Результат интеллектуальной деятельности: КОДЕР И СПОСОБ КОДИРОВАНИЯ АУДИОСИГНАЛА С УМЕНЬШЕННЫМ ФОНОВЫМ ШУМОМ С ИСПОЛЬЗОВАНИЕМ КОДИРОВАНИЯ С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ
Вид РИД
Изобретение
Настоящее изобретение относится к кодеру для кодирования аудиосигнала с уменьшенным фоновым шумом с использованием кодирования с линейным предсказанием, соответствующему способу и системе, содержащей кодер и декодер. Иными словами, настоящее изобретение относится к подходу совмещенного улучшения и/или кодирования речи, такому как, например, совмещенное улучшение и кодирование речи, путем внесения в кодек CELP (линейного предсказания с возбуждением посредством кодовой книги).
Поскольку устройства речи и связи стали повсеместными и имеют большую вероятность использования в неблагоприятных условиях, спрос на способы улучшения речи, которые могут справиться с неблагоприятными средами, увеличился. Следовательно, например, в мобильных телефонах сейчас является обычным использовать способы уменьшения шума в качестве блока/этапа предварительной обработки для всей последующей обработки речи, такой как кодирование речи. Существуют различные подходы, которые вносят улучшение речи в кодеры речи [1, 2, 3, 4]. Хотя такие проектирования действительно улучшают качество передаваемой речи, каскадная обработка не обеспечивает возможности совмещенной перцепционной оптимизации/минимизации качества, или совмещенная минимизация шума квантования и помех по меньшей мере была сложна.
Целью кодеков речи является обеспечить возможность передачи высококачественной речи с минимальным количеством передаваемых данных. Для того чтобы достичь этой цели, необходимы эффективные представления сигнала, такие как моделирование спектральной огибающей сигнала речи путем линейного предсказания, основной частоты путем долговременного средства предсказания и невязки с помощью кодовой книги шума. Это представление является основой кодеков речи с использованием парадигмы линейного предсказания с кодовым возбуждением (CELP), которая используется в основных стандартах кодирования речи, таких как адаптивное многоскоростное кодирование (AMR), широкополосное AMR (AMR-WB), объединенное кодирование речи и аудио (USAC) и улучшенная голосовая служба (EVS) [5, 6, 7, 8, 9, 10, 11].
Для голосовой связи в естественных условиях говорящие часто используют устройства в режимах громкой связи. В таких сценариях микрофон обычно находится далеко ото рта, из-за чего сигнал речи может легко становиться искаженным помехами, такими как реверберация или фоновый шум. Это ухудшение влияет не только на перцепционное качество речи, но также на разборчивость сигнала речи, и может, таким образом, существенно препятствовать естественности разговора. Для того чтобы улучшить впечатления от связи, следовательно, выгодно применять способы улучшения речи, чтобы подавить шум и уменьшить эффекты реверберации. Область техники улучшения речи развита, и много способов общедоступно [12]. Однако большинство существующих алгоритмов основано на методах перекрытия со сложением, таких как преобразования, такие как оконное преобразование Фурье (STFT), которые применяют схемы применения окна на основе перекрытия со сложением, в то время как в отличие от этого кодеки CELP моделируют сигнал посредством средства линейного предсказания/фильтра линейного предсказания и применяют применение окна только в отношении невязки. Такие фундаментальные различия усложняют слияние способов улучшения и кодирования. Однако ясно, что совмещенная оптимизация улучшения и кодирования может потенциально улучшить качество, уменьшить задержку и вычислительную сложность.
Таким образом, существует необходимость в улучшенном подходе.
Целью настоящего изобретения является обеспечить улучшенную концепцию для обработки аудиосигнала с использованием кодирования с линейным предсказанием. Эта цель достигается предметом независимых пунктов формулы изобретения.
Варианты осуществления настоящего изобретения показывают кодер для кодирования аудиосигнала с уменьшенным фоновым шумом с использованием кодирования с линейным предсказанием. Кодер содержит средство оценки фонового шума, сконфигурированное с возможностью оценивать фоновый шум аудиосигнала, средство уменьшения фонового шума, сконфигурированное с возможностью генерировать аудиосигнал с уменьшенным фоновым шумом путем вычитания оцененного фонового шума аудиосигнала из аудиосигнала, и средство предсказания, сконфигурированное с возможностью подвергать аудиосигнал анализу методом линейного предсказания, чтобы получить первый набор коэффициентов фильтра линейного предсказания (LPC), и подвергать аудиосигнал с уменьшенным фоновым шумом анализу методом линейного предсказания, чтобы получить второй набор коэффициентов фильтра линейного предсказания (LPC). Кроме того, кодер содержит фильтр анализа, состоящий из каскада фильтров временной области, управляемых полученным первым набором коэффициентов LPC и полученным вторым набором коэффициентов LPC.
Настоящее изобретение основано на обнаружении, что улучшенный фильтр анализа в среде кодирования с линейным предсказанием увеличивает свойства обработки сигналов кодера. Более конкретным образом, использование каскада или последовательности последовательно подключенных фильтров временной области улучшает скорость обработки или время обработки входного аудиосигнала, если упомянутые фильтры применяются к фильтру анализа среды кодирования с линейным предсказанием. Это имеет преимущества, поскольку обычно используемое временно-частотное преобразование и обратное частотно-временное преобразование входного аудиосигнала временной области для уменьшения фонового шума путем фильтрации полос частот, на которых преобладает шум, опускаются. Иными словами, путем выполнения уменьшения или подавления фонового шума в рамках фильтра анализа уменьшение фонового шума может выполняться во временной области. Таким образом, процедура наложения и сложения, например, MDCT/IDMCT ([обратного] модифицированного дискретного косинусного преобразования), которая может быть использована для преобразования "время/частота/время", опускается. Этот способ наложения и сложения ограничивает характеристику обработки в реальном времени кодера, поскольку уменьшение фонового шума не может выполняться в отношении единственного кадра, а только в отношении последовательных кадров.
Иными словами, описанный кодер имеет возможность выполнять уменьшение фонового шума и, следовательно, полную обработку фильтра анализа в отношении единственного аудиокадра и, таким образом, обеспечивает возможность обработки аудиосигнала в реальном времени. Обработкой в реальном времени может называться обработка аудиосигнала без заметной задержки для участвующих пользователей. Заметная задержка может происходить, например, в телеконференции, если один пользователь вынужден ожидать ответа других пользователей ввиду задержки обработки аудиосигнала. Эта максимальная допустимая задержка может быть менее 1 секунды, предпочтительно менее 0,75 секунды или, еще более предпочтительно, менее 0,25 секунды. Следует заметить, что эти отрезки времени обработки относятся ко всей обработке аудиосигнала от отправителя до приемника и, таким образом, включают в себя помимо обработки сигналов кодера также и время передачи аудиосигнала и обработки сигналов в соответствующем декодере.
Согласно вариантам осуществления, каскад фильтров временной области, и, следовательно, фильтр анализа, содержит два раза фильтр линейного предсказания с использованием полученного первого набора коэффициентов LPC и один раз обратную функцию дополнительного фильтра линейного предсказания с использованием полученного второго набора коэффициентов LPC. Эта обработка сигналов может называться фильтрацией Винера. Таким образом, иными словами, каскад фильтров временной области может содержать фильтр Винера.
Согласно дополнительным вариантам осуществления, средство оценки фонового шума может оценить автокорреляцию фонового шума в качестве представления фонового шума аудиосигнала. Кроме того, средство уменьшения фонового шума может генерировать представление аудиосигнала с уменьшенным фоновым шумом путем вычитания автокорреляции фонового шума из оцененной автокорреляции аудиосигнала, причем оцененная автокорреляция аудиосигнала является представлением аудиосигнала и причем представление аудиосигнала с уменьшенным фоновым шумом является автокорреляцией аудиосигнала с уменьшенным фоновым шумом. Использование оценки функций автокорреляции вместо использования аудиосигнала временной области для вычисления коэффициентов LPC и для выполнения уменьшения фонового шума обеспечивает возможность обработки сигналов полностью во временной области. Следовательно, автокорреляция аудиосигнала и автокорреляция фонового шума может быть вычислена путем свертывания или посредством интеграла свертывания аудиокадра или составной части аудиокадра. Таким образом, автокорреляция фонового шума может выполняться в кадре или даже только в подкадре, который может быть определен как кадр или часть кадра, где (почти) никакого аудиосигнала переднего плана, такого как речь, не присутствует. Кроме того, автокорреляция аудиосигнала с уменьшенным фоновым шумом может быть вычислена путем вычитания автокорреляции фонового шума и автокорреляции аудиосигнала (содержащего фоновый шум). Использование автокорреляции аудиосигнала с уменьшенным фоновым шумом и аудиосигнала (обычно имеющего фоновый шум) обеспечивает возможность вычисления коэффициентов LPC для аудиосигнала с уменьшенным фоновым шумом и аудиосигнала, соответственно. Коэффициенты LPC уменьшенного фонового шума могут называться вторым набором коэффициентов LPC, причем коэффициенты LPC аудиосигнала могут называться первым набором коэффициентов LPC. Таким образом, аудиосигнал может быть полностью обработан во временной области, поскольку применение каскада фильтров временной области также выполняет их фильтрацию в отношении аудиосигнала во временной области.
Прежде чем варианты осуществления будут описаны подробно с использованием сопроводительных чертежей, следует указать, что одни и те же или функционально эквивалентные элементы наделяются одними и теми же ссылочными позициями на чертежах и что повторное описание для элементов, обеспеченных одними и теми же ссылочными позициями, опускается. Следовательно, описания, обеспеченные для элементов, имеющих одни и те же ссылочные позиции, взаимозаменяемы.
