Результат интеллектуальной деятельности: СБОР ПОЛЬЗОВАТЕЛЬСКОЙ ИНФОРМАЦИИ ИЗ КОМПЬЮТЕРНЫХ СИСТЕМ
Вид РИД
Изобретение
ПРИТЯЗАНИЕ НА ПРИОРИТЕТ
[0001] Эта заявка испрашивает приоритет китайской заявки за номером №201610532453.8, поданной 7 июля 2016, и заявки США за номером №15/643963, полное содержание каковой тем самым включено в документ путем ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее раскрытие относится к осуществлению сбора пользовательской информации из компьютерных систем, конкретно из мобильных и связанных вычислительных систем.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[0003] В условиях продолжающегося развития и использования технологий Интернет, в частности связанных с мобильными вычислительными устройствами, функциями и связанной технологией, объем генерируемых данных возрастает экспоненциально. Выделенная из сгенерированных данных пользовательская информация (например, дополнительные сведения о пользователе или другая информация) может быть полезной для организаций и других объектов. Например, выделенная пользовательская информация может обеспечивать значимые данные, полезные для различных решений и работы объекта.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0004] Настоящее раскрытие описывает способы и системы, включая реализуемые с помощью компьютера способы, компьютерные программные продукты и компьютерные системы для осуществления сбора пользовательской информации из компьютерных систем, в частности из мобильных и связанных вычислительных систем.
[0005] В реализации, идентифицируют текстовую информацию, связанную с пользовательской информацией, из пользовательской информации об услугах. Многоуровневое сопоставление выполняется на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, причем многоуровневое сопоставление включает в себя различные способы многоуровневого сопоставления, и заранее заданный список включает в себя ряд элементов, сохраняющих различную заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией. Пользовательскую информацию определяют на основе многоуровневого сопоставления.
[0006] Вышеописанная реализация является осуществимой с использованием реализуемого с помощью компьютера способа; невременного, читаемого компьютером носителя, сохраняющего читаемые компьютером команды, чтобы выполнять реализуемый с помощью компьютера способ; и реализуемой с помощью компьютера системы, содержащей компьютерную память, функционально связанную с аппаратно-реализованным процессором, сконфигурированным для выполнения реализуемого с помощью компьютера способа /команд, сохраненных на невременном, читаемом компьютером носителе.
[0007] Объект изобретения, представленный в этом описании, может быть осуществлен в конкретных реализациях с тем, чтобы реализовывать одно или более из следующих преимуществ. Во-первых, представленный подход может использоваться, чтобы автоматически собирать пользовательскую информацию (например, пользовательскую дополнительную (background) информацию, такую как текущий работодатель пользователя, адрес, номер телефона, день рождения, сведения об образовании, схемы расходов, данные о передвижении, партнеры и принадлежности к организациям, или другую информацию), путем выполнения подхода с сопоставлением многоуровневого типа на основе текстовой информации, полученной из пользовательской информации об услугах, и заранее заданного списка дополнительной идентификационной информации. Многоуровневое сопоставление может включать в себя различные способы многоуровневого сопоставления для выделения пользовательской информации из текстовой информации. Многоуровневое сопоставление также позволяет способам сопоставления быть выбираемыми, чтобы разрешать сравнение текстовой информации отличающегося качества (например, текстовой информации структурированной/организованной или свободного формата, независимо, получена ли из известных или неизвестных источников). Во-вторых, описанный подход может повысить эффективность сбора пользовательской дополнительной информации путем снижения потребности ручного ввода информации пользователем. В-третьих, описанный подход может предоставлять пользовательскую информацию в определенном стандартном формате, например, путем предоставления официальных названий университетов вместо сокращенных версий официальных названий. В-третьих, описанный подход может быть объединен с технологиями мобильного Интернет и онлайновыми активностями по использованию Интернет. Другие преимущества будут очевидны средним специалистам в данной области техники.
[0008] Подробности одной или большего количества реализаций объекта изобретения по этому описанию излагаются в Подробном описании изобретения, пунктах формулы изобретения и на сопроводительных чертежах, и формуле изобретения. Другие признаки, аспекты и преимущества объекта изобретения станут очевидными из Подробного описания изобретения, пунктов формулы изобретения и сопроводительных чертежей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0009] Фиг.1 - структурная схема, иллюстрирующая примерный способ для осуществления сбора пользовательской информации, согласно реализации.
[0010] Фиг.2 - добавочная структурная схема, иллюстрирующая примерный способ для осуществления сбора пользовательской информации, согласно реализации.
[0011] Фиг.3 - добавочная структурная схема, иллюстрирующая конкретный примерный способ для осуществления сбора пользовательской информации, согласно реализации.
[0012] Фиг.4 - блок-схема иллюстрации примерного вычислительного устройства для осуществления сбора пользовательской информации, согласно реализации.
[0013] Фиг.5 - другая блок-схема, иллюстрирующая примерное вычислительное устройство для осуществления сбора пользовательской информации, согласно реализации.
[0014] Фиг.6 - блок-схема, иллюстрирующая примерную компьютерную систему, используемую для обеспечения вычислительных функциональных возможностей в увязке с описанными алгоритмами, способами, функциями, процессами, последовательностями операций и процедурами, как описано в текущем раскрытии, согласно реализации.
[0015] Одинаковые числовые ссылочные позиции и обозначения на различных чертежах указывают одинаковые элементы.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0016] Последующее подробное описание изобретения описывает осуществление сбора пользовательской информации из вычислительных систем, конкретно из мобильных и связанных вычислительных систем, и представлено, чтобы дать возможность любому специалисту в данной области техники выполнять и использовать раскрытый объект изобретения в контексте одной или нескольких конкретных реализаций. Могут делаться различные модификации, изменения и перестановки в раскрытых реализациях и будут легко очевидны средним специалистам в данной области техники, и получившие определения общие принципы могут применяться к другим реализациям и применениям без выхода за рамки объема раскрытия. В некоторых случаях, подробности, излишние для получения понимания описанного объекта изобретения, могут опускаться, чтобы не затенять одну или несколько описанных реализаций излишней подробностью, и по существу подробности находятся в рамках компетентности некоторого среднего специалиста в данной области техники. Настоящее раскрытие не подразумевается ограниченным описанными или проиллюстрированными реализациями, а получает самое широкую область определения, соответствующую описанным принципам и признакам.
[0017] Традиционные способы для осуществления сбора пользовательской информации (например, пользовательской дополнительной информации, такой как текущий работодатель пользователя, адрес, номер телефона, день рождения, сведения об образовании, схемы расходов, данные о передвижении, партнеры и принадлежности к организациям, или другой пользовательской информации) обычно требуют, чтобы пользователь вручную вводил требуемую информацию в вычислительное устройство (такое как, переносной компьютер, мобильное вычислительное устройство или другое вычислительное устройство). Например, когда пользователь обращается за кредитной картой в банк, пользователь должен обычно предоставить общие сведения, включая информацию об образовании (такую как, конкретное учебное заведение(я) и другие связанные с обучением данные). Информация об обучении затем может использоваться для выделения дополнительной информации, например, подробных сведений об образовании. Однако эти традиционные способы являются неэффективными для получения дополнительной информации для большого количества пользователей. Кроме того, традиционные способы обычно выполняются в режиме офлайн (например, используя формы «перо-и-бумага» или вычислительные устройства ограниченной функциональности, которые связаны интерфейсом с закрытой сетью). В свете современных технологий Интернет, и конкретно по отношению к мобильным вычислительным устройствам, традиционные способы являются ограниченными и излишне ресурсоемкими (например, рассматривая использование банковского персонала для обработки форм, ввода данных, и подобное).
[0018] На высоком уровне, описанный подход обеспечивает механизм для выделения автоматически пользовательской информации на основе текстовой информации, полученной из услуг пользователя (например, услуг онлайнового совершения покупок, транзакции или диалогового взаимодействия). Подход сопоставления многоуровневого типа выполняется между полученной текстовой информацией и заранее заданным дополнительным идентификационным списком. Пользовательскую информацию определяют на основе результата многоуровневого сопоставления. В некоторых реализациях многоуровневое сопоставление может включать в себя различные способы многоуровневого сопоставления для выделения пользовательской информации из полученной текстовой информации. Многоуровневое сопоставление также позволяет способам сопоставления быть выбираемыми, чтобы разрешать сравнение текстовой информации отличающегося качества (например, текстовой информации структурированной/организованной или свободной формы, независимо, получена ли из известных или неизвестных источников).
[0019] Фиг.1 является структурной схемой, иллюстрирующей примерный способ 100 для осуществления сбора пользовательской информации, согласно реализации. Для ясности представления описание, которое следует, в общих чертах описывает способ 100 в контексте других фигур чертежей в этом описании. Однако будет подразумеваться, что способ 100 может выполняться, например, посредством любой подходящей системы, среды, программного обеспечения и аппаратных средств, или комбинации систем, сред, программного обеспечения и аппаратных средств, как необходимо. В некоторых реализациях различные этапы способа 100 могут выполняться параллельно, в комбинации, в циклах или в любом порядке.
[0020] На этапе 101, текстовую информацию, связанную с пользовательской информацией, получают, используя некоторую информацию из применяемых для пользователя услуг. В некоторых реализациях услуги пользователя могут включать в себя, например, услуги транзакции, пометки, регистрации или диалогового взаимодействия, используемые пользователем ежедневно, или из других онлайновых услуг. В некоторых реализациях текстовая информация включает в себя алфавитно-цифровые, читаемые пользователем данные. Как поймут средние специалисты в данной области техники, описанный подход может также использоваться с другими типами/форматами данных (например, двоичными, шестнадцатеричными и зашифрованными данными) в соответствии с этим раскрытием.
[0021] Пользовательская информация может включать в себя информацию об образовании (например, учебные заведения, которые пользователь посещает в настоящий момент или посещал ранее), информацию о трудоустройстве (например, текущие или предшествующие работодатели пользователя), или другую информацию, в соответствии с этим раскрытием. В некоторых реализациях можно выполнять избирательные конфигурации согласно запросам на услугу. Например, относительно информации об образовании, текстовая информация, связанная с названиями учебных заведений, может быть собрана из различных применяемых услуг, таких как услуга регистрации в общежитии учебного заведения, услуга студенческого кредита, услуга оплаты по университетской карточке, услуга платежей в учебном заведении, и другие применяемые услуги. Например, полученная текстовая информация относительно сведений об образовании пользователя может включать в себя ʺFudan Universityʺ или ʺX campus of Fudan Universityʺ (кампус X университета Fudan). Относительно дополнительной информации о трудоустройстве, текстовая информация, связанная с именами работодателей, может быть собрана из различных применяемых услуг, таких как информация об адресе доставки пользователя, информация об адресе работодателя, полученная из услуг доставки, или других применяемых услуг. От этапа 101, способ 100 переходит к этапу 102.
[0022] На этапе 102, методика многоуровневого сопоставления выполняется на полученной текстовой информации. В некоторых реализациях многоуровневое сопоставление основывается на заранее заданной дополнительной идентификационной информации, сохраненной в хранилище данных (например, в виде списка в базе данных или плоском файле). Операции многоуровневого сопоставления могут включать в себя множественные, с назначенным приоритетом уровни сопоставления, где каждый уровень сопоставления соответствует отличающемуся способу(ам) сопоставления. В некоторых реализациях способы многоуровневого сопоставления, упорядоченность среди способов сопоставления, число способов сопоставления или другие аспекты выполнения методики многоуровневого сопоставления могут конфигурироваться ручным или динамическим образом. Например, один или более способов сопоставления могут задаваться заранее в данных конфигурации или динамически на основе, например, найденных типов, объемов или качества текстовой информации. В некоторых реализациях многоуровневое сопоставление может динамически корректироваться относительно эффективности (например, быстродействия сопоставления, точности, или по иным основаниям, в соответствии с этим раскрытием).
[0023] В некоторых реализациях заранее заданный список может сохранять заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией. В некоторых реализациях заранее заданная дополнительная идентификационная информация может включать в себя названия учебных заведений, именования работодателей и другие идентифицирующие названия, связанные с конкретным пользователем (или группой пользователей) и пользовательской информацией. Например, заранее заданный список может включать в себя множество элементов, каждый элемент соответствует отличающемуся названию учебного заведения или отличающемуся именованию работодателя. В некоторых реализациях, относительно дополнительной информации об образовании, национально стандартизированный список названий учебных заведений может быть получен из базы данных (например, общедоступной, национально-доступной базы данных, частной базы данных или другого источника данных) и предоставлен в виде заранее заданного списка. В случаях, где учебные заведения были закрыты, объединены и изменили свое название, или в других особых ситуациях, заранее заданный список может включать в себя первоначальные названия учебных заведений и устанавливать отношения поэлементного отображения между первоначальными названиями и текущими названиями. В случаях, где названия учебных заведений включают сокращения, такие как ʺBeidaʺ (то есть, сокращение для ʺBeijing Universityʺ) и ʺZhedaʺ (то есть, сокращение для ʺZhejiang Universityʺ), заранее заданный список может включать в себя сокращения названий учебных заведений и устанавливать отношение отображения между сокращениями и названием учебного заведения (например, частичным названием, полным названием, или и полным названием, и частичным названием).
