Результат интеллектуальной деятельности: СПОСОБ ОРГАНИЗАЦИИ ХРАНЕНИЯ ЧАСТИЧНО СОВПАДАЮЩИХ БОЛЬШИХ ОБЪЕКТОВ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
[1] Данное техническое решение относится к области вычислительной техники, в частности к способу организации хранения частично совпадающих больших объектов (LOB).
УРОВЕНЬ ТЕХНИКИ
[2] Из уровня техники известен патент на изобретение US 6738790 В1 «Approach for accessing large objects», патентообладатель: Oracle International Corporation, дата публикации: 18.05.2004. В данном патенте описывается способ и система для доступа к большим объектам, который находится в ячейке таблицы. В указанном решении перед модификацией фрагмента LOB, его сначала копируют, а потом над копией осуществляют модификацию. Указанное изобретение отличается от заявляемого решения тем, что в нем не реализован поиск частично повторяемых фрагментов среди хранящихся в ЗУ фрагментов других объектов.
[3] Также известно решение US 6144970A «Technique for inplace reorganization of a LOB table space». В данном патенте описывается способ и устройство реорганизации больших объектов. Один или несколько фрагментов в таблице выделяются для идентифицированных больших объектов. Сама суть патента несколько другая, чем в данном техническом решении: в таблице для идентифицированных больших объектов выделяется пространство для фрагментов, в которых далее размещаются большие объекты посредством деления на фрагменты.
[4] Указанные выше технические решения обеспечивают хранение данных в LOB объектах (или их аналогах), но не учитывают возможные совпадения в разных экземплярах объектов, что может привести к нерациональному использованию оперативной памяти, пространства на ЗУ, скорости чтения, скорости групповых модификаций для объектов, содержащих большое количество идентичных фрагментов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[5] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям хранения связанных данных.
[6] Технической задачей или проблемой, поставленной в данном решении, является обеспечение учета возможных совпадений при хранении данных в LOB объектах.
[7] Технический результат, проявляющийся при решении вышеуказанной задачи, заключается в повышении производительности системы управления базами данных.
[8] Также дополнительным техническим результатом является повышение скорости групповых модификаций для объектов, содержащих большое количество идентичных объектов.
[9] Дополнительно при решении вышеуказанной задачи рационально используется оперативная память в техническом решении.
[10] Вышеуказанный технический результат достигается посредством осуществления способа организации хранения частично совпадающих больших объектов (LOB), в котором получают по меньшей мере один большой объект (LOB) для осуществления его модификации или добавления в базу данных на запоминающее устройство; выполняют поиск совпадающих фрагментов полученного большого объекта с хранящимися в базе данных фрагментами больших объектов, причем находящиеся в базе данных большие объекты разбиты на фрагменты, где каждый фрагмент имеет уникальный идентификатор; в случае нахождения совпадающих фрагментов, разбивают полученный большой объект на совпадающие в базе данных фрагменты и на уникальные фрагменты; получают идентификаторы совпадающих фрагментов больших объектов из запоминающего устройства; присваивают каждому уникальному фрагменту полученного большого объекта идентификатор и сохраняют в запоминающее устройство; сохраняют в базу данных большой объект как упорядоченную последовательность идентификаторов фрагментов, из которых он состоит.
[11] В некоторых вариантах осуществления технического решения большой объект является двоичным (BLOB) или символьным (CLOB), или национальным символьным (NCLOB).
[12] В некоторых вариантах осуществления технического решения большой объект является внутренним или внешним.
[13] В некоторых вариантах осуществления технического решения осуществляют поиск совпадающих объектов посредством алгоритма Кнута-Морриса-Пратта или алгоритма шингла или Frequent Subsequence Mining (FSM) или алгоритма CloSpan или перцептивной хеш-функции.
[14] В некоторых вариантах осуществления технического решения выполняют предварительную обработку полученного большого объекта посредством разбиения большого объекта на фрагменты.
[15] В некоторых вариантах осуществления технического решения при разбиении полученного большого объекта на совпадающие в базе данных фрагменты и на уникальные фрагменты, фрагменты имеют не нулевую длину.
[16] В некоторых вариантах осуществления технического решения идентификатор фрагмента большого объекта является целочисленным значением.
[17] В некоторых вариантах осуществления технического решения присваивают каждому уникальному фрагменту полученного большого объекта идентификатор инкрементно.
[18] В некоторых вариантах осуществления технического решения после поиска повторяемых, а также после сохранения уникальных фрагментов, каждый большой объект представляют как последовательность идентификаторов фрагментов.