Варианты осуществления настоящего изобретения будут рассмотрены далее со ссылками на прилагаемые чертежи, на которых:
фиг.1 изображает схематичную структурную схему системы, содержащей кодер для кодирования аудиосигнала и декодер;
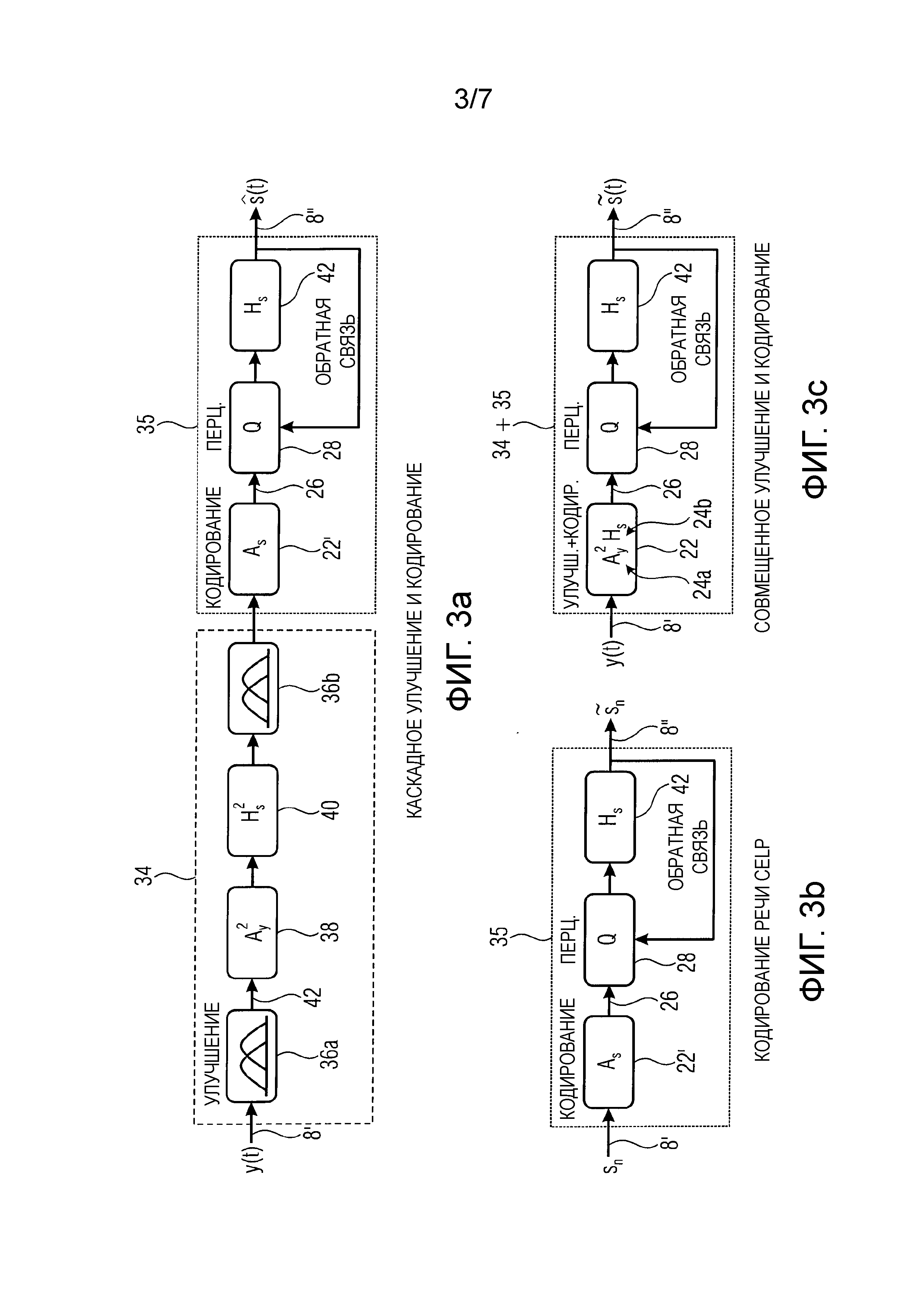
фиг.2 изображает схематичную структурную схему a) схемы каскадного кодирования улучшения, b) схемы кодирования речи CELP и c) изобретательской схемы совмещенного кодирования улучшения;
фиг.3 изображает схематичную структурную схему варианта осуществления с фиг.2 с другими обозначениями;
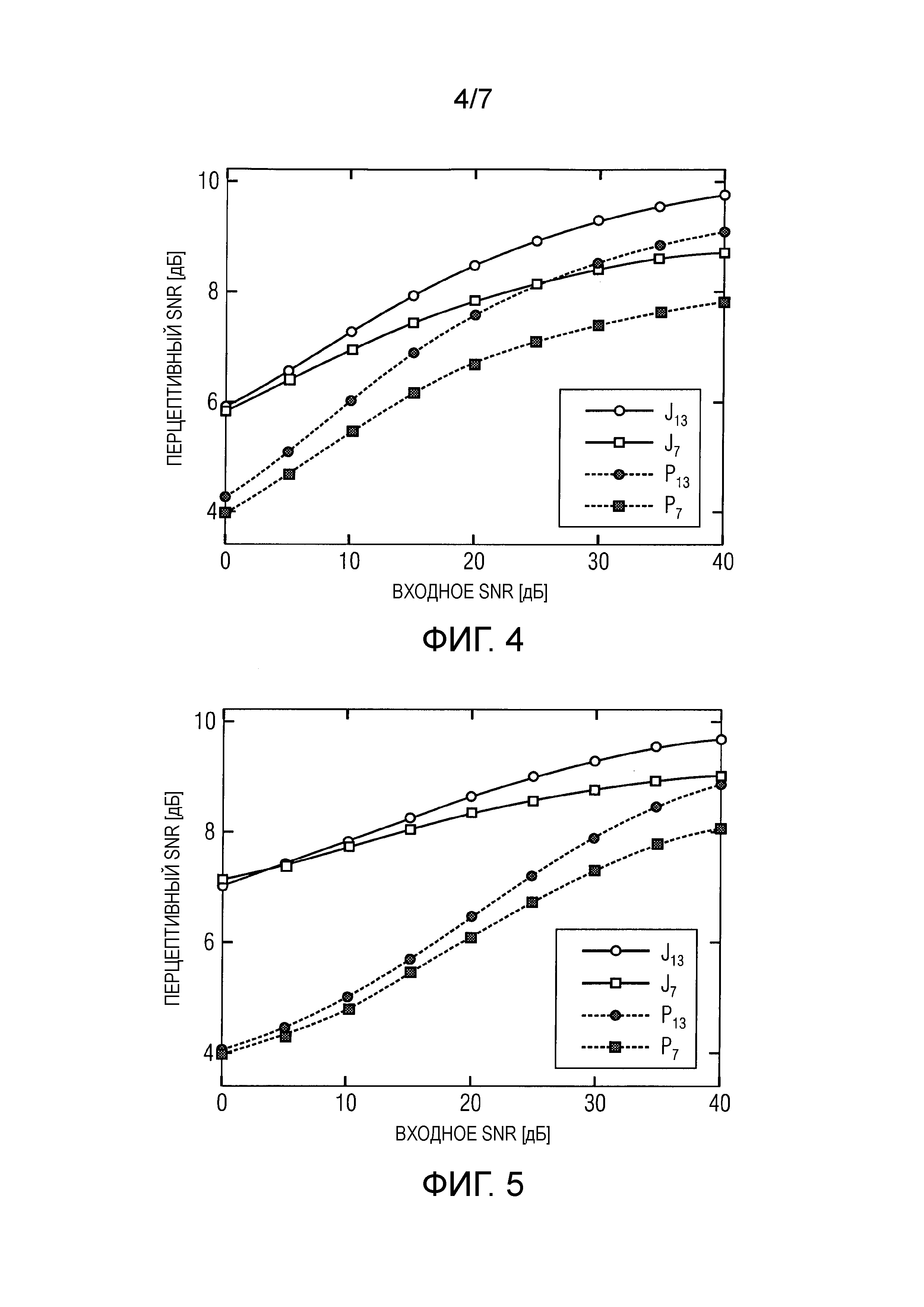
фиг.4 изображает схематический линейный график перцепционного SNR (отношения сигнала к шуму) интенсивности, как определено в уравнении 23 для предлагаемого совмещенного подхода (J) и каскадного способа (C), причем входной сигнал был ухудшен нестационарным шумом автомобиля, и результаты представляются для двух различных скоростей передачи битов (7,2 кбит/с, указанной индексом 7, и 13,2 кбит/с, указанной индексом 13);
фиг.5 изображает схематический линейный график перцепционного SNR интенсивности, как определено в уравнении 23 для предлагаемого совмещенного подхода (J) и каскадного способа (C), причем входной сигнал был ухудшен стационарным белым шумом, и результаты представляются для двух различных скоростей передачи битов (7,2 кбит/с, указанной индексом 7, и 13,2 кбит/с, указанной индексом 13);
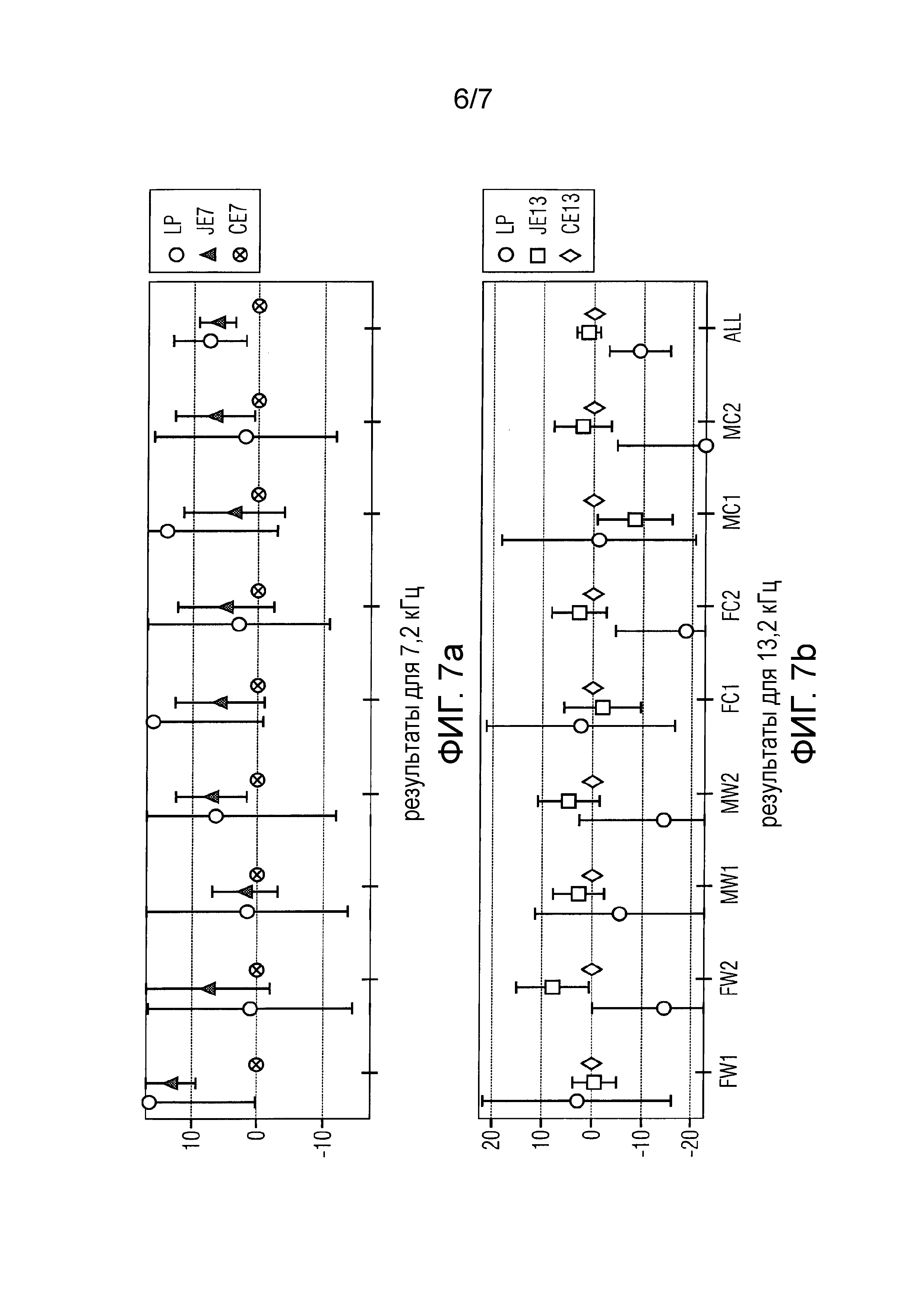
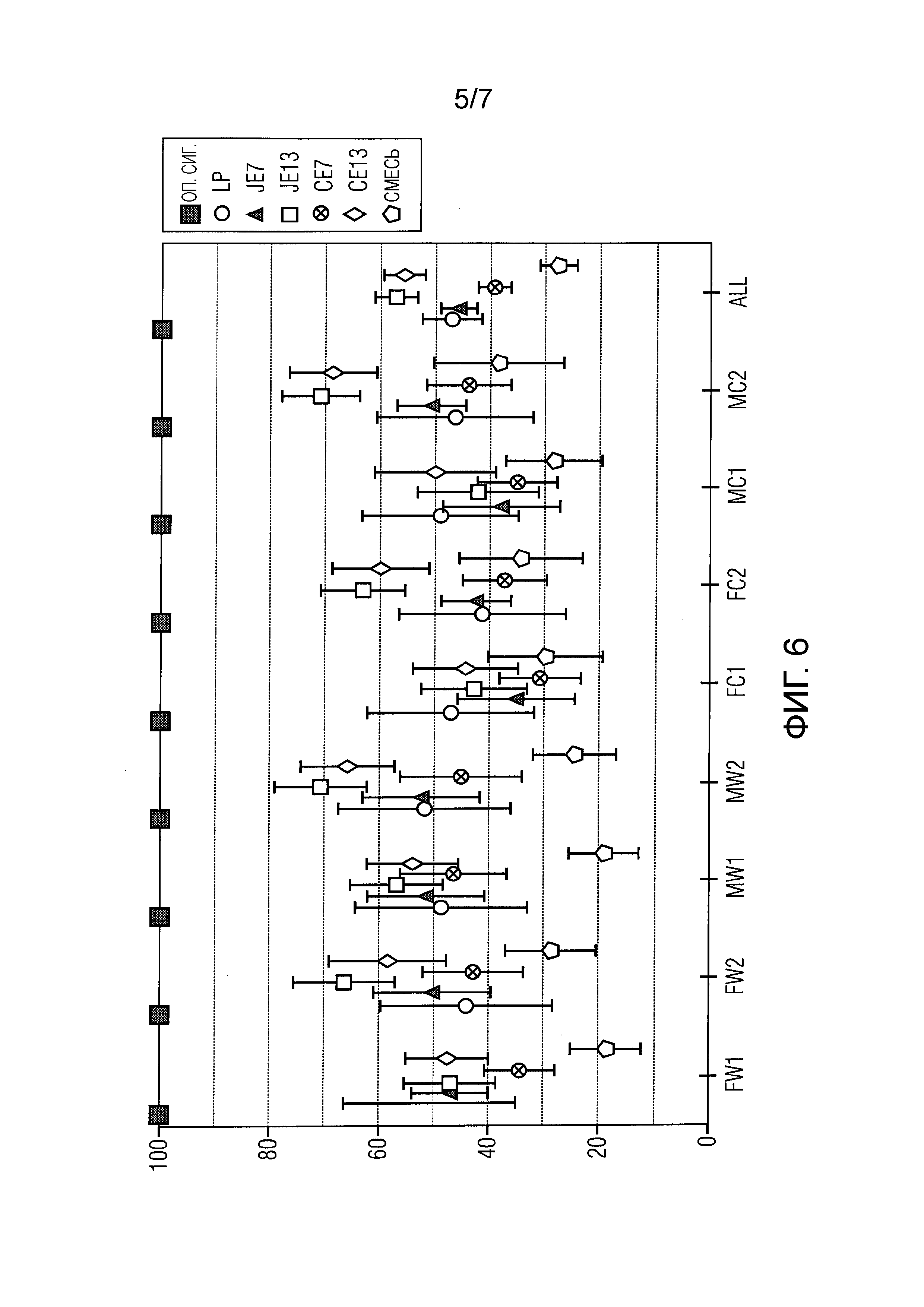
фиг.6 изображает схематический план, показывающий иллюстрацию оценок MUSHRA для различных англоговорящих людей (женщины (F) и мужчины (M)) для двух различных помех (белого шума (W) и шума автомобиля (C)), для двух различных входных SNR (10 дБ (1) и 20 дБ (2)), причем все элементы были закодированы на двух скоростях передачи битов (7,2 кбит/с (7) и 13,2 кбит/с (13)), для предлагаемого совмещенного подхода (JE) и каскадного улучшения (CE), где "оп. сиг." - скрытый опорный сигнал, LP - 3,5 кГц низкочастотная привязка, и "смесь" - искаженная смесь;
фиг.7 изображает план различных оценок MUSHRA, смоделированных на двух различных скоростях передачи битов, сравнивающий новое совмещенное улучшение (JE) с каскадным подходом (CE); и
фиг.8 изображает схематическую блок-схему способа кодирования аудиосигнала с уменьшенным фоновым шумом с использованием кодирования с линейным предсказанием.
Далее варианты осуществления изобретения будут описаны более подробно. С элементами, показанными на соответственных чертежах, имеющими одни и те же или подобные функциональные возможности, ассоциированы одни и те же позиционные обозначения.
Далее будет описан способ совмещенного улучшения и кодирования на основе фильтрации Винера [12] и кодирования CELP. Преимущества этого слияния состоят в том, что 1) включение фильтрации Винера в цепочку обработки не увеличивает низкой алгоритмической задержки кодека CELP, и в том, что 2) совмещенная оптимизация одновременно минимизирует искажение ввиду квантования и фонового шума. Кроме того, вычислительная сложность совмещенной схемы ниже одного из каскадных подходов. Осуществление полагается на недавнюю работу по применению окна невязки в кодеках CELP-стиля [13, 14, 15], что обеспечивает возможность внести фильтрацию Винера в фильтры кодека CELP новым образом. С этим подходом может быть продемонстрировано, что и объективное, и субъективное качество улучшается по сравнению с каскадной системой.
Предлагаемый способ совмещенного улучшения и кодирования речи тем самым избегает накопления ошибок ввиду каскадной обработки и дополнительно улучшает перцепционное выходное качество. Иными словами, предлагаемый способ избегает накопления ошибок ввиду каскадной обработки, поскольку совмещенная минимизация помех и искажения квантования осуществляется оптимальной фильтрацией Винера в перцепционной области.
