Результат интеллектуальной деятельности: СПОСОБ И УСТРОЙСТВО ДЛЯ ИЗМЕНЕНИЯ ФОРМЫ ГУБ И ПОЛУЧЕНИЯ АНИМАЦИИ ГУБ В УПРАВЛЯЕМОЙ ГОЛОСОМ АНИМАЦИИ
Вид РИД
Изобретение
Область техники
Изобретение относится к технологиям видеоанимации, а более конкретно - к способу и устройству для изменения формы губ и получения анимации губ в управляемой голосом анимации.
Уровень техники
Система Интерактивного Речевого Ответа (система ИРО) представляет собой продукт, основанный на передаче голоса. Большинство пользователей сети Интернет пользуются средствами самопредставления и отображения индивидуальности. Поэтому необходимы технологические и концептуальные усовершенствования системы ИРО, например, для улучшения выразительности голоса, что можно обеспечить при помощи технологий видеоанимации. В качестве платформы для технологии видеоанимации можно использовать мобильный телефон или веб-страницу, на которых можно осуществлять конфигурирование голоса с использованием самоопределяемой видеоанимации, чтобы тем самым придать голосу выразительность.
Одной из важных технологий видеоанимации является технология изменения формы губ в управляемой голосом анимации. Из уровня техники известно решение, согласно которому аудиосигналам путем использования режима машинного самообучения сопоставляются формы губ в параметрах анимации лица. Однако это техническое решение характеризуется сложностью алгоритма и высокой стоимостью вычислений.
Сущность изобретения
Задача настоящего изобретения заключается в разработке таких способа и устройства для изменения формы губ и получения анимации губ в управляемой голосом анимации, которые характеризовались бы упрощенным алгоритмом изменения формы губ в управляемой голосом анимации и уменьшенной стоимостью вычислений.
Сущность предложенных решений пояснена ниже.
Настоящее изобретение относится к способу изменения формы губ в управляемой голосом анимации, включающему:
получение аудиосигналов и получение пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
получение введенной пользователем модели исходной формы губ, а также генерацию величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ
и генерацию набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ.
Кроме того, изобретение относится к устройству для изменения формы губ в управляемой голосом анимации, содержащему:
модуль получения, выполненный с возможностью получения аудиосигналов и получения пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
