Результат интеллектуальной деятельности: СПОСОБ СОВМЕСТНОГО СЖАТИЯ И ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ
Вид РИД
Изобретение
Заявленное техническое решение относится к области электросвязи и информационных технологий, а именно к технике сжатия избыточной двоичной информации и ее помехоустойчивого кодирования при обмене данными по каналам передачи с ошибками.
Заявленное изобретение может быть использовано для обеспечения достоверности избыточной двоичной информации, передаваемой по каналам с ошибками.
Известен способ адаптивного помехоустойчивого кодирования по патенту РФ 2375824 МПК H04L 1/20 (2006.01) от 10.12.2009, заключающийся в том, что на передающей стороне исходную информацию кодируют помехоустойчивым кодом с переменными параметрами, далее помехоустойчивый код передают в канал связи, на приемной стороне помехоустойчивый код декодируют с обнаружением и исправлением ошибок в зависимости от корректирующей способности выбранного кода, по результатам декодирования помехоустойчивого кода оценивают качество канала связи и выбирают переменные параметры помехоустойчивого кода, обеспечивающие заданную вероятность правильного приема помехоустойчивого кода, и далее эти параметры помехоустойчивого кода сообщают на передающую сторону, отличающийся тем, что на приемной стороне по результатам декодирования помехоустойчивого кода рассчитывают начальную величину избыточности помехоустойчивого кода, обеспечивающую заданную вероятность правильного приема помехоустойчивого кода, оценивают вероятность правильного приема помехоустойчивого кода с выбранными параметрами, вычисляют величину отклонения полученной вероятности правильного приема помехоустойчивого кода от заданной вероятности правильного приема кода и в зависимости от величины этого отклонения корректируют величину избыточности помехоустойчивого кода, которую передают на передающую сторону, где формируют помехоустойчивый код с полученной избыточностью.
Недостатком указанного аналога является неэффективное использование пропускной способности канала передачи, вызванное отсутствием сжатия избыточной двоичной информации при обмене данными по каналам передачи с ошибками.
Известен также способ совместного сжатия и помехоустойчивого кодирования речевых сообщений описанный, например, в книге С.Н. Кириллов, В.Т. Дмитриев, Д.Е. Крысяев, С.С. Попов "Исследование качества передаваемой речевой информации при различном сочетании алгоритмов кодирования источника и канала связи в условиях воздействия помех". - Рязань, Вестник РГРТУ, Выпуск 23, 2008. Данный способ заключается в том, что предварительно формируют множество способов сжатия речевого сигнала, таких как импульсно-кодовая модуляция, адаптивная дельта-модуляция, адаптивная дифференциальная импульсно-кодовая модуляция, и множество способов помехоустойчивого кодирования, таких как кодирование Хэмминга, кодирование Боуз-Чоудхури-Хоквингема, на передающей стороне от отправителя получают очередную часть речевого сигнала длиною речевая фраза, который преобразуют в сжатую двоичную последовательность с помощью одного из способов сжатия речевого сигнала, выполняют помехоустойчивое кодирование сжатой двоичной последовательности с помощью одного из способов помехоустойчивого кодирования, передают на приемную сторону по каналу прямой связи очередную часть кодированной последовательности вместе с информацией об использованном способе сжатия речевого сигнала и способе помехоустойчивого кодирования, на приемной стороне получают очередную часть принятой последовательности, очередную часть принятой последовательности последовательно декодируют с использованием соответствующих способа помехоустойчивого декодирования и способа восстановления речевого сигнала, вычисляют оценку качества восстановленного речевого сигнала и полученную оценку сравнивают с пороговым значением качества, если вычисленная оценка качества восстановленного речевого сигнала не хуже предварительно установленного порогового значения качества, то передают получателю очередную часть восстановленной информационной последовательности и передающей стороне от отправителя получают очередную часть речевого сигнала и выполняют последующие действия, иначе передают по каналу обратной связи требование изменить способ сжатия речевого сигнала и способ помехоустойчивого кодирования, и выполняют последующие действия.
Недостатком указанного аналога является большая задержка передачи сообщений по каналу связи, вызванная необходимостью перебора подходящих способа сжатия речевого сигнала и способа помехоустойчивого кодирования.
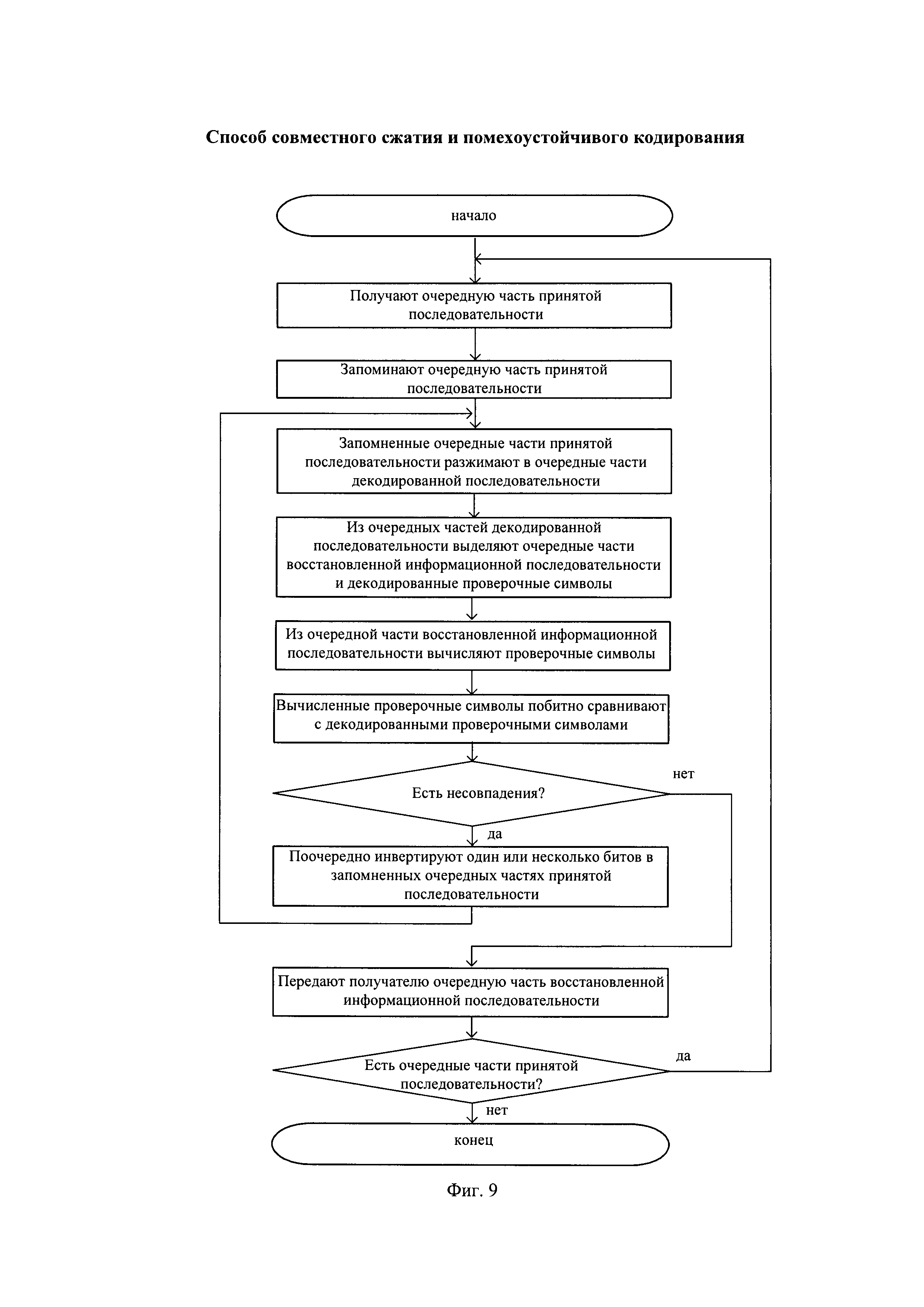
Наиболее близким по своей технической сущности к заявленному способу совместного сжатия и помехоустойчивого кодирования является способ совместного сжатия и помехоустойчивого кодирования по патенту США 6892343 МПК H04M 13/00 (2006.01) от 10.05.2005. Способ-прототип совместного сжатия и помехоустойчивого кодирования заключается в том, что на передающей стороне от отправителя получают очередную часть информационной последовательности длиной k≥1 бит, из предварительно сформированного множества выбирают проверочные символы длиной r≥1 бит и записывают вместе с очередной частью информационной последовательности в очередную часть помехоустойчивой последовательности, выполняют сжатие очередной части помехоустойчивой последовательности в очередную часть сжатой последовательности, преобразуют очередную часть сжатой последовательности в очередную часть модулированной последовательности, передают очередную часть модулированной последовательности на приемную сторону, выполняют на передающей стороне перечисленные действия до тех пор, пока поступают очередные части информационной последовательности, на приемной стороне получают очередную часть принятой последовательности, преобразуют ее в двоичную последовательность, которую запоминают, запомненные очередные части принятой последовательности разжимают в очередные части декодированной последовательности, из которых выделяют очередные части восстановленной информационной последовательности и декодированные проверочные символы, если декодированные проверочные символы принадлежат предварительно сформированному множеству проверочных символов, то делают вывод об отсутствии ошибок передачи и передают получателю очередную часть восстановленной информационной последовательности, иначе поочередно инвертируют один или несколько битов в запомненных очередных частях принятой последовательности, которые разжимают и выполняют последующие действия до достижения вывода об отсутствии ошибок передачи, выполняют перечисленные действия на приемной стороне до тех пор, пока поступают очередные части принятой последовательности.
Способ-прототип совместного сжатия и помехоустойчивого кодирования обеспечивает возможность обнаружения и исправления ошибок канала передачи.
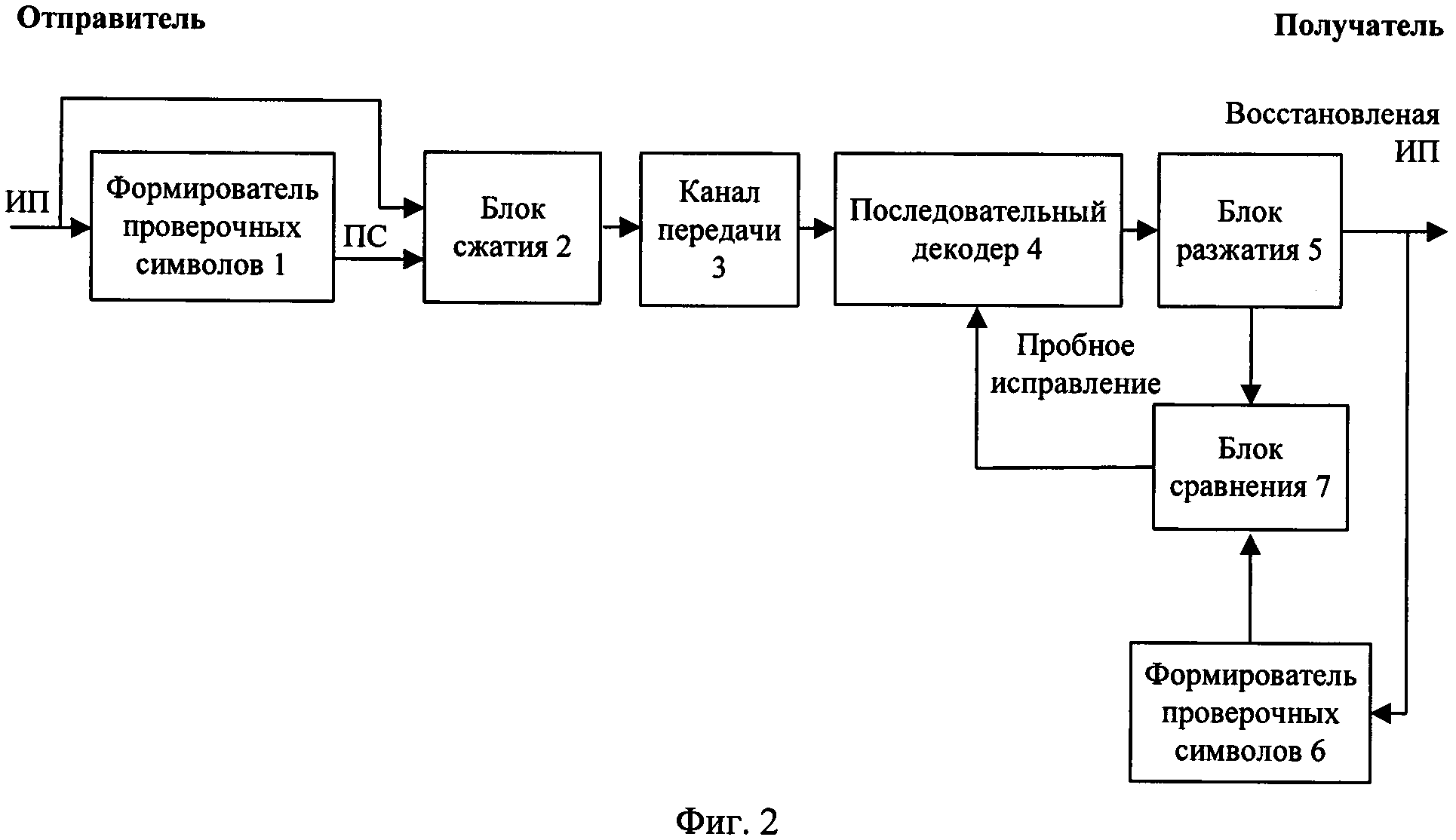
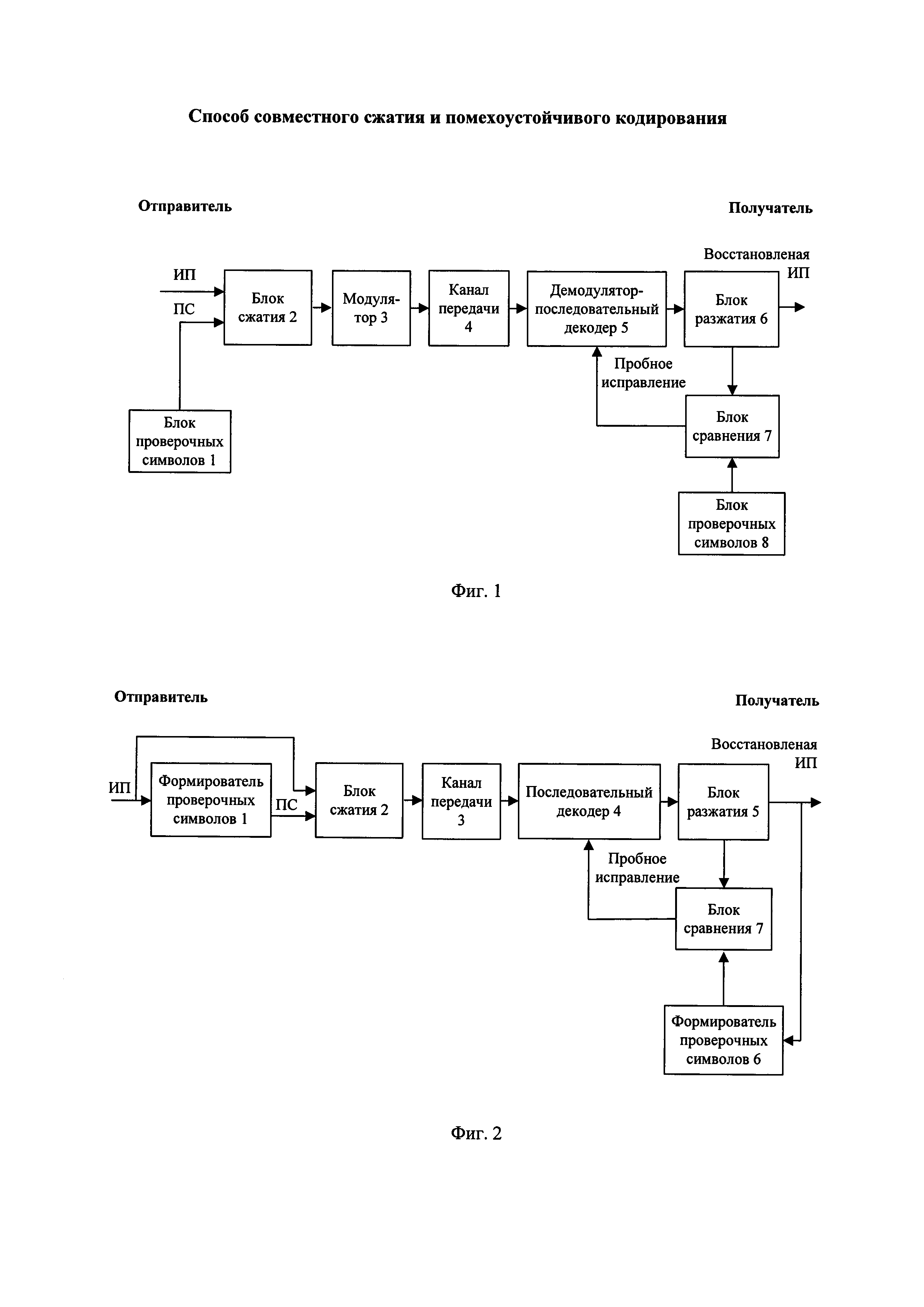
Общая схема способа-прототипа совместного сжатия и помехоустойчивого кодирования представлена на фиг. 1. На передающей стороне выполняют совместное сжатие и помехоустойчивое кодирование очередных частей информационной последовательности (ИП), а на приемной стороне - совместное разжатие с обнаружением и исправлением ошибок канала передачи. На передающей стороне при получении от отправителя очередной части информационной последовательности в блоке проверочных символов 1 из предварительно сформированного множества проверочных символов выбирают проверочные символы (ПС), которые вместе с очередной частью информационной последовательности сжимают в блоке сжатия 2. Затем в модуляторе 3 преобразуют очередную часть сжатой последовательности в очередную часть модулированной последовательности, которую передают по каналу передачи 4. На приемной стороне получают очередную часть принятой последовательности и в демодуляторе - последовательном декодере 5 демодулируют ее в двоичную последовательность, которую запоминают. Запомненные очередные части принятой последовательности разжимают в блоке разжатия 6 в очередные части декодированной последовательности, из каждой выделяют очередную часть восстановленной информационной последовательности и декодированные проверочные символы. Декодированные проверочные символы из очередных частей декодированной последовательности в блоке сравнения 7 сравнивают со считанными из блока проверочных символов 8 соответствующими проверочными символами, и при нахождении случая совпадения делают вывод об отсутствии ошибок передачи и передают получателю очередную часть восстановленной информационной последовательности. Иначе в демодуляторе - последовательном декодере 5 поочередно инвертируют один или несколько битов в запомненных очередных частях принятой последовательности, которые разжимают и выполняют последующие действия до достижения вывода об отсутствии ошибок передачи.
