Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО РАСПОЗНАВАНИЯ ЛИЧНОСТИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Настоящее изобретение относится к сетевым технологиям и, в частности, к способу и устройству распознавания личности.
Уровень техники
С развитием тенденции регистрации реального имени для доступа к Интернету в Китае все больше и больше Интернет-сценариев требует аутентификации реального имени, в частности, в отраслях типа финансов и электронной торговли. Чтобы скрывать свои истинные личности в отношении такой тенденции, мошенники, которые осуществляют мошенничество и обманные коммерческие действия, зачастую получают много идентификационной информации других людей через утечку информации в Интернете или при закупке большого объема, предполагающей ID-номера и имена других людей, и используют номера мобильных телефонов под их управлением для регистрации учетной записи и аутентификации в Интернет-сценариях, совершают мошенничество в кредитных заявках, таких как заявки на кредитную карту или ссуду, тем самым, вызывая потери коммерческих организаций и финансовых институтов.
Существующие способы аутентификации личности реализуются для распознавания мошенничества, главным образом, на сетевом уровне или уровне устройства. Например, хищение идентификационной информации может быть распознано с помощью модели распознавания согласно IP-адресу, MAC-адресу или идентификатору устройства типа IMEI для устройства, используемого человеком, который похищает идентификационную информацию. Однако, многие мошенники являются профессиональными хакерами, которые имеют сильные профессиональные знания сети и могут обходить существующие модели распознавания личности, выполняя некоторые стратегии и затрудняя распознавание личностей.
Сущность изобретения
Ввиду этого, настоящее изобретение предоставляет способ и устройство распознавания личности, чтобы осуществлять обнаружение подделки идентификационной информации.
Например, настоящее изобретение применяет следующие технические решения:
первый аспект предоставляет способ распознавания личности, содержащий:
сбор больших данных адресных книг, причем большие данные адресных книг содержат адресные книги множества пользователей, каждая адресная книга содержит множество пар идентификационной информации, и каждая пара идентификационной информации содержит имя и номер мобильного телефона;
сравнение пары идентификационной информации, которая должна быть распознана, с большими данными адресных книг, чтобы получать результат сравнения информации, причем пара идентификационной информации, которая должна быть распознана, содержит имя и номер мобильного телефона пользователя, который должен быть распознан; и
если результат сравнения информации удовлетворяет условию риска, определение того, что пользователь является пользователем, имеющим риск.
Второй аспект предоставляет устройство распознавания личности, содержащее:
модуль сбора данных, сконфигурированный для сбора больших данных адресных книг, причем большие данные адресных книг содержат адресные книги множества пользователей, каждая адресная книга содержит множество пар идентификационной информации, и каждая пара идентификационной информации содержит имя и номер мобильного телефона;
модуль сравнения пары идентификационной информации, сконфигурированный, чтобы сравнивать пару идентификационной информации, которая должна быть распознана, с большими данными адресных книг, чтобы получать результат сравнения информации, причем пара идентификационной информации, которая должна быть распознана, содержит имя и номер мобильного телефона пользователя, который должен быть распознан; и
модуль определения риска, сконфигурированный, чтобы определять, удовлетворяет ли результат сравнения информации условию риска, что пользователь, который должен быть распознан, является пользователем, имеющим риск.
Способ и устройство распознавания личности согласно вариантам осуществления настоящего изобретения устанавливают базу данных идентификационной информации, собирая большие данные адресных книг, и могут определять, является ли пара идентификационной информации из имени и номера мобильного телефона подлинной, сравнивая пару идентификационной информации, которая должна быть распознана, с данными в базе данных идентификационной информации, тем самым, определяя, является ли личность пользователя сфальсифицированной, и выполняя обнаружение подделки идентификационной информации.
Краткое описание чертежей
Фиг. 1 - это блок-схема последовательности операций способа распознавания личности согласно некоторым вариантам осуществления настоящего изобретения;
Фиг. 2 - это схематичный чертеж больших данных адресных книг пользователей согласно некоторым вариантам осуществления настоящего изобретения;
Фиг. 3 - это блок-схема последовательности операций другого способа распознавания личности согласно некоторым вариантам осуществления настоящего изобретения;
Фиг. 4 - это схематичный структурный чертеж устройства распознавания личности согласно некоторым вариантам осуществления настоящего изобретения;
Фиг. 5 - это схематичный структурный чертеж другого устройства распознавания личности согласно некоторым вариантам осуществления настоящего изобретения.
