Результат интеллектуальной деятельности: СПОСОБ И ОБОРУДОВАНИЕ РАСПОЗНАВАНИЯ ЭМОЦИЙ В РЕЧИ
Вид РИД
Изобретение
Область техники, к которой относится изобретение
[0001] Данная заявка относится к области техники обработки естественного языка, а более конкретно, к способу и оборудованию распознавания эмоций в речи.
Уровень техники
[0002] Искусственный интеллект (Artificial Intelligence, AI) представляет собой теорию, способ, технологию или прикладную систему, которая моделирует, разворачивает и расширяет человеческий интеллект посредством использования цифрового компьютера или машины, управляемой посредством цифрового компьютера, чтобы считывать окружение, получать знания и достигать оптимального результата посредством использования знаний. Другими словами, искусственный интеллект представляет собой ветвь компьютерной науки и предназначен для того, чтобы понимать сущность интеллектуальности и формировать новую интеллектуальную машину, которая может реагировать способом, аналогичным человеческому интеллекту. Искусственный интеллект должен изучать принципы проектирования и способы реализации различных интеллектуальных машин, так что машины имеют функции восприятия, обоснования и принятия решений.
[0003] При непрерывной разработке технологий искусственного интеллекта, взаимодействие с использованием эмоций играет важную роль в обмене информацией между людьми. Технология распознавания эмоций представляет собой одну из базовых технологий человеко–машинного взаимодействия. В настоящее время, исследователи работают для того, чтобы заставлять искусственного интеллектуального помощника понимать эмоции людей через голос и реализовывать более персонифицированную связь посредством изучения и распознавания эмоций, таких как беспокойство, волнение и гнев, в голосе.
[0004] Большинство существующих технологий распознавания эмоций в речи главным образом распознают эмоцию говорящего на основе анализа речи одного предложения (текущего речевого фрагмента) без учета речевого контекста, приводя к неточному распознаванию эмоций.
Сущность изобретения
[0005] Эта заявка предоставляет способ и оборудование распознавания эмоций в речи, чтобы достигать эффекта более точного распознавания эмоций в речи.
[0006] Согласно первому аспекту, предоставляется способ распознавания эмоций в речи, и способ включает в себя: определение, на основе первой нейронной сетевой модели, множества фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в текущий речевой фрагмент (utterance) в целевом диалоге, причем один речевой кадр соответствует одному фрагменту информации эмоционального состояния, и информация эмоционального состояния представляет эмоциональное состояние, соответствующее речевому кадру; выполнение статистической операции над множеством фрагментов информации эмоционального состояния, чтобы получать статистический результат, причем статистический результат представляет собой статистический результат, соответствующий текущему речевому фрагменту; и определение, на основе второй нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, соответствующих n–1 речевым фрагментам перед текущим речевым фрагментом, информации эмоционального состояния, соответствующей текущему речевому фрагменту, причем n–1 речевых фрагментов находятся во взаимно-однозначном соответствии с n–1 статистическими результатами, статистический результат, соответствующий любому из n–1 речевых фрагментов, получается посредством выполнения статистической операции над множеством фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в речевой фрагмент, n–1 речевых фрагментов принадлежат целевому диалогу, и n является целым числом, большим 1.
[0007] Согласно способу, предоставленному в этой заявке, множество фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров в текущем речевом фрагменте, могут получаться на основе первой нейронной сетевой модели; и информация эмоционального состояния, соответствующая текущему речевому фрагменту, может получаться на основе второго нейронного сетевого устройства, статистического результата, соответствующего текущему речевому фрагменту, и статистических результатов, соответствующих множеству речевых фрагментов перед текущим речевым фрагментом. Следовательно, посредством использования двухуровневой нейронной сетевой модели, которая включает в себя первую нейронную сетевую модель и вторую нейронную сетевую модель, влияние контекста текущего речевого фрагмента на информацию эмоционального состояния, соответствующую текущему речевому фрагменту, может полностью изучаться, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0008] Необязательно, статистическая операция включает в себя, но не только, одну или более из операций значения получения среднего, дисперсии, экстремума, линейного подгоночного коэффициента и подгоночного коэффициента высшего порядка. Соответственно, статистический результат включает в себя, но не только, одно или более из среднего значения, дисперсии, экстремума, линейного подгоночного коэффициента и подгоночного коэффициента высшего порядка.
[0009] В отношении первого аспекта, в некоторых реализациях первого аспекта, n–1 речевых фрагментов включают в себя голосовые данные множества говорящих. Другими словами, n–1 речевых фрагментов представляют собой диалог между множеством говорящих.
[0010] На основе этого решения, распознавание речи выполняется на основе диалога между множеством говорящих. По сравнению с распознаванием эмоций в речи, которое выполняется на основе одного предложения говорящего в предшествующем уровне техники, это решение позволяет достигать эффекта более точного распознавания эмоций в речи.
[0011] В отношении первого аспекта, в некоторых реализациях первого аспекта, множество говорящих включают в себя говорящего, соответствующего текущему речевому фрагменту; и
– определение, на основе второй нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, соответствующих n–1 речевым фрагментам перед текущим речевым фрагментом, информации эмоционального состояния, соответствующей текущему речевому фрагменту, включает в себя:
– определение, на основе второй нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, n–1 статистических результатов и полов множества говорящих, информации эмоционального состояния, соответствующей текущему речевому фрагменту.
[0012] Распознавание эмоций в речи выполняется со ссылкой на пол говорящего, так что может получаться более точный результат распознавания эмоций в речи.
[0013] В отношении первого аспекта, в некоторых реализациях первого аспекта, n–1 речевых фрагментов являются смежными во времени. Другими словами, отсутствуют другие голосовые данные между любыми двумя из n–1 речевых фрагментов.
[0014] В отношении первого аспекта, в некоторых реализациях первого аспекта, определение, на основе второй нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, соответствующих n–1 речевым фрагментам перед текущим речевым фрагментом, информации эмоционального состояния, соответствующей текущему речевому фрагменту, включает в себя: определение, на основе статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, признаков раундов, надлежащим образом соответствующих w раундам, соответствующим n речевым фрагментам, а именно, текущему речевому фрагменту и n–1 речевым фрагментам, причем признак раунда, соответствующий любому раунду, определяется на основе статистических результатов, соответствующих речевым фрагментам всех говорящих в раунде, и w является целым числом, большим или равным 1; и определение, на основе второй нейронной сетевой модели и признаков раундов, надлежащим образом соответствующих w раундам, информации эмоционального состояния, соответствующей текущему речевому фрагменту.
[0015] В частности, например, каждый раунд включает в себя голосовые данные двух говорящих A и B. Признак раунда, соответствующий любому раунду, определяется на основе статистического результата, соответствующего A, и статистического результата, соответствующего B, в раунде диалога. Например, признак раунда, соответствующий текущему раунду, соответствующему текущему речевому фрагменту, представляет собой векторную комбинацию статистических результатов, соответствующих речевым фрагментам, включенным в текущий раунд. Дополнительно, признак раундов дополнительно может определяться со ссылкой на полы A и B. Например, признак раунда, соответствующий текущему раунду, соответствующему текущему речевому фрагменту, представляет собой векторную комбинацию статистических результатов, соответствующих речевым фрагментам, включенным в текущий раунд, и полов говорящих, соответствующих текущему раунду. В этой заявке, w признаков раундов могут вводиться во вторую нейронную сетевую модель, и информация эмоционального состояния, соответствующая текущему речевому фрагменту, выводится из второй нейронной сетевой модели.
[0016] Необязательно, один речевой фрагмент представляет собой одно предложение, и в силу этого один речевой фрагмент соответствует одному говорящему.
[0017] Следовательно, согласно способу, предоставленному в этой заявке, распознавание эмоций в речи выполняется на основе голосовых данных множества говорящих в речевых фрагментах перед текущим речевым фрагментом, другими словами, на основе многораундовой диалоговой контекстной информации. По сравнению с распознаванием эмоций в речи, которое выполняется на основе одного предложения в предшествующем уровне техники, этот способ позволяет достигать эффекта более точного распознавания эмоций в речи.
[0018] В отношении первого аспекта, в некоторых реализациях первого аспекта, w представляет собой значение, введенное пользователем.
[0019] В отношении первого аспекта, в некоторых реализациях первого аспекта, способ дополнительно включает в себя: представление, пользователю, информации эмоционального состояния, соответствующей текущему речевому фрагменту.
[0020] В отношении первого аспекта, в некоторых реализациях первого аспекта, способ дополнительно включает в себя: получение операции коррекции, выполняемой пользователем над информацией эмоционального состояния, соответствующей текущему речевому фрагменту.
[0021] Дополнительно, способ дополнительно включает в себя: обновление значения w.
[0022] Другими словами, если результат прогнозирования не является таким, как ожидается пользователем, пользователь может корректировать результат прогнозирования. После распознавания операции модификации, выполняемой пользователем, оборудование распознавания эмоций в речи может обновлять значение w, чтобы получать более точный результат прогнозирования.
[0023] В отношении первого аспекта, в некоторых реализациях первого аспекта, первая нейронная сетевая модель представляет собой модель на основе долгой краткосрочной памяти (long short-term memory, LSTM), и/или вторая нейронная сетевая модель представляет собой LSTM.
[0024] Поскольку LSTM–модель имеет отличные характеристики памяти, влияние диалогового контекста на информацию эмоционального состояния, соответствующую текущему речевому фрагменту, может полностью изучаться, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0025] Следует понимать, что первая нейронная сетевая модель и вторая нейронная сетевая модель могут быть идентичными или могут отличаться. Это не ограничено в этой заявке.
[0026] В отношении первого аспекта, в некоторых реализациях первого аспекта, определение, на основе первой нейронной сетевой модели, множества фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в текущий речевой фрагмент в целевом диалоге, включает в себя:
– определение, для каждого из множества речевых кадров на основе первой нейронной сетевой модели, собственного вектора, соответствующего речевому кадру, и собственных векторов, надлежащим образом соответствующих q–1 речевым кадрам перед речевым кадром, информации эмоционального состояния, соответствующей речевому кадру, причем q–1 речевых кадров представляют собой речевые кадры говорящего, соответствующего текущему речевому фрагменту, q является целым числом, большим 1, и собственный вектор речевого кадра k представляет акустический признак речевого кадра k.
[0027] Необязательно, акустический признак включает в себя, но не только, одно или более из энергии, основной частоты, частоты переходов через нуль, мел–частотного кепстрального коэффициента (Mel frequency cepstral coefficient, MFCC) и т.п. Например, собственный вектор каждого речевого кадра может получаться посредством комбинирования вышеприведенных акустических функций.
[0028] В отношении первого аспекта, в некоторых реализациях первого аспекта, любые два из q речевых кадров разделяются посредством m речевых кадров, и m является целым числом, большим или равным 0.
[0029] На основе этого технического решения, когда m не равен 0, контекст, включенный в окно, соответствующее речевому кадру, может расширяться без задания последовательности окон чрезмерно длинной, за счет этого дополнительно повышая точность результата прогнозирования.
[0030] Согласно второму аспекту, предоставляется оборудование распознавания эмоций в речи, и оборудование включает в себя модуль, выполненный с возможностью осуществлять способ согласно первому аспекту.
[0031] Согласно третьему аспекту, предоставляется оборудование распознавания эмоций в речи, и оборудование включает в себя: запоминающее устройство, выполненное с возможностью хранить программу; и процессор, выполненный с возможностью выполнять программу, хранимую в запоминающем устройстве, и при выполнении программы, хранимой в запоминающем устройстве, процессор выполнен с возможностью осуществлять способ согласно первому аспекту.
[0032] Согласно четвертому аспекту, предоставляется машиночитаемый носитель. Машиночитаемый носитель сохраняет программный код, который должен выполняться посредством устройства, и программный код используется для того, чтобы осуществлять способ согласно первому аспекту.
[0033] Согласно пятому аспекту, предоставляется компьютерный программный продукт, включающий в себя инструкцию. Когда компьютерный программный продукт выполняется на компьютере, компьютер осуществляет способ согласно первому аспекту.
[0034] Согласно шестому аспекту, предоставляется микросхема, причем микросхема включает в себя процессор и интерфейс передачи данных, и процессор считывает, посредством использования интерфейса передачи данных, инструкцию, хранимую в запоминающем устройстве, чтобы осуществлять способ согласно первому аспекту.