Особенностью способа-прототипа является то, что на передающей стороне выполняют сначала внесение помехоустойчивой избыточности в информационную последовательность, а затем ее сжатие, а на приемной стороне при разжатии обнаруживают ошибки канала передачи при их наличии, а при их обнаружении методом проб и ошибок выполняют их исправление.
Однако в данном способе-прототипе совместного сжатия и помехоустойчивого кодирования проверочные символы не зависят от информационной последовательности. Поэтому на приемной стороне формально выполняют проверку наличия ошибок канала передачи в декодированных проверочных символах, и по результату этой проверки делают вывод об отсутствии ошибок передачи также и в восстановленной информационной последовательности. В то же самое время известно, что максимальной обнаруживающей и исправляющей способностью по обнаружению и исправлению ошибок передачи обладают помехоустойчивые коды, в которых проверочные символы вычисляют из информационной последовательности таким образом, чтобы каждый проверочный символ равновероятно зависел от каждого бита информационной последовательности, как описано в статье К. Шеннона "Математическая теория связи. Работы по теории информации и кибернетике". - М., ИЛ, 1963, стр. 587-621.
Таким образом, недостатком ближайшего аналога (прототипа) является сравнительно малая обнаруживающая и исправляющая способность по обнаружению и исправлению ошибок передачи, обусловленная использованием проверочных символов, не зависящих от информационной последовательности.
Техническим результатом заявляемого решения является совместное сжатие и помехоустойчивое кодирование избыточной двоичной информационной последовательности с повышением обнаруживающей и исправляющей способностью по обнаружению и исправлению ошибок передачи.
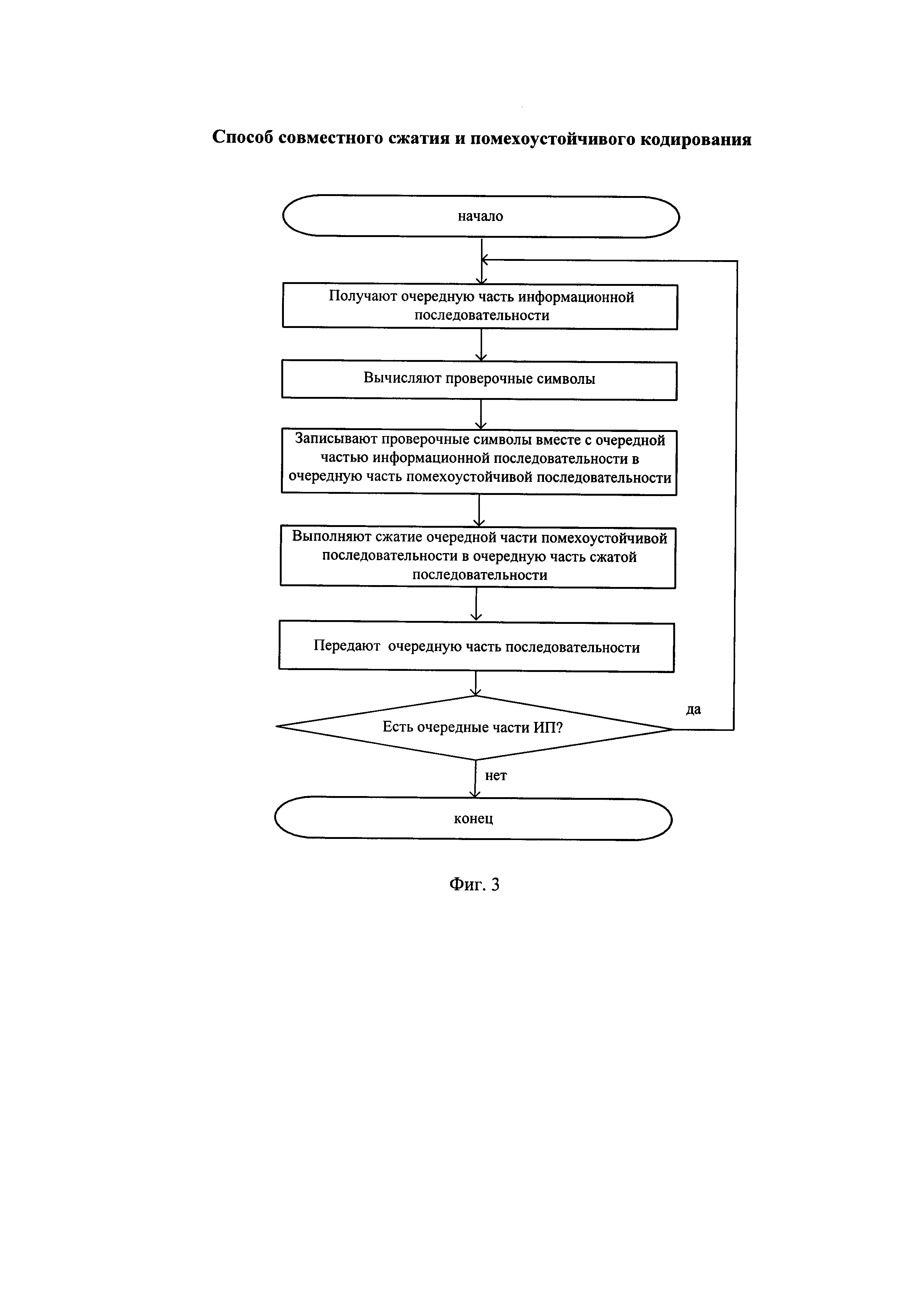
Указанный технический результат в заявляемом способе совместного сжатия и помехоустойчивого кодирования достигается тем, что в известном способе совместного сжатия и помехоустойчивого кодирования, заключающимся в том, что на передающей стороне от отправителя получают очередную часть информационной последовательности длиной k≥1 бит, записывают проверочные символы длиной r≥1 бит вместе с очередной частью информационной последовательности в очередную часть помехоустойчивой последовательности, выполняют сжатие очередной части помехоустойчивой последовательности в очередную часть сжатой последовательности, передают очередную часть последовательности на приемную сторону, выполняют на передающей стороне перечисленные действия до тех пор, пока поступают очередные части информационной последовательности, на приемной стороне получают очередную часть принятой последовательности, которую запоминают, запомненные очередные части принятой последовательности разжимают в очередные части декодированной последовательности, из которых выделяют очередные части восстановленной информационной последовательности и декодированные проверочные символы, делают вывод об отсутствии ошибок передачи и передают получателю очередную часть восстановленной информационной последовательности, иначе поочередно инвертируют один или несколько битов в запомненных очередных частях принятой последовательности, которые разжимают и выполняют последующие действия до достижения вывода об отсутствии ошибок передачи, выполняют перечисленные действия на приемной стороне до тех пор, пока поступают очередные части принятой последовательности, дополнительно после получения очередной части информационной последовательности из нее вычисляют проверочные символы, передают очередную часть сжатой последовательности на приемную сторону, на приемной стороне из очередной части восстановленной информационной последовательности вычисляют проверочные символы и вычисленные проверочные символы побитно сравнивают с декодированными проверочными символами и при их побитном совпадении делают вывод об отсутствии ошибок передачи, причем для сжатия используют арифметическое кодирование или кодирование Хаффмана, а для разжатия используют, соответственно, арифметическое декодирование или декодирование Хаффмана.
