Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ ВОССТАНОВЛЕНИЯ ДЕДУПЛИЦИРОВАННЫХ ДАННЫХ
Вид РИД
Изобретение
Область техники
Настоящее изобретение относится к области средств связи и, в частности, к способу и устройству восстановления дедуплицированных данных.
Уровень техники
В настоящее время имеющиеся технологии хранения позволяют только дедуплицировать на самом сервере при удалении дуплицированных данных, но не могут использовать эффективную сеть для удаления дуплицированных данных во всей системе; помимо этого, когда число доступов к базе данных, которая была дедуплицирована, становится массовым, проблема ухудшения качества доступа решается просто за счет возврата данных, что все равно не может решить упомянутую проблему.
А при решении по восстановлению дедуплицированных данных часто возникает чрезмерное число доступов к одному и тому же блоку данных, что приводит к снижению эффективности доступов и влияет на эффективность работы распределенной файловой системы.
При рассмотрении упомянутой проблемы на известном уровне техники не было представлено эффективного решения упомянутой проблемы.
Раскрытие изобретения
При рассмотрении проблемы на известном уровне техники, имеется чрезмерное число доступов к одному и тому же блоку данных, и настоящее раскрытие сущности изобретения предлагает способ и устройство восстановления дедуплицированных данных, чтобы по меньшей мере решить упомянутую проблему.
В соответствии с вариантом осуществления настоящего изобретения, предлагается способ восстановления дедуплицированных данных, включающий в себя: получение первого числа количества доступов к первому блоку данных, при этом первое число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к файлу; первое число количества доступов сравнивается с первым пределом и вторым пределом соответственно, при этом первый предел меньше второго; и первый блок данных восстанавливается в первом носителе данных и втором носителе данных в соответствии с результатами сравнения, при этом первый блок данных восстанавливается в первом носителе данных, когда первое число количества доступов больше первого предела и меньше второго предела, и первый блок данных восстанавливается во втором носителе данных, когда первое число количества доступов больше второго предела; второй носитель данных имеет более высокую эффективность доступа, чем у первого носителя данных.
Перед тем, как первое число количества доступов к соответствующему файлов получено, способ включает в себя: получение второго числа количества доступов, при этом второе число количества доступов представляет собой число посетителей в текущий момент и одновременно получающих доступ к первому блоку данных; и когда второе число количества доступов больше, чем третий предел, обнаруживается файл, соответствующий первому блоку данных.
Перед тем, как второе число количества доступов к первому блоку данных получено, способ включает в себя: получение описания признаков первого блока данных, при этом описание признаков используется для представления содержимого, которое есть только в первом блоке данных; и текущая распределенная файловая система и другие распределенные файловые системы, связанные с текущей распределенной файловой системой, информируются об описании признаков, при этом описание признаков используется для выполнения дедуплицирующей обработки в текущей распределенной файловой системе и других распределенных файловых системах.
Информирование текущей распределенной файловой системы об описании признаков включает в себя: информирование узлового сервера об описании признаков.
Восстановление первого блока данных в первом носителе данных или втором носителе данных включает в себя: первый блок данных дублируется для получения второго блока данных; и второй блок данных дублируется в первом носителе данных или втором носителе данных.
После того, как второй блок данных продублирован в первом носителе данных или втором носителе данных, способ далее включает в себя: первое число количества доступов вычитается из второго числа количества доступов для получения актуального числа количества доступов к первому блоку данных, и 1 вычитается из значения счетчика механизма ссылок первого блока данных.
В соответствии с другим вариантом осуществления изобретения, предлагается устройство, восстанавливающее дедуплицированные данные, которое включает в себя: первый получающий модуль, выполненный с возможностью получения первого числа количества доступов к файлу, соответствующему первому блоку данных, при этом первое число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к файлу; сравнивающий модуль, выполненный с возможностью сравнения первого числа количества доступов с первым пределом и вторым пределом соответственно, при этом первый предел меньше, чем второй предел; и восстанавливающий модуль, выполненный с возможностью восстановления первого блока данных в первом носителе данных или втором носителе данных в соответствии с результатами сравнения, при этом восстанавливающий модуль восстанавливает первый блок данных в первом носителе данных, когда первое число количества доступов больше, чем первый предел, и меньше, чем второй предел, и восстанавливающий модуль восстанавливает первый блок данных во втором носителе данных, когда первое число количества доступов больше, чем второй предел; второй носитель данных имеет более высокую эффективность доступа, чем у первого носителя данных.
Устройство также включает в себя: второй получающий модуль, выполненный с возможностью получения второго числа количества доступов к первому блоку данных, при этом второе число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к первому блоку данных; и модуль поиска, выполненный с возможностью, когда второе число количества доступов больше, чем третий предел, поиска файла, соответствующего первому блоку данных.
Устройство также включает: третий получающий модуль, выполненный с возможностью получения описания признаков первого блока данных, при этом описание признаков используется для представления содержимого, которое есть только в первом блоке данных; информирующий модуль, выполненный с возможностью информировать текущую распределенную файловую систему и другие распределенные файловые системы, связанные с текущей распределенной файловой системой, об описании признаков, при этом описание признаков используется для выполнения дедуплицирующей обработки в текущей распределенной файловой системе и других распределенных файловых системах.
Устройство также включает: считающий модуль, выполненный с возможностью, после дупликации второго блока данных в первом носителе данных или втором носителе данных, вычитания первого числа количества доступов из второго числа количества доступов для получения актуального числа количества доступов к первому блоку данных, и вычитания 1 из значения счетчика механизма ссылок первого блока данных.
С применением технических средств сравнения числа количества доступов к файлу, соответствующего первому блоку данных, с первым пределом и вторым пределом соответственно, и, в соответствии с результатами сравнения, определения восстанавливать первый блок данных в первом носителе данных или втором носителе данных, настоящее изобретение решает проблему известного уровня техники, при котором имеется чрезмерное число доступов к одному и тому же блоку данных, таким образом повышая эффективность доступа к файлам.
