Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ СОПОСТАВЛЕНИЯ ИМЕН
Вид РИД
Изобретение
Область техники
[0001] Настоящая заявка относится к области технологий компьютерного программного обеспечения, и в частности, к способу и устройству для сопоставления имен.
Предшествующий уровень техники
[0002] Сопоставление имени личности является очень важной технологией в области управления рисками. Например, система управления рисками записывает имена личностей определенных неавторизованных пользователей в черный список. Затем, при выполнении операции управления рисками, для каждого пользователя, который в настоящее время выполняет услугу, имя личности каждого пользователя сопоставляется с каждым именем личности в черном списке через сканирование. Если сопоставление успешно, пользователь может рассматриваться как неавторизованный пользователь, и услуга пользователя отклоняется, чтобы предотвратить определенные риски.
[0003] Сопоставление имени личности можно классифицировать на точное сопоставление имени личности и нечеткое сопоставление имени личности. Для сравнения, нечеткое сопоставление имени личности является более сложным в вопросах технологий, поскольку сложно управлять подходящей степенью нечеткости.
[0004] В существующей технологии, алгоритм сопоставления строк (последовательностей символов) обычно используется для выполнения нечеткого сопоставления имени личности, и порог степени совпадения строк определяет степень нечеткости. Однако порог степени совпадения строк устанавливается в соответствии с опытом. Чтобы уменьшить упущение, порог степени совпадения строк обычно устанавливается в относительно низкое значение. Следовательно, точность сопоставления является относительно низкой, и частота ложной тревоги системы управления рисками является относительно высокой.
Краткое описание сущности изобретения
[0005] Реализации настоящей заявки обеспечивают способ и устройство для сопоставления имен, чтобы преодолеть следующую техническую проблему: В существующей технологии, относительно низкая точность сопоставления и относительно высокая частота ложной тревоги системы случаются, когда нечеткое сопоставление имени личности выполняется с использованием алгоритма сопоставления строк.
[0006] Чтобы преодолеть предыдущую техническую проблему, реализации настоящей заявки осуществлены, как описано далее:
[0007] Реализация настоящей заявки обеспечивает способ для сопоставления имен, включающий в себя следующее: получение имени, подлежащего сопоставлению; определение стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению; обнаружение имени, подлежащего сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки (символы) имен не идентичны; и определение результата сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения.
[0008] Реализация настоящей заявки обеспечивает устройство для сопоставления имен, включающее в себя следующее: модуль получения, сконфигурированный, чтобы получать имя, подлежащее сопоставлению; модуль определения, сконфигурированный, чтобы определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению; модуль обнаружения, сконфигурированный, чтобы обнаруживать имя, подлежащее сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны; и модуль сопоставления, сконфигурированный, чтобы определять результат сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения.
[0009] По меньшей мере одно техническое решение, использованное в реализациях настоящей заявки, может достигать следующих полезных результатов: имя может включать в себя имя личности. На практике, имя личности, подлежащее сопоставлению, может отличаться от действительного имени личности ввиду своевременности и неопределенности во время ввода данных и вариативности имени личности. Это также является причиной для выполнения нечеткого сопоставления. В решении настоящей заявки, по этой причине, имя личности, подлежащее сопоставлению, обнаруживается, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны, и результат сопоставления имени личности определяется на основе результата обнаружения. По сравнению с существующей технологией, когда степень нечеткости управляется только с использованием порога степени совпадения строк, установленного в соответствии с опытом, настоящая заявка больше способствует улучшению точности управления степенью нечеткости. По существу, точность сопоставления может быть улучшена, и частота ложной тревоги системы управления рисками может быть уменьшена. Поэтому, некоторые или все из проблем в существующих технологиях можно преодолеть.
Краткое описание чертежей
[0010] Чтобы описать технические решения в реализациях настоящей заявки или в существующей технологии более ясно, ниже кратко описаны прилагаемые чертежи, требуемые для описания реализаций или существующей технологии. Очевидно, прилагаемые чертежи в следующем описании показывают только некоторые реализации настоящей заявки, и специалист в данной области техники может также получить другие чертежи из этих прилагаемых чертежей без творческих усилий.
[0011] Фиг. 1 является схематичной блок-схемой последовательности операций, иллюстрирующей способ для сопоставления имен, в соответствии с реализацией настоящей заявки;
[0012] Фиг. 2 является схематичной блок-схемой последовательности операций, иллюстрирующей реализацию предварительного скрининга в способе для сопоставления имен в действительном сценарии применения, в соответствии с реализацией настоящей заявки;
[0013] Фиг. 3 является схематичной блок-схемой последовательности операций, иллюстрирующей реализацию выполнения нечеткого сопоставления с использованием интегрированного алгоритма в способе для сопоставления имен в действительном сценарии применения, в соответствии с реализацией настоящей заявки;
[0014] Фиг. 4 является схематичной блок-схемой последовательности операций, иллюстрирующей реализацию способа для сопоставления имен в действительном сценарии применения, в соответствии с реализацией настоящей заявки; и
[0015] Фиг. 5 является схематичной структурной диаграммой, иллюстрирующей устройство для сопоставления имен и соответствующей фиг. 1, в соответствии с реализацией настоящей заявки.
Описание реализаций
[0016] Реализации настоящей заявки обеспечивают способ и устройство для сопоставления имен.
[0017] Чтобы помочь специалисту в данной области техники лучше понять технические решения в настоящей заявке, далее ясно и полно описаны технические решения в реализациях настоящей заявки со ссылкой на прилагаемые чертежи в реализациях настоящей заявки. Очевидно, описанные реализации являются только некоторыми, а не всеми реализациями настоящей заявки. Все другие реализации, полученные специалистом в данной области техники на основе реализаций настоящей заявки без творческих усилий, должны входить в объем защиты настоящей заявки.
[0018] Как описано выше, на практике, имя личности, подлежащее сопоставлению, может отличаться от действительного имени личности из-за своевременности и неопределенности во время ввода данных и вариативности имени личности (которая главным образом указывает изменение в "форме (а именно, знаке)" имени личности). Для простоты понимания, английское имя личности используется в качестве примера. Общие типы и экземпляры вариантов английского имени личности показаны в Таблице 1.
Таблица 1
|
[0019] Если используется только способ сопоставления строк для сопоставления имени личности, возможно, что может предприниматься сопоставление для типа варианта "неверного написания" определенной буквы (действительно, сопоставление успешно случайно, и не существует твердой основы). Однако точность сопоставления является очень низкой для других типов вариантов.
[0020] В решениях настоящей заявки, конкретное обнаружение, такое как обнаружение сокращения, обнаружение обращения, обнаружение нескольких языков или обнаружение прозвища, может выполняться для других типов вариантов, так что ситуация, в которой имена людей синонимичны, но знаки имен людей не идентичны (другими словами, имена синонимичны, но отличаются по формам), может рассматриваться в полном объеме, и дополнительная точность сопоставления может быть улучшена. Стоит отметить, что "разные формы" могут быть разными формами, которые являются "неправильными" из-за неверного написания; но в следующих реализациях, могут быть главным образом разными формами, которые являются "приемлемыми и верными" из-за других типов вариантов.
[0021] Решения настоящей заявки применимы не только к сопоставлению имени личности, но также применимы к сопоставлению названий, отличных от имени личности, например, названию места или названию объекта.
[0022] Решения настоящей заявки описаны ниже подробно.
