Результат интеллектуальной деятельности: СОПОСТАВЛЕНИЕ БОЛЬНИЦ ИЗ ОБЕЗЛИЧЕННЫХ БАЗ ДАННЫХ ЗДРАВООХРАНЕНИЯ БЕЗ ОЧЕВИДНЫХ КВАЗИИДЕНТИФИКАТОРОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение в общем относится к медицинским исследованиям и разработкам, медицинским базам данных, интеллектуальному анализу медицинских данных и подобным областям.
УРОВЕНЬ ТЕХНИКИ
В многочисленных областях медицинских научных исследований и разработок используются базы данных здравоохранения, содержащие медицинские данные пациентов. Истории болезни или другие клинические данные, данные о выставлении счетов пациентам, административные записи, относящиеся к таким вопросам, как занятость больничных койко-мест и т. п., ведут больницы или иные медицинские учреждения и/или отдельные больничные отделения, такие как отделение кардиологии (ОК), отделение интенсивной терапии (ОИТ) или отделение неотложной госпитализации. Эти базы данных хранят конфиденциальные данные пациентов, которые обычно должны держаться в секрете в соответствии с законами о финансовой и/или медицинской тайне, такими как (в США) «Закон о преемственности страхования и отчетности в области здравоохранения» (HIPAA).
Вместе с тем признано, что такие базы данных являются ценным источником информации для выполнения широкого диапазона аналитических обработок медицинских данных для клинических, больнично-административных или иных целей. Известно, что для обеспечения возможности использования базы данных пациентов в таких целях при сохранении конфиденциальности пациентов, базу данных обезличивают путем удаления персональных данных пациентов. Информация, которую требуется обезличить, включает в себя имя, фамилию, отчество и/или идентификационный номер пациента (соответствующим образом заменяемые назначенным случайным образом номером и т. п.), адрес и т. д. Однако обезличивать следует и другую информацию, которая в совокупности является персональными данными. Например, согласно оценкам, сочетание пола, даты рождения и пятизначного почтового индекса позволяют однозначно идентифицировать 87% населения США. Поскольку пол и дата рождения, вероятно, будут полезны для многих медицинских анализов, эти результаты исследования предполагают, что почтовый индекс следует считать персональными данными, которые следует обезличивать.
Сведения о больнице тоже могут быть персональными данными в сочетании с другими сведениями, и их следует обезличивать путем замены идентификатором, выбранным случайным образом. Сведения о медицинском учреждении (например, больнице, больничном отделении) обычно не удаляют полностью, а, заменяют выбранным случайным образом идентификатором для каждой больницы (или клинического отделения, или другого медицинского учреждения), поскольку многие методы медицинской аналитики используют корреляции с медицинским учреждением. Например, доля успешных результатов пересадок сердца может сильно коррелировать с больницей или кардиологическим отделением.
Даже при вышеуказанном обезличивании определенные «редкие» пациенты все равно могут быть идентифицированы по обезличенным данным. Например, рассмотрим пациента мужского пола, который умер в возрасте 115 лет в больнице в США в 2011 г. Хотя этого сочетания (пола, возраста, даты смерти) может, как правило, оказаться недостаточно для однозначной идентификации пациента, очень большой возраст данного конкретного пациента при его смерти может сделать однозначную идентификацию возможной, поскольку пациентов мужского пола, умерших в возрасте 115 лет в США в конкретном году, может быть всего лишь несколько, или даже один. Аналогичным образом, основной диагноз очень редкой болезни может быть однозначно идентифицирующим в сочетании всего лишь с несколькими демографическими данными. Соответственно, при обезличивании возможно дополнительное удаление редких атрибутов пациента, которые могут быть персональными данными в сочетании с общими демографическими сведениями. Например, удаление таких «нечасто встречающихся» персональных данных может включать удаление возраста пациентов старше некоторого максимального возраста (например, старше 90 лет), удаление любого основного диагноза, которого нет в списке выбора (достаточно) распространенных диагнозов, и т. д.
Обезличенная база данных, тем не менее, обеспечивает большой объем информации для выполнения на нем различных видов анализа медицинских данных с обеспечением при этом конфиденциальности пациентов.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Согласно одному из аспектов настоящего изобретения раскрыто устройство для обработки двух или более обезличенных баз данных здравоохранения, при этом каждая обезличенная база данных здравоохранения имеет персональные данные, обезличенные в том числе путем замены медицинских учреждений заполнителями (плейсхолдерами) для медицинских учреждений. Устройство содержит электронный процессор, запрограммированный на выполнение процесса объединения баз данных, включающего следующие операции. Для каждого заполнителя для медицинского учреждения в обезличенных базах данных здравоохранения, - рассчитываются распределения статистических характеристик для набора характеристик пациентов по всем пациентам этого заполнителя медицинского учреждения. Заполнители для медицинских учреждений в одной обезличенной базе (X) данных сопоставляют с заполнителями для медицинских учреждений в другой обезличенной базе (Y) данных путем установления соответствия между статистическими распределениями характеристик, рассчитанными по всем пациентам соответствующих сопоставляемых заполнителей для медицинских учреждений. Для каждой сопоставленной пары заполнителей для медицинских учреждений в соответствующих обезличенных базах данных здравоохранения пациентов заполнителя для медицинских учреждений обезличенной базы (X) данных здравоохранения, сопоставляют с пациентами сопоставленного заполнителя для медицинских учреждений другой базы (Y) данных здравоохранения путем сопоставления характеристик пациентов соответствующих сопоставляемых пациентов.
Согласно еще одному аспекту настоящего изобретения раскрыт некратковременный носитель, хранящий инструкции, исполняемые электронным устройством обработки данных для выполнения процесса объединения баз данных, который объединяет две или более обезличенные базы данных здравоохранения. Каждая обезличенная база данных здравоохранения имеет персональные данные, обезличенные в том числе путем замены медицинских учреждений заполнителями для медицинских учреждений. Процесс объединения баз данных включает:
расчет статистических распределений характеристик пациентов по всем заданным интервалам времени для заполнителей для медицинских учреждений в обезличенных базах данных здравоохранения;
сопоставление заполнителей для медицинских учреждений в обезличенной базе X данных здравоохранения и обезличенной базе Y данных путем установления соответствия между статистическими распределениями характеристик пациентов для соответствующих заполнителей медицинских учреждений;
сопоставление пациентов в обезличенной базе X данных здравоохранения и обезличенной базе Y данных здравоохранения в сопоставленных парах заполнителей для медицинских учреждений; и
формирование одного из (i) таблицы совмещения баз данных, идентифицирующей сопоставленных пациентов, и (ii) объединенной обезличенной базы данных здравоохранения, которая объединяет характеристики пациентов в обезличенных базах X, Y данных здравоохранения для каждого сопоставленного пациента в единую запись пациента.
Согласно другому аспекту настоящего изобретения раскрыт способ, который объединяет две или более обезличенных баз данных. Каждая обезличенная база данных здравоохранения имеет персональные данные, обезличенные в том числе путем замены медицинских учреждений заполнителями для медицинских учреждений. Способ объединения баз данных включает:
расчет статистических распределений характеристик пациентов для заполнителей для медицинских учреждений в обезличенных базах данных здравоохранения;
сопоставление заполнителей для медицинских учреждений в разных обезличенных базах данных здравоохранения путем сопоставления статистических распределений характеристик пациентов для соответствующих заполнителей для медицинских учреждений;
сопоставление пациентов в разных обезличенных базах данных здравоохранения, причем сопоставление пациентов выполняют в сопоставленных парах заполнителей для медицинских учреждений; и
формирование таблицы совмещения баз данных, идентифицирующей сопоставленных пациентов, или объединенной обезличенной базы данных здравоохранения, которая объединяет характеристики пациентов в различных обезличенных базах данных здравоохранения для каждого сопоставленного пациента в единую запись пациента.
Способ объединения баз данных соответствующим образом реализуется компьютером.
Одно из преимуществ заключается в обеспечении для выполнения аналитической обработки медицинских данных более крупных баз данных путем объединения или комбинирования двух или более обезличенных баз данных здравоохранения.
