Результат интеллектуальной деятельности: ФОРМИРОВАНИЕ ПОИСКОВОГО ЗАПРОСА НА ОСНОВЕ КОНТЕКСТА
Вид РИД
Изобретение
УРОВЕНЬ ТЕХНИКИ
[0001] Многие поиски в Internet запускаются посредством веб-страницы, которую просматривает пользователь. То есть, пользователь решает инициировать поиск после потребления контента на веб-странице. Для того чтобы реализовать поиск, пользователь должен покинуть веб-страницу, чтобы осуществить доступ к поисковой машине. Пользователь может копировать и вставлять слова из веб-страницы в поле поиска или вручную составлять поисковый запрос для ввода в поле поиска или веб-страницу поисковой машины. Каждый способ для генерирования поискового запроса может страдать от недостатков, таких как неконкретность, поисковые термины с многочисленными смысловыми значениями и неоднозначные взаимосвязи между поисковыми терминами.
[0002] После того как возвращены результаты поиска, пользователь может покинуть поисковый интерфейс и вернуться к просмотру веб-страницы. Эта смена между веб-страницей и поисковым интерфейсом является неэффективной. Более того, взаимодействие с различными пользовательскими интерфейсами (например, выбора текста, копирования, вставки и т.д.) может стать утомительным, в частности, на устройствах небольшого форм-фактора или устройствах с ограниченной способностью ввода текста, таких как мобильные телефоны, планшетные компьютеры, игровые консоли, телевизоры и т.д. По мере того, как все большее число пользователей осуществляет доступ к веб-страницам и другим электронным документам посредством устройств, отличных от традиционных компьютеров, будет увеличиваться необходимость гладкой интеграции потребления и осуществления поиска документов. Система, которая может так делать и дополнительно предоставлять улучшенные поисковые запросы, будет приносить пользу пользователям.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] Это краткое изложение сущности изобретения предоставлено для введения подборки концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Это краткое изложение сущности изобретения не предназначено ни для того, чтобы идентифицировать ключевые признаки или существенные признаки заявленного изобретения, ни для использования для ограничения объема заявленного изобретения.
[0004] Это раскрытие разъясняет способы для использования как области внимания пользователя на веб-странице или в другом документе, так и окружающего контекста для генерирования и ранжирования многочисленных поисковых запросов. Во время просмотра веб-страницы пользователь выбирает текст с веб-страницы. Выбор текста также генерирует команду для использования этого текста в качестве начальной точки для генерирования запросов-кандидатов - поисковых запросов, которые могут дать результаты, релевантные выбранному тексту. Многочисленные типы способов расширения поисковых запросов или переформулирования поисковых запросов могут быть применены для генерирования многочисленных запросов-кандидатов из выбранного текста. Пользователь может затем выбрать один из этих поисковых запросов для представления в поисковую машину. Таким образом, действие просмотра объединяется с действием поиска, создавая интерфейс, который обеспечивает возможность "просмотра для поиска" посредством простого выбора текста из веб-страницы и затем выбора одного из запросов-кандидатов.
[0005] Для того чтобы направить пользователя к поисковому запросу из набора запросов-кандидатов, учитывается контекст документа. Оценка запросов-кандидатов в свете контекста, предоставляемого просматриваемой веб-страницей, используется для ранжирования соответствующих запросов-кандидатов. Учет окружающего контекста помогает при ранжировании запросов-кандидатов, так как просматриваемая веб-страница может содержать слова, которые могут быть использованы (возможно с модификациями) для устранения неоднозначности терминов в запросах-кандидатах и сравнения запросов-кандидатов с предыдущими поисковыми запросами, относящимися к той же веб-странице.
[0006] Ранжирование запросов-кандидатов может быть выполнено посредством языковой модели, способа классификации или их комбинации. Языковая модель может быть реализована как модель, которая определяет вероятность запроса-кандидата, при заданном выбранном тексте и окружающем контексте. Способ классификации использует обучающие данные, которые содержат выбранный текст на веб-странице и ассоциированные запросы. Люди-инспектора определяют, приведет ли, скорее всего, выбранный текст веб-страницы в результате к выполнению ассоциированного поискового запроса пользователем. Если это так, то пара выбранного текста и запроса используется системой машинного обучения для обучения функции, которая предсказывает уровень достоверности для запроса-кандидата, при заданном выбранном тексте и контексте.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Подробное описание изложено со ссылкой на прилагаемые фигуры. На фигурах самая левая цифра(ы) ссылочного номера идентифицирует фигуру, на которой ссылочный номер впервые появляется. Использование одинаковых ссылочных номеров на разных фигурах указывает аналогичные или идентичные элементы.
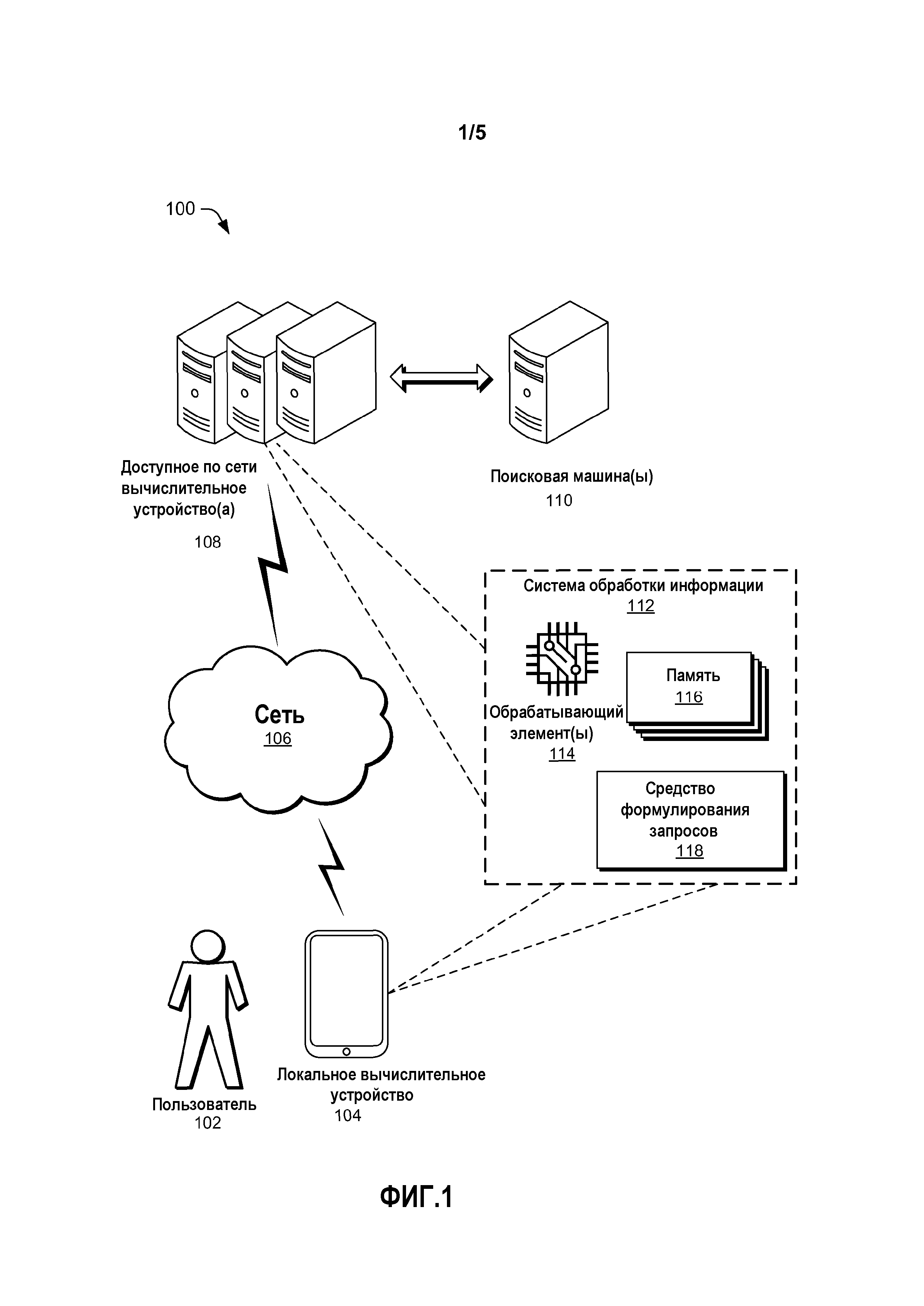
[0008] Фиг. 1 является иллюстративной архитектурой, показывающей систему обработки информации, включающую в себя средство формулирования запросов.