[0035] Необязательно, в реализации, микросхема дополнительно может включать в себя запоминающее устройство. Запоминающее устройство сохраняет инструкцию, процессор выполнен с возможностью выполнять инструкцию, хранимую в запоминающем устройстве, и при выполнении инструкции, процессор выполнен с возможностью осуществлять способ согласно первому аспекту.
[0036] Согласно седьмому аспекту, предоставляется электронное устройство, и электронное устройство включает в себя оборудование распознавания действий согласно любому из второго–четвертого аспектов.
Описание чертежей
[0037] Фиг. 1 является принципиальной схемой системы обработки естественного языка;
[0038] Фиг. 2 является принципиальной схемой другого сценария применения системы обработки естественного языка;
[0039] Фиг. 3 является принципиальной структурной схемой архитектуры системы согласно варианту осуществления этой заявки;
[0040] Фиг. 4 является принципиальной структурной схемой аппаратных средств микросхемы согласно варианту осуществления этой заявки;
[0041] Фиг. 5 является блок–схемой последовательности операций способа распознавания эмоций в речи согласно варианту осуществления этой заявки;
[0042] Фиг. 6 является принципиальной схемой разделения голосового потока на речевые фрагменты;
[0043] Фиг. 7 является принципиальной схемой разделения речевого фрагмента на речевые кадры;
[0044] Фиг. 8 является принципиальной блок–схемой оборудования распознавания эмоций в речи согласно варианту осуществления этой заявки;
[0045] Фиг. 9 является принципиальной структурной схемой аппаратных средств нейронного сетевого обучающего оборудования согласно варианту осуществления этой заявки; и
[0046] Фиг. 10 является принципиальной структурной схемой аппаратных средств оборудования распознавания эмоций в речи согласно варианту осуществления этой заявки.
Подробное описание вариантов осуществления
[0047] Далее описываются технические решения этой заявки со ссылкой на прилагаемые чертежи.
[0048] Чтобы обеспечивать лучшее понимание этой заявки для специалистов в данной области техники, сначала кратко описывается сценарий, к которому может применяться эта заявка, со ссылкой на фиг. 1 и фиг. 2.
[0049] Фиг. 1 является принципиальной схемой системы обработки естественного языка. Ссылаясь на фиг. 1, система включает в себя абонентское устройство и устройство обработки данных. Абонентское устройство включает в себя пользователя и интеллектуальный терминал, такой как мобильный телефон, персональный компьютер или центр обработки информации. Абонентское устройство представляет собой инициирующий конец обработки данных естественного языка. В качестве инициатора запроса для языкового задания вопросов и выдачи ответов, выполнения запросов и т.п., пользователь обычно инициирует запрос посредством использования абонентского устройства.
[0050] Устройство обработки данных может представлять собой устройство или сервер, который имеет функцию обработки данных, такой как облачный сервер, сетевой сервер, сервер приложений или сервер администрирования. Устройство обработки данных принимает, из интеллектуального терминала через интерфейс взаимодействия, опросное утверждение в форме запросного утверждения, голоса, текста и т.п.; и затем выполняет обработку языковых данных способом машинного обучения, глубокого обучения, выполнения поиска, обоснования, принятия решений и т.п. посредством использования запоминающего устройства, которое сохраняет данные, и процессора, который обрабатывает данные. Запоминающее устройство может представлять собой собирательный термин, включающий в себя локальное устройство хранения данных и базу данных, которая сохраняет статистические данные. База данных может быть расположена на устройстве обработки данных или может быть расположена на другом сетевом сервере.
[0051] Фиг. 2 показывает другой сценарий применения системы обработки естественного языка. В этом сценарии, интеллектуальный терминал непосредственно служит в качестве устройства обработки данных, непосредственно принимает ввод от пользователя и непосредственно выполняет обработку посредством использования аппаратных средств интеллектуального терминала. Конкретный процесс является аналогичным процессу на фиг. 1, и следует обратиться к вышеприведенному описанию. Подробности не описываются повторно в данном документе.
[0052] Взаимодействие с использованием эмоций играет важную роль в обмене информацией между людьми. Исследование показывает, что 80% информации в человеческом общении представляют собой эмоциональную информацию. Следовательно, эмоциональные вычисления представляют собой существенную часть в процессе реализации удобного для пользователя человеко–машинного взаимодействия, и технология распознавания и понимания эмоций представляет собой одну из базовых технологий человеко–машинного взаимодействия.
[0053] Большинство существующих интеллектуальных помощников, к примеру, Siri Apple и Alexa Amazon, главным образом предоставляют основанное на знаниях взаимодействие на основе вопросов и ответов. Тем не менее, исследователи пытаются помогать искусственному интеллектуальному помощнику понимать эмоции людей через голос и реализовывать более персонифицированную связь посредством изучения и распознавания эмоций, таких как беспокойство, волнение и гнев, в голосе. Например, при распознавании низкого тона в голосе пользователя, интеллектуальный помощник воспроизводит веселую песню для пользователя или говорит пользователю безобидную ложь, или говорит пользователю, что друг пользователя кажется подавленным, и советует пользователю сопровождать друга при просмотре вдохновляющего кино.
[0054] Эмоции в голосе затрагиваются посредством речевого контекста, но большинство существующих технологий распознавания эмоций в речи главным образом распознают эмоцию говорящего на основе анализа речи одного предложения (текущего речевого фрагмента) без учета речевого контекста, приводя к неточному распознаванию эмоций.
[0055] Дополнительно, в диалоге, не только слова, ранее произнесенные говорящим, могут затрагивать текущую эмоцию, и слова и эмоциональное состояние другого пользователя также могут затрагивать текущую эмоцию. В фактической ситуации, эмоциональное состояние в диалоге затрагивается посредством двух различных уровней речевых контекстов. Один представляет собой уровень голосового потока, конкретно, предыдущий кадр и следующий кадр влияют на артикуляцию в текущем кадре; и другой представляет собой влияние предыдущего раунда на утверждение в текущем раунде в диалоге. В том случае, если эмоция говорящего распознается просто на основе анализа речи одного предложения (текущего речевого фрагмента) без учета речевого контекста, результат прогнозирования в многораундовом сценарии взаимодействия является неточным и несоответствующим.
[0056] Чтобы разрешать вышеприведенную проблему, эта заявка предоставляет способ и оборудование распознавания эмоций в речи. Речевая контекстная информация вводится в процесс распознавания эмоций в речи, чтобы достигать более точного эффекта распознавания эмоций.
[0057] Способ распознавания эмоций в речи, предложенный в этой заявке, может применяться к области техники, которая требует естественного человеко–машинного взаимодействия. В частности, согласно способу в этой заявке, распознавание эмоций в речи может выполняться для входного потока диалоговых голосовых данных, чтобы идентифицировать эмоциональное состояние, например, радость или гнев, соответствующее текущей речи. Затем, согласно различным сценариям применения, идентифицированное эмоциональное состояние в реальном времени может использоваться для того, чтобы формулировать политику диалоговых ответов, распределять вызов соответствующему агенту по обслуживанию клиентов, регулировать ход выполнения обучения и т.п. Например, голосовой помощник может регулировать политику голосовых ответов на основе идентифицированного изменения эмоций в диалоговом процессе с пользователем, чтобы реализовывать более персонифицированное человеко–машинное взаимодействие. Помимо этого, голосовой помощник в системе обслуживания клиентов может использоваться для того, чтобы сортировать пользователей в центре обслуживания вызовов на основе степеней экстренности, с тем чтобы повышать качество обслуживания. Например, пользователь в относительно сильном отрицательном настроении обнаруживается вовремя, и вызов от пользователя переводится на агента по обслуживанию клиентов вовремя, чтобы оптимизировать пользовательское восприятие. Голосовой помощник в системе дистанционного образования может использоваться для того, чтобы отслеживать эмоциональное состояние пользователя в удаленном онлайн–курсе в процессе обучения, регулировать фокус в обучении или ход выполнения обучения во времени. Голосовой помощник в больнице может использоваться для того, чтобы отслеживать эмоциональное изменение больного депрессией, предоставлять основу для диагностики и лечения болезни, и может использоваться для того, чтобы предоставлять аутичному ребенку помощь и руководство по изучению понимания эмоций и характеристик выражений.
[0058] Оборудование распознавания эмоций в речи, предоставленное в этой заявке, может представлять собой устройство обработки данных, показанное на фиг. 1, блок или модуль в устройстве обработки данных, показанном на фиг. 1, и т.п. Помимо этого, оборудование распознавания эмоций в речи, предоставленное в этой заявке, альтернативно может представлять собой абонентское устройство, показанное на фиг. 2, блок или модуль в устройстве обработки данных, показанном на фиг. 2, и т.п. Например, устройство обработки данных, показанное на фиг. 1, может представлять собой облачный сервер, и оборудование распознавания эмоций в речи может представлять собой интерфейс прикладного программирования (application programming interface, API) для предоставления услуг распознавания эмоций в диалоговой речи на облачном сервере. В качестве другого примера, речевое оборудование может представлять собой приложение (application, APP) голосового помощника в абонентском устройстве, показанном на фиг. 2.
[0059] Например, оборудование распознавания эмоций в речи, предоставленное в этой заявке, может представлять собой независимый программный продукт для распознавания эмоций в диалоговой речи, API для предоставления услуг распознавания эмоций в диалоговой речи в открытом облаке или функциональной модуль, встраиваемый в продукт для речевого взаимодействия, такой как интеллектуальная приставка с громкоговорителями, APP голосового помощника на мобильном телефоне, интеллектуальное программное обеспечение для обслуживания клиентов либо модуль распознавания эмоций в системе дистанционного образования. Следует понимать, что формы продуктов, перечисленные в данном документе, предназначены для иллюстративного описания, но не составляют ограничения на эту заявку.
[0060] Со ссылкой на архитектуру системы, показанную на фиг. 3, далее описывается процесс обучения модели, применяемой к этой заявке.
[0061] Как показано на фиг. 3, вариант осуществления этой заявки предоставляет архитектуру 100 системы. На фиг. 3, устройство 160 сбора данных выполнено с возможностью собирать обучающий корпус. В этой заявке, речь диалога между множеством пользователей (например, двумя или более пользователей) может использоваться в качестве обучающего корпуса. Обучающий корпус включает в себя два типа комментариев. Один тип представляет собой комментарий по информации эмоционального состояния в каждом кадре, и другой тип представляет собой комментарий по информации эмоционального состояния в каждом речевом фрагменте. Помимо этого, говорящий каждого речевого фрагмента отмечается в обучающем корпусе. Дополнительно, пол говорящего также может отмечаться. Следует понимать, что каждый речевой фрагмент может разделяться на множество речевых кадров. Например, каждый речевой фрагмент может кадрироваться на основе длины кадра в 25 мс и сдвига кадра в 10 мс, чтобы получать множество речевых кадров, соответствующих речевому фрагменту.
[0062] Следует отметить, что информация эмоционального состояния в этой заявке может использовать любой способ представления эмоционального состояния. В настоящее время, предусмотрено два обычно используемых типа представлений эмоционального состояния в отрасли: дискретное представление в форме адъективных меток, таких как "счастливый" и "сердитый", и представление в виде размерностей, в котором эмоциональное состояние описывается как точка (x, y) в многомерном пространстве эмоций. Например, информация эмоционального состояния в этом варианте осуществления этой заявки может представляться посредством использования модели пространства "активации–валентности" (пространства "пробуждения–валентности"), другими словами, информация эмоционального состояния может представляться посредством использования (x, y). В пространственной модели "активации–валентности", вертикальная ось представляет собой размерность активации и используется для того, чтобы описывать степень эмоциональной интенсивности, и горизонтальная ось представляет собой размерность валентности и используется для того, чтобы оценивать степень положительности или отрицательности эмоции. Например, x и y могут описываться посредством использования значения от 1 до 5, что не ограничивается в этой заявке.
[0063] После того, как обучающие корпусы собираются, устройство 160 сбора данных сохраняет эти обучающие корпусы в базе 130 данных. Обучающее устройство 120 получает целевую модель/правило 101 посредством обучения на основе обучающего корпуса, поддерживаемого в базе 130 данных.
