Результат интеллектуальной деятельности: СПОСОБ И СИСТЕМА ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ, КОТОРЫЕ СОКРАЩАЮТ ВРЕМЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ, ПОТЕНЦИАЛЬНО НЕ СОДЕРЖАЩИХ СИМВОЛЫ
Вид РИД
Изобретение
ОБЛАСТЬ ТЕХНИКИ
Настоящий документ относится к автоматической обработке изображений отсканированных документов и других содержащих текст изображений и, в частности, к способам и системам, которые эффективно конвертируют изображения символов в цифровые кодировки соответствующих символов и которые на раннем этапе процесса конвертации обнаруживают изображения, содержащие несимвольные элементы, и прерывают процесс конвертации изображений, содержащих несимвольные элементы.
УРОВЕНЬ ТЕХНИКИ
Печатные, машинописные и рукописные документы на протяжении долгого времени используют для записи и хранения информации. Несмотря на современные тенденции отказа от бумажного делопроизводства, печатные документы продолжают широко использовать в коммерческих организациях, учреждениях и домах. С развитием современных компьютерных систем создание, хранение, поиск и передача электронных документов превратились, наряду с непрекращающимся применением печатных документов, в чрезвычайно эффективный и экономически выгодный альтернативный способ записи и хранения информации. Из-за подавляющего преимущества в эффективности и экономической выгоде, обеспечиваемого современными средствами хранения и передачи электронных документов, печатные документы часто преобразуются в электронные с помощью различных способов и систем, включающих конвертацию печатных документов в цифровые изображения отсканированных документов с применением электронных оптико-механических сканирующих устройств, цифровых камер, а также других устройств и систем, и последующую автоматическую обработку изображений отсканированных документов для генерации электронных документов, закодированных в соответствии с одним или более различными стандартами кодирования электронных документов. Например, в настоящее время можно использовать настольный сканер и сложные программы оптического распознавания символов (OCR), позволяющие персональному компьютеру конвертировать печатный документ в соответствующий электронный документ, который можно просматривать и редактировать с помощью текстового редактора.
Хотя современные системы OCR развились до такой степени, что позволяют автоматически конвертировать в электронные документы сложные печатные документы, включающие в себя изображения, рамки, линии границ и другие нетекстовые элементы, а также текстовые символы множества распространенных алфавитных языков, остается нерешенной проблема конвертации печатных документов, содержащих китайские и японские иероглифы или корейские морфо-слоговые блоки.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящий документ относится к способам и системам обнаружения китайских, японских, корейских иероглифов или символов похожих языков, которые соответствуют изображениям символов, представленным в изображении отсканированного документа или другом содержащем текст изображении. На первой стадии обработки каждое изображение символа связывается со множеством потенциальных графем. На второй стадии обработки каждое изображение символа оценивается относительно множества потенциальных графем, обнаруженного для изображения символа на первой стадии. Во время обработки потенциальных графем представленные в настоящем документе способы и системы наблюдают за прогрессом обнаружения подходящей графемы и, если наблюдается недостаточный прогресс, прерывают обработку потенциальных графем и распознают изображение символа как область, содержащую несимвольный элемент, в изображении отсканированного документа или другом содержащем текст изображении.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фигуры 1А-В иллюстрируют печатный документ.
Фигура 2 иллюстрирует обычный настольный сканер и персональный компьютер, которые применяются вместе для конвертации печатных документов в оцифрованные электронные документы, хранящиеся на запоминающих устройствах и/или в электронной памяти.
Фигура 3 иллюстрирует функционирование оптических компонентов настольного сканера, представленного на фигуре 2.
На фигуре 4 представлена общая архитектурная схема разных типов компьютеров и других устройств, управляемых процессором.
Фигура 5 иллюстрирует цифровое представление отсканированного документа.
На фигуре 6 представлено гипотетическое множество символов.
Фигуры 7А-В иллюстрируют различные объекты множества символов для естественных языков.
Фигуры 8А-В иллюстрируют параметры и значения параметров, рассчитанные для изображений символов.
На фигуре 9 представлена таблица значений параметров, рассчитанных для всех символов из множества, изображенного в качестве примера на фигуре 6.
Фигура 10 иллюстрирует трехмерный график для символов из множества, представленного в качестве примера на фигуре 6, в трехмерном пространстве, каждое измерение которого представляет значения одного из трех разных параметров.
На фигурах 11А-В показаны символы, содержащиеся в каждом из кластеров, представленных точками трехмерного пространства, изображенного на фигуре 10.
Фигура 12А иллюстрирует отдельный параметр, который можно использовать в сочетании с тремя параметрами, соответствующими каждому из измерений трехмерного пространства параметров, представленного на фигуре 10, для полного распознавания каждого из символов в кластере 8.
Фигура 12В иллюстрирует значение дополнительного параметра для каждого символа из кластера 8, которое следует рассматривать со ссылкой на фигуру 12А.
Фигура 13 иллюстрирует небольшое изображение, содержащее текст, которое было изначально обработано системой OCR для генерации сетки окон символов 1300, в каждом из которых содержится изображение символа.
Фигура 14 иллюстрирует общий подход к обработке сетки окон символов, представленной на фигуре 13.
Фигура 15 иллюстрирует первый подход к реализации подпрограммы «process» (1404 на фигуре 14).
Фигуры 16А-В иллюстрируют второй способ реализации подпрограммы «process» (1404 на фигуре 14).
Фигура 17 иллюстрирует третий способ реализации подпрограммы «process», рассмотренной в предыдущем подразделе, с использованием тех же иллюстраций и условных обозначений в псевдокоде, которые использовались в предыдущем подразделе.
Фигура 18 иллюстрирует структуры данных, обеспечивающие кластеризацию и предварительную обработку в одном варианте осуществления системы OCR, включающем в себя третий способ реализации подпрограммы «process», представленный выше.
Фигуры 19А-Е иллюстрируют предварительную обработку изображения символа с использованием структур данных, рассмотренных выше со ссылкой на фигуру 18.
Фигуры 20A-G иллюстрируют мультикластерную OCR-обработку документа, содержащего изображения символов.
Фигура 21 иллюстрирует вторую стадию способов OCR, на которой выполняется связывание кодов символов с изображениями символов.
Фигура 22 иллюстрирует один подход к распараллеливанию второй стадии обработки изображений символов относительно потенциальных графем.
Фигуры 23А-В иллюстрируют распараллеленную обработку отдельного изображения символа относительно потенциальных графем, обнаруженных для изображения символа.
Фигура 24 иллюстрирует пример способов наложения изображений.
Фигура 25 иллюстрирует проблему, которая может возникнуть при обработке изображения отсканированного документа.
Фигура 26 иллюстрирует общую функцию сравнения, которая сопоставляет изображение символа с потенциальной графемой и которая применяется на второй стадии обработки изображения отсканированного документа для оценки потенциальных графем, связанных с каждым изображением символа в таблице обработанных изображений символов.
Фигуры 27А-В иллюстрируют кривые прогресса распознавания для конвертации изображения символа в код символа с использованием способа и системы OCR.
Фигуры 28A-D иллюстрируют различные способы реализации функции отсечки, которая определяет необходимость прерывания обработки для улучшения эффективности обработки и предотвращения возникновения потенциальных дефектов при обработке изображений, содержащих несимвольные элементы.
На фигурах 29А-В представлены блок-схемы, иллюстрирующие применение функции отсечки на второй стадии обработки изображения отсканированного документа для прерывания обработки изображения символа до оценки всех потенциальных графем, связанных с изображением символа.
Фигуры 30А-С иллюстрируют различные типы стратегий отсечки.
Фигура 31 иллюстрирует способ второй стадии обработки, подходящий для вариантов осуществления, в которых для распознавания изображений символов могут применяться составные графемы.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Настоящий документ относится к способам и системам обнаружения символов, соответствующих изображениям символов в изображении отсканированного документа. В одном варианте осуществления способы и системы, к которым относится настоящий документ, осуществляют стадию начальной обработки одного или более отсканированных изображений для обнаружения множества потенциальных графем для изображений отдельных символов в отсканированном документе. На второй стадии изображения символов оцениваются относительно потенциальных графем. В некоторых случаях изображение символа может быть неправильно распознано на первой стадии обработки документа, в результате чего предполагаемое изображение не содержит изображение символа. При оценке всех потенциальных графем, связанных с таким символом, потребуются существенные дополнительные расчеты, которые не обеспечат эффективную обработку документа. В настоящем документе описаны способы, позволяющие прервать вторую стадию обработки изображения символа в тот момент, когда можно определить, что изображение не включает в себя изображение символа.
Последующее описание разделено на две части. В первом подразделе рассматриваются сканирование документов и архитектура компьютера. Во втором подразделе рассматривается оптическое распознавание символов вместе с подробным описанием первой стадии обработки документа, на которой обнаруживаются потенциальные графемы для изображений символов и осуществляется связь между ними. В третьем подразделе описывается раннее распознавание изображений, содержащих несимвольные элементы, и сокращение времени второй стадии обработки изображений, содержащих несимвольные элементы.
Изображения отсканированных документов и электронные документы
Фигуры 1А-В иллюстрируют печатный документ.
На фигуре 1А представлен исходный документ с текстом на японском языке. Печатный документ 100 включает в себя фотографию 102 и пять разных содержащих текст областей 104-108, включающих в себя японские иероглифы. Этот документ будет использоваться в качестве примера при рассмотрении способа и систем определения смысла, к которым относится настоящая заявка. Текст на японском языке может быть написан слева направо, построчно, как пишется текст на английском языке, но также может использоваться способ написания сверху вниз в вертикальных столбцах. Например, область 107 явно содержит вертикально написанный текст, в то время как текстовый блок 108 включает в себя текст, написанный горизонтально. На фигуре 1В печатный документ, представленный на фигуре 1А, показан переведенным на английский язык.
Печатные документы могут быть конвертированы в оцифрованные изображения отсканированных документов с помощью различных средств, включающих электронные оптико-механические сканирующие устройства и цифровые камеры. Фигура 2 иллюстрирует обычный настольный сканер и персональный компьютер, которые применяются вместе для конвертации печатных документов в оцифрованные электронные документы, хранящиеся на запоминающих устройствах и/или в электронной памяти. Настольное сканирующее устройство 202 включает в себя прозрачное стекло 204, на которое лицевой стороной вниз помещается документ 206.
Запуск сканирования приводит к генерации оцифрованного изображения отсканированного документа, которое можно передать на персональный компьютер (ПК) 208 для хранения на запоминающем устройстве. Программа, предназначенная для отображения отсканированного документа, может вывести оцифрованное изображение отсканированного документа для отображения 210 на устройстве отображения 212 ПК.
Фигура 3 иллюстрирует функционирование оптических компонентов настольного сканера, представленного на фигуре 2. Оптические компоненты этого сканера с полупроводниковой светочувствительной матрицей (CCD) расположены под прозрачным стеклом 204. Перемещаемый фронтально источник яркого света 302 освещает фрагмент сканируемого документа 304, свет от которого отражается вниз. Этот свет отражается от фронтально перемещаемого зеркала 306 на неподвижное зеркало 308, которое отражает излучаемый свет на массив CCD-элементов 310, генерирующих электрические сигналы пропорционально интенсивности света, поступающего на каждый из них. Цветные сканеры могут включать в себя три отдельных строки или массива CCD-элементов с красным, зеленым и синим фильтрами. Перемещаемые фронтально источник яркого света и зеркало двигаются вместе вдоль документа, генерируя изображение сканируемого документа. Другой тип сканера, использующего контактный датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми цветными светодиодами (LED), при этом отраженный свет светодиодов улавливается массивом фотодиодов, который перемещается вместе с цветными светодиодами.
На фигуре 4 представлена общая архитектурная схема разных типов компьютеров и других устройств, управляемых процессором. Архитектурная схема высокого уровня позволяет описать современную компьютерную систему (например, ПК, представленный на фигуре 2), в которой программы отображения отсканированного документа и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи в электронную память и выполнения одним или более процессорами, что позволяет преобразовать компьютерную систему в специализированную систему оптического распознавания символов. Компьютерная система содержит один или несколько центральных процессоров (ЦП) 402-405, один или более модулей электронной памяти 408, соединенных с ЦП при помощи шины подсистемы ЦП/память 410 или нескольких шин, первый мост 412, который соединяет шину подсистемы ЦП/память 410 с дополнительными шинами 414 и 416 или другими средствами высокоскоростного взаимодействия, включающими в себя несколько высокоскоростных последовательных линий. Эти шины или последовательные линии, в свою очередь, соединяют ЦП и память со специализированными процессорами, такими как графический процессор 418, а также с одним или более дополнительными мостами 420, взаимодействующими с высокоскоростными последовательными линиями или несколькими контроллерами 422-427, например, с контроллером 427, которые предоставляют доступ к различным типам запоминающих устройств 428, электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
Фигура 5 иллюстрирует цифровое представление отсканированного документа. На фигуре 5 небольшой круглый фрагмент изображения 502 печатного документа 504, используемого в качестве примера, представлен в увеличенном виде 506. Соответствующий фрагмент оцифрованного изображения отсканированного документа 508 также представлен на фигуре 5. Оцифрованный отсканированный документ включает в себя данные, которые представляют собой двухмерный массив значений пикселей. В представлении 508 каждая ячейка сетки под символами (например, ячейка 509) представляет квадратную матрицу пикселей. Небольшой фрагмент 510 сетки показан с еще большим увеличением (512 на фигуре 5), при котором отдельные пиксели представлены в виде элементов матрицы (например, элемента матрицы 514). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения света заданной яркости. В файле оцифрованного отсканированного документа каждый пиксель представлен фиксированным количеством битов, при этом кодирование пикселей осуществляется последовательно. Заголовок файла содержит информацию о типе кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодировок пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Для представления оцифрованного отсканированного документа в виде монохромных изображений с оттенками серого обычно применяют 8-разрядное или 16-разрядное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в зависимости от стандарта кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-разрядных значения, закодированных с помощью 24-разрядного значения. Таким образом, оцифрованное отсканированное изображение по существу представляет собой документ в той же степени, в какой цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении закодированных пикселей, например информация, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ. Фрагменты изображения, соответствующие изображениям символов, могут обрабатываться для генерации битов изображения символа, в котором биты со значением «1» соответствуют изображению символа, а биты со значением «О» соответствуют фону. Растровые отображения удобны для представления как полученных изображений символов, так и эталонов, используемых системой OCR для обнаружения конкретных символов.
В отличие от этого обычный электронный документ, созданный с помощью текстового редактора, содержит различные типы команд рисования линий, ссылки на представления изображений, таких как оцифрованные фотографии, а также оцифрованные текстовые символы. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие неалфавитные текстовые языки. Большая часть вычислительной работы, которую выполняет программа OCR, связана с обнаружением изображений текстовых символов, полученных из оцифрованного изображения отсканированного документа, и с конвертацией изображений символов в соответствующие кодировки стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения растровых изображений текстовых символов. Кроме того, текстовые символы стандарта Юникод можно редактировать, используя различные шрифты, а также обрабатывать всеми доступными в текстовых редакторах способами, в то время как оцифрованные изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
На начальной стадии конвертации изображения отсканированного документа в электронный документ печатный документ (например, документ 100, представленный на фигуре 1) анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие обнаруженные области. Дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу, и шесть конечных узлов, каждый из которых соответствует одной обнаруженной области. Области можно обнаружить, применяя к изображению разные методы, среди которых различные типы статистического исследования распределения пикселей или значений пикселей. Например, в цветном документе фотографию можно выделить по большему изменению цвета в области фотографии, а также по более частым изменениям значений яркости пикселей по сравнению с областями, содержащими текст.
Как только начальное исследование выявит различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR для обнаружения и конвертации текстовых символов в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать содержащие текст области, определяется начальная ориентация содержащей текст области, благодаря чему подпрограммы OCR эффективно используют различные способы наложения эталона для обнаружения текстовых символов. Следует отметить, что изображения в документах могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в позиционировании документа на сканере или другом устройстве, создающем изображение, из-за нестандартной ориентации содержащих текст областей или по другим причинам. Области, содержащие текст, затем делят на фрагменты изображений, содержащие отдельные иероглифы или символы, после чего эти фрагменты по существу масштабируются и ориентируются, а изображения символов центрируются относительно этих фрагментов для облегчения последующего автоматического распознавания символов, соответствующих изображениям символов.
Примеры способов и систем OCR
Для перехода к конкретному обсуждению различных методов оптического распознавания символов в качестве примера будет использоваться множество символов для некоторого гипотетического языка. На фигуре 6 представлено гипотетическое множество символов. На фигуре 6 представлены 48 различных символов, расположенных в 48 прямоугольных областях, таких как прямоугольная область 602. В правом верхнем углу каждой прямоугольной области указан числовой индекс, или код, символа, вписанный в круг; например, индекс, или код, «1» 604 соответствует первому символу 606, представленному в прямоугольной области 602. Данный пример выбран для иллюстрации работы как существующих в настоящее время способов и систем OCR, так и новых способов и систем, описанных в настоящем документе. Фактически в письменных иероглифических языках, включая китайский и японский языки, для печати и письма могут использоваться десятки тысяч различных символов.
Фигуры 7А-В иллюстрируют различные объекты множества символов для естественных языков. На фигуре 7А в столбце представлены различные формы изображения восьмого символа из множества, показанного на фигуре 6. В столбце 704 для восьмого символа 702 из множества символов, показанного на фигуре 6, представлены разные формы написания, встречающиеся в разных стилях текста. Во многих естественных языках могут использоваться различные стили текста, а также различные варианты написания каждого символа.
На фигуре 7В представлены разные подходы к распознаванию символов естественного языка. На фигуре 7В конкретный символ естественного языка представлен узлом 710 на графе 712. Конкретный символ может иметь множество различных общих письменных или печатных форм. В целях оптического распознавания символов каждую из этих общих форм представляют в виде отдельной графемы. В некоторых случаях определенный символ может содержать две или более графем. Например, китайские иероглифы могут содержать комбинацию из двух или более графем, каждая из которых присутствует в других иероглифах. Корейский язык, на самом деле, основан на алфавите, при этом в нем используются корейские морфо-слоговые блоки, содержащие ряд буквенных символов в различных позициях. Таким образом, корейский морфо-слоговой блок может представлять символ более высокого уровня, состоящий из нескольких компонентов графем. Для символа 710, представленного на фигуре 7В, существуют шесть различных графем 714-719. Кроме того, существуют одна или более различных печатных или письменных форм написания графем, каждая из которых представлена соответствующим эталоном. На фигуре 7В каждая из графем 714 и 716 имеет два возможных варианта написания, представленных эталонами 720-721 и 723-724 соответственно. Каждая из графем 715 и 717-719 связана с одним из эталонов 722 и 725-727 соответственно. Например, восьмой символ из множества, представленного в качестве примера на фигуре 6, может быть связан с тремя графемами, первая из которых соответствует написаниям 702, 724, 725 и 726, вторая - 728 и 730, а третья - 732. В этом случае к первой графеме относятся написания, в которых используются прямые горизонтальные элементы, ко второй графеме относятся написания, в которых используются горизонтальные элементы и короткие вертикальные элементы с правой стороны, а к третьей графеме относятся написания, включающие в себя изогнутые (а не прямые) элементы. Кроме того, все написания восьмого символа 702, 728, 724, 732, 725, 726 и 730 можно представить в виде эталонов, связанных с единственной графемой для восьмого символа. В определенной степени выбор графем осуществляется произвольно. В некоторых типах иероглифических языков можно определить множество тысяч разных графем. Эталоны можно рассматривать в качестве альтернативного представления или изображения символа, при этом они могут быть представлены в виде множества пар «параметр - значение параметра», как описано ниже.
Хотя отношение между символами, графемами и эталонами представлено на фигуре 7В как строго иерархическое, при котором каждая графема связана с одним конкретным родительским символом, фактические отношения не могут быть так просто структурированы. Фигура 7С иллюстрирует несколько более сложное множество отношений, в котором два символа 730 и 732 являются родительскими для двух разных графем 734 и 736. В качестве еще одного примера можно привести следующие символы английского языка: строчная буква «о», прописная буква «О», цифра «0» и символ градусов «°», которые могут быть связаны с кольцеобразной графемой. Отношения также могут быть представлены в виде графов или сетей. В некоторых случаях графемы (в отличие от символов или в дополнение к ним) могут отображаться на самых высоких уровнях в рамках выбранного представления отношений. В сущности, обнаружение символов, графем, выбор эталонов для конкретного языка, а также определение отношений между ними осуществляются в большой степени произвольно.
Фигуры 8А-В иллюстрируют параметры и значения параметров, рассчитанные для изображений символов. Следует заметить, что словосочетание «изображение символа» может описывать печатный, рукописный или отображаемый на экране символ или графему. В следующем примере параметры и значения параметров рассматриваются применительно к изображениям символов, но в фактическом контексте реального языка параметры и значения параметров часто применяются для характеристики и представления изображений графем. На фигуре 8А представлено изображение прямоугольного символа 802, полученное из содержащего текст изображения, которое включает в себя 22-й символ из множества, показанного в качестве примера на фигуре 6. На фигуре 8В представлено изображение прямоугольного символа 804, полученное из содержащего текст изображения, которое соответствует 48-му символу из множества, показанного в качестве примера на фигуре 6. При печати и письме на гипотетическом языке, соответствующем множеству символов, приведенному в качестве примера, символы размещаются в середине прямоугольных областей. Если это не так, системы OCR произведут начальную обработку изображений, изменив ориентацию, масштаб и положение полученных изображений символов относительно фоновой области для нормализации полученных изображений символов в целях дальнейшей обработки.
Фигура 8А иллюстрирует три разных параметра, которые могут использоваться системой OCR для получения отличительных признаков символов. Следует заметить, что область изображения символа, или окно символа, характеризуется вертикальным размером окна символа 806, обозначаемым сокращенно «vw», и горизонтальным размером окна символа 808, обозначаемым сокращенно «hw». Первым параметром является самый длинный в изображении символа непрерывный горизонтальный отрезок линии, обозначаемый «h» 810. Это самая длинная последовательность смежных темных пикселей на фоне по существу белых пикселей в окне символа. Вторым параметром является самый длинный в изображении символа непрерывный вертикальный отрезок линии 812. Третий параметр представляет собой долю пикселей изображения символа от общего числа пикселей в окне символа, выраженное в процентах; в данном примере это доля черных пикселей в по существу белом окне символа. Во всех трех случаях значения параметров могут быть непосредственно рассчитаны сразу после создания растрового отображения окна символа. На фигуре 8В представлены два дополнительных параметра. Первым параметром является количество внутренних горизонтальных белых полос в изображении символа; изображение символа, представленное на фигуре 8В, имеет одну внутреннюю горизонтальную белую полосу 816. Вторым параметром является количество внутренних вертикальных белых полос в изображении символа. В 48-м символе из множества, представленном изображением в окне символа 804 на фигуре 8В, имеется одна внутренняя вертикальная белая полоса 818. Количество горизонтальных белых полос обозначается как «hs», а количество внутренних вертикальных белых полос - «vs».
На фигуре 9 представлена таблица значений параметров, рассчитанных для всех символов из множества, изображенного в качестве примера на фигуре 6. В каждой строке таблицы 902, показанной на фигуре 9, представлены значения параметров, рассчитанные для конкретного символа. Параметры включают в себя: (1) отношение самого длинного непрерывного горизонтального отрезка линии к окну символа, 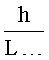 , 904; (2) отношение самого длинного непрерывного вертикального отрезка линии к вертикальному размеру окна символа, 906; (3) выраженная в процентах общая площадь, соответствующая изображению символа или черной области,
, 904; (2) отношение самого длинного непрерывного вертикального отрезка линии к вертикальному размеру окна символа, 906; (3) выраженная в процентах общая площадь, соответствующая изображению символа или черной области, 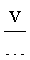 , 908; (4) количество внутренних вертикальных полос, vs, 910; (5) количество внутренних горизонтальных полос, hs, 912; (6) общее количество внутренних вертикальных и горизонтальных полос, vs+hs, 914; и (7) отношение самого длинного непрерывного вертикального отрезка к самому длинному непрерывному горизонтальному отрезку,
, 908; (4) количество внутренних вертикальных полос, vs, 910; (5) количество внутренних горизонтальных полос, hs, 912; (6) общее количество внутренних вертикальных и горизонтальных полос, vs+hs, 914; и (7) отношение самого длинного непрерывного вертикального отрезка к самому длинному непрерывному горизонтальному отрезку, 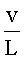 , 916. Как и следовало ожидать, в первой строке 920 таблицы 902, представленной на фигуре 9, первый символ множества (606 на фигуре 6) представляет собой вертикальную черту, и численное значение параметра
, 916. Как и следовало ожидать, в первой строке 920 таблицы 902, представленной на фигуре 9, первый символ множества (606 на фигуре 6) представляет собой вертикальную черту, и численное значение параметра 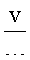 , равное 0,6, значительно больше численного значения параметра
, равное 0,6, значительно больше численного значения параметра  , равного 0,2. Символ 606 занимает всего 12 процентов от площади окна символа 602. У символа 606 нет ни внутренних горизонтальных, ни внутренних вертикальных белых полос, поэтому значения параметров vs, hs и vs+hs равны 0. Соотношение
, равного 0,2. Символ 606 занимает всего 12 процентов от площади окна символа 602. У символа 606 нет ни внутренних горизонтальных, ни внутренних вертикальных белых полос, поэтому значения параметров vs, hs и vs+hs равны 0. Соотношение 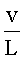 равно 3. Поскольку используемые в качестве примера символы имеют относительно простую блочную структуру, то значения каждого из параметров в таблице 902 отличаются незначительно.
равно 3. Поскольку используемые в качестве примера символы имеют относительно простую блочную структуру, то значения каждого из параметров в таблице 902 отличаются незначительно.
Несмотря на то что значения каждого из параметров, рассмотренных выше в отношении фигуры 9, имеют относительно небольшие отличия для используемых в качестве примера 48 символов, всего трех параметров достаточно для разделения всех этих символов на 18 частей или кластеров. Фигура 10 иллюстрирует трехмерный график для символов из множества, представленного в качестве примера на фигуре 6, в трехмерном пространстве, каждое измерение которого представляет значения одного из трех разных параметров. На фигуре 10 первая горизонтальная ось 1002 представляет параметр (916 на фигуре 9), вторая горизонтальная ось 1004 представляет параметр+hs (914 на фигуре 9), а третья вертикальная ось 1006 представляет параметр b (908 на фигуре 9). На график нанесены 18 различных точек (таких как нанесенная точка 1008), каждая из которых представлена в виде небольшого черного диска с вертикальной проекцией на горизонтальную плоскость, проходящую через оси 1002 и 1004; эта проекция представлена в виде вертикальной пунктирной линии, такой как вертикальная пунктирная линия 1010, соединяющая точку 1008 с ее проекцией на горизонтальную плоскость 1012. Код, или номер последовательности, символов, которые соответствуют определенной точке на графике, представлен в скобках справа от соответствующей точки. Например, символы 14, 20 и 37 (1014) соответствуют одной точке 1016 с координатами (1, 0, 0, 32) относительно осей 1002, 1004 и 1006. Каждая точка связана с номером части или кластера, который указан в небольшом прямоугольнике слева от точки. Например, точка 1016 связана с кластером под номером «14» 1018. На фигурах 11А-В показаны символы, содержащиеся в каждом из кластеров, представленных точками трехмерного пространства, изображенного на фигуре 10. Рассмотрев символы, входящие в состав этих кластеров или частей, можно легко заметить, что три параметра, используемые для распределения символов в трехмерном пространстве, представленном на фигуре 10, эффективно разбивают 48 символов, используемых в качестве примера, на связанные множества символов.
Можно использовать дополнительные параметры для однозначного распознавания каждого символа в каждом кластере или части. Рассмотрим, например, кластер 8 (1102), представленный на фигуре 11А. Этот кластер символов включает в себя четыре угловых (L-образных) символа, отличающихся углом поворота и имеющих коды 26, 32, 38 и 44, а также Т-образный символ с кодом 43 и крестообразный символ с кодом 45. Фигура 12А иллюстрирует отдельный параметр, который можно применять в сочетании с тремя параметрами, соответствующими каждому из измерений трехмерного пространства параметров, представленного на фигуре 10, для полного распознавания каждого из символов в кластере 8. Как показано на фигуре 12А, окно символа 1202 делится на четыре квадранта: Q1 1204, Q2 1205, Q3 1206 и Q4 1207. После этого в каждом квадранте вычисляется площадь, занимаемая изображением символа, которая указывается рядом с квадрантом. Например, в квадранте Q1 1204 фрагмент изображения символа занимает 13,5 единиц площади 1210. Затем вычисленные значения единиц площади каждого квадранта присваиваются переменным Q1, Q2, Q3 и Q4. Следовательно, в примере, представленном на фигуре 12А, переменной Q1 присвоено значение 13,5, переменной Q2 присвоено значение 0, переменной Q3 присвоено значение 18, а переменной Q4 присвоено значение 13,5. Затем согласно небольшому фрагменту псевдокода 1212, представленному на фигуре 12А под окном символа, рассчитывается значение нового параметра р. Например, если все четыре переменные Q1, Q2, Q3 и Q4 имеют одинаковые значения, то параметру p будет присвоено значение 0 (1214), что указывает на равенство четырех квадрантов в окне символа относительно количества единиц площади, занимаемой изображением символа. Фигура 12В иллюстрирует значение дополнительного параметра для каждого символа из кластера 8, которое следует рассматривать со ссылкой на фигуру 12А. Как можно увидеть из значений параметров, связанных с символами на фигуре 12В, новый параметр, описанный выше относительно фигуры 12А, имеет разное значение для каждого из шести символов в кластере 8. Другими словами, для однозначной идентификации всех символов в кластере 8 можно использовать комбинацию трех параметров, применяемых для формирования трехмерного графика, представленного на фигуре 10, и дополнительного параметра, рассмотренного выше в отношении фигуры 12А.
Представленные выше способы распознавания символов входят в общий класс способов, называемый способами распознавания символов «на основе элементов» или «на основе параметров». Существуют дополнительные классы способов распознавания символов, многие из которых могут применяться вместе или в качестве альтернативы способам распознавания символов на основе элементов. Дополнительные классы способов распознавания символов включают в себя: (1) способы наложения эталонов, в которых путем масштабирования и вращения изображения символов сравниваются со множеством канонических эталонов для нахождения наиболее подходящих канонических эталонов; (2) способы наложения на основе элементов и/или эталонов, применяемые к внешним контурам изображений символов; (3) способы наложения на основе элементов и/или эталонов, применяемые к структурам, определенным для изображений символов, структурам, представляющим результат непрерывного вычисления типа центра массы, который генерирует представления изображений символов в виде контурных изображений; и (4) дополнительные способы. Описанные выше способы распознавания символов на основе элементов или на основе эталонов представляют собой только подмножество различных типов способов распознавания символов, которые могут применяться при обработке изображений документа системами оптического распознавания символов, описываемых в настоящей заявке.
Фигура 13 иллюстрирует небольшое изображение, содержащее текст, которое было изначально обработано системой OCR для генерации сетки окон символов 1300, в каждом из которых содержится изображение символа. Для большей наглядности на фигуре 13 представлена сетка окон символов 1300, не содержащая изображений символов. Для упорядочивания окон символов используется вертикальный индекс i 1302 и горизонтальный индекс j 1304. Для облегчения понимания примера, рассматриваемого ниже, в нем будет идти речь о символах и изображениях символов, а не о графемах. В этом примере предполагается, что существует однозначное соответствие между символами, графемами и эталонами, используемыми для распознавания изображений символов в окнах символов. Кроме сетки окон символов 1300, на фигуре 13 также представлен массив, или матрица, 1306 эталонов, каждая ячейка которой (например, ячейка 1308) включает в себя эталон. Эталоны представляют собой множество пар «параметр - значение параметра», где параметры выбираются для однозначного распознавания изображений символов, как было описано выше со ссылкой на фигуры 8А-12В. На фигуре 13 также представлен массив параметров 1310, представленный в виде множества пар фигурных скобок, таких как фигурные скобки 1312. Каждая пара фигурных скобок представляет собой функционал, который рассчитывает значение параметра относительно изображения символа.
Фигура 14 иллюстрирует общий подход к обработке сетки окон символов, представленной на фигуре 13. На самом высоком уровне обработка может рассматриваться как вложенный цикл for 1402, в котором вызывается подпрограмма «process» 1404, исследующая каждое окно символа 1406 для генерации соответствующего кода символа 1408. Другими словами, в примере с псевдокодом сетка окон символов представляет собой двухмерный массив «page_of_text», а система OCR формирует двухмерный массив кодов символов «processed_text» на основе двухмерного массива окон символов «page_of_text». На фигуре 14 дугообразные стрелки, такие как дугообразная стрелка 1410, используются для демонстрации порядка обработки первой строки двухмерного массива, или сетки, окон символов 1300, а горизонтальные стрелки, такие как стрелка 1412, показывают обработку следующих строк, осуществляемую в цикле for 1402. Другими словами, сетка окон символов 1300 обрабатывается согласно указанному выше порядку обработки, при этом каждое окно символа в сетке обрабатывается отдельно для генерации соответствующего кода символа.
Фигура 15 иллюстрирует первый подход к реализации подпрограммы «process» (1404 на фигуре 14). Изображение символа, находящееся в окне символа 1502, используется в качестве входного параметра для подпрограммы «process». Подпрограмма «process» используется для расчета значений восьми разных параметров р1-р8, используемых в данном примере для получения отличительных признаков изображений символов путем восьмикратного вызова подпрограммы «parameterize» 1504, как показано на фигуре 15. Подпрограмма «parameterize» получает в качестве аргументов изображение символа и целое число, указывающее, для какого параметра необходимо рассчитать значение, и возвращает рассчитанное значение. Значения параметров хранятся в массиве значений параметров «p_values». Затем, как показано дугообразными стрелками, такими как дугообразная стрелка 1506, подпрограмма «process» перебирает все эталоны 1508, соответствующие символам языка, сравнивая рассчитанные значения параметров для изображения символа, хранящиеся в массиве «p_values», с предварительно рассчитанными значениями параметров каждого эталона, как показано на иллюстрации операции сравнения 1510 на фигуре 15. Эталон, параметры которого больше всего соответствуют рассчитанным параметрам для изображения символа, выбирается в качестве эталона соответствия, а код символа, который соответствует этому эталону, используется в качестве возвращаемого значения подпрограммы «process». В качестве примера псевдокода, используемого для этого первого способа реализации подпрограммы «process», представлен псевдокод 1512 на фигуре 15. В первом цикле for 1514 рассчитываются значения параметров для входного символа s. Затем в нескольких вложенных циклах for внешнего цикла for 1516 анализируется каждый эталон из массива, или вектора, эталонов 1508 согласно порядку, указанному дугообразными стрелками, такими как дугообразная стрелка 1506. Во внутреннем цикле for 1518 вызывается подпрограмма «compare» для сравнения каждого рассчитанного значения параметра изображения символа с соответствующим предварительно рассчитанным значением параметра эталона, а общий результат сравнения записывается в локальную переменную t. Максимальное значение, накопленное в результате сравнения, хранится в локальной переменной score, а индекс эталона, который наиболее точно соответствует изображению символа, хранится в переменной p 1520. Код символа, связанный с эталоном p, возвращается подпрограммой «process» 1520 в качестве результата.
Наконец, на фигуре 15 представлена грубая оценка вычислительной сложности первого способа реализации подпрограммы «process» 1522. Количество окон символов для содержащего текст изображения равно N=i×j. В текущем примере N=357. Конечно, количество изображений символов, которые необходимо обработать, зависит от типа документа и количества изображений в нем, а также от языка и других параметров. Однако обычно количество изображений символов N может изменяться от нескольких десятков до нескольких сотен для каждого изображения документа. Количество эталонов, с которыми сравниваются изображения символов, представлено параметром Р. Для многих алфавитных языков, включая большинство европейских языков, количество эталонов может быть относительно небольшим, что соответствует относительно небольшому множеству символов алфавита. Однако для таких языков, как китайский, японский и корейский, количество эталонов может изменяться от десятков тысяч до сотен тысяч. Поэтому при обработке таких языков значение параметра P значительно превышает значение параметра N. Количество параметров, используемых для получения отличительных признаков каждого изображения символа и эталона, представлено параметром R. Следовательно, общая вычислительная сложность оценивается как NPR. Коэффициент N берется из внешних вложенных циклов for, представленных на фигуре 14. Коэффициенты PR берутся из вложенных циклов for 1516 и 1518 способа реализации подпрограммы «process» 1512, представленного на фигуре 15. Другими словами, подпрограмма «process» вызывается один раз для каждого из N изображений символов, при этом каждый вызов или обращение к подпрограмме «process» приводит к R сравнениям с каждым из Р эталонов. При таком способе анализа изначально вычисленное значение параметра считается постоянной величиной. Вариант осуществления алгоритма, представленного на фигуре 15, можно улучшить различными способами. Например, можно сравнивать только определенное подмножество параметров из общего количества параметров, необходимое для однозначного сопоставления изображения символа с конкретным эталоном. Таким образом, может потребоваться произвести среднее количество сравнений параметров 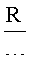 , а не R сравнений. Кроме того, вместо сравнения каждого изображения символа со всеми эталонами можно задать относительно высокий порог значения соответствия, при превышении которого последовательный перебор эталонов будет прекращаться. В этом случае количество эталонов, которые сравниваются с каждым изображением символа, будет равно
, а не R сравнений. Кроме того, вместо сравнения каждого изображения символа со всеми эталонами можно задать относительно высокий порог значения соответствия, при превышении которого последовательный перебор эталонов будет прекращаться. В этом случае количество эталонов, которые сравниваются с каждым изображением символа, будет равно 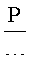 , а не P. Но даже при подобных улучшениях вычислительная сложность будет близка к значению наибольшего из параметров NPR.
, а не P. Но даже при подобных улучшениях вычислительная сложность будет близка к значению наибольшего из параметров NPR.
Фигуры 16А-В иллюстрируют второй способ реализации подпрограммы «process» (1404 на фигуре 14). Во втором способе реализации изображение символа 1602 также используется в качестве входного параметра подпрограммы «process». Однако в данном способе реализации алгоритма эталоны группируются в кластеры, такие как кластеры, рассмотренные ранее на примере фигур 11А-В. Подпрограмма «process» вычисляет определенное количество значений параметров 1604, достаточное для обнаружения наиболее подходящего кластера при переборе кластеров эталонов 1606. Таким образом, для выбора наиболее подходящего кластера эталонов сначала используется относительно простая операция сравнения 1608. Затем эталоны 1610 из выбранного кластера эталонов 1611 перебираются с помощью второй довольно простой операции сравнения 1612, для которой используется некоторое дополнительное количество значений параметров 1614, необходимое для определения наиболее подходящего эталона среди относительно малого количества эталонов 1610, содержащихся в кластере эталонов. Псевдокод для второго способа реализации подпрограммы «process» представлен на фигуре 16В. В первом вложенном цикле for 1620 выбирается наиболее подходящий или лучший среди имеющихся кластер эталонов, а во втором вложенном цикле for 1622 определяется наиболее подходящий эталон среди представленных в выбранном кластере. Начальное множество параметров, используемых для определения наилучшего кластера, рассчитывается в цикле for 1624, а дополнительные параметры, необходимые для выбора эталона из числа эталонов выбранного кластера, рассчитываются в цикле for 1626. На фигуре 16В также представлена приблизительная оценка вычислительной сложности второго способа реализации подпрограммы «process» 1630. Как указано, оценочная вычислительная сложность для второго способа реализации подпрограммы «process» составляет:
N(CR1+P′R2),
где количество символов на странице = N;
количество кластеров = С;
количество эталонов/кластер = Р′;
количество исходных параметров = R;
количество дополнительных параметров = R2.
Поскольку значение Р′ по существу намного меньше значения Р, а значение С еще меньше, то вычислительная сложность второго способа реализации подпрограммы «process» вполне приемлема по сравнению с вычислительной сложностью первого способа реализации подпрограммы «process».
Другим подходом к улучшению первого способа реализации подпрограммы «process», рассмотренного выше со ссылкой на фигуру 15, является сортировка эталонов в векторе, или массиве, эталонов, чтобы наиболее вероятные эталоны, соответствующие наиболее часто встречающимся символам, рассматривались в самом начале перебора вектора, или массива, эталонов. Когда поиск подходящего эталона прерывается вследствие нахождения эталона, результат сравнения которого превышает некоторое пороговое значение, и когда эталоны отсортированы по частоте употребления, соответствующей вероятности появления символов в обрабатываемом изображении, содержащем текст, вычислительная сложность значительно снижается. Однако частота появления символов в конкретных изображениях, содержащих текст, может сильно варьироваться в зависимости от типа документа или страницы, которые были отсканированы для генерации изображения, и неизвестна до обработки системой OCR. Сортировка эталонов, приводящая к значительному снижению вычислительной сложности для одного типа документа, может значительно повысить вычислительную сложность для другого типа документа. Например, общий статистический анализ различных типов текстовых документов на определенном языке, включая романы, рекламные объявления, учебники и другие подобные документы, может позволить получить общий вариант сортировки эталонов по частоте появления символов. Однако в некоторых документах и текстах, относящихся к профильным сферам деятельности, частота появления символов может совершенно отличаться. В этом случае для документов, относящихся к определенным сферам деятельности, наиболее часто встречающиеся символы могут оказаться расположены ближе к концу обрабатываемого вектора, или матрицы, эталонов, отсортированных в соответствии с общей частотой появления символов. Второй способ реализации подпрограммы «process», рассмотренный выше со ссылкой на фигуры 16А-В, по существу приводит к значительному уменьшению вычислительной сложности и соответствующему увеличению скорости обработки. Как правило, требуется произвести значительно меньше сравнений, для того чтобы найти соответствующий эталон для каждого изображения символа. Однако второй способ реализации связан с потенциально серьезной проблемой, которая состоит в том, что при неудачном выполнении первого вложенного цикла for, в котором осуществляется выбор кластера, подпрограмма «process» не сможет найти правильный соответствующий символ. В этом случае правильный соответствующий символ будет находиться в другом кластере, который не будет анализироваться во втором вложенном цикле for. Хотя примеры множества символов и кластеров, представленные выше, являются относительно простыми, как и параметры, используемые для определения их отличительных особенностей, для таких языков, как китайский и японский, подобная задача является более сложной и подверженной ошибкам из-за несовершенства печати, повреждения документа, а также из-за различных типов ошибок, которые могут возникнуть при сканировании и на начальных стадиях процесса OCR. Таким образом, вероятность неправильного выбора кластера в реальных условиях очень высока.
Фигура 17 иллюстрирует третий способ реализации подпрограммы «process», рассмотренной в предыдущем подразделе, с использованием тех же иллюстраций и условных обозначений в псевдокоде, которые применялись в предыдущем подразделе. Как показано на фигуре 17, третий способ реализации подпрограммы «process» применяет дополнительную структуру данных 1702, обозначаемую как «votes» («голоса»). Структура данных votes включает в себя целочисленное значение для каждого эталона. При начальной инициализации эта структура содержит нулевые значения для всех эталонов. После этого на первой стадии предварительной обработки, представленной двойным вложенным циклом for 1704 на фигуре 17, для каждого изображения символа в текстовом документе 1300 назначается новое множество кластеров, а эталоны в кластерах упорядочиваются согласно голосам, собранным в структуре данных «votes». Другими словами, эталоны упорядочиваются в заново выделенном множестве, или списке, кластеров, благодаря чему эталоны, с наибольшей вероятностью соответствующие изображению текущего символа, встречаются в начале перебора эталонов. Значения множества сравниваемых параметров, рассчитанные для текущего изображения символа, сравниваются со значениями параметров каждого эталона, при этом голоса отдаются тем эталонам, которые (по результатам сравнения) имеют сходство с изображением символа, превышающее установленный порог. В некоторых вариантах осуществления кластеры также могут быть отсортированы в пределах множества кластеров по общему сходству их эталонов с изображением символа.
После стадии предварительной обработки, осуществляемой вложенными циклами for 1704, каждое изображение символа обрабатывается третьим способом реализации подпрограммы «process». Псевдокод для третьего способа реализации подпрограммы «process» 1710 представлен на фигуре 17. В данном способе реализации подпрограмма «process» получает в качестве входных параметров изображение символа и множество кластеров, подготовленное для изображения символа на стадии предварительной обработки и хранящееся в массиве NxtLvlClusters, а возвращает указатель на список потенциально соответствующих эталонов. В первом цикле for 1712 рассчитываются значения параметров, которые используются для распознавания эталонов, соответствующих полученному изображению символа. Во втором внешнем цикле for 1714 рассматриваются все кластеры, пока не заполнится список потенциально соответствующих эталонов. Другими словами, когда находится максимальное количество потенциально соответствующих эталонов, этот внешний цикл for прерывается. Во внутреннем цикле for 1716 для каждого эталона в кластере вызывается функция «similar», осуществляющая определение того, является ли эталон достаточно похожим на изображение символа, чтобы его можно было добавить в список потенциально соответствующих эталонов. Когда список потенциально соответствующих эталонов заполнен, внутренний цикл for также прерывается. На фигуре 17 представлена оценка вычислительной сложности третьего способа реализации подпрограммы «process» 1720. Поскольку как внешний, так и внутренний циклы for 1714 и 1716 прерываются, когда найдено достаточное количество потенциально соответствующих эталонов, а векторы, или списки, эталонов в каждом кластере отсортированы по частоте появления в обрабатываемом документе, то в третьем способе реализации подпрограммы «process» требуется выполнить лишь относительно небольшое количество сравнений по сравнению со вторым способом реализации подпрограммы, что и показано дробью 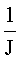 1722. Существует, конечно, штраф за начальную предварительную обработку, представленный коэффициентом «е» 1744. Однако, как указывалось выше, количество обрабатываемых изображений символов N по существу значительно меньше значения параметров P или Р′ для таких языков, как китайский, японский и корейский, и, следовательно, третий способ реализации подпрограммы «process» обеспечивает значительное снижение вычислительной сложности по сравнению как с первым, так и со вторым способами реализации, рассмотренными выше. Что более важно, третий способ реализации подпрограммы «process» гарантирует просмотр всех кластеров, пока не будет обнаружено некоторое максимальное количество потенциально соответствующих символов. Когда порог сходства для кластеров имеет относительно низкое значение, а порог сходства для эталонов имеет относительно высокое значение, существует очень большая вероятность, что список потенциально соответствующих символов, возвращаемый подпрограммой «process», будет включать в себя именно тот символ, который наиболее точно соответствует входному изображению символа.
1722. Существует, конечно, штраф за начальную предварительную обработку, представленный коэффициентом «е» 1744. Однако, как указывалось выше, количество обрабатываемых изображений символов N по существу значительно меньше значения параметров P или Р′ для таких языков, как китайский, японский и корейский, и, следовательно, третий способ реализации подпрограммы «process» обеспечивает значительное снижение вычислительной сложности по сравнению как с первым, так и со вторым способами реализации, рассмотренными выше. Что более важно, третий способ реализации подпрограммы «process» гарантирует просмотр всех кластеров, пока не будет обнаружено некоторое максимальное количество потенциально соответствующих символов. Когда порог сходства для кластеров имеет относительно низкое значение, а порог сходства для эталонов имеет относительно высокое значение, существует очень большая вероятность, что список потенциально соответствующих символов, возвращаемый подпрограммой «process», будет включать в себя именно тот символ, который наиболее точно соответствует входному изображению символа.
Рассмотренная выше информация, включая третий вариант осуществления, представленный на фигуре 17, создает основу для описания определенного объекта этого обобщенного третьего варианта осуществления, к которому относится настоящий документ. Следует четко понимать, что описанные выше варианты осуществления представляют собой обобщенные варианты осуществления и что конкретный вариант осуществления системы OCR может применять любой из большого количества возможных альтернативных вариантов осуществления.
Логику управления и структуры данных в системе OCR можно использовать как для кластеризации эталонов, так и на стадии предварительной обработки, рассмотренной выше, в ходе которой графемы в эталонах могут быть отсортированы по частоте появления в отсканированном изображении, содержащем текст, или во множестве отсканированных изображений. Эти логика управления и структуры данных применяются в системе OCR для реализации стадий предварительной обработки/кластеризации, в ходе которых фиксированное множество параметров связывается с каждым кластером и применяется при сравнении изображения символа с эталонами, содержащимися в кластере. Кластеры можно применять в различных локальных операциях или на разных стадиях сложной задачи оптического распознавания символов, при этом конкретные параметры (а также количество этих параметров), используемые для сравнения изображения символа с эталонами, содержащимися в кластере, могут отличаться в различных локальных операциях и на разных стадиях, а также часто могут быть различными в разных кластерах. Фигура 18 иллюстрирует структуры данных, обеспечивающие кластеризацию и предварительную обработку в одном варианте осуществления системы OCR, включающей в себя третий способ реализации подпрограммы «process», описанный выше. Первой структурой данных является массив, или вектор, 1802, обозначенный как «votes» («голоса»). В представленном варианте осуществления массив «votes» содержит один элемент для каждой графемы языка. Массив «votes» индексируется целыми значениями кодов графем. Другими словами, каждой графеме присваивается уникальный целочисленный идентификатор, или код, графемы, который используется в качестве индекса массива «votes». Как показано на фигуре 18, массив «votes» может содержать n элементов, где n представляет собой количество графем в языке, а коды графем монотонно возрастают от 0 до n. Конечно, структура данных «votes» может быть альтернативно реализована в виде разреженного массива, когда коды графем возрастают немонотонно, в виде списка, или с использованием других типов структур данных.
На фигуре 18 представлена вторая структура данных 1804, которая представляет собой массив экземпляров класса «parameter» («параметр»). Как и в случае со структурой данных «votes», массив «parameters» может быть реализован альтернативными способами с применением разных структур данных, включая списки, разреженные массивы и другие структуры данных. В текущем представленном варианте осуществления массив «parameters» включает в себя p записей или элементов, которые проиндексированы с помощью монотонно увеличивающихся чисел 0, 1, 2, …, р. Каждый экземпляр класса «parameter» представляет один из различных параметров, используемых для определения отличительных признаков изображений символов и эталонов, как описывалось выше.
На фигуре 18 также представлена структура данных кластера 1806, которая представляет собой кластер, или множество, эталонов. Структура данных кластера включает в себя массив «clusterParameters» 1808, в котором содержатся параметры, применяемые для определения отличительных признаков эталонов в кластере в определенный момент времени, а также для определения отличительных признаков изображений символов для их сравнения с эталонами, содержащимися в кластере. Каждый элемент в массиве «clusterParameters» содержит индекс для массива «parameters» 1804. Используя индексы в массиве «parameters» 1804, можно легко изменить или переконфигурировать конкретные параметры, а также количество параметров, используемых для сравнения, вследствие чего конфигурация кластера может быть эффективно изменена для различных локальных операций или стадий. Структура данных кластера также включает в себя целочисленный параметр num 1810, который указывает на количество индексов параметров, содержащихся в массиве «clusterParameters». Структура данных кластера дополнительно содержит параметр «cutoff» («отсечка») 1812, имеющий формат с плавающей запятой (или формат двойной точности) и содержащий пороговое весовое значение для оценки эталонов, находящихся в кластере, на предмет их соответствия изображению символа. Наконец, структура данных кластера 1806 включает в себя ряд структур данных эталона 1814-1822. Структуры данных эталона рассматриваются ниже.
Фигуры 19А-Е иллюстрируют предварительную обработку изображения символа с использованием структур данных, рассмотренных выше со ссылкой на фигуру 18. На фигуре 19А представлена структура данных «votes» 1802, рассмотренная выше со ссылкой на фигуру 18, а также структура данных одного эталона 1902, выбранная из эталонов, содержащихся в структуре данных кластера 1806, также рассмотренной выше со ссылкой на фигуру 18. Каждая структура данных эталона содержит номер эталона 1904 и множество значений параметров 1905, рассчитанных для эталона с помощью параметров, ссылки на которые получены из индексов, содержащихся в массиве «clusterParameters» 1808, который находится в структуре данных кластера 1806. Как отмечалось выше, важно помнить, что изображения символов масштабируются, поворачиваются и преобразуются для формирования нормированных изображений, чтобы облегчить процедуру сравнения изображений символов и эталонов на основе параметров. Структура данных эталонов дополнительно включает в себя целочисленный параметр 1906, указывающий на количество индексов в структуре данных эталона, а также значения самих индексов 1908. Эти индексы связаны с различными возможными весовыми значениями, которые могут быть рассчитаны при сравнении изображения символа с эталоном. В одном варианте осуществления в структуре данных эталона может быть столько индексов, сколько имеется возможных рассчитанных весовых значений, при этом каждый индекс включает в себя целочисленный индекс и рассчитанное весовое значение, связанное с этим индексом. Возможны и другие варианты осуществления. Весовое значение формируется, когда рассчитываются параметры для изображения символа и значения параметров изображения символа сравниваются с эталоном, представленным структурой данных эталона. Чем больше весовое значение, тем меньше изображение символа похоже на эталон. Это весовое значение применяется для выбора из указателей соответствующего индекса, который используется для выбора количества графем, соответствующих эталону, за которые необходимо проголосовать на стадии предварительной обработки. Каждая структура данных эталона включает в себя целочисленное значение, указывающее количество графем, соответствующих эталону 1910, а также коды всех графем множества, соответствующих эталону 1912. Во многих вариантах осуществления эти коды графем сортируются по сходству или близости к эталону в порядке убывания сходства.
Фигуры 19А-Е иллюстрируют предварительную обработку изображения одного символа, выбранного из отсканированного изображения, содержащего текст. В примере, представленном на фигурах 19А-Е, изображение символа 1914 представляет иероглиф одного из азиатских языков. На фигуре 19А также представлены массив «parameters» 1804, рассмотренный выше со ссылкой на фигуру 18, и небольшой фрагмент структуры данных кластера 1806, включающей в себя массив «clusterParameters» 1808 и целочисленный параметр num 1810.
Как показано на фигуре 19В, для всех параметров num, индексы которых включены в массив «clusterParameters» 1808, индекс параметра 1916 извлекается из массива «clusterParameters» 1808 и применяется для доступа к экземпляру класса «parameter» 1918 в массиве «parameters» 1804. Для расчета значения параметра 1920, которое затем хранится в локальной переменной 1922, вызывается функция-член «parameterize» экземпляра класса «parameter» 1918. Фигура 19В иллюстрирует расчет значения первого параметра для изображения символа. Когда все экземпляры num класса «parameter» задействованы для расчета значений параметров num для изображения символа, формируется список, или массив, значений параметров изображения символа 1924, как показано на фигуре 19С.
Затем, как показано на фигуре 19С, из предварительно рассчитанного значения параметра для эталона, представленного структурой данных эталона, вычитается соответствующий параметр для изображения символа с целью генерации ряда рассчитанных значений, по одному для каждого параметра. Например, как показано на фигуре 19F, для генерации промежуточного значения 1928 из первого значения параметра 1926, хранящегося в структуре данных эталона 1902, вычитается первое значение параметра 1922, рассчитанное для изображения символа. Аналогичным образом из остальных предварительно заданных значений параметров для эталона 1930-1933 вычитаются остальные значения параметров для изображения символа 1934-1938 для генерации дополнительных промежуточных расчетных значений 1940-1944. Абсолютные величины этих промежуточных значений 1928 и 1940-1944 суммируются 1946 для получения весового значения 1948, которое численно представляет собой основанное на параметрах сравнение изображения символа и эталона, представленного структурой данных эталона 1902. И в этом случае, чем больше рассчитанное весовое значение, тем меньше изображение символа похоже на эталон, поскольку весовое значение представляет собой накопленное различие между значениями параметров для изображения символа и эталона.
Как показано на фигуре 19D, когда рассчитанное весовое значение 1948 превышает вес отсечки «cutoff» 1812 для кластера, предварительная обработка изображения символа в отношении рассматриваемого эталона, представленного структурой данных эталона 1902, прекращается 1950. В противном случае на стадии предварительной обработки изображения символа происходит голосование за одну или более графем, соответствующих эталону, представленному структурой данных эталона 1952.
Фигура 19Е иллюстрирует случай, когда рассчитанное весовое значение, представляющее сравнение изображения символа с эталоном, представленным структурой данных эталона, меньше или равно весу отсечки для данного кластера. В этом случае для выбора индекса 1954 из множества индексов 1908 используется рассчитанное весовое значение 1948. Как описывалось выше, каждый из индексов 1908 может содержать индекс и связанное с ним весовое значение, что позволяет выбрать один конкретный индекс 1954 согласно рассчитанному весовому значению 1948 из индекса, который является индексом извлекаемых кодов графем. Этот извлеченный индекс указывает 1956 на конкретный код графемы 1958 во множестве кодов графем 1912, хранящемся в структуре данных эталонов для представления тех графем, которые соответствуют эталону. Затем для всех кодов графем, начиная с первого кода графемы 1960 и до кода графемы 1958, на который указывает извлеченный индекс 1956, увеличивается соответствующий элемент из структуры данных «votes» 1802, как показано стрелками (такими как стрелка 1962), исходящими из элементов, содержащих коды графем между элементами 1960 и 1958 включительно.
Таким образом, если рассчитанное весовое значение, используемое для сравнения изображения символа с эталоном, меньше веса отсечки, значит изображение символа достаточно похоже на эталон, чтобы по меньшей мере за некоторые из графем, соответствующих эталону, были отданы голоса на стадии предварительной обработки. Графемы, достаточно похожие на изображение символа, выбираются на основе рассчитанного весового значения с использованием индекса, выбранного из индексов 1908 в соответствии с рассчитанным весовым значением. Затем элементы структуры данных «votes», соответствующие этим графемам, увеличиваются для отражения количества голосов, отданных этим графемам во время предварительной обработки изображения символа.
Далее представлен псевдокод на языке, подобном C++, для иллюстрации обработки изображения символа относительно эталонов в кластере, как показано на фигурах 19А-Е. Используется относительно простой псевдокод на языке, подобном C++, который включает в себя массивы фиксированного размера и простые структуры управления. Конечно, в реальных системах OCR могут использоваться более эффективные, но и более сложные варианты осуществления, включающие итераторы, структуры данных, реализующие ассоциативную память, а также другие подобные структуры данных и связанные с ними способы.
Сначала определяется ряд структур данных и объявляются классы:
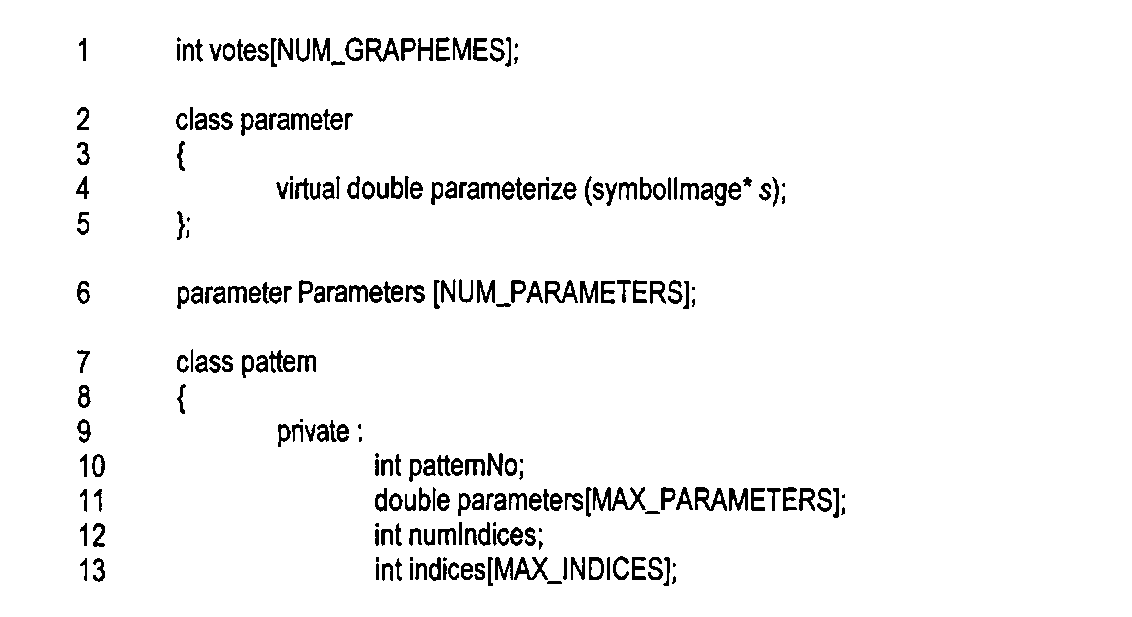

В строке 1 осуществляется объявление структуры данных «votes» 1802. Частичное объявление класса «parameter» представлено в строках 2-5. В данном примере единственно важным аспектом класса «parameter» является то, что базовый класс включает в себя виртуальную функцию-член «parameterize», которая в качестве входных данных получает изображение символа, а возвращает значение параметра с плавающей запятой. Конечно, в некоторых случаях конкретный параметр может иметь только целые значения, а не значения с плавающей запятой. Структура данных «parameters» 1804 объявляется в строке 6. Частичное объявление класса «pattern» происходит в строках 7-21. Класс «pattern» включает в себя следующие закрытые поля: «patternNo» (1904 на фигуре 19А), объявленный в строке 10, массив значений параметра «parameters» (1906 на фигуре 19А), объявленный в строке 11, количество индексов «numlndices» (1906 на фигуре 19А), объявленное в строке 12, множество индексов (1908 на фигуре 19А) элементов множества «numlndices», объявленное в строке 13, целочисленное значение «numGraphemes» (1910 на фигуре 19А), а также множество кодов графем «graphemes» (1912 на фигуре 19А) элементов множества «numGraphemes». Класс «pattern» включает функцию-член «getParameter», объявленную в строке 17, которая возвращает значение параметра из множества значений «parameters», функцию-член «getlndex», объявленную в строке 18, которая возвращает индекс, соответствующий рассчитанному весовому значению, а также функцию-член «getGrapheme», объявленную в строке 19, которая возвращает код графемы из множества кодов «graphemes», объявленного в строке 15. Наконец, в строках 22-37 объявляется класс «cluster», который представляет структуру данных кластера 1806 на фигуре 18. Класс «cluster» включает в себя следующие закрытые поля: num (1810 на фигуре 18), объявленное в строке 25, «clusterParameters» (1808 на фигуре 18), объявленное в строке 26, «cutoff» (1812 на фигуре 18), объявленное в строке 27, целочисленное значение «numPatterns», указывающее на количество эталонов в кластере, объявленное в строке 28, а также указатель на эталоны в кластере «patterns», объявленный в строке 29. Класс «cluster» включает функции-члены «getCutoff» и «getNum», используемые для получения веса отсечки и количества эталонов, объявленные в строках 31 и 32, функцию-член «getParameter», используемую для выбора индексов параметров из массива «clusterParameters», объявленную в строке 32, функцию-член «getPattern», объявленную в строке 33, которая возвращает определенный эталон, хранящийся в кластере, и функцию-член «getNumPatterns», объявленную в строке 34, которая возвращает количество эталонов, хранящееся в структуре данных кластера.
На примере следующего псевдокода подпрограммы «vote» показана реализация способа предварительной обработки для одного изображения символа и одного кластера:

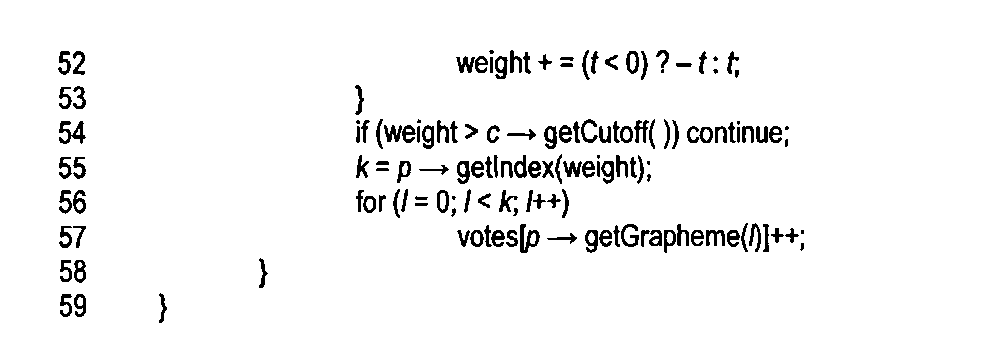
Подпрограмма «vote» получает в качестве аргументов указатель на изображение символа и указатель на кластер. Локальные переменные включают в себя массив «params», объявленный в строке 38, в котором хранятся рассчитанные значения параметров для изображения символа, итерационные целочисленные значения i, j, k и l, объявленные в строке 39, переменные с плавающей запятой «weight» и «t» используемые для хранения рассчитанного весового значения, полученного в результате сравнения входного изображения символа и эталона из кластера, а также указатель p, объявленный в строке 41 и указывающий на эталон во входном кластере. В цикле for, в строках 43-44, значения всех параметров, используемых кластером, рассчитываются для входного изображения символа и сохраняются в массив «params» (1924 на фигуре 19С). Затем во внешнем цикле for, содержащем вложенные циклы for, представленные в строках 45-58, рассматривается каждый параметр входного кластера. В строке 46 получается указатель на рассматриваемый эталон путем вызова функции-члена кластера «getPattern». В строке 48 локальной переменной «weight» присваивается значение 0. Затем в цикле for, в строках 49-53, рассчитывается весовое значение, которое представляет сравнение входного изображения символа с эталоном, как описывалось выше со ссылкой на фигуру 19F. Когда весовое значение превышает вес отсечки для кластера, как определено в строке 54, текущая итерация, выполняемая во внешнем цикле for, в строках 44-58, прерывается, поскольку входное изображение символа недостаточно похоже на рассматриваемый эталон, чтобы можно было за него проголосовать. В противном случае локальная переменная к получает значение последнего индекса кода графемы для голосования в строке 55. Затем в цикле for, в строках 56-57, выполняется голосование за все графемы до графемы с индексом k.
Существует множество различных альтернативных подходов к осуществлению предварительной обработки и формированию представленных выше структур данных. Например, вместо использования веса отсечки для всего кластера можно использовать вес отсечки для конкретных эталонов, при этом вес отсечки может включаться в структуру данных эталона. В другом примере индексы, хранящиеся в эталоне, могут представлять собой экземпляры классов, которые содержат списки кодов графем, а не индексы, указывающие на упорядоченный список кодов графем, как это реализуется в последнем варианте осуществления. Также возможны и многие другие альтернативные варианты осуществления. Например, подпрограмма «vote» может получать в качестве второго аргумента указатель на массив «params», а в цикле for, в строках 43-44, могут вычисляться значения параметров только в том случае, если они еще не были рассчитаны при обработке изображения символа для других кластеров. В других вариантах осуществления можно применять разные типы расчета весового значения и сравнения изображения символа с эталоном. В некоторых случаях большее весовое значение может указывать на большее сходство изображения символа с эталоном в отличие от приведенного выше примера, когда увеличение весового значения означало уменьшение сходства изображения символа с эталоном. В ряде систем OCR с графемами могут связываться вещественные коэффициенты, позволяющие при голосовании использовать дробные значения и значения больше 1. В некоторых системах OCR графемы, эталоны и/или кластеры могут быть отсортированы на основании голосов, накопленных в течение предварительной обработки, для более эффективного последующего распознавания символов. В определенных вариантах осуществления структура данных кластера может включать в себя только ряд структур данных эталона или ссылок на структуры данных эталона, при этом вес отсечки и эталоны, связанные с кластером, указываются в алгоритме управления, а не хранятся в структуре данных кластера.
Фигура 20А иллюстрирует данные и структуры данных, использованные в одном примере мультикластерной OCR-обработки документа. Условные обозначения на иллюстрациях, использованные на фигуре 20А, также используются на последующих фигурах 20B-G. На фигуре 20А снова представлены многие структуры данных, показанные на фигурах 18 и 19A-G. Они включают в себя массив параметров 2002 (представлен как массив 1804 на фигуре 18), массив голосов 2004 (представлен как массив голосов 1802 на фигуре 18), три структуры данных кластера 2006-2008, каждая из которых совпадает со структурой данных кластера 1806 на фигуре 18, и массив рассчитанных значений параметров 2010, аналогичный массиву рассчитанных значений параметров 1924, представленному на фигуре 19F. Следует заметить, что структурам данных при инициализации присваиваются соответствующие значения, в то время как всему массиву голосов присваиваются нулевые значения. Каждая структура данных кластера, такая как структура данных кластера 2006, включает в себя массив параметров 2012, похожий на массив clusterParameters 1808, представленный на фигуре 18, величину num 2014 и величину cutoff 2016, аналогичные соответственно величинам num и cutoff 1810 и 1812, представленным в кластере 1806 на фигуре 18, а также несколько структур данных эталона, таких как структура данных эталона 2018, идентичных структуре данных эталона 1902 на фигуре 19А. Кроме того, на фигуре 20А в виде двухмерного массива представлена структура данных 2020, представляющая отсканированное изображение страницы документа, которая включает в себя похожий на сетку массив, каждая ячейка которого, например ячейка 2022, представляет изображение символа. Также на фигуре 20А представлена переменная 2024, содержащая обрабатываемое в настоящий момент изображение символа.
Структуры данных, представленные на фигуре 20А, могут быть реализованы различными способами с помощью различных языков программирования и методов хранения данных. Структуры данных могут включать в себя дополнительные данные и подструктуры данных. В одном из вариантов осуществления, например, каждая структура данных эталона в каждом кластере представляет собой ссылки из отсортированного массива ссылок структуры данных кластера. В других вариантах осуществления каждая структура данных эталона в каждом кластере связывается с цифровой последовательностью, что позволяет проходить по структурам данных эталона в определенном порядке. В некоторых вариантах осуществления структура данных кластера может включать в себя структуры данных эталона, в то время как в других вариантах осуществления структура данных кластера может ссылаться на структуры данных эталона. В большинстве вариантов осуществления структуры данных могут быть динамически расширены или сжаты, чтобы соответствовать изменениям типов OCR-обработки, в которых они используются. Таким образом, несмотря на то что для описания структуры данных голосов применяется термин «массив», данная структура может быть реализована с использованием структур данных, отличных от простых массивов, но позволяющих при этом индексировать элементы, как в массивах.
Структура данных текста 2020 представляет страницу документа, которую необходимо обработать способом мультикластерной OCR-обработки документа для преобразования исходного отсканированного документа, содержащего изображения символов, в эквивалентный электронный документ, содержащий коды символов. Термины «документ», «страница» и «изображение символа» могут иметь различные значения в зависимости от контекста. В данном примере документ состоит из нескольких страниц, и каждая страница включает в себя несколько изображений символов. Конечно, тот же самый или похожий способ мультикластерной OCR-обработки документов может применяться для множества различных типов документов вне зависимости от того, включают ли они страницы с одним или более изображениями символов или нет.
На первом этапе, представленном на фигуре 20В, переменная текущего изображения символа 2024 считывает или ссылается на исходное изображение символа 2026, как показано дугообразной стрелкой 2027. Затем, как показано на фигуре 20С, каждая вычисляющая параметры функция или подпрограмма из массива параметров 2002 применяется к текущему изображению символа из переменной 2024 для формирования соответствующих значений параметров, сохраняемых в массиве рассчитанных значений параметров 2010, как показывают стрелки 2028-2031 и эллипсы 2032-2033. Таким образом, в одном варианте осуществления массив рассчитанных значений параметров 2010 включает в себя числовые значения параметров, соответствующие каждому из параметров, представленных функциями массива параметров 2002 или ссылками на эти функции, которые рассчитаны для текущего изображения символа. Вычисление значений параметров ранее описывалось со ссылкой на фигуры 19C-D.
Затем, как показано на фигуре 20D, в первой структуре данных кластера 2006 выбирается первая структура данных эталона 2034; значения параметров, связанных с первой структурой данных эталона, вместе с соответствующими значениями параметров из массива рассчитанных значений 2010 используются для расчета весового значения W 2035, как было описано ранее со ссылкой на фигуру 19F. Следует заметить, что массив параметров структуры данных кластера (2012 на фигуре 20А) применяется для индексации массива рассчитанных значений параметров. Как было описано ранее со ссылкой на фигуру 19G, затем вычисленное весовое значение сравнивается с весом отсечки (2016 на фигуре 20А) 2036, чтобы определить, может ли структура данных эталона 2034 из первой структуры данных кластера 2006 отдать голос графемам, как было описано выше со ссылкой на фигуру 19Н. В настоящем примере, как показано на фигуре 20Е, рассчитанное весовое значение 2035 меньше веса отсечки, в результате чего происходит накопление голосов, формируемых первой структурой данных эталона 2034 из первой структуры данных кластера 2006, в массиве голосов 2024. Как было описано ранее со ссылкой на фигуру 19Н, рассчитанное весовое значение 2035 применяется в качестве указателя на множество индексов 2038 в первой структуре данных эталона 2034, а содержимое выбранного элемента является указателем 2039 на некоторый фрагмент кодов графем в первой структуре данных эталона 2040. Голоса формируются для всех графем, соответствующих кодам графем из фрагмента кодов графем первой структуры данных эталона, начиная с первого кода и заканчивая кодом графемы, на которую указывает индекс, выбранный из фрагмента индексов структуры данных эталона. На фигуре 20Е голоса, формируемые первой структурой данных эталона 2034 из первой структуры данных кластера 2006, представлены дугообразными стрелками 2042-2046. Пустые значения в массиве голосов (2004 на фигуре 20А) представляют нулевые значения (0). Начальное голосование для первой структуры данных эталона 2034 из первой структуры данных кластера 2006 увеличивает значения накопленных голосов 2047-2051 в массиве голосов с 0 до 1 для тех графем, для которых выбираются соответствующие коды из первой структуры данных эталона. В других вариантах осуществления при голосовании к значениям элементов массива голосов могут прибавляться числа, отличные от 1.
Тот же способ применяется для каждой последующей структуры данных эталона из первой структуры данных кластера, причем все голоса, формируемые оставшимися структурами данных эталонов, накапливаются в массиве голосов 2004. Затем выбирается первая структура данных эталона во второй структуре данных кластера, и для нее выполняются этапы, представленные на фигурах 20D-E. Необходимо отметить, что параметры, на которые ссылается массив параметров в каждом кластере, например массив параметров 2012 в кластере 2006, могут отличаться от параметров, на которые ссылаются другие кластеры. Другими словами, каждая структура данных кластера включает в себя массив параметров, который может ссылаться на уникальное множество параметров, связанных с данным кластером. Между параметрами, на которые ссылаются два разных кластера, может не быть никаких совпадений или же могут быть частичные или существенные совпадения. Каждый кластер представляет специализированный механизм обнаружения семейств или множеств похожих символов. Поскольку различные семейства или множества символов наилучшим образом обнаруживаются с помощью соответствующих множеств параметров, каждый кластер включает в себя массив параметров, который ссылается на конкретные параметры из глобального массива параметров (2002 на фигуре 20А) и который используется кластером для обнаружения тех символов из семейства или множества символов, для обнаружения которых этот кластер предназначается. Кроме того, каждый кластер может использовать разное количество структур данных эталона, а значит, как и в случае с параметрами, на которые ссылаются кластеры, между структурами данных параметров, на которые ссылаются два разных кластера, может не быть никаких совпадений или же могут быть частичные или существенные совпадения. Обработка продолжается для каждой последующей структуры данных эталона из второй структуры данных кластера, а также всех остальных структур данных кластера, включая последнюю структуру данных кластера. Все голоса, формируемые структурами данных эталона, накапливаются в массиве голосов 2004. Так выглядит обработка первого изображения символа, выбранного из текстовой страницы 2020.
Далее, как показано на фигуре 20F, голоса, накопленные в массиве голосов для первого изображения символа, выбранного из текстовой страницы, применяются для подготовки отсортированного списка кодов графем, которые чаще всего соответствовали изображению символа в процессе обработки, описанном выше со ссылкой на фигуры 20А-Е, согласно накопленным голосам для кодов графем в массиве голосов. Массив голосов 2004 представлен в верхней части фигуры 20F. Каждая ячейка в массиве голосов содержит количество отданных голосов; индексы ячеек соответствуют кодам графем. Голоса и индексы кодов графем затем сортируются в порядке убывания количества голосов, генерируя, таким образом, отсортированный массив 2067, в котором каждая ячейка содержит код графемы, а индексы слева направо монотонно возрастают, упорядочивая коды графем по количеству голосов, полученных ими в процессе обработки, представленной на фигурах 20А-Е. Например, наибольшее количество голосов, равное 16, получил код графемы «9» 2066, а значит, код графемы «9» будет стоять на первой позиции 2068 в отсортированном массиве кодов графем 2067. Затем отсортированный массив 2067 урезается, генерируя усеченный отсортированный массив кодов графем 2069. Усеченный отсортированный массив кодов графем включает в себя отсортированный список кодов графем, получивших голоса в процессе обработки, описанной выше со ссылкой на фигуры 20А-Е. В способе, описанном на фигурах 20А-Е, голоса получили только 14 кодов графем, а значит, усеченный отсортированный массив кодов графем 2069 включает в себя только 14 элементов. Это первые 14 элементов в отсортированном массиве кодов графем 2067. Остальные элементы отсортированного массива кодов графем 2067, следующие за четырнадцатым элементом с индексом 13, содержат коды графем, которые не получили голоса. Далее, как показывает дугообразная стрелка 2070, усеченный массив кодов графем включается в первый элемент 2071 таблицы обработанных изображений символа 2072. Каждый элемент таблицы обработанных изображений символа включает в себя поле (представлено первым столбцом 2073), указывающее на количество или порядок символа в пределах текстовой структуры данных (2020 на фигуре 20А); поле, содержащее количество кодов графем, получивших голоса в ходе обработки символа (второй столбец 2074 в таблице обработанных изображений символа), и отсортированный усеченный массив кодов графем (третий столбец 2075 в таблице обработанных изображений символа 2072).
В настоящем варианте осуществления отсортированные усеченные массивы кодов графем для изображений символов накапливаются в таблице обработанных изображений символа для каждой страницы документа. Отсортированные усеченные массивы кодов графем затем используются на второй стадии для преобразования изображений символов, представленных на странице документа, в символы, включенные в обработанную страницу документа. Отсортированный усеченный массив кодов графем представляет результат начальной обработки, которая определяет множество потенциальных кодов графем, наиболее вероятно связанных с каждым изображением символа в пределах изображения страницы документа. В представленном варианте осуществления все коды графем, получивших голоса, включены в отсортированные усеченные массивы кодов графем. В других вариантах осуществления в отсортированные усеченные массивы кодов графем включаются только те коды графем, количество голосов которых превышает заданный порог.
Как только завершается обработка первого изображения символа, извлеченного из страницы документа, и в таблице обработанных изображений символов создается соответствующая запись, второе изображение символа 2078 выбирается из структуры данных текста (2020 на фигуре 20А) и помещается в переменную 2024. Затем значения параметров для следующего символа рассчитываются и сохраняются в массиве рассчитанных значений параметров. Затем обрабатывается второе изображение символа для генерации нового множества накопленных голосов в массиве голосов 2004 для второго изображения символа. Накопленные голоса для второго изображения символа 2004 сортируются по количеству голосов, генерируя отсортированный массив кодов графем. После этого отсортированный массив кодов графем урезается для генерации усеченного отсортированного массива кодов графем, который включается во вторую запись таблицы обработанных изображений символов.
Как показано на фигуре 20G, каждое изображение символа в текстовом документе 2020 последовательно проходит обработку по этапам, описанным выше со ссылкой на фигуры 20A-F, как показано стрелками 2084-2093, при этом для каждого изображения символа в массиве 2004 накапливаются голоса. Накопленные голоса для каждого изображения символа затем формируют отсортированные усеченные массивы кодов графем для каждого изображения символа, после чего эти массивы добавляются в виде записей в таблицу обработанных изображений символа 2072. В результате обработки изображений символа текстового документа, использующей кластеры, формируется таблица обработанных изображений символа 2072, содержащая отдельную запись для каждого изображения символа текстового документа. Каждый элемент таблицы обработанных изображений символа представляет начальное множество графем, потенциально соответствующих изображению символа. Множество потенциально соответствующих графем помещается в усеченный массив кодов графем, отсортированный в порядке убывания накопленных голосов, таким образом, коды графем, получивших наибольшее количество голосов, располагаются первыми в отсортированном усеченном массиве кодов графем. Множество потенциально соответствующих кодов графем, представленное в виде отсортированного усеченного массива кодов графем, может быть в дальнейшем использовано в дополнительном алгоритме распознавания символов для определения наилучшего кода символов для изображения символа, для которого был сформирован отсортированный усеченный массив кодов графем в процессе обработки, описанном выше со ссылкой на фигуры 20А-О.
Сокращение второй стадии обработки для изображений, содержащих несимвольные элементы
Фигура 21 иллюстрирует вторую стадию способов OCR, на которой выполняется связывание кодов символов с изображениями символов. На фигуре 21 показана большая таблица обработанных изображений символов 2102, аналогичная таблице обработанных изображений символов 2072, представленной на фигуре 20G. Каждая строка в таблице включает в себя указатель на изображение символа в пределах страницы документа или другого содержащего текст изображения 2104, целое число, представляющее количество потенциальных графем, обнаруженных для изображения символа 2106, и по существу очень длинный список потенциальных графем 2108, отсортированных в порядке от максимально соответствующих до минимально соответствующих. Вторая стадия обработки документа представлена на фигуре 21 дугообразными стрелками, такими как дугообразная стрелка 2110, и столбцом 2112 распознанных символов, соответствующих изображениям символа. На второй стадии обработки изображение символа, представленное указателем в первом столбце 2104 таблицы обработанных изображений символов, сравнивается с потенциальными графемами, перечисленными в строке таблицы обработанных изображений символов 2108, и наиболее подходящая из потенциальных графем выбирается в качестве символа, соответствующего изображению символа. Таким образом, во время второй стадии обработки документа, как показано дугообразными стрелками, такими как дугообразная стрелка 2110, обрабатывается каждая последующая строка в таблице обработанных изображений символов для формирования соответствующего символа или кода символа, сохраняемого в столбце кодов символов или символов 2112, который представляет результаты работы способов и систем OCR для преобразования изображения символа в код символа. Впоследствии итоговые символы или коды символов 2112 применяются для формирования электронного документа, эквивалентного исходному изображению отсканированного документа или другому содержащему текст изображению, к которому применялись способы и системы OCR. Следует отметить, что во многих случаях для любого конкретного изображения символа может быть обнаружено большое количество потенциальных графем.
Фигура 22 иллюстрирует один подход к распараллеливанию второй стадии обработки изображений символов относительно потенциальных графем. Как показано на фигуре 22, таблица обработанных изображений символов 2202 может быть разделена на отдельные строки 2204-2211, каждая из которых может быть введена в процессорные модули 2212-2219, которые затем обнаруживают наиболее соответствующую графему или код символа 2220-2227. Когда процессорных модулей меньше, чем строк в таблице обработанных изображений символов 2202, последующие группы строк могут быть распределены между процессорными модулями для параллельной обработки каждой группы строк. Процессорные модули могут представлять собой процессоры в рамках многопроцессорных систем или распределенных вычислительных систем, виртуальные процессоры в рамках виртуализированных вычислительных систем, процессы, которые параллельно выполняются в вычислительных системах и виртуализированных вычислительных системах, аппаратные потоки или потоки внутри операционной системы, а также другие подобные вычислительные модули. Когда в конкретной системе доступны вычислительные ресурсы для параллельной обработки строк таблицы обработанных изображений символа, можно добиться существенного увеличения эффективности OCR путем распараллеливания способов обработки изображения отсканированного документа.
Фигуры 23А-В иллюстрируют распараллеленную обработку отдельного изображения символа относительно потенциальных графем, обнаруженных для изображения символа. Как показано на фигуре 23А, обработку отдельной строки таблицы обработанных изображений символа 2302 также можно распараллелить, при этом последовательные блоки потенциальных графем, например блок 2304, назначаются различным процессорным модулям 2306-2309, а процессорный модуль выявляет отсутствие подходящего совпадения 2310, единственную наиболее подходящую потенциальную графему из блока потенциальных графем 2312 либо две или более подходящих потенциальных графем 2314. В некоторых вариантах осуществления изобретения формируется только одна наиболее соответствующая потенциальная графема для заданного блока кодов графем. В процессе обработки последующих блоков кодов графем одна наиболее соответствующая графема перепроверяется и обновляется. В других вариантах осуществления изобретения при обработке изображения символа относительно потенциальных графем может формироваться множество из двух или более кодов графем, которое представляет наиболее соответствующие потенциальные графемы.
Как показано на фигуре 23В, возможна реализация альтернативных способов распараллеливания обработки изображения символа. В случае, представленном на фигуре 23В, доступны четыре процессорных модуля 2320-2323. Первая потенциальная графема 2326 назначается первому процессорному модулю 2320, вторая потенциальная графема 2327 назначается второму процессорному модулю 2321, третья потенциальная графема 2328 назначается третьему процессорному модулю 2322, а четвертая потенциальная графема 2329 назначается четвертому процессорному модулю 2323, как показано дугообразными стрелками, включая дугообразную стрелку 2330. Затем данный способ распределения повторяется снова, начиная с пятой потенциальной графемы 2332, которая назначается первому процессорному модулю 2320. Распределение кодов графем может продолжаться до тех пор, пока каждому процессорному модулю не будет назначено определенное количество кодов графем, соответствующее размеру блока. Процессорные модули, выполнив обработку назначенных им блоков потенциальных графем, формируют тот же тип результатов, что и процессорные модули, представленные на фигуре 23А. Затем между процессорными модулями распределяется следующее множество блоков кодов графем для обработки. Таким образом, на второй стадии OCR-обработки распараллеливание может выполняться не только за счет параллельной обработки строк таблицы обработанных изображений символа, но и за счет параллельной обработки блоков потенциальных графем относительно одного изображения символа или, другими словами, параллельной обработки отдельных строк таблицы обработанных изображений символа.
Необходимо отметить, что на второй стадии обработки документа, на которой изображения символа сравниваются с потенциальными графемами, обнаруженными на первой стадии обработки документа для изображения символа, сравнения по существу являются значительно более сложными с точки зрения вычислений, чем сравнения, которые выполнялись на первой стадии обработки документа, как показано на фигуре 19С, когда весовое значение формируется на основе сравнения относительно небольшого множества значений параметров, связанных с эталоном, и эквивалентного множества значений параметров, рассчитанных для конкретного изображения символа. На второй стадии обработки документа может использоваться множество дополнительных параметров и типов параметров. Кроме того, в дополнение к сравнению на основе значений параметров, где параметры формируются посредством относительно простых вычислений, как показано на фигурах 8А-В и 12А, может выполняться более сложное наложение на основе изображений. Фигура 24 иллюстрирует некоторые примеры способов наложения на основе изображений. На фигуре 24 пример изображения символа представлен в первом столбце 2402, а потенциальная графема, которая оценивается в отношении изображения символа, представлена во втором столбце 2404. В одном методе изображение символа может накладываться на изображение графемы, как показано в третьем столбце 2406, а на втором этапе изображение графемы может накладываться на изображение символа, как показано на фигуре 2408. В одном примере может вычисляться отдельный показатель, сочетающий относительную область изображения графемы, не охватываемую изображением символа, и относительную область изображения символа, не охватываемую изображением графемы, обозначенные затемненными фрагментами наложений, представленных в столбцах 2406 и 2408. Конечно, эти относительные неохваченные области вычисляются после допустимого вращения и поиска наилучшего варианта наложения в пространстве. В этом случае, как видно из сравнения строк 2410 и 2412, чем меньше относительных неохваченных фрагментов в наложениях, тем больше изображение символа соответствует графеме. Изображение символа 2414 не соответствует потенциальной графеме 2416, в результате чего образуются существенные затемненные фрагменты в двух наложениях 2418 и 2419, сгенерированные из изображения символа 2414 и представления графемы 2416. Напротив, изображение символа 2414 очень хорошо соответствует представлению графемы 2420, в результате чего образуются всего лишь маленькие неохваченные фрагменты в наложениях 2422 и 2424. Как показано в последних двух строках 2430 и 2432 на фигуре 24, метод наложения может использоваться для обнаружения частичного соответствия и, таким образом, для обнаружения комбинаций графем, которые вместе могут обеспечивать приемлемое соответствие для конкретного изображения символа. В этих случаях большое несоответствие между относительными неохваченными фрагментами двух наложений указывает на частичное соответствие и может использоваться для обнаружения частичного соответствия между представлением графемы, например представлением графемы 2434, и изображением символа, например изображением символа 2414. Аналогичным образом, частичное соответствие между представлением графемы 2436 и изображением символа 2414 обнаруживается из-за несоответствия в относительных неохваченных областях двух наложений 2438 и 2440. Путем проверки комбинации графем 2434 и 2436 может быть сгенерирована комбинированная графема, эквивалентная графеме 2420, обеспечивающая практически точное соответствие. Эти типы методов требуют гораздо большего объема вычислений по сравнению с вычислением значений простых параметров, применяемом для формирования списка потенциальных графем на первой стадии обработки документа, описанной выше.
Фигура 25 иллюстрирует проблему, которая может возникнуть при обработке изображения отсканированного документа. На фигуре 25 представлен тот же пример изображения отсканированного документа, что и на фигурах 1А-В. На фигуре 25 вокруг некоторых символов нарисованы небольшие прямоугольники, например прямоугольник 2502, которые обозначают области изображения, выделенные в качестве изображений символов. Хотя некоторые из этих выделенных изображений символов, например изображение 2502, могут действительно содержать изображения символов, некоторые из других выделенных изображений символов, например выделенные изображения 2504-2507, были выбраны ошибочно. Вместо изображений символов эти выделенные изображения содержат фрагменты графического изображения. Следовательно, изображения символов, обнаруженные на первой стадии OCR-обработки, вероятно, лучше описать как «возможные изображения символов», поскольку они не всегда представляют собой изображения символов. В большинстве случаев в процессе конвертации изображения символа в код символа OCR не удастся сгенерировать соответствующий символ для изображения, содержащего несимвольные элементы, например для выделенных изображений символа 2504-2507 на фигуре 25. Конечно, даже если в процессе OCR-обработки случайно удастся сгенерировать соответствующий символ для изображения, содержащего несимвольные элементы, предположительно соответствующий символ будет представлять ложное соответствие.
Существует множество проблем, связанных с применением на второй стадии затратных методов распознавания изображения символа для изображений, содержащих несимвольные элементы. Во-первых, в простейшем варианте осуществления изобретения потребуется обработать большой объем данных для сопоставления каждой потенциальной графемы с изображением, содержащим несимвольные элементы, но в итоге ни одна потенциальная графема может не соответствовать изображению, содержащему несимвольные элементы. Таким образом, присутствие изображений, содержащих несимвольные элементы, во множестве изображений символов, сформированном на основе изображения отсканированного документа, может существенно понизить эффективность обработки изображения отсканированного документа. Более серьезные последствия могут возникнуть в различных вариантах осуществления OCR, в которых применяются адаптивные способы и несколько уровней обратной связи для настройки распознавания изображений символов во время обработки определенного изображения отсканированного документа. В этом случае ложные результаты, полученные для изображений, содержащих несимвольные элементы, могут отрицательно повлиять на способность системы адаптивно настраиваться для более эффективного распознавания символов в процессе обработки изображения отсканированного документа. В настоящем документе описываются способы и системы OCR, которые предотвращают потерю эффективности или повышают эффективность и устраняют другие неблагоприятные воздействия изображений, содержащих несимвольные элементы, во время конвертации изображений символов в коды символов.
Фигура 26 иллюстрирует общую функцию сравнения, которая сопоставляет изображение символа с потенциальной графемой и которая используется на второй стадии обработки изображения отсканированного документа для оценки потенциальных графем, связанных с каждым изображением символа в таблице обработанных изображений символов. Функция сравнения может использовать любой из множества различных типов рассчитанных значений параметров, например описанные выше со ссылкой на фигуры 8А-В и 12А, а также может включать в себя дополнительные методы и способы сравнения изображений, например описанные выше со ссылкой на фигуру 24, а также способы на основе наложения эталонов, на основе контуров и на основе структур, описанные выше. Функция сравнения 2602 получает в качестве аргументов изображение символа s и потенциальную графему g и генерирует в качестве результата вещественное значение r. Во многих вариантах осуществления изобретения r принимает значение из диапазона [0, 1]. Таким образом, рассчитанное значение r подобно весовому значению, вычисленному на первой стадии обработки и рассматриваемому со ссылкой на фигуру 19С. Однако могут применяться любые из множества правил обозначения r, включая правила, в которых более высокие значения r обозначают более точные соответствия.
На фигуре 26 в виде линейного графика представлен диапазон строки вещественных чисел, в который попадают вычисленные значения r, формируемые функцией сравнения 2604. Как и в случае с описанными ранее весовыми значениями, идеальное соответствие между потенциальной графемой и изображением символа генерирует значение r=0, 0 (2606). Во многих случаях получается немного большее значение rmn 2608, которое представляет минимальное значение r для пары «изображение символа и несоответствующая потенциальная графема». Конечно, значение rmn зависит от конкретного множества символов и языка, а также от специфических внутренних показателей и значений параметров, которые комбинируются функцией сравнения для генерации результирующего значения r. Значительно более высокое значение rmх 2610 представляет максимальное результирующее значение, формируемое функцией сравнения для изображения символа и соответствующей потенциальной графемы. И в этом случае rmx также зависит от конкретной функции сравнения и от множества символов и языка. Независимо от фактических числовых значений rmn и rmx, ясно, что при любом множестве символов, языке и конкретной функции сравнения, когда функция сравнения формирует значение r для изображения символа и потенциальной графемы менее rmn, потенциальная графема соответствует изображению символа и маловероятно, что другая потенциальная графема при сравнении с изображением символа сгенерирует более низкое значение r. Аналогично, когда функция сравнения формирует значение r выше rmx для конкретного изображения символа и потенциальной графемы, потенциальная графема, вероятнее всего, не соответствует изображению символа. На фигуре 26 представлено дополнительное количество значений r вдоль фрагмента линии вещественных чисел от 0,0 до 1,0, включая r1 2612, r2 2614, r3 2616, r6 2618, r5 2620 и r4 2622. Эти дополнительные значения r будут рассматриваться ниже.
Фигуры 27А-В иллюстрируют кривые прогресса распознавания для конвертации изображения символа в код символа с использованием способа и системы OCR. На фигуре 27А представлен график, где горизонтальная ось 2702 соответствует количеству блоков потенциальных символов, которые оценивались при попытке конвертировать изображение символа в код символа, а вертикальная ось 2704 представляет r значения, сформированные функцией сравнения, как описано выше со ссылкой на фигуру 26. Следует заметить, что блоки могут иметь разные размеры: от одного потенциального символа до 5, 10 или более потенциальных символов. В частности, кривая 2706, построенная в пределах графика, представляет самое низкое из наблюдаемых значений r при сравнении потенциальных графем с изображением символа в процессе обработки последовательных блоков потенциальных графем. Изначально перед оценкой любых потенциальных графем минимальному наблюдаемому значению г условно присваивается максимальное значение r 1,0 (2708). Кривая, представленная на фигуре 27А, является гипотетической кривой обработки содержащего символ изображения или, другими словами, изображения символа, соответствующего символу языка, в рамках которого распознаются символы. Как описывалось выше, потенциальные графемы упорядочены от наиболее соответствующей до наименее соответствующей, чтобы в общем случае OCR-обработка быстро находила относительно хорошие соответствия в первых блоках оцениваемых потенциальных графем. Таким образом, кривая резко обрывается после оценки первого блока потенциальных графем, генерируя приемлемое значение r 2710. В ходе обработки первых блоков потенциальных графем самое низкое из наблюдаемых значений r продолжает снижаться с уменьшением крутизны кривой, как представлено самыми низкими наблюдаемыми значениями r 2712 и 2714, но затем в конце концов кривая приобретает тенденцию к выравниванию. Для любого конкретного изображения символа могут наблюдаться различные кривые прогресса распознавания. Во многих случаях, к примеру, кривая может опуститься до очень низкого значения сразу после завершения обработки первого блока потенциальных графем, а затем выровняться от этой точки после обнаружения идеального или практически идеального соответствия в первом из оцениваемых блоков потенциальных графем. Тем не менее, в среднем кривые прогресса распознавания имеют формы, похожие или связанные с экспоненциально затухающими кривыми 2706, как показано на фигуре 27А.
Напротив, на фигуре 27В представлена кривая прогресса распознавания для изображения, содержащего несимвольные элементы. В этом случае кривая обрывается с самого начала, как представлено линейным сегментом между максимальным значением r 2716 и первым самым низким из наблюдаемых значений r 2718, после оценки первого блока потенциальных графем, но затем по существу выравнивается гораздо быстрее на значительно более высоком значении по сравнению с кривой прогресса распознавания, представленной на фигуре 27А. В общем случае кривая никогда не опускается ниже rmx 2720. И это неудивительно, поскольку маловероятно, что для изображений, содержащих несимвольные элементы, способ и система OCR смогут найти соответствующую потенциальную графему. Конечно, существуют возможные исключения, когда фрагменты, содержащие несимвольные элементы, все же содержат эталоны линий, которые по случайному совпадению соответствуют форме отдельного символа. Однако в общем случае кривые прогресса распознавания для изображений, содержащих несимвольные элементы, имеют аналогичную или такую же форму, что и кривая прогресса распознавания 2722, представленная на фигуре 27В.
Эти характерные различия кривых прогресса распознавания для изображений, содержащих символы, и изображений, содержащих несимвольные элементы, представляют основания для наблюдения за прогрессом распознавания во время обработки изображения символа для определения (задолго до того, как будут оценены все потенциальные графемы), содержит ли изображение несимвольные элементы, формируя кривую прогресса распознавания, похожую на кривую 2722, представленную на фигуре 27В, или изображение содержит символ - в этом случае наблюдаемый прогресс напоминает кривую прогресса распознавания 2706, представленную на фигуре 27А. К примеру, даже после оценки трех блоков потенциальных графем в примерах, представленных на фигурах 27А-В, ранние фрагменты двух кривых прогресса распознавания будут отчетливо различаться для содержащего символ изображения, представленного на фигуре 27А, и изображения, содержащего несимвольные элементы, представленного на фигуре 27 В.
Фигуры 28A-D иллюстрируют различные способы реализации функции отсечки, которая определяет необходимость прерывания обработки для улучшения эффективности обработки и предотвращения возникновения потенциальных дефектов при обработке изображений, содержащих несимвольные элементы. На фигуре 28А представлена таблица, которая содержит пары диапазонов значений r и доли от общего количества потенциальных графем, оцененных во время обработки изображения символа. Для конкретного самого низкого из наблюдаемых значений r во время обработки изображения символа, когда значение r попадает в диапазон, определенный в первом столбце 2804 таблицы 2802, и когда доля уже оцененных потенциальных графем больше или равна доле, представленной во втором столбце 2806 той же строки, обработка должна немедленно прерваться. Процесс обработки должен прерваться, по существу, когда ясно, что изображение символа является изображением, содержащим несимвольные элементы, либо когда при дальнейшей обработке маловероятно обнаружение соответствия, которое будет лучше текущего наилучшего соответствия между изображением символа и потенциальной графемой. Другими словами, процесс обработки прерывается, когда в процессе наблюдения за прогрессом определяется, что обнаруженное возможное изображение символа фактически не содержит изображение символа, или когда вычислительные затраты на продолжение обработки потенциальных графем не компенсируются вероятностью обнаружения потенциальной графемы, которая сгенерирует значение сравнения относительно возможного изображения символа, указывающее лучшее соответствие, чем уже оцененные потенциальные графемы.
Первая строка таблицы 2808 показывает, что если оценка потенциальной графемы относительно изображения символа генерирует значение r меньше rmn то необходимо прервать дальнейшую обработку. Как описывалось выше, маловероятно, что любая другая потенциальная графема сгенерирует более низкое значение r. Вторая строка 2810 таблицы 2804 показывает, что когда самое низкое из наблюдаемых значений r больше r4 или меньше r1 и доля уже оцененных потенциальных графем больше или равна ω, необходимо прервать дальнейшую обработку. Когда самое низкое из наблюдаемых значений r больше r4, как видно на фигуре 26, это указывает на то, что кривая прогресса распознавания скорее принадлежит к семейству кривых, представленных кривой 2722 на фигуре 27В, чем к семейству кривых, представленных кривой 2706 на фигуре 27А. Когда самое низкое из наблюдаемых значений r меньше r1, тогда (поскольку потенциальные графемы упорядочены от наибольшего соответствия до наименьшего соответствия) маловероятно, что при дальнейшей обработке будет обнаружена более подходящая потенциальная графема. Записи 2812 и 2814 представляют дополнительное сужение диапазона самых низких из наблюдаемых значений r, которые оправдают продолжение обработки. Наконец, запись 2816 показывает, что, когда оценена относительно большая доля потенциальных графем и когда самое низкое из наблюдаемых значений r меньше или равно rmx, вероятнее всего, самое низкое из наблюдаемых значений r представляет наименьшее значение r, которое может быть получено даже при оценке других потенциальных графем, особенно учитывая тот факт, что потенциальные графемы отсортированы в порядке от наибольшего соответствия до наименьшего соответствия.
На фигуре 28В представлена меньшая таблица 2820 с записями, которые представляют несколько иной подход к определению момента прерывания обработки изображения символа. В этом случае существует единственный вес отсечки rcut. Первая запись таблицы 2822 показывает, что когда самое низкое из наблюдаемых значений r больше rcut и когда уже оценена доля k1 потенциальных графем, необходимо прервать дальнейшую обработку, поскольку кривая прогресса распознавания отчетливо попадает скорее в семейство кривых, представленных кривой 2722 на фигуре 27В, чем в семейство кривых, представленных кривой 2706 на фигуре 27А. Вторая запись 2824 показывает, что когда самое низкое из наблюдаемых значений r меньше или равно rcut и когда уже оценена доля k2 потенциальных графем, то маловероятно, что дальнейшая обработка сгенерирует более подходящую потенциальную графему.
На фигуре 28С представлен другой подход к определению момента отсечки. В этом случае выбираются две непрерывные функции 2830 и 2832 для генерации двух кривых, которые образуют область, заштрихованную на фигуре 28С, причем продолжение обработки является оправданным, когда точка с координатами, определенными самым низким из наблюдаемых значений r, при обработке определенного количества блоков потенциальных графем и доле уже обработанных блоков потенциальных графем по отношению к общему количеству блоков попадает в заштрихованную область поиска. Другими словами, можно использовать непрерывные функции для определения необходимости прерывания дальнейшей обработки на основе заданного самого низкого из наблюдаемых значений r и заданной доли уже оцененных потенциальных графем.
Наконец, как показано на фигуре 28D, все различные подходы к определению необходимости прерывания дальнейшей обработки изображения символа в результате наблюдения за прогрессом распознавания во время обработки изображения символа можно объединить в функцию отсечки, которая возвращает логическое значение и получает в качестве аргумента самое низкое из текущих наблюдаемых значений r при сравнении изображения символа с потенциальной графемой, а также количество уже оцененных потенциальных графем и общее количество потенциальных графем, связанных с изображением символа.
На фигурах 29А-В представлены блок-схемы, иллюстрирующие применение функции отсечки на второй стадии обработки изображения отсканированного документа для прерывания обработки изображения символа до оценки всех потенциальных графем, связанных с изображением символа. В примере, представленном на фигурах 29А-В, предполагается, что множество графем для языка символов в изображении отсканированного документа полностью охватывает символы языка. Другими словами, для любого допустимого символа языка существует по меньшей мере одна графема, которая однозначно совпадает с этим символом и соответствует коду символа, который связан с этим символом. Для отдельных языков существуют варианты осуществления изобретения, в которых, как описывалось выше со ссылкой на фигуру 24, в процессе распознавания могут использоваться две или более графем, которые частично соответствуют изображению символа, для создания составной соответствующей графемы для символа, причем составные графемы, которые соответствуют символам, связываются с кодами, которые могут быть назначены символам. В этих случаях, как описывается ниже, продемонстрированная на фигурах 29А-В логика может немного изменяться, чтобы самые низкие из наблюдаемых значений г вычислялись не только на основе самых низких значений r, наблюдаемых для любого отдельного вызова функции сравнения, но на основе этих значений и значений r, рассчитанных для составных графем.