Другим преимуществом является обеспечение для выполнения аналитической обработки данных баз данных с более разнообразной информацией (например, сочетающих клинические и финансовые данные) путем объединения или комбинирования двух или более обезличенных баз данных здравоохранения.
Еще одно преимущество заключается в обеспечении вышеуказанных преимуществ с сохранением конфиденциальности пациентов.
Данный вариант реализации может не обеспечивать или обеспечивать одно, два, более или все из вышеупомянутых преимуществ и/или может обеспечивать другие преимущества, которые будут понятны специалисту в данной области после прочтения и осмысления настоящего описания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Изобретение может быть реализовано в виде различных компонентов или групп компонентов, а также различных этапов или схем организации этапов. Чертежи представлены исключительно в целях иллюстрации предпочтительных вариантов реализации и не должны рассматриваться как ограничивающие изобретение.
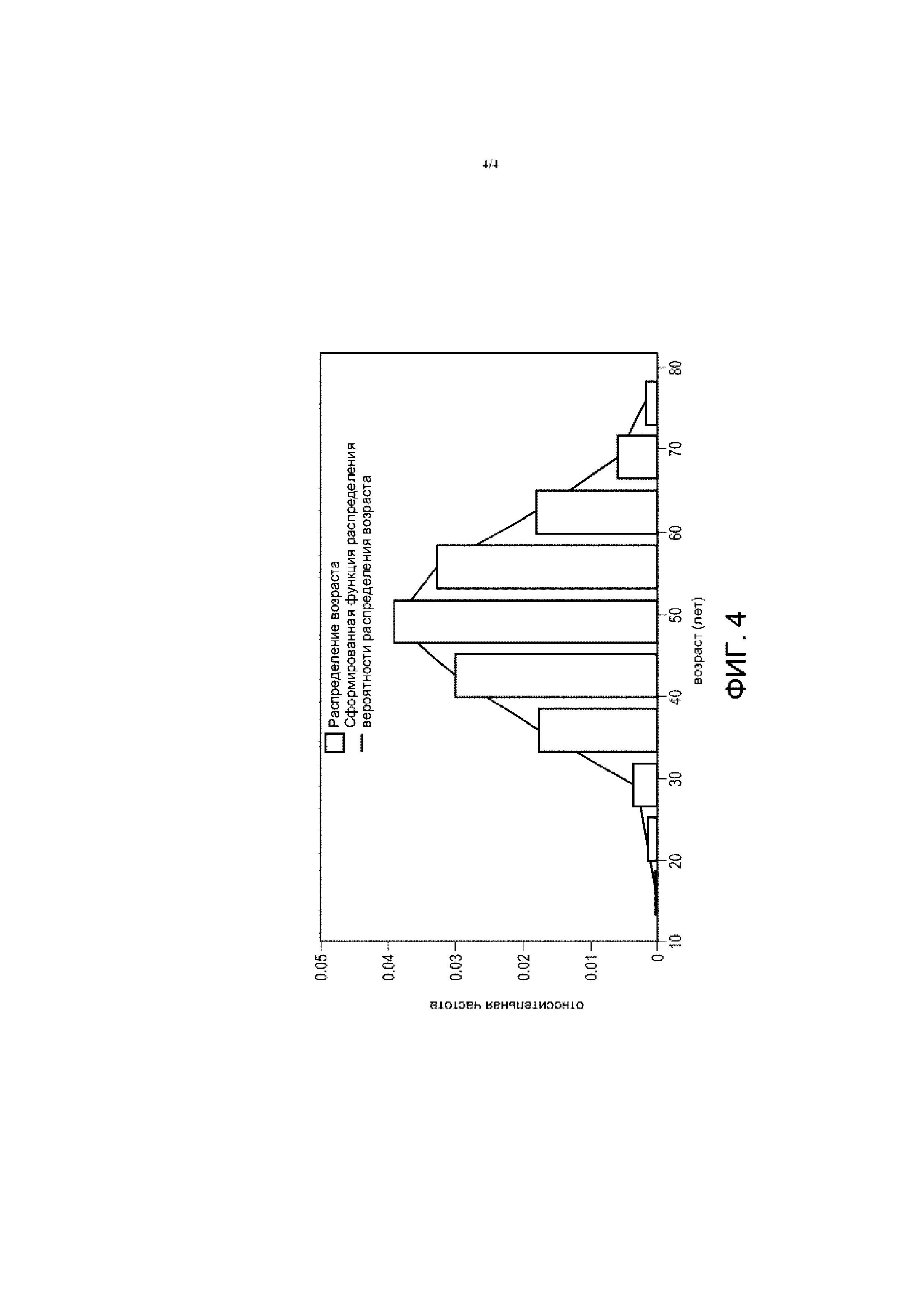
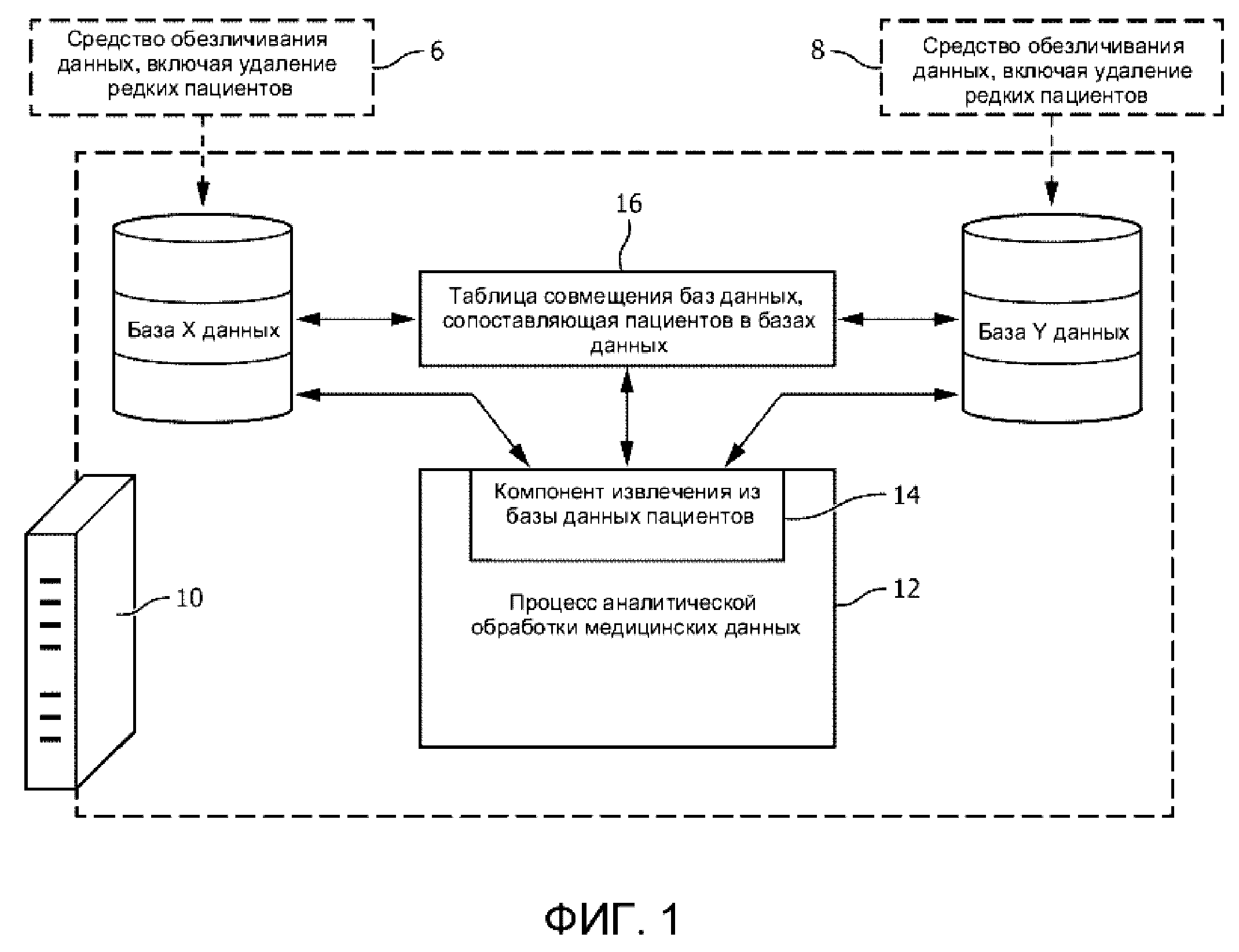
На ФИГ. 1 схематически изображена система медицинской аналитической обработки, которая использует данные пациентов, объединенные из двух обезличенных баз данных здравоохранения.