[0064] Целевая модель/правило 101 представляет собой двухуровневую нейронную сетевую модель устройства, конкретно, первую нейронную сетевую модель и вторую нейронную сетевую модель. Далее описывается процесс, в котором обучающее устройство 120 получает первую нейронную сетевую модель и вторую нейронную сетевую модель на основе обучающего корпуса.
[0065] Каждый речевой фрагмент каждого говорящего в обучающем корпусе кадрируется на основе конкретной длины кадра и сдвига кадра, чтобы получать множество речевых кадров, соответствующих речевому фрагменту. Затем собственный вектор каждого кадра получается. Собственный вектор представляет акустический признак речевого кадра. Акустический признак включает в себя, но не только, одно или более из энергии, основной частоты, частоты переходов через нуль, мел–частотного кепстрального коэффициента (Mel frequency cepstral coefficient, MFCC) и т.п. Например, собственный вектор каждого речевого кадра может получаться посредством комбинирования вышеприведенных акустических функций. Собственный вектор каждого текущего кадра и собственные векторы q–1 кадров перед текущим кадром комбинируются, чтобы формировать последовательность окон, длина которой составляет q, где q является целым числом, большим 1. Необязательно, для того, чтобы развертывать контекст, включенный в окно, без задания последовательности окон чрезмерно длинной, может использоваться способ понижающей дискретизации, конкретно, один кадр извлекается с интервалом в m кадров и добавляется в последовательность, где m является положительным целым числом. Каждая последовательность окон используется в качестве обучающей выборки, и первая нейронная сетевая модель может получаться посредством обучения посредством использования всех обучающих выборок в качестве ввода. В этой заявке, первая нейронная сетевая модель может представлять собой LSTM–модель, что не ограничивается в этой заявке. Например, в этой заявке, первая нейронная сетевая модель может иметь двухуровневую структуру, предусмотрено, соответственно, 60 и 80 нейронных элементов на скрытых уровнях, и функция потерь представляет собой среднеквадратическую ошибку (mean squared error, MSE).
[0066] Статистический результат, соответствующий каждому речевому фрагменту, определяется. В частности, первая нейронная сетевая модель может выводить результат прогнозирования информации эмоционального состояния для каждого речевого кадра. Статистический результат, соответствующий каждому речевому фрагменту, может получаться посредством выполнения статистической операции над информацией эмоционального состояния, соответствующей всем или некоторым речевым кадрам, соответствующим каждому речевому фрагменту. Например, статистическая операция включает в себя, но не только, одну или более из операций значения получения среднего, дисперсии, экстремума, линейного подгоночного коэффициента и подгоночного коэффициента высшего порядка. Соответственно, статистический результат включает в себя, но не только, одно или более из среднего значения, дисперсии, экстремума, линейного подгоночного коэффициента и подгоночного коэффициента высшего порядка.
[0067] Затем статистическая величина, соответствующая каждому речевому фрагменту, и статистические величины, надлежащим образом соответствующие множеству речевых фрагментов перед речевым фрагментом, могут комбинироваться и использоваться в качестве ввода, чтобы получать вторую нейронную сетевую модель посредством обучения. Дополнительно, статистическая величина и говорящий, который соответствует каждому речевому фрагменту, и статистические величины и говорящие, которые надлежащим образом соответствуют множеству речевых фрагментов перед речевым фрагментом, могут комбинироваться и использоваться в качестве ввода, чтобы получать вторую нейронную сетевую модель посредством обучения. Альтернативно, признак раундов, который соответствует каждому раунду, и признаки раундов, которые надлежащим образом соответствуют множеству раундов перед раундом, могут использоваться в качестве ввода, чтобы получать вторую нейронную сетевую модель посредством обучения. Например, признак раунда, соответствующий любому раунду, может получаться посредством комбинирования статистических результатов, соответствующих речевым фрагментам, соответствующим всем говорящим в раунде. Дополнительно, признак раунда, соответствующий любому раунду, может получаться посредством комбинирования статистических результатов, соответствующих речевым фрагментам, соответствующим всем говорящим в раунде и полам всех говорящих. Комбинация может представлять собой векторную комбинацию либо может представлять собой операцию суммирования со взвешиванием. Конкретный способ комбинирования не ограничен в этой заявке. В этой заявке, вторая нейронная сетевая модель может представлять собой LSTM–модель, что не ограничивается в этой заявке. Например, вторая нейронная сетевая модель может иметь одну многоуровневую структуру, предусмотрено 128 нейронных элементов на скрытом уровне, и функция потерь представляет собой MSE.
[0068] Поскольку LSTM–модель имеет отличные характеристики памяти, влияние диалогового контекста на информацию эмоционального состояния, соответствующую текущему речевому фрагменту, может полностью изучаться, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0069] Следует понимать, что в этой заявке, первая нейронная сетевая модель и вторая нейронная сетевая модель могут представлять собой рекуррентные нейронные сетевые модели, и первая нейронная сетевая модель и вторая нейронная сетевая модель могут быть идентичной или могут отличаться. Это не ограничено в этой заявке.
[0070] После того как обучение целевой модели/правила 101 завершается, другими словами, после того, как первая нейронная сетевая модель и вторая нейронная сетевая модель получаются, способ распознавания эмоций в речи в этом варианте осуществления этой заявки может реализовываться посредством использования целевой модели/правила 101, конкретно, информация эмоционального состояния текущего речевого фрагмента может получаться посредством ввода целевого диалога в целевую модель/правило 101. Следует понимать, что процесс обучения модели, описанный выше, представляет собой просто пример реализации этой заявки и не составляет ограничения на эту заявку.
[0071] Следует отметить, что при фактическом применении, обучающие корпусы, поддерживаемые в базе 130 данных, не обязательно собираются посредством устройства 160 сбора данных, и некоторые обучающие корпусы могут приниматься из другого устройства. Помимо этого, следует отметить, что обучающее устройство 120 может не обучать целевую модель/правило 101 полностью на основе обучающих корпусов, поддерживаемых в базе 130 данных, или может обучать модель посредством получения обучающего корпуса из облака или другого места. Вышеприведенное описание не должно истолковываться в качестве ограничения на этот вариант осуществления этой заявки.
[0072] Целевая модель/правило 101, полученное посредством обучающего устройства 120 посредством обучения, может применяться к различным системам или устройствам, например, применяться к устройству 110 выполнения, показанному на фиг. 3. Устройство 110 выполнения может представлять собой терминал, такой как мобильный телефонный терминал, планшетный компьютер, ноутбук, терминал с поддержкой дополненной реальности (augmented reality, AR)/виртуальной реальности (virtual reality, VR) или терминал в транспортном средстве, либо может представлять собой сервер, облако и т.п. На фиг. 3, устройство 110 выполнения содержит интерфейс 112 ввода–вывода (input/output, I/O) и выполнено с возможностью обмениваться данными с внешним устройством. Пользователь может вводить данные в интерфейс 112 ввода–вывода посредством использования клиентского устройства 140. Входные данные в этом варианте осуществления этой заявки могут включать в себя целевой диалог, вводимый посредством использования клиентского устройства.
[0073] Модуль 113 предварительной обработки и модуль 114 предварительной обработки выполнены с возможностью предварительно обрабатывать входные данные (например, целевой диалог), принимаемые посредством интерфейса 112 ввода–вывода. В этом варианте осуществления этой заявки, могут отсутствовать модуль 113 предварительной обработки и модуль 114 предварительной обработки (или может быть предусмотрен только один модуль предварительной обработки), и модуль 111 вычисления непосредственно выполнен с возможностью обрабатывать входные данные.
[0074] В процессе, в котором устройство 110 выполнения предварительно обрабатывает входные данные, либо в процессе, в котором модуль 111 вычисления устройства 110 выполнения выполняет вычисление и т.п., устройство 110 выполнения может активировать данные, код и т.п. в системе 150 хранения данных для соответствующей обработки; и также может сохранять, в системе 150 хранения данных, данные, инструкцию и т.п., которые получаются посредством соответствующей обработки.
[0075] В завершение, интерфейс 112 ввода–вывода возвращает результат обработки, такой как вышеприведенная полученная информация эмоционального состояния текущего речевого фрагмента, в клиентское устройство 140, за счет этого предоставляя результат обработки для пользователя. Следует понимать, что интерфейс 112 ввода–вывода может не возвращать информацию эмоционального состояния текущего речевого фрагмента в клиентское устройство 140, что не ограничивается в этой заявке.
[0076] Следует отметить, что обучающее устройство 120 может формировать, на основе различных фрагментов обучающих данных, соответствующие целевые модели/правила 101 для различных целей или различных задач. Соответствующие целевые модели/правила 101 могут использоваться для того, чтобы реализовывать вышеприведенные цели или выполнять вышеприведенные задачи, за счет этого предоставляя требуемый результат для пользователя.
[0077] В случае, показанном на фиг. 3, пользователь может вручную выбирать входные данные, и взаимный выбор может выполняться в пользовательском интерфейсе, предоставленном посредством интерфейса 112 ввода–вывода. В другом случае, клиентское устройство 140 может автоматически отправлять входные данные в интерфейс 112 ввода–вывода. Если необходимо то, что клиентское устройство 140 должно получать разрешение на передачу от пользователя для автоматической отправки входных данных, пользователь может задавать соответствующее разрешение в клиентском устройстве 140. Пользователь может просматривать, на клиентском устройстве 140, результат, выводимый посредством устройства 110 выполнения. Конкретная форма представления может представлять собой конкретный способ, такой как отображение, голос или действие. Клиентское устройство 140 также может служить в качестве конца сбора данных; и собирать, в качестве нового обучающего корпуса, входные данные, которые вводятся в интерфейс 112 ввода–вывода, и выходной результат, который выводится из интерфейса 112 ввода–вывода, показанного на чертеже, и сохраняет новый обучающий корпус в базе 130 данных. Безусловно, альтернативно, входные данные, которые вводятся в интерфейс 112 ввода–вывода, и выходной результат, который выводится из интерфейса 112 ввода–вывода, показанного на чертеже, могут непосредственно сохраняться в базе 130 данных в качестве нового обучающего корпуса посредством интерфейса 112 ввода–вывода, без сбора посредством клиентского устройства 140.
[0078] Следует отметить, что фиг. 3 является просто принципиальной схемой архитектуры системы согласно варианту осуществления этой заявки. Взаимосвязь местоположений между устройством, компонентом, модулем и т.п., показанными на чертеже, не составляет ограничения. Например, на фиг. 3, система 150 хранения данных представляет собой внешнее запоминающее устройство относительно устройства 110 выполнения, но в другом случае, система 150 хранения данных может располагаться в устройстве 110 выполнения.
[0079] Фиг. 4 показывает аппаратную структуру микросхемы согласно варианту осуществления этой заявки, и микросхема включает в себя нейронный сетевой процессор 20. Микросхема может располагаться в устройстве 110 выполнения, показанном на фиг. 3, чтобы осуществлять вычисление, выполняемое посредством модуля 111 вычисления. Микросхема альтернативно может располагаться в обучающем устройстве 120, показанном на фиг. 3, чтобы осуществлять обучение, выполняемое посредством обучающего устройства 120, и выводить целевую модель/правило 101.
[0080] Нейронный сетевой процессор 20 (NPU) смонтирован в хост–CPU (host CPU) в качестве сопроцессора, и задача выделяется посредством хост–CPU. Базовая часть NPU представляет собой функциональную схему 20, и контроллер 204 управляет функциональной схемой 203 с возможностью извлекать данные из запоминающего устройства (запоминающего устройства весовых коэффициентов или входного запоминающего устройства) и выполнять операцию.
[0081] В некоторых реализациях, функциональная схема 203 включает в себя множество блоков обработки (движок программы, PE). В некоторых реализациях, функциональная схема 203 представляет собой двумерный систолический массив. Функциональная схема 203 альтернативно может представлять собой одномерный систолический массив или другую электронную схему, которая может выполнять арифметические операции, такие как умножение и суммирование. В некоторых реализациях, функциональная схема 203 представляет собой матричный процессор общего назначения.
