Результат интеллектуальной деятельности: СПОСОБ ВЫДЕЛЕНИЯ СЕГМЕНТОВ ОБРАБОТКИ РЕЧИ НА ОСНОВЕ ПОСЛЕДОВАТЕЛЬНОГО СТАТИСТИЧЕСКОГО АНАЛИЗА
Вид РИД
Изобретение
Изобретение относится к области цифровой связи и может быть использовано в системах инфокоммуникаций при кодировании и обработке речевого сигнала.
В настоящее время достаточно большую часть телетрафика в различных приложениях составляет передача речевого сигнала. Большинство систем обработки и кодирования речи используют фиксированный сегмент анализа речевых данных, что является существенным недостатком данных устройств, в условиях перехода к системам с пакетной передачей и переменной скоростью кодирования. При цифровом представлении речевого сигнала необходимо решить задачу качественной обработки и компактного представления речевых данных для их передачи по цифровым каналам связи. Решение этой задачи позволит в условиях заданного критерия качества связи увеличить пропускную способность линейных трактов и каналов передачи. При этом предполагается снизить скорость передачи речи при сохранении качественных показателей ее восприятия. Широкое распространение в инфокоммуникациях в настоящее время получили методы кодирования речевого сигнала с переменной скоростью передачи и асинхронным вводом в канал связи.
Кодирование с переменной скоростью передачи находит применение в системах связи использующих IP-технологии передачи информации, но постепенно оно также начинает использоваться и в большинстве наиболее важных приложений систем телекоммуникаций связанных с обработкой речевого сигнала (Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония: учеб. пособие для вузов - М.: Радио и связь, 2003. - 144 с.: ил.).
В кодеках речевого сигнала с переменной скоростью передачи, ориентированных на использование в системах связи основанных на принципе коммутации пакетов уместно говорить о снижении средней скорости передачи при сохранении качественных показателей синтезированного речевого сигнала.
Известны и описаны различные способы кодирования и обработки речевого сигнала, отличающиеся его различным аналитическим представлением при синтезе в том числе и реализующих переменную скорость кодирования (О.И. Шелухин, Н.Ф. Лукьянцев Цифровая обработка и передача речи. М., Радио и Связь, 2000 г. - С. 102-112, С. 123-146, US №6385577 от 07.05.2002, RU №2445718 от 31.08.2010).
В устройствах, реализующих данные способы, осуществляется обработка речевого сигнала и его эффективное кодирование, при этом сегмент анализа остается постоянным, что приводит к повышению скорости передачи речи. Анализ речевых фрагментов позволяет сделать вывод о том, что возможно использование более длинных сегментов анализа, особенно на сегментах имеющих квазипериодическую вокализованную природу образования. (Шалимов Игорь Анатольевич. Теоретико-информационные принципы компрессии речевого сигнала на основе его квазипериодических свойств: диссертация доктора технических наук: 05.13.17 Москва, 2005 241 с. РГБ ОД, 71:06-5/528). Существуют технические решения реализующие переменную скорость кодирования и основанные на увеличении длины анализируемого сегмента. Они основаны на использовании корреляционных связей между отсчетами речевого сигнала, которые выявляются с помощью анализа автокорреляционной функции (АКФ):
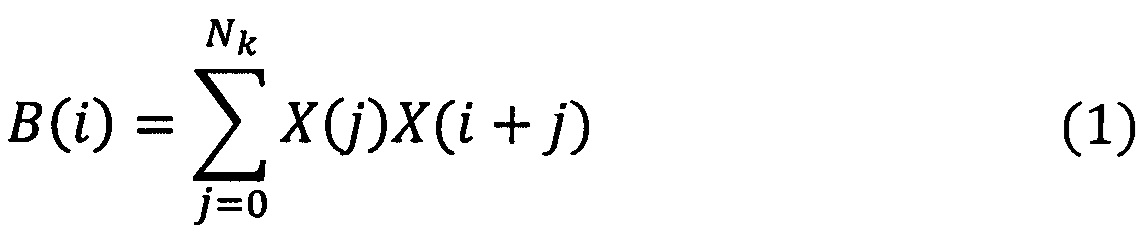
где X(j) - значение отсчета речевого сигнала.
Однако применение данных лишь о корреляционных связях между отсчетами, во-первых: предполагает нормальность распределения результатов наблюдений, а во вторых не полностью устраняет статистическую избыточность речевого сигнала при кодировании связанную с выбором длительности сегмента анализа. В задачах прикладного характера распределение значений речевого сигнала отличается от нормального, однако сам вид распределения остается неизвестным. Таким образом, увеличение границ анализируемого сегмента может быть основано на использовании более полной информации о статистических взаимосвязях между мгновенными значениями речевого сигнала, получаемой с помощью непараметрических методов, т.е. при отсутствии данных о характере распределения.