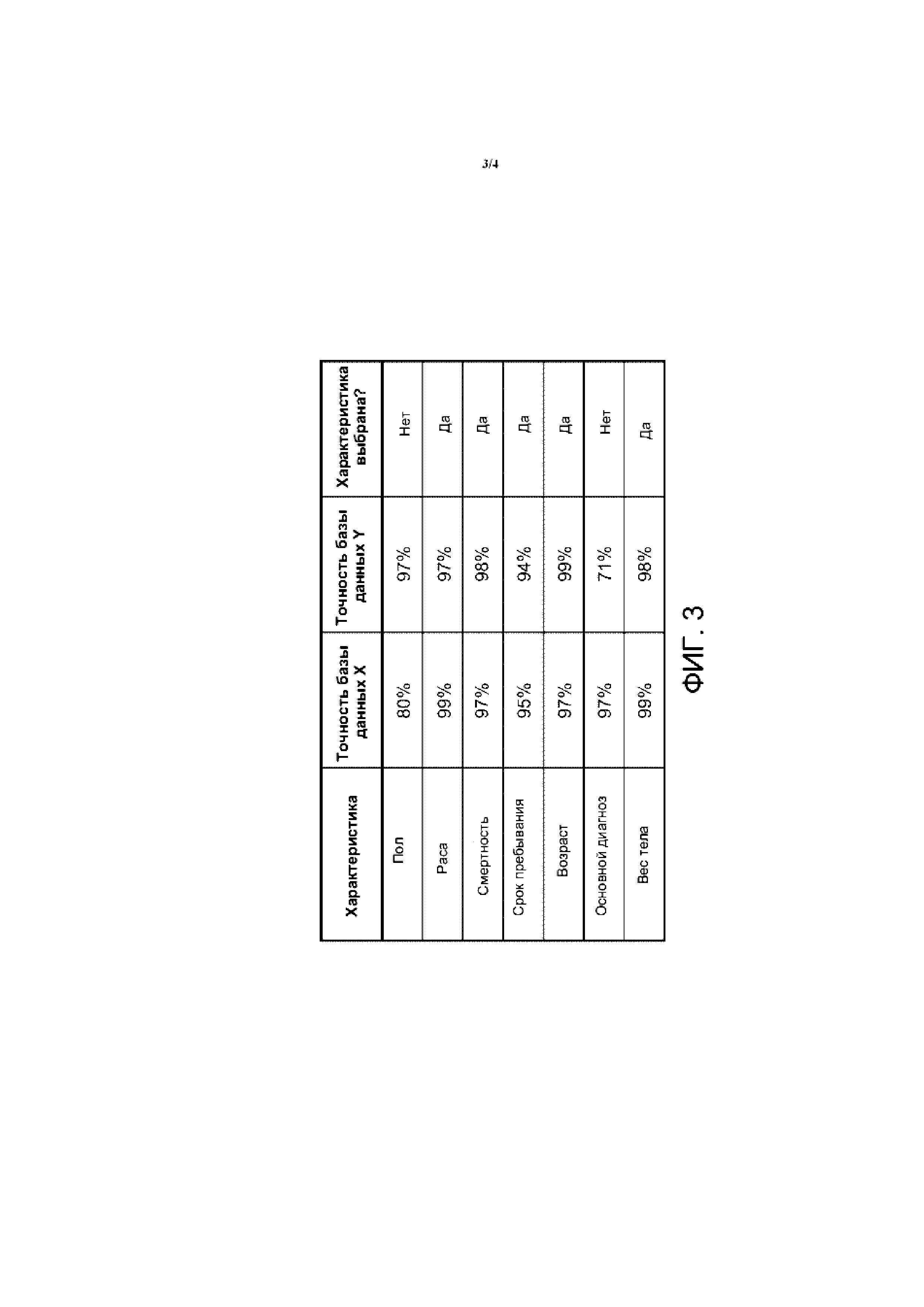
На ФИГ. 2 схематически изображена система для формирования таблицы совмещения баз данных системы медицинской аналитики, показанной на ФИГ. 1.
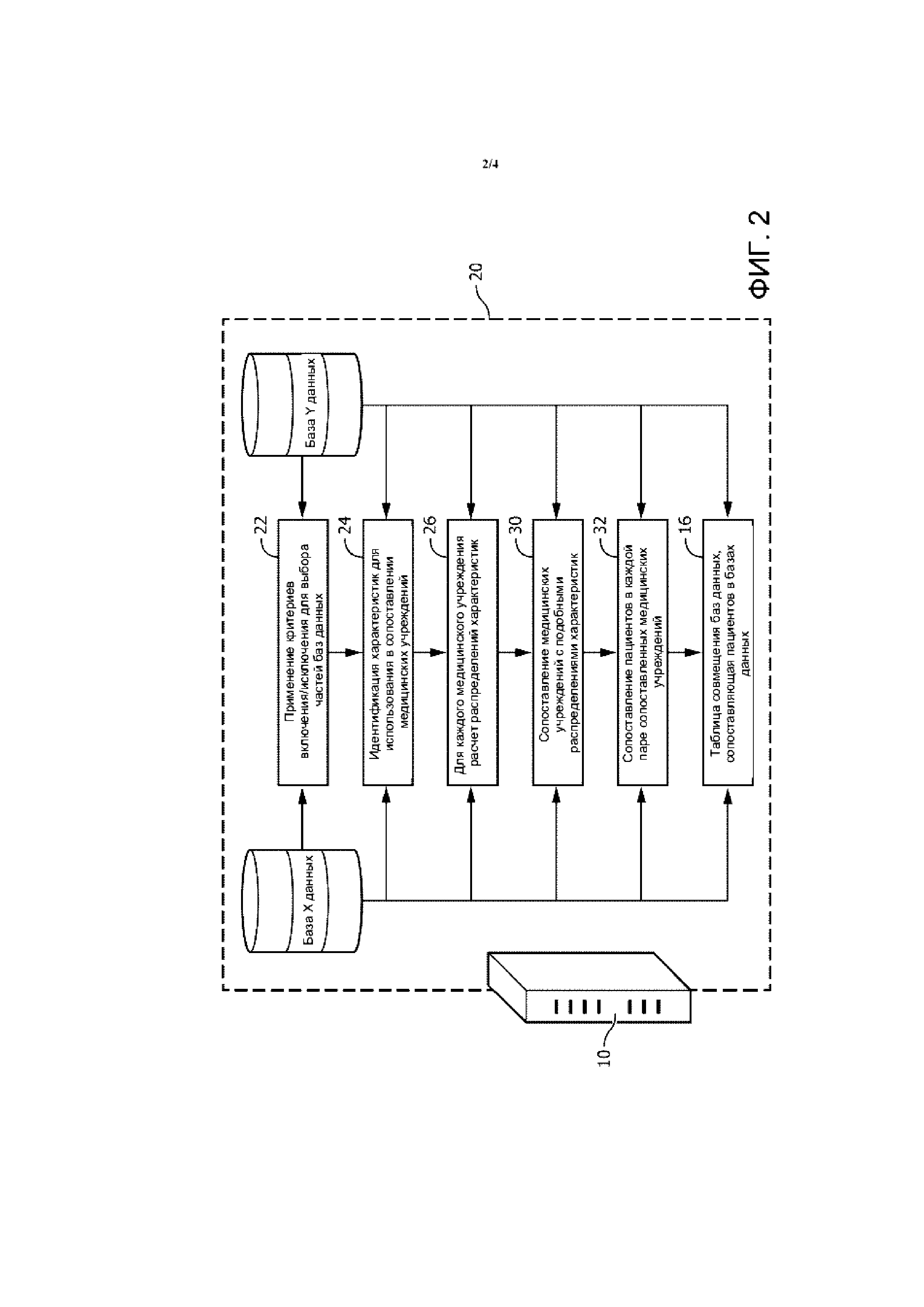
На ФИГ. 3 приведен пример таблицы выбора характеристики.
