повышения перцептивного качества аудиосигнала, потерям на мел-спектрограмме назначается меньший вес, например, 15 вместо 45 в исходном коде HiFi-GAN. Дополнительно, в настоящем изобретении, спектральная нормализация в одном из дискриминаторов MSD не используется, и темп обучения для дискриминатора снижается по сравнению с уровнем техники, что дополнительно улучшает результаты. Эксперименты показали, что для настройки обучения, параметры могут изменять в зависимости от начальной задачи. Улучшение результатов будет более подробно описано ниже со ссылкой на таблицу 1.
Следует отметить, что, в общем случае, система, отвечающая изобретению, может обучаться 5 исходными дискриминаторами MPD и 3 дискриминаторами MSD, как упомянуто выше и без необходимости уменьшения весовых коэффициентов в нейронной сети, однако заявитель выяснил, что идентичные дискриминаторы и уменьшенные весовые коэффициенты позволяют получить более простую реализацию с приемлемым качеством выходного аудиосигнала.
В настоящем изобретении, генератор HiFi++ обучается на основе по меньшей мере трех дискриминаторов одной и той же упрощенной структуры в состязательном режиме. Генераторная сеть HiFi++ обучается отображению из входного аудиосигнала с шумом или уменьшенной частотной полосой в аудиосигналы высокого качества, пока дискриминаторы учатся отличать реальные сигналы высокого качества от сигналов, вырабатываемых генератором HiFi++. Таким образом, дискриминаторы предписывают генератору HiFi++ создавать выборки, неотличимые от высококачественных. Обратная связь между дискриминаторами и выходом генератора HiFi++ осуществляется стандартными методами обучения нейронной сети и не является предметом этой патентной заявки.
Далее описан термин "потери при обучении". Функция потерь представляет собой особые критерии, согласно которым модели предписывается прогнозировать высококачественный аудиосигналы, она измеряет, насколько далеки модельные прогнозы от высококачественных аудиосигналов, и модель обучается минимизировать эту функцию потерь, таким образом, она обучается прогнозировать аудиосигналы высокого качества.
a) Потери GAN.
Поскольку используется обучение с множественной дискриминацией, существует k идентичных дискриминаторов D1, ..., Dk (k=3 во всех экспериментах BWE (расширение частотной полосы) и SE (улучшение качества, удаление шума). Поскольку целью используемого состязательного обучения является LS-GAN, которая обеспечивает неисчезающие градиентные потоки (см., например, Mao et al., 2017) по сравнению с потерями первоначальной GAN (Goodfellow et al., 2014). Потери LS-GAN для генератора Gи с параметрами и и дискриминаторами Dϕ1, …, Dϕk с параметрами ϕ1, …, ϕk задаются как
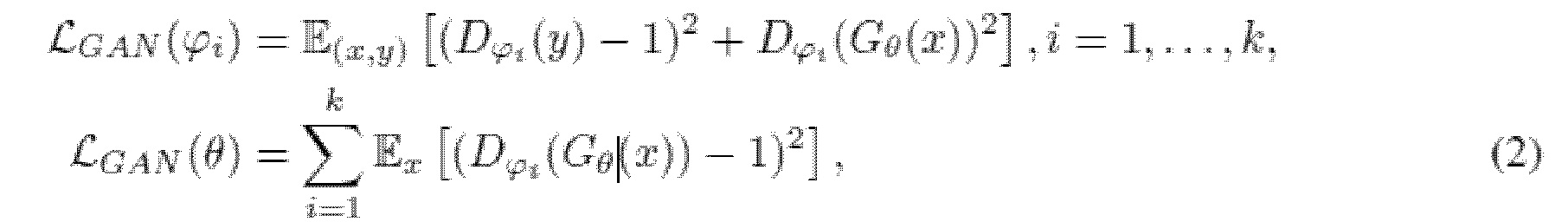
где y обозначает эталонный аудиосигнал (эталон означает чисто речевые записи, критерий того, что модель будет способна прогнозировать из зашумленных аудиозаписей), и x=f(y) обозначает входное условие, и преобразование f может быть мел-спектрограммой, фильтром нижних частот или добавлением шума.
b) Потери на согласование особенностей (активаций).
Потери на согласование особенностей вычисляются как расстояние L1 между картами промежуточных особенностей (активаций) дискриминаторов, вычисленными для эталонной выборки, и условно сгенерированными (Larsen et al., 2016; Kumar et al., 2019). Это успешно применялось к синтезу речи (Kumar et al., 2019) для стабилизации процесса состязательного обучения. Потери на согласование особенностей вычисляются как
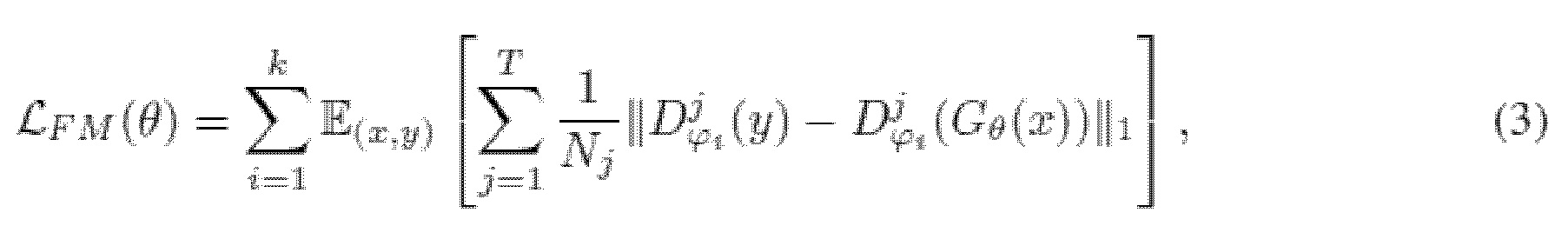
где T обозначает количество слоев в дискриминаторе;  и Nj обозначают активации и число активаций в j-м слое i-го дискриминатора, соответственно. E - математическое ожидание, G - генераторная нейронная сеть, D - дискриминатор. Активации представляют собой промежуточные тензоры, возникающие в нейронной сети в ходе обработки входного тензора, N обозначает количество таких тензоров.
и Nj обозначают активации и число активаций в j-м слое i-го дискриминатора, соответственно. E - математическое ожидание, G - генераторная нейронная сеть, D - дискриминатор. Активации представляют собой промежуточные тензоры, возникающие в нейронной сети в ходе обработки входного тензора, N обозначает количество таких тензоров.
с) Потери на мел-спектрограмме.
Потери на мел-спектрограмме — это расстояние L1 между мел-спектрограммой формы волны, синтезированной генератором, и мел-спектрограммой эталонной формы волны. Другими словами, расстояние между мел-спектрограммами образует функцию потерь. Она определяется как
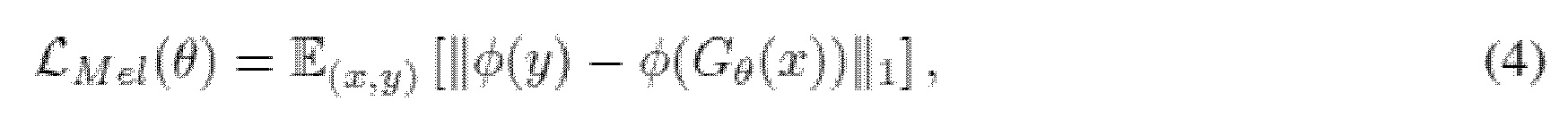
где φ - функция, которая преобразует форму волны в соответствующую мел-спектрограмму.
d) Окончательные потери. Окончательные потери для генератора и дискриминатор выражаются в виде
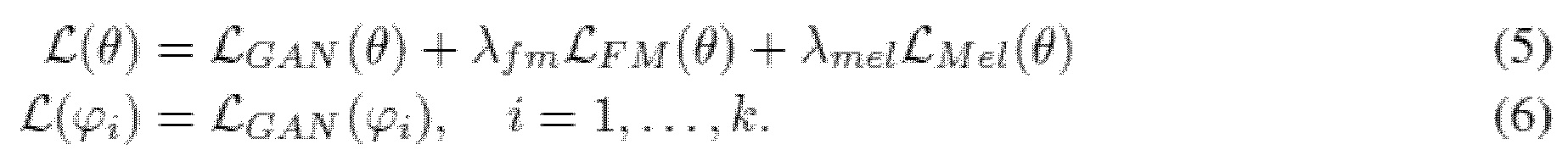
где λfm=2 и λmel=45 для экспериментов BWE и SE, что найдено оптимально через поиск по сетке.
