Результат интеллектуальной деятельности: РАНЖИРОВАНИЕ РЕЗУЛЬТАТОВ ПОИСКА С ИСПОЛЬЗОВАНИЕМ РАССТОЯНИЯ РЕДАКТИРОВАНИЯ И ИНФОРМАЦИИ О ДОКУМЕНТЕ
Вид РИД
Изобретение
УРОВЕНЬ ТЕХНИКИ
Типичная услуга поисковой машины позволяет пользователю вводить запрос, выбирая наиболее релевантные документы из индексированной совокупности URL (унифицированных указателей ресурса), которые соответствуют запросу. Чтобы обслуживать запросы быстро, поисковая машина использует один или более способов (например, структуру данных с инвертированным индексом), которая отображает ключевые слова в документы. Например, первым этапом, выполняемым машиной, может быть идентификация набора документов-кандидатов, которые содержат в себе ключевые слова, заданные пользовательским запросом. Эти ключевые слова могут быть расположены в теле документа или метаданных либо в дополнительных метаданных этого документа, которые фактически хранятся в других документах или хранилищах данных (таких как текст привязки).
В большой индексной совокупности мощность множества у набора документов-кандидатов может быть большой, в зависимости от общности термов запроса (например, потенциально, миллионами). Вместо возврата полного набора документов-кандидатов, поисковая машина выполняет второй этап ранжирования документов-кандидатов по релевантности. Типично, поисковая машина использует функцию ранжирования для предсказания степени релевантности документа по отношению к конкретному запросу. Функция ранжирования берет многочисленные признаки из документа в качестве входных данных и вычисляет число, которое предоставляет поисковой машине возможность сортировать документ по предсказанной релевантности.
Качество функции ранжирования в отношении того, насколько точно функция предсказывает релевантность документа, в конечном счете, определяется удовлетворением пользователя результатами поиска или тем, сколько раз в среднем пользователь находит ответ на поставленный вопрос. Общая удовлетворенность пользователя системой может быть приближенно выражена одним числом (или метрикой), так как число может быть оптимизировано изменением функции ранжирования. Обычно метрики вычисляются на репрезентативном наборе запросов, которые выбраны наперед посредством случайной выборки регистрационных записей запросов, и включают в себя назначение меток релевантности каждому результату, возвращенному машиной для каждого из запросов оценки. Однако эти последовательности операций для ранжирования и релевантности документов по-прежнему неэффективны в предоставлении требуемых результатов.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Последующее представляет упрощенную сущность изобретения, для того чтобы обеспечить базовое понимание некоторых вариантов осуществления настоящего изобретения, описанных в материалах настоящей заявки. Эта сущность изобретения не является исчерпывающим обзором, и она не предназначена для идентификации ключевых/критических элементов или установления границ его объема. Ее единственная цель состоит в том, чтобы представить в упрощенном виде некоторые концепции в качестве вступления в более подробное описание, которое представлено позже.
Архитектура предусматривает механизм для извлечения информации о документе из документов, принятых в качестве результатов поиска на основании строки запроса, и вычисления расстояния редактирования между строкой данных и строкой запроса. Строка данных может быть кратким и точным описанием документа, полученным из информации о документе, например, такой как о TAUC (заголовок, текст привязки, URL) и щелчках кнопкой мыши. Расстояние редактирования применяется при определении релевантности документа в качестве части ранжирования результатов. Механизм улучшает релевантность результатов поиска ранжированием, совершаемым с применением набора связанных с близостью признаков для обнаружения ближайших соответствий всего запроса или части запроса.
Расстояние редактирования обрабатывается для оценки, насколько близка строка запроса к данному потоку данных, который включает в себя информацию о документе. Архитектура включает в себя разбиение во время индексации составных термов в URL для предоставления возможности более эффективного обнаружения термов запроса. Дополнительно, фильтрация во время индексации текста привязки используется для нахождения N самых лучших привязок одного или более документов-результатов. Использование информации о TAUC может вводиться в нейронную сеть (например, 2-уровневую) для улучшения метрик релевантности для ранжирования результатов поиска.
Для достижения вышеизложенных и связанных целей, некоторые иллюстративные аспекты описаны в материалах настоящей заявки в связи с последующим описанием и прилагаемыми чертежами. Эти аспекты, однако, указывают только на несколько различных способов, которыми могут применяться принципы, раскрытые в материалах настоящей заявки, и имеют намерением включать в себя все такие аспекты и эквиваленты. Другие преимущества и новые признаки станут очевидными из последующего подробного описания при рассмотрении совместно с чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует реализуемую компьютером систему релевантности.
Фиг.2 иллюстрирует блок-схему последовательности операций способа примерного алгоритма сопоставления для вычисления расстояния редактирования.
Фиг.3 иллюстрирует обработку и формирование значений расстояния редактирования на основании строки запроса и строки данных с использованием модифицированного расстояния редактирования и алгоритма сопоставления.
Фиг.4 иллюстрирует еще один пример обработки и формирования значений расстояния редактирования на основании строки запроса и строки данных с использованием модифицированного расстояния редактирования и алгоритма сопоставления.
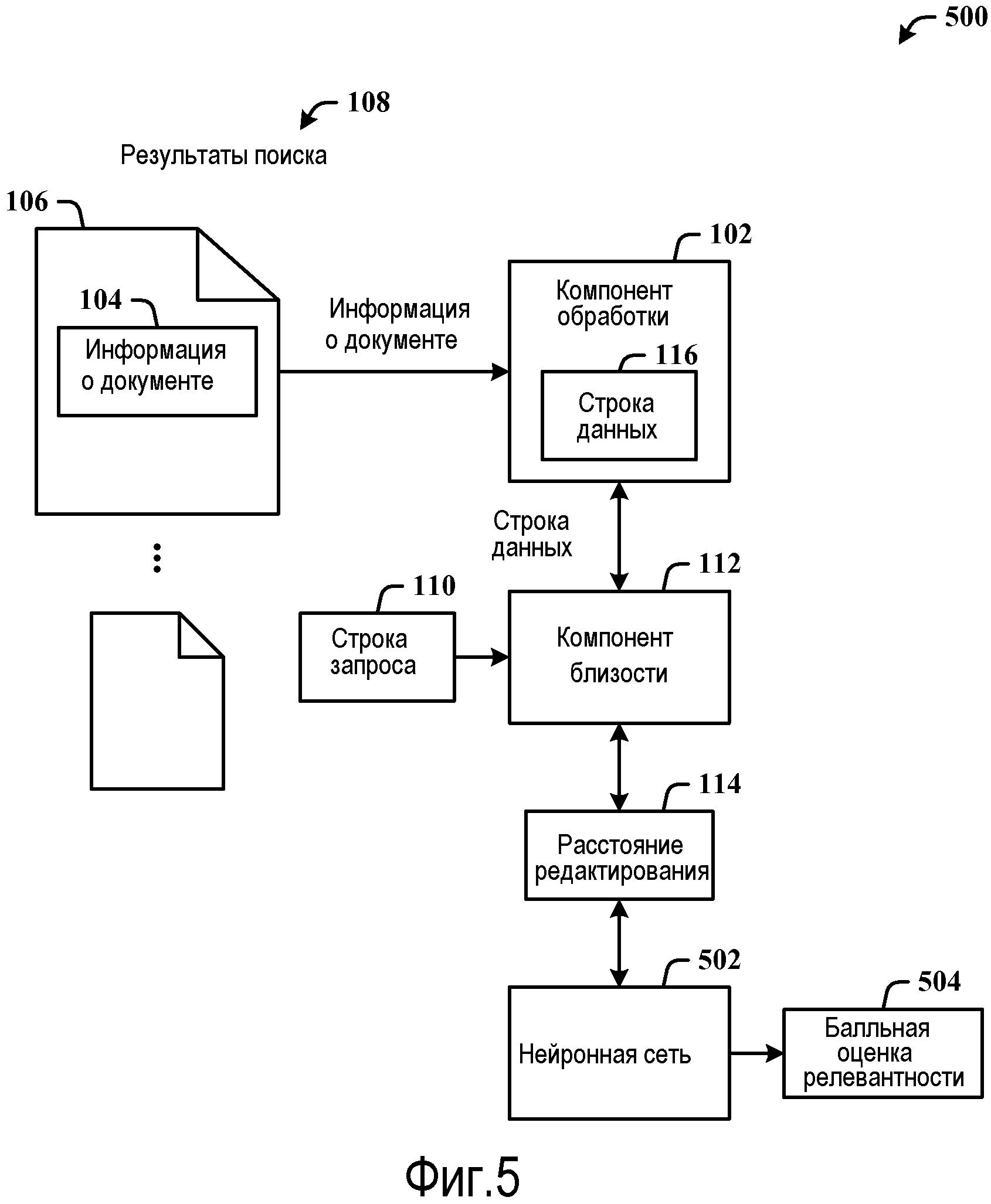
Фиг.5 иллюстрирует реализуемую компьютером систему релевантности, которая применяет нейронную сеть для содействия в формировании балльной оценки релевантности для документа.
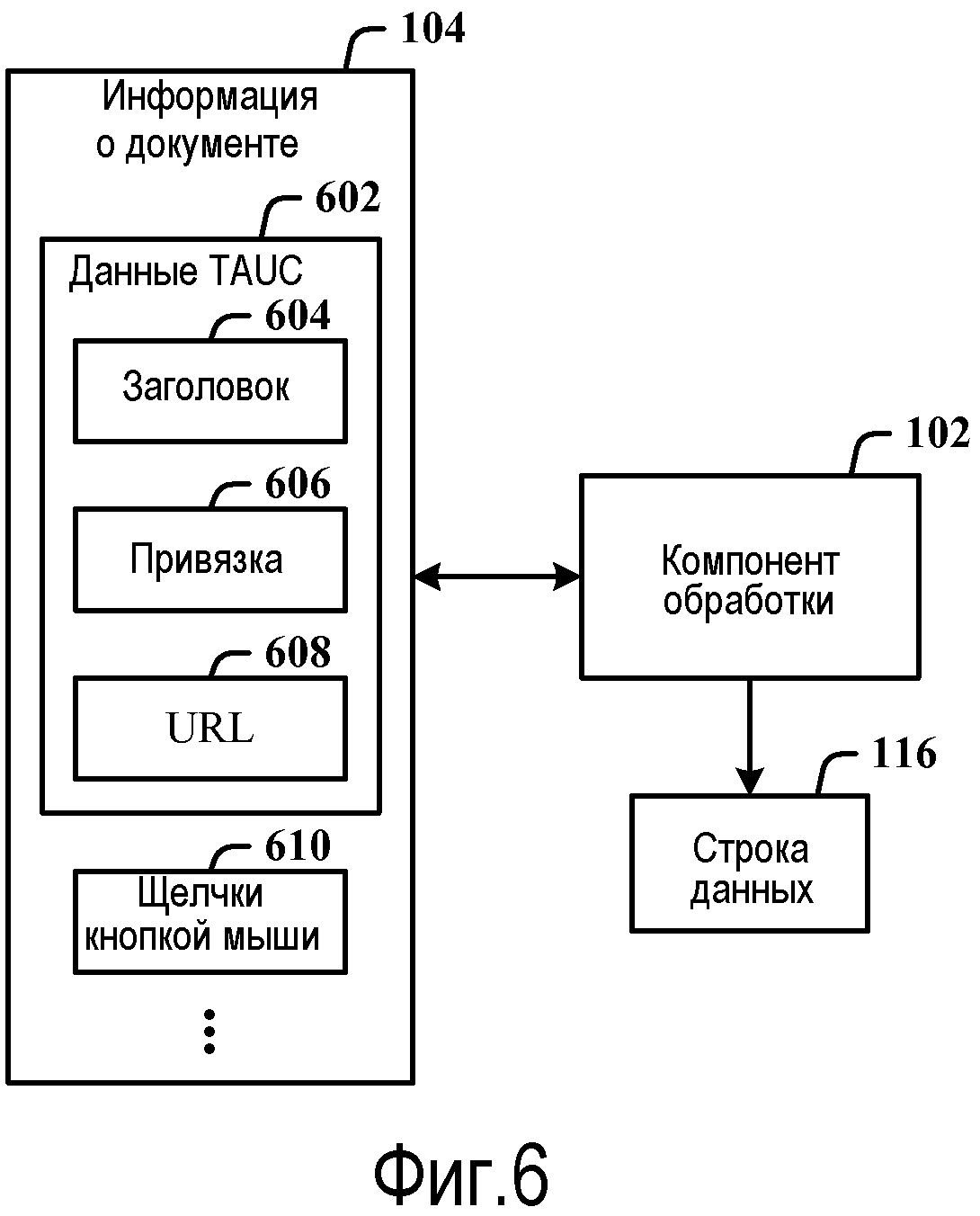
Фиг.6 иллюстрирует типы данных, которые могут использоваться в информации о документе для определения расстояния редактирования между строкой запроса и строкой данных.