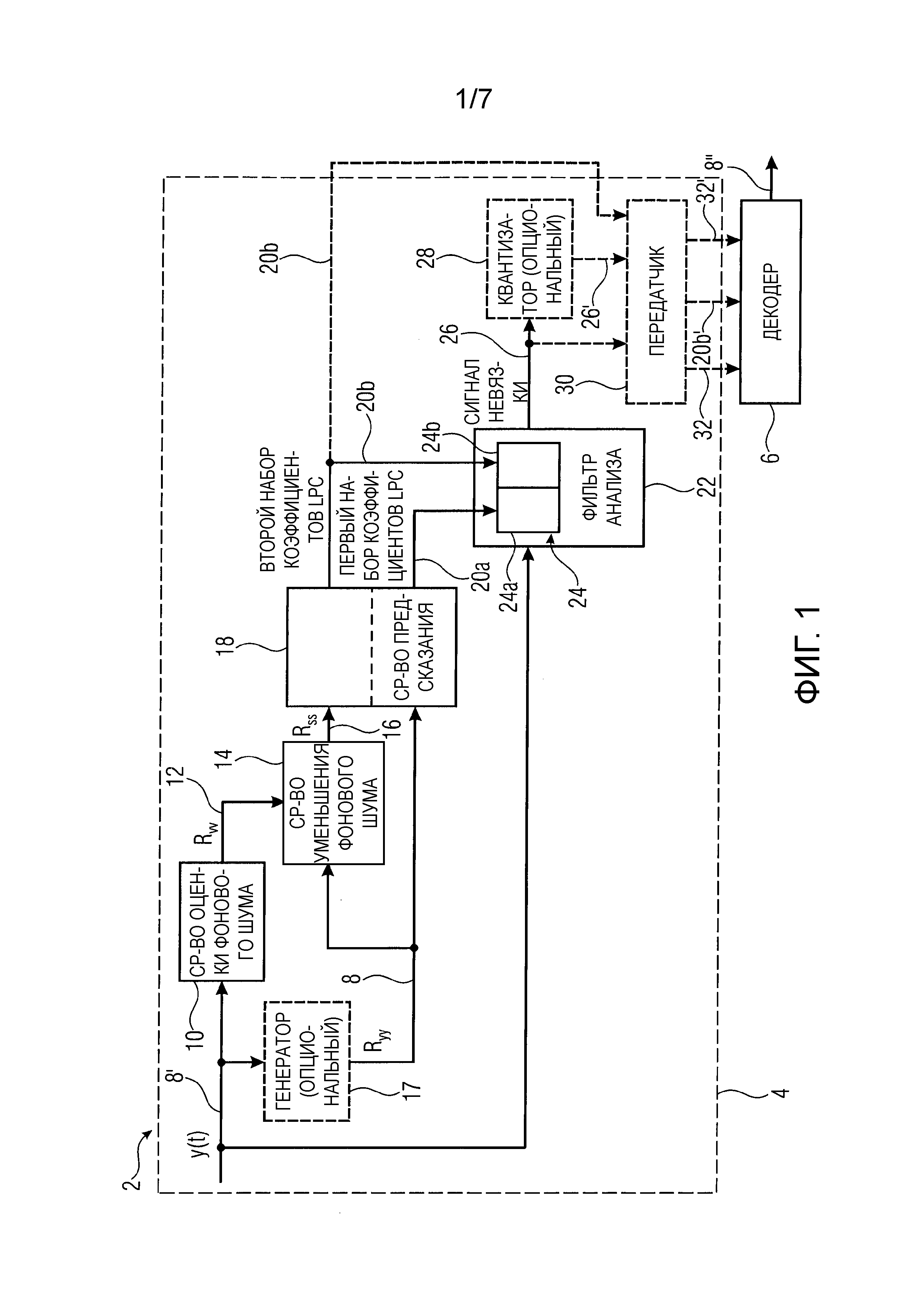
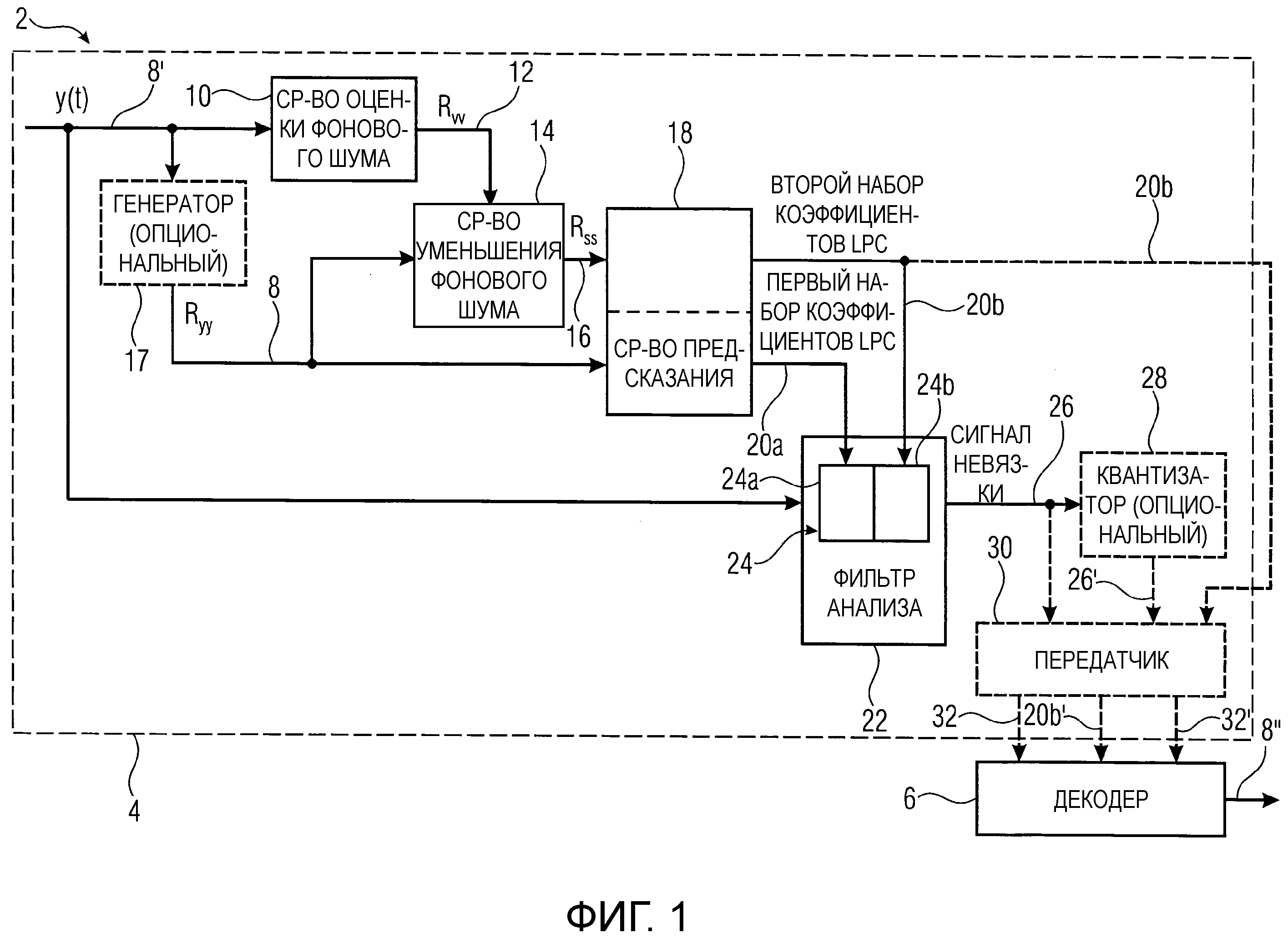
Фиг.1 изображает схематичную структурную схему системы 2, содержащей кодер 4 и декодер 6. Кодер 4 сконфигурирован для кодирования аудиосигнала 8' с уменьшенным фоновым шумом с использованием кодирования с линейным предсказанием. Таким образом, кодер 4 может содержать средство 10 оценки фонового шума, сконфигурированное с возможностью оценить представление фонового шума 12 аудиосигнала 8'. Кодер может дополнительно содержать средство 14 уменьшения фонового шума, сконфигурированное с возможностью генерировать представление аудио сигнала 16 с уменьшенным фоновым шумом путем вычитания представления оцененного фонового шума 12 аудиосигнала 8' из представления аудиосигнала 8. Таким образом, средство 14 уменьшения фонового шума может принимать представление фонового шума 12 от средства 10 оценки фонового шума. Дополнительным входным сигналом средства уменьшения фонового шума может быть аудиосигнал 8' или представление аудиосигнала 8. Опционально, средство уменьшения фонового шума может содержать генератор, сконфигурированный с возможностью внутренним образом генерировать представление аудиосигнала 8, такое как, например, автокорреляция 8 аудиосигнала 8'.
Кроме того, кодер 4 может содержать средство 18 предсказания, сконфигурированное с возможностью подвергать представление аудиосигнала 8 анализу методом линейного предсказания, чтобы получить первый набор коэффициентов 20a фильтра линейного предсказания (LPC), и подвергать представление аудиосигнала 16 с уменьшенным фоновым шумом анализу методом линейного предсказания, чтобы получить второй набор коэффициентов 20b фильтра линейного предсказания. Подобно средству 14 уменьшения фонового шума, средство 18 предсказания может содержать генератор, чтобы внутренним образом генерировать представление аудиосигнала 8 из аудиосигнала 8'. Однако может быть выгодно использовать общий или центральный генератор 17, чтобы вычислять представление 8 аудиосигнала 8' единожды и чтобы обеспечивать представление аудиосигнала, такое как автокорреляция аудиосигнала 8', средству 14 уменьшения фонового шума и средству 18 предсказания. Таким образом, средство предсказания может принимать представление аудиосигнала 8 и представление аудиосигнала 16 с уменьшенным фоновым шумом, например автокорреляцию аудиосигнала и автокорреляцию аудиосигнала с уменьшенным фоновым шумом, соответственно, и определять на основе входных сигналов первый набор коэффициентов LPC и второй набор коэффициентов LPC, соответственно.
Иными словами, первый набор коэффициентов LPC может быть определен из представления аудиосигнала 8, и второй набор коэффициентов LPC может быть определен из представления аудиосигнала 16 с уменьшенным фоновым шумом. Средство предсказания может выполнять алгоритм Левинсона-Дарбина, чтобы вычислить первый и второй набор коэффициентов LPC из соответственной автокорреляции.
Кроме того, кодер содержит фильтр 22 анализа, состоящий из каскада 24 фильтров 24a, 24b временной области, управляемых полученным первым набором коэффициентов 20a LPC и полученным вторым набором коэффициентов 20b LPC. Фильтр анализа может применить каскад фильтров временной области, в котором коэффициенты фильтра первого фильтра 24a временной области являются первым набором коэффициентов LPC, и коэффициенты фильтра второго фильтра 24b временной области являются вторым набором коэффициентов LPC, к аудиосигналу 8', чтобы определить сигнал 26 невязки. Сигнал невязки может содержать компоненты сигнала аудиосигнала 8', которые не могут быть представлены линейным фильтром, имеющим первый и/или второй набор коэффициентов LPC.