Очевидно, что при адаптивном изменении границ сегмента анализа речевого сигнала, количество наблюдаемых отсчетов, составляющих данный участок, априорно является неизвестной величиной. Она может принимать различные значения в зависимости от особенностей произносимой речи. Соответственно количество наблюдений (отсчетов) составляющих анализируемый участок зависит в данном случае от исхода самих наблюдений. Поэтому для определения границы предлагается применять методы последовательной проверки статистических гипотез, суть которых сводится к определению т.н. «эффективных» выборок, при которых будет иметь место продолжение эксперимента, и как следствие увеличение набора отсчетов. В данном случае используется метод, основанный на последовательном критерии отношения вероятностей (критерий Вальда). То есть вычисляется отношение вероятностей получения выборок (функций правдоподобия) на каждом этапе эксперимента. При этом, основная гипотеза имеет вид: H0:F(X,m)=F0(X,m), альтернативная - H1:F(X,m)=F1(X,m). В данном случае, в силу отсутствия информации о характере (виде) распределения функция плотности вероятности, необходимая для вычисления правдоподобия, оценивается методом непараметрического ядерного сглаживания Парзена (В.Н. Вапник 1979. Восстановление зависимостей по эмпирическим данным. М.: Наука. 448 с. - с. 323):
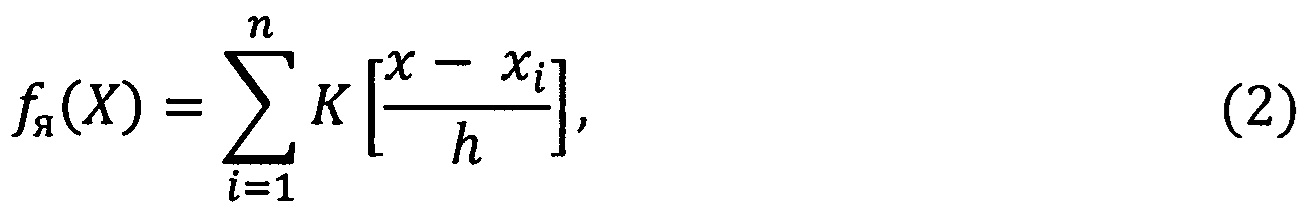
где ƒя(X) - ядерная оценка плотности, K(u) - ядерная функция (окно), h - ширина окна 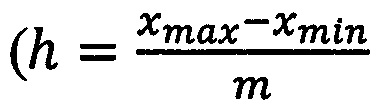 , m - количество окон сглаживания), х - среднее значение величины отсчетов в сегменте, xi - текущее значение отсчета. В качестве ядерной функции используется гауссов профиль
, m - количество окон сглаживания), х - среднее значение величины отсчетов в сегменте, xi - текущее значение отсчета. В качестве ядерной функции используется гауссов профиль 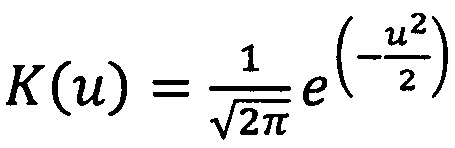 (Е.Л. Косарев 2008. Методы обработки экспериментальных данных. М.: ФИЗМАТЛИТ. 208 с. - с. 32)
(Е.Л. Косарев 2008. Методы обработки экспериментальных данных. М.: ФИЗМАТЛИТ. 208 с. - с. 32)
Количество окон сглаживания, m для каждого начального сегмента анализа, напрямую зависящее от их ширины, является статистически обоснованным и определяется с помощью информационного критерия Акаике (AIC). Данный критерий использует соотношение между относительной информацией (расстоянием) Кульбака-Лейблера (между истинной неизвестной функцией распределения и ее приближенной моделью) и логарифмической функцией правдоподобия (Akaike Н. Likelihood of a model and information criteria // Journal of Econometrics. 1981. Vol. 16. Pp. 3-14.):
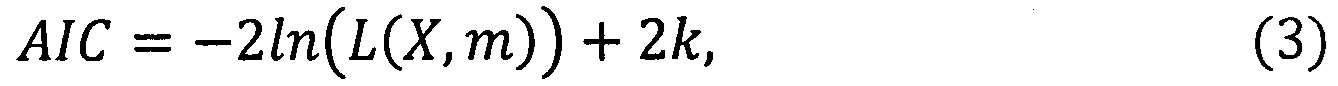
где L(X, m) функция правдоподобия для анализируемого набора отсчетов, зависящая от числа окон (ширины окна), k - количество параметров (в данном случае число окон, m). Решение принимается в пользу модели с минимальным значением AIC.
Получаемая в результате ядерного сглаживания кривая плотности распределения начального сегмента анализа ƒ0(X, m), является основой для вычисления значения функции правдоподобия, в случае справедливости гипотезы Н0, для последующих наборов отсчетов, получаемых на каждом этапе эксперимента:
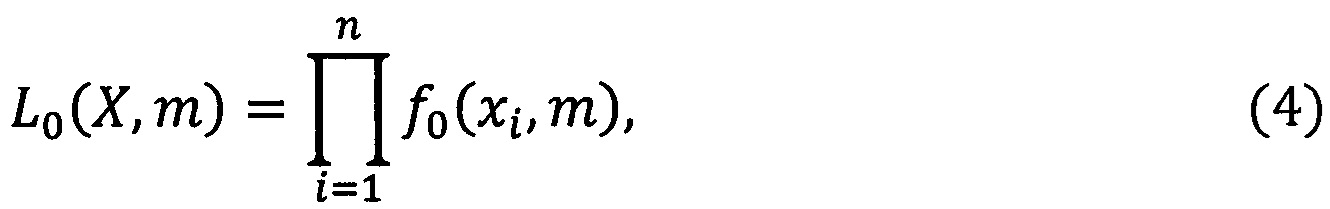
где, n - количество отсчетов составляющих анализируемый сегмент, ƒ0(xi, m) - значение плотности вероятности в точке при данном числе окон сглаживания. В случае попадания значения отсчета xi, между абсциссами кривой ƒ0(X, m), вычисление значения плотности в данной точке ƒ(xi) производится с помощью линейной интерполяции.
Выражение (3) с учетом (4) и измененным знаком, является основой для определения оптимального числа окон ядерного сглаживания:
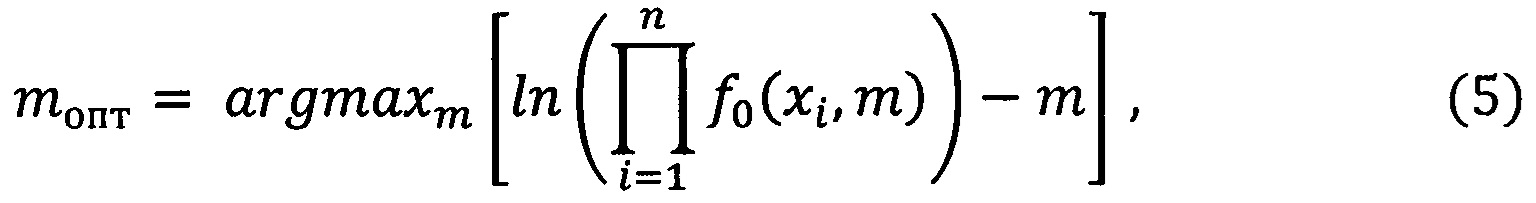
Определенное таким образом, оптимальное число окон сглаживания используется и для оценивания функции плотности распределения для вновь получаемого сегмента, при справедливости гипотезы Н0, на каждом этапе эксперимента L1(X, m).
При каждом увеличении сегмента на величину 5 мс с принятием границы вблизи «нуля» (следующая стадия эксперимента), на основе вновь полученного набора отсчетов речевого сигнала производятся следующие операции:
1. Вычисляется значение правдоподобия при справедливости гипотезы Н0 на основе кривой плотности вероятности ƒ0(xi, m) по соотношению (4).