Подробное описание изобретения
Варианты осуществления настоящего изобретения предоставляют способ распознавания личности, который может быть использован для распознавания подделки идентификационной информации. Например, мошенники присваивают себе ID-номера и имена других людей и используют номера мобильных телефонов под своим управлением для регистрации учетной записи и аутентификации в Интернет-сценариях, совершая мошенничество в кредитных заявках, таких как заявки на получение кредитной карты или ссуды. Чтобы распознавать подделку идентификационной информации, даже когда мошенники обходят модели распознавания на уровне сетевого устройства, настоящая заявка предоставляет схему распознавания, которая "определяет, является ли номер мобильного телефона, используемый пользователем, номером мобильного телефона, обычно используемым пользователем".
Основной идеей схемы распознавания является то, что, после получения достаточного количества адресных книг пользователей, объект распознавания личности, который должен выполнять распознавание личности по клиентам, получает номера мобильных телефонов почти всех потенциальных клиентов, которые используются для формирования базы данных адресных книг. Если впоследствии клиент, личность которого должна быть подтверждена, не находится в базе данных адресной книги или имеет очень низкий весовой коэффициент при появлении в базе данных, то очень вероятно, что это - не сам клиент, который использует идентификационную информацию, и человек, использующий идентификационную информацию клиента, скорее всего самозванец.
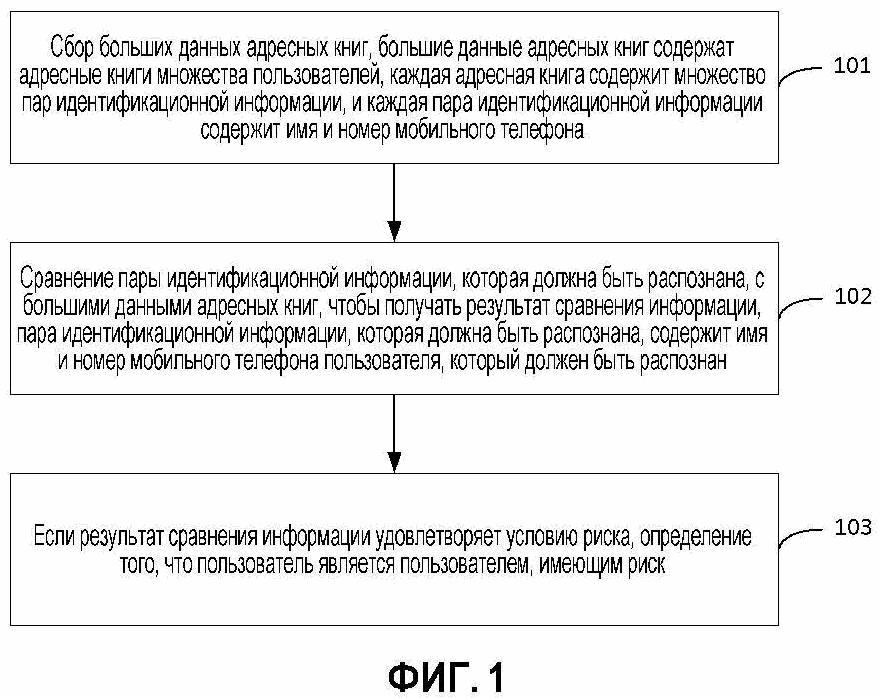
На основе вышеупомянутой идеи способ распознавания личности согласно некоторым вариантам осуществления настоящего изобретения имеет последовательность операций, показанную на фиг. 1. Способ может включать в себя следующие этапы.
Этап 101, сбор больших данных адресных книг, причем большие данные адресных книг содержат адресные книги множества пользователей, каждая адресная книга содержит множество пар идентификационной информации, и каждая пара идентификационной информации содержит имя и номер мобильного телефона.
Например, большие данные адресных книг могут содержать данные адресных книг множества пользователей. Фиг. 2 иллюстрирует данные адресных книг пользователя 1, пользователя 2, пользователя 3 вплоть до пользователя y. Объем адресных книг является достаточно большим, чтобы охватывать всех потенциальных деловых клиентов, насколько возможно, так что данные адресных книг могут быть использованы на последующих этапах, чтобы выполнять подтверждение личности по деловым клиентам. Каждая адресная книга содержит множество пар идентификационной информации, и каждая пара идентификационной информации содержит имя и номер мобильного телефона. Рассматривая адресную книгу пользователя 1 в качестве примера, "имя N11 - номер P11" является парой идентификационной информации, указывающей, что номер мобильного телефона, используемый человеком или организацией, представленной именем N11, является P11, а "имя N12 - номер P12" является другой парой идентификационной информации, указывающей, что номер мобильного телефона, используемый человеком или организацией, представленной именем N12, является P12.