Согласно вариантам осуществления, сигнал невязки может быть обеспечен квантователю 28, сконфигурированному с возможностью квантовать и/или кодировать сигнал невязки и/или второй набор коэффициентов 24b LPC перед передачей. Квантователь может, например, выполнять возбуждение, кодируемое с преобразованием (TCX), линейное предсказание с кодовым возбуждением (CELP) или кодирование без потерь, такое как, например, энтропийное кодирование.
Согласно дополнительному варианту осуществления, кодирование сигнала невязки может выполняться в передатчике 30 в качестве альтернативы кодированию в квантователе 28. Таким образом, передатчик, например, выполняет возбуждение, кодируемое с преобразованием (TCX), линейное предсказание с кодовым возбуждением (CELP) или кодирование без потерь, такое как, например, энтропийное кодирование, чтобы закодировать сигнал невязки. Кроме того, передатчик может быть сконфигурирован с возможностью передавать второй набор коэффициентов LPC. Опциональный приемник является декодером 6. Таким образом, передатчик 30 может принимать сигнал 26 невязки или квантованный сигнал 26' невязки. Согласно одному варианту осуществления, передатчик может кодировать сигнал невязки или квантованный сигнал невязки, если по меньшей мере квантованный сигнал невязки еще не закодирован в квантователе. После опционального кодирования сигнала невязки или, в качестве альтернативы, квантованного сигнала невязки соответственный сигнал, обеспеченный передатчику, передается в качестве закодированного сигнала 32 невязки или в качестве закодированного и квантованного сигнала 32' невязки. Кроме того, передатчик может принимать второй набор коэффициентов 20b' LPC, опционально кодировать его, например тем же самым способом кодирования, что и используемый для кодирования сигнала невязки, и дополнительно передавать закодированный второй набор коэффициентов 20b' LPC, например, декодеру 6 без передачи первого набора коэффициентов LPC. Иными словами, первый набор коэффициентов 20a LPC нет необходимости передавать.
Декодер 6 может дополнительно принимать закодированный сигнал 32 невязки или, в качестве альтернативы, закодированный квантованный сигнал 32' невязки и, в качестве дополнения к одному из сигналов 32 или 32' невязки, закодированный второй набор коэффициентов 20b' LPC. Декодер может декодировать единственные принятые сигналы и обеспечивать декодированный сигнал 26 невязки синтезирующему фильтру. Синтезирующий фильтр может быть обратной функцией фильтра линейного предсказания FIR (с конечной импульсной характеристикой), имеющего второй набор коэффициентов LPC в качестве коэффициентов фильтра. Иными словами, фильтр, имеющий второй набор коэффициентов LPC, инвертируется, чтобы сформировать синтезирующий фильтр декодера 6. Выходной сигнал синтезирующего фильтра и, таким образом, выходной сигнал декодера является декодированным аудиосигналом 8''.
Согласно вариантам осуществления, средство оценки фонового шума может оценить автокорреляцию 12 фонового шума аудиосигнала в качестве представления фонового шума аудиосигнала. Кроме того, средство уменьшения фонового шума может генерировать представление аудиосигнала 16 с уменьшенным фоновым шумом путем вычитания автокорреляции фонового шума 12 из автокорреляции аудиосигнала 8, причем оцененная автокорреляция 8 аудиосигнала является представлением аудиосигнала и причем представление аудиосигнала 16 с уменьшенным фоновым шумом является автокорреляцией аудиосигнала с уменьшенным фоновым шумом.