Краткое описание чертежей
Прилагаемые чертежи, описываемые здесь, используются для обеспечения более глубокого понимания раскрытия сущности настоящего изобретения и являются частью заявки; схематические варианты осуществления изобретения и описание таковых используются для иллюстрирования настоящего раскрытия сущности изобретения и не предназначены для формирования неверного ограничения раскрытия настоящего изобретения. Прилагаемые чертежи включают в себя:
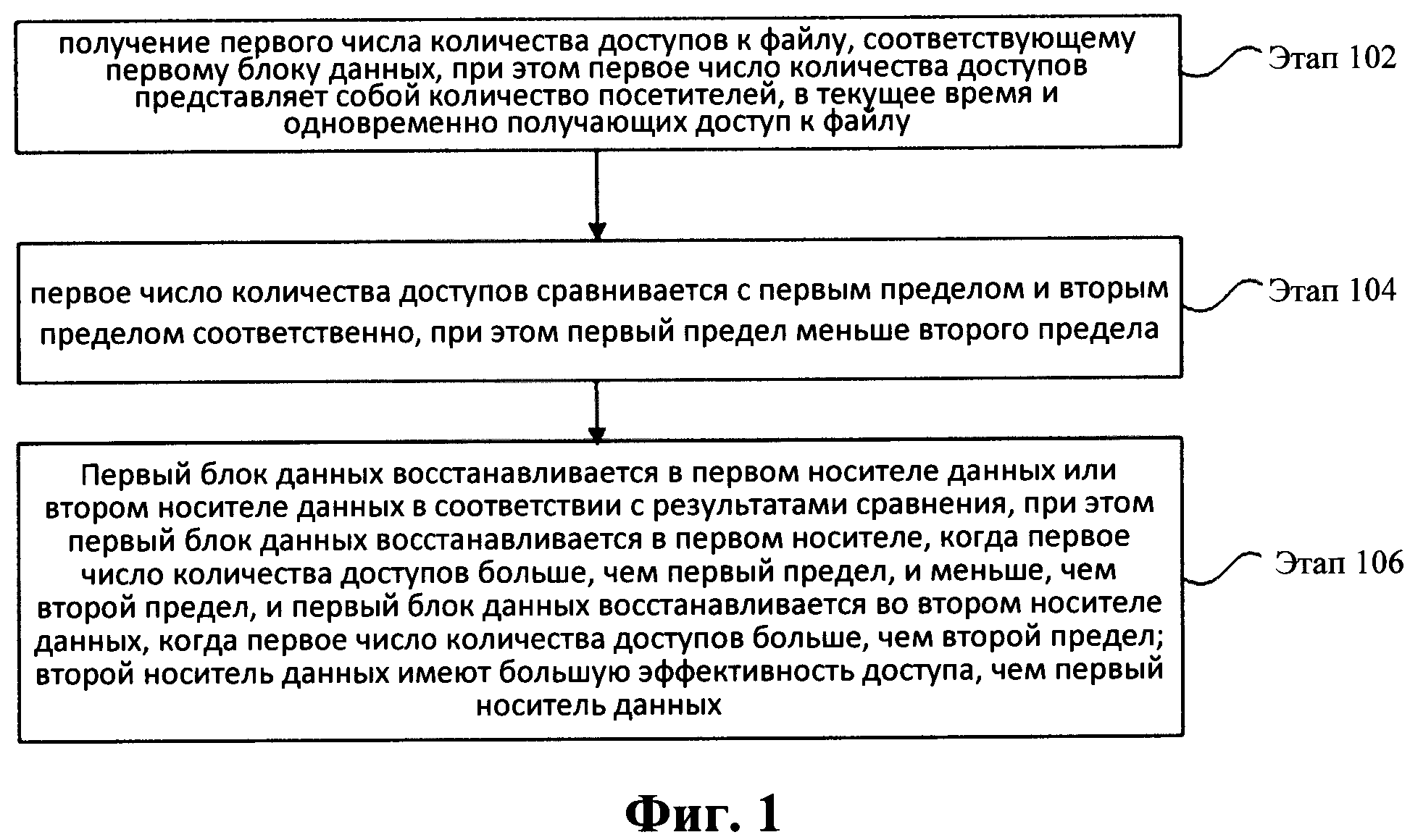
Фиг. 1 демонстрирует схему способа восстановления дедуплицированных данных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 2 демонстрирует принципиальную блочную схему устройства восстановления дедуплицированных данных в соответствии с вариантом осуществления настоящего изобретения;
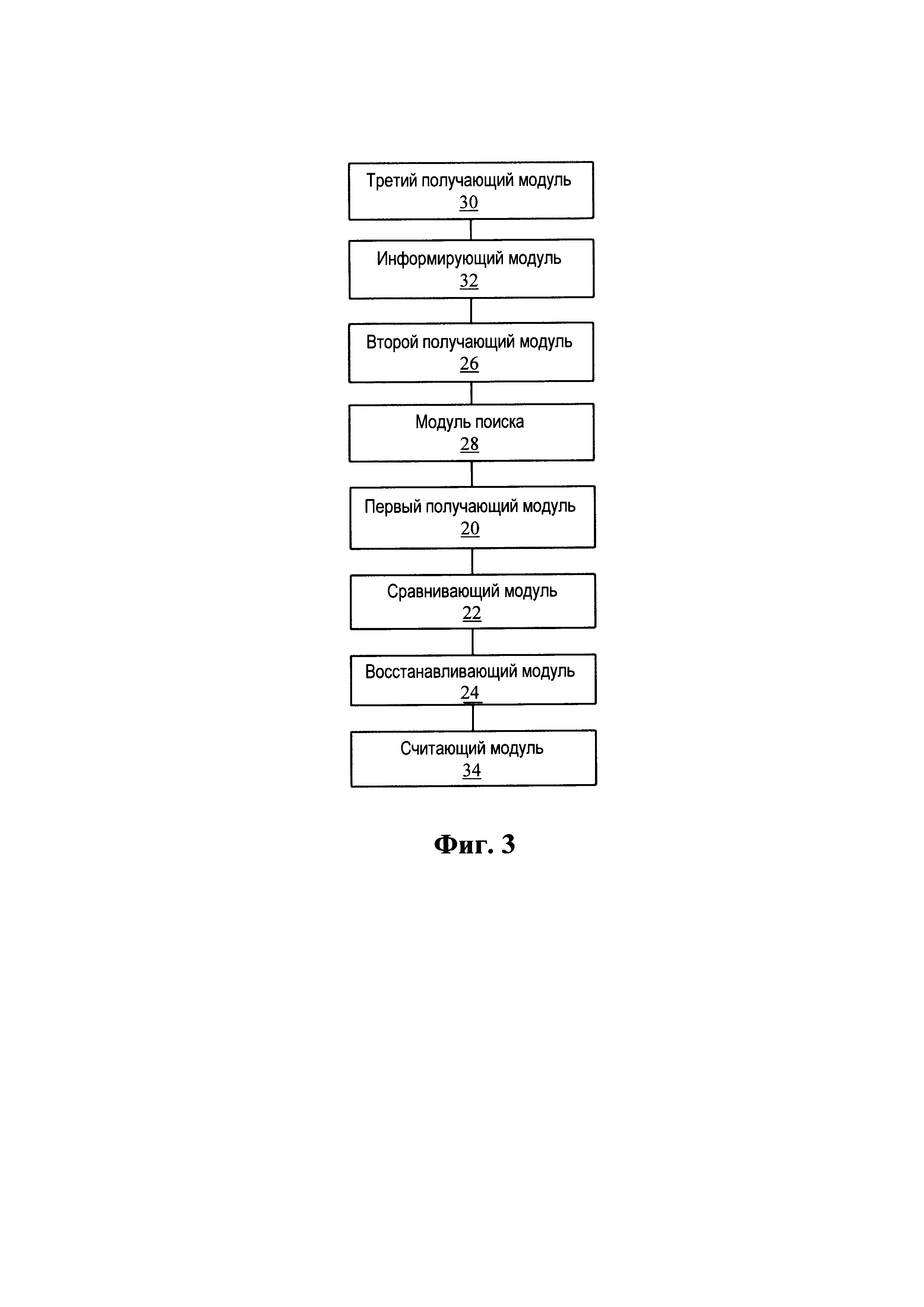
Фиг. 3 демонстрирует другую принципиальную блочную схему устройства восстановления дедуплицированных данных в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 4 демонстрирует принципиальную блочную схему распределенной файловой системы в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг. 5 демонстрирует схему дедупликации блоков данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг. 6 демонстрирует схему восстановления блоков данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
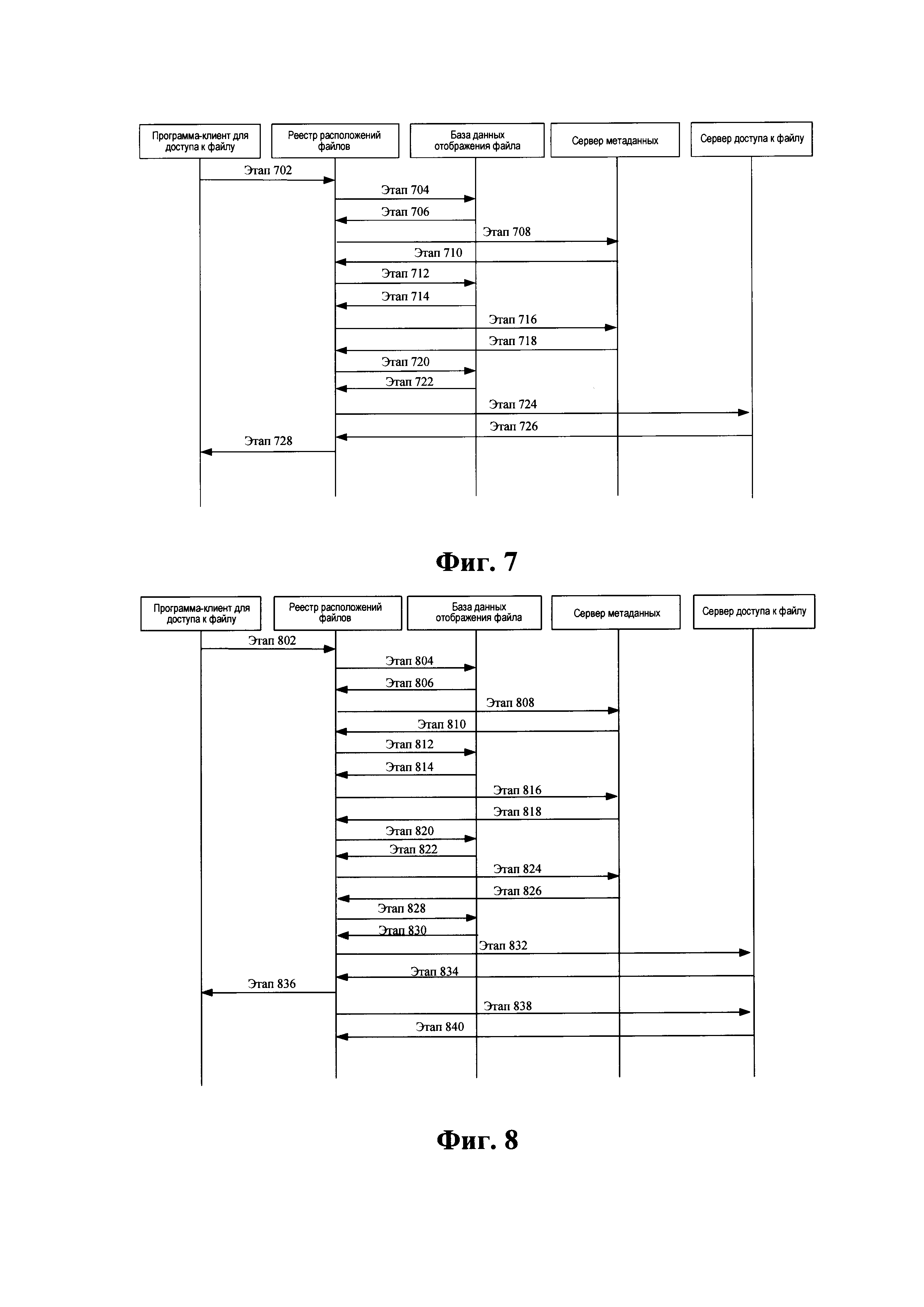
