Результат интеллектуальной деятельности: КОДИРОВАНИЕ ЗВУКОВЫХ СЦЕН
Вид РИД
Изобретение
Перекрестная ссылка на родственные заявки
Данная заявка заявляет приоритет предварительной заявки на патент США № 61/827246, поданной 24 мая 2013 года, описание которой включено в настоящую заявку в полном объеме посредством ссылки.
Область изобретения
Изобретение, описанное в настоящей заявке, в целом относится к области кодирования и декодирования звука. В частности, оно относится к кодированию и декодированию звуковой сцены, содержащей звуковые объекты.
Предпосылки создания изобретения
Существуют системы кодирования звука для параметрического пространственного кодирования звука. Например, формат MPEG Surround описывает систему для параметрического пространственного кодирования многоканального звука. Формат MPEG SAOC (пространственное кодирование звуковых объектов) описывает систему для параметрического кодирования звуковых объектов.
На кодирующей стороне данные системы, как правило, низводят каналы/объекты в понижающее микширование, которое обычно является моно (один канал) или стерео (два канала) понижающим микшированием, и извлекают дополнительную информацию, описывающую свойства каналов/объектов посредством параметров, таких как разности уровней и взаимная корреляция. Затем понижающее микширование и дополнительная информация кодируются и отправляются на декодирующую сторону. На декодирующей стороне каналы/объекты восстанавливаются, т.е. аппроксимируются, из понижающего микширования под управлением параметров дополнительной информации.
Недостатком данных систем является то, что восстановление, как правило, является математически сложным и часто приходится полагаться на предположения о свойствах звукового содержимого, которое явно не описано параметрами, отправляемыми в качестве дополнительной информации. Такие предположения могут, например, заключаться в том, что каналы/объекты считаются некоррелированными, если параметр взаимной корреляции не отправлен, или в том, что понижающее микширование каналов/объектов генерируется определенным образом. К тому же математическая сложность и необходимость дополнительных предположений значительно увеличивают количество каналов понижающего микширования.
Кроме того, необходимые допущения, по существу, отражаются в алгоритмических деталях обработки, применяемой на декодирующей стороне. Это означает, что на декодирующей стороне должен содержаться довольно высокий уровень искусственного интеллекта. Это представляет собой недостаток, заключающийся в том, что может быть трудно обновить или изменить алгоритмы, когда декодеры используются, например, в бытовых устройствах, которые трудно или даже невозможно обновить.
Краткое описание графических материалов
В дальнейшем будут более подробно описаны примерные варианты осуществления со ссылками на прилагаемые графические материалы, на которых:
фиг. 1 представляет собой схематическое изображение системы кодирования/декодирования звука в соответствии с примерными вариантами осуществления;
фиг. 2 представляет собой схематическое изображение системы кодирования/декодирования звука, содержащей устаревший декодер согласно примерным вариантам осуществления;
фиг. 3 представляет собой схематическое изображение кодирующей стороны системы кодирования/декодирования звука согласно примерным вариантам осуществления;
фиг.4 представляет собой блок-схему способа кодирования согласно примерным вариантам осуществления;
фиг. 5 представляет собой схематическое изображение кодера согласно примерным вариантам осуществления;
фиг. 6 представляет собой схематическое изображение декодирующей стороны системы кодирования/декодирования звука согласно примерным вариантам осуществления;
фиг. 7 представляет собой блок-схему способа декодирования согласно примерным вариантам осуществления;
фиг. 8 представляет собой схематическое изображение декодирующей стороны системы кодирования/декодирования звука согласно примерным вариантам осуществления; и
фиг. 9 представляет собой схематическое изображение частотно-временных преобразований, выполняемых на декодирующей стороне системы кодирования/декодирования звука согласно примерным вариантам осуществления.
Все фигуры являются схематическими и в большинстве случаев на них показаны только те части, которые необходимы для объяснения изобретения, в то время как другие части могут быть опущены или только предполагаться. Если не указано иное, подобные части на разных фигурах обозначены подобными позициями.
Подробное описание
В свете вышесказанного целью настоящего изобретения является обеспечение кодера и декодера и связанных с ними способов, которые обеспечивают менее сложное и более гибкое восстановление звуковых объектов.
I. Обзор кодера
В соответствии с первым аспектом в примерных вариантах осуществления предложены способы кодирования, кодеры и компьютерные программные продукты для кодирования. Предлагаемые способы, кодеры и компьютерные программные продукты могут, как правило, иметь одни и те же признаки и преимущества.
В соответствии с примерными вариантами осуществления предложен способ кодирования частотно-временного мозаичного элемента звуковой сцены, которая содержит по меньшей мере N звуковых объектов. Способ включает: прием N звуковых объектов; генерирование M сигналов понижающего микширования на основе по меньшей мере N звуковых объектов; генерирование матрицы восстановления с матричными элементами, которые обеспечивают возможность восстановления по меньшей мере N звуковых объектов из M сигналов понижающего микширования; и генерирование битового потока, содержащего M сигналов понижающего микширования и по меньшей мере некоторые из матричных элементов матрицы восстановления.
Количество N звуковых объектов может быть равно или больше единицы. Количество M сигналов понижающего микширования может быть равно или больше единицы.
Таким образом, посредством данного способа генерируется битовый поток, который содержит M сигналов понижающего микширования и по меньшей мере некоторые из матричных элементов матрицы восстановления в качестве дополнительной информации. Благодаря включению отдельных матричных элементов матрицы восстановления в битовый поток на декодирующей стороне требуется очень небольшой уровень искусственного интеллекта. Например, на декодирующей стороне не нужно осуществлять сложное вычисление матрицы восстановления на основе переданных параметров объекта и дополнительных предположений. Таким образом, на декодирующей стороне существенно снижается математическая сложность. Кроме того, увеличивается гибкость в отношении количества сигналов понижающего микширования по сравнению со способами предыдущего уровня техники, поскольку сложность способа не зависит от количества используемых сигналов понижающего микширования.
В данном контексте термин «звуковая сцена», как правило, относится к трехмерной звуковой среде, которая содержит звуковые элементы, связанные с положениями в трехмерном пространстве, которые могут представляться при воспроизведении в звуковой системе.
В данном контексте термин «звуковой объект» относится к элементу звуковой сцены. Звуковой объект обычно содержит звуковой сигнал и дополнительную информацию, такую как положение объекта в трехмерном пространстве. Дополнительная информация обычно используется для оптимального представления звукового объекта в данной системе воспроизведения.
В данном контексте термин «сигнал понижающего микширования» относится к сигналу, который представляет собой комбинацию по меньшей мере из N звуковых объектов. Другие сигналы звуковой сцены, такие как основные каналы (которые будут описаны ниже), также могут комбинироваться в сигнале понижающего микширования. Например, M сигналов понижающего микширования могут соответствовать представлению звуковой сцены с заданной конфигурацией громкоговорителей, например стандартной конфигурацией 5.1. Количество сигналов понижающего микширования, обозначенных в данной заявке как М, обычно (но не обязательно) меньше, чем сумма количества звуковых объектов и основных каналов, что объясняет, почему M сигналов понижающего микширования называется понижающим микшированием.
Системы кодирования/декодирования звука, как правило, делят частотно-временное пространство на частотно-временные мозаичные элементы, например, путем применения подходящих банков фильтров для входных звуковых сигналов. Под частотно-временным мозаичным элементом, как правило, подразумевается часть частотно-временного пространства, соответствующая временному интервалу и частотному поддиапазону. Временной интервал может обычно соответствовать длительности временного кадра, используемого в системе кодирования/декодирования звука. Частотный поддиапазон может, как правило, соответствовать одному или нескольким соседним частотным поддиапазонам, определенных банком фильтров, используемым в системе кодирования/декодирования. В случае, если частотный поддиапазон соответствует нескольким соседним частотным поддиапазонам, определенным банком фильтров, это обеспечивает наличие неравномерных частотных поддиапазонов в процессе декодирования звукового сигнала, например, более широких частотных поддиапазонов для звукового сигнала верхних частот. В случае широкого диапазона частот, когда система кодирования/декодирования звука работает во всем диапазоне частот, частотный поддиапазон частотно-временного мозаичного элемента может соответствовать всему диапазону частот. В вышеописанном способе описаны этапы кодирования для кодирования звуковой сцены в течение одного такого частотно-временного мозаичного элемента. Тем не менее, следует понимать, что способ можно повторять для каждого частотно-временного мозаичного элемента системы кодирования/декодирования звука. Также следует понимать, что несколько частотно-временных мозаичных элементов могут кодироваться одновременно. Как правило, соседние частотно-временные мозаичные элементы могут немного перекрываться по времени и/или частоте. Например, перекрытие по времени может быть эквивалентно линейной интерполяции элементов матрицы восстановления во времени, то есть от одного интервала времени до следующего. Тем не менее, это раскрытие предназначено для прочих частей системы кодирования/декодирования, и любое перекрытие по времени и/или частоте между соседними частотно-временными мозаичными элементами остается для реализации специалистам.
Согласно примерным вариантам осуществления М сигналов понижающего микширования располагаются в первом поле битового потока с применением первого формата, а матричные элементы располагаются во втором поле битового потока с применением второго формата, тем самым обеспечивая возможность декодеру, который поддерживает только первый формат, декодировать и воспроизводить M сигналов понижающего микширования в первом поле и отбрасывать матричные элементы во втором поле. Это является предпочтительным в том, что M сигналов понижающего микширования в битовом потоке имеют обратную совместимость с существующими устаревшими декодерами, которые не осуществляют восстановление звуковых объектов. Другими словами, устаревшие декодеры все еще могут декодировать и воспроизводить М сигналов понижающего микширования битового потока, например, путем отображения каждого сигнала понижающего микширования на выходе канала декодера.
Согласно примерным вариантам осуществления способ может дополнительно включать этап приема данных о положении, соответствующих каждому из N звуковых объектов, при этом M сигналов понижающего микширования генерируются на основе данных о положении. Данные о положении, как правило, связывают каждый звуковой объект с положением в трехмерном пространстве. Положение звукового объекта может изменяться со временем. При применении данных о положении при понижающем микшировании звуковых объектов, звуковые объекты будут включаться в M сигналов понижающего микширования таким образом, что если M сигналов понижающего микширования, например, прослушиваются на системе с М выходными каналами, звуковые объекты будут звучать так, как если бы они были приблизительно размещены в их соответствующих положениях. Это, например, является предпочтительным, если M сигналов понижающего микширования должны быть обратно совместимыми с устаревшим декодером.
Согласно примерным вариантам осуществления матричные элементы матрицы восстановления являются переменными во времени и по частоте. Другими словами, матричные элементы матрицы восстановления могут отличаться для разных частотно-временных мозаичных элементов. Таким образом, достигается большая гибкость при восстановлении звуковых объектов.
Согласно примерным вариантам осуществления звуковая сцена дополнительно содержит множество основных каналов. Это, например, распространено в звуковых применениях кинематографии, где звуковое содержимое включает основные каналы в дополнение к звуковым объектам. В таких случаях M сигналов понижающего микширования могут быть сгенерированы на основе по меньшей мере N звуковых объектов и множества основных каналов. Под основным каналом, как правило, подразумевается звуковой сигнал, который соответствует фиксированному положению в трехмерном пространстве. Например, основной канал может соответствовать одному из выходных каналов системы кодирования/декодирования звука. Таким образом, основной канал следует понимать как звуковой объект, имеющий соответствующее положение в трехмерном пространстве, точно такое же, как и положение одного из выходных громкоговорителей системы кодирования/декодирования звука. Поэтому основной канал может связываться с меткой, которая указывает исключительно положение соответствующего выходного громкоговорителя.
Если звуковая сцена содержит основные каналы, матрица восстановления может содержать матричные элементы, которые обеспечивают возможность восстановления основных каналов из M сигналов понижающего микширования.
В некоторых ситуациях звуковые сцены могут содержать очень большое количество объектов. С целью уменьшения сложности и объема данных, требуемых для представления звуковой сцены, звуковая сцена может быть упрощена путем уменьшения количества звуковых объектов. Таким образом, если звуковая сцена изначально содержит K звуковых объектов, где K>N, способ может дополнительно включать этапы приема K звуковых объектов и уменьшения K звуковых объектов до N звуковых объектов посредством кластеризации K объектов в N кластеров и представления каждого кластера одним звуковым объектом.
С целью упрощения сцены способ может дополнительно включать этап приема данных о положении, соответствующих каждому из K звуковых объектов, при этом кластеризация K объектов в N кластеров основывается на пространственном расстоянии между K объектами, которое задано данными о положении K звуковых объектов. Например, звуковые объекты, которые расположены близко друг к другу с точки зрения положения в трехмерном пространстве, могут быть подвергнуты кластеризации вместе.
Как рассматривалось выше, примерные варианты осуществления способа являются гибкими в отношении количества применяемых сигналов понижающего микширования. В частности, способ может предпочтительно применяться при наличии более двух сигналов понижающего микширования, то есть когда М больше чем два. Например, могут применяться пять или семь сигналов понижающего микширования, соответствующих установкам с общепринятой конфигурацией звука 5.1 или 7.1. Это является предпочтительным, поскольку в отличие от систем предыдущего уровня техники математическая сложность предложенных принципов кодирования остается той же, независимо от количества применяемых сигналов понижающего микширования.
С целью дальнейшего обеспечения улучшения восстановления N звуковых объектов способ может дополнительно включать: формирование L дополнительных сигналов из N звуковых объектов; включение матричных элементов в матрицу восстановления, которые обеспечивают возможность восстановления по меньшей мере N звуковых объектов из M сигналов понижающего микширования и L дополнительных сигналов; и включение L дополнительных сигналов в битовый поток. Дополнительные сигналы, таким образом, служат в качестве вспомогательных сигналов, которые, например, могут захватывать аспекты звуковых объектов, которые трудно восстановить из сигналов понижающего микширования. Дополнительные сигналы также могут быть основаны на основных каналах. Количество дополнительных сигналов может быть равным или большим единицы.
Согласно одному примерному варианту осуществления дополнительные сигналы могут соответствовать особо важным звуковым объектам, таким как звуковой объект, представляющий диалог. Таким образом, по меньшей мере один из L дополнительных сигналов может быть равным одному из N звуковых объектов. Это обеспечивает возможность представления важных объектов в более высоком качестве, чем если бы они были восстановлены только из M каналов понижающего микширования. На практике некоторые из звуковых объектов могли быть приоритетными и/или помеченными создателем звукового содержимого в качестве звуковых объектов, которые в предпочтительном варианте отдельно включаются в качестве вспомогательных объектов. Кроме того, это делает изменения/обработку этих объектов перед представлением менее склонной к искажениям. В качестве компромисса между битовой скоростью и качеством, можно также отправлять микс из двух или более звуковых объектов в качестве дополнительного сигнала. Другими словами, по меньшей мере один из L дополнительных сигналов может быть сформирован в виде комбинации из по меньшей мере двух из N звуковых объектов.
Согласно одному примерному варианту осуществления дополнительные сигналы представляют размеры сигнала звуковых объектов, которые пропали в процессе генерирования M сигналов понижающего микширования, например, поскольку количество независимых объектов, как правило, выше, чем количество каналов понижающего микширования, или поскольку два объекта связаны с такими положениями, что они подвергаются микшированию в том же сигнале понижающего микширования. Примером последнего случая является ситуация, когда два объекта разделены только вертикально, но имеют одно и то же положение при проекции на горизонтальную плоскость, а это означает, что они, как правило, будут представлены в том же канале (каналах) понижающего микширования установки окружающих громкоговорителей стандартной конфигурации 5.1, где все громкоговорители находятся в одной горизонтальной плоскости. В частности, M сигналов понижающего микширования проходят в гиперплоскости в пространстве сигнала. При формировании линейных комбинаций M сигналов понижающего микширования могут быть восстановлены только звуковые сигналы, которые лежат в гиперплоскости. С целью улучшения восстановления могут быть включены дополнительные сигналы, которые не лежат в гиперплоскости, тем самым также обеспечивая возможность восстановления сигналов, которые не лежат в гиперплоскости. Другими словами, в соответствии с примерными вариантами осуществления, по меньшей мере один из множества дополнительных сигналов не лежит в гиперплоскости, в которой проходят М сигналов понижающего микширования. Например, по меньшей мере один из множества дополнительных сигналов может быть ортогональным относительно гиперплоскости, в которой проходят М сигналов понижающего микширования.
Согласно примерным вариантам осуществления предлагается машиночитаемый носитель, содержащий команды машинного кода, приспособленные для выполнения любого способа согласно первому аспекту при выполнении на устройстве, имеющем возможность обработки.
Согласно примерным вариантам осуществления предлагается кодер для кодирования частотно-временного мозаичного элемента звуковой сцены, которая содержит по меньшей мере N звуковых объектов, содержащий: принимающий компонент, выполненный с возможностью приема N звуковых объектов; компонент генерирования понижающего микширования, выполненный с возможностью приема N звуковых объектов от принимающего компонента и генерирования M сигналов понижающего микширования на основе по меньшей мере N звуковых объектов; анализирующий компонент, выполненный с возможностью генерирования матрицы восстановления с матричными элементами, которые обеспечивают восстановление по меньшей мере N звуковых объектов из M сигналов понижающего микширования; и компонент генерирования битового потока, выполненный с возможностью приема M сигналов понижающего микширования из компонента генерирования понижающего микширования и матрицы восстановления из анализирующего компонента и генерирования битового потока, содержащего M сигналов понижающего микширования и по меньшей мере некоторые из матричных элементов матрицы восстановления.
II. Обзор декодера
Согласно второму аспекту в примерных вариантах осуществления предложены способы декодирования, декодирующие устройства и компьютерные программные продукты для декодирования. Предлагаемые способы, устройства и компьютерные программные продукты могут, как правило, иметь одни и те же функции и преимущества.
Преимущества в отношении функций и установок, представленные в обзоре кодера выше, могут в большинстве случаев быть применимыми для соответствующих функций и установок для декодера.
Согласно примерным вариантам осуществления предлагается способ декодирования частотно-временного мозаичного элемента звуковой сцены, которая по меньшей мере содержит N звуковых объектов, при этом способ включает этапы: приема битового потока, содержащего М сигналов понижающего микширования и по меньшей мере некоторые матричные элементы матрицы восстановления; генерирования матрицы восстановления с применением матричных элементов; и восстановления N звуковых объектов из M сигналов понижающего микширования с применением матрицы восстановления.
Согласно примерным вариантам осуществления М сигналов понижающего микширования расположены в первом поле битового потока с применением первого формата, а матричные элементы расположены во втором поле битового потока с применением второго формата, тем самым обеспечивая возможность декодеру, который поддерживает только первый формат, декодировать и воспроизводить M сигналов понижающего микширования в первом поле и отбрасывать матричные элементы во втором поле.
Согласно примерным вариантам осуществления матричные элементы матрицы восстановления являются переменными во времени и по частоте.
Согласно примерным вариантам осуществления звуковая сцена дополнительно содержит множество основных каналов, причем способ дополнительно включает восстановление основных каналов из M сигналов понижающего микширования с применением матрицы восстановления.
Согласно примерным вариантам осуществления количество М сигналов понижающего микширования больше двух.
Согласно примерным вариантам осуществления способ дополнительно включает: прием L дополнительных сигналов, сформированных из N звуковых объектов; восстановление N звуковых объектов из M сигналов понижающего микширования и L дополнительных сигналов с применением матрицы восстановления, при этом матрица восстановления содержит матричные элементы, которые обеспечивают возможность восстановления по меньшей мере N звуковых объектов из M сигналов понижающего микширования и L дополнительных сигналов.
Согласно примерным вариантам осуществления по меньшей мере один из L дополнительных сигналов равен одному из N звуковых объектов.
Согласно примерным вариантам осуществления по меньшей мере один из L дополнительных сигналов представляет собой комбинацию из N звуковых объектов.
Согласно примерным вариантам осуществления M сигналов понижающего микширования проходят в гиперплоскости, и при этом по меньшей мере один из множества дополнительных сигналов не лежит в гиперплоскости, в которой проходят М сигналов понижающего микширования.
Согласно примерным вариантам осуществления по меньшей мере один из множества дополнительных сигналов, которые не лежат в гиперплоскости, ортогонален относительно гиперплоскости, в которой проходят М сигналов понижающего микширования.