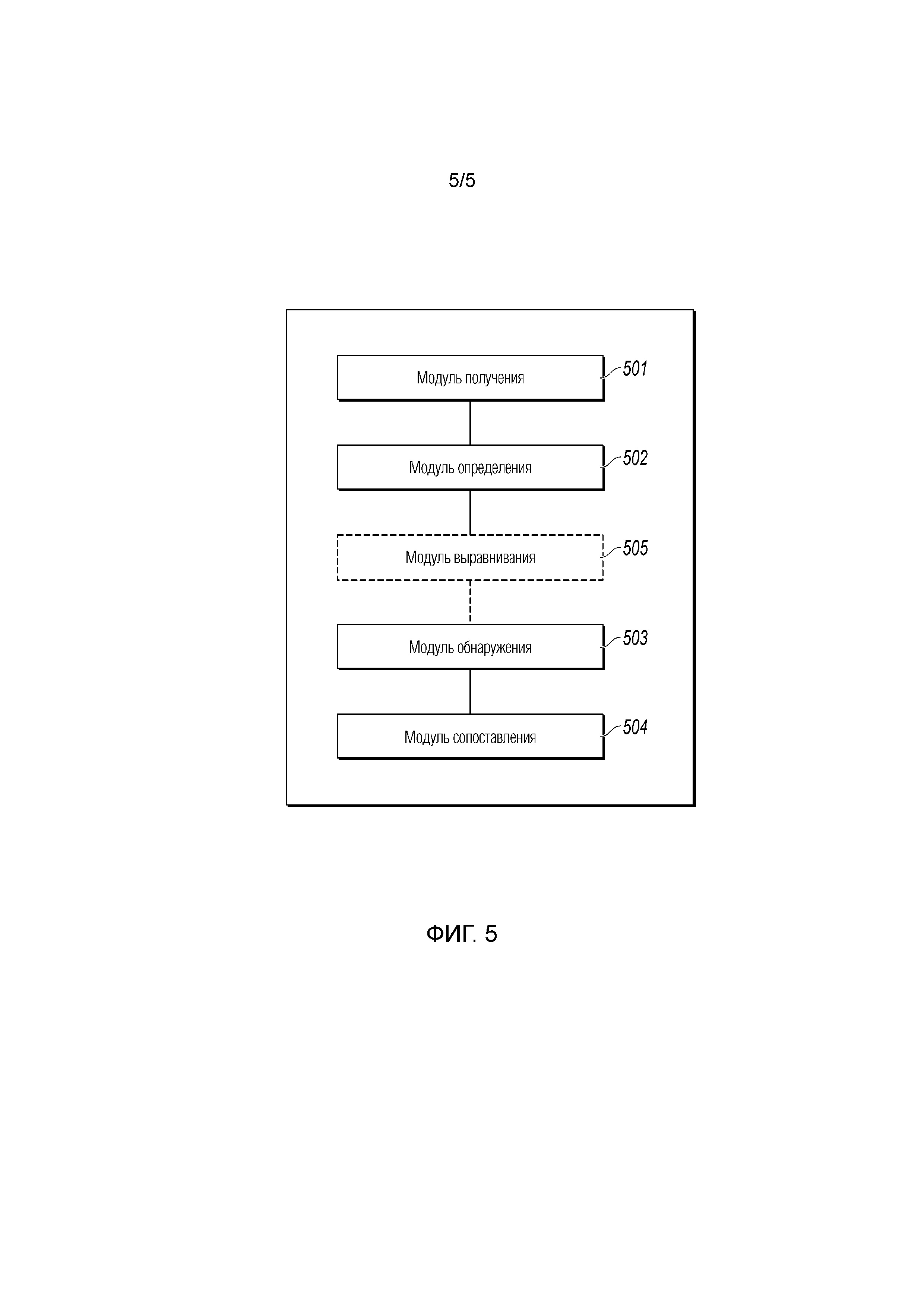
[0023] Фиг. 1 является схематичной блок-схемой последовательности операций, иллюстрирующей способ для сопоставления имен, в соответствии с реализацией настоящей заявки. Устройство, на котором может быть установлена программа, исполняющая процедуру, включает в себя, но без ограничения, персональный компьютер, большой или средний компьютер, кластер компьютеров, мобильный телефон, планшет, носимое смарт-устройство, устройство транспортного средства и т.д. Этот процесс обычно может использоваться в области управления рисками и исполняется системой управления рисками или связанной системой.
[0024] Процедура, показанная на фиг. 1, может включать в себя следующие этапы:
[0025] S101. Получить имя, подлежащее сопоставлению.
[0026] В настоящей реализации настоящей заявки, язык, которому принадлежит имя, подлежащее сопоставлению, не ограничен, и может быть английским, русским, испанским или китайским. Для простоты описания, следующая реализация главным образом описана с использованием примера, в котором язык, которому принадлежит имя, подлежащее сопоставлению, является английским.
[0027] S102. Определить стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению.
[0028] В настоящей реализации настоящей заявки, стандартный набор имен может быть поднабором, отсеянным из большего набора имен, или может быть непосредственно большим набором имен. Для простоты описания, скрининг здесь может называться "предварительным скринингом". Например, в сценарии в предшествующем уровне техники, больший набор имен может быть черным списком, поддерживаемым системой управления рисками.
[0029] В предыдущей ситуации, поднабор может быть набором, который включает в себя только имена, сходные с именем, подлежащим сопоставлению. "Сходный" здесь может не быть таким строгим, поскольку существует серия последовательных операций дополнительного определения сходства. Это означает, что "тонкий скрининг" выполняется последовательно. Диапазон сопоставления может быть быстро уменьшен через предварительный скрининг, так что рабочая нагрузка последовательного тонкого скрининга может быть уменьшена, и применимость тонкого скрининга может быть улучшена, что благоприятно для улучшения эффективности решений настоящей заявки.
[0030] S103. Обнаружить имя, подлежащее сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0031] В настоящей реализации настоящей заявки, "имена синонимичны, но знаки имен не идентичны", что требуется обнаружить и определить, главным образом вызывается одним или несколькими типами вариантов в Таблице 1, и обнаружение может включать в себя по меньшей мере одно из обнаружений, такое как обнаружение сокращения, обнаружение обращения, обнаружение нескольких языков или обнаружение прозвища, которые описаны ниже подробно.
[0032] В настоящей реализации настоящей заявки, когда существует множество обнаружений, множество обнаружений может последовательно выполняться по порядку. Оставшиеся обнаружения не могут выполняться, если результат сопоставления имени, подлежащего сопоставлению, может быть определен в процессе обнаружения. Разумеется, чтобы улучшить эффективность исполнения, множество обнаружений может выполняться параллельно, и затем результаты обнаружения могут быть подытожены.
[0033] S104. Определить результат сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения.
[0034] В настоящей реализации настоящей заявки, путем выполнения этапа S103, результат сопоставления имени, подлежащего сопоставлению, может быть непосредственно определен, если определено, что имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны. В этой ситуации, процесс обнаружения на этапе S103 является действительным полным процессом сопоставления имени, подлежащего сопоставлению.
[0035] Если определено, что имя, подлежащее сопоставлению, не удовлетворяет следующему условию: имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны, сопоставление может дополнительно выполняться на имени, подлежащем сопоставлению, с использованием другого способа сопоставления, чтобы определить результат сопоставления имени, подлежащего сопоставлению.
[0036] В способе, показанном на фиг. 1, имя может включать в себя имя личности. На практике, имя личности, подлежащее сопоставлению, может отличаться от действительного имени личности из-за своевременности и неопределенности во время ввода данных и вариативности имени личности. Это также является причиной для выполнения нечеткого сопоставления. В решении настоящей заявки, по этой причине, имя личности, подлежащее сопоставлению, обнаруживается, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны, и результат сопоставления имени личности определяется на основе результата обнаружения. По сравнению с существующей технологией, в которой степень нечеткости управляется только с использованием порога степени совпадения строк, установленного в соответствии с опытом, настоящая заявка больше способствует улучшению точности управления степенью нечеткости. Например, точность сопоставления может быть улучшена, и частота ложной тревоги системы управления рисками может быть уменьшена. Поэтому, некоторые или все из проблем в существующих технологиях можно преодолеть.
[0037] На основе способа на фиг. 1, настоящая реализация настоящей заявки дополнительно обеспечивает некоторые реализации способа и решение расширения, которые описаны ниже.
[0038] В настоящей реализации настоящей заявки, сложность разных имен, подлежащих сопоставлению, может быть разной, и включенная информация может также быть разной. Для некоторых имен, подлежащих сопоставлению, которые имеют малый объем информации или простой признак информации, для значения полученного результата сопоставления сложно достичь ожидания, даже если сопоставление выполняется на именах, подлежащих сопоставлению. Например, если имя является слишком простым и общим, таким как английское имя личности "Jim", "Jimmy", "David", "John" или "Mike", сложно определить определенную личность, даже если сопоставление успешно.
[0039] Чтобы преодолеть нерациональное использование ресурсов обработки, используемых для сопоставления имени из-за этой ситуации, имя, подлежащее сопоставлению, может сначала фильтроваться после получения, чтобы определить, следует ли продолжать сопоставление. К тому же, если имя, подлежащее сопоставлению, включено в белый список, существует сходная проблема, и имя, подлежащее сопоставлению, может также обрабатываться с использованием этого способа.
[0040] Для этапов S101 и S102, после того, как получено имя, подлежащее сопоставлению, и до того, как стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению, определен, могут дополнительно выполняться следующие этапы: получение предопределенного набора имен, которые не требуется сопоставлять; определение того, включено ли имя, подлежащее сопоставлению, в набор имен, которые не требуется сопоставлять; и если да, продолжение выполнять последовательные этапы. Напротив, сопоставление может не выполняться на имени, подлежащем сопоставлению.
[0041] В настоящей реализации настоящей заявки, реализация этапа S102 (который соответствует предыдущей ситуации "предварительного скрининга") используется в качестве примера для описания. Для этапа S102, определение стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, может включать в себя следующее: определение первого набора имен, который может использоваться для сопоставления имени, подлежащего сопоставлению; и определение стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, путем выполнения сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом слове, включенном в имя в первом наборе имен.
