Результат интеллектуальной деятельности: УСТРОЙСТВО, СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МАТРИЦАМИ
Вид РИД
Изобретение
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение, в основном, относится к области электроники.
Более конкретно, пример воплощения изобретения относится к методике управления блоками матриц системы на кристалле (OSF).
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
В электронной конструкции полупроводниковый интеллектуальный блок (также называемый "ядром IP" или "логическим ядром" или, в основном, "логическим блоком") является повторно используемым модулем логической схемы, ячейки или проекта топологии микросхемы. Например, такие логические блоки могут использоваться одноразово или повторно, как стандартные блоки в различных микросхемах или при проектировании на логическом уровне.
По мере увеличения числа блоков IP, их интеграция в систему становится более трудной. Кроме того, при проектировании блоки IP, возможно, не включают сложных схем (например, с целью сокращения затрат). С этой целью, некоторые задачи, связанные с обработкой адреса, возможно, должны быть выполнены главным процессором, а не логикой в блоке IP. Это может вызвать задержку времени, например, связанную с обработкой адреса посредством частого переключения режима соединения между пользователем и ядром главного процессора.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Подробное описание связано со ссылками на приложенные чертежи. На чертежах крайняя левая цифра или цифры номера позиции обозначают фигуру, в которой сначала появляется номер ссылки. Использование одних и тех же цифровых позиций на различных фигурах указывает на подобные или идентичные элементы.
Фигуры 1 и 6-7 иллюстрируют блок-схемы примеров воплощения вычислительных систем, которые могут быть использованы для реализации различных обсужденных здесь примеров воплощения изобретения.
Фигура 2 иллюстрирует сниппеты кода на уровне пользователя, согласно одному примеру воплощения.
Фигура 4 иллюстрирует примеры вводов в таблицу страниц OS и TLB, согласно некоторым примерам воплощения.
Фигуры 3 и 5 иллюстрируют блок-схемы способов, согласно некоторым примерам воплощения.
ПОДРОБНОЕ ОПИСАНИЕ
В последующем описании формулируются многочисленные конкретные детали, чтобы обеспечить полное понимание различных примеров воплощения. Однако некоторые примеры воплощения могут быть осуществлены без этих конкретных деталей. В других примерах известные способы, процедуры, компоненты и схемы подробно не описываются, чтобы не затенять конкретные примеры воплощения.
Некоторые примеры воплощения относятся к методикам управления блоками IP или логическими блоками, связанными через матрицу системы на кристалле (OSF). В одном примере воплощения управление может быть организовано на пользовательском уровне. Кроме того, OSF может связывать ядро(ядра) процессора с блоками IP (такими как устройства ввода-вывода в некоторых примерах воплощения). Блок IP, возможно, не будет включать блок управления памятью (MMU), например, в целях сокращения затрат, таким образом, OSF должна передавать физические адреса в блок IP. Один метод поддержки при обработке адреса состоит в том, чтобы использовать драйверы устройства в ядре для блока IP. Такие драйверы устройства могут управлять физическими адресами. Однако эта модель может оказаться неэффективной для увеличения быстродействия из-за высокой стоимости частого переключения между пользователем и режимами ядра и/или проходом по таблице страниц. Управление на уровне пользователя сталкивается с проблемой передачи физических адресов в блок IP.
Чтобы решить эту проблему, в одном примере воплощения используется затенение физического адреса. Например, может быть выполнено обращение к операционной системе (OS), чтобы создать затенение физических номеров страниц или адресов (например, используя иным образом недействительный диапазон физических адресов), который также упоминается здесь как "перераспределение" («remap»). Далее, аппаратные средства (например, в месте связи с OSF) могут извлечь реальный физический адрес из теневого адреса (также упомянутый здесь как перераспределение-1 ("remap-1"). В одном примере воплощения аппаратные средства для перераспределения-1 могут включить зеркальное отражение или инвертирование самых высоких одного или двух битов адреса. В одном примере воплощения приложения (например, выполняемые на уровне пользователя) могут использовать обычную команду памяти x86 пространства пользователя, чтобы передать адреса памяти и другие параметры в блок IP. Это было бы на порядок величины быстрее, чем захват в ядро, чтобы получить доступ к таблице страниц, и на порядок величины дешевле, чем создание дополнительного MMU в блоке IP.
Кроме того, в некоторых примерах воплощения, пользовательские приложения могут инициировать выполнение блока IP с четырьмя признаками: (1) никакого расширения архитектуры системы команд (ISA); (2) никакой излишней коммутации режима ядра пользователя; (3) никакого дополнительного MMU; и/или (4) ядро процессора и блок IP могут разделить адреса, которые не фиксированы, а известны только во время выполнения. Такие признаки могут привести к намного меньшему ограничению использования блока IP. Это может также учитывать более широкое развертывание мелкомодульных ускорителей через OSF.
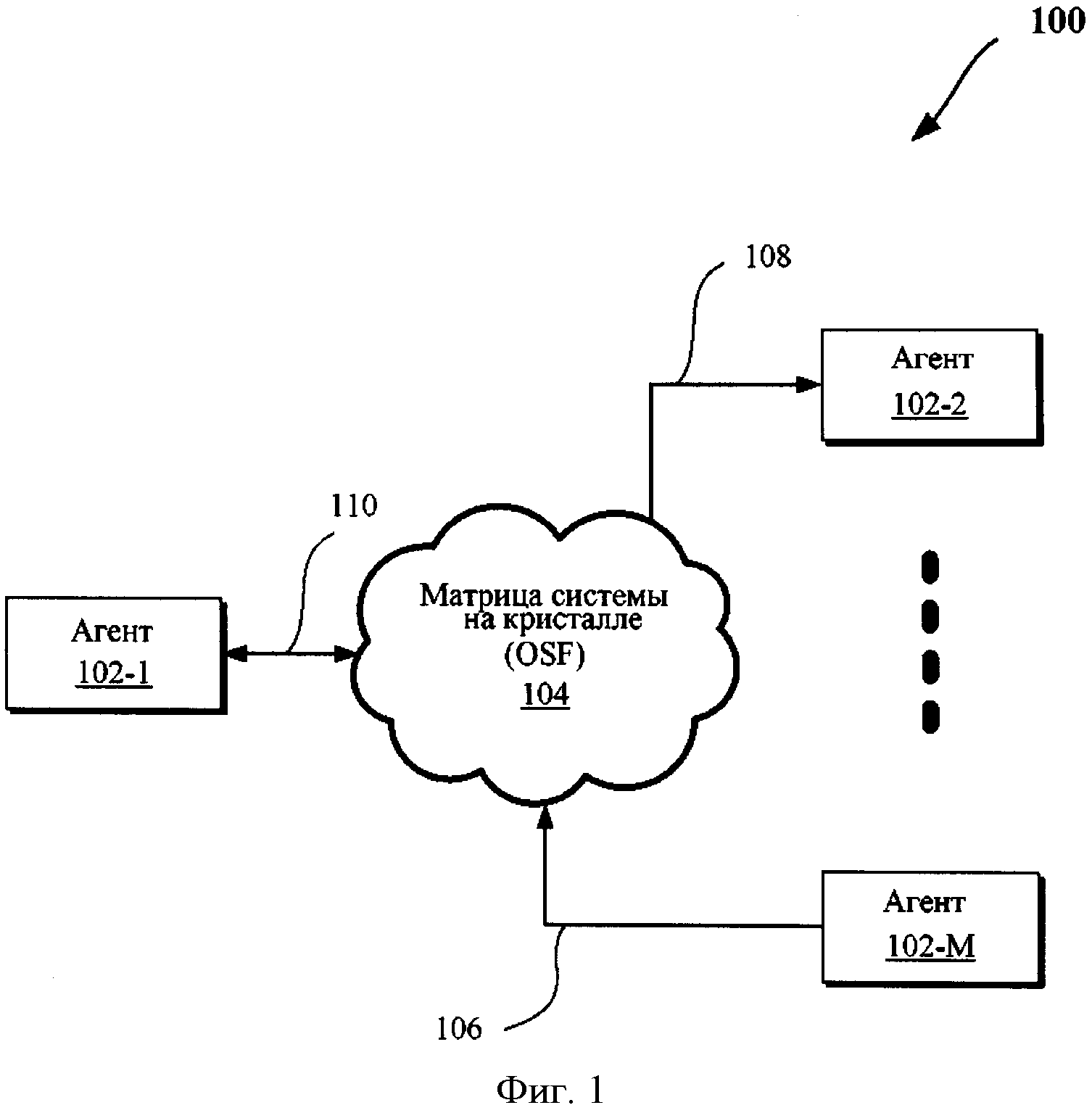
Обсужденные здесь методики могут быть применены в различных вычислительных системах, таких как системы, обсужденные со ссылками на фигуру 1 и фигуры 6-7. Более конкретно, фигура 1 иллюстрирует блок-схему вычислительной системы 100, согласно одному примеру воплощения изобретения. Система 100 может включать один или несколько агентов в диапазоне от 102-1 до 102-М, все вместе упоминаемые здесь как "агенты 102" или как "агент 102". В примере воплощения, один или несколько агентов 102 могут быть любыми из компонентов вычислительной системы, в частности, вычислительных систем, обсуждаемых со ссылками на фигуры 6-7.
Как показано на фигуре 1, агенты 102 могут быть связаны через коммутирующую матрицу 104, такую как OSF. Следовательно, агенты 102 и коммутирующая матрица 104 могут присутствовать на одном кристалле интегральной схеме в данном примере воплощения. Как обсуждено здесь, "OSF" может отнести к коммутирующей матрице системы на кристалле, которая является масштабируемым, конфигурируемым и/или конкретным продуктом. Например, каждый из агентов 102 может быть мостом (например, для связи с другой матрицей), блоком IP или другим компонентом электронного устройства, которые связаны через коммутирующую матрицу 104. В одном примере воплощения коммутирующая матрица 104 может включать компьютерную сеть, которая позволяет различным агентам (таким как вычислительные устройства) передавать данные. В одном примере воплощения коммутирующая матрица 104 может включать одно или несколько межсоединений (или соединительных сетей), которые связаны через последовательную (например, "от точки к точке") линию и/или совместно используемую сеть связи. Например, некоторые примеры воплощения могут облегчить отладку компонентов или проверку линий, которые обеспечивают связь с полностью буферизованным набором в линейных модулях (FBD), например, где линия FBD - последовательная линия, используемая для связи модулей памяти с устройством хост-контроллера (таким как процессор или концентратор памяти). Отладочная информация может быть передана от хоста FBD в линию связи так, что отладочная информация, может наблюдаться вдоль линию связи приборами слежения трассировки графика линии связи (такими как один или несколько логических анализаторов).
В одном примере воплощения система 100 может поддерживать многоуровневую схему протокола, которая может включать физический уровень, уровень линии связи, уровень маршрутизации, транспортный уровень и/или уровень протокола. Коммутирующая матрица 104 также может облегчить передачу данных (например, в виде пакетов) из одного протокола (например, кэшируя процессор или кэшируя осведомленный о памяти контроллер) к другому протоколу через "двухточечную" или совместно используемую сеть. Кроме того, в некоторых примерах воплощения коммутирующая матрица 104 может обеспечить передачу, которая осуществляется по кэш-когерентному протоколу. Альтернативно, коммутирующая матрица 104 может работать с некогерентными протоколами.
Кроме того, как показано направлением стрелок на фигуре 1, агенты 102 могут передавать и/или принимать данные через матрицу 104. Следовательно, некоторые агенты могут использовать однонаправленную линию связи, тогда как другие могут использовать двустороннюю линию связи для передачи. Например, один или несколько агентов (таких как агент 102-М) могут передавать данные (например, через однонаправленную линию связи 106), другой агент(агенты) (такие как агент 102-2) могут принимать данные (например, через однонаправленную линию связи 108), тогда как некоторый другой агент (такой как агент 102-1) может передавать и принимать данные (например, через двустороннюю линию связи 110). В некоторых примерах воплощения линии 106-110 могут быть интерфейсами OSF, которые обеспечивают протокол и/или сигналы, позволяющие блоку IP взаимодействовать по различным схемам.
В одном примере воплощения интерфейсы OSF, которые связывают агентов 102 (например, линии 106-110), могут обеспечить два порта, именуемые как основной канал и канал боковой полосы. Основной канал может: (а) быть высокопроизводительным интерфейсом для передачи данных между одноранговыми узлами и/или по восходящей линии; (b) поддерживать память (например, 32 бита, 64 бита), устройством ввода/вывода (IO), выполнять конфигурацию и передачу сообщений; (с) поддерживать правила взаимодействия периферийных компонентов (PCI) и/или их нумерацию; (d) поддерживать протокол разделения пакетов и/или (е) отображать информацию заголовка PCI-е. Канал боковой полосы может: (i) обеспечить стандартный интерфейс, чтобы передавать всю информацию боковой полосы и устранить необходимость выделенных проводных линий; (ii) обеспечить двухточечную сеть; (iii) использоваться для управления электропитанием, затенения конфигурации, в тестовых режимах и т.д., и/или (iv) использоваться для низкой пропускной способности (например, не предназначенный для передачи основных данных).
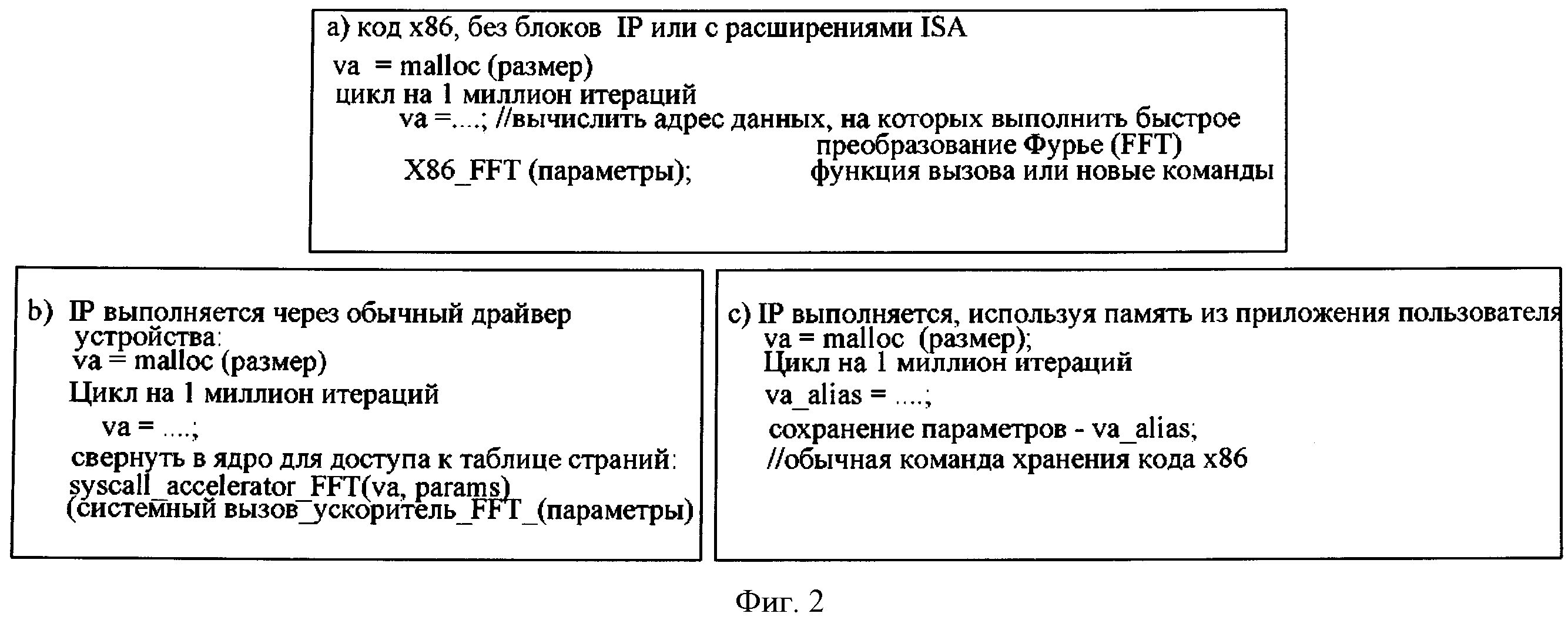
На Фигуре 2 показаны сниппеты кода на уровне пользователя для быстрого преобразования Фурье (FFT) с и без присоединенных блоков IP OSF, согласно некоторым примерам воплощения. Часть (с) является одним примером воплощения изобретения, обсуждаемым ниже.
Драйверы устройства в ядре, блоки IP могут быть связаны с ядром процессора через основанное на пакете межсоединение, такое как OSF. Блок IP могут управляться драйверами устройства OS. В особых случаях, таких как драйвер сетевого интерфейса (NIC), буферы памяти могут быть направлены на задачу передачи начального адреса драйверу. В некоторых примерах воплощения имеет место более общий случай использования, например, там, где каждый раз функция вызывается на блок IP, "буферные" изменения адреса. Чтобы инициировать выполнение на блоке IP, начиная с произвольного виртуального адреса пространства пользователя (ВА), приложение пользователя делает системный вызов, который входит в ядро и инициирует драйвер устройства (см., например, фигуру 2b)). Драйвер устройства (такой как драйвер устройства на фигуре 6) получает физический адрес (РА), находя его в таблице страниц в памяти (не используя буфер опережающей выборки при передачах (TLB)). Затем устройство передает РА в блок IP. Однако частое переключение режима пользователь-ядро и обзор таблицы переадресации страниц могут отобрать тысячи часов процессора, смещая выигрыш в ускорении производительности в блок IP. Кроме того, некоторые драйверы устройства на уровне пользователя для устройств IO могут либо ограничить приложение и ядро по совместному использованию некоторой предварительно выделенного постоянного буфера памяти, либо потребуют дополнительной MMU в системе памяти преобразования виртуальных адресов приложения в физические адреса.
Как показано на фигуре 2, часть (с) иллюстрирует модель программирования, которая обеспечивается в соответствии с одним примером воплощения. Например, приложение делает один системный вызов после интервала (). После этого устройство сможет передавать адреса данных в блок IP, используя обычные команды памяти (например, х86) к виртуальным адресам пространства пользователя (va_alias на фигуре 2). На следующей фигуре будет показан пример того, как блок IP может принимать физические адреса памяти, которые поддерживают виртуальные адреса приложения.
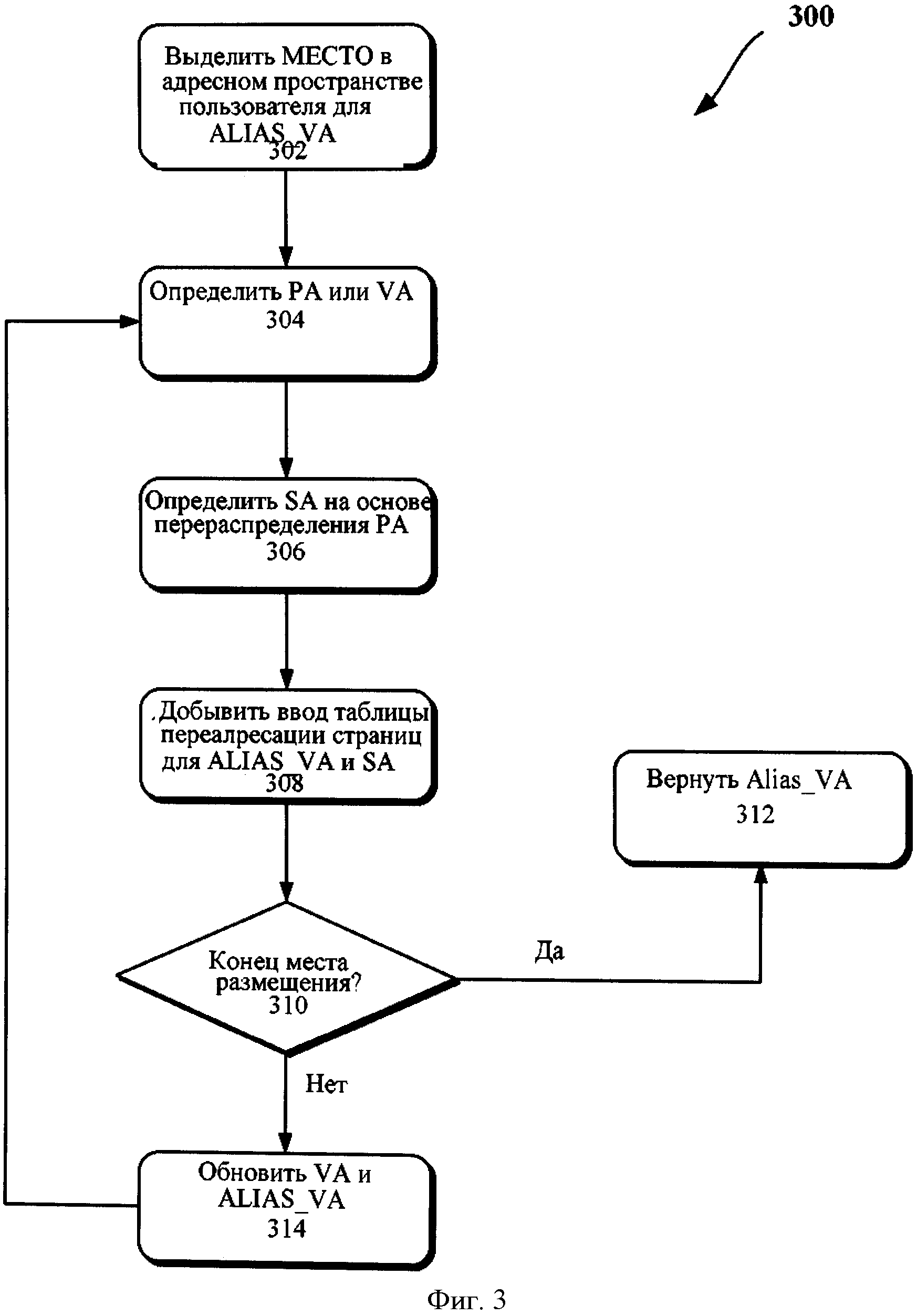
Более конкретно, на фигуре 3 показана блок-схема способа 300 при выполнении операции перераспределения памяти в соответствии с одним примером воплощения. Операция перераспределения памяти может быть реализована как системный вызов в OS, чтобы создать теневые физические номера страниц или теневые физические адреса, например, используя иным образом недействительный или неиспользованный диапазон физических адресов. В одном примере воплощения обсуждаются данные или команды связи со ссылками на способ 300, которые могут быть выполнены через основной канал, обсужденный со ссылкой на фигуру 1.