В предлагаемой совокупности действий на передающей стороне из очередной части информационной последовательности вычисляют проверочные символы, а на приемной стороне из очередной части декодированной последовательности выделяют очередную часть восстановленной информационной последовательности и декодированные проверочные символы, из очередной части восстановленной информационной последовательности вычисляют проверочные символы и вычисленные проверочные символы побитно сравнивают с декодированными проверочными символами и при их побитном совпадении делают вывод об отсутствии ошибок передачи. Проверочные символы полностью зависят от информационной последовательности, их вычисляют в соответствии с правилами формирования помехоустойчивых кодов, обеспечивающих максимально достижимую обнаруживающую и исправляющую способность по обнаружению и исправлению ошибок передачи.
Поэтому указанная новая совокупность действий позволяет при выполнении совместного сжатия и помехоустойчивого кодирования избыточной двоичной информационной последовательности повысить обнаруживающую и исправляющую способность по обнаружению и исправлению ошибок передачи.
Заявленный способ поясняется чертежами, на которых показаны:
- на фиг. 1 - общая схема совместного сжатия и помехоустойчивого кодирования в ближайшем аналоге (прототипе);
- на фиг. 2 - общая схема совместного сжатия и помехоустойчивого кодирования в предлагаемом способе;
- на фиг. 3 - алгоритм совместного сжатия и помехоустойчивого кодирования на передающей стороне;
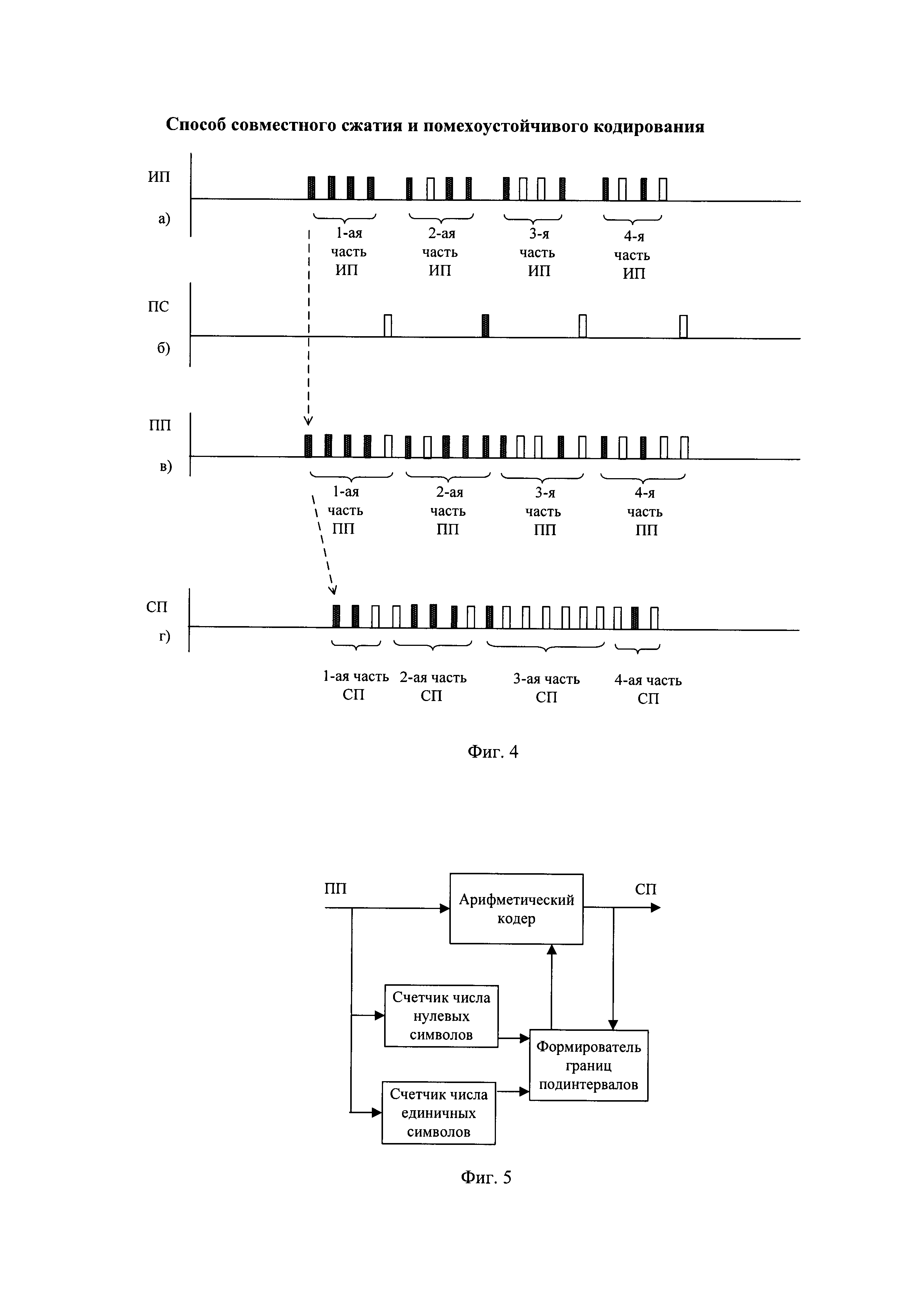
- на фиг. 4 - временные диаграммы совместного сжатия и помехоустойчивого кодирования на передающей стороне;
- на фиг. 5 - схема сжатия помехоустойчивой последовательности на основе арифметического кодирования;
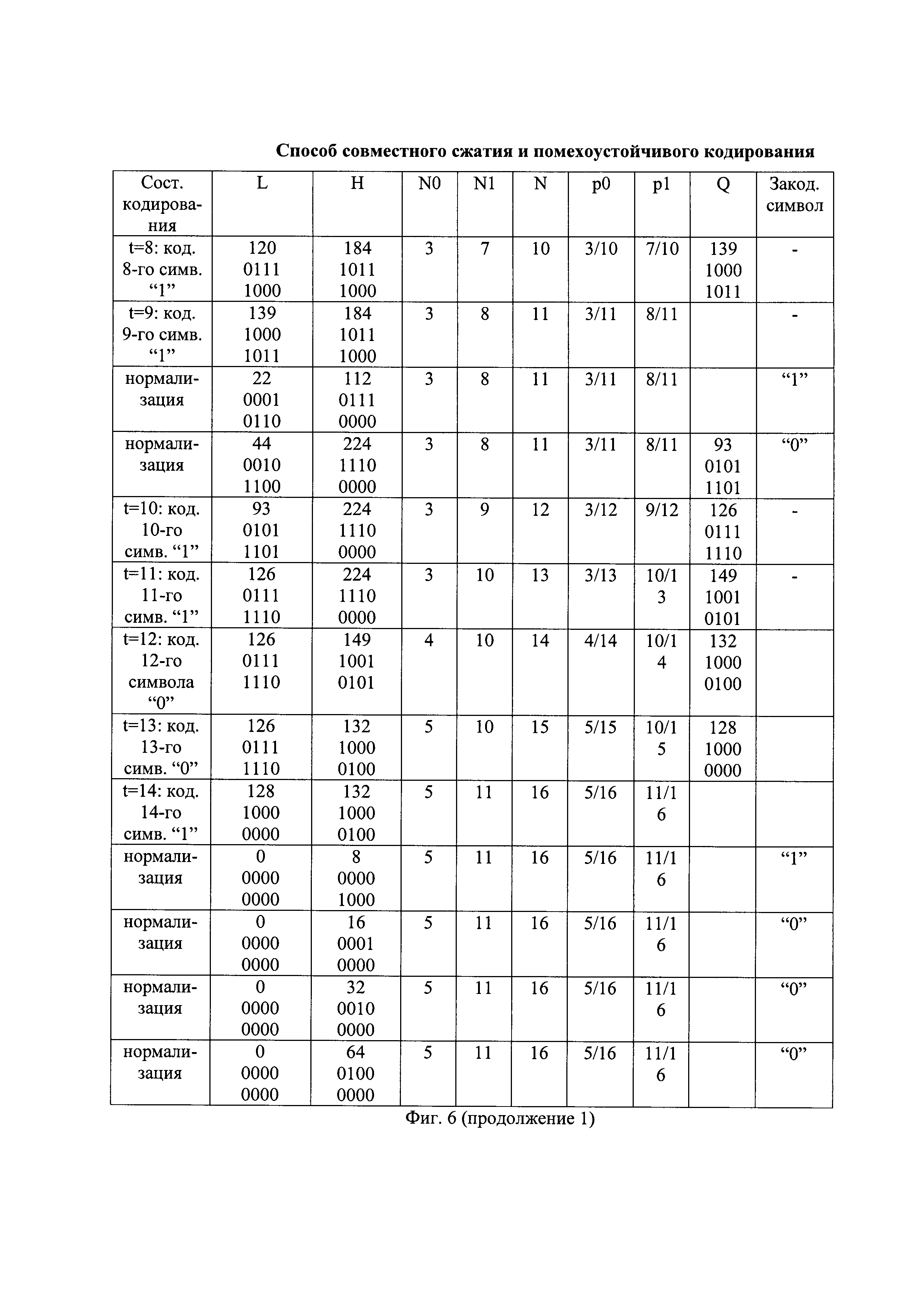
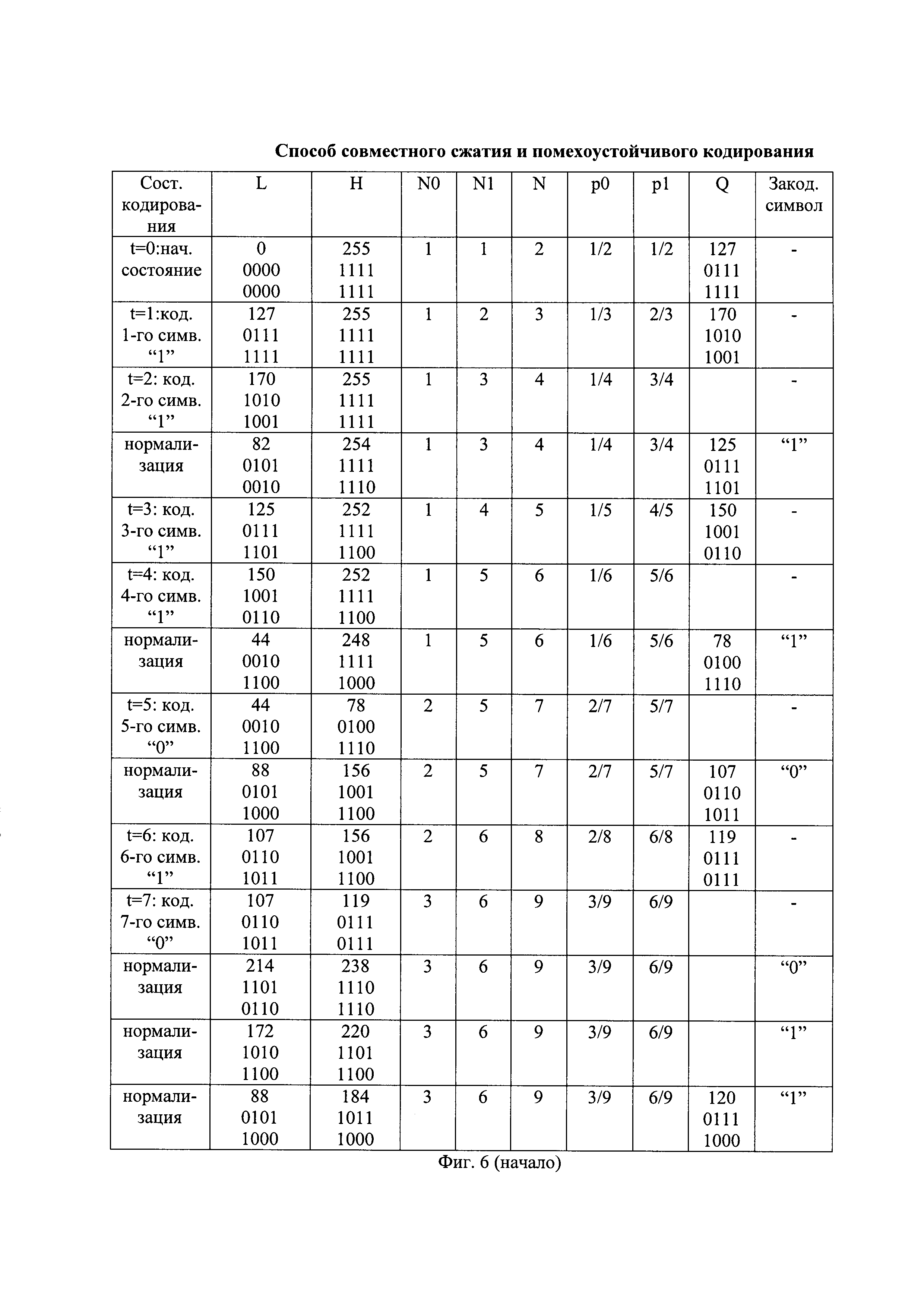
- на фиг. 6 - таблица состояний арифметического кодирования первых четырех очередных частей помехоустойчивой последовательности;
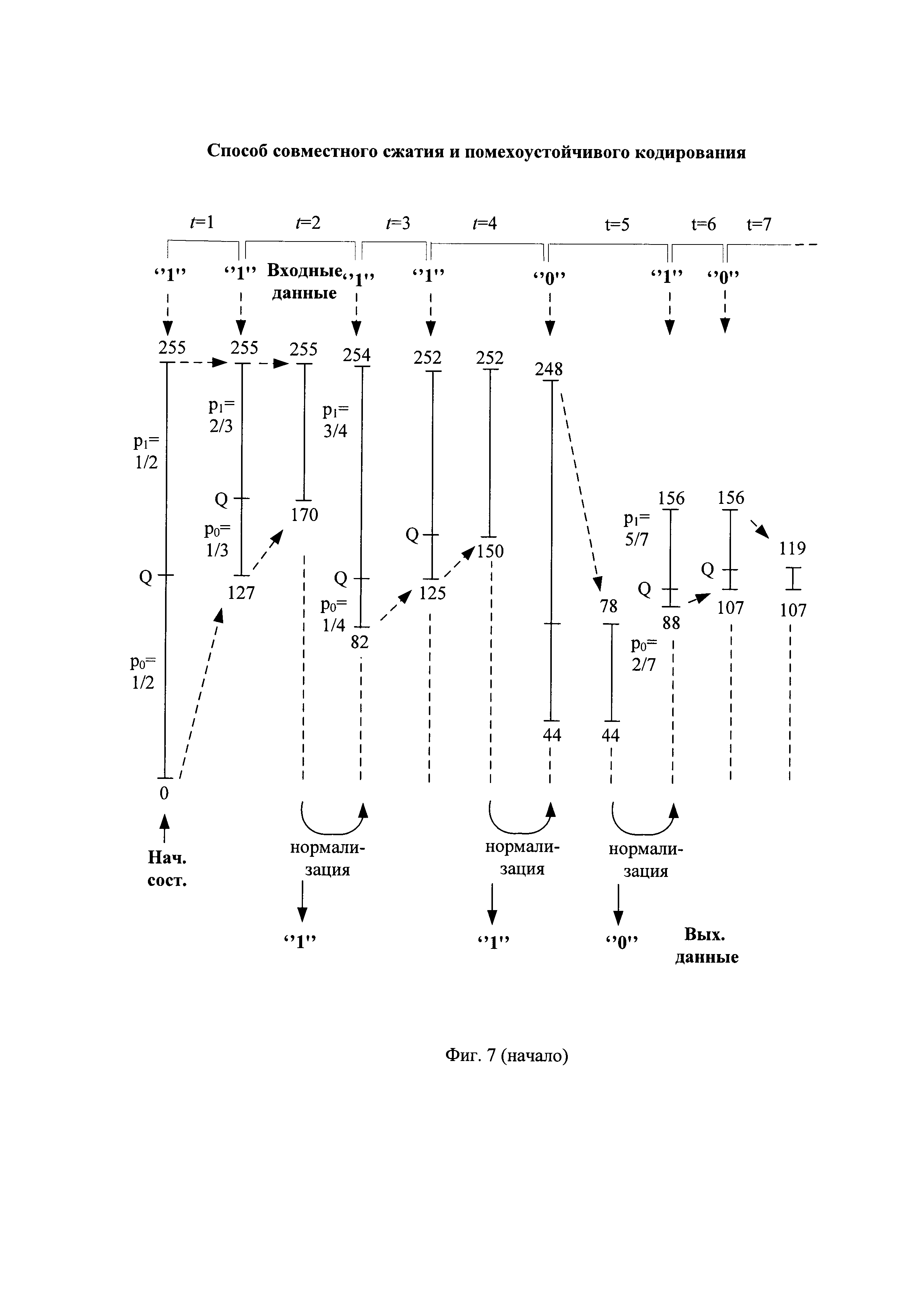
- на фиг. 7 - временные диаграммы арифметического кодирования первых четырех очередных частей помехоустойчивой последовательности;
- на фиг. 8 - временные диаграммы совместного разжатия и исправления ошибок на приемной стороне;
- на фиг. 9 - алгоритм совместного разжатия и исправления ошибок на приемной стороне;
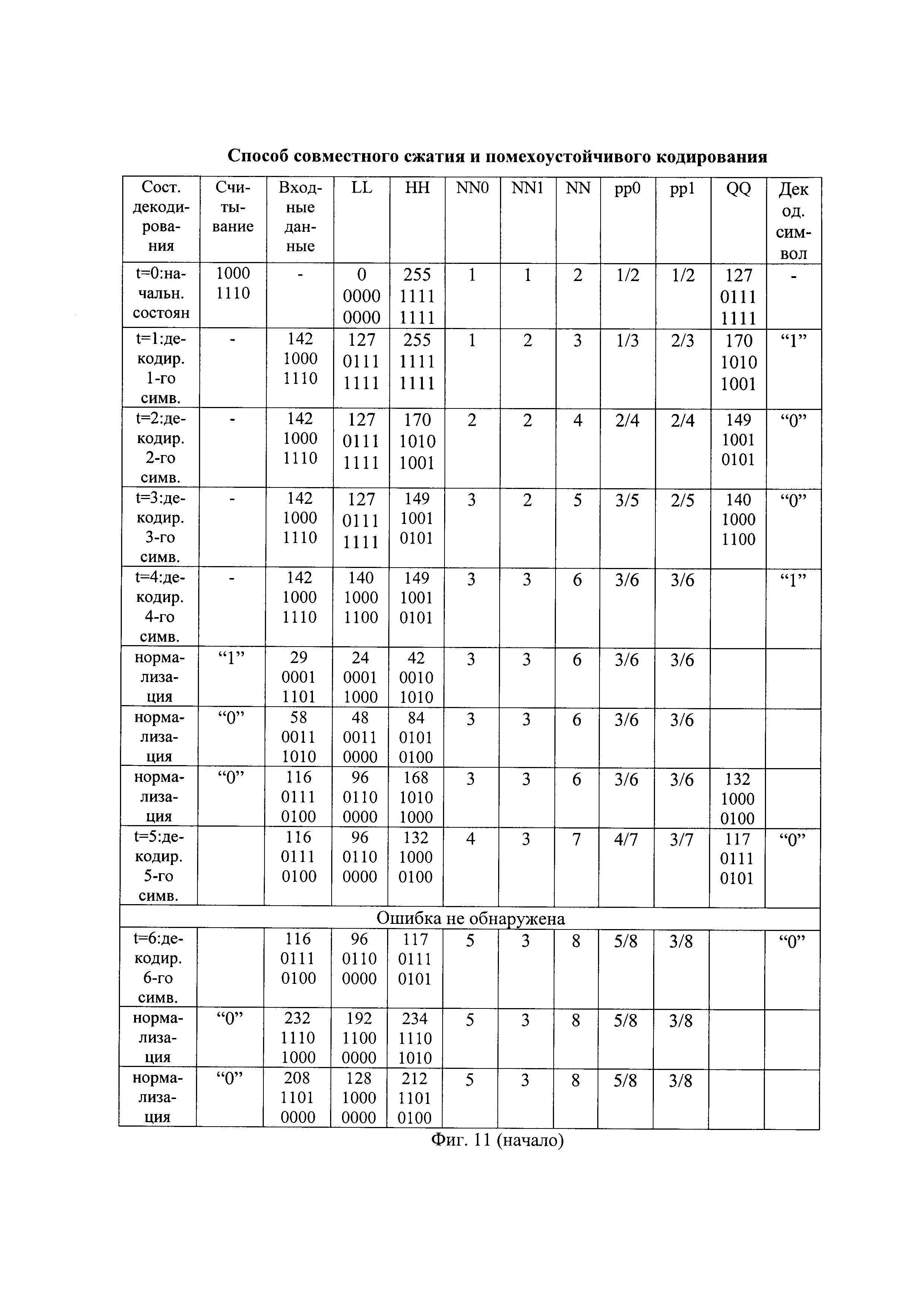
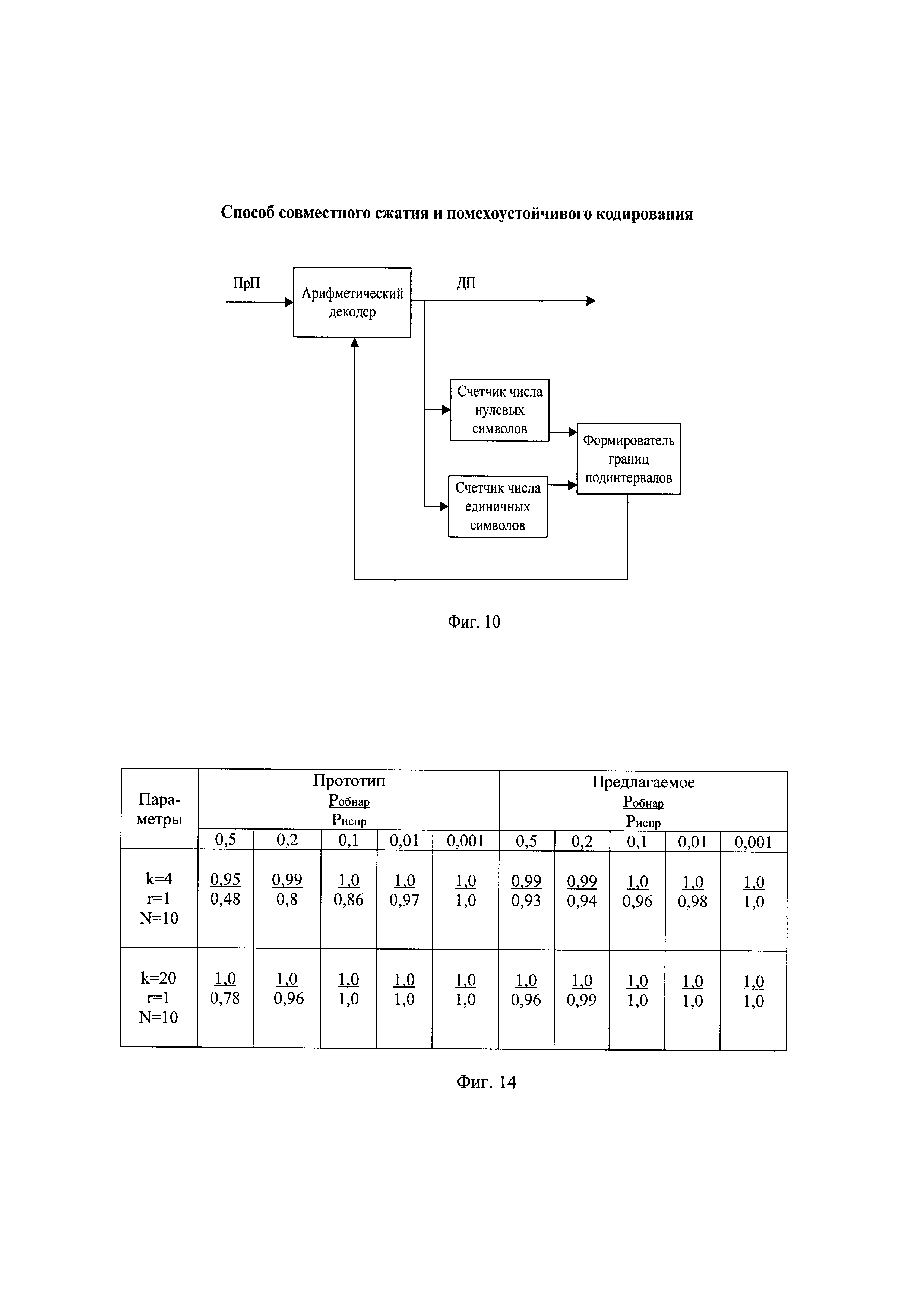
- на фиг. 10 - схема разжатия принятой последовательности на основе арифметического декодирования;
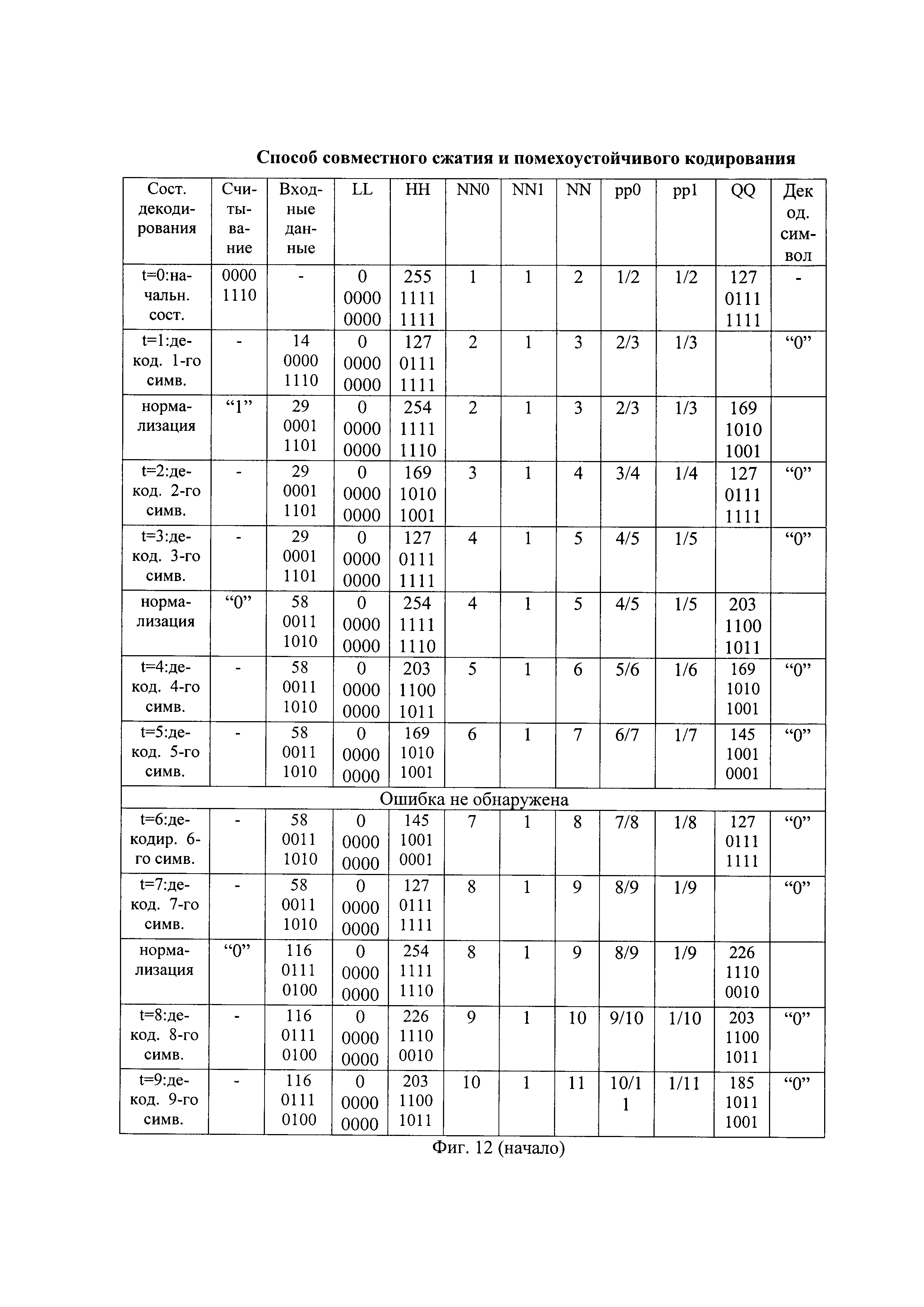
- на фиг. 11 - таблица состояний арифметического декодирования принятой последовательности с ошибкой передачи;
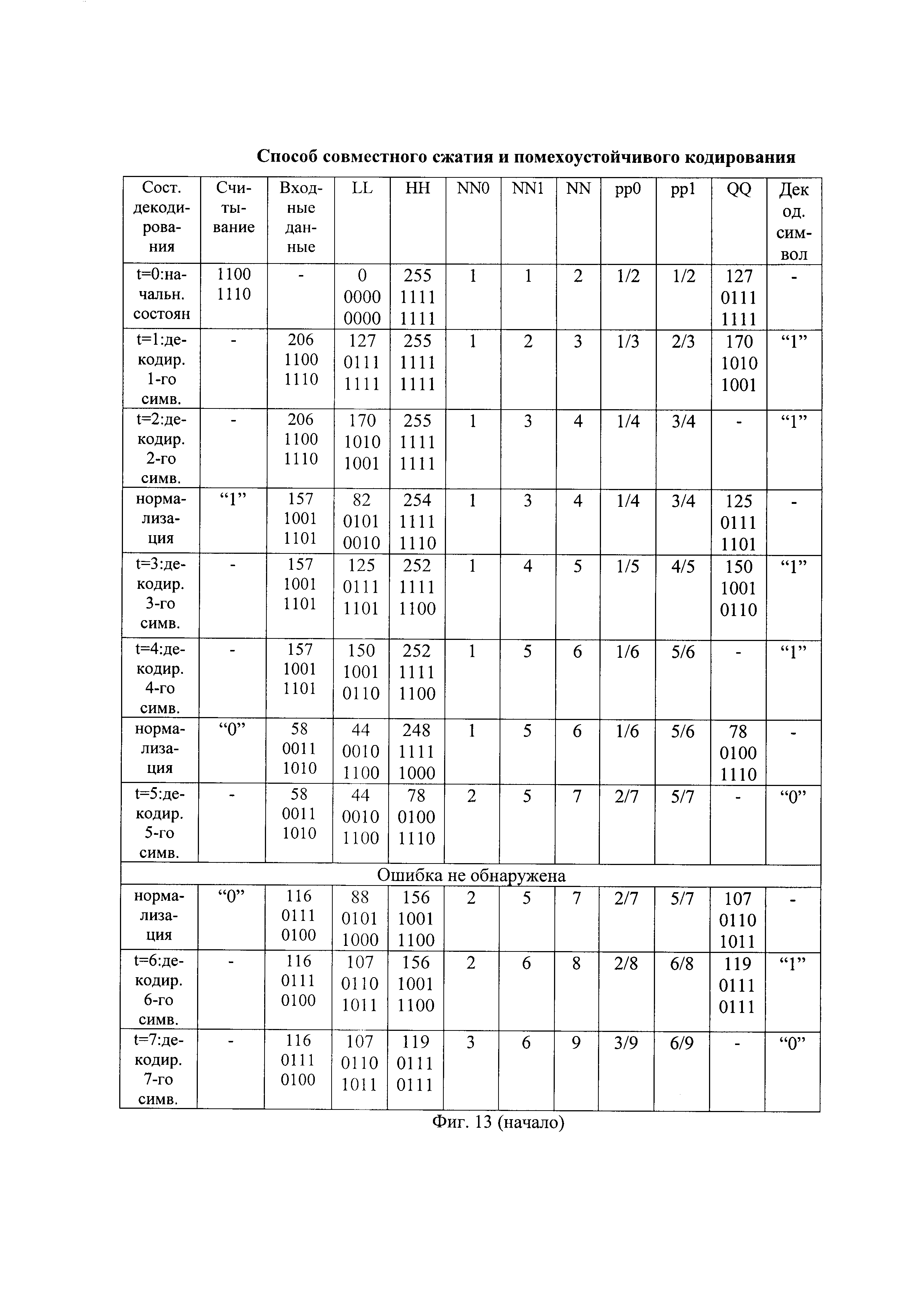
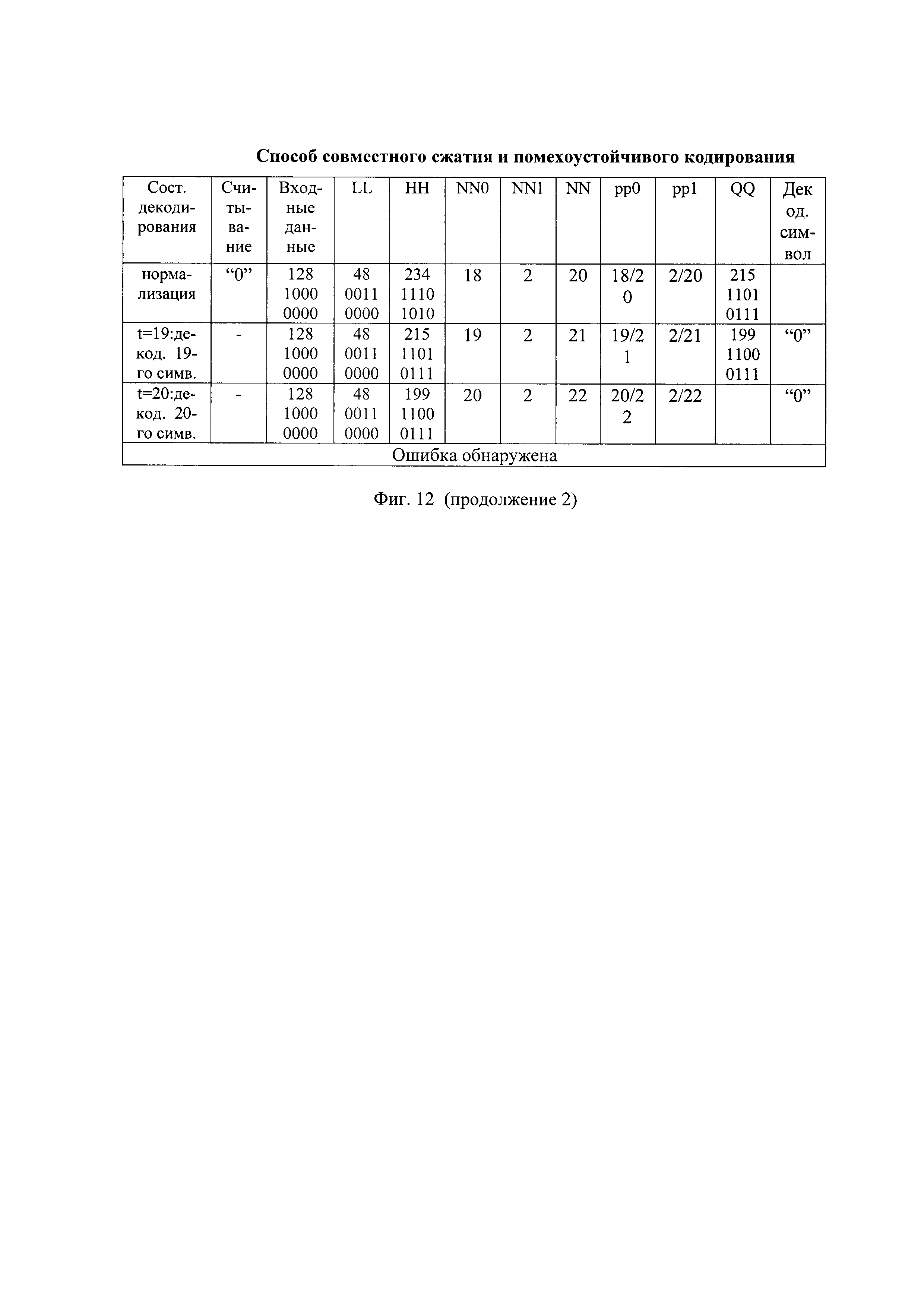
- на фиг. 12 - таблица состояний арифметического декодирования принятой последовательности с ошибкой передачи при инвертировании ее первого бита;
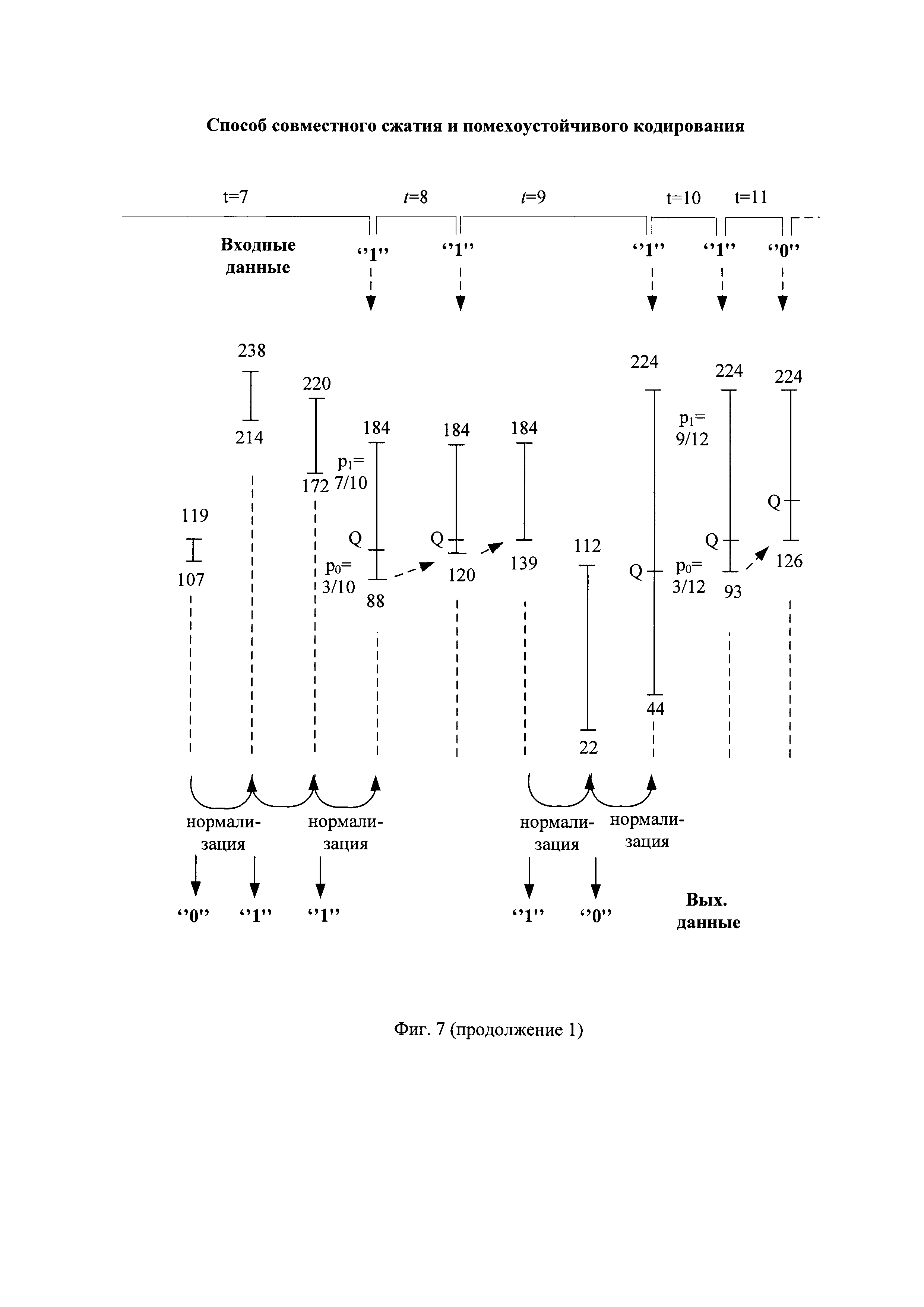
- на фиг. 13 - таблица состояний арифметического декодирования принятой последовательности с ошибкой передачи при инвертировании ее второго бита;
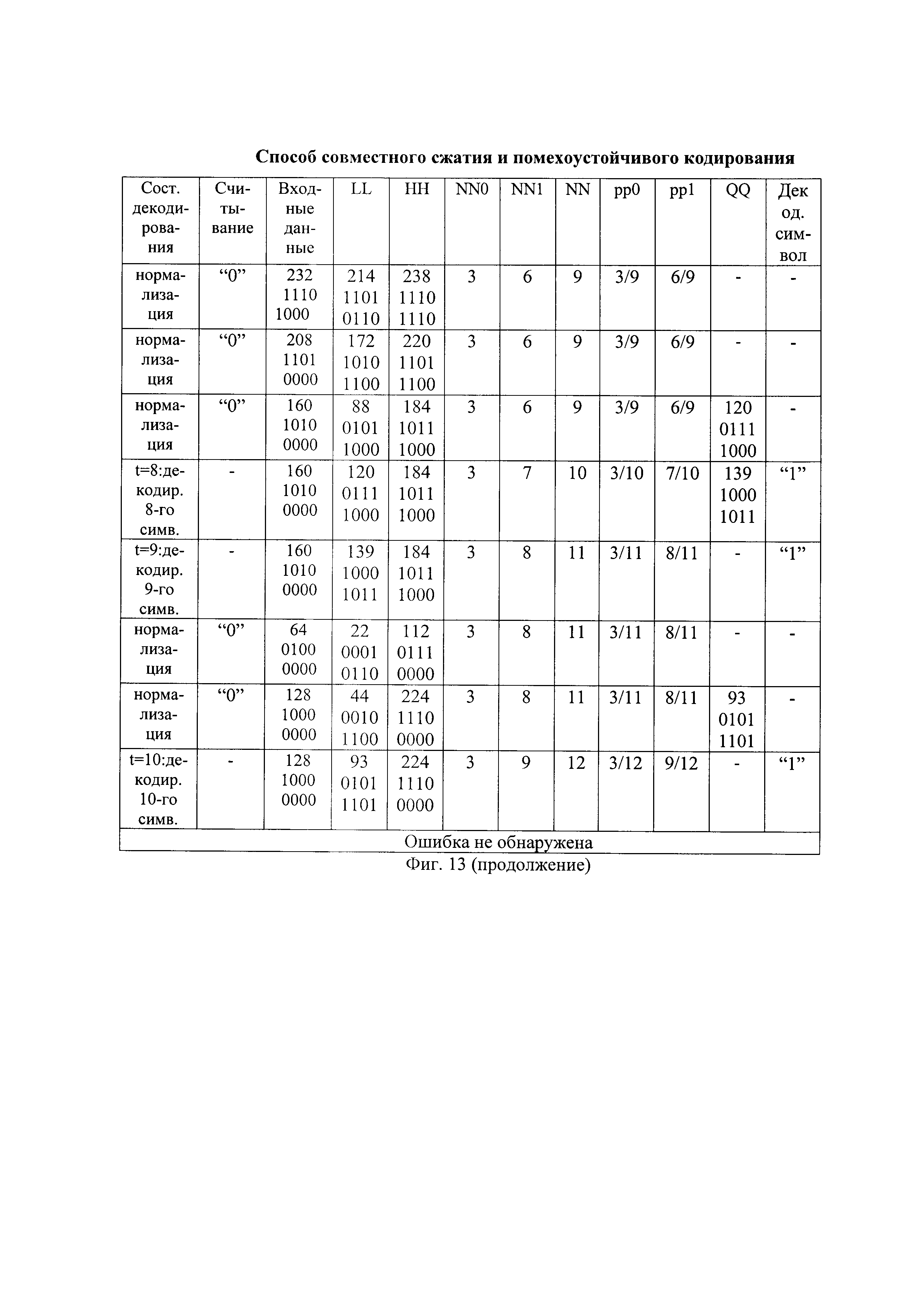
- на фиг. 14 - сравнение исправляющей и обнаруживающей способности для способа-прототипа и заявленного способа.
Реализация заявленного способа представлена на примере системы совместного сжатия и помехоустойчивого кодирования, показанной на фиг. 2. На передающей стороне выполняют совместное сжатие и помехоустойчивое кодирование очередных частей информационной последовательности, а на приемной стороне - совместное разжатие с обнаружением и исправлением ошибок канала передачи. На передающей стороне при получении от отправителя очередной части информационной последовательности из нее в формирователе проверочных символов 1 формируют проверочные символы, которые вместе с очередной частью информационной последовательности сжимают