Результат интеллектуальной деятельности: Способ содержательного анализа текстовой информации
Вид РИД
Изобретение
Изобретение относится к вычислительной технике. Предлагаемый способ предназначен для идентификации текстовой информации в случаях определения ее автора.
Из информационных источников известно устройство, обеспечивающее техническое решение задачи определения авторства текстовой информации. Описание указанного устройства представлено в статье: алгоритм идентификации текстовой информации / А.В. Полтавский, Н.К. Юрков, А.В. Гриншкун // Надежность и качество сложных систем. - 2017. - №1 (17). - С. 77-84. DOI 10.21685/2307-4205-2017-1-10. Представленное в информационном источнике устройство осуществляет способ содержательного анализа текстовой информации.
Известен способ наиболее близкий по технической сущности к предлагаемому изобретению, описание которого представлено в патенте РФ №2568272, кл. G06F 17/00 2014.16.04. В известном способе содержательного анализа текстовой информации, позволяющем определять авторство текстовой информации, выполняют совокупность описанных ниже операций, действие которых в пространстве и времени инициируют управляющими сигналами, подаваемыми по соответствующим нумеруемым линиям связи, которые соединяют каждый из блоков (акторов), выполняющих соответствующую операцию, и управляющий блок, который своевременно формирует сигнал (импульс) и передает его по соответствующей нумеруемой линии для инициирования операции в акторе. Указанный способ выбран в качестве прототипа. В прототипе предусмотрено выполнение следующей совокупности операций.
Подсчитывают в каждом из двух анализируемых текстов «а» и «б» общее количество букв, обозначаемое соответственно Na и Nб.
Генерируют начальный управляющий сигнал, который синхронизирует операцию сохранения подсчитанных величин Na, Nб для их последующего использования, инициируемого вторым сигналом управления.
Подсчитывают количества каждой буквы алфавита в анализируемых текстах, при этом количество i-й буквы в тексте «а» обозначают mai, а количество j-й буквы в тексте «б» обозначают mбj.
Сохраняют по начальному управляющему сигналу величины mai, mбj для их последующего использования, инициируемого вторым управляющим сигналом.
Задают количество букв, имеющихся в используемом алфавите, которое обозначают n.
Сохраняют по начальному управляющему сигналу величину , для последующего использования, инициируемого третьим управляющим сигналом.
Задают фиксированную величину, обозначаемую ΔРд, которую сохраняют по начальному управляющему сигналу для последующего использования, инициируемого четвертым управляющим сигналом.
Вычисляют по второму управляющему сигналу первый набор n величин и второй набор n величин, каждую из которых получают в результате выполнения операции деления согласно следующим формулам 1 и 2.

где i=1, …, n.

где j=1, …, При этом каждая величина, полученная в результате выполнения операции деления, характеризует вероятность появления соответствующей буквы в соответствующем тексте.
Определяют набор, состоящий из n величин, для получения каждой из которых вычисляют модуль разности между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б».
Выполняют операцию суммирования определенных ранее n величин, каждая из которых соответствует модулю разности между величинами, соответствующими вероятностям появления конкретной буквы в текстах «а» и «б».
Выполняют по третьему управляющему сигналу операцию деления на величину n вычисленного ранее значения суммы величин модулей разностей между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б» для получения среднего значения указанной разности согласно следующей формулы (3).
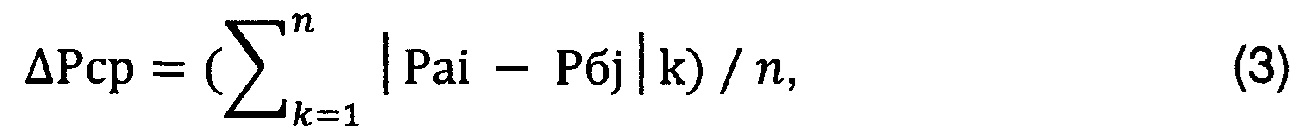
где k=1, …, n, i=1, …, n, j=1, …, n.
Сравнивают по четвертому управляющему сигналу вычисленную величину ΔРср с допустимым фиксированным значением ΔРд и при выполнении неравенства ΔРср≤ΔРд вырабатывают сигнал оповещения о принадлежности двух анализируемых текстов «а» и «б» одному автору.
Указанный прототип имеет существенный недостаток, заключающийся в том, что способ-прототип обеспечивает весьма низкую достоверность определения авторства текстовой информации из-за использования только одного параметра анализируемого текста. В прототипе в качестве параметра используют среднее значение разности между вероятностью появления i-й буквы в первом анализируемом тексте и вероятностью появления i-й буквы во втором анализируемом тексте. Если значение параметра не превышает допустимой величины, то вырабатывают сигнал оповещения о принадлежности обоих анализируемых текстов одному автору.
Другим недостатком прототипа является использование самого нижнего уровня структурно-иерархической модели анализируемого текста (уровень букв). В исследовании А.С. Сурковой приводится утверждение о том, что на нижних уровнях (уровень букв) в большей степени проявляются универсальные инварианты текста. Вероятность появления отдельной буквы в тексте не зависит от текста и автора. На верхних уровнях (уровни предложений и слов) ярче проявляются авторские инварианты, индивидуальные особенности владения языком. Результаты исследования опубликованы в журнале Информационные технологии. Вестник Нижегородского университета им. Н.И. Лобачевского, 2014, №3 (1), с. 145-149. Идентификация авторства текстов на основе информационных портретов.
В задаче, на решение которой направлено заявляемое техническое решение, требуется создать способ, позволяющий идентифицировать текстовую информацию в случаях определения ее автора.
Технический результат заявляемого изобретения заключается в повышении достоверности определения авторства текстовой информации. Полученный технический результат обеспечивает возможность принятия объективных решений при защите авторских прав создателей текста и других подобных объектов, связанных с правом интеллектуальной собственности.
Указанный технический результат получают за счет того, что способ содержательного анализа текстовой информации, согласно которому подсчитывают в каждом из двух анализируемых текстов «а» и «б» общее количество букв, обозначаемое соответственно Na и Nб, генерируют начальный управляющий сигнал, который синхронизирует операцию сохранения подсчитанных величин Na, Nб для их последующего использования, инициируемого вторым сигналом управления, подсчитывают количества каждой буквы алфавита в анализируемых текстах, при этом количество i-й буквы в тексте «а» обозначают mai, а количество j-й буквы в тексте «б» обозначают mбj, сохраняют по начальному управляющему сигналу величины mai, mбj для их последующего использования, инициируемого вторым управляющим сигналом, задают количество букв, имеющихся в используемом алфавите, которое обозначают n, сохраняют по начальному управляющему сигналу величину n для последующего использования, инициируемого третьим управляющим сигналом, задают фиксированную величину, обозначаемую ΔРд, которую сохраняют по начальному управляющему сигналу для последующего использования, инициируемого четвертым управляющим сигналом, вычисляют по второму управляющему сигналу первый набор n величин и второй набор n величин, каждую из которых получают в результате выполнения операции деления согласно следующим формулам Pai=mai/Na, где i=1, …, n, Pбj=mбj/Nб, где j=1, …, n, при этом каждая величина, полученная в результате выполнения операции деления, характеризует вероятность появления соответствующей буквы в соответствующем тексте, определяют набор, состоящий из n величин, для получения каждой из которых вычисляют модуль разности между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б», выполняют операцию суммирования определенных ранее n величин, каждая из которых соответствует модулю разности между величинами, соответствующими вероятностям появления конкретной буквы в текстах «а» и «б», выполняют по третьему управляющему сигналу операцию деления на величину n вычисленного ранее значения суммы величин модулей разностей между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б» для получения среднего значения указанной разности согласно следующей формулы 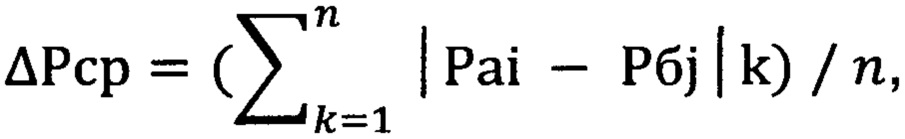 где k=1, …, n, i=1, …, n, j=1, …, n, сравнивают по четвертому управляющему сигналу вычисленную величину ΔРср с допустимым фиксированным значением ΔРд и при выполнении неравенства ΔРср≤ΔРд вырабатывают сигнал оповещения о принадлежности двух анализируемых текстов «а» и «б» одному автору, дополнительно расчленяют первый и второй анализируемые тексты на нумеруемые фрагменты, при этом количество выделенных фрагментов первого текста равно количеству выделенных фрагментов второго текста, выделяют пять психолингвистических параметров, используемых при содержательном анализе текстовой информации, а именно процент служебных слов, содержащихся в анализируемом тексте (%сс), коэффициент лексического разнообразия (клр), коэффициент логической связности (клс), среднюю длину слова (Дс), среднюю длину предложения (Дп), при этом подсчитывают для каждого вычлененного фрагмента первого и второго текстов значение первого параметра по формуле %сс=ксс/K*100, где ксс соответствует количеству служебных слов в анализируемом тексте, K соответствует количеству всех слов в тексте, подсчитывают значение второго параметра по формуле
где k=1, …, n, i=1, …, n, j=1, …, n, сравнивают по четвертому управляющему сигналу вычисленную величину ΔРср с допустимым фиксированным значением ΔРд и при выполнении неравенства ΔРср≤ΔРд вырабатывают сигнал оповещения о принадлежности двух анализируемых текстов «а» и «б» одному автору, дополнительно расчленяют первый и второй анализируемые тексты на нумеруемые фрагменты, при этом количество выделенных фрагментов первого текста равно количеству выделенных фрагментов второго текста, выделяют пять психолингвистических параметров, используемых при содержательном анализе текстовой информации, а именно процент служебных слов, содержащихся в анализируемом тексте (%сс), коэффициент лексического разнообразия (клр), коэффициент логической связности (клс), среднюю длину слова (Дс), среднюю длину предложения (Дп), при этом подсчитывают для каждого вычлененного фрагмента первого и второго текстов значение первого параметра по формуле %сс=ксс/K*100, где ксс соответствует количеству служебных слов в анализируемом тексте, K соответствует количеству всех слов в тексте, подсчитывают значение второго параметра по формуле  где кспип соответствует количеству слов в тексте после исключения повторяющихся, подсчитывают значение третьего параметра по формуле клс=ксс/3N, где N соответствует количеству предложений в тексте, подсчитывают значение четвертого параметра по формуле Дс=кб/K, где кб соответствует количеству букв в тексте, подсчитывают значение пятого параметра по формуле Дп=K/N, на основании подсчитанных значений параметров первого и второго текстов вычисляют с помощью метода факторного анализа соответственно первый и второй наборы нумеруемых значений общего фактора, создают, используя первый и второй вычисленные наборы нумеруемых значений общего фактора, первую и вторую последовательности величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами соответствующего набора значений общего фактора, выделяют в первой и второй созданных числовых последовательностях соответственно первую и вторую совокупности равных чисел, при этом величину числа из первой выделенной совокупности обозначают Δ1, а величину числа из второй выделенной совокупности обозначают Δ2, делают вывод о принадлежности первого и второго текстов одному автору, если
где кспип соответствует количеству слов в тексте после исключения повторяющихся, подсчитывают значение третьего параметра по формуле клс=ксс/3N, где N соответствует количеству предложений в тексте, подсчитывают значение четвертого параметра по формуле Дс=кб/K, где кб соответствует количеству букв в тексте, подсчитывают значение пятого параметра по формуле Дп=K/N, на основании подсчитанных значений параметров первого и второго текстов вычисляют с помощью метода факторного анализа соответственно первый и второй наборы нумеруемых значений общего фактора, создают, используя первый и второй вычисленные наборы нумеруемых значений общего фактора, первую и вторую последовательности величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами соответствующего набора значений общего фактора, выделяют в первой и второй созданных числовых последовательностях соответственно первую и вторую совокупности равных чисел, при этом величину числа из первой выделенной совокупности обозначают Δ1, а величину числа из второй выделенной совокупности обозначают Δ2, делают вывод о принадлежности первого и второго текстов одному автору, если 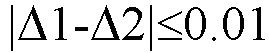 , а в противном случае авторы указанных текстов различны.
