Результат интеллектуальной деятельности: СПОСОБ И ДИСКРИМИНАТОР ДЛЯ КЛАССИФИКАЦИИ РАЗЛИЧНЫХ СЕГМЕНТОВ СИГНАЛА
Вид РИД
Изобретение
Изобретение касается подхода для классификации различных сегментов сигнала, включающих, по крайней мере, сегменты первого и второго типов. Изобретение относится к области аудиокодирования и, в частности, к различению речи/музыки при кодировании аудиосигнала.
Известны схемы кодирования в частотной области, такие как МР3 или ААС. Эти кодирующие устройства основаны на преобразовании временного представления в частотное, последующей стадии квантизации, на которой управляют ошибкой квантизации, используя информацию от физико-акустического (psychoacoustic) модуля, и стадии кодирования, на которой квантованные спектральные коэффициенты и соответствующая информация кодируются без потери информации с использованием кодовых таблиц.
С другой стороны, есть кодирующие устройства, которые очень хорошо подходят для обработки речи, например, AMR-WB+, описанное в 3GPP TS 26.290. Такие речевые кодирующие схемы выполняют фильтрацию с линейным предсказанием (ЛП) сигнала на временном интервале. ЛП фильтрация получается из анализа линейного предсказания входного сигнала на временном интервале. Получающиеся в результате ЛП фильтрации коэффициенты кодируются и передаются как информация передающей стороны. Процесс известен как линейное предсказывающее кодирование (LPC). На выходе фильтра разностный сигнал предсказания или сигнал ошибки предсказания, который также известен как сигнал возбуждения, кодируется с использованием кодирующего устройства ACELP или с использованием кодирующего устройства, которое осуществляет Фурье-преобразование с наложением. Выбор между ACELP кодированием и кодированием преобразованного возбуждения, которое также называют кодированием ТСХ, делается с использованием алгоритмов замкнутого или разомкнутого контура.
Схемы аудиокодирования в частотной обасти, такие как схема высокоэффективного ААС кодирования, которая комбинирует схему кодирования ААС и технику повторения спектральных полос (восстановления спектра в области высоких частот), может также быть присоединена к объединенному стерео или многоканальному кодирующему устройству, которое известно как “MPEG окружение”. При этом кодирующие схемы в частотной области имеют преимущества, так как они показывают высокое качество при низких битрейтах для музыкальных сигналов. Проблематичным, однако, оказывается качество речевых сигналов при низких битрейтах.
С другой стороны, у речевых кодирующих устройств, таких как AMR-WB+, также есть уровень (блок) высокочастотного улучшения и функциональность в области стереосигнала. Речевые кодирующие схемы показывают высокое качество для речевых сигналов даже при низких битрейтах, но показывают низкое качество для музыкальных сигналов при низких битрейтах.
Ввиду упомянутых выше доступных кодирующих схем, некоторые из которых лучше для того, чтобы закодировать речь и другие, лучше подходящие для того, чтобы закодировать музыку, автоматическая сегментация и классификация кодируемого аудиосигнала является важным инструментом во многих мультимедийных приложениях и может использоваться, чтобы выбрать соответствующий процесс для каждого различного класса аудиосигналов. Эффективность работы приложения сильно зависит от надежности классификации аудиосигнала. Действительно, неправильная классификация приводит к ошибочному выбору и настройке последующей обработки.
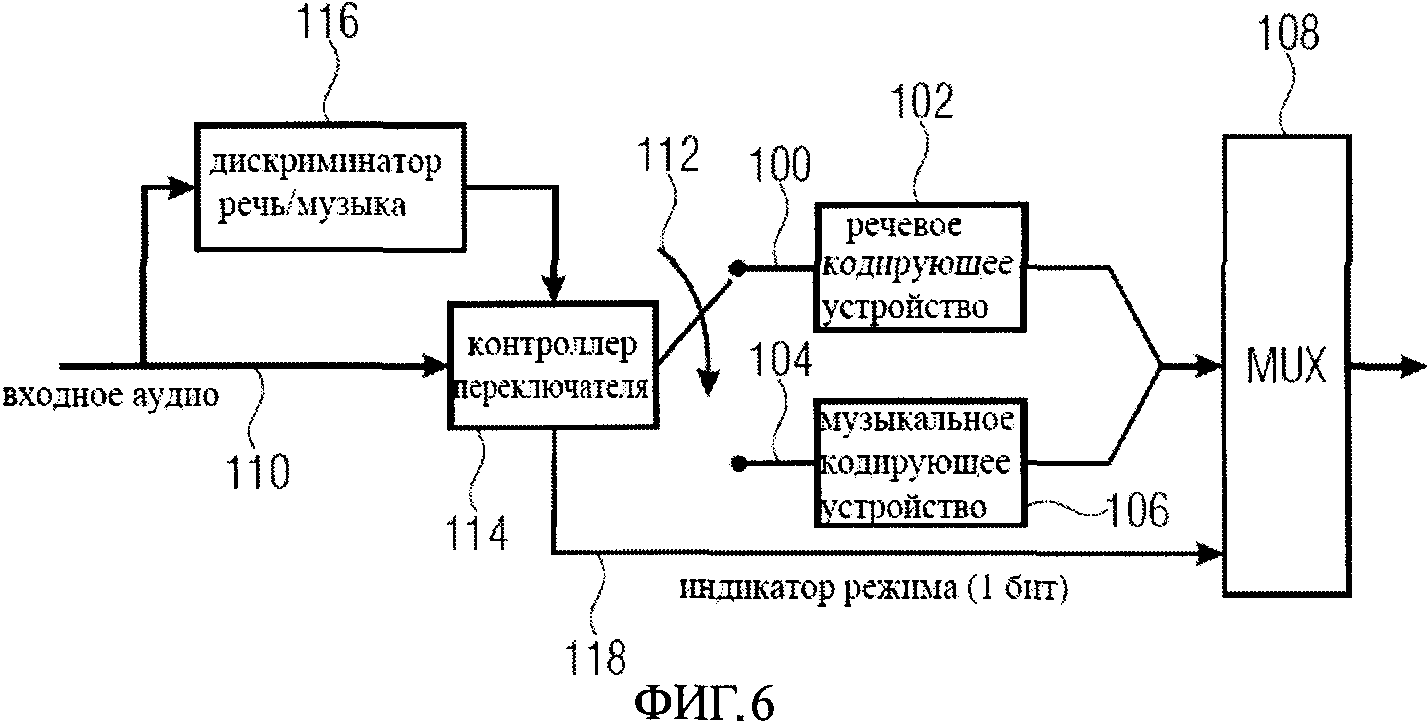
На Фиг.6 изображен обычный дизайн кодера, используемый для того, чтобы отдельно закодировать речь и музыку в зависимости от типа аудиосигнала. Дизайн кодера включает канал кодирования речи 100, включая соответствующее кодирующее устройство для речи 102, например, AMR-WB+кодирующее устройство для речи, описанное в технической спецификации “Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec”, 3GPP TS 26.290 V6.3.0, 2005-06. Далее, дизайн кодера включает канал кодирования музыки 104, включающий кодирующее устройство для музыки 106, например, кодирующее устройство для музыки ААС, описанное в Generic Coding of Moving Pictures and Associated Audio: Advanced Audio Coding. International Standard 13818-7, ISO/IEC JTC1/SC29/WG11 Moving Pictures Expert Group, 1997.
Выходы кодирующих устройств 102 и 106 соединены с входом мультиплексора 108. Входы кодирующих устройств 102 и 106 являются выборочно соединяемыми с линией 110 входа аудиосигнала. Входной аудиосигнал подается выборочно на речевое кодирующее устройство 102 или музыкальное кодирующее устройство 106 с использованием переключателя 112, показанного схематично на фиг.6 и управляемого контроллером переключателя 114. Кроме того, кодер включает дискриминатор речи/музыки 116, также получающий входной аудиосигнал и формирующий сигнал управления контроллером переключателя 114. Контроллер переключателя 114 также формирует сигнал индикатора способа (моды) на линии 118, которая является входной линией второго входа мультиплексора 108 так, чтобы сигнал индикатора способа можно было послать вместе с кодируемым сигналом. Однобитный сигнал индикатора способа указывает, что блок данных, связанных с ним, или закодированная речь или музыка, так что в декодере не надо осуществлять дискриминацию. На основе бита индикатора способа, подаваемого вместе с закодированными данными к декодеру, может быть сгенерирован соответствующий сигнал переключения для направления полученных и закодированных данных к соответствующему декодеру речи или музыки.
На фиг.6 изображен традиционный дизайн кодера, который используется, чтобы в цифровой форме закодировать речь и музыкальные сигналы, подаваемые на линию 110. Вообще, речевые кодирующие устройства более эффективны для речи, и аудиокодирующие устройства более эффективны для музыки. Универсальная кодирующая схема может быть разработана при использовании системы мультикодера, который переключается от одного кодера к другому согласно природе входного сигнала. Нетривиальная проблема здесь состоит в том, чтобы разработать подходящий входной классификатор сигнала, который управляет переключателем. Классификатор это дискриминатор речи/музыки 116, показанный в фиг.6. Обычно надежная классификация аудиосигнала вносит большую задержку, тогда как с другой стороны задержка - это важный фактор в приложениях реального времени.
Вообще, желательно, чтобы полная алгоритмическая задержка, введенная дискриминатором речи/музыки, была достаточно мала, чтобы можно было использовать переключаемые кодеры в приложениях, работающих в реальном времени.