На фигуре 29А представлена блок-схема для подпрограммы «process image» («обработка изображения»), которая выполняет оценку потенциальных графем, связанных с изображением символа, для поиска соответствующей потенциальной графемы, из которой можно будет получить код символа для представления символа, содержащегося в изображении. На этапе 2902 подпрограмма «process image» получает изображение символа s, а также множество потенциальных графем g, обнаруженное для символа на первой стадии обработки изображения отсканированного документа. Для изображения символа было обнаружено num потенциальных графем s. Далее на этапе 2904 локальной переменной num_blocks присваивается значение количества потенциальных графем num, разделенное на размер блоков потенциальных графем, которые обрабатываются на каждой стадии параллельной обработки, представленный константой block_size. Следует заметить, что размер блока может изменяться от 1 до количества потенциальных графем num и что соответствующее количество блоков может изменяться от количества потенциальных графем num до 1. Локальной переменной eval присваивается значение 0, локальной переменной best присваивается значение -1, локальной переменной lowR присваивается значение 2, локальной переменной skip присваивается значение False, а локальной переменной currentB присваивается значение 0. Если определенное на этапе 2906 вычисленное количество блоков num_blocks меньше порогового значения, на этапе 2908 локальной переменной skip присваивается значение true. Когда количество блоков потенциальных графем меньше некоторого порогового значения, нет смысла в наблюдении за прогрессом распознавания с целью определения необходимости прерывания обработки. Далее в цикле while на этапах 2910-2916 выполняется оценка потенциальных графем g относительно изображения символа s. На этапе 2911 локальной переменной block_extent присваивается текущее значение currentB плюс константа block_size - 1. Таким образом, следующий блок потенциальных графем для оценки начинается с индекса currentB и заканчивается индексом block_extent, причем предполагается, что потенциальные графемы являются частью линейного массива. Когда локальной переменной block_extent присваивается значение больше num, что определяется на этапе 2912, переменной block_extent присваивается значение num на этапе 2913. На этапе 2914 вызывается подпрограмма «process block» («обработка блока») для обработки следующего блока потенциальных графем. В общем случае обработка следующего блока потенциальных графем выполняется параллельно. Когда обработка завершается и подпрограмма «process block» возвращает значение, если подпрограмма «process block» вернула логическое значение False или если локальная переменная block_extent имеет значение num, что определяется на этапе 2915, подпрограмма «process image» возвращает текущие значения локальных переменных best и lowR, которые представляют наилучшую соответствующую потенциальную графему и соответствующее значение r для сравнения потенциальной графемы с изображением символа. В противном случае переменной currentB присваивается текущее значение block_extent+1 на этапе 2916, и управление передается на этап 2911 для выполнения следующей итерации цикла while на этапах 2910-2916.
На фигуре 29В представлена блок-схема подпрограммы «process block», вызываемой на этапе 2914 на фигуре 29А. На этапе 2920 подпрограмма «process block» распределяет текущий блок потенциальных графем для обработки между одним или более вычислительными модулями. На этапе 2922 подпрограмма «process block» присваивает локальной переменной localBest значение -1, локальной переменной localLowR - значение 2 и локальной переменной numF - значение 0. Далее в цикле, содержащем этапы 2924-2927, подпрограмма «process block» ожидает, пока следующий процессорный модуль завершит обработку своего фрагмента блока потенциальных графем, и после этого на этапе 2925 определяет, меньше ли наилучшее значение r, возвращенное процессорным модулем, чем текущее значение локальной переменной localLowR. Если наилучшее значение г меньше, тогда на этапе 2926 локальной переменной localLowR присваивается наилучшее значение г, возвращенное процессорным модулем, а локальной переменной localBest присваивается код графемы, соответствующей наилучшему значению r, возвращенному процессорным модулем. На этапе 2927 значение локальной переменной numF увеличивается. Когда значение, сохраненное в локальной переменной numF, меньше количества процессорных модулей, что определяется на этапе 2928, управление возвращается на этап 2924 для ожидания завершения обработки следующим процессорным модулем. После того как все процессорные модули завершают обработку, если текущее значение, сохраненное в переменной localLowR, меньше значения переменной lowR, что определяется на этапе 2930, то на этапе 2932 переменной lowR присваивается значение, в текущий момент сохраненное в переменной localLowR, а переменной best присваивается значение, в текущий момент сохраненное в локальной переменной localBest. Таким образом, lowR отражает самое низкое значение r, наблюдаемое в любом процессорном модуле до текущего момента времени, а в переменной best сохраняется код графемы, на основе которого формируется самое низкое значение r путем сравнения потенциальной графемы с изображением символа s. На этапе 2934 размер только что обработанного блока потенциальных графем прибавляется к значению переменной eval. Когда переменная skip принимает значение True, что определяется на этапе 2936, подпрограмма «process block» возвращает значение True. В противном случае подпрограмма «process block» вызывает функцию отсечки, описанную выше со ссылкой на фигуру 28D, чтобы определить необходимость продолжения обработки изображения символа s. Если функция отсечки возвращает значение True, подпрограмма «process block» возвращает значение False. В противном случае подпрограмма «process block» возвращает значение True.
Фигуры 30А-С иллюстрируют различные типы стратегий отсечки. На всех этих иллюстрациях применяются те же обозначения, что и на фигуре 28С. Горизонтальная ось представляет долю потенциальных графем, уже оцененных во время обработки изображения символа, а вертикальная ось представляет самое низкое из наблюдаемых значений r. Фигура 30А иллюстрирует стратегию, описанную ранее со ссылкой на фигуру 28 В. После оценки доли k1 потенциальных графем 3002, если самое низкое из наблюдаемых значений r больше rcut 3004, обработка прерывается. После оценки доли потенциальных графем, если самое низкое из наблюдаемых значений r меньше rcut 3006, обработка также прерывается.
В стратегии, представленной на фигуре 30В, две непрерывные кривые 3008 и 3009 образуют область «самое низкое из наблюдаемых значений r/доля оцененных пар», которая гарантирует продолжение OCR-обработки. В этом случае диапазон самых низких из наблюдаемых значений r при любой доле оцененных потенциальных графем, например при доле, представленной в точке 3010, соответствующей диапазону значений r, обозначенному двунаправленной стрелкой 3012, постоянно уменьшается по мере оценки новых блоков потенциальных графем.
На фигуре 30С представлена альтернативная стратегия, в которой используются непрерывная функция 3014 и частично ступенчатая функция 3016 для определения точек типа «самое низкое из наблюдаемых значений r/доля оцененных пар» в пределах области, в которой дополнительная OCR-обработка является необходимой.
Фигура 31 иллюстрирует способ второй стадии обработки, подходящий для вариантов осуществления изобретения, в которых для распознавания изображения символа могут применяться составные графемы. В этих случаях, когда блок 3102 потенциальных графем распределен между несколькими процессорными модулями 3104-3107 для обработки, процессорные модули возвращают список вероятных потенциальных графем и связанных с ними значений r 3110. При обработке следующего блока потенциальных графем 3112 список вероятных потенциальных графем может увеличиваться, а функция отсечки 3114, которая получает в качестве аргументов указатель на список вероятных потенциальных графем, количество уже оцененных потенциальных графем и общее количество потенциальных графем, генерирует логическое значение, определяющее необходимость прерывания обработки. В этом случае текущие самые низкие из наблюдаемых значений r должны включать в себя самое низкое из наблюдаемых значений r для любого прямого сравнения изображения символа с потенциальной графемой, а также самое низкое значение r, наблюдаемое для всех возможных составных графем, составленных из вероятных потенциальных графем 3110.
Для выполнения множества различных стратегий прерывания обработки изображений отсканированных документов могут быть реализованы разнообразные альтернативные функции сравнения и функции отсечки. Вместо простого отслеживания самого низкого из наблюдаемых значений r система OCR также может наблюдать за скоростью изменения самого низкого из наблюдаемых значений r во времени в качестве альтернативного или дополнительного способа сравнения текущего прогресса распознавания с семейством кривых, которые представляют характеристики кривых прогресса распознавания для обработки изображений, содержащих несимвольные элементы, с целью обнаружения и прерывания обработки изображений, содержащих несимвольные элементы. Для этого может использоваться множество других характеристик и показателей. В дополнение к раннему прерыванию обработки в результате низкой вероятности обнаружения лучшего соответствия и из-за низкой вероятности обнаружения любого соответствия в альтернативных функциях отсечки могут быть учтены другие факторы.
Хотя настоящее изобретение представлено на примере конкретных вариантов осуществления, предполагается, что оно не будет ограничено только этими вариантами осуществления. Специалистам в данной области будут очевидны возможные модификации сущности настоящего изобретения. К примеру, могут отличаться любые из множества различных вариантов осуществления и конфигураций параметров, включая операционную систему, язык программирования, структуры управления, структуры данных, модульную организацию и другие подобные параметры, обеспечивающие альтернативные варианты осуществления способа раннего прерывания, который может быть включен в состав систем OCR-обработки. Как описывалось выше, существует множество альтернативных подходов к разработке и реализации функций подсчета и отсечки. Кроме того, способ раннего прерывания может применяться в различных вариантах осуществления разнообразных OCR, реализующих разные типы стратегий обработки, способы распараллеливания и другие подобные отличия.
Следует понимать, что описанные выше заявленные варианты осуществления предоставлены для того, чтобы дать возможность любому специалисту в данной области повторить или применить настоящее изобретение. Специалистам в данной области будут очевидны возможные модификации представленных вариантов осуществления, при этом общие принципы, представленные в настоящем описании, могут применяться к другим вариантам осуществления без отступления от сущности или объема описания. Таким образом, настоящее описание не ограничено представленными в нем вариантами осуществления, оно соответствует широкому кругу задач, связанных с принципами и новыми отличительными признаками, раскрытыми в настоящем документе.
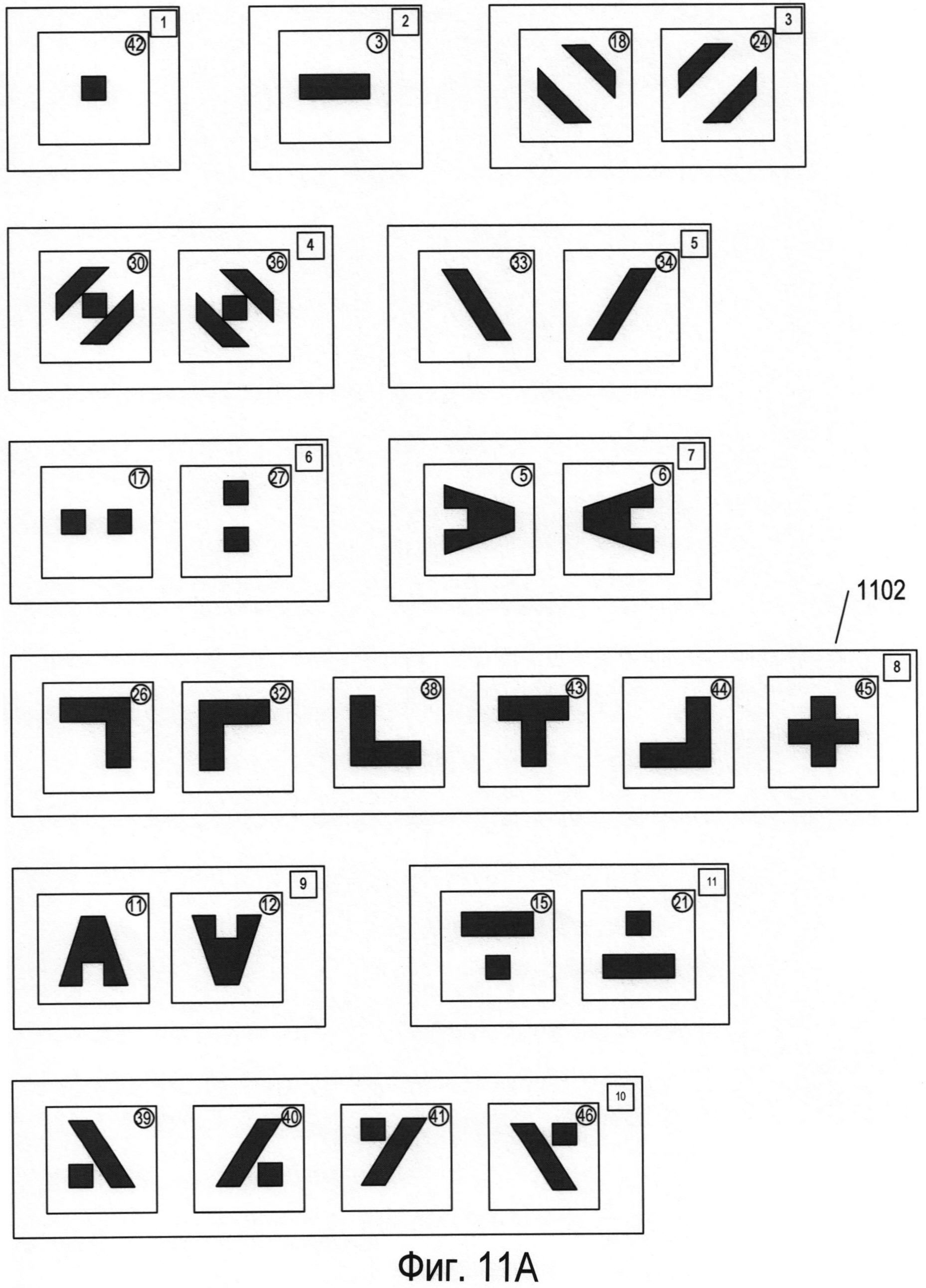
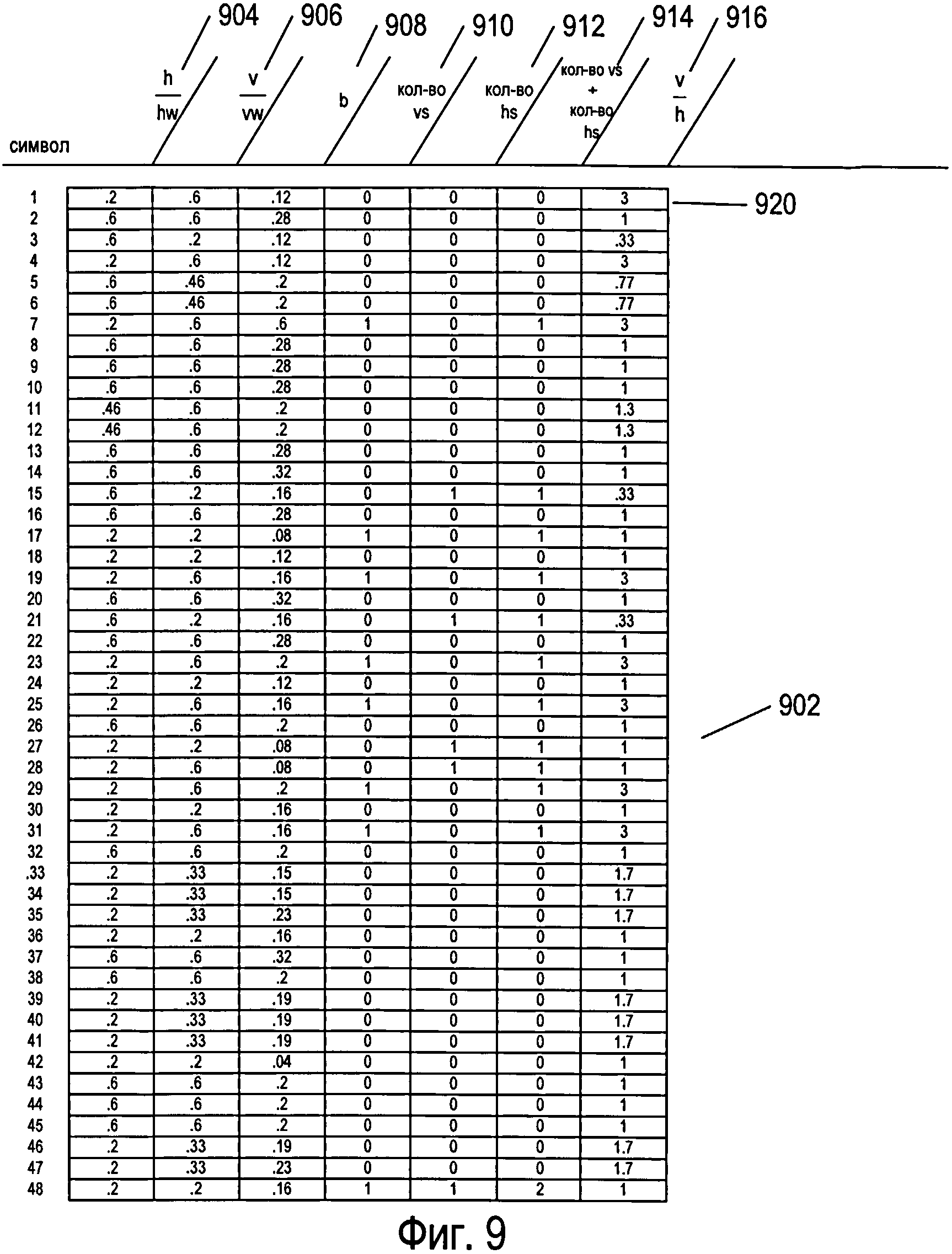

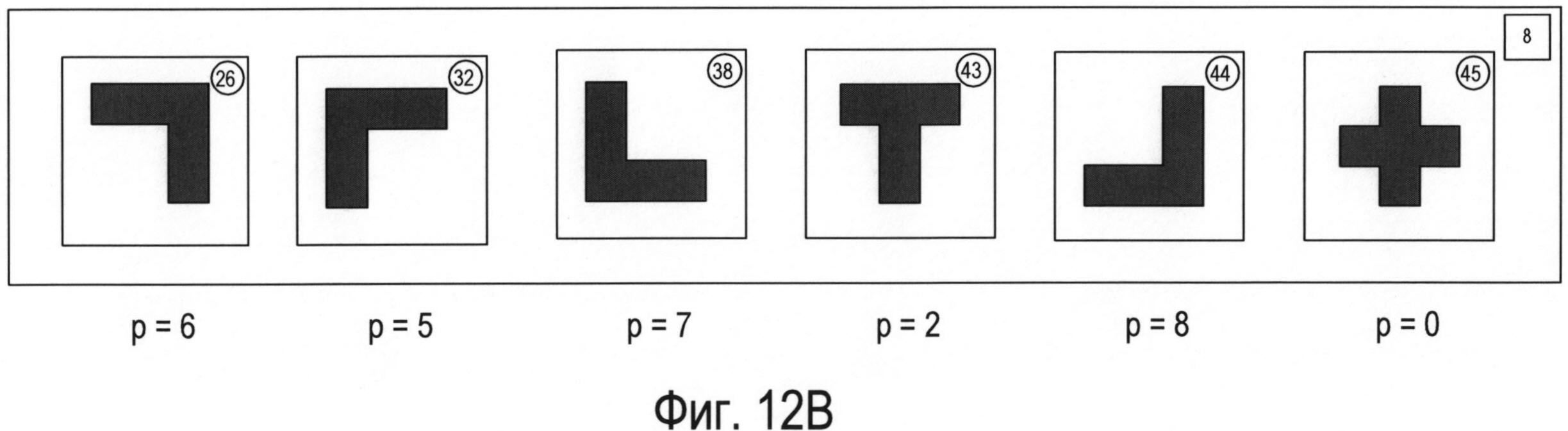

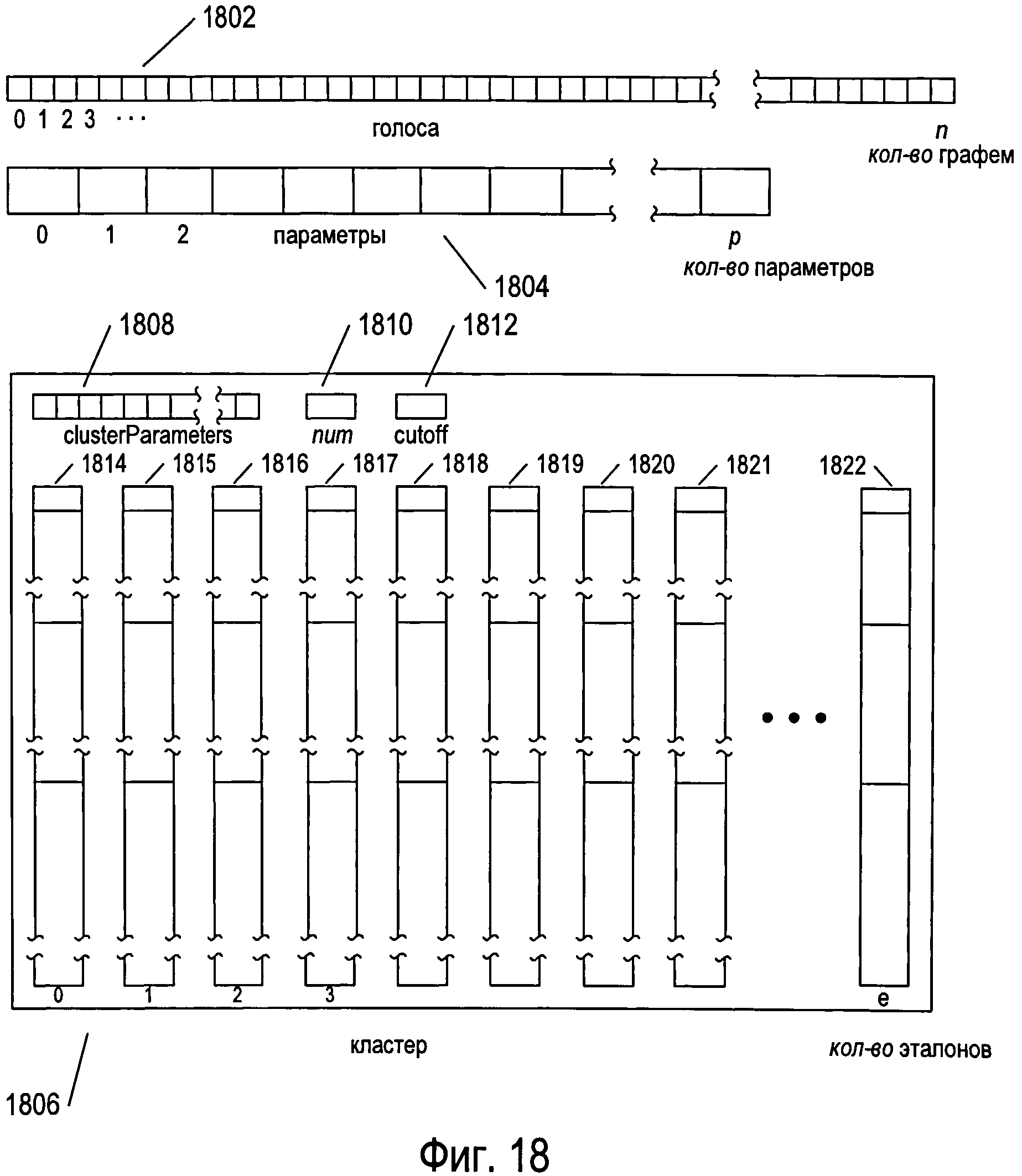
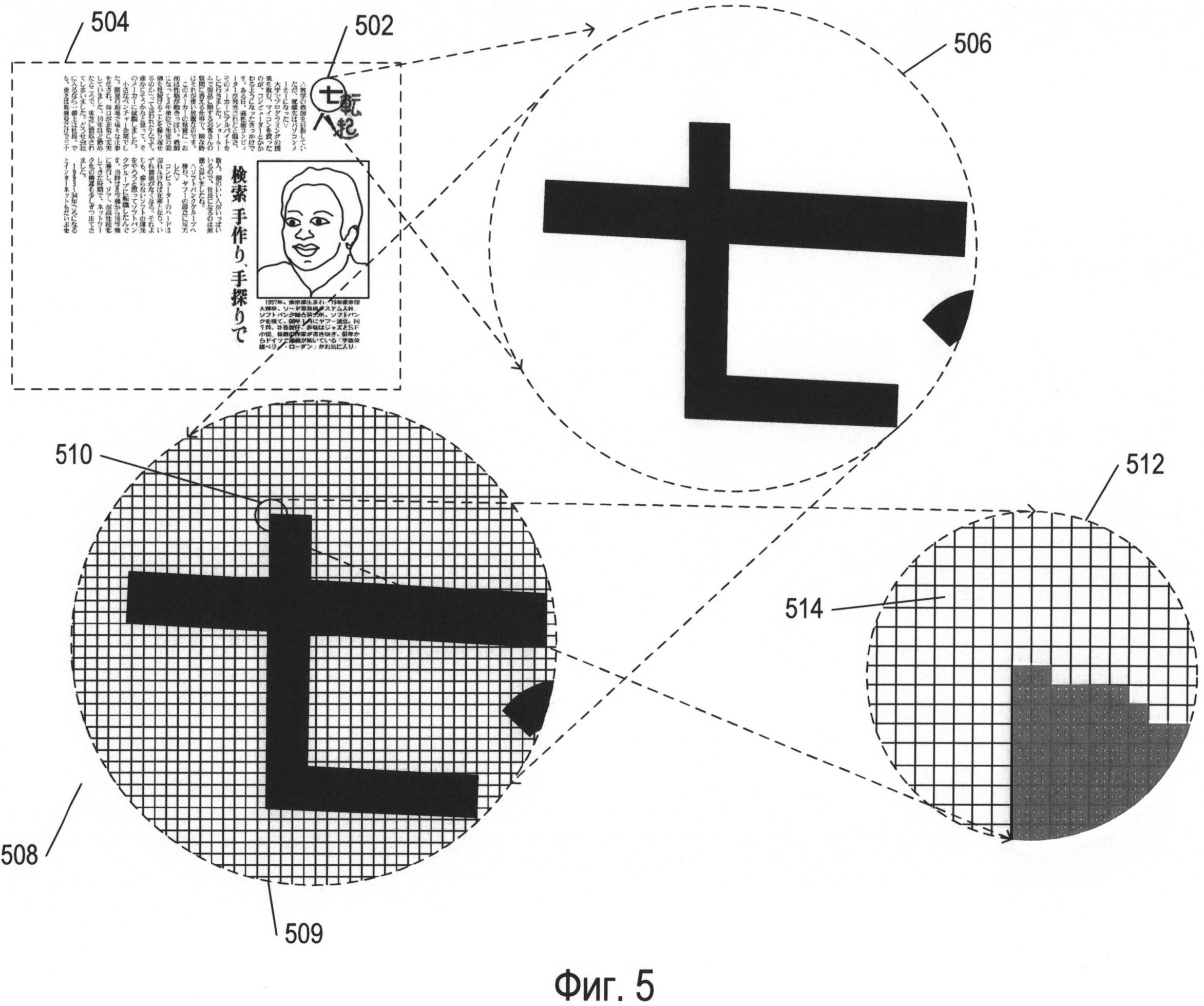
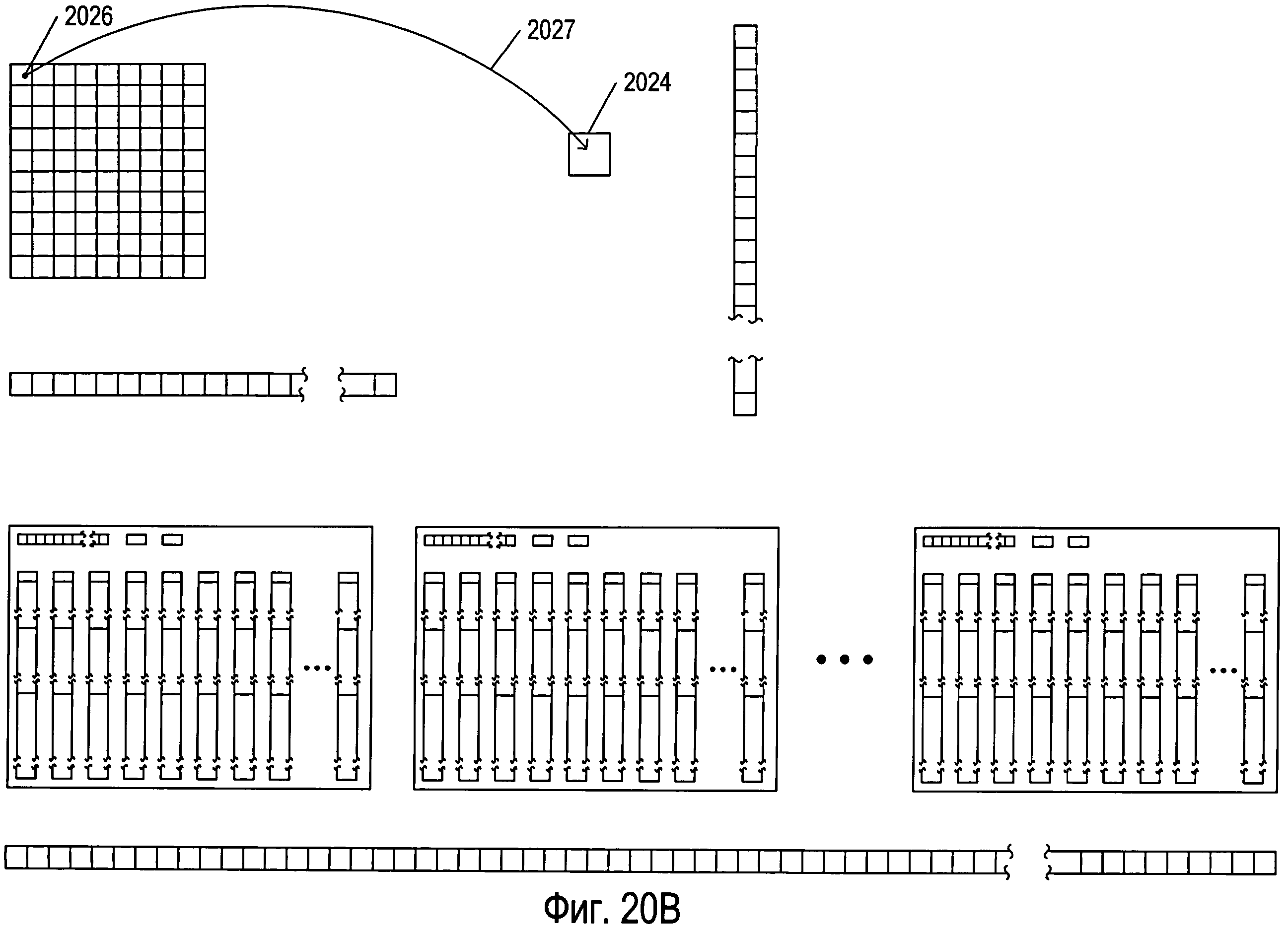
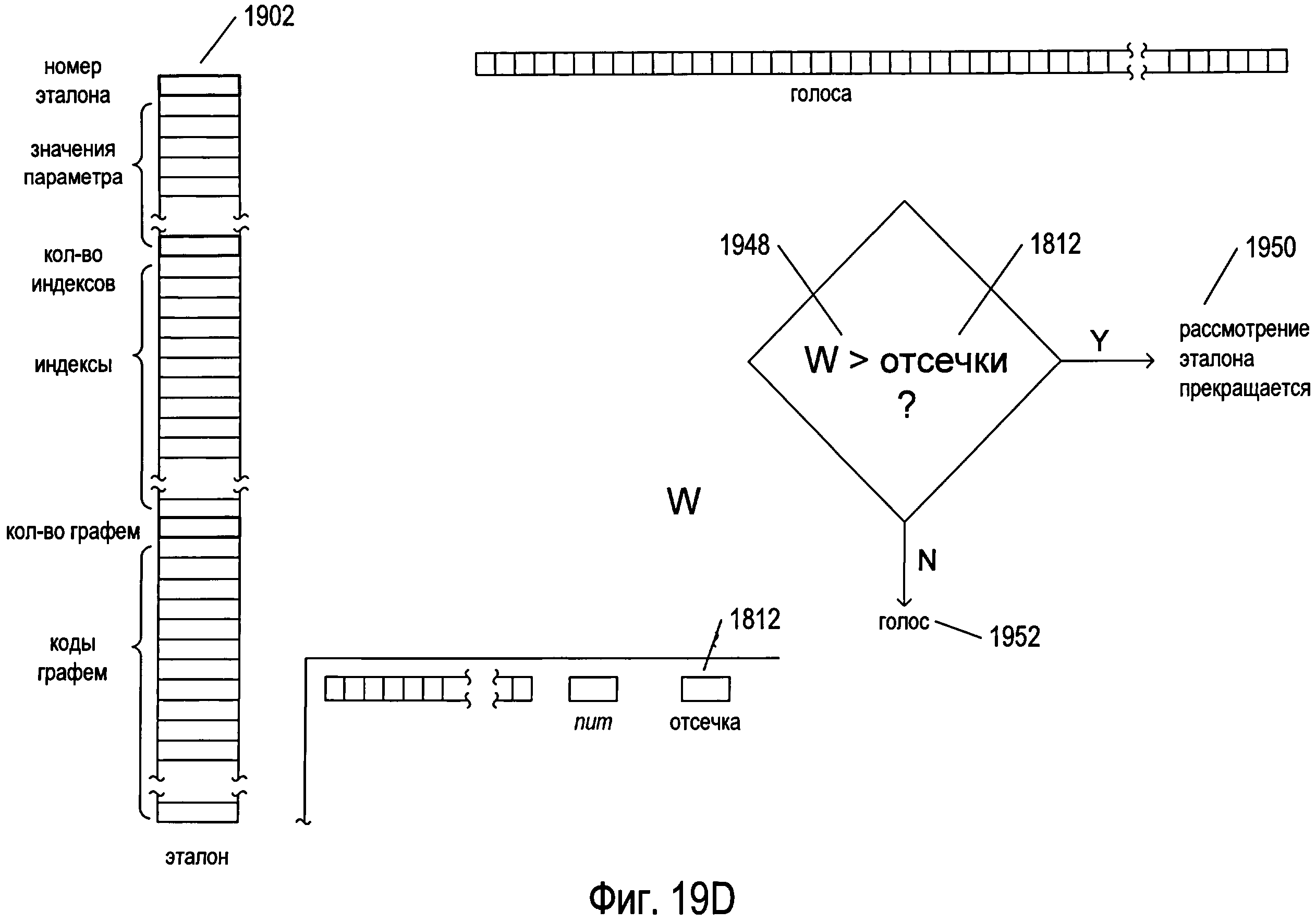
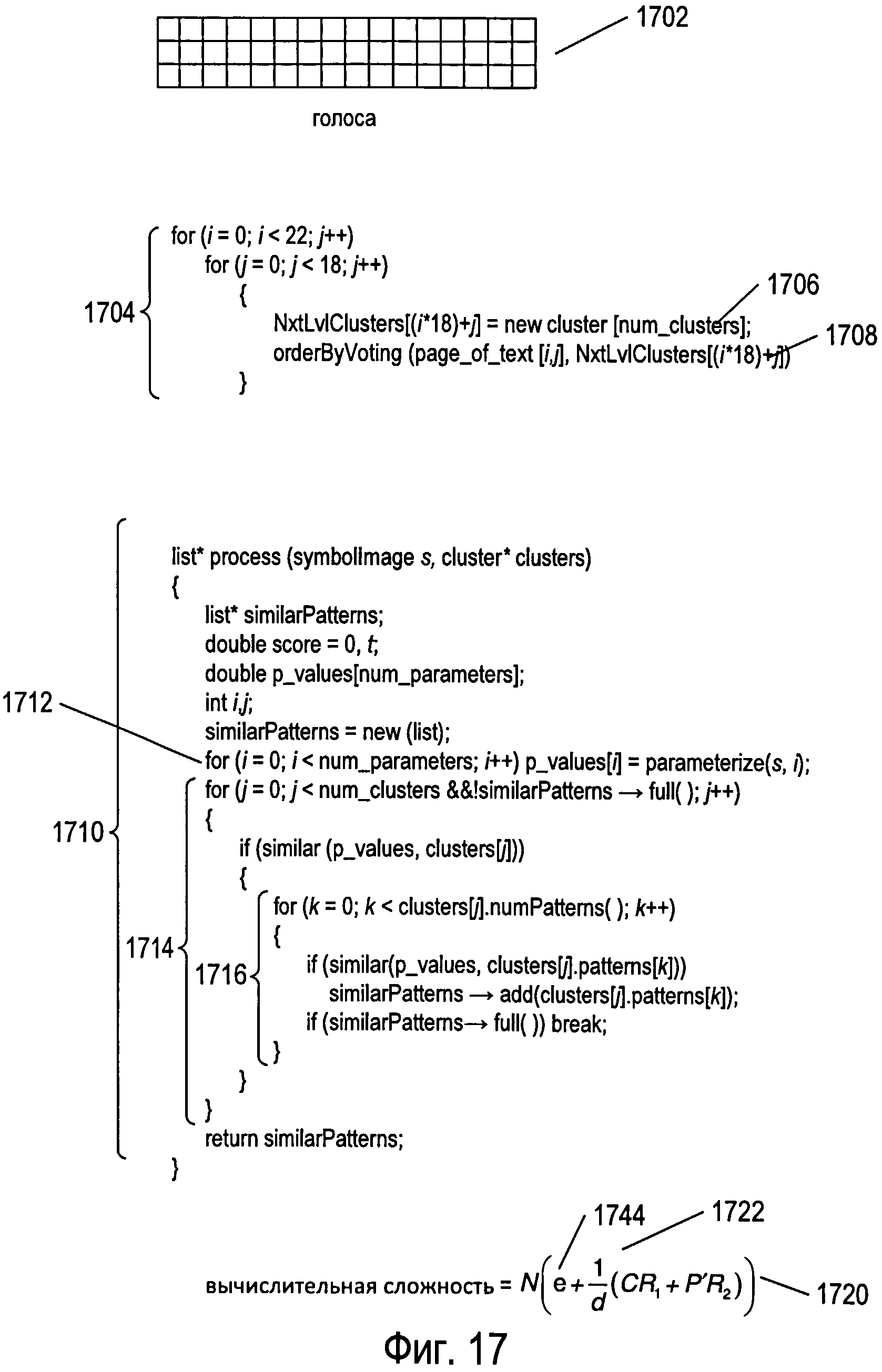
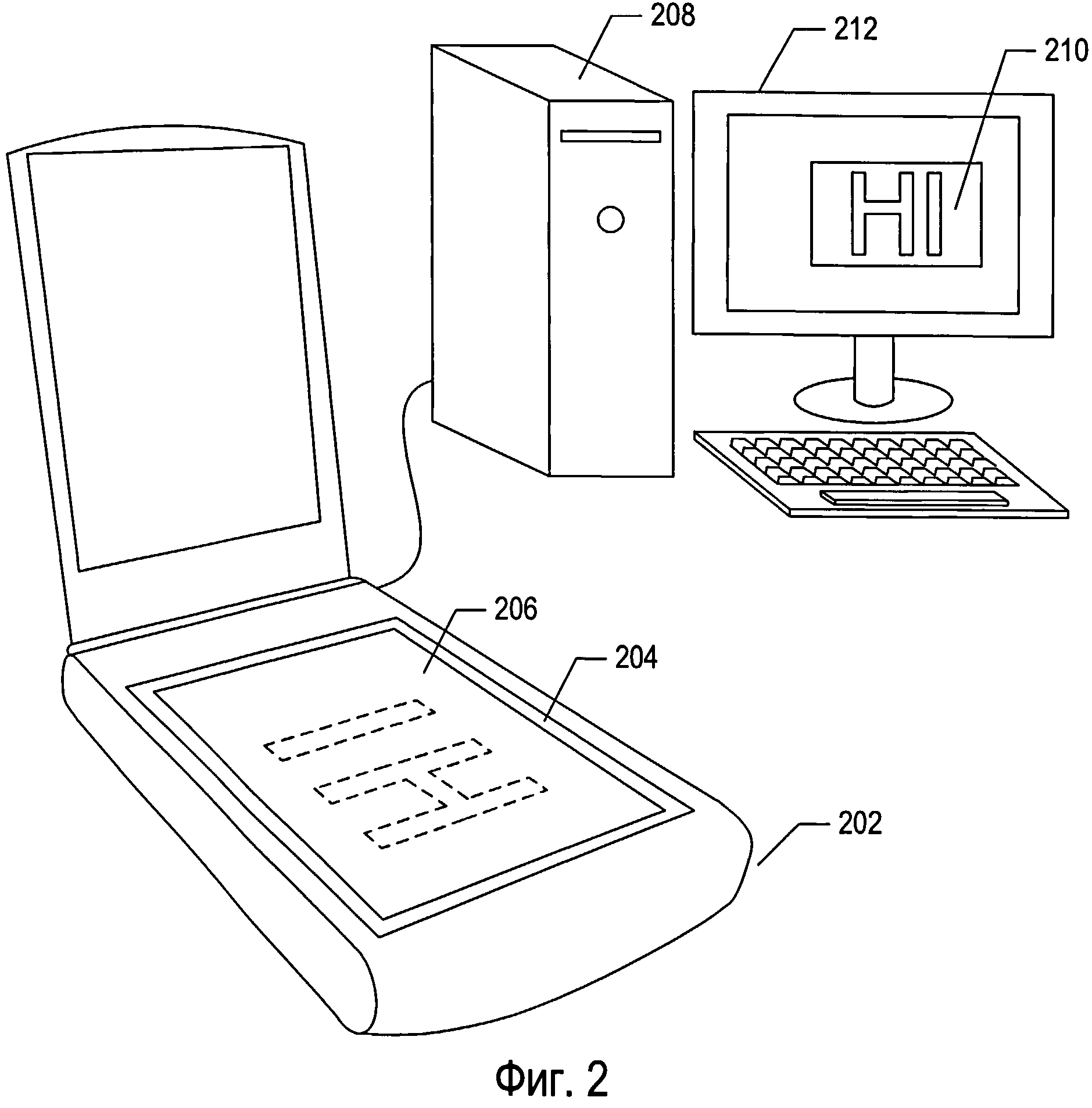
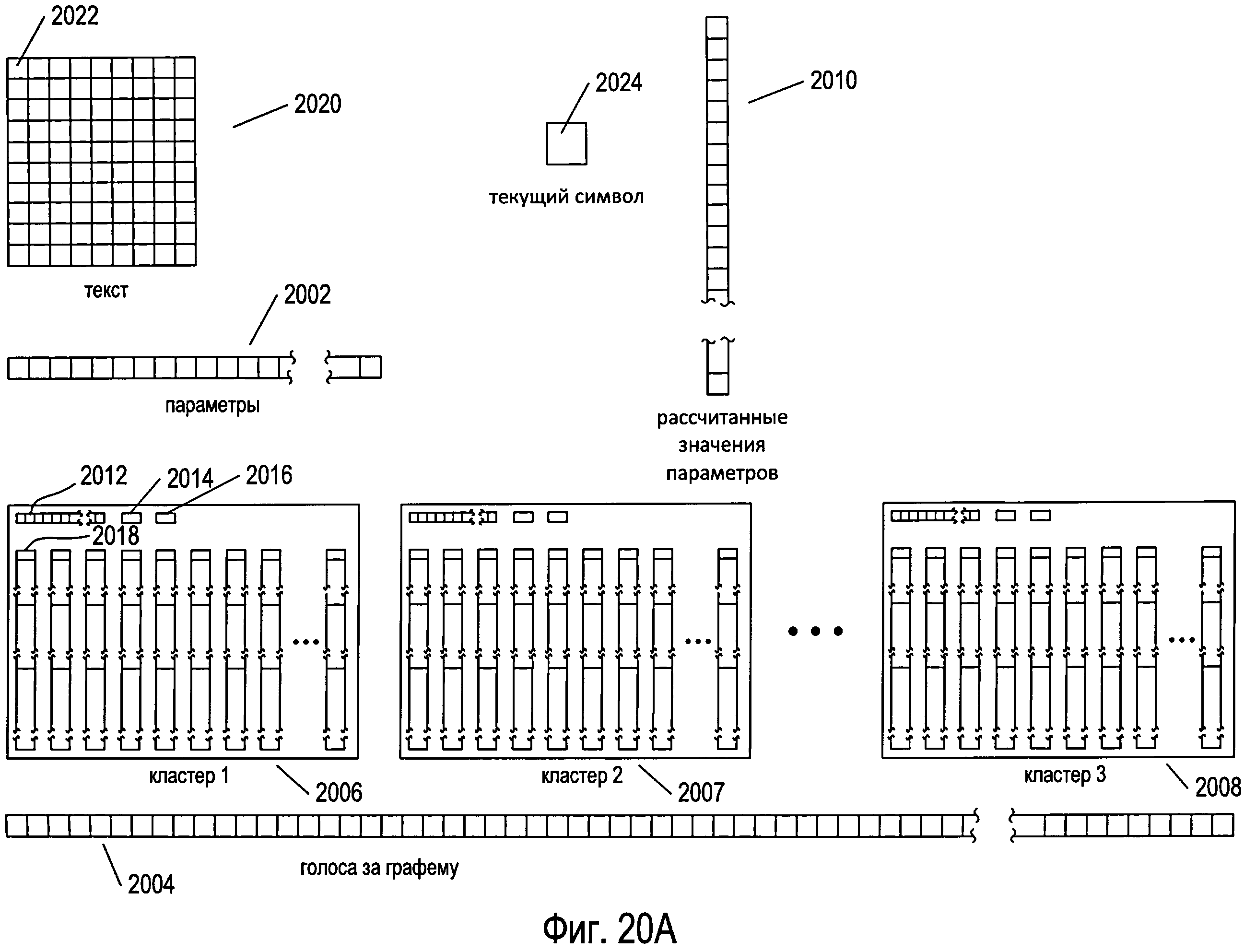
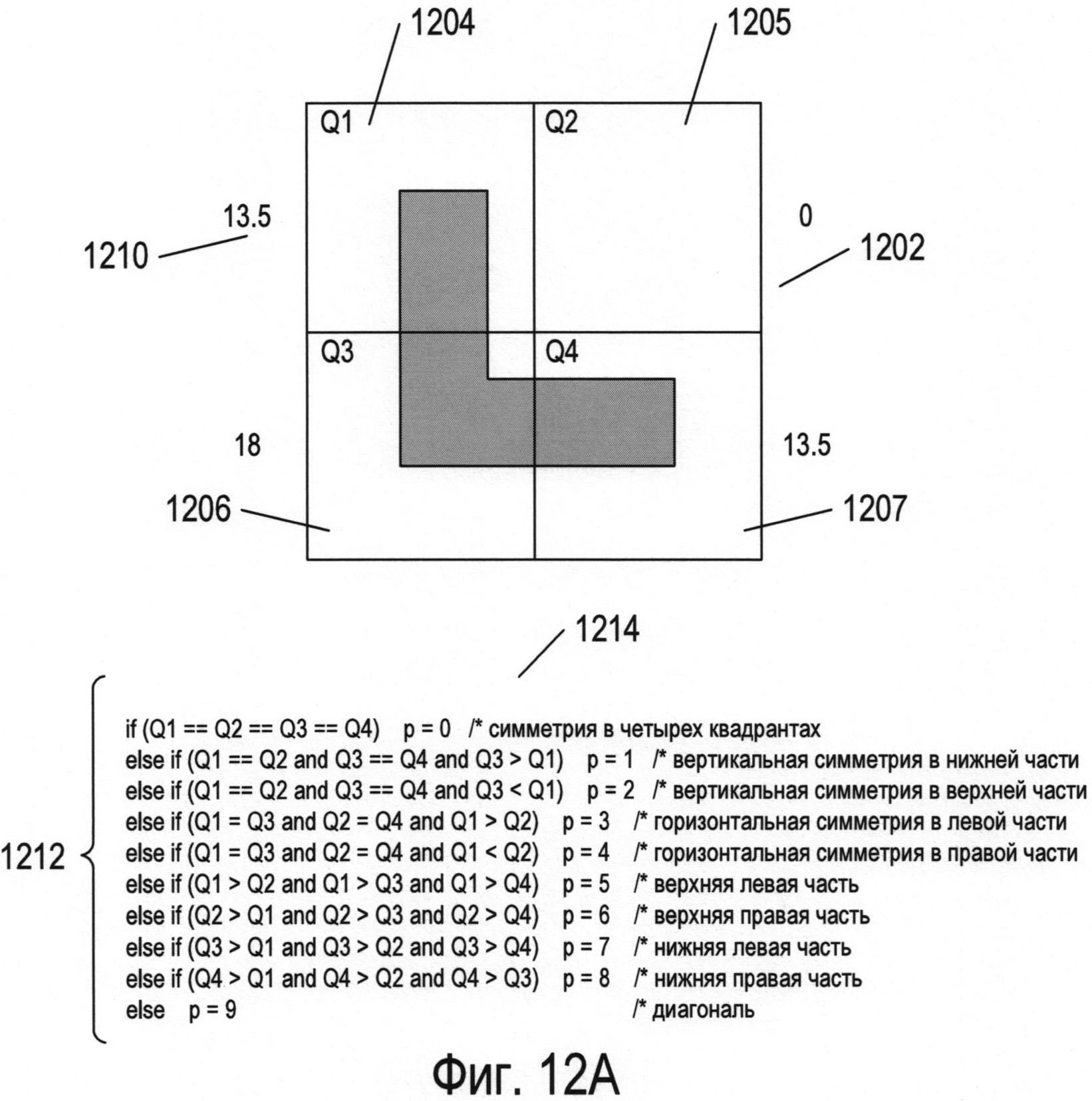
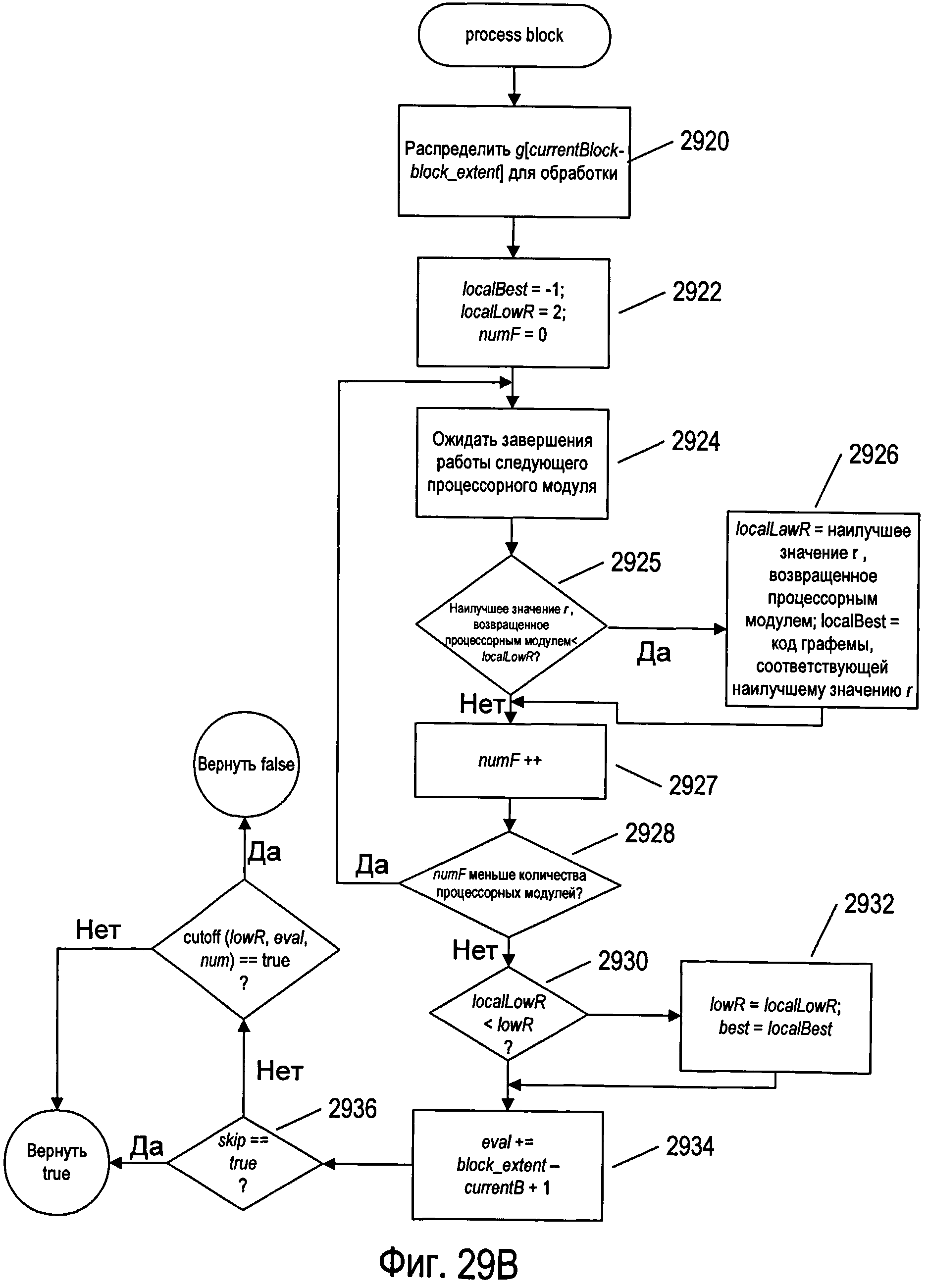
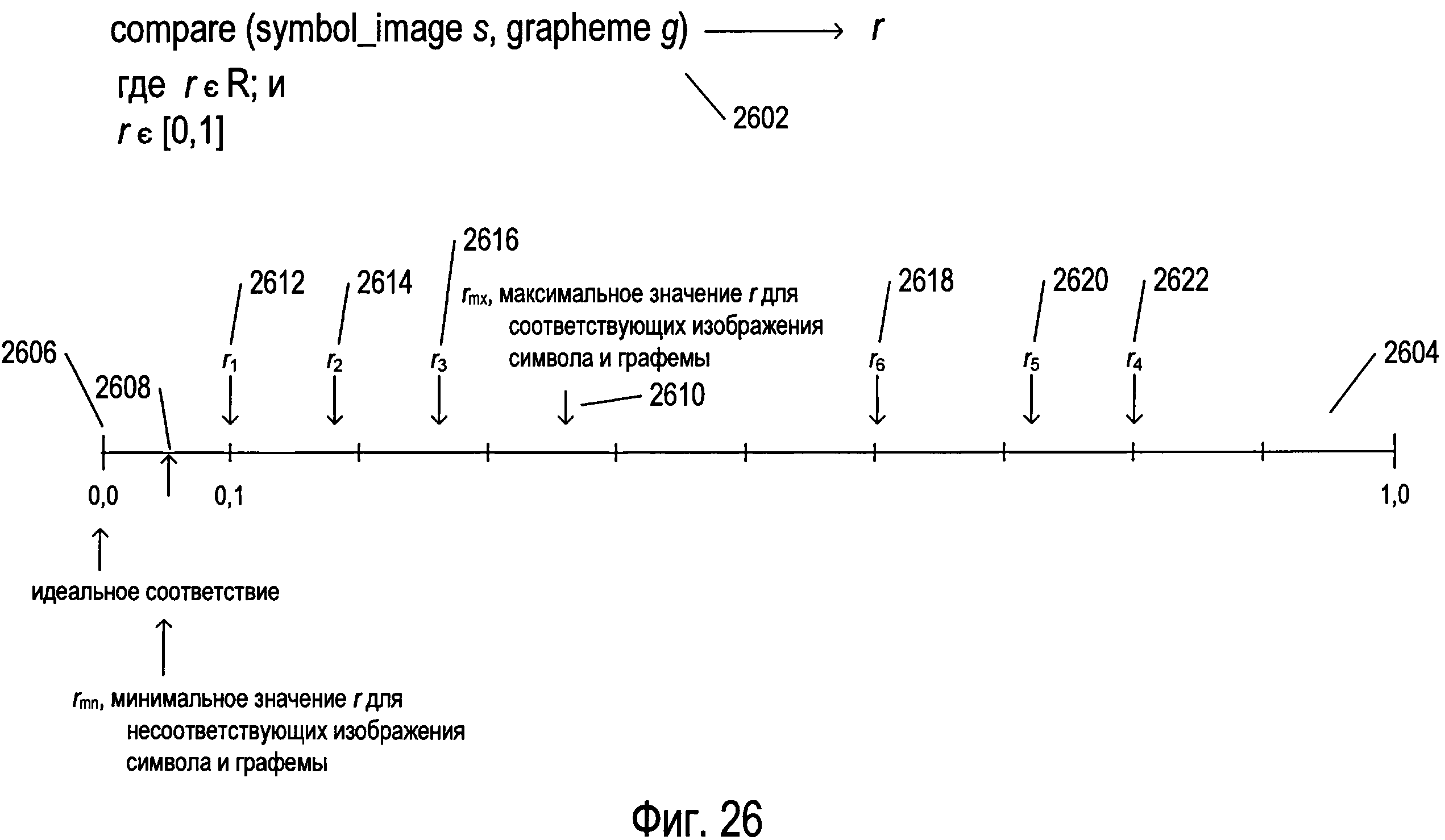
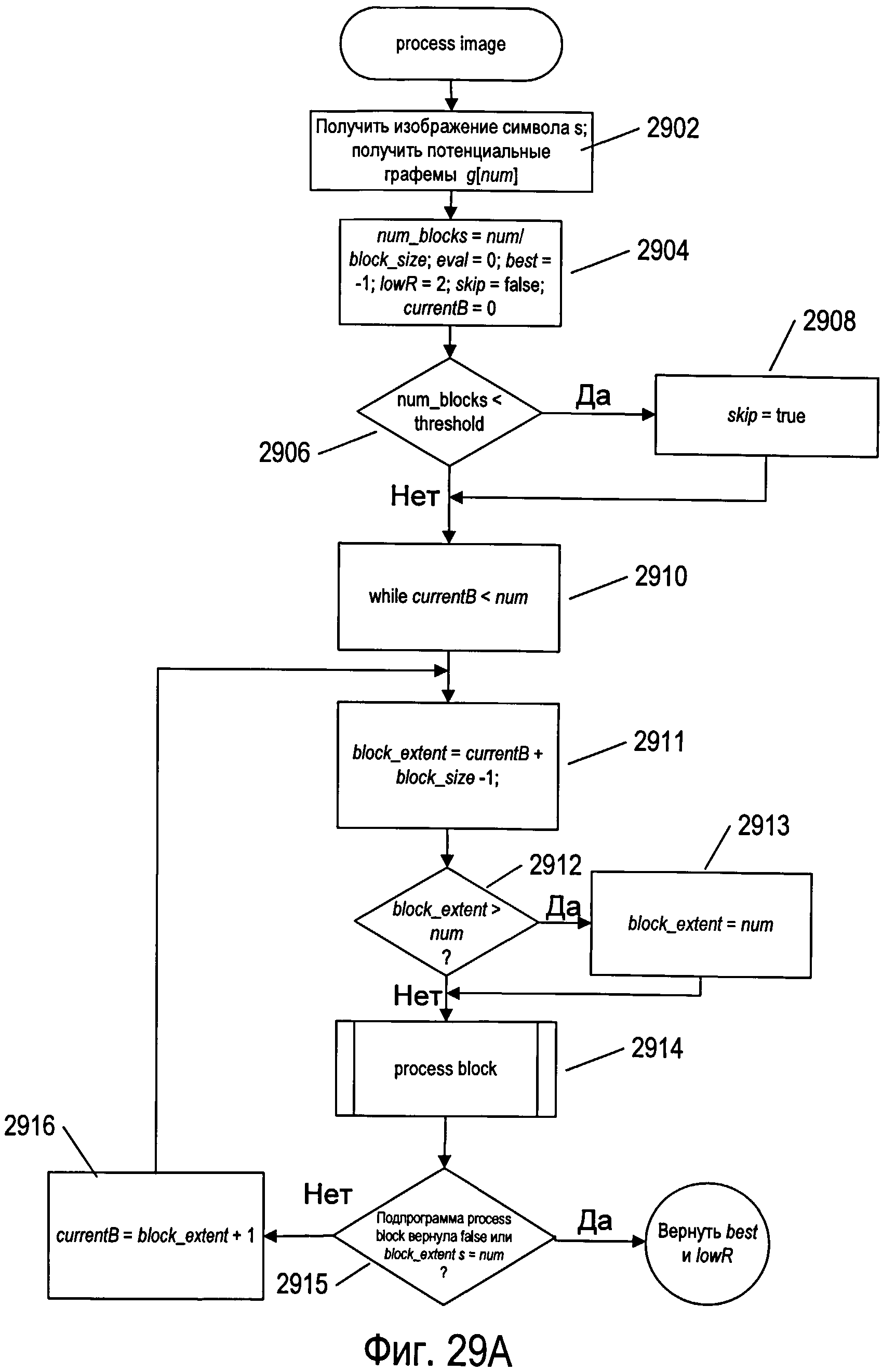
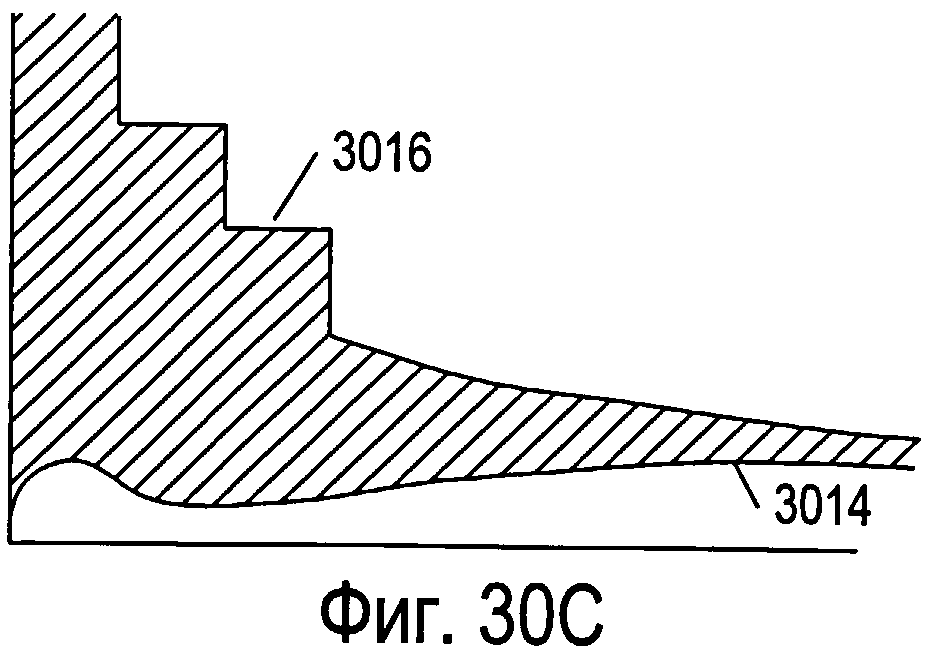
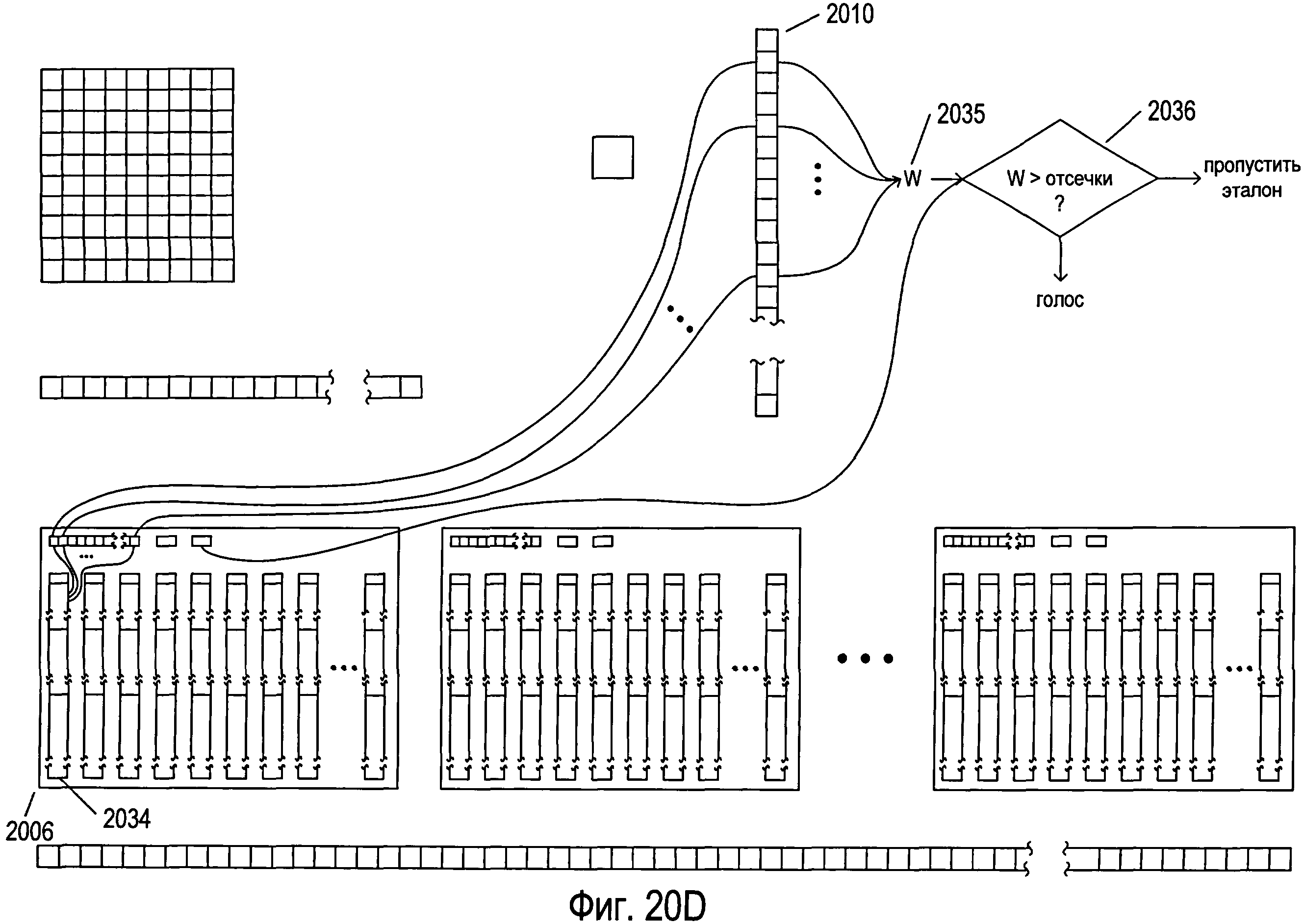
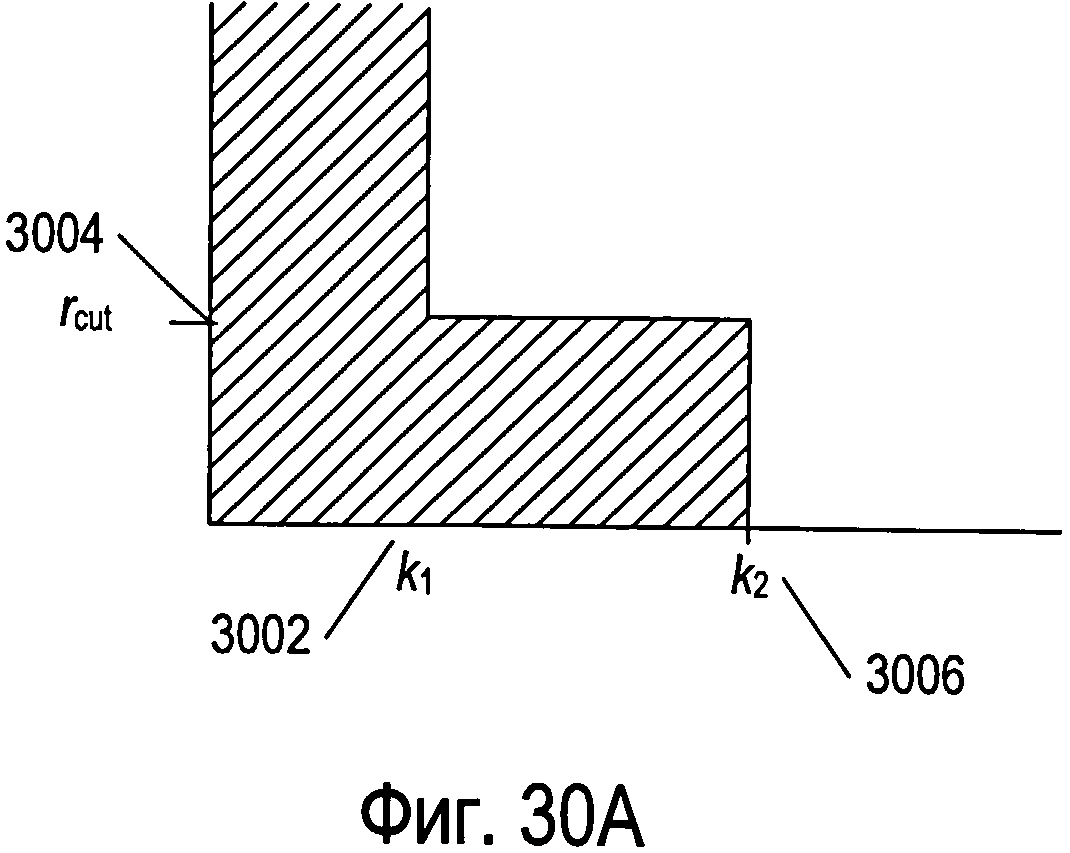
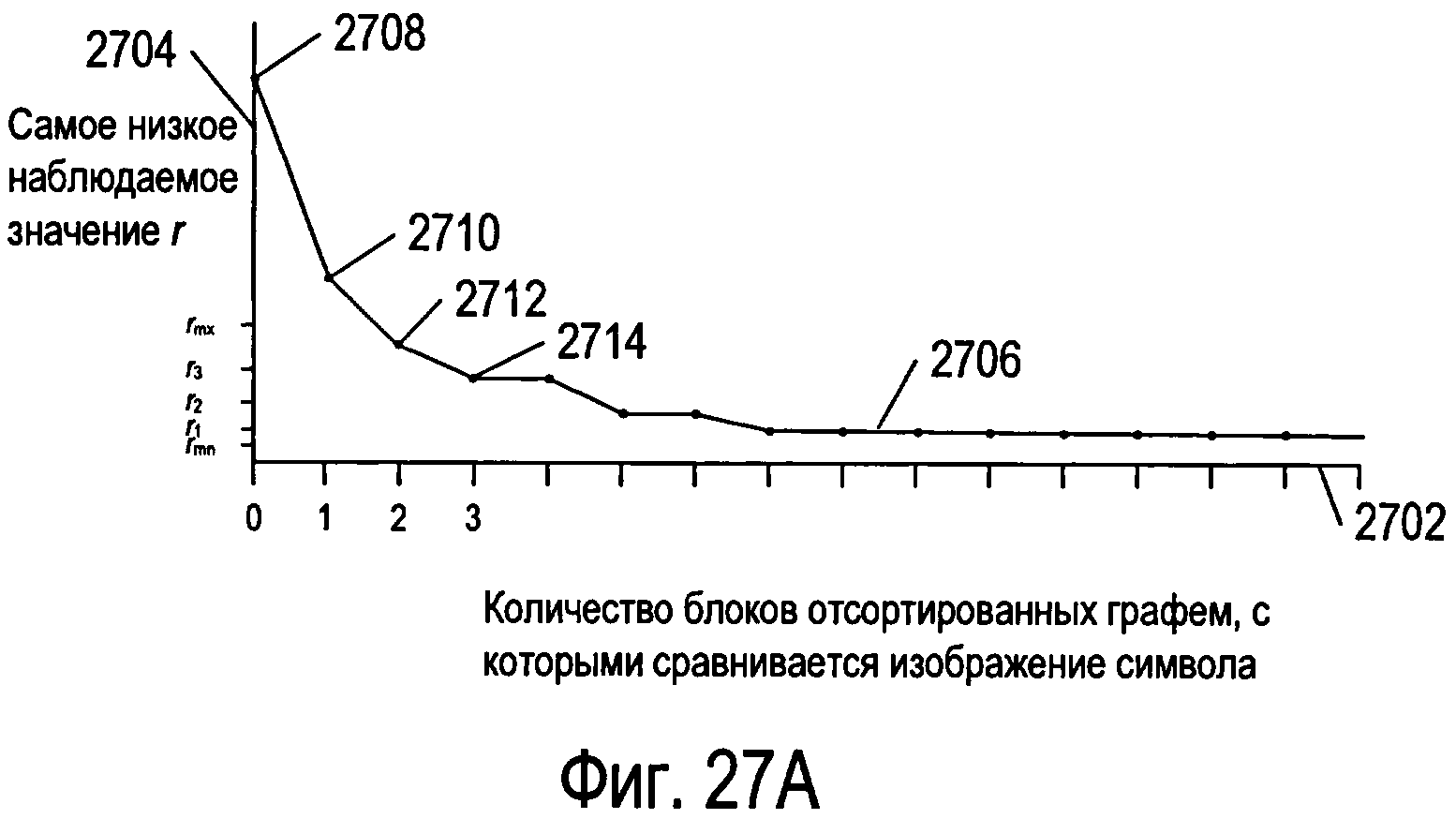
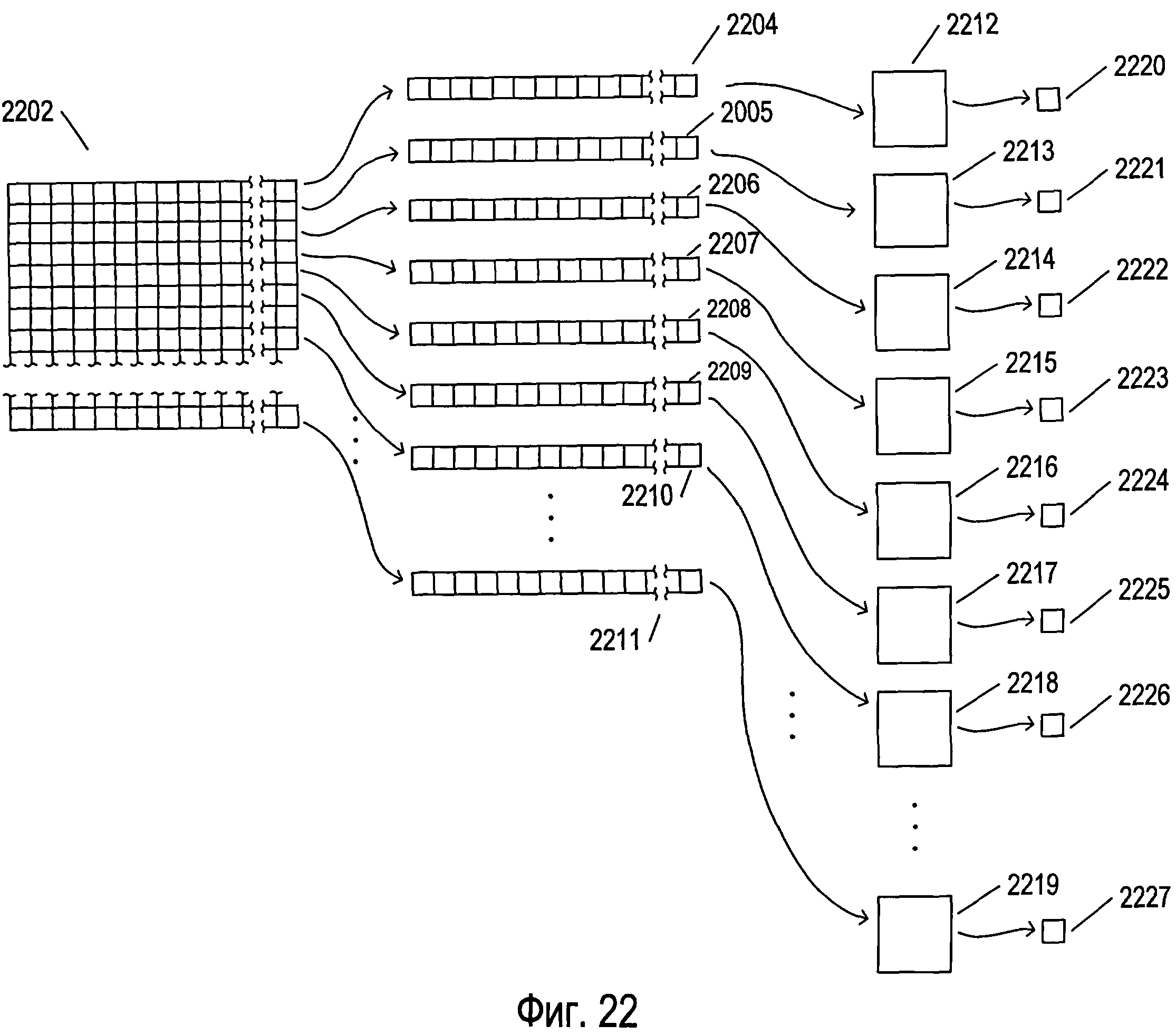
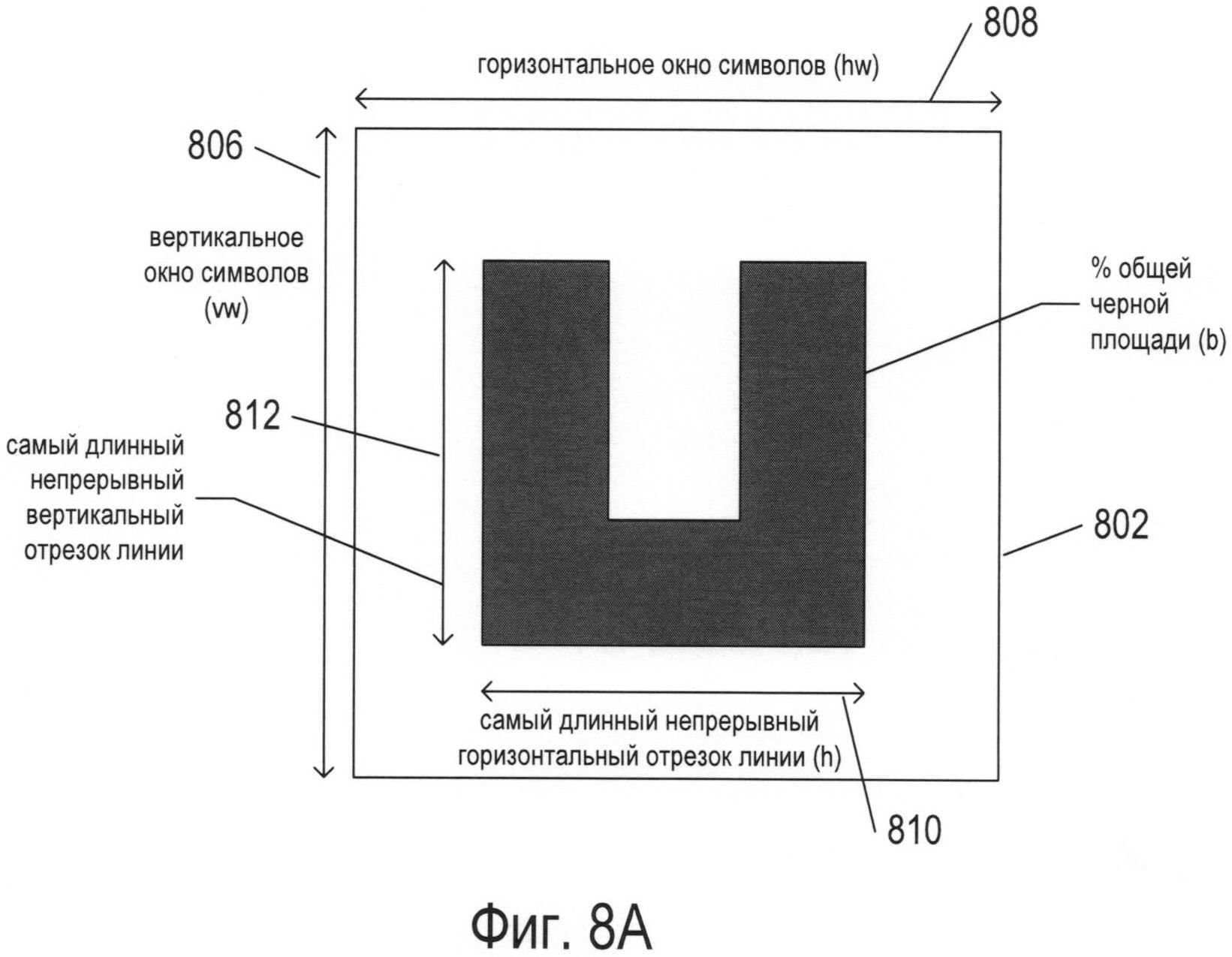

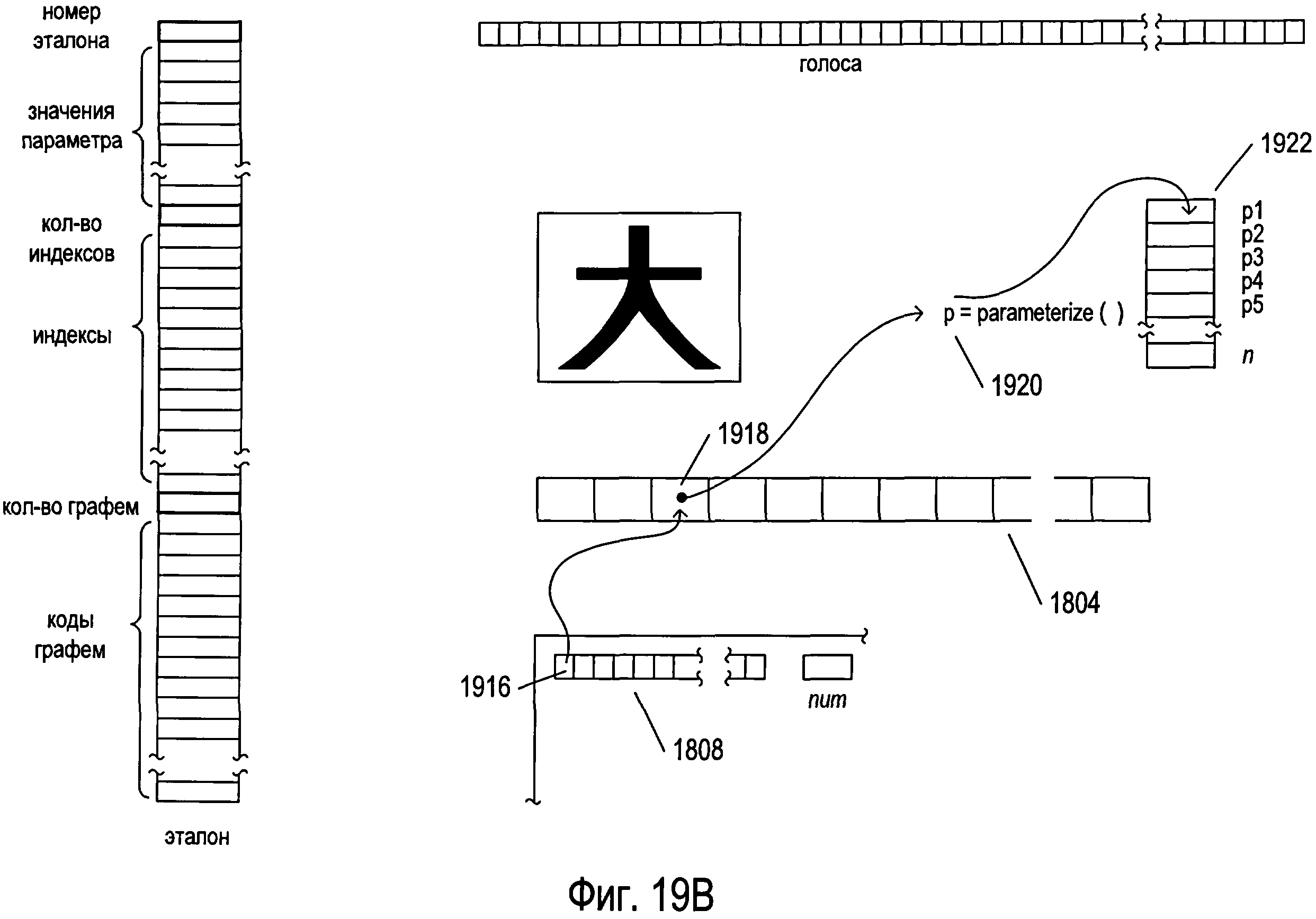


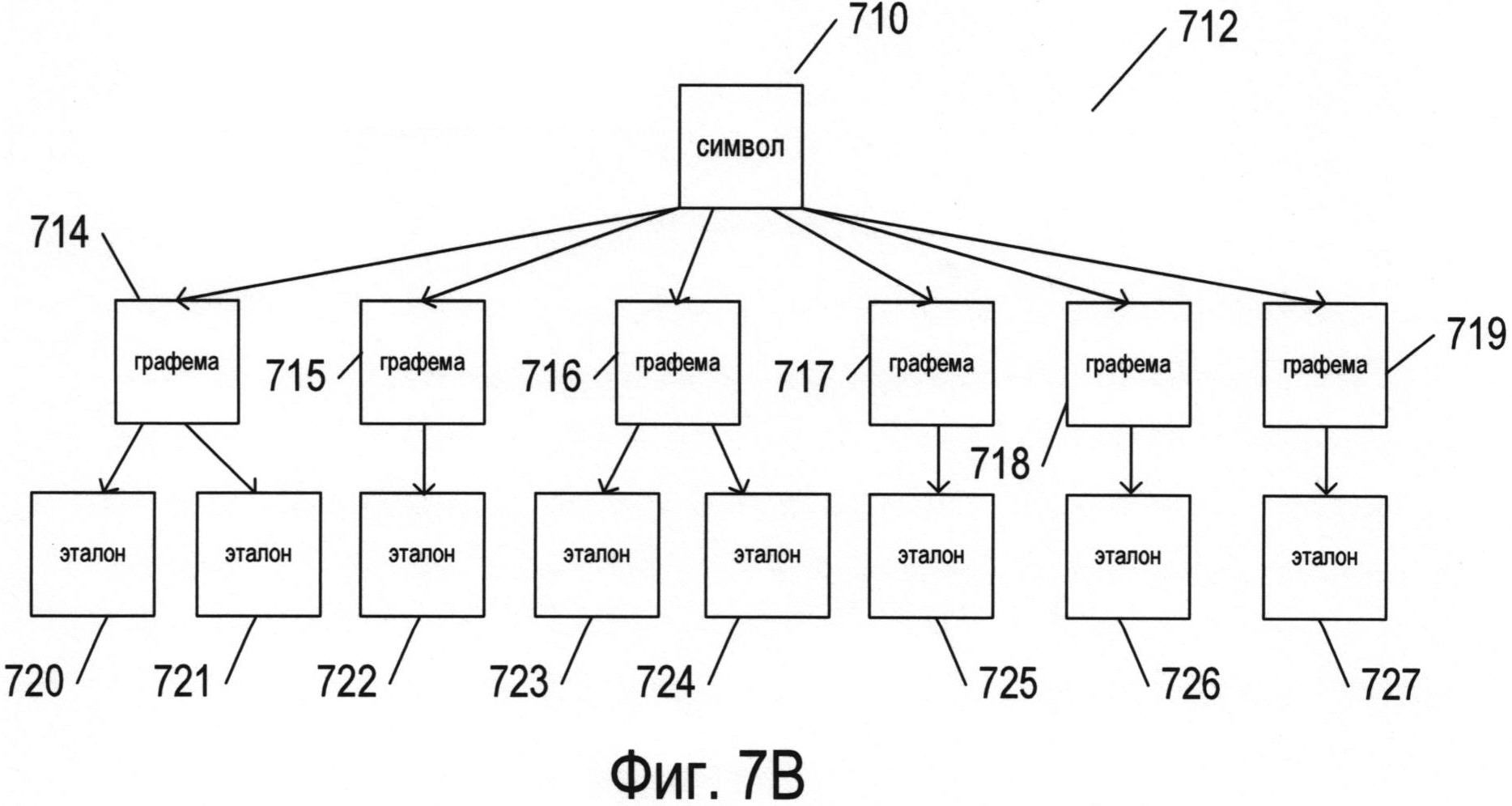
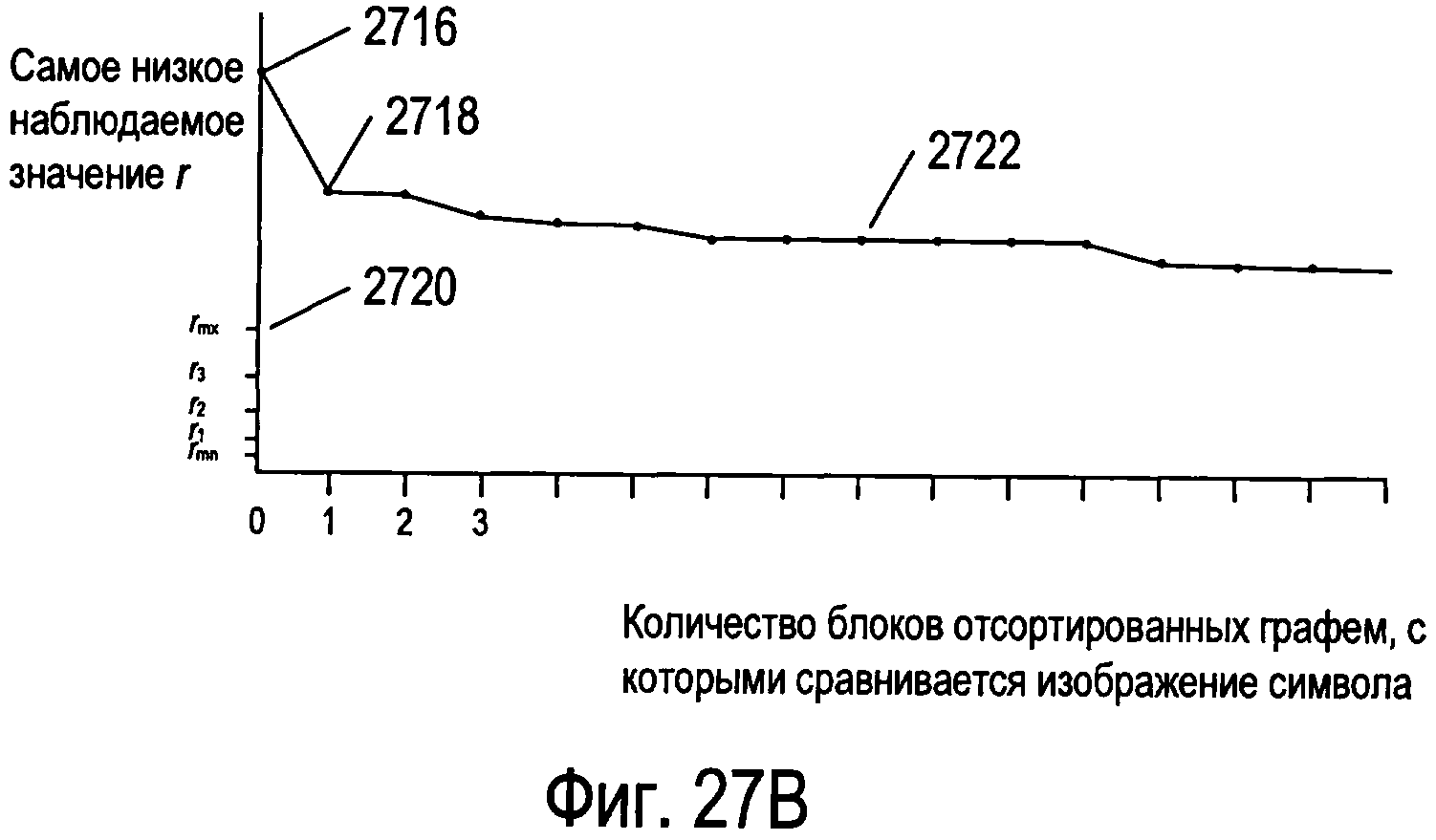
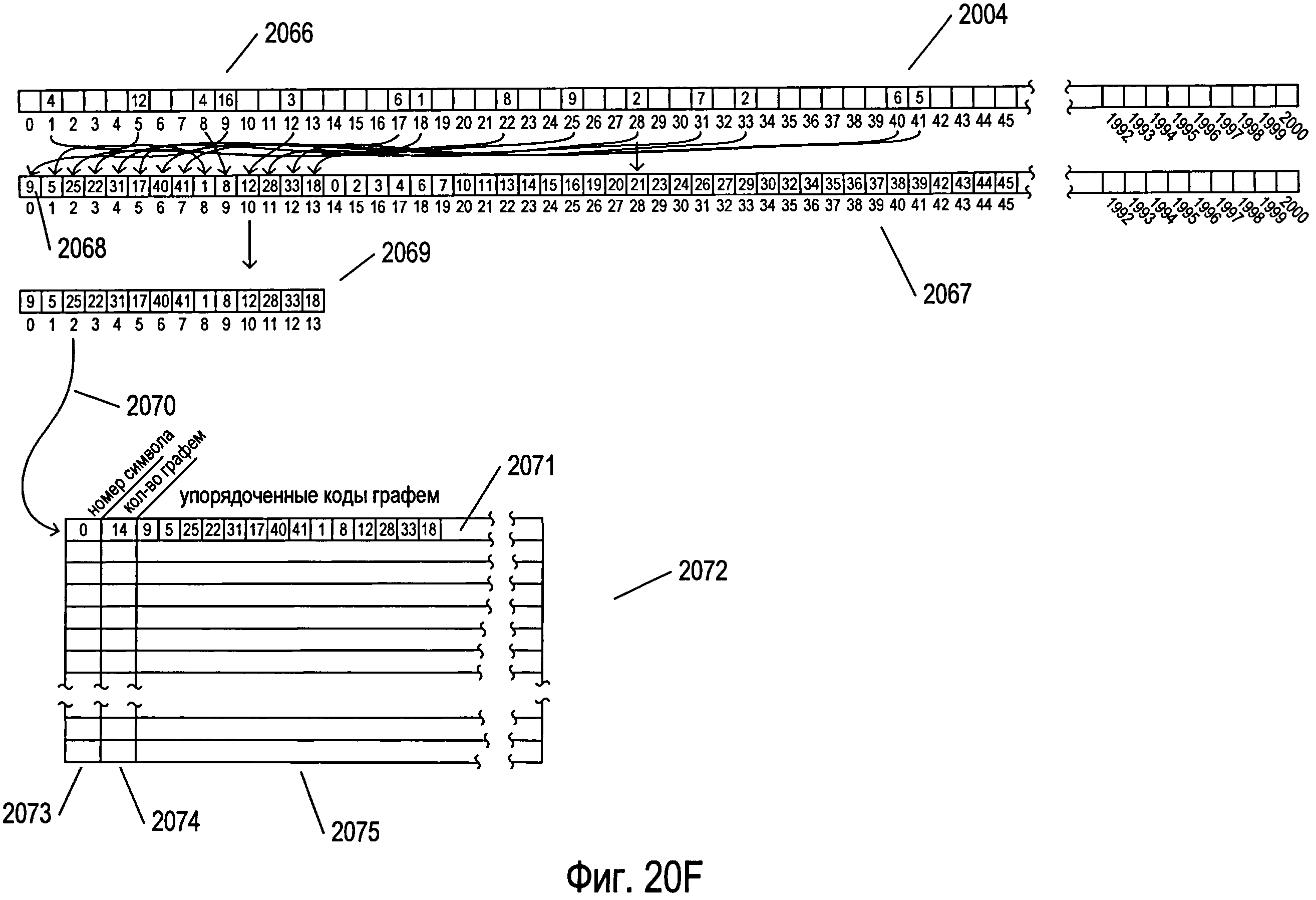
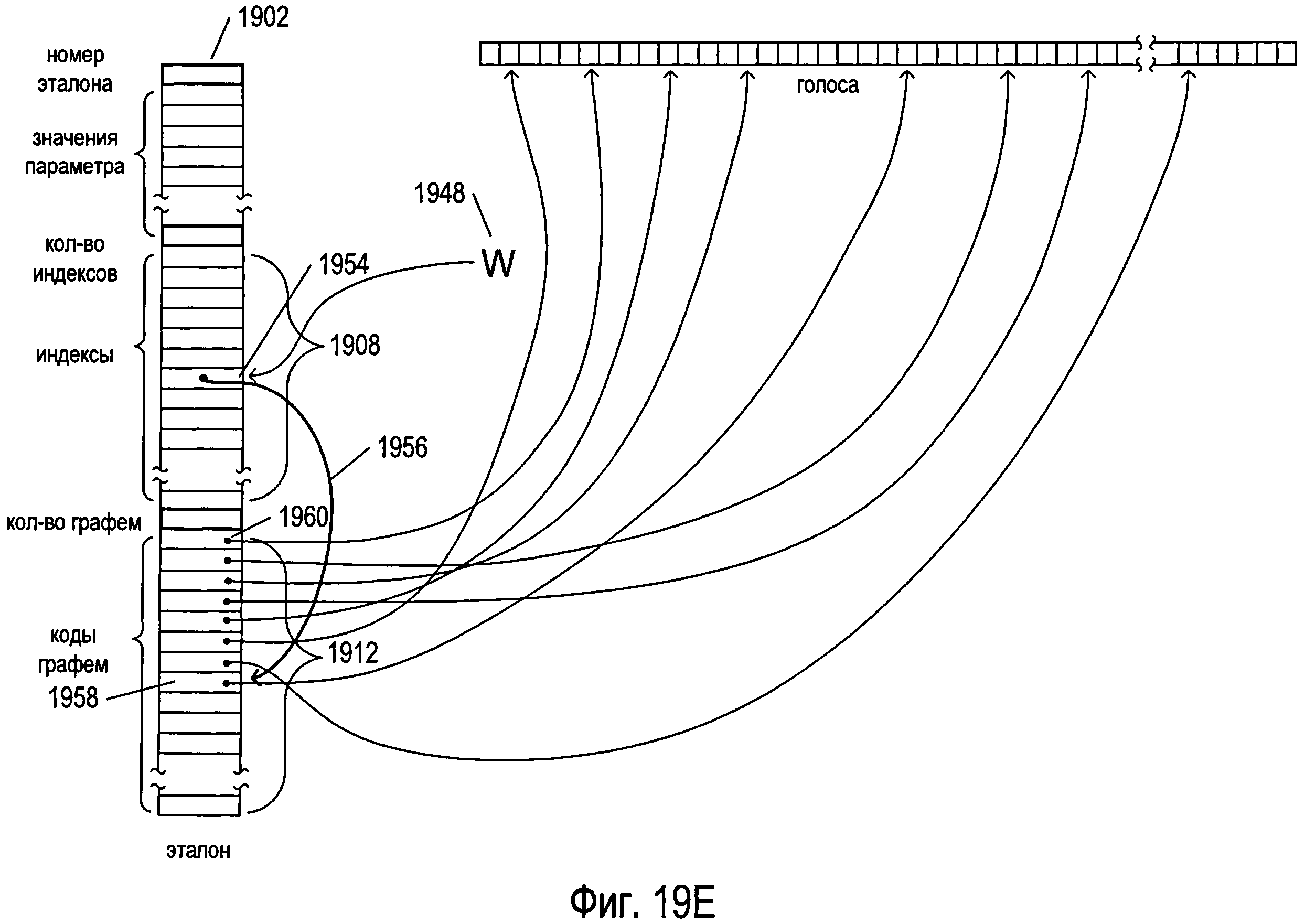
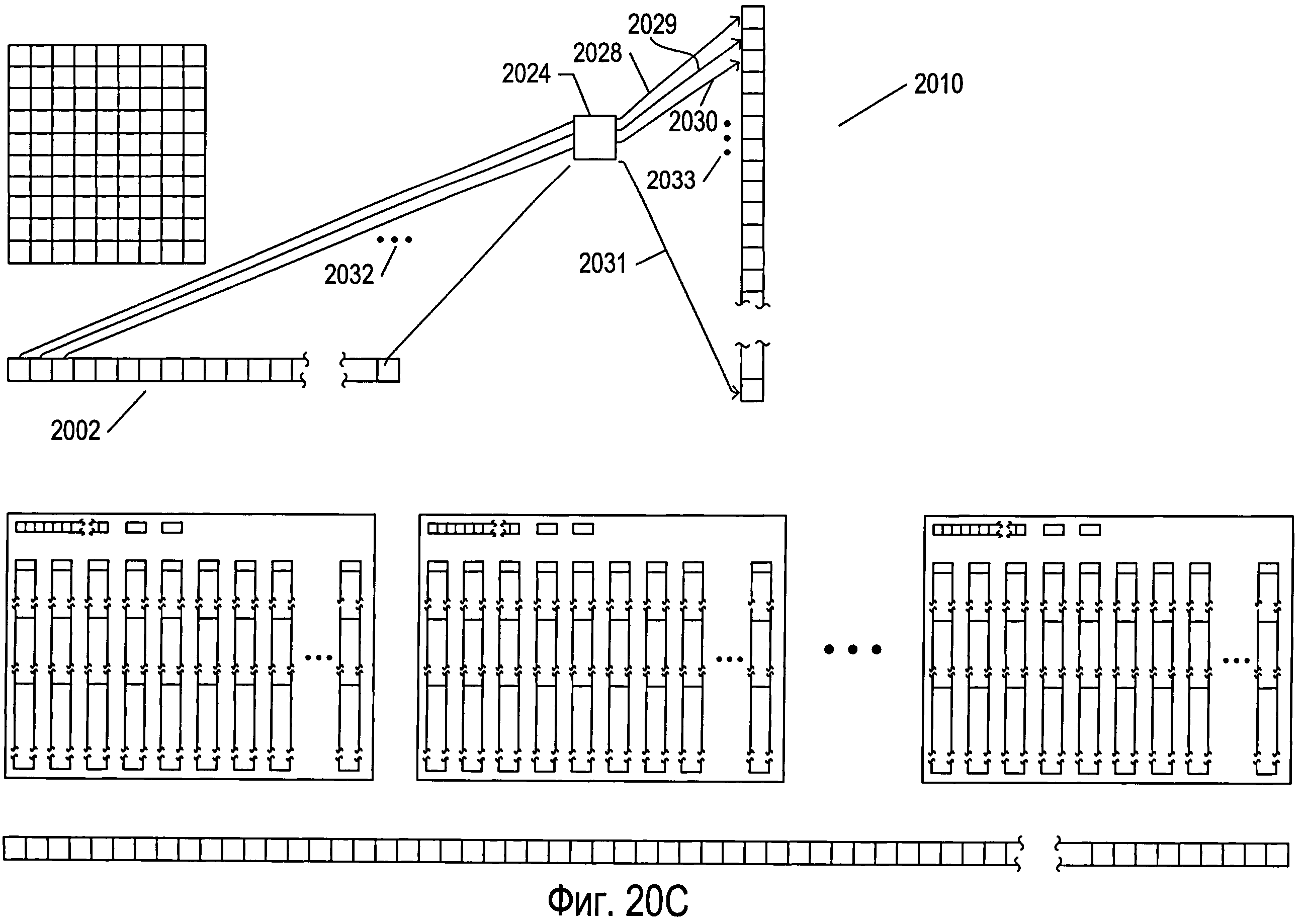
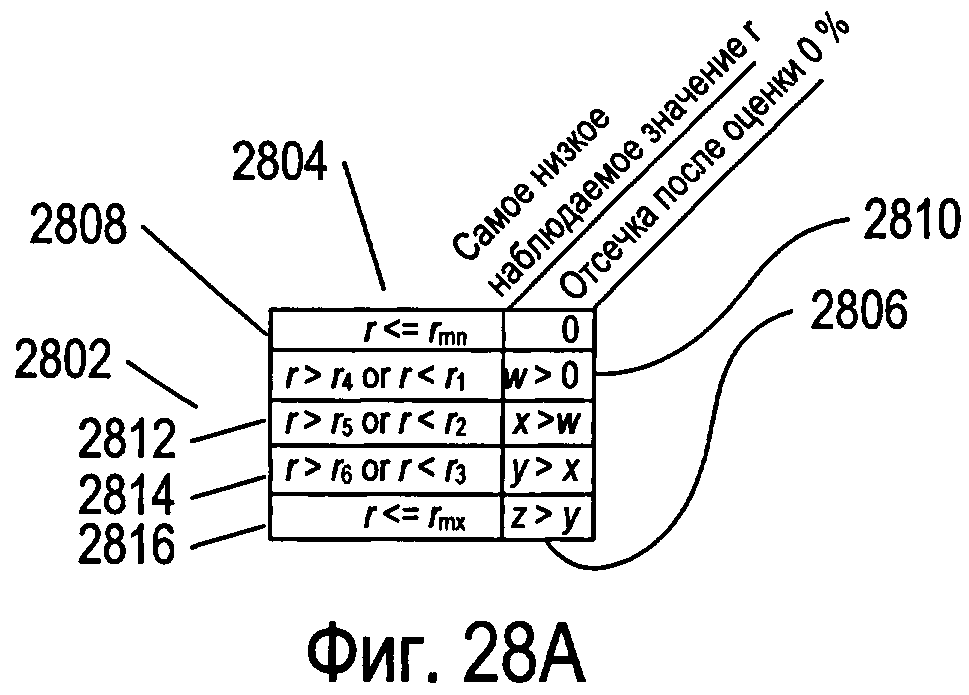
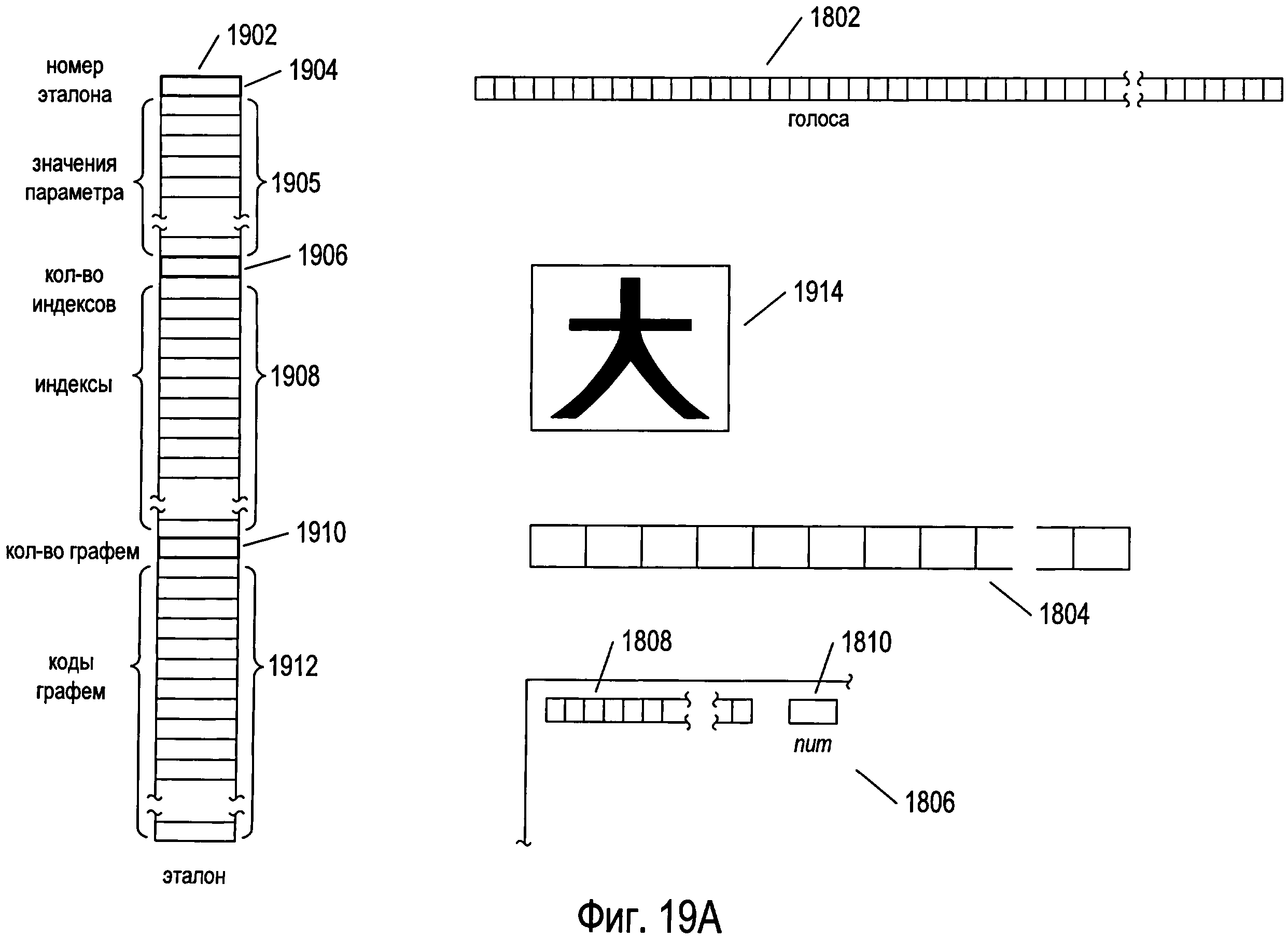
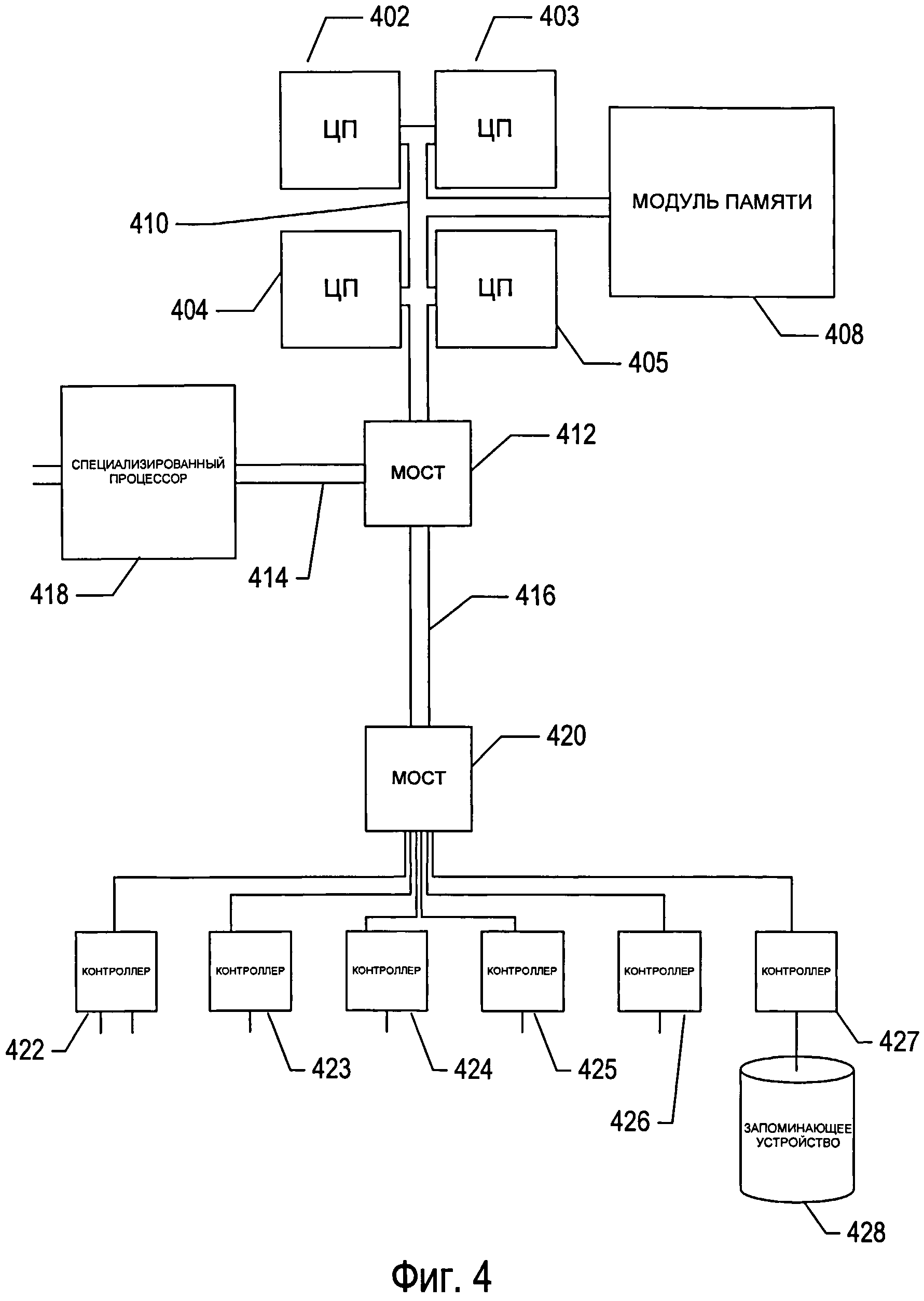
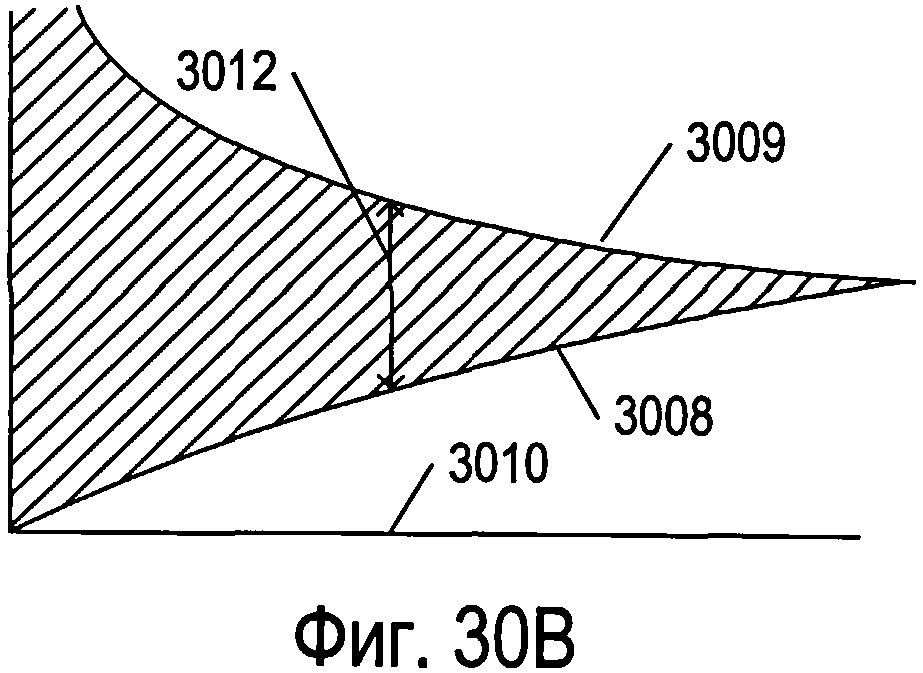
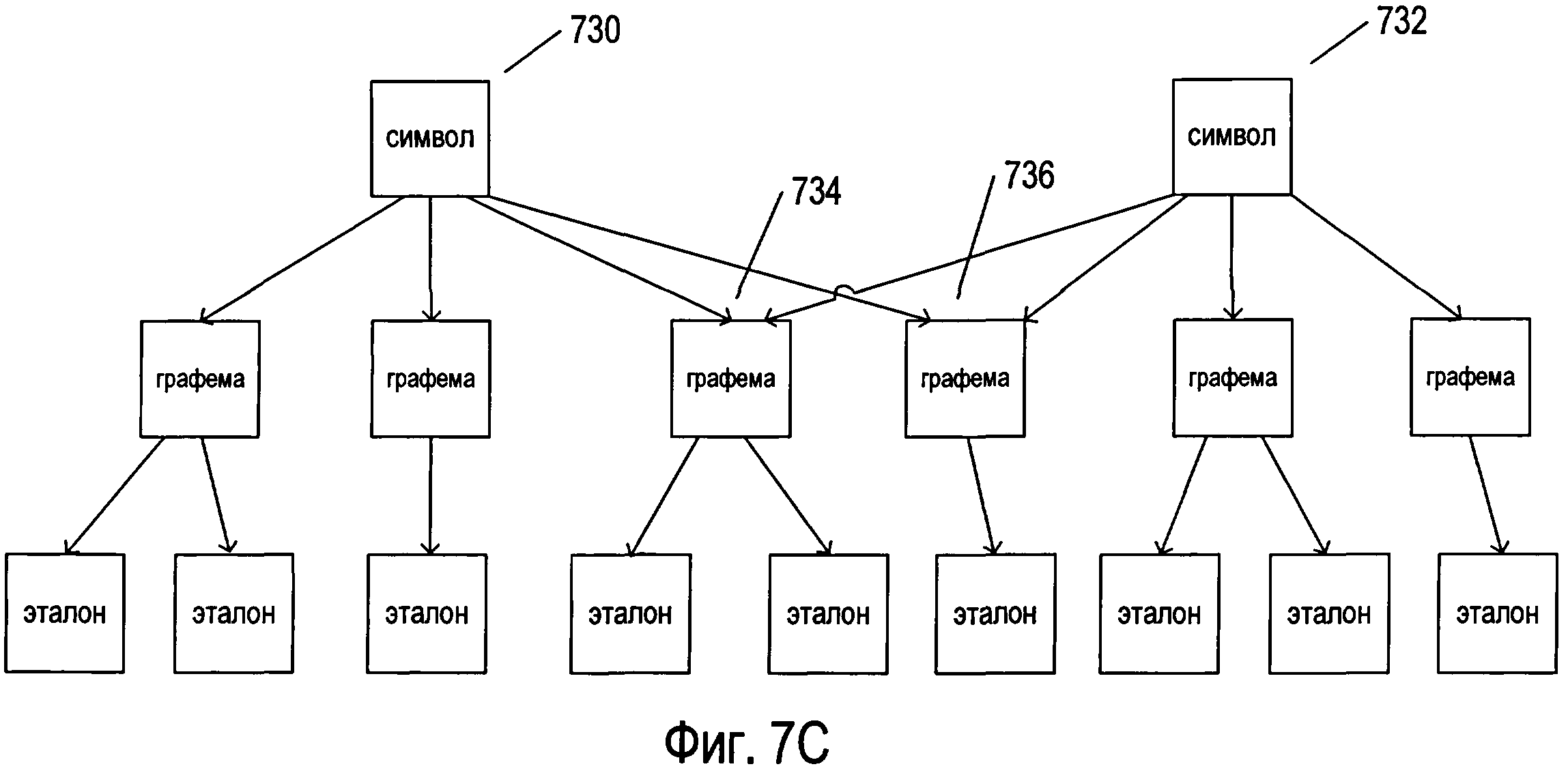
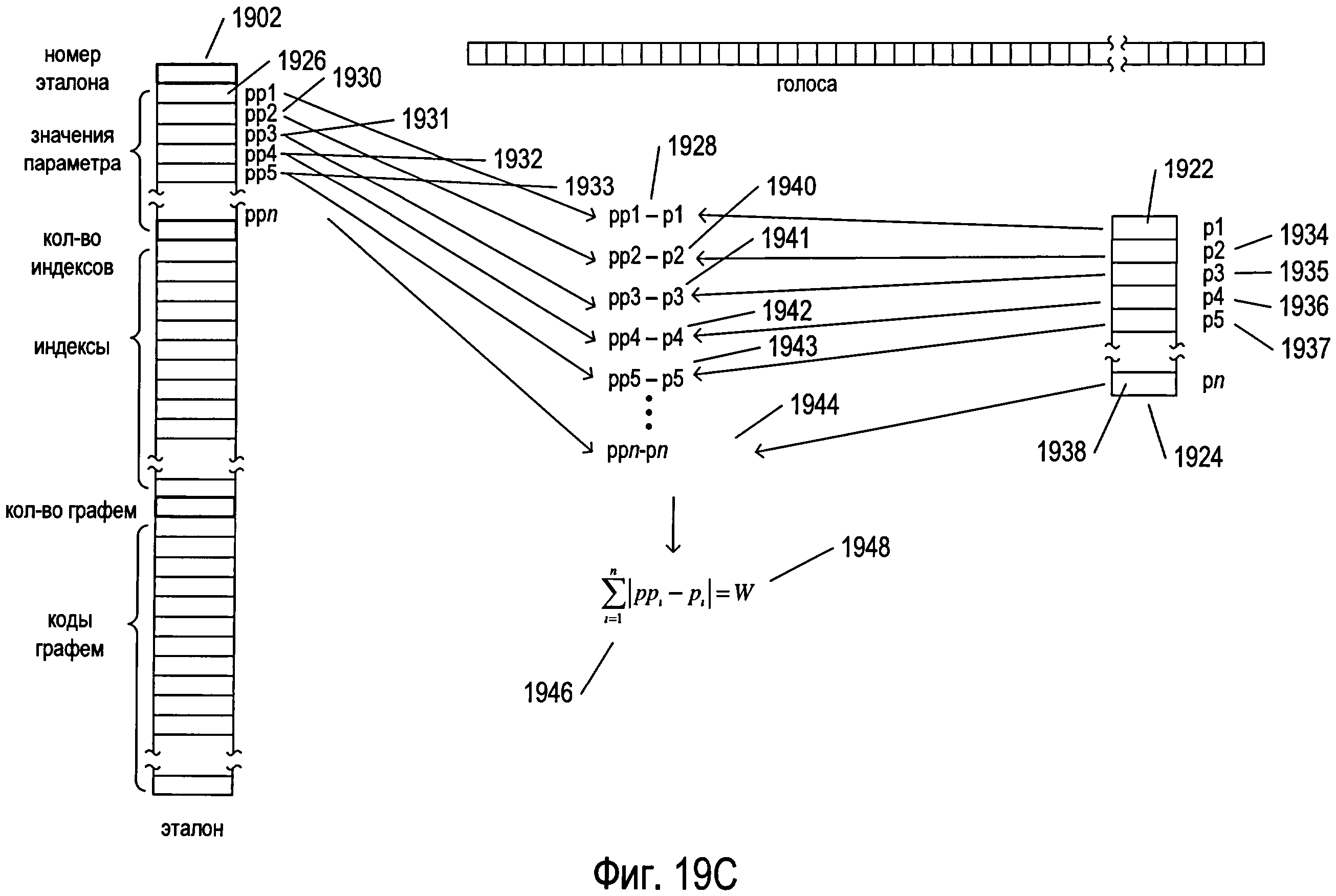
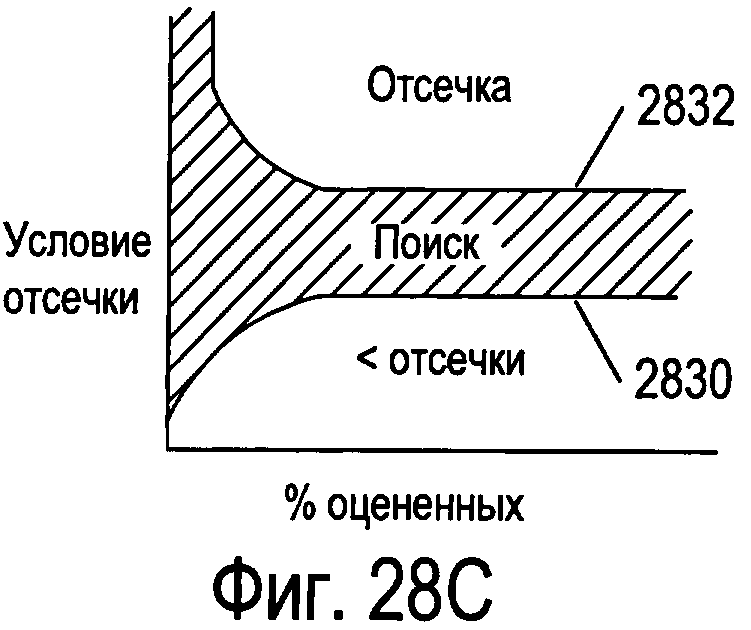
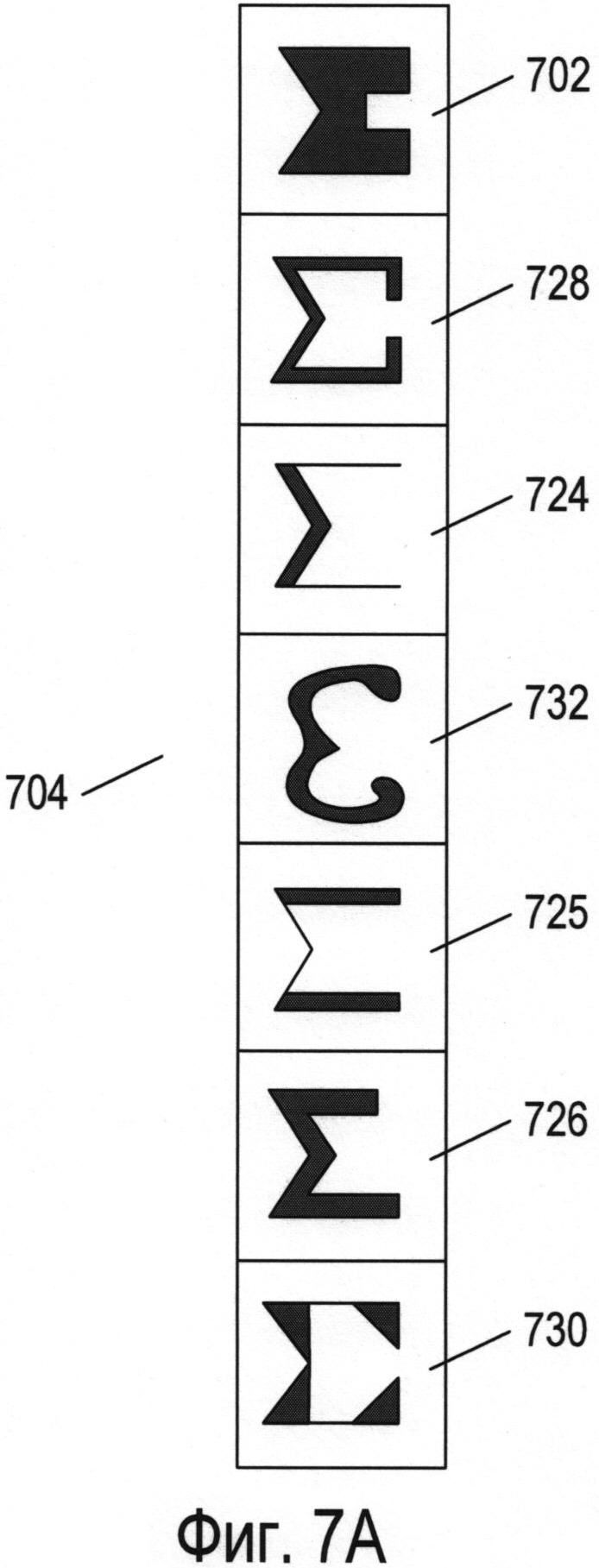
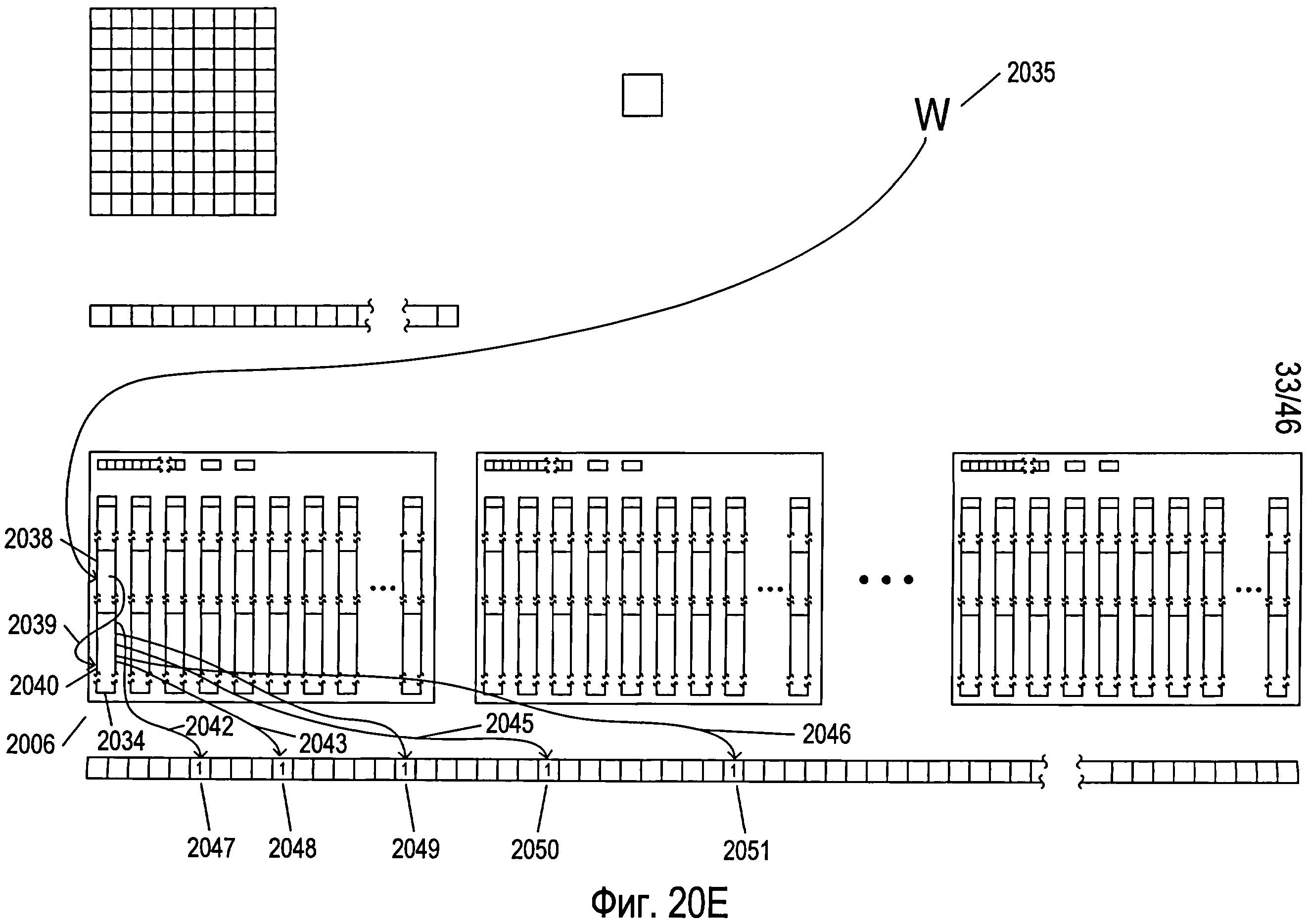
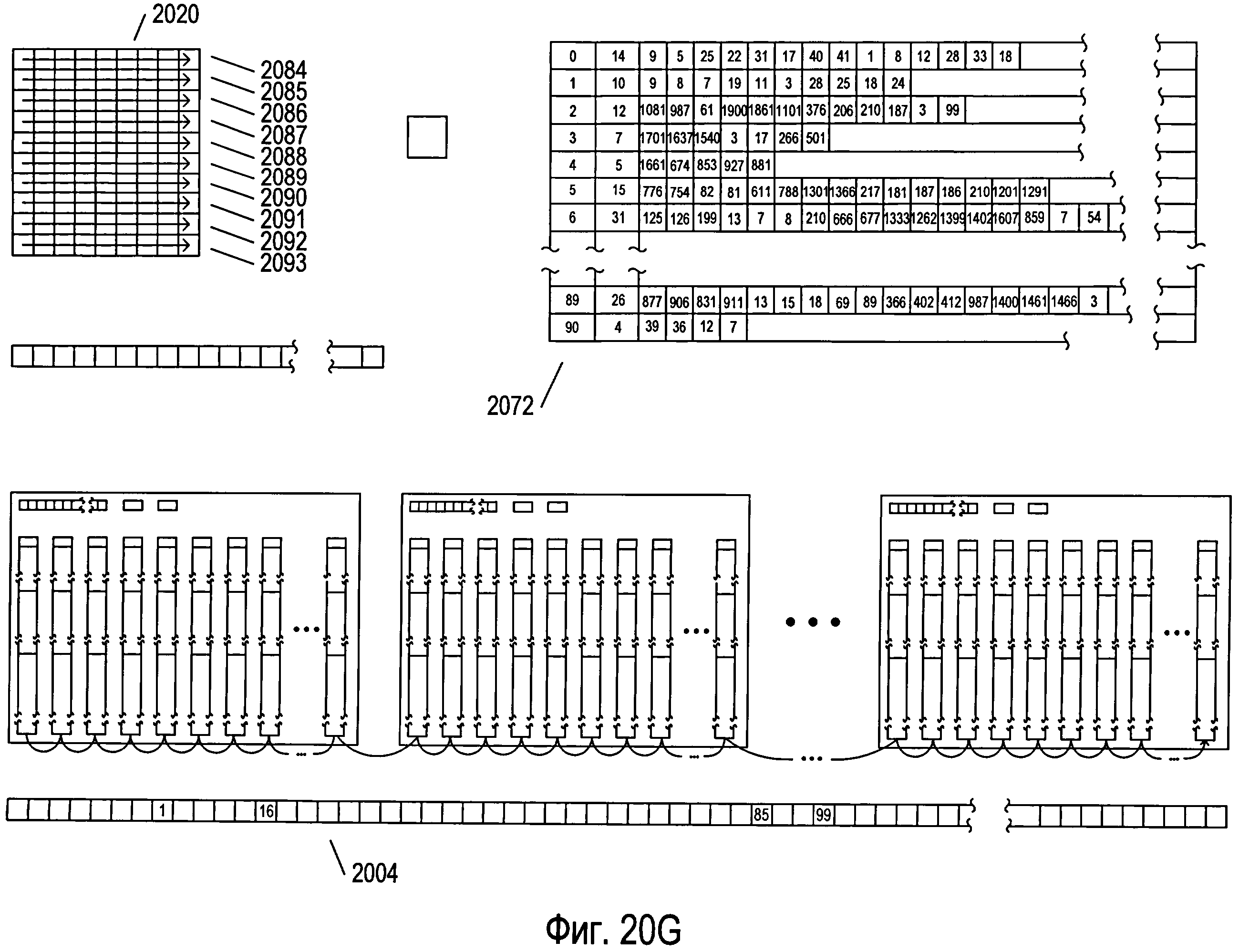
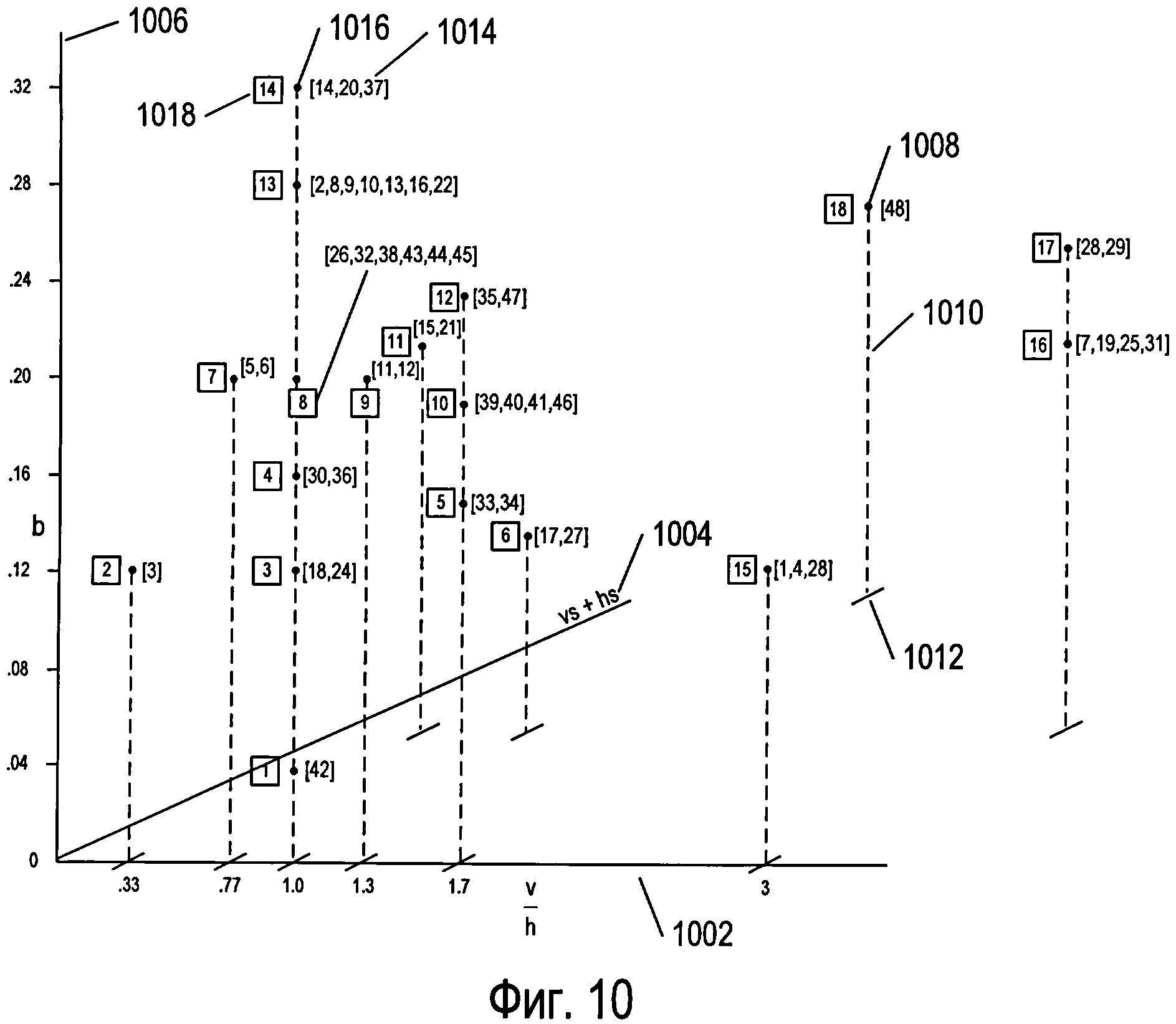
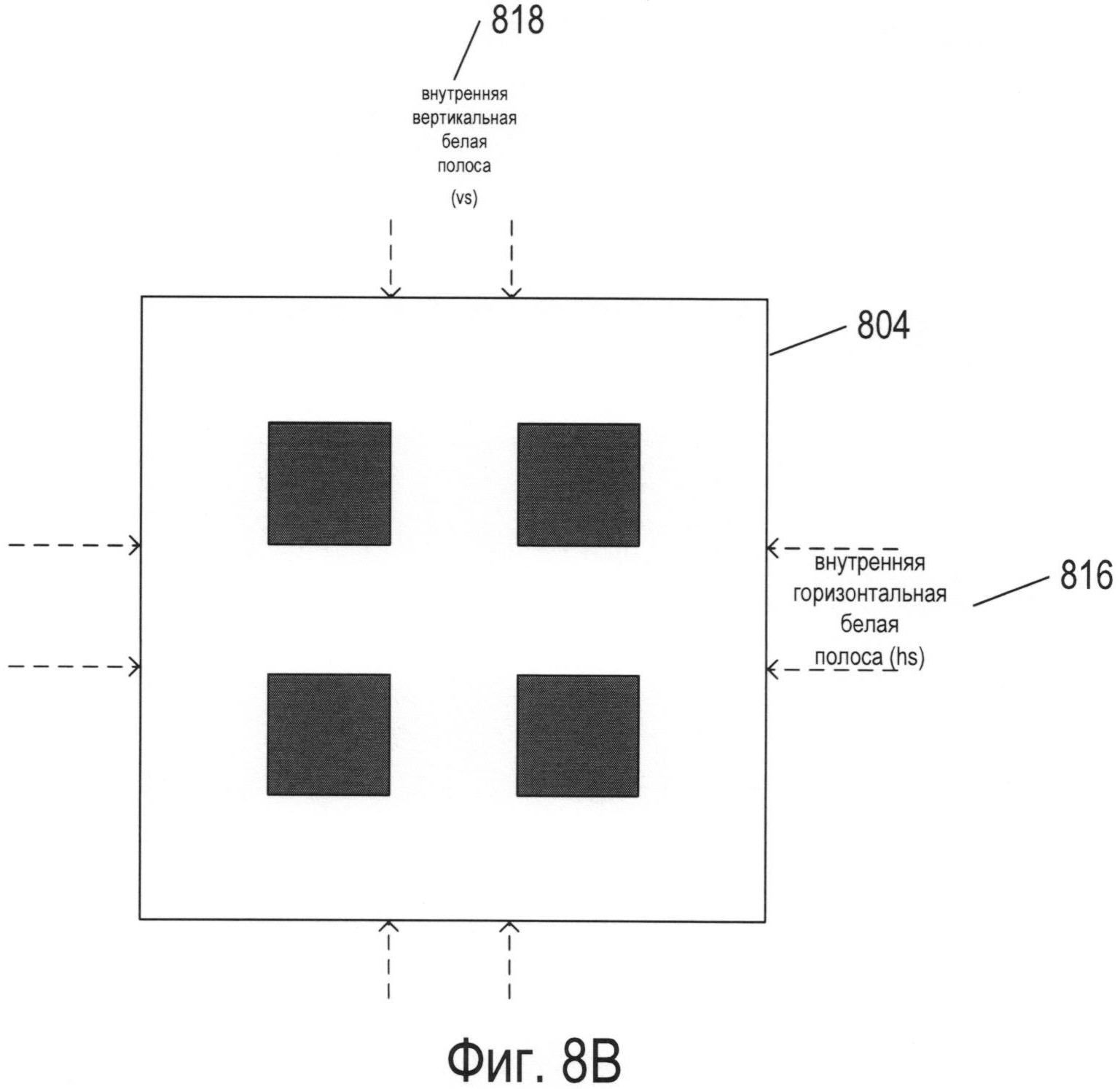
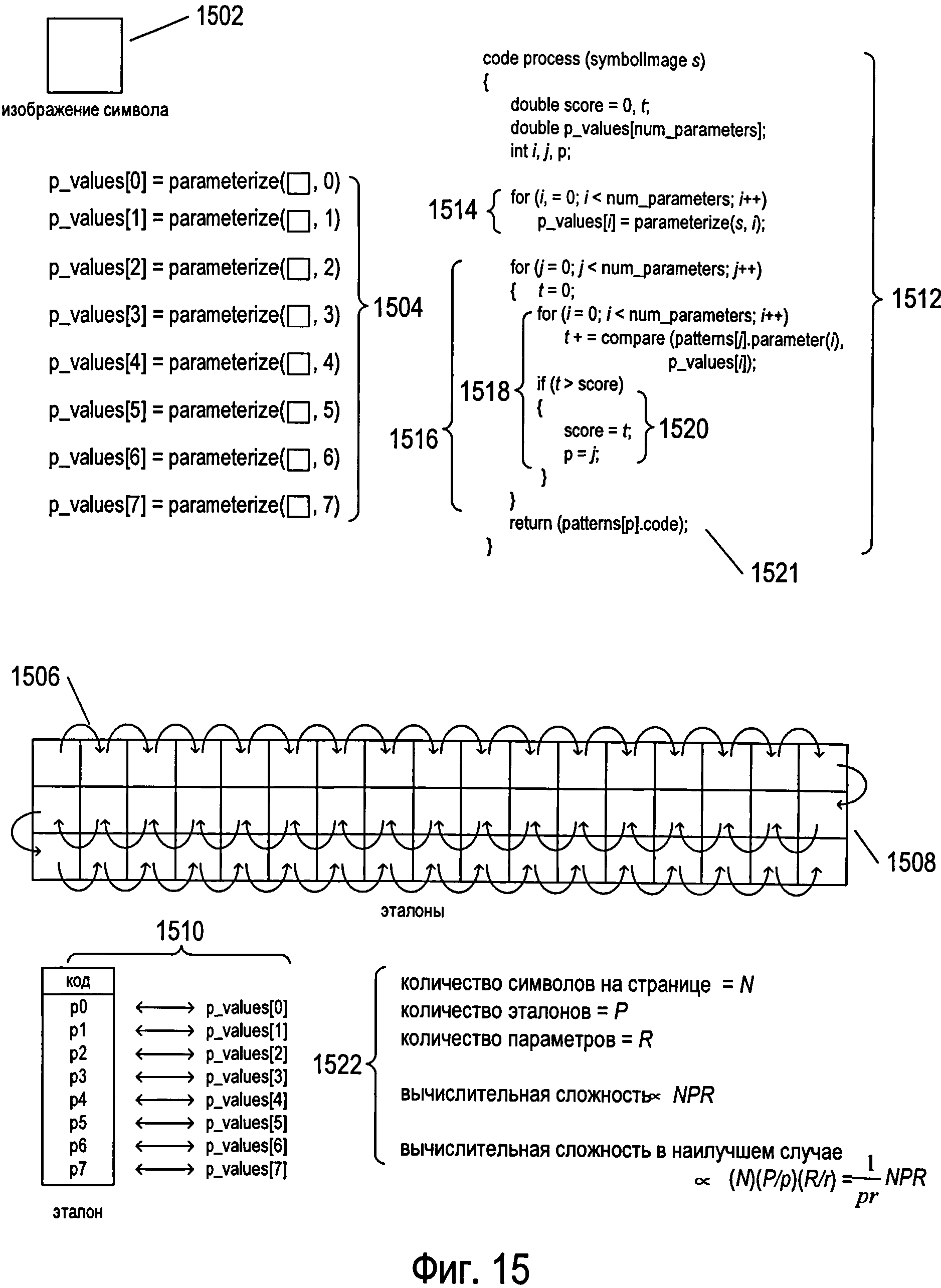
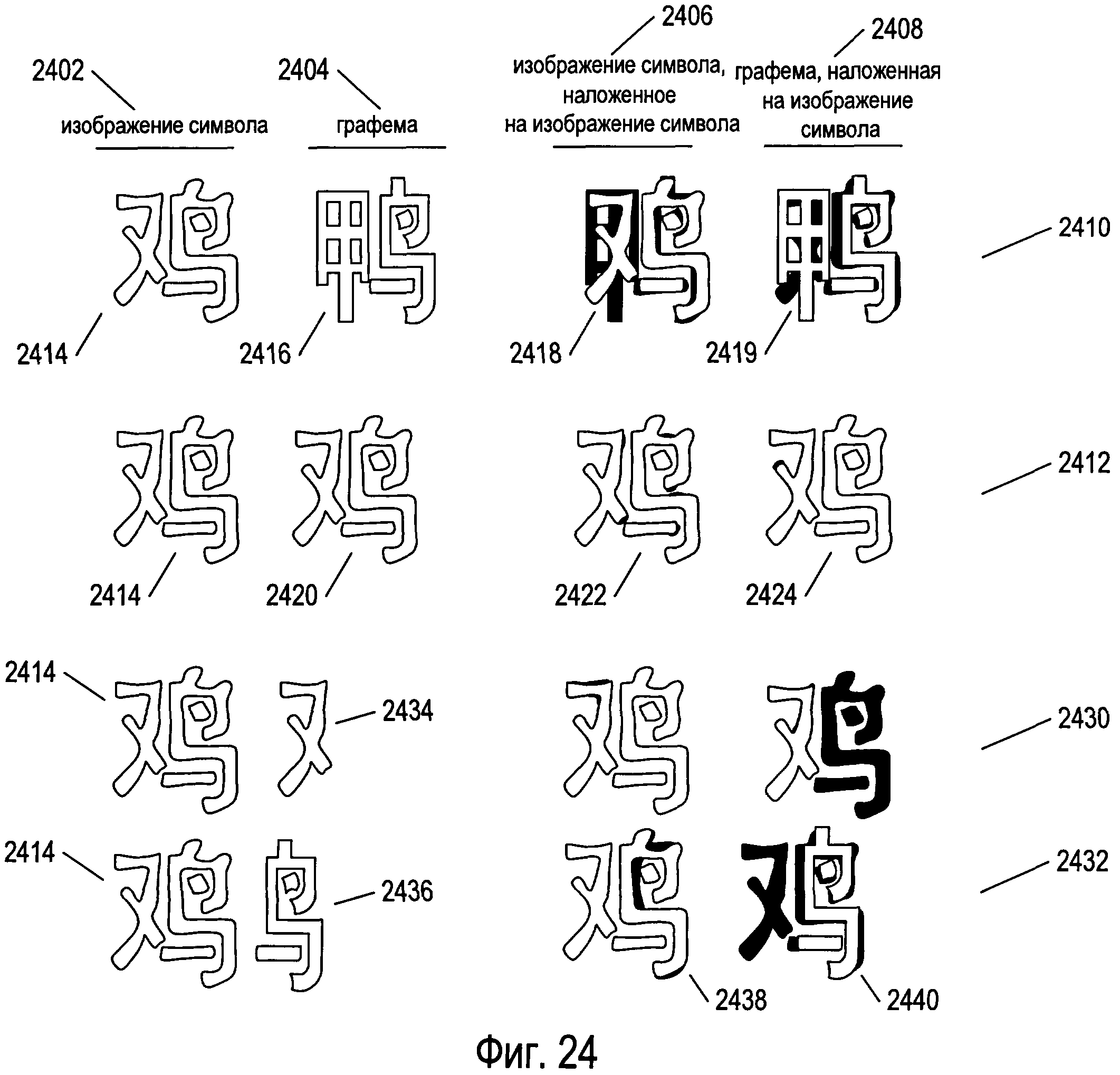
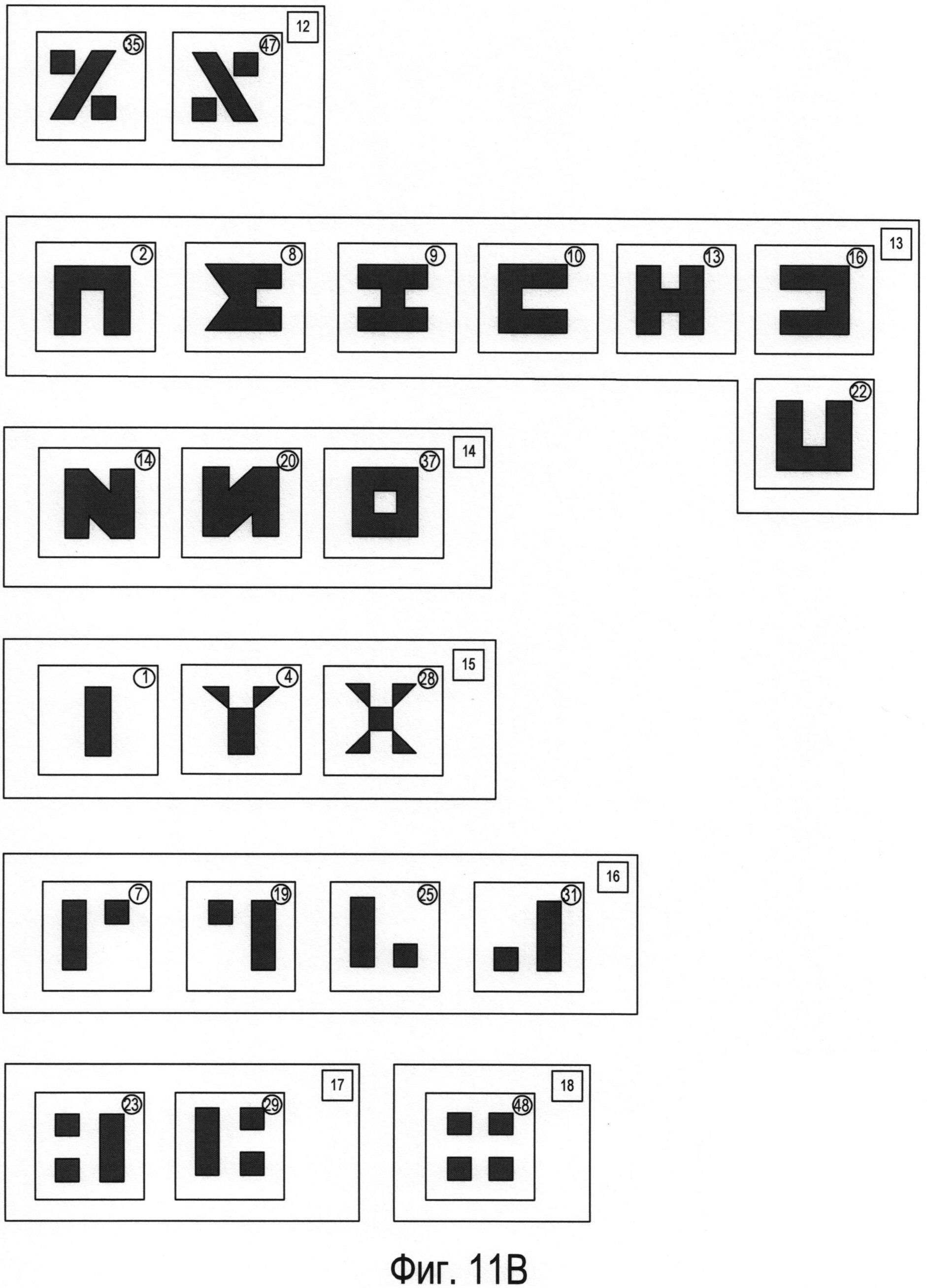

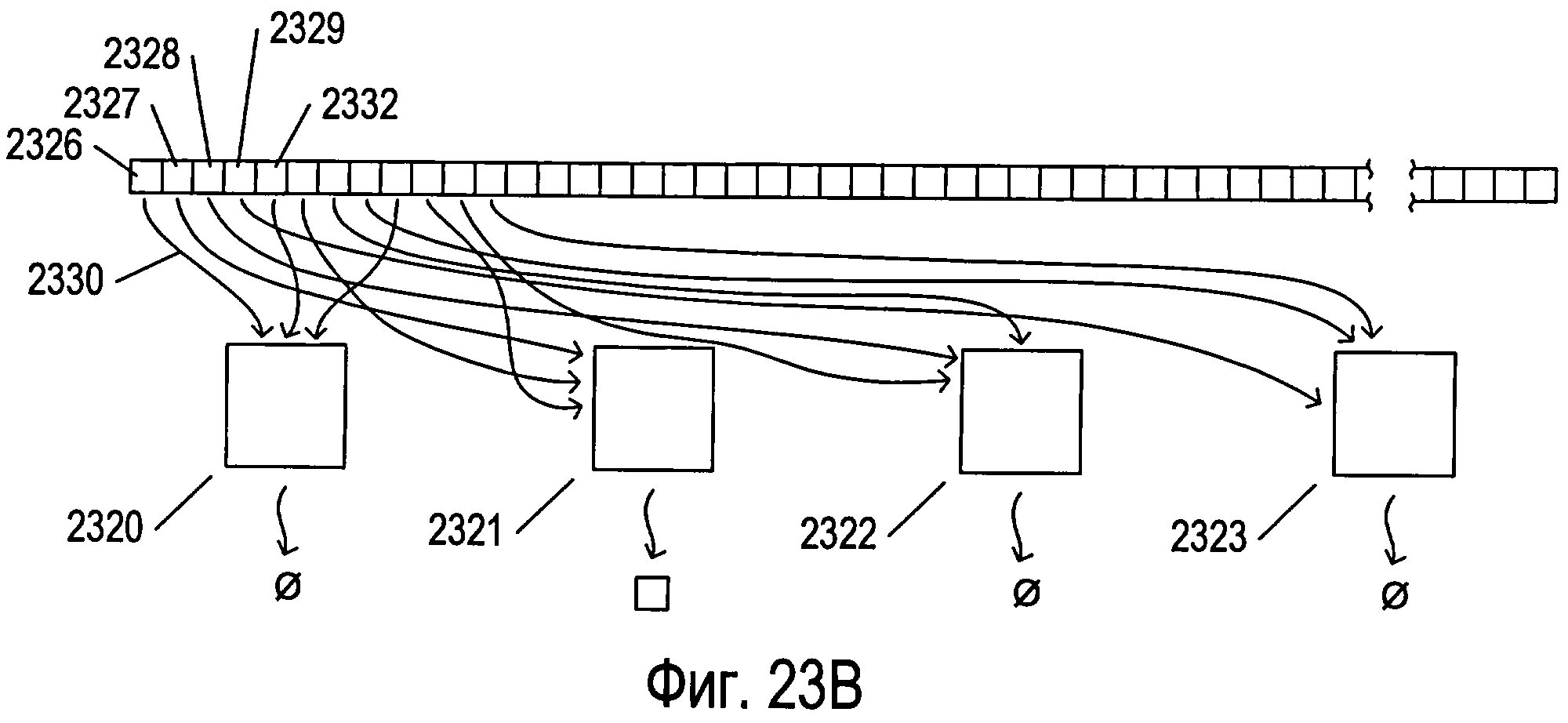
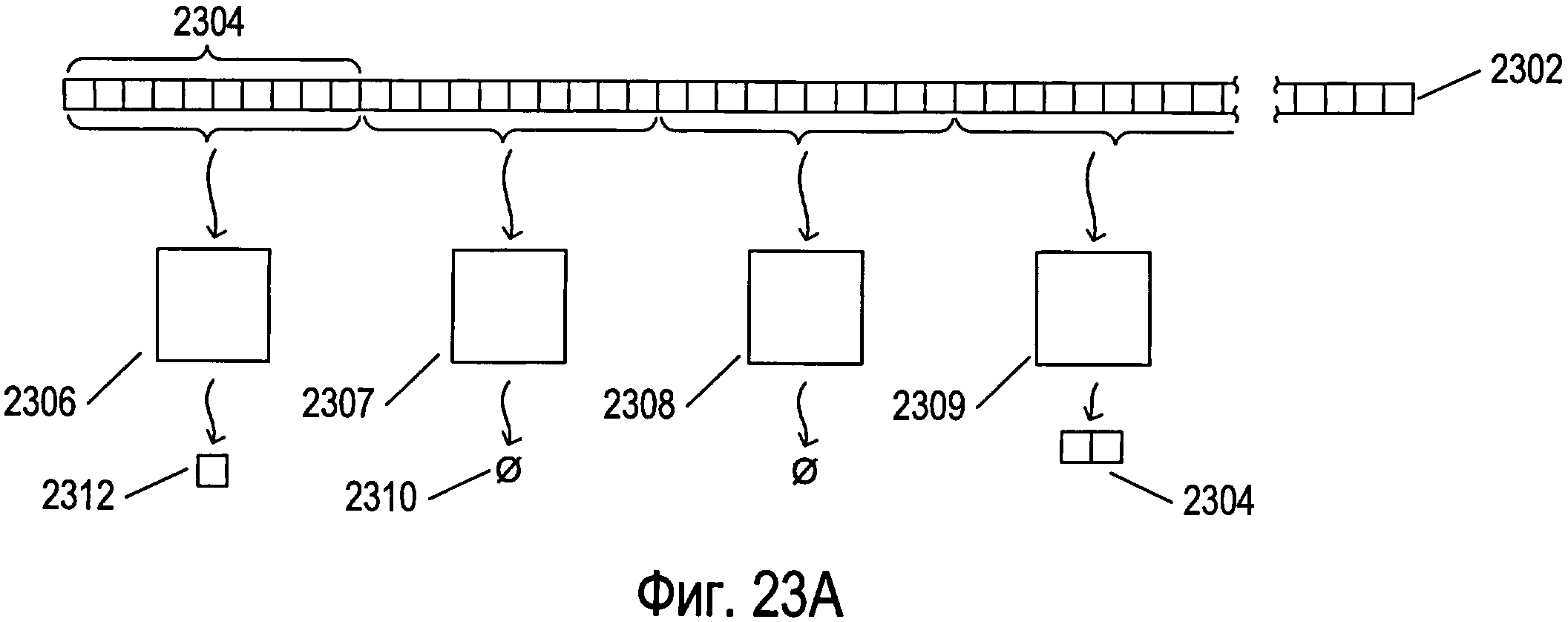
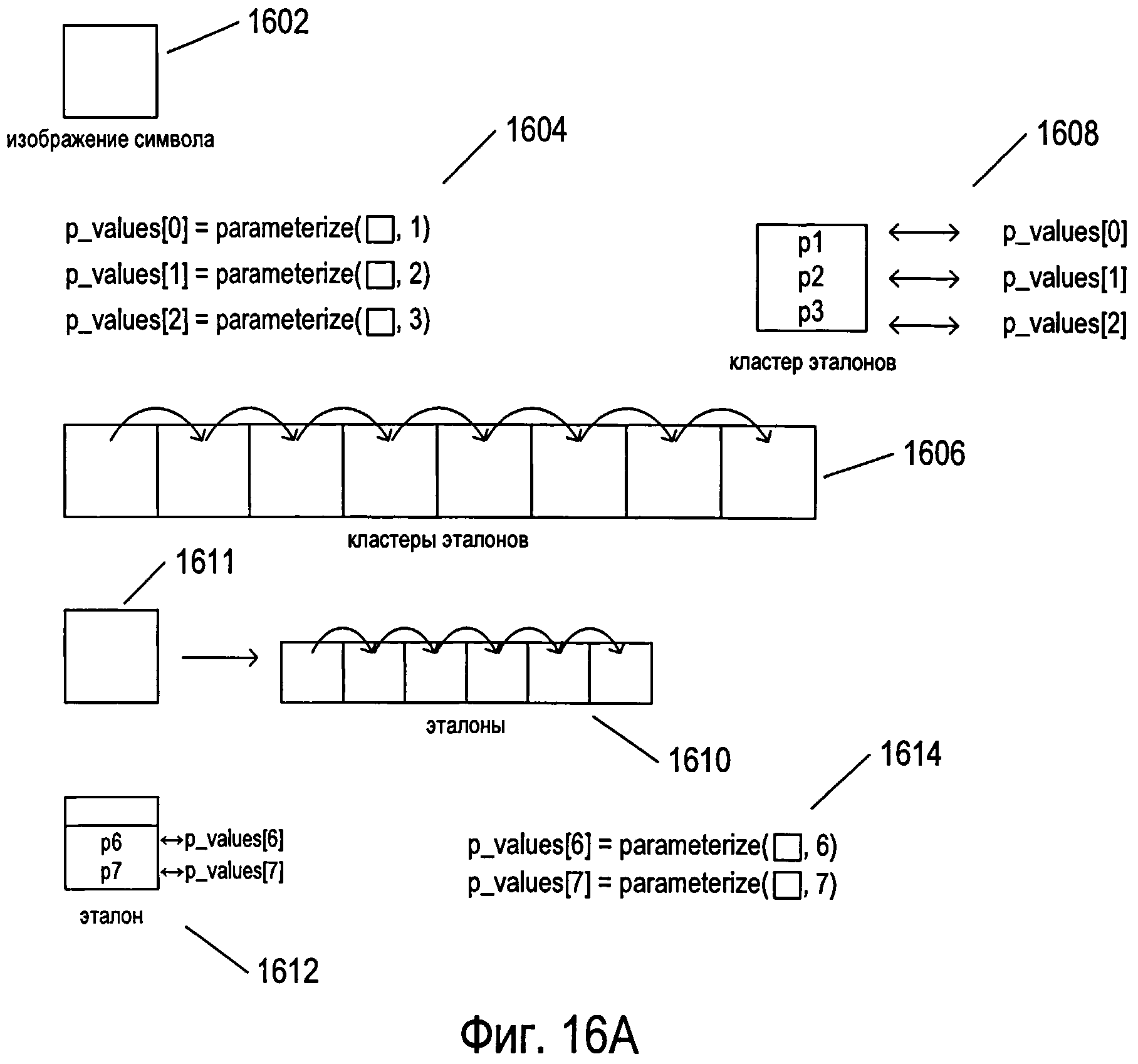
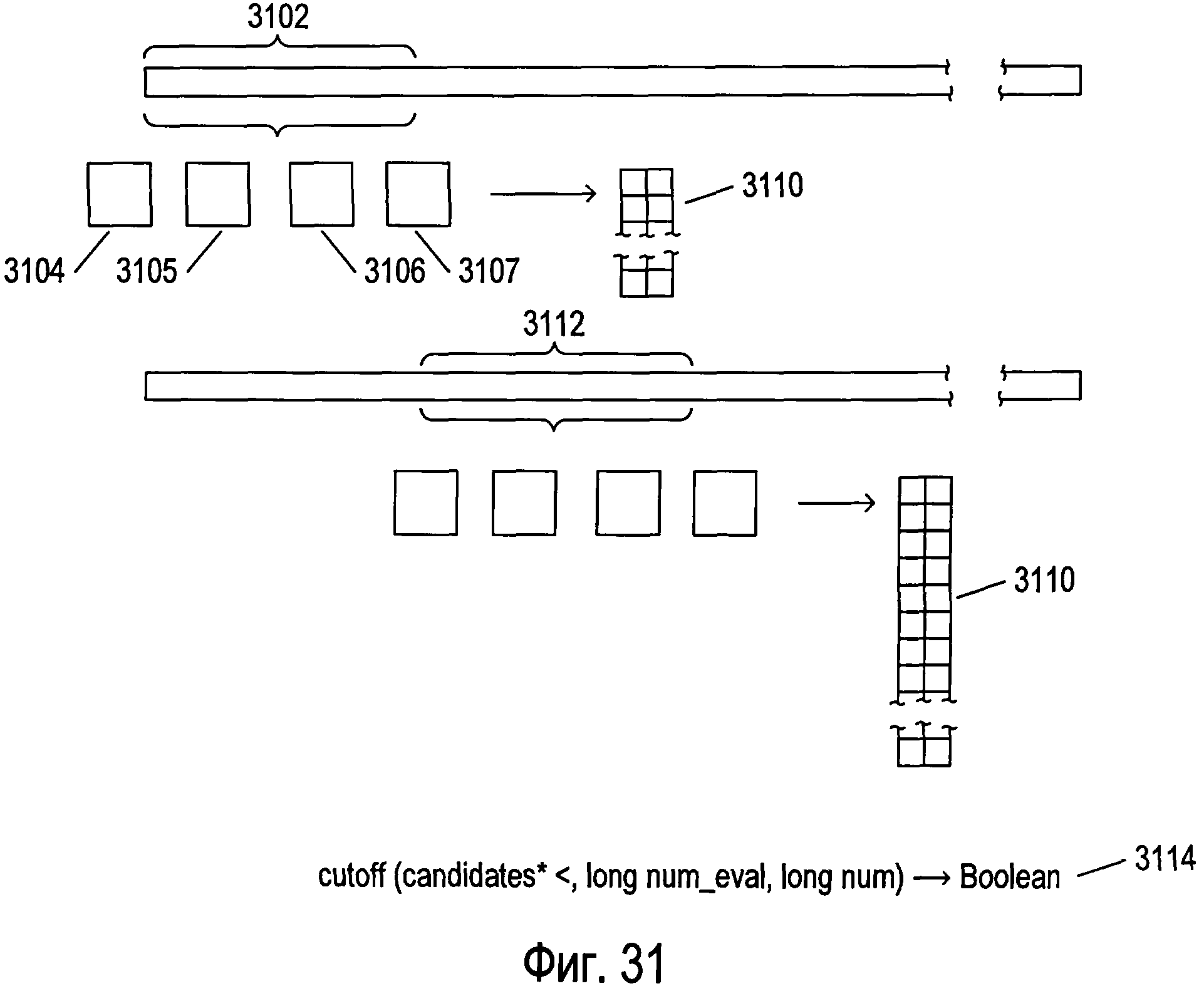
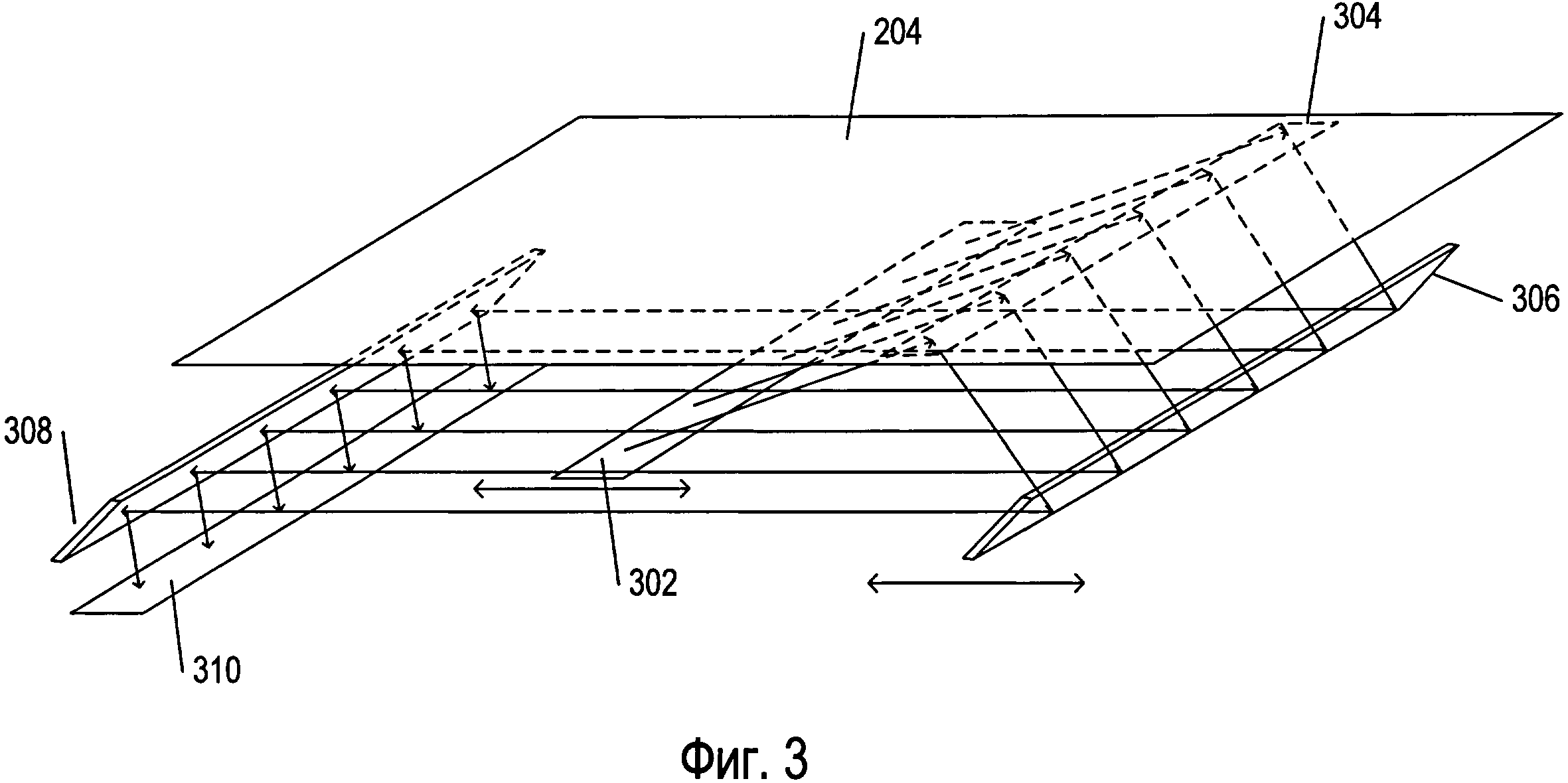
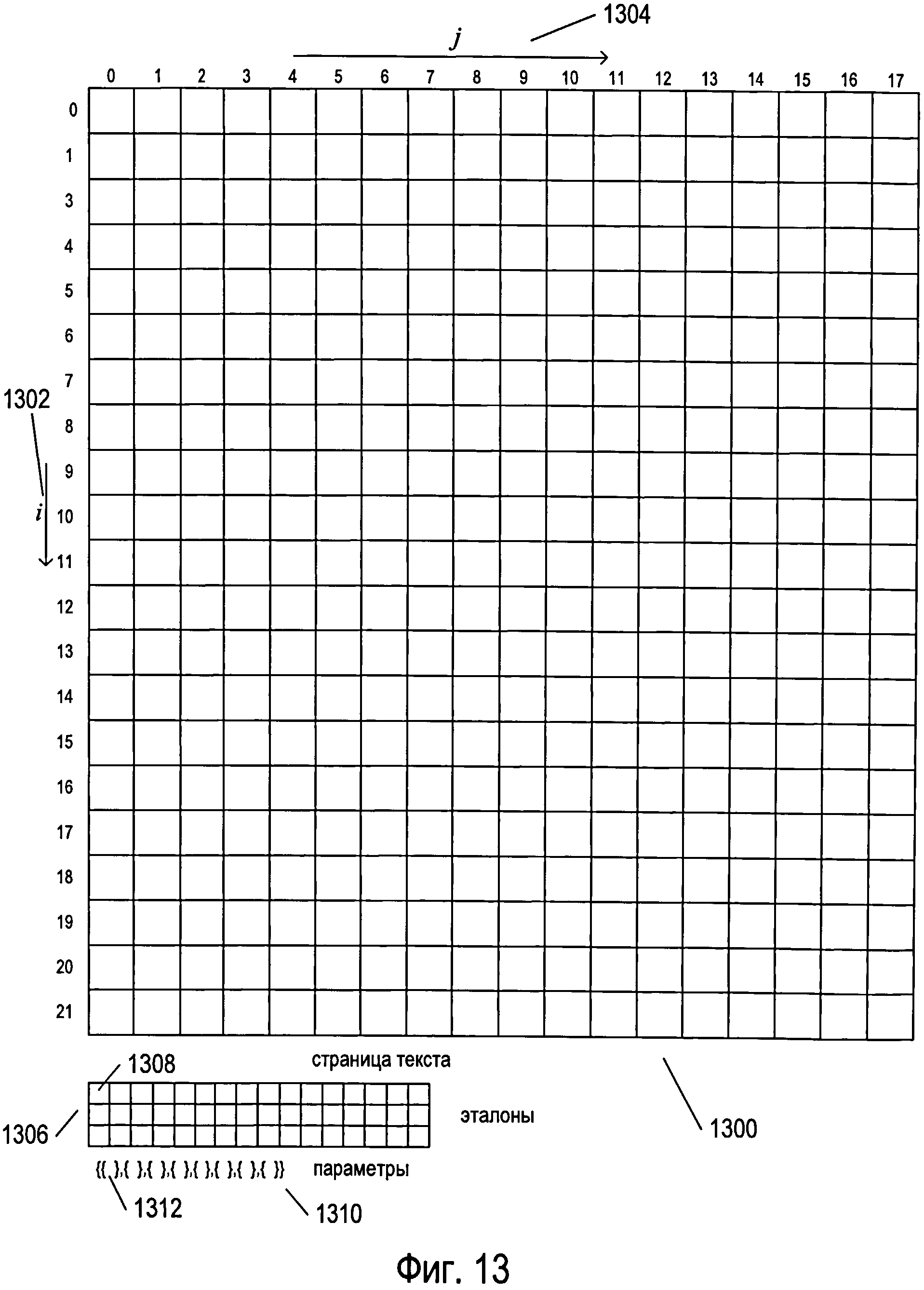
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Определение преобразований изображения для повышения качества оптического распознавания символов
Улучшения качества распознавания за счет повышения разрешения изображений
Автоматическая съемка документа с заданными пропорциями
Устройство и способ поиска различий в документах
Интеллектуальная обработка электронного документа
Способ и система для верификации в процессе чтения
Метод и устройство, использующие увеличение изображения для подавления визуально заметных дефектов на изображении
Классификация изображений документов на основании контента
Обработка документа с использованием нескольких потоков обработки
Способы и системы эффективного автоматического распознавания символов с использованием леса решений
Определение преобразований изображения для повышения качества оптического распознавания символов