, а в противном случае авторы указанных текстов различны.
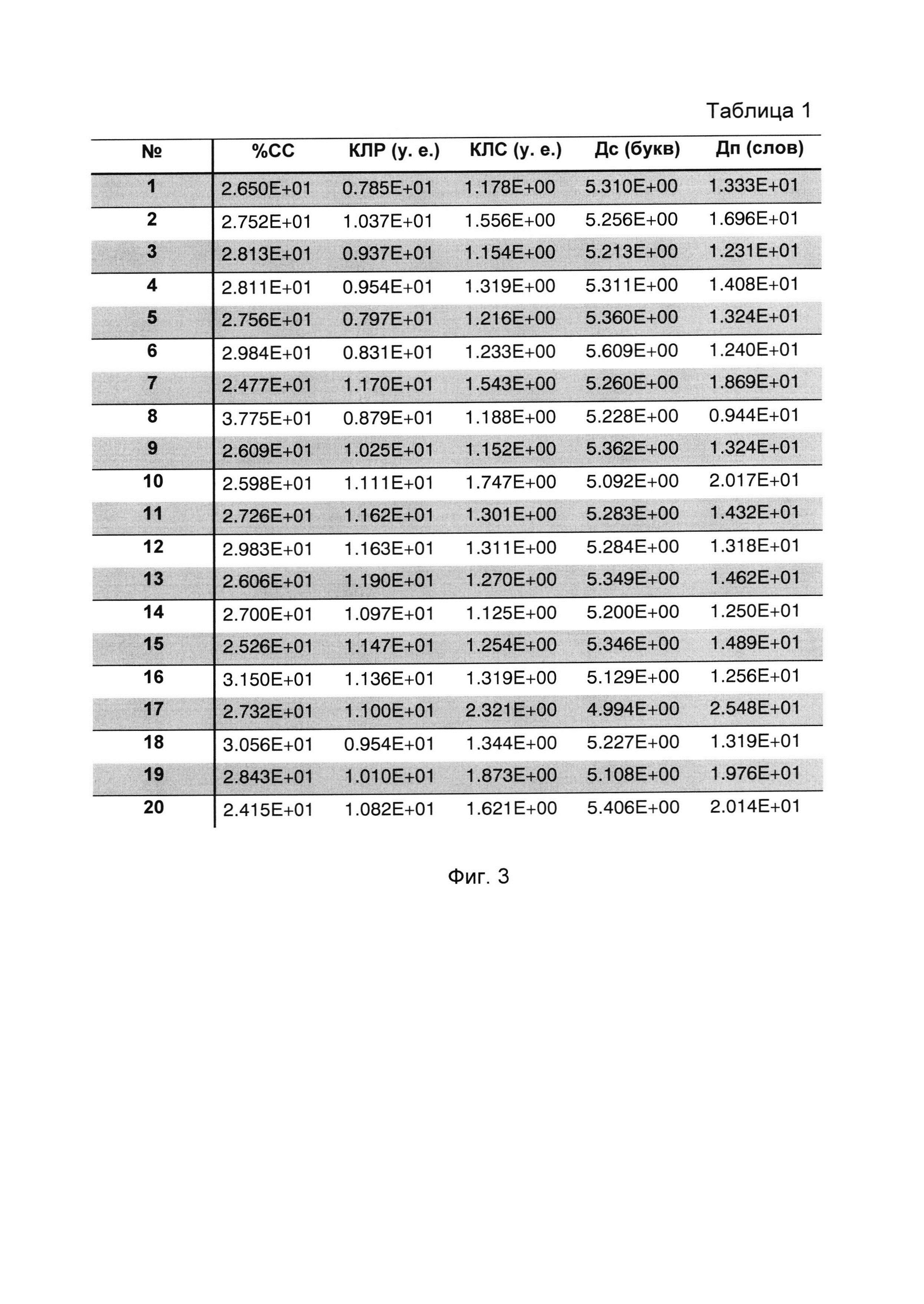
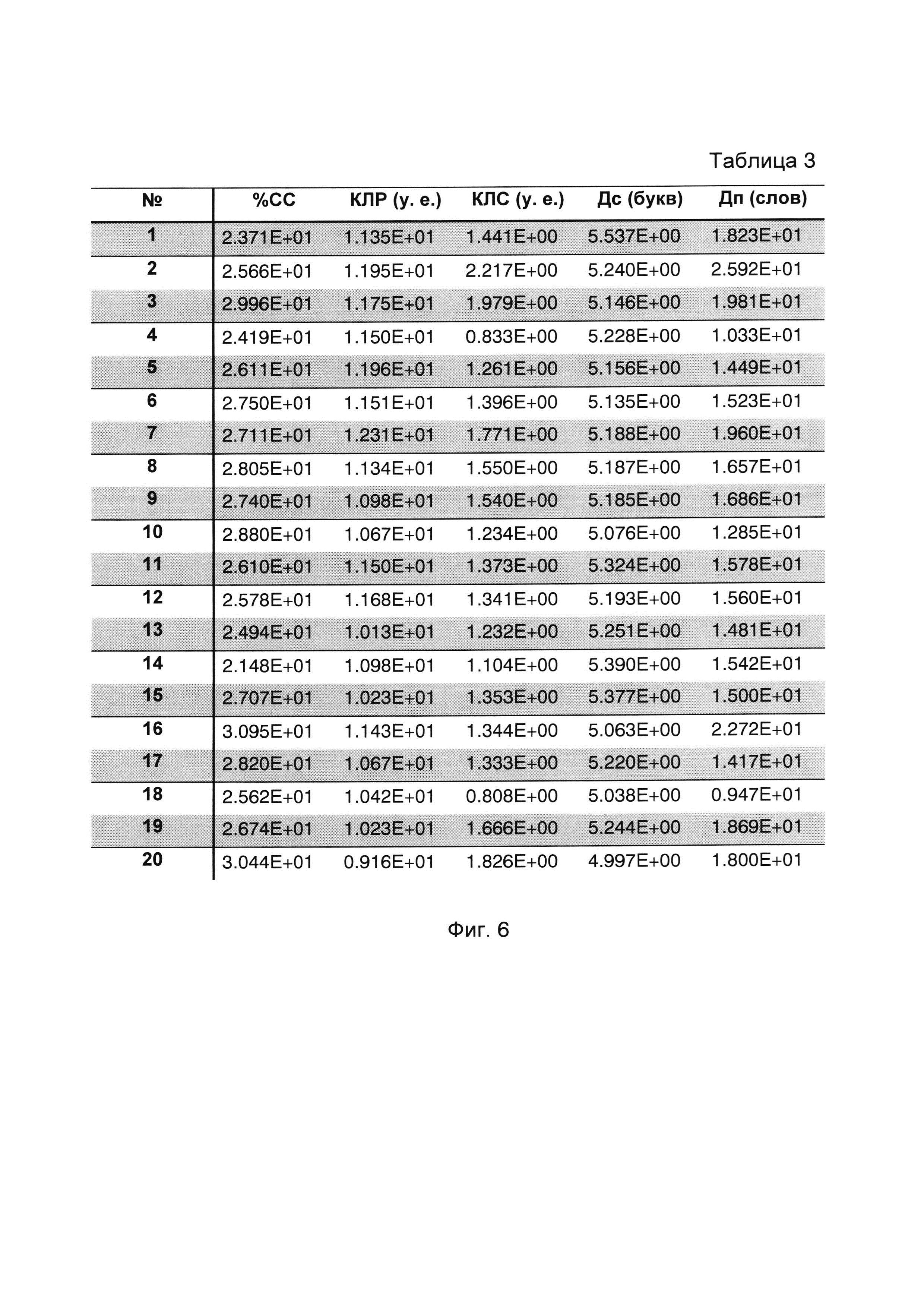
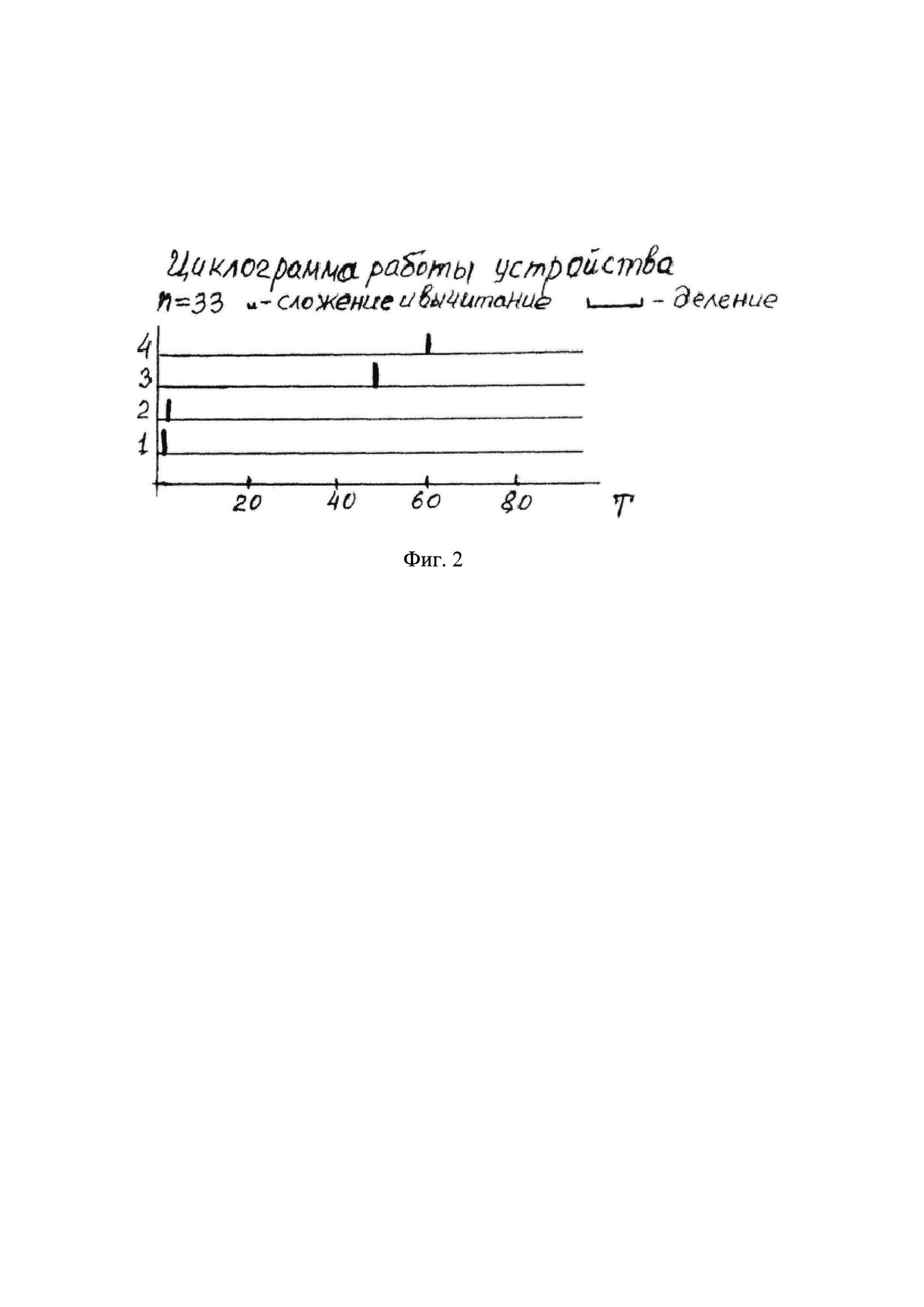
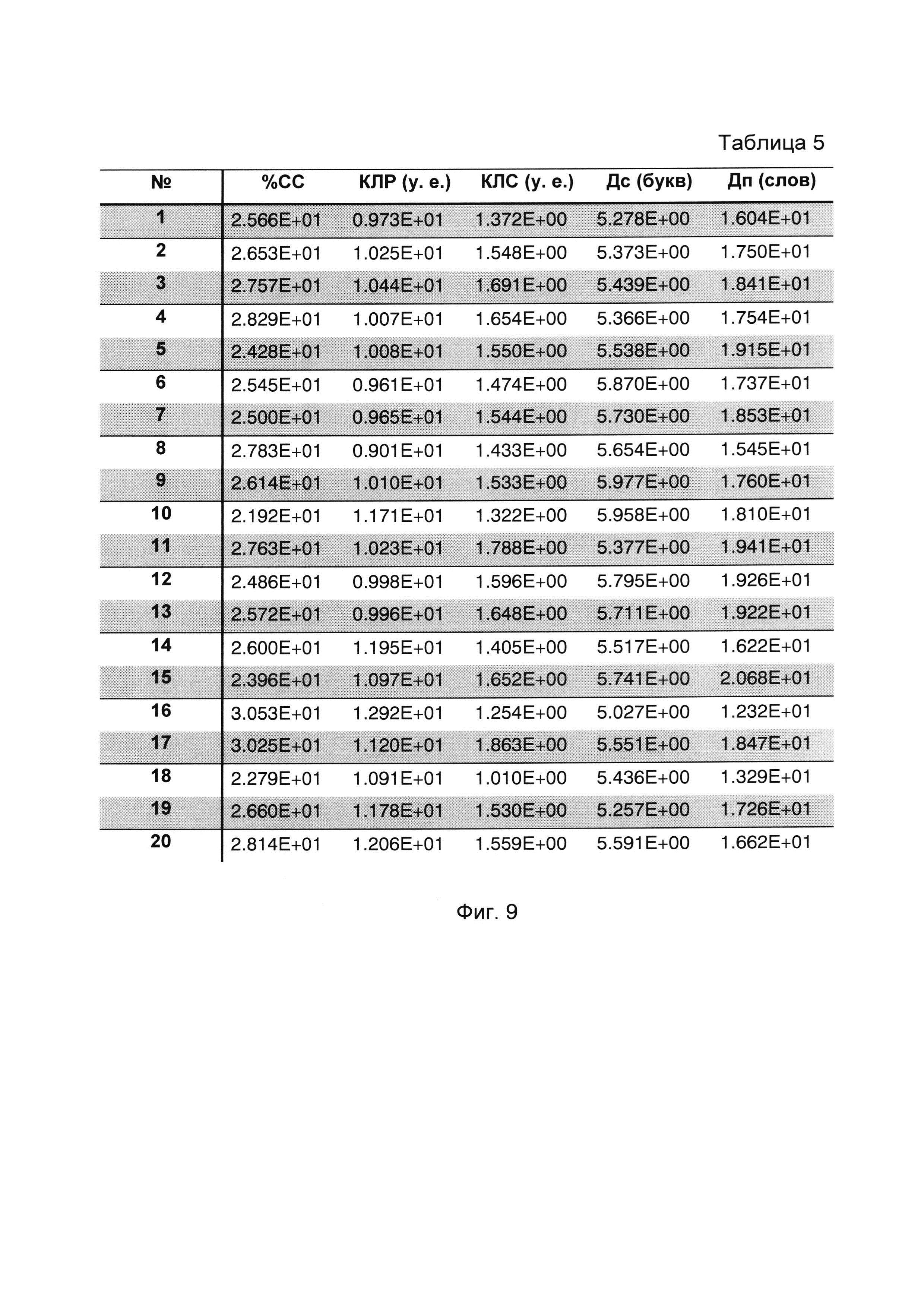
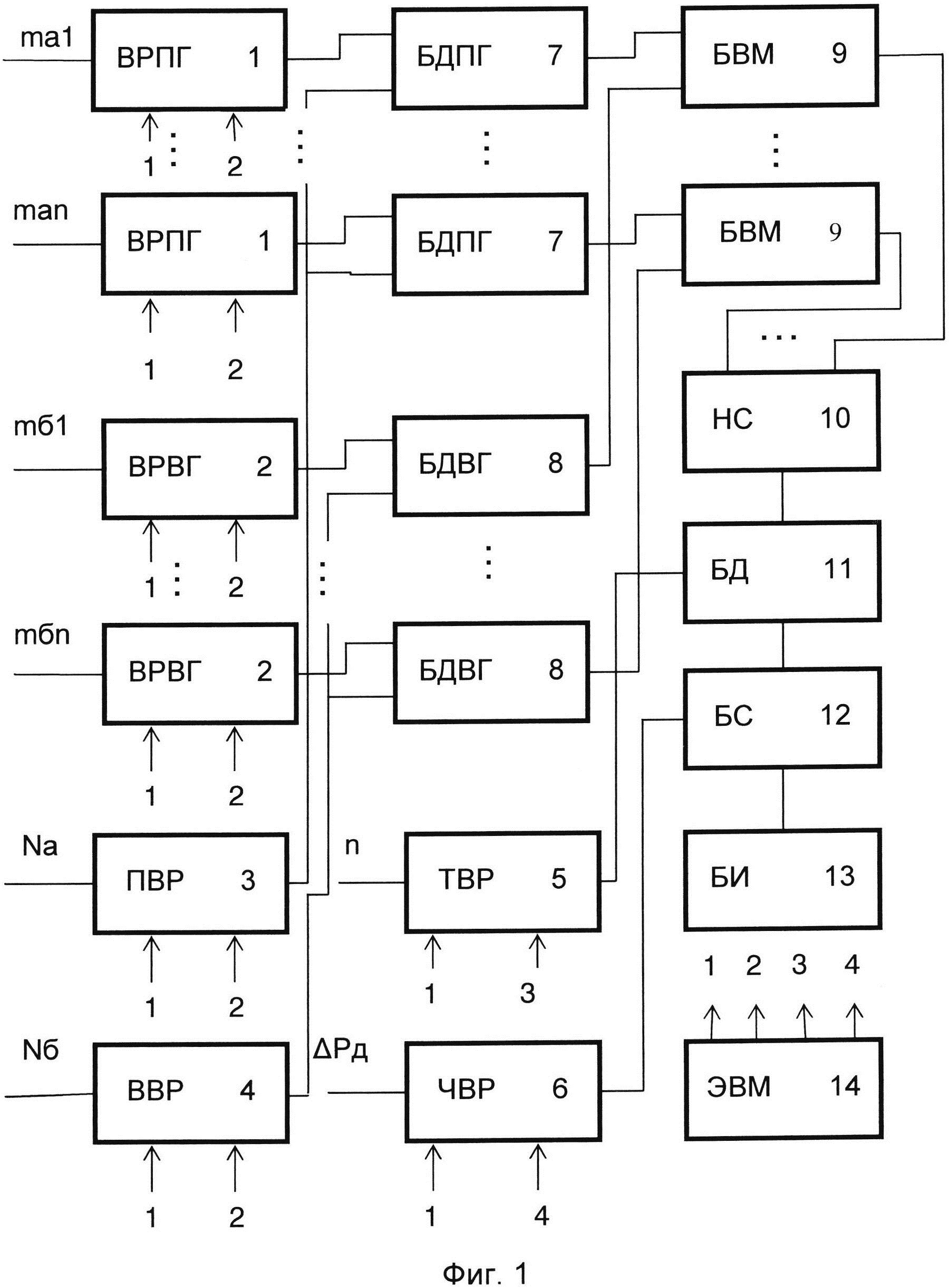
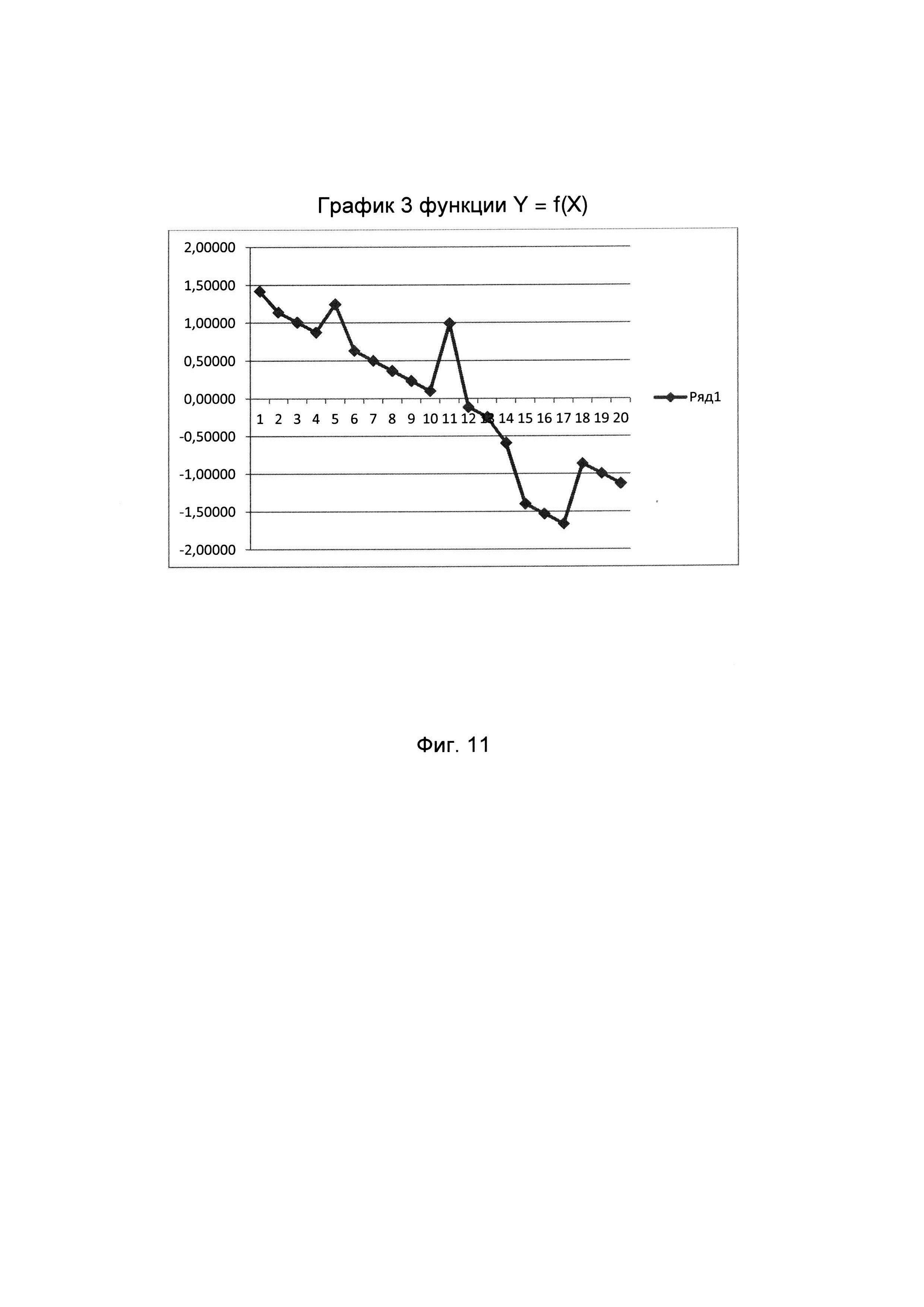
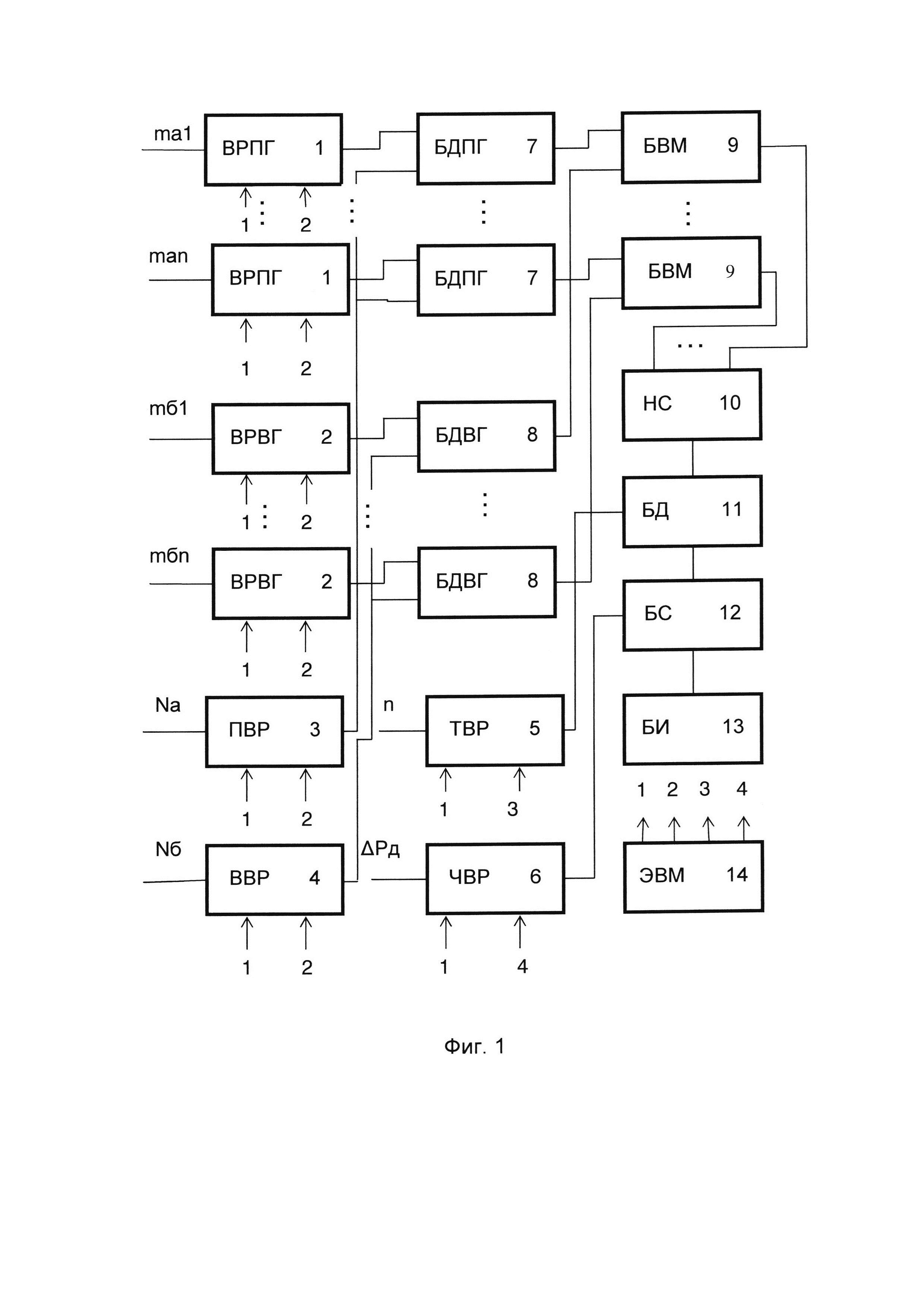
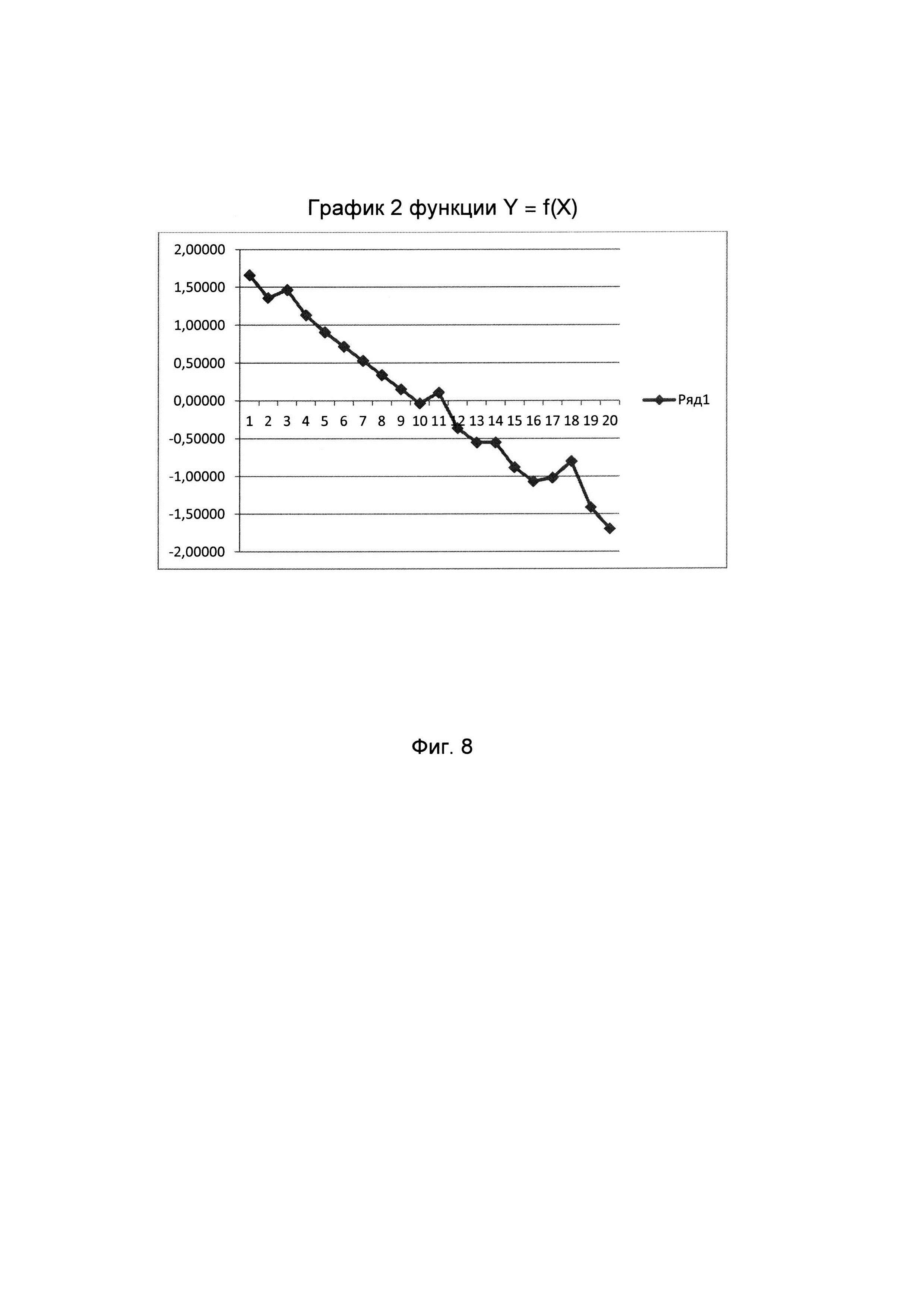
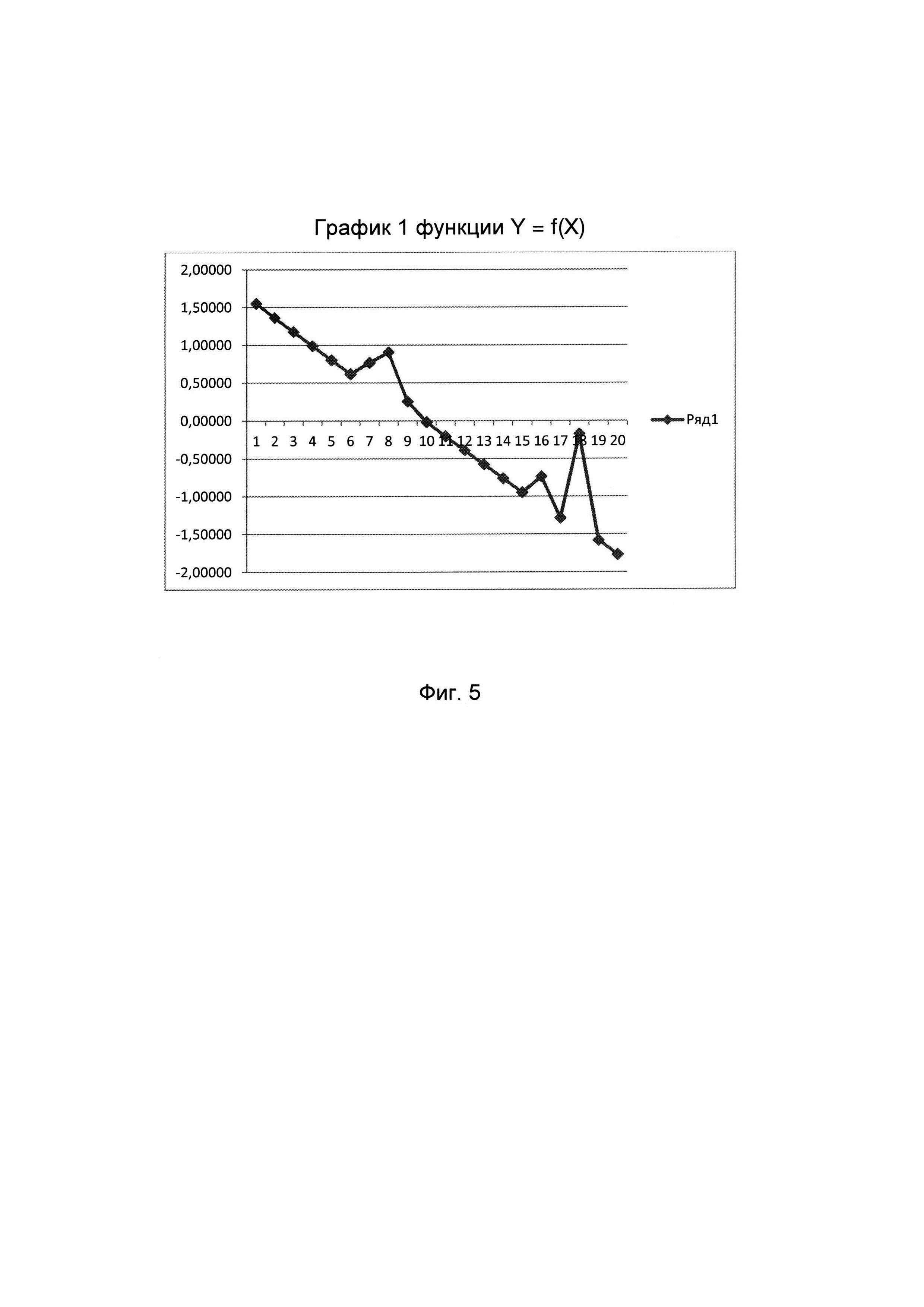
Сущность заявляемого изобретения поясняется на фигурах, где на фиг. 1 изображена функциональная схема устройства, реализующего способ содержательного анализа текстовой информации (с целью улучшения наглядности схемы связи между ЭВМ и управляющими входами соответствующих блоков показаны не полностью, а обозначены путем нумерации входов и выходов); на фиг. 2 изображена циклограмма работы устройства (на оси ординат обозначены номера выходов ЭВМ, а на оси абсцисс - число тактов), причем длительность различных вычислительных операций (сложение и вычитание - один такт, деление - двенадцать тактов) представлена в верхней части фиг. 2; на фиг. 3 изображена табл. 1, состоящая из пяти столбцов и двадцати строк, нумеруемых сверху вниз, в каждой из которых приведены числовые значения пяти психолингвистических параметров (%сс, клр, клс, Дс, Дп), расчитанных для соответственно пронумерованных текстовых фрагментов, принадлежащих литературному произведению А.П. Чехова «Мужики» (https://ilibrarv.ru/text/1160/Р.1/index.html), называемого для удобства изложения первым исследуемым текстом; на фиг. 4 изображена табл. 2, содержащая только один столбец, в котором приведен набор числовых значений фактора, вычисленных для исходных данных, представленных в табл. 1; на фиг. 5 изображен график 1 кусочно-линейной функции Y=f(X), где Y числовое значение фактора, а X порядковый номер соответствующего анализируемого текстового фрагмента; на фиг. 6 изображена табл. 3, состоящая из пяти столбцов и двадцати строк, нумеруемых сверху вниз, в каждой из которых приведены числовые значения пяти психолингвистических параметров (%сс, клр, клс, Дс, Дп), рассчитанных для соответственно пронумерованных текстовых фрагментов, принадлежащих литературному произведению А.П. Чехова «Бабье царство» (https://libkina.ru/books/prose-/prose-classic/169368-anton-chehov-babe-tsarstvo.html), называемого для удобства изложения вторым исследуемым текстом; на фиг. 7 изображена табл. 4, содержащая только один столбец, в котором приведен набор числовых значений общего фактора, вычисленных для исходных данных, представленных в табл. 3; на фиг. 8 изображен график 2 кусочно-линейной функции Y=f(X), где Y числовое значение фактора, а X порядковый номер соответствующего анализируемого текстового фрагмента; на фиг. 9 изображена табл. 5, состоящая из пяти столбцов и двадцати строк, нумеруемых сверху вниз, в каждой из которых приведены числовые значения пяти психолингвистических параметров (%сс, клр, клс, Дс, Дп), рассчитанных для соответственно пронумерованных текстовых фрагментов, принадлежащих литературному произведению В.Г. Короленко «История моего современника» (https://ruslit.traumlibrarv.net/book/korolenko-ss10-05/korolenko-ss10-05.html), называемого для удобства изложения третьим исследуемым текстом; на фиг. 10 изображена табл. 6, содержащая только один столбец, в котором приведен набор числовых значений общего фактора, вычисленных для исходных данных, представленных в табл. 5; на фиг. 11 изображен график 3 кусочно-линейной функции Y=f(X), где Y числовое значение общего фактора, а X порядковый номер соответствующего анализируемого текстового фрагмента.