Фиг.7 иллюстрирует поток данных обработки во время индексации.
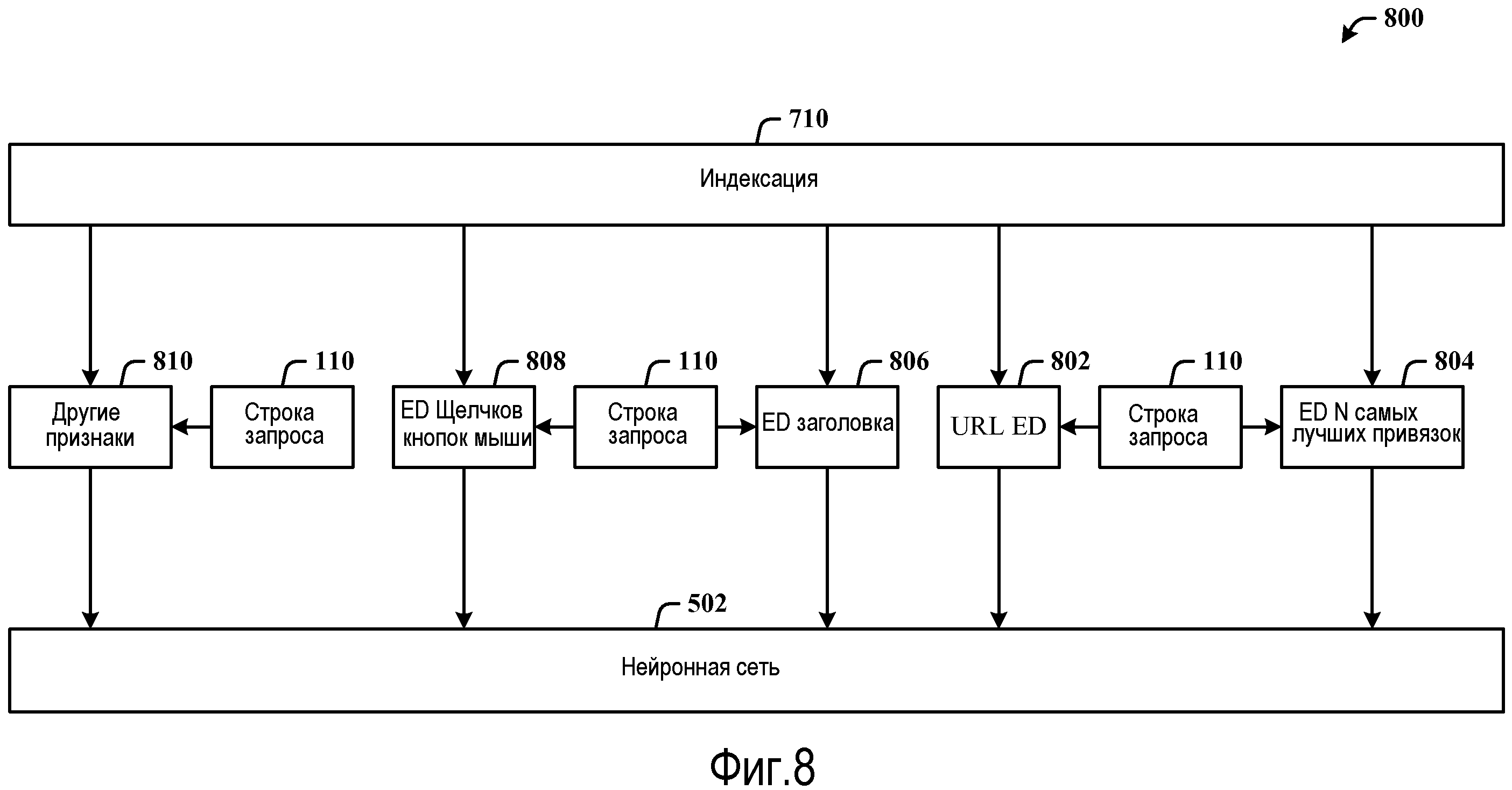
Фиг.8 иллюстрирует структурную схему, показывающую входные данные в нейронную сеть из последовательности операций индексации по фиг.7 для ранжирования результатов.
Фиг.9 иллюстрирует примерную реализацию системы нейронной сети, входных данных расстояния редактирования и необработанных входных данных признаков для вычисления с формированием результатов поиска.
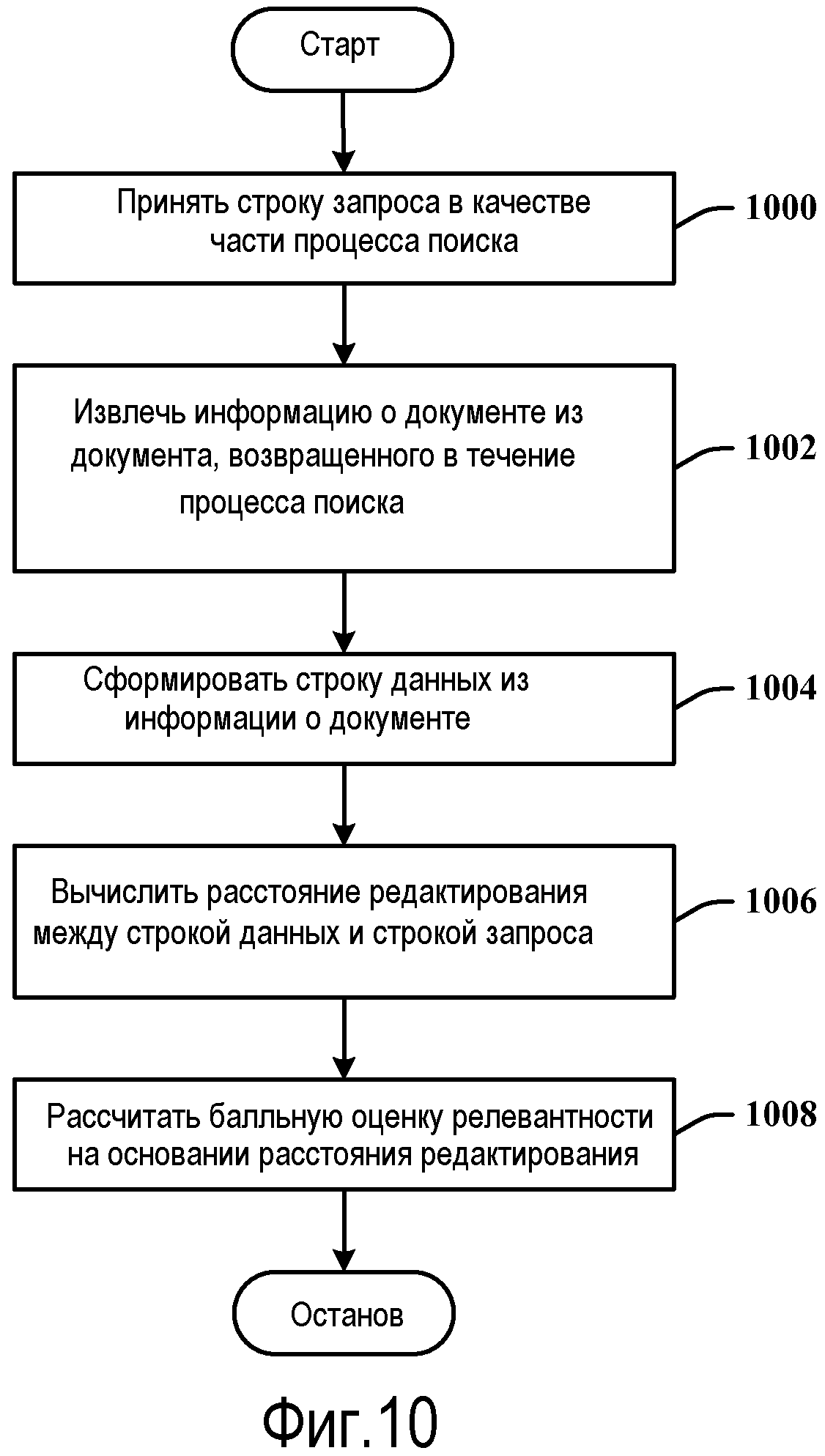
Фиг.10 иллюстрирует способ определения релевантности документа из набора документов-результатов.
Фиг.11 иллюстрирует способ вычисления релевантности документа.
Фиг.12 иллюстрирует структурную схему вычислительной системы, работоспособной для выполнения обработки расстояния редактирования для ранжирования результатов поиска с использованием признаков TAUC в соответствии с раскрытой архитектурой.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Раскрытая архитектура улучшает релевантность результатов поиска ранжированием посредством реализации набора связанных с близостью признаков для обнаружения ближайших соответствий всего запроса или соответствий с точными метаданными о документе, такими как заголовки, привязки, URL или щелчки кнопкой мыши. Например, рассмотрим запрос «company store» («магазин компании»), заголовок документа «company store online» («онлайновый магазин компании») первого документа и заголовок документа «new NEC LCD monitors in company store» («новые ЖКИ-мониторы NEC в магазине компании») второго документа. При условии, что другие свойства одинаковы для обоих, первого и второго, документов, архитектура назначает балльную оценку для документа на основании того, сколько усилий по редактированию уделяется, чтобы заставить выбранный поток соответствовать запросу. В этом примере заголовок документа выбран для оценки. Заголовок первого документа требует всего лишь одной операции удаления (удалить терм «online» («онлайновый»)), чтобы создать полное соответствие, наряду с тем что заголовок второго документа требует пяти удалений (удалить термы «new» («новый»), «NEC», «LCD» («ЖКИ»), «monitors» («мониторы») и «in» («в»)). Таким образом, вычисляется, что первый документ должен быть более релевантным.
Заголовок является одним из элементов TAUC (заголовка, привязки, URL и щелчков кнопкой мыши) информации о документе, для которого обработка может применяться к некоторым потокам данных (например, URL), так что термы (условия) запроса могут быть найдены из составных термов. Например, вновь рассмотрим запрос «company store», и URL является «www.companystore.com». Результатом является то, что URL разбивается на четыре части (или терма): «www», «company», «store» и «com».
Далее даются ссылки на чертежи, на которых одинаковые ссылочные позиции используются для указания подобных элементов. В последующем описании, в целях пояснения, изложены многочисленные специфичные детали, чтобы обеспечить его исчерпывающее понимание. Однако может быть очевидно, что новые варианты осуществления могут быть осуществлены на практике без этих специфичных деталей. В других случаях хорошо известные конструкции и устройства показаны в виде структурной схемы, для того чтобы облегчить их описание.
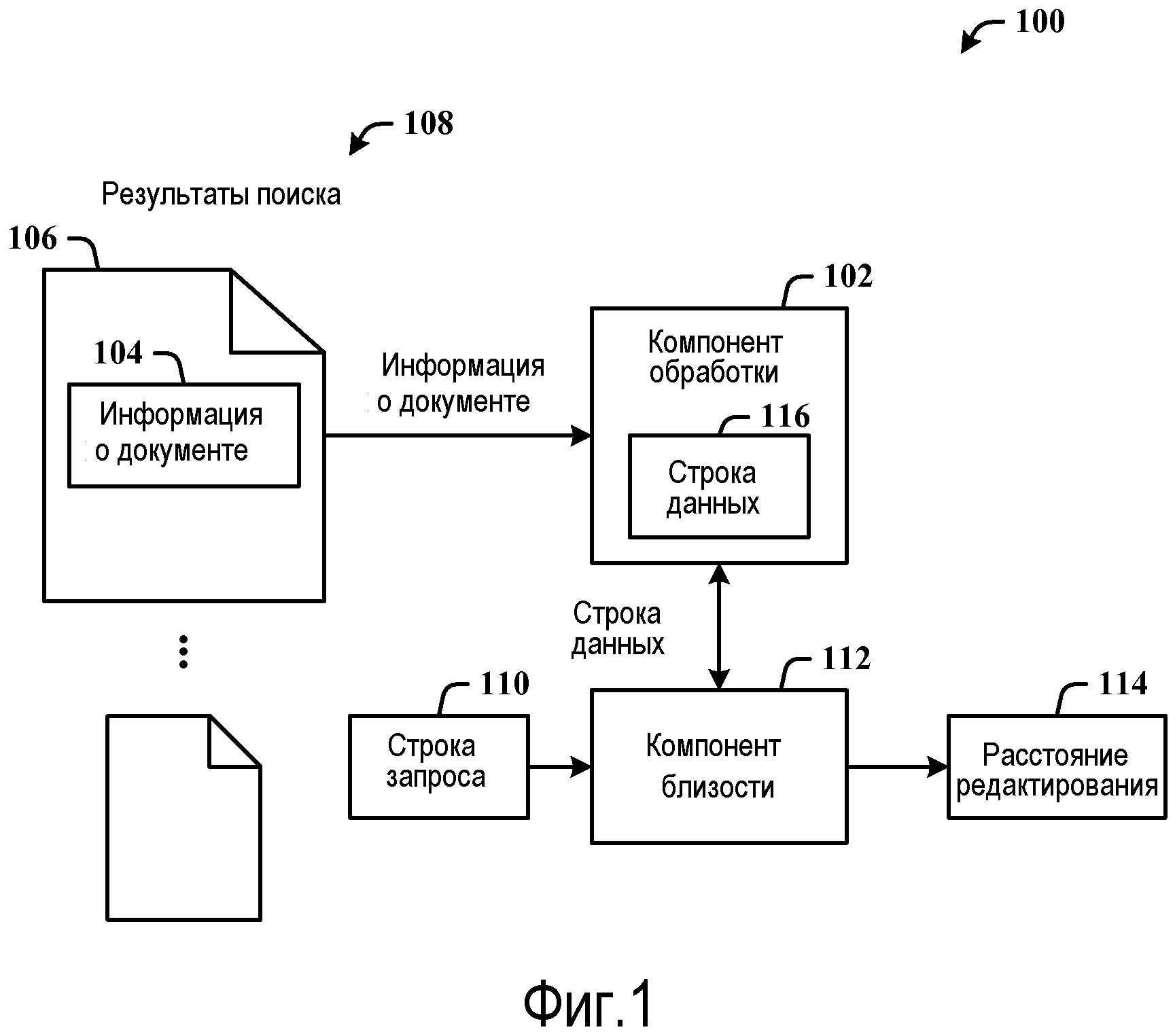
Фиг.1 иллюстрирует реализуемую компьютером систему 100 релевантности. Система 100 включает в себя компонент 102 обработки для извлечения информации 104 о документе из документа 106, принятого в качестве результатов 108 поиска на основании строки 110 запроса. Система 100 также может включать в себя компонент 112 близости для вычисления расстояния 114 редактирования между строкой 116 данных, извлеченной из информации 104 о документе, и строкой 110 запроса. Расстояние 114 редактирования применяется при определении релевантности документа 106 в качестве части результатов 108 поиска.
Информация 104 о документе, используемая для формирования строки 116 данных, например, может включать в себя информацию (или символы) о заголовке, информацию о гиперссылке (например, символы URL), информацию о потоке щелчков кнопкой мышки и/или текст (или символы) привязки. Компонент 102 обработки разбивает составные термы информации 104 о документе во время индексирования, чтобы вычислять расстояние 114 редактирования. Компонент 102 обработки также фильтрует информацию о документе, такую как текст привязки, во время индексирования для вычисления ранжированного в качестве самого лучшего набора текста привязки.
Вычисление расстояния 114 редактирования основано на вставке и удалении термов для увеличения близости (сближения) между строкой 116 данных и строкой 110 запроса. Вычисление расстояния 114 редактирования также может быть основано на затратах, ассоциированных с вставкой и удалением термов для увеличения близости (сближения) между строкой 116 данных и строкой 110 запроса.
Рассмотрим сценарий формирования строки 116 данных (например, TAUC) на основании вставки и/или удаления термов из строки 110 запроса. Эта обработка термов может выполняться согласно четырем операциям: вставить слово не из запроса в строку 110 запроса; вставить терм запроса в строку 110 запроса; удалить терм TAUC из строки 110 запроса и/или удалить терм не TAUC из строки 110 запроса.
Расстояние 114 редактирования основано на операциях вставки и удаления, но не замены. Может быть два типа затрат, определенных для вставки. Рассмотрим сценарий формирования строки 116 данных из строки 110 запроса. При формировании, в строку 110 запроса может быть вставлено слово, которое существует в исходной строке 110 запроса, в таком случае затраты определяется в качестве единицы; иначе, затраты определяется в качестве w1 (≥1). Здесь w1 - весовой параметр, который настраивается. Например, если строкой 110 запроса является AB, то затраты на формирования строки данных ABC выше, чем таковая у строки ABA данных. Интуиция такова, что вставка «нерелевантных слов» в строку 116 данных делает всю строку 116 данных (например, TAUC) более нерелевантной.
Может быть два типа затрат для удаления. Вновь рассмотрим сценарий формирования строки 116 данных из строки 110 запроса. При удалении терма в строке 110 запроса такой терм существует в исходной строке 116 данных, в таком случае затраты определяются как единица; иначе, затраты определяются как w2 (≥1).
Другим типом затрат являются затраты расположения. Если удаление или вставка происходят в первом расположении строки 116 данных, то есть дополнительные затраты (+w3). Интуитивно, соответствию в начале двух строк (строки 110 запроса и строки 116 данных) придается большая важность, чем более поздним соответствиям в строках. Рассмотрим следующий пример, где строкой 110 запроса является «cnn», строкой 116 данных является заголовок = «cnn.com -blur blur». Если вставка и удаление происходят в первом расположении, они могут значительно уменьшать результативность решения.
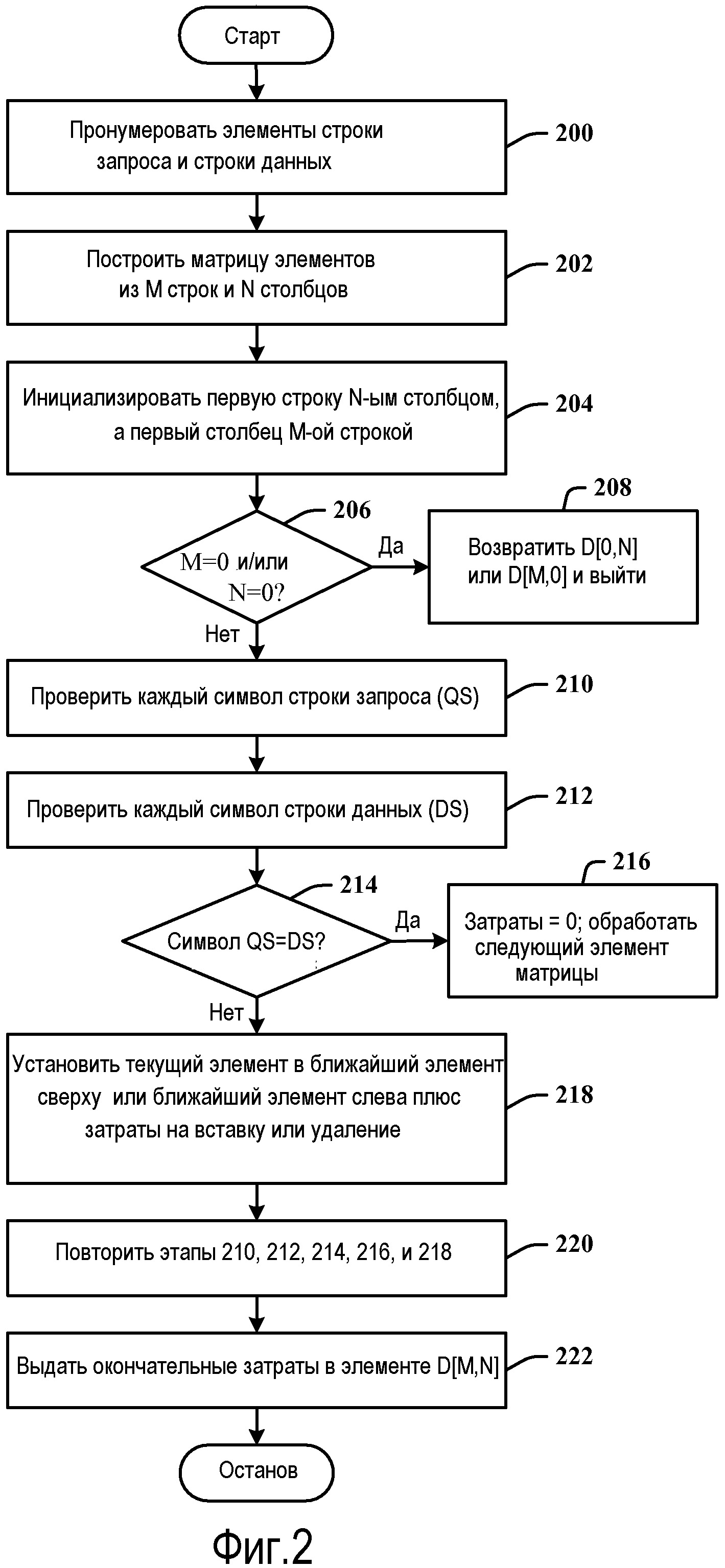
Фиг.2 иллюстрирует блок-схему последовательности операций способа примерного модифицированного алгоритма 200 сопоставления для вычисления расстояния редактирования. Хотя для простоты пояснения одна или более методологий, показанных здесь, например, в виде блок-схемы алгоритма или схемы последовательности операций, показаны и описаны как последовательность действий, должно быть понято и принято во внимание, что обобщенные способы не ограничены очередностью действий, так как некоторые действия могут, в соответствии с ним, происходить в ином порядке и/или одновременно с другими действиями из показанных и описанных в материалах настоящей заявки. Например, специалистам в данной области техники должно быть понятно, что обобщенный способ, в качестве альтернативы, мог бы быть представлен как последовательность взаимосвязанных состояний или событий, таких как на диаграмме состояний. Более того, не все действия, проиллюстрированные в обобщенном способе, могут требоваться для новой реализации.
На этапе 200 элементы строки запроса и строки (или целевой строки) данных, нумеруются. Это достигается посредством установки n как длины строки запроса (где каждый терм в строке запроса является s[i]), и установки m как длины целевой строки (или данных) (где каждый терм в целевой строке обозначен t[j]). На этапе 202 формируется матрица, которая содержит строки 0...m и столбцы 0...n (где каждый терм в матрице обозначен в качестве d[j,i]). На этапе 204 первая строка инициализируется значением, которое зависит от разных затрат на удаление, а первый столбец инициализируется значением, которое зависит от разных затрат вставки. На этапе 206, если n=0, то возвращается d[m, 0] и выполняется выход, а если m=0, то возвращается d[0, n] и выполняется выход, как указано в 208. На этапе 210 проверяется каждый символ строки запроса (i от 1 до n). На этапе 212 проверяется каждый символ целевой строки данных (j от 1 до m). На 214, если строка символов в строке запроса равна символу в строке данных, происходит переход к 216, причем затраты являются нулевыми, и обрабатывается следующий элемент матрицы. Другими словами, если s[i] равно t[j], затраты имеют значение 0 и d[j,i]=d[j-1,i-1].
Если символ в элементе строки запроса не равен символу в элементе строки данных, происходит переход от 214 к 218, где текущий элемент устанавливается в ближайший элемент сверху или ближайший элемент слева плюс затраты на вставку или удаление. Другими словами, если s[i] не равно t[j], элемент d[j,i] устанавливается равным минимуму из элемента непосредственно сверху плюс соответствующие затраты вставки, представленные посредством d[j-1,i]+cost_insertion, или элемента непосредственно слева плюс соответствующие затраты на удаление, представленные посредством d[j,i-1]+cost_deletion. На этапе 220 этапы 210, 212, 214, 216 и 218 повторяются до завершения. На этапе 222 выводятся заключительные затраты, найденные в элементе d[m, n]. Отметим, что как cost_insertion, так и cost_deletion в примере имеют две разновидности значений; например w1=1, w3=4 для затрат вставки и w2=1, w4=26 для затрат на удаления.
Другими словами, d[j,i] содержит расстояние редактирования между строками s[0..i] и t[0...j]. d[0,0]=0 по определению (никакие редактирования не нужны, чтобы сделать пустую строку равной пустой строке). d[0, y]=d[0,y-1]+(w2 или w4). Если известно, сколько редактирований используется, чтобы создать строку d[0,y-1], то d[0,y] может рассчитываться как d[0, y-1] + затраты на удаление текущего символа из целевой строки, каковыми затратами может быть w2 или w4. Затраты w2 используются, если текущий символ представлен в обеих, s[0...n], t[0...m]; а w4 в ином случае. d[x, 0]=d[x-1,0]+(w1 или w3). Если известно, сколько редактирований используется, чтобы создать строку d[x-1,0], то d[x,0] может рассчитываться как d[x-1,0] + затраты на вставку текущего символа из s в t, каковыми затратами могут быть w1 или w3. Затраты w1 используются, если текущий символ представлен в обеих, s[0...n], t[0...m]; а w3 в ином случае.
Для каждых (j,i), d[j,i] может быть равным d[j-1,i-1], если s[i]=t[j]. Расстояние редактирования может вычисляться между строками t[j-1], s[i-l], и если s[i]=t[j], общий символ может прикрепляться к обеим строкам, чтобы делать строки равными, не вызывая редактирований. Таким образом, есть три используемых перемещения, где выбирается перемещение, которое дает минимальное расстояние редактирования для текущего d[j,i]. Предложим еще один способ
d[j,i]=min(
d[j-1,i-1] if s[i]=t[j];
d[j-1,i]+(w1, если s[j] представлен в обеих строках; иначе, w3);
d[j,i-1]+(w2, если t[i] представлен в обеих строках; иначе, w4)
).
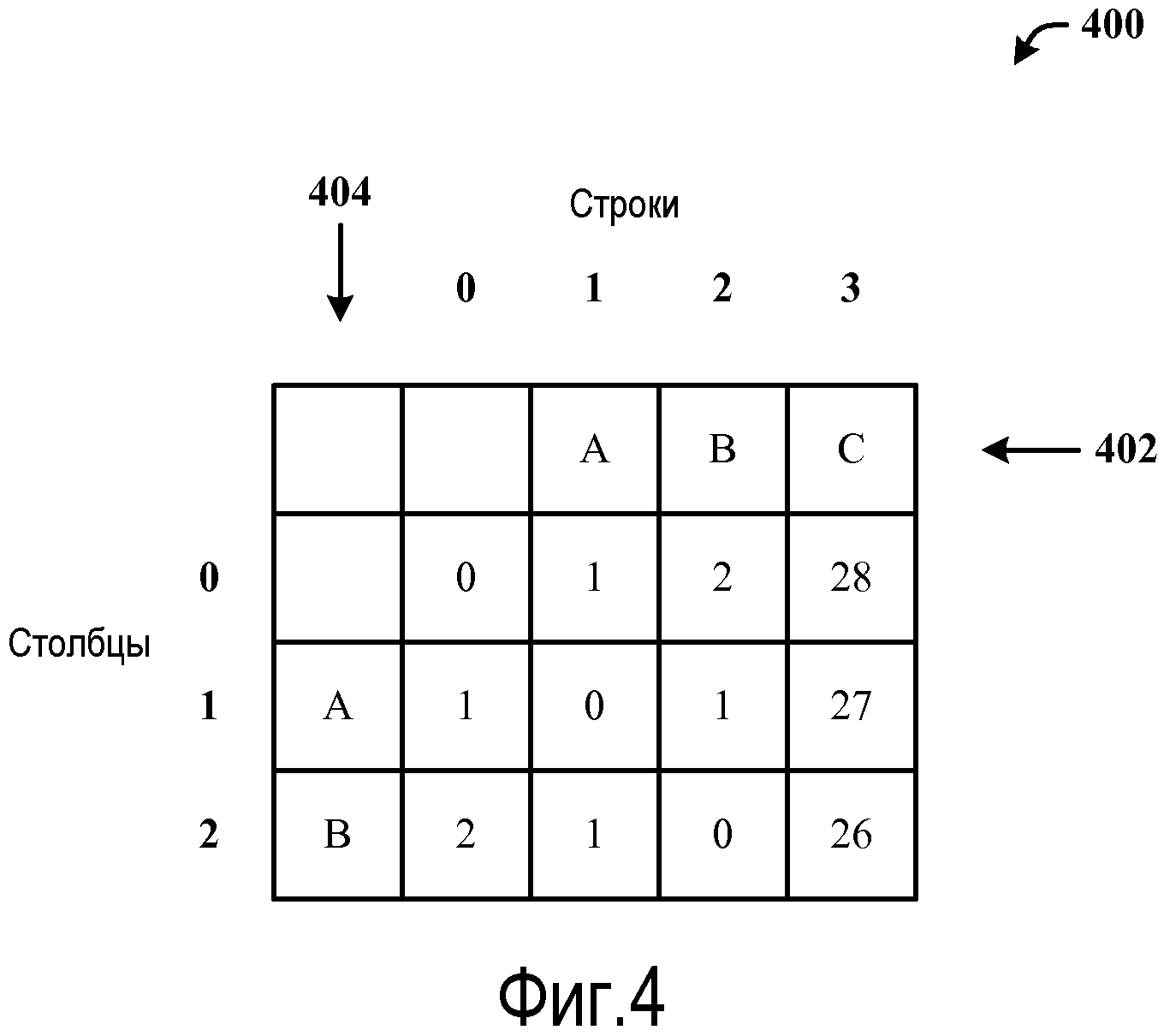
Фиг.3 иллюстрирует обработку и формирование значений расстояния редактирования на основании строки запроса и строки данных с использованием модифицированного расстояния редактирования и алгоритма сопоставления. Последовательность операций включает в себя одно или более из вычислений слева направо, сверху вниз и по диагонали. Строка запроса из термов «A B C» обрабатывается по сравнению с целевой строкой данных из термов «C B A X» (где X обозначает терм, не находящийся в строке запроса). Последовательность операций для вычисления расстояния редактирования может выполняться разными способами, однако специфичные детали для выполнения модифицированного варианта расстояния редактирования являются разными по вычислению согласно раскрытой архитектуре. Матрица 300 4×5 составляется на основании n×m, где n=3 для строки запроса, а m=4 для строки данных. Строка 302 запроса помещена по горизонтальной оси, а целевая строка 304 данных - по вертикальной оси матрицы 300.
Описание будет использовать матрицу 300, обозначенную четырьмя столбцами (0-3) и пятью строками (0-4). Применяя алгоритм сопоставления расстояния редактирования, описанный на фиг.2, слева направо, начиная в строке 0, столбце 0, элемент d[0,0] пересечения принимает «0», поскольку сравнение пустого элемента строки ABC запроса с пустым элементом целевой строки CBAX данных не вызывает вставку или удаление терма, чтобы сделать строку запроса такой же, как целевая строка данных. «Термы» («terms») одинаковы, значит расстояние редактирования является нулевым.
Перемещение вправо для сравнения терма A строки 302 запроса с пустым элементом строки 0 использует одно удаление, чтобы сделать строки одинаковыми; таким образом, элемент d[0,1] принимает значение «1». Вновь перемещаясь вправо в столбец 2, далее производится сравнение между термами AB строки 302 запроса с пустым элементом столбца целевой строки данных. Таким образом, два удаления в строке 302 запроса используется, чтобы сделать строки идентичными, давая в результате расстояние редактирования «2», помещаемое в элемент d[0,2]. Такая же последовательность операций применяется к столбцу 3, где термы ABC строки 302 запроса сравниваются с пустым элементом в столбце целевой строки, с использованием трех удалений, чтобы сделать строки тождественными, давая в результате расстояние редактирования «3» в элементе d[0,3].
Опускаясь в строку 1 и продолжая слева направо, пустой элемент в строке строки запроса сравнивается с первым термом C целевой строки 304 данных. Одно удаление используется, чтобы сделать строки одинаковыми, с расстоянием редактирования «1» в d[1,0]. С перемещением вправо в столбец 1, производится сравнение между термом A строки 302 запроса с термом C целевой строки 304 данных. Удаление и вставка используются, чтобы сделать строки тождественными, таким образом, значение «2» вставляется в элемент d[1,1]. Перескакивая на последний элемент d[1,3], последовательность операций сопоставления для сопоставления ABC с C дает в результате использование двух удалений для расстояния редактирования «2» в элементе d[1,3]. Перемещаясь в строку 4 и столбец 3 для краткости и чтобы найти полное расстояние редактирования, сопоставление термов ABC с термами CBAX имеет следствием расстояние редактирования «8» в элементе d[4,3], использующее вставку/удаление в первом терме C целевой строки на значение «2», значение «0» для соответствия между термами B, вставку/удаление для соответствия третьего терма C и A на значение «2», вставку терма X на значение «1» и значение «3» для затраты расположения, давая в результате окончательное значение расстояния редактирования «8» в элементе d[4,3].
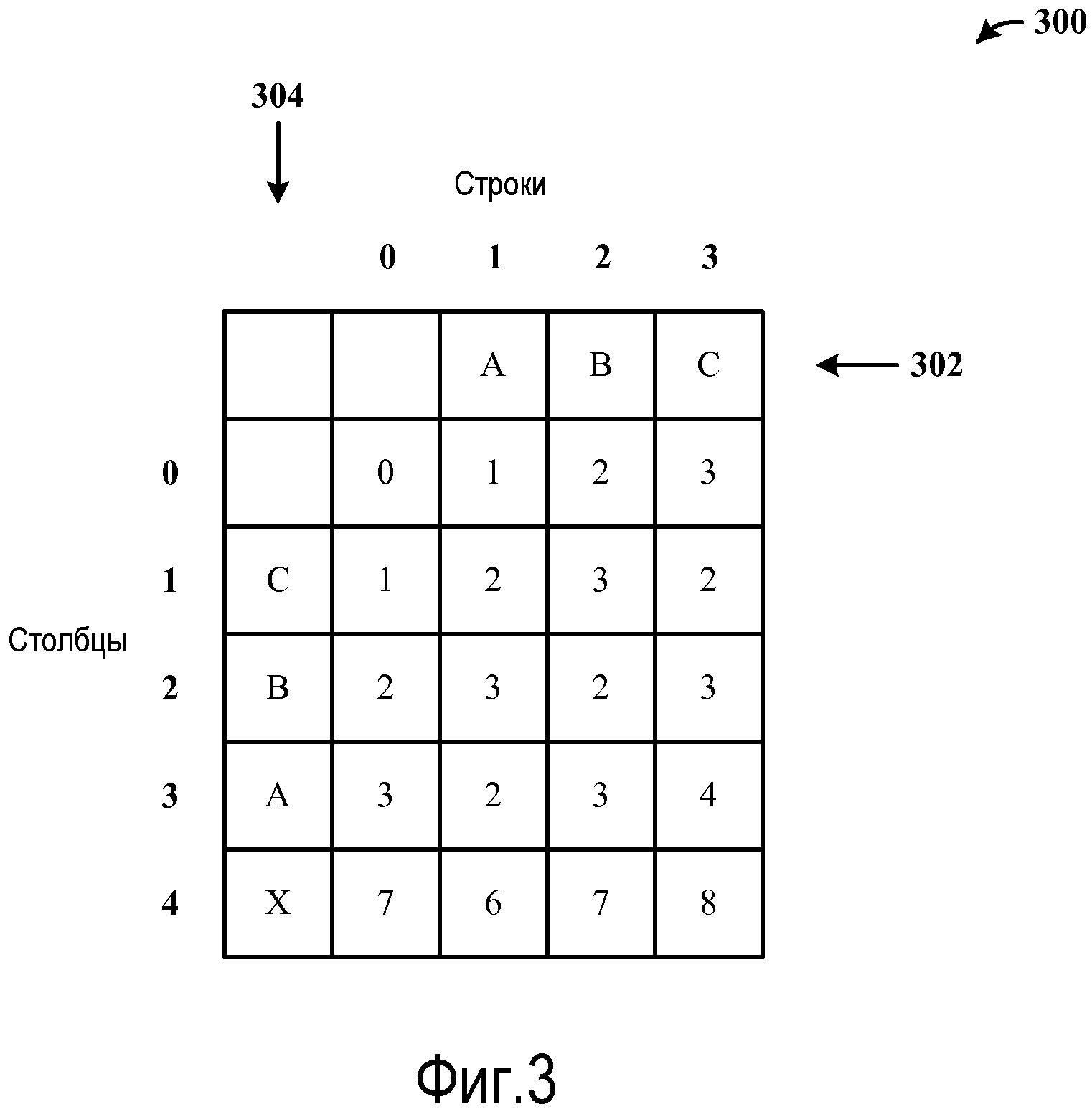
Фиг.4 иллюстрирует еще один пример обработки и формирования значений расстояния редактирования на основании строки запроса и целевой строки данных с использованием модифицированного расстояния редактирования и алгоритма сопоставления. Здесь формируется матрица 400 для сравнения строки 402 запроса ABC с целевой строкой 404 данных AB на основании взвешенных значений для cost_jnsertion w1=1, w3=4 для затрат на вставку, а также w2=1 и w4=26 для затрат на удаление. Другими словами, обрабатывая строку 0 слева направо, сопоставление терма A строки 402 запроса с пустым элементом перед целевой строкой 404 дает в результате одну вставку в целевой строке 404 терма A для элемента d[0,1] со значением «1». Сопоставление термов AB строки 402 запроса с пустым элементом перед целевой строкой 404 дает в результате две вставки в целевой строке 404 термов AB для элемента d[0,2] со значением «2», а сопоставление термов ABC строки 402 запроса с пустым элементом перед целевой строкой 404 дает в результате значение двух вставок в целевой строке 404 термов AB плюс значение w4=26 для терма C, что касается значения «28» в элементе d[0,3], поскольку терм C не находится в обеих строках.
Обрабатывая строку 1 слева направо (с пониманием, что d[1,0]=1), сопоставление терма A строки 402 запроса с термом A целевой строки 404 дает в результате одинаковость в целевой строке 404 и строке 402 запроса для значения «0» в элементе d[1,1], принимая значение из d[j-1,i-1]=d[0,0]=«0». Сопоставление термов AB строки 402 запроса с термом A целевой строки 404 имеет следствием одну вставку в целевой строке 404 для терма B для элемента d[1,2] с минимальным значением «1». Сопоставление термов ABC строки 402 запроса с термом A целевой строки 404 для элемента d[1,3] дает в результате минимальное значение, ассоциативно связанное со значением d[j-1,i]=d[0,3] плюс w3, что касается значения «28» в элементе d[1,3], сравненного со значением d[j,i-1]=d[1,2] на 1 плюс 26 для 27, поскольку терм C не находится в обеих строках, давая в результате минимальное значение «27» в d[1,3].
Обрабатывая строку 2 слева направо, сопоставление терма A строки 402 запроса с термами AB целевой строки 404 дает в результате удаление в целевой строке 404 для значения «1» в элементе d[2,1]. Сопоставление термов AB строки 402 запроса с термами AB целевой строки 404 ради расстояния в элементе d[2,2] дает в результате равенство, тем самым вытягивая значение из d[j-1,i-1]=d[1,1] в качестве значения «0» для элемента d[2,2]. Сопоставление термов ABC строки 402 запроса с термом AB целевой строки 404 для элемента d[2,3] дает в результате минимальное значение, ассоциативно связанное со значением d[j-1,i]=d[2,1]=27 плюс w3, что касается значения «28», подвергнутого сравнению, поскольку терм C не находится в целевой строке (также на основании значения d[i,j-1]=d[2,2]=0 плюс 26 для 26, поскольку терм C не находится в обеих строках), для минимального значения «26» в d[2,3].
Фиг.5 иллюстрирует реализуемую компьютером систему 500 релевантности, которая применяет нейронную сеть 502 для содействия в формировании балльной оценки 504 релевантности для документа 106. Система 500 включает в себя компонент 102 обработки для извлечения информации 104 о документе из документа 106, принятого в качестве результатов 108 поиска на основании строки 110 запроса, и компонент 112 близости для вычисления расстояния 114 редактирования между строкой 116 данных, извлеченной из информации 104 о документе, и строкой 110 запроса. Расстояние 114 редактирования применяется при определении релевантности документа 106 в качестве части результатов 108 поиска.
Нейронная сеть 502 может использоваться для приема информации 104 о документе в качестве входных данных для вычисления балльной оценки релевантности для документа 106. Исключительно или частично на основании балльных оценок релевантности для некоторых или всех из результатов 108 поиска документы в результатах 108 поиска могут ранжироваться. Система 500 применяет нейронную сеть 502 и основание кода для формирования балльной оценки релевантности для ранжирования ассоциативно связанного документа в результатах 108 поиска.
Последующее является описанием алгоритма расстояния редактирования для расчета расстояния редактирования между строкой запроса и каждой из строк данных, чтобы получать балльную оценку TAUC для каждой пары.
Так как в документе есть только один заголовок, балльная оценка TAUC может рассчитываться по отношению к заголовку, как изложено ниже:
TAUC(Title)=ED(Title),
где TAUC(Title) используется позже в качестве входных данных в нейронную сеть после применения функции преобразования, ED(Title) - расстояние редактирования заголовка.
Может иметься множество экземпляров текста привязки для документа, а также URL и щелчков кнопкой мыши (где щелчок кнопкой мыши является ранее выполненным запросом, для которого этот документ выбирался щелчком кнопкой мыши). Идея состоит в том, что этот документ является более релевантным для подобных запросов. Во время индексации выбираются N текстов привязки, имеющих наивысшие частоты. Затем балльная оценка ED рассчитывается для каждой выбранной привязки. В заключение балльная оценка TAUC определяется для привязки, как изложено ниже:
TAUC(Anchor)=Min{ED(Anchor i)} i: N самых лучших привязок.
Интуиция такова, что если существует хорошее соответствие с одной из привязок, то оно является достаточным. TAUC(Anchor) используется в качестве входных данных нейронной сети после применения функции преобразования.
Специальная обработка используется перед расчетом ED для строк URL. Во время индексации строки URL разбиваются на части с использованием набора символов в качестве разделителей. Затем термы отыскиваются в каждой части из словаря термов заголовка и привязки. Каждое появление терма из словаря сохраняется в индексе с расположением, измеренным в символах от начала строки URL.
Во время запроса все появления термов запроса считываются из индекса, сохраненного во время индексации, и разрывы заполняются термами «non-query» («не из запроса»). После этой обработки рассчитывается ED. Результат обработки ED является входными данными нейронной сети после применения функции преобразования.
Еще одним свойством, которое может обрабатываться, является количество «щелчков кнопкой мыши» («clicks»), которые пользователь вводит для данного информационного наполнения документа. Каждый раз, когда пользователь щелкает кнопкой мыши на документе, поток вводится в базу данных и ассоциативно связывается с документом. Эта последовательность операций также может применяться к потоковым данным в тексте информации о документе, таким как короткие потоки данных.
Алгоритм обработки URL во время индексации разбивает целый URL на части с использованием набора символов в качестве разделителей. Функция разбиения также устанавливает urlpart.startpos в расположение части в исходной строке. Функция разбиения выполняет фильтрацию незначащих частей URL.
Например, «http://www.companymeeting.com/index.html» фильтруется в «companymeeting/index» и разбивается на «companymeeting» («собрание компании») и «index» («индекс»).
Startpos: 0
Urlparts = split (url, dictionary)
// найти термы в разных частях url
For each (term in dictionary)
{
Int pos = 0;
For each (urlpart in urlparts)
{
pos = urlpart.Find (term, pos);
while (pos >= 0)
{
// parts_separator (разделитель частей) используется для распознавания разных частей во время запроса
storeOccurrence(term, pos + urlpart.startpos*parts_separator);
pos = url.Find(term, pos + term.length);
}
}
setIndexStreamLength(parts_separator * urlparts.Count);
}
При условии, что словарь содержит в себе «company meeting comp» («контрамарка собрания компании»), могут быть сгенерированы следующие ключи: Company: 0; Meeting: 7 и Comp: 0. Общей длиной строки является parts_separator*2 (разделитель_частей*2).
Что касается обработки во время запроса перед ED, во время запроса считываются появления термов запроса, строка термов запроса, сконструированная в порядке появления в исходной строке URL, и пробел между термами заполняется словесными маркерами «non-query». Например, рассмотрим строку запроса «company policy» («политика компании») и получающуюся в результате строку «company» «non-query term» «policy» «non-query term» («политика» «терм не из запроса» «компании» «терм не из запроса»).
Разделитель частей, расположения термов запроса и длина потока определяются, чтобы знать, сколько частей в исходной строке URL и какая часть содержит в себе данный запрос. Считается, что каждая часть без термов должна содержать в себе «non-query term». Если часть не начинается с терма запроса, «non-query term» вставляется перед термом. Все пробелы между термами запроса заполняются «non-query term».
Фиг.6 иллюстрирует типы данных, которые могут использоваться в информации 104 о документе для определения расстояния редактирования между строкой запроса и строкой данных. Информация 104 о документе может включать в себя данные 602 TAUC, такие как текст 604 заголовка, текст 606 привязки, текст или символы URL 608 и информация 610 о щелчках кнопкой мыши, например, для обработки компонентом 102 обработки и формирования строки 116 (или целевой строки) данных. Информация 104 о документе также может включать в себя информацию 610 о щелчках кнопкой мыши, имеющую отношение к количеству раз, которое пользователь щелкает кнопкой мыши на информационном наполнении документа, типу информационного наполнения, которое выбирает пользователь (посредством щелчка кнопкой мыши), количеству щелчков кнопкой мыши на информационном наполнении, документу в общем и т.д.
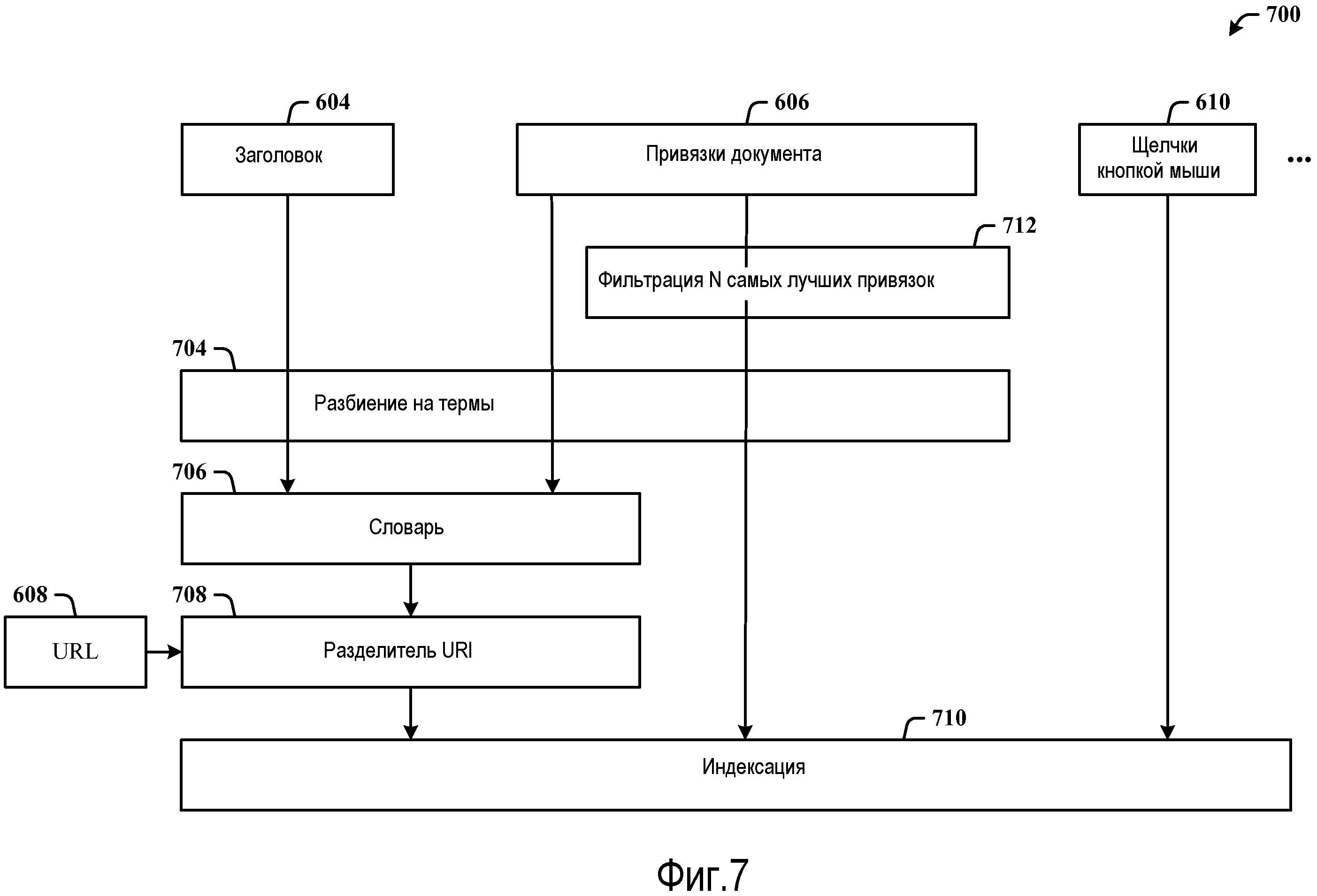
Фиг.7 иллюстрирует поток 700 данных обработки во время индексации. В верхней части информация о документе в виде информации о заголовке 604, привязках 606 документа, щелчках 610 кнопкой мыши и т.д. принимается на основании анализа и выборки документа. Заголовок 604 обрабатывается посредством алгоритма 704 разбиения термов, а затем в отношении словаря 706. Словарь 706 является временным хранилищем разных термов, найденных в информации о заголовке 604, привязках 606, щелчках 610 кнопкой мыши и т.д. Словарь 706 используется для разбиения URL 608 с помощью алгоритма 708 разбиения URL. Выходные данные алгоритма 708 разбиения URL отправляются в последовательность 710 операций индексации для обработки релевантности и ранжирования. Привязки 606 документа также могут обрабатываться посредством фильтра 712 ради N самых лучших привязок. Информация 610 о щелчках кнопкой мыши может обрабатываться непосредственно с помощью последовательности 710 операций индексации. Другая информация о документе может обрабатываться соответствующим образом (например, разбиением термов, фильтрацией и т.д.).
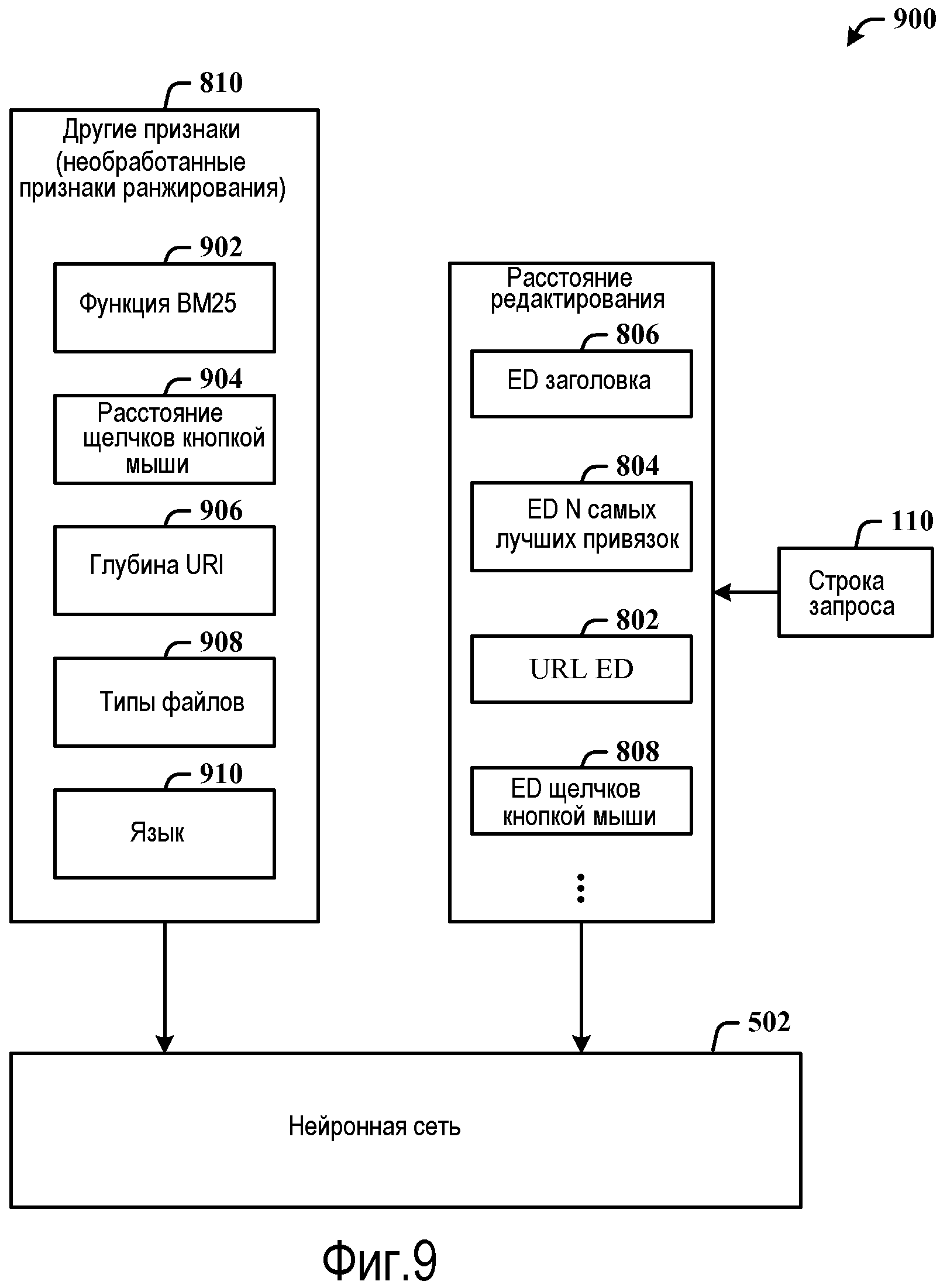
Фиг.8 иллюстрирует структурную схему 800, показывающую входные данные в нейронную сеть из последовательности 710 операций индексации по фиг.7 для ранжирования результатов. Последовательность 710 операций индексации может использоваться для вычисления расстояния 802 редактирования (ED) URL относительно строки 110 запроса, ED 804 N самых лучших привязок относительно строки 110 запроса, ED 808 щелчков кнопкой мыши относительно строки 110 запроса, а также других признаков 810, не имеющих отношения к расстоянию редактирования, некоторые или все из которых (ED 802 URL, ED 804 N самых лучших привязок, ED 806 заголовка, ED 808 щелчков кнопкой мыши и другие признаки 810) могут применяться в качестве входных данных в нейронную сеть 502, чтобы, в конечном счете, находить балльную оценку релевантности для ассоциативно связанного документа, а затем ранжирования документа среди других результатов поиска документов. Нейронная сеть 502 может быть 2-уровневой моделью, которая принимает, по меньшей мере, признаки TAUC в качестве необработанных входных признаков, которые вносят вклад в идентификацию релевантности документа. Нейронная сеть определяет, как эти признаки комбинируются в одиночное число, которое может использоваться для сортировки поисковой машиной.
