Результат интеллектуальной деятельности: УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ АУДИОСИГНАЛОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к устройству и способу обработки аудиосигналов. В частности, настоящее изобретение относится к устройству и способу обработки аудиосигналов для системы виртуальной пространственной аудиоконференции.
УРОВЕНЬ ТЕХНИКИ
В прошлом голоса говорящих участников (дикторов) многосторонней аудиоконференции, как правило, воспроизводились слушателям как монофонический аудиопоток - по существу, наложенными друг на друга, и обычно представлялись слушателю "внутри головы" при использовании наушников.
Система виртуальной пространственной аудиоконференции, которая является специальной формой многостороннего телесовещания, как определено рекомендацией P.1301 ITU-T "Subjective quality evaluation of audio and audiovisual multiparty telemeetings" ("Субъективная качественная оценка аудио и аудиовизуальных многосторонних телесовещаний"), обеспечивает возможность трехмерной (3D) рендеризации аудиосигналов голосов участников. Таким образом, голоса участников помещаются в разные "виртуальные" местоположения в пространстве с использованием пространственных фильтров, выведенных из импульсных характеристик слухового аппарата (HRIR) или их соответствующих представлений в частотной области, т.е. передаточных функций слухового аппарата (HRTF), и/или бинауральных импульсных характеристик окружающего пространства (BRIR) или их соответствующих представлений в частотной области, т.е. бинауральных передаточных функций окружающего пространства (BRTF). Эти фильтры кодируют слуховые ориентиры, которые люди используют для пространственного звукового восприятия, а именно, интерауральное различие во времени (ITD), интерауральное различие по уровню (ILD), спектральные признаки, а также информацию об акустике помещения, такую как реверберация в случае характеристик BRIR. Благоприятный эффект трехмерной рендеризации аудиосигнала относительно монофонического аудиопотока голосов участников состоит не только в том, что восприятие конференции является более естественным, но и в том, что в значительной степени улучшается разборчивость речи. Было показано, что этот психоакустический эффект, с научной точки зрения известный как пространственный бинауральный анализ (пространственное освобождение от маскировки), может улучшить разборчивость речи до 12-13 дБ, когда целевой диктор и конкурирующие дикторы, обычно называемые маскерами, (виртуально) разносятся в пространстве.
Документ US7391877 описывает пространственный процессор аудиосигналов, который виртуально распределяет дикторов по не равноудаленным позициям вдоль круга, центром которого является позиция слушателя. На основе результатов психоакустических испытаний по речевой идентификации система начинает с относительно малого виртуального пространственного разнесения дикторов, размещенных перед слушателем. Виртуальное пространственное разнесение между дикторами затем увеличивается, когда дикторы размещаются в более боковых позициях. Для направлений ±90 градусов по азимуту предлагаются два виртуальных местоположения дикторов, одно в дальней зоне и одно в ближней зоне. Аналогичные решения на основе либо равноудаленных, либо не равноудаленных дикторов описаны в документах WO2013/142641 и WO2013/142668.
Предпринимались некоторые попытки использовать информацию, содержащуюся в самих голосовых сигналах, чтобы улучшить разборчивость речи. Эти попытки, т.е. использование голосовой информации для отделения маскеров от дикторов, полагаются в большой степени на величину спектрального наложения, которое существует между целевым диктором и маскерами, т.е. энергетическую маскировку. Были предложены идеальные частотно-временные двоичные маски, например, в документе Brungart et al "Isolating the energetic component of speech-on-speech masking with ideal time-frequency segregation" ("Изоляция энергетического компонента маскировки речи речью с идеальной частотно-временной сегрегацией"), J. Acoust. Soc. Am., volume 120, no. 6, 2006, чтобы удалять частотно-временные области, в которых преобладает энергия маскера (маскеров), и обеспечивать сохранность только тех частотно-временных областей, в которых преобладает энергия целевого голоса. Они являются идеальными, поскольку требуется доступ к чистым (первоначальным) речевым сигналам от целевого диктора и маскера (маскеров). Более конкретно, требуется априорное знание о целевом дикторе и маскерах, чтобы можно было обеспечить сохранность тех частотно-временных областей в акустической смеси, в которых преобладает целевой диктора. Однако на практике иногда целевой диктор априорно не известен или является непостоянным. В виртуальной пространственной аудиоконференции, например, каждый участник может являться целевым диктором в течение определенного периода времени.
Таким образом, существует потребность в улучшенном устройстве и способе обработки аудиосигналов, в частности, в устройстве и способе обработки аудиосигналов, улучшающих разборчивость речи, в системе виртуальной пространственной аудиоконференции.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задача изобретения состоит в том, чтобы обеспечить устройство и способ обработки аудиосигналов, улучшающие разборчивость речи, в системе виртуальной пространственной аудиоконференции.
Эта задача решается посредством предмета независимых пунктов формулы изобретения. Дополнительные формы реализации приведены в зависимых пунктах формулы изобретения, в описании и на чертежах.
В соответствии с первым аспектом, изобретение относится к устройству обработки аудиосигналов для обработки множества аудиосигналов, определяющих множество спектров аудиосигналов, причем множество аудиосигналов должны быть переданы слушателю таким образом, чтобы слушатель воспринимал, что множество аудиосигналов исходят из виртуальных позиций множества источников аудиосигналов. Устройство обработки аудиосигналов содержит селектор, выполненный с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов относительно слушателя из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя, причем каждое возможное пространственное размещение виртуальных позиций множества источников аудиосигналов связано с множеством передаточных функций, и причем селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, и фильтр, выполненный с возможностью фильтровать множество аудиосигналов на основе выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя, причем множество фильтрованных аудиосигналов воспринимаются слушателем как исходящие из виртуальных позиций множества источников аудиосигналов, определенных посредством выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя.
Таким образом, предложено устройство обработки аудиосигналов, дающее возможность, например, улучшать разборчивость речи в системе виртуальной пространственной аудиоконференции с использованием и голосовой (т.е. спектры аудиосигналов), и дирекциональной (т.е. передаточные функции) информации для выбора улучшенного пространственного размещения.
Множество аудиосигналов может содержать N аудиосигналов, и виртуальные позиции множества источников аудиосигналов могут содержать L виртуальных позиций. Передаточные функции могут представлять собой передаточные функции слухового аппарата (HRTF) или бинауральные передаточные функции окружающего пространства (BRTF).
В первой возможной форме реализации первого аспекта изобретения селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством объединения множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, для получения множества дирекционально-спектральных профилей дикторов, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, и выбора пространственного размещения виртуальных позиций множества источников аудиосигналов на основе множества дирекционально-спектральных профилей дикторов.
В этой форме реализации голосовая и дирекциональная информация объединяются в дирекционально-спектральные профили дикторов для выбора улучшенного пространственного размещения.
Во второй возможной форме реализации первой возможной формы реализации первого аспекта изобретения селектор выполнен с возможностью объединять множество спектров аудиосигналов и множество передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, для получения множества дирекционально-спектральных профилей дикторов, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством умножения множества спектров аудиосигналов на множество передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов.
Эта форма реализации обеспечивает эффективную в вычислительном отношении форму для объединения голосовой и дирекциональной информации в дирекционально-спектральный профиль диктора посредством перемножения спектров.
В третьей возможной форме реализации первой или второй формы реализации первого аспекта изобретения селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством выбора одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между множеством дирекционально-спектральных профилей диктора больше предопределенного порогового значения, предпочтительно является максимальным.
Эта форма реализации обеспечивает хорошую разборчивость речи с использованием спектрального различия для определения выгодных пространственных размещений. На основе спектрального различия эта форма реализации позволяет определять оптимальное пространственное размещение.
В четвертой возможной форме реализации третьей формы реализации первого аспекта изобретения селектор выполнен с возможностью определять спектральное различие между дирекционально-спектральными профилями дикторов, связанными с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, с использованием следующих уравнений:
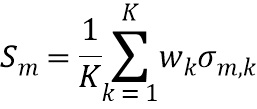 ,
,
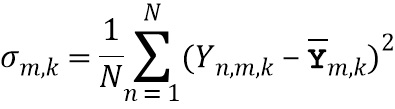 , и
, и
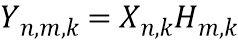 ,
,
где 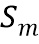 обозначает скалярное значение, представляющее спектральное различие между множеством дирекционально-спектральных профилей дикторов, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос,
обозначает скалярное значение, представляющее спектральное различие между множеством дирекционально-спектральных профилей дикторов, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос, 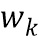 обозначает весовой коэффициент,
обозначает весовой коэффициент, 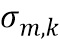 обозначает дисперсию по дирекционально-спектральным профилям дикторов для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов,
обозначает дисперсию по дирекционально-спектральным профилям дикторов для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов, 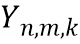 обозначает значение n-ого дирекционально-спектрального профиля диктора в k-ой частотной полосе,
обозначает значение n-ого дирекционально-спектрального профиля диктора в k-ой частотной полосе, 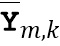 обозначает среднее значение дирекциональных профилей диктора в k-ой частотной полосе,
обозначает среднее значение дирекциональных профилей диктора в k-ой частотной полосе, 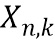 обозначает значение спектра аудиосигнала n-ого аудиосигнала в k-ой частотной полосе, и
обозначает значение спектра аудиосигнала n-ого аудиосигнала в k-ой частотной полосе, и 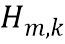 обозначает значение передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в k-ой частотной полосе.
обозначает значение передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в k-ой частотной полосе.
