Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ СРАВНЕНИЯ СХОЖИХ ЭЛЕМЕНТОВ ВЫСОКОРАЗМЕРНЫХ ПРИЗНАКОВ ИЗОБРАЖЕНИЙ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящая заявка относится к области техники компьютера, в частности, к способу и устройству для сравнения схожих элементов высокоразмерных признаков изображений.
УРОВЕНЬ ТЕХНИКИ
В сегодняшнем Интернет-окружении, пользователи Интернета также желают извлекать мультимедийные контенты, такие как голос, изображения и видео, в дополнение к необходимости извлечения текста. Касательно извлечения изображения, пользователь ожидает, что поставщики Интернет-услуг найдут набор потенциально подходящих изображений (изображений-кандидатов), сходных с изображением, предоставленным им/ею для запроса. Примеры применимых сценариев включают в себя организации электронной коммерции, рекомендующие одинаковые или схожие стили товаров на основе изображений товаров, предоставленных пользователями, поисковые сайты, отображающие схожие изображения согласно ландшафтным изображениям, предоставленным пользователями, и т.д.
Обыкновенное извлечение изображения обычно совершается посредством представления показателя сходства на основе вручную заданных признаков изображения. Из-за семантически неструктурированных характеристик данных изображения, сложно вручную обнаружить репрезентативные признаки. Метод глубокого обучения для нейронной сети, предложенный Hinton и другими, обеспечивает возможность извлечения признаков, т.е. эффективного отображения из высокоразмерного пространства собственных векторов в низкоразмерное пространство собственных векторов необработанного изображения, посредством самообучения, что значительно повышает эффективность для представления признаков в области изображения.
В Интернет-индустрии, сервисные компании часто имеют огромное хранилище изображений. Касательно пользовательских потребностей извлечения, если результаты извлечения должны быть получены в пределах времени отклика на уровне секунд, в дополнение к использованию крупномасштабной технологии параллельного вычисления, также требуется увеличить скорость в уменьшении размерности, индексации и алгоритмах сопоставления. Алгоритм локально-чувствительного хэширования (LSH) является видом метода кодирования для уменьшения размерностей, который характеризуется тем, что удерживает относительное положение в первоначальном пространстве собственного вектора в сгенерированном HASH-коде, и таким образом может быть использован для быстрого извлечения изображений.
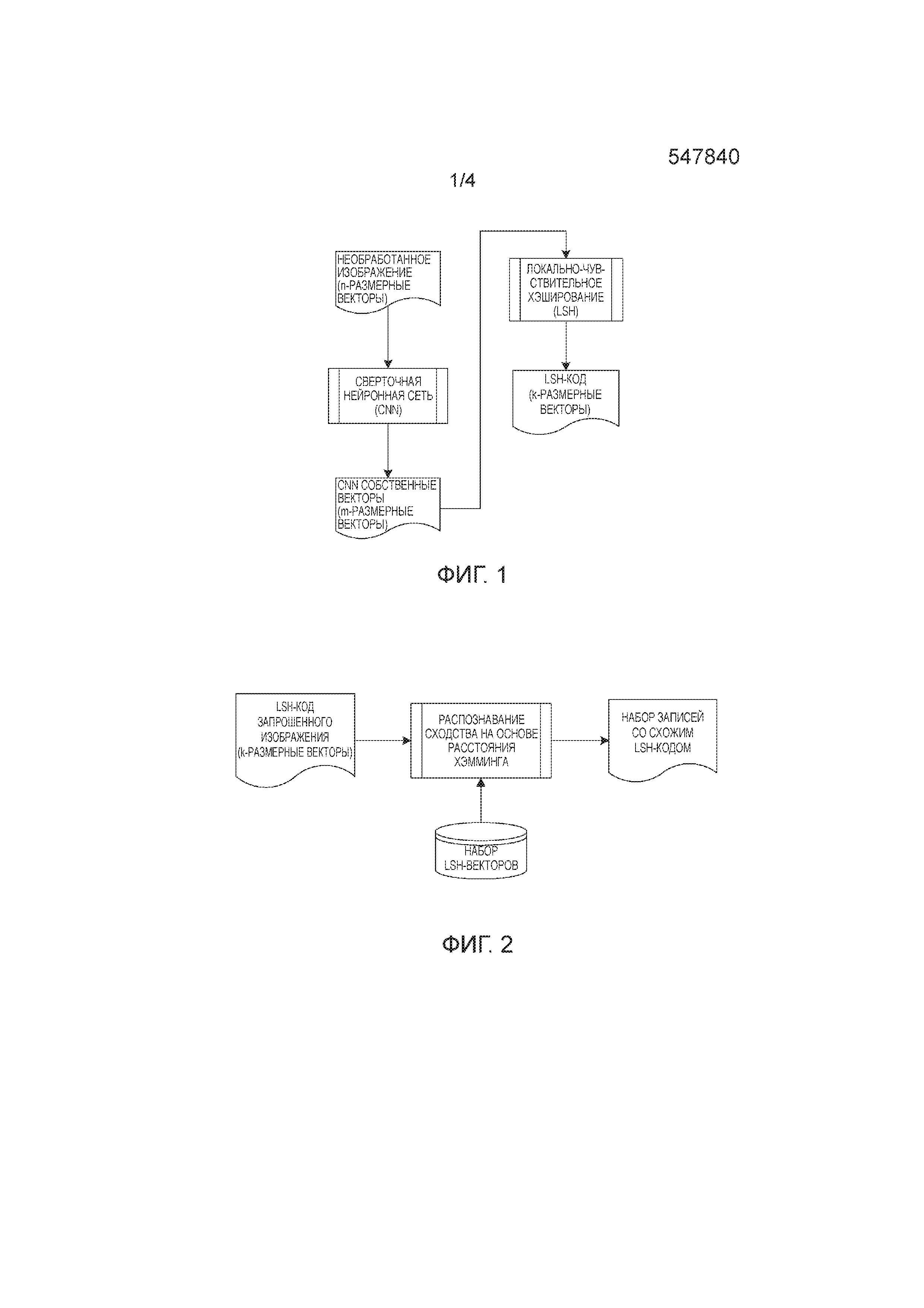
В предшествующем уровне техники, LSH-алгоритм для извлечения изображения в основном включает в себя нижеследующие этапы:
1. LSH-кодирования для изображения
Процесс LSH-кодирования для изображения показан на Фиг. 1. Необработанное изображение представляется как n-размерный вектор для канала RGB, и затем выход скрытых слоев (обычно с предпоследнего слоя по четвертый слой снизу), полученных путем кодирования n-размерного вектора посредством сверточной нейронной сети (CNN), берется как m-размерный собственный вектор изображения (обычная длина размерности составляет 4096). Собственный вектор затем преобразовывается в k-размерный (k намного меньше, чем m) LSH-код после применения набора векторных операций LSH к m-размерному собственному вектору. Согласно этому способу, сервисные предприятия преобразовывают все изображения в такие коды, и затем извлечение схожих элементов для последующих изображений совершается на основе такого представления изображения.
2. Извлечения схожих элементов для изображения