Как было описано выше, системы кодирования/декодирования звука обычно работают в частотной области. Таким образом, системы кодирования/декодирования звука выполняют частотно-временное преобразование звуковых сигналов с применением банков фильтров. Могут применяться различные типы частотно-временного преобразования. Например, M сигналов понижающего микширования могут быть представлены по отношению к первой частотной области, а матрица восстановления может быть представлена по отношению ко второй частотной области. С целью уменьшения затрат вычислительных ресурсов в декодере целесообразно выбирать первую и вторую частотные области детально продуманным образом. Например, первая и вторая частотные области могут быть выбраны в качестве одной и той же частотной области, такой как область модифицированного дискретного косинусного преобразования (MDCT). Таким образом, можно избежать преобразования M сигналов понижающего микширования из первой частотной области во временную область с последующим преобразованием во вторую частотную область в декодере. В альтернативном варианте можно выбрать первую и вторую частотные области таким образом, что преобразование из первой частотной области во вторую частотную область может быть реализовано совместно, так что нет необходимости в прохождении всего пути через временную область между ними.
Способ может дополнительно включать прием данных о положении, соответствующих N звуковым объектам, и представление N звуковых объектов с применением данных о положении для создания по меньшей мере одного выходного звукового канала. Таким образом, N восстановленных звуковых объектов отображаются в выходных каналах системы кодирования/декодирования звука на основе их положения в трехмерном пространстве.
Представление данных предпочтительно осуществляют в частотной области. С целью уменьшения затрат вычислительных ресурсов в декодере частотная область представления предпочтительно выбирается детально продуманным образом по отношению к частотной области, в которой восстанавливаются звуковые объекты. Например, если матрица восстановления представлена по отношению ко второй частотной области, соответствующей второму банку фильтров, а представление выполняется в третьей частотной области, соответствующей третьему банку фильтров, то второй и третий банки фильтров предпочтительно выбирают таким образом, что они по меньшей мере частично являются одним и тем же банком фильтров. Например, второй и третий банки фильтров могут содержать область квадратурного зеркального фильтра (QMF). В альтернативном варианте вторая и третья частотные области могут содержать банк фильтров MDCT. Согласно примерному варианту осуществления третий банк фильтров может состоять из последовательности банков фильтров, таких как банк фильтров QMF с последующим банком фильтров Найквиста. В этом случае по меньшей мере один из банков фильтров последовательности (первый банк фильтров последовательности) является точно таким же, что и второй банк фильтров. Таким образом, второй и третий банки фильтров, можно сказать, по меньшей мере частично являются одним и тем же банком фильтров.
Согласно примерным вариантам осуществления предлагается машиночитаемый носитель, содержащий команды машинного кода, приспособленные для выполнения любого способа согласно второму аспекту при выполнении на устройстве, имеющем возможность обработки.
Согласно примерным вариантам осуществления предлагается декодер для декодирования частотно-временного мозаичного элемента звуковой сцены, которая содержит по меньшей мере N звуковых объектов, содержащий: принимающий компонент, выполненный с возможностью приема битового потока, содержащего М сигналов понижающего микширования и по меньшей мере некоторые матричные элементы матрицы восстановления; компонент генерирования матрицы восстановления, выполненный с возможностью приема матричных элементов из принимающего компонента и генерирования на их основе матрицы восстановления; и восстанавливающий компонент, выполненный с возможностью приема матрицы восстановления из компонента генерирования матрицы восстановления и восстановления N звуковых объектов из M сигналов понижающего микширования с применением матрицы восстановления.
III. Примерные варианты осуществления
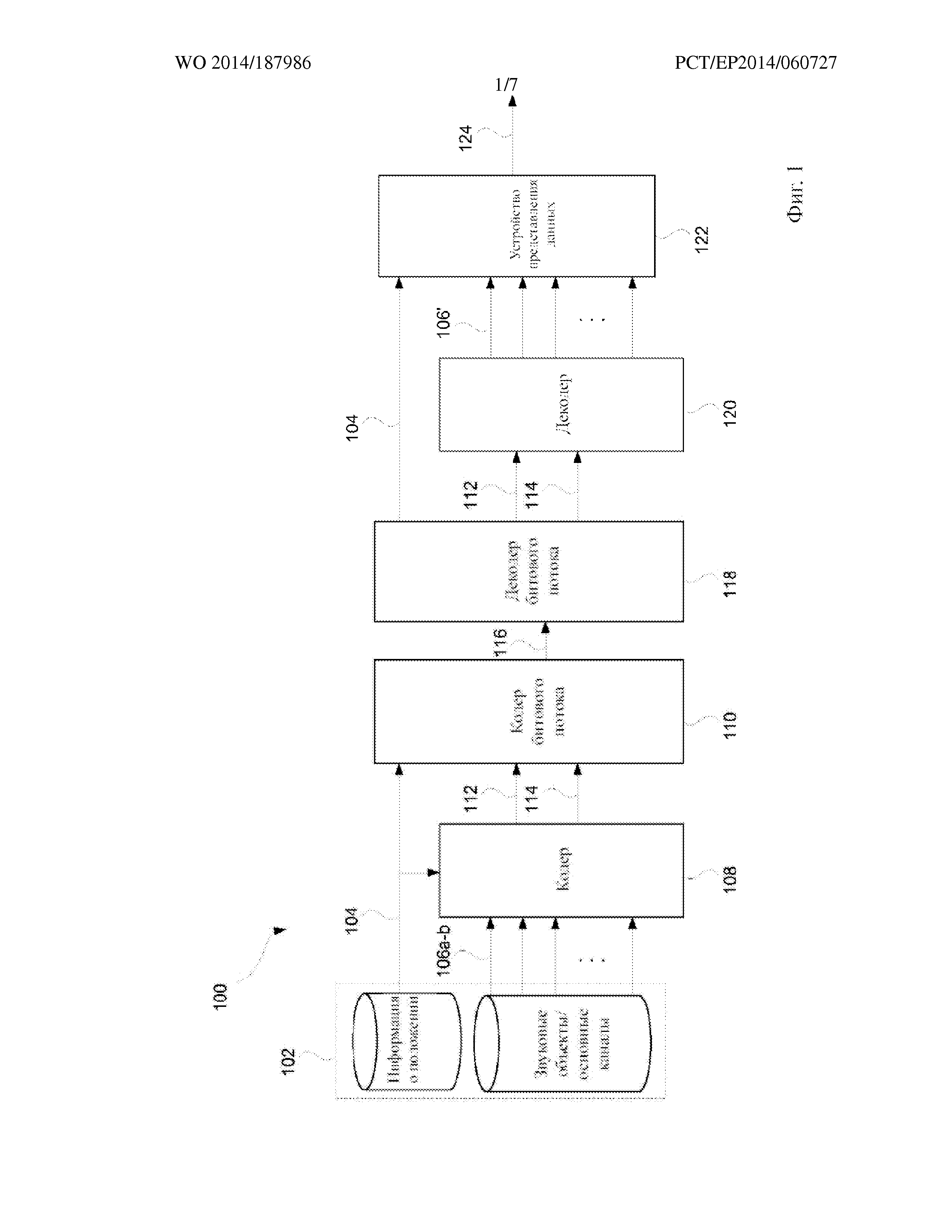
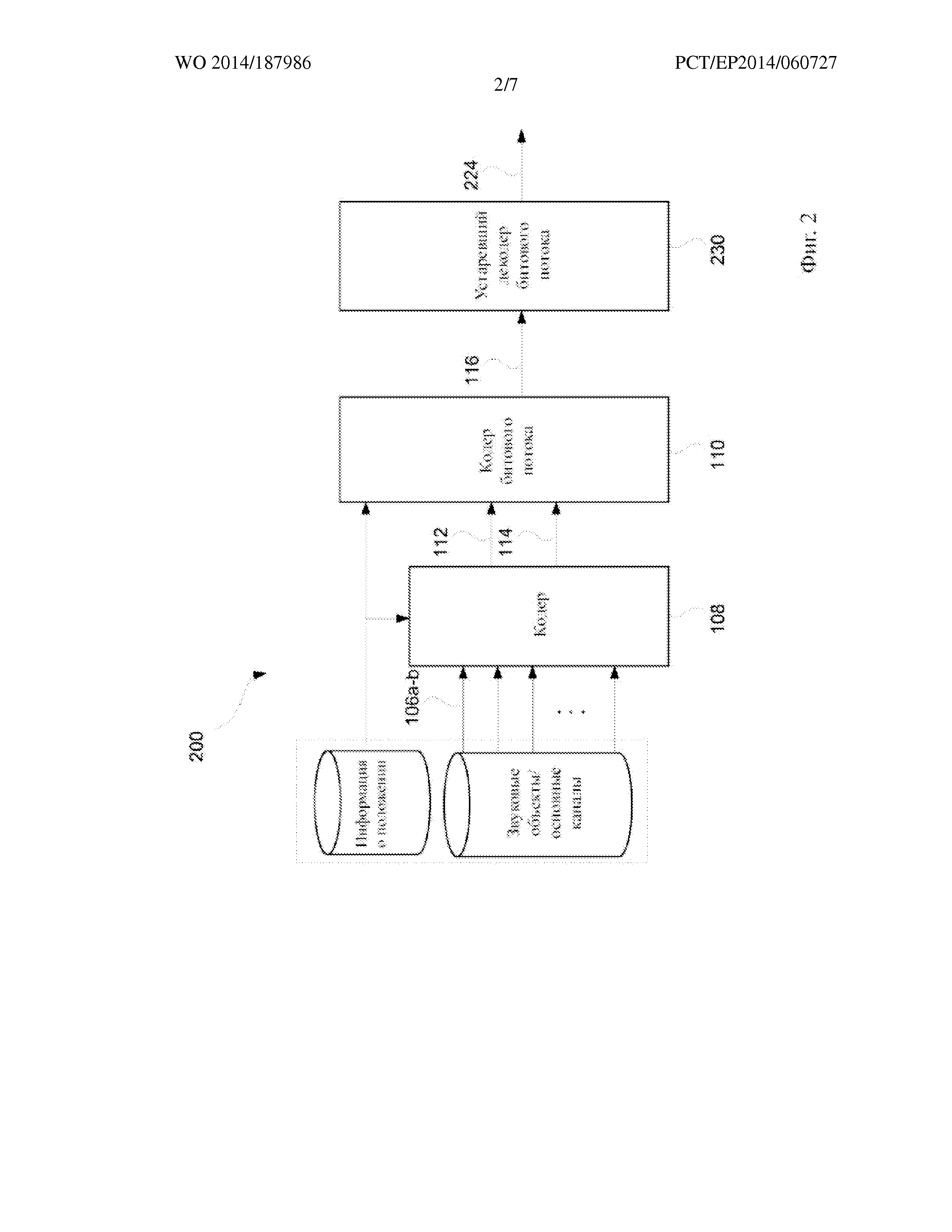
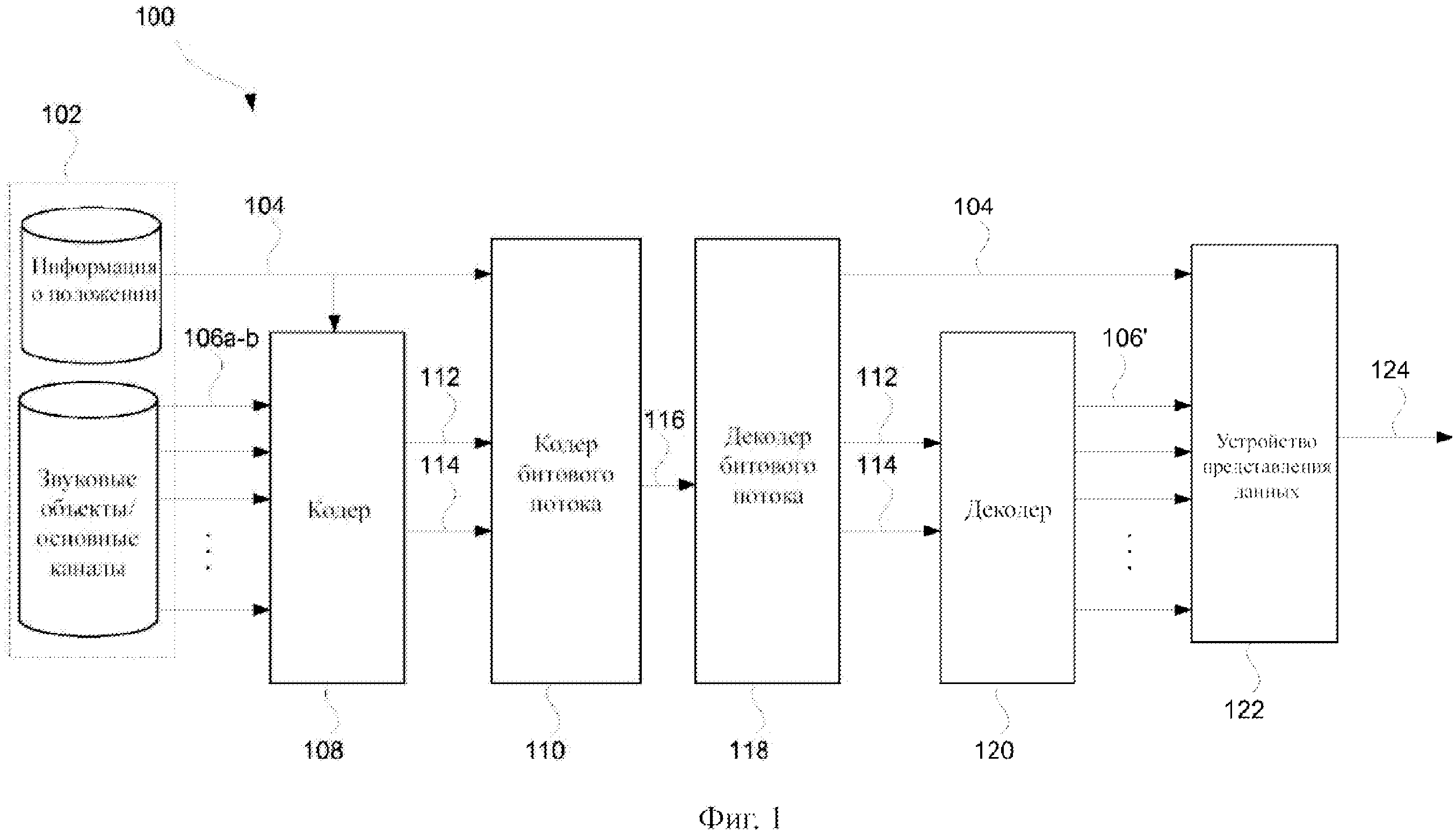
На фиг. 1 представлена система 100 кодирования/декодирования для кодирования/декодирования звуковой сцены 102. Система 100 кодирования/декодирования содержит кодер 108, компонент 110 генерирования битового потока, компонент 118 декодирования битового потока, декодер 120 и устройство 122 представления данных.
Звуковая сцена 102 представлена одним или несколькими звуковыми объектами 106а, т.е. звуковыми сигналами, такими как N звуковых объектов. Звуковая сцена 102 может дополнительно содержать один или несколько основных каналов 106b, то есть сигналов, которые непосредственно соответствуют одному из выходных каналов устройства 122 представления данных. Звуковая сцена 102 дополнительно представлена метаданными, содержащими информацию 104 о положении. Информация 104 о положении применяется, например, устройством 122 представления данных при представлении звуковой сцены 102. Информация 104 о положении может связывать звуковые объекты 106а и, возможно, также основные каналы 106b с пространственным положением в трехмерном пространстве в зависимости от времени. Метаданные могут дополнительно содержать другой тип данных, который подходит для представления звуковой сцены 102.