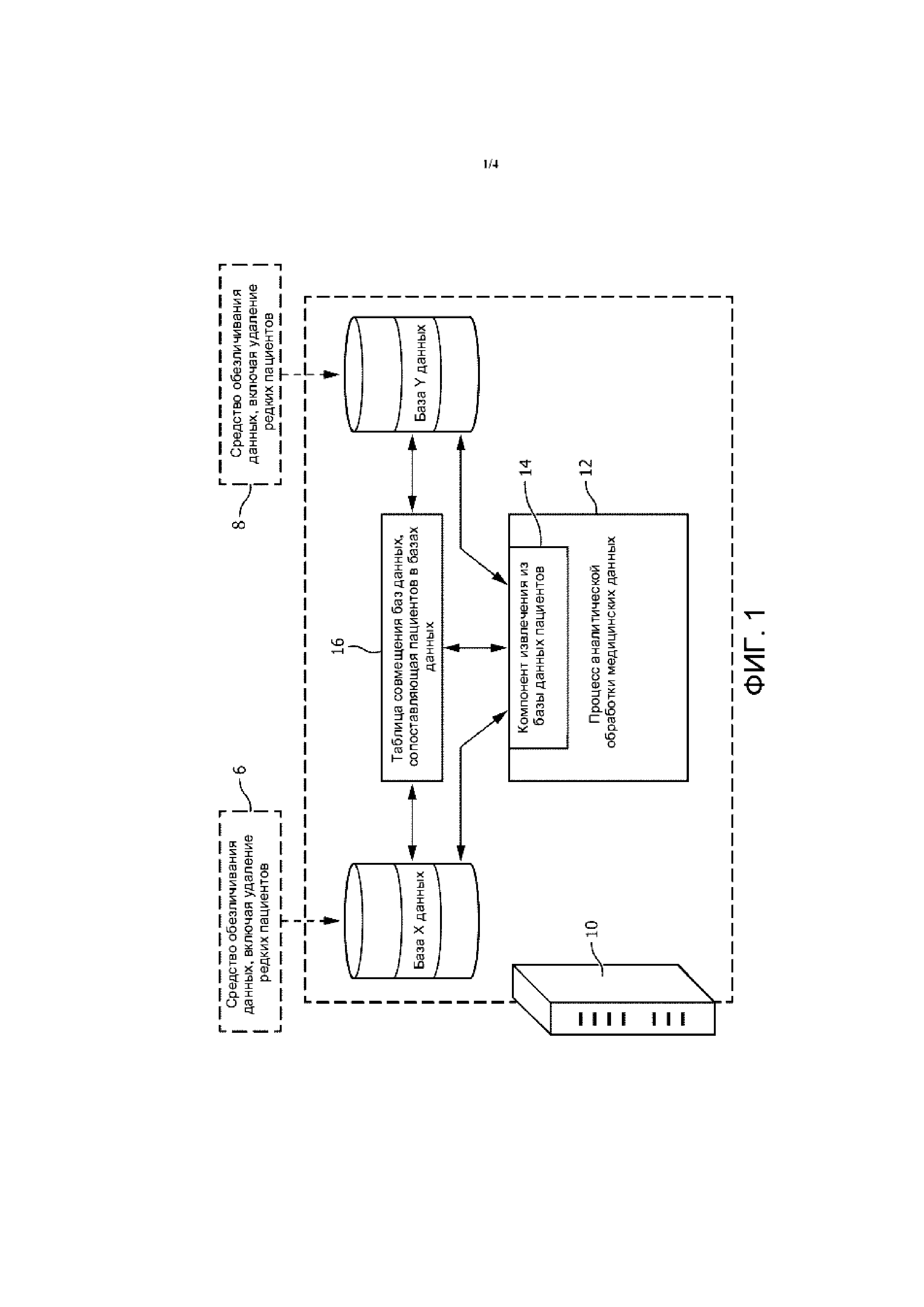
На ФИГ. 4 приведен пример распределения возраста для медицинского учреждения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Как уже было отмечено, обезличенная база данных здравоохранения может предоставлять большой информационный массив для выполнения на нем самых разных аналитических обработок медицинских данных с обеспечением при этом конфиденциальности пациентов. Для того чтобы оценить значение обезличенной базы данных здравоохранения, отмечается, что такая база данных может, в некоторых случаях, содержать данные свыше миллиона пациентов или более. Такая база данных является ценным источником для интеллектуального анализа различных корреляций, статистических закономерностей, трендов и т. д.
Тем не менее, недостатком, отмеченным в настоящем описании, является то, что данные, содержащиеся в обезличенной базе данных здравоохранения, обычно ограничиваются данными, которые доступны одной организации или группе. Например, можно обезличить электронную медицинскую запись (EMR), содержащую клинические данные для всех пациентов, обращавшихся в сеть больниц, чтобы обеспечить большую базу данных здравоохранения, содержащую клинические данные. Аналогичным образом, в той же самой сети больниц возможно наличие административного отдела, который может формировать обезличенную больничную административную базу данных, содержащую информацию о коэффициентах занятости коек, нагрузке медсестер и т.д. Однако в некоторых случаях формирование комбинированной обезличенной базы данных здравоохранения, которая объединяет базу данных EMR и больничную административную базу данных этой сети больниц, может оказаться невозможным. Такое объединение может выполняться путем получения доступа к обеим базам данных для осуществления синхронизированного обезличивания, но HIPAA или другие законы о конфиденциальности не разрешают такого широкого доступа. Возможно, для создания такой комбинированной обезличенной клинической/административной базы данных также потребуется сотрудничество между отделениями, но такого сотрудничества может и не быть. В результате медицинские научно-исследовательские работники могут иметь доступ только к обособленным обезличенной базе данных EMR и обезличенной административной базе данных. Если научно-исследовательский проект требует объединения клинических и больнично-административных данных, этих обособленных обезличенных баз данным может оказаться недостаточно.
Аналогичные проблемы могут возникать в других ситуациях. Например, две различные сети больниц сети могут независимо создать обезличенные клинические базы данных на основе своих соответствующих систем EMR. Однако они не могут создать комбинированную обезличенную базу данных EMR, так как каждая сеть больниц запрещает доступ к EMR другой сети больниц. В результате дополнительная информация, которая могла бы быть получена из анализа пациентов, которым оказывались медицинские услуги в обеих сетях больниц, утрачивается из-за независимых процессов обезличивания.
В настоящем изобретении предложены подходы для преодоления этих трудностей. В частности, предложенные в настоящем изобретении подходы объединяют две или более обезличенные базы данных здравоохранения после того, как они обезличены. Другими словами, система объединения обезличенных баз данных, предложенная в настоящем изобретении, имеет доступ только к обезличенным базам данных и не нуждается в доступе к базовым необезличенным данным пациентов. Таким образом, предложенные в настоящем изобретении методы могут быть применены для комбинирования любых двух или более обезличенных баз данных вне зависимости от наличия у владельца системы объединения баз данных доступа к базовым необезличенным данным. Кроме того, предложенные подходы не опираются на деобезличивание или повторную идентификацию обезличенных данных. Они не используют, например, перекрестную ссылку на необезличенные источники данных для повторной идентификации обезличенных данных. Следовательно, конфиденциальность пациентов сохраняется при объединении обезличенных баз данных здравоохранения.