Процесс извлечения схожих элементов для изображения показан на Фиг. 2. Сначала, LSH-код (вектор A) изображения, загруженного пользователем для запроса, получают посредством вышеуказанного этапа 1, и затем для каждого вектора (вектора B) в таблице LSH-векторов, вычисляется расстояние Хэмминга между вектором A и B. Впоследствии, векторы сортируются в порядке возрастания согласно вычисленным расстояниям, и, наконец, необработанные изображения, соответствующие нескольким верхним векторам, возвращаются пользователю как результат извлечения схожих элементов.
Однако, применение существующего LSH-алгоритма к способу извлечения изображения имеет следующие недостатки при использовании:
1. Скорость извлечения схожих элементов на основе LSH-кодирования является все еще низкой, в том случае, когда набор изображений является относительно большим (например, содержащим миллионы, десятки миллионов изображений и больше).
2. Хотя показатель расстояния Хэмминга быстрее, чем показатель евклидова расстояния и показатель манхэттенского расстояния и т.д., в том, что касается скорости вычисления, их точность значительно снижается, и результат извлечения является неудовлетворительным.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Ввиду этого, настоящее изобретение предусматривает способ и устройство для сравнения схожих элементов высокоразмерных признаков изображений. Посредством способа индексирования сегментов и извлечения сегментов LSH-коды изображений, и применения манхэттенского расстояния к показателю сходства, скорость извлечения и точность извлечения повышаются при извлечении схожих элементов из огромного количества изображений на основе LSH-кодирования.
Чтобы достигнуть вышеуказанной цели, согласно одному аспекту настоящего изобретения, предусматривается способ сравнения схожих элементов высокоразмерных признаков изображений.
Способ сравнения схожих элементов высокоразмерных признаков изображений согласно настоящему изобретению содержит: уменьшение размерностей извлеченных собственных векторов изображений посредством алгоритма локально-чувствительного хэширования (LSH) для получения низкоразмерных собственных векторов; сегментирование с усреднением низкоразмерных собственных векторов и создание таблицы индексов сегментов; извлечение сегментированного низкоразмерного собственного вектора запрошенного изображения из таблицы индексов сегментов для получения набора выборок-кандидатов; и представление показателя сходства между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения.
Опционально, собственные векторы изображения извлекаются с помощью нейронной сети, сконструированной с использованием метода глубокого обучения.
Опционально, нейронная сеть является сверточной нейронной сетью.
Опционально, до этапа сегментирования с усреднением низкоразмерных собственных векторов, способ дополнительно содержит определение экспериментальным образом оптимальной длины сегмента на меньшем наборе верификации.
Опционально, этап сегментирования с усреднением низкоразмерных собственных векторов и создания таблицы индексов сегментов содержит: сегментирование с усреднением низкоразмерных собственных векторов, с использованием сегментированных собственных векторов в качестве индексных элементов, и вычисление отличительного признака каждого из индексных элементов; выполнение операции деления по модулю в отношении отличительного признака с простым числом, которое наиболее близко к предварительно определенному числу записей, содержащихся в таблице индексов сегментов, чтобы получить адреса записей для индексных элементов; и вставку низкоразмерных собственных векторов в таблицу индексов сегментов согласно полученным адресам записей для создания таблицы индексов сегментов.
