Результат интеллектуальной деятельности: Способ шифрования данных
Вид РИД
Изобретение
Область техники, к которой относится изобретение
Предполагаемое изобретение относится к способам шифрования данных, в частности к блочному шифрованию данных с применением вычислительных платформ с SIMD-архитектурой.
Уровень техники
Шифрование является традиционным способом обеспечения конфиденциальности данных при их передаче и хранении. К одним из наиболее распространенных методов шифрования относятся алгоритмы, основанные на применении блочных шифров. Такие шифры оперируют фрагментами данных фиксированной длины - блоками, и сочетают в себе стойкость и высокую скорость работы.
Тенденция на увеличение объемов хранимой информации и скорости передаваемых данных требует от используемых блочных шифров высокой производительности. Эффективным методом увеличения быстродействия алгоритма шифрования является использование параллельных вычислений. Одним из способов организации параллельных вычислений в случае программной реализации алгоритма является использование SIMD-технологий, в основе которых лежит применение одной инструкции процессора для одновременной обработки нескольких фрагментов данных, предварительно размещенных на одном регистре.
SIMD-технологии получили широкое распространение и поддерживаются на большинстве современных вычислительных платформ, в том числе на процессорах общего назначения Intel и AMD. В настоящее время существует несколько типовых наборов SIMD-инструкций, каждый из которых предназначен для работы с регистрами определенной длины.
Применительно к программной реализации алгоритмов блочного шифрования, SIMD-технологии, как правило, используются для эффективной обработки сразу нескольких входных блоков данных. С помощью SIMD-технологий алгоритм шифрования, предназначенный для обработки одного блока, выполняют одновременно для нескольких блоков. Эффективность такого подхода напрямую зависит от возможности параллельного выполнения использующихся в алгоритме шифрования преобразований и операций, которая, в свою очередь, определяется наличием в вычислительной платформе соответствующих им SIMD-инструкций. В случае возможности распараллеливания каждой из операций такой подход позволяет выполнять обработку нескольких блоков данных за время, необходимое для обработки одного блока данных, то есть производительность алгоритма растет пропорциональному количеству одновременно обрабатываемых блоков. Поскольку число одновременно обрабатываемых блоков определяется длиной используемых регистров, производительность в этом случае растет пропорционально увеличению длины используемых регистров.
Национальный стандарт Российской Федерации ГОСТ Р 34.12-2015 специфицирует два блочных шифра: «Кузнечик» и «Магма» [1]. Для алгоритма шифрования «Магма» известен способ выполнения, допускающий эффективное применение SIMD-технологий в случае его программной реализации [2]. Под эффективностью здесь и далее будем подразумевать достаточно высокую скорость выполнения относительно других способов и пропорциональный рост производительности программных реализаций на основе способа при увеличении длины используемых регистров.
Рассмотрим существующие способы выполнения алгоритма зашифрования блочного шифра «Кузнечик». При описании преобразований шифра «Кузнечик» будем придерживаться обозначений, принятых в [1], опуская при этом, для простоты, вспомогательные преобразования, введенные для установления соответствия между двоичными строками, числами и элементами поля.
Известен способ выполнения алгоритма зашифрования блочного шифра «Кузнечик» в соответствии с его описанием в [1]. Недостатками способа являются низкая производительность алгоритма в случае его программного исполнения без использования SIMD-технологий, а также невозможность эффективного применения существующих SIMD-инструкций при реализации способа.
Известен способ выполнения алгоритма зашифрования блочного шифра «Кузнечик» на основе использования таблиц большого размера [3]. Все вычисления при использовании такого способа сводятся к операциям загрузки данных из больших таблиц и побитовому сложению двоичных строк. Способ обладает достаточно высокой скоростью работы в случае его программного исполнения даже без применения SIMD-технологий, а в случае их применения производительность способа может быть дополнительно увеличена.
Недостатком способа является неэффективность применения существующих SIMD-инструкций для параллельного выполнения операций загрузки данных из больших таблиц, что приводит к тому, что производительность реализаций на основе способа растет непропорционально увеличению длины используемых регистров.
Другим недостатком является потенциальная уязвимость программных реализаций на основе способа к атакам по времени обращения к кэш-памяти вычислительной платформы [4], что приводит к недопустимости применения этих реализаций в случае возможности осуществления такого рода атак.
Известен способ выполнения нелинейного преобразования алгоритма «Кузнечик», являющегося частью алгоритма зашифрования, основанный на декомпозиции этого преобразования [5]. Согласно данному способу, преобразование π: V8→V8, использующееся в блочном шифре «Кузнечик» для определения нелинейного преобразования [1], вычисляют следующим образом:
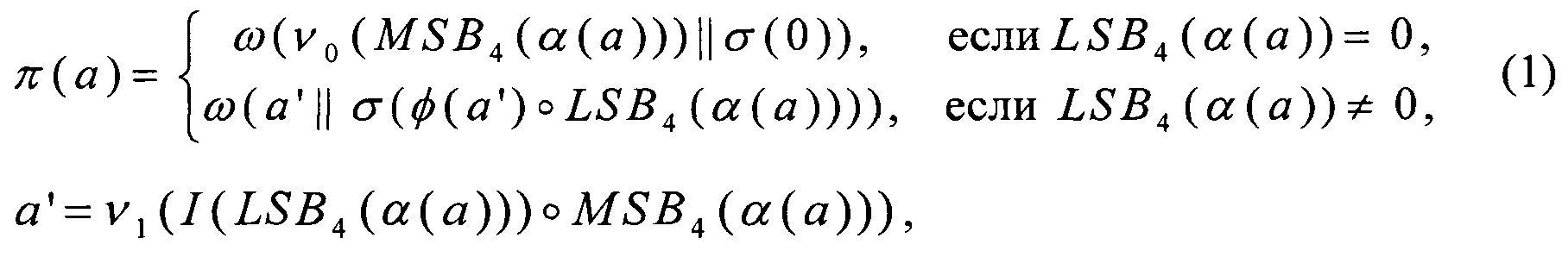
где
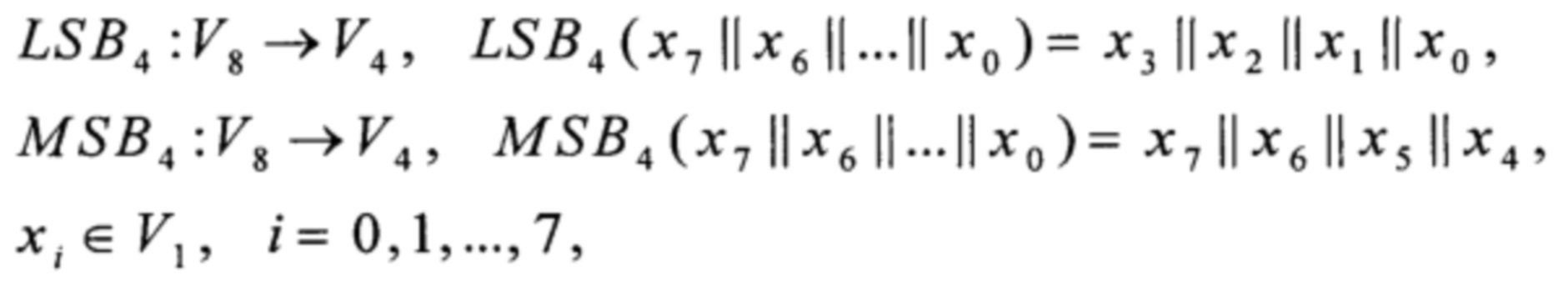
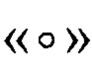 - операция умножения в поле GF(24)[Х]/(Х4⊕X3⊕1), а линейные преобразования α, ω вида V8→V8 и нелинейные преобразования ν0, ν1, σ, φ, I вида V4→V4 определены в [5].
- операция умножения в поле GF(24)[Х]/(Х4⊕X3⊕1), а линейные преобразования α, ω вида V8→V8 и нелинейные преобразования ν0, ν1, σ, φ, I вида V4→V4 определены в [5].
Данный способ расширяет возможности применения SIMD-технологий в случае программной реализации преобразования π. В частности, он позволяет свести ряд вычислений к преобразованиям вида V4→V4, имеющим эффективную реализацию с помощью SIMD-технологий.
Недостатком способа является наличие преобразований вида V8→V8 и операций умножения в поле GF(24)[Х]/(Х4⊕X3⊕1), имеющих относительно высокую сложность реализации в случае применения SIMD-технологий.
Наиболее близким к предлагаемому способу является способ выполнения алгоритма зашифрования блочного шифра «Кузнечик» с помощью слайсинг техники, представленный в [3]. Способ основан на применении преобразований, эквивалентных имеющимся в шифре, но обладающих при этом более эффективной реализацией с использованием SIMD-технологий.
Согласно данному способу, алгоритм зашифрования блочного шифра «Кузнечик» выполняют в соответствии с соотношениями, приведенными в [1]:
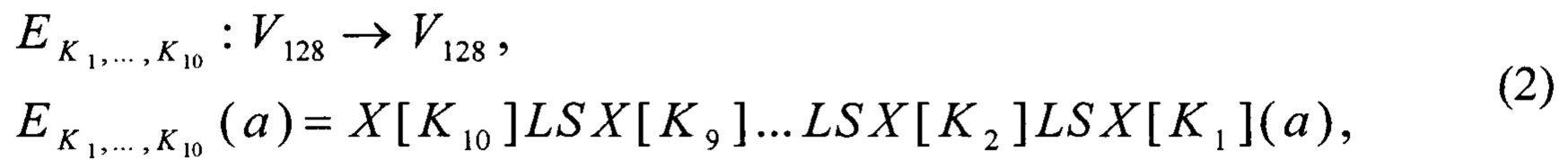
где
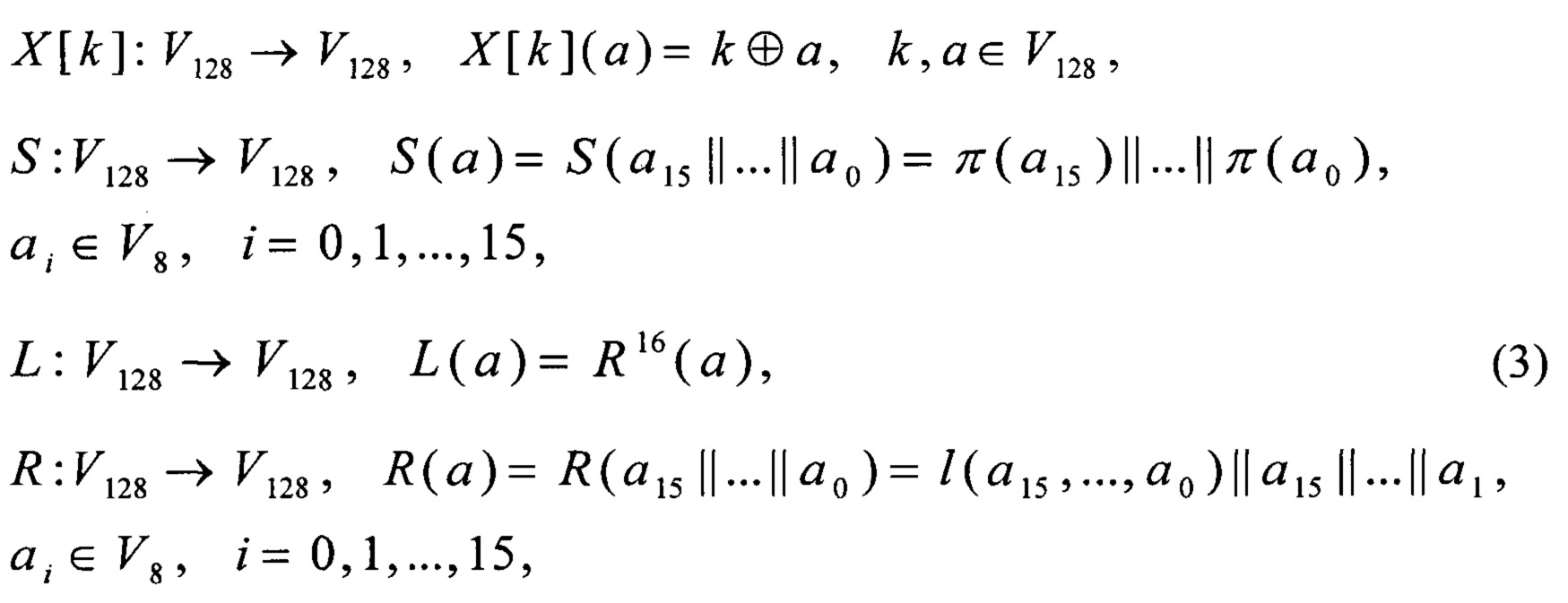
K1, …, K10∈V128 - итерационные ключи.
Вычисление преобразования  :(V8)16→V8 основывают на алгоритме, приведенном в [1]:
:(V8)16→V8 основывают на алгоритме, приведенном в [1]:

где «⋅» - операция умножения в поле GF(28)[Х]/(Х8⊕X7⊕X6⊕Х⊕1).