Фиг. 7 демонстрирует схему способа восстановления дедуплицированных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг. 8 демонстрирует другую схему способа восстановления дедуплицированных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения.
Подробное описание вариантов осуществления изобретения
Настоящее раскрытие сущности изобретения будет детально описано ниже со ссылкой на прилагаемые чертежи и варианты осуществления изобретения. Обратите внимание, что варианты осуществления изобретения и признаки вариантов осуществления изобретения могут комбинироваться друг с другом при условии отсутствия конфликтов.
Следующие варианты осуществления изобретения могут применяться для компьютеров, например, Персонального Компьютера (ПК), и могут также применяться для мобильных терминалов, в которых в текущее время используется интеллектуальная операционная система; но варианты осуществления изобретения не ограничиваются применением к этим устройствам. Нет специальных требования к операционной системе на компьютере или в мобильном терминале, поскольку операционная система поддерживает запуск приложений.
Например, следующие варианты осуществления изобретения могут применяться к операционной системе Windows.
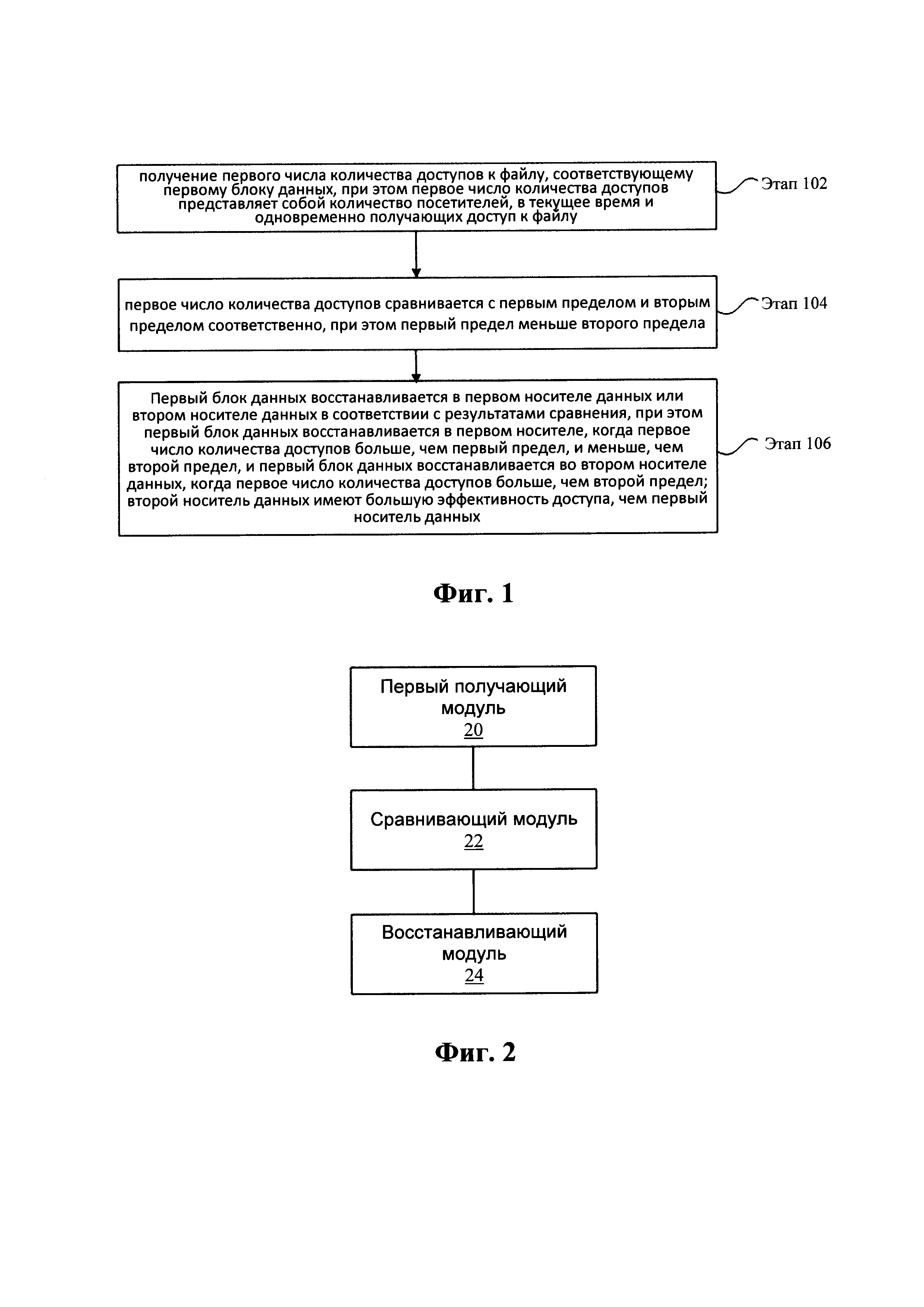
Фиг. 1 демонстрирует схему способа восстановления дедуплицированных данных в соответствии с вариантом осуществления настоящего изобретения. Как показано на Фиг. 1, способ может включать следующие этапы.
Этап 102: получается первое число количества доступов к файлу, соответствующему первому блоку данных, при этом первое число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к файлу.
В настоящем варианте осуществления изобретения, для дальнейшего повышения эффективности доступа к блоку данных, перед этапом 102 также необходимо учесть количество доступов к первому блоку данных; а именно, получается второе число количества доступов к первому блоку данных, при этом второе число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к первому блоку данных; когда второе число количества доступов больше, чем третий предел, обнаруживается файл, соответствующий первому блоку данных; и получается первое число количества доступа к файлу.
Для внедрения кросс-системной и кросс-серверной дедуплицирующей обработки также необходимо выполнить следующую обработку: получается описание признаков первого блока данных, при этом описание признаков используется для представления содержимого, которое есть только в первом блоке данных; и текущая распределенная файловая система и другие распределенные файловые системы, связанные с текущей распределенной файловой системой, информируются об описании признаков, при этом описание признаков используется для выполнения дедуплицирующей обработки в другие распределенные файловые системы. При этом, перед выполнением кросс-серверной дедуплицирующей обработки, необходимо проинформировать узловой сервер в текущей распределенной файловой системе об описании признаков.
Этап 104: первое число количества доступов сравнивается с первым пределом и вторым пределом соответственно, при этом первый предел меньше, чем второй предел.
Этап 106: первый блок данных восстанавливается в первом носителе данных или втором носителе данных в соответствии с результатами сравнения, при этом первый блок данных восстанавливается в первом носителе данных, когда первое число количества доступов больше, чем первый предел, и меньше, чем второй предел, и первый блок данных восстанавливается во втором носителе данных, когда первое число количества доступов больше, чем второй предел; второй носитель данных имеет более высокую эффективность доступа, чем у первого носителя данных.
Восстановление первого блока данных в первом носителе данных или втором носителе данных может выглядеть как следующая обработка: первый блок данных дуплицируется для получения второго блока данных; и второй блок данных дуплицируется в первом носителе данных или втором носителе данных.
После того, как второй блок данных дуплицируется в первом носителе данных или втором носителе данных, первое число количества доступов вычитается из второго числа количества доступов для получения актуального числа количества доступов к первому блоку данных, и 1 вычитается из значения счетчика механизма ссылок первого блока данных.
В настоящем варианте осуществления изобретения также предлагается устройство восстановления дедуплицированных данных, которое используется для реализации упомянутого варианта осуществления и предпочтительного осуществления изобретения, причем описанное выше больше не будет повторено здесь. Модули, входящие в состав устройства, описаны ниже. Термин «модуль», используемый ниже, может включать в себя комбинацию программного обеспечения и/или аппаратные средства с желаемыми функциями. Несмотря на то, что устройство, описываемое в следующем варианте осуществления изобретения, реализуется предпочтительно с помощью программного обеспечения, реализация с помощью аппаратных средств или комбинации программного обеспечения и аппаратных средств возможна и предлагается. Фиг. 2 демонстрирует принципиальную блочную схему устройства восстановления дедуплицированных данных в соответствии с вариантом осуществления настоящего изобретения; как показано на Фиг. 2 устройство включает в себя:
первый получающий модуль 20, выполненный с возможностью получения первого числа количества доступов к файлу, соответствующему первому блоку данных, при этом первое число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к файлу;
сравнивающий модуль 22, соединенный с первым получающим модулем 20, и выполненный с возможностью сравнения первого числа количества доступов с первым пределом и вторым пределом соответственно, при этом первый предел меньше, чем второй предел; и
и восстанавливающий модуль 24, соединенный со сравнивающим модулем 22, и выполненный с возможностью восстановления первого блока данных в первом носителе данных или втором носителе данных в соответствии с результатами сравнения; при этом восстанавливающий модуль восстанавливает первый блок данных в первом носителе данных, когда первое число количества доступов больше, чем первый предел, и меньше, чем второй предел, и восстанавливающий модуль восстанавливает первый блок данных во втором носителе данных когда первое число количества доступов больше, чем второй предел; при этом второй носитель данных имеет более высокую эффективность доступа, чем у первого носителя данных.
В настоящем варианте осуществления изобретения, как показано на Фиг. 3, устройство также включает в себя: второй получающий модуль 26, выполненный с возможностью получения второго числа количества доступов к первому блоку данных, при этом второе число количества доступов представляет собой число посетителей, в текущее время и одновременно получающих доступ к первому блоку данных; и модуль поиска 28, соединенный со вторым получающим модулем 26, и выполненный с возможностью, когда второе число количества доступов больше, чем третий предел, поиска файла, соответствующего первому блоку данных.
В качестве варианта осуществления изобретения, как показано на Фиг. 3, устройство может также включать в себя следующие обрабатывающие модули: третий получающий модуль 30, выполненный с возможностью получения описания признаков первого блока данных, при этом описание признаков используется для представления содержимого, которое есть только в первом блоке данных; информирующий модуль 32, выполненный с возможностью информировать текущую распределенную файловую систему и другие распределенные файловые системы, связанные с текущей распределенной файловой системой, об описании признаков, при этом описание признаков используется для выполнения дедуплицирующей обработки в текущую распределенную файловую систему и другие распределенные файловые системы. Значение «Соединение» здесь может быть таким: два устройства могут обмениваться данными друг с другом.
В качестве варианта осуществления изобретения, как показано на Фиг. 3, устройство может также включать в себя следующие обрабатывающие модули: считающий модуль 34, выполненный с возможностью, после дупликации второго блока данных в первом носителе данных или втором носителе данных, вычитания первого числа количества доступов из второго числа количества доступов для получения актуального числа количества доступов к первому блоку данных, и вычитания 1 из значения счетчика механизма ссылок первого блока данных.