[0024] В некоторых реализациях различные способы многоуровневого сопоставления, используемые методикой многоуровневого сопоставления, могут быть сконфигурированы с различными значениями точности соответствия. В типовой реализации различные способы многоуровневого сопоставления использованы для сопоставления согласно упорядоченности по убыванию значений точности соответствия. Например, способ точного соответствия может первым выполняться путем сравнения полученной текстовой информации с заранее заданной дополнительной идентификационной информацией из заранее заданного списка. Полученная текстовая информация может сравниваться с каждым элементом в заранее заданном списке на точное соответствие. Если полученная текстовая информация точно соответствует элементу в заранее заданном списке (например, ʺBeijing Universityʺ из текстовой информации точно соответствует ʺBeijing Universityʺ в заранее заданном списке), считается, что найдено точное соответствие, и результат точного соответствия (например, ʺBeijing Universityʺ) сохраняется в первом наборе данных результатов. В некоторых реализациях совпавший результат может дополнительно обрабатываться до его сохранения в первом наборе данных результатов. Например, дополнительная обработка может включать в себя компрессию, шифрование, кодирование и другую обработку, в соответствии с этим раскрытием. В некоторых реализациях первый набор данных результатов может сохраняться в памяти вычислительного устройства, которое выполняет операции примерного способа 100, или в другом местоположении.
[0025] В некоторых реализациях, если точное соответствие не может быть сформировано, способ поиска нечеткого соответствия затем может выполняться на полученной текстовой информации путем определения, содержит ли полученная текстовая информация элемент заранее заданного списка или содержится в таком элементе. Например, если полученная текстовая информация содержит или содержится в элементе заранее заданного списка, может быть сформировано нечеткое соответствие и сохранено соответствующее отношение соответствия. Например, если в заранее заданном списке имеется элемент ʺFudan University,ʺ то текстовая информация ʺFudanʺ содержится в этом элементе, тогда как текстовая информация ʺFudan University student dormitoryʺ (студенческое общежитие университета Fudan) содержит этот элемент. Следовательно, и ʺFudanʺ, и ʺстуденческое общежитие университета Fudanʺ могут нечетко соответствовать элементу ʺFudan Universityʺ заранее заданного списка. Кроме того, если полученная текстовая информация может считаться нечетко соответствующей одному и только одному элементу заранее заданного списка, может быть сформировано уникальное нечеткое соответствие (то есть, нечеткое соответствие удовлетворяет условию уникальности), и соответствующий результат нечеткого соответствия (например, название учебного заведения или наименование работодателя в одном и только одном совпавшем элементе заранее заданного списка) может сохраняться во втором наборе данных результатов. В некоторых реализациях условие уникальности удовлетворяется, если полученная текстовая информация содержит или содержится в одном и только одном элементе заранее заданного списка. Образом, подобным первому набору данных результатов, совпавший результат может дополнительно обрабатываться (например, с помощью компрессии, шифрования, кодирования и других типов обработки в соответствии с этим раскрытием) до его сохранения во втором наборе данных результатов. В некоторых реализациях второй набор данных результатов может сохраняться в памяти вычислительного устройства, которое выполняет операции примерного способа 100, или в другом местоположении.
[0026] В некоторой реализации, если не может быть найден результат нечеткого соответствия, или не может быть сформировано уникальное нечеткое соответствие, может выполняться третий тип способа сопоставления на полученной текстовой информации, использующий алгоритм (поиска) наибольшей общей под-последовательности. В алгоритме наибольшей общей под-последовательности вычисляется подобие строк между полученной текстовой информацией и каждым элементом в заранее заданном списке. Элемент, который считается наиболее подобным полученной текстовой информации (например, элемент, имеющий наивысшее значение подобия строк), может считаться результатом сопоставления и сохраняться в третьем наборе данных результатов. Образом, подобным первому и второму наборам данных результатов, совпавший результат может дополнительно обрабатываться (например, с помощью компрессии, шифрования, кодирования и другой обработки, в соответствии с этим раскрытием) до его сохранения в третьем наборе данных результатов. В некоторых реализациях третий набор данных результатов может сохраняться в памяти вычислительного устройства, которое выполняет операции примерного способа 100, или в другом местоположении.
[0027] В некоторых реализациях, элемент, соответствующий наивысшему значению подобия, может считаться результатом сопоставления, если значение подобия выше, чем заданное пороговое значение. В некоторых реализациях это пороговое значение может быть вручную или динамически сконфигурировано на основе точности соответствия или другого значения в соответствии с этим раскрытием. В виде примера, порог может иметь значения, такие как 60%, 70% или другое значение. От этапа 102, способ 100 переходит к этапу 103.
[0028] На этапе 103, пользовательскую информацию определяют на основе результата многоуровневого сопоставления (то есть, одного или более наборов результатов сопоставления, если применимо) с использованием полученной текстовой информации. В качестве конкретного примера, если название учебного заведения посредством многоуровневого сопоставления определено являющимся ʺBeijing Universityʺ, название учебного заведения может использоваться, чтобы определять дополнительную информацию «образовательного» типа относительно пользователя. В некоторых реализациях дополнительная информация об образовании может включать в себя ранжирование учебных заведений пользователя. Например, в некоторых реализациях, информация ранжирования университетов может сохраняться в базе данных или памяти вычислительного устройства, которое выполняет операции примерного способа 100, или в другом местоположении. Ранговая оценка учебного заведения пользователя может быть извлечена из базы данных или конкретной ячейки памяти. В этом примере, поскольку Beijing University считается университетом с высокой ранговой оценкой (в рамках лучших десяти ранжированных университетов в Китае), образование пользователя тогда можно считать имеющим относительно более высокое качество, чем другие более низко ранжированные университеты. Напротив, если название учебного заведения определяют являющимся университетом разряда сто, образование пользователя может считаться имеющим относительно более низкое качество, чем таковое в ʺBeijing Universityʺ. После этапа 103, способ 100 останавливается.
[0029] Фиг.2 является добавочной структурной схемой, иллюстрирующей способ 200 для осуществления сбора пользовательской информации, согласно реализации. Способ 200 представлен как низкоуровневый вид операций способа 100, описанного на Фиг.1. Для ясности представления описание, которое следует, в целом описывает способ 200 в контексте остальных фигур чертежей в этом описании. Однако будет подразумеваться, что способ 200 может выполняться, например, посредством любой подходящей системы, среды, программного обеспечения и аппаратных средств, или комбинации систем, сред, программного обеспечения и аппаратных средств, как необходимо. В некоторых реализациях различные этапы способа 200 могут выполняться параллельно, в комбинации, в циклах или в любом порядке.
[0030] На этапе 201 (подобно этапу 101 по Фиг.1), текстовую информацию, связанную с пользовательской информацией, получают из пользовательской информации об услугах. В некоторых реализациях текстовая информация, полученная из услуг пользователя, может усекаться или очищаться, и поуровневое сопоставление, описанное на этапе 102 по Фиг.1 и этапах 202-204 по Фиг.2, может выполняться на усеченной или очищенной текстовой информации. Усеченная или очищенная текстовая информация может повысить показатель результативности методики многоуровневого сопоставления. Например, текстовой информацией, полученной из услуги, является ʺZhejiang University of Technology (плата за учебник и регистрационный сбор за экзамен)ʺ. Чтобы для текстовой информации формировать точное соответствие с названием учебных заведений в заранее заданном списке, скобки и текст в скобках (то есть, ʺ(плата за учебник и регистрационный сбор за экзамен)ʺ) могут быть удалены, чтобы сохранять краткую форму текстовой информации (здесь, ʺZhejiang University of Technologyʺ), так что точное соответствие может быть сформировано.
[0031] В качестве другого примера, для текстовой информации ʺкампус (отделение) X университета Yʺ, такой как ʺShenbei campus of Chinese Medical Science Universityʺ и ʺQinhuangdao branch of Northeast Petroleum Universityʺ, данные ʺкампус (отделение) Xʺ в текстовой информации могут быть отфильтрованы так, что оставшаяся текстовая информация может сформировать точное соответствие с заранее заданным списком. От этапа 201, способ 200 переходит к этапу 202.
[0032] На этапе 202, первый способ сопоставления может выполняться на полученной текстовой информации путем определения, точно ли соответствует полученная текстовая информация заранее заданной дополнительной идентификационной информации в заранее заданном списке. Как рассмотрено на Фиг.1, заранее заданный список хранит заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией, такую как названия работодателей и названия учебных заведений. Полученная текстовая информация может сравниваться с каждым элементом в заранее заданном списке. Если текстовый элемент в заранее заданном списке является таким же, как полученная текстовая информация (например, "Beijing"="Beijing"), указывается точное соответствие, и результат первого сопоставления считается найденным. Если нет элемента в заранее заданном списке, который точно соответствует полученной текстовой информации, результат первого сопоставления не считается найденным. От этапа 202 способ 200 переходит к этапу 203.
[0033] На этапе 203, если результат первого сопоставления не считается найденным, второй способ сопоставления может выполняться на полученной текстовой информации путем определения, содержит ли полученная текстовая информация один и только один элемент заранее заданного списка или содержится в таковом. Например, если полученной текстовой информацией является ʺdormitory building of Beijing Universityʺ и содержит один и только один элемент в заранее заданном списке названий учебных заведений (то есть, ʺBeijing Universityʺ), то может считаться, что полученный текст нечетко соответствует элементу ʺBeijing Universityʺ и удовлетворяет условию уникальности. В результате считается найденным результат ʺBeijing Universityʺ второго сопоставления.
[0034] В качестве второго примера, полученной текстовой информацией является ʺteaching building of Tsinghua University and dormitory building of Beijing Universityʺ (учебное здание университета Tsinghua и здание общежития университет Beijing), и в заранее заданном списке названий учебных заведений имеется один элемент ʺTsinghua Universityʺ и другой элемент ʺBeijing Universityʺ. В этом случае может считаться, что полученная текстовая информация нечетко соответствует заранее заданному списку, но не удовлетворяет условию уникальности, поскольку полученная текстовая информация содержит два элемента заранее заданного списка. В результате не считается найденным результат второго сопоставления.
[0035] В качестве третьего примера, если полученная текстовая информация составляет ʺFudanʺ и содержится в одном и только одном элементе заранее заданного списка названий учебных заведений, которым является ʺFudan Universityʺ, то может считаться, что полученный текст нечетко соответствует элементу ʺFudan Universityʺ и удовлетворяет условию уникальности. В итоге результат ʺFudan Universityʺ второго сопоставления считается найденным.
[0036] В качестве четвертого примера, полученной текстовой информацией является "Beijing", и заранее заданный список названий учебных заведений имеет множество элементов, содержащих полученный текст, например, ʺBeijing Universityʺ, ʺBeijing Institute of Technologyʺ и ʺBeijing University of Aeronautics and Astronauticsʺ. В этом случае, может считаться, что полученная текстовая информация нечетко соответствует заранее заданному списку, но не удовлетворяет условию уникальности, поскольку полученная текстовая информация содержится во многих элементах заранее заданного списка. В итоге результат второго сопоставления не считается найденным. В некоторых реализациях второй способ сопоставления может также определять совпадающий элемент из заранее заданного списка для сокращенного названия учебного заведения или имени работодателя.
[0037] В некоторых реализациях, если результат второго сопоставления считается найденным на этапе 203, заранее заданный список может быть обновлен согласно результату второго сопоставления. Например, если результатом второго сопоставления для полученной текстовой информации ʺFudanʺ является совпадающий элемент ʺFudan Universityʺ, текст ʺFudanʺ (то есть, сокращенное название ʺFudan Universityʺ) может быть сохранен в заранее заданном списке названий учебных заведений и связан с совпадающим несокращенным элементом ʺFudan Universityʺ. В некоторых реализациях второй способ сопоставления можно выполнять на другой полученной текстовой информации, используя обновленный заранее заданный список, чтобы найти больше результатов сопоставления первого типа или второго типа. После того, как заранее заданный список обновлен путем включения сокращенного названия учебного заведения "Fudan", текстовая информация ʺFudanʺ может быть точно совпадающей для результата первого типа сопоставления, и несокращенный элемент ʺFudan Universityʺ, связанный с сокращенным элементом ʺFudanʺ, может быть сохранен в первом наборе данных результатов. Обновленный заранее заданный список дает возможность более высокоскоростного сопоставления между полученной текстовой информацией, повышает точность многоуровневого сопоставления и дополнительно повышает точность отбора для пользовательской информации. От этапа 203, способ 200 переходит к этапу 204.
