Результат интеллектуальной деятельности: ОПТИМИЗАЦИЯ ФОРМАТА ПОИСКОВОГО ИНДЕКСА
Вид РИД
Изобретение
Уровень техники, к которой относится изобретение
Поиск ключевых слов или подобных элементов данных в области поиска, составленного из ряда документов, как правило, подразумевает применение индекса. Зачастую он является инвертированным индексом, сопоставляющим ключевые слова с документами.
В случае если поисковый индекс является по своему характеру универсальным, то он должен поддерживать множество типов поиска. Одним общим примером является поиск ключевого слова, в котором пользователь задает одно или несколько ключевых слов или значений, а результатом поиска являются все документы из области поиска, содержащие все ключевые слова. Другим примером является поиск по фразе, в котором пользователь задает фразу, составленную из двух или более слов в установленном порядке. Результатом поиска в данном случае являются все документы из области поиска, содержащие такую же фразу, как и заданная (то есть со всеми смежными словами и в том же порядке). Индекс, который поддерживает запросы по фразе, должен содержать значительно больше данных, чем тот, который его не поддерживает, поскольку первый должен включать в себя местоположение каждого вхождения слова в документе.
В целях удовлетворения потребностей пользователя поиск должен быть как быстрым, так и точным. На уровне индекса это приводит к конфликту требований. Для точности индекс должен быть полным, но это приводит к потребности в увеличении индекса. Для ускорения доступа к индексу он должен быть маленьким, но это приводит к потребности в устранении данных. Могут применяться схемы сжатия для сокращения количества считываемых данных, но этого может быть недостаточно для удовлетворения потребности пользователя в быстрых результатах.
Раскрытие изобретения
Данное раскрытие изобретения приведено для введения в упрощенной форме набора понятий, которые в дальнейшем описываются ниже в подробном описании изобретения. Данное раскрытие изобретения не предназначается для определения основных характеристик или существенных характеристик заявленного объекта, и при этом она не предназначается для применения ее в качестве ограничения объема заявленного объекта.
Различные аспекты заявленного объекта, раскрываемые в настоящем документе, относятся к структуре поискового индекса, в которой расширение существующей ранее структуры применяется для оптимизации поисков не по фразе. Данная оптимизация включает в себя устранение информации о местоположении вхождений ключевого слова в документ.
Другие аспекты относятся к устранению данных посредством структурирования индекса таким образом, чтобы его можно было вычислять, а не сохранять. Сопоставление полей частоты вхождения переменной длины с логическими категориями позволяет выводить размер поля из категории, а не сохранять его. Применение непрерывных символьных значений в пределах и между категориями позволяет вычислять символьные значения, а не сохранять их в категории. Упорядочение символьных записей в категории и совпадение его с упорядочением таблицы кодирования позволяет вычислять символ, соответствующий коду, а не сохранять его.
Описанный ниже подход может быть реализован в качестве компьютерного процесса, вычислительной системы или в качестве такого изделия, как компьютерный программный продукт. Компьютерный программный продукт может являться компьютерным носителем данных, считываемым посредством компьютерной системы и кодирующим команду компьютерной программы для выполнения компьютерного процесса. Компьютерный программный продукт также может являться накапливаемым несущей сигналом, считываемым посредством вычислительной системы и кодирующим команду компьютерной программы для выполнения компьютерного процесса.
Более полное понимание вышеупомянутого раскрытия изобретения может быть получено путем обращения к сопровождающим чертежам, краткая характеристика которых приведена ниже, к последующему подробному описанию настоящих вариантов осуществления, а также к приложенной формуле изобретения.
Краткое описание чертежей
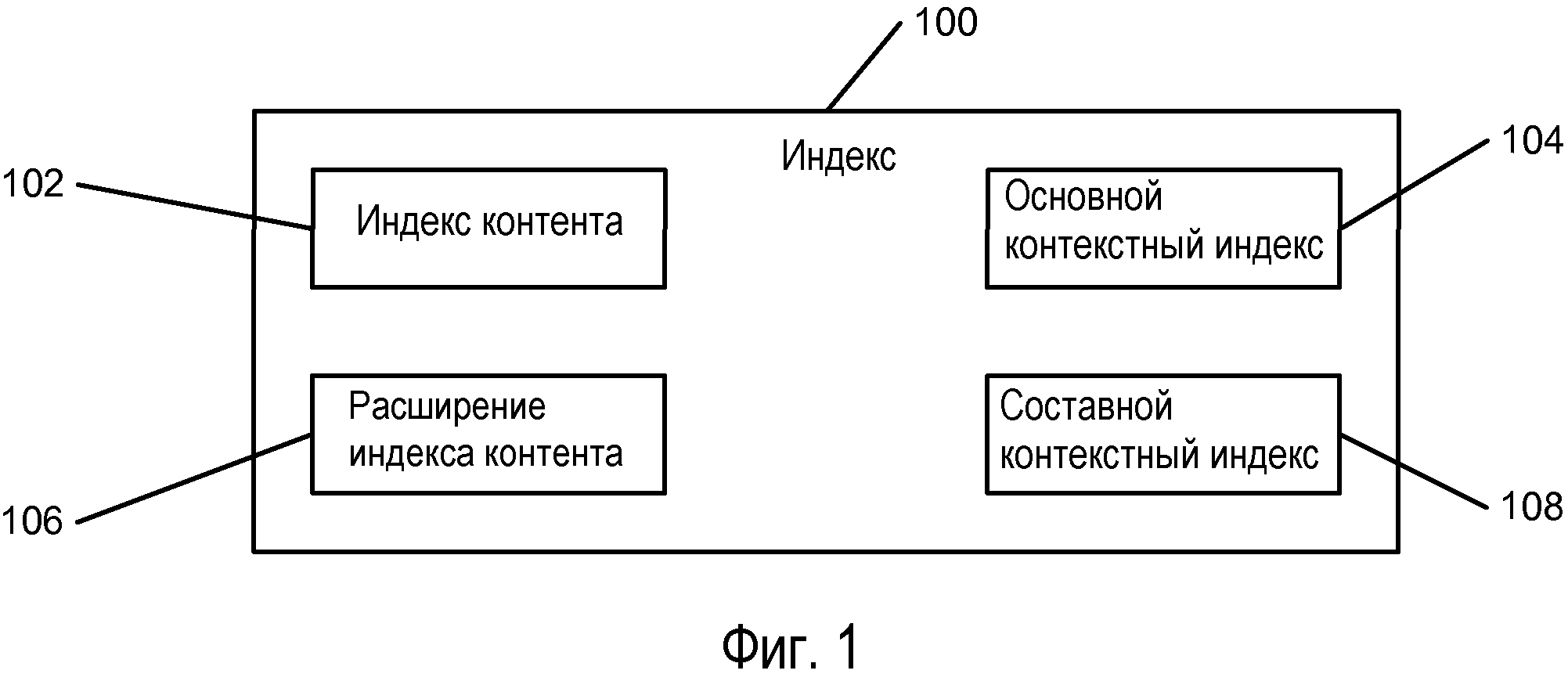
Фиг.1 изображает вариант осуществления структуры составного поискового индекса.