На ФИГ. 1 показаны две обезличенные базы здравоохранения, обозначенные как «База X данных» и «База Y данных». Обезличенная база X данных здравоохранения формируется средством 6 обезличивания данных, а обезличенная база Y дынных формируется средством 8 обезличивания данных. Средства 6, 8 обезличивания предпочтительно автоматизированы (например, реализованы на компьютерах, причем компьютеры запрограммированы на удаление определенных классов или типов данных), чтобы обезличивать большие базы данных, например, миллион записей пациентов в некоторых вариантах реализации. Необязательно, одно или оба из средств 6, 8 обезличивания могут также включать в себя какую-либо ручную обработку, например, удаление определенных редких пациентов или урегулирования других необычных ситуаций. Эти два средства 6, 8 обезличивания могут быть идентичными или неидентичными, и могут обезличивать одну и ту же или различную информацию. В некоторых вариантах реализации каждое средство 6, 8 обезличивания обезличивает персональные данные, которые могут непосредственно идентифицировать пациента, такие как имя, фамилия и отчество пациента, адрес пациента и т.д., а также информацию, которая может быть потенциально персональными данными в сочетании с другой информацией, такую как название больницы, почтовый индекс и т.д. Когда информация может быть персональными данными в сочетании с другой информацией, может потребоваться обезличивать только часть этого сочетания. Например, сочетание почтового индекса, пола и даты рождения может быть персонально идентифицирующим, но за счет обезличивания только информации о почтовом индексе можно достичь приемлемой анонимности пациента. Средства 6, 8 обезличивания могут также удалять редкую информацию, которая может быть идентифицирующей для определенных пациентов. К такой редкой информации можно отнести, например, любой возраст выше определенного максимума, например 90 лет; диагнозы, которые не входят в список наиболее распространенных диагнозов, и т.д.
В целом, обезличивание конкретных данных может быть выполнено путем удаления (изъятия) данных или путем замены данных заполнителем, причем последний вариант предпочтительнее в ситуациях, когда корреляции с этим конкретным типом информации желательно сохранить, хотя и с обезличиванием. Например, в предложенных методах предполагается, что записи медицинского учреждения (например, больницы или больничного отделения) заменяются заполнителями, которые внутренне согласованы для базы данных. Эти заполнители внутренне согласованы с конкретной базой данных, но меняются по существу случайным образом между базами данных. Например, в базе X данных больница общего профиля N-ска может всегда заменяться заполнителем «8243», а городской медицинский центр M-ска может всегда заменяться заполнителем «1238». В этом примере каждый экземпляр медицинского учреждения «Больница общего профиля N-ска» в базе X данных заменяется (одним и тем же) заполнителем для медицинского учреждения «8243», а каждый экземпляр медицинского учреждения «Городской медицинский центр M-ска» в базе X данных заменяется (одним и тем же) заполнителем для медицинского учреждения «1238». С другой стороны, в продолжение примера для базы Y, каждый экземпляр медицинского учреждения «Больница общего профиля N-ска» базы Y данных может быть заменен одним и тем же заполнителем для медицинского учреждения «EADF» (который отличается от заполнителя «8243», используемого для N-ска в базе X данных), а каждый экземпляр «Городской медицинский центр M-ска» может быть заменен одним и тем же заполнителем для медицинского учреждения «JSDF» (который тоже отличается от заполнителя «1238», используемого для M-ска в базе X данных). Такое обезличивание медицинского учреждения с помощью заполнителей для медицинских учреждений, которые согласуются внутри обезличенной базы данных, позволяет медицинской аналитике, действующей на базе данных, идентифицировать корреляции с конкретным медицинским учреждением при сохранении анонимности. Например, если в N-ске статистически более значимая доля успешных пересадок сердца, чем в средней больнице, это проявится в базе X данных (в предположении, что она хранит данные по результатам пересадок сердца) в виде статистически более значимой доли успешных пересадок сердца, выполненных в обезличенной больнице «8243».
С другой стороны, некоторая информация может быть обезличена путем изъятия, то есть удаления. Например, информация об адресе места жительства может быть изъята полностью, поскольку она является в высокой степени идентифицирующей, а полезные корреляции с адресом места жительства не предполагаются. В альтернативном варианте реализации, если корреляции с адресом места жительства полагаются полезными входными данными для аналитической обработки медицинских данных, обезличивание адреса можно выполнить путем замены адреса места жительства более широкой географической единицей, например, городом проживания, если численность населения этого города достаточно большая. Город или район с достаточно малочисленным населением могут быть изъяты полностью во избежание сохранения «редких» данных, которые могли бы персонально идентифицировать, или могут быть заменены подходящей более крупной географической единицей, такой как область проживания.
Каждая из обезличенной базы X данных и обезличенной базы Y данных отформатирована в некотором структурированном формате, например, в формате реляционной базы данных или в другом структурированном формате базы данных, таком как электронные таблицы, выполненные с возможностью поиска, редактируемые текстовые файлы с разделителями-колонками и т. д. Обезличенная база X данных и обезличенная база Y данных или их объединенная комбинация, как описано в настоящем документе, доступны для системы аналитической обработки медицинских данных, реализованной на компьютере 10, который может быть, например, сетевым серверным компьютером, облачным вычислительным ресурсом, кластером серверов и т.д. Компьютер 10 для аналитической обработки медицинских данных выполняет по меньшей мере один процесс 12 аналитической обработки медицинских данных, который осуществляет поиск содержимого одной или обеих обезличенных баз X, Y данных для выявления в этих данных корреляций, статистических закономерностей, трендов и т.д., которые могут представлять интерес для улучшения клинических результатов, эффективности административного руководства больницы, финансовой эффективности и т.д., или которые могут представлять интерес для обнаружения плохих клинических результатов, административной и/или финансовой неэффективности и т.д. Процесс аналитической обработки медицинских данных может быть реализован в виде специально разработанной компьютерной программы или может быть построен в кодированном формате высокого уровня, например, в виде запроса на языке структурированных запросов (SQL) или в виде SQL-программы в вариантах реализации, где обезличенные базы X, Y данных являются реляционными базами данных системы управления реляционными базами данных (RDBMS). В дополнение к извлечению данных из одной или обеих баз X, Y данных процесс 12 аналитической обработки медицинских данных может выполнять широкий диапазон статистических, графических или иных операций обработки данных, таких как вычисление статистического математического ожидания, среднего значения, стандартного отклонения или дисперсии либо других статистических характеристик данных, нанесение данных на график с использованием различных форматов (гистограмма, секторная диаграмма, линия тренда и т.д.) и т.п.
Как показано на ФИГ. 1, процесс 12 аналитической обработки медицинских данных включает в себя или имеет доступ (например, посредством вызова функции, вызова подпрограммы, указателя-связки и т.п.) к компоненту 14 извлечения из базы данных пациентов, который извлекает из одной или обеих баз X, Y данных данные, удовлетворяющие некоторому критерию запроса (например, определенному с помощью SQL-запроса). Если процесс 12 аналитической обработки медицинских данных имеет доступ только к обезличенной базе X данных или только к обезличенной базе Y данных, то компонент 14 извлечения из базы данных пациентов может непосредственно обращаться к соответствующей базе.
С другой стороны, для получения доступа к объединенным обезличенным базам X, Y данных компонент 14 извлечения из базы данных пациентов ссылается на таблицу 16 совмещения баз данных, которая сопоставляет обезличенных пациентов в двух базах X, Y данных и комбинирует данные сопоставленных пациентов из двух баз X, Y данных. Если обе записи сопоставленных пациентов в соответствующих базах X, Y данных хранят одно и то же значение для характеристики пациентов, то извлеченное значение для этой характеристики пациентов будет этим общим значением. Если только одна из записей сопоставленных пациентов в соответствующих базах X, Y данных хранит значение для характеристики пациентов, то извлеченное значение для этой характеристики пациентов будет этим одним хранимым значением. Если записи сопоставленных пациентов в соответствующих базах X, Y данных хранят разные значения для характеристики пациентов, это несоответствие можно разрешить различными путями, такими как возвращение среднего значения двух значений или возвращение значения ошибки для этой характеристики пациентов. В одном подходе среднее значение возвращается, если два разных сохраненных значения достаточно близки (например, в пределах назначенного процентного значения), тогда как значение ошибки возвращается, если эти два значения отличаются больше, чем на это пороговое процентное значение.