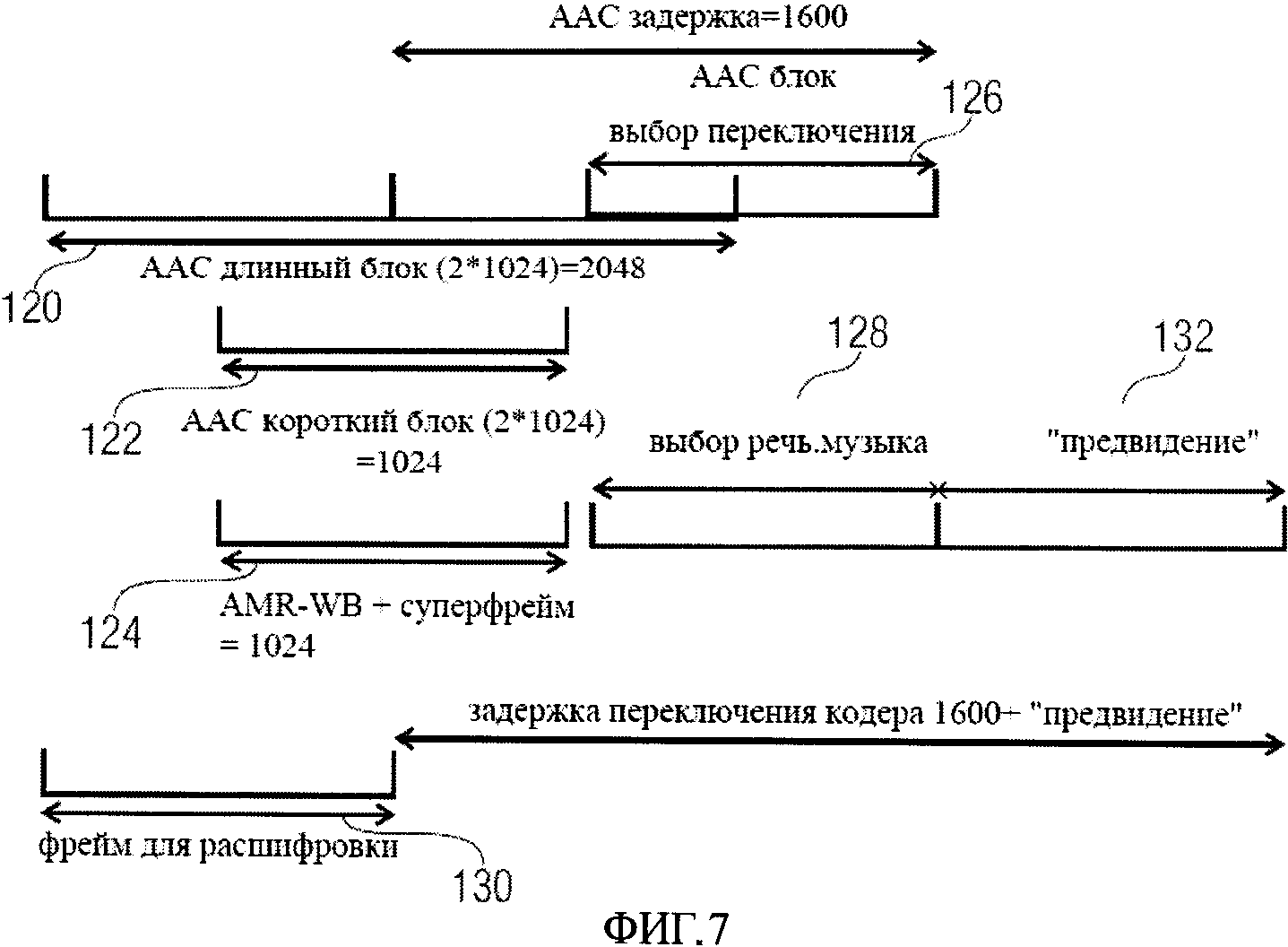
Фиг.7 иллюстрирует задержки кодера, представленного на фиг.6. Предполагается, что сигнал, подаваемый на входную линию 110, кодируется фреймами по 1024 отсчета (выборки) при частоте дискретизации 16 кГц, так что различение речи/музыки должно осуществляться для каждого блока, то есть каждые 64 миллисекунды. Переход между двумя кодирующими устройствами может быть произведен согласно описанию WO 2008/071353 А2, и дискриминатор речи/музыки не должен значительно увеличить алгоритмическую задержку переключаемых декодеров, которая в целом составляет 1600 отсчетов, не учитывая задержку, необходимую для различения речи/музыки. Далее, желательно обеспечить выбор речь/музыка для того же самого фрема, на котором решается переключение устройства ААС. Ситуация изображена в фиг.7, иллюстрирующей ААС длинный блок 120, имеющий длину 2048 отсчетов, то есть длинный блок 120 включает два фрейма по 1024 отсчета, АСС короткие блоки 122 включают один фрейм из 1024 отсчетов, и AMR-WB+суперфрейм 124 включают один фрейм из 1024 отсчетов.
На фиг.7 выбор переключения ААС блока и выбор речь/музыка осуществляются на фреймах 126 и 128 соответственно с размерами по 1024 отсчетов, которые покрывают тот же самый промежуток времени. Эти два выбора находятся в таком временном положении для того, чтобы сделать кодирование способным использовать момент времени переключения окон, чтобы правильно перейти от одного способа кодирования к другому. Впоследствии этими двумя выборами вносится минимальная задержка 512+64 отсчета. Эта задержка должна быть добавлена к задержке длиной 1024 отсчета, образованной 50%-ым наложением ААС MDCT, что создает минимальную задержку 1600 отсчетов. В обычном ААС присутствует только переключение блока, и задержка составляет точно 1600 отсчетов. Эта задержка необходима для того, чтобы переключиться единовременно от длинного блока до коротких блоков, когда обнаружен переход во фрейме 126. Это переключение длины преобразования желательно для того, чтобы избежать помехи пре-эхо. Фрейм для расшифровки 130, изображенный на фиг.7, представляет собой первый целый фрейм, который может быть распознан декодером в любом случае (длинные или короткие блоки).
В переключаемом кодере с использованием ААС в качестве музыкального кодирующего устройства выбор переключения, осуществляемый из стадии решения, не должен добавлять слишком много дополнительной задержки к оригинальной задержке ААС. Дополнительная задержка образуется из предварительного фрейма 132, который необходим для анализа сигнала на стадии решения.
Например, при осуществлении выборки с частотой 16 кГц задержка ААС составляет 100 миллисекунд, в то время как обычный дискриминатор речи/музыки использует приблизительно 500 миллисекунд подготовки, которая приводит к переключению кодирующей структуры с задержкой 600 миллисекунд. Полная задержка тогда будет в шесть раз больше, чем оригинальная задержки ААС.
Обычные подходы, описанные выше, невыгодны для надежной классификации аудиосигнала. Высокая нежелательная задержка вызывает необходимость в новом подходе для того, чтобы различить сегменты различных типов сигнала, при котором дополнительная алгоритмическая задержка, введенная дискриминатором, достаточно низка так, чтобы переключаемые кодеры могли использоваться в реальном времени.
J. Wang, et. al. ”Real-time speech/music classification with a hierarchical oblique decision tree”, ICASSP 2008, IEEE International Conference on Acoustics, Speech and Signal Processing, 2008, March 31, 2008 to April 4, 2008 описывают подход для классификации речи/музыки, использующий краткосрочные и долгосрочные особенности, полученные из того же самого числа фреймов. Эти краткосрочные и долгосрочные особенности используются для того, чтобы классифицировать сигнал, но используются только ограниченные свойства краткосрочных особенностей, например, не используется инерционность классификации, хотя она играет важную роль для большинства кодирующих аудиоприложений.
Решением изобретения является обеспечение улучшенного подхода для того, чтобы различить в сигнале сегменты различного типа, сохраняя низкой любую задержку, внесенную дискриминатором.
Это решение достигается заявленным методом 1 и заявленным дискриминатором 14. Одно решение изобретения обеспечивает способ, классифицирующий различные сегменты сигнала, включающего по крайней мере, сегменты первого типа и второго типа. Способ включает краткосрочную классификацию сигнала на основе по крайней мере одной краткосрочной особенности, извлеченной из сигнала, и формирование результата краткосрочной классификации; долгосрочную классификацию сигнала на основе по крайней мере одной краткосрочной особенности и по крайней мере одной долгосрочной особенности, извлеченной из сигнала, и формирование результата долгосрочной классификации; объединение результатов краткосрочной классификации и долгосрочной классификации, чтобы обеспечить выходной сигнал, указывающий, имеет ли сегмент сигнала первый или второй тип.
Другое решение изобретения - дискриминатор, включающий: краткосрочный классификатор, предназначенный для того, чтобы получить сигнал и сформировать результат краткосрочной классификации сигнала на основе по крайней мере одной краткосрочной особенности, извлеченной из сигнала, включающего сегменты, по крайней мере, первого типа и второго типов; долгосрочный классификатор, предназначенный для того, чтобы получить сигнал и сформировать результат долгосрочной классификации сигнала на основе по крайней мере одной краткосрочной особенности и по крайней мере одной долгосрочной особенности, извлеченной из сигнала; схему выбора, предназначенную для того, чтобы объединить результат краткосрочной классификации и результат долгосрочной классификации, и сформировать выходной сигнал, указывающий, имеет ли сегмент сигнала первый или второй тип.
Решения изобретения обеспечивают выходной сигнал на основе сравнения краткосрочного результата анализа и долгосрочного результата анализа.
Решения изобретения касаются подхода к классификации различных неперекрывающихся сегментов коротких промежутков аудиосигнала как речь или как не речь или как другие классы. Подход основан на извлечении особенностей и анализе их статистики с использованием двух различных длин анализируемых окон. Первое длинное окно направлено, главным образом, к прошлому. Первое окно используется, чтобы получить надежную, но отсроченную подсказку решения для классификации сигнала. Второе окно короткое и рассматривает, главным образом, обрабатываемый в настоящее время или текущий сегмент. Второе окно используется, чтобы получить мгновенную подсказку решения. Две подсказки решения оптимально объединены, с использованием решения с гистерезисом, которое получает информацию из памяти от отсроченной подсказки и мгновенную информацию от мгновенной подсказки.
Решения изобретения используют краткосрочные особенности и в краткосрочном классификаторе и в долгосрочном классификаторе так, чтобы эти два классификатора использовали различную статистику той же самой особенности. Краткосрочный классификатор извлекает только мгновенную информацию, потому что у него есть доступ только к одному набору особенностей. Например, он может использовать средние из особенностей. С другой стороны у долгосрочного классификатора есть доступ к нескольким наборам особенностей, потому что он рассматривает несколько фреймов. Как следствие, долгосрочный классификатор может использовать больше особенностей сигнала, обрабатывая статистику большего количества фреймов чем краткосрочный классификатор. Например, долгосрочный классификатор может использовать различие особенностей или развитие особенностей во времени. Таким образом, долгосрочный классификатор может использовать больше информации, чем краткосрочный классификатор, но это вносит задержку или время ожидания. Однако, долгосрочные особенности, несмотря на внесение задержки или времени ожидания, делают долгосрочные результаты классификации более правильными и надежными. В некоторых решениях краткосрочные и долгосрочные классификаторы могут рассмотреть те же самые краткосрочные особенности, которые могут быть вычислены один раз и использоваться обоими классификаторами. Таким образом, в таком решении долгосрочный классификатор может получить краткосрочные особенности непосредственно от краткосрочного классификатора.