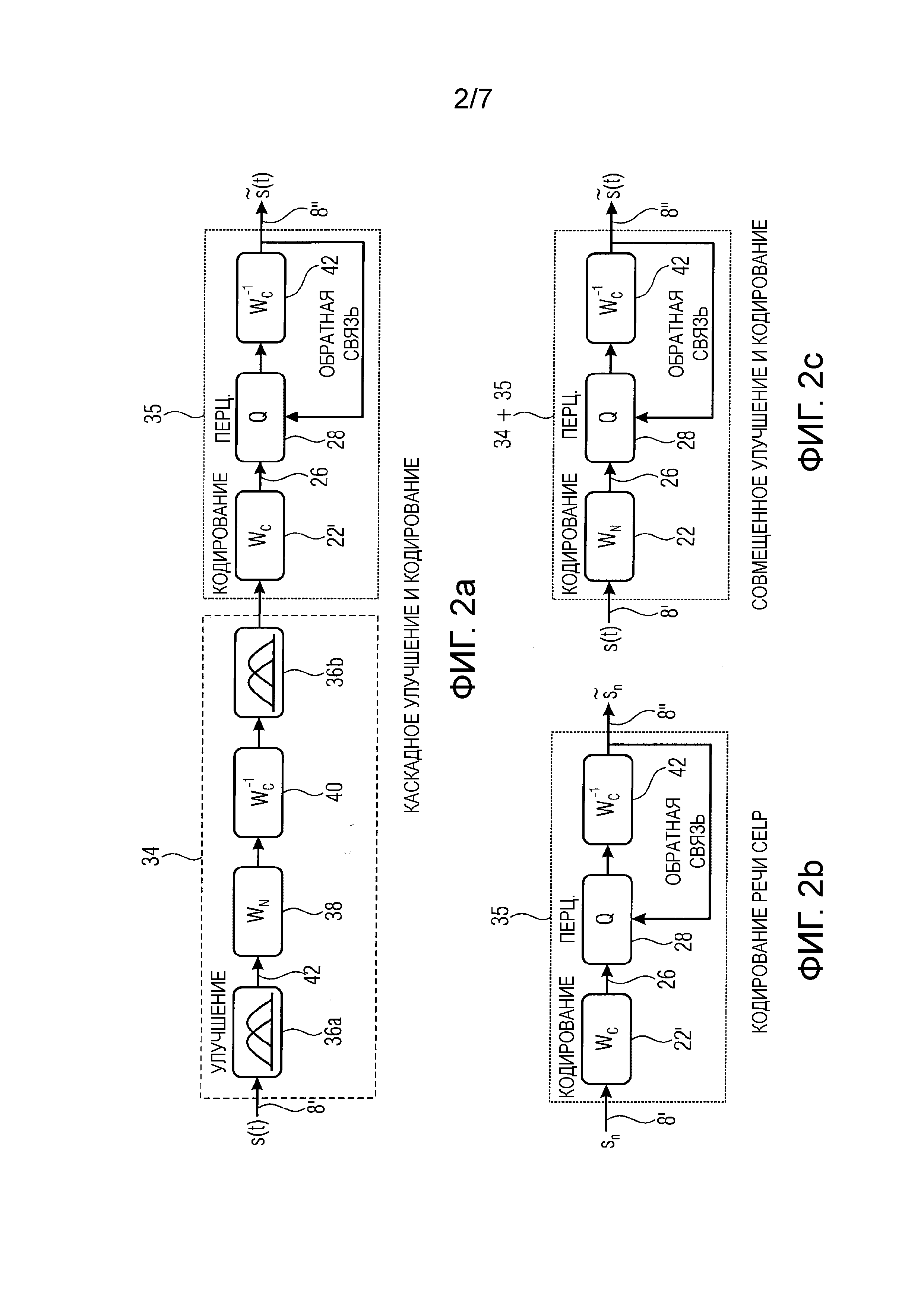
Фиг.2 и фиг.3 относятся к одному и тому же варианту осуществления, однако с использованием разных обозначений. Таким образом, фиг.2 изображает иллюстрации подходов каскадного и совмещенного улучшения/кодирования, где WN и WC представляют отбеливание зашумленных и чистых сигналов, соответственно, и WN-1 и WC-1 - их соответствующие обратные функции. Однако фиг.3 изображает иллюстрации подходов каскадного и совмещенного улучшения/кодирования, где Ay и As представляют отбеливающие фильтры зашумленного и чистого сигналов, соответственно, и Hy и Hs являются фильтрами реконструкции (или синтеза), их соответствующими обратными функциями.
Как фиг.2a, так и фиг.3a изображают часть улучшения и часть кодирования из цепочки обработки сигнала, таким образом выполняющие каскадное улучшение и кодирование. Часть 34 улучшения может оперировать в частотной области, причем блоки 36a и 36b могут выполнять временно-частотное преобразование с использованием, например, MDCT и частотно-временное преобразование с использованием, например, IMDCT или любого другого подходящего преобразования, чтобы выполнить временно-частотное и частотно-временное преобразование. Фильтры 38 и 40 могут выполнять уменьшение фонового шума частотно преобразованного аудиосигнала 42. Здесь те частотные части фонового шума могут фильтроваться путем уменьшения их влияния на спектр частот аудиосигнала 8'. Частотно-временной преобразователь 36b может, таким образом, выполнять обратное преобразование из частотной области во временную область. После того как уменьшение фонового шума было выполнено в части 34 улучшения, часть 35 кодирования может выполнять кодирование аудиосигнала с уменьшенным фоновым шумом. Таким образом, фильтр 22' анализа вычисляет сигнал 26'' невязки с использованием надлежащих коэффициентов LPC. Сигнал невязки может быть квантован и обеспечен синтезирующему фильтру 44, который в случае с фиг.2a и фиг.3a является обратным для фильтра 22' анализа. Поскольку синтезирующий фильтр 42 является обратным для фильтра 22' анализа, в случае с фиг.2a и фиг.3a коэффициенты LPC, используемые, чтобы определить сигнал 26 невязки, передаются декодеру, чтобы определить декодированный аудиосигнал 8''.
Фиг.2b и фиг.3b изображают этап 35 кодирования без ранее выполненного уменьшения фонового шума. Поскольку этап 35 кодирования уже описан в отношении фиг.2a и фиг.3a, дополнительное описание опускается, чтобы избежать одного лишь повторения описания.
Фиг.2c и фиг.3c относятся к главной концепции совмещенного улучшения и кодирования. Показано, что фильтр 22 анализа содержит каскад фильтров временной области с использованием фильтров Ay и Hs. Точнее, каскад фильтров временной области содержит дважды фильтр линейного предсказания с использованием полученного первого набора коэффициентов 20a LPC (Ay2) и единожды обратную функцию дополнительного фильтра линейного предсказания с использованием полученного второго набора коэффициентов LPC 20b (Hs). Эта компоновка фильтров или эта структура фильтров может называться фильтром Винера. Однако следует заметить, что один фильтр предсказания Hs взаимно уничтожаются с фильтром анализа As. Иными словами, может также применяться дважды фильтр Ay (что обозначено как Ay2), дважды фильтр Hs (что обозначено как Hs2) и единожды фильтр As.
Как уже описано в отношении фиг.1, коэффициенты LPC для этих фильтров были определены, например, с использованием автокорреляции. Поскольку автокорреляция может выполняться во временной области, никакое временно-частотное преобразование не обязано выполняться, чтобы осуществить совмещенное улучшение и кодирование. Кроме того, этот подход имеет преимущества, поскольку дополнительная цепочка обработки квантования, передающая синтезирующую фильтрацию, остается одной и той же по сравнению с этапом 35 кодирования, описанным в отношении фиг.2a и 3a. Однако следует заметить, что коэффициенты фильтра LPC на основе сигнала с уменьшенным фоновым шумом должны передаваться к декодеру для надлежащей синтезирующей фильтрации. Однако, согласно дополнительному варианту осуществления, вместо передачи коэффициентов LPC уже вычисленные коэффициенты фильтра для фильтра 24b (представленного обратной функцией коэффициентов 20b фильтра) могут передаваться, чтобы избежать дополнительной инверсии линейного фильтра, имеющего коэффициенты LPC, чтобы найти синтезирующий фильтр 42, поскольку эта инверсия уже была выполнена в кодере. Иными словами, вместо передачи коэффициентов 20b фильтра обратная матрица этих коэффициентов фильтра может передаваться, что помогает избежать выполнения инверсии дважды. Кроме того, следует заметить, что фильтр 24b стороны кодера и синтезирующий фильтр 42 могут быть одним и тем же фильтром, применяемым в кодере и декодере соответственно.
Иными словами, в отношении фиг.2 кодеки речи на основе модели CELP основаны на модели речеобразования, которая предполагает, что корреляция входного сигнала речи sn может быть смоделирована фильтром линейного предсказания с коэффициентами a=[α0,α1,...,αM]T, где M - порядок модели [16]. Невязка rn=an*sn, которая является частью сигнала речи, которая не может быть предсказана фильтром линейного предсказания, затем квантуется с использованием векторного квантования.
Пусть sk=[sk, sk-1,..., sk-M]T является вектором входного сигнала, где верхний индекс T обозначает транспонирование. Тогда невязка может быть выражена следующим образом
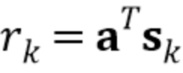 . (1)
. (1)
При заданной автокорреляционной матрице Rss вектора сигнала речи sk
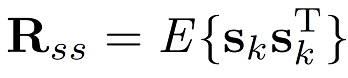 (2)
(2)
оценка фильтра предсказания порядка M может быть дана следующим образом [20]
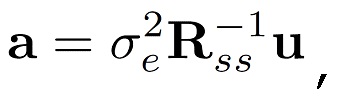 (3)
(3)
где u=[1, 0, 0,..., 0]T, и скалярная ошибка предсказания σe2 выбирается так, что α0=1. Обратите внимание, что фильтр линейного предсказания αn является отбеливающим фильтром, в силу чего rk является некоррелированным белым шумом. Кроме того, исходный сигнал sn может быть реконструирован из невязки rn посредством фильтрации IIR со средством предсказания αn. Следующим этапом является квантование векторов невязки rk=[rkN, rkN-1,..., rkN-N+1]T посредством векторного квантователя в 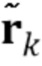 так, чтобы перцепционное искажение было минимизировано. Пусть вектором выходного сигнала является sk'=[skN, skN-1,..., sk-N+1]T, и
так, чтобы перцепционное искажение было минимизировано. Пусть вектором выходного сигнала является sk'=[skN, skN-1,..., sk-N+1]T, и 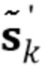 - его квантованное соответствие, и W - матрица свертывания, которая применяет перцепционное взвешивание к выходному сигналу. Задача перцепционной оптимизации может тогда быть записана следующим образом
- его квантованное соответствие, и W - матрица свертывания, которая применяет перцепционное взвешивание к выходному сигналу. Задача перцепционной оптимизации может тогда быть записана следующим образом
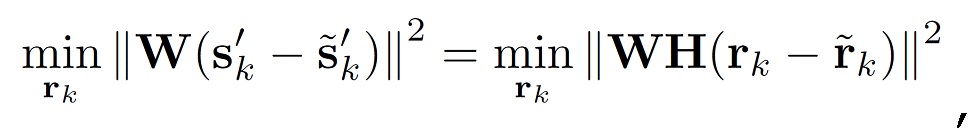 (4)
(4)
где H - матрица свертывания, соответствующая импульсной характеристике средства предсказания αn.
Процесс кодирования речи типа CELP изображен на фиг.2b. Входной сигнал сначала отбеливается посредством фильтра 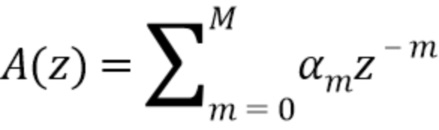 , чтобы получить сигнал невязки. Вектора невязки затем квантуются в блоке Q. Наконец, затем структура спектральной огибающей реконструируется путем IIR-фильтрации A-1(z), чтобы получить квантованный выходной сигнал
, чтобы получить сигнал невязки. Вектора невязки затем квантуются в блоке Q. Наконец, затем структура спектральной огибающей реконструируется путем IIR-фильтрации A-1(z), чтобы получить квантованный выходной сигнал 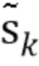 . Поскольку повторно синтезированный сигнал оценивается в перцепционной области, этот подход известен как способ анализа через синтез.