первый модуль генерации, выполненный с возможностью получения введенной пользователем модели исходной формы губ, а также с возможностью генерации величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ;
и второй модуль генерации, выполненный с возможностью генерации набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Также изобретение относится к способу получения анимации губ в управляемой голосом анимации, включающему:
получение аудиосигналов и получение пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
получение введенной пользователем модели исходной формы губ, а также генерацию величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ;
генерацию набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ
и генерацию анимации губ согласно набору сеточных моделей формы губ.
Наконец, изобретение также относится к устройству для получения анимации губ в управляемой голосом анимации, содержащему:
модуль получения, выполненный с возможностью получения аудиосигналов и получения пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
первый модуль генерации, выполненный с возможностью получения введенной пользователем модели исходной формы губ, а также с возможностью генерации величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ;
второй модуль генерации, выполненный с возможностью генерации набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ;
и третий модуль генерации, выполненный с возможностью генерации анимации губ согласно набору сеточных моделей формы губ.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Краткое описание чертежей
Ниже приведено краткое описание чертежей, иллюстрирующих аспекты настоящего изобретения, а также примеры, характеризующие известный уровень техники. Разумеется, описанные ниже чертежи относятся не ко всем, а только к некоторым вариантам изобретения, но специалистам данной области техники должно быть понятно, что на основе этих чертежей можно получить и другие чертежи, причем выполняемые для этого действия не требуют от специалиста изобретательского шага.
Фиг.1 изображает блок-схему, иллюстрирующую способ изменения формы губ в управляемой голосом анимации, соответствующий первому аспекту изобретения.
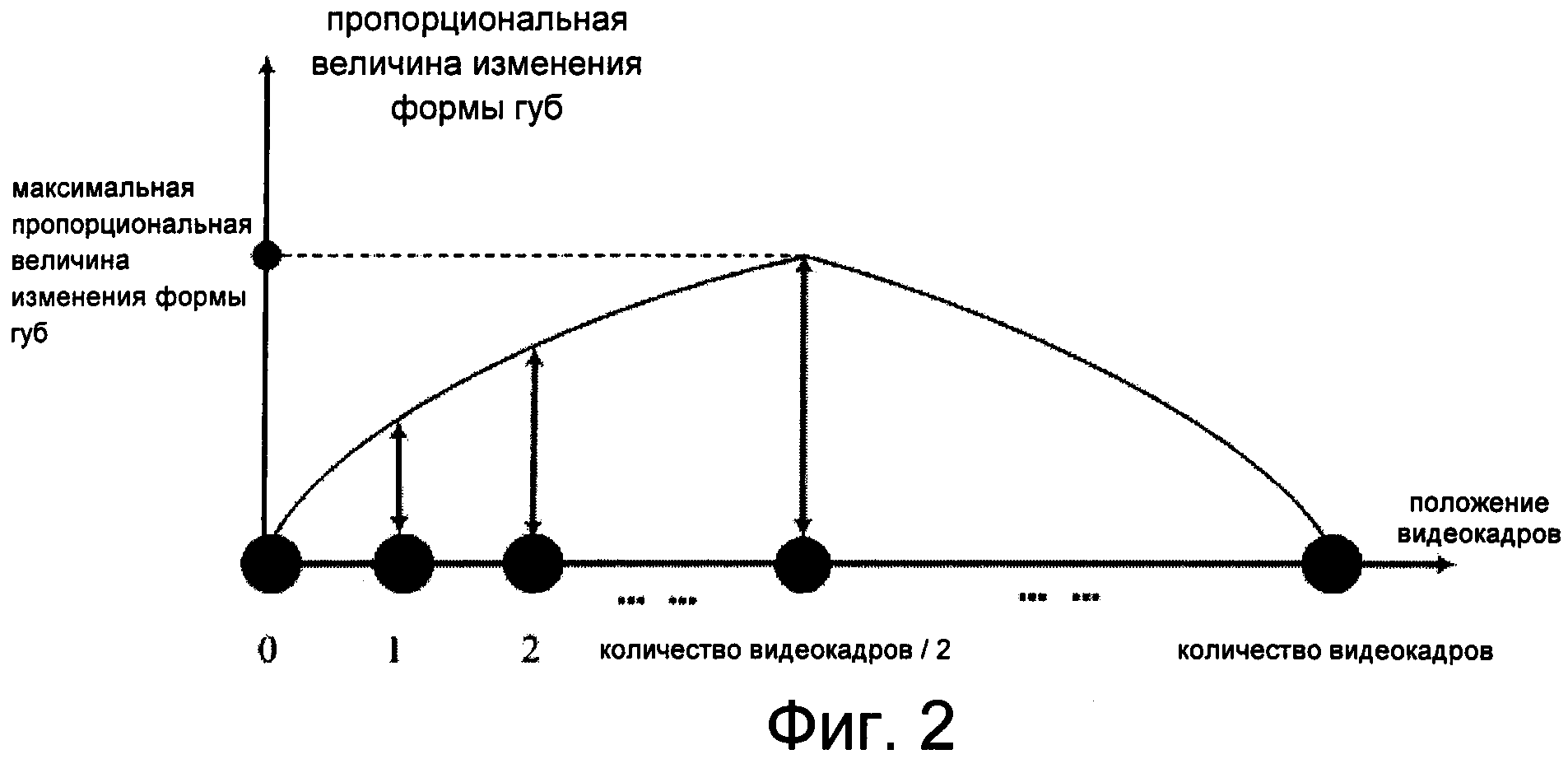
Фиг.2 изображает соответствующую первому аспекту изобретения зависимость между количеством видеокадров и пропорциональной величиной изменения формы губ.
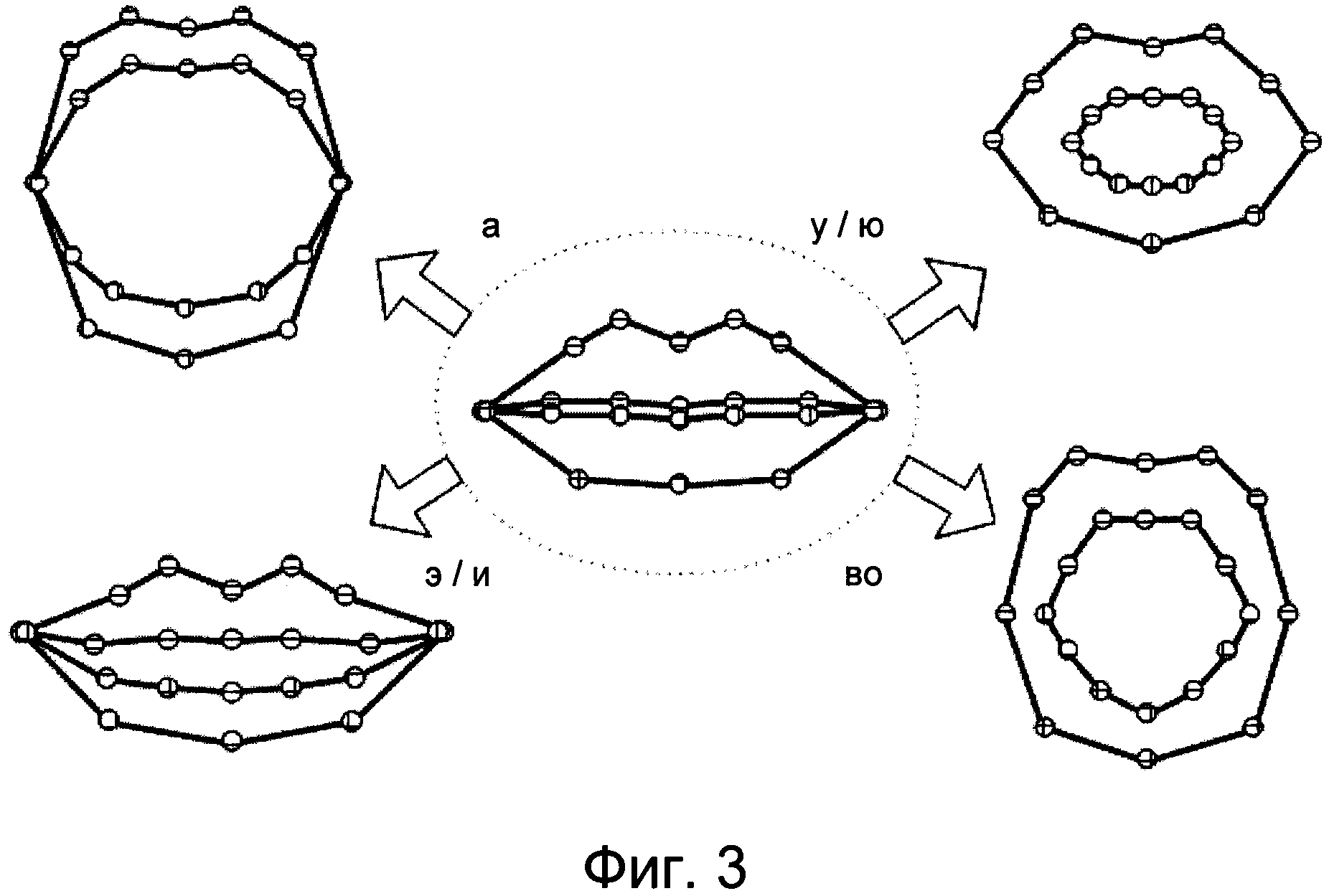
Фиг.3 изображает схему, иллюстрирующую библиотеку моделей артикуляции губ, соответствующую первому аспекту изобретения.