Таким образом, новый подход обеспечивает правильную классификацию, вводя низкую задержку. В отличие от обычного подхода решения изобретения ограничивают задержку, введенную выбором речи/музыки, сохраняя надежность выбора. В одном решении изобретения подготовка ограничена 128 отсчетами, что приводит к задержке только 108 миллисекунд.
Краткое описание рисунков
Решения изобретения описаны ниже со ссылками на соответствующие рисунки, в числе которых:
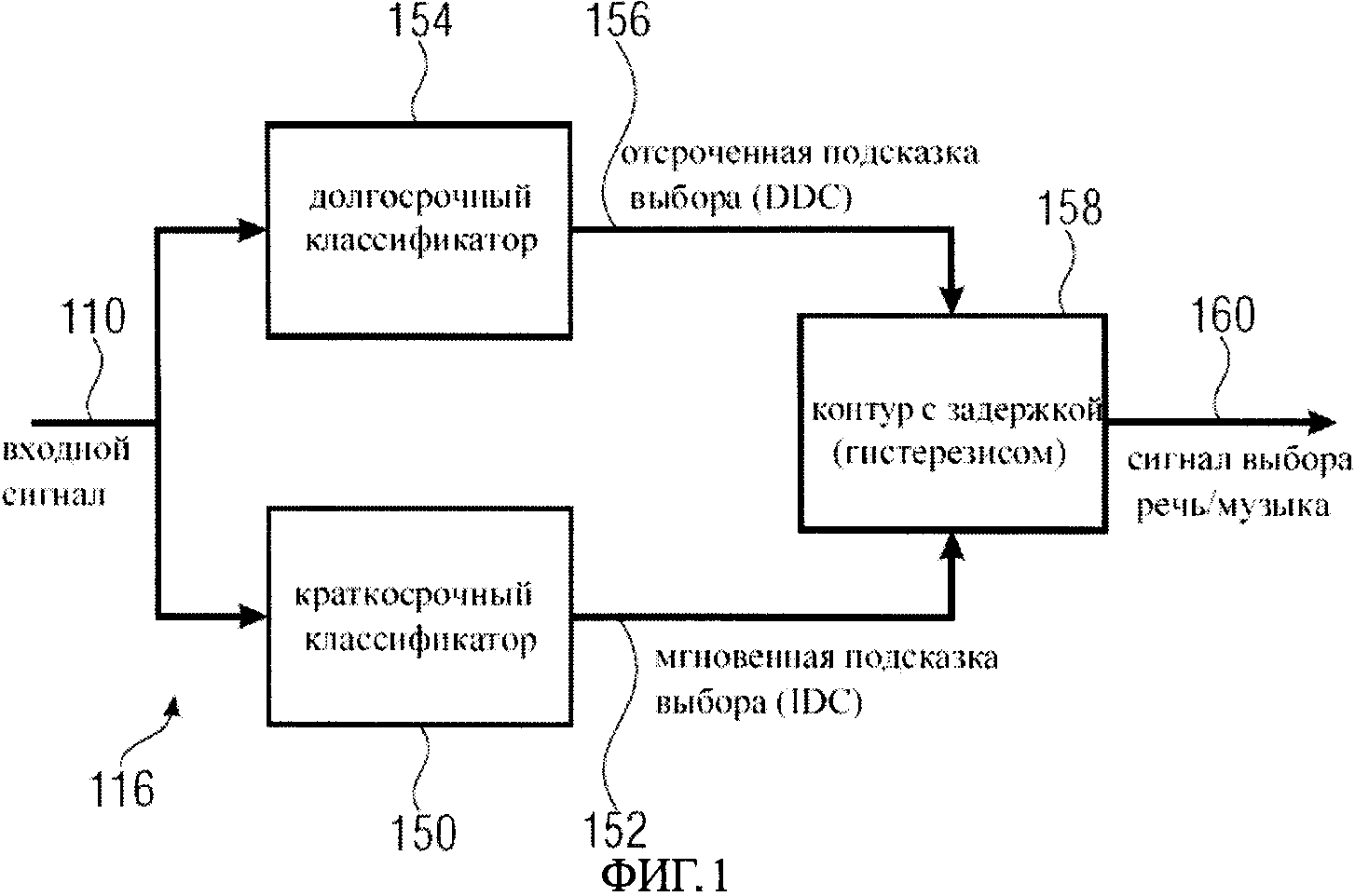
Фиг.1 - блок-схема дискриминатора речи/музыки в соответствии с решением изобретения;
Фиг.2 - иллюстрирует аналитические окна, используемые долгосрочным и краткосрочными классификаторами дискриминатора на фиг.1;
Фиг.3 - иллюстрирует решение с гистерезисом, используемое в дискриминаторе фиг.1;
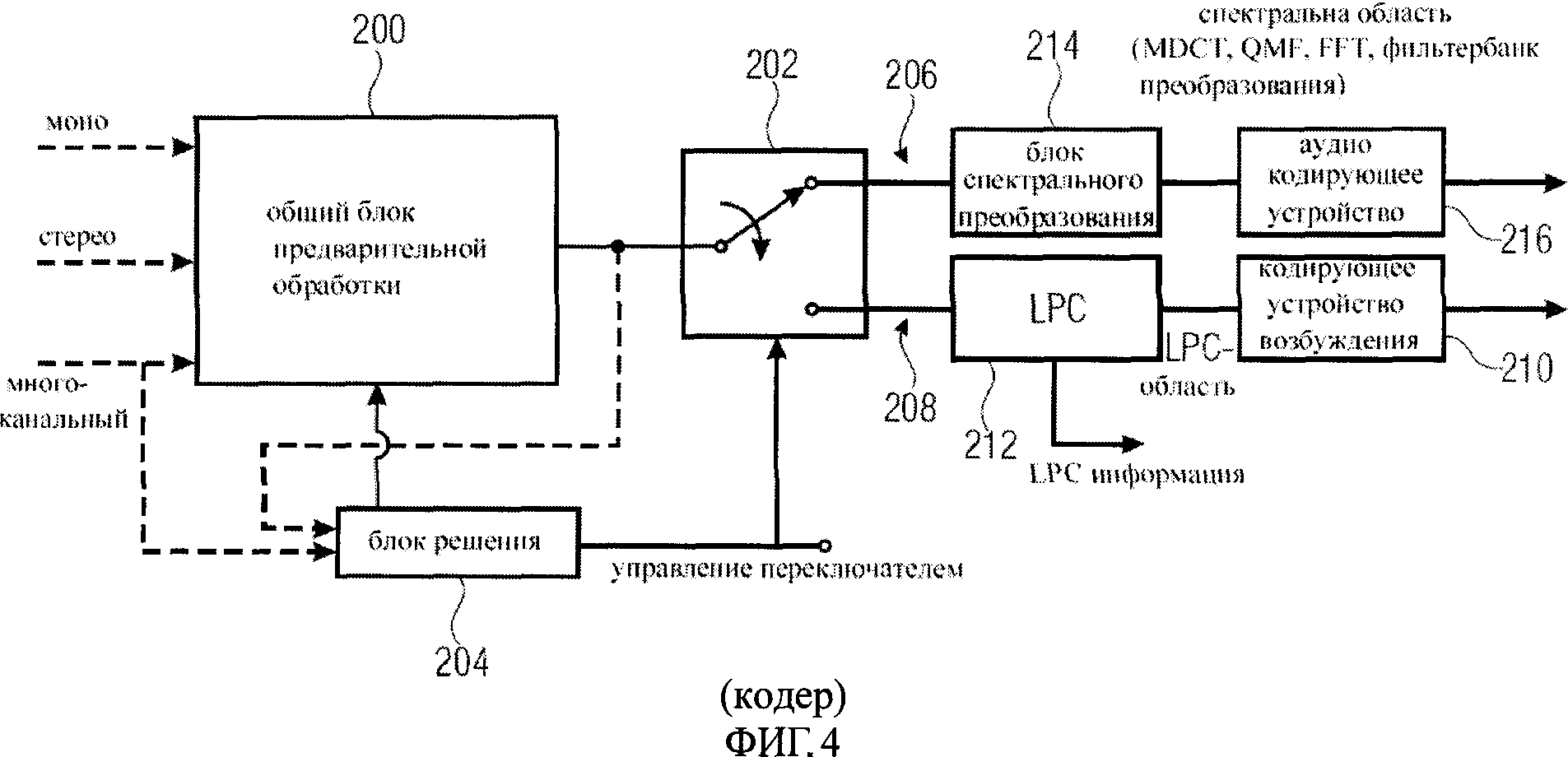
Фиг.4 - блок-схема образца схемы кодирования, включающей дискриминатор в соответствии с решениями изобретения;
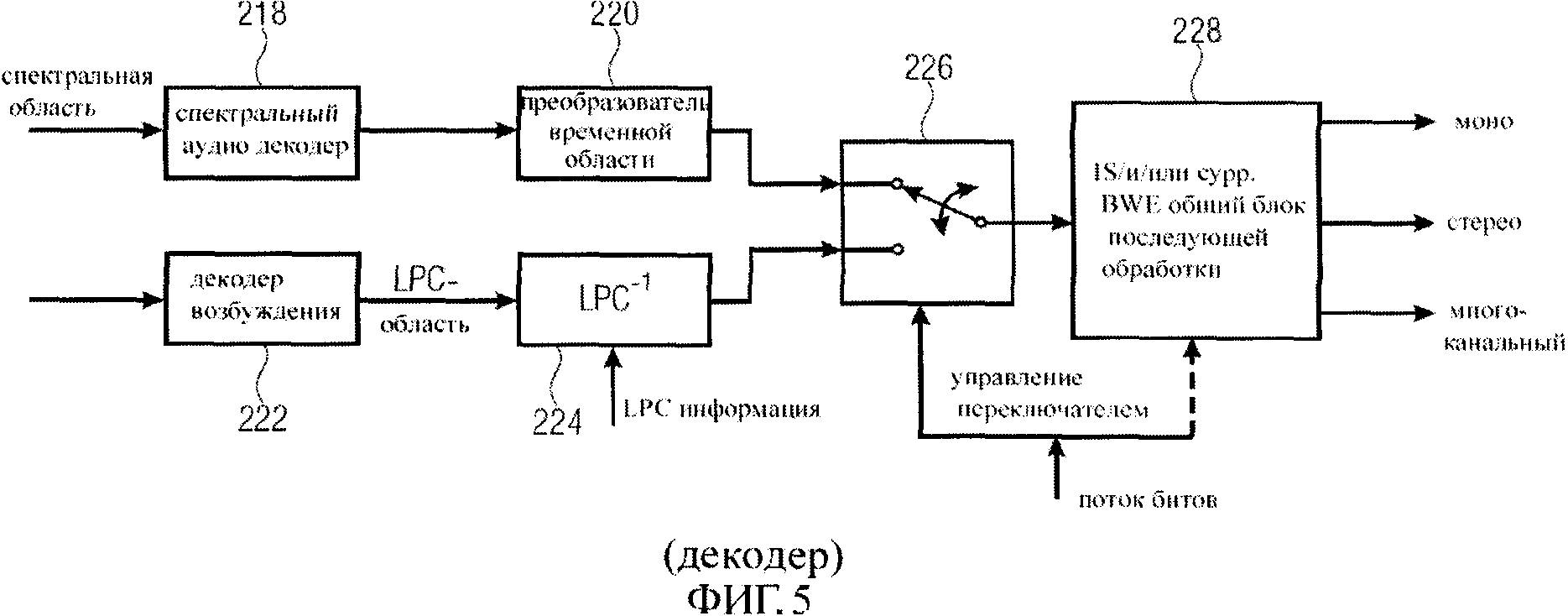
Фиг.5 - блок-схема декодирования, соответствующая схеме кодирования на фиг.4;
Фиг.6 показывает обычный дизайн кодера, используемый для того, чтобы отдельно закодировать речь и музыку, зависящую от типа аудиосигнала;
Фиг.7 иллюстрирует задержки, полученные в кодере, показанном в фиг.6.
На фиг.1 изображена блок-схема дискриминатора речи/музыки 116 в соответствии с решением изобретения. Дискриминатор речи/музыки 116 включает краткосрочный классификатор 150, на который поступает входной сигнал, например аудиосигнал, включающий музыкальные сегменты и речь. Краткосрочный классификатор 150 формирует на выходной линии 152 результат краткосрочной классификации - мгновенную подсказку решения. Дискриминатор 116 далее включает долгосрочный классификатор 154, на который также поступает входной сигнал и формирует на выходной линии 156 результат долгосрочный классификации - отсроченную подсказку решения. Далее, реализуется контур с задержкой 158, который объединяет выходные сигналы краткосрочного классификатора 150 и долгосрочного классификатора 154 способом, описанным в деталях ниже, чтобы сформировать сигнал выбора речи/музыки, который подается на выходную линию 160 и может использоваться для того, чтобы управлять дальнейшей обработкой сегмента входного сигнала способом, описанным выше и представленным на фиг.6, то есть сигнал 160 выбора речи/музыки может использоваться для направления классифицированного входного сегмента сигнала к речевому кодирующему устройству или к аудиокодирующему устройству.
Таким образом, в соответствии с решениями изобретения два различных классификатора 150 и 154 используются параллельно для обработки входного сигнала, подаваемого к данным классификаторам через входную линию 110. Эти два классификатора называют долгосрочным классификатором 154 и краткосрочным классификатором 150, причем эти два классификатора отличаются, анализируя статистику особенностей с использованием аналитических окон. Эти два классификатора формируют выходные сигналы 152 и 156, а именно мгновенную подсказку выбора (IDC) и отсроченную подсказку выбора (DDC). Краткосрочный классификатор 150 формирует IDC на основе краткосрочных особенностей с целью обеспечить мгновенную информацию о природе входного сигнала. Она связана с краткосрочными признаками сигнала, которые могут быстро и в любое время измениться. Впоследствии краткосрочные особенности будут быстрыми и не внесут большую задержку в процесс дискриминации. Например, так как речь квазипостоянна на 5-20 миллисекундных интервалах, краткосрочные особенности могут быть вычислены для каждого 16 миллисекундного фрейма при частоте дискретизации 16 кГц. Долгосрочный классификатор 154 формирует DDC на основе особенностей, следующих из более длительных наблюдений за сигналом (долгосрочные особенности), и поэтому позволяет достигать более надежной классификации.
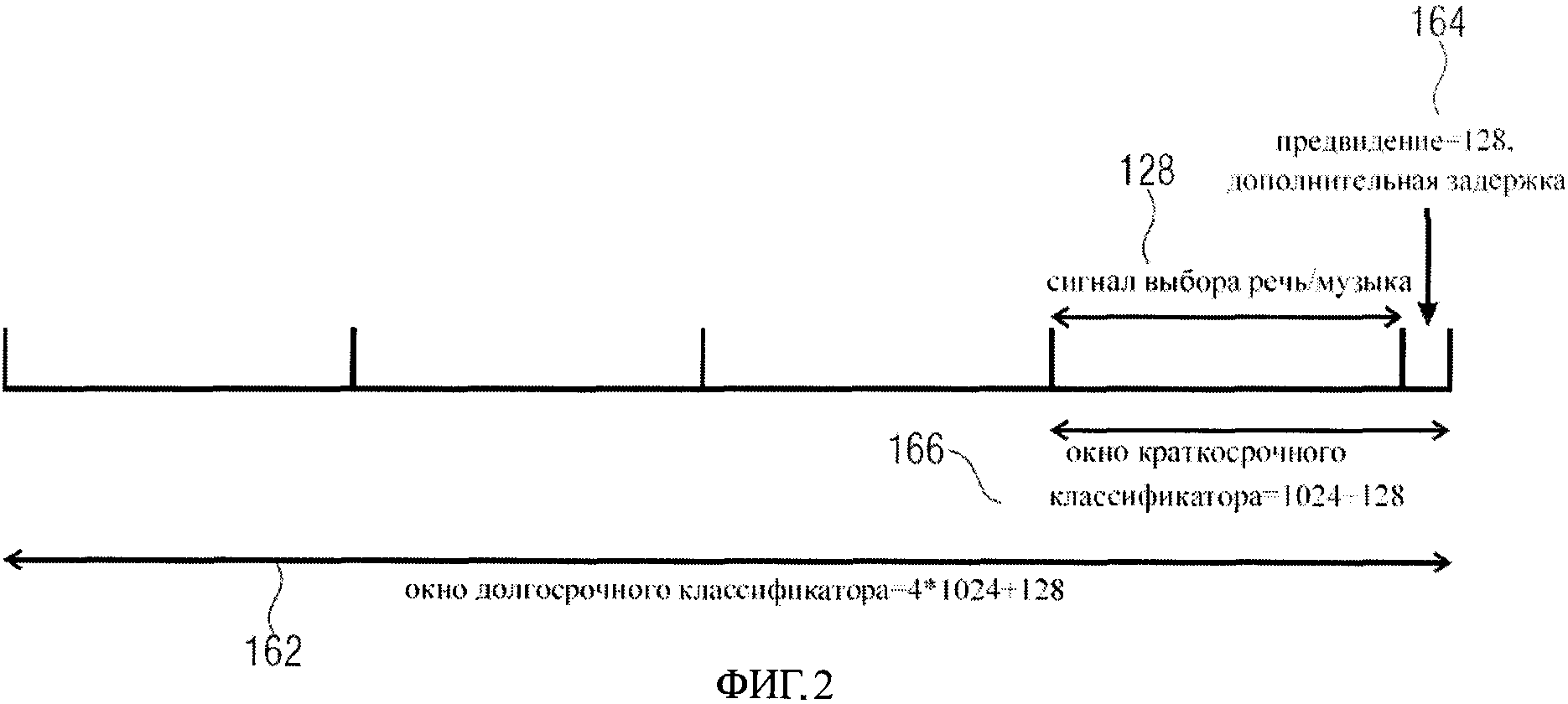
Фиг.2 иллюстрирует аналитические окна, используемые долгосрочным классификатором 154 и краткосрочным классификатором 150, показанными в фиг.1. Для фрейма длиной 1024 отсчета при частоте дискретизации 16 кГц длина долгосрочного окна классификатора 162 составляет 4∗1024+128 отсчетов, то есть долгосрочное окно 162 классификатора охватывает четыре фрейма аудиосигнала, и дополнительные 128 отсчетов необходимы долгосрочному классификатору 154, чтобы выполнить анализ. Эта дополнительная задержка, которая упоминается как "предвидение", обозначена на фиг.2 ссылкой 164. Фиг.2 также показывает краткосрочное окно классификатора 166 длиной 1024+128 отсчетов, то есть охватывает один фрейм аудиосигнала и дополнительную задержку, необходимую для того, чтобы проанализировать текущий сегмент. Текущий сегмент, обозначенный ссылкой 128, это сегмент, для которого должен быть сделан выбор речь/музыка.
Долгосрочное окно классификатора, обозначенное на фиг.2, достаточно длинное, чтобы определить характеристики модуляции речи с частотой 4 Гц. Энергетическая модуляция частотой 4 Гц является существенной отличительной особенностью речи, которая традиционно используется в дискриминаторах речи/музыки, например, Scheirer Е. and Slaney M., “Construction and Evaluation of a Robust Multifeature Speech/Music Discriminator”, ICASSP'97, Munich, 1997. Энергетическая модуляция частотой 4 Гц - это особенность, которая может быть определена при наблюдении сигнала на длинном временном сегменте. Дополнительная задержка, которая вносится дискриминатором речи/музыки за счет «предвидения», составляет 164 из 128 отсчетов, необходима каждому из классификаторов 150 и 154, чтобы сделать соответствующий анализ, то есть перцепционный анализ линейного предсказания, как это описано в работах Н. Hermansky, “Perceptive linear prediction (pip) analysis of speech,” Journal of the Acoustical Society of America, vol. 87, no. 4, pp.1738-1752, 1990 и Н. Hermansky, et al., “Perceptually based linear predictive analysis of speech,” ICASSP 5.509-512, 1985. Таким образом, используя дискриминатор кодирующего устройства, представленного на фиг.6, полная задержка переключения кодеров 102 и 106 будет определяться 1600+128 отсчетами, что равняется 108 миллисекундам, и достаточно мало для приложений реального времени.
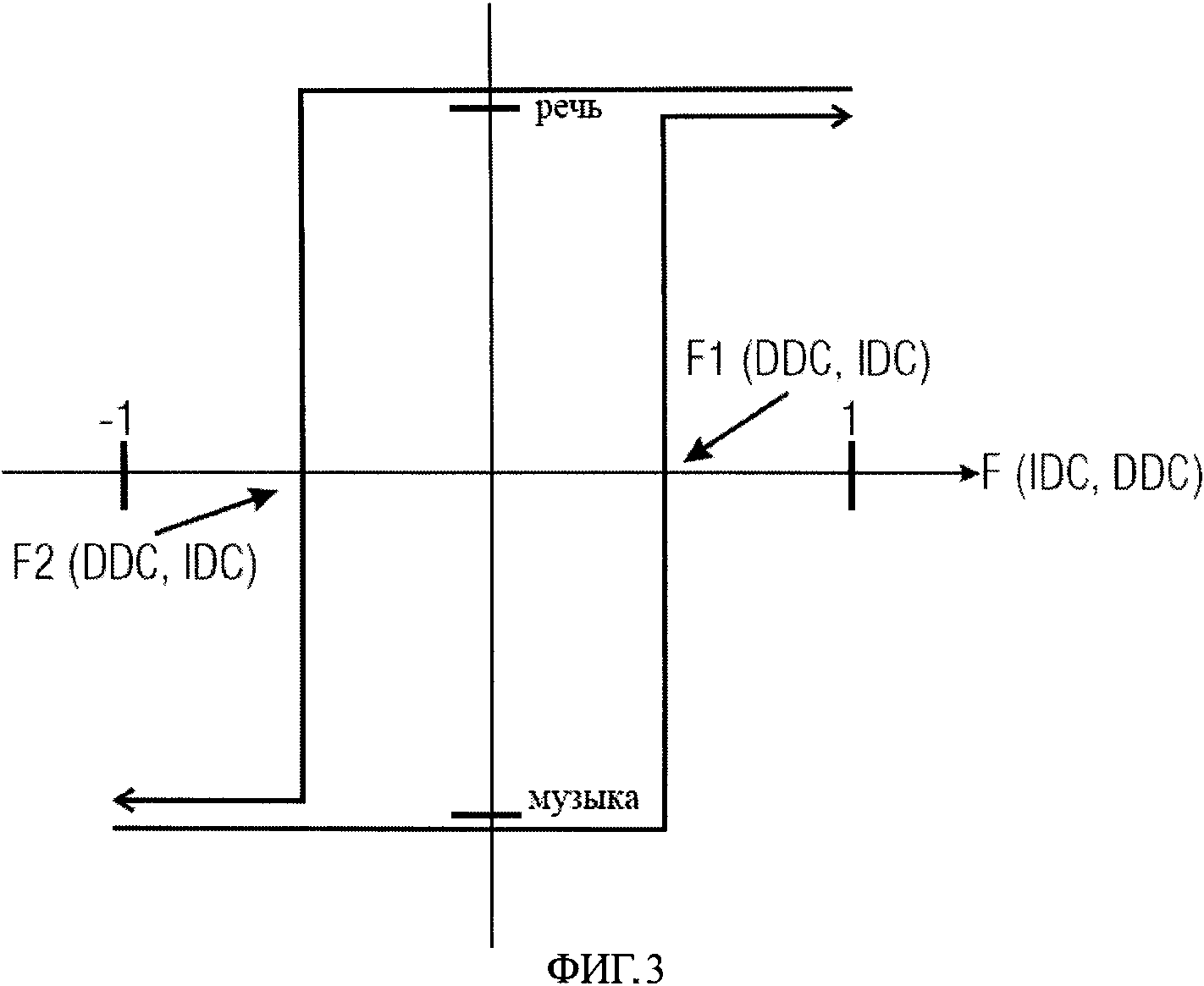
На фиг.3 описано объединение выходных сигналов 152 и 156 классификаторов 150 и 154 дискриминатора 116 для того, чтобы получить сигнал 160 выбора речь/музыка. Отсроченная подсказка решения DDC и мгновенная подсказка решения IDC в соответствии с решением изобретения объединяются с использованием гистерезиса. Процессы с гистерезисом широко используются, чтобы зафиксировать решения и стабилизировать их. Фиг.3 иллюстрирует двухстадийный процесс решения с гистерезисом как функцию DDC и IDC, чтобы определить, должен ли сигнал выбора речь/музыка указать, что в настоящее время обрабатываемый сегмент входного сигнала является речевым сегментом или музыкальным сегментом. На фиг.3 можно видеть характерный цикл гистерезиса, где сигналы IDC и DDC нормализованы классификаторами 150 и 154 так, что принимают значения между -1 и 1, причем -1 означает, что фрагмент полностью подобен музыке, а 1 означает, что фрагмент полностью подобен речи.
Решение основано на значении функции F(IDC, DDC), примеры которой будут описаны ниже. На фиг.3 функция F1(DDC, IDC) указывает на порог, который должна пересечь функция F(IDC, DDC), чтобы перейти от состояния «музыка» до состояния «речь». Функция F2 (DDC, IDC) иллюстрирует порог, который функция F(IDC, DDC) должна пересечь, чтобы перейти от состояния «речь» до состояния «музыка». Окончательное решение D (n) для текущего сегмента или текущего фрейма, имеющего индекс n, может быть вычислено на основе следующего псевдокода:
Псевдо Код выбора с задержкой
%Hysteresis Decision Pseudo Code
If(D(n-1)=music)
If(F(IDC,DDC)<F1(DDC,IDC))
D(n)==music
Else
D(n)=speech
Else
If(F(IDC,DDC)>F2(DDC,IDC))
D(n)=speech
Else
D(n)==music
%End Hysteresis Decision Pseudo Code
В соответствии с решениями изобретения функция F (IDC, DDC) и вышеупомянутые пороги определены следующим образом:
F(IDC,DDC)=IDC
F1(IDC,DDC)=0.4-0.4∗DDC
F2(IDC,DDC)=-0.4-0.4∗DDC
Альтернативно, могут использоваться следующие определения:
F(IDC,DDC)=(2∗IDC+DDC)/3
F1(IDC,DDC)=-0.75∗DDC
F2(IDC,DDC)=-0.75∗DDC
При использовании последнего определения цикл гистерезиса исчезает, и решение принимается только на основе уникального адаптивного порога.
Изобретение не ограничено решением с гистерезисом, описанным выше. Далее будут описаны другие решения для того, чтобы объединить аналитические результаты и получить выходной сигнал.
Вместо решения с гистерезисом может использоваться простая пороговая обработка путем использования особенностей DDC и IDC. Считается, что DDC обеспечивает более надежную подсказку, потому что она получается из более длительного наблюдения за сигналом. Однако, вычисления DDC базируются частично на прошлом наблюдении за сигналом. Обычный классификатор, который сравнивает только значение DDC с порогом 0, классифицируя сегмент как подобный речи при DDC>0, или как подобный музыке, в противном случае формирует отсроченное (задержанное) решение. В этом решении изобретения мы можем использовать пороговую обработку на основе IDC и принять решение быстрее. При этом порог может быть вычислен на основе следующего псевдокода:
% Pseudo code of adaptive thresholding
If(DDO>-0.5∗IDC)
D(n)==speech
Else
D(n)==music
%End of adaptive thresholding
В другом решении DDC может использоваться для того, чтобы сделать более надежным IDC. IDC, как известно, является быстрым, но не столь надежным, как DDC. Кроме того, анализ развития DDC между прошлым и текущим сегментом может дать другой признак, показывающий, как фрейм 166 на фиг.2 влияет на DDC, вычисленный на сегменте 162. Запись DDC (п) используется для текущего значения DDC и DDC (n-1) - для прошлого значения. Используя оба значения: DDC (n) и DDC(n-1), IDC может быть сделан более надежным при использовании дерева решений, как это описано ниже:
% Псевдокод дерева решений
% Pseudo code of decision tree
If(IDC>0&&DDC(n)>0)
D(n)=speech
Else if(IDC<0&&DDC(n)<0)
D(n)=music
Else if(IDC>0&&DDC(n)-DDC(n-1)>0)
D(n)=speech
Else if(IDC<0&&DDC(n)-DDC(n-1)<0)
D(n)=music
Elseif(DDC>0)
D(n)=speech
Else
D(n)=music
%End of decision tree
В вышеупомянутом дереве решение принимается непосредственно, если обе подсказки показывают одинаковый результат. Если эти две подсказки дают противоречащие признаки, мы смотрим на развитие DDC. Если разность DDC (n)-DDC (n-1) положительна, мы можем предположить, что текущий сегмент подобен речи. Иначе, мы можем предположить, что текущий сегмент подобен музыке. Если этот новый признак идет в том же направлении, как IDC, принимается окончательное решение. Если обе попытки не в состоянии дать ясное решение, решение принимается на основании только отсроченной подсказки DDC, так как достоверность IDC недостаточна.
Далее в соответствии с решениями изобретения будут описаны классификаторы 150 и 154.
Прежде всего для долгосрочного классификатора 154 отметим, что требуется для того, чтобы извлечь ряд особенностей из каждого подфрейма длиной 256 отсчетов. Первая особенность - коэффициент перцепционного линейного предсказания (Perceptual Linear Prediction Cepstral Coefficient - PLPCC), который описан в работах Н. Hermansky, “Perceptive linear prediction (pip) analysis of speech,” Journal of the Acoustical Society of America, vol. 87, no. 4, pp.1738-1752, 1990 и Н. Hermansky, et al., “Perceptually based linear predictive analysis of speech,” ICASSP 5.509-512, 1985. Коэффициент PLPCC эффективен для классификации диктора при использовании человеческой слуховой оценки восприятия. Эти коэффициенты могут быть использованы, чтобы отличить речь и музыку, они действительно позволяют различать особенность формант (formants) речи, так же как и силлабической модуляции (модуляции по слогам) речи на частоте 4 Гц, при анализе изменений особенностей во времени.
Однако для усиления признаков различия коэффициенты PLPCC объединены с другой особенностью, которая в состоянии захватить информацию об основном тоне, которая является другой важной особенностью речи и может быть важна при кодировании. Действительно, речевое кодирование основывается на условии, что входной сигнал - псевдомонопериодический сигнал. Речевые кодирующие схемы эффективны для такого сигнала. С другой стороны характеристики высоты тона речи вредят эффективности кодирования музыкальных кодеров. Плавное колебание высоты тона, данное естественное вибрато речи, делает частотное представление сигнала в музыкальных кодерах неподходящим для сильного сжатия, которое требуется для того, чтобы получить высокую эффективность кодирования.
Можно выделить следующие особенности тона:
Отношение голосовых энергетических импульсов:
Эта особенность вычисляет отношение энергии между голосовым импульсом и разностным сигналом LPC. Голосовой пульс извлекается из разностного сигнала LPC с использованием алгоритма выбора максимума (pick-peaking). Обычно LPC голосовой сегмент проявляет ярко выраженную подобную пульсу структуру, возникающую из-за вибрации гортани. Эта особенность велика для голосовых сегментов.
