Результат интеллектуальной деятельности: СПОСОБ ОРГАНИЗАЦИИ ВЫЧИСЛЕНИЙ НА ГРАФИЧЕСКИХ ПРОЦЕССОРАХ ДЛЯ МОДЕЛИРОВАНИЯ ПОМЕХОУСТОЙЧИВОСТИ НИЗКОПЛОТНОСТНЫХ КОДЕКОВ
Вид РИД
Изобретение
Изобретение относится к автоматизированному проектированию, технике моделирования и проверки кодов и может быть использовано при цифровом моделировании характеристик помехоустойчивых низкоплотностных кодеков в однопроцессорных гетерогенных компьютерных системах малой производительности для ускорения производимых вычислений.
Техническим результатом является увеличение производительности вычислений, производимых в процессе моделирования.
Известен способ моделирования, описанный в патенте США «Lithographic simulations using graphical processing units», US 2006/0242618 A1, МПК G06F 17/50, опубл. 26.10.2006. Способ заключается в инициализации хостовой части основным вычислителем - CPU (англ. central processing unit - центральный процессор), инициализации данных дополнительного вычислителя - GPU (англ. graphics processing unit - графический процессор), передачи данных от хостовой части к GPU, запуске вычислений на GPU, синхронизируемых хостовой частью и передаче результатов вычислений от GPU обратно хостовой части.
Недостатком такого подхода является неполное использование доступных вычислительных мощностей CPU.
Наиболее близким по своей технической сущности к заявленному способу является способ, описанный в патенте США «Model implementation on GPU», US 7979814 B1, МПК G06F 17/50, опубл. 12.07.2011. Способ заключается в подготовке и передаче хостовой частью данных GPU части, запуске основного потока для CPU и старте потока вычислений на GPU, передаче результатов вычислений хостовой части по завершении моделирования.
Недостатком способа является неполная загрузка основного вычислителя гетерогенной системы вследствие того, что он реализует лишь инициализацию и сопровождение (синхронизацию) вычислений GPU части. В отношении вычислений в гетерогенных системах низкой производительности, такая схема организации моделирования становится схемой с неполным использованием потенциала гетерогенной системы в условиях, когда выигрыш в скорости вычислений на GPU невелик, а гетерогенная система содержит в качестве основного вычислителя лишь однопроцессорное устройство.
Сущность изобретения
Решаемой технической задачей изобретения является увеличение производительности вычислений, выполняемых в процессе моделирования.
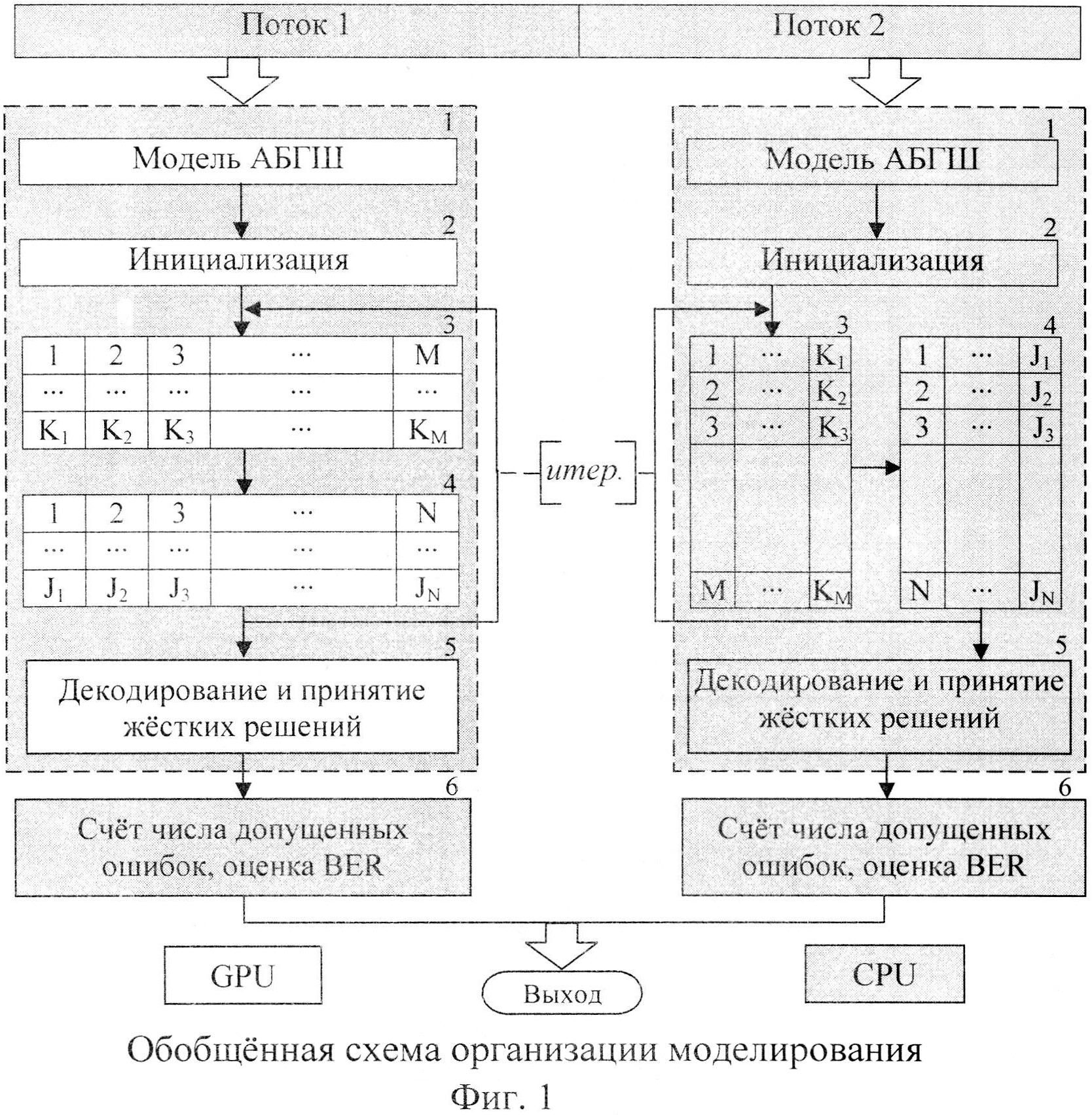
Сущность изобретения поясняется приведенными далее чертежами в отношении моделирования и проверки низкоплотностных кодов (N, J, K), где N - длина кода, J - количество единиц в столбце, а K - количество единиц в строке проверочной матрицы кода. На фиг. 1 представлена архитектура программной реализации предлагаемых решений, содержащая в своем составе: 1 - блок моделирования канала с аддитивным белым гауссовским шумом (АБГШ); 2 - блок инициализирующих процедур; 3 и 4 - блоки условной архитектуры итеративного декодера по итеративному алгоритму распространения доверия; 5 - блок финального декодирования и принятия жестких решений, 6 - блок оценки BER (англ. Bit Error Rate - вероятность битовой ошибки). Блоки 3 и 4 в обоих потоках отвечают за передачу сообщений от проверочных вершин к кодовым и обратно, однако в первом потоке, соответствующем вычислениям на GPU, блоки выполняются параллельно, а в потоке, соответствующем вычислениям на CPU, блоки выполняются последовательно.
Предлагаемый способ увеличения производительности заключается в следующем.
1. Сначала производят предварительную оценку производительности вычислений на CPU и GPU в отдельности друг от друга в соответствии с процедурой, псевдокод которой представлен в листинге 1.

Эмпирически было установлено, что моделирование декодирования 200 000 бит достаточно для приблизительной оценки производительности вычислений на CPU и GPU и при этом не так велико, чтобы загрузить гетерогенную систему на значительное время (более 10 сек). Домножение на коэффициент 1, 2 является поправочным; коэффициент вычислен также эмпирически. Функция ceil(x) в листинге 1 возвращает ближайшее целое к значению х, округленное вверх.