Объединение баз X, Y данных может быть полезными, если, например, база X данных и база Y данных хранят различную информацию для данного обезличенного пациента. В качестве иллюстрации, если обезличенная база X данных является клинической базой данных, а обезличенная база Y данных является больнично-административной базой данных, то для пациента может быть получена комбинация медицинской процедуры, выполненной над пациентом (из базы X данных), и характеристик операционного блока, в котором выполнялась операция (из базы Y данных), которая позволяет получать аналитические данные, такие как влияние хирургического оборудования на результаты медицинской процедуры. Преимуществом является то, что таблица 16 совмещения баз данных сама обезличена в том смысле, что она не идентифицирует никакого пациента или не опирается на персональные данные при совмещении пациентов двух обезличенных баз X, Y данных. Более того, построение таблицы 16 совмещения баз данных не опирается на процедуры деобезличивания или повторной идентификации.
Вообще, компьютер 10 для аналитической обработки медицинских данных не имеет доступа к исходной (-ым) базе (-ам) данных, из которой (-ых) обезличенные базы X, Y данных формируются средствами 6, 8 обезличивания. Это схематически показано на ФИГ. 1 путем помещения средств 6, 8 обезличивания за пределами компьютера 10 для аналитической обработки медицинских данных и отображения средств 6, 8 обезличивания пунктирными линиями. В более общем смысле базы X, Y данных обезличены, и процесс 12 аналитической обработки медицинских данных не имеет доступа к базовым необезличенным данным. (Например, предполагается, что исходные необезличенные базы данных доступны компьютеру 10 для аналитической обработки медицинских данных, но защищены от доступа процесса 12 аналитической обработки медицинских данных с использованием подходящих процедур защиты электронных данных, например, с помощью уровней доступа к данным, защиты паролем, шифрования и т.д.)
Система для формирования таблицы 16 совмещения баз данных описана со ссылкой на ФИГ. 2 Система на ФИГ. 2 содержит компьютер 10, выполняющий процесс 20 объединения, который объединяет две обезличенных базы X, Y данных путем формирования таблицы 16 совмещения баз данных. На иллюстративной ФИГ. 2 процесс 20 объединения реализован на том же самом компьютере 10, который также выполняет процесс 12 аналитической обработки медицинских данных; однако это не является обязательным требованием и предлагается вместо выполнения процесса 20 объединения на другом компьютере, а не на компьютере, который выполняет процесс 12 аналитической обработки медицинских данных. Как и в случае процесса 12 аналитической обработки медицинских данных, процесс 20 объединения также не имеет доступа к базовым необезличенным данным. Например, предполагается, что исходные необезличенные базы данных доступны компьютеру 10 для аналитической обработки медицинских данных, но защищены от доступа процесса 20 объединения с использованием подходящих процедур защиты электронных данных, например, с помощью уровней доступа к данным, защиты паролем, шифрования и т. д. В альтернативном варианте реализации, исходные необезличенные базы данных могут быть вообще недоступны компьютеру 10. Процесс 20 объединения выполняет объединение обезличенных баз X, Y данных, то есть формирует таблицу 16 совмещения баз данных, используя только информацию, содержащуюся в обезличенных базах X, Y данных. Можно также отменить, что хотя в иллюстративном варианте реализации результатом процесса 20 объединения является таблица 16 совмещения баз данных, в других вариантах осуществления результатом может быть фактическая объединенная база данных, которая содержит единую запись пациента для каждой сопоставленной пары пациентов в двух базах X, Y данных, содержащую всю (объединенную) информацию из баз X, Y данных для сопоставленной пары пациентов. (То есть сформированная объединенная обезличенная база данных здравоохранения объединяет характеристики пациентов в обезличенных базах X, Y данных здравоохранения для каждого сопоставленного пациента в единую запись пациента.)
В принципе, две базы X, Y данных могут быть объединены с помощью исчерпывающего поиска. В этом исчерпывающем подходе, начиная с первой записи базы X данных, выполняют поиск каждой записи базы Y данных, и ту запись базы Y данных, которая наиболее близко совпадает с первой записью базы X данных, сопоставляют первой записи базы X данных (необязательно, только в том случае, если совмещение удовлетворяет некоторому минимальному пороговому значению). Это повторяется для второй записи базы X данных и т. д. до тех пор, пока все записи базы X данных не будут обработаны. Однако этот исчерпывающий подход требует большого объема вычислений. Например, если база X данных и база Y данных обе содержат по одному миллиону записей, то выполнение исчерпывающего поиска потребует сравнения 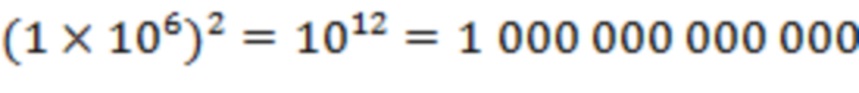 записей.
записей.
В подходах с объединением, предложенных в настоящем изобретении, это затруднение с вычислениями преодолевается с помощью следующего подхода. В настоящем описании принимается, что в большинстве обезличенных баз данных медицинские учреждения (например, больницы или отделения больницы) обезличены путем замены каждого медицинского учреждения внутренне согласованным заполнителем (например, каждый экземпляр больницы в конкретной обезличенной базе данных заменен одним и тем же заполнителем). Заполнители эффективно сохраняют возможность выявлять корреляции, статические тренды и т.п. на уровне больницы или отделения больницы. Такие корреляции, тренды и т. д. невозможно было бы выделить, если название больницы было бы изъято. Кроме того, использование внутренне согласованных заполнителей для медицинских учреждений при обезличивании медицинских учреждений может облегчить выполнение аудита, если средство контроля (которое не является процессом 12 аналитической обработки медицинских данных и не является процессом 20 объединения), собирает и сохраняет информацию, в которой каждому заполнителю для медицинского учреждения соответствует фактическое медицинское учреждение. Таким образом, если процесс 12 аналитической обработки медицинских данных был бы предназначен (в качестве иллюстрации) для выявления в данной больнице некой проблемы, которая влияет на безопасность пациентов, то можно было бы обратиться к этому средству контроля, чтобы идентифицировать данную больницу и решить проблему, связанную с безопасностью.
В подходах с объединением, предложенных в настоящем изобретении, медицинские учреждения, обезличенные с помощью внутренне согласованных заполнителей для медицинских учреждений, используются для сопоставления соответствующих медицинских учреждений в разных обезличенных медицинских базах X, Y данных. Такое сопоставление меньше на несколько порядков величины по сложности, чем исчерпывающее сопоставление по каждому пациенту. Например, иллюстративный пример с одним миллионом пациентов в каждой базе X, Y данных может соответствовать (в качестве иллюстрации) 2000 больницам (или, более точно, 2000 заполнителям для больниц) для каждой базы X, Y, если вклад каждой больницы составляет в среднем 500 записей пациентов. Тогда сопоставление больниц влечет 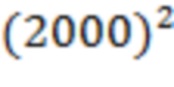 или четыре миллиона сравнений (по сравнению с одним триллионом сравнений при исчерпывающем поиске для каждого пациента, что равносильно снижению сложности примерно на пять порядков величины). Когда больницы сопоставлены, сопоставление пациентов выполняют для каждой пары сопоставленных больниц в базах X, Y данных. В рассматриваемом примере каждая больница в среднем имеет 500 записей пациентов, что влечет лишь около
или четыре миллиона сравнений (по сравнению с одним триллионом сравнений при исчерпывающем поиске для каждого пациента, что равносильно снижению сложности примерно на пять порядков величины). Когда больницы сопоставлены, сопоставление пациентов выполняют для каждой пары сопоставленных больниц в базах X, Y данных. В рассматриваемом примере каждая больница в среднем имеет 500 записей пациентов, что влечет лишь около 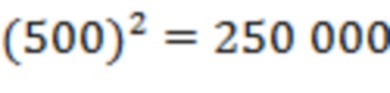 сравнений на больницу. Поэтому объединение баз X, Y данных легко разрешимо даже для больших баз данных.
сравнений на больницу. Поэтому объединение баз X, Y данных легко разрешимо даже для больших баз данных.