Фиг.4 изображает блок-схему, иллюстрирующую способ получения анимации губ в управляемой голосом анимации, соответствующий второму аспекту изобретения.
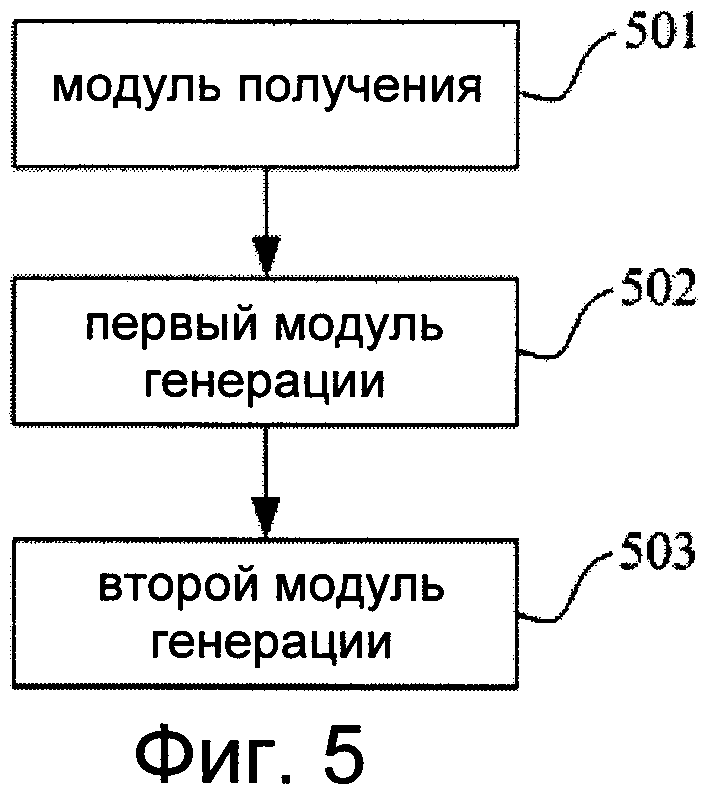
Фиг.5 изображает схему, иллюстрирующую устройство для изменения формы губ в управляемой голосом анимации, соответствующее третьему аспекту изобретения.
Фиг.6 изображает схему, иллюстрирующую другое устройство для изменения формы губ в управляемой голосом анимации, соответствующее третьему аспекту изобретения.
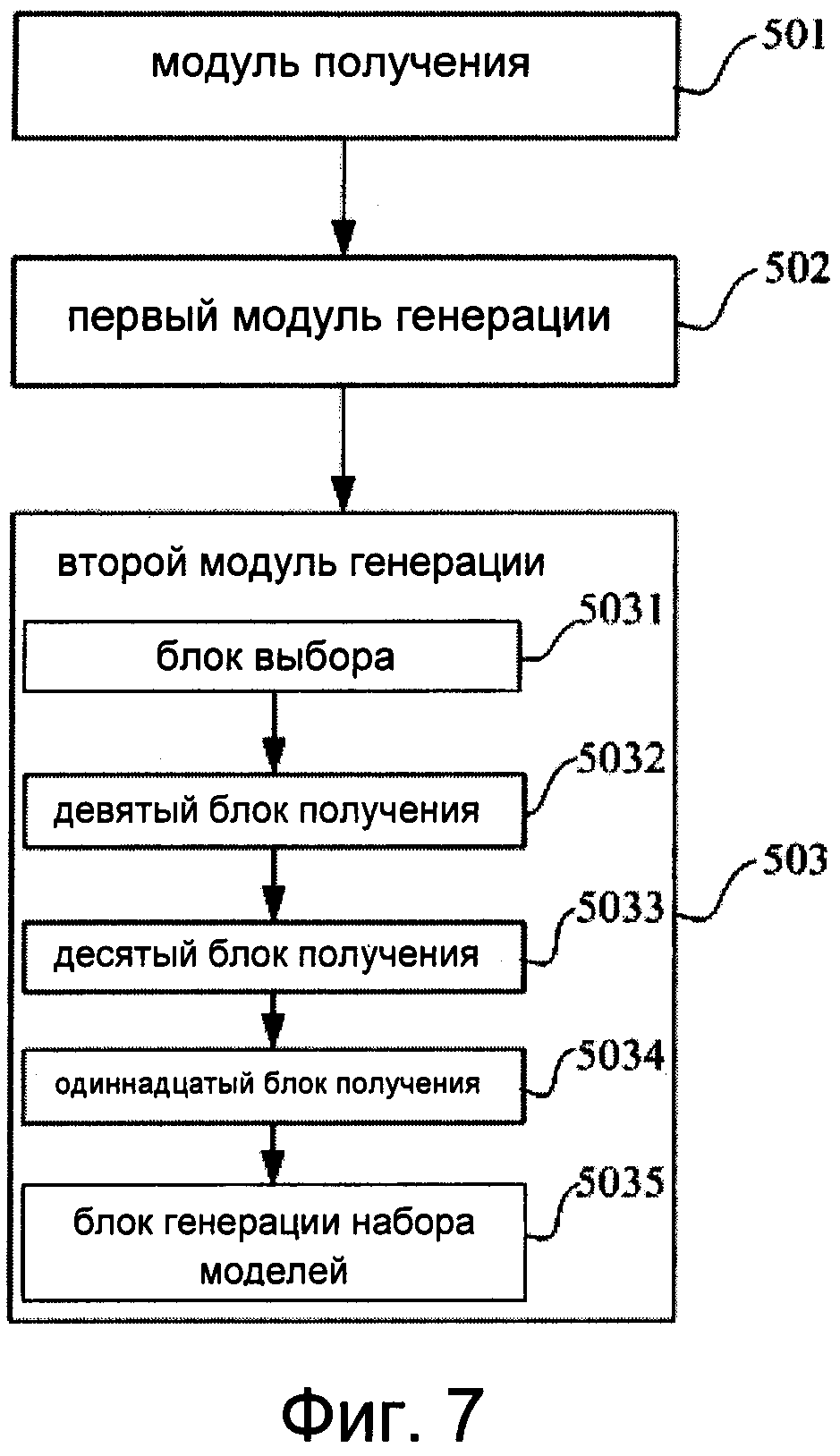
Фиг.7 изображает схему, иллюстрирующую еще одно устройство для изменения формы губ в управляемой голосом анимации, соответствующее третьему аспекту изобретения.