2. Затем осуществляют разбиение задачи в соотношении  , причем:
, причем:
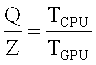 ,
,
где TCPU и TGPU - время, затраченное на расчеты центральным и графическим процессором в процессе выполнения вышеописанной процедуры соответственно. В отношении моделирования низкоплотностных кодеков разделить задачу оказывается возможным по точкам значений SNR, так как обычно их симулируется достаточное количество. Разбиение вычислительной задачи осуществляют следующим образом: Вводят вспомогательный коэффициент
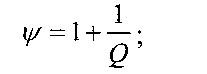
Вычисляют общее число точек моделирования:

Вычисляют границы интервалов моделирования:


Здесь SNRinit - минимальное значение сигнал/шум; SNRfinal - максимальное значение сигнал/шум; SNRincr - величина инкремента значения сигнал/шум.
3. После этого осуществляют организацию многопоточных вычислений, где моделирование части точек - Q производят основным потоком на вспомогательном вычислителе (GPU) с синхронизацией хостовой (CPU) частью, а моделирование части точек Ζ осуществляют дополнительным потоком вычислений на CPU. Основной поток (GPU, синхронизируемый CPU) моделирует точки SNR1: SNRinit≤SNR1≤SNRQ.
Дополнительный поток (CPU) моделирует точки SNR2: SNRZ≤SNR2≤SNRfinal.
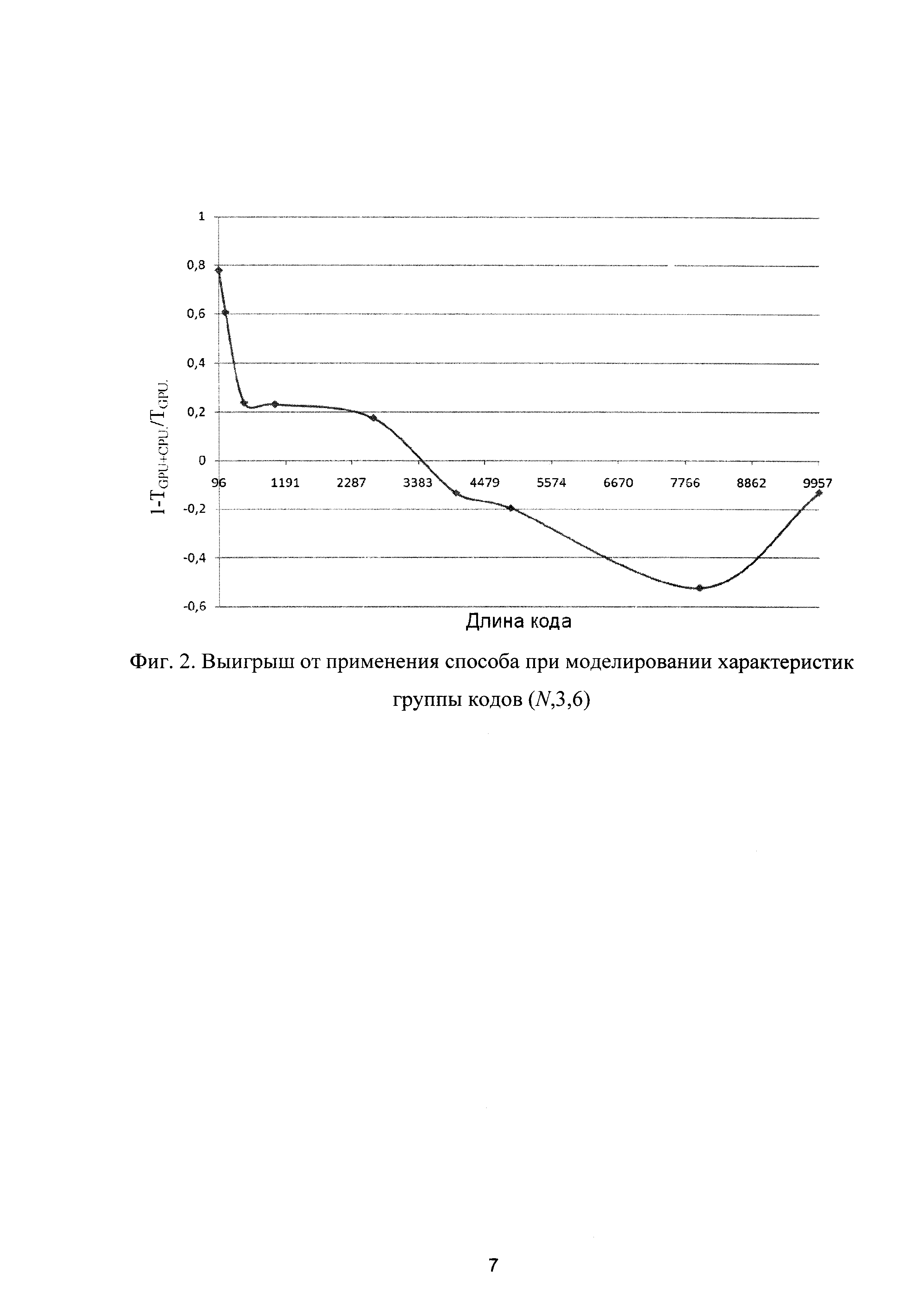