Вышеприведенные иллюстративные варианты осуществления являются примерами и не подлежат рассмотрению в порядке ограничения. Кроме того, описание иллюстративных вариантов осуществления призвано быть иллюстративным, но не ограничивать объем формулы изобретения, и специалисты в данной области техники смогут предложить многочисленные альтернативы, модификации и вариации.
Эксперименты
Используется публичный массив данных LJ-Speech (Ito & Johnson, 2017) (лицензия публичной области), который является стандартным в области синтеза речи. LJ-Speech представляет собой массив данных, который состоит из 13100 аудиоклипов суммарной длительностью приблизительно 24 часов. Используется разбиение удостоверения обучения из документа HiFi (Kong et al., 2020) размером 12950 обучающих клипов и 150 валидационных клипов. Выборки аудиосигнала имеют частоту дискретизации 22 кГц.
В контексте анализа дискриминаторов генератор HiFi обучается, эти эксперименты служат для мотивации использования этого набора дискриминаторов при обучении HiFi++, затем они используются при обучении HiFi++.
Расширение частотной полосы
Используется общедоступный массив данных VCTK (Yamagishi et al., 2019) (лицензия CC BY 4,0), который включает в себя 44200 речевых записей, принадлежащих 110 спикерам. 6 спикеров из обучающего набора и 8 записей из высказываний, соответствующих каждому спикеру, исключаются во избежание утечки данных текстового уровня и уровня спикера в обучающий набор. Для оценивания, используются 48 высказываний, соответствующих 6 спикерам, исключенным из обучающих данных. Следует обратить внимание на то, что текст, соответствующий оценочным высказываниям, не читается ни в одной из записей, образующих обучающие данные.
Деление на обучающие и тренировочные выборки призвано исключить возможность переобучения алгоритма на тренировочных данных (их запоминания), это стандартная процедура, необходимая для тестирования алгоритма на независимых данных, то есть на тех, которые он не может запомнить в процессе обучения.
Пример обеспечения расширения частотной полосы: в объеме предложенного изобретения формы волны аудиосигнала с частотными полосами 1 кГц, 2 кГц и 4 кГц рассматриваются как входные сигналы в модель, причем модель создает формы волны аудиосигнала с частотной полосой 8 кГц, которая соответствует улучшение до 3 пунктов средней экспертной оценки разборчивости речи, измеренному посредством человеческой обратной связи. Однако специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретными входными и выходными частотными полосами.
Модель обучается создавать аудиосигнал с увеличенной частотной полосой. В ходе обучения модель снабжается примерами входных аудиосигналов с уменьшенной частотной полосой и выходных аудиосигналов с нормальной (увеличенной) частотной полосой. Таким образом, модель обучается создавать аудиосигналы с нормальной (увеличенной) частотной полосой из аудиосигналов с уменьшенной частотной полосой.
Подавление шума в речевом сигнале
В экспериментах по подавлению шума используется массив данных VCTK-DEMAND (Valentini-Botinhao et al., 2017) (лицензия CC BY 4,0). Обучающие наборы (11572 высказывания) состоят из 28 спикеров с 4 значениями отношение сигнал-шум (SNR) (15, 10, 5 и 0 дБ). Испытательный набор (824 высказывания) состоит из 2 спикеров с 4 значениями SNR (17,5, 12,5, 7,5 и 2,5 дБ).
Пример обеспечения улучшения речевого сигнала: в объеме предложенного изобретения формы волны аудиосигнала со средним отношением сигнал-шум 8,4 рассматриваются как входные сигналы в модель, причем модель создает формы волны аудиосигнала с повышенным средним отношением сигнал-шум 18,4, которое соответствует улучшению до 1 пункта средней экспертной оценки разборчивости речи, измеренному посредством человеческой обратной связи. Однако специалистам в данной области техники очевидно, что принцип изобретения не ограничивается конкретным отношением сигнал-шум на входе и выходе.
Модель обучается создавать аудиосигнал с увеличенной частотной полосой. В ходе обучения, модель снабжается примерами входных аудиосигналов с шумом и выходных аудиосигналов без шума. Модель обучается создавать аудиосигналы без шума из аудиосигналов с шумом.
Оценивание
Для объективного оценивания выборок в задаче SE (удаление шума) используются традиционные метрики WB-PESQ (Rix et al., 2001), STOI (Taal et al., 2011), масштабно-инвариантное отношение сигнал-искажение (SI-SDR) (Le Roux et al., 2019).
Для субъективного оценивания качества используются 5-масштабные испытания MOS. Все аудиоклипы были нормализованы во избежание влияния различий в громкости аудиосигнала для экспертов. Эксперты выбирались англоговорящими с надлежащим оборудованием для прослушивания.
Средняя экспертная оценка разборчивости речи (MOS) модели представляет собой меру, использующую краудсорсинговую адаптацию стандартной процедуры оценивания абсолютной категории. Предложена следующая процедура вычисления MOS.
1. Выбрать поднабор из 40 случайных выборок из испытательного набора (по одному для каждой задачи, т.е. для расширения частотной полосы или улучшения речевого сигнала).
2. Выбрать набор оцениваемых моделей; вывести их прогнозы на основании выбранного поднабора.
3. Произвольно смешать прогнозы и разбить их на страницы размером 20 почти равномерно.
 равномерно означает, что на каждой странице присутствует по меньшей мере выборок из каждой модели.
равномерно означает, что на каждой странице присутствует по меньшей мере выборок из каждой модели.
4. Вставить 4 дополнительные захватывающие выборки в случайные места на каждой странице: 2 выборки из эталона и 2 выборки шума безо всякой речи.
5. Выгрузить страницы на краудсорсинговую платформу, задать количество оценщиков для каждой страницы равной по меньшей мере 30.
Оценщиков просят работать в наушниках в тихом окружении; они должны прослушать аудиозапись до конца, прежде чем оценить его.
6. Отфильтровать результаты, где эталонные выборки получают любую оценку, кроме 4 (хорошо) и 5 (отлично), или выборки без голоса получают любую оценку, кроме 1 (плохо).
7. Разбить произвольным образом оставшиеся рейтинги для каждой модели на 5 групп почти равного размера, вычислить их среднее и стандартное отклонение.
Поскольку модели равномерно распределены по страницам, предвзятость оценщика одинаково влияет на все модели, поэтому относительный порядок моделей остается. С другой стороны, оценщик будет иметь доступ ко всему разнообразию моделей на одной странице и, таким образом может лучше масштабировать свои рейтинги. С другой стороны, рейтинги моделей не являются независимыми друг от друга в этой настройке, поскольку оценщики склонны оценивать качество выборки относительно средней выборки страницы, т.е. чем с более плохими моделями производится сравнение, тем большие MOS назначаются хорошим. 4 захватывающие выборки на страницу также является приемлемым выбором, поскольку просто невозможно случайно догадаться скорректировать ответы на эти вопросы.
Недостаток MOS состоит в том, что иногда требуется слишком много оценщиков для каждой выборки, чтобы достоверно определить, какая модель лучше. Возможное решение состоит в том, чтобы использовать упрощенную версию рейтинга сравнения категорий, т.е. исследование предпочтений. Это исследование сравнивает две модели, оценщика просят выбрать модель, создающую наилучший выходной сигнал для одного и того же входного сигнала. Если оценщик не слышит разницы, нужно выбрать вариант “одинаковые”.
1. Выбрать поднабор из 40 случайных выборок из испытательного набора.
2. Произвольно перемешать этот набор, разбить его на страницы размером 20.
3. Выбрать произвольно на каждой странице 10 позиций, где первым будет прогноз Model1.