Изображенные на фиг. 1 компоненты имеют буквенное обозначение и каждому компоненту сопоставлен номер. Номер 1 сопоставлен входным регистрам, составляющим первую группу и обозначаемым буквами ВРПГ. Номер 2 сопоставлен входным регистрам, составляющим вторую группу и обозначаемым буквами ВРВГ. Номера 3, 4, 5, 6 сопоставлены соответственно первому входному регистру (ПВР), второму входному регистру (ВВР), третьему входному регистру (ТВР), четвертому входному регистру (ЧВР). Блокам деления первой группы (БДПГ) сопоставлен номер 7, а блокам деления второй группы (БДВГ) сопоставлен номер 8. Номер 9 сопоставлен блокам вычитания по модулю (БВМ). Номер 10 сопоставлен накопительному сумматору (НС), имеющему n входов. Номер 11 сопоставлен блоку деления (БД). Блоку сравнения (БС) сопоставлен номер 12. Блоку индикации сопоставлен номер 13. Номер 14 сопоставлен ЭВМ.
Устройство, реализующее предлагаемый способ содержательного анализа текстовой информации (фиг. 1), содержит первую 1 и вторую 2 группы входных регистров, каждая из которых состоит из n элементов, первый 3, второй 4, третий 5 и четвертый 6 входные регистры, первую 7 и вторую 8 группы блоков деления, каждая из которых состоит из n элементов, группу 9 блоков вычитания по модулю, состоящую из n элементов, накопительный сумматор 10, блок 11 деления, блок 12 сравнения, блок 13 индикации, ЭВМ 14, соответствующие выходы которой подключены к управляющим входам соответствующих блоков устройства.
Способ содержательного анализа текстовой информации осуществляется следующим образом. На информационные входы с первого по n-й элементов первой группы 1 входных регистров (фиг. 1) подаются соответственно величины mа1, …, mai, …, man, а на информационные входы с первого по n-й элементов второй группы 2 входных регистров подаются соответственно значения mб1, …, mбi, …, mбn.
На информационные входы первого 3, второго 4, третьего 5 и четвертого 6 входных регистров направляются соответственно величины Na, Nб, n и ΔРд, а управляющий сигнал на входы записи всех элементов этих групп входных регистров и входных регистров подается с первого выхода ЭВМ 14. При этом в качестве первого, второго, третьего и четвертого выходов ЭВМ используют соответствующие контакты разьема порта LPT ЭВМ (пример дан в информационном источнике http://altay-krylov.ru/poleznaia_shemotehnika/proqrammirovanie_lpt_porta.html).
Управляющие сигналы, подаваемые на соответствующие контакты разьема порта LPT, формируют программно, с помощью таймера (пример дан в информационном источнике http://portal.tpu.ru/departments/kafedra/eafu/books_eafu1/Tab/LAB5.pdf).
По сигналу со второго выхода ЭВМ 14 на входы считывания первой 1 и второй 2 групп входных регистров величины mai и mбj с их выходов засылаются на входы делимого соответственно первой 7 и второй 8 групп блоков деления. На входы делителя этих групп направляются по сигналу со второго выхода ЭВМ 14 с выходов соответственно первого 3 и второго 4 входных регистров значения Na и Nб. С выходов первой 7 и второй 8 групп блоков деления величины Pai, и Pбj, определяемые по формулам (1) и (2), поступают соответственно на входы уменьшаемого и входы вычитаемого группы 9 блоков вычитания по модулю. С выходов этой группы величины 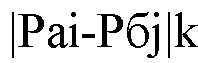 засылаются на входы накопительного сумматора 10, с выхода которого значение
засылаются на входы накопительного сумматора 10, с выхода которого значение 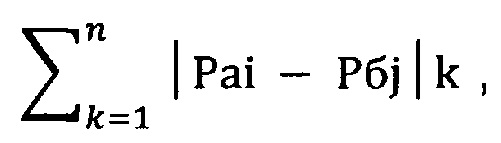 подается на вход делимого блока 11 деления. На вход делителя этого блока по сигналу с третьего выхода ЭВМ 14 направляется с выхода третьего входного регистра 5 величина n. С выхода блока 11 деления значение ΔРср, определяемое по формуле (3), поступает на информационный вход блока 12 сравнения, на пороговый вход которого по сигналу с четвертого выхода ЭВМ 14 засылается с выхода четвертого входного регистра 6 величина ΔРд.
подается на вход делимого блока 11 деления. На вход делителя этого блока по сигналу с третьего выхода ЭВМ 14 направляется с выхода третьего входного регистра 5 величина n. С выхода блока 11 деления значение ΔРср, определяемое по формуле (3), поступает на информационный вход блока 12 сравнения, на пороговый вход которого по сигналу с четвертого выхода ЭВМ 14 засылается с выхода четвертого входного регистра 6 величина ΔРд.
Если ΔРср≤ΔРд (отрывки «а» и «б» принадлежат одному автору) на выходе блока 12 сравнения появится сигнал, который приведет к загоранию блока 13 индикации. В противном случае, когда ΔРср>ΔРд сигнала на выходе блока 12 сравнения не будет и блок 13 индикации не засветится, это будет свидетельствовать о том, что отрывки «а» и «б» принадлежат разным авторам. Порядок функционирования блоков устройства представлен на циклограмме его работы (фиг. 2).
Дополнительно расчленяют первый и второй анализируемые тексты на нумеруемые фрагменты, при этом количество выделенных фрагментов первого текста равно количеству выделенных фрагментов второго текста.
Выделяют пять психолингвистических показателей (параметров), используемых при содержательном анализе текстовой информации, а именно процент служебных слов, содержащихся в анализируемом тексте (%сс), коэффициент лексического разнообразия (клр), коэффициент логической связности (клс), среднюю длину слова (Дс), среднюю длину предложения (Дп).
Подсчитывают для каждого вычлененного фрагмента первого и второго текстов значение первого параметра по формуле %сс=ксс/K*100, где ксс соответствует количеству служебных слов в анализируемом тексте, K соответствует количеству всех слов в тексте.
Подсчитывают значение второго параметра по формуле где кспип соответствует количеству слов в тексте после исключения повторяющихся.
Подсчитывают значение третьего параметра по формуле клс=ксс/3N, где N соответствует количеству предложений в тексте.
Подсчитывают значение четвертого параметра по формуле Дс=кб/К, где кб соответствует количеству букв в тексте.
Подсчитывают значение очередного пятого параметра по формуле Дп=K/N.
На основании подсчитанных значений параметров первого и второго текстов вычисляют с помощью метода факторного анализа соответственно первый и второй наборы нумеруемых значений общего фактора.
Создают, используя первый и второй вычисленные наборы нумеруемых значений общего фактора, первую и вторую последовательности величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами соответствующего набора значений общего фактора.
Выделяют в первой и второй созданных числовых последовательностях соответственно первую и вторую совокупности равных чисел, при этом величину числа из первой выделенной совокупности обозначают Δ1, а величину числа из второй выделенной совокупности обозначают Δ2.
Делают вывод о принадлежности первого и второго текстов одному автору, если , а в противном случае авторы указанных текстов различны.
Для подтверждения возможности определения авторства текстовой информации с помощью разработанного способа, целесообразно рассмотрение двух примеров содержательного анализа текстовой информации. В первом примере предлагается использование двух литературных текстов, принадлежащих одному автору. Во втором примере предлагается использование двух литературных текстов, принадлежащих различным авторам.
В первом примере в качестве первого и второго исследуемых текстов предлагается использовать указанные выше произведения А.П. Чехова «Мужики» (1897 год) и «Бабье Царство» (1894 год). Во втором примере предлагается в качестве первого исследуемого текста использовать произведение А. П. Чехова «Мужики», а в качестве другого исследуемого текста использовать текст, соответствующий указанному выше произведению В.Г. Короленко «История моего современника». При этом исследуемый текст В.Г. Короленко представлен предложениями, принадлежащими только первым пяти главам (первый том 1906 - 1909 годы) произведения.
Согласно предложенному изобретению в рассматриваемых примерах каждый исследуемый текст расчленяют на двадцать последовательно нумеруемых фрагментов. Количество используемых текстовых фрагментов соответствует количеству наблюдений (измерений) при проведении факторного анализа. В информационном источнике (https://nafi.ru/upload/spss/Lection_8.pdf) рекомендуют использовать количество наблюдений как минимум в два раза больше количества используемых переменных (параметров). Количество предложений, содержащихся в исследуемом текстовом фрагменте, соответствует числу, размещенному внутри круглых скобок, перед которыми указан номер фрагмента.