Достигаемое повышение производительности подтверждается программно полученными данными вычислений, представленными на фиг. 2 в виде графика временного выигрыша, в зависимости от длины кода, при моделировании в гетерогенной системе посредством открытого стандарта реализации техники GPGPU (англ. General-purpose graphics processing units - вычислений общего назначения на графических процессорах) OpenCL (англ. Open Computing Language - открытый язык вычислений) характеристик группы кодов (N, 3, 6) при 10 точках SNR (англ. signal-to-noise ratio - отношение сигнал/шум).
Таким образом, при малых значениях длины (N=96) выигрыш достигает 80% и снижается до 60% при N=204 и 41% при N=273. Затем наблюдается установившийся участок со средним значением выигрыша 21% при длине кода от N=504 до N=3000. Говоря об актуальности и практической важности полученных результатов, упомянутые выше значения длины кода рекомендованы следующими современными техническими стандартами в области телекоммуникаций: 802.11 - WiFi (беспроводные локальные и городские сети, N:648-1944); 802.16 - Mobile WiMAX (местные и городские беспроводные сети, N:576-2304); 802.22 - WRAN (беспроводные региональные сети, N:384-2304).
Область применимости способа ограничены условием Q<Maxsim. Стоит отметить, что принципиально способ реализуем и в гетерогенных системах с многопроцессорным CPU, с учетом полной загрузки всех ядер CPU.
Патенты
1. Патент США «Lithographic simulations using graphical processing units», US 2006/0242618 A1, МПК G06F 17/50, опубл. 26.10.2006.
2. Патент США «Model implementation on GPU», US 7979814 B1, МПК G06F 17/50, опубл. 12.07.2011.