В одном примере воплощения, после выполнения перераспределения памяти, показанного на фигуре 3, может быть выполнена операция перераспределения-1, используя аппаратные средства в OSF, чтобы извлечь реальный физический адрес из теневого адреса. В одном примере воплощения перераспределение-1 может быть реализовано, зеркально отражая один или два самых высоких бита адреса (в некоторых примерах воплощения более чем двухбитовые).
В некоторых примерах воплощения при перераспределении-1 может быть выполнена операция преобразования теневого значения в физическое значение, где используется физический адрес, такой как в системном межсоединении или внутри блока IP. Выполнение этой операции в системном межсоединении может переместить эту операцию в критическую точку передачи памяти, которая в некоторых ситуациях не предназначена для блоков IP. Выполнение этой операции в ускорителях может потребовать встраивания логики перераспределения-1 в каждый блок IP. Альтернативно, такие аппаратные средства могут быть предусмотрены в OSF. С такой поддержкой приложения могут использовать единственную команду памяти Х86, чтобы назначить использование адреса памяти для блока IP.
Обращаясь к фигурам 1-3, мы видим, что при операции 302 многие байты (например, "размер" на фигуре 2с)), могут быть выделены в адресном пространстве пользователя для алиаса ВА (также взаимозаменяемо упоминаемый здесь как "VA_Alias"). В операции 304 адрес РА может быть определен для адреса VA. В операции 306, SA (теневой адрес) может быть определен на основе РА. Например, в операции 306, Remap_to_shadow (преобразование в тень) может обеспечить отображение, у которого есть простая обратная функция с тем, чтобы система OSF могла бы легко извлечь истинный физический адрес. В некоторых системах фактическая установленная память занимает менее половины физического адресного пространства. На такой машине функции перераспределения Remap() и Remap-1() могут быть реализованы, зеркально отражая самые высокие один или два бита адреса. Например, где:
Remap(PA)=0×80000000 XOR PA
Remap(PA)-1(SA)=0×80000000 XOR SA
В некоторых примерах воплощения не ускоренные части приложения могут продолжать использовать исходный виртуальный адрес VA. Далее, операция syscall_OSF_remap() после операции malloc() может быть выполнена только один раз, например, в фазе инициализации приложения (см., например, фигуру 2с).
В одном примере воплощения перераспределение-1 (SA) может быть выполнено аппаратными средствами OSF в каждом вызове функции блока IP. В одном примере воплощения OS должна хранить теневую таблицу страниц соответствующей исходной странице.
В операции 308 может быть добавлен ввод таблицы переадресации страниц для Alias_VA и SA. В одном примере воплощения атрибут страницы ввода в операции 308 может быть установлен как некэшируемый (такой как обсуждено со ссылкой на фигуру 4). В операции 310, если достигнут конец выделенного размера операции 302, может быть возвращен Alias_VA; в противном случае VA и Alias_VA могут быть обновлены (например, VA и Alias_VA могут быть увеличены на выбранный размер страницы) в операции 314. После операции 314, способ 300 возобновляет операцию 304.
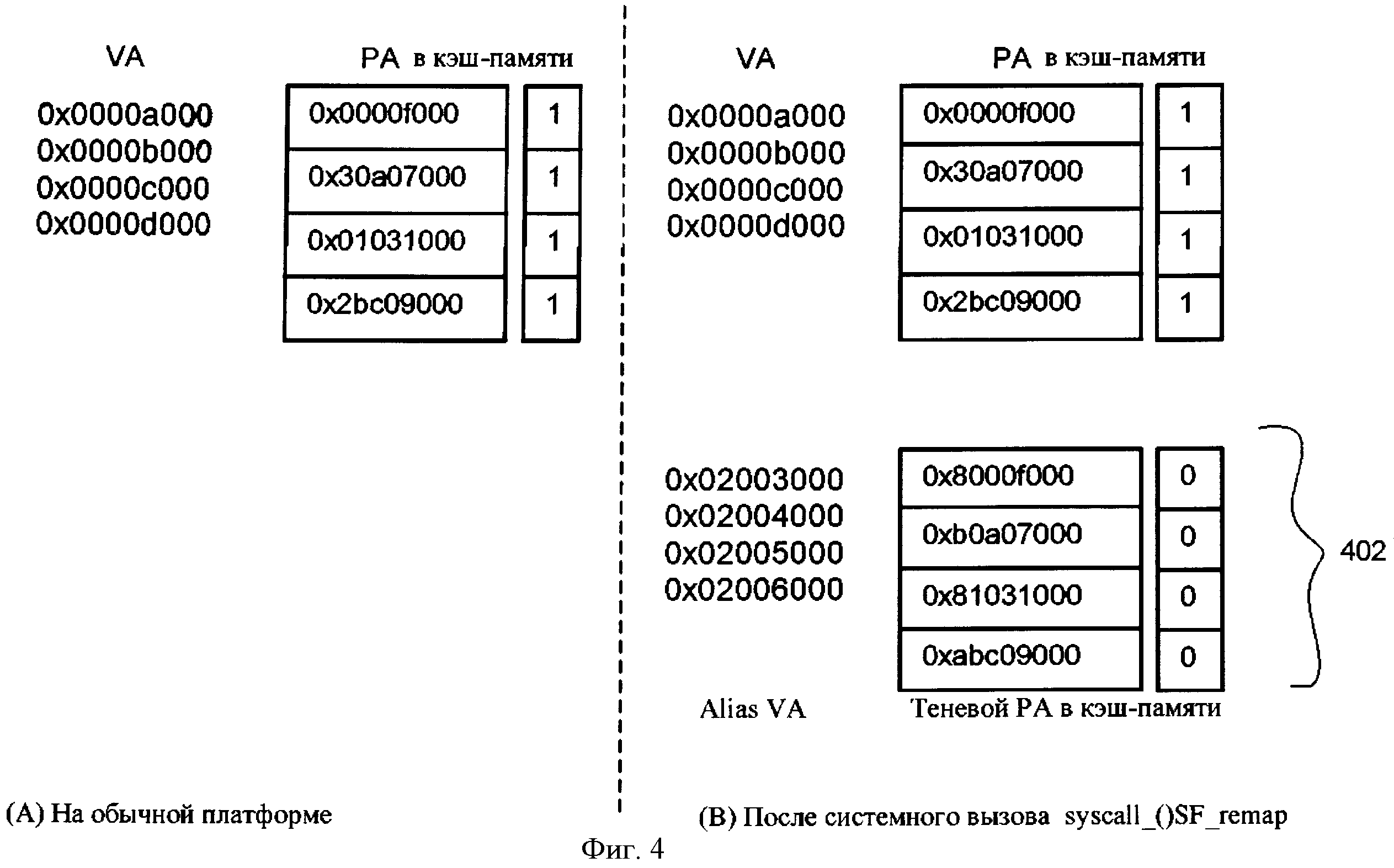
фигура 4 иллюстрирует образцы вводов в таблице страниц OS и TLB согласно некоторым примерам воплощения. Например, 0×0200400 - виртуальный адрес пользователя, выделенный операцией syscall_OSF_remap(). Как алиас к VA 0×0000b000, он поддерживается физической страницей 0×30а07000. Однако в таблице страниц мы сознательно зеркально отразили самый высокий бит и, таким образом, физическая страница стала 0×b0a07000 (0×80000000 XOR 0×30а07000=0×b0a07000). В одном примере воплощения TLB и TLB не заботятся о том, является ли РА тенью или нет.