[0082] Например, предполагается, что имеются входная матрица A, матрица B весовых коэффициентов и выходная матрица C. Функциональная схема извлекает данные, соответствующие матрице B, из запоминающего устройства 202 весовых коэффициентов и буферизует данные по каждому PE в функциональной схеме. Функциональная схема извлекает данные матрицы A из входного запоминающего устройства 201, выполняет матричную операцию над данными матрицы A и матрицы B и сохраняет некоторые результаты или конечный результат полученной матрицы в накопителе 208 (accumulator).
[0083] Блок 207 векторного вычисления может выполнять последующую обработку, такую как векторное умножение, векторное сложение, экспонентная операция, логарифмическая операция или сравнение значений, для вывода функциональной схемы. Например, блок 207 векторного вычисления может быть выполнен с возможностью выполнять сетевое вычисление, к примеру, пулинг (pooling), пакетную нормализацию (batch normalization) или нормализацию на основе локального отклика (local response normalization), на несверточном/не–FC–уровне в нейронной сети.
[0084] В некоторых реализациях, блок 207 векторного вычисления может сохранять, в унифицированном кэше 206, выходной вектор, который обработан. Например, блок 207 векторного вычисления может применять нелинейную функцию к выводу функциональной схемы 203, например, к вектору накопленного значения, с тем чтобы формировать значение активации. В некоторых реализациях, блок 207 векторного вычисления формирует нормализованное значение, комбинированное значение либо и то, и другое. В некоторых реализациях, выходной вектор, который обработан, может использоваться в качестве активационного входа функциональной схемы 203, например, который должен использоваться на последующем уровне в нейронной сети.
[0085] Унифицированное запоминающее устройство 206 выполнено с возможностью сохранять входные данные и выходные данные.
[0086] Для данных весовых коэффициентов, контроллер 205 доступа к единицам хранения (direct memory access controller, DMAC) непосредственно используется для того, чтобы передавать входные данные во внешнем запоминающем устройстве во входное запоминающее устройство 201 и/или унифицированное запоминающее устройство 206, сохранять данные весовых коэффициентов во внешнем запоминающем устройстве в запоминающее устройство 202 весовых коэффициентов и сохранять данные в унифицированном запоминающем устройстве 206 во внешнее запоминающее устройство.
[0087] Шинный интерфейсный блок 210 (bus interface unit, BIU) выполнен с возможностью реализовывать взаимодействие между хост–CPU, DMAC и запоминающим устройством 209 для выборки инструкций посредством использования шины.
[0088] Запоминающее устройство 209 для выборки инструкций (instruction fetch buffer), соединенное с контроллером 204, выполнено с возможностью сохранять инструкцию, используемую посредством контроллера 204.
[0089] Контроллер 204 выполнен с возможностью активировать инструкцию, буферизованную в запоминающем устройстве 209 для выборки инструкций, с тем чтобы реализовывать рабочий процесс управления функциональным ускорителем.
[0090] Запись: Данные в данном документе могут описываться как описательные данные согласно фактическому изобретению, например, как определенная скорость транспортного средства, расстояние до препятствия и т.п.
[0091] Обычно, унифицированное запоминающее устройство 206, входное запоминающее устройство 201, запоминающее устройство 202 весовых коэффициентов и запоминающее устройство 209 для выборки инструкций представляют собой внутрикристальное (On-Chip) запоминающее устройство. Внешнее запоминающее устройство представляет собой запоминающее устройство за пределами NPU. Внешнее запоминающее устройство может представлять собой синхронное динамическое оперативное запоминающее устройство с удвоенной скоростью передачи данных (double data rate synchronous dynamic random access memory, сокращенно DDR SDRAM), запоминающее устройство с высокой пропускной способностью (high bandwidth memory, HBM) или другое читаемое и записываемое запоминающее устройство.
[0092] Устройство 110 выполнения на фиг. 3, описанное выше, может выполнять этапы способа распознавания эмоций в речи в вариантах осуществления этой заявки. Микросхема, показанная на фиг. 3, также может быть выполнена с возможностью выполнять этапы способа распознавания эмоций в речи в вариантах осуществления этой заявки. Далее подробно описывается способ распознавания эмоций в речи в вариантах осуществления этой заявки со ссылкой на прилагаемые чертежи.
[0093] Фиг. 5 является блок–схемой последовательности операций способа распознавания эмоций в речи согласно этой заявке. Далее описываются этапы в способе. Следует понимать, что способ может осуществляться посредством оборудования распознавания эмоций в речи.
[0094] S310. Определение, на основе первой нейронной сетевой модели, множества фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в текущий речевой фрагмент (utterance) в целевом диалоге.
[0095] Информация эмоционального состояния представляет эмоциональное состояние, соответствующее речевому кадру. На предмет информации по способу представления информации эмоционального состояния, следует обратиться к вышеприведенному описанию. Подробности не описываются в данном документе.
[0096] Целевой диалог представляет собой поток голосовых данных, который вводится в оборудование распознавания эмоций в речи, и может представлять собой поток голосовых данных в реальном времени пользователя, что не ограничивается в этой заявке. Оборудование распознавания эмоций в речи может разделять целевой диалог на сегменты на основе существующего способа распознавания речи или нового способа распознавания речи, который может появиться в силу технического прогресса, и отмечать говорящего каждого сегмента.
[0097] Например, оборудование распознавания речи может разделять целевой диалог на сегменты посредством использования технологии распознавания отпечатка голоса и на основе переключения говорящих, причем один сегмент может рассматриваться как один речевой фрагмент. Например, ссылаясь на фиг. 6, на основе переключения говорящих, целевой диалог может разделяться на сегменты A1, B1, A2, B2, …, At–1, Bt–1, At и Bt, где A представляет одного говорящего, и B представляет другого говорящего.
[0098] В качестве другого примера, оборудование распознавания речи может рассматривать, на основе временной непрерывности голосовых данных, то, что сегмент голосовых данных, время паузы которого превышает предварительно установленное время (например, 200 мс), представляет собой речевой фрагмент. Например, для A2 на фиг. 6, если говорящий A имеет паузу в речевом фрагменте в течение определенного периода времени, к примеру, 230 мс, можно считать, что голосовые данные перед паузой в A2 представляют собой один речевой фрагмент A2–0, и голосовые данные, которые начинаются с паузы и заканчиваются в A2, представляют собой другой речевой фрагмент A2–1.
[0099] Очевидно, что различные речевые фрагменты определяются посредством использования различных способов распознавания речи. В общем, считается, что один речевой фрагмент представляет собой одно предложение, или речевой фрагмент может представлять собой голосовые данные говорящего от начала речи до конца речи без прерывания другим пользователем. Тем не менее, этот вариант осуществления этой заявки не ограничен этим.
[0100] Каждый речевой фрагмент может разделяться на множество речевых кадров. Например, каждый речевой фрагмент может кадрироваться на основе длины кадра в 25 мс и сдвига кадра в 10 мс, чтобы получать множество речевых кадров, соответствующих речевому фрагменту.
[0101] Текущий речевой фрагмент используется в качестве примера. Множество речевых кадров могут получаться посредством кадрирования текущего речевого фрагмента. "Множество речевых кадров, включенных в текущий речевой фрагмент", описанные в этом подробном описании, могут представлять собой некоторые или все (количество составляет g) речевые кадры, которые получаются посредством кадрирования текущего речевого фрагмента. Например, текущий речевой фрагмент может кадрироваться на основе длины кадра в 25 мс и сдвига кадра в 10 мс. Затем один кадр извлекается с интервалом в h кадров, и всего g кадров извлекаются и используются в качестве множества речевых кадров, где h является положительным целым числом, и g является целым числом, большим 1.
[0102] После того, как g речевых кадров получаются из текущего речевого фрагмента, информация эмоционального состояния, надлежащим образом соответствующая g речевых кадров, может получаться на основе первой нейронной сетевой модели.
[0103] В реализации, эта информация эмоционального состояния, надлежащим образом соответствующая g речевых кадров, определяется на основе первой нейронной сетевой модели, включает в себя: определение, для каждых из g речевых кадров на основе первой нейронной сетевой модели, собственного вектора, соответствующего речевому кадру, и собственных векторов, надлежащим образом соответствующих q–1 речевым кадрам перед речевым кадром, информации эмоционального состояния, соответствующей речевому кадру. q–1 речевых кадров представляют собой речевые кадры говорящего, соответствующего текущему речевому фрагменту. На предмет информации по значению q, следует обратиться к вышеприведенному описанию. Собственный вектор речевого кадра k представляет акустический признак речевого кадра k.
[0104] В частности, для любого речевого кадра k, собственные векторы, надлежащим образом соответствующие q речевых кадров, могут комбинироваться, чтобы формировать последовательность окон, длина которой составляет q, последовательность окон вводится в первую нейронную сетевую модель, и информация эмоционального состояния, соответствующая речевому кадру k, выводится из первой нейронной сетевой модели. Как описано выше, акустический признак речевого кадра k включает в себя, но не только, одно или более из энергии, основной частоты, частоты переходов через нуль, мел–частотного кепстрального коэффициента (Mel frequency cepstral coefficient, MFCC) и т.п., и собственный вектор речевого кадра k может получаться посредством комбинирования вышеприведенных акустических функций.
[0105] Следует понимать, что q речевых кадров, соответствующие речевому кадру k, могут включать в себя только речевой кадр в речевом фрагменте, которому принадлежит речевой кадр k, либо может включать в себя как речевой кадр в речевом фрагменте, которому принадлежит речевой кадр k, так и речевой кадр другого речевого фрагмента. Конкретный случай связан с местоположением речевого кадра в речевом фрагменте, которому принадлежит речевой кадр.
[0106] Следует дополнительно понимать, что q может составлять фиксированное установленное на заводе значение оборудования распознавания эмоций в речи либо может составлять нефиксированное значение. Например, q может задаваться пользователем, что не ограничивается в этой заявке.
[0107] Необязательно, любые два из q речевых кадров могут разделяться посредством m речевых кадров, и определение m описывается выше.
[0108] Речевые фрагменты Bt и Bt–1, показанные на фиг. 7, используются в качестве примера для описания. Ссылаясь на фиг. 7, речевой фрагмент Bt разделяется на речевые кадры Ft, 0, Ft, 1, Ft, 2… и т.п., и речевой фрагмент Bt–1 разделяется на речевые кадры Ft–1, 0, Ft–1, 1, Ft–1, 2, Ft–1, 3, Ft–1, 4, Ft–1, 5. Предполагается, что q=4 и g речевых кадров, включенные в речевой фрагмент Bt, включают в себя речевой кадр Ft, 0. В том случае, если m=0, q речевых кадров, соответствующие речевому кадру Ft, 0, могут составлять Ft, 0, Ft–1, 5, Ft–1, 4 и Ft–1, 3. Если m=1, q речевых кадров, соответствующие речевому кадру Ft, 0, могут составлять Ft, 0, Ft–1, 4, Ft–1, 2 и Ft–1, 0.
[0109] На основе этого технического решения, когда m не равен 0, контекст, включенный в окно, соответствующее речевому кадру k, может расширяться без задания последовательности окон чрезмерно длинной, за счет этого дополнительно повышая точность результата прогнозирования.
[0110] S320. Выполнение статистической операции над g фрагментами информации эмоционального состояния, чтобы получать статистический результат, причем статистический результат представляет собой статистический результат, соответствующий текущему речевому фрагменту.
[0111] Например, статистическая величина в этой заявке включает в себя, но не только, среднее значение, дисперсию, экстремум, линейный подгоночный коэффициент и подгоночный коэффициент высшего порядка.
[0112] S330. Определение, на основе второй рекуррентной нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, соответствующих n–1 речевым фрагментам перед текущим речевым фрагментом, информации эмоционального состояния, соответствующей текущему речевому фрагменту.
[0113] n–1 речевых фрагментов находятся во взаимно-однозначном соответствии с n–1 вторыми статистическими результатами, другими словами, один речевой фрагмент соответствует одному статистическому результату. Помимо этого, статистический результат, соответствующий любому из n–1 речевых фрагментов, получается посредством выполнения статистической операции над g фрагментами информации эмоционального состояния, соответствующими g речевым кадрам, включенным в речевой фрагмент. n–1 речевых фрагментов принадлежат целевому диалогу, и n является целым числом, большим 1.
