Результат интеллектуальной деятельности: Система и способ двухэтапной классификации файлов
Вид РИД
Изобретение
Область техники
Изобретение относится к области классификации файлов, а именно к системам и способам двухэтапной классификации файлов.
Уровень техники
В настоящий момент вычислительные устройства - смартфоны, компьютеры, планшеты и т.п.- стали обязательным атрибутом практически каждого человека. При помощи таких устройств люди выполняют множество повседневных задач: от общения по электронной почте до оплаты покупок в магазинах. Широкое распространение таких устройств мотивирует злоумышленников создавать вредоносные программы - программы, в частности предназначенные для неправомерного доступа к данным пользователя, а также к ресурсам вычислительных устройств в целом.
На данный момент для борьбы с вредоносными программами широко используются антивирусные приложения - программы, предназначенные для обнаружения вредоносных программ и защиты вычислительных устройств от упомянутых вредоносных программ. Для обеспечения такой защиты применяются различные подходы и технологии: сигнатурный анализ, поведенческий анализ, эвристические правила и т.д. Но по мере развития антивирусных технологий злоумышленниками совершенствуются и способы обхода этих защитных механизмов. Таким образом развитие антивирусных технологий всегда является актуальной задачей, целью которой является повышение качества обнаружения вредоносных программ - снижение ошибок первого и второго рода при обнаружении вредоносных программ.
Для повышения качества обнаружения вредоносных программ все более часто применяются классифицирующие модели, полученные в результате машинного обучения (англ. Machine Learning). Такие модели выделяют всевозможные признаки (информация о компиляторах, использованных при создании приложений, информация о размерах исполняемых файлов, наборы машинных инструкций и т.д.) из анализируемых приложений, в частности исполняемых файлов (например РЕ-файлов), и на основании данных признаков относят анализируемое приложение к одному из классов приложений, соответственно обнаружение вредоносного приложения осуществляется при отнесении анализируемого приложения к классу вредоносных приложений. Однако даже такие способы обнаружения вредоносных приложений требуют постоянного усовершенствования для того, чтобы обеспечить защиту вычислительных устройств пользователя. И на смену простым классифицирующим моделям приходят более сложные, например - двухэтапные.
Например в публикации US 9349006 B2 описан подход, в соответствии с которым каждый анализируемый файл сначала проходит грубую классификацию, в соответствии с которой относится к одному из классов, например "класс обращения к сетевым ресурсам", затем атрибуты файла проходят более тонкую классификацию при помощи классификатора, обученного на каком-то конкретном классе файлов, с целью последующего отнесения в вредоносным или безопасным файлам.
Однако даже такой подход обладает недостатком - грубая классификация очень поверхностно классифицирует анализируемые файлы и не учитывает, являются ли файлы из одного класса похожими. Настоящее изобретение призвано преодолеть недостатки существующих подходов и еще больше повысить качество обнаружения вредоносных программ.
Раскрытие изобретения
Настоящее изобретение предназначено для обнаружения вредоносных файлов.
Технический результат настоящего изобретения заключается в реализации заявленного назначения.
Еще один технический результат настоящего изобретения заключается в снижении количество ошибок первого и второго рода при обнаружении вредоносных файлов.
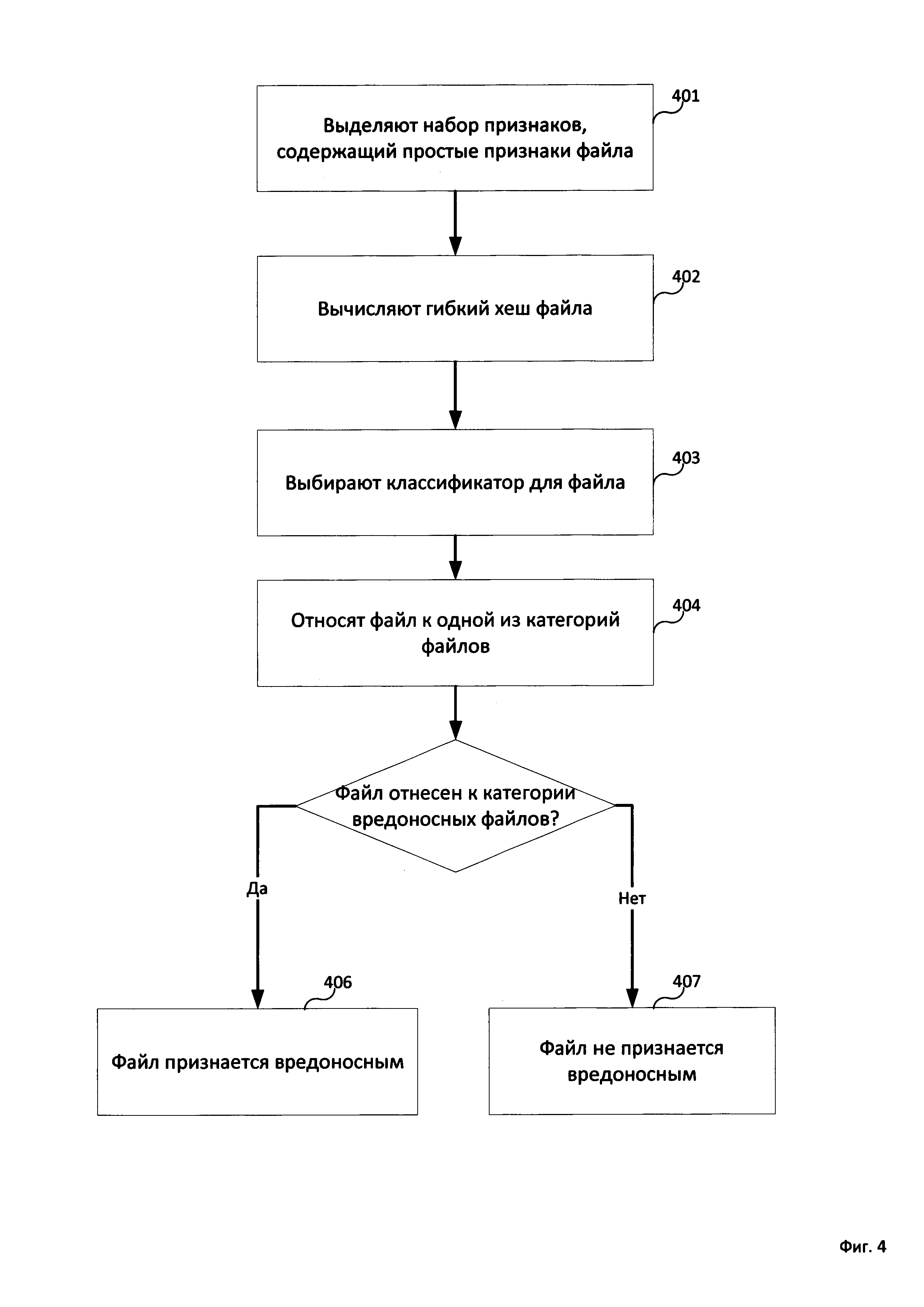
Способ обнаружения вредоносных файлов, согласно которому: выделяют при помощи средства вычисления хеша набор признаков файла; при этом набор признаков файла содержит по меньшей мере простые признаки файла; при этом простым признаком является признак, выделение которого не требует существенных вычислительных затрат; вычисляют при помощи средства вычисления хеша гибкий хеш файла на основании выделенного набора признаков файла; при этом гибкий хеш устойчив к изменениям признаков из выделенного набора признаков; при помощи средства классификации выбирают классификатор, соответствующий вычисленному значению гибкого хеша файла, из набора классификаторов, состоящего из по меньшей мере одного классификатора; при этом классификатор соответствует гибкому хешу, когда для обучения классификатора использовались по меньшей мере файлы, значения гибких хешей которых совпадают со значением упомянутого гибкого хеша; относят при помощи средства классификации файл к одной из категорий файлов при помощи классификатора, выбранного на этапе ранее; признают при помощи средства классификации файл вредоносным, если он был отнесен к категории вредоносных файлов.