При этом для возможности эффективной реализации преобразования с использованием SIMD-технологий в данный алгоритм вносят ряд изменений.
Для каждой константы const ∈ {1, 148, 32, 133, 16, 194, 192, 251} вводят преобразования вида V4→V8:
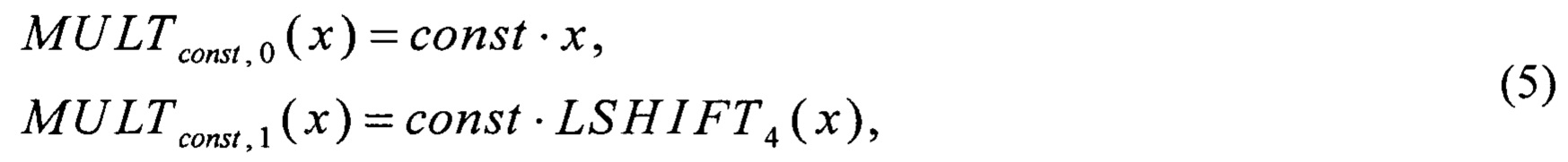
где
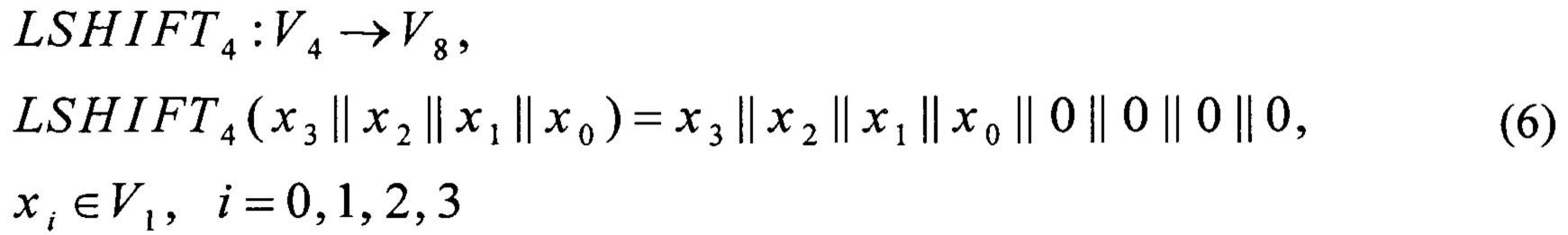
Операции умножения в поле, имеющиеся в (4), выполняют на основе преобразований из (5) и соотношений:
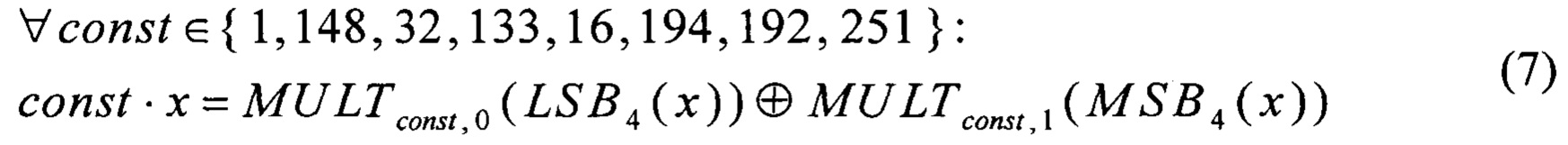
Эффективность использования преобразований из (5) обуславливается тем, что любое преобразование вида V4→V8 может быть реализовано с помощью таблицы, состоящей из 24 элементов, длиной 8 бит каждый. Вычисление преобразования в этом случае сводится к загрузке выходного значения из таблицы по входному значению, используемому в качестве индекса для выбора соответствующего элемента таблицы. Преимуществом применения таблиц такого размера является возможность эффективного распараллеливания операции загрузки из этих таблиц при помощи существующих SIMD-инструкций. Данное замечание справедливо и для таблиц, состоящих из меньшего числа элементов и/или из элементов меньшей длины.
Вычисление преобразования π: V8→V8 основывают на алгоритме, предложенном в [5] и описанном в (1). Для повышения эффективности реализации преобразования π с использованием SIMD-технологий вводят следующие преобразования вида V4→V8:
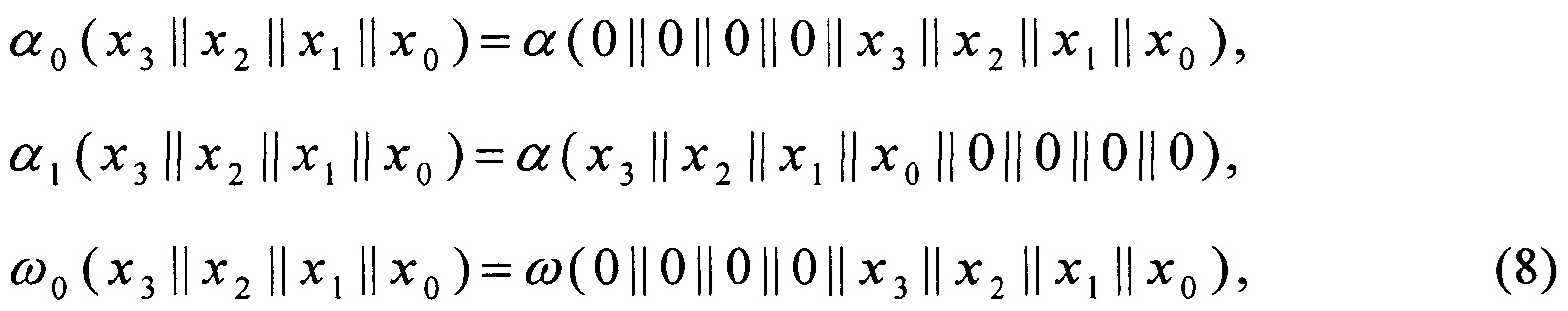
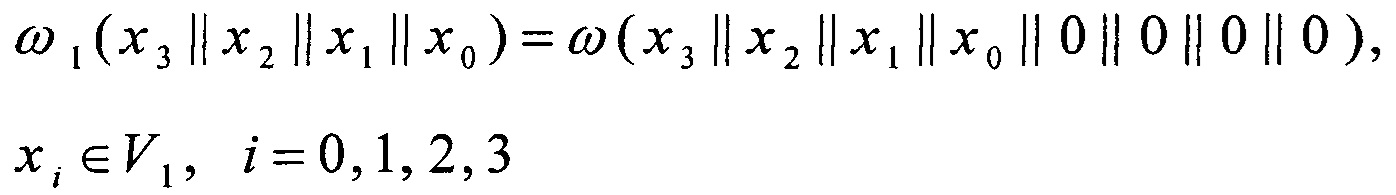
Преобразования α и ω выполняют на основе преобразований (8) и соотношений, справедливых в силу линейности α и ω:
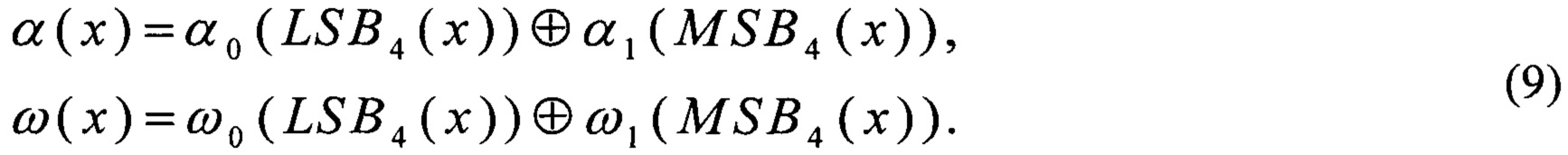
Поскольку преобразования α0, α1, ω0, ω1, ν0, ν1, σ, φ, I имеют вид V4→V4, V4→V8, их вычисление может быть эффективно распараллелено при помощи существующих SIMD-инструкций по аналогии с преобразованиями (5).
Описанный способ принимается за прототип. Преимуществом способа является возможность эффективного применения существующих SIMD-инструкций для используемых операций, в том числе для загрузки данных из используемых таблиц. Это приводит к пропорциональному росту скорости программных реализаций на основе способа при увеличении длины используемых регистров.
Еще одним преимуществом способа является возможность получения на его основе программных реализаций, стойких к атакам по времени обращения к кэш-памяти вычислительной платформы, в силу задействования только малых по размеру вспомогательных таблиц.
Недостатком способа является его относительно невысокая производительность, обусловленная, в том числе, выполнением преобразования 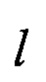 без учета взаимосвязи между константными элементами поля, содержащимися в (4), а также необходимостью выполнения трудоемкой операции умножения в поле GF(24)[Х]/(Х4⊕X3⊕1) при вычислении преобразования π.
без учета взаимосвязи между константными элементами поля, содержащимися в (4), а также необходимостью выполнения трудоемкой операции умножения в поле GF(24)[Х]/(Х4⊕X3⊕1) при вычислении преобразования π.
Раскрытие изобретения
Техническим результатом является повышение производительности процесса зашифрования.
При этом предлагаемый способ сохраняет возможность эффективного применения SIMD-технологий при его реализации, выражающуюся в пропорциональном росте производительности в случае увеличения длины используемых регистров, а также сохраняет возможность получения реализаций на основе способа, стойких к атакам по времени обращения к кэш-памяти вычислительной платформы.