в блоке сжатия 2 с использованием арифметического кодирования или кодирования Хаффмана. С выхода блока сжатия 2 очередную часть сжатой последовательности передают по двоичному каналу передачи 3. На приемной стороне получают очередную часть принятой последовательности и в последовательном декодере 4 ее запоминают. Запомненные очередные части принятой последовательности разжимают в блоке разжатия 5 с использованием арифметического декодирования или декодирования Хаффмана в очередные части декодированной последовательности, из которых выделяют очередные части восстановленной информационной последовательности и декодированные проверочные символы. Из каждой очередной части восстановленной информационной последовательности в формирователе проверочных символов 6 вычисляют проверочные символы, и вычисленные проверочные символы в блоке сравнения 7 побитно сравнивают с декодированными проверочными символами. При их побитном совпадении делают вывод об отсутствии ошибок передачи и передают получателю очередную часть восстановленной информационной последовательности, иначе в последовательном декодере 4 поочередно инвертируют один или несколько битов в запомненных очередных частях принятой последовательности, которые разжимают в блоке разжатия 5 до тех пор, пока побитно не совпадут вычисленные проверочные символы и декодированные проверочные символы, что означает исправление ошибок канала передачи.
Алгоритм совместного сжатия и помехоустойчивого кодирования на передающей стороне представлен на фигуре 3.
В способе совместного сжатия и помехоустойчивого кодирования реализуется следующая последовательность действий.
На передающей стороне от отправителя получают очередную часть информационной последовательности длиной k≥1 бит. Примерный вид первых четырех очередных частей двоичной ИП длиной k=4 бита показан на фиг. 4(a). Например, первая часть ИП имеет вид "1111", вторая часть - "1011", третья часть - "1001". Единичные значения битов на фигурах показаны в виде заштрихованных импульсов, нулевые значения битов - в виде незаштрихованных импульсов.
Способы вычисления проверочных символов длиной r≥1 бит из очередной части информационной последовательности известны и описаны, например, в книге В.В. Золотарев "Теория и алгоритмы многопорогового декодирования". - М., Радио и связь, Горячая линия-Телеком, 2006, 22-27. Очередную часть информационной последовательности длиной k≥1 бит записывают в последовательный двоичный регистр с k ячейками памяти. В соответствии с порождающей матрицей помехоустойчивого кода с выходов соответствующих ячеек памяти считывают двоичные разряды информационной последовательности и суммируют в r сумматорах по модулю 2. Выходные двоичные значения r данных сумматоров являются проверочными символами длиной r≥1 бит. Чем больше число r проверочных символов и чем меньше отношение 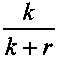 , тем выше обнаруживающая и исправляющая способность по обнаружению и исправлению ошибок передачи, как описано в статье К. Шеннона "Математическая теория связи. Работы по теории информации и кибернетике". - М., ИЛ, 1963, стр. 587-621. Простейшим случаем вычисления проверочных символов является формирование единственного проверочного символа (r=1 бит) при суммировании по модулю 2 всех выходов ячеек памяти с использованием единственного сумматора. Такой простейший помехоустойчивый код называется код с проверкой на четность и способен обнаружить произвольные ошибки канала передачи кратностью 1, 3, 5 и так далее числа ошибок. Примерный вид проверочных символов длиной r=1 бит, вычисленных из первых четырех очередных частей двоичной ИП, показан на фиг. 4(б). Например, проверочный символ первой части ИП является нулевым двоичным символом, проверочный символ второй части ИП является единичным двоичным символом и т.д.
, тем выше обнаруживающая и исправляющая способность по обнаружению и исправлению ошибок передачи, как описано в статье К. Шеннона "Математическая теория связи. Работы по теории информации и кибернетике". - М., ИЛ, 1963, стр. 587-621. Простейшим случаем вычисления проверочных символов является формирование единственного проверочного символа (r=1 бит) при суммировании по модулю 2 всех выходов ячеек памяти с использованием единственного сумматора. Такой простейший помехоустойчивый код называется код с проверкой на четность и способен обнаружить произвольные ошибки канала передачи кратностью 1, 3, 5 и так далее числа ошибок. Примерный вид проверочных символов длиной r=1 бит, вычисленных из первых четырех очередных частей двоичной ИП, показан на фиг. 4(б). Например, проверочный символ первой части ИП является нулевым двоичным символом, проверочный символ второй части ИП является единичным двоичным символом и т.д.
Способы записи проверочных символов вместе с очередной частью информационной последовательности в очередную часть помехоустойчивой последовательности известны и описаны, например, в книге В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной и последовательной записью/считыванием двоичных последовательностей. Для этого очередная часть двоичной информационной последовательности с первого по k-ый бит параллельно записывают в первые по счету ячейки памяти регистр сдвига длиной k+r бит. Проверочные символы в виде двоичной последовательности длиной r бит параллельно записывают в последующие, начиная с k+1-ой, ячейки памяти этого же регистра сдвига. В результате в регистре сдвига записана очередная часть помехоустойчивой последовательности длиной k+r бит. Например, первая часть помехоустойчивой последовательности (ПП) имеет вид "11110", вторая часть - "10111", третья часть - "10010".
Способы сжатия очередной части помехоустойчивой последовательности в очередную часть сжатой последовательности известны и описаны, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 31-49. Например, сжатие может выполняться с использованием арифметического кодирования или кодирования Хаффмана.
Способы сжатия очередной части помехоустойчивой последовательности в очередную часть сжатой последовательности с использованием арифметического кодирования описаны, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 35-43. Они заключаются в последовательном сжатии двоичных символов очередной части помехоустойчивой последовательности в очередную часть сжатой последовательности в соответствии с текущими значениями интервала кодирования арифметического кодирования и текущими значениями вероятностей кодируемых нулевых символов и единичных символов. Схема сжатия помехоустойчивой последовательности на основе арифметического кодирования показана на фиг. 5, в которой по мере поступления на вход двоичных символов подсчитывают число нулевых символов кодирования и число единичных символов кодирования, пропорционально которым интервал кодирования арифметического кодирования делят на подинтервал нулевых символов кодирования и подинтервал единичных символов кодирования, в соответствии с которыми арифметический кодер последовательно формирует сжатую последовательность (СП).
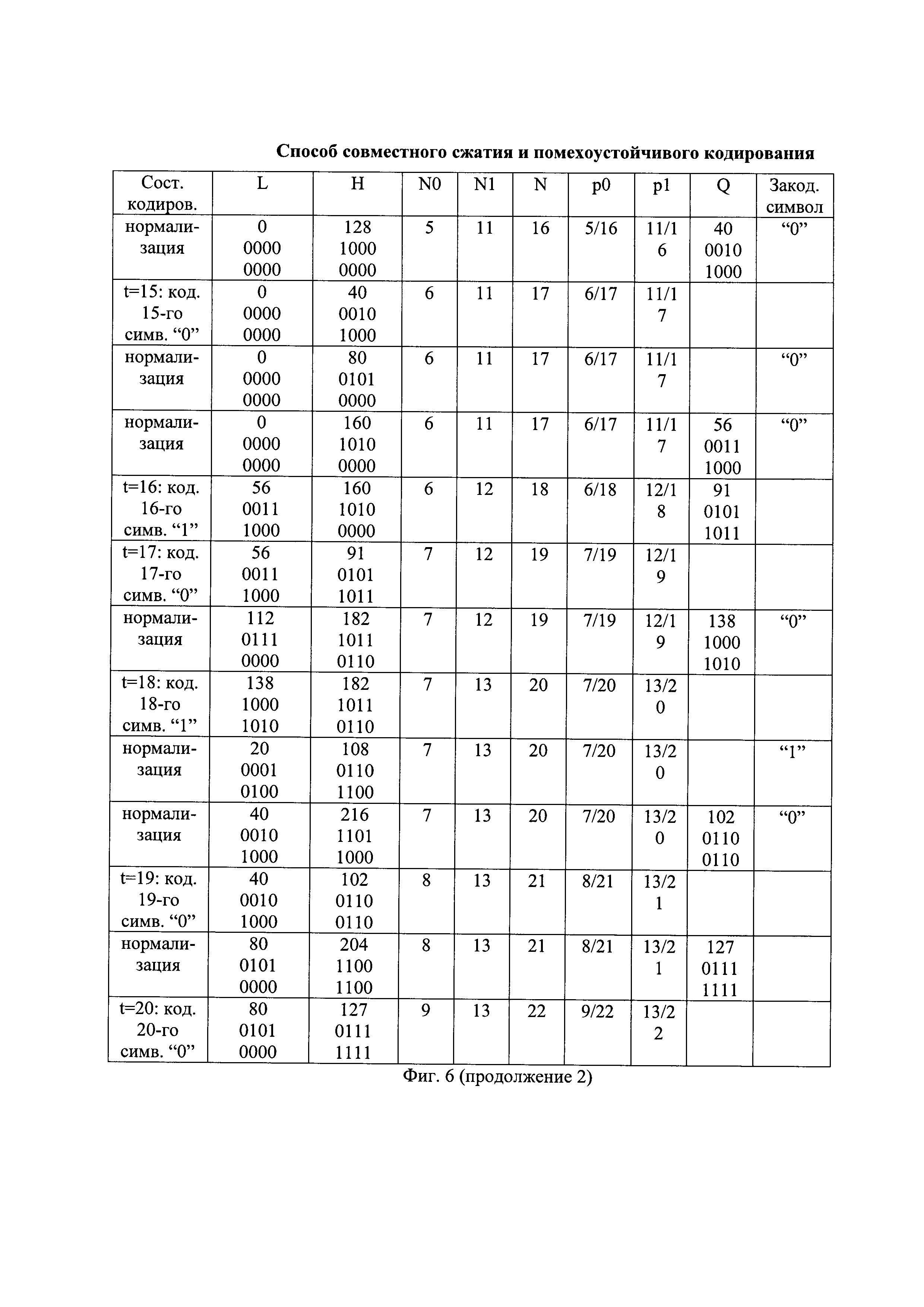
Перед сжатием первой части помехоустойчивой последовательности устанавливают начальные значения первого и второго регистров кодирования. Начальное нижнее значение интервала кодирования устанавливают в минимальное значение, а начальное верхнее значения интервала кодирования - в максимальное значение. Например, при представлении значений интервала кодирования восемью двоичными символами, начальное нижнее значение интервала кодирования арифметического кодирования L[0] устанавливают в минимальное значение, равное нулевому значению в десятичном представлении или 00000000 в двоичном представлении, где старшие двоичные символы записывают слева, а начальное верхнее значение интервала кодирования арифметического кодирования H[0] устанавливают в максимальное значение, равное 255 в десятичном представлении или 11111111 в двоичном представлении. Пример начального состояния (Нач. сост.) арифметического кодирования представлен на фиг. 6.
Начальное состояние арифметического кодирования также заключается в установке начального значения вероятности кодируемых нулевых символов p0[0] и начального значения вероятности кодируемых единичных символов p1[0]. При установке начального значения вероятности кодируемых нулевых символов p0[0] и начального значения вероятности кодируемых нулевых символов р1[0] в выбранные значения должно выполняться ограничение вида: p0[0]+p1[0]=1. Начальное значение вероятности кодируемых нулевых символов p0[0] вычисляют по формуле вида 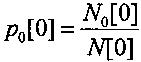 , а начальное значение вероятности кодируемых единичных символов p1[0] вычисляют по формуле вида
, а начальное значение вероятности кодируемых единичных символов p1[0] вычисляют по формуле вида 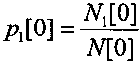 , где N0[0] - начальное число закодированных нулевых символов, N1[0] - начальное число закодированных единичных символов, а N[0] - начальное число закодированных нулевых и единичных символов, равное N[0]=N0[0]+N1[0]. В известных способах, описанных, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 124-130, устанавливают начальное число закодированных нулевых символов равным N0[0]=1, а начальное число закодированных единичных символов - равным N1[0]=1, то есть начальные значения вероятности кодируемых единичных и нулевых символов устанавливают равными: p1[0]=p0[0].
, где N0[0] - начальное число закодированных нулевых символов, N1[0] - начальное число закодированных единичных символов, а N[0] - начальное число закодированных нулевых и единичных символов, равное N[0]=N0[0]+N1[0]. В известных способах, описанных, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 124-130, устанавливают начальное число закодированных нулевых символов равным N0[0]=1, а начальное число закодированных единичных символов - равным N1[0]=1, то есть начальные значения вероятности кодируемых единичных и нулевых символов устанавливают равными: p1[0]=p0[0].
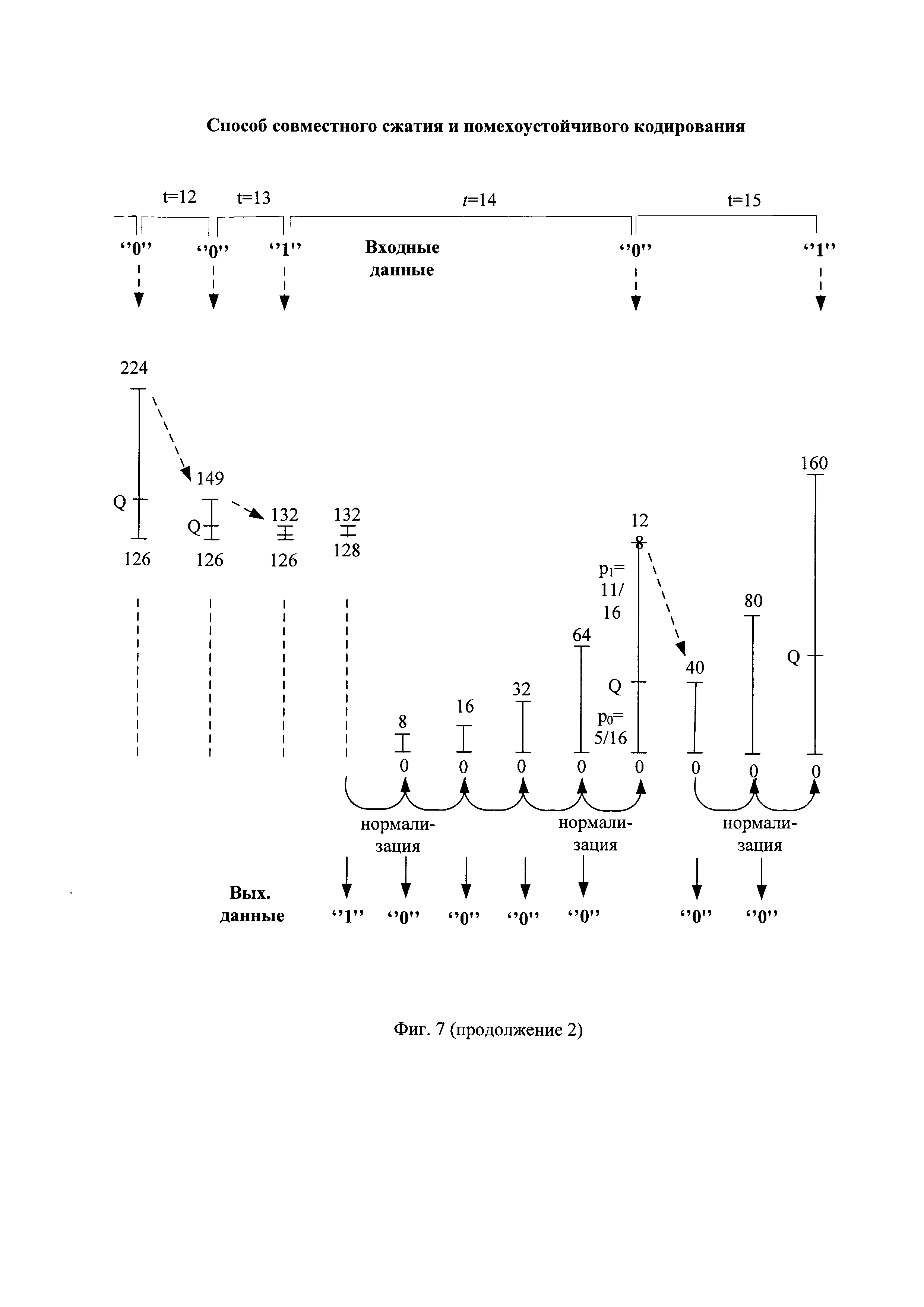
Начальное значение интервала кодирования арифметического кодирования I[0], равное I[0]=H[0]-L[0], разделяют на начальные значения подинтервала нулевых символов D0[0] и подинтервала единичных символов D1[0], длины которых прямо пропорциональны начальным значениям вероятностей кодируемых нулевых символов p0[0] и единичных символов p1[0], соответственно. Начальную длину подинтервала единичных символов D1[0] определяют по формуле вида D1[0]=I[0]×p1[0], а начальную длину подинтервала нулевых символов D0[0] определяют по формуле вида D0[0]=I[0]-D1[0]. Например, начальная длина подинтервала единичных символов D1[0] имеет десятичное значение 128 или 10000000 в двоичном представлении, а начальная длина подинтервала нулевых символов D0[0] имеет десятичное значение 127 или 01111111 в двоичном представлении. Подинтервал единичных символов расположен сверху подинтервала нулевых символов, как показано, например, на фиг. 7. Верхнюю границу подинтервала нулевых символов обозначают как значение Q, и данный подинтервал начинается снизу от нижней границы интервала кодирования арифметического кодирования до значения Q исключительно, а подинтервал единичных символов простирается от значения Q включительно до верхней границы интервала кодирования арифметического кодирования исключительно. Начальное значение Q имеет десятичное значение 127, как показано на фиг. 6 в первой строке при t=0.
Примерный вид сжатия первых четырех очередных частей помехоустойчивой последовательности вида "11110 10111 10010 10100" в первые четыре очередные части сжатой последовательности (СП) показан на фиг. 4(г).
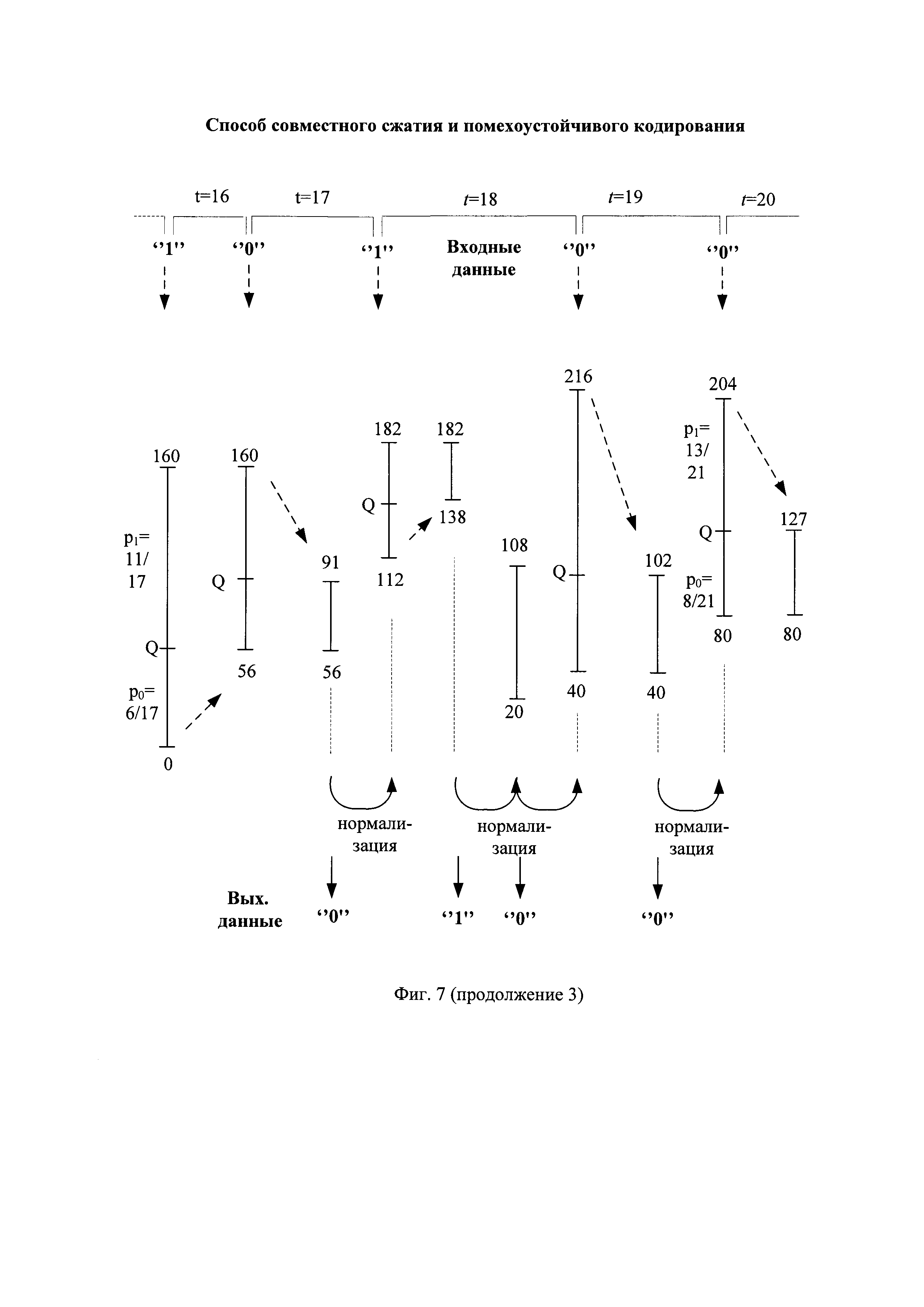
При поступлении на вход арифметического кодирования первого сжимаемого символа, являющегося единичным двоичным символом, нижнее значение интервала кодирования первого символа L[1] устанавливают равным значению Q, равному, например, 127, а верхнее значение интервала кодирования первого символа арифметического кодирования H[1] устанавливают равным начальному верхнему значению интервала кодирования арифметического кодирования H[0], равному, например, 255, как показано на фиг. 6 и на фиг. 7 при t=1.
Самый левый бит двоичного представления значения L[1] сравнивают с самым левым битом двоичного представления значения H[1], например, вида 01111111 и 11111111, соответственно, как показано на фиг. 6 при t=1. При их несовпадении переходят к сжатию следующего символа.
После выполнения сжатия каждого очередного символа уточняют число закодированных нулевых символов и единичных символов. Так как первый сжатый символ является единичным, то число закодированных единичных символов увеличивают на единичное значение и оно составляет N1[1]=2, и число закодированных нулевых и единичных символов становится равным N[1]=N0[1]+N1[1]=3. Пересчитывают текущее значение вероятности кодируемых нулевых символов 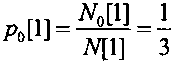 и текущее значение вероятности кодируемых единичных
и текущее значение вероятности кодируемых единичных 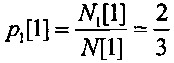 . В соответствии с этим длина подинтервала нулевых символов D0[1] становится в 2 раза меньше длины подинтервала единичных символов D1[1], а параметр Q принимает значение 170, как показано на фиг. 6, вторая строка сверху и на фиг. 7.
. В соответствии с этим длина подинтервала нулевых символов D0[1] становится в 2 раза меньше длины подинтервала единичных символов D1[1], а параметр Q принимает значение 170, как показано на фиг. 6, вторая строка сверху и на фиг. 7.
При поступлении на вход арифметического кодирования второго сжимаемого символа, являющегося единичным двоичным символом, нижнее значение интервала кодирования второго символа L[2] устанавливают равным значению Q, равному, например, 170, а верхнее значение интервала кодирования второго символа арифметического кодирования H[2] устанавливают равным верхнему значению интервала кодирования арифметического кодирования H[1], равному, например, 255, как показано на фиг. 6 при t=2.
После выполнения сжатия каждого очередного символа уточняют число закодированных нулевых символов и единичных символов. Так как второй сжатый символ является единичным, то число закодированных единичных символов увеличивают на единичное значение и оно составляет N1[2]=3, и число закодированных нулевых и единичных символов становится равным N[2]=N0[2]+N1[2]=4. Пересчитывают текущее значение вероятности кодируемых нулевых символов 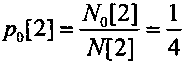 и текущее значение вероятности кодируемых единичных
и текущее значение вероятности кодируемых единичных 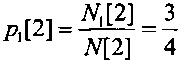 . В соответствии с этим длина подинтервала нулевых символов D0[2] становится в 3 раза меньше длины подинтервала единичных символов D1[2], как показано на фиг. 6, третья строка сверху и на фиг. 7.
. В соответствии с этим длина подинтервала нулевых символов D0[2] становится в 3 раза меньше длины подинтервала единичных символов D1[2], как показано на фиг. 6, третья строка сверху и на фиг. 7.