[0042] Существует также множество реализаций того, как выполнять сопоставление сходства. Сопоставление сегментации слов может выполняться на имени, подлежащем сопоставлению, или сопоставление полного текста может выполняться на имени, подлежащем сопоставлению, и т.д.
[0043] В примере сопоставления сегментации слов, определение стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, путем выполнения сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом слове, включенном в имя в первом наборе имен, может включать в себя следующее: получение индекса каждого имени, включенного в первый набор имен, где индекс имени представляет собой любое слово, включенное в имя; сегментирование имени, подлежащего сопоставлению, чтобы получить каждое слово, включенное в имя, подлежащее сопоставлению; выполнение сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе, чтобы получить поднабор первого набора имен. Полученный поднабор включает в себя имя, индексированное каждым индексом, который успешно совпадает; и определение стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, на основе каждого поднабора.
[0044] Индекс в предыдущем примере устанавливается предварительно, и преимущество выполнения сопоставления сегментации слов на основе индекса состоит в том, что скорость получения имени, требуемого в наборе в процессе сопоставления, может эффективно ускоряться. Если сопоставление сегментации слов не выполняется на основе индекса, сопоставление сегментации слов все еще может быть реализовано (например, из таблицы данных, которая хранит набор, непосредственно запрашивается требуемое имя с использованием оператора 'Выбрать' для сопоставления сегментации слов), за исключением случаев, когда эффективность может подвергаться воздействию.
[0045] Дополнительно, выполнение сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе может включать в себя следующее: выполнение сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе с использованием алгоритма сопоставления строк, где алгоритм сопоставления строк может включать в себя один или несколько алгоритмов, например, алгоритм сопоставления дерева префиксов, алгоритм сопоставления дерева словарей, алгоритм сопоставления сходства строк и алгоритм сопоставления сходства произношения. Здесь, использование алгоритма сопоставления строк является только лучшим способом, или может использоваться другой алгоритм, такой как алгоритм сопоставления текста, который может использоваться для реализации сопоставления сходства.
[0046] Может существовать множество реализаций определения стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, на основе каждого поднабора. Например, если используются N алгоритмов сопоставления строк, для каждого из M слов, полученных через сегментацию слов, каждый алгоритм сопоставления строк используется для сопоставления слова с каждым индексом, чтобы соответственно получить N поднаборов. Затем берут объединенный набор из N поднаборов. Получают все из M объединенных наборов, и каждое имя, для которого суммарное число появлений в M объединенных наборах превышает заданный порог, выбирается и определяется в качестве стандартного набора имен. Для другого примера, получают N поднаборов, и затем набор пересечения N поднаборов берется и определяется в качестве стандартного набора имен.
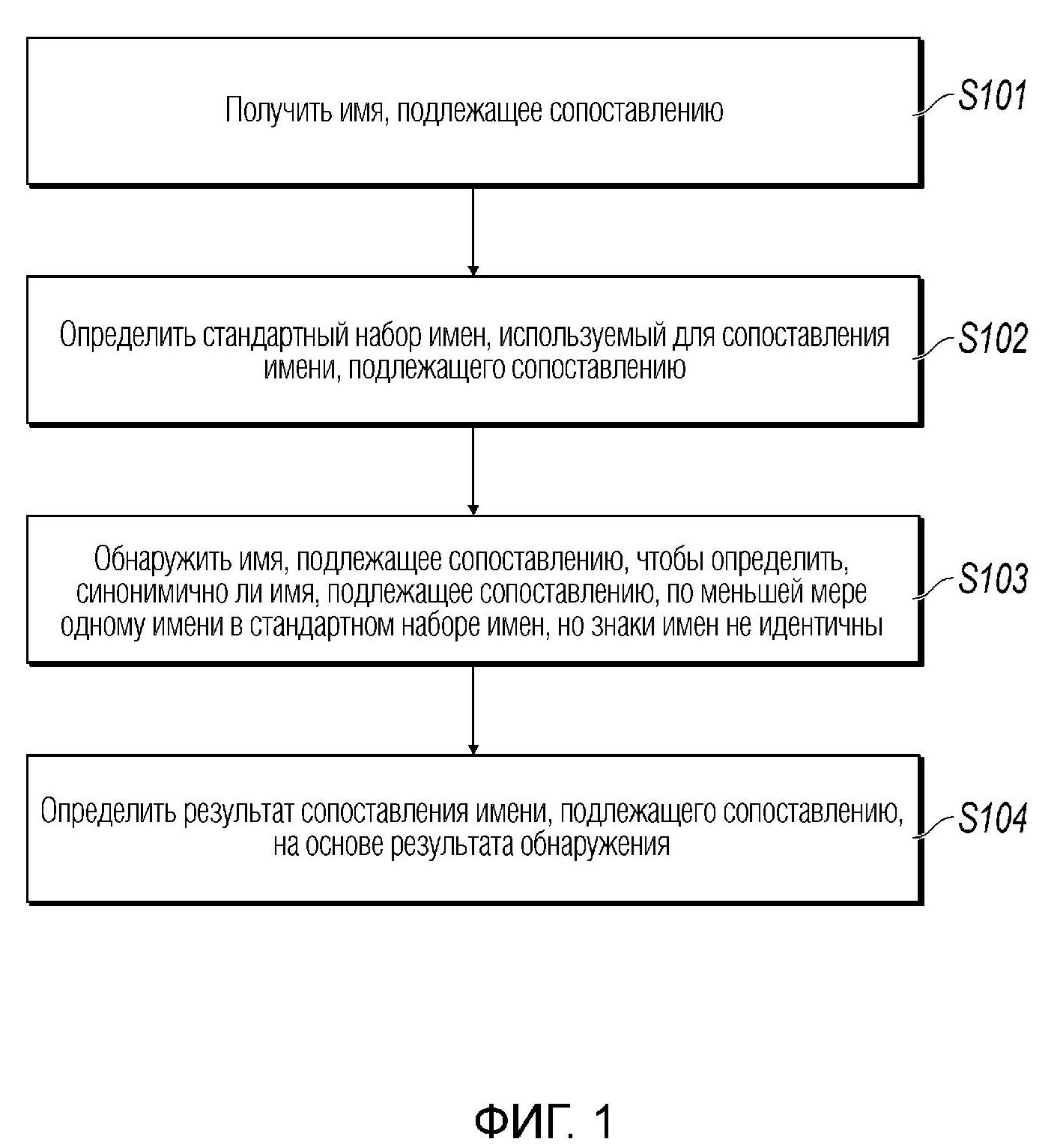
[0047] Процесс "предварительного скрининга" описан выше. Для простоты понимания, реализация настоящей заявки дополнительно обеспечивает схематичную блок-схему последовательности операций, иллюстрирующую реализацию предварительного скрининга в способе для сопоставления имен в действительном сценарии применения, как показано на фиг. 2.
[0048] В действительном сценарии применения, положим, что первый набор имен является списком английских имен людей, индекс каждого имени в списке предопределен (связанная информация, отличная от соответствующего имени, может индексироваться с использованием индекса), индекс представляет собой слово в имени, которое соответствует индексу, каждый индекс включен в таблицу индексов, установленную с использованием слова, которое соответствует индексу, в качестве первичного ключа, имя, подлежащее сопоставлению, является английским именем "Kit Wai Jackson Wong" личности, и пробел используется в качестве разделителя, чтобы сегментировать имя личности, и результат сегментации слова показан в Таблице 2.
Таблица 2
|
[0049] На фиг. 2, M=4, и результат сегментации слова представляет собой {Kit, Wai, Jackson, Wong}. Каждое слово, полученное через сегментацию слова, сопоставляется с каждым индексом с использованием алгоритма сопоставления дерева префиксов, алгоритма сопоставления дерева словарей, алгоритма сопоставления сходства строк (такого как алгоритм Simstring) и алгоритма сопоставления сходства произношения (такого как метафонический алгоритм), чтобы вывести набор имен, который соответствует индексам одного слова, которые получены с использованием четырех алгоритмов сопоставления: результаты 1, 2, 3 и 4 сопоставления.
[0050] Объединенный набор результатов сопоставления каждого слова берется, чтобы получить исчерпывающий результат сопоставления каждого слова.
[0051] Имена, включенные в по меньшей мере два исчерпывающих результата сопоставления, выбираются для образования набора, и набор используется как сгенерированный результат предварительного скрининга.
[0052] В настоящей реализации настоящей заявки после того, как определен стандартный набор имен, может обнаруживаться имя, подлежащее сопоставлению. Однако один или несколько типов предварительной обработки могут дополнительно выполняться до обнаружения. Предварительная обработка способствует улучшению надежности последовательного результата обнаружения. Предварительная обработка может включать в себя обработку выравнивания, обработку унификации заглавных и строчных букв, упрощенную традиционную обработку и т.д.