Информация о количестве предложений, содержащихся во фрагментах, представлена следующим образом. Для первого текста: 1(15), 2(24), 3(26), 4(24), 5(17), 6(20), 7(35), 8(32), 9(33), 10(29), 11(41), 12(44), 13(42), 14(40), 15(38), 16(45), 17(27), 18(31), 19(21), 20(22). Для второго текста: 1(34), 2(26), 3(33), 4(66), 5(51), 6(42), 7(35), 8(40), 9(37), 10(47), 11(41), 12(43), 13(33), 14(35), 15(33), 16(29), 17(39), 18(68), 19(26), 20(25). Для третьего текста: 1(26), 2(28), 3(27), 4(26), 5(20), 6(19), 7(19), 8(20), 9(20), 10(30), 11(22), 12(19), 13(18), 14(37), 15(22), 16(84), 17(34), 18(34), 19(39), 20(34).
Подсчет количества служебных слов в исследуемых предложениях осуществляется с помощью известного программного средства (https://progaonline.com/syntax). Указанное программное средство осуществляет пометку каждого служебного слова текста, предоставляемого программе для анализа. Пользовательский интерфейс указанного программного средства обеспечивает возможность прочтения на экране монитора ЭВМ размеченного текста и подсчета количества служебных слов в тексте. Количество служебных слов, содержащихся в исследуемом текстовом фрагменте, представляется ниже числом, размещенным внутри круглых скобок, перед которыми указан номер исследуемого текстового фрагмента.
Результаты подсчета количества служебных слов в текстовых фрагментах представлены ниже для каждого из трех исследуемых текстов. Для первого текста: 1(53), 2(112), 3(26), 4(24), 5(62), 6(74), 7(162), 8(114), 9(114), 10(152), 11(160), 12(173), 13(160), 14(135), 15(143), 16(178), 17(188), 18(125), 19(118), 20(107). Для второго текста: 1(147), 2(173), 3(196), 4(165), 5(193), 6(176), 7(186), 8(186), 9(171), 10(174), 11(169), 12(173), 13(122), 14(116), 15(134), 16(204), 17(156), 18(165), 19(130), 20(137). Для третьего текста: 1(107), 2(130), 3(137), 4(129), 5(93), 6(84), 7(88), 8(86), 9(92), 10(119), 11(118), 12(91), 13(89), 14(156), 15(109), 16(316), 17(190), 18(103), 19(179), 20(159).
Подсчет в текстовых фрагментах количества всех слов и количества слов после исключения повторяющихся осуществляется с помощью известного программного средства (http://wpcalc.com/kolichestvo-slov/). Количество всех слов и количество слов после исключения повторяющихся, содержащихся в исследуемом текстовом фрагменте, представляется ниже парой чисел, размещенных внутри круглых скобок, перед которыми указан номер исследуемого текстового фрагмента.
Результаты подсчета количества всех слов (K) и количества слов после исключения повторяющихся (кспип) в текстовых фрагментах представлены ниже для каждого из трех исследуемых текстов. Для первого текста: 1(200, 157), 2(407, 296), 3(320, 237), 4(338, 248), 5(225, 169), 6(248, 185), 7(654, 423), 8(302, 216), 9(437, 303), 10(585, 380), 11(587, 398), 12(580, 396), 13(614, 417), 14(500, 347), 15(566, 386), 16(565, 382), 17(688, 408), 18(409, 273), 19(415, 291), 20(443, 322). Для второго текста: 1(620, 400), 2(674, 439), 3(654, 425), 4(682, 425), 5(739, 460), 6(640, 412), 7(686, 456), 8(663, 413), 9(624, 388), 10(604, 371), 11(647, 414), 12(671, 428), 13(489, 317), 14(540, 361), 15(495, 322), 16(659, 415), 17(553, 355), 18(644, 374), 19(486, 319), 20(450, 275). Для третьего текста: 1(417, 281), 2(490, 322), 3(497, 329), 4(456, 304), 5(383, 279), 6(330, 247), 7(352, 256), 8(309, 224), 9(352, 268), 10(543, 386), 11(427, 299), 12(366, 270), 13(346, 262), 14(600, 414), 15(455, 331), 16(1035, 588), 17(628, 397), 18(452, 328), 19(673, 432), 20(565, 387).
Подсчет количества букв в исследуемых текстовых фрагментах осуществляется с помощью текстового редактора Microsoft Word. Количество букв, содержащихся в исследуемом текстовом фрагменте, представляется ниже числом, размещенным внутри круглых скобок, перед которыми указан номер исследуемого текстового фрагмента.
Результаты подсчета количества букв в текстовых фрагментах представлены ниже для каждого из трех исследуемых текстов. Для первого текста: 1(1062), 2(2139), 3(1668), 4(1795), 5(1206), 6(1391), 7(3440), 8(1579), 9(2343), 10(2979), 11(3101), 12(3065), 13(3284), 14(2600), 15(3026), 16(2898), 17(3436), 18(2138), 19(2120), 20(2395). Для второго текста: 1(3433), 2(3532), 3(3366), 4(3566), 5(3811), 6(3287), 7(3559), 8(3439), 9(3236), 10(3066), 11(3445), 12(3485), 13(2568), 14(2911), 15(2662), 16(3337), 17(2887), 18(3245), 19(2549), 20(2249). Для третьего текста: 1(2201), 2(2633), 3(2703), 4(2447), 5(2121), 6(1937), 7(2017), 8(1747), 9(2104), 10(3235), 11(2296), 12(2121), 13(1976), 14(3310), 15(2612), 16(5203), 17(3486), 18(2457), 19(3538), 20(3159).
Для первого, второго и третьего исследуемых литературных текстов вычисляют значения пяти психолингвистических параметров, используя приведенные выше результаты подсчетов и соответствующие формулы. Вычисленные по формулам значения параметров размещают в соответствующих таблицах (табл. 1, 3, 5), номера строк которых соответствуют номерам анализируемых текстовых фрагментов.
В соответствии с демонстрационным примером 1 на основании подсчитанных значений параметров первого (табл. 1) и второго (табл. 3) текстов вычисляют с помощью метода факторного анализа соответственно первый и второй наборы нумеруемых значений общего фактора. Набор из двадцати значений общего фактора для первого текста представлен в табл. 2. Набор из двадцати значений общего фактора для второго текста представлен в табл. 4.
Создают, используя первый (табл. 2) и второй (табл. 4) вычисленные наборы нумеруемых значений общего фактора, первую и вторую последовательности величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами соответствующего набора значений общего фактора.
Первая последовательность содержит следующие величины: 0.18622, 0.18621, 0.18622, 0.18622, 0.18622, 0.15135, 0.13763, 0.65305, 0.27061, 0.18622, 0.18622, 0.18622, 0.18622, 0.18622, 0.20999, 0.54941, 1.11573, 1.41168, 0.18621. Вторая последовательность содержит следующие величины: 0.30038, 0.10799, 0.33490, 0.22547, 0.18801, 0.18801, 0.18800, 0.18801, 0.18801, 0.14326, 0.47195, 0.18800, 0.00128, 0.32997, 0.18801, 0.04861, 0.22002, 0.61492, 0.28265.
Выделяют в первой и второй созданных числовых последовательностях соответственно первую и вторую совокупности равных чисел, при этом величину числа из первой выделенной совокупности обозначают Δ1, а величину числа из второй выделенной совокупности обозначают Δ2. В результате выделения первой и второй совокупностей равных величин получают Δ1=0.1862 и Δ2=0.1880. При этом в первой совокупности содержится 11 равных элементов, а во второй совокупности содержится 7 равных элементов. Числовое значение модуля разности величин Δ1 и Δ2 равно 0.0018.
Делают вывод о принадлежности первого и второго текстов одному автору, так как .
Ниже излагаются дополнительные пояснения процесса осуществления способа содержательного анализа текстовой информации. Для обеспечения наглядности и удобства создания последовательностей величин, указанных выше, и выделения среди созданных последовательностей равных величин, обозначаемых Δ1 и Δ2, целесообразно использовать графическое представление функции Y=f(X), где Y является числовым значением общего фактора, зависящим от порядкового номера X соответствующего текстового фрагмента.
Строят с помощью программы EXCEL кусочно-линейные графики функции Y=f(X) для двух созданных наборов значений общего фактора. График 1 представлен на фиг. 5, а график 2 представлен на фиг. 8.
На графике 1 выявляют отрезки, имеющие одинаковый отрицательный угол наклона. На графике 1 концам (точкам) таких отрезков соответствуют абсциссы X 1_2_3_4_5_6, 10_11_12_13_14_15, 19_20. Для выявленных отрезков рассчитывают значение углового коэффициента по формуле 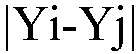 , где Yi=f(Xi), Yj=f(Xj), Xj>Xi и Xj-Xi=1, а упорядоченные пары (Xi,Yi) и (Xj,Yj) являются графиком, изображаемым в виде отрезка. Значения Y общего фактора представлены в табл. 2 и на графике 1.
, где Yi=f(Xi), Yj=f(Xj), Xj>Xi и Xj-Xi=1, а упорядоченные пары (Xi,Yi) и (Xj,Yj) являются графиком, изображаемым в виде отрезка. Значения Y общего фактора представлены в табл. 2 и на графике 1.
Рассчитанное значение углового коэффициента представляет собой величину Δ1, значение которой равно 0.1862.
На графике 2 выявляют отрезки, имеющие одинаковый отрицательный угол наклона. На графике 2 концам (точкам) таких отрезков соответствуют абсциссы X 5_6_7_8_9_10, 12_13, 15_16. Для выявленных отрезков рассчитывают значение углового коэффициента по формуле , где Yi=f(Xi), Yj=f(Xj), Xj>Xi и Xj-Xi=1, a упорядоченные пары (Xi,Yi) и (Xj,Yj) являются графиком, изображаемым в виде отрезка. Значения Y общего фактора представлены в табл. 4 и на графике 2.
Рассчитанное значение углового коэффициента представляет собой величину Δ2, значение которой равно 0.1880.