В другом варианте реализации способа признаком, выделение которого из файла не требует существенных вычислительных затрат, является по меньшей мере атрибут заголовка исполняемого файла, идентификатор объекта, описанного в заголовке исполняемого файла, размер упомянутого объекта или порядок его следования в исполняемом файле.
В еще одном варианте реализации способа существенными вычислительными затратами, требующимися для выделения признака файла, являются по меньшей мере: выделение области памяти размером больше порогового значения с целью выделения признака, выделение признака файла за время, большее порогового значения.
В еще одном варианте реализации способа устойчивость гибкого хеша означает идентичность хешей для наборов выделенных признаков из двух похожих файлов.
В еще одном варианте реализации способа похожими файлами считаются файлы, степень сходства между которыми превышает заранее установленный порог.
В еще одном варианте реализации способа классификатором может являться меньшей мере:
- дерево принятия решений;
- градиентный бустинг;
- случайный лес;
- классифицирующая модель на основе нейронных сетей.
В еще одном варианте реализации способа набор классификаторов формируется средством классификации путем обучения с учителем классификаторов на обучающей выборке файлов, содержащей по меньшей мере файлы из категории вредоносных файлов.
Система обнаружения вредоносных файлов, которая содержит: средство вычисления хеша, предназначенное для выделения набора признаков файла, а также для вычисления гибкого хеша файла на основании выделенного набора признаков файла; при этом набор признаков файла содержит по меньшей мере простые признаки файла; при этом гибкий хеш устойчив к изменениям признаков из выделенного набора признаков; при этом простым признаком является признак, выделение которого не требует существенных вычислительных затрат; средство классификации, предназначенное для выбора классификатора, соответствующего вычисленному значению гибкого хеша файла, из набора классификаторов, состоящего из по меньшей мере одного классификатора, для отнесения файла к одной из категорий файлов при помощи выбранного классификатора, а также для признания файла вредоносным, если он был отнесен к категории вредоносных файлов; при этом классификатор соответствует гибкому хешу, когда для обучения классификатора использовались по меньшей мере файлы, значения гибких хешей которых совпадают со значением упомянутого гибкого хеша.
В другом варианте реализации системы признаком, выделение которого из файла не требует существенных вычислительных затрат, является по меньшей мере атрибут заголовка исполняемого файла, идентификатор объекта, описанного в заголовке исполняемого файла, размер упомянутого объекта или порядок его следования в исполняемом файле.
В еще одном варианте реализации системы существенными вычислительными затратами, требующимися для выделения признака файла, являются по меньшей мере: выделение области памяти размером больше порогового значения с целью выделения признака, выделение признака файла за время, большее порогового значения.
В еще одном варианте реализации системы устойчивость гибкого хеша означает идентичность хешей для наборов выделенных признаков из двух похожих файлов.
В еще одном варианте реализации системы похожими файлами считаются файлы, степень сходства между которыми превышает заранее установленный порог.
В еще одном варианте реализации системы классификатором может являться меньшей мере:
- дерево принятия решений;
- градиентный бустинг;
- cлучайный лес;
- классифицирующая модель на основе нейронных сетей.
В еще одном варианте реализации системы набор классификаторов формируется средством классификации путем обучения с учителем классификаторов на обучающей выборке файлов, содержащей по меньшей мере файлы из категории вредоносных файлов.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 иллюстрирует примерную схему компонентов системы двухэтапной классификации файлов.
Фиг. 2 иллюстрирует пример вычисления гибкого хеша файла.
Фиг.3 иллюстрирует пример классификации файлов.
Фиг. 4 иллюстрирует примерный вариант способа двухэтапной классификации файлов.
Фиг. 5 иллюстрирует вариант схемы компьютерной системы общего назначения.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является не чем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
Введем ряд определений и понятий, которые будут использоваться при описании вариантов осуществления изобретения.
Вредоносное приложение - приложение, способное нанести вред вычислительному устройству или данным пользователя вычислительного устройства (иными словами, компьютерной системы: персонального компьютера, сервера, мобильного телефона и т.п.), например: сетевой червь, клавиатурный шпион, компьютерный вирус. В качестве нанесенного вреда может выступать неправомерный доступ к ресурсам компьютера, в том числе к данным, хранящимся на компьютере, с целью хищения, а также неправомерное использование ресурсов, в том числе для хранения данных, проведения вычислений и т.п.
Доверенное приложение - приложение, которое не наносит вреда компьютеру или его пользователю. Доверенным приложением может считаться приложение, разработанное доверенным производителем ПО (программного обеспечения), загруженное из доверенного источника (например, сайт, занесенный в базу данных доверенных сайтов) или приложение, идентификатор (или другие данные, по которым можно однозначно определить приложение) которого (например, хеш-сумма файла приложения) хранится в базе данных доверенных приложений. Идентификатор производителя, например, цифровой сертификат, может также храниться в базе данных доверенных приложений.
Недоверенное приложение - приложение, которое не является доверенным, но также не признано вредоносным, например, при помощи антивирусного приложения. При этом недоверенное приложение может впоследствии быть признано вредоносным, например, при помощи антивирусной проверки.
Вредоносный файл - файл, являющийся компонентом вредоносного приложения и содержащий программный код (исполняемый или интерпретируемый код).
Недоверенный файл - файл, являющийся компонентом недоверенного приложения и содержащий программный код (исполняемый или интерпретируемый код).
Доверенный файл - файл, являющийся компонентом доверенного приложения.