[0053] Обработка выравнивания используется в качестве примера. Для этапа S103, перед обнаружением имени, подлежащего сопоставлению, следующая обработка может дополнительно выполняться: выравнивание каждого слова, включенного в имя в стандартном наборе имен, по каждому слову, включенному в имя, подлежащее сопоставлению, на основе сходства между каждым словом, включенным в имя в стандартном наборе имен, и каждым словом, включенным в имя, подлежащее сопоставлению.
[0054] На практике, принцип выполнения обработки выравнивания на основе сходства может быть принципом максимизации на основе сходства. Более конкретно, выравниваются местоположения имен, которые включают в себя слова с максимальным сходством.
[0055] Например, положим, что имя, подлежащее сопоставлению, представляет собой "Kate Lee Smith", и результат выравнивания имени, такого как "Smith Catherine Lee" в стандартном наборе имен, показан в Таблице 3.
Таблица 3
|
[0056] Дополнительно, когда выполняется обработка выравнивания, для этапа S103, обнаружение имени, подлежащего сопоставлению, может включать в себя следующее: обнаружение имени, подлежащего сопоставлению, на основе выровненного стандартного набора имен, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0057] В настоящей реализации настоящей заявки, обнаружение на этапе S103 является ключевой частью для улучшения точности сопоставления нечеткого сопоставления имени личности. Для этапа S103, обнаружение имени, подлежащего сопоставлению, включает в себя следующее: выполнение по меньшей мере одного из обнаружения сокращения, обнаружения обращения, обнаружения нескольких языков или обнаружения прозвища на имени, подлежащем сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны. Несколько обнаружений отдельно описаны ниже.
[0058] В настоящей реализации настоящей заявки, обнаружение акронима является наиболее общим в обнаружении сокращения. В дополнение к обнаружению акронима, существует обнаружение сокращения с опущением разделителя. В реализации, выполнение обнаружения сокращения на имени, подлежащем сопоставлению, может включать в себя следующее: получение предопределенных данных противоположной (противопоставляемой) комбинации сокращений, где каждая противоположная комбинация сокращений отражает отношение отображения сокращений между по меньшей мере одним словом и сокращением слова; обнаружение того, имеет ли слово, включенное в имя, подлежащее сопоставлению, отношение отображения сокращений со словом, включенным в имя в стандартном наборе имен, на основе данных противоположной комбинации сокращений; и определение, на основе результата обнаружения, того, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0059] Например, если предопределено, что английское имя личности "Ben Williams" может быть сокращено до "B. Williams", "Ben Williams" и "B. Williams" могут использоваться в качестве противоположной комбинации сокращений. Если обнаружено, что имя, подлежащее сопоставлению, и имя в стандартном наборе имен представляют собой противоположную комбинацию сокращений, может быть определено, что существует ситуация, в которой имена синонимичны, но знаки имен не идентичны.
[0060] В настоящей реализации настоящей заявки, выполнение обнаружения обращения на имени, подлежащем сопоставлению, может включать в себя следующее: получение предопределенных данных обращения; обнаружение того, включает ли в себя имя, подлежащее сопоставлению, обращение, где учитывается, что обращение не влияет на значение имени, которое включает в себя обращение; и определение, на основе результата обнаружения, того, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0061] В выражении имени личности, обращение является обычно словом, прикрепленным к по меньшей мере части исходного имени личности, таким как почтительное обращение (такое как Mr. (мистер) или Miss. (миссис)) или званием (таким как Dr. (доктор) или Prof. (профессор)). В среде сопоставления имени личности, обращение не влияет на значение по меньшей мере части исходного имени личности, которое соответствует обращению. Поэтому, если определено, что имя, подлежащее сопоставлению, включает в себя обращение, и другие части, отличные от обращения, могут совпадать с именем в стандартном наборе имен, может быть определено, что имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0062] В настоящей реализации настоящей заявки, выполнение обнаружения прозвища на имени, подлежащем сопоставлению, может включать в себя следующее: получение предопределенных данных противоположной комбинации прозвища, где каждая противоположная комбинация прозвища отражает отношение отображения прозвища между по меньшей мере одним словом и прозвищем слова; обнаружение того, имеет ли слово, включенное в имя, подлежащее сопоставлению, отношение отображения прозвища со словом, включенным в имя в стандартном наборе имен, на основе данных противоположной комбинации прозвища; и определение, на основе результата обнаружения, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0063] На практике, прозвище может включать в себя уменьшительное имя (например, Mick в Таблице 1 является уменьшительным именем от Mikey) от имени, которое соответствует прозвищу, или синонимичное имя от имени, которое соответствует прозвищу в разных областях. Для последнего, разные области могут быть разными регионами (например, разными странами или разными провинциями), разными языками (например, языками разных стран или языками разных национальностей), разных отраслей промышленности и т.д.
[0064] Соответственно, выполняется по меньшей мере одно из следующего: обнаруживается уменьшительное имя от имени, подлежащего сопоставлению, или обнаруживается синонимичное имя от имени, подлежащего сопоставлению, в разных областях.
[0065] Прозвище также не влияет на значение имени, которое соответствует прозвищу. Поэтому, если определено, что имя, подлежащее сопоставлению, является прозвищем имени в стандартном наборе имен, может быть определено, что имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0066] Стоит отметить, что формы хранения данных противоположной комбинации и данных обращения, описанные выше, не ограничены в настоящей заявке. Общий способ предназначен для хранения данных противоположной комбинации и данных обращения в соответствующей таблице данных и считывания данных из базы данных, когда требуется использовать данные.
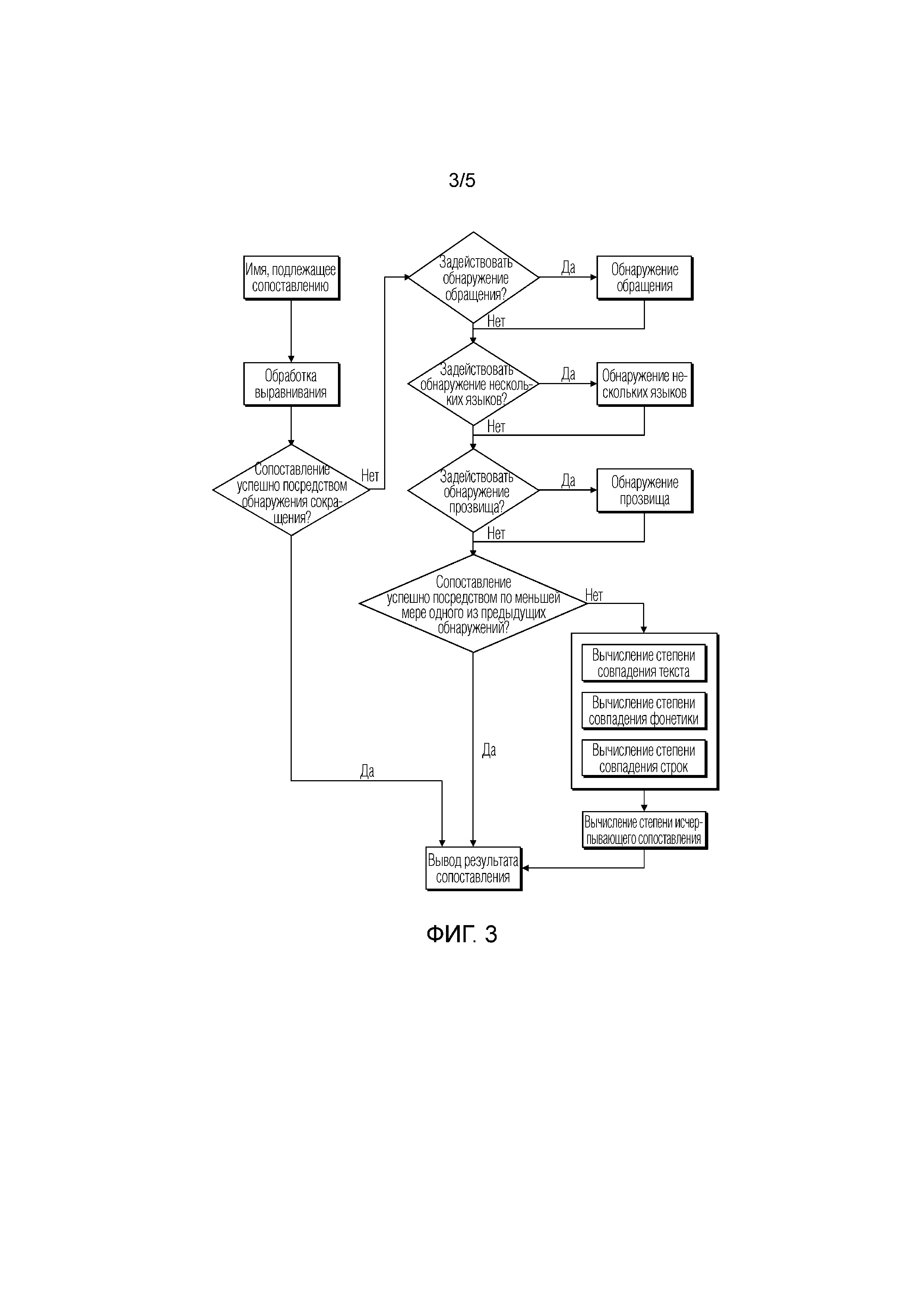
[0067] В настоящей реализации настоящей заявки, выполнение обнаружения нескольких языков на имени, подлежащем сопоставлению, может включать в себя следующее: определение языка, который соответствует имени, подлежащему сопоставлению; получение по меньшей мере одного из правила искажения синонима при написании или правила искажения омонима при написании по меньшей мере одного из языка или другого языка; и обнаружение имени, подлежащего сопоставлению, в соответствии с по меньшей мере одним из правила искажения синонима при написании или правила искажения омонима при написании, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0068] Обнаружение нескольких языков главным образом направлено на следующую ситуацию, например, английское "Pooh" пишется как "puh" в немецком, и два слова синонимичны при появлении в именах людей.