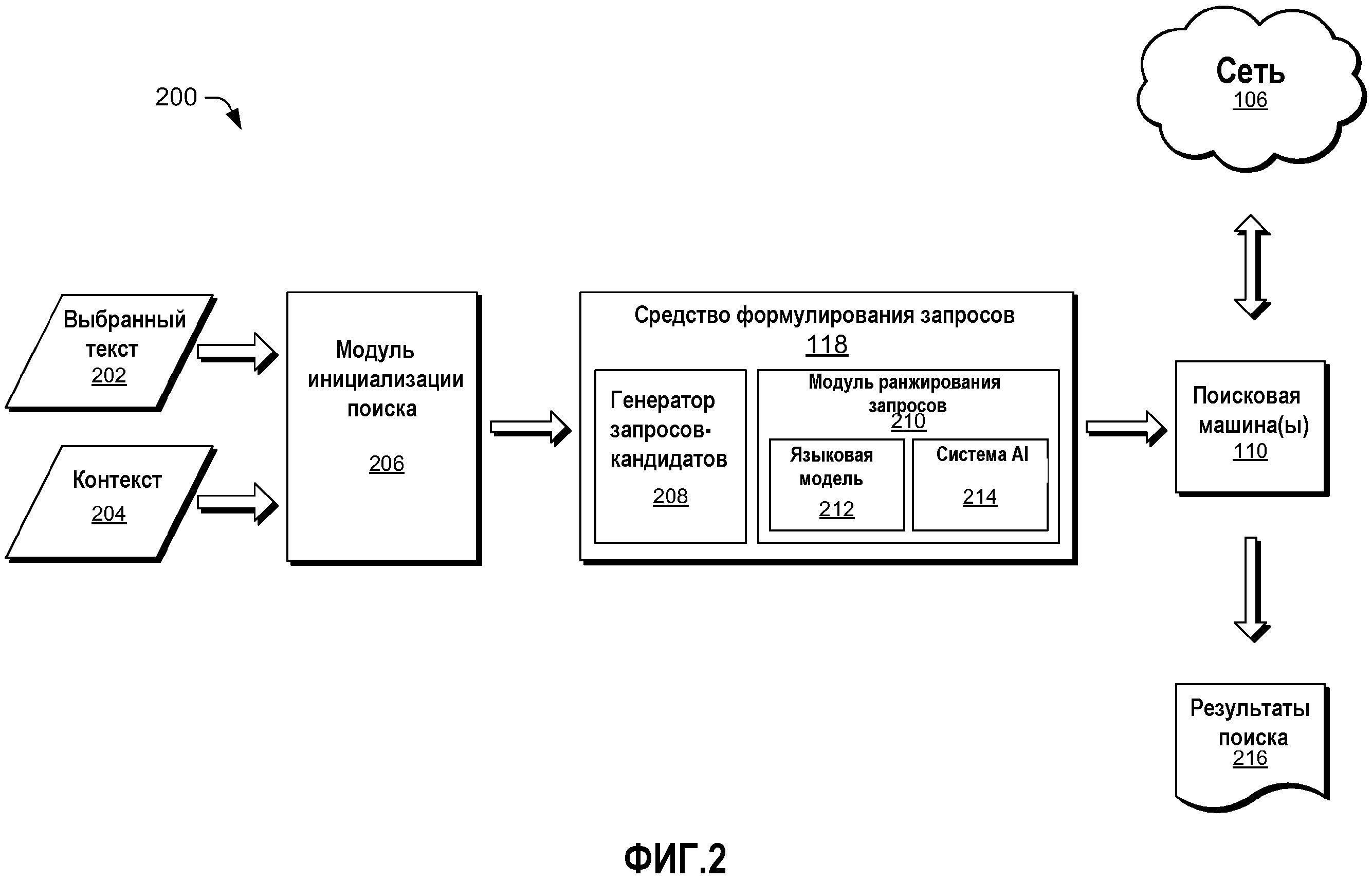
[0009] Фиг. 2 показывает схематичное представление иллюстративных данных и компонентов из архитектуры по Фиг. 1.
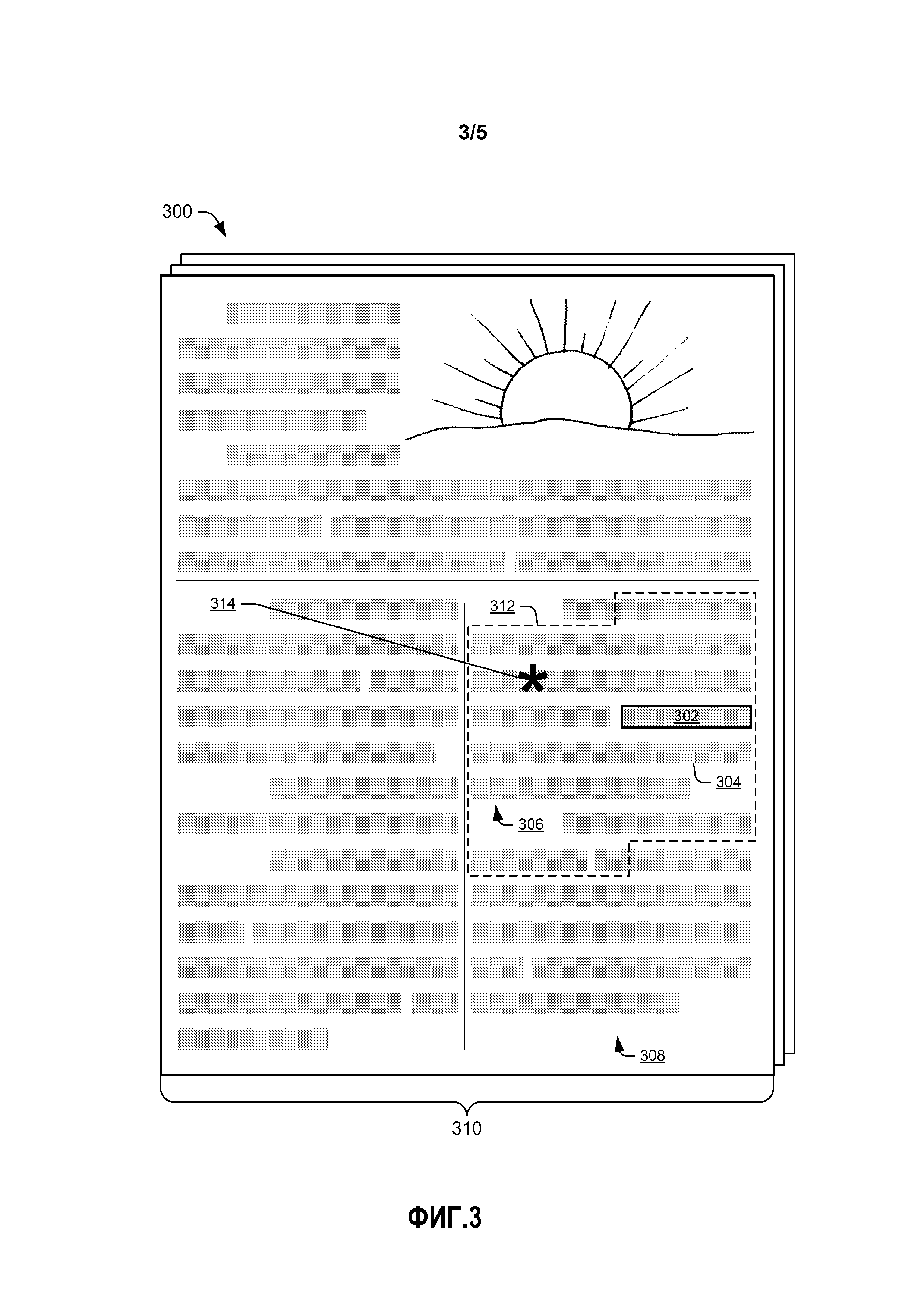
[0010] Фиг. 3 показывает иллюстративный документ с выбранным текстом.
[0011] Фиг. 4 показывает два иллюстративных пользовательских интерфейса для осуществления выбора текста.
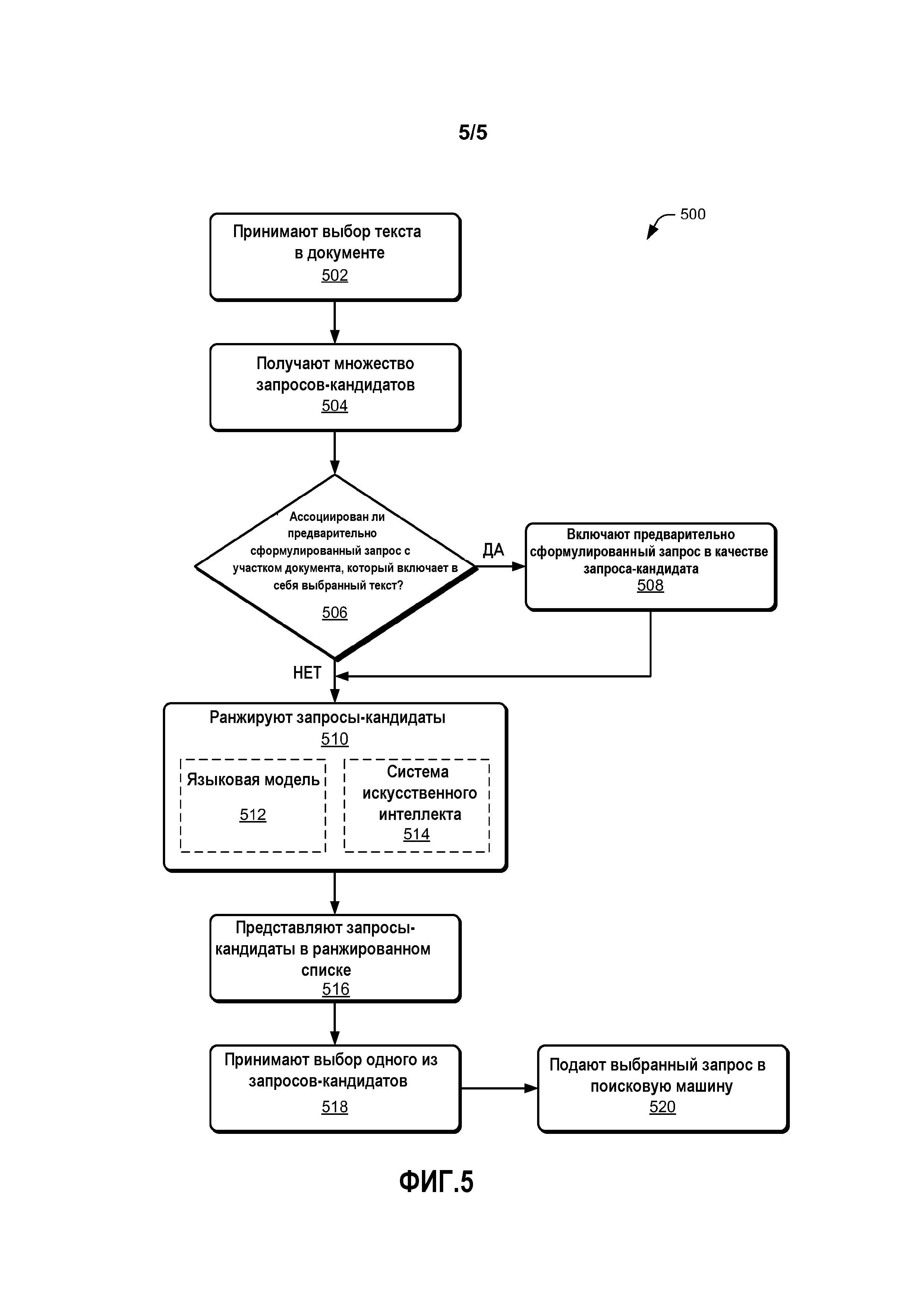
[0012] Фиг. 5 является иллюстративной схемой последовательности операций, показывающей иллюстративный способ предоставления ранжированного списка запросов-кандидатов в ответ на пользовательский выбор текста.