[0038] На этапе 204, если результат второго сопоставления не считается найденным на этапе 203, может выполняться третий способ сопоставления на полученной текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия. Заранее заданная формула подобия может использоваться для вычисления значения подобия, которое указывает сходство между двумя строками, векторами слов или другими форматами данных в соответствии с этим раскрытием. Например, и как обсуждено выше, вычисление подобия может основываться на алгоритме наибольшей общей под-последовательности.
[0039] В некоторых реализациях значение подобия вычисляют между полученной текстовой информацией и каждым элементом заранее заданного списка, используя заранее заданную формулу подобия, и определяют наибольшее значение подобия. Например, если заранее заданный список имеет 100 элементов, могут быть вычислены 100 значений подобия. Может быть определено наибольшее значение подобия из 100 вычисленных значений подобия. Если наибольшее значение подобия больше чем или равно заранее заданному пороговому значению, элемент, соответствующий наибольшему значению подобия, может использоваться в качестве результата третьего сопоставления.
[0040] В некоторых реализациях заранее заданное пороговое значение может быть вручную или динамически сконфигурировано на основе требуемой точности соответствия. Например, порог может иметь значение 60%, 70% или некоторое другое значение. В некоторых случаях, элемент в заранее заданном списке, в наибольшей степени подобный полученному тексту, может не являться корректным соответствием, и пороговое значение может использоваться, чтобы управлять точностью соответствия для учета этой ситуации. Например, заранее заданное пороговое значение может быть большим значением для требуемой высокой точности соответствия и малым значением для низкой точности соответствия. Например, пороговое значение в 90% требует высокой степени подобия между полученным текстом и элементом в заранее заданном списке, чтобы третий способ сопоставления считался успешным, тогда как пороговое значение 40% потребует более низкой степени подобия между полученным текстом и элементом в заранее заданном списке, чтобы третий способ сопоставления считался успешным.
[0041] В некоторых реализациях может использоваться алгоритм наибольшей общей под-последовательности, чтобы вычислять значение подобия между полученной текстовой информацией и элементом в заранее заданном списке. Например, наибольшая длина общей подстроки может вычисляться для полученного текста и элемента. Значение подобия затем вычисляется путем деления наибольшей длины общей подстроки на длину строки элемента. Например, значение подобия D(A,B) между полученной текстовой информацией A и элементом B в заранее заданном списке, в некоторых реализациях, может быть вычислено по следующей заранее заданной формуле подобия:
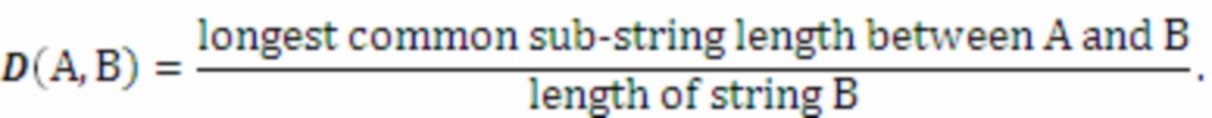
(наибольшая длина общей подстроки между A и B/длина строки)
[0042] В некоторых реализациях длина общей подстроки и длина строки элемента могут зависеть от конкретного языка текстовой информации. Например, если текст существует на китайском языке, длины общей подстроки и строки могут вычисляться в количестве китайских символов. Если текст существует на английском языке, длины подстроки и строки могут вычисляться в количестве слов. В качестве примера, можно рассмотреть, что полученным текстом A является ʺTongji dormitory buildingʺ с длиной строки 3 (три слова), и элементом B в заранее заданном списке названий учебных заведений является ʺTongji Universityʺ с длиной строки 2 (два слова). Самой длинной общей подстрокой между A и B является ʺTongjiʺ с длиной 1, и D(A,B) =1/2. От этапа 204 способ 200 переходит к этапу 205.
[0043] На этапе 205, дополнительная идентификационная информация относительно пользователя может быть найдена из первого, второго или третьего результата сопоставления из трех способов сопоставления на этапах 202-204. Если многоуровневое сопоставление является успешным, один результат из первого, второго или третьего результата сопоставления считается найденным и может рассматриваться как дополнительная идентификационная информация относительно пользователя. От этапа 205, способ 200 переходит к этапу 206.
[0044] На этапе 206, пользовательская информация может быть определена на основе дополнительной идентификационной информации, найденной на этапе 205. Если, например, выполняется многоуровневое сопоставление на текстовой информации, связанной с информацией об образовании пользователя, и результат второго сопоставления считается найденным, название учебного заведения, соответствующее пользователю, может быть получено из результата второго сопоставления (например, ʺTsinghua Universityʺ). Название учебного заведения может использоваться, чтобы определить образование пользователя. После этапа 206, способ 200 останавливается.
[0045] В некоторых реализациях может быть получено большое количество текстовой информации, которое отражает пользовательскую информацию. Многоуровневое сопоставление и анализ, описанные на этапе 102 по Фиг.1 или этапах 202-204 по Фиг.2, могут выполняться на всей полученной текстовой информации или ее подмножестве. Кроме того, точность соответствия для первого способа сопоставления может быть выше чем таковая для второго способа сопоставления, и точность соответствия для второго способа сопоставления может быть выше чем таковая для третьего способа сопоставления.
[0046] Фиг.3 является добавочной блок-схемой, иллюстрирующей конкретный примерный способ 300 для осуществления сбора пользовательской информации, согласно реализации. Для ясности представления, описание, которое следует, в целом описывает способ 300 в контексте остальных фигур чертежей в этом описании. Однако будет понято, что способ 300 может выполняться, например, посредством любой подходящей системы, среды, программного обеспечения и аппаратных средств, или посредством комбинаций систем, сред, программного обеспечения и аппаратных средств, как необходимо. В некоторых реализациях различные этапы способа 300 могут исполняться параллельно, в комбинации, в циклах или в любом порядке.
[0047] На этапе 301, текстовую информацию, связанную с образованием пользователя, собирают исходя из различных услуг, таких как информация об адресах доставки пользователя, информация о кредите на образование, или другой. От этапа 301, способ 300 переходит к этапу 302.
[0048] На этапе 302, очистка данных выполняется на полученной текстовой информации, как описано на этапе 201 по Фиг.2. Очищенная текстовая информация можно считаться записью (названия) учебного заведения. От этапа 302, способ 300 переходит к этапу 303.
[0049] На этапе 303, выполняется первый способ сопоставления (например, как описано выше). Запись учебного заведения сравнивается с каждым названием учебного заведения в заранее заданном списке названий учебных заведений. Если запись учебного заведения является одинаковой с названием учебного заведения в заранее заданном списке названий учебных заведений, то считается, что найдено точное соответствие, и результат первого сопоставления (например, совпавшее название учебного заведения из списка) считается найденным. От этапа 303 способ 300 переходит к этапу 304.
[0050] На этапе 304, результат первого сопоставления сохраняется в первом наборе S1 результатов. От этапа 304, способ 300 переходит к этапу 305.
[0051] На этапе 305, если на этапе 303 запись учебного заведения не может быть совпавшей точно, может выполняться второй способ сопоставления (например, как описано выше). Если запись учебного заведения содержит или содержится в одном и только одном названии учебного заведения в заранее заданном списке названий учебных заведений, запись учебного заведения может считаться нечетко соответствующей и удовлетворяющей условию уникальности, и результат второго сопоставления (например, совпавшее одно и только одно название учебного заведения из заранее заданного списка названий учебных заведений) считается найденным. От этапа 305 способ 300 переходит к этапу 306.
[0052] На этапе 306, результат второго сопоставления сохраняется во втором наборе S2 результатов. От этапа 306 способ 300 переходит к этапу 307.
[0053] На этапе 307, список названий учебных заведений обновляется согласно результату второго сопоставления. Например, запись учебного заведения может быть добавлена к заранее заданному списку названий учебных заведений и связана с совпадающим названием учебного заведения. Первый и второй способы многоуровневого сопоставления могут выполняться на других несовпавших записях учебных заведений на основе заранее заданного списка названий учебных заведений.
[0054] На этапе 308, если на этапе 305 запись учебного заведения не может быть совпавшей, может выполняться третий способ сопоставления с использованием заранее заданной формулы подобия. Например, значение подобия может вычисляться между записью учебного заведения и каждым названием учебного заведения в заранее заданном списке названий учебных заведений. В некоторых реализациях, если наибольшее вычисленное значение подобия больше чем или равно заранее заданному пороговому значению, третий результат сопоставления (название учебного заведения, соответствующее наибольшему значению подобия), считается найденным. От этапа 308, способ 300 переходит к этапу 309.
[0055] На этапе 309, третий результат сопоставления сохраняется в третьем наборе S3 результатов. В итоге название учебного заведения, соответствующее пользователю, может быть получено из S1, S2 или S3. После этапа 309, способ 300 останавливается.
[0056] Фиг.4 является блок-схемой иллюстрации примерного вычислительного устройства для осуществления сбора пользовательской информации, согласно реализации. Вычислительное устройство 400 может включать в себя блок 41 получения, блок 42 сопоставления и блок 43 сбора, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Блок 41 получения может получать текстовую информацию, связанную с пользовательской информацией, из пользовательской информации об услугах, как обсуждено на этапе 101 по Фиг.1 и этапе 201 по Фиг.2. Блок 42 сопоставления может выполнять многоуровневое сопоставление на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, как обсуждено на этапе 102 по Фиг.1 и этапах 202-204 по Фиг.2. Блок 43 сбора может осуществлять сбор пользовательской информации согласно результату многоуровневого сопоставления, как обсуждено на этапе 103 по Фиг.1 и этапах 205-206 по Фиг.2.
[0057] Фиг.5 является другой блок-схемой, иллюстрирующей примерное вычислительное устройство 500 для осуществления сбора пользовательской информации, согласно реализации. Фигура Фиг.5 представлена как низкоуровневый вид компонентов примерного вычислительного устройства 400, описанного на Фиг.4.
[0058] Вычислительное устройство 500 может включать в себя блок 51 получения, блок 52 сопоставления и блок 53 сбора, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Блок 51 получения может получать текстовую информацию, связанную с пользовательской информацией, из пользовательской информации об услугах, как обсуждено на этапе 101 по Фиг.1 и этапе 201 по Фиг.2. Блок 52 сопоставления может выполнять многоуровневое сопоставление на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, как обсуждено на этапе 102 по Фиг.1 и этапах 202-204 по Фиг.2. Блок 53 сбора может осуществлять сбор пользовательской информации согласно результату многоуровневого сопоставления, как обсуждено на этапе 103 по Фиг.1 и этапах 205-206 по Фиг.2.
[0059] Блок 52 сопоставления может включать в себя модуль 521 вычисления, модуль 522 получения и модуль 523 сопоставления, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Модуль 521 вычисления может вычислять значение подобия между текстовой информацией и каждым элементом заранее заданной дополнительной идентификационной информации в заранее заданном списке, используя заранее заданную формулу подобия. Например, как обсуждено выше, модуль 521 вычисления может вычислять наибольшую длину общей подстроки между текстовой информацией и заранее заданной дополнительной идентификационной информацией и делить наибольшую длину общей подстроки на длину строки заранее заданной дополнительной идентификационной информации, чтобы получить значение подобия. Модуль 522 получения может определять заранее заданную дополнительную идентификационную информацию, соответствующую наибольшему значению подобия. Модуль 523 сопоставления может выполнять третье сопоставление на текстовой информации путем определения, является ли наибольшее значение подобия больше чем или равно заранее заданному пороговому значению.
[0060] Блок 53 сбора может включать в себя модуль 531 получения и модуль 532 сбора, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Модуль 531 получения может получать дополнительную идентификационную информацию относительно пользователя из первого, второго или третьего результата сопоставления. В некоторых реализациях первый, второй или третий результат сопоставления можно сохранять в базе данных или памяти вычислительного устройства 500, или в другом местоположении. Модуль 532 сбора может осуществлять сбор пользовательской информации согласно дополнительной идентификационной информации, полученной модулем 531 получения.
[0061] Вычислительное устройство 500 может включать в себя блок 54 обновления, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Как обсуждено выше, если имеется какой-либо результат второго сопоставления, блок 54 обновления может обновить заранее заданный список согласно результату второго сопоставления, например, путем добавления результата второго сопоставления к заранее заданному списку.