Опционально, этап извлечения сегментированного низкоразмерного собственного вектора запрошенного изображения из таблицы индексов сегментов для получения набора выборок-кандидатов содержит: осуществление доступа к адресу записи сегментированного низкоразмерного собственного вектора запрошенного изображения для получения конфликтного набора; извлечение низкоразмерных собственных векторов, соответствующих узлу из конфликтного набора, который имеет такой же отличительный признак, как отличительный признак сегментированного низкоразмерного собственного вектора запрошенного изображения, в качестве набора кандидатов; и объединение набора кандидатов, полученного посредством соответствующих извлечений сегментов и удаление из него дублированных низкоразмерных собственных векторов для получения набора выборок-кандидатов.
Опционально, этап представления показателя сходства между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения содержит: вычисление оценок манхэттеновских расстояний между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения; и сортировку оценок в порядке возрастания, и принятие изображений, соответствующих выборкам с предварительно определенным числом наивысших оценок, в качестве схожих изображений запрошенного изображения.
Согласно другому аспекту настоящего изобретения, предусматривается устройство для сравнения схожих элементов высокоразмерных признаков изображений.
Устройство для сравнения схожих элементов высокоразмерных признаков изображений согласно настоящему изобретению содержит: модуль уменьшения размерностей признаков для уменьшения размерностей извлеченных собственных векторов изображений посредством LSH-алгоритма для получения низкоразмерных собственных векторов; модуль индексации сегментов для сегментирования с усреднением низкоразмерных собственных векторов и создания таблицы индексов сегментов; модуль запрашивания схожих элементов для извлечения сегментированного низкоразмерного собственного вектора запрошенного изображения из таблицы индексов сегментов для получения набора выборок-кандидатов; и модуль сравнения показателей для представления показателя сходства между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения.
Опционально, собственные векторы изображения извлекаются с помощью нейронной сети, сконструированной с использованием метода глубокого обучения.
Опционально, нейронная сеть является сверточной нейронной сетью.
Опционально, до этапа сегментирования с усреднением низкоразмерных собственных векторов, модуль индексации сегментов дополнительно определяет экспериментальным образом оптимальную длину сегмента на меньшем наборе верификации.
Опционально, модуль индексации сегментов служит дополнительно для: сегментирования с усреднением низкоразмерных собственных векторов, с использованием сегментированных собственных векторов в качестве индексных элементов, и вычисления отличительного признака каждого из индексных элементов; выполнения операции деления по модулю в отношении отличительного признака с простым числом, которое наиболее близко к предварительно определенному числу записей, содержащихся в таблице индексов сегментов, чтобы получить адреса записей для индексных элементов; и вставки низкоразмерных собственных векторов в таблицу индексов сегментов согласно полученным адресам записей для создания таблицы индексов сегментов.
Опционально, модуль запрашивания схожих элементов служит дополнительно для: осуществления доступа к адресу записи сегментированного низкоразмерного собственного вектора запрошенного изображения для получения конфликтного набора; извлечения низкоразмерных собственных векторов, соответствующих узлу из конфликтного набора, который имеет такой же отличительный признак, как отличительный признак сегментированного низкоразмерного собственного вектора запрошенного изображения, в качестве набора кандидатов; и объединения набора кандидатов, полученного посредством соответствующих извлечений сегментов, и удаления из него дублированных низкоразмерных собственных векторов для получения набора выборок-кандидатов.
Опционально, модуль сравнения показателей служит дополнительно для: вычисления оценок манхэттеновских расстояний между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения; и сортировки оценок в порядке возрастания, и принятия изображений, соответствующих выборкам с предварительно определенным числом наивысших оценок, в качестве схожих изображений запрошенного изображения.
Согласно техническому решению настоящего изобретения, посредством создания индекса сегмента для собственных векторов с уменьшенными размерностями для LSH-кода для изображений, скорость извлечения может быть ускорена для повышения эффективности извлечения. При извлечении схожих элементов изображения, посредством использования показателя манхэттенского расстояния при замене обыкновенного показателя расстояния Хэмминга, количественная информация расстояния, содержащаяся в LSH-коде, может быть в достаточной мере использована для повышения точности извлечения при извлечении сегментов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Чертежи служат для лучшего понимания настоящего изобретения, и не составляют ненадлежащие ограничения для данного изобретения.
Фиг. 1 является принципиальной схемой процесса генерирования LSH-кода изображения в предшествующем уровне техники.
Фиг. 2 является принципиальной схемой процесса извлечения схожих элементов изображения в предшествующем уровне техники.
Фиг. 3 является принципиальной схемой основных этапов способа сравнения схожих элементов высокоразмерных признаков изображений согласно варианту осуществления настоящего изобретения.
Фиг. 4 является принципиальной схемой процесса генерирования LSH-кода изображения и создания индекса сегмента согласно реализации настоящего изобретения.
Фиг. 5 является структурной схемой таблицей индексов хэша сегментов согласно реализации настоящего изобретения.
Фиг. 6 является принципиальной схемой процесса извлечения схожих элементов изображения на основе индекса сегмента согласно реализации настоящего изобретения.
Фиг. 7 является принципиальной схемой основных модулей устройства для сравнения схожих элементов высокоразмерных признаков изображений согласно варианту осуществления настоящего изобретения.