2. Производится альтернативная ядерная оценка плотности распределения увеличенного сегмента ƒ1(xi, m), с помощью (2).
3. Аналогично (4) производится вычисление значения правдоподобия L1(X, m) на основе кривой ƒ1(xi, m).
Далее вычисляется статистика критерия Вальда (Вальд Абрахам. Последовательный статистический анализ: под редакцией А.Ф. Лапко, Государственное издательство физико-математической литературы.; М: - 1960. 328 с. - с. 62-64):
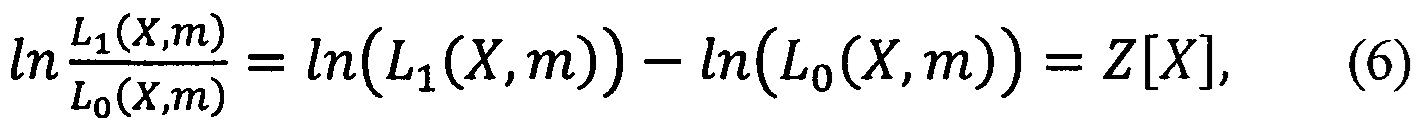
При этом анализируемые выборки (сегменты) принадлежат к «эффективной» области Сэф пространства выборок при выполнении:
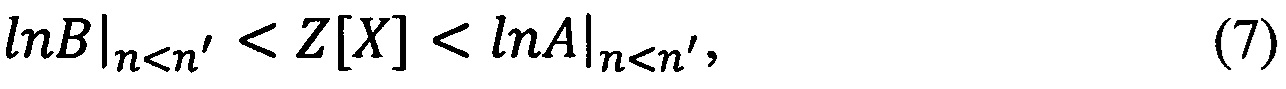
где n - общее количество отсчетов в анализируемом сегменте, n' - максимально возможное число отсчетов в сегменте, с учетом ограничений МСЭ.
В случае:

набор отсчетов принадлежит к «абсолютно эффективной» области 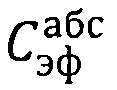 пространства. Оставшийся вариант при
пространства. Оставшийся вариант при 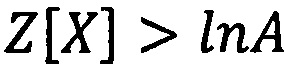 , определяет набор отсчетов принадлежащим к «неэффективной» области Сн.эф
, определяет набор отсчетов принадлежащим к «неэффективной» области Сн.эф
Ограничительные константы А и В, определяются на основании ошибок первого α и второго β рода:

где α=0,002 и β=0,001.
Анализ функции отношения вероятностей позволяет выделить важный показатель, характеризующий случайный речевой сигнал. Это интервал, характеризующий промежуток времени для речевого сигнала, мгновенные значения которого статистически взаимосвязаны, следовательно, имеют одну структуру образования при формировании. Данный факт полностью соотносится с природой образования вокализованных и шумоподобных сигналов.
На фиг. 1 и фиг. 2 представлены временное представление и значения отношения вероятностей при сдвиге сегмента анализа на 5 мс с принятием границы вблизи «нуля», относительно приходящего речевого сигнала при переходе с шумового на вокализованный участок и наоборот. Данные рисунки получены при произношении звуков слитной речи с использованием микропроцессорной техники и соответствующего программного обеспечения. Аналого-цифровое преобразование речевого сигнала реализовано на временных интервалах в 160 мс с частотой дискретизации 8 кГц с использованием 8 битного квантователя.
Анализ фиг. 1 и фиг. 2 позволяет сделать вывод о том, что при сохранении формы образования речевого сигнала значения логарифма отношения вероятностей лежат в области либо принятия гипотезы Н0, либо продолжения эксперимента. При этом сегмент анализа берется длиной 20 мс, расширение сегмента осуществляется на 5 мс от значения начальной границы сегмента. При этом граница сегмента анализа речевого сигнала формируется в момент смены структуры образования речевого сигнала. Критерием принятия решения о смене структуры природы формирования речи последовательный критерий отношения вероятностей Вальда, в основе которого лежит разделение m-мерного пространства отсчетов речевого сигнала на три попарно непересекающиеся области. Описание применения критерия Вальда рассмотрено в (Вальд Абрахам. Последовательный статистический анализ: под редакцией А.Ф. Лапко, Государственное издательство физико-математической литературы.; М: - 1960. 328 с. - с. 62). При анализе речевых данных решение о продлении наблюдений, т.е. о расширении границы сегмента анализа принимается в случае принадлежности анализируемой выборки двум из трех областей пространства, «эффективной» либо «абсолютно эффективной». Решение о прекращении расширения границы принимается в случае принадлежности выборки к «неэффективной» области, либо переходе между «абсолютно эффективной» и «эффективной» областями. При этом в случае перехода из «эффективной» в «абсолютно-эффективную» область граница сегмента сохраняется на данном этапе эксперимента. В случае же перехода из «абсолютно эффективной» в «эффективную» область граница сегмента определяется по данным предыдущего этапа эксперимента.
Максимально возможный сегмент одновременно анализируемых данных составляет 80 мс, что связано с требованиями по задержке речевого сигнала при передаче, определяемыми рекомендаций G.114 Международного союза электросвязи. Если на протяжении 80 мс не произошло перехода между областями, то расширение границы прекращается. Экспериментально установлено, что принадлежность значения логарифма отношения «эффективной» области, соответствует переходному процессу, и, в случае нахождения анализируемой выборки в «эффективной» области, по достижении 80 мс процесс заканчивается принятием основной гипотезы.
Показателем принадлежности сегмента анализа, получаемого на каждом этапе эксперимента, к определенной области является логарифм отношения функций правдоподобия Z[X], вычисляемый по соотношению (6).
Использование такого подхода к формированию сегментов обработки речи позволяет наиболее полно использовать статистическую взаимосвязь между случайными значениями речевого сигнала для выделения сегментов анализа, имеющих одинаковую природу формирования в речевом аппарате человека.