Предопределенные категории приложений - по меньшей мере категория доверенных приложений, категория недоверенных приложений, категория вредоносных приложений.
Гибкий хеш (англ. "similarity preserving hash"1(1 Sparse similarity-preserving hashing, Jonathan Masci et al., https://arxiv.org/pdf/1312.5479.pdf), в частности "locality sensitive hash2(2 Locality Sensitive Hashing, Ravi Kumar, https://users.soe.ucsc.edu/~niejiazhong/slides/kumar.pdf") - хеш файла, вычисляемый на основании данных, хранящихся в файле, и значение которого остается неизменным при частичном изменении таких данных. В одном из примеров реализации изобретения такими данными, хранящимися в файле, являются простые признаки. В одном из вариантов реализации гибкий хеш - хеш, который для двух похожих файлов будет иметь одно и то же значение (значения гибких хешей, вычисленных на основании признаков файлов, совпадает). Под гибким хешем группы файлов (гибкий хеш, соответствующий группе файлов) будем понимать гибкий хеш, значение которого для каждого файла из упомянутой группы одинаково. Файлы с совпадающим значением гибкого хеша, в частности файлы из такой группы, можно считать похожими с некоторой точностью (под точностью в данном контексте можно понимать среднее или среднеквадратичное значение степени сходства, например между каждыми двумя файлами из такой группы), которая определяется точностью самого метода вычисления гибкого хеша.
Простой признак файла - признак файла (данные, описывающие некоторым образом файл), выделение которого не требует существенных вычислительных затрат (такие признаки, как правило, можно выделить из файла в первоначальном виде, без выполнения дополнительных вычислений с использованием выделенных данных). Примерами простых признаков являются атрибуты заголовка исполняемого файла, идентификаторы (например, названия) объектов, описанных в заголовке исполняемого файла, размеры упомянутых объектов и порядок их следования в исполняемом файле (первыми будут следовать объекты с меньшими адресами в файле). Под объектами, описанными в заголовке исполняемого файла, понимают по меньшей мере секции файла, в том числе ресурсов файла, таблицы: импорта, экспорта, настроек адресов. В частном случае реализации в качестве объектов, описанных в заголовке исполняемого файла, также понимаются аналогичные объекты, но в образе исполняемого файла, который формируется в оперативной памяти при запуске исполняемого файла.
Сложный признак файла - признак файла (данные, описывающие некоторым образом файл), выделение которого требует существенных вычислительных затрат. Примерами сложных признаков являются:
- статистическая информация секций файла: энтропия и распределение значений байт;
- фрагменты исполняемого кода файла;
- строковые константы.
Существенными вычислительными затратами, требующимися для выделения признака файла, являются по меньшей мере: выделение области памяти размером больше порогового значения с целью выделения признака, также выполнение операции выделения признака файла за время, большее порогового значения, а также превышение объемом данных файла, необходимых для считывания с устройства хранения данных с целью выделения признака файла, установленного порога.
Два файла будем считать похожими, если степень сходства между ними превышает заранее установленный порог (например, превышает 85%, иными словами превышает 0.85). Степень сходства может быть вычислена при помощи любого из известных подходов, например, основанных на вычислении мер:
- Жаккара;
- Дайса;
- Левенштейна;
- Хэмминга;
- и т.п.
Под средствами системы двухэтапной классификации файлов в настоящем изобретении понимаются реальные устройства, системы, компоненты, группы компонентов, реализованные с использованием аппаратных средств, таких как интегральные микросхемы (англ. application-specific integrated circuit, ASIC) или программируемые вентильные матрицы (англ. field-programmable gate array, FPGA) или, например, в виде комбинации программных и аппаратных средств, таких как микропроцессорная система и набор программных инструкций, а также на нейроморфных чипах (англ. neurosynaptic chips) Функциональность указанных средств системы может быть реализована исключительно аппаратными средствами, а также в виде комбинации, где часть функциональности средств системы реализована программными средствами, а часть аппаратными. В некоторых вариантах реализации часть средств, или все средства, могут быть исполнены на процессоре компьютера общего назначения (например, который изображен на Фиг. 5). При этом компоненты системы могут быть реализованы в рамках как одного вычислительного устройства, так и разнесены между несколькими, связанными между собой вычислительными устройствами.
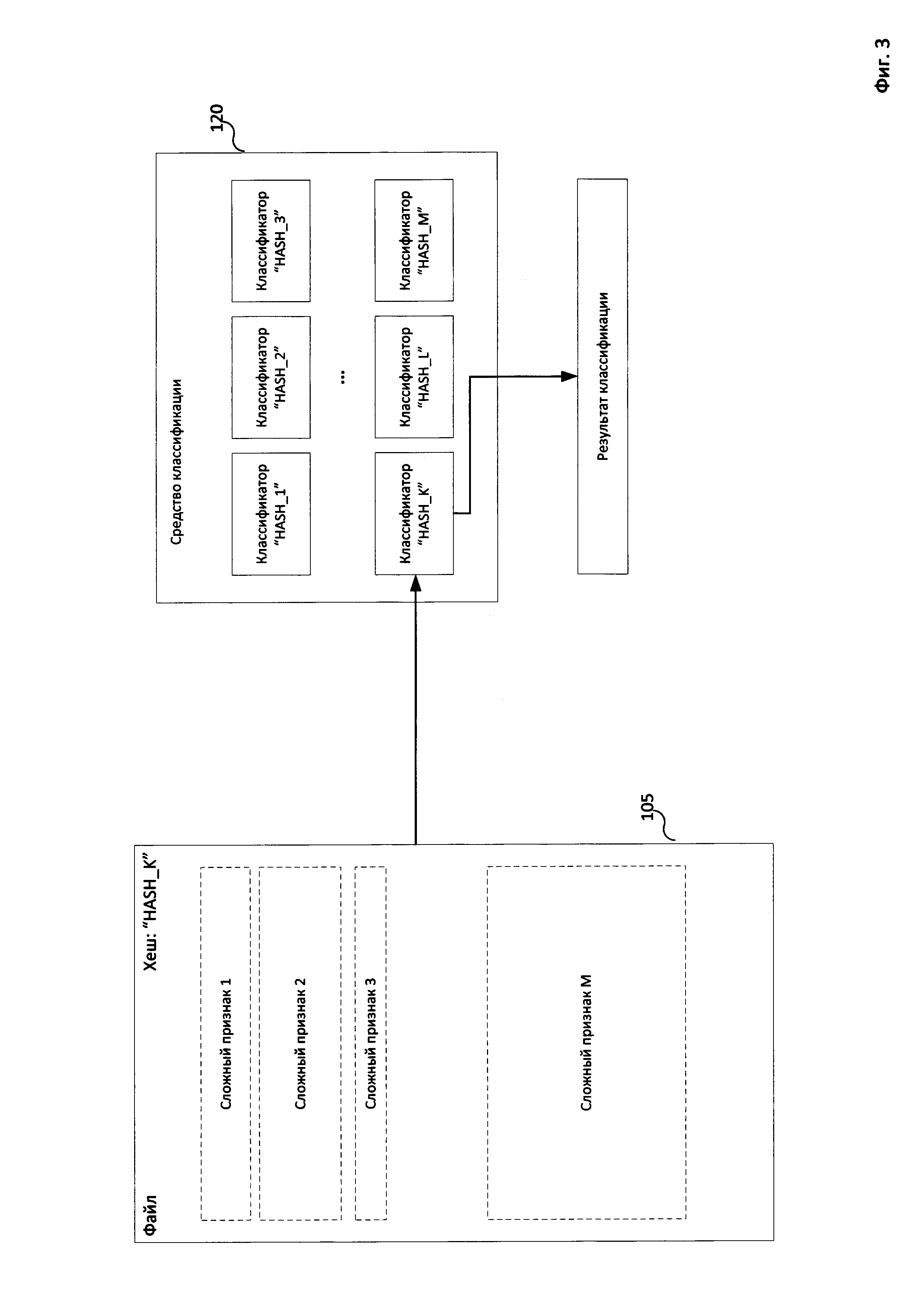
На Фиг. 1 приведена примерная схема компонентов системы двухэтапной классификации файлов. Настоящая система включает в себя следующие компоненты: средство вычисления хеша 110, средство классификации 120 и базу данных файлов 130. В одном из вариантов реализации изобретения средство вычисления хеша 110 и средство классификации 120 располагаются на одном вычислительном устройстве. В другом варианте реализации средство вычисления хеша 110 располагается на вычислительном устройстве-клиенте (например, персональном компьютере пользователя), а средство классификации 120 расположено на вычислительном устройстве-сервере. При этом база данных файлов 130 может располагаться как на устройстве-сервере, так и на вычислительном устройстве-клиенте.
Средство вычисления хеша 110 предназначено для выделения из файла набора простых признаков, а также для вычисления гибкого хеша файла на основании выделенного набора простых признаков. Существуют различные способы вычисления гибкого хеша таким образом, чтобы для двух похожих файлов значение такого хеша совпадали, например lsh (англ. "locality sensitive hashing"), а также другие хеш-функции, сформированные при помощи обучения с учителем или частичного обучения с учителем с условием удовлетворения условия "similarity preserving" - устойчивости значения хеша к изменению данных, на основании которых хеш вычисляется. Случай совпадения значения хеша - коллизия - для двух файлов будет означать, что эти файлы похожие. Один из примеров вычисления такого хеша описан в публикации RU 2013129552 (там понятие хеш заменяется сверткой).
Для создания гибкого хеша 115 средство вычисления хеша 110 выделяет из файла 105 набор простых признаков. В одном из вариантов реализации изобретения средство вычисления хеша 110 дополняет упомянутый набор признаков сложными признаками для одной секции файла 105.
Выделенный вышеупомянутым способом набор признаков файла 105 используется средством вычисления хеша 110 для вычисления гибкого хеша 115.
В одном из вариантов реализации изобретения для вычисления гибкого хеша 115 используется следующий метод: гибкий хеш формируется как конкатенация представления (например, байтового) признаков из выделенного набора признаков файла 105. В одном из вариантов реализации представление каждого сложного признака файла 105, входящего в упомянутый набор признаков, перед включением в гибкий хеш предварительно проходит обработку при помощи хеш-функции. В одном из вариантов реализации такой хеш-функцией является хеш-функция, удовлетворяющая условию "similarity preserving", например locality sensitive hash или semi-supervised hash. Стоит отметить, что методика вычисления гибкого хеша, обеспечивает для двух похожих файлов, у которых отличаются некоторые (например, два из всего набора) признаки из выделенного набора признаков, совпадение значений хешей 115.
Вычисленный гибкий хеш 115 файла 105 передается средством вычисления хеша 110 средству классификации 120.
Средство классификации 120 в общем случае предназначено для отнесения файла 105 к одной из категорий файлов. В одном из вариантов реализации такой категорией является некоторая предопределенная категория, например: категория доверенных файлов, категория вредоносных файлов или категория недоверенных файлов. В одном из вариантов реализации изобретения еще одной категорией файлов может быть категория, к которой будет отнесен файл 105, если он не был отнесен ни к одной из предопределенных категорий (например, категория "неизвестных файлов"). Для того, чтобы отнести файл 105 к некоторой категории средство классификации 120 использует классификатор. Под классификатором будем понимать классифицирующую модель (иными словами, алгоритм классификации). Примерами таких классификаторов могу являться следующие классифицирующие модели (типы классификаторов):
- дерево принятия решений;
- градиентный бустинг (англ. "gradient boosting");
- случайный лес (англ. "random forest");
- модели на основе нейронных сетей.
Соответственно, средство классификации 120 также осуществляет выбор классификатора, который впоследствии применяется для отнесения файла 105 к одной из категорий файлов. В одном из вариантов реализации изобретения выбор классификатора осуществляется на основании гибкого хеша 115 файла 105. В таком случае за каждым классификатором закреплено по меньшей одно значение гибкого хеша. В одном из вариантов реализации изобретения все доступные для использования средством классификации 120 классифицирующие модели, хранятся в средстве классификации 120, например в предназначенной для этого базе данных.