В пятой возможной форме реализации четвертой формы реализации первого аспекта изобретения селектор выполнен с возможностью определять значение спектра аудиосигнала n-ого аудиосигнала в k-ой частотной полосе, т.е. , и/или значение передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в k-ой частотной полосе, т.е. , посредством выполнения операции усреднения по множеству элементов разрешения по частоте (используемых для дискретного преобразования Фурье) на основе следующих уравнений:
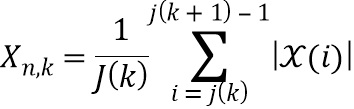 , и
, и
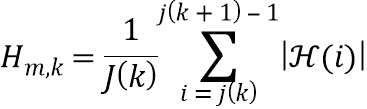 ,
,
где 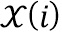 обозначает значение дискретного преобразования Фурье n-ого аудиосигнала в i-ом элементе разрешения по частоте,
обозначает значение дискретного преобразования Фурье n-ого аудиосигнала в i-ом элементе разрешения по частоте, 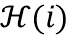 обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте, и
обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте, и 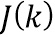 обозначает количество элементов разрешения по частоте k-ой частотной полосы.
обозначает количество элементов разрешения по частоте k-ой частотной полосы.
В шестой возможной форме реализации с третьей по пятую формы реализации первого аспекта изобретения селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством объединения множества спектров аудиосигналов и множества передаточных функций для левого уха, связанных с виртуальными позициями источников аудиосигнала относительно левого уха слушателя, чтобы получить множество дирекционально-спектральных профилей диктора для левого уха, и множества спектров аудиосигнала и множества передаточных функций для правого уха, связанных с виртуальными позициями источников аудиосигнала относительно правого уха слушателя, чтобы получить множество дирекционально-спектральных профилей диктора для правого уха, и посредством выбора одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между дирекционально-спектральными профилями диктора для левого уха и дирекционально-спектральными профилями диктора для правого уха меньше предопределенного порога, в частности, является минимальным.
В седьмой возможной форме реализации первого аспекта изобретения как таковой селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя, виртуальные позиции множества источников аудиосигналов размещены на круге с центром в позиции слушателя и имеют постоянное угловое разнесение, на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством определения одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между множеством передаточных функций больше предопределенного порогового значения, предпочтительно является максимальным.
В восьмой возможной форме реализации седьмой формы реализации первого аспекта изобретения селектор выполнен с возможностью определять спектральное различие между передаточными функциями, связанными с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, с использованием следующих уравнений:
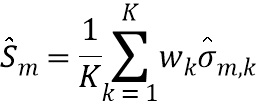 , и
, и
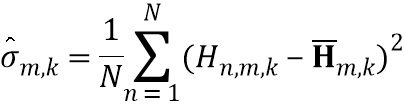 ,
,
где 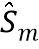 обозначает скалярное значение, представляющее спектральное различие между множеством передаточных функций, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос, обозначает весовой коэффициент,
обозначает скалярное значение, представляющее спектральное различие между множеством передаточных функций, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос, обозначает весовой коэффициент, 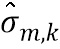 обозначает дисперсию по множеству передаточных функций для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов,
обозначает дисперсию по множеству передаточных функций для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов, 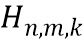 обозначает значение n-ой передаточной функции в k-ой частотной полосе, и
обозначает значение n-ой передаточной функции в k-ой частотной полосе, и 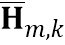 обозначает среднее значение передаточных функций в k-ой частотной полосе.
обозначает среднее значение передаточных функций в k-ой частотной полосе.
В девятой возможной форме реализации седьмой или восьмой формы реализации первого аспекта изобретения, в которой селектор выполнен с возможностью определять значение n-ой передаточной функции в k-ой частотной полосе, т.е. , определяется посредством выполнения операции усреднения по множеству элементов разрешения по частоте, используемых для дискретного преобразования Фурье, на основе следующего уравнения:
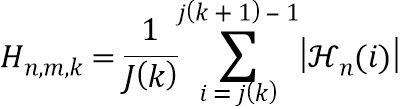 ,
,
где 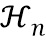 обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте и , обозначает количество элементов разрешения по частоте частоты k-ой частотной полосы.
обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте и , обозначает количество элементов разрешения по частоте частоты k-ой частотной полосы.
В десятой возможной форме реализации седьмой или восьмой формы реализации первого аспекта изобретения селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством ранжирования множества спектров аудиосигналов в соответствии со значением подобия множества спектров аудиосигналов.
В одиннадцатой возможной форме реализации десятой формы реализации первого аспекта изобретения селектор выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством назначения ранжированного множества спектров аудиосигналов на виртуальные позиции выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов таким образом, что максимизируется угловое разнесение между спектрами аудиосигналов, имеющими большое значение подобия.
В двенадцатой возможной форме реализации десятой или одиннадцатой формы реализации первого аспекта изобретения селектор выполнен с возможностью вычислять значение подобия для множества спектров аудиосигналов (i) посредством вычисления среднего спектра аудиосигнала и спектральных различий между каждым спектром аудиосигнала и средним спектром аудиосигнала или (ii) посредством вычисления функции корреляции между спектрами аудиосигналов.
В соответствии со вторым аспектом изобретение относится к способу обработки сигналов для обработки множества аудиосигналов, определяющих множество спектров аудиосигналов, множество аудиосигналов должны быть переданы слушателю таким образом, чтобы слушатель воспринимал, что множество аудиосигналов исходят из виртуальных позиций множества источников аудиосигналов. Способ обработки аудиосигналов содержит этап выбора пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя, причем каждое возможное пространственное размещение виртуальных позиций множества источников аудиосигналов связано с множеством передаточных функций, причем пространственное размещение виртуальных позиций множества источников аудиосигналов выбирается на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, и этап фильтрации множества аудиосигналов на основе выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя, причем множество отфильтрованных аудиосигналов воспринимаются слушателем как исходящие из виртуальных позиций множества источников аудиосигналов, определенных посредством выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя.
Способ обработки аудиосигналов в соответствии со вторым аспектом изобретения может быть выполнен устройством обработки аудиосигналов в соответствии с первым аспектом изобретения. Дополнительные признаки способа обработки аудиосигналов в соответствии со вторым аспектом изобретения являются непосредственным результатом функциональности устройства обработки аудиосигналов в соответствии с первым аспектом изобретения и его разных форм реализации.
В соответствии с третьим аспектом изобретение относится к компьютерной программе, содержащей программный код для выполнения способа в соответствии со вторым аспектом изобретения при его исполнении на компьютере.
Изобретение может быть реализовано в аппаратных средствах и/или программном обеспечении.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Дополнительные варианты осуществления изобретения будут описаны относительно следующих чертежей.
Фиг. 1 показывает схему устройства обработки аудиосигналов в соответствии с вариантом осуществления;
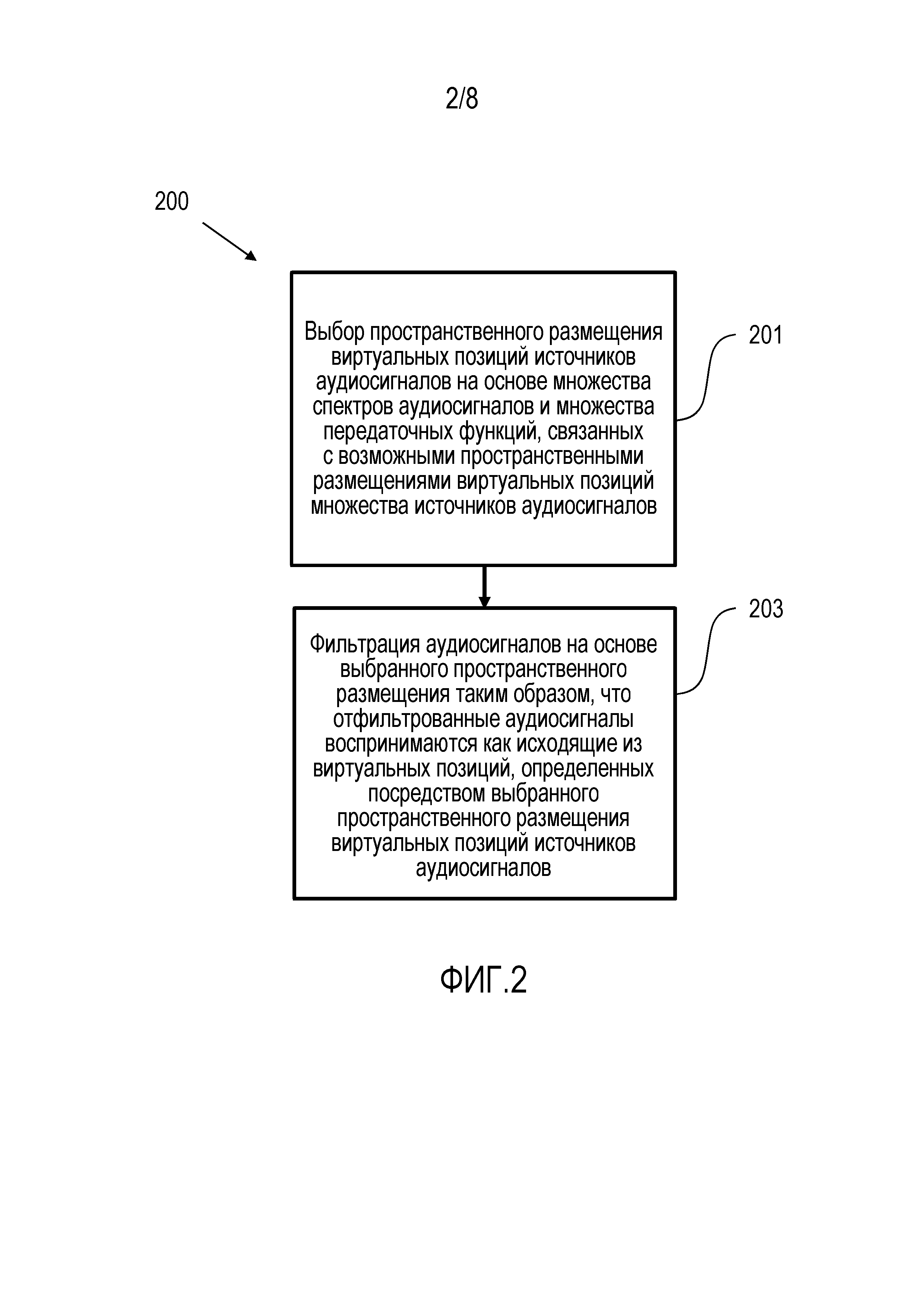
Фиг. 2 показывает схему способа обработки аудиосигналов в соответствии с вариантом осуществления;
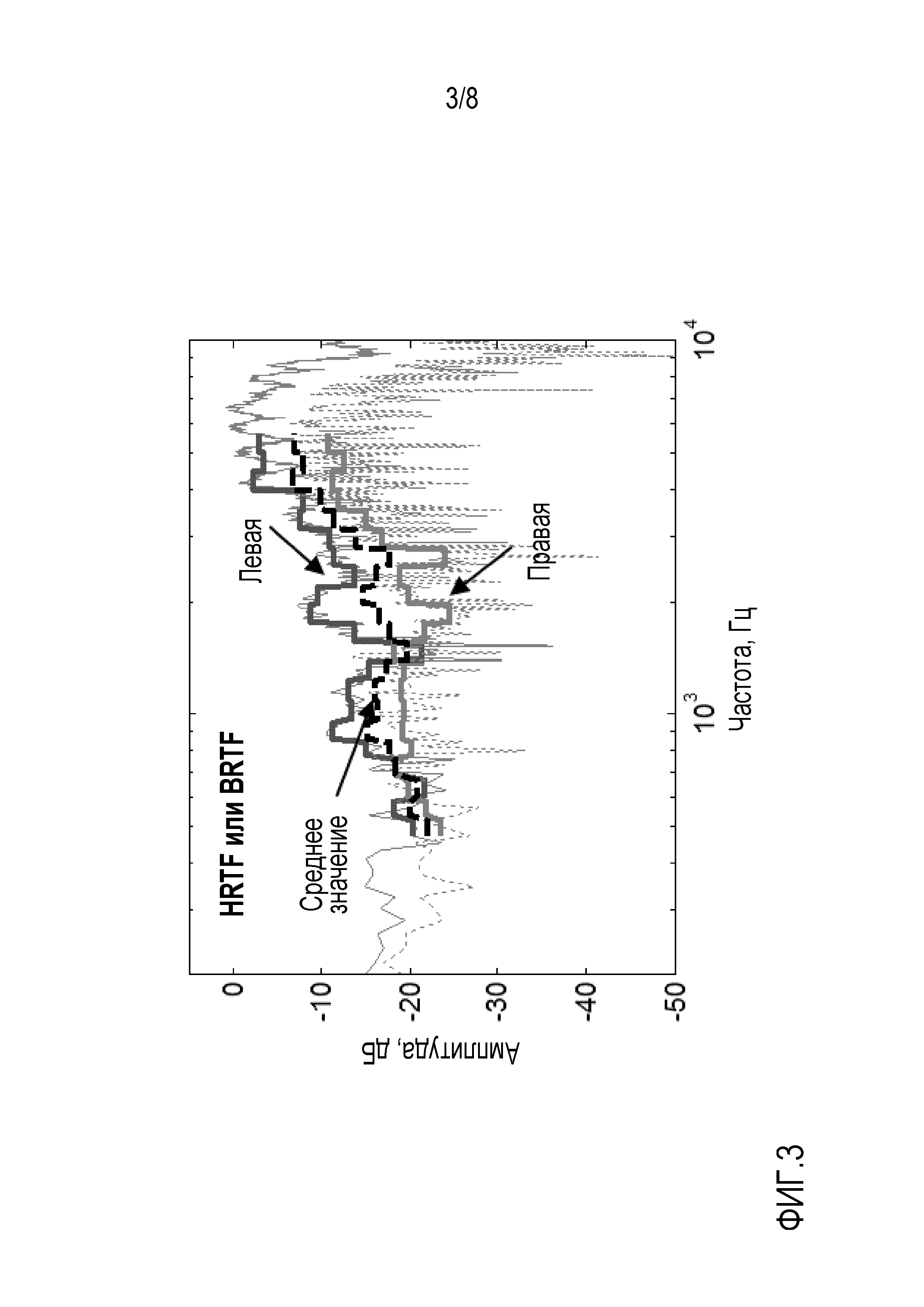
Фиг. 3 показывает иллюстративные левую, правую и среднюю бинауральные передаточные функции окружающего пространства, которые могут использоваться с устройством и способом обработки аудиосигналов в соответствии с вариантом осуществления;
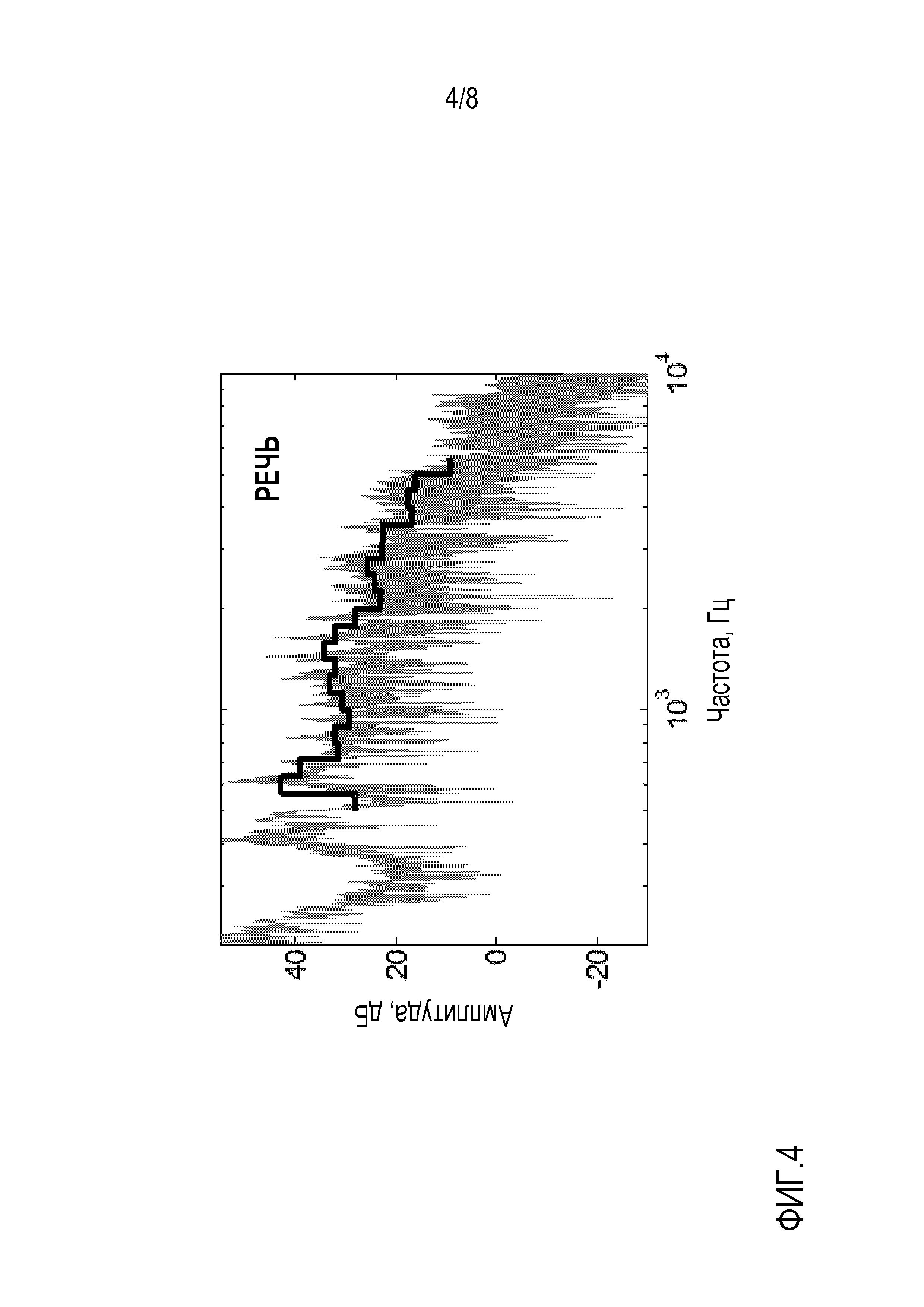
Фиг. 4 показывает иллюстративный спектр аудиосигнала, который может использоваться с устройством и способом обработки аудиосигналов в соответствии с вариантом осуществления;
Фиг. 5 показывает иллюстративный дирекционально-спектральный профиль диктора, который может быть получен и использован с устройством и способом обработки аудиосигналов в соответствии с вариантом осуществления;
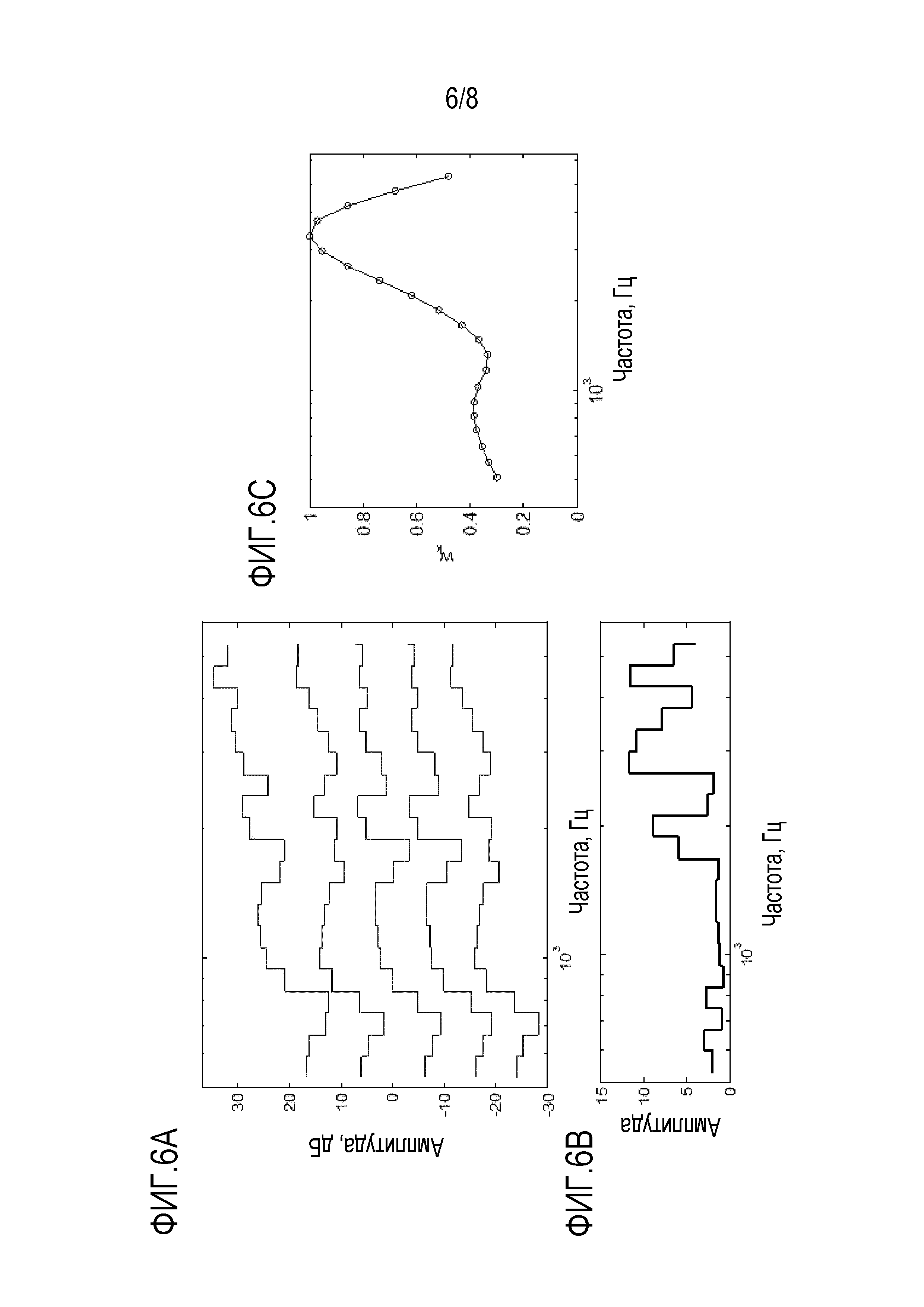