Для лучшего понимания упомянутого варианта осуществления изобретения детальное описание приводится ниже в сочетании с предпочтительными вариантами осуществления изобретения.
Вариант осуществления изобретения 1
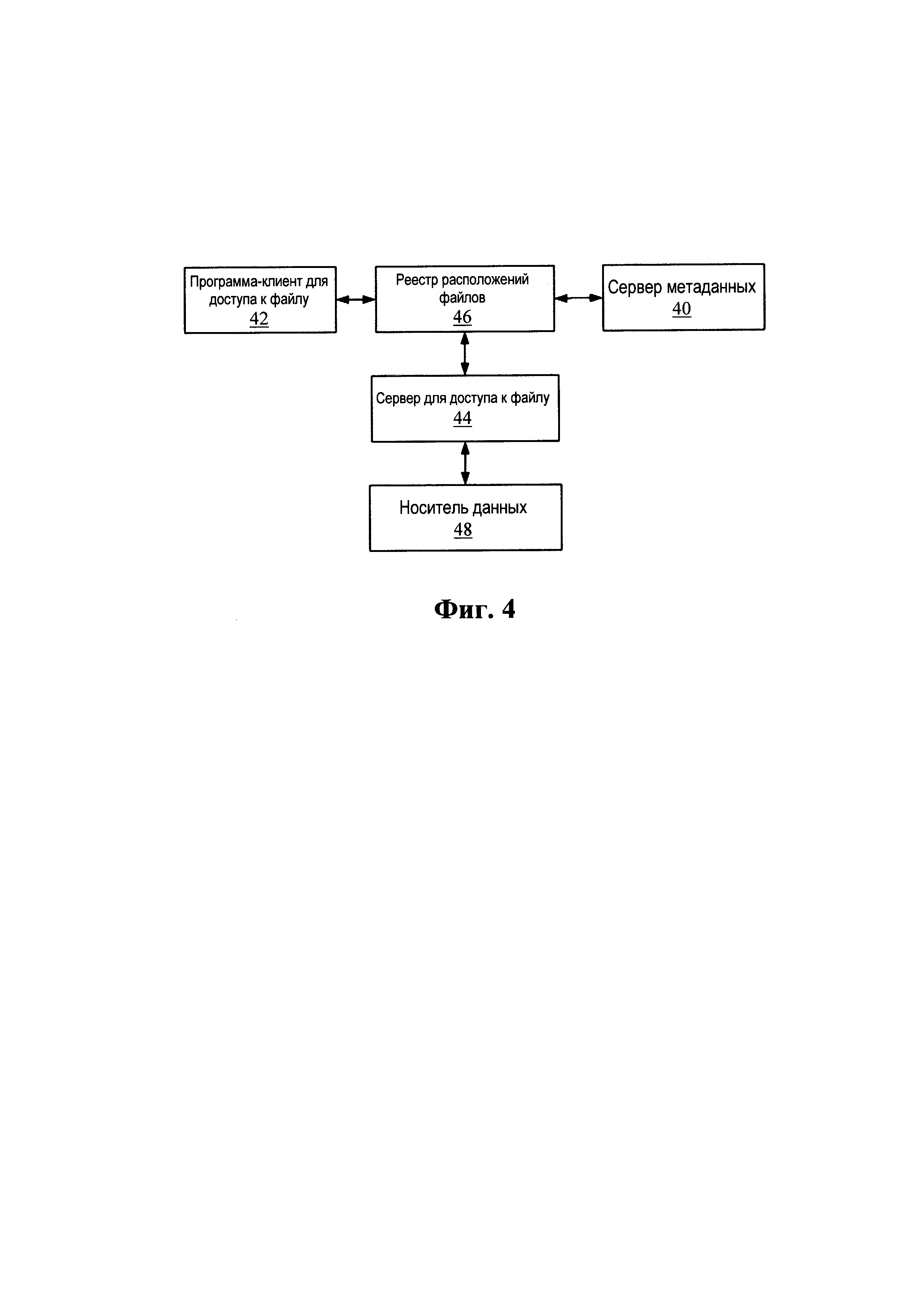
Фиг. 4 демонстрирует принципиальную блочную схему распределенной файловой системы в соответствии с предпочтительным вариантом осуществления настоящего изобретения; Как показано на Фиг. 4, система включает в себя:
сервер 40 метаданных, который берет на себя контроль за управлением именами файлов всех файлов в файловой системе, блоки данных и другую информацию метаданных, и предоставляет программу-клиент для доступа к файлу с такими операциями как запись и запрос метаданных; на основе блока исходных метаданных для реализации функции дедупликации добавлен счетчик ссылок блока метаданных; например, содержимое определенного блока данных файла А такое же как у блока данных файла Б, требующего дедупликации, тогда блок данных файла Б может быть удален и файл Б направляется на блок данных файла А путем добавления 1 к подсчету ссылок блока файла А; в то же время число раз срабатывания блока записывается в соответствии со счетчиком считывания и записи блока, когда число превышает настроенный предел, реестр расположений файлов должен восстановить дедуплицированный блок так, чтобы справиться с проблемой большого количества доступов;
программа-клиент 42 для доступа к файлу, которая берет на себя предоставление интерфейса обработки вызовов, аналогичного стандартной файловой системе для приложения, на которое нацелена файловая система;
сервер 44 для доступа к файлу, который берет на себя взаимодействие с носителем данных в файловой системе для чтения и записи блока актуальных данных, отвечающий на запросы чтения и записи данных от программы-клиента для доступа к файлу и считывающий данные из программы-клиента для доступа к данным и записывающий данные в носитель данных;
реестр 46 расположений файлов, который берет на себя контроль доступа к файлам, распределение файлов данных и управление различными данными; реестр расположений файлов может также включать базу данных отображения, которая берет на себя сохранение таблицы отображения файла и блока, при этом ведя статистику числа посетителей, одновременно получающих доступ к файлу; и
носитель 48 данных, которым в общем случае является одно из следующего: общий диск Интерфейса дисковых устройств (IDE), диск Последовательного интерфейса ATA (SATA), Засекречивающий цифровой диск (SD), Твердотельный диск (SSD).