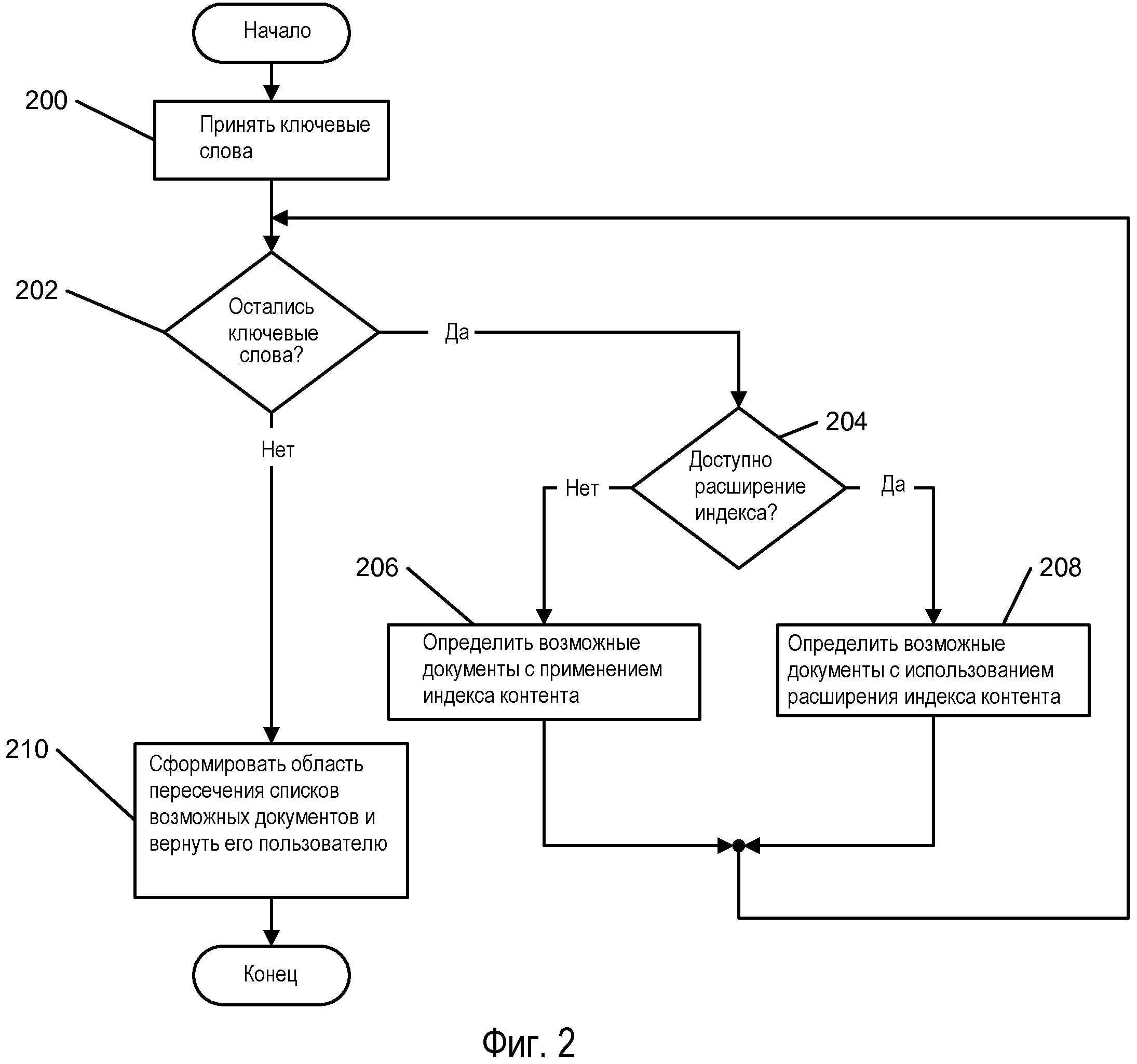
Фиг.2 показывает логическую последовательность высокого уровня варианта осуществления способа выполнения запроса из нескольких слов, не по фразе.
Фиг.3 показывает логическую последовательность высокого уровня варианта осуществления способа выполнения запроса по фразе.
Фиг.4 изображает вариант осуществления структуры высшего уровня расширения индекса контента.
Фиг.5 изображает вариант осуществления структуры страницы таблицы кодирования.
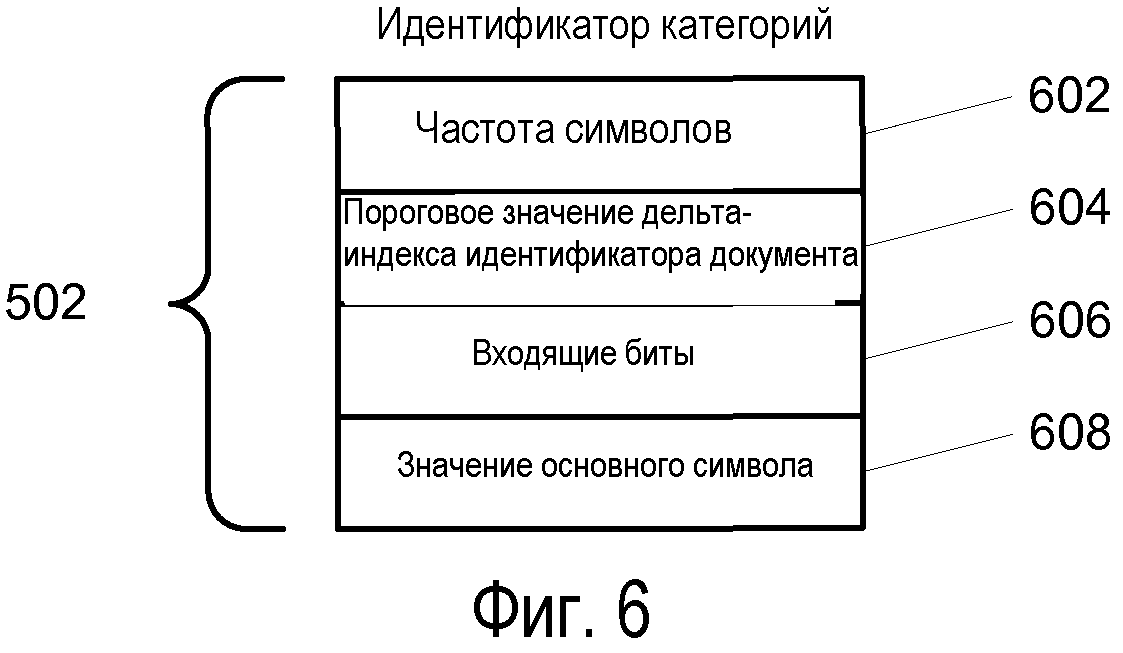
Фиг.6 изображает вариант осуществления структуры идентификатора категорий.
Фиг.7 изображает вариант осуществления структуры страницы данных.
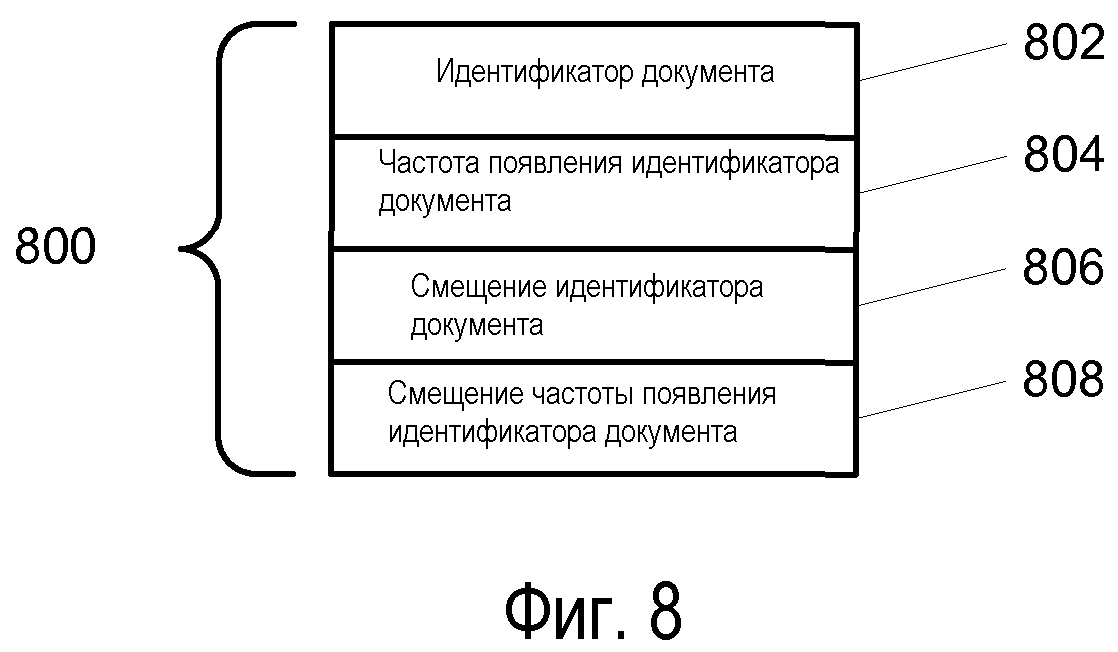
Фиг.8 изображает вариант осуществления структуры записи каталога страниц.
Фиг.9 изображает вариант осуществления структуры записи битового потока идентификатора ID документа.
Фиг.10 показывает обобщенную последовательность процесса сжатия.
Фиг.11 изображает обобщенную последовательность процесса распаковки.
Осуществление изобретения
Данное подробное описание изобретения приведено со ссылкой на сопровождающие чертежи, которые являются его частью и которые в целях иллюстрации показывают определенные варианты осуществления. Данные варианты осуществления описаны достаточно детально, чтобы позволить специалистам в данной области техники осуществить на практике то, что указано ниже, и должно быть понятно, что могут применяться и другие варианты осуществления и что могут быть разработаны логические, механические, электрические и другие изменения, без отступления от сущности или объема заявленного объекта. Следовательно, нижеследующее подробное описание изобретения не должно приниматься в смысле ограничения, а его объем определяется исключительно посредством приложенной формулы изобретения.
Краткий обзор
Настоящее раскрытие относится к поиску набора документов (или файлов) в области поиска для нахождения наиболее важных из них для пользователя. Поиск, как правило, подразумевает получение от пользователя набора ключевых слов для направления поиска, а затем определение всех документов в области поиска, которые соответствуют этим ключевым словам. При попытке определения этих возможных документов механизм поиска может искать ключевые слова в основной части документа или в заданных блоках или свойствах документа (например, заголовка, реферата и т.д.).
Итоговый набор возможных документов содержит все документы из области поиска, которые могут быть важны. Затем, к возможным документам может быть применен классификационный алгоритм для прогнозирования важности документов для пользователя. Затем, возможные документы, как правило, представляются пользователю в порядке убывания по спрогнозированной важности.
Варианты осуществления данного типа поиска, как правило, используют структуру инвертированного индекса, которая сопоставляет ключевые слова с документами. Как показано на Фиг.1, можно заметить, что такой индекс 100 может состоять из нескольких компонентов. Первостепенным значением настоящего раскрытия являются индекс 102 контента и расширение 106 индекса контента. Несмотря на важность для всего процесса поиска, основной контекстный индекс 104 и составной контекстный индекс 108 напрямую не относятся к настоящему раскрытию.
Индекс 102 контента является полным индексом ключевых слов, найденных в документах в области поиска. Он имеет структуру для поддержки различных типов поисков и может применяться независимо от расширения 106 индекса контента. Разделитель в индексе 102 контента указывает на то, имеется ли доступная для применения информация в расширении 106 индекса контента. Данный разделитель существует для каждого ключевого слова, предоставляя управление над тем, как и когда применяется расширенная информация.
Один тип поиска, поддерживаемый индексом 102 контента, является запросом "по фразе". Он является запросом, в котором пользователь ищет заданную комбинацию слов, появляющихся в определенном порядке. Простым примером является поиск фразы «быстрая коричневая лиса». Документ является возможным при условии содержания этой фразы в точности, но не в случае содержания всех слов, разбросанных по всему документу или в различном порядке. Для эффективности данному типу запроса требуется, чтобы индекс содержал информацию о том, где появляется каждое ключевое слово в документе, с тем чтобы механизм поиска мог определять, являются ли они смежными, и находятся ли в надлежащем порядке. Данная информация увеличивает размер индекса и, следовательно, количества данных, которые должны быть считаны с носителя данных (например, дисковода), содержащего индекс. Для больших областей поиска, в которых в большом проценте документов возникает одно или несколько задаваемых ключевых слов, время, требуемое для считывания этих данных, содержит требуемый для выполнения поиска значительный отрезок времени.
Расширение 106 индекса контента оптимизируется для запросов не по фразе, подразумевающих появление ключевых слов в большом количестве документов. Одно из применений предназначается для ситуаций, в которых пользователь задает набор ключевых слов, каждое из которых должно появляться в каждом возможном документе, но не обязательно в каком-либо конкретном порядке. Другое применение предназначается для начального фильтрования запросов по фразе, которое исключает документы, не содержащие каждое из слов, перед использованием индекса 102 контента для выполнения более точного определения того, содержится ли установленная фраза в оставшихся документах.
Поскольку расширению 106 индекса контента не требуется поддерживать запросы по фразе, то ему не требуется содержать информацию о заданном(ых) местоположении(ях), в котором появляется каждое ключевое слово в каждом документе (называемую данными о вхождении). Главным образом, это сохраняет частоту вхождения слова, т.е. частоту вхождения. Это одиночное значение намного меньше набора числовых значений, необходимых для представления каждого местоположения в документе, в особенности в случае широкого применения слова в документе. Устранение этих данных сокращает количество данных для каждого ключевого слова, которые должны быть считаны из запоминающего устройства. Это сокращает время, требуемое для обработки каждого ключевого слова, ускоряя поиск.
В настоящем раскрытии, для простоты и ясности, индекс будет описываться как состоящий из отдельных файлов для каждого из компонентов. Очевидно, что применение файлов является только одним вариантом осуществления и не предназначено для ограничения раскрытия. Также, индекс описывается в контексте "ключевых слов", существующих в "документах". Ключевое слово не ограничивается исключительно понятием "слова". Оно может являться фразой, числом, кодом или любым подобным значением, поиск которых будет вестись в документах. Подобным образом, термин "документ" будет применяться по отношению к отыскиваемым и содержащим ключевые слова элементам. Они могут являться документами, файлами, картами или любой другой логической структурой, имеющей необходимые параметры.
Для дополнительного сокращения количества считываемых из запоминающего устройства данных части расширения 106 индекса контента сжимаются описываемым ниже способом. Один вариант осуществления использует кодирование Хаффмана, которое является свободной от потерь схемой энтропийного кодирования, имеющей характерную особенность использования более коротких кодов для наиболее часто появляющихся элементов данных. В случае если кодирование применяется к отличиям (или размерам шагов) между идентификаторами ID документов, то сжатие становится более эффективным в случае увеличения частоты вхождения ключевого слова в область поиска. Это хорошо совпадает с раскрытым подходом, в котором расширение индекса контента применяется исключительно для широко применяемых ключевых слов.
Расширение 106 индекса контента может применяться для поддержки поиска ключевого слова множеством способов. Одно применение иллюстрировано на Фиг.2, которая показывает логическую последовательность высокого уровня запроса из нескольких слов, не по фразе. Ключевые слова получаются от пользователя на этапе 200. Решение 202 цикла управляет обработкой каждого ключевого слова. В пределах данного цикла каждое ключевое слово на этапе 204 отдельно отыскивается в индексе 102 контента, чтобы определить, доступно ли для ключевого слова расширение индекса контента ("CIX"). Это может быть выполнено без считывания большого количества данных о вхождении, поскольку необходимые данные могут храниться в информации заголовка ключевого слова. Если разделитель устанавливается в индекс 102 контента, то он будет дополняться посредством смещения расширения 106 индекса контента, в котором располагается слово. Это позволяет получать непосредственный доступ к соответствующей информации. Затем используется информация индексации из расширения 106 индекса контента для определения списка документов, содержащих текущее слово на этапе 208. Если доступной записи расширения 106 индекса контента нет, то будет сформирован список возможных документов с применением данных о вхождении индекса 102 контента на этапе 206. После получения списка возможных документов для каждого ключевого слова по отдельности будет сформирована 210 область пересечения данных списков, генерирующая одиночный список всех документов, в которых возникают все ключевые слова. Он является результатом поиска, который будет доступен пользователю.
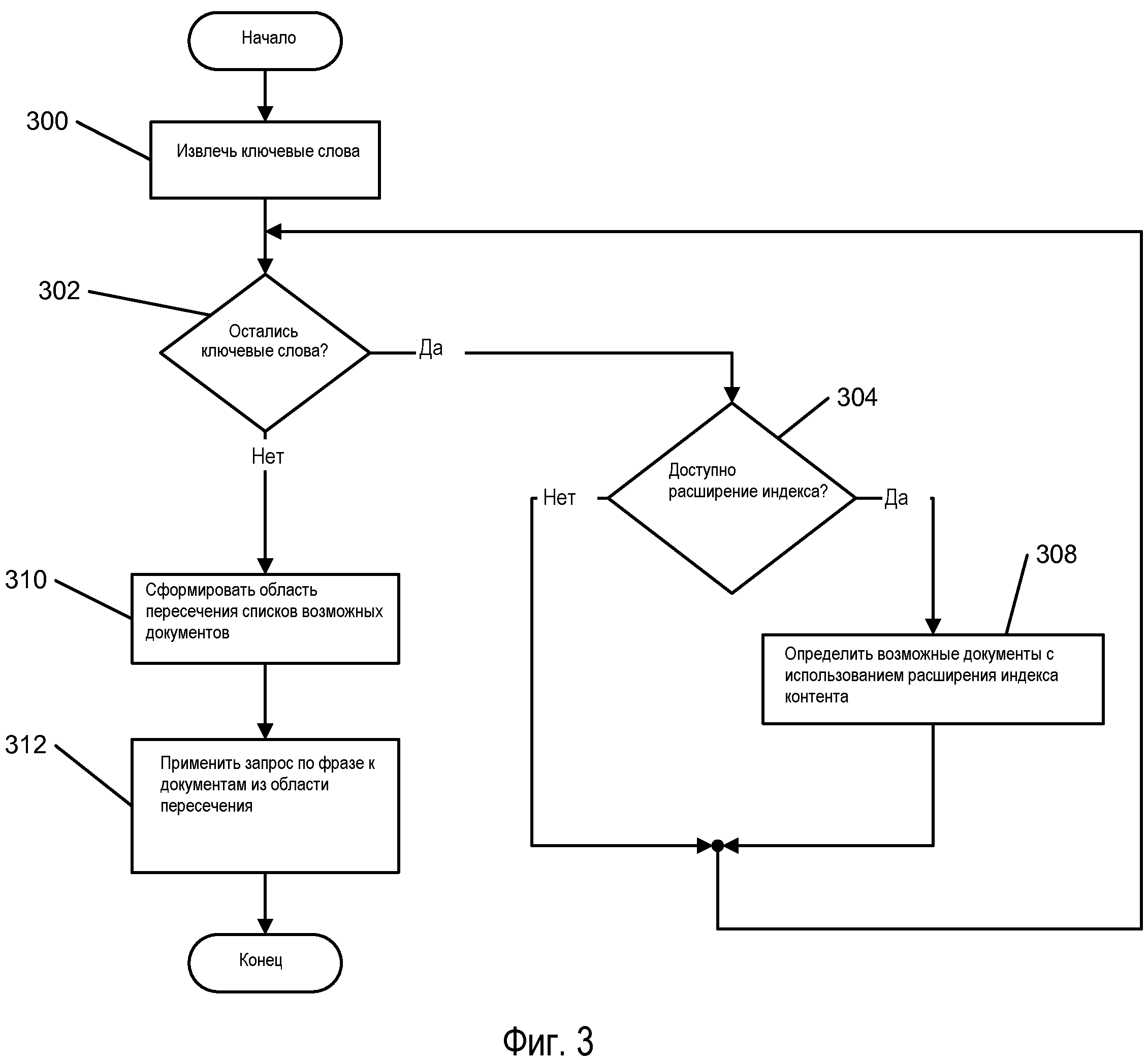
Второе применение изображено на Фиг.3, показывающей этапы высокого уровня, которые могут использоваться для выполнения запроса по фразе. Этапы 300, 302, 304 и 308 являются такими же рассмотренными выше этапами 200, 202, 204 и 208, относящимися к Фиг.2. Обработка в цикле отличается тем, что если для использования с ключевым словом не имеется доступного расширения 106 индекса контента, то вместо генерирования списка, применяющего индекс 104 контента, слово пропускается. Причина состоит в том, что обработка в цикле действует как фильтр и не генерирует окончательный ответ. При поиске фразы имеется необходимость только в проверке фраз тех файлов, в которые входят все ключевые слова. Этот набор файлов непременно является подмножеством файлов, в которых появляется любая комбинация ключевых слов. Хотя развитие возможного списка для всех ключевых слов для формирования области пересечения является желательным, в то же время оно не является необходимым. Даже фильтрация по отдельному слову может сократить непроизводительные потери в достаточной степени, чтобы ускорить поиск. После формирования 310 области пересечения всех списков возможных документов оставшиеся документы обрабатываются 312 с применением индекса 104 контента для определения того, в каком из них содержится точная фраза, если вообще содержится. Данный список является результатом поиска, который будет доступен пользователю.
Структура расширения индекса контента.
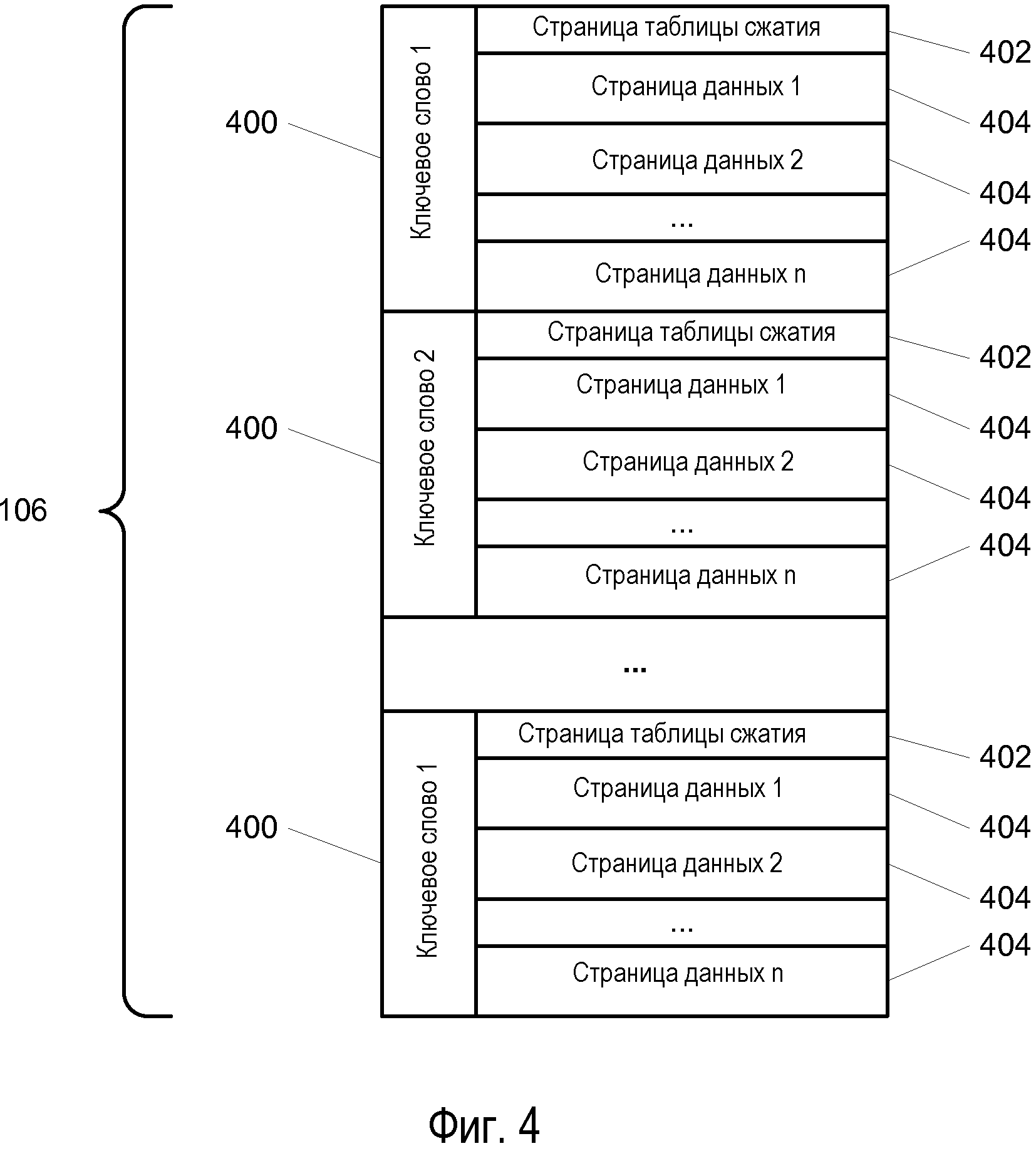
Как показано на Фиг.4, можно увидеть структуру высшего уровня расширения 106 индекса контента. Для каждого ключевого слова в индексе имеется отдельный сегмент 400. В одном варианте осуществления каждый сегмент начинается с 4096-байтовой границы страницы. Тогда сегмент может охватывать так много страниц, сколько необходимо для содержания данных. В каждом сегменте ключевого слова имеется два различных набора данных. Началом начальной границы страницы является страница 402 таблицы сжатия. После нее, начиная со следующей границы страницы, идет последовательность из одной или нескольких страниц 404 данных. Нужно отметить, что для реализации концепции настоящего раскрытия расположение страниц по порядку не требуется, но оно может предложить улучшенную производительность.
Вариант осуществления настоящего раскрытия кодирует данные для каждого слова в отдельности. Данный подход позволяет применять отдельную таблицу 504 кодирования (см. Фиг.5) для каждого набора данных ключевого слова, оптимизируя сжатие в каждом ключевом слове. В целях распаковки данных для каждого ключевого слова может быть доступна информация декодирования. Один вариант осуществления сохраняет таблицу 504 кодирования вместе с ключевым словом как часть страницы таблицы сжатия. Это сделано потому, что требуемая таблица декодирования может получаться из таблицы 504 кодирования, а таблица 504 кодирования меньшего размера, в связи с экономией места запоминающего устройства. Как только сгенерирована таблица декодирования, могут быть распакованы и использованы страницы 404 данных.
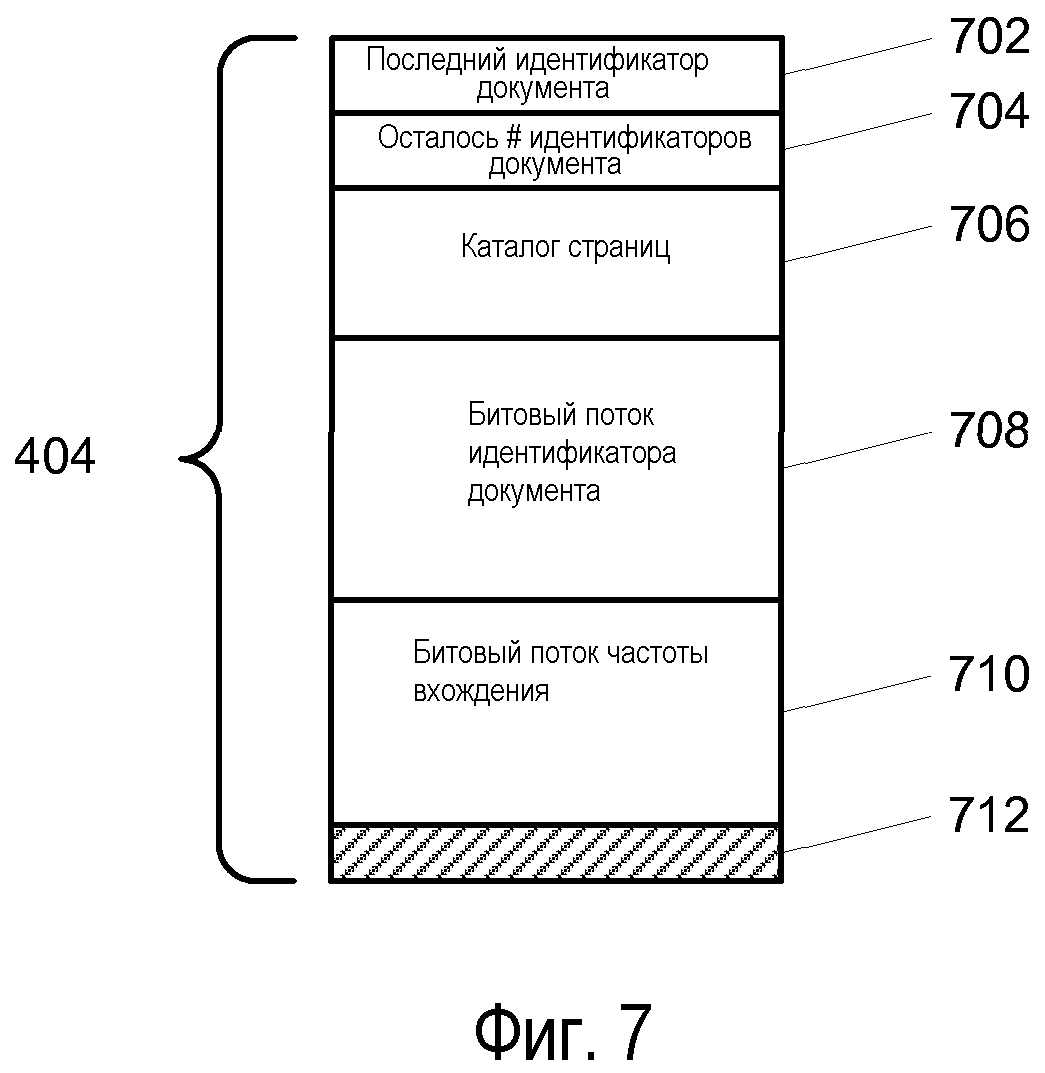
Фиг.5 изображает структуру страницы 402 таблицы сжатия. Также, эта структура может быть лучше всего понята посредством ссылки на страницу 404 данных, как изображено на Фиг.7. На высоком уровне, данные, сохраненные для каждого ключевого слова, являются последовательностью ссылок на документы, содержащие ключевое слово. Для каждого документа необходимы две единицы информации: идентификатор ID документа (DocID) и частота вхождения (OccurCnt) количества появлений в документе ключевого слова. Они сохраняются в отдельных разделах страницы данных, битовом потоке 708 идентификатора DocID и битовом потоке 710 частоты OccurCnt. Частично является фактом то, что данные о вхождении применяются не всегда, а хранение их отдельно означает то, что они не должны извлекаться с идентификатором DocID. Обе эти единицы информации кодируются с применением страницы 402 таблицы сжатия, но различными способами.
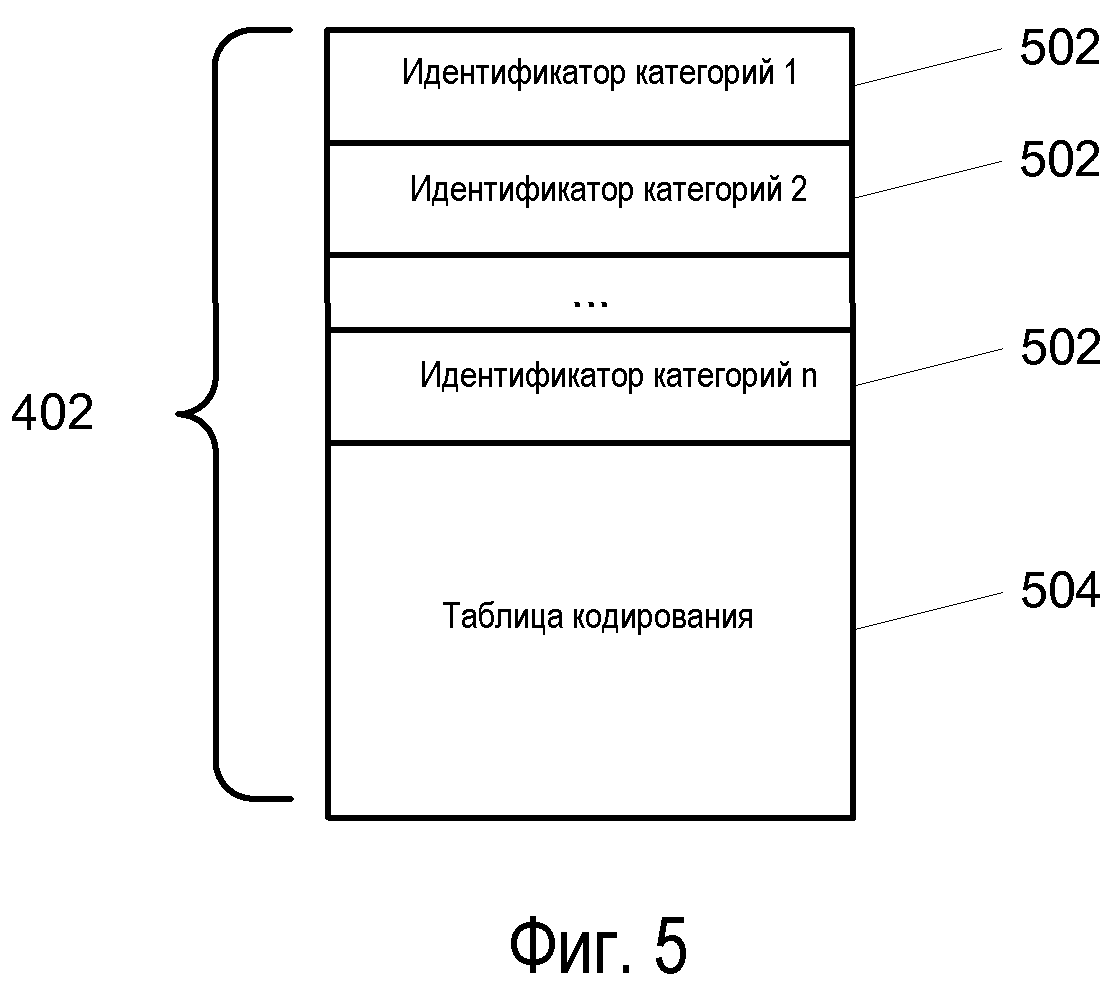
Частоты OccurCnts сохраняются в битовом потоке 710 частоты OccurCnt как последовательность битовых полей переменной длины. Значения частоты OccurCnt во всех документах могут значительно различаться. Также, из-за этого различается и количество битов, требуемых для сохранения частоты OccurCnt. В одном варианте осуществления, для сохранения частоты OccurCnt применяется постоянное количество различных размеров. Например, поле может иметь одну из длин в 0, 3, 7, 12 или 20 битов. В результате, каждый документ будет иметь частоту OccurCnt, которая сохраняется в поле, имеющем одну из данных конечных длин. Затем, с использованием данного параметра, документы могут быть сгруппированы по длинам соответствующих им частот OccurCnt. В странице 402 таблицы сжатия данные группы называются категориями, и каждая из них представляется посредством идентификатора 502 категорий. Поскольку все документы в каждой конкретной категории имеют одну и ту же длину поля частоты OccurCnt, то данная длина должна сохраняться только единожды, как биты в поле 606 вхождения идентификатора 502 категорий, а не с каждым идентификатором DocID. Это устраняет значительное количество избыточных данных из расширения 106 индекса контента. Значение вхождения битов, равное 0, используется для указания на то, что значение частоты OccurCnt является тем же, что и для предыдущего идентификатора DocID. Для этих записей записей в битовом потоке 710 частоты OccurCnt не существует. Первая категория содержит все дельта-индексы идентификатора DocID, имеющие этот необходимый параметр.
Фиг.6 изображает вариант осуществления идентификатора 502 категорий. Частота 602 символов задает количество символов в категории. Пороговое значение 604 дельта-индекса идентификатора DocID задает верхний предел дельта-индексов идентификатора DocID, который будет закодирован в категории. Вхождение 606 битов определяет количество битов, применяемых для хранения каждой записи частоты OccurCnt в битовом потоке 710, соответствующем символу в категории. Основное значение 608 символа ("BSV") устанавливает значение, которое добавляется к каждому значению дельта-индекса идентификатора DocID, чтобы сделать его однозначно определяемым для этой категории.
Каждый символ, используемый в категории, является суммой дельта-индекса идентификатора DocID и значения BSV для данной категории. Значения дельта-индексов идентификатора DocID для каждой категории заключаются в пределах от нуля (0) до порогового значения идентификатора DocID (1). Значение BSV для первой категории равно нулю (0), а значение BSV для всех других категорий равно значению BSV предыдущей категории плюс количество символов в категории. В результате, полный набор символов, представленных всеми категориями, является непрерывной последовательностью от наименьшего дельта-индекса идентификатора DocID (0) до значения BSV последней категории плюс наибольший закодированный дельта-индекс идентификатора DocID. В этой последовательности набор различных дельта-индексов идентификатора DocID, закодированный как особый символ посредством использования особого значения BSV, повторяется в каждой категории. Из этого получается каждое значение дельта-индекса идентификатора DocID, появляющегося в каждой категории, таким образом, соединяемое с каждым доступным значением входящих битов.
Также в варианте осуществления применяются последовательные значения дельта-индексов идентификатора DocID в каждой категории. Каждая категория будет содержать одну и ту же последовательность значений. Это позволяет вычислять значение дельта-индекса идентификатора DocID из символа и идентификатора категорий. Значение символа служит индексом для последовательности дельта-индексов идентификатора DocID, представленных посредством категорий. То, под какую категорию оно подпадает, определяет соответствующее значение появления битов и значение BSV для категории. Вычитание значения BSV из символа устанавливает значение дельта-индекса идентификатора DocID. Поскольку упорядочение определяет значения символов в каждой категории, то сохранение символов не является необходимым. Скорее, значение символа может вычисляться по мере необходимости. Для достижения того же результата также может применяться и другое постоянное упорядочение значений в категории.
Коды в таблице 504 кодирования хранятся в порядке, соответствующем записям в идентификаторах 502 категорий. Количество записей в таблице 504 кодирования равно общему количеству записей во всех категориях в целом. Данное совпадение позволяет преобразовывать код в символ посредством применения кода из таблицы 504 кодирования к индексу в категории. Это дает возможность прямого вычисления дельта-индекса идентификатора DocID или генерирования таблицы декодирования из характеристик категории и таблицы 504 кодирования. Поскольку декодирование может выполняться таким способом, то не требуется сохранения дискретных значений символов в таблице 504 кодирования наряду с кодами, что было бы типично для схемы кодирования Хаффмана.
Одной из концепций настоящего раскрытия является то, что информация о вхождении в расширении 106 индекса контента не содержит никаких данных о том, где ключевое слово входит в сопоставленный с ним документ. Единственными данными является количество вхождений ключевого слова в документ. Эти данные частоты вхождения поддерживают запросы, в которых применяются алгоритмы классификации по важности, которые разграничивают возможные документы на основе частоты появления слова. Это может выполняться со значительно меньшим количеством данных, чем может требоваться для запросов по фразе, которые, в частности, не поддерживаются расширением 106 индекса контекста настоящего раскрытия. Другая концепция настоящего раскрытия состоит в том, что данные частоты вхождения хранятся в потоке битов, отделенном от информации дельта-индексов идентификатора DocID. Это позволяет проводить извлечение данных идентификатора DocID, без извлечения данных о вхождении. Кроме того, она оптимизирует индекс для применения его в случаях, если достаточно одного индекса DocID. Длина документа, также используемая в некоторых алгоритмах классификации по важности, также не сохраняется в расширении 106 индекса контента, дополнительно сокращая количество сохраненных данных.
Как показано на Фиг.7, идентификаторы DocIDs сохраняются в битовом потоке 708 DocID как серия символов, сгенерированных посредством алгоритма кодирования Хаффмана. Первый этап должен преобразовывать каждый идентификатор DocID в размер этапа (или дельта-индекс) предыдущего идентификатора DocID. Этот дельта-индекс идентификатора DocID является числовой разницей между 2 последовательными идентификаторами DocIDs. Если известен текущий идентификатор DocID, то значение дельта-индекса позволяет вычислять следующий идентификатор DocID. Поскольку дельта-индекс меньше идентификатора DocID, то применение дельта-индекса сокращает количество сохраняемых данных. Также это преобразует список однозначно определенных идентификаторов DocIDs в намного меньший конечный набор числовых значений, требуемых для сжатия Хаффмана.
Для дополнительного ограничения количества возможных значений все дельта-индексы идентификатора DocID, превышающие выбранное пороговое значение 604 дельта-индекса идентификатора DocID, явным образом сохраняются в битовом потоке 708 идентификатора DocID, а не как закодированное значение. Как показано на Фиг.9, в закодированных записях идентификатора DocID будет находиться исключительно код 902 символа. Идентификаторы DocIDs со значением дельта-индекса, превышающим пороговое значение приращения идентификатора DocID, будут представляться посредством отдельного значения символа, а значение дельта-индекса явным образом будет сохранено в следующем поле как незакодированный дельта-индекс 904 идентификатора DocID. В варианте осуществления применяется значение (значение BSV+пороговое значение дельта-индекса идентификатора DocID) в качестве отдельного символа. Это является модификацией стандартной схемы кодирования Хаффмана. Она имеет преимущество в сокращении количества символов, которые должны быть закодированы, и подвергается минимальным потерям из-за размера. Причина состоит в том, что в области поиска, в которой большой процент документов содержит ключевое слово, значения дельта-индексов идентификатора DocID будут, как правило, распределяться через набор относительно малых значений. Большие значения дельта-индексов будут возникать редко. В схеме кодирования Хаффмана это бы привело к назначению им самых длинных кодов. Различие по длине между кодом, который бы применялся и, непосредственно, значением дельта-индекса, является относительно малым, так что затраты на сохранение дельта-индекса в качестве незакодированного значения являются минимальными. В некоторых случаях объединенная длина незакодированного дельта-индекса и сопоставленного с ней отдельного значения символа фактически может быть меньше символа, назначаемого при стандартном подходе к кодированию. В дальнейшем варианте осуществления применяются два различных отдельных значения символов для выбора двух различных размеров запоминающих устройств для явного значения дельта-индекса идентификатора DocID (то есть два байта против четырех байтов) для дополнительной оптимизации применения запоминающего устройства.
Как показано на Фиг.7, можно заметить, что каждая страница 404 данных начинается со служебной информации. В одном варианте осуществления она включает в себя последний идентификатор DocID 702, который задает последний идентификатор ID документа, сохраненный на этой странице, и количество оставшихся 704 идентификаторов DocIDs, которое определяет количество оставшихся идентификаторов ID документов, включающее в себя идентификаторы на текущей странице. Это используется при перемещении по страницам 404 данных. Следующим блоком страницы 404 данных является каталог 706 страниц, который является каталогом идентификаторов DocIDs на текущей странице. Для каждого идентификатора DocID имеется запись 800 каталога страниц. Вариант ее осуществления показан на Фиг.8. Поле 802 идентификатора DocID определяет заданный идентификатор ID документа, к которому применяется запись. Поле 804 идентификатора DocID частоты Cnt определяет количество идентификаторов DocIDs на странице до текущего идентификатора DocID. Поле 806 смещения идентификатора DocID задает смещение в битах от начала битового потока 708 идентификатора DocID до местоположения закодированной записи идентификатора DocID в битовом потоке 708 идентификатора DocID. Поле 808 смещения частоты OccurCnt определяет смещение в битах от начала битового потока 710 частоты OccurCnt до местоположения записи частоты OccurCnt в битовом потоке 710 частоты OccurCnt. Эти числовые значения разрешают прямой доступ идентификатора DocID к информации страницы, выбранной в пределах страницы 404 данных, в которой просмотр списка для нахождения информации не желателен.