Наиболее близким по технической сущности является патент RU №2445718 от 31.08.2010 г., заключающийся в том, что используют автокорреляционную функцию для вычисления интервала корреляции, используя аппроксимацию полиномом 2-й степени дискретных значений автокорреляционной функции, далее сдвигают сегмент анализа на 40 мс по 2,5 мс, после чего заново рассчитывают автокорреляционную функцию и интервал корреляции, данную операцию повторяют, формируя последовательность значений интервалов корреляции сегментов, после этого анализируют данную последовательность, используя F-критерий (Фишера), основанный на формальном статистическом тесте для оценки соотношения между уменьшением остаточной дисперсии и потерей числа степеней свободы при замене единого уравнения регрессии кусочно-линейной моделью (тест Чоу), при доверительной вероятности p=0,95, при этом границу сегмента анализа речевого сигнала формируют в момент кардинального изменения величины интервала корреляции, критерием принятия решения о смене структуры природы формирования речи является F-критерий, если на протяжении 60 мс не произошло смены природы формирования речевого сигнала, то новый анализ начинают, используя данные об интервалах корреляции предыдущего сегмента.
Согласно известному способу речевой сигнал подвергают аналого-цифровому преобразованию, после чего разделяют его на участки квазистационарности и подвергают кодированию на основе разновидности метода линейного предсказания.
Недостатком данного способа является невысокий уровень использования статистических взаимосвязей при устранении избыточности.
Применение анализа АКФ к последовательности случайных величин, предполагает их распределение по нормальному закону. Однако нет оснований предполагать нормальность распределения результатов анализа речевых данных. В задачах прикладного характера распределение результатов наблюдений практически всегда, так или иначе, отличается от нормального распределения. Причем вид распределения остается неизвестным. Следовательно, это допущение о нормальном законе распределения и использование АКФ при анализе, позволяет использовать лишь корреляционные зависимости при компрессии речевого сигнала. Участки речевого сигнала, имеющие однородность, но не подтвержденные результатами анализа АКФ при формировании сегмента анализа не используются. Тем самым статистическая избыточность речевого сигнала при низкоскоростном кодировании устраняется не в полной мере.
В предлагаемом способе увеличение длительности сегмента анализа на основе метода, не требующего информации о законе распределения, приводит к тому, что увеличение границ анализируемого сегмента будет происходить не только на участках с чистой вокализацией, но и на так называемых участках со смешанным возбуждением при переходе с «шума» на «вокал» и наоборот. Это дает возможность эффективнее устранять статистическую избыточность при формировании сегментов анализа, снижая при этом среднюю скорость кодирования, за счет того, что параметры формирующей (передаточной) функции системы обработки и сигнала возбуждения будут сохраняться на всем протяжении сегмента анализа.
Анализ фиг. 1 и фиг. 2 показывает, что наряду с вокализованными (звонкими) и невокализованными (глухими), значительную часть занимают участки со смешанным возбуждением (переходные процессы, сонанты), что также подтверждается другими исследованиями (Михайлов В.Г., Златоустова Л.В. Измерение параметров речи. - М.: Радио и связь, 1987. - 168 с. - с. 30-31). Предлагаемый способ, в отличие от всех известных, обладает чувствительностью к таким участкам и позволяет расширять границы сегмента анализа и на них.
Технической проблемой исследуемой области является уменьшение объема данных выделяемых для кодирования речевого сигнала при переменной скорости передачи.
Эта техническая проблема решается тем, что в способе выделения сегментов обработки речи на основе последовательного статистического анализа, заключающемся в том, что на выходе аналого-цифрового преобразователя с частотой дискретизации 8 кГц и 256 уровнями квантования последовательность мгновенных отсчетов подвергают буферизации и сегментированию, с выделением участка анализа 20 мс с последующим его увеличением и проверкой на «однородность», дополнительно сохраняют начальную границу участка анализа в буфере памяти. Затем методом ядерного сглаживания Парзена оценивают кривую плотности вероятности начального участка анализа, при этом количество окон сглаживания определяют с помощью информационного критерия Акаике. Данные о кривой плотности распределения мгновенных значений начального участка анализа сохраняют в буфере памяти, затем получают первый участок анализа путем увеличения длины сегмента анализа, после чего рассчитывают начальное значение логарифма правдоподобия для первого сегмента анализа по данным о кривой плотности для начального сегмента, оценивают кривую плотности вероятности первого участка анализа. Полученные данные сохраняют в буфере памяти и рассчитывают первое значение логарифма правдоподобия, определяют логарифм отношения правдоподобия как разность первого значения логарифма правдоподобия и начального значения логарифма правдоподобия и сохраняют логарифм отношения правдоподобия в буфере памяти. Далее при значении логарифма отношения правдоподобия, соответствующему «неэффективной» области принадлежности мгновенных значений участка анализа, за конечную границу участка анализа принимают значения 20 мс и сохраняют конечную границу участка анализа в буфере памяти. В случае значения значения логарифма отношения правдоподобия соответствующему «абсолютно эффективной» области принадлежности мгновенных значений участка анализа увеличивают длину сегмента анализа и оценивают кривую плотности вероятности первого участка анализа, увеличение длины первого участка анализа продолжают до достижения длины участка анализа 80 мс или до перехода значения логарифма отношения правдоподобия в «эффективную» область принадлежности мгновенных значений участка анализа либо в «неэффективную» область «абсолютно эффективной» области принадлежности мгновенных значений участка анализа, при этом за конечную границу участка анализа принимают ту, при которой значение логарифма отношения правдоподобия принадлежит «абсолютно эффективной» области принадлежности мгновенных значений участка анализа. После чего сохраняют конечную границу участка анализа в буфере памяти. В случае, если после первого увеличения длины участка анализа, значение логарифма отношения правдоподобия принадлежит «эффективной» области принадлежности мгновенных значений участка анализа увеличение длины сегмента анализа продолжают до перехода логарифма отношения правдоподобия в абсолютно «эффективную» область принадлежности мгновенных значений участка анализа, либо до достижения размера участка анализа 80 мс, при этом за конечную границу участка анализа принимают ту, которая соответствует этому переходу логарифма отношения правдоподобия. Следующий шаг - сохранение конечной границы участка анализа в буфере памяти и формирование сегмента обработки речи на основе начальной границы участка анализа и конечной границы участка анализа, с последующим сохранением сформированного сегмента обработки речи в буфере памяти.