Вычисляют модуль разности величин Δ1 и Δ2. Вычисленная величина 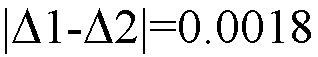 меньше величины 0.01, поэтому делают вывод о принадлежности первого (А.П. Чехов) и второго (А.П. Чехов) текстов одному автору.
меньше величины 0.01, поэтому делают вывод о принадлежности первого (А.П. Чехов) и второго (А.П. Чехов) текстов одному автору.
В соответствие с демонстрационным примером 2 в качестве исследуемых текстов используют первый и третий тексты. При этом анализ первого текста не требуется, а используются готовые результаты расчета величины Δ1 (0.1862), полученные при выполнении примера 1. На основании подсчитанных значений параметров третьего (табл. 5) текста вычисляют с помощью метода факторного анализа для третьего исследуемого текста набор нумерованных значений общего фактора. Набор из двадцати значений общего фактора для третьего текста представлен в табл. 6.
Создают, используя вычисленный набор нумеруемых значений общего фактора, последовательность величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами вычисленного набора значений общего фактора.
Последовательность содержит следующие величины: 0.28001, 0.13234, 0.13235, 0.37305, 0.61476, 0.13235, 0.13234, 0.13235, 0.13234, 0.89011, 1.10584, 0.13234, 0.34611, 0.80845, 0.13234, 0.13235, 0.79877, 0.13235, 0.13234.
Выделяют в созданной числовой последовательности совокупность равных чисел, при этом величину числа из выделенной совокупности обозначают Δ3. В результате выделения совокупности равных величин получают Δ3=0.1323. При этом в выделенной совокупности содержится 11 равных элементов. Числовое значение модуля разности величин Δ1 и Δ3 равно 0.0539.
Делают вывод о принадлежности первого и третьего текстов различным авторам, так как неравенство 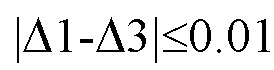 не выполняется.
не выполняется.
Ниже излагаются пояснения процесса осуществления способа содержательного анализа текстовой информации с использованием графического представления функции Y=f(X). Строят с помощью программы EXCEL кусочно-линейный график 3 для созданного набора значений общего фактора. График 3 представлен на фиг.11.
На графике 3 выявляют отрезки, имеющие одинаковый отрицательный угол наклона. На графике 3 концам (точкам) таких отрезков соответствуют абсциссы X 2_3_4, 6_7_8_9_10, 12_13, 15_16_17, 18_19_20. Для выявленных отрезков рассчитывают значение углового коэффициента по формуле 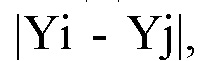 где Yi=f(Xi), Yj=f(Xj), Xj>Xi и Xj-Xi=1, а упорядоченные пары (Xi,Yi) и (Xj,Yj) являются графиком, изображаемым в виде отрезка. Значения Y общего фактора представлены в табл. 6 и на графике 3.
где Yi=f(Xi), Yj=f(Xj), Xj>Xi и Xj-Xi=1, а упорядоченные пары (Xi,Yi) и (Xj,Yj) являются графиком, изображаемым в виде отрезка. Значения Y общего фактора представлены в табл. 6 и на графике 3.
Рассчитанное значение углового коэффициента представляет собой величину Δ3, значение которой равно 0.1323.
Вычисляют модуль разности величин Δ1 и Δ3. Вычисленная величина 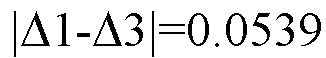 больше величины 0.01, поэтому делают вывод о принадлежности первого (А.П. Чехов) и третьего (В.Г. Короленко) текстов различным авторам. Неравенство
больше величины 0.01, поэтому делают вывод о принадлежности первого (А.П. Чехов) и третьего (В.Г. Короленко) текстов различным авторам. Неравенство 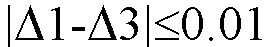 не выполняется.
не выполняется.
Продемонстрированная последовательность действий для определения авторства текстовой информации доказывает возможность осуществления заявляемого способа.
Таким образом, последовательность действий, представляющих заявляемый способ содержательного анализа текстовой информации, позволяет идентифицировать текстовую информацию в случаях определения ее авторства.
Следовательно, решена задача создания способа, позволяющего идентифицировать текстовую информацию в случаях определения ее авторства, и получен технический результат, заключающийся в повышении достоверности определения авторства текстовой информации. Полученный технический результат обеспечивает возможность принятия объективных решений при защите авторских прав создателей текста и других подобных объектов, связанных с правом интеллектуальной собственности.
Способ содержательного анализа текстовой информации, согласно которому подсчитывают в каждом из двух анализируемых текстов «а» и «б» общее количество букв, обозначаемое соответственно Na и Nб, генерируют начальный управляющий сигнал, который синхронизирует операцию сохранения подсчитанных величин Na, Nб для их последующего использования, инициируемого вторым сигналом управления, подсчитывают количества каждой буквы алфавита в анализируемых текстах, при этом количество i-й буквы в тексте «а» обозначают mai, а количество j-й буквы в тексте «б» обозначают mбj, сохраняют по начальному управляющему сигналу величины mai, mбj для их последующего использования, инициируемого вторым управляющим сигналом, задают количество букв, имеющихся в используемом алфавите, которое обозначают n, сохраняют по начальному управляющему сигналу величину n для последующего использования, инициируемого третьим управляющим сигналом, задают фиксированную величину, обозначаемую ΔРд, которую сохраняют по начальному управляющему сигналу для последующего использования, инициируемого четвертым управляющим сигналом, вычисляют по второму управляющему сигналу первый набор n величин и второй набор n величин, каждую из которых получают в результате выполнения операции деления согласно следующим формулам Pai=mai/Na, где i=1, …, n, Pбj=mбj/Nб, где j=1, …, n, при этом каждая величина, полученная в результате выполнения операции деления, характеризует вероятность появления соответствующей буквы в соответствующем тексте, определяют набор, состоящий из n величин, для получения каждой из которых вычисляют модуль разности между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б», выполняют операцию суммирования определенных ранее n величин, каждая из которых соответствует модулю разности между величинами, соответствующими вероятностям появления конкретной буквы в текстах «а» и «б», выполняют по третьему управляющему сигналу операцию деления на величину n вычисленного ранее значения суммы величин модулей разностей между величиной вероятности появления конкретной буквы в тексте «а» и величиной вероятности появления этой же буквы в тексте «б» для получения среднего значения указанной разности согласно следующей формуле где k=1, …, n, i=1, …, n, j=1, …, n, сравнивают по четвертому управляющему сигналу вычисленную величину ΔРср с допустимым фиксированным значением ΔРд и при выполнении неравенства ΔРср≤ΔРд вырабатывают сигнал оповещения о принадлежности двух анализируемых текстов «а» и «б» одному автору, отличающийся тем, что дополнительно расчленяют первый и второй анализируемые тексты на нумеруемые фрагменты, при этом количество выделенных фрагментов первого текста равно количеству выделенных фрагментов второго текста, выделяют пять психолингвистических параметров, используемых при содержательном анализе текстовой информации, а именно процент служебных слов, содержащихся в анализируемом тексте (%сс), коэффициент лексического разнообразия (клр), коэффициент логической связности (клс), среднюю длину слова (Дс), среднюю длину предложения (Дп), при этом подсчитывают для каждого вычлененного фрагмента первого и второго текстов значение первого параметра по формуле %сс=ксс/K⋅100, где ксс соответствует количеству служебных слов в анализируемом тексте, K соответствует количеству всех слов в тексте, подсчитывают значение второго параметра по формуле где кспип соответствует количеству слов в тексте после исключения повторяющихся, подсчитывают значение третьего параметра по формуле клс=ксс/3N, где N соответствует количеству предложений в тексте, подсчитывают значение четвертого параметра по формуле Дс=кб/K, где кб соответствует количеству букв в тексте, подсчитывают значение пятого параметра по формуле Дп=K/N, на основании подсчитанных значений параметров первого и второго текстов вычисляют с помощью метода факторного анализа соответственно первый и второй наборы нумеруемых значений общего фактора, создают, используя первый и второй вычисленные наборы нумеруемых значений общего фактора, первую и вторую последовательности величин, каждая из которых представляет собой модуль разности между соседними числовыми элементами соответствующего набора значений общего фактора, выделяют в первой и второй созданных числовых последовательностях соответственно первую и вторую совокупности равных чисел, при этом величину числа из первой выделенной совокупности обозначают Δ1, а величину числа из второй выделенной совокупности обозначают Δ2, делают вывод о принадлежности первого и второго текстов одному автору, если |Δ1-Δ2|≤0.01, а в противном случае авторы указанных текстов различны.

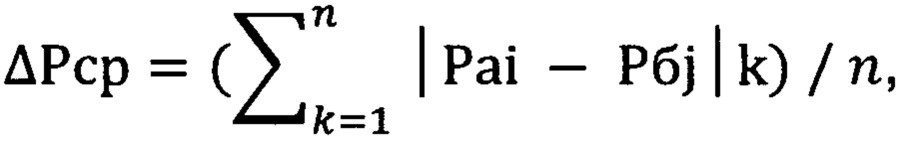


Способ получения монокристаллического sic
Способ получения монокристалла sic
Способ получения монокристаллического sic
Способ определения количественного содержания самородного золота в руде
Устройство измерения коэффициента сцепления колес с аэродромным покрытием
Способ спектрального анализа полигармонических сигналов
Способ дистанционной диагностики механического транспортного средства
Способ формирования индивидуального эндопротеза тазобедренного сустава
Способ получения покрытия из карбида титана на внутренней поверхности медного анода генераторной лампы
Способ аналого-цифрового измерения параметров при автоматической фрагментации электрокардиосигналов
Способ дистанционной диагностики механического транспортного средства
Способ определения остаточного ресурса электропроводки