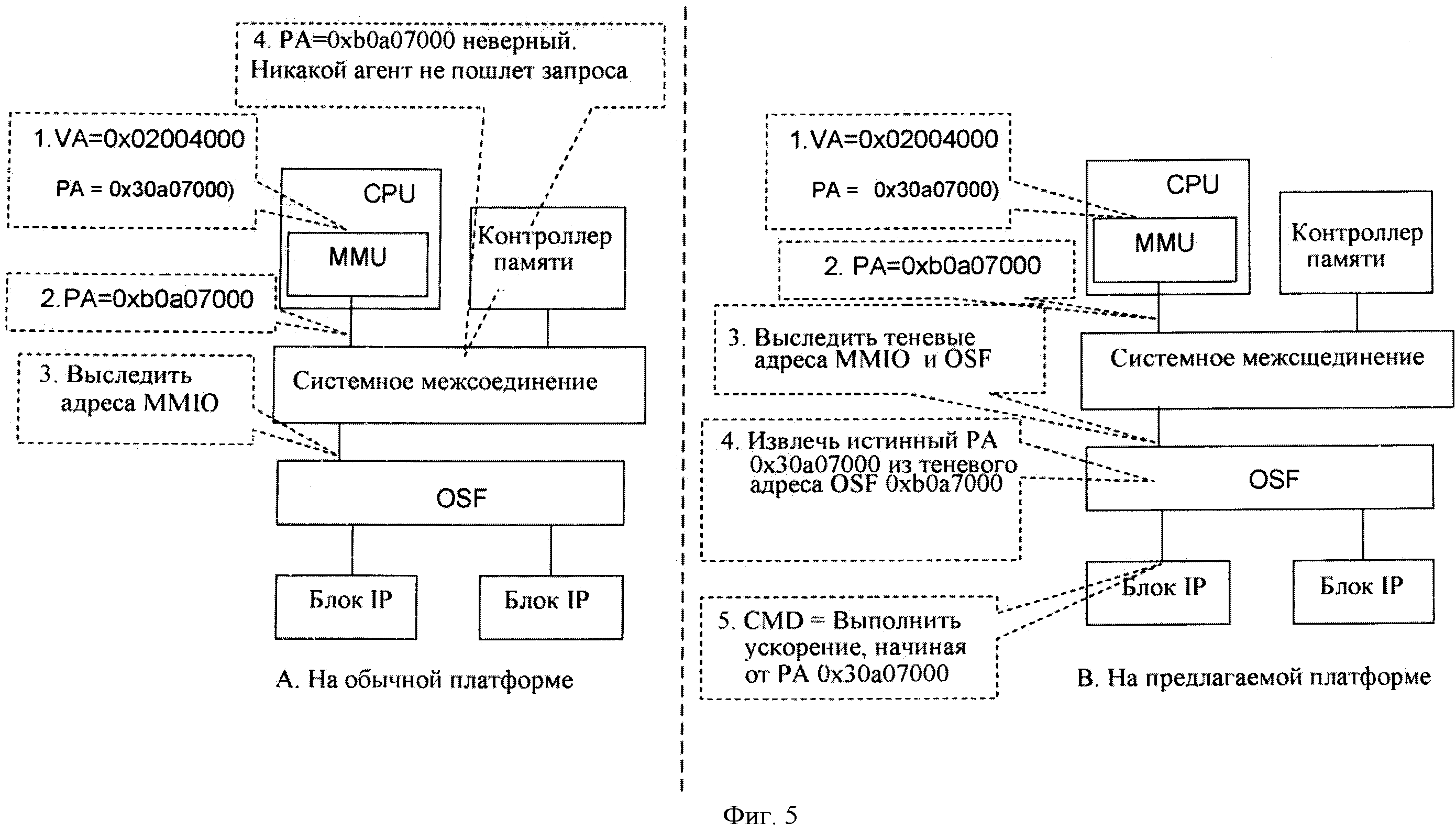
Как показано на фигуре 4, преобразования адресов изменяются для вызывающего приложения в результате создания системного вызова. В этом примере любой адрес РА, который выше, чем 0×40000000, в базовой платформе является неправильным. Виртуальные алиасные адреса все переходят в недействительную область физического адресного пространства 402. Достоверный диапазон РА в обеих системах: 0×0~0×40000000 (включая установленную память и отображенный в памяти IO (MMIO)).
На фигуре 5 показано сравнение событий, когда приложение выполняет команду памяти Х86 "регистр st -> 0×02004000" на платформе со специальной логикой и без нее в OSF (части (В) и (А) на фигуре 5, соответственно). В обоих случаях процессор (CPU)MMU преобразует VA в PA 0×b0a07000 на основе таблицы страниц, показанной на фигуре 4(В). Поскольку бит атрибута страницы некэшируемый, запись обходит кэши процессора и поступает непосредственно в системное межсоединение (операция 2 на фигуре 5).
На фигуре 5(А), поскольку РА находится вне действительного диапазона адресов РА (например, где действительный диапазон РА: 0×0~0×40000000 (включая установленную память и MMIO)), аппаратные средства вводят исключение. На фигуре 5(В) OSF извлекает иным образом недействительный физический адрес 0×b0a07000 (операция 3), выполняет перераспределение-1 на нем (операция 4) и преобразует передачу записи в командный пакет, из которого блок IP получит действительный физический адрес 0×30а07000 (операция 5).
