Результат интеллектуальной деятельности: ВЫДЕЛЕНИЕ ВРЕМЕННЫХ ВЫРАЖЕНИЙ ДЛЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее раскрытие в целом относится к области обработки естественного языка и более конкретно к способу выделения временных выражений в текстах на естественном языке.
УРОВЕНЬ ТЕХНИКИ
Выделение временных выражений является задачей Обработки Естественного Языка (NLP). Оно также связано с задачей Информационного Поиска по текстам. Задачами, тесно связанными с задачей выделения временных выражений, являются резюмирование текстов.
Распознавание Именованных Сущностей и системы QA
Существует два основных подхода для решения задачи выделения временных выражений: подход, основанный на правилах и способы машинного обучения.
Идея основанных на правилах способов состоит в том, чтобы сопоставить фразы на естественном языке списку регулярных выражений. Обычно список выражений составляется лингвистом, экспертом в языке, таким образом, список является зависимым от языка. В патенте US 8538909 B2 описан способ выделения временных признаков из последовательностей на естественном языке посредством основанного на правилах подхода.
Другой способ решения рассматриваемой проблемы состоит в сведении всего к разметке последовательности слов. Предполагается, что каждое слово в тексте имеет признаки: лексические, орфографические, грамматические и т.д. На основе списка признаков может осуществляться обучение статистического классификатора. Такой классификатор может назначать метку независимо каждому слову, или обрабатывать подпоследовательности произвольной длины, или обрабатывать все предложение с учетом контекста.
Разметка последовательностей может быть реализована посредством различных классификаторов. Однако самые популярные способы являются Условными Случайными Полями, SVM и Нейронными Сетями.
Для маркировки временных и событийных выражений группой комплекса TERQAS в течение шести месяцев совершенствовался язык TimeML. В 2009 TimeML был принят в качестве стандарта ISO: ISO 24617-1:2009.
Также для разметки последовательностей могут использоваться схемы разметки IO, BIO, BMEWO. Каждая буква в названии схемы задает действующую метку в последовательности: «В» означает «В начале», «I» означает «Внутри», «М» означает «В середине», «W» означает «Во всем», «Е» означает «В конце» и «О» означает «Вне».
Главные проблемы основанного на правилах подхода состоят в следующем:
- обработка только заданных классов временных выражений,
- зависимость от языка и участка текста,
совершенствование системы правил, поддерживающих редкие случаи, занимает много времени.
Проблемы подхода машинного обучения состоят в:
- потребности в размеченных данных для обучения и испытаний. Разметка данных занимает очень много времени,
- потребности в предварительной обработке (например, выделение признаков),
- зависимости от выборки для испытаний.
На сегодняшний день существуют языки, которые не имеют общедоступных вручную размеченных корпусов с временной и событийной разметкой, подходящей для обучения алгоритмов машинного обучения. Таким образом, применение способов машинного обучения для этих языков является трудным. И на сегодняшний день русский язык находится среди этих языков.
В статье Чанга А.X. и Маннинга С. «SUTime: Библиотека для распознавания и нормализации временных выражений» (LREC, с.с. 3735-3740, Европейская Ассоциация Языковых Ресурсов ELRA (2012) (by Chang A.X. and Manning C. «SUTime: A library for recognizing and normalizing time expressions» (LREC, pp. 3735-3740, European Language Resources Association ELRA, 2012)) описывается чистая основанная на правилах система для разметки временных выражений на английском языке.
В статье «Сравнение обучающихся статистически и выведением правил методом индукции систем для автоматической маркировки временных выражений на английском языке» Хорди Поведа, Михаи Сурдеану, Хорди Турмо (В докладе 14-го Международного Симпозиума по Временному Представлению и Рассуждению (TIME 2007), IEEE, с.с. 141-149) («A comparison of statistical and rule-induction learners for automatic tagging of time expressions in English» by Jordi Poveda, Mihai Surdeanu, Jordi Turmo (In Proc. of the 14th International Symposium on Temporal Representation and Reasoning (TIME 2007), IEEE, pp. 141-149)) описана практика использования способов машинного обучения и основанных на правилах способов для выделения временных выражений на английском языке, и дается их сравнение. Описываются типы признаков для классификатора SVM. TimeML используется для разметки выражений.
Результаты использования Условных Случайных Полей в задачах NLP приведены в статье «Модели условных случайных полей для обработки русского языка» Соловьев А.Н., Антонова А.И. (Компьютерная Лингвистика и Интеллектуальные Технологии: Доклады Международной конференции «Диалог 2013», 2013, с.с. 27-43) («Conditional random field models for the processing of Russian» by Soloviev A.N., Antonova A.Y. (Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference "Dialog 2013", 2013, pp. 27-43)). Даются некоторые полезные примеры (задача Распознавания Именованных Объектов, задача Смыслового Анализа) применения основанного на CRF подхода к русскому языку. Для обучения и испытаний использовались вручную размеченные данные.
Известные способы, использующие машинное обучение и основанный на правилах подход, нуждаются в большом количестве предварительно обученных данных, не поддерживают статистический подход для редких случаев и не позволяют использовать лингвистическую интуицию для общих случаев.
Целью настоящего изобретения является предоставление способа, объединяющего основанную на правилах систему для разметки с обучением алгоритма машинного обучения и устранение вышеупомянутых недостатков машинного обучения и основанного на правилах подхода. Дополнительной целью является предоставление способа, который делает возможным совершенствование высококачественной системы для Выделения Временных Выражений для нового языка или нового участка за короткое время.
Технический результат предложенного изобретения заключается в предоставлении возможности маркировки неразмеченных текстовых данных автоматически и затем использования алгоритма машинного обучения для разметки временных выражений в тексте на естественном языке, например на русском языке.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Цель настоящего изобретения достигается за счет того, что предлагается способ выделения временных выражений в текстах на естественном языке, при этом способ содержит этапы, на которых:
- разделяют упомянутый текст на два непересекающихся поднабора: неразмеченных текстовых данных для испытаний и неразмеченных текстовых данных для обучения, при этом поднабор неразмеченных текстовых данных для испытаний является малым поднабором, а поднабор неразмеченных текстовых данных для обучения является большим поднабором;
- вручную размечают неразмеченные текстовые данные для испытаний для того, чтобы получить «золотой» набор;
- совершенствуют список регулярных выражений и механизм для разметки текстовых данных посредством упомянутого списка регулярных выражений;
- выполняют процедуру разработки алгоритма, содержащую следующие этапы, на которых:
(i) размечают неразмеченные текстовые данные для обучения посредством упомянутого механизма и упомянутого списка регулярных выражений, для того чтобы получить грамматически размеченный текст с частичной маркировкой временных выражений;
(ii) обучают алгоритм машинного обучения с использованием текстовых данных для обучения, размеченных на этапе (i);
(iii) размечают неразмеченные текстовые данные для испытаний посредством упомянутого алгоритма машинного обучения, обученного на этапе (ii);
(iv) оценивают качество разметки посредством сравнения результатов разметки, полученных на этапе (iii), с «золотым набором»; и
- в случае если получена предварительно заданная мера качества разметки, выделяют временные выражения, иначе изменяют список регулярных выражений и механизм для разметки текстовых данных посредством упомянутого измененного списка регулярных выражений и повторяют процедуру разработки алгоритма.
В одном варианте осуществления алгоритм машинного обучения является моделью CRF (условного случайного поля) для линейной цепи.
В одном варианте осуществления мера качества разметки является мерой точности, полноты, F-мерой или мерой достоверности. Предварительно заданная мера качества разметки может быть получена, например, когда F-мера достигает предварительно заданной пороговой величины.
В одном варианте осуществления этап разметки неразмеченных текстовых данных для обучения выполняют посредством следующих методов маркировки: IO, BIO или BMEWO.
В одном варианте осуществления этап ручной разметки неразмеченных текстовых данных для испытаний для того, чтобы получить «золотой» набор, и этап совершенствования списка регулярных выражений и механизма для разметки текстовых данных выполняют посредством использования языка маркировки TimeML.
В одном варианте осуществления текст на естественном языке является текстом на русском языке.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Предшествующие варианты осуществления данного изобретения станут с большей готовностью приняты во внимание, а также станут лучше понятыми посредством ссылки на последующее подробное описание при рассмотрении совместно с сопроводительными чертежами, на которых:
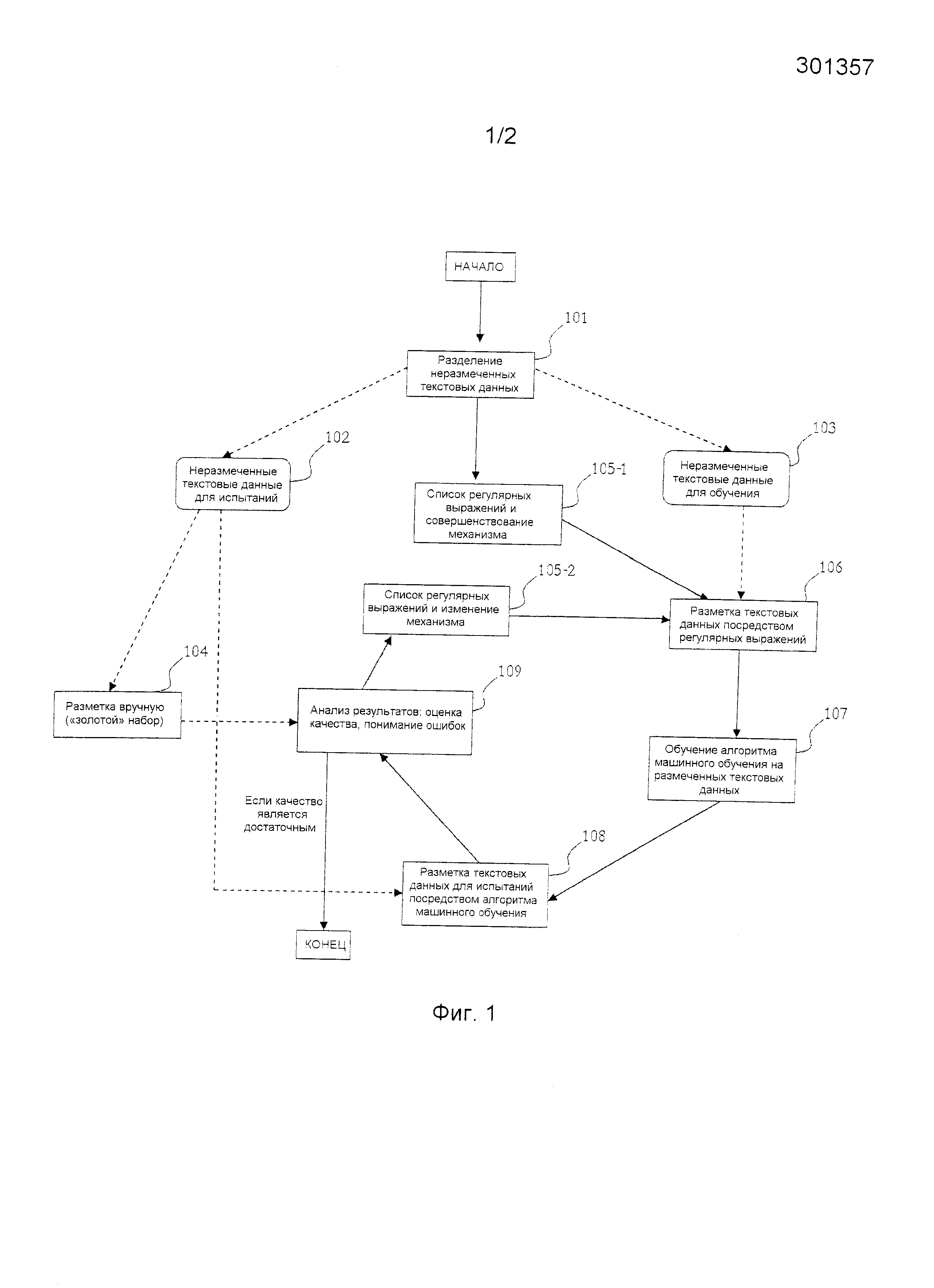
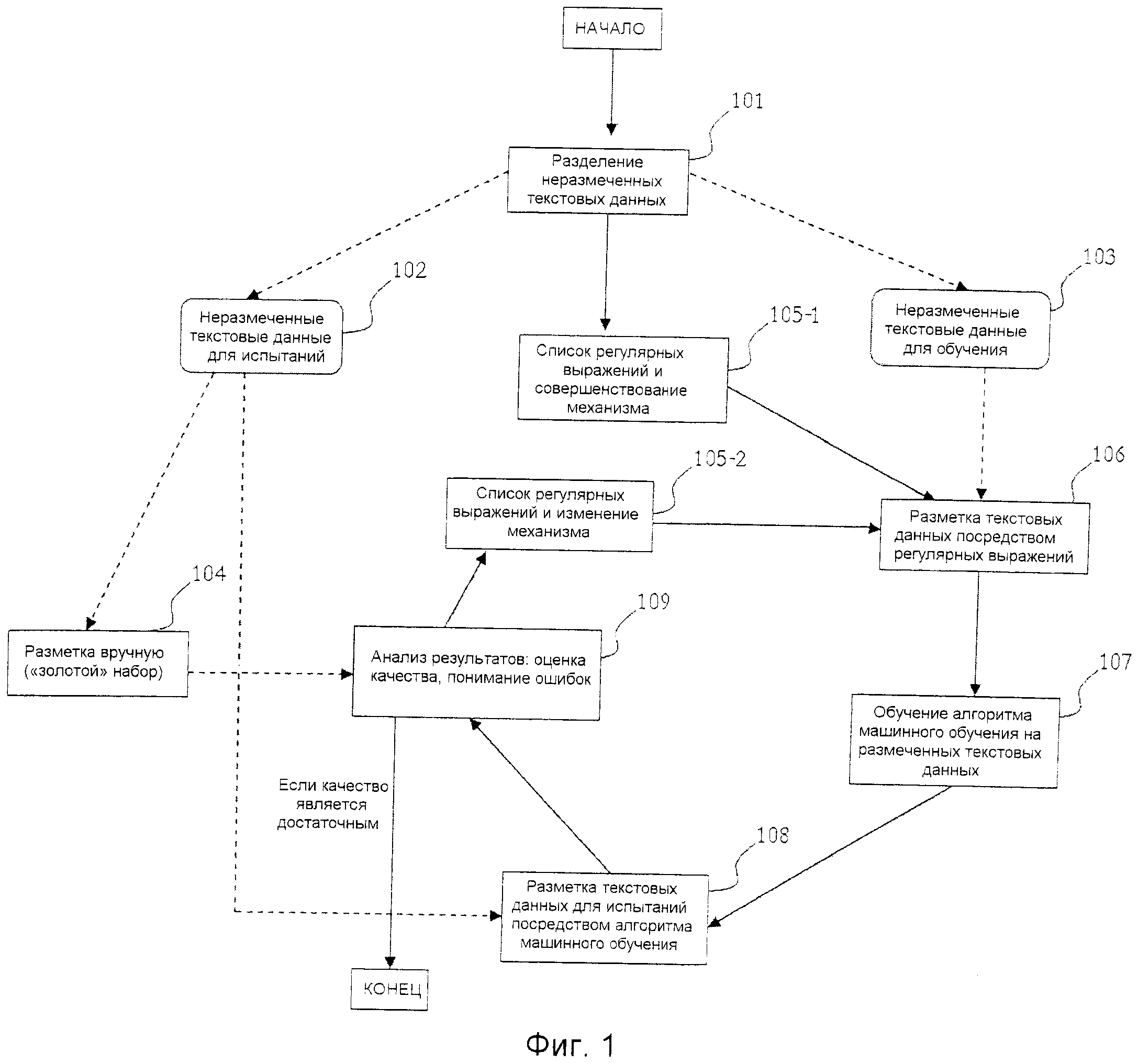
Фиг. 1 является схемой способа согласно лучшему варианту осуществления;
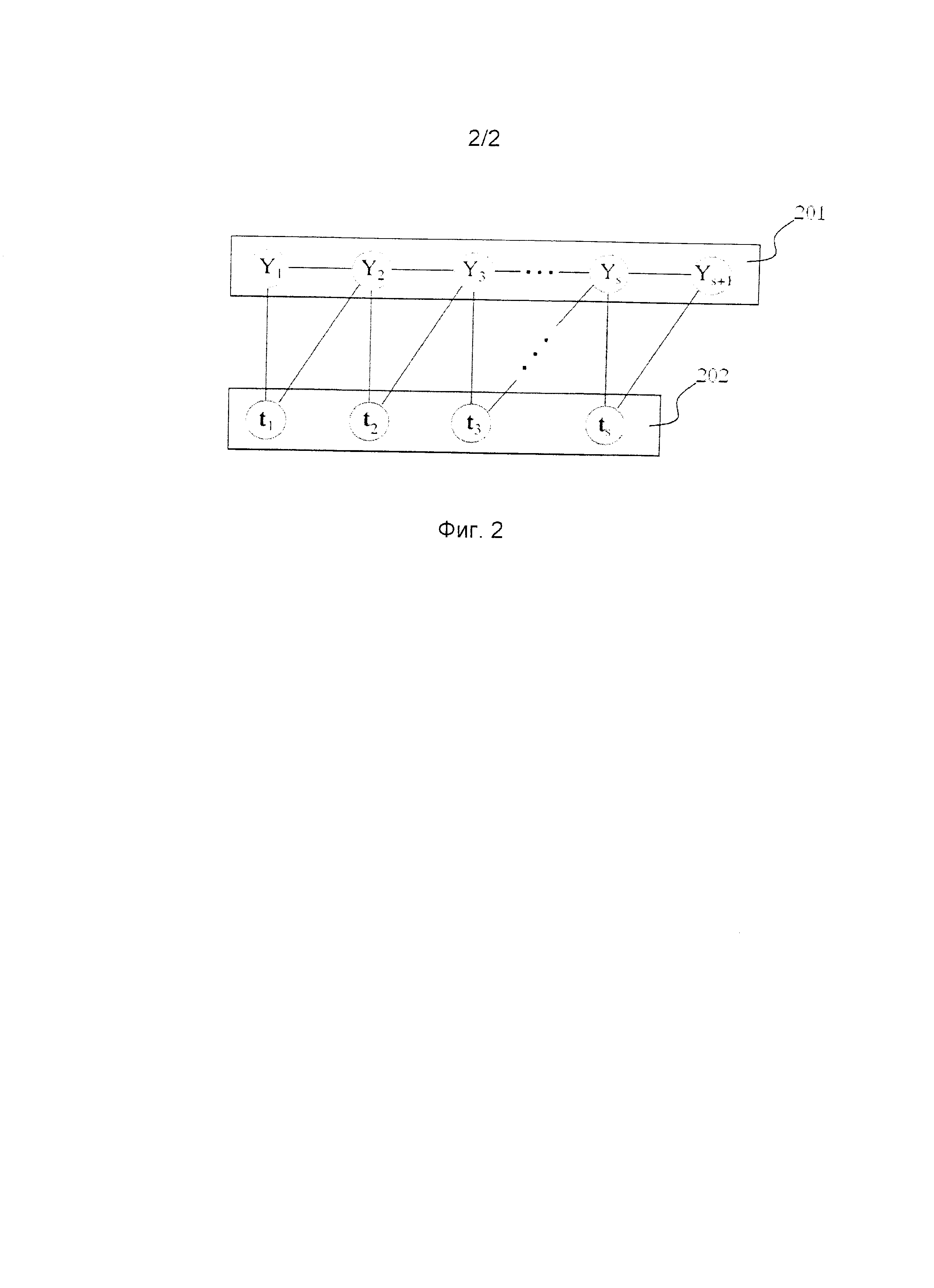
Фиг. 2 является схемой модели CRF для разметки временных выражений на русском языке.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
В целом описанное настоящее раскрытие направлено на распознавание временных выражений в текстах на естественном языке.
Предложенный способ является приемлемым для разметки временных выражений в текстовых данных в текстах на естественном языке без повторений (то есть нет никаких совпадающих текстов), например на русском языке. В настоящее время не существует каких-либо общедоступных корпусов русского языка с маркировкой временных выражений, выполненной экспертами (как в случае английского языка). Описание заявленного варианта реализации предложенного способа описывается ниже. Схема способа предложена на Фиг. 1.
Сначала предоставляется корпус текстов на русском языке только с грамматической разметкой. Затем, на этапе 101, корпус текста разделяется на два непересекающихся поднабора: 102 и 103. На этапе 104 поднабор 102 размечается вручную, так что размер данного поднабора является относительно малым. Он содержит размеченные временные выражения и называется «золотым» набором. Поднабор 103 размечается автоматически на этапе 106 и используется для обучения, так что он является большим поднабором. Для объективного испытания поднаборы 102 и 103 выполняются непересекающимися. Согласно комбинаторной теории переобучения (см. «Оценка зависимостей на основе эмпирических данных», Вапник В.Н., Наука, 1979 («Estimation of Dependencies Based on Empirical Data», Vapnik V.N., Nauka, 1979)), чем больше размер поднабора для обучения, тем меньше вероятность его переобучения; чем больше размер поднабора для испытаний, тем более достоверная оценка качества алгоритма будет получена. Не существует каких-либо ограничений на размеры упомянутых поднаборов, однако логично использовать большой поднабор для обучения и оставшуюся часть - для испытаний.
На этапе 105-1 совершенствуется список регулярных выражений, которые используются для разметки поднабора 103. Эти регулярные выражения должны покрывать некоторые виды временных выражений. Он используется для разметки конкретных (не всех) видов временных выражений посредством механизма для разметки текстовых данных посредством данного списка регулярных выражений. Таким образом, данный механизм и список регулярных выражений, усовершенствованный на этапе 105-1, используются для разметки поднабора 103 на этапе 106. Результатом этапа 106 является поднабор грамматически размеченных текстов с частичной маркировкой временных выражений. На этапе 107 поднабор 103 используется в качестве набора для обучения для алгоритма машинного обучения. В одном варианте осуществления используется модель CRF (условного случайного поля) для линейной цепи, несмотря на то что выбор алгоритма не важен. Граф, кодирующий зависимости в CRF, изображен на Фиг. 2. 201 является последовательностью пометок для предложения длиной s. 202 является последовательностью грамматических меток слов в предложении из корпуса.
На этапе 108 поднабор 102 размечается посредством алгоритма машинного обучения с помощью модели, обученной на этапе 107. Качество разметки оценивается (этап 109) по «золотому» набору из этапа 104: таким образом вычисляются меры точности, полноты, F-мера и мера достоверности. Выражения, не покрытые списком регулярных выражений (этап 105-1), и последовательности слов, ложно размеченных в качестве временных, также отыскиваются и анализируются на данном этапе. Анализ разметки результатов по «золотому» набору включает в себя нахождение ошибок при разметке; нахождение того, какие виды временных выражений не покрыты регулярными выражениями и какие последовательности слов ложно размечены в качестве временных выражений. После анализа изменяется список регулярных выражений (этап 105-2) и этапы 106, 107, 108 и 109 повторяются. Это является итерационной процедурой, и она останавливается, когда на этапе 109 получается предварительно заданный достаточный уровень качества разметки по «золотому» набору. Например, итеративный процесс останавливается, когда F-мера по «золотому» набору составляет ~94%. Это улучшает качество разметки посредством регулярных выражений «золотого» набора на ~1%.
Данная процедура используется для одновременного улучшения обучаемого алгоритма и увеличения количества размеченных данных. В результате данной итерационной процедуры получаются основанная на правилах система для выделения временных выражений, алгоритм машинного обучения, решающий ту же самую задачу, малый набор текстов с временными выражениями, маркированными экспертами, и большие текстовые данные с автоматически размеченными временными выражениями.
Дополнительно следует отметить, что заявляемое изобретение является промышленно применимым, а именно способ может использоваться для подготовки данных для обучения алгоритмов в задачах NLP, в извлечении информации из текстовых данных. Таким образом, оно может быть частью автоматизированной IT-системы, применяемой в медицине, спорте, развлечениях и т.д.
Раскрытый способ обработки текста подходит для любого естественного языка. Однако представляется, что способ является самым подходящим для применения и релевантным для языков со сложной морфологией и обильной синонимией. Способ также релевантен для любого естественного языка при маркировке большого количества данных, так как маркировка реализуется автоматически.
Нужно подчеркнуть, что в вышеописанные варианты осуществления могут быть внесены многие изменения и модификации, элементы которых, как следует понимать, находятся среди других приемлемых примеров. Подразумевается, что все такие модификации и вариации включаются в данном документе в объем данного раскрытия и защищаются следующей формулой изобретения.
Способ и устройство для воспроизведения видеоизображений с измененной скоростью
Носитель информации и способ и устройство для записи и/или воспроизведения данных
Способ и устройство для кодирования и декодирования блока кодирования границы картинки
Способ и устройство для предоставления контента через сеть, способ и устройство для приема контента через сеть, способ и устройство для резервного копирования данных через сеть, устройство предоставления данных резервного копирования и система резервного копирования
Способ и устройство для кодирования и декодирования вектора движения на основании сокращенных предсказателей-кандидатов вектора движения
Способ и устройство для воспроизведения трехмерного звукового сопровождения
Способ и устройство для кодирования и декодирования изображения и способ и устройство для декодирования изображения с помощью адаптивного порядка сканирования коэффициентов
Способ и устройство для совместного использования функций между устройствами через сеть
Способ кодирования видео и устройство для кодирования видео на основе единиц кодирования, определенных в соответствии с древовидной структурой, и способ декодирования видео и устройство для декодирования видео на основе единиц кодирования, определенных в соответствии с древовидной структурой
Способ и устройство для кодирования видео, и способ и устройство для декодирования видео
Устройство и способ передачи и приема информации быстрой обратной связи в широкополосной системе беспроводной связи
Способ и система для обработки освобождения адреса межсетевого протокола версии 4 по протоколу динамической конфигурации хостов
Способ и устройство для воспроизведения видеоизображений с измененной скоростью
Носитель информации и способ и устройство для записи и/или воспроизведения данных
Способ и устройство для кодирования и декодирования блока кодирования границы картинки
Способ и устройство для предоставления контента через сеть, способ и устройство для приема контента через сеть, способ и устройство для резервного копирования данных через сеть, устройство предоставления данных резервного копирования и система резервного копирования
Способ и устройство для кодирования и декодирования вектора движения на основании сокращенных предсказателей-кандидатов вектора движения
Способ и устройство для воспроизведения трехмерного звукового сопровождения
Способ и устройство для кодирования и декодирования изображения и способ и устройство для декодирования изображения с помощью адаптивного порядка сканирования коэффициентов
Способ и устройство для совместного использования функций между устройствами через сеть