4. Вставить 4 дополнительные захватывающие выборки в случайные места на каждой странице: каждая захватывающая выборка является парой чистой речи из эталона и ее заметно искаженной версии. Порядок моделей в захватывающей выборке является случайным, но на каждой странице существует 2 выборки с одним порядком и 2 выборки с другим.
5. Выгрузить страницы на краудсорсинговую платформу, задать количество оценщиков для каждой страницы равной по меньшей мере 30.
Оценщиков просят работать в наушниках в тихом окружении; они должны прослушать аудиозапись до конца, прежде чем оценить его.
6. Отфильтровать результаты, где захватывающие выборки классифицированы неправильно.
7. Использовать знаковый статистический тест, чтобы отбрасывать гипотезу о том, что модели генерируют речь одинакового [медианного] перцептивного качества.
Инструментарий дискриминации
Причины эффективности инструментария HiFi-GAN исследуются путем дублирования абляции документа HiFi-GAN. Архитектура генератора HiFi V3 обучается различными наборами дискриминаторов в течение одного миллиона итераций для решения проблемы вокодирования речевых сигналов на массиве данных LJ-Speech. Осуществляются обширное оценивание генерируемых выборок и измерение сложности инструментария дискриминации. Для сравнения эмпирической сложности обучения, общее время обучения измеряется на единственном GPU NVIDIA GeForce GTX 1080 Ti. Результаты приведены в таблице 1.
Таблица 1 демонстрирует результаты оценивания важности инструментария дискриминации на нейронном вокодировании речевых сигналов. Эталон означает желаемый выходной сигнал, без шума или с увеличенной частотной полосой. MSD означает многомасштабный дискриминатор. MPD означает многопериодный дискриминатор. SSD означает дискриминатор с одним разрешением. k - количество дискриминаторов. MOS (средняя экспертная оценка разборчивости речи) средняя оценка качества аудиосигнала, назначенная слушателями, чем выше, тем лучше. Размер D (млн.) означает количество параметров дискриминаторов в миллионах. D MAC (G) обозначает количество операций умножения с накоплением в миллиардах в секунду. Время обучения (D) вычисляется на единственном GPU NVIDIA GeForce GTX 1080 Ti в днях.
Таблица 1
|
Авторы HiFi-GAN показали, что без дискриминаторов MPD система теряет почти 2 пункта MOS, что является очень большим снижением. Такое снижение в основном обусловлено неправильным выбором гиперпараметров. Если просто удалить дискриминаторы MPD из обучающего конвейера с использованием исходного кода HiFi-GAN, качество генерируемых аудиосигналов фактически снижается (см. исход. MSD в таблице 1). Однако качество можно значительно повысить путем настройки гиперпараметров.
Одна из ключевых причин ухудшения качества состоит в том, что относительный вес состязательных потерь становится значительно меньше (состязательные потери для различных дискриминаторов суммируются) по сравнению с весом потерь на мел-спектрограмме. Таким образом, генератор в основном управляется потерями на мел-спектрограмме, которые лишают аудиосигналы естественного звучания. Перцептивное качество аудиосигнала можно повысить, назначив меньший вес потерям на мел-спектрограмме (15 вместо 45 в исходном коде HiFi-GAN).
Кроме того, авторы HiFi-GAN используют спектральную нормализацию в одном из дискриминаторов MSD, что не рекомендовано авторами статьи MelGAN. Настройка темпа обучения для дискриминатора (1*10−5 вместо 2*10−4) дополнительно улучшает результаты. Это изменение гиперпараметров обеспечивает улучшение примерно на 1,5 пунктов MOS (см. настроенный MOS MSD=3,90 (результат предложенного изобретения), исход. MOS MSD=2,39 в таблице 1).
Дополнительно исследованы важность дискриминации с несколькими уровнями разрешения путем удаления среднего пулинга из дискриминаторов MSD (таким образом, все три дискриминатора действуют при одном и том же разрешении и отличаются только инициализацией). Этот дискриминатор с одним разрешением (SSD) оказывает дополнительное положительное влияние на качество генерируемых выборок и повышает MOS на 0,1 пункта. В настоящем изобретении, дискриминаторы SSD можно значительно облегчить, уменьшив количество каналов в каждом слое с коэффициентом 4 без существенного ухудшения качества (SSD (k=3) (предлагаемый). Дополнительно, качество инструментария дискриминации можно дополнительно улучшить за счет увеличения количества дискриминаторов SSD с 3 до 5. Это изменение приводит к дополнительному улучшению качества MOS на 0,1 пункта (SSD (k=5) (наш)). В целом, результаты проливают свет на возможные причины успеха инструментария дискриминации HiFi-GAN. Действительно, можно видеть, что с настройкой гиперпараметров и использованием нескольких идентичных дискриминаторов, можно достигать качества, аналогичного исходной инструментария дискриминации HiFi-GAN (исход. MSD+MPD). Таким образом, для обучения модели HiFi++ на задачах расширения частотной полосы и улучшения речевого сигнала используется 3 идентичных дискриминатора SSD.
Расширение частотной полосы
В экспериментах по расширению частотной полосы, в качестве целей используются записи с частотой дискретизации 16 кГц и для входных данных рассматриваются три частотных полосы: 1 кГц, 2 кГц и 4 кГц. До прореживания сигнала до желаемой частоты дискретизации (2 кГц, 4 кГц или 8 кГц) применяется фильтр нижних частот, произвольно выбранный из фильтров Баттеруорта, Чебышева, Бесселя и эллиптического фильтра различных порядков во избежание нежелательных паразитных частот и для повышения устойчивости модели Liu et al. (2021). Затем прореженный сигнал передискретизируется обратно до частоты дискретизации 16 кГц с использованием полифазной фильтрации.
Результаты и сравнение с другими методами приведены в таблице 2. Предложенная модель HiFi++ обеспечивает более удачный компромисс между размером модели и качеством расширения частотной полосы, чем другие методы. В частности, предложенная модель в 5 раз меньше, чем ближайшая базовая модель SEANet (Li et al., 2021) при этом превосходя ее для всех входных частотных полос. Для удостоверения превосходства HiFi++ над SEANet помимо испытаний MOS, проводится попарное сравнение между этими двумя моделями и наблюдается статистически значимое преобладание предложенной модели (p-значения равны 2,8*10−22 для частотной полосы 1 кГц, 0,003 для 2 кГц, и 0,02 для 4 кГц для биномиальной проверки).
Эти результаты подчеркивают важность состязательных задач для моделей расширения частотной полосы речевого сигнала. Вопреки ожиданиям, модель SEANet (Li et al., 2021) оказалась самой сильной базовой линией среди испытанных аналогов, оставив других далеко позади. Эта модель использует состязательную задачу, аналогичную нашей. Модели TFilm (Birnbaum et al., 2019) и 2S-BWE (Lin et al., 2021, TSN - временная сверточная сеть, CRN - сверточная рекуррентная сеть) используют задачи контролируемой реконструкции и достигают очень низкой производительности, особенно для низких входных частотных полос.
Таблица 2 демонстрирует результаты расширения частотной полосы (BWE) на массиве данных VCTK (* указывает повторную реализацию). BWE обозначает расширение частотной полосы. #Param (млн.) - количество параметров модели (в миллионах). Модель обеспечивает более высокое качество, чем испытанные решения из литературы, за счет доставки более высокого качества MOS, имея при этом наименьшее количество параметров (1,7 миллиона). Предложенный генератор обеспечивает MOS, (равную 4,10 при BW (1 кГц), равную 4,44 при BWE(2 кГц), равную 4,51 при BWE (4 кГц)), что превышает все значения других традиционных генераторов во всех указанных диапазонах BWE. В то же время, предложенный генератор использует наименьшее количество параметров, равное 1,7 миллиона.
Таблица 2
|
Улучшение речевого сигнала
Сравнение HiFi++ с базовыми моделями продемонстрировано в таблице 3. SI-SDR - масштабно-инвариантное отношение сигнал-искажение (Le Roux et al., 2019). STOI (мера кратковременной объективной разборчивости) (Taal et al., 2011). PESQ (оценка перцептивного качества речевого сигнала) (Rix et al., 2001) являются традиционными метриками. Предложенная модель достигает сравнимой производительности с аналогами VoiceFixer (Liu et al., 2021) и DEMUCS (Defossez et al., 2020) при гораздо меньшем (#Param(млн.)=1,7). В частности, например, MOS=4,33 для HiFi++, MOS=4,32 для VoiceFixer, MOS=4,22 для DEMUCS. Что интересно, VoiceFixer достигает высокого субъективного качества, уступая при этом другим моделям согласно объективным метрикам, особенно SI-SDR и STOI. Действительно, VoiceFixer не использует информацию формы волны напрямую и принимает на входе только мел-спектрограмму, таким образом, она пропускает части входного сигнала и не ставит задачей точную реконструкцию исходного сигнала, что приводит к низкой производительности в отношении классических относительных метрик, например, SI-SDR, STOI и PESQ. Предложенная модель HiFi++ обеспечивает подходящие метрики относительного качества (MOS=4,33; SI-SDR=18,4, STOI=0,95, PESQ=2,76). В то же время предложенная модель учитывает весь спектр сигнала, который очень информативен для улучшения речевого сигнала, чтобы было продемонстрировано успехом классических спектральных способов. Заслуживает внимания тот факт, что предложенное изобретение значительно превосходит модель SEANet (Tagliasacchi et al., 2020), которая обучается в аналогичном состязательном режиме и имеет большее количество параметров, но не учитывает спектральную информацию (MOS=4,33 для HiFi++, MOS=3,99 для SEANet, SI-SDR=18,4 для HiFi++, SI-SDR=13,5 для SEANet, STOI=0,95 для HiFi++, STOI=0,92 для SEANet, PESQ=2,76 для HiFi++, PESQ=2,36 для SEANet).
Таблица 3 демонстрирует результаты подавления шума в речевом сигнале на массиве данных Voicebank-DEMAND. (* указывает повторную реализацию). Модель обеспечивает более высокое качество, чем испытанные решения из литературы, за счет доставки более высокого качества MOS (которая является основной мерой производительности системы, поскольку вычисляется непосредственно из человеческой обратной связи), имея при этом наименьшее количество параметров (1,7 миллиона).
Таблица 3
|
Абляционное исследование
Абляция представляет собой исследование важности отдельных компонентов, которые составляют решение. Для удостоверения эффективности предложенных модификаций, осуществляется абляционное исследование введенных модулей SpectralUNet, WaveUNet и SpectralMaskNet. Для каждого модуля рассматривается архитектура без этого модуля с увеличенной емкостью части генератора HiFi для согласования размера начальной архитектуры HiFi++.
Результаты абляционного исследования приведены в таблице 4, где указан вклад каждого модуля в производительность HiFi++. Также демонстрируется сравнение с базовой моделью генератора HiFi, на вход которого поступает только мел-спектрограмма. Структура базового генератора HiFi такая же, как в версиях V1 и V2 из документа HiFi-GAN, за исключением того, что параметр "дискретизировать с повышением начальный канал" задается равным 256 (он равен 128 для V2 и 512 для V1). WaveUNet и SpectralMaskNet являются важными компонентами архитектуры, поскольку их отсутствие заметно снижает производительность модели.
SpectralUNet не оказывает влияния на качество SE, и оказывает незначительное положительное влияние на BWE (статистическая значимость улучшения гарантируется парной проверкой).
Таблица 4 демонстрирует вклад каждого модуля архитектуры HiFi++ в BWE (расширение частотной полосы) и SE (улучшение речевого сигнала).
Можно видеть, что базовая линия (HiFi++) в ее полном наборе дает наилучшие результаты.
Таблица 4
|
Вывод
Настоящее изобретение может быть реализовано аппаратными, программными и программно-аппаратными средствами. Кроме того, указание реализации изобретения в форме нейронной сети не означает, что его невозможно реализовать в форме специализированного оборудования, где каждый модуль может быть реализован и как отдельный блок, и как единая структура (например, интегральная схема).
Предложенное изобретение предусматривает универсальный инструментарий HiFi++ для расширения частотной полосы и улучшения речевого сигнала. Ряд обширных экспериментов указывает, что предложенная модель достигает таких же результатов, как базовые линии уровня техники для задач BWE (расширение частотной полосы) и SE (улучшение речевого сигнала, удаление шума).
Отличительные особенности настоящего изобретения:
a) предложено использовать модуль SpectralUNet для увеличения разрешения мел-спектрограммы. Мел-спектрограмма имеет двухмерную структуру, и двухмерные сверточные блоки модели SpectralUnet предназначены для облегчения работы с этой структурой на начальной стадии преобразования мел-спектрограммы в форму волны.
b) предложено применять модуль WaveUNet к сигналу после сверточных блоков модели HiFi. Модуль WaveUNet является полностью сверточной нейронной сетью, которая продемонстрировала свою эффективность в задачах удаления шума и расширения частотной полосы.
c) модуль SpectralMaskNet предложен как оконечная часть генератора. SpectralMaskNet является обучаемым спектральным маскированием. Модуль прогнозирует мультипликативные коэффициенты для абсолютных величин Фурье оконного преобразования Фурье. Модуль предназначен для постобработки сигнала в частотной области.
d) предложено использовать 3 идентичных вычислительно эффективных и принципиально простых дискриминатора вместо 8 различных, вычислительно неэффективных дискриминатора известной модели HiFi-GAN. Предложенный инструментарий дискриминации принципиально снижает сложность обучения как в отношении вычислений, так и времени, в то же время обеспечивая производительность, сравнимую с моделью HiFi-GAN.
e) Эффективность предложенного способа показана для задач расширения частотной полосы и удаления шума в речевых аудиозаписях.
Предложенная модель HiFi++ превосходит существующие базовые линии в каждой задаче со значительно меньшей сложностью модели. Инструментарий HiFi++ надежен и пригоден для различных задач, связанных с речью.
Вышеприведенные иллюстративные варианты осуществления являются примерами и не подлежат рассмотрению в порядке ограничения. Кроме того, описание иллюстративных вариантов осуществления призвано быть иллюстративным, но не ограничивать объем формулы изобретения, и специалисты в данной области техники смогут предложить многочисленные альтернативы, модификации и вариации.
Ссылки
Baevski, A., Zhou, H., Mohamed, A., and Auli, M. wav2vec 2,0: A framework for self-supervised learning of speech representations. arXiv preprint arXiv:2006,11477, 2020.
Bai, S., Kolter, J. Z., and Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803,01271, 2018.
Birnbaum, S., Kuleshov, V., Enam, Z., Koh, P. W., and Ermon, S. Temporal film: Capturing long range sequence dependencies with feature-wise modulations. arXiv preprint arXiv:1909,06628, 2019.
Dйfossez, A., Usunier, N., Bottou, L., and Bach, F. Music source separation in the waveform domain. arXiv preprint arXiv:1911,13254, 2019.
Defossez, A., Synnaeve, G., and Adi, Y. Real time speech enhancement in the waveform domain. In Interspeech, 2020.
Durugkar, I., Gemp, I., and Mahadevan, S. Generative multi-adversarial networks. arXiv preprint arXiv:1611,01673, 2016.
Fu, S.-W., Liao, C.-F., Tsao, Y., and Lin, S.-D. Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement. In International Conference on Machine Learning, pp. 2031-2041. PMLR, 2019.
Fu, S.-W., Yu, C., Hsieh, T.-A., Plantinga, P., Ravanelli, M., Lu, X., and Tsao, Y. Metricgan+: An improved version of metricgan for speech enhancement. arXiv preprint arXiv:2104,03538, 2021.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., and Pang, R. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proc. Interspeech 2020, pp. 5036-5040, 2020. doi: 10,21437/Interspeech.2020-3015.
Ito, K. and Johnson, L. The lj speech dataset. https://keithito.com/LJ-Speech-Dataset/, 2017.
Jansson, A., Humphrey, E., Montecchio, N., Bittner, R., Kumar, A., and Weyde, T. Singing voice separation with deep u-net convolutional networks. 2017.