Самый левый бит двоичного представления значения L[2] сравнивают с самым левым битом двоичного представления значения H[2], например, вида 10101001 и 11111111, соответственно, как показано на фиг. 6 при t=2. При их совпадении значение самого левого бита двоичных представлений значений L[2] и H[2] считывают в качестве очередного бита сжатой последовательности (Закод. символ на фиг. 6). Например, при сжатии первой части помехоустойчивой последовательности первым битом первой части сжатой последовательности является совпавший при сравнении единичный двоичный символ, как показано на фиг. 6, четвертая строка сверху. Считанный бит удаляют из двоичных представлений значений L[2] и H[2], которые уменьшаются до длины 7 бит вида 0101001 и 1111111, соответственно. Двоичные символы двоичных представлений значений L[2] и Н[2] сдвигают справа налево на один разряд и справа к ним дописывают по нулевому двоичному символу. Например, двоичные представления значений L[2] и H[2] приобретают вид 01010010 и 11111110, соответственно. Способы считывания двоичных символов с удалением считанных символов известны и описаны, например, в книге: В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной и последовательной записью/считыванием двоичных последовательностей. Операции сдвига справа налево на один разряд и дописывания справа нулевого двоичного символа увеличивают значения L[2] и H[2] в 2 раза и называются нормализацией параметров арифметического кодирования. Способы сдвига на один разряд в сторону старших разрядов двоичных последовательностей и записи в освободившийся младший разряд нулевого двоичного символа известны и описаны, например, в книге: В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной и последовательной записью/считыванием двоичных последовательностей, и по своей сути являются умножением на два десятичных значений нижнего и верхнего значений интервала кодирования.
После каждого выполнения нормализации повторно самый левый бит двоичного представления нижнего значения интервала кодирования сравнивают с самым левым битом двоичного представления верхнего значения интервала кодирования. При их совпадении значение самого левого бита этих двоичных представлений считывают в качестве следующего сжатого бита, иначе переходят к сжатию следующего очередного символа и так далее, как показано на фиг. 6.
При поступлении на вход арифметического кодирования очередного символа ИП, являющегося нулевым двоичным символом, нижнее значение интервала кодирования устанавливают равным предыдущему нижнему значению интервала кодирования арифметического кодера, а верхнее значение интервала кодирования устанавливают равным текущему значению Q. Например, при поступлении на вход арифметического кодирования пятого по счету символа ИП, являющегося нулевым двоичным символом, нижнее значение интервала кодирования пятого символа L[5] устанавливают равным предыдущему нижнему значению интервала кодирования арифметического кодера L[4], равному, например, 44, а верхнее значение интервала кодирования пятого символа арифметического кодирования Н[5] устанавливают равным текущему значению Q, равному, например, 78, как показано на фиг. 6 при t=5.
Примерный вид сжатия первых четырех очередных частей помехоустойчивой последовательности вида "11110 10111 10010 10100" в соответствующие очередные части сжатой последовательности вида "110 01110 1000000 010" показан на фиг. 4(г).
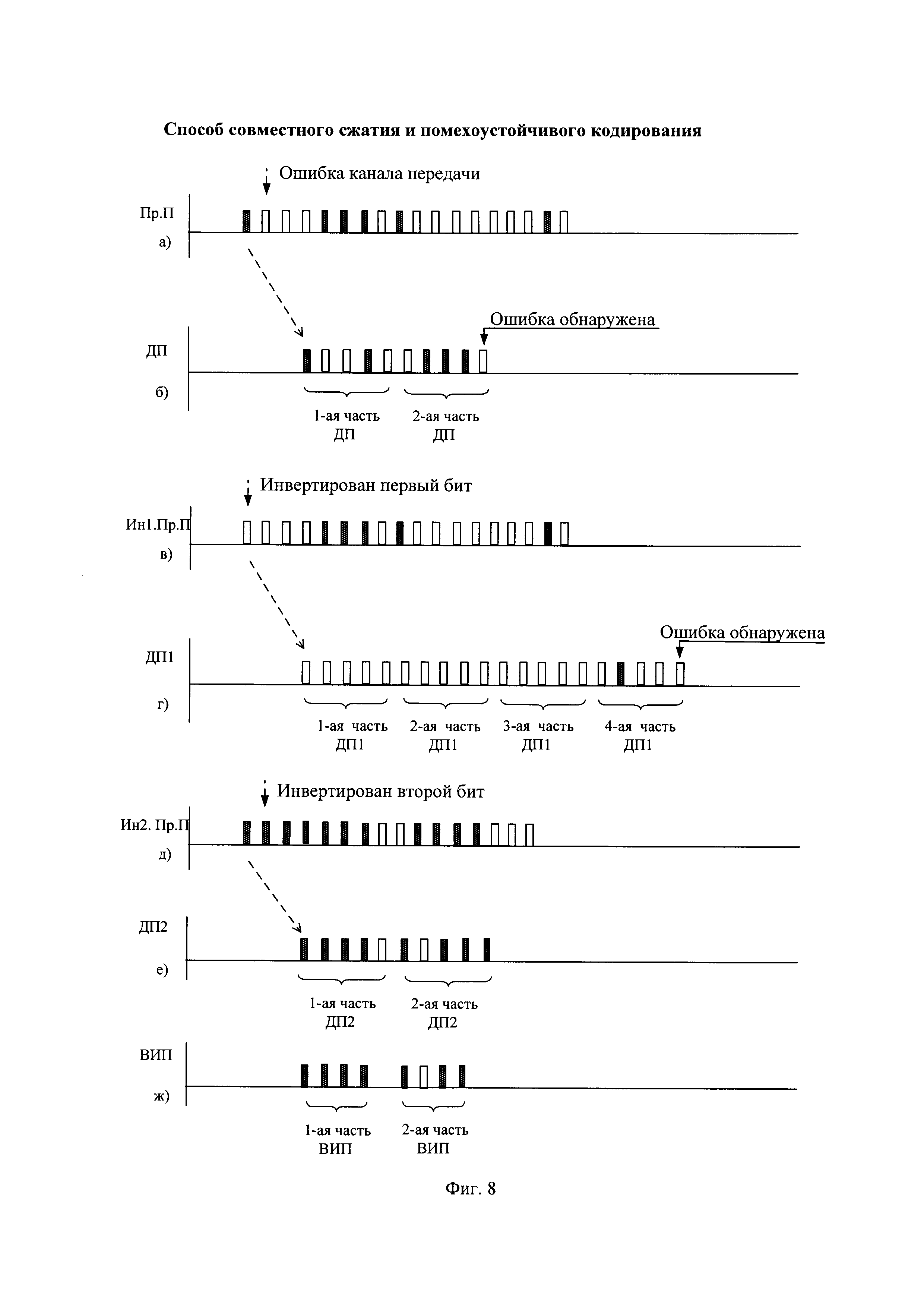
Способы передачи на приемную сторону очередной части сжатой последовательности известны и описаны, например, в книге А.Г. Зюко, Д.Д. Кловский, М.В. Назаров, Л.М. Финк "Теория передачи сигналов". - М.: Радио и связь, 1986, стр. 11. Примерный вид принятой последовательности (Пр. П) показан на фиг. 8(a). Принятая последовательность при передаче искажена во втором бите и имеет вид "100011101000000010".
Алгоритм совместного разжатия и исправления ошибок на приемной стороне представлен на фиг. 9. Схема разжатия на основе арифметического декодирования представлена на фиг. 10, в которой по мере декодирования подсчитывают число нулевых символов декодирования и число единичных символов декодирования, пропорционально которым интервал декодирования арифметического декодирования делят на подинтервал нулевых символов декодирования и подинтервал единичных символов декодирования, в соответствии с которыми арифметический декодер последовательно декодирует принятую последовательность.
Способы запоминания очередных частей принятой последовательности известны и описаны, например, в книге: В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной и последовательной записью/считыванием двоичных последовательностей.
Способы разжатия запомненной очередной части принятой последовательности в очередную часть декодированной последовательности с использованием арифметического декодирования описаны, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 35-43. Они заключаются в последовательном декодировании с использованием арифметического декодирования очередной части принятой последовательности в соответствии с текущими значениями интервала декодирования арифметического декодирования и текущими значениями вероятности декодируемых нулевых символов и единичных символов.
Перед разжатием первой части принятой последовательности устанавливают начальные значения первого и второго регистров декодирования. Начальное нижнее значение интервала декодирования устанавливают в минимальное значение, а начальное верхнее значения интервала декодирования - в максимальное значение. Например, при представлении значений интервала кодирования восемью двоичными символами, начальное нижнее значение интервала декодирования арифметического декодирования LL[0] устанавливают в минимальное значение, равное нулевому значению в десятичном представлении или 00000000 в двоичном представлении, где старшие двоичные символы записывают слева, а начальное верхнее значение интервала декодирования арифметического декодирования HH[0] устанавливают в максимальное значение, равное 255 в десятичном представлении или 11111111 в двоичном представлении. Пример начального состояния (начальн. состоян.) арифметического декодирования представлен на фиг. 11. Начальные состояния арифметического кодирования и арифметического декодирования устанавливают идентично.
Начальное состояние арифметического декодирования также заключается в установке начального значения вероятности декодируемых нулевых символов pp0[0] и начального значения вероятности декодируемых единичных символов pp1[0]. При установке начального значения вероятности декодируемых нулевых символов pp0[0] и начального значения вероятности декодируемых нулевых символов pp1[0] в выбранные значения должно выполняться ограничение вида: pp0[0]+pp1[0]=1. Начальное значение вероятности декодируемых нулевых символов pp0[0] вычисляют по формуле вида 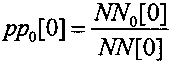 , а начальное значение вероятности декодируемых единичных символов pp0[0] вычисляют по формуле вида
, а начальное значение вероятности декодируемых единичных символов pp0[0] вычисляют по формуле вида 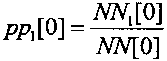 , где NN0[0] - начальное число декодированных нулевых символов, NN1[0] - начальное число декодированных единичных символов, а NN[0] - начальное число декодированных нулевых и единичных символов, равное NN[0]=NN0[0]+NN1[0]. В известных способах, описанных, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 124-130, устанавливают начальное число декодированных нулевых символов равным NN0[0]=1, а начальное число декодированных единичных символов - равным NN1[0]=1, то есть начальные значения вероятности декодируемых единичных и нулевых символов устанавливают равными: pp1[0]=pp0[0].
, где NN0[0] - начальное число декодированных нулевых символов, NN1[0] - начальное число декодированных единичных символов, а NN[0] - начальное число декодированных нулевых и единичных символов, равное NN[0]=NN0[0]+NN1[0]. В известных способах, описанных, например, в книге Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин "Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео". - М., ДИАЛОГ-МИФИ, 2002, стр. 124-130, устанавливают начальное число декодированных нулевых символов равным NN0[0]=1, а начальное число декодированных единичных символов - равным NN1[0]=1, то есть начальные значения вероятности декодируемых единичных и нулевых символов устанавливают равными: pp1[0]=pp0[0].
Начальное значение интервала декодирования арифметического декодирования II[0], равное II[0]=HH[0]-LL[0], разделяют на начальные значения подинтервала декодирования нулевых символов DD0[0] и подинтервала декодирования единичных символов DD1[0], длины которых прямо пропорциональны начальным значениям вероятностей декодируемых нулевых символов pp0[0] и единичных символов pp1[0], соответственно. Начальную длину подинтервала декодирования единичных символов DD1[0] определяют по формуле вида DD1[0]=II[0]×pp1[0], а начальную длину подинтервала декодирования нулевых символов DD0[0] определяют по формуле вида DD0[0]=II[0]-DD1[0]. Например, начальная длина подинтервала декодирования единичных символов DD1[0] имеет десятичное значение 128 или 10000000 в двоичном представлении, а начальная длина подинтервала декодирования нулевых символов DD0[0] имеет десятичное значение 127 или 01111111 в двоичном представлении. Подинтервал декодирования единичных символов расположен сверху подинтервала декодирования нулевых символов. Верхнюю границу подинтервала декодирования нулевых символов обозначают как значение QQ, и данный подинтервал начинается снизу от нижней границы интервала декодирования арифметического кодирования до значения QQ исключительно, а подинтервал декодирования единичных символов простирается от значения QQ включительно до верхней границы интервала декодирования арифметического декодирования исключительно. Начальное значение QQ имеет десятичное значение 127, как показано на фиг. 11 в первой строке при t=0.
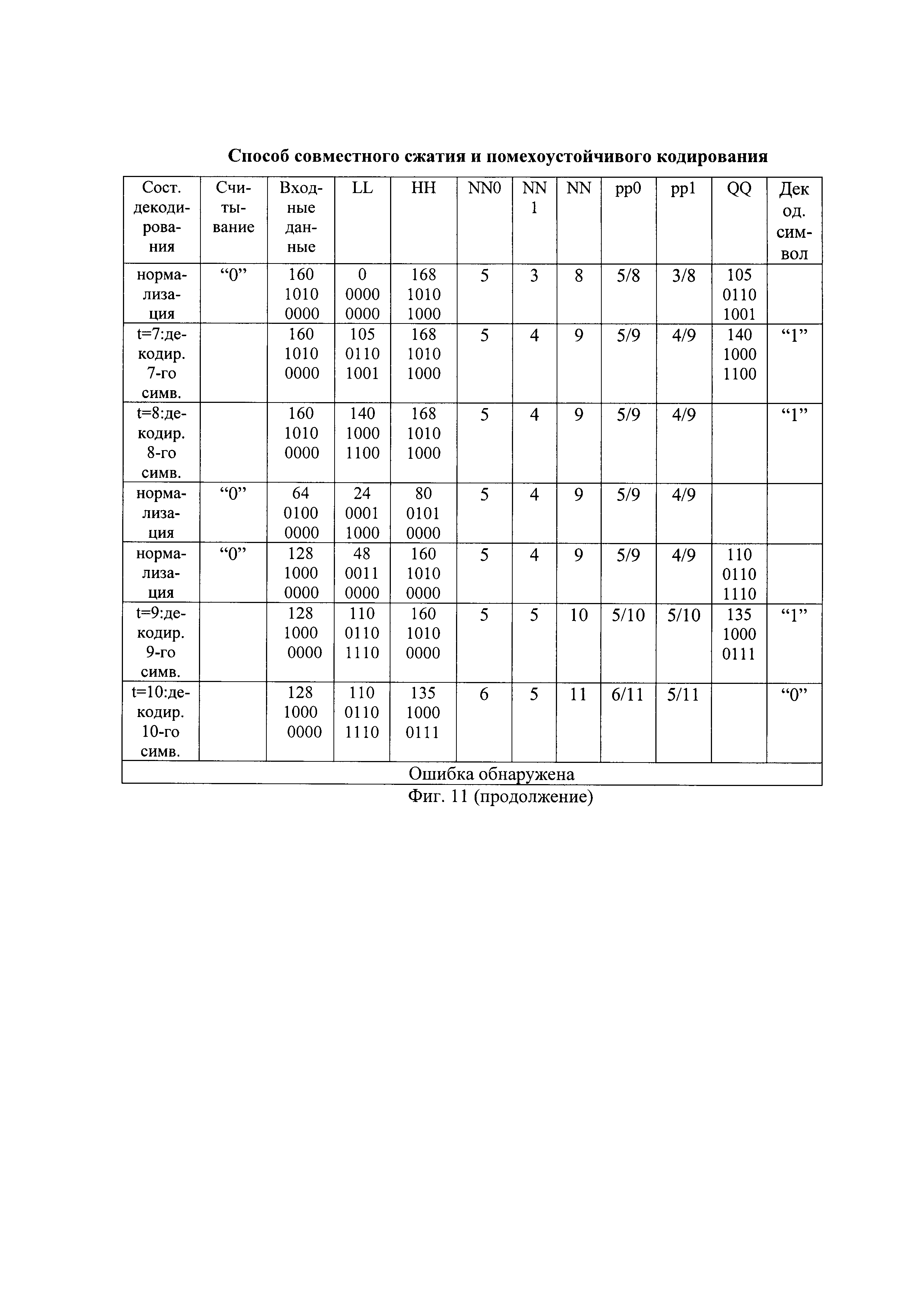
Примерный вид разжатия искаженной во втором бите принятой последовательности вида "100011101000000010" в декодированную последовательность показан на фиг. 11.