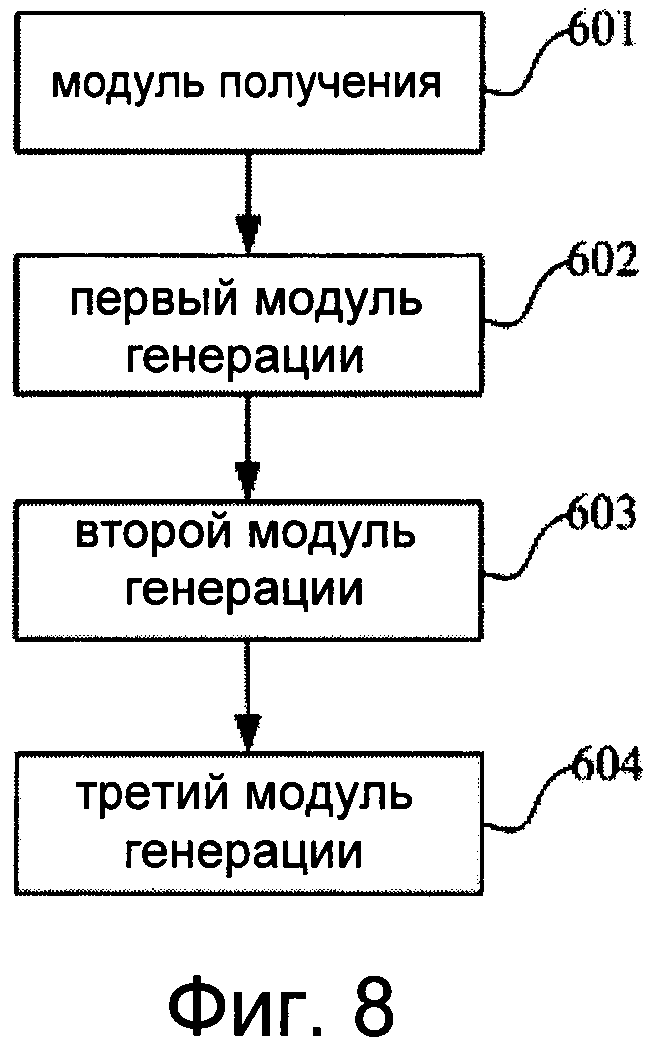
Фиг.8 изображает схему, иллюстрирующую устройство для получения анимации губ, соответствующее четвертому аспекту изобретения.
Подробное описание изобретения
Ниже изобретение описано более подробно со ссылкой на прилагаемые чертежи, поясняющие его назначение, преимущества и модификации. Разумеется, описанные ниже примеры являются только частными примерами изобретения, не исчерпывающими все его возможные варианты. Соответственно, объем правовой охраны изобретения распространяется и на другие варианты, которые основаны на раскрытых в заявке примерах осуществления и могут быть получены специалистами данной области техники без применения изобретательского шага.
Согласно первому аспекту изобретения, оно относится к способу изменения формы губ на основе голоса. Как показано на фиг.1, данный способ включает следующие этапы.
Этап 101: получают аудиосигналы и получают пропорциональную величину изменения формы губ на основе характеристик этих аудиосигналов.
Говоря более конкретно, этап, на котором получают пропорциональную величину изменения формы губ на основе характеристик аудиосигналов, включает нижеперечисленные этапы.
Этап 101А: анализируют аудиосигналы и получают максимальное значение maxSampleValue дискретных данных аудиосигналов.
Этап 101В: разделяют аудиосигналы по окнам, разделяют каждое окно на группы; получают среднее значение дискретных данных в каждой группе; получают среднее значение avgGroup группы в каждом окне, причем это среднее значение avgGroup группы состоит из средних значений, соответствующих группам в окне получают максимальное значение из средних значений avgGroup групп в каждом окне; и получают максимальное значение windowPeak по группам, которое содержит максимальные значения, соответствующие всем окнам.
Основной речевой единицей является слог. В частности, в китайском языке каждый слог соответствует одному типу формы губ, и при слитном произношении требуется 200-300 миллисекунд, чтобы произнести один слог. Во время произнесения каждого слога может происходить изменение голоса, поэтому необходимо разделять слог на фонемы. Согласно вышеизложенному принципу, полученные аудиосигналы разделяют по окнам, имеющим определенную длину, причем каждое окно соответствует одному слогу; далее каждое окно разделяют на группы, имеющие определенную длину, причем каждая группа соответствует одной фонеме. Предположим, что для произнесения слога требуется x секунд, а длина окна обозначается как WindowLen, тогда WindowLen=x*частота дискретизации аудиосигнала; предположим, что для произнесения фонемы требуется у секунд, а длина группы обозначается как GroupLen, тогда GroupLen=y*частота дискретизации аудиосигнала.