[19] В некоторых вариантах осуществления технического решения последовательность фрагментов хранится в теле записи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[20] Признаки и преимущества настоящего изобретения станут очевидными из приведенного ниже подробного описания изобретения и прилагаемых чертежей, на которых:
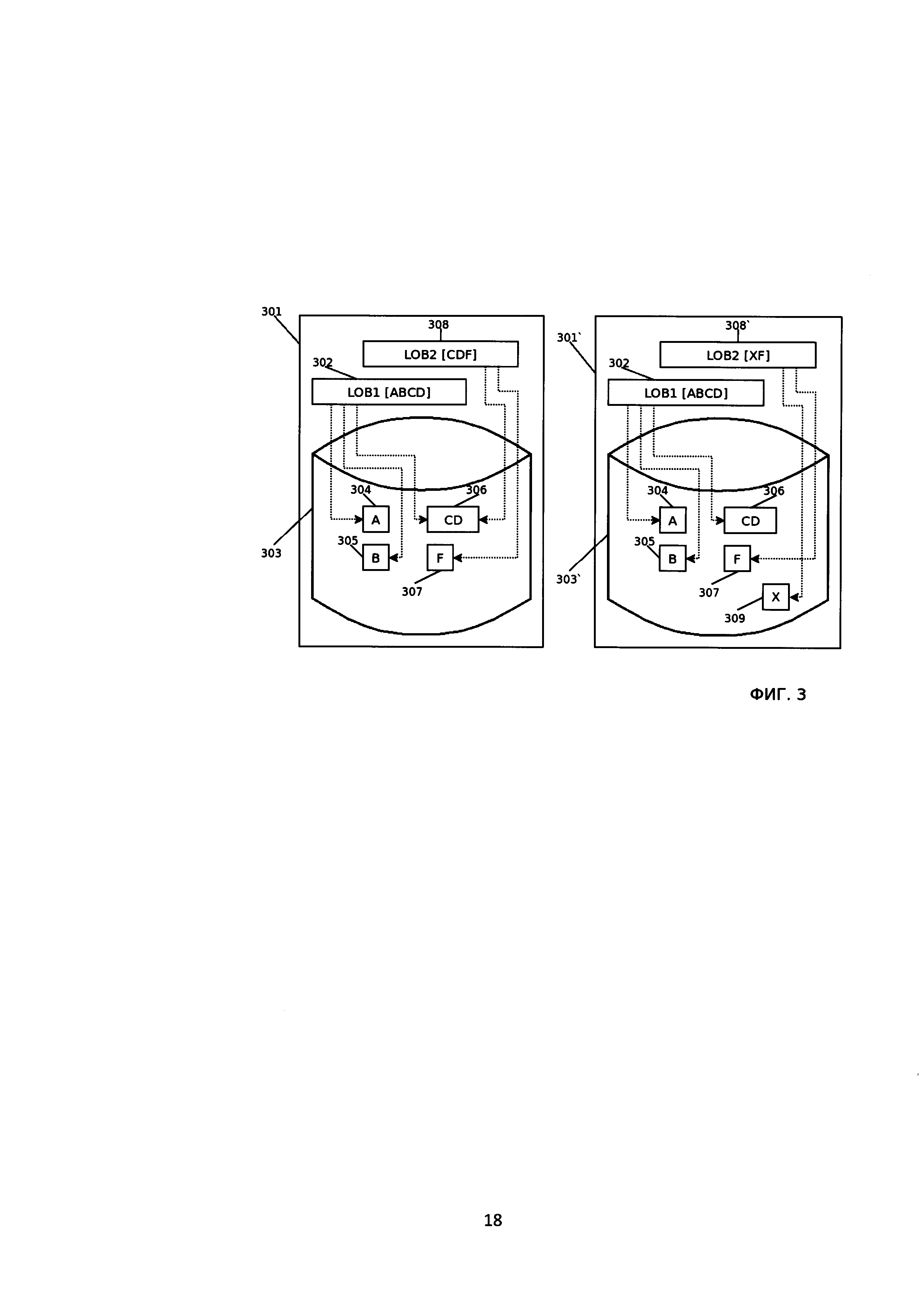
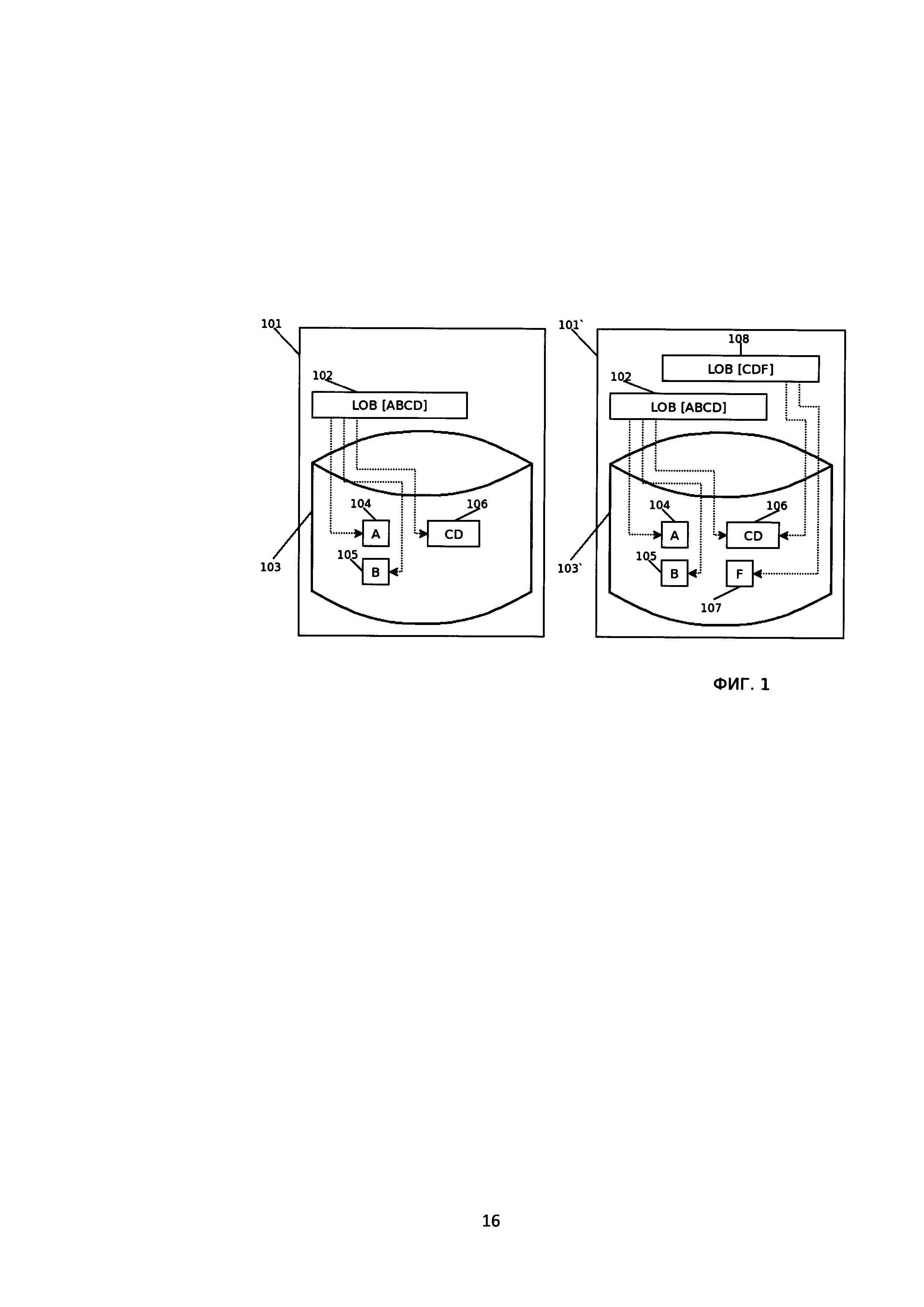
[21] На Фиг. 1 изображены состояния системы хранения больших объектов до (101) и после (101`) добавления нового объекта LOB2 (108), частично совпадающего с другим объектом LОВ1(102). Отображены изменения в ЗУ (103,103`) после добавления нового фрагмента (107).