Фиг. 6А показывает иллюстративные дирекционально-спектральные профили дикторов для случая пяти дикторов, которые могут использоваться с устройством и способом обработки аудиосигналов в соответствии с вариантом осуществления;
Фиг. 6B показывает дисперсию иллюстративных дирекционально-спектральных профилей диктора на фиг. 6A;
Фиг. 6C показывает иллюстративные весовые коэффициенты, используемые для интеграции слуховой чувствительности человека в устройстве и способе обработки аудиосигналов в соответствии с вариантом осуществления;
Фиг. 7 показывает четыре иллюстративных пространственных размещения виртуальных позиций множества источников аудиосигналов относительно слушателя в соответствии с вариантом осуществления; и
Фиг. 8А и 8B иллюстрируют, как следует выбрать оптимальное пространственное размещение виртуальных позиций множества источников аудиосигналов относительно слушателя в соответствии с вариантом осуществления.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
В последующем подробном описании делается ссылка на приложенные чертежи, которые являются частью раскрытия и на которых посредством иллюстрации показаны конкретные аспекты, в которых может быть осуществлено раскрытие. Подразумевается, что могут быть использованы другие аспекты и структурные или логические изменения могут быть внесены без отступления от объема настоящего раскрытия. Последующее подробное описание, таким образом, не должно рассматриваться в ограничивающем смысле, и объем настоящего раскрытия определен приложенной формулой изобретения.
Подразумевается, что раскрытие в связи с описанным способом также может распространяться на соответствующее устройство или систему, выполненные с возможностью выполнять способ, и наоборот. Например, если описан конкретный этап способа, соответствующее устройство может включать в себя блок для выполнения описанного этапа способа, даже если такой блок явно не описан и не проиллюстрирован на чертежах. Кроме того, подразумевается, что функции различных иллюстративных аспектов, описанных в настоящем документе, могут сочетаться друг с другом, если специально не указано иное.
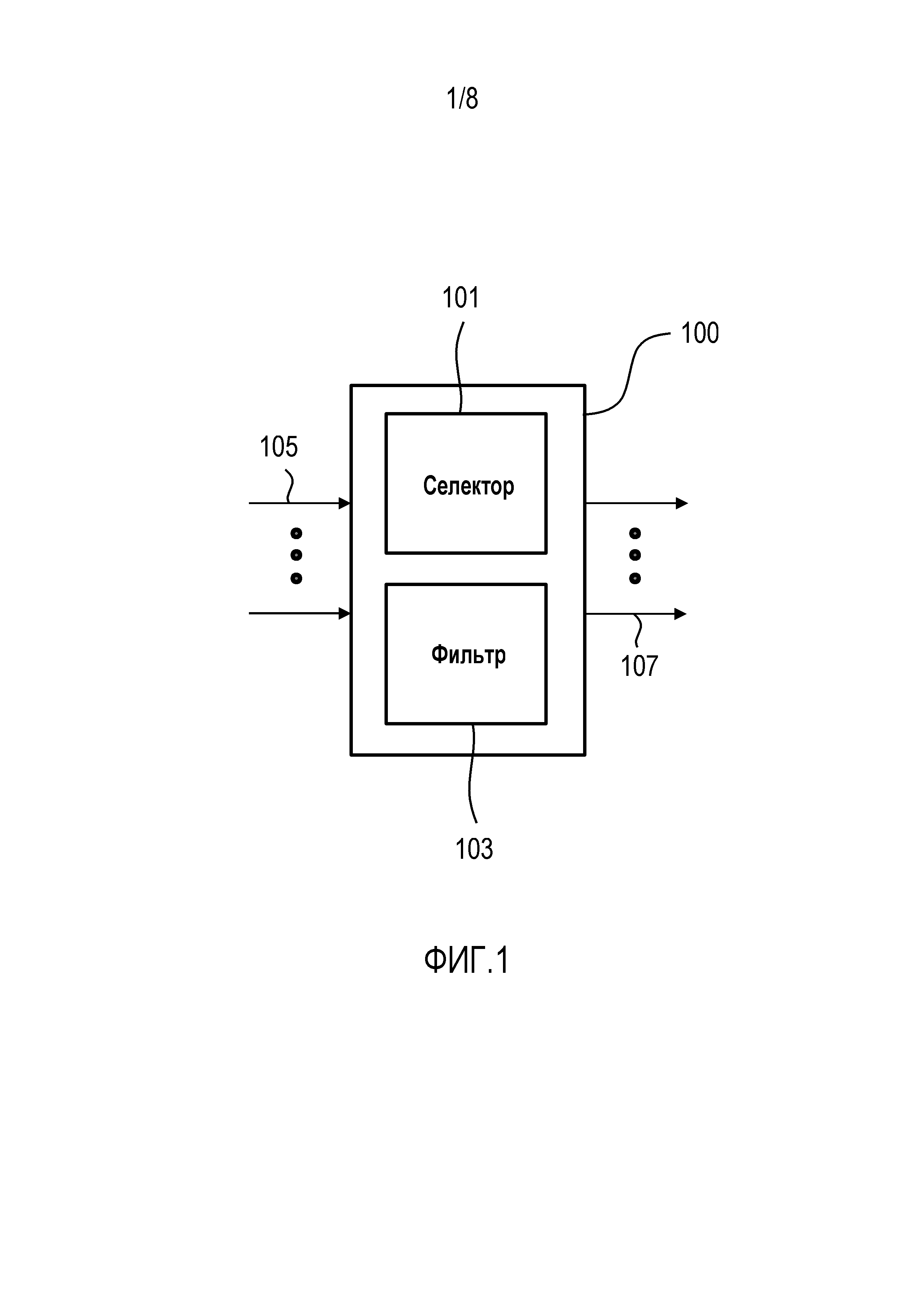
Фиг. 1 показывает схему устройства 100 обработки аудиосигналов в соответствии с вариантом осуществления. Устройство 100 обработки аудиосигналов выполнено с возможностью обрабатывать множество аудиосигналов 105, определяющих множество спектров аудиосигналов. Множество аудиосигналов 105 должны быть переданы слушателю таким образом, чтобы слушатель воспринимал, что множество аудиосигналов исходят из виртуальных позиций множества источников аудиосигналов. В варианте осуществления устройство обработки аудиосигналов является частью системы виртуальной пространственной аудиоконференции, и аудиосигналы являются голосовыми сигналами участников виртуальной пространственной аудиоконференции.
Устройство 100 обработки аудиосигналов содержит селектор 101, выполненный с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов относительно слушателя из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя.
Каждое возможное пространственное размещение виртуальных позиций множества источников аудиосигналов имеет отношение к множеству передаточных функций, в частности, передаточных функций слухового аппарата (HTRF) и/или бинауральных передаточных функций окружающего пространства (BTRF). Как известно специалисту в области техники, существует прямое соответствие между функциями HTRF/BTRF и их импульсными характеристиками, а именно, импульсными характеристиками слухового аппарата (HRIR) и бинауральными импульсными характеристиками окружающего пространства (BRIR).
Кроме того, селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов.
Термин "виртуальная позиция" известен специалисту в области техники обработки аудиосигналов. Посредством выбора подходящих передаточных функций для позиции слушатель воспринимает, что принимает аудиосигнал, испускаемый (виртуальным) источником аудиосигнала. Эта позиция является "виртуальной позицией", используемой в настоящем документе, и может включать в себя методики, в которых источники/дикторы, воспроизведенные с помощью наушников, представляются исходящими от любого желаемого направления (т.е. из виртуальной позиции) в пространстве.
Устройство 100 обработки аудиосигналов также содержит фильтр 103, выполненный с возможностью фильтровать множество аудиосигналов 105 на основе выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя и производить множество отфильтрованных аудиосигналов 107. Множество отфильтрованных аудиосигналов 107 воспринимаются слушателем как исходящие из виртуальных позиций множества источников аудиосигналов, определенных посредством выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя.