[0114] Выше используется текущий речевой фрагмент в качестве примера и подробно описывается то, как определять информацию эмоционального состояния, надлежащим образом соответствующую g речевых кадров, включенным в текущий речевой фрагмент, чтобы дополнительно определять статистический результат, соответствующий текущему речевому фрагменту. Для любых из n–1 речевых фрагментов, способ для определения информации эмоционального состояния, надлежащим образом соответствующей множеству речевых кадров, включенных в речевой фрагмент, является аналогичным способу для определения информации эмоционального состояния, надлежащим образом соответствующей g речевых кадров, включенным в текущий речевой фрагмент, и подробности не описываются повторно в данном документе. Таким образом, n–1 статистических результатов, соответствующие n–1 речевых фрагментов, дополнительно могут определяться.
[0115] Следует понимать, что в конкретной реализации, оборудование распознавания эмоций в речи может фактически определять, согласно временной последовательности, соответствующий статистический результат каждый раз, когда речевой фрагмент принимается. Другими словами, если текущий речевой фрагмент представляет собой Bt, показанный на фиг. 6, оборудование распознавания эмоций в речи может последовательно определять статистические результаты, соответствующие речевым фрагментам до Bt.
[0116] Следует отметить, что способ, предоставленный в этой заявке, может применяться к двум сценариям: (1) Соответствующая информация эмоционального состояния выводится для каждого речевого фрагмента, который вводится в оборудование распознавания эмоций в речи. В этом сценарии, если количество речевых фрагментов перед текущим речевым фрагментом меньше n–1, например, если текущий речевой фрагмент представляет собой A1, показанный на фиг. 6, n–1 речевых фрагментов могут получаться через дополнение посредством использования первого значения по умолчанию (например, 0), и считается, что статистический результат, соответствующий каждому речевому фрагменту со значением по умолчанию, представляет собой второе значение по умолчанию. Следует понимать, что первое значение по умолчанию и второе значение по умолчанию могут быть идентичными или могут отличаться. (2) Оборудование распознавания эмоций во входной речи выводит информацию эмоционального состояния только тогда, когда количество речевых фрагментов, которые вводятся в оборудование распознавания эмоций в речи, достигает n. Другими словами, соответствующая информация эмоционального состояния не выводится для первого речевого фрагмента в (n–1)–й речевой фрагмент. Другими словами, проблема в первом сценарии, описанном выше, не должна рассматриваться.
[0117] Согласно способу, предоставленному в этой заявке, множество фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров в текущем речевом фрагменте, могут получаться на основе первой нейронной сетевой модели; и информация эмоционального состояния, соответствующая текущему речевому фрагменту, может получаться на основе второго нейронного сетевого устройства, статистического результата, соответствующего текущему речевому фрагменту, и статистических результатов, соответствующих множеству речевых фрагментов перед текущим речевым фрагментом. Следовательно, посредством использования двухуровневой нейронной сетевой модели, которая включает в себя первую нейронную сетевую модель и вторую нейронную сетевую модель, влияние контекста текущего речевого фрагмента на информацию эмоционального состояния, соответствующую текущему речевому фрагменту, может полностью изучаться, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0118] Необязательно, способ дополнительно может включать в себя: представление, пользователю, информации эмоционального состояния, соответствующей текущему речевому фрагменту.
[0119] Конкретно, после того, как информация эмоционального состояния, соответствующая текущему речевому фрагменту, определяется, результат прогнозирования может представляться пользователю.
[0120] Дополнительно, способ может включать в себя: получение операции коррекции, выполняемой пользователем над информацией эмоционального состояния, соответствующей текущему речевому фрагменту.
[0121] В частности, если представленный результат прогнозирования является неточным, пользователь дополнительно может корректировать результат прогнозирования.
[0122] Необязательно, n–1 речевых фрагментов являются смежными во времени. Другими словами, отсутствуют другие голосовые данные между любыми двумя из n–1 речевых фрагментов.
[0123] С использованием фиг. 6 в качестве примера, если текущий речевой фрагмент представляет собой Bt, n–1 речевых фрагментов могут представлять собой A1, B1, A2, B2, ..., At–1, Bt–1 и At или могут представлять собой A2, B2, ..., At–1 и Bt–1. Следует понимать, что два речевых фрагмента, к примеру, A1 и A2, не могут упоминаться как смежные речевые фрагменты, поскольку два речевых фрагмента разделяются посредством одного речевого фрагмента, а именно, B1.
[0124] Помимо этого, любые два из n–1 речевых фрагментов могут не быть смежными. Например, если целевой диалог представляет собой диалог между двумя говорящими, любые два из n–1 речевых фрагментов могут разделяться посредством одного или двух речевых фрагментов.
[0125] Дополнительно, n–1 речевых фрагментов включают в себя голосовые данные множества говорящих. Другими словами, n–1 речевых фрагментов представляют собой диалог между множеством говорящих.
[0126] Например, если текущий речевой фрагмент представляет собой B2, показанный на фиг. 6, n–1 речевых фрагментов могут включать в себя A1, B1, A2, конкретно, n–1 речевых фрагментов включают в себя голосовые данные A и B.
[0127] Помимо этого, n–1 речевых фрагментов альтернативно могут включать в себя только речевой фрагмент говорящего, соответствующего текущему речевому фрагменту. Например, текущий речевой фрагмент соответствует говорящему A, и только говорящий A говорит перед текущим речевым фрагментом, и в этом случае, n–1 речевых фрагментов не включают в себя речевой фрагмент, соответствующий другому пользователю.
[0128] На основе этого решения, распознавание речи выполняется на основе контекста говорящего. По сравнению с распознаванием эмоций в речи, которое выполняется на основе одного предложения говорящего в предшествующем уровне техники, это решение позволяет достигать эффекта более точного распознавания эмоций в речи.
[0129] В реализации S330, n статистических результатов, а именно, статистический результат, соответствующий текущему речевому фрагменту, и n–1 статистических результатов, могут вводиться во вторую нейронную сетевую модель, и информация эмоционального состояния, соответствующая текущему речевому фрагменту, выводится из второй нейронной сетевой модели.
[0130] Другими словами, n статистических результатов вводятся во вторую нейронную сетевую модель. На основе этого решения, статистические результаты не должны обязательно обрабатываться каким–либо образом, и в силу этого реализация является относительно простой.
[0131] Дополнительно, информация эмоционального состояния, соответствующая текущему речевому фрагменту, дополнительно может определяться со ссылкой на полы говорящих, которые соответствуют текущему речевому фрагменту и n–1 речевых фрагментов.
[0132] Например, n статистических результатов и полов говорящих, которые соответствуют текущему речевому фрагменту, и n–1 речевых фрагментов вводятся во вторую нейронную сетевую модель, и информация эмоционального состояния, соответствующая текущему речевому фрагменту, выводится из второй нейронной сетевой модели.
[0133] Распознавание эмоций в речи выполняется со ссылкой на пол говорящего, так что может получаться более точный результат распознавания.
[0134] В другой реализации S330, информация эмоционального состояния, соответствующая текущему речевому фрагменту, может определяться на основе второй нейронной сетевой модели и w признаков раундов.
[0135] n речевых фрагментов, а именно, n–1 речевых фрагментов и текущий речевой фрагмент, соответствуют w раундов диалогов. Другими словами, n речевых фрагментов соответствуют w раундов, где w является целым числом, большим 1. Необязательно, раунды могут разделяться на основе говорящих. С использованием фиг. 6 в качестве примера для описания, определяется то, что говорящий, соответствующий A2, представляет собой A, и последний речевой фрагмент, соответствующий A, представляет собой A1. Затем речевые фрагменты, начиная с A1 до речевого фрагмента перед A2, классифицируются на один раунд, конкретно, A1 и B1 представляют собой раунд диалога.
[0136] Как описано выше, n речевых фрагментов, а именно, n–1 речевых фрагментов и текущий речевой фрагмент, соответствуют w раундов. Признак раунда, соответствующий любому раунду, может определяться на основе статистических результатов, соответствующих речевым фрагментам всех говорящих в раунде.
[0137] В частности, например, каждый раунд включает в себя голосовые данные двух говорящих A и B. Признак раунда, соответствующий любому раунду, определяется на основе статистического результата, соответствующего A, и статистического результата, соответствующего B, в раунде диалога. Например, признак раунда, соответствующий текущему раунду, соответствующему текущему речевому фрагменту, представляет собой векторную комбинацию статистических результатов, соответствующих речевым фрагментам, включенным в текущий раунд. Дополнительно, признак раундов дополнительно может определяться со ссылкой на полы A и B. Например, признак раунда, соответствующий текущему раунду, соответствующему текущему речевому фрагменту, представляет собой векторную комбинацию статистических результатов, соответствующих речевым фрагментам, включенным в текущий раунд, и полов говорящих, соответствующих текущему раунду. В этой заявке, w признаков раундов могут вводиться во вторую нейронную сетевую модель, и информация эмоционального состояния, соответствующая текущему речевому фрагменту, выводится из второй нейронной сетевой модели.
[0138] Следовательно, согласно способу, предоставленному в этой заявке, распознавание эмоций в речи выполняется на основе голосовых данных множества говорящих в речевых фрагментах перед текущим речевым фрагментом, другими словами, на основе многораундовой диалоговой контекстной информации. По сравнению с распознаванием эмоций в речи, которое выполняется на основе одного предложения в предшествующем уровне техники, этот способ позволяет достигать эффекта более точного распознавания эмоций в речи.
[0139] Эта реализация отличается от предыдущей реализации S330 в том, статистические что результаты, соответствующие речевым фрагментам в каждом раунде, обрабатываются и затем вводятся во вторую нейронную сетевую модель.
[0140] Следует понимать, что когда ввод второй нейронной сетевой модели представляет собой признак раундов, значение w должно задаваться, и значение n не должно обязательно задаваться. Когда ввод второй нейронной сетевой модели представляет собой статистический результат, соответствующий речевому фрагменту, значение n должно задаваться, и значение w не должно обязательно задаваться.
[0141] Необязательно, w может представлять собой полученный ввод пользователя. Например, пользовательский интерфейс, который требует от пользователя вводить значение w, может представляться пользователю, и пользователь может определять значение w. В качестве другого примера, множество значений w могут представляться пользователю, и пользователь выбирает одно из значений w.
[0142] Необязательно, после того, как информация эмоционального состояния, соответствующая текущему речевому фрагменту, определяется, информация эмоционального состояния, соответствующая текущему речевому фрагменту, может дополнительно представляться пользователю. Пользователь может корректировать результат прогнозирования и может обновлять значение w, если получается операция коррекции, выполняемая пользователем над информацией эмоционального состояния, соответствующей текущему речевому фрагменту.
[0143] Дополнительно, процесс обновления значения w может представлять собой процесс задания значения w. Информация эмоционального состояния, соответствующая текущему речевому фрагменту, повторно прогнозируется. Если результат прогнозирования совпадает с результатом, вводимым пользователем, значение w, которое задается в этом случае, используется в качестве обновленного значения w. В противном случае, значение w сбрасывается, и информация эмоционального состояния, соответствующая текущему речевому фрагменту, прогнозируется до тех пор, пока результат прогнозирования не совпадает с результатом, вводимым пользователем, и значение w, которое совпадает с результатом, вводимым пользователем, используется в качестве обновленного значения w.
[0144] Другими словами, если результат прогнозирования не является таким, как ожидается пользователем, пользователь может корректировать результат прогнозирования. После распознавания операции модификации, выполняемой пользователем, оборудование распознавания эмоций в речи может обновлять значение w, чтобы получать более точный результат прогнозирования.
[0145] Следует отметить, что, если текущий раунд, соответствующий текущему речевому фрагменту, включает в себя только голос говорящего, соответствующего текущему речевому фрагменту, статистический результат, соответствующий другому говорящему в текущем раунде, может задаваться равным значению по умолчанию.
[0146] Нижеприведенная таблица 1 показывает результат эксперимента выполнения распознавания эмоций в речи согласно способу в этой заявке. Следует понимать, что число в первой строке в таблице 1 составляет значение w.
[0147] В частности, эксперимент выполняется посредством использования общедоступной базы IEMOCAP данных. База данных включает в себя пять диалогов, и каждый диалог включает в себя несколько сегментов диалоговых речей. Каждый сегмент диалога включает в себя 10–90 речевых фрагментов, и длина каждого речевого фрагмента равна 2–5 секунд.