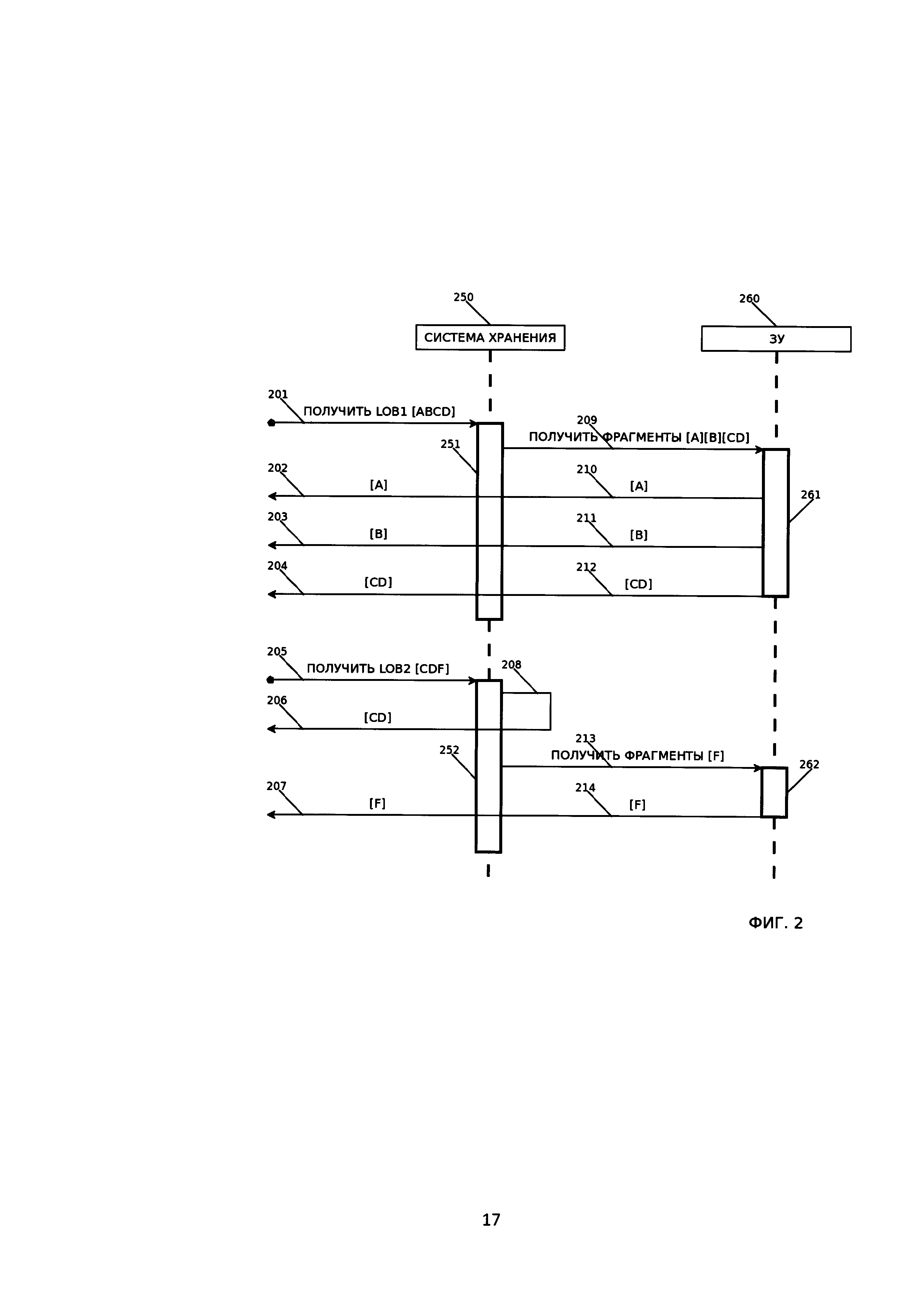
[22] На Фиг. 2 изображена последовательность взаимодействия и жизненный цикл исполнения последовательных запросов на извлечение LOB1 (201) и LOB2 (205), на которой отображен (208, 206) возврат повторяемых фрагментов, прочтенных ранее (212, 204) без повторного обращения к ЗУ (260).
[23] На Фиг. 3 изображены состояния системы хранения больших объектов до (301) и после (301`) изменения объекта LOB2 (308, 308`). Отображены изменения в ЗУ (303, 303`) после добавления нового фрагмента (309).
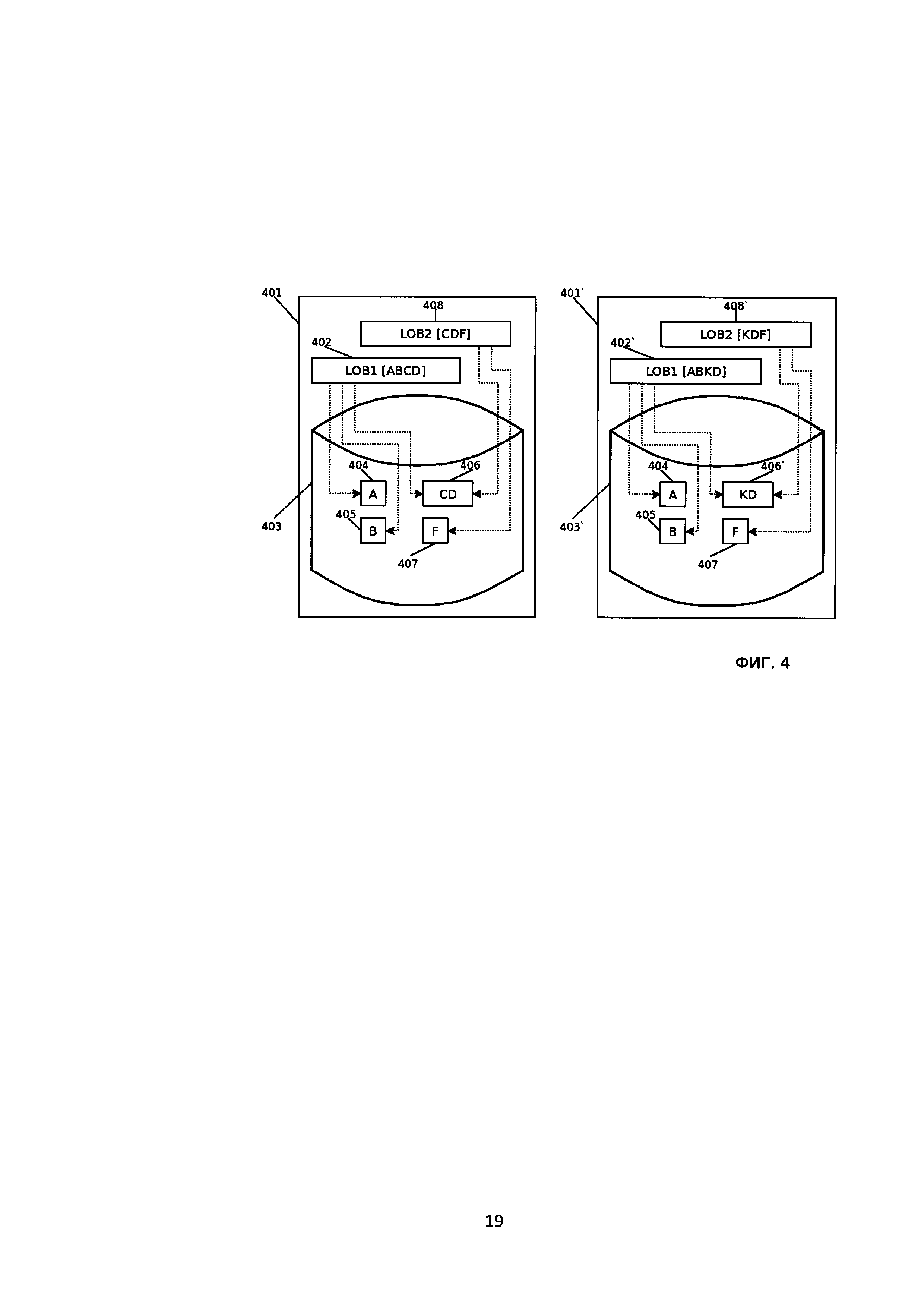
[24] На Фиг. 4 изображены состояния системы хранения больших объектов до (401) и после (4001`) группового изменения частично совпадающих объектов LOB1 (402, 402`) и LOB2 (408, 408`) посредством изменения повторяемого фрагмента (408,408`).
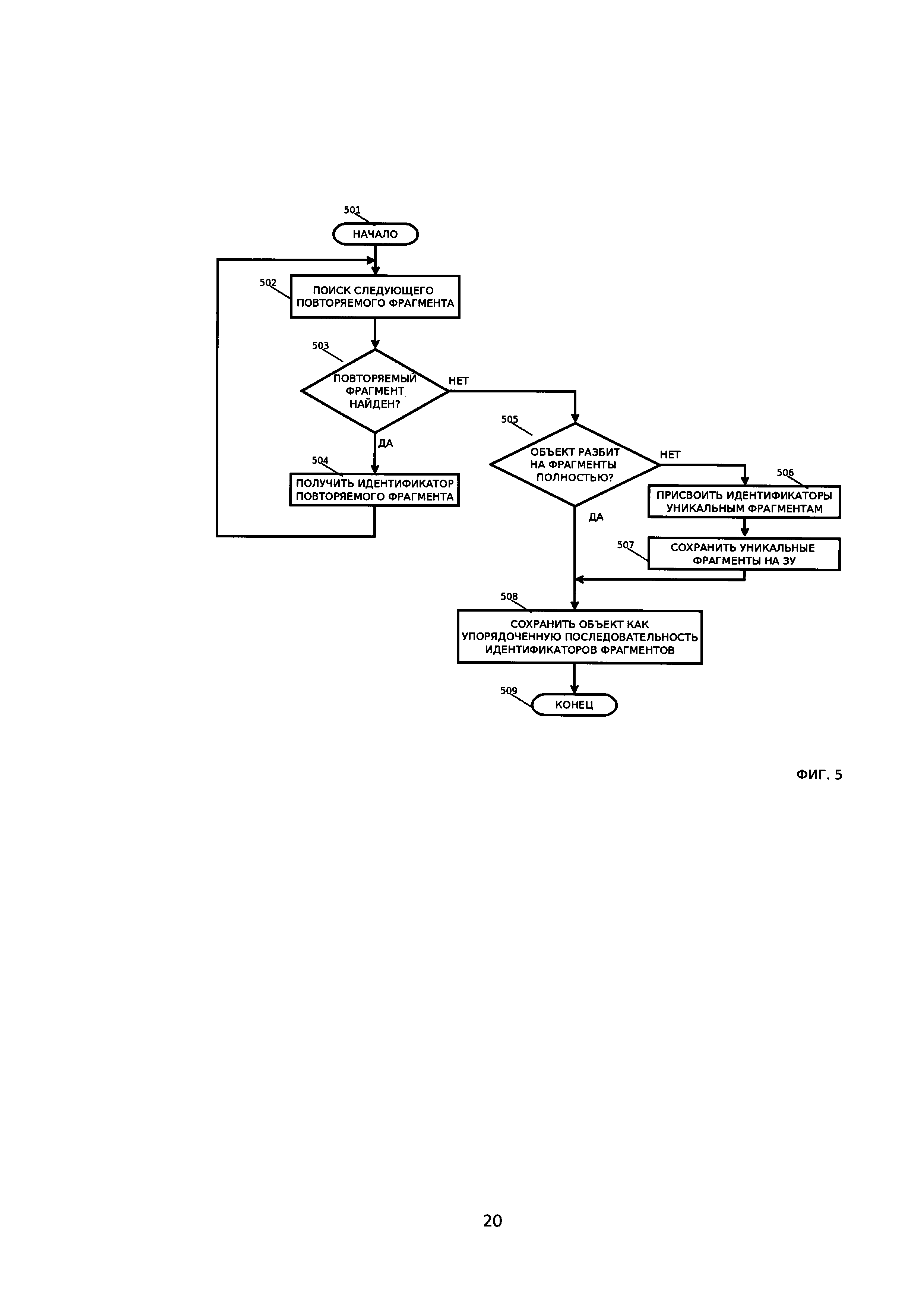
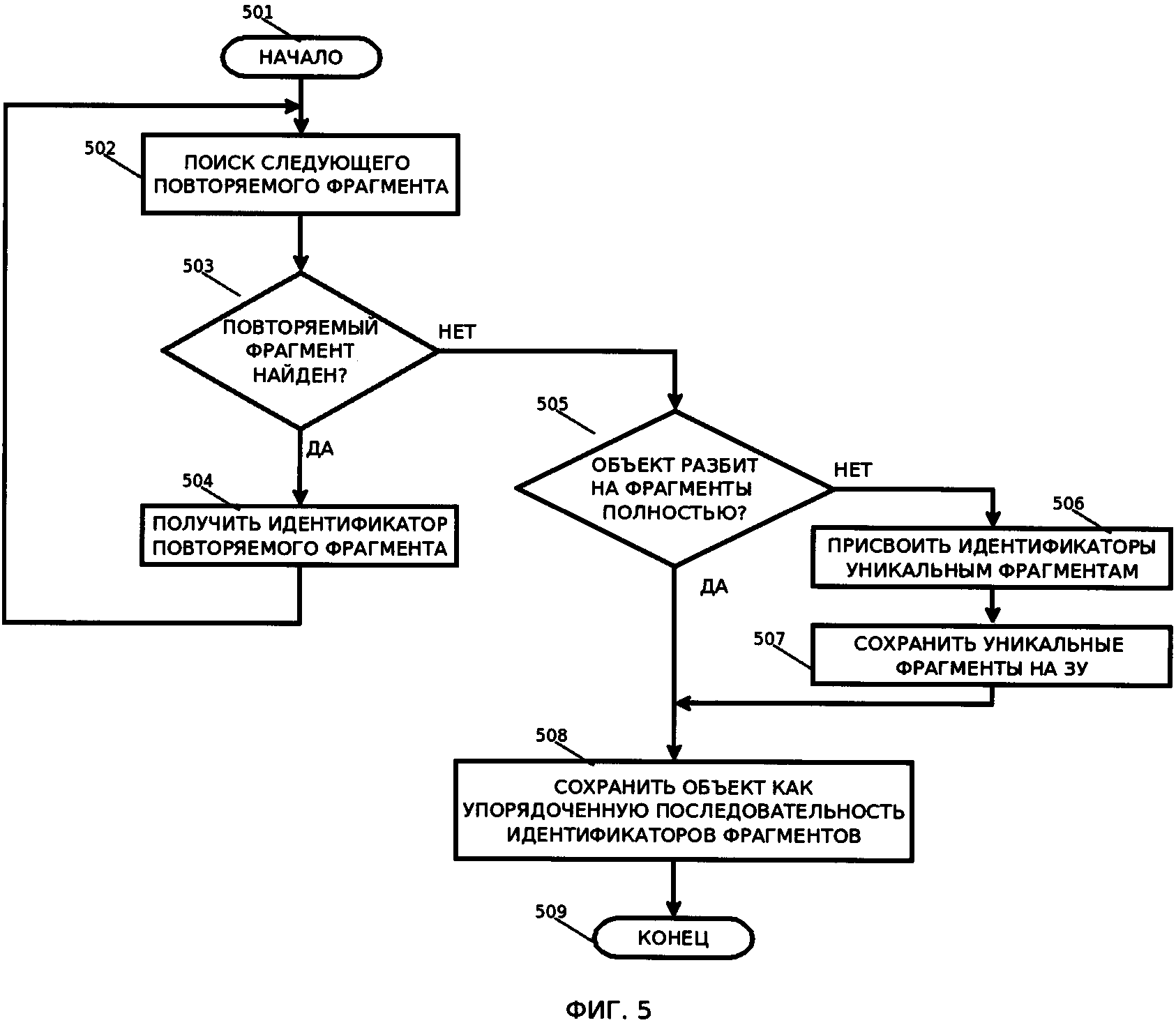
[25] На Фиг. 5 приведена блок-схема, иллюстрирующая способ осуществления для записи нового объекта.