ПОДРОБНОЕ ОПИСАНИЕ
Иллюстративная архитектура
[0013] Фиг. 1 показывает архитектуру 100, в которой пользователь 102 может взаимодействовать с локальным вычислительным устройством 104 для получения поисковых запросов. Локальным вычислительным устройством 104 может быть любой тип вычислительного устройства, такой как настольный компьютер, компьютер типа "ноутбук", планшетный компьютер, интеллектуальный телефон, игровая консоль, телевизор и т.д. Локальное вычислительное устройство 104 может осуществлять связь через сеть 106 с одним или более доступными по сети вычислительными устройствами 108. Сетью 106 может быть любой из одного или более типов сетей обмена данными, такой как локальная сеть, глобальная сеть, Интернет, телефонная сеть, кабельная сеть, одноранговая сеть, ячеистая сеть и подобные. Доступные по сети вычислительные устройства 108 могут быть реализованы как любой тип или комбинация типов вычислительных устройств, таких как сетевые серверы, веб-серверы, файловые серверы, суперкомпьютеры, настольные компьютеры и подобные. Доступные по сети вычислительные устройства 108 могут включать в себя или быть коммутативно соединены с одной или более поисковыми машинами 110. Поисковая машина(ы) 110 может быть реализована на одном или более выделенных вычислительных устройствах, обслуживаемых организацией, которая предоставляет услуги поиска.
[0014] Система 112 обработки информации содержит один или более обрабатывающих элементов 114 и память 116, распределенные по одному или более местоположениям. Обрабатывающие элементы 114 могут включать в себя любую комбинацию из центральных процессоров (CPU), графических процессоров (GPU), одноядерных процессоров, многоядерных процессоров, специализированных интегральных схем (ASIC) и подобных. Один или более обрабатывающих элементов 114 могут быть реализованы в программном обеспечении и/или программно-аппаратных средствах в дополнение к аппаратным реализациям. Программные или программно-аппаратные реализации обрабатывающего элемента(ов) 114 могут включать в себя исполняемые компьютером или машиной инструкции, написанные на любом подходящем языке программирования для выполнения различных описанных функций. Программные реализации обрабатывающего элемента(ов) 114 могут храниться полностью или частично в памяти 116.
[0015] Память 116 может хранить программы инструкций, которые загружаются в обрабатывающий элемент(ы) 114 и исполняются на нем, также как и данные, сгенерированные во время исполнения этих программ. Примеры программ и данных, хранящихся в памяти 116, могут включать в себя операционную систему для управления операциями аппаратных средств и программных ресурсов, доступных локальному вычислительному устройству 104, доступному по сети вычислительному устройству(ам) 108, драйверам для взаимодействия с аппаратными устройствами, протоколам связи для отправки данных в сеть 106 и/или приема из нее, также как и другим вычислительным устройствам и дополнительным программным приложениям. В зависимости от конфигурации и типа локального вычислительного устройства 104 и/или доступного по сети вычислительного устройства (устройств) 108, память 116 может быть энергозависимой (такой как RAM) и/или энергонезависимой (такой как ROM, флэш-память и т.д.).
[0016] Система 112 обработки информации может также включать в себя дополнительные машиночитаемые носители, такие как съемное хранилище, несъемное хранилище, локальное хранилище и/или удаленное хранилище. Память 116 и любые ассоциированные машиночитаемые носители могут обеспечить хранение машиночитаемых инструкции, структур данных, программных модулей и других данных. Машиночитаемые носители включают в себя, по меньшей мере, два типа машиночитаемых носителей, а именно, компьютерные носители информации и коммуникационные среды.
[0017] Компьютерные носители информации включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные носители информации включают в себя, но не ограничены этим, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другие оптические накопители, магнитные кассеты, магнитную пленку, хранилище на магнитных дисках или другие магнитные запоминающие устройства, или любой другой непередающий носитель, который может быть использован для хранения информации для осуществления доступа посредством вычислительного устройства.
[0018] В отличие от этого, коммуникационные среды могут воплотить машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна, или другом механизме передачи. Как задано в настоящем документе, компьютерные носители информации не включают в себя коммуникационные среды.
[0019] Система 112 обработки информации может существовать полностью или частично либо на локальном вычислительном устройстве 104, либо на доступном по сети вычислительном устройстве(ах) 108, или на обоих. Таким образом, система 112 обработки информации может быть распределенной системой, в которой различные физические компоненты и компоненты данных существуют в одном или более размещениях и функционируют совместно для выполнения роли системы 112 обработки информации. В некоторых реализациях все признаки системы 112 обработки информации могут быть представлены на локальном вычислительном устройстве 104. В других реализациях локальное вычислительное устройство 104 может быть тонким клиентом, который лишь принимает данные отображения и передает сигналы пользовательского ввода другому устройству, такому как доступное по сети вычислительное устройство(а) 108, которое содержит систему 112 обработки информации.
[0020] Система 112 обработки информации может содержать средство 118 формулирования запросов, которое формулирует поисковые запросы для пользователя 102. В некоторых реализациях средство 118 формулирования запросов может храниться полностью или частично в памяти 116. В других реализациях средство 118 формулирования запросов может быть реализовано как часть обрабатывающего элемента(ов) 114, такая как участок ASIC. Подобно самой системе 112 обработки информации, средство 118 формулирования запросов может существовать полностью или частично либо на локальном вычислительном устройстве 104, либо на доступном по сети вычислительном устройстве(ах) 108, или на обоих. В реализациях, в которых все или часть средства 118 формулирования запросов размещена избыточно на многочисленных вычислительных устройствах, выбор того, какое вычислительное устройство использовать для реализации средства 118 формулирования запросов, может быть основан на относительных скоростях обработки, скорости передачи информации по сети 106 и/или других факторах.
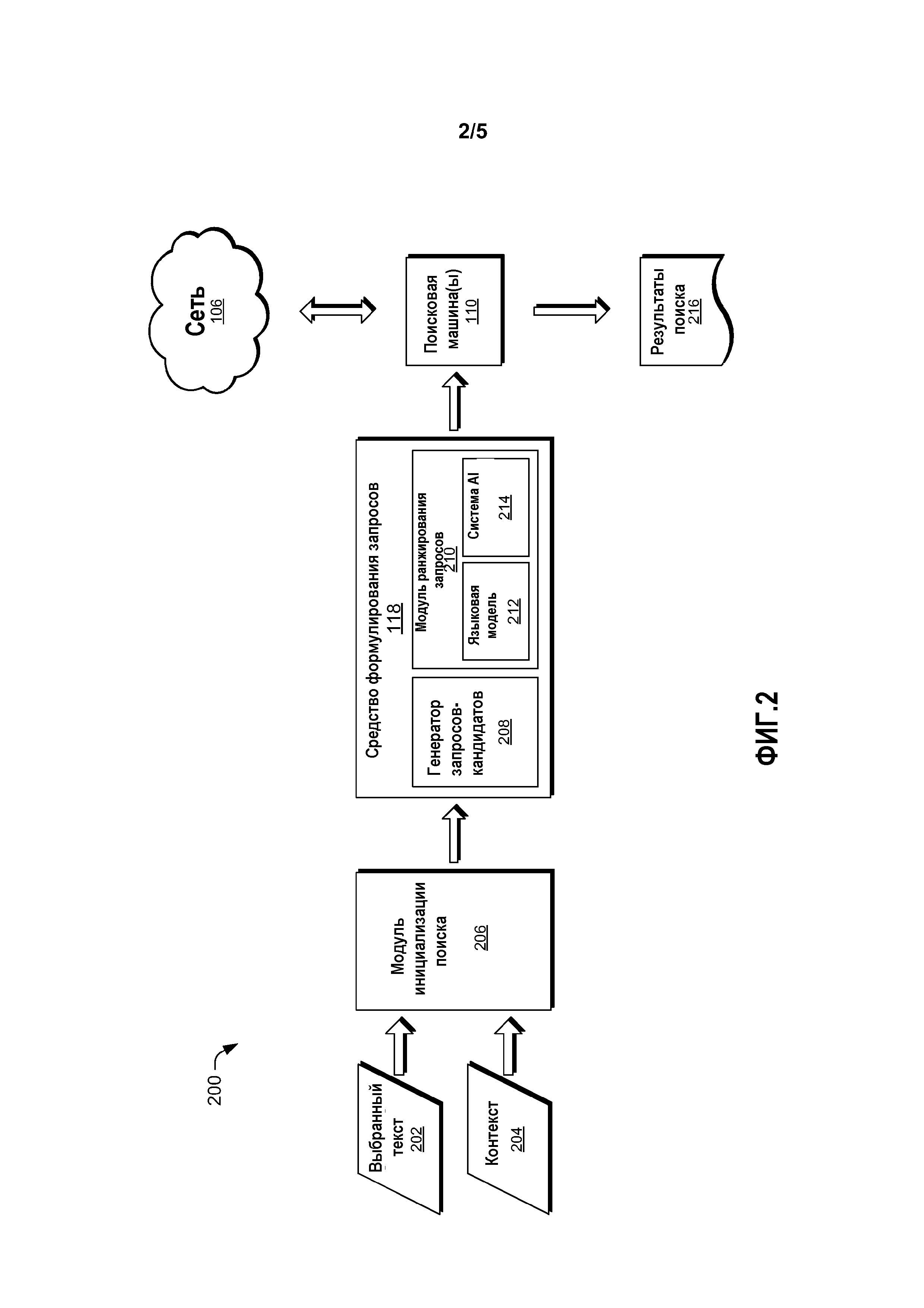
[0021] Фиг. 2 показывает поток информации и данных через средство 118 формулирования запросов и другие участки архитектуры 100, показанной на Фиг. 1. Когда пользователь 102 выбирает текст из документа, это предоставляет входные сигналы для средства 118 формулирования запросов, чтобы сформулировать запросы. Выбранный текст 202 и контекст 204 принимаются модулем 206 инициализации поиска. Выбранный текст 202 может быть выбран пользователем 102, взаимодействующим с локальным вычислительным устройством 104, для выбора или указания прохода или проходов текста посредством любого традиционного механизма для выбора текста из документа. Контекст 204 может включать в себя другой текст в документе, который окружает выбранный текст 202 или размещается вблизи него. Контекст 204 может также включать в себя классификацию документа на основе намеченного или вероятного использования документа. Например, если документом является веб-страница и веб-страница идентифицирована как веб-страница продавца для продажи товаров и услуг, то контекст 204 может распознать, что пользователь 102 вероятно ищет товар или услугу для покупки. Предыдущие действия пользователя 102 до выбора текста 202 могут также предоставить контекст 204. Например, поисковые запросы, недавно предъявленные пользователем 102, могут предоставить контекст 204 касательно темы или области, которую пользователь 102 ищет в текущий момент.
[0022] Модуль 206 инициализации поиска может интерпретировать одиночный ввод от пользователя, который выбирает выбранный текст 202, как выбор текста и как команду для генерирования поискового запроса на основе выбранного текста 202. Например, если пользователь 102 перемещает курсор, чтобы выбрать прилегающую последовательность текста из документа, пользователю 102 не требуется вставлять или перемещать этот текст в другой интерфейс для приема предложений поисковых запросов. Сам выбор текста может быть интерпретирован модулем 206 инициализации поиска как команда для генерирования одного или более поисковых запросов. Эта двойная роль модуля 206 инициализации поиска обеспечивает пользователю возможность как выбора текста, так и запроса поисковых запросов с помощью только одиночного ввода или взаимодействия с локальным вычислительным устройством 104.
[0023] Модуль 206 инициализации поиска пересылает выбранный текст 202, контекст 204 и команду для генерирования поисковых запросов в средство 118 формулирования запросов. Средство 118 формулирования запросов может включать в себя генератор 208 запросов-кандидатов, который генерирует запросы-кандидаты, исходя из выбранного текста 202. Генератор 208 запросов-кандидатов может применить способы расширения запросов или переформулирования запросов к выбранному тексту 202. Генератор 208 запросов-кандидатов может создать запросы-кандидаты из выбранного текста 202 посредством включения синонимов, добавления замещающих морфологических слов, правильных произношений искаженных слов и/или предоставления замещающих произношений слов. Когда пользователям не удается точно выбрать представляющий интерес текст, например, когда текст выбран посредством обрисовки овала вокруг него (с использованием пальца), слово или фраза могут случайно быть разбиты на две части. Работа по постобработке может включать в себя удаление нерелевантных букв или приставление/добавление релевантных букв из выбранного текста. В некоторых реализациях журнал запросов для запросов, ассоциированных с документом, используется для генерирования запросов-кандидатов. Способы расширения запросов, которые используют журнал запросов, могут включать в себя применение алгоритма k-средних (k-means) к журналу запросов, проведение случайного поиска по двухкомпонентному графику запрос-документ, сгенерированному посредством осуществления анализа журнала запросов, выполнение алгоритма PageRank в отношении графика запрос-поток, сгенерированного из журнала запросов, или интеллектуальный анализ шаблонов ассоциации с терминами из журнала запросов.
[0024] Генератор 208 запросов-кандидатов может непосредственно генерировать запросы-кандидаты, или генератор 208 запросов-кандидатов может переадресовать выбранный текст 202 в другой модуль или систему вне средства 118 формулирования запросов (например, модуль средства переформулирования запросов, ассоциированный с поисковой машиной). Генератор 208 запросов-кандидатов может эффективно генерировать запросы-кандидаты посредством передачи выбранного текста 202 в другую систему или модуль и затем приема запросов-кандидатов извне модуля или системы. Генератор 208 запросов-кандидатов может сгенерировать любое число запросов из выбранного текста 202. В некоторых реализациях число запросов-кандидатов, сгенерированных генератором 208 запросов-кандидатов, может быть ограничено предварительно заданным числом, таким как 3 запроса, 10 запросов и т.д.
[0025] Как только получено некоторое число запросов-кандидатов, модуль 210 ранжирования запросов может ранжировать запросы-кандидаты на основе возможности или вероятности того, что эти запросы соответствуют выбранному тексту 202 и контексту 204. Средство 118 формулирования запросов может выполнить как генерирование запросов-кандидатов, так и ранжирование этих запросов-кандидатов без подачи запросов в поисковую машину 110, тем самым уменьшая нагрузку на поисковую машину 110.
[0026] Модуль 210 ранжирования запросов может ранжировать один или более запросов-кандидатов на основе одного или более способов ранжирования. Способы ранжирования, которые могут быть использованы, включают в себя языковую модель 212 и систему 214 искусственного интеллекта (AI). Каждая может быть использована независимо или совместно.
[0027] Языковая модель 212 может создать биграммное представление контекста 204 выбранного текста 202. Контекст 204 может включать в себя участок текста из документа, который включает в себя выбранный текст 202. Таким образом, контекстом 204 может быть выбранный текст 202 плюс дополнительный текст из документа. Языковая модель 212 может определить относительные ранги запросов-кандидатов из генератора 208 запросов-кандидатов на основе числа слов в каждом из соответствующих запросов-кандидатов, числа слов в выбранном тексте 202 и числа слов в участке текста, который образует контекст 204. Подробности языковой модели 212 рассмотрены ниже.
[0028] Система 214 искусственного интеллекта может быть реализована как любой тип системы искусственного интеллекта или машины, такой как машина опорных векторов, нейронная сеть, экспертная система, Байесовская сеть доверия, механизм нечеткой логики, механизм слияния данных и подобные. Система 214 искусственного интеллекта может быть создана из маркированных человеком обучающих данных. Совокупность кортежей <документ, запрос>, представляющая документы и запросы, ассоциированные с этими документами, полученные из последнего потребления документов и поведения при поиске одного или более пользователей, может служить в качестве всех или части обучающих данных. В некоторых реализациях кортежи могут быть получены из журналов поиска из поисковой машины 110 от пользователей, которые выбрали предоставлять их поведение при просмотре и поиске поисковой машине 110. Данные просмотра и поиска могут быть анонимизированы для защиты конфиденциальности пользователей, которые выбрали внести свои данные. Люди-маркировщики, обозревающие кортежи, определяют, есть ли причинно-следственная связь между документом и запросом. Другими словами, люди-маркировщики присваивают маркер каждому кортежу на основе их субъективной оценки вероятности того, что содержимое документа в кортеже побуждает пользователей представлять запрос в этом кортеже. Подробности одной реализации системы 214 искусственного интеллекта рассмотрены ниже.
[0029] Как только средство 118 формулирования запросов сформулировало запросы и проранжировало эти запросы, пользователю 102 может быть представлен ранжированный список запросов. Запросы с более высокими рангами могут быть приведены раньше или в более заметном положении в списке, чем те запросы с более низкими рангами. Пользователь 102 может выбрать один из запросов-кандидатов, чтобы инициировать запрос на одной или более поисковых машинах 110 на основе запроса.
[0030] Поисковая машина(ы) 110 может подать запрос в сеть 106 или другое хранилище данных и принять результаты 216 поиска на основе алгоритма поиска, выбранного запроса и данных, доступных в сети 106. Поисковая машина(ы) 110 может использовать любой традиционный способ поиска для обработки выбранного поискового запроса.
Иллюстративная языковая модель
[0031] Языковая модель 212 ранжирует запросы-кандидаты на основе контекста 204. Запросы-кандидаты ранжируются по условной вероятности p(q|s,c), которая представляет возможность генерирования одного из запросов из запросов-кандидатов, запроса q, при заданном выбранном тексте 202, представленном как s, и контексте 204, представленном как c. Языковая модель 212 предполагает, что q=qw1, qw2, qwNq, s=sw1, sw2, swNs и с=cw1, cw2, cwNc, где qwi, swi и cwi представляют собой i-ое слово в запросе q, выбранном тексте s и контексте с, соответственно. В языковой модели 212 Nq обозначает длину слова запроса q, Ns обозначает длину слова выбранного текста s, и Nc обозначает длину слова контекста c.
[0032] Языковая модель 212 включает в себя дополнительное предположение, что обусловленное выбранным текстом s и контекстом c каждое слово qwi запроса зависит только от его предшествующего слова qwi-1. Это предположение аналогично предположению, сделанному для биграммной языковой модели. Биграммное представление желательно для некоторых реализаций, так как униграммная модель может не улавливать взаимосвязь на уровне терминов внутри запроса. И наоборот, n-граммные (n≥3) подходы могут иметь высокую вычислительную сложность, что может потенциально быть слишком затратным по времени для предложения запросов по сети. Однако, по мере продолжения увеличения способностей обработки, вычислительная сложность 3-граммных (или более высоких) подходов будет вероятно становиться менее затратной по времени, и предполагается, что языковая модель 212 может быть адаптирована, чтобы согласовываться с n-граммными (n≥3) подходами.