При необходимости чтения и записи файла пользователь отправляет инструкцию по чтению и записи в программу-клиент для доступа к файлу и затем получает информацию блока данных, соответствующую файлу, через реестр расположений файлов и сервер метаданных; в конце определенная информация о диске файла возвращается пользователю через сервер для доступа к файлу. В частности, указанный процесс может выглядеть как следующая обработка:
Этап А: реестр расположений файлов регулярно посылает запрос на сервер метаданных, чтобы выяснить есть ли блок данных, на котором не проводился подсчет идентификационной метки; если есть, блок данных, на котором необходим подсчет идентификационной метки, возвращается, затем, реестр информирует сервер доступа о необходимости подсчета идентификационной метки и информирует сервер метаданных системы и реестры других систем, соединенных с ней, о подсчитанной идентификационной метке, таким образом может быть проведена операция дедупликации на всех базах данных, соединенных с реестром, для достижения кросс-серверной дедупликации блока данных;
Этап Б: сервер метаданных создает статистику числа количества доступов к блоку данных А; если число одновременных доступов больше, чем предел n, информируется реестр расположений файлов, а затем реестр осуществляет поиск файла, соответствующего блоку данных, в базе данных отображения файла;
Этап В: база данных отображения подсчитывает число одновременных доступов к обнаруженному файлу; если число одновременных доступов больше, чем предел общего доступа, и меньше, чем предел производительности, то реестр информируется о восстановлении блока данных на общем диске; если число одновременных доступов обнаруженного файла больше, предел производительности, то реестр информируется о восстановлении блока данных на твердотельном диске (SSD);
Этап Г: реестр расположений файлов информирует сервер метаданных о вновь добавленном блоке данных и информирует сервер о числе количества доступов к файлу, который необходимо восстановить; сервер метаданных создает блок данных Б, при этом вычитая число количества доступов файла из исходного блока данных, и вычитая 1 из подсчета ссылок; и
Этап Д: реестр расположений файлов информирует, в соответствии с информацией, которую необходимо скопировать, сервер для доступа к файлу о копировании файла в соответствующий носитель данных.
Общий диск или твердотельный диск (SSD).
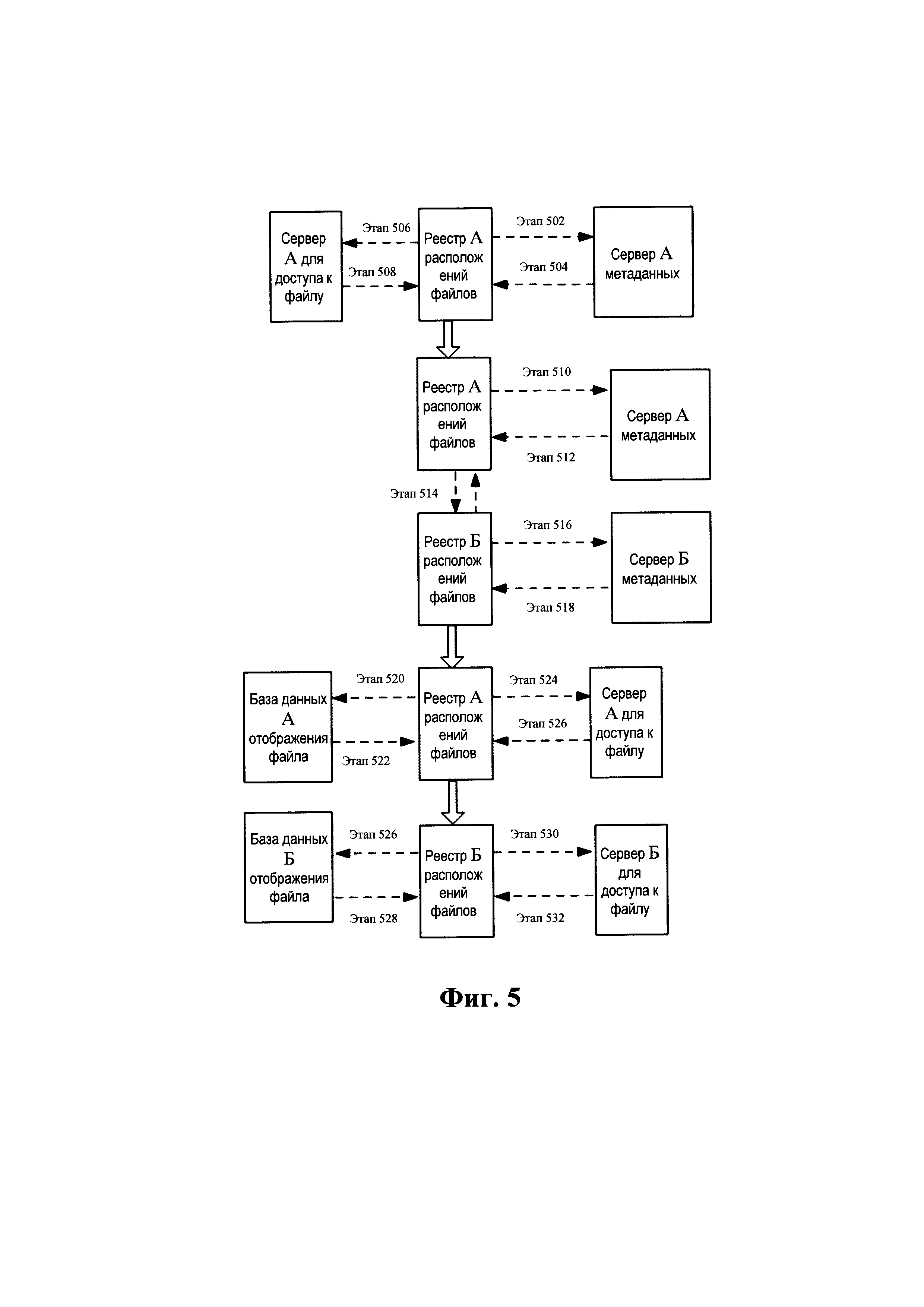
Для лучшего понимания упомянутого процесса реализации детальное описание приведено ниже в сочетании с Фиг. 5 и Фиг. 6.
Как показано на Фиг. 5, реестр расположений файлов регулярно отправляет запрос на сервер метаданных сервера, чтобы выяснить есть ли блок данных, на котором необходимо провести подсчет идентификационной метки; если есть, блок данных, на котором необходим подсчет идентификационной метки, возвращается, реестр осуществляет подсчет идентификационной метки на сервере доступа, отправляет подсчитанную идентификационную метку на сервер метаданных сервера и сервер смежного узла, и достигает цели дедупликации каждого сервера через каждый запрос метаданных; таким образом, настоящий вариант осуществления изобретения реализует не только дедупликацию сервера, но и дедупликацию серверов всей системы с помощью передачи сообщений, тем самым решая проблему эффективности дедупликации и сохраняя больше пространства по сравнению со старым одиночным сервером. Конкретный процесс реализации представляет собой следующее:
Этап 502: регулярно делается запрос, чтобы выяснить есть ли блок данных, на котором не проводился подсчет идентификационной метки;
Этап 504: блок данных, на котором необходим подсчет
идентификационной метки, возвращается; Этап 506:
возвращенный блок данных А информируется о подсчете
идентификационной метки; Этап 508: значение подсчитанной
идентификационной метки сообщается;
Этап 510: значение подсчитанной идентификационной метки сообщается, и выясняется есть ли блок данных А, требующий дедупликации;
Этап 512: блок данных Б, требующий дедупликации, возвращается;
Этап 514: значение идентификационной метки блока данных А сообщается, и выясняется есть ли то же самое на блоке данных Б;
Этап 516: значение подсчитанной идентификационной метки сообщается, и выясняется есть ли блок данных А, требующий дедупликации;
Этап 518: блок данных В, требующий удаления, возвращается;
Этап 520: сообщается о необходимости отобразить файл, которому соответствует блок данных Б, в блок данных А;
Этап 522: отображение успешно;
Этап 524: сообщается о необходимости удалить блока данных Б;
Этап 526: удаление успешно, сообщается о необходимости отобразить файл, которому соответствует блок данных Б, в блок данных А;
Этап 528: отображение успешно;
Этап 530: сообщается о необходимости удалить блока данных Б; и
Этап 532: удаление успешно.