[0062] Вычислительное устройство 500 может также включать в себя блок 55 очистки, каковое может быть реализовано аппаратными средствами, программными средствами или обоими. Как обсуждено выше, блок 55 очистки может выполнять очистку данных на текстовой информации. Блок 52 сопоставления может выполнять многоуровневое сопоставление на очищенных текстовых данных.
[0063] Вычислительное устройство 400 или 500 для осуществления сбора пользовательской информации может включать в себя, по меньшей мере, процессор и память. Блок 41 или 51 получения, блок 42 или 52 сопоставления, блок 43 или 53 сбора, блок 54 обновления и блок 55 очистки могут сохраняться в памяти в виде программных модулей и исполняться процессором, чтобы реализовывать соответствующие функции. Компьютерный программный продукт, содержащий одну или несколько команд, исполнимых компьютером, может использоваться, чтобы выполнять этапы способов, описанных, по меньшей мере, на фигурах Фиг.1-3.
[0064] Фиг.6 является блок-схемой примерной компьютерной системы 600, используемой для предоставления вычислительных функциональных возможностей в увязке с описанными алгоритмами, способами, функциями, процессами, последовательностями операций, и процедурами, как описано в текущем раскрытии, согласно реализации. Иллюстрируемый компьютер 602 подразумевается охватывающим любое вычислительное устройство, такое как сервер, настольный компьютер, переносной/блокнотный компьютер, беспроводной порт данных, смартфон, персональный ассистент данных (PDA), планшетное вычислительное устройство, один или более процессоров в рамках этих устройств, или любое другое подходящее устройство обработки, включая физический или виртуальный варианты (или оба) вычислительного устройства. Кроме того, компьютер 602 может содержать компьютер, который включает в себя устройство ввода данных, такое как клавишная панель, клавиатура, сенсорный экран или другое устройство, которое может воспринимать пользовательскую информацию, и устройство вывода, которое передает информацию в увязке с операцией компьютера 602, включая цифровые данные, визуальную или аудио информацию (или комбинацию информации), или графический пользовательский интерфейс (GUI).
[0065] Компьютер 602 может использоваться в роли клиента, компонента сети, сервера, базы данных или другого постоянного хранения, или любого другого компонента (или комбинации ролей) компьютерной системы, чтобы выполнять объект изобретения, описанный в текущем раскрытии. Иллюстрируемый компьютер 602 является с возможностью взаимодействия связанным с сетью 630. В некоторых реализациях один или более компонентов компьютера 602 могут быть сконфигурированы для работы в рамках сред, включая основанную на "облачных" вычислениях, локальную, глобальную или другую среду (или комбинацию сред).
[0066] На высоком уровне компьютер 602 является электронным вычислительным устройством, выполненным с возможностью принимать, передавать, обрабатывать, сохранять данные и информацию или управлять таковыми, связанными с описанным объектом изобретения. Согласно некоторым реализациям, компьютер 602 может также включать в себя или являться с возможностью взаимодействия связанным с сервером приложений, сервером электронной почты, веб-сервером, сервером с кэшированием, сервером потоковых данных или другим сервером (или комбинацией серверов).
[0067] Компьютер 602 может принимать запросы по сети 630 от клиентского приложения (например, исполняющегося на другом компьютере 602) и отвечать на принятые запросы путем обработки принятых запросов с использованием надлежащего программно-реализованного приложения(ий). Кроме того, запросы также могут посылаться на компьютер 602 от внутренних пользователей (например, от командной консоли или посредством другого подходящего способа доступа), внешних или третьих сторон, других автоматизированных приложений, а также любых других соответствующих объектов, отдельных лиц, систем или компьютеров.
[0068] Каждый из компонентов компьютера 602 может обмениваться информацией, используя системную шину 603. В некоторых реализациях какие-либо компоненты или все из компонентов компьютера 602, аппаратных средств или программного обеспечения (или комбинации и аппаратных средств, и программного обеспечения) могут поддерживать интерфейс друг с другом или с интерфейсом 604 (или комбинацию обоего) по системной шине 603, используя интерфейс 612 прикладного программирования (API) или уровень 613 услуг (или комбинацию API 612 и уровня 613 услуг). API 612 может включать в себя технические условия на подпрограммы, структуры данных и классы объектов. API 612 может быть либо независимым, либо зависимым от машинного языка, и обращаться к полному интерфейсу, одиночной функции или даже набору API. Уровень 613 услуг предоставляет программные услуги компьютеру 602 или другим компонентам (независимо, иллюстрируемым или нет), которые с возможностью взаимодействия связаны с компьютером 602. Функциональность компьютера 602 может быть доступной для всех потребителей услуг, использующих этот уровень услуг. Программные услуги, такие как предоставляемые уровнем 613 услуг, обеспечивают допускающие повторное использование, определяемые функциональные возможности через определяемый интерфейс. Например, интерфейс может быть программным обеспечением, написанным на языке JAVA, C++ или другом подходящем языке, обеспечивающем данные в формате расширяемого языка разметки (XML) или другом подходящем формате. Хотя проиллюстрировано как встроенный компонент компьютера 602, альтернативные реализации могут иллюстрировать API 612 или уровень 613 услуг как автономные компоненты относительно других компонентов компьютера 602 или других компонентов (независимо, иллюстрируемых или нет), которые с возможностью взаимодействия связаны с компьютером 602. Кроме того, какие-либо или все части API 612 или уровня 613 услуг могут быть реализованы как дочерние модули или подмодули другого программного модуля, приложения масштаба предприятия или аппаратно-реализованного модуля, без выхода за рамки объема этого раскрытия.
[0069] Компьютер 602 включает в себя интерфейс 604. Хотя на Фиг.6 интерфейс 604 проиллюстрирован как одиночный, два или более интерфейсов 604 могут использоваться согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602. Интерфейс 604 используется компьютером 602 для осуществления связи с другими системами, которые подключены к сети 630 (независимо, иллюстрируемой или нет) в распределенной среде. Обычно, интерфейс 604 содержит логику, закодированную в программном обеспечении или аппаратных средствах (или комбинации программного обеспечения и аппаратных средств), и выполнен с возможностью связи с сетью 630. Более конкретно, интерфейс 604 может содержать программное обеспечение, поддерживающее один или более протоколов связи, связанных с обменом информацией, так что сеть 630 или аппаратные средства интерфейса пригодны к обмену физическими сигналами внутри и вне иллюстрируемого компьютера 602.
[0070] Компьютер 602 включает в себя процессор 605. Хотя на Фиг.6 процессор 605 проиллюстрирован как одиночный, два или более процессоров могут использоваться согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602. Обычно процессор 605 исполняет команды и манипулирует данными, чтобы выполнять операции компьютера 602 и любые алгоритмы, способы, функции, процессы, последовательности операций и процедуры, как описано в текущем раскрытии.
[0071] Компьютер 602 также включает в себя базу 606 данных, которая может хранить данные для компьютера 602 или других компонентов (или комбинации обоих), которая может быть подключена к сети 630 (независимо, иллюстрируемой или нет). Например, база 606 данных может быть внутренней, традиционной или другим типом базы данных, сохраняющей данные, в соответствии с этим раскрытием. В некоторых реализациях база 606 данных может быть комбинацией двух или большего числа различных типов баз данных (например, гибридной внутренней и традиционной базой данных) согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602 и описанной функциональности. Хотя на Фиг.6 база 606 данных проиллюстрирована как одиночная, две или большее число баз данных (одинакового типа или комбинации типов) могут использоваться согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602 и описанной функциональности. Хотя база 606 данных проиллюстрирована как встроенный компонент компьютера 602, в альтернативных реализациях база 606 данных может быть внешней по отношению к компьютеру 602.
[0072] Компьютер 602 также включает в себя память 607, которая может хранить данные для компьютера 602 или других компонентов (или комбинации обоих), которая может быть подключена к сети 630 (независимо, иллюстрируемой или нет). Память 607 может сохранять любые данные в соответствии с этим раскрытием. В некоторых реализациях память 607 может быть комбинацией двух или большего числа различных типов памяти (например, комбинацией полупроводниковой и магнитной памяти) согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602 и описанной функциональности. Хотя на Фиг.6 память 607 проиллюстрирована как одиночная, две или более единиц памяти 607 (одинакового или комбинации типов) могут использоваться согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602 и описанной функциональности. Хотя память 607 проиллюстрирована как встроенный компонент компьютера 602, в альтернативных реализациях память 607 может быть внешней к компьютеру 602.
[0073] Приложение 608 является алгоритмической программно-реализованной подсистемой, обеспечивающей функциональность согласно конкретным потребностям, требованиям или конкретным реализациям компьютера 602, конкретно относительно функциональности, описанной в этом раскрытии. Например, приложение 608 может использоваться одним или более компонентами, модулями или приложениями. Кроме того, хотя приложение 608 проиллюстрировано как одиночное, приложение 608 может быть реализовано как множество приложений 608 на компьютере 602. Кроме того, хотя проиллюстрировано внутренним к компьютеру 602, в альтернативных реализациях, приложение 608 может быть внешним по отношению к компьютеру 602.
[0074] Компьютер 602 может также включать в себя блок 614 электропитания. Блок 614 электропитания может включать в себя перезаряжаемую или неперезаряжаемую аккумуляторную батарею, которая может быть сконфигурирована либо допускающей, либо не допускающей смену пользователем. В некоторых реализациях блок 614 электропитания может включать в себя схемы преобразования или управления электропитанием (включая повторную зарядку, дежурный режим или другую функциональность управления электропитанием). В некоторых реализациях блок 614 электропитания может включать в себя разъем электропитания, чтобы позволять включение компьютера 602 в стенную розетку или другой источник электропитания, чтобы, например, подавать питание на компьютер 602 или повторно заряжать аккумулятор.
[0075] Может быть любое число компьютеров 602, связанных с компьютерной системой или внешних к таковой системе, содержащей компьютер 602, каждый компьютер 602 осуществляет связь по сети 630. Кроме того, термин "клиент", "пользователь" и другая соответствующая терминология может использоваться взаимозаменяемо, как необходимо, без выхода за рамки объема этого раскрытия. Кроме того, это раскрытие предполагает, что многие пользователи могут использовать один компьютер 602, или что один пользователь может использовать множество компьютеров 602.
[0076] Описанный подход для осуществления сбора пользовательской информации из компьютерных систем технически совершенствует традиционный сбор пользовательской информации. Например, описанный подход многоуровневого сопоставления может быть вручную или динамически сконфигурирован, чтобы улучшать полную функциональность сопоставления как части сбора пользовательской информации. Кроме того, другие технические аспекты, применяемые к сбору пользовательской информации (такие как шифрование данных, динамическое/статическое кэширование, регулирование (количества запросов) в сети, управление процессором, управление хранением данных, рассмотрения времени/географического местоположения и объединение в кластер компьютера/базы данных), могут быть сконфигурированы (вручную или динамически) вместе с использованием подхода многоуровневого сопоставления, чтобы повысить, например, быстродействие, эффективность, использование вычислительных ресурсов, полосу пропускания сети, или (характеристику) хранилище данных компьютера.
[0077] В качестве конкретного примера, один или более способов для подхода многоуровневого сопоставления могут выбираться посредством одного или более компонентов описанных вычислительных систем (например, на фигурах Фиг. 4, 5, или 5), чтобы максимально повысить обработку сервера на основе задания конфигурации одного или более атрибутов сервера (таких как тип процессора, объем памяти/быстродействие и характеристика хранилища данных). В качестве другого примера, технологии кэширования могут использоваться одним или несколькими вычислительными компонентами для повышения быстродействия приема полученных текстовых данных и повышения максимально характеристики обработки для сервера (например, обработанные совпадения могут обрабатываться настолько быстро, какова техническая характеристика сервера, и кэшироваться в памяти для последующего использования описанными вычислительными системами). Кроме того, использование технологий кэширования может помочь улучшить управление и оптимизацию сетевого трафика. В качестве другого примера, поскольку описанный подход может использоваться, чтобы повысить полную эффективность сопоставления, эффективность обработки может повышаться и лучше управляться. Повышенная эффективность сопоставления разрешает более быстрое определение данных результатов для использования различными компонентами описанных вычислительных систем, ускоренные возвраты данных пользователям и более быстрореагирующие прикладное программное обеспечение и мобильные вычислительные устройства.
[0078] Описанные реализации объекта изобретения могут включать в себя один или более признаков, по одному или в комбинации.