Способ организации вычислений на графических процессорах для моделирования помехоустойчивых низкоплотностных кодеков, заключающийся в том, что хостовой частью выполняют подготовку и передачу данных GPU части (англ. graphics processing unit - графический процессор), после чего запускают основной поток вычислений на GPU, синхронизируемый CPU (англ. central processing unit - центральный процессор), и по завершении моделирования осуществляют передачу результатов вычислений хостовой части, отличающийся тем, что перед запуском вычислений на графическом процессоре производят предварительную оценку значений производительности вычислений на CPU (T) и GPU (T) в отдельности друг от друга, затем разбивают общее число точек моделирования в соотношении Q/Z=T/T, после чего часть точек Q моделируют в основном потоке вычислений на GPU, синхронизируемых с помощью CPU, который одновременно моделирует часть точек Ζ в дополнительном потоке вычислений.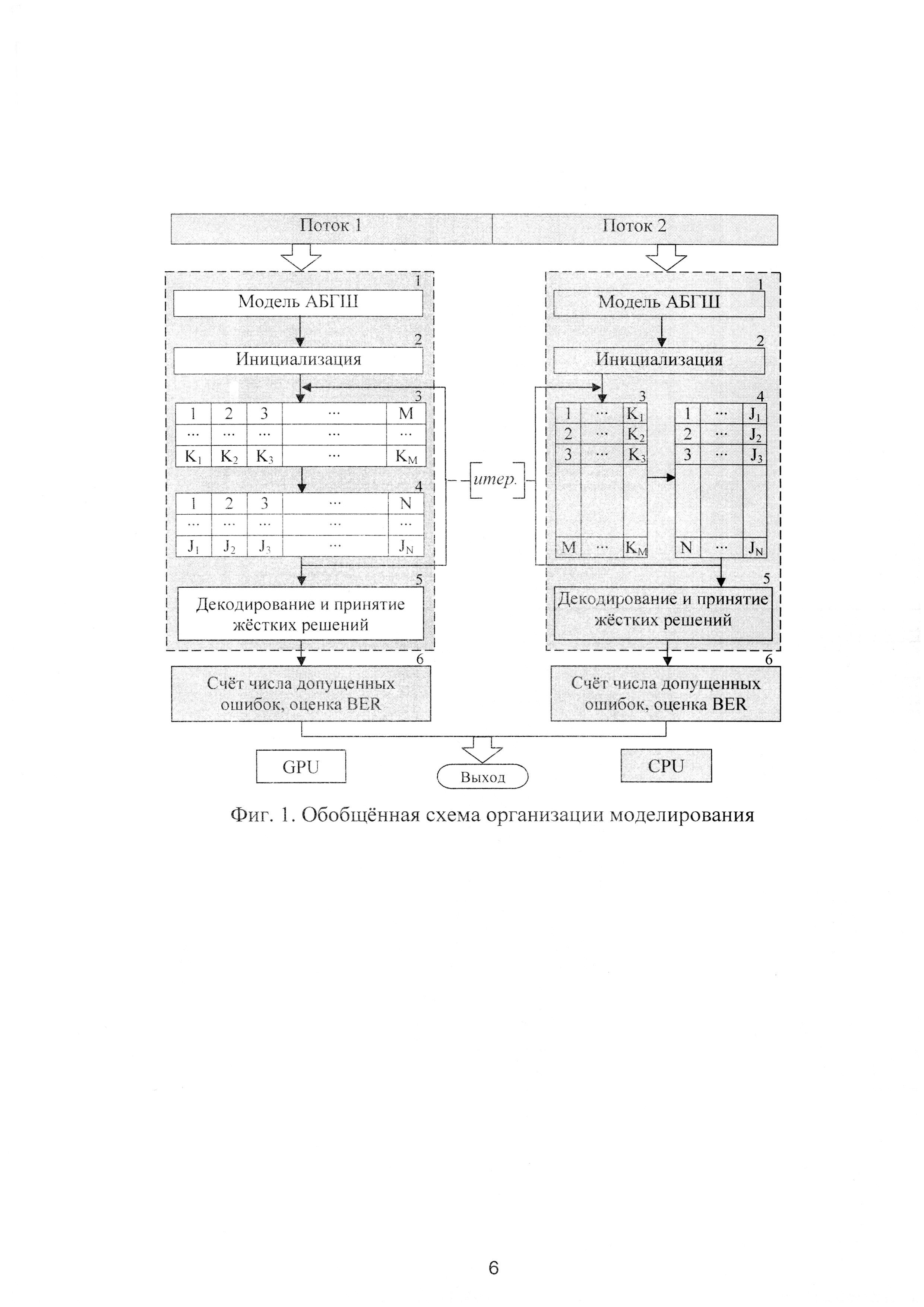
Плоская антенна вытекающей волны
Цифровой демодулятор сигналов с квадратурной амплитудной манипуляцией
Плоская антенна вытекающей волны
Цифровой демодулятор сигналов с квадратурной амплитудной манипуляцией
Плоская антенна с управляемой поляризационной характеристикой