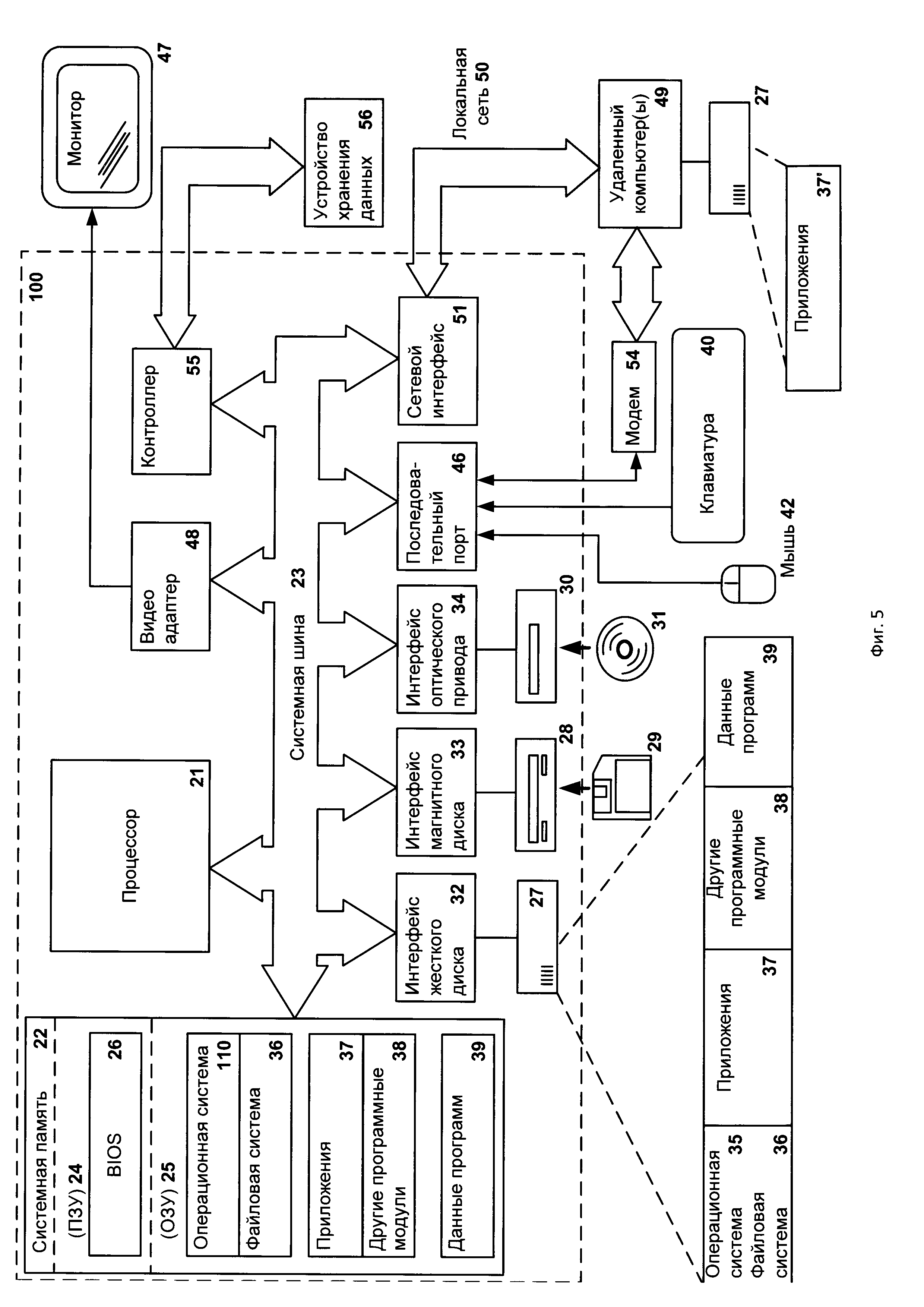
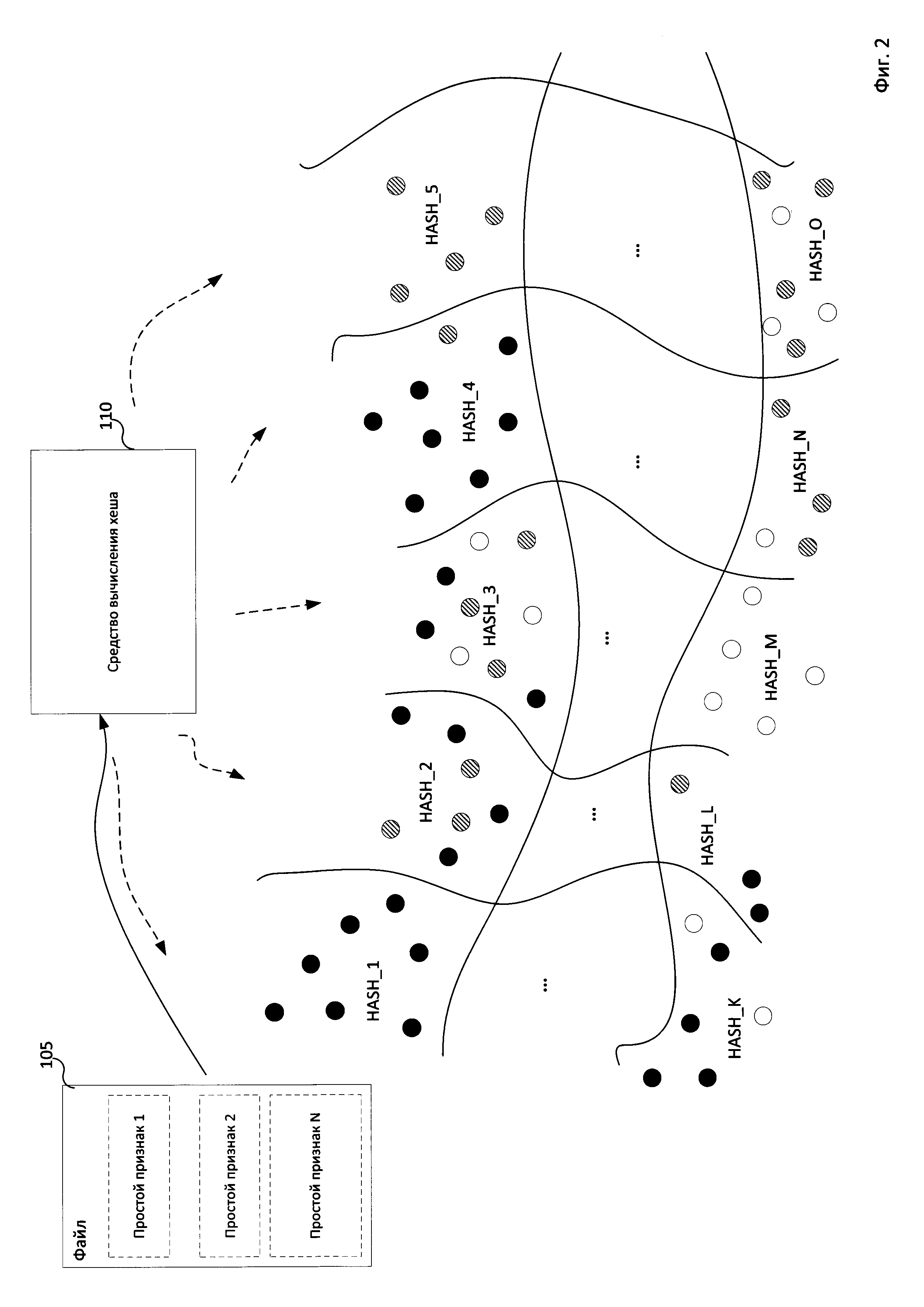
На Фиг. 2 изображена схема работы средства вычисления хеша 110, где для файла 105 вычисляется гибкий хеш при помощи средства вычисления хеша 110. Стоит отметить, что этапу вычисления гибкого хеша 115 средством вычисления хеша 110 предшествует этап обучения данного средства 110 (данный этап не отражен на фигурах).