Kim, E. and Seo, H. SE-Conformer: Time-Domain Speech Enhancement Using Conformer. In Proc. Interspeech 2021, pp. 2736-2740, 2021. doi: 10,21437/Interspeech.2021-2207.
Kim, S. and Sathe, V. Bandwidth extension on raw audio via generative adversarial networks. arXiv preprint arXiv:1903,09027, 2019.
Kong, J., Kim, J., and Bae, J. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. arXiv preprint arXiv:2010,05646, 2020.
Kong, Q., Cao, Y., Liu, H., Choi, K., and Wang, Y. Decoupling magnitude and phase estimation with deep resunet for music source separation. arXiv preprint arXiv:2109,05418, 2021.
Kuleshov, V., Enam, S. Z., and Ermon, S. Audio super resolution using neural networks. arXiv preprint arXiv:1708,00853, 2017.
Kumar, K., Kumar, R., de Boissiere, T., Gestin, L., Teoh, W. Z., Sotelo, J., de Brйbisson, A., Bengio, Y., and Courville, A. Melgan: Generative adversarial networks for conditional waveform synthesis. arXiv preprint arXiv:1910,06711, 2019.
Larsen, A. B. L., Sшnderby, S. K., Larochelle, H., and Winther, O. Autoencoding beyond pixels using a learned similarity metric. In International conference on machine learning, pp. 1558-1566. PMLR, 2016.
Le Roux, J., 404 Wisdom, S., Erdogan, H., and Hershey, J. R. Sdr-half-baked or well done? In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 626-630. IEEE, 2019.
Li, Y., Tagliasacchi, M., Rybakov, O., Ungureanu, V., and Roblek, D. Real-time speech frequency bandwidth extension. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 691-695. IEEE, 2021.
Lin, J., Wang, Y., Kalgaonkar, K., Keren, G., Zhang, D., and Fuegen, C. A two-stage approach to speech bandwidth extension. Proc. Interspeech 2021, pp. 1689-1693, 2021.
Liu, H., Kong, Q., Tian, Q., Zhao, Y., Wang, D., Huang, C., and Wang, Y. Voicefixer: Toward general speech restoration with neural vocoder. arXiv preprint arXiv:2109,13731, 2021.
Lo, C.-C., Fu, S.-W., Huang, W.-C., Wang, X., Yamagishi, J., Tsao, Y., and Wang, H.-M. Mosnet: Deep learning based objective assessment for voice conversion. arXiv preprint arXiv:1904,08352, 2019.
Lorenzo-Trueba, J., Yamagishi, J., Toda, T., Saito, D., Villavicencio, F., Kinnunen, T., and Ling, Z. The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods. arXiv preprint arXiv:1804,04262, 2018.
Mao, X., Li, Q., Xie, H., Lau, R. Y., Wang, Z., and Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE international conference on computer vision, pp. 2794-2802, 2017.
Pascual, S., Bonafonte, A., and Serra, J. Segan: Speech enhancement generative adversarial network. arXiv preprint arXiv:1703,09452, 2017.
Prenger, R., Valle, R., and Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3617-3621. IEEE, 2019.
Rix, A. W., Beerends, J. G., Hollier, M. P., and Hekstra, A. P. Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs. In 2001
IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No.01CH37221), volume 2, pp. 749-752. IEEE, 2001.
Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pp. 234-241. Springer, 2015.
Stoller, D., Ewert, S., and Dixon, S. WaveUNet: A multi-scale neural network for end-to-end audio source separation. arXiv preprint arXiv:1806,03185, 2018.