На этом этапе данные адресных книг могут быть собраны посредством множества образов. Например, данные адресной книги на мобильном телефоне пользователя могут быть собраны посредством клиентского программного обеспечения, работающего на мобильном телефоне пользователя.
Этап 102, сравнение пары идентификационной информации, которая должна быть распознана, с большими данными адресных книг, чтобы получать результат сравнения информации, причем идентификационная информация, которая должна быть распознана, содержит имя и номер мобильного телефона пользователя, который должен быть распознан.
Результатом сравнения информации на этом этапе, например, может быть то, включают ли в себя большие данные адресных книг пару идентификационной информации, которая является такой же, что и пара идентификационной информации, которая должна быть распознана, или множество пар идентификационной информации в больших данных адресных книг, которые являются такими же, что и пара идентификационной информации, которая должна быть распознана, и т.д.
Этап 103, если результат сравнения информации удовлетворяет условию риска, определение того, что пользователь является пользователем, имеющим риск.
Например, условие риска может быть задано как множество условий. Например, условие риска может быть задано так, что пользователь, который должен быть распознан, является пользователем, имеющим риск, если большие данные адресных книг не имеют пары идентификационной информации, которая является такой же, что и пара идентификационной информации, которая должна быть распознана; альтернативно, пользователь, который должен быть распознан, является пользователем, имеющим риск, если большие данные адресных книг содержат пары идентификационной информации, такие же, что и пара идентификационной информации, которая должна быть распознана, но число пар идентификационной информации, таких же, что и пара идентификационной информации, которая должна быть распознана, является небольшим.
Способ распознавания личности в настоящем примере устанавливает базу данных идентификационной информации, собирая большие данные адресных книг, и может определять, является ли пара идентификационной информации из имени и номера мобильного телефона подлинной, согласно большим данным, тем самым, определяя, является ли личность пользователя поддельной и выполняя обнаружение подделки идентификационной информации.
В одном примере распознавание личности может также быть выполнено согласно способу, показанному на фиг. 3. Способ, показанный на фиг. 3, создает таблицу весовых коэффициентов информации согласно большим данным адресных книг. Таблица весовых коэффициентов информации может быть использована для последующего подтверждения личностей пользователей. Как показано на фиг. 3, процесс может содержать следующие этапы.
Этап 301, сбор больших данных адресных книг. Этап 302, выполнение статистического анализа по парам идентификационной информации в больших данных адресных книг, чтобы получать весовой коэффициент информации, соответствующий каждой паре идентификационной информации, и формирование таблицы весовых коэффициентов информации.
Весовой коэффициент информации на этом этапе может быть использован для указания степени доверия паре идентификационной информации. Например, если пара идентификационной информации "имя N11 - номер P11" появляется в адресных книгах множества пользователей, то очень вероятно, что информация пары идентификационной информации является подлинной и признается множеством пользователей; иначе, это указывает, что пара идентификационной информации имеет низкую степень доверия, и информация может быть сфальсифицирована.
Весовые коэффициенты информации могут быть вычислены согласно различным способам. Различия между весовыми коэффициентами для различных пар идентификационной информации могут быть отражены посредством различных статистических данных или соотношений между парами идентификационной информации в адресных книгах.
Например, число адресных книг, содержащих пару идентификационной информации, может быть подсчитано и использовано в качестве весового коэффициента информации пары идентификационной информации. Предположим, что пара идентификационной информации "имя N11 - номер P11" появляется в пяти адресных книгах пользователей, тогда соответствующий весовой коэффициент информации может быть равен пяти. Предположим, что пара идентификационной информации "имя N12 - номер P12" появляется в восьми адресных книгах, тогда соответствующий весовой коэффициент информации может быть равен восьми.