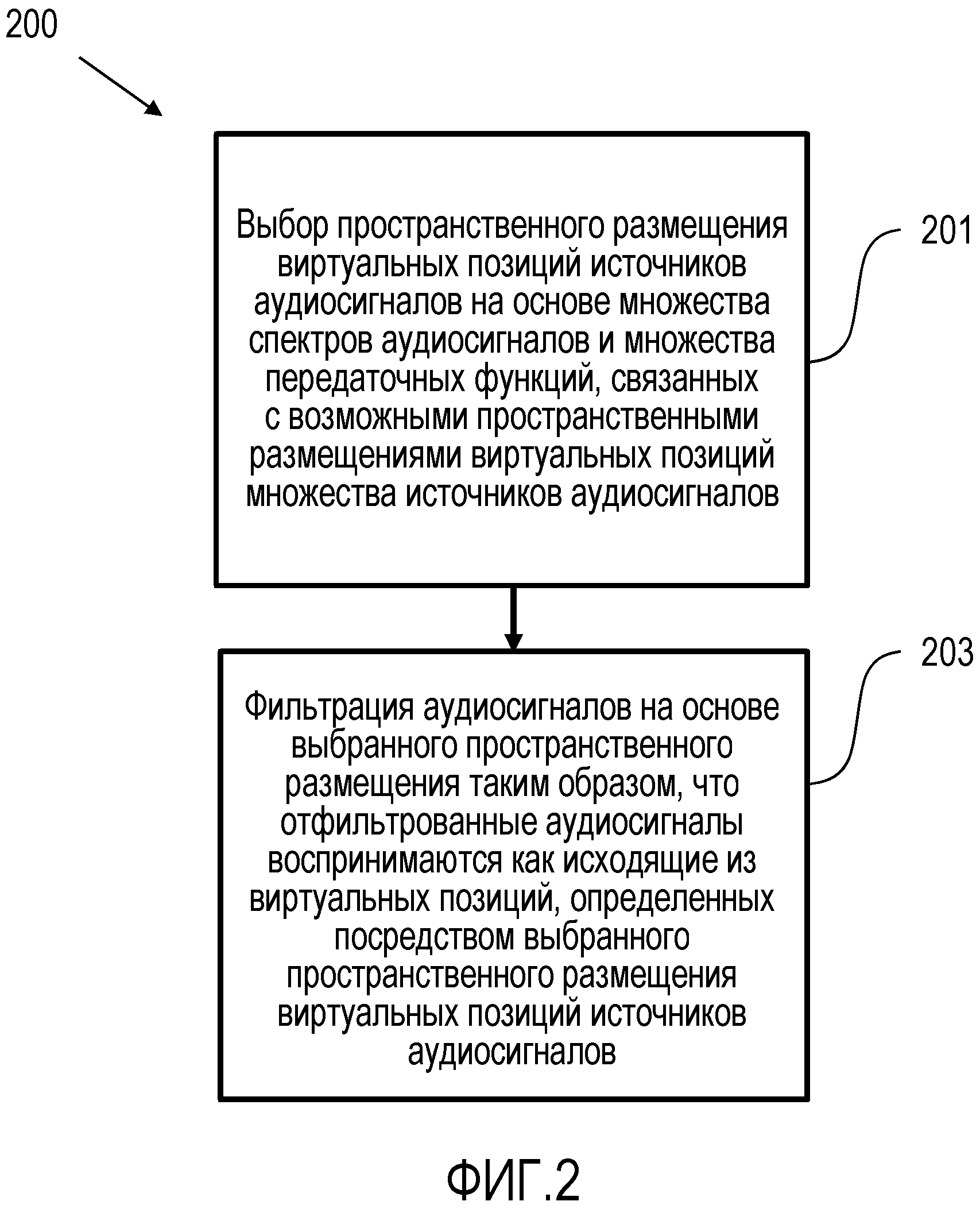
Фиг. 2 показывает схему варианта осуществления способа 200 обработки аудиосигналов для обработки множества аудиосигналов 105, определяющих множество спектров аудиосигналов, при этом множество аудиосигналов должны быть переданы слушателю таким образом, чтобы слушатель воспринимал, что множество аудиосигналов исходят из виртуальных позиций множества источников аудиосигналов.
Способ 200 обработки аудиосигналов содержит этап 201 выбора пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя, причем каждое возможное пространственное размещение виртуальных позиций множества источников аудиосигналов связано с множеством передаточных функций. Пространственное размещение виртуальных позиций множества источников аудиосигналов выбирается на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов.
Кроме того, устройство 200 обработки аудиосигналов содержит этап 203 фильтрации множества аудиосигналов 105 на основе выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя для получения множества отфильтрованных аудиосигналов 107. Множество отфильтрованных аудиосигналов 107 воспринимаются слушателем как исходящие из виртуальных позиций множества источников аудиосигналов, определенных посредством выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов относительно слушателя.
Способ 200 обработки аудиосигналов может быть выполнен, например, устройством 100 обработки аудиосигналов в соответствии с первым аспектом изобретения.
Далее описываются дополнительные формы реализации и варианты осуществления устройства 100 обработки аудиосигналов и способа 200 обработки аудиосигналов.
В варианте осуществления селектор 101 устройства 100 обработки аудиосигналов выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством объединения множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов. В варианте осуществления множество спектров аудиосигналов и множество передаточных функций объединяются посредством перемножения множества спектров аудиосигналов и множества передаточных функций для получения множества дирекционально-спектральных профилей дикторов, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов.
Фиг. 3 показывает иллюстративную передаточную функцию, полученную посредством вывода среднего значения левой функции BRTF и правой функции BRTF. Для получения иллюстративной передаточной функции левая функция BRTF и правая функция BRTF усредняются в соответствующих частотных полосах. Этот анализ подполос может быть сделан различными способами, такими как использование квадратурных зеркальных фильтров (QMF), гамматоновых фильтров или полос с шириной октавы или трети октавы. Для примера, показанного на фиг. 3, спектры, профили и передаточные функции вычисляются с использованием анализа с полосой с шириной одной шестой октавы, т.е. 1/n-октавной полосы, где n=6 представляет ширину полосы набора фильтров. Анализ приближает набор фильтров с постоянным Q посредством усреднения по элементам разрешения по интенсивности дискретного преобразования Фурье (DFT), которое вычисляется с использованием алгоритма быстрого преобразования Фурье (FFT). Набор фильтров с постоянным Q означает, что отношение между центральной частотой и шириной полосы фильтра остается одинаковым во всех фильтрах. В варианте осуществления анализ подполос выполняется по диапазону частот, релевантному для речи, и установлен на частотах между 500 и 6300 Гц. Этот диапазон частот дает в результате анализ подполос с 21 разными 1/6-октавными полосами. Другие возможные варианты для верхнего предела частоты могут составлять 7000 или 8000 Гц.
Специалисту в области техники будет очевидно, что получение среднего значения между левой и правой функциями HRTF является всего одним подходом для вывода передаточной функции, которая может использоваться в контексте устройства 100 обработки аудиосигнала и способа 200 обработки аудиосигнала. Например, любая из левой или правой функций HRTF/BRTF может использоваться в качестве передаточной функции. Передаточные функции, например, функции HRTF и/или BRTF, могут быть вычислены один раз и сохранены для последующего использования.
Фиг. 4 показывает иллюстративный спектр аудиосигнала, который может использоваться с устройством 100 обработки аудиосигнала и способом 200 в соответствии с вариантом осуществления. Тонкая линия на фиг. 4 показывает дискретное преобразование Фурье иллюстративного речевого аудиосигнала, т.е. иллюстративный спектр аудиосигнала. Толстая линия в фиг. 4 показывает усредненное представление или представление по подполосам спектра аудиосигнала, который используется в варианте осуществления в вычислительных целях.
В варианте осуществления значение спектра аудиосигнала n-ого аудиосигнала в k-ой частотной полосе, т.е. , и/или значение передаточной функции, связанной с виртуальной позицией m-ого пространственного размещения источника аудиосигнала, связанного с n-ым аудиосигналом в k-ой частотной полосе, т.е. , определяются посредством выполнения операции усреднения по множеству элементов разрешения по частоте, используемых для дискретного преобразования Фурье, на основе следующих уравнений:
, и
,
где обозначает значение дискретного преобразования Фурье n-ого аудиосигнала в i-ом элементе разрешения по частоте, обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте, и обозначает количество элементов разрешения по частоте k-ой частотной полосы.
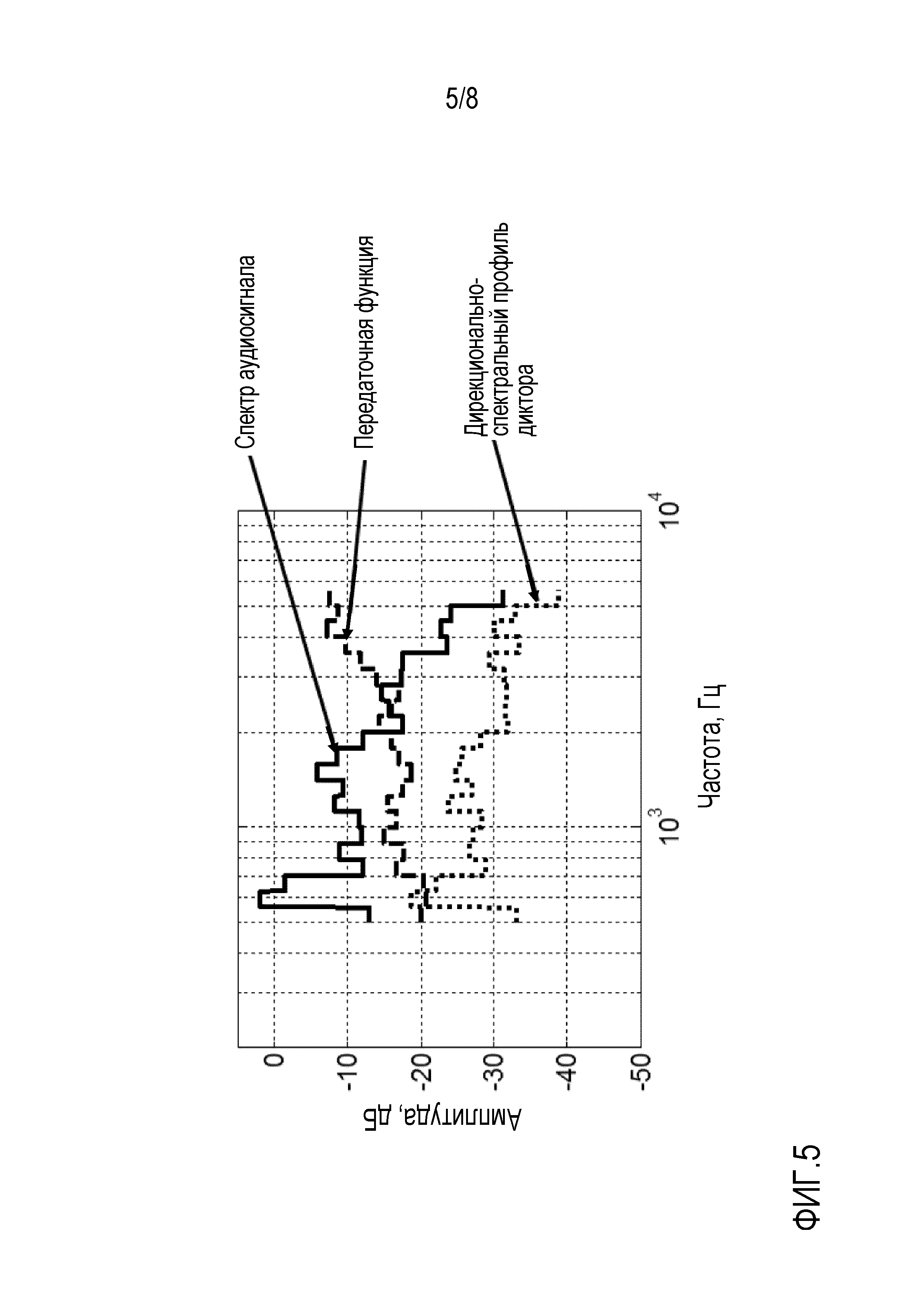
Фиг. 5 показывает, как передаточная функция, такая как передаточная функция, показанная на фиг. 3, и спектр аудиосигнала, такой как спектр аудиосигнала, показанный на фиг. 4, могут быть объединены селектором 101 для получения дирекционально-спектрального профиля диктора. Как может быть видно из фиг. 5, дирекционально-спектральный профиль диктора получен посредством перемножения (усредненной по подполосам) передаточной функции с (усредненным по подполосам) спектром аудиосигнала, или в качестве альтернативы посредством суммирования их соответствующих логарифмических характеристик интенсивности. В контексте настоящего изобретения перемножение передаточной функции со спектром аудиосигнала представляет собой поточечное перемножение двух векторов, заданных посредством усредненной или дискретизированной передаточной функции и усредненного или дискретизированного спектра аудиосигнала, соответственно. В математическом смысле селектор 101 выполнен с возможностью вычислять
,
причем обозначает значение n-ого дирекционально-спектрального профиля диктора, связанного с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов в k-ой частотной полосе.
В варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества дирекционально-спектральных профилей дикторов. В варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством выбора одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между множеством дирекционально-спектральных профилей дикторов больше предопределенного порогового значения, предпочтительно является максимальным.
В варианте осуществления селектор 101 выполнен с возможностью определять спектральное различие между дирекционально-спектральными профилями дикторов, связанными с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов с использованием следующих уравнений:
, и
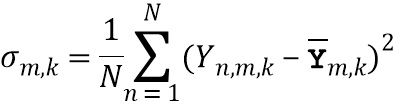 ,
,
где обозначает скалярное значение, представляющее спектральное различие между множеством дирекционально-спектральных профилей дикторов, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос, обозначает весовой коэффициент, обозначает дисперсию по дирекционально-спектральным профилям дикторов для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов, и обозначает среднее значение дирекциональных профилей диктора в k-ой частотной полосе.
Фиг. 6A показывает иллюстративные дирекционально-спектральные профили дикторов для случая пяти дикторов, которые могут использоваться с устройством 100 обработки аудиосигнала и способом 200 обработки аудиосигнала в соответствии с вариантом осуществления. Фиг. 6B показывает дисперсию для пяти иллюстративных дирекционально-спектральных профилей дикторов, показанных на фиг. 6A для разных частотных полос.
В варианте осуществления все весовые коэффициенты , используемые для вычисления , т.е. спектральных различий между множеством дирекционально-спектральных профилей дикторов, могут быть установлены равными единице. В качестве альтернативы, весовые коэффициенты могут представлять слуховую чувствительность человека на центральных частотах разных частотных полос. В этом случае весовые коэффициенты могут быть вычислены как обратная величина абсолютного порога слышимости, нормализованная посредством минимального порога, т.е., порога частотной полосы, в которой средняя слышимость человека самая чувствительная. Эти иллюстративные весовые коэффициенты , выведенные из абсолютного порога слышимости человека, показаны на фиг. 6C.
Чтобы учесть возможность, что селектор 101 определяет по меньшей мере два пространственных размещения виртуальных позиций множества источников аудиосигналов, имеющих одинаковое максимальное спектральное различие, в варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов посредством объединения множества спектров аудиосигналов и множества передаточных функций для левого уха, связанных с виртуальными позициями источников аудиосигналов относительно левого уха слушателя, чтобы получить множество дирекционально-спектральных профилей диктора для левого уха, и множества спектров аудиосигналов и множества передаточных функций для правого уха, связанных с виртуальными позициями источников аудиосигнала относительно правого уха слушателя, чтобы получить множество дирекционально-спектральных профилей диктора для правого уха, и посредством выбора одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между дирекционально-спектральными профилями диктора для левого уха и дирекционально-спектральными профилями диктора для правого уха меньше предопределенного порога, в частности, является минимальным.
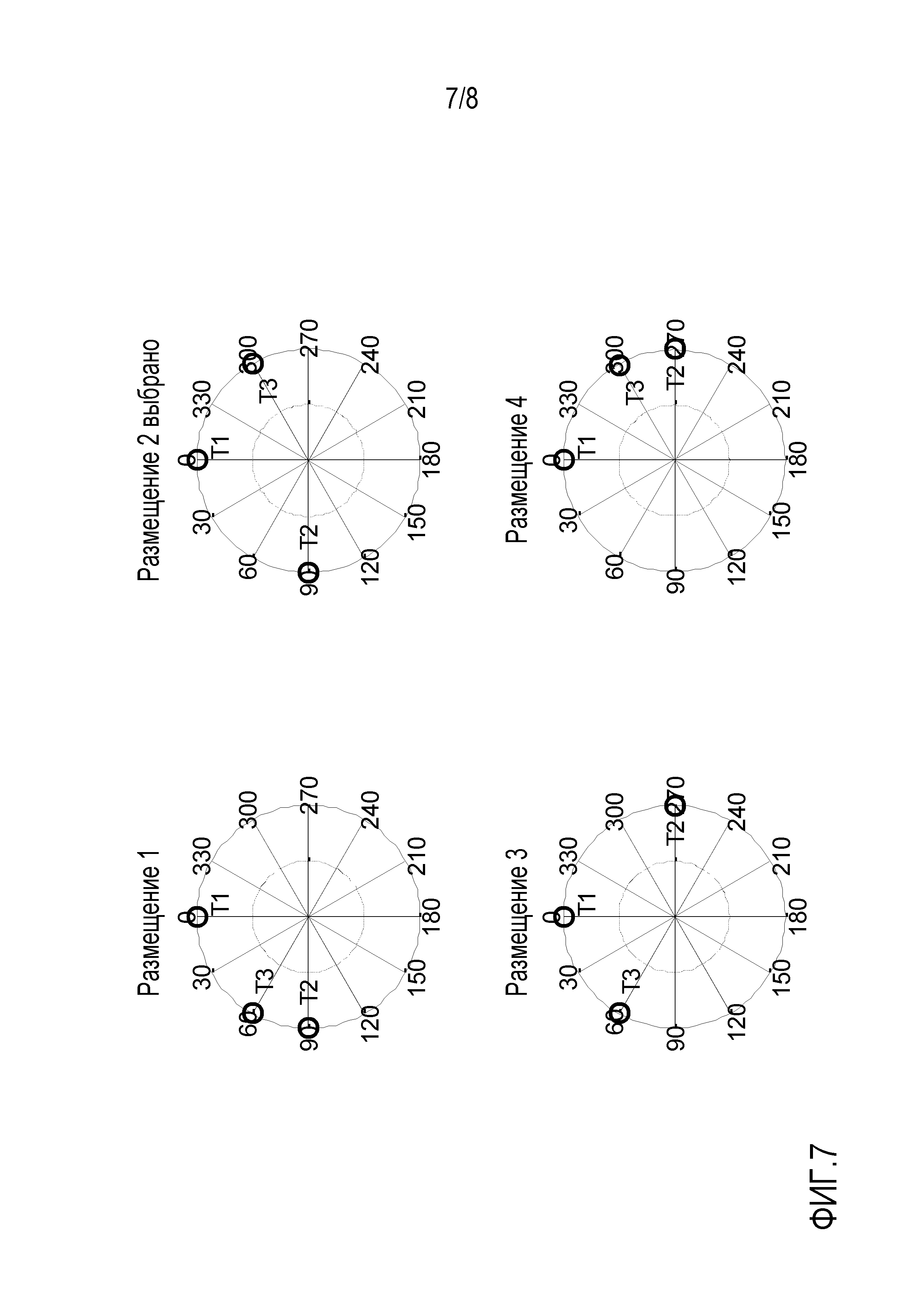
Фиг. 7 показывает четыре иллюстративных пространственных размещения виртуальных позиций множества источников аудиосигналов для случая трех дикторов, т.е. аудиосигналы и двенадцать возможных виртуальных позиций, т.е. передаточных функций. Для N дикторов на виртуальной пространственной конференции, способной реализовать в общей сложности L разных виртуальных местоположений, т.е. L различных передаточных функций, общее количество возможных пространственных размещений M задается как
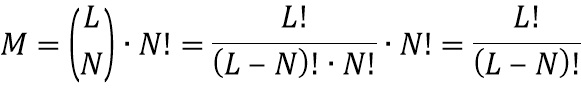
Таким образом, например, если N=3 диктора и L=12 пространственных местоположений, тогда существует M=1320 возможных пространственных размещений. Для примера, показанного на фигуре 7, все четыре размещения обеспечивают максимальное спектральное различие на основе множества усредненных передаточных функций. При помощи передаточных функций для левого уха и передаточных функций для правого уха вариант осуществления настоящего изобретения позволяет выбрать размещение 2 как оптимальное пространственное размещение виртуальных позиций множества источников аудиосигналов, которое минимизирует спектральное различие между дирекционально-спектральными профилями диктора для левого уха и дирекционально-спектральными профилями диктора для правого уха.
В варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов относительно слушателя, виртуальные позиции множества источников аудиосигналов размещены на круге с центром в позиции слушателя и имеют постоянное угловое разнесение, на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством определения одного из множества возможных пространственных размещений виртуальных позиций множества источников аудиосигналов, для которого спектральное различие между множеством передаточных функций больше предопределенного порогового значения, предпочтительно является максимальным.
В варианте осуществления селектор 101 выполнен с возможностью определять спектральное различие между передаточными функциями, связанными с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, с использованием следующих уравнений:
, и
,
где обозначает скалярное значение, представляющее спектральное различие между множеством передаточных функций, связанных с m-ым пространственным размещением виртуальных позиций множества источников аудиосигналов, K обозначает общее количество частотных полос, обозначает весовой коэффициент, обозначает дисперсию по множеству передаточных функций для k-ой частотной полосы, N обозначает общее количество спектров аудиосигналов, обозначает значение n-ой передаточной функции в k-ой частотной полосе, и обозначает среднее значение передаточных функций в k-ой частотной полосе.
В варианте осуществления значение n-ой передаточной функции в k-ой частотной полосе, т.е. , определяется посредством выполнения операции усреднения по множеству элементов разрешения по частоте, используемых для дискретного преобразования Фурье, на основе следующего уравнения:
,
где обозначает значение дискретного преобразования Фурье импульсной характеристики передаточной функции, связанной с виртуальной позицией источника аудиосигнала, связанного с n-ым аудиосигналом в i-ом элементе разрешения по частоте и , обозначает количество элементов разрешения по частоте частоты k-ой частотной полосы.
В варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством ранжирования множества спектров аудиосигналов в соответствии с подобием множества спектров аудиосигнала. В варианте осуществления селектор 101 выполнен с возможностью вычислять значение подобия для множества спектров аудиосигналов (i) посредством вычисления среднего спектра аудиосигнала и спектральных различий между каждым спектром аудиосигнала и средним спектром аудиосигнала или (ii) посредством вычисления функции корреляции между спектрами аудиосигналов.
В варианте осуществления селектор 101 выполнен с возможностью выбирать пространственное размещение виртуальных позиций множества источников аудиосигналов на основе множества спектров аудиосигналов и множества передаточных функций, связанных с каждым возможным пространственным размещением виртуальных позиций множества источников аудиосигналов, посредством назначения ранжированного множества спектров аудиосигналов на виртуальные позиции выбранного пространственного размещения виртуальных позиций множества источников аудиосигналов таким образом, что максимизируется угловое разнесение между спектрами аудиосигналов, имеющими малое спектральное различие, т.е. "подобными" спектрами аудиосигналов.
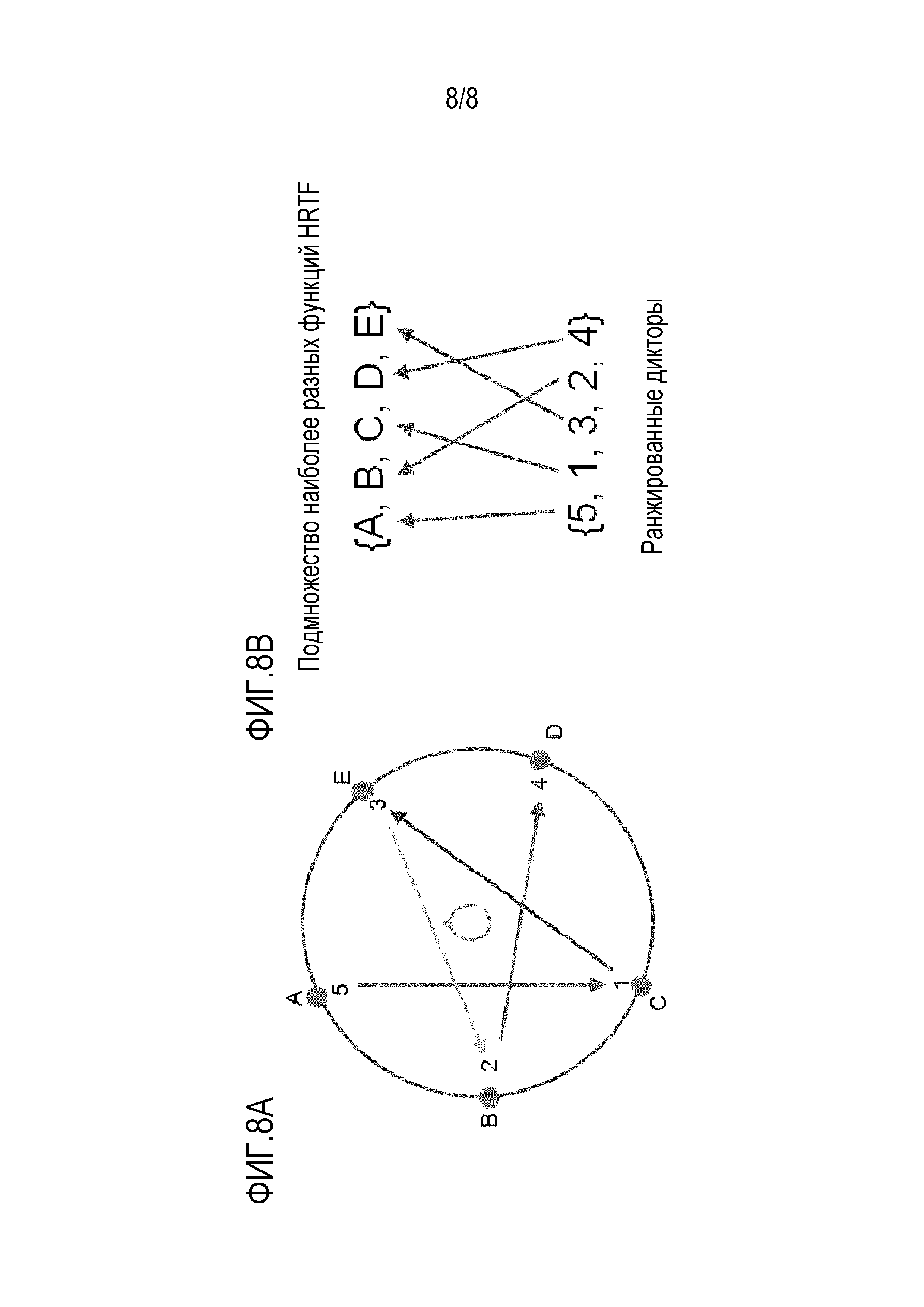
Фиг. 8A и 8B иллюстрируют пример того, как следует выбрать оптимальное пространственное размещение виртуальных позиций множества дикторов, т.е. источников аудиосигналов относительно слушателя в соответствии с вариантом осуществления. Заданный диктор произвольным образом выбирается из N дикторов, и вычисляется корреляция между спектром аудиосигнала выбранного диктора и каждым из спектров аудиосигналов других N-1 дикторов. Затем выбирается спектр аудиосигнала диктора, который приводит к самой высокой корреляции. Такой же самый процесс повторяется для нового выбранного диктора, пока все спектры аудиосигналов дикторов не будут ранжированы.
В примере, проиллюстрированном на фиг. 8А и 8B, имеются N=5 дикторов (упорядочены от 1 до 5 в соответствии со временем, в которое они впервые вошли в виртуальную пространственную аудиоконференцию), и формируется оптимальное пространственное размещение посредством 5 направлений с метками A, B, C, D и E. Ранжирование дикторов в соответствии с подобием спектров аудиосигналов распределяет их как последовательность 5, 1, 3, 2 и 4. Назначение передаточных функций начинается посредством произвольного назначения первого диктора в списке дикторов, т.е. диктора 5, на первое направление в списке направлений, т.е. направление A. Следующий диктор, т.е., диктор 1, спектр аудиосигнала которого более подобен спектру аудиосигнала диктора 5, чем другим дикторам, назначается на направление с наибольшим угловым разнесением от направления A. В этом конкретном примере существует два варианта, а именно, направления C и D. Эта двойная альтернатива является следствием ограничения, что направления имеют постоянное угловое разнесение. Здесь отдается предпочтение поиску против часовой стрелки, и выбирается направление C, как показано стрелкой, соединяющей A и C. Процесс продолжается посредством назначения диктора 3 на направление E, поскольку это направление дает наибольшее угловое разнесение от C. Такой же процесс повторяется для диктора 2 (стрелка, соединяющая направления E и B) и диктора 4 (стрелка, соединяющая направления B и D), пока не будут заняты все доступные направления.