Как показано на ФИГ. 2, иллюстративный процесс 20 объединения включает следующие операции. В операции 22 критерии включения/исключения применяются для выбора в базах X, Y данных соответствующих частей баз данных, подлежащих объединению. Операция 22 может также включать стандартизацию формата данных, перевод единиц измерения или другую предварительную обработку. В операции 24 определяется набор характеристик пациентов для использования в сопоставлении медицинских учреждений. В операции 26 для каждого медицинского учреждения рассчитывается статистическое распределение (например, функция распределения вероятностей) каждой характеристики пациентов по всем пациентам этого медицинского учреждения. Распределения характеристик могут быть, необязательно, рассчитаны на годовой основе (или на основе некоторых иначе определенных интервалов времени, например, на двухлетней основе, на месячной основе и т. д.) При таком подходе сравнения профилей распределения характеристик для различных медицинских учреждений выполняются на интервалах времени, для которых в обеих базах X, Y данных имеются данные пациентов. Распределения характеристик могут, необязательно, быть моделированы, например, путем аппроксимации с получением гауссовской модели, аппроксимации с получением сплайновой кривой или другой параметризованной модели, чтобы сократить число значений, представляющих каждое распределение (например, гауссовская модель параметризируется по значениям амплитуды, математического ожидания и дисперсии), и/или облегчить сравнение аналитических распределений, и/или получить возможность обработки распределений характеристик пациентов как гладких непрерывных функций. Операция 26 формирует набор (по каждому году) профилей распределения характеристики (необязательно, представленных моделью), представляющих различные медицинские учреждения (или, более точно, заполнители для медицинских учреждений), и эти профили распределения характеристик пациентов затем используются в операции 30 для сопоставления медицинских учреждений в соответствующих базах X, Y данных с помощью схожих профилей распределения характеристик пациентов. Операция 30 основана на ожидании того, что распределения характеристик пациентов популяции пациентов, (основанной на годичном или ином интервале времени) должны быть аналогичны для двух баз X, Y данных, поскольку обе базы X, Y данных регистрируют данные во многом одних и тех же пациентов. Операция 30 выполняет дальнейшую рационализацию на основе ожидания того, что даже если некоторые пациенты, зарегистрированные в базе X данных за конкретным медицинским учреждением, не зарегистрированы в базе Y данных за этим медицинским учреждением (или наоборот), то базовые демографические данные пациентов, обслуживаемых медицинским учреждением, являются теми же самыми, так что распределения характеристик должны быть аналогичными. Когда медицинские учреждения (или, более точно, заполнители для медицинских учреждений) соответствующих баз X, Y сопоставлены, в операции 32 сопоставляют пациентов (или записи пациентов) в каждой сопоставленной паре медицинских учреждений соответствующих баз X, Y данных. Операция сопоставления 32 может быть выполнена исчерпывающим образом, поскольку, как уже объяснялось, операцию 32 сопоставления пациентов выполняют на меньших подмножествах пациентов в базах X, Y данных.
Далее каждая из этих операций — 22, 24, 26, 30, 32 — описывается более подробно и/или на иллюстративных примерах.
Операция 22 применяет критерии включения и исключения. Чтобы сопоставить больницы (или другие медицинские учреждения) из двух разных больших обезличенных баз X, Y данных здравоохранения, подмножества этих двух баз данных, которые, возможно, связаны, выделяются в операции 22. Например, если одна база данных охватывает только данные пациентов хирургического и ожогового отделений интенсивной терапии ОИТ из другой базы данных, то, соответственно, рассматривается подмножество пациентов, которые во время госпитализации были приняты в хирургическое и ожоговое отделения ОИТ (ICU). Операция 22 может, необязательно, включать другие предварительные обработки, такие как стандартизация представлений данных.
Операция 24 выбора характеристики идентифицирует подмножество характеристик, идентифицирующих не единственным образом (так как базы X, Y данных обезличены), для которых могут быть сформированы приемлемо точные функции плотности вероятностей или другие статистические распределения. Идентифицированный набор характеристик пациентов используется в последующем сопоставлении медицинских учреждений. Для включения в набор характеристик пациентов характеристика должна присутствовать в обеих базах X, Y данных. Некоторые потенциально пригодные характеристики сведены в таблицу на ФИГ. 3. Кроме того, авторы настоящего изобретения обнаружили, что некоторые обезличенные базы данных здравоохранения содержат высокие проценты или доли неточной информации по определенным характеристикам пациентов, очевидно из-за ошибок ввода и/или транскрибирования данных, причем характеристики пациентов с существенной неточностью предпочтительно не включаются в набор характеристик пациентов, используемых для статистического описания медицинских учреждений. Хотя обезличивание затрудняет оценку точности, для оценки (статистическим образом) точности данной характеристики в данной обезличенной базе данных могут быть использованы различные подходы. Например, если пациент указан как имеющий пол «мужской» и основной диагноз «беременность», то один или оба этих элементов данных неверны. Невероятные значения характеристики могут быть также признаны ошибочными, например, возраст пациента 200 лет. Невероятные распределения характеристик тоже могут быть признаны ошибочными, например, если (заполнитель) больница имеет срок пребывания 30 суток для каждого пациента, то это почти наверняка ошибка данных. В целях выбора характеристики опускаемое значение характеристики может, необязательно, рассматриваться как «ошибка», так как отсутствующие данные характеристики снижают полезность характеристики пациента для охарактеризования медицинских учреждений. Например, если возраст зарегистрирован только для двух третей пациентов, это высокий процент ошибок, который снижает полезность возраста для охарактеризования медицинских учреждений.
На ФИГ. 3, например, в качестве возможного примера использования точности баз X, Y данных для различных потенциальных характеристик сведены в таблицу. Как показано на ФИГ. 3, база X данных демонстрирует низкую точность в 80% для пола (т. е. 20% записей пола определены как неверные), тогда как база Y данных имеет низкую точность в 71% для основного диагноза (т.е. 29% основных диагнозов определены как неверные). Все остальные точности характеристик, сведенные в таблицу на ФИГ. 3, превышают 90%. Таким образом, из таблицы на ФИГ. 3 идентифицированы характеристики «раса», «смертность», «срок пребывания», «возраст» и «вес тела», но не «пол» и не «основной диагноз». В более общем смысле, чтобы характеристика была выбрана в операции 24, точность этой характеристики в обеих базах X, Y данных должна быть высокой.
Операция 26 рассчитывает статистические распределения для характеристик, идентифицированных в операции 24. На ФИГ. 4 показан пример возможного использования функции распределения вероятностей для возраста. В этом иллюстративном примере возраст пациентов сгруппирован по девяти возрастным интервалам, охватывающим диапазон возрастов 20–80 лет, чтобы сформировать гистограмму, вид которой напоминает кривую колоколообразной формы. Необязательно, гистограмму можно аппроксимировать параметризованной моделью, как показано линией на ФИГ. 4, такой как гауссовская модель, аппроксимировать сплайновой кривой и т. п., чтобы сократить число параметров и/или облегчить аналитический расчет, и/или сделать возможной обработку статистических распределений характеристик как гладких, непрерывных функций.