В другом примере значение ссылочного ранга каждой пары идентификационной информации может быть вычислено согласно методу ссылочного ранжирования (pagerank), и значение ссылочного ранга используется в качестве весового коэффициента информации пары идентификационной информации. Здесь, когда создается графовая модель веб-ресурса, используемая методом ссылочного ранжирования, каждая пара идентификационной информации может быть использована в качестве узла страницы (эквивалентного узлу страницы в ссылочном ранжировании), и исходящая ссылка узла страницы указывает на другую пару идентификационной информации в адресной книге пользователя, к которой пара идентификационной информации принадлежит. Например, пользователь, которому узел "имя N11 - номер P11" принадлежит, является пользователем, имеющим имя "N11", адресная книга пользователя дополнительно содержит пару идентификационной информации "имя N12 - номер P12", и тогда исходящая ссылка узла "имя N11 - номер P11" указывает на узел "имя N12 - номер P12". Входящая ссылка узла страницы приходит от пар идентификационной информации пользователей в адресных книгах, содержащих пару идентификационной информации, соответствующую узлу страницы. Аналогично, в вышеприведенном примере, входящая ссылка узла "имя N12 - номер P12" существует от узла "имя N11 - номер P11", в то время как адресная книга пользователя в узле "имя N11 - номер P11" для пользователя узла содержит пару "имя N12 - номер P12".
После того как графовая модель веб-ресурса создана, метод ссылочного ранжирования может быть использован для вычисления значения ссылочного ранга каждой пары идентификационной информации, и значение ссылочного ранга используется в качестве весового коэффициента информации для пары идентификационной информации.
Здесь, вычисление, использующее метод ссылочного ранжирования, может быть основано на следующих двух гипотезах:
Количественная гипотеза: в графовой модели веб-ресурса, чем больше входящих ссылок от других веб-страниц узел страницы принимает, тем более важной является эта страница. В примере настоящего варианта осуществления, если пара идентификационной информации включена в большее количество адресных книг, это указывает, что пара идентификационной информации является более достоверной.
Качественная гипотеза: различные страницы имеют различные качественные характеристики. Высококачественная страница передает более тяжелый вес другим страницам через ссылки. Следовательно, когда страницы с более высоким качеством указывают на другую страницу, другая страница является более важной. В примере настоящего изобретения учитывается влияние пользователя, которому принадлежит адресная книга, имеющая пару идентификационной информации. Когда пара идентификационной информации появляется в адресной книге хорошо известной публичной фигуры, степень доверия информации в паре идентификационной информации может отличаться от степени доверия, когда пара идентификационной информации появляется в адресной книге неизвестного обычного человека.
Таблица весовых коэффициентов, показанная в Таблице 1 ниже, может быть получена после вычисления на этом этапе. Следует отметить, что в решении настоящего изобретения сформированная таблица весовых коэффициентов информации, главным образом, включает в себя пары идентификационной информации и соответствующие весовые коэффициенты информации. Пары идентификационной информации и их весовые коэффициенты информации могут быть сохранены в структуре данных, отличной от таблицы.
Таблица 1
Таблица весовых коэффициентов информации
|
Кроме того, могут быть нестандартные записи в парах идентификационной информации, записанных в адресной книге. Например, реальным именем пользователя является "Wang, Xiaoyue", например,  на китайском языке. Но при записи имени пользователя и номера мобильного телефона друг пользователя случайно вводит
на китайском языке. Но при записи имени пользователя и номера мобильного телефона друг пользователя случайно вводит 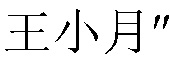 [английский перевод: Wang, Xiaoyue], т.е., ошибается в наборе
[английский перевод: Wang, Xiaoyue], т.е., ошибается в наборе 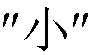 [английский перевод: Xiao]. В этом случае, обработка исправления несоответствия может быть выполнена, чтобы исправлять несоответствие, которое возникает в различных адресных книгах во время записи первоначально идентичной пары идентификационной информации. В одном примере ситуация может быть обработана следующим образом: перед выполнением статистического вычисления весовых коэффициентов информации для пар идентификационной информации в больших данных адресных книг, при записи пар идентификационной информации в таблицу весовых коэффициентов информации, пары "
[английский перевод: Xiao]. В этом случае, обработка исправления несоответствия может быть выполнена, чтобы исправлять несоответствие, которое возникает в различных адресных книгах во время записи первоначально идентичной пары идентификационной информации. В одном примере ситуация может быть обработана следующим образом: перед выполнением статистического вычисления весовых коэффициентов информации для пар идентификационной информации в больших данных адресных книг, при записи пар идентификационной информации в таблицу весовых коэффициентов информации, пары " [английский перевод: Wang, Xiaoyue] -номер H" и "