[0069] Стоит отметить, что алгоритм, используемый для вычисления степени совпадения строк, может использоваться в обнаружениях, выполняемых ранее.
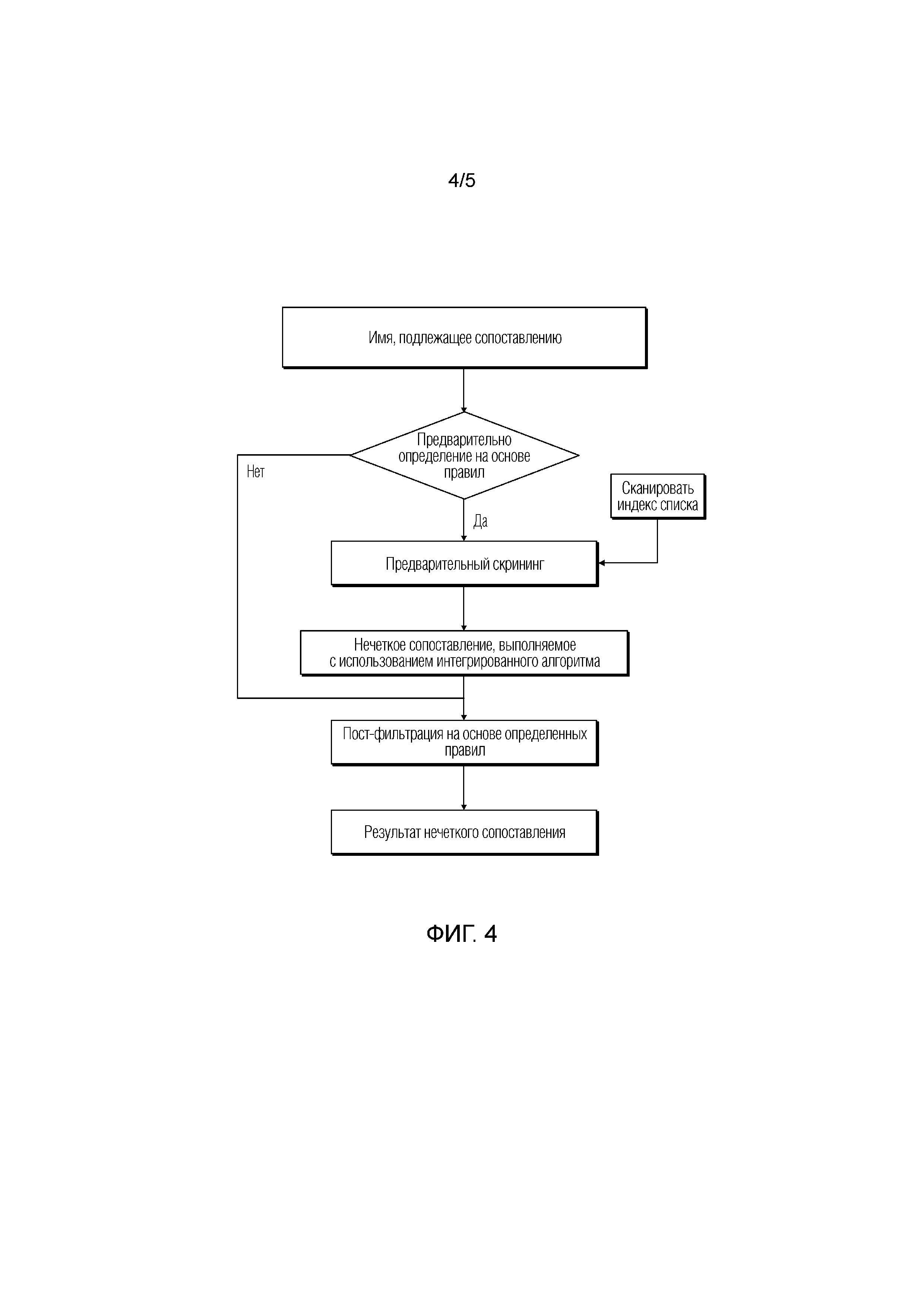
[0070] В настоящей реализации настоящей заявки, определение результата сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения может включать в себя следующее: определение по меньшей мере одного имени как результата сопоставления имени, подлежащего сопоставлению, если определено, что имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны; или напротив (более конкретно, когда сопоставление неуспешно посредством предыдущего обнаружения), определение результата сопоставления имени, подлежащего сопоставлению, путем сопоставления имени, подлежащего сопоставлению, с именем в стандартном наборе имен с использованием одного или нескольких алгоритмов сходства.
[0071] В настоящей реализации настоящей заявки, множество алгоритмов сходства может быть основано на разных измерениях, и поэтому может содействовать улучшению надежности результата сопоставления. В соответствии с такой идеей, алгоритм сходства может быть алгоритмом (таким как n-gram алгоритм), используемым для вычисления степени совпадения текста, алгоритмом (таким как алгоритм Phonex), используемым для вычисления степени совпадения фонетики, алгоритмом (таким как алгоритм Jaro-Winkler), используемым для вычисления степени совпадения строк, и т.д.
[0072] Когда используется множество алгоритмов сходства, результаты сопоставления, которые соответствуют алгоритмам сходства, могут быть в полном объеме измерены, чтобы получить исчерпывающий результат сопоставления. Способ измерения не ограничен в настоящей заявке, и общий способ представляет собой весовое суммирование.
[0073] Например, когда используется n-gram алгоритм, ввод алгоритма является каждым словом, включенным в имя, подлежащее сопоставлению, и каждым словом в выровненном местоположении слова, и вывод алгоритма является степенью совпадения текста каждой пары выровненных слов, и обозначается как F1.
[0074] Когда используется алгоритм Jaro-Winkler, ввод алгоритма является каждым словом, включенным в имя, подлежащее сопоставлению, и каждым словом в выровненном местоположении слова, и вывод алгоритма является степенью совпадения строк каждой пары выровненных слов, и обозначается как F2.
[0075] Когда используется алгоритм Phonex, ввод алгоритма является каждым словом, включенным в имя, подлежащее сопоставлению, и каждым словом в выровненном местоположении слова, и вывод алгоритма является степенью совпадения фонетики каждой пары выровненных слов, и обозначается как F3.
[0076] Исчерпывающую степень F совпадения каждой пары выровненных слов получают путем выполнения весового суммирования на степени совпадения текста, степени совпадения строк и степени совпадения фонетики, как показано в следующем уравнении:
F=w1*F1+w2*F2+w3*F3, где w1+w2+w3=1.
[0077] На основе исчерпывающей степени F совпадения каждой пары слов, результат сопоставления между именем, подлежащим сопоставлению, и именем в стандартном наборе имен получают путем вычисления среднего значения. Например, для пары имен в Таблице 3, полученный результат сопоставления показан в Таблице 4.
Таблица 4
|
[0078] Процесс обнаружения и сопоставления после предварительного скрининга описан выше. В этом процессе, может использоваться множество связанных с сопоставлением алгоритмов. Во время реализации решений настоящей заявки, алгоритмы, которые могут использоваться, могут интегрироваться, и этот процесс является процессом выполнения нечеткого сопоставления с использованием интегрированного алгоритма.
[0079] В настоящей реализации настоящей заявки, после того, как нечеткое сопоставление выполнено с использованием алгоритма интеграции, может дополнительно выполняться некоторая пост-фильтрация на основе определенных правил, например, степень совпадения в результате сопоставления отображается на информацию текстового описания, или степень совпадения должным образом восполняется или уменьшается на основе определенного сценария.