ПРЕДПОЧТИТЕЛЬНЫЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
Примерные варианты осуществления настоящего изобретения описаны ниже со ссылкой на прилагаемые чертежи, на которых различные сведения вариантов осуществления настоящего изобретения включены для способствования пониманию, и должны рассматриваться лишь как примерные. Соответственно, специалисты в данной области техники поймут, что различные изменения и модификации могут быть внесены в варианты осуществления, описанные в настоящем документе, без отступления от объема и сущности данного изобретения. Также, для ясности и краткости, описания хорошо известных функций и конструкций исключены из нижеследующих описаний.
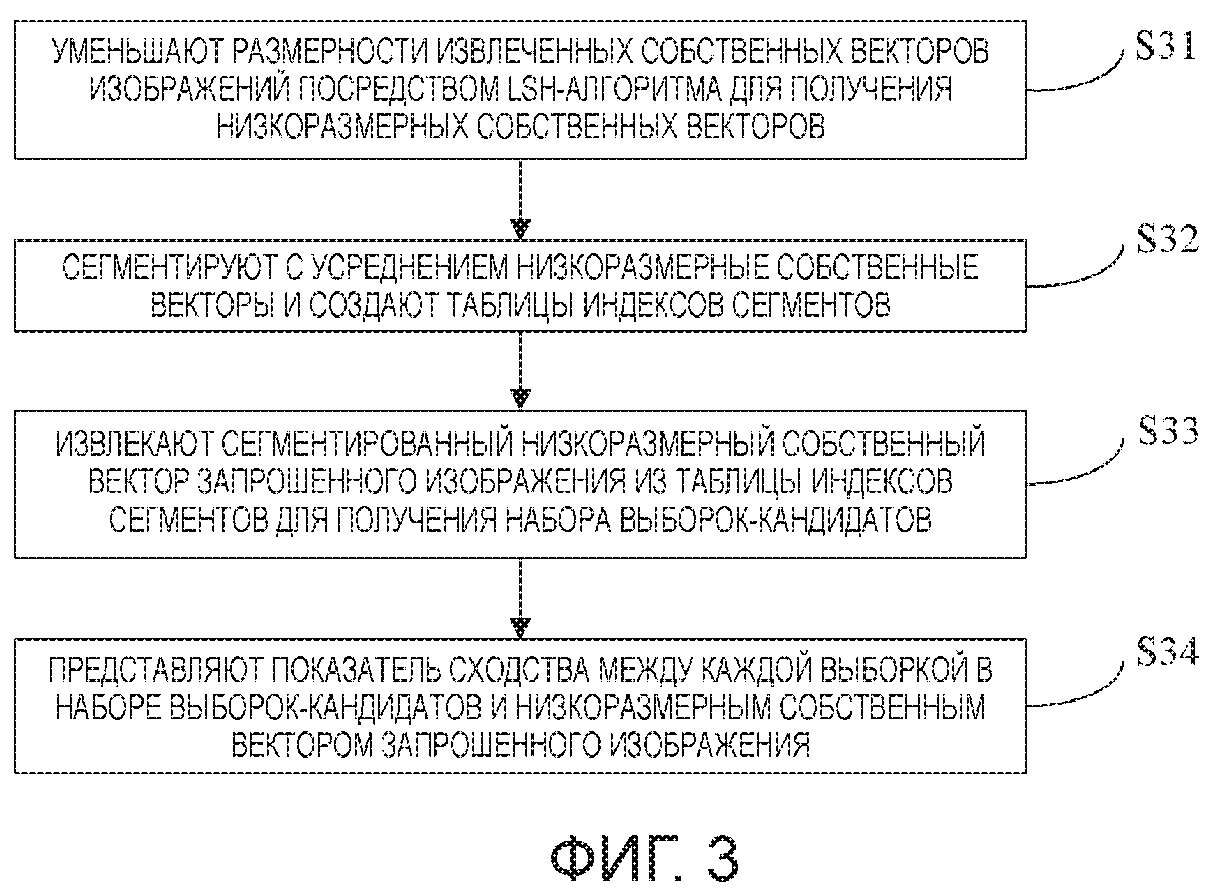
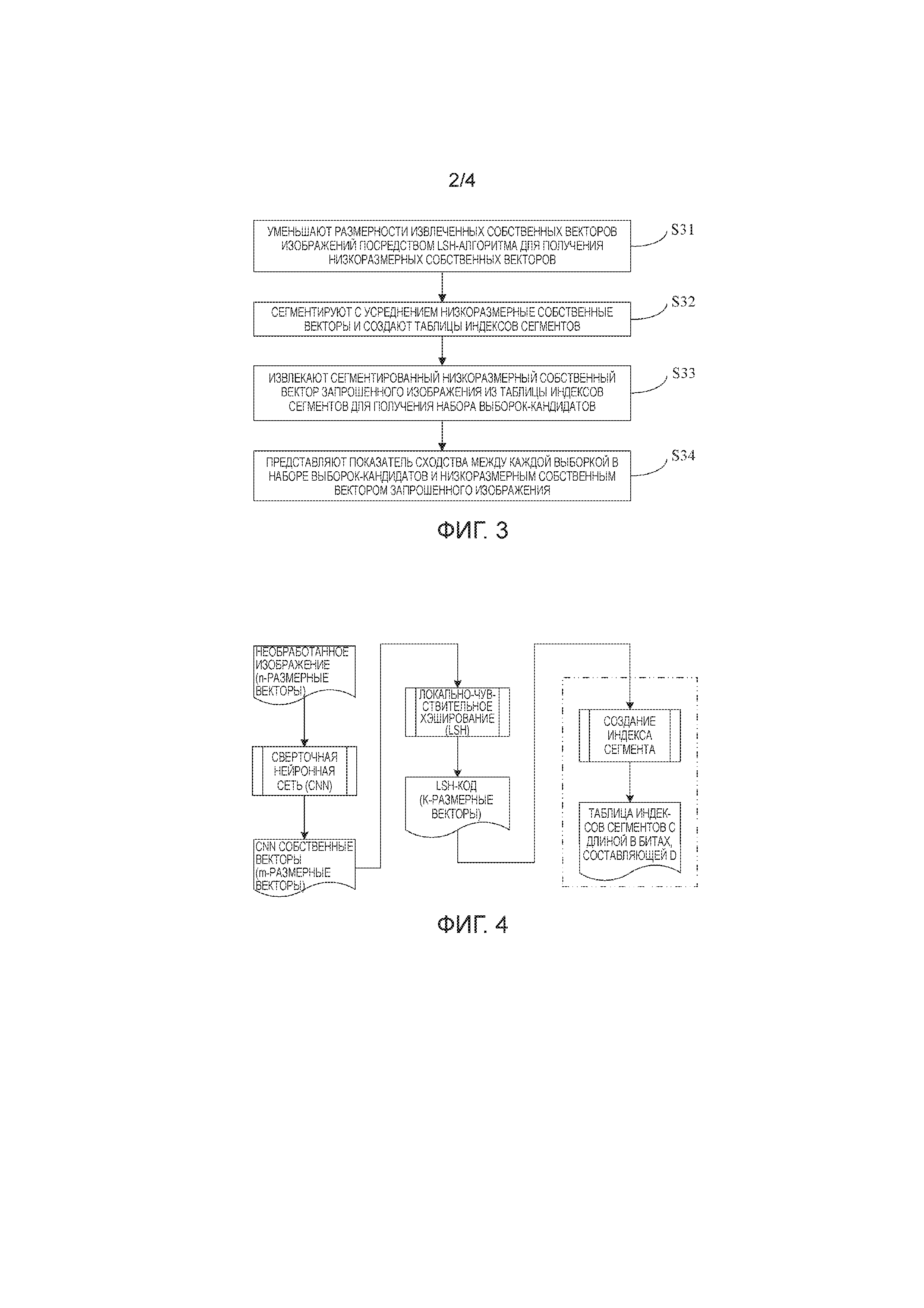
Реализация настоящего изобретения будет описана ниже со ссылкой на Фиг. 3 - Фиг. 6. Фиг. 3 является принципиальной схемой основных этапов способа сравнения схожих элементов высокоразмерных признаков изображений согласно варианту осуществления настоящего изобретения. Как показано на Фиг. 3, способ для сравнения схожих элементов высокоразмерных признаков изображений согласно настоящему изобретению включает в себя нижеследующие этапы S31-S34.
Этап S31: уменьшение размерностей извлеченных собственных векторов изображений посредством LSH-алгоритма для получения низкоразмерных собственных векторов. Собственные векторы изображений на данном этапе могут быть извлечены с помощью нейронной сети, сконструированной с использованием метода глубокого обучения. В основном используемая нейронная сеть является сверточной