Краткий обзор сжатия
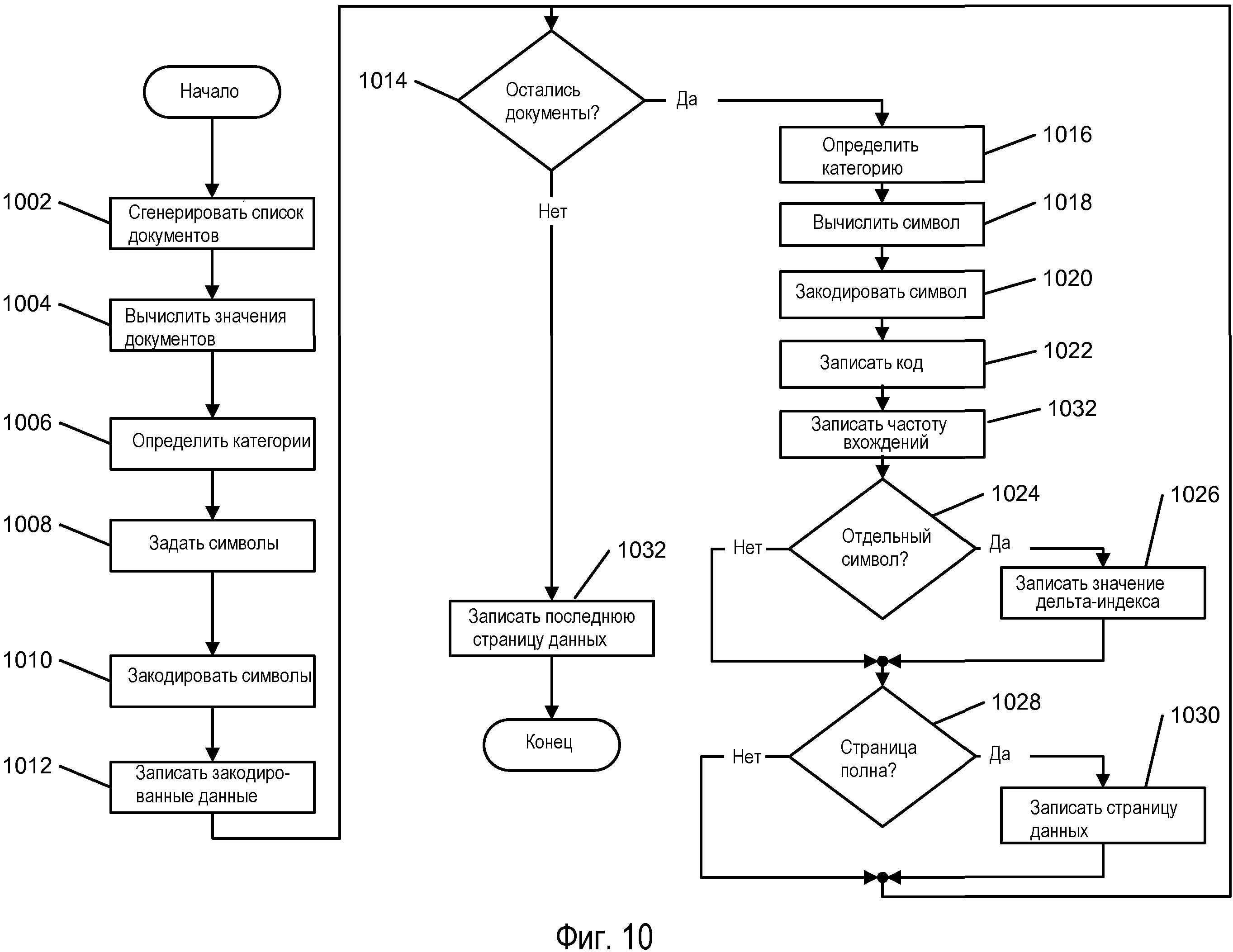
Генерирование сжатых данных для расширения 106 индекса контента подразумевает два отличных друг от друга процесса высокого уровня: генерирование кодированных данных и кодирование каждой записи. Каждый из них повторяется для каждого ключевого слова, чтобы быть перечисленным в расширении 106 индекса контента. Один из подходов описан ниже и изображен на Фиг.10.
Генерирование кодированных данных
Первый этап при генерировании кодированных данных должен определять список документов 1002, содержащих ключевое слово, в данной области поиска. Для каждого документа значения дельта-индекса идентификатора DocID и частоты OccurCnt определяются 1004 наряду со значением входящих битов, необходимым для хранения частоты OccurCnt. Полный набор этих значений, по всем соответствующим документам, сохраняется в одиночном списке документов. При применении данного списка значение порогового значения дельта-индекса идентификатора DocID, используемое в категории, определяется на основе значения дельта-индекса идентификатора DocID.
С информацией, доступной из списка документов, могут быть установлены 1006 категории и заданы идентификаторы 502 категорий. Для каждой категории устанавливается частота 602 символов, как одно из значений порогового значения дельта-индекса идентификатора DocID. Частота 602 символов и значения порогового значения 604 дельта-индекса идентификатора DocID распространяются на все категории. Каждой категории назначается отличное от других значение поля 606 входящих битов, выбираемое последовательно из предварительно определенного набора значений. Затем, каждой категории назначается отличное от других основное значение 608 символа (BSV), начиная с нуля (0), и дающее дельта-индекс посредством частоты 602 символов для каждой последующей категории.
С установленными категориями задается 1008 полный набор символов, охватывающий все категории. Каждый символ вычисляется как значение BSV категории плюс соответствующий дельта-индекс идентификатора DocID. Затем используется кодирование Хаффмана для генерирования различных кодов для каждого символа 1010, с использованием частотной информации, полученной из списка документов. Количество вхождений в список каждой однозначно определяемой пары дельта-индексов идентификаторов DocID и входящих битов является информацией на входе в процесс кодирования с наиболее часто используемыми парами, которым даются более короткие коды. Эти коды объединяются для создания таблицы 504 кодирования в рассмотренном выше формате. Тогда объединенный набор идентификаторов 502 категорий и таблица 504 кодирования могут быть записаны 1012 в расширение 106 индекса контента как страница 402 таблицы сжатия ключевого слова.
Кодирование данных для каждого документа
С доступными для кодирования данными может быть закодирована каждая из пар дельта-индексов идентификатора DocID/частоты OccurCnt из списка документов. Для каждого документа в списке 1014 сопоставленное с ним значение 606 входящих битов применяется для определения того, в какую из категорий будут закодированы 1016 данные. Значение 608 BSV категории прибавляется к дельта-индексу идентификатора DocID для определения символа 1018. Данный символ преобразуется в сопоставленный с ним код с применением таблицы 1020 кодирования для завершения битового потока 708 идентификатора DocID. Если значение входящих битов является отличным от нуля, то частота OccurCnt прилагается 1026 к окончанию битового потока 710 частоты OccurCnt этим количеством битов.
В особом случае 1024, в котором дельта-индекс идентификатора DocID превышает пороговое значение 604 дельта-индекса идентификатора DocID, соответствующий отдельному символу код будет применяться, начиная с этапа 1020, а дельта-индекс идентификатора DocID будет записан 1026 в битовый поток 708 идентификатора DocID сразу после закодированного символа, как показано на Фиг.9.
Если на этапе 1028 накоплено достаточное количество данных в битовом потоке 708 идентификатора DocID и в битовом потоке 710 частоты OccurCnt для заполнения страницы 404 данных, то генерируется информация заголовка, содержащая последний идентификатор 702 DocID, количество оставшихся 704 идентификаторов DocIDs и каталог 706 страниц, а полная страница данных записывается 1030 в расширение 106 индекса контента в формате, показанном на Фиг.7, и начинается новая страница 404 данных. Это продолжается до тех пор, пока вся информация документа не закодирована и не записана в расширение 106 индекса контента, включая запись 1032 последней, возможно неполной страницы данных. Затем, обработка перемещается на следующее ключевое слово, которое будет вставляться в расширение 106 индекса контента.