Благодаря новой совокупности существенных признаков системы, обеспечивающих возможность непараметрического оценивания функций плотности распределения значений отсчетов речевого сигнала для начального сегмента в 20 мс и каждого последующего, при увеличении на 5 мс, вычисление на основании этих данных логарифмов функций правдоподобия, вычисления логарифма отношения вероятностей, как показателя принадлежности к сегменту анализа, получаемому на каждом этапе увеличения, к определенной области пространства отсчетов, анализа этих показателей с помощью критерия Вальда для определения границы сегмента представляется возможным уменьшить объем данных для низкоскоростного кодирования речевого сигнала на основе использования базового метода линейного предсказания.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности "новизна".
Анализ существующих технических решений в данной и смежных областях техники показал, что введенные отличительные признаки в них отсутствуют и не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на достижение указанного технического результата. Следовательно, заявленное техническое решение удовлетворяет критерию "изобретательский уровень".
Заявленное техническое решение поясняется чертежом, на которых представлены:
- на фиг. 1 - поведение логарифма отношения правдоподобия при переходе с шумового участка речевого сигнала на вокализованный;
- на фиг. 2 - поведения логарифма отношения правдоподобия при переходе с вокализованного участка речевого сигнала на шумоподобный 4
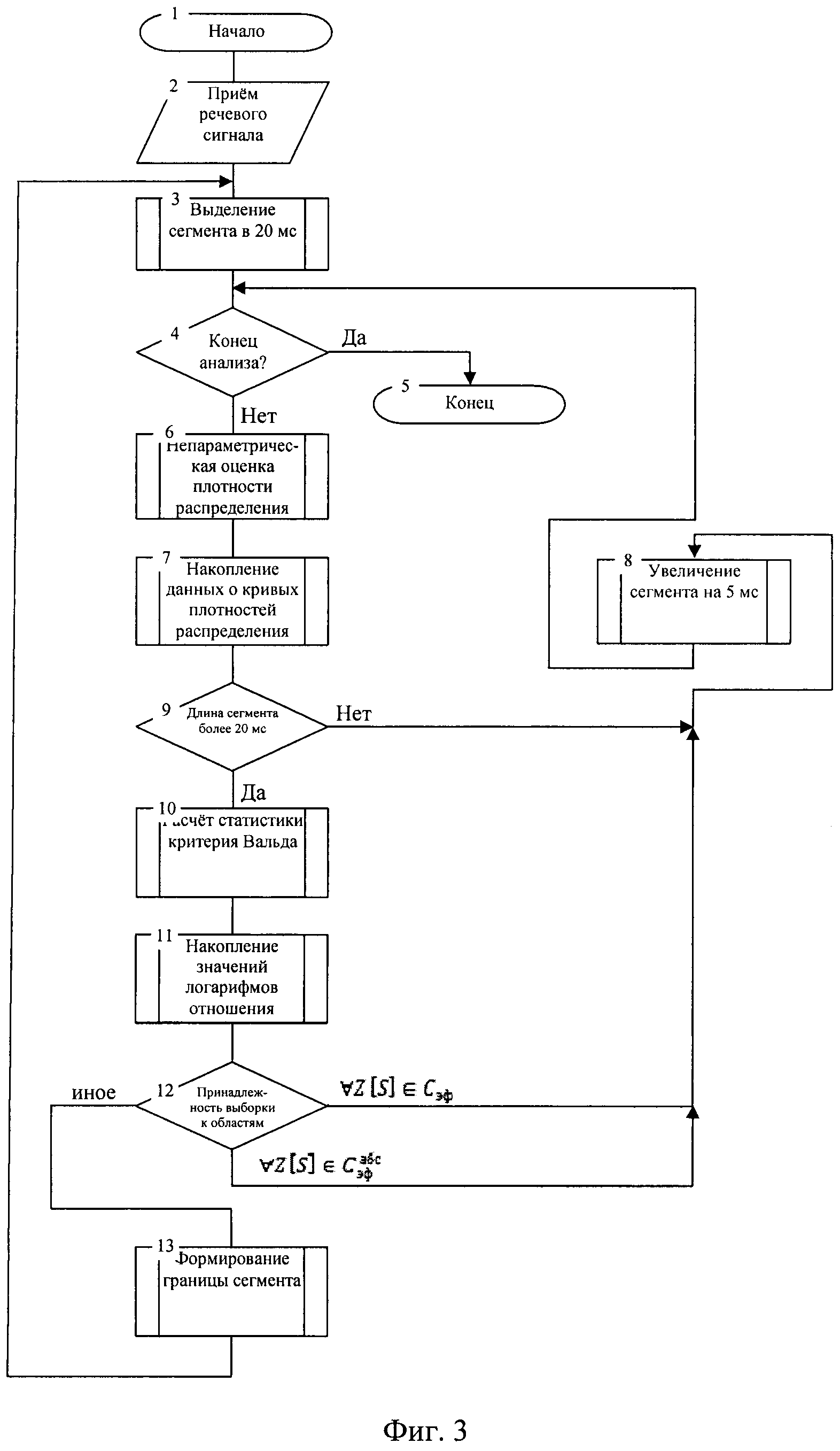
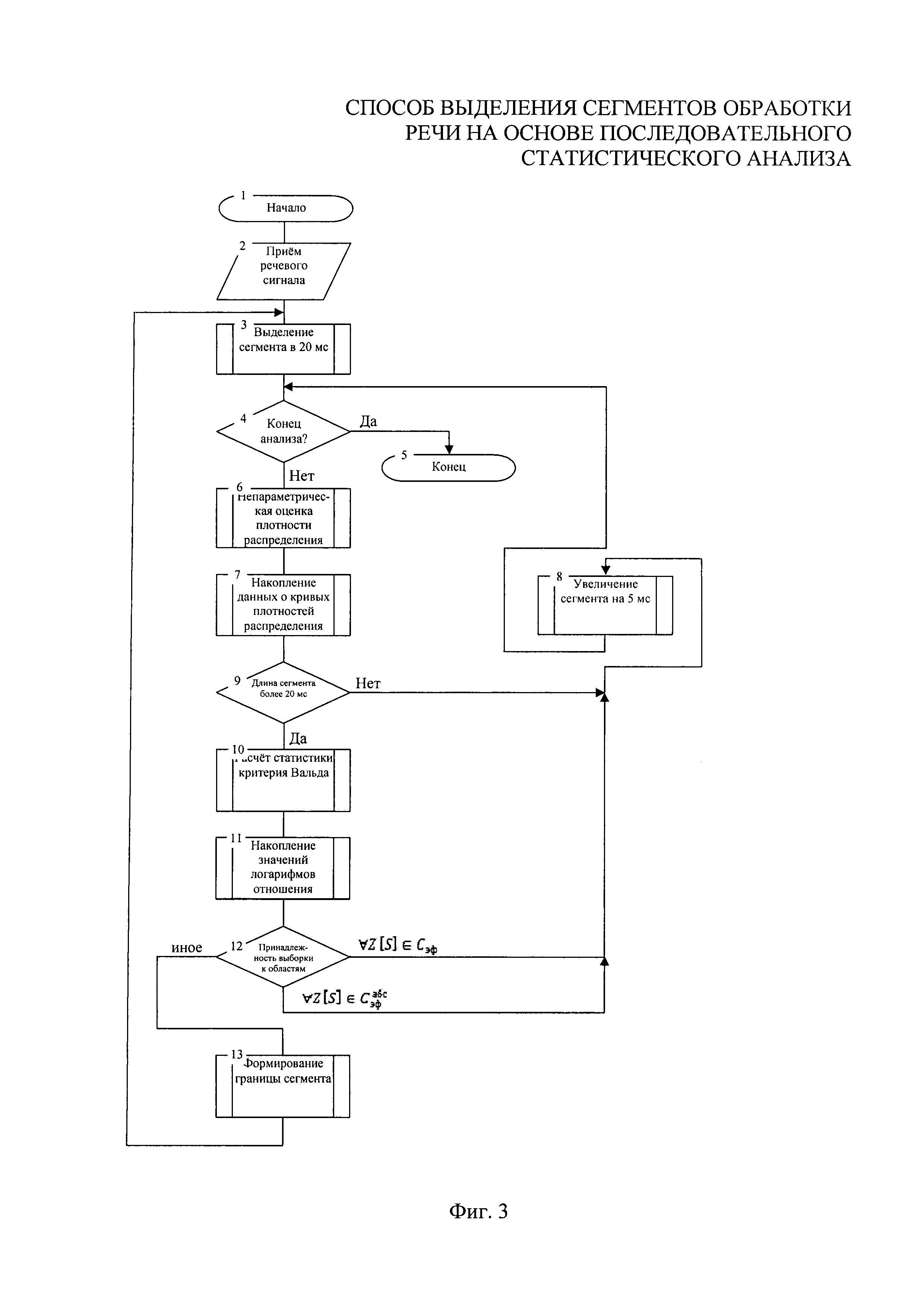
- на фиг. 3 - алгоритм функционирования устройства;
- на фиг. 4 - функциональная схема устройства, реализующего способ выделения сегментов обработки речи на основе последовательного статистического анализа;
- на фиг. 5 - кривая эффективности заявленного способа по отношению к прототипу.
Устройство выделения сегментов обработки речи на основе последовательного статистического анализа состоит из блока 1 аналого-цифрового преобразования речевого сигнала с частотой дискретизации 8 кГц и 256 уровнями квантования, выход которого соединен со входом блока 2 сегментации речевого сигнала на участки длительностью 20 мс с возможностью увеличения на 5 мс, выход которого соединен со входом блока непараметрической оценки функции плотности распределения 3, выход которого соединен со входом блока 4 накопления данных о кривых плотности распределения, выход которого соединен со входом блока 5 вычисления статистики критерия Вальда, на другой вход которого поступает сигнал со второго выхода блока 2 сегментации речевого сигнала. Выход блока 5 соединен со входом блока 6 накопления данных о значениях логарифмов отношения вероятностей и принятия решения о завершении процесса увеличения сегмента, выход которого соединен со входом блока 7 накопления данных для реализации процедуры кодирования, на другой вход которого поступает информационный сигнал с третьего выхода блока 2.