Долгосрочное предсказание уровня передачи:
Уровень передачи обычно вычисляется в речевых кодерах (см. например, “Extended Adaptive Multi-Rate - Wideband (AMR-WB+) codec”, 3GPP TS 26.290 V6.3.0, 2005-06, Technical Specification) во время долгосрочного предсказания. Эта особенность измеряет периодичность сигнала и основана на оценке понижения тона.
Колебание понижения тона:
Эта особенность определяет различие существующей оценки понижения тона по сравнению с последним подфреймом. Для голосовой речи эта особенность низкая, но не ноль и изменяется плавно.
Как только долгосрочный классификатор извлек необходимый набор особенностей, используется статистический классификатор этих извлеченных особенностей. Классификатор сначала обучается, извлекая особенности по речевому и музыкальному учебным наборам. Извлеченные особенности нормализованы и изменяются на 1 относительно значения 0 для данных наборов. Для каждого учебного набора извлеченные и нормализованные особенности собраны в пределах долгосрочного окна классификатора и смоделированы с использованием смешанной модели Гаусса (Gaussians Gaussians Mixture Model - GMM) с использованием пяти Гауссианов. В результате проведения последовательности обучения получается и сохраняется ряд параметров нормализации и два набора параметров GMM.
Для классификации особенности сначала извлекаются для каждого фрейма и нормализуются с параметрами нормализации. Максимальная вероятность для речи (11d_speech) и максимальная вероятность для музыки (11d_music) вычисляются для извлеченных и нормализованных особенностей, используя GMM речевого класса и GMM музыкального класса, соответственно. Тогда отсроченная подсказка решения DDC вычисляется следующим образом:
DDC=(11d_speech-11d_music)/(abs(11d_music)+abs(11d_speech))
DDC лежит между -1 и 1 и положителен, когда вероятность речи выше, чем вероятность для 11d_speech>11d_music.
Краткосрочный классификатор использует в качестве краткосрочной особенности коэффициент PLPCC. В отличие от долгосрочного классификатора эта особенность анализируется в окне 128. Статистические данные по этой особенности используются на этом коротком промежутке времени в смешанной модели Гаусса (Gaussians Gaussians Mixture Model - GMM) с использованием пяти гауссианов. Обучаются две модели, одна для музыки, другая для речи. Заметим, что эти две модели отличаются от моделей, полученных для долгосрочного классификатора. Для классификации каждого фрейма сначала извлекаются коэффициенты PLPCC, максимальная вероятность для речи (11d_speech) и максимальная вероятность для музыки (11d_music), вычисленные для того, чтобы использовать GMM речевого класса и GMM музыкального класса, соответственно. Мгновенная подсказка решения IDC тогда вычисляется следующим образом
IDC=(11d_speech-11d_music)/(abs(11d_music)+abs(11d_speech))
IDC изменяется от -1 до 1.
Таким образом, краткосрочный классификатор 150 формирует краткосрочный результат классификации сигнала на основе особенности “коэффициент перцепционного линейного предсказания (PLPCC)”, и долгосрочный классификатор 154 формирует долгосрочный результат классификации сигнала на основе той же самой особенности “коэффициент перцепционного линейного предсказания (PLPCC)” и вышеупомянутой дополнительной функции (или функций), т.е. характеристики (или характеристик) основного тона речевого сигнала. Кроме того, долгосрочный классификатор может использовать различные особенности общей особенности, то есть коэффициента PLPCC, поскольку у долгосрочного классификатора есть доступ к более длинному окну наблюдения. Таким образом, после объединения краткосрочных и долгосрочных результатов краткосрочные особенности существенно принимаются во внимание для классификации, то есть их свойства существенно используются.
Ниже описано в деталях дальнейшее решение для соответствующих классификаторов 150 и 154.
Краткосрочные особенности, проанализированные краткосрочным классификатором в соответствии с решением, соответствуют, главным образом, коэффициентам перцепционного линейного предсказания, упомянутым выше как коэффициенты PLPCC. Коэффициенты PLPCC широко используются в речи и идентификации диктора так же, как и MFCC (см. выше). Коэффициенты PLPCC оставлены, потому что они разделяют большую часть функциональности линейного предсказания (LP), которое используются в большей части современных речевых кодеров и реализовано в переключаемом аудиокодере. Используя PLPCC, можно извлечь структуру формант речи, как это делает LP, но принимая во внимание перцепционные соображения, PLPCC более независимы от диктора (говорящего) и, таким образом, более значимы в отношении лингвистической информации. Для сигнала с частотой дискретизации 16 кГц используется набор из 16.
Кроме коэффициентов PLPCC, вычисляется сила голоса как краткосрочная особенность. Силу голоса обычно не используют отдельно, но она выгодна при совместном использовании с PLPCC. Сила голоса позволяет выделить при измерении особенностей по крайней мере две группы, относящиеся соответственно к голосовому и неголосовому произношению речи. Метод выделения этих групп основан на вычислении характерных свойств с использованием различных параметров, называемых число пересечений нуля (Zero crossing Counter - zc), спектральный наклон (spectral tilt - tilt), стабильность основного тона речи (pitch stability - ps), и нормализованная корреляция основного тона речи (normalized correlation of the pitch - nc). Все эти четыре параметра нормализованы между 0 и 1 способом, при котором 0 соответствует типичному неголосовому сигналу, а 1 соответствует типичному голосовому сигналу. В данном решении сила голоса берется из критерия классификации речи, используемого в речевом кодере VMR-WB, описанном в работе Milan Jelinek and Redwan Salami, "Wideband speech coding advances in vmr-wb standard," IEEE Trans. on Audio, Speech and Language Processing, vol. 15, no. 4, pp.1167-1179, May 2007. В основу критерия положена динамика следящего фильтра высоты тона, основанного на автокорреляции. Для фрейма с индексом k сила голоса u (k) имеет следующую форму:
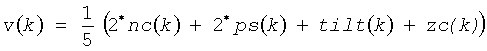
Способность к различению у краткосрочных особенностей вычисляется с использованием смешанных моделей Гаусса (Gaussian Mixture Models - GMMS) как классификатора. Используются две GMM, одна для речевого класса и другая для музыкального класса. Число смешиваемых компонент гауссовой плотности сделано переменным, чтобы оценить влияние на рабочие характеристики. Таблица 1 показывает степени точности для различного числа смешиваемых компонент. Значения вычислены для каждого сегмента четырех последовательных фреймов. Полная задержка равна 64 миллисекундам, что является подходящим для переключаемого аудиокодирования. Можно заметить, что точность увеличивается с ростом числа смешиваемых компонент. Разрыв между 1-GMMs и 5-GMMs особенно важен и может быть объяснен фактом, что представление речи в виде формант слишком сложно, чтобы быть достаточно определенным только одним Гауссианом.
|
Табл. 1: Точность классификации в % с использованием краткосрочных особенностей
Рассматривая долгосрочный классификатор 154, отметим что во многих работах, например, М. J. Carey, et. al. “A comparison of features for speech and music discrimination,” Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, ICASSP, vol. 12, pp.149 to 152, March 1999, полагается, что статистические различия особенностей лучше подходят для различения, чем особенности непосредственно. Как грубое общее правило, музыку можно считать более постоянной, обычно демонстрирующей небольшие изменения. Напротив, речь можно легко отличить из-за ее значительной энергетической модуляции с частотой 4 Гц, поскольку сигнал периодически изменяется между голосовым и неголосовым сегментами. Более того, последовательность различных фонем делает речевые особенности менее постоянными. Согласно предлагаемому решению рассматриваются две долгосрочных особенности: одна, основанная на вычислении различия, и другая, основанная на априорном знании контура основного тона речи. Долгосрочные особенности приспособлены к низкой задержке SMD (дискриминации речи/музыки).
Динамическое изменение PLPCC состоит в вычислении различия для каждого набора коэффициентов PLPCC по накладывающемуся аналитическому оконному покрытию нескольких фреймов так, чтобы придать особое значение последнему фрейму. Чтобы ограничить вносимое время ожидания, аналитическое окно асимметрично и «рассматривает» только текущий фрейм и прошлое. На первом шаге вычисляется скользящее среднее значение mam(k) коэффициентов PLPCC по последним N фреймам следующим образом:
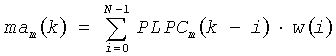
где PLPm (k) - m-тый коэффициент косинусного преобразования Фурье, из М коэффициентов, полученных для k-того фрейма. Динамическое различие mvm (k) тогда определено как:
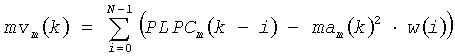
где w - окно длины N, которое согласно решению имеет наклон ската, определенный следующим образом:
w(i)=(N-i)/N·(N+1)/2
Динамическое различие в конце усредняется по m:
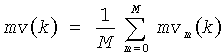
У основного тона речи есть замечательные свойства и часть их может наблюдаться только на длинных аналитических окнах. Действительно основной тон речи плавно колеблется во время голосовых сегментов, но редко является постоянным. Напротив, музыка показывает очень часто постоянный основной тон во время всей продолжительности ноты и резкие изменения во время переходов. Долгосрочные особенности охватывают эту особенность, при наблюдении контура основного тона на длинном временном сегменте. Параметр контура основного тона pc(k) определен как:
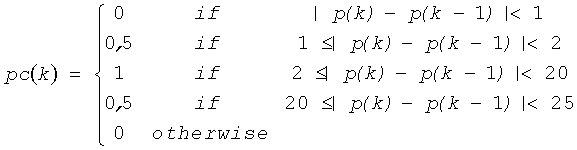
где р (k) является задержкой основного тона, вычисленной на фрейме с индексом k на LP разностном сигнале с частой дискретизации 16 Гц. Качество речи sm(k) вычисляется из параметра контура основного тона способом, при котором речь, как ожидают, покажет плавно колеблющуюся задержку основного тона во время голосовых сегментов и сильный спектральный наклон к высоким частотам во время неголосовых сегментов:
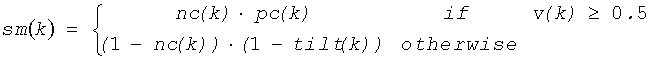
где nc(k), tilt(k) и v(k) определены выше (см. краткосрочный классификатор). Характеристика «качество речи» нагружена весовыми коэффициентами окна w, определенного выше и объединяющего последние N фреймов:
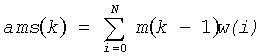
Контур основного тона также важный признак того, что сигнал является подходящим для речевого или аудиокодирования. Действительно, речевые кодеры работают, главным образом, во временном интервале и делают предположение, что сигнал гармонический и квазипостоянен на сегментах короткого промежутка времени приблизительно 5 миллисекунд. С этими предположениями они могут смоделировать эффективно естественное колебание тона речи. Напротив, то же самое колебание вредит эффективности обычных аудиокодирующих устройств, которые используют линейные преобразования на длинных аналитических окнах. Основная энергия сигнала тогда распространяется по нескольким коэффициентам преобразования.