[английский перевод: Wang, Xiaoyue] -номер H" и "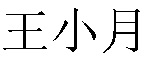 [английский перевод: Wang, Xiaoyue] -номер H", обе записываются как одна и та же пара "wangxiaoyue-номер H", а именно обрабатываются китайские имена
[английский перевод: Wang, Xiaoyue] -номер H", обе записываются как одна и та же пара "wangxiaoyue-номер H", а именно обрабатываются китайские имена 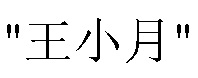 [английский перевод: Wang, Xiaoyue] и
[английский перевод: Wang, Xiaoyue] и  [английский перевод: Wang, Xiaoyue] как одинаковая идентификационная информация, и весовой коэффициент информации, соответствующий паре идентификационной информации "wangxiaoyue-номер H", может быть равен 2 (т.е., "wangxiaoyue-номер H" появляется дважды в данных адресных книг). Когда пара идентификационной информации, которая должна быть распознана, впоследствии сравнивается с таблицей весовых коэффициентов информации, совпадающий номер "H" сначала обнаруживается согласно номеру в паре идентификационной информации, которая должна быть распознана, а затем имя преобразуется в пиньинь для проверки, существует ли совпадающее имя в пиньине. Таким образом, вычисление весовых коэффициентов информации может становиться более точным. Однако, обработка исправления несовпадения может применяться к другим типам ошибок согласно фактическим бизнес-ситуациям или экспериментам.
[английский перевод: Wang, Xiaoyue] как одинаковая идентификационная информация, и весовой коэффициент информации, соответствующий паре идентификационной информации "wangxiaoyue-номер H", может быть равен 2 (т.е., "wangxiaoyue-номер H" появляется дважды в данных адресных книг). Когда пара идентификационной информации, которая должна быть распознана, впоследствии сравнивается с таблицей весовых коэффициентов информации, совпадающий номер "H" сначала обнаруживается согласно номеру в паре идентификационной информации, которая должна быть распознана, а затем имя преобразуется в пиньинь для проверки, существует ли совпадающее имя в пиньине. Таким образом, вычисление весовых коэффициентов информации может становиться более точным. Однако, обработка исправления несовпадения может применяться к другим типам ошибок согласно фактическим бизнес-ситуациям или экспериментам.
Кроме того, другие способы реализации могут быть использованы. Например, в случае вышеописанного примера, когда пиньинь для имен является одинаковым, китайские символы имен отличаются, и номера являются одинаковыми, строка символов пиньинь может быть записана в таблице весовых коэффициентов информации, чтобы исправлять несовпадение. В других вариантах осуществления, когда ошибки набора не происходят, китайские символы могут быть использованы для записи имен в таблице весовых коэффициентов информации. Чтобы распознавать пару идентификационной информации, совпадающий номер H обнаруживается в таблице весовых коэффициентов информации сначала согласно номеру в паре. Затем, сначала определяется, может ли быть найдено совпадающее имя в китайских символах, и если не существует совпадающее имя в китайских символах, имя преобразуется в пиньинь для проверки того, существует ли совпадающее имя в пиньине. Когда и имя, и номер в паре совпадают, обнаруживается совпадающая пара идентификационной информации, и может быть получен соответствующий весовой коэффициент информации.
В другом примере, при поиске совпадающей пары идентификационной информации, может также быть использован способ сопоставления, который предоставляет возможность ошибок в некотором диапазоне. Например, в таблице весовых коэффициентов информации записывается "xiaoyue-номер H" (т.е., фамилия отсутствует), и парой идентификационной информации, которая должна быть распознана, является  [английский перевод: Wang, Xiaoyue]-номер H". Во время сопоставления обнаруживается, что номера в этих двух парах идентификационной информации оба являются "H" и могут быть сопоставлены. Дополнительно, в поле имени "xiaoyue" является очень похожим на пиньинь для
[английский перевод: Wang, Xiaoyue]-номер H". Во время сопоставления обнаруживается, что номера в этих двух парах идентификационной информации оба являются "H" и могут быть сопоставлены. Дополнительно, в поле имени "xiaoyue" является очень похожим на пиньинь для 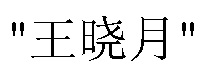 [английский перевод: Wang, Xiaoyue], т.е., "wangxiaoyue". Например, сходство между именами вычисляется согласно алгоритму и достигает выше 70%. Тогда может быть определено, что "xiaoyue" соответствует
[английский перевод: Wang, Xiaoyue], т.е., "wangxiaoyue". Например, сходство между именами вычисляется согласно алгоритму и достигает выше 70%. Тогда может быть определено, что "xiaoyue" соответствует  [английский перевод: Wang, Xiaoyue]. В этом случае, может быть установлено пороговое значение сходства. Когда сходство между двумя именами выше порогового значения, два имени считаются соответствующими друг другу, даже если они не являются идентичными. В отношении "xiaoyue" и "Wang, Jiahui
[английский перевод: Wang, Xiaoyue]. В этом случае, может быть установлено пороговое значение сходства. Когда сходство между двумя именами выше порогового значения, два имени считаются соответствующими друг другу, даже если они не являются идентичными. В отношении "xiaoyue" и "Wang, Jiahui  ", с другой стороны, два имени существенно различаются, и сходство между ними ниже порогового значения, и, таким образом, они определяются как несовпадающие.