[0033] Исходя из вышеуказанных определений и предположений, возможность генерирования одного из запросов из запросов-кандидатов, при заданном выбранном тексте 202 и контексте 204, может быть представлена как:
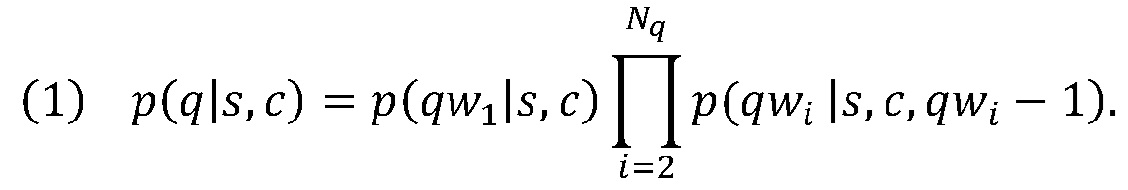
[0034] При вышеуказанной формулировке для более длинных запросов характерны меньшие вероятности. Чтобы уменьшить этот эффект, вероятность умножается на дополнительный вес, и более длинному запросу присваивается больший вес. Пересмотренная вероятность может быть вычислена посредством:
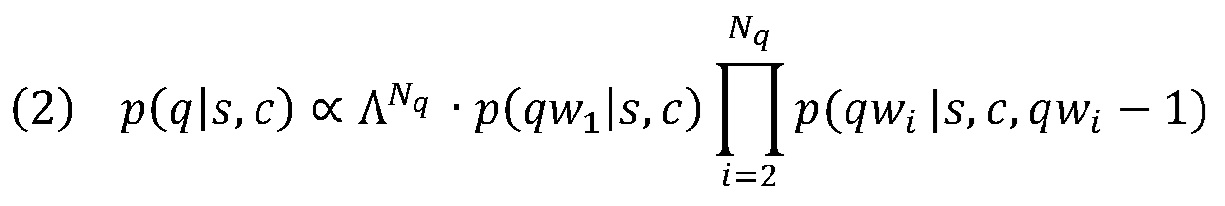 ,
,
где Λ является константой, большей, чем 1.
[0035] Формулировка для вычисления p(qwi|s,c):
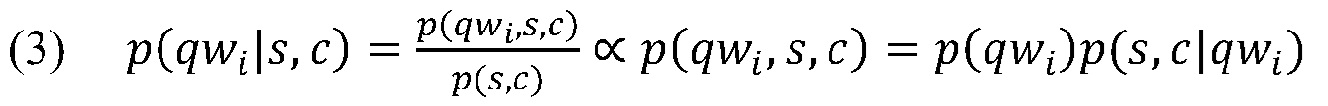 .
.
p(s,c) может быть здесь проигнорирована, так как каждый из запросов-кандидатов, которые ранжируются, основывается на одном и том же выбранном тексте s и контексте c.
[0036] Глобальная совокупность запросов может быть использована для оценки значения p(qwi). При заданной совокупности Q запросов значение p(qwi) может быть вычислено посредством:
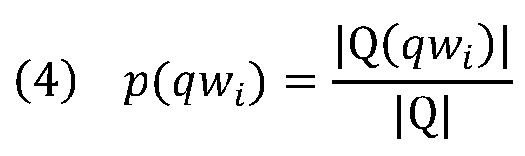 ,
,
где |Q(qwi)| обозначает число запросов в совокупности запросов, которая содержит слово qwi, и |Q| выражает общее число запросов в глобальной совокупности запросов.
[0037] Может быть использована сглаженная версия уравнения 4:
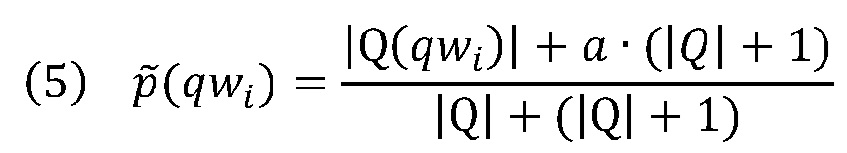 ,
,
где a является константой между 0 и 1.
[0038] Другая вероятность в уравнении 3 может быть получена как следует ниже. Предположим, что выбранный текст s и контекст с независимо обусловлены каким-либо словом qwi запроса:
(6) p(s,c|qwi)=p(s|qwi)p(c|qwi).
[0039] Чтобы упростить данную функцию, языковая модель 212 дополнительно предполагает, что, будучи обусловленными каким-либо словом qwi запроса, слова выбранного текста s или контекста с могут быть сгенерированы независимо. Таким образом,
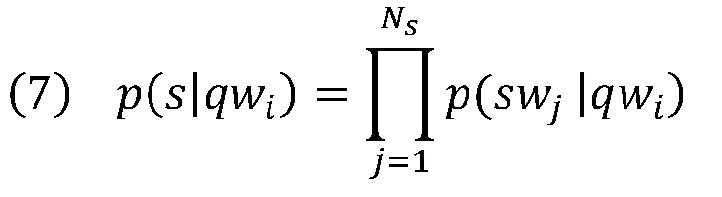
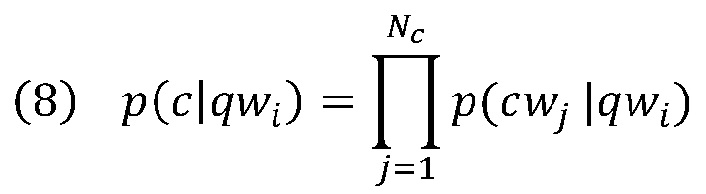 ,
,
где p(swj|qwi) является вероятностью появления swj вместе с qwi, когда qwi существует. Эта вероятность может быть оценена с использованием глобальной совокупности запросов:
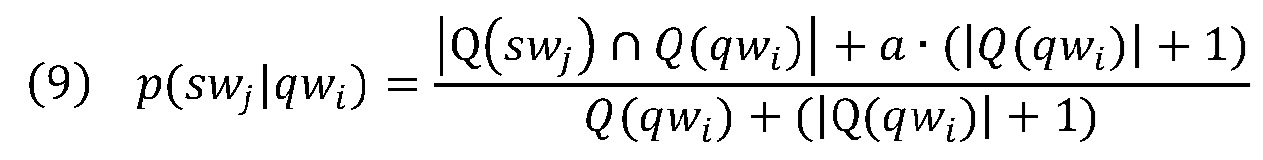 ,
,
где |Q(swj)∩Q(qwi)| является числом запросов, содержащих swj и qwi, одновременно в глобальной совокупности запросов, |Q(qwi)| обозначает число запросов в совокупности запросов, которая содержит слово qwi, и a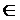 (0,1) используется для сглаживания.
(0,1) используется для сглаживания.
[0040] Значение p(cwj|qwi) может быть вычислено аналогично. Согласно уравнениям 7 и 8, значения p(s|qwi) и p(c|qwi) являются несбалансированными, так как Ns всегда гораздо меньше, чем Nc. Нормализованные значения p(s|qwi) и p(c|qwi) могут быть использованы для решения этого дисбаланса.
[0041] Нормализованная формулировка p(s|qwi):
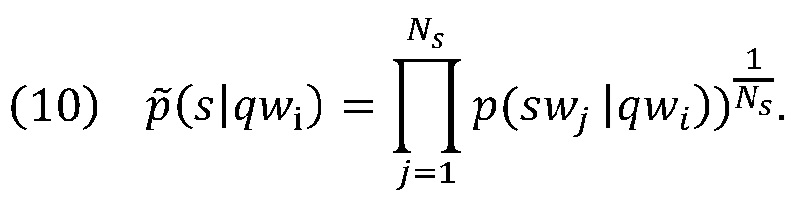
[0042] Аналогично, нормализованное значение p(c|qwi) может быть вычислено посредством:
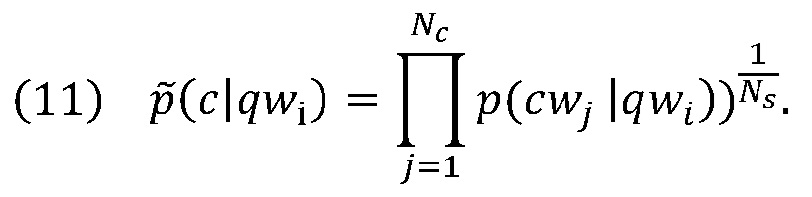
[0043] Формулировка для вычисления p(qwi-1|s,c,qwi-1):
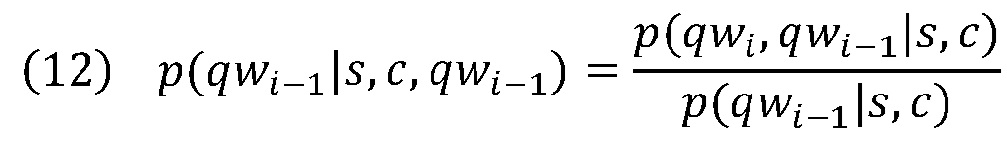 ,
,
где p(qwi-1|s,c) может быть вычислена посредством уравнения 3. Так как p(s,c) принимает одно и то же значение для всех запросов-кандидатов на основе одного и того же выбранного текста 202 и того же контекста 204:
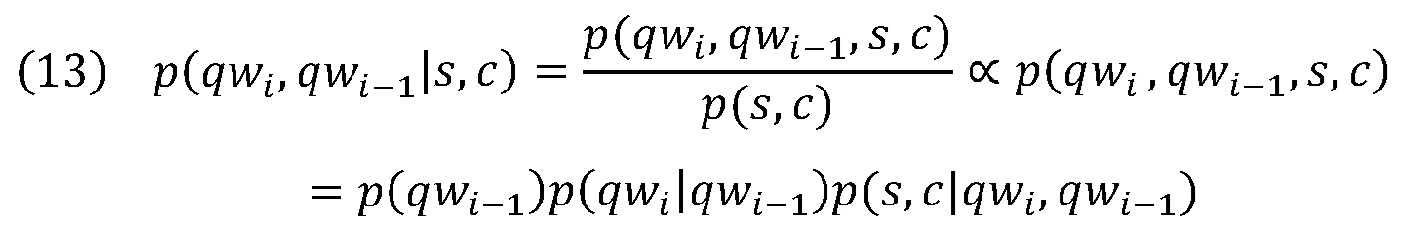 ,
,
где p(qwi-1) может быть вычислена посредством уравнения 5. p(qwi|qwi-1) является вероятностью появления qwi сразу после qwi-1, когда qwi-1 существует. Однако, при вычислении этой вероятности с использованием глобальной совокупности запросов слова qwi-1 и qwi могут редко появляться последовательно, так как глобальная совокупность запросов является разреженной. Для учета этой вероятности p(qwi|qwi-1) может быть оценена как вероятность появления qwi вместе с qwi-1, когда qwi-1 существует (не требуя, чтобы qwi и qwi-1 появлялись в прямой последовательности), которая может быть вычислена согласно уравнению 9.