Как краткосрочные особенности, так и долгосрочные особенности оцениваются с использованием статистического классификатора, формирующего, таким образом, долгосрочный результат классификации (DDC). Вычислены две особенности с использованием N=25 фреймов при анализе 400 миллисекунд предыстории сигнала. Перед использованием 3-GMM в сокращенном одномерном пространстве применен линейный дискриминантный анализ (LDA). Таблица 2 показывает точность классификации, определенной на наборах обучения и тестирования, при классифицикации сегментов четырех последовательных фреймов.
|
Табл. 2: Точность классификации в % с использованием долгосрочных особенностей
Объединенная система классификаторов согласно решениям изобретения сочетает соответственно краткосрочные и долгосрочные функции способом, при которым они приносят собственный определенный вклад в окончательное решение. С этой целью может использоваться стадия окончательного решения с гистерезисом, как описано выше, где эффект памяти управляется DDC или долгосрочной отличительной подсказкой (LTDC), в то время как мгновенные данные получаются из IDC или краткосрочной отличительной подсказки (STDC). Эти две подсказки формируются на выходе долгосрочных и краткосрочных классификаторов, как иллюстрируется на фиг.1. Решение принимается на основе IDC, но утверждается DDC, который управляет динамически порогами, вызывающими изменение состояния.
Долгосрочный классификатор 154 использует долгосрочные и краткосрочные особенности, ранее определенные с использованием LDA, сопровождаемым 3-GMM. DDC равен логарифмическому отношению долгосрочной вероятности классификатора речевого класса и музыкального класса, вычисленного по последним 4 Х К фреймам. Число принятых во внимание фреймов может меняться в зависимости от параметра К, чтобы добавить в большей или меньшей степени эффект памяти в окончательном решении. Напротив, краткосрочный классификатор использует только краткосрочные функции с 5-GMM, которые показывают хороший компромисс между эффективностью и сложностью. IDC равен логарифмическому отношению краткосрочной вероятности классификатора речевого класса и музыкального класса, вычисленного только по последним 4 фреймам.
Чтобы оценить данный подход специально для переключаемого аудиокодирования, были оценены три различных вида действий. Первое измерение эффективности проводилось с использованием обычной речи против музыки (SvM). Оценка получена по большому набору речевых знаков и музыки. Второе измерение эффективности сделано на большом уникальном материале, включающем речь и музыкальные сегменты, чередующиеся каждые 3 секунды. Точностью различения тогда называется различение речи после/прежде музыки (SabM) и отражает, главным образом, быстродействие системы. Наконец, устойчивость различения оценена путем выполнения классификации на большом наборе речевых фрагментов поверх музыкальных. Смешивание речи и музыки сделано на разных уровнях. Характеристика речь поверх музыки (SoM) получена путем вычисления отношения числа переключений, которые произошли на общем количестве фреймов.
Долгосрочный и краткосрочный классификаторы используются в качестве ссылок для того, чтобы оценить обычные подходы с использованием одиночных классификаторов. Краткосрочный классификатор показывает хорошее быстродействие, имея более низкую устойчивость и способность различения (дискриминации) повсюду. С другой стороны долгосрочный классификатор, сильно увеличивая число фреймов 4 Х К, может достигнуть лучшей устойчивости и способности различения музыки и речи, ставя под угрозу быстродействие решения. При сравнении с упомянутым обычным подходом у предложенной объединенной системы классификаторов в соответствии с изобретением есть несколько преимуществ. Одно преимущество состоит в том, что предложенное решение поддерживает хорошую чистую речь в отличие от музыкальных дискриминаторов, сохраняя быстродействие системы. Другое преимущество - хороший баланс между быстродействием и устойчивостью.
На фиг.4 и 5 иллюстрируются примеры схем кодирования и расшифровки, которые включают дискриминатор или блок, работающий в соответствии с решениями изобретения.
В соответствии с представленной схемой кодирования, показанной на фиг.4, моносигнал, сигнал стерео или многоканальный сигнал подаются на общий блок предварительной обработки 200.
У общего блока 200 предварительной обработки может быть функциональность объединенного стерео (joint stereo), многоканального стерео (surround stereo), и/или функциональность расширения полосы частот. На выходе блока 200 есть моноканал, стереоканал или много каналов, в которые являются входными каналами в один или более переключателей 202. Переключатель 202 может быть реализован для каждого выхода блока 200, когда у блока 200 есть два или больше выходов, то есть, когда блок 200 формирует стерео или многоканальный сигналы. Например, первый канал сигнала стерео может быть речевым каналом, и второй канал сигнала стерео может быть музыкальным каналом. В этом случае выбор блока 204 решения может в один и тот же момент времени отличаться между этими двумя каналами.
Переключателем 202 управляет блок 204 решения. Блок выбора включает дискриминатор в соответствии с решениями изобретения и получает в качестве входных данных сигнал, поступающий на блок 200, или сигнал на выходе блока 200. Альтернативно, блок 204 решения может также получить внешнюю информацию, которая включена в моносигнал, сигнал стерео или многоканальный сигнал или по крайней мере связана с таким информационным сигналом, который был, например, сформирован из первоначального моно, стереосигнала или многоканального сигнала.
В одном решении блок выбора не управляет блоком 200 предварительной обработки, и стрелка, соединяющая блоки 204 и 200, отсутствует. В дальнейшей реализации, обработкой в блоке 200 управляет до известной степени блок выбора 204, чтобы установить основанный на выборе один или более параметров в блоке 200. Это, однако, не влияет на общий алгоритм блока 200 так как его основная функциональность 200 остается независимо от решения, вырабатываемого блоком 204.
Вырабатывающий решение блок 204 приводит в действие переключатель 202, чтобы подать выходные данные общего блока предварительной обработки на блок кодирования частоты 206, расположенный в верхней части фиг.4 или блок LPC-кодирования 208, расположенный в нижней части фиг.4.
В одном решении переключатель 202 переключается между двумя кодирующими каналами 206, 208. В дальнейших разработках могут быть дополнительные каналы кодирования, такие как третий канал кодирования, четвертый канал кодирования или даже больше каналов кодирования. В решении с тремя каналами кодирования третий канал кодирования может быть подобным второму каналу кодирования, но включает кодирующее устройство возбуждения, отличающееся от кодирующего устройства возбуждения 210 во втором канале 208. В таком воплощении второй канал включает блок 212 LPC и кодирующее устройство возбуждения 210, такое как в ACELP, основанное на таблице кодов, а третий канал включает блок LPC и кодирующее устройство возбуждения, воздействующее на спектральное представление выходного сигнала блока LPC.
Канал кодирования частотной области включает блок спектрального преобразования 214, который осуществляет преобразование выходного сигнала общего блока предварительной обработки в спектральную область. Блок спектрального преобразования может включать алгоритмы MDCT (модифицированное дискретное косинусное преобразование), QMF, алгоритм FFT (быстрое преобразование Фурье), вейвлет анализ или блок фильтров, такой как критически выбранный блок фильтров (блок фильтров, в котором сбалансировано частотное и временное разрешение), имеющий определенное количество каналов, сигналы в которых могут быть реальными, или комплексными сигналами. Выходные данные блока спектрального преобразования 214 кодируются, используя спектральное аудиокодирующее устройство 216, которое может включать блоки обработки, известные из ААС кодирующих схем.
Канал кодирования 208 включает исходную модель анализатора, такую как LPC 212, которая формирует два вида сигналов. Один сигнал - информационный LPC сигнал, который используется для того, чтобы управлять характеристиками фильтра LPC синтеза. Эта LPC информация передается к декодеру. Другой выходной сигнал блока LPC 212-сигнал возбуждения или сигнал LPC-области, который поступает в устройство 210, кодирующее сигнал возбуждения. В качестве кодирующего устройства возбуждения 210 может быть выбрано любое кодирующее устройство, такое как кодирующее устройство CELP, кодирующее устройство ACELP или любое другое кодирующее устройство, которое обрабатывает сигнал LPC.
Другое выполнение кодирующего устройства возбуждения может быть кодированием преобразованного сигнала возбуждения. В таком воплощении сигнал возбуждения не кодируется с использованием ACELP, а преобразуется в спектральное представление, и спектральные коэффициенты представления, такие как сигналы подгруппы в случае блока фильтров, или частотные коэффициенты в случае преобразования FFT, кодируются, чтобы получить сжатие данных. Реализация этого вида устройства, кодирующего сигнал возбуждения, является способом кодирования ТСХ, известным из AMR-WB+.
Сигнал выбора, формируемый блоком 204, должен быть сформирован так, чтобы блок выбора 204 выполнил дискриминацию музыки/речи и управлял выключателем 202 таким способом, при которым музыкальные сигналы поступают в верхний канал 206, а речевые сигналы поступают в нижний канал 208. В одном решении блок 204 формирует свою информацию о решении в виде выходного битового потока, так, чтобы декодер мог использовать эту информацию о выборе и выполнить правильные операции по расшифровке.
Такой декодер иллюстрирован на фиг.5. После передачи сигнал, сформированный спектральным аудиокодирующим устройством 216, поступает на спектральный аудиодекодер 218. Выходные данные спектрального аудиодекодера 218 поступают на преобразователь временной области 220. Выходные данные кодирующего устройства возбуждения, 210 из фиг.4 поступают в декодер возбуждения 222, который формирует сигнал LPC-области. Сигнал LPC-области поступает в блок 224 синтеза LPC, который получает на другой вход информацию LPC, сформированную соответствующим аналитическим LPC блоком 212. Выход преобразователя временной области 220 и/или выход блока 224 синтеза LPC соединен с переключателем 226. Переключателем 226 управляет сигнал управления переключателем, который был, например, сформирован блоком выбора 204 и является внешним, сформированным создателем оригинального моносигнала, стереосигнала или многоканального сигнала.
Выходной сигнал переключателя 226 является полным моносигналом, который впоследствии поступает в общий блок 228 последующей обработки, который может выполнить обработку объединенного стерео, или обработку расширения полосы частот и т.д. Альтернативно, выходной сигнал переключателя может также быть сигналом стерео или многоканальным сигналом. Это сигнал стерео, когда предварительная обработка включает сжатие в двух каналах. Это может быть даже многоканальный сигнал, когда осуществляется сжатие данных трех каналов или сжатие не осуществляется вообще, но осуществляется только технология восстановления спектра.
В зависимости от определенной функциональности общего блока последующей обработки формируется моно сигнал, сигнал стерео или многоканальный сигнал, который имеет большую спектральную полосу, чем входной сигнал блока 228 в случае, если общий блок 228 последующей обработки выполняет операцию по расширению полосы частот.
В одном решении переключатель 226 переключается между двумя каналами расшифровки 218, 220 и 222, 224. В другом решении могут быть дополнительные каналы расшифровки, такие как третий канал расшифровки, четвертый канал расшифровки или даже больше каналов расшифровки. В решении с тремя каналами расшифровки третий канал расшифровки может быть подобным второму каналу расшифровки, но включает декодер возбуждения, отличающийся от декодера возбуждения 222 во втором канале 222, 224. В таком воплощении второй канал включает блок 224 LPC и декодер возбуждения, такой как в ACELP, основанный на таблице кодов, а третий канал включает блок LPC и декодирующее устройство сигнала возбуждения, воздействующее на спектральное представление выходного сигнала блока 224 LPC.
В другом решении общий блок предварительной обработки включает блок многоканального/объединенного (surround/joint) стерео, который формирует на выходе объединенные параметры стерео и моно выходной сигнал, которые образуются сжатием со смешением входного сигнала имеющего два или больше каналов. Вообще, сигнал, формируемый блоком, может также быть сигналом, имеющим больше каналов, но из-за операции по сжатию со смешением (микшированием) число каналов, формируемых блоком, будет меньшим, чем число входных каналов в блок. В этом решении канал кодирования частоты включает спектральное преобразование и впоследствии связанную обработку квантования/кодирования. Блок квантования/кодирования может включать любую из функциональностей известных в современных частотных кодирующих устройствах, таких как кодирующее устройство ААС. Кроме того, операцией по квантизации на стадии квантования/кодирования можно управлять через физикоакустический модуль, который формирует физикоакустическую информацию, поступающую в блок, такую как психоакустический маскирующий частотный порог. Спектральное преобразование с использованием операции MDCT предпочтительно, еще более предпочтительной является операция MDCT с временными предискажениями (time-warped MDCT), где величиной предискажения можно управлять между нулем и большим значением. Известно, что при величине предискажения ноль операция MDCT является прямой операцией MDCT. Кодирующее устройство LPC-области может включать ядро ACELP, вычисляющее передачу звука, задержку звука и/или информацию о наборе кодов, такую как индекс набора кодов и передача кода.
Хотя некоторые из рисунков иллюстрируют блок-схемы устройства, отметим, что эти рисунки в то же самое время иллюстрируют метод, где функциональность блока соответствует шагам метода.
Выше были описаны решения изобретения, охватывающего входной звуковой сигнал, включающий различные сегменты или фреймы, связываемые с информацией о речи или информацией о музыке. Изобретение не ограничено такими решениями, скорее это подход для того, чтобы классифицировать различные сегменты сигнала, включающего сегменты, по крайней мере, первого типа и второго типа, метод может также быть применен к аудиосигналам, включающим три или больше различных типа сегментов, каждый из которых должен быть закодирован с использованием различных схемам кодирования. Примеры для таких типов сегментов:
- Стационарные/нестационарные сегменты могут быть обработаны с использованием различных блоков фильтров, окон или кодирующих устройств. Например, переходный процесс должен быть закодирован с использованием блока фильтров с хорошим временным разрешением, в то время как чистая синусоида должна быть закодирована блоком фильтров с хорошим частотным разрешением.
- Голосовой/неголосовой: голосовые сегменты хорошо обрабатываются речевым кодером, таким как CELP, но для неголосовых сегментов при этом тратится впустую слишком много битов. Параметрическое кодирование будет более эффективным.
- Тишина/Активность: тишина может быть закодирована с меньшим количеством битов, чем активные сегменты.
- Гармонический/негармонический: Для гармонического кодирования сегментов выгодно использовать линейное предсказание в области частоты.
Кроме того, изобретение не ограничено областью аудиометодов, вышеописанный подход к классификации может быть применен к другим видам сигналов, таким как видеосигналы или сигналы данных, причем эти сигналы включают сегменты различных типов, которые требуют различной обработки.
Данное изобретение может быть адаптировано ко всем приложениям, которые нуждаются во временной сегментации сигнала. Например, обнаружение лица от видеокамеры наблюдения может быть основано на классификаторе, который определяет для каждого пиксела фрейма (здесь фрейм соответствует снимку, сделанному в момент n), принадлежит ли он лицу человека или нет. Классификация (то есть сегментация лица) должна быть сделана для каждого фрейма видеопотока. Однако, используя данное изобретение, сегментация существующего фрейма может принять во внимание прошлые последовательные фреймы для того, чтобы получить лучшую точность сегментации, основанную на том, что последовательные снимки сильно коррелированы. Тогда могут быть применены два классификатора. Один для анализа только существующей структуры и другой для анализа ряда фреймов, включая настоящее и прошлое. Последний классификатор может объединить набор фреймов и определить область вероятного положения лица. Выбор классификатора, сделанный только на текущем фрейме, тогда будет сравнивать с этой вероятной областью. При этом выбор может быть утвержден или изменен.
Решения изобретения используют переключатель для того, чтобы переключиться между каналами так, чтобы только один канал получил обрабатываемый сигнал, а другой канал не получил. В альтернативном решении переключатель может также быть встроен после блоков обработки или каналов, например, аудиокодирующее устройство и речевое кодирующее устройство так, чтобы оба канала обработали тот же самый сигнал параллельно. Сигнал, сформированный одним из этих каналов, поступает на выход, чтобы попасть в выходной поток данных.
В то время как решения изобретения были описаны на основе цифровых сигналов, сегменты которых были определены предопределенным числом отсчетов, полученных при определенной частоте выборки, изобретение не ограничено такими сигналами, оно также применимо к аналоговым сигналам, в которых сегмент был бы тогда определен определенным частотным диапазоном или периодом времени аналогового сигнала. Кроме того, решения изобретения были описаны в комбинации с кодирующими устройствами включая дискриминатор. Отметим, что в целом в соответствии с решениями изобретения подход к классифицикации сигналов может быть применен к декодерам, получающим кодируемое сообщение, для которого могут быть выбраны различные схемы кодирования, таким образом, обеспечивается обработка кодируемого сообщения соответствующим декодером.
В зависимости от определенных требований предложенные методы могут быть осуществлены в аппаратных средствах или в программном обеспечении. Выполнение может быть осуществлено с использованием цифрового носителя данных, в частности, диска DVD или компакт-диска, хранящего в электронном виде управляющие коды, которые исполняются программируемыми компьютерными системами, таким образом, что выполняются предложенные алгоритмы. Вообще, данное изобретение является компьютерной программой, сохраненной на электронном носителе, выполняемый на компьютере код программы осуществляет предложенные методы. Другими словами, предложенные методы - это компьютерная программа, имеющая программный код того, чтобы выполнить по крайней мере один из предложенных методов при выполнении этой компьютерной программы на компьютере.
Описанные выше решения являются простой иллюстрацией принципов данного изобретения. Подразумевается, что модификации и изменения описанных здесь средств и деталей будут очевидны для специалистов. Поэтому есть намерение ограничиться набором утверждений формулы изобретения, а не определенными и описанными здесь деталями решений.
В вышеупомянутых решениях описан сигнал, включающий множество фреймов, где оценен текущий фрейм для выбора переключения. Отмечено, что текущий сегмент сигнала, который оценен для выбора переключения, может быть одним фреймом, однако, изобретение не ограничено такими решениями. Сегмент сигнала может также включить множество, то есть два или больше фреймов.
Далее, в описанных решениях краткосрочный классификатор и долгосрочный классификаторы использовали ту же самую краткосрочную функцию. Этот подход может использоваться по различным причинам, как необходимость вычисления краткосрочных особенностей только однажды и использование их двумя классификаторами, что уменьшает сложность системы, поскольку, например, краткосрочная особенность может быть вычислена одним из краткосрочных или долгосрочных классификаторов и передана другому классификатору. Кроме того, сравнение результататов краткосрочного и долгосрочного классификаторов может быть более значимым, поскольку вклад текущего фрейма в долгосрочный результат классификации выводится более легко по сравнению с краткосрочным результатом классификации, так как эти два классификатора используют общие свойства.
Изобретение, однако, не ограничено таким подходом, и долгосрочный классификатор может использовать те же самые краткосрочные особенности, как краткосрочный классификатор, то есть и краткосрочный классификатор, и долгосрочный классификатор могут вычислить соответствующую краткосрочную особенность (и), которые отличаются друг от друга.
В то время как описанные выше решения используют PLPCC как краткосрочную особенность, отметим, что можно рассмотреть другие особенности, например, разнообразие PLPCC.
Устройство и способ для извлечения сигнала окружающей среды в устройстве и способ получения весовых коэффициентов для извлечения сигнала окружающей среды
Аудиокодирование с использованием повышающего микширования
Низкоскоростная аудиокодирующая/декодирующая схема с общей предварительной обработкой
Устройство и способ декодирования кодированного звукового сигнала
Вычислитель контура временной деформации, кодера аудиосигнала, кодированное представление аудиосигнала, способы и программное обеспечение
Устройство и способ преобразования звукового сигнала в параметрическое представление, устройство и способ модификации параметрического представления, устройство и способ синтеза параметрического представления звукового сигнала
Звуковое кодирующее устройство и звуковое декодирующее устройство
Устройство и способ для вычисления числа огибающих спектра
Устройство и метод для обработки аудиосигнала, содержащего переходный сигнал
Синтезатор аудиосигнала и кодирующее устройство аудиосигнала
Устройство и способ для извлечения сигнала окружающей среды в устройстве и способ получения весовых коэффициентов для извлечения сигнала окружающей среды
Аудиокодирование с использованием повышающего микширования
Низкоскоростная аудиокодирующая/декодирующая схема с общей предварительной обработкой
Устройство и способ декодирования кодированного звукового сигнала
Вычислитель контура временной деформации, кодера аудиосигнала, кодированное представление аудиосигнала, способы и программное обеспечение
Устройство и способ преобразования звукового сигнала в параметрическое представление, устройство и способ модификации параметрического представления, устройство и способ синтеза параметрического представления звукового сигнала
Звуковое кодирующее устройство и звуковое декодирующее устройство
Устройство и способ для вычисления числа огибающих спектра
Устройство и метод для обработки аудиосигнала, содержащего переходный сигнал
Синтезатор аудиосигнала и кодирующее устройство аудиосигнала