Промышленная применимость введенных элементов обусловлена наличием элементной базы, на основе которой они могут быть выполнены.
Устройство выделения сегментов обработки речи на основе последовательного статистического анализа функционирует следующим образом. Речевой сигнал подается на блок 1, где осуществляют его аналого-цифровое преобразование, далее в блоке 2 выделяют начальный сегмент длительностью 20 мс и подают его на блок 3 в котором производится оценка функции плотности вероятности. В блоке 4 производят накопление данных о кривых плотности распределения. Далее в блоке 2 производят увеличение сегмента анализа на 5 мс, после чего в блоке 3 вычисляют оценку плотности вновь полученного набора отсчетов с передачей полученных данных на накопление в блок 4. Далее в блоке 5 осуществляют вычисление логарифмов функций правдоподобия для текущей выборки отсчетов, используя данные о двух видах кривых плотности распределения и информацию о значениях отсчетов текущего сегмента, получаемых со второго выхода блока 2, с последующим вычислением статистики критерия Вальда - разности двух полученных логарифмов. Далее полученные значения логарифмов отношения (разностей логарифмов) вероятностей поступают на блок 6, где происходит их накопление с последующим принятием решения об определении границы сегмента. Информация о принятом решении поступает на блок 7, в котором производится формирование данных с целью их последующей обработки при низкоскоростном кодировании речи с переменной скоростью передачи.
К достоинствам способа следует отнести тот факт, что уменьшение объема данных при низкоскоростном кодировании речи приведет к снижению средней скорости передачи речевого сигнала по каналам цифровой связи, а также уменьшит количество требуемых вычислений при реализации процедуры кодирования.
Были проведены экспериментальные исследования для выявления возможности применения предлагаемого способа, которые показали, что использование непараметрических методов оценки функции плотности вероятности в сочетании с последовательным критерием отношения вероятности Вальда, позволило использовать не только зависимости между отсчетами, выявление которых возможно с помощью интервалов корреляции, но и статистические зависимости, присутствующие в речи, определение которых с помощью автокорреляционного анализа затруднительно, в силу вероятностного распределения отсчетов речевого сигнала, отличающегося от нормального. Такое распределение особенно характерно для смешанных участков, которые возникают при произношении промежуточных (между гласными и согласными) звуков - сонант.