[0148] Способ перекрестной проверки достоверности используется в эксперименте. Конкретно, четыре диалога циклически используются для обучения, оставшийся диалог используется для теста, и в завершение, результаты прогнозирования всех пяти диалогов получаются. Средний процент запоминаемости (UAR) используется в качестве индикатора оценки, и эмоциональное состояние прогнозируется из двух размерностей: валентность и активация. Результат эксперимента является следующим.
Табл. 1
|
[0149] Вышеприведенная таблица 1 показывает UAR, полученные посредством использования окон контекста различных длин в LSTM–модели диалогового уровня.
[0150] По сравнению с одноуровневой LSTM–моделью, можно видеть, что результат прогнозирования значительно улучшается после того, как рассматривается статистический раунд диалога. Наибольший UAR в валентности составляет 72,32%, и наибольший UAR в активации составляет 68,20%.
[0151] Следовательно, согласно способу, предоставленному в этой заявке, распознавание эмоций в речи выполняется на основе многораундовой диалоговой контекстной информации, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0152] Выше подробно описывается способ распознавания эмоций в речи в вариантах осуществления этой заявки со ссылкой на фиг. 5 в фиг. 7. Далее описывается оборудование распознавания эмоций в речи в вариантах осуществления этой заявки со ссылкой на фиг. 8. Следует понимать, что этапы в вышеприведенном способе, показанном на фиг. 5, могут выполняться посредством оборудования распознавания эмоций в речи, показанного на фиг. 8. Соответствующие описания и ограничения вышеприведенного способа распознавания эмоций в речи также являются применимыми к оборудованию распознавания эмоций в речи, показанному на фиг. 8. Повторные описания надлежащим образом опускаются в нижеприведенном описании оборудования распознавания эмоций в речи, показанного на фиг. 8.
[0153] Фиг. 8 является принципиальной блок–схемой оборудования распознавания эмоций в речи согласно варианту осуществления этой заявки. Оборудование 400 распознавания эмоций в речи, показанное на фиг. 8, включает в себя модуль 410 определения и статистический модуль 420.
[0154] Модуль 410 определения выполнен с возможностью определять, на основе первой нейронной сетевой модели, множество фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в текущий речевой фрагмент в целевом диалоге, причем один речевой кадр соответствует одному фрагменту информации эмоционального состояния, и информация эмоционального состояния представляет эмоциональное состояние, соответствующее речевому кадру.
[0155] Статистический модуль 420 выполнен с возможностью выполнять статистическую операцию над множеством фрагментов информации эмоционального состояния, с тем чтобы получать статистический результат, причем статистический результат представляет собой статистический результат, соответствующий текущему речевому фрагменту.
[0156] Модуль 410 определения дополнительно выполнен с возможностью определять, на основе второй нейронной сетевой модели, статистического результата, соответствующего текущему речевому фрагменту, и n–1 статистических результатов, соответствующих n–1 речевым фрагментам перед текущим речевым фрагментом, информацию эмоционального состояния, соответствующую текущему речевому фрагменту, причем:
– n–1 речевых фрагментов находятся во взаимно-однозначном соответствии с n–1 статистическими результатами, статистический результат, соответствующий любому из n–1 речевых фрагментов, получается посредством выполнения статистической операции над множеством фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров, включенных в речевой фрагмент, n–1 речевых фрагментов принадлежат целевому диалогу, и n является целым числом, большим 1.
[0157] Согласно оборудованию, предоставленному в этой заявке, множество фрагментов информации эмоционального состояния, соответствующих множеству речевых кадров в текущем речевом фрагменте, могут получаться на основе первой нейронной сетевой модели; и информация эмоционального состояния, соответствующая текущему речевому фрагменту, может получаться на основе второго нейронного сетевого устройства, статистического результата, соответствующего текущему речевому фрагменту, и статистических результатов, соответствующих множеству речевых фрагментов перед текущим речевым фрагментом. Следовательно, посредством использования двухуровневой нейронной сетевой модели, которая включает в себя первую нейронную сетевую модель и вторую нейронную сетевую модель, влияние контекста текущего речевого фрагмента на информацию эмоционального состояния, соответствующую текущему речевому фрагменту, может полностью изучаться, за счет этого достигая эффекта более точного распознавания эмоций в речи.
[0158] Следует понимать, что вышеприведенное разделение на модули представляет собой просто функциональное подразделение, и в фактической реализации может быть предусмотрен другой способ разделения.
[0159] Фиг. 9 является принципиальной структурной схемой аппаратных средств нейронного сетевого обучающего оборудования согласно варианту осуществления этой заявки. Нейронное сетевое обучающее оборудование 500 (оборудование 500, в частности, может представлять собой компьютерное устройство), показанное на фиг. 9, включает в себя запоминающее устройство 501, процессор 502, интерфейс 503 связи и шину 504. Соединение связи реализуется между запоминающим устройством 501, процессором 502 и интерфейсом 503 связи посредством использования шины 504.
[0160] Запоминающее устройство 501 может представлять собой постоянное запоминающее устройство (read only memory, ROM), устройство статического хранения данных, устройство динамического хранения данных или оперативное запоминающее устройство (random access memory, RAM). Запоминающее устройство 501 может сохранять программу. Когда программа, сохраненная в запоминающем устройстве 501, выполняется посредством процессора 502, процессор 502 и интерфейс 503 связи выполнены с возможностью выполнять этапы способа обучения нейронной сети в вариантах осуществления этой заявки.
[0161] Процессор 502 может представлять собой центральный процессор общего назначения (central processing unit, CPU), микропроцессор, специализированную интегральную схему (application specific integrated circuit, ASIC), графический процессор (graphics processing unit, GPU) либо одну или более интегральных схем и выполнен с возможностью выполнять связанную программу, с тем чтобы реализовывать функции, которые должны выполняться посредством блоков в нейронном сетевом обучающем оборудовании в этом варианте осуществления этой заявки, или осуществлять способ обучения нейронной сети в вариантах осуществления этой заявки.
[0162] Альтернативно, процессор 502 может представлять собой микросхему с интегральными схемами и имеет характеристики обработки сигналов. В процессе реализации, этапы способа обучения нейронной сети в этой заявке могут осуществляться посредством использования интегральной логической схемы в форме аппаратных средств или инструкции в форме программного обеспечения в процессоре 502. Альтернативно, процессор 502 может представлять собой процессор общего назначения, процессор цифровых сигналов (digital signal processing, DSP), специализированную интегральную схему (ASIC), программируемую пользователем вентильную матрицу (field programmable gate array, FPGA) или другое программируемое логическое устройство, дискретный логический элемент или устройство на транзисторной логике либо дискретный аппаратный компонент. Процессор 502 может реализовывать или осуществлять способы, этапы и логические блок–схемы, которые раскрыты в вариантах осуществления этой заявки. Процессор общего назначения может представлять собой микропроцессор, либо процессор может представлять собой любой традиционный процессор и т.п. Этапы способов, раскрытых со ссылкой на варианты осуществления этой заявки, могут непосредственно выполняться и осуществляться посредством аппаратного процессора декодирования или могут выполняться и осуществляться посредством использования комбинации аппаратных и программных модулей в процессоре декодирования. Программный модуль может быть расположен в носителе хранения данных, стандартном для данной области техники, таком как оперативное запоминающее устройство, флэш–память, постоянное запоминающее устройство, программируемое постоянное запоминающее устройство, электрически стираемое программируемое запоминающее устройство или регистр. Носитель хранения данных расположен в запоминающем устройстве 501. Процессор 502 считывает информацию в запоминающем устройстве 501 и осуществляет, в комбинации с аппаратными средствами процессора 502, функции, которые должны выполняться посредством блоков, включенных в нейронное сетевое обучающее оборудование в этом варианте осуществления этой заявки, либо осуществлять способ обучения нейронной сети в вариантах осуществления способа этой заявки.
[0163] Интерфейс 503 связи использует приемопередающее оборудование, например, но не только, приемопередатчик для того, чтобы реализовывать связь между оборудованием 500 и другим устройством или сетью связи. Например, обучающий корпус может получаться посредством использования интерфейса 503 связи.
[0164] Шина 504 может включать в себя канал, через который информация передается между частями (например, запоминающим устройством 501, процессором 502 и интерфейсом 503 связи) оборудования 500.
[0165] Фиг. 10 является принципиальной структурной схемой аппаратных средств оборудования распознавания эмоций в речи согласно варианту осуществления этой заявки. Оборудование 600 распознавания эмоций в речи (оборудование 600, в частности, может представлять собой компьютерное устройство), показанное на фиг. 10, включает в себя запоминающее устройство 601, процессор 602, интерфейс 603 связи и шину 604. Соединение связи реализуется между запоминающим устройством 601, процессором 602 и интерфейсом 603 связи посредством использования шины 604.
[0166] Запоминающее устройство 601 может представлять собой ROM, устройство статического хранения данных и RAM. Запоминающее устройство 601 может сохранять программу. Когда программа, сохраненная в запоминающем устройстве 601, выполняется посредством процессора 602, процессор 602 и интерфейс 603 связи выполнены с возможностью выполнять этапы способа распознавания эмоций в речи в вариантах осуществления этой заявки.
[0167] Процессор 602 может представлять собой CPU общего назначения, микропроцессор, ASIC, GPU либо одну или более интегральных схем и выполнен с возможностью выполнять связанную программу, с тем чтобы реализовывать функции, которые должны выполняться посредством модулей в оборудовании распознавания эмоций в речи в этом варианте осуществления этой заявки, либо осуществлять способ распознавания эмоций в речи в вариантах осуществления способа этой заявки.
[0168] Альтернативно, процессор 602 может представлять собой микросхему с интегральными схемами и имеет характеристики обработки сигналов. В процессе реализации, этапы способа распознавания эмоций в речи в вариантах осуществления этой заявки могут реализовываться посредством использования интегральной логической схемы в форме аппаратных средств или инструкции в форме программного обеспечения в процессоре 602. Альтернативно, процессор 602 может представлять собой процессор общего назначения, DSP, ASIC, FPGA или другое программируемое логическое устройство, дискретный логический элемент или устройство на транзисторной логике либо дискретный аппаратный компонент. Процессор 602 может реализовывать или осуществлять способы, этапы и логические блок–схемы, которые раскрыты в вариантах осуществления этой заявки. Процессор общего назначения может представлять собой микропроцессор, либо процессор может представлять собой любой традиционный процессор и т.п. Этапы способов, раскрытых со ссылкой на варианты осуществления этой заявки, могут непосредственно выполняться и осуществляться посредством аппаратного процессора декодирования или могут выполняться и осуществляться посредством использования комбинации аппаратных и программных модулей в процессоре декодирования. Программный модуль может быть расположен в носителе хранения данных, стандартном для данной области техники, таком как оперативное запоминающее устройство, флэш–память, постоянное запоминающее устройство, программируемое постоянное запоминающее устройство, электрически стираемое программируемое запоминающее устройство или регистр. Носитель хранения данных расположен в запоминающем устройстве 601. Процессор 602 считывает информацию в запоминающем устройстве 601 и осуществляет, в комбинации с аппаратными средствами процессора 602, функции, которые должны выполняться посредством модулей, включенных в оборудование распознавания эмоций в речи в этом варианте осуществления этой заявки, либо осуществлять способ распознавания эмоций в речи в вариантах осуществления способа этой заявки.
[0169] Интерфейс 603 связи использует приемопередающее оборудование, например, но не только, приемопередатчик для того, чтобы реализовывать связь между оборудованием 600 и другим устройством или сетью связи. Например, обучающий корпус может получаться посредством использования интерфейса 603 связи.
[0170] Шина 604 может включать в себя канал, через который информация передается между частями (например, запоминающим устройством 601, процессором 602 и интерфейсом 603 связи) оборудования 600.
[0171] Следует понимать, что модуль 410 определения и статистический модуль 420 в оборудовании 400 распознавания эмоций в речи являются эквивалентными процессору 602.