[0044] Наконец, формулировка для вычисления вероятности p(s,с|qwi, qwi-1) предоставлена ниже. Для упрощения языковая модель 212 предполагает, что выбранный текст s и контекст с независимо обусловлены двумя словами qwi и qwi-1 запроса. Это дает:
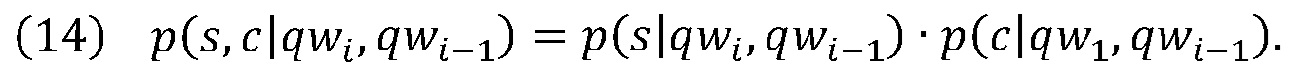
[0045] Аналогично уравнению 7, языковая модель 212 предполагает, что обусловленные двумя словами qwi и qwi-1 запроса, слова в выбранном тексте s или контексте с могут быть сгенерированы независимо. Таким образом,
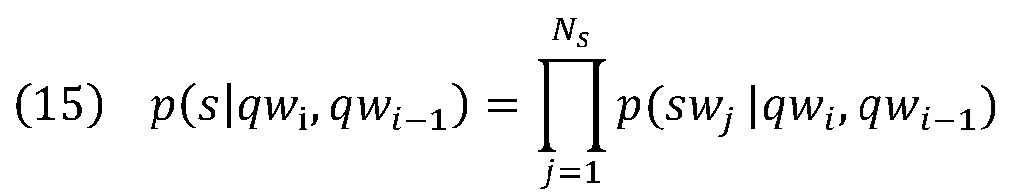
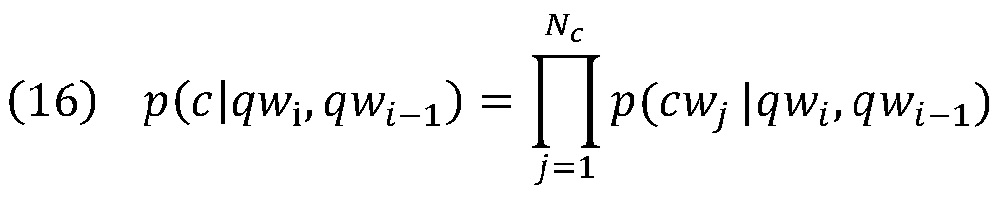 ,
,
где p(swj|qwi, qwi-1) может быть оценена посредством глобальной совокупности запросов:
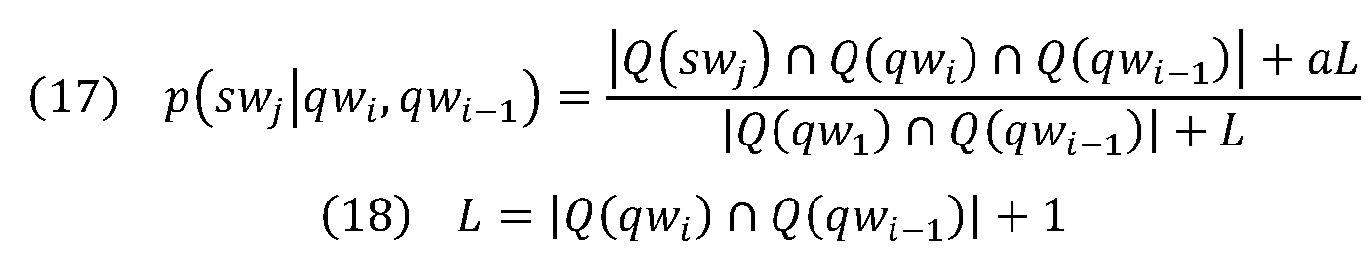 ,
,
где |Q(swj)∩Q(qwi)∩Q(qwi-1)| выражает число запросов в глобальной совокупности запросов, которая содержит слова swj, qwi и qwi-1 одновременно. |Q(qwi)∩Q(qwi-1)| и a имеют аналогичные значения как в уравнении 9.
[0046] Аналогично уравнению 10, вероятность p(s|qwi, qwi-1) может быть нормализована:
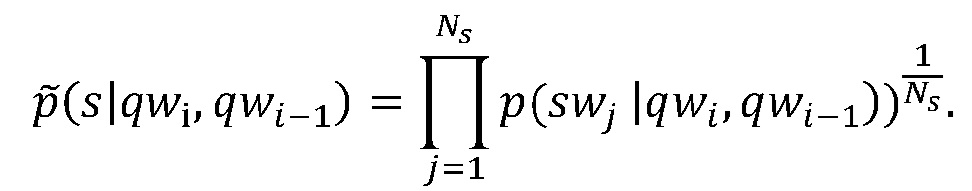
Значение p(c|qwi, qwi-1) может быть вычислено и нормализовано аналогичным образом.
Иллюстративная система искусственного интеллекта
[0047] Система 214 искусственного интеллекта может реализовать способ классификации для ранжирования запросов-кандидатов. В способе классификации люди-инспектора оценивают ассоциации между документами и запросами q, ассоциированными с этими документами. До маркировки людьми-инспекторами может быть неизвестно, вызвало ли запрос содержимое документа, или является ли ассоциация между документом и запросом лишь случайной или не относящейся к документу.
[0048] Люди-маркировщики классифицируют запрос, исходя из одной из пар документ-запрос, либо как ассоциированный с контекстом документа, либо как не ассоциированный с контентом документа, либо как неоднозначно относящийся к контенту документа. Таким образом, люди-маркировщики обозревают совокупность кортежей <документ, запрос>. Кортежи могут быть сгенерированы посредством фактического поведения пользователей при просмотре и поиске и сохранены в глобальной совокупности запросов. Это может быть также самая глобальная совокупность запросов, используемая языковой моделью 212. Каждый документ в кортежах <документ, запрос> может быть представлен как выбранный текст s из документа и контекст с, который включает в себя выбранный текст s. Вследствие этого, работа людей-маркировщиков может быть представлена как пары маркировки <s, c> и q, которые затем используются как обучающие данные для системы 214 искусственного интеллекта. В некоторых реализациях в качестве обучающих данных могут быть использованы только пары <s, c> и q, в которых запрос может быть промаркирован как ассоциированный с контентом документа.
[0049] Система 214 искусственного интеллекта использует обучающие данные для обучения функции f(‹s, c›q)→{-1, +1}. Функция f может быть применена к новым данным, таким как выбранный текст 202, контекст 204 и запросы-кандидаты с Фиг. 2, чтобы предсказать уровень достоверности того, что соответствующие запросы-кандидаты ассоциированы с контентом документа. Уровень достоверности для различных запросов-кандидатов может быть использован для ранжирования запросов-кандидатов посредством модуля 210 ранжирования запросов.
[0050] Ручная маркировка взаимосвязей документ-запрос может быть утомительной. Псевдообучающие данные могут быть использованы для уменьшения объемов работ по ручной маркировке и для получения большего количества обучающих данных, чтобы улучшить точность функции f. Псевдообучающие данные могут быть созданы посредством идентификации поисковых запросов в глобальной совокупности запросов, которые были предъявлены пользователями вскоре после просмотра пользователями документа, спаренного с запросом. Эта близкая временная взаимосвязь может подсказать, что контент документа побудил пользователя сгенерировать запрос q. Автоматическое текстовое сравнение аналогии между поисковым запросом q и контентом с документа может, или не может, идентифицировать фразу p в документе, которая аналогична поисковому запросу q. Если такая фраза p идентифицирована посредством автоматического анализа, предполагается, что фраза p, при заданном окружающем контексте c, могла вызвать или породить поисковый запрос q. Это генерирует пары (<p, c>, q) без ручной маркировки, которые могут быть добавлены к обучающим данным для системы 214 искусственного интеллекта.
Иллюстративные пользовательские интерфейсы
[0051] Фиг. 3 показывает иллюстративный документ 300, который может быть отображен на локальном вычислительном устройстве 104. Документом 300 может быть веб-страница, текстовый документ, документ обработки текста, документ электронных таблиц или любой другой тип документа, содержащий текст в любом формате, включая, но не ограниченный этим, документ, написанный на языке разметки, таком как язык разметки гипертекста (HTML) или расширяемый язык разметки (XML). Документ 300 иллюстрирует многочисленные примеры контекста для текста, выбранного пользователем 102.
[0052] Выбранный пользователем текст 302 показан жирным прямоугольником, окружающим слово или слова, выбранные пользователем 102. Пользователь 102 может также выбрать части слов или одиночные буквы. Выбранный текст 302 указывает участок документа 300, на который обращено внимание пользователя. Выбранный текст 302 существует внутри контекста документа 300. Объем документа 300, который рассматривается как контекст языковой моделью 212 или системой 214 искусственного интеллекта, может варьироваться.
[0053] В некоторых реализациях весь документ 300 может предоставить контекст для выбранного текста 302. Весь документ 300 может включать в себя многочисленные страницы, некоторые из которых не отображены и некоторые из которых могут не быть просмотрены пользователем. Более узкий вид контекста может включать в себя только предложение 304, которое включает в себя выбранный текст 302. В других реализациях контекст может быть задан как абзац 306, который включает в себя выбранный текст 302, колонку 308 (или фрейм в раскладке веб-страницы), которая включает в себя выбранный текст 302, или страница 310 документа 300, которая включает в себя выбранный текст 302. Для любого типа документа, включающего в себя эти документы без предложений, абзацев и/или страниц, контекст может быть задан как относительно больший или относительно меньший участок всего документа 300.
[0054] Контекстом может также быть участок текста 312, который имеет предварительно заданное число слов или букв и включает в себя выбранный текст 302. Например, сегмент из 60 слов документа 300, включающего в себя выбранный текст 302, может быть использован в качестве контекста. Этот участок текста 312 может перекрывать многочисленные предложения, абзацы, колонки или подобное и начинаться или заканчиваться в середине предложения, абзаца, колонки и т.д. Длина в 60 слов является лишь иллюстративной, и контекст может быть любой длины, такой как 100 слов, 20 слов, или, в качестве альтернативы, быть основанным на буквах и включать в себя 20 букв, 100 букв, 500 букв или некоторое другое число слов или букв.
[0055] В некоторых реализациях выбранный текст 302 размещается по существу в середине участка текста 312. Например, если выбранный текст 302 имеет три слова и участок текста 312 включает в себя 60 слов, то выбранный текст 302 может быть размещен на отдалении около 23 или 24 слов (т.е. 60-3=57; 57÷2=23,5) от начала участка текста 312, который образует контекст. В некоторых реализациях выбранный текст 302 может быть размещен в середине 50% участка текста 312 (т.е. не в первой ¼ и не в последней ¼) или в середине 20% участка текста 308 (т.е. не в первых 40% и не в последних 40%).
[0056] Вычисление числа слов, или букв, в участке текста 308 может исключать игнорируемые слова для того, чтобы основывать контекст на словах, которые могут быть наиболее полезными для ранжирования поисковых запросов. Например, контекст из 20 слов, расположенный по центру вокруг выбранного текста 302, может быть менее полезным при ранжировании поисковых запросов, если слова, такие как "a", "the", "and", "it" и другие типы игнорируемых слов, включены в 20 слов контекста. Таким образом, предварительно определенным числом слов в участке текста 302, который образует контекст, может быть предварительно определенное число слов, за исключением игнорируемых слов.
[0057] Фиг. 3 также иллюстрирует размещение предварительно сформулированного поискового запроса 314 внутри документа 300. Предварительно сформулированный поисковый запрос 314 может быть ассоциирован с участком документа до выбора текста пользователем. Например, предварительно сформулированный поисковый запрос 314 может быть ассоциирован с конкретным словом, предложением, абзацем, колонкой, страницей и т.д. в документе 300. Этот пример показывает предварительно сформулированный поисковый запрос 314 как ассоциированный с предложением сразу перед выбранным текстом 302. В зависимости от размера документа 300, который рассматривается как контекст для выбранного текста 302, предварительно сформулированный поисковый запрос 314 может быть или может не быть включен в тот же участок документа 300, что и выбранный текст 302. Если, например, предложение 304, которое содержит выбранный текст 302, является контекстом, то предварительно сформулированный поисковый запрос 314 не ассоциирован с той же частью документа 300, что и выбранный текст 302. Однако, если контекстом является абзац 306, то предварительно сформулированный поисковый запрос 314 ассоциирован с той же частью документа 300, что и выбранный текст 302.
[0058] Документ 300 может содержать ноль, один или многочисленные предварительно сформулированные поисковые запросы 314. Предварительно сформулированный поисковый запрос(ы) 314 может быть запросом, который пользователь осуществил бы с наибольшей вероятностью при потреблении ассоциированного участка документа 300. Предварительно сформулированный поисковый запрос(ы) 314 может быть создан вручную человеком-автором для вставки в конкретном участке документа 300. В качестве альтернативы или дополнительно, один или более предварительно сформулированных поисковых запросов 314 могут быть определены на основе анализа журналов запросов от других пользователей, которые просматривали документ 300 и впоследствии сгенерировали поисковый запрос.
[0059] Генератор 208 запросов-кандидатов, показанный на Фиг. 2, может получить предварительно сформулированный поисковый запрос(ы) 314 вместе с другими поисковыми запросами, сгенерированными из выбранного текста 302. В некоторых реализациях генератор 208 запросов-кандидатов может включать в себя все предварительно сформулированные поисковые запросы 314, ассоциированные с документом 300, в списке поисковых запросов, представленном пользователю. В других реализациях генератор 208 запросов-кандидатов может включать в себя только предварительно определенный поисковый запрос(ы) 314, который ассоциирован с тем же участком, на основе определения контекста, документа 300, что и выбранный текст 302. В еще одной дополнительной реализации только пороговое число (например, 1, 2, 3) предварительно определенных поисковых запросов 314, которые ассоциированы с размещением в документе 300, которое является ближайшим к выбранному тексту 302, включается в список поисковых запросов, представляемый пользователю.
[0060] Как только пользователь выбирает запрос из списка запросов-кандидатов, этот выбранный запрос может быть использован как предварительно определенный поисковый запрос 314 для последующих представлений документа 300. Этот предварительно определенный поисковый запрос 314 может быть ассоциирован с размещением выбранного текста 302, который изначально сгенерировал поисковый запрос. Таким образом, число предварительно определенных поисковых запросов 314, ассоциированных с документом 300, может увеличиться по мере увеличения использования системы.
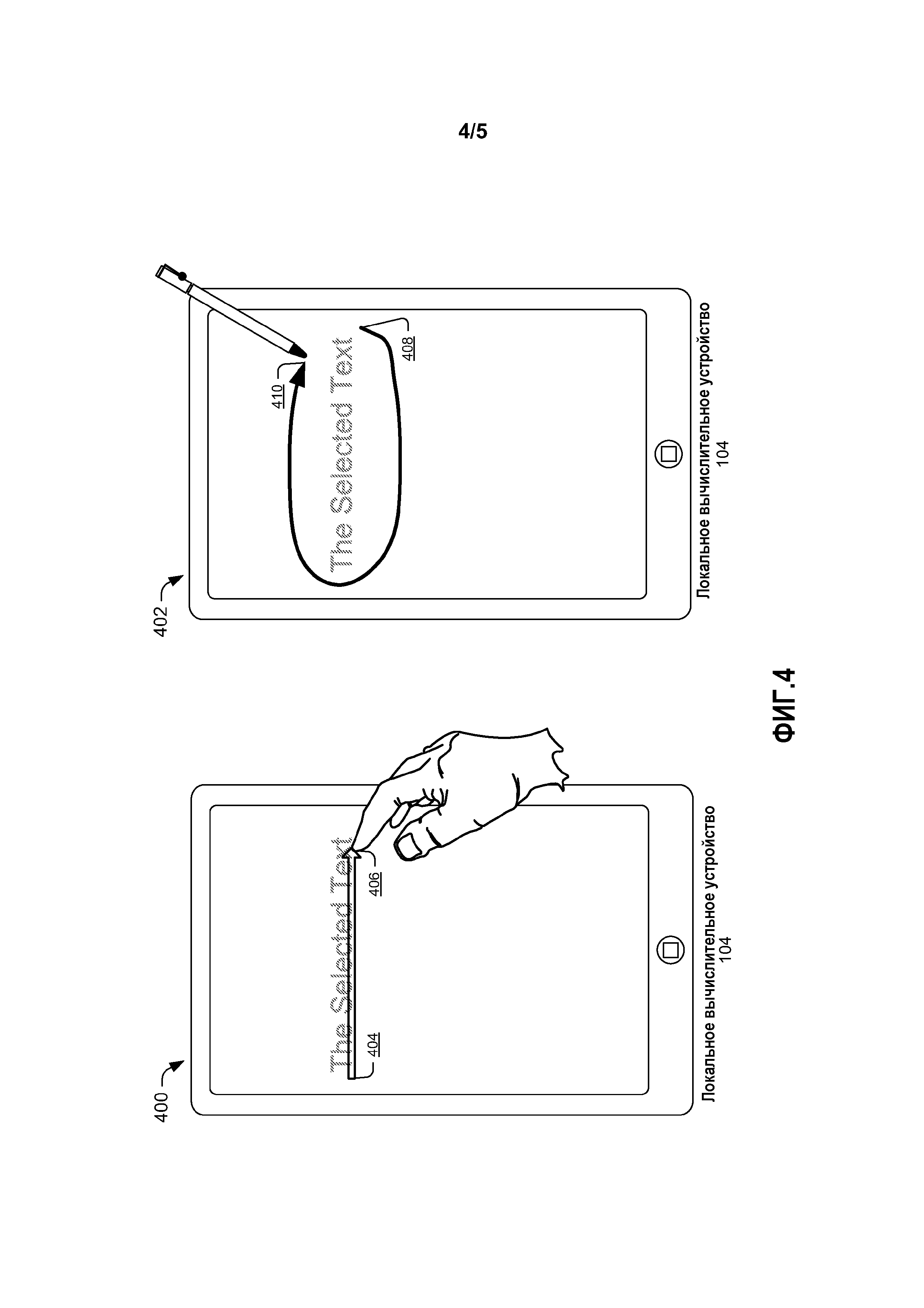
[0061] Фиг. 4 показывает два иллюстративных пользовательских интерфейса 400 и 402 для осуществления выбора текста на устройстве с сенсорным экраном. Локальное вычислительное устройство 104 с Фиг. 1 может быть реализовано как устройство, которое имеет дисплей с сенсорным экраном. В первом пользовательском интерфейсе 400 пользователь проводит своим пальцем (или другим указывающим инструментом, таким как стилус) по поверхности сенсорного экрана от точки 404 в начале текста, который должен быть выбран, до точки 406 в конце текста, который он или она хочет выбрать. Пользователь может нарисовать своим пальцем через середину текста, вдоль нижней части текста, как если он или она подчеркивают текст, или другим движением, которое в общем согласуется с направлением текста (например, слева направо для английского, но направление перемещения может быть разным для разных языков). Сигналом для системы сформулировать поисковые запросы из выбранного текста может быть прекращение перемещения пальца, когда он останавливается в конечной точке 406, поднятие пальца от поверхности воспринимающего касания экрана, нажатие на сенсорный экран в конечной точке 406 и т.д.