Кодирующая часть системы 100 содержит кодер 108 и компонент 110 генерирования битового потока. Кодер 108 принимает звуковые объекты 106а, основные каналы 106b, если они присутствуют, и метаданные, содержащие информацию 104 о положении. На их основе кодер 108 генерирует один или несколько сигналов 112 понижающего микширования, например, M сигналов понижающего микширования. В качестве примера, сигналы 112 понижающего микширования могут соответствовать каналам [Lf Rf Cf Ls Rs LFE] аудиосистемы конфигурации 5.1. («L» означает левый, «R» означает правый, «С» означает центральный, «f» означает передний, «s» означает окружающий и «LFE» означает низкочастотные эффекты).
Кодер 108 дополнительно генерирует дополнительную информацию. Дополнительная информация содержит матрицу восстановления. Матрица восстановления содержит матричные элементы 114, которые обеспечивают восстановление по меньшей мере звуковых объектов 106а из сигналов 112 понижающего микширования. Матрица восстановления может дополнительно обеспечивать возможность восстановления основных каналов 106b.
Кодер 108 передает M сигналов 112 понижающего микширования и по меньшей мере некоторые из матричных элементов 114 компоненту 110 генерирования битового потока. Компонент 110 генерирования битового потока генерирует битовый поток 116, содержащий M сигналов понижающего микширования 112 и по меньшей мере некоторые из матричных элементов 114 посредством выполнения квантования и кодирования. Компонент 110 генерирования битового потока дополнительно принимает метаданные, содержащие информацию 104 о положении, для включения в битовый поток 116.
Декодирующая часть системы содержит компонент 118 декодирования битового потока и декодер 120. Компонент 118 декодирования битового потока принимает битовый поток 116 и выполняет декодирование и деквантизацию с целью извлечения M сигналов 112 понижающего микширования и дополнительной информации, содержащей по меньшей мере некоторые из матричных элементов 114 матрицы восстановления. Затем M сигналов 112 понижающего микширования и матричные элементы 114 поступают на декодер 120, который на их основе генерирует восстановление 106’ N звуковых объектов 106а и, возможно, также основных каналов 106b. Восстановление 106’ N звуковых объектов, следовательно, является приблизительным представлением N звуковых объектов 106а и, возможно, также основных каналов 106b.
В качестве примера, если сигналы 112 понижающего микширования соответствуют каналам [Lf Rf Cf Ls Rs LFE] конфигурации 5.1, декодер 120 может восстанавливать объекты 106’ с применением только каналов полного диапазона [Lf Rf Cf Ls Rs], таким образом, игнорируя LFE. Это также относится к другим конфигурациям каналов. Канал LFE понижающего микширования 112 может быть отправлен (в основном без изменений) на устройство 122 представления данных.
Восстановленные звуковые объекты 106’ вместе с информацией 104 о положении затем подаются на устройство 122 представления данных. На основе восстановленных звуковых объектов 106’ и информации 104 о положении устройство 122 представления данных представляет выходной сигнал 124, имеющий формат, который подходит для воспроизведения, на требуемой конфигурации громкоговорителей или наушников. Типовыми форматами являются установка окружающего звука конфигурации 5.1 (3 передних громкоговорителя, 2 окружающих громкоговорителя и 1 громкоговоритель низкочастотных эффектов LFE) или установка конфигурации 7.1 +4 (3 передних громкоговорителя, 4 окружающих громкоговорителя, 1 громкоговоритель LFE, и 4 громкоговорителя верхнего расположения).
В некоторых вариантах осуществления исходная звуковая сцена может содержать большое количество звуковых объектов. Обработка большого количества звуковых объектов происходит за счет высокой вычислительной сложности. Кроме того, количество дополнительной информации (информации 104 о положении и элементов 114 матрицы восстановления) для встраивания в битовый поток 116 зависит от количества звуковых объектов. Как правило, количество дополнительной информации растет линейно с количеством звуковых объектов. Таким образом, в целях снижения вычислительной сложности и/или уменьшения скорости цифрового потока, необходимого для кодирования звуковой сцены, может быть предпочтительным уменьшение количества звуковых объектов перед кодированием. С этой целью система 100 кодирования/декодирования звука может дополнительно содержать модуль упрощения сцены (не показан), расположенный перед кодером 108. Модуль упрощения сцены принимает исходные звуковые объекты и, возможно, также основные каналы в качестве входных данных и выполняет обработку с целью вывода звуковых объектов 106а. Модуль упрощения сцены уменьшает количество, скажем K, исходных звуковых объектов до более целесообразного количества N звуковых объектов 106а, посредством выполнения кластеризации. Точнее, модуль упрощения сцены группирует K исходных звуковых объектов и, возможно, также основных каналов в N кластеров. Как правило, кластеры определяются на основе пространственной близости в звуковой сцене K исходных звуковых объектов/основных каналов. С целью определения пространственной близости модуль упрощения сцены может принимать информацию о положении исходных звуковых объектов/основных каналов в качестве входных данных. Когда модуль упрощения сцены сформировал N кластеров, он приступает к представлению каждого кластера одним звуковым объектом. Например, звуковой объект, представляющий кластер, может быть выполнен в виде суммы звуковых объектов/основных каналов, образующих часть кластера. Более конкретно, для генерирования звукового содержимого представляющего звукового объекта может добавляться звуковое содержимое звуковых объектов/основных каналов. Кроме того, положения звуковых объектов/основных каналов в кластере могут усредняться для задания положения представляющего звукового объекта. Модуль упрощения сцены включает положения представляющих звуковых объектов в данных 104 о положении. Кроме того, модуль упрощения сцены выводит представляющие звуковые объекты, которые составляют N звуковых объектов 106а на фиг. 1.
M сигналов 112 понижающего микширования могут быть расположены в первом поле битового потока 116 с применением первого формата. Матричные элементы 114 могут быть расположены во втором поле битового потока 116 с применением второго формата. Таким образом, декодер, который поддерживает только первый формат, способен декодировать и воспроизводить M сигналов 112 понижающего микширования в первом поле и отбрасывать матричные элементы 114 во втором поле.
Система 100 кодирования/декодирования звука на фиг. 1 поддерживает первый и второй формат. Точнее, декодер 120 выполнен с возможностью декодирования первого и второго форматов, это означает, что он способен восстанавливать объекты 106’ на основе M сигналов 112 понижающего микширования и матричных элементов 114.
На фиг. 2 представлена система 200 кодирования/декодирования звука. Кодирующая часть 108, 110 системы 200 соответствует части, показанной на фиг. 1. Однако декодирующая часть системы 200 кодирования/декодирования звука отличается от декодирующей части системы 100 кодирования/декодирования звука на фиг. 1. Система 200 кодирования/декодирования звука содержит устаревший декодер 230, который поддерживает первый формат, но не поддерживает второй формат. Таким образом, устаревший декодер 230 системы 200 кодирования/декодирования звука не способен восстанавливать звуковые объекты/основные каналы 106a-b. Однако, поскольку устаревший декодер 230 поддерживает первый формат, он все еще может декодировать M сигналов 112 понижающего микширования для генерирования выходного сигнала 224, который является представлением, основанным на каналах, таким как представление конфигурации 5.1, подходящее для непосредственного воспроизведения на соответствующей многоканальной установке громкоговорителей. Это свойство сигналов понижающего микширования называется обратной совместимостью, означающей также, что устаревший декодер, который не поддерживает второй формат, то есть не может декодировать дополнительную информацию, содержащую матричные элементы 114, все равно может декодировать и воспроизводить M сигналов 112 понижающего микширования.
Функционирование на кодирующей стороне системы 100 кодирования/декодирования звука далее будет описано более подробно со ссылкой на фиг. 3 и блок-схему на фиг. 4.
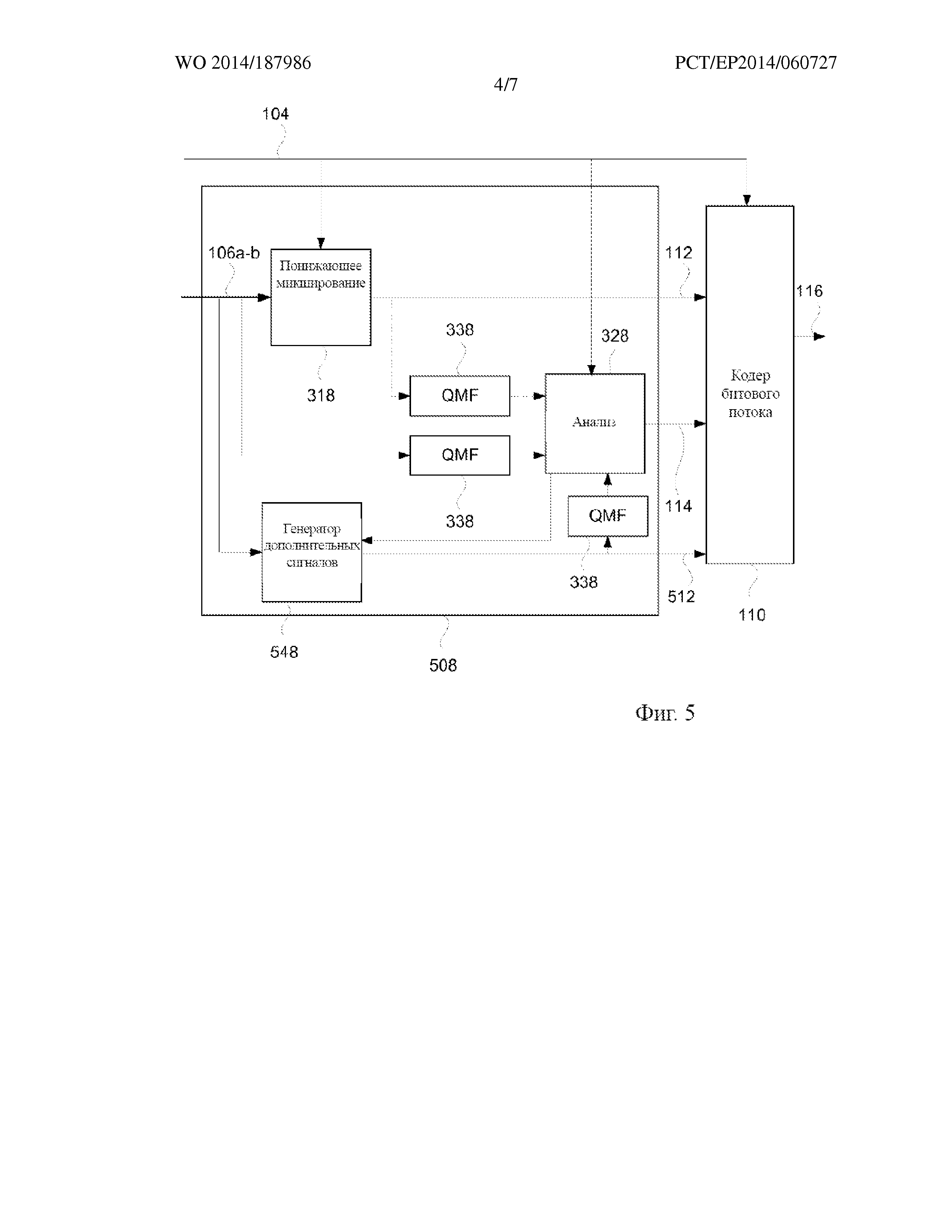
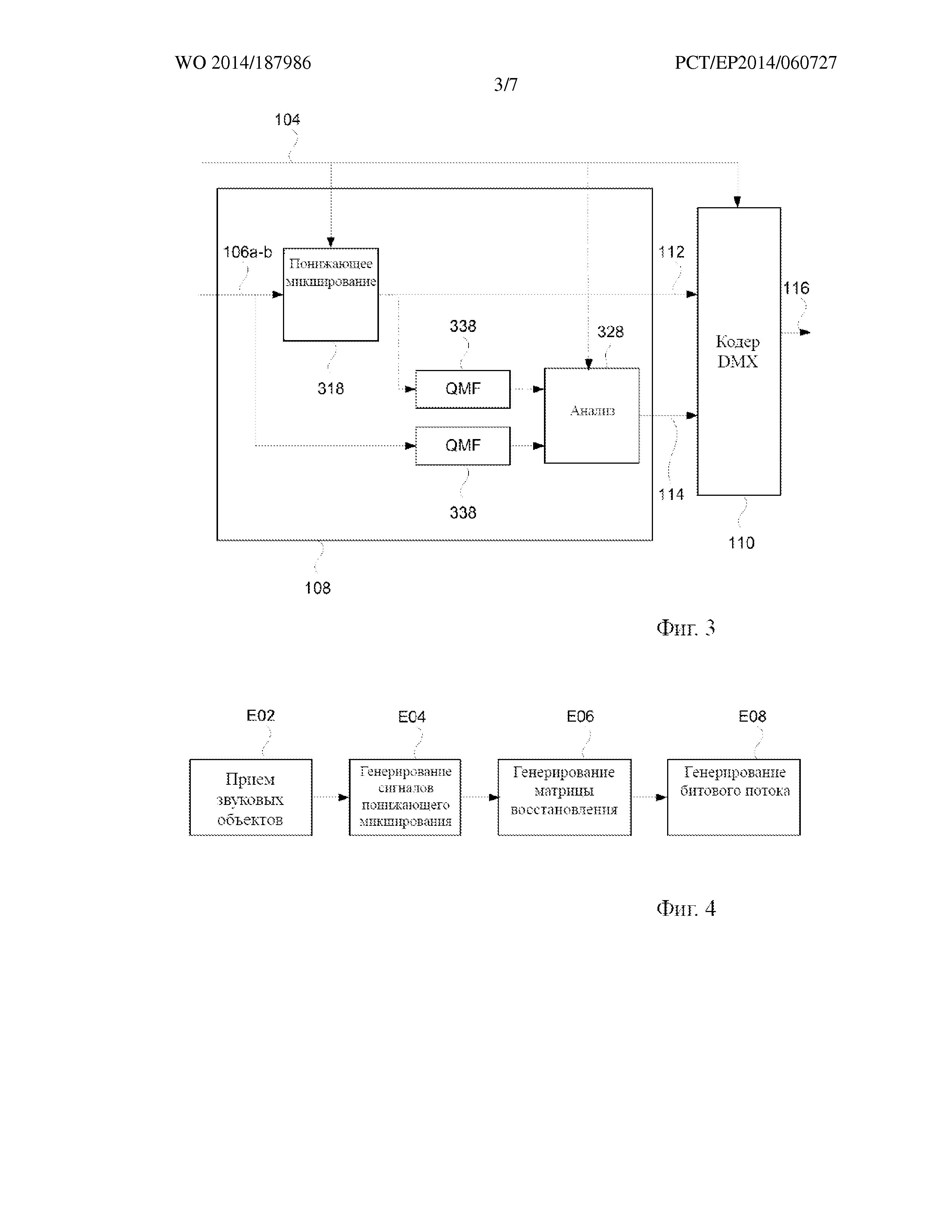
На фиг. 4 более подробно представлен кодер 108 и компонент 110 генерирования битового потока, приведенный на фиг. 1. Кодер 108 содержит принимающий компонент (не показан), компонент 318 генерирования понижающего микширования и анализирующий компонент 328.