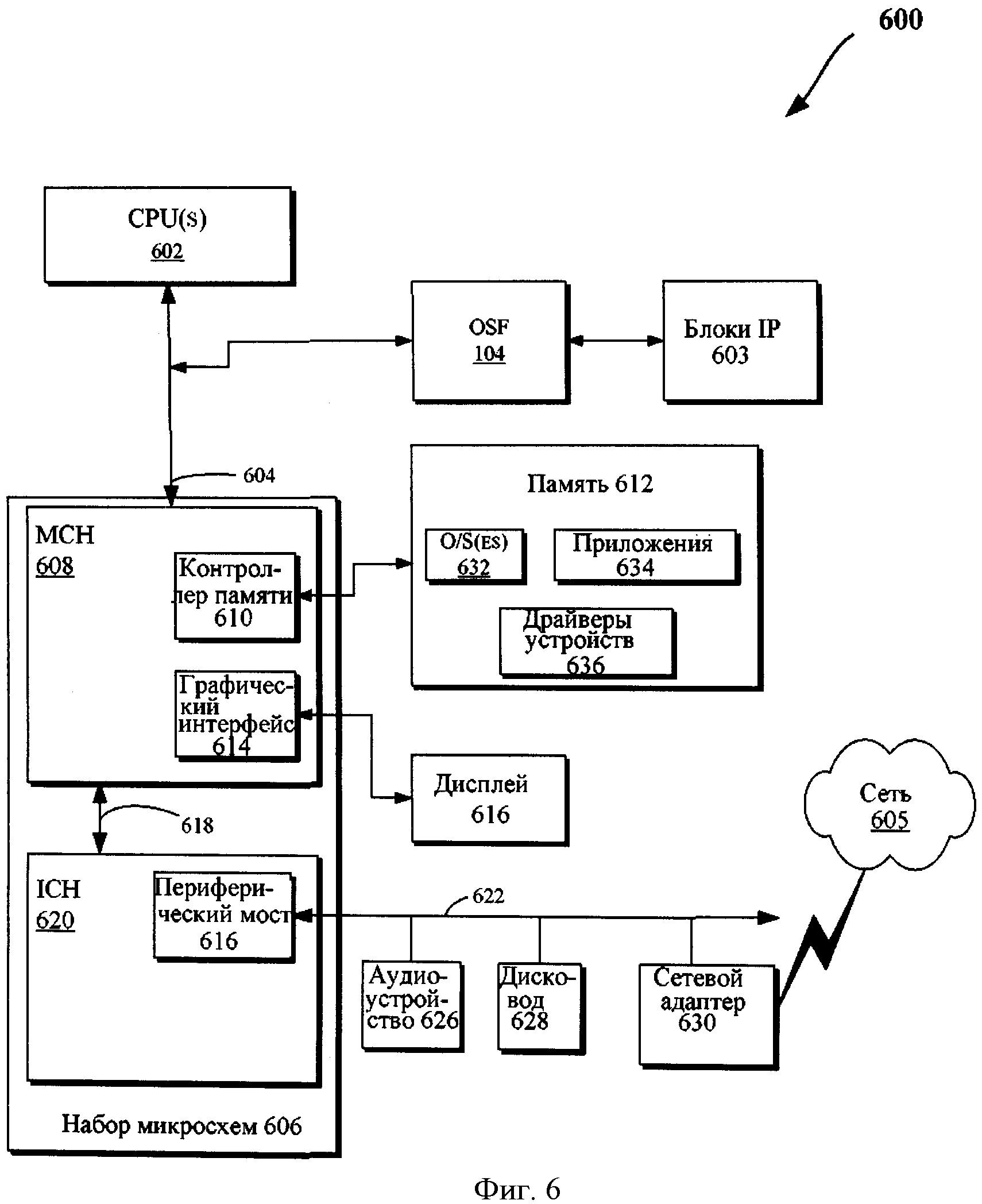
Для реализации обсужденных здесь примеров воплощения (например, обсужденных со ссылками на фигуры 1-5) могут использоваться различные типы вычислительных систем. Например, фигура 6 иллюстрирует блок-схему вычислительной системы 600. Один или несколько агентов 102 из фигуры 1 могут содержать один или несколько компонентов вычислительной системы 600. Вычислительная система 600 может включать один или несколько центральных процессоров (CPU) 602 (которые все вместе могут упоминаться здесь, как "процессоры 602" или в общем смысле - "процессор 602"), связанный со схемой соединений (или шиной) 604. Процессоры 602 могут быть процессорами любого типа, такого как процессор общего назначения, сетевой процессор (который может обрабатывать данные, переданные по компьютерной сети 605), и т.д., (включая компьютер с сокращенным набором команд (RISC) процессор или компьютер со сложным набором команд (CISC)). Кроме того, процессор 602 может иметь одноядерную или многоядерную конструкцию. Многоядерные процессоры 602 могут включать различные типы ядер процессора на одной плате на кристалле с интегральными схемами (IC). Кроме того, многоядерные процессоры 602 могут быть реализованы как симметричные или асимметричные многопроцессорные системы.
Процессор 602 может включать один или несколько кэш-модулей и/или блоков управления памятью MMU (типа обсужденных со ссылками на фигуры 1-5) (не показаны). Кэш-модули в различных примерах воплощения могут быть частными и/или общими. В основном, кэш-модуль хранит данные, соответствующие исходным данным, ранее хранившимся в памяти или вычисленные в другом месте. Чтобы уменьшить время задержки доступа к памяти при хранении данных в кэше, будущее их использование может быть осуществлено, получая доступ к кэшируемой копии вместо того, чтобы повторно выбирать или повторно вычислять исходные данные. Кэш-модули могут быть любым типом кэш-памяти, такой как кэш уровня 1 (L1), кэш уровня 2 (L2), кэш уровня 3 (L3), кэш среднего уровня, кэш последнего уровня (LLC) и т.д. для хранения электронных данных (включая команды), которые используются одним или несколькими компонентами системы 600.
Как показано на фигуре 6, система OSF 104 может быть расположена между одним или несколькими блоками IP 603 и процессором 602 (например, через межсоединение 604). Как обсуждено выше со ссылками на фигуры 1-5, OSF 104 может включать логику для выполнения операции перераспределения remap-1,
Набор микросхем 606 может быть дополнительно связан со схемой межсоединений 604. Дополнительно, набор микросхем 606 может включать концентратор управления памятью (МСН) 608. МСН 608 может включать контроллер памяти 610, который соединяется с памятью 612. Память 612 может хранить данные, например, последовательности команд, которые выполняются процессором 602, или любым другим устройством в связи с компонентами вычислительной системы 600. В одном примере воплощения память 612 может использоваться для хранения данных, таких как данные, обсужденные со ссылками на фигуры 1-5 (например, таблица страниц). Кроме того, в одном примере воплощения изобретения память 612 может включать одно или несколько устройств энергозависимой памяти, такой как оперативная память (RAM), динамическая память RAM (DRAM), синхронная память DRAM (SDRAM), статическая память RAM (SRAM) и т.д. Со схемой межсоединений 604 также может быть связана энергонезависимая память в виде жесткого диска. Со схемой межсоединений 604 могут быть связаны дополнительные устройства, такие как ряд процессоров и/или ряд устройств системной памяти.
МСН 608 может дополнительно включать графический интерфейс 614 связанный с дисплеем 616 (в частности, в одном примере воплощения через графический ускоритель). В одном примере воплощения графический интерфейс 614 может быть связан с дисплеем 616 через ускоренный графический порт (AGP). В одном примере воплощения изобретения дисплей 616 (такой как плоскопанельный дисплей) может быть связан с графическим интерфейсом 614, например, через преобразователь сигнала, который преобразует цифровое представление изображения, сохраненного в устройстве хранения, таком как видеопамять или системная память (например, память 612) в сигналы дисплея, которые интерпретируются и выводятся на экран дисплея 616.