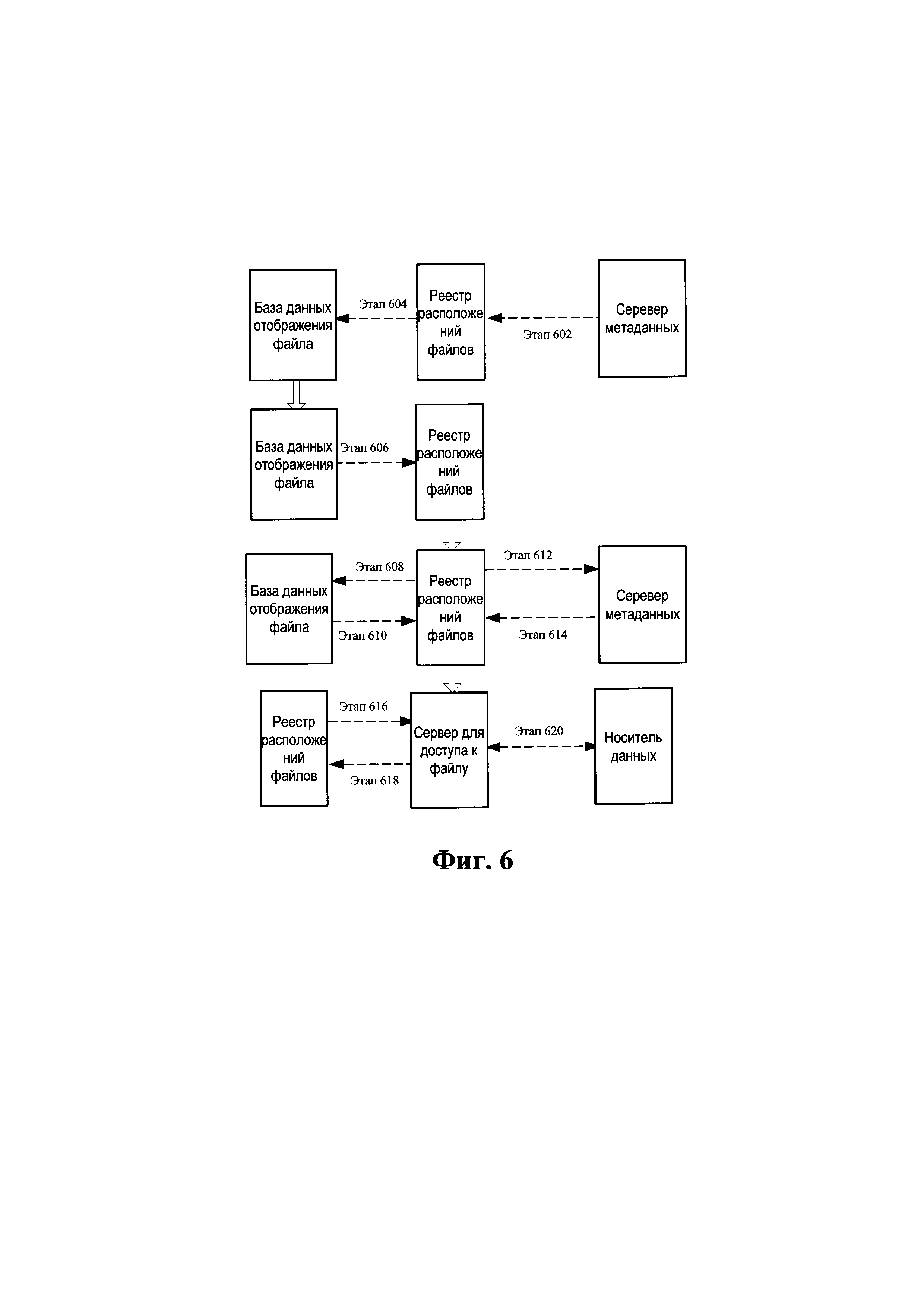
Как показано на Фиг. 6, сервер метаданных подсчитывает доступ к сохраненному блоку данных; когда значение счетчика доступа к блоку данных превышает предел n, информация блока данных сообщается в реестр расположений файлов; реестр расположений файлов осуществляет поиск, в соответствии с блоком данных, соответствующий файл, занимающий блок данных, и сортирует число количества доступов ко всем файлам; если число количества доступов к файлу больше, чем предел общего доступа, но меньше, чем предел производительности, то блок данных напрямую восстанавливается на общем диске; если число количества доступов больше, чем предел производительности, то соответствующий дедуплицированный блок данных файла восстанавливается на твердотельном диске (SSD) с высокой эффективностью доступа. Конкретный процесс реализации представляет собой следующее:
Этап 602: ведется статистика с целью проверить, превышает ли число
одновременных доступов блока данных предел n (n - натуральное число);
если число одновременных доступов блока данных больше, чем n, и
подсчет ссылок больше, чем 1, то уведомляется реестр;
Этап 604: идентификатор соответствующего файла находится в соответствии
с блоком данных;
Этап 606: если число одновременных доступов найденного идентификатора файла больше, чем 1, но меньше, чем m (m - натуральное число), то реестру необходимо восстановить блок данных на общем диске; если число одновременных доступов найденного идентификатора файла больше, чем m, то блок данных восстанавливается на твердотельном диске (SSD);
Этап 608: блок данных Б отображается в файл, который
необходимо восстановить; Этап 610: возврат успешен;
Этап 612: сообщается, что блок данных вновь добавлен, и 1 вычитается из
подсчета ссылок исходного блока данных;
Этап 614: вновь добавленный блок данных Б возвращается;
Этап 616: информация блока данных копируется на общий диск или
твердотельный диск (SDD);
Этап 618: возврат успешен; и
Этап 620: копирование выполнено.
Вариант осуществления изобретения 2
Когда файл открыт, после того, как программа-клиент отправляет информацию файла в реестр расположений файловой системы по умолчанию, реестр расположений ищет блок данных, соответствующий файлу через базу данных отображения, и ищет, чтобы блок данных не был сохранен системой; затем, реестр расположений сообщает программе-клиенту для доступа о запросе в файловой системе, где находится блок данных, таким образом очень просто реализуется кросс-системный доступ к файлу.
Осуществление настоящего изобретения иллюстрируется открытием файла А. Как показано на Фиг. 7, процесс включает следующие этапы обработки:
Этап 702: файл А открыт;
Этап 704: блок данных находится в соответствии с файлом А, при этом ведется статистика числа количества доступов к файлу;
Этап 706: блок данных А возвращается;
Этап 708: сообщается о необходимости ведения статистики числа одновременных доступов к блоку данных А;
Этап 710: обнаруживается, что число одновременных доступов к блоку данных А больше, чем предел доступа n, а подсчет ссылок больше 1;
Этап 712: соответствующий файл находится в соответствии с блоком данных
А;
Этап 714: файл А и файл Б, соответствующий блоку данных А, возвращаются, при этом, число количества доступов к файлу А больше, чем предел производительности m;
Этап 716: сообщается, что блок данных вновь добавлен, и сообщается число количества доступов к файлу А;
Этап 718: вновь добавленный блок данных Б возвращается, и число количества доступов к файлу А вычитается из числа количества доступов к блоку данных А, при этом 1 вычитается из подсчета ссылок блока данных А, и расформировывается отношение отображения между файлом А и блоком данных А;
Этап 720: файлу А сообщается об отображении с блоком
данных Б; Этап 722: база данных файла выдает успех
отображения;
Этап 724: сообщается о необходимости копировать содержимое блока данных А в блок данных Б, и копировать блок данных Б на твердотельном диске (SSD), чтобы повысить эффективность доступа;
Этап 726: сервер для доступа к файлу выдает успех копирования; и Этап
728: реестр расположений возвращает блок данных Б.