На этапе E02 принимающий компонент кодера 108 принимает N звуковых объектов 106а и основные каналы 106b, если они присутствуют. Кодер 108 может дополнительно принимать данные 104 о положении. С применением векторного обозначения N звуковых объектов могут обозначаться вектором S = [S1 S2 ...SN]T, а основные каналы – вектором B. N звуковых объектов и основные каналы вместе могут быть представлены вектором A = [BT ST]T.
На этапе E04 компонент 318 генерирования понижающего микширования генерирует M сигналов 112 понижающего микширования из N звуковых объектов 106а и основных каналов 106b, если они присутствуют. С применением векторного обозначения M сигналов понижающего микширования могут быть представлены в виде вектора D = [D1 D2 ... DM]T, содержащего M сигналов понижающего микширования. Как правило, понижающее микширование множества сигналов представляет собой комбинацию сигналов, такую как линейная комбинация сигналов. В качестве примера, M сигналов понижающего микширования могут соответствовать конкретной конфигурации громкоговорителей, например конфигурации громкоговорителей [Lf Rf Cf Ls Rs LFE] в конфигурации громкоговорителей 5.1.
Компонент 318 генерирования понижающего микширования может использовать информацию 104 о положении при генерировании M сигналов понижающего микширования таким образом, что объекты будут комбинироваться в разные сигналы понижающего микширования на основе их положения в трехмерном пространстве. Это особенно важно, когда М сигналов понижающего микширования сами соответствуют определенной конфигурации громкоговорителей, как в приведенном выше примере. В качестве примера, компонент 318 генерирования понижающего микширования может получать матрицу представления Pd (в соответствии с матрицей представления, применяемой в устройстве 122 представления данных на фиг. 1) на основе информации о положении и использовать ее для генерирования понижающего микширования в соответствии с D =Pd* [BT ST]T.
N звуковых объектов 106а и основные каналы 106b, если они присутствуют, также подаются на анализирующий компонент 328. Анализирующий компонент 328, как правило, работает на отдельных частотно-временных мозаичных элементах звукового сигнала 106a-b. Для этой цели N звуковых объектов 106а и основные каналы 106b могут подаваться через банк 338 фильтров, например, банк QMF, который выполняет частотно-временное преобразование входных звуковых сигналов 106a-b. В частности, банк 338 фильтров связан с множеством частотных поддиапазонов. Разрешающая способность по частоте частотно-временного мозаичного элемента соответствует одному или нескольким из этих частотных поддиапазонов. Разрешающая способность по частоте частотно-временных мозаичных элементов может быть неравномерной, т.е. она может изменяться в зависимости от частоты. Например, разрешение по нижним частотам может применяться для высоких частот, что означает, что частотно-временной мозаичный элемент в высокочастотном диапазоне может соответствовать нескольким частотным поддиапазонам, определенным банком 338 фильтров.
На этапе Е06 анализирующий компонент 328 генерирует матрицу восстановления, обозначенную в данной заявке как R1. Сгенерированная матрица восстановления состоит из множества матричных элементов. Матрица восстановления R1 является такой, что обеспечивает возможность восстановления (приблизительного представления) N звуковых объектов 106а и, возможно, также основных каналов 106b из M сигналов 112 понижающего микширования в декодере.
Анализирующий компонент 328 может принимать разные подходы к генерированию матрицы восстановления. Например, может применяться подход прогнозирования минимальной среднеквадратичной ошибки (MMSE), в котором принимают одновременно N звуковых объектов/основные каналы 106a-b в качестве входных данных, а также M сигналов 112 понижающего микширования в качестве входных данных. Он может быть описан как подход, который направлен на нахождение матрицы восстановления, которая сводит к минимуму среднеквадратичную ошибку восстановленных звуковых объектов/основных каналов. В частности, в результате выполнения подхода восстанавливают N звуковых объектов/основных каналов с применением потенциальной матрицы восстановления и сравнивают их с входными звуковыми объектами/основными каналами 106a-b в отношении среднеквадратичной ошибки. Потенциальная матрица восстановления, которая сводит к минимуму среднеквадратичную ошибку, выбирается в качестве матрицы восстановления, а ее матричные элементы 114 представляют собой выходные данные анализирующего компонента 328.
Подход MMSE требует оценки корреляции и ковариации матриц N звуковых объектов/основных каналов 106a-b и M сигналов 112 понижающего микширования. В соответствии с вышеуказанным подходом, данные корреляции и ковариации определяются на основе N звуковых объектов/основных каналов 106a-b и М сигналов 112 понижающего микширования. В альтернативном варианте основанного на модели подхода анализирующий компонент 328 принимает данные 104 о положении в качестве входных данных, вместо M сигналов 112 понижающего микширования. Делая определенные предположения, например, предполагая, что N звуковых объектов являются взаимно некоррелированными, и используя это предположение в сочетании с правилами понижающего микширования, применяемыми в компоненте 318 генерирования понижающего микширования, анализирующий компонент 328 может вычислять необходимые корреляции и ковариации, необходимые для выполнения способа MMSE, описанного выше.
Элементы матрицы 114 восстановления и M сигналов 112 понижающего микширования затем подаются на компонент 110 генерирования битового потока. На этапе E08 компонент 110 генерирования битового потока осуществляет квантование и кодирование M сигналов 112 понижающего микширования и по меньшей мере некоторых из матричных элементов 114 матрицы восстановления и размещает их в битовом потоке 116. В частности, компонент 110 генерирования битового потока может размещать M сигналов 112 понижающего микширования в первом поле битового потока 116 с применением первого формата. Кроме того, компонент 110 генерирования битового потока может размещать матричные элементы 114 во втором поле битового потока 116 с применением второго формата. Как описано выше со ссылкой на фиг. 2, это позволяет устаревшему декодеру, который поддерживает только первый формат, декодировать и воспроизводить М сигналов 112 понижающего микширования и отбрасывать матричные элементы 114 во втором поле.
На фиг. 5 представлен альтернативный вариант осуществления кодера 108. По сравнению с кодером, показанным на фиг. 3, кодер 508 на фиг. 5 дополнительно обеспечивает возможность включения одного или нескольких дополнительных сигналов в битовый поток 116.
С этой целью кодер 508 содержит компонент 548 генерирования дополнительных сигналов. Компонент 548 генерирования дополнительных сигналов принимает звуковые объекты/основные каналы 106a-b, и на их основе генерируются один или несколько дополнительных сигналов 512. Компонент 548 генерирования дополнительных сигналов, например, может генерировать дополнительные сигналы 512 в качестве комбинации звуковых объектов/основных каналов 106a-b. Обозначая дополнительные сигналы вектором C = [C1 C2 ... CL]T, дополнительные сигналы могут генерироваться в виде C = Q *[BT ST]T, где Q является матрицей, которая может быть переменой во времени и по частоте. Это включает в себя случай, когда дополнительные сигналы равны одному или нескольким звуковым объектам и когда дополнительные сигналы представляют собой линейные комбинации звуковых объектов. Например, дополнительный сигнал может представлять особенно важный объект, такой как диалог.
Дополнительные сигналы 512 предназначены для улучшения восстановления звуковых объектов/основных каналов 106a-b декодера. Точнее, на декодирующей стороне звуковые объекты/основные каналы 106a-b могут быть восстановлены на основе M сигналов 112 понижающего микширования, а также L дополнительных сигналов 512. Поэтому матрица восстановления будет содержать матричные элементы 114, которые обеспечивают возможность восстановления звуковых объектов/основных каналов из M сигналов 112 понижающего микширования, а также L дополнительных сигналов.
Следовательно, L дополнительных сигналов 512 могут подаваться на анализирующий компонент 328 таким образом, что они учитываются при генерировании матрицы восстановления. Анализирующий компонент 328 может также отправлять сигнал управления на компонент 548 генерирования дополнительных сигналов. Например, анализирующий компонент 328 может контролировать, какие звуковые объекты/основные каналы включать в дополнительные сигналы и как они должны быть включены. В частности, анализирующий компонент 328 может контролировать выбор Q-матрицы. Контроль может, например, основываться на подходе MMSE, описанном выше, таким образом, что дополнительные сигналы выбираются так, чтобы восстановленные звуковые объекты/основные каналы были как можно ближе к звуковым объектам/основным каналам 106a-b.
Далее будет описана более подробно работа декодирующей стороны системы 100 кодирования/декодирования звука со ссылкой на фиг. 6 и блок-схему на фиг. 7.