. Поскольку повторно синтезированный сигнал оценивается в перцепционной области, этот подход известен как способ анализа через синтез.
Фильтрация Винера
В улучшении речи с единственным каналом предполагается, что получается сигнал yn, который является аддитивной смесью желаемого чистого сигнала речи sn и некоторых нежелательных помех vn, то есть
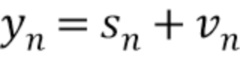 . (5)
. (5)
Целью процесса улучшения является оценить чистый сигнал речи sn, в то время как доступны только зашумленный сигнал yn и оценки корреляционных матриц
R ss =E{skskT} и Ryy=E{ykykT} (6)
Где yk=[yk, yk-1,..., yk-M]T. С использованием матрицы фильтра H оценка чистого сигнала речи 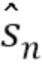 определяется следующим образом
определяется следующим образом
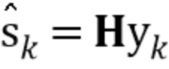 . (7)
. (7)
Оптимальный фильтр в смысле минимальной среднеквадратической ошибки (MMSE), известный как фильтр Винера, может быть легко получен следующим образом [12]
 . (8)
. (8)
Обычно фильтрация Винера применяется к накладывающимся окнам входного сигнала и реконструируется с использованием метода перекрытия со сложением [21, 12]. Этот подход иллюстрируется в блоке улучшения с фиг.2a. Он, однако, приводит к увеличению алгоритмической задержки, соответствующей длине наложения между окнами. Чтобы избежать такой задержки, целью является объединить фильтрацию Винера со способом на основе линейного предсказания.
Чтобы получить такое соединение, оцененный сигнал речи 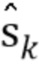 подставляется в уравнение 1, в силу чего
подставляется в уравнение 1, в силу чего
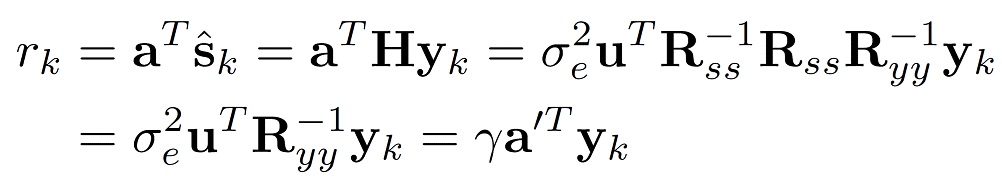 (9)
(9)
где γ является коэффициентом масштабирования, и
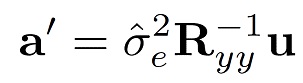 (10)
(10)
является оптимальным средством предсказания для зашумленного сигнала yn. Иными словами, путем фильтрации зашумленного сигнала посредством a' (масштабируемая) невязка оцененного чистого сигнала получается. Масштабирование является соотношением между соотношением между ожидаемыми ошибками невязки чистого и зашумленного сигналов 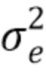 и
и 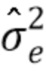 , соответственно, то есть
, соответственно, то есть 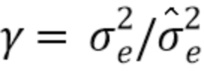 . Эта формула, таким образом, показывает, что фильтрация Винера и линейное предсказание являются близко родственными способами, и в следующем разделе это соединение будет использовано, чтобы разработать способ совмещенного улучшения и кодирования.
. Эта формула, таким образом, показывает, что фильтрация Винера и линейное предсказание являются близко родственными способами, и в следующем разделе это соединение будет использовано, чтобы разработать способ совмещенного улучшения и кодирования.
Внесение фильтрации Винера в кодек CELP
Целью является объединить фильтрацию Винера и кодеки CELP (описанные в разделе 3 и разделе 2) в совмещенный алгоритм. Благодаря объединению этих алгоритмов задержка применения оконной функции перекрытия со сложением, требуемая для обычных осуществлений фильтрации Винера, может избегаться, и уменьшается вычислительная сложность.
Осуществление совмещенной структуры тогда прямолинейное. Показано, что невязка улучшенного сигнала речи может быть получена посредством уравнения 9. Улучшенный сигнал речи может, таким образом, быть реконструирован путем фильтрации IIR невязки с моделью линейного предсказания αn чистого сигнала.
Для квантования невязки уравнение 4 может быть модифицировано путем замены чистого сигнала 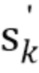 оцененным сигналом
оцененным сигналом 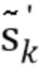 , чтобы получить
, чтобы получить
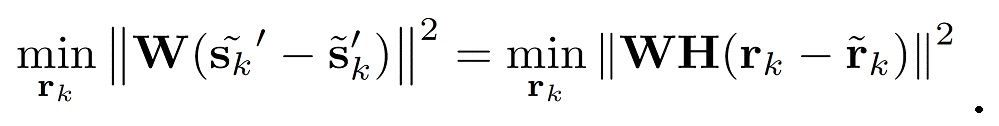 (11)
(11)
Иными словами, объективная функция с улучшенным целевым сигналом остается той же самой, что и в случае наличия доступа к чистому входному сигналу .
В заключение, единственной модификацией относительно стандартного CELP является замена фильтра анализа a чистого сигнала фильтром анализа зашумленного сигнала a'. Остальные части алгоритма CELP остаются неизмененными. Предлагаемый подход изображается на фиг.2(c).
Ясно, что предлагаемый способ может применяться в любых кодеках CELP с минимальными изменениями всегда, когда ослабление шума желательно и когда имеется доступ к оценке автокорреляции чистого сигнала речи Rss. Если оценка автокорреляции чистого сигнала речи недоступна, она может оцениваться с использованием оценки автокорреляции сигнала шума Rvv посредством Rss≈Ryy-Rvv или других обычных оценок.
Способ может быть легко расширен на такие сценарии, как многоканальные алгоритмы с образованием лучей, при условии, что оценка чистого сигнала может быть получена с использованием фильтров временной области.
Преимущество в вычислительной сложности предлагаемого способа может быть охарактеризовано следующим образом. Следует заметить, что в стандартном подходе необходимо определить матрицу-фильтр H, данную уравнением 8. Требуемое обращение матрицы имеет сложность  . Однако в предлагаемом подходе только уравнение 3 нужно решить для зашумленного сигнала, что может осуществляться посредством алгоритма Левинсона-Дарбина (или подобного) со сложностью
. Однако в предлагаемом подходе только уравнение 3 нужно решить для зашумленного сигнала, что может осуществляться посредством алгоритма Левинсона-Дарбина (или подобного) со сложностью 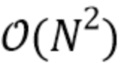 .
.
Линейное предсказание с кодовым возбуждением
Иными словами, в отношении фиг.3 кодеки речи на основе парадигмы CELP задействуют модель речеобразования, которая предполагает, что корреляция и, таким образом, спектральная огибающая входного сигнала речи sn могут быть смоделированы фильтром линейного предсказания с коэффициентами a=[α0,α1,...,αM]T, где M - порядок модели, определенный моделью базовой трубки [16]. Невязка rn=an*sn, часть сигнала речи, которая не может быть предсказана фильтром линейного предсказания (также называемого средством 18 предсказания), затем квантуется с использованием векторного квантования.
Фильтр линейного предсказания as для одного кадра входного сигнала s может быть получен путем минимизации
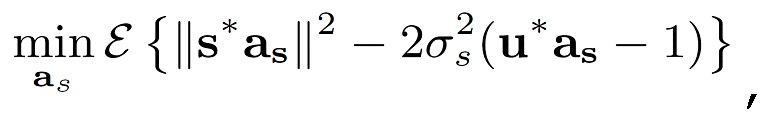 (12)
(12)
где u=[1 0 0... 0]T. Решение является следующим:
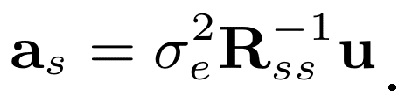 (13)
(13)
При определении матрицы свертывания As, состоящей из коэффициентов фильтра α для as
 (14)
(14)
сигнал невязки может быть получен путем умножения входного кадра речи на матрицу свертывания As
e s =As⋅s. (15)
Применение окна здесь выполняется, как в CELP-кодеках, путем вычитания отклика при отсутствии входного сигнала из входного сигнала и повторного его внесения в повторный синтез [15].
Умножение в уравнении 15 идентично свертыванию входного сигнала с фильтром предсказания и, таким образом, соответствует фильтрации FIR. Исходный сигнал может быть реконструирован из невязки путем умножения на фильтр реконструкции Hs
s=Hs⋅es. (16)
где Hs состоит из импульсной характеристики η=[1,η1,...,ηN-1] фильтра предсказания
 (17)
(17)
так, что это операция соответствует фильтрации IIR.
Вектор невязки квантуется путем применения векторного квантования. Таким образом, выбирается квантованный вектор 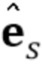 , минимизирующий перцепционное расстояние, в смысле 2-нормы, для желаемого реконструированного чистого сигнала:
, минимизирующий перцепционное расстояние, в смысле 2-нормы, для желаемого реконструированного чистого сигнала:
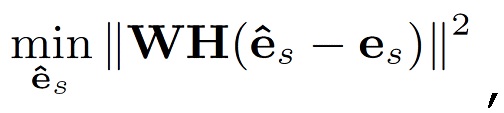 (18)
(18)
где es - неквантованная невязка, и W(z)=A(0,92z) - перцепционный взвешивающий фильтр, используемый в кодеке речи AMR-WB [6].
Применение фильтрации Винера в кодеке CELP
Для применения одноканального улучшения речи, предполагая, что полученный сигнал микрофона yn является аддитивной смесью желаемого чистого сигнала речи sn и некоторых нежелательных помех vn так, что yn=sn+vn. В Z-области эквивалентно Y(z)=S(z)+V(z).
Путем применения фильтра Винера B(z) существует возможность реконструировать сигнал речи S(z) из зашумленного наблюдения Y(z) путем фильтрации так, что оцененный сигнал речи является  (z):=B(z)Y(z)≈S(z). Минимальное среднеквадратическое решение для фильтра Винера является следующим [12]
(z):=B(z)Y(z)≈S(z). Минимальное среднеквадратическое решение для фильтра Винера является следующим [12]
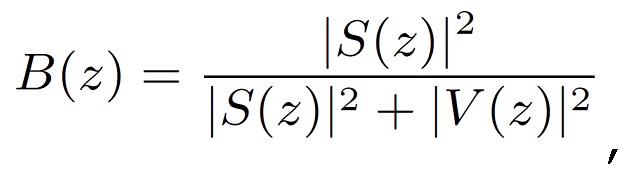 (19)
(19)
с учетом предположения, что сигналы речи и шума sn и vn, соответственно, некоррелированы.
В кодеке речи оценка спектра мощности доступна для зашумленного сигнала yn в форме импульсной характеристики модели линейного предсказания |Ay(z)|-2. Иными словами, |S(z)|2+|V(z)|2≈γ|Ay(z)|-2, где γ - коэффициент масштабирования. Зашумленное средство линейного предсказания может быть вычислено из автокорреляционной матрицы Ryy зашумленного сигнала, как обычно.