[0079] Например, в первой реализации, реализуемый с помощью компьютера способ содержит: идентификацию текстовой информации, связанной с пользовательской информацией, из пользовательской информации об услугах; выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, причем многоуровневое сопоставление включает в себя различные способы многоуровневого сопоставления, и заранее заданный список включает в себя ряд элементов, сохраняющих различную заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией; и определение пользовательской информации на основе многоуровневого сопоставления.
[0080] Предшествующие и другие описанные реализации могут каждая необязательно включать в себя один или более из следующих признаков:
[0081] Первый признак, комбинируемый с любым из следующих признаков, причем выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке дополнительно содержит: выполнение первого сопоставления на текстовой информации путем определения, является ли текстовая информация такой же, как один элемент в заранее заданном списке; в ответ на неуспешное первое сопоставление выполнение второго сопоставления на текстовой информации путем определения, текстовая информация содержит ли или содержится в одном и только одном элементе заранее заданного списка; и в ответ на неуспешное второе сопоставление выполнение третьего сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия.
[0082] Второй признак, комбинируемый с любым из предшествующих или последующих признаков, причем выполнение третьего сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия дополнительно содержит: вычисление значения подобия между текстовой информацией и каждым элементом в заранее заданном списке с использованием заранее заданной формулы подобия; определение наибольшего значения подобия; и определение, является ли наибольшее значение подобия больше чем или равно заранее заданному пороговому значению.
[0083] Третий признак, комбинируемый с любым из предшествующих или последующих признаков, причем вычисление значения подобия между текстовой информацией и каждым элементом в заранее заданном списке с использованием заранее заданной формулы подобия дополнительно содержит: вычисление наибольшей длины общей подстроки между текстовой информацией и этим конкретным элементом в заранее заданном списке; и деление наибольшей длины общей подстроки на длину строки этого конкретного элемента.
[0084] Четвертый признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно содержит, в ответ на успешное второе сопоставление, обновление заранее заданного списка на основе второго сопоставления.
[0085] Пятый признак, комбинируемый с любым из предшествующих или последующих признаков, причем определение пользовательской информации на основе многоуровневого сопоставления дополнительно содержит определение пользовательской информации на основе первого сопоставления, второго сопоставления или третьего сопоставления.
[0086] Шестой признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно содержит: выполнение очистки данных на текстовой информации; и выполнение многоуровневого сопоставления на очищенной текстовой информации.
[0087] Во второй реализации, Компьютерно-читаемый носитель, сохраняющий одну или несколько команд, исполнимых компьютерной системой, чтобы выполнять операции, содержащие: идентификацию текстовой информации, связанной с пользовательской информацией, из пользовательской информации об услугах; выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, причем многоуровневое сопоставление включает в себя различные способы многоуровневого сопоставления, и заранее заданный список включает в себя ряд элементов, сохраняющих различную заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией; и определение пользовательской информации на основе многоуровневого сопоставления.
[0088] Предшествующие и другие описанные реализации могут каждая дополнительно включать в себя один или несколько признаков из следующих признаков:
[0089] Первый признак, комбинируемый с любым из следующих признаков, причем выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке дополнительно содержит одну или несколько команд, чтобы: выполнять первое сопоставление на текстовой информации путем определения, является ли текстовая информация такой же, как один элемент в заранее заданном списке; в ответ на неуспешное первое сопоставление, выполнять второе сопоставление на текстовой информации путем определения, текстовая информация содержит ли или содержится в одном и только одном элементе заранее заданного списка; и в ответ на неуспешное второе сопоставление, выполнять третье сопоставление на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия.
[0090] Второй признак, комбинируемый с любым из предшествующих или последующих признаков, причем выполнение третьего сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия дополнительно содержит одну или несколько команд, чтобы: вычислять значение подобия между текстовой информацией и каждым элементом в заранее заданном списке, используя заранее заданную формулу подобия; определять наибольшее значение подобия; и определять, является ли наибольшее значение подобия больше чем или равно заранее заданному пороговому значению.
[0091] Третий признак, комбинируемый с любым из предшествующих или последующих признаков, причем вычисление значения подобия между текстовой информацией и каждым элементом в заранее заданном списке с использованием заранее заданной формулы подобия дополнительно содержит одну или несколько команд, чтобы: вычислять наибольшую длину общей подстроки между текстовой информацией и этим конкретным элементом в заранее заданном списке; и делить наибольшую длину общей подстроки на длину строки этого конкретного элемента.
[0092] Четвертый признак, комбинируемый с любым из предшествующих или последующих признаков, причем операции дополнительно содержат одну или несколько команд, чтобы в ответ на успешное второе сопоставление обновлять заранее заданный список на основе второго сопоставления.
[0093] Пятый признак, комбинируемый с любым из предшествующих или последующих признаков, причем определение пользовательской информации на основе многоуровневого сопоставления дополнительно содержит одну или несколько команд, чтобы определять пользовательскую информацию на основе первого сопоставления, второго сопоставления или третьего сопоставления.
[0094] Шестой признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно содержит одну или несколько команд, чтобы: выполнять очистку данных на текстовой информации; и выполнять многоуровневое сопоставление на очищенной текстовой информации.
[0095] В третьей реализации, реализуемая с помощью компьютера система содержит: память компьютера; и аппаратно-реализованный процессор, функционально связанный с памятью компьютера и сконфигурированный для выполнения операций, содержащих: идентификацию текстовой информации, связанной с пользовательской информацией, из пользовательской информации об услугах; выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, причем многоуровневое сопоставление включает в себя различные способы многоуровневого сопоставления, и заранее заданный список включает в себя ряд элементов, сохраняющих различную заранее заданную дополнительную идентификационную информацию, связанную с пользовательской информацией; и определение пользовательской информации на основе многоуровневого сопоставления.
[0096] Предшествующие и другие описанные реализации могут каждая дополнительно включать в себя один или более из следующих признаков:
[0097] Первый признак, комбинируемый с любым из следующих признаков, причем выполнение многоуровневого сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке, дополнительно сконфигурировано, чтобы: выполнять первое сопоставление на текстовой информации путем определения, является ли текстовая информация такой же, как один элемент в заранее заданном списке; в ответ на неуспешное первое сопоставление, выполнять второе сопоставление на текстовой информации путем определения, текстовая информация содержит ли или содержится в одном и только одном элементе заранее заданного списка; и в ответ на неуспешное второе сопоставление, выполнять третье сопоставление на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия.
[0098] Второй признак, комбинируемый с любым из предшествующих или последующих признаков, причем выполнение третьего сопоставления на текстовой информации на основе заранее заданной дополнительной идентификационной информации в заранее заданном списке и заранее заданной формулы подобия дополнительно сконфигурировано, чтобы: вычислять значение подобия между текстовой информацией и каждым элементом в заранее заданном списке, используя заранее заданную формулу подобия; определять наибольшее значение подобия; и определять, является ли наибольшее значение подобия больше чем или равно заранее заданному пороговому значению.
[0099] Третий признак, комбинируемый с любым из предшествующих или последующих признаков, причем вычисление значения подобия между текстовой информацией и каждым элементом в заранее заданном списке с использованием заранее заданной формулы подобия дополнительно сконфигурировано с возможностью: вычислять наибольшую длину общей подстроки между текстовой информацией и этим конкретным элементом в заранее заданном списке; и делить наибольшую длину общей подстроки на длину строки этого конкретного элемента.
[00100] Четвертый признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно сконфигурирован с возможностью, в ответ на успешное второе сопоставление, обновлять заранее заданный список на основе второго сопоставления, и при этом определение пользовательской информации на основе многоуровневого сопоставления дополнительно сконфигурировано с возможностью определять пользовательскую информацию на основе первого сопоставления, второго сопоставления или третьего сопоставления.
[00101] Пятый признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно сконфигурирован с возможностью выполнять очистку данных на текстовой информации.
[00102] Шестой признак, комбинируемый с любым из предшествующих или последующих признаков, дополнительно сконфигурирован с возможностью выполнять многоуровневое сопоставление на очищенной текстовой информации.
[00103] Реализации объекта изобретения и функциональные операции, представленные в этом описании изобретения, могут быть реализованы в цифровой электронной схеме, в материально осуществленном программном обеспечении или микропрограммном обеспечении компьютера, в аппаратных средствах компьютера, включая структуры, раскрытые в этом описании, и их структурные эквиваленты, или в виде комбинаций из одного или нескольких из них. Программные реализации описанного объекта изобретения могут быть реализованы в виде одной или нескольких компьютерных программ, то есть, одного или нескольких модулей команд компьютерной программы, закодированных на материальном, невременном, читаемом компьютером носителе данных компьютера для исполнения посредством аппаратуры обработки данных или для управления ее работой. Альтернативно или дополнительно, команды программы могут быть закодированы в/на искусственно генерируемом распространяемом сигнале, например, машинно-формируемом электрическом, оптическом или электромагнитном сигнале, который генерируют, чтобы закодировать информацию для передачи на подходящую аппаратуру приемника для исполнения аппаратурой обработки данных. Носитель данных компьютера может быть машиночитаемым устройством хранения данных, машиночитаемой подложкой хранения данных, устройством памяти со случайным или с последовательным доступом, или комбинацией носителей данных компьютера.
[00104] Термин "в реальном масштабе времени", ʺреальное времяʺ, ʺв реальном времениʺ, ʺреальное (быстрое) время (RFT)ʺ, ʺблизко(ое) к реальному времени (NRT)ʺ, ʺквази-реальное времяʺ, или подобные термины (как понято средним специалистом в данной области техники) означает, что действие и ответ являются ближайшими во времени, так что человек воспринимает действие и ответ происходящими по существу одновременно. Например, разность во времени для ответа, чтобы отобразить (или для инициации отображения) данные после действия человека по доступу к данным, может составлять менее чем 1 мс, менее чем 1 секунду, или менее чем 5 секунд. Хотя запрошенные данные не должны отображаться (или инициироваться для отображения) мгновенно, они отображаются (или инициируются для отображения) без какой-либо преднамеренной задержки, принимая во внимание ограничения обработки для описанной вычислительной системы и время, требуемое, чтобы, например, собрать, точно измерить, проанализировать, обработать, сохранить или передать данные.
[00105] Термины ʺаппаратура обработки данныхʺ, ʺкомпьютерʺ, или ʺэлектронное компьютерное устройствоʺ (или эквивалентные как понято средним специалистом в данной области техники) относятся к аппаратно-реализованным средствам обработки данных и охватывают все виды аппаратуры, устройств и машин для обработки данных, включая в качестве примера, программируемый процессор, компьютер или множество процессоров или компьютеров. Аппаратурой также может быть, или она дополнительно включает в себя, специализированные логические схемы, например, центральный процессор (CPU), базовый матричный кристалл (FPGA) или специализированную интегральную схему (ASIC). В некоторых реализациях аппаратура обработки данных или специализированные логические схемы (или комбинация и аппаратуры обработки данных, и специализированных логических схем) могут быть аппаратно- или программно-реализованными (или комбинацией аппаратно- или программно-реализованных). Аппаратура может необязательно включать в себя код, который создает среду выполнения для компьютерных программ, например, код, который составляет микропрограммное обеспечение процессора, стек протоколов, систему управления базами данных, операционную систему, или комбинацию сред выполнения. Настоящее раскрытие предполагает использование аппаратур обработки данных с наличием или без традиционных операционных систем, например, LINUX, UNIX, WINDOWS, MAC OS, ANDROID, IOS, или любой другой подходящей традиционной операционной системы.
[00106] Компьютерная программа, которая также может упоминаться или описываться как программа, программное обеспечение, программно-реализованное приложение, модуль, программный модуль, сценарий или код, могут быть написаны на языке программирования любой формы, включая компилируемые или интерпретируемые языки, либо декларативные или процедурные языки, и ее можно развертывать в любой форме, включая в виде автономной программы или в виде модуля, компонента, подпрограммы или другого модуля, подходящего для использования в вычислительной среде. Компьютерная программа может, но не требует, соответствовать файлу в файловой системе. Программа может сохраняться в порции файла, который содержит другие программы или данные, например, один или более сценариев, сохраняемых в документе на языке разметки, в одиночном файле, предназначенном для рассматриваемой программы, или в множестве скоординированных файлов, например, файлов, которые сохраняют один или более модулей, подпрограмм или порций кода. Компьютерная программа может быть развернута, чтобы исполняться на одном компьютере или на множестве компьютеров, которые размещены на одном сайте или распределены по множеству сайтов и взаимосвязаны сетью связи. Хотя порции программ, иллюстрируемых на различных фигурах чертежей, показаны как отдельные модули, которые реализуют различные характеристики и функциональность через посредство различных объектов, способов или других процессов, программы могут вместо этого включать в себя ряд подмодулей, сторонних услуг, компонентов, библиотек и т.п., как необходимо. Напротив, характеристики и функциональность различных компонентов могут быть объединены в единые компоненты, как необходимо. Пороговые значения, используемые для выполнения вычислительных определений, могут определяться статически, динамически, или и статически, и динамически.