[0080] На основе предыдущего описания, более наглядно, реализация настоящей заявки дополнительно обеспечивает схематичную блок-схему последовательности операций, иллюстрирующую реализацию выполнения нечеткого сопоставления с использованием интегрированного алгоритма в способе для сопоставления имен в действительном сценарии применения, как показано на фиг. 3. На фиг. 3, последовательность выполнения различных обнаружений и вычисления степеней совпадения в различных способах является только примером и не предназначена для ограничения настоящей заявки.
[0081] На фиг. 3, если сопоставление имени, подлежащего сопоставлению, успешно посредством любого одного из предыдущих обнаружений, результат сопоставления может выводиться напрямую; напротив, результат сопоставления имени, подлежащего сопоставлению, может определяться и выводиться с использованием одного или нескольких способов для вычисления степени совпадения (например, вычисление степени совпадения текста, вычисление степени совпадения фонетики и вычисление степени совпадения строк).
[0082] Разумеется, различные обнаружения и вычисления степени совпадения в различных способах могут также выполняться полностью, и затем различные результаты обнаружения и результаты вычисления степени совпадения в различных способах могут рассматриваться в полном объеме, чтобы определить результат сопоставления строки, подлежащей сопоставлению.
[0083] Дополнительно, реализация настоящей заявки дополнительно обеспечивает схематичную блок-схему последовательности операций, иллюстрирующую реализацию способа для сопоставления имен в действительном сценарии применения, как показано на фиг. 4. На фиг. 4, предварительное определение на основе определенных правил может включать в себя следующее: определение того, не включено ли имя, подлежащее сопоставлению, в набор имен, которые не требуется сопоставлять, где индекс списка сканирования является индексом имен в стандартном наборе имен.
[0084] Этапы на фиг. 3 и фиг. 4 описаны выше подробно, и подробности опущены здесь для простоты.
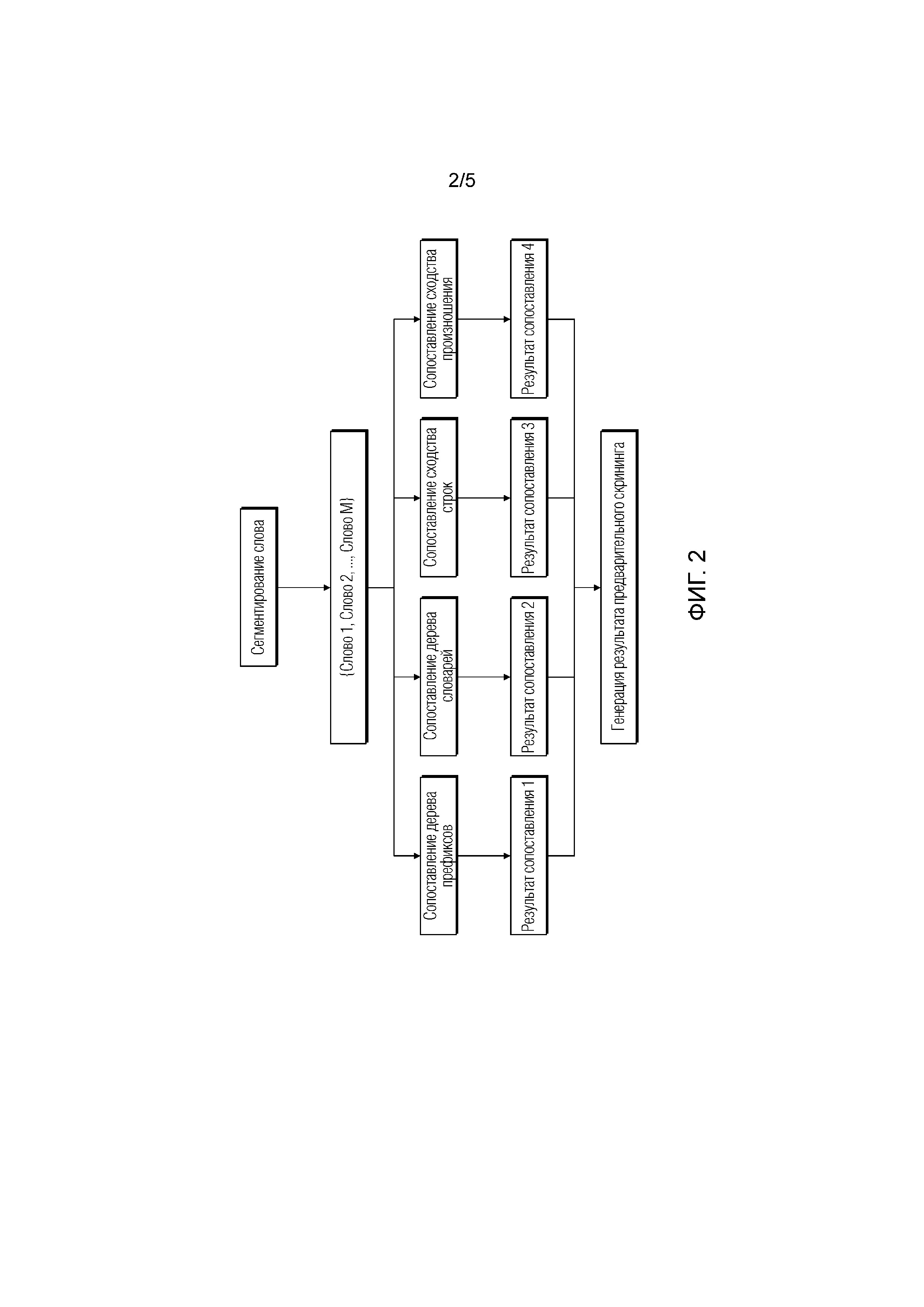
[0085] Способ для сопоставления имен, обеспеченный в настоящей реализации настоящей заявки, описан выше. Как показано на фиг. 5, на основе той же самой соответствующей изобретению идеи, реализация настоящей заявки дополнительно обеспечивает соответствующее устройство.
[0086] Фиг. 5 является схематичной структурной диаграммой, иллюстрирующей устройство для сопоставления имен и соответствующей фиг. 1, в соответствии с реализацией настоящей заявки. Пунктирная линия представляет опциональный модуль, и устройство включает в себя следующее: модуль 501 получения, сконфигурированный, чтобы получать имя, подлежащее сопоставлению; модуль 502 определения, сконфигурированный, чтобы определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению; модуль 503 обнаружения, сконфигурированный, чтобы обнаруживать имя, подлежащее сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны; и модуль 504 сопоставления, сконфигурированный, чтобы определять результат сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения.
[0087] Опционально, до определения стандартного набора имен, используемого для сопоставления имени, подлежащего сопоставлению, модуль 502 определения сконфигурирован, чтобы получать предопределенный набор имен, которые не требуется сопоставлять, и определять, что имя, подлежащее сопоставлению, не включено в набор имен, которые не требуется сопоставлять.
[0088] Опционально, то, что модуль 502 определения сконфигурирован, чтобы определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению, включает в себя следующее:
[0089] Модуль 502 определения сконфигурирован, чтобы получать первый набор имен, который может использоваться для сопоставления имени, подлежащего сопоставлению, и определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению, путем выполнения сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом слове, включенном в имя в первом наборе имен.
[0090] Опционально, то, что модуль 502 определения, сконфигурирован, чтобы определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению, путем выполнения сопоставления сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом слове, включенном в имя в первом наборе имен, включает в себя следующее:
[0091] Модуль 502 определения сконфигурирован, чтобы получать индекс каждого имени, включенного в первый набор имен, где индекс имени является любым словом, включенным в имя; сегментировать имя, подлежащее сопоставлению, чтобы получать каждое слово, включенное в имя, подлежащее сопоставлению; выполнять сопоставление сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе, чтобы получать поднабор первого набора имен. Полученный поднабор включает в себя имя, индексированное каждым индексом, который успешно совпадает; и определять стандартный набор имен, используемый для сопоставления имени, подлежащего сопоставлению, на основе поднабора.
[0092] Опционально, то, что модуль 502 определения, сконфигурирован, чтобы выполнять сопоставление сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе, включает в себя следующее:
[0093] Модуль 502 определения сконфигурирован, чтобы выполнять сопоставление сходства на каждом слове, включенном в имя, подлежащее сопоставлению, и каждом индексе с использованием алгоритма сопоставления строк, где алгоритм сопоставления строк включает в себя по меньшей мере одно из следующего: алгоритм сопоставления дерева префиксов, алгоритм сопоставления дерева словарей, алгоритм сопоставления сходства строк или алгоритм сопоставления сходства произношения.