Средство вычисления хеша 110 обучается таким образом, чтобы для двух похожих файлов, а именно для двух наборов признаков этих файлов, значение вычисленного гибкого хеша совпадало. Для этого может быть использован метод обучения с учителем. При этом на этапе обучения данного средства 110 используется предназначенное для этого множество файлов (из которых выделяются наборы признаков) для обучения из базы данных файлов 130, при чем такое множество содержит не только файлы, но и информацию в отношении сходства файлов между собой (степень сходства файлов между собой). В одном из вариантов реализации отношение сходства файлов - это степень сходства файлов. В другом варианте реализации отношение сходства файлов - указание на то, являются ли файлы похожими: "файлы похожи" или "файлы не похожи". В одном из вариантов реализации изобретения данная база данных 130 также содержит информацию о категориях (категория доверенных, вредоносных или недоверенных файлов), к которым относятся файлы из упомянутого множества файлов. Такая информация может в том числе использоваться на этапе обучения для снижения количества ошибок первого и второго рода при вычислении гибкого хеша 115 средством вычисления хеша 110. Это делается в том числе для того, чтобы уменьшить вероятность вычисления одного и того же значения гибкого хеша 115 для двух файлов, один из которых, например, относится к категории доверенных файлов, а другой - к категории вредоносных. В одном из вариантов реализации изобретения информация, которая хранится в упомянутой базе данных файлов 130, вносится туда специалистом в области информационных технологий.
При вычислении гибкого хеша средство вычисления хеша 110 выделяет набор признаков, который содержит по меньшей мере простые признаки, из файла 105, эти признаки условно обозначены как "простой признак 1", "простой признак 2" и так далее. В данном примере файл 105 -файл, относительно которого не известно, вредоносный он или доверенный, и к каким категориям файлов он относится. Обученное одним из способов средство вычисления хеша 110 на основании признаков файла 105 вычисляет его гибкий хеш 115.
На Фиг. 2 круглыми маркерами обозначены файлы, относительно которых известна их принадлежность к некоторым категориям, такие файлы и информация о принадлежности файлов к категориям могут храниться в базе данных файлов 130. Черными маркерами отмечены файлы, относящиеся к первой категории, белыми - ко второй, частично закрашенными маркерами -назовем их серыми маркерами - к третьей. В частном случае реализации таким категориями являются предопределенные категории файлов. В качестве примера примем, что первая категория файлов - категория вредоносных, вторая категория файлов - категория доверенных файлов, третья категория файлов - категория недоверенных файлов. Стоит отметить, что множество упомянутых файлов совпадает с множеством файлов, использованных для обучения средства вычисления хеша 110. В другом же варианте реализации изобретения множество упомянутых файлов (файлов, представленных маркерами на Фиг. 2) может отличаться от множества файлов, использованных для обучения средства вычисления хеша 110, например такое множество может быть дополнено новыми файлами (но принадлежность таких файлов к некоторым категориям также известна), эти дополнительные файлы могут быть добавлены, например, в базу данных файлов 130 специалистом в области информационных технологий.
Упомянутые файлы (которые соответствуют маркерам на Фиг. 2) предварительно разбиваются средством вычисления хеша 110 на группы файлов путем вычисления гибкого хеша. Каждая группа файлов соответствует некоторому значению гибкого хеша (HASH_1, HASH 2 и т.д.), вычисленного для файла из этой группы, то есть в группу попадают файлы с совпадающим значением гибкого хеша. Например, для каждого файла из группы, условно обозначенной как HASH1, вычисленный на основании набора признаков файла средством вычисления хеша 110 гибкий хеш будет иметь значение, которое обозначим как HASH1. Стоит отметить, что средство вычисления хеша 110 вполне может в одну и ту же группу помещать файлы из разных категорий (путем вычисления для таких файлов гибких хешей с совпадающим значением). Соответственно, в каждой из групп, соответствующих некоторому значению гибкого хеша, могут находиться как файлы только из одной категории (например, категории вредоносных файлов, как в группе HASH_1),так и из нескольких (например, категории вредоносных файлов и недоверенных, как в группе HASH 2, НАSН_4или HASH_L).
Таким образом, вычисление гибкого хеша для файла 105 средством вычисления хеша 110 можно назвать отнесением файла 105 к некоторой группе файлов с совпадающим значением гибкого хеша (группы HASH1, HASH_2, HASH_3 и т.д.).
Значение гибкого хеша 115 (являющийся идентификатором группы, к которой отнесен файл 105) для файла 105 передается средством вычисления хеша 110 средству классификации 120.
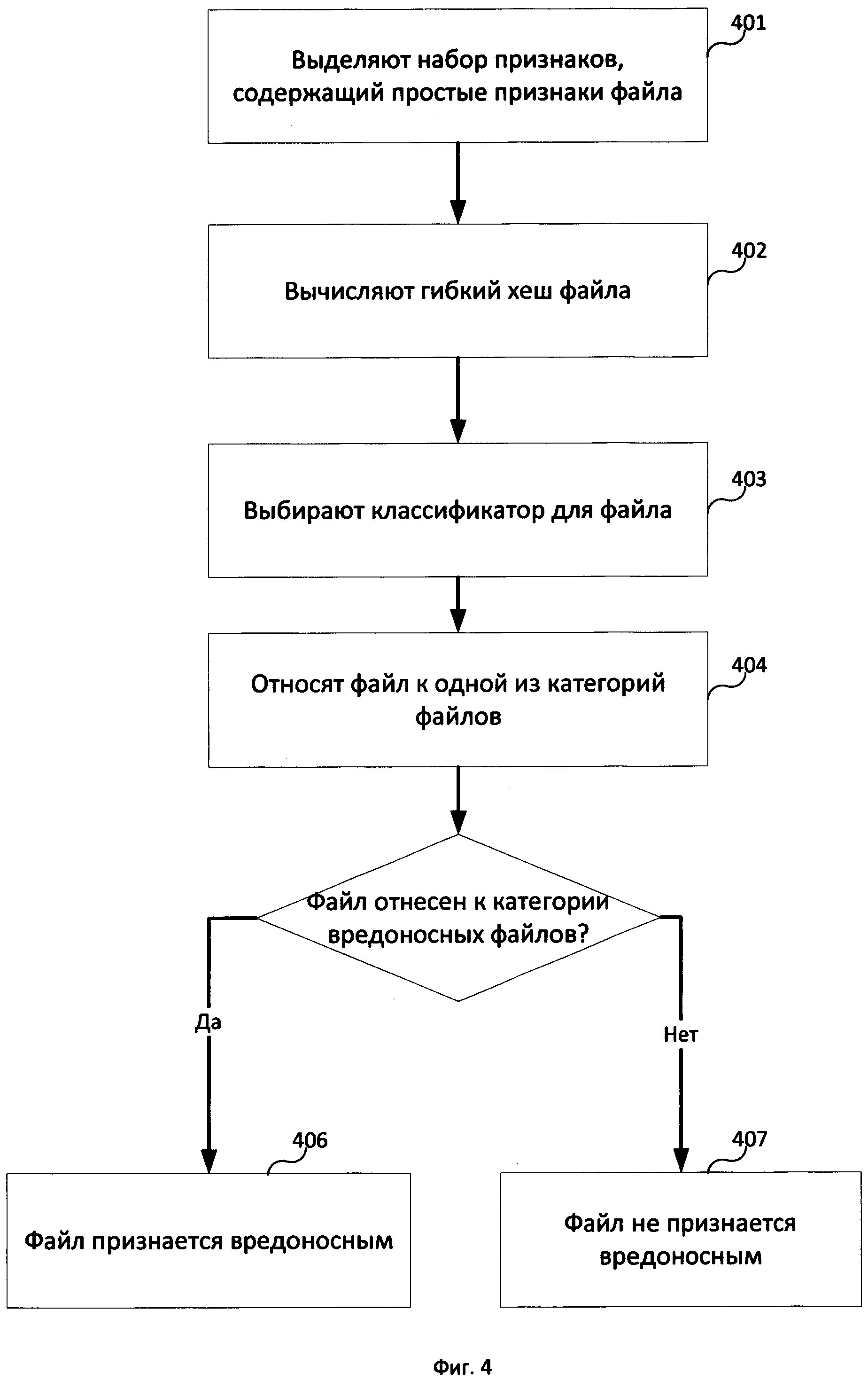