Операция 30 сопоставления заполнителей для медицинских учреждений сопоставляет заполнители для медицинских учреждений в одной обезличенной базе X данных с заполнителями для медицинских учреждений в другой обезличенной базе Y данных путем установления соответствия между статистическими распределениями характеристик, рассчитанными по всем пациентам соответствующих сопоставляемых заполнителей для медицинских учреждений. В одном иллюстративном подходе операция 30 сопоставления медицинского учреждения соответствующим образом применяет статистический критерий, такой как критерий Коломогорова-Смирнова, критерий хи-квадрат и т.д., для расчета мер подобия для соответствующих распределений характеристики двух (заполнителей) медицинских учреждений в соответствующих базах X, Y. Критерий Коломогорова-Смирнова или критерий хи-квадрат формирует значение вероятности (p-значение) в предположении, что обе сформированные функции распределения вероятности каждой характеристики за определенный год (например) для больницы A из базы X данных и больницы B их базы Y данных принадлежат одному и тому же распределению. Мера подобия между больницей A и больницей B за определенный год может быть создана путем перемножения p-значений набора характеристик для этого же года (в следующем примере используется 2010 год). Например, если (как на иллюстративной ФИГ. 3) в операции 24 выбраны пять характеристик («раса», «смертность», «срок пребывания», «возраст» и «вес тела»), мера подобия между больницей A и больницей B в 2010 году будет равна 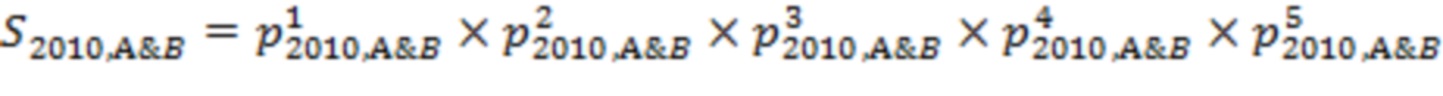 , где верхний индекс указывает характеристику пациентов, а нижний индекс определяет год (или другой заданный интервал времени, на котором рассчитываются профили распределения). Затем, для каждого года, больницы из двух баз X, Y данных связываются на основании наивысших значений мер подобия среди всех пар. Два (заполнителя) медицинских учреждений в соответствующих базах X, Y данных сопоставляют друг другу в операции 30, если их мера подобия
, где верхний индекс указывает характеристику пациентов, а нижний индекс определяет год (или другой заданный интервал времени, на котором рассчитываются профили распределения). Затем, для каждого года, больницы из двух баз X, Y данных связываются на основании наивысших значений мер подобия среди всех пар. Два (заполнителя) медицинских учреждений в соответствующих базах X, Y данных сопоставляют друг другу в операции 30, если их мера подобия  превышает выбранный порог на некоторый процент от порогового значения сравниваемых лет (например, 75% от порогового значения сравниваемых лет в одном варианте реализации). Это всего лишь один иллюстративный критерий сопоставления, и предполагаются другие критерии согласования, рассчитываемые как совокупная мера подобия распределений характеристики в сравниваемых медицинских учреждениях.
превышает выбранный порог на некоторый процент от порогового значения сравниваемых лет (например, 75% от порогового значения сравниваемых лет в одном варианте реализации). Это всего лишь один иллюстративный критерий сопоставления, и предполагаются другие критерии согласования, рассчитываемые как совокупная мера подобия распределений характеристики в сравниваемых медицинских учреждениях.
После этого операция 32 сопоставления пациентов сопоставляет соответствующих пациентов в каждой сопоставленной паре медицинских учреждений в соответствующих базах X, Y данных, идентифицированной операцией 30 сопоставления медицинских учреждений путем установления соответствия между функциям пациентов соответствующих сопоставляемых пациентов. В исчерпывающем подходе, начиная с первого пациента больницы A в базе X данных, выполняют поиск каждого пациента больницы B в базе Y данных, и тот пациент больницы B в базе Y данных, характеристики пациентов которого наиболее близко совпадают с соответствующими характеристиками пациентов первого пациента больницы A в базе X данных, сопоставляют первому пациенту больницы A в базе X данных (необязательно, только в том случае, если совмещение удовлетворяет некоторому минимальному пороговому значению). Это повторяется для каждого последующего пациента больницы A в базе X данных до тех пор, пока все пациенты больницы A базы данных X не будут обработаны. Операция 32 сопоставления пациентов обычно использует те же самые характеристики пациентов, которые были идентифицированы в операции 24 для использования при сопоставлении медицинских учреждений, хотя это не существенно (например, в операции 32 сопоставления пациентов может быть использовано меньшее количество характеристик, либо могут быть использованы дополнительные или другие характеристики. В альтернативном подходе пациенты сначала группируются по интервалам, на которые разбивается выбранная характеристика, такая как возраст (возможно, с некоторым перекрытием интервалов), и сравнения выполняются для пациентов в соответствующих интервалах. Если интервалы выбраны надлежащим образом, это может сократить общее количество сравнений.
Полученные в результате сопоставления пациентов затем используются для построения таблицы 16 совмещения баз данных, например, путем сохранения таблицы подстановки, идентифицирующей пациентов в базе Y данных, которые соответствуют пациентам в базе X данных, и наоборот. В альтернативном варианте объединение может быть выполнено путем формирования новой объединенной базы данных, которая сочетает данные из соответствующих баз X, Y данных в соответствии с результатами операции 32 сопоставления пациентов.
Поскольку операция 30 сопоставления медицинских учреждений использует распределения характеристик, сформированные операцией 26, это сопоставление не зависит от наличия «редких» данных, которые иногда изымают из обезличенных баз данных (например, значения возраста свыше 90 лет, редкие основные диагнозы и т.д.). Чаще всего изъятие этих редких данных, если они соответствуют характеристикам, влияет на статистическую точность этих характеристик. Однако редкие значения по определению встречаются редко, и поэтому их изъятие вряд ли значительно скажется на статистической точности характеристики в базе данных (например, как показано в таблице на ФИГ. 3).
Как отмечено ранее, медицинские учреждения наиболее часто регистрируются как больницы, но могут, в качестве альтернативы, быть другими медицинским учреждениями, таким как сети больниц, отдельные больничные отделения и т. п. Также отмечено, что объединение баз X, Y данных может не сопоставить каждого пациента в базе X данных пациенту в базе Y данных, и наоборот. Это может произойти из-за отсутствия у пациента соответствующей пары в другой базе данных, или потому, что операции 32 не удалось найти соответствие с достаточной вероятностью. В случае несопоставленного пациента таблица 16 совмещения баз данных соответствующим образом сохраняет специальное значение (например, <null>), чтобы указать на отсутствие сопоставления.
Понятно также, что вышеуказанную обработку можно повторять для объединения трех (или более) баз данных здравоохранения. Могут быть использованы различные подходы. Например, если даны три базы X, Y и Z, обработка может включать: (i) объединение баз X, Y данных; (ii) объединение баз X, Z данных; и (iii) объединение баз Y, Z данных. Может быть выполнена необязательная проверка согласованности, например, если пациент A в базе X данных сопоставлен с пациентом M в базе Y данных в операции (i) и пациент A в базе X данных сопоставлен с пациентом F в базе Z данных в операции (ii), то для того, чтобы быть согласованной, операция (iii) должна сопоставлять пациента M в базе Y данных с пациентом F в базе Z данных.
Понятно, что раскрытые функциональные возможности процесса 12 аналитической обработки медицинских данных и/или процесса 20 объединения баз данных, приведенные в настоящем описании, могут быть реализованы в виде некратковременного носителя для хранения, хранящего инструкции, которые могут быть считаны и исполнены электронным процессором 10 для осуществления описанных функциональных возможностей. Некратковременный носитель для хранения может быть выполнен, например, в виде накопителя на жестком диске или другого магнитного запоминающего устройства, оптического диска или другого оптического запоминающего устройства, флэш-памяти, постоянного запоминающего устройства (ПЗУ) и другого электронного запоминающего устройства, их различных сочетаний и т.д.
Настоящее изобретение описано со ссылкой на предпочтительные варианты реализации. По прочтении и осмыслении предшествующего описания другими людьми могут появиться модификации и изменения настоящего изобретения. Подразумевается, что настоящее изобретение должно рассматриваться как включающее в себя все такие модификации и изменения в той мере, в какой они охвачены объемом прилагаемой формулы изобретения или ее эквивалентов.
Вытяжная решетка
Устройство для использования в блендере
Передача длины элемента кадра при кодировании аудио
Волновод
Широкополосная магнитно-резонансная спектроскопия в сильном статическом (b) магнитном поле с использованием переноса поляризации
Магнитный резонанс, использующий квазинепрерывное рч излучение
Устройство для очистки газа
Кодер аудио и декодер, имеющий гибкие функциональные возможности конфигурации
Магнитно-резонансная спектроскопия с автоматической коррекцией фазы и в0 с использованием перемеженного эталонного сканирования воды
Матрица vcsel с повышенным коэффициентом полезного действия