Говоря более конкретно, среднее значение дискретных данных в каждой группе определяют как сумму всех значений дискретных данных в группе, деленную на значение GroupLen, и это среднее значение используют в качестве среднего значения avgGroup группы; выбирают максимальное значение из средних значений avgGroup групп и используют как максимальное значение windowPeak по группам.
Если возникает необходимость исключить избыточность изменения формы губ и обеспечить плавность их изменения, то при получении аудиосигналов их обрабатывают для подавления шумов.
Этап 101С: получают максимальную величину изменения формы губ, соответствующую текущему окну, согласно полученному максимальному значению windowPeak по группам и полученному максимальному значению дискретных данных.
Говоря более конкретно, определяют среднее значение дискретных данных по каждой группе в текущем окне i(i≥0), определяют максимальное значение windowPeak[i] из средних значений, соответствующих группам в текущем окне i; вычисляют отношение scale[i] максимального значения windowPeak[i] к максимальному значению дискретных аудиоданных maxSampleValue. Для каждого значения scale[i] масштабируемой группы вычисляют максимальную величину extent[i] изменения формы губ, соответствующую текущему окну i, т.е. extent[i]=scale[i]*maxLen, где maxLen является максимальной величиной изменения формы губ по всем окнам.
Этап 101D: получают пропорциональную величину изменения формы губ в каждом видеокадре, соответствующем текущему окну, согласно максимальной величине изменения формы губ, соответствующей текущему окну.
Говоря более конкретно, определяют пропорциональную величину scaleForFrame[k] изменения формы губ в j-м видеокадре, соответствующем текущему окну i, т.е. scaleForFrame[k]=j*(scale[i]/(frameNumber/2)), где k=frameNumber*i+j, 0≤k< общее количество видеокадров, frameNumber является количеством видеокадров, соответствующих каждому окну, frameNumber=х*частота дискретизации видеосигнала, x является продолжительностью произнесения каждого слога. В данном варианте изобретения значение по умолчанию для частоты дискретизации видеосигнала составляет 30 кадров в секунду, причем это значение может быть изменено пользователем согласно требованиям; значение j увеличивается от 0 до frameNumber/2 и затем уменьшается от frameNumber/2 до 0, j является целым числом.
Этап 102: получают введенную пользователем модель исходной формы губ и генерируют величину изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ.
Говоря более конкретно, величина изменения формы губ включает: величину изменения формы губ в вертикальном направлении и величину изменения формы губ в горизонтальном направлении; величина изменения в горизонтальном направлении равна Length*scaleForFrame[k], а величина изменения в вертикальном направлении равна Width*scaleForFrame[k], где 0≤k< общее количество видеокадров, при этом Length и Width являются, соответственно, длиной и шириной исходной формы губ.
Следует отметить, что введенная пользователем модель исходной формы губ может варьироваться в зависимости от целей применения.
Этап 103: генерируют набор сеточных моделей формы губ согласно полученной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ.
На этом этапе образуют библиотеку моделей артикуляции губ, основанную на особенностях произношения в китайском языке. В китайском языке слово состоит из начального согласного звука и гласного звука, поэтому форма губ в основном определяется произношением гласного звука. Гласные звуки подразделяются на одиночные гласные, сложные гласные и носовые гласные. Одиночный гласный звук состоит из одного гласного, и когда он произносится, форма губ остается неизменной. Сложный гласный звук состоит из двух или трех гласных, и когда он произносится, форма губ постепенно изменяется. При произнесении носового гласного звука форма губ изменяется незначительно. Следовательно, модели артикуляции, устанавливаемые для формы губ, в целом основываются на особенностях произношения одиночных гласных звуков. Произношение одиночных гласных звуков включает произношение звуков "а", "во", "э", "и", "у", "ю", представляющих шесть китайских символов, произношение которых соответствует одиночным гласным звукам. Звукам "у" и "ю" соответствуют одинаковые формы губ, поэтому эти два вида формы губ объединяются в один вид формы губ. Звукам "э" и "и" соответствуют одинаковые формы губ, поэтому эти два вида формы губ объединяются в один вид формы губ. Следовательно, в библиотеке моделей артикуляции губ содержатся четыре типа моделей артикуляции губ, используемые для представления формы губ при произношении одиночных гласных звуков (см. фиг.3). Библиотека моделей артикуляции губ должна содержать: одну модель исходной формы губ и различные модели артикуляции губ, установленные согласно вышеизложенному принципу и основанные на модели исходной формы губ. Следует отметить, что состав библиотеки моделей артикуляции губ не ограничивается только вышеуказанными четырьмя моделями артикуляции губ для одиночных гласных звуков. Модели артикуляции губ в библиотеке моделей артикуляции губ могут варьироваться в зависимости от особенностей произношения в различных языках. Например, согласно особенностям произношения в английском языке, в библиотеку моделей артикуляции губ включаются модели артикуляции губ, соответствующие гласным звукам "а", "е", "и", "о", "у" английского языка.
Говоря более конкретно, этап генерации набора сеточных моделей формы губ согласно величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ, включает нижеперечисленные этапы.
Этап 103A: произвольным образом выбирают одну модель артикуляции губ из предварительно сконфигурированной библиотеки моделей артикуляции губ и принимают эту модель в качестве исходной модели артикуляции для текущей формы губ.