На Фиг. 3 изображен пример работы средства классификации 120. Для того, чтобы отнести файл 105 к одной из категорий файлов, например к одной из предопределенных, средство классификации выбирает для файла 105 классификатор, который соответствует гибкому хешу 115 файла 105. В одном из вариантов реализации соответствие классификатора некоторому гибкому хешу определяется следующим образом: если для обучения классификатора использовалась группа файлов из базы данных файлов 130, и значения гибкого хеша для файлов из упомянутой группы совпадает, то классификатор соответствует этому гибкому хешу. Например, если для обучения классификатора использовалась группа файлов HASH_3 (см. Фиг. 2), то такой классификатор будет соответствовать гибкому хешу HASH_3 (и, соответственно, обозначаться "классификатор HASH_3").
Для того, чтобы средство классификации 120 могло выбрать классификатор для файла 105, средство 120 предварительно формирует набор таких классификаторов, из которого впоследствии будет выбран необходимый для категоризации файла 105 - набор классификаторов-претендентов. Для формирования классификатора, соответствующего некоторому известному гибкому хешу (т.е. гибкому хешу, значение которого одинаково для файлов, для которых известна их принадлежность к некоторой категории файлов, например к категории вредоносных или к категориям и вредоносных, и доверенных), например хешу HASH_4, применяется следующий подход. Файлы из группы файлов, например обозначенной как HASH_4, используются как обучающая выборка для обучения с учителем классифицирующих моделей разных типов, примеры таких классифицирующих моделей даны выше. При чем на этапе обучения используется информация о принадлежности файлов из данной группы, в частности HASH_4, к различным категориям файлов (в частности, вредоносным, доверенным или недоверенным). Стоит отметить, что обучение любого из классификаторов средством классификации 120 осуществляется не просто на файлах из некоторой обучающей выборки, а на основании набора признаков этих файлов, при чем каждый такой набор состоит из по меньшей мере сложных признаков файла.
После обучения классификаторы-претенденты (где каждый из классификаторов претендует на позицию классификатора, соответствующего некоторому гибкому хешу, в частности гибкому хешу HASH_4), проходят этап проверки (в частности проверки качества работы классификатора). На этапе проверки может быть использована выборка файлов с большим количеством файлов (выборка файлов для проверки), не только файлы из группы HASH_4 (для нашего примера). Задача этапа проверки - выбор классификатора из обученных ранее в качестве соответствующего некоторому, в частности HASH_4, значению гибкого хеша. Для каждого из файлов, используемых на этапе проверки, также известна принадлежность этого файла к одной из категорий файлов. В результате проверки все файлы, используемые для проверки, категоризируются каждым из классификаторов-претендентов. Используя ранее известную информацию о принадлежности файлов из выборки для проверки каждого классификатора-претендента на роль классификатора, соответствующего некоторому гибкому хешу (а, следовательно, и группе файлов с совпадающим значением хеша), вычисляется коэффициент ложных срабатываний. В качестве классификатора, соответствующего некоторому гибкому хешу, выбирается классификатор с наименьшим коэффициентом ложных срабатываний.
Коэффициент ложных срабатываний - число, например от 0 до 1, чем больше которое, тем больше ошибок первого и/или второго рода было допущено на этапе проверки классификатора. В одном из вариантов реализации коэффициент ложных срабатываний вычисляется по следующей формуле:

где: FP (False Positive) - число ложных срабатываний - ошибочных отнесений файлов к некоторой категории (например, если для файла из выборки для проверки известна его принадлежность к категории доверенных файлов, но классификатор ошибочно отнес этот файл к категории вредоносных), Nc - общее количество файлов в этой "некоторой" категории, (для вышеупомянутого примера Nc - количество файлов в категории доверенных файлов), F - коэффициент ложных срабатываний.
В другом варианте реализации может использоваться любая другая формула, в соответствии с которой коэффициент ложных срабатываний F увеличивается с ростом количества ложных срабатываний FP.
В еще одном варианте реализации в качестве классификатора, соответствующего некоторому гибкому хешу, выбирается классификатор с наименьшим коэффициентом ложных срабатываний, и у которого не было ложных срабатываний на выделенном наборе файлов. Этот набор файлов может содержать файлы, не входящие в группу файлов с совпадающим значением хеша, для которого выбирается соответствующий классификатор. В частном случае реализации таким файлами являются доверенные файлы, созданные доверенными разработчиками ПО. Список доверенных разработчиков может храниться в средстве классификации 120, либо за его пределами, на удаленном сервере, и обновляться специалистом в области информационных технологий. В частном случае реализации изобретения доверенными разработчиками ПО являются компании "Microsoft", "Google", "McAfee", "Intel", "Kaspersky Lab" и другие.
В другом варианте реализации в качестве классификатора, соответствующего некоторому гибкому хешу, выбирается классификатор, коэффициент ложных срабатываний которого не выше некоторого порогового значения, например 10-5, и который имеет наибольший коэффициент обнаружения. При этом коэффициент обнаружения вычисляется по следующей формуле:

где TP - количество безошибочных отнесений файлов из выборки для проверки к соответствующим категориям.