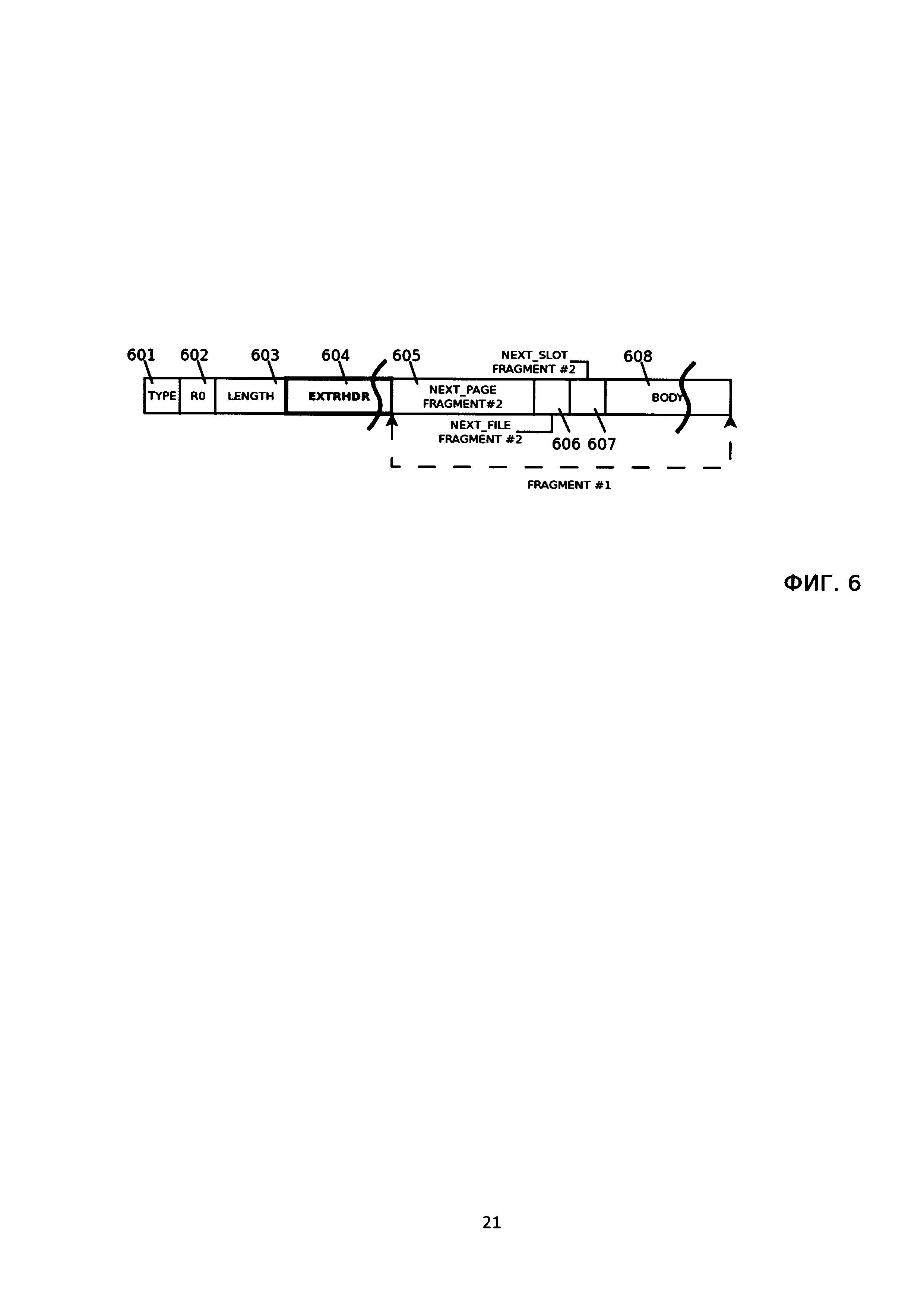
[26] На Фиг. 6 показан вариант осуществления формата порции фрагмента большого объекта, на которые он разбивается.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[27] Ниже будут описаны понятия и определения, необходимые для подробного раскрытия осуществляемого изобретения.
[28] Запись - набор значений различных типов, предназначенный к хранению в ЗУ.
[29] Группа - совокупность записей, которая рассматривается как самостоятельная единица в операциях чтения/записи, предполагающая физически объединенное хранение в ЗУ.
[30] LOB, LOB-тип - в PL/SQL, SQL1999 - тип данных, используемый для хранения больших объектов (Large OBject). При выборе значения любого LOB-типа посредством оператора SELECT возвращается указатель, а не само значение; кроме того, типы LOB могут быть и внешними. Внешний LOB хранит большой объект (или его часть) в отдельном файле, внутренний - в файлах базы данных.
[31] Большой объект, Large OBject, LOB - объект, предназначенный для эффективного хранения и доступа к двоичным данным произвольной структуры и размера.
[32] Частично совпадающие большие объекты - два или более больших объекта, имеющих хотя бы один общий фрагмент в их представлении в ЗУ.
[33] Запоминающее устройство, ЗУ - устройство, предназначенное для записи и хранения данных.
[34] Фрагмент большого объекта - непрерывный участок представления большого объекта на запоминающем устройстве.