нейронной сетью CNN. Теперь обращаясь к принципиальной схеме процесса генерирования LSH-кода изображения и создания индекса сегмента согласно реализации настоящего изобретения, как показано на Фиг. 4, необработанное изображение подвергается извлечению признаков посредством сверточной нейронной сети CNN для получения m-размерных собственных векторов для CNN. Впоследствии, m-размерные собственные векторы подвергаются уменьшению размерностей посредством LSH для получения LSH-кода более низкоразмерных (например, k которая гораздо меньше, чем m) собственных векторов.
Этап S32: сегментирование с усреднением низкоразмерных собственных векторов и создание таблицы индексов сегментов. Перед этапом сегментирования с усреднением LSH-кода и создания индекса сегмента, оптимальная длина сегмента может быть определена экспериментальным образом на меньшем наборе верификации, так что техническое решение настоящего изобретения получает относительно удовлетворительный компромисс между скоростью извлечения и точностью. Впоследствии, низкоразмерные векторы LSH-кода сегментируются с усреднением согласно определенной оптимальной длине d сегмента. В качестве примера, LSH-кодом выборки с номером 1001 является:
[0,1,1,0,0,3,1,0,1,0,2,1,0,1,2,1,1,0,1,-1,2,1,0,1,1,1,0,0].
Если оптимальная длина d сегмента составляет 7, он должен быть разделен на четыре сегмента, и полученными индексными элементами сегментов являются:
1[0,1,1,0,0,3,1], 2[0,1,0,2,1,0,1], 3[2,1,1,0,1,-1,2], 4[1,0,1,1,1,0,0]
при этом число перед каждым сегментом представляет номер позиции: первый сегмент - 1, второй сегмент - 2 и т.д.