Процедура аналого-цифрового преобразования выполняемая в блоке 1 достаточно подробно освещена в (Радзишевский А.Ю. Основы аналогового и цифрового звука. - М.: Изд. дом «Вильяме», 2006. - с. 157-210). Описание сегментирования и накопления данных как о речевом сигнале, так и о значениях кривой плотности распределения и статистики критерия Вальда, выполняемые блоками 2, 4, 6 и 7 представлено в (Быков С.В., Журавлев В.И., Шалимов И.А. Цифровая телефония: Учеб. пособие для вузов. - М.: Радио и связь, 2003. - с. 66-72). Функционирование блоков 3 и 4 подробно изложено в (А.Г. Зюко, Д.Д. Кловский, В.И. Коржик, М.В. Назаров. Теория электрической связи: Учебник для вузов / Под ред. Д.Д. Кловского. - М.: Радио и связь, 1998. - с. 36-44, 56-60). Операция, выполняемая блоком 5 подробно изложена в (Вальд Абрахам. Последовательный статистический анализ: под редакцией А.Ф. Лапко, Государственное издательство физико-математической литературы.; М: - 1960. 328 с. - с. 62-64)
Все процессы, происходящие в описанных блоках могут быть реализованы программно, например на базе многоядерных сигнальных микропроцессорах серии «Мультикор» 1892 ВМхх производимьгх АО НПЦ «Элвис». Описание которых приведено, например в интернет ресурсе www.multicore.ru
Эффективность предложенного способа проявляется не на всех участках речевого сигнала, а на тех, которые содержат участки со смешанным возбуждением. В качестве оцениваемого параметра использовалось количество сегментов анализа, N одного и того же участка речевого сигнала после обработки его способом на основе последовательного статистического анализа, и способом на основе анализа корреляционных зависимостей (прототип). С учетом заявленной эффективности прототипа по отношению к обычно применяемым способам с фиксированной длиной сегмента в 20 мс, и минимальной длительностью сонантных звуков в 60 мс, а также частотой появления сонант в речевом сигнале (Михайлов В.Г., Златоустова Л.В. Измерение параметров речи. - М.: Радио и связь, 1987. - 168 с.), было получено следующее соотношение для оценки эффективности предлагаемого способа:

где, Nprot, N - количество сегментов анализа, получаемых при использовании способа, предлагаемого прототипом, и способа, с использованием последовательного статистического анализа, участка речевого сигнала одинаковой длины, D - доля участков речевого сигнала со смешанным возбуждением (сонант).
Из статистических наблюдений звукового состава русской речи известно, что сонантные звуки занимают от 0,445 до 20,675% (Михайлов В.Г., Златоустова Л.В. Измерение параметров речи. - М.: Радио и связь, 1987. - 168 с. - с. 30-31), - средние значения - от 0,635% до 20,94% (0,00635 до 0,2094)) русской речи. Для расчета эффективности указанное распределение представляется в виде числового ряда:

С учетом вышеуказанного статистического распределения сонантных звуков в русской речи (9), и соотношения (8), эффективность предлагаемого способа может быть представлена в виде Фиг. 5. Однако ввиду того, что значение величины доли участков с промежуточным возбуждением, носит случайный характер, необходимо рассчитать значения вероятностей получения значений доли сонант и, как следствие, вероятности достижения определенных значений эффективности. Частоты появления каждой сонанты в общем количестве сонант были рассчитаны на основании статистических данных о звуковом составе русской речи и представляются в следующем виде:
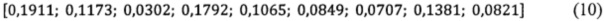
Вероятность получения каждого последующего члена числового ряда (9), рассчитывалась начиная с вероятности появления хотя бы одной сонанты, с дальнейшим последовательным увеличением обязательного количества сонант и заканчивалась вероятностью одновременного появления всех сонант в речи. Результаты представлены в таблице 1.

Выражение (8) с учетом значения ряда (9) дает значения выигрыша от применения заявленного способа, при этом значения вероятностей появления этого ряда (табл. 1) определяет множество значений вероятностей получения показателей, указывающих на выигрыш от применения заявленного способа.
Таким образом, информация об эффективности способа выделения сегментов обработки речи на основе последовательного статистического анализа включает в себя не только значение показателей выигрыша, но и множество значений вероятности достижения определенных значений эффективности (фиг. 5).
Анализ фиг. 5 показывает, что с вероятностью 100% достигается значение показателей эффективности функционирования в 0,7%, при этом с вероятностью от 67 до 71% эффективность заявленного способа составит 2,4-4,2%. Возможно также получение более выраженного эффекта (значение показателей вплоть до 20%), однако вероятность этого стремится к 0.
Приведенное техническое решение показывает, что устройство, воплощающее изобретение, при его осуществлении, способно уменьшить объем данных при низкоскоростном кодировании речевого сигнала с переменной скоростью передачи, что приведет к снижению средней скорости передачи речи по каналам цифровой связи (снижение нагрузки на канал связи), а также уменьшит количество требуемых вычислений при реализации процедуры кодирования.