Кроме того, может оцениваться спектр мощности чистого сигнала речи |S(z)|2 или, эквивалентно, автокорреляционная матрица Rss чистого сигнала речи. Алгоритмы улучшения часто предполагают, что сигнал шума стационарен, в силу чего автокорреляция сигнала шума, обозначенная как Rvv, может оцениваться из кадра без речи входного сигнала. Автокорреляционная матрица чистого сигнала речи Rss может затем оцениваться как 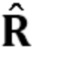 ss=Ryy-Rvv. Здесь выгодно принять обычные меры предосторожности для обеспечения, чтобы ss оставалась положительно определенной.
ss=Ryy-Rvv. Здесь выгодно принять обычные меры предосторожности для обеспечения, чтобы ss оставалась положительно определенной.
С использованием оцененной автокорреляционной матрицы для чистой речи ss может быть определено соответствующее средство линейного предсказания, импульсной характеристикой которого в Z-области является 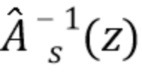 . Таким образом, |S(z)|2≈|
. Таким образом, |S(z)|2≈|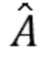 s(z)|-2 и уравнение 19 могут быть записаны следующим образом
s(z)|-2 и уравнение 19 могут быть записаны следующим образом
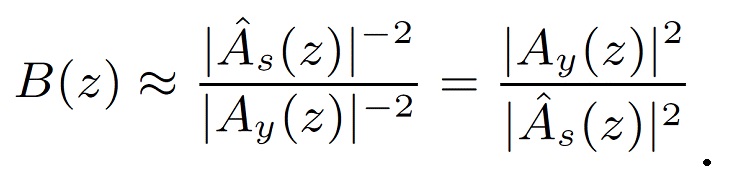 (20)
(20)
Иными словами, путем фильтрации дважды посредством средств предсказания зашумленного и чистого сигналов в режиме FIR и IIR, соответственно, оценка Винера чистого сигнала может быть получена.
Матрицы свертывания могут быть обозначены в соответствии с фильтрацией FIR со средствами предсказания 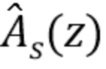 и
и 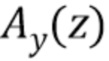 через As и Ay, соответственно. Подобным образом, пусть Hs и Hy являются соответственными матрицами свертывания, соответствующими фильтрации с предсказанием (IIR). С использованием этих матриц стандартное кодирование CELP может быть проиллюстрировано блок-схемой, как на фиг.3b. Здесь существует возможность фильтровать входной сигнал sn с As, чтобы получить невязку, квантовать ее и реконструировать квантованный сигнал путем фильтрации с Hs.
через As и Ay, соответственно. Подобным образом, пусть Hs и Hy являются соответственными матрицами свертывания, соответствующими фильтрации с предсказанием (IIR). С использованием этих матриц стандартное кодирование CELP может быть проиллюстрировано блок-схемой, как на фиг.3b. Здесь существует возможность фильтровать входной сигнал sn с As, чтобы получить невязку, квантовать ее и реконструировать квантованный сигнал путем фильтрации с Hs.
Стандартный подход к объединению улучшения с кодированием изображается на фиг.3a, где фильтрация Винера применяется в качестве блока предварительной обработки перед кодированием.
Наконец, в предлагаемом подходе фильтрация Винера комбинируется с кодеками речи типа CELP. При сравнении каскадного подхода с фиг.3a с совмещенным подходом, изображенным на фиг.3b, очевидно, что дополнительная схема применения оконной функции перекрытия со сложением (OLA) может быть опущена. Кроме того, входной фильтр As в кодере взаимно уничтожается с Hs. Таким образом, как показано на фиг.3c, оцененный чистый сигнал невязки 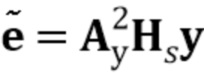 получается путем фильтрации ухудшенного входного сигнала y посредством комбинации фильтров As2Hs. Таким образом, минимизация ошибки следует формуле:
получается путем фильтрации ухудшенного входного сигнала y посредством комбинации фильтров As2Hs. Таким образом, минимизация ошибки следует формуле:
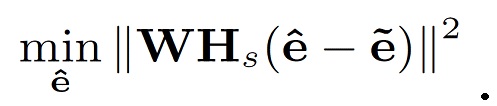 (21)
(21)
Таким образом, этот подход совмещенным образом минимизирует расстояние между чистой оценкой и квантованным сигналом, в силу чего совмещенная минимизация помех и шума квантования в перцепционной области является возможной.
Производительность подхода совмещенного кодирования и улучшения речи была оценена с использованием как объективных, так и субъективных мер. Для того чтобы изолировать выполнение нового способа, используется упрощенный кодек CELP, где только сигнал невязки был квантован, но задержка и усиление долговременного предсказания (LTP), кодирование с линейным предсказанием (LPC) и коэффициенты усиления не были квантованы. Невязка была квантована с использованием попарного итерационного способа, где два импульса добавляется последовательно путем попыток их помещения на каждую позицию, как описано в [17]. Кроме того, во избежание какого-либо влияния алгоритмов оценки корреляционная матрица чистого сигнала речи Rss предполагалась как известная во всех симулированных сценариях. При предположении, что речь и сигнал шума являются некоррелированными, получается, что Rss=Ryy-Rvv. В любом практическом приложении корреляционная матрица шума Rvv или, в качестве альтернативы, корреляционная матрица чистой речи Rss должна оцениваться из полученного сигнала микрофона. Общий подход состоит в том, чтобы оценить корреляционную матрицу шума в перерывах в речи, предполагая, что помехи стационарны.
Оцененный сценарий состоял из смеси желаемого чистого сигнала речи и аддитивных помех. Два типа помех были рассмотрены: стационарный белый шум и сегмент записи шума автомобиля из библиотеки Звуковой среды цивилизации (Civilisation Soundscapes) [18]. Векторное квантование невязки было выполнено со скоростью передачи битов 2,8 кбит/с и 7,2 кбит/с в соответствии с общей скоростью передачи битов 7,2 кбит/с и 13,2 кбит/с, соответственно, для кодека AMR-WB [6]. Частота выборки 12,8 кГц была использована для всех симуляций.
Улучшенные и закодированные сигналы были оценены с использованием как объективных, так и субъективных мер, таким образом, было проведено слуховое испытание, и было вычислено перцепционное отношение сигнала к шуму (SNR) интенсивности, как определено в уравнении 23 и уравнении 22. Это перцепционное SNR интенсивности было использовано, поскольку процесс совмещенного улучшения не имеет влияния на фазу фильтров, поскольку и синтезирующие фильтры, и фильтры реконструкции связаны ограничением фильтров минимальной фазы в соответствии с проектированием фильтров предсказания.
При определении преобразования Фурье как оператора 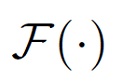 абсолютные спектральные значения реконструированного чистого опорного сигнала и оцененного чистого сигнала в перцепционной области являются следующими:
абсолютные спектральные значения реконструированного чистого опорного сигнала и оцененного чистого сигнала в перцепционной области являются следующими:
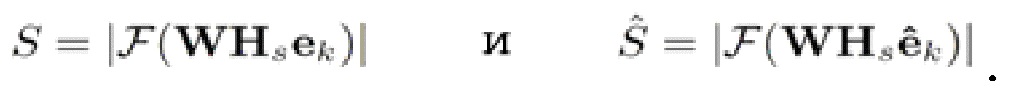 (22)
(22)
Определение модифицированного перцепционного отношения сигнала к шуму (PSNR) является следующим:
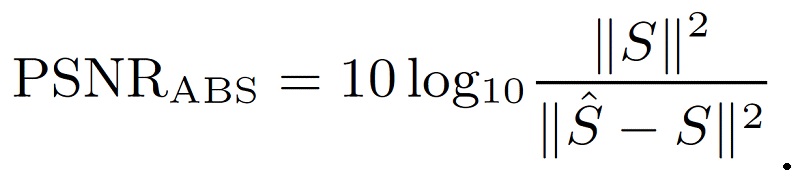 (23)
(23)
Для субъективной оценки элементы речи были использованы из испытательного набора, используемого для стандартизации USAC [8], поврежденного белым и автомобильным шумом, как описано выше. Было проведено слуховое испытание множества стимулов со скрытым опорным сигналом и привязкой (MUSHRA) [19] с 14 участниками с использованием электростатических наушников STAX в звуконепроницаемой среде. Результаты слухового испытания иллюстрируются на фиг.6, а дифференциальные оценки MUSHRA - на фиг.7, изображающей среднее значение и доверительные интервалы 95%.
Абсолютные результаты испытания MUSHRA на фиг.6 показывают, что скрытый опорный сигнал всегда верно приписывался 100 пунктам. Исходная зашумленная смесь получила самую низкую среднюю оценку для каждого элемента, что указывает, что все способы улучшения улучшили перцепционное качество. Средние оценки для более низкой скорости передачи битов показывают статистически значимое улучшение 6,4 пункта MUSHRA для среднего значения по всем элементам по сравнению с каскадным подходом. Для более высокой скорости передачи битов среднее значение по всем элементам изображает улучшение, которое, однако, не является статистически значимым.
Чтобы получить более подробное сравнение совмещенных и предварительно улучшенных способов, дифференциальные оценки MUSHRA представляются на фиг.7, где различие между предварительно улучшенными и совмещенными способами вычисляется для каждого слушателя и элемента. Дифференциальные результаты подтверждают абсолютные оценки MUSHRA, показывая статистически значимое улучшение для более низкой скорости передачи битов, в то время как улучшение для более высокой скорости передачи битов не является статистически значимым.
Иными словами, показан способ совмещенного улучшения и кодирования речи, который обеспечивает возможность минимизации общих помех и квантования шума. В отличие от этого, стандартные подходы применяют улучшение и кодирование в каскадных этапах обработки. Совмещение обоих этапов обработки также перспективно в плане вычислительной сложности, поскольку повторяющиеся операции применения окна и фильтрации могут опускаться.
Кодеки речи типа CELP выполнены с возможностью предлагать очень низкую задержку и, таким образом, избегать наложения окон обработки с будущими окнами обработки. В отличие от этого, стандартные способы улучшения, применяемые в частотной области, полагаются на применение оконной функции перекрытия со сложением, что представляет дополнительную задержку, соответствующую длине наложения. Совмещенный подход не требует применения оконной функции перекрытия со сложением, но использует схему применения окна, как применяется в кодеках речи [15], в силу чего избегая увеличения в алгоритмической задержке.
Известная проблема предлагаемого способа состоит в том, что в отличие от стандартной спектральной фильтрации Винера, где сигнальная фаза остается нетронутой, предлагаемый способ применяет фильтры временной области, которые модифицируют фазу. Такие модификации фазы могут легко обрабатываться путем применения подходящих всечастотных фильтров. Однако поскольку не было замечено какого-либо перцепционного ухудшения, относящегося к модификациям фазы, такие всечастотные фильтры были опущены, чтобы сохранить вычислительную сложность низкой. Однако следует заметить, что в объективной оценке перцепционное SNR интенсивности было измерено, чтобы обеспечить возможность справедливого сравнения способов. Это объективное измерение показывает, что предлагаемый способ в среднем на три дБ лучше каскадной обработки.
Преимущество производительности предлагаемого способа было дополнительно подтверждено результатами слухового испытания MUSHRA, которое показало среднее улучшение 6,4 пункта. Эти результаты демонстрируют, что применение совмещенного улучшения и кодирования выгодно для общей системы как в плане качества, так и в плане вычислительной сложности, при этом сохраняя низкую алгоритмическую задержку кодеков речи CELP.
Фиг.8 изображает схематичную структурную схему способа 800 кодирования аудиосигнала с уменьшенным фоновым шумом с использованием кодирования с линейным предсказанием. Способ 800 содержит этап S802, на котором оценивают представление фонового шума аудиосигнала, этап S804, на котором генерируют представление аудиосигнала с уменьшенным фоновым шумом путем вычитания представления оцененного фонового шума аудиосигнала из представления аудиосигнала, этап S806, на котором подвергают представление аудиосигнала анализу методом линейного предсказания, чтобы получить первый набор коэффициентов фильтра линейного предсказания, и подвергают представление аудиосигнала с уменьшенным фоновым шумом анализу методом линейного предсказания, чтобы получить второй набор коэффициентов фильтра линейного предсказания, и этап S808, на котором управляют каскадом фильтров временной области путем полученного первого набора коэффициентов LPC и полученного второго набора коэффициентов LPC, чтобы получить сигнал невязки из аудиосигнала.
Следует понимать, что в этом техническом описании сигналы в линиях иногда называются по ссылочным позициям для линий или иногда указываются самими ссылочными позициями, которые были приписаны линиям. Таким образом, обозначения таковы, что линия, имеющая конкретный сигнал, указывает сам сигнал. Линия может быть физической линией в аппаратном осуществлении. В компьютеризованном осуществлении, однако, физической линии не существует, но сигнал, представленный линией, передается от одного модуля вычисления к другому модулю вычисления.
Хотя настоящее изобретение было описано в контексте структурных схем, где блоки представляют фактические или логические аппаратные компоненты, настоящее изобретение может также осуществляться компьютерно-реализованным способом. В последнем случае блоки представляют соответствующие этапы способа, где эти этапы обозначают функциональные возможности, выполняемые соответствующими логическими или физическими аппаратными блоками.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут исполняться посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер или электронная цепь. В некоторых вариантах осуществления один или несколько из самых важных этапов способа могут исполняться таким устройством.
Изобретательский передаваемый или кодируемый сигнал может сохраняться на цифровом носителе данных или может передаваться в среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как Интернет.
В зависимости от конкретных требований осуществления варианты осуществления изобретения могут осуществляться в аппаратных средствах или в программных средствах. Осуществление может выполняться с использованием цифрового носителя данных, например гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно читаемые управляющие сигналы, сохраненные на нем, которые взаимодействуют (или имеют возможность взаимодействовать) с программируемой компьютерной системой так, чтобы соответственный способ выполнялся. Таким образом, цифровой носитель данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно читаемые управляющие сигналы, которые имеют возможность взаимодействовать с программируемой компьютерной системой так, чтобы один из способов, описанных здесь, выполнялся.
В общем случае варианты осуществления настоящего изобретения могут осуществляться в качестве компьютерного программного продукта с программным кодом, причем программный код имеет возможность операции для выполнения одного из способов, когда компьютерный программный продукт запущен на компьютере. Программный код может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных здесь, сохраненных на машиночитаемом носителе.
Иными словами, вариант осуществления изобретательского способа является, таким образом, компьютерной программой, содержащей программный код для выполнения одного из способов, описанных здесь, когда компьютерная программа запущена на компьютере.
Дополнительный вариант осуществления изобретательского способа является, таким образом, носителем данных (или некратковременным носителем данных, таким как цифровой носитель данных или машиночитаемый носитель), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных здесь. Носитель данных, цифровой носитель данных или записанный носитель обычно являются материальными и/или некратковременными.
Дополнительный вариант осуществления изобретательского способа является, таким образом, потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных здесь. Поток данных или последовательность сигналов могут, например, быть сконфигурированы, которые должны быть перенесены посредством соединения передачи данных, например через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированное или выполненное с возможностью, чтобы выполнять один из способов, описанных здесь.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных здесь.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную, чтобы переносить (например, электронным или оптическим образом) компьютерную программу для выполнения одного из способов, описанных здесь, к приемнику. Приемник может, например, быть компьютером, мобильным устройством, устройством памяти или подобным. Устройство или система могут, например, содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано, чтобы выполнять некоторые или все из функциональных возможностей способов, описанных здесь. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для того, чтобы выполнять один из способов, описанных здесь. В общем случае способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Понятно, что модификации и вариации компоновок и подробностей, описанных здесь, будут очевидны другим специалистам в данной области техники. Предполагается, таким образом, ограничение только объемом дальнейшей формулы изобретения, а не конкретными подробностями, представленными здесь посредством описания и объяснения вариантов осуществления.
ССЫЛКИ
[1] M. Jeub and P. Vary, ʺEnhancement of reverberant speech using the CELP postfilter,ʺ in Proc. ICASSP, April 2009, pp. 3993-3996.
[2] M. Jeub, C. Herglotz, C. Nelke, C. Beaugeant, and P. Vary, ʺNoise reduction for dual-microphone mobile phones exploiting power level differences,ʺ in Proc. ICASSP, March 2012, pp. 1693-1696.
[3] R. Martin, I. Wittke, and P. Jax, ʺOptimized estimation of spectral parameters for the coding of noisy speech,ʺ in Proc. ICASSP, vol. 3, 2000, pp. 1479-1482 vol.3.
[4] H. Taddei, C. Beaugeant, and M. de Meuleneire, ʺNoise reduction on speech codec parameters,ʺ in Proc. ICASSP, vol. 1, May 2004, pp. I-497-500 vol.1.
[5] 3GPP, ʺMandatory speech CODEC speech processing functions; AMR speech Codec; General description,ʺ 3rd Generation Partnership Project (3GPP), TS 26.071, 12 2009. [Online]. Available: http://www.3gpp.org/ftp/Specs/html-info/26071.htm
[6] --, ʺSpeech codec speech processing functions; Adaptive Multi-Rate - Wideband (AMR-WB) speech codec; Transcoding functions,ʺ 3rd Generation Partnership Project (3GPP), TS 26.190, 12 2009. [Online]. Available: http://www.3gpp.org/ftp/Specs/html-info/26190.htm
[7] B. Bessette, R. Salami, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola, and K. Jarvinen, ʺThe adaptive multirate wideband speech codec (AMR-WB),ʺ IEEE Transactions on Speech and Audio Processing, vol. 10, no. 8, pp. 620-636, Nov 2002.
[8] ISO/IEC 23003-3:2012, ʺMPEG-D (MPEG audio technologies), Part 3: Unified speech and audio coding,ʺ 2012.
[9] M. Neuendorf, P. Gournay, M. Multrus, J. Lecomte, B. Bessette, R. Geiger, S. Bayer, G. Fuchs, J. Hilpert, N. Rettelbach, R. Salami, G. Schuller, R. Lefebvre, and B. Grill, ʺUnified speech and audio coding scheme for high quality at low bitrates,ʺ in Acoustics, Speech and Signal Processing, 2009. ICASSP 2009. IEEE International Conference on, April 2009, pp. 1-4.
[10] 3GPP, ʺTS 26.445, EVS Codec Detailed Algorithmic Description; 3GPP Technical Specification (Release 12),ʺ 3rd Generation Partnership Project (3GPP), TS 26.445, 12 2014. [Online]. Available: http://www.3gpp.org/ftp/Specs/html-info/26445.htm
[11] M. Dietz, M. Multrus, V. Eksler, V. Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z.Wang, L. Laaksonen, A. Vasilache, Y. Kamamoto, K. Kikuiri, S. Ragot, J. Faure, H. Ehara, V. Rajendran, V. Atti, H. Sung, E. Oh, H. Yuan, and C. Zhu, ʺOverview of the EVS codec architecture,ʺ in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, April 2015, pp. 5698-5702.
[12] J. Benesty, M. Sondhi, and Y. Huang, Springer Handbook of Speech Processing. Springer, 2008.
[13] T. Bäckström, ʺComputationally efficient objective function for algebraic codebook optimization in ACELP,ʺ in Proc. Interspeech, Aug. 2013.
[14] --, ʺComparison of windowing in speech and audio coding,ʺ in Proc. WASPAA, New Paltz, USA, Oct. 2013.
[15] J. Fischer and T. Bäckström, ʺComparison of windowing schemes for speech coding,ʺ in Proc EUSIPCO, 2015.
[16] M. Schroeder and B. Atal, ʺCode-excited linear prediction (CELP): High-quality speech at very low bit rates,ʺ in Proc. ICASSP. IEEE, 1985, pp. 937-940.
[17] T. Bäckström and C. R. Helmrich, ʺDecorrelated innovative codebooks for ACELP using factorization of autocorrelation matrix,ʺ in Proc. Interspeech, 2014, pp. 2794-2798.
[18] soundeffects.ch, ʺCivilisation soundscapes library,ʺ accessed: 23.09.2015. [Online]. Available: https://www.soundeffects.ch/de/geraeusch-archive/soundeffects.ch- produkte/civilisation-soundscapes-d.php
[19] Method for the subjective assessment of intermediate quality levels of coding systems, ITU-R Recommendation BS.1534, 2003. [Online]. Available: http://www.itu.int/rec/R-REC-BS.1534/en.
[20] P. P. Vaidyanathan, \The theory of linear prediction," in Synthesis Lectures on Signal Processing, vol. 2, pp. 1{184. Morgan & Claypool publishers, 2007.
[21] J. Allen, \Short-term spectral analysis, and modification by discrete Fourier transform," IEEE Trans. Acoust., Speech, Signal Process., vol. 25, pp. 235{238, 1977.
Способ сварки и конструктивный элемент
Силовой полупроводниковый модуль с боковыми стенками слоистой конструкции
Устройство, способ и компьютерная программа для обеспечения набора пространственных указателей на основе сигнала микрофона и устройство для обеспечения двухканального аудиосигнала и набора пространственных указателей
Способ получения прозрачного проводящего покрытия из оксида металла путем импульсного высокоионизирующего магнетронного распыления
Транспортное средство с отражателем звуковых волн
Устройство, способ и компьютерная программа для выработки широкополосного сигнала с использованием управляемого расширения ширины полосы и слепого расширения ширины полосы
Аудио или видео кодер, аудио или видео и относящиеся к ним способы для обработки многоканальных аудио или видеосигналов с использованием переменного направления предсказания
Поставщик транспортного потока, поставщик сигнала dab, анализатор транспортного потока, приемник dab, способ, компьютерная программа и сигнал транспортного потока
Способ и кодер и декодер для воспроизведения без промежутка аудио сигнала
Аудиокодек, поддерживающий режимы кодирования во временной области и в частотной области
Кодер, декодер и способ кодирования и декодирования
Принцип кодирования информации
Аудиокодер и способ для кодирования аудиосигнала