Этап 103В: получают вершины исходной модели артикуляции и модель исходной формы губ в библиотеке моделей артикуляции губ, вычисляют пропорциональную величину смещения для каждой вершины в исходной модели артикуляции. Говоря подробнее, смещение между вершиной z в исходной модели артикуляции и вершиной z в модели исходной формы губ в библиотеке моделей артикуляции губ составляет x_hor в горизонтальном направлении и y_ver в вертикальном направлении, причем пропорциональная величина смещения вершины z в горизонтальном направлении равна x_hor/modelLength, а пропорциональная величина смещения вершины z в вертикальном направлении равна y_ver/modelWidth, где modelLength и modelWidth являются, соответственно, длиной и шириной модели исходной формы губ в библиотеке моделей артикуляции губ, 0≤z<количество вершин в исходной модели артикуляции.
Этап 103С: получают смещения вершин в текущем видеокадре путем умножения пропорциональной величины смещения каждой вершины в исходной модели артикуляции на величину изменения формы губ в текущем видеокадре, соответствующем этой вершине.
Этап 103D: получают модель формы губ в текущем видеокадре путем наложения соответствующих смещений вершин в текущем видеокадре на введенную пользователем модель исходной формы губ.
Этап 103E: упорядочивают модели формы губ по всем видеокадрам согласно аудиопоследовательности и генерируют набор сеточных моделей формы губ.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Согласно второму аспекту изобретения, предложен способ получения анимации губ. Как показано на фиг.4, этот способ включает следующие этапы.
Этап 201: получают аудиосигналы и получают пропорциональную величину изменения формы губ на основе характеристик этих аудиосигналов.
Этап 201 идентичен этапу 101 и поэтому здесь не описывается.
Этап 202: получают введенную пользователем модель исходной формы губ и генерируют величину изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ.
Этап 202 идентичен этапу 102 и поэтому здесь не описывается.
Этап 203: генерируют набор сеточных моделей формы губ согласно полученной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ.
Этап 203 идентичен этапу 103 и поэтому здесь не описывается.
Этап 204: генерируют анимацию губ согласно набору сеточных моделей формы губ.
Говоря более подробно, анимация губ может быть сгенерирована с использованием общей технологии интерполяции на основе набора сеточных моделей формы губ и модели исходной формы губ.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Согласно своему третьему аспекту, изобретение относится к устройству для изменения формы губ в управляемой голосом анимации. Как показано на фиг.5, это устройство содержит:
модуль 501 получения, выполненный с возможностью получения аудиосигналов и получения пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
первый модуль 502 генерации, выполненный с возможностью получения введенной пользователем модели исходной формы губ, а также с возможностью генерации величины изменения формы губ согласно этой модели исходной формы губ и полученной пропорциональной величине изменения формы губ;
и второй модуль 503 генерации, выполненный с возможностью генерации набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ.
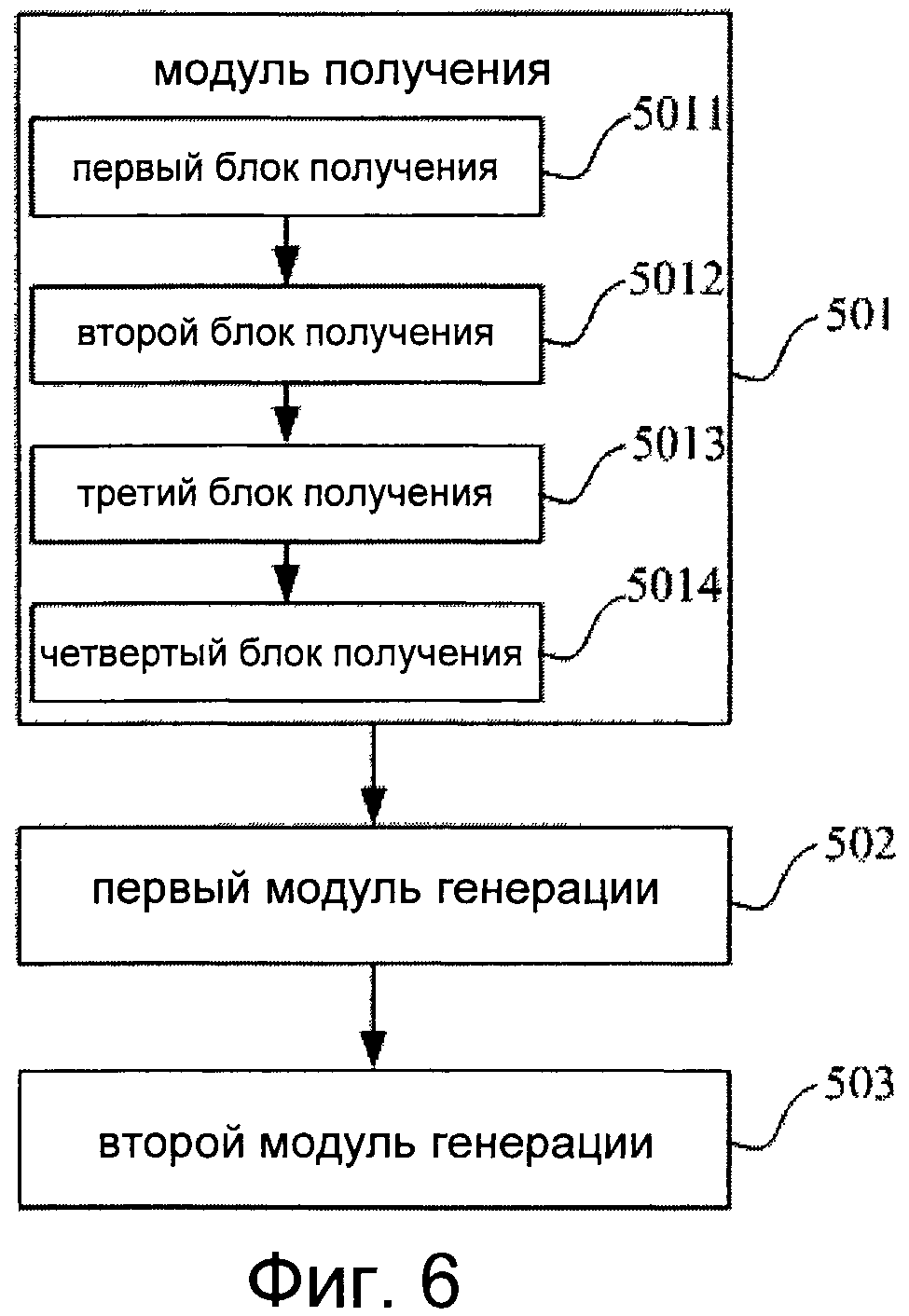
Как следует из фиг.6, в состав модуля 501 получения входят:
первый блок 5011 получения, выполненный с возможностью прослеживания аудиосигналов и получения максимального значения дискретных данных;
второй блок 5012 получения, выполненный с возможностью совершения следующих действий: разделение аудиосигналов по окнам; разделение каждого окна на группы; получение среднего значения дискретных данных в каждой группе; получение среднего значения avgGroup группы в каждом окне, причем среднее значение avgGroup группы содержит средние значения, соответствующие группам в окне; получение максимального значения из средних значений avgGroup групп в каждом окне и получение максимального значения windowPeak по группам, которое содержит максимальные значения, соответствующие всем окнам;
третий блок 5013 получения, выполненный с возможностью получения максимальной величины изменения формы губ, соответствующей текущему окну i, согласно полученному максимальному значению windowPeak по группам и полученному максимальному значению дискретных данных;