Предлагаемый способ шифрования s сообщений m1, m2, …, ms, представленных в двоичном виде и имеющих длину равную 128 бит каждый, где s=t⋅n, причем t, n - натуральные числа, реализуемый посредством вычислительной системы, имеющей процессор с SIMD-архитектурой, заключается в том, что
 вычисляют
вычисляют
u=0;
(А) вычисляют параллельно с использованием SIMD-инструкций процессора значения cut+1, cut+2, cut+3, …, cut+t∈V128:
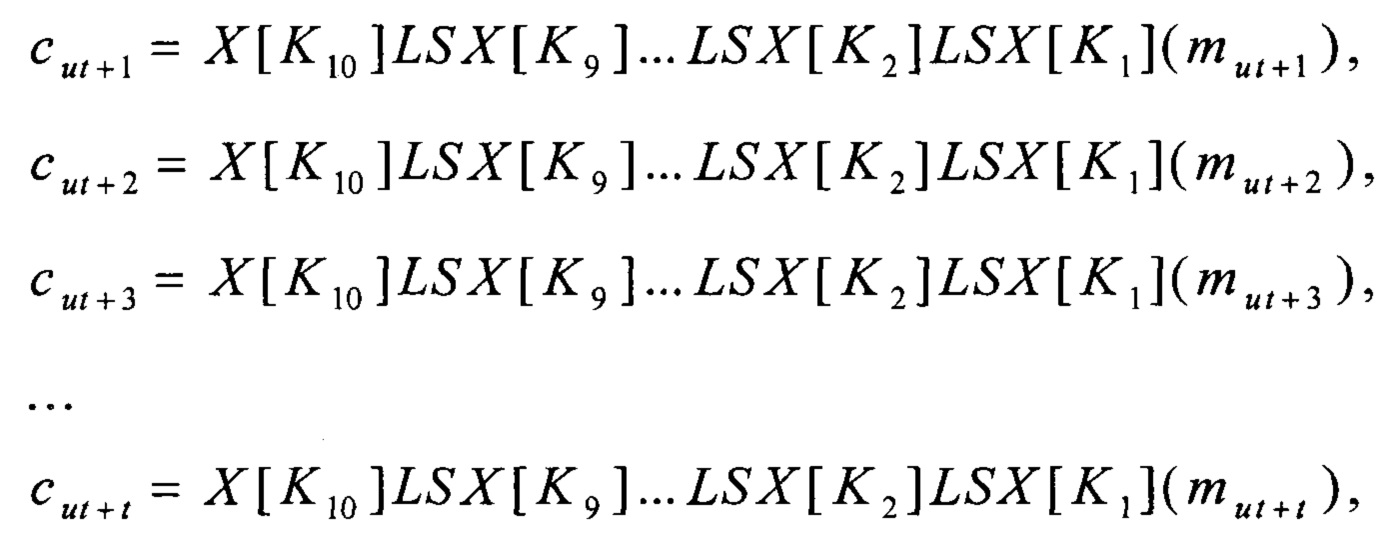
где
X[k]:V128→V128, X[k](x)=k⊕x, причем k, x∈V128;
S:V128→V128, 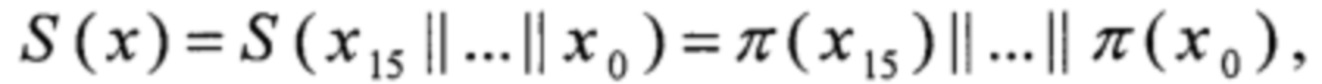 причем
причем
xi∈V8, i=0, 1,…, 15;
L: V128→V128, L(x)=R16(x), причем x∈V128;
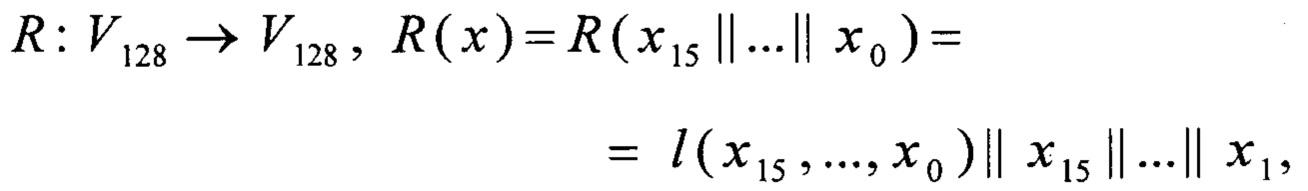 причем
причем
xi∈V8, i=0, 1,…, 15;
K1, …, K10∈V128 - итерационные ключи;
Vp - множество всех двоичных строк длины р;
р - неотрицательное целое число;
причем для получения значения π(α)∈V8, для произвольного a∈V8, вычисляют
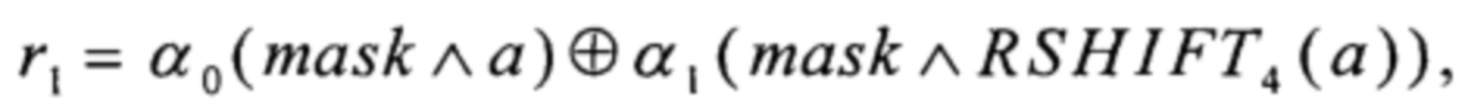
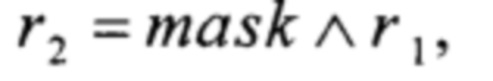
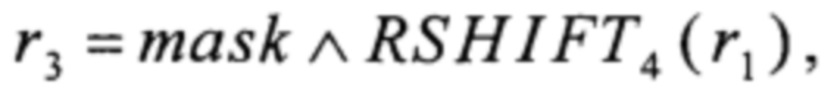
r4=T2(r2)+256T3(r3),
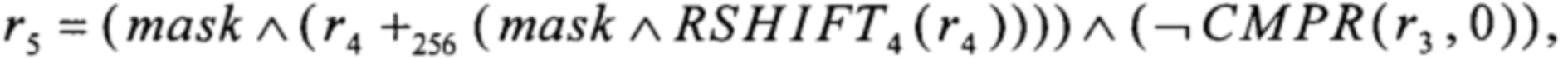
r6=T4(r5)+256T3(r2),
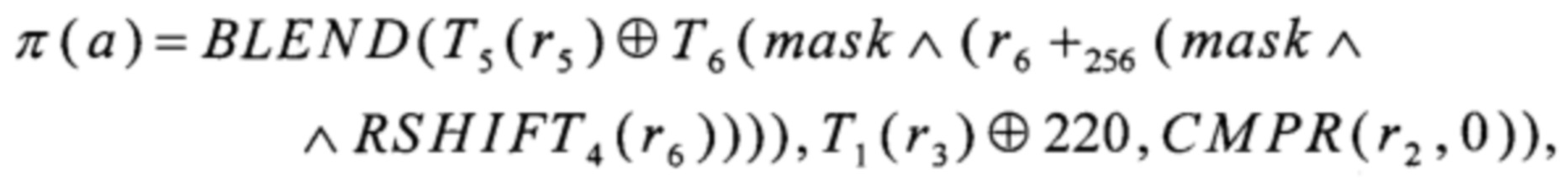
где «+256» - операция сложения в кольце вычетов по модулю 256;
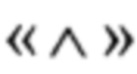 - операция побитового "И";
- операция побитового "И";
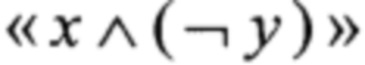 - операция побитового "И" с отрицанием одного из аргументов;
- операция побитового "И" с отрицанием одного из аргументов;
«⊕» - операция побитового сложения;
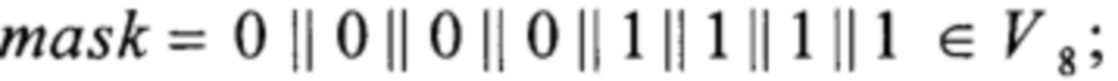
преобразование RSHIFT4 вида V8→V8 преобразование CMPR вида V8×V8→V8 и преобразование BLEND вида V8×V8×V8→V8 вычисляют в соответствии с соотношениями
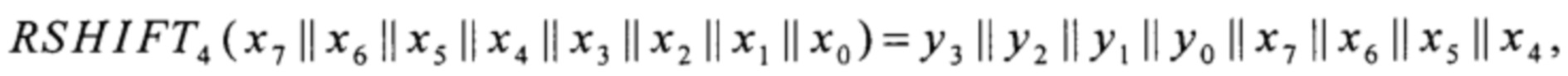
где значения yi∈V1, i=0, 1, 2, 3,
значения xi∈V1, i=0, 1,…, 7,
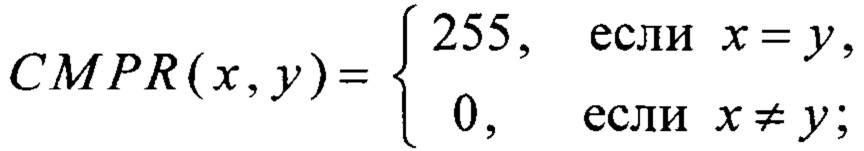
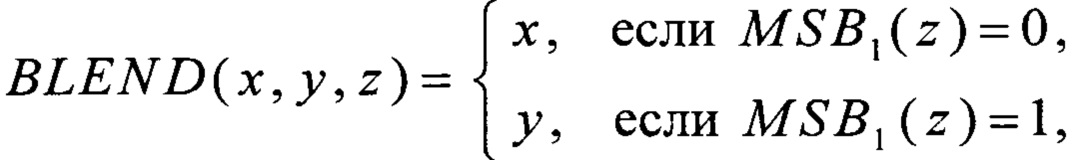
где MSB1: V8→V1, 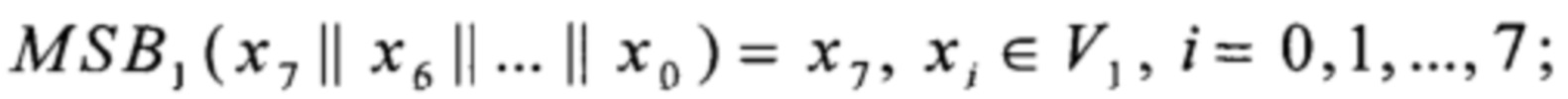 преобразования T2, Т3, T4 вида V4→V4 и преобразования α0, α1, T1, T5, T6 вида V4→V8 вычисляют путем загрузки данных из вспомогательных таблиц, содержащих векторы значений этих преобразований:
преобразования T2, Т3, T4 вида V4→V4 и преобразования α0, α1, T1, T5, T6 вида V4→V8 вычисляют путем загрузки данных из вспомогательных таблиц, содержащих векторы значений этих преобразований:
α0=(0, 112, 58, 74, 20, 100, 46, 94, 154, 234, 160, 208, 142, 254, 180, 196),
α1=(0, 2, 17, 19, 116, 118, 101, 103, 24, 26, 9, 11, 108, 110, 125, 127),
Т1=(32, 20, 48, 34, 36, 2, 54, 50, 0, 4, 38, 16, 18, 6, 22, 52),
Т2=(0, 15, 14, 3, 13, 6, 2, 8, 12, 11, 5, 10, 1, 4, 7, 9),
Т3=(0, 15, 1, 12, 2, 9, 13, 7, 3, 4, 10, 5, 14, 11, 8, 6),
Т4=(14, 8, 5, 14, 2, 13, 9, 1, 3, 5, 3, 5, 12, 13, 12, 15),
Т5=(52, 22, 0, 4, 20, 54, 50, 16, 48, 38, 34, 32, 2, 18, 6, 36),
Т6=(220, 0, 152, 147, 153, 146, 215, 78, 214, 11, 69, 1, 68, 10, 79, 221),
где векторы значений приведены в виде
ƒ=(ƒ(0), ƒ(1), …, ƒ(15)),
где ƒ - произвольное преобразование, множеством входных аргументов которого является V4;
для получения значения 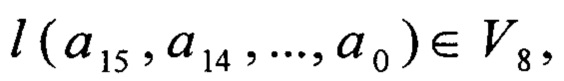 для произвольных
для произвольных
а15, а14, …, а0∈V8, вычисляют
t1=а3⊕а13,
t2=а8+256a8,
t3=a1⊕a15⊕t1⊕BLEND(t2, t2⊕195, a8),
t4=a2⊕a14,
t5=t4+256t4,
t6=BLEND(t5, t5⊕195, t4)⊕t1⊕a4⊕a12⊕a8,
t7=a6⊕a10,
t8=t7+256t7,
t9=a5⊕a11⊕t7,
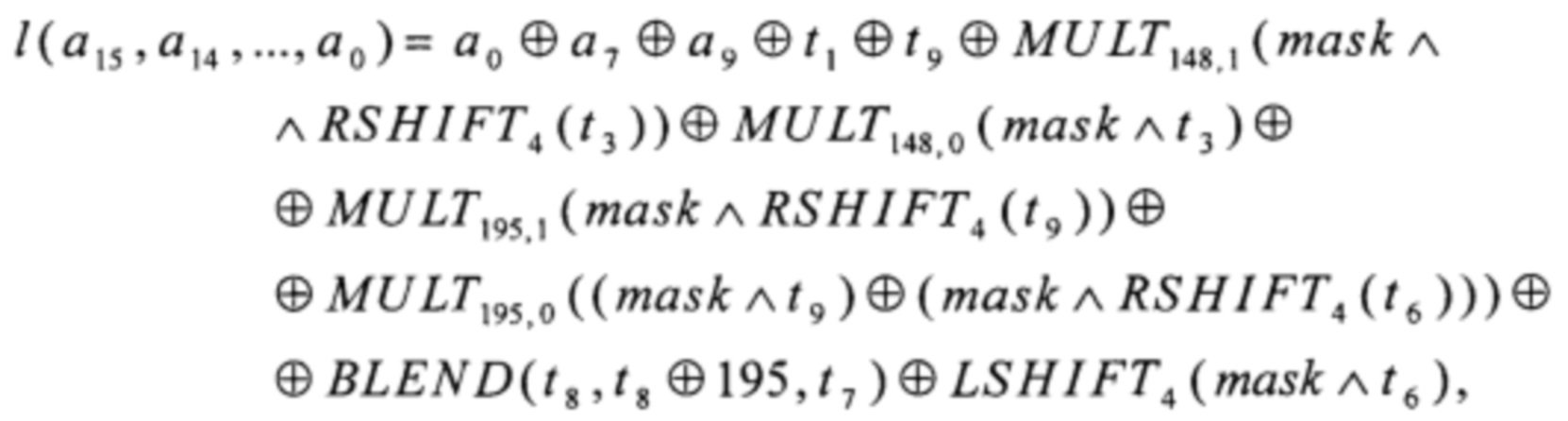
где преобразование LSHIFT4 вида V4→V8 вычисляют в соответствии с соотношением
LSHIFT4: V4→V8, 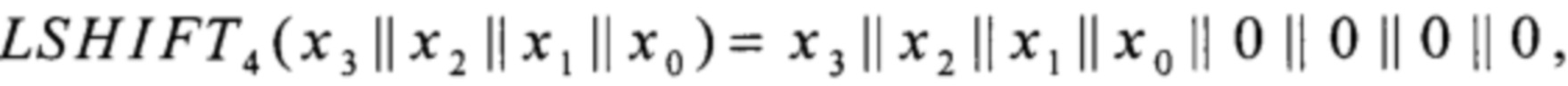
xi∈V1, i=0, 1, …, 3;
преобразования MULT148,0, MULT148,1, MULT195,0, MULT195,1 вида V4→V8
вычисляют путем загрузки данных из вспомогательных таблиц, содержащих векторы значений этих преобразований:
MULT148,0=(0, 148, 235, 127, 21, 129, 254, 106, 42, 190, 193, 85, 63, 171, 212, 64),
MULT148,1=(0, 84, 168, 252, 147, 199, 59, 111, 229, 177, 77, 25, 118, 34, 222, 138),
MULT195,0=(0, 195, 69, 134, 138, 73, 207, 12, 215, 20, 146, 81, 93, 158, 24, 219),
MULT195,1=(0, 109, 218, 183, 119, 26, 173, 192, 238, 131, 52, 89, 153, 244, 67, 46),
где векторы значений приведены в виде
ƒ=(ƒ(0), ƒ(1), …, ƒ(15)),
где ƒ - произвольное преобразование, множеством входных аргументов которого является V4;
 вычисляют
вычисляют
u=u+1;
если u<n, то переходят к этапу (А);
получают зашифрованные сообщения ci, i=1, 2, …, s.