Должно быть принято во внимание, что нейронная сеть 502 является только одним примером математических или вычислительных моделей, которые могут применяться для обработки релевантности и ранжирования. Могут применяться другие разновидности статистической регрессии, которые могут использоваться, такие как простой подход Байеса, байесовские сети, деревья решений, модели нечеткой логики, и могут использоваться другие модели статистической классификации, представляющие разные формы независимости, где классификация является включающей в себя способы, используемые для назначения ранга и/или приоритета.
Фиг.9 иллюстрирует примерную реализацию системы 900 нейронной сети 502, входных данных расстояния редактирования и необработанных входных данных признаков для вычисления с формированием результатов поиска. Набор необработанных признаков 810 ранжирования на входе(ах) нейронной сети 502 может включать в себя функцию 902 BM25 (например, BM25F), расстояние 904 щелчков кнопкой мыши, глубину 906 URL, типы 908 файлов и языковое соответствие 910. Компоненты BM25, например, могут включать в себя тело, заголовок, автора, текст привязки, наименование отображения URL, извлеченный заголовок.
Фиг.10 иллюстрирует способ определения релевантности. На этапе 1000 строка запроса принимается в качестве части процесса поиска (1000). На этапе 1002 информация о документе извлекается из документа, возвращенного в течение процесса поиска. На этапе 1004 строка данных формируется из информации о документе. На этапе 1006 вычисляется расстояние редактирования между строкой данных и строкой запроса. На этапе 1008 балльная оценка релевантности рассчитывается на основании расстояния редактирования.
Другие аспекты способа могут включать в себя применение вставки терма в качестве части вычисления расстояния редактирования и оценку затрат на вставку терма в строке запроса для формирования строки данных, затраты представлены в качестве весового параметра. Способ дополнительно может содержать применение удаления терма в качестве части вычисления расстояния редактирования, и оценивают затраты на удаление терма в строке запроса для формирования строки данных, затраты представлены в качестве весового параметра. Затраты на расположения могут вычисляться в качестве части вычисления расстояния редактирования, затраты на расположение ассоциативно связаны с вставкой терма и/или удалением терма у расположения терма в строке данных. Дополнительно, последовательность операций сопоставления выполняется между символами строки данных и символами строки запроса для вычисления общих затрат вычисления расстояния редактирования.
Разбиение составных термов URL строки данных может происходить во время индексации. Способ дополнительно может содержать фильтрацию текста привязки строки данных, чтобы находить ранжированный самым лучшим набор текста привязки на основании частоты появления в документе и вычисление балльной оценки расстояния редактирования для текста привязки в наборе. Балльная оценка расстояния редактирования, полученная из вычисления расстояния редактирования, может вводиться в двухуровневую нейронную сеть после применения функции преобразования, балльная оценка вырабатывается на основании расчета расстояния редактирования, ассоциативно связанного с, по меньшей мере, одной из информации о заголовке, информации о привязке, информации о щелчках кнопкой мыши или информации об URL.
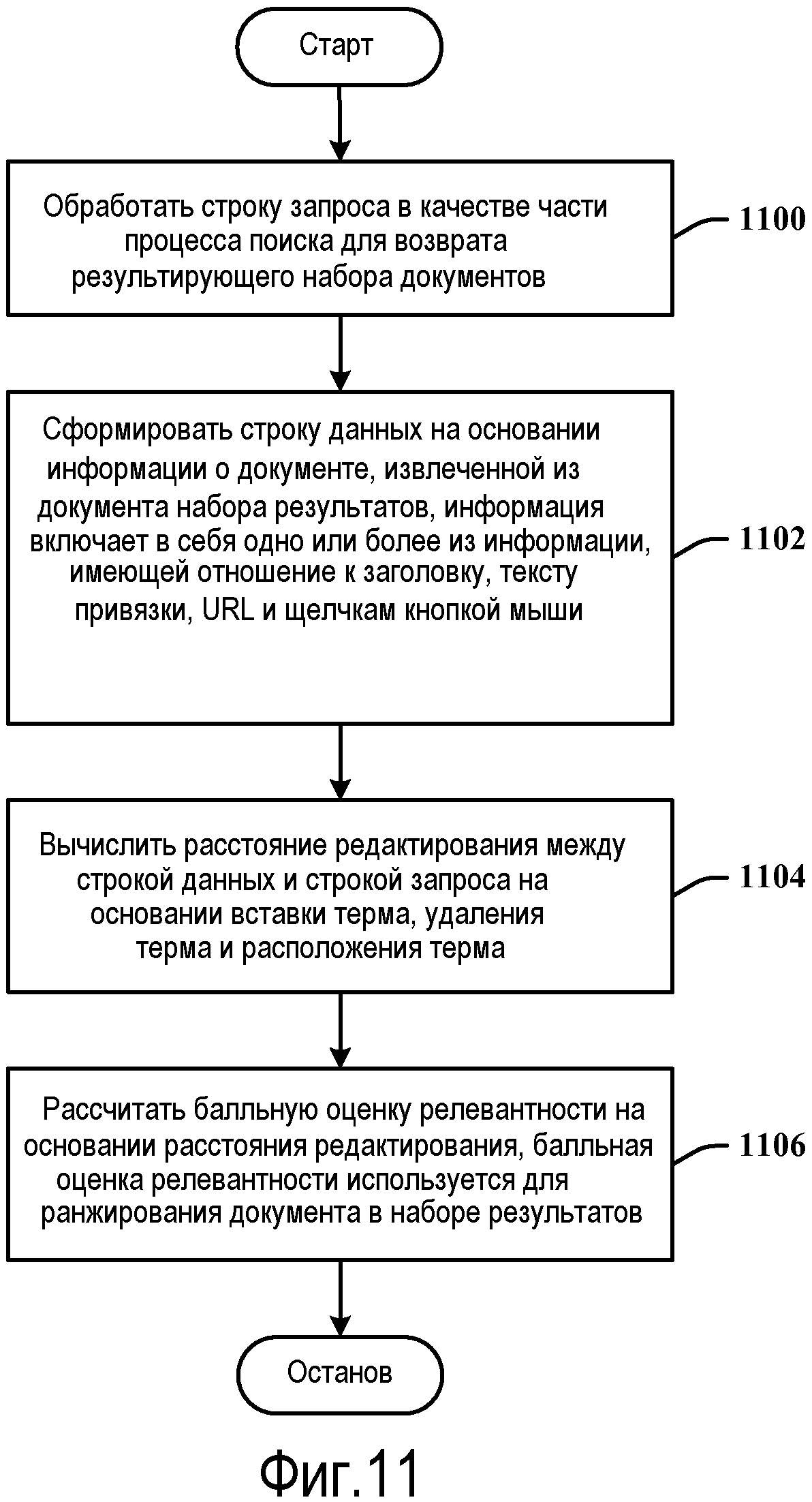
Фиг.11 иллюстрирует способ вычисления релевантности документа. На этапе 1100 строка запроса обрабатывается в качестве части процесса поиска для возврата результирующего набора документов. На этапе 1102 строка данных формируется на основании информации о документе, извлеченной из документа результирующего набора, информация о документе включает в себя одну или более из информации о заголовке, информации о тексте привязки, информации о щелчках кнопкой мыши и информации об URL из документа. На этапе 1104 вычисляется расстояние редактирования между строкой данных и строкой запроса на основании вставки терма, удаления терма и расположения терма. На этапе 1106 балльная оценка релевантности рассчитывается на основании расстояния редактирования, балльная оценка релевантности используется для ранжирования документа в результирующем наборе.
Способ дополнительно может содержать вычисление затрат, ассоциативно связанных с каждым из терма вставки, удаления терма и расположения терма, и включение затрат в вычисление балльной оценки релевантности, а также разбиение составных термов информации об URI во время индексации и фильтрацию информации о тексте привязки во время индексации, чтобы находить ранжированный самым лучшим набор текста привязки на основании частоты появления текста привязки в документе. Считывание появлений термов строки запроса может выполняться для составления строки термов запроса в порядке появления в исходной строке URL и заполнения пробела между термами словесными маркерами.
В качестве используемых в этой заявке, термины «компонент» и «система» предназначены для указания ссылкой на связанную с компьютером сущность, любую из аппаратных средств, комбинации аппаратных средств и программного обеспечения, программного обеспечения или программного обеспечения в ходе выполнения. Например, компонент может быть, но не в качестве ограничения, процессом, работающим на процессоре, процессором, накопителем на жестком диске, многочисленными запоминающими накопителями (оптического и/или магнитного запоминающего носителя), объектом, исполняемым файлом, потоком управления, программой и/или компьютером. В качестве иллюстрации, как приложение, работающее на сервере, так и сервер могут быть компонентом. Один или более компонентов могут находиться в пределах процесса и/или потока управления, и компонент может быть локализован на одном компьютере и/или распределен между двумя или более компьютерами.
Далее, со ссылкой на фиг.12 проиллюстрирована структурная схема вычислительной системы 1200, работоспособной для выполнения обработки расстояния редактирования для ранжирования результатов поиска с использованием признаков TAUC в соответствии с раскрытой архитектурой. Для того чтобы обеспечить дополнительный контекст для его различных аспектов, фиг.12 и последующее обсуждение предназначены для предоставления краткого общего описания пригодной вычислительной системы 1200, в которой могут быть реализованы различные аспекты изобретения. Хотя описание, приведенное выше, находится в общем контексте машинно-исполняемых команд, которые могут работать на одном или более компьютерах, специалистам в данной области техники должно быть понятно, что новый вариант осуществления также может быть реализован в сочетании с другими программными модулями и/или в качестве комбинации аппаратных средств и программного обеспечения.
Как правило, программные модули включают в себя процедуры, программы, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Более того, специалистам в данной области техники должно быть понятно, что обладающие признаками изобретения способы могут быть осуществлены на практике с другими конфигурациями компьютерных систем, в том числе однопроцессорными или многопроцессорными компьютерными системами, мини-компьютерами, универсальными электронно-вычислительными машинами, а также персональными компьютерами, карманными вычислительными устройствами, основанной на микропроцессорах и/или программируемой бытовой электроникой и тому подобным, каждое из которых может быть оперативно присоединено к одному или более ассоциированным устройствам.
Проиллюстрированные аспекты также могут быть осуществлены на практике в распределенных вычислительных средах, где определенные задачи выполняются удаленными устройствами обработки, которые связаны через сеть передачи данных. В распределенной вычислительной среде, программные модули могут быть расположены как в локальном, так и в удаленном запоминающих устройствах памяти.