На вход арифметического декодирования поступает часть принятой последовательности длиной R бит, равной разрядности выполняемых операций, как и при ранее описанном арифметическом кодировании. Первоначально на вход арифметического декодирования считывают первые по очереди 8 бит вида "10001110", что соответствует десятичному числу 142. Текущее значение считанной последовательности, сравнивают с границами начального значения подинтервала декодирования нулевых символов DD0[0], находящимися, например, в пределах от 0 до 127 и с границами начального значения подинтервала декодирования единичных символов DD1[0], находящимися, например, в пределах от 127 до 255. В зависимости от того, в пределах какого подинтервала декодирования символов оказалось текущее значение считанной последовательности, принимают решение о декодировании очередного символа декодированной последовательности.
Например, так как текущее значение считанной последовательности оказалось больше значения QQ, то первый декодированный символ является единичным и следующие границы интервала декодирования устанавливают соответствующими границам значения подинтервала декодирования единичных символов DD0[0]. В результате декодирования первого символа устанавливают нижнее значение интервала декодирования арифметического кодирования LL[1] равным значению QQ, например, LL[1]=127, а верхнее значение интервала декодирования арифметического кодирования HH[1] - равным предыдущему значению HH[0], например, HH[1]=255, как показано на фиг. 11 во второй строке при t=1. После декодирования каждого символа пересчитывают текущее значение вероятности декодируемых нулевых символов и текущее значение вероятности декодируемых нулевых символов, например, после декодирования первого символа, являющегося единичным, по формуле вида 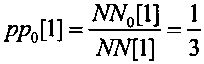 и по формуле вида
и по формуле вида 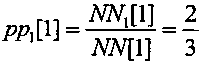 , соответственно. Устанавливают текущие длины подинтервалов декодирования единичных символов и нулевых символов и устанавливают текущее значение QQ=170 с двоичным представлением вида "10101001", как показано на фиг. 11 при t=1.
, соответственно. Устанавливают текущие длины подинтервалов декодирования единичных символов и нулевых символов и устанавливают текущее значение QQ=170 с двоичным представлением вида "10101001", как показано на фиг. 11 при t=1.
Декодированный единичный символ считывают с выхода арифметического декодирования в качестве первого символа декодированной последовательности.
После каждого изменения состояния арифметического декодирования самый левый бит двоичного представления значения LL сравнивают с самым левым битом двоичного представления значения HH, например, при t=1 вида "01111111" и "11111111", соответственно. При их совпадении выполняют нормализацию арифметического декодирования, иначе продолжают декодирование, например, декодируют второй символ принятой последовательности. На вход арифметического декодирования по прежнему считаны входные данные вида "10001110", что соответствует десятичному числу 142. Текущее значение считанной последовательности, сравнивают с границами значения подинтервала декодирования нулевых символов DD0[1], находящимися, например, в пределах от 127 до 170 и с границами значения подинтервала декодирования единичных символов DD1[1], находящимися, например, в пределах от 170 до 255. В зависимости от того, в пределах какого подинтервала декодирования символов оказалось текущее значение считанной последовательности, принимают решение о декодировании очередного символа принятой двоичной информационной последовательности. Например, так как текущее значение считанной последовательности оказалось меньше значения QQ, то второй декодированный символ является нулевым и следующие границы интервала декодирования устанавливают соответствующими границам значения подинтервала декодирования нулевых символов DD0[1]. В результате декодирования второго символа устанавливают нижнее значение интервала декодирования арифметического кодирования LL[2] равным предыдущему значению LL[1], например, LL[2]=127, а верхнее значение интервала декодирования арифметического кодирования HH[2] - равным значению QQ, например, HH[2]=170, как показано на фиг. 11 в третьей строке при t=2. После декодирования каждого символа пересчитывают текущее значение вероятности декодируемого нулевого символа и декодируемого нулевого символа, например, после декодирования второго символа, являющегося нулевым, по формуле вида 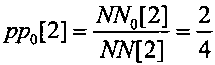 и по формуле вида
и по формуле вида 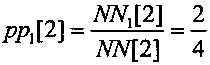 , соответственно. Устанавливают текущие длины подинтервалов декодирования единичных символов и нулевых символов и таким образом уточняют значения первого и второго регистров декодирования.
, соответственно. Устанавливают текущие длины подинтервалов декодирования единичных символов и нулевых символов и таким образом уточняют значения первого и второго регистров декодирования.
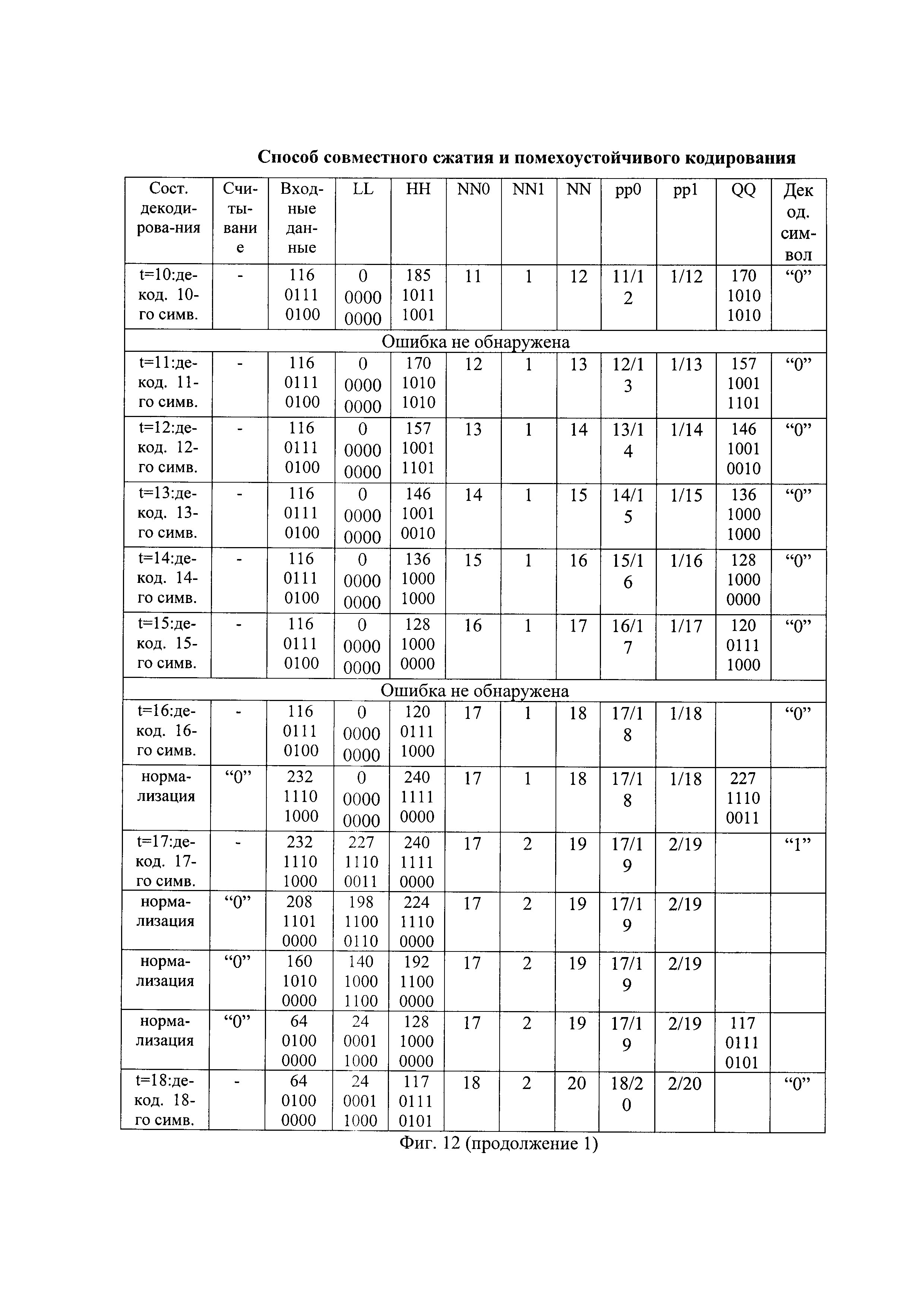
После декодирования каждого символа самый левый бит двоичного представления значения LL сравнивают с самым левым битом двоичного представления значения HH. Например, после декодирования четвертого символа самый левый бит двоичного представления значения LL[4] вида "10001100" сравнивают с самым левым битом двоичного представления значения HH[4] вида "10010101" и при их совпадении выполняют нормализацию арифметического декодирования: значение самого левого бита двоичных представлений значений LL и HH удаляют и двоичные символы двоичных представлений значений LL и HH сдвигают справа налево на один разряд и справа к ним в младший разряд дописывают по нулевому двоичному символу. Одновременно с этим, значение самого левого бита входных данных удаляют и двоичные символы входных данных сдвигают справа налево на один разряд и справа к ним дописывают следующий двоичный символ принятой последовательности, например, девятый по счету символ принятой последовательности, являющийся единичным символом, как показано на фиг. 11 в шестой строке "нормализация". С учетом дописанного двоичного символа, входные данные приобретают двоичное представление "00011101" и десятичное значение 29. Переменная LL принимает десятичное значение 24 и двоичное представление "00011000", а HH - десятичное значение 42 и двоичное представление "00101010". Так как самые левые биты двоичных представлений LL и HH снова совпадают, то выполняют повторную нормализацию идентичным образом и т.д.
В результате арифметического декодирования первых по очереди символов принятой последовательности декодируют первую и вторую часть декодированной последовательности (ДП), имеющие, например, вид "10010" и "01110", как показано, например, на фиг. 8(б) и на фиг. 11.
Способы выделения из очередной части декодированной последовательности очередной части восстановленной информационной последовательности и декодированных проверочных символов известны и описаны, например, в книге В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной и последовательной записью/считыванием двоичных последовательностей. Очередную часть декодированной последовательности последовательно записывают в ячейки памяти регистра сдвига длиной k+r бит. Из первых по счету ячеек памяти этого регистра сдвига параллельно считывают очередную часть восстановленной информационной последовательности длиной k бит. Из последующих, начиная с k+1-ой, ячейки памяти этого же регистра сдвига параллельно считывают декодированные проверочные символы длиной r бит. Например, из первой части ДП вида "10010" выделяют первую часть восстановленной информационной последовательности (ВИП) вида "1001" и декодированный проверочный символ вида "0".
Из очередной части восстановленной информационной последовательности вычисляют проверочные символы точно так же, как на передающей стороне проверочные символы вычисляют из очередной части информационной последовательности. Например, из первой части восстановленной информационной последовательности вида "1001" вычисляют проверочный символ вида "0".
Вычисленные проверочные символы побитно сравнивают с декодированными проверочными символами и при их побитном совпадении делают вывод об отсутствии ошибок передачи. Например, в первой части вычисленный проверочный символ совпал с декодированным проверочным символом и ошибка канала передачи не обнаружена. Но во второй части декодированной последовательности вида "01110" из восстановленной информационной последовательности вида "0111" вычисляют проверочный символ вида "1", который не совпадает с декодированным проверочным символом вида "0". Поэтому ошибка передачи в принятой последовательности обнаружена.
Для исправления ошибки передачи поочередно инвертируют один или несколько битов в запомненной очередной части принятой последовательности. Способы инвертирования битов в запомненной очередной части принятой последовательности известны и описаны, например, в книге В. Шило "Популярные цифровые микросхемы". - М., Радио и связь, 1987, 104-123, с использованием регистров сдвига с параллельной записью/считыванием двоичных последовательностей и двоичных инверторов. Инвертируемый бит из регистра сдвига параллельно считывают на вход инвертора и с выхода инвертора параллельно записывают в эту же ячейку памяти регистра сдвига.
Например, в запомненной принятой последовательности инвертируют первый бит (Ин 1. Пр. П) и она приобретает вид "000011101000000010", показанный на фиг. 8(в). Порядок сжатия запомненной принятой последовательности с инвертированным первым битов показан на фиг. 12. В результате арифметического декодирования Ин 1. Пр. П декодируют первые четыре части декодированной последовательности при инвертированном первом бите (ДП1), имеющие, например, вид "00000", "00000", "00000" и "01000", как показано, например, на фиг. 8(г) и на фиг. 12. Неисправленная ошибка передачи в принятой последовательности обнаружена только в четвертой части декодированной последовательности.
Так как инвертирование первого (или только первого) бита принятой последовательности не привело к исправлению ошибки передачи, то в запомненной принятой последовательности инвертируют второй бит (Ин 2. Пр. П) и она приобретает вид "110011101000000010", показанный на фиг. 8(д). Порядок сжатия запомненной принятой последовательности с инвертированным вторым битов показан на фиг. 13. В результате арифметического декодирования Ин 2. Пр. П декодируют первые две части декодированной последовательности при инвертированном втором бите (ДП2), имеющие, например, вид "11110" и "10111", как показано, например, на фиг. 8(e) и на фиг. 13. По результатам побитного сравнения вычисленных проверочных символов с соответствующим декодированными проверочными символами сделан вывод об отсутствии ошибок передачи. Действительно, первые две части декодированные последовательности идентичны первым двум частям помехоустойчивой последовательности, показанным на фиг. 4(в).
При отсутствии ошибка передачи передают получателю очередные части восстановленной информационной последовательности, например, первые две части восстановленной информационной последовательности вида "1111" и "1011", показанные на фиг. 8(ж).
Для сжатия очередных частей помехоустойчивой последовательности можно использовать кодирование Хаффмана, а для разжатия принятой последовательности использовать декодирование Хаффмана, аналогично, как описанное арифметическое кодирование и арифметическое декодирование.
Проверка теоретических предпосылок заявленного способа совместного сжатия и помехоустойчивого кодирования проверялась путем его аналитических исследований.
Было выполнено совместное сжатие и помехоустойчивое кодирования нескольких очередных частей информационной последовательности с использованием способа-прототипа и предлагаемого способа, результаты показаны на фиг. 14. Выполнялось совместное сжатие и помехоустойчивое кодирование N=10 очередных частей информационной последовательности длиной k=4 бит и k=20 бит, при использовании проверочных символов длиной r=1 бит. Сжатию и помехоустойчивому кодированию подвергались очередные части двоичной информационной последовательности с вероятностью единичных символов 0.5, 0.2, 0.1, 0.01 и 0.001, соответственно. Передаваемая по каналу передачи сжатая последовательность случайным образом искажалась одной ошибкой. На приемной стороне подсчитывалась вероятность обнаружения ошибки Pобнар и вероятность исправления ошибки Pисправ. Выявлено, что по мере повышения избыточности информационной последовательности повышается вероятность обнаружения ошибки и вероятность исправления ошибки. Также вероятность обнаружения ошибки и вероятность исправления ошибки повышается с увеличением длины очередной части информационной последовательности с k=4 бит до k=20 бит. Для всех исследованных случаев предлагаемый способ обеспечивает повышение обнаруживающей и исправляющей способностью по обнаружению и исправлению ошибок передачи по сравнению со способом-прототипом.
Таким образом, в заявленном способе совместного сжатия и помехоустойчивого кодирования избыточной двоичной информационной последовательности обеспечивается повышение обнаруживающей и исправляющей способностью по обнаружению и исправлению ошибок передачи.
Способ автоматического обнаружения сигналов
Способ обнаружения сглаженных блоков электронного изображения с использованием вейвлет преобразования
Способ обнаружения модификации электронного изображения (варианты)
Способ автоматического обнаружения узкополосных сигналов
Способ автоматического обнаружения сигналов
Способ обнаружения сигналов без несущей
Способ сжатия графических файлов
Способ обнаружения сигналов без несущей
Способ уменьшения шума электронного изображения
Способ сжатия графических файлов
Способ обнаружения сглаженных блоков электронного изображения с использованием вейвлет преобразования
Способ обнаружения модификации электронного изображения (варианты)
Способ сжатия графических файлов
Способ обнаружения сигналов без несущей
Способ уменьшения шума электронного изображения
Способ сжатия графических файлов
Способ сжатия графических файлов
Способ обнаружения сигналов без несущей
Устройство автоматизированного управления полупроводниковыми элементами мостового выпрямителя
Тестер уровня инновационного интеллекта личности