[0062] Пользователь может также выбрать текст, как показано на втором пользовательском интерфейсе 402, посредством перемещения стилуса (или другого указывающего инструмента, такого как палец) по, в основном, округлой форме вокруг текста, который пользователь намерен выбрать. В основном округлая форма может быть скорее овальной, чем круглой по форме, и она может быть либо закрытым кругом, в котором начальная точка 408 и конечная точка 410 соприкасаются, либо открытой дугой, в которой начальная точка 408 находится в другом месте, чем конечная точка 410.
[0063] В этом примере, круг рисуется в направлении по часовой стрелке, начинаясь в точке 408 снизу справа от выбранного текста, перемещаясь вокруг к точке 410 сверху справа от выбранного текста. В некоторых реализациях круги, нарисованные либо в направлении по часовой стрелке, либо в направлении против часовой стрелки, могут оба приводить к одному и тому же результату. Однако, в других реализациях, инициирование генерирования поисковых запросов может произойти, только когда круг нарисован в направлении по часовой стрелке (или, в качестве альтернативы, против часовой стрелки). Сигналом для системы сформулировать поисковые запросы из выбранного текста может быть прекращение перемещения стилуса, когда он останавливается в конечной точке 410, поднятие стилуса от поверхности воспринимающего касания экрана, замыкание круга, когда стилус возвращается к начальной точке 408, нажатие на сенсорный экран в конечной точке 410 или некоторый другой жест, представляющий окончание выбора текста и запрашивающий инициирование генерирования поисковых запросов.
[0064] Каждый из пользовательских интерфейсов 402 и 404, показанных на Фиг. 4, предоставляет удобный способ для пользователя, чтобы инициировать процесс поиска без многочисленных команд, использования клавиатуры или переключения на интерфейс, отличный от документа, который он или она потребляет.
Иллюстративные процессы
[0065] Для простоты понимания процессы, рассмотренные в этом раскрытии, изображены как отдельные операции, представленные как независимые этапы. Однако эти по отдельности изображенные операции не должны толковаться как обязательный порядок, зависящий от их выполнения. Порядок, в котором описаны процессы, не предназначен для толкования как ограничения, и любое число описанных этапов процессов может быть скомбинировано в любом порядке для реализации процесса или замещающего процесса. Более того, также возможно, что одна или более из предоставленных операций могут быть модифицированы или опущены.
[0066] Процессы проиллюстрированы как группа этапов на логических схемах последовательности операций, которые представляют собой последовательность операций, которые могут быть реализованы в аппаратных средствах, программном обеспечении или комбинации аппаратных средств и программного обеспечения. В целях рассмотрения, процессы описаны со ссылкой на архитектуры, системы и пользовательские интерфейсы, показанные на Фиг. 1-4. Однако процессы могут быть выполнены с использованием разных архитектур, систем и/или пользовательских интерфейсов.
[0067] Фиг. 5 иллюстрирует схему последовательности операций процесса 500 для идентификации и представления запросов-кандидатов пользователю. На этапе 502 принимают выбор пользователем текста в документе. Пользователем может быть пользователь 102, показанный на Фиг. 1, и выбор может быть принят системой 112 обработки информации. Выбранным текстом может быть прилегающая последовательность текста, такая как одно, два, три, четыре и т.д. слов подряд, или выборы множественных слов или комбинации слов из многочисленных мест в документе. Документом может быть веб-страница, текстовый документ, документ обработки текста, электронная книга или любой другой тип документа.
[0068] На этапе 504 могут быть получены многочисленные запросы-кандидаты. Запросы-кандидаты могут быть получены прямо или косвенно из генератора 208 запросов-кандидатов. Запросы-кандидаты генерируются посредством применения одного или более способов расширения запросов к тексту, выбранному на этапе 502. Способ расширения запросов может включать в себя любой способ, который сравнивает выбранный текст с предыдущим журналом запросов, чтобы идентифицировать один или более запросов из предыдущего журнала запросов на основе выбранного текста. Иллюстративные способы включают в себя применение алгоритма k-средних к журналу запросов, проведение случайного поиска по двухкомпонентному графику запрос-документ, сгенерированному посредством осуществления анализа журнала запросов, выполнение алгоритма PageRank в отношении графика запрос-поток, сгенерированного из журнала запросов, или интеллектуальный анализ шаблонов ассоциации с терминами из журнала запросов.
[0069] На этапе 506 определяют, есть ли какие-либо предварительно сформулированные запросы, ассоциированные с документом. Предварительно сформулированные запросы могут быть идентифицированы на основе журналов запросов поведения при последнем поиске, созданные человеком-редактором или сгенерированные любым другим способом создания поисковых запросов. Предварительно сформулированные запросы могут быть ассоциированы с конкретным участком документа, таким как конкретное слово, предложение, абзац, страница и т.д., такие как, например, предварительно сформулированный запрос 314, показанный на Фиг. 3. Когда текст, выбранный пользователем, является из того же участка документа, что и предварительно сформулированный запрос, процесс 500 идет по пути "да" к этапу 508. Если, однако, документ не ассоциирован с какими-либо предварительно сформулированными запросами или если предварительно сформулированные запросы, ассоциированные с документом, не ассоциированы с участком документа, который включает в себя выбранный текст, то процесс 500 идет по пути "нет" к этапу 510.
[0070] На этапе 508 предварительно сформулированный запрос включается в набор запросов-кандидатов, полученных на этапе 504. Предварительно сформулированный запрос может быть получен быстрее, чем другие запросы, полученные на этапе 504, так как он предварительно сформулирован и может не требовать обработки или анализа для генерирования.
[0071] На этапе 510 ранжируют запросы-кандидаты, полученные на этапе 504, включающие в себя предварительно сформулированные запросы, идентифицированные на этапе 508. Ранжирование запросов-кандидатов предоставляет наивысший ранг тем запросам, которые с наибольшей вероятностью возвращают результаты, желаемые пользователем, на основе текста, выбранного на этапе 502. Ранжирование может быть на основе языковой модели 512, которая учитывает контекст, предоставляемый документом. Контекст может быть представлен текстом в документе, который включает в себя текст, выбранный пользователем на этапе 502, и дополнительный текст (т.е. контекст включает в себя по меньшей мере на одно дополнительное слово или букву больше, чем текст, выбранный пользователем). Ранжирование может, дополнительно или в качестве альтернативы, основываться на системе 514 искусственного интеллекта. Система 514 искусственного интеллекта обучается с помощью набора пар документов и запросов (т.е. обучающих данных), который подтвержден посредством обзора человеком. Люди-инспектора оценивают пары документов и запросов, чтобы идентифицировать пары, которые имеют запрос, который относится к содержимому документа, спаренного с данным запросом.
[0072] На этапе 516 запросы-кандидаты представляются пользователю в ранжированном списке, упорядоченном согласно ранжированию. Ранжированный список может быть показан пользователю в интерфейсе, который также отображает документ, из которого пользователь выбрал текст, так, чтобы пользователь мог просматривать документ и выбранный текст во время выбора поискового запроса. В качестве альтернативы, документ может больше не показываться, но, вместо этого, документ может быть заменен списком (например, на устройствах с областями отображения, слишком малыми, чтобы показать и то, и другое). Предполагаются также дополнительные способы отображения списка, такие как представление списка в всплывающем окне, выпадающем меню и т.д. Таким образом, выбор текста на этапе 502 может вызвать отображение списка рекомендованных запросов, ранжированных в порядке релевантности на основе выбранного текста и окружающего контекста.
[0073] На этапе 518 принимают выбор пользователем одного из запросов-кандидатов из списка. Пользователь может сделать выбор любым традиционным способом выбора элемента из списка. Таким образом, пользователь имеет возможность взять поисковый запрос из списка, который наиболее близко представляет его или ее намерение при выборе слов на этапе 502 для поиска.
[0074] На этапе 520 запрос, выбранный пользователем, предъявляют одной или более поисковым машинам, таким как поисковая машина(ы) 110. Пользователь может затем принять результаты поиска от поисковой машины. Таким образом, с помощью этого способа 500 пользователь может получить результаты поиска, основанные на поисковом запросе, который лучше сконструирован для генерирования эффективных результатов, чем просто для осуществления поиска слов в выбранном документе и использования, пользователь может принять эти результаты с помощью только минимальных взаимодействий с документом и/или интерфейсом поисковой машины.
Заключение
[0075] Изобретение, описанное выше, может быть реализовано в аппаратных средствах, программном обеспечении или и в аппаратных средствах, и в программном обеспечении. Хотя реализации были описаны на языке, характерном для структурных признаков и методологических действий, следует понимать, что объем изобретения, определяемый в прилагаемой формуле изобретения, не обязательно ограничен конкретными признаками или описанными выше действиями. Скорее, характерные признаки и действия раскрыты как иллюстративные формы иллюстративных реализаций генерирования поисковых запросов.
Регулировка громкости на основании местоположения слушателя
Смоделированное видео с дополнительными точками обзора и повышенной разрешающей способностью для камер наблюдения за движением транспорта
Выбираемые пользователем операционные среды для устройств мобильной связи
Система и способ для выбора вкладки в браузере с вкладками
Поддержание возможности отмены и возврата при объединениях метаданных
Синхронизация частей файла с использованием серверной модели хранения информации
Контрольные точки для файловой системы
Захват и загрузка состояний операционной системы
Использование предварительной обработки на сервере для развертывания представлений электронных документов в компьютерной сети
Управление виртуальными портами
Регулировка громкости на основании местоположения слушателя
Смоделированное видео с дополнительными точками обзора и повышенной разрешающей способностью для камер наблюдения за движением транспорта
Выбираемые пользователем операционные среды для устройств мобильной связи
Система и способ для выбора вкладки в браузере с вкладками
Поддержание возможности отмены и возврата при объединениях метаданных
Синхронизация частей файла с использованием серверной модели хранения информации
Контрольные точки для файловой системы
Захват и загрузка состояний операционной системы
Использование предварительной обработки на сервере для развертывания представлений электронных документов в компьютерной сети
Управление виртуальными портами