После сегментирования с усреднением низкоразмерных собственных векторов LSH-кода, для низкоразмерных собственных векторов в памяти создается таблица индексов хэша сегментов. Можно подытожить основные этапы:
Этап S321: сегментирование с усреднением низкоразмерных собственных векторов, с использованием сегментированных собственных векторов в качестве индексных элементов, и вычисление отличительного признака каждого из индексных элементов;
Этап S322: выполнение операции деления по модулю в отношении отличительного признака с простым числом, которое наиболее близко к предварительно определенному числу записей, содержащихся в таблице индексов сегментов, чтобы получить адреса записей для индексных элементов; и
Этап S323: вставка низкоразмерных собственных векторов в таблицу индексов сегментов согласно полученным адресам записей для создания таблицы индексов сегментов.
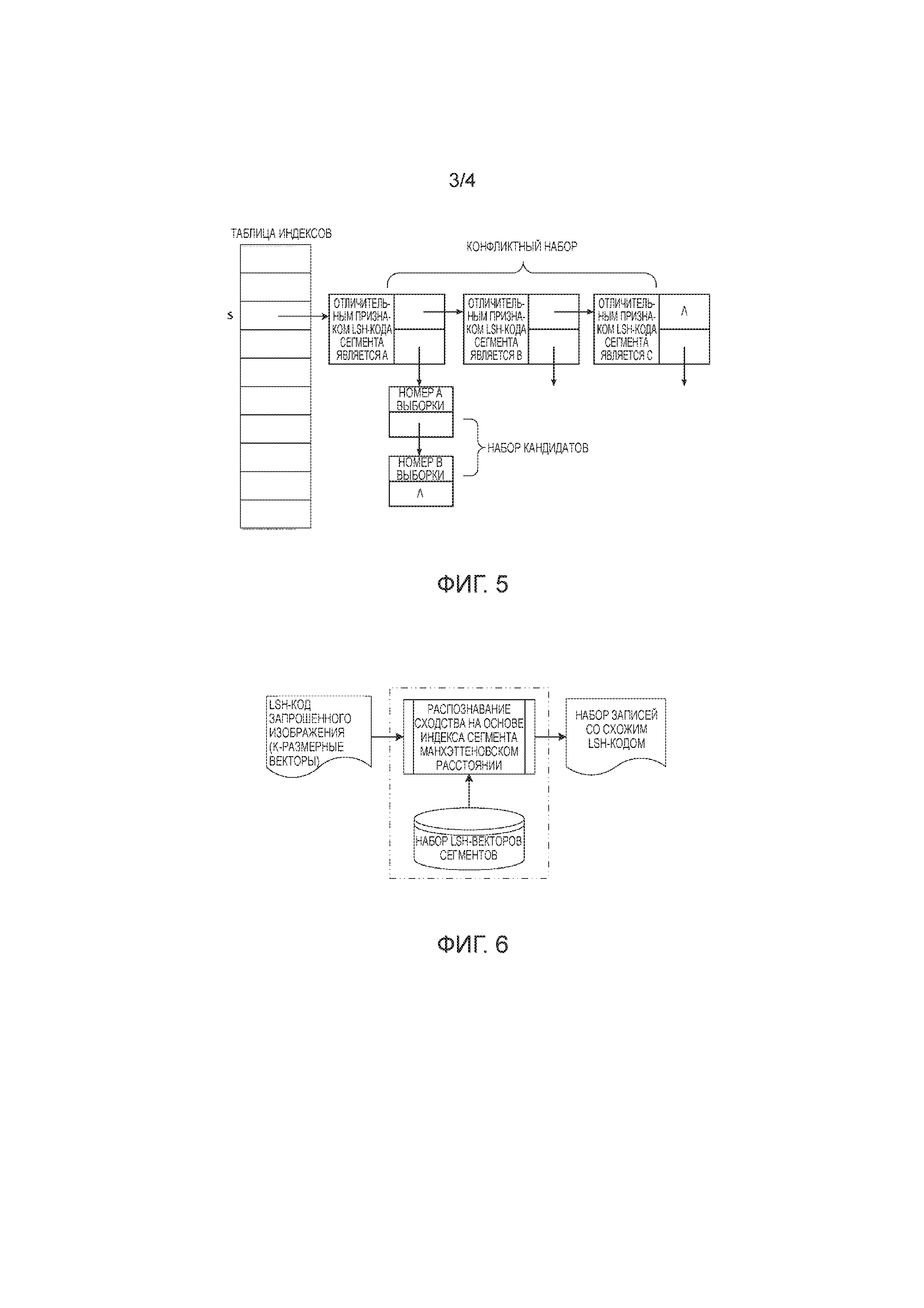
Со ссылкой на структурную схему таблицы индексов хэша сегментов согласно реализации настоящего изобретения, показанной на Фиг. 5, вышеприведенная выборка с номером 1001 берется в качестве примера для описания. После разделения выборки на четыре сегмента, сегментированные собственные векторы используются в качестве индексного элемента, и вычисляется отличительный признак каждого индексного элемент сегмента. Например, отличительный признак каждого индексного элемента может быть получен посредством вычисления с помощью пятого поколения алгоритма дайджеста сообщения (то есть, функции MD5). Затем, операция деления по модулю в отношении отличительного признака с простым числом, которое наиболее близко к предварительно определенному числу записей, содержащихся в таблице индексов сегментов, чтобы получить адрес записи для каждого из индексных элементов. Число записей N таблицы индексов сегментов может быть задано по необходимости, например, согласно размеру памяти машины или требования для реализации функции, и т.д. На практике, так как число индексных элементов сегментов является большим, адреса записей индексных элементов могут дублироваться, что обычно называется "конфликтом ключей". Индексные элементы с конфликтом ключей сохраняются в виде связного списка для конфликтного набора. Наконец, низкоразмерные собственные векторы LSH-кода вставляются в таблицу индексов сегментов согласно полученным адресам записей для создания таблицы индексов сегментов.