Результат достигается за счет сведения базовых преобразований алгоритма зашифрования блочного шифра «Кузнечик» к эквивалентным преобразованиям, имеющим более эффективную реализацию с помощью существующих SIMD-инструкций, а также за счет учета особенностей базовых преобразований с целью минимизации количества требуемых для их выполнения операций.
Согласно предлагаемому способу, алгоритм зашифрования блочного шифра «Кузнечик» выполняют в соответствии с (2). Преобразования X, S, L вычисляют в соответствии с (3).
Рассмотрим способ выполнения преобразования  Заметим, что в силу свойства дистрибутивности операции умножения относительно сложения в поле GF(28)[X]/(X8⊕X7⊕X6X⊕1), а также в силу равенств, справедливых
Заметим, что в силу свойства дистрибутивности операции умножения относительно сложения в поле GF(28)[X]/(X8⊕X7⊕X6X⊕1), а также в силу равенств, справедливых 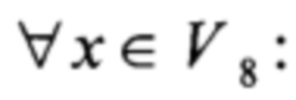
133⋅х=(1⊕16⊕148)⋅х=1⋅x⊕16⋅х⊕148⋅х,
32⋅х=(16⋅2)⋅х=16⋅(2⋅х),
251⋅х=(148⋅2⊕16)⋅х=148⋅(2⋅х)⊕16⋅х,
192⋅х=(194⊕2)⋅х=194⋅х⊕2⋅х,
194⋅х=(195⊕1)⋅х=195⋅х⊕1⋅х,
16⋅х=195⋅MSB4(х)⊕LSHIFT4(LSB4(х)),
преобразование 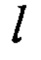 для любых а15, а14, …, а0∈V8 может быть вычислено следующим образом:
для любых а15, а14, …, а0∈V8 может быть вычислено следующим образом:
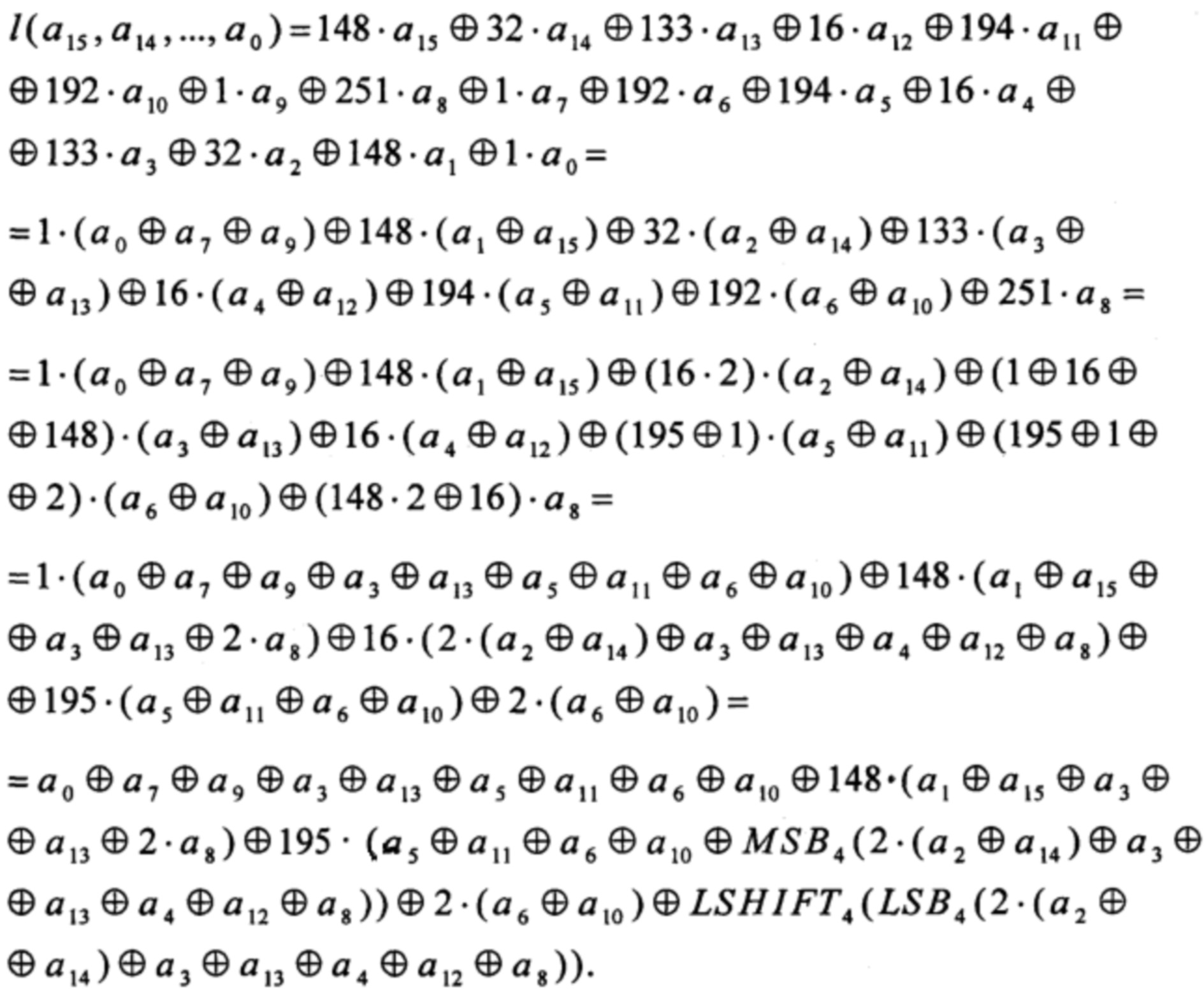
Для выполнения операций умножения в поле введем следующие преобразования:
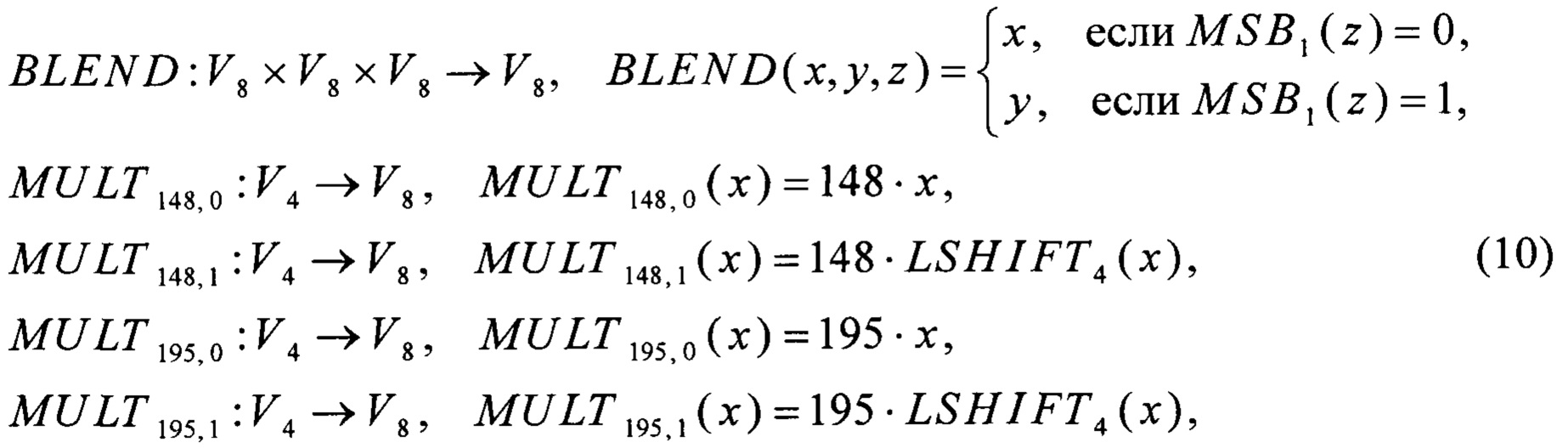
где
MSB1:V8→V1, 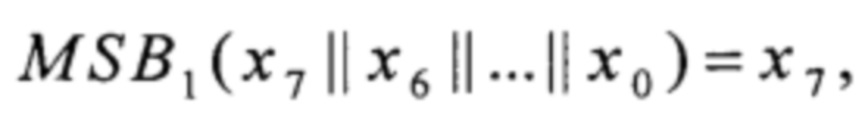 xi∈V1, i=0, 1, ..., 7
xi∈V1, i=0, 1, ..., 7
С учетом (10) и равенства
2⋅128=195,
где 2, 128, 195∈GF(28)[X]/(X8⊕X7⊕Х6⊕X⊕1),
получаем, что 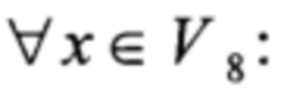
2⋅х=BLEND(x+256х, (х+256х)⊕195, х),
148⋅х=MULT148,0(LSB4(х))⊕MULT148,1(MSB4(х)),
195⋅х=MULT195,0(LSB4(x))⊕MULT195,1(MSB4(x)),
где «+256» - операция сложения в кольце вычетов по модулю 256.
Для выполнения преобразования LSHIFT4 воспользуемся (6). Для выполнения преобразований MSB4, LSB4 воспользуемся соотношениями
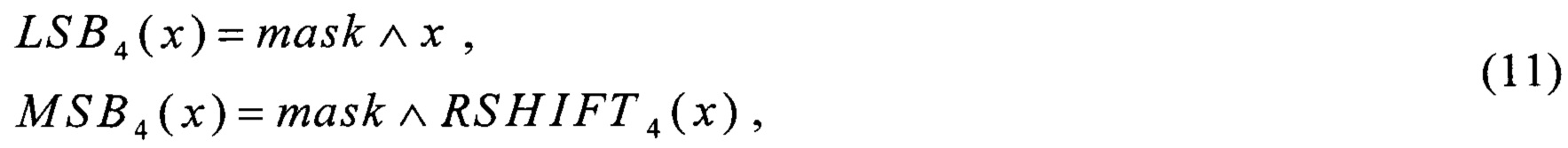
где  - операция побитового "И",
- операция побитового "И",
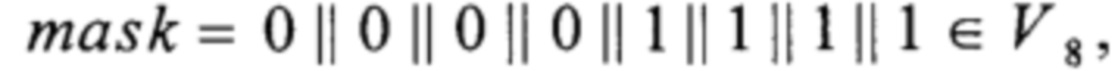
RSHIFT4:V8→V8,
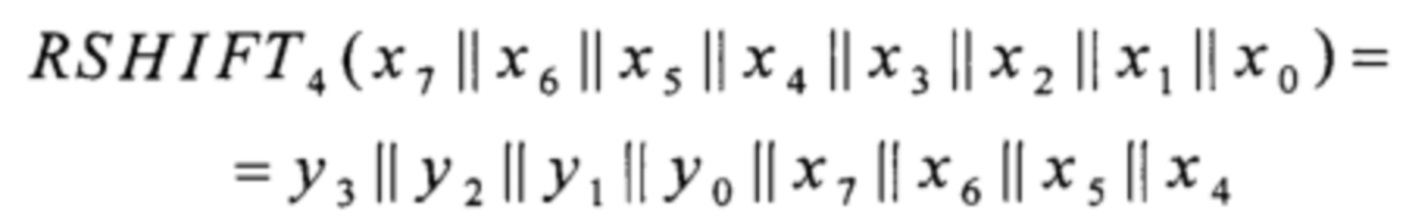
причем yj∈V1, i=0, 1, 2, 3 - не зависящие от xi∈V1, i=0, 1, …, 7 значения.
В результате способ вычисления преобразования 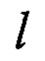 принимает следующий вид:
принимает следующий вид:
- на вход преобразованию 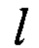 поступают значения а15, a14,…, а0∈V8;
поступают значения а15, a14,…, а0∈V8;
- вычисляют значения

Предложенный способ позволяет вычислять преобразование 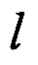 при помощи пяти преобразований вида V4→V8: MULT148,0, MULT148,1, MULT195,0, MULT195,1, LSHIFT4; преобразования RSHIFT4 вида V8→V8; преобразования BLEND вида V8×V8×V8→V8; а также операций сложения в кольце вычетов по модулю 256 («+256»), побитового "И" (
при помощи пяти преобразований вида V4→V8: MULT148,0, MULT148,1, MULT195,0, MULT195,1, LSHIFT4; преобразования RSHIFT4 вида V8→V8; преобразования BLEND вида V8×V8×V8→V8; а также операций сложения в кольце вычетов по модулю 256 («+256»), побитового "И" ( ) и побитового сложения («⊕»).
) и побитового сложения («⊕»).
Преобразования MULT148,0, MULT148,1, MULT195,0, MULT195,1 могут быть вычислены с помощью вспомогательных таблиц, содержащих векторы значений этих преобразований:
MULT148,0=(0, 148, 235, 127, 21, 129, 254, 106, 42, 190, 193, 85, 63, 171, 212, 64),
MULT148,1=(0, 84, 168, 252, 147, 199, 59, 111, 229, 177, 77, 25, 118, 34, 222, 138),
MULT195,0=(0, 195, 69, 134, 138, 73, 207, 12, 215, 20, 146, 81, 93, 158, 24, 219),
MULT195,1=(0, 109, 218, 183, 119, 26, 173, 192, 238, 131, 52, 89, 153, 244, 67, 46),
где векторы значений получены из (10) и приведены в виде
ƒ=(ƒ(0), ƒ(1), …, ƒ(15)),
где ƒ - произвольное преобразование, множеством входных аргументов которого является V4.