Краткий обзор распаковки
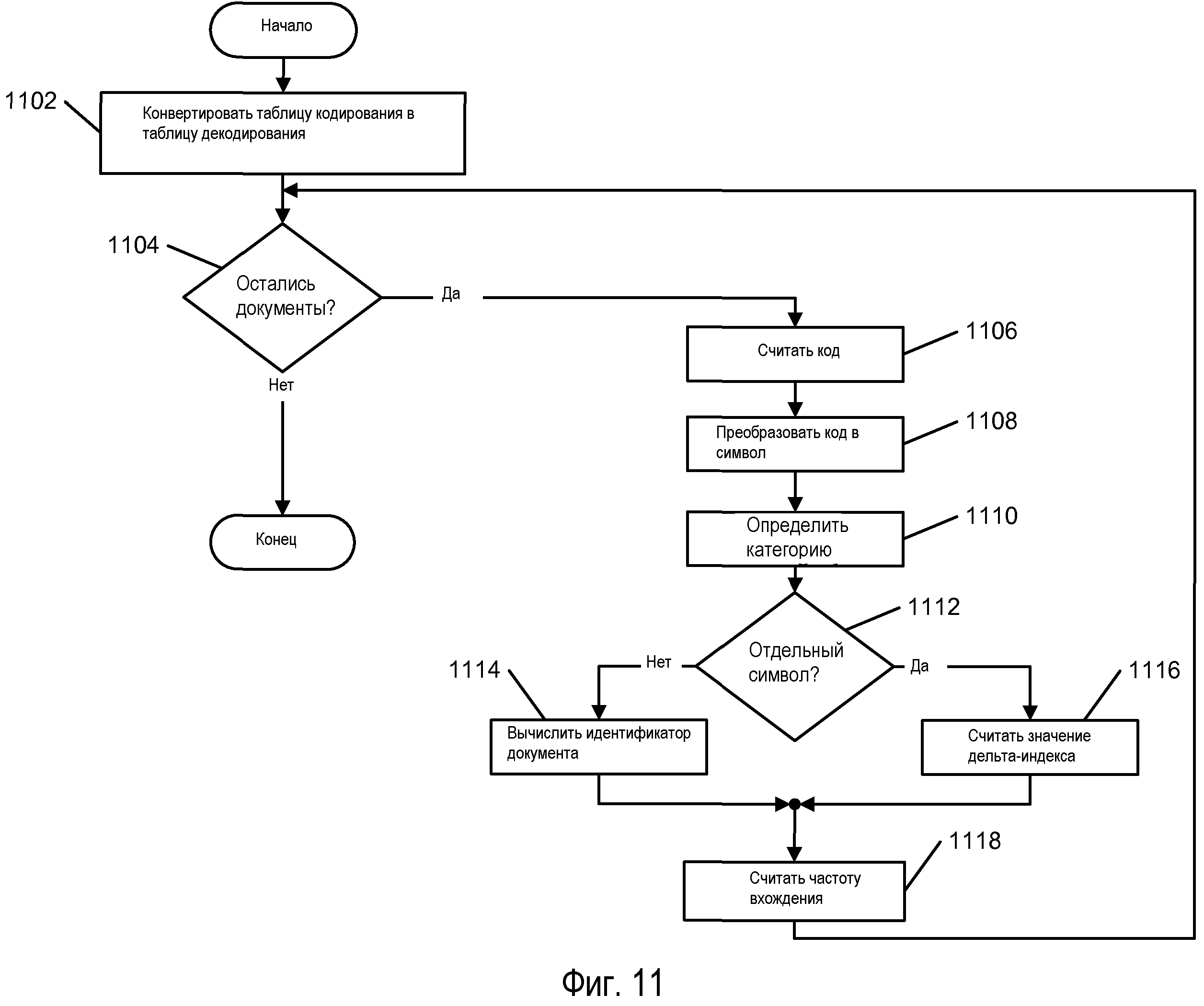
Способом, подобным сжатию, распаковка подразумевает два главных процесса: генерирование информации декодирования; а затем декодирование информации для каждого документа. Как правило, это делается для независимых ключевых слов, определяемых в запросе, а не для всего списка ключевых слов сразу. Один из подходов описан ниже и изображен на Фиг.11.
Формирование таблицы декодирования
Таблица 504 кодирования, сохраненная в странице 402 таблицы сжатия, преобразуется в таблицу 1102 декодирования по отношению к идентификаторам 502 категорий. Поскольку коды таблицы 504 кодирования сохраняются в том же самом порядке, как появляются символы в категориях, код для преобразования символов может быть обновлен в качестве таблицы декодирования, посредством перечисления символов и соответствующих им кодов, в такой последовательности, в которой они сохранены в таблице 504 кодирования.
Декодирование данных для каждого документа
Для каждого документа 1104 считывается 1106 код из битового потока 708 идентификатора DocID и преобразуется в символ 1108 с применением таблицы декодирования. Сравнение символа со значениями BSVs идентификаторов 508 категорий позволяет определять 1110 правильную категорию. Это определяет значение входящих 606 битов, которые должны использоваться. Символ проверяется 1112 для определения, является ли он нормальным символом или отдельным символом. Если он является нормальным, то вычисляется 1114 дельта-индекс идентификатора DocID. Вычитание значения BSV 608 категории из символа генерирует соответствующее значение дельта-индекса идентификатора DocID. Прибавление дельта-индекса идентификатора DocID к обработанному ранее идентификатору DocID генерирует текущий идентификатор DocID. Если необходима частота OccurCnt, то она может быть считана 1118 из битового потока 710 частоты OccurCnt с применением значений входящих 606 битов.
В отдельном случае, когда считанный из битового потока 708 идентификатора DocID код преобразуется в отдельный символ, указывающий дельта-индекс идентификатора DocID, которое превышает пороговое значение 604 дельта-индекса идентификатора DocID, значение дельта-индекса идентификатора DocID считывается 1116 из битового потока 708 идентификатора DocID 708 сразу после кода. После этапа 1118 последовательность возвращается на этап 1104.
В одном варианте осуществления поддерживаются два режима доступа к битовым потокам. Последовательный доступ доступен посредством запуска в начале каждого битового потока и поддержания указателя на текущее местоположение в каждом из них. Указатель для битового потока 708 идентификатора DocID продвигается вперед на один бит за каждый считанный код. Поскольку в кодировании Хаффмана используется беспрефиксные коды, то коды разнятся по длине и могут распознаваться посредством последовательности битов в них. Это означает, что код может быть распознан с любым прочитанным битом. Указатель для битового потока 710 частоты OccurCnt осуществляет приращение посредством значения вхождения битов, соответствующего символу. Также доступен прямой доступ через каталог 706 страниц. В каталоге может проводиться поиск для нахождения записи 800 каталога страниц, содержащей поле 802 идентификатора DocID, соответствующего документу, к которому получен доступ. Смещение 804 идентификатора DocID поддерживает смещение в битовом потоке 708 идентификатора DocID, а смещение 808 частоты OccurCnt поддерживает смещение в битовом потоке 710 частоты OccurCnt. Затем, могут быть извлечены данные для документа, к которому получен доступ, или с этой точки может быть запущен последовательный доступ.
Несмотря на то что заявленный объект описан языком, определенным для структурных характеристик и/или методологических действий, подразумевается, что объект, определенный в приложенной формуле изобретения, не обязательно ограничивается отдельными характеристиками или действиями, описанными выше. Вместо этого отдельные характеристики и действия, описанные выше, раскрыты как формы примеров реализации формулы изобретения. Специалистам в данной области техники будет понятно, что многие изменения в структуре и совершенно разные варианты осуществления могут быть предусмотрены без отступления от объема раскрытого объекта.

Архитектура для онлайновых коллективных и объединенных взаимодействий
Интеллектуальное редактирование реляционных моделей
Создание и развертывание распределенных расширяемых приложений
Использование устройства флэш-памяти для препятствования несанкционированному использованию программного обеспечения
Гибкое редактирование гетерогенных документов
Доверительная среда для обнаружения вредоносных программ
Интеграция рекламы и расширяемые темы для операционных систем
Перемещение сущностей, обладающих учетными записями, через границы безопасности без прерывания обслуживания
Криптографическое управление доступом к документам
Предоставление цифровых удостоверений
Архитектура для онлайновых коллективных и объединенных взаимодействий
Интеллектуальное редактирование реляционных моделей
Создание и развертывание распределенных расширяемых приложений
Использование устройства флэш-памяти для препятствования несанкционированному использованию программного обеспечения
Гибкое редактирование гетерогенных документов
Доверительная среда для обнаружения вредоносных программ
Интеграция рекламы и расширяемые темы для операционных систем
Перемещение сущностей, обладающих учетными записями, через границы безопасности без прерывания обслуживания
Криптографическое управление доступом к документам
Предоставление цифровых удостоверений