В еще одном варианте реализации, когда категориями файлов являются по меньшей мере категория доверенных и вредоносных файлов, коэффициент обнаружения вычисляется по следующей формуле:

где TP - количество файлов в выборке файлов для проверки, из категории вредоносных файлов, и которые были безошибочно отнесены к категории вредоносных файлов, Np - количество файлов в выборке файлов для проверки, из категории вредоносных.
Стоит отметить, что если ни один из классификаторов-претендентов не удовлетворяет условиям выбора классификатора, например коэффициенты ложных срабатываний всех классификаторов-претендентов выше установленного порога, то средство классификации 120 не ставит ни одного классификатора в соответствие некоторому гибкому хешу.
Вышеупомянутый этап проверки и назначения классификатора осуществляется средством классификации 120 в отношении каждого из известных гибких хешей, а, соответственно, и в отношении каждой известной группы файлов. Известный гибкий хеш - гибкий хеш, вычисленный на основании файла (а именно, на основании набора признаков файла), принадлежность которого к некоторой категории известна. Известная группа файлов - группа файлов с идентичным значением известного гибкого хеша. Файлы, используемые средством классификации 120 на этапе формирования набора классификаторов, а также файлы, используемые для проверки классификаторов, могут храниться в базе данных файлов 130. Стоит отметить, что для двух значений гибких хешей, например HASH_3 и HASH_L, могут быть поставлены в соответствие классификаторы одного типа, но обученные на разных выборках файлов, например классификатор HASH_3 обучается на выборке файлов, состоящих в группе файлов с совпадающим значением гибкого хеша HASH_3, а классификатор HASH_L обучается на выборке файлов, состоящих в группе файлов с совпадающим значением гибкого хеша HASH_L.
Выбранный средством классификации 120 на основании гибкого хеша 115 классификатор применяется к набору признаков, состоящему из сложных признаков. Упомянутый набор признаков выделяется из файла 105 средством классификации 120 и передается классификатору, соответствующему гибкому хешу 115 файла 105. На основании данного набора признаков обученный ранее классификатор относит файл 105 к одной из предопределенных категорий файлов.
В одном из вариантов реализации изобретения, если гибкий хеш 115 файла 105 соответствует классификатору, который был обучен на такой выборке файлов, которая содержит группу файлов с идентичным значением гибкого хеша, что все файлы из данной группы относятся к некоторой одной категории (скажем, "категория X" или категория вредоносных файлов), то средство классификации относит файл 105 к этой категории без применения классификатора, соответствующего упомянутой группе. Такой подход позволяет при категоризации некоторого множества файлов снизить время, потраченное на определение категории каждого файла, так как определение категории некоторых файлов будет осуществляться без применения классификатора и выделения сложных признаков из файла 105, а, следовательно, быстрее. При этом коэффициент обнаружения при такой категоризации не будет меньше, чем в ситуации, когда каждый файл проходил бы категоризацию с использованием классификатора.
В случае, если файл 105 относится к категории вредоносных файлов, то файл 105 признается средством классификации 120 вредоносным. В случае, если файл 105 относится к категории доверенных файлов, то файл 105 признается средством классификации 120 доверенным.
На Фиг. 4 отображен пример способа двухэтапной классификации. На этапе 401 средство вычисления хеша 110 выделяет из файла 105 набор признаков, который содержит по меньшей мере простые признаки файла 105. При этом файл 105 - файл, принадлежность которого к некоторой категории файлов необходимо определить. После этого, на этапе 402 средство вычисления хеша 110 вычисляет гибкий хеш 115 файла 105 на основании выделенного набора признаков. Впоследствии вычисленный гибкий хеш 115 используется средством классификации 120 для выбора соответствующего гибкому хешу 115 классификатора на этапе 403. В одном из вариантов реализации изобретения за каждым классификатором (предварительно обученным) средства классификации 120, закреплено по меньшей одно значение гибкого хеша, характеризующее группу файлов (т.е. файлы из группы, у которых значение гибкого хеша совпадает), включенных в обучающую выборку для упомянутого классификатора. Используя выбранный классификатор, средство классификации 120 осуществляет категоризацию файла 105 - средство классификации 120 относит файл 105 к одной из категорий файлов на этапе 404 (в частности - к одной из категорий, к которым относились файлы из выборки, использованной для обучения соответствующего классификатора, использованного средством классификации 120). Если файл 105 отнесен к категории вредоносных файлов, то на этапе 406 файл 105 признается средством классификации 120 вредоносным. В противном случае файл 105 на этапе 407 не признается вредоносным.
Настоящий способ двухэтапной классификации файлов обладает следующим преимуществом по отношению к способам, основанным на использовании одного классификатора для определения категории файлов. Использование множества классификаторов, соответствующих гибким хешам, позволяет достичь меньшего количества ошибок первого и второго рода при категоризации множества неизвестных файлов (категории которых неизвестны), так как для каждой группы файлов, в частности группы файлов с совпадающим значением гибкого хеша, определен (поставлен в соответствие) классификатор, который имеет, например, наименьший коэффициент ложных срабатываний и/или наибольший коэффициент обнаружения. Таким образом, применения настоящего способа в разках заявленного изобретения позволяет достичь технического результата - повышение качества (снижение количества ошибок первого и второго рода) категоризации файлов, а в частности, снизить количество ошибок первого и второго рода при обнаружении вредоносных файлов.
Фиг. 5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканнер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
Система и способ настройки антивирусной проверки
Способ обнаружения вредоносного приложения на устройстве пользователя
Способ блокировки доступа к данным на мобильных устройствах с использованием api для пользователей с ограниченными возможностями
Способ поиска входной строки в дереве поиска с индексацией используемых при построении дерева строк
Система и способ задания уровня безопасности подключения
Способ обнаружения вредоносных исполняемых файлов, содержащих интерпретатор, посредством комбинирования эмуляторов
Система и способ обнаружения фишинговых сценариев
Способ поиска входной строки в дереве поиска с индексацией узлов дерева поиска
Способ установки обновления модуля полнодискового шифрования
Способ выполнения инструкций в системной памяти
Система и способ обнаружения вредоносных компьютерных систем
Способ обнаружения вредоносных составных файлов
Способ обнаружения аномальных событий по популярности свертки события
Система и способ обнаружения вредоносных файлов с использованием обученной модели обнаружения вредоносных файлов
Система и способ обнаружения вредоносных файлов с использованием элементов статического анализа
Система и способ управления вычислительными ресурсами для обнаружения вредоносных файлов
Способ эмуляции исполнения файлов
Способ эмуляции исполнения файлов, содержащих инструкции, отличные от машинных
Способ контроля доступа к составным файлам
Система и способ выявления вредоносного cil-файла