", с другой стороны, два имени существенно различаются, и сходство между ними ниже порогового значения, и, таким образом, они определяются как несовпадающие.
На основе сформированной таблицы весовых коэффициентов информации таблица весовых коэффициентов информации будет использоваться на последующих этапах для распознавания идентификационной информации. Пара идентификационной информации, которая должна быть распознана, может быть сравнена с предварительно сформированной таблицей весовых коэффициентов информации, чтобы получать результат сравнения информации. Пара идентификационной информации, которая должна быть распознана, содержит имя и номер мобильного телефона пользователя, который должен быть распознан. Если результат сравнения информации удовлетворяет условию риска, определяется, что пользователь является пользователем, имеющим риск.
Этап 303, получение пары идентификационной информации пользователя, который должен быть распознан.
Например, некоторая идентификационная информация пользователя, который регистрируется, может быть получена, чтобы распознавать, является ли пользователь мошенником, который присваивает себе идентификационную информацию другого человека. Идентификационная информация может содержать ID-номер, имя, номер мобильного телефона, адрес и другую контактную информацию, где имя и номер мобильного телефона могут называться парой идентификационной информации в настоящем примере.
Этап 304, подтверждение ID-номера пользователя и права на использование номера мобильного телефона.
На этом этапе ID-номер и имя могут быть подтверждены посредством сети общественной безопасности на основе реальных имен. Альтернативно, распознавание лица может быть выполнено между лицом пользователя и фотографией в сети общественной безопасности, ассоциированной с ID. Кроме того, подтверждение может быть выполнено в других формах. Кроме того, номер мобильного телефона пользователя может быть подтвержден, чтобы гарантировать, что пользователь обладает правом использовать номер мобильного телефона в настоящее время.
Если подтверждение проходит на этом этапе, способ переходит к этапу 305; иначе, способ переходит к этапу 309.
Этап 305, запрашивание того, возникает ли пара идентификационной информации пользователя, который должен быть распознан, в таблице весовых коэффициентов информации.
Если пара идентификационной информации появляется в таблице весовых коэффициентов информации, способ переходит к этапу 306; иначе, если таблица весовых коэффициентов информации не включает в себя пару идентификационной информации пользователя, который должен быть распознан, способ переходит к этапу 309.
Этап 306, получение соответствующего весового коэффициента информации из таблицы весовых коэффициентов информации.
Например, весовой коэффициент информации, соответствующий паре идентификационной информации, обнаруженной на этапе 303, может быть получен из предварительно сформированной таблицы весовых коэффициентов информации.
Этап 307, определение того, действительно ли весовой коэффициент информации больше или равен пороговому значению весового коэффициента.
Предположим, что пороговое значение весового коэффициента равно t0, пороговое значение весового коэффициента может быть установлено согласно факторам, таким как охват всех потенциальных клиентов, по объему больших данных, собранных для формирования таблицы весовых коэффициентов информации, степени управления для риска подделки идентификационной информации коммерческой организацией, использующей этот способ распознавания личности, и т.п. Например, предположим, что коммерческая организация строго контролирует личности пользователей, пороговое значение весового коэффициента может быть задано в большое значение, чтобы гарантировать высокую аутентичность и достоверность информации. В другом примере, если объем собранных больших данных имеет низкий охват всех потенциальных клиентов, порог весового коэффициента может быть задан в большое значение, чтобы улучшать аутентичность и достоверность информации.