[0172] Следует отметить, что хотя проиллюстрированы только запоминающее устройство, процессор и интерфейс связи каждого из оборудования 500 и 600, показанных на фиг. 9 и фиг. 10, в конкретном процессе реализации, специалисты в данной области техники должны понимать, что оборудование 500 и 600 дополнительно включает в себя другие компоненты, необходимые для реализации нормального режима работы. Помимо этого, на основе конкретного требования, специалисты в данной области техники должны понимать, что оборудование 500 и 600 дополнительно может включать в себя аппаратные компоненты для реализации других дополнительных функций. Помимо этого, специалисты в данной области техники должны понимать, что оборудование 500 и 600 может включать в себя только компоненты, необходимые для реализации вариантов осуществления этой заявки, но не обязательно включать в себя все компоненты, показанные на фиг. 9 или фиг. 10.
[0173] Очевидно, что оборудование 500 является эквивалентным обучающему устройству 120 в 1, и оборудование 600 является эквивалентным устройству 110 выполнения на фиг. 1.
[0174] Согласно способу, предоставленному в вариантах осуществления этой заявки, эта заявка дополнительно предоставляет компьютерный программный продукт, и компьютерный программный продукт включает в себя компьютерный программный код. Когда компьютерный программный код выполняется на компьютере, компьютер осуществляет каждый способ, описанный выше.
[0175] Согласно способу, предоставленному в вариантах осуществления этой заявки, эта заявка дополнительно предоставляет машиночитаемый носитель, и машиночитаемый носитель сохраняет программный код. Когда программный код выполняется на компьютере, компьютер осуществляет каждый способ, описанный выше.
[0176] Все или некоторые вышеприведенные варианты осуществления могут реализовываться посредством программного обеспечения, аппаратных средств, микропрограммного обеспечения либо любой комбинации вышеозначенного. Когда программное обеспечение используется для того, чтобы реализовывать варианты осуществления, вышеприведенные варианты осуществления могут реализовываться полностью или частично в форме компьютерного программного продукта. Компьютерный программный продукт включает в себя одну или более компьютерных инструкций. Когда компьютерные программные инструкции загружаются или выполняются на компьютере, процедура или функции согласно вариантам осуществления настоящего изобретения формируются полностью или частично. Компьютер может представлять собой компьютер общего назначения, специализированный компьютер, компьютерную сеть или другое программируемое оборудование. Компьютерные инструкции могут сохраняться в машиночитаемом носителе хранения данных или могут передаваться с машиночитаемого носителя хранения данных на другой машиночитаемый носитель хранения данных. Например, компьютерные инструкции могут передаваться из веб–узла, компьютера, сервера или центра обработки и хранения данных в другой веб–узел, компьютер, сервер или центр обработки и хранения данных проводным (например, с помощью инфракрасных волн, радиоволн и микроволн) способом. Машиночитаемый носитель хранения данных может представлять собой любой применимый носитель, доступный посредством компьютера или устройства хранения данных, такого как сервер или центр обработки и хранения данных, интегрирующего один или более применимых носителей. Применимый носитель может представлять собой магнитный носитель (такой как гибкий диск, жесткий диск или магнитная лента), оптический носитель (такой как универсальный цифровой диск (digital versatile disc, DVD)) или полупроводниковый носитель. Полупроводниковый носитель может представлять собой полупроводниковый накопитель.
[0177] Следует понимать, что порядковые номера вышеприведенных процессов не означают последовательности выполнения в различных вариантах осуществления этой заявки. Последовательности выполнения процессов должны определяться согласно функциям и внутренней логике процессов и не должны истолковываться в качестве ограничения на процессы реализации вариантов осуществления этой заявки.
[0178] Также следует понимать, что в этой заявке, "когда" и "если" означают то, что терминальное устройство или сетевое устройство выполняет соответствующую обработку в объектном падеже, вместо наложения ограничения на время, и не предписывают то, что терминальное устройство или сетевое устройство должно выполнять действие определения в реализации, и не составляют какие–либо другие ограничения.
[0179] Термин "и/или" в этом подробном описании описывает только взаимосвязь на основе ассоциирования для описания ассоциированных объектов и представляет то, что могут существовать три взаимосвязи. Например, A и/или B может представлять следующие три случая: существует только A, существуют как A, так и B, и существует только B.
[0180] Термин "по меньшей мере, один из", "по меньшей мере, один тип" или "по меньшей мере, один элемент" в этом подробном описании указывает все или любую комбинацию перечисленных элементов, например, "по меньшей мере, один из A, B и C" может указывать следующие шесть случаев: существует только A, существует только B, существует только C, существуют как A, так и B, существуют как B, так и C, и существуют A, B и C.
[0181] Следует понимать, что в вариантах осуществления этой заявки, "B, соответствующий A" указывает то, что B ассоциирован с A, и B может определяться на основе A. Тем не менее, следует дополнительно понимать, что определение B на основе A не означает то, что B определяется только согласно A, и B также может определяться согласно A и/или другой информации.