[0094] Опционально, устройство дополнительно включает в себя следующее: модуль 505 выравнивания, сконфигурированный, чтобы выравнивать каждое слово, включенное в имя в стандартном наборе имен, по каждому слову, включенному в имя, подлежащее сопоставлению, на основе сходства между каждым словом, включенным в имя в стандартном наборе имен, и каждым словом, включенным в имя, подлежащее сопоставлению, до того, как модуль 503 обнаружения обнаруживает имя, подлежащее сопоставлению.
[0095] То, что модуль 503 обнаружения сконфигурирован, чтобы обнаруживать имя, подлежащее сопоставлению, включает в себя следующее:
[0096] Модуль 503 обнаружения сконфигурирован, чтобы обнаруживать имя, подлежащее сопоставлению, на основе выровненного стандартного набора имен, чтобы определять, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0097] Опционально, то, что модуль 503 обнаружения сконфигурирован, чтобы обнаруживать имя, подлежащее сопоставлению, включает в себя следующее: модуль 503 обнаружения сконфигурирован, чтобы выполнять по меньшей мере одно из обнаружения сокращения, обнаружения обращения, обнаружения нескольких языков или обнаружения прозвища на имени, подлежащем сопоставлению, чтобы определить, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0098] Опционально, то, что модуль 503 обнаружения сконфигурирован, чтобы выполнять обнаружение сокращения на имени, подлежащем сопоставлению, включает в себя следующее:
[0099] Модуль обнаружения сконфигурирован, чтобы получать предопределенные данные противоположной комбинации сокращений, где каждая противоположная комбинация сокращений отражает отношение отображения сокращений между по меньшей мере одним словом и сокращением слова; обнаруживать, имеет ли слово, включенное в имя, подлежащее сопоставлению, отношение отображения сокращений со словом, включенным в имя в стандартном наборе имен, на основе данных противоположной комбинации сокращений; и определять, на основе результата обнаружения, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0100] Опционально, то, что модуль 503 обнаружения сконфигурирован, чтобы выполнять обнаружение обращения на имени, подлежащем сопоставлению, включает в себя следующее:
[0101] Модуль 503 обнаружения сконфигурирован, чтобы получать предопределенные данные обращения; обнаруживать, включает ли в себя имя, подлежащее сопоставлению, обращение, где учитывается, что обращение не влияет на значение имени, которое включает в себя обращение; и определять, на основе результата обнаружения, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0102] Опционально, прозвище включает в себя уменьшительное имя имени, которое соответствует прозвищу, или синонимичное имя имени, которое соответствует прозвищу в разных областях. То, что модуль 503 обнаружения сконфигурирован, чтобы выполнять обнаружение прозвища на имени, подлежащем сопоставлению, включает в себя следующее:
[0103] Модуль 503 обнаружения сконфигурирован, чтобы выполнять по меньшей мере одно из следующего: обнаружение уменьшительного имени от имени, подлежащего сопоставлению, или обнаружение синонимичного имени от имени, подлежащего сопоставлению, в разных областях.
[0104] Опционально, то, что модуль 503 обнаружения сконфигурирован, чтобы выполнять обнаружение нескольких языков на имени, подлежащем сопоставлению, включает в себя следующее: модуль 503 обнаружения сконфигурирован, чтобы определять язык, который соответствует имени, подлежащему сопоставлению; получать по меньшей мере одно из правила искажения синонима при написании или правила искажения омонима при написании языка; и обнаруживать имя, подлежащее сопоставлению, в соответствии с по меньшей мере одним из правила искажения синонима при написании или правила искажения омонима при написании, чтобы определять, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0105] Опционально, то, что модуль 503 обнаружения сконфигурирован, чтобы выполнять обнаружение прозвища на имени, подлежащем сопоставлению, включает в себя следующее:
[0106] Модуль 503 обнаружения сконфигурирован, чтобы получать предопределенные данные противоположной комбинации прозвища, где каждая противоположная комбинация прозвища отражает отношение отображения прозвища между по меньшей мере одним словом и прозвищем слова; обнаруживать, имеет ли слово, включенное в имя, подлежащее сопоставлению, отношение отображения прозвища со словом, включенным в имя в стандартном наборе имен, на основе данных противоположной комбинации прозвища; и определять, на основе результата обнаружения, синонимично ли имя, подлежащее сопоставлению, по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны.
[0107] Опционально, то, что модуль 504 сопоставления сконфигурирован, чтобы определять результат сопоставления имени, подлежащего сопоставлению, на основе результата обнаружения, включает в себя следующее:
[0108] Модуль 504 сопоставления сконфигурирован, чтобы определять по меньшей мере одно имя в качестве результата сопоставления имени, подлежащего сопоставлению, если модуль 503 обнаружения определяет, что имя, подлежащее сопоставлению, синонимично по меньшей мере одному имени в стандартном наборе имен, но знаки имен не идентичны; или напротив, определять результат сопоставления имени, подлежащего сопоставлению, путем сопоставления имени, подлежащего сопоставлению, с именем в стандартном наборе имен с использованием одного или нескольких алгоритмов сходства.
[0109] Опционально, алгоритм сходства включает в себя по меньшей мере одно из следующего: алгоритм, используемый для вычисления степени совпадения текста, алгоритм, используемый для вычисления степени совпадения фонетики, или алгоритм, используемый для вычисления степени совпадения строк.
[0110] Опционально, имя представляет собой имя личности.
[0111] Устройства, обеспеченные в реализациях настоящей заявки, находятся в прямом соответствии со способами. Поэтому, устройства и способы имеют аналогичные полезные технические результаты. Полезные технические результаты способов были описаны выше подробно, и поэтому полезные технические результаты устройств опущены здесь для простоты.
[0112] К тому же, сценарии применения предыдущих устройств и способов не ограничены в настоящей заявке. В дополнение к области управления рисками (например, областям, таким как противодействие отмыванию денег и аутентификация пользователя), упомянутой в вышеизложенном описании, решения настоящей заявки применимы к любым другим областям, которым может потребоваться использовать технологию сопоставления имен.
[0113] В 1990-х, может явно различаться то, является ли техническое усовершенствование совершенствованием аппаратных средств (например, улучшением структуры схемы, таким как диод, транзистор или переключатель) или совершенствованием программного обеспечения (улучшением процедуры способа). Однако, с развитием технологий, текущие усовершенствования множества процедур способа могут рассматриваться как непосредственные улучшения структур схемы аппаратных средств. Разработчик обычно программирует улучшенную процедуру способа в схему аппаратных средств, чтобы получить соответствующую структуру схемы аппаратных средств. Поэтому, процедура способа может быть улучшена с использованием модуля объекта аппаратных средств. Например, программируемое логическое устройство (PLD) (например, программируемая вентильная матрица (FPGA)) является такой интегральной схемой, и логическая функция PLD определяется пользователем через программирование устройства. Разработчик выполняет программирование, чтобы "интегрировать" цифровую систему в PLD без запрашивания производителя чипа проектировать и производить чип специализированной интегральной схемы. К тому же, в настоящее время, вместо производства чипа интегральной схемы вручную, такое программирование в основном реализуется с использованием программного обеспечения "логического компилятора". Программное обеспечение логического компилятора аналогично компилятору программного обеспечения, используемому для разработки и написания программы. Исходный код требуется написать на конкретном языке программирования для компиляции. Язык упоминается как язык описания аппаратных средств (HDL). Существует множество HDL, таких как усовершенствованный язык булевых выражений (ABEL), язык описания аппаратных средств Altera (AHDL), Confluence, язык программирования Корнеллского университета (CUPL), HDCal, язык описания аппаратных средств Java (JHDL), Lava, Lola, MyHDL, PALASM и язык описания аппаратных средств Ruby (RHDL). Язык описания аппаратных средств на высокоскоростных интегральных схемах (VHDL) и Verilog используются наиболее часто. Специалист в данной области техники должен также понимать, что схема аппаратных средств, которая реализует логическую процедуру способа, может с легкостью быть получена, когда процедура способа логически программируется с использованием нескольких описанных языков описания аппаратных средств и программируется в интегральную схему.
[0114] Контроллер может быть реализован с использованием любого подходящего способа. Например, контроллер может быть микропроцессором или процессором и считываемым компьютером носителем, хранящим считываемый компьютером программный код (такой как программное обеспечение или прошивка), который может исполняться микропроцессором или процессором, логической схемой, переключателем, специализированной интегральной схемой (ASIC), программируемым логическим контроллером или встроенным микроконтроллером. Примеры контроллера включают в себя, но без ограничения, следующие микропроцессоры: ARC 625D, Atmel AT91SAM, Microchip PIC18F26K20 и Silicone Labs C8051F320. Контроллер памяти может также быть реализован как часть управляющей логики памяти. Специалист в данной области техники также знает, что, в дополнение к реализации контроллера с использованием считываемого компьютером программного кода, логическое программирование может выполняться на этапах способа, чтобы позволить контроллеру реализовывать ту же самую функцию в формах логической схемы, переключателя, специализированной интегральной схемы, программируемого логического контроллера и встроенного микроконтроллера. Поэтому, контроллер может рассматриваться как компонент аппаратных средств, и устройство, сконфигурированное, чтобы реализовывать различные функции в контроллере, может также рассматриваться как структура в компоненте аппаратных средств. Или устройство, сконфигурированное, чтобы реализовывать различные функции, может даже рассматриваться и как модуль программного обеспечения, реализующий способ, и как структура в компоненте аппаратных средств.