Посредством вышеуказанных этапов S31 и S32, процесс генерирования LSH-кода изображения и создания индекса сегмента согласно реализации настоящего изобретения может быть применен на практике. Процесс извлечения схожих элементов изображения на основе индекса сегмента будет описан ниже со ссылкой на прилагаемые чертежи.
Этап S33: извлечение сегментированного низкоразмерного собственного вектора запрошенного изображения из таблицы индексов сегментов для получения набора выборок-кандидатов. Процесс извлечения схожего изображения может быть реализован на основе нижеследующих этапов:
Этап S331: осуществление доступа к адресу записи сегментированного низкоразмерного собственного вектора запрошенного изображения для получения конфликтного набора;
Этап S332: извлечение низкоразмерных собственных векторов, соответствующих узлу из конфликтного набора, который имеет такой же отличительный признак, как отличительный признак сегментированного низкоразмерного собственного вектора запрошенного изображения, в качестве набора кандидатов; и
Этап S333: объединение набора кандидатов, полученного посредством соответственно извлечения при извлечениях сегментов, и удаления из него дублированных низкоразмерных собственных векторов для получения набора выборок-кандидатов.
Со ссылкой на структуру таблицы индексов хэша сегментов, показанной на Фиг. 5, процесс извлечения для набора выборок-кандидатов вводится посредством принятия вышеприведенной выборки с номером 1001 в качестве примера. Например, на этапе S331, сначала, вычисляется отличительный признак каждого индексного элемента сегмента, чтобы найти адрес S записи каждого индексного элемента сегмента в таблице индексов, и соответствующий связный список для конфликтного набора получают посредством осуществления доступа к адресу S записи. Указатель вправо каждого узла в связном списке для конфликтного набора используется для указания связного списка для конфликтного набора, и указатель вниз используется для указания связного списка для набора кандидатов. Так называемый набор кандидатов служит для набора выборок-кандидатов, соответствующего индексным элементам сегментов для узлов, которые будут подвергнуты сравнению конкретных расстояний, при этом отличительные признаки "LSH-кодов сегментов" (индексных элементов сегментов) для узлов являются такими же как отличительные признаки индексных элементов сегментов некоторого запрошенного изображения. Здесь выборками-кандидатами являются низкоразмерные собственные векторы. Как указано на этапе S332, извлекаются наборы кандидатов. Наконец, как указано на этапе S333, после завершения всех извлечений сегментов, все полученные наборы кандидатов объединяются, и дублированные низкоразмерные собственные векторы удаляются, чтобы в итоге получить набор выборок-кандидатов для сравнения расстояний.
Этап S34: представление показателя сходства между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения. В показателе сходства, сначала вычисляются оценки манхэттенского расстояния между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения, и оценки сортируются в порядке возрастания, и изображения, соответствующие выборкам с предварительно определенным числом из наивысших оценок, считаются схожими изображения запрошенного изображения.
Согласно принципу манхэттенского расстояния, чем меньше оценка, тем выше сходство. Вследствие этого, на основе вычисленной оценки манхэттенского расстояния можно сравнивать и сортировать схожие элементы. На практике, число схожих изображений, которые должны быть отображены, может быть предварительно задано согласно потребностям приложения, или может быть выбрано самим пользователем.
Процесс изображения извлечения схожих элементов на основе индекса сегмента согласно реализации настоящего изобретения, показанный на Фиг. 6, может быть реализован посредством этапа S33 и этапа S34. То есть, сходство между низкоразмерным собственным вектором запрошенного изображения и каждым одним из набора векторов для LSH-кода сегмента соответственно распознается на основе индекса сегмента и манхэттенского расстояния. Наконец, получают набор записей со схожим LSH-кодом, чтобы получить соответствующие схожие изображения.