Способ выделения сегментов обработки речи на основе последовательного статистического анализа, заключающийся в том, что на выходе аналого-цифрового преобразователя с частотой дискретизации 8 кГц и 256 уровнями квантования последовательность мгновенных отсчетов подвергают буферизации и сегментированию с выделением участка анализа 20 мс с последующим его увеличением и проверкой на «однородность», отличающийся тем, что сохраняют начальную границу участка анализа в буфере памяти, методом ядерного сглаживания Парзена оценивают кривую плотности вероятности начального участка анализа, при этом количество окон сглаживания определяют с помощью информационного критерия Акаике, данные о кривой плотности распределения мгновенных значений начального участка анализа сохраняют в буфере памяти, получают первый участок анализа путем увеличения длины сегмента анализа, рассчитывают начальное значение логарифма правдоподобия для первого сегмента анализа по данным о кривой плотности для начального сегмента, после чего оценивают кривую плотности вероятности первого участка анализа, полученные данные сохраняют в буфере памяти и рассчитывают первое значение логарифма правдоподобия, далее определяют к какой области пространства выборок принадлежит первый участок анализа, для чего вычисляют статистику критерия Вальда полученного участка как разность первого и начального значений логарифмов правдоподобия, сохраняют статистику критерия Вальда в буфере памяти и сравнивают ее значение со значениями логарифмов ограничительных констант «А» и «В», в случае если значение статистики критерия Вальда полученного участка больше, чем значение логарифма константы «А», то определяют, что полученный участок принадлежит к «неэффективной» области, и за конечную границу участка анализа принимают значение 20 мс, после чего сохраняют конечную границу в буфере памяти, в случае если значение статистики критерия Вальда на первом увеличении меньше, чем значение логарифма константы «В», то определяют, что первый участок анализа принадлежит к «абсолютно эффективной» области и вновь увеличивают участок анализа с подтверждением принадлежности нового участка к «абсолютно эффективной» области по аналогии с первым увеличением, такое последовательное увеличение продолжают либо до достижения максимально возможной длины участка анализа, что составляет 80 мс, либо до перехода анализируемого сегмента на любом этапе увеличения в «эффективную» область, что подтверждается значением статистики критерия Вальда, принадлежащей к диапазону с нижним и верхним пределами, равными значениям логарифмов констант «В» и «А» соответственно, в этом случае за конечную границу принимают предыдущую, то есть до его последнего увеличения, и сохраняют ее в буфере памяти, в случае если после первого увеличения участка анализа значение статистики критерия Вальда определяет его принадлежность к «эффективной» области, то аналогично предыдущему случаю выполняют последовательное увеличение участка анализа либо до достижения длины 80 мс, либо до перехода анализируемого сегмента в любую другую область принадлежности, при этом в случае перехода в «неэффективную» область за конечную границу принимается граница участка до его последнего увеличения, если же анализируемый сегмент перешел в «абсолютно эффективную» область, то за конечную границу принимается текущая граница, но не более 80 мс, сохраняют конечную границу участка анализа в буфере памяти, формируют сегмент обработки речи на основе начальной и конечной границ участка анализа, сохраняют сформированный сегмент обработки речи в буфере памяти.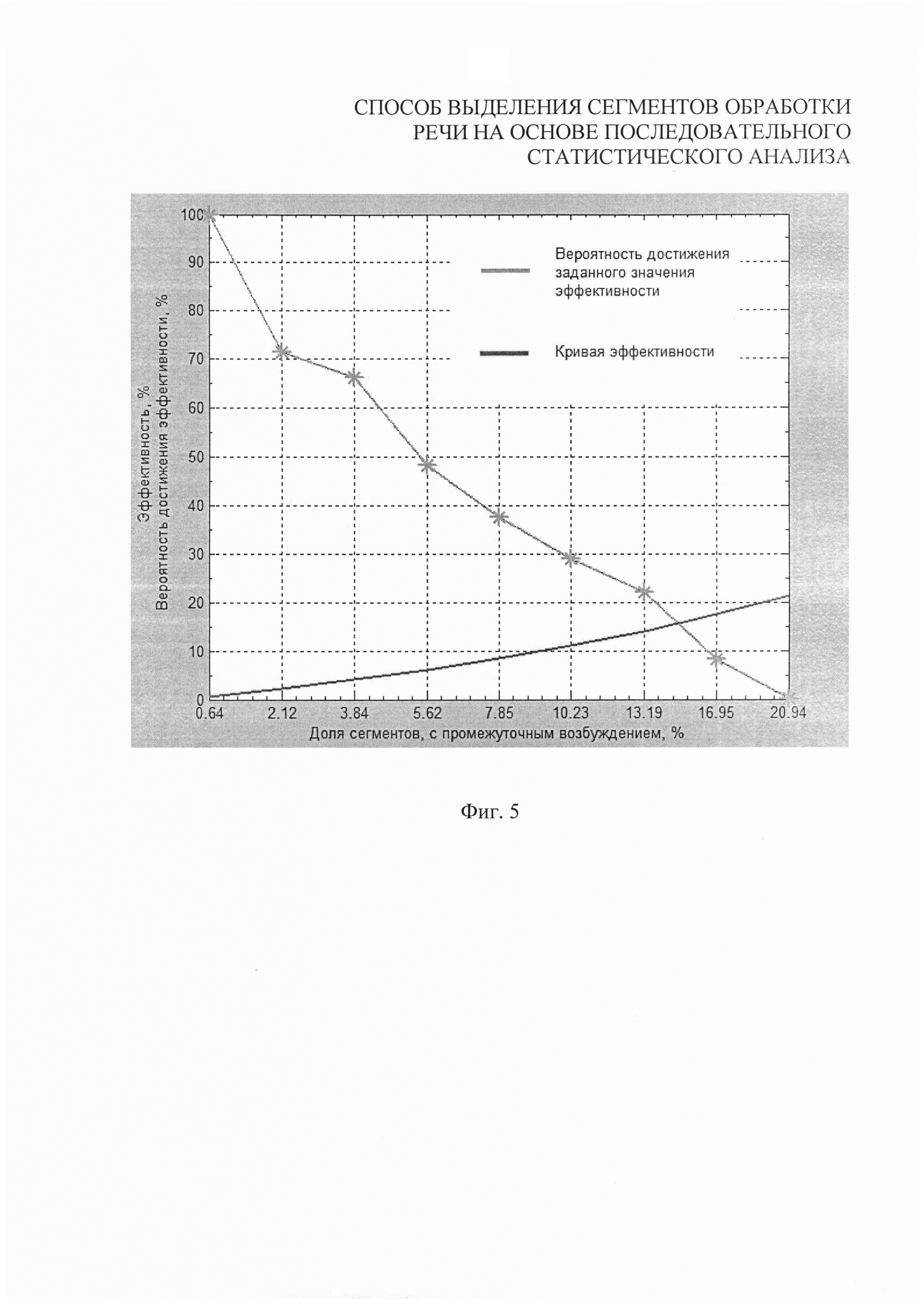



Способ измерения времени задержки на двустороннее распространение для трафика данных с переменной скоростью передачи битов и устройство для его осуществления
Способ динамического управления параметрами сети связи в признаковом пространстве
Способ обеспечения живучести распределенной абонентской сети связи
Способ идентификации массивов бинарных данных
Способ сглаживания приоритетного трафика данных и устройство для его осуществления
Способ мультимедийного вывода
Способ измерения расхода жидкости
Способ встраивания информации в графический файл, сжатый фрактальным методом
Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа
Способ определения местоположения станции сети связи vsat
Устройство контроля ошибок в цифровых системах передачи на базе технологии ethernet