Sulun, S. and Davies, M. E. On filter generalization for music bandwidth extension using deep neural networks. IEEE Journal of Selected Topics in Signal Processing, 15(1):132-142, 2020. Taal, C. H., Hendriks, R. C., Heusdens, R., and Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Transactions on Audio, Speech, and Language Processing, 19(7):2125-2136, 2011.
Tagliasacchi, M., Li, Y., Misiunas, K., and Roblek, D. Seanet: A multi-modal speech enhancement network. arXiv preprint arXiv:2009,02095, 2020.
Tan, K. and Wang, D. A convolutional recurrent neural network for real-time speech enhancement. In Interspeech, pp. 3229-3233, 2018.
Tian, Q., Chen, Y., Zhang, Z., Lu, H., Chen, L., Xie, L., and Liu, S. Tfgan: Time and frequency domain based generative adversarial network for high-fidelity speech synthesis. arXiv preprint arXiv:2011,12206, 2020.
Valentini-Botinhao, C. et al. Noisy speech database for training speech enhancement algorithms and tts models. 2017.
Wang, H. and Wang, D. Time-frequency loss for cnn based speech super-resolution. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 861-865. IEEE, 2020.
Wang, H. and Wang, D. Towards robust speech super-resolution. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021.
Wisdom, S., Hershey, J. R., Wilson, K., Thorpe, J., Chinen, M., Patton, B., and Saurous, R. A.
Differentiable consistency constraints for improved deep speech enhancement. In ICASSP 2019-IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 900-904. IEEE, 2019.