Как показано на фигуре 6, концентратор взаимодействует через интерфейс 618, который может связать МСН 608 с концентратором ввода/элемента управления выводом (ICH) 620. ICH 620 может обеспечить ввод/вывод (I/O или IO) устройств, связанных с вычислительной системой 600. ICH 620 может быть связан с шиной 622 через периферийный мост (или контроллер) 624, такой шина PCI, которая может быть совместима с универсальной последовательной шиной (USB), контроллером и т.д. Мост 624 может обеспечить канал передачи данных между процессором 602 и периферийными устройствами. Могут быть использованы другие типы топологии. Кроме того, множество шин может быть связано с ICH 620, например, через множество мостов или контроллеров. Например, шина 622 может отвечать спецификации PCI, версии 3.0, 2004, доступной от Специальной группы PCI, Портленд, Орегон, США (называемая в дальнейшем "шиной PCI"). Альтернативно, шина 622 может содержать шину, которая отвечает спецификации PCI-X. 3.0а, 2003 (именуемая в дальнейшем "шиной PCI-X") и/или спецификации PCI Express (PCI, версия 2.0, 2006), доступный от вышеупомянутой Специальной группы PCI, Портленд, Орегон, США. Дополнительно, шина 622 может содержать другие типы и конфигурации соединительных систем. Кроме того, в различных примерах воплощения изобретения другие периферийные устройства, связанные с ICH 620, могут включать дисковод со встроенным контроллером (IDE) или интерфейс малых компьютерных систем (SCSI), жесткий диск, порты USB, клавиатуру, мышь, параллельный порт, последовательный порт, дисководы для гибких дисков, внешнее цифровое устройство (например, интерфейс цифрового видео (DVI)) и т.д.
Шина 622 может быть связана с аудиоустройством 626, одним или несколькими дисководами 628 и с сетевым адаптером 630 (который в одном примере воплощения может быть драйвером сетевого интерфейса NIC). В одном примере воплощения сетевой адаптер 630 или другие устройства, связанные с шиной 622, могут быть соединены с набором микросхем 606 через коммутирующую логику 612 (которая в некоторых примерах воплощения может быть подобна логике 412 из фигуры 4). С шиной 622 могут быть связаны и другие устройства. Кроме того, в некоторых примерах воплощения с МСН 608 могут быть связаны различные другие компоненты (такие как сетевой адаптер 630). Кроме того, процессор 602 и МСН 608 могут быть объединены, чтобы сформировать однокристальную схему.
Дополнительно, вычислительная система 600 может включать энергозависимую и/или энергонезависимую память (или хранилище). Например, энергонезависимая память может включать один или несколько следующих компонентов: постоянную память (ROM), программируемую память ROM(PROM), стираемую память PROM(EPROM), электрическую память EPROM(EEPROM), дисковод (например, 628), гибкий диск, компакт-диск (CD-ROM), цифровой универсальный диск (DVD), флэш-память, магнитный оптический диск или другие типы энергонезависимых машиночитаемых носителей, способных сохранять электронные данные (включая команды).
В одном примере воплощения память 612 может включать один или несколько следующих компонентов: операционную систему (O/S) 632, приложение 634 и/или драйвер устройства 636 (такой как OS, приложения и/или драйверы устройства, обсужденные со ссылками на фигуры 1-5). Память 612 может также включать области, выделенные для операций MMIO. Программы и/или данные, хранившие в памяти 612, могут быть подкачаны в дисковод 628, как часть операций управления памятью. Приложение (приложения) 634 может выполняться, например, на процессоре (процессорах) 602 с передачей одного или нескольких пакетов данных одному или нескольким вычислительным устройствам, связанным с сетью 605. В одном примере воплощения пакет может быть последовательностью одного или несколько символов и/или величин, которые могут быть закодированы одним или несколькими электрическими сигналами, переданными, по меньшей мере, одним отправителем, по меньшей мере, одному получателю (например, по сети, такой как сеть 605). Каждый пакет может иметь заголовок, который включает различную информацию, которая может быть использована при маршрутизации и/или обработке пакета, например, исходный адрес, адрес получателя, тип пакета и т.д. Каждый пакет может также содержать полезную информацию, которая включает несформированные данные (или контент), причем пакет передается между различными вычислительными устройствами по компьютерной сети (такой как сеть 605).
В одном примере воплощения приложение 634 может использовать O/S 632, чтобы связаться с различными компонентами системы 600, например, через драйвер 636. Указанный драйвер 636 может включать конкретные команды для сетевого адаптера (530), чтобы обеспечить связь между O/S 632 и сетевым адаптером 630 или с другими устройствами ввода-вывода, связанным с системой 600, например, через набор микросхем 606.
В одном примере воплощения O/S 632 может включать пакет сетевых протоколов. Пакет протоколов, в основном, включает пакет процедур или программ, которые могут быть выполнены, чтобы обработать пакеты, отправленные по сети (605), где пакеты могут соответствовать указанному протоколу. Например, пакет TCP/IP (протокол управления передачей/интернет-протокол) может быть обработан, используя пакет TCP/IP. Драйвер 636 может указать на буферы 638, которые должны быть обработаны, например, через пакет протокола.
Сеть 605 может быть компьютерной сетью любого типа. Сетевой адаптер 630 может дополнительно включать механизм 652 прямого доступа к памяти (DMA), который переписывает пакеты в буферы (например, хранящиеся в памяти 612), предоставленные имеющимися дескрипторами (например, сохраненные в памяти 612) для передачи/приема данных по сети 605.
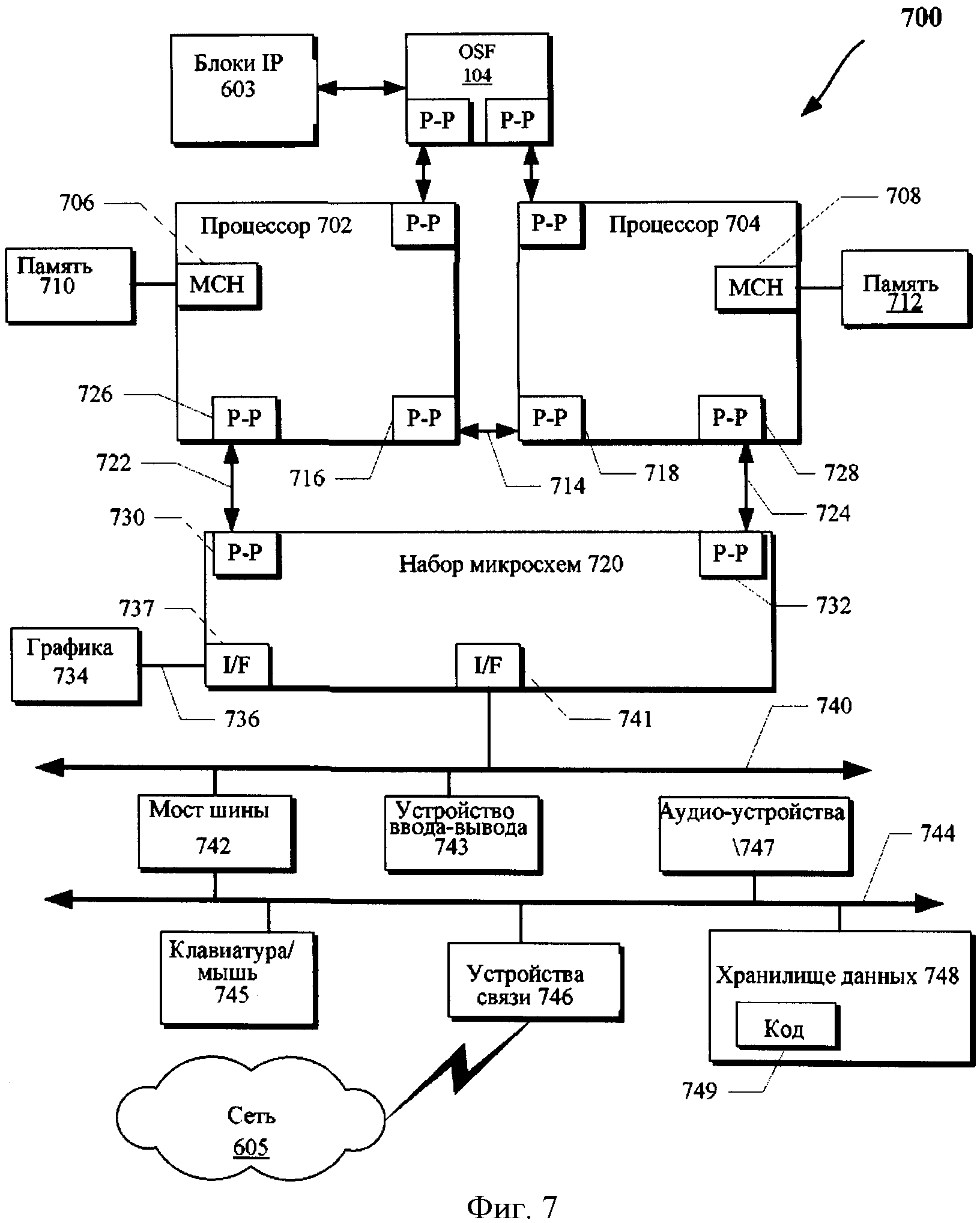
На фигуре 7 представлена вычислительная система 700, которая организована по "двухточечной" конфигурации (PtP), в соответствии с одним примером воплощения изобретения. В частности, на фигуре 7 показана система, в которой процессоры, память и устройства ввода-вывода соединены многими "двухточечными" интерфейсами. Операции, обсуждаемые со ссылкой на фигуры 1-6, могут быть выполнены одним или несколькими компонентами системы 700.