и четвертый блок 5014 получения, выполненный с возможностью получения пропорциональной величины изменения формы губ в текущем видеокадре, соответствующем текущему окну i, согласно максимальной величине изменения формы губ, соответствующей текущему окну i.
В состав второго блока 5012 получения входят:
пятый блок получения, выполненный с возможностью получения среднего значения дискретных данных в каждой группе в текущем окне i;
шестой блок получения, выполненный с возможностью получения максимального значения windowPeak[i] из средних значений, соответствующих группам в текущем окне i;
седьмой блок получения, выполненный с возможностью вычисления отношения scale[i] максимального значения windowPeak[i] к максимальному значению дискретных аудиоданных maxSampleValue,
восьмой блок получения, выполненный с возможностью вычисления максимальной величины extent[i] изменения формы губ, соответствующей текущему окну i, причем extent[i]=scale[i]*maxLen,
где i≥0 и maxLen является максимальной величиной изменения формы губ по всем окнам.
Кроме того, четвертый блок 5014 получения выполнен с возможностью получения пропорциональной величины scaleForFrame[k] изменения формы губ в j-м видеокадре, соответствующем текущему окну i, то есть scaleForFrame[k]=j*(scale[i]/(frameNumber/2)), где k=frameNumber*i+j, 0≤k<общее количество видеокадров, frameNumber является количеством видеокадров, соответствующих каждому окну, frameNumber=х*частота дискретизации видеосигнала, x является продолжительностью произнесения каждого слога; значение j увеличивается от 0 до frameNumber/2 и затем уменьшается от frameNumber/2 до 0, значение j является целым числом.
Для первого модуля 502 генерации, генерирующего величину изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ, также справедливо следующее:
первый модуль 502 генерации выполнен с возможностью вычисления величины Length*scaleForFrame[k] изменения формы губ в горизонтальном направлении и вычисления величины Width*scaleForFrame[k] изменения формы губ в вертикальном направлении, где 0≤k<общее количество видеокадров, Length и Width являются, соответственно, длиной и шириной исходной формы губ.
Как показано на фиг.7, в состав второго модуля 503 генерации входят:
блок 5031 выбора, выполненный с возможностью произвольного выбора одной модели артикуляции губ из предварительно сконфигурированной библиотеки моделей артикуляции губ, а также с возможностью принятия этой модели в качестве исходной модели артикуляции для текущей формы губ;
девятый блок 5032 получения, выполненный с возможностью получения вершин исходной модели артикуляции и модели исходной формы губ в библиотеке моделей артикуляции губ, а также с возможностью вычисления пропорциональной величины смещения каждой вершины в исходной модели артикуляции;
десятый блок 5033 получения, выполненный с возможностью получения смещений вершин в текущем видеокадре путем умножения пропорциональной величины смещения каждой вершины в исходной модели артикуляции на величину изменения формы губ в текущем видеокадре, соответствующем вершине;
одиннадцатый блок 5034 получения, выполненный с возможностью получения модели формы губ в текущем видеокадре путем наложения соответствующих смещений вершин в текущем видеокадре на введенную пользователем полученную модель исходной формы губ;
блок 5035 генерации набора моделей, выполненный с возможностью упорядочивания моделей формы губ по всем видеокадрам и с возможностью генерации набора сеточных моделей формы губ.
Для девятого блока 5032 получения, вычисляющего пропорциональную величину смещения каждой вершины в исходной модели артикуляции, также справедливо следующее:
девятый блок 5032 получения выполнен с возможностью вычисления пропорциональной величины x_hor/modelLength смещения вершины z в исходной модели артикуляции в горизонтальном направлении и с возможностью вычисления пропорциональной величины y_ver/modelWidth смещения вершины z в вертикальном направлении, где modelLength и modelWidth являются, соответственно, длиной и шириной модели исходной формы губ в библиотеке моделей артикуляции губ; 0≤z<количество вершин в исходной модели артикуляции.
Кроме того, модуль 501 получения выполнен с возможностью обработки аудиосигналов для подавления шумов.