Если результат определения на этом этапе является положительным, способ переходит к этапу 308; иначе, способ переходит к этапу 309.
Этап 308, определение того, что пользователь, который должен быть распознан, проходит подтверждение и является легальным пользователем.
Этап 309, определение того, что пользователь, который должен быть распознан, является пользователем, имеющим риск.
После того как пользователь определяется как пользователь, имеющий риск, мошенническое действие пользователя может быть соответственно локализовано.
Способ распознавания личности в настоящем примере создает таблицу весовых коэффициентов информации согласно большим данным адресной книги, определяет достоверность каждой пары идентификационной информации заранее и может определять, на основе порогового значения весового коэффициента, является ли пара идентификационной информации из имени и номера мобильного телефона подлинной, тем самым, определяя, является ли личность пользователя поддельной и выполняя обнаружение подделки идентификационной информации.
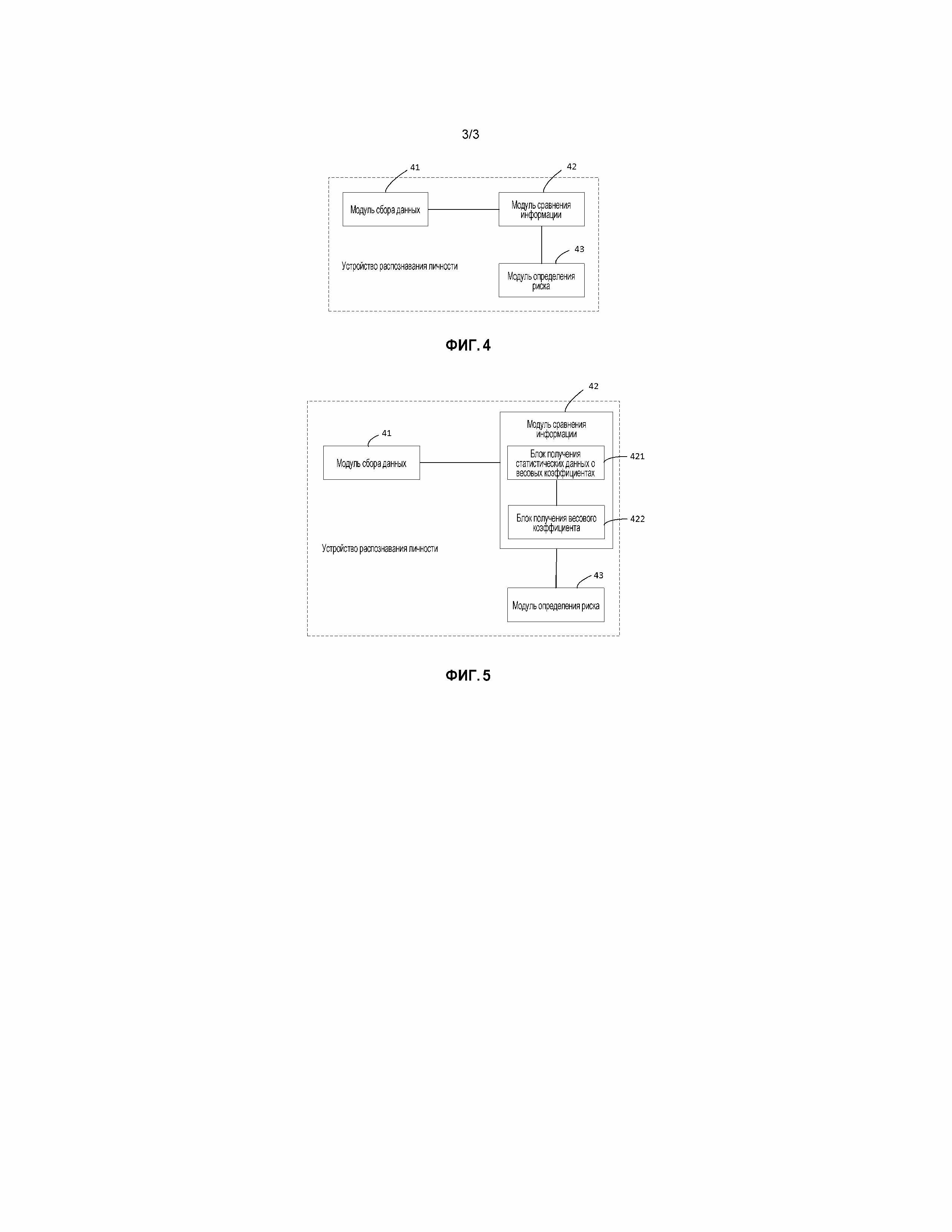
Чтобы реализовать вышеописанный способ, варианты осуществления настоящего изобретения предоставляют устройство распознавания личности, как показано на фиг. 4. Устройство может содержать: модуль 41 сбора данных, модуль 42 сравнения информации и модуль 43 определения риска.