Рассмотрим способ выполнения преобразования π. Согласно [5], преобразование π может быть вычислено в соответствии с (1).
Для выполнения операции умножения в поле GF(24)[Х]/(Х4⊕X3⊕1) перейдем от векторного представления элементов поля к степенному представлению. Для этого введем преобразования:
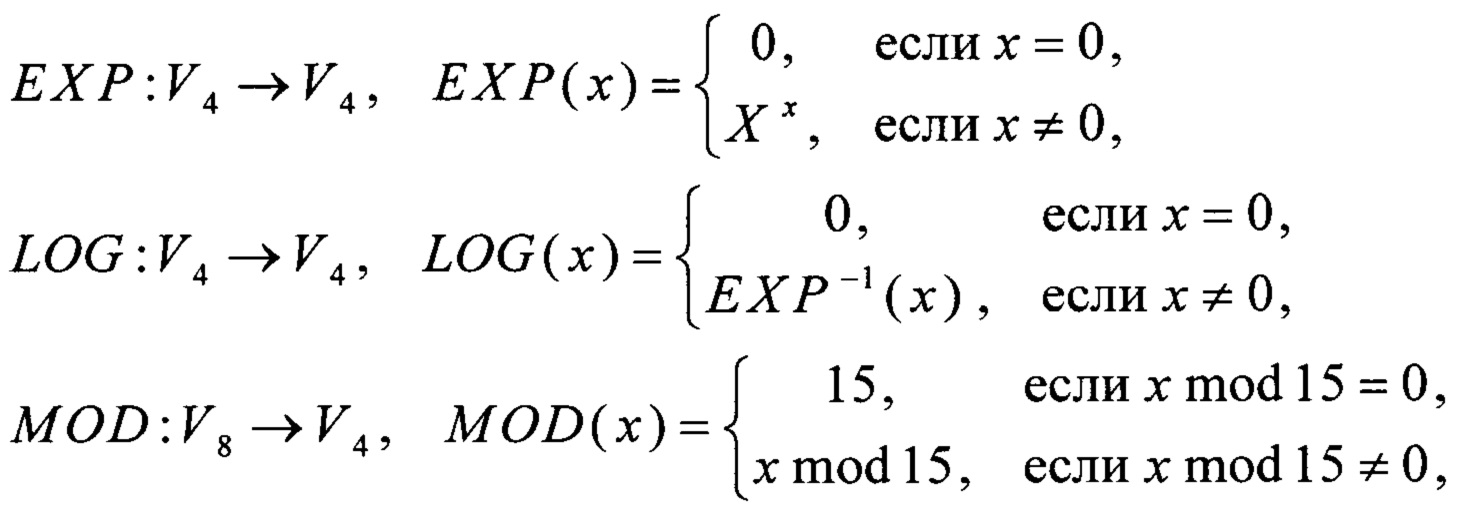
где X=2 - элемент поля GF(24)[Х]/(Х4⊕X3⊕1), являющийся образующим элементом мультипликативной группы этого поля.
Тогда 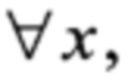 y∈V4, х≠0, у≠0:
y∈V4, х≠0, у≠0:
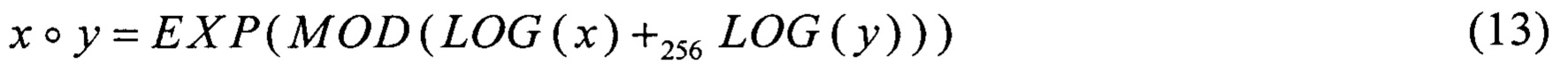
С учетом (8), (9) и (13), а также соотношений
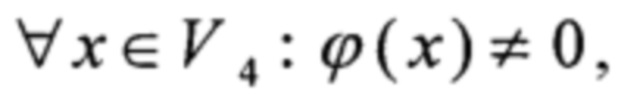
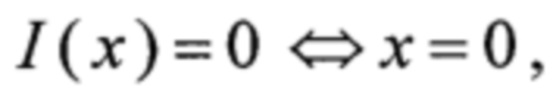
преобразование π может быть вычислено как
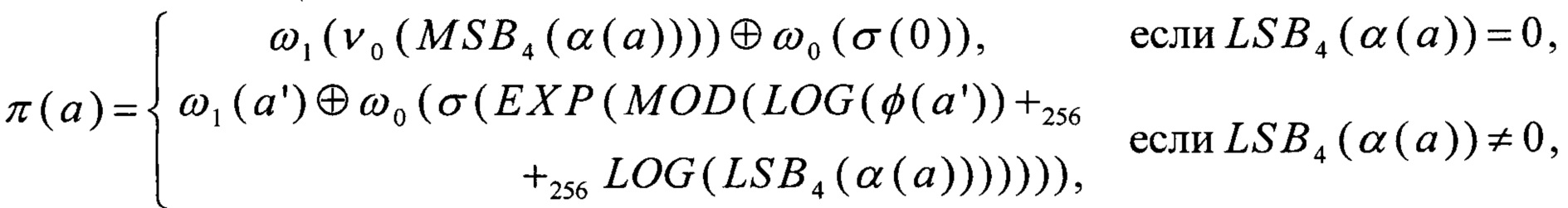
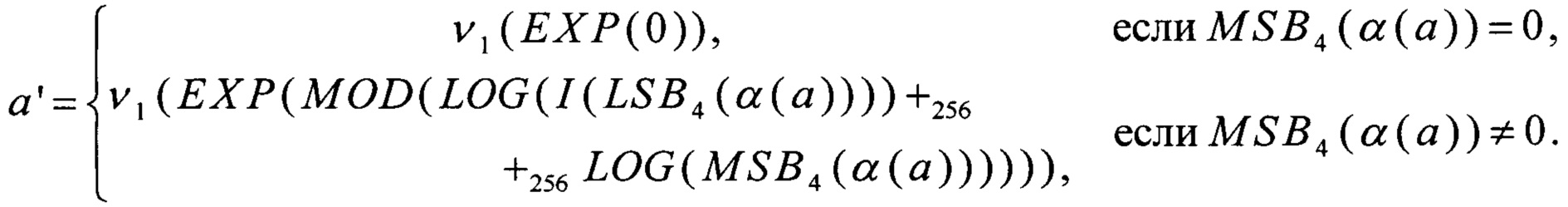
Перейдем от величины а' к величине а''=EXP-1(ν1-1(a')). С учетом того, что
ω0(σ(0))=220∈V8,
получаем, что
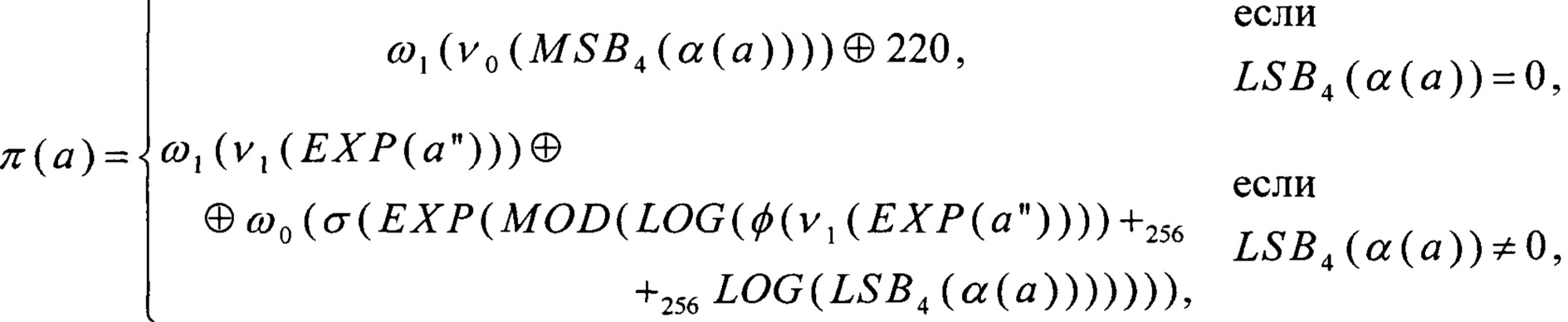
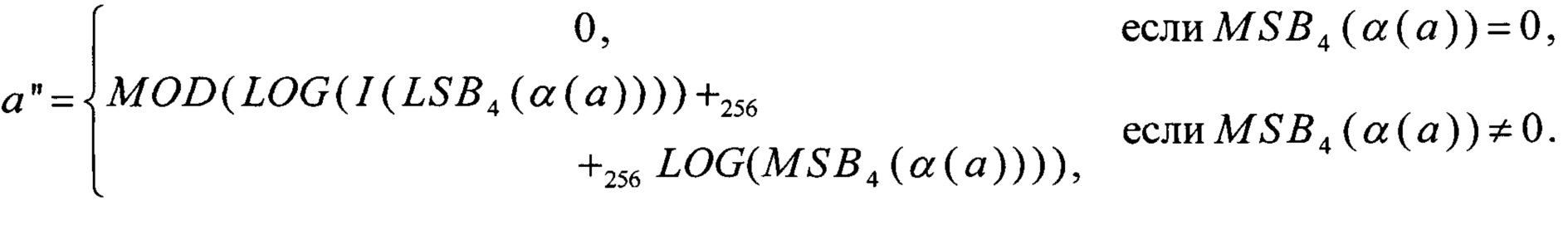
Введем преобразования
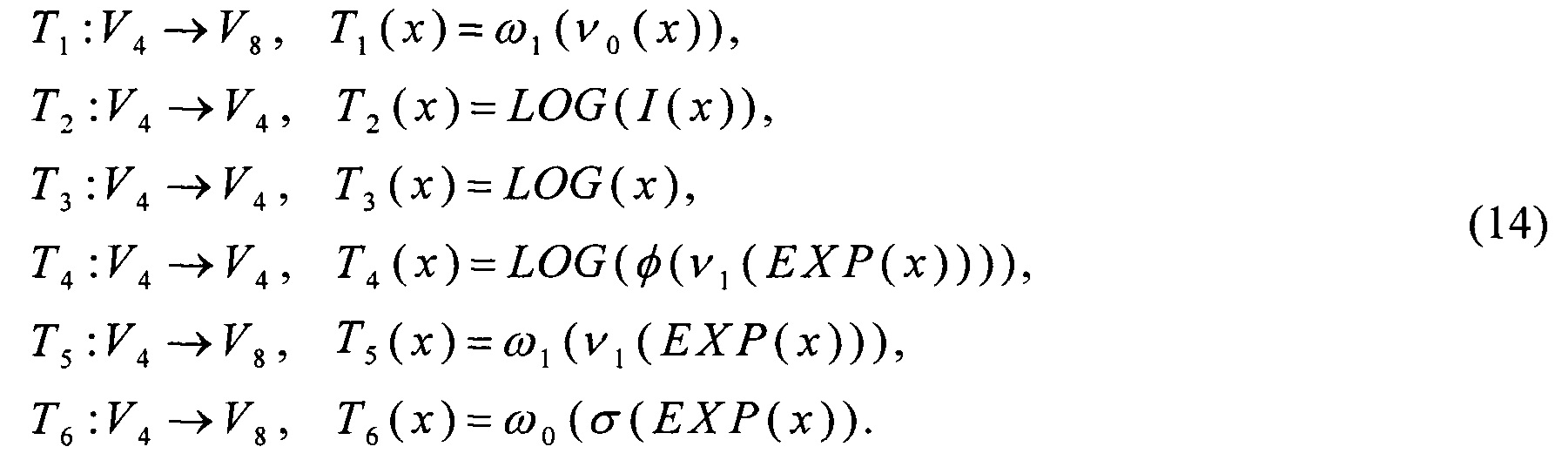
Тогда
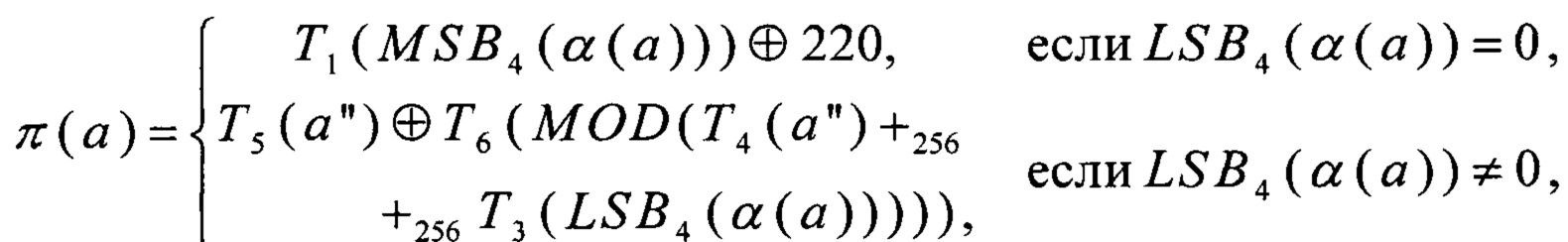
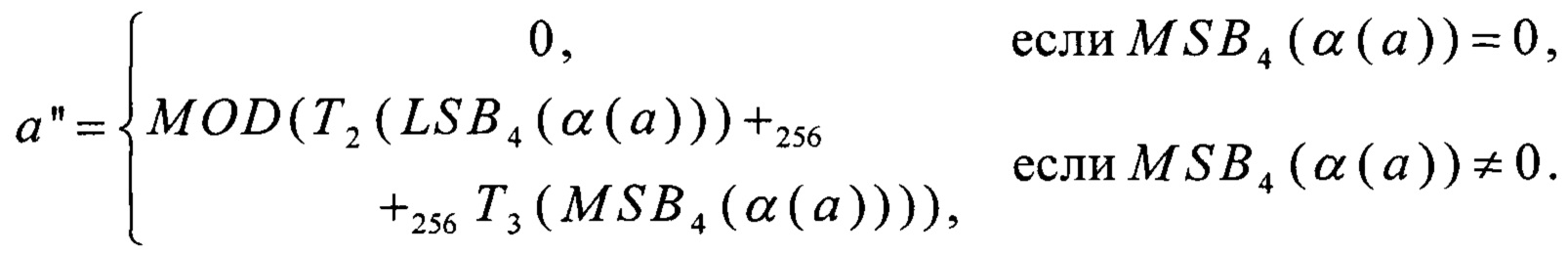
Для выполнения преобразования MOD заметим, что
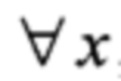 , y∈V4, х≠0, у≠0: LOG(х)+256LOG(у)∈{2, 3,…,30},
, y∈V4, х≠0, у≠0: LOG(х)+256LOG(у)∈{2, 3,…,30},
=2, 3, …, 30∈V8: MOD(х)=LSB4(х+256MSB4(x))
Для выполнения преобразований α, LSB4, MSB4 воспользуемся (9) и (11).