[0182] Специалисты в данной области техники могут знать, что блоки и этапы в примерах, описанных в отношении вариантов осуществления, раскрытых в данном документе, могут реализовываться посредством электронных аппаратных средств или комбинации компьютерного программного обеспечения и электронных аппаратных средств. То, выполняются эти функции посредством аппаратных средств или программного обеспечения, зависит от конкретных вариантов применения и проектных ограничений технических решений. Специалисты в данной области техники могут использовать различные способы для того, чтобы реализовывать описанные функции для каждого конкретного варианта применения, но не следует считать, что такая реализация выходит за пределы объема этой заявки.
[0183] Специалисты в данной области техники могут безусловно понимать, что в целях удобного и краткого описания, на предмет подробного рабочего процесса вышеприведенной системы, оборудования и блока следует обратиться к соответствующему процессу вышеприведенных в вариантах осуществления способа, и подробности не описываются повторно в данном документе.
[0184] В нескольких вариантах осуществления, предоставленных в настоящей заявке, следует понимать, что раскрытая система, оборудование и способ могут реализовываться другими способами. Например, описанные варианты осуществления устройства представляют собой просто примеры. Например, разделение на блоки представляет собой просто разделение по логическим функциям и может представлять собой другое разделение в фактической реализации. Например, множество блоков или компонентов могут комбинироваться или интегрироваться в другую систему, либо некоторые признаки могут игнорироваться или не выполняться. Помимо этого, отображаемые или поясненные взаимные связи либо прямые связи, либо соединения связи могут быть реализованы посредством использования некоторых интерфейсов. Косвенные связи или соединения связи между устройствами или блоками могут быть реализованы в электронных, механических или других формах.
[0185] Блоки, описанные в качестве отдельных частей, могут быть или не быть физически отдельными, и части, отображаемые в качестве блоков, могут представлять собой или не представлять собой физические блоки, могут быть расположены в одной позиции либо могут быть распределены по множеству сетевых блоков. Некоторые или все из блоков могут быть выбраны на основе фактических требований для достижения целей решений вариантов осуществления.
[0186] Помимо этого, функциональные блоки в вариантах осуществления этой заявки могут быть интегрированы в один процессор, либо каждый из блоков может существовать отдельно физически, либо два или более блоков интегрируются в один блок.
[0187] В вариантах осуществления этой заявки, если не указано иное или возникает логический конфликт, термины и/или описания между различными вариантами осуществления являются согласованными и могут взаимно упоминаться, и технические признаки в различных вариантах осуществления могут комбинироваться согласно своей внутренней логической взаимосвязи, с тем чтобы формировать новый вариант осуществления.
[0188] Когда функции реализуются в форме программного функционального блока и продаются или используются в качестве независимых продуктов, функции могут сохраняться на машиночитаемом носителе хранения данных. На основе такого понимания, технические решения этой заявки по существу или их часть, вносящая усовершенствование в предшествующий уровень техники либо в часть технических решений, могут реализовываться в форме программного продукта. Компьютерный программный продукт сохраняется на носителе хранения данных и включает в себя несколько инструкций для инструктирования компьютерному устройству (которое может представлять собой персональный компьютер, сервер или сетевое устройство) выполнять все или некоторые из этапов способов, описанных в вариантах осуществления этой заявки. Вышеуказанный носитель хранения данных включает в себя: любой носитель, который может сохранять программный код, такой как USB–флэш–накопитель, съемный жесткий диск, постоянное запоминающее устройство (read-only memory, ROM), оперативное запоминающее устройство (random access memory, RAM), магнитный диск или оптический диск.
[0189] Вышеприведенные описания представляют собой просто конкретные реализации этой заявки и не имеют намерение ограничивать объем охраны этой заявки. Все варьирования или замены, очевидные для специалистов в данной области техники в пределах объема, раскрытого в этой заявке, должны попадать в пределы объема охраны этой заявки. Следовательно, объем охраны этой заявки должен зависеть от объема охраны формулы изобретения.
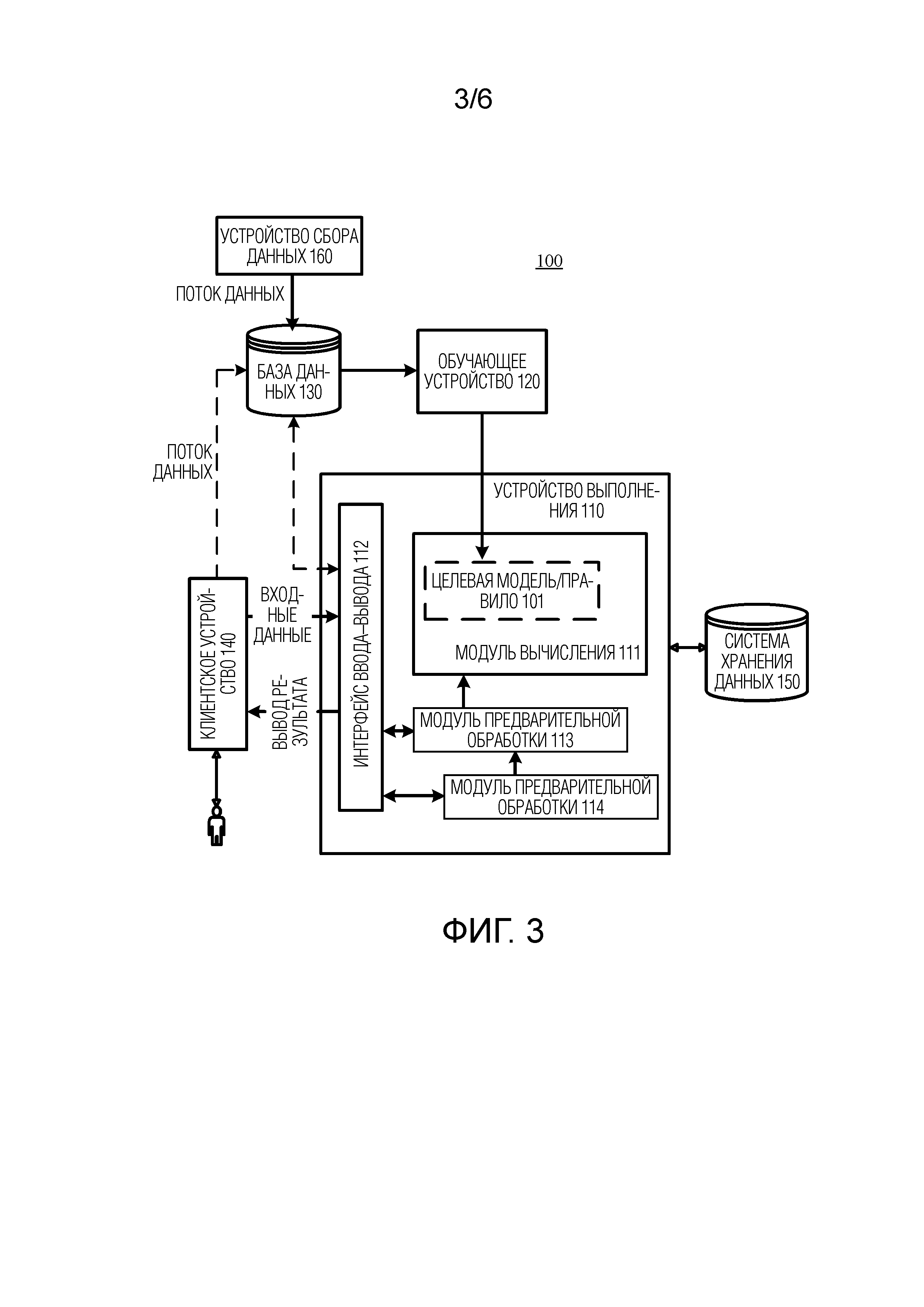

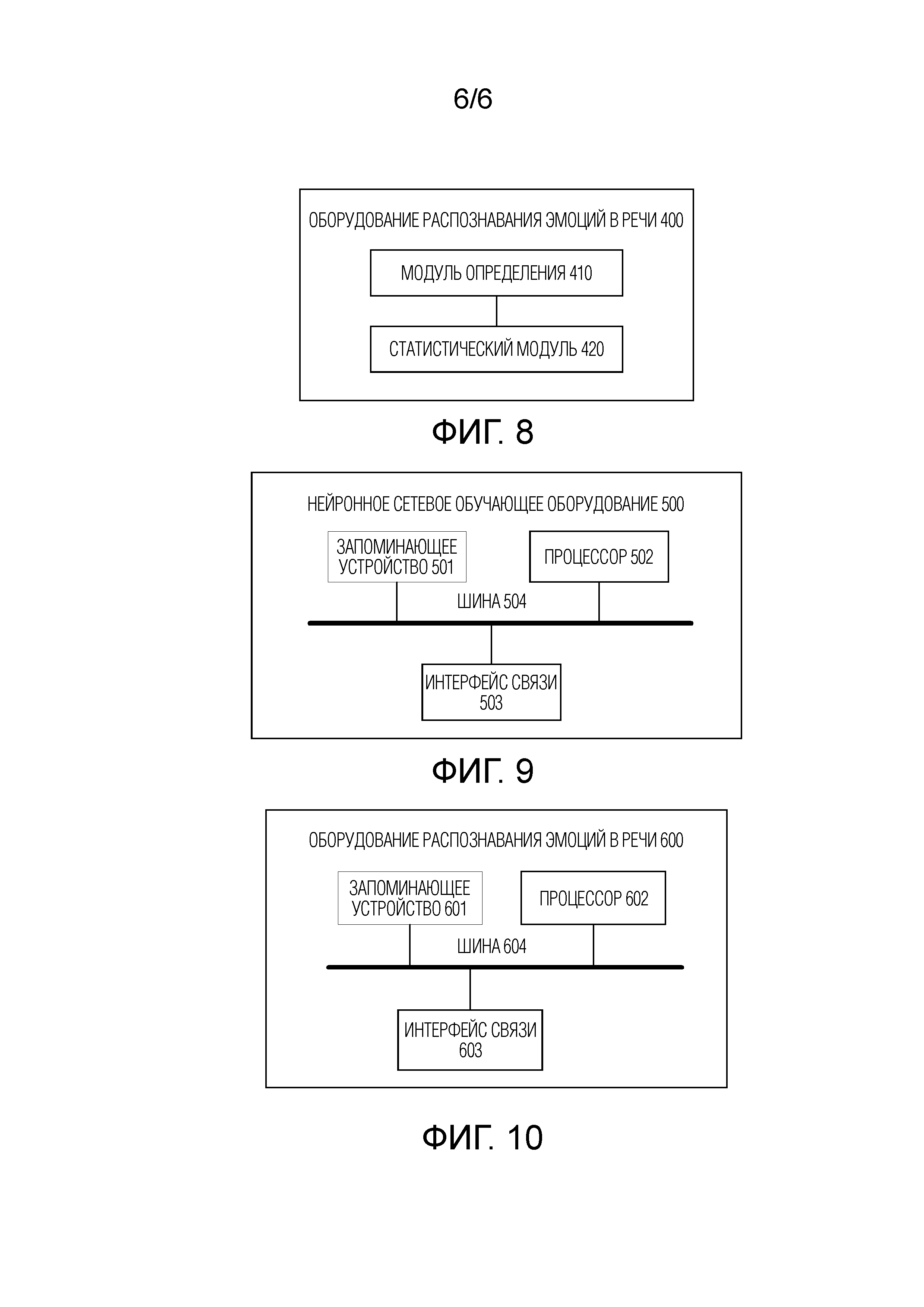
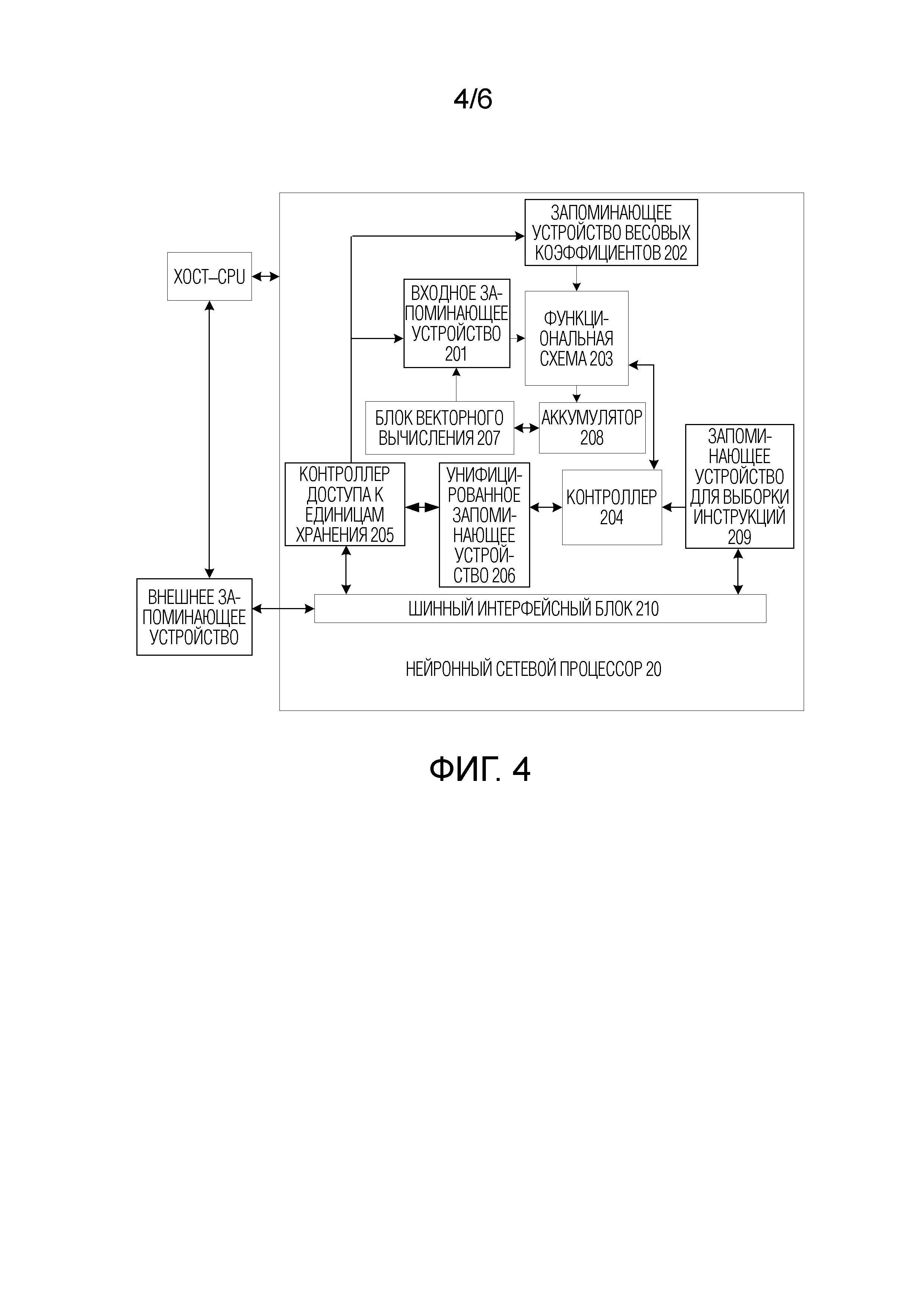
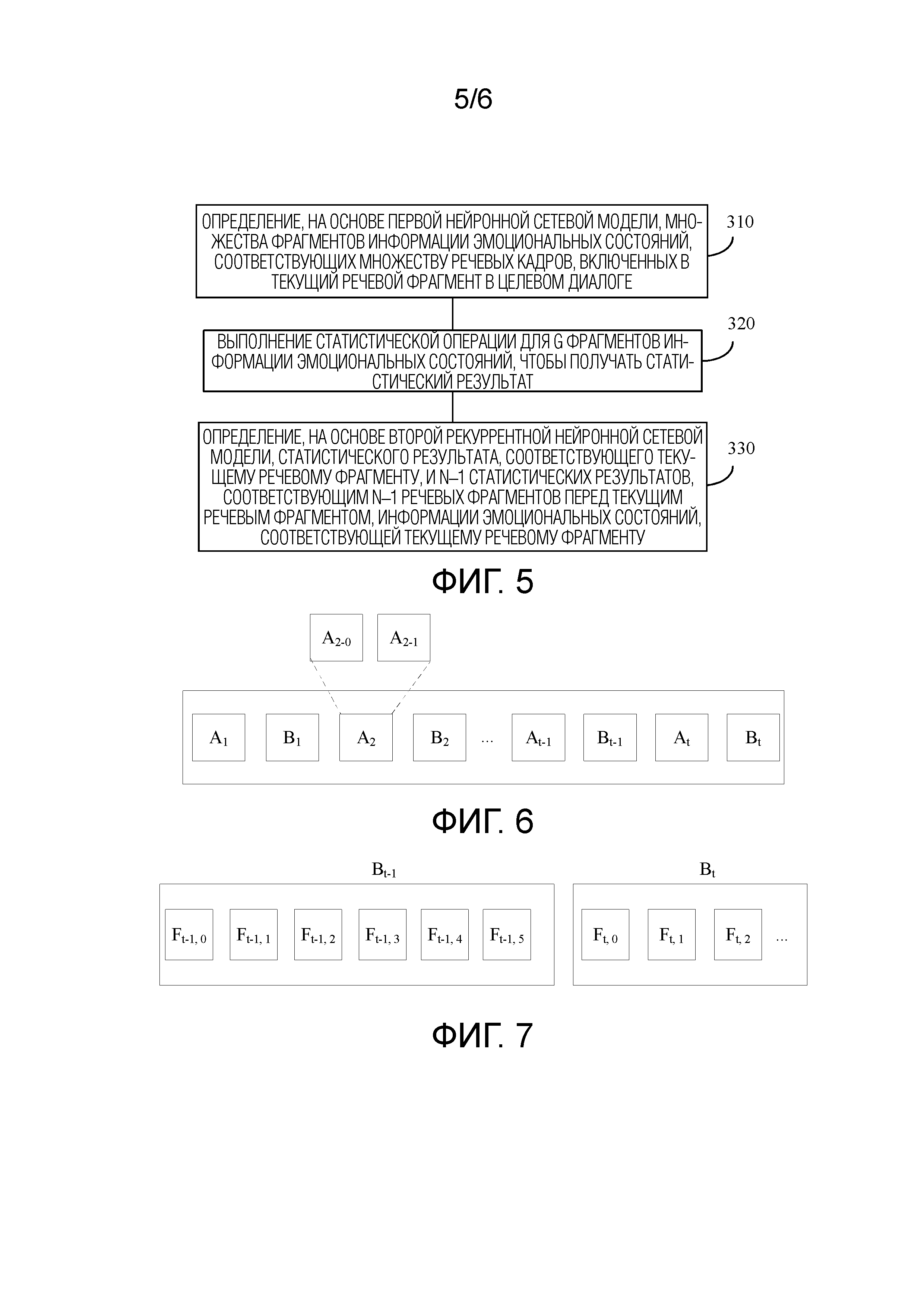
Способ и устройство кодирования сигнала, способ для кодирования объединенного сигнала обратной связи
Способ разъединения вызова и устройство для его осуществления
Способ и устройство передачи данных
Способ и устройство кодирования сигнала обратной связи
Прозрачный обходной путь и соответствующие механизмы
Способ поиска тракта тсм, способ создания тракта тсм, система управления поиском тракта и система управления созданием тракта
Мобильная станция, способ и устройство для назначения канала
Способ сообщения информации о способности терминала, способ и устройство для выделения ресурсов временного слота и соответствующая система
Способ и устройство для выделения ресурсов и обработки информации подтверждения
Способ, сетевое устройство и система для определения распределения ресурсов при скоординированной многоточечной передаче