[35] Повторяющийся фрагмент - фрагмент, который входит в состав более чем одного объекта или имеет повторения в составе одного объекта.
[36] Уникальный фрагмент - фрагмент, который входит в состав только одного объекта и не имеет повторений в составе одного объекта.
[37] База данных, database - представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ).
[38] Система управления базами данных, Database Management System, СУБД, DBMS - совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
[39] Система Хранения Данных (СХД) - это комплексное программно-аппаратное решение по организации надежного хранения информационных ресурсов и предоставления гарантированного доступа к ним.
[40] Префикс функция - это такая функция от строки, которая для каждого элемента строки с номером i показывает наибольшую длину собственного суффикса подстроки с 0 до i элемента включительно, совпадающий с ее префиксом. Префикс - это подстрока, начинающаяся с начала строки.
[41] Согласно Фиг. 1, способ организации хранения частично совпадающих больших объектов (LOB) осуществляется следующим образом.
[42] Шаг 101: получают по меньшей мере один большой объект (LOB) (108, 308) для осуществления его модификации (Фиг. 3) или добавления (Фиг. 1) в базу данных на запоминающее устройство (103, 303);
[43] Под модификацией большого объекта предполагается любое изменение в объекте, приводящее к изменению набора двоичных данных, представляющих его и хранящихся в ЗУ.
[44] Шаг 102: выполняют поиск (502) совпадающих фрагментов полученного большого объекта с хранящимися в базе данных фрагментами больших объектов (304, 305, 306, 307, 104, 105, 106), причем находящиеся в базе данных большие объекты разбиты на фрагменты, где каждый фрагмент имеет уникальный идентификатор;
[45] В некоторых вариантах осуществления могут использоваться несколько способов осуществления поиска совпадающих объектов, например, алгоритм Кнута-Морриса-Пратта, алгоритмов шинглов, Frequent Subsequence Mining (FSM), CloSpan (алгоритм поиска закрытых последовательных шаблонов), алгоритм кластеризации дубликатов (для поиска повторяемых фрагментов изображений), перцептивная хеш-функция (для поиска повторяемых фрагментов объекта произвольной структуры), или их комбинация, не ограничиваясь.
[46] Рассмотрим в качестве примера осуществления использование алгоритма Кнута-Морриса-Пратта. Пусть входной LOB (обозначим как haystack) содержит упорядоченную последовательность байт длиной n байт. Необходимо определить, входит ли уже сохраненный фрагмент (обозначим как needle) длиной m байт в него. В случае использования алгоритма Кнута-Морриса-Пратта для всех фрагментов, которые уже были сохранены в БД, хранятся предварительно вычисленные значения префикс функции (их размер будет совпадать с размером фрагмента). Префикс функция фрагмента π(S,i) - это длина наибольшего префикса фрагмента S[1..i], который не совпадает с этим фрагментом и одновременно является его суффиксом. Проще говоря, это длина наиболее длинного начала фрагмента, являющегося также и его концом. Фрагмент «перемещается» по данным LOB слева направо с целью обнаружения совпадения. С помощью префикс функции избегаются заведомо бесполезные сдвиги. Результатом применения алгоритма Кнута-Морриса-Пратта является смещение фрагмента во входном LOB (если фрагмент найден) или информация о том, что фрагмента не найдено. Если фрагмент не найден, то переходят к следующему хранящемуся объекту и пытаются найти его. Если фрагмент найден, то в последующих поисках этот найденный участок во входящем LOB более не учитывается.
[47] В некоторых вариантах осуществления выполняют предварительную обработку полученного большого объекта, например, разбиение объекта на фрагменты, которое определяется потребностями алгоритма поиска совпадающих объектов.
[48] В некоторых вариантах для поиска повторяемых фрагментов в объектах, порождаемых из существующих в базе, возможно использование описания изменений. Допустим, что в СУБД хранятся следующие фрагменты:


[49] из которых состоит следующий большой объект:

[50] Тогда условная команда INSERT REPLACE (LOB1, 'Test', 'desk'), которая явно указывает, что новый объект (LOB2) получен из содержимого объекта LOB1 путем замены слова «Test» на слово «desk», приводит к тому, что поиск повторяемых объектов не нужен, поскольку пользователь явно указал их - это все части строки, совпадающие с исходной строкой. Необходим только поиск возможного повторения для фрагмента «desk». Выполнение команды приведет тогда к хранению следующих фрагментов в СУБД:

[51] А большие объекты будут представлены как:

[52] Шаг 103: в случае нахождения совпадающих фрагментов, разбивают (Фиг, 5) полученный большой объект на совпадающие в базе данных фрагменты и на уникальные фрагменты.
[53] Результаты поиска используют для разбиения большого объекта на повторяющиеся и уникальные фрагменты.
[54] Пусть в результате поиска обнаружили, что входной LOB (длиной n байт) содержит два уже хранимых в базе данных фрагмента: needleA с позиции а1 до а2 и needleB с позиции b1 и b2. При этом, как было сказано ранее - фрагменты не должны пересекаться, т.е.
0≤a1<a2≤n и 0≤b1<b2≤n
[55] Пусть в примерном варианте осуществления needleA будет расположен «левее» needleB, тогда
0≤a1<a2≤b1<b2≤n
[56] Таким образом LOB [0, n] может быть разбит на следующие фрагменты:
[0,а1) [а1,а2] (а2,b1) [b1,b2] (b2,n]
[57] Пусть все эти фрагменты имеют не нулевую длину (фрагменты нулевой длины просто далее не учитываются в работе). Тогда имеем следующие уникальные фрагменты:
[0,а1), (а2,b1), (b2,n]
[58] и следующие повторяющиеся:
[а1,а2] (needleA), [b1,b2] (needleB)
[59] Результатом поиска повторяемых фрагментов является множество непрерывных участков в наборе двоичных данных, которые встречаются как минимум в одном из уже хранимых объектов.