Реализация, при которой число количества доступов к другому файлу, соответствующему блоку данных, также превышает предел обнаруживается при открытии файла А. Как показано на Фиг. 8, процесс включает следующие этапы:
Этап 802: файл А открыт;
Этап 804: блок данных находится в соответствии с файлом А, при этом ведется статистика числа количества доступов к файлу;
Этап 806: блок данных А возвращается;
Этап 808: сообщается о необходимости ведения статистики числа одновременных доступов к блоку данных А;
Этап 810: обнаруживается, что число одновременных доступов к блоку данных А больше, чем предел доступа n, а подсчет ссылок больше 1;
Этап 812: соответствующий файл находится в соответствии с блоком данных
А;
Этап 814: файл А и файл Б, соответствующий блоку данных А возвращаются, при этом число количества доступов к файлу Б больше, чем предел производительности m, и число количества доступов к файлу А больше, чем общий предел I;
Этап 816: сообщается, что блок данных вновь добавлен, и сообщается число количества доступов к файлу А;
Этап 818: вновь добавленный блок данных Б возвращается, и число
количества раз доступа к файлу А вычитается из числа количества доступов
к блоку данных А, при этом 1 вычитается из подсчета ссылок блока данных
А, и расформировывается отношение отображения между файлом А и
блоком данных А;
Этап 820: файлу А сообщается об отображении с
блоком данных Б;
Этап 822: база данных файла выдает успех
отображения;
Этап 824: сообщается, что блок данных вновь добавлен, и сообщается число количества доступов к файлу Б;
Этап 826: вновь добавленный блок данных В возвращается, и число
количества доступов к файлу Б вычитается из числа количества доступов к
блоку данных А, при этом 1 вычитается из подсчета ссылок блока данных А,
и расформировывается отношение отображения между файлом Б и блоком
данных А;
Этап 828: файлу Б сообщается об отображении с блоком
данных В;
Этап 830: база данных файла выдает успех отображения;
Этап 832: сообщается о необходимости копировать содержимое блока
данных А в блок данных Б; поскольку в этот раз число превышает общий
предел, содержимое копируется на общий диск;
Этап 834: сервер для доступа к файлу выдает успех копирования;
Этап 836: реестр расположений возвращает блок данных Б;
Этап 838: сообщается о необходимости копировать содержимое блока данных А в блок данных В при работе файла А; поскольку в этот раз число превышает предел производительности, содержимое копируется на твердотельный диск (SSD); и
Этап 840: сервер для доступа к файлу выдает успех копирования.
Подводя итоги, настоящее раскрытие достигает следующих положительных эффектов:
При рассмотрении упомянутой проблемы на известном уровне техники, при котором имеется чрезмерное количество доступов к одному и тому же блоку данных в связи с дедупликацией, что понижает эффективность доступа, настоящее раскрытие определяет имеется ли чрезмерное количество доступов путем ведения статистики числа одновременных доступов к блоку данных и числа одновременных доступов к файлу, и в то же время, классифицирует доступы файла по числу общих доступов и числу доступов производительности, и восстанавливает блок данных на общем диске и твердотельном диске (SSD) в соответствии с двумя числами, таким образом, восстанавливая, на основе классификации, блок данных в соответствии с числом количества доступов, и достигая унификации эффективности и экономии. В дополнение, с помощью дедупликации метаданных, повышается грануляция дедупликации, и реализуется кросс-системная дедупликация, что сохраняет больше пространства на диске; в то же время, использую подход подсчета ссылок, вероятность поиска таблицы отображения файла может быть снижена с помощью изменения блока данных, тем самым, повышая эффективность работы системы.
В другом варианте осуществления изобретения предлагаются компоненты программных средств, которые используются для осуществления технических решений, описанных в упомянутых вариантах осуществления изобретения и предпочтительных вариантах осуществления изобретения.
В другом варианте осуществления изобретения также предлагается носитель данных, предназначенный для хранения упомянутого программного обеспечения; носитель данных включает без ограничений такие носители информации, как компакт-диск, гибкий диск, жесткий диск, стираемая память и т.д.
Очевидно, что специалисты в данной области оценят указанные модули и этапы раскрытия сущности настоящего изобретения, могут быть реализованы с помощью вычислительного устройства общего назначения, и они могут быть централизованы в одиночное вычислительное устройство или распределены в сеть, состоящую из нескольких вычислительных устройств; в качестве варианта они могут быть реализованы с помощью программного кода, который способен выполняться вычислительным устройством таким образом, чтобы они могли храниться в накопительном устройстве и выполняться вычислительным устройством; и в некоторых ситуациях представленные и упомянутые этапы могут выполняться в порядке, отличном от описанного здесь; или они объединены в единые электронные модули, соответственно; или несколько модулей, и их этапы объединены в единый электронный модуль для реализации. Таким образом, раскрытие сущности настоящего изобретения не ограничивается какой-либо конкретной комбинацией программных и аппаратных средств.
Упомянутое является только предпочтительным вариантом осуществления изобретения и не должно ограничивать раскрытие сущности настоящего изобретения; для специалистов в данной области раскрытие сущности настоящего изобретения может иметь различные модификации и изменения. Любые модификации, равнозначное замещение, улучшение и т.п., вносимое в рамках принципов настоящего раскрытия, должно оставаться в пределах объема правовой охраны, определяемого формулой настоящего изобретения.
Промышленная применимость
Технические решения, представленные в раскрытии сущности настоящего изобретения, могут быть применены в процессе восстановления дедуплицированных данных; с помощью применения технических средств сравнения числа количества доступов к файлу, соответствующему первому блоку данных, с первым пределом и вторым пределом соответственно, и, в соответствии с результатами сравнения, определяется, восстанавливать ли первый блок данных в первом носителе данных или втором носителе данных, настоящее раскрытие решает проблему известного уровня техники, при котором имеется чрезмерное число доступов к одному и тому же блоку данных, таким образом повышая эффективность доступа к файлам.
Автономный хэндовер, способы и устройства обработки хэндовера для пользовательского оборудования (по) в транкинговой группе
Способ и устройство обнаружения голосовой активности
Способ и устройство изменения ресурса виртуальной вычислительной машины и устройство для функционирования виртуальной сети передачи данных
Схема, способ и устройство для совместного использования интерфейса usb
Способ и устройство регулировки скорости вращения вентилятора в электронном устройстве
Способ и устройство промежуточного узла многопротокольной коммутации по меткам (mpls) для выполнения многоадресной рассылки и его узел
Способ и устройство обработки конфликта маршрутизации коммутатора
Способ, система и машиночитаемый носитель для выполнения миграции с физических машин на виртуальные
Способ и устройство переадресации, основанный на быстрой перемаршрутизации и сетевом устройстве