Следует отметить, что детали процесса, выполняемого модулем 501 получения и заключающегося в получении аудиосигналов, а также в получении пропорциональной величины изменения формы губ согласно характеристикам аудиосигналов, можно узнать, обратившись к этапу 101, описанному в отношении первого аспекта изобретения.
Следует отметить, что детали процесса, выполняемого первым модулем 502 генерации и заключающегося в получении введенной пользователем модели исходной формы губ, а также в генерации величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ, можно узнать, обратившись к этапу 102, описанному в отношении первого аспекта изобретения.
Следует отметить, что детали процесса, выполняемого вторым модулем 503 генерации и заключающегося в генерации набора сеточных моделей формы губ согласно полученной величине изменения формы губ, а также предварительно сконфигурированной библиотеке моделей артикуляции губ, можно узнать, обратившись к этапу 103, описанному в отношении первого варианта изобретения.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Четвертый аспект изобретения относится к устройству для получения анимации губ. Как следует из фиг.8, это устройство содержит:
модуль 601 получения, выполненный с возможностью получения аудиосигналов и получения пропорциональной величины изменения формы губ на основе характеристик этих аудиосигналов;
первый модуль 602 генерации, выполненный с возможностью получения введенной пользователем модели исходной формы губ, а также с возможностью генерации величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ;
второй модуль 603 генерации, выполненный с возможностью генерации набора сеточных моделей формы губ согласно сгенерированной величине изменения формы губ и предварительно сконфигурированной библиотеке моделей артикуляции губ;
и третий модуль 604 генерации, выполненный с возможностью генерации анимации губ согласно набору сеточных моделей формы губ.
Модуль 601 получения, первый модуль 602 генерации и второй модуль 603 генерации эквивалентны, соответственно, модулю получения, первому модулю генерации и второму модулю генерации, относящимся к третьему аспекту изобретения, и поэтому не описываются здесь подробно.
Следует отметить, что детали процесса, выполняемого модулем 601 получения и заключающегося в получении аудиосигналов, а также в получении пропорциональной величины изменения формы губ согласно характеристикам аудиосигналов, можно узнать, обратившись к этапу 101, описанному в отношении первого аспекта изобретения.
Следует отметить, что детали процесса, выполняемого первым модулем 602 генерации и заключающегося в получении введенной пользователем модели исходной формы губ, а также в генерации величины изменения формы губ согласно модели исходной формы губ и полученной пропорциональной величине изменения формы губ, можно узнать, обратившись к этапу 102, описанному в отношении первого аспекта изобретения.
Следует отметить, что детали процесса, выполняемого вторым модулем 603 генерации и заключающегося в генерации набора сеточных моделей формы губ согласно полученной величине изменения формы губ, а также предварительно сконфигурированной библиотеке моделей артикуляции губ, можно узнать, обратившись к этапу 103, описанному в отношении первого аспекта изобретения.
В соответствии с настоящим изобретением, изменение формы губ производят на основе голоса с использованием библиотеки моделей артикуляции губ; по сравнению с известным уровнем техники решения, предложенные в рамках настоящего изобретения, отличаются простым алгоритмом и низкой стоимостью.
Технические решения, соответствующие четырем вышеописанным аспектам изобретения, можно применять, в частности, для видеоанимации на терминалах или видеоанимации на веб-страницах в развлекательных целях, причем возможно использование не только китайского языка, но и английского, французского или других языков. Настоящее изобретение, во всех его четырех аспектах, для удобства описано на примере китайского языка; однако обработка других языков выполняется аналогичным образом и поэтому здесь не рассматривается. Вводимая пользователем модель исходной формы губ может быть получена из изображений человеческих лиц, морд животных, персонажей мультфильмов и так далее; аудиосигналы также определяются пользователем, например, используется аудиосигнал обычного разговора или пения либо специально обработанный аудиосигнал.
Специалисты данной области техники должны понимать, что все этапы предложенных способов или только часть этих этапов могут быть реализованы с использованием аппаратных средств, управляемых программным обеспечением, причем это программное обеспечение может храниться на считываемом компьютером носителе данных, а в качестве такого носителя данных можно использовать гибкий диск, жесткий диск или компакт-диск.
Выше были описаны предпочтительные варианты изобретения, не ограничивающие объем его правовой охраны. Все модификации, замены и усовершенствования, соответствующие сущности настоящего изобретения, должны рассматриваться как входящие в объем его правовой охраны.


Способ динамической компоновки программы на встроенной платформе и встроенная платформа
Система и способ управления аватаром на платформе мгновенного обмена сообщениями
Способ и устройство блокировки нежелательных сообщений электронной почты
Клиент для рабочего стола, клиентская платформа и игровой объект в системе многопользовательских сетевых игр для рабочего стола
Способ и устройство для создания видеоанимации
Система и способ передачи файла от нескольких источников при мгновенном обмене сообщениями
Способ и устройство для инерционного перемещения оконного объекта
Система, способ и клиент для присоединения к группе
Способ и система передачи информации в социальной сети
Устройство синхронизации времени сетевой игры и соответствующий способ
Способ динамической компоновки программы на встроенной платформе и встроенная платформа
Система и способ управления аватаром на платформе мгновенного обмена сообщениями
Способ и устройство блокировки нежелательных сообщений электронной почты
Клиент для рабочего стола, клиентская платформа и игровой объект в системе многопользовательских сетевых игр для рабочего стола
Способ и устройство для создания видеоанимации
Система и способ передачи файла от нескольких источников при мгновенном обмене сообщениями
Способ и устройство для инерционного перемещения оконного объекта
Система, способ и клиент для присоединения к группе
Способ и система передачи информации в социальной сети
Устройство синхронизации времени сетевой игры и соответствующий способ