[60] Каждый повторяющийся фрагмент уже хранится в базе данных и, соответственно, может быть идентифицирован уникальным идентификатором.
[61] Каждый непрерывный участок представления большого объекта, не являющийся повторяемым, считается уникальным.
[62] Например, пусть добавляемый большой объект содержит строку «abcdefghicde», в результате поиска найден только один повторяемый фрагмент [cde], тогда оставшиеся непрерывные фрагменты являются уникальными.

[63] Шаг 104: получают (504) идентификаторы совпадающих фрагментов больших объектов из запоминающего устройства;
[64] Поскольку повторяемые фрагменты по определению уже содержатся в базе данных, то имеется возможность получить их идентификатор. Тип идентификатора не является ограничивающим и может быть, например, целочисленным числом.
[65] Каждый фрагмент может храниться в одной или более страницах размером, например 4096 байт. Поскольку размер страницы меньше размера возможного размера всего фрагмента, то фрагмент разделен на порции, каждая помещается в страницу. Каждая порция имеет формат, показанный на Фиг. 6, где TYPE (601) - тип, записи (в нашем случае - фрагмент). R0 (602) - зарезервировано, не используется. LENGTH (603) - размер порции в байтах. EXTRHDR (604) - расширенный заголовок, включает помимо всего прочего и идентификатор фрагмента, NEXT_PAGE_FRAGMENT (605) - номер страницы следующей порции, NEXT_FILE_FRAGMENT (606) - номер файла со страницей NEXT_PAGE_FRAGMENT, NEXT_SLOT_FRAGMENT (607) - номер слота на странице в котором расположена следующая порция, BODY (608) - непосредственно запись.
[66] Например, добавляемый большой объект содержит строку «abcdefghicde», и в результате поиска найден только один повторяемый фрагмент [cde] с идентификатором 22:

[67] Шаг 105: присваивают (505) каждому уникальному фрагменту полученного большого объекта идентификатор и сохраняют в запоминающее устройство;
[68] Поскольку уникальные фрагменты объекта полученного большого объекта по определению не содержатся в базе данных, то имеется необходимость их сохранить, назначив им уникальный идентификатор. Тип идентификатора не является ограничивающим и, например, может быть целочисленным числом. В некоторых вариантах осуществления идентификатор назначается инкрементно, и основным условием является, чтобы он был уникальным.
[69] Например, добавляемый большой объект содержит строку «abcdefghicde», и в результате поиска найден только один повторяемый фрагмент [cde] с идентификатором 22, и выделено два уникальных фрагмента: [ab], [fghi], которым при сохранении назначены уникальные идентификаторы 23 и 24 соответственно:

[70] Шаг 106: сохраняют (508) в базу данных большой объект как упорядоченную последовательность идентификаторов фрагментов, из которых он состоит.
[71] В результате поиска повторяемых, а также после сохранения уникальных фрагментов, каждый большой объект может быть представлен как последовательность идентификаторов фрагментов.
[72] Пусть добавляемый большой объект содержит строку «abcdefghicde», и в результате поиска найден один повторяемый фрагмент [cde] с идентификатором 22, и выделено два уникальных фрагмента: [ab], [fghi], которые были сохранены как фрагменты с идентификаторами 23 и 24 соответственно. Тогда исходный большой объект может быть представлен как последовательность следующих идентификаторов: [23][22][24][22]. Именно эта последовательность и сохраняется в базе данных как LOB объект.
[73] Последовательность фрагментов может храниться непосредственно в теле записи. Каждый идентификатор имеет фиксированный размер, и в теле записи фиксируется в префиксе количество фрагментов, а затем идут их значения. Например:
[LEN:3][ID=511][ID=551][ID=552]
[74] или
[LEN:5][ID=112][ID=122][ID=222][ID=875][ID=555]
[75] В некоторых вариантах осуществления, размер поля LEN и каждого поля ID - 4 байта и для хранения LOB-a из n фрагментов нужно (n+1)*4 байт.
[76] В некоторых вариантах осуществления изменяют повторяющийся фрагмент (406) для групповой модификации частично совпадающих объектов одной операцией (Фиг. 4).
[77] Поскольку большой объект представлен последовательностью идентификаторов фрагментов, из которых он состоит, то изменение любого фрагмента без изменения его идентификатора приводит к модификации содержимого всех объектов, в состав которых он входит.
[78] Например, база данных содержит следующие фрагменты:

[79] И следующие LOB объекты из них состоящие:

[80] Пусть одной операцией содержимое фрагмента с идентификатором 1 было заменено на «XX», тогда содержимое больших объектов будет изменено следующим образом:


[81] Поскольку большой объект представлен последовательностью идентификаторов фрагментов, из которых он состоит, то нет необходимости в повторном чтении фрагмента, ранее уже почтенного с ЗУ. (Фиг. 2)
[82] Например, два каких-либо объекта LOB1 и LOB2 содержат общий повторяемый фрагмент [CD].
[83] Тогда, в ходе чтения содержимого объекта LOB1 (201) будет прочтен (212) и фрагмент [CD], который может остаться в оперативном ЗУ.
[84] Тогда, в ходе чтения LOB2 (205) можно избежать (208) обращения к ЗУ (260) для получения фрагмента [CD], поскольку он уже прочтен ранее (212) и уже содержится в оперативном ЗУ (250).
Способ организации хранения исторических дельт записей
Способ организации хранения связанных данных
Способ организации хранения исторических дельт записей
Способ и система адаптивного управления свободным пространством памяти на запоминающем устройстве при работе с базами данных
Способ проведения разделения объектов базы данных на основе меток конфиденциальности