[0115] Система, устройство, модуль или блок, проиллюстрированные в предыдущих реализациях, могут быть реализованы с использованием компьютерного чипа или объекта или могут быть реализованы с использованием продукта, имеющего определенную функцию. Обычным устройством реализации является компьютер. Компьютер может быть, например, персональным компьютером, ноутбуком, сотовым телефоном, камерофоном, смартфоном, персональным цифровым ассистентом, медиапроигрывателем, устройством навигации, устройством электронной почты, игровой консолью, планшетом, носимым устройством или комбинацией любых из этих устройств.
[0116] Для простоты описания, устройство выше описано путем разделения функций на различные блоки. Разумеется, когда настоящая заявка реализуется, функции блоков могут быть реализованы в одном или нескольких элементах программного обеспечения и/или аппаратных средств.
[0117] Специалист в данной области техники должен понимать, что реализация настоящего раскрытия может быть обеспечена как способ, система или компьютерный программный продукт. Поэтому, настоящее раскрытие может использовать форму реализаций только в аппаратных средствах, реализаций только в программном обеспечении или реализаций с комбинацией программного обеспечения и аппаратных средств. Более того, настоящее раскрытие может использовать форму компьютерного программного продукта, который реализован на одном или нескольких используемых компьютером носителях хранения (включающих в себя, но без ограничения, память на диске, CD-ROM, оптическую память и т.д.), которые включают в себя используемый компьютером программный код.
[0118] Настоящее раскрытие описано со ссылкой на блок-схемы последовательностей операций и/или блок-схемы способа, устройства (системы) и компьютерного программного продукта на основе реализаций настоящего раскрытия. Стоит отметить, что компьютерные программные инструкции могут использоваться для реализации каждого процесса и/или каждого блока в блок-схемах последовательностей операций и/или блок-схемах устройств и комбинации процесса и/или блока в блок-схемах последовательностей операций и/или блок-схемах устройств. Эти компьютерные программные инструкции могут быть обеспечены для универсального компьютера, специализированного компьютера, встроенного процессора или процессора другого программируемого устройства обработки данных для генерации машины, так что инструкции, исполняемые компьютером или процессором другого программируемого устройства обработки данных, генерируют устройство для реализации заданной функции в одном или нескольких процессах в блок-схемах последовательностей операций и/или в одном или нескольких блоках в блок-схемах устройств.
[0119] Эти компьютерные программные инструкции могут храниться в считываемой компьютером памяти, которая может инструктировать компьютер или другое программируемое устройство обработки данных работать конкретным образом, так что инструкции, хранящиеся в считываемой компьютером памяти, генерируют артефакт, который включает в себя устройство инструкций. Устройство инструкций реализует заданную функцию в одном или нескольких процессах в блок-схемах последовательностей операций и/или в одном или нескольких блоках в блок-схемах устройств.
[0120] Эти компьютерные программные инструкции могут загружаться на компьютер или другое программируемое устройство обработки данных, так что выполняются серии операций и операции и этапы на компьютере или другом программируемом устройстве, тем самым генерируя реализуемую компьютером обработку. Поэтому, инструкции, исполняемые на компьютере или другом программируемом устройстве, обеспечивают этапы для реализации специфицированной функции в одном или нескольких процессах в блок-схемах последовательностей операций и/или в одном или нескольких блоках в блок-схемах устройств.
[0121] В обычной конфигурации, вычислительное устройство включает в себя один или несколько процессоров (CPU), один или несколько интерфейсов ввода/вывода, один или несколько сетевых интерфейсов и одно или несколько устройств памяти.
[0122] Память может включать в себя непостоянную память, память с произвольным доступом (RAM), энергонезависимую память и/или другую форму, которые находятся в считываемом компьютером носителе, например, постоянной памяти (ROM) или флэш-памяти (flash RAM). Память является примером считываемого компьютером носителя.
[0123] Считываемый компьютером носитель включает в себя постоянные, непостоянные, съемные и несъемные носители, которые могут хранить информацию с использованием любого способа или технологии. Информация может быть считываемой компьютером инструкцией, структурой данных, программным модулем или другими данными. Примеры компьютерного носителя хранения включают в себя, но без ограничения, память с произвольным доступом с фазовыми изменениями (PRAM), статическую память с произвольным доступом (SRAM), динамическую память с произвольным доступом (DRAM), другой тип памяти с произвольным доступом (RAM), постоянную память (ROM), электрически перепрограммируемую постоянную память (EEPROM), флэш-память или другую технологию памяти, постоянную память на компакт-диске (CD-ROM), цифровой универсальный диск (DVD) или другое оптическое хранилище, магнитную ленту кассеты, хранилище на магнитной ленте/магнитном диске или другое магнитное устройство хранения, или любой другой носитель, не относящийся к среде передачи. Компьютерный носитель хранения может использоваться для хранения информации, доступ к которой осуществляется вычислительным устройством. На основе описания в настоящей спецификации, считываемый компьютером носитель не включает в себя временные (переходные) считываемые компьютером носители (переходные носители), такие как модулированный сигнал данных и несущая.
[0124] Стоит дополнительно отметить, что термины "включать в себя", "содержать" или их любые другие варианты предназначены для охвата не-исключающего включения, так что процесс, способ, продукт или устройство, которое включает в себя список элементов, не только включает в себя эти элементы, но также включает в себя другие элементы, которые не перечислены явно, или дополнительно включает в себя элементы, присущие такому процессу, способу, продукту или устройству. Без дополнительных ограничений, элемент, которому предшествует "включает в себя …", не препятствует существованию дополнительных идентичных элементов в процессе, способе, продукте или устройстве, которое включает в себя этот элемент.
[0125] Специалист в данной области техники должен понимать, что реализация настоящей заявки может быть обеспечена как способ, система или компьютерный программный продукт. Поэтому, настоящая заявка может использовать форму реализаций только в аппаратных средствах, реализаций только в программном обеспечении или реализаций с комбинацией программного обеспечения и аппаратных средств. К тому же, настоящая заявка может использовать форму компьютерного программного продукта, который реализован на одном или нескольких используемых компьютером носителях хранения (включающих в себя, но без ограничения, память на диске, CD-ROM, оптическую память и т.д.), которые включают в себя используемый компьютером программный код.
[0126] Настоящая заявка может быть описана в общем контексте исполняемых компьютером инструкций, исполняемых компьютером, например, программным модулем. В общем, программный модуль включает в себя стандартную программу, программу, объект, компонент, структуру данных и т.д., исполняющие конкретную задачу или реализующие конкретный абстрактный тип данных. Настоящая заявка может также применяться в распределенных вычислительных средах. В распределенных вычислительных средах, задачи выполняются устройствами удаленной обработки, соединенными через сеть связи. В распределенной вычислительной среде, программный модуль может быть расположен как в локальном, так и в удаленном компьютерных носителях хранения, включающих в себя устройства хранения.
[0127] Реализации настоящей спецификации описаны постепенным образом. Для одних и тех же или аналогичных частей реализаций, могут даваться ссылки на реализации. Каждая реализация фокусируется на отличии от других реализаций. Конкретно, реализация системы в основном аналогична реализации способа и поэтому описана кратко. Для связанных частей, могут даваться ссылки на связанные описания в реализации способа.
[0128] Предыдущие описания являются реализациями настоящей заявки и не предназначены для ограничения настоящей заявки. Специалист в данной области техники может выполнять различные модификации и изменения с настоящей заявкой. Любая модификация, эквивалентная замена или улучшение, выполненные без отклонения от сущности и принципов настоящей заявки, должны соответствовать объему формулы изобретения в настоящей заявке.

Способ и устройство проверки
Способ и аппарат для получения информации о местоположении
Способ и устройство регистрации и аутентификации информации
Поиск, основанный на комбинировании пользовательских данных отношений
Способ и устройство распределенной обработки потоковых данных
Схема доменных имен для перекрестных цепочечных взаимодействий в системах цепочек блоков
Перекрестные цепочечные взаимодействия с использованием схемы доменных имен в системах цепочек блоков
Защита данных цепочек блоков с использованием гомоморфного шифрования
Способ и устройство для обработки запроса услуги
Управление связью между консенсусными узлами и клиентскими узлами