Компьютер обычно включает в себя многообразие машиночитаемых носителей. Машиночитаемые носители могут быть любыми имеющимися в распоряжении носителями, к которым может быть осуществлен доступ компьютером, и включают в себя энергозависимые и энергонезависимые носители, съемные и несъемные носители. В качестве примера, а не ограничения, машиночитаемые носители могут содержать компьютерные запоминающие носители и среду связи. Компьютерные запоминающие носители включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные запоминающие носители включают в себя, но не в качестве ограничения, ОЗУ (оперативное запоминающее устройство, RAM), ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое программируемое ПЗУ, EEPROM), флэш-память или другую технологию памяти, CD-ROM (ПЗУ на компакт диске), цифровой видеодиск (DVD) или другое оптическое дисковое запоминающее устройство, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства или любой другой носитель, который может быть использован для хранения требуемой информации и к которому может быть осуществлен доступ компьютером.
Согласно фиг.12, примерная вычислительная система 1200 для реализации различных аспектов включает в себя компьютер 1202, имеющий блок 1204 обработки данных, системную память 1206 и системную шину 1208. Системная шина 1208 предоставляет интерфейс для компонентов системы, в том числе, но не в качестве ограничения, системной памяти 1206 к блоку 1204 обработки данных. Блок 1204 обработки данных может быть любым из различных доступных для коммерческого приобретения процессоров. Двухмикропроцессорные и другие многопроцессорные архитектуры также могут применяться в качестве блока 1204 обработки данных.
Системная шина 1208 может иметь любой из нескольких типов шинных структур, которые, кроме того, могут присоединяться к шине памяти (с контроллером памяти или без него), периферийной шине и локальной шине с использованием любой из многообразия доступных для коммерческого приобретения шинных архитектур. Системная память 1206 может включать в себя энергонезависимую память 1210 (NON-VOL) и/или энергозависимую память 1212 (например, оперативное запоминающее устройство (ОЗУ)). Базовая система ввода/вывода (BIOS) может храниться в энергонезависимой памяти 1210 (например, ПЗУ, СППЗУ (стираемом программируемом ПЗУ, EPROM), ЭСППЗУ и т.д.), такая BIOS является базовыми процедурами, которые помогают передавать информацию между элементами в пределах компьютера 1202, к примеру, во время запуска. Энергозависимая память 1212 также может включать в себя высокоскоростное ОЗУ, такое как статическое ОЗУ для кэширования данных.
Компьютер 1202, кроме того, включает в себя внутренний накопитель 1214 на жестком магнитном диске (HDD) (например, EIDE (усовершенствованных электронных схем управления встроенным дисководом), SATA (последовательного подключения улучшенной технологии), причем внутренний HDD 1214 также может быть сконфигурирован для внешнего использования в подходящем шасси, накопитель 1216 на гибких магнитных дисках (FDD) (например, для считывания с или записи на съемную дискету 1218) и накопитель 1220 на оптических дисках (например, считывающий диск 1222 CD-ROM или для считывания с или записи на другие оптические носители большой емкости, такие как DVD). HDD 1214, FDD 1216 и накопитель 1220 на оптических дисках могут быть присоединены к системной шине 1208 посредством интерфейса 1224 HDD, интерфейса 1226 FDD и интерфейса 1228 накопителя на оптических дисках, соответственно. Интерфейс 1224 HDD для реализаций с внешним накопителем может включать в себя, по меньшей мере, одну или обе из интерфейсных технологий универсальной последовательной шины (USB) и стандарта IEEE 1394 (Института инженеров по электротехнике и электронике).
Накопители и ассоциированные машиночитаемые носители обеспечивают энергонезависимое хранение данных, структур данных, машинно-исполняемых команд и так далее. Что касается компьютера 1202, накопители и носители обеспечивают хранение данных в подходящем цифровом формате. Хотя описание машиночитаемых носителей, приведенное выше, ссылается на HDD, съемную магнитную дискету (например, FDD) и съемные оптические диски, такие как CD или DVD, специалистами в данной области техники должно быть принято во внимание, что другие типы носителей, которые являются дающими возможность считывания компьютером, такие как zip-дисководы, магнитные кассеты, карты флэш-памяти, картриджи и тому подобное, также могут использоваться в примерной операционной среде, а кроме того, что любые такие носители могут содержать исполняемые компьютером команды для выполнения новых способов раскрытой архитектуры.
Некоторое количество программных модулей может храниться в накопителях и энергозависимой памяти 1212, в том числе операционная система 1230, одни или более прикладных программ 1232, других программных модулей 1234 и данных 1236 программ. Одни или более прикладных программ 1232, других программных модулей 1234 и данных 1236 программ могут включать в себя систему 100 и ассоциированные блоки, систему 500 и ассоциированные блоки, информацию 104 о документе, данные 602 TAUC, информацию 610 о щелчках кнопкой мыши, поток 700 данных (и алгоритмы) и структурную схему 800 (и ассоциированные блоки).
Взятые в целом или части операционной системы, приложений, модулей и/или данных также могут кэшироваться в энергозависимой памяти 1212. Должно быть принято во внимание, что раскрытая архитектура может быть реализована с различными доступными для коммерческого приобретения операционными системами или комбинациями операционных систем.
Пользователь может вводить команды и информацию в компьютер 1202 через одно или более проводных/беспроводных устройств ввода, например, клавиатуру 1238 и координатно-указательное устройство, такое как мышь 1240. Другие устройства ввода (не показаны) могут включать в себя микрофон (инфракрасный, IR) ИК-пульт дистанционного управления, джойстик, игровую панель, стило, сенсорный экран или тому подобное. Эти и другие устройства ввода часто присоединены к блоку 1204 обработки данных через интерфейс 1242 устройств ввода, который присоединен к системной шине 1208, но могут быть присоединены посредством других интерфейсов, таких как параллельный порт, последовательный порт стандарта IEEE 1394, игровой порт, порт USB, ИК-интерфейс и т.д.
Монитор 1244 или другой тип устройства отображения также присоединен к системной шине 1208 через интерфейс, такой как видеоадаптер 1246. В дополнение к монитору 1244, компьютер типично включают в себя другие периферийные устройства вывода (не показаны), такие как динамики принтеры и т.д.
Компьютер 1202 может работать в сетевой среде с использованием логических соединений через проводную или беспроводную связь с одним или более удаленными компьютерами, такими как удаленный компьютер 1248. Удаленный компьютер 1248 может быть рабочей станцией, серверным компьютером, маршрутизатором, персональным компьютером, портативным компьютером, основанным на микропроцессоре развлекательным бытовым прибором, одноранговым устройством или другим общим узлом сети и типично включает в себя многие или все из элементов, описанных касательно компьютера 1202, хотя, в целях краткости, проиллюстрированы только устройство 1250 памяти/хранения. Изображенные логические соединения включают в себя возможность проводного/беспроводного присоединения к локальной сети 1252 (LAN) и/или сети большего масштаба, например глобальной сети 1254 (WAN). Такие сетевые среды LAN и WAN обычны в офисах и компаниях и содействуют корпоративным компьютерным сетям, таким как интранет (локальная сеть, использующая технологии Интернет), все из которых могут присоединяться к глобальной сети передачи данных, например сети Интернет.
При использовании в сетевой среде LAN компьютер 1202 присоединен к LAN 1252 через интерфейс или адаптер 1256 проводной и/или беспроводной сети передачи данных. Адаптер 1256 может содействовать проводной или беспроводной передаче данных в LAN 1252, которая также может включать в себя беспроводную точку доступа, размещенную в ней, для поддерживания связи с беспроводными функциональными возможностями адаптера 1256.
При использовании в сетевой среде WAN компьютер 1202 может включать в себя модем 1258 или присоединяться к серверу связи в WAN 1254 или имеет другое средство для установления связи через WAN 1254, к примеру, в виде сети Интернет. Модем 1258, который может быть внутренним или внешним и проводным и/или беспроводным, присоединен к системной шине 1208 через интерфейс 1242 устройств ввода. В сетевой среде программные модули, изображенные касательно компьютера 1202, или их части могут храниться в удаленном устройстве 1250 памяти/хранения. Будет принято во внимание, что показанные сетевые соединения являются примерными и может быть использовано другое средство установления линии связи между компьютерами.
Компьютер 1202 действует для поддержания связи с проводными и беспроводными устройствами или сущностями, использующими семейство стандартов IEEE 802, такими как беспроводные устройства, оперативно размещенные на беспроводной связи (например, технологии эфирной модуляции стандарта IEEE 802.11), например, с принтерами, сканерами, настольным и/или портативным компьютером, персональным цифровым секретарем (PDA), спутником связи или любой единицей оборудования или местоположением, ассоциированным с обнаруживаемыми беспроводным способом ярлыками (например, телефонной будкой, газетным киоском, комнатой отдыха) и телефоном. Это включает в себя, по меньшей мере, беспроводные технологии Wi-Fi, WiMax и Bluetooth™. Таким образом, связь может быть предопределенной структурой, как с традиционной сетью, или просто эпизодической связью между, по меньшей мере, двумя устройствами. Сети Wi-Fi используют технологии радиосвязи, называемые IEEE 802.11x (a, b, g и т.д.), чтобы предоставлять возможность защищенного, надежного высокоскоростного беспроводного соединения. Сеть Wi-Fi может использоваться, чтобы присоединять компьютеры друг к другу, к сети Интернет и к проводным сетям (которые используют связанные со стандартом IEEE 802.3 среду и функции).
Выше описаны примеры раскрытой архитектуры. Конечно, невозможно описать каждое мыслимое сочетание компонентов и/или обобщенных способов, но рядовой специалист в данной области техники может осознать, что возможны многие дополнительные комбинации и перестановки. Соответственно, новейшая архитектура предназначена для охвата всех тех изменений, модификаций и вариантов, которые подпадают под сущность и объем прилагаемой формулы изобретения. Более того, в тех пределах, в которых термин «включает в себя» используется в подробном описании или формуле изобретения, такой термин подразумевается включающим некоторым образом, подобным тому, как термин «содержащий» интерпретируется в качестве «содержащего», когда используется в качестве переходного слова в формуле изобретения.
Архитектура для онлайновых коллективных и объединенных взаимодействий
Интеллектуальное редактирование реляционных моделей
Создание и развертывание распределенных расширяемых приложений
Использование устройства флэш-памяти для препятствования несанкционированному использованию программного обеспечения
Гибкое редактирование гетерогенных документов
Доверительная среда для обнаружения вредоносных программ
Интеграция рекламы и расширяемые темы для операционных систем
Перемещение сущностей, обладающих учетными записями, через границы безопасности без прерывания обслуживания
Криптографическое управление доступом к документам
Предоставление цифровых удостоверений
Архитектура для онлайновых коллективных и объединенных взаимодействий
Интеллектуальное редактирование реляционных моделей
Создание и развертывание распределенных расширяемых приложений
Использование устройства флэш-памяти для препятствования несанкционированному использованию программного обеспечения
Гибкое редактирование гетерогенных документов
Доверительная среда для обнаружения вредоносных программ
Интеграция рекламы и расширяемые темы для операционных систем
Перемещение сущностей, обладающих учетными записями, через границы безопасности без прерывания обслуживания
Криптографическое управление доступом к документам
Предоставление цифровых удостоверений