Для вычисления кусочно-заданных функций воспользуемся соотношениями:
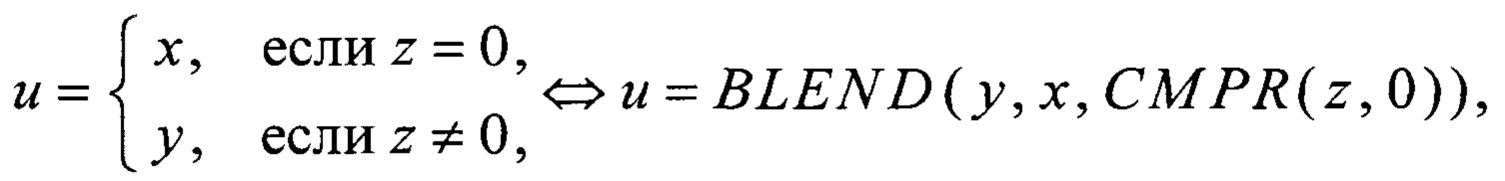
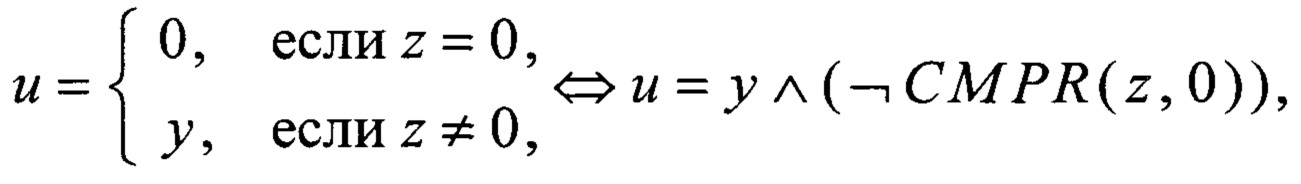
где «¬» - операция побитового отрицания,
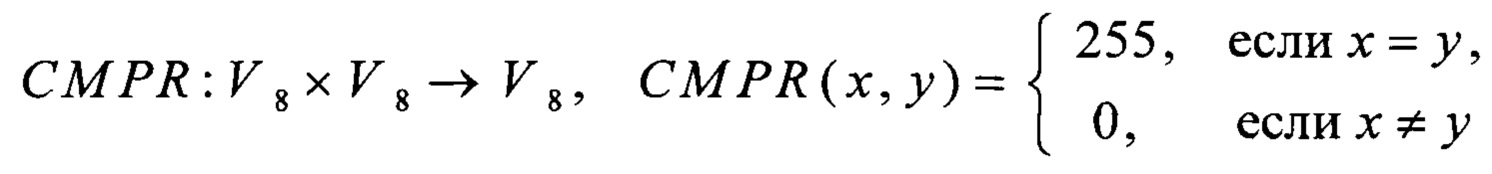
В результате, способ вычисления преобразования π принимает следующий вид:
- на вход преобразованию π поступает значение а∈V8;
- вычисляют значения

Предложенный способ позволяет вычислять преобразование π при помощи трех преобразований вида V4→V4: Т2, Т3, Т4; пяти преобразований вида V4→V8: α0, α1, T1, Т5, Т6; преобразования RSHIFT4 вида V8→V8; преобразования CMPR вида V8×V8→V8; преобразования BLEND вида V8×V8×V8→V8; а также операций сложения в кольце вычетов по модулю 256 («+256»), побитового "И" ( ), побитового "И" с отрицанием одного из аргументов («х
), побитового "И" с отрицанием одного из аргументов («х (¬у)») и побитового сложения («⊕»).
(¬у)») и побитового сложения («⊕»).
Преобразования α0, α1, T1, Т2, Т3, Т4, Т5, Т6 могут быть вычислены с помощью вспомогательных таблиц, содержащих векторы значений этих преобразований:
α0=(0, 112, 58, 74, 20, 100, 46, 94, 154, 234, 160, 208, 142, 254, 180, 196),
α1=(0, 2, 17, 19, 116, 118, 101, 103, 24, 26, 9, 11, 108, 110, 125, 127),
T1=(32, 20, 48, 34, 36, 2, 54, 50, 0, 4, 38, 16, 18, 6, 22, 52),
T2=(0, 15, 14, 3, 13, 6, 2, 8, 12, 11, 5, 10, 1, 4, 7, 9),
T3=(0, 15, 1, 12, 2, 9, 13, 7, 3, 4, 10, 5, 14, 11, 8, 6),
Т4=(14, 8, 5, 14, 2, 13, 9, 1, 3, 5, 3, 5, 12, 13, 12, 15),
Т5=(52, 22, 0, 4, 20, 54, 50, 16, 48, 38, 34, 32, 2, 18, 6, 36),
Т6=(220, 0, 152, 147, 153, 146, 215, 78, 214, 11, 69, 1, 68, 10, 79, 221),
где векторы значений получены из формул (8), (14) и приведены в виде
ƒ=(ƒ(0), ƒ(1), …, ƒ(15)),
где ƒ - произвольное преобразование, множеством входных аргументов которого является V4.
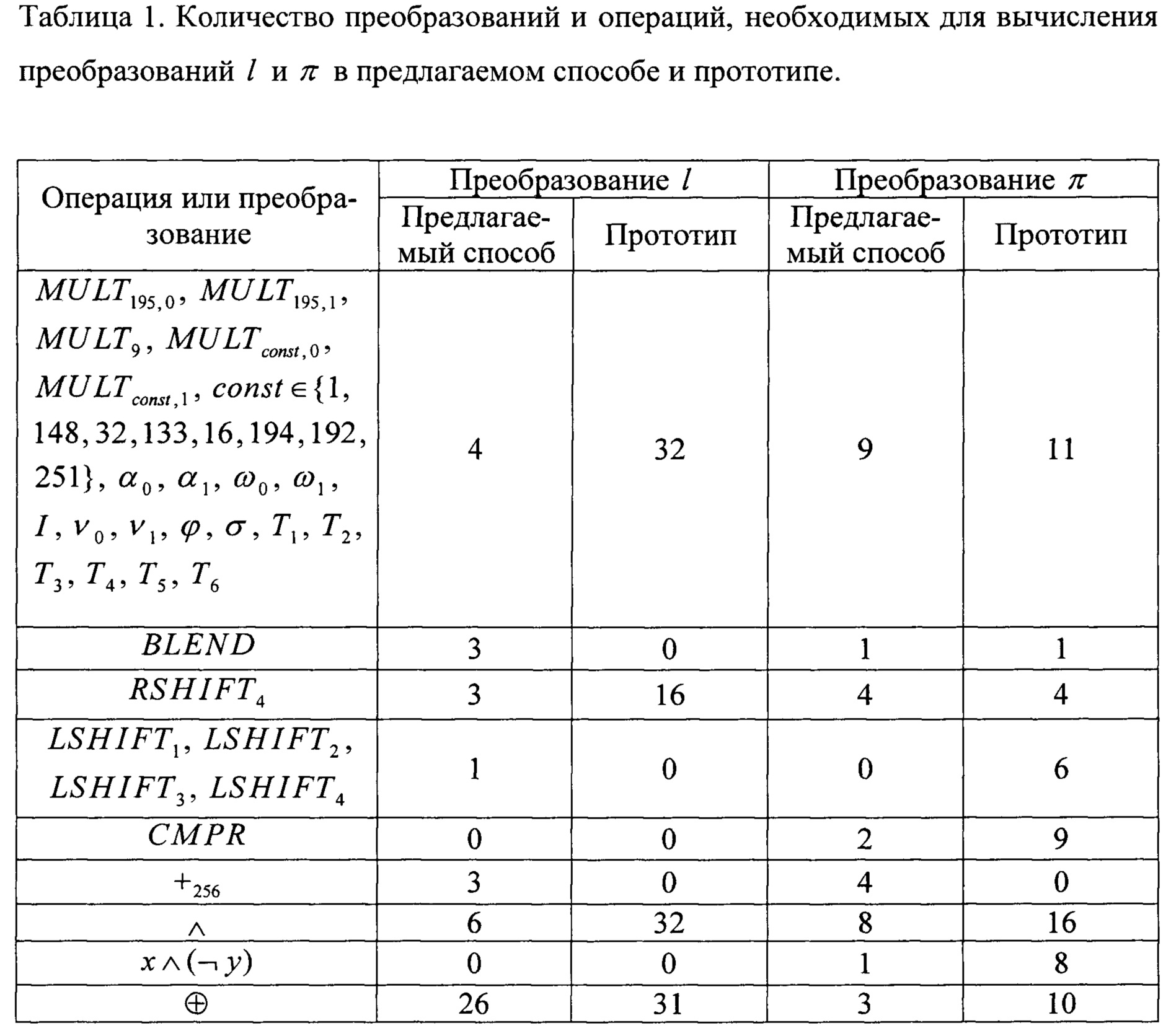
Итоговое количество преобразований и операций, необходимых для вычисления преобразований 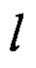 и π предлагаемым способом, а также способом, выбранным в качестве прототипа, приведено в табл. 1. Для наглядности, однотипные преобразования, предполагающие одинаковый способ выполнения при реализации, например, использование вспомогательных таблиц, объединены в одной строке, при этом численные значения в соответствующей строке означают суммарное количество применений преобразований данного типа в конкретном способе.
и π предлагаемым способом, а также способом, выбранным в качестве прототипа, приведено в табл. 1. Для наглядности, однотипные преобразования, предполагающие одинаковый способ выполнения при реализации, например, использование вспомогательных таблиц, объединены в одной строке, при этом численные значения в соответствующей строке означают суммарное количество применений преобразований данного типа в конкретном способе.