Техническое решение настоящего изобретения может быть реализовано посредством вышеуказанных этапов S31-S34. Посредством экспериментов, касательно набора в миллион изображений, LSH-код в 512 битов будет получен из собственного вектора третьего слоя из нижней части сверточной нейронной сети. Если выбрана длина d сегмента в 24 бита, и создан индекс, в том, что касается извлечения схожих элементов изображения, скорость извлечения составляет примерно в 1000 раз быстрее, чем прямое попарное сравнение без сегмента. То есть, скорость извлечения с индексом сегмента была значительно улучшена относительно сравнения, непосредственно основанного на первоначальном LSH-коде. В дополнение, так как LSH-код содержит количественную информацию расстояния, информация расстояния может быть использована эффективно, когда манхэттенское расстояние используется для показателя сходства, тогда как расстояние Хэмминга является более подходящим для сравнения равнозначности цифр. Так точность извлечения для показателя сходства на основе манхэттенского расстояния выше, чем точность извлечения для показателя сходства на основе расстояния Хэмминга. Большое число экспериментальных данных показывает, что точность их извлечения выше примерно на 5%.
Фиг. 7 является принципиальной схемой основных модулей устройства для сравнения схожих элементов высокоразмерных признаков изображений согласно варианту осуществления настоящего изобретения. Как показано на Фиг. 7, устройство для сравнения схожих элементов высокоразмерных признаков изображений 70 в варианте осуществления настоящего изобретения в основном содержит модуль 71 уменьшения размерностей признаков, модуль 72 индексации сегментов, модуль 73 запрашивания схожих элементов и модуль 74 сравнения показателей.
Модуль 71 уменьшения размерностей признаков служит для уменьшения размерностей извлеченных собственных векторов изображений посредством LSH-алгоритма для получения низкоразмерных собственных векторов.
Модуль 72 индексации сегментов служит для сегментирования с усреднением низкоразмерных собственных векторов и создания таблицы индексов сегментов. До этапа сегментирования с усреднением низкоразмерных собственных векторов, модуль 72 индексации сегментов дополнительно определяет экспериментальным образом оптимальную длину сегмента на меньшем наборе верификации.
Модуль 72 индексации сегментов служит дополнительно для: сегментирования с усреднением низкоразмерных собственных векторов, с использованием сегментированных собственных векторов в качестве индексных элементов, и вычисления отличительного признака каждого из индексных элементов; выполнения операции деления по модулю в отношении отличительного признака с простым числом, которое наиболее близко к предварительно определенному числу записей, содержащихся в таблице индексов сегментов, чтобы получить адреса записей для индексных элементов; и вставки низкоразмерных собственных векторов в таблицу индексов сегментов согласно полученным адресам записей для создания таблицы индексов сегментов.
Модуль 73 запрашивания схожих элементов служит для извлечения сегментированного низкоразмерного собственного вектора запрошенного изображения из таблицы индексов сегментов для получения набора выборок-кандидатов.
Модуль 73 запрашивания схожих элементов служит дополнительно для: осуществления доступа к адресу записи для сегментированного низкоразмерного собственного вектора запрошенного изображения для получения конфликтного набора; извлечения низкоразмерных собственных векторов, соответствующих узлу из конфликтного набора, который имеет такой же отличительный признак, как отличительный признак сегментированного низкоразмерного собственного вектора запрошенного изображения, в качестве набора кандидатов; и объединения набора кандидатов, полученного посредством соответствующих извлечений сегментов, и удаления из него дублированных низкоразмерных собственных векторов для получения набора выборок-кандидатов.
Модуль 74 сравнения показателей служит для представления показателя сходства между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения.
Модуль 74 сравнения показателей служит дополнительно для: вычисления оценок манхэттеновских расстояний между каждой выборкой в наборе выборок-кандидатов и низкоразмерным собственным вектором запрошенного изображения; и сортировки оценок в порядке возрастания, и принятия изображений, соответствующих выборкам с предварительно определенным числом наивысших оценок, как схожих изображений запрошенного изображения.
Согласно техническому решению варианта осуществления настоящего изобретения, посредством создания индекса сегмента собственных векторов с уменьшенными размерностями для LSH-кода для изображений, скорость извлечения может быть ускорена для повышения эффективности извлечения. При извлечении схожих элементов изображения, посредством использования показателя манхэттенского расстояния при замене обыкновенного показателя расстояния Хэмминга, количественная информация расстояния, содержащаяся в LSH-коде, может быть в достаточно мере использована для повышения точности извлечения при извлечении сегментов.
В дополнение, процесс создания индекса сегмента в техническом решении настоящего изобретения может не ограничиваться выполнением на одной машине и может выполняться параллельно в распределенной системе планирования. Таким образом, могут быть обработаны данные большого масштаба.
Вышеуказанная конкретная реализация не накладывает какого-либо ограничения на объем правовой охраны настоящего изобретения. Специалистам в данной области техники должно быть понятно, что различные модификации, комбинации, подкомбинации и перемены могут происходить в зависимости от проектных требований и других факторов. Любые модификации, эквивалентные замены, улучшение и т.д., сделанные в рамках сущности и принципа настоящего изобретения, должны быть включены в объем правовой охраны настоящего изобретения.
Система и способ для ограничения запросов доступа
Устройство, способ и аппаратное устройство для измерения размеров предмета
Способ имитационного моделирования и управления виртуальной сферой в мобильном устройстве
Способ и система загрузки веб-страниц
Способ и устройство обработки данных действия пользователя
Система повторной проверки заказов
Способ и устройство ограничения пакетных запросов услуги
Система и способ отображения страницы
Способ и система для увеличения скорости загрузки страницы
Способ и устройство выявления сходства
Способ и устройство обработки данных действия пользователя