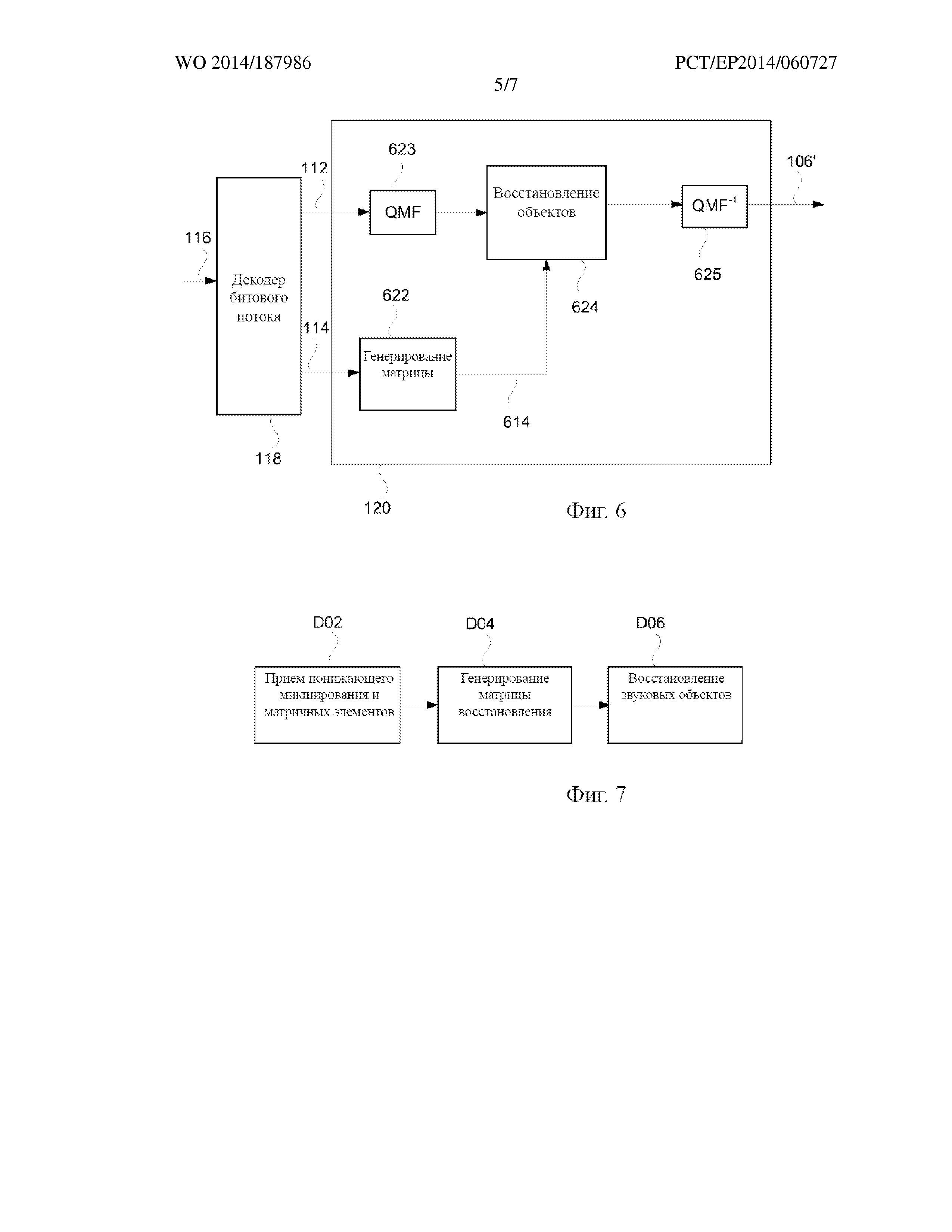
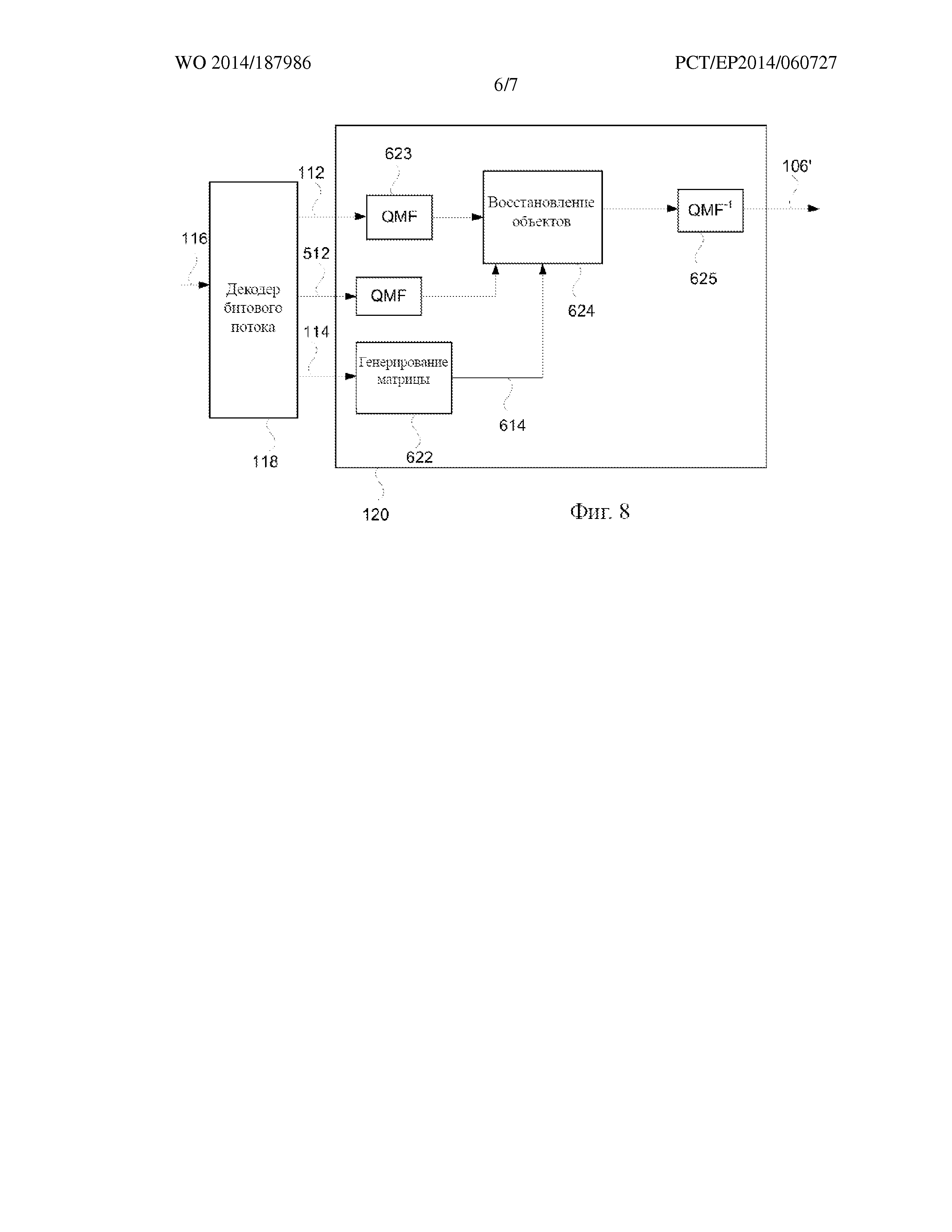
На фиг. 6 более подробно представлен компонент 118 декодирования битового потока и декодер 120, приведенный на фиг. 1. Декодер 120 содержит компонент 622 генерирования матрицы восстановления и компонент 624 восстановления.
На этапе D02 компонент 118 декодирования битового потока принимает битовый поток 116. Компонент 118 декодирования битового потока осуществляет декодирование и деквантование информации в битовом потоке 116 с целью извлечения M сигналов 112 понижающего микширования и по меньшей мере некоторых из матричных элементов 114 матрицы восстановления.
Компонент 622 генерирования матрицы восстановления принимает матричные элементы 114 и переходит к генерированию матрицы 614 восстановления на этапе D04.
Компонент 622 генерирования матрицы восстановления генерирует матрицу 614 восстановления посредством расположения матричных элементов 114 в соответствующих позициях в матрице. Если получены не все матричные элементы матрицы восстановления, компонент 622 генерирования матрицы восстановления может, например, вставлять нули вместо недостающих элементов.
Затем матрица 614 восстановления и M сигналов понижающего микширования подаются на восстанавливающий компонент 624. Затем восстанавливающий компонент 624 на этапе D06 восстанавливает N звуковых объектов и, если это необходимо, основные каналы. Другими словами, восстанавливающий компонент 624 генерирует приблизительное представление 106’ N звуковых объектов/основных каналов 106a-b.
В качестве примера, M сигналов понижающего микширования могут соответствовать конкретной конфигурации громкоговорителей, например конфигурации громкоговорителей [Lf Rf Cf Ls Rs LFE] в конфигурации громкоговорителей 5.1. В таком случае восстановление объектов 106’ восстанавливающим компонентом 624 может быть основано только на сигналах понижающего микширования, соответствующих каналам полного диапазона конфигурации громкоговорителей. Как описано выше, сигнал с ограниченным диапазоном (низкочастотный сигнал LFE) может быть отправлен в основном без изменений на устройство представления данных.
Восстанавливающий компонент 624 обычно работает в частотной области. Точнее, восстанавливающий компонент 624 работает на отдельных частотно-временных мозаичных элементах входных сигналов. Поэтому M сигналов 112 понижающего микширования, как правило, подлежат преобразованию 623 время-частота перед подачей на восстанавливающий компонент 624. Преобразование 623 время-частота, как правило, является таким же или подобным преобразованию 338, применяемому на кодирующей стороне. Например, преобразование 623 время-частота может быть преобразованием QMF.
С целью восстановления звуковых объектов/основных каналов 106’ восстанавливающий компонент 624 применяет операцию матрицирования. Более конкретно, используя введенное ранее обозначение, восстанавливающий компонент 624 может генерировать приблизительное представление A' звуковых объектов/основных каналов как A' = R1 * D. Матрица восстановления R1 может изменяться в зависимости от времени и частоты. Таким образом, матрица восстановления может изменяться среди различных частотно-временных мозаичных элементов, обработанных восстанавливающим компонентом 624.
Восстановленные звуковые объекты/основные каналы 106’, как правило, преобразуются обратно во временную область 625 до вывода из декодера 120.
На фиг. 8 представлена ситуация, когда битовый поток 116 дополнительно содержит дополнительные сигналы. По сравнению с вариантом осуществления на фиг. 7 компонент 118 декодирования битового потока теперь дополнительно декодирует один или несколько дополнительных сигналов 512 из битового потока 116. Дополнительные сигналы 512 поступают на восстанавливающий компонент 624, где они включаются в восстановление звуковых объектов/основных каналов. Более конкретно, восстанавливающий компонент 624 генерирует звуковые объекты/основные каналы, применяя матричную операцию A' = R1* [DT CT]T.