Для возможности сравнения предлагаемого способа со способом, выбранным в качестве прототипа, используется следующий вариант выполнения умножения в поле GF(24)[Х]/(Х4⊕X3⊕1), допускающий применение SIMD-инструкций для каждой из имеющихся операций:
- на вход операции умножения поступают значения x, y∈V4;
- вычисляют значения
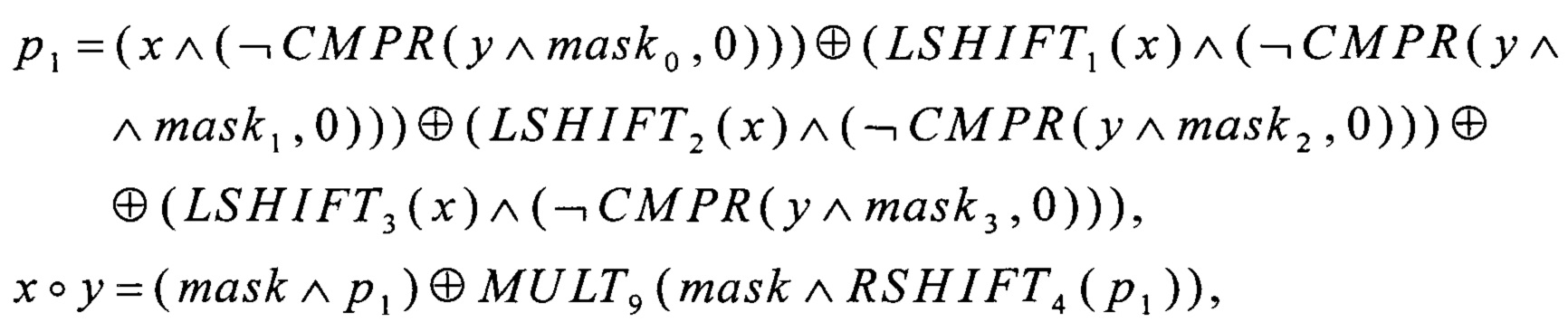
где
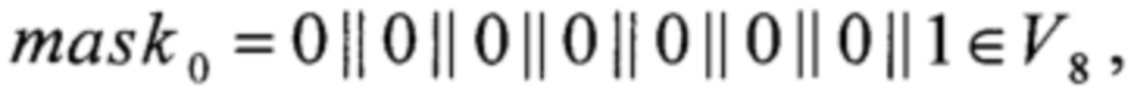
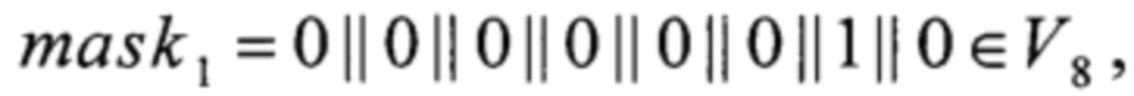
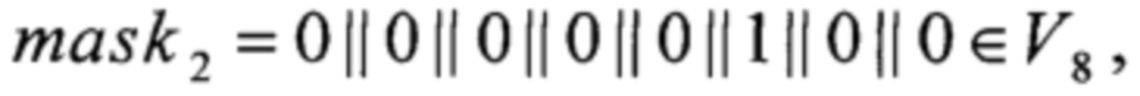
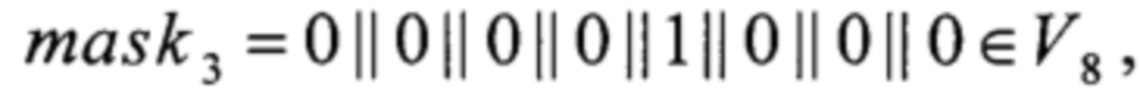
LSHIFT1, LSHIFT2, LSHIFT3:V4→V8,
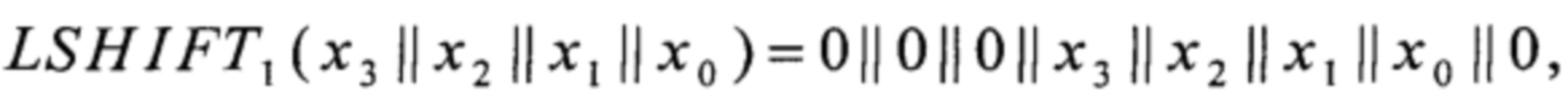
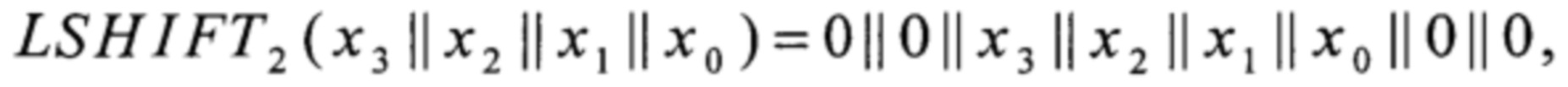
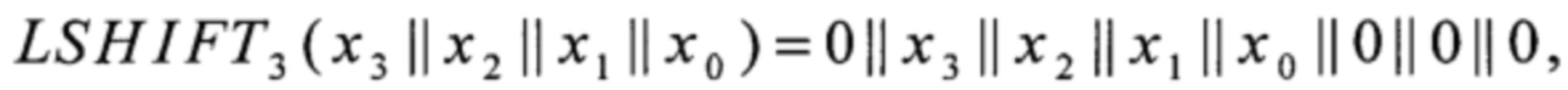
xi∈V1, i=0, 1, 2, 3,
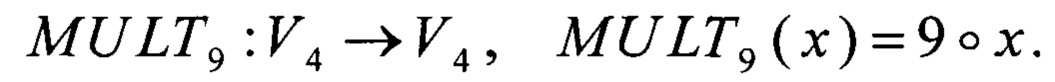
Тогда алгоритм вычисления преобразования π согласно способу, выбранному в качестве прототипа, принимает следующий вид:
- на вход преобразованию π поступает значение a∈V8;
- вычисляют значения

причем умножение в поле GF(24)[X]/(X4⊕X3⊕1) выполняют описанным выше способом.
Преобразование 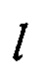 в прототипе выполняется в соответствии с (4), (5), (7).
в прототипе выполняется в соответствии с (4), (5), (7).
Таким образом, практически по каждому типу преобразований и операций, использующемуся в прототипе, удается добиться существенного сокращения количества преобразований и операций этого типа в случае применения предлагаемого способа. При этом в предлагаемом способе появляется необходимость выполнения незначительного числа новых типов преобразований и операций, однако, малочисленность и эффективность этих операций позволяет утверждать, что негативный эффект от их введения значительно меньше позитивного эффекта от сокращения количества имеющихся в прототипе преобразований и операций.
В связи с тем, что предлагаемый способ и способ, выбранный в качестве прототипа, отличаются только в части вычисления преобразования 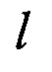 и π, а производительность выполнения этих преобразований выше в предлагаемом способе, общая производительность предлагаемого способа превосходит общую производительность прототипа. Следует отметить, что данное соотношение производительности способов справедливо как в случае обработки одного блока данных, так и в случае параллельной обработки нескольких блоков данных с помощью SIMD-инструкций.
и π, а производительность выполнения этих преобразований выше в предлагаемом способе, общая производительность предлагаемого способа превосходит общую производительность прототипа. Следует отметить, что данное соотношение производительности способов справедливо как в случае обработки одного блока данных, так и в случае параллельной обработки нескольких блоков данных с помощью SIMD-инструкций.
При этом предлагаемый способ сохраняет важные свойства прототипа. Сохраняется пропорциональный рост скорости программных реализаций на основе способа при увеличении длины используемых регистров, поскольку все использующиеся в предлагаемом способе преобразования и операции эффективно распараллеливаются с помощью существующих SIMD-инструкций. Также сохраняется возможность получения на основе способа реализаций, стойких к атакам по времени обращения к кэш-памяти вычислительной платформы, поскольку в предлагаемом способе используются только малые по размеру вспомогательные таблицы и, как следствие, появляется возможность задействования только инструкций с фиксированным временем выполнения.
Осуществление изобретения
Для осуществления предложенного способа рассмотрим вариант его программной реализации на вычислительной платформе с SIMD-архитектурой.
В качестве вычислительной платформы с SIMD-архитектурой используем процессор общего назначения Intel Core i7-4700. Для повышения эффективности параллельных вычислений задействуем регистры максимальной для данной модели процессора длины - 256 бит. Для работы с этими регистрами используем SIMD-инструкций из наборов AVX и AVX2.
Рассмотрим пример одновременного зашифрования 32 блоков данных, длиной 128 бит каждый. Будем считать, что итерационные ключи K1, …, K10∈V128 уже вычислены и алгоритм зашифрования получает их на вход вместе с шифруемыми данными а1, а2, …, а32∈V128.
Для осуществления предложенного способа выполняют следующие предварительные процедуры:
- для каждого преобразования MULT148,0, MULT148,1, MULT195,0, MULT195,1, α0, α1, T1, T2, T3, T4, T5, T6 формируют переменную длиной 256 бит, необходимую для табличного вычисления соответствующего преобразования, и
- побайтно заполняют младшие 128 бит каждой переменной элементами вектора значений соответствующего преобразования, причем в младшем (первом) байте размещают первый элемент вектора значений, во втором байте - второй элемент вектора значений и т.д.;
- заполняют старшие 128 бит переменной аналогично младшим 128 битам переменной;
- для константы mask формируют переменную длиной 256 бит и побайтно заполняют ее значениями константы mask;
- для итерационного ключа формируют переменную rk к длиной 256 бит;
- для данных формируют 16 переменных длиной 256 бит каждая: data1, data2, …, data16, и
- побайтно заполняют переменную datai, i=1, 2, …, 16, размещая в ней i-е байты каждого из 32 блоков а1, а2, …, а32∈V128: в младшем (первом) байте размещают i-й байт блока а1, во втором байте размещают i-й байт блока а2 и т.д.
Для одновременного зашифрования блоков ai, i=1, 2, …, 32, в соответствии с формулой:
EK1, …, K10 : V128→V128,
ЕК1,…, K10 (ai)=X[K10]LSX[K9]…LSX[K2]LSX[K1(ai),
последовательно осуществляют изменение значений переменных data1, data2, …, data16, соответствующее выполнению преобразований: X[Kj], j=1, 2, …, 10, L и S.
Для выполнения преобразования X[Kj], j=1, 2, …, 10: для каждого i=1, 2, …, 16
- побайтно заполняют переменную rk значениями i-го байта ключа Kj;
- вычисляют datai:=datai⊕rk.
Для выполнения линейного преобразования L: для каждого i=0, 1, …, 15 последовательно вычисляют
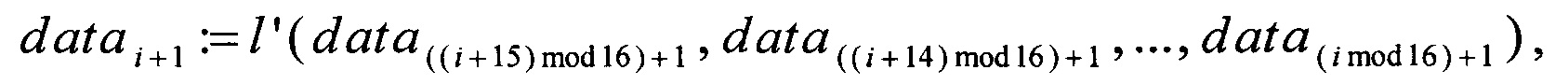
где 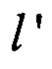 представляет собой параллельное применение преобразования
представляет собой параллельное применение преобразования 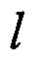 к j-м байтам аргументов
к j-м байтам аргументов 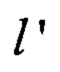 для получения j-го байта результата преобразования
для получения j-го байта результата преобразования 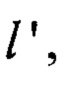 j=1, 2, …, 32.
j=1, 2, …, 32.
Преобразование 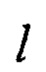 выполняют в соответствии (12), а параллельное применение
выполняют в соответствии (12), а параллельное применение 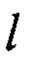 осуществляют с использованием следующих SIMD-инструкций:
осуществляют с использованием следующих SIMD-инструкций:
- "vpshufb" для реализации преобразований MULT148,0, MULT148,1, MULT195,0, MULT195,1;
- "vpblendvb" для реализации преобразования BLEND;
- "vpsrlw" для реализации преобразования RSHIFT4;
- "vpsllw" для реализации преобразования LSHIFT4;
- "vpaddb" для реализации операции «+256»;
- "vpand" для реализации операции 
- "vpxor" для реализации операции «⊕».
При реализации преобразований MULT148,0, MULT148,1, MULT195,0, MULT195,1, и задействовании константы mask используют введенные для них переменные.
Для осуществления нелинейного преобразования S: для каждого i=1, 2, …, 16 вычисляют
datai:=π'(datai),
где π' представляет собой параллельное применение преобразования π к j-му байту аргумента π' для получения j-го байта результата π', j=1, 2, …, 32.
Преобразование π выполняют в соответствии с (15), а параллельное применение π осуществляют с использованием следующих SIMD-инструкций:
- "vpshufb" для реализации преобразований α0, α1, Т1, Т2, Т3, Т4, Т5, Т6;
- "vpblendvb" для реализации преобразования BLEND;
- "vpsrlw" для реализации преобразования RSHIFT4;
- "vpcmpeqb" для реализации преобразования CMPR;
- "vpaddb" для реализации операции «+256»;
- "vpand" для реализации операции
- "vpandn" для реализации операции 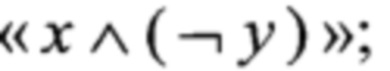
- "vpxor" для реализации операции «⊕».
При реализации преобразований α0, α1, Т1, Т2, Т3, Т4, Т5, Т6 и задействовании константы mask используют введенные для них переменные.
Для получения зашифрованных блоков b1, b2, …, b32∈V128 из итоговых значений переменных data1, data2, …, data16, выполняют перекомпоновку байт, обратную той, что применялась при начальном заполнении переменных data1, data2, …, data16, для чего побайтно заполняют блок bi, i=1, 2, …, 32, размещая в нем i-e байты каждой из 16 переменных data1, data2, …, data16, причем в младшем (первом) байте размещают i-й байт переменной data1, во втором байте размещают i-й байт переменной data2 и т.д.
В случае необходимости применения алгоритма зашифрования к большему числу блоков данных выполняют разбиение всех входных блоков на группы, состоящие не более чем из 32 блоков, после чего обрабатывают каждую группу в отдельности. При этом, если обрабатываемая группа содержит менее 32 блоков, ее предварительно дополняют произвольными блоками в количестве, необходимом для получения 32 блоков в группе, а результат зашифрования добавленных блоков игнорируют.