Модуль 41 сбора данных сконфигурирован для сбора больших данных адресных книг, причем большие данные адресных книг содержат адресные книги множества пользователей, каждая адресная книга содержит множество пар идентификационной информации, и каждая пара идентификационной информации содержит имя и номер мобильного телефона.
Модуль 42 сравнения информации сконфигурирован, чтобы сравнивать пару идентификационной информации, которая должна быть распознана, с большими данными адресных книг, чтобы получать результат сравнения информации, причем пара идентификационной информации, которая должна быть распознана, содержит имя и номер мобильного телефона пользователя, который должен быть распознан.
Модуль 43 определения риска сконфигурирован, чтобы определять, что пользователь, который должен быть распознан, является пользователем, имеющим риск, если результат сравнения информации удовлетворяет условию риска.
В одном примере, как показано на фиг. 5, модуль 42 сравнения информации в устройстве может содержать:
блок 421 получения статистических данных о весовых коэффициентах, сконфигурированный, чтобы выполнять статистический анализ по парам идентификационной информации в больших данных адресных книг, чтобы получать весовой коэффициент информации, соответствующий каждой паре идентификационной информации, весовой коэффициент информации используется для указания степени достоверности пары идентификационной информации; и блок 422 получения весового коэффициента, сконфигурированный, чтобы получать весовой коэффициент информации, соответствующий паре идентификационной информации, которая должна быть распознана, на основе результата статистического анализа.
В одном примере модуль 43 определения риска сконфигурирован, чтобы, например, если результат статистического анализа не имеет весового коэффициента информации, соответствующего паре идентификационной информации, которая должна быть распознана, или если весовой коэффициент информации, соответствующий паре идентификационной информации, которая должна быть распознана, ниже предварительно заданного порогового значения весового коэффициента, определять, что пользователь, который должен быть распознан, является пользователем, имеющим риск.
В одном примере блок 421 получения статистических данных весовых коэффициентов сконфигурирован, чтобы, например, использовать число адресных книг, содержащих пару идентификационной информации, в качестве весового коэффициента информации для пары идентификационной информации; альтернативно, вычислять значение ссылочного ранга каждой пары идентификационной информации с помощью метода ссылочного ранжирования и использовать значение ссылочного ранга в качестве весового коэффициента информации для пары идентификационной информации.
В одном примере блок 421 получения статистических данных весовых коэффициентов дополнительно сконфигурирован, чтобы выполнять обработку исправления несовпадения по парам идентификационной информации в различных адресных книгах перед анализом пар идентификационной информации в больших данных адресных книг.
Устройство распознавания личности в настоящем примере создает таблицу весовых коэффициентов информации согласно большим данным адресных книг, определяет достоверность каждой пары идентификационной информации заранее и может определять, на основе порогового значения весового коэффициента, является ли пара идентификационной информации из имени и номера мобильного телефона подлинной, тем самым, определяя, является ли личность пользователя поддельной и выполняя обнаружение подделки идентификационной информации.
Выше описаны только предпочтительные варианты осуществления настоящего изобретения, которые не используются, чтобы ограничивать настоящее изобретение. Любая модификация, эквивалентная замена или улучшение, выполненное в соответствии с сущностью и принципами настоящего изобретения, должно быть охвачено объемом охраны настоящего изобретения.


Способ и устройство проверки
Способ и аппарат для получения информации о местоположении
Способ и устройство регистрации и аутентификации информации
Поиск, основанный на комбинировании пользовательских данных отношений
Способ и устройство распределенной обработки потоковых данных
Схема доменных имен для перекрестных цепочечных взаимодействий в системах цепочек блоков
Перекрестные цепочечные взаимодействия с использованием схемы доменных имен в системах цепочек блоков
Защита данных цепочек блоков с использованием гомоморфного шифрования
Способ и устройство для обработки запроса услуги
Управление связью между консенсусными узлами и клиентскими узлами