[00107] Способы, процессы или логические последовательности операций, представленные в этом описании изобретения, могут выполняться посредством одного или нескольких программируемых компьютеров, исполняющих одну или несколько компьютерных программ, чтобы выполнять функции путем оперирования входными данными и формирования выходных данных. Способы, процессы или логические последовательности операций также могут выполняться посредством, и аппаратура также может быть реализована в виде, специализированных логических схем, например, CPU, FPGA или ASIC.
[00108] Компьютеры, подходящие для исполнения компьютерной программы, могут иметь в основе универсальные или специализированные микропроцессоры, оба вида, или любой другой вид CPU. Обычно, CPU будет принимать команды и данные из памяти и записывать их в нее. Существенными компонентами компьютера являются CPU, предназначенный для выполнения или исполнения команд, и одно или более запоминающих устройств для хранения команд и данных. Обычно, компьютер будет также включать в себя, или являться функционально связанным, для приема данных от них или передачи данных на них, или обоего, с одним или несколькими устройствами массовой памяти для сохранения данных, например, магнитными, магнето-оптическими дисками или оптическими дисками. Однако компьютеру не обязательно иметь такие устройства. Кроме того, компьютер может быть встроенным в другое устройство, например, мобильный телефон, персональный цифровой секретарь (PDA), мобильный аудиоплеер или видеоплеер, игровую приставку, приемник глобальной системы определения местоположения (GPS) или переносимое устройство хранения данных, например, флеш-память с интерфейсом универсальной последовательной шины (USB), если назвать только некоторые.
[00109] Читаемый компьютером носитель (временный или невременный, как необходимо), подходящий для сохранения команд компьютерной программы и данных, включает в себя все формы постоянной/ непостоянной или энергозависимой/ энергонезависимой памяти, носителей и запоминающих устройств, включая в качестве примера, устройства полупроводниковой памяти, например, оперативную память (RAM), постоянную память (ROM), память с записью методом фазового перехода (PRAM), статическую оперативную память (SRAM), динамическую оперативную память (DRAM), стираемую программируемую постоянную память (EPROM), электрически стираемую программируемую постоянную память (EEPROM), и устройства флэш-памяти; магнитные устройства, например, накопители на ленте, картриджи, кассеты, накопители на внутренних/ съемных дисках; магнето-оптические диски; и устройства оптической памяти, например, цифровой видеодиск (DVD), диски CD-ROM, DVD +/-R, DVD-RAM, DVD-ROM, HD-DVD и по технологии BLU-RAY (BD), и другие технологии оптической памяти. Память может сохранять различные объекты или данные, включая кэши, классы, инфраструктуры, приложения, модули, данные для резервного копирования, задания, веб-страницы, шаблоны веб-страниц, структуры данных, таблицы баз данных, хранилища данных, сохраняющие динамическую информацию, и любую другую надлежащую информацию, включая любые параметры, переменные, алгоритмы, команды, правила, ограничения или ссылки на таковое. Кроме того, память может включать в себя любые другие надлежащие данные, такие как журналы, политики, данные обеспечения безопасности или доступа, файлы отчетов, а также другие. Процессор и память могут быть дополнены специализированными логическими схемами или включены в них.
[00110] Для обеспечения взаимодействия с пользователем, реализации объекта изобретения, представленного в этом описании изобретения, могут быть реализованы на компьютере, имеющем устройство отображения, например, CRT (с электронно-лучевой трубкой), LCD (с жидкокристаллическим экраном), LED (на светоизлучающих диодах) или плазменный монитор, чтобы отображать информацию пользователю, и клавиатуру и манипулятор, например, мышь, шаровой манипулятор или сенсорную площадку, с помощью какового пользователь может обеспечивать ввод в компьютер. Ввод также может обеспечиваться в компьютер, использующий сенсорный экран, такой как поверхность планшетного компьютера с чувствительностью к давлению, мультисенсорный экран, использующий емкостное или электрическое восприятие, или другой тип сенсорного экрана. Другие виды устройств могут использоваться, чтобы также обеспечивать взаимодействие с пользователем; например, обратная связь, предоставляемая пользователю, может быть любой формой сенсорной обратной связи, например, визуальной обратной связью, слуховой обратной связью или тактильной обратной связью; и ввод от пользователя может приниматься в любой форме, включая акустический, речевой или тактильный ввод. Кроме того, компьютер может взаимодействовать с пользователем путем посылки документов на устройство и приема документов от устройства, которое используется пользователем; например, путем посылки веб-страницы веб-браузеру на клиентском устройстве пользователя в ответ на запросы, принятые от веб-браузера.
[00111] Термин ʺграфический пользовательский интерфейсʺ, или "GUI", может использоваться в единственном или множественном числе, чтобы описать один или более графических пользовательских интерфейсов и каждое из отображений конкретного графического пользовательского интерфейса. Следовательно, GUI может представлять любой графический пользовательский интерфейс, включая, но без ограничения указанным, веб-браузер, сенсорный экран или интерфейс командной строки (CLI), который обрабатывает информацию и эффективно представляет пользователю информационные результаты. Вообще, GUI может включать в себя ряд элементов пользовательского интерфейса (UI), некоторые или все в увязке с веб-браузером, такие как интерактивные поля, выпадающие списки и кнопки. Эти и другие элементы UI могут относиться к функциям веб-браузера или представлять таковые.
[00112] Реализации объекта изобретения, представленного в этом описании изобретения, могут быть осуществлены в вычислительной системе, которая включает в себя серверный компонент, например, в виде сервера данных, или которая включает в себя компонент промежуточного программного обеспечения, например, сервер приложений, или которая включает в себя интерфейсный компонент, например, клиентский компьютер, имеющий графический пользовательский интерфейс или Веб-браузер, через который пользователь может взаимодействовать с реализацией объекта изобретения, представленного в этом описании изобретения, или любую комбинацию из одного или нескольких таких серверных, промежуточного ПО или интерфейсных компонентов. Компоненты системы могут быть взаимосвязаны с помощью любой формы или носителя проводной или беспроводной передачи цифровых данных (или комбинации (форм) передачи данных), например, сети связи. Примеры сетей связи включают в себя локальную сеть (LAN), сеть с радиодоступом (RAN), городскую вычислительную сеть (MAN), глобальную сеть (WAN), сеть стандарта глобального широкополосного беспроводного доступа (WIMAX), беспроводную локальную сеть (WLAN), использующую, например, протоколы 802.11 a/b/g/n или 802.20 (или комбинацию 802.11x и 802.20 или другие протоколы, в соответствии с этим раскрытием), всю или часть сети Интернет, или любую другую систему или системы связи в одном или нескольких местоположениях (или комбинацию сетей связи). Сеть может осуществлять обмен информацией с помощью, например, пакетов по протоколу Internet (IP), кадров по протоколу Frame Relay (ретрансляции кадров), ячеек по протоколу асинхронного режима передачи (ATM), речи, видео, данных или другой подходящей информации (или комбинации видов обмена информацией) между сетевыми адресами.
[00113] Вычислительная система может включать в себя клиенты и серверы. Клиент и сервер являются обычно удаленными друг от друга и обычно взаимодействуют через сеть связи. Отношение клиента и сервера возникает благодаря компьютерным программам, работающим на соответственных компьютерах и имеющим отношение клиент-сервер друг к другу.
[00114] Хотя это описание изобретения содержит многие конкретные подробности реализации, они не должны рассматриваться как ограничения на объем какого-либо изобретения или на объем того, что может быть заявлено в формуле, а предпочтительнее как описания признаков, которые могут быть специфическими для конкретных реализаций конкретных изобретений. Некоторые признаки, которые представлены в этом описании в контексте отдельных реализаций, также могут реализовываться в комбинации, в одиночной реализации. Напротив, различные признаки, которые описаны в объеме одной реализации, также могут реализовываться во множестве реализаций, отдельно, или в любой подходящей подкомбинации. Кроме того, хотя вышеописанные признаки могут быть описаны действующими в некоторых комбинациях и даже первоначально заявлены таковыми, один или несколько признаков из заявленной комбинации могут быть, в некоторых случаях, удалены из комбинации, и заявленная комбинация может быть направлена на подкомбинацию или изменение подкомбинации.
[00115] Были описаны конкретные реализации объекта изобретения. Другие реализации, изменения и перестановки описанных реализаций находятся в рамках объема следующих пунктов формулы изобретения, как будет очевидно специалистам в данной области техники. Хотя операции изображены на чертежах или в формуле изобретения в конкретном порядке, это не следует понимать требующим обязательного выполнения таких операций в конкретном показанном порядке или в последовательном порядке, или что все иллюстрируемые операции должны выполняться (некоторые операции могут считаться необязательными) для достижения желательных результатов. В некоторых обстоятельствах многозадачность или параллельная обработка (или комбинация многозадачности и параллельной обработки) могут быть полезными и выполняться, как полагают надлежащим.
[00116] Кроме того, разделение или объединение различных модулей и компонентов системы в вышеописанных реализациях не следует понимать требующими такого разделения или объединения во всех реализациях, и следует понять, что описанные программные компоненты и системы обычно могут объединяться вместе в единый программный продукт или пакетироваться в множество программных продуктов.
[00117] Соответственно, вышеописанные примерные реализации не определяют и не ограничивают это раскрытие. Другие изменения, подстановки и модификации также являются возможными без выхода за рамки существа и объема этого раскрытия.
[00118] Кроме того, любая заявленная реализация считается применяемой к, по меньшей мере, реализуемому компьютером способу; невременному, читаемому компьютером носителю, сохраняющему читаемые компьютером команды, чтобы выполнять реализуемый с помощью компьютера способ; и компьютерной системе, содержащей память компьютера, функционально связанную с аппаратно-реализованным процессором, сконфигурированным для выполнения реализуемого с помощью компьютера способа или команд, сохраненных на невременном, читаемом компьютером носителе.