Как показано на фигуре 7, система 700 может включать несколько процессоров, из которых для ясности показаны только два (процессоры 702 и 704). Каждый из процессоров 702 и 704 может включать концентратор контроллера локальной памяти (МСН) 706 и 708, чтобы обеспечить связь с блоками памяти 710 и 712 (которые могут сохранять области MMIO, как обсуждено выше со ссылками на пункты 2-3). Блоки памяти 710 и/или 712 могут хранить различные данные, такие как данные, обсужденные выше со ссылкой на память 612 фигуры 6. Как показано на фигуре 7, процессоры 702 и 704 также могут включать один или несколько модулей кэш-пямяти, таких, как обсужденные со ссылкой на фигуры 4 и 6.
В одном примере воплощения процессоры 702 и 704 могут быть типа процессоров 602, обсужденных со ссылкой на фигуру 6. Процессоры 702 и 704 могут обмениваться данными через "двухточечный" интерфейс (PtP) 714, используя схемы интерфейса PtP 716 и 718, соответственно. Кроме того, каждый из процессоров 702 и 704 может обмениваться данными с набором микросхем 720 через отдельные интерфейсы PtP 722 и 724, используя "двухточечные" интерфейсные схемы 726, 728, 730 и 732. Набор микросхем 720 может дополнительно обмениваться данными с высокоскоростной графической схемой 734 через высокоскоростной графический интерфейс 736, например, используя схему интерфейса PtP 737.
По меньшей мере, в одном примере воплощения OSF 104 может связать процессоры 702, 704 (например, через интерфейсы PtP) с одним или несколькими блоками IP 603. Однако в других примерах воплощения изобретения могут существовать и другие схемы логических устройств в пределах системы 700 на фигуре 7. Кроме того, другие примеры воплощения могут быть распределены по нескольким схемам, логическим устройствам или устройствам, показанным на фигуре 7. Кроме того, процессоры 702, 704 могут включать MMU (например, типа устройств, обсужденных выше со ссылкой на фигуру 5). Дополнительно, OSF 104 может включать логику перераспределения remap-1 или эта логика может быть расположена в другом месте в системе 700, например, в наборе микросхем 720, коммуникационном устройстве 746 или в устройствах, соединенных шиной 740/744 и т.д.
Набор микросхем 720 может быть связан с шиной 740 через схему интерфейса PtP 741. Шина 740 может иметь одно или несколько устройств, которые связаны с этой шиной, например, через мост шины 742 и устройства ввода-вывода 743. Через шину 744, мост шины 742 может быть соединен с другими устройствами, такими как клавиатура или мышь 745, коммуникационные устройства 746 (такие как модемы, сетевые интерфейсы или другие устройства связи, которые могут связываться с компьютерной сетью 605), аудио устройство ввода-вывода и/или устройство хранения данных 748. Устройство хранения данных 748 может сохранять код 749, который может обрабатываться процессорами 702 и/или 704.
В различных примерах воплощения изобретения, обсужденные здесь операции, например, со ссылкой на фигуры 1-7, могут быть реализованы с помощью аппаратных средств (например, схемными решениями), программного обеспечения, встроенного микропрограммного обеспечения, микрокода или их комбинации, которые могут быть предусмотрены в виде продукта компьютерной программы, включая машиночитаемый носитель, на котором хранятся команды (или шаги программы), используемые компьютером для выполнения обсужденного выше процесса. Кроме того, термин "логика" в качестве примера может включать программное обеспечение, аппаратные средства или комбинацию программного и аппаратного обеспечения. Машиночитаемый носитель может включать устройства хранения, такие как устройства, обсужденные со ссылкой на фигуры 1-7. Дополнительно, такие считываемые компьютером носители могут быть загружены как компьютерная программа, в которой эта программа может быть передана от удаленного (например, сервера) запрашивающему компьютеру (например, клиенту) через сигналы данных на несущей частоте или другом носителе, действующем через канал связи (например, шина, модем, или сетевое соединение).
Выражение в описании изобретения "один пример воплощения" или "пример воплощения" означает, что определенный признак, структура или характеристика, описанная в соединении с примером воплощения, могут быть включены, по меньшей мере, в одну реализацию изобретения. Фраза "в одном примере воплощения" в различных местах описания изобретения не обязательно относиться к одному и тому же примеру воплощения.
Кроме того, в описании и пунктах патентования могут использоваться термины "связаны" и "соединены" вместе с их производными. В некоторых примерах воплощения изобретения, термин "соединены" может использоваться, чтобы указать, что два или больше двух элементов находятся в прямом физическом или электрическом контакте друг с другом. Слово "связаны" может означать, что два или больше двух элементов могут находиться в прямом физическом или электрическом контакте. Однако "связанный" может также означать, что два или больше двух элементов, возможно, не находятся в прямом контакте друг с другом, но все еще могут взаимодействовать друг с другом.
Таким образом, хотя примеры воплощения изобретения были описаны на языке, конкретно относящимся к структурным признакам и/или методологическим действиям, следует понимать, что заявленный предмет изобретения не может быть ограничен конкретными признаками или описанными действиями. Скорее конкретные признаки и действия раскрываются как примеры формы реализации заявленного предмета изобретения.
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении
Устройство и способ иерархической маршрутизации в многопроцессорных системах с ячеистой структурой
Совмещение игрового поля на основе модели
Системная плата, включающая модуль над кристаллом, непосредственно закрепленным на системной плате
Технологии для управления использованием энергии питания
Обработка гибридного автоматического запроса повторной передачи в системах радиосвязи
Способ расчета скорости без столкновений для агента в среде имитации толпы
Способы кооперативной связи
Установка, способ и система кэширования
Адаптивная организация кэша для однокристальных мультипроцессоров
Способ и устройство для уменьшения шумов в видеоизображении