Специалисту в области техники будет очевидно, что варианты осуществления настоящего изобретения также могут использоваться для вычисления оптимального пространственного размещения, т.е. пространственного размещения для воспроизведения с помощью громкоговорителей, которое включает в себя, но без ограничения, воспроизведение стерео, каналов 5.1, 7.1 и 22.2. Независимо от количества громкоговорителей и их пространственных местоположений эти варианты осуществления используют спектры аудиосигналов для ранжирования дикторов в соответствии со спектральными различиями таким методом, который эквивалентен описанной выше процедуре. В зависимости от количества громкоговорителей, их пространственных местоположений и максимального углового промежутка Θ, который они покрывают, назначение местоположения разным дикторам может быть сделано двумя методами.
В варианте осуществления дикторы разносятся в пространстве на основе простых угловых расстояний. Таким образом, дикторы с наиболее подобными спектрами аудиосигналов размещаются в местоположения с самым большим угловым расстоянием, и дикторы с наиболее отличающимися спектрами аудиосигналов размещаются в местоположения с наименьшим угловым расстоянием. Эти местоположения могут находиться в точных позициях реальных громкоговорителей или в позициях между громкоговорителями, которые затем создаются посредством методик панорамирования или других технологий рендеризации звукового поля, например, синтеза волнового поля.
В альтернативном варианте осуществления дикторы разносятся в пространстве на основе дирекционально-спектральных профилей дикторов, как описано выше, или на основе передаточных функций, как описано выше. В особом случае систем устранения перекрестных помех описанные выше варианты осуществления могут быть реализованы тем же самым образом, как для воспроизведения с помощью наушников. Когда найдено оптимальное пространственное размещение, методики панорамирования или методики рендеризации звукового поля могут быть использованы для размещения дикторов в их оптимальных позициях.
Специалисту в данной области техники будет очевидно, что заявленное изобретение охватывает также варианты осуществления, в которых аудиосигналы и их спектры не анализируются в реальном времени, а вместо этого множество спектров аудиосигналов пользователя определяет пользовательский профиль, который в свою очередь представлен спектром аудиосигнала профиля, выведенным из него, например, среднее значение спектров аудиосигналов пользователя.
Варианты осуществления изобретения могут быть реализованы в компьютерной программе для выполнения на компьютерной системе, по меньшей мере включающей в себя части кода для выполнения этапов способа в соответствии с изобретением при их исполнении на программируемом устройстве, таком как компьютерная система, или дающей возможность программируемому устройству выполнять функции устройства или системы в соответствии с изобретением.
Компьютерная программа представляет собой список инструкций, таких как конкретная прикладная программа и/или операционная система. Компьютерная программа, например, может включать в себя один или более элементов группы, состоящей из подпрограммы, функции, процедуры, метода объекта, реализации объекта, исполняемого приложения, апплета, сервлета, исходного кода, объектного кода, совместно используемой библиотеки/динамически загружаемой библиотеки и/или другой последовательности инструкций, разработанных для исполнения на компьютерной системе.
Компьютерная программа может быть сохранена внутри машиночитаемого запоминающего носителя или передана компьютерной системе через машиночитаемую передающую среду. Вся или часть компьютерной программы может быть обеспечена на энергозависимых или энергонезависимых машиночитаемых носителях, соединенных с системой обработки информации на постоянной основе, сменным образом или удаленным образом. Машиночитаемые носители могут включать в себя, например, но без ограничения, любое количество следующих элементов: магнитные запоминающие носители, в том числе запоминающие носители на диске и на ленте; оптические запоминающие носители, такие как компакт-диск (например, компакт-диск, предназначенный только для чтения (CD-ROM), записываемый компакт диск (CD-R) и т.д.) и цифровой видеодиск; энергонезависимые запоминающие носители, в том числе полупроводниковые блоки памяти, такие как флэш-память, ЭСППЗУ (EEPROM), СППЗУ (EPROM), ПЗУ (ROM); ферромагнитные цифровые запоминающие устройства; MRAM; энергозависимые запоминающие носители, в том числе регистры, буферы или кэши, оперативная память, ОЗУ (RAM) и т.д.; и среда передачи данных, в том числе компьютерные сети, оборудование для двухточечной связи и среда передачи несущей.
Компьютерный процесс, как правило, включает в себя исполнение (выполнение) программы или части программы, текущих значений программы и информации состояния и ресурсы, используемые операционной системой для управления исполнением процесса. Операционная система (OS) представляет собой программное обеспечение, которое управляет совместным использованием ресурсов компьютера и предоставляет программистам интерфейс, используемый для осуществления доступа к этим ресурсам. Операционная система обрабатывает системные данные и пользовательский ввод и отвечает посредством распределения и управления задачами и внутренними системными ресурсами как службой для пользователей и программ системы.
Компьютерная система, например, может включать в себя по меньшей мере один процессор, соответствующую память и несколько устройств ввода/вывода (I/O). При исполнении компьютерной программы компьютерная система обрабатывает информацию в соответствии с компьютерной программой и производит получаемую в результате выходную информацию через устройства ввода/вывода.
Обсуждаемые в настоящем документе соединения могут представлять собой соединения любого типа, подходящие для переноса сигналов от соответствующих узлов, блоков или устройств или к ним, например, через промежуточные устройства. В соответствии с этим, если не подразумевается или заявлено иначе, соединения могут являться, например, прямыми соединениями или не прямыми соединениями. Соединения могут быть проиллюстрированы или описаны как одиночное соединение, множество соединений, однонаправленные соединения или двунаправленные соединения. Однако разные варианты осуществления могут менять реализацию соединений. Например, могут использоваться отдельные одиночные соединения, а не двунаправленные соединения, и наоборот. Кроме того, множество соединений может быть заменено одиночным соединением, которое переносит несколько сигналов последовательно или с мультиплексированием по времени. Аналогичным образом, одиночные соединения, несущие несколько сигналов, могут быть разделены на различные соединения, несущие подмножества этих сигналов. Таким образом, существует много вариантов для переноса сигналов.
Специалистам в области техники очевидно, что границы между логическими блоками являются лишь иллюстративными, и что альтернативные варианты осуществления могут осуществлять слияние логических блоков или элементов схем, или накладывать альтернативное разделение функциональности на различные логические блоки или элементы схем. Таким образом, следует понимать, что архитектура, изображенная в настоящем документе, является лишь иллюстративной, и что фактически могут быть реализованы многие другие архитектуры, которые достигают такой же функциональности.
Таким образом, любое размещение компонентов для достижения одной и той же функциональности является эффективно "связанным", если в результате достигается желаемая функциональность. Следовательно, любые два компонента, объединенные для достижения конкретной функциональности, могут рассматриваться как "связанные" друг с другом, если в результате достигается желаемая функциональность, независимо от архитектуры или промежуточных компонентов. Аналогично, любые два компонента, связанные таким образом, также могут рассматриваться как "функционально соединенные" или "функционально присоединенные" друг к другу для достижения желаемой функциональности.
Кроме того, специалистам в данной области техники должно быть очевидно, что границы между описанными выше операциями являются лишь иллюстративными. Несколько операций могут быть объединены в единую операцию, единая операция может быть распределена в дополнительных операциях, и операции могут быть исполнены по меньшей мере частично с наложением во времени. Кроме того, альтернативные варианты осуществления могут включать в себя несколько экземпляров конкретной операции, и порядок операций может быть изменен в различных других вариантах осуществления.
Также примеры или их части могут быть реализованы как программные или кодовые представления физической схемы или логические представления, преобразуемые в физическую схему, например, на языке описания аппаратных средств любого подходящего типа.
Кроме того, изобретение не ограничено физическими устройствами или блоками, реализованными в непрограммируемых аппаратных средствах, а также может быть применено в программируемых устройствах или блоках, которые способны выполнять желаемые функции устройства, работая в соответствии с подходящим программным кодом, например, универсальные компьютеры, миникомпьютеры, серверы, рабочие станции, персональные компьютеры, ноутбуки, карманные персональные компьютеры, электронные игры, автомобильные и другие встроенные системы, сотовые телефоны и различные другие беспроводные устройства, обычно обозначаемые в этой заявке как "компьютерные системы".
Однако также возможны другие модификации, изменения и альтернативы. В соответствии с этим описания и чертежи должны рассматриваться в иллюстративном, а не в ограничивающем смысле.
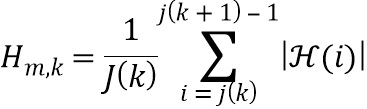
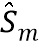
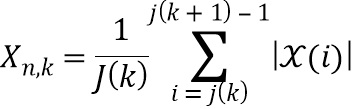
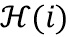
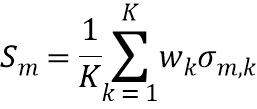
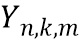
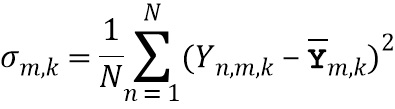
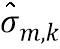
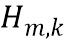
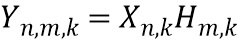
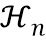
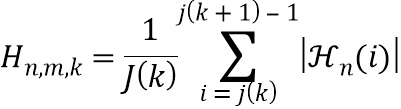
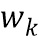
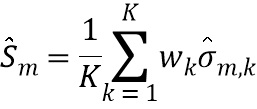
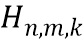
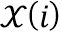
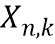
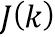
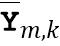
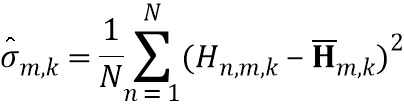
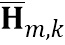
Способ и устройство кодирования сигнала, способ для кодирования объединенного сигнала обратной связи
Способ разъединения вызова и устройство для его осуществления
Способ и устройство передачи данных
Способ и устройство кодирования сигнала обратной связи
Прозрачный обходной путь и соответствующие механизмы
Способ поиска тракта тсм, способ создания тракта тсм, система управления поиском тракта и система управления созданием тракта
Мобильная станция, способ и устройство для назначения канала
Способ сообщения информации о способности терминала, способ и устройство для выделения ресурсов временного слота и соответствующая система
Способ и устройство для выделения ресурсов и обработки информации подтверждения
Способ, сетевое устройство и система для определения распределения ресурсов при скоординированной многоточечной передаче
Устройство и способ для управления входным аудиосигналом