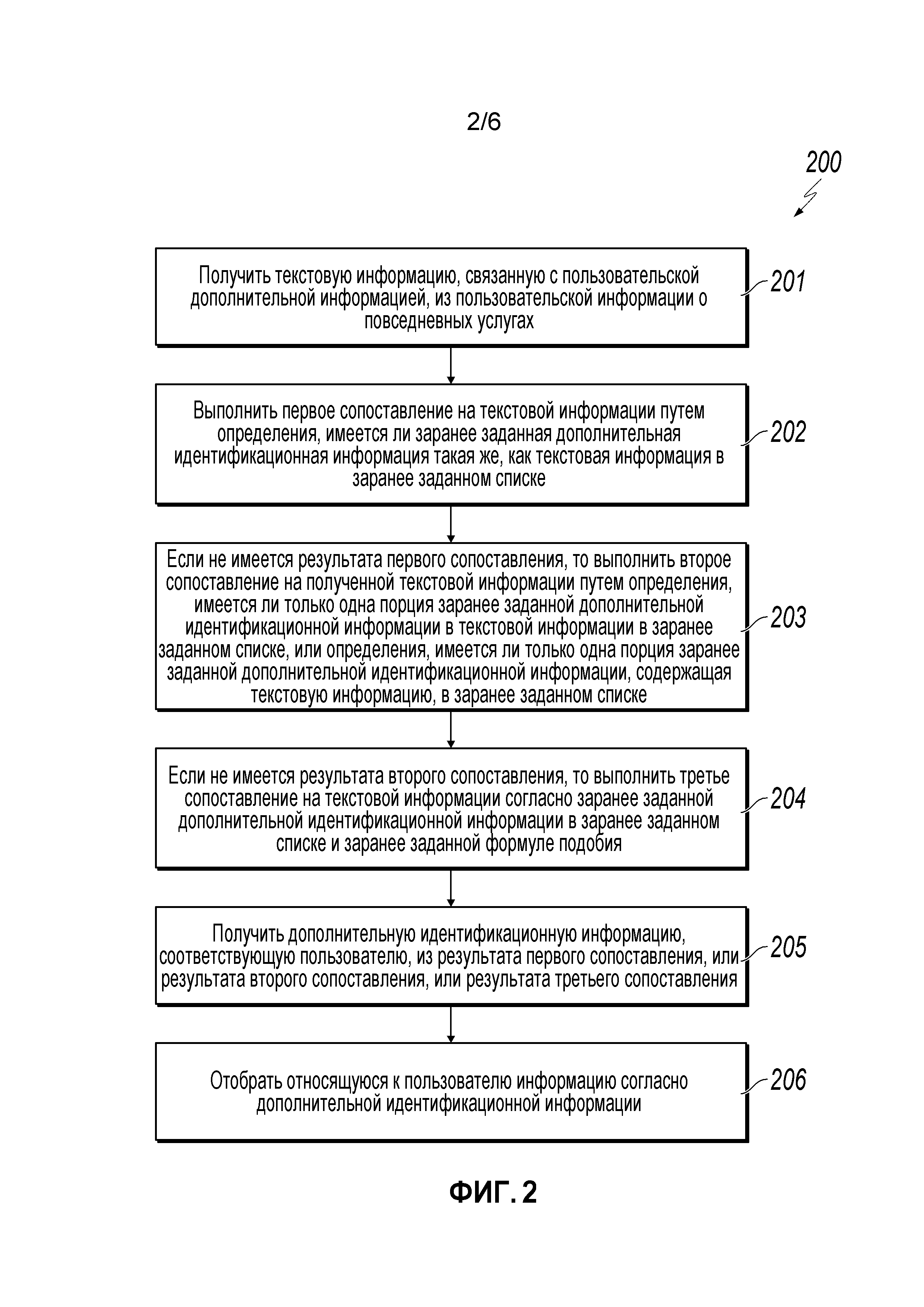
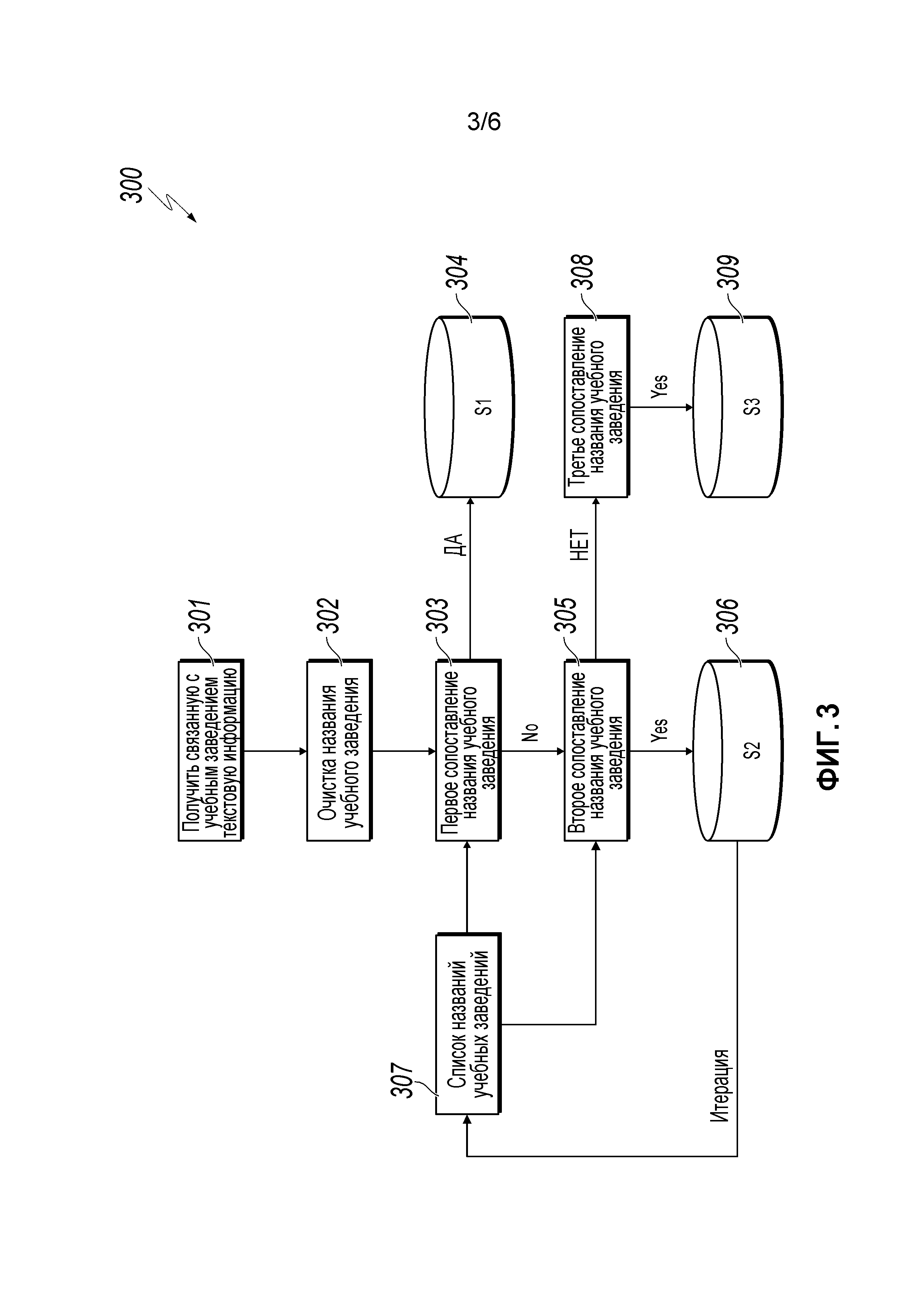
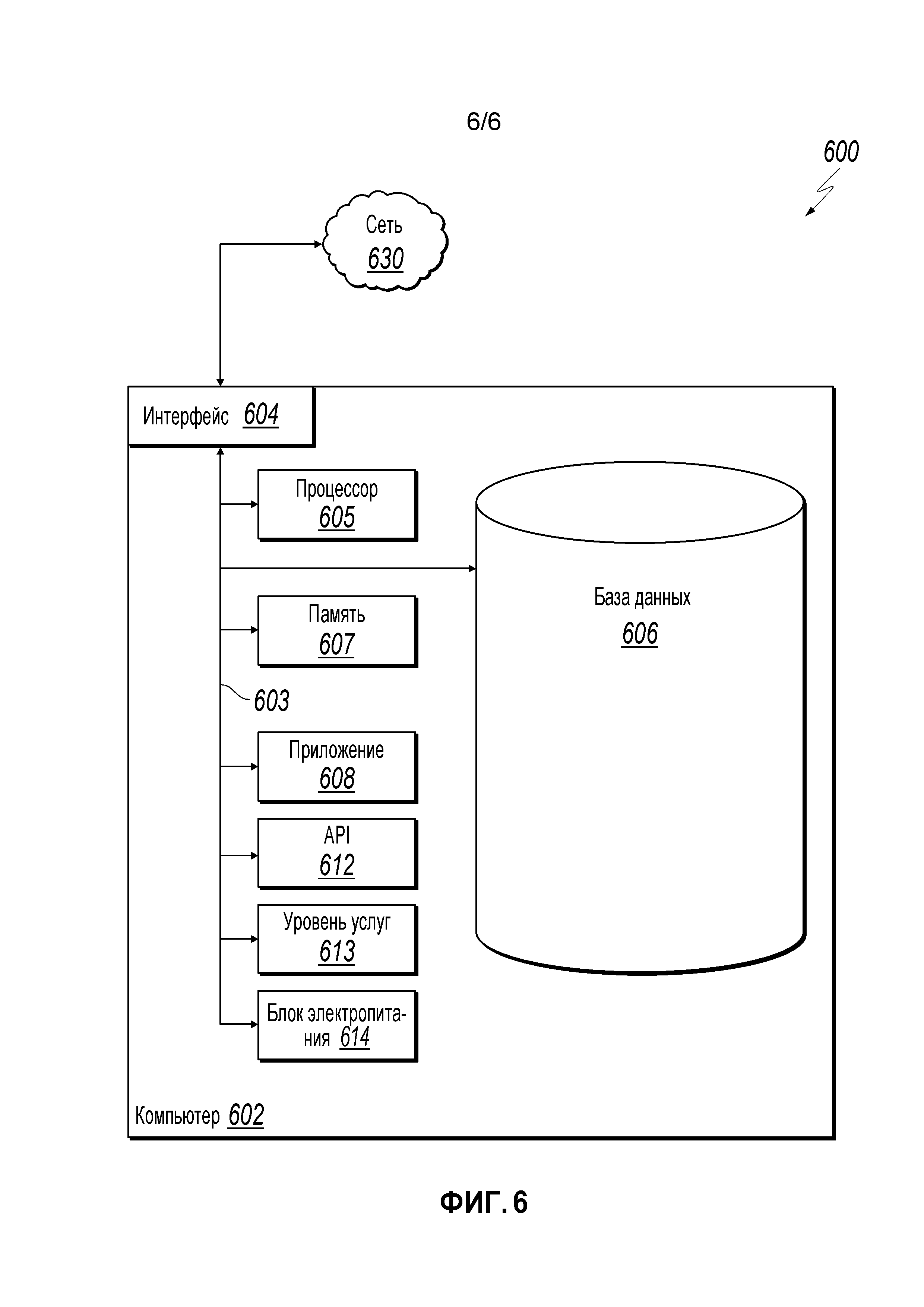
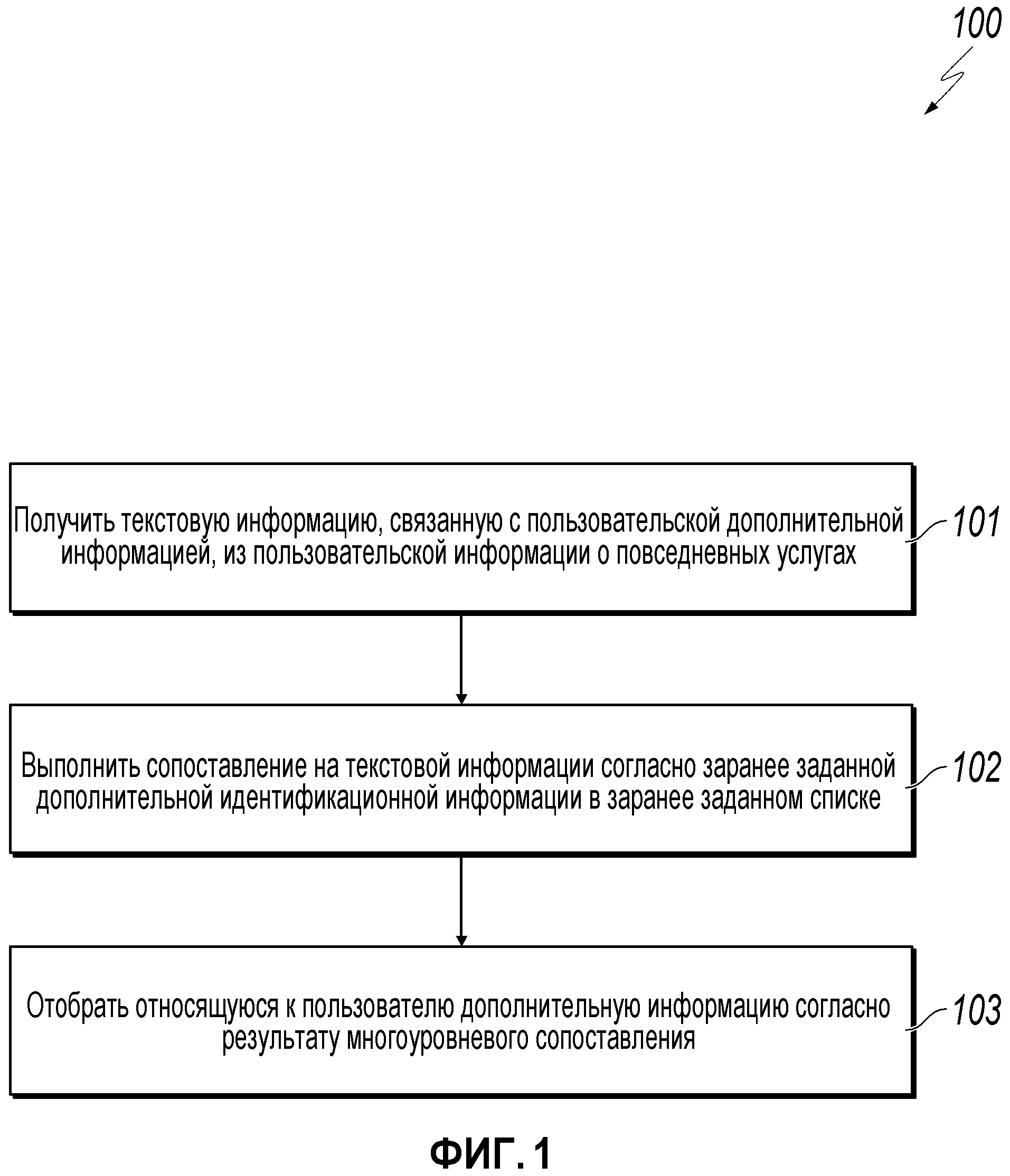
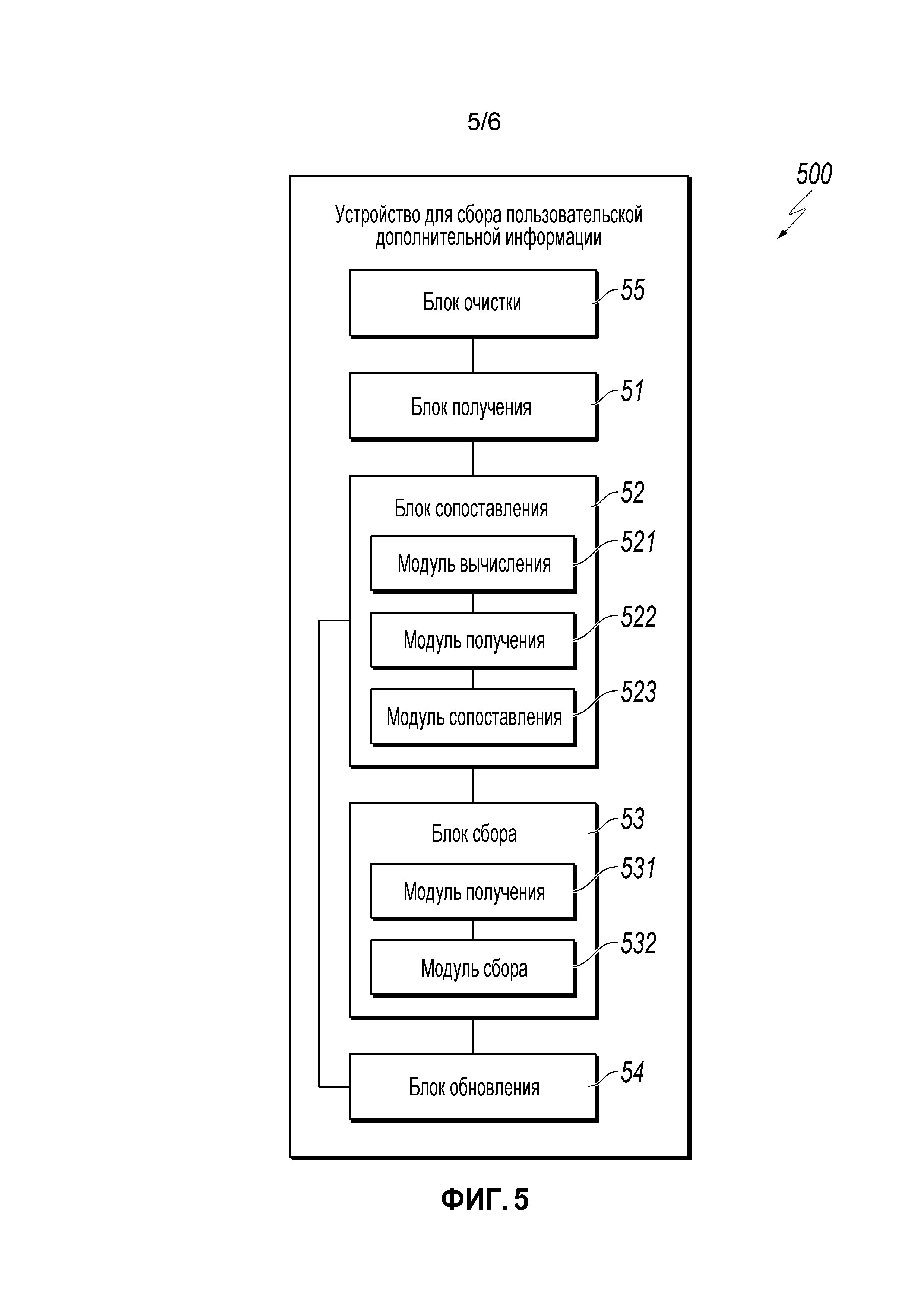
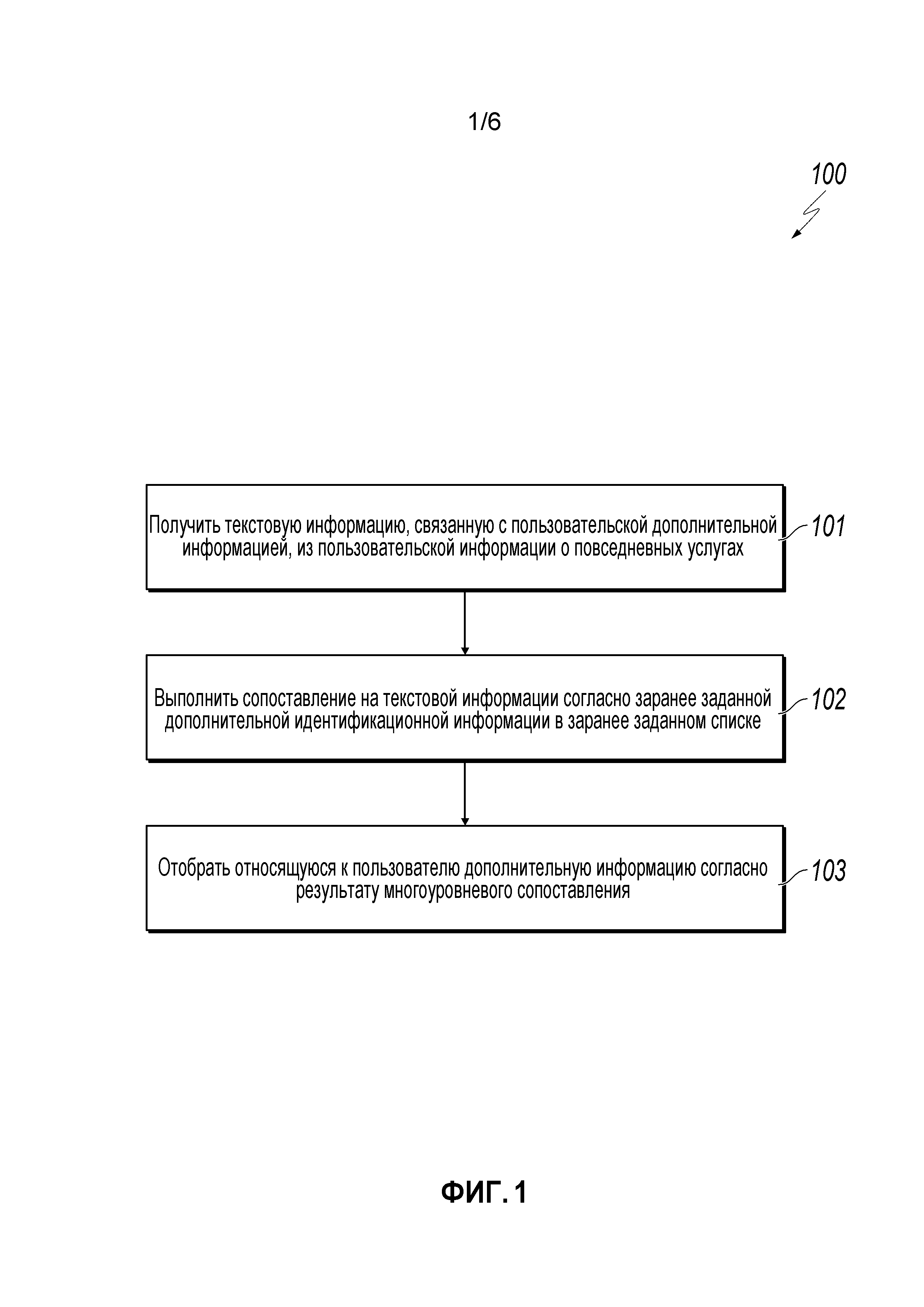
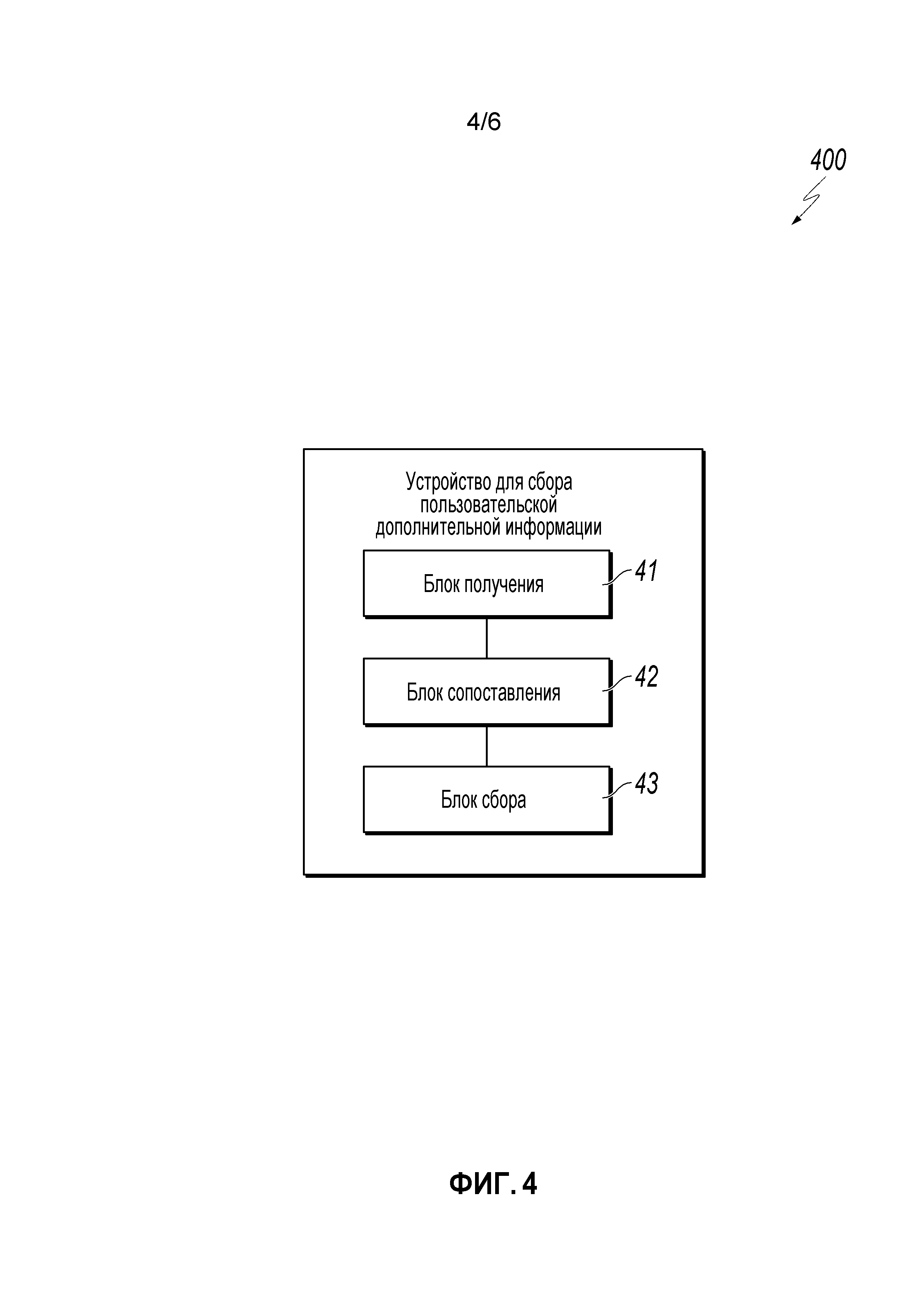
Способ и устройство проверки
Способ и аппарат для получения информации о местоположении
Способ и устройство регистрации и аутентификации информации
Поиск, основанный на комбинировании пользовательских данных отношений
Способ и устройство распределенной обработки потоковых данных
Схема доменных имен для перекрестных цепочечных взаимодействий в системах цепочек блоков
Перекрестные цепочечные взаимодействия с использованием схемы доменных имен в системах цепочек блоков
Защита данных цепочек блоков с использованием гомоморфного шифрования
Способ и устройство для обработки запроса услуги
Управление связью между консенсусными узлами и клиентскими узлами
Способ и устройство для управления цифровым контентом
Способ, система, ретрансляционная станция и базовая станция для передачи данных в мобильной связи
Способ, сервер, устройство, система и приспособление для установления сеанса
Разъем головного телефона, штекер головного телефона, головной телефон и электронное устройство
Устройство для защиты схемы и электронное устройство
Способ и устройство для запуска исполнения инструкции работы
Способ связи в беспроводной локальной сети с группой, состоящей из ретрансляторов и узлов радиодоступа