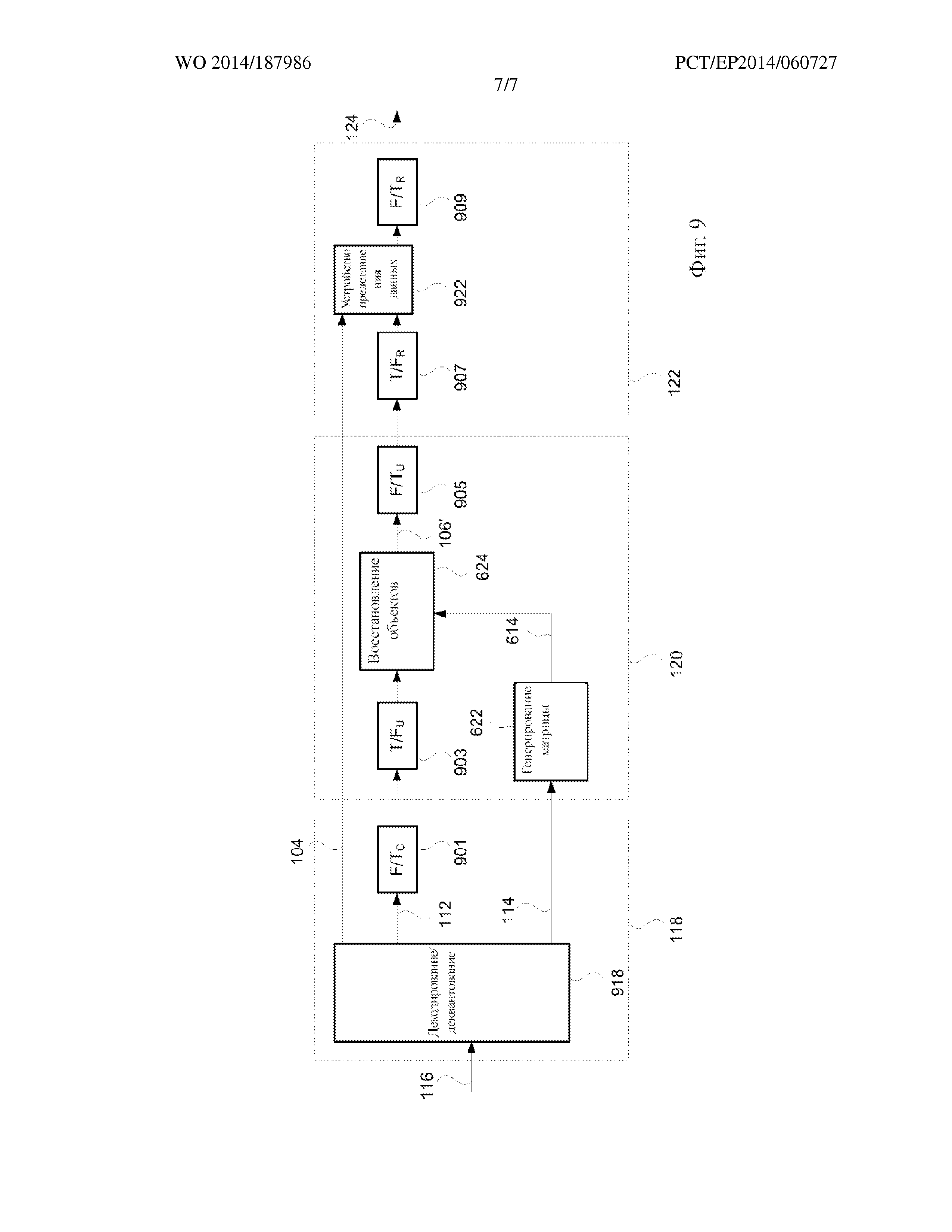
На фиг. 9 представлены различные частотно-временные преобразования, используемые на декодирующей стороне в системе 100 кодирования/декодирования звука на фиг. 1. Компонент 118 декодирования битового потока принимает битовый поток 116. Компонент 918 декодирования и деквантования осуществляет декодирование и деквантование битового потока 116 с целью извлечения информации 104 о положении, M сигналов 112 понижающего микширования и матричных элементов 114 матрицы восстановления.
На этом этапе M сигналы 112 понижающего микширования, как правило, представляются в первой частотной области, соответствующей первой группе банков частотно-временных фильтров, обозначенных в данной заявке как T/Fc и F/Tc, для преобразования из первой временной области в первую частотную область и из первой частотной области во временную область соответственно. Как правило, банки фильтров, соответствующие первой частотной области, могут реализовать перекрывающее оконное преобразование, такое как MDCT и обратное MDCT. Компонент 118 декодирования битового потока может содержать преобразующий компонент 901, который преобразует M сигналов 112 понижающего микширования во временную область с применением банка фильтров F/Tc.
Декодер 120 и, в частности, восстанавливающий компонент 624, как правило, обрабатывает сигналы в отношении второй частотной области. Вторая частотная область соответствует второй группе банков частотно-временных фильтров, обозначенных в данной заявке как T/Fu и F/Tu, для преобразования из временной области во вторую частотную область и из второй частотной области во временную область соответственно. Поэтому декодер 120 может содержать преобразующий компонент 903, который преобразует M сигналов 112 понижающего микширования, которые представлены во временной области, во вторую частотную область с применением банка фильтров T/Fu. После восстановления восстанавливающим компонентом 624 объектов 106’ на основе M сигналов понижающего микширования посредством выполнения обработки во второй частотной области, преобразующий компонент 905 может преобразовывать восстановленные объекты 106' назад во временную область с применением банка фильтров F/Tu.
Устройство 122 представления данных, как правило, обрабатывает сигналы по отношению к третьей частотной области. Третья частотная область соответствует третьей группе банков частотно-временных фильтров, обозначенных в данной заявке как T/FR и F/TR, для преобразования из временной области в третью частотную область и из третьей частотной области во временную область соответственно. Таким образом, устройство 122 представления данных может содержать преобразующий компонент 907, который преобразует восстановленные звуковые объекты 106’ из временной области в третью частотную область с применением банка фильтров T/FR. После того как устройство 122 представления данных посредством компонента 922 представления данных представляет выходные каналы 124, выходные каналы могут быть преобразованы во временную область посредством преобразующего компонента 909 с применением банка фильтров F/TR.
Как видно из приведенного выше описания, декодирующая сторона системы кодирования/декодирования звука включает ряд этапов частотно-временного преобразования. Однако если определенным образом выбраны первая, вторая, и третья частотные области, то некоторые этапы частотно-временного преобразования становятся лишними.
Например, некоторые из первой, второй и третьей частотных областей могут быть выбраны как одна и та же частотная область или могут быть реализованы совместно для перехода непосредственно от одной частотной области к другой без прохождения всего пути к временной области между ними. Примером последнего является случай, когда единственное различие между второй и третьей частотными областями является то, что преобразующий компонент 907 в устройстве 122 представления данных использует банк фильтров Найквиста для увеличенного разрешения по частоте на низких частотах в дополнение к банку QMF фильтров, который является общим для обоих преобразующих компонентов 905 и 907. В таком случае преобразующие компоненты 905 и 907 могут быть реализованы совместно в виде банка фильтров Найквиста, тем самым снижая вычислительную сложность.
В другом примере вторая и третья частотные области являются одинаковыми. Например, и вторая, и третья частотные области могут быть частотной областью QMF. В таком случае преобразующие компоненты 905 и 907 являются лишними и могут быть удалены, тем самым снижая вычислительную сложность.
Согласно другому примеру первая и вторая частотные области могут быть одинаковыми. Например, и первая, и вторая частотные области могут быть областью MDCT. В таком случае первый и второй преобразующие компоненты 901 и 903 могут быть удалены, тем самым снижая вычислительную сложность.
ЭКВИВАЛЕНТЫ, ДОПОЛНЕНИЯ, АЛЬТЕРНАТИВЫ И ПРОЧЕЕ
Дополнительные варианты осуществления настоящего изобретения будут очевидны для специалиста в данной области техники после изучения описания, приведенного выше. Хотя в настоящем описании и на графических материалах раскрыты некоторые конкретные варианты осуществления и примеры, но раскрытие этими конкретными примерами не ограничивается. Возможны многочисленные модификации и изменения в пределах объема настоящего изобретения, определенного прилагаемой формулой изобретения. Любые ссылочные позиции, встречающиеся в формуле изобретения, не должны рассматриваться как ограничивающие ее объем.
Кроме того, после изучения графических материалов, описания и прилагаемой формулы изобретения специалисту могут быть понятны изменения раскрытых вариантов осуществления и могут использоваться им при практической реализации изобретения. В формуле изобретения слово «содержащий» не исключает другие элементы или этапы, и единственное число не исключает множественное. Сам факт, что некоторые признаки упоминаются во взаимно отличных зависимых пунктах формулы изобретения, не говорит о том, что не может быть использовано с выгодой сочетание этих признаков.
Системы и способы, описанные выше, могут быть реализованы в виде программного обеспечения, программно-аппаратного обеспечения, аппаратных средств или их сочетания. При реализации в виде аппаратных средств разделение задач между функциональными блоками, о которых говорилось в вышеприведенном описании, не обязательно соответствует разделению на физические блоки; наоборот, один физический компонент может выполнять несколько функций, и одно задание может выполняться несколькими взаимодействующими физическими компонентами. Некоторые компоненты или все компоненты могут быть реализованы в виде программного обеспечения, выполняемого процессором цифровых сигналов или микропроцессором, или быть реализованы в виде аппаратных средств или в виде специализированной интегральной микросхемы. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут содержать компьютерные носители информации (или постоянные носители) и каналы передачи информации (или временные носители). Как хорошо известно специалисту в области техники, к которой относится изобретение, термин «компьютерные носители информации» включает энергозависимые и энергонезависимые, сменные и несменные носители, реализованные в любом способе или технологии для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители информации включают без ограничения RAM, ROM, EEPROM, флеш-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другие оптические дисковые запоминающие устройства, магнитные кассеты, магнитную ленту, магнитный диск для хранения информации или другие магнитные устройства для хранения информации, или любой другой носитель, который может быть использован для хранения необходимой информации и который может быть доступным с применением компьютера. Дополнительно специалисту хорошо известно, что в каналах передачи информации, как правило, осуществлены машиночитаемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как несущая волна или другой механизм переноса, и включены любые средства для доставки информации.
Блок модулированных фильтров с малым запаздыванием
Эффективное комбинированное гармоническое преобразование
Улучшение звукового сигнала fm-стереофонического радиоприемника путем использования параметрического стереофонического кодирования
Усовершенствованное гармоническое преобразование
Передискретизация в комбинированном банке фильтров транспозитора
Гармоническое преобразование, усовершенствованное перекрестным произведением
Перцептивная оценка темпа с масштабируемой сложностью
Аутентификация потоков данных
Усовершенствованное гармоническое преобразование на основе блока поддиапазонов
Усовершенствованное стереофоническое кодирование на основе комбинации адаптивно выбираемого левого/правого или среднего/побочного стереофонического кодирования и параметрического стереофонического кодирования
Блок модулированных фильтров с малым запаздыванием
Эффективное комбинированное гармоническое преобразование
Улучшение звукового сигнала fm-стереофонического радиоприемника путем использования параметрического стереофонического кодирования
Усовершенствованное гармоническое преобразование
Передискретизация в комбинированном банке фильтров транспозитора
Гармоническое преобразование, усовершенствованное перекрестным произведением
Перцептивная оценка темпа с масштабируемой сложностью
Аутентификация потоков данных
Усовершенствованное гармоническое преобразование на основе блока поддиапазонов
Усовершенствованное стереофоническое кодирование на основе комбинации адаптивно выбираемого левого/правого или среднего/побочного стереофонического кодирования и параметрического стереофонического кодирования