Скорость описанной программной реализации алгоритма зашифрования блочного шифра «Кузнечик», основанной на предлагаемом способе, составляет 360 Мбайт/с при выполнении вычислений в одном потоке на одном ядре процессора Intel Core i7-4700. Программная реализация алгоритма зашифрования блочного шифра «Кузнечик», основанная на способе, выбранном в качестве прототипа, согласно [3], имеет скорость равную 300 Мбайт/с на аналогичной вычислительной платформе. Таким образом, прирост производительности предлагаемого способа относительно прототипа составляет порядка 20%.
Источники информации, принятые во внимание при составлении заявки
1. ГОСТ Р 34.12-2015. Информационная технология, Криптографическая защита информации, Блочные шифры. Москва, Стандартинформ, 2016.
2. Евразийский патент №021803, приоритет от 25.04.2012 г.
3. Rybkin A. S. On software implementation of Kuznyechik on Intel CPUs. Математические вопросы криптографии, 9:2 (2018), с. 117-127.
4. Bernstein D. J. Cache-timing attacks on AES. 2005 (статья по адресу: https://cr.yp.to/antiforgery/cachetiming-20050414.pdf).
5. Biryukov, A., Perrin, L., Udovenko, A. Reverse-engineering the S-box of Streebog, Kuznyechik and STRIBOBrl. In Annual International Conference on the Theory and Applications of Cryptographic Techniques (2016), 372-402, Springer, Berlin, Heidelberg.
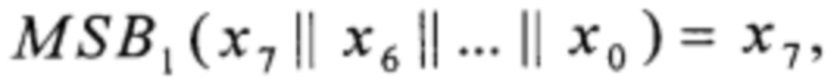
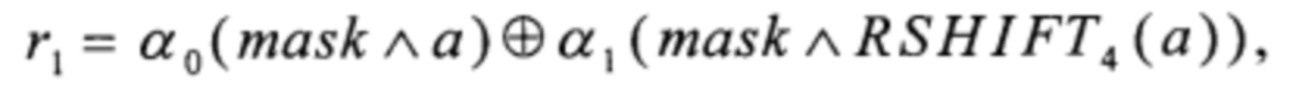
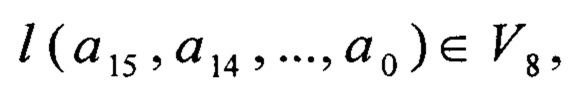
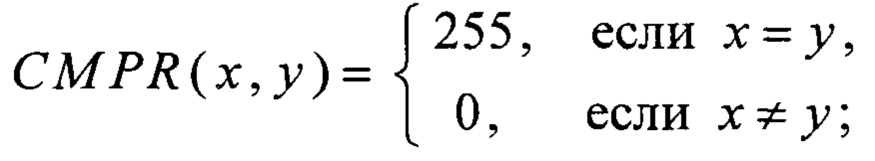
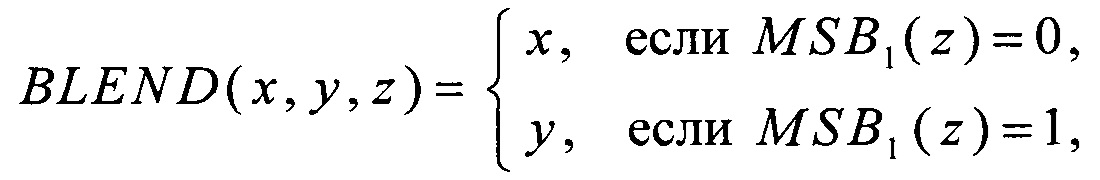
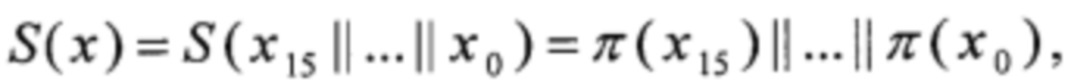
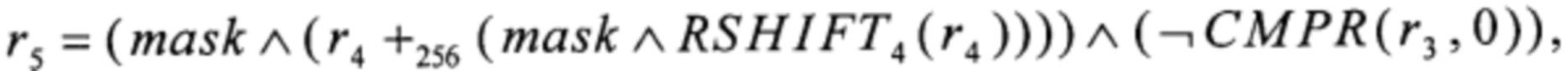
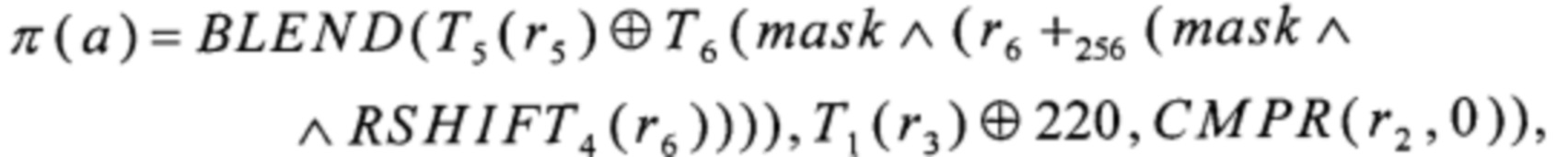
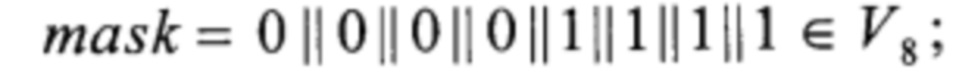
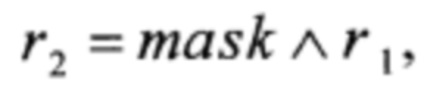
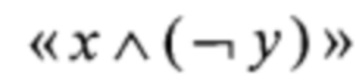
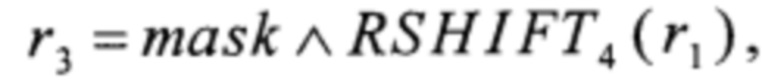
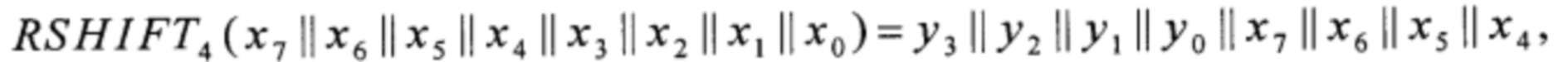
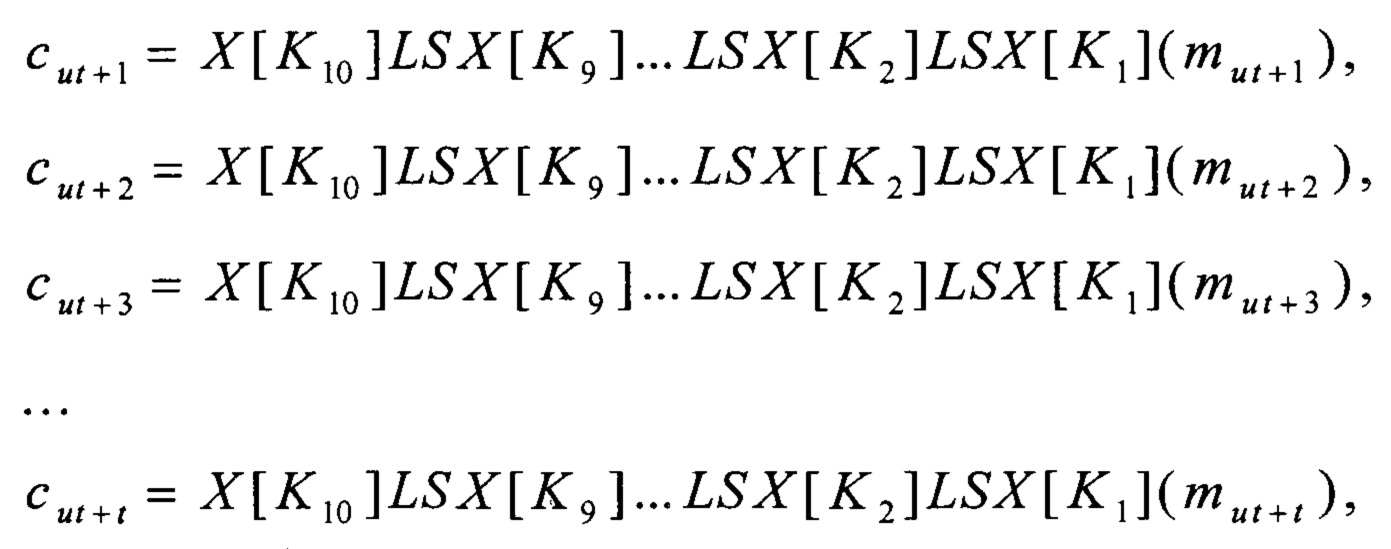
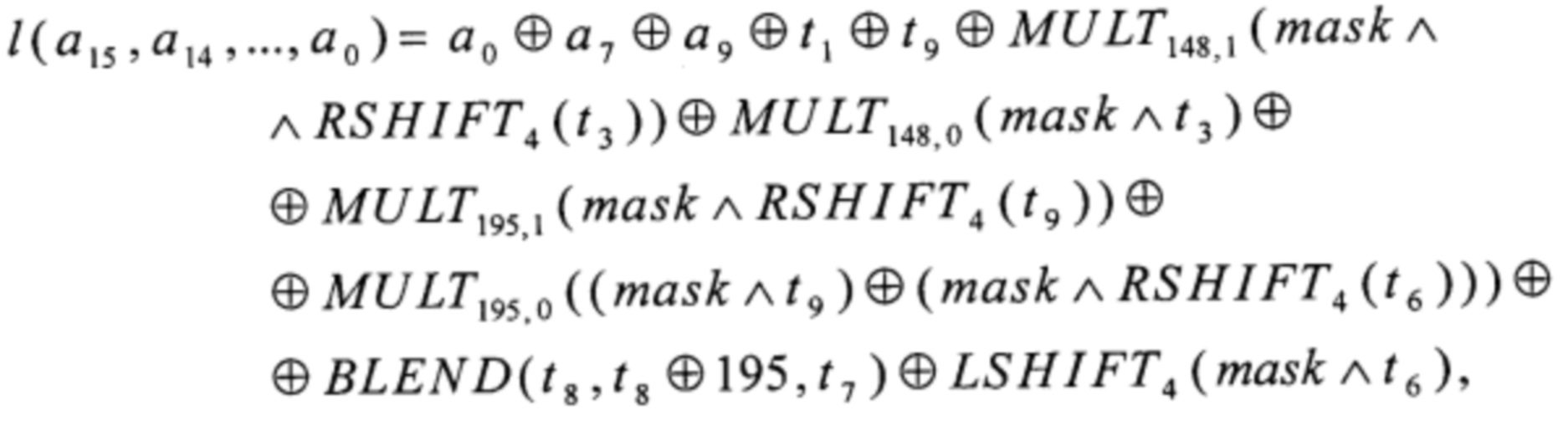
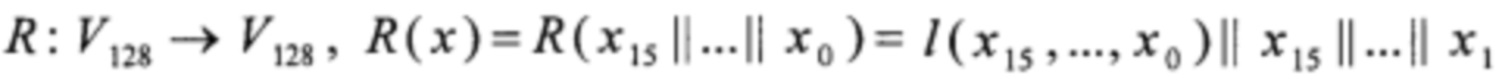
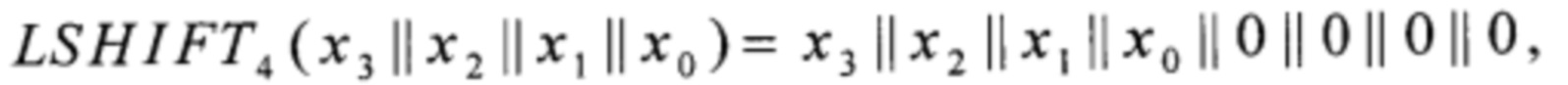
Способ параллельной обработки упорядоченных потоков данных
Способ обнаружения вредоносного программного обеспечения в ядре операционной системы
Способ управления соединениями в межсетевом экране
Способ синхронизации доступа к разделяемым ресурсам вычислительной системы и обнаружения и устранения повисших блокировок с использованием блокировочных файлов
Способ передачи данных в цифровых сетях передачи данных по протоколу тср/ip через нттр
Способ предотвращения повторного использования пакетов цифровых данных в сетевой системе передачи данных
Способ обнаружения компьютерных атак на сетевую компьютерную систему
Способ кодирования и вычисления даты с использованием упрощенного формата в цифровых устройствах
Способ криптографического преобразования
Способ разрешения конфликта адресации узлов в асинхронных сетях с топологией "общая шина"
Способ криптографического преобразования
Способ работы регистра сдвига с линейной обратной связью
Способ распределения симметричных ключей между узлами вычислительной сети с системой квантового распределения ключей