Yamagishi, J., Veaux, C., MacDonald, K., et al. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0,92). 2019.
You, J., Kim, D., Nam, G., Hwang, G., and Chae, G. Gan vocoder: Multi-resolution discriminator is all you need. arXiv preprint arXiv:2103,05236, 2021.
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 586-595, 2018.
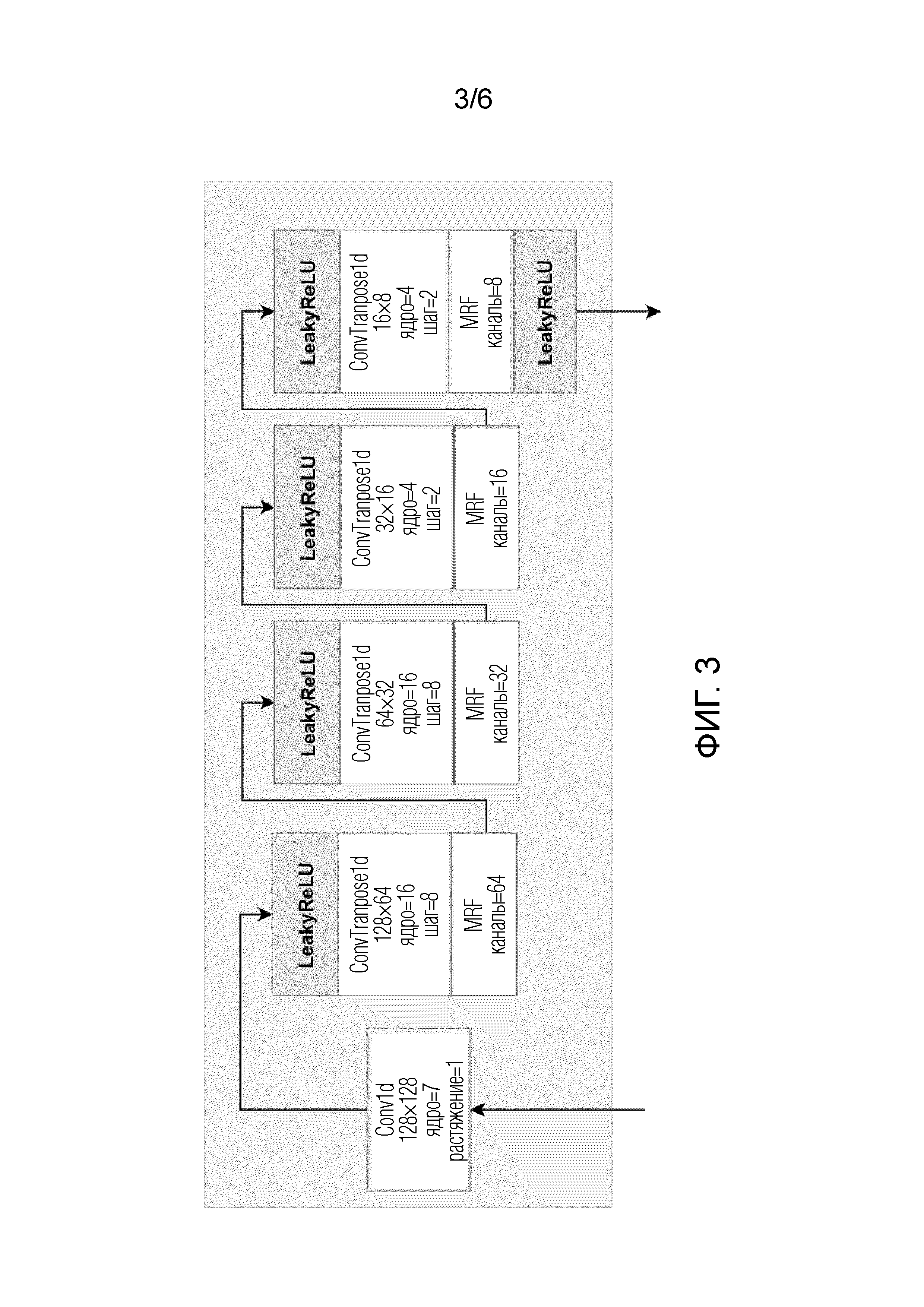
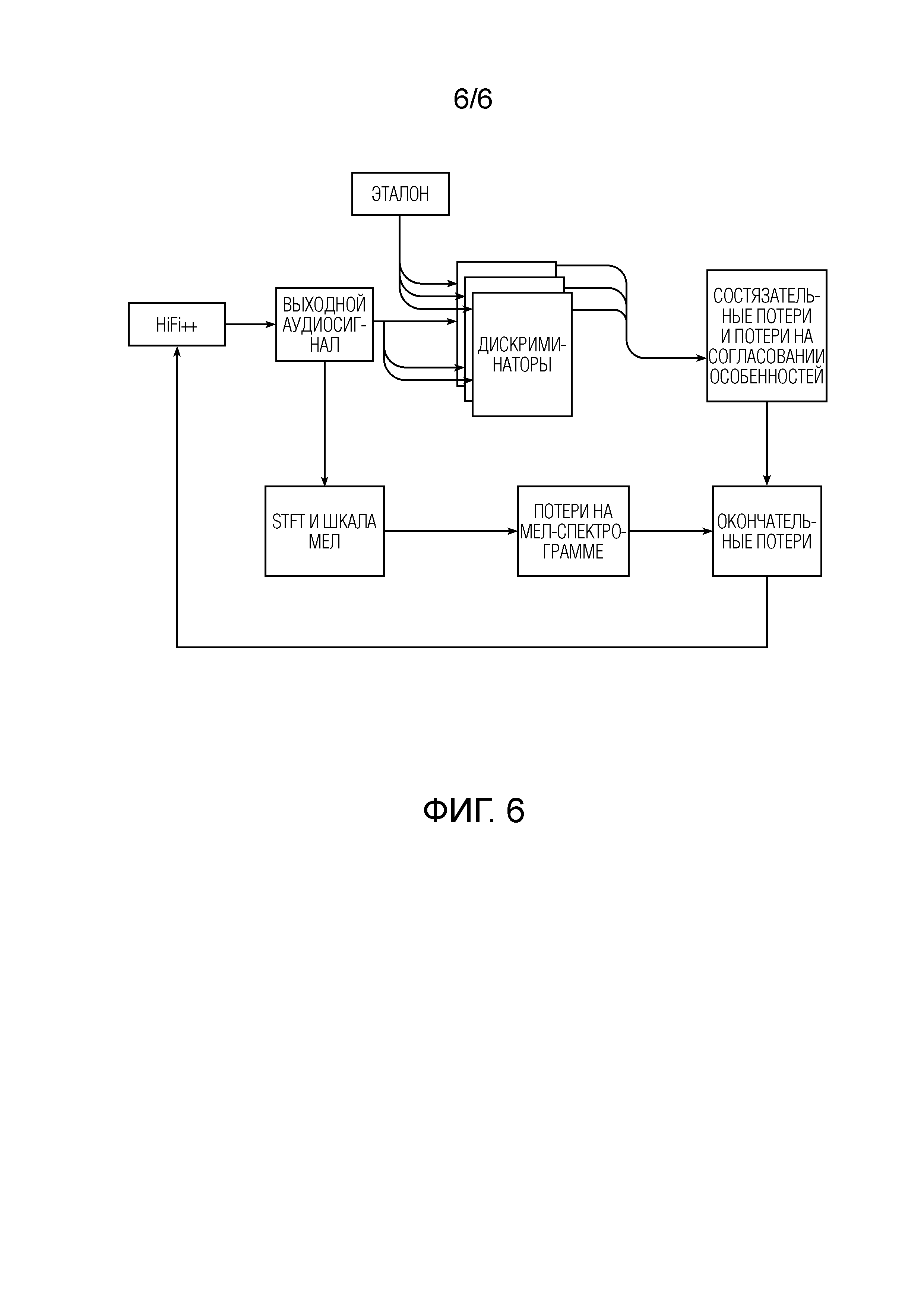
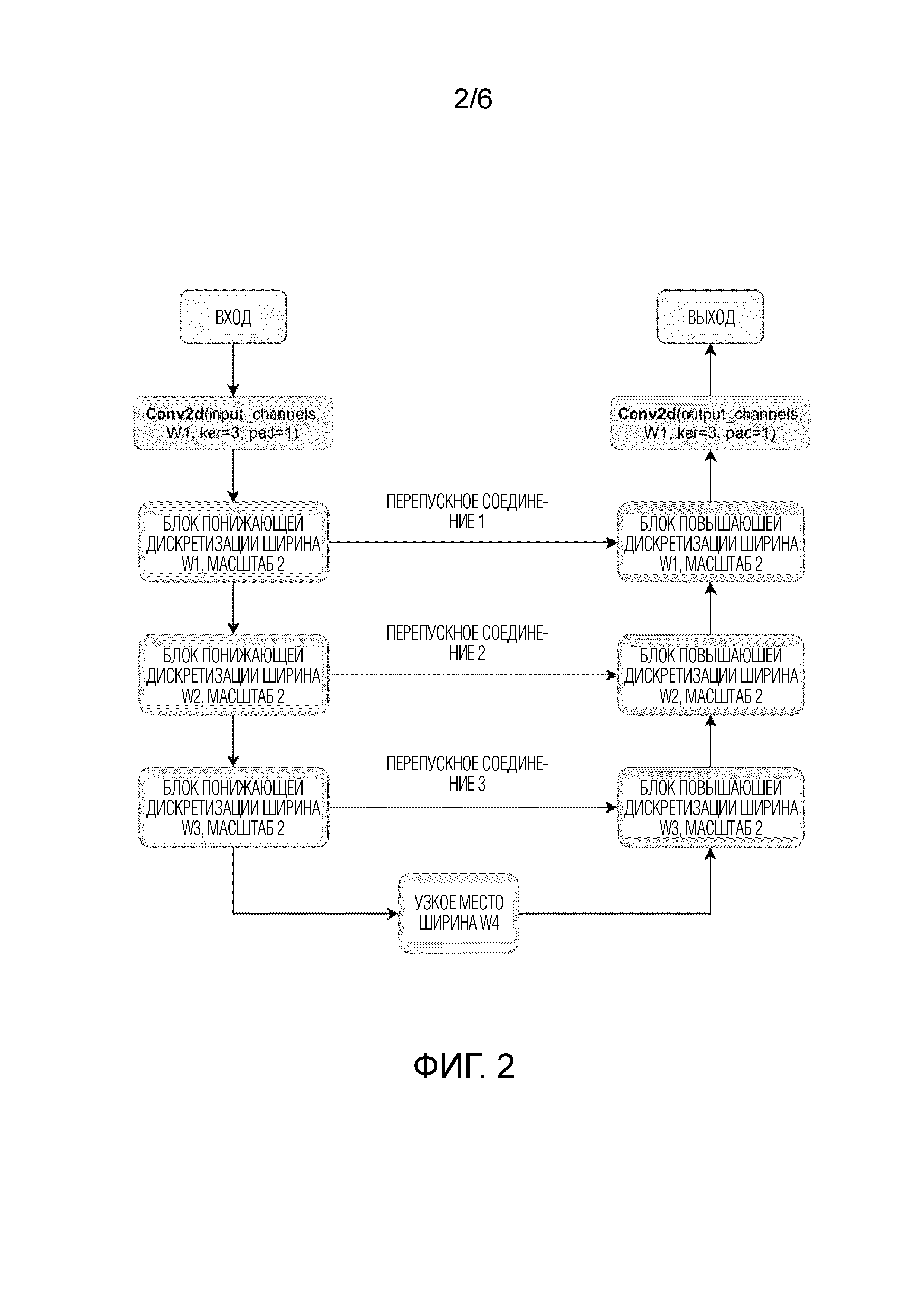
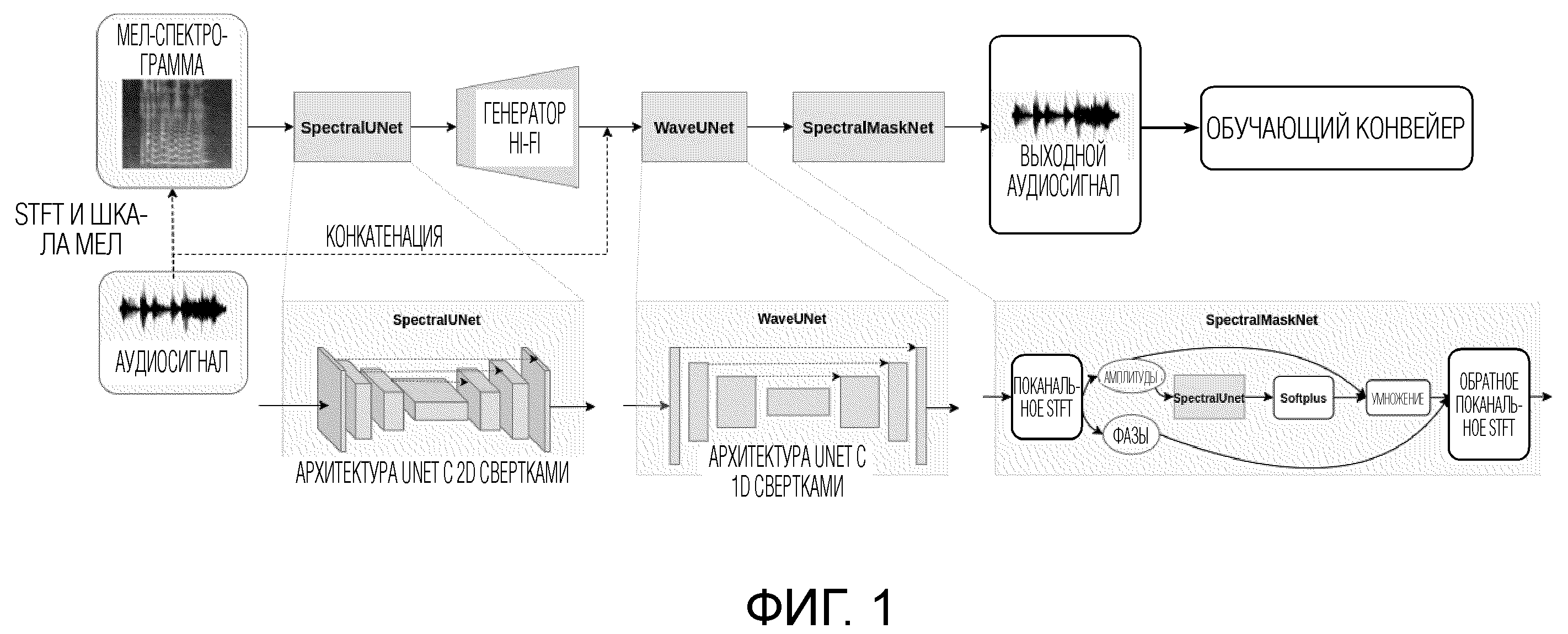
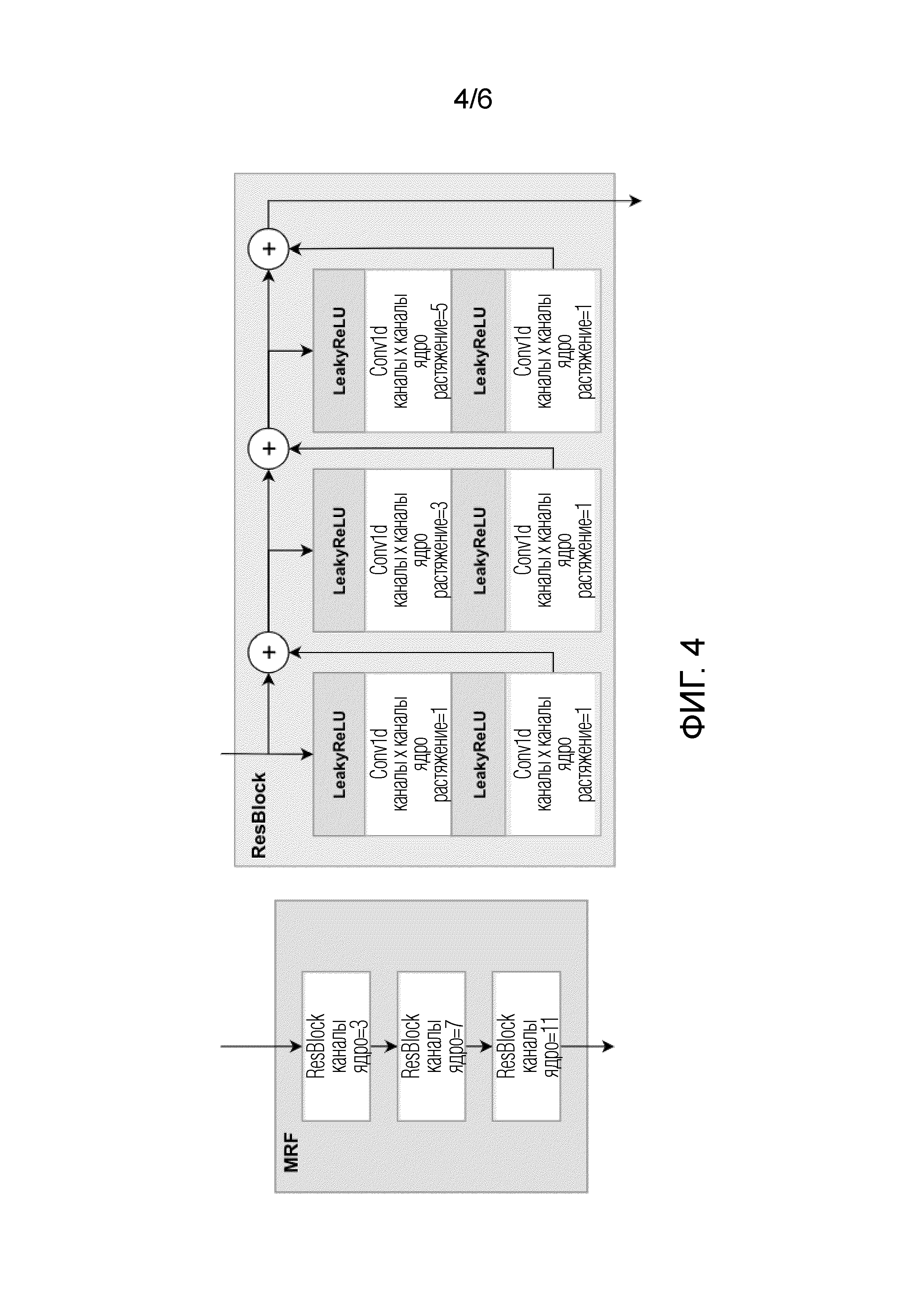
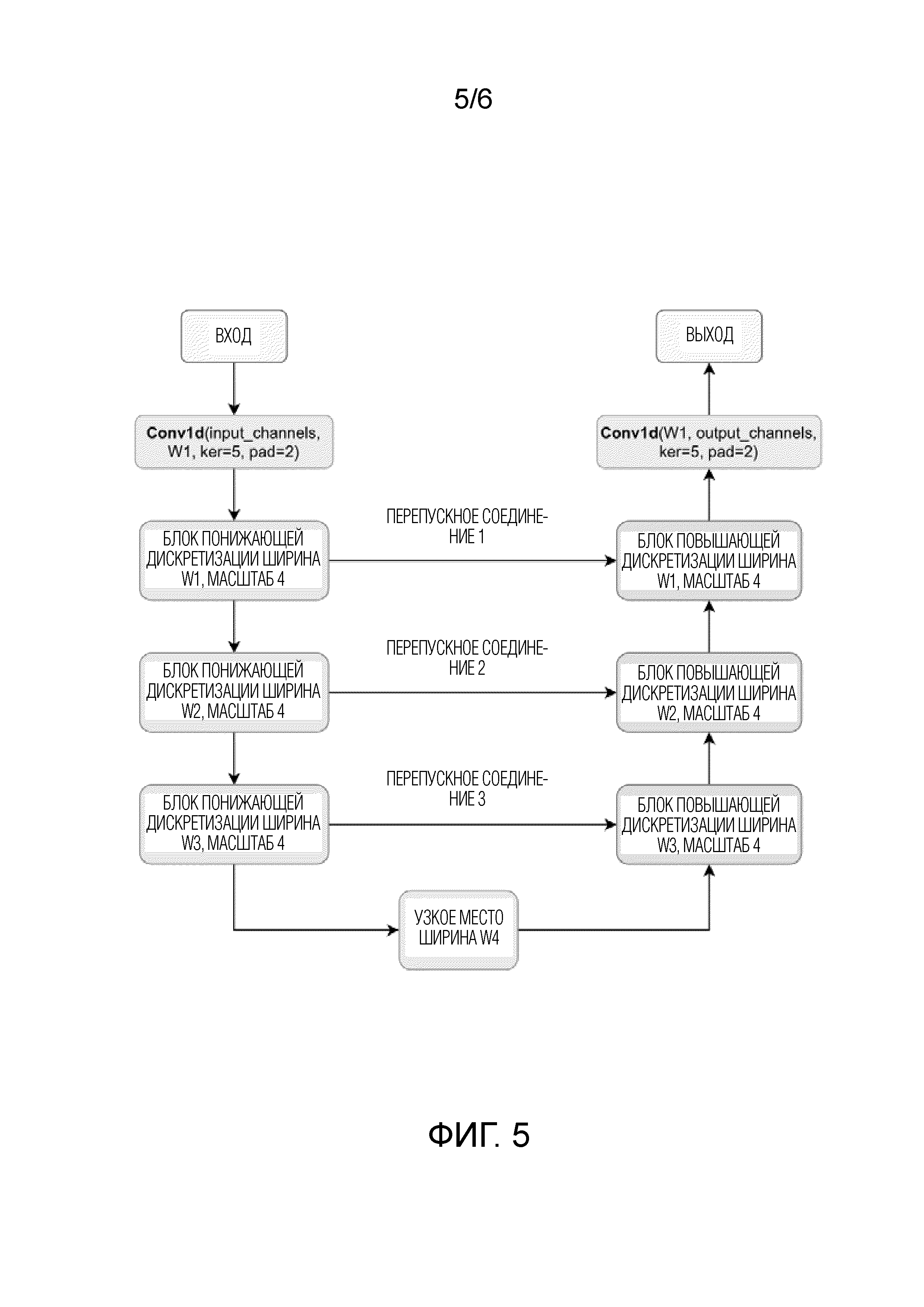
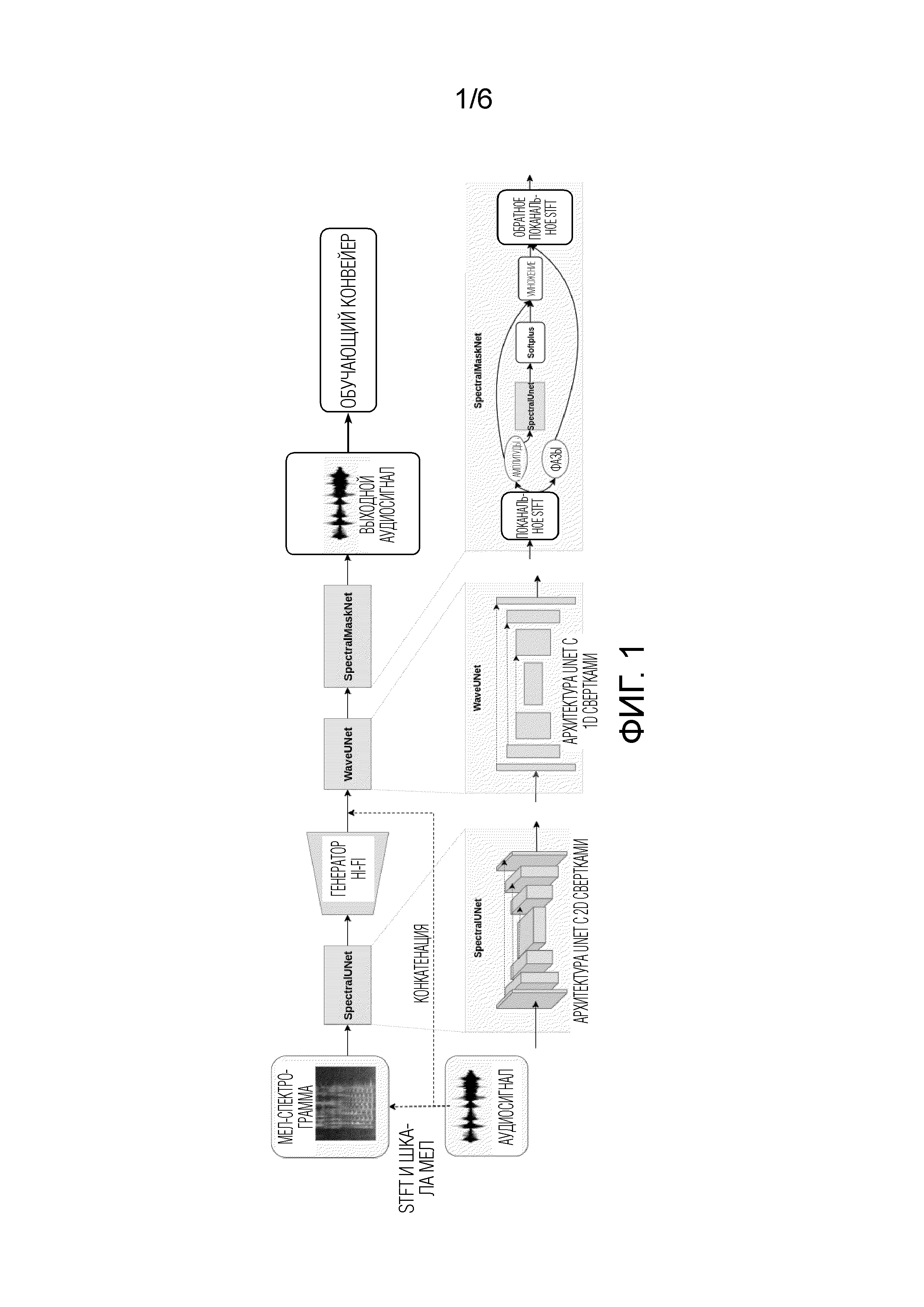
Способ и устройство для уменьшения служебных данных для проверки целостности данных в беспроводной системе связи
Способ и устройство для обработки сигнала для трехмерного воспроизведения дополнительных данных
Способ передачи зондирующего опорного сигнала в системе lte tdd
Способ и система для распределения пилот-сигналов в многопоточных передачах
Устройство и способ для формирования протокольного модуля данных мас в системе беспроводной связи
Способ и устройство для кодирования и декодирования изображения с использованием крупной единицы преобразования
Способы и устройство для быстрого и энергоэффективного восстановления соединения в системе связи на основе видимого света (vlc)
Способ и устройство для кодирования и декодирования вектора движения
Способ и устройство для кодирования видео, и способ и устройство для декодирования видео
Способ сверточного турбокодирования и устройство для реализации способа кодирования